Weekly Pickup
Weekly Pickup will select major product updates from GitHub issues and pr for you. Welcome to follow us on GitHub so that you'll be the first to know our latest updates.
Studio v1.1.0-beta was uncovered with a major feature: supporting the LOOKUP syntax. Besides, it is also armed with these updates:
- On Explore:
- Supports vertex query by Index
- Supports pre-processing data to generate a VID for a vertex query
- On Console
- Supports importing results of vertex query into Explore for visualized graph exploration
- Bug fixes
- Fixed the bug that the console cannot correctly display the result for a vertex query for a boolean property
You are more than welcome to give Studio a shot and raise issues. Here is where you can get it: https://github.com/vesoft-inc/nebula-web-docker
The updates of Nebula Graph in the last week:
- When a query is partially successful, a warning message will appear to keep users informed of the failure. For more information, check this pull request: https://github.com/vesoft-inc/nebula/pull/2290
- Some configuration options are added for dynamically configuring RocksDB. For more information, check this pull request: https://github.com/vesoft-inc/nebula/pull/2291, which is contributed by @chenxu14
- Fixed the bug that multiple services cannot be started on the same node in some cases. For more information, check this pull request: https://github.com/vesoft-inc/nebula/pull/2289
- The snapshot design is enhanced. Snapshots are created only when necessary and the performance is improved. For more information, check this pull request: https://github.com/vesoft-inc/nebula/pull/2287
The updates of Nebula in the last week:
- Optimizes the GO syntax. The query performance of a GO statement is optimized by allocating memory in advance, avoiding string copy, and so on. For more information, check this pull request: https://github.com/vesoft-inc/nebula/pull/2268, which is contributed by @xuguruogu
- Fixed the bug that the logs cannot be output because of the second try of starting the meta, storage, or graph service. For more information, check these pull requests: https://github.com/vesoft-inc/nebula/pull/2289 and https://github.com/vesoft-inc/nebula/pull/2278
- Fixed the bug that the validity of the raft lease may be incorrect when replica_factor is set to 1. For more information, check this pull request: https://github.com/vesoft-inc/nebula/pull/2276
- Fixed the bug during compiling of JNI. For more information, check this pull request: https://github.com/vesoft-inc/nebula/pull/2271
Here are some updates in the last week:
-
Supports using the
FETCH RPOP ONstatement to retrieve the properties of multiple tags for more than one vertex. When this syntax is used together with another syntax in one statement, the pipe (|) can be used to pass the output of the previous syntax as the input of theFETECH PROP ONsyntax. TheFETCH PROP ON *statement supports retrieving the properties for multiple vertices. For more information, check the following pull requests: https://github.com/vesoft-inc/nebula/pull/2222 https://github.com/vesoft-inc/nebula-docs/pull/117 -
Supports exposing RocksDB statistics through Webservice. For more information, check this pull request: https://github.com/vesoft-inc/nebula/pull/2262
-
Removed the lock for
FunctionManager, improving the performance of frequent invocation by multiple threads. For more information, check this pull request: https://github.com/vesoft-inc/nebula/pull/2273 -
Fixed the issue that Leader vote may fail during the
BALANCE LEADERexecution. For more information, check this pull request: https://github.com/vesoft-inc/nebula/pull/2232 -
Restructured
VertexHolder::getDefaultProp, improving the performance of retrieving the default value of a property. For more information, check this pull request: https://github.com/vesoft-inc/nebula/pull/2249
GO syntax supports input of the int type for graph traversal
Now you can use the GO syntax in Nebula Graph to retrieve data by passing a value of the int type. This update empowers you to traverse a graph in more scenarios and improves query performance by simplifying the query operation.
Vertex A has a property of the timestamp type for one TAG; and Vertex B uses Vertex A's timestamp property value as its VID for another TAG. With the new feature of the GO syntax, you can use the FETCH or the LOOKUP syntax to filter vertices and then pass the timestamp property values as the input of the GO statement to query the records at the specified time point.
Now let's use an example to show the benefits of the new feature.
We will create an example graph and explore it in Nebula Studio. The figure below shows how the exploration result looks like.

Follow these steps to create the example graph and to perform the query:
- Create a tag, t4, representing a user type. Its action_time property indicates the specified time point when a user performs an action.
CREATE TAG t4(user_name string, action_time timestamp);
- Create a tag, t5, representing an action type that users perform.
CREATE TAG t5(user_action string);
- Create an edge type representing the relationship between a user and an action and the relationship is play_games.
CREATE EDGE play_games();
 4. Insert a vertex to represent a user. Its `VID` is set to `730`.
```nGQL
INSERT VERTEX t4(user_name, action_time) VALUES 730:("xiaowang", 1596103557);
```
5. Insert a vertex to represent an action, `play smart phone games`, and its `VID` is set to the `action_time` value of Vertex 730, representing that the user was playing smart phone games at the specified time point.
```nGQL
INSERT VERTEX t5(user_action) VALUES 1596103557:("play smart phone games");
```
6. Insert an edge to represent the relationship of `play_games` between the user and the action.
```nGQL
INSERT EDGE play_games() VALUES 730->1596103557:();
```
4. Insert a vertex to represent a user. Its `VID` is set to `730`.
```nGQL
INSERT VERTEX t4(user_name, action_time) VALUES 730:("xiaowang", 1596103557);
```
5. Insert a vertex to represent an action, `play smart phone games`, and its `VID` is set to the `action_time` value of Vertex 730, representing that the user was playing smart phone games at the specified time point.
```nGQL
INSERT VERTEX t5(user_action) VALUES 1596103557:("play smart phone games");
```
6. Insert an edge to represent the relationship of `play_games` between the user and the action.
```nGQL
INSERT EDGE play_games() VALUES 730->1596103557:();
```

With this new feature, only one statement as follows is needed for query. This statement will do these tasks:
- querying all properties of Vertex 730 for all TAGs
- renaming the
t4.action_timeproperty as a variable, namedtimeid - passing the
timeidvariable to theGOstatement to do the reversal query on theplay-gamesedge - showing the
t5.user_actionproperty of the edge's source vertex with a new name,player_action
FETCH PROP ON * 730 YIELD t4.action_time AS timeid | GO FROM $-.timeid OVER play_games REVERSELY YIELD $^.t5.user_action AS players_action;

This week, the FETCH syntax has been armed with new features that let you retrieve the properties of multiple vertices for all their tags and facilitate your query for properties of multiple vertices further.
In Nebula Graph, the FETCH syntax is used to query the properties of a vertex or an edge. Together with the variable and the pipe features, its new features make the FETCH syntax more powerful in querying the properties of vertices.
Now, let's see what the FETCH syntax is able to do.
For example, we have two vertices and their IDs are 21 and 20 and we want to query all the properties of both vertices for all their tags and order the result by vertex ID. We cannot do that before, because the FETCH syntax cannot be used to retrieve properties from multiple vertices for more than one tag. But now, we can use the FETCH PROP ON * 21, 20; statement to get it done, as shown in the following figure.

Before this update, when you used the FETCH syntax to retrieve the properties from two vertices for two tags, such as FETCH PROP ON t1, t2 20, 21; as shown in the following figure, an error was returned.

Now the FETCH syntax supports querying properties based on vertex IDs that were passed by the PIPE ( | ) feature. For example, run the YIELD 20 AS id | FETCH PROP ON t2 $-.id; statement to pass the id variable as the input of the FETCH statement, as shown in the following figure.
With this new feature, you can use the GO syntax and the FETCH syntax in one statement.

This update enables you to store the queried vertex IDs as a variable and then retrieve the properties from the vertices for multiple tags by using the variable. For example, run the statements as follows and you will get the properties for the vertex (vid 20), as shown in the following figure.
$var = YIELD 20 AS id;
FETCH PROP ON t2, t3 $var.id;

There are some time-consuming tasks running at the storage layer of Nebula Graph. For such tasks, we provide Job Manager, a management tool, for releasing, managing, and querying the jobs.
We currently provide Compact and Flush for task releasing. Compact is usually used to clear data that has been marked for deletion from the storage layer, and flush is used to write back the memfile in memory to the hard disk.
Scenario #1: Release RocksDB Compact Task To release a RocksDB compact task, you can run the SUBMIT JOB COMPACT; command and a Job ID is returned, as shown in the following figure:

To write the RocksDB memfile in the memory to the hard disk, you can run the SUBMIT JOB FLUSH; command and a Job ID is returned, as shown in the following figure:

Scenario #2: Query Tasks. In terms of task query, we support to list a single job or all jobs for task querying. To find all the jobs, you can run the SHOW JOBS; statement to do the full job query. All the job IDs are returned, as shown in the following figure:

In this job list, you can see information such as Job ID, Task ID, commands and the landing nodes.
After obtaining the specific ID of a job, you can use SHOW JOB JOB ID; to query the details. From the job details, you can get the Task ID of each task. Generally, each node for the storaged service has one Task ID, so the number of Task IDs depends on the number of nodes for the storaged service

STOP JOB ; can be used to suspend ongoing tasks.

You can also use RECOVER JOB; to resume suspended tasks.

In Nebula Graph, you can add a TTL attribute to any tag or edge type so that expired data can be automatically deleted.
To use the TTL feature, you need to specify the values of start time (ttl_col) and lifespan (ttl_duration). The start time (ttl_col) uses the UNIX timestamp format and supports calling the now function to acquire the current time, and the data type is int. If the current time is greater than the start time plus the lifespan, the Tag or Edge will be discarded.
Pro Tip: The TTL function and the Index function cannot be used for a single Tag or Edge at the same time.
Below are several common use cases where TTL is used.
Scenario #1: When a vertex has multiple tags. When a vertex has multiple tags, only the one with the TTL property is discarded. The other properties of this vertex can be accessed. See the below example:
- CREATE TAG tag1(a timestamp) ttl_col = "a", ttl_duration = 5;
- CREATE TAG tag2(a string);
- INSERT VERTEX tag1(a),tag2(a) values 200:(now(), "hello");
- fetch prop on * 200;
You can see there are two tags attached to the Vertex 200 and the lifespan for property data on tag1 is five seconds:

Fetch the properties on Vertex 200 after five seconds, only tag2 is returned:

Scenarios #2: When a vertex has only one Tag with a TTL property;
Fetch properties on Vertex 101 and the tag1 is returned:
- fetch prop on * 101;

Query properties on Vertex 101 again after five seconds, no result is returned because the data is expired.

You can delete the TTL property of a Tag or Edge by setting ttl_col to null or deleting this field. Setting ttl_col to null means the data will not expire. See the example code below:
- ALTER TAG tag1 ttl_col = "";
- INSERT VERTEX tag1(a),tag2(a) values 202:(now(), "hello");
- fetch prop on * 202;

Delete the ttl_col field, the data does not expired.
- ALTER TAG tag1 DROP (a);
- INSERT VERTEX tag1(a),tag2(a) values 203:(now(), "hello");
- fetch prop on * 203;

When ttl_duration is set to 0, the TTL function exists, but all data does not expired.
- ALTER TAG tag1 ttl_duration = 0;
- INSERT VERTEX tag1(a),tag2(a) values 204:(now(), "hello");
- fetch prop on * 204;

After creating or rebuilding the index, you can use LOOKUP to query data. The biggest advantage of using an index is not only the speed but also querying without the VID.
The LOOKUP query returns the basic information of vertices or edges by default. You can specify the returned data by using the YIELD statement, such as the properties of the point or edge.
Note: WHERE clause does not support the following operations in LOOKUP:
-
$- and $ ^ - In relational expressions, expressions with field-names on both sides of the operator are not currently supported, such as (tagName.column1> tagName.column2)
- Nested AliasProp expressions in operation expressions and function expressions are not supported at this time.
Now let's try some queries using an index.
# Lookup player whose name is Marco Belinelli
(user@nebula) [nba]> LOOKUP ON player WHERE player.name == "Marco Belinelli";
============
| VertexID |
============
| 104 |
------------
# Lookup player whose name is Marco Belinelli or whose age is greater than 40
(user@nebula) [nba]> LOOKUP ON player WHERE player.name == "Marco Belinelli" OR player.age > 40;
============
| VertexID |
============
| 140 |
------------
| 100 |
------------
| 136 |
------------
| 125 |
------------
| 148 |
------------
| 141 |
------------
| 104 |
------------
| 144 |
------------
| 127 |
------------
Display the above vertices in Nebula Graph Studio.

# Lookup player whose name is Marco Belinelli. And starting from it, traverse along edge serve to find his team.
(user@nebula) [nba]> LOOKUP ON player WHERE player.name == "Marco Belinelli" YIELD player.name AS name | GO FROM $-.VertexID OVER serve YIELD $-.name, serve.start_year, serve.end_year, $$.team.name;
======================================================================
| $-.name | serve.start_year | serve.end_year | $$.team.name |
======================================================================
| Marco Belinelli | 2007 | 2009 | Warriors |
----------------------------------------------------------------------
| Marco Belinelli | 2015 | 2016 | Kings |
----------------------------------------------------------------------
| Marco Belinelli | 2009 | 2010 | Raptors |
----------------------------------------------------------------------
| Marco Belinelli | 2018 | 2018 | 76ers |
----------------------------------------------------------------------
| Marco Belinelli | 2012 | 2013 | Bulls |
----------------------------------------------------------------------
| Marco Belinelli | 2017 | 2018 | Hawks |
----------------------------------------------------------------------
| Marco Belinelli | 2018 | 2019 | Spurs |
----------------------------------------------------------------------
| Marco Belinelli | 2010 | 2012 | Hornets |
----------------------------------------------------------------------
| Marco Belinelli | 2013 | 2015 | Spurs |
----------------------------------------------------------------------
| Marco Belinelli | 2016 | 2017 | Hornets |
----------------------------------------------------------------------
# The following example returns edges whose degree is 90.
(user@nebula) [nba]> LOOKUP ON follow WHERE follow.degree == 90;
=============================
| SrcVID | DstVID | Ranking |
=============================
| 142 | 117 | 0 |
-----------------------------
| 118 | 120 | 0 |
-----------------------------
| 128 | 116 | 0 |
-----------------------------
| 138 | 115 | 0 |
-----------------------------
| 140 | 114 | 0 |
-----------------------------
| 133 | 114 | 0 |
-----------------------------
| 143 | 150 | 0 |
-----------------------------
| 136 | 117 | 0 |
-----------------------------
| 129 | 116 | 0 |
-----------------------------
| 121 | 116 | 0 |
-----------------------------
| 114 | 103 | 0 |
-----------------------------
| 127 | 114 | 0 |
-----------------------------
| 147 | 136 | 0 |
-----------------------------
Indexes are built to fast process graph queries. Nebula Graph supports indexing, too. Different from relational databases, whose index is based on columns, Nebula graph indexes the properties of the tags or edge types.
It the data is written after index creation, Nebula graph will automatically generate the index information. If data is written before index creation, you need to create the index for the original data with the REBUILD statement.
In general, to ensure index utilization, we recommend creating a single property index, which is more flexible. However, for a certain business scenario, a composite index is more efficient.
Create Index
Create a Single Property Index
(user@nebula) [nba]> CREATE TAG INDEX player_index_0 on player(name);
Execution succeeded (Time spent: 1.00587/1.00693 s)Create a Composite Index
(user@nebula) [nba]> CREATE TAG INDEX player_index_1 on player(name,age);
Execution succeeded (Time spent: 3.085/3.977 ms)Show Indexes
(user@nebula) [nba]> SHOW TAG INDEXES;
=============================
| Index ID | Index Name |
=============================
| 34 | player_index_0 |
-----------------------------
| 35 | player_index_1 |
-----------------------------
Got 2 rows (Time spent: 868/1704 us)Describe Index
(user@nebula) [nba]> DESCRIBE TAG INDEX player_index_0;
==================
| Field | Type |
==================
| name | string |
------------------
Got 1 rows (Time spent: 771/1550 us)Drop Index
(user@nebula) [nba]> DROP TAG INDEX player_index_1;
Execution succeeded (Time spent: 2.09/2.768 ms)Confirm the Previous Step
(user@nebula) [nba]> SHOW TAG INDEXES;
=============================
| Index ID | Index Name |
=============================
| 34 | player_index_0 |
-----------------------------
Got 1 rows (Time spent: 575/1279 us)Rebuild Index
(user@nebula) [nba]> REBUILD TAG INDEX player_index_0 OFFLINE;
Execution succeeded (Time spent: 3.193/5.055 ms)UPSERT is a combination of INSERT and UPDATE.
If the vertex or edge does not exist, a new one will be created. The property columns not specified by the SET statement use the default values of the columns, if there are no default values, an error will be returned; If the vertex or edge exists and the WHEN condition is met, the vertex or edge will be updated. Otherwise, nothing will be done.
UPSERT simplifies the validation of the existence of a vertex or edge before inserting new data. The performance of UPSERT is much lower than that of INSERT, so it is not suitable for large concurrent write scenarios.
Following are some examples
- In this example, we use tag player, no default values are specified for the tag.
nebula> SHOW CREATE TAG player;
==========================================================================================
| Tag | Create Tag |
==========================================================================================
| player | CREATE TAG player (
name string,
age int
) ttl_duration = 0, ttl_col = "" |
------------------------------------------------------------------------------------------
Got 1 rows (Time spent: 1.024/1.973 ms)- Insert vertex 100, then update its name and age property.
nebula> INSERT VERTEX player(name, age) VALUES 100:("Ben Simmons", 22);
Execution succeeded (Time spent: 1.039/1.711 ms)
nebula> UPSERT VERTEX 100 SET player.name = "Dwight Howard", player.age = $^.player.age + 11 WHEN $^.player.name == "Ben Simmons" && $^.player.age > 20 YIELD $^.player.name AS Name, $^.player.age AS Age;
=======================
| Name | Age |
=======================
| Dwight Howard | 33 |
-----------------------
Got 1 rows (Time spent: 2.834/3.612 ms)
- Vertex 400 does not exist. When updating its age property with
INSERT, an error is thrown for there is no default value for the age property.
nebula> FETCH PROP ON * 400;
Execution succeeded (Time spent: 5.038/5.875 ms)
nebula> UPSERT VERTEX 400 SET player.age = $^.player.age + 1;
[ERROR (-8)]: Maybe vertex does not exist, part: 1, error code: -100!The INSERT statement is an important basic function in Nebula Graph to create data records. The INSERT statement supports inserting a vertex or edge. After creating the schema, you can use the INSERT statement to insert data. The INSERT statement supports batch insertion of data through a list. When the insert operation is performed multiple times on the same vertex or edge, only the last written values can be read. Nebula Graph allows inserting empty content, but when an error occurs in the INSERT statement, no data will be written.
# Insert a vertex with no properties
nebula> INSERT VERTEX t1 () VALUES 10:();
nebula> fetch prop on * 10;
============
| VertexID |
============
| 10 |
------------
Got 1 rows (Time spent: 995/1678 us)
# Insert two vertices
nebula> INSERT VERTEX t2 (name, age) VALUES 13:("n3", 12), 14:("n4", 8);
nebula> fetch prop on t2 13,14;
===============================
| VertexID | t2.name | t2.age |
===============================
| 13 | n3 | 12 |
-------------------------------
| 14 | n4 | 8 |
-------------------------------
Got 2 rows (Time spent: 874/1507 us)
# Insert a vertex with two tags
nebula> INSERT VERTEX t1 (i1), t2(s2) VALUES 21: (321, "hello”);
nebula> fetch prop on * 21;
============================
| VertexID | t1.i1 | t2.s2 |
============================
| 21 | 321 | hello |
----------------------------
Got 1 rows (Time spent: 820/1489 us)# Insert an edge with no properties
nebula> CREATE EDGE e1 ();
Execution succeeded (Time spent: 16.544/17.903 ms)
nebula> INSERT EDGE e1() VALUES 10->11:()
Execution succeeded (Time spent: 1.434/2.161 ms)
nebula> fetch prop on e1 10->11;
================================
| e1._src | e1._dst | e1._rank |
================================
| 10 | 11 | 0 |
--------------------------------
Got 1 rows (Time spent: 9.65/11.269 ms)
# Insert two edges
nebula> INSERT EDGE e2 (name, age) VALUES 12->13:("n1", 1), 13->14:("n2", 2);
nebula> fetch prop on e2 12 -> 13,13 -> 14;
===================================================
| e2._src | e2._dst | e2._rank | e2.name | e2.age |
===================================================
| 13 | 14 | 0 | n2 | 2 |
---------------------------------------------------
| 12 | 13 | 0 | n1 | 1 |
---------------------------------------------------
Got 2 rows (Time spent: 916/1579 us)Graph traversal is an important function in the graph database and you can traverse vertices with direct or indirect relationships. In Nebula Graph, we use the GO statement to traverse a graph.
Based on the GO N STEPS, the newly added GO M TO N STEPS traverses from M to N hops. Same as GO N STEPS, GO M TO N STEPS supports reverse traversal, bi-direct traversal, and traversing from multiple vertices along multiple edges.
When M is equal to N, GO M TO N STEPS is equivalent to GO N STEPS. The GO M TO N STEPS function simplifies the graph traversal operation that needs to be performed multiple times to a single command, which improves the efficiency of large-scale vertices filtering.
Here are some examples:
- Starting from 101, traverse along with all the edge types, return 3 to 5 hops.
nebula> GO 3 TO 5 STEPS FROM 101 OVER *
================================================
| follow._dst | serve._dst | e1._dst | e2._dst |
================================================
| 100 | 0 | 0 | 0 |
------------------------------------------------
| 101 | 0 | 0 | 0 |
------------------------------------------------
| 105 | 0 | 0 | 0 |
------------------------------------------------
| 0 | 200 | 0 | 0 |
------------------------------------------------
| 0 | 208 | 0 | 0 |
------------------------------------------------
| 0 | 218 | 0 | 0 |
------------------------------------------------
| 0 | 219 | 0 | 0 |
------------------------------------------------
| 0 | 221 | 0 | 0 |
------------------------------------------------
| 0 | 222 | 0 | 0 |
------------------------------------------------
| 0 | 204 | 0 | 0 |
------------------------------------------------
- Traversing from 100 reversely along edge type follow, return 2 to 4 hops.
nebula> GO 2 TO 4 STEPS FROM 100 OVER follow REVERSELY YIELD DISTINCT follow._dst;
===============
| follow._dst |
===============
| 133 |
---------------
| 105 |
---------------
| 140 |
---------------
- Traversing from 101 bi-directly along edge type follow, return 4 to 5 hops.
nebula> GO 4 TO 5 STEPS FROM 101 OVER follow BIDIRECT YIELD DISTINCT follow._dst;
===============
| follow._dst |
===============
| 100 |
---------------
| 102 |
---------------
| 104 |
---------------
| 105 |
---------------
| 107 |
---------------
| 113 |
---------------
| 121 |
---------------
- Introduction to Pipe
Nebula Graph supports the pipe operation to nest sub-queries to form a statement. This marks one of the major differences between nGQL and SQL. On the left of | is the input, on the right of | is the output. Together with YIELD, you can specify the returned results.
nebula> GO FROM 100 OVER follow YIELD follow._dst AS dstid, \
$$.player.name AS name | GO FROM $-.dstid OVER follow \
YIELD follow._dst, follow.degree, $-.name;
$- is the input. The output (i.e. the dstid and Name in the above example) of the previous query is the input (i.e. $-.dstid) of the next query. The alias name mentioned right after placeholder $- must be defined in the previous YIELD statement, such as the dstid or Name in the above example.
-
Time-consuming task management The job here refers to the long tasks running at the storage layer. For example, compact and flush. The manager means to manage the jobs. For example, you can run, show, stop and recover jobs. We use the Job Manager to handle time-consuming tasks on the storage layer, such as compact and flush. You can use Job Manager to submit, stop, recover and show jobs. By listing the job statuses, you can enable or disenable jobs to improve efficiency and avoid resource occupancy of large jobs during peak hours. Moreover, you can count job information to perform more reasonable storage-related operations.
# Submit Jobs ## Submit Compact Jobs nebula> SUBMIT JOB COMPACT; ============== | New Job Id | ============== | 40 | -------------- # Submit Flush Jobs nebula> SUBMIT JOB FLUSH; ============== | New Job Id | ============== | 2 | --------------
If you can't submit jobs successfully, please check the availability of the storage HTTP service via
curl "http://{storaged-ip}:12000/admin?space={test}&op=compact".# Job Management # List All Jobs Information nebula> SHOW JOBS; ============================================================================= | Job Id | Command | Status | Start Time | Stop Time | ============================================================================= | 22 | flush test2 | failed | 12/06/19 14:46:22 | 12/06/19 14:46:22 | ----------------------------------------------------------------------------- | 23 | compact test2 | stopped | 12/06/19 15:07:09 | 12/06/19 15:07:33 | ----------------------------------------------------------------------------- | 24 | compact test2 | stopped | 12/06/19 15:07:11 | 12/06/19 15:07:20 | ----------------------------------------------------------------------------- | 25 | compact test2 | stopped | 12/06/19 15:07:13 | 12/06/19 15:07:24 | -----------------------------------------------------------------------------
# List Single Job Information nebula> SHOW JOB 40; ===================================================================================== | Job Id(TaskId) | Command(Dest) | Status | Start Time | Stop Time | ===================================================================================== | 40 | flush nba | finished | 12/17/19 17:21:30 | 12/17/19 17:21:30 | ------------------------------------------------------------------------------------- | 40-0 | 192.168.8.5 | finished | 12/17/19 17:21:30 | 12/17/19 17:21:30 | -------------------------------------------------------------------------------------
# Stop Job nebula> STOP JOB 22; ========================= | STOP Result | ========================= | stop 1 jobs 2 tasks | -------------------------
# Re-Executes the Failed Jobs nebula> RECOVER JOB; ===================== | Recovered job num | ===================== | 5 job recovered | ---------------------
-
CONTAINS: String Comparison Functions and Operators.We supported string comparison operator
CONTAINSnow.CONTAINSperforms string filtering at any position on the query results. It is case-sensitive and can be used with logical operators.CONTAINSmakes the query more flexible. CombiningCONTAINSand logical operators make searching in queries more accurate.For example, the following query traverses teams vertex 107 served, filtering team names that contain "riors".
nebula> GO FROM 107 OVER serve WHERE $$.team.name CONTAINS "riors" YIELD $^.player.name, serve.start_year, serve.end_year, $$.team.name; ===================================================================== | $^.player.name | serve.start_year | serve.end_year | $$.team.name | ===================================================================== | Aron Baynes | 2001 | 2009 | Warriors | --------------------------------------------------------------------- -
Function: Supported scientific notations. PR: https://github.com/vesoft-inc/nebula/pull/2079 -
Client: Upgraded Java client dependence Guava. PR: https://github.com/vesoft-inc/nebula-java/pull/86 -
Tools: Supported importing remote files in Nebula Importer. PR: https://github.com/vesoft-inc/nebula-importer/pull/64
We separated the Chinese Forum from the English one, the original domain is English forum now. What's more, we used new classification and tags for the Chinese Forum to help you find what you want more easily.
Share your ideas about classifications or tags on our Forum. Help us improve our community to better serve all the users.
-
Doc: Added TTL example when creating tag/edgeType. For example:
nebula> CREATE EDGE marriage(location string, since timestamp)
TTL_DURATION = 0, TTL_COL = "since"; -- negative or zero, not expire
nebula> CREATE TAG icecream(made timestamp, temperature int)
TTL_DURATION = 100, TTL_COL = "made"; -- Data expires after TTL_DURATION

-
storage: If you added a new property column to a tag and create an index for it, then insert data will cause storaged core dump. We fixed it. PR: https://github.com/vesoft-inc/nebula/pull/2073.
Nebula Graph Studio is a visualization web application that integrates data import and graph exploration.
The Nebula Graph Studio 1.0.2-beta version supports displaying edge properties and tagging vertices in graph exploration, making the visualization more vivid.

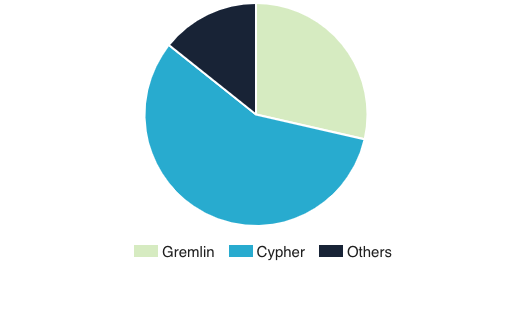
We posted a poll on Nebula Graph forum this week: What graph QL are you using? At present, Cypher leads Gremlin. What's your opinion? Click the post to tell us.
-
Doc: Added keywords and reserved words documentation. See the doc here.
# Non-reserved keywords are permitted as identifiers without quoting. All the non-reserved keywords are automatically converted to lower case. Non-reserved keywords are case-insensitive. Reserved words are permitted as identifiers if you quote them with back quotes such as `AND`.
nebula> CREATE TAG TAG(name string);
[ERROR (-7)]: SyntaxError: syntax error near `TAG'
nebula> CREATE TAG `TAG` (name string); -- TAG is reserved.
Execution succeeded-
bugfix: Fixed the invalidation of TTL inFETCH PROP ONsyntax. PR: https://github.com/vesoft-inc/nebula/pull/1937 -
bugfix: Fixed edge timestamp property can't be assigned with a default value. PR: https://github.com/vesoft-inc/nebula/pull/2038
The RC4 version supports INDEX, you can query the indexed data with LOOKUP ON. RC4 provides space-based access control and ACL authentication. For maintenance, we supported the monitor system by connecting Nebula Stats Exporter with Grafana and Prometheus.
We redesigned our official site homepage, adding a blog column to it. We also added labels for our blogs to tag different topics. If you want a new tag, tell us on our forum.
-
Install: We supported customized installation directory. PR: https://github.com/vesoft-inc/nebula/pull/1906. -
Storage: We configured the RocksDB filter policy to decrease the disk reading time and improve query performance. PR: https://github.com/vesoft-inc/nebula/pull/1959.
-
Storage: Updated the dependent RocksDB version. PR: https://github.com/vesoft-inc/nebula/pull/1948、https://github.com/vesoft-inc/nebula/pull/1953, https://github.com/vesoft-inc/nebula/pull/1973 -
Compilation: Nebula will exit when being compiled on unsupported operation systems. This PR comes from our community, thanks for the contribution. PR: https://github.com/vesoft-inc/nebula/pull/1951 -
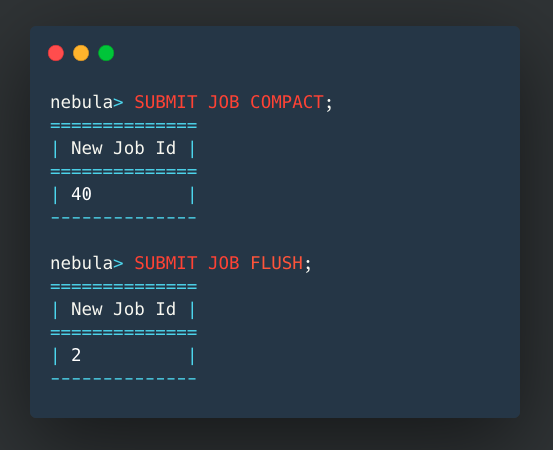
Documentation: Added flush submit example to the job manager doc. PR: https://github.com/vesoft-inc/nebula/pull/1957. For example:
-
Tricks you must know about the Nebula importer
We released a post on the FAQs of the Nebula importer to make it easy for you to use the tool. Click here to see the detail.
-
Security: Supported access control list (ACL). PR: https://github.com/vesoft-inc/nebula/pull/1842. See the example statements in the following picture. Doc PR: https://github.com/vesoft-inc/nebula/pull/1929.

-
Config: We added production configurations for Nebula Graph. It's suggested to use in production. PR: https://github.com/vesoft-inc/nebula/pull/1908.
- Reservoir Sampling
Reservoir sampling is used to deal with super vertex in graph. A super vertex is a vertex with a large number of edges. Often you just need some of the edges of such vertices. Now you can truncate with the reservoir sampling algorithm. Based on the algorithm, a certain number of edges are truncated with equal probability from the total n edges.
How to use: Set the enable_reservoir_sampling parameter in the configuration file storaged-conf to true to enable the reservoir sampling. Set the sampling number with the parameter max_edge_returned_per_vertex. PR: https://github.com/vesoft-inc/nebula/pull/1746
-
Account management: Supported account management with statementsCREATE USER,GRANT ROLEandREVOKE ROLE. There are four roles currently:GOD,ADMIN,DBAandGUEST. PR: https://github.com/vesoft-inc/nebula/pull/1842 -
INDEX: Supported index rebuilding. If data is updated or newly inserted after the index creation, it is necessary to rebuild the indexes in order to ensure that the indexes contain the previously added data. PR: https://github.com/vesoft-inc/nebula/pull/1566
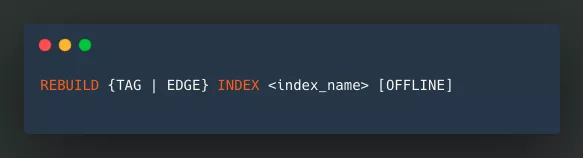
REBUILD {TAG | EDGE} INDEX <index_name> [OFFLINE]-
CI/CD: Integrated the coverage testing tool. PR: https://github.com/vesoft-inc/nebula/pull/1856
-
k8s: Simplified Nebula Graph's deployment on Kubernetes via Helm. PR: https://github.com/vesoft-inc/nebula/pull/1473
-
nGQL:GOsupportsBIDIRECTkeyword to traverse the outgoing edge and incoming edge. PR:https://github.com/vesoft-inc/nebula/pull/1740, https://github.com/vesoft-inc/nebula/pull/1752
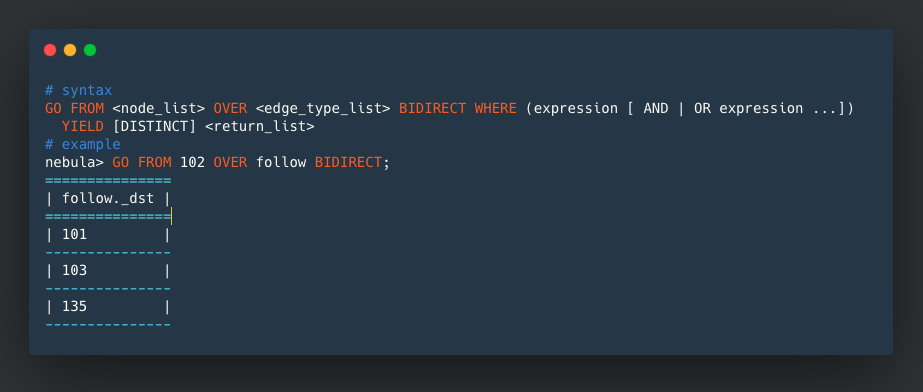
# syntax
GO FROM <node_list> OVER <edge_type_list> BIDIRECT WHERE (expression [ AND | OR expression ...])
YIELD [DISTINCT] <return_list>
# example
nebula> GO FROM 102 OVER follow BIDIRECT;
===============
| follow._dst |
===============
| 101 |
---------------
| 103 |
---------------
| 135 |
----------------
KV Inferface: We now support returning the partial results in theStorage multiGetinterface. -
Documentation: We updated the method on modifying the RocksDB block cache. PR: https://github.com/vesoft-inc/nebula/pull/1829
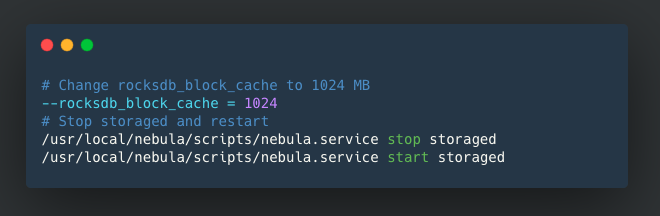
# Change rocksdb_block_cache to 1024 MB
--rocksdb_block_cache = 1024
# Stop storaged and restart
/usr/local/nebula/scripts/nebula.service stop storaged
/usr/local/nebula/scripts/nebula.service start storaged- 2020 H1 RoadMap
We released the first half-year road map 2020 for Nebula Graph. You can see the details on our official forum Announcements section.

- The Nebula Graph forum is officially online.
Since the first announcement two weeks ago, we have officially launched the Nebula Graph forum today. We optimized the default page, content classification during the public test to support our users. Feel free to ask your first question on our forum and our developers are there for you 7*24. In the Announcements section, you can find the latest news and road map of Nebula Graph. Keep yourself updated on the Blog section to know more about the architecture and design behind Nebula Graph. Enjoy our forum here: https://discuss.nebula-graph.io/.
Last but not least, give us your suggestions or feedback on the Site Feedback section. Your thoughts matter.
-
benchmarking: Supported retrieve data on the storage engine via properties with the keywordLOOKUP. PR: https://github.com/vesoft-inc/nebula/pull/1738.

=====================================================
src/storage/test/StorageLookupBenchmark.cpprelative time/iter iters/s
=====================================================
PreciseScan_10000 9.65ms 103.65
PreciseScan_100 5.23ms 191.03
PreciseScan_10 4.14ms 241.64
FilterScan_10 1.47s 679.35m
=====================================================-
Graph space: Supported charset and collate when creating graph spaces. PR: https://github.com/vesoft-inc/nebula/pull/1709. For example:
nebula> CREATE SPACE my_space_4(partition_num=10, replica_factor=1, charset = utf8, collate = utf8_bin);-
benchmarking: Supported scan in partitions. PR: https://github.com/vesoft-inc/nebula/pull/1807
- Supported index and query properties. You can retrieve vertices or edges with the specific properties. PR: https://github.com/vesoft-inc/nebula/pull/1705

-
task scheduler: Added job manager to manage long-time running tasks. Currently flush and compact are supported. You can start/stop/list/recover job. Use theRECOVER JOBcommand to read the failed tasks to the execution queue. PR: https://github.com/vesoft-inc/nebula/pull/1424

-
index: When runningDROP INDEX, the GC is completed by compaction. PR: https://github.com/vesoft-inc/nebula/pull/1776
-
The official forum is now LIVE for Nebula Graph users. Join our community here.
-
Monitor: AddedNebula Stats Exporterto collect and send cluster monitor and performance information to Prometheus. We use Grafana as the visualization component. PR: https://github.com/vesoft-inc/nebula-stats-exporter/pull/2 -
TTL: Supported TTL to specify the live time. PR: -
OLAP: Added spark to connect with Nebula Graph. PR: https://github.com/vesoft-inc/nebula-java/pull/56

{kind=link}
-
DB-Engine trend in Feb. 2020
In general, there is no drastic change in the ranking of the graph database. The top nine are the same. The new tenth is temporal database FaunaDB. Nebula Graph is doing well and rises to the 21st.

- RC3 release note
Main features and fixes for this release include
dump_toolsto export data by specific filters, graph data exploring tool Nebula Graph Studio, and vertex/edge scan interface for OLAP scenarios. -
Storage engine: Supporting assigning results of set operations to variables. PR: https://github.com/vesoft-inc/nebula/pull/1572
-
nGQL: Optimized the performance of multi-step queries. PR: https://github.com/vesoft-inc/nebula/pull/1471 -
Client: Added pre-heat function in storage client. PR: https://github.com/vesoft-inc/nebula/pull/1627 -
Optimization: Dramatically improved the performance of reverse query by storing edge properties in in/out edges. PR: https://github.com/vesoft-inc/nebula/pull/1717 -
Documentation: Added FAQs to compiling. PR: https://github.com/vesoft-inc/nebula/pull/1671
-
Nebula Graph Studio
Nebula Graph Studio is a visualization application that combines data import and graph exploration.
-
Adding batch scanning interface in
storage. PR: https://github.com/vesoft-inc/nebula/pull/1381 -
nGQL: Returning vertex ID, edge src, dst and rank inFETCH PROP.

nebula> FETCH PROP ON person 1016,1017,1018
=======================================================
| VertexID | person.name | person.age | person.gender |
=======================================================
| 1017 | HeNa | 11 | female |
-------------------------------------------------------
| 1016 | Sonya | 11 | male |
-------------------------------------------------------
| 1018 | Tom | 12 | male |
-------------------------------------------------------
nebula> FETCH PROP ON is_schoolmate 1016->1017,1016->1018
=====================================================================================================================
| is_schoolmate._src | is_schoolmate._dst | is_schoolmate._rank | is_schoolmate.start_year | is_schoolmate.end_year |
=====================================================================================================================
| 1016 | 1017 | 0 | 2015 | 2019 |
---------------------------------------------------------------------------------------------------------------------
| 1016 | 1018 | 0 | 2014 | 2019 |
---------------------------------------------------------------------------------------------------------------------
- Supports inserting data from different sources into the same tag/edge-type in Spark Writer. PR: https://github.com/vesoft-inc/nebula/pull/1512
-
Index: Supporting fetch all the properties of the given vertex. PR: https://github.com/vesoft-inc/nebula/pull/1468
- Nebula Graph UI 1.0 Under Inner Test
You can use the GUI to connect Nebula Graph services, create schema, import data and explore your graph. Try our GUI in the GitHub Repository. Please refer to GUI tutorial on details.
- Support Creating Tag/Edge Index
Implemented index in storage and query engine so you can create index for tag/edge. Currently supported index management operations are SHOW INDEX, DESCRIBE INDEX and DROP INDEX. Please refer to code pr for details. https://github.com/vesoft-inc/nebula/pull/1360, https://github.com/vesoft-inc/nebula/pull/1459, https://github.com/vesoft-inc/nebula/pull/1598

-
Schema: KeywordIF EXISTSis supported when dropping tag/edge-type/space. This keyword automatically detects if the corresponding tag/edge-type/space exists. If it exists, it will be deleted. Otherwise, no tag/edge-type/space is deleted. https://github.com/vesoft-inc/nebula/pull/1505 -
Data import: Supported asynchronous import, hash and uuid functions in Spark Writer. https://github.com/vesoft-inc/nebula/pull/1405
- Simplified the compiling, supporting most Linux systems with kernels above 2.6.32, e.g.CentOS 6/7/8, Debian 7/8/9 and Ubuntu 16.04/18.04/19.04. https://github.com/vesoft-inc/nebula/pull/1332
-
dump_tool: Dump vertices or edges with specified conditions https://github.com/vesoft-inc/nebula/pull/1479 - Supporting setting meta heartbeat by updating parameter
heartbeat_interval_secshttps://github.com/vesoft-inc/nebula/pull/1540 - Get
git_info_sha, the commit ID of the binary with the commandcurl http://ip:port/statushttps://github.com/vesoft-inc/nebula/pull/1573
If you like Nebula Graph, please leave us a star.
