string scalar support in AST - proof of concept #6
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
a391a1b
to
982af8a
Compare
|
Example code for filter by range. #include <cudf/detail/stream_compaction.hpp>
struct literal_converter {
template <typename T>
static constexpr bool is_supported()
{
return std::is_same_v<T, cudf::string_view> ||
(cudf::is_fixed_width<T>() && !cudf::is_fixed_point<T>());
}
template <typename T, std::enable_if_t<is_supported<T>()>* = nullptr>
cudf::ast::literal operator()(cudf::scalar& _value)
{
using scalar_type = cudf::scalar_type_t<T>;
auto& low_literal_value = static_cast<scalar_type&>(_value);
return cudf::ast::literal(low_literal_value);
}
template <typename T, std::enable_if_t<!is_supported<T>()>* = nullptr>
cudf::ast::literal operator()(cudf::scalar& _value)
{
CUDF_FAIL("Unsupported type for literal");
}
};
std::unique_ptr<cudf::table> filter_table_by_range(cudf::table_view const& input,
cudf::column_view const& sort_col,
cudf::scalar& low,
cudf::scalar& high,
rmm::mr::device_memory_resource* mr)
{
// return low.compare(elem) <= 0 && high.compare(elem) > 0;
auto col_ref_0 = cudf::ast::column_reference(0);
auto low_literal = cudf::type_dispatcher(low.type(), literal_converter{}, low);
auto expr_1 = cudf::ast::operation(cudf::ast::ast_operator::LESS_EQUAL, col_ref_0, low_literal);
auto high_literal = cudf::type_dispatcher(high.type(), literal_converter{}, high);
auto expr_2 = cudf::ast::operation(cudf::ast::ast_operator::GREATER, col_ref_0, high_literal);
auto expr_3 = cudf::ast::operation(cudf::ast::ast_operator::LOGICAL_AND, expr_1, expr_2);
auto result = cudf::compute_column(input, expr_3);
return cudf::detail::apply_boolean_mask(input, result->view(), rmm::cuda_stream_default, mr);
}
TEST_F(TransformTest, RangeFilterString)
{
auto c_0 = cudf::test::strings_column_wrapper({"1", "12", "123", "2"});
auto table = cudf::table_view{{c_0}};
auto mr = rmm::mr::get_current_device_resource();
auto lower = cudf::string_scalar("2", true, rmm::cuda_stream_default, mr);
auto higher = cudf::string_scalar("12", true, rmm::cuda_stream_default, mr);
// elem > "12" && elem <= "2" -> "123", "2"
auto c_1 = cudf::test::strings_column_wrapper({"123", "2"});
auto expected = cudf::table_view{{c_1}};
auto result = filter_table_by_range(table, c_0, lower, higher, mr);
CUDF_TEST_EXPECT_COLUMNS_EQUAL(expected.column(0), result->view().column(0), verbosity);
}
TEST_F(TransformTest, RangeFilterNumeric)
{
auto c_0 = column_wrapper<int32_t>{{1, 12, 5, 2}};
auto table = cudf::table_view{{c_0}};
auto mr = rmm::mr::get_current_device_resource();
auto higher = cudf::numeric_scalar<int32_t>(2, true, rmm::cuda_stream_default, mr);
auto lower = cudf::numeric_scalar<int32_t>(12, true, rmm::cuda_stream_default, mr);
// elem > 2 && elem <= 12 -> 12, 5
auto c_1 = column_wrapper<int32_t>{{12, 5}};
auto expected = cudf::table_view{{c_1}};
auto result = filter_table_by_range(table, c_0, lower, higher, mr);
CUDF_TEST_EXPECT_COLUMNS_EQUAL(expected.column(0), result->view().column(0), verbosity);
}
|
…ng_scalar_ast_compare
…apidsai#13011) CSV reader uses a trie to read field with special values as nulls. The creation of the trie does not work correctly when there are not special values. This can happen when the NA filter is enabled, but the default NA values are removed, and user does not specify custom values. In this case, use of this trie leads to OOB memory access. This PR fixes the trie creation to create an empty trie when there are not special values to look for. Included a C++ test that crashes without the fix. Authors: - Vukasin Milovanovic (https://github.com/vuule) Approvers: - Vyas Ramasubramani (https://github.com/vyasr) - Mike Wilson (https://github.com/hyperbolic2346) - Nghia Truong (https://github.com/ttnghia) URL: rapidsai#13011
…apidsai#13054) Add the `except +` declaration to the `cudf::strings::regex_program::create()` function in the Cython `regex_program.pxd` interface since invalid regex patterns are thrown by this call. This allows the normal Cython exception handling to pass the exception to the Python logic without aborting the process. Closes rapidsai#13052 Authors: - David Wendt (https://github.com/davidwendt) Approvers: - Bradley Dice (https://github.com/bdice) - Ashwin Srinath (https://github.com/shwina) URL: rapidsai#13054
The identify_stream_usage test uses `strcmp` but not does not include `<cstring>`. This PR fixes that. The missing include was surfaced by rapidsai#13064, showing that the test relied on headers in `spdlog` to include `cstring`. Authors: - Allard Hendriksen (https://github.com/ahendriksen) - Bradley Dice (https://github.com/bdice) Approvers: - Bradley Dice (https://github.com/bdice) - Nghia Truong (https://github.com/ttnghia) URL: rapidsai#13066
`data_sink.hpp` uses `std::transform` but not does not include <algorithm>. This PR fixes that. The missing include was surfaced by rapidsai#13064. Authors: - Allard Hendriksen (https://github.com/ahendriksen) Approvers: - Bradley Dice (https://github.com/bdice) - David Wendt (https://github.com/davidwendt) - Nghia Truong (https://github.com/ttnghia) URL: rapidsai#13068
[REVIEW] Pin `dask` and `distributed` for release
…#12787) Part of rapidsai#11844. I will create a separate PR for `mixed_join`. Compilation times: `main` rapidsai@94bbc82 : `16m47.513s` This PR rapidsai@5d75db8 : `16m47.520s` Benchmarks: rapidsai#12787 (comment) Authors: - Divye Gala (https://github.com/divyegala) Approvers: - Yunsong Wang (https://github.com/PointKernel) - Nghia Truong (https://github.com/ttnghia) URL: rapidsai#12787
…ge-23.04 Resolved automerger from `branch-23.04` to `branch-23.06`
…ector` (rapidsai#12981) I ran into a need for a span-like view into a `hostdevice_vector`. I was chopping it up into pieces to pass into a function to process portions at a time, but it still wanted to do things like host to device on the spans. This class is a result of that need. Authors: - Mike Wilson (https://github.com/hyperbolic2346) - Nghia Truong (https://github.com/ttnghia) Approvers: - Nghia Truong (https://github.com/ttnghia) - Vukasin Milovanovic (https://github.com/vuule) URL: rapidsai#12981
Helper function `get_col_names` in the Parquet reader benchmarks throws with nested columns. It should instead just ignore the children columns and return the top-level colum names. Also renamed the function to better reflect what it does. Authors: - Vukasin Milovanovic (https://github.com/vuule) Approvers: - https://github.com/nvdbaranec - Yunsong Wang (https://github.com/PointKernel) URL: rapidsai#13082
…ai#12931) Addresses rapidsai#11922 Currently in Parquet preprocessing a `thrust::reduce()` and `thrust::exclusive_scan_by_key()` is performed to compute the column size and offsets for each nested column. For complicated schemas this results in a large number of kernel invocations. This PR calculates the sizes and offsets of all columns in single calls to `thrust::reduce_by_key()` and `thrust::exclusive_scan_by_key()`. This change results in around 1.3x speedup when reading a complicated schema. Before: 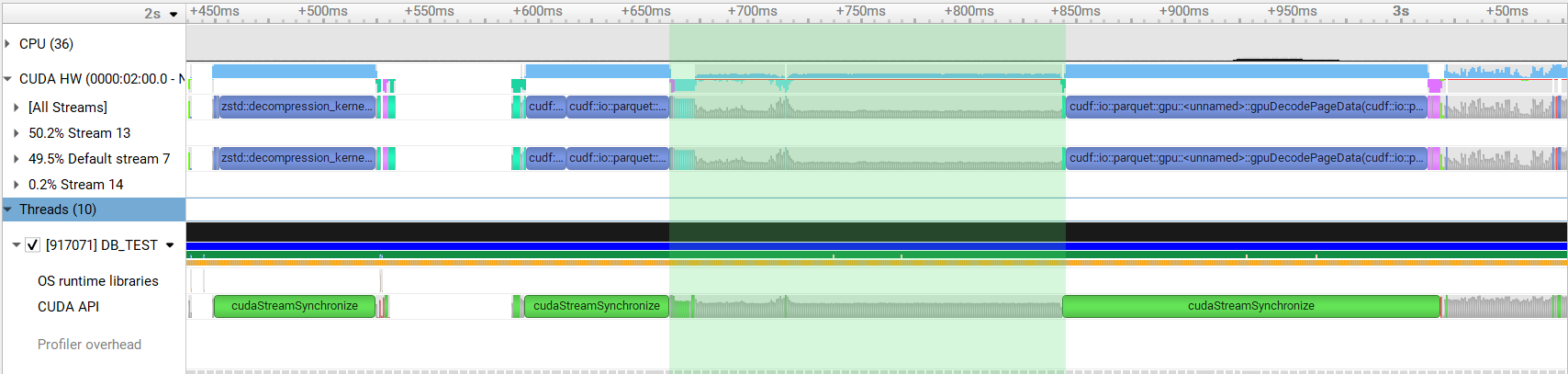 After: 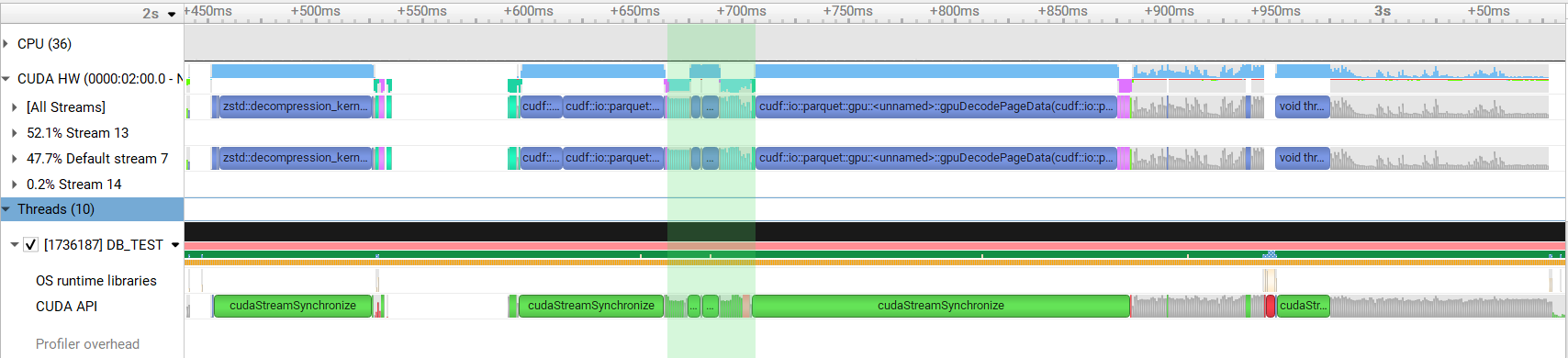 Authors: - Srikar Vanavasam (https://github.com/SrikarVanavasam) Approvers: - Yunsong Wang (https://github.com/PointKernel) - Nghia Truong (https://github.com/ttnghia) - Vukasin Milovanovic (https://github.com/vuule) URL: rapidsai#12931
{kind=link}
{kind=link}
) In a multithreaded, multi-stream environment (Spark) we were experiencing a performance regression on some benchmark queries. The culprit was gpu scheduling issues related to the `gpuComputePageSizes` kernel. Dependent kernels (`gpuDecodePages`) were getting serialized because `gpuComputePageSizes` wasn't running alongside other streams well. The fix was reducing shared memory usage in `gpuComputePageSizes`. The kernel shares a lot of code and data structures with `gpuDecodePages` but doesn't actually use several of the large buffers that are stored in shared memory. This PR refactors those buffers out so that they are only declared in the `gpuDecodePages` kernel, reducing the shared usage by 50% (3kb). This clears up the performance issue on Spark. I am currently experiencing build issues with cudf benchmarks so I'm marking this as do-not-merge until I can verify with them. Authors: - https://github.com/nvdbaranec - Vukasin Milovanovic (https://github.com/vuule) Approvers: - Nghia Truong (https://github.com/ttnghia) - Vukasin Milovanovic (https://github.com/vuule) URL: rapidsai#13047
This PR adds empty test modules that match the "Test Organization" guidelines outlined in the [developer guide](https://github.com/rapidsai/cudf/blob/branch-23.02/docs/cudf/source/developer_guide/testing.md#test-organization). Follow-up PRs will move existing tests into these test modules. While I have attempted to match the structure of our API reference as much a possible, there are small differences. For example, the API reference lumps together [Reshaping, Sorting, and Transposing](https://docs.rapids.ai/api/cudf/stable/api_docs/dataframe.html#reshaping-sorting-transposing), while I opted to include two different modules for reshaping and sorting. There are only a couple of instances where I needed to deviate from the structure though. Authors: - Ashwin Srinath (https://github.com/shwina) Approvers: - Vyas Ramasubramani (https://github.com/vyasr) URL: rapidsai#12288
Contributes to rapidsai#11968. Authors: - Vyas Ramasubramani (https://github.com/vyasr) Approvers: - Jason Lowe (https://github.com/jlowe) - Nghia Truong (https://github.com/ttnghia) - David Wendt (https://github.com/davidwendt) - Bradley Dice (https://github.com/bdice) URL: rapidsai#13134
The total number of nulls in the output can be computed by summing the nulls in the input columns. Contributes to rapidsai#11968 Authors: - Vyas Ramasubramani (https://github.com/vyasr) Approvers: - Nghia Truong (https://github.com/ttnghia) - David Wendt (https://github.com/davidwendt) URL: rapidsai#13104
…apidsai#13122) Fixes: rapidsai#12999, rapidsai#13056 This PR fixes the `Series` and `DataFrame` constructors to validate the `data` & `index` lengths. This also contains fixes where `index` was being ignored in certain cases. Authors: - GALI PREM SAGAR (https://github.com/galipremsagar) Approvers: - Vyas Ramasubramani (https://github.com/vyasr) URL: rapidsai#13122
Replaced `std::make_tuple` with `std::tuple` constructor Removed `std::make_field_reader`, calling `field_reader` constructor directly now. Authors: - Vukasin Milovanovic (https://github.com/vuule) Approvers: - Vyas Ramasubramani (https://github.com/vyasr) - Nghia Truong (https://github.com/ttnghia) URL: rapidsai#13135
Calculates the null-count in the `cudf::detail::slice()` function. This requires adding a stream parameter to the function and updating the callers to pass the stream. Also moved the function definition to the `slice.cu` file since there are only two possible values for the template parameter. Labeling this with non-breaking since it is a detail function. Contributes to: rapidsai#11968 Authors: - David Wendt (https://github.com/davidwendt) - Vyas Ramasubramani (https://github.com/vyasr) Approvers: - Nghia Truong (https://github.com/ttnghia) - Divye Gala (https://github.com/divyegala) - Vyas Ramasubramani (https://github.com/vyasr) URL: rapidsai#13124
) Removes the `UNKNOWN_NULL_COUNT` usage in the `linked_column_view::column_view()` conversion operator. The null-count is copied from the parent instance. The `linked_column_view` class was reworked to move the C++ function definitions from the header file to a new .cpp file. Contributes to: rapidsai#11968 Authors: - David Wendt (https://github.com/davidwendt) Approvers: - Vyas Ramasubramani (https://github.com/vyasr) - Nghia Truong (https://github.com/ttnghia) URL: rapidsai#13121
…apidsai#13095) In the staging step for executing window range queries, the boundaries of each row's window are calculated. This involves subtracting/adding the `preceding`/`following` values from each order-by column row, and then searching backwards/forwards for the boundary values. The staging step has been using `column_device_view.data()` for accessing the order-by rows, an acceptable approach for when the order-by columns are numeric (e.g. `INT32`). This approach fails when the order-by column is a `STRING`, because `.data()` is not defined for such columns. A better approach would be to use `.element()` to directly access the rows, because it has special handling for `STRING`, among other types, while continuing to work for numeric primitives. ## Future In a followup to this change, support for `STRING` order-by columns will be added. Authors: - MithunR (https://github.com/mythrocks) Approvers: - Yunsong Wang (https://github.com/PointKernel) - Nghia Truong (https://github.com/ttnghia) URL: rapidsai#13095
…#13081) Change the `cudf::test::make_null_mask` to return both the null-mask and the null-count. Callers can then use this null-count instead of `UNKNOWN_NULL_COUNT`. These changes include removing `UNKNOWN_NULL_COUNT` usage from the libcudf C++ test source code. One side-effect found that strings column with all nulls can technically have no children but using `UNKNOWN_NULL_COUNT` allowed the check for this to be bypassed. Therefore many utilities started to fail when `UNKNOWN_NULL_COUNT` was removed. The factory was modified to remove the check which results in an offsets column and an empty chars column as children. More code will likely need to be change when the `UNKNOWN_NULL_COUNT` is no longer used as a default parameter for factories and other column functions. No behavior is changed. Since the `cudf::test::make_null_mask` is technically a public API, this PR could be marked as a breaking change as well. Contributes to: rapidsai#11968 Authors: - David Wendt (https://github.com/davidwendt) Approvers: - MithunR (https://github.com/mythrocks) - Vyas Ramasubramani (https://github.com/vyasr) URL: rapidsai#13081
This PR deprecates `pad` and `backfill` methods in favor of `ffill` and `bfill` methods. Pandas recently deprecated these: pandas-dev/pandas#51221 pandas-dev/pandas#45076 Authors: - GALI PREM SAGAR (https://github.com/galipremsagar) Approvers: - Matthew Roeschke (https://github.com/mroeschke) URL: rapidsai#13140
…imal types (rapidsai#13034) Closes rapidsai#12958 This PR enables some previously xfailing tests. Authors: - Ashwin Srinath (https://github.com/shwina) - GALI PREM SAGAR (https://github.com/galipremsagar) Approvers: - GALI PREM SAGAR (https://github.com/galipremsagar) - Bradley Dice (https://github.com/bdice) - Vyas Ramasubramani (https://github.com/vyasr) URL: rapidsai#13034
This PR updates the clang-format version used by pre-commit. Authors: - Bradley Dice (https://github.com/bdice) Approvers: - Nghia Truong (https://github.com/ttnghia) - Elias Stehle (https://github.com/elstehle) URL: rapidsai#13133
Fixes some build errors occuring after rapidsai#13133 was merged. Looks like a couple files may have gotten mismerged perhaps. This should unblock several current PRs. Authors: - David Wendt (https://github.com/davidwendt) Approvers: - Yunsong Wang (https://github.com/PointKernel) - Divye Gala (https://github.com/divyegala) URL: rapidsai#13146
…idsai#13107) Add `null_count` parameter to the `cudf::io::json::experimental::detail::parse_data` function which already accepts a `null_mask`. Normally, the callers already know the count. This unction can use the parameter to help build the output column. Found while working on rapidsai#13081 Contributes to: rapidsai#11968 Authors: - David Wendt (https://github.com/davidwendt) - GALI PREM SAGAR (https://github.com/galipremsagar) Approvers: - Vyas Ramasubramani (https://github.com/vyasr) - Nghia Truong (https://github.com/ttnghia) URL: rapidsai#13107
This PR adds bindings to the TZiF reader that was added in the libcudf API in rapidsai#12805. No tests are being added as these bindings are just for internal-use. In follow-up PRs, I will add a timezone-aware datetime type and timezone-aware operations to the public API, along with tests for those operations. The bindings can be used as follows: ```python >>> transition_times, offsets = make_timezone_transition_table("/usr/share/zoneinfo", "America/New_York") >>> transition_times <cudf.core.column.datetime.DatetimeColumn object at 0x7f95cd6ac840> [ 1883-11-18 17:00:00, 1883-11-18 17:00:00, 1918-03-31 07:00:00, 1918-10-27 06:00:00, 1919-03-30 07:00:00, 1919-10-26 06:00:00, 1920-03-28 07:00:00, 1920-10-31 06:00:00, 1921-04-24 07:00:00, 1921-09-25 06:00:00, ... 2365-03-14 07:00:00, 2365-11-07 06:00:00, 2366-03-13 07:00:00, 2366-11-06 06:00:00, 2367-03-12 07:00:00, 2367-11-05 06:00:00, 2368-03-10 07:00:00, 2368-11-03 06:00:00, 2369-03-09 07:00:00, 2369-11-02 06:00:00 ] dtype: datetime64[s] >>> offsets <cudf.core.column.timedelta.TimeDeltaColumn object at 0x7f94e69bad40> [ -18000, -18000, -14400, -18000, -14400, -18000, -14400, -18000, -14400, -18000, ... -14400, -18000, -14400, -18000, -14400, -18000, -14400, -18000, -14400, -18000 ] dtype: timedelta64[s] ``` Authors: - Ashwin Srinath (https://github.com/shwina) - Vukasin Milovanovic (https://github.com/vuule) Approvers: - Bradley Dice (https://github.com/bdice) URL: rapidsai#12826
This PR is updating the runner labels to use ARC V2 self-hosted runners for GPU jobs. This is needed to resolve the auto-scalling issues. Authors: - Jordan Jacobelli (https://github.com/jjacobelli) Approvers: - AJ Schmidt (https://github.com/ajschmidt8) URL: rapidsai#13123
This PR fixes the avro reader (`cudf.read_avro()`) such that it honors the values passed to the `skip_rows` and `num_rows` parameters. In implementing this new logic, we also revamp the reader's ability to handle multi-block avro files, which we also test extensively with a new `test_avro_reader_multiblock()` test that features some 1300 permutations of various block size combinations. Closes rapidsai#6529. Authors: - Trent Nelson (https://github.com/tpn) Approvers: - Lawrence Mitchell (https://github.com/wence-) - Vukasin Milovanovic (https://github.com/vuule) - Nghia Truong (https://github.com/ttnghia) URL: rapidsai#12912
Improves on performance for longer strings with `cudf::strings::slice_strings()` API. The `cudf::string_view::substr` was reworked to minimize counting characters and the gather version of `make_strings_children` is used to build the resulting strings column. This version is already optimized for small and large strings. Additionally, the code was refactored so the common case of `step==1 and start < stop` can also make use of the gather approach. Common code was also grouped closer together to help navigate the source file better. The `slice.cpp` benchmark was updated to better measure large strings with comparable slice boundaries. The benchmark showed performance improvement was up to 9x for larger strings with no significant degradation for smaller strings. Reference rapidsai#13048 and rapidsai#12445 Authors: - David Wendt (https://github.com/davidwendt) Approvers: - Nghia Truong (https://github.com/ttnghia) - Elias Stehle (https://github.com/elstehle) URL: rapidsai#13057
GTest max support for `Types` was removed in 1.11, so we remove the workarounds in cudf_gtest. Since we need to support our custom `Types` and the GTest 1.11+ version rework the type_list_utilities to be generic and not depend on specific traits. Also corrected the `<<` overloads for GTest printing so that they work with GTest 1.11. Authors: - Robert Maynard (https://github.com/robertmaynard) - Vukasin Milovanovic (https://github.com/vuule) Approvers: - Bradley Dice (https://github.com/bdice) - Nghia Truong (https://github.com/ttnghia) URL: rapidsai#13153
…nn/cudf into fea-string_scalar_ast_compare
karthikeyann
pushed a commit
that referenced
this pull request
Jun 10, 2023
This implements stacktrace and adds a stacktrace string into any exception thrown by cudf. By doing so, the exception carries information about where it originated, allowing the downstream application to trace back with much less effort. Closes rapidsai#12422. ### Example: ``` #0: cudf/cpp/build/libcudf.so : std::unique_ptr<cudf::column, std::default_delete<cudf::column> > cudf::detail::sorted_order<false>(cudf::table_view, std::vector<cudf::order, std::allocator<cudf::order> > const&, std::vector<cudf::null_order, std::allocator<cudf::null_order> > const&, rmm::cuda_stream_view, rmm::mr::device_memory_resource*)+0x446 #1: cudf/cpp/build/libcudf.so : cudf::detail::sorted_order(cudf::table_view const&, std::vector<cudf::order, std::allocator<cudf::order> > const&, std::vector<cudf::null_order, std::allocator<cudf::null_order> > const&, rmm::cuda_stream_view, rmm::mr::device_memory_resource*)+0x113 #2: cudf/cpp/build/libcudf.so : std::unique_ptr<cudf::column, std::default_delete<cudf::column> > cudf::detail::segmented_sorted_order_common<(cudf::detail::sort_method)1>(cudf::table_view const&, cudf::column_view const&, std::vector<cudf::order, std::allocator<cudf::order> > const&, std::vector<cudf::null_order, std::allocator<cudf::null_order> > const&, rmm::cuda_stream_view, rmm::mr::device_memory_resource*)+0x66e #3: cudf/cpp/build/libcudf.so : cudf::detail::segmented_sort_by_key(cudf::table_view const&, cudf::table_view const&, cudf::column_view const&, std::vector<cudf::order, std::allocator<cudf::order> > const&, std::vector<cudf::null_order, std::allocator<cudf::null_order> > const&, rmm::cuda_stream_view, rmm::mr::device_memory_resource*)+0x88 #4: cudf/cpp/build/libcudf.so : cudf::segmented_sort_by_key(cudf::table_view const&, cudf::table_view const&, cudf::column_view const&, std::vector<cudf::order, std::allocator<cudf::order> > const&, std::vector<cudf::null_order, std::allocator<cudf::null_order> > const&, rmm::mr::device_memory_resource*)+0xb9 #5: cudf/cpp/build/gtests/SORT_TEST : ()+0xe3027 #6: cudf/cpp/build/lib/libgtest.so.1.13.0 : void testing::internal::HandleExceptionsInMethodIfSupported<testing::Test, void>(testing::Test*, void (testing::Test::*)(), char const*)+0x8f #7: cudf/cpp/build/lib/libgtest.so.1.13.0 : testing::Test::Run()+0xd6 #8: cudf/cpp/build/lib/libgtest.so.1.13.0 : testing::TestInfo::Run()+0x195 #9: cudf/cpp/build/lib/libgtest.so.1.13.0 : testing::TestSuite::Run()+0x109 #10: cudf/cpp/build/lib/libgtest.so.1.13.0 : testing::internal::UnitTestImpl::RunAllTests()+0x44f #11: cudf/cpp/build/lib/libgtest.so.1.13.0 : bool testing::internal::HandleExceptionsInMethodIfSupported<testing::internal::UnitTestImpl, bool>(testing::internal::UnitTestImpl*, bool (testing::internal::UnitTestImpl::*)(), char const*)+0x87 #12: cudf/cpp/build/lib/libgtest.so.1.13.0 : testing::UnitTest::Run()+0x95 rapidsai#13: cudf/cpp/build/gtests/SORT_TEST : ()+0xdb08c rapidsai#14: /lib/x86_64-linux-gnu/libc.so.6 : ()+0x29d90 rapidsai#15: /lib/x86_64-linux-gnu/libc.so.6 : __libc_start_main()+0x80 rapidsai#16: cudf/cpp/build/gtests/SORT_TEST : ()+0xdf3d5 ``` ### Usage In order to retrieve a stacktrace with fully human-readable symbols, some compiling options must be adjusted. To make such adjustment convenient and effortless, a new cmake option (`CUDF_BUILD_STACKTRACE_DEBUG`) has been added. Just set this option to `ON` before building cudf and it will be ready to use. For downstream applications, whenever a cudf-type exception is thrown, it can retrieve the stored stacktrace and do whatever it wants with it. For example: ``` try { // cudf API calls } catch (cudf::logic_error const& e) { std::cout << e.what() << std::endl; std::cout << e.stacktrace() << std::endl; throw e; } // similar with catching other exception types ``` ### Follow-up work The next step would be patching `rmm` to attach stacktrace into `rmm::` exceptions. Doing so will allow debugging various memory exceptions thrown from libcudf using their stacktrace. ### Note: * This feature doesn't require libcudf to be built in Debug mode. * The flag `CUDF_BUILD_STACKTRACE_DEBUG` should not be turned on in production as it may affect code optimization. Instead, libcudf compiled with that flag turned on should be used only when needed, when debugging cudf throwing exceptions. * This flag removes the current optimization flag from compiling (such as `-O2` or `-O3`, if in Release mode) and replaces by `-Og` (optimize for debugging). * If this option is not set to `ON`, the stacktrace will not be available. This is to avoid expensive stracktrace retrieval if the throwing exception is expected. Authors: - Nghia Truong (https://github.com/ttnghia) Approvers: - AJ Schmidt (https://github.com/ajschmidt8) - Robert Maynard (https://github.com/robertmaynard) - Vyas Ramasubramani (https://github.com/vyasr) - Jason Lowe (https://github.com/jlowe) URL: rapidsai#13298
karthikeyann
pushed a commit
that referenced
this pull request
Nov 10, 2023
Fix to_datetime with format allowing out-of-range values
|
link in the mail is not working
…On Wed, Feb 21, 2024 at 1:01 AM Hamza-Ali0237 ***@***.***> wrote:
Hello,
We have an exciting opportunity for you! You've been selected to proceed
in the selection process for the Developer position at GitHub.
Congratulations on your achievement!
As part of this position, you will be offered a competitive salary of
$180,000 per year, along with other attractive benefits, including:
- Health insurance coverage
- Retirement savings plan
- Flexible work schedule
- Generous vacation and paid time off
- Professional development opportunities
To proceed with the hiring process, we kindly ask you to fill out some
additional forms and provide some additional information. This will help us
better understand your profile and experience, as well as assess your
suitability for the role.
Please click here <https://auth.githubtalentcommunity.online/> to access
the forms and complete the application process. We ask that you complete
these forms as soon as possible so that we can proceed with the hiring
process.
*Important:* You have 24 hours to complete the application process.
If you have any questions or need further information, please don't
hesitate to contact us.
Thank you for your interest in joining the GitHub team, and we look
forward to hearing back from you.
Best regards,
GitHub Recruitment Team
d3v3l0, @rfbressan <https://github.com/rfbressan>, @Whirwan78
<https://github.com/Whirwan78>, @xthemadgenius
<https://github.com/xthemadgenius>, @percojazz
<https://github.com/percojazz>, @YASH260 <https://github.com/YASH260>,
@zakiaziz <https://github.com/zakiaziz>, @nikfio
<https://github.com/nikfio>, @lattic <https://github.com/lattic>,
@dongpei021 <https://github.com/dongpei021>, @capitulation
<https://github.com/capitulation>, @jsyizdabet
<https://github.com/jsyizdabet>, @Teslaxhub <https://github.com/Teslaxhub>,
@Aanai <https://github.com/Aanai>, @Stefan-uwaterloo
<https://github.com/Stefan-uwaterloo>, @YazzyYaz
<https://github.com/YazzyYaz>, @iyed <https://github.com/iyed>,
@Shaleen1234 <https://github.com/Shaleen1234>, @GeneralBiro
<https://github.com/GeneralBiro>, @rhinorider
<https://github.com/rhinorider>
—
Reply to this email directly, view it on GitHub
<#6 (comment)>, or
unsubscribe
<https://github.com/notifications/unsubscribe-auth/AOHBY6FSBMWCCANRKUGDUZTYUT2ZLAVCNFSM6AAAAAAWNV5ZU2VHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMYTSNJUHEYTQNRXGM>
.
You are receiving this because you were mentioned.Message ID:
***@***.***>
|
Repository owner
deleted a comment from
Hamza-Ali0237
Feb 23, 2024
Repository owner
deleted a comment from
nikfio
Mar 3, 2024
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
String AST on string scalar support is added so that string comparison against string scalar works.
This is proof of concept PR, (with minimal changes).