High load on some devices after v2017.1.x update #1243
Comments
|
I've seen the issue on a WR841ND (I think it was v9 or v10). Possibly, all models with 32MB are affected? |
|
Unaffected:
Partially affected:
|
|
we also noticed that devices with more mesh neighbours are more likely to be affected - what a surprise! |
|
I can confirm that dir Freifunk Nord |
|
Device loads by model on the FFDA network where load > 2.0 {
"TP-Link TL-MR3420 v1": [
8.63
],
"TP-Link TL-WR841N/ND v11": [
7.85,
12.47,
3.44,
3.9
],
"TP-Link TL-WR940N v4": [
4.48
],
"Ubiquiti AirRouter": [
3.09
],
"TP-Link TL-WR710N v1": [
6.2
],
"TP-Link TL-WR842N/ND v2": [
2.28,
12.43,
8.98,
15.45,
8.98,
3.47,
7.22,
10.07,
12.14,
9.2,
7.25,
8.48,
2.91,
6.22,
8.91,
3.14,
2.13,
9.9,
10.92
],
"Ubiquiti PicoStation M2": [
9.97
],
"Linksys WRT160NL": [
4.69
],
"TP-Link TL-WR710N v2.1": [
4.19,
11.26
],
"TP-Link TL-WR1043N/ND v1": [
6.98,
3.57,
6.25,
2.23,
5.62
],
"TP-Link TL-WR841N/ND v9": [
4.98,
4.55,
4.08,
2.67,
4.89,
2.57,
9.66,
7.81
],
"TP-Link TL-WA850RE v1": [
7.71
],
"TP-Link TL-WR841N/ND v10": [
2.87,
5.32,
5.59
],
"TP-Link TL-WA901N/ND v3": [
7.96
],
"Ubiquiti NanoStation loco M2": [
4.94
],
"TP-Link TL-WR842N/ND v1": [
2.49
]
} |
|
Affected nodes on the FFDA Network grouped by SoC: AR9341TP-Link TL-WR842N/ND v2 19 QCA9533TP-Link TL-WR841N/ND v9 7 AR9132TP-Link TL-WR1043N/ND v1 4 AR9331TP-Link TL-WR710N v2.1 2 AR7240Ubiquiti NanoStation loco M2 1 AR7241TP-Link TL-MR3420 v1 1 AR9130Linksys WRT160NL 1 |
|
Hi! I don't got any nodes with a higher load than 0.8 in our network. Could you please provide these information:
I think this could be related. Maybe you could try to update your batman-adv gateways and disable multicast optimizations with "batctl mm 0" (don't forget your mapserver ;)) If the behaviour is related, you could try to eliminate the fulltable orgy by disabling all vpn tunnels for a minute to make the mismarked packages disappear |
Multicast optimizations are still disabled on v2017.1.x, see c6a3afa. |
|
I think the MO Bug is still not addressed. As already mentioned our load is in normal range (but we have a smaller network). If you are able to, I would like to ask you to check if the load goes down if you disable MO at all gateways via batctl mm 0 i would like to make sure it's not still this mo thing..... Our Network went stable after ALL Sources of mismarked packages were eliminated... Gateways had the biggest effect. I'm not sure, but if my memories are correct it was you who had a look at our network dump... if so: can you see these full table requests? |
|
This issue was fixed in https://git.open-mesh.org/batman-adv.git/commit/382d020fe3fa528b1f65f8107df8fc023eb8cacb, no? |
|
Am 25.10.2017 14:53 schrieb "hexa-" <notifications@github.com>:
This issue was fixed in https://git.open-mesh.org/batman-adv.git/commit/
382d020fe3fa528b1f65f8107df8fc023eb8cacb, no?
My Bauchgefühl still says that a part of the problem is still not fixed.
Wirh mo disabled everwhere we don`t got the load problems. thats why i have
asked you for trying to disable it.
The other idea is, that the mismarked packages from some nodes are enough
to corrubtvthe table of fixed batman versions.
I can't say if this is the point. i just want to make sure that ithis is
not related.
The fix in batman-adv is something like untested. the problem appears just
in big networks, so the feedback goes to zero. They consider it is
fixed... but i don't think that someone dumped the traffic.
I can sure tell you that broken nodes affect the load of the fixed nodes.
|
|
Disabled Looking at this node for example at this time of day (3:00)
5,2 MB of "free" RAM does not seem to be enough if we suspect the issue arises due to high memory fragmentation. |
|
thank you for testing.
i'll have a look at free mem tomorrow. I'm interested in why we don't got
this problem anymore.....
Am 27.10.2017 2:57 vorm. schrieb "hexa-" <notifications@github.com>:
… Disabled mm on our gateways.
Looking at this node for example at this time of day (3:00)
https://meshviewer.darmstadt.freifunk.net/#/de/map/30b5c2c2ead4
- Model 841 v9
- Load average 4,83
- RAM 74,7% used
"memory": {
"total": 27808,
"free": 5236,
"buffers": 992,
"cached": 1696
},
- Clients 0
- Traffic neglible
5,2 MB of "free" RAM does not seem to be enough if we suspect the issue
arises due to high memory fragmentation.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#1243 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AIA7UnQvkNo3fLOux3Dx6JeQXflSxkaqks5swSp7gaJpZM4QBx-M>
.
|
|
|
@mweinelt Do you have any custom ash-scripts running on your nodes? |
|
@CodeFetch No, we're not running anything custom. |
|
perhaps this issue is actually the same as #753 - only that it appears earlier than before |
|
Looking at the issue by SoC alone does not seem to yield a clear result. [
{
"family": "AR9531",
"loadavg": 0.17,
"devices": {
"TP-Link TL-WR842N/ND v3": 0.17
}
},
{
"family": "QCA9558",
"loadavg": 0.18,
"devices": {
"TP-Link TL-WR1043N/ND v3": 0.16,
"TP-Link Archer C7 v2": 0.19,
"TP-Link TL-WR1043N/ND v2": 0.2,
"TP-Link Archer C5 v1": 0.21
}
},
{
"family": "QCA9563",
"loadavg": 0.19,
"devices": {
"TP-Link TL-WR1043N/ND v4": 0.19
}
},
{
"family": "AR7240",
"loadavg": 0.67,
"devices": {
"Ubiquiti NanoStation loco M2": 0.59,
"Ubiquiti NanoStation M2": 1.61,
"TP-Link TL-WA801N/ND v1": 1.25,
"TP-Link TL-WR740N/ND v4": 1.18,
"TP-Link TL-WR740N/ND v1": 0.3,
"TP-Link TL-WA901N/ND v1": 0.04,
"TP-Link TL-WA830RE v1": 0.17,
"TP-Link TL-WR741N/ND v1": 0.41,
"TP-Link TL-WR841N/ND v5": 0.06
}
},
{
"family": "QCA9533",
"loadavg": 1.05,
"devices": {
"TP-Link TL-WR841N/ND v11": 0.79,
"TP-Link TL-WR841N/ND v10": 1.18,
"TP-Link TL-WR841N/ND v9": 1.1
}
},
{
"family": "AR2316A",
"loadavg": 1.49,
"devices": {
"Ubiquiti PicoStation M2": 1.49
}
},
{
"family": "AR9344",
"loadavg": 0.21,
"devices": {
"TP-Link CPE210 v1.1": 0.21,
"TP-Link TL-WDR4300 v1": 0.2,
"TP-Link CPE210 v1.0": 0.24,
"TP-Link TL-WDR3600 v1": 0.17
}
},
{
"family": "AR9341",
"loadavg": 2.5,
"devices": {
"TP-Link TL-WR842N/ND v2": 3.5,
"TP-Link TL-WA850RE v1": 1.42,
"TP-Link TL-WR841N/ND v8": 1.25,
"TP-Link TL-WA801N/ND v2": 0.18,
"TP-Link TL-WR941N/ND v5": 0.07,
"TP-Link TL-WA901N/ND v3": 2.26,
"TP-Link TL-WA860RE v1": 0.15
}
},
{
"family": "AR9331",
"loadavg": 2.76,
"devices": {
"TP-Link TL-WR710N v2.1": 6.76,
"TP-Link TL-MR3020 v1": 1.15,
"TP-Link TL-WR710N v1": 3.62,
"TP-Link TL-WR741N/ND v4": 0.21,
"TP-Link TL-WR710N v2": 0.12,
"TP-Link TL-WA701N/ND v2": 0.61
}
},
{
"family": "AR9132",
"loadavg": 1.95,
"devices": {
"TP-Link TL-WR1043N/ND v1": 2.51,
"TP-Link TL-WR941N/ND v2": 0.18,
"TP-Link TL-WA901N/ND v2": 0.11
}
},
{
"family": "AR7241",
"loadavg": 2.56,
"devices": {
"TP-Link TL-MR3420 v1": 2.78,
"TP-Link TL-WR842N/ND v1": 2.12,
"Ubiquiti AirRouter": 2.77
}
},
{
"family": "TP9343",
"loadavg": 1.06,
"devices": {
"TP-Link TL-WR941N/ND v6": 0.44,
"TP-Link TL-WR940N v4": 2.07,
"TP-Link TL-WA901N/ND v4": 0.07
}
},
{
"family": "MT7621AT",
"loadavg": 0.08,
"devices": {
"D-Link DIR-860L B1": 0.08
}
},
{
"family": "AR7161",
"loadavg": 0.26,
"devices": {
"Buffalo WZR-HP-AG300H/WZR-600DHP": 0.26
}
},
{
"family": "AR1311",
"loadavg": 0.21,
"devices": {
"D-Link DIR-505 rev. A2": 0.21
}
},
{
"family": "AR9350",
"loadavg": 0.15,
"devices": {
"TP-Link CPE510 v1.0": 0.15,
"TP-Link CPE510 v1.1": 0.14
}
},
{
"family": "AR9130",
"loadavg": 7.59,
"devices": {
"Linksys WRT160NL": 7.59
}
},
{
"family": "AR9342",
"loadavg": 0.02,
"devices": {
"Ubiquiti Loco M XW": 0.02
}
}
] |
|
hey All, on an Ubiquiti NanoStation loco M2 the issue seems to go away when the mesh wlan is deactivated. at least it looks that way since 2 days. this is kbu freifunk, where the wireless mesh config looks like this ..ede |
|
Does this NSM2 Loco have a VPN connection or is it otherwise connected to the Mesh after disabling the WiFi-Mesh? How big is the batadv L2 domain? Originators? Transtable (global) size? |
|
At least the three devices in the original post are all 32MB RAM and 8MB flash devices. Is this ticket a duplicate of #1197 maybe? Or could we somehow separate these two tickets more clearly? Just a crazy idea... As decently fast microSD cards seem to have gotten quite cheap: I'd be curious whether attaching some flash storage to the USB port of a router and configuring one partition for swap and one for /tmp/ would make a difference. For instance this plus this would cost less than 10€. Maybe there's even a decently fast, usable USB flash stick for less than 5€. Not suggesting this as a fix, but curious whether that'd change anything. Also, if some people with devices constantly having high loads could recompile with CONFIG_KERNEL_SLABINFO=y and could dump /proc/slabinfo, that could be helpful (I asked for this in #1197, too). |
|
We tested an image for the 1043v1 without additional USB modules, that are currently being loaded unconditionally - and the device seemed to behave fine again. @blocktrron can maybe tell us more about what he saw during tests. |
|
At Freifunk Darmstadt, we were able to observe that 8MB/32MB devices rebooted frequently, most likely due to additional RAM usage of the integrated USB support. We were also able to recreate the problems (High load/crashing) on an OpenWRT based Gluon by writing to tmpfs. Crashing/High load only occurred, when RAM was filled before the batman transglobal table was initialized, in case the router was already connected to the mesh. When the Router ist booted without visible neighbors, then filling RAM and connecting to the Network, the node was not affected by crashing or high load. |
|
Fyi: We're building images from master with slabinfo enabled and without additional USB modules tonight. If we can trigger the issue with those, we'll post slabinfo, else we'll retry again with the USB modules installed, |
|
From our 1043v1 rebooting in circles: OOM Reboot Slabinfo |
|
Behaviour does not improve when:
Memory usage on the device looks like this after boot and before connecting to the mesh: Slabinfo`after bootup, as stated on IRC it looks like the OOM happens as soon as the device connects to the mesh. |
|
testing with a 1043v1 sounds a bit like "trying to fix 2 issues with one shot", since (at least everybody seems to know for sure) that 1043v1 is instable by design, even in CC and BB. (eventhough it's just a hanging wifi, not a high load or a reboot.) |
|
As Freifunk Darmstadt now completed the migration of it's network, we now have domains with max. 70 Nodes per Domain. We already see the problems regarding high load greatly improve, if not gone completely. Surely, this is not a fix. I would also go as far to say that there is probably no real fix. We should probably accept that those devices just do not have enough ram to fulfil their task (And even the split is probably only a temporary improvement). Another example of a very problematic node: |


|
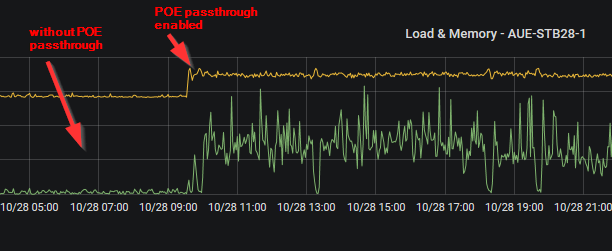
Same issue here on a Nanostation M2 (XM) with a webcam connected to the second ethernet port... without POE passthrough enabled, the device is running fine, POE passthrough activated causes the error to occur. the effect was previously reproducible at any time. |
|
@hauetaler: Can you try whether the same issue happens with PoE passthrough disabled and using a PoE-injector for the webcam instead? Does the same happen with PoE passthrough enabled but no webcam connected? I'm wondering whether this is really an issue of PoE. Or whether this could be caused by the traffic the webcam generates instead. Thirdly, do you have a scale for the y-axis? |
|
@hauetaler could you try to disable as many ebtables rules as possible for a test? |
|
I'm very sorry, but there's no PoE-injector availiable at the moment. Since gluon 2018.1.3 the Nanostation works again without any problems. |
|
@T-X Ok, today the problem occured again. PoE is disabled now, so you're right, it's not an issue of PoE. @Adorfer next time I'll try to disable ebtables rules |
|
@hauetaler Wow, 15-25% memory increase is really much. Can you please give me access to the router? My public key is |
|
@hauetaler: Could you check whether the issue also occurs if you swap the Pi with a plain, simple switch with nothing else connected to it? |
|
@T-X Just tested it, no problems at all. It seems there must be traffic for the error to occur. |
|
@hauetaler Can you flash the router manually in case it gets unresponsive? I'd like to test our nightly firmware as it uses OpenWrt and afterwards a firmware with tracing and profiling support. I have had installed vH11, but it seems you have downgraded the router to vH10 again?! The strange thing with your router is that I almost freed 5 MB of RAM and the load bug still occured. BTW I've moved to Freifunk Hannover a few months ago... |
|
@CodeFetch Flashing this router manually is no problem. Should I reconnect the raspberry again? |
|
@hauetaler Sorry for my late reply. I'd like to test it on sunday. It would be nice if you could plug in the raspberry then. |
|
Using the Gluon master the load decreased from average 5 to 0.5. Which is still high as it did nearly nothing and routers with more RAM that actively serve clients have a load of average < 0.1. Between 22:10 and 22:30 you can see what happens, when I slowly fill the RAM (up to approximately 1MB). The load did go up to 3 and then the router rebooted due to a OOM. Next step for me is to watch the inodes that are being decompressed to find out what files are being repeatedly read which causes the high load. The 32 MB RAM routers are definitely OOM. It's a matter of a few 100 KBs if the load bug appears or not. When it appears once it is hard to fix even if you free a lot of RAM. This is a thing I don't have an explanation for. @hauetaler I've just flashed a firmware with SquashFS debug messages enabled. Unfortunately the router is not reachable since then. I suspect that it generates too many messages. Sorry, but you need to flash it manually now :(... Please use our nightly firmware: http://build.ffh.zone/job/gluon-nightly/ws/download/images/sysupgrade/ |
|
@CodeFetch thanks for your time and effort in further investigating this bug! |
|
I've to unbrick it first by TFTP recovery. It's impossible to flash a new firmware at the moment. Hopefully the router will be back online in a few minutes. |
|
@hauetaler The node looks very good now. Load in average 0.1 like 64 MB devices and only 62% memory consumption. Did you unplug the raspberry? If not, please try to generate some traffic over LAN and then over WiFi. I've build a setup at home with which I can reproduce the load issue for further investigation now. Thank you very much for your help. We will release a firmware for Freifunk Hannover based on 2018.2 after we have checked if the 4 MB devices run as smoothly as yours or if the SquashFS block size needs to be reduced for them, too. |
|
@CodeFetch load average seems to be ok at the moment, but memory consumption increases after connecting the node to vpn mesh again.
|

|
The problem seems to be gone or at least mitigated for us (FF Münsterland) in 2018.2.x. Maybe even earlier, we never used 2018.1.*. https://karte.freifunk-muensterland.de/map04/#!v:m;n:a42bb0d21ba4 I tested explicitly the wired mesh case, in which the problem occurred very often in 2017 based Gluons. |
|
@MPW1412 With 2018.1.4 the bug is easily reproducible. With 2018.2/switch to OpenWrt the router seems to reboot directly after the load begins to increase to about 3, but that only happens when I manually fill the memory. I'm happy to see that your 4 MB flash device also seems to have less memory pressure. Can you please post a dump of /proc/meminfo and /proc/slabinfo with the old and the new firmware? |
|
This was the thread I've found on our issue: The question is: Did the thrashing detection really improve or do we just have more memory available due to more efficient packet handling by ath9k, different SquashFS cache sizes etc.? I've looked through all linux commits I could find that were related to thrashing and memory handling. There were many commits that could possibly have improved the situation, but I could be sure for none of them. I'd like to do some tests with torvalds/linux@b1d29ba and torvalds/linux@95f9ab2. We should have a look at some of these commits, as they might be able to detect the SquashFS thrashing state or make it worse or better (these were all I've found that come into question): Please help me to exclude some of them. I'm not that much into kernel page cache handling and some of them might be obviously irrelevant. We should find out whether the load bug was just a cosmetic issue or whether we are near the OOM justifiably. |
|
My high load scenario is still reproducable with 2018.2 or even with a build from master (7/2/2019) Alter 2-3 hours the load raises. |

|
Well, everything here is in the green. If anybody still sees this on v2019.1.x and newer please speak up. |
The devices were fine before, but with 2017.1.x high loads appeared. They seem to originate somewhere in the kernelspace.
Only some models are affected, but then all devices of that model experience this issue:
Probably more, but since our Grafana is currently down it's cumbersome to find more.
The text was updated successfully, but these errors were encountered: