[ECCV 2024 Oral] Yuheng Liu1,2, Xinke Li3, Xueting Li4, Lu Qi5, Chongshou Li1, Ming-Hsuan Yang5,6
1Southwest Jiaotong University, 2University of Leeds, 3City University of HongKong, 4NVIDIA, 5The University of Cailfornia, Merced, 6Yonsei University

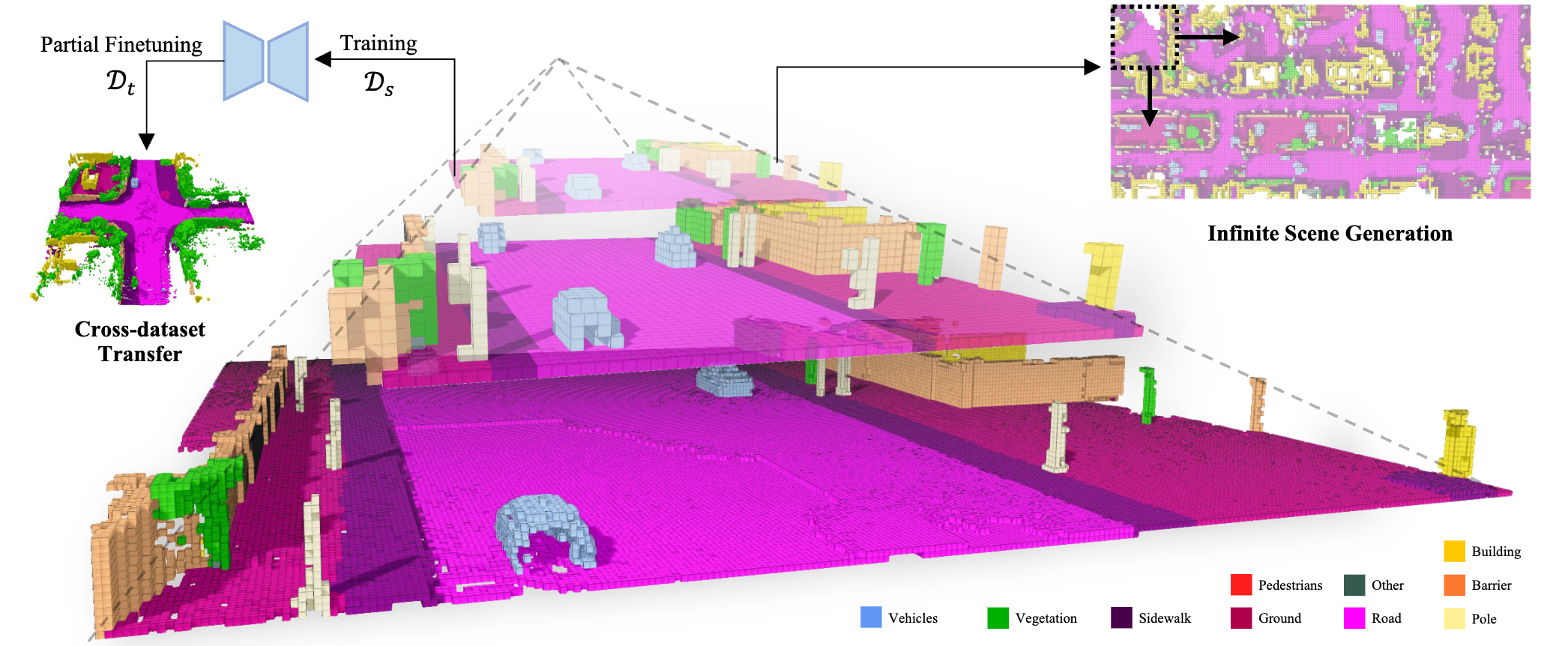
Diffusion models have shown remarkable results in generating 2D images and small-scale 3D objects. However, their application to the synthesis of large-scale 3D scenes has been rarely explored. This is mainly due to the inherent complexity and bulky size of 3D scenery data, particularly outdoor scenes, and the limited availability of comprehensive real-world datasets, which makes training a stable scene diffusion model challenging. In this work, we explore how to effectively generate large-scale 3D scenes using the coarse-to-fine paradigm. We introduce a framework, the Pyramid Discrete Diffusion model (PDD), which employs scale-varied diffusion models to progressively generate high-quality outdoor scenes. Experimental results of PDD demonstrate our successful exploration in generating 3D scenes both unconditionally and conditionally. We further showcase the data compatibility of the PDD model, due to its multi-scale architecture: a PDD model trained on one dataset can be easily fine-tuned with another dataset.
- [2024/09/05] Train and Inference code has been released.
- [2024/08/12] 🎉 Our work has been accepted as Oral Presentation.
- [2024/07/02] 🎉 Our work has been accepted by ECCV 24.
- [2023/11/22] Our work is now on arXiv.
- [2023/11/20] Official repo is created, code will be released soon, access our Project Page for more details.
If you find our work useful, please cite:
@article{liu2024pyramiddiffusionfine3d,
title={Pyramid Diffusion for Fine 3D Large Scene Generation},
author={Yuheng Liu and Xinke Li and Xueting Li and Lu Qi and Chongshou Li and Ming-Hsuan Yang},
year={2024},
booktitle={arXiv preprint arXiv:2311.12085}
}For the main experiments in this work, we use the CarlaSC dataset, an open-source outdoor road radar point cloud dataset. You don’t need to download the full version of the dataset, only Finer Resolution Part should be downloaded.
Pre-trained models are available as:
conda create -n pdd python=3.9
conda activate pdd
# Choose version you want: https://pytorch.org/get-started/previous-versions/
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
conda install pyyaml numba
conda install -c conda-forge prettytable tensorboard einopsgit clone git@github.com:yuhengliu02/pyramid-discrete-diffusion.git
cd pyramid-discrete-diffusionExtract the CarlaSC Finer Dataset you downloaded into the data folder, and then sequentially run the following script commands. These will automatically process the dataset for you.
chmod +x run_carla_process.sh
./run_carla_process.sh -q 32,32,4 # Quantize the original size to 32*32*4.
./run_carla_process.sh -q 64,64,8 # Quantize the original size to 64*64*8.
./run_carla_process.sh -q 256,256,16 # Label remapping.Note: The cross-dataset transfer functionality using the SemanticKITTI data is not yet implemented in the current code. We will release a supported version of the code in the future.
| Stage | Resolution |
|---|---|
| (32 |
|
| (64 |
|
| (256 |
We provide config files (under configs folder) to help users intuitively and easily complete model training. Below is an introduction to the important parameters in the config file.
prev_stage : This is used to guide the training/inference of the current model with a coarser resolution stage. For example, you can select none, s_1, or s_2.
next_stage : This specifies the model that is about to undergo training/inference. For example, you can select s_1, s_2, or s_3.
resume : Whether to load a pre-trained model.
resume_path : The path to the pre-trained model.
generation_num : The total number of scenes to generate during the inference stage.
mode : Select the current program mode. For example, train, inference, or infinity_gen.
infer_data_source : Select dataset to generate based on the coarse-resolution scenes from the original dataset, or select generation to generate from the coarse-resolution scenes you've already created.
prev_scene_path : When infer_data_source is set to generation, this parameter will be used to read the previously generated coarse-resolution scenes, serving as the condition for the next stage of generation.
mask_ratio : The overlap ratio between sub-scenes during training/inference in the
infinite_ratio : The overlap ratio between the next scene and the previous scene during infinite scene generation training/inference.
mask_prob : The probability of random sampling when training models for the
infinity_size : Set the total size limit for generating infinite scenes. For example, (3, 2) represents that the generated scene will consist of 3 * 2 high-resolution scene blocks.
train_data_path : The dataset path used for training the model in the current stage.
quantized_train_data_path : The dataset path from the previous stage used as the condition for the current training stage.
infer_data_path : The dataset path used for inference in the current stage model.
quantized_infer_data_path : The dataset path from the previous stage used as the condition for the current inference stage.
distribution : If you have multiple GPUs on the same server and want to use all of them, set this to true. If the GPUs are located across multiple servers, configure the num_node, node_rank, and dist_url parameters.
check_every : Specify how many epochs should pass before saving checkpoints.
- Training Scripts
python launch.py -c <config path> -n <exp_name>For example:
- Training for
$S_1$
python launch.py -c configs/train_s_1.yaml -n s_1- Training for
$S_1$ to$S_2$
python launch.py -c configs/train_s_1_to_s_2.yaml -n s_1_to_s_2- Training for
$S_2$ to$S_3$
python launch.py -c configs/train_s_2_to_s_3.yaml -n s_2_to_s_3The saved models and log files will all be placed in the checkpoints folder.
For Infinite Scene Generation Model Training, you just need to follow the Training for
Follow the steps below, and you will be guided through the process of generating high-resolution scenes step by step.
- Step 1: Remember to download the pre-trained model we provide, or you can follow the tutorial in the Training section to complete the training of your own model.
-
Step 2: Fill in the path of the downloaded pre-trained model into the
resume_pathparameter in the config filesconfigs/infer_s_1.yaml,configs/infer_s_1_to_s_2.yaml, andconfigs/infer_s_2_to_s_3.yamlrespectively. -
Step 3: Run inference script below, the scenes generated in the
$S_1$ stage will be saved in thegenerated/s_1/Generated/folder.
python launch.py -c configs/infer_s_1.yaml -n s_1- Step 4: Write the path of the generated scenes into the
prev_scene_pathparameter in theinfer_s_1_to_s_2.yamlfile, and ensure that theinfer_data_sourceparameter in this config file is set togeneration.
infer_data_source: 'generation' # choices: dataset, generation
prev_scene_path: './generated/s_1/Generated/'-
Step 5: Run inference script below, the scenes generated in the
$S_2$ stage will be saved in thegenerated/s_1_to_s_2/Generated/folder.
python launch.py -c configs/infer_s_1_to_s_2.yaml -n s_1_to_s_2- Step 6: Repeat Step 4, update the relevant parameters in the
infer_s_2_to_s_3.yamlfile, and run the following script to complete the scene generation. The generated files will be saved in thegenerated/s_2_to_s_3/GeneratedFusion/folder.
python launch.py -c configs/infer_s_2_to_s_3.yaml -n s_2_to_s_3Follow the next step and create your own infinite scenes.
-
Step 1: Check the
resume_pathin theinfinite_s_1.yamlfile and set an appropriateinfinity_size. It can theoretically be set to a very large value for generating infinite scenes, but considering the potential high memory demands during the subsequent visualization stage, we recommend starting with smaller values, such as(3, 2). -
Step 2: Run inference script below, the infinite scenes generated in the
$S_1$ stage will be saved in theinfinite_generation/s_1/Generated/andinfinite_generation/s_1/InfiniteScene/folders.
python launch.py -c configs/infinite_s_1.yaml -n s_1- Step 3: Write the path of the generated scenes into the
prev_scene_pathparameter in theinfer_s_1_to_s_2.yamlfile, and ensure that theinfer_data_sourceparameter in this config file is set togeneration.
infer_data_source: 'generation' # choices: dataset, generation
prev_scene_path: './infinite_generation/s_1/Generated/'-
Step 4: Run inference script below, the scenes generated in the
$S_2$ stage will be saved in thegenerated/infinite_s_1_to_s_2/Generated/folder.
python launch.py -c configs/infer_s_1_to_s_2.yaml -n infinite_s_1_to_s_2- Step 6: Repeat Step 3, update the relevant parameters in the
infinite_s_2_to_s_3.yamlfile, and run the following script to complete the scene generation. The generated files will be saved in theinfinite_generation/s_2_to_s_3/GeneratedFusion/andinfinite_generation/s_2_to_s_3/InfiniteScene/folder.
python launch.py -c configs/infinite_s_2_to_s_3.yaml -n s_2_to_s_3We provide script to help you visualize the generated scenes. We recommend performing the visualization on your local computer.
- You need to follow the tutorial at https://www.open3d.org/ to complete the installation of Open3D.
- Clone our repo to your local computer.
parser.add_argument('--frame', default='0')
parser.add_argument('--folder', default='') # Set the folder path that contains the generated scenes.
parser.add_argument('--dataset', default = "carla")
parser.add_argument('--voxel_grid', default = False)
parser.add_argument('--config_file', default = 'carla.yaml') # Dataset config path.
parser.add_argument('--label_map', default = False)cd ./pyramid-discrete-diffusion/Tools/visualize/
python visualizer.pyNext, you can use your keyboard's left and right arrows (←, →) to control the display of the visualized scene, and use the mouse to drag and view it from different angles.
Our code is based on the following open-source project: scene-scale-diffusion. Many thanks to the developers for providing the code to the community and for the support offered during our work.