[READY] C/C++ semantic highlighting. #291
Conversation
|
Do you know https://github.com/jeaye/color_coded? It does the thing you want. True, you would have to pay for two parsing time since you would not reuse the parsed AST. We already had this kind of proposal ycm-core/YouCompleteMe#933 and apparently we turned that down, I don't know if @Valloric changed his mind around this. @jeaye you might be interested. |
|
Yes I came across color_coded while researching libclang interface for the syntax highlighting. BTW: @jeaye taking this opportunity to ask; you are adding matches only for the visible lines, and updating them on viewport change. Are you doing this for performance reasons? |
|
@davits Thank your for the PR and your hard work, but I still think syntax highlighting is out-of-scope for YCM. I don't think it provides enough value to be worth the extra complexity. OTOH, this PR is pretty convincing by demonstrating that this wouldn't really be that much extra code in ycmd. So I'm somewhat on the fence about this now. I'm curious what the necessary impact in YCM itself would be. Also, I'd like to hear what others think about this: @puremourning @micbou And as @vheon pointed out, |
|
Honestly, I was pretty stoked when I looked at this earlier. I think it is a neat feature, and I think the simplicity of the implementation is pretty compelling. It's really nice work. I'm also, as I think you know, in favour of more IDE-like features in Vim and only having one thing to configure for all my code-comprehension features (particularly for C/C++), which in fairness, is a goal of YCM. (FWIW, YCM's I would like to give it a test drive though - I've not tried On the actual implementation, the server-side stuff looks pretty neat - it provides the annotated tokens in the On the Vim client side, though, I have more pressing concerns; I understand the caveats around application of the highlighting as an "overlay" in Vim are quite stark - Vim syntax highlighting really isn't currently designed for this type of thing - I read a thread where someone complained about design choices in Also, as always, client performance is a of a worry - i particular if it requires Vim to do lots of redrawing (i don't know tbh). I very often work with exported X display over a somewhat annoyingly slow network, which means that redraw performance (strictly, I guess, frequency) is actually pretty important. I'm somewhat less worried about server performance, but testing it out would certainly be on the TODO list. |
|
I was also puzzled by the little code that was necessary to implement this feature; I don't know if it is because |
|
@Valloric I can see why this is out-of-scope for YCM, but on the other hand with YCM becoming de-facto code completion standard for the Linux systems and editors, it is just a matter of time when necessity of this will rise again. @puremourning There will be some lag between typing and highlighting updates. I checked the semantic highlighting in Visual C++ few days ago, it reparses file after cursor idle and updates the highlighting, so you can literally see the lag between type and highlight. Beside semantic highlighting is mostly useful when you are exploring an alien source code. I don't know much about eclim, but there was a goal to add semantic highlighting support to neovim. @tarruda are you planning to add new mechanism for the semantic highlighting, or reusing/improving matchaddpos() ? |
|
Looking at the code of |
Oh yeah. It's unimaginably slow, scrolling through a highlighted 2K line buffer on a powerful machine. This is entirely due to vim's rendering, not extra work being done in color_coded. I keep track of what's visible and update only when needed; the performance becomes much better. A common complaint is having two plugins, which have two separate configs, for clang-based work. There's a simple solution to that: https://github.com/rdnetto/YCM-Generator which can generate both YCM and color_coded configs. As far as the duplicate parsing goes, the option to which I was looking forward requires a vim-based (or vim-compatible) generic libclang plugin which just exposes all of the annotated tokens for others to use. YCM could do this, or another could, and color_coded could be reworked to just pull the tokens from there. The benefit, as Valloric has been saying since I originally proposed this feature for YCM, is that we keep highlighting logic separated. |
|
@jeaye You make an excellent point with separating the highlighting logic. I could see us merging the necessary changes in ycmd to expose tokens to clients. YCM could then expose an external function that color_coded could use to pull tokens out and do whatever it wants. I just really don't want to see more vimscript nastiness in YCM. If we could decouple this so that we mention in the YCM readme "hey if you want semantic syntax highlighting, go install this other plugin," that would just be dandy. I'll openly admit that my apprehension about this feature lies entirely with the necessary Vim client layer. I can't see how it would be fast or anything but annoying to implement such that the whole thing works satisfiably enough. Not with Vim the way it is. Maybe with Neovim in the future (@tarruda :)). But "the Vim client would be nasty" is not a good reason to not implement support for this in ycmd. Emacs, Sublime Text, Atom etc clients should not suffer because of Vim. So begrudgingly, I'll admit we should have it in ycmd. Exposing a nice hook in YCM so that other plugins that want to deal with the syntax highlighting hassle can go do it makes sense as well. So I'm curious to hear what others (especially you @jeaye) think about such a design. How do you envision a good hook in YCM for this data to look like? |
|
I don't think ycmd needs to do more than provide an API which dumps a JSON version of the annotated cursors. This will allow it to remain editor-agnostic, so the Vim, Emacs, etc folks can all do their own thing outside of ycmd. If I can get my hands on that JSON, I'd rework color_coded to use it and we can ride on the existing efforts put into color_coded on the vim/highlighting front, as well as its existing user base. One thing that worries me is the potential dichotomy between YCM's highlighting and color_coded's highlighting, as well as the expanded feature set of YCM. If we have several hundred/some thousand people using color_coded, adding this functionality into YCM will lead to duplicate efforts with little gain. I'd like to push to keep both projects going and I think color_coded can only be strengthened by the induction of a ycmd backend. |
|
To expand on my point a bit, I think that addressing the duplicate compilation issue transcends the highlighting discussion to encompass other possible uses of libclang within editors. Refactoring, searching, documenting, etc all can make use of ycmd sharing the results of the heavy lifting it's already doing. If we bring in highlighting, as part of the C-style editing suite of YCM, what's next? Will the refactoring and other IDE-like behaviors also make it in? Nay, it'd be prudent to generalize the problem by providing the JSON API and let plugin writers have at it. |
|
When I started working on this, I implemented very first version as a new handler in ycmd/handlers.py which calls completer's GetSemanticTokens function. But I failed to integrate syntax highlighting into YCM in a way I envisioned it, so I switched to this approach. For the Vim it isn't obvious when or where to call the handler, or what to do when file is reparsing at the moment, of course this isn't problem for editors with async support. Another thing is that I'm currently extracting tokens from the whole translation unit, but libclang has interface to extract tokens only from certain source range. We can expose this in the ycmd API, and let user/editor to decide whether to extract all the tokens once, or by portions. This will allow us to have ultra-fast token extraction for the visible source range. Conclusion: How I see it. |
|
Follow up: I also did some performance testing for token extraction (CPU AMD-FX8350 4Ghz, test is single threaded, time is measured with clock() function): Compared with the compilation time, token extraction does not have impact on performance. Passing the tokens of the whole translation unit also shouldn't be a problem, currently we are passing the whole unsaved buffer from client to server. @Valloric have you ever measured how long it takes to pass the buffer? It should be a RAM to RAM copy, but it is interesting anyway. |
|
I'll write this here because is related to the whole change. I don't think I'm comfortable with the bare name "semantics". Reviewed 1 of 12 files at r1. Comments from the review on Reviewable.io |
|
Me neither :) I will change it to "SemanticTokens". Comments from the review on Reviewable.io |
My point is that YCM itself would not be doing any highlighting, it would only provide an API for color_coded to get a token stream.
Fair point, but I'd like to see YCM gain all those features to the extent that separate plugins for this aren't necessary... with the exception of semantic syntax highlighting.
Yes! We already do GoTo, FixIts, error diagnostics and now the ever-awesome @puremourning is working on rename support (for JS at least).
I agree that it would be ideal to provide some general way to interact with a YCM-managed instance of ycmd, but this PR is probably not where we should be tackling it. A problem worth solving though. I agree that we should have a ycmd handler that accepts a range of locations (which are |
|
@Valloric I've changed the handler to be range specific, but the old approach when tokens are extracted for the whole file after parsing. GetSemanticTokens returns correct sub-vector for the specified range. |
I didn't think much about this subject yet, but ideas are welcome(PRs are even better :)) |
|
Well there is neovim/neovim#1817 which kinda is an incremental improvement of |
|
@bfredl Great Job! You addressed all issues/concerns we raised here. Because in my tests for 7000 lines source file (NOT counting include files):
|
|
That is something we definitely want as well (notifictations for changed buffer contents). Some disscussion in neovim/neovim#2224 |
|
FWIW, I tried to change the compile diagnostics of YCM to use the new buffer highlight api here. Obviously we should define a python interface for this rather than using the raw session requests, but it works pretty well (responds better to line linenumberings and buffer switches in the same window). |
|
@bfredl that's quite cool, but unless i'm missing something it only works in neovim, so we can't really support it (yet). Certainly, I don't think we have any plans to drop support for Vim. Though, I must confess, it's pretty cool what is going on in the nevim world. Next up: a proper API for auto-completion, rather than the hacks YCM client has for auto triggering... |
|
True, the current branch was just for testing, if YCM wants to add it it would either be in a |
Interesting. I don't know much about this API. Do you have a reduced test case for it (maybe using |
|
This is solid work, so thanks a ton!! I've added some comments here and there, and there are a couple of overall things below:
Reviewed 1 of 12 files at r1, 1 of 12 files at r2, 9 of 10 files at r3, 1 of 1 files at r4. cpp/ycm/ClangCompleter/ClangCompleter.h, line 113 [r4] (raw file): cpp/ycm/ClangCompleter/Token.cpp, line 1 [r4] (raw file): Typically, we mark these with cpp/ycm/ClangCompleter/Token.cpp, line 3 [r4] (raw file): cpp/ycm/ClangCompleter/Token.cpp, line 26 [r4] (raw file): cpp/ycm/ClangCompleter/Token.cpp, line 89 [r4] (raw file): This will help in the future if any new kinds are added. It also helps reviewers to check that we're covering everything we need, like objective-c stuff, etc. cpp/ycm/ClangCompleter/Token.cpp, line 118 [r4] (raw file):
cpp/ycm/ClangCompleter/Token.cpp, line 148 [r4] (raw file): cpp/ycm/ClangCompleter/Token.h, line 21 [r4] (raw file): cpp/ycm/ClangCompleter/Token.h, line 29 [r4] (raw file): cpp/ycm/ClangCompleter/Token.h, line 31 [r4] (raw file): cpp/ycm/ClangCompleter/TranslationUnit.cpp, line 402 [r4] (raw file): cpp/ycm/ClangCompleter/TranslationUnit.cpp, line 409 [r4] (raw file): cpp/ycm/ClangCompleter/TranslationUnit.cpp, line 418 [r4] (raw file): if so, that's cool, but it would help to make a comment here to say that. cpp/ycm/ClangCompleter/TranslationUnit.cpp, line 543 [r4] (raw file): The docs on cpp/ycm/ClangCompleter/TranslationUnit.cpp, line 550 [r4] (raw file): cpp/ycm/ycm_core.cpp, line 201 [r4] (raw file): ycmd/completers/completer.py, line 292 [r4] (raw file): ycmd/handlers.py, line 133 [r4] (raw file): ycmd/handlers.py, line 138 [r4] (raw file): ycmd/responses.py, line 137 [r4] (raw file): Comments from the review on Reviewable.io |
|
☔ The latest upstream changes (presumably #311) made this pull request unmergeable. Please resolve the merge conflicts. |
Added new Variable and TemplateNonTypeParameter tokens, updated some token names. Added semantic_token.py file representing single semantic token, and providing complete list of all supported tokens.
Added utility functions for building token and skipped range response.
Needed to cover semantic_token.py file. Renamed Struct -> Structure.
|
@micbou @puremourning @Valloric @vheon |
|
Hi @davits, thanks for this amazing effort! I really hope that it would be merged to mainstream ycmd soon. |
|
Hi @aeremin, |
|
I didn't realize that the requests for the About the extra fields in the similarly to a Reviewed 1 of 13 files at r17, 1 of 8 files at r24, 3 of 5 files at r25, 6 of 6 files at r26, 1 of 1 files at r27, 4 of 4 files at r28, 6 of 6 files at r29. ycmd/tests/clang/get_semantic_tokens_test.py, line 27 at r29 (raw file):
Parentheses are not needed. ycmd/tests/clang/get_semantic_tokens_test.py, line 80 at r29 (raw file):
This is a generic test, independent to the Clang completer so it should be moved to the ycmd/tests/clang/get_skipped_ranges_test.py, line 27 at r29 (raw file):
Parentheses are not needed. ycmd/tests/clang/get_skipped_ranges_test.py, line 31 at r29 (raw file):
Parentheses are not needed. ycmd/tests/clang/testdata/token_test_data/.ycm_extra_conf.py, line 3 at r29 (raw file):
The include flag does not seem useful for the tests. Comments from Reviewable |
|
(sighs) It's been implemented this way from the beginning (9 months)... If you want this PR to reach the Ideal state and then merge it: 1. ideal is subjective, 2. sorry I'm not the guy. I wanted to write this 2 times already, but I said to myself "you are near the end, it's the last push". The feature is implemented, it's working (using in everyday work for over two months now, with other ~10 people from my organization), it's covered. Yes there are some minor polishing to be done, but it doesn't affect the functionality. Nothing personal, I understand that you want the best for the project. I want the best for the project too, otherwise I wouldn't be pushing this for over a 9 months. Review status: all files reviewed at latest revision, 8 unresolved discussions. Comments from Reviewable |
|
@davits Sorry for this PR taking this long, there's been delays on both sides. We could have done better here, absolutely. But when it comes to the HTTP API, we can't just release it in a "good enough" state. We have a policy of never breaking backwards compatibility with ycmd. We also have a policy of "every commit is a release." So once we submit this, it becomes part of our API going forward and can't change. This is also the reason why we're extremely careful about PRs that add things to the API: we'll be maintaining it forever. You're implementing a very large feature that comes with new handlers and we really need to get it right the first time; there's parts of our current API that could be better but that we can't change now without breaking lots of clients. I think this PR is pretty close to being done, so stay strong! :)
I have to agree with @micbou here; requests should ideally be similar to other requests clients make. I've reviewed this PR several times but it has also changed several times and I can't constantly keep it all in my head so I'm glad @micbou found an issue I agree should be fixed. With big PRs like this one, it's often hard to see the forest from the trees so an issue like this can easily be missed through multiple rounds of reviews. With regards to copies on the wire, it's not really a problem for a localhost server. I did benchmarks on this 3 years ago and it has stayed true since then. If it ever became a problem, the "standard" request also includes a filepath param in addition to the buffer so we could always just not populate the buffer in the request and have the server read it. But we really want to have that buffer to support unsaved changes in the editor (so the buffer contents we send are not the same as the one on disk); it's the way YCM currently works and it's not at all slow. For libclang, initial parsing is slow, but subsequent parsing is fast, even if we provide the full buffer. |
It is now is more JSONish Seperated tokens for static member variables and static member functions.
Request is similar, but
Clients can get tokens from the whole file by passing
So my approximation of the buffer copy time was close :) . When I was testing token extraction for 50 lines on YouCompleteMe side it was taking
I understand why the buffer content is needed for the
No buffer content copy, No reparsing - for the token extraction, it should be blazingly fast. Clients should take care of sending Review status: 9 of 20 files reviewed at latest revision, 8 unresolved discussions. Comments from Reviewable |
|
Please read penultimate paragraph as:
Subsequent parsing is fast because of the precompiled header. But when you change/add/delete include it's same as initial parse time. Also subsequent is fast compared to the relative, it takes >100ms to complete. Review status: 9 of 20 files reviewed at latest revision, 8 unresolved discussions. Comments from Reviewable |
|
Review status: 9 of 20 files reviewed at latest revision, 8 unresolved discussions. ycmd/tests/clang/get_semantic_tokens_test.py, line 27 at r29 (raw file):
|
|
So still Regarding the buffer contents, I'm inclined to agree with @davits - it's YAGNI right now. We're not currently using it, and in practice we can always add it later if/when we need it for other completers. We just make it API-mandatory for those completers. And in fairness, the API isn't really totally stable right now anyway :) Reviewed 1 of 13 files at r17, 3 of 8 files at r24, 11 of 11 files at r30. Comments from Reviewable |
|
I think we now need @micbou to share his thoughts. :) |
i.e. variables declared in namespace or translation unit scope.
|
Closing due to lack of interest. Sorry everyone who was waiting for this to be merged. I've been in a state of anticipation for so long that it started getting on my nerves. I don't want to wait/worry for this PR anymore. I want to break free :) I will continue to maintain my fork, and it will be easier to keep it up to date with this PR closed. |
|
@davits It's really sad that mainline ycmd is not interested enough in this. BTW, are you interested in further contributions? E.g. I wanted to add ability to differentiate const/mutable entities. |
|
@davits I commend you for this PR. I've started following the issue for quite some time now hoping for some merge. |
|
@aeremin Sure, you are welcome to contribute, though you should wait a little bit. I want to separate type modifiers/qualifiers from token names, otherwise soon it will be impossible to deal with all combinations. |
That's perhaps for the best. I don't think we, the ycmd maintainers, really handled this PR as well as we could have. I think the root cause of this was that none of us are really excited about this functionality. "Lack of interest" is really the best term here; it's not that we're against it (we're not), it's obviously something that makes sense in ycmd, but eh... it doesn't solve a problem any of us really have. Couple that with lots of back-and-forth discussion on the design that really tired everyone out (including @davits), and you get the current unfortunate situation. @davits Even with this being closed, thank you for sending your PR! It has made us really think through about how this feature should look like and do we really want to have it/maintain it. Thanks again and no hard feelings! :) |
Absolutely not :) Huge thanks for the review, it made this PR much better then it was. |
|
Sorry to comment on an ancient/closed issue. The killer feature here is the ability to visualize active blocks of code. For code-bases that extensively use macros to activate/deactivate significant bits of code, the ability for the editor to help me visually ignore large tracts of code is quite helpful. That said, I could also see myself wanting to turn this macro-aware hightlight/lowlight behavior off at times when I just want to treat all blocks as equal. I'll also note briefly that there have been times in the past when I've misconfigured my build system and ended-up with macros defined (or not defined) incorrectly, thus resulting in unexpected code being included/excluded. In these cases, an editor feature to highlight active |
|
@mellery451, you could try using ccls or cquery which support semantic highlighting. |
Hi Guys and Happy New Year,
I've decided to turn on Christmas lights in the Vim for the occasion :)
This is a proof of a concept and lot more polishing needs to be done.
I just wanted to share the initial results, and see your concerns and remarks about the current implementation and the direction it is going. The process of extraction and usage of semantic tokens is pretty much similar to the one with diagnostics, so I implemented semantics by changing return value of file reparse function to be pair of diagnostics and semantics.
For now it supports/returns tokens of the following types: namespace, class, struct, union, typedef, enum, enum constant, macro, function, function argument. And all these token types can be linked to the different highlighting groups.
PS
I will create another pull request for YouCompleteMe, so you can test this.
PPS
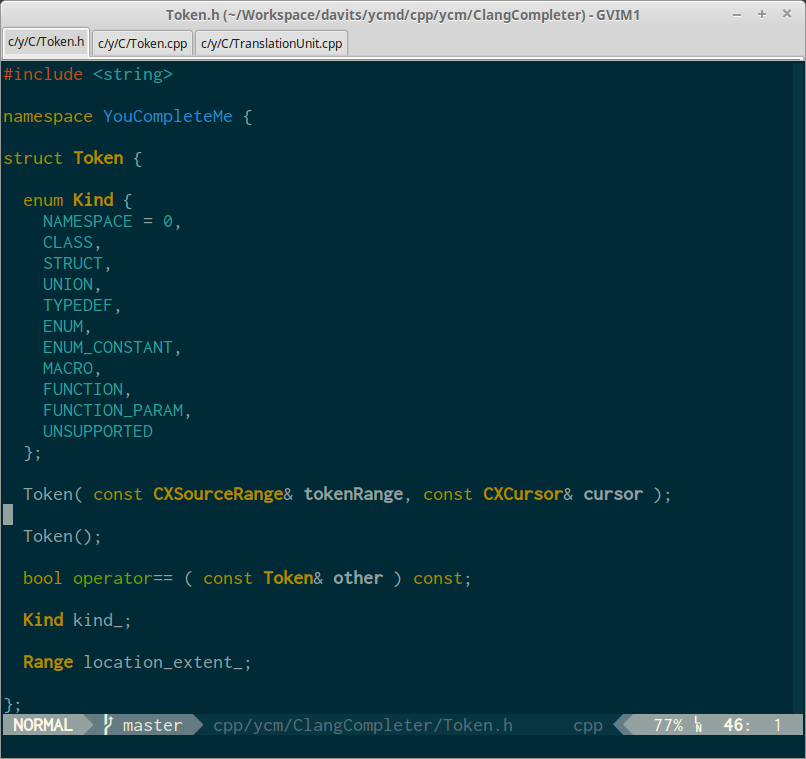
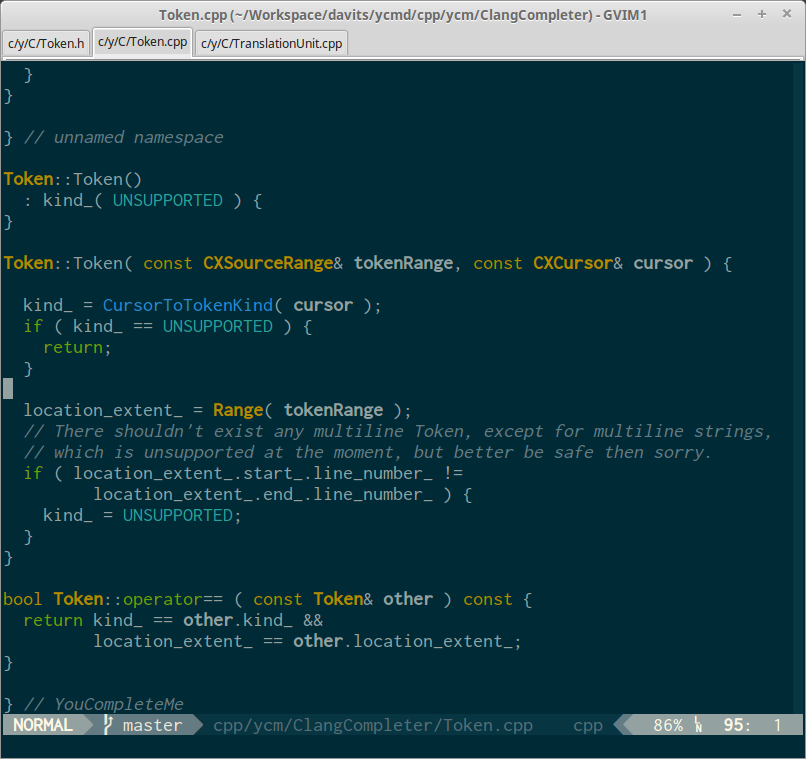
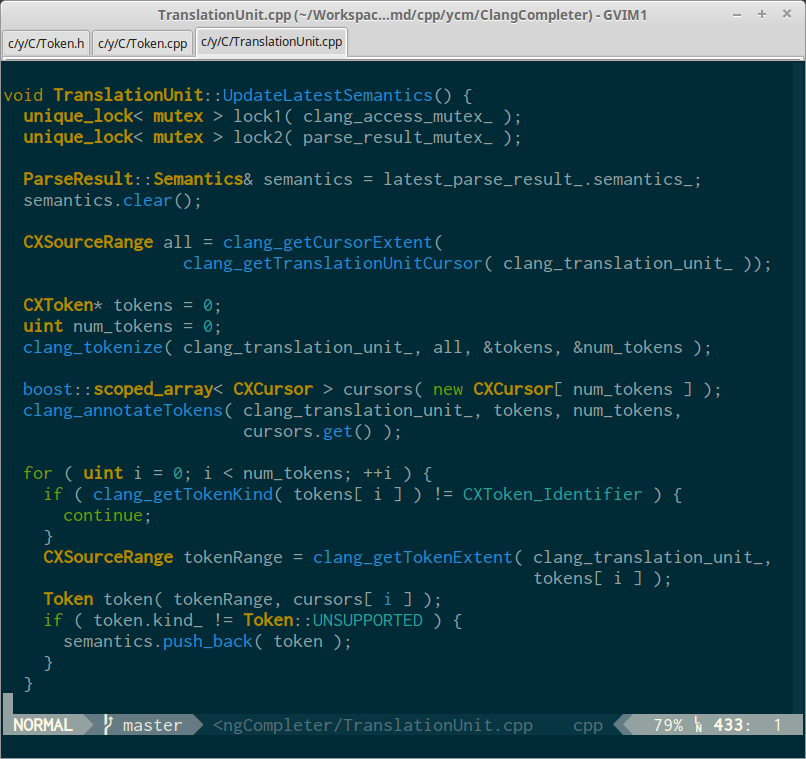
Here are some screenshots to please your eyes. (Note that bold version of Type used to highlight user defined types, and bold version of Normal to highlight function arguments).