A movie recommendation system is a type of recommendation engine specifically designed to suggest films to users based on their past viewing habits, preferences, and other relevant data. Such systems are integral to streaming platforms, such as Netflix and Amazon Prime, where they aim to provide personalized content to increase user engagement and satisfaction.
This project is a content-based movie recommendation system built with the TMDb 5000 Movies and Credits datasets. It processes and combines movie metadata, including genres, keywords, cast, crew, production companies, and overview descriptions, to recommend movies based on similarity.
There are three primary approaches for a movie recommendation system:
-
Content-Based Filtering:
- How It Works: Content-based filtering recommends movies similar to those a user has liked or interacted with in the past. This is achieved by analyzing movie metadata (such as genre, cast, director) and matching it with user preferences.
- Advantages: No dependence on other users’ data; good for niche items. Works well even with new or infrequent users if enough metadata is available.
- Limitations: Limited to known preferences and metadata, often leading to recommendations that lack variety or novelty.
- Example Techniques:
- TF-IDF and Cosine Similarity: Compute similarity between movies based on their metadata.
- Word Embeddings: Represent words or metadata as vectors in a continuous vector space, making it possible to compute more nuanced similarities.
-
Collaborative Filtering:
- How It Works: Collaborative filtering bases its recommendations on user-item interactions across the entire user base. There are two main types:
- User-Based Collaborative Filtering: Recommends items based on users with similar viewing patterns.
- Item-Based Collaborative Filtering: Recommends items similar to those the user has liked or interacted with.
- Advantages: Can uncover hidden patterns and recommend diverse content by leveraging user similarity.
- Limitations: Requires a substantial amount of user interaction data; struggles with the “cold start” problem for new users or movies.
- Example Techniques:
- Matrix Factorization (e.g., SVD): Decomposes the user-item interaction matrix into lower-dimensional matrices, capturing latent factors representing user preferences and movie attributes.
- Alternating Least Squares (ALS): Optimizes user and item matrices to predict missing values in the user-item matrix.
- How It Works: Collaborative filtering bases its recommendations on user-item interactions across the entire user base. There are two main types:
-
Hybrid Approaches:
- How It Works: Hybrid methods combine both content-based and collaborative filtering to achieve better accuracy and cover each technique's weaknesses.
- Types of Hybrids:
- Weighted Hybrid: A weighted average of content and collaborative scores for each recommendation.
- Switching Hybrid: Switches between methods based on criteria like user activity or availability of metadata.
- Meta-Level Hybrid: Uses the output of one recommender as input for another.
- Advantages: Greater personalization and diversity, ability to balance recommendation novelty with relevance.
- Limitations: More complex to implement and computationally intensive.
- Example Techniques:
- Deep Learning Models: Neural Collaborative Filtering, recurrent neural networks (RNNs) for sequential recommendations, or transformers to capture more sophisticated patterns in user-item interactions.
In this Project we have developed Content filtering based Movie Recommendation System
Content-Based filtering doesn’t involve other users, but based on our preference, the algorithm will simply pick items with similar content to generate recommendations for us.
- Deep Learning Models: Neural Collaborative Filtering, recurrent neural networks (RNNs) for sequential recommendations, or transformers to capture more sophisticated patterns in user-item interactions.
In this Project we have developed Content filtering based Movie Recommendation System
TF-IDF (Term Frequency-Inverse Document Frequency) is a commonly used text vectorization technique in natural language processing (NLP) and information retrieval to represent documents and words in a way that highlights the most important words in each document within a corpus. It measures the relevance of a term in a document by balancing two factors:
- Term Frequency (TF): How often a word appears in a document. A higher count increases the word's relevance within that document. For term ttt in document ddd, TF is calculated as:
TF(t,d)=Total number of terms in d/Number of times t appears in d
- Inverse Document Frequency (IDF): How common or rare a word is across the entire corpus of documents. Words that appear in many documents have lower IDF scores, while unique words have higher scores, helping to identify terms that are particularly significant to certain documents. For term t in a corpus of N documents where df documents contain the term t:
IDF(t)=log(N/df+1)
Adding 1 to df avoids division by zero.
The final TF-IDF score for a term in a document is the product of the term’s TF and IDF scores:
TF-IDF(t,d)=TF(t,d)×IDF(t)

Cosine Similarity
Cosine Similarity can be defined as a method to measure the difference between two non-zero vectors. In our case, the film title and the key movie features represent the coordinates of a movie vector. Thus, in order to calculate the similarity between the two movies, if we know the film title and key features of both the movies, we just need to calculate the difference between the two movie vectors.
The cosine similarity formula can be mathematically described as shown below.
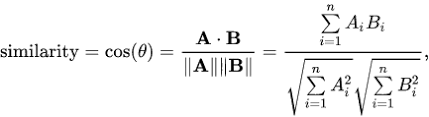
Fig 3.2. Cosine Similarity formula
A.B = Dot product between the two movies vectors,
||A||||B|| = Product of the magnitudes of the two movie vectors
Fig 3.3. Movie vectors representation
`` ├── app.py # Main Streamlit app file ├── data_processing/ # Directory for data processing scripts │ ├── load_data.py # Loads and merges datasets │ ├── clean_data.py # Cleans and preprocesses data │ ├── process_data.py # Contains feature engineering functions │ └── recommend.py # Computes similarity and recommends movies ├── tmdb_5000_credits.csv # TMDb credits dataset ├── tmdb_5000_movies.csv # TMDb movies dataset ├── movie_dict.pkl # Pickle file with movie data ├── sparse_cosine_sim.pkl # Pickle file with sparse cosine similarity matrix ├── requirements.txt # Lists all required libraries and dependencies └── README.md # Project README file`
- Genres: Movie genres such as Action, Drama, Comedy, etc.
- Keywords: Keywords associated with the movie plot.
- Cast: Top 3 cast members.
- Crew: Director information.
- Overview: Movie synopsis.
- Production Companies: Top 3 production companies involved in the movie.
-
Clone this repository.
-
Install the required packages:
bash
Copy code
pip install -r requirements.txt -
Add your TMDb API key to a
.envfile:plaintext
Copy code
API_KEY=your_tmdb_api_key
The datasets used in this project are:
tmdb_5000_credits.csv: Contains cast and crew information for each movie.tmdb_5000_movies.csv: Contains movie metadata such as genres, keywords, and overview.
The data processing pipeline is modularized into different scripts:
- Load Data: Reads and merges the
tmdb_5000_creditsandtmdb_5000_moviesdatasets. - Clean Data: Removes missing values and duplicates.
- Feature Engineering:
- Extracts and processes fields like genres, keywords, cast, crew, and production companies.
- Combines these features into a single
tagscolumn for easier vectorization.
- Text Processing:
- Stemming: Reduces words to their root forms for consistency.
- Vectorization: Uses TF-IDF on the
tagsfield to create a matrix of features.
- Cosine Similarity: Calculates cosine similarity between movies to find the most similar movies for recommendations.
convert_list: Extracts names from JSON-like fields for genres and keywords.convert_top3: Extracts the top 3 entries for cast and production companies.fetch_director: Extracts director information from the crew.create_tags_column: Combines features into a singletagscolumn for each movie.apply_stemming: Applies stemming to thetagsfield.vectorize_tags: Vectorizes thetagsusing TF-IDF.
- movie_dict.pkl: Dictionary of movies and their associated data.
- sparse_cosine_sim.pkl: Sparse cosine similarity matrix for recommendations.
The recommendation system is built using cosine similarity. Here’s how it works:
- Cosine Similarity Matrix: Measures similarity between movies based on the
tagscolumn. - Sparse Matrix: Only the top 10 similar movies are retained for efficiency.
- Recommendation Function: Returns the titles and posters of the top 9 most similar movies.
- Saving Model: The processed data (
movie_dict.pkl) and similarity matrix (sparse_cosine_sim.pkl) are saved for future use.
The Streamlit app serves as the frontend for the recommendation system:
- Movie Selection: Users select a movie title from a dropdown menu.
- Recommendations: Upon clicking "Recommend," the app displays the top 9 recommended movies along with their posters.
fetch_poster(movie_id): Fetches the movie poster from TMDb API using the movie ID.recommend(movie, movies, similarity): Generates recommendations based on cosine similarity.load_model_data(): Loads the similarity matrix and movie data from pickle files.build_streamlit_app(): Constructs the Streamlit interface.
To run the Streamlit app:
bash
Copy code
streamlit run app.py
The main function in app.py runs the data loading, preprocessing, and recommendation flow:
python
Copy code
main('tmdb_5000_credits.csv', 'tmdb_5000_movies.csv', 'Avatar')
This script loads the data, processes it, calculates similarities, and recommends movies based on the provided movie title.
Here’s an updated README.md file that includes all the sections from your code:
python
Copy code
`# Fetch recommendations for a movie recommend('Avatar', new_movies_df, similarity)``
- Python 3.7+
- Libraries:
pandas,numpy,requests,streamlit,scikit-learn,python-dotenv,scipy``nltk - TMDb API Key: Required to fetch movie posters.
- Collaborative Filtering: Combine with collaborative filtering for better recommendations.
- Improved NLP: Implement lemmatization and additional preprocessing.
- Enhanced UI: Add more filtering options, such as genre-based recommendations.
- GitHub Repository: Movie Recommendation System
- Website: Live Demo