
- 4214 GCS_Beijing_1954
- 4326 GCS_WGS_1984
- 4490 GCS_China_Geodetic_Coordinate_System_2000 4555 GCS_New_Beijing
- 4610 GCS_Xian_1980
根据国家规定,推荐使用CGCS2000的投影坐标系
将要素类从地理数据库粘贴到要素数据集中将返回以下消息:
“无法粘贴 <要素类> 空间参考不匹配”
![[O-Image] Failed to paste The spatial references do not match](https://raw.githubusercontent.com/xiaoyinshang/blogImage/main/202310121627830.png)
当源和目标要素类之间存在不同的范围、分辨率和容差值时,将会出现此问题。
错误消息的后半部分“空间参考不匹配”适用于 X 和 Y 坐标、XY 容差、XY 分辨率以及 Z 或 M 分辨率。 要确保数据在所有这些区域中具有相同的属性,请使用以下步骤:
- 将数据加载到地理数据库中的相同要素数据集。
- 使用从源要素类导入的坐标系来创建新要素数据集。
- 要将要素类导入或复制到新创建的要素数据集,请使用“要素类至要素类”或“要素类至地理数据库”地理处理工具。
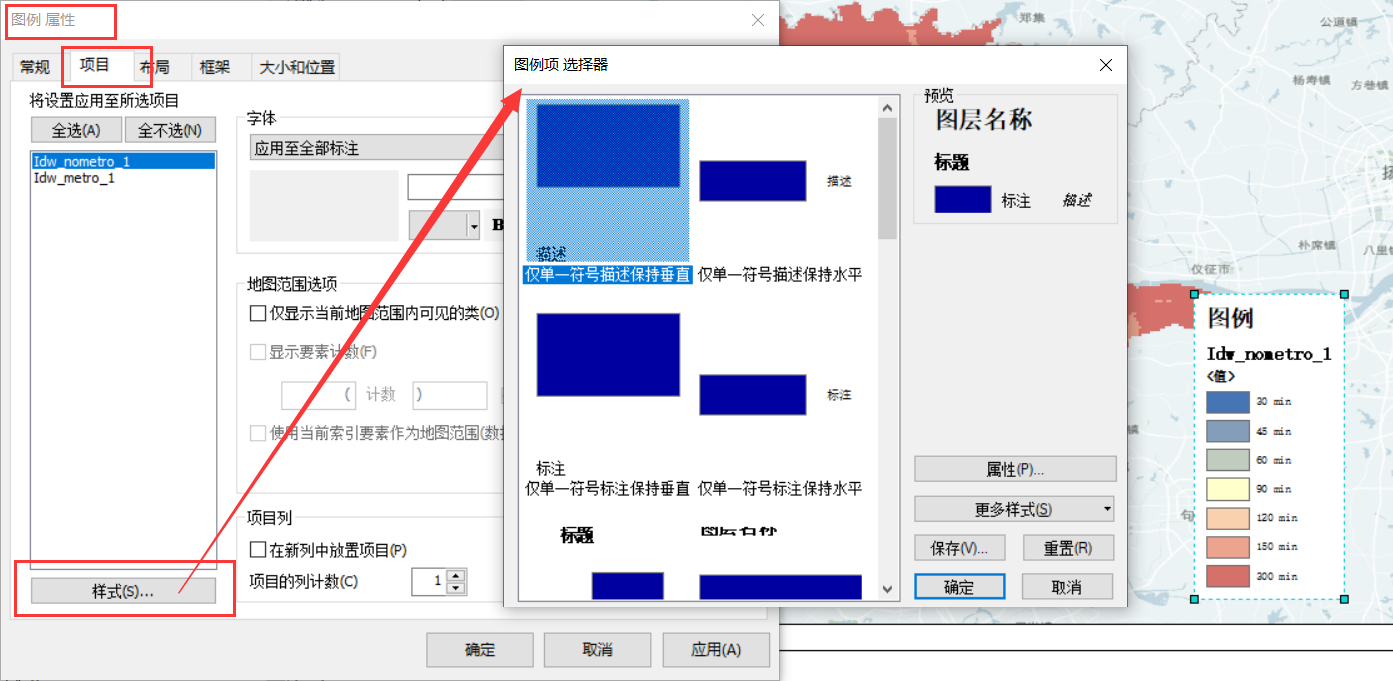
使用ArcGIS 自动插入图例时候,经常会遇到很多问题,而修改图例样式的时候又比较耗费时间,所以很多时候,大家往往会直接将图例转成graphics,直接以图形的方式编辑图例,这样会带来一个严重的问题,那就是一旦修改了地图的颜色、专题样式等内容时,必须再重新制作图例。我在研究了图例功能后,做了如下总结。
1、插入图例后,如果有不满意的地方,不要着急重新生成图例或者转为图形,右击图例->属性,一般你想要的结果都可以在这里面修改
2、删除legend下面的图层名称及字段名称,也可以在属性对话框中进行,点击“items”选项卡,选择你需要修改的图层,点击“style...”,选择你想要的样式即可。这样做出来的图例可以反复使用,更改了地图样式后,图例也会自动更新。
- 同一篇文章的图片颜色要注意色调的整体性,不宜出现特别鲜明刺眼的颜色(尤其是荧光绿 XD)。
- 同一张图片色系最好统一,看起来会更加协调。
- 同一个指标在全篇图片中最好都使用同一个颜色贯彻始终。
- 一般用红色表示上调,绿色/蓝色表示下调。
- 可以用渐变色来表示程度,颜色越深越多,颜色越浅越少,能够使数据显示更加直观。
-
分辨率:通常,分辨率期刊会有规定,但肯定是适度地好,分辨率约3000*3000以上,1200dpi不建议,建议300dpi,很多人使用72dpi,PS新建面板默认的是72dpi。
-
图片格式:多数期刊要求图片为 TIFF 格式或 EPS 矢量图,导出的时候尽量多导出几版,JPG、PNG的发给导师看。
-
颜色:配色这东西可太重要了,无奈我对画画一点天赋也没有,也不懂色彩搭配,通常都是各种试,唯一的缺点是浪费时间而且也不一定会好看。建议:一定选用浅色搭配,特别花里胡哨的并不建议。 参考:https://blog.csdn.net/weixin_42638388/article/details/104439779









红黑这种万能,而且不犯错的搭配方法,Science也是经常使用的。一般红色用于重点数据线,黑色用于参考线。
如果你用腻了红黑,可以试试上面的红蓝配色。将颜色的饱和度略微降低,看起来就不会那么死板了。
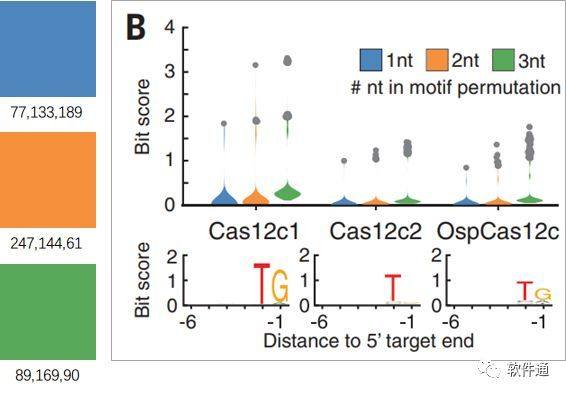
上面的方案是最常见的了,简单直接。往往用于平行实验数据,无须突出某一数据,比如重复实验、平行实验等等。
一暖二冷,更能突出重点
形成对比,是数据展示最重要的作用了。毋庸置疑,通过颜色区分是更高效的。Science最喜欢用上面的冷暖色搭配了,红色和深浅蓝色搭配,相当和谐。
到了五种颜色以上,确实很难搭配。说实话颜色都不够用了,而且整体看起来也会很乱,主次不分,上图就是最好的例子。选的颜色都很清晰,但放在一起就很不美观。
**▍万能的灰色:**254种灰色用不完,用来衬托主题最好不过了,用作背景色、参考色也是首先。
灰色衬托主色
经典多色搭配1
图片来源:Lézine et al., Science 363, 177–181 (2019)
经典多色搭配2
图片来源:Akilesh et al., Science 363, 142 (2019)
看看上面两个正面例子后,不知你发现没有:它们都要灰色做主色或背景色,彩色种类虽多,但是面积小。
这种留白处理,非常值得我们借鉴。不仅层次分明,重点突出,又简约大方。
Jupyter Notebook是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。——Jupyter Notebook官方介绍
简而言之,Jupyter Notebook是以网页的形式打开,可以在网页页面中直接编写代码和运行代码,代码的运行结果也会直接在代码块下显示。如在编程过程中需要编写说明文档,可在同一个页面中直接编写,便于作及时的说明和解释。
网页应用即基于网页形式的、结合了编写说明文档、数学公式、交互计算和其他富媒体形式的工具。简言之,网页应用是可以实现各种功能的工具。
即Jupyter Notebook中所有交互计算、编写说明文档、数学公式、图片以及其他富媒体形式的输入和输出,都是以文档的形式体现的。
这些文档是保存为后缀名为.ipynb的JSON格式文件,不仅便于版本控制,也方便与他人共享。
此外,文档还可以导出为:HTML、LaTeX、PDF等格式。
-
编程时具有语法高亮、缩进、tab补全的功能。
-
可直接通过浏览器运行代码,同时在代码块下方展示运行结果。
-
以富媒体格式展示计算结果。富媒体格式包括:HTML,LaTeX,PNG,SVG等。
-
对代码编写说明文档或语句时,支持Markdown语法。
-
支持使用LaTeX编写数学性说明。
如果看了以上对Jupyter Notebook的介绍你还是拿不定主意究竟是否适合你,那么不要担心,你可以先免安装试用体验一下,戳这里(https://try.jupyter.org/),然后再做决定。
值得注意的是,官方提供的同时试用是有限的,如果你点击链接之后进入的页面如下图所示,那么不要着急,过会儿再试试看吧。
安装Jupyter Notebook的前提是需要安装了Python(3.3版本及以上,或2.7版本)。
如果你是小白,那么建议你通过安装Anaconda来解决Jupyter Notebook的安装问题,因为Anaconda已经自动为你安装了Jupter Notebook及其他工具,还有python中超过180个科学包及其依赖项。
你可以通过进入Anaconda的官方下载页面自行选择下载;如果你对阅读英文文档感到头痛,或者对安装步骤一无所知,甚至也想快速了解一下什么是Anaconda,那么可以前往我的另一篇文章Anaconda介绍、安装及使用教程。你想要的,都在里面!
常规来说,安装了Anaconda发行版时已经自动为你安装了Jupyter Notebook的,但如果没有自动安装,那么就在终端(Linux或macOS的“终端”,Windows的“Anaconda Prompt”,以下均简称“终端”)中输入以下命令安装:
conda install jupyter notebook
如果你是有经验的Python玩家,想要尝试用pip命令来安装Jupyter Notebook,那么请看以下步骤吧!接下来的命令都输入在终端当中的噢!
- 把pip升级到最新版本
- Python 3.x
pip3 install --upgrade pip
- Python 2.x
pip install --upgrade pip
- 注意:老版本的pip在安装Jupyter Notebook过程中或面临依赖项无法同步安装的问题。因此强烈建议先把pip升级到最新版本。
- 安装Jupyter Notebook
- Python 3.x
pip3 install jupyter
- Python 2.x
pip install jupyter
如果你有任何jupyter notebook命令的疑问,可以考虑查看官方帮助文档,命令如下:
jupyter notebook --help
或
jupyter notebook -h
在终端中输入以下命令:
jupyter notebook
执行命令之后,在终端中将会显示一系列notebook的服务器信息,同时浏览器将会自动启动Jupyter Notebook。
启动过程中终端显示内容如下:
$ jupyter notebook
[I 08:58:24.417 NotebookApp] Serving notebooks from local directory: /Users/catherine
[I 08:58:24.417 NotebookApp] 0 active kernels
[I 08:58:24.417 NotebookApp] The Jupyter Notebook is running at: http://localhost:8888/
[I 08:58:24.417 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
- 注意:之后在Jupyter Notebook的所有操作,都请保持终端不要关闭,因为一旦关闭终端,就会断开与本地服务器的链接,你将无法在Jupyter Notebook中进行其他操作啦。
浏览器地址栏中默认地将会显示:http://localhost:8888。其中,“localhost”指的是本机,“8888”则是端口号。

URL
如果你同时启动了多个Jupyter Notebook,由于默认端口“8888”被占用,因此地址栏中的数字将从“8888”起,每多启动一个Jupyter Notebook数字就加1,如“8889”、“8890”……
如果你想自定义端口号来启动Jupyter Notebook,可以在终端中输入以下命令:
jupyter notebook --port <port_number>
其中,“<port_number>”是自定义端口号,直接以数字的形式写在命令当中,数字两边不加尖括号“<>”。如:jupyter notebook --port 9999,即在端口号为“9999”的服务器启动Jupyter Notebook。
如果你只是想启动Jupyter Notebook的服务器但不打算立刻进入到主页面,那么就无需立刻启动浏览器。在终端中输入:
jupyter notebook --no-browser
此时,将会在终端显示启动的服务器信息,并在服务器启动之后,显示出打开浏览器页面的链接。当你需要启动浏览器页面时,只需要复制链接,并粘贴在浏览器的地址栏中,轻按回车变转到了你的Jupyter Notebook页面。
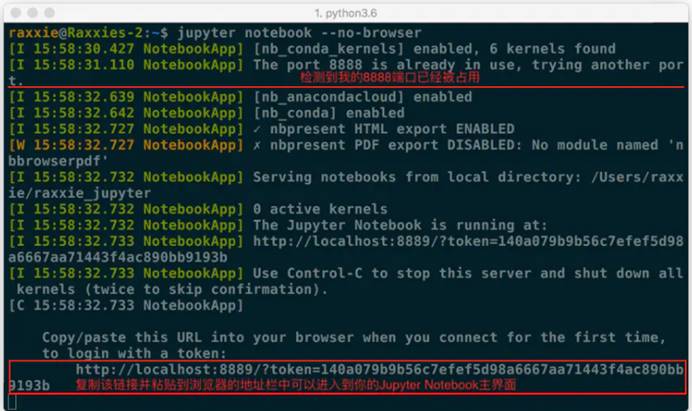
no_browser
例图中由于在完成上面内容时我同时启动了多个Jupyter Notebook,因此显示我的“8888”端口号被占用,最终分配给我的是“8889”。
当执行完启动命令之后,浏览器将会进入到Notebook的主页面,如下图所示。
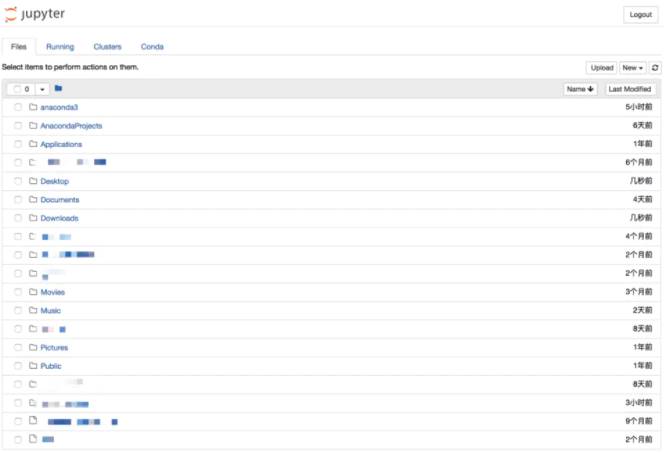
Notebook Dashboard
如果你的主页面里边的文件夹跟我的不同,或者你在疑惑为什么首次启动里边就已经有这么多文件夹,不要担心,这里边的文件夹全都是你的家目录里的目录文件。你可以在终端中执行以下2步来查看:
① cd 或 cd - 或 cd ~ 或cd /Users/<user_name>
- 这个命令将会进入你的家目录。
- “<user_name>” 是用户名。用户名两边不加尖括号“<>”。
② ls
- 这个命令将会展示你家目录下的文件。
如果你不想把今后在Jupyter Notebook中编写的所有文档都直接保存在家目录下,那你需要修改Jupyter Notebook的文件存放路径。
· Windows用户在想要存放Jupyter Notebook文件的磁盘中新建文件夹并为该文件夹命名;双击进入该文件夹,然后复制地址栏中的路径。
· Linux/macOS用户在想要存放Jupyter Notebook文件的位置创建目录并为目录命名,命令为:mkdir <directory_name>;进入目录,命令为:cd <directory_name>;查看目录的路径,命令为:pwd;复制该路径。
· 注意:“<directory_name>”是自定义的目录名。目录名两边不加尖括号“<>”。
- 一个便捷获取配置文件所在路径的命令:
jupyter notebook --generate-config
- 注意: 这条命令虽然可以用于查看配置文件所在的路径,但主要用途是是否将这个路径下的配置文件替换为默认配置文件。 如果你是第一次查询,那么或许不会出现下图的提示;若文件已经存在或被修改,使用这个命令之后会出现询问“Overwrite /Users/raxxie/.jupyter/jupyter_notebook_config.py with default config? [y/N]”,即“用默认配置文件覆盖此路径下的文件吗?”,如果按“y”,则完成覆盖,那么之前所做的修改都将失效;如果只是为了查询路径,那么一定要输入“N”。

命令
常规的情况下,Windows和Linux/macOS的配置文件所在路径和配置文件名如下所述:
- Windows系统的配置文件路径:C:\Users<user_name>.jupyter\
- Linux/macOS系统的配置文件路径:/Users/<user_name>/.jupyter/ 或 ~/.jupyter/
- 配置文件名:jupyter_notebook_config.py
- 注意:
① “<user_name>”为你的用户名。用户名两边不加尖括号“<>”。
② Windows和Linux/macOS系统的配置文件存放路径其实是相同的,只是系统不同,表现形式有所不同而已。
③ Windows和Linux/macOS系统的配置文件也是相同的。文件名以“.py”结尾,是Python的可执行文件。
④ 如果你不是通过一步到位的方式前往配置文件所在位置,而是一层一层进入文件夹/目录的,那么当你进入家目录后,用ls命令会发现找不到“.jupyter”文件夹/目录。这是因为凡是以“.”开头的目录都是隐藏文件,你可以通过ls -a命令查看当前位置下所有的隐藏文件。
· Windows系统的用户可以使用文档编辑工具或IDE打开“jupyter_notebook_config.py”文件并进行编辑。常用的文档编辑工具和IDE有记事本、Notepad++、vim、Sublime Text、PyCharm等。其中,vim是没有图形界面的,是一款学习曲线较为陡峭的编辑器,其他工具在此不做使用说明,因为上手相对简单。通过vim修改配置文件的方法请继续往下阅读。
· Linux/macOS系统的用户建议直接通过终端调用vim来对配置文件进行修改。具体操作步骤如下:
打开终端,输入命令:
vim ~/.jupyter/jupyter_notebook_config.py

vim打开配置文件
执行上述命令后便进入到配置文件当中了。
进入配置文件后查找关键词“c.NotebookApp.notebook_dir”。查找方法如下:
进入配置文件后不要按其他键,用英文半角直接输入/c.NotebookApp.notebook_dir,这时搜索的关键词已在文档中高亮显示了,按回车,光标从底部切换到文档正文中被查找关键词的首字母。
按小写i进入编辑模式,底部出现“--INSERT--”说明成功进入编辑模式。使用方向键把光标定位在第二个单引号上(光标定位在哪个字符,就在这个字符前开始输入),把“⑴ 创建文件夹/目录”步骤中复制的路径粘贴在此处。
把该行行首的**井号(#)**删除。因为配置文件是Python的可执行文件,在Python中,井号(#)表示注释,即在编译过程中不会执行该行命令,所以为了使修改生效,需要删除井号(#)。
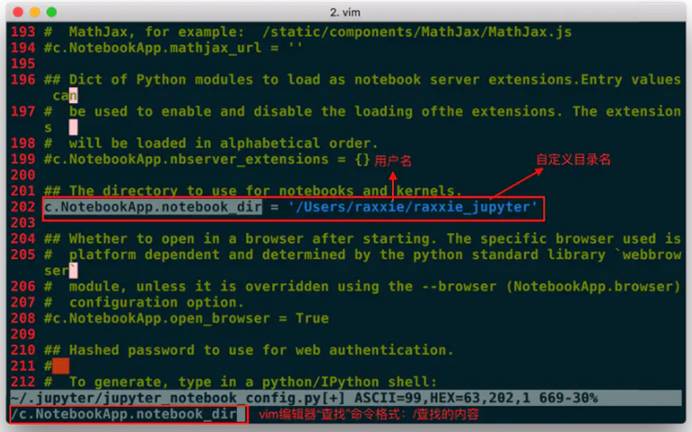
先按ESC键,从编辑模式退出,回到命令模式。
再用英文半角直接输入:wq,回车即成功保存且退出了配置文件。
注意:
- 冒号(:) 一定要有,且也是英文半角。
- w:保存。
- q:退出。
在终端中输入命令jupyter notebook打开Jupyter Notebook,此时你会看到一个清爽的界面,恭喜!
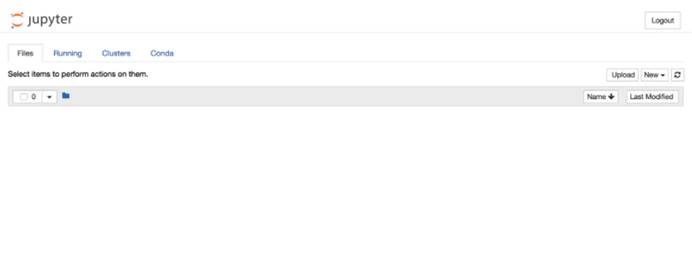
modified
· 以上所有命令均以英文半角格式输入,若有报错,请严格检查这两个条件,英文且半角。
· 这里仅介绍了vim编辑器修改配置文件的方法,没有对vim编辑器的详细使用进行讲解,所以无需了解vim编辑器的具体使用方法,只需要按照上述步骤一定可以顺利完成修改!
· 推荐有时间和经历时学习一下vim编辑器的使用。这款强大的编辑器将会成为你未来工作中的利器。
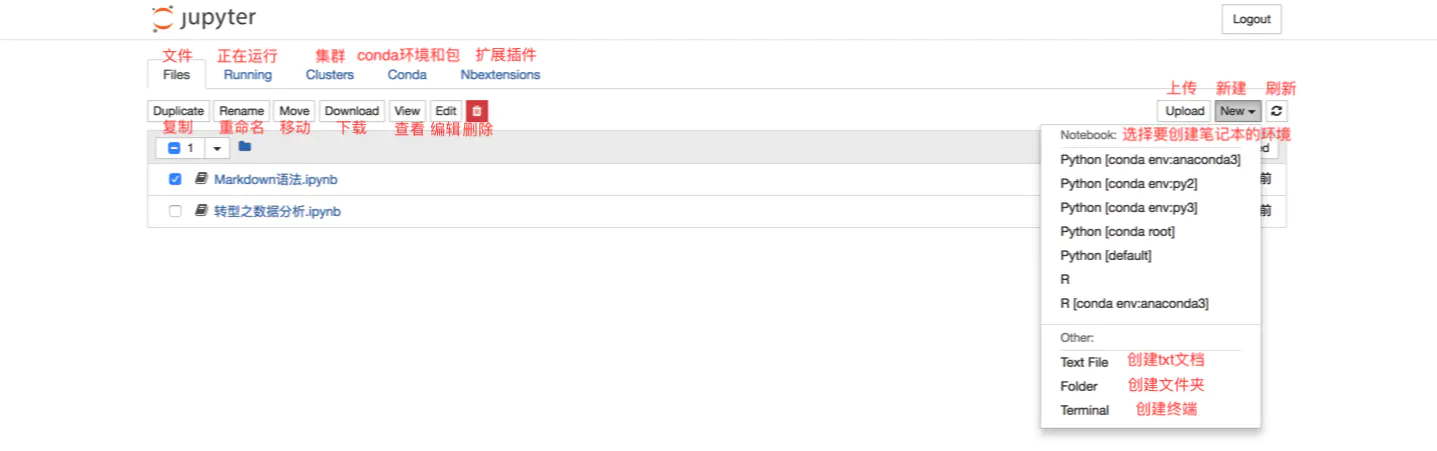
Files页面
此时你的界面当中应该还没有“Conda”和“Nbextensions”类目。不要着急,这两个类目将分别在“五、拓展功能”中的“1.关联Jupyter Notebook和conda的环境和包——‘nb_conda’”和“2.Markdown生成目录”中安装。
Files页面是用于管理和创建文件相关的类目。
对于现有的文件,可以通过勾选文件的方式,对选中文件进行复制、重命名、移动、下载、查看、编辑和删除的操作。
同时,也可以根据需要,在“New”下拉列表中选择想要创建文件的环境,进行创建“ipynb”格式的笔记本、“txt”格式的文档、终端或文件夹。如果你创建的环境没有在下拉列表中显示,那么你需要依次前往“五、拓展功能”中的“1.关联Jupyter Notebook和conda的环境和包——‘nb_conda’”和“六、增加内核——‘ipykernel’”中解决该问题。
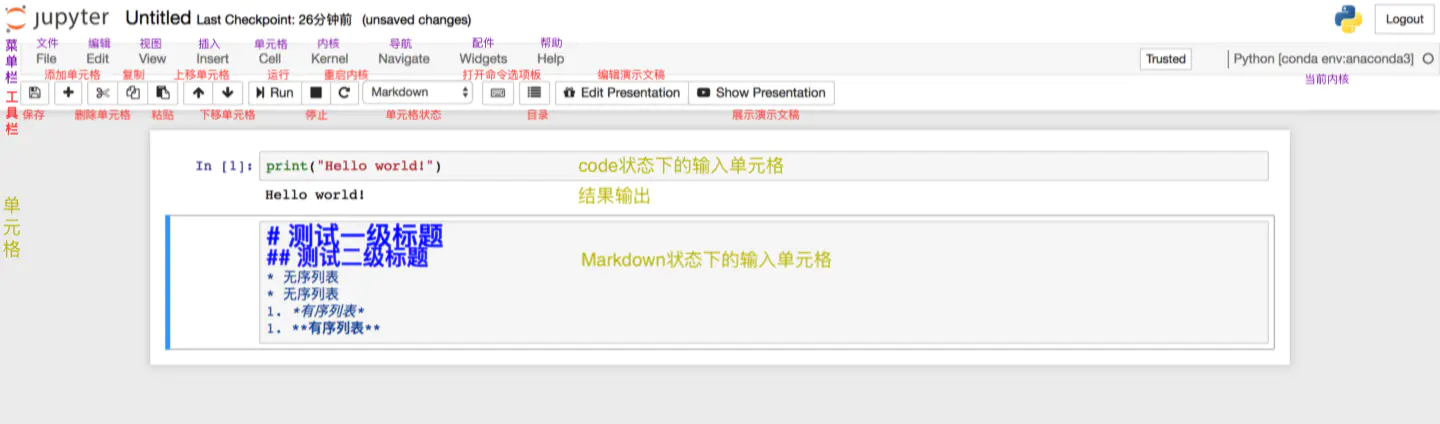
笔记本的使用
上图展示的是笔记本的基本结构和功能。根据图中的注解已经可以解决绝大多数的使用问题了!
工具栏的使用如图中的注解一样直观,在此不过多解释。需要特别说明的是“单元格的状态”,有Code,Markdown,Heading,Raw NBconvert。其中,最常用的是前两个,分别是代码状态,Markdown编写状态。Jupyter Notebook已经取消了Heading状态,即标题单元格。取而代之的是Markdown的一级至六级标题。而Raw NBconvert目前极少用到,此处也不做过多讲解。
菜单栏涵盖了笔记本的所有功能,即便是工具栏的功能,也都可以在菜单栏的类目里找到。然而,并不是所有功能都是常用的,比如Widgets,Navigate。Kernel类目的使用,主要是对内核的操作,比如中断、重启、连接、关闭、切换内核等,由于我们在创建笔记本时已经选择了内核,因此切换内核的操作便于我们在使用笔记本时切换到我们想要的内核环境中去。由于其他的功能相对比较常规,根据图中的注解来尝试使用笔记本的功能已经非常便捷,因此不再做详细讲解。
在使用笔记本时,可以直接在其内部进行重命名。在左上方“Jupyter”的图标旁有程序默认的标题“Untitled”,点击“Untitled”然后在弹出的对话框中输入自拟的标题,点击“Rename”即完成了重命名。
若在使用笔记本时忘记了重命名,且已经保存并退出至“Files”界面,则在“Files”界面勾选需要重命名的文件,点击“Rename”然后直接输入自拟的标题即可。
Running页面主要展示的是当前正在运行当中的终端和“ipynb”格式的笔记本。若想要关闭已经打开的终端和“ipynb”格式的笔记本,仅仅关闭其页面是无法彻底退出程序的,需要在Running页面点击其对应的“Shutdown”。更多关闭方法可以查阅“八、关闭和退出”中的“1.关闭笔记本和终端”
Clusters tab is now provided by IPython parallel. See 'IPython parallel' for installation details.
Clusters类目现在已由IPython parallel对接,且由于现阶段使用频率较低,因此在此不做详细说明,想要了解更多可以访问IPython parallel的官方网站。
Conda页面主要是Jupyter Notebook与Conda关联之后对Conda环境和包进行直接操作和管理的页面工具。详细信息请直接查阅“五、拓展功能”中的“1.关联Jupyter Notebook和conda的环境和包——‘nb_conda’”。这是目前使用Jupyter Notebook的必备环节,因此请务必查阅。
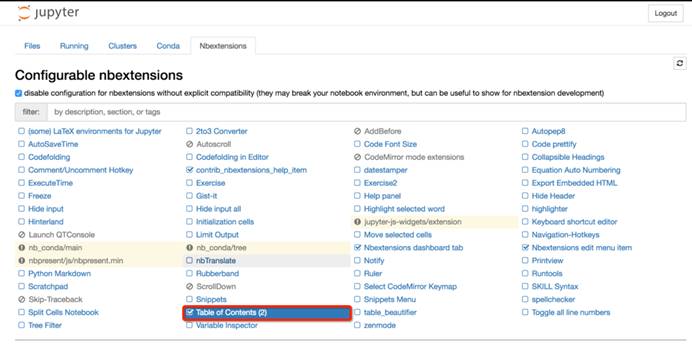
nbextensions
Nbextensions页面提供了多个Jupyter Notebook的插件,使其功能更加强大。该页面中主要使用的插件有nb_conda,nb_present,Table of Contents(2)。这些功能我们无需完全掌握,也无需安装所有的扩展功能,根据本文档提供的学习思路,我们只需要安装Talbe of Contents(2)即可,该功能可为Markdown文档提供目录导航,便于我们编写文档。该安装指导请查阅“五、拓展功能”中的“2.Markdown生成目录”。
conda install nb_conda
执行上述命令能够将你conda创建的环境与Jupyter Notebook相关联,便于你在Jupyter Notebook的使用中,在不同的环境下创建笔记本进行工作。
· 可以在Conda类目下对conda环境和包进行一系列操作。
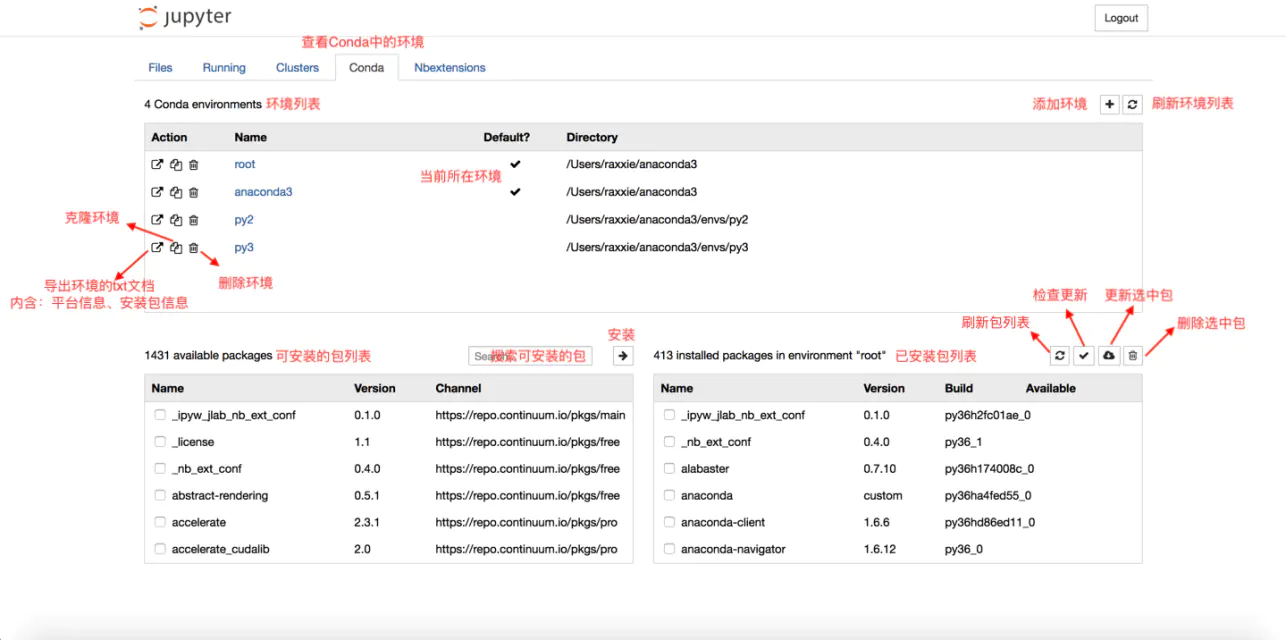
conda类目
· 可以在笔记本内的“Kernel”类目里的“Change kernel”切换内核。
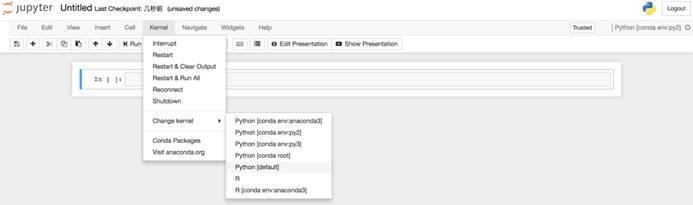
切换内核
conda remove nb_conda
执行上述命令即可卸载nb_conda包。
- 不同于有道云笔记的Markdown编译器,Jupyter Notebook无法为Markdown文档通过特定语法添加目录,因此需要通过安装扩展来实现目录的添加。
conda install -c conda-forge jupyter_contrib_nbextensions
· 执行上述命令后,启动Jupyter Notebook,你会发现导航栏多了“Nbextensions”的类目,点击“Nbextensions”,勾选“Table of Contents ⑵”
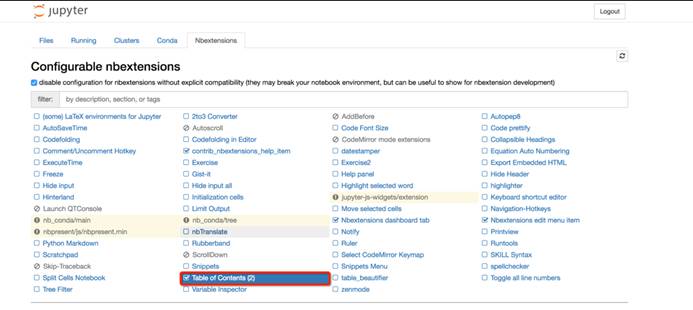
Nbextensions
· 之后再在Jupyter Notebook中使用Markdown,点击下图的图标即可使用啦。
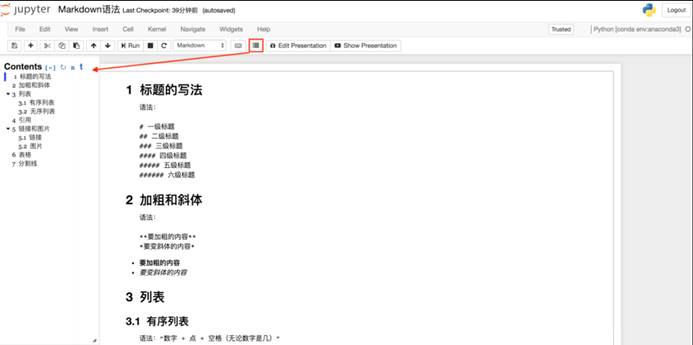
添加目录
在使用Markdown编辑文档时,难免会遇到需要在文中设定链接,定位在文档中的其他位置便于查看。因为Markdown可以完美的兼容html语法,因此这种功能可以通过html语法当中“a标签”的索引用法来实现。
语法格式如下:
[添加链接的正文](#自定义索引词)
<a id=自定义索引词>跳转提示</a>
· 注意:
- 语法格式当中所有的符号均是英文半角。
- “自定义索引词”最好是英文,较长的词可以用下划线连接。
- “a标签”出现在想要被跳转到的文章位置,html标签除了单标签外均要符合“有头()必有尾()”的原则。头尾之间的“跳转提示”是可有可无的。
- “a标签”中的“id”值即是为正文中添加链接时设定的“自定义索引值”,这里通过“id”的值实现从正文的链接跳转至指定位置的功能。
想要在Jupyter Notebook中直接加载指定网站的源代码到笔记本中。
执行以下命令:
%load URL
其中,URL为指定网站的地址。
想在Jupyter Notebook中加载本地的Python文件并执行文件代码。
执行以下命令:
%load Python文件的绝对路径
- Python文件的后缀为“.py”。
- “%load”后跟的是Python文件的绝对路径。
- 输入命令后,可以按
CTRL ``回车来执行命令。第一次执行,是将本地的Python文件内容加载到单元格内。此时,Jupyter Notebook会自动将“%load”命令注释掉(即在前边加井号“#”),以便在执行已加载的文件代码时不重复执行该命令;第二次执行,则是执行已加载文件的代码。
不想在Jupyter Notebook的单元格中加载本地Python文件,想要直接运行。
执行命令:
%run Python文件的绝对路径
或
!python3 Python文件的绝对路径
或
!python Python文件的绝对路径
- Python文件的后缀为“.py”。
- “%run”后跟的是Python文件的绝对路径。
- “!python3”用于执行Python 3.x版本的代码。
- “!python”用于执行Python 2.x版本的代码。
- “!python3”和“!python”属于
!shell``命令语法的使用,即在Jupyter Notebook中执行shell命令的语法。 - 输入命令后,可以按
CTRL ``回车来执行命令,执行过程中将不显示本地Python文件的内容,直接显示运行结果。
想要在Jupyter Notebook中获取当前所在位置的绝对路径。
%pwd
或
!pwd
- 获取的位置是当前Jupyter Notebook中创建的笔记本所在位置,且该位置为绝对路径。
- “!pwd”属于
!shell``命令语法的使用,即在Jupyter Notebook中执行shell命令的语法。
!shell命令
- 在Jupyter Notebook中的笔记本单元格中用英文感叹号“!”后接shell命令即可执行shell命令。
在Jupyter Notebook主界面,即“File”界面中点击“New”;在“New”下拉框中点击“Terminal”即新建了终端。此时终端位置是在你的家目录,可以通过pwd命令查询当前所在位置的绝对路径。
在Jupyter Notebook的“Running”界面中的“Terminals”类目中可以看到正在运行的终端,点击后边的“Shutdown”即可关闭终端。
在Jupyter Notebook的笔记本中无论是编写文档还是编程,都有输入(In [])和输出(Out [])。当我们编写的代码或文档使用的单元格较多时,有时我们只想关注输出的内容而暂时不看输入的内容,这时就需要隐藏输入单元格而只显示输出单元格。
from IPython.display import display
from IPython.display import HTML
import IPython.core.display as di # Example: di.display_html('<h3>%s:</h3>' % str, raw=True)
# 这行代码的作用是:当文档作为HTML格式输出时,将会默认隐藏输入单元格。
di.display_html('<script>jQuery(function() {if (jQuery("body.notebook_app").length == 0) { jQuery(".input_area").toggle(); jQuery(".prompt").toggle();}});</script>', raw=True)
# 这行代码将会添加“Toggle code”按钮来切换“隐藏/显示”输入单元格。
di.display_html('''<button onclick="jQuery('.input_area').toggle(); jQuery('.prompt').toggle();">Toggle code</button>''', raw=True)
在笔记本第一个单元格中输入以上代码,然后执行,即可在该文档中使用“隐藏/显示”输入单元格功能。
· 缺陷:此方法不能很好的适用于Markdown单元格。
from IPython.display import HTML
HTML('''<script>
code_show=true;
function code_toggle() {
if (code_show){
$('div.input').hide();
} else {
$('div.input').show();
}
code_show = !code_show
}
$( document ).ready(code_toggle);
</script>
<form action="javascript:code_toggle()"><input type="submit" value="Click here to toggle on/off the raw code."></form>''')
在笔记本第一个单元格中输入以上代码,然后执行,即可在该文档中使用“隐藏/显示”输入单元格功能。
- 缺陷:此方法不能很好的适用于Markdown单元格。
由于目前暂时用不到过多的魔术命令,因此暂时先参考官网的文档。
\1. 场景一:同时用不同版本的Python进行工作,在Jupyter Notebook中无法切换,即“New”的下拉菜单中无法使用需要的环境。
\2. 场景二:创建了不同的虚拟环境(或许具有相同的Python版本但安装的包不同),在Jupyter Notebook中无法切换,即“New”的下拉菜单中无法使用需要的环境。
接下来将分别用“命令行模式”和“图形界面模式”来解决以上两个场景的问题。顾名思义,“命令行模式”即在终端中通过执行命令来一步步解决问题;“图形界面模式”则是通过在Jupyter Notebook的网页中通过鼠标点击的方式解决上述问题。
其中,“图形界面模式”的解决方法相对比较简单快捷,如果对于急于解决问题,不需要知道运行原理的朋友,可以直接进入“3. 解决方法之图形界面模式”来阅读。
“命令行模式”看似比较复杂,且又划分了使用场景,但通过这种方式来解决问题可以更好的了解其中的工作原理,比如,每进行一步操作对应的命令是什么,而命令的执行是为了达到什么样的目的,这些可能都被封装在图形界面上的一个点击动作来完成了。对于想更深入了解其运作过程的朋友,可以接着向下阅读。
- 首先安装Python 2的ipykernel包。
python2 -m pip install ipykernel
- 再为当前用户安装Python 2的内核(ipykernel)。
python2 -m ipykernel install --user
- 注意:“--user”参数的意思是针对当前用户安装,而非系统范围内安装。
- 首先创建Python版本为2.x且具有ipykernel的新环境,其中“<env_name>”为自定义环境名,环境名两边不加尖括号“<>”。
conda create -n <env_name> python=2 ipykernel
- 然后切换至新创建的环境。
Windows: activate <env_name>
Linux/macOS: source activate <env_name>
- 为当前用户安装Python 2的内核(ipykernel)。
python2 -m ipykernel install --user
- 注意:“--user”参数的意思是针对当前用户安装,而非系统范围内安装。
- 首先安装Python 3的ipykernel包。
python3 -m pip install ipykernel
- 再为当前用户安装Python 2的内核(ipykernel)。
python3 -m ipykernel install --user
- 注意:“--user”参数的意思是针对当前用户安装,而非系统范围内安装。
- 首先创建Python版本为3.x且具有ipykernel的新环境,其中“<env_name>”为自定义环境名,环境名两边不加尖括号“<>”。
conda create -n <env_name> python=3 ipykernel
- 然后切换至新创建的环境。
Windows: activate <env_name>
Linux/macOS: source activate <env_name>
- 为当前用户安装Python 3的内核(ipykernel)。
python3 -m ipykernel install --user
- 注意:“--user”参数的意思是针对当前用户安装,而非系统范围内安装。
Windows: activate <env_name>
Linux/macOS: source activate <env_name>
- 注意:“<env_name>”是需要安装内核的环境名称,环境名两边不加尖括号“<>”。
conda list
执行上述命令查看当前环境下安装的包,若没有安装ipykernel包,则执行安装命令;否则进行下一步。
conda install ipykernel
- 若该环境的Python版本为2.x,则执行命令:
python2 -m ipykernel install --user --name <env_name> --display-name "<notebook_name>"
- 若该环境的Python版本为3.x,则执行命令:
python3 -m ipykernel install --user --name <env_name> --display-name "<notebook_name>"
- 注意:
\1. “<env_name>”为当前环境的环境名称。环境名两边不加尖括号“<>”。
\2. “<notebook_name>”为自定义显示在Jupyter Notebook中的名称。名称两边不加尖括号“<>”,但双引号必须加。
\3. “--name”参数的值,即“<env_name>”是Jupyter内部使用的,其目录的存放路径为~/Library/Jupyter/kernels/。如果定义的名称在该路径已经存在,那么将自动覆盖该名称目录的内容。
\4. “--display-name”参数的值是显示在Jupyter Notebook的菜单中的名称。
使用命令jupyter notebook启动Jupyter Notebook;在“Files”下的“New”下拉框中即可找到你在第⑶步中的自定义名称,此时,你便可以尽情地在Jupyter Notebook中切换环境,在不同的环境中创建笔记本进行工作和学习啦!
① 你创建了一个新的环境,但却发现在Jupyter Notebook的“New”中找不到这个环境,无法在该环境中创建笔记本。
② 进入Jupyter Notebook → Conda → 在“Conda environment”中点击你要添加ipykernel包的环境 → 左下方搜索框输入“ipykernel” → 勾选“ipykernel” → 点击搜索框旁的“→”箭头 → 安装完毕 → 右下方框内找到“ipykernel”说明已经安装成功。
③ 在终端CTRL C关闭Jupyter Notebook的服务器然后重启Jupyter Notebook,在“File”的“New”的下拉列表里就可以找到你的环境啦。
| 符号 | Mac按键 | Windows按键 |
|---|---|---|
| ⌘ | command | 无 |
| ⌃ | control | ctrl |
| ⌥ | option | alt |
| ⇧ | shift | shift |
| ↩ | return | return |
| ␣ | space | space |
| ⇥ | tab | tab |
| ⌫ | delete | backspace |
| ⌦ | fn delete | delete |
| - | - | - |
· 命令模式将键盘命令与Jupyter Notebook笔记本命令相结合,可以通过键盘不同键的组合运行笔记本的命令。
· 按esc键进入命令模式。
· 命令模式下,单元格边框为灰色,且左侧边框线为蓝色粗线条。
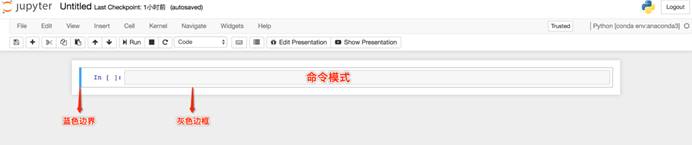
命令模式
· 编辑模式使用户可以在单元格内编辑代码或文档。
· 按enter或return键进入编辑模式。
· 编辑模式下,单元格边框和左侧边框线均为绿色。
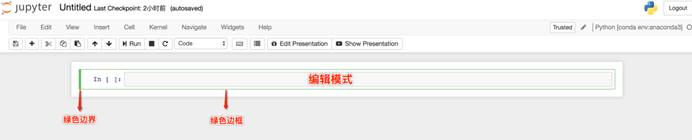
编辑模式
① 进入Jupyter Notebook主界面“File”中。
② 在“New”的下拉列表中选择环境创建一个笔记本。
③ 点击“Help”。
④ 点击“Keyboard Shortcuts”。
① 进入Jupyter Notebook主界面“File”中。
② 在“New”的下拉列表中选择环境创建一个笔记本。
③ 点击“Help”。
④ 点击“Keyboard Shortcuts”。
⑤ 弹出的对话框中“Command Mode (press Esc to enable)”旁点击“Edit Shortcuts”按钮。
① 进入Jupyter Notebook主界面“File”中。
② 在“New”的下拉列表中选择环境创建一个笔记本。
③ 点击“Help”。
④ 点击“Edit Keyboard Shortcuts”。
当我们在Jupyter Notebook中创建了终端或笔记本时,将会弹出新的窗口来运行终端或笔记本。当我们使用完毕想要退出终端或笔记本时,仅仅关闭页面是无法结束程序运行的,因此我们需要通过以下步骤将其完全关闭。
⑴ 进入“Files”页面。
⑵ 勾选想要关闭的“ipynb”笔记本。正在运行的笔记本其图标为绿色,且后边标有“Running”的字样;已经关闭的笔记本其图标为灰色。
⑶ 点击上方的黄色的“Shutdown”按钮。
⑷ 成功关闭笔记本。
- 注意:此方法只能关闭笔记本,无法关闭终端。
⑴ 进入“Running”页面。
⑵ 第一栏是“Terminals”,即所有正在运行的终端均会在此显示;第二栏是“Notebooks”,即所有正在运行的“ipynb”笔记本均会在此显示。
⑶ 点击想要关闭的终端或笔记本后黄色“Shutdown”按钮。
⑷ 成功关闭终端或笔记本。
- 注意:此方法可以关闭任何正在运行的终端和笔记本。
⑴ 只有“ipynb”笔记本和终端需要通过上述方法才能使其结束运行。
⑵ “txt”文档,即“New”下拉列表中的“Text File”,以及“Folder”只要关闭程序运行的页面即结束运行,无需通过上述步骤关闭。
如果你想退出Jupyter Notebook程序,仅仅通过关闭网页是无法退出的,因为当你打开Jupyter Notebook时,其实是启动了它的服务器。
你可以尝试关闭页面,并打开新的浏览器页面,把之前的地址输进地址栏,然后跳转页面,你会发现再次进入了刚才“关闭”的Jupyter Notebook页面。
如果你忘记了刚才关闭的页面地址,可以在启动Jupyter Notebook的终端中找到地址,复制并粘贴至新的浏览器页面的地址栏,会发现同样能够进入刚才关闭的页面。
因此,想要彻底退出Jupyter Notebook,需要关闭它的服务器。只需要在它启动的终端上按:
- Mac用户:
control c - Windows用户:
ctrl c
然后在终端上会提示:“Shutdown this notebook server (y/[n])?”输入y即可关闭服务器,这才是彻底退出了Jupyter Notebook程序。此时,如果你想要通过输入刚才关闭网页的网址进行访问Jupyter Notebook便会看到报错页面。
-
知乎:jupyter notebook 可以做哪些事情?猴子的回答
作者:Raxxie 链接:https://www.jianshu.com/p/91365f343585 来源:简书 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
windows删除jupyter notebook 没办法的办法
pip uninstall jupyter -y pip uninstall jupyter_core -y pip uninstall jupyter-client -y pip uninstall jupyter-console -y pip uninstall notebook -y pip uninstall qtconsole -y pip uninstall nbconvert -y pip uninstall nbformat -y
好久不见各位~
今天给大家带来炫酷MapBox的具体应用!
相信大家在绘制平面类分析图时都遇到过地图获取的问题
在此之前我们也提供给了其他的类型的方式来绘制分析底图~
如百度个性地图http://developer.baidu.com/map/custom/、谷歌个性地图
但是真要说到可操控性,可调整性,非MapBox莫属
参考技术文档https://docs.mapbox.com/help/tutorials/mapbox-arcgis-qgis/#add-mapbox-maps-in-arcmap
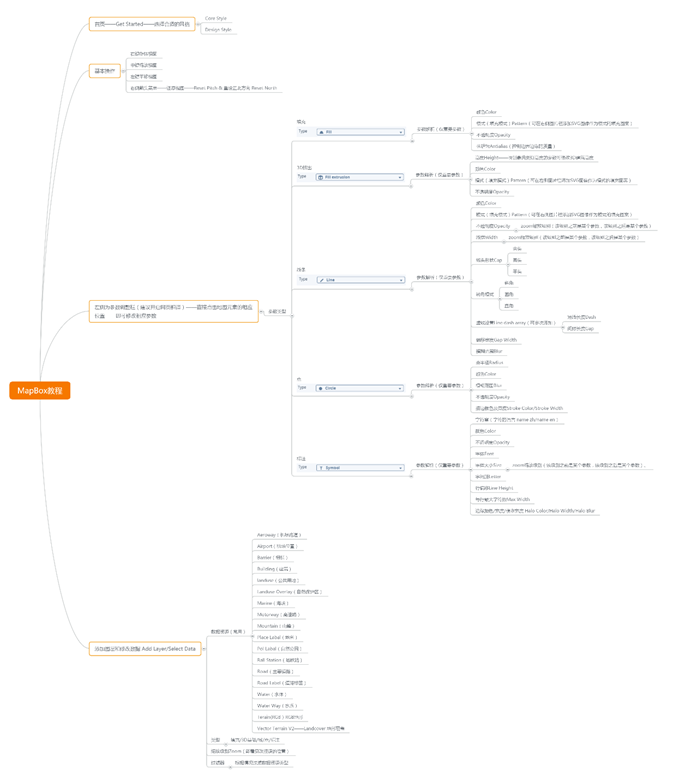
- 在Mapbox Studio中创建新样式或编辑现有样式。https://studio.mapbox.com/
- 完成地图样式编辑后,点击右上角的Share按钮分享,会弹出一个对话框,他的意思就是把这个地图样式分享出去。我们点击**“Third party”第三方**,我们看到了熟悉的ArcGIS字样,而上面标识了这是**“WMTS”服务**。直接复制下面的链接,也就是Integration URL这里,复制这个链接:
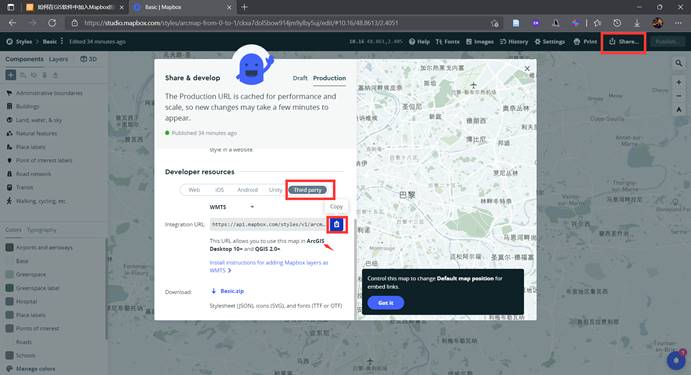
- 打开ArcGIS,进入之后,右侧的工具里面,找到WMTS服务:
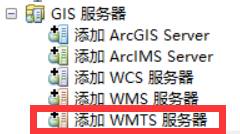
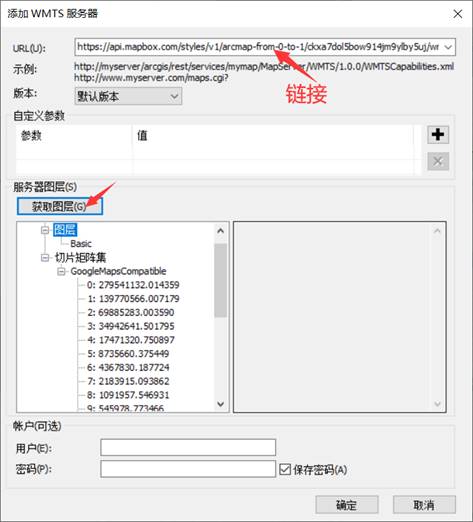
- 双击WMTS服务,把链接复制进去,点击获取图层,然后确定。如果询问你用户名密码,取消即可。这样目录就会出现一个新的Mapbox的api项,双击显示图层,拖到数据框内,即显示已编辑的地图样式。
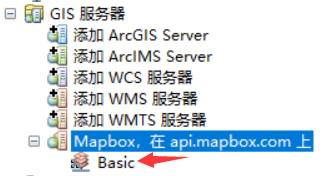
- 若后续在Mapbox Studio 中更新样式,则需要在GIS中刷新服务!
- 其他注意事项:Mapbox是wgs84坐标系,另外mapbox是国外网站,有时候会比较慢,当然,还需注意国界问题,虽然mapbox针对中国地区专门的审核过,但是地图类的东西,用起来还是自己多多留心。
参考技术文档 https://docs.mapbox.com/help/troubleshooting/change-language/
要在“图层”选项卡中更改各个图层的语言,请执行以下操作:
\1. 在Mapbox Studio中创建新样式或编辑现有样式。
- 切换到“Layers”选项卡。
- 选择包含要编辑的标签的图层。
- 在“Text”选项卡下,单击“Text field”。将出现一个面板,其中包含该层的所有语言选项。
- 单击所需的语言;地图将在选择时更新。
$$之间放置公式,使用$$...$$可以使公式居中。
公式中有中文可以用\text{}渲染从而可以插入空格,更美观。
| 公式 | 对应代码 | 对应渲染效果 |
|---|---|---|
| 分数 | \frac{a}{b} | |
| 根号 | \sqrt{2} \sqrt[n]{3} | |
| 下标 | a_b,_c | |
| 上标 | a^{b*c} | |
| 上划线 | \overline{X} | $ \overline{X}$ |
| ^ | \hat{x} | $ \hat{x}$ |
| 矢量 | \vec{a} | |
| 上波浪线 | \tilde{a} | |
| 累和 | \sum | |
| \sum_{i=1}^{n} | ||
| \sum\limits_{i=1}^{m} | ||
| 累积 | \prod | |
| \prod_{i=1}^{m} | ||
| \prod\limits_{i=1}^{m} | ||
| lim | \lim_\limits{n\rightarrow+\infty} n | |
| 积分 | \int ^3_0 | |
| log | \log_2 10 | |
| 向上取整 | \lceil \rceil | |
| 向下取整 | \lfloor \rfloor | |
| max下面添符号 | \max\limits_m | |
| 下括号 | \underbrace{aaa}_{b} | |
| 属于∈ | \in | |
| 并集∪ | \cup | |
| 交集∩ | \cap | |
| 含于⊆ | \subseteq | |
| 不等于 | \ne | |
| 约等于 ≈ | \approx | |
| 小于等于 ≤ | \leq | |
| 大于等于 ≥ | \ge | |
| ± | \pm | |
| ⊕ | \oplus | \oplus |
| × | \times | \times |
| ÷ | \div | \div |
| ∗ | \ast | \ast |
| 无穷 | \infty | |
| ∀ | \forall | \forall |
| ∃ | \exists | \exists |
| {} | \lbrace \rbrace | \lbrace \rbrace |
| ⋅ | \cdot | \cdot |
| ⋯ | \cdots | \cdots |
| ⋮ | \vdot | \vdot |
| ⋱ | \ddot | \ddot |
| … | \ldots | \ldots |
| 4个空格 | \quad | |
| 换行 | \ \ | |
| 特殊符号 | 对应符号 | 对应渲染效果 |
|---|---|---|
| λ | \lambda | \lambda |
| ρ | \rho | \rho |
| σ | \sigma | \sigma |
| Θ | \Theta | \Theta |
| θ | \theta | \theta |
| ∂ | \partial | \partial |
| ϕ | \phi | \phi |
| φ | \varphi | \varphi |
| π | \pi | \pi |
| Ω | \Omega | \Omega |
| ω | \omega | \omega |
| ψ | \psi | \psi |
| μ | \mu | \mu |
| ε | \varepsilon | \varepsilon |
| γ | \gamma | \gamma |
| ζ | \zeta | \zeta |
| η | \eta | \eta |
| Δ | \Delta | \Delta |
| ∇ | \nabla | \nabla |
| ← | \gets | \gets |
| → | \to | \to |
| ↑ | \uparrow | \uparrow |
| ↓ | \downarrow | \downarrow |
| ⇒ | \Rightarrow | \Rightarrow |
| ⇐ | \Leftarrow | \Leftarrow |
- 创建独立的一块公式区域。
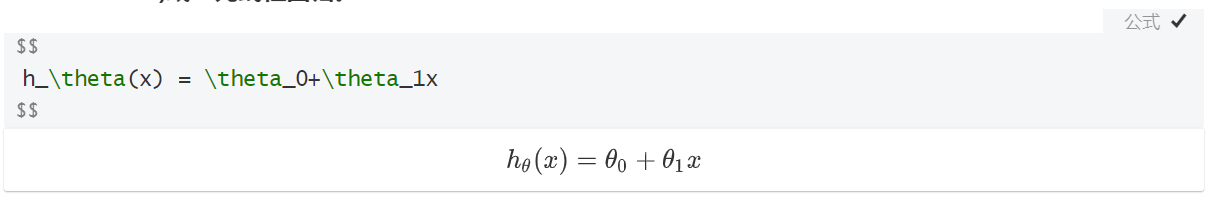
- 上部分为公式输入区
- 下部分为效果展示区
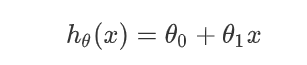
编辑别处时展示效果图。
方法一:左上角点击“段落”,再点击“公式块”
方法一:在文中输入$$,再按下回车
- 将公式嵌入文字内。

方法一: 在$$的中间加入需要的公式
简便的方法一:先按 $ ,再按 “esc”(键盘左上角)
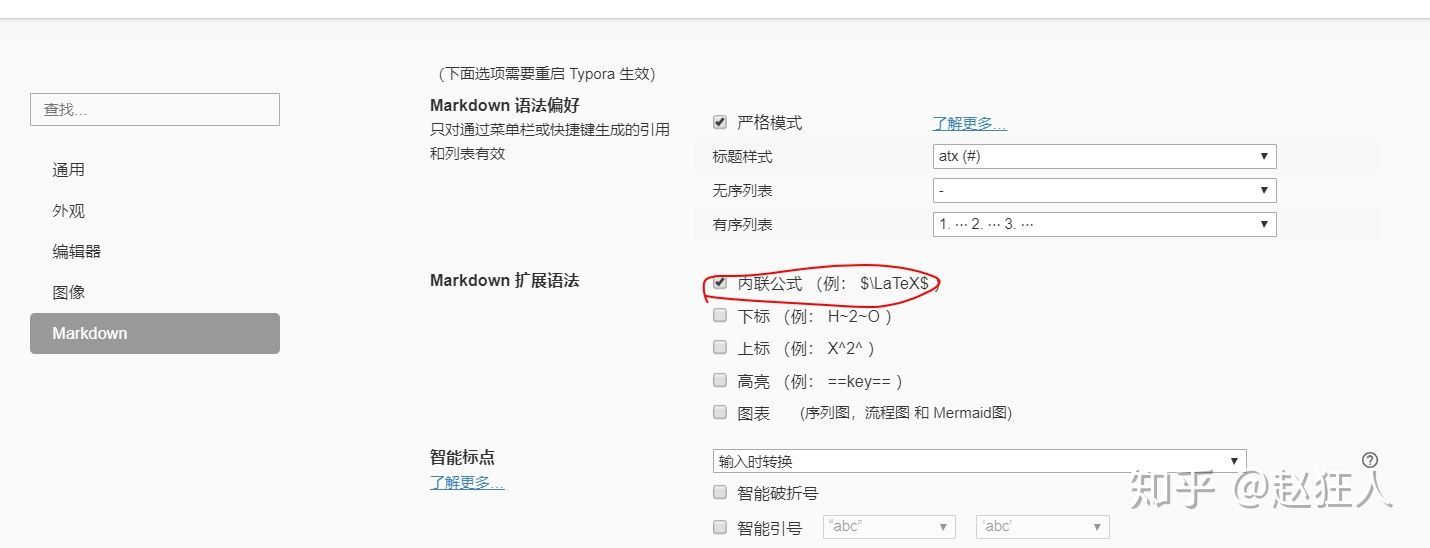
(行内公式是需要先设置一下)
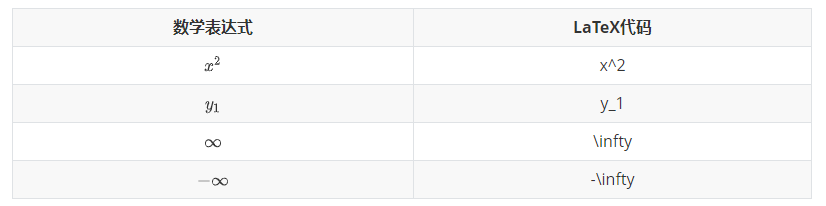
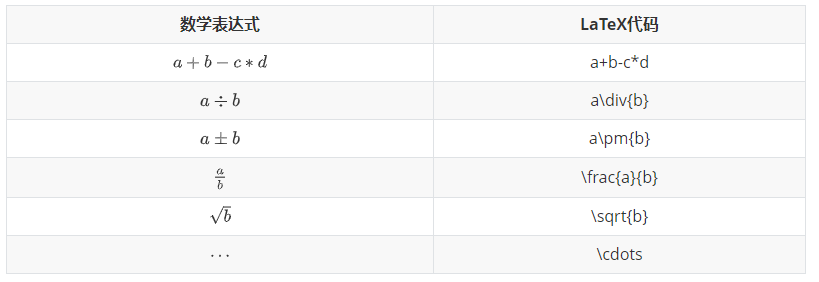
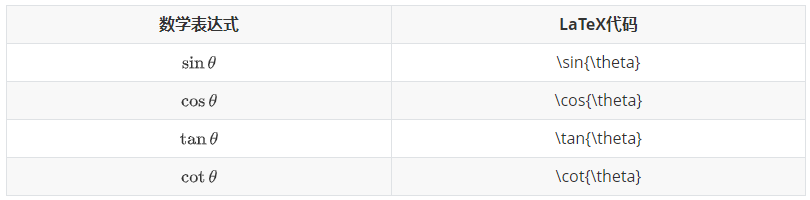
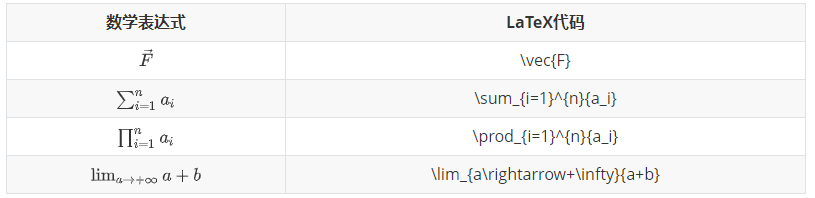

使用\begin{matrix}…\end{matrix}生成, 每一行以\\结尾表示换行,元素间以&间隔,式子的表示序号\tag{1}(右边的序号)。

$$
\begin{matrix}
1 & 2 & 3 \\
4 & 5 & 6 \\
7 & 8 & 9
\end{matrix} \tag{1}
$$
方法一:在\begin{}之前和\end{}之后添加左右括号的代码。
大括号:
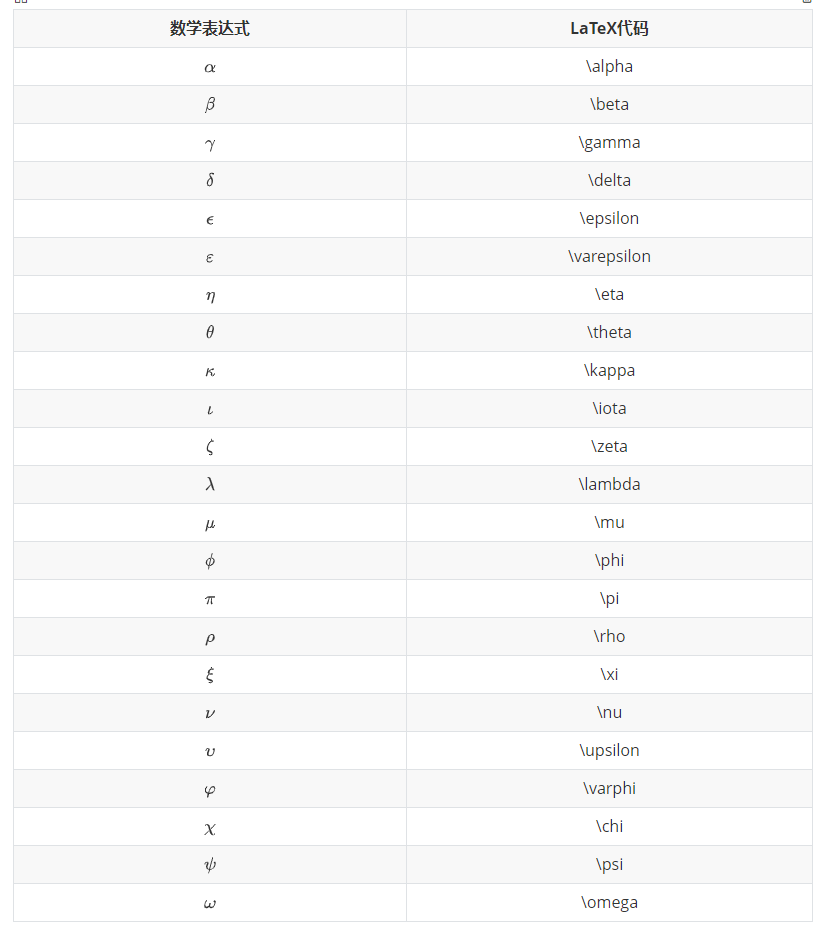
$$
\left\{
\begin{matrix}
1 & 2 & 3 \\
4 & 5 & 6 \\
7 & 8 & 9
\end{matrix}
\right\} \tag{2}
$$
中括号:
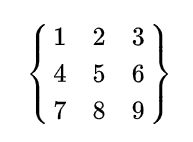
$$
\left[
\begin{matrix}
1 & 2 & 3 \\
4 & 5 & 6 \\
7 & 8 & 9
\end{matrix}
\right] \tag{3}
$$
小括号:
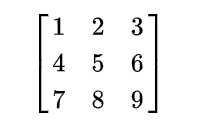
$$
\left(
\begin{matrix}
1 & 2 & 3 \\
4 & 5 & 6 \\
7 & 8 & 9
\end{matrix}
\right) \tag{4}
$$
方法二:改变\begin{matrix}和\end{matrix}中{matrix}
大括号:
$$
\begin{Bmatrix}
1 & 2 & 3 \\
4 & 5 & 6 \\
7 & 8 & 9
\end{Bmatrix} \tag{5}
$$
中括号:
$$
\begin{bmatrix}
1 & 2 & 3 \\
4 & 5 & 6 \\
7 & 8 & 9
\end{bmatrix} \tag{6}
$$
行省略号\cdots,列省略号\vdots,斜向省略号(左上至右下)\ddots。

$$
\left\{
\begin{matrix}
1 & 2 & \cdots & 5 \\
6 & 7 & \cdots & 10 \\
\vdots & \vdots & \ddots & \vdots \\
\alpha & \alpha+1 & \cdots & \alpha+4
\end{matrix}
\right\}
$$
公式序号
见“矩阵”小节,代码最后的一行即表示右端序号
......
\tag{6}
行列式相关语法与矩阵类似
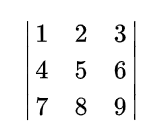
$$
\begin{vmatrix}
1 & 2 & 3 \\
4 & 5 & 6 \\
7 & 8 & 9
\end{vmatrix}
\tag{7}
$$
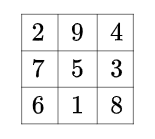
$$
\begin{array}{|c|c|c|}
\hline 2&9&4\\
\hline 7&5&3\\
\hline 6&1&8\\
\hline
\end{array}
$$
开头结尾: \begin{array} , \end{array}
定义式:例:{|c|c|c|},其中c l r 分别代表居中、左对齐及右对齐。
分割线:①竖直分割线:在定义式中插入 |, (||表示两条竖直分割线)。
②水平分割线:在下一行输入前插入 \hline,以下图真值表为例。
其他:每行元素间均须要插入 & ,每行元素以 \\ 结尾。
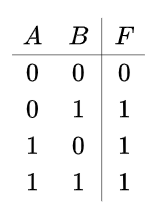
$$
\begin{array}{cc|c}
A&B&F\\
\hline 0&0&0\\
0&1&1\\
1&0&1\\
1&1&1\\
\end{array}
$$
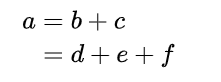
$$
\begin{aligned}
a &= b + c \\
&= d + e + f
\end{aligned}
$$
方程组:
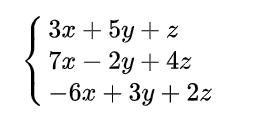
$$
\begin{cases}
3x + 5y + z \\
7x - 2y + 4z \\
-6x + 3y + 2z
\end{cases}
$$
同理,条件表达式:
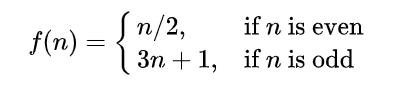
$$
f(n) =
\begin{cases}
n/2, & \text{if }n\text{ is even} \\
3n+1, & \text{if }n\text{ is odd}
\end{cases}
$$
紧贴 + 无空格 + 小空格 + 中空格 + 大空格 + 真空格 + 双真空格
$$
a\!b + ab + a\,b + a\;b + a\ b + a\quad b + a\qquad b
$$
紧贴\!
无空格 小空格\, 中空格\; 大空格\
真空格\quad 双真空格\qquad
import math //引入数学模块(有些运算的函数需要)
import latexify //引入latexify模块
@latexify.with_latex //特定语法,表示之后定义的函数可以转化为LaTeX代码
def f(x,y,z): //包含的参数
pass //此处填写可能需要的数学表达式
return result //也可以直接体现数学关系
print(f) //直接print(函数名)特别说明,生成的表达式为定义式,即 ,如果只需要等式 ,可以把生成表达式中的\triangleq改成= !
更多细节和实例可以浏览我新的文章:
点点星河:使用Python一键生成LaTeX数学公式57 赞同 · 4 评论文章
ps:好像知乎不支持markdown表格,离谱了。
原理上Typora中使用Markdown语法进行操作,在Markdown中添加公式只需要知道LaTex语法,再在前后加入$
- 使用Typora添加数学公式(https://blog.csdn.net/mingzhuo_126/article/details/82722455)
- [CSDN_Markdown] 使用LaTeX写矩阵(https://blog.csdn.net/bendanban/article/details/44221279)
- Markdown下的LaTeX公式笔记 (https://www.bilibili.com/read/cv1578688/)
- typora行内公式插入(https://www.zhihu.com/answer/809450524)
CSDN-MarkDown编辑器使用的公式定界符为和$,单美元符号包围的是行内公式,双美元符号包围的是块公式。 \ 关键字(字符转义序列)表示特殊显示符号,如\frac表示分数,其后面可以跟随参数,参数多少与关键字有关。
^表示上标, _表示下标, 如果上(下)标内容多于一个字符就需要使用{},注意不是( ), 因为( )经常是公式本身组成部分,为避免冲突,所以选用了{ } 将其包起来。
示例:$x^{y^z}=(1+e^x)^{-2xy^w}$
效果:$x^{y^z}=(1+e^x)^{-2xy^w}$ 上面输入的上下标都是在字符的右侧,要想在左侧或者两侧都写上下标,那么需要使用\sideset语法。
示例:$\sideset{^1_2}{^3_4}\bigotimes$
效果:$\sideset{^1_2}{^3_4}\bigotimes$
( )和[ ]就是自身了,由于{ } 是Tex的元字符,所以表示它自身时需要转义。
示例:$f(x,y) = x^2 + y^2, x\epsilon[0,100]$
效果:$f(x,y) = x^2 + y^2, x\epsilon[0,100]$ 有时候括号需要大号的,普通括号不好看,此时需要使用\left和\right加大括号的大小。
示例:$(\frac{x}{y})^8,\left(\frac{x}{y}\right)^8$
效果:$(\frac{x}{y})^8,\left(\frac{x}{y}\right)^8$ \left和\right必须成对出现,对于不显示的一边可以使用 . 代替。
示例:$\left.\frac{{\rm d}u}{{\rm d}x} \right| _{x=0}$
效果:$\left.\frac{{\rm d}u}{{\rm d}x} \right| _{x=0}$
使用\frac{分子}{分母}格式,或者 分子\over 分母。
示例:$\frac{1}{2x+1}或者1\over{2x+1}$$
效果:$\frac{1}{2x+1}或者1\over{2x+1}$
示例:$\sqrt[9]{3}和\sqrt{3}$
效果:$\sqrt[9]{3}和\sqrt{3}$
有两种省略号,\ldots 表示语文本底线对其的省略号,\cdots表示与文本中线对其的省略号。
示例:$f(x_1, x_2, \ldots, x_n)=x_1^2 + x_2^2+ \cdots + x_n^2$
效果:$f(x_1, x_2, \ldots, x_n)=x_1^2 + x_2^2+ \cdots + x_n^2$
示例:$\vec{a} \cdot \vec{b}=0$
效果:
示例:$\int_0^1x^2{\rm d}x $
效果:$\int_0^1x^2{\rm d}x $
示例:$\lim_{n\rightarrow+\infty}\frac{1}{n(n+1)}$
效果:$\lim_{n\rightarrow+\infty}\frac{1}{n(n+1)}$
示例:$\sum_1^n\frac{1}{x^2},\prod_{i=0}^n\frac{1}{x^2}$
效果:$\sum_1^n\frac{1}{x^2},\prod_{i=0}^n\frac{1}{x^2}$
加粗:$\pmb{字母}$
加粗倾斜:$\boldsymbol{字母}$
希腊字符示例:$$\alpha A \beta B \gamma \Gamma \delta \Delta \epsilon E \varepsilon \zeta Z \eta H \theta \Theta \vartheta \iota I \kappa K \lambda \Lambda \mu M \nu N \xi \Xi o O \pi \Pi \varpi \rho P \varrho \sigma \Sigma \varsigma \tau T \upsilon \Upsilon \phi \Phi \varphi \chi X \psi \Psi \omega \Omega$$
效果:
± :\pm × :\times ÷:\div ∣:\mid
⋅:\cdot ∘:\circ ∗: \ast ⨀:\bigodot ⨂:\bigotimes ⨁:\bigoplus ≤:\leq ≥:\geq ≠:\neq ≈:\approx ≡:\equiv ∑:\sum ∏:\prod ∐:\coprod
∅:\emptyset ∈:\in ∉:\notin ⊂:\subset ⊃ :\supset ⊆ :\subseteq ⊇ :\supseteq ⋂ :\bigcap ⋃ :\bigcup ⋁ :\bigvee ⋀ :\bigwedge ⨄ :\biguplus ⨆:\bigsqcup
log :\log lg :\lg ln :\ln
⊥:\bot ∠:\angle 30∘:30^\circ sin :\sin cos :\cos tan :\tan cot :\cot sec :\sec csc :\csc
y′x:\prime ∫:\int ∬ :\iint ∭ :\iiint ⨌:\iiiint ∮ :\oint lim :\lim ∞ :\infty ∇:\nabla
∵:\because ∴ :\therefore ∀ :\forall ∃ :\exists ≠ :\not= ≯:\not> ⊄:\not\subset
ŷ :\hat{y} yˇ:\check{y} y˘:\breve{y}
a+b+c+d⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯:\overline{a+b+c+d} a+b+c+d⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯:\underline{a+b+c+d} a+b+c⏟1.0+d2.0:\overbrace{a+\underbrace{b+c}_{1.0}+d}^{2.0}
↑:\uparrow ↓:\downarrow ⇑ :\Uparrow ⇓:\Downarrow →:\rightarrow ← :\leftarrow ⇒ :\Rightarrow ⇐ :\Leftarrow ⟶ :\longrightarrow ⟵ :\longleftarrow ⟹:\Longrightarrow ⟸ :\Longleftarrow
要输出字符 空格 # $ % & _ { } ,用命令: \空格 # $ % & _ { }
{\rm text}如: 使用罗马字体:text text 其他的字体还有: \rm 罗马体 \it 意大利体 \bf 黑体 \cal 花体 \sl 倾斜体 \sf 等线体 \mit 数学斜体 \tt 打字机字体 \sc 小体大写字母
作者:吐痰高手 链接:https://www.jianshu.com/p/7c34f5099b7e 来源:简书 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
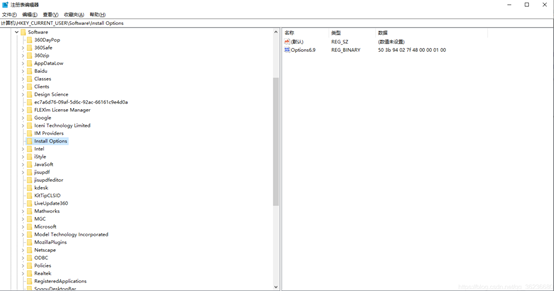
关闭mathtype打开电脑的注册表编辑器(按住win+R快捷键运行,然后输入regedit.exe)
找到一级目录HKEY_CURRENT_USER下的software目录,在该级目录里找到install option目录,删除注册列表中的第二项名为option6.9的文件。
最后重启word或mathtype即可(或者重启电脑)。
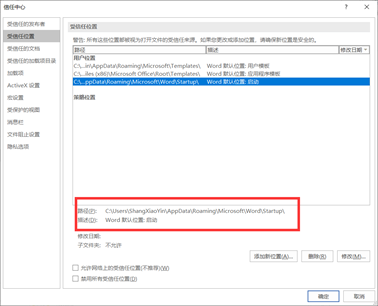
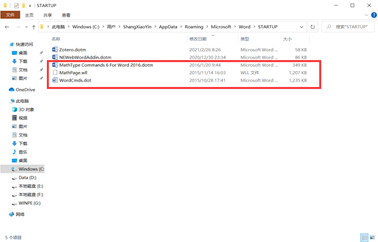
拷贝三个文件到如下路径:
第一个 MathPage.wll:MathType安装路径\MathPage\32
(很奇怪,我的电脑是64位,64文件夹里的mathpage.wll总是出错,换了32的就好使了)
(原来我的word是32的哈哈哈)
第二个MathType Commands 6 For Word 2013.dotm:MathType安装路径\Office Support\64
第三个 WordCmds.dot:C:\Program Files (x86)\MathType\Office Support\64
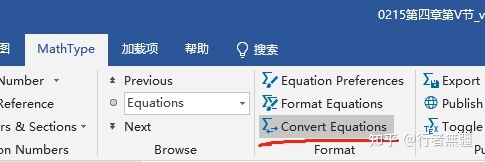
在word段落中,插入公式时,公式常常出现相对于段落文字的位置偏上或偏下,体积大一点的公式还可能显示不完全。可以通过调整行间距减轻这个问题,但显示效果很差。
一种比较好的方法是使用mathtype的convert equation 将公式转化,(convert后公式在后台自动变为tex或mathxl),可以非常好的解决段落中的公式显示问题。
具体操作很简单:
- 选择包含公式的整个段落,(也可以仅选择需要convert的公式对象)
- 在word的菜单栏中找到mathtype那一栏
- 在mathtype栏中找到convert equation,点击即可完成。
这个方法也可以解决word里面的公式显示效果与mathtype编辑器不一样的问题。
MySQL的二进制日志可以说是MySQL最重要的日志了,它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。
一般来说开启二进制日志大概会有1%的性能损耗(参见MySQL官方中文手册 5.1.24版)。二进制有两个最重要的使用场景: 其一:MySQL Replication在Master端开启binlog,Mster把它的二进制日志传递给slaves来达到master-slave数据一致的目的。 其二:自然就是数据恢复了,通过使用mysqlbinlog工具来使恢复数据。
二进制日志包括两类文件:二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件,二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件。
1.查看所有binlog日志列表
mysql> show master logs;
2.查看master状态,即最后(最新)一个binlog日志的编号名称,及其最后一个操作事件pos结束点(Position)值
mysql> show master status;
3.刷新log日志,自此刻开始产生一个新编号的binlog日志文件
mysql> flush logs;
注:每当mysqld服务重启时,会自动执行此命令,刷新binlog日志;在mysqldump备份数据时加 -F 选项也会刷新binlog日志;
4.重置(清空)所有binlog日志
mysql> reset master;
在Windows系统的命令行窗口中使用type命令可以实现文本文件合并。这里我是将D盘test目录下的所有.sql文件(三个)合并为一个aaa.sql的文件,命令type *.sql >> aaa.sql,会在当前目录下生成aaa.sql文件。
C:\Users\Administrator>D:
D:\>cd test
D:\test>type *.sql >> aaa.sql
111.sql
222.sql
333.sql
D:\test>
在Navicat for MySQL中,选中一个数据库,右键点击运行SQL文件。然后选中合并完毕的SQL文件,点击开始运行。
导出向导 — csv — 高级 — 选项 — 选择10008 (MAC - Simplified Chinese GB 2312)
LOAD DATA INFILE语句用于高速地从一个文本文件中读取行,并写入一个表中。文件名称必须为一个文字字符串。 LOAD DATA INFILE 是 SELECT ... INTO OUTFILE 的相对语句。把表的数据备份到文件使用SELECT ... INTO OUTFILE,从备份文件恢复表数据,使用 LOAD DATA INFILE。
==路径问题?==
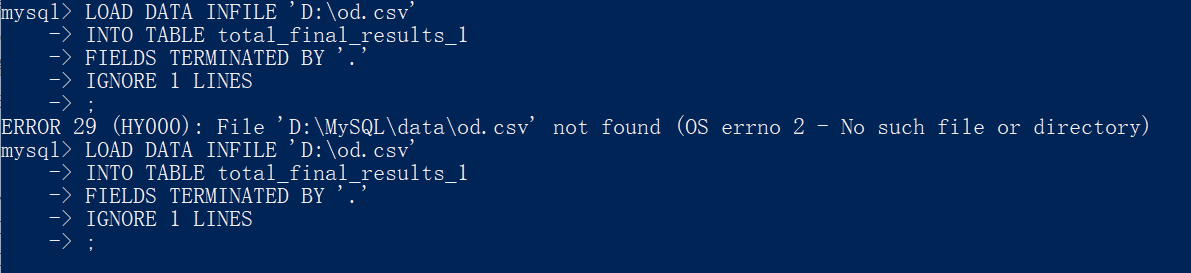
LOAD DATA [LOW_PRIORITY | CONCURRENT] [LOCAL] INFILE 'file_name.txt'
[REPLACE | IGNORE]
INTO TABLE tbl_name
[FIELDS
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char' ]
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
[IGNORE number LINES]
[(col_name_or_user_var,...)]
[SET col_name = expr,...)]标准示例
LOAD DATA LOCAL INFILE 'data.txt' INTO TABLE tbl_name
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'只载入一个表的部分列
LOAD DATA LOCAL INFILE 'persondata.txt' INTO TABLE persondata (col1,col2)该参数适用于表锁存储引擎,比如MyISAM, MEMORY, 和 MERGE,在写入过程中如果有客户端程序读表,写入将会延后,直至没有任何客户端程序读表再继续写入。
使用该参数,允许在写入过程中其它客户端程序读取表内容。
L0CAL关键字影响数据文件定位和错误处理。只有当 mysql-server 和 mysql-client 同时在配置中指定允许使用,L0CAL关键字才会生效。如果 mysqld 的 local_infile系统变量设置为 disabled,L0CAL关键字将不会生效。详见Section 6.1.6, “Security Issues with LOAD DATA LOCAL”.
L0CAL关键字影响在哪里找到数据文件:
如果指定了LOCAL,数据文将被客户端程序从客户端主机读取,然后发送给服务器主机。文件路径可以使用绝对路径或相对路径。如果使用相对路径,数据文件实际路径相对于客户端程序启动时的当前路径。
使用LOCAL,将在服务器主机的临时目录创建一个数据文件的副本(linux 使用 /tmp,windows 使用 C:\WINDOWS\TEMP),如果临时目录剩余空间不足,将导致语句执行失败。
如果没有指定LOCAL,数据五年间必须位于服务器值机上,直接由 mysql-server 读取。mysql-serve 使用如下规则来定位文件:
1. 数据文件使用绝对路径,直接使用
2. 数据文件使用相对路径并且有前导的部分,将相对于 mysql-server 的数据目录查找,例如 ./myfile.txt
3. 数据文件使用相对路径并且没有前导的部分,将相对于默认数据库的数据文件目录查找,例如 myfile.txt
根据上面的规则,./myfile.txt 将被定位到 mysql-server 的 data directory,而 myfile.txt 将被定位到 default database 的 database directory。
如果 db1 时默认数据库,则下面的语句将从 db1 的数据库目录读取 data.txt,即使明确指定把数据装载到 db2
LOAD DATA INFILE 'data.txt' INTO TABLE db2.my_table;Non-LOCAL load operations 从服务器主机上读取数据文将。出于安全原因,这个操作需要文件权限。 如果secure_file_priv 系统变量的value 不为空,数据文件必须放在该变量指定的目录。如果该变量为空,数据文件必须可读。
使用LOCAL将比让服务器直接存取文件慢些,因为文件的内容必须从客户主机传送到服务器主机。在另一方面,你不需要file权限装载本地文件。
- 使用 LOAD DATA INFILE,data-interpretation 和 duplicate-key 错误会终止操作
- 使用 LOAD DATA LOCAL INFILE,data-interpretation 和 duplicate-key 错误会发出警告,操作将继续执行。对于duplicate-key错误,效果和指定了 IGNORE 关键字一样。
REPLACE和IGNORE关键词控制对现有的唯一键记录的重复的处理。如果你指定REPLACE,新行将代替有相同的唯一键值的现有行。如果你指定IGNORE,跳过有唯一键的现有行的重复行的输入。如果你不指定任何一个选项,当找到重复键键时,出现一个错误,并且文本文件的余下部分被忽略时。
如果你指定一个FIELDS子句,它的每一个子句(TERMINATED BY, [OPTIONALLY] ENCLOSED BY和ESCAPED BY)也是可选的,但是你必须至少指定一个。
如果你不指定 FIELDS 或 LINES ,缺省值为:
FIELDS TERMINATED BY '\t' ENCLOSED BY '' ESCAPED BY '\\'
LINES TERMINATED BY '\n' STARTING BY ''换句话说,缺省值导致读取输入时,LOAD DATA INFILE表现如下:
- 在 \n 处寻找行边界
- 在 \t 处将行分进字段
- 不要期望字段由任何引号字符封装
- 将由“\”开头的定位符、换行符或“\”解释成转义序列。例如 \t, \n, and \ 分别解释成 定位符,换行,反斜杠。
相反,缺省值导致在写入输出时,SELECT ... INTO OUTFILE表现如下:
- 在字段之间写 \t 2 .不用任何引号字符封装字段
- 使用“\”转义出现在字段中的 定位符、换行符或“\”字符
- 在行尾处写换行符
FIELDS [OPTIONALLY] ENCLOSED BY 控制哪些字段应该包裹在引号里面。
对于SELECT ... INTO OUTFILE 输出,如果不包含OPTIONALLY选项,所有的字段将会被ENCLOSED BY指定的字符包裹,例如:
"1","a string","100.20"
"2","a string containing a , comma","102.20"
"3","a string containing a \" quote","102.20"
"4","a string containing a \", quote and comma","102.20" 如果我们指定OPTIONALLY,只有string数据类型(如 CHAR, BINARY, TEXT, 或 ENUM)的字段才会被ENCLOSED BY指定的字符包裹,例如:
1,"a string",100.20
2,"a string containing a , comma",102.20
3,"a string containing a \" quote",102.20
4,"a string containing a \", quote and comma",102.20 注意,如果在字段值内出现ENCLOSED BY字符,则通过使用ESCAPED BY字符作为前缀,对ENCLOSED BY字符进行转义。另外,要注意,如果指定了一个空ESCAPED BY值,则可能会生成不能被LOAD DATAINFILE 正确读取的输出值。例如:
1,"a string",100.20
2,"a string containing a , comma",102.20
3,"a string containing a " quote",102.20
4,"a string containing a ", quote and comma",102.20 用来控制如何对特殊字符进行读写,如上面一个例子,导出和导入时指定FIELDS ESCAPED BY为双引号["]才能被正确的导入,导出的格式如下,对字段内的双引号["]进行了转义。
1,"a string",100.20
2,"a string containing a , comma",102.20
3,"a string containing a #" quote",102.20
4,"a string containing a #", quote and comma",102.20 对于输入: 假如FIELDS ESCAPED BY指定字符非空,则输入时该字符被移除,后续的内容被添加到字段里。一些两个字符的字符串序列且第一个字符是转义字符的例外 。这些字符序列见下表。
Character| Escape Sequence
-------|---------- \0 | An ASCII NUL (X'00') character \b | A backspace character \n | A newline (linefeed) character \r | A carriage return character \t | A tab character. \Z | ASCII 26 (Control+Z) \N | NULL
假如FIELDS ESCAPED BY指定字符为空,将不会发生转义序列的解释。
对于输出: 如果FIELDS ESCAPED BY指定字符非空,字符作为以下输出的前缀。
-
FIELDS ESCAPED BY 字符,例如 \
-
FIELDS [OPTIONALLY] ENCLOSED BY 字符,例如 "
-
FIELDS TERMINATED BY and LINES TERMINATED BY 的 value 的第一个字符,例如\n
-
ASCII 0
如果LINES TERMINATED BY是空字符串,FIELDS TERMINATED BY非空,字符将不会被转义,NULL 将输出为 NULL而不是 \N。指定LINES TERMINATED BY为空字符串并不是个好主意,特别当内容中包含上表列出的特殊字符时。
如果所有希望读入的行都含有一个我们希望忽略的共用前缀,则可以使用 LINES STARTING BY 'prefix_string' 来跳过前缀(以及该前缀前的所有字符)。如果某行不包括前缀,则整个行被跳过。例如:
LOAD DATA INFILE '/tmp/test.txt' INTO TABLE test
FIELDS TERMINATED BY ',' LINES STARTING BY 'xxx';假如/tmp/test.txt文件内容如下
xxx"abc",1
something xxx"def",2
"ghi",3 则我们读入的内容包括("abc",1) 和 ("def",2),第三行直接被跳过。
该选项可以被用于在文件的开始处忽略行。例如,我们可以使用IGNORE 1 LINES来跳过一个包含列名称的起始标题行。
LOAD DATA INFILE '/tmp/test.txt' INTO TABLE test IGNORE 1 LINES;- 如果LINES TERMINATED BY是空字符串,FIELDS TERMINATED BY非空,行以FIELDS TERMINATED BY指定的字符串作为结尾。
- 如果FIELDS TERMINATED BY 与 FIELDS ENCLOSED BY值均为空(''),将使用固定行(无分割)格式。使用固定行格式,字段之间将没有分隔符(行终止符依然可使用),列字段数据的读取和写入均按照字段定义的宽度去操作,如 TINYINT, SMALLINT, MEDIUMINT, INT, 和 BIGINT, 字段宽度分别为4, 6, 8, 11, 和 20。
- 使用固定行格式(即FIELDS TERMINATED BY 和 FIELDS ENCLOSED BY 均为空),列字段类型为BLOB或TEXT。
- 指定分隔符与其它选项前缀一样,LOAD DATA INFILE不能对输入做正确的解释。例如:
FIELDS TERMINATED BY '"' ENCLOSED BY '"' - 如果 FIELDS ESCAPED BY 为空,字段值包含 FIELDS ENCLOSED BY 指定字符,或者 LINES TERMINATED BY 的字符在 FIELDS TERMINATED BY 之前,都会导致过早的停止 LOAD DATA INFILE操作。因为LOAD DATA INFILE不能准确的确定行或列的结束。
IGNORE number LINES选项可以被用于在文件的开始处忽略行。 您可以使用IGNORE 1 LINES来跳过一个包含列名称的起始标题行:
LOAD DATA INFILE '/tmp/test.txt' INTO TABLE test IGNORE 1 LINES;下面的语句会导入文件的所有列
LOAD DATA INFILE 'persondata.txt' INTO TABLE persondata;如果我们想导入表的某些列,需要指定列的列表
LOAD DATA INFILE 'persondata.txt' INTO TABLE persondata (col1,col2,...);如果输入文件与表的列顺序不同,我们必须指定一个列清单,否则mysql不能把输入文件的字段与表的列匹配起来。
mysql> LOAD DATA INFILE '/tmp/loadtest.txt' INTO TABLE loadtest
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
ESCAPED BY '#'
LINES TERMINATED BY '\n'
(c1, c2, c4, c3); 列的清单可以包含列名或者用户变量,在写入列前我们需要使用SET语句对用户变量进行转换。对set语句及用户变量有如下使用方法:
方法1:在用户变量用于第一列之前,先把第一列的值赋予用户变量,进行除法操作后输入到c1。
LOAD DATA INFILE 'file.txt'
INTO TABLE t1
(column1, @var1)
SET column2 = @var1/100;方法2:The SET clause can be used to supply values not derived from the input file. 。使用下面例子把c3列设为当前时间
LOAD DATA INFILE 'file.txt'
INTO TABLE t1
(column1, column2)
SET column3 = CURRENT_TIMESTAMP;方法3:把输入赋予用户变量,而不把用户变量赋予表中的列,来丢弃此输入值。
LOAD DATA INFILE 'file.txt'
INTO TABLE t1
(column1, @dummy, column2, @dummy, column3);在unix系统中,如果我们想要从管道(pipe)中load data,需要用如下方法:
[root@localhost tmp]# mkfifo /tmp/ls.dat
[root@localhost tmp]# chmod 666 /tmp/ls.dat
[root@localhost tmp]# find / -ls > /tmp/ls.dat &
[root@localhost tmp]# mysql -e "LOAD DATA INFILE '/tmp/ls.dat' INTO TABLE test.tb1 FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' ESCAPED BY '#' LINES TERMINATED BY '\n'"
注意:sql-mode使用严格事物模式STRICT_TRANS_TABLES会报错
在另一窗口将数据写入管道
[root@localhost /]# cat /tmp/loadtest.txt > /tmp/ls.dat
注:可以先读或者先写管道,谁先谁后都可以,在写入管道的数据被全部读出前,处于阻塞状态。
作者:ahcj_11 链接:https://www.jianshu.com/p/bcafd8f3ad8e 来源:简书 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
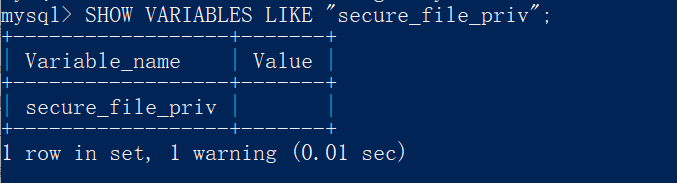
一些版本的mysql对通过文件导入导出作了限制,默认不允许,
查看配置,执行mysql命令
SHOW VARIABLES LIKE "secure_file_priv";如果value值为null,则为禁止,如果有文件夹目录,则只允许改目录下文件(测试子目录也不行),如果为空,则不限制目录;
修改配置可修改mysql配置文件,查看是否有
secure_file_priv =
这样一行内容,如果没有,则手动添加,
secure_file_priv = /home
表示限制为/home文件夹
secure_file_priv =
表示不限制目录,等号一定要有,否则mysql无法启动
修改完配置文件后,重启mysql生效
-
首先把mysql的服务先停掉
-
更改MySQL配置文件My.ini中的数据库存储主路径
打开MySQL默认的安装文件夹C:\Program Files\MySQL\MySQL Server 5.1中的my.ini文件(我是AppServ打包安装的,所以路径是C:\AppServ\MySQL)
点击记事本顶部的“编辑”,“查找”,在查找内容中输入datadir后并点击“查找下一个”转到“Path to the database root数据库存储主路径”参数设置,找到datadir="C:/Documents and Settings/All Users/Application Data/MySQL/MySQL Server 5.1/Data/"即是默认的数据库存储主路径设置,现将它改到D:\MySQL\data(你希望的)文件夹,正确的设置是datadir="D:\MySQL\data"。
更改完成后点击菜单栏的“文件”,再点击“保存”。
-
将老的数据库存储主路径中的数据库文件和文件夹复制到新的存储主路径
将C:/Documents and Settings/All Users/Application Data/MySQL/MySQL Server 5.1/Data/文件夹中的所有文件和文件夹拷贝到你新建的文件夹目录下。
-
重启MySQL服务
-
验证更改数据库存储主路径的操作是否成功
网盘下载地址:
链接: https://pan.baidu.com/s/11PH7oGOaegG00e8x-bx_aQ
提取码: 3y6d
操作教程:https://www.jb51.net/article/199525.htm
- 下载激活软件,断网即可进行激活,激活软件Navicat_Keygen_Patch(以管理员身份运行,并在运行前将杀毒软件关闭)
- 激活软件下载地址——永久有效
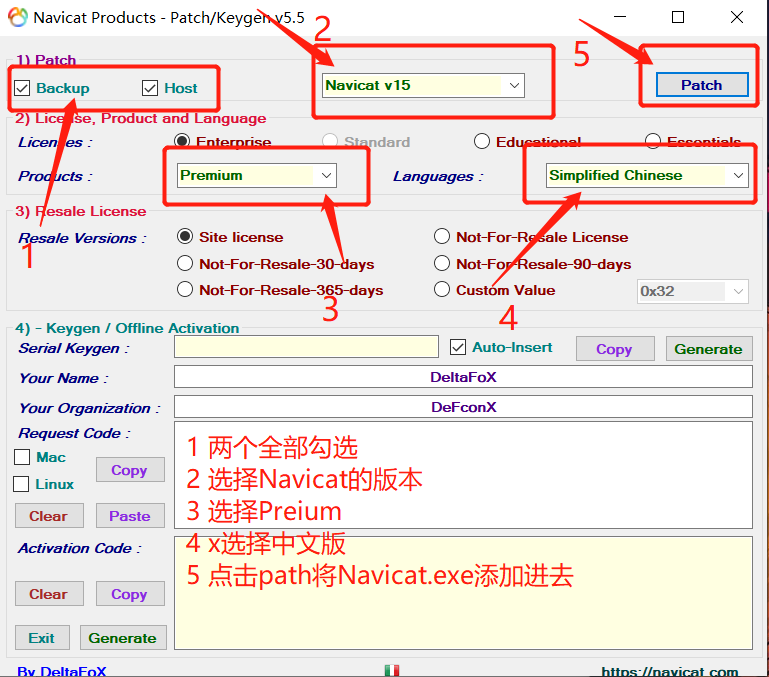
出现下列界面说明路径添加成功
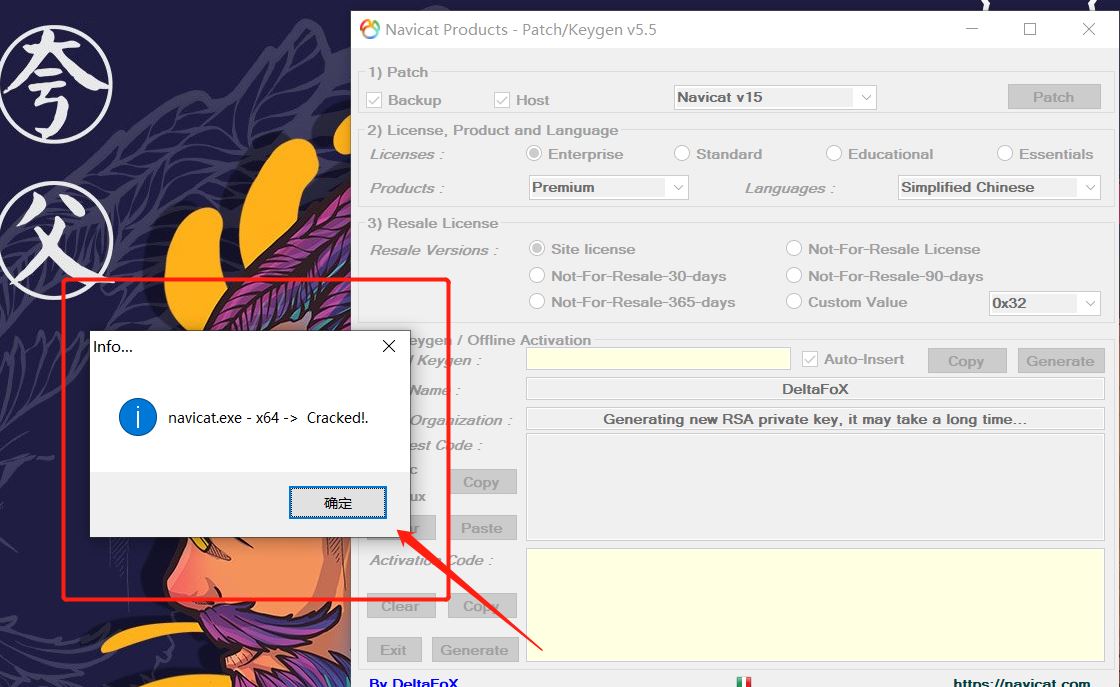
生成及复制注册码
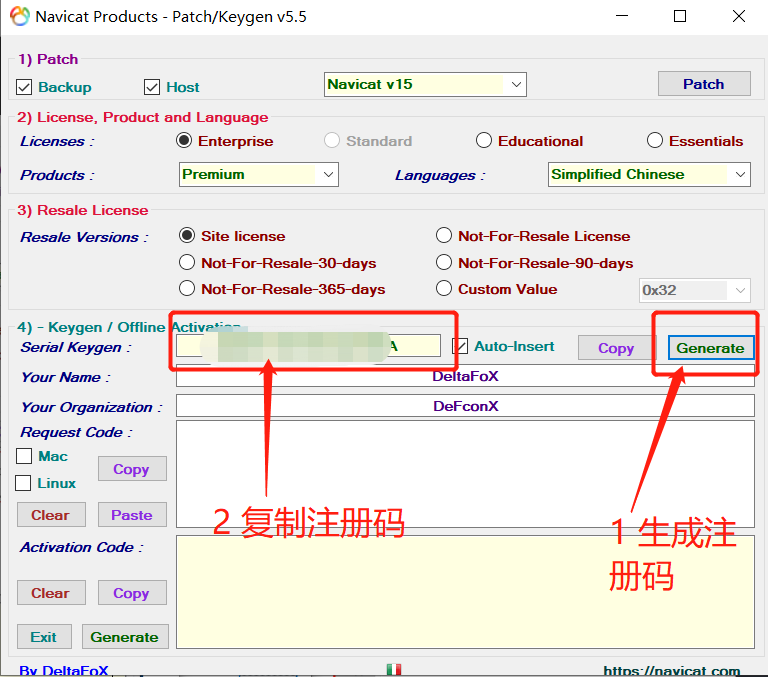
打开Navicat进行注册
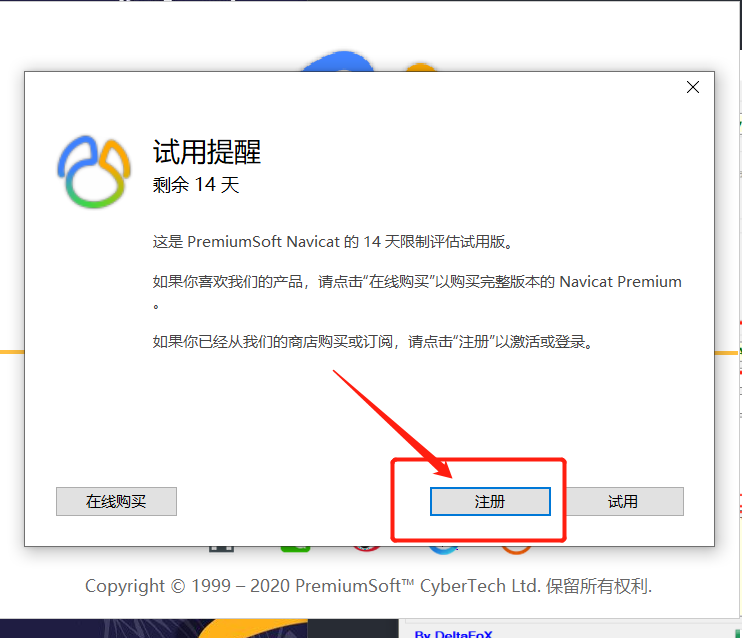
首次打开Navicat会弹出下述界面,选择注册
将复制的注册码填入,点击激活
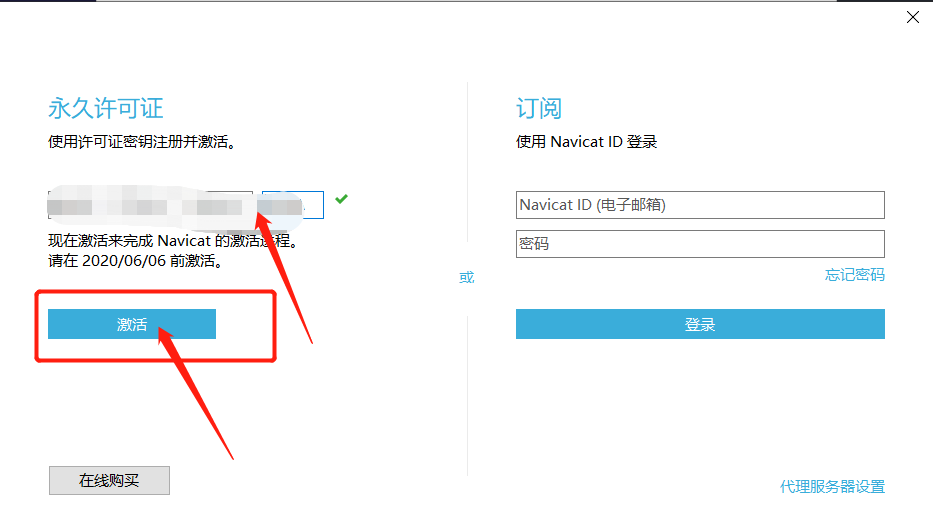
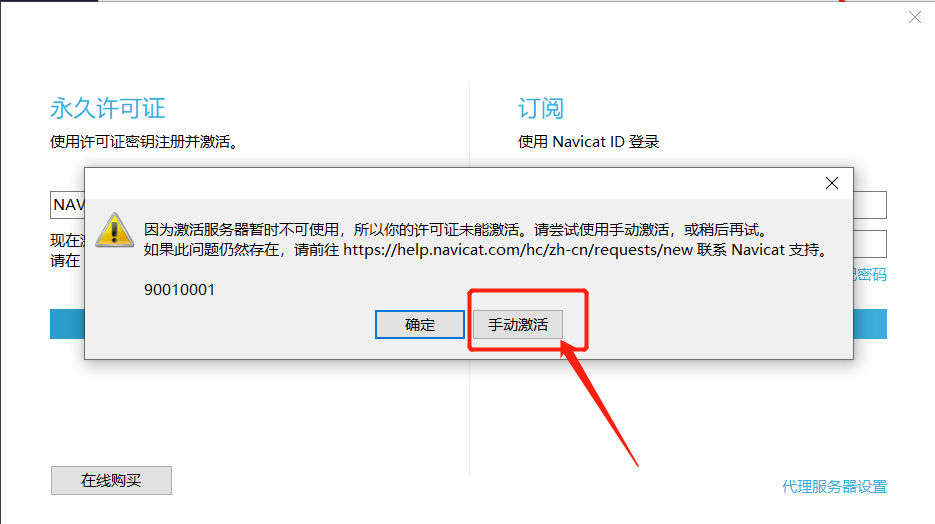
选择手动激活
会产生请求码,将请起码复制到激活软件中,生成激活码
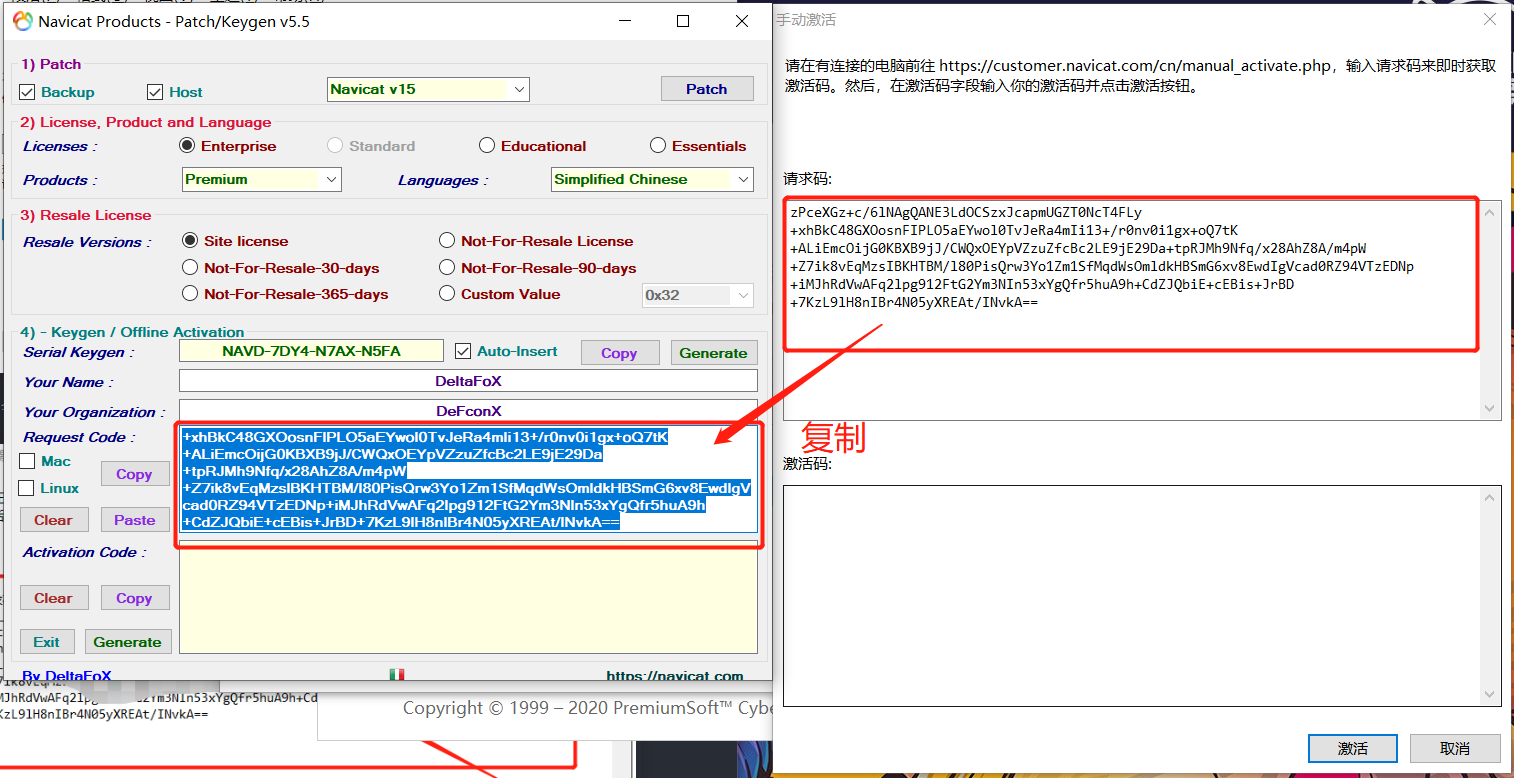
点击generate生成激活码,复制激活码,点击激活
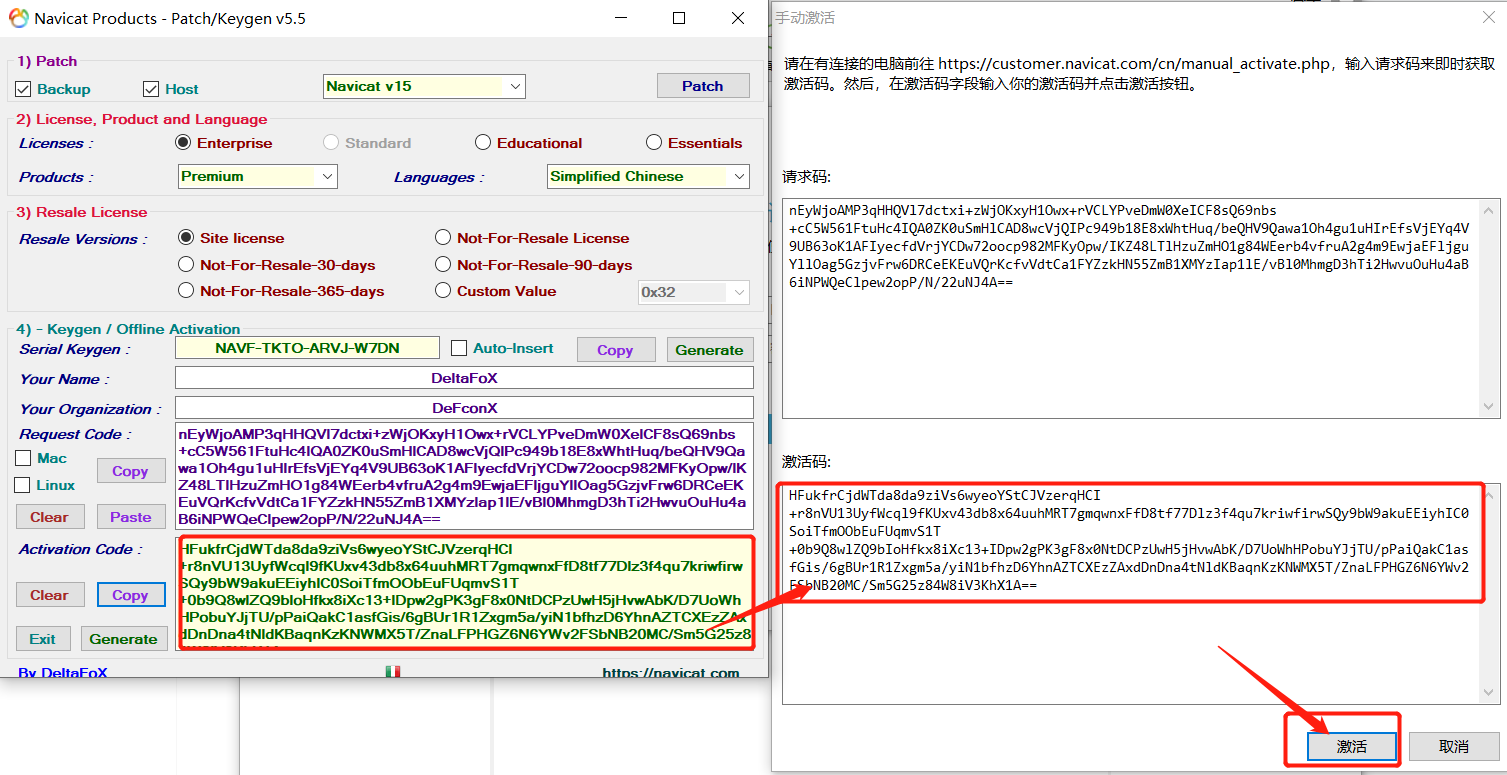
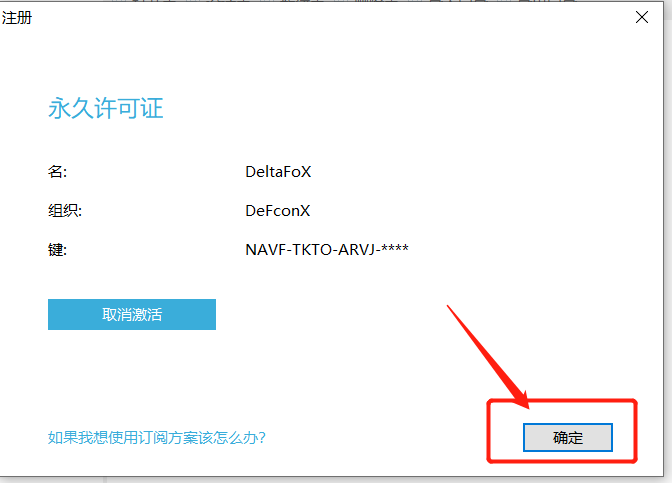
点击确定——永久激活
- 安装完成后不要运行软件,然后打开注册机;
- 行注册机时最好关闭电脑的杀毒软件;
- 运行注册机请断网,无需将注册机放到Navicat Premium安装目录下;
- 请选择对各个版本,Products那块;
- 可能你没有断网
- 如果在已经断网的情况下,你以前装过这个软件,需要彻底卸载,具体步骤如下:
- 通过命令行win+R打开命令行,输入regedit打开注册表,找到下述路径
- HKEY_CURRENT_USER\Software\PremiumSoft,删除即可,在去其他盘中删除与navicat相关的文件夹
- 重新安装之后,首先不要打开navicat客户端,而是直接打开破解软件,直接点patch,如果出现cracked!表示成功,打开navicat客户端将激活码复制至客户端,再按照步骤操作即可。
- 如果重新安装后还出现问题的话,无需再次卸载,重新点击安装包重新安装即可,再按照上述3的描述进行破解即可
- 需要注意的是:安装完成后不要直接打开navicat客户端,而是先打开破解软件,点解patch
pycharm是一款功能强大的python编辑器,具有跨平台性,鉴于目前最新版pycharm使用教程较少,为了节约大家摸索此IDE的时间,来介绍一下pycharm在windows下是如何安装的。
这是PyCharm的下载地址:http://www.jetbrains.com/pycharm/download/#section=windows
进入该网站后,我们会看到如下界面
professional表示专业版,community是社区版,推荐安装社区版,因为是免费使用的。
1、当下载好以后,点击安装,记得修改安装路径,我这里放的是E盘,修改好以后,Next
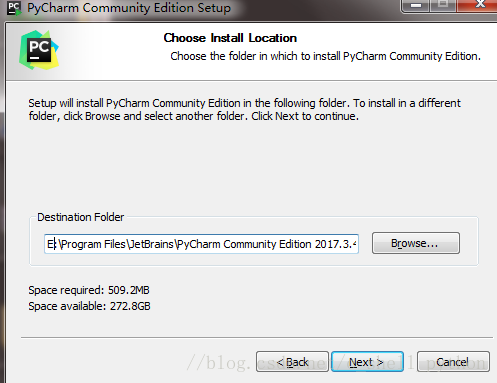
2、接下来是
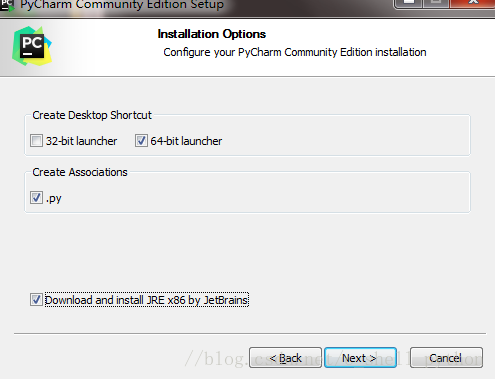
3、如下
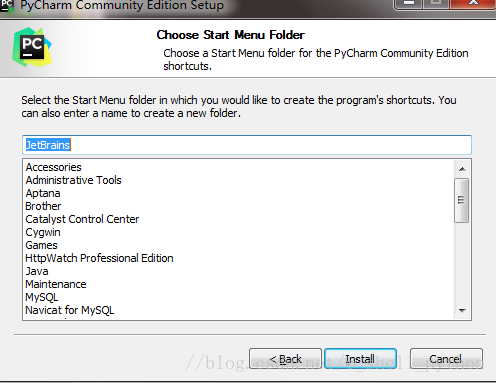
点击Install,然后就是静静的等待安装了。如果我们之前没有下载有Python解释器的话,在等待安装的时间我们得去下载python解释器,不然pycharm只是一副没有灵魂的驱壳
4、进入python官方网站:https://www.python.org/
点击Downloads,进入选择下载界面
5、如下所示,选择我们需要的python版本号,点击Download
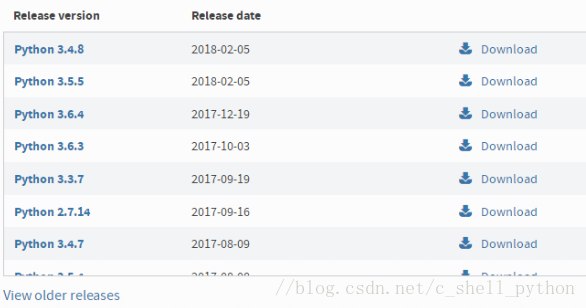
6、我选择的是python3.5.1,会看到如下界面
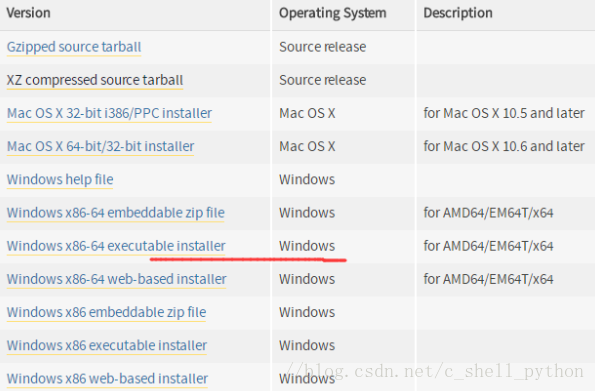
因为我们需要用到的是Windows下的解释器,所以在Operating System中可以选择对应的Windows版本,有64位和32位可以选择,我选择的是画红线的这个,executable表示可执行版,需要安装后使用,embeddable表示嵌入版,就是解压以后就可以使用的版本。
可执行版安装比较简单,一直默认就好了。embeddable需要注意,当我们解压 好以后,会看到里面还有一个压缩包
好以后,会看到里面还有一个压缩包 这个也是需要解压到同一路径的,这里面放着pip、setuptools等工具,如果不解压,我们将无法在pycharm中更新模块,比如需要用到pymysql,就无法下载。虽然也能用,但是就是“阉割版”的python解释器了。
这个也是需要解压到同一路径的,这里面放着pip、setuptools等工具,如果不解压,我们将无法在pycharm中更新模块,比如需要用到pymysql,就无法下载。虽然也能用,但是就是“阉割版”的python解释器了。
如果是embeddable版,记得把解释器所在的路径添加到环境变量里,不然pycharm无法自动获得解释器位置。
7、添加环境变量
(1)右键我的电脑,点击属性,弹出如下界面
(2)点击高级系统设置,出现下图
(3)点击环境变量
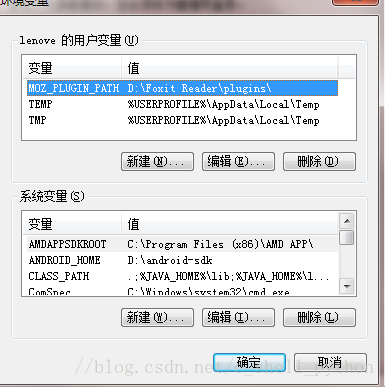
(4)找到系统变量里面的Path,编辑它,将python解释器所在路径粘贴到最后面,再加个分号。
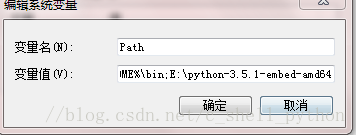
环境变量配置结束
8、这时候Pycharm也装好了,我们进入该软件。

9、点击Create New Project,接下来是重点
Location是我们存放工程的路径,点击这个三角符号,可以看到pycharm已经自动获取了Python 3.5。
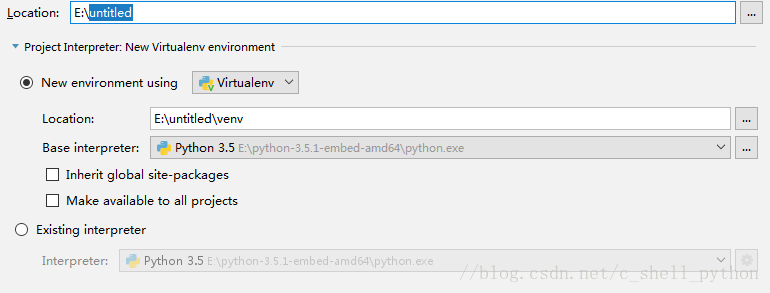
点击第一个我们可以选择Location的路径,比如
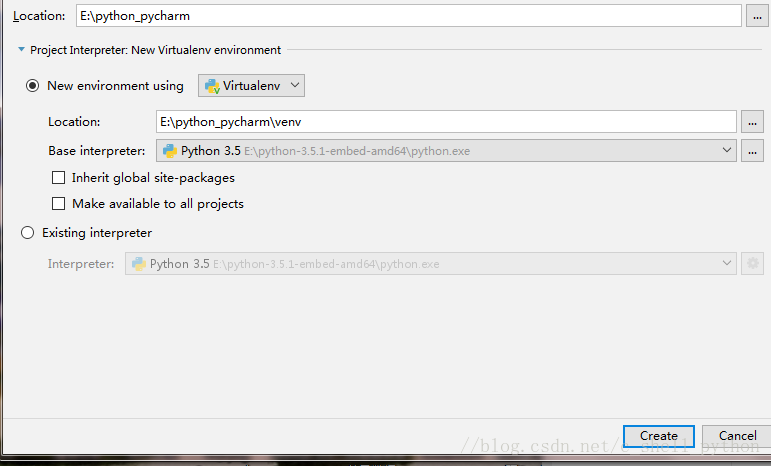
记住,我们选择的路径需要为空,不然无法创建,第二个Location不用动它,是自动默认的,其余不用点,然后点击Create。出现如下界面,这是Pycharm在配置环境,静静等待。最后点击close关掉提示就好了。
10、建立编译环境
右键 点击New,选择Python File
点击New,选择Python File
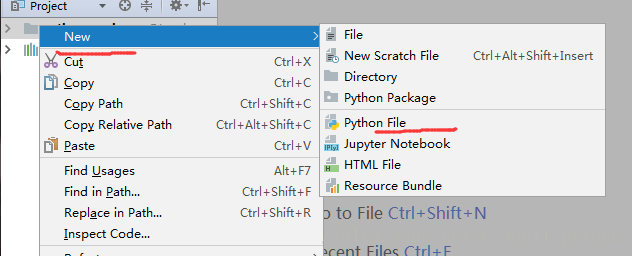
给file取个名字,点击OK
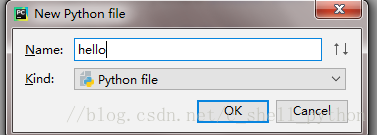
系统会默认生成hello.py

好了,至此,我们的初始工作基本完成。
11、我们来编译一下
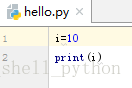
快捷键ctrl+shift+F10或者点击绿色三角形,就会编译,编译结果如下

12、对了,因为我之前已经添加过了,所以可以直接编译,还有很重要的一步没说,不然pycharm无法找到解释器,将无法编译。
点击File,选择settings,点击 ,再点击
,再点击
添加解释器

最后点击Apply。等待系统配置。
如果我们需要添加新的模块,点击绿色+号

然后直接搜索pymysql

然后点安装
以上就是pycharm的安装过程以及初始化,还有Python解释器的安装配置。
如果您觉得本文章有帮助到您,请轻轻移动一下鼠标,把它顶(赞)起来,分享给更多的需要的伙伴。
———————————————— 版权声明:本文为CSDN博主「梁光林」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/c_shell_python/article/details/79647627
1、 pycharm左边项目路径栏目中文有乱码
选择一个支持中文的编码格式:
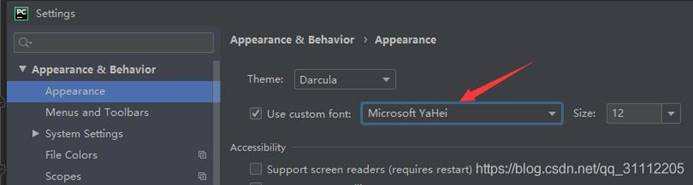
2、 输出控制台显示为乱码
如下选择utf-8
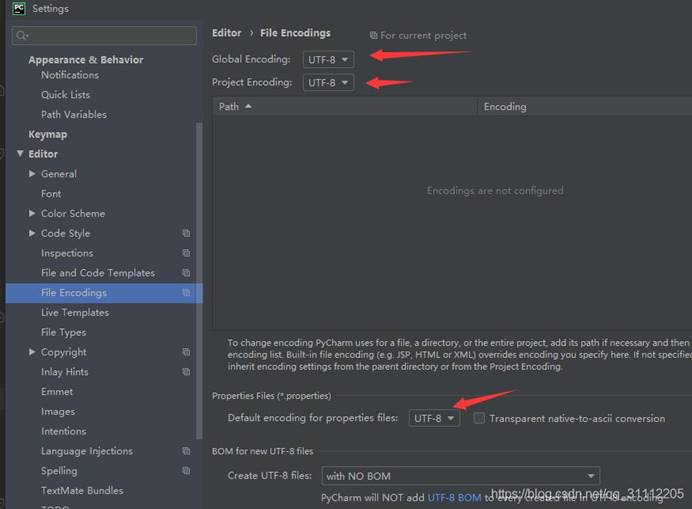
文件顶部也添加如下代码:
# #!/usr/bin/python
# -- coding: utf-8 --
3、 中文注释有乱码
字体中选择一个中文字体,如下:
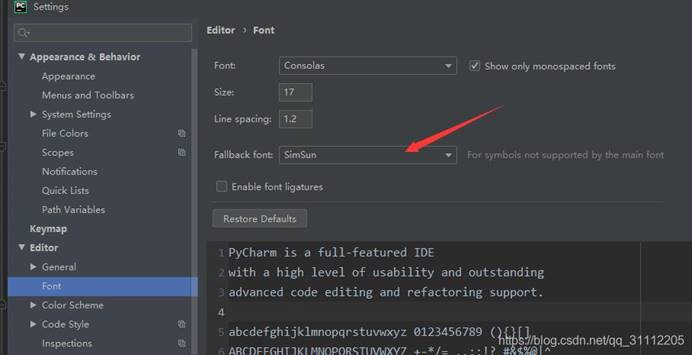
**4、 在window下如果还是乱码,**可以如下设置:
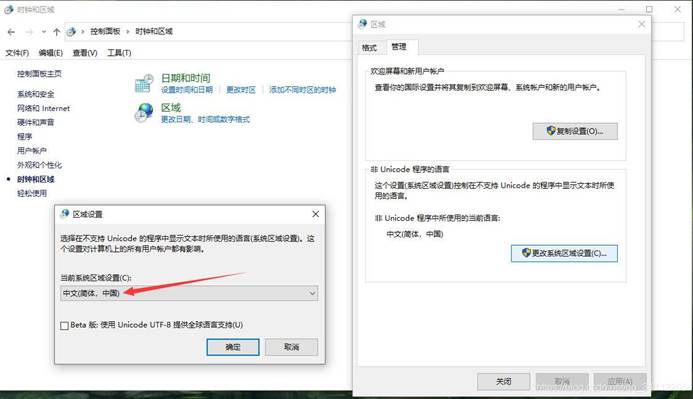
pycharm是一个可以设置环境的强大程序,许多用户还不知道如何设置一个正确的python环境,看一下有关的设置方式,帮助用户成功搭建python环境。
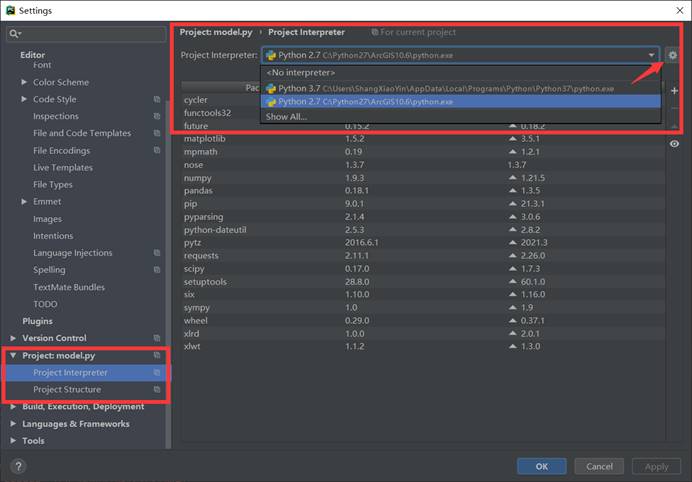
1.打开项目File -> Open... -> Open a file or project
根据上面的路径在您的pycharm软件中依次选择这样的目录,
然后后在菜单栏中依次点击File -> setting -> 左侧 project : project-name -> Project Interpreter-> 点击解释器右侧齿轮 即设置 -> Add local... -> Virtual Environment -> 可以选择 Bash Interpreter 和localtion
这时就可以 创建一个独立的虚拟环境了。
接下来配置requirements.txt,例如scipy==1.23.0
配置好之后,如果存在未安装的包,pycharm会自动提示, 点击Install Packages就行了。
移除没有引用的包快捷键:Ctrl+alt+o
2.pycharm导入python环境具体步骤
打开PyCharm软件,在左上角菜单栏依次选择【File→Open】,在弹窗中选择需要打开的目标文件夹;
打开python项目之后,需要配置项目对应的python环境才能运行;先点击File→settings;
在打开的设置窗口中选择Project Interpreter,之后点击add;
在弹窗里面选择New environment 或者 Existing environment皆可,设置路径为本地配置的python.exe路径,接下来就可以运行python程序了。
1、国际惯例,文件编码和 Python 编码格式全部为 utf-8 ,例如:在 Python 代码的开头,要统一加上 # -- coding: utf-8 --。 2、Python 代码中,非 ascii 字符的字符串,请需添加u前缀 3、若出现 Python编 码问题,可按照以下操作尝试解决:
import sys
reload(sys)
sys.setdefaultencoding('utf-8')**
模块尽量使用小写命名,首字母保持小写,尽量不要用下划线(除非多个单词,且数量不多的情况)
# 正确的模块名
import decoder
import html_parser
# 不推荐的模块名
import Decoder类名使用驼峰(CamelCase)命名风格,首字母大写,私有类可用一个下划线开头
class Farm():
pass
class AnimalFarm(Farm):
pass
class _PrivateFarm(Farm): # 私有
pass函数名一律小写,如有多个单词,用下划线隔开
def run():
pass
def run_with_env():
pass注:私有函数在函数前加一个下划线_
class Person():
def _private_func():
pass变量名尽量小写, 如有多个单词,用下划线隔开
if __name__ == '__main__':
count = 0
school_name = ''常量采用全大写,如有多个单词,使用下划线隔开。
MAX_CLIENT = 100
MAX_CONNECTION = 1000
CONNECTION_TIMEOUT = 600注:
变量名、类名取名必须有意义,严禁用单字母
变量名不要用系统关键字,如 dir type str等等建议:
bool变量一般加上前缀 is_ 如:is_success1、标准库
2、第三方库
3、项目本身
例如:
# 正确的写法
import os
import sys
# 不推荐的写法
import sys,os
# 正确的写法
from foo.bar import Bar
# 不推荐的写法
from ..bar import Bar
(注:每一行只导入一个库,不要用(,)多个引入。 并且各import类型之间需要用空行隔开)模块级函数和类定义之间空两行;类成员函数之间空一行;
class A:
def __init__(self):
pass
def hello(self):
pass
def main():
pass# 正确的写法
i = i + 1
submitted += 1
x = x * 2 - 1
hypot2 = x * x + y * y
c = (a + b) * (a - b)
# 不推荐的写法
i=i+1
submitted +=1
x = x*2 - 1
hypot2 = x*x + y*y
c = (a+b) * (a-b)# 正确的写法
def complex(real, imag):
pass
# 不推荐的写法
def complex(real,imag):
pass# 正确的写法
def complex(real, imag=0.0):
pass
# 不推荐的写法
def complex(real, imag = 0.0):
pass# 正确的写法
spam(ham[1], {eggs: 2})
# 不推荐的写法
spam( ham[1], { eggs : 2 } )# 正确的写法
dict['key'] = list[index]
# 不推荐的写法
dict ['key'] = list [index]# 正确的写法
x = 1
y = 2
long_variable = 3
# 不推荐的写法
x = 1
y = 2
long_variable = 31. All database fields
2. Custom manager attributes
3. class Meta
4. def (str)
5. def save()
6. def get_absolute_url()
7. Any custom methods尽量只包含容易出错的位置,不要把整个函数 try except 对于不会出现问题的代码,就不要再用 try except了 只捕获有意义,能显示处理的异常 能通过代码逻辑处理的部分,就不要用 try except 异常忽略,一般情况下异常需要被捕获并处理,但有些情况下异常可被忽略,只需要用 log 记录即可,可参考一下代码:
def ignored():
try:
yield
except Exceptions as e:
logger.warning(e)
pass两种的话改为 true/false,多种改为 enum 可读性更好
def enum(**enums):
return type("Enum", (), enums)
StatusEnum = enum(
SUCCESS=True,
FAIL=False,
)对于资源的具体操作类型,由HTTP动词表示。常用的HTTP动词有下面四个(括号里是对应的SQL命令)。
GET(SELECT):从服务器取出资源(一项或多项)
POST(CREATE):在服务器新建一个资源。
PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)
DELETE(DELETE):从服务器删除资源实际举例如下:
GET /product:列出所有商品
POST /product:新建一个商品
GET /product/ID:获取某个指定商品的信息
PUT /product/ID:更新某个指定商品的信息
DELETE /product/ID:删除某个商品
GET /product/ID/purchase :列出某个指定商品的所有投资者
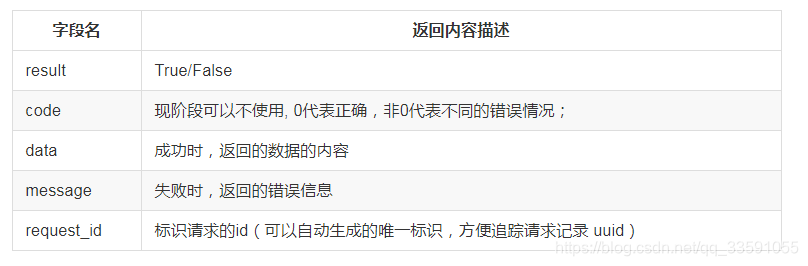
get /product/ID/purchase/ID:获取某个指定商品的指定投资者信息接口返回内容开发建议直接参考蓝鲸 apigateway 规范,返回的内容中包含 result code data message request_id 这几个字段
**建议充分利用 HTTP Status Code 作为响应结果的基本状态码,基本状态码不能区分的 status,
再用响应 body 中"约定"的 code 进行补充
http状态码详细说明请参考:https://baike.baidu.com/item/HTTP%E7%8A%B6%E6%80%81%E7%A0%81/5053660常用状态码如下:
200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)。
201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。
202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务)
204 NO CONTENT - [DELETE]:用户删除数据成功。
400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作,该操作是幂等的。
401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。
403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。
404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。
406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。
410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。
422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。
500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。- 以
#开头,#右边的所有东西都被当做说明文字,而不是真正要执行的程序,只起到辅助说明作用 - 示例代码如下:
# 这是第一个单行注释
print("hello python")
print("hello python") # 输出 `hello python`
注:如在代码后面注释,为了保证代码的可读性,注释和代码之间至少要有两个空格- 如果希望编写的 注释信息很多,一行无法显示,就可以使用多行注释
- 要在 Python 程序中使用多行注释,可以用 一对 连续的 三个 引号(单引号和双引号都可以)
- 示例代码如下:
"""
这是一个多行注释
在多行注释之间,可以写很多很多的内容……
"""
print("hello python")1、【必须】去除代码中的 print,否则导致正式和测试环境 uwsgi 输出大量信息
2、逻辑块空行分隔
3、变量和其使用尽量放到一起
4、【必须】 import过长,要放在多行的时候,使用 from xxx import(a, b, c),不要用 \ 换行
5、Django Model 定义的 choices 直接在定义在类里面Python官方提供有一系列 PEP(Python Enhancement Proposals) 文档- PEP 8规范文档地址:https://blog.csdn.net/ratsniper/article/details/78954852
app = QApplication(sys.argv)每一个PyQt5程序都需要有一个QApplication对象。sys.argv是从命令行传入的参数列表。Python脚本可以从shell中运行。这是一种通过参数来选择启动脚本的方式。
window = QWidget()QWidget控件是PyQt5中所有用户界面的父类,QWidget对象创建成为一个应用的顶层窗口。这里使用了没有参数的默认构造函数,它没有父类,我们称没有父类的控件为窗口。
由于所有的窗口和控件都是继承与QWidget类,所以如果不为控件指定一个父对象,那么控件就会被当作窗口处理,这时 setWindowTitle() 和 setWindowIcon() 函数就会生效
- app.exec_() 的作用是运行主循环,必须调用此函数才能开始事件处理,调用该方法进入程序的主循环直到调用 exit() 结束。主事件循环从窗口系统接收事件,并将其分派给应用程序小部件。如果没有该方法,那么在运行的时候还没有进入程序的主循环就直接结束了,所以运行的时候窗口会闪退。
- app.exec_()在退出时会返回状态代码
- 不用 sys.exit(app.exec_()),只使用 app.exec_(),程序也可以正常运行,但是关闭窗口后进程却不会退出。
- sys.exit(n)的作用是退出应用程序并返回n到父进程。
QApplication 类管理图形用户界面应用程序的控制流和主要设置。 可以说QApplication是Qt的整个后台管理的命脉。
它包含主事件循环,在其中来自窗口系统和其它资源的所有事件被处理和调度。它也处理应用程序的初始化和结束,并且提供对话管理。它也处理绝大多数系统范围和应用程序范围的设置。对于任何一个使用Qt的图形用户界面应用程序,都正好存在一个QApplication对象,而不论这个应用程序在同一时间内是不是有0、1、2或更多个窗口。
QApplication 对象是可以通过全局变量qApp访问。它的负责的主要范围有:
- 它使用用户的桌面设置,例如palette()、font()和doubleClickInterval()来初始化应用程序。如果用户改变全局桌面,例如通过一些控制面板,它会对这些属性保持跟踪。
- 它执行事件处理,也就是说它从低下的窗口系统接收事件并且把它们分派给相关的窗口部件。通过使用sendEvent()和postEvent(),你可以发送你自己的事件到窗口部件。
- 它分析命令行参数并且根据它们设置内部状态。关于这点的详细情况请参考下面的构造函数文档。
- 它定义了由QStyle对象封装的应用程序的观感。在运行状态下,可以通过setStyle()来改变。
- 它指定了应用程序如何分配颜色。详细情况请参考setColorSpec()。
- 它定义了默认文本编码(请参考setDefaultCodec())并且提供了通过translate()用户可见的本地化字符串。
- 它提供了一些像desktop()和clipboard()这样的魔术般的对象。
- 它知道应用程序的窗口。你可以使用widgetAt()来询问在一个确定点上存在哪个窗口部件,得到一个topLevelWidgets()(顶级窗口部件)的列表和通过closeAllWindows()来关闭所有窗口,等等。
- 它管理应用程序的鼠标光标处理,请参考setOverrideCursor()和setGlobalMouseTracking()。
- 在X窗口系统上,它提供刷新和同步通讯流的函数,请参考flushX()和syncX()。
- 它提供复杂的对话管理支持。这使得当用户注销时,它可以让应用程序很好地结束,如果无法终止,撤消关闭进程并且甚至为未来的对话保留整个应用程序的状态。详细情况请参考isSessionRestored()、sessionId()、commitData()和saveState()。
应用程序排演实例包含了一个QApplication通常用法的典型完整的main()。
因为QApplication对象做了如此多的初始化,它必须在所有与用户界面相关的其它类被创建之前被创建。
因为它也处理命令行参数,在应用程序中对argv解释和修改之前创建它通常是一个好主意。(注意,也对于X11,setMainWidget()可以根据-geometry选项来改变主窗口部件。为了保持这个功能,你必须在setMainWidget()和它的任何重载之前设置你的默认。)
QApplication::QApplication ( int & argc, char ** argv )
初始化窗口系统并且使用在argv中的argc个命令行参数构造一个应用程序对象。
全局指针qApp指向这个应用程序对象。应该只有一个应用程序对象被创建。
这个应用程序对象必须在任何绘制设备(包括窗口部件、像素映射、位图等等)之前被构造。
argc和argv是命令行传进去的参数。
字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
-
Decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。
-
Encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码。
因此,转码的时候一定要先搞明白,字符串str是什么编码,然后decode成unicode,然后再encode成其他编码。代码中字符串的默认编码与代码文件本身的编码一致。python在安装时,默认的编码是ascii,当程序中出现非ascii编码时,python的处理常常会报这样的错UnicodeDecodeError: 'ascii' codec can't decode byte 0x?? in position 1: ordinal not in range(128),python没办法处理非ascii编码的,此时需要自己设置将python的默认编码,一般设置为utf8的编码格式。
解决方法有三种:
1.在命令行修改,仅本会话有效:
1)通过>>>sys.getdefaultencoding()查看当前编码(若报错,先执行>>>import sys >>>reload(sys))
2)通过>>>sys.setdefaultencoding('utf8')设置编码
2.较繁琐,最有效 在程序文件中加入以下三句
import sys
reload(sys)
sys.setdefaultencoding('utf8')3.修改Python本环境(推荐) 在Python的Lib\site-packages文件夹下新建一个sitecustomize.py文件,内容为:
#coding=utf8
import sys
reload(sys)
sys.setdefaultencoding('utf8')重启Python解释器,发现编码已被设置为utf8,与方案二同效;这是因为系统在Python启动的时候,自行调用该文件,设置系统的默认编码,而不需要每次都手动加上解决代码,属于一劳永逸的解决方法。
对于 Python 2.X:
import sys
reload(sys)
sys.setdefaultencoding("utf-8")对于 <= Python 3.3:
import imp
imp.reload(sys)注意:
- Python 3 与 Python 2 有很大的区别,其中Python 3 系统默认使用的就是utf-8编码。
- 所以,对于使用的是Python 3 的情况,就不需要sys.setdefaultencoding("utf-8")这段代码。
- 最重要的是,Python 3 的 sys 库里面已经没有 setdefaultencoding() 函数了。
对于 >= Python 3.4:
import importlib
importlib.reload(sys)最近在使用pip 安装插件的时候,出现下面的警告信息:
WARNING: Ignoring invalid distribution -ip (e:\python\python_dowmload\lib\site-packages)
解决方法:
找到警告信息中报错的目录,然后删掉~开头的文件夹,那种是之前安装插件失败/中途退出,导致插件安装出现异常导致的,虽说警告信息不影响,但是有强迫症 哈哈 。
使用遥感影像头文件时,需要获得里面的日期和时间信息,得到的字符串两端带有双引号,可以使用eval()函数去除。
a='"srting"'
print(a)
b=eval(a)
print(b)
结果:
"srting"
srting偶尔看到一些代码在定义函数时,在def那一行后面会加一个->。这个玩意儿有个专门的名词叫 type hint,即类型提示。
官方网站:https://www.python.org/dev/peps/pep-0484/
比如:
def add(a:int, b:int) -> int:
return a+b
这个表示并没有多么的神奇,意思是:告诉你期待的输入类型和输出类型。上面代码期待的类型为int。
这个网站(https://mypy-lang.org,有墙)对这个功能进行了说明:
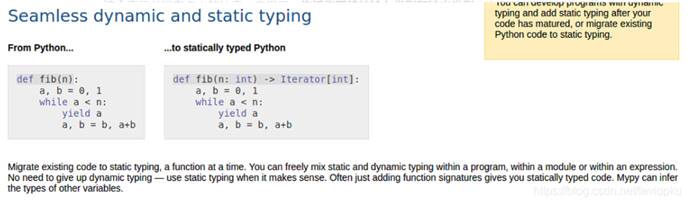
其实就是变量类型的动态定义和静态定义的区别。同样一个函数可以不加->表示动态定义和加->表示静态定义。
对于上面左边函数,对n的数据类型不一定为int,也可以为float等等…而右边限定了只能int。
这就是动静态的区别。
我试着寻找这两者的区别和各自优势。有以下发现:
\1. 将动态类型函数改为静态类型函数并不能使计算加快;
\2. 就算你静态限定了int,输入为float的时候也不会报错,输出也不会变成期待的int类型。所以在使用上,动静态类型并没有区别。
那么这个type hint看起来是比较鸡肋。
它的用处有以下:
\1. 增加代码可读性;
\2. 比较容易用其他语言改写。
————————————————
版权声明:本文为CSDN博主「木盏」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/leviopku/article/details/105236840
| 函数 | 含义 |
|---|---|
| min() | 计算最小值 |
| max() | 计算最大值 |
| sum() | 求和 |
| mean() | 计算平均值 |
| count() | 计数(统计非缺失元素的个数) |
| size() | 计数(统计所有元素的个数) |
| median() | 计算中位数 |
| var() | 计算方差 |
| std() | 计算标准差 |
| quantile() | 计算任意分位数 |
| cov() | 计算协方差 |
| corr() | 计算相关系数 |
| skew() | 计算偏度 |
| kurt() | 计算峰度 |
| mode() | 计算众数 |
| describe() | 描述性统计(一次性返回多个统计结果) |
| groupby() | 分组 |
| aggregate() | 聚合运算(可以自定义统计函数) |
| argmin() | 寻找最小值所在位置 |
| argmax() | 寻找最大值所在位置 |
| any() | 等价于逻辑“或” |
| all() | 等价于逻辑“与” |
| value_counts() | 频次统计 |
| cumsum() | 运算累计和 |
| cumprod() | 运算累计积 |
| pct_change() | 运算比率(后一个元素与前一个元素的比率) |
| 函数 | 含义 |
|---|---|
| duplicated() | 判断序列元素是否重复 |
| drop_duplicates() | 删除重复值 |
| hasnans() | 判断序列是否存在缺失(返回TRUE或FALSE) |
| isnull() | 判断序列元素是否为缺失(返回与序列长度一样的bool值) |
| notnull() | 判断序列元素是否不为缺失(返回与序列长度一样的bool值) |
| dropna() | 删除缺失值 |
| fillna() | 缺失值填充 |
| ffill() | 前向后填充缺失值(使用缺失值的前一个元素填充) |
| bfill() | 后向填充缺失值(使用缺失值的后一个元素填充) |
| dtypes() | 检查数据类型 |
| astype() | 类型强制转换 |
| pd.to_datetime | 转日期时间型 |
| factorize() | 因子化转换 |
| sample() | 抽样 |
| where() | 基于条件判断的值替换 |
| replace() | 按值替换(不可使用正则) |
| str.replace() | 按值替换(可使用正则) |
| str.split.str() | 字符分隔 |
| 函数 | 含义 |
|---|---|
| isin() | 成员关系判断 |
| between() | 区间判断 |
| loc() | 条件判断(可使用在数据框中) |
| iloc() | 索引判断(可使用在数据框中) |
| compress() | 条件判断 |
| nlargest() | 搜寻最大的n个元素 |
| nsmallest() | 搜寻最小的n个元素 |
| str.findall() | 子串查询(可使用正则) |
| 函数 | 含义 |
|---|---|
| hist() | 绘制直方图 |
| plot() | 可基于kind参数绘制更多图形(饼图,折线图,箱线图等) |
| map() | 元素映射 |
| apply() | 基于自定义函数的元素级操作 |
| 函数 | 含义 |
|---|---|
| dt.date() | 抽取出日期值 |
| dt.time() | 抽取出时间(时分秒) |
| dt.year() | 抽取出年 |
| dt.mouth() | 抽取出月 |
| dt.day() | 抽取出日 |
| dt.hour() | 抽取出时 |
| dt.minute() | 抽取出分钟 |
| dt.second() | 抽取出秒 |
| dt.quarter() | 抽取出季度 |
| dt.weekday() | 抽取出星期几(返回数值型) |
| dt.weekday_name() | 抽取出星期几(返回字符型) |
| dt.week() | 抽取出年中的第几周 |
| dt.dayofyear() | 抽取出年中的第几天 |
| dt.daysinmonth() | 抽取出月对应的最大天数 |
| dt.is_month_start() | 判断日期是否为当月的第一天 |
| dt.is_month_end() | 判断日期是否为当月的最后一天 |
| dt.is_quarter_start() | 判断日期是否为当季度的第一天 |
| dt.is_quarter_end() | 判断日期是否为当季度的最后一天 |
| dt.is_year_start() | 判断日期是否为当年的第一天 |
| dt.is_year_end() | 判断日期是否为当年的最后一天 |
| dt.is_leap_year() | 判断日期是否为闰年 |
| 函数 | 含义 |
|---|---|
| append() | 序列元素的追加(需指定其他序列) |
| diff() | 一阶差分 |
| round() | 元素的四舍五入 |
| sort_values() | 按值排序 |
| sort_index() | 按索引排序 |
| to_dict() | 转为字典 |
| tolist() | 转为列表 |
| unique() | 元素排重 |
在数据清洗时,需要按照一定条件删除某些数据样本,利用布尔表达式、索引和
drop方法可以实现。
df = df.drop(df[<some boolean condition>].index)
一个例子,删除dataframe中满足条件x所在的行:
df_clear = df.drop(df[df['x']<0.01].index)
# 也可以使用多个条件
df_clear = df.drop(df[(df['x']<0.01) | (df['x']>10)].index) #删除x小于0.01或大于10的行虽然Series有一个to_frame()方法,但是当Series的index也需要转变为DataFrame的一列时,这个方法转换会有一点问题。所以,下面我采用将Series对象转换为list对象,然后将list对象转换为DataFrame对象。
这里的month为一个series对象:
type(month)
pandas.core.series.Series它的index为月份,values为数量,下面将这两列都转换为DataFrame的columns。
import pandas as pd
dict_month = {'month':month.index,'numbers':month.values}
df_month = pd.DataFrame(dict_month)我选取了一个DataFrame的一部分数据得到了df1,但是index还是原来df的index,我想让新的df的index重新按照从0开始计数。
比如说,我的df1是这样的
>>> df1
col1 col2
2 0.5 0.9
6 1.1 3.2
11 2.1 0.5我希望的是
>>> df1
col1 col2
0 0.5 0.9
1 1.1 3.2
2 2.1 0.5df1.reset_index(drop=True, inplace=True)- 读取
../../Data/ModelResult目录下,所有的CSV文件 - 对所有的文件进行遍历操作
- 依次拼接所有文件
- os: 用来找出指定文件夹下所有文件
- pandas:用来读取和拼接所有CSV文件
import pandas as pd
import os
file_dir = '../../Data/ModelResult'
files = os.listdir(file_dir)
df1 = pd.read_csv(os.path.join(file_dir, files[0]))
for e in files[1:]:
df2 = pd.read_csv(os.path.join(file_dir, e))
df1 = pd.concat((df1, df2), axis=0, join='inner')
print(df1) Duplicated函数功能:查找并显示数据表中的重复值 这里需要注意的是:
- 当两条记录中所有的数据都相等时duplicated函数才会判断为重复值
- duplicated支持从前向后(first),和从后向前(last)两种重复值查找模式
- 默认是从前向后进行重复值的查找和判断,也就是后面的条目在重复值判断中显示为True
data.duplicated() #返回布尔型数据,告诉重复值的位置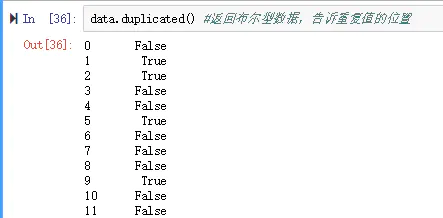
data.duplicated().sum() #说明有4个重复值
data[data.duplicated()]#打印重复值
或者
data[data.duplicated()==True]#打印重复值
data[data.duplicated()==False]#打印重复值drop_duplicates函数功能是:删除数据表中的重复值,判断标准和逻辑与duplicated函数一样
#inplace=True表示直接在源数据上进行操作
data.drop_duplicates(inplace=True) data.reset_index()pd.to_datetime 把时间字符串转换为时间格式 pd.to_timedelta 可以把时间差转换为timedelta格式 dt.total_seconds() 可以计算时间差的总秒数
1.把时间字符串转换为datetime格式
df['起始时间'] = pd.to_datetime(df['起始时间'])
df['终止时间'] = pd.to_datetime(df['终止时间'])2.计算时间差
df['时间差'] = df['终止时间'] - df['起始时间']
df['时间差'] = pd.to_timedelta(df['时间差'])3.把时间差转换为总秒数
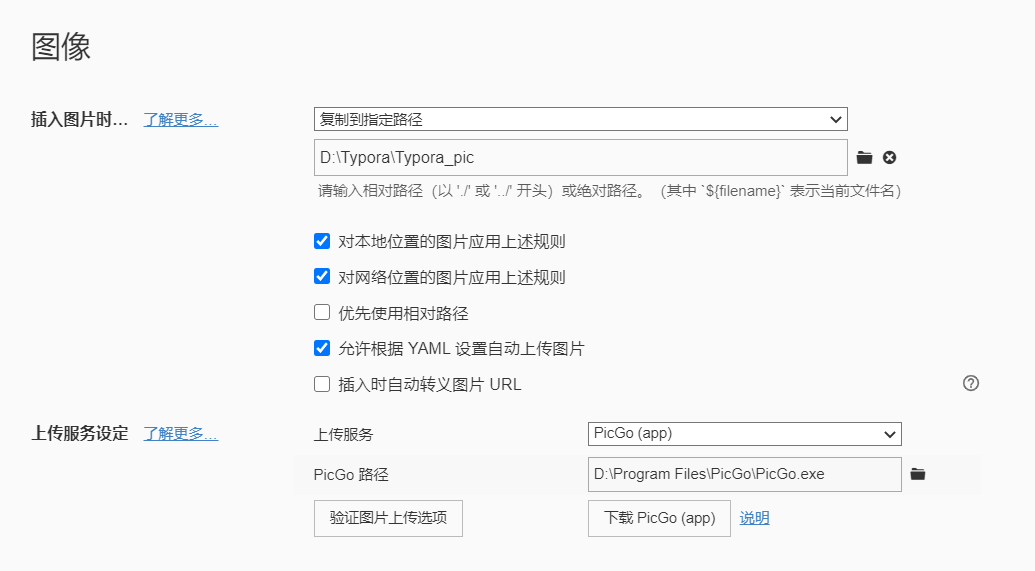
df['总秒数'] = df['时间差'].dt.total_seconds()- Typora设置
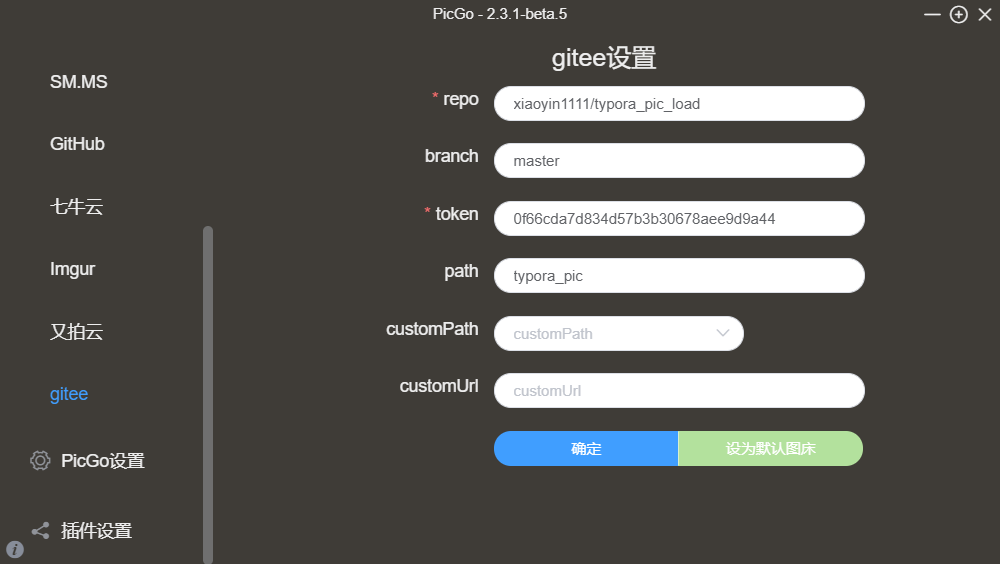
- PicGo设置
-
github设置
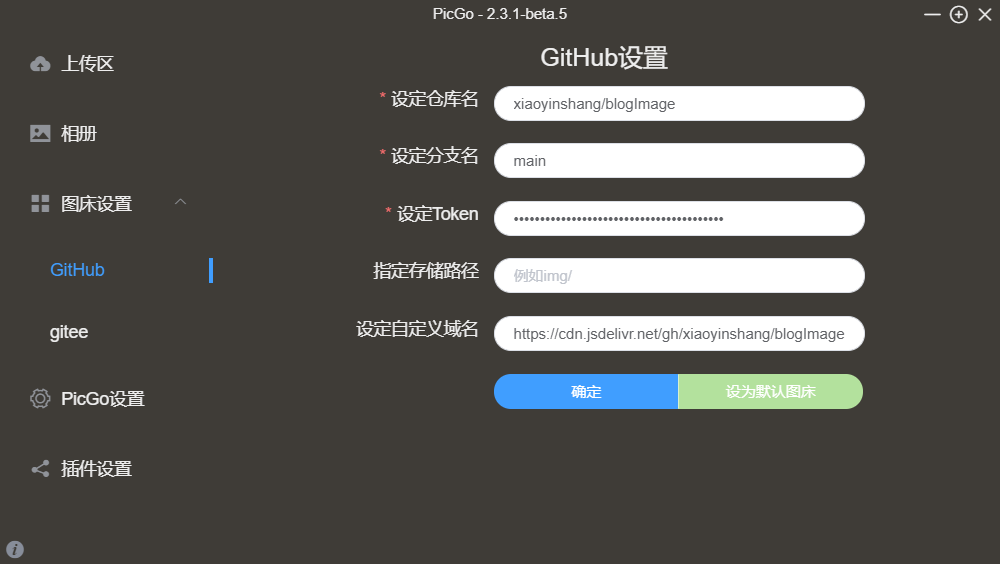
-
-
原因:
ERR_CERT_COMMON_NAME_INVALID就是用一个错误的域名访问了某个节点的https资源。导致这个错误的原因,基本是:- dns污染
- host设置错误
- 官方更新了dns,但是dns缓存没有被更新,导致错误解析。
-
解决办法:
-
打开域名解析网址,输入
raw.githubusercontent.com,如下图: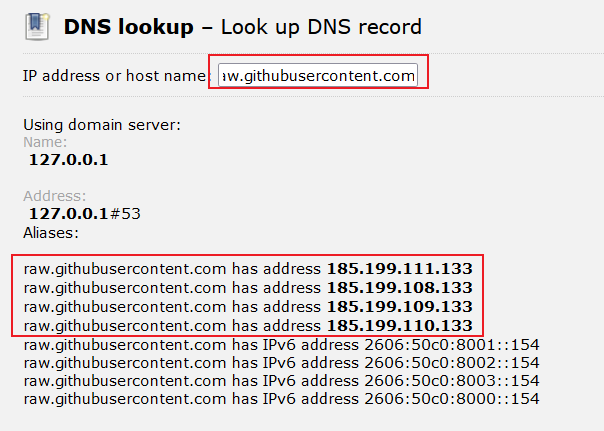
-
找到
C:\Windows\System32\drivers\etc\hosts文件 -
使用Notepad++(文本编辑器)打开
-
在文件后面添加以下内容。
# GitHub Start 185.199.111.133 raw.githubusercontent.com 185.199.110.133 raw.githubusercontent.com 185.199.109.133 raw.githubusercontent.com 185.199.108.133 raw.githubusercontent.com # GitHub End
-
刷新本机DNS解析
保存后,输入
cmd打开黑窗口,输入ipconfig /flushdns刷新一下本机的DNS解析。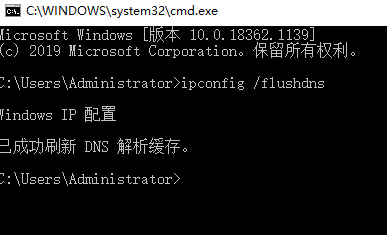
然后重启软件即可看到图片成功加载出来啦!
-
检查cmd-ping raw.githubusercontent.com命令
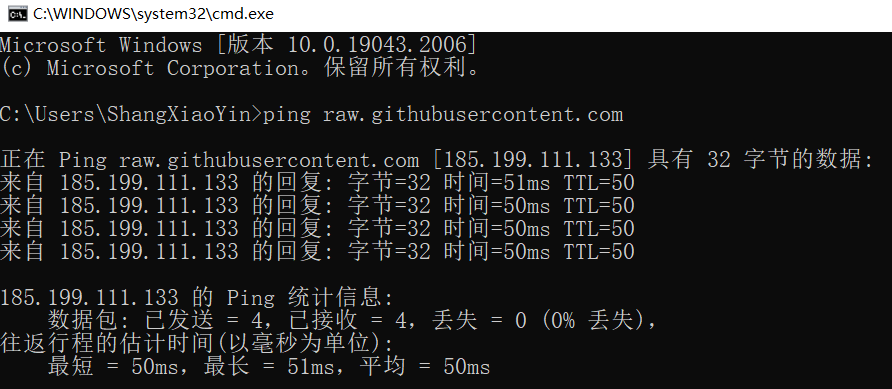
-
-
The beta version of typora is expired, please download and install a newer version
解决:
删掉以下两个文件:
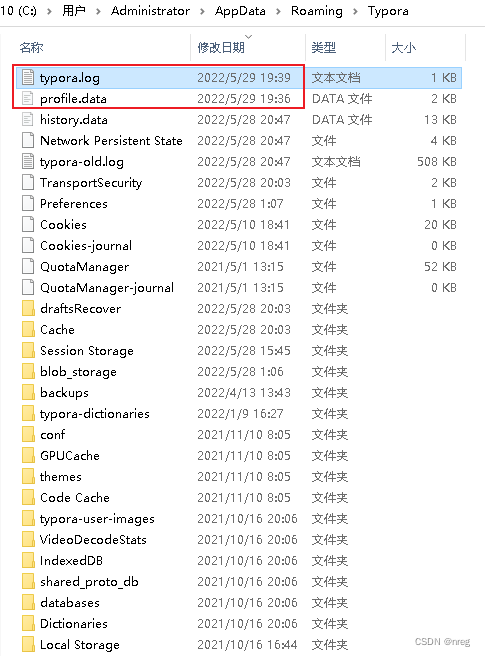
一劳永逸的解决方式:
bat 脚本:typora-clear.bat
cd "C:%HOMEPATH%\AppData\Roaming\Typora
del "typora.log"
del "profile.data"
将bat脚本放在开机自启目录即可:
C:\ProgramData\Microsoft\Windows\Start Menu\Programs\StartUp
或 C:%HOMEPATH%\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup

———————————————— 版权声明:本文为CSDN博主「nreg」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/northernice/article/details/125035682
==上述方法失效==
目前使用旧版本安装包 https://www.jianguoyun.com/p/DQj9hY8Q743yBxjNudYEIAA