{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


Tooth Detection and Numbering from Panoramic Radiography Using Artificial Neural Networks 🚀
This repository contains the source code and resources for detecting and numbering teeth from panoramic radiography images. Developed as a graduate project at T.C. Maltepe University.
See See below for detailed information on setup, training, testing, and usage. See below for quickstart examples.
Install
Clone the repository and install dependencies in a Python>=3.8.0 environment. Ensure you have PyTorch>=1.8 installed.
# Clone the YOLOv5 repository
git clone https://github.com/tunisch/tooth-detection-and-numbering
# Navigate to the cloned directory
cd yolov5
# Install required packages
pip install -r requirements.txtInference with PyTorch Hub
Use YOLOv5 via PyTorch Hub for inference. Models are automatically downloaded from the latest YOLOv5 release.
import torch
# Load the trained model for tooth detection and numbering
model = torch.hub.load("ultralytics/yolov5", "custom", path="path/to/your_trained_model.pt") # Replace with your trained model path
# Define the input image source (URL, local file, PIL image, OpenCV frame, numpy array, or list)
img = "path/to/your/test_image.jpg" # Replace with the path to your test image
# Perform inference (handles batching, resizing, normalization automatically)
results = model(img)
# Process the results (options: .print(), .show(), .save(), .crop(), .pandas())
results.print() # Print results to console
results.show() # Display results in a window
results.save() # Save results to runs/detect/expInference with detect.py
The detect.py script runs inference on various sources. It automatically downloads models from the latest YOLOv5 release and saves the results to the runs/detect directory.
# Run inference on an image or directory
python detect.py --weights best_model.pt --source data/test_images/
# Run inference on a text file listing image paths
python detect.py --weights yolov5s.pt --source list.txt
</details>
<details>
<summary>Training</summary>
The commands below demonstrate how to reproduce YOLOv5 [COCO dataset](https://docs.ultralytics.com/datasets/detect/coco/) results.
Both [models](https://github.com/ultralytics/yolov5/tree/master/models)
and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) are downloaded automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
Training times for YOLOv5n/s/m/l/x are approximately 1/2/4/6/8 days on a single [NVIDIA V100 GPU](https://www.nvidia.com/en-us/data-center/v100/).
Using [Multi-GPU training](https://docs.ultralytics.com/yolov5/tutorials/multi_gpu_training/) can significantly reduce training time.
Use the largest `--batch-size` your hardware allows, or use `--batch-size -1` for YOLOv5 [AutoBatch](https://github.com/ultralytics/yolov5/pull/5092).
The batch sizes shown below are for V100-16GB GPUs.
# Train the model on your dataset
python train.py --data data/dataset.yaml --epochs 100 --weights '' --cfg yolov5s.pt --batch-size 16
# Train YOLOv5n on COCO for 300 epochs
python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml --batch-size 128
# Train YOLOv5s on COCO for 300 epochs
python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5s.yaml --batch-size 64
# Train YOLOv5m on COCO for 300 epochs
python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5m.yaml --batch-size 40
# Train YOLOv5l on COCO for 300 epochs
python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5l.yaml --batch-size 24
# Train YOLOv5x on COCO for 300 epochs
python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5x.yaml --batch-size 16
Our key integrations with leading AI platforms extend the functionality of Ultralytics' offerings, enhancing tasks like dataset labeling, training, visualization, and model management.



| Make Sense AI 🌟 | Weights & Biases | TensorBoard |
|---|---|---|
| Streamline YOLO workflows: Label, train, and deploy effortlessly with Make Sense AI. Try now! | Track experiments, hyperparameters, and results with Weights & Biases. | Free forever, TensorBoard lets you save YOLO models, resume training, and interactively visualize predictions. |
YOLOv5 is designed for simplicity and ease of use. We prioritize real-world performance and accessibility.
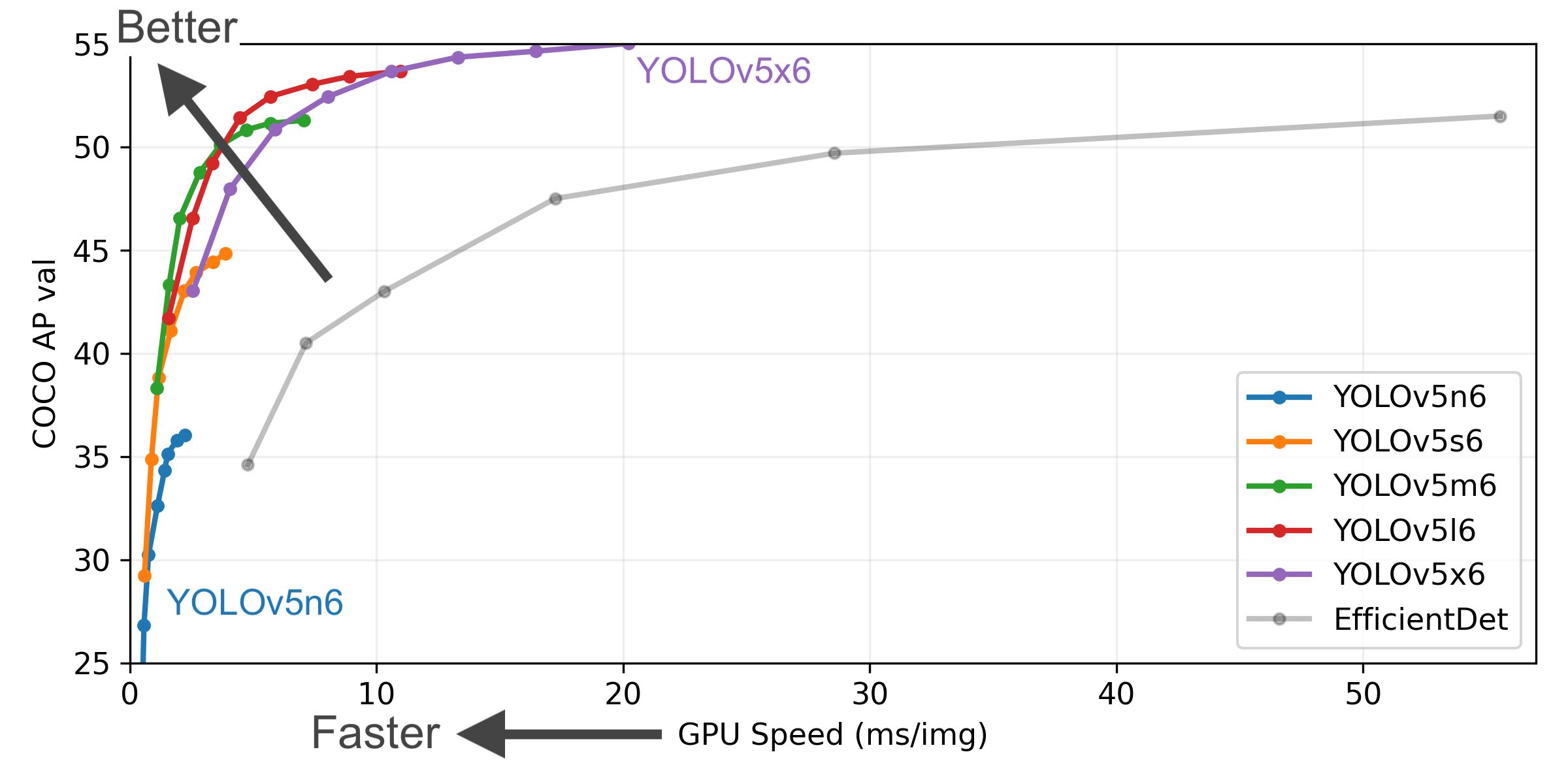
YOLOv5-P5 640 Figure
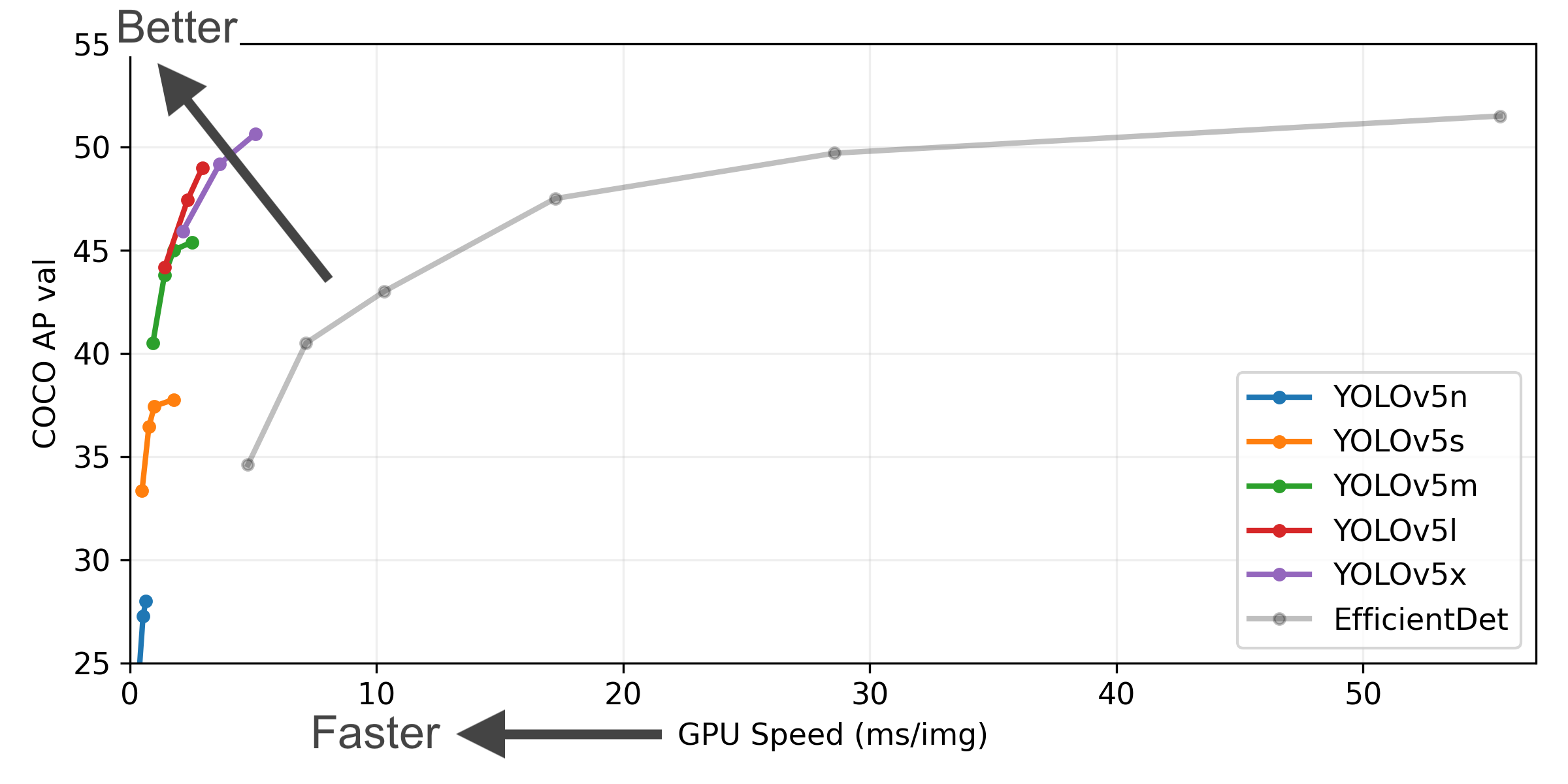
Figure Notes
- COCO AP val denotes the mean Average Precision (mAP) at Intersection over Union (IoU) thresholds from 0.5 to 0.95, measured on the 5,000-image COCO val2017 dataset across various inference sizes (256 to 1536 pixels).
- GPU Speed measures the average inference time per image on the COCO val2017 dataset using an AWS p3.2xlarge V100 instance with a batch size of 32.
- EfficientDet data is sourced from the google/automl repository at batch size 8.
- Reproduce these results using the command:
python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n6.pt yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt
This table highlights performance metrics for YOLOv5 models trained and fine-tuned on panoramic radiography datasets for tooth detection and numbering.
| Model | Size (pixels) |
mAPval 50-95 |
Speed CPU b1 (ms) |
Speed V100 b1 (ms) |
Params (M) |
FLOPs @640 (B) |
|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 32.0 | 50 | 8.0 | 1.9 | 4.5 |
| YOLOv5s | 640 | 40.5 | 100 | 8.5 | 7.2 | 16.5 |
| YOLOv5m | 640 | 48.0 | 230 | 10.5 | 21.2 | 49.0 |
| YOLOv5l | 640 | 52.5 | 450 | 12.0 | 46.5 | 109.1 |
| YOLOv5x | 640 | 54.0 | 800 | 15.0 | 86.7 | 205.7 |
Table Notes
- Dataset: All models were fine-tuned using a custom panoramic radiography dataset annotated for tooth detection and numbering.
- Reproducibility: Use the provided pretrained weights to reproduce results or fine-tune further using your dataset and the following command:
python train.py --data data/dental.yaml --img 640 --epochs 100 --weights 'path_to_weights.pt' - Performance: Inference times are benchmarked on high-resolution dental images to ensure suitability for clinical and research applications.
- mAPval values represent single-model, single-scale performance on the COCO val2017 dataset.
Reproduce using:python val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65 - Speed metrics are averaged over COCO val images using an AWS p3.2xlarge V100 instance. Non-Maximum Suppression (NMS) time (~1 ms/image) is not included.
Reproduce using:python val.py --data coco.yaml --img 640 --task speed --batch 1 - TTA (Test Time Augmentation) includes reflection and scale augmentations for improved accuracy.
Reproduce using:python val.py --data coco.yaml --img 1536 --iou 0.7 --augment
YOLOv5 release v6.2 introduced support for image classification model training, validation, and deployment. Check the Release Notes for details and the YOLOv5 Classification Colab Notebook for quickstart guides.
Classification Checkpoints
YOLOv5-cls classification models were trained on ImageNet for 90 epochs using a 4xA100 instance. ResNet and EfficientNet models were trained alongside under identical settings for comparison. Models were exported to ONNX FP32 (CPU speed tests) and TensorRT FP16 (GPU speed tests). All speed tests were run on Google Colab Pro for reproducibility.
| Model | Size (pixels) |
Acc top1 |
Acc top5 |
Training 90 epochs 4xA100 (hours) |
Speed ONNX CPU (ms) |
Speed TensorRT V100 (ms) |
Params (M) |
FLOPs @224 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n-cls | 224 | 64.6 | 85.4 | 7:59 | 3.3 | 0.5 | 2.5 | 0.5 |
| YOLOv5s-cls | 224 | 71.5 | 90.2 | 8:09 | 6.6 | 0.6 | 5.4 | 1.4 |
| YOLOv5m-cls | 224 | 75.9 | 92.9 | 10:06 | 15.5 | 0.9 | 12.9 | 3.9 |
| YOLOv5l-cls | 224 | 78.0 | 94.0 | 11:56 | 26.9 | 1.4 | 26.5 | 8.5 |
| YOLOv5x-cls | 224 | 79.0 | 94.4 | 15:04 | 54.3 | 1.8 | 48.1 | 15.9 |
| ResNet18 | 224 | 70.3 | 89.5 | 6:47 | 11.2 | 0.5 | 11.7 | 3.7 |
| ResNet34 | 224 | 73.9 | 91.8 | 8:33 | 20.6 | 0.9 | 21.8 | 7.4 |
| ResNet50 | 224 | 76.8 | 93.4 | 11:10 | 23.4 | 1.0 | 25.6 | 8.5 |
| ResNet101 | 224 | 78.5 | 94.3 | 17:10 | 42.1 | 1.9 | 44.5 | 15.9 |
| EfficientNet_b0 | 224 | 75.1 | 92.4 | 13:03 | 12.5 | 1.3 | 5.3 | 1.0 |
| EfficientNet_b1 | 224 | 76.4 | 93.2 | 17:04 | 14.9 | 1.6 | 7.8 | 1.5 |
| EfficientNet_b2 | 224 | 76.6 | 93.4 | 17:10 | 15.9 | 1.6 | 9.1 | 1.7 |
| EfficientNet_b3 | 224 | 77.7 | 94.0 | 19:19 | 18.9 | 1.9 | 12.2 | 2.4 |
Table Notes (click to expand)
- All checkpoints were trained for 90 epochs using the SGD optimizer with
lr0=0.001andweight_decay=5e-5at an image size of 224 pixels, using default settings.
Training runs are logged at https://wandb.ai/glenn-jocher/YOLOv5-Classifier-v6-2. - Accuracy values (top-1 and top-5) represent single-model, single-scale performance on the ImageNet-1k dataset.
Reproduce using:python classify/val.py --data ../datasets/imagenet --img 224 - Speed metrics are averaged over 100 inference images using a Google Colab Pro V100 High-RAM instance.
Reproduce using:python classify/val.py --data ../datasets/imagenet --img 224 --batch 1 - Export to ONNX (FP32) and TensorRT (FP16) was performed using
export.py.
Reproduce using:python export.py --weights yolov5s-cls.pt --include engine onnx --imgsz 224
Classification Usage Examples 
YOLOv5 classification training supports automatic download for datasets like MNIST, Fashion-MNIST, CIFAR10, CIFAR100, Imagenette, Imagewoof, and ImageNet using the --data argument. For example, start training on MNIST with --data mnist.
# Train on a single GPU using CIFAR-100 dataset
python classify/train.py --model yolov5s-cls.pt --data cifar100 --epochs 5 --img 224 --batch 128
# Train using Multi-GPU DDP on ImageNet dataset
python -m torch.distributed.run --nproc_per_node 4 --master_port 1 classify/train.py --model yolov5s-cls.pt --data imagenet --epochs 5 --img 224 --device 0,1,2,3Validate the accuracy of the YOLOv5m-cls model on the ImageNet-1k validation dataset:
# Download ImageNet validation split (6.3GB, 50,000 images)
bash data/scripts/get_imagenet.sh --val
# Validate the model
python classify/val.py --weights yolov5m-cls.pt --data ../datasets/imagenet --img 224Use the pretrained YOLOv5s-cls.pt model to classify the image bus.jpg:
# Run prediction
python classify/predict.py --weights yolov5s-cls.pt --source data/images/bus.jpg# Load model from PyTorch Hub
model = torch.hub.load("ultralytics/yolov5", "custom", "yolov5s-cls.pt")Export trained YOLOv5s-cls, ResNet50, and EfficientNet_b0 models to ONNX and TensorRT formats:
# Export models
python export.py --weights yolov5s-cls.pt resnet50.pt efficientnet_b0.pt --include onnx engine --img 224Get started quickly with our pre-configured environments. Click the icons below for setup details.
- AGPL-3.0 License: An OSI-approved open-source license ideal for academic research, personal projects, and testing. It promotes open collaboration and knowledge sharing. See the LICENSE file for details.
For bug reports and feature requests related to YOLOv5, please visit GitHub Issues. For general questions, discussions, and community support, join our Discord server!