- The input frames are .jpg, not .png (see TorchDB.py)
- The model is loaded in a different way in train.py, to use the pretrained models linked in https://github.com/sniklaus/sepconv-slomo
- In TestModule.py, the test folders are not fixed but are obtained dynamically, using os.listdir(input_dir); also, the filenames were changed to frame0.jpg / frame1.jpg / frame2.jpg
- In test.py, the kernel_size was fixed to 51 (which is the one of the pretrained model), and in general the loading of the model is similar to the one in train.py
- model.cuda() was added in test.py
The whole notebooks folder is new: it contains python notebooks ready to run on Google Colab
This is a reference implementation of Video Frame Interpolation via Adaptive Separable Convolution [1] using PyTorch. Given two frames, it will make use of adaptive convolution [2] in a separable manner to interpolate the intermediate frame. Should you be making use of the work, please cite the paper [1].
This is a modified version of original code.

- This is a backpropagation implemented version, therefore trainable.
- run.py was devided into model.py, train.py and test.py
- A module to read dataset(TorchDB.py) was added.
- Test module(TestModule.py) for the evaluation with Middlebury dataset was added.
The separable convolution layer is implemented in CUDA using CuPy, which is why CuPy is a required dependency. It can be installed using pip install cupy or alternatively using one of the provided binary packages as outlined in the CuPy repository.
Two input frames and one output frame are in a folder and the input frames should be named as frame0.png, frame2.png and the output frame should be named as frame1.png. You can name each folder freely.
The training dataset is not provided. We prepared training dataset by cropping UCF101 dataset. When creating training dataset, we measured Optical Flow of each frame to balance the motion magnitude of whole dataset.
An example of train dataset is in db folder.
python train.py --train ./your/datset/dir --out_dir ./output/folder/tobe/created --test_input ./test/input/of/Middlebury/data --gt ./gt/of/Middlebury/data
python test.py --input ./test/input/of/Middlebury/data --gt ./gt/of/Middlebury/data --output ./output/folder/tobe/created --checkpoint --./dir/for/pytorch/checkpoint
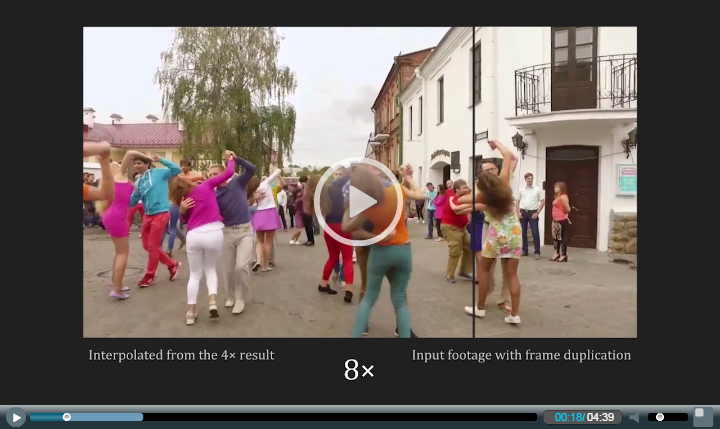
The provided implementation is strictly for academic purposes only. Should you be interested in using our technology for any commercial use, please feel free to contact us.
[1] @inproceedings{Niklaus_ICCV_2017,
author = {Simon Niklaus and Long Mai and Feng Liu},
title = {Video Frame Interpolation via Adaptive Separable Convolution},
booktitle = {IEEE International Conference on Computer Vision},
year = {2017}
}
[2] @inproceedings{Niklaus_CVPR_2017,
author = {Simon Niklaus and Long Mai and Feng Liu},
title = {Video Frame Interpolation via Adaptive Convolution},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition},
year = {2017}
}
This work was supported by NSF IIS-1321119. The video above uses materials under a Creative Common license or with the owner's permission, as detailed at the end.