使用request+cheerio+mysql+async爬取网站
-
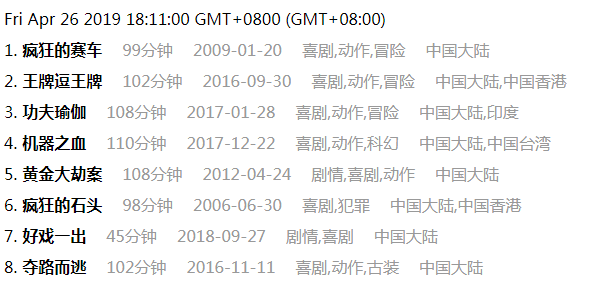
本地爬虫:爬取猫眼电影top100,爬取电影标题,电影排名,电影封面。使用request+cheerio+async,爬虫入口文件是根目录下的/crawler.js。,Node环境下执行爬虫命令是:npm run crawler

-
数据库爬虫:爬取猫眼电影详情页,爬取电影标题,电影类型,电影上市时间,电影简介,电影时长,电影上映的地方。使用request+cheerio+mysql,爬虫入口是/database/crawler.js。Node环境下执行爬虫命令是:npm run crawler_db
- url管理器
- download下载器
- parser解析器
- output导出数据
- crawler爬虫调度器
- 项目已经包含的node_modules目录,不再需要npm install了(避免了npm install不成功,如需要可以从新安装)
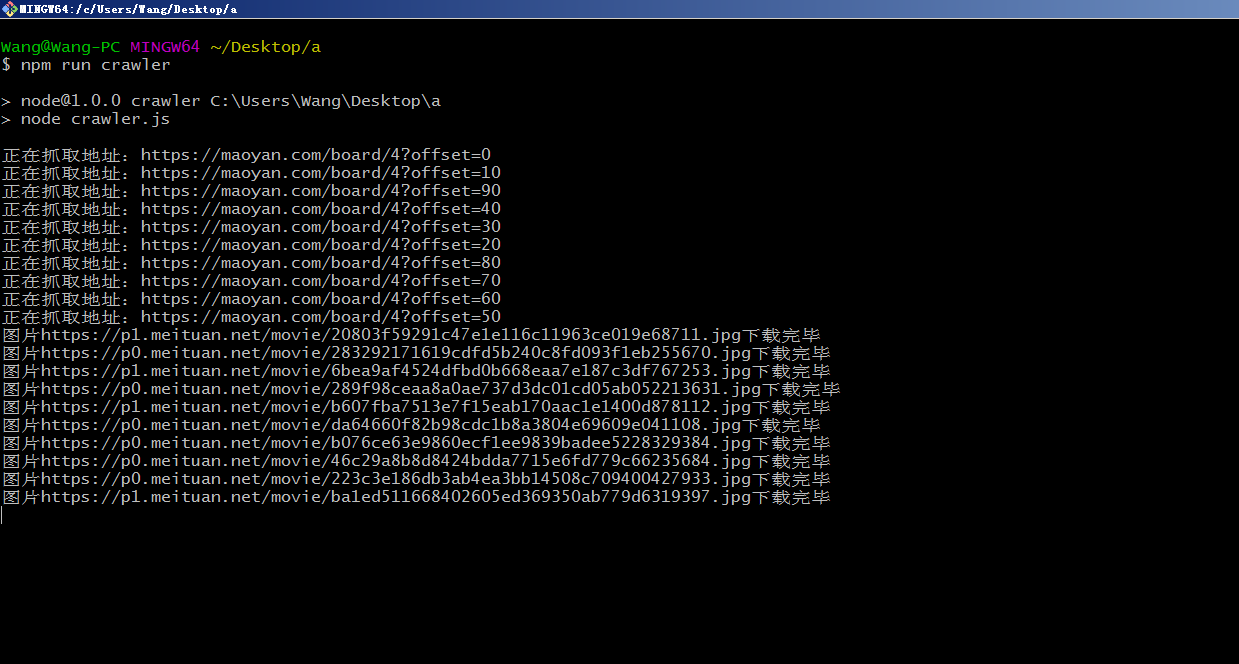
- 运行本地爬虫不需要安装mysql数据库,直接运行npm run crawler,执行图如下:
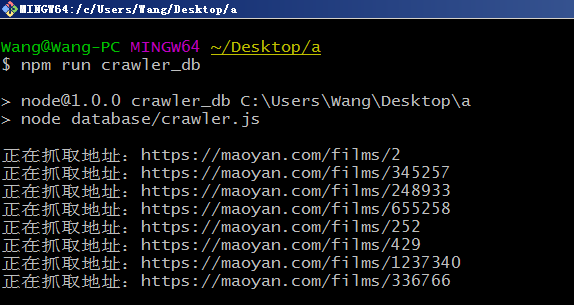
- 运行数据库爬虫需要安装并且配置mysql数据库,配置方法查看后面,执行图如下:
- host: 'localhost'
- port: 3306
- user: 'root'
- password: '88888888'
- database: 'crawler'
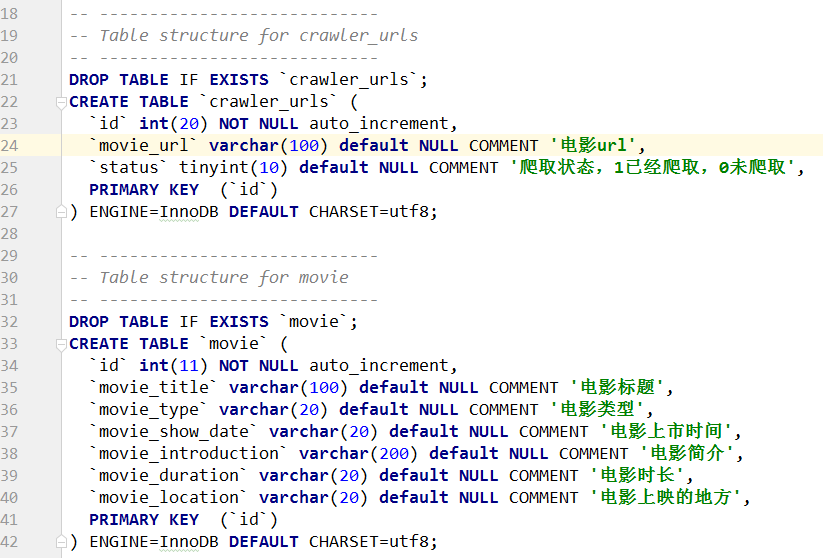
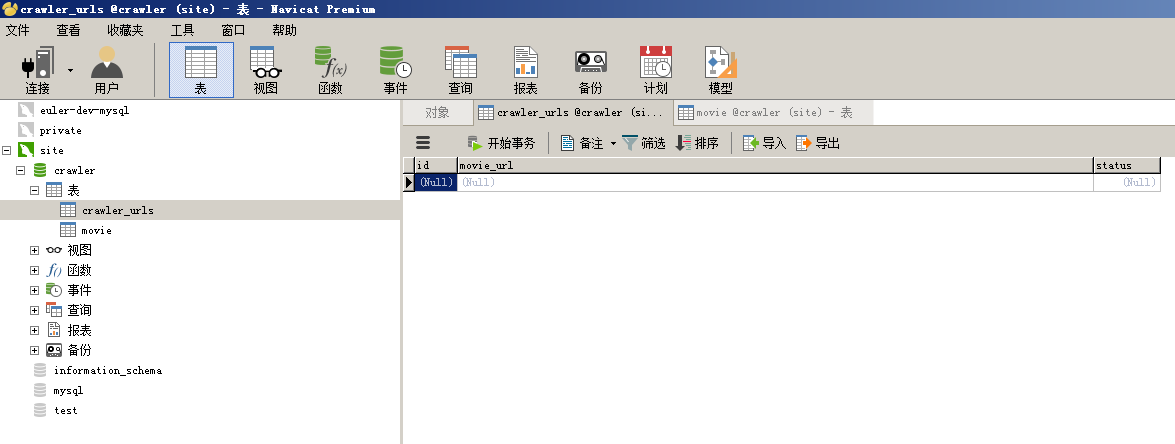
- crawler_urls表,存储待爬取的url
- movie表,存储爬取的电影详情页数据
-
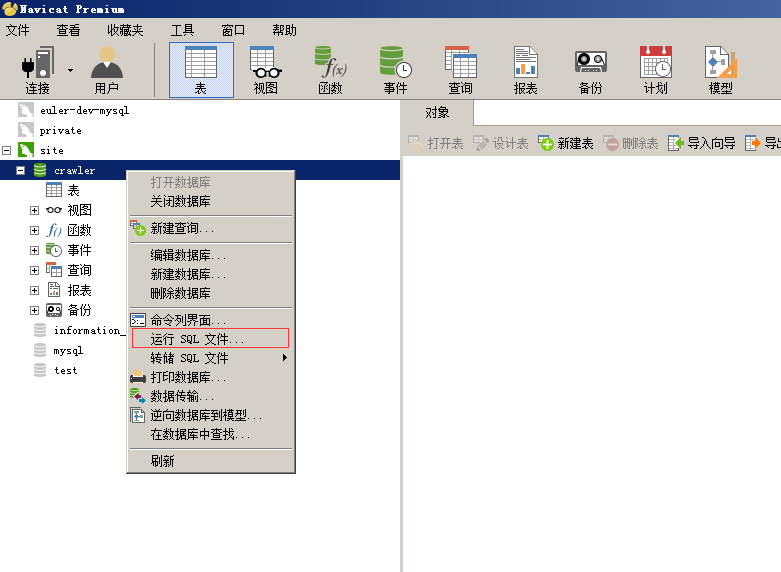
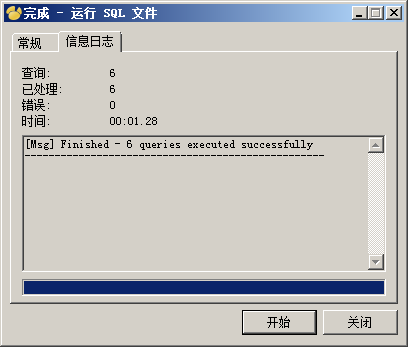
crawler.sql包含两个表结构,下面以Navicat为例将crawler.sql导入到数据库中
- Node.js版本是:11.14.0
- MySQL版本是:5.0.90
- MySQL引擎是:InnoDB
- MySQL字符集是:utf8 -- UTF-8 Unicode
- MySQL排序规则是:utf8_general_ci
- 代码编写于2019/04/26,不能保证之后时间,项目一直运行成功