


{kind=link}
Pipecat Flows provides a framework for building structured conversations in your AI applications. It enables you to create both predefined conversation paths and dynamically generated flows while handling the complexities of state management and LLM interactions.
The framework consists of:
- A Python module for building conversation flows with Pipecat
- A visual editor for designing and exporting flow configurations
- Static Flows: When your conversation structure is known upfront and follows predefined paths. Perfect for customer service scripts, intake forms, or guided experiences.
- Dynamic Flows: When conversation paths need to be determined at runtime based on user input, external data, or business logic. Ideal for personalized experiences or complex decision trees.
If you're already using Pipecat:
pip install pipecat-ai-flowsIf you're starting fresh:
# Basic installation
pip install pipecat-ai-flows
# Install Pipecat with specific LLM provider options:
pip install "pipecat-ai[daily,openai,deepgram,cartesia]" # For OpenAI
pip install "pipecat-ai[daily,anthropic,deepgram,cartesia]" # For Anthropic
pip install "pipecat-ai[daily,google,deepgram,cartesia]" # For GoogleHere's a basic example of setting up a static conversation flow:
from pipecat_flows import FlowManager
# Initialize flow manager with static configuration
flow_manager = FlowManager(task, llm, tts, flow_config=flow_config)
@transport.event_handler("on_first_participant_joined")
async def on_first_participant_joined(transport, participant):
await transport.capture_participant_transcription(participant["id"])
await flow_manager.initialize()
await task.queue_frames([context_aggregator.user().get_context_frame()])For more detailed examples and guides, visit our documentation.
Each conversation flow consists of nodes that define the conversation structure. A node includes:
Nodes use two types of messages to control the conversation:
- Role Messages: Define the bot's personality or role (optional)
"role_messages": [
{
"role": "system",
"content": "You are a friendly pizza ordering assistant. Keep responses casual and upbeat."
}
]- Task Messages: Define what the bot should do in the current node
"task_messages": [
{
"role": "system",
"content": "Ask the customer which pizza size they'd like: small, medium, or large."
}
]Role messages are typically defined in your initial node and inherited by subsequent nodes, while task messages are specific to each node's purpose.
Functions come in two types:
- Node Functions: Execute operations within the current state
{
"type": "function",
"function": {
"name": "select_size",
"handler": select_size_handler,
"description": "Select pizza size",
"parameters": {
"type": "object",
"properties": {
"size": {"type": "string", "enum": ["small", "medium", "large"]}
}
},
}
}- Edge Functions: Create transitions between states
{
"type": "function",
"function": {
"name": "next_step",
"handler": select_size_handler, # Optional handler
"description": "Move to next state",
"parameters": {"type": "object", "properties": {}},
"transition_to": "target_node" # Required: Specify target node
}
}Functions can:
- Have a handler (for data processing)
- Have a transition_to (for state changes)
- Have both (process data and transition)
- Have neither (end node functions)
There are two types of actions available:
pre_actions: Run before the LLM inference. For long function calls, you can use a pre_action for the TTS to say something, like "Hold on a moment..."post_actions: Run after the LLM inference. This is handy for actions like ending or transferring a call.
"pre_actions": [
{
"type": "tts_say",
"text": "Processing your order..."
}
],
"post_actions": [
{
"type": "end_conversation"
}
]Learn more about built-in actions and defining your own action in the docs.
Pipecat Flows automatically handles format differences between LLM providers:
OpenAI Format
"functions": [{
"type": "function",
"function": {
"name": "function_name",
"description": "description",
"parameters": {...}
}
}]Anthropic Format
"functions": [{
"name": "function_name",
"description": "description",
"input_schema": {...}
}]Google (Gemini) Format
"functions": [{
"function_declarations": [{
"name": "function_name",
"description": "description",
"parameters": {...}
}]
}]The FlowManager handles both static and dynamic flows through a unified interface:
# Define flow configuration upfront
flow_config = {
"initial_node": "greeting",
"nodes": {
"greeting": {
"role_messages": [
{
"role": "system",
"content": "You are a helpful assistant. Your responses will be converted to audio."
}
],
"task_messages": [
{
"role": "system",
"content": "Start by greeting the user and asking for their name."
}
],
"functions": [{
"type": "function",
"function": {
"name": "collect_name",
"description": "Record user's name",
"parameters": {...},
"handler": collect_name_handler, # Specify handler
"transition_to": "next_step" # Specify transition
}
}]
}
}
}
# Create and initialize the FlowManager
flow_manager = FlowManager(task, llm, tts, flow_config=flow_config)
await flow_manager.initialize()def create_initial_node() -> NodeConfig:
return {
"role_messages": [
{
"role": "system",
"content": "You are a helpful assistant."
}
],
"task_messages": [
{
"role": "system",
"content": "Ask the user for their age."
}
],
"functions": [
{
"type": "function",
"function": {
"name": "collect_age",
"handler": collect_age,
"description": "Record user's age",
"parameters": {
"type": "object",
"properties": {
"age": {"type": "integer"}
},
"required": ["age"]
}
}
}
]
}
# Initialize with transition callback
flow_manager = FlowManager(task, llm, tts, transition_callback=handle_transitions)
await flow_manager.initialize()
@transport.event_handler("on_first_participant_joined")
async def on_first_participant_joined(transport, participant):
await transport.capture_participant_transcription(participant["id"])
await flow_manager.initialize()
await flow_manager.set_node("initial", create_initial_node())
await task.queue_frames([context_aggregator.user().get_context_frame()])The repository includes several complete example implementations in the examples/ directory.
In the examples/static directory, you'll find these examples:
food_ordering.py- A restaurant order flow demonstrating node and edge functionsmovie_explorer_openai.py- Movie information bot demonstrating real API integration with TMDBmovie_explorer_anthropic.py- The same movie information demo adapted for Anthropic's formatmovie_explorer_gemini.py- The same movie explorer demo adapted for Google Gemini's formatpatient_intake.py- A medical intake system showing complex state managementrestaurant_reservation.py- A reservation system with availability checkingtravel_planner.py- A vacation planning assistant with parallel paths
In the examples/dynamic directory, you'll find these examples:
insurance_openai.py- An insurance quote system using OpenAI's formatinsurance_anthropic.py- The same insurance system adapted for Anthropic's formatinsurance_gemini.py- The insurance system implemented with Google's format
Each LLM provider (OpenAI, Anthropic, Google) has slightly different function calling formats, but Pipecat Flows handles these differences internally while maintaining a consistent API for developers.
To run these examples:
-
Setup Virtual Environment (recommended):
python3 -m venv venv source venv/bin/activate -
Installation:
Install the package in development mode:
pip install -e .Install Pipecat with required options for examples:
pip install "pipecat-ai[daily,openai,deepgram,cartesia,silero,examples]"If you're running Google or Anthropic examples, you will need to update the installed options. For example:
# Install Google Gemini pip install "pipecat-ai[daily,google,deepgram,cartesia,silero,examples]" # Install Anthropic pip install "pipecat-ai[daily,anthropic,deepgram,cartesia,silero,examples]"
-
Configuration:
Copy
env.exampleto.envin the examples directory:cp env.example .env
Add your API keys and configuration:
- DEEPGRAM_API_KEY
- CARTESIA_API_KEY
- OPENAI_API_KEY
- ANTHROPIC_API_KEY
- GOOGLE_API_KEY
- DAILY_API_KEY
Looking for a Daily API key and room URL? Sign up on the Daily Dashboard.
-
Running:
python examples/static/food_ordering.py -u YOUR_DAILY_ROOM_URL
The package includes a comprehensive test suite covering the core functionality.
-
Create Virtual Environment:
python3 -m venv venv source venv/bin/activate # On Windows: venv\Scripts\activate
-
Install Test Dependencies:
pip install -r dev-requirements.txt -r test-requirements.txt pip install "pipecat-ai[google,openai,anthropic]" pip install -e .
Run all tests:
pytest tests/Run specific test file:
pytest tests/test_state.pyRun specific test:
pytest tests/test_state.py -k test_initializationRun with coverage report:
pytest tests/ --cov=pipecat_flowsA visual editor for creating and managing Pipecat conversation flows.
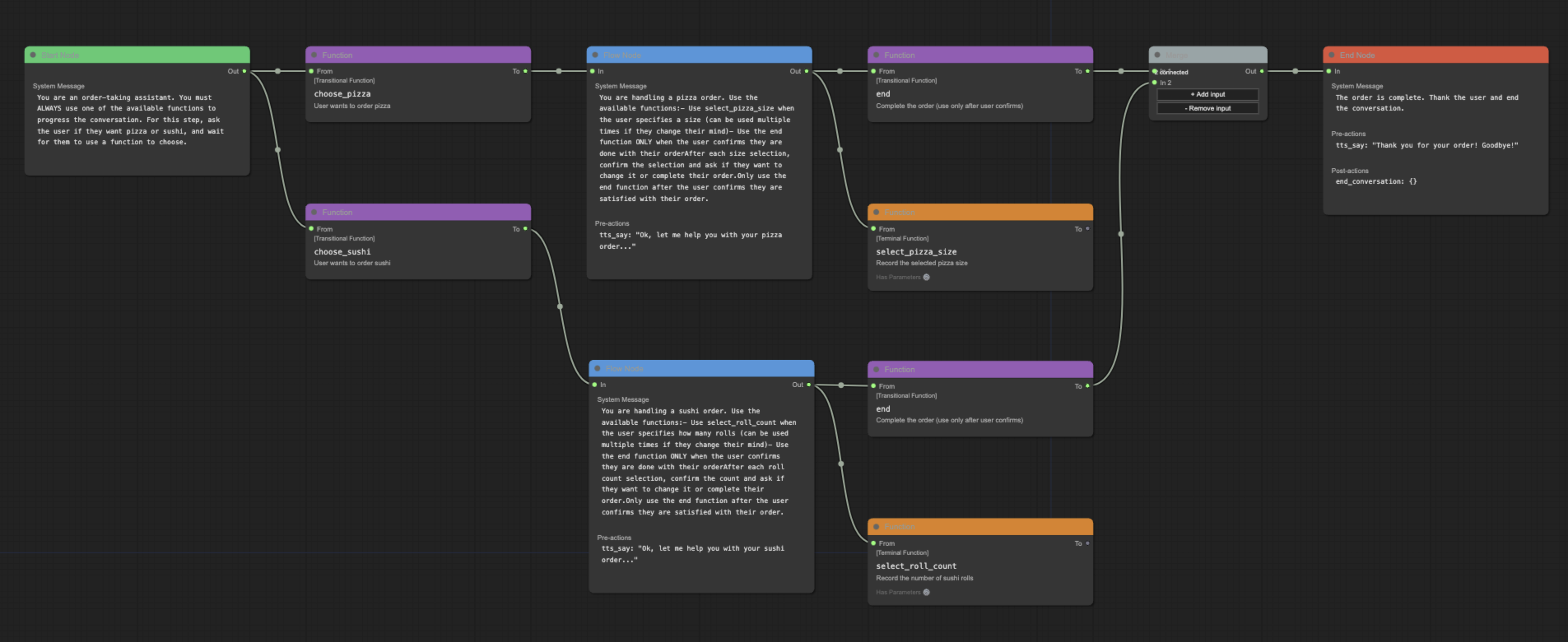
- Visual flow creation and editing
- Import/export of flow configurations
- Support for node and edge functions
- Merge node support for complex flows
- Real-time validation
While the underlying system is flexible with node naming, the editor follows these conventions for clarity:
- Start Node: Named after your initial conversation state (e.g., "greeting", "welcome")
- End Node: Conventionally named "end" for clarity, though other names are supported
- Flow Nodes: Named to reflect their purpose in the conversation (e.g., "get_time", "confirm_order")
These conventions help maintain readable and maintainable flows while preserving technical flexibility.
The editor is available online at flows.pipecat.ai.
- Node.js (v14 or higher)
- npm (v6 or higher)
Clone the repository
git clone git@github.com:pipecat-ai/pipecat-flows.gitNavigate to project directory
cd pipecat-flows/editorInstall dependencies
npm installStart development server
npm run devOpen the page in your browser: http://localhost:5173.
- Create a new flow using the toolbar buttons
- Add nodes by right-clicking in the canvas
- Start nodes can have descriptive names (e.g., "greeting")
- End nodes are conventionally named "end"
- Connect nodes by dragging from outputs to inputs
- Edit node properties in the side panel
- Export your flow configuration using the toolbar
The editor/examples/ directory contains sample flow configurations:
food_ordering.jsonmovie_explorer.pypatient_intake.jsonrestaurant_reservation.jsontravel_planner.json
To use an example:
- Open the editor
- Click "Import Flow"
- Select an example JSON file
See the examples directory for the complete files and documentation.
npm start- Start production servernpm run dev- Start development servernpm run build- Build for productionnpm run preview- Preview production build locallynpm run preview:prod- Preview production build with base pathnpm run lint- Check for linting issuesnpm run lint:fix- Fix linting issuesnpm run format- Format code with Prettiernpm run format:check- Check code formattingnpm run docs- Generate documentationnpm run docs:serve- Serve documentation locally
The Pipecat Flows Editor project uses JSDoc for documentation. To generate and view the documentation:
Generate documentation:
npm run docsServe documentation locally:
npm run docs:serveView in browser by opening: http://localhost:8080
We welcome contributions from the community! Whether you're fixing bugs, improving documentation, or adding new features, here's how you can help:
- Found a bug? Open an issue
- Have a feature idea? Start a discussion
- Want to contribute code? Check our CONTRIBUTING.md guide
- Documentation improvements? Docs PRs are always welcome
Before submitting a pull request, please check existing issues and PRs to avoid duplicates.
We aim to review all contributions promptly and provide constructive feedback to help get your changes merged.