- Table of Contents
- Purpose
- How-To-Ask-Questions-The-Smart-Way
- engineer-ability-visualizer
- 最初から強いやつの特徴
- Installation
- Step1 Install Python3.6-32bit
- Step2 Upgrade pip
- Step3 Install VirtualEnv & Install VirtualEnvWrapper-win
- Step4 Make virtualenv
- Step5 Set Project Directory
- Step6 Deactivate
- Step7 Workon
- Step8 Install modules
- Step9 Check installed mdules
- Step10 Install modules manually
- Step11 Double Check installed mdules
- Step12 Dump installed modules inot requirement.txt
- Installing python2.7 hosts on python3.6 Laptop
- how-to-use-args-and-kwargs-in-python-3
- if name == 'main' ?
- method, @classmethod, @staticmethod
- moudle improt
- python モジュールimport方法について
- [Python] importの躓きどころ
- Python の init.py とは何なのか * 1. モジュール検索のためのマーカー * 2. 名前空間の初期化 * 3. ワイルドカード(wild card) import の対象の定義 (all の定義) * 4. 同じディレクトリにある他のモジュールの名前空間の定義
- Python init.pyの書き方
- import雜談之一———import路徑的相對論
- import雜談之二———export機制以及namespace package
- import雜談之三———sys.path的洪荒之時
- python import雜談之四
- break、continue、pass
- Understanding slice notation
- a[[0], 0, 0:1] in NumPy
- Closure and Decorator
- Rye
- Environment
- Troubleshooting
- Reference
- h1 size
Created by gh-md-toc
Take some note of python
How-To-Ask-Questions-The-Smart-Way
慎選提問的論壇
Stack Overflow
網站和IRC論壇
第二步,使用專案郵件列表
使用有意義且描述明確的標題
使問題容易回覆
用清晰、正確、精準並合法文法的語句
使用易於讀取且標準的文件格式發送問題
精確的描述問題並言之有物
話不在多而在精
別動輒聲稱找到Bug
別用低聲下氣取代你真正該做的事
描述問題症狀而非猜測
按發生時間先後列出問題症狀
描述目標而不是過程
別要求使用私人電郵回覆
清楚明確的表達你的問題以及需求
詢問有關程式碼的問題時
別把自己家庭作業的問題貼上來
去掉無意義的提問句
即使你很急也不要在標題寫緊急
禮多人不怪,而且有時還很有幫助
問題解決後,加個簡短的補充說明
RTFM和STFW:如何知道你已完全搞砸了
如果還是搞不懂
處理無禮的回應
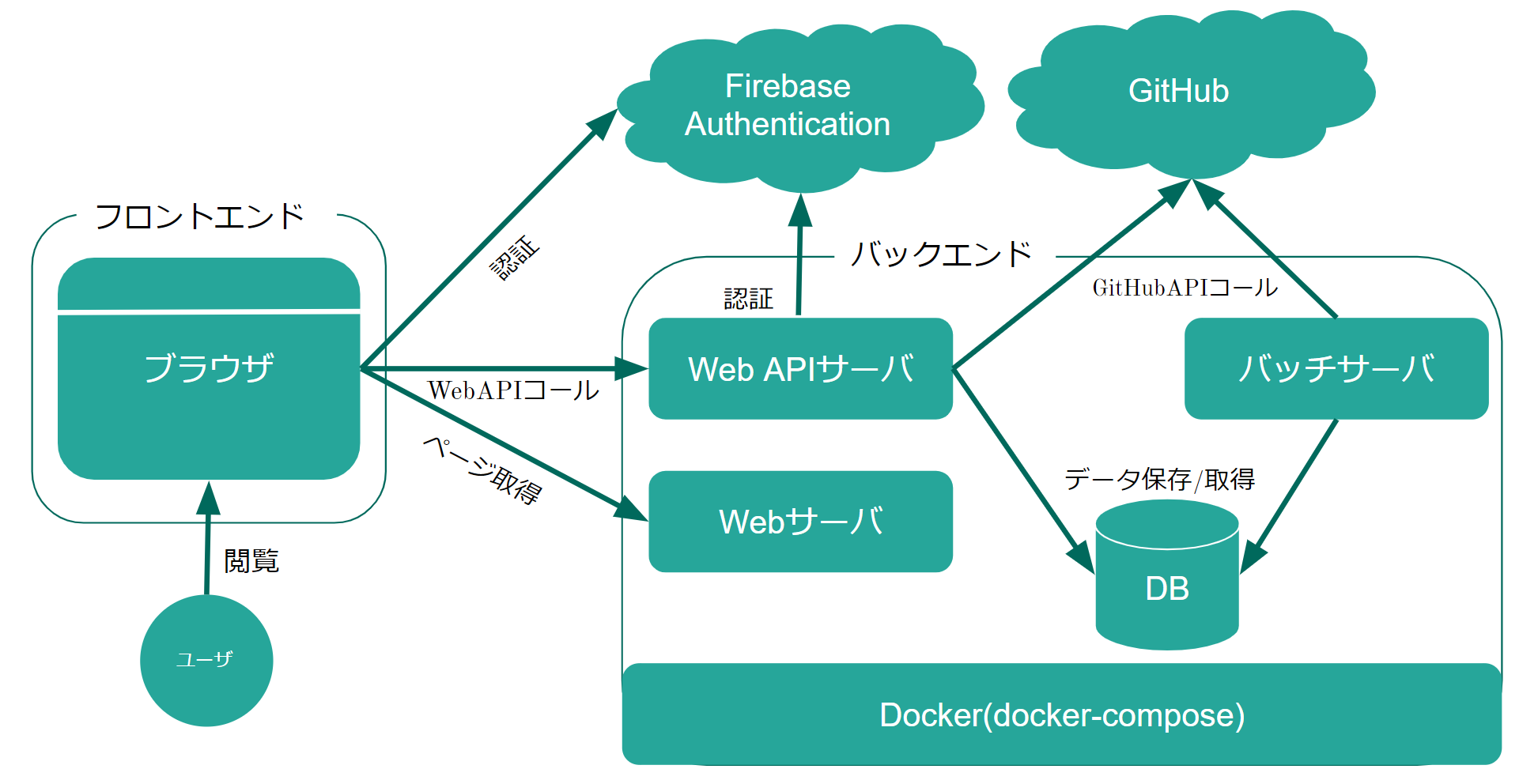
ocoteron /engineer-ability-visualizer
本プロダクトは、新卒エンジニア採用担当向けのエンジニアの能力を可視化するWebサービスです。
採用担当の「会社にマッチしているエンジニアを採用したいがミスマッチがある」といった課題を解決するために作成しました。
現状の選考方法の例としては以下のようなものがあります。
書類選考
面接
筆記試験
コーディイングテスト
これらは、本番一発勝負であったり選考のためだけに準備をしてくる場合が多いと思います。 その場合、エンジニアが本当はどんな人でどんな能力に長けているのかといった点は見えづらいのではないかと考えています。
その問題を解決するために本プロダクトでは、エンジニアのGitHubの普段の活動を分析し、能力として可視化します。
エンジニアの評価軸は、以下の通りです。
発見力 (課題を発見する能力)
イシュースコア
解決力 (課題に取り組む能力)
リポジトリスコア
コミットスコア
プルリクスコア
スピード (課題に取り組む速さ)
コミットスピードスコア


最初から強いやつの特徴 updated at 2021-10-23
平日の稼働時間以外も勉強 or 開発する
土日も勉強 or 開発する
公式ドキュメントをちゃんと読む
以上のような当たり前のことは、最初から強い人じゃなくてもやるので特徴に入れません。
タスクのスコープが広範囲すぎると、自分でもゴールを見失いやすく、レビュワーも「これ何をレビューすればいいの?」という大変不幸な状態になります。
また、スコープが広いので、実装に時間がかかってしまい、どうしても停滞している感が否めなくなってきます。
最初から強い人は、何故かこのタスクの粒度設定が信じられないくらいうまいです。タスクが大きすぎたり難しすぎたりすると、細かくタスクを分割し、周りの人の協力を得ながら、着実に階段を登って行きます。
ベテランのエンジニアと一緒にストーリーの作成をすることがあるが、抽象的なイメージでモヤモヤしている状態から、明確にストーリーが出来上がってくる様は、ある種の感動を覚えます。最初から強い人は、ベテランのエンジニアと同じ視点を持っていると思っています。
羨ましい限りである。
どうしても私は「うわっ!」って思ってしまう。
強い人たちは「ちゃんと読めばわからないわけがない」というマインドもさることながら、常に何か新しいことを探していて、隙あらば使おうとしている。(個人ではすでに使用している。)
「もう動くから今のままでええやん..」というのは普通の人の考え方である。



pip install -r requiremenets.txt


d:\project\Python\moneyhunter (master -> origin)
(moneyhunter) λ pip list
Package Version
------------------------ ----------
beautifulsoup4 4.6.3
bs4 0.0.1
cachetools 3.0.0
certifi 2018.10.15
chardet 3.0.4
cycler 0.10.0
google-api-core 1.5.2
google-api-python-client 1.7.4
google-auth 1.6.1
google-auth-httplib2 0.0.3
google-cloud-core 0.28.1
google-cloud-firestore 0.30.0
google-cloud-storage 1.13.0
google-resumable-media 0.3.1
googleapis-common-protos 1.5.5
greenlet 0.4.15
gspread 3.0.1
gunicorn 19.9.0
h5py 2.8.0
httplib2 0.12.0
idna 2.7
kiwisolver 1.0.1
lxml 4.2.5
matplotlib 2.2.3
mpl-finance 0.10.0
numpy 1.15.4
oauth2client 4.1.3
pandas 0.23.4
Pillow 5.3.0
pip 19.0.3
protobuf 3.6.1
pyasn1 0.4.4
pyasn1-modules 0.2.2
PyDrive 1.3.1
pyparsing 2.3.0
python-dateutil 2.7.5
pytz 2018.7
PyYAML 3.13
requests 2.20.1
rsa 4.0
setuptools 40.9.0
six 1.11.0
twstock 1.1.1
uritemplate 3.0.0
urllib3 1.24.1
wheel 0.33.1
xlrd 1.1.0
xlutils 2.0.0
xlwt 1.3.0
pip install TA_Lib-0.4.17-cp36-cp36m-win32.whl

(moneyhunter) λ pip list
Package Version
------------------------ ----------
beautifulsoup4 4.6.3
bs4 0.0.1
cachetools 3.0.0
certifi 2018.10.15
chardet 3.0.4
cycler 0.10.0
google-api-core 1.5.2
google-api-python-client 1.7.4
google-auth 1.6.1
google-auth-httplib2 0.0.3
google-cloud-core 0.28.1
google-cloud-firestore 0.30.0
google-cloud-storage 1.13.0
google-resumable-media 0.3.1
googleapis-common-protos 1.5.5
greenlet 0.4.15
gspread 3.0.1
gunicorn 19.9.0
h5py 2.8.0
httplib2 0.12.0
idna 2.7
kiwisolver 1.0.1
lxml 4.2.5
matplotlib 2.2.3
mpl-finance 0.10.0
numpy 1.15.4
oauth2client 4.1.3
pandas 0.23.4
Pillow 5.3.0
pip 19.0.3
protobuf 3.6.1
pyasn1 0.4.4
pyasn1-modules 0.2.2
PyDrive 1.3.1
pyparsing 2.3.0
python-dateutil 2.7.5
pytz 2018.7
PyYAML 3.13
requests 2.20.1
rsa 4.0
setuptools 40.9.0
six 1.11.0
TA-Lib 0.4.17
twstock 1.1.1
uritemplate 3.0.0
urllib3 1.24.1
wheel 0.33.1
xlrd 1.1.0
xlutils 2.0.0
xlwt 1.3.0
d:\project\Python\moneyhunter\test (master -> origin)
pip freeze > ..\requiremenets.txt
c:\Python27\Scripts
λ virtualenv -p c:\Python27\python.exe c:\Users\amyfa\Envs\pholus
c:\Python27\Scripts
λ Workon pholus
c:\Python27\Scripts
(pholus) λ python -V
Python 2.7.16
c:\Python27\Scripts
(pholus) λ pip2 list

how-to-use-args-and-kwargs-in-python-3 November 20, 2017
def multiply(*args):
z = 1
for num in args:
z *= num
print(z)
multiply(4, 5)
multiply(10, 9)
multiply(2, 3, 4)
multiply(3, 5, 10, 6)
def print_values(**kwargs):
for key, value in kwargs.items():
print("The value of {} is {}".format(key, value))
print_values(
name_1="Alex",
name_2="Gray",
name_3="Harper",
name_4="Phoenix",
name_5="Remy",
name_6="Val"
)
Output
The value of name_2 is Gray
The value of name_6 is Val
The value of name_4 is Phoenix
The value of name_5 is Remy
The value of name_3 is Harper
The value of name_1 is Alex
【python】if name == 'main':とは? updated at 2020-06-08
・ファイルをimportしたときに、if以下は実行しない。
デフォルトとして、.pyファイルをインポートすると、ファイルの中身が実行される。
if __name__ == '__main__':以下に記述することで、import時の実行を回避できる。
変数 __name__が、importした場合と、ファイル実行した場合で挙動が異なる性質を利用。
「__name__」
importした場合は "モジュール名" に置き換わる。
ファイルを実行した場合は、"main"に置き換わる。
hello.py
def hello():
print("hello world")
if __name__ == "__main__":
hello()
何も出力しない。
__name__にモジュール名「"hello"」が代入される
"hello world"を出力
__name__に「__main__」が代入される
Pythonで、呼び出し方によってメソッドの振る舞いを変える posted at 2017-04-29
Pythonのクラスのメソッドは3種類ある。
通常のメソッド(インスタンスメソッド)
第1引数は必須で、慣例としてselfにする。
インスタンス経由で呼び出すと、呼び出したインスタンスが第1引数に入る。
クラス経由で呼び出すと、呼び出したときの引数がそのまま渡される。
クラスメソッド
@classmethodを付けて定義する。第1引数は必須で、慣例としてclsにする。
インスタンス経由で呼び出すと、呼び出したインスタンスのクラスが第1引数に入る。
クラス経由で呼び出すと、そのクラスが第1引数に入る。
スタティックメソッド
@staticmethodを付けて定義する。引数は必須ではない。
呼び出したときの引数がそのまま渡される。
class C:
val = 20
def __init__(self):
self.val = 1
def normal_method(self, v):
return self.val + v + 2
@classmethod
def class_method(cls, v):
return cls.val + v + 3
@staticmethod
def static_method(v):
return C.val + v + 4
i = C()
i.normal_method(5) # i.val + 5 + 2 = 1 + 5 + 2 = 8
i.class_method(6) # C.val + 6 + 3 = 20 + 6 + 3 = 29
i.static_method(7) # C.val + 7 + 4 = 20 + 7 + 4 = 31
C.normal_method(5) # requires 2 args but 1: error
C.normal_method(i, 6) # i.val + 6 + 2 = 1 + 6 + 2 = 9
C.normal_method(C, 7) # C.val + 7 + 2 = 20 + 7 + 2 = 29
C.class_method(8) # C.val + 8 + 3 = 20 + 8 + 3 = 31
C.static_method(9) # C.val + 9 + 4 = 20 + 9 + 4 = 33
通常のメソッドも関数であることに変わりはない。
第1引数がselfというのは単なるお約束であって、selfの型については制約はない。
インスタンス経由で呼び出すと、処理系が勝手に第1引数にそのインスタンスを入れている。
これを逆手にとって、第1引数によって振る舞いを変えることができる。
class C:
# 上記に追加
def trick_method(arg, v):
if isinstance(arg, C):
return arg.val * 2 * v
else:
return C.val + arg * v
i.trick_method(4) # i.val * 2 * 4 = 1 * 2 * 4 = 8
C.trick_method(5) # requires 2 args but 1: error
C.trick_method(6, 7) # C.val + 6 * 7 = 20 + 6 * 7 = 62
C.trick_method(i, 8) # i.val * 2 * 8 = 1 * 2 * 8 = 16
C.trick_method(C, 9) # C.val + C * v: error
Pythonで classmethod、staticmethod を使う updated at 2018-01-18
インスタンス変数やインスタンスメソッドにアクセスしないとき(メソッド内でselfを使わないとき)は classmethod、staticmethodを使おう。
classmethod: クラス変数にアクセスすべきときや、継承クラスで動作が変わるべきときは classmethodを使おう。
staticmethod: 継承クラスでも動作が変わらないときはstaticmethodを使おう
どちらもデコレーターで定義できる。classmethodでは第一引数にclsを与えて定義する。
class Student:
def __init__(self, name, school):
self.name = name
self.school = school
self.marks = []
def average(self):
"""平均成績を返す
インスタンス変数にアクセスしたいのでinstancemethodを使う。
"""
return sum(self.marks) / len(self.marks)
@classmethod
def friend(cls, origin, friend_name, *args):
"""同じ学校の友達を追加する。
継承クラスで動作が変わるべき(継承クラスでは salaryプロパティがある)
なのでclassmethodを使う。
子クラスの初期化引数は *argsで受けるのがいい
"""
return cls(friend_name, origin.school, *args)
@staticmethod
def say_hello():
"""先生に挨拶する
継承しても同じ動きでいいのでstaticmethodを使う
"""
print("Hello Teacher!")
class WorkingStudent(Student):
def __init__(self, name, school, salary):
super().__init__(name, school)
self.salary = salary
hiro = WorkingStudent("Hiro", "Stanford", 20.00)
mitsu = WorkingStudent.friend(hiro, "Mitsu", 15.00)
print(mitsu.salary)
PythonのABC - 抽象クラスとダック・タイピング posted at Dec 08, 2015
抽象メソッドを示すデコレータです。
抽象メソッドですが、デコレータを指定したメソッドに処理を記述し、サブクラスから呼び出すことも可能です。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from abc import ABCMeta, abstractmethod
class Animal(metaclass=ABCMeta):
@abstractmethod
def sound(self):
print("Hello")
# 抽象クラスを継承
class Cat(Animal):
def sound(self):
# 継承元のsoundを呼び出す
super(Cat, self).sound()
print("Meow")
if __name__ == "__main__":
print(Cat().sound())
super(Cat, self).sound()で継承元の抽象メソッドを呼び出すことができます。Javaとは少し違う印象ですね。
class Animal(metaclass=ABCMeta):
@classmethod
@abstractmethod
def sound_classmethod(self):
pass
class Animal(metaclass=ABCMeta):
@staticmethod
@abstractmethod
def sound_staticmethod(self):
pass
"If it walks like a duck and quacks like a duck, it must be a duck."
- 「アヒルのように歩き、鳴けば、それはアヒルだ。」
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from abc import ABCMeta, abstractmethod
class Animal(metaclass=ABCMeta):
@abstractmethod
def sound(self):
pass
class Cat(Animal):
def sound(self):
print("Meow")
class Dog():
def sound(self):
print("Bow")
class Book():
pass
Animal.register(Dog)
def output(animal):
print(animal.__class__.__name__, end=": ")
animal.sound()
if __name__ == "__main__":
c = Cat()
output(c)
d = Dog()
output(d)
b = Book()
output(b)
Cat: Meow
Dog: Bow
AttributeError: 'Book' object has no attribute 'sound'
python モジュールimport方法について posted at 2020-02-06
| Left align | Right align |
|---|---|
| モジュールを読み込む | import module |
| モジュールからメソッド,クラスを読み込む | from module import method, class |
| パッケージからモジュールを読み込む | from package import module |
| パッケージの中のモジュールのメソッド,クラスを読み込む | from package.module import method, class |
[Python] importの躓きどころ updated at 2017-06-09
Python3.3以降の話。
$ tree
.
├── mypackage1
│ ├── __init__.py
│ └── subdir1
│ ├── __init__.py.bak
│ └── mymodule1.py
└── mypackage2
└── subdir1
└── mymodule2.py
$ python3
Python 3.5.2 (default, Aug 4 2016, 09:38:15)
[GCC 4.2.1 Compatible Apple LLVM 7.3.0 (clang-703.0.31)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import mypackage1
>>> import mypackage2
>>> dir(mypackage1)
['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__']
>>> dir(mypackage2)
['__doc__', '__loader__', '__name__', '__package__', '__path__', '__spec__']
のように、__init__.pyがなくてもimportできている。
__init__.pyがあるmypackage1をregular package、
__init__.pyがないmypackage2をnamespace packageと呼ぶ。
>>> import sys
>>> sys.path.append('./mypackage1')
>>> sys.path.append('./mypackage2')
>>> import subdir1
>>> dir(subdir1)
['__doc__', '__loader__', '__name__', '__package__', '__path__', '__spec__']
>>> subdir1.__path__
_NamespacePath(['./mypackage1/subdir1', './mypackage2/subdir1'])
として、違うパスだが同じ名前のディレクトリも同じnamespaceに属するpackageとして
_NamespacePathオブジェクトに格納されている。
import xxxが実行されると、
sys.pathにxxx/__init__.pyが存在する場合、regular packageとして取得できる
sys.pathにxxx/__init__.pyは存在しないがxxx.{py,pyc,so}が存在する場合、moduleとして取得できる
sys.pathにxxx/__init__.pyもxxx.{py,pyc,so}も存在しないが同名のディレクトリが存在する場合、namespace packageとして取得できる
違いとして、
namespace packageには__file__属性がない
regular packageの__path__はリストだが、namespace packageの__path__は_NamespacePathオブジェクトである。
などがある。
さらに、namespace packageにする(__init__.pyをなくす)ことで、
Python の init.py とは何なのか updated at 2020-03-19
python コードの例は、主に 3.6/3.5 を使用しています。
1. 「モジュール」と「パッケージ」と「名前空間」
2. モジュールと階層構造
単一ファイルのモジュール
ディレクトリによる階層構造と名前空間
ディレクトリと名前空間のマッピング
3.__init__.py の役割
モジュール検索のためのマーカー
名前空間の初期化
ワイルドカード import の対象の定義 (__all__ の定義)
同じディレクトリにある他のモジュールの名前空間の定義
4.まとめ
5.unittest についての注意事項 (@methane さんからのコメントにより追記)
1.__init__.py は、モジュール検索のためのマーカーとなる。
2.__init__.py は、それが存在するディレクトリ名を名前とする名前空間の初期化を行う。
3.__init__.py は、同、名前空間におけるワイルドカード import の対象を定義する (__all__ の定義) 。
4.__init__.py は、同じディレクトリにある他のモジュールの名前空間を定義する。
2. ~ 4. をひとまとめにして、「モジュールあるいはパッケージの初期化」ということもできますが、ここでは分けてみました。
Regular packages
Python defines two types of packages, regular packages and namespace packages.
Regular packages are traditional packages as they existed in Python 3.2 and earlier.
A regular package is typically implemented as a directory containing an __init__.py file.
サンプル4
./
├─ sample0040.py ... 実行ファイル
└─ module04.py ..... モジュール
sample0040.py
from module04 import *
hello1()
hello2()
hello3()
module04.py
__all__ = ['hello1', 'hello2']
def hello1():
print( "Hello, this is hello1" )
def hello2():
print( "Hello, this is hello2" )
def hello3():
print( "Hello, this is hello3" )
実行結果
$ python sample0040.py
Hello, this is hello1
Hello, this is hello2
Traceback (most recent call last):
File "sample0040.py", line 5, in <module>
hello3()
hello3() の呼び出しは未定義として "NameError: name 'hello3' is not defined" というエラーになってしまいました。__all__ のリストに無いためです。
これは、hello3() が隠蔽されているわけではなく、あくまでも import * としたときの動作です。
試しに、* を使わずに import し、module04 を明示的に呼べば、hello3() も呼び出し可能です。
sample0041.py
import module04
module04.hello1()
module04.hello2()
module04.hello3()
実行結果
$ python sample0041.py
Hello, this is hello1
Hello, this is hello2
Hello, this is hello3
サンプル5
./
├─ sample0050.py ...... 実行ファイル
└─ module05
├─ __init__.py .... "module05" の初期化ファイル
├─ _module05.py ... "module05" の実体
└─ module06.py .... "module05" の追加モジュール
#./module05/_module05.py
print( "in _module05.py" )
def hello(caller=""):
print( "Hello, world! in _module05 called by {}".format(caller) )
#./module05/module06.py
print( "in module06.py" )
def hello(caller=""):
print( "Hello, world! in module06 called by {}".format(caller) )
#./module05/__init__.py
print( "in __init__.py" )
# import _module05.hello() as hello05() in the same directory
from ._module05 import hello as hello05
# import module06.hello() as hello06() in the same directory
from .module06 import hello as hello06
__all__ = ['hello05', 'hello06']
# Do initialize something bellow
hello05("__init__.py")
hello06("__init__.py")
Python init.pyの書き方 updated at 2019-06-18
_init__.pyとは
__init__.pyは2つの意味がある
1つはPythonディレクトリを表す役割を担う
1つはモジュールをimportするときの初期化処理を行う
📁test_imt
├──📄__init__.py
├──📄main.py
└──📄sub.py
#main.pyの中身
import test_imt.sub as ts
def chkprint2():
ts.chkprint()
print("You use main.py!")
#sub.pyの中身
def chkprint():
print("You use sub.py!")
#__init__.py
from test_imt.main import *
#test.py
import test_imt as ti
ti.chkprint2()
#結果
#You use sub.py!
#You use main.py!
import雜談之一———import路徑的相對論 2018-01-10 01:42:18
議題一:當我們在建構一個package會出現一個議題, 那就是當sub_module1裡的ex1_1.py想要去import位在sub_module2裡的ex2_1.py, 我們要用絕對路徑去import還是用相對路徑呢?
如果我們是用絕對路徑去import會出現一個維護性的問題:
所以python有提供一個相對路徑import(relative import),其方法如下:
In ex1_1.py:
import ..sub_module2.ex2_1 # ..回溯到上一層路徑,也就是main_module/
from .. import sub_module2.ex2_1 # 這句與上一句同義
如果這個想要回溯上兩層路徑的話,比如說sub_module2_1裡的ex2_1_1.py想要去import位於sub_module3的ex3_1.py:
In ex2_1_1.py:
import ...sub_module3.ex3_1.py
議題二:既然import可以支援相對路徑,而我們直覺上也希望python可以正確讀取相對路徑字串,像是'.'代表的是這個py檔目前所在目錄, 但實際上這是行不通的,比如說位於main_module的ex0_1.py希望讀取位於同一個資料夾的some_data.data, 但沒辦法用像是open('./some_data.data','r').read()這種相對路徑的方式去open他,這看起來不合我們的直覺,這是為什麼呢?
在思考這個原因之前,先來觀察python實際上的行為:
In ex0_1.py:
import os
import os.path
print(os.path.abspath('.')) # 用os.path模組來查看這個相對路經的起始目錄是否是我們所預期的
data = open('./some_data.data','r').read()
In main_module/../test.py(想要使用main_module裏面的ex0_1的外部檔案):
from main_module import ex0_1
In bash(位於main_module/../):
$ python3 test.py
/home/shnovaj30101/note/python/contest # 這個路徑是位於"main_module/../",正好是執行檔所在目錄
Traceback (most recent call last):
File "test.py", line 1, in <module>
from main_module import ex0_1
File "/home/shnovaj30101/note/python/contest/main_module/ex0_1", line 4, in <module>
data = open('./some_data.data','r').read()
FileNotFoundError: [Errno 2] No such file or directory: './some_data.data'
雖然python的'.'是被設定在執行檔的工作目錄, 但python還是有一些內置變數紀錄了module檔案本身(比如說ex0_1.py)或是最上層的整體package(比如說main_module)的資訊: (1) package:這變數紀錄了整體package的資訊 (2) file:這變數紀錄了module檔案本身的資訊
如果想要獲取當下所在的目錄或是整體package的路徑只要使用os.path.abspath()就行了:
In ex0_1.py:
import os
import os.path as path
print(os.path.abspath('.'))
print(os.path.abspath(__file__))
print(os.path.abspath(__package__))
data = open(os.path.join(os.path.dirname(os.path.abspath(__file__)),'foo.py'),'r').read() # 阿...似乎挺長
In main_module/../test.py(想要使用main_module裏面的ex0_1的外部檔案):
from main_module import ex0_1
In bash(位於main_module/../):
$ python3 test.py # 沒有出error代表open成功
/home/shnovaj30101/note/python/contest # 執行檔位置
/home/shnovaj30101/note/python/contest/main_module/ex0_1.py # 檔案本身位置
/home/shnovaj30101/note/python/contest/main_module # package的位置
import雜談之二———export機制以及namespace package 2018-01-11 00:09:58
議題三:當寫好了一個module,還會有一個設計上的考量是我只希望提供module中的特定對象給使用者使用, 對於一些只用於內部操作的變數、函數或是類別我不想要直接開放給使用者取用, 所以應該要有一個限制使用者的機制,那實際上python有沒有這機制呢?
是有,但python似乎沒有很嚴格的限制使用者使用一些module內的對象,相對寬鬆的方法只要在變數名稱前面加一個'_',比如說:
In module.py:
pub_var = 'I\'m public variance.'
_pri_var = 'I\'m private variance.'
def pub_func():
return 'I\'m public func.'
def _pri_func():
return 'I\'m private func.'
class pub_obj():
def __init__():
self.str = 'I\'m public obj.'
class _pri_obj():
def __init__():
self.str = 'I\'m private obj.'
In python3 shell:
>>> from module import *
>>> dir() # 可以輸出目前可以使用的對象,可以看出_pri開頭的對象無法直接被使用
['__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'pub_func', 'pub_obj', 'pub_var']
>>> _pri_var
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name '_pri_var' is not defined
>>> module._pri_var # 還是可以用這種方式取得pri資料
"I'm private variance."
另外除了'_'符號,也可以在module定義一個list對象__all__, 當使用者利用"from [module_name] import *"這種語法時,__all__可以決定只對使用者提供某些對象:
In module.py:
pub_var = 'I\'m public variance.'
_pri_var = 'I\'m private variance.'
def pub_func():
return 'I\'m public func.'
def _pri_func():
return 'I\'m private func.'
class pub_obj():
def __init__():
self.str = 'I\'m public obj.'
class _pri_obj():
def __init__():
self.str = 'I\'m private obj.'
__all__ = [pub_var, pub_func, _pri_var]
In python3 shell:
>>> from module import *
>>> dir() # pub_obj不見了,但是多了_pri_var
['__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', '_pri_var', 'pub_func', 'pub_var']
議題四:在開發大型模組時,通常不是一個人單打獨鬥,而是一個團隊在進行, 但當很多人想要共同開發模組時,我們想要在不同的路徑做開發,卻希望最後能直接整合在一起, 甚至希望最後連合併的時間都沒有那就更好了,可以直接上線使用!這話聽起來頗神奇,但確實能夠辦到, 實際上,這個需求只是要把不同路徑開發的模組歸到一個共同的命名空間霸了, python其實有不只一種方法能辦到這件事。(最近時間不多,只好先稍微抄一下cookbook範例,不要見怪嗚嗚)
當我們想要去import命名空間lalala裏面的模組A和模組B,我們可以先在sys.path來導入A碼農和B碼農耕作目錄:
In python3 shell:
>>> import sys
>>> sys.path.extend(['A碼農的耕作目錄/', 'B碼農的耕作目錄'])
>>> import lalala.A
>>> import lalala.B
import雜談之三———sys.path的洪荒之時 2018-01-12 02:29:56
議題一:今天我想要去import別人寫好的一個module,但他不存在當下的工作目錄底下,那我應該有什麼方法可以得到這個module呢?
sys.path.insert(0, 'some path') sys.path.append('some path') sys.path.extend(['some path','some path'....])
但這方法的缺點在於我們會把路徑寫死在程式碼裏面,當我們把這個被引入的模組更換一下路徑, 那所有寫死路徑的程式碼都要被叫出來改掉,萬一這個模組有剛好是很通用的模組, 被一堆不同部份的code所import,那真的是改路徑改到人仰馬翻。
既然在程式碼中加入module可能會遇到這種麻煩的問題,那只能訴諸程式碼外的解決方式了。
其中一個是利用設定PYTHONPATH的方式來新增尋找module的路徑:
In bash:
$ env PYTHONPATH='/home/shnovaj30101' python3
Python 3.4.3 (default, Nov 17 2016, 01:08:31)
[GCC 4.8.4] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> sys.path
['', '/home/shnovaj30101', '/usr/lib/python3.4', '/usr/lib/python3.4/plat-x86_64-linux-gnu', '/usr/lib/python3.4/lib-dynload', '/usr/local/lib/python3.4/dist-packages', '/usr/lib/python3/dist-packages']
>>>
先來說明一下看source code的心法,其實沒什麼,就是一個懶字而已, 切記當一個source code牽涉到的東西比較複雜時,很多東西能忽略就忽略,能假設就假設, 不要一次把他全看完,注意對自己重要的東西就好。
與其辛苦的把他從頭讀完,一次就讀到懂,不如只看重要的東西,然後看很多次, 發現還是有不懂的地方,就在看細一點,這樣比較不會喪失焦點,也不會太耗腦力,更能省時間。
python import雜談之四 2018-01-13 01:07:05
好拉,總結一下,site.py對於sys.path的添加的順序如下:
addusersitepackages(known_paths)會試著添加 "/home/shnovaj30101/.local/lib/python3.4/site-packages" "/home/shnovaj30101/.local/lib/python3.4/dist-packages" "/home/shnovaj30101/.local/local/lib/python3.4/dist-packages" 等等路徑,並尋找裏面的pth檔。
addsitepackages(known_paths)會試著添加 "/usr/local/lib/python3.4/dist-packages" "/usr/lib/python3/dist-packages" "/usr/lib/python3.4/dist-packages" "/usr/lib/dist-python" 等等路徑,並尋找裏面的pth檔。
1 分鐘搞懂 Python 迴圈控制:break、continue、pass Aug 6, 2018
break:強制跳出 ❮整個❯ 迴圈
continue:強制跳出 ❮本次❯ 迴圈,繼續進入下一圈
pass:不做任何事情,所有的程式都將繼續



pass 就像是 To do 的概念,在寫程式的時候,有時候想的比實際寫出來的速度快,例如定義一個函數, 但還沒有實作出來,空著內容不寫又會產生語法錯誤🤦♂️, 這時就會使用 pass 來替代,當作是個指標,提醒自己之後要來完成。
def myfunction():
pass #提醒自己之後要來完成
Pythonのクラスにおける__call__メソッドの使い方 updated at 2016-03-20
クラスを作るときに、initは頻繁に使うけど、callって何ってなったときに自分なりに解釈
class A:
def __init__(self, a):
self.a = a
print("A init")
def __call__(self, b):
print("A call")
print(b + self.a)
class B(A):
def __init__(self, a, c):
super().__init__(a)
self.c = c
print("B init")
def __call__(self, d):
print("B call")
print(self.a + self.c + d)
>>> a = A(1)
A init
>>> a(2)
A call
3
>>> b = B(1,3)
A init
B init
>>> b(4)
B call
8
インスタンス生成では__init__しか呼び出されない。
しかし、一度生成されたインスタンスを関数っぽく引数を与えて呼び出せば、__call__が呼び出されるという仕組み
もちろん、__call__に返り値をつければ,インスタンスから得られた値を別の変数に使ったりもできるということ。
a[start:stop] # items start through stop-1
a[start:] # items start through the rest of the array
a[:stop] # items from the beginning through stop-1
a[:] # a copy of the whole array
a[start:stop:step] # start through not past stop, by step
The other feature is that start or stop may be a negative number, which means it counts from the end of the array instead of the beginning. So:
a[-1] # last item in the array
a[-2:] # last two items in the array
a[:-2] # everything except the last two items
Similarly, step may be a negative number:
a[::-1] # all items in the array, reversed
a[1::-1] # the first two items, reversed
a[:-3:-1] # the last two items, reversed
a[-3::-1] # everything except the last two items, reversed
Python♪NumPyのa[[0], 0, 0:1]は何次元の配列になる?
#コード01
import numpy as np
a = np.arange(24).reshape(2, 3, 4)
'''
a =
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
'''
print(a) #3次元配列を出力
print(a[:, :, :]) #3次元配列を出力
print(a[0, :, :]) #2次元配列を出力
print(a[:, 1, :]) #2次元配列を出力
print(a[:, :, 2]) #2次元配列を出力
print(a[:, 1, 2]) #1次元配列を出力
print(a[0, :, 2]) #1次元配列を出力
print(a[0, 1, :]) #1次元配列を出力
print(a[0, 1, 2]) #値(スカラー)を出力
#出力01
※読みやすいように実際の出力にコメント文を追加しています。
# a =
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
# a[:, :, :] =
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
# a[0, :, :] =
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
# a[:, 1, :] =
[[ 4 5 6 7]
[16 17 18 19]]
# a[:, :, 2] =
[[ 2 6 10]
[14 18 22]]
# a[:, 1, 2] =
[ 6 18]
# a[0, :, 2] =
[ 2 6 10]
# a[0, 1, :] =
[4 5 6 7]
# a[0, 1, 2] =
6
#コード03
import numpy as np
a = np.arange(24).reshape(2, 3, 4)
print(a[:, :, :]) #3次元配列を出力
print(a[:, 0:2, :]) #3次元配列を出力
print(a[:, 0:1, :]) #3次元配列を出力
print(a[0:1, :, 0:1]) #3次元配列を出力
print(a[0:1, 0:1, 0:1]) #3次元配列を出力
#出力03
# a[:, :, :] =
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
# a[:, 0:2, :] =
[[[ 0 1 2 3]
[ 4 5 6 7]]
[[12 13 14 15]
[16 17 18 19]]]
# a[:, 0:1, :] =
[[[ 0 1 2 3]]
[[12 13 14 15]]]
# a[0:1, :, 0:1] =
[[[0]
[4]
[8]]]
# a[0:1, 0:1, 0:1]) =
[[[0]]]
#コード05
import numpy as np
d3 = np.array([[[ 0., 1., 2., 3.],
[ 10., 11., 12., 13.],
[ 20., 21., 22., 23.]],
[[100., 101., 102., 103.],
[110., 111., 112., 113.],
[120., 121., 122., 123.]]])
print(d3.shape) #(2, 3, 4)
print(d3)
print(d3[:, [0, 1, 0], 0].shape) #(2, 3)
print(d3[:, [0, 1, 0], 0])
print(d3[:, [0, 1, 0], [0]].shape) #(2, 3)
print(d3[:, [0, 1, 0], [0]])
print(d3[:, [0, 1, 0], [0, 0, 0]].shape) #(2, 3)
print(d3[:, [0, 1, 0], [0, 0, 0]])
#コード05
(2, 3, 4)
[[[ 0. 1. 2. 3.]
[ 10. 11. 12. 13.]
[ 20. 21. 22. 23.]]
[[100. 101. 102. 103.]
[110. 111. 112. 113.]
[120. 121. 122. 123.]]]
(2, 3)
[[ 0. 10. 0.]
[100. 110. 100.]]
(2, 3)
[[ 0. 10. 0.]
[100. 110. 100.]]
(2, 3)
[[ 0. 10. 0.]
[100. 110. 100.]]
#コード06
import numpy as np
d3 = np.array([[[ 0., 1., 2., 3.],
[ 10., 11., 12., 13.],
[ 20., 21., 22., 23.]],
[[100., 101., 102., 103.],
[110., 111., 112., 113.],
[120., 121., 122., 123.]]])
print(d3[:, [0], [0]].shape) #(2, 1)
print(d3[:, [0], [0]])
print(d3[:, [[0, 1, 0]], [0, 0, 0]].shape) #(2, 1, 3)
print(d3[:, [[0, 1, 0]], [0, 0, 0]])
#出力06
(2, 1)
[[ 0.]
[100.]]
(2, 1, 3)
[[[ 0. 10. 0.]]
[[100. 110. 100.]]]
このようにスライス以外の部分は、ブロードキャストによって形状がそろえられるということを覚えておいてください。従って、コード07では出力07のようにbroadcastのエラーが発生します。
#コード07
import numpy as np
d3 = np.array([[[ 0., 1., 2., 3.],
[ 10., 11., 12., 13.],
[ 20., 21., 22., 23.]],
[[100., 101., 102., 103.],
[110., 111., 112., 113.],
[120., 121., 122., 123.]]])
print(d3[:, [0, 1, 0], [0, 0, 0, 0]].shape)
#出力07
IndexError: shape mismatch: indexing arrays could not be broadcast together with shapes (3,) (4,)
What does -1 mean in numpy reshape? edited Jun 13, 2022
Reshape your data using array.reshape(-1, 1) if your data has a single feature i.e. single column
Reshape your data using array.reshape(1, -1) if it contains a single sample i.e. single row
both dimension as unknown i.e new shape as (-1,-1) array.reshape(-1, -1) ValueError: can only specify one unknown dimension
python中的閉包&裝飾器 提高程式碼品質的神器 2023-03-23
python中的裝飾器小補充 2023-03-24
DAY09-搞懂Python的裝飾器 2018-10-10
DAY10-搞懂Python裝飾器的進階內容 2018-10-11
Rye
久しぶりのPython環境をRyeで整える 2023/05/27
Rye uv おっかけ 202403 2024/03/13
Pythonのパッケージ管理は「rye」が使いやすい! 2024-04-19
Rye!就决定是你了!Python 环境及包管理工具 2024/4/12日
windows 10 64bit
python 3.6.2
Fixing the “GH001: Large files detected. You may want to try Git Large File Storage.” Jun 12, 2017
remote: error: GH001: Large files detected. You may want to try Git Large File Storage — https://git-lfs.github.com.
remote: error: Trace: b5116d865251981c96d4b32cdf7ef464
remote: error: See http://git.io/iEPt8g for more information.
remote: error: File fixtures/11_user_answer.json is 131.37 MB; this exceeds GitHub’s file size limit of 100.00 MB
It turned out that GitHub only allows for 100 MB file.
The problem is that I can’t simply remove the file because it is tracked inside the previous commits so I have to remove this file completely from my repo.
The command that allow you to do it is:
git filter-branch -f --index-filter 'git rm --cached --ignore-unmatch fixtures/11_user_answer.json'
Github :git push檔案過大報錯remote: error: GH001: Large files detected.處理方法
首先執行git log 檢視你之前的提交日誌(比如我的就很簡單嗯/複雜一點地久仔細看下時間進行判斷吧)
然後執行git reset XXX,恢復到你沒有新增大檔案的那次commit記錄,實在是妙
完了之後再按命令去git push 即可,提前恭喜成功~~~~~~
報錯到解決問題全過程截圖👇

Windows
From the Command Prompt, you can install the package for your user only, like this:
pip install <package> --user
OR
You can install the package as Administrator, by following these steps:
Right click on the Command Prompt icon.
Select the option Run This Program As An Administrator.
Run the command pip install <package>
Python 3 ImportError: No module named 'ConfigParser'
In Python 3, ConfigParser has been renamed to configparser for PEP 8 compliance. It looks like the package you are installing does not support Python 3.
1. 安裝 Microsoft VSCode
2. 安裝 Cmder
3. 安裝 Anaconda(記得勾選加入環境變數)
4. 安裝 virtualenv (在終端機使用:pip install virtualenv 安裝)
5. 在桌面創建一個 python_example 資料夾,打開 Microsoft VSCode 後開啟該專案資料夾,創建一個 hello.py 的檔案並在裡面打上 print('hello python!!')
6. 打開 cmder 終端機 cd 移動到 hello.py 所在資料夾
7. 執行 python hello.py,恭喜你完成第一個 Python 程式!
How can I download Anaconda for python 3.6
As suggested here, with an installation of the last anaconda you can create an environment
just like Cleb explained or downgrade python :
conda install python=3.6.0
With this second solution, you may encouter some incompatibility issues with other packages.
I tested it myself and did not encouter any issue but I guess it depends on the packages you installed.
If you don't want to handle environments or face incompatibilities issues,
you can download any Anaconda version here: https://repo.continuum.io/archive/.
For example, Anaconda3-5.1.0-XXX or Anaconda3-5.2.0-XXX provides python 3.6
(the sufffix XXX depends on your OS).
結論
其實Python在Windows有很多因為路徑爆炸的問題,目前有遇到兩個
1.路徑太長
2.路徑不能有空白
這就是為什麼不安裝在預設地C:\Program Files\Python36
所以不要把Python安裝在Program Files裡面是最佳解
1. 最好選擇 Python 3.x, 因為選 2.7 會有檔名多國語言問題, dos 下讀檔會亂碼, py 3 就沒有這問題
2. 最好選 32bit 的, 因為如果要打包成單一執行檔(exe file), 打包完在 32 bit 的環境跑不起來, 且有 include dll 批配的問題
3. 要選 32bit 還是 64 bit, 基本上要看你用到的 DLL 決定, 例如你有些額外的 dll 是使用 w32 的, 那基本上你使用 64bit 的 ptyhon 就不行, 使用而且 64 bit dll 還有 ctype call address 的問題, 建議如果不想搞死自己, 那就最好是選 32bit 的比較保險
安裝時請注意以下幾點
請注意安裝路徑, 他預設是在"使用者"目錄下面, 最好換到非中文目錄底下
要移除時, 必須執行安裝程式後, 裡面有個uninstall, 在 window 那邊好像找不到移除方式
安裝時選 customize install, 這樣才可以自選安裝路徑
也順便選 Add python 3.6 to path
SETUP
4 Steps:
Install Python
Install Pip
Install VirtualEnv
Install VirtualEnvWrapper-win
USAGE
7 Steps:
Make a Virtual Environment
Connect our project with our Environment
Set Project Directory
Deactivate
Workon
Pip Install
Flask!
Using the Python kwargs Variable in Function Definitions
Okay, now you’ve understood what *args is for, but what about **kwargs? **kwargs works just like *args,
but instead of accepting positional arguments it accepts keyword (or named) arguments. Take the following example:
再次參考網路的文章, 試試看用輪子吧!
https://www.lfd.uci.edu/~gohlke/pythonlibs/
strongstrong
strongstrong
quote
quote
- checklist1
- checklist2
- 1
- 2
- 3
- 1
- 2
- 3