There are various practices of authoring patches or commits in version control systems.
If you are, like me, annoyed by fix typo fix up commits in pull or merge requests
you get at work or in a open source project,
or if you simply get too much contributions (which is good place to be, tell me how get there),
then git-badc0de is the tool for you.
The problem is clearly that it is too easy to make new commits.
The solution is make creating commits harder.
Git developers make git interface saner with each release,
and there are various tools (like GitHub web editing),
which make writing fix typo commits child play easy.
git-badc0de (GitHub: phadej/git-badc0de)
takes an out-of-the-box approach.
Instead of trying to encourage (or force) humans to put more effort
into each commit, it makes their machines do the work.
git-badc0de takes the HEAD commit, and creates an altered copy,
such that the commit hash starts with some (by default badc0de) prefix.
Obviously, I use git-badc0de in the development process of git-badc0de itself.
Check the tail of git log:
badc0dea Add CONTRIBUTING.md
badc0ded Make prefix configurable.
badc0de4 Add message to do git reset
badc0de6 Comment out some debug output
badc0de5 Initial commit
It's up to the project owners to decide how long prefix you want to have. Seven base16 characters (i.e. 28 bits out of 160) is doable on modern multi-core hardware in a minute, with good luck in less1. These seconds are important. It is an opportunity to reflect, maybe even notice a typo in the commit message. Modern machines are so fast, and even some compilers too2, that we don't pause and think of what we have just done.
Git is content-addressable file system is how
a chapter in Pro Git book on Git objects starts.
Very nice model, very easy to tinker with.
You can try out to git cat-file -p HEAD in your current Git project to see
the HEAD commit object data. In git-badc0de one commit looks like:
tree 91aaad77e68aa7bf94219a5b9cea97f26e2cce2b
parent badc0dea0106987c4edfb1d169b5a43d95845569
author Oleg Grenrus <oleg.grenrus@iki.fi> 1596481157 +0300
committer Oleg Grenrus <oleg.grenrus@iki.fi> 1596481157 +0300
Rewrite README.md
PoW: HRYsAAAAAAF
Git commit hash is a hash of a header and these contents. A header for commit object looks like
commit <content length as ASCII number><NUL>
git-badc0de takes the most recent commit data,
and by adding some PoW: DECAFC0FFEE salts to the end,
tries to find one which makes commit hash with the correct prefix.
It takes 11 characters to encode 64 bits in base64.
Why base64, no particular reason.
Based on this StackOverflow answer
we could put salts into commit headers,
to hide them from git log.
Something to do in the future.
When a valid salt is found, git-badc0de writes the new commit object
to the Git object store.
At this point nothing is changed, only a new dangling object inside .git directory.
You can reset your branch to point to the new commit with
git reset, and git-badc0de invites you to do so.
Yes, I'm dead serious (No). But I had fun implementing git-badc0de.
I was surprised that getting seven characters "right" in a hash is an easy job.
That causes nice artifacts in GitHub web interface.
The top commit shown on the project main page is always badc0de...
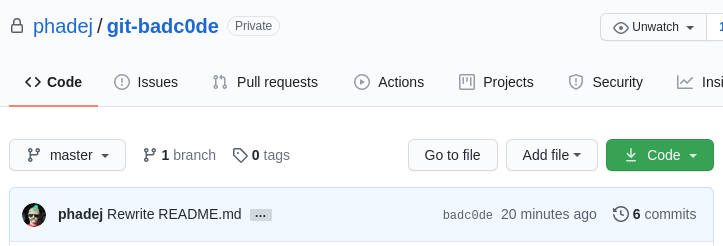
... and in fact all commits seem to have the same hash (prefix)...
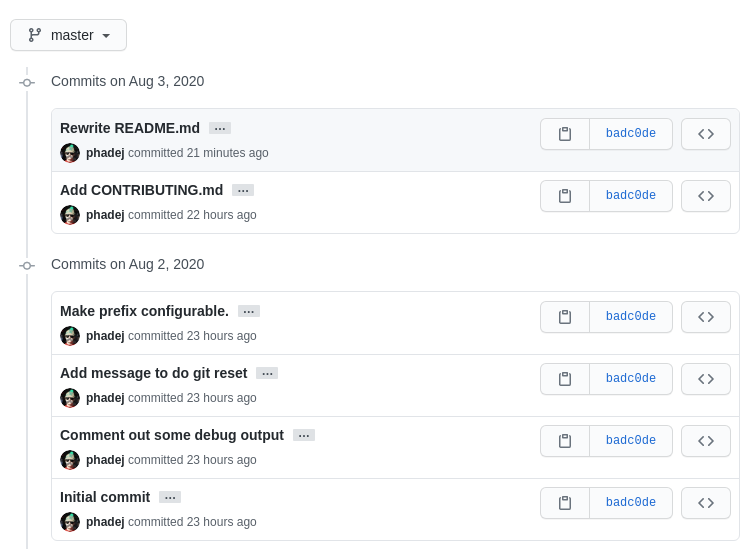
Note how command line git log is smart to show enough characters to make
prefixes unambiguous. It is deliberate, check on some of your smaller projects,
there git log --oneline probably prints seven character abbreviations.
In GHC (Haskell compiler) git log --oneline prints ten characters for me
(GitHub still shows just seven, so I assume it is hardcoded).
We can also use git-badc0de to produce commits with ordered hashes!
The downside is that you have to decide the maximum commit count at the start.
Yet
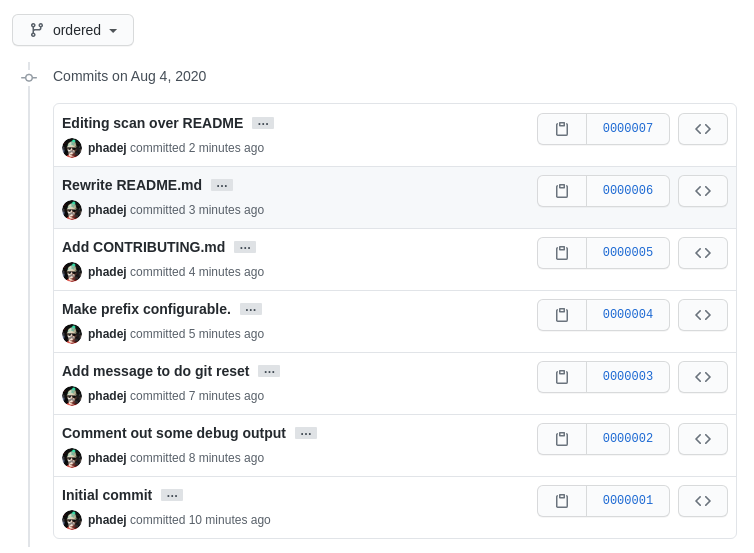
How git-badc0de is implemented?
I have to confess: I started with a Python prototype.
Python comes with all pieces needed, though I essentially only needed hashlib.
The Haskell implementation has eleven dependencies at the moment of writing. Five of them are bundled with compiler, the rest six are not. Even for some basic tasks you have to go package shopping:
asyncto parallelize computationsbase16-bytestringcryptohash-sha1primitiveto write some low level codeutf8-stringto convert from byte UTF-8ByteStringrepresentation toStringand back.zlibto compress git objects, as they are stored compressed.
My first Haskell implementation was noticeably faster than Python3 version. I suspect that is because Haskell is simply better at gluing bytes together.
The motivation to use Haskell had two parts:
- I just use Haskell for everything. (Except for prototyping silly ideas). This is the most important reason.
- Haskell is good for writing parallel programs. This is a bonus.
To my surprise, my first Haskell parallelization attempt didn't work at all. An idea is to spawn multiple workers, which would try different salts. And then make them race, until one worker finds a valid salt. Adding more workers should not slowdown the overall program, minus maybe some small managerial overhead.
The overhead turned out to be quite large.
Parallelism in Haskell works well when you deal with Haskell "native" data.
git-badc0de use case is however gluing bytes (ByteStrings) together
and calling out to C implementation of SHA1 algorithm.
The nasty detail of, I guess any, higher level languages is that
foreign function interface has culprits.
I run into foreign import unsafe issue.
You may read about foreign import unsafe in the excellent GHC User Guide.
GHC guarantees that garbage collection will never occur during an unsafe call, ...
With many threads generating some amount of garbage,
but also calling unsafe foreign functions in a tight loop caused problems.
Surprisingly, both cryptohash-sha1 and bytestring use plenty of unsafe calls
(cryptonite uses too).
My solution was to redo the loop. Less garbage generation and less foreign calls.
cryptohash-sha1 (and cryptonite) import _init, _update and _finalize
C functions. The hashing context is allocated and plumbing done in Haskell.
However, we can setup things in way such that we pass a single continuous block of memory to be hashed.
This functionality is missing from the library, so I copied cbits/ from
cryptohash-sha1 and added small C function, to do C plumbing in C:
void
hs_cryptohash_sha1(const uint8_t *data, size_t len, uint8_t *out)
{
struct sha1_ctx ctx;
hs_cryptohash_sha1_init(&ctx);
hs_cryptohash_sha1_update(&ctx, data, len);
hs_cryptohash_sha1_finalize(&ctx, out);
}This way we can have one safe foreign call to calculate the hash.
We have to make sure that pointers are pointing at pinned memory,
i.e. memory which garbage collector won't move.
Next, the same problem is in the bytestring library,
I was naive to think that as byte data I work with is so small,
that concatenating it (and thus memcpying) won't be noticeable,
hashing should dominate.
Usually it isn't a problem, but as copying was done on each loop
iteration and memcpy is foreign import unsafe in bytestring
library, that also contributed to slowdown.
That was my hypothesis.
Figuring out how to do it better with bytestring seemed difficult,
so I opted for a different solution. Write some C-in-Haskell.
Now each worker creates own mutable template, which is updated with new salt
on each loop iteration.
Salt length is fixed, so we don't need to change the commit object header.
As a bonus, the loop become essentially non-allocating (I didn't check though).
After that change, git-badc0de started to use all the cores, and not just spin in GC locks.
The runtime system statistics are nice to look at
Tot time (elapsed) Avg pause Max pause
Gen 0 0 colls, 0 par 0.000s 0.000s 0.0000s 0.0000s
Gen 1 1 colls, 0 par 0.000s 0.000s 0.0004s 0.0004s
...
Productivity 100.0% of total user, 99.9% of total elapsed
No time is spent in garbage collection. Productivity is an amount of time used to do actual work and not collecting garbage. Disclaimer: it seems that waiting for GC locks is not counted towards GC time, but as there was only a single collection, that doesn't matter.
I could optimize further:
as the salt is at the end of the content it is silly
to rehash whole commit object every time.
Yet, git-badc0de is silly project to begin with,
and I am satisfied with the current state.
The lesson here is that foreign function interface (FFI) is not easy, you have to think and test.
"Luckily" I learned about the unsafe issue recently
in postgresql-libpq,
so was able to think about it causing my problems.
In this case, unsafe doesn't mean that "I know what I'm doing" (as e.g. with unsafePerformIO),
but rather the opposite.
Also, I don't think that we (= Haskell ecosystem) have a good tooling to benchmark how code behaves in highly parallel environments.
I hope that Data.ByteString.Builder, for example, doesn't use any unsafe foreign calls,
Ecosystem relies on that module for constructing JSON (in aeson) and HTML (both blaze-markup and lucid).
Something for someone to test, maybe fix and document.
Does this mean that Haskell is crap, and the promise for easy parallel and concurrent programming is a lie, and we should all use Rust instead?
Well, no. In this isolated example, Rust would probably shine. There are, however, also other parts than hashing loop even in this simple program, and they have to be written as well. There Haskell feels a lot like Python, in a sense that I can just write consice code which works.
Python was quite nice in the very early prototyping stage, as it happened to have all needed functionality available in the repl. The "early prototyping stage" lasted for maybe 10 or 15 minutes, that was enough to verify that basic idea might work. With Haskell, you would need to restart repl to add a new library, losing all the context, which would killed the flow. For some other "problem"I might start to prototype directly in Haskell. I have no experience with how nice repl experience Rust has.
If git-badc0de project were to develop further, I would rewrite
the hashing loop in C, instead of writing C-in-Haskell. Maybe.
Or in Rust, if I that was easier to setup.
(GHC knows how to invoke C compiler).
Haskell is a great glue language, among many other great properties it has. Don't believe anyone who tells you otherwise.
Footnotes
-
Eight base16 characters (i.e. 4 bytes) took one and half hour of CPU time or "just" 5.5 minutes of wall clock time. I run that experiment only few times. Take a look at deadc0de branch. ↩
-
If your programming language of choice is a compiled one. ↩