纯python,无需js,主要重写了非正常的base64解码和使用数组进行AES解密的方法
本来觉得这都是一个被做烂的玩意了,但是实际去看的时候,想要完全隔绝掉js环境还是需要下一些心思去看人家代码和找资料
通过这些学到了一点内容,不过和时间成本相比还是太大了
讲一下主要内容
ps: 逆向后的加密参数,例如key,iv等都是固定的,可能随着时间变化就改变了,如果失效了大概是这个原因
Translater.py 主要负责接口设置与请求,YDDecoder.py 主要负责解密返回的数据,lang.json 里存放着所有语言对应的键,默认使用英文转中文
仅限学术交流,如有冒犯等联系我删除
关于sign之类的参数和接口这里就不再赘述,简单地跟栈就可以直接找到,没有任何难度,如果是小白可以去b站上找一下教程,这个案例的教程很多
一句话 crypto.createCipheriv("aes-128-cbc", key, iv); 就完事了,key与iv都是通过md5加密输出digest()得到的一串uint8序列
下面将对这个方法的内部实现聊上几句,以便手动实现python版本的解码与解密
返回的数据并非使用常规的base64所加密,可以尝试使用下面python或js验证:
import base64
a = "..." #返回的数据
b = base64.b64decode(a)var a = "" #返回的数据
var b = window.atob(a)或许会解码成功,或许会直接报错,我这里大部分是报错的,即使解码成功,在后面的AES解密也会出错,因为解码结果和实际正确的结果完全不同(至少我这里是这样的)
在nodejs中,存在一个叫 Buffer.from() 的方法,该方法可以传入字符串并以合适的格式解码返回
这其中就支持base64,它与正常的base64加解密不同(下面我说的内容或许并不正确,实在找不到确切的资料)
根据网上找的资料来看,python的base64与js的atob这类方法会自动根据规则在原数据上删除或者添加内容以便解密,具体情况看下面
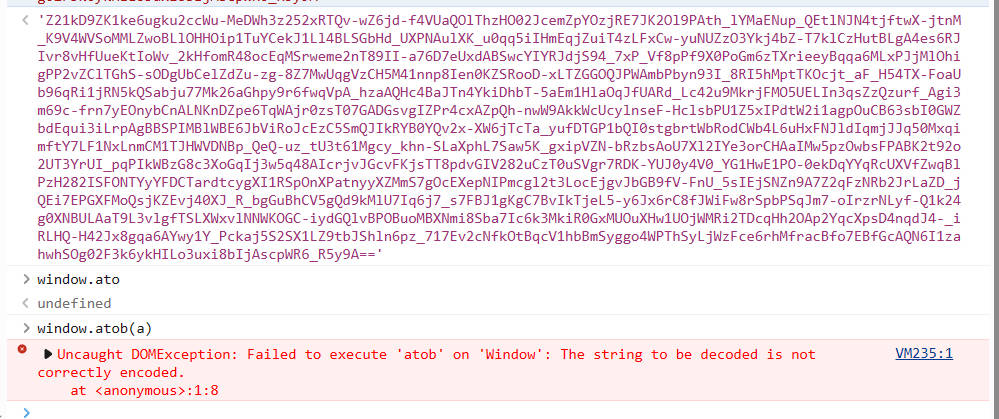
使用自定义的或者Buffer.from就可以成功解码并解密

var a = "..." #返回的数据
var b = Buffer.from(a, "base64")如果使用这两句,base64的解码问题就迎刃而解了,很简单吧,如果只是想简单地逆向出来一个接口,这一步就已经够了
但我试图尽力降低要求,可惜python中貌似并不存在类似Buffer.from直接可以解码base64的方法
所幸,我直接跟进了解码的源头一步步找,下面是源码:
// 初始化i (i是一个用来对照的表,其中有许多空值,只在特定位置放东西)
for (var r = [], i = [], s = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/", a = 0, u = s.length; a < u; a++)
r[a] = s[a],
i[s.charCodeAt(a)] = a;
i["-".charCodeAt(0)] = 62,
i["_".charCodeAt(0)] = 63
// 计算补位('=')的数量与字符串总长
function h(t) {
var e = t.length;
if (e % 4 > 0)
throw new Error("Invalid string. Length must be a multiple of 4");
var n = t.indexOf("=");
-1 === n && (n = e);
var r = n === e ? 0 : 4 - n % 4;
return [n, r]
}
// 计算解码后数据的长度
function c(t, e, n) {
return 3 * (e + n) / 4 - n
}
// 解码的总方法
function l(t) {
var e, n, r = h(t), s = r[0], a = r[1], u = new o(c(t, s, a)), f = 0, l = a > 0 ? s - 4 : s;
for (n = 0; n < l; n += 4)
e = i[t.charCodeAt(n)] << 18 | i[t.charCodeAt(n + 1)] << 12 | i[t.charCodeAt(n + 2)] << 6 | i[t.charCodeAt(n + 3)],
u[f++] = e >> 16 & 255,
u[f++] = e >> 8 & 255,
u[f++] = 255 & e;
// return u
return 2 === a && (e = i[t.charCodeAt(n)] << 2 | i[t.charCodeAt(n + 1)] >> 4,
u[f++] = 255 & e),
1 === a && (e = i[t.charCodeAt(n)] << 10 | i[t.charCodeAt(n + 1)] << 4 | i[t.charCodeAt(n + 2)] >> 2,
u[f++] = e >> 8 & 255,
u[f++] = 255 & e),
u
}所幸这段代码不长,且大部分工作都只是手艺活不需要动太多的脑子改语法,下面是修改过后使用类进行包装后的代码片段
class BufferFromb64Decoder:
def __init__(self):
self.i = self.initI()
def initI(self):
s = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
r = [None] * len(s)
i = [None] * 123
for a in range(len(s)):
r[a] = s[a],
i[ord(s[a])] = a
i[ord("-")] = 62
i[ord("_")] = 63
return i
def h(self, t: str):
e = len(t)
if e % 4 > 0:
raise Exception("Invalid string. Length must be a multiple of 4")
n = t.index("=") if "=" in t else -1
if n == -1:
n = e
if n == e:
r = 0
else:
r = 4 - n % 4
return [n, r]
def c(self, t, e, n):
return int(3 * (e + n) / 4 - n)
def deocde(self, t):
r = self.h(t)
s = r[0]
a = r[1]
u = np.zeros(self.c(t, s, a), dtype="uint8")
f = 0
if a > 0:
l = s - 4
else:
l = s
n = 0
while n < l:
e = self.i[ord(t[n])] << 18 | self.i[ord(t[n + 1])] << 12 | self.i[ord(t[n + 2])] << 6 | self.i[ord(t[n + 3])]
u[f] = e >> 16 & 255
f += 1
u[f] = e >> 8 & 255
f += 1
u[f] = 255 & e
f += 1
n += 4
if a == 2:
e = self.i[ord(t[n])] << 2 | self.i[ord(t[n + 1])] >> 4
u[f] = 255 & e
f += 1
if a == 1:
e = self.i[ord(t[n])] << 10 | self.i[ord(t[n + 1])] << 4 | self.i[ord(t[n + 2])] >> 2
u[f] = e >> 8 & 255
f += 1
u[f] = 255 & e
f += 1
return u这样就已经完成了base64的解码工作
AES解密的部分很简单,跟着来就完事了,涉及到的代码很少
AES解密的key与iv也与平常使用的有所不同,key与iv是固定在js文件里的,但却被转换为了uint8的一串序列,但具体实现方法很简单:
crypto.createHash("md5").update(text).digest()输出长度位16的uint8序列,转为python代码如下,稍微复杂一两句话:
def getMD5(self, text: str):
return hashlib.md5(text.encode("UTF-8"))
def toUint8(self, text):
dig = self.getMD5(text).digest()
byte = bytearray(dig)
return np.frombuffer(byte, dtype="uint8")完事之后直接配合base64解码下来的数据进行正常的AES解密即可
def decode(self, text):
key = self.toUint8(self.decode_key).tobytes()
iv = self.toUint8(self.decode_iv).tobytes()
text = self.b64Decoder.deocde(text)
cipher = AES.new(key, AES.MODE_CBC, iv)
decrypt = cipher.decrypt(text.tobytes())
data = unpad(decrypt, AES.block_size).decode("utf-8")
return data需要注意的是,解密下来的内容是存在非正常字符的,在最后面,使用unpad去除padding即可
由于本人才疏学浅,这里面更加细致的密码学内容并未涉及到我的脑子里,所以具体原理本人并不清楚,只是根据逆向的结果配合代码和实验下来的成果所反推的