Add MultiObjective Optimization Notebook #155
Conversation
|
Check out this pull request on See visual diffs & provide feedback on Jupyter Notebooks. Powered by ReviewNB |
portfolio_optimization_nsga2/portfolio-optimization-nsga2-cpp.ipynb
Outdated
Show resolved
Hide resolved
|
Also, since we are waiting for custom inputs from user, I'm not sure how the CI will handle this. Any ideas there? |
I would just go with some predefined parameters and add a comment to let the user know how and what to change. |
|
@zoq Thanks for the help! Do you have any further queries? I think this notebook is good to go. |
I'll test it out later, right now I have to manfully pull the latest ensmallen branch right? I have the conda package for ensmallen ready, I just have to do the same thing for mlpack. |
|
Maybe it already works, you can add |
|
Yeah, I tested it manually and it worked. Anyway the integration test should confirm it for you. I've written a small script to automate the process of pulling the latest ensmallen https://gist.github.com/jonpsy/de2e1f7e49a93a393beadcdae679784a. Just checkout this branch and go to terminal and copy all the code from the script, it will do everything for you. After that, just run this notebook and voila. Let me know if you find difficulty somewhere? |
|
Looks like our build broke |
|
Restarted let's see. |
Something like this? |
|
Almost, |
|
Sorry for dragging this on, you mean under dependencies right? |
|
Correct, right below mlpack is good. |
|
Looks like the test pass 🥳 |
| "metadata": {}, | ||
| "outputs": [], | ||
| "source": [ | ||
| "#define ARMA_DONT_USE_WRAPPER" |
There was a problem hiding this comment.
It's already part of #include <mlpack/xeus-cling.hpp> so we can remove the extra line here.
| "metadata": {}, | ||
| "outputs": [], | ||
| "source": [ | ||
| "opt.Optimize(objectives, coords);" |
There was a problem hiding this comment.
Looks like this takes some time, would be a good idea to add some callbacks (https://ensmallen.org/docs.html#callback-documentation) to show some output in between and at the end (PrintLoss, Report).
There was a problem hiding this comment.

Looks kinda redundant. PrintLoss() is doing nothing, and Report() has the output as shown in the picture. I think we need to work on MOO callbacks.
There was a problem hiding this comment.
Interesting, yes I think we have to adapt the callbacks so that they work for multi-objective optimizers as well.
portfolio_optimization_nsga2/portfolio-optimization-nsga2-cpp.ipynb
Outdated
Show resolved
Hide resolved
| "outputs": [], | ||
| "source": [ | ||
| "plt::figure_size(800, 800);\n", | ||
| "plt::scatter(frontX, frontY, 50);\n", |
There was a problem hiding this comment.
Do you think we could plot the optimization process as well, something like - https://www.machinelearningplus.com/wp-content/uploads/2020/10/ef-300x230.gif
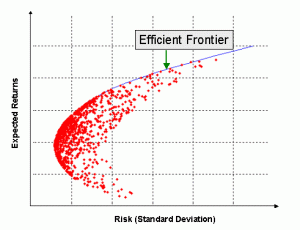{kind=link}
There was a problem hiding this comment.
We would need to query the generated Pareto Front per x number of generations, looks like the job of a callback?
There was a problem hiding this comment.
Yes, this can be a custom callback, that is implemented as part of the notebook.
There was a problem hiding this comment.
BTW, please try and run the notebook once. Our final pareto front isn't as cool as theirs :(.
There was a problem hiding this comment.
Agreed, I used https://lab.mlpack.org/ entered your fork and branch to run it, worked pretty well, except that the optimization step took a really long time.
There was a problem hiding this comment.
Reg. our results, I do find it kinda odd for the results to be this slow in xeus-cling, my mid-tier laptop can knock it off within seconds. Also, I'm worried about the diversity of the solution, if you recall one of the goals of MOEA is to have a uniform distribution of solutions, what's happening in our algorithm is producing a "cluster" of solutions.
Arguably, since each of the clusters is far apart the solution set is indeed "diverse" so we can't really blame the algorithm. I'm not sure if NSGA-II is to blame or whether our implementation is wrong. It's also possible that our population size is too low to observe the actual Pareto Front but I'm not going to let our users wait an eternity for that.
There was a problem hiding this comment.
Yeah, seems odd to me, we should run some more experiments with different parameters. But I think for now this is good, the solution is still valid.
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "### 5. Final Thoughts" |
There was a problem hiding this comment.
Maybe it's a good idea to add a section about "How to read the Efficient Frontier?
" see https://www.machinelearningplus.com/machine-learning/portfolio-optimization-python-example/ for an example to the example as well, what do you think?
There was a problem hiding this comment.
I've written something similar under the Plotting section. The documentation you suggested explains efficient frontier by comparing it with other fronts, the problem is we can't generate multiple pareto fronts as of now.
There was a problem hiding this comment.
I have seen that, but maybe we can improve that section a little bit e.g. by going into some more details what the plot is trying to visualize.
…ipynb Co-authored-by: Marcus Edel <marcus.edel@fu-berlin.de>
This reverts commit af0085e2884af9c5a69af0f8746944d57d5593ba. Added callback
|
@jonpsy Let me know if you like to change anything here, or if this is good to go and we update the notebook in another PR. |
|
I'll make a few changes, it should be done before kick-off meeting. We can discuss some nitpicks in the meeting and then we can approve by night. Cool? |
- Add dominance relation in Optimize section. - Explain X and Y-Axis in Plotting section. - Use the parameters from the blog.
…nto nsga2-notebook
|
@zoq Please feel free to merge |
No description provided.