Transform not giving expected results for similar data #741
Comments
|
This is an excellent analysis -- and yes, it all looks right. Thanks for taking the time to look into this, and also for providing such a well documented report on the issue. I'll look at the PR soon and hopefully we can get it merged very quickly. Again, many thinks for this! |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
There seems to be an issue where the transform on new data does not give the expected results.
If we fit_transform on some data X, then transform Y = X + e (for some small perturbation e), the transforms are quite different (see picture and reproducing code below).
We see that the two datasets X and Y, which are approximately the same in the original space, are mapped to different regions by UMAP. This could be a problem for people using UMAP in an ML pipeline (e.g. light purple points are closer to dark red than dark purple, and may be misclassified)
Upon some investigation, I think that this is caused by two problems: One where the initial embedding is off (init_graph_transform); and another where optimize_layout... is called.
In init_graph_transform we have the line
Which gives an initial embedding for Y which can be different to that of X, even though Y≈X. This is fixed by normalising via the row sum instead of the num_neighbours.
After this change, the initial embeddings for X and Y are practically identical, and this greatly improves the resulting transform:
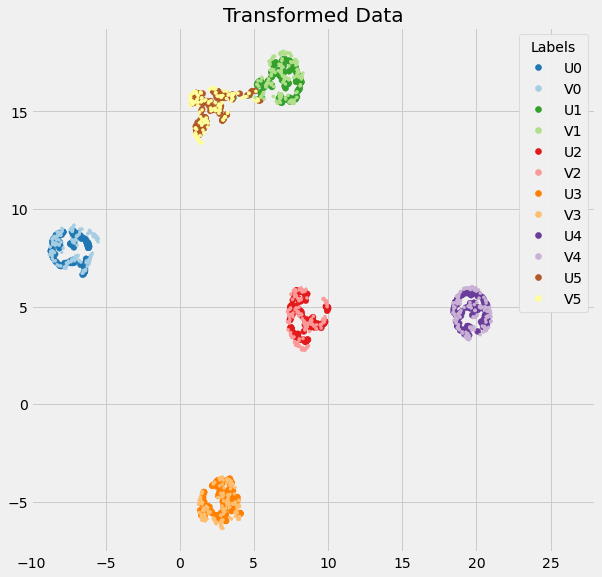
However, it's still not quite right (you'll notice that the blue points in particular are slightly off). This is due to the optimize_layout... functions, and when their move_other argument is activated. I think that move_other should only be True in the fit_transform(), not in the transform(). The way this is currently coded is a check on the shape of the tail/head embeddings:
However, this is inaccurate when new 'to be transformed' data is the same shape as the old fit_transform data. I suggest that move_other should be passed in as an argument depending on where the optimize_layout functions are called from. If we force move_other=False in the transform step, we arrive at the final embedding for the new data, which seems to be accurate (that is to say, it is what one might intuitively expect):
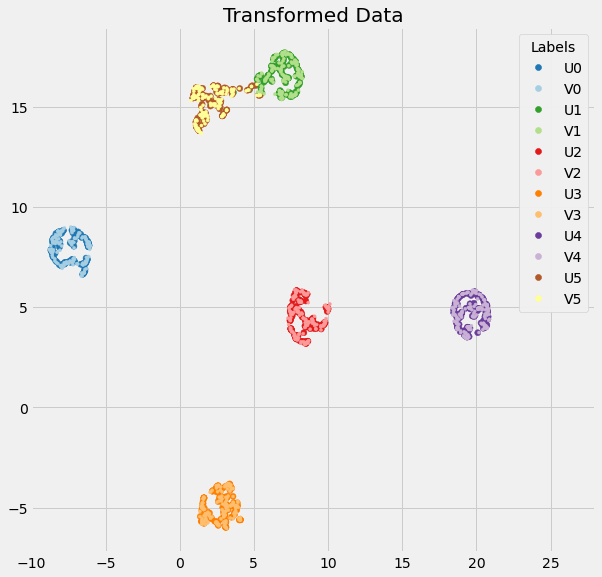
I have a pull request ready with these changes implemented that I'll put in shortly, but do let me know if I've got the wrong end of the stick somewhere.
Many thanks
The text was updated successfully, but these errors were encountered: