This repository contains solutions to LeetCode problems written in Python3, stored in different folders based on their topics.
💡 The current file is a cheatsheet that contains the most important algorithms and data structures and what kind of problems they are useful for.
- Two pointers / 双指针
- Binary trees / 二叉树
- Traversal / 遍历
- Divide and conquer / 分治
- Depth-first search (DFS) / 深度优先搜索
- Breadth-first search (BFS) / 广度优先搜索
- DFS vs. BFS / 深度优先搜索 vs. 广度优先搜索
- Arrays / 数组
- Prefix sum algorithm / 前缀和数组
- Difference array / 差分数组
- Sliding window / 滑动窗口
- Binary search / 二分查找
- Find left-most target / 查找左边界
- Find right-most target / 查找右边界
- Heap
- Stack
- Queue
- Matrix / 二维数组、矩阵
- Linked lists
- Recursion
- Math
- Graph algorithms / 图
- String
- Palindrome problems / 回文串
- Interesting problems
- Selling and buying stocks / 股票买卖
- Trapping rain water / 接水
- Palindrome problems / 回文串
- Palindrome problems on strings / 字符串回文串
- Palindrome problems on linked lists / 链表回文串
- Palindrome problems on arrays / 数组回文串
- Palindrome problems on integers / 整数回文串
- Backtracking / 回溯
- Dynamic programming / 动态规划
- Breadth-first search (BFS) / 广度优先搜索
- Islands / 岛屿问题
如果题目中提到array is sorted,那么大概率可以用双指针来解决问题。
- 快慢指针 Slow and fast pointers, in the same direction
- Linked Lists
- 找链表中点 Find the middle point of a linked list (慢指针走一步,快指针走两步)
- 找链表第n个节点 Find the n-th node from the end of a linked list (快指针先走n步,然后快慢指针同时前进)
- 判断链表是否有环 Check if a linked list has a cycle(慢指针走一步,快指针走两步)
- 判断两个链表是否相交 Find if two linked lists intersect(两个指针从两个链表的头部开始,然后从一个链表跳到另一个链表,每个指针都要把两个链表走完)
- Array
- Remove redundant elements in a sorted array (慢指针左侧是已经处理好的元素,快指针指向现在要处理的元素)
- Move zeroes (慢指针左侧是已经处理好的元素,快指针指向现在要处理的元素)
- Merge sorted arrays (两个指针从两个数组的尾部开始向前处理,直到两个指针都到位置0)
- String
- String compression (e.g. "aabbccc" -> "a2b2c3")
- 滑动窗口 More complicated scenario: Sliding Window
- 什么时候扩大窗口?什么时候缩小窗口?什么时候更新结果?
- Linked Lists
- 反向指针 Pointers that move in the opposite direction
- 对撞指针:指针由外向内收缩
- Binary Search
- 有序数组两数之和 Two sum in a sorted array
- 判断回文串 Check palindrome (两个指针从两端向中间收缩,检查元素是否相等)
- Trapping rain water
- 反转数组 Reverse an array (两个指针从两端向中间收缩,互换元素)
- 扩散指针:
- 寻找回文串 Find palindrome (两个指针从中间向两端扩散,寻找回文串)
- 对撞指针:指针由外向内收缩
- 分离指针 Pointers on different arrays
- Merge two sorted arrays
- Merge sort
- 找两个数组的交集:sort后用分离双指针
Whenever you see a binary tree question, ask yourself the following questions:
- 能否遍历二叉树得到结果? / Can I solve this problem by traversing the tree once?
- 能否用分治的思想,用子问题(子树)的解来得到原问题(树)的解? / Can I use divide and conquer, and use the solution of the sub-problem (subtree) to find the answer to the original problem (tree)?
- 在每个节点,我应该做什么?我应该在什么时候(前中后序)做?/ What should I do at each node? When should I do it (i.e. pre-order, in-order, post-order)?
All binary tree problems can be solved using either traversal or divide and conquer.
The return type of traversal helper method is usually None.
No value is returned.
Instead, this method updates a global variable to store the result.
The key is to choose the correct order of traversal.
result = None # global variable
def traverse(root):
if not root:
return
# Pre-order traversal
...
traverse(root.left)
# In-order traversal
...
traverse(root.right)
# Post-order traversal
...The return type of divide and conquer helper method is usually the same type as the output, but it depends on the problem.
- Pre-order traversal / 前序遍历 = 根左右
- 通常如果题目对遍历位置不敏感,就用前序遍历,没什么特别的。
- 一棵二叉树的前序遍历结果 = 根节点 + 左子树的前序遍历结果 + 右子树的前序遍历结果
- Time complexity O(N), space complexity O(h) where h is height of tree. If we don't consider call stack, then space complexity is O(1).
- e.g. Quick sort
- In-order traversal / 中序遍历 = 左根右
- 主要用于Binary search tree (BST)
- BST 的中序遍历结果为 non-decreasing order
- Time complexity O(N), space complexity O(h) where h is height of tree. If we don't consider call stack, then space complexity is O(1).
- e.g. Binary search tree
- Post-order traversal / 后序遍历 = 左右根
- 后续遍历十分特殊,因为 post-order operations have access to information passed up from the children (sub-trees).
- 一旦题目和子树有关,大概率要给函数设置一个返回值,然后用后续遍历。
- Use cases: e.g. merge sort, delete a node from a binary tree, subtree problems
Summary:
- 前序位置的代码执行是自顶向下的,后续位置的代码执行是自底向上的。
- 前序位置的代码只能access从parent node传递下来的数据,而后续位置的代码可以利用children nodes传递上来的数据。
- 前序位置的代码在刚刚进入某个节点时执行,中序位置的代码在左子树遍历完成,即将开始遍历右子树的时候执行,后续位置的代码在将要离开某个节点时执行。
- Use FIFO queue
- In Python, use
collections.dequeto implement queue, more efficient thanqueue.Queue
- In Python, use
- Add root node to queue first
- While queue is not empty, pop first node, add its children to queue
When to use DFS? When to use BFS?
- BFS uses O(w) extra memory, where w is the maximum width of the tree
- Maximum width of a binary tree is 2^(h), where h is the height of the tree and h starts from 0
- Worst case: a binary tree is a linked list, then h is equal to N
- Height of a balanced tree is O(log N)
- DFS uses extra space because of the functional call stack, O(h) extra space.
- 如果 tree 是 balanced,那么BFS需要的extra space更多;如果 tree 是 linked list,那么DFS需要的extra space更多。
- DFS 通常都是 recursive code, use call stack, BFS 通常都是 iterative code, use queue.
- BFS starts visiting from root, DFS starts visiting from leaves. 如果你要找的target更接近于root,那么BFS更适合。
构造二叉树问题一般都用divide and conquer, 构造一棵树 = 构造根节点 + 构造左子树 + 构造右子树。
序列化和反序列化二叉树,需要利用对不同遍历顺序的理解,总结为:
当二叉树中的节点没有重复时:
- 如果序列化结果不包含空指针信息 / If serialization result does not contain null pointers ...
- 只用一种遍历顺序是无法还原二叉树的,需要两种遍历顺序!
- 如果用两种遍历顺序,以下组合可以还原二叉树:
- 前序遍历 + 中序遍历 / Pre-order + In-order
- 中序遍历 + 后序遍历 / In-order + Post-order
- 如果用前序+后序,是无法还原二叉树的。
- 如果序列化结果包含空指针信息 / If serialization result contains null pointers
- 仅用前序遍历(Preorder)就可以还原二叉树!😄
- 仅用后序遍历(Postorder)也可以还原二叉树!✌️
- 如果是中序遍历(Inorder),是无法还原二叉树的。😢
- For every node in a BST, the value of all nodes in its left subtree is less than the value of the node, and the value of all nodes in its right subtree is greater than the value of the node.
- All subtrees of a BST are also BSTs.
- BST 的中序遍历(inorder)结果是升序的。
- BST
containsKey()runtime:- Perfectly balanced (best case):
$T(n)=\begin{cases}T(n/2)+1 & \text{if }n\gt 1\\ 3 & \text{otherwise}\end{cases} \\ T(n) = \Theta(\log n) \\ $ - Degenerate case (worst case):
$T(n)=\begin{cases}T(n-1)+1 & \text{if }n\gt 1\\ 3 & \text{otherwise}\end{cases} \\ T(n) = \Theta(n)$
- Perfectly balanced (best case):
基本框架:
def find(root: TreeNode, val1: int, val2: int) -> TreeNode:
# base case
if not root:
return None
# 前序位置,看看 root 是不是目标值
if root.val == val1 or root.val == val2:
return root
# 去左右子树寻找
left = find(root.left, val1, val2)
right = find(root.right, val1, val2)
# 后序位置,已经知道左右子树是否存在目标值
return left if left else right如何找到两个节点q和p的最近公共祖先?只需要在后序位置判断,是否已经找到了q和p。
- 在
find()的后序位置,如果left和right都不为空,那么root就是q和p的最近公共祖先。 - 还有一种情况,
q或p本身可能是LCA,所以直接遇到其中一个就可以返回。因为题目中说了q和p一定存在于树中。所以如果遇到了一个,没有遇到另一个,那么遇到的这个就是LCA。
注意:这种情况,必须要求q和p一定存在于树中,且不能有重复节点。
def lowestCommonAncestor(root: TreeNode, p: TreeNode, q: TreeNode) -> TreeNode:
# 在二叉树中寻找 val1 和 val2 的最近公共祖先节点
def find(root, val1, val2):
if not root:
return None
# 前序位置
if root.val == val1 or root.val == val2:
# 如果遇到目标值,直接返回
return root
left = find(root.left, val1, val2)
right = find(root.right, val1, val2)
# 后序位置,已经知道左右子树是否存在目标值
if left and right:
# 当前节点是 LCA 节点
return root
return left if left else right
return find(root, p.val, q.val)"前缀和技巧适用于快速、频繁地计算一个索引区间内的元素之和。" (Source)
The idea is to store an array preSum, in which preSum[i] is the sum of nums[0 ... i-1], which means that preSum[i] = preSun[i-1] + nums[i]. For example:
arr = [1, 2, 3, 4, 5]
preSum = [0, 1, 3, 6, 10, 15]To find the sum of elements within the range [1, 3], we can do the following:
- The sum of elements within the range
[1, 3]is equal topreSum[4] - preSum[1] = 9
Example: 303. Range Sum Query
注意:前缀和数组比原input数组的size大一个。
差分数组:迅速、频繁地对一个区间内的元素进行加减。
Difference array is used for fast, efficient addition and subtraction of numbers within a range of indices. For example, add all numbers within range [0, 3] by 6, subtract all numbers within [2, 5] by 3, ..., etc. The idea is that, for every operation to add or subtract a number on all numbers within the range [i, j], we only change the value of diff[i] and diff[j+1], and then based on the result of diff array, find the result array.
diff[i] is the difference between nums[i] and nums[i-1].
diff = [0] * len(nums)
diff[0] = nums[0]
for i in range(1, len(nums)):
diff[i] = nums[i] - nums[i - 1]用差分数组迅速有效地进行区域中数字的加减,然后利用差分数组还原出result。比如想要[i, j]区间所有数字都+5,那么就把diff[i] += 5,diff[j+1] -= 5,然后还原结果。注意:差分数组和原input数组的size相等。
The sliding window technique is used to solve subarray and substring problems.
时间复杂度:O(N)因为每个元素只会被加入窗口一次,被移出窗口一次。指针只会向右移动,不会向左移动。
指针初始化:设计为开区间能避免不必要的麻烦。left, right = 0, 0,初始化后窗口内没有元素。
关键问题:
- 什么时候扩大窗口?(什么时候移动
right指针?) - 什么时候缩小窗口?(什么时候移动
left指针?)缩小窗口时需要更新哪些数据? - 什么时候更新结果?(在扩大窗口的时候还是缩小窗口的时候?)
left, right = 0, 0
while left < right and right < len(nums):
# 1. Expand window
window.add(nums[right])
right += 1
...
# 2. Shrink window
while window_needs_shrink:
...
window.remove(nums[left])
left += 1
# 3. Update result
...
right += 1def sliding_window(s: str, t: str):
left = 0
right = 0
window = dict() # what we have currently in our window
need = dict() # the chars we need (keys) and each char's corresponding count (values)
valid = 0 # total number of valid keys
# a valid key's count in window must be greater or same as in need
# store chars in t in dictionary need
for c in t:
need[c] = need.get(c, 0) + 1
while right < len(s):
c = s[right]
right += 1 # increment immediately after getting c
# update window data
...
# check whether window needs shrink
while left < right and window_needs_shrink:
d = s[left]
left += 1
# update window data
...Key points:
- Initialize
leftandrightto be zero, immediately incrementleftandrightright after getting the corresponding character - Time complexity is O(N) because even through there is an embedded
whileloop, the pointersleftandrightwill only increase, and never decrease. Every single element in array (or string) will only be added to thewindowonce, and removed from it once (at max). ...means we need to update data stored inwindow. The first instance is when we add new element, the second is when we remove an element.
Example Questions:
二分查找的思路很简单,但是细节处理很复杂。比如while里用<还是<=,更新左右指针时是等于mid还是mid + 1还是mid - 1。
left和right指针的初始位置有两种情况,一种是right指向len(nums)(non-inclusive),另一种是right指向len(nums) - 1(inclusive)while循环的条件:left < right或left <= rightmid的计算:mid = left + (right - left) // 2,避免溢出;(left + right) / 2和left + (right - left) / 2结果一样,但是后者可以预防left和right过大导致两者相加溢出。- 更新指针的时候,
left和right的更新有两种情况,一种是left = mid + 1,另一种是right = mid - 1
def search(nums: list, target: int):
left = 0
right = ...
while ...:
mid = left + (right - left) // 2 # use // operator and avoid overflow
if nums[mid] == target:
...
elif nums[mid] < target:
left = ...
elif nums[mid] > target:
right = ...
def search(nums: list, target: int):
left = 0
right = len(nums)
while left < right:
mid = left + (right - left) // 2 # use // operator and avoid overflow
if nums[mid] == target:
return mid
elif nums[mid] < target:
left = mid + 1
elif nums[mid] > target:
right = mid
return -1- 为什么
while循环的条件是left < right?- 因为
right指向的是len(nums),所以left和right所定义的是一个开区间。 - 什么时候搜索范围为空?是当
left == right,这时搜索范围为空。 - 所以,
while循环的终止条件是,要么找到了目标元素,要么搜索范围为空。所以这里循环条件是left < right。
- 因为
- 最后要判断
left是否越界,因为最后循环结束是,左右指针应该是相等的,left可能是len(nums),这时left就越界了。 - 最后也要判断
left是否是目标元素,因为left和right是相等的,所以返回left和right都是一样的。
def search(nums: list, target: int):
left = 0
right = len(nums) - 1
while left <= right:
mid = left + (right - left) // 2 # use // operator and avoid overflow
if nums[mid] == target:
return mid
elif nums[mid] < target:
left = mid + 1
elif nums[mid] > target:
right = mid - 1
return -1- 为什么这里while循环的条件是
left <= right?- 因为
right指向的是len(nums) - 1,所以left和right所定义的是一个闭区间。 - 这种情况下,
left和right指向的两个元素也都属于搜索范围内。 - 什么时候搜索范围为空?是当
left > right,也就是left指向了right的右边。 - 什么时候搜索范围只有一个元素?是当
left == right,也就是left和right指向了同一个元素。 - 所以,
while循环的终止条件是,要么找到了目标元素,要么搜索范围为空。所以这里循环条件是left <= right。
- 因为
- 为什么更新
left和right的时候,left要等于mid + 1?(right同理)- 因为
left和right所定义的是一个闭区间。 - 如果
mid元素不是目标元素,那么mid元素肯定不是我们要找的元素,所以我们可以把mid元素排除在搜索范围之外。
- 因为
def search_left_bound(nums: list, target: int):
left = 0
right = len(nums) # ** important **
while left < right: # ** important **
mid = left + (right - left) // 2
if nums[mid] == target:
right = mid # ** important **
elif nums[mid] > target:
right = mid
elif nums[mid] < target:
left = mid + 1
# make sure that index `right` is not out of bounds
if right == len(nums) or nums[right] != target:
return -1
else:
return right # or return left because they are equal大致跟3.4.2.开区间的模板一样,只是更新right的时候,right = mid。为什么呢?因为我们要
找到等于target的最左边的元素,所以当nums[mid] == target的时候,我们要继续在左边搜索,所以要right = mid。
最后要检查right是否越界,因为最后循环结束是,左右指针应该是相等的,right可能是len(nums),这时right就越界了。
检查left也是一样的,反正最后循环结束后,左右指针应该是相等的。
如何确定target是否找到了?
- If
targetwas found,leftwill be the index of the target - If
targetwas not found,leftwill be the index of the first element that is greater thantarget - Prior to returning, check if the element at
leftis equal totarget:return nums[left] == target ? left : -1
def search_right_bound(nums: list, target: int):
left = 0
right = len(nums) # ** important **
while left < right: # ** important **
mid = left + (right - left) // 2
if nums[mid] == target:
left = mid + 1 # ** important **
elif nums[mid] < target:
left = mid + 1
elif nums[mid] < target:
right = mid
# make sure that index `left - 1` is not out of bounds
if left == 0 or nums[left - 1] != target:
return -1
else:
return left - 1 # ** important **为什么left = mid + 1?因为我们要找最右侧的target,所以当nums[mid] == target的时候,我们要继续在右边搜索,所以要left = mid + 1
(mid已经搜索过了,不需要再看)
为什么最后返回left - 1?关键在于每当我们找到一个等于target的元素时,我们都要继续在右边搜索,left = mid + 1。
这就意味着,当循环结束的时候,left指向的是第一个大于target的元素,所以left - 1就是最右侧的target。
由于left和right在循环结束之后是相等的,所以返回right - 1也是一样的。
如何确定target是否找到了? 在返回之前,check if the element at left - 1 is equal to target: return nums[left - 1] == target ? left - 1 : -1
为什么要检查left - 1是否越界?因为left可能等于0,这时left - 1就越界了。
In Python, use the heapq package to initialize and operate heaps.
# Initialize heap
h = []
# Add element
heapq.heappush(h, (priority, element))
# Peek element
h[0]
# Pop element
priority, element = heapq.heappop(h)heapq runtime:
- Push:
$O(\log n)$ - Pop:
$O(\log n)$ - Push all elements in an array to heap:
$O(n \log n)$
Related topics: 二维数组的花式遍历
Key idea: each row becomes a column, and each column becomes a row.
- 顺时针旋转90度:先沿左上-右下对角线翻转矩阵,然后反转每一行。
- 逆时针旋转90度:先沿右上-左下对角线翻转矩阵,然后反转每一列。
Example: Rotate a matrix 90 degrees clockwise
m = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
# First, transpose the matrix
m = [[1, 4, 7],
[2, 5, 8],
[3, 6, 9]]
# Then, reverse each row
m = [[7, 4, 1],
[8, 5, 2],
[9, 6, 3]]- 用一个
while循环,每次循环都是一次完整的遍历一圈。可以用while n <= num_rows * num_cols来控制循环次数,要记得更新n。 - 每次遍历一圈,都要遍历四条边,分别是上、右、下、左。
- 每次遍历一条边之前,都要检查边界是否合法。比如,遍历上边界之前,要检查
top <= bottom。遍历右边界之前,要检查left <= right。 - 每次遍历一条边,都要更新边界。一共四个边界:上边界
top、下边界bottom、左边界left、右边界right。比如,遍历完上边界后,top += 1。 - 遍历边的时候用一个
for循环,比如遍历上边界的时候,for i in range(left, right + 1)。遍历下边界的时候,for i in range(right, left - 1, -1)。
Example problems
- Usually, we use two pointers to solve linked list questions.
- Use
slowandfastpointers,slowmoves one step at a time,fastmoves two steps at a time. Two pointers move in the same direction. - Use
p1andp2pointers,p1moves one step at a time,p2moves one step at a time. Two pointers move in the opposite direction, either from middle to two ends, or from two ends to middle. - Or use
p1andp2, one on each linked list, to compare or merge two linked lists.
dummy node is a very useful technique when dealing with linked lists.
Sometimes, it will be more complicated when we don't use dummy node.
Use two pointers p1 and p2, one for linked list 1 and one for linked list 2.
Compare the value of nodes pointed to by p1 and p2, and add the smaller one to the result linked list.
Put all nodes that are less than value x to the left of all nodes that are greater than or equal to x.
Use two dummy nodes dummy1 and dummy2 to store the head nodes of left and right parts.
Use two pointers p1 and p2 to traverse the original linked list, and use two pointers p1 and p2 to traverse the two linked lists.
Connect two parts together at the end.
Similar to Merge Two Sorted Linked Lists, but use a heap to store the first node of each linked list. The heap decides which node to add to the result linked list.
Time complexity is O(N log k), where N is the total number of nodes in all linked lists, and k is the number of linked lists.
寻找中点
Use two pointers slow and fast, slow moves one step at a time, fast moves two steps at a time.
When fast reaches the end of the linked list, slow will be at the middle node.
寻找倒数第k个node
To find the k-th node from the end of the list, then it means we are looking for the
n-k+1-th node from the beginning of the list, where n is the length of the list.
In this case, make fast move k steps first, and then make slow and fast move
together until fast reaches the end of the list.
Similar Questions:
检查链表中是否含有环:
Use slow and fast pointers, slow moves one step at a time, fast moves two steps at a time.
If fast reaches the end of the linked list, then there is no cycle.
If fast and slow meet, then there is a cycle, because fast will eventually catch up with slow.
找链表中环的起点:
Use slow and fast pointers, slow moves one step at a time, fast moves two steps at a time.
When fast and slow meet, fast must have walked 2 times the length of slow.
Since fast walked k more steps, it means that the k steps must be walked within the cycle.
Thus, k must be a multiple of the length of the cycle.
Let's say that the distance from the beginning of the cycle to where two pointers meet is m, and slow walked k steps,
so the distance from head to beginning of the cycle is k-m.
From the point where the two pointers meet, if we walk k-m steps, we will get to the beginning of the cycle.
If two linked lists intersect, return the intersecting node, otherwise return None.
How to make sure that two pointers reach the intersection node at the same time? This can be difficult because there can be any number of nodes before the intersection node, if we let two pointers start from the beginning of each linked list, it will take different number of steps for each pointer to reach the intersection node.
The solution is to make two pointers start from the beginning of each linked list, and when one pointer reaches the end of the linked list, make it start from the beginning of the other linked list. In this way, the two pointers will reach the intersection node at the same time.
For example, p1 starts from linked list A and then B, p2 starts from linked list B and then A.
Eventually, the two pointers will meet at the intersection node, or None if there is no intersection.
Graphs are made up of nodes and edges. Graphs can be directed or undirected, and can be cyclic or acyclic.
图的逻辑结构跟多叉树节点的结构几乎一样。适用于树的DFS和BFS算法也适用于图。
class Vertex:
def __init__(self):
self.id = 0
self.neighbors = None
class TreeNode:
def __init__(self, val: int):
self.val = val
self.children = []不过实际上,很少用到以上逻辑结构来表示图。通常用邻接表或邻接矩阵来表示图。
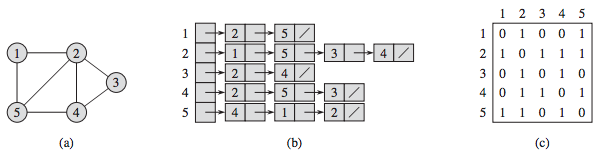
在邻接表里,用一个array of lists来表示图,每个节点的邻居都是一个list。占用空间更少,但无法快速判断两个节点是否相连。
在邻接矩阵里,如果节点a和b相连,就把matrix[a][b]设为1。可以快速判断两个节点是否相连,但是占用空间更多。
度(Degree):一个节点的度是指与它相连的边的数量。In-degree和out-degree分别是指指向节点的边的数量和从节点出发的边的数量。
如果是weighted directed graph,邻接矩阵里的元素可以是边的权重。如果值为0,表示没有edge连接两个节点。邻接表里的list里的元素可以是一个tuple,包含邻居节点的id和边的权重。
需要一个visited来记录已经访问过的节点,避免重复访问。尤其是因为图可能有环,所以需要visited来避免死循环。
处理路径相关的问题,需要用到一个onPath来记录从起点到当前节点的路径。比如拓扑排序。对于onPath的操作很像
回溯算法里做选择和撤销选择的动作。区别在于位置:回溯算法的「做选择」和「撤销选择」在 for 循环里面,而对 onPath 数组的操作在 for 循环外面。
因为回溯算法是在树枝上进行操作,而对于图,应该用 DFS 算法,即把 onPath 的操作放到 for 循环外面,否则会漏掉记录起始点的遍历。
# 记录被遍历过的节点
visited = []
# 记录从起点到当前节点的路径
onPath = []
def traverse(graph, s):
if visited[s]:
return
# 经过节点 s,标记为已遍历
visited[s] = True
# 做选择:标记节点 s 在路径上
onPath[s] = True
for neighbor in graph.neighbors(s):
traverse(graph, neighbor)
# 撤销选择:节点 s 离开路径
onPath[s] = False- 判断回文串:对撞指针,从两端收缩,判断回文串 (Example: 125. Valid Palindrome)
- 寻找回文串:中心扩散法,从中间向两端扩散,寻找回文串 (Example: 5. Longest Palindromic Substring)
More on palindrome problems: Palindrome Problems
To get the ASCII code of a char: ord(char)
For example, ord('A') = 65
We can also do ord('Z') - ord('A') = 25. If we want to use an array of size 26 to store the count (or something else) of 26 upper case English characters, ord(char) - ord('A') will be the index of char in this array.
- Reverse all characters in the string first, then reverse each word one by one.
- Take care of leading and trailing spaces, and multiple spaces between words.
股票买卖问题都可以用 dynamic programming 的方法来解决。
- 题解及思路
- Solution to Problem 121. Best Time to Buy and Sell Stock
- Solution to Problem 122. Best Time to Buy and Sell Stock II
思路:不要去思考整体能装多少水,而是每个位置i能装多少水。每个位置i能装多少水取决于i左边最高的柱子和i右边最高的柱子中较矮的那个。
方法:用对撞指针,从两端收缩,每次收缩较矮的那个柱子,同时更新结果。Use two pointers that move in the opposite direction (moving towards the middle), and each time move the pointer that is pointing to the shorter bar. Update the result at each step.
Palindrome problems can be divided into multiple categories based on the data structure used to store the palindrome:
- String
- Linked list
- Array
- Integer
Palindrome problems on strings are usually solved using two pointers.
- 判断回文串 Check palindrome:
- 用对撞指针,从两端收缩,判断回文串
- Example: 125. Valid Palindrome
- 寻找回文串 Find palindrome
- 用中心扩散法,从中间向两端扩散,寻找回文串
- Example: 5. Longest Palindromic Substring
先找链表中点,再反转后半段链表。
Because you can only move in a single direction in a linked list, we can't use two pointers and make then move in opposite directions. However, we can find the mid-point of a linked list, and then reverse the latter half of the linked list.
# Input
1 -> 2 -> 3 -> 2 -> 1
# After processing
1 -> 2 -> 3 <- 2 <- 1Example: 234. Palindrome Linked List
Basically the same as palindrome problems on strings.
Do not convert the integer to a string and then check if the string is a palindrome! Very inefficient.
The intuition is to reverse the integer and simply use == to check if reversed integer is equal to the original integer.
Use two variables: y is the reversed integer, and temp is an integer we use to find each digit of input x.
Initialize temp = x, while temp > 0, find the last digit using digit = temp % 10, and then update temp using integer division temp = temp // 10.
Update y at each step, y = y * 10 + digit. Finally, check if y == x.
Example: 9. Palindrome Number
回溯问题相当于遍历决策树。每个节点都是一个合法答案,可以通过遍历所有的节点得到所有的合法答案。 在每一个回溯树节点上,需要考虑:
- 路径:已经做出的选择
- 选择列表:当前可以做的选择
- 结束条件:到达决策树底层,无法再做选择的条件
回溯算法是遍历树枝,DFS是遍历节点。
细节注意:
-
将合法答案加入结果集的时候,要注意深拷贝:
new_list = path[:]- 原来可以用
self.result.append(path.copy()),但最近总是报错。
- 原来可以用
-
做出选择:
path.append(choice) -
撤销选择:
path.pop()
result = []
def backtrack(path, choices):
if end_condition:
result.append(path)
return
for choice in choices:
# make a choice
...
# backtrack
backtrack(path, choices)
# undo the choice
...- 在
for循环里,在backtrack()之前做出选择,在结束后撤销选择。 end_condition可以是到达决策树底层,也就是choices为空的时候。path和choices是每个节点的属性。想要在正确的时间点操作,需要在前序位置和后序位置两个特殊位置操作。def traverse(node): for child in node.children: # pre-order ... traverse(child) # post-order ...
- 前序位置:刚进入某个节点的位置进行操作
- 后序位置:正要离开某个节点的位置进行操作
排列,组合,子集问题的几个类型:
nums元素不重复,不可以重复选取。nums元素可以重复,但不可以重复选取。nums元素不重复,可以重复选取。每个元素可以选取多次。
附加条件: 求和为target且个数为k的组合
无论提醒如何变化,本质都是穷举所有可能的结果,可以用树状结构来表示。可以使用回溯算法来解决。
nums = [1, 2, 3]
[]
/ | \
[1] [2] [3]
/ \ \
[1,2] [1,3] [2,3]
/
[1,2,3]- 在每个树枝上,进行一个选择。
- 保持元素的相对顺序不变,避免重复的选择。比如在选择
2以后,不能再选择1(数组中出现在2之前的元素)。 - 用
start来保证元素nums[start]之后只会出现nums[start+1...]之后的元素。
例题:78. Subsets
同上,只是end_condition变为len(path) == k。
- 与组合问题不同,在
nums中第i个元素被选中后,nums中位置在i之前的元素还可以被选中。 - 用
used数组来记录哪些元素已经被选中。每次做选择的时候,标记used[i] = True,撤销选择的时候,标记used[i] = False。 - 如果题目要求给出个数为
k的排列,只需要改变end_condition为len(path) == k。
nums = [1, 2, 2]
[]
/ | \X
[1] [2] [2]
/ \X \
[1,2] [1,2] [2,2]
/
[1,2,2]- 如上所示,在第一个
2被选中后,第二个2还可以被选中。但是这样会导致重复的结果。 - 所以,如果有重复的元素在同一层的树枝上,就需要跳过重复的元素。比如从第0层到第1层的树枝上,第二个
2就需要跳过。 - 在开始回溯之前,先将
nums排序,这样重复的元素就会相邻:sort(nums)。 - 在
forloop里做选择的时候,如果i > start并且nums[i] == nums[i-1],就跳过这个元素。 - 为什么要
i > start?因为start之前的元素不能被选了,start相当于我们现在要创建的节点的parent node,只有在start之后的元素才能被选。 - 如果设置
i > 0,就会有bug,因为如果值相同的元素不在同一层(不是同层相邻的树枝),那么就不能跳过。比如[2, 2]里,第一个2和第二个2不在同一层,所以不能跳过。
- 因为元素可以重复,所以需要排序,方便之后的pruning。
- 因为答案不能有duplicates,所以需要用
start来保证不选择之前出现的元素。 - 因为元素可以重复,所以在
forloop里,要检查当i > start并且nums[i] == nums[i-1]时,continue,跳过重复的元素。 - 合法答案需要和为
target,所以需要一个path_sum参数,每次做选择和撤销选择的时候更新。 end_condition是path_sum == target。- 当
path_sum > target的时候,可以直接return,因为之后的元素都会更大,不可能再有合法答案了。可以节省不必要的计算。
标准的组合问题通过start来保证不重复使用元素。这一层从start开始,那下一层就是从start+1开始选择元素,来保证nums[start]不会被重复使用。
这道题中,想要让每个元素可以被重复使用,只需要把i+1改成i:
def backtrack(nums, start):
for i in range(len(nums)):
...
backtrack(nums, i)
...这样在保证每个元素可以重复使用的同时,也保证了不会出现结果中有同一个组合不同排列的情况。假设nums = [1, 2, 3]:
[]
1/ 2| \3
[1] [2] [3]
/ | \ # Note: 这里不会有[2,1]出现,因为在[2]这个节点,start=1,接下来不会检查index 0
[1,1][1,2][1,3]
动态规划问题一般是求最值。比如minimum edit distance。
动态规划的核心思路是穷举,为了求最值,要把所有可能都穷举出来,然后在其中找最值。
动态规划三要素:
- 状态转移方程
- 比如斐波那契数列,
f(n) = f(n-1) + f(n-2), n > 2,f(1) = 1, f(2) = 1。 - 如果我们发现每次状态转移只需要 DP table 中的一部分,那么可以尝试缩小 DP table 的大小,只记录必要的数据,从而降低空间复杂度。
- 比如斐波那契数列,
- 最优子结构
- 重叠子问题
- 重叠子问题:在递归树中,有很多节点是重复的,比如斐波那契数列,计算
f(4)的时候,要计算f(3)和f(2),计算f(3)的时候,要计算f(2)和f(1),f(2)被重复计算了。
- 重叠子问题:在递归树中,有很多节点是重复的,比如斐波那契数列,计算
如何定义状态转移方程:
- 明确 base case
- 明确状态
- 明确选择
- 明确 dp 数组的定义
递归的问题,最好都画出递归树,对分析算法的复杂度,寻找算法低效的原因都有巨大帮助。
递归算法的时间复杂度就是用子问题个数乘以解决一个子问题需要的时间。
为了避免递归算法的重复计算,可以使用备忘录memo,算出每个子问题答案后,都保存在memo里,下次遇到相同的子问题,就直接在memo里查找。
动态规划的两种实现方式:(source)
- 自顶向下,递归求解
- 比如斐波那契数列,计算
f(10)时,逐渐分解规模,直到f(1)和f(2),然后逐渐返回,直到f(10)。
- 比如斐波那契数列,计算
- 自底向上,迭代求解
- 比如斐波那契数列,从
f(1)和f(2)开始,自底向上推导出f(10)。
- 比如斐波那契数列,从
# 自顶向下递归的动态规划
def dp(状态1, 状态2, ...):
for 选择 in 所有可能的选择:
# 此时的状态已经因为做了选择而改变
result = 求最值(result, dp(状态1, 状态2, ...))
return result
# 自底向上迭代的动态规划
# 初始化 base case
dp[0][0][...] = base case
# 进行状态转移
for 状态1 in 状态1的所有取值:
for 状态2 in 状态2的所有取值:
for ...
dp[状态1][状态2][...] = 求最值(选择1,选择2...)斐波那契数列:
- 根据状态转移方程可以发现,不需要存储所有的状态,只需要存储
f(n-1)和f(n-2)就可以了。 - 这样可以把空间复杂度降到
O(1)。
BFS的本质就是让在一幅「图」中找到从起点 start 到终点 target 的最近距离。 比如走迷宫,哪些格子可以走,哪些格子是墙。两个单词,把一个换成另一个,每次只能替换一个字母,最少需要换几次。
class Node:
def __init__(self, val: int):
self.val = val
self.neighbors = []
def BFS(start: Node, target: Node) -> int:
q = deque() # Use a queue to store nodesu
visited = set() # Mark nodes as visited to avoid duplicates
q.append(start) # Append starting point to queue
visited.add(start)
step = 0 # 记录扩散的步数
while q:
step += 1
size = len(q)
# 将当前队列中的所有节点向四周扩散
for i in range(size):
cur = q.popleft()
# 划重点:这里判断是否到达终点
if cur == target:
return step
# 将cur相邻节点加入队列
for x in cur.neighbors:
if x not in visited:
q.append(x)
visited.add(x)
# 如果走到这里,说明在图中没有找到目标节点
return -1- 回溯问题中的剪枝(当寻找combination时,如何避免结果里含有同一个数组的不同排列)