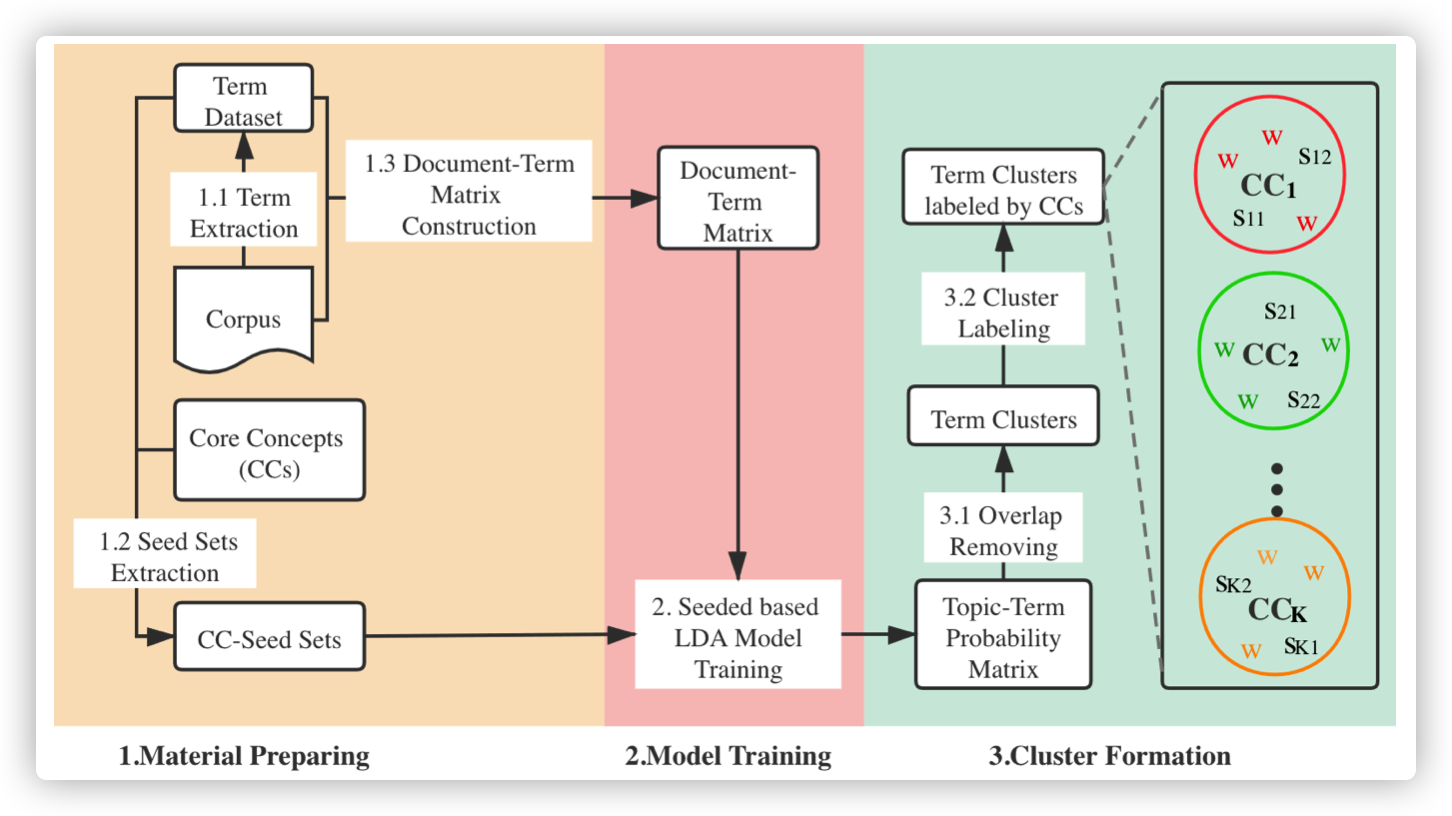
Core-Concept-Seeded LDA as a Term Clustering Method based on Seeded LDA for core concept formation
We share the code of LDA, Zlabels, and Seeded LDA. For Seeded LDA M1 and Seeded LDA M2, one can obtain them by making a little change from Seeded LDA.
Description
The code is implemented by C++ Code4KES2021/LDAs, and wrappered by python (the pybind11 tool) Code4KES2021/LDAs_python.
My Environments:
- Windows10
- Visual Studio 2017
- pybind11 for compile C++ code
- Python3.6
- pip install pybind11
For C++ code:
If you want to make changes in C++ code and use the compiled .pyd for your python project. I have written a easy pybind11 tutorial for how to use it.
For Python code:
You can also use the Python code directly for your own project.
- make sure you had the
LDAs.pyd(compiled from C++ code by Visual Studio 2017) inLDAs_python/pybind_module. This file will loaded byLDAs_python/load_module/lda_loader.py. - make sure you have installed the pybind11 by
pip install pybind11for your Python interpreter (Python 3.6 is guranteed to be work). - The implementation of all LDA models is coded in
LDAs_python/load_module/lda_wrapper.py.
For LDA
lda_model = LDA(K=3, alpha=0.1, beta=0.01, iteration=20)
docs = [["1", "2", "1", "2", "1"], ["1", "2", "1", "3"], ["2", "1", "1"], ["2", "1", "3", "2", "3"]]
lda_model.fit(X=docs)
lda_model.phi()
lda_model.theta()
For Zlabel
from gensim.corpora import Dictionary
lda_model = Z_labels(K=3, alpha=0.1, beta=0.01, pi=0.7, iteration=20)
docs = [["1", "2", "1", "2", "1"], ["1", "2", "1", "3"], ["2", "1", "1"], ["2", "1", "3", "2", "3"]]
dictionary = Dictionary(docs)
dig_docs = [dictionary.doc2idx(doc) for doc in docs]
SS = [["1"], ["2"], ["3"]] # three groups of seed sets, each contains 1 seed word
TIDS = [[0], [1], [2]] # the first group of seed set is used to guide topic 0, the seconde group is for topic 1, the third group is for topic 2
lda_model.fit(X=docs, SS=SS, TIDS=TIDS, ditionary=dictionary, Docs=dig_docs)
lda_model.phi()
lda_model.theta()
For Seeded LDA
from gensim.corpora import Dictionary
lda_model = Seeded_LDA(K=3, alpha=0.1, beta=0.01, pi=0.7, iteration=20)
docs = [["1", "2", "1", "2", "1"], ["1", "2", "1", "3"], ["2", "1", "1"], ["2", "1", "3", "2", "3"]]
dictionary = Dictionary(docs)
dig_docs = [dictionary.doc2idx(doc) for doc in docs]
SS = [["1"], ["2"], ["3"]] # three groups of seed sets, each contains 1 seed word
TIDS = [[0], [1], [2]] # the first group of seed set is used to guide topic 0, the seconde group is for topic 1, the third group is for topic 2
lda_model.fit(X=docs, SS=SS, TIDS=TIDS, ditionary=dictionary, Docs=dig_docs)
lda_model.phi()
lda_model.theta()
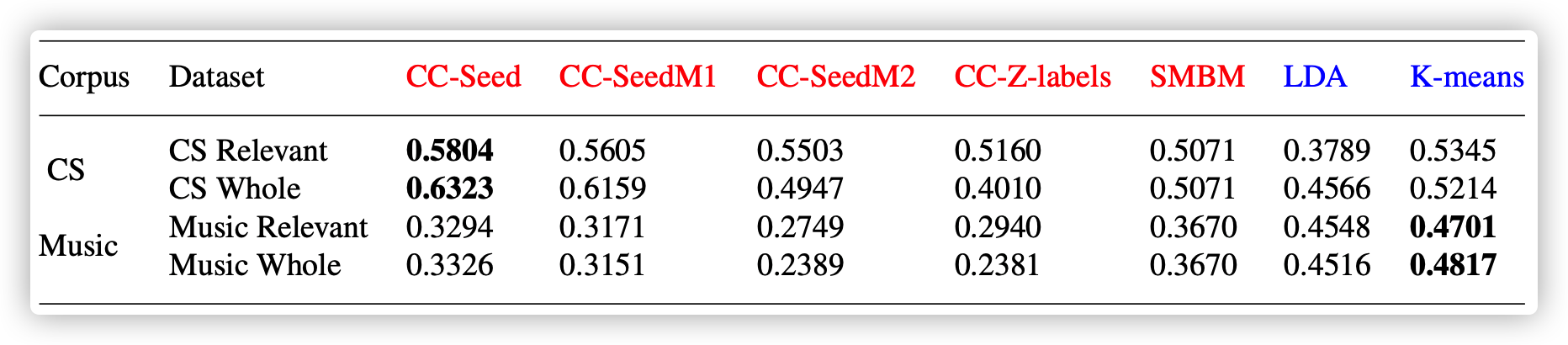
Our experiment results on Two corpus.
Methods includes all LDA models , K-means, and SMBM are posted in supplementary materials.pdf.
The experiment material (data.rar) includes clean corpus, noisy corpus, seed words of CS and Music, gold standard, manually labeled terms.