v0.10.1
We are excited to introduce the new v0.10.1 release, with many new exciting features and post-training algorithms. The highlights are as follows:
Online DPO

Online DPO is a new alignment method from DeepMind to boost the performance of LLMs. With Online DPO, data is generated on the fly by the trained model (instead of pre-collected). For each prompt, two completions are generated, with a reward model selecting the preferred one. This approach:
- Eliminates the need for a pre-collected preference dataset (it's generated online)
- Enables continuous model improvement
- Yields better results than traditional DPO
To train models with this method, use the OnlineDPOTrainer
Liger Triton kernels for supercharged SFT

- We've integrated LinkedIn's Liger Triton kernels to the
SFTTrainerfor faster throughput and lower memory usage. To use them, setuse_liger_kernelinSFTConfig
DPO for VLMs
- We've added support to align vision-language models with DPO, now covering architectures LLaVa-1.5, PaliGemma, and Idefics2. To train VLMs with DPO, use the
dpo_visual.pyscript as follows
accelerate launch examples/scripts/dpo_visual.py \
--dataset_name HuggingFaceH4/rlaif-v_formatted \
--model_name_or_path google/paligemma-3b-pt-224 \
--trust_remote_code \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 8 \
--output_dir dpo_paligemma_rlaif-v \
--bf16 \
--torch_dtype bfloat16WinRate callback for LLM as a judge
- We've added support to compute win rates over the reference model for methods like DPO. To do so, configure the callback to point to the LLM as judge API (OpenAI or Hugging Face Inference API) and then add:
trainer = DPOTrainer(...)
win_rate_callback = WinRateCallback(..., trainer=trainer)
trainer.add_callback(win_rate_callback)Anchored Preference Optimisation (APO) for fine-grained human/AI feedback
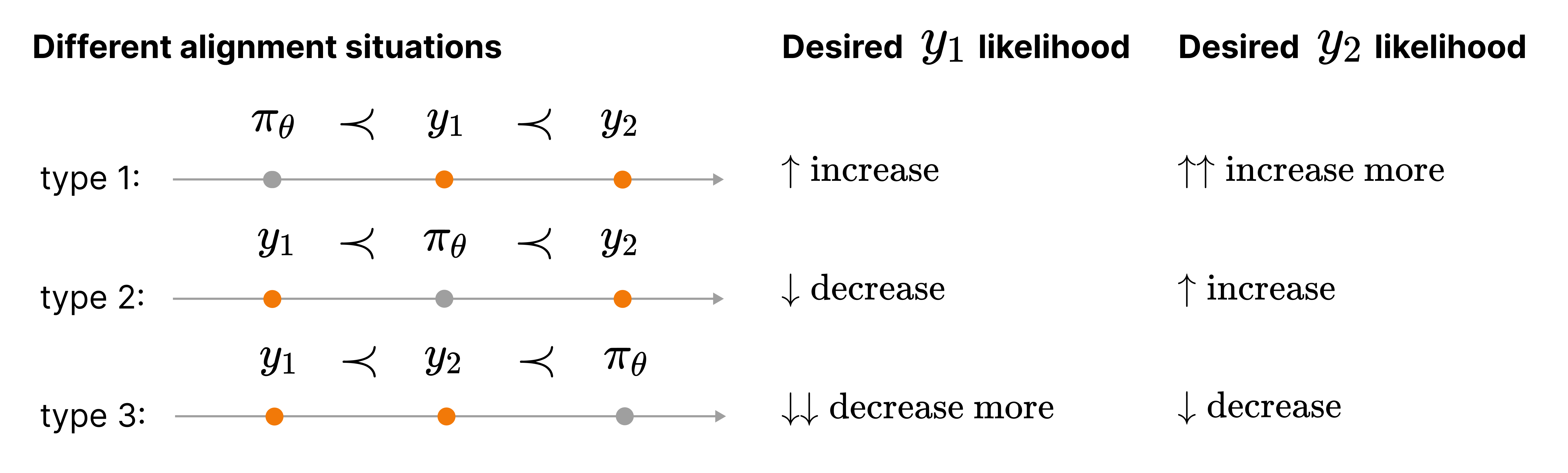
- Added the APO method, which is an "anchored" version of the alignment objective. There are two variants:
apo_zeroandapo_down. Theapo_zeroloss increases the likelihood of winning outputs while decreasing the likelihood of losing outputs, making it suitable when the model is less performant than the winning outputs. On the other hand,apo_downdecreases the likelihood of both winning and losing outputs, but with a stronger emphasis on reducing the likelihood of losing outputs. This variant is more effective when the model is better than the winning outputs. To use these losses, setloss_type="apo_zero"orloss_type="apo_down"in theDPOConfig
What's Changed
- Set dev version by @vwxyzjn in #1817
- Upgrade GitHub actions by @qgallouedec in #1818
- DPO Llava 1.5 and PaliGemma support by @qgallouedec in #1797
- Delete unused benchmark.yml workflow by @AdnaneKhan in #1822
- Consistent use of trust_remote_code by @qgallouedec in #1806
- Fix: authentication token kwarg not passed when loading PEFT adapters by @mkopecki in #1825
- refactor trainer callbacks by @kashif in #1826
- Uniform
model_refnaming by @qgallouedec in #1835 - fix ppov2_trainer tensorboard logging bug by @DZ9 in #1836
- Fix issues of KTOTrainer by @MAOJIASONG in #1840
- add link to DPO datasets collection by @davanstrien in #1845
- fix arg parsing in chat.py by @lvwerra in #1846
- DPO for VLM blog post in doc by @qgallouedec in #1844
- Add WinRateCallback and Judges by @lewtun in #1598
- Remove
CI_HUB_USER_TOKENby @qgallouedec in #1852 - Online DPO and Online trainer refactor by @vwxyzjn in #1809
- [online-DPO] online dpo cleanups by @kashif in #1864
- arXiv to HF Papers by @qgallouedec in #1870
- fix fsdp & qlora support by @eliebak in #1863
- Import missing
setup_chat_formatby @Rishav-hub in #1862 - Bug Fix while training using SFTTrainer with DataCollatorForCompletionOnlyLM by @Rishav-hub in #1861
- Small fixes to online dpo example by @edbeeching in #1879
- Skip BigBird save and load test until next transformers version by @qgallouedec in #1874
- Llama in modelling value head tests by @qgallouedec in #1878
- Improve judges by @qgallouedec in #1856
- [Do not merge] Re-add BigBird Pegasus save/load test by @qgallouedec in #1876
- Re-add BigBird Pegasus save/load test by @qgallouedec in #1882
- Move BCO to separate BCOTrainer with fixes by @claralp in #1869
- Update example overview documentation section by @qgallouedec in #1883
- fix dpo_trainer bug for LLMs without bos_token in config by @DZ9 in #1885
- Fix SFT for VLM example by @qgallouedec in #1865
evaluation_strategy->eval_strategyby @qgallouedec in #1894- fix serialization of RunningMoments on multiple GPUs by @claralp in #1892
- [WIP] Fix CI by @qgallouedec in #1897
- Drop
setUpClassin reward tester by @qgallouedec in #1895 - Support
IterableDatasetforSFTTrainerby @qgallouedec in #1899 - Fix data processing in ORPO example script by @qgallouedec in #1903
- [RPO] use loss from v3 of paper by @kashif in #1904
- Support Rank Stabilized LoRA in the ModelConfig/LoraConfig by @JohnGiorgi in #1877
- [Online-DPO] num_generation_per_prompt is fixed by @kashif in #1898
- Fix GPT2 sentiment notebook reward by @cemiu in #1738
- Fix
AlignPropTrainerimport by @qgallouedec in #1908 - Various args and test fix by @qgallouedec in #1909
lr_scheduler.step()afteroptimizer.step()by @qgallouedec in #1918torch.cuda.amp.autocast()->torch.amp.autocast("cuda")by @qgallouedec in #1921- Fix orpo trainer loss device by @SunMarc in #1919
- Add transformers library name for TRL repos by @lewtun in #1922
- Standardize
dataset_num_procusage by @qgallouedec in #1925 PartialState().local_main_process_first()when map in examples by @qgallouedec in #1926- minor BCO fixes by @claralp in #1923
- Improve DPO/loss doc by @qgallouedec in #1929
- feat: anchored pref optimization by @karel-contextual in #1928
- Add tests for DPO for VLM by @qgallouedec in #1935
- fix model to save in ppov2 by @mnoukhov in #1776
- Optional Additional Loss to Center Reward Models' Outputs by @RylanSchaeffer in #1932
- Properly label all models when pushed to the hub by @qgallouedec in #1940
- Skip token in
push_to_hubby @qgallouedec in #1945 - Fix model wrapping for online DPO by @lewtun in #1946
- Don't mark issues as stale if nobody answered by @qgallouedec in #1949
- Add a simple-to-understand example for online DPO by @vwxyzjn in #1947
- Log WandB tables on main process by @lewtun in #1951
- [ODPO] Fix global step for consistent checkpointing with global updates by @lewtun in #1950
- "help wanted" in label to exempt from stale by @qgallouedec in #1956
- Fix response truncation in examples/notebooks/gpt2-sentiment.ipynb by @qgallouedec in #1957
- [ODPO] Refactor training script to use messages API by @lewtun in #1958
- Support LLaVA-NeXT in Vision SFT by @qgallouedec in #1959
- Add issue/PR templates, code of conduct & better contributing guide by @lewtun in #1963
- Fix issue with precompute_ref_log_probs not working when rpo_alpha is None by @mina-parham in #1961
- add arg
padding_freeto DataCollatorForCompletionOnlyLM by @RhuiDih in #1887 - Optimize DPO log probability calculation by retaining necessary cache, saving up to 30GB of memory (#1968) by @SeungyounShin in #1969
- New mismatch pair creation strategy by @qgallouedec in #1970
- Fix issue templates location by @qgallouedec in #1973
- Use weights_only for load by @kit1980 in #1933
- Fix flaky Hub tests by @lewtun in #1981
- fix a few minor bugs in ppo.py by @kykim0 in #1966
- Test for #1970 by @qgallouedec in #1974
- Restore reruns for flaky tests by @lewtun in #1982
- Promote
PairRMJudgeto top-level import by @qgallouedec in #1985 - [DPO] TR-DPO gather the target model params as well when syncing by @kashif in #1978
torch.loadwithweights_only=Trueby @qgallouedec in #1988- Skip the failing Online DPO test by @qgallouedec in #1989
- Refactor Online DPO by @vwxyzjn in #1839
- [DPO] tokenize and process DPO data via batches by @kashif in #1914
- [RPO] Add ignore_index in DPOTrainer's nn.CrossEntropyLoss by @akakakakakaa in #1987
- Relax numpy upper bound and bump deepspeed version by @hvaara in #1990
- Adds experimental Liger support to SFT script by @edbeeching in #1992
New Contributors
- @AdnaneKhan made their first contribution in #1822
- @mkopecki made their first contribution in #1825
- @DZ9 made their first contribution in #1836
- @MAOJIASONG made their first contribution in #1840
- @davanstrien made their first contribution in #1845
- @eliebak made their first contribution in #1863
- @Rishav-hub made their first contribution in #1862
- @cemiu made their first contribution in #1738
- @SunMarc made their first contribution in #1919
- @karel-contextual made their first contribution in #1928
- @RylanSchaeffer made their first contribution in #1932
- @mina-parham made their first contribution in #1961
- @RhuiDih made their first contribution in #1887
- @SeungyounShin made their first contribution in #1969
- @kit1980 made their first contribution in #1933
- @akakakakakaa made their first contribution in #1987
- @hvaara made their first contribution in #1990
Full Changelog: v0.9.6...v0.10
Contributors
kashif, kit1980, and 25 other contributors