Essential learning for people building an API that is performant, scalable and maintainable.


Joking aside, starting a project "from scratch" is a opportunity (and privilege) few people get; it's a Golden Ticket!

If you are fortunate enough to be
in that position, do not take the task lightly.
Do your homework before you start!
Learn from as many experienced people as possible
and make your API the best it can be!
- Learn API Design 🏙️
- Why? 🤷♀️
- Who? 🤓
- What? 💭
RESTfulAPI Design and Best Practices- Provide sensible
Resourcenames - Use adequate
HTTPresponse codes to indicate status - Use
query parametersto filter, sort or search resources - Show meaningful Errors
- Favour
JSONoverXMLsupport - Avoid chattiness in your API
- Consider
connectedness - Always use
SSL - Lint your responses and add
gzipsupport - Accept
JSONinPOST,PATCH,PUTbodies - Pagination
- Rate Limiting
- Caching
- Versioning your API?
- API Documentation
- API Testing
- API Monitoring
- References
- Provide sensible
- Further General Background Reading + Watching
Having a great API will make or break your project/product.
We expect a significant percentage
of the people using our App
to access the API
either for automation -
e.g: via a Voice Assistant -
or simply to extract, analyze & visualize their data in interesting ways.
in many ways, we think
the API is the Product!
With that in mind,
we want to research and learn
how to build the best API we possibly can
and document as much as possible
so others can learn from our quest!
This guide is meant as both
an internal reference for us @dwyl;
everyone in the team/community should read,
understand and attempt to improve/extend it ...
and a fully Open Source resource
that anyone can read and learn from.
As always, if you find it helpful/useful please star the repo on GitHub ⭐ 🙏 Thanks!
If you get stuck or have any questions/suggestions, please open an issue.
The term API
stands for
"Application Programming Interface"
~
wikipedia.org/wiki/API
An API is a way of communicating with a system programmatically.
It is a structured way for one program to offer services to other programs.
A few quotes from
Joshua Bloch's
Google Talk on
"How To Design A Good API and Why it Matters"
and Kevin Lacker's (@Parse)
"How to Design Great APIs"
"You have one chance to get it right." 3:17
"A bad API can be among a company's greatest liabilities... can cause an un-ending stream of support phonecalls ... and it can inhibit a company's ability to move forward" 2:51
"Once you have a bad API, you can't change it, you are pretty much stuck with it forever." 3:12
" ... A good API needs to appeal to the most powerful emotion: Laziness". 3:23
"You need to be opinionated even when there is no right and wrong" 31:02
"Always make your REST API as small/short as possible" 31:19
"The user of an API should never be surprised by its behaviour... it's even sometimes worth reduced performance not to surprise users of the API." 48:32
- Easy to learn (notice the priority placement of learn-ability...)
- Intuitive / Easy to use even without documentation
- Hard to misuse (write tests for "undesirable" behaviour)
- Easy to read and maintain code that uses it
- Sufficiently powerful to satisfy requirements
- Easy to evolve (the simpler the initial API the easier it will be to extend)
- Appropriate to audience (make it beginner friendly...)
- Opinionated (means people don't have to think)
An API comes in different forms.
When a developer get down to building an API,
they first decide which specification to use.
Most of the time, they go for REST.
But, analyzing product requirements,
a tech team may come to the conclusion
that calls for a different approach.
RESTful APIs weren't always the de facto way of building APIs.
In fact, there is an historical precedence to it.
The earliest and simplest form of an API
was RPC Remote Procedure Call,
hailing from the 80's.
The name speaks for itself. It's a straightforward interaction where a local client sends commands to a remote server.
Here's a closer look at how it works. Both client and server use different call parameters, so they must be converted so it is understood by the other side. This conversion is made inside stubs.

RPC started with XML and later JSON-based versions.
However, in 2015, Google created
gRPC,
a general-purpose RPC framework.
Systems like
Apache Thrift
or Twitch's
Twirp
use gRPC for internal communication between (micro)services.
In 1999, engineers at
Microsoft created SOAP -
Simple Object Access Protocol.
Initially, XML RPC had a problem -
it didn't distinguish between data types.
So devs had to add additional metadata
to label a field with a data type.
Aiming for consistency,
SOAP carved the format of the transmitted message in stone.
It was informative but rather verbose.

A SOAP message is framed with an envelope tag
(root element that starts and ends the message),
a header and a body.
Although SOAP is not as popular as REST,
it's still around, especially in financial services.
This is because it uses
(WS-Security).
SOAP WS-Security extension to encrypt messages
and only the recipient with a security token can read it.
Representational State Transfer (REST) is a software architecture
style consisting of guidelines and best practices for creating
scalable web services.
This is an architectural pattern
that describes how systems
can expose a consistent interface.
When people use the term REST API,
they are referring to an API accessed via HTTP protocol
at a predefined set of URLs.
Whilst SOAP allows for stateful interactions -
where the server is aware of previous requests -
RESTful APIs are stateless,
thus treating every request as distinct.
RESTful APIs are resource-based,
meaning the user is manipulating
(creating, updating, deleting or fetching) resources.
When using a RESTful API,
we are specifying the URI - Uniform Resource Identifier
and performing an action -
e.g: GET HTTP(fetching) request.
The response is a JSON object
that can be interpreted in any programming language.

REST is a structured way of building web services and applications. When something is described as "RESTful" it simply means it follows a predefined predictable pattern for how it responds to requests.
For a system to be considered 100% RESTful,
it ought to follow six constraints:
- Uniform Interface
- Identification of resources
- Manipulation of resources through representations
- Self-descriptive messages
- Hypermedia as the engine of the application state.
- Statelessness
- Client-server
- Cacheable
- Layered System
- Code-on-demand
While the uniform interface constraint is fundamental
to the design of any RESTful system,
code-on-demand is optional.
Although not mandatory to implement all of the aforementioned,
doing so will result in better,
more usable services.
We recommend the following videos
for an "easy-to-digest" introduction
to these concepts an REST as a whole.
- Intro to REST: http://youtu.be/llpr5924N7E
- What is REST API?: https://youtu.be/-mN3VyJuCjM
- RESTful APIs in 100 seconds: https://youtu.be/-MTSQjw5DrM
Google Cloud TechYoutube channel for API management, design patterns and summit talks of APIs on the cloud: https://www.youtube.com/channel/UCJS9pqu9BzkAMNTmzNMNhvg
For web RESTful services-specific resources,
we encourage you to skim through the following resources.
- Beginners Guide: http://www.restapitutorial.com/
- What are RESTful web services: http://stackoverflow.com/a/3636470/1148249
- What is "CRUD"? http://en.wikipedia.org/wiki/Create,_read,_update_and_delete
HTTP verbs represent one of the pillars of the uniform interface constraint we have mentioned earlier. Resources are manipulated (CRUD) and each operation is invoked by these verbs.
- GET = read an existing record or collection (list of records)
- POST = create and partial update.
- PUT = create and idempotent update (always send all the fields required - not partial update)
- PATCH = partial update (send only the fields to update)
- DELETE = does exactly what it says
The word "idempotence" may be funky but it represents a rather simple concept. For a
RESTfulservice standpoint, for an operation to be idempotent, clients can make the same call repeatedly while producing the same result. TheGETorPUToperation on ausers/12345URI, for example, are great examples of this. Each time they are called, the same result is yielded.
Each operation concerns to a resource, which in turn is identified/located through an URI. Here's how these operations are applied to resources:s
- GET /comments - Returns a list of all comments
- GET /comments/:id - Returns a comment with the given id
- POST /comments - Creates a new comment
- PUT /comments/:id - Updates a comment with the given id
- PATCH /comments/:id - Partially update a comment with the given id
- DELETE /comments/:id - Deletes a comment with the given id
This is an overview of how these are implemented.
If you are curious or want to learn more
about the differences between PUT, POST and PATCH,
skim through the following links for a better understanding.
- PUT vs POST in REST: http://stackoverflow.com/questions/630453/put-vs-post-in-rest
- PUT vs PATCH in REST: https://stackoverflow.com/questions/28459418/rest-api-put-vs-patch-with-real-life-examples
You can find endless public APIs across the world-wide-web. Some of them don't have documentation, others have decent and there are others with exceptional and comprehensive guides.
Here is a list of examples of public RESTful APIs
that have awesome documentation.
- Parse REST API: docs.parseplatform.org/rest/guide (really good example of good interactive documentation)
- GitHub: developer.github.com
- Twitter: developer.twitter.com
- Google: developers.google.com/custom-search
- Stripe: stripe.com/docs/api
- Twilio: twilio.com/docs/usage/api
The
Twitter API.
allows developers to query tweets by person, topic, tag or trends.
We could use it to write a bot that displays the top tweets of the day.
As users of the API,
we don't need to know about the internal details
of Twitter's systems,
nor does Twitter want us to.
But using their API,
we are able to do specific/pre-defined things
(like making a post or reading a timeline).
Twitter is exposing features to us
through an interface that we can consume.
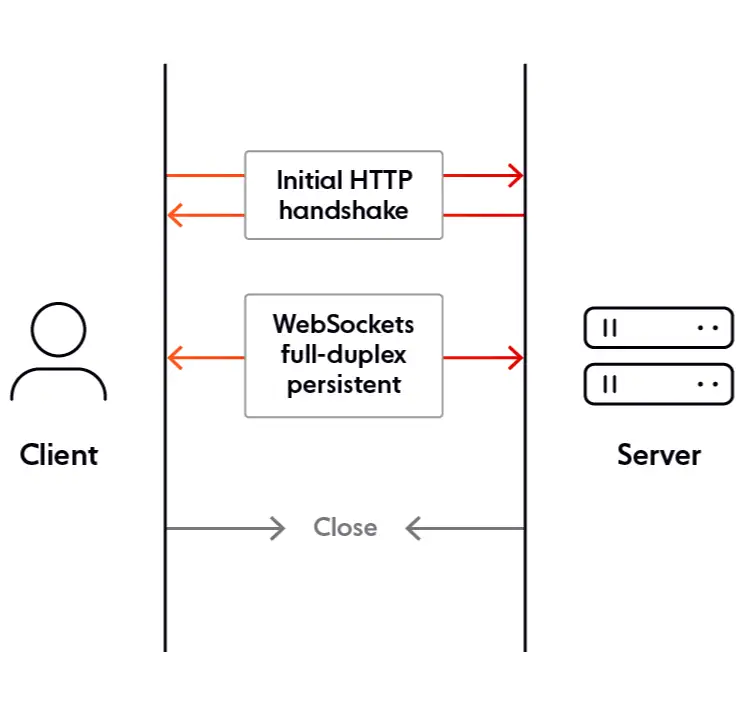
A WebSocket is a realtime protocol that enables bidirectional communication between a web client and a web server over a single-socket connection. Excellent Deep Dive: https://ably.com/topic/websockets
Similarly to HTTP, WebSocket works on top of the TCP,
in the application layer.
However, unlike HTTP, they are stateful,
which makes them highly suitable for
event-driven services that require high-frequency communication.
If you don't know what a
socketis, or ifTCPis foreign to you, we recommend you getting familiar with `TCP/IP``, also known as Internet Protocol Suite.

To create an WebSocket connection,
an initial HTTP handshake is made,
and then establishes a persistent connection
where both parties exchange data.
Therefore, a WebSocket uses a single TCP connection for data exchange,
while RESTful APIs require a new TCP connection
on every request/response.
If you want to learn more
about WebSockets,
you should visit our learn-websockets
repo for a more comprehensive introduction.
A few useful resources if you want to expand knowledge about this topic:
- Q: Can we use WebSockets? http://caniuse.com/#feat=websockets
Answer: YES! IE 10+, Safari/iOS Safari 7.1+, Android 4.4+ & Android Chrome - WebSockets in 100 seconds: https://youtu.be/1BfCnjr_Vjg
- WebSocket MDN: https://developer.mozilla.org/en/docs/WebSockets
- W3C WebSocket API: http://www.w3.org/TR/2011/WD-websockets-20110419/
- CloudFlare WebSockets (good intro): https://developers.cloudflare.com/workers/learning/using-websockets/
- SitePoint article on WebSockets in HTML5: http://www.sitepoint.com/introduction-to-the-html5-websockets-api/
- Socket.io Chat Example (uses express): http://socket.io/get-started/chat/
- Socket.io Max Connections? 250k: http://stackoverflow.com/questions/10161796/how-many-users-nodejs-socket-io-can-support
One of the biggest uses of realtime APIs is in the finance world - specifically stock/options/crypto trading.
Polygon.io
is one of the most widely used APIs
for stock market data visualization.
They offer a RESTful API
but also provide a WebSocket API,
where the user connects to a
WebSocket URI (e.g. wss://socket.polygon.io/stocks)
and receives data as the stock prices change in near real-time.
The response object of this API doesn't differ from the "regular ones".
The previous endpoint returns a response object
with a JSON format:
{
"ev": "AM",
"sym": "GME",
"v": 4110,
"av": 9470157,
"op": 0.4372,
"vw": 0.4488,
"o": 0.4488,
"c": 0.4486,
"h": 0.4489,
"l": 0.4486,
"a": 0.4352,
"z": 685,
"s": 1610144640000,
"e": 1610144700000
}The s and e fields pertain to the timestamp of the starting and ending tick
of the aggregate window in Unix Milliseconds, respectfully.
These fields are necessary to differentiate
the incoming data overtime.
Besides Polygon.io,
there are other examples worth mentioning:
- Twitter Streaming API: https://dev.twitter.com/streaming/overview
- Salesforce Streaming API: http://www.salesforce.com/developer/docs/api_streaming/
- Google Real Time Reporting API: https://developers.google.com/analytics/devguides/reporting/realtime/v3
In this section, we are going to be outlining
the best design and implementation practices
you should follow to get
a performant, scalable, easy-to-use and maintainable API.
This list has no specific order. They are a "bundle" of tips you can follow to make implementing the API and using it much easier.
Creating a URL hierarchy representing resources is important so there's clarity and context of what a given request does.
For example:
/customers/12345/orders
Here are a few tips:
- use identifiers in your URLs instead of query params.
Query params are awesome for filtering, not for resource names.
/customers/12345✅/api?type=customers&id=23❌
- resource names should be nouns, instead of verbs.
The
HTTP Verbshould be logical, likeGET requests✅ (instead ofGET requesting, for example ❌). - use plurals in URL segments.
/users/123/orders/2/items/1✅/user_list/123/order/2/item/1❌
- use lower-case in URL segments.
If you need to separate words, use
_(underscore) or-(hyphen). Some servers ignore case, so it's best to be clear.
Response status codes are part of the HTTP specification.
It only makes sense our REST API should return relevant HTTP status codes.
For example, when a resource is created (POST customer),
the API should return HTTP status code 201.
There are various codes to choose from. Check the following link to see the ones that are available and the ones that are mostly used.
- List of possible HTTP Status Codes: https://www.restapitutorial.com/httpstatuscodes.html
The resource URLs should be as lean as possible,
meaning that advanced search requirements
should be shifted to be used with query params
on top of the base resource URL.
We can use a unique query param for each field
that we want to filter to.
Suppose we have /items.
We may filter these items according
to a status field, like so:
GET /items?status=soldThe same principle can be applied to sorting.
To support sorting by multiple fields,
we can take in a comma-separated list
and use - (unary operator)
to specify ascending or descending sort.
GET /items?sort=-pricewill list items in descending order of price.GET /items?sort=price,created_atwill list items in ascending order of price, with more recent tickets being ordered first.
We can do a full text search using query params.
We may use a query param with a letter like q
and pass a value.
GET /items?q=phone&status=sold&sort=-price,created_at
will yield the highest priced item
that was most recently sold
with a name containing "phone".
Usually you would use a dedicated full-text search engine
like Elastic Search
in which you would feed the q=phone designation.
In cases where you know specific sets of conditions are frequently fetched/required by the consumer of the API, you could package these into a single resource path, to make it easier for the user to query data.
GET /items/highest_pricedYou can also leverage query params
to choose the fields you want to receive.
This is extremely useful because it can minimize network traffic
and speed up the usage of the API.
We can use a fields query parameter that takes a comma-separated list
(similarly to the sorting example mentioned prior)
pertaining to each field we want to retrieve.
GET /items?fields=id,price,name&status=sold&sort=-created_atYou can also extend this feature to load related resources to the one we are fetching.
For example, consider we have a Car
and each Car has many Wheels.
Car -> Wheel is a 1-to-many relationship.
If we wanted to get a Car object
and load each Wheel object,
we could use an embed term as query parameter,
similarly to sorting a resource.
An embed term would be a comma-separated list of fields
that would be loaded and embedded to the JSON object.
To refer to sub-fields, we could use . (dot-notation).
For example:
GET /cars/1?embed=wheel.positionThis would yield:
{
"id" : 1,
"model" : "Miata",
"wheel" : {
"position" : "Front left",
"position" : "Front right",
"position" : "Back left",
"position" : "Back right",
}
}Implementing this depends on the complexity of your requirements.
This also reduces chattiness,
so the user doesn't have to call the API repeatedly for resource information.
An API should provide useful and clear error messages, just like any other interface.
Besides returning adequate HTTP status codes,
a JSON error body should provide a template
that is consistent in case something errors out.
Here's what kind of information should be returned to the consumer.
{
"code" : 4124,
"message" : "Something bad happened.",
"description" : "Error description goes here."
}This template is useful for GET requests.
On the other hand,
When we make PUT, PATCH or POST operations,
having a field breakdown is useful for the user
to know what and where it went wrong.
We could add detailed errors for each field
that was invalid/was the cause for the request to error.
Like so.
{
"code" : 123,
"message" : "Some error message",
"errors" : [
{
"code" : 55,
"field" : "open",
"message" : "Status has to be a boolean"
},
{
"code" : 52,
"field" : "message",
"message" : "Message cannot be blank"
}
]
}You should favour JSON support.
Unless your requirements require XML, you should add support for it.
Be aware that adding this opens doors for other implementation details
like schema validation
or namespaces.
This is a costly operation and, unless it's a mandatory requirement, it's a "nice-to-have". But having this support is outweighed by the time/cost of implementing it.
When starting to build your API, we tend to build the URI paths
according to the business domain or database architecture of your system.
Eventually, you will want to aggregate services that make use of multiple resources to reduce chattiness.
Chattiness is an important concept to take into account when building an API. A "chatty API" is one that requires the consumer to make distinct API calls to get needed information about a resource.
This is bad because it will require multiple network calls, slowing down an application. This is because each call contains data overhead (i.e. sender information, headers, authentication) which will slow down an application as well as network latency per each request.
However, it is much easier to create larger resources later from individual resources than it is to create fine-grained resources from larger aggregates.
Start with small, easily-defined resources. You can create use-case-specific resources with low levels of chattiness later.
This is the dichotomy between chunkiness and chattiness. Chatty services tend to be ones that return simplified information and use more fine-grained operations. Chunky services tend to return complex hierarchies of information and use coarse operations.
Let's go over an example:
Imagine a dev wants to get product reviews.
But our API only offers a GET method to list products
(/api/products/1).
{
"name": "Mobile phone",
"cost": 500.0,
"reviews": [
"/api/reviews/1",
"/api/reviews/2",
"/api/reviews/3"
...
]
}To get the reviews for a product,
the developer needs to make N amount of API requests.
This is a major flaw in our API.
Instead, let's use a resource-oriented approach.
We can fix it by adding a new path -
/api/products/{id}/reviews .
By calling (GET operation) this endpoint,
the developer would get all reviews
for the product with a single API call.
We can extend this with query params
to filter the result.
{
"name": "Mobile phone",
"cost": 500.0,
"reviews":[
{ "id": "1", "text": "Good one!"},
{ "id": "2", "text": "Bad one!"},
{ "id": "3", "text": "Meh"},
...
]
}As we've stated prior,
one of the principles of REST is uniform interface.
One of his tenets is "Hypermedia as the engine of the application state.".
What does this mean?
This is called HATEOAS (acronym), and it means that
when a client interacts with an API,
it expects it to provide information of "where to go next".
Let's look at an example. This is the old Twitter.

You will notice that there are many options one can take in this page. We can retweet, follow, favourite... There are many possible states we can transition into. In case you were wondering, there are 32 possible states here.

These are the possible state transitions for this single node. So, in this case, we are making this request (this is not real, just an example).
GET user/1/tweets/1 HTTP/1.1
Host: twitter.comThe response, following HATEOAS,
would include an array of links(states)
which the user can transition into.
{
"id": 12345,
"num_likes": 50,
"links": {
"retweet": "/tweets/12345/retweet",
"report_user": "/user/1/reports",
"follow_user": "/user1/12345/followers",
}
}If you want to have an opinionated introduction to HATEOAS,
we recommend you watch this video from Google.
https://www.youtube.com/watch?v=6UXc71O7htc&ab_channel=Apigee
However, there are people who think that adding HATEOAS
translates into adding more complexity
to the REST API
and its main advantage can easily be achieved
through a well-crafted documentation.
Regardless, the user needs to easily know
where to transition to next.
If proper documentation or making use of HATEOAS achieves it,
you can pick whichever suits your project's requirements.
SSL certificates create an encrypted connection
and establish trust.
Several common authentication schemes are not secure over plain HTTP.
For example, Basic Authentication send unencrypted credentials.
To make these connections secure,
when creating links between networked computers,
we ought to use SSL so the connection is encrypted.
You might have heard of TLS.
It is simply SSL's successor (which is deprecated).
The acronym SSL refers to protocol
of these related technologies,
so it is used interchangeably.
Make sure you beautify your JSON
when returning it to the user.
When you encode a JSON using a given decoder,
most remove all whitespace
and encode it in a single line.
Instead, you could (and should!)
properly format your JSON object,
even if extra whitespace is added to make it more readable.
This extra whitespace is negligible when transferring data,
especially when sending data when compressed with gzip.
So, it's more readable for the user
when the JSON is properly formatted,
and gzip compression is enabled.
When creating resources (POST)
or updating (PATCH/PUT),
the API needs to receive input.
This is usually in the form of a JSON object.
To maintain consistency, if your API returns a JSON object,
it should also receive input in the same format.
You should accept a Content-Type HTTP Header
that has to be set to application/json.
If any other is sent,
you should throw a 415 Unsupported Media Type HTTP status code.
There are a handful of ways of implementing pagination
following the RESTful standards.
Instead of detailing them,
we highly recommend you reading the following link,
as it explains this topic in a fast and simple manner.
- What’s the best RESTful method to return total number of items in an object?: https://stackoverflow.com/a/43968710/20281592
Just know you can do a combination of HTTP Headers
like Link,
and X-Total-Count
and enveloping (this means wrapping the JSON object in a field).
It is highly advisable to add rate limiting to an API, to prevent abuse from malicious users that can flood the API with requests, causing it to crash.
It can be useful to notify the API consumer of their limits.
You can notify your API users with
HTTP response headers.
You should include the following headers:
X-Rate-Limit-Limit- the rate limit ceiling for that given endpoint.X-Rate-Limit-Remaining- the number of requests left for the 15 minute window.X-Rate-Limit-Reset- the remaining window before the rate limit resets, in UTC epoch seconds.
Consider the following resources to implement rate-limiting into your API.
- Rate-limiting strategies and techniques by Google: https://cloud.google.com/architecture/rate-limiting-strategies-techniques
- Everything you need to know about API rate limiting: https://nordicapis.com/everything-you-need-to-know-about-api-rate-limiting/#:~:text=To%20prevent%20an%20API%20from,instead%20of%20disconnecting%20them%20immediately.
- API Rate Limiter System Design: https://www.enjoyalgorithms.com/blog/design-api-rate-limiter
If some recurring requests produce the same response, we can use a cached version of the response to avoid the excessive load.
Caching enables us to store copies of frequently accessed data along the request-response path. There are many frameworks and technologies that makes it easy to integrate caching - Redis, for example.
However, we can integrate a rudimentary cache system
because HTTP provides a simple built-in caching framework.
All we need to do is adding response headers back to the user
and do validation when receiving response headers from the user.
We have two possible approaches:
-
ETag: anEtagHTTPheader contains a hash of the data representation. This value changes whenever the data changes. If an inboundHTTPrequest has aIf-None-Matchheader with a matchingETagvalue, it means the data is the same, so the API returns a303 Not ModifiedHTTPstatus code. -
Last-Modified: works the same way asETagbut uses timestamps. The response headerLast-Modifiedcontains a timestamp which is validated againstIf-Modified-Since.
This is a useful, albeit simple framework that can be used. However, some projects might require more complex requirements that call for robust frameworks.
If you are interested in learning more about caching, check out the following links.
- Caching API Requests: http://robots.thoughtbot.com/caching-api-requests
- Caching your REST API http://restcookbook.com/Basics/caching/
- API Caching http://www.fastly.com/blog/api-caching-part-1/
- Thoughtbot caching insights (mostly ruby-focussed): http://robots.thoughtbot.com/caching-api-requests
- System Design Caching: https://dev.to/karanpratapsingh/system-design-caching-18j4

It's highly unlikely that an API will remain static. As business requirements evolve, new collections of resources ought to be added, relationships changed and data structure might be affected.
It is imperative to enable existing client applications to continue functioning, while allowing new users to take advantages of new features/resources added.
Versioning enables the API to indicate the features/resources that it exposes, and a consumer can make requests that are directed to a specific version. This allows users to not be impacted when an API makes breaking changes.
There is on-going debate on whether APIs should be versioned, and if so, how should this be done. There is no "correct way of doing things". In fact, many popular APIs usually do one of three approaches.
Let's briefly discuss the three most popular approaches.
Each time the API is modified, a version number is added to the URI for reach resource.
HTTP GET:
https://haveibeenpwned.com/api/v2/breachedaccount/fooThis versioning mechanism is very simple but depends on the server routing the request to the appropriate endpoint.
It can become unwieldy as the API matures and more versions are added. From a purist's perspective, some endpoints aren't affected between versions, so it doesn't make sense for the URI to change.
Implementing HATEOAS is harder,
as all links need to change according to the version number.
We could implement a custom header that indicates the version of the resource. This approach requires the consumer adding the appropriate header to all requests (the API could default to a specific version if none was sent, though).
HTTP GET:
https://haveibeenpwned.com/api/breachedaccount/foo
Custom-Header: api-version=1Implementing HATEOAS has the same hurdle
as in the previous approach.
When an API client sends an HTTP request,
it should stipulate the format of the content that it wants,
by passing an Accept header.
Usually, the purpose of this Accept header is to specify
the format of the body (JSON or XML, for example) -
this is called content negotiation.
However, it can be used to define custom media types that include information enabling the consumer to indicate which version of a resource it is expecting.
HTTP GET:
https://haveibeenpwned.com/api/breachedaccount/foo
Accept: application/vnd.haveibeenpwned.v2+jsonIf the Accept header does not specify valid media types,
the API should return HTTP 406 Not Acceptable.
This is arguably the purest of the versioning mechanism,
allowing for easier HATEOAS support.
When selecting a versioning strategy, you should consider performance and caching implications of each one.
For example, URI versioning are cache-friendly, since the same URI combination refers to the same data each time.
On the other hand, Header and Media Type versioning
will require additional logic to examine the values
of the passed headers (custom or Accept).
In a large-scale scenario, having different versions of API
will result in a significant amount of duplicated data in the cache.
Regardless of the one you choose, there are pros or cons to each one and consider possible side-effects accordingly. Maybe all of these 3 approaches are wrong? 😉.
We recommend you giving the following links a read to learn more about each approach, and how popular APIs are doing their versioning.
- Microsoft's Versioning API practices: https://learn.microsoft.com/en-us/azure/architecture/best-practices/api-design
- Issues with API version in the URL/URI: https://www.mnot.net/blog/2012/12/04/api-evolution
- Evolving HTTP APIs https://www.mnot.net/blog/2012/12/04/api-evolution
- SemVer: http://semver.org/
- Stripe's API Versioning: https://stripe.com/docs/api#versioning
- Comprehensive List of how others are doing versioning: http://www.lexicalscope.com/blog/2012/03/12/how-are-rest-apis-versioned/
Implementing the aforementioned guidelines and best practices will pave the way to having an API that is scalable and maintainable for other developers.
However, it is crucial to have proper documentation so it's easier for customers to onboard into the API.
Before delving into the options for documenting your API and what specifications you should adhere to, we should clarify the following definitions:
-
API documentation - pertains to the reference manual for an API. It is meant for humans to read and understand how to use the API, and make the onboarding process easier. There are many tools available for generating and maintaining API documentation. Many of these can automatically generate API documentation as web applications, with guides for common languages and interactive tutorials
-
API specification - is meant to provide an understanding of how the API behaves and links to other APIs. It's an holistic explanation of the API. While API documentation is a detailed discussion of how the API functions and how to utilize it, the API specification is an understanding of the functionality and the expected result of each API function.
While these to terms are often used interchangeably, and you can derive documentation from specification (and vice-versa), they mean two completely different things.
Depending on the type of the API, you should aim to use different specifications.
gRPCAPIs use Protocol Buffers.- Event-driven APIs use AsyncAPI.
RESTfulAPIs use Open API Specification.
Let's focus on RESTful APIs,
as they are more widely used
and you are most likely going to be implementing one.
Swagger
is the de facto tool for creating API documentation.
They created the Open API Specification (OAS) industry standard.
From these OAS files,
you can generate documentation that is accessible through a web-app.
However, although being the most widely used,
Swagger is not the only option for documenting your API.
Stripe's API docs
are often considered a great example of a well-designed,
reader-centric and comprehensive documentation -
it feels like an application.
While the front-end is based on React
and is mostly built in-house,
they've recently open-sourced
the platform they use to generate documentation
and integrate it with their front-end code -
Markdoc.
Markdoc is one of the many options
one may use to produce API documentation.
Stripe's documentation is maintained by a very large team of developers,
but we can leverage a few frameworks to create
easy-to-use docs for our users without having to spend
millions of dollars
to do so.
We recommend you checking the following list of options
to generate your own API documentation.
Most of these derive documentation
from OAS definitions,
so we advise creating OAS files based on your API first.
These frameworks were chosen with specific criteria;
each one allows versioning for different releases,
includes codesandbox for mocking API calls,
includes page analytics
and serves content in different languages.
- ApiDocJS: inline documentation for RESTful web APIs.
- ReadTheDocs: often used by the open-source community to rapidly generate docs.
- Docusaurus: open-source doc generator maintained by Meta.
- GitBook: documentation platform for public APIs and technical briefs.
- Readme.com: mature doc platform + offers API calls and metrics.
- Theneo: paid Stripe-like API doc generator service.
- Redocly: Docs-like-code with integrated delivery pipeline
API testing and its automation is a crucial part of the API development lifecycle. It helps avoid regressions and make sure our API performs the way it's supposed to, meaning it returns exactly what we want and with appropriate response times.
Testing needs to cover the most important aspects of an API - those being performance, availability and functionality.
- Functionality testing checks if the API works and does exactly what it's supposed to do.
- Reliability testing checks if API can be consistently connected to and lead to consistent results.
- Load testing checks if the API can handle a large amount of requests.
Luckily, there are many testing frameworks that make it easy for developers to create test suites, execute and integrate them in CI pipelines.
Here's a list of frameworks we recommend using. All of these might have paid plans but also have free plans for single developers (unless explicitly stated otherwise).
- SoapUI: open-source testing tool that covers the entire testing spectrum (functional, security, load and mocking).
- Postman: Postman is a full API platform that is not limited to testing. Besides managing different collaboratively APIs, creating Open API specifications, documentation and monitoring.
- Hoppscotch: Previously called "Postwoman", it's a free, open-source alternative to Postman, with many of the same features of the latter. This tool can be used for defining, documenting and testing your API.
- Insomnia:
similar to Postman, it's a API platform
to design and test APIs with built-in automation.
You can learn more on how to use it
in our
learn-insomniarepository. - Locust: free, open-source load testing tool. Swarm an API endpoint with Python with millions of simultaneous users. Can be integrated with Github Actions.
- Apache JMeter and Apache AB are a load tester and HTTP server benchmarking tool, respectfully.
- Siege is an open-source API regression tester and benchmark utility.
- Gatling: paid API load tester designed for Devops and CI/CD.
- Katalon: quality management platform for validation, functional, security and load testing APIs.
API monitoring is extremely important to manage uptime and possible performance degradation/ general API behaviour.
Having access to these metrics is critical not only for debugging purposes but to make calculated decisions that will affect the revenue/bottomline of your project.
With performance monitoring, you will gain insights of how developers are using your API, which endpoints are most frequently used. This can provide a better understanding of areas that need improvement.
There are two predominant methods of API monitoring:
- Synthetic monitoring is a performance monitoring practice that emulates the paths users might take when engaging with an application.
- Real User Monitorimg (RUM) monitors how a user interacts with the API, instead of emulating them. In layman's terms, it "records" the journey of the user along the API calls and makes it easy to zero in on which step is failing.
There are some frameworks that are free and others that open-source (or both!) that allow you to use these two methods. and you can use in to track the health of your API, whilst attaining useful insights for analytical and debugging purposes.
Here's a comprehensive list of frameworks that you can integrate with your API to monitor it. Each one has a free plan that you can use.
- Grafana: Grafana is an open-source, full-stack platform that allows you to visualize, alert and understand metrics of your API.
- Fusio Project: open-source API management platform.
- Checkly: monitoring and validation of site transactions. Collects logs and error traces.
- Uptime Kuma: an open-source, self-hosted monitoring tool.
- Cronitor: platform to monitor uptime and performance, with locations worldwide.
- Blackbox Exporter: allows blackbox probing of endpoints over HTTP, HTTPS, DNS, TCP, ICMP and gRPC.
- Swagger: Swagger not only allows you to create, test and document your API, but also monitor it.
If you are looking for more information and guidelines to design your API, do check these links for more in-depth knowledge:
- Best Practices for Designing a Pragmatic RESTful API (Great article): http://www.vinaysahni.com/best-practices-for-a-pragmatic-restful-api
- RESTful web API design by Microsoft: https://learn.microsoft.com/en-us/azure/architecture/best-practices/api-design
- REST API Design Best Practices Handbook: https://www.freecodecamp.org/news/rest-api-design-best-practices-build-a-rest-api/
- API design guide by Google: https://cloud.google.com/apis/design
- What is an API? (very basic intro): http://youtu.be/B9vPoCOP7oY
- BASIC Introduction to APIs by Derek Dahmer
- Wikipedia: http://en.wikipedia.org/wiki/Application_programming_interface
- The REST Cookbook: http://restcookbook.com (comprehensive guide)
- How to Design Great APIs - Parse: https://www.youtube.com/watch?v=qCdpTji8nxo
- How To Design A Good API and Why it Matters: http://youtu.be/heh4OeB9A-c + http://lcsd05.cs.tamu.edu/slides/keynote.pdf (mostly related to the Java Language API but a few general insights)
- Parse interactive API reference: http://youtu.be/qCdpTji8nxo?t=21m15s
- Building Hypermedia APIs with HTML5 and Node: http://www.amazon.com/Building-Hypermedia-APIs-HTML5-Node/dp/1449306578
- Designing APIs for Asynchrony: http://blog.izs.me/post/59142742143/designing-apis-for-asynchrony
- API Design Principles: http://qt-project.org/wiki/API-Design-Principles (general principals. ignore the QT-specific parts)
- Build an API under 30 lines of code with Python and Flask: https://impythonist.wordpress.com/2015/07/12/build-an-api-under-30-lines-of-code-with-python-and-flask/
- REST API Tutorial: http://www.restapitutorial.com/
- API Design Guidelines: http://apistylebook.com/design/guidelines/