WorkerThreadStart volatile read+cmpxchg loop #6516
Conversation
b41a828
to
7d72132
Compare
|
With last commit (3) it pushes the native functions out of the top function hotspots so more "work" is being done in the managed stack. |

22850f1
to
b8b6462
Compare
|
Still getting some false sharing |
|
|

0a70101
to
7387b82
Compare
|
@benaadams Thank you for fine tuning thread pool scalability. I would like @kouvel to take a look at this since he has been looking into similar scalability issues. He is on vacation, but he will be back next week, |
|
Last commit needs a triple check that the logic is right. I believe it to be correct, but it may be wrong. It changes 3x More significantly, it changes what happens when they are read and set a group. It uses 2x regular The two spots are: Store fence comes first which I believe matches and: Load fence comes last which I believe matches |
|
Also VTune is still reporting false sharing for static variable access, which doesn't seem to be eliminated by ordered definition of with static padding blocks. Will try a static POD struct with member items with padding and see if that works instead. |
3f8f9dd
to
9e5fbcd
Compare
|
|
||
| LONG count = (LONG) s_appDomainIndexList.GetCount(); |
There was a problem hiding this comment.
Does this need another read? Its not an atomic read+update
There was a problem hiding this comment.
It looks like s_appDomainIndexList.GetCount() can increase but never decrease. I think the extra call to GetCount() here doesn't help much. If s_ADHint is initially -1 or 0, and a new app domain is created during the loop above, it would have a chance to set s_ADHint to the new app domain's index upon exiting, and that app domain would get a chance to perform its work next time. If s_ADHint started with any other value (the common case), it would skip over the new app domain anyway. I think it's fine to remove the extra call to GetCount().
9e5fbcd
to
f96f4b4
Compare
|
These changes mostly effect "twilight" threading where there is a enough fine grained work to keep the system busy (enqueue and dequeue both pulse the threadpool); yet not enough work to keep the threads busy so there is "waiting for work" churn; rather than top end throughput. It has a bigger effect on 8xHT than 4x regular; but the HT take a general perf dive, it just takes less of one, however is faster on slower items with more work (e.g. Tasks vs QUWI), which also the HT starts to preform better on. Before (on 8xHT some variances due to GC) After Most significant changes are top left corners, which are single producer multiple consumer. |
| @@ -266,15 +267,15 @@ FCIMPL0(FC_BOOL_RET, ThreadPoolNative::NotifyRequestComplete) | |||
| { | |||
| HELPER_METHOD_FRAME_BEGIN_RET_0(); | |||
|
|
|||
| if (needReset) | |||
There was a problem hiding this comment.
What's the purpose of this change?
There was a problem hiding this comment.
It gave better throughput, I'm not 100% convinced by it as was moving things around that were showing up as hot - so is an experimental change rather than one with a well thought out reason.
If I was to guess, its because needReset is set before shouldAdjustWorkers so its result is available earlier in the pipeline?
Could probably get the same effect by swapping bool needReset = and bool shouldAdjustWorkers = except shouldAdjustWorkers is memory fenced - so I'm not sure they'd swap.
There was a problem hiding this comment.
I don't see any dependencies on the order, so it's probably fine. But moving pThread->InternalReset() up also moves it into the 'tal' lock which may or may not make any difference. I would prefer to keep this as before until this perf boost is understood better.
There was a problem hiding this comment.
How significant is the increase in throughput?
There was a problem hiding this comment.
Wasn't significant for throughput, just improved the CPI a little; will revert.
|
Sorry for the delay on the review, and thanks for doing this, those are some nice improvements!
_WIN64 is intended to cover all 64-bit platforms (currently amd64 and arm64), see CMakeLists.txt in the root.
I'm still wondering why there is a pipeline stall before the loop and not inside the loop, thoughts? What you have is still better, but just curious. |
| // VolatileLoad x64 bit read is atomic | ||
| return DangerousGetDirtyCounts(); | ||
| #else // !_WIN64 | ||
| // VolatileLoad may result in torn read | ||
| LIMITED_METHOD_CONTRACT; |
There was a problem hiding this comment.
This contract should be at the top of the function for all architectures
There is if it loops (contested); but not if it doesn't. Its the two So currently when not contested it still has a dependency as if it was contested:
This change is to break the first dependency
Obviously if it gets a dirty read or it is contested then it will hit the same dependency e.g.
but not in the common case. I assume its a historic behaviour as its a 64bit field so it uses the 64bit cmpxchg on x86 to achieve an atomic read; whereas on x64 mov is an atomic read so it isn't necessary. Also for the other places I've changed GetCleanCounts->DangerousGetDirtyCounts its because they are immediately followed by a Interestingly the other/IOCP threadpool already does this and it uses the same data structure for the counts. |
Use GetCleanCounts where result is used directly and DangerousGetDirtyCounts when used as part of compare exchange loop
f96f4b4
to
2e0332a
Compare
|
Feedback incorporated. Still question on the memory barrier |
I see, makes sense.
Makes sense as well, thanks |
|
@kouvel is the last commit what you meant? |
|
I meant like this: DWORD priorTime = PriorCompletedWorkRequestsTime;
MemoryBarrier(); // read fresh value for NextCompletedWorkRequestsTime below
DWORD requiredInterval = NextCompletedWorkRequestsTime - priorTime;And: PriorCompletedWorkRequests = totalNumCompletions;
NextCompletedWorkRequestsTime = currentTicks + ThreadAdjustmentInterval;
MemoryBarrier(); // flush previous writes (especially NextCompletedWorkRequestsTime)
PriorCompletedWorkRequestsTime = currentTicks;
CurrentSampleStartTime = endTime; |
|
LGTM, thanks! |
|
@dotnet-bot retest Linux ARM Emulator Cross Debug Build |
|
No space left on device :( |
- MSVC seems to require alignment specification to be on the declaration as well as the definition - Ignore warning about padding parent struct due to __declspec(align()), as that is intentional Original change PR: dotnet#6516 [tfs-changeset: 1622589]
WorkerThreadStart volatile read+cmpxchg loop Commit migrated from dotnet/coreclr@a521502
- MSVC seems to require alignment specification to be on the declaration as well as the definition - Ignore warning about padding parent struct due to __declspec(align()), as that is intentional Original change PR: dotnet/coreclr#6516 [tfs-changeset: 1622589] Commit migrated from dotnet/coreclr@b6be3a0
Currently ThreadPoolMgr::WorkerThreadStart and ThreadPoolMgr::MaybeAddWorkingWorker use
FastInterlockCompareExchangeLongto do read and couple with aFastInterlockCompareExchangeLongloop to do set.Current Code:
It looks like the
lock cmpxchg"write read" causes a pipeline stall. As its then followed by alock cmpxchgloop to set the value it should be able to use a volatile read to get the initial value as that will then be validated by the set.Changed code:
Also changed GetCleanCounts to use the VolatileLoad on x64.
Before WorkerThreadStart is 2nd most expensive function and MaybeAddWorkingWorker is 10th for multicore contested QUWI
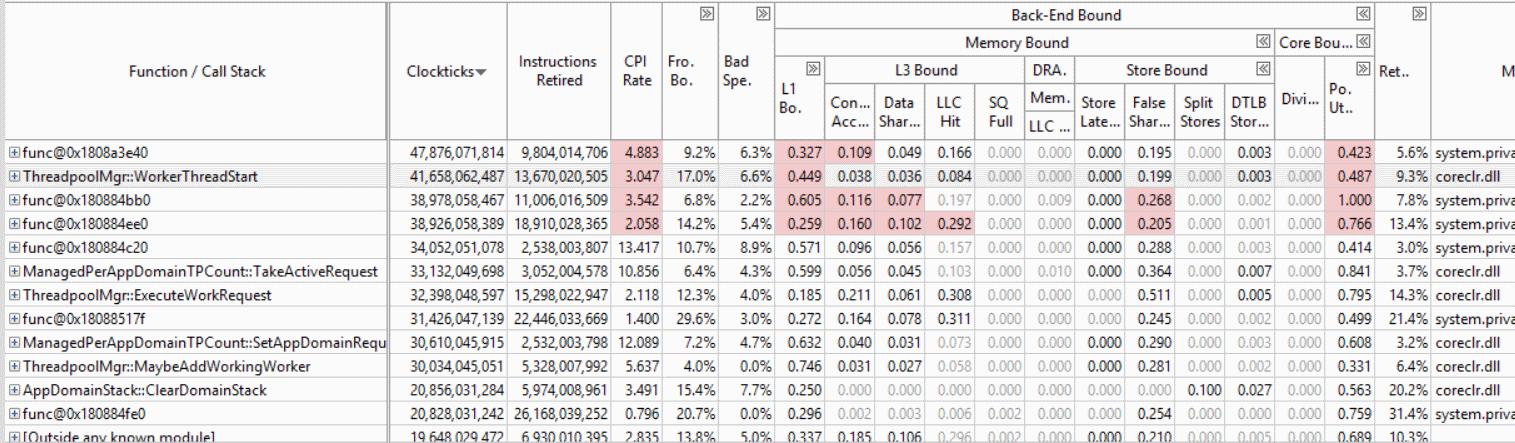
After (3 commits) WorkerThreadStart drops to 17th and the rest of the native functions are also pushed out of the top hot spots:
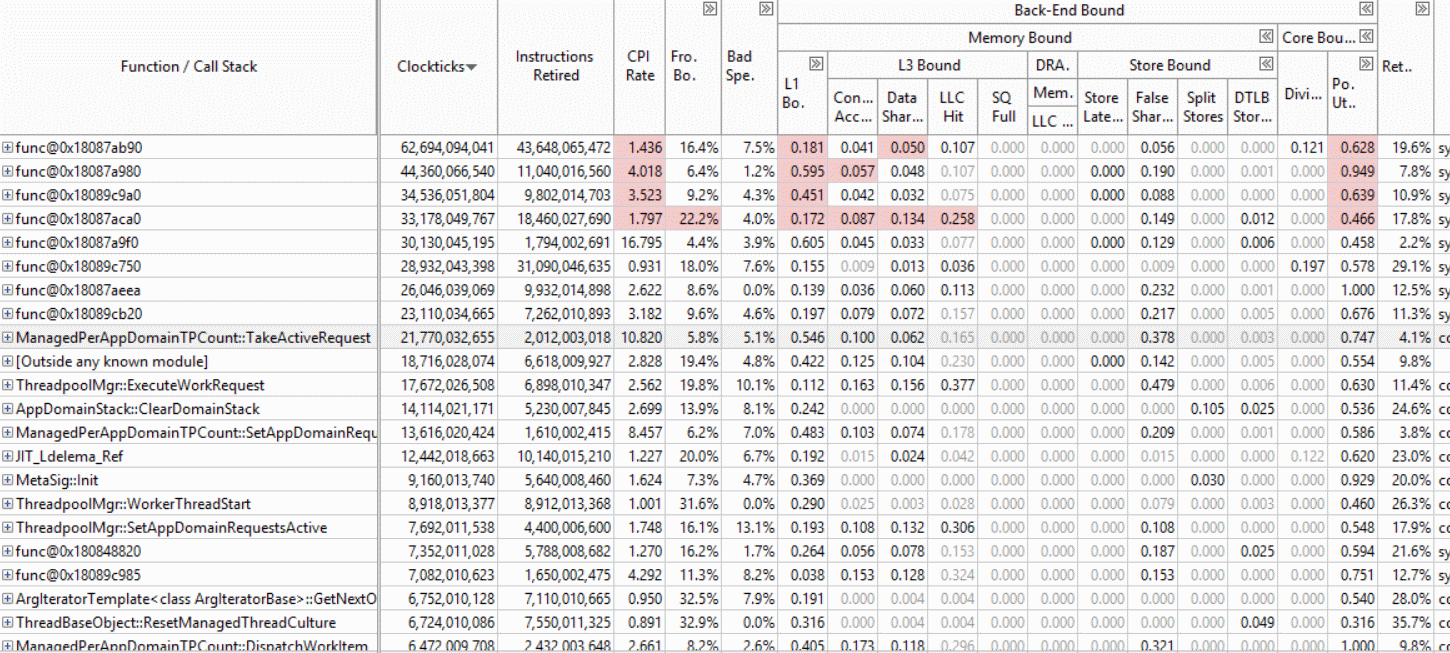
Resolves #6132
Resolves #6476
Questions:
_WIN64the correct ifdef to used for x64? (Or_TARGET_64BIT_orAMD64etc)/cc @kouvel @jkotas @stephentoub