Ollama Anywhere is a proof of concept project designed to enable seamless interaction with Ollama and the LLM's you have installed being able to access from anywhere, using any device. This allows users to leverage the power of models like Llama 2, Mistral, Mixtral, etc. That they have locally on their computer, making them accessible for inference directly from your computer or device. The project is crafted with responsiveness in mind, ensuring a smooth user experience on any device, whether it's your phone, tablet, or laptop.
The project is divided into two main components:
- A Next.js application that can be deployed to Vercel.
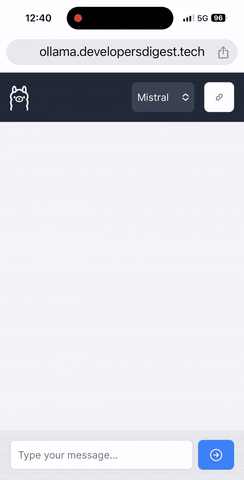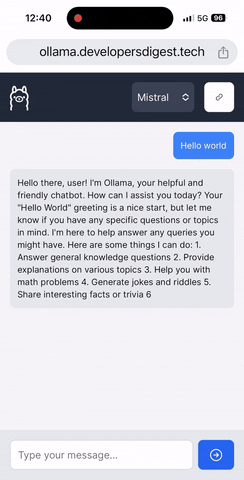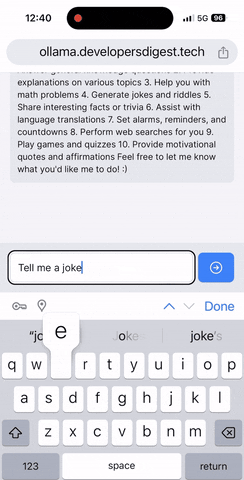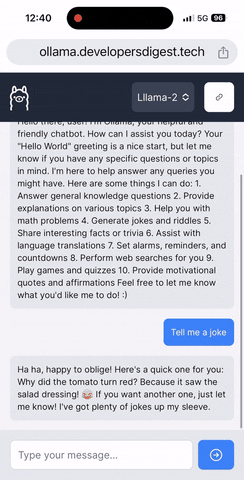
- Features a chat UI for real-time interaction with the LLMs you have set up.
- Responsive design to work seamlessly across devices.
- To get started, deploy the Next.js app to Vercel following standard procedures.
- A local server that creates a secure tunnel to your machine, enabling access to your LLMs from anywhere.
- Requires a free ngrok account and an auth token.
- Visit Ollama's website to download the application for macOS & Linux (Windows coming soon).
- After installation, select and download at least one model for inference from Ollama's library.
- Sign up for a free ngrok account here.
- Obtain your ngrok auth token from this page.
- Place the auth token in the
.envfile within thengrok-serverdirectory.
Ensure to install dependencies for both the ngrok-server and the next-web-app directories by running npm i in each.
Open up each project in separate terminal tabs.
- To run the ngrok-server, execute
node index.js. - To run the Next.js app, use
npm run dev.
- For a staging instance, run the
vercelcommand. - For a production deployment, use
vercel --prod.
Once everything is set up and the app is running locally or deployed to Vercel, running the ngrok server will allow you to access the deployed version/local host version from the terminal output. From there, enjoy interacting with your LLMs through Ollama Anywhere.