forked from daattali/beautiful-jekyll
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
formix
committed
Jul 27, 2024
1 parent
b0de136
commit d0719b5
Showing
1 changed file
with
65 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,65 @@ | ||
| --- | ||
| layout: post | ||
| title: "A Fascinating Experiment: How ChatGPT Iteratively Enhances Its Own Content" | ||
| published: true | ||
| date: 2024-07-27 | ||
| excerpt: "Explore an intriguing experiment where ChatGPT takes on multiple roles to improve its own content. This post examines the process, results, and raises questions about single AI multi-role approaches versus true multi-agent systems." | ||
| --- | ||
|
|
||
| Introduction | ||
| ============ | ||
|
|
||
| We're all familiar with large language models' ability to assume different roles. When multiple AI agents interact, they often take on distinct personas. But what happens when an AI is asked to play the same role repeatedly within a single conversation? This intriguing question led to an experiment exploring how ChatGPT might iteratively improve its own content. | ||
|
|
||
| The Experiment | ||
| ============== | ||
|
|
||
| To investigate this, I designed a simple yet revealing test: I asked ChatGPT to create a blog post and then immediately requested improvements on its own work. This process allowed us to observe how the AI might refine and enhance its output when given the opportunity to review and revise. | ||
|
|
||
| write a blog post 200 words about the civil warnd and ask the assistant for improvments, the you show the improvements and change yourself change it in the post. you do this twice. at the end you show table with before and after imrpvoe 1 and 2. and the suggseted improvmenet itsel f(the critic) | ||
|
|
||
| Step 1: Initial Blog Post Creation | ||
| ================================== | ||
|
|
||
| The experiment began with a prompt for ChatGPT to generate a small blog post on a specific topic, followed by an immediate request for improvements within the same instruction set. | ||
|
|
||
| 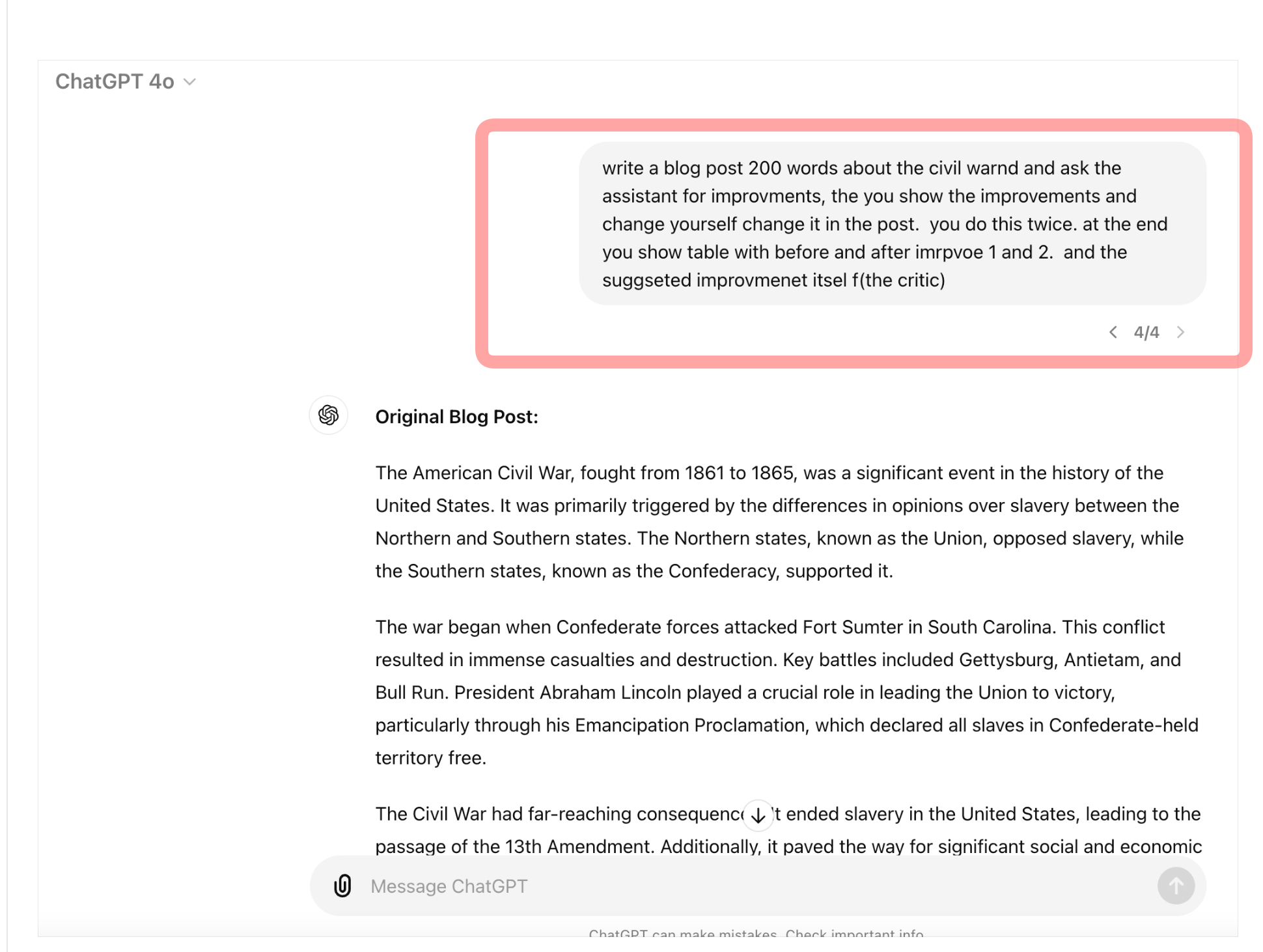 | ||
|
|
||
| Step 2: The First Improvement Iteration | ||
| ======================================= | ||
|
|
||
| What happened next was particularly intriguing. ChatGPT, in response to the request for improvements, created for itself an "imaginary" assistant. This assistant then provided a set of suggestions for enhancing the original post. ChatGPT then applied these self-generated improvements to create a refined version of the content. | ||
|
|
||
| 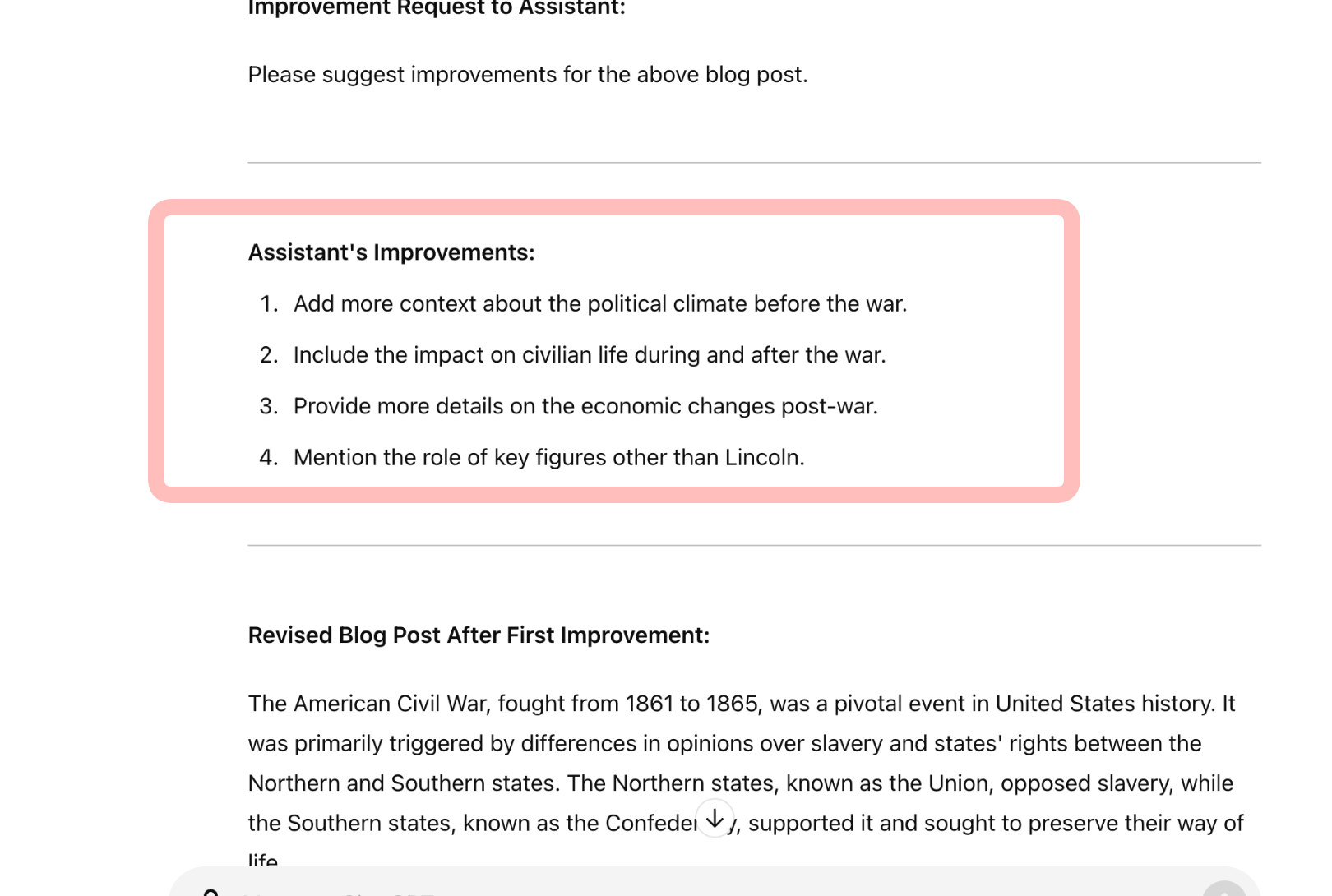 | ||
|
|
||
| Step 3: Quantifying the Enhancements | ||
| ==================================== | ||
|
|
||
| After going through all iterations, ChatGPT itself generated a summary table detailing the enhancements made during the iterative process. This table, created by the AI, highlights how the content was refined through multiple passes. | ||
|
|
||
|  | ||
|
|
||
| Step 4: Third-Party Evaluation | ||
| ============================== | ||
|
|
||
| To ensure an unbiased assessment of the improvements, I engaged Claude, another AI, to compare the original and final versions of the blog post. | ||
|
|
||
|  | ||
|
|
||
| Evaluation Results: | ||
|
|
||
|  | ||
|
|
||
| Claude's evaluation confirmed that the final version exhibited significant improvement, offering a more comprehensive and nuanced account of the topic. | ||
|
|
||
| Conclusion and Further Questions | ||
| ================================ | ||
|
|
||
| This experiment provided an interesting look at how ChatGPT can iteratively improve its own content within a single conversation. By simulating multiple roles (writer and editor), the AI was able to refine its initial output. | ||
|
|
||
| However, this raises some questions for future exploration: | ||
|
|
||
| 1. How would the results differ if we used separate AI instances for each role instead of one AI simulating multiple roles? | ||
| 2. Is there a significant quality difference between this approach and traditional single-pass content generation? | ||
|
|
||
| What are your thoughts on this? Have you tried similar experiments? Share your experiences or ideas for further exploration in the comments below. |