Transform datasets at scale.
Optimize data for fast AI model training.
Transform Optimize ✅ Parallelize data processing ✅ Stream large cloud datasets ✅ Create vector embeddings ✅ Accelerate training by 20x ✅ Run distributed inference ✅ Pause and resume data streaming ✅ Scrape websites at scale ✅ Use remote data without local loading




Lightning AI • Quick start • Optimize data • Transform data • Features • Benchmarks • Templates • Community
LitData scales data processing tasks (data scraping, image resizing, distributed inference, embedding creation) on local or cloud machines. It also enables optimizing datasets to accelerate AI model training and work with large remote datasets without local loading.
First, install LitData:
pip install litdataChoose your workflow:
🚀 Speed up model training
🚀 Transform datasets
Advanced install
Install all the extras
pip install 'litdata[extras]'
Accelerate model training (20x faster) by optimizing datasets for streaming directly from cloud storage. Work with remote data without local downloads with features like loading data subsets, accessing individual samples, and resumable streaming.
Step 1: Optimize the data This step will format the dataset for fast loading. The data will be written in a chunked binary format.
import numpy as np
from PIL import Image
import litdata as ld
def random_images(index):
fake_images = Image.fromarray(np.random.randint(0, 256, (32, 32, 3), dtype=np.uint8))
fake_labels = np.random.randint(10)
# You can use any key:value pairs. Note that their types must not change between samples, and Python lists must
# always contain the same number of elements with the same types.
data = {"index": index, "image": fake_images, "class": fake_labels}
return data
if __name__ == "__main__":
# The optimize function writes data in an optimized format.
ld.optimize(
fn=random_images, # the function applied to each input
inputs=list(range(1000)), # the inputs to the function (here it's a list of numbers)
output_dir="fast_data", # optimized data is stored here
num_workers=4, # The number of workers on the same machine
chunk_bytes="64MB" # size of each chunk
)Step 2: Put the data on the cloud
Upload the data to a Lightning Studio (backed by S3) or your own S3 bucket:
aws s3 cp --recursive fast_data s3://my-bucket/fast_dataStep 3: Stream the data during training
Load the data by replacing the PyTorch DataSet and DataLoader with the StreamingDataset and StreamingDataloader
import litdata as ld
train_dataset = ld.StreamingDataset('s3://my-bucket/fast_data', shuffle=True, drop_last=True)
train_dataloader = ld.StreamingDataLoader(train_dataset)
for sample in train_dataloader:
img, cls = sample['image'], sample['class']Key benefits:
✅ Accelerate training: Optimized datasets load 20x faster.
✅ Stream cloud datasets: Work with cloud data without downloading it.
✅ Pytorch-first: Works with PyTorch libraries like PyTorch Lightning, Lightning Fabric, Hugging Face.
✅ Easy collaboration: Share and access datasets in the cloud, streamlining team projects.
✅ Scale across GPUs: Streamed data automatically scales to all GPUs.
✅ Flexible storage: Use S3, GCS, Azure, or your own cloud account for data storage.
✅ Compression: Reduce your data footprint by using advanced compression algorithms.
✅ Run local or cloud: Run on your own machines or auto-scale to 1000s of cloud GPUs with Lightning Studios.
✅ Enterprise security: Self host or process data on your cloud account with Lightning Studios.
Accelerate data processing tasks (data scraping, image resizing, embedding creation, distributed inference) by parallelizing (map) the work across many machines at once.
Here's an example that resizes and crops a large image dataset:
from PIL import Image
import litdata as ld
# use a local or S3 folder
input_dir = "my_large_images" # or "s3://my-bucket/my_large_images"
output_dir = "my_resized_images" # or "s3://my-bucket/my_resized_images"
inputs = [os.path.join(input_dir, f) for f in os.listdir(input_dir)]
# resize the input image
def resize_image(image_path, output_dir):
output_image_path = os.path.join(output_dir, os.path.basename(image_path))
Image.open(image_path).resize((224, 224)).save(output_image_path)
ld.map(
fn=resize_image,
inputs=inputs,
output_dir="output_dir",
)Key benefits:
✅ Parallelize processing: Reduce processing time by transforming data across multiple machines simultaneously.
✅ Scale to large data: Increase the size of datasets you can efficiently handle.
✅ Flexible usecases: Resize images, create embeddings, scrape the internet, etc...
✅ Run local or cloud: Run on your own machines or auto-scale to 1000s of cloud GPUs with Lightning Studios.
✅ Enterprise security: Self host or process data on your cloud account with Lightning Studios.
✅ Stream large cloud datasets
Use data stored on the cloud without needing to download it all to your computer, saving time and space.
Imagine you're working on a project with a huge amount of data stored online. Instead of waiting hours to download it all, you can start working with the data almost immediately by streaming it.
Once you've optimized the dataset with LitData, stream it as follows:
from litdata import StreamingDataset, StreamingDataLoader
dataset = StreamingDataset('s3://my-bucket/my-data', shuffle=True)
dataloader = StreamingDataLoader(dataset, batch_size=64)
for batch in dataloader:
process(batch) # Replace with your data processing logicAdditionally, you can inject client connection settings for S3 or GCP when initializing your dataset. This is useful for specifying custom endpoints and credentials per dataset.
from litdata import StreamingDataset
storage_options = {
"endpoint_url": "your_endpoint_url",
"aws_access_key_id": "your_access_key_id",
"aws_secret_access_key": "your_secret_access_key",
}
dataset = StreamingDataset('s3://my-bucket/my-data', storage_options=storage_options)Also, you can specify a custom cache directory when initializing your dataset. This is useful when you want to store the cache in a specific location.
from litdata import StreamingDataset
# Initialize the StreamingDataset with the custom cache directory
dataset = StreamingDataset('s3://my-bucket/my-data', cache_dir="/path/to/cache")✅ Streams on multi-GPU, multi-node
Data optimized and loaded with Lightning automatically streams efficiently in distributed training across GPUs or multi-node.
The StreamingDataset and StreamingDataLoader automatically make sure each rank receives the same quantity of varied batches of data, so it works out of the box with your favorite frameworks (PyTorch Lightning, Lightning Fabric, or PyTorch) to do distributed training.
Here you can see an illustration showing how the Streaming Dataset works with multi node / multi gpu under the hood.
from litdata import StreamingDataset, StreamingDataLoader
# For the training dataset, don't forget to enable shuffle and drop_last !!!
train_dataset = StreamingDataset('s3://my-bucket/my-train-data', shuffle=True, drop_last=True)
train_dataloader = StreamingDataLoader(train_dataset, batch_size=64)
for batch in train_dataloader:
process(batch) # Replace with your data processing logic
val_dataset = StreamingDataset('s3://my-bucket/my-val-data', shuffle=False, drop_last=False)
val_dataloader = StreamingDataLoader(val_dataset, batch_size=64)
for batch in val_dataloader:
process(batch) # Replace with your data processing logic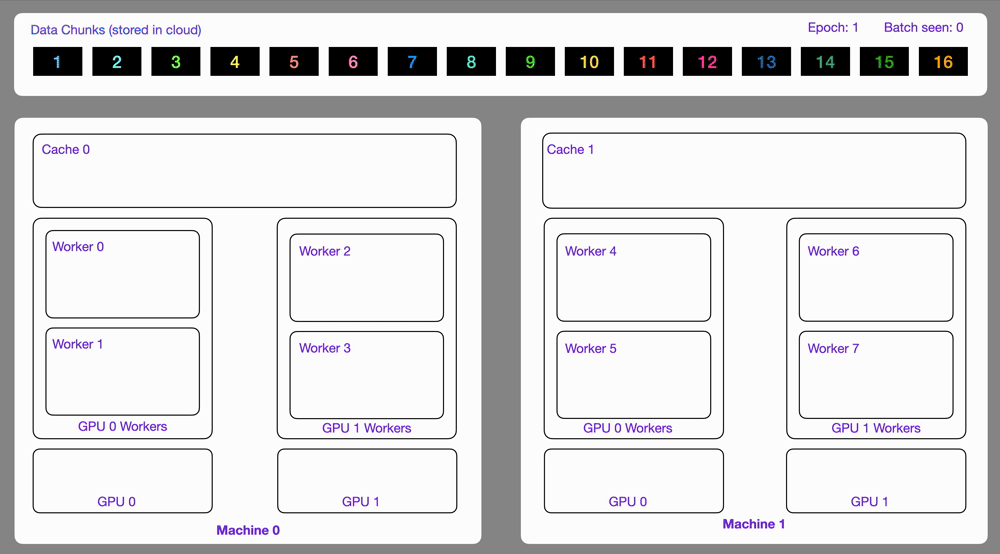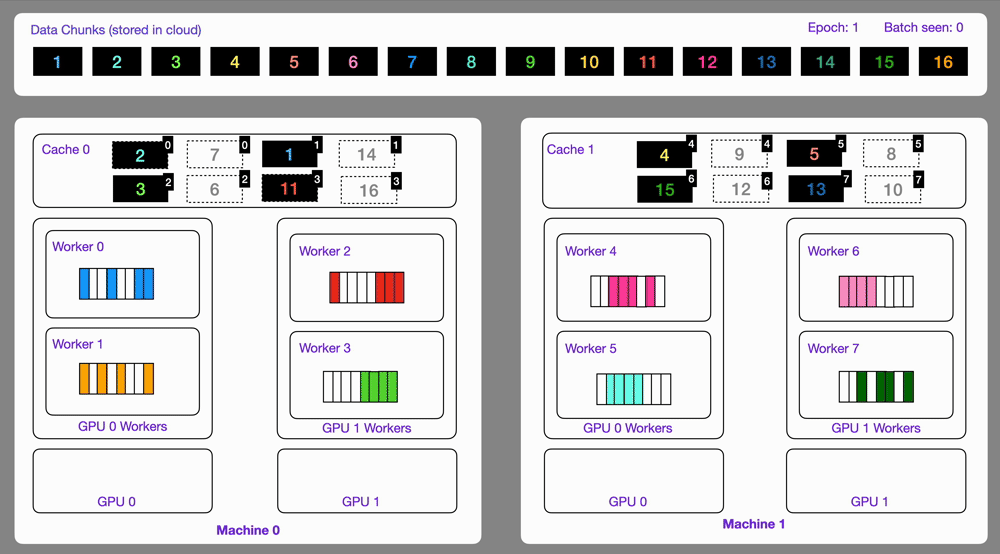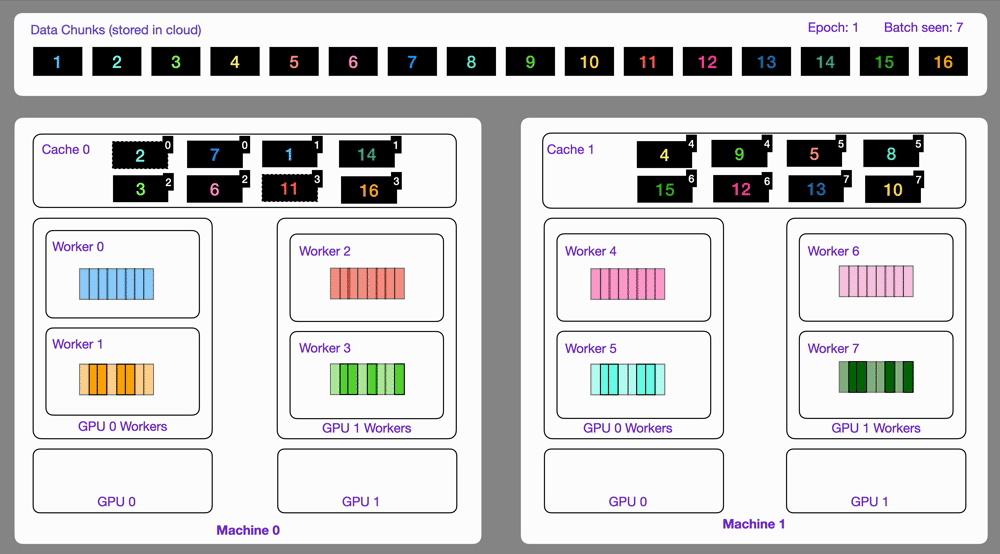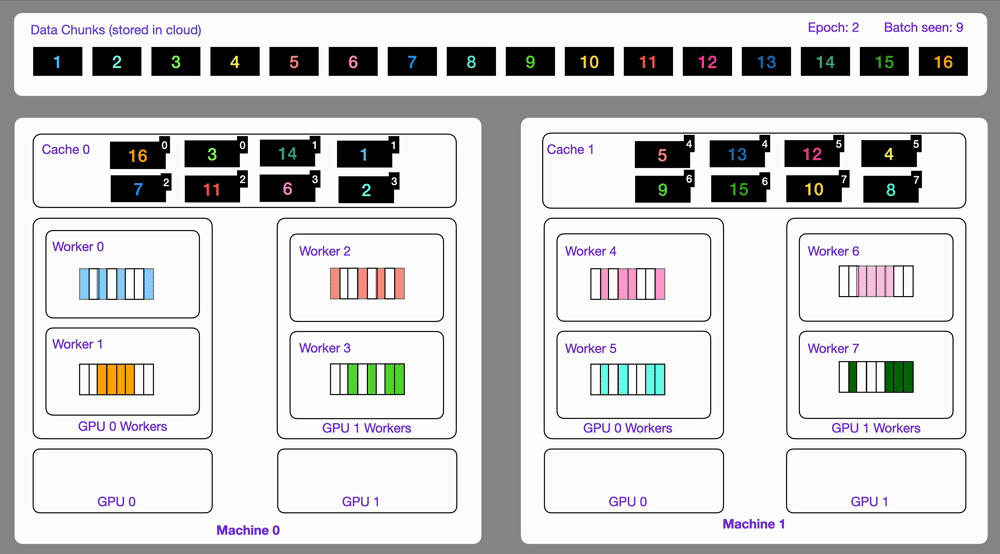
✅ Stream from multiple cloud providers
The StreamingDataset supports reading optimized datasets from common cloud providers.
import os
import litdata as ld
# Read data from AWS S3
aws_storage_options={
"AWS_ACCESS_KEY_ID": os.environ['AWS_ACCESS_KEY_ID'],
"AWS_SECRET_ACCESS_KEY": os.environ['AWS_SECRET_ACCESS_KEY'],
}
dataset = ld.StreamingDataset("s3://my-bucket/my-data", storage_options=aws_storage_options)
# Read data from GCS
gcp_storage_options={
"project": os.environ['PROJECT_ID'],
}
dataset = ld.StreamingDataset("gs://my-bucket/my-data", storage_options=gcp_storage_options)
# Read data from Azure
azure_storage_options={
"account_url": f"https://{os.environ['AZURE_ACCOUNT_NAME']}.blob.core.windows.net",
"credential": os.environ['AZURE_ACCOUNT_ACCESS_KEY']
}
dataset = ld.StreamingDataset("azure://my-bucket/my-data", storage_options=azure_storage_options)✅ Pause, resume data streaming
Stream data during long training, if interrupted, pick up right where you left off without any issues.
LitData provides a stateful Streaming DataLoader e.g. you can pause and resume your training whenever you want.
Info: The Streaming DataLoader was used by Lit-GPT to pretrain LLMs. Restarting from an older checkpoint was critical to get to pretrain the full model due to several failures (network, CUDA Errors, etc..).
import os
import torch
from litdata import StreamingDataset, StreamingDataLoader
dataset = StreamingDataset("s3://my-bucket/my-data", shuffle=True)
dataloader = StreamingDataLoader(dataset, num_workers=os.cpu_count(), batch_size=64)
# Restore the dataLoader state if it exists
if os.path.isfile("dataloader_state.pt"):
state_dict = torch.load("dataloader_state.pt")
dataloader.load_state_dict(state_dict)
# Iterate over the data
for batch_idx, batch in enumerate(dataloader):
# Store the state every 1000 batches
if batch_idx % 1000 == 0:
torch.save(dataloader.state_dict(), "dataloader_state.pt")✅ LLM Pre-training
LitData is highly optimized for LLM pre-training. First, we need to tokenize the entire dataset and then we can consume it.
import json
from pathlib import Path
import zstandard as zstd
from litdata import optimize, TokensLoader
from tokenizer import Tokenizer
from functools import partial
# 1. Define a function to convert the text within the jsonl files into tokens
def tokenize_fn(filepath, tokenizer=None):
with zstd.open(open(filepath, "rb"), "rt", encoding="utf-8") as f:
for row in f:
text = json.loads(row)["text"]
if json.loads(row)["meta"]["redpajama_set_name"] == "RedPajamaGithub":
continue # exclude the GitHub data since it overlaps with starcoder
text_ids = tokenizer.encode(text, bos=False, eos=True)
yield text_ids
if __name__ == "__main__":
# 2. Generate the inputs (we are going to optimize all the compressed json files from SlimPajama dataset )
input_dir = "./slimpajama-raw"
inputs = [str(file) for file in Path(f"{input_dir}/SlimPajama-627B/train").rglob("*.zst")]
# 3. Store the optimized data wherever you want under "/teamspace/datasets" or "/teamspace/s3_connections"
outputs = optimize(
fn=partial(tokenize_fn, tokenizer=Tokenizer(f"{input_dir}/checkpoints/Llama-2-7b-hf")), # Note: You can use HF tokenizer or any others
inputs=inputs,
output_dir="./slimpajama-optimized",
chunk_size=(2049 * 8012),
# This is important to inform LitData that we are encoding contiguous 1D array (tokens).
# LitData skips storing metadata for each sample e.g all the tokens are concatenated to form one large tensor.
item_loader=TokensLoader(),
)import os
from litdata import StreamingDataset, StreamingDataLoader, TokensLoader
from tqdm import tqdm
# Increase by one because we need the next word as well
dataset = StreamingDataset(
input_dir=f"./slimpajama-optimized/train",
item_loader=TokensLoader(block_size=2048 + 1),
shuffle=True,
drop_last=True,
)
train_dataloader = StreamingDataLoader(dataset, batch_size=8, pin_memory=True, num_workers=os.cpu_count())
# Iterate over the SlimPajama dataset
for batch in tqdm(train_dataloader):
pass✅ Filter illegal data
Sometimes, you have bad data that you don't want to include in the optimized dataset. With LitData, yield only the good data sample to include.
from litdata import optimize, StreamingDataset
def should_keep(index) -> bool:
# Replace with your own logic
return index % 2 == 0
def fn(data):
if should_keep(data):
yield data
if __name__ == "__main__":
optimize(
fn=fn,
inputs=list(range(1000)),
output_dir="only_even_index_optimized",
chunk_bytes="64MB",
num_workers=1
)
dataset = StreamingDataset("only_even_index_optimized")
data = list(dataset)
print(data)
# [0, 2, 4, 6, 8, 10, ..., 992, 994, 996, 998]You can even use try/expect.
from litdata import optimize, StreamingDataset
def fn(data):
try:
yield 1 / data
except:
pass
if __name__ == "__main__":
optimize(
fn=fn,
inputs=[0, 0, 0, 1, 2, 4, 0],
output_dir="only_defined_ratio_optimized",
chunk_bytes="64MB",
num_workers=1
)
dataset = StreamingDataset("only_defined_ratio_optimized")
data = list(dataset)
# The 0 are filtered out as they raise a division by zero
print(data)
# [1.0, 0.5, 0.25] ✅ Combine datasets
Mix and match different sets of data to experiment and create better models.
Combine datasets with CombinedStreamingDataset. As an example, this mixture of Slimpajama & StarCoder was used in the TinyLLAMA project to pretrain a 1.1B Llama model on 3 trillion tokens.
from litdata import StreamingDataset, CombinedStreamingDataset, StreamingDataLoader, TokensLoader
from tqdm import tqdm
import os
train_datasets = [
StreamingDataset(
input_dir="s3://tinyllama-template/slimpajama/train/",
item_loader=TokensLoader(block_size=2048 + 1), # Optimized loader for tokens used by LLMs
shuffle=True,
drop_last=True,
),
StreamingDataset(
input_dir="s3://tinyllama-template/starcoder/",
item_loader=TokensLoader(block_size=2048 + 1), # Optimized loader for tokens used by LLMs
shuffle=True,
drop_last=True,
),
]
# Mix SlimPajama data and Starcoder data with these proportions:
weights = (0.693584, 0.306416)
combined_dataset = CombinedStreamingDataset(datasets=train_datasets, seed=42, weights=weights, iterate_over_all=False)
train_dataloader = StreamingDataLoader(combined_dataset, batch_size=8, pin_memory=True, num_workers=os.cpu_count())
# Iterate over the combined datasets
for batch in tqdm(train_dataloader):
pass✅ Merge datasets
Merge multiple optimized datasets into one.
import numpy as np
from PIL import Image
from litdata import StreamingDataset, merge_datasets, optimize
def random_images(index):
return {
"index": index,
"image": Image.fromarray(np.random.randint(0, 256, (32, 32, 3), dtype=np.uint8)),
"class": np.random.randint(10),
}
if __name__ == "__main__":
out_dirs = ["fast_data_1", "fast_data_2", "fast_data_3", "fast_data_4"] # or ["s3://my-bucket/fast_data_1", etc.]"
for out_dir in out_dirs:
optimize(fn=random_images, inputs=list(range(250)), output_dir=out_dir, num_workers=4, chunk_bytes="64MB")
merged_out_dir = "merged_fast_data" # or "s3://my-bucket/merged_fast_data"
merge_datasets(input_dirs=out_dirs, output_dir=merged_out_dir)
dataset = StreamingDataset(merged_out_dir)
print(len(dataset))
# out: 1000✅ Split datasets for train, val, test
Split a dataset into train, val, test splits with train_test_split.
from litdata import StreamingDataset, train_test_split
dataset = StreamingDataset("s3://my-bucket/my-data") # data are stored in the cloud
print(len(dataset)) # display the length of your data
# out: 100,000
train_dataset, val_dataset, test_dataset = train_test_split(dataset, splits=[0.3, 0.2, 0.5])
print(train_dataset)
# out: 30,000
print(val_dataset)
# out: 20,000
print(test_dataset)
# out: 50,000✅ Load a subset of the remote dataset
Work on a smaller, manageable portion of your data to save time and resources.
from litdata import StreamingDataset, train_test_split
dataset = StreamingDataset("s3://my-bucket/my-data", subsample=0.01) # data are stored in the cloud
print(len(dataset)) # display the length of your data
# out: 1000✅ Easily modify optimized cloud datasets
Add new data to an existing dataset or start fresh if needed, providing flexibility in data management.
LitData optimized datasets are assumed to be immutable. However, you can make the decision to modify them by changing the mode to either append or overwrite.
from litdata import optimize, StreamingDataset
def compress(index):
return index, index**2
if __name__ == "__main__":
# Add some data
optimize(
fn=compress,
inputs=list(range(100)),
output_dir="./my_optimized_dataset",
chunk_bytes="64MB",
)
# Later on, you add more data
optimize(
fn=compress,
inputs=list(range(100, 200)),
output_dir="./my_optimized_dataset",
chunk_bytes="64MB",
mode="append",
)
ds = StreamingDataset("./my_optimized_dataset")
assert len(ds) == 200
assert ds[:] == [(i, i**2) for i in range(200)]The overwrite mode will delete the existing data and start from fresh.
✅ Use compression
Reduce your data footprint by using advanced compression algorithms.
import litdata as ld
def compress(index):
return index, index**2
if __name__ == "__main__":
# Add some data
ld.optimize(
fn=compress,
inputs=list(range(100)),
output_dir="./my_optimized_dataset",
chunk_bytes="64MB",
num_workers=1,
compression="zstd"
)Using zstd, you can achieve high compression ratio like 4.34x for this simple example.
| Without | With |
|---|---|
| 2.8kb | 646b |
✅ Access samples without full data download
Look at specific parts of a large dataset without downloading the whole thing or loading it on a local machine.
from litdata import StreamingDataset
dataset = StreamingDataset("s3://my-bucket/my-data") # data are stored in the cloud
print(len(dataset)) # display the length of your data
print(dataset[42]) # show the 42th element of the dataset✅ Use any data transforms
Customize how your data is processed to better fit your needs.
Subclass the StreamingDataset and override its __getitem__ method to add any extra data transformations.
from litdata import StreamingDataset, StreamingDataLoader
import torchvision.transforms.v2.functional as F
class ImagenetStreamingDataset(StreamingDataset):
def __getitem__(self, index):
image = super().__getitem__(index)
return F.resize(image, (224, 224))
dataset = ImagenetStreamingDataset(...)
dataloader = StreamingDataLoader(dataset, batch_size=4)
for batch in dataloader:
print(batch.shape)
# Out: (4, 3, 224, 224)✅ Profile data loading speed
Measure and optimize how fast your data is being loaded, improving efficiency.
The StreamingDataLoader supports profiling of your data loading process. Simply use the profile_batches argument to specify the number of batches you want to profile:
from litdata import StreamingDataset, StreamingDataLoader
StreamingDataLoader(..., profile_batches=5)This generates a Chrome trace called result.json. Then, visualize this trace by opening Chrome browser at the chrome://tracing URL and load the trace inside.
✅ Reduce memory use for large files
Handle large data files efficiently without using too much of your computer's memory.
When processing large files like compressed parquet files, use the Python yield keyword to process and store one item at the time, reducing the memory footprint of the entire program.
from pathlib import Path
import pyarrow.parquet as pq
from litdata import optimize
from tokenizer import Tokenizer
from functools import partial
# 1. Define a function to convert the text within the parquet files into tokens
def tokenize_fn(filepath, tokenizer=None):
parquet_file = pq.ParquetFile(filepath)
# Process per batch to reduce RAM usage
for batch in parquet_file.iter_batches(batch_size=8192, columns=["content"]):
for text in batch.to_pandas()["content"]:
yield tokenizer.encode(text, bos=False, eos=True)
# 2. Generate the inputs
input_dir = "/teamspace/s3_connections/tinyllama-template"
inputs = [str(file) for file in Path(f"{input_dir}/starcoderdata").rglob("*.parquet")]
# 3. Store the optimized data wherever you want under "/teamspace/datasets" or "/teamspace/s3_connections"
outputs = optimize(
fn=partial(tokenize_fn, tokenizer=Tokenizer(f"{input_dir}/checkpoints/Llama-2-7b-hf")), # Note: Use HF tokenizer or any others
inputs=inputs,
output_dir="/teamspace/datasets/starcoderdata",
chunk_size=(2049 * 8012), # Number of tokens to store by chunks. This is roughly 64MB of tokens per chunk.
)✅ Limit local cache space
Limit the amount of disk space used by temporary files, preventing storage issues.
Adapt the local caching limit of the StreamingDataset. This is useful to make sure the downloaded data chunks are deleted when used and the disk usage stays low.
from litdata import StreamingDataset
dataset = StreamingDataset(..., max_cache_size="10GB")✅ Change cache directory path
Specify the directory where cached files should be stored, ensuring efficient data retrieval and management. This is particularly useful for organizing your data storage and improving access times.
from litdata import StreamingDataset
from litdata.streaming.cache import Dir
cache_dir = "/path/to/your/cache"
data_dir = "s3://my-bucket/my_optimized_dataset"
dataset = StreamingDataset(input_dir=Dir(path=cache_dir, url=data_dir))✅ Optimize loading on networked drives
Optimize data handling for computers on a local network to improve performance for on-site setups.
On-prem compute nodes can mount and use a network drive. A network drive is a shared storage device on a local area network. In order to reduce their network overload, the StreamingDataset supports caching the data chunks.
from litdata import StreamingDataset
dataset = StreamingDataset(input_dir="local:/data/shared-drive/some-data")✅ Optimize dataset in distributed environment
Lightning can distribute large workloads across hundreds of machines in parallel. This can reduce the time to complete a data processing task from weeks to minutes by scaling to enough machines.
To apply the optimize operator across multiple machines, simply provide the num_nodes and machine arguments to it as follows:
import os
from litdata import optimize, Machine
def compress(index):
return (index, index ** 2)
optimize(
fn=compress,
inputs=list(range(100)),
num_workers=2,
output_dir="my_output",
chunk_bytes="64MB",
num_nodes=2,
machine=Machine.DATA_PREP, # You can select between dozens of optimized machines
)If the output_dir is a local path, the optimized dataset will be present in: /teamspace/jobs/{job_name}/nodes-0/my_output. Otherwise, it will be stored in the specified output_dir.
Read the optimized dataset:
from litdata import StreamingDataset
output_dir = "/teamspace/jobs/litdata-optimize-2024-07-08/nodes.0/my_output"
dataset = StreamingDataset(output_dir)
print(dataset[:])✅ Encrypt, decrypt data at chunk/sample level
Secure data by applying encryption to individual samples or chunks, ensuring sensitive information is protected during storage.
This example shows how to use the FernetEncryption class for sample-level encryption with a data optimization function.
from litdata import optimize
from litdata.utilities.encryption import FernetEncryption
import numpy as np
from PIL import Image
# Initialize FernetEncryption with a password for sample-level encryption
fernet = FernetEncryption(password="your_secure_password", level="sample")
data_dir = "s3://my-bucket/optimized_data"
def random_image(index):
"""Generate a random image for demonstration purposes."""
fake_img = Image.fromarray(np.random.randint(0, 255, (32, 32, 3), dtype=np.uint8))
return {"image": fake_img, "class": index}
# Optimize data while applying encryption
optimize(
fn=random_image,
inputs=list(range(5)), # Example inputs: [0, 1, 2, 3, 4]
num_workers=1,
output_dir=data_dir,
chunk_bytes="64MB",
encryption=fernet,
)
# Save the encryption key to a file for later use
fernet.save("fernet.pem")Load the encrypted data using the StreamingDataset class as follows:
from litdata import StreamingDataset
from litdata.utilities.encryption import FernetEncryption
# Load the encryption key
fernet = FernetEncryption(password="your_secure_password", level="sample")
fernet.load("fernet.pem")
# Create a streaming dataset for reading the encrypted samples
ds = StreamingDataset(input_dir=data_dir, encryption=fernet)Implement your own encryption method: Subclass the Encryption class and define the necessary methods:
from litdata.utilities.encryption import Encryption
class CustomEncryption(Encryption):
def encrypt(self, data):
# Implement your custom encryption logic here
return data
def decrypt(self, data):
# Implement your custom decryption logic here
return dataThis allows the data to remain secure while maintaining flexibility in the encryption method.
✅ Parallelize data transformations (map)
Apply the same change to different parts of the dataset at once to save time and effort.
The map operator can be used to apply a function over a list of inputs.
Here is an example where the map operator is used to apply a resize_image function over a folder of large images.
from litdata import map
from PIL import Image
# Note: Inputs could also refer to files on s3 directly.
input_dir = "my_large_images"
inputs = [os.path.join(input_dir, f) for f in os.listdir(input_dir)]
# The resize image takes one of the input (image_path) and the output directory.
# Files written to output_dir are persisted.
def resize_image(image_path, output_dir):
output_image_path = os.path.join(output_dir, os.path.basename(image_path))
Image.open(image_path).resize((224, 224)).save(output_image_path)
map(
fn=resize_image,
inputs=inputs,
output_dir="s3://my-bucket/my_resized_images",
)
In this section we show benchmarks for speed to optimize a dataset and the resulting streaming speed (Reproduce the benchmark).
Data optimized and streamed with LitData achieves a 20x speed up over non optimized data and 2x speed up over other streaming solutions.
Speed to stream Imagenet 1.2M from AWS S3:
| Framework | Images / sec 1st Epoch (float32) | Images / sec 2nd Epoch (float32) | Images / sec 1st Epoch (torch16) | Images / sec 2nd Epoch (torch16) |
|---|---|---|---|---|
| LitData | 5800 | 6589 | 6282 | 7221 |
| Web Dataset | 3134 | 3924 | 3343 | 4424 |
| Mosaic ML | 2898 | 5099 | 2809 | 5158 |
Benchmark details
- Imagenet-1.2M dataset contains
1,281,167 images. - To align with other benchmarks, we measured the streaming speed (
images per second) loaded from AWS S3 for several frameworks.
LitData optimizes the Imagenet dataset for fast training 3-5x faster than other frameworks:
Time to optimize 1.2 million ImageNet images (Faster is better):
| Framework | Train Conversion Time | Val Conversion Time | Dataset Size | # Files |
|---|---|---|---|---|
| LitData | 10:05 min | 00:30 min | 143.1 GB | 2.339 |
| Web Dataset | 32:36 min | 01:22 min | 147.8 GB | 1.144 |
| Mosaic ML | 49:49 min | 01:04 min | 143.1 GB | 2.298 |
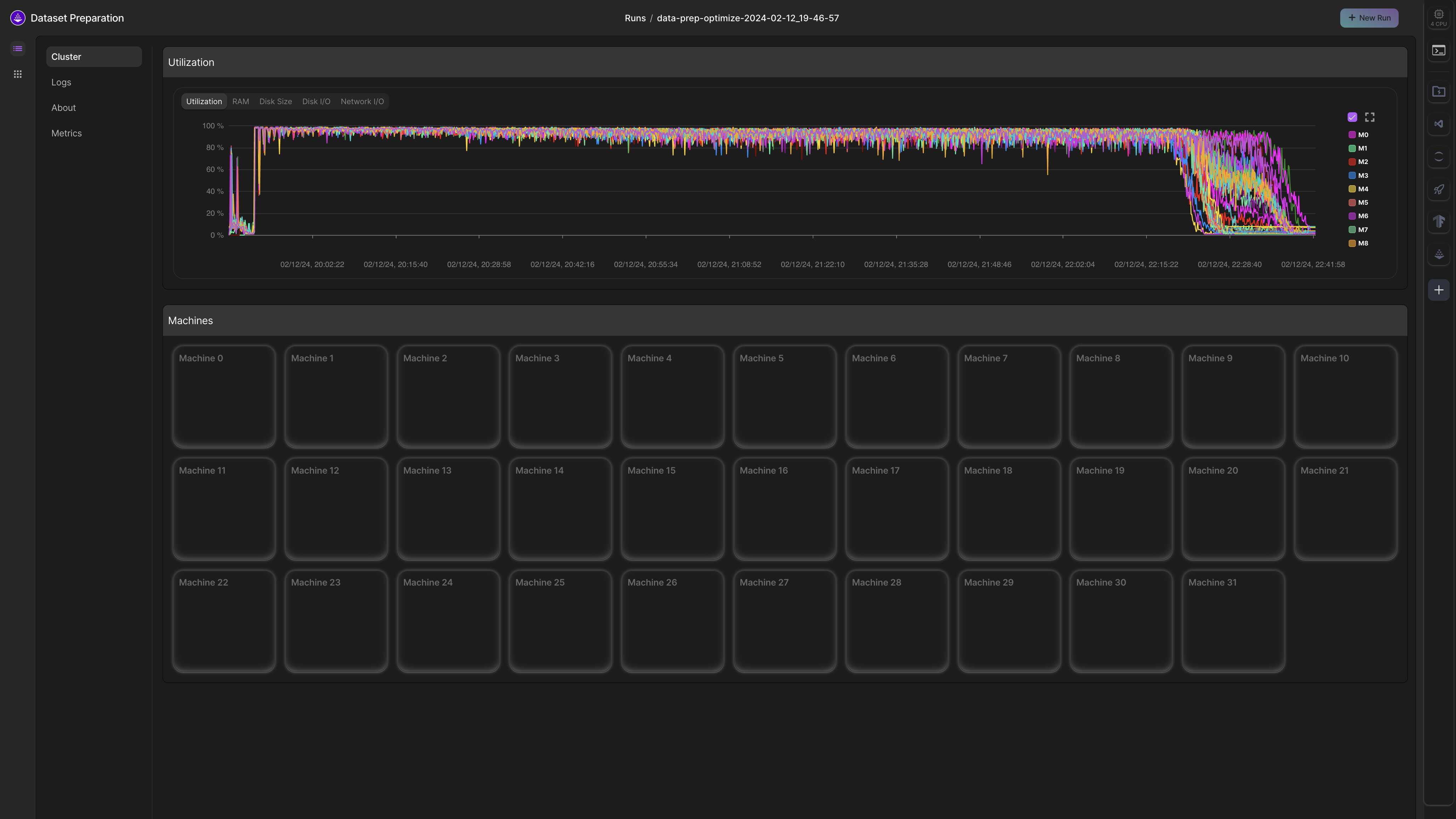
Transformations with LitData are linearly parallelizable across machines.
For example, let's say that it takes 56 hours to embed a dataset on a single A10G machine. With LitData, this can be speed up by adding more machines in parallel
| Number of machines | Hours |
|---|---|
| 1 | 56 |
| 2 | 28 |
| 4 | 14 |
| ... | ... |
| 64 | 0.875 |
To scale the number of machines, run the processing script on Lightning Studios:
from litdata import map, Machine
map(
...
num_nodes=32,
machine=Machine.DATA_PREP, # Select between dozens of optimized machines
)To scale the number of machines for data optimization, use Lightning Studios:
from litdata import optimize, Machine
optimize(
...
num_nodes=32,
machine=Machine.DATA_PREP, # Select between dozens of optimized machines
)
Example: Process the LAION 400 million image dataset in 2 hours on 32 machines, each with 32 CPUs.
Below are templates for real-world applications of LitData at scale.
| Studio | Data type | Time (minutes) | Machines | Dataset |
|---|---|---|---|---|
| Download LAION-400MILLION dataset | Image & Text | 120 | 32 | LAION-400M |
| Tokenize 2M Swedish Wikipedia Articles | Text | 7 | 4 | Swedish Wikipedia |
| Embed English Wikipedia under 5 dollars | Text | 15 | 3 | English Wikipedia |
| Studio | Data type | Time (minutes) | Machines | Dataset |
|---|---|---|---|---|
| Benchmark cloud data-loading libraries | Image & Label | 10 | 1 | Imagenet 1M |
| Optimize GeoSpatial data for model training | Image & Mask | 120 | 32 | Chesapeake Roads Spatial Context |
| Optimize TinyLlama 1T dataset for training | Text | 240 | 32 | SlimPajama & StarCoder |
| Optimize parquet files for model training | Parquet Files | 12 | 16 | Randomly Generated data |
LitData is a community project accepting contributions - Let's make the world's most advanced AI data processing framework.