This is our micro-tiny GPT model (😁 we are still learning), built from scratch and inspired by the innovative approaches of Hugging Face Transformers and OpenAI architectures. Developed during our internship at 3D Smart Factory, this model showcases our committed efforts to create an advanced AI solution.


Important: This project involves fine-tuning various GPT family models (small, medium, large, etc.) to develop two distinct chatbots: one for question and answer interactions here and another for context-based question and answer interactions here. Additionally, we have implemented a question and answer system based on the core transformer architecture which was initially used for translation tasks here.
Note: This is a learning project and does not represent a production-grade solution. The focus is on educational growth and experimentation.
**Note:** This is an important notice. It provides additional information or a reminder.- Introduction
- OverView
- Data
- Background on GPT
- Model Architecture
- Features of this project
- Benefits of Utilizing MT-GPT
- Explanatory Videos
- Training
- Inference
- Fine Tuning
- Contributors
- Contact Us
- About Me
Welcome to the Micro-Tiny GPT Model repository! This project is an exploration into building a compact GPT model from scratch, taking inspiration from the Hugging Face Transformers and OpenAI architectures. Developed during an internship at 3D Smart Factory, this model represents our dedication to creating advanced AI solutions despite our learning phase.
the Following Readme file offers a thorough exploration of the meticulous process involved in building the foundational GPT model from its inception. Our journey covers vital phases, including data collection, model architecture design, training protocols, and practical applications. Throughout this chapter, we illuminate the intricate nature of developing such a potent language model and its profound potential across various applications in the field of natural language processing.
To train GPT, OpenAI needed a substantial corpus of 40 GB of high-quality text. While Common Crawl provided the necessary scale for modern language models, its quality was often inconsistent. Manually curating data from Common Crawl was an option but a costly one. Fortunately, Reddit provided a decentralized curation approach by design, proving to be a crucial innovation for creating the WebText dataset.
The WebText generation process can be summarized as follows:
- Retrieve URLs of all Reddit submissions until December 2017 with a score of 3 or higher.
- Deduplicate retrieved content based on URLs.
- Exclude Wikipedia content, as OpenAI already had a separate Wikipedia dataset.
- Further deduplicate the remaining content using an undisclosed "heuristic" cleaning method, including the removal of non-English web pages.
Neither the resulting corpus nor the source code for its generation was made public, which later inspired Aaron Gokaslan and Vanya Cohen to create the OpenWebText corpus.
OpenWebText2 is an enhanced version of the original OpenWebText corpus, covering all Reddit submissions from 2005 to April 2020, with additional months becoming available after the publication of corresponding PushShift backup files.

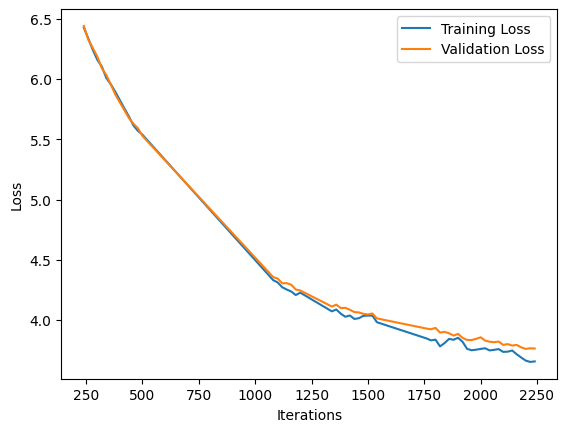
Due to resource constraints, it is important to note that we trained GPT on only a quarter of the OpenWebText dataset. This limitation in training data was necessary to optimize computational resources while still achieving significant language model performance.
We combined approximately 5 million files from the OpenWebText dataset, roughly equivalent to a quarter of the entire OpenWebText corpus. Subsequently, we performed the following steps:
- We used the GPT tokenizer, also known as "r50k_base" to tokenize the dataset.
import tiktoken
tokenizer = tiktoken.get_encoding("r50k_base")
- Following established conventions for dataset splitting, we divided the data into training and validation sets, allocating 80% for training and 10% for validation.
- To optimize data management and efficiency, we stored the data as a binary stream in the 'train.bin' and 'val.bin' files.
data_dir = "your data path"
for prefix in [list of folers in case you are using openwebtext]:
f_dir = "dest dir"
for idx, filename in enumerate(os.listdir(f_dir)):
src_file = os.path.join(f_dir, f'f{idx+1}.txt')
with open(src_file, 'r', encoding='utf-8') as f:
content = f.read()
dset = tokenizing(content)
content = None
arr_len = np.sum(dset['len'], dtype=np.uint64)
dest_file = os.path.join(f"{data_dir}/file_{prefix}/", f'f{idx+1}.bin')
dtype = np.uint16
arr = np.memmap(dest_file, dtype=dtype, mode='w+', shape=(arr_len,))
arr[0:arr_len] = np.array(dset['ids'])
arr.flush()
print(f"✅ f[{idx+1}].txt saved successfully to f{idx+1}.bin")
for split_name in ["test", "val", "train"]:
data_dir = "your data dir"
f_dir = "dir to where you want to put your data"
with open(os.path.join(f_dir, f'{split_name}.bin'), 'wb') as outf:
for idx, filename in enumerate(os.listdir(data_dir)):
src_path = os.path.join(f"{data_dir}", filename)
with open(src_path, 'rb') as input_file:
file_contents = input_file.read()
outf.write(file_contents)
print(f"Concatenation of {split_name} complete.")
Our dataset is currently accessible on Kaggle:
The Generative Pre-trained Transformer 2 (GPT), developed by OpenAI, is the second installment in their fundamental series of GPT models. GPT was pretrained on the BookCorpus dataset, consisting of over 7,000 unpublished fiction books of various genres, and then fine-tuned on a dataset comprising 8 million web pages. It was partially unveiled in February 2019, followed by the full release of the 1.5 billion parameter model on November 5, 2019.
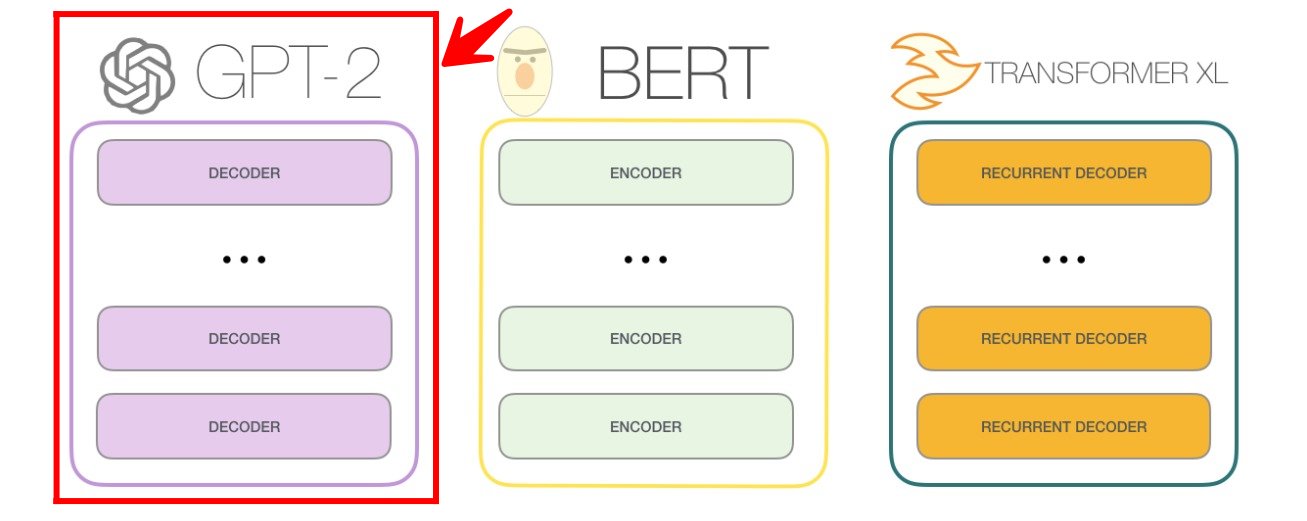
GPT represents a "direct scale-up" from its predecessor, GPT-1, with a tenfold increase in both the number of parameters and the size of the training dataset. This versatile model owes its ability to perform various tasks to its intrinsic capacity to accurately predict the next element in a sequence. This predictive capability enables GPT to accomplish tasks such as text translation, answering questions based on textual content, summarizing text passages, and generating text that can sometimes closely resemble human style. However, it may exhibit repetitive or nonsensical behavior when generating long passages.
There is a family of GPT models; below, we can see the pretrained GPT model family:

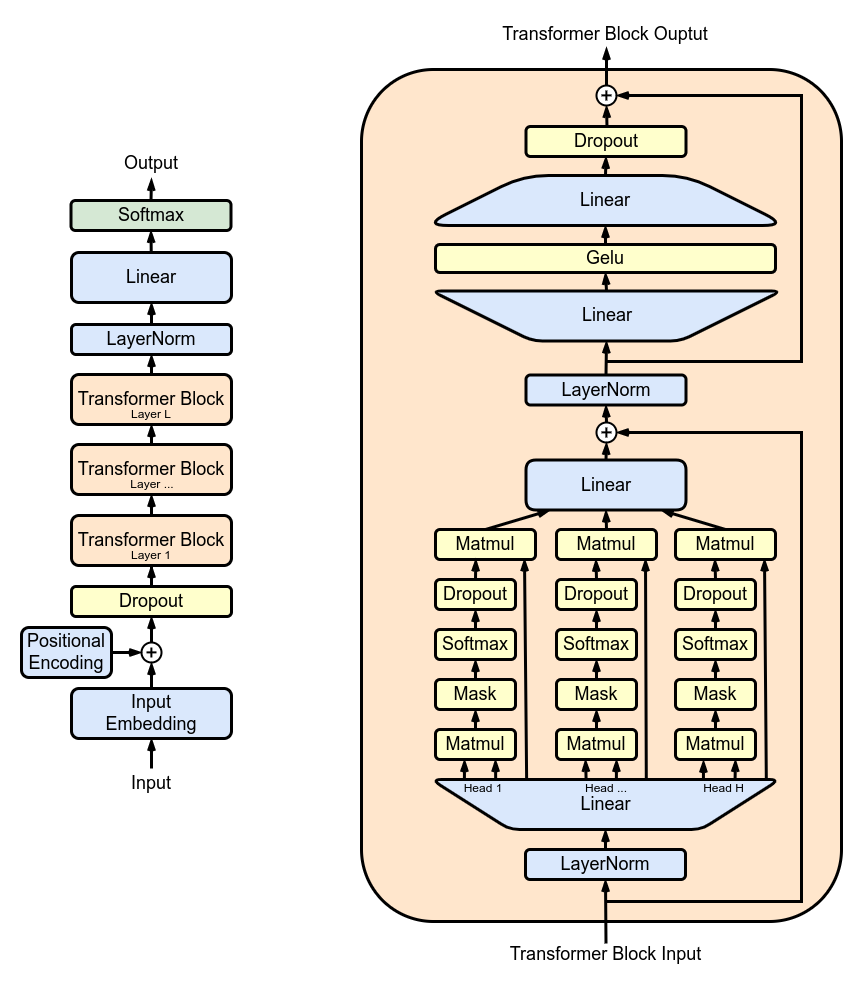
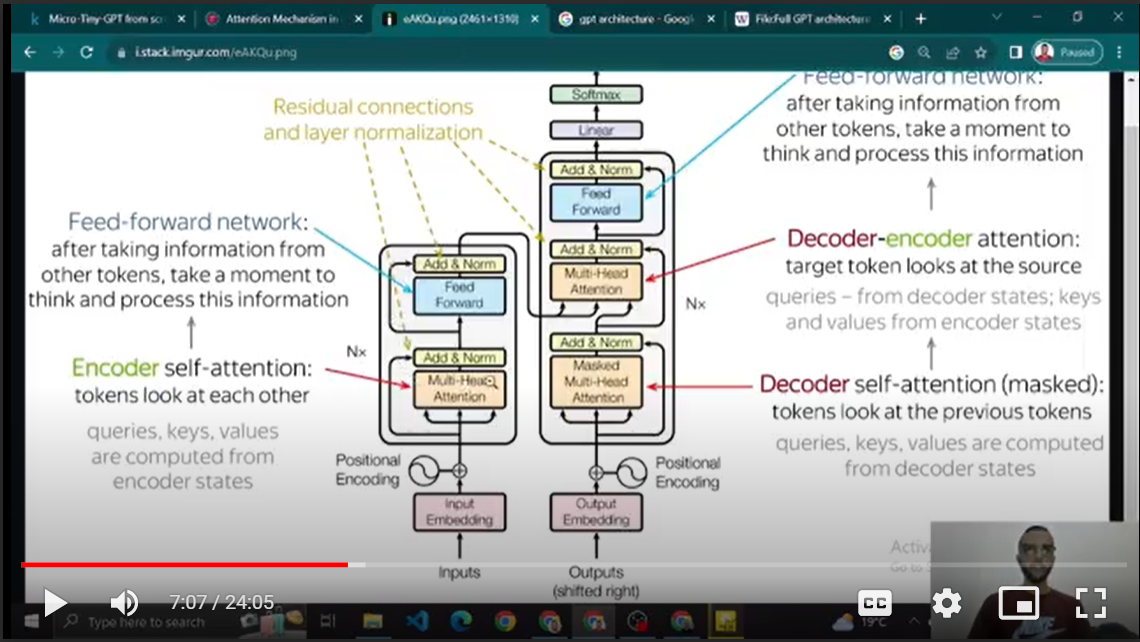
The architecture of GPT, a groundbreaking language model, represents a notable evolution of deep learning-based transformer models. Initially, it followed the traditional transformer architecture with both encoder and decoder components, but subsequent research simplified the design by removing one.
This led to models with exceptionally high stacks of transformer blocks and massive volumes of training data, often requiring significant computational resources and costs. This chapter explores the architecture of GPT and its relationship with transformers, highlighting innovative developments that shaped its evolution into a powerful language model.
-
Micro-Tiny Scale: This GPT model is intentionally designed to be on a micro-tiny scale, showcasing our learning journey and commitment to innovation.
-
Inspired by Industry Leaders: Influenced by the Hugging Face Transformers and OpenAI architectures, we've incorporated industry best practices into our model's design.
-
Internship Project: Developed during our internship at 3D Smart Factory, this project reflects real-world experience and hands-on learning.
Within the realm of Micro-Tiny GPT notebook, there exists a multitude of advantageous applications:
-
Enhanced Textual Performance: Leveraging the ability to train MT-GPT on larger datasets can significantly improve its text generation capabilities.
-
ABC Model Integration: You will find a demonstrative example of integrating MT-GPT with the ABC model in my GitHub repository, showcasing its adaptability to diverse frameworks.
-
Voice Training Capabilities: MT-GPT can be trained on voice data, opening up opportunities for voice-related applications.
-
Sequential Problem Solving: The versatility of MT-GPT extends to addressing various sequential challenges within the field of AI.
I've created explanatory videos to help you understand the intricate link between the architecture and the code, as it might not be immediately obvious.


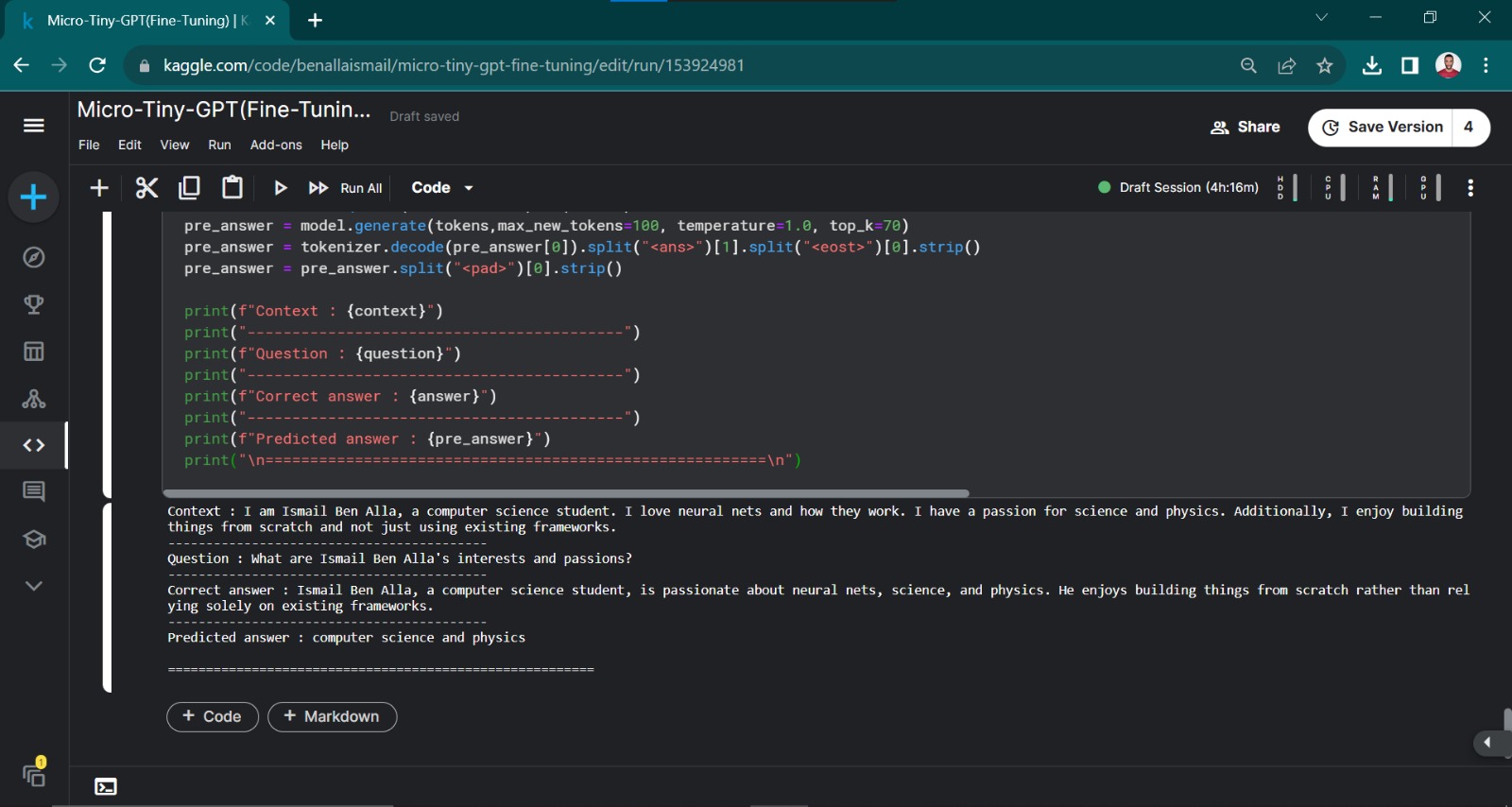
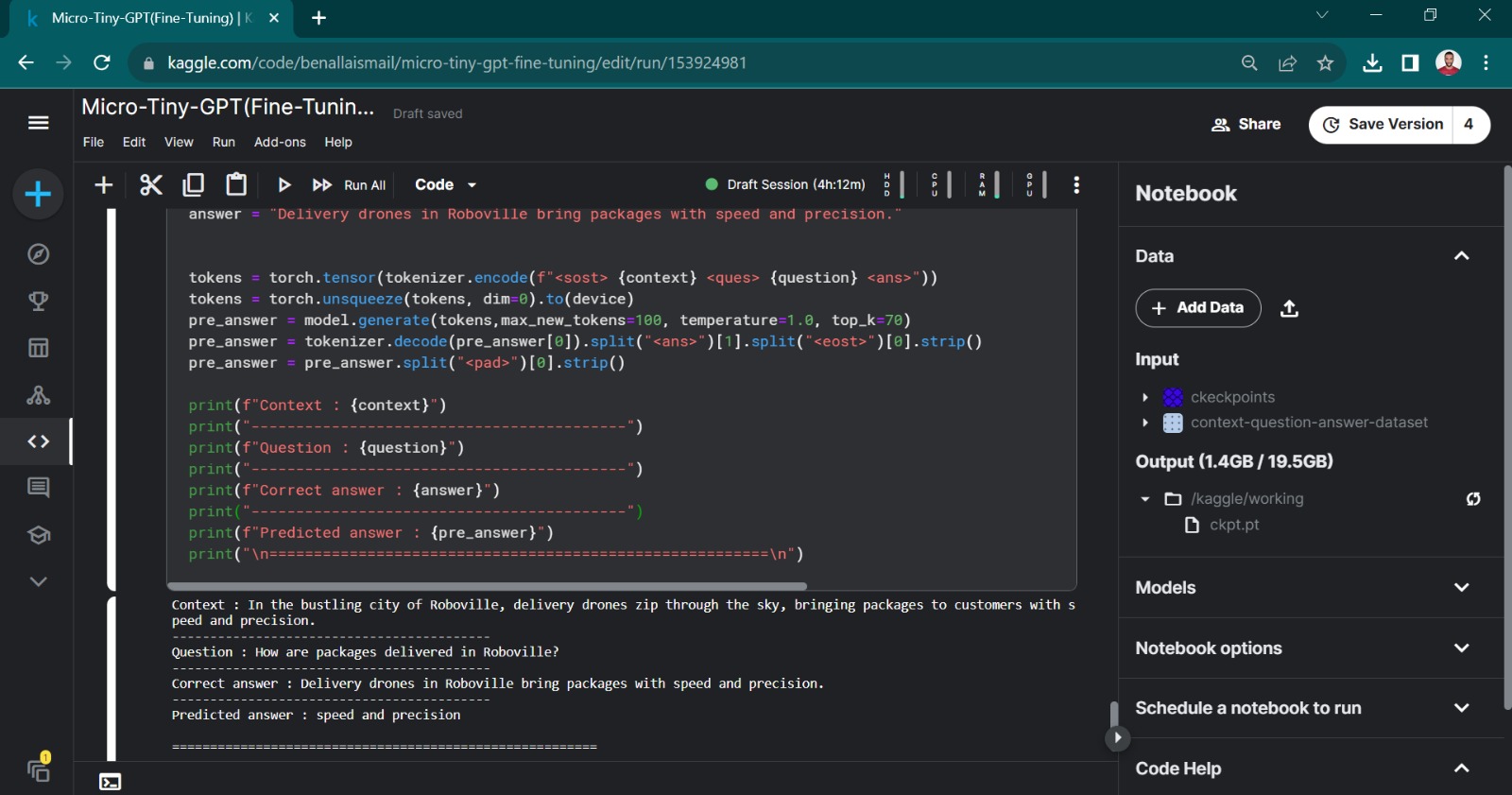
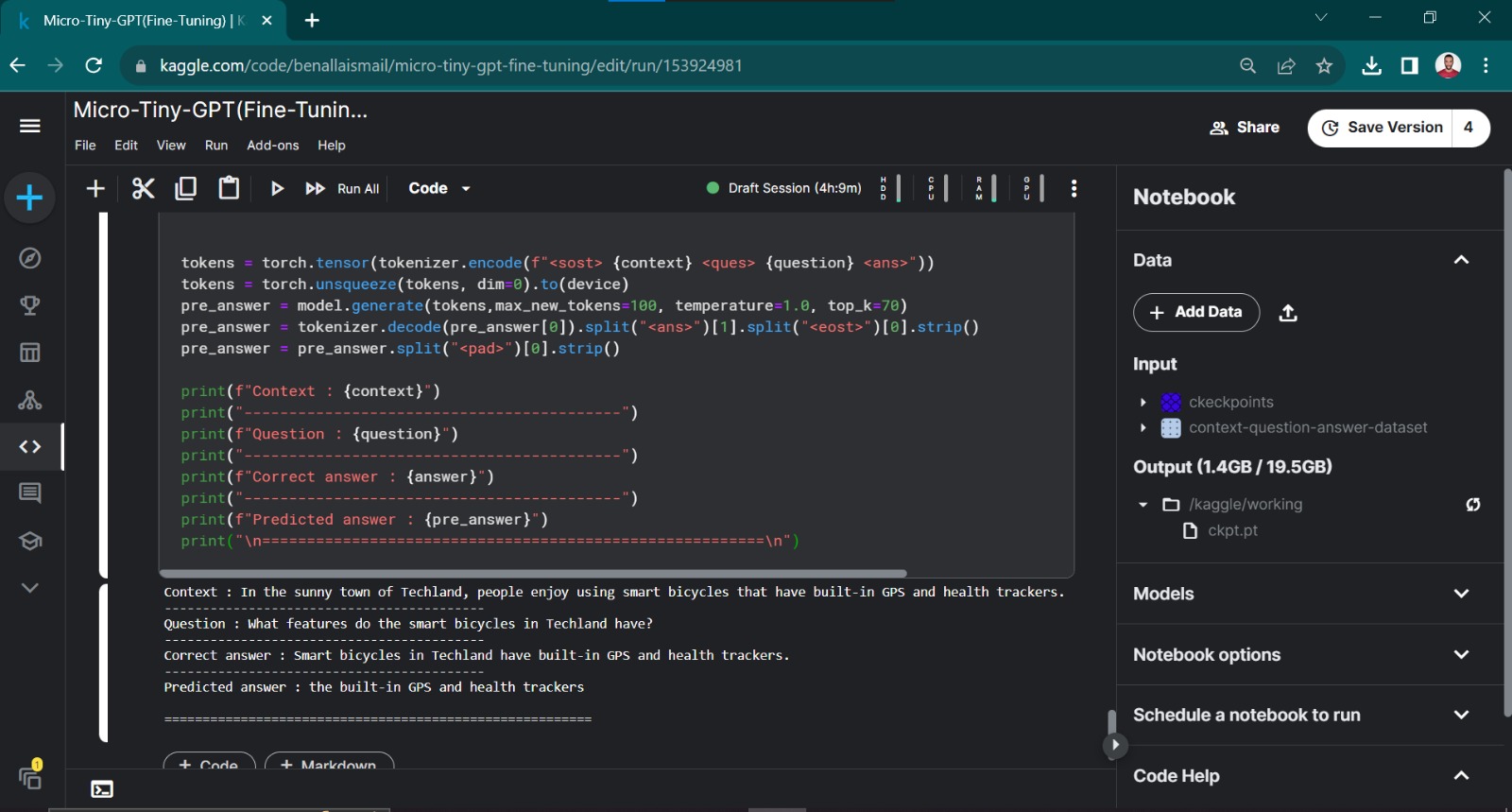
For detailed information, refer to the project Fine-Tuning Pretrained GPT-2, where GPT-2 has been fine-tuned specifically for context-question-answer scenarios.
Acknowledge the significant contributions of your colleagues, attributing specific roles and responsibilities to each individual:
For inquiries or suggestions, please contact:
- Project Lead: Ben alla ismail (ismailbenalla52@gmail.com)
- Co-lead: mhaoui Siham (mahouisiham@gmail.com)
🎓 I'm Ismail Ben Alla, and I have a deep passion for neural networks 😍. My mission is to assist neural networks in unraveling the mysteries of our universe.
⛵ I'm an enthusiast when it comes to AI, Deep Learning, and Machine Learning algorithms.
✅ I'm an optimist and a dedicated hard worker, constantly striving to push the boundaries of what's possible.
🌱 I'm committed to continuously learning and staying updated with advanced computer science technologies.
😄 I absolutely love what I do, and I'm excited about the endless possibilities in the world of AI and machine learning!
Let's connect and explore the fascinating world of artificial intelligence together! 🤖🌟
