Deploy the Athena PostgreSQL Connector without using SAM
Don’t forget to replace placeholder values in file templates and commands with your own!!!
First step is deploying the athena-postgresql connector without using SAM is to do the following.
Create two json files creating the necessary IAM Role and Policy for the Lambda:
First, create AssumeRolePolicyDocument.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal":
{
"Service": [
"lambda.amazonaws.com"
]
},
"Action": [
"sts:AssumeRole"
]
}
]
}
The purpose of the AssumeRolePolicyDocument is to contain the trust relationship policy that grants an entity permission to assume the role, in our case we are granting the Lambda service the ability to assume.
Next, create LambdaExecutionPolicy.json
Note: The following Policy was configured according to the **FunctionExecutionPolicy **from athena-postgresql.yaml, converted into JSON format. So while the following example is for athena-postgresql, you can adapt the same idea for any of the other available connectors by looking at their athena-*.yaml files.
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"logs:CreateLogGroup"
],
"Effect": "Allow",
"Resource": [
"arn:aws:logs:<--FILL IN REGION-->:<--FILL IN ACCOUNT_ID-->:*"
]
},
{
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Effect": "Allow",
"Resource": [
"arn:aws:logs:<--FILL IN REGION-->:<--FILL IN ACCOUNT_ID-->:log-group:/aws/lambda/<--FILL IN LAMBDA_FUNCTION_NAME-->:*"
]
},
{
"Action" : [
"athena:GetQueryExecution",
"s3:ListAllMyBuckets"
],
"Effect": "Allow",
"Resource": "*"
},
{
"Action": [
"ec2:CreateNetworkInterface",
"ec2:DeleteNetworkInterface",
"ec2:DescribeNetworkInterfaces",
"ec2:DetachNetworkInterface"
],
"Effect": "Allow",
"Resource": "*"
},
{
"Action": [
"s3:GetObject",
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:GetObjectVersion",
"s3:PutObject",
"s3:PutObjectAcl",
"s3:GetLifecycleConfiguration",
"s3:PutLifecycleConfiguration",
"s3:DeleteObject"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::<--FIll IN SPILL_BUCKET-->",
"arn:aws:s3:::<--FIll IN SPILL_BUCKET-->/*"
]
}
]
}
This policy identifies the Permissions such as writing to Cloudwatch logs or accessing S3 location all necessary for Lambda to execute Federated query.
Before continuing please make sure that you have AWS cli installed, as well as the JAR file for Postgres connector available.
First we are going to create an IAM role for the Lambda:
aws iam create-role --role-name <--ROLE NAME--> --assume-role-policy-document file://AssumePolicyDocument.json --region <--REGION-->
Next, create IAM Policy:
aws iam create-policy --policy-name <--POLICY NAME--> --policy-document file://LambdaExecutionPolicy.json
After the two are created, attach the newly created policy to the newly created role.
aws iam attach-role-policy --policy-arn <--EXECUTION POLICY ARN--> --role-name <--ROLE NAME-->
As well as attaching another existing policy for if your Postgres instance is in a VPC:
aws iam attach-role-policy --policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaVPCAccessExecutionRole --role-name <--ROLE NAME-->
Now we will upload the JAR file to an S3 bucket.
aws s3 cp ./<path>/<to>/<connector_jar_file> s3://<bucket_name>/<path_where_to_save_file>
Last, we will create a file code.json, to store the location of our code.
code.json
{
"S3Bucket": <--S3 BUCKET NAME-->,
"S3Key": <--PATH TO CONNECTOR JAR-->
}
Finally, we are ready to deploy our connector to Lambda:
aws lambda create-function --function-name <--LAMBDA FUNCTION NAME--> \
--runtime java11 \
--code file://code.json \
--handler com.amazonaws.athena.connectors.postgresql.<--COMPOSITE HANDLER--> \
--role <--Lambda Role Name ARN-->
--memory-size 3008 \
--timeout 900
<--COMPOSITE HANDLER--> Use "PostGreSqlMuxCompositeHandler" to access multiple postgres instances and "PostGreSqlCompositeHandler" to access single instance using DefaultConnectionString
LambdaMemory (--memory-size) Lambda memory in MB (min 128 - 3008 max).
LambdaTimeout (--timeout) Maximum Lambda invocation runtime in seconds. (min 1 - 900 max)
Once Lambda is deployed we need to take a couple more steps before we can start executing queries against it.
First being adding necessary environment variables. Navigate to newly created Lambda, select Configurations → Environment Variables and add the following:
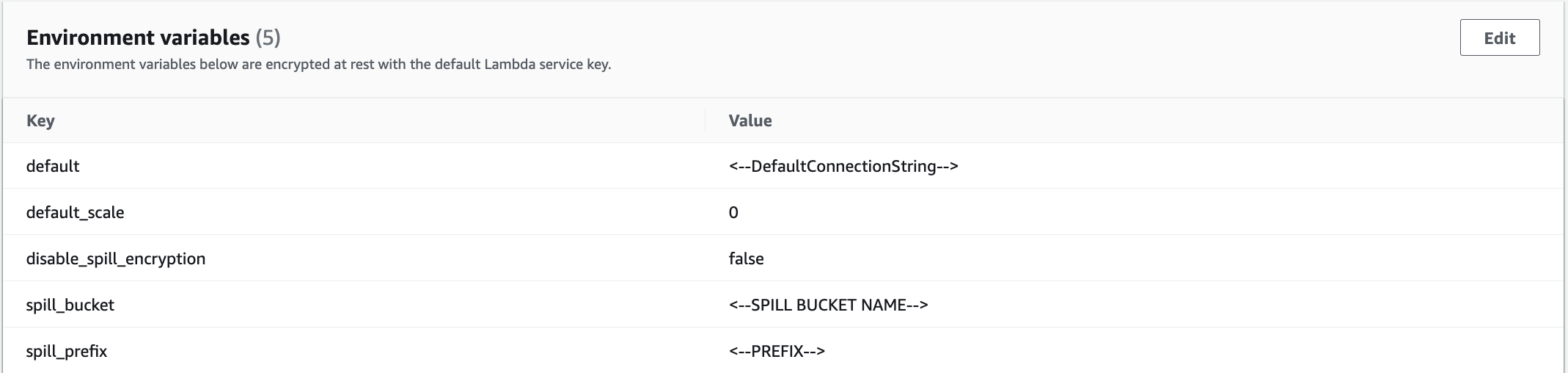
-
default:
The default connection string is used when the catalog in the Athena query is "lambda:your_postgres_lambda". Catalog specific Connection Strings can be added later. Format:
${DatabaseType}://${NativeJdbcConnectionString}. - default_scale: Default value for scale of type Numeric, representing the decimal digits in the fractional part, to the right of the decimal point.
- disable_spill_encryption: If set to 'false' data spilled to S3 is encrypted with AES GCM
- spill_bucket: The name of the bucket where this function can spill data.
- spill_prefix: The prefix within SpillBucket where this function can spill data.
Finally, if your Postgres instance is located in a VPC, navigate to Configuration → VPC and add the applicable VPC, subnets and security groups.
Once the connector has been deployed and configured, there is one final step: adding a datasource in the Athena catalog. This requires navigating to Athena console, opening up the left hand menu and selecting Data sources.

Then, continue to Create data source.

Search for PostgreSQL, select icon and Next.

This will take you to the final step, where it will prompt you to input a Data source name, which will be the Catalog name in Athena. As well as give the option of selecting newly created connector as the Lambda Function. Once both have been filled in, finish the process by selecting Next.

Now return to the main Athena Query Editor console and use the drop down on the left hand side, under Datasource, to select the newly added Datasource. Then proceed to select Database of choice, which should then allow the connector to populate the available Tables and Views.

And now you are able to execute queries against your PostgreSQL data source!
