[QNN] Implement 'qnn.softmax' #14536
Conversation
|
Thanks for contributing to TVM! Please refer to the contributing guidelines https://tvm.apache.org/docs/contribute/ for useful information and tips. Please request code reviews from Reviewers by @-ing them in a comment.
Generated by tvm-bot |
2fd2829
to
461769a
Compare
|
Thank you for the review, @masahi. I've just modified the code. |
src/relay/qnn/op/softmax.cc
Outdated
| const Expr q = Divide(Negative(x_p), x_0); | ||
| const Expr r = Subtract(x_p, Multiply(q, Negative(x_0))); | ||
| const Expr x_b = Add(RightShift(r, const_i32(1)), x_0); | ||
| const Expr exps = RightShift(LeftShift(x_b, const_i32(n)), q); |
There was a problem hiding this comment.
Could q be bigger than n? If so, aren't we ending up doing a left shift by a negative number?
There was a problem hiding this comment.
From the paper, it's not clear to me why it is always safe to right-shift by q. I don't see an obvious bound on it.
There was a problem hiding this comment.
Actually I'm not sure their eq. 14 is correct for a positive exponent, since we cannot decompose S * I into (-q) + fraction where q is positive... thought?
There was a problem hiding this comment.
I believe the decomposition can be thought of as treating S * I as the "real number" represented by I. For all real numbers we can take the integer and decimal components. The integer component in real-number space becomes a shift, and decimal component has to be quantized using S to get an integer r in the paper.
It can always be done, though whether it can be done efficiently is I think the issue. If we look at Algo 1, when S >>1 then I think the way they calculate r and q is wrong.
There was a problem hiding this comment.
Yeah but the point is to decompose in a way that the integer part is negative, so that we can "divide" (right shift) by this integer. I don't see how such decomposition is possible if the input is positive.
There was a problem hiding this comment.
Hmm, I believe it is due to the fact that the integers are all normalized by subtracting the maximum value (eq 12). Therefore all values are either <= 0
There was a problem hiding this comment.
Ok. But I'm still not sure about my first question #14536 (comment).
There was a problem hiding this comment.
Ah yes I think it can which is bad. I think the way around this might be exploring decomposing 2^[(S * 2^-k * I_p) * 2^k] instead of 2^(S * I_p) for some well chosen k.
| op = relay.qnn.op.quantize(op, relay.const(0.0038), relay.const(-128), out_dtype="int8") | ||
| op = relay.qnn.op.dequantize(op, relay.const(0.0038), relay.const(-128)) | ||
|
|
||
| x_np = np.random.random_sample([5, 10]).astype(np.float32) * 20.0 - 6 |
There was a problem hiding this comment.
Please test on more inputs, ideally on sampling from all int8 / uint8 range. This choice looks very contrived.
There was a problem hiding this comment.
What do you think about this: 35b5548#diff-3068125dc5426cffbc64c13858f102aa8f7eaee8565a6aaacb4badde71faf7b1
There was a problem hiding this comment.
Yes it looks good. We should also test on uint8. A new feature involving subtle arithmetic like this should be tested very thoroughly. See also the remark by @ibsidorenko
|
cc @AndrewZhaoLuo @ibsidorenko @Icemist please help review. |
Co-authored-by: Toshiki Maekawa <toshiki.maekawa-aoha-renesas@aoha.co.jp>
461769a
to
35b5548
Compare
| @@ -1114,5 +1114,36 @@ def test_fake_quantize_take(): | |||
| compare_fq_to_int(op, [x_np]) | |||
|
|
|||
|
|
|||
| def test_fake_quantize_softmax(): | |||
There was a problem hiding this comment.
Looks like this test does not allow to check accuracy in full.
I have printed out output and found that ~70% of output values is equal to 0.0 in this test. This is because output after qnn.quantize operation is equal to "-128". It is not very interesting/representative case for "int8" data type.
Can you slightly modify this test in the following way:
- Remove second
qnn.dequantize. Let's check output ofqnn.dequantize+softmax+qnn.quantizeonly - Play with QNN parameters (zero point, scale) in a such way that output from quantize will be in the range [-100, +100] for example. Not only "-128" like now
P.S.
I have checked output after qnn.quantize and see that some of value have diff by 7. I think it is too much and the accuracy is unsatisfactory... any thoughts?
There was a problem hiding this comment.
- Play with QNN parameters (zero point, scale) in a such way that output from quantize will be in the range [-100, +100] for example. Not only "-128" like now
I'm not sure why we need to modify QNN parameters (of qnn.quantize).
I think that it's enough to change the value range specified in x_np = np.random.randint(-128, 127, ...) to satisfy the qnn.quantize output to be in the range of [-100, +100].
(Sorry if my understanding is wrong)
There was a problem hiding this comment.
P.S.
I have checked output after qnn.quantize and see that some of value have diff by 7. I think it is too much and the accuracy is unsatisfactory... any thoughts?
In case all computation performed in integer-only arithmetic, how big diff is allowed for softmax operation generally? I'm not sure about this.
I'm also not sure if any other algorithms outperform the current implementation.
There was a problem hiding this comment.
Yes, sure, it's up to you. My main concern here is to avoid the case when all (or almost all) output values are equal to "-128" (it is not representative case for "int8" data type.)
|
Hi, @maekawatoshiki ! Thank you for your PR, really very interesting work! |
There was a problem hiding this comment.
Very interesting PR. I agree with folks that if this is the default implementation, it better be fairly accurate across a wide range of scales and inputs. While the paper you reference targets ViTs, we cannot assume only ViTs will use this implementation.
The paper itself is kind of poor when it comes to consistent notation but I think I've deciphered the intention.
Unfortunately, I have doubts on the base-line implementation discussed in the paper on the grounds of accuracy, much like many of the others have commented.
Furthermore, I believe a main issue with the algorithm is it can only deal with small input scale factors. I think this is probably a tenable problem but requires more work and rigorous testing.
src/relay/qnn/op/softmax.cc
Outdated
| const Expr quantized_data = | ||
| Subtract(Cast(new_args[0], DataType::Int(32)), Cast(input_zero_point, DataType::Int(32))); | ||
|
|
||
| const Expr x_0 = ConvertDtype( |
There was a problem hiding this comment.
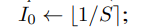
This is in ShiftExp under algorithm 1
First off, if S > 1 then we already have issues as x_0 (I_0 in paper) maybe 0...
For attention I would expect output activation range to potentially be very large (see LLM int8 paper) so having a high scale factor is not unreasonable for some schemes.
There was a problem hiding this comment.
Maybe I am not understanding something but seems like an obvious flaw...
I think you can get around this by not rounding I_0 in algorithm1 but keeping it a float and rounding when needed. However this would introduce runtime FLOPS.
There was a problem hiding this comment.
Another option is when decomposing 2^(S * I_p) into integer and decimal components, you instead decompose:
2^[(S * 2^-n * I_p) * 2^n]. At compile time we can choose an n to make S * 2^-n << 1 to get around this problem. You can then apply the decomposition routine to the internal terms in parentheses and the outer 2^n now merely becomes another shift.
There was a problem hiding this comment.
I believe S here is defined as:
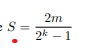
Which can be be artbirary depending on the range m.
There was a problem hiding this comment.
We can fallback to the fp32-based impl when S > 1.
There was a problem hiding this comment.
Yeah I think that is another reasonable thing to do.
| shape = [50, 10] | ||
| x = relay.var("x", shape=shape, dtype="int8") | ||
|
|
||
| x = relay.qnn.op.dequantize(x, relay.const(0.08), relay.const(-48)) |
There was a problem hiding this comment.
Things we probably want to test:
- Different dtypes
- Different scale factors
- Different distributions along the axis of reduction (e.g. flat distribution should give flat probabilities, muiltiple spikes, etc.)
|
I appreciate your review! I found a quantized softmax implementation in tensorflow lite: (https://github.com/tensorflow/tensorflow/blob/305fec9fddc3bdb5bb574a134b955bf4b07fd795/tensorflow/lite/kernels/internal/reference/softmax.h#L60), so I'm going to try it and compare the accuracy with my current implementation. Besides, from #14536 (comment) and #14536 (comment), the current unit tests need to be improved, I acknowledged. |
src/relay/qnn/op/softmax.cc
Outdated
| // Refer to the Algorithm 1 in https://arxiv.org/pdf/2207.01405.pdf | ||
|
|
||
| const Expr quantized_data = | ||
| Subtract(Cast(new_args[0], DataType::Int(32)), Cast(input_zero_point, DataType::Int(32))); |
There was a problem hiding this comment.
Is it necessary to cast input_zero_point to int32? It is assumed that input_zero_point is of type int32.
There was a problem hiding this comment.
This is apparently a redundant cast. I should remove it.
|
I took a look at the latest tensorflow implementation and noticed it is, for some reason, using float arithmetic: https://github.com/tensorflow/tensorflow/blob/98a187a8bfcdcf0c55c16f07b4a06b50e06a9a26/tensorflow/lite/kernels/internal/optimized/optimized_ops.h#L3471-L3477. I also found another paper proposing quantized softmax (https://arxiv.org/pdf/2101.01321.pdf) and its implementation (https://github.com/kssteven418/I-BERT/blob/1b09c759d6aeb71312df9c6ef74fa268a87c934e/fairseq/quantization/utils/quant_modules.py#L578). I realized that it's difficult to implement integer-only quantized softmax with satisfying quality in a variety of input scales. Let me abandon this PR for now to investigate further, and hopefully, I'll make another PR. |
|
Yeah it is challenging problem. I would not necessarily constrain yourself to making a single implementation that can handle all cases however. Feel free to plan for several future specialization with fallbacks if needed imo. Just make sure tests reflect this. Though, will leave up to you. |
|
Does this make sense to add this
I guess it's OK to relax checks of unittests if this feature is optional? What are your thoughts? |
|
@shinh Sounds good to me, as long as things won't break by default, I don't see any problem. |
Co-authored-by: Toshiki Maekawa <toshiki.maekawa-aoha-renesas@aoha.co.jp>
Co-authored-by: Toshiki Maekawa <toshiki.maekawa-aoha-renesas@aoha.co.jp>
Co-authored-by: Toshiki Maekawa <toshiki.maekawa-aoha-renesas@aoha.co.jp>
Co-authored-by: Toshiki Maekawa <toshiki.maekawa-aoha-renesas@aoha.co.jp>
Co-authored-by: Toshiki Maekawa <toshiki.maekawa-aoha-renesas@aoha.co.jp>
| const auto const_input_scale = new_args[1].as<ConstantNode>(); | ||
| ICHECK(const_input_scale) << "Input scale should be constant."; | ||
| ICHECK(const_input_scale->is_scalar()) << "Input scale should be scalar."; | ||
| const float input_scale = static_cast<float*>(const_input_scale->data->data)[0]; | ||
| ICHECK(input_scale <= 1.f) << "Input scale should be less than or equal to 1."; |
There was a problem hiding this comment.
The assertion fails when the input scale does not meet the condition.
| mod_int = tvm.relay.transform.FakeQuantizationToInteger( | ||
| hard_fail=True, optional_qnn_ops=["nn.softmax"] | ||
| )(mod) |
There was a problem hiding this comment.
The pass does not use the fully-integer implementation for nn.softmax, unless it is specified in optional_qnn_ops.
| # Check at least the softmax output is in ascending order, | ||
| # since it is difficult to use allclose due to not-so-good accuracy. | ||
| for qdq, qop in zip(result, result_int): | ||
| assert is_sorted(qdq) | ||
| assert is_sorted(qop) | ||
|
|
||
| try: | ||
| np.testing.assert_allclose(result_int, result, atol=1) | ||
| except AssertionError as e: | ||
| # To see the difference | ||
| print(e) |
There was a problem hiding this comment.
What do you think about this?
I checked the max absolute difference here is, in most cases, 0~6.
Also the overall trend of the softmax output didn't differ much between the QOp and QDQ implementation.
There was a problem hiding this comment.
As long as this implementation is useful for your use case, I'm fine with this. cc @ibsidorenko @AndrewZhaoLuo
Co-authored-by: Toshiki Maekawa <toshiki.maekawa-aoha-renesas@aoha.co.jp>
This PR implements
qnn.softmaxwhich is the quantized operator ofnn.softmax.The implementation is based on the algorithm proposed in https://arxiv.org/pdf/2207.01405.pdf.