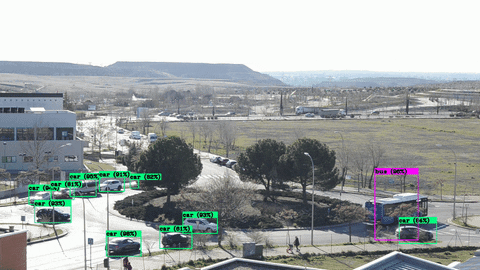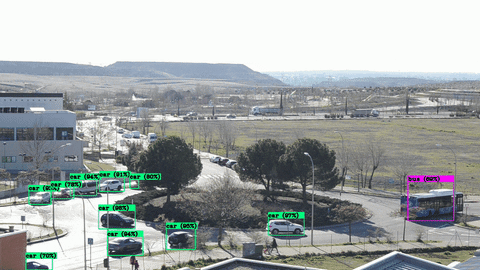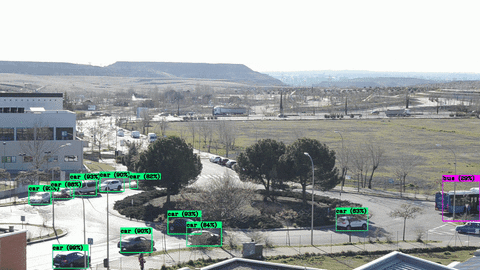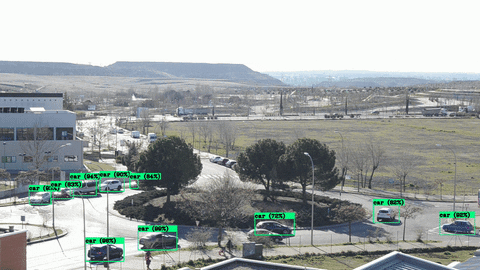
This tutorial shows how to train a YOLOv4 vehicle detector using Darknet and the RoundaboutTraffic dataset on a NVIDIA Jetson Nano 2GB.
- Setup
- Installing Darknet
- Downloading training data
- Configuring YOLO architecture
- Training the model
- Testing the model
- Optimizations
First you need to setup your Jetson Nano. In order to do that please refer to the Getting Started Guide. If you are using the Jetson Nano 4GB version, you can find the Getting Started Guide here.
Don't forget to check the swap memory. You must have at least 4GB of swap. The following procedure for changing the swap value was taken from Getting Started with AI on Jetson Nano :
# Disable ZRAM:
$ sudo systemctl disable nvzramconfig
# Create 4GB swap file
$ sudo fallocate -l 4G /mnt/4GB.swap
$ sudo chmod 600 /mnt/4GB.swap
$ sudo mkswap /mnt/4GB.swap
# Append the following line to /etc/fstab
$ sudo su
$ echo "/mnt/4GB.swap swap swap defaults 0 0" >> /etc/fstab
$ sudo rebootNow pull the current repository:
$ mkdir -p ${HOME}/tutorial
$ cd ${HOME}/tutorial
$ git clone https://github.com/alxandru/yolov4_roundabout_traffic.gitIf you followed the instructions in the Getting Started Guide, you should have a properly installed environment and can proceed to the next steps.
Next step is to download and build the Darknet framework.
- Pull the Git repository:
$ cd ${HOME}/tutorial
$ git clone https://github.com/AlexeyAB/darknet.git- Modify the
darknet/Makefile:
We are reconfigure the Makefile to run with the following flags activated:
GPU=1
CUDNN=1
CUDNN_HALF=1
OPENCV=1Add the following architecture for Jetson Nano:
ARCH= -gencode arch=compute_53,code=sm_53 \
-gencode arch=compute_53,code=[sm_53,compute_53]You can make the above changes manually or by running the following script that uses sed:
$ bash yolov4_roundabout_traffic/utils/modify_makefile.shFor more information about these settings please refer to How to compile on Linux (using make).
- (Optional) By default Darknet backups the trained weights of your model every 100 epochs or when it reaches a new best mAP score. Training on a Jetson Nano can be frustrating and slow due to limited resources. I recommend to modify the code in order to change the backup to every 25 epochs or so. This way you can start the training where you left off without waiting to train another 100 epochs if the process is killed by the OS when it consumes all the resources (it may happen more often than you think on a such limited device). I created a patch that does all these modifications:
$ cd ${HOME}/tutorial
$ cp ${HOME}/tutorial/yolov4_roundabout_traffic/utils/darknet_epochs.patch darknet/
$ cd darknet
$ git apply darknet_epochs.patch
$ git diff # to check the changes- Compile Darknet:
$ cd darknet
$ make- Download yolov4 pre-trained weights to make a sample prediction:
$ wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights- Now you can check weather the installation is successful:
$ ./darknet detector test cfg/coco.data cfg/yolov4.cfg \
yolov4.weights data/person.jpgRun the get_data.sh script in the data/ subdirectory. It will download the "RoundaboutTraffic" dataset that's already has the directory structure and the YOLO txt files necessary to train a YOLO network. After the download is completed, it will copy the dataset into the darknet/data folder. The images and their annotations are only linked. You could refer to data/README.md for more information about the dataset. You could also check How to train (to detect your custom objects) for an explanation of YOLO txt files.
$ cd ${HOME}/tutorial/yolov4_roundabout_traffic/data
$ bash get_data.shYOLO comes with various architectures. Some are large, other are small. For training and testing on a limited embedded device like Jetson Nano, I picked the yolov4-tiny architecture, which is the smallest one, and change it for the RoundaboutTraffic dataset.
For a step by step guide on how to configure a YOLO architecture please refer to How to train (to detect your custom objects).
You can just copy the cfg/yolov4-tiny-bus-car.cfg to darknet/cfg folder or check the script utils/configure_arch.sh and run it. It will make a copy of darknet/cfg/yolov4-tiny-custom.cfg file and modify it to suit the training data and the Jetson Nano.
$ cd ${HOME}/tutorial/yolov4_roundabout_traffic/utils
$ bash configure_arch.sh
# Check weather the cfg file was created
$ less ${HOME}/tutorial/darknet/cfg/yolov4-tiny-bus-car.cfgWe download the yolov4-tiny.conv.29 pre-trained weights:
$ cd ${HOME}/tutorial/darknet
$ wget https://github.com/AlexeyAB/darknet/releases/download/yolov4/yolov4-tiny.conv.29Finally, we train the model:
$ ./darknet detector train data/obj.data cfg/yolov4-tiny-bus-car.cfg \
yolov4-tiny.conv.29 -dont_show -mjpeg_port 8090 -mapThe training will last for a long time and after a couple of hours most likely the process is killed by the OS due to high memory/cpu consumption. If you applied the patch described in Installing Darknet Step 3, the weights are backup every 25 epochs. You can continue the training with the weight of the last backup:
$ cd backup
$ cp yolov4-tiny-bus-car_last.weights yolov4-tiny-bus-car_last1.weights
$ cd ..
$ ./darknet detector train data/obj.data cfg/yolov4-tiny-bus-car.cfg \
backup/yolov4-tiny-bus-car_last1.weights \
-dont_show -mjpeg_port 8090 -mapNormally when the model is being trained, you could monitor its progress on the loss/mAP chart (since the -map option is used). But since the process is restarted various time due to limited resources the chart is fragmented (for every restart there is a new chart). Hence, I don't include the loss/mAP chart here.
I trained the model for 1525 epochs and took about 3 days.
After the training is done you can check the mAP of the best model on an new video like this:
$ ./darknet detector map data/obj.data cfg/yolov4-tiny-bus-car.cfg \
backup/yolov4-tiny-bus-car_best.weights \
${HOME}/tutorial/test002.mp4I got (mAP@0.50) = 0.953121, or 95.31 % when tested my best custom trained model:
calculation mAP (mean average precision)...
Detection layer: 30 - type = 28
Detection layer: 37 - type = 28
detections_count = 5667, unique_truth_count = 2857
class_id = 0, name = bus, ap = 93.85% (TP = 83, FP = 0)
class_id = 1, name = car, ap = 96.77% (TP = 2618, FP = 43)
for conf_thresh = 0.25, precision = 0.98, recall = 0.95, F1-score = 0.96
for conf_thresh = 0.25, TP = 2701, FP = 43, FN = 156, average IoU = 78.67 %
IoU threshold = 50 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.50) = 0.953121, or 95.31 %And if tested with an IoU threshold = 75%:
$ ./darknet detector map data/obj.data cfg/yolov4-tiny-bus-car.cfg \
backup/yolov4-tiny-bus-car_last.weights \
${HOME}/tutorial/test002.mp4 -iou_thresh 0.75the mAP decreases to mAP@0.75) = 0.609026, or 60.90 %:
calculation mAP (mean average precision)...
Detection layer: 30 - type = 28
Detection layer: 37 - type = 28
detections_count = 5667, unique_truth_count = 2857
class_id = 0, name = bus, ap = 48.82% (TP = 55, FP = 28)
class_id = 1, name = car, ap = 72.98% (TP = 2158, FP = 503)
for conf_thresh = 0.25, precision = 0.81, recall = 0.77, F1-score = 0.79
for conf_thresh = 0.25, TP = 2213, FP = 531, FN = 644, average IoU = 66.81 %
IoU threshold = 75 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.75) = 0.609026, or 60.90 %Here is a video snippet with the darknet detector running only with yolov4-tiny.conv.29 pre-trained weights (click on image to open the Youtube video):

As you can see the occlusions (trees, other cars) in the roundabout and some of the angles the vehicles were caught in different frames clearly affect the detection. The IoU percentage is also not so great.
On the other hand with the best custom trained model the detection and IoU percentage improve significantly with 1525 epochs of training.

In terms of FPS processed by darknet with the trained model and with an input video of 1920x1080@30FPS it gives us around 10 FPS on average:
Finally, let's run a benchmark test on the test video to see the performance in terms of FPS processed by darknet:
$ ./darknet detector demo data/obj.data cfg/yolov4-tiny-bus-car.cfg \
backup/yolov4-tiny-bus-car_best.weights \
${HOME}/tutorial/test002.mp4 -benchmarkWith the trained model for an input video of 1920x1080@30FPS darknet processes around 10 FPS on average:
FPS:9.9 AVG_FPS:10.0
Objects:
FPS:9.9 AVG_FPS:10.0
Objects:
FPS:9.9 AVG_FPS:10.0
Objects:
FPS:9.9 AVG_FPS:10.0
Objects:
FPS:9.9 AVG_FPS:10.0
Objects:
FPS:9.9 AVG_FPS:10.0
Objects:
...Next we will see how to improve the inference performance using DeepStream-Yolo.
Once we have all the requirements installed, we download the DeepStream-Yolo repo.
$ cd ${HOME}/tutorial
$ git clone https://github.com/marcoslucianops/DeepStream-Yolo.git
$ cd DeepStream-YoloCompile the library for the Jetson platform:
$ CUDA_VER=10.2 make -C nvdsinfer_custom_impl_YoloEdit the config_infer_primary.txt for our custom yolov4-tiny model:
[property]
gpu-id=0
net-scale-factor=0.0039215697906911373
model-color-format=0
custom-network-config=${HOME}/project/darknet/cfg/yolov4-tiny-bus-car.cfg
model-file=${HOME}/project/darknet/backup/yolov4-tiny-bus-car_best.weights
model-engine-file=model_b1_gpu0_fp32.engine
#int8-calib-file=calib.table
labelfile-path=${HOME}/project/darknet/data/obj.names
batch-size=1
## 0=FP32, 1=INT8, 2=FP16 mode
network-mode=0
num-detected-classes=2
interval=0
gie-unique-id=1
process-mode=1
network-type=0
cluster-mode=2
maintain-aspect-ratio=0
parse-bbox-func-name=NvDsInferParseYolo
custom-lib-path=nvdsinfer_custom_impl_Yolo/libnvdsinfer_custom_impl_Yolo.so
engine-create-func-name=NvDsInferYoloCudaEngineGet
[class-attrs-all]
nms-iou-threshold=0.5
pre-cluster-threshold=0.25Note: If you don't have the YOLO weights you can use the cfg/yolov4-tiny-bus-car_best.weights.
Also edit the deepstream_app_config.txt file to specify the input video and to save the output to a mp4 file:
...
[source0]
enable=1
type=3
uri=file://<path to the input mp4 file>
num-sources=1
gpu-id=0
cudadec-memtype=0
[sink0]
enable=1
type=3
#1=mp4 2=mkv
container=1
#1=h264 2=h265
codec=1
sync=0
bitrate=2000000
output-file=<path to the output file>
source-id=0
...Note: You can use this video as the input video.
Run the deepstream-app that was installed with the DeepStream SDK with our configuration.
deepstream-app -c deepstream_app_config.txtBy converting the model to TRT a small increase in inference performance in terms of FPS may be observed:
**PERF: 13.54 (13.44)
**PERF: 13.52 (13.52)
**PERF: 13.50 (13.48)
**PERF: 13.50 (13.51)
**PERF: 13.50 (13.49)
**PERF: 13.48 (13.47)We gained around 3.5 FPS comparing to the baseline model. But can we do better? Let's change the FP32 inference to FP16 (precision will be lost).
Change the config_infer_primary.txt:
...
model-engine-file=model_b1_gpu0_fp32.engine
...
network-mode=0
...to:
...
model-engine-file=model_b1_gpu0_fp16.engine
...
network-mode=2
...And run the deepstream-app again:
deepstream-app -c deepstream_app_config.txtWe can observer a significant improvement in terms of FPS comparing to the baseline model (around 12.5 FPS more):
**PERF: 22.54 (22.44)
**PERF: 22.52 (22.52)
**PERF: 22.50 (22.48)
**PERF: 22.50 (22.51)
**PERF: 22.50 (22.49)
**PERF: 22.48 (22.47)Although DeepStream-Yolo offers support for INT8 inference, the Jetson Nano does not support it. It requires GPU architecture > 7.x. Details can be found here.