-
Notifications
You must be signed in to change notification settings - Fork 31
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
feat: support for pdf download (#109)
- Loading branch information
Showing
6 changed files
with
104 additions
and
15 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,56 @@ | ||
| # Case study: convert a page and download the PDFs referenced on the page | ||
|
|
||
| Page to consider: https://main--hlxsite--kptdobe.hlx.page/content/page-with-pdf | ||
|
|
||
| This is dummy page, do not worry about the look and feel or if the content is meaningful. The goal is to convert that page to docx AND to tell the importer to download the referenced PDF. | ||
|
|
||
| Here is an import.js example: | ||
|
|
||
| ```js | ||
| export default { | ||
| transform: ({ | ||
| // eslint-disable-next-line no-unused-vars | ||
| document, | ||
| url, | ||
| }) => { | ||
| const main = document.body; | ||
| const results = []; | ||
|
|
||
| // main page import - "element" is provided, i.e. a docx will be created | ||
| results.push({ | ||
| element: main, | ||
| path: new URL(url).pathname | ||
| }); | ||
|
|
||
| // find pdf links | ||
| main.querySelectorAll('a').forEach((a) => { | ||
| const href = a.getAttribute('href'); | ||
| if (href && href.endsWith('.pdf')) { | ||
| const u = new URL(href, url); | ||
| const newPath = WebImporter.FileUtils.sanitizePath(u.pathname); | ||
| // no "element", the "from" property is provided instead - importer will download the "from" resource as "path" | ||
| results.push({ | ||
| path: newPath, | ||
| from: u.toString(), | ||
| }); | ||
|
|
||
| // update the link to new path on the target host | ||
| // this is required to be able to follow the links in Word | ||
| // you will need to replace "main--repo--owner" by your project setup | ||
| const newHref = new URL(newPath, 'https://main--repo--owner.hlx.page').toString(); | ||
| a.setAttribute('href', newPath); | ||
| } | ||
| }); | ||
|
|
||
| return results; | ||
| }, | ||
| }; | ||
| ``` | ||
|
|
||
| Using the `transform` method and multiple outputs, you can return the page to be transformed and each pdf to be downloaded. When running the import on the url above, you get the following files: | ||
|
|
||
| 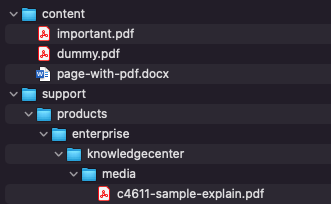 | ||
|
|
||
| Notes: | ||
| - if you do not need the page as a docx, you can remove the first part - only the PDFs will be downloaded | ||
| - this would potentially work with other type of resource |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters