![]()





使用文档: ReadTheDocs | 语言: English / 中文
链接: API文档 | 示例 | PyPI | 发布日志 | 源代码 | 下载 | 知乎/Zhihu | arXiv
论文: IMBENS: Ensemble Class-imbalanced Learning in Python
imbalanced-ensemble(IMBENS)是一个 Python 库/软件包。它主要用于在类别不平衡数据上快速实现和部署集成学习算法。截至目前(2021/06),IMBENS已实现了14种不同的不平衡集成学习算法,从经典的SMOTEBoost (2003) 到最近的 SPE (2020),从欠采样、过采样到代价敏感学习,全部包括在内。IMBENS实现的大部分方法都具有详细的 文档和使用手册,并将在未来继续更新加入其他方法。
- ⭐ 如果此项目对您有帮助,请点一个STAR~ ⭐
- 如果您发现了bug或者有其他建议,请open issue/PR。
- 我们非常感谢任何可能的帮助,Contributors✨一节会记录所有的贡献者!
IMBENS的主要特性有:
- 🍎 统一易用的API设计,便于使用和二次开发,详细的 文档 和 示例
- 🍎 所有实现的方法均原生支持多分类不平衡问题
- 🍎 在可能的情况下,使用 joblib 实现并行训练/预测以优化性能
- 🍎 强大的、可定制的、交互式的模型训练日志记录和可视化工具
- 🍎 完全兼容其他的流行软件包,如 scikit-learn 和 imbalanced-learn
API 使用示例:
# Train an SPE classifier
from imbens.ensemble import SelfPacedEnsembleClassifier
clf = SelfPacedEnsembleClassifier(random_state=42)
clf.fit(X_train, y_train)
# Predict with an SPE classifier
y_pred = clf.predict(X_test)如果IMBENS帮助了您的工作或研究, 我们将非常感谢对以下 论文 的引用:
@article{liu2021imbens,
title={IMBENS: Ensemble Class-imbalanced Learning in Python},
author={Liu, Zhining and Wei, Zhepei and Yu, Erxin and Huang, Qiang and Guo, Kai and Yu, Boyang and Cai, Zhaonian and Ye, Hangting and Cao, Wei and Bian, Jiang and Wei, Pengfei and Jiang, Jing and Chang, Yi},
journal={arXiv preprint arXiv:2111.12776},
year={2021}
}推荐使用pip进行安装:
$ pip install imbalanced-ensemble # 正常安装
$ pip install --upgrade imbalanced-ensemble # 升级安装IMBENS更新较为频繁,请确认安装的是最新版本以规避可能的问题。
或者从Github克隆到本地安装:
$ git clone https://github.com/ZhiningLiu1998/imbalanced-ensemble.git
$ cd imbalanced-ensemble
$ pip install .imbalanced-ensemble 具有以下依赖项:
- Python (>=3.6)
- numpy (>=1.16.0)
- pandas (>=1.1.3)
- scipy (>=0.19.1)
- joblib (>=0.11)
- scikit-learn (>=0.24)
- matplotlib (>=3.3.2)
- seaborn (>=0.11.0)
- tqdm (>=4.50.2)
目前,IMBENS实现了16种集成学习方法(点击类名可跳转至文档页面):
- 基于重采样的方法
- 降采样 + 集成
- 过采样 + 集成
- 基于重加权的方法
- 代价敏感学习 + 集成
AdaCostClassifier[8]AdaUBoostClassifier[9]AsymBoostClassifier[10]
- 代价敏感学习 + 集成
- 兼容方法
本节中我们提供一些简单的指南来帮助您快速开始使用 IMBENS。
我们强烈希望您查看 示例仓库 中的更全面的使用示例,其中演示了 IMBENS 的许多高级特性。

一个可运行的示例:以 SPE[1] 为例,仅需少于10行的代码就可以部署它:
>>> from imbens.ensemble import SelfPacedEnsembleClassifier
>>> from sklearn.datasets import make_classification
>>> from sklearn.model_selection import train_test_split
>>>
>>> X, y = make_classification(n_samples=1000, n_classes=3,
... n_informative=4, weights=[0.2, 0.3, 0.5],
... random_state=0)
>>> X_train, X_test, y_train, y_test = train_test_split(
... X, y, test_size=0.2, random_state=42)
>>> clf = SelfPacedEnsembleClassifier(random_state=0)
>>> clf.fit(X_train, y_train)
SelfPacedEnsembleClassifier(...)
>>> clf.predict(X_test)
array([...])imbens.visualizer子模块提供了一个可视化器类ImbalancedEnsembleVisualizer。它可对集成分类器进行直观的可视化来获取更多信息或比较不同方法的性能。请阅读 可视化工具的文档 以及 使用示例 以获取更详细的信息。
拟合一个可视化器
from imbens.ensemble import SelfPacedEnsembleClassifier
from imbens.ensemble import RUSBoostClassifier
from imbens.ensemble import EasyEnsembleClassifier
from sklearn.tree import DecisionTreeClassifier
# Fit ensemble classifiers
init_kwargs = {'estimator': DecisionTreeClassifier()}
ensembles = {
'spe': SelfPacedEnsembleClassifier(**init_kwargs).fit(X_train, y_train),
'rusboost': RUSBoostClassifier(**init_kwargs).fit(X_train, y_train),
'easyens': EasyEnsembleClassifier(**init_kwargs).fit(X_train, y_train),
}
# Fit visualizer
from imbens.visualizer import ImbalancedEnsembleVisualizer
visualizer = ImbalancedEnsembleVisualizer().fit(ensembles=ensembles)使用可视化器展示不同方法的性能曲线(performance curve)
fig, axes = visualizer.performance_lineplot()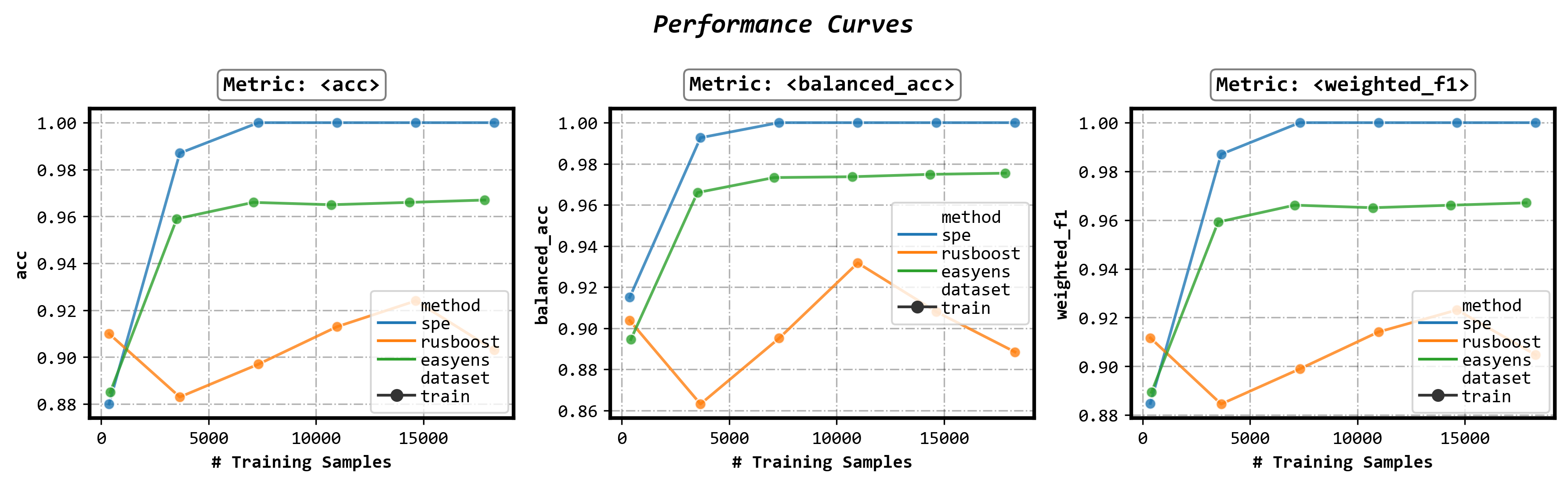
使用可视化器展示不同方法的混淆矩阵(confusion matrices)
fig, axes = visualizer.confusion_matrix_heatmap()
IMBENS 中实现的所有集成分类器都支持打印可自定义的训练日志。训练日志由 fit() 方法的 eval_datasets、eval_metrics 和 training_verbose 3 个参数控制。请阅读 fit() 方法的文档 来获得更详细的使用方法。
启用训练日志
clf.fit(..., train_verbose=True)自定义训练日志的粒度和内容
clf.fit(...,
train_verbose={
'granularity': 10,
'print_distribution': False,
'print_metrics': True,
})增加验证集(可以有多个名字不重复的验证集)
clf.fit(...,
eval_datasets={
'valid': (X_valid, y_valid)
})自定义所使用的评价指标
from sklearn.metrics import accuracy_score, f1_score
clf.fit(...,
eval_metrics={
'acc': (accuracy_score, {}),
'weighted_f1': (f1_score, {'average':'weighted'}),
})“类别不平衡”指一个分类任务的数据中来自不同类别的样本数目相差悬殊。传统的机器学习模型假设数据的边缘分布P(Y)是大致均匀的,因此它们通常被设计为优化分类的准确率(accuracy),并未考虑不同类别的样本数量差异。在类别不平衡的情况下,样本数量少的类别对分类准确率的影响很小,因此直接优化分类准确率的模型会难以学习到少数类的模式,导致对于少数类的预测结果较差。尽管少数类的样本个数更少,表示的质量也更差,但其通常会携带更重要的信息,因此一般我们更关注模型正确分类少数类样本的能力。因此我们希望能够使用某些手段修正不平衡数据给模型带来的偏见,得到一个无偏的预测模型。从类别不平衡数据中学习无偏模型的问题通常被称为不平衡学习,在多类别场景下也被称为长尾学习。
更多有关不平衡学习的背景、定义、评价准则等,请参考:极端类别不平衡数据下的分类问题S02:问题概述,模型选择及人生经验 - 知乎 (zhihu.com) 。
我们可以大致对常见的不平衡学习技术做出如下分类:
- 重采样 (re-sampling): 直接更改训练集中不同类别样本的数量
- 欠采样 (under-sampling): 丢弃多数类中的样本
- 过采样 (over-sampling): 为少数类生成新的样本
- 数据清洁 (cleaning): 根据特定的规则清除一些样本
- 混合采样 (hybrid-sampling): 结合上述方法,常见组合为过采样+数据清洁
- 重加权 (re-weighting): 更改不同样本在模型训练中的权重
- 类别重加权 (class-wise reweighting): 为不同类别的样本分配不同权重,如代价敏感学习 (cost-sensitive learning) 类方法
- 样本重加权 (instance-wise reweighting): 为不同的样本分配不同权重,如难例挖掘 (hard example mining) 类方法
- 其他方法,如后验概率调整 (posterior probability adjustment) 等。
若对相关的研究论文以及子领域划分感兴趣,请参考有关类别不平衡(长尾)机器学习的一切:论文,代码,框架与库 -知乎 (zhihu.com) 以及 ZhiningLiu1998/awesome-imbalanced-learning: A curated list of awesome imbalanced learning papers, codes, frameworks, and libraries. (github.com) 。
| # | Reference |
|---|---|
| [1] | Liu, Z., Cao, W., Gao, Z., Bian, J., Chen, H., Chang, Y., & Liu, T. Y. (2020, April). Self-paced ensemble for highly imbalanced massive data classification. In 2020 IEEE 36th International Conference on Data Engineering (ICDE) (pp. 841-852). IEEE. |
| [2] | Liu, X. Y., Wu, J., & Zhou, Z. H. (2008). Exploratory undersampling for class-imbalance learning. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 39(2), 539-550. |
| [3] | Chen, Chao, Andy Liaw, and Leo Breiman. “Using random forest to learn imbalanced data.” University of California, Berkeley 110 (2004): 1-12. |
| [4] | C. Seiffert, T. M. Khoshgoftaar, J. Van Hulse, and A. Napolitano, Rusboost: A hybrid approach to alleviating class imbalance. IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans, vol. 40, no. 1, pp. 185–197, 2010. |
| [5] | Maclin, R., & Opitz, D. (1997). An empirical evaluation of bagging and boosting. AAAI/IAAI, 1997, 546-551. |
| [6] | N. V. Chawla, A. Lazarevic, L. O. Hall, and K. W. Bowyer, Smoteboost: Improving prediction of the minority class in boosting. in European conference on principles of data mining and knowledge discovery. Springer, 2003, pp. 107–119 |
| [7] | S. Wang and X. Yao, Diversity analysis on imbalanced data sets by using ensemble models. in 2009 IEEE Symposium on Computational Intelligence and Data Mining. IEEE, 2009, pp. 324–331. |
| [8] | Fan, W., Stolfo, S. J., Zhang, J., & Chan, P. K. (1999, June). AdaCost: misclassification cost-sensitive boosting. In Icml (Vol. 99, pp. 97-105). |
| [9] | Shawe-Taylor, G. K. J., & Karakoulas, G. (1999). Optimizing classifiers for imbalanced training sets. Advances in neural information processing systems, 11(11), 253. |
| [10] | Viola, P., & Jones, M. (2001). Fast and robust classification using asymmetric adaboost and a detector cascade. Advances in Neural Information Processing System, 14. |
| [11] | Freund, Y., & Schapire, R. E. (1997). A decision-theoretic generalization of on-line learning and an application to boosting. Journal of computer and system sciences, 55(1), 119-139. |
| [12] | Breiman, L. (1996). Bagging predictors. Machine learning, 24(2), 123-140. |
| [13] | Guillaume Lemaître, Fernando Nogueira, and Christos K. Aridas. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning. Journal of Machine Learning Research, 18(17):1–5, 2017. |
查看 我 的其他开源机器学习项目!
 Self-paced Ensemble [ICDE] 
|
 Meta-Sampler [NeurIPS] 
|
 Imbalanced Learning [Awesome] 
|
 Machine Learning [Awesome] 
|
Thanks goes to these wonderful people (emoji key):
 Zhining Liu 💻 🤔 🚧 🐛 📖 |
 leaphan 🐛 |
 hannanhtang 🐛 |
 H.J.Ren 🐛 |
This project follows the all-contributors specification. Contributions of any kind welcome!