本项目针对NLP的NER方向开源目前业界流行的解决方案,该方案提供了从线下训练到线上部署的一整套闭环流程。
具体模型包括:
1)基于bert进行微调【已集成】;
2)bert+crf【已集成】;
3)bert+bilstm+crf【已集成】;
4)bert+mrc机制【已集成】;
【整体环境配置】
- Python3.6
- tensorflow-gpu==1.14.0
- tensorflow-serving-api==1.14.0
- transformers==2.10.0
- pytorch==1.5.0
为了增加独立性,方便复现,将每一个模型作为单独的模块进行维护。项目构成如下所示:
-
---bert_ce:基于bert微调的方案
- ---run_ner_bert_ce.py:ner训练的主程序入口;
- ---modeling.py:引自bert源码;
- ---optimization.py:引自bert源码;
- ---tokenization.py:引自bert源码;
- ---tf_metrics.py:性能指标计算;
- ---utils_.py:工具函数封装;
- ---infer_offline.py:线下推理;
- ---infer_online.py:线上推理;
- ---checkpoint:存储模型的文件夹;
- ---exported_model:存储导出的pb格式模型的文件夹;
- ---start_tfs_single_model.sh:启动docker的tf-serving容易的命令;
-
---bert_blstm_crf:bert+crf和bert+bilstm+crf两种方案
- ---run_ner_bert_blstm_crf.py:ner训练的主程序入口;
- ---modeling.py:引自bert源码;
- ---optimization.py:引自bert源码;
- ---tokenization.py:引自bert源码;
- ---tf_metrics.py:性能指标计算;
- ---utils_.py:工具函数封装;
- ---infer_offline.py:线下推理;
- ---infer_online.py:线上推理;
- ---checkpoint:存储模型的文件夹;
- ---exported_model:存储导出的pb格式模型的文件夹;
- ---start_tfs_single_model.sh:启动docker的tf-serving容易的命令;
-
---china-people-daily-data
中国人民日报的NER数据集,包括train/dev/test,格式如下:
海 钓 比 赛 地 点 在 厦 门 与 金 门 之 间 的 海 域 。-seq-O O O O O O O B-LOC I-LOC O B-LOC I-LOC O O O O O O
-
---china-people-daily-data-lie
同是中国人民日报的NER数据集,只不过格式发生了变化:
海 O 钓 O 比 O 赛 O 地 O 点 O 在 O 厦 B-LOC 门 I-LOC 与 O 金 B-LOC 门 I-LOC 之 O 间 O 的 O 海 O 域 O 。 O
-
---msra_data
MSRA的NER数据集,包含内容以及数据格式与‘china-people-daily-data’一致。
-
---msra_data_lie
MSRA的NER数据集,包含内容以及数据格式与‘china-people-daily-data-lie’一致。
接下来将针对以下模型来叙述从线下训练到线上部署的闭环流程: bert_ce bert_bilstm_crf bert_mrc
【前置:预训练模型配置】
下载chinese_L-12_H-768_A-12(链接:https://pan.baidu.com/s/1uLrGC6jDWZkf85QdaTLHwQ 提取码:ll38),并将放置到‘pretrained_models’文件夹中;
该模型直接在BERT的后面加入一个全连接层,然后使用交叉熵损失函数进行学习优化指标,具体模型图如下所示:

准备训练的数据集,包含train/dev/test.txt,格式如下:
海 O
钓 O
比 O
赛 O
地 O
点 O
在 O
厦 B-LOC
门 I-LOC
与 O
金 B-LOC
门 I-LOC
之 O
间 O
的 O
海 O
域 O
。 O本项目直接使用china-people-daily-data-lie数据集,包含‘PER’(人物)、‘ORG’(组织机构)、‘LOC’(地点)三种实体类型;
进入bert_ce文件夹,运行‘run_ner_bert.py’;
注意设置下列参数:
do_train:True
do_eval:True
do_predict:False
do_infer:False$ cd bert_ce
$ python run_ner_bert.py运行后取得的评估结果如下:

关于模型的其它参数已封装在run_ner_bert.py文件中,可自行查看。
针对‘run_ner_bert.py’设置如下参数:
do_train:False
do_eval:False
do_predict:True
do_infer:True随后再次运行:
$ python run_ner_bert.py运行后可在exported_model文件中查看导出的pb模型:

运行‘infer_offline.py’:
$ python infer_offline.py
线上服务是基于docker和tf-serving来启动的。
首先安装docker,然后拉取tf-serving镜像:
$ sudo docker pull tensorflow/serving 随后使用脚本来启动服务:
$ bash start_tfs_single_model.sh
启动成功后运行‘infer_online.py’:
$ python infer_online.py
该模型是在BERT之后加入一个双向LSTM网络,随后使用CRF进行解码优化,具体模型图如下:

此处训练/预测使用‘run_ner_bert_lstm_crf.py’文件。
后面的训练到部署事宜与2.1节一致,请自行查看。
在使用这个方案时,若你想切换bert_bilstm_crf和bert_crf两种模型,可在‘bert_blstm_crf/models.py’文件中设置:
#位于models.py文件的第101行
#crf_only=True:表示模型为bert_crf;
#crf_only=False:表示模型为bert_bilstm_crf;
rst = blstm_crf.add_blstm_crf_layer(crf_only=True)(1)模型架构

基于BERT的MRC机制核心思想是对于要抽取的各类实体,构造关于该类实体的query,随后将该query与原文本拼接放入BERT转换成阅读理解问题(原文本对应阅读理解中的上下文Context),预测待抽取实体在Context中的位置(start_index和end_index)。可以看出转换成阅读理解任务后NER任务就变成了一个多标签二分类问题,若原始文本的序列长度为m,那么就是m个二分类问题。
该方法具有两大优势:
- 1)通过构造query引入了与实体类型相关的先验知识,通过注意力交互模块可以让模型学到与指定实体类型相关的信息特征进而促进实体信息的捕捉;
- 2)更好的解决实体嵌套问题。该方法额外设计了一个loss:match loss,对于模型学习到的所有实体的start、end位置,构造首尾实体匹配任务,即判断某个start位置是否与某个end位置匹配为一个实体,是则预测为1,否则预测为0,相当于转换为一个二分类问题,正样本就是真实实体的匹配,负样本是非实体的位置匹配。
(2)如何运行?
步骤1:准备数据。
step1.1:为每个实体类型构建query,具体配置见data/queries/ccf_ner.json;
step1.2:将原生数据集转换成符合MRC格式的训练数据,运行data/ccfner2mrc.py即可;
step1.3:预训练模型下载。该bert_mrc方法使用的是roberta_wwm_ext_base,可以在查看文件prev_trained_model/chinese_roberta_wwm_ext__base_pytorch/download.txt下载,将下载的完整模型文件置于prev_trained_model/chinese_roberta_wwm_ext__base_pytorch目录下;
步骤2:模型训练。
step2.1:参数设置。具体设置见finetuning_argparse.py,注意这里支持两种loss:ce_loss和dice_loss;
step2.2:执行训练。
$ python train.py模型将会被保存在output/best_f1_checkpoint。
由于是mrc机制,且数据扩充很多,在训练时尽可能增大epoch次数。
【注意:本方法提供了一个toy-model,供读者快速验证,只训练了7个epoch,可以去这里**"output/best_f1_checkpoint/download.txt"**下载】
步骤3:推理预测。
模型训练好之后,执行bert_mrc/ccf_predict_offline.py即可进行预测。示例如下:
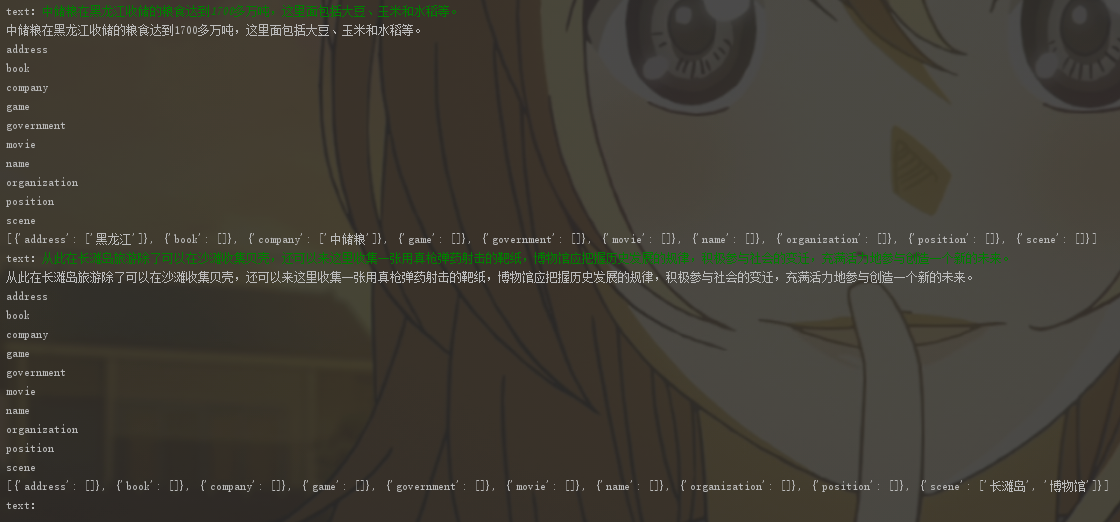
后续将继续集成NER相关的模型,一种是传统NER性能优化,一种是嵌套问题解决;
模型如下:
[2] BERT-NER