| layout | title | subtitle | date | author | header-img | catalog | tags |
|---|---|---|---|---|---|---|---|
post |
实例分割 |
nnUnet分割X线片椎骨 |
2023-11-27 |
BY ThreeStones1029 |
img/about_bg.jpg |
true |
图像分割 |
[TOC]
分割椎体侧位X线片,主要分割==椎体、椎弓根、肋骨==,植入物,分割示例如下图:

相比nnUnet,MedNeXT升点不多,可以先用nnUnet对x线片做个分割,方法如下: step1: 先把椎骨区域检测出来
Step2:对每节检测到的椎骨 (可以把原有椎骨检测框区域放大一倍,cover上下椎骨),进一步实施语义分割,分割出椎体、椎弓、肋骨(胸骨有,腰椎没有)三块区域,棘突显影应该很浅所以可以暂时不考虑分割棘突区域。
可以DRR预训练,然后再用术前X线片调优,然后用术中X线片进一步调优,最后用一些边界修正算法(上次你论文里的) 修正下就行
nnUnet也称no-new U-Net,自适应的U-Net网络,首次提出使用在医学图像分割数据集上,在不同数据集(或不同的部位)的医学图像上进行分割时,往往需要具有不同结构的网络和不同的训练方案,自适应是指模型在对不同的数据集进行训练时,可以自动的调整 batch-size、patch-size 等,以达到很好的效果。
作者在一个医学图像分割十项全能比赛当中的 6 个数据集集中都取到了当时最好的结果,这个比赛一共 10 个数据集,它会给出 7 个数据集让你训练,然后在其他 3 个数据集上进行验证。
nnU-Net 由三种基础的 U-Net 网络组成,分别是 2D U-Net,3D U-Net 和 U-Net Cascade。其中,2D 和 3D U-Net 产生一个全像素的分割结果,U-Net Cascade 先产生一个低像素的分割结果,再对其进行微调。

目前X线片数据集还没有制作,可以先下载别的数据集跑通,计划先跑通眼底数据集。
需要制作数据集,计划使用label-studio这个工具,可以多人标注
先不加载预训练模型训练,看看分割效果
训练过程中可以去做DRR的数据集,再做预训练

环境要求,需要根据自己的电脑显卡配置安装
根据官方文档,最好使用python3.9
torch与自己的硬件匹配
(1)创建虚拟环境
conda create -n nnunet python==3.9(2)安装torch
需要先进入虚拟环境 conda activate nnunet
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
==更新==
==代码需要用到torch._dynamo,在官方上发现它只在2.0.0以上版本出现,所以我安装了2.0.0。如果你的显卡驱动不支持2.0.0.可以先更新驱动,2.0.0.最低cuda版本11.7==
如果你的系统也是ubuntu,可以
sudo apt-get install nvidia-driver-版本号
最后重启或者直接在软件中更新即可
我更新驱动后
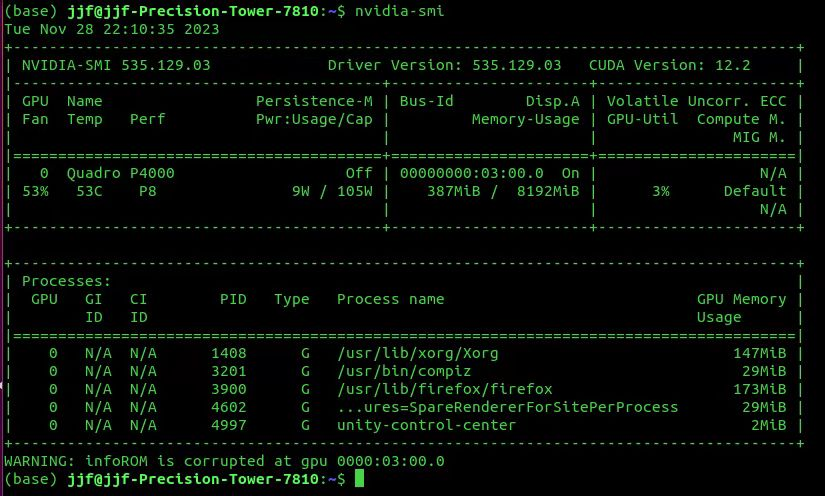
如果你是windows可以去官网查看一下你的显卡型号,选择支持的版本
安装完后,重新安装命令(Ps可以重新删除那个环境,避免包版本冲突)
# 删除环境
conda remove -n nnunet --all
# 重新新建环境
conda create -n nnunet python==3.9
conda activate nnunet
pip install torch==2.0.0 torchvision==0.15.1 torchaudio==2.0.1 如果还是不行可以更新自己的cuda版本,我的cuda和cudnn版本如下
cuda11.7
cudnn8.5.0(3)安装其余包
如果你安装的torch版本小于2.0.0,需要修改pyproject.toml的第33行
torch>=2.0.0修改为你安装的版本号(若你安装的版本号大于2.0.0不需要修改),由于我安装的1.12.1所以我修改为了torch>=1.12.1
==更新==
==可以不修改了,torch>=2.0.0即可==
# 在根目录下
pip install -e .(4)新建文件夹
在nnunetv2文件夹下新建三个文件夹
nnUNet_raw # 原数据集放置的文件夹
nnUNet_preprocessed # 预处理后数据保存的地方
nnUnet_results # 训练模型权重将会保存的地方(5)设置环境变量
ubuntu系统可以设置
export nnUNet_raw="/home/jjf/Desktop/nnUNet/nnuetv2/nnUNet_raw"
export nnUNet_preprocessed="/home/jjf/Desktop/nnUNet/nnuetv2/nnUNet_preprocessed"
export nnUNet_results="/home/jjf/Desktop/nnUNet/nnuetv2/nnUnet_results"windows可以不设置
修改nnunetv2/paths.py
# 注释掉这三行
# nnUNet_raw = os.environ.get('nnUNet_raw')
# nnUNet_preprocessed = os.environ.get('nnUNet_preprocessed')
# nnUNet_results = os.environ.get('nnUNet_results')
# 加上以下三行
nnUNet_raw = "你新建的这个对应文件夹路径"
nnUNet_preprocessed = "新建的这个对应文件夹路径"
nnUNet_results = "新建的这个对应文件夹路径"==这里路径写绝对路径==
计划采用label-studio
访问方式:10.201.178.193:8080
标注案例:待确定
待写
目前我们还没有数据集,所以先测试一下能不能跑通CHASEDB1数据集
把下好的数据集解压后放在前面新建的nnUNet_raw文件夹

(原图像和mask需要同一个格式)
我们将原图jpg修改为png,不能单纯修改后缀,可以使用PIL.Image修改
可以新建一个tools文件夹,里面新建data_format_preprocess.py文件,代码如下:
from PIL import Image
import os
class DataFormatConversion:
def __init__(self, images_folder, save_images_folder):
"""
param, images_folder:raw images folder path
param, save_images_folder: images save path
"""
self.images_folder = images_folder
self.save_images_folder = save_images_folder
def jpgs2pngs(self):
for root, dirs, files in os.walk(self.images_folder):
for file in files:
if file.endswith(".jpg"):
image = Image.open(os.path.join(self.images_folder, file))
file_name = file.split('.')[0]
image.save(os.path.join(self.save_images_folder, file_name + ".png"))
print('The ', file, ' conversion from JPG to PNG is successful')
if __name__ == "__main__":
data_format_conversion = DataFormatConversion(images_folder="nnunetv2/nnUNet_raw/CHASEDB1", save_images_folder="nnunetv2/nnUNet_raw/CHASEDB1")
data_format_conversion.jpgs2pngs()在nnUnet文件夹下运行
python nnunetv2/tools/data_format_preprocess.py运行后,再把文件夹里面的jpg删除了,只留下png
因为只做测试,可以手动划分一下,原数据集总共84张图片,包括28张原图,每一张原图对应两张mask(两名医生分别标注了一张),总共56张mask,我们选任意一个人的标注就行,我统一选的1st那个人标注的。在CHASEDB1文件夹下新建train以及val文件夹,里面分别再新建images以及masks,其中images放原图,masks放医生标注的图。这里我手动选择了前20张原图作为训练集images,对应的mask作为训练集masks,剩下的作为测试集的images和masks。
├── train
│ ├── images
│ └── masks
└── val
├── images
└── masks训练集如下图
训练集mask
mask与image生成json时,名字要相同,可以手动把mask的名字改成和image一样,删除"_1stHO"即可
例如"Image_01L_1stHO.png"修改为"Image_01L.png"
也可以用代码修改
def rename_images(images_folder):
for root, dirs, files in os.walk(images_folder):
for file in files:
new_filename = file.split('_')[0] + '_' + file.split('_')[1] + ".png"
os.rename(os.path.join(root, file),os.path.join(root, new_filename))CHASEDB1数据集mask为0,1,其实已经满足需求,但为了后续方便使用,这里我们尽量不做大的改动
另外写份代码将0,1的mask转为0,255的mask。
转换代码
import os
from PIL import Image
import numpy as np
class MasksPreprocess:
def __init__(self, images_folder) -> None:
self.images_folder = images_folder
def conver_to_binary_images(self):
"""把label转换为二值图像,也即只有0, 255两个值"""
for root, dirs, files in os.walk(self.images_folder):
for file in files:
img = Image.open(os.path.join(root, file))
img_array = np.array(img)
binary_array = np.where(img_array == 0, 0, 255)
binary_img = Image.fromarray(binary_array.astype(np.uint8))
binary_img.save(os.path.join(root, file))
if __name__ == "__main__":
Data_preprocess = MasksPreprocess("masks的路径") # 测试集训练集的mask都需要
Data_preprocess.conver_to_binary_images()我们需要生成数据集的信息,同时把mask0,255转为0,1的格式
需要修改dataset_conversion/Dataset120_RoadSegmentation.py
修改后的代码可以到这下载,主要就是修改了一些文件路径。
运行修改后的Dataset120_RoadSegmentation.py生成Dataset100_CHASEDB1文件夹。
这里的DATASET_ID就是我们的数据集Dataset100_CHASEDB1名字的id,也即100
nnUNetv2_plan_and_preprocess -d DATASET_ID --verify_dataset_integrity也即运行
nnUNetv2_plan_and_preprocess -d 100 --verify_dataset_integrity如果上一步没有问题,我们就可以开始训练了
nnUNetv2_train DATASET_NAME_OR_ID UNET_CONFIGURATION FOLDDATASET_NAME_OR_ID即为100,UNET_CONFIGURATION我们只用2dunet,就填2d, FOLD为交叉验证,我们这里只训练一趟就行,填0就可以。运行以下命令就行
nnUNetv2_train 100 2d 0正常的话就可以训练了,默认训练1000趟,可以修改nnunetv2/training/nnUNetTrainer/nnUNetTrainer.py的第147行修改训练迭代次数。
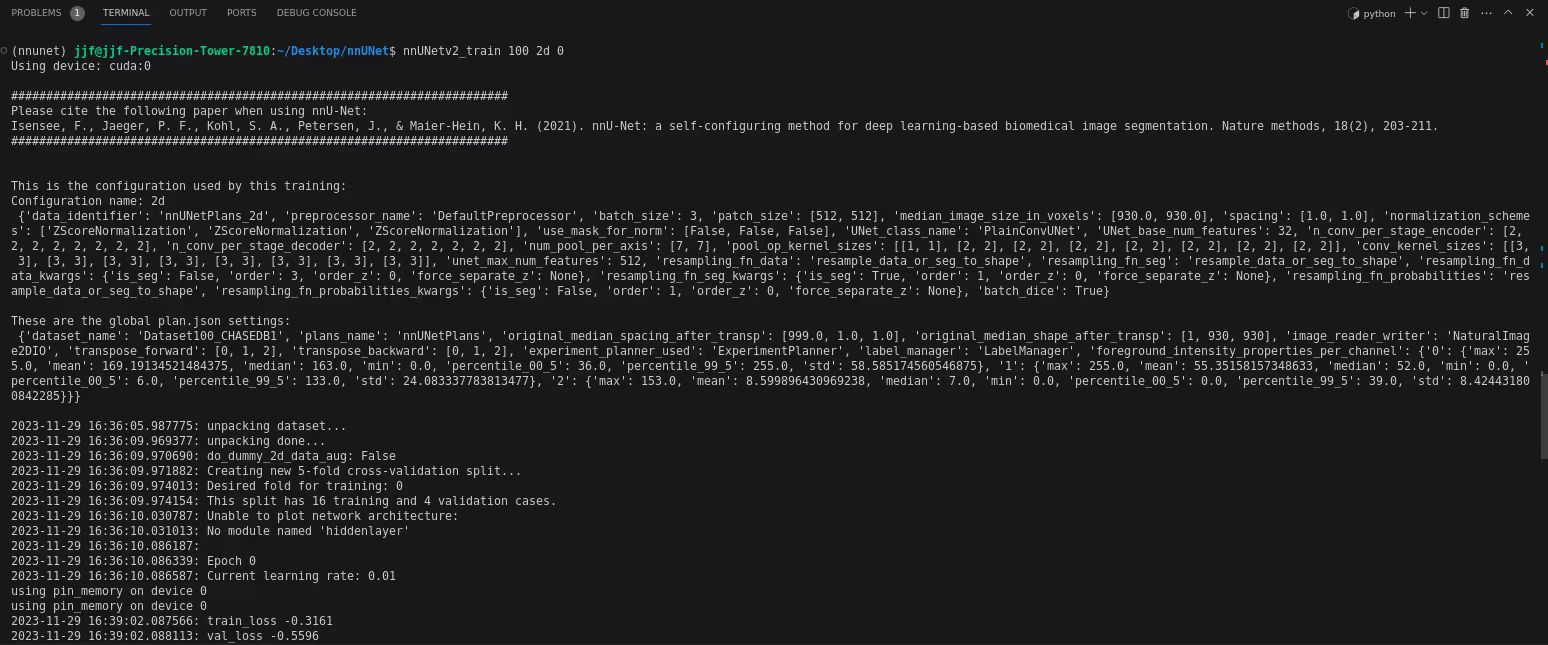
会实时生成训练过程loss和dice曲线,在nnUNet_results/Dataset100_CHASEDB1/nnUNetTrainer__nnUNetPlans__2d/fold_0可以看到
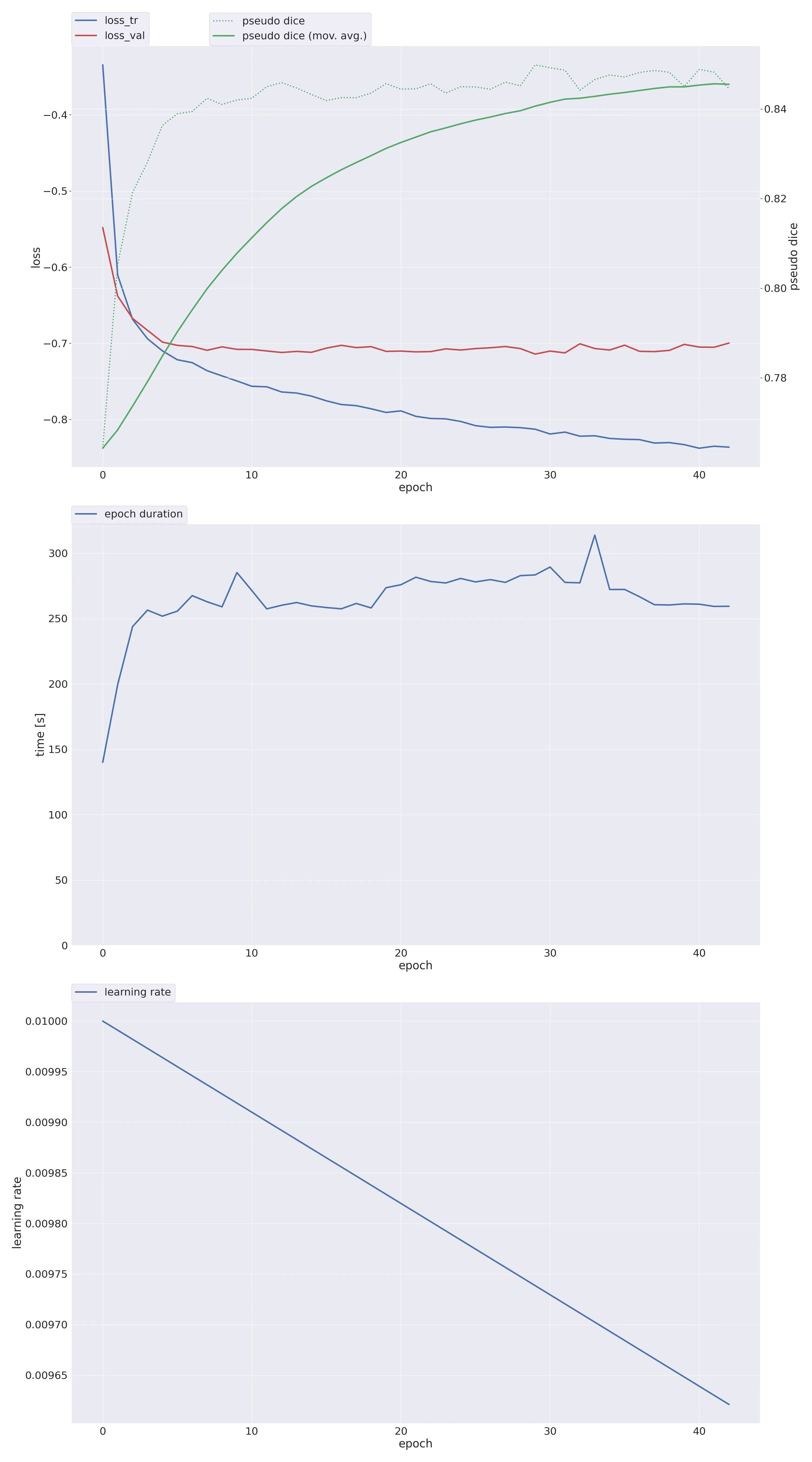
可以同时看看当前预测效果,预测命令
如果想在模型训练完之前查看结果,可以把model_best.pth复制一个重命名为model_final.pth,因为默认推理文件选的model_final推理
nnUNetv2_predict -i nnunetv2/nnUNet_raw/Dataset100_CHASEDB1/imagesTs -o nnunetv2/nnUNet_predict -d 100 -p nnUNetPlans -c 2d -f 0 --save_probabilities-i 后面为验证集路径
-o 后面为预测结果保存的路径
-d 后面为数据集id
-p 表示训练计划,这个是前面生成的会在nnUnet_preprocessed/Dataset100_CHASEDB1/nnUNetPlan.json
-c 2d 为训练时使用的网络架构
-f 0 表示选第0折的模型来推理
--save_probabilities 表示保存结果的小数形式
预测结果是0,1的图需要查看的话,需要自己写代码转换为0,255的mask
import os
from PIL import Image
import numpy as np
class MasksPreprocess:
def __init__(self, images_folder) -> None:
self.images_folder = images_folder
def conver_to0_255images(self):
"""把label转换为二值图像,也即只有0, 255两个值"""
for root, dirs, files in os.walk(self.images_folder):
for file in files:
if file.endswith(".png"):
img = Image.open(os.path.join(root, file))
img_array = np.array(img)
binary_array = np.where(img_array == 0, 0, 255)
binary_img = Image.fromarray(binary_array.astype(np.uint8))
binary_img.save(os.path.join(root, file))
if __name__ == "__main__":
Data_preprocess = MasksPreprocess("nnunetv2/nnUNet_predict")
Data_preprocess.conver_to0_255images()Image_11L.png预测与真实对比,可以看到在10多轮时模型结果已经不错

predict

ground truth
评估代码还没有仔细看,官网没有提供这部分的命令,我们先可以自己写一个看看效果,注意需要评估同一种类型,假如真实的的是0,255mask则预测也需要是0,255的mask
import cv2
import numpy as np
import os
import glob
class DiceEvaluation:
def __init__(self, GT_folder_path, Pre_floder_path):
self.GT_folder_path = GT_folder_path
self.Pre_floder_path = Pre_floder_path
def gen_imgs_path_list(self, image_folder):
imgs_path = glob.glob(os.path.join(image_folder, '*.png'))
return imgs_path
def calculate_image_dice(self, gt_img_path, pre_img_path):
"""
计算两张二值化图片的Dice系数
:param gt_img_path: 真实二值化图片路径
:param pre_img_path: 预测二值化图片路径
:return: Dice系数
"""
# 读取二值化图片
gt = cv2.imread(gt_img_path, cv2.IMREAD_GRAYSCALE)
pre = cv2.imread(pre_img_path, cv2.IMREAD_GRAYSCALE)
# 计算交集和并集
intersection = np.logical_and(gt, pre)
union = np.logical_or(gt, pre)
# 计算Dice系数
dice_coefficient = (2.0 * intersection.sum()) / (gt.sum() + pre.sum())
return dice_coefficient
def calculate_images_mean_dice(self):
sum_dice = 0
gt_files = self.gen_imgs_path_list(self.GT_folder_path)
pre_files = self.gen_imgs_path_list(self.Pre_floder_path)
try:
if len(gt_files) != len(pre_files):
raise ValueError("Check that the number of true and predicted images are the same")
except ValueError as e:
print(f"error:{e}")
num_imgs = len(gt_files)
for _ in range(num_imgs):
file_name = os.path.basename(gt_files[_])
gt_img_path = os.path.join(self.GT_folder_path, file_name)
pre_img_path = os.path.join(self.Pre_floder_path, file_name)
dice = self.calculate_image_dice(gt_img_path, pre_img_path)
print(file_name, dice)
sum_dice += dice
return sum_dice / num_imgs
if __name__ == "__main__":
# 计算Dice系数
pre_gt_eval = DiceEvaluation("nnunetv2/nnUNet_raw/Dataset100_CHASEDB1/labelsTs",
"nnunetv2/nnUNet_predict")
mean_dice = pre_gt_eval.calculate_images_mean_dice()
print(f"Mean Dice is: {mean_dice}")明天可以开始准备做X线片的的分割数据集