A Toolkit for Neural Review-based Recommendation models with Pytorch. 基于评论文本的深度推荐系统模型库 (Pytorch)
Update: 2021.03.29
Add a branch (PL) to use PyTorch Lightning to wrap the framework for further distributed training.
git clone https://github.com/ShomyLiu/Neu-Review-Rec.git
git checkout pl
And the usage:
python3 pl_main.py run --use_ddp=True --gpu_id=2
# indicating that using ddp mode for distributed training with 2 gpus. refer `config/config.py`.
In this repository, we reimplement some important review-based recommendation models, and provide an extensible framework NRRec with Pytorch. Researchers can implement their own methodss easily in our framework (just in models folder).
E-commerce platforms allow users to post their reviews towards products, and the reviews may contain the opinions of users and the features of the items. Hence, many works start to utilize the reviews to model user preference and item features. Traditional methods always use topic modelling technology to capture the semantic informtion. Recently, many deep learning based methods are proposed, such as DeepCoNN, D-Attn etc, which use the neural networks, attention mechanism to learn representations of users and items more comprehensively.
More details please refer to my blog.
Note: since each user and each item would have multiple reviews, we categorize the existing methods into two kinds:
- document-level methods: concatenate all the reviews into a long document, and then learn representations from the doc, we denote as Doc feature.
- review-level methods: model each review seperately and then aggregate all reviews together as the user item latent feature.
Besides, the rating feature of users and items (i.e., ID embedding) is usefule when there are few reviews. So there would be three features in all (i.e., document-level, review-level, ID).
We plan to follow the state-of-art review-based recommendation methods and involve them into this repo, the baseline methods are listed here:
| Method | Feature | Status |
|---|---|---|
| DeepCoNN(WSDM'17) | Doc | ✓ |
| D-Attn(RecSys'17) | Doc | ✓ |
| ANR(CIKM'18) | Doc, ID | ☒ |
| NARRE(WWW'18) | Review, ID | ✓ |
| MPCN(KDD'18) | Review | ✓ |
| TARMF(WWW'18) | Review, ID | ☒ |
| CARL(TOIS'19) | Doc, ID | ☒ |
| CARP(SIGIR'19) | Doc, ID | ☒ |
| DAML(KDD'19) | Doc, ID | ✓ |
We will release the rest unfinished baseline methods later.
- Zheng L, Noroozi V, Yu P S. Joint deep modeling of users and items using reviews for recommendation[C]//Proceedings of the Tenth ACM International Conference on Web Search and Data Mining. ACM, 2017: 425-434.
- Sungyong Seo, Jing Huang, Hao Yang, and Yan Liu. 2017. Interpretable Convolutional Neural Networks with Dual Local and Global Attention for Review Rating Prediction. In Proceedings ofthe Eleventh ACMConference on Recommender Systems.
- Chin J Y, Zhao K, Joty S, et al. ANR: Aspect-based neural recommender[C]//Proceedings of the 27th ACM International Conference on Information and Knowledge Management. 2018: 147-156.
- Chen C, Zhang M, Liu Y, et al. Neural attentional rating regression with review-level explanations[C]//Proceedings of the 2018 World Wide Web Conference. 2018: 1583-1592.
- Tay Y, Luu A T, Hui S C. Multi-pointer co-attention networks for recommendation[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 2309-2318.
- Lu Y, Dong R, Smyth B. Coevolutionary recommendation model: Mutual learning between ratings and reviews[C]//Proceedings of the 2018 World Wide Web Conference. 2018: 773-782.
- Wu L, Quan C, Li C, et al. A context-aware user-item representation learning for item recommendation[J]. ACM Transactions on Information Systems (TOIS), 2019, 37(2): 1-29.
- Li C, Quan C, Peng L, et al. A capsule network for recommendation and explaining what you like and dislike[C]//Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. 2019: 275-284.
- Liu D, Li J, Du B, et al. Daml: Dual attention mutual learning between ratings and reviews for item recommendation[C]//Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019: 344-352.
Requirements
- Python >= 3.6
- Pytorch >= 1.0
- fire: commend line parameters (in
config/config.py) - numpy, gensim etc.
Use the code
- Preprocessing the origin Amazon or Yelp dataset via
pro_data/data_pro.py, then somenpyfiles will be generated indataset/, including train, val, and test datset.cd pro_data python3 data_pro.py Digital_Music_5.json # details in data_pro.py (e.g., the pretrained word2vec.bin path) - Train the model. Take DeepCoNN and NARRE as examples, the command lines can be customized:
Note that the
python3 main.py train --model=DeepCoNN --num_fea=1 --output=fm python3 main.py train --model=NARRE --num_fea=2 --output=lfmnum_fea (1,2,3)corresponds how many features used in the methods, (ID feature, Review-level and Doc-level denoted above). - Test the model using the saved pth file in
checkpointsin the test datase: for example:python3 main.py test --pth_path="./checkpoints/THE_PTH_PATH" --model=DeepCoNN
An output sample:
loading train data
loading val data
train data: 51764; test data: 6471
start training....
2020-07-28 12:27:58 Epoch 0...
train data: loss:107503.6215, mse: 2.0768;
evaluation reslut: mse: 1.2466; rmse: 1.1165; mae: 0.9691;
model save
******************************
2020-07-28 12:28:13 Epoch 1...
train data: loss:80552.2573, mse: 1.5561;
evaluation reslut: mse: 1.0296; rmse: 1.0147; mae: 0.8384;
model save
******************************
2020-07-28 12:28:29 Epoch 2...
train data: loss:70202.6199, mse: 1.3562;
evaluation reslut: mse: 0.9926; rmse: 0.9963; mae: 0.8146;
model save
******************************
An overview of the package dir:
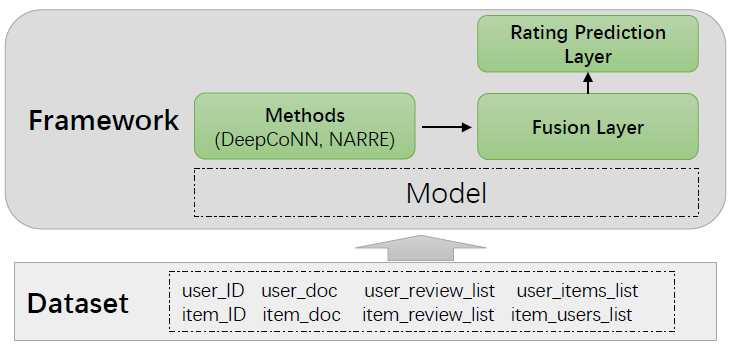
After data processing, one record of the training/validation/test dataset is:
user_id, item_id, ratings
For example the training data triples are stored as Train.npy, Train_Score.npy in dataset/Digital_Music_data/train/.
The review information of users and items are preprocessed in the following format:
- user_id
- user_doc: the word index sequence of the document of the user,
[w1, w2, ... wn] - user_reviews list: the list of all the review of the user,
[[w1,w2..], [w1,w2,..],...[w1,w2..]] - user_item2id: the item ids that the user have purchased,
[id1, id2,...]
The same as the items. Hence in the code, we orgnize our batch data as:
uids, iids, user_reviews, item_reviews, user_item2id, item_user2id, user_doc, item_doc
This is all the information involved in review-based recommendation, researchers can utilize this data format to build own models. Note that the review in validation/test dataset is excluded.
Note that the review processing methods are usually different among these papers (e.g., the vocab, padding), which would influence their performance. In this repo, to be fair, we adopt the same pre-poressing approach for all the methods. Hence the performance may be not consistent with the origin papers.
In order to make our framework more extensible, we define three modules in our framework:
- User/Item Representation Learning Layer (in
models/*py): the main part of most baseline methods, such as the CNN encoder in DeepCoNN. - Fusion Layer in
framework/fusion.py: combine the user/item different features (e.g., ID feature and review/doc feature), and then fuse the user and item feature into one feature vector, we pre-define the following methods:- sum
- add
- concatenation
- self attention
- Prediction Layer in
framework/prediction.py: prediction the score that user towards item (i.e., a regression layer), we pre-define the following rating prediction layers:- (Neural) Factorization Machine
- Latent Factor Model
- MLP
Hence, researchers could build their models in user/item representation learning layer.
Note that if you would like to add new method or datset, please remember to declare in the
__init__.py
If you use the code, please cite:
@inproceedings{liu2019nrpa,
title={NRPA: Neural Recommendation with Personalized Attention},
author={Liu, Hongtao and Wu, Fangzhao and Wang, Wenjun and Wang, Xianchen and Jiao, Pengfei and Wu, Chuhan and Xie, Xing},
booktitle={Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages={1233--1236},
year={2019}
}