fread with large csv (44 GB) takes a lot of RAM in latest data.table dev version #2073
Comments
|
This is the output from the non-parallel fread implementation (data.table 1.10.5 IN DEVELOPMENT built 2017-02-09)
And I double checked the amount of memory used and it just goes up to 84GB. Guillermo |

|
Yes you're right. Thanks for the great report. The estimated nrow looks about right (858,881 vs 872,505) but then the allocation is 4.2X bigger than that (3,683,116) and way off. I've improved the calculation and added more details to the verbose output. Hold off retesting for now though until a few more things have been done. |
|
Ok please retest - should be fixed now. |
|
I just installed data.table dev: The first thing I got when I tried to read the same 44 GB file was this message: DT <- fread('dt.daily.4km.csv') Then I just re-run the same command and started to work fine. However, this version is not using a multi-core mode. It is taking ~ 25 minutes to load, same as before you put the fread-parallel version. Guillermo |
|
I closed all r-sessions and re-run a test and I'm getting an error: The guessed column type was insufficient for 34711745 values in 508 columns. The first in each column was printed to the console. Use colClasses to set these column classes manually. See below, I get several messages regarding "guessed integer but contains <<0....>> Read 872505 rows x 12785 columns from 43.772GB file in 15:27.024 wall clock time (can be slowed down by any other open apps even if seemingly idle) |
|
Wow - your file is really testing the edge cases. Great. In future please run with What field is this data from? Are you creating the file? It feels like it has been twisted to wide format where normal best practice is to write (and keep it in memory too) in long format. I'd normally expect to see the 508 columns names such as "D_19810618" as values in a column, not as columns themselves. Which is why I ask if you are creating the file and can you create it in long format. If not, suggest to whoever is creating the file that they can do it better. I guess that you are applying operations through columns perhaps using But I'll still try and make I hope that other people are testing and finding no problems at all on their files! |
|
Do those 508 columns mean something to you and you agree they should be numeric? You can pass a range of columns to colClasses like this: colClasses=list("numeric"=11:518) This table contains time series by row. IDx,IDy, Time1_value, Time2_value, Time3_value... and all the TimeN_value columns contain only numeric values. If I use colClasses, I'm going to need to do it for 12783: list("numeric"=2:12783). I'll try this. What field is this data from? I'll get back with some results. |
|
Ok good. You don't need No - data.table is almost never faster when it's wide! Long is almost always faster and more convenient. Have you seen and have you tried |
|
melt'ing this table reach the 2^31 limit. I'm getting the error: "negative length vectors are not allowed". I'll get back to the source to see if I can generate it in the long-format. |
I don't have the application on a public server. Essentially, user can click on a map and then I capture those coordinates and perform the search above, get the time series, and create a plot. |
|
Found and fixed another stack overflow for very large number of columns : d0469e6. Forgot to tag this issue number in the commit msg. |
|
Oh. That's a point. 872505 rows * 12780 cols is 11 billion rows. So my suggestion to go long format won't work for you as that's > 2^31. Sorry - I should have spotted that. We'll just have to bite the bullet and go > 2^31 then. In the meantime let's stick with the wide format you have working and I'll nail that down. |
|
Please try again. The memory usage should be back to normal and it should automatically reread the 508 out of 12,785 columns with out-of-sample type exceptions. To avoid the auto rerun time you can set |
|
Ok... Four main points to mention:
Some comments/questions: In the previous version of fread, the cores' activity always was ~ 90-80%. In this version stayed around ~2-3 % each core as shown in the image above. I don't understand why fread is doing bumps from integer to numeric: e.g. I double checked those rows and it seems ok. Why is detected as integer and need to be 'bumped' to 'numeric' if is already numeric (see summary for the rows suggested below)? or am I understanding this line wrongly? This happens for 508 lines. Are the NA's causing trouble? Below some verbose out of the test. OUTPUT This last summary took a lot of time to finish it (~6 minutes). If we count this verbose summary the whole fread took ~ 11 minutes. It is re-reading those 508 columns, I can even see the message "Rereading 508 columns due to out-of-sample type exceptions" without using the verbose=TRUE. Check it out without "verbose=TRUE" fwrite test |

|
The "Reread" is taking quite of time. It is like reading the file twice. |
|
Excellent! Thanks for all the info.
Can you paste the output of |
|
My mistake in one point of my previous post. The Here is the lscpu output: |
|
Ok got it. Thanks. Reading your first comments again, would it make more sense if it said "bumping from integer to double" rather than "bumping from integer to numeric"? What do you mean by 'created with NA's'? All the table is full of NAs, just the 508 columns? What is 'DT was loaded normal (~106MB in RAM)'. It's a 44GB file so how can 106MB be normal? |
|
|
Maybe another typo then : 106MB should have been 106GB. |
… 30% of them sometimes. Increased sample to 10,000 rows. #2073
|
Ok - please try again. The guessing sample has increased to 10,000 (it'll be interesting to see how long that takes) and the buffer sizes now have a minimum imposed. |
|
Sorry, it was "GB" instead of "MB". I didn't have enough coffee. |
|
Testing with latest data.table dev.: data.table 1.10.5 IN DEVELOPMENT built 2017-03-30 16:31:45 UTC : Summary: Test 1: Without using Test 2: Now using |
|
Ok great - we're getting there. The corrected sample size plus increasing it to 100 lines at 100 points (10,000 sample lines) was enough to guess the types correctly then - great. Since there are 12,875 columns and the line length is average 80,000 characters in the 44GB file, it it took 11s to sample. But that time was worth it because it avoided a reread which would have taken an extra 90s. We'll stick with that then. I'm thinking the 2nd time is faster just because it was the 2nd time and your operating system has warmed up and cached the file. Anything else at all running on the box will affect the wall clock timings. That's addressed by running 3 identical consecutive runs of the 1st test. Then changing one thing only and running 3 identical consecutive runs again. At 44GB size you'll see a lot of natural variance. 3 runs is usually enough to make a conclusion but it can be a black art. Yes the 112GB in memory vs 44GB in disk is partly because the data is bigger in memory because all the columns are type double; there is no in-memory compression in R and there are quite a lot of NA values which take no space in this CSV (just When you specified the column type for all the columns, it still sampled, though. It should skip sampling when user has specified every column. (TODO2) Since all your data is double, it's making 11 billion calls to C library function strtod(). The long wished for specialization of that function should in theory make a significant speedup for this file. (DONE) |
|
Thanks for that, great explanation. Let me know if you want me to test something else with this file. I'm working on another data set that is more on the long-format, with ~21 million rows x 1432 columns. |
|
Adding an additional data point to this. 89G I am also happy to test on this. |
|
If it helps, here are results on a very long database: 419,124,196 x 42 (~2^34) with one header row and colClasses passed. A couple of notes. I would have suggested putting [09] before [07] in that if colClasses are passed there isn't a reason to check. Also, Windows showed about 160GB in use after each run. memory.size() probably does some cleaning. With 532GB RAM on this server, memory caching may have what to do with the increase in speed on the second run. Hope that helps. |
|
Test on a wide "real-world" table (hospital data): 30M rows × 125 columns v readr ‘1.2.0’ and
|
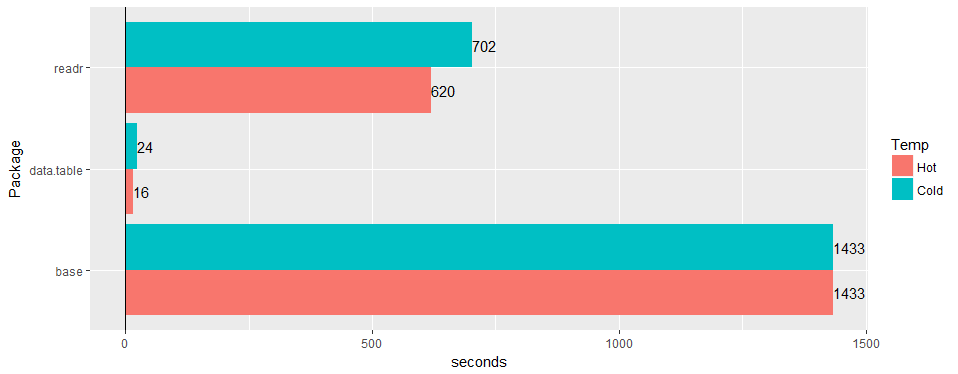
|
any chance to confirm issue is still valid on 1.11.4? or code to produce example data. |
Hi,
Hardware and software:
Server: Dell R930 4-Intel Xeon E7-8870 v3 2.1GHz,45M Cache,9.6GT/s QPI,Turbo,HT,18C/36T and 1TB in RAM
OS:Redhat 7.1
R-version: 3.3.2
data.table version: 1.10.5 built 2017-03-21
I'm loading a csv file (44 GB, 872505 rows x 12785 cols). It loads very fast, in 1.30 minutes using 144 cores (72 cores from the 4 processors with hyperthreading enabled to make it 144 cores box).
The main issue is that when the DT is loaded the amount of memory on-use increases significantly in relation to the size of the csv file. In this case the 44 GB csv (saved with fwrite, saved with saveRDS and compress=FALSE creates a file of 84GB) is using ~ 356 GB of RAM.
Here is the output using "verbose=TRUE"
Allocating 12785 column slots (12785 - 0 dropped)
madvise sequential: ok
Reading data with 1440 jump points and 144 threads
Read 95.7% of 858881 estimated rows
Read 872505 rows x 12785 columns from 43.772GB file in 1 mins 33.736 secs of wall clock time (affected by other apps running)
0.000s ( 0%) Memory map
0.070s ( 0%) sep, ncol and header detection
26.227s ( 28%) Column type detection using 34832 sample rows from 1440 jump points
0.614s ( 1%) Allocation of 3683116 rows x 12785 cols (350.838GB) in RAM
0.000s ( 0%) madvise sequential
66.825s ( 71%) Reading data
93.736s Total
It is showing a similar issue that sometimes arises when working with the parallel package, where one rsession is launched per core when using functions like "mclapply". See the Rsessions created/listed in this screenshot:
if I do "rm(DT)" RAM goes back to the initial state and the "Rsessions" get removed.
Already tried e.g. "setDTthreads(20)" and still using same amount of RAM.
By the way, if the file is loaded with the non-parallel version of "fread", the memory allocation only gets up to ~106 GB.
Guillermo
The text was updated successfully, but these errors were encountered: