
Q-learning |

Dyna-Q |

Dyna-Q+ |
This repository contains the code used to generate the experiment described in the article: Temporal-Difference Learning and the importance of exploration: An illustrated guide, published in Towards Data Science.
This project aims to compare several Temporal Difference learning algorithms (Q-learning, Dyna-Q, and Dyna-Q+) in the context of an evolving grid world.
The results obtained during the training outline the importance of continuous exploration in a changing environment and the limits of epsilon-greedy policies as the only source of exploration.
- 🐍 Straightforward Numpy implementation of model-free and model-based RL agents
- 🤖 Algorithms: Q-Learning, Dyna-Q, and Dyna-Q+
- 🌐 Dynamic Grid World encouraging continuous exploration
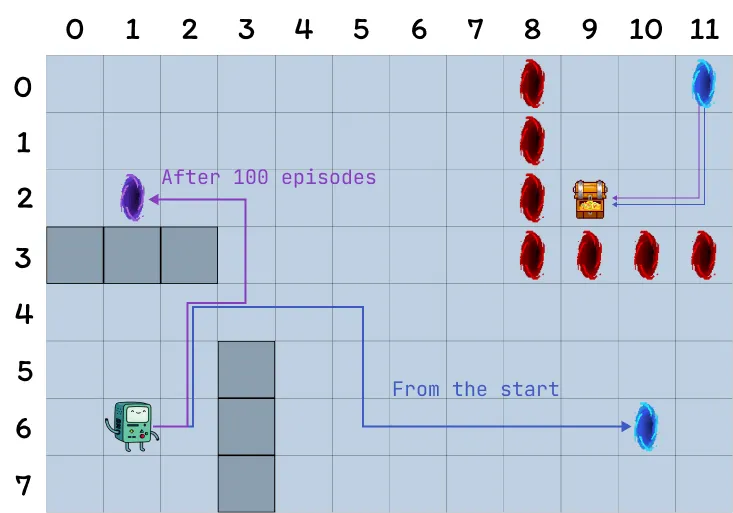
- The grid is 12 by 8 cells.
- The agent starts in the bottom left corner of the grid, the objective is to reach the treasure located in the top right corner (a terminal state with reward 1).
- The blue portals are connected, going through the portal located on the cell (10, 6) leads to the cell (11, 0). The agent cannot take the portal again after its first transition.
- The purple portal only appears after 100 episodes but enables the agent to reach the treasure faster. This encourages continually exploring the environment.
- The red portals are traps (terminal states with reward 0) and end the episode.
- Bumping into a wall causes the agent to remain in the same state.
This experiment aims to compare the behavior of Q-learning, Dyna-Q, and Dyna-Q+ agents in a changing environment. Indeed, after 100 episodes, the optimal policy is bound to change and the optimal number of steps during a successful episode will decrease from 17 to 12.
Find the detailed breakdown of model performances and comparisons in the article.
| Algorithm | Type | Updates per step (real step + planning steps) | Runtime (400 episodes, single CPU) | Discovered optimal strategy (purple portal) | Average cumulative reward |
|---|---|---|---|---|---|
| Q-learning | Model-free | 1 | 4.4 sec | No | 0.70 |
| Dyna-Q | Model-based | 1 + 100 | 31.7 sec | No | 0.87 |
| Dyna-Q+ | Model-based | 1 + 100 | 39.5 sec | Yes | 0.79 |

Comparison of the cumulative reward per episode averaged over 100 runs

Comparison of the number of steps per episode averaged over 100 runs
Q-learning
Dyna-Q
Dyna-Q+
To install and set up the project, follow these steps:
-
Clone the repository to your local machine:
git clone https://github.com/RPegoud/Temporal-Difference-learning.git
-
Navigate to the project directory:
cd Temporal-Difference-learning -
Install Poetry (if not already installed):
python -m pip install poetry
-
Install project dependencies using Poetry:
poetry install
-
Activate the virtual environment created by Poetry:
poetry shell
-
Modify the main.py file depending on the test you want to perform and run:
python main.py
Sutton, R. S., & Barto, A. G. . Reinforcement Learning: An Introduction (2018), Cambridge (Mass.): The MIT Press.