El objetivo de este proyecto es potenciar el éxito de Olist (E-commerce brasileña) transformando los datos con acciones estratégicas como un análisis exhaustivo y el uso de herramientas avanzadas.
ECO DATA es una iniciativa que desarrolla un MVP (Minimum Viable Product) para que los eCommerce puedan usar sus datos de forma inteligente entendiendo y segmentando a sus clientes a través de los datos.
Para ello, diseñamos un servicio completamente automatizado en el que los datos provenientes de una API, base de datos o cualquier otra fuente son extraidos, transformados y cargados en sistemas de información robustos que permiten analizar y comprender el comportamiento de los usuarios de cualquier eCommerce.
Gracias a esta solución los eCommerce podrán tomar las mejores decisiones e implementar las estrategias más efectivas en el área de 'Customer Success', que abarcan actividades de retención, atracción y fidelización de los clientes, generando en última instancia grandes beneficios para la compañía.
Para cumplir con nuestro propósito desarrollamos modelos de Machine Learning, Cuadros de mando (KPI's) y Canalizaciones de Datos (Data Pipelines) completamente automatizadas y funcionales.
El proyecto constó de 4 etapas principales y una etapa transversal. Se destinaron 4 semanas para el desarrollo de este proyecto y en cada semana se estableció una épica o milestone a completar como sigue:
- ETL (Semana 1): ETL completo incluyendo la automatización de la extracción, transformación y carga de los datos. Documentación de los procedimientos y los Scripts
- EDA y Modelo de ML (Semana 2): Análisis exploratorio de los datos y desarrollo de los modelos de Machine Learning. Gráficas, Estadísticas, Hallazgos, Relaciones de los datos, Documentación, Usos, Entrenamiento y Testeo de los modelos de ML
- Scripts, Referencias y Pruebas (Semana 3): Desarrollo y testeo de los scripts necesarios para automatizar los procesos correspondientes al ETL, EDA y el desarrollo de los modelos de ML
- Desarrollo del Dashboard y la base de datos (Semana 4): Creación de Scripts para crear y cargar la información a la base de datos, así como el desarrollo de un cuadro de mando en PowerBI
Adicional a las 4 etapas mencionadas anteriormente, se estableció una épica para llevar el seguimiento de toda la documentación del proyecto.
ETL, EDA, Data Analysis, Machine Learning, Data Base, Automation, Data Pipelines, Scripts, Data Visualizations, Data Science
| Nombre | Rol | Contacto |
|---|---|---|
| Camilo Díaz Salinas | Data Engineer & Scientist | |
| David Echajaya Murcia | Project Manager & DBA | |
| Facundo Cuello | Data Analyst & Scientist |
├── LICENSE
|
├── README.md <- README para desarrolladores que utilizan este proyecto.
|
├── install.md <- Instrucciones detalladas para configurar este proyecto.
|
├── data
│ ├── processed <- Los datos canónicos finales para el modelado.
│ └── raw <- Los datos original e inmutable.
│
├── notebooks <- Cuadernos Jupyter con el código y gráficas completas.
│ ├── datasets <- Archivos usados en los Notebooks.
│ | ├── olist_geolocation_dataset.csv <- Utilizado en 'EDA.ipynb'.
| | └── processed_dataset.pkl <- Contiene el dataset final 'olist_df.csv' obtenido
| | en 'ETL.ipynb'.
│ ├── Plots <- Graficas estaticas para reemplazarlas por las
| | generadas con Plotly (Para mostrarlas en el Repo).
| ├── functions.ipynb <- Notebook explicando a detalle el archivo
| | '/c17_97_t_data_bi/data/make_dataset.py'.
| ├── ETL.ipynb <- Fragmento del ETL.
| ├── EDA.ipynb <- Fragmento del EDA.
| ├── Model RFM and Clustering K-means.ipynb <- Fragmento del modelo de Clustering K-means
| | (Conjutos de Clientes).
| ├── Product Price Prediction Models.ipynb <- Fragmento de los modelos de predicción de valor de
| | transacción (Red Neuronal, XGBoost, Regresión
| | Lineal, Regresor Random Forest).
| └── E_Commerce_Completed.ipynb <- Notebook con completo.
|
├── references <- Data dictionaries, manuals, and all other explanatory materials.
│ ├── data_dictionary.xlsx <- Excel dando mas información acerca de los datasets
| | iniciales.
| └── dataset_overview.md <- Descriptción completa de los datasets iniciales y
| la conexión entre ellos.
|
├── environment.yml <- El archivo de requisitos para reproducir el entorno de análisis.
|
├── requirements.txt <- Archivo para gestionar las dependencias del proyecto.
│
├── .gitignore <- Archivo para especificar qué archivos o directorios deben ser ignorados
| por Git y no deben ser rastreados.
│
├── .here <- Archivo que detendrá la búsqueda si ninguno de los demás criterios se
| aplica al buscar jefe de proyecto.
│
├── setup.py <- Hace que el pip del proyecto sea instalable (pip install -e .) para
| que se pueda importar e_commerce_project.
│
├── sql_scripts <- Contiene los scripts SQL utilizados para crear y cargar datos.
│ ├── Data Ingestion.sql <- Ingesta de los archivos en 'data/processed'
| ├── Database Creation.sql <- Cración del Database
| └── Database Queries.sql <- Queries del Database
|
└── e_commerce_project <- Código fuente para usar en este proyecto.
├── __init__.py <- Convierte e_commerce_project en un módulo de Python.
│
├── data
│ ├── __init__.py
| └── make_dataset.py <- Script para generar datos.
│
├── features <- Scripts para hacer descarga, exploración y procesamiento de datos de
| | los datasets
│ ├── __init__.py
| ├── download_data.py <- Script para usar la función downloadData de
| | 'make_dataset.py'
| ├── data_collection.py <- Script para usar descargar los datasets
| ├── data_exploratory.py <- Script para hacer la exploración de los datasets
| └── data_preprocessing.py <- Script para procesamiento de datos
│
├── models <- Scripts para entrenar los modelos y luego usar modelos entrenados para
| | hacer predicciones.
│ ├── __init__.py
│ ├── model_kmeans.py <- Script para el modelo de Clustering K-means
| | (Conjutos de Clientes).
│ └── model_predict_vproduct.py <- Script para los modelos de predicción de valor de
| transacción
│
└── utils <- Scripts para ayudar con tareas comunes.
├── __init__.py
└── paths.py <- Funciones auxiliares para referencias relativas
de archivos en todo el proyecto.
Para lograr el objetivo planeado, seguimos el siguiente roadmap:
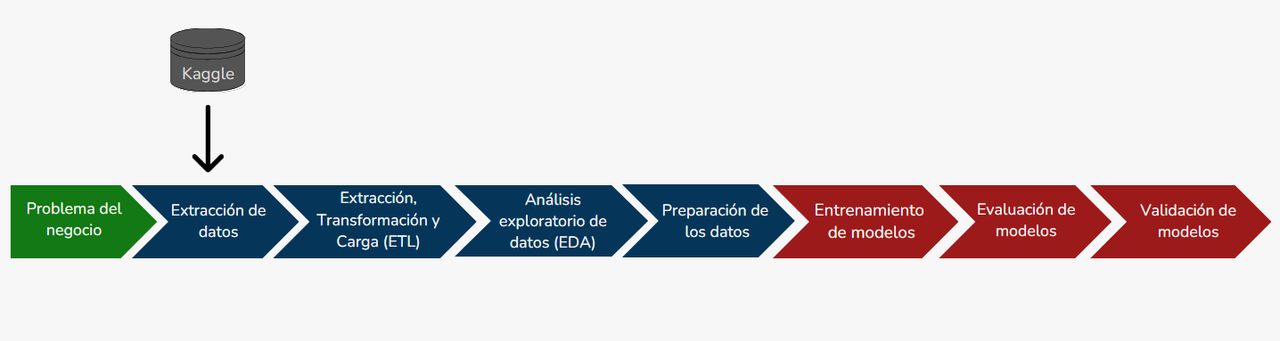
-
Problema del negocio: El dataset esta fragmentado, presentan defectos como valores NaN, requeriere un análisis exploratorio para comprender los datos y trazar algunos gráficos para aclarar los conceptos y obtener información útil. Requiere un analisis predictivo usando ML y una segmentación de clientes para desarrollar mejores estrategias de Marketing.
-
ETL: Se hace la "Extracción de los datos" del dataset en Kaggle. Se "Transforman los datos" para que sean más adecuados para el análisis (Preprocesamiento y un merge para obetener solo un dataset). Se "cargan los datos" en la base de datos de MySQL para posteriormente usarlos en PowerBI.
-
EDA: Se hace un análisis exploratorio de datos usando graficas y visualizaciones tanto en el Notebook como en PowerBI, para explorar el dataset final (con el merging).
-
Preparación de los datos: Se crea una copia y se filtran los valores numéricos del dataset, se crea una matriz de covarianza para evidenciar las columnas con mayor relación entre sí, se separan los datos por grupos de entrenamiento (80%) y grupos de validación (20%), se estandarizan las caracteristicas numéricas de ambos grupos de datos.
-
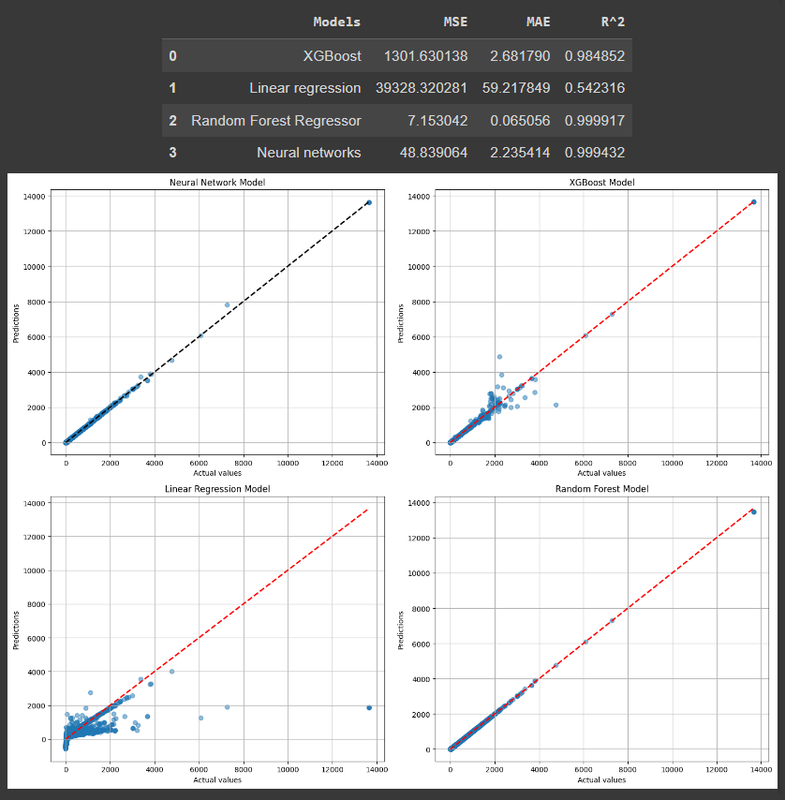
Entrenamiento de modelos: Se crea un modelo de aprendizaje "No Supervisado" usando agrupamiento(Clustering) con la tecnica RFM y el algoritmo K-means, haciendo una división por grupos de clientes con caracteristicas similares. Se crean 4 modelos de aprendizaje "Supervisado" usando el problema de clasificación con los algoritmos de Red Neuronal, XGBoost, Regresión Lineal, Regresor de bosque aleatorio (Random Forest). Esto con el fin de predecir el precio de los productos.
-
Evaluación de modelos: Se hace la evaluación de los modelos utilizando el conjunto de datos validación o prueba. La evaluación del modelo proporciona una estimación del rendimiento del modelo en datos no vistos, lo que ayuda a determinar cómo se generaliza el modelo a nuevos datos.
-
Validación de modelos: Durante la validación de los modelos, se ajustan los hiperparámetros y se evalúa su rendimiento. El propósito es ajustar los hiperparámetros del modelo para obtener el mejor rendimiento posible en los datos de entrenamiento y validación.
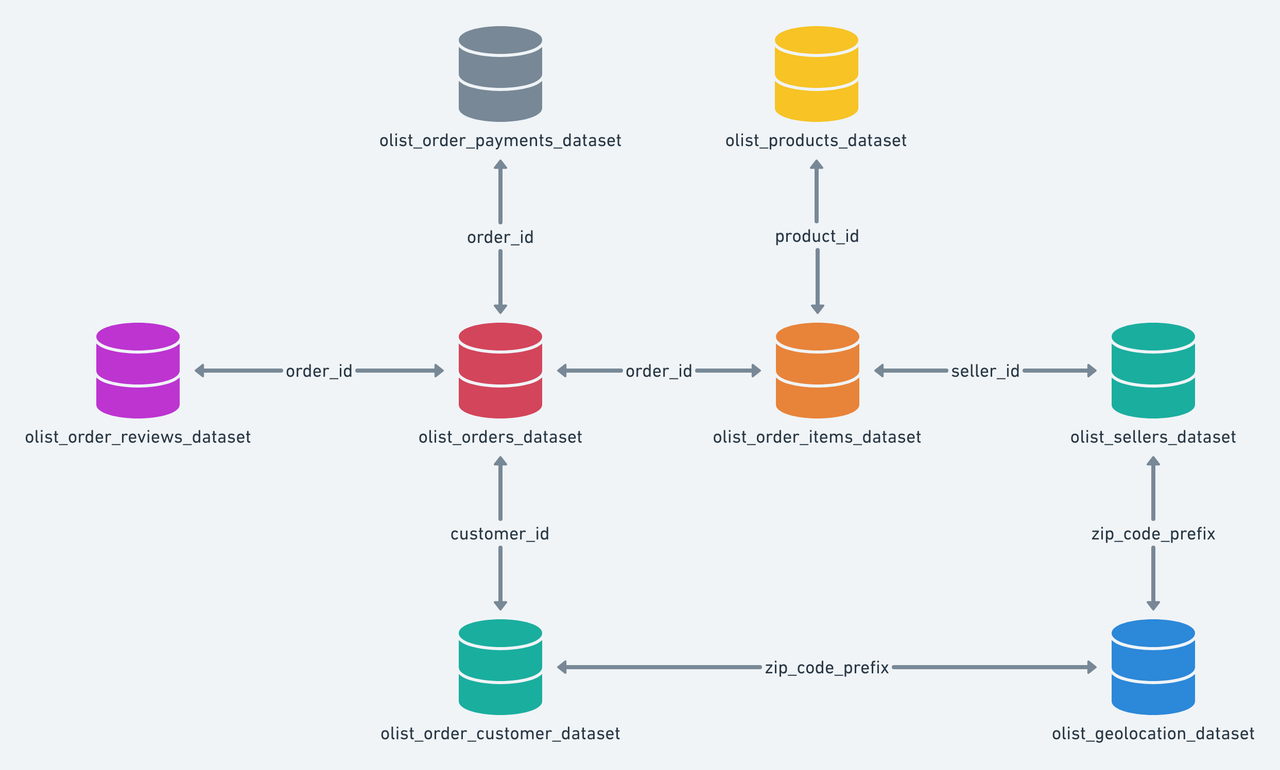
El conjunto de datos tiene información de 100.000 pedidos de 2016 a 2018 realizados en múltiples mercados de Brasil.
Sus características permiten ver un pedido desde múltiples dimensiones: desde el estado del pedido, el precio, el pago y el rendimiento del flete hasta la ubicación del cliente, los atributos del producto y finalmente las reseñas escritas por los clientes. También tiene un conjunto de datos de geolocalización que relaciona los códigos postales con las coordenadas de latitud/longitud.
Se trata de datos comerciales reales, se han puesto en anonimos y las referencias a las empresas y socios en el texto de la reseña se han sustituido por los nombres de las grandes casas de "Juego de Tronos"(Serie de TV).
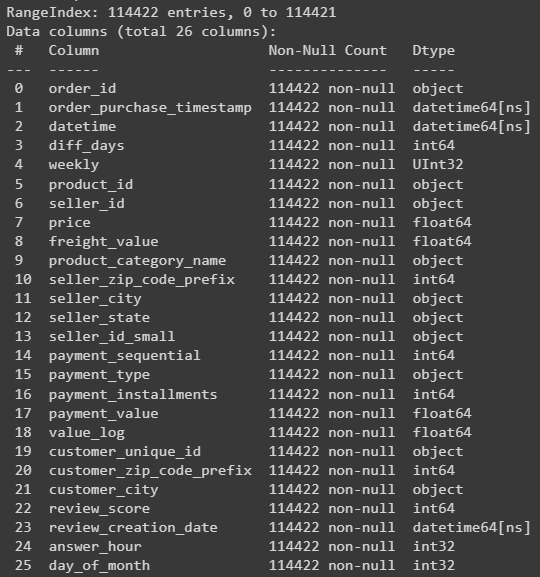
- Se obtuvo el dataset final olist_df en la etapa "Procesamiento de datos(Feature Engineer)" con el que se realizará todo:
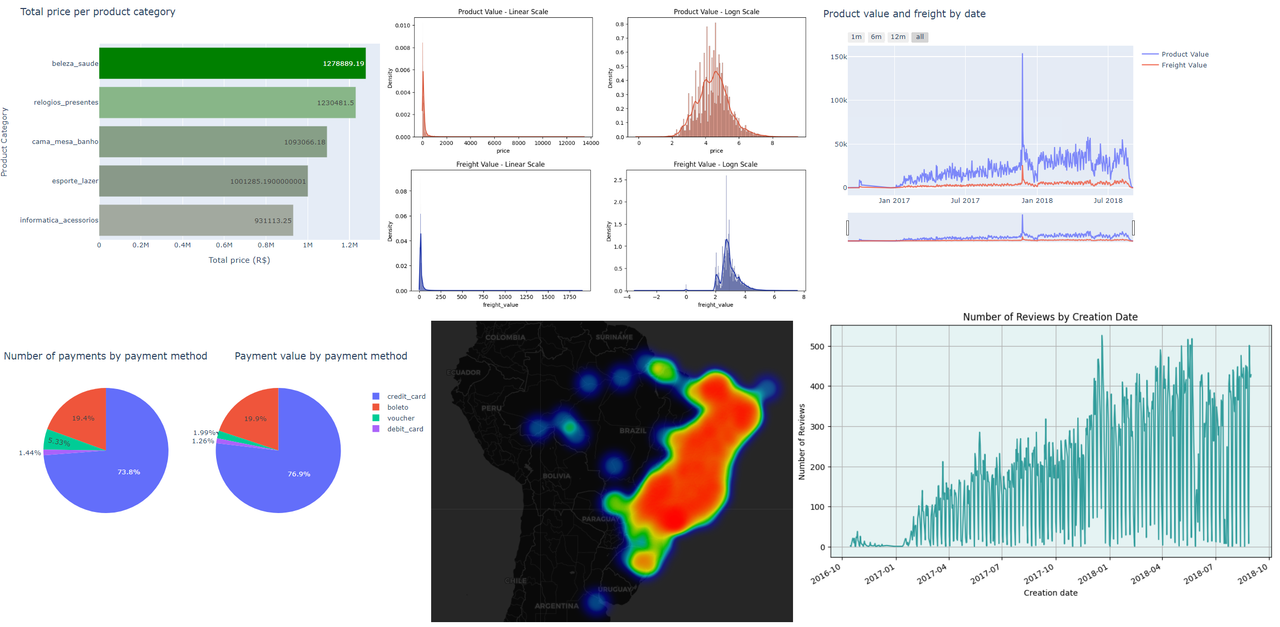
- Se hizo el analisis del dataset con varias graficas que describen información importante:
- Se obtuvo la división por grupos de clientes con caracteristicas similares con el modelo de aprendizaje "No Supervisado" usando agrupamiento(Clustering) con la tecnica RFM y el algoritmo K-means:
- Para predecir el precio del producto se hizo 4 modelos de aprendizaje "Supervisado" usando el problema de clasificación con los algoritmos de Red Neuronal, XGBoost, Regresión Lineal, Regresor de bosque aleatorio (Random Forest). Se selecciona el mejor según sus resultados, en este caso puede ser la red neuronal o el Regresor de bosque aleatorio:

Lea install.md para obtener detalles sobre cómo configurar este proyecto.
Olist, and André Sionek. (2018). Brazilian E-Commerce Public Dataset by Olist [Data set]. Kaggle. https://doi.org/10.34740/KAGGLE/DSV/195341
Se publica bajo la licencia MIT. Consulte el archivo LICENSE para obtener más detalles.