DMS 的迁移部署耗时约十分钟.
-
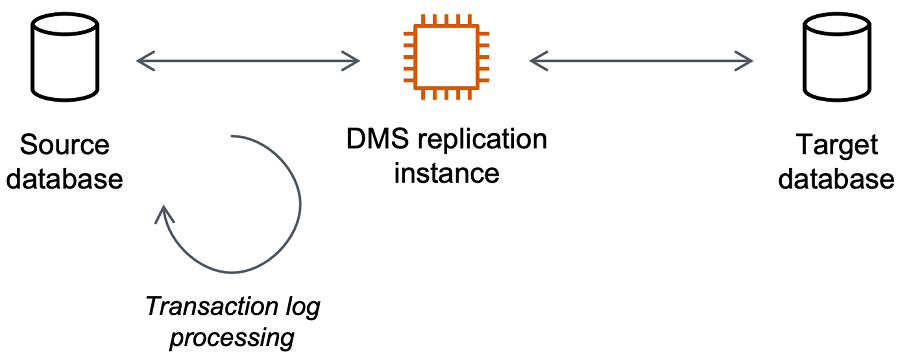
源: 您需要迁移数据的来源, 在这里的源为您的 MongoDB 数据库
-
目标: 您需要迁移数据的目的地, 在这里目标为您的 S3 桶
-
复制实例: 您可以将复制实例理解为一台虚拟主机. AWS DMS 执行数据迁移时, 会先从源数据库中读取数据到复制实例, 再对数据进行相应的调整( 如格式转换)后, 最终将数据载入到目标数据库
-
持续复制( 也叫做数据捕获, CDC ): 在实际生产中, 当源数据库中数据发生改变时, 我们需要在目标数据库中也应用这些改变, 如若达到这种目的, 可以使用CDC.
特别的, CDC 只会读取您改变的那一部分数据, 即增量迁移
- MongoDB 版本: 若将 MongoDB 作为源, 则 MongoDB 的版本必须为 2.6.x 或 3.x
- 若要使用 CDC 功能, AWS DMS 必须要具有对 oplog 的访问权限, 因此请确保您的 MongoDB 具有可用的副本集. 有关更多的信息, 请参阅 MongoDB 文档
重要
在本文中所涉及参数设置仅为演示作用
通常情况下, 您都需要根据您的实际情况, 设置适合您自己的参数
更多的参数细节请参考 DMS 最佳实践
-
在 IAM 导航中选择角色, 并点击创建角色

-
在创建角色面板的选择受信任实体的类型中选择 AWS 产品, 在选择将使用此角色的服务中选择 DMS, 最后点击下一步

-
在附加权限策略中搜索 EC2, 并勾选 AmazonEC2FullAccess. 再搜索 S3, 并勾选 AmazonS3FullAccess, 再点击下一步


-
在审核页面中, 自定义您的角色名称( 本文中设置为了dms-mongo-s3 )及角色描述( 可选 ), 最后点击创建角色

-
在完成页面点击角色名

在摘要页面中记录下角色 ARN








-
在 DMS 导航中选择复制实例, 并选择创建复制实例

-
在创建复制实例页面, 按以下内容配置, 未说明的配置项即采用默认配置
- 名称: 用户自定义, 本文采用dms-mongo-s3
- 描述: 用自定义
- 实例类: 请根据您的数据情况选择合适的实例类型, 本文中采用为 dms.t2.large
- VPC: 请采用能连接到您 MongoDB 数据库所在的 VPC
- 多可用区部署: 请根据您的需要选择是否启用, 本文采用否
- 公开访问: 请根据您的需要选择是否启用, 本文采用是

再点开高级
- VPC 安全组: 选择合适的安全组, 确保您的复制实例能连接到您的 MongoDB 数据库

-
点击创建复制实例



在配置源端前, 请确保您的 MongoDB 已满足使用 AWS DMS 的条件
-
在 DMS 导航中选择终端节点, 并选择创建终端节点

-
在创建终端节点, 按以下内容配置, 未说明的配置项即采用默认配置
- 终端节点类型: 源
- 终端节点标识符: 自定义, 本文中采用 dms-mongo
- 源引擎: mongodb
- 服务器名称: <您 MongoDB 数据库所在的 IP 地址>
- 端口: <您 MongoDB 数据库的的端口号>
- 身份验证模式: 若您的数据库需要用户身份验证, 请选择 password, 然后填写以下四项内容
- 用户名: 请填入具有合适权限 的MongoDB 用户的用户名, 关于将 MongoDB 用作 AWS DMS 的源时所需的权限, 请参考将 MongoDB 作为 AWS DMS 源
- 密码: 您 MongoDB用户对应的密码
- 身份验证来源: 您 MongoDB用户所在的身份库, 本文中为 MongoDB 默认的身份库admin
- 数据库名称: 您要迁移的数据库名称
- 元数据模式: document

-
在测试终端节点连接中,按以下内容配置,并选择运行测试
- VPC: 选择您在配置复制实例这一步骤中创建的复制实例所在的VPC
- 复制实例: 选择您在配置复制实例这一步骤中创建的复制实例

-
在点击运行测试完成后, 等待一段时间后, 如若配置成功, 则会出现已成功测试连接的字样, 之后点击 Save





请先在 S3 中建立您需要存放迁移后数据的桶, 本文所使用的桶为 dms-mongo-s3
- 在 DMS 导航中选择终端节点, 并选择创建终端节点

-
在创建终端节点, 按以下内容配置, 未说明的配置项即采用默认配置
- 终端节点类型: 源
- 终端节点标识符: 自定义, 本文中采用 dms-s3
- 目标引擎: s3
- 服务访问角色 ARN: 您在配置 IAM 角色这一步骤中创建的角色的 ARN
- 存储桶名称: 存放迁移后数据的桶的名称, 本文为 dms-mongo-s3
在测试终端节点连接下
- VPC: 选择您在配置复制实例这一步骤中创建的复制实例所在的VPC
- 复制实例: 选择您在配置复制实例这一步骤中创建的复制实例
点击运行测试

-
在点击运行测试完成后, 等待一段时间后, 如若配置成功, 则会出现已成功测试连接的字样, 之后点击 Save



-
在 DMS 导航中选择任务, 并选择创建任务

-
在创建任务页面, 按以下内容配置, 未说明的配置项即采用默认配置
- 任务名称: 用户自定义, 这里采用 dms-mongo-s3
- 复制实例: 选择您在配置复制实例这一步中创建的复制实例
- 源终端节点: 选择您在配置源端中创建的源
- 目标端节点: 选择您在配置目标端中创建的目标
- 迁移类型: 迁移现有数据并复制持续更改
- 在创建时启动任务: 勾选
- 启用日志记录: 勾选(十分建议您勾选此项)

-
在表映像块下,输入以下内容, 并选择添加选择规则
- 架构名称是: 选择输入架构
- 架构名称: %



-
点击创建任务


当您按照以上步骤中完成所有的配置后,若出现以下内容, 则意味着您开启了一个具有增量迁移功能的从 MongoDB 到 S3 的数据迁移任务.

此任务不仅会在第一次启动时从 MongoDB 迁移所有的数据到 S3, 还会在之后每当您在 MongoDB中的数据有所改变时, 把改变情况也反应到 S3
本文所使用的 MongoDB 数据库中含有两张表, BookSpider 与 test

-
BookSpider 中的表结构

-
test 中的表结构



当迁移完成后, 如果源数据库中的数据未发生改变, 则意味不会触发 CDC
此时 S3 中目录结构为
- Scrapy_data(文件夹, 与源数据库同名)
- BookSpider(文件夹, 其中一个表同名)
- LOAD00000001.csv
- test( 文件夹, 与另一个表同名)
- LOAD00000001.csv
- BookSpider(文件夹, 其中一个表同名)
这两个 csv 文件即保存了 MongoDB 中对应表的所有的数据信息, 选取 BookSpider 表的LOAD00000001.csv

如上图, 所有的数据都以 json 格式保存了下来
我们对 BookSpider 表增加一条数据, 修改一条数据, 再删除一条数据, 使其能够触发 CDC
- 增

- 改

- 删

此时打开 S3, 其目录结构变为了
Scrapy_data
- BookSpider
- LOAD00000001.csv
- 20180902-104149271.csv(新增)
- 20180902-104505261.csv(新增)
- test( 文件夹, 与另一个表同名)
- LOAD00000001.csv
打开两个文件新增的 csv 文件
-
20180902-104505261.csv

-
20180902-104149271.csv


可以看到, 三个改变都被记录了下来, 切前面多了 U D I 三个字母, 这意味着这三条操作分别为 Update, Delete,Insert