{kind=link}
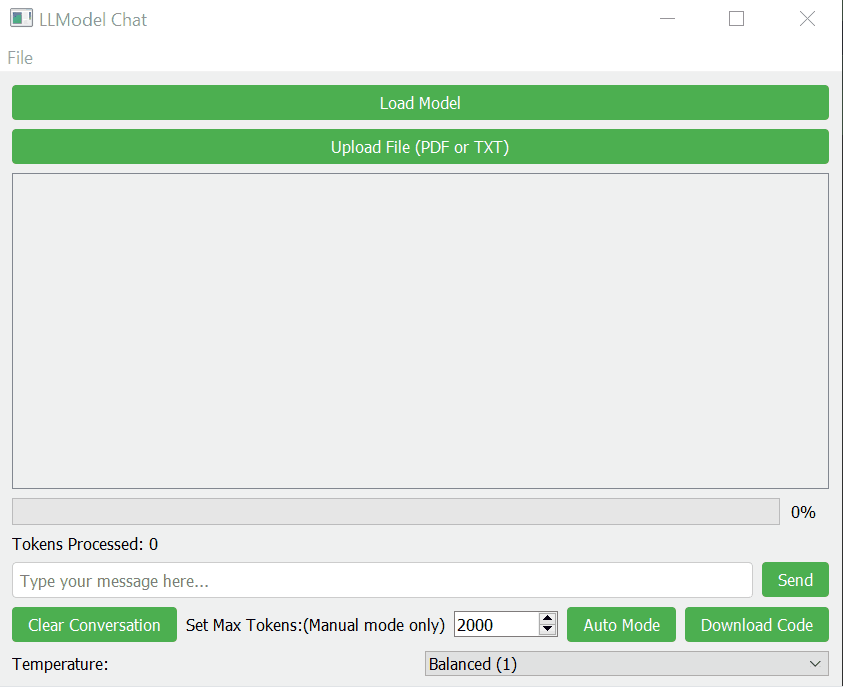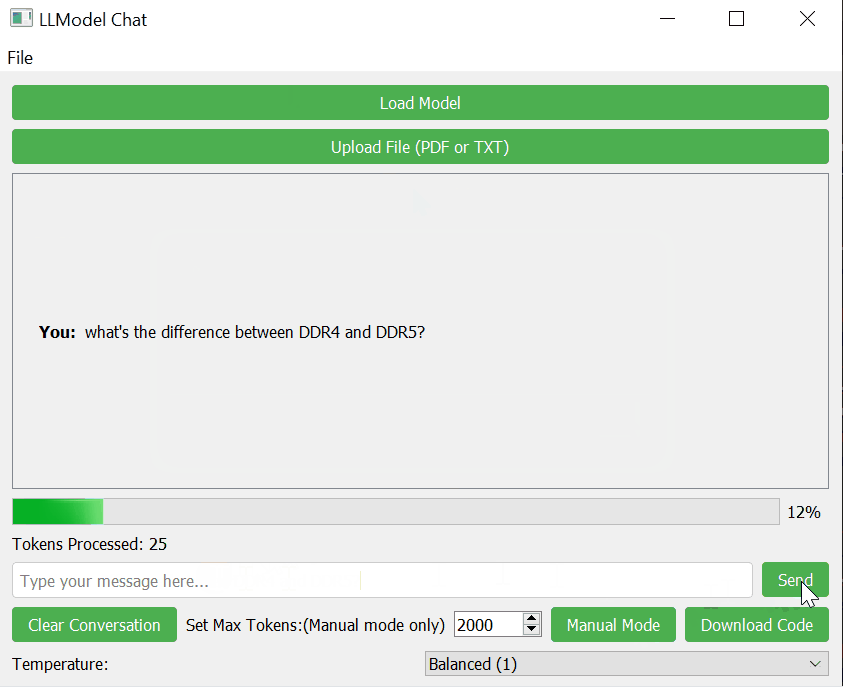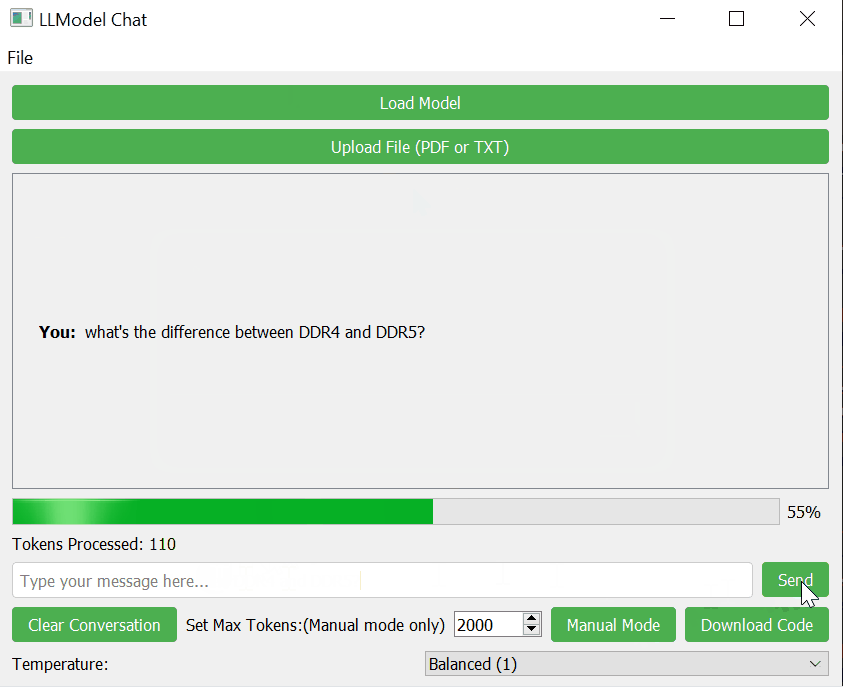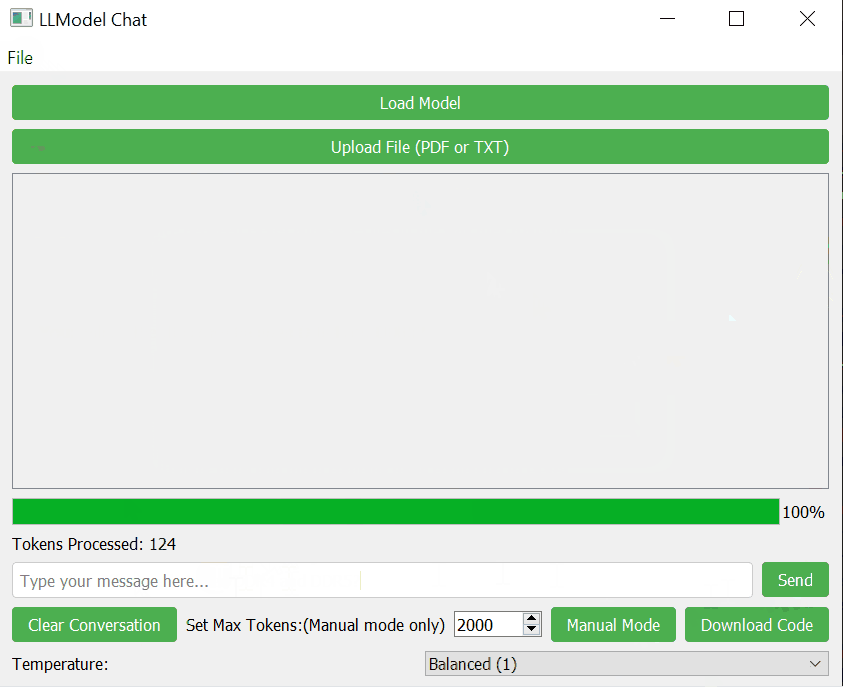
LLModel Chat is a CPU only PyQt5-based graphical user interface (GUI) application that allows users to interact with a local large language model (LLM) using the Llama library. This application provides a user-friendly interface for loading and using LLM models, engaging in conversations, and even processing uploaded text or PDF files as context for the AI responses.
The main concept behind LLModel Chat is to provide an easy-to-use interface for interacting with local LLM models. It combines the power of LLMs with a clean, intuitive GUI, making it accessible for users who may not be comfortable with command-line interfaces.
Key features include:
- Model Loading: Users can load a local GGUF (GPT-Generated Unified Format) model file.
- File Upload: Ability to upload and process text or PDF files as additional context for the AI.
- Conversation Interface: A chat-like interface for interacting with the AI model.
- Adjustable Parameters: Users can modify max tokens and temperature settings.
- Code Extraction: Automatically detects Python code in AI responses and allows downloading.
- Progress Indication: Shows the progress of AI response generation.
- Conversation Management: Option to clear the conversation history.
- Text2Speech: Option to play the AI response.
- Copy text: Option to copy the text of the AI response.
- Save/load conversation: Option to save and load previous conversations.
To run this application, you'll need to install the following libraries:
- PyQt5: For the graphical user interface
- llama-cpp-python: For interfacing with the Llama models
- PyMuPDF (fitz): For handling PDF files.
- pyttsx3: Text to speech.
You can install these libraries using pip:
pip install PyQt5 llama-cpp-python PyMuPDF pyttsx3
-
Ensure you have Python 3.6+ installed on your system.
-
Install the required libraries as mentioned above.
-
Download the
LLModel.pyfile to your local machine. -
Open a terminal or command prompt and navigate to the directory containing
LLModel.py. -
Run the script using Python:
-
The LLModel Chat window should appear.
- Load Model: Click the "Load Model" button and select your GGUF model file.
- Upload Context File (Optional): You can upload a text or PDF file to provide additional context for the AI responses.
- Start Chatting: Type your message in the input field and click "Send" or press Enter.
- Adjust Settings: You can modify the max tokens and temperature using the controls at the bottom of the window.
- Download Code: If the AI generates Python code, you can download it using the "Download Code" button.
- Clear Conversation: Use the "Clear Conversation" button to start a new chat session.
- Auto/Menual mode: Use auto or menual mode for tokens count.
This application requires a compatible GGUF model file to function. Make sure you have a suitable model before running the application. The model should be compatible with the llama-cpp-python library.
GGUF libraries: https://huggingface.co/models?library=gguf
Recommended GGUF models:
-
Phi-3-mini-4k-instruct-gguf (Q5_K_M) https://huggingface.co/bartowski/Phi-3.1-mini-4k-instruct-GGUF
-
Meta-Llama-3.1-8B-Instruct-GGUF (Q5_K_M) https://huggingface.co/bartowski/Meta-Llama-3.1-8B-Instruct-GGUF
Contributions to improve the application are welcome. Please feel free to submit issues or pull requests to enhance functionality, fix bugs, or improve the user interface.