트로트 열풍을 분석해보겠습니다. 크롤링에는 많은 방식들이 있지만, R Selenium을 이용해 크롤링하도록 하겠습니다.
- R Selenium
R Selenium에 대한 방법은 따로 설명하지 않겠습니다. 아래 블로그에 잘 정리되어 참고하시면 좋을 것 같습니다.
- 데이터 수집 및 정제
library(RSelenium)
library(seleniumPipes)
library(rvest)
library(httr)
library(tidyverse)
library(psych)
library(gplots)
library(ggplot2)
library(xml2)
크롤링에 필요한 패키지들을 library 함수를 통해 미리 불러와줍니다.
잠깐, 코드 청크에 관한 설명을 하자면, {r} 옆에 명령어를 더 넣으면 다른 기능을 사용할 수 있습니다. warning = FALUSE는 ~~라는 뜻. message = FALUSE로 조절이 가능합니다.
\3. 음원 차트(지니) 데이터 수집
RSelenium을 통해 국내 음원 사이트 지니(genie) TOP 200 월간 차트, “사랑의 콜센터” 등의 특정 키워드 검색으로 나오는 데이터과 특정 장르 내 차트 등을 크롤링하여 원하는 내용의 데이터를 수집했습니다.
3.1.
remD <- remoteDriver(port = 4445L, browserName = “chrome”)
remD$open()
remoteDriver() 함수를 통해 4445번 포트와 크롬을 연결시켜준 뒤, remDr$open() 함수를 입력하여 크롬 웹창이 열리도록 합니다.
```{r}
search <- function(name, page){
remD$navigate(paste0("https://www.genie.co.kr/search/searchSong?query=", name, "&page=", page))
html <- remD$getPageSource()[[1]]
html <- read_html(html)
title <- NULL
artist <- NULL
number <- NULL
remDr$navigate() 함수 내부에 크롤링하고자 하는 지니 사이트를 입력하면 해당 주소로 이동하여 크롤링할 수 있게 됩니다. 수집하고자 하는 title, artist, number에는 먼저 NULL값을 주고 크롤링을 통해 값을 채워주겠습니다.
artist <- html %>% html_nodes(".info .artist") %>%
html_text()
artist <- gsub("\n", "", artist)
artist <- trimws(artist)
number <- html %>% html_nodes("tbody > tr") %>%
html_attrs()
for(i in 1:length(number)){
number[[i]] <- number[[i]][2]
}
number <- gsub("songid", "", number)
df <- data.frame(number, artist)
genre <- c()
title <- c()
heart <- c()
t.listener <- c()
t.listen <- c()
for(i in df$number){
url <- paste0("http://www.genie.co.kr/detail/songInfo?xgnm=", i)
url_n <- read_html(url)
genres_nodes_n <- html_nodes(url_n, 'li>span.value')
genres_n <- html_text(genres_nodes_n)
genre <- append(genre, genres_n[3])
title_nodes_n <- html_nodes(url_n, '#body-content > div.song-main-infos > div.info-zone > h2')
title_n <- html_text(title_nodes_n)
title_n <- gsub("\n", "", title_n)
title_n <- trimws(title_n)
title <- append(title, title_n)
heart_nodes_n <- html_nodes(url_n, '#emLikeCount')
heart_n <- html_text(heart_nodes_n)
heart <- append(heart, heart_n)
t.listener_nodes_n <- html_nodes(url_n, '#body-content > div.song-main-infos > div.aside-zone.daily-chart > div.total > div:nth-child(1) > p')
t.listener_n <- html_text(t.listener_nodes_n)
t.listener <- append(t.listener, t.listener_n)
t.listen_nodes_n <- html_nodes(url_n, '#body-content > div.song-main-infos > div.aside-zone.daily-chart > div.total > div:nth-child(2) > p')
t.listen_n <- html_text(t.listen_nodes_n)
t.listen <- append(t.listen, t.listen_n)
}
df <- data.frame(df, title, genre, heart, t.listener, t.listen)
return(df)
}
.name에 특정 키워드를 입력하고 page에 원하는 페이지를 검색하여 나오는 데이터 수집 과정을 반복하기 위해 function을 만들었습니다.
수집한 데이터는 각각 title(노래 제목), artist(가수), number(곡 id), genre(곡의 장르), heart(좋아요 수), t.listener(전체 청취자 수), t.listen(전체 재생 수)에 저장 되도록 했습니다.
곡에 대한 상세한 정보는 상세정보 보여주는 url에 각 노래의 고유 id를 붙여 검색하면 나오는 방식입니다.
이로써, R selenium을 이용하여 지니의 다양한 트로트 데이터를 수집했습니다.
수집한 데이터의 전처리와 통계 분석으로 가설을 검증하는 과정까지 보여드릴테니, 집중해서 읽어주세요!!
- 데이터 분석 및 가설 검증
*음원 차트가 증명하는 트로트의 인기*
트로트 열풍, 사실일까?
: 2019~21년(3월까지) TOP 200 차트 내 장르 분포 분석
앞서 크롤링으로 수집하여 csv 파일로 저장했던 데이터를 이용했습니다. 필요한 정보만을 데이터 전처리를 통해 추출한 뒤에 트로트 열풍이 정말 불었는지, 그만큼 트로트의 선호도가 높아졌는지 알아보기 위한 기술통계 -빈도수 분석을 실시하겠습니다.
- 데이터 전처리
genie_chart_2019 <- read.csv(“genie_chart_2019.csv”)
genie_chart_2020 <- read.csv(“genie_chart_2020.csv”)
genie_chart_2021 <- read.csv(“genie_chart_2021.csv”)
read.csv 함수로 2019.01~2021.03 지니 TOP 200 차트를 불러오겠습니다.
genie_chart <- rbind(genie_chart_2019, genie_chart_2020, genie_chart_2021)
genie_chart <- genie_chart[,-c(1,2,6,7)]
year <- c(rep(2019, 2400))
year <- append(year, c(rep(2020, 2400)))
year <- append(year, c(rep(2021, 600)))
month <- c(rep(gettextf(‘%02d’, 01), 200))
for (a in 02:12){
month <- append(month,c(rep(gettextf(‘%02d’, a), 200)))
}
month <- rep(month, 2)
month_2021 <- c(rep(gettextf(‘%02d’, 01), 200))
for (a in 02:03){
month_2021 <- append(month_2021,c(rep(gettextf(‘%02d’, a), 200)))
}
month <- append(month, month_2021)
genie_chart <- cbind(genie_chart, year, month)
genie_chart_2019 <- subset(genie_chart, genie_chart$year==2019)
genie_chart_2020 <- subset(genie_chart, genie_chart$year==2020)
genie_chart_2021 <- subset(genie_chart, genie_chart$year==2021)
genie_chart <- unite(genie_chart, “yearmonth”, year, month, sep = “”)
genie_chart$yearmonth <- as.integer(genie_chart$yearmonth)
분석에 필요하지 않은 데이터를 없앤 후 각 데이터에 연도, 월을 추가하여 구분이 쉽도록 한다.
- 데이터 시각화
a <- ggplot(genie_chart, aes(factor(yearmonth)))
a + geom_bar(aes(fill=factor(genre))) + ggtitle(“2019년~2021년 차트 TOP 200 내 장르별 분포”) + labs(x = “가수”)

2019년 1월부터 2021년 3월 차트 TOP 200의 장르별 분포를 보여준다. 각 장르의 변화 추이는 확인할 수 있지만 장르별로 경계가 뚜렷하지 않으며 정확한 수치를 알 수 없다. 그렇기에 기술통계를 활용해 각 장르의 빈도수 등을 분석하고자 한다.
- 기술통계 — 빈도표 분석
각 연도의 TOP 200 차트 데이터 중 장르 변수에 대해 Freq(빈도) / Cumul(누적 빈도) / relative(비율) / Cum.prop(누적 비율)을 출력한다.
<2019년 1월~12월>
cbind(Freq = table(genie_chart_2019$genre),
Cumul=cumsum(table(genie_chart_2019$genre)),
relative = prop.table(table(genie_chart_2019$genre)),
Cum.prop = cumsum(prop.table(table(genie_chart_2019$genre))))
<2020년 1월~12월>
cbind(Freq = table(genie_chart_2020$genre),
Cumul=cumsum(table(genie_chart_2020$genre)),
relative = prop.table(table(genie_chart_2020$genre)),
Cum.prop = cumsum(prop.table(table(genie_chart_2020$genre))))
<2021년 1월~3월>
cbind(Freq = table(genie_chart_2021$genre),
Cumul=cumsum(table(genie_chart_2021$genre)),
relative = prop.table(table(genie_chart_2021$genre)),
Cum.prop = cumsum(prop.table(table(genie_chart_2021$genre))))

결과해석 :
+ 2019년~2021년 3월의 비율을 보았을 때, 3년 연속 발라드 장르가 1위를 차지하고 있다. + 2021년은 1,2,3월의 데이터밖에 없기에 2019년과 2020년의 빈도수를 비교한다. 차트 TOP 200 내 2019년의 트로트 장르의 빈도는 9인 반면 2020년의 빈도는 121로 10배 이상의 증가를 보였다. 따라서 트로트의 인기가 높아진 것으로 분석할 수 있다. + 각 연도 별 트로트의 비율을 소수점 넷째자리에서 반올림하여 보면 2019년 0.0038, 2020년 0.050, 2021년 0.043이다. 2019년과 비교해 본다면, 차트 TOP 200 내 트로트 장르가 차지하는 비율이 증가했다. 또한, 2021년 지금까지 그 선호가 이어지는 것으로 보인다.
*2019년에 비해 2020년에 트로트를 듣는 사람이 늘고 선호도가 증가하였으며 지금까지도 이어지고 있다.*
미스터트롯 방영 전, 후 트로트 차트 분석
: 미스터트롯 방영이 트로트의 음원 차트에 영향을 미쳤을까 ?
+ 앞서 데이터 크롤링으로 수집하여 csv 파일로 저장했던 2019년2021년 3월 차트 TOP 200 데이터를 이용해 분석한다.
+ <미스터트롯> 방영시기 : 2020.01.02. 2020.03.12.
+ 2020년 1월부터 방영했기에 그 전 해인 2019년과 2020년 두 그룹 간 차이가 있는지를 알아보기 위해 독립표본 t-검정이 아닌 표본 간의 상호연관성을 고려한 대응표본 t-검정을 실시하고자 한다.
- 데이터 전처리
월별 지니 차트 T0P200 내 트로트 장르 음원의 개수를 구해보고자 한다.
<2019년>
genie_chart_2019<-tibble(read.csv(‘genie_chart_2019.csv’,header = T))[]
genie_chart_2020<-tibble(read.csv(‘genie_chart_2020.csv’,header = T))
trot_genre <- filter(genie_chart_2019, genre==”트로트”)
cnt_trot <- table(trot_genre$month)
# cnt_trot <-
for(i in 1:12){
if(i %in% names(cnt_trot)){
# cnt_trot <- append(cnt_trot, cnt_trot[names(cnt_trot) == i])
next
}
else{
cnt_trot <- append(cnt_trot, 0, after = i — 1)
names(cnt_trot)[i] <- i
}
}
month <- 1:12
genie_2019 <- data.frame(month, cnt_trot)
<2020년>
```{r}
genie_chart_2019<-tibble(read.csv(‘genie_chart_2019.csv’,header = T))[]
genie_chart_2020<-tibble(read.csv(‘genie_chart_2020.csv’,header = T))
trot_genrea <- filter(genie_chart_2020, genre==”트로트”)
cnt_trota <- table(trot_genrea$month)
# cnt_trot <-
for(i in 1:12){
if(i %in% names(cnt_trota)){
# cnt_trot <- append(cnt_trot, cnt_trot[names(cnt_trot) == i])
next
}
else{
cnt_trota <- append(cnt_trota, 0, after = i — 1)
names(cnt_trota)[i] <- i
}
}
month <- 1:12
genie_2020 <- data.frame(month, cnt_trota)
genie_2020 <-genie_2020[,-2]
names(genie_2020)<-c(‘month’,’cnt_trot’)
대응표본 T-test 분석 * <연구가설> : <미스터트롯(2020)> 방영 전(2019)과 후(2020)의 월간 TOP200 차트 내의 트로트 장르 음원의 개수는 차이가 있다. - H0 : <미스터트롯(2020)> 방영 전(2019)과 후(2020)의 월간 TOP200 차트 내의 트로트 장르 음원의 개수는 차이가 없다. - H1 : <미스터트롯(2020)> 방영 전(2019)과 후(2020)의 월간 TOP200 차트 내의 트로트 장르 음원의 개수는 차이가 있다.
\1. 자료 생성 : <미스터트롯> 방영 전과 후의 트로트 음원 개수 자료를 생성한다. 전과 후의 차이값을 나타내는 diff변수를 추가해준다. 이는 2019년과 2020년의 트로트 음원 개수가 유의미한 차이가 있는지 검증하기 위함이다.
dat<-data.frame(genie_2019$month,genie_2019$cnt_trot,genie_2020$cnt_trot)
dat_diff<-genie_2019$cnt_trot-genie_2020$cnt_trot
dat<-data.frame(month,genie_2019$cnt_trot,genie_2020$cnt_trot,dat_diff)
\2. 정규성 가정 확인 : 정규분포를 따르지 않으면 t-test 대신에 ‘wilcoxen test’를 사용해야 한다.
- 정규성 검증 : Shapiro-wilk test
shapiro.test(dat_diff)

Shapiro-wilk test의 귀무가설은 ‘H0:정규분포를 따른다’는 것으로 p-value가 0.05보다 크면 정규성을 가정하게 된다. Shapiro-wilk 검정 결과p-value = 0.5801로 나타나기 때문에 정규성을 가정하고 t-test를 진행하기로 한다.
3.가설 검증 : t-test를 이용한다.
t.test(genie_2020$cnt_trot,genie_2019$cnt_trot,paired = TRUE)

결과 해석 : p-value = 0.0000227으로 유의수준 0.05에서 귀무가설을 기각한다. 따라서 <미스터트롯(2020)> 방영 전(2019)과 후(2020)의 월간 TOP200 차트 내의 트로트 장르 음원의 개수는 차이가 있다고 할 수 있다.
\4. 기술통계량 구하기 : ‘psych’ 패키지를 이용하여 기술통계량을 구한다.
des_year<-dat[,-c(1,4)]
describe(des_year)

출력된 기술통계량을 살펴보면, 2019년의 트로트 음원 개수의 평균은 0.75이고,2020년은 10.08로 나타나고 있어 연도별평균의 차이는 9.33이다.
- 데이터 시각화
des_year_new<-data.frame(c(1:12),genie_2019$cnt_trot,genie_2020$cnt_trot)
names(des_year_new)<-c(‘month’,’before’,’after’)
ggplot(data = des_year_new,
mapping = aes(x= month,
y= before)) + geom_line()+ geom_point()+
coord_cartesian(xlim=c(1,12), ylim=c(0,18.5))+
ggtitle(“2019년”)
ggplot(data = des_year_new,
mapping = aes(x= month,
y= after)) + geom_line()+geom_point()+
coord_cartesian(xlim=c(1,12), ylim=c(0,18.5))+
ggtitle(“2020년”)
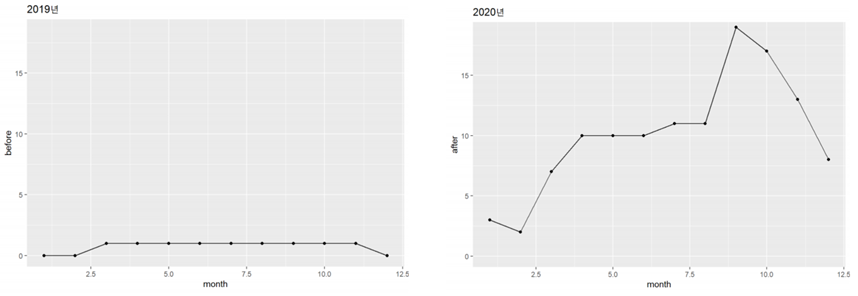
- before(2019)에 비해 after(2020)의 트로트 음원 개수가 확연히 많은 것을 시각적으로 확인할 수 있다. + 위의 결과로 보았을 때, <미스터 트롯> 방영 이후 차트의 트로트 장르 음원의 개수가 유의하게 증가했다고 할 수 있다.
*미스터트롯 방영이 트로트의 음원 차트에 긍정적인 영향을 미쳤다.*
트로트의 인기가 아닌, “미스터트롯”의 인기인가?
: 트로트 음원 차트 내 앨범의 유형 분석
+ 앞서 데이터 크롤링으로 수집하여 csv 파일로 저장했던 세 시점(미스터트롯 종영 직후, 미스터트롯 종영 직후와 현재 사이, 현재)의 트로트 음원차트를 이용해 분석한다. + 미스터트롯이 끝난 직후, 미스터트롯 종영 직후와 현재 사이, 현재 세 시점에서의 트로트 차트 TOP 100 내 앨범의 유형을 분석하여 과연 트로트의 인기가 맞는지, 단순히 미스터트롯 등 방송의 인기인지 알아보고자 한다.
- 데이터 전처리
트로트 음악, 예능 방송인 미스터트롯, 미스트롯, 사랑의 콜센타, 뽕숭아학당 방송에서 발매된 음원과 일반 음원 발매를 구분한다.
trot_chart_old <- tibble(read.csv(“trot_chart_old.csv”))
trot_chart_between <- tibble(read.csv(“trot_chart_between.csv”))
trot_chart_recent <- tibble(read.csv(“trot_chart_recent.csv”))
<미스터트롯 종영 직후 (2020.03.13)>
tv_program <- c(“미스터트롯”, “미스트롯”, “미스트롯2”, “사랑의 콜센타”, “뽕숭아학당”)
is_program <- str_detect(trot_chart_old$album, tv_program[1])
for(program in 2:length(tv_program)){
is_program <- (is_program | str_detect(trot_chart_old$album, tv_program[program]))
}
trot_chart_old$is_program <- is_program
date <- c(rep(“2020.03.13(미스터트롯 종영 직후)”, 100))
trot_chart_old <- cbind(trot_chart_old, date)
<미스터트롯 종영 직후와 현재 사이 (2020.09.18)>
tv_program <- c(“미스터트롯”, “미스트롯”,”미스트롯2", “사랑의 콜센타”, “뽕숭아학당”)
is_program <- str_detect(trot_chart_between$album, tv_program[1])
for(program in 2:length(tv_program)){
is_program <- (is_program | str_detect(trot_chart_between$album, tv_program[program]))
}
trot_chart_between$is_program <- is_program
date <- c(rep(“2020.09.18(종영 직후와 현재 사이)”, 100))
trot_chart_between <- cbind(trot_chart_between, date)
<현재 (2021.04.23)>
tv_program <- c(“미스터트롯”, “미스트롯”,”미스트롯2", “사랑의 콜센타”, “뽕숭아학당”)
is_program <- str_detect(trot_chart_recent$album, tv_program[1])
for(program in 2:length(tv_program)){
is_program <- (is_program | str_detect(trot_chart_recent$album, tv_program[program]))
}
trot_chart_recent$is_program <- is_program
date <- c(rep(“2021.04.23(현재)”, 100))
trot_chart_recent <- cbind(trot_chart_recent, date)
trot_chart <- rbind(trot_chart_old, trot_chart_between, trot_chart_recent)
trot_chart <- trot_chart[,-c(1,2)]
- 데이터 시각화
```{r}
c <- ggplot(data = trot_chart, aes(x=factor(is_program), fill=factor(is_program))) + geom_bar() + facet_grid(.~date)
c + geom_bar() + facet_grid(.~date) + ggtitle(“트로트 차트 내 방송 음원 수”)
```

- 미스터트롯 종영 직후부터 현재 시점까지 TRUE(방송 음원)의 개수가 FALSE(일반 음원)의 개수보다 지속적으로 많은 것을 시각적으로 확인할 수 있다. + 트로트 차트 내 상당수의 부분이 방송을 통해 발매된 음원임을 알 수 있다.
미스터트롯 종영 직후부터 현재 시점까지 트로트 음원 차트 내에 방송을 통해 발매된 음원의 개수가 일반 음원의 개수보다 지속적으로 많다.
*트로트를 음악으로써 먼저 접하기보다, 방송을 통해 접하게 된다.*
: 트로트 차트 내 가수 분포 분석
+ 앞서 데이터 크롤링으로 수집하여 csv 파일로 저장했던 2021년 4월 23일 기준 트로트 음원차트를 이용해 분석한다. + 미스터트롯이 종영한 지 일년이 넘어가는 현재 시점에서, 트로트 TOP 100 차트 내의 가수 별 노래 수 분포를 분석하고자 한다.
trot_chart_n <- read.csv(“trot_chart_n.csv”)
- 데이터 시각화
a <- ggplot(trot_chart_n, aes(factor(artist)))
a + geom_bar() + ggtitle(“2021년 4월 23일 기준 트로트 차트 내 가수 별 노래 수 분포”) + labs(x = “가수”)
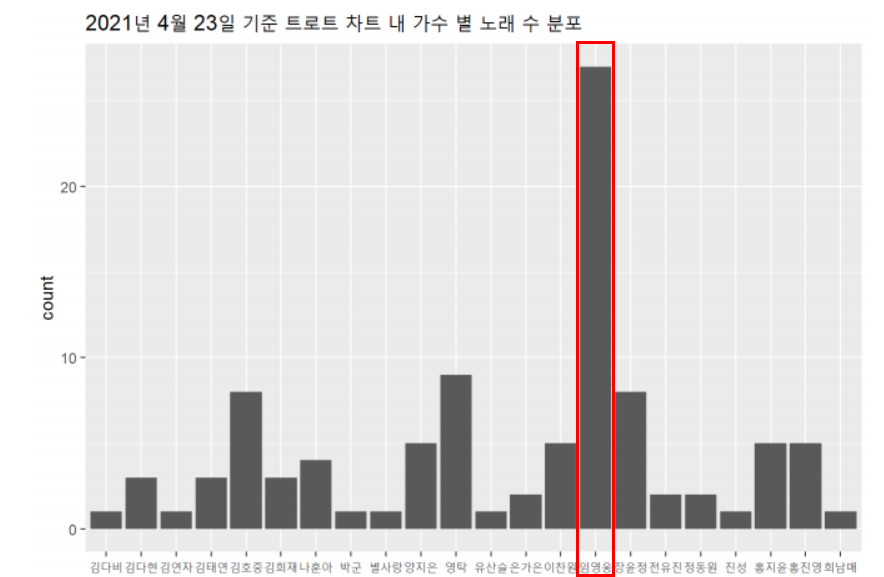
- 미스터트롯이 종영한 지 일년이 넘어가는 2021년 4월 23일 현재 시점에서 미스터트롯 “진” 임영웅의 트로트 TOP 200차트 내 분포가 압도적으로 많은 것을 확인할 수 있다.
- 데이터 전처리 미스터트롯 오디션으로 알려진 가수를 미스터트롯으로 묶어 분포를 살펴보고자 한다.
mr.trot <- c(“임영웅”, “영탁”, “이찬원”, “김호중”, “정동원”, “장민호”, “김희재”)
ms.trot <- c(“홍지윤”, “김태연”, “양지은”, “김다현”, “별사랑”, “은가은”, “전유진”)
trot_chart_n$artist <- gsub(“임영웅”, “미스터트롯”, trot_chart_n$artist)
for(a in 2:length(mr.trot)){
trot_chart_n$artist <- gsub(mr.trot[a], “미스터트롯”, trot_chart_n$artist)
}
trot_chart_n$artist <- gsub(“홍지윤”, “미스트롯”, trot_chart_n$artist)
for(a in 2:length(mr.trot)){
trot_chart_n$artist <- gsub(ms.trot[a], “미스터트롯”, trot_chart_n$artist)
}
- 데이터 시각화
a <- ggplot(trot_chart_n, aes(factor(artist)))
a + geom_bar() + ggtitle(“2021년 4월 23일 기준 트로트 차트 내 가수 별 노래 수 분포”) + labs(x = “가수”)
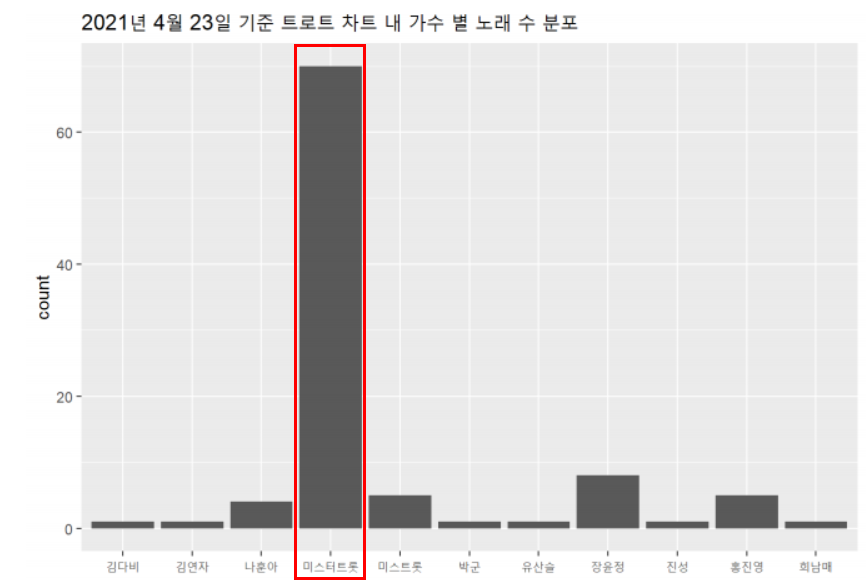
미스터트롯 출신 가수들의 분포가 압도적이다.
*미스터트롯 출신 가수들이 트로트의 인기에 주역이다.*
미스터트롯 TOP6 내 인기 분석
+ 앞서 데이터 크롤링으로 수집하여 csv 파일로 저장했던 미스터트롯 TOP6(임영웅, 영탁, 이찬원, 정동원, 장민호, 김희재) 개인 유튜브 채널의 정보가 담긴 데이터를 이용해 분석한다. + 위에서 미스터트롯 종영이 일년이 넘어가는 현재 시점에도 트로트 차트 TOP 100 내 미스터트롯 출신 가수들(TOP6)의 분포가 압도적임을 알아냈다. 이후 TOP6내의 인기를 알아보고자 유튜브 채널 데이터를 통해 다음과 같은 분석을 실시하였다.
youtube_df_modfied <- read.csv(“youtube_df_modfied.csv”)
youtube_df_modfied <- youtube_df_modfied[-4,]
순위 <- c(1:6)
youtube_df_modfied <- cbind(youtube_df_modfied, 순위)
barplot(구독자수~가수,youtube_df_modfied,main=”구독자수”)
barplot(영상별.평균.조회수~가수,youtube_df_modfied,main=”영상별 평균 조회수”)

- 가수와 유튜브 채널의 관심도를 알 수 있는 구독자 수와 영상별 평균 조회수를 barplot을 통해 나타냈다. + 미스터트롯 TOP6 중 임영웅의 구독자 수와 영상별 평균 조회수가 압도적으로 높은 결과가 나왔다.
‘사랑의 콜센타’ 음원 내 트로트/비트로트 선호도 분석
+ 앞서 데이터 크롤링으로 수집하여 csv 파일로 저장했던 ‘사랑의 콜센타’ 방송을 통해 발매된 모든 음원에 대한 데이터를 정제한 파일을 이용해 분석한다. + 미스터트롯이 종영한 후 결승에 진출한 미스터트롯 TOP6가 출연한 ‘사랑의 콜센타’ 프로그램을 통해 발매된 음원의 장르를 트로트와 트로트가 아닌 장르로 나누어 분석한다. + 이에 따라 트로트 / 비트로트 중 어떤 장르의 선호가 높을지 등을 분석하고자 한다.
- 데이터 전처리
미스터트롯 TOP6를 세 그룹으로 나눈 후 그들이 부른, 트로트가 아닌 장르를 모두 비트로트로 바꾼다.
singers_a <- c(“임영웅”, “영탁”)
singers_b <- c(“이찬원”, “정동원”)
singers_c <- c(“장민호”, “김희재”)
love_call_center <- read.csv(“love_call_center_total.csv”)
# 임영웅 영탁
singers_a_1 <- love_call_center %>%
filter(str_detect(love_call_center$artist, singers_a[1]))
singers_a_2 <- love_call_center %>%
filter(str_detect(love_call_center$artist, singers_a[2]))
singers_a <- rbind(singers_a_1, singers_a_2)
singers_a <- singers_a[,c(-1, -2, -4, -7, -8)]
singers_a$artist <- 1
singers_a$genre[singers_a$genre != “트로트”] <- “비트로트”
singers_a$genre[singers_a$genre == “트로트”] <- 1
singers_a$genre[singers_a$genre == “비트로트”] <- 2
# 이찬원 정동원
singers_b_1 <- love_call_center %>%
filter(str_detect(love_call_center$artist, singers_b[1]))
singers_b_2 <- love_call_center %>%
filter(str_detect(love_call_center$artist, singers_b[2]))
singers_b <- rbind(singers_b_1, singers_b_2)
singers_b <- singers_b[,c(-1, -2, -4, -7, -8)]
singers_b$artist <- 2
singers_b$genre[singers_b$genre != “트로트”] <- “비트로트”
singers_b$genre[singers_b$genre == “트로트”] <- 1
singers_b$genre[singers_b$genre == “비트로트”] <- 2
# 장민호 김희재
singers_c_1 <- love_call_center %>%
filter(str_detect(love_call_center$artist, singers_c[1]))
singers_c_2 <- love_call_center %>%
filter(str_detect(love_call_center$artist, singers_c[2]))
singers_c <- rbind(singers_c_1, singers_c_2)
singers_c <- singers_c[,c(-1, -2, -4, -7, -8)]
singers_c$artist <- 3
singers_c$genre[singers_c$genre != “트로트”] <- “비트로트”
singers_c$genre[singers_c$genre == “트로트”] <- 1
singers_c$genre[singers_c$genre == “비트로트”] <- 2
singers_group <- rbind(singers_a, singers_b, singers_c)
ㄴㅊㄴㅊ
singers_group <- rbind(singers_a, singers_b, singers_c)
singers_group$artist.factor <- factor(singers_group$artist,
levels=c(1,2,3), labels=c(“상위 그룹”, “중위 그룹”, “하위 그룹”))
singers_group$genre.factor <- factor(singers_group$genre,
levels=c(1,2), labels=c(“트로트”, “비트로트”))
singers_group$heart <- gsub(“,”, “”, singers_group$heart)
- 독립표본 T-test 분석
\1. 데이터 전처리 및 자료 생성
love_call_center <- read.csv(“love_call_center_total.csv”)
love_call_center$genre[love_call_center$genre != “트로트”] <- “비트로트”
love_call_center <- love_call_center[-528,-c(1,2,3,4,7,8)]
love_call_center$heart <- gsub(“,”, “”, love_call_center$heart)
group_trot <- subset(love_call_center, genre==”트로트”)
group_not_trot <- subset(love_call_center, genre==”비트로트”)
group_not_trot$heart <- as.integer(group_not_trot$heart)
group_trot$heart <- as.integer(group_trot$heart)
group_trot <- group_trot[,-1]
group_not_trot <- group_not_trot[,-1]
singers_group$heart <- as.integer(singers_group$heart)
\2. 분산 동질성 검증 : 두 집단의 분산이 같지 않을 경우 t-test의 수정버전인 ‘Welch’s test’를 사용해야 한다.
var.test(heart ~ genre.factor, data = singers_group)

등분산 검증 결과 분석 :
+ F값은 0.25283이고 트로트, 비트로트 두 집단의 자유도는 각각 479, 217이다. + 유의도는 영가설을 기각할 수 있는 수준인 0.05보다 작기 때문에 분산이 같지 않음. -> ‘Welch’s test’을 사용해야 한다.
\3. 연구가설 검증 — ‘Welch’s test’
‘Welch’s test’는 t-test와 같은 function을 활용하지만 속성값의 var.equal = TRUE을 없애면 default값인 FALSE가 적용되어 ‘Welch’s test’가 된다.
t.test(heart ~ genre.factor, data = singers_group)
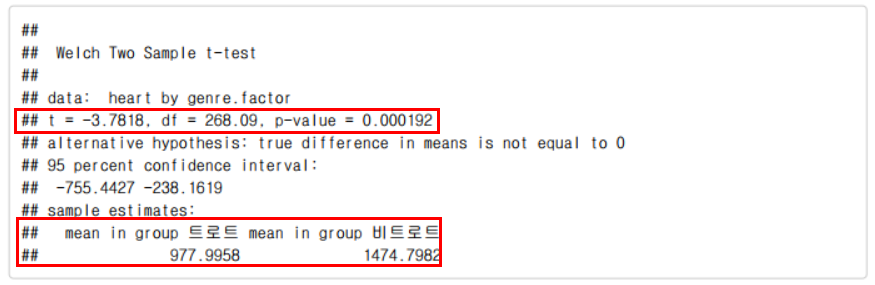
결과분석 :
+ T값은 -3.7818이고, 자유도는 268.09로 유의도가 0.000192이다. + 독립변수인 장르(트로트/비트로트)의 평균은 각각 977.9958, 1474.7982으로 집단 간 평균은 약 496.8점의 차이가 있다. + 유의도가 0.05보다 작기 때문에 장르(트로트/비트로트)에 띠라 선호도의 차이가 없다는 영가설이 기각되어 집단 간의 평균 차이가 통계적으로 유의한 차이라 볼 수 있다.
\4. 기술통계량 출력
describeBy(singers_group$heart, singers_group$genre.factor)

\5. 도표 출력
plotmeans(heart ~ genre.factor, data = singers_group, xlab=”장르”,
ylab=”선호도(좋아요 수)”, ci.label=TRUE, mean.label=TRUE, ylim=c(500, 2000),
barwidth=5, main=”장르 별 선호도 차이”, digits=4, pch=”*”)

##### ’사랑의 콜센타’는 트로트 프로그램임에도 불구하고 트로트 음원의 선호보다 비트로트 음원의 선호가 높다. ##### 이는 트로트의 선호, 인기보다는 출연진의 선호, 인기가 앞선다는 것을 보여준다.
*트로트라는 장르를 선호하기보다는 출연진의 선호가 앞서고, 자신이 좋아하는 출연진이 불러주는 다른 음악 장르를 선호함을 의미한다.*
### 4. 결론 도출 #### 4.1. 결론 트로트 열풍이 불었는지 확인하기 위하여 음원 차트를 분석한 결과, 2019년과 2020년 사이에는 TOP200 내 트로트 장르의 빈도는 10배 이상 늘어난 것을 알 수 있었다. 음원 차트가 음악의 인기를 대변한다고 봤을 때 트로트의 인기 증가가 확실하게 나타났다는 결론을 도출했다. 또한 19년 부터 21년까지의 TOP200 차트 내 트로트가 차지하는 비율이 증가했으므로 트로트는 반짝 열풍이 아니라 1년 넘게 지속되어 오고 있다는 사실을 알아냈다. 그러한 트로트의 인기의 주요 요인으로 <미스터트롯>으로 선정했는데, 대응 t-검증과 기술 통계를 이용한 결과 방영 전 후, 트로트 음원 개수의 평균은 약 10배 증가했고, 미스터트롯 방영이 트로트의 음원 차트에 긍정적인 영향을 미쳤다. 따라서 트로트의 인기를 음원 차트 데이터가 증명해주었다.
미스터 트롯 방영이 트로트 인기에 영향을 미쳤다는 것을 알고 나서, 그렇다면 현재의 트로트 열풍은 트로트의 인기가 아니라 미스터 트롯의 인기인가?에 대한 의문을 해결하기 위해 먼저 트로트 음원 차트 내 앨범 유형을 분석했다. 그 결과, 트로트를 음악으로써 먼저 접하기보다, 방송을 통해 접하게 된다는 사실을 알게 되었다. 다음으로, 사랑의 콜센타’ 음원 내 트로트/비트로트 선호도 분석한 결과, 사랑의 콜센타’는 트로트 프로그램임에도 불구하고 트로트 음원의 선호보다 비트로트 음원의 선호가 높았고, 이는 트로트 장르 보다는 출연진의 선호, 인기가 앞선다는 것을 보여준다. 나아가, 트로트 인기에서 미스터 트롯이 어느 정도 비중을 차지하는지에 대해서도 알아보았다. 트로트 음원 차트 분석 결과, 미스터트롯 출신 가수들의 분포가 압도적이고, 그 중에서도 임영웅의 트로트 TOP 200차트 내 분포가 압도적으로 많은 것을 확인할 수 있었다. 또한 미스터트롯 내의 인기를 증명하기 위한 유튜브 데이터 분석에서도 미스터트롯 TOP6 중 임영웅의 구독자 수와 영상별 평균 조회수가 압도적으로 높다는 결과가 나왔다.
*종합적으로 트로트의 인기는 상승한게 맞지만, 트로트라는 장르를 선호하기보다는 출연진의 선호가 앞서기 떄문에 지금의 트로트 인기는 <미스터 트롯> 출연 가수와 파생 음원에 의존적이다는 결론을 도출했다.*