经过一个月的面试, 留下来一些材料, 整理部署一下.
周期上, 快的话一个月,慢的话两个月。
第一周可以一天 1 面,或者一天 2 面。第二周第三周一天 3 面,加上HR面可以到 4 面,第四周开始减少。
市场情况: 好的时候可以密集面试, 基本还是大厂需求多. 市场疲软的时候, 多刷题吧🐶.
-
力扣 刷题
刷题400道以上, 建议用
Python, 提高效率, 根据题单快速刷, 每天十多道. -
hit-alibaba-iOS 首选材料
iOS部分都过一遍, 基本满足绝大部分面试的
objc部分的问题. -
CS-Note 计算机基础
过一遍, 社招看看常考的就行。面到一些leader面时, 容易考底层知识, 进程调度等。
-
io-wiki 很不错的IO网站, [Optional]
-
iOS 面试八股文 作为补充
-
HR面试问题 开放性问题
提莫攻击, 模拟整个过程
from typing import List
class Solution:
def findPoisonedDuration(self, timeSeries: List[int], duration: int) -> int:
ans = 0
expired = 0
for begin in timeSeries:
if expired > begin:
ans += begin + duration - expired # 本次需要增加的数值
else:
ans += duration
expired = begin + duration
return ans按序列打印:锁交替
import threading
class Foo:
# 一种先后顺序的约束,first, second, third, 保护 2在1之后,3在2之后
# Lock 对应的是一种单个资源的互斥,我们很难只用它模拟出对于多个资源的互斥。
def __init__(self):
self.fl = threading.Lock() # first
self.sl = threading.Lock() # second
self.fl.acquire()
self.sl.acquire()
pass
def first(self, printFirst: 'Callable[[], None]') -> None:
# printFirst() outputs "first". Do not change or remove this line.
printFirst()
self.fl.release()
def second(self, printSecond: 'Callable[[], None]') -> None:
# printSecond() outputs "second". Do not change or remove this line.
with self.fl:
printSecond()
self.sl.release()
def third(self, printThird: 'Callable[[], None]') -> None:
with self.sl:
# printThird() outputs "third". Do not change or remove this line.
printThird()H2O: 信号量生成水
import threading
class H2O:
# 一种数量约束,保护生成第二个o之前上个o有2个h, 保护生成第3个h之前前2个h有1个o
# 信号量对应的是一种多个资源整体的互斥, 很难用单一的锁来模拟
# sema.release() 可以在没有acquire的时候调用,不会crash, 内部counter + 1. 这个用锁很难模拟。
def __init__(self):
self.osm = threading.Semaphore(1) # 可进入一次
self.hsm = threading.Semaphore(2) # 可进入两次, 需要用信号量,可以释放超过1次
self.no = 0
self.nh = 0
pass
def hydrogen(self, releaseHydrogen: 'Callable[[], None]') -> None:
# releaseHydrogen() outputs "H". Do not change or remove this line.
self.hsm.acquire()
releaseHydrogen()
self.nh += 1
if self.nh == 2:
self.nh = 0
self.osm.release()
def oxygen(self, releaseOxygen: 'Callable[[], None]') -> None:
# releaseOxygen() outputs "O". Do not change or remove this line.
self.osm.acquire()
releaseOxygen()
self.no += 1
if self.no == 1:
self.no = 0
self.hsm.release()
self.hsm.release() # 如果只生产一个H, 用信号量,这里才不会出错交替打印字符串:通过共享的变量,判定需要释放哪一个锁
import threading
""" 约束调用与否,以及调用顺序 """
class FizzBuzz:
def __init__(self, n: int):
self.n = n
self.numLock = threading.Lock()
self.fizLock = threading.Lock()
self.buzLock = threading.Lock()
self.fizbuzLock = threading.Lock()
# 去number判断顺序
self.fizLock.acquire()
self.buzLock.acquire()
self.fizbuzLock.acquire()
# printFizz() outputs "fizz"
def fizz(self, printFizz: 'Callable[[], None]') -> None:
for i in range(1, self.n + 1):
if i % 5 != 0 and i % 3 == 0:
self.fizLock.acquire()
printFizz()
self.numLock.release() # 去number判断顺序
# printBuzz() outputs "buzz"
def buzz(self, printBuzz: 'Callable[[], None]') -> None:
for i in range(1, self.n + 1):
if i % 3 != 0 and i % 5 == 0:
self.buzLock.acquire()
printBuzz()
self.numLock.release() # 去number判断顺序
# printFizzBuzz() outputs "fizzbuzz"
def fizzbuzz(self, printFizzBuzz: 'Callable[[], None]') -> None:
for i in range(1, self.n + 1):
if i % 3 == 0 and i % 5 == 0:
self.fizbuzLock.acquire()
printFizzBuzz()
self.numLock.release() # 去number判断顺序
# printNumber(x) outputs "x", where x is an integer.
def number(self, printNumber: 'Callable[[int], None]') -> None:
for i in range(1, self.n + 1):
self.numLock.acquire()
if not (i % 3 == 0 or i % 5 == 0):
printNumber(i)
self.numLock.release() # 去number判断顺序
elif i % 3 == 0 and i % 5 == 0:
self.fizbuzLock.release()
elif i % 3 == 0:
self.fizLock.release()
elif i % 5 == 0:
self.buzLock.release()哲学家进餐
from threading import Lock
class DiningPhilosophers:
def __init__(self):
self.lock = Lock() # 单个锁, 只让一个人吃
# call the functions directly to execute, for example, eat()
def wantsToEat(self,
philosopher: int,
pickLeftFork: 'Callable[[], None]',
pickRightFork: 'Callable[[], None]',
eat: 'Callable[[], None]',
putLeftFork: 'Callable[[], None]',
putRightFork: 'Callable[[], None]') -> None:
with self.lock:
pickLeftFork()
pickRightFork()
eat()
putLeftFork()
putRightFork()
""" 奇数先拿左, 偶数先拿右
from threading import Lock
class DiningPhilosophers:
def __init__(self):
self.forklocks = [Lock() for _ in range(5)]
# call the functions directly to execute, for example, eat()
def wantsToEat(self,
philosopher: int,
pickLeftFork: 'Callable[[], None]',
pickRightFork: 'Callable[[], None]',
eat: 'Callable[[], None]',
putLeftFork: 'Callable[[], None]',
putRightFork: 'Callable[[], None]') -> None:
l = philosopher
r = (philosopher + 1) % 5
# 奇数先拿左边叉子
if philosopher % 2 == 1:
self.forklocks[l].acquire()
self.forklocks[r].acquire()
else:
self.forklocks[r].acquire()
self.forklocks[l].acquire()
pickLeftFork()
pickRightFork()
eat()
putLeftFork()
putRightFork()
self.forklocks[l].release()
self.forklocks[r].release()
"""
""" 限制就餐人数+叉子锁
import threading
class DiningPhilosophers:
def __init__(self):
self.limit = threading.Semaphore(4)
self.forklocks = [threading.Lock() for _ in range(5)]
# call the functions directly to execute, for example, eat()
def wantsToEat(self,
philosopher: int,
pickLeftFork: 'Callable[[], None]',
pickRightFork: 'Callable[[], None]',
eat: 'Callable[[], None]',
putLeftFork: 'Callable[[], None]',
putRightFork: 'Callable[[], None]') -> None:
self.limit.acquire()
l = philosopher
r = (philosopher + 1) % 5
self.forklocks[l].acquire()
self.forklocks[r].acquire()
pickLeftFork()
pickRightFork()
eat()
putLeftFork()
self.forklocks[l].release()
putRightFork()
self.forklocks[r].release()
self.limit.release()
"""class Solution:
def isSubsequence(self, s: str, t: str) -> bool:
n = len(s)
m = len(t)
i = j = 0
while i < n and j < m:
if s[i] == t[j]: # 如果有,查看下个s的字符
i += 1
j += 1
return i == nclass Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
if not strs:
return ""
s = strs[0] # 随便找一个,逐个看看
for i, c in enumerate(s):
for t in strs[1:]:
if i < len(t) and t[i] == c:
continue
else:
return s[:i]
return sclass Solution:
def convert(self, s: str, numRows: int) -> str:
n = len(s)
lines = [""] * (numRows + 1) # 每一行的字符串
down = True
index = 0
for i in range(n):
lines[index] += s[i]
index = index + 1 if down else index - 1
index %= numRows
if down and index == numRows - 1:
down = not down
elif (not down) and index == 0:
down = not down
return "".join(lines)class Solution:
def strStr(self, haystack: str, needle: str) -> int:
n = len(haystack)
m = len(needle)
for i in range(n):
if n - i >= m and haystack[i] == needle[0]:
rst = True
for j in range(m):
if haystack[i + j] != needle[j]:
rst = False
break
if rst:
return i
return -1class Solution:
def isPalindrome(self, s: str) -> bool:
s = [x.lower() for x in s if x.isalpha() or x.isdigit()]
n = len(s)
print(s)
for i in range(n // 2):
if s[i] != s[n - i - 1]:
return False
return Trueclass Solution:
def isFlipedString(self, s1: str, s2: str) -> bool:
if len(s1) != len(s2):
return False
return (s1 + s1).find(s2) != -1 # 这个还挺有意思的class Solution:
SYMBOL_VALUES = {
'I': 1,
'V': 5,
'X': 10,
'L': 50,
'C': 100,
'D': 500,
'M': 1000,
}
def romanToInt(self, s: str) -> int:
ans = 0
n = len(s)
for i, ch in enumerate(s):
value = Solution.SYMBOL_VALUES[ch]
if i < n - 1 and value < Solution.SYMBOL_VALUES[s[i + 1]]: # IV是4, 小的数字在左边的情况下,就减去这个数值
ans -= value
else:
ans += value
return ansclass Solution:
def intToRoman(self, num: int) -> str:
# m = {'I' : 1, 'IV' : 4, 'V' : 5, 'IX' : 9, 'X' : 10, 'XL' : 40, 'L' : 50, 'XC' : 90, 'C' : 100, 'CD' : 400, 'D' : 500, 'CM' : 900, 'M' : 1000}
m = {1 : 'I', 4 : 'IV', 5 : 'V', 9 : 'IX', 10 : 'X', 40 : 'XL', 50 : 'L', 90 : 'XC', 100 : 'C', 400 : 'CD', 500 : 'D', 900 : 'CM', 1000 : 'M'}
k = list(m.keys())
k.reverse()
rst = ""
i = 0
while num:
v = k[i]
if num // v: # 多次整除
rst = rst + m[v]
num -= v
else:
i += 1
return rstclass Solution:
def lengthOfLastWord(self, s: str) -> int:
n = len(s)
rst = 0
for i in range(n - 1, -1, -1):
if rst == 0 and s[i] == ' ':
continue
if s[i] != ' ':
rst += 1
if rst > 0 and s[i] == ' ':
break
return rstfrom typing import List
class Solution:
def search(self, nums: [int], target: int) -> int:
left = 0
right = len(nums) - 1
while left <= right:
mid = (left + right) // 2
if nums[mid] == target:
return mid
elif nums[mid] < target:
left = mid + 1
elif nums[mid] > target:
right = mid - 1
return left # left为最终找到的位置, 没找到则为插入位置
# 左边界
def left_bound(nums, target):
left = 0
right = len(nums) - 1
while left <= right: # right < left时, break
mid = (left + right) // 2
if nums[mid] == target:
right = mid - 1 # 收缩右边界
elif nums[mid] < target:
left = mid + 1
elif nums[mid] > target:
right = mid - 1
if left >= len(nums) or nums[left] != target:
return -1
return left
# 右边界
def right_bound(nums, target):
left = 0
right = len(nums) - 1
while left <= right: # left > right时, break
mid = (left + right) // 2
if nums[mid] == target: # 收缩左边
left = mid + 1
elif nums[mid] < target:
left = mid + 1
elif nums[mid] > target:
right = mid - 1
if right < 0 or nums[right] != target:
return -1
return right
return [left_bound(nums, target), right_bound(nums, target)]from typing import List
class Solution:
def missingNumber(self, nums: List[int]) -> int:
# 冒泡排序
def bubbleSort(nums: List[int]):
n = len(nums)
for i in range(n):
for j in range(n - 1 - i): # n - 1 - i
if nums[j] > nums[j + 1]:
nums[j], nums[j + 1] = nums[j + 1], nums[j]
# 选择排序, 选择最大值,放到有序的尾巴
def selectSort(nums: List[int]):
n = len(nums)
for i in range(n):
selmax = i
for j in range(i + 1, n):
if nums[selmax] > nums[j]:
sel = j
nums[selmax], nums[i] = nums[i], nums[selmax]
# 插入排序,选择一个,往回交换到有序的位置
def insertSort(nums: List[int]):
n = len(nums)
for i in range(0, n - 1):
j = i + 1 # 选择下一个
while j >= 1 and nums[j] < nums[j - 1]: # 往回插入
nums[j], nums[j - 1] = nums[j - 1], nums[j]
j -= 1
# qsort
def quickSort(nums: List[int]):
n = len(nums)
def qsort(nums, left, right):
if left >= right: return
mid = nums[left] # 取得空位
lo = left
hi = right
while lo < hi:
while lo < hi and nums[hi] > mid:
hi -= 1
nums[lo] = nums[hi] # 右边小的,置换
while lo < hi and nums[lo] < mid:
lo += 1
nums[hi] = nums[lo] # 左边大的置换
nums[lo] = mid # lo == hi, 赋值为mid
qsort(nums, left, lo - 1) # 排列两边
qsort(nums, lo + 1, right)
qsort(nums, 0, n - 1)
# 归并排序
def mergeSort(nums: list[int]):
def merge(nums1, nums2): # 归并
rst = []
n1 = 0
n2 = 0
while n1 < len(nums1) and n2 < len(nums2):
if nums1[n1] < nums2[n2]:
rst.append(nums1[n1])
n1 += 1
else:
rst.append(nums2[n2])
n2 += 1
rst = rst + nums1[n1:]
rst = rst + nums2[n2:]
return rst
if len(nums) <= 1:
return nums
mid = len(nums) // 2
left = mergeSort(nums[:mid])
right = mergeSort(nums[mid:])
return merge(left, right)
# 希尔排序
def shellSort(nums):
n = len(nums)
gap = n // 2
while gap > 0: # 枚举gap
for i in range(gap, n, 1): # 不同的gap终点
tmp = nums[i]
j = i
while j >= gap and tmp < nums[j - gap]:
nums[j] = nums[j - gap]
j -= gap
nums[j] = tmp
gap = gap // 2
nums = mergeSort(nums)
# quickSort(nums)
# insertSort(nums)
# selectSort(nums)
# bubbleSort(nums)
# shellSort(nums)
# nums.sort() Tim排序
print(nums)
for i, v in enumerate(nums):
if i != v:
return i
return len(nums)from typing import List
import functools
class Solution:
def minNumber(self, nums: List[int]) -> str:
def compare(x, y):
a, b = x + y, y + x
if a > b:
return 1
elif a < b:
return -1
else:
return 0
nums = [str(x) for x in nums]
nums.sort(key=functools.cmp_to_key(compare))
return "".join(nums)- 排序 + 遍历 + 两侧双指针,帮助减小搜索范围 0i[j..k]n
from typing import List
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
nums.sort()
n = len(nums)
rst = []
for i in range(n):
if i > 0 and nums[i] == nums[i - 1]:
continue
left = i + 1
right = n - 1
while left < right:
if left > i + 1 and nums[left] == nums[left - 1]:
left += 1
continue
if right < n - 1 and nums[right] == nums[right + 1]:
right -= 1
continue
tmp = nums[i] + nums[left] + nums[right]
if tmp == 0:
rst.append([nums[i], nums[left], nums[right]])
left += 1
right -= 1
elif tmp > 0: # 收缩右边
right -= 1
elif tmp < 0: # 收缩左边
left += 1
return rstfrom typing import List
class Solution:
def merge(self, A: List[int], m: int, B: List[int], n: int) -> None:
pa = m - 1
pb = n - 1
cur = m + n - 1
while pa >= 0 and pb >= 0:
if A[pa] >= B[pb]:
A[cur] = A[pa]
pa -= 1
else:
A[cur] = B[pb]
pb -= 1
cur -= 1
if pb >= 0: # 如果B还有剩,添加到A的前头
A[:pb + 1] = B[:pb + 1]
print(pa, pb, cur)from typing import List
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
n = len(nums)
rst = []
used = [0] * (n + 1) # 防止重复访问
def dfs(path):
if len(path) == n:
rst.append(path.copy())
for i in range(n):
if not used[i]:
used[i] = 1 # 记忆的方式
path.append(nums[i])
dfs(path)
path.pop()
used[i] = 0
dfs([])
return rst
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
rst = []
def backtrace(nums, tmp):
if not nums:
rst.append(tmp)
for i in range(len(nums)):
backtrace(nums[:i]+nums[i + 1:], [nums[i]] + tmp) # 切片的方式
backtrace(nums, [])
return rst
from typing import List
class Solution:
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
n = len(nums)
nums.sort()
rst = []
used = [0] * (n + 1)
def dfs(path):
if len(path) == n:
rst.append(path.copy())
for i in range(n):
if i > 0 and nums[i] == nums[i - 1] and not used[i - 1]:
continue # 剪枝,避免回头
if not used[i]:
used[i] = 1
path.append(nums[i])
dfs(path)
path.pop()
used[i] = 0
dfs([])
return rsthttps://leetcode.cn/problems/combination-sum-ii/
from typing import List
class Solution:
def combinationSum2(self, candidates: List[int], target: int) -> List[List[int]]:
# 排序剪枝
rst = []
n = len(candidates)
def dfs(cur, target, tmp):
if target == 0:
rst.append(tmp[:])
return
for i in range(cur, n):
if candidates[i] > target:
continue
if i > cur and candidates[i] == candidates[i - 1]: # 相等剪枝
continue
# 这个防止的是,x 1 1 6 取得[x 1 6] [x 1 6]两次
# 而不是116取得[116],当前的cur是可以取1的,
# 然后cur+1下次递归也可以取到1
val = candidates[i]
tmp.append(val) # 取
dfs(i + 1, target - val, tmp) # 取
tmp.pop() # 不取
candidates.sort()
dfs(0, target, [])
return rstfrom typing import List
class Solution:
def subsets(self, nums: List[int]) -> List[List[int]]:
# 逐个枚举
rst = []
tmp = []
n = len(nums)
def dfs(cur):
if cur == n:
rst.append(tmp.copy())
return
tmp.append(nums[cur]) # pick
dfs(cur + 1) # pick
tmp.pop() # drop
dfs(cur + 1) # drop 也是算次数的
dfs(0)
return rst
""" 按位枚举法
rst = []
n = len(nums)
for mask in range(0, 1 << n):
tmp = []
for i in range(n):
if (mask & 1 << i):
tmp.append(nums[i])
rst.append(tmp)
return rst
"""
""" 分片遍历, 更快
rst = [[]]
tmp = []
def dfs(arr):
# print(arr, rst, tmp)
for i, x in enumerate(arr):
tmp.append(x)
rst.append(tmp.copy())
# print(nums[:i], nums[i + 1:])
dfs(arr[i+1:])
tmp.pop()
dfs(nums)
return rst
"""from typing import List
class Solution:
def hanota(self, A: List[int], B: List[int], C: List[int]) -> None:
"""
Do not return anything, modify C in-place instead.
"""
n = len(A)
self.move(n, A, B, C)
def move(self, n, A, B, C):
if n == 1:
C.append(A[-1])
A.pop()
return
else:
self.move(n - 1, A, C, B) # A上n-1移动到B
C.append(A[-1])
A.pop()
self.move(n - 1, B, A, C) # B上n-1移动到C面试题 08.09. 括号 有条件的回溯 [ "((()))", "(()())", "(())()", "()(())", "()()()" ]
from typing import List
class Solution:
def generateParenthesis(self, n: int) -> List[str]:
rst = []
def dfs(left, right, path:str): # 用参变量,可以不用
if left > right:
return
if left == 0 and right == 0:
rst.append(path[:])
if left > 0:
dfs(left - 1, right, path + "(") # 先枚举左括号
if left < right: # 条件是左括号要比右括号来的少
dfs(left, right - 1, path + ")")
dfs(n ,n, "")
return rstclass ListNode:
def __init__(self, x):
self.val = x
self.next = None
def detectCycle(self, head: ListNode) -> ListNode:
fast = slow = head
while fast:
if not fast or not fast.next:
return None
slow = slow.next
fast = fast.next.next
if fast == slow: # 相遇第一次
p = head # 从头开始的P,会和slow指针相遇
while p != slow:
slow = slow.next
p = p.next
if p == slow:
return p
return None
"""
---a----[---b---相遇---c--]
fast: a + n(b + c) + b
slow: a + b
a + (n + 1)b + nc = 2a + 2b
a = c + (n - 1)(b + c)
[p] [slow]
"""def reverse(head, tail):
pre = None # 尾部节点
cur = head
while cur:
nxt = cur.next
cur.next = pre
pre = cur
cur = nxt
return pre
# None -> 1 -> 2 -> 3 -> 4 -> 5 -> tail
# | | |
# pre cur nxt
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
class Solution:
def reverseBetween(self, head: ListNode, left: int, right: int) -> ListNode:
def printList(root, tail=None):
while root and tail and root != tail.next:
print(root.val, "->", end="")
root = root.next
print()
def reverse(head, tail):
pre = tail.next # 取到tail的next, 也可以为None
cur = head
while pre != tail:
nxt = cur.next
cur.next = pre
pre = cur
cur = nxt
return head, tail # 反转后, tail为头, head为尾
# 1 -> 2 -> 3 -> 4 -> 5
# | |
# head tail
# | | |
# pre cur nxt
dummy = ListNode() # dummy方便了链表的操作, 因为有可能改动到头
dummy.next = head
pre = dummy
end = dummy
ptr = dummy
i = 0
while ptr:
if i == left - 1:
pre = ptr
elif i == right:
end = ptr
ptr = ptr.next
i += 1
print(pre.val, end.val)
_, pre.next = reverse(pre.next, end)
printList(pre)
return dummy.nextclass Node:
def __init__(self, x):
self.val = x
self.next = None
class Solution:
def __init__(self):
self.map = {}
def copyRandomList(self, head: 'Node') -> 'Node':
if head is None:
return head
if head in self.map:
return self.map[head]
new_head = Node(head.val)
self.map[head] = new_head
new_head.next = self.copyRandomList(head.next) # 会先拷贝next,创建出所有的节点
new_head.random = self.copyRandomList(head.random)
return new_head# Definition for singly-linked list.
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
class Solution:
def partition(self, head: ListNode, x: int) -> ListNode:
dummyMax = ListNode(-1)
dummyMax.next = head
dummyMin = ListNode(-1)
d = dummyMin
pre = dummyMax
cur = head
while cur:
if cur.val < x:
pre.next = cur.next
d.next = cur
d = d.next
cur = pre.next
else:
pre = pre.next
cur = cur.next
d.next = dummyMax.next
return dummyMin.next
class Solution:
def maxDepth(self, root: Optional[TreeNode]) -> int:
if not root:
return 0
l = self.maxDepth(root.left)
r = self.maxDepth(root.right)
return max(l, r) + 1class Solution:
def isSameTree(self, p: Optional[TreeNode], q: Optional[TreeNode]) -> bool:
if not p and not q:
return True
if (not p and q) or (p and not q):
return False
l = self.isSameTree(p.left, q.left)
r = self.isSameTree(p.right, q.right)
return p.val == q.val and l and rclass Solution:
def invertTree(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
if not root:
return None
l = self.invertTree(root.left)
r = self.invertTree(root.right)
root.left = r
root.right = l
return rootclass Solution:
def isSymmetric(self, root: TreeNode) -> bool:
def dfs(p, q):
if not p and not q:
return True
if (not p and q) or (not q and p):
return False
return p.val == q.val and dfs(p.left, q.right) and dfs(p.right, q.left)
if not root:
return True
return dfs(root.left, root.right)class Solution:
def connect(self, root: 'Node') -> 'Node':
if not root:
return root
queue = [root]
while queue:
size = len(queue)
last = None
for i in range(size):
node = queue.pop(0)
if not last:
last = node
else:
last.next = node
last = node
if node.left: queue.append(node.left)
if node.right: queue.append(node.right)
return rootclass Solution:
def flatten(self, root: TreeNode) -> None:
nodes = []
def preorder(root): # 先记住顺序,再连接
if not root:
return
nodes.append(root)
if root.left: preorder(root.left)
if root.right: preorder(root.right)
preorder(root)
pre = None
for n in nodes:
n.left = None
if not pre:
pre = n
else:
pre.right = n
pre = n
def flatten2(self, root: TreeNode) -> None:
if not root:
return []
stack = []
stack.append(root)
pre = None
while stack:
cur = stack.pop() # 直接pop
if pre:
pre.left = None
pre.right = cur
if cur.right:
stack.append(cur.right) # right先压栈
if cur.left:
stack.append(cur.left)
pre = cur
def flatten3(self, root: TreeNode) -> None:
if not root:
return None
stack = []
nodes = []
while root or stack:
while root:
nodes.append(root)
stack.append(root)
root = root.left
cur = stack.pop()
root = cur.right
pre = None
for n in nodes:
n.left = None
if not pre:
pre = n
else:
pre.right = n
pre = nclass Solution:
def sumNumbers(self, root: Optional[TreeNode]) -> int:
rst = 0
def dfs(root, mul):
if not root.left and not root.right:
nonlocal rst
rst += mul * 10 + root.val
return
if root.left:
dfs(root.left, mul * 10 + root.val)
if root.right:
dfs(root.right, mul * 10 + root.val)
dfs(root, 0)
return rst# 树的遍历
from typing import List, Optional
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
def dfs(root:TreeNode): # 迭代的方式,模拟函数栈
stack = []
while root or stack:
while root:
# visit 前序遍历
stack.append(root)
root = root.left
root = stack.pop()
# visit 中序遍历
root = root.right
# 后序遍历 https://leetcode.cn/problems/binary-tree-postorder-traversal/
def postorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
if not root:
return list()
res = list()
stack = list()
prev = None
while root or stack:
while root:
stack.append(root)
root = root.left # 首先所有左孩子入栈
root = stack.pop()
if not root.right or root.right == prev: # 没有右孩子,或者访问完右孩子
res.append(root.val)
prev = root
root = None
else:
stack.append(root) # 然后所有的右孩子入栈
root = root.right
return res
class Solution:
def postorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
rst = []
def dfs(root):
if not root:
return
if root.left: dfs(root.left)
if root.right:dfs(root.right)
rst.append(root.val)
dfs(root)
return rst
## 层序遍历
# [剑指 Offer 32 - III. 从上到下打印二叉树 III](https://leetcode.cn/problems/cong-shang-dao-xia-da-yin-er-cha-shu-iii-lcof/)
class Solution:
def levelOrder(self, root: TreeNode) -> List[List[int]]:
if not root:
return []
queue = [root]
d = False
rst = []
while queue:
size = len(queue) # 当前层的size
tmp = []
for i in range(size):
node = queue.pop(0)
tmp.append(node.val)
if node.left:
queue.append(node.left)
if node.right:
queue.append(node.right)
if d:
tmp.reverse()
d = not d
rst.append(tmp)
return rstclass TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
class Solution:
def checkSubTree(self, t1: TreeNode, t2: TreeNode) -> bool:
def sameTree(t1, t2): # 判断是否是一样的树
if not t2 and not t1:
return True
if not (t1 and t2):
return False
if t1.val != t2.val:
return False
return sameTree(t1.left, t2.left) and sameTree(t1.right, t2.right)
# -------------
if not t2:
return True
if not t1 and t2:
return False
if sameTree(t1, t2): # 是否和root树一样
return True # 是否和left树一样 # 是否和right树一样
return self.checkSubTree(t1.left, t2) or self.checkSubTree(t1.right, t2)
"""
class Solution {
public:
bool checkSubTree(TreeNode* t1, TreeNode* t2) {
if(t1 == NULL || t2 == NULL) return false;
if(t1->val == t2->val) return dfs(t1, t2);
return checkSubTree(t1->left, t2) || checkSubTree(t1->right, t2);
}
bool dfs(TreeNode *t1, TreeNode *t2){
if(t2 == NULL) return true;
if(t1 == NULL) return false;
if(t1->val != t2->val) return false;
return dfs(t1->left, t2->left) && dfs(t1->right, t2->right);
}
};
"""左叶子之和 注意就是,对于树的子结构的观察。这里, 一个节点, 如果左子节点为空,ans直接加左子节点的值, 不然递归获取左子树、右子树中的左叶子之和。 这个实际上也是数学归纳法的思想,确定好子结构,边界条件,递归处理出来。
from typing import List,Optional
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
class Solution:
def sumOfLeftLeaves(self, root: Optional[TreeNode]) -> int:
def dfs(root):
if not root:
return 0
ans = 0
if root.left:
if root.left.left is None and root.left.right is None: # 如果是左叶子节点
ans += root.left.val
else:
ans += dfs(root.left) # 如果不是,下一层
if root.right:
if not (root.right.left is None and root.right.right is None): # 如果右节点不是叶子节点
ans += dfs(root.right)
return ans
return dfs(root)# Definition for a binary tree node.
class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
class Solution:
def isSubStructure(self, A: TreeNode, B: TreeNode) -> bool:
# 先序遍历
def isSame(a, b):
if not b:
return True
if not a or a.val != b.val: return False
return isSame(a.left, b.left) and isSame(a.right, b.right)
if A and B and isSame(A, B):
return True
return bool(A and B) and (self.isSubStructure(A.left, B) or self.isSubStructure(A.right, B))105. 从前序与中序遍历序列构造二叉树 106. 从中序与后序遍历序列构造二叉树
from typing import List
# Definition for a binary tree node.
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
class Solution:
def buildTree(self, inorder: List[int], postorder: List[int]) -> TreeNode:
if not postorder or not inorder:
return None
cur = postorder[-1]
index = inorder.index(cur)
node = TreeNode(cur)
# index
# inorder [9]3[15,20,7]
# postorder [9][15,20,7]3 <-- root
pleft = postorder[0:index]
pright = postorder[index:-1]
ileft = inorder[0:index]
iright = inorder[index + 1:]
node.left = self.buildTree(ileft, pleft)
node.right = self.buildTree(iright, pright)
return node
class SolutionPreAndInOrder:
def buildTree(self, preorder: List[int], inorder: List[int]) -> TreeNode:
if not preorder or not inorder:
return None
cur = preorder[0]
index = inorder.index(cur)
node = TreeNode(cur)
# index
# inorder [9]3[15,20,7]
# preorder root --> 3[9][15,20,7]
pleft = preorder[1:index+1]
pright = preorder[index+1:]
ileft = inorder[0:index]
iright = inorder[index + 1:]
node.left = self.buildTree(pleft, ileft) # 递归子区间和子树
node.right = self.buildTree(pright, iright)
return node# [1,2,3,null,null,4,5]
# ['1', '2', '3', 'None', 'None', '4', '5', 'None', 'None', 'None', 'None']
import collections
class TreeNode(object):
def __init__(self, x):
self.val = x
self.left = None
self.right = None
class Codec:
def serialize(self, root):
if not root:
return ""
rst = []
queue = [root]
while queue: # 层序遍历的直接串联,没有for循环
node = queue.pop(0)
if node:
rst.append(str(node.val))
queue.append(node.left)
queue.append(node.right)
else:
rst.append("None")
print(rst)
return "["+ ",".join(rst) + "]"
def deserialize(self, data):
if not data:
return []
dataList = data[1:-1].split(',')
root = TreeNode(int(dataList[0])) # 构建第一个节点
queue = [root]
i = 1 # 下一个节点
while queue:
node = queue.pop(0)
if dataList[i] != 'None':
node.left = TreeNode(int(dataList[i]))
queue.append(node.left)
i += 1 # 构建做节点,或者抛掉 None
if dataList[i] != 'None':
node.right = TreeNode(int(dataList[i]))
queue.append(node.right)
i += 1 # 构建右节点,或者抛掉 None
return rootclass Trie:
# 前缀树
# trie
# node
# |_a b c d e f g h i j k l m n o p q r s t u v w x y z
# | |_a b c d e f g h i j k l m n o p q r s t u v w x y z
# |_a b c d e f g h i j k l m n o p q r s t u v w x y z
def __init__(self):
self.children = [None] * 26
self.isEnd = False
def insert(self, word: str) -> None:
node = self
for c in word:
ch = ord(c) - ord("a")
if not node.children[ch]:
node.children[ch] = Trie()
node = node.children[ch]
node.isEnd = True
def search(self, word: str) -> bool:
node = self
for c in word:
ch = ord(c) - ord("a")
if node and node.children[ch]:
node = node.children[ch]
else:
return False
return node.isEnd
def startsWith(self, prefix: str) -> bool:
node = self
for c in prefix:
ch = ord(c) - ord("a")
if node and node.children[ch]:
node = node.children[ch]
else:
return False
return Truefrom typing import List
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
class Solution:
def pathSum(self, root: TreeNode, target: int) -> List[List[int]]:
rst = []
path = []
def dfs(root, target):
if not root:
return
path.append(root.val) # 添加
if target == root.val and not root.left and not root.right:
rst.append(path.copy())
dfs(root.left, target - root.val)
dfs(root.right, target - root.val)
path.pop() # 退出
dfs(root, target)
return rstfrom typing import List, Optional
import collections
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
class Solution:
def pathSum(self, root: Optional[TreeNode], targetSum: int) -> int:
prefix = collections.defaultdict(int) # key是前缀和, value是该前缀和的个数
prefix[0] = 1
def dfs(root, cur):
if not root:
return 0
rst = 0
cur += root.val # 增加前缀和
rst += prefix[cur - targetSum]
prefix[cur] += 1 # 这个1,实际上记录了路径
rst += dfs(root.left, cur)
rst += dfs(root.right, cur)
prefix[cur] -= 1 # 回退
return rst
return dfs(root, 0)
class SolutionMe: # 暴力枚举
def pathSum(self, root: Optional[TreeNode], targetSum: int) -> int:
def rootSum(root, targetSum) -> int: # 递归往下,遍历所有的节点,满足的数目
if not root:
return 0
rst = 0
if root.val == targetSum:
rst += 1
rst += rootSum(root.left, targetSum - root.val)
rst += rootSum(root.right, targetSum - root.val)
return rst
if not root:
return 0
rst = rootSum(root, targetSum)
rst += self.pathSum(root.left, targetSum)
rst += self.pathSum(root.right, targetSum)
return rstfrom typing import Optional
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
class Solution:
def deleteNode(self, root: Optional[TreeNode], key: int) -> Optional[TreeNode]:
if not root:
return root
if root.val > key:
root.left = self.deleteNode(root.left, key) # 如果大于,去左子树删除
elif root.val < key:
root.right = self.deleteNode(root.right, key) # 如果小于,去右子树删除
else: # 如果相等, 删除当前节点
if not root.left: return root.right # 无左,返回右子树
elif not root.right: return root.left # 无右, 返回左子树
else:
# 左右都有, 找到右子树的最小节点, 挂载左子树,返回右子树
node = root.right
while node.left:
node = node.left
node.left = root.left
return root.right
return root二叉搜索树,中序遍历有序
左子树节点值<=root.val<=右子树节点值
# Definition for a Node.
class Node:
def __init__(self, val, left=None, right=None):
self.val = val
self.left = left
self.right = right
class Solution:
def treeToDoublyList(self, root: 'Node') -> 'Node':
last, head = None, None
def dfs(root):
if not root:
return None
# left
dfs(root.left)
# visit
nonlocal last
if last: # 中序遍历,看last指针
last.right = root
root.left = last
else:
nonlocal head
head = root
# right
last = root
dfs(root.right)
if not root:
return
dfs(root)
head.left, last.right = last, head
return head# Definition for a binary tree node.
class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
class Solution:
def isValidBST(self, root: TreeNode) -> bool:
def dfs(root, lower=float('-inf'), upper=float('inf')): # 递归合法区间
if not root:
return True
val = root.val
if val <= lower or val >= upper:
return False
if not dfs(root.left, lower, val):
return False
if not dfs(root.right, val, upper):
return False
return True
return dfs(root)
class SolutionMid: ## 中序遍历,有序pre节点。
pre = float("-inf")
def isValidBST(self, root: TreeNode) -> bool:
if not root:
return True
if not self.isValidBST(root.left) or root.val <= self.pre:
return False
self.pre = root.val
return self.isValidBST(root.right)class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
class Solution:
def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
if root is None or root.val == p.val or root.val == q.val: # 如果满足一个节点,返回
return root
left = self.lowestCommonAncestor(root.left, p, q)
right = self.lowestCommonAncestor(root.right, p, q)
if not left:
return right
if not right:
return left
return root # 这个时候,就是左边,右边,都满足# Definition for a binary tree node.
class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
class Solution:
def isBalanced(self, root: TreeNode) -> bool:
def dfs(root):
if not root:
return 0
left = dfs(root.left) # 后续遍历
if left == -1: return -1
right = dfs(root.right) # 后续遍历
if right == -1: return -1
if abs(left - right) <= 1:
return max(left, right) + 1
return -1
return dfs(root) != -1class Solution:
# 快慢指针
def removeDuplicates(self, nums: List[int]) -> int:
n = len(nums)
slow = 2
fast = 2
while fast < n:
if nums[slow - 2] != nums[fast]:
nums[slow] = nums[fast]
slow += 1
fast += 1
return slow
def removeDuplicates2(self, nums: List[int]) -> int:
left = 0
for num in nums:
# 因为有序,第三个数要么比left-2大,要么相等
if left < 2 or num > nums[left - 2]:
nums[left] = num
left += 1
return leftclass Solution:
# 滑动窗口
def canJump(self, nums: List[int]) -> bool:
n = len(nums)
right = 0
left = 0
while left <= right and right < n:
if nums[left] + left > right:
right = nums[left] + left
left += 1
return right >= n - 1
# 模拟
def canJump2(self, nums: List[int]) -> bool:
n = len(nums)
rst = [False] * (n + 1)
rst[0] = True
for i in range(n):
if not rst[i]:
continue
num = nums[i]
for j in range(i + 1, min(i + num + 1, n)):
rst[j] = True
return rst[n - 1]class Solution:
def jump(self, nums: List[int]) -> int:
n = len(nums)
left = 0
right = 0
end = 0 # 当前能跳到的最远处
rst = 0
while left < n - 1:
if nums[left] + left >= right:
right = nums[left] + left
if left == end:
rst += 1
end = right
left += 1
return rst
def jump2(self, nums: List[int]) -> int:
n = len(nums)
dp = [1001] * (n + 1)
dp[0] = 0
for i in range(1, n):
tmp = dp[i]
for j in range(i): # dp 复杂度太高
if nums[j] + j >= i:
tmp = min(tmp, dp[j] + 1)
dp[i] = tmp
return dp[n - 1] class Solution:
def hIndex(self, citations: List[int]) -> int:
n = len(citations)
citations.sort(reverse = True) # 先反向排序
h = 0
i = 0
while i < n and citations[i] > h: # 再一步一步累加 h
h += 1
i += 1
return himport random
class RandomizedSet:
def __init__(self):
self.array = []
self.dict = {}
def insert(self, val: int) -> bool:
if val in self.dict:
return False
else:
self.dict[val] = len(self.array)
self.array.append(val)
return True
def remove(self, val: int) -> bool:
if val not in self.dict:
return False
else:
index = self.dict[val]
self.array[index] = self.array[-1] # 要删除的元素交换到尾部,更新index
self.dict[self.array[index]] = index
self.array.pop()
del self.dict[val]
return True
def getRandom(self) -> int:
n = len(self.array)
i = random.randint(0, n - 1)
return self.array[i]class Solution:
def productExceptSelf(self, nums: List[int]) -> List[int]:
n = len(nums)
left = [1] * (n + 1)
right = [1] * (n + 1)
for i in range(1, n):
left[i] = left[i - 1] * nums[i - 1] # 左侧
for i in range(n - 2, -1, -1):
right[i] = right[i + 1] * nums[i + 1]
for i in range(n):
nums[i] = left[i] * right[i]
return numsfrom typing import List
class Solution:
def removeElement(self, nums: List[int], val: int) -> int:
n = len(nums)
left = 0 # 从左往右,覆盖写入
for i in range(n):
if nums[i] != val:
nums[left] = nums[i]
left += 1
return leftclass Solution:
def removeDuplicates(self, nums: List[int]) -> int:
n = len(nums)
slow = 2
fast = 2
while fast < n:
if nums[slow - 2] != nums[fast]:
nums[slow] = nums[fast]
slow += 1
fast += 1
return slow
def removeDuplicates2(self, nums: List[int]) -> int:
left = 0
for num in nums:
# 因为有序,第三个数要么比left-2大,要么相等
if left < 2 or num > nums[left - 2]:
nums[left] = num
left += 1
return left学生出勤记录 I 注意单词遍历的顺序性质, “连续多个”的实现, 可以在不满足连续条件的时候断开。
class Solution:
def checkRecord(self, s: str) -> bool:
cnta = 0
cntl = 0
n = len(s)
for i in range(n):
if s[i] == 'A' :
cnta += 1
if cnta >= 2: return False
elif s[i] == 'L': # 连续多天
cntl += 1
if cntl >= 3: return False
else: # 无法连续, 断开
cntl = 0
return True
class Solution2:
def checkRecord(self, s: str) -> bool:
countA = 0
for i, c in enumerate(s):
if c is 'A':
countA += 1
countL = 0
elif c is 'L' and i >= 2 and s[i - 1] == 'L' and s[i - 2] == 'L':
# 直接异常处判断也行,更容易一点
return False
return countA < 2数组翻转
https://leetcode.cn/problems/rotate-array/description/
from typing import List
class Solution:
def rotate(self, matrix: List[List[int]]) -> None:
"""
Do not return anything, modify matrix in-place instead.
"""
n = len(matrix)
# 先水平翻转,再沿着主对角线翻转
for i in range(n // 2):
for j in range(n):
matrix[i][j], matrix[n - 1 - i][j] = matrix[n - 1 - i][j] , matrix[i][j]
for i in range(n):
for j in range(i): # 注意是i, 如果到n, 会翻转多次
matrix[i][j], matrix[j][i] = matrix[j][i] , matrix[i][j]
# 拷贝的方式
# n = len(matrix)
# new_matrix = [[0]* n for _ in range(n)]
# # 第i行j列, 到底n - 1 - i 列, j行
# for i in range(n):
# for j in range(n):
# new_matrix[j][n - 1 - i] = matrix[i][j]
# for i in range(n):
# for j in range(n):
# matrix[i][j] = new_matrix[i][j]from typing import List
class Solution:
def rotate(self, nums: List[int], k: int) -> None:
def swap(left, right):
while left < right:
nums[left], nums[right] = nums[right], nums[left]
left += 1
right -= 1
n = len(nums)
k %= n
# 三次翻转
swap(0, n - k - 1)
swap(n - k, n - 1)
swap(0, n - 1)
def rotateSlice(self, nums: List[int], k: int) -> None:
# 切片,空间O(n)
n = len(nums)
k %= n
nums[:]=nums[n-k:] + nums[:n-k]from typing import List
class Solution:
def minArray(self, numbers: List[int]) -> int:
n = len(numbers)
left, right = 0, n - 1
while left < right:
mid = (left + right) // 2
if numbers[right] < numbers[mid]:
left = mid + 1
elif numbers[right] > numbers[mid]:
right = mid
elif numbers[right] == numbers[mid]:
right -= 1
return numbers[left]from typing import List
class Solution:
def maxAreaOfIsland(self, grid: List[List[int]]) -> int:
dxy = [[0, 1], [0, -1], [1, 0], [-1, 0]]
n = len(grid)
m = len(grid[0])
area = 0
def dfs(i, j):
if grid[i][j] == 1:
nonlocal area
area += 1
grid[i][j] = 2 # 把走过的岛屿记录为2
for dx, dy in dxy:
x = i + dx
y = j + dy
if x >= 0 and x < n and y >= 0 and y < m and grid[x][y] == 1:
dfs(x, y)
rst = 0
for i in range(n):
for j in range(m):
if grid[i][j] == 1:
area = 0
dfs(i, j)
rst = max(rst, area)
return rstfrom typing import List
def spiralOrder(self, matrix: List[List[int]]) -> List[int]:
if not matrix or not matrix[0]:
return []
n = len(matrix)
m = len(matrix[0])
visited = [[0] * m for _ in range(n)]
direct = [[0, 1], [1, 0], [0, -1], [-1, 0]]
x = 0
y = 0
d = 0
total = n * m
rst = [0] * total
for i in range(total): # 迭代在个数达到之后停止
rst[i] = matrix[x][y]
visited[x][y] = 1
nx, ny = x + direct[d][0], y + direct[d][1]
if not (0 <= nx < n and 0 <= ny < m and not visited[nx][ny]): # 当越界的时候,换方向
d = (d + 1) % 4
x = x + direct[d][0] # 使用换方向后的,正确的坐标
y = y + direct[d][1]
return rst
## 套圈, 圈缩小的方式
def spiralOrder(self, matrix: List[List[int]]) -> List[int]:
if not matrix or not matrix[0]:
return []
n = len(matrix)
m = len(matrix[0])
left = 0
right = m - 1
top = 0
bottom = n - 1
rst = []
while True:
for i in range(left, right + 1): rst.append(matrix[top][i]) # left to right
top += 1 # top 缩小
if top > bottom: break
for i in range(top, bottom + 1): rst.append(matrix[i][right]) # top to bottom
right -= 1 # right 缩小
if right < left: break
for i in range(right, left - 1, -1): rst.append(matrix[bottom][i]) # right to left
bottom -= 1 # bottom缩小
if bottom < top: break
for i in range(bottom, top - 1, -1): rst.append(matrix[i][left]) # bottom to top
left += 1 # left缩小
if left > right: break
return rstclass Solution:
def setZeroes(self, matrix: List[List[int]]) -> None:
"""
Do not return anything, modify matrix in-place instead.
"""
n = len(matrix)
m = len(matrix[0])
def makeZero(row, col):
for i in range(m):
if matrix[row][i] != 0:
matrix[row][i] = None # 用None作为占位
for i in range(n):
if matrix[i][col] != 0:
matrix[i][col] = None
for i in range(n):
for j in range(m):
if matrix[i][j] != None and matrix[i][j] == 0:
makeZero(i, j)
for i in range(n):
for j in range(m):
if not matrix[i][j]:
matrix[i][j] = 0
class Solution:
def isValidSudoku(self, board: List[List[str]]) -> bool:
m = [[[] for _ in range(3)] for _ in range(3)]
row = [[] for _ in range(9)]
col = [[] for _ in range(9)]
n = len(board)
for i in range(n):
for j in range(n):
c = board[i][j]
if c == ".":
continue
if c in m[i//3][j//3] or c in row[i] or c in col[j]: # 3x3 区域内 or row or col
return False
else:
m[i//3][j//3].append(c)
row[i].append(c)
col[j].append(c)
return Truefrom typing import List
class Solution:
def searchMatrix(self, matrix: List[List[int]], target: int) -> bool:
m = len(matrix)
n = len(matrix[0])
x, y = 0, n - 1
while x <= m - 1 and y >=0:
cur = matrix[x][y]
if cur == target:
return True
elif cur < target:
x += 1
elif cur > target:
y -= 1
return Falsefrom typing import List
class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
if not board:
return False
n = len(board)
m = len(board[0])
w = len(word)
def dfs(i, j, k):
if not 0 <= i < n or not 0 <= j < m:
return False
if board[i][j] != word[k]: # 判断
return False
if k == w - 1:
return True
board[i][j] = '' # 禁止返回
res = dfs(i + 1, j, k + 1) or \
dfs(i - 1, j, k + 1) or \
dfs(i, j + 1, k + 1) or \
dfs(i, j - 1, k + 1)
board[i][j] = word[k] # 允许返回
return res
for i in range(n):
for j in range(m):
if dfs(i, j, 0):
return True
return Falsedef digitsum(n):
ans = 0
while n:
ans += n % 10
n //= 10
return ans
class Solution:
def movingCount(self, m: int, n: int, k: int) -> int:
from queue import Queue
q = Queue()
q.put((0, 0))
s = set()
while not q.empty():
x, y = q.get()
if (x, y) not in s and 0 <= x < m and 0 <= y < n and digitsum(x) + digitsum(y) <= k:
s.add((x, y)) # 如果满足条件,visit
for nx, ny in [(x + 1, y), (x, y + 1)]: # 向右向下传播
q.put((nx, ny))
return len(s)
class SolutionDFS:
def movingCount(self, m: int, n: int, k: int) -> int:
board = [[0] * (n + 1) for _ in range(m + 1)]
rst = 0
def isOK(i, j):
rst = 0
while i or j:
rst += i % 10 + j % 10
i //= 10
j //= 10
return rst <= k
def dfs(i, j):
if not 0 <= i < m or not 0 <= j < n:
return
if board[i][j]:
return
if isOK(i, j):
board[i][j] = 1
nonlocal rst
rst += 1
dfs(i + 1, j)
dfs(i - 1, j)
dfs(i, j + 1)
dfs(i, j - 1)
dfs(0,0)
return rstfrom typing import List
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
class Solution:
def pathSum(self, root: TreeNode, target: int) -> List[List[int]]:
rst = []
tmp = []
def dfs(root, target):
if not root:
return
tmp.append(root.val)
if target == root.val and not root.left and not root.right:
rst.append(tmp.copy())
dfs(root.left, target - root.val)
dfs(root.right, target - root.val)
tmp.pop()
dfs(root, target)
return rst[蛇形矩阵]对角线
https://leetcode.cn/problems/diagonal-traverse/description/ https://leetcode.cn/circle/discuss/RZeoZi/
"""
[1, 2, 6, 7]
[3, 5, 8, 11]
[4, 9, 10, 12]
==============
0 3 # 因为和是3, 0 - 3, 遍历会有四个,从右上,到左下
1 2
2 1
3 0 # 反方向,交换xy即可
"""
m = 4
n = 3
nums = [[0] * n for _ in range(m)]
cur = 1
for cnt in range(m + n - 1): # 和是cnt
print("\n".join([str(x) for x in nums]))
print("=" * 10)
if cnt % 2 == 1:
for i in range(cnt + 1):
if 0 <= i < m and 0 <= cnt - i < n:
nums[i][cnt - i] = cur
cur += 1
else:
for i in range(cnt + 1):
if 0 <= cnt - i < m and 0 <= i < n:
nums[cnt - i][i] = cur
cur += 1
print("\n".join([str(x) for x in nums]))from typing import List
def allPathsSourceTarget(self, graph: List[List[int]]) -> List[List[int]]:
rst = []
n = len(graph) # graph 邻接表
def dfs(i, tmp):
if i == n - 1: # 到达n节点
rst.append(tmp)
for nb in graph[i]: # 下一步遍历邻居
dfs(nb, tmp + [nb])
dfs(0, [0])
return rstimport collections
from typing import List
class Solution:
def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
edges = collections.defaultdict(list) # 邻接表 k -> [i,j,s,t]
indeg = [0] * numCourses # 入度
for c1, c2 in prerequisites:
edges[c1].append(c2) # 构建邻接表
indeg[c2] += 1 # 计算入度
queue = []
for i, v in enumerate(indeg): # 入度为0,入栈
if v == 0:
queue.append(i)
while queue: # 队列
node = queue.pop(0)
for pre in edges[node]: # 移出入度为0的点
indeg[pre] -= 1
if indeg[pre] == 1: # 判断剩下节点的度是否为
queue.append(pre)
for i in indeg: # 如果最终有节点,入度仍然不为0,则存在环
if i:
return False
return True- 方法一 找最长路中点
由于 n 个点的连通图只有 n-1 条边,那么任意两个点只有一条路径。
不难证明最小高度就在最长路上而且在 中点,找出最长路返回中点就是答案。
所以根据最长路的奇偶性,中点的节点不是 1 个就是 2 个:
- 使用经典的 dfs / bfs 求最长路并记录路径然后返回中点
- 最长路的求法也是个经典问题,先随便找个点跑到最远节点 x,那么 x 一定是最长路的一端, 再从 x 跑到最远节点 y,则 x,y 为最长路的两个端点。
- 拓扑的思路不断删除所有度为 1 的叶节点,每次将最长路长度减 2,直到节点数小于等于 2 时候,即最长路长为 0 或者 1 时,到达中点结束。
- 方法二 通用做法树形 dp 将原本的暴力 O(N^2)用记忆化的方式,通过记录每个点为根往出度方向和入度方向的高度, 那么以每个点为根的高度可以 dfs 时候顺便递推出来,将复杂度降到 O(n)。
from typing import List
import collections
class Solution:
def findMinHeightTrees(self, n: int, edges: List[List[int]]) -> List[int]:
if not edges:
return [i for i in range(n)]
medges = collections.defaultdict(list) # 无向图的邻接表
indeg = [0] * n # 无向图的度。
for p, c in edges:
medges[p].append(c)
medges[c].append(p)
indeg[p] += 1
indeg[c] += 1
queue = [i for i,v in enumerate(indeg) if v == 1] # 度为一的队列
ans = []
while queue:
ans = queue.copy()
size = len(queue)
for i in range(size):
node = queue.pop(0)
for nb in medges[node]: # 遍历相邻节点, 度减一
indeg[nb] -= 1
if indeg[nb] == 1: # 减完,如果度为1,则加入队列
queue.append(nb)
return ansimport queue
import collections
class MaxQueue:
"""
[1 1 2 3 2 1]
[ 3 2 1] # 这里维护单调递减的队列,队列头为最大值,插入2的时候,清空到=2的地方,[3 2]
"""
def __init__(self):
self.queue = collections.deque()
self.max_queue = collections.deque()
def max_value(self) -> int:
if not self.max_queue:
return -1
return self.max_queue[0]
def push_back(self, value: int) -> None:
self.queue.append(value)
while self.max_queue and self.max_queue[-1] < value:
self.max_queue.pop()
self.max_queue.append(value)
def pop_front(self) -> int:
if not self.queue:
return -1
value = self.queue.popleft()
if value == self.max_queue[0]:
self.max_queue.popleft()
return valuefrom typing import List
import collections
class Solution:
def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
max_queue = collections.deque() # 单调队列
n = len(nums)
rst = []
for i in range(k):
while max_queue and max_queue[-1] < nums[i]:
max_queue.pop()
max_queue.append(nums[i])
rst.append(max_queue[0])
for i in range(k, n):
# pop
if max_queue and nums[i - k] == max_queue[0]:
max_queue.popleft()
# append
while max_queue and max_queue[-1] < nums[i]:
max_queue.pop()
max_queue.append(nums[i])
rst.append(max_queue[0])
return rstclass MinStack:
def __init__(self):
"""
# 单调栈,
[-1,-2, 1, 3, 5, -3 top
[-1, -2, -3 top
"""
self.stack = []
self.min_stack = []
def push(self, x: int) -> None:
self.stack.append(x)
if not self.min_stack or self.min_stack[-1] >= x:
self.min_stack.append(x)
def pop(self) -> None:
x = self.stack.pop()
if self.min_stack[-1] == x:
self.min_stack.pop()
def top(self) -> int:
return self.stack[-1]
def min(self) -> int:
return self.min_stack[-1]下一个更大元素 , 栈中存储的是数值
from typing import List
class Solution:
def nextGreaterElement(self, nums1: List[int], nums2: List[int]) -> List[int]:
rst = {}
stack = []
# 单调递增栈,右侧更大的元素
for n in reversed(nums2):
while stack and n >= stack[-1]: # 栈顶有值,且小于n
stack.pop(-1)
rst[n] = stack[-1] if stack else -1
stack.append(n) # 放入n
return [rst[n] for n in nums1]栈中存储的是index
from typing import List
class Solution:
def nextGreaterElements(self, nums: List[int]) -> List[int]:
n = len(nums)
rst = [-1] * n
stack = []
for i in range((2*n - 1)):
while stack and nums[stack[-1]] < nums[i % n]:
rst[stack.pop()] = nums[i % n]
# 在弹出的这个时机, 弹出的index是尚未找到右侧第一个更大值的,下一个要入栈的,就是第一个更大值
stack.append(i % n)
return rstfrom typing import List
class Solution:
def largestRectangleArea(self, heights: List[int]) -> int:
n = len(heights)
stack = []
left = [0] * n
right = [n] * n
for i, h in enumerate(heights): # 单调递增栈
while stack and heights[stack[-1]] >= h:
right[stack.pop()] = i # 右侧最小为出栈时的入栈元素
left[i] = stack[-1] if stack else -1 # 栈顶:左侧小于h的第一个元素
stack.append(i)
ans = max((right[i] - left[i] - 1) * heights[i] for i in range(n)) if n else 0
return ansfrom typing import List
class Solution:
def findRedundantConnection(self, edges: List[List[int]]) -> List[int]:
n = len(edges)
parent = list(range(n + 1))
def find(index: int) -> int: # 找到根节点
if parent[index] != index:
parent[index] = find(parent[index])
return parent[index]
def union(index1, index2):
parent[find(index1)] = find(index2)
for node1, node2 in edges:
if find(node1) != find(node2): # 如果当前根节点不同, 则构建共同根节点
union(node1, node2)
else:
return [node1, node2] # 当前根节点相同,找到环,返回当前边
return []给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串的长度。 示例 1: 输入: s = "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
rst = 0
n = len(s)
win = set() # 字符合集 window
left, right = 0, 0
while left < n:
while right < n and s[right] not in win: # 右侧增长
win.add(s[right])
right += 1
rst = max(rst, right - left)
win.remove(s[left]) # 左侧移除
left += 1
return rst最小覆盖子串 HARD
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。 注意: 对于 t 中重复字符,我们寻找的子字符串中该字符数量必须不少于 t 中该字符数量。 如果 s 中存在这样的子串,我们保证它是唯一的答案。
示例 1: 输入:s = "ADOBECODEBANC", t = "ABC" 输出:"BANC" 解释:最小覆盖子串 "BANC" 包含来自字符串 t 的 'A'、'B' 和 'C'。
import collections
class Solution:
def minWindow(self, s: str, t: str) -> str:
count_t = collections.Counter(t)
count_w = collections.Counter()
n = len(s)
left = 0
right = 0
rst_left = -1
rst_right = n
while right < n:
count_w[s[right]] += 1
right += 1
while count_w >= count_t: # Counter是可比的
if right - left < rst_right - rst_left:
rst_left = left
rst_right = right
count_w[s[left]] -= 1
left += 1
return "" if rst_left < 0 else s[rst_left : rst_right]给定一个含有 n 个正整数的数组和一个正整数 target 。 找出该数组中满足其总和大于等于 target 的长度最小的子数组 [numsl, numsl+1, ..., numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,返回 0 。
# 和大于等于 target 的最短子数组 : 滑动伸缩窗口
from typing import List
class Solution:
def minSubArrayLen(self, target: int, nums: List[int]) -> int:
left = 0
right = 0
s = 0
rst = float("inf")
n = len(nums)
while right < n: # 都从0开始滑动
s += nums[right]
while s >= target and left < n: # 收缩窗口
rst = min(rst, right - left + 1)
s -= nums[left]
left += 1
right += 1
return rst if rst != float("inf") else 0class Solution:
def twoSum(self, numbers: List[int], target: int) -> List[int]:
n = len(numbers)
left = 0
right = n - 1
while left < right:
val = numbers[left] + numbers[right] # 看起来是二分,其实是向内收缩的滑动窗口
if val == target:
return [left + 1, right + 1]
elif val > target:
right -= 1
elif val < target:
left += 1
return [left, right]class Solution:
def maxArea(self, height: List[int]) -> int:
n = len(height)
left = 0
right = n - 1
rst = 0
while left < right:
v = (right - left) * min(height[left], height[right])
rst = max(rst, v)
if height[left] >= height[right]:
right -= 1
else:
left += 1
return rstimport functools
from typing import List
class Solution:
def singleNumbers(self, nums: List[int]) -> List[int]:
ret = functools.reduce(lambda x,y: x ^ y, nums) # 异或的结果, 最终是 a ^ b
div = 1
while div & ret == 0: # 找到 a,b 不同的第一位
div <<= 1
a, b = 0, 0
for n in nums:
if n & div: # 使用这一位,取得 a,b
a ^= n
else:
b ^= n
return [a, b]from typing import List
class Solution:
def swapNumbers(self, numbers: List[int]) -> List[int]:
a, b = numbers
b = a + b
a = b - a
b = b - a
return [a, b]https://leetcode.cn/problems/powx-n/
class Solution:
def myPow(self, x: float, n: int) -> float:
def pow(x, n): # 迭代版本
ans = 1
factor = x
while n:
if n % 2 == 1: # 高位是否为1
ans *= factor
factor *= factor
n //= 2
return ans
def pow(x, n): # 递归版本
if n == 0:
return 1
y = pow(x, n // 2)
if n % 2 == 0:
return y * y
else:
return x * y * y # 当前幂
if n >= 0: # 符号判断
return pow(x, n)
else:
return 1 / pow(x, -n)class Solution:
def divide(self, dividend: int, divisor: int) -> int:
def div(a, b): # 快速除
if a < b: return 0
rst = 1
tmp_b = b
while tmp_b + tmp_b < a:
rst = rst + rst
tmp_b = tmp_b + tmp_b
return rst + div(a - tmp_b, b)
neg = (dividend < 0) ^ (divisor < 0)
dividend = abs(dividend)
divisor = abs(divisor)
ans = div(dividend, divisor)
ans = -ans if neg else ans
if ans < -(1 << 31) or ans > ((1 << 31) - 1):
return (1 << 31) - 1
return ans数字转换为十六进制数 注意 -1 , 补码表示,除以任何数都是-1。
class Solution:
def toHex(self, num: int) -> str:
CONV = "0123456789abcdef"
ans = []
# 32位2进制数,转换成16进制 -> 4个一组,一共八组
for _ in range(8):
ans.append(num % 16)
num //= 16
if not num: # 如果是0, 则跳出, 注意-1是不会跳出
break
return "".join(CONV[n] for n in ans[::-1])from typing import List
class Solution:
def combinationSum2(self, candidates: List[int], target: int) -> List[List[int]]:
rst = []
def backtrace(target, nums, tmp):
if target < 0:
return
if target == 0:
rst.append(tmp)
return
for i, n in enumerate(nums):
if n <= target:
backtrace(target - n, nums[i + 1:], tmp + [n])
backtrace(target, candidates, [])
return rstclass Solution:
def canCompleteCircuit(self, gas: List[int], cost: List[int]) -> int:
n = len(gas)
i = 0
while i < n:
sum_gas = 0
sum_cos = 0
cnt = 0
while cnt < n:
j = (i + cnt) % n
sum_gas += gas[j]
sum_cos += cost[j]
if sum_gas < sum_cos:
break
cnt += 1
if cnt == n: #跳了n轮
return i
else:
i = i + cnt + 1 #跳过
return -11903. 字符串中的最大奇数, 最优解的特性是, 以奇数结尾的最长的串
class Solution:
def largestOddNumber(self, num: str) -> str:
n = len(num)
for i in range(n - 1, -1, -1):
if int(num[i]) % 2 == 1:
return num[:i + 1]
return ""class Solution:
def climbStairs(self, n: int) -> int:
dp0, dp1 = 1, 1
for i in range(2, n + 1):
dp1, dp0 = dp0 + dp1, dp1
return dp1class Solution:
def rob(self, nums: List[int]) -> int:
n = len(nums)
dp = [0] * (n + 1)
dp[1] = nums[0]
for i in range(1, n):
dp[i + 1] = max(dp[i], dp[i - 1] + nums[i])
return dp[n]给你一个字符串 s 和一个字符串列表 wordDict 作为字典。如果可以利用字典中出现的一个或多个单词拼接出 s 则返回 true。 注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1: 输入: s = "leetcode", wordDict = ["leet", "code"] 输出: true 解释: 返回 true 因为 "leetcode" 可以由 "leet" 和 "code" 拼接成。
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
n = len(s)
dp = [False] * (n + 1)
dp[0] = True
for i in range(n):
for j in range(i+1, n + 1):
if (dp[i] and (s[i:j] in wordDict)): # 寻找是否有合适的单词
dp[j] = True
return dp[-1]动态规划, 当前状态是持有股票、未持有股票下的最大收益 121. 买卖股票的最佳时机 122. 买卖股票的最佳时机 II: 123. 买卖股票的最佳时机 III: 188. 买卖股票的最佳时机 IV: 309. 买卖股票的最佳时机含冷冻期:
from typing import List
class Solution:
def maxProfit(self, prices: List[int]) -> int:
n = len(prices)
if n < 2:
return 0
dp = [[0] * 2 for _ in range(n + 1)]
dp[0][0] = 0
dp[0][1] = -prices[0] # 持有第0个股票的利润
for i in range(1, n):
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] + prices[i]) # 之前没持有,或者当前持有后卖出
dp[i][1] = max(dp[i - 1][1], 0 - prices[i]) # 之前持有,之前没持有,现在买入, 0-prices[i]确保只买卖一次,
return dp[n - 1][0] # 否则位dp[i - 1][0] - prices
class Solution: ## 状态压缩
def maxProfit(self, prices: List[int]) -> int:
n = len(prices)
if n < 2:
return 0
dp0 = 0
dp1 = -prices[0] # 持有第0个股票的利润
for i in range(1, n):
dp0, dp1 = max(dp0, dp1 + prices[i]), max(dp1, - prices[i]) # 之前持有..之前没持有,现在买入
return dp0from typing import List
class Solution:
def maxProfit(self, prices: List[int]) -> int:
# dp[i][0] 第i天, 手上没有股票的最大收益
# dp[i][1] 第i天, 手上有股票的最大收益
n = len(prices)
dp0 = 0
dp1 = -prices[0]
maxv = 0
for i in range(1, n):
dp0 = max(dp0, dp1 + prices[i])
dp1 = max(dp1, dp0 - prices[i])
maxv = max(dp1, dp0)
return maxv
"""
# dp[i][0] 第i天, 手上没有股票的最大收益
# dp[i][1] 第i天, 手上有股票的最大收益
n = len(prices)
dp = [[0] * 2 for _ in range(n)]
dp[0][1] = - prices[0]
maxv = 0
for i in range(1, n):
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] + prices[i])
dp[i][1] = max(dp[i-1][1], dp[i - 1][0] - prices[i])
maxv = max(dp[n - 1][0], dp[n - 1][1])
return maxv
"""带费用的交易
from typing import List
class Solution:
def maxProfit(self, prices: List[int], fee: int) -> int:
n = len(prices)
if n <= 0:
return 0
dp = [[0] * 2 for _ in range(n)]
# dp[i][j] 有无限次次交易, j是当前是否持有股票, i是在第i天, 表示在第i天的最大收益
# dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] + p[i]) # 完成一笔交易
# dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] - p[i]) # 购入一笔交易
for i in range(n):
# for k in range(1,nk + 1):
if i == 0:
dp[i][1] = - prices[i]
else:
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] + prices[i] - fee)
dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] - prices[i])
# rst = max(dp[n - 1][nk - 1][0], dp[n - 1][nk - 1][1])
rst2 = max(dp[n - 1][0], dp[n - 1][1])
return rst2只能交易k次
from typing import List
class Solution:
def maxProfit(self, prices: List[int]) -> int:
n = len(prices)
nk = 2
dp = [[[0] * 2 for _ in range(nk + 1)] for _ in range(n)]
# dp[i][k][j] 有k次交易, j是当前是否持有股票, i是在第i天, 表示在第i天的最大收益
# dp[i][k][0] = max(dp[i - 1][k][0], dp[i - 1][k][1] + p[i]) # 完成一笔交易
# dp[i][k][1] = max(dp[i - 1][k][1], dp[i - 1][k - 1][0] - p[i]) # 购入一笔交易
for i in range(n):
for k in range(1,nk + 1):
if i == 0:
dp[i][k][1] = - prices[i]
else:
dp[i][k][0] = max(dp[i - 1][k][0], dp[i - 1][k][1] + prices[i])
dp[i][k][1] = max(dp[i - 1][k][1], dp[i - 1][k - 1][0] - prices[i])
# rst = max(dp[n - 1][nk - 1][0], dp[n - 1][nk - 1][1])
rst2 = max(dp[n - 1][nk][0], dp[n - 1][nk][1])
return rst2from typing import List
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
n = len(nums)
dp = [-101] * (n + 1)
for i in range(1, n + 1):
dp[i] = max(dp[i - 1] + nums[i - 1], nums[i - 1]) # 子数组,只与 i - 1 有关
return max(dp)
# 超时
def maxSubArrayWrong(self, nums: List[int]) -> int:
n = len(nums)
dp = [-101] * (n + 1)
for i in range(1, n + 1):
for j in range(i):
dp[i] = max(dp[j] + nums[i - 1], nums[i - 1]) # 子序列才需要与 < i - 1 的都有关
return max(dp)from typing import List
class SolutionDP:
def lengthOfLIS(self, nums: List[int]) -> int:
n = len(nums)
dp = [1] * (n + 1) # 长度为i的nums最大的子序列数字为nums[i]
if n == 1:
return 1
rst = float('-inf')
for i in range(1, n):
for j in range(0, i): # dp数组迭代方式,与之前的所有选项对比,连接
if (nums[i] > nums[j]):
dp[i] = max(dp[j] + 1, dp[i])
# else:
# dp[i] = max(dp[i], 1)
rst = max(rst, dp[i])
return rst
"""
DP + 贪心: 可能更偏向于贪心一些.
[0,8,4,12,2]
dp: 长度为i的最长上升子序列,末尾元素的最小值
0 [0]
1 [0, 8]
2 [0, 4] # 当小于的时候,替换
3 [0, 4, 12] # 当大于的时候,添加
4 [0, 2, 12] # 替换的意义在于,dp[1]代表的长度为2的最长上升子序列,尾巴更小了,能够帮助找到更长的子序列
12,0,1,2,3
[12] # 比如这里,如果不替换,讲究无法找到最长的
[0]
[0, 1]
[0, 1, 2]
[0, 1, 2, 3]
"""
class Solution:
def lengthOfLIS(self, nums: List[int]) -> int:
d = []
for n in nums:
if not d or n > d[-1]: # 如果大于尾部元素,添加
d.append(n)
else: # 如果小于,找到位置
l, r = 0, len(d) - 1
loc = r # location / position, bisect.bisect_left()
while l <= r:
mid = (l + r) // 2
if d[mid] >= n:
loc = mid
r = mid - 1
else:
l = mid + 1
d[loc] = n # 替换掉
return len(d)class Solution:
def minimumTotal(self, triangle: List[List[int]]) -> int:
n = len(triangle)
dp = [ [0] * (n + 1) for _ in range(n + 1)]
dp[0][0] = triangle[0][0]
rst = float("inf")
if n == 1:
return dp[0][0]
for i in range(n):
for j in range(i + 1):
if j == 0:
dp[i][j] = dp[i - 1][j] + triangle[i][j]
elif i == j:
dp[i][j] = dp[i - 1][j - 1] + triangle[i][j]
else:
dp[i][j] = min(dp[i - 1][j - 1], dp[i - 1][j]) + triangle[i][j]
if i == n - 1:
rst = min(rst, dp[i][j])
return rst
# n = len(triangle)
# rst = float("inf")
# def dfs(i, j, s):
# if i == n:
# nonlocal rst
# rst = min(rst, s)
# return
# nums = triangle[i]
# if j < len(nums): dfs(i + 1, j, s + nums[j])
# if j + 1 < len(nums): dfs(i + 1, j + 1, s + nums[j + 1])
# dfs(0, 0, 0)
# return rstclass Solution:
def minPathSum(self, grid: List[List[int]]) -> int:
n = len(grid)
m = len(grid[0])
dp = [[float("inf")] * (m + 1) for _ in range(n + 1)]
for i in range(n):
for j in range(m):
if i == 0 and j == 0:
dp[i + 1][j + 1] = grid[i][j]
else:
dp[i + 1][j + 1] = min(dp[i][j + 1], dp[i + 1][j]) + grid[i][j]
return dp[n][m]class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
n = len(s)
dp = [0] * (n + 1)
rst = 0
for i in range(1, n + 1):
j = i - 1
while j >= 0 and s[i - 1] != s[j - 1]:
j -= 1
if dp[i - 1] < i - j: # 说明重复字符越界
dp[i] = dp[i - 1] + 1
else:
dp[i] = i - j
rst = max(rst, dp[i])
return rst
## 滑动窗口的方式
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
ans = 0
left, right = 0, 0
cset = set()
while left < len(s):
if left > 0:
cset.remove(s[left - 1]) # 删除,左边收缩
while right < len(s) and not s[right] in cset:
cset.add(s[right]) # 添加,往右扩张
right += 1
ans = max(ans, right - left)
left += 1
return ans异形DP 264. 丑数 II
class Solution:
def nthUglyNumber(self, n: int) -> int:
dp = [0] * (n + 1)
dp[1] = 1
p2 = p3 = p5 = 1
for i in range(2, n + 1):
num2, num3, num5 = dp[p2] * 2, dp[p3] * 3, dp[p5] * 5
dp[i] = min(num2, num3, num5)
if dp[i] == num2:
p2 += 1
if dp[i] == num3:
p3 += 1
if dp[i] == num5:
p5 += 1
return dp[n]class Solution:
def integerBreak(self, n: int) -> int:
dp = [1] * (n + 1)
dp[0] = 0
dp[1] = 1
dp[2] = 1
for i in range(3, n + 1):
for j in range(1, i):
dp[i] = max(max(dp[i], dp[i - j] * j), (i - j) * j )
print(dp)
return dp[n]概率dp 剑指 Offer 60. n个骰子的点数
from typing import List
class Solution:
def dicesProbability(self, n: int) -> List[float]:
dp = [1 / 6] * 6
for i in range(2, n + 1):
tmp = [0] * (5 * i + 1)
for j in range(len(dp)):
for k in range(6):
tmp[j + k] += dp[j] / 6
dp = tmp
return dp# 从终点返回进行DP, 然后从起点获取结果
from typing import List
class Solution:
def pathWithObstacles(self, obstacleGrid: List[List[int]]) -> List[List[int]]:
m = len(obstacleGrid)
n = len(obstacleGrid[0])
ans = []
if obstacleGrid[-1][-1] != 0:
return ans
obstacleGrid[-1][-1] = 2
for i in reversed(range(m)): # reversed 遍历
for j in reversed(range(n)):
if obstacleGrid[i][j] > 1:
if 0 < i and not obstacleGrid[i - 1][j]: # 右,左
obstacleGrid[i - 1][j] = 2
if 0 < j and not obstacleGrid[i][j - 1]: # 下,上
obstacleGrid[i][j - 1] = 3
if obstacleGrid[0][0] > 1: # 获取结果
i, j = 0, 0
while i < m and j < n:
ans.append([i, j])
if obstacleGrid[i][j] == 2:
i += 1
else:
j += 1
# print("\n".join([str(x) for x in obstacleGrid]))
return ans
# 一般回溯
class SolutionDFS:
def pathWithObstacles(self, obstacleGrid: List[List[int]]) -> List[List[int]]:
m = len(obstacleGrid)
n = len(obstacleGrid[0])
rst = []
def dfs(x, y, path):
if rst:
return
if x == m - 1 and y == n - 1 and obstacleGrid[x][y] == 0:
path.append([x, y])
rst.extend(path)
return
if not(0<=x<m and 0<=y<n) or obstacleGrid[x][y] == 1 or obstacleGrid[x][y] == 2:
return
path.append([x, y])
obstacleGrid[x][y] = 1
dfs(x + 1, y, path)
dfs(x, y + 1, path)
path.pop(-1)
dfs(0, 0, [])
return rst基本型:
class Solution:
def waysToChange(self, n: int) -> int:
M = 10 ** 9 + 7
coins = [1, 5, 10, 25]
dp = [[0] * (n + 1) for _ in range(4)]
for i in range(4):
dp[i][0] = 1
for i in range(4):
for j in range(coins[i], n + 1):
if j >= coins[i]: # 如果容量够大
dp[i][j] = (dp[i - 1][j] + dp[i][j - coins[i]]) % M
else:
dp[i][j] = dp[i - 1][j]
print("\n".join([str(x) for x in dp]))
""" n = 10, coins=[1, 5, 10, 25], 乱序coins也是OK的
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
[1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3]
[1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 4]
[1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 4] 从上边,以及左边间隔coins[i]的地方,相加,或者获取最大值
"""
return dp[3][n]
def waysToChange2(self, n: int) -> int: # 状态压缩
M = 10 ** 9 + 7
coins = [25, 10, 5, 1]
dp = [0] * (n + 1)
dp[0] = 1
for c in coins:
for i in range(c, n + 1):
dp[i] = (dp[i] + dp[i - c]) % M
return dp[n]import functools
from typing import List
class Solution:
def coinChange(self, coins: List[int], amount: int) -> int:
n = amount
m = len(coins)
dp = [[float("inf")] * (n + 1) for _ in range(m + 1)]
for i in range(m):
dp[i][0] = 0
for i in range(m): # 二维DP, 背包大小 m
for j in range(1, n + 1): # 容量 n
if j >= coins[i]:
dp[i][j] = min(dp[i - 1][j], dp[i][j - coins[i]] + 1)
else:
dp[i][j] = min(dp[i - 1][j], dp[i][j])
# print("\n".join([str(x) for x in dp]))
return dp[m - 1][n] if dp[m - 1][n] != float("inf") else -1
def coinChangeDP(self, coins: List[int], amount: int) -> int: # 动态规划, 完全背包
n = amount
dp = [float("inf")] * (n + 1)
dp[0] = 0
for c in coins:
for i in range(c, amount + 1): # 枚举
dp[i] = min(dp[i], dp[i - c] + 1) # 这里取的是min值
return dp[amount] if dp[amount] != float("inf") else -1
def coinChange(self, coins: List[int], amount: int) -> int: # 递归搜索 + 缓存
@functools.lru_cache(amount)
def dp(rem) -> int:
if rem < 0: return -1
if rem == 0: return 0
mini = int(1e9)
for coin in self.coins:
res = dp(rem - coin)
if res >= 0 and res < mini:
mini = res + 1
return mini if mini < int(1e9) else -1
self.coins = coins
if amount < 1: return 0
return dp(amount)
class Solution:
def coinChange(self, coins: List[int], amount: int) -> int:
n = len(coins)
dp = [[amount+1] * (amount+1) for _ in range(n+1)] # 初始化为一个较大的值,如 +inf 或 amount+1
# 合法的初始化
dp[0][0] = 0 # 其他 dp[0][j]均不合法
# 完全背包:套用0-1背包【遍历硬币数目k】
for i in range(1, n+1): # 第一层循环:遍历硬币
for j in range(amount+1): # 第二层循环:遍历背包
for k in range(j//coins[i-1]+1): # 第三层循环:当前硬币coin取k个 (k*coin<=amount)
dp[i][j] = min( dp[i][j], dp[i-1][j-k*coins[i-1]] + k )
ans = dp[n][amount]
return ans if ans != amount+1 else -1
class Solution:
def coinChange(self, coins: List[int], amount: int) -> int:
n = len(coins)
dp = [[amount+1] * (amount+1) for _ in range(n+1)] # 初始化为一个较大的值,如 +inf 或 amount+1
# 合法的初始化
dp[0][0] = 0 # 其他 dp[0][j]均不合法
# 完全背包:优化后的状态转移
for i in range(1, n+1): # 第一层循环:遍历硬币
for j in range(amount+1): # 第二层循环:遍历背包
if j < coins[i-1]: # 容量有限,无法选择第i种硬币
dp[i][j] = dp[i-1][j]
else: # 可选择第i种硬币
dp[i][j] = min(dp[i-1][j], dp[i][j-coins[i-1]] + 1)
ans = dp[n][amount]
return ans if ans != amount+1 else -1from typing import List
class Solution:
def canPartition(self, nums: List[int]) -> bool:
total = sum(nums)
if total % 2 == 1:
return False
target = total // 2
n = len(nums)
dp = [[False] * (target + 1) for _ in range(n + 1)]
# dp[i][j] 从前i个元素选出刚好组成j
dp[0][0] = True
for i in range(1, n + 1):
for j in range(target + 1):
if j < nums[i - 1]: # 容量存不下
dp[i][j] = dp[i - 1][j]
else:
dp[i][j] = dp[i - 1][j] | dp[i - 1][j - nums[i - 1]]
return dp[n][target]from typing import List
class Solution:
def findMaxForm(self, strs: List[str], m: int, n: int) -> int:
lenstr = len(strs)
dp = [[[0] * (n + 1) for _ in range(m + 1)] for _ in range(lenstr + 1)]
for i in range(1, lenstr + 1):
c0 = strs[i - 1].count('0')
c1 = strs[i - 1].count('1')
for j in range(m + 1): # 0 背包
for k in range(n + 1): # 1 背包
if j < c0 or k < c1:
dp[i][j][k] = dp[i - 1][j][k]
else:
dp[i][j][k] = max(dp[i - 1][j][k], dp[i - 1][j - c0][k - c1] + 1)
return dp[lenstr][m][n]from typing import List
class Solution:
def findTargetSumWays(self, nums: List[int], target: int) -> int:
total = sum(nums)
if abs(target) > total:
return 0
if (target + total) % 2 == 1:
return 0
pos = (target + total) // 2 # 这里比较有意思是,背包的大小是隐藏的,是这样计算出来的
neg = (total - target) // 2
cap = min(pos, neg)
n = len(nums)
dp = [[0] * (cap + 1) for _ in range(n + 1)]
dp[0][0] = 1
for i in range(1, n + 1):
for j in range(cap + 1):
if j < nums[i - 1]:
dp[i][j] = dp[i - 1][j]
else:
dp[i][j] = dp[i - 1][j] + dp[i - 1][j - nums[i - 1]]
return dp[n][cap]from typing import List
class Solution:
def lastStoneWeightII(self, stones: List[int]) -> int:
total = sum(stones)
if max(stones) >= total // 2: # 最大值>=总和的一半,可直接返回结果【最大石头依次与其他石头粉碎】
return 2 * max(stones) - total
# 初始化
n = len(stones)
target = total // 2 # 凑出石头重量的最大目标值
dp = [[False] * (target+1) for _ in range(n+1)]
# dp[i][j]: 前i个石头能否组成重量j
dp[0][0] = True # 其他 dp[0][j]均为False
# 状态更新
for i in range(1, n+1):
for j in range(target+1):
if j < stones[i-1]: # 容量有限,无法选择第i个石头
dp[i][j] = dp[i-1][j]
else: # 可选择第i个石头,也可不选
dp[i][j] = dp[i-1][j] | dp[i-1][j-stones[i-1]]
# 结果回溯
ans = total
for j in range(target, -1, -1):
if dp[n][j]: # 能凑出重量为j的石头
ans = total - 2*j
break # 倒序,第一个即为能凑出的最大neg
return anspublic int countEval(String s, int result) {
//特例
if (s.length() == 0) {
return 0;
}
if (s.length() == 1) {
return (s.charAt(0) - '0') == result ? 1 : 0;
}
char[] ch = s.toCharArray();
//定义状态
int[][][] dp = new int[ch.length][ch.length][2];
//base case
for (int i = 0; i < ch.length; i++) {
if (ch[i] == '0' || ch[i] == '1') {
dp[i][i][ch[i] - '0'] = 1;
}
}
//套区间dp模板
//枚举区间长度len,跳步为2,一个数字一个符号
for (int len = 2; len <= ch.length; len += 2) {
//枚举区间起点,数字位,跳步为2
for (int i = 0; i <= ch.length - len; i += 2) {
//区间终点,数字位
int j = i + len;
//枚举分割点,三种 '&','|', '^',跳步为2
for (int k = i + 1; k <= j - 1; k += 2) {
if (ch[k] == '&') {
//结果为0 有三种情况: 0 0, 0 1, 1 0
//结果为1 有一种情况: 1 1
dp[i][j][0] += dp[i][k - 1][0] * dp[k + 1][j][0] + dp[i][k - 1][0] * dp[k + 1][j][1] + dp[i][k - 1][1] * dp[k + 1][j][0];
dp[i][j][1] += dp[i][k - 1][1] * dp[k + 1][j][1];
}
if (ch[k] == '|') {
//结果为0 有一种情况: 0 0
//结果为1 有三种情况: 0 1, 1 0, 1 1
dp[i][j][0] += dp[i][k - 1][0] * dp[k + 1][j][0];
dp[i][j][1] += dp[i][k - 1][0] * dp[k + 1][j][1] + dp[i][k - 1][1] * dp[k + 1][j][0] + dp[i][k - 1][1] * dp[k + 1][j][1];
}
if (ch[k] == '^') {
//结果为0 有两种情况: 0 0, 1 1
//结果为1 有两种情况: 0 1, 1 0
dp[i][j][0] += dp[i][k - 1][0] * dp[k + 1][j][0] + dp[i][k - 1][1] * dp[k + 1][j][1];
dp[i][j][1] += dp[i][k - 1][1] * dp[k + 1][j][0] + dp[i][k - 1][0] * dp[k + 1][j][1];
}
}
}
}
return dp[0][ch.length - 1][result];
}海伦公式 a,b,c 为三边长 s = (a + b + c) / 2 A = sqrt(s * (s - a) * (s - b) * (s - c))
class Solution:
# 数学
def lastRemaining(self, n: int, m: int) -> int:
x = 0
for i in range(2, n + 1):
x = (x + m) % i
return x
class SolutionSimulate:
def lastRemaining(self, n: int, m: int) -> int:
nums = [x for x in range(n)]
last = 0
while len(nums) > 1:
n = len(nums)
last = (last + m - 1) % n
nums.pop(last)
return nums[0]class Solution:
def __init__(self):
self.maxSum = float("-inf")
def maxPathSum(self, root: TreeNode) -> int:
def maxGain(node):
if not node:
return 0
# 递归计算左右子节点的最大贡献值
# 只有在最大贡献值大于 0 时,才会选取对应子节点
leftGain = max(maxGain(node.left), 0)
rightGain = max(maxGain(node.right), 0)
# 节点的最大路径和取决于该节点的值与该节点的左右子节点的最大贡献值
priceNewpath = node.val + leftGain + rightGain
# 更新答案
self.maxSum = max(self.maxSum, priceNewpath)
# 返回节点的最大贡献值
return node.val + max(leftGain, rightGain)
maxGain(root)
return self.maxSum给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
示例 1: 输入:height = [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
示例 2: 输入:height = [4,2,0,3,2,5] 输出:9
class Solution:
def trap(self, height: List[int]) -> int:
n = len(height)
left = [0] * (n + 1)
right = [0] * (n + 1)
left_max = 0
right_max = 0
for i in range(n):
left_max = max(left_max, height[i])
left[i] = left_max
for i in range(n - 1, -1, -1):
right_max = max(right_max, height[i])
right[i] = right_max
rst = 0
for i in range(n):
l = left[i]
r = right[i]
h = min(l, r) - height[i]
rst += h
return rstn 个孩子站成一排。给你一个整数数组 ratings 表示每个孩子的评分。 你需要按照以下要求,给这些孩子分发糖果: 每个孩子至少分配到 1 个糖果。 相邻两个孩子评分更高的孩子会获得更多的糖果。 请你给每个孩子分发糖果,计算并返回需要准备的 最少糖果数目。
示例 1: 输入:ratings = [1,0,2] 输出:5 解释:你可以分别给第一个、第二个、第三个孩子分发 2、1、2 颗糖果。
示例 2: 输入:ratings = [1,2,2] 输出:4 解释:你可以分别给第一个、第二个、第三个孩子分发 1、2、1 颗糖果。 第三个孩子只得到 1 颗糖果,这满足题面中的两个条件。
class Solution:
def candy(self, ratings: List[int]) -> int:
n = len(ratings)
left = [0] * (n + 1) # 左侧糖果个数
for i in range(0, n):
if ratings[i] > ratings[i - 1]:
left[i] = left[i - 1] + 1
else:
left[i] = 1
right = [1] * (n + 1) # 右侧糖果个数
rst = 0
for i in range(n - 1, -1, -1):
if i < n -1 and ratings[i] > ratings[i + 1]:
right[i] = right[i + 1] + 1
else:
right[i] = 1
rst += max(left[i], right[i])
return rst给定一个字符串 s 和一个字符串数组 words。 words 中所有字符串 长度相同。 s 中的 串联子串 是指一个包含 words 中所有字符串以任意顺序排列连接起来的子串。
例如,如果 words = ["ab","cd","ef"], 那么 "abcdef", "abefcd","cdabef", "cdefab","efabcd", 和 "efcdab" 都是串联子串。 "acdbef" 不是串联子串,因为他不是任何 words 排列的连接。 返回所有串联子串在 s 中的开始索引。你可以以 任意顺序 返回答案。
import collections
from typing import List
class Solution:
def findSubstring(self, s: str, words: List[str]) -> List[int]:
wordmap = collections.Counter(words)
wordlen = len(words[0])
allwordlen = wordlen * (len(words)) # 目标子q 1串长度
rst = []
n = len(s)
for i in range(0, n - allwordlen + 1):
ss = s[i : i + allwordlen] # 区间枚举
if len(ss) != allwordlen:
print(ss, len(ss))
break
ss = [ss[i : i + wordlen] for i in range(0, len(ss), wordlen)] # 切分单词
ssmap = collections.Counter(ss) # 计数
if ssmap == wordmap: # 对比
rst.append(i)
return rstfrom typing import List, Optional
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class Solution:
def mergeKLists(self, lists: List[Optional[ListNode]]) -> Optional[ListNode]:
def merge(l1, l2):
dummy = ListNode()
ptr = dummy
while l1 and l2:
if l1.val < l2.val:
ptr.next = l1
l1 = l1.next
else:
ptr.next = l2
l2 = l2.next
ptr = ptr.next
if l1: ptr.next = l1
if l2: ptr.next = l2
return dummy.next
def mergeLinks(linklists):
if not linklists:
return None
if len(linklists) == 1:
return linklists[0]
mid = len(linklists) // 2
left = mergeLinks(linklists[:mid])
right = mergeLinks(linklists[mid:])
return merge(left, right)
return mergeLinks(lists)class Solution:
def isMatch(self, s: str, p: str) -> bool:
n = len(s)
m = len(p)
dp = [[False] * (m + 1) for _ in range(n + 1)]
dp[0][0] = True
for i in range(1, m + 1):
if p[i - 1] == '*':
dp[0][i] = True
else:
break
for i in range(1, n + 1):
for j in range(1, m + 1):
if s[i - 1] == p[j - 1]:
dp[i][j] = dp[i - 1][j - 1]
elif p[j - 1] == "*":
dp[i][j] = dp[i][j - 1] or dp[i - 1][j]
elif p[j - 1] == "?":
dp[i][j] = dp[i - 1][j - 1]
# print("\n".join([str(x) for x in dp]))
return dp[n][m]class Solution:
def isMatch(self, s: str, p: str) -> bool:
m, n = len(s), len(p)
def matches(i: int, j: int) -> bool:
if i == 0:
return False
if p[j - 1] == '.':
return True
return s[i - 1] == p[j - 1]
f = [[False] * (n + 1) for _ in range(m + 1)]
f[0][0] = True
for i in range(0, m + 1): # 注意需要从0开始,因为 a* 这样的模式,是可以匹配空串的
for j in range(1, n + 1):
if p[j - 1] == '*':
f[i][j] |= f[i][j - 2]
if matches(i, j - 1):
f[i][j] |= f[i - 1][j] # 这里这个 f[i - 1][j] 比较精髓,适配 b* 的1到多个的情况
else:
if matches(i, j):
f[i][j] |= f[i - 1][j - 1]
return f[m][n]from typing import List
class Solution:
def solveNQueens(self, n: int) -> List[List[str]]:
def check(matrix, row, col) -> bool:
# 列
for i in range(n):
if matrix[i][col] == "Q":
return False
# 正对角线
for i in range(n):
if col + i < n and matrix[row - i][col + i] == "Q":
return False
# 反对角线
for i in range(n):
if col >= i and matrix[row - i][col - i] == "Q":
return False
return True
matrix = [["."] * n for _ in range(n)]
rst = []
def dfs(cur, matrix): # 枚举当前的行,结果是存储当前的棋盘
# select a Queen and check
# print(cur)
# print("\n".join([" ".join(x) for x in matrix]))
if cur == n:
tmp = ["".join(x) for x in matrix]
rst.append(tmp)
return
for i in range(n):
if not check(matrix, cur, i):
continue
matrix[cur][i] = "Q"
dfs(cur + 1, matrix)
matrix[cur][i] = "."
dfs(0, matrix)
return rst
class Solution: # 另一种代码风格
def solveNQueens(self, n: int) -> List[List[str]]:
matrix = [["."] * (n) for _ in range(n)]
rst = []
def isOK(x, y):
# -
for i in range(n):
if matrix[x][i] == "Q":
return False
# |
for i in range(n):
if matrix[i][y] == "Q":
return False
# \
for i in range(n):
if y + i < n and matrix[x - i][y + i] == "Q":
return False
# /
for i in range(n):
if y - i >= 0 and matrix[x - i][y - i] == "Q":
return False
return True
def dfs(row):
if row == n:
tmp = ["".join(x) for x in matrix]
rst.append(tmp)
return
for col in range(n):
if isOK(row, col):
matrix[row][col] = "Q"
dfs(row + 1)
matrix[row][col] = "."
dfs(0)
return rstdp的结果,有一定的特点,定义为以右括号为最后一个字符的连续有小括号长度
class Solution:
def longestValidParentheses(self, s: str) -> int:
n = len(s)
dp = [0] * (n + 1)
ans = 0
for i in range(1,n):
if s[i] == ')':
if s[i-1] == '(': # .......()
if i >= 2:
dp[i] = dp[i - 2] + 2
else:
dp[i] = 2
elif i - dp[i - 1] > 0 and s[i - dp[i - 1] - 1] == '(': # ........))
if i - dp[i - 1] >= 2:
dp[i] = dp[i - 1] + dp[i - dp[i - 1] - 2] + 2 # ........(....))
else:
dp[i] = dp[i - 1] + 2 # .(())
ans = max(ans, dp[i])
return ansimport bisect
from typing import List
class Solution:
def maxEnvelopes(self, envelopes: List[List[int]]) -> int:
dp = []
envelopes.sort(key=lambda x: (x[0], - x[1]))
for w, h in envelopes:
pos = bisect.bisect_left(dp, h) # 两个为度排序与选择
dp[pos:pos + 1] = [h]
return len(dp)from typing import List,Optional
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class Solution:
def reverseKGroup(self, head: Optional[ListNode], k: int) -> Optional[ListNode]:
def printList(root):
while root:
print(root.val, "->", end="")
root = root.next
print()
def reverse(head, tail): # 翻转的代码
pre = tail.next if tail else None # pre是结尾的下一个
cur = head # cur是当前的每一个
while pre != tail:
nxt = cur.next # 存储cur.next
cur.next = pre # 转移cur.next指针
pre = cur # 切换到下一个节点
cur = nxt # 切换到下一个节点
return tail, head
# 美丽的dummy帮助我们把问题结构化
dummy = ListNode()
dummy.next = head
pre = dummy # 前一个节点
begin = head # 需要翻转的第一个节点
end = head # 需要翻转的最后一个节点
while begin:
end = begin
for i in range(k - 1): # 移动到最后一个节点
end = end.next
if not end: # 如果不够长,直接返回结果
return dummy.next
nxt = end.next # 缓存nxt
begin, end = reverse(begin, end)
pre.next = begin # 连接头
end.next = nxt # 连接尾
pre = end # 移动
begin = end.next # 移动
return dummy.next滑动窗口+hashMap
import collections
class Solution:
def minWindow(self, s: str, t: str) -> str:
mt = collections.Counter(t)
ms = collections.defaultdict(int)
left = 0
right = 0
ns = len(s)
nt = len(t)
ans = ""
def check():
for k, v in mt.items():
if k not in ms or ms[k] < v:
return False
return True
while right < ns:
if s[right] in mt: # 扩张窗口
ms[s[right]] += 1
while check() and left <= right: # 收缩窗口
ans = s[left : right + 1] if not ans or (right - left + 1) < len(ans) else ans
ms[s[left]] -= 1
left += 1
right += 1
return ans单调栈 找到,左侧比我小的第一个元素,右侧比我小的第一个元素。
from typing import List
class Solution:
def largestRectangleArea(self, heights: List[int]) -> int:
n = len(heights)
stack = []
left = [0] * n
right = [n] * n
for i, h in enumerate(heights): # 单调递增栈
while stack and heights[stack[-1]] >= h:
right[stack.pop()] = i # 弹出的元素都小于自己,构建right
left[i] = stack[-1] if stack else -1 # 栈顶左侧小于h的第一个元素, 构建left
stack.append(i)
stack = []
# 单独构建right,也是可以的
# for i in range(n - 1, -1, -1): # 单调递增栈,从右侧开始入栈
# while stack and heights[stack[-1]] >= heights[i]:
# stack.pop()
# right[i] = stack[-1] if stack else n # 栈顶为右侧小于h的第一个元素
# stack.append(i)
ans = max((right[i] - left[i] - 1) * heights[i] for i in range(n)) if n else 0
return ans
# # 按照高度进行枚举, 超时
# n = len(heights)
# ans = heights[0]
# for i in range(n):
# left = i
# right = i
# height = heights[i]
# while left - 1 >= 0 and height <= heights[left - 1]:
# left -= 1
# while right + 1 < n and height <= heights[right + 1]:
# right += 1
# ans = max(ans, height * (right - left + 1))
# # print(i, ans, left, right)
# return ans
# 枚举, 宽度,寻找最小高度 O(n^2)
# 这边有个技巧
# 枚举left, right, 区间从最小到最大,这个过程中通过right的枚举,一并寻找最小高度
# n = len(heights)
# ans = 0
# for left in range(n):
# minh = float("inf")
# for right in range(left, n):
# minh = min(minh, heights[right])
# ans = max(ans, (right - left + 1) * minh)
# return ans单调栈, 预处理成高度,找矩形
from typing import List
class Solution:
def maximalRectangle(self, matrix: List[List[str]]) -> int:
n = len(matrix)
m = len(matrix[0])
left = [[0] * m for _ in range(n)]
for i in range(n):
for j in range(m):
if matrix[i][j] == "1":
if j > 0:
left[i][j] = left[i][j - 1] + 1
else:
left[i][j] = 1
# 列遍历, 对每一列, left[j]为高度
ans = 0
for j in range(m):
stack = []
lmin = [0] * n
rmin = [n] * n
tmp = 0
for i in range(n):
while stack and left[stack[-1]][j] >= left[i][j]:
rmin[stack.pop()] = i
lmin[i] = stack[-1] if stack else -1
stack.append(i)
heights = [ (rmin[i] - lmin[i] - 1) * left[i][j] for i in range(n)]
tmp = max(heights)
ans = max(ans, tmp)
return ansfrom typing import List
import collections
class Solution:
def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
max_queue = collections.deque()
n = len(nums)
rst = []
for i in range(k):
while max_queue and max_queue[-1] < nums[i]:
max_queue.pop()
max_queue.append(nums[i])
rst.append(max_queue[0])
for i in range(k, n):
# pop
if max_queue and nums[i - k] == max_queue[0]:
max_queue.popleft()
# append
while max_queue and max_queue[-1] < nums[i]:
max_queue.pop()
max_queue.append(nums[i])
rst.append(max_queue[0])
return rstfrom typing import List
class Solution:
def pileBox(self, box: List[List[int]]) -> int:
n = len(box)
dp = [0] * (n + 1) # 以第i个箱子为结尾的上升子序列的最大总高度
box.sort(key=lambda x: x[0])
dp[0] = box[0][2] # 第一堆的最大高度
ans = dp[0]
for i in range(1, n):
maxh = 0 #
for j in range(i): # 看看能不能往上堆
if box[i][0] > box[j][0] and \
box[i][1] > box[j][1] and \
box[i][2] > box[j][2]:
maxh = max(maxh, dp[j]); # if not avaliable, maxh = 0, dp[i] should be box[i][2]
dp[i] = maxh + box[i][2] # 以当前堆为结尾的最大高度
ans = max(ans, dp[i])
return ansimport heapq
class MedianFinder:
def __init__(self):
self.queMin = list()
self.queMax = list()
def addNum(self, num: int) -> None:
queMin_ = self.queMin
queMax_ = self.queMax
if not queMin_ or num <= -queMin_[0]:
heapq.heappush(queMin_, -num)
if len(queMax_) + 1 < len(queMin_):
heapq.heappush(queMax_, -heapq.heappop(queMin_))
else:
heapq.heappush(queMax_, num)
if len(queMax_) > len(queMin_):
heapq.heappush(queMin_, -heapq.heappop(queMax_))
def findMedian(self) -> float:
queMin_ = self.queMin
queMax_ = self.queMax
if len(queMin_) > len(queMax_):
return -queMin_[0]
return (-queMin_[0] + queMax_[0]) / 2class BiNode:
def __init__(self, k=None, v=None):
self.k = k
self.v = v
self.prev = None
self.next = None
class LRUCache:
def __init__(self, capacity: int):
self.m = {}
self.head = BiNode()
self.tail = BiNode()
self.cap = capacity
self.cnt = 0
self.head.next = self.tail
self.tail.prev = self.head
def get(self, key: int) -> int:
if key in self.m:
head = self.head
node = self.m[key]
node.prev.next = node.next
node.next.prev = node.prev
node.next = head.next
node.prev = head
head.next.prev = node
head.next = node
return node.v
else:
return -1
def put(self, key: int, value: int) -> None:
if key in self.m: # 如果已经有,更新value, 移动到队尾
node = self.m[key]
node.prev.next = node.next # 新节点连接上
node.next.prev = node.prev
head = self.head
node.prev = head # 头节点更新
node.next = head.next
head.next.prev = node # next节点更新
head.next = node
node.v = value # 只更新值,不更新cnt
else:
if self.cnt + 1 > self.cap: # 超过了,删除
tail = self.tail
d = tail.prev
d.prev.next = d.next
d.next.prev = d.prev
del self.m[d.k]
self.cnt -= 1
node = BiNode(key, value)
head = self.head
self.m[key] = node
node.prev = self.head
node.next = self.head.next
self.head.next.prev = node
self.head.next = node
self.cnt += 1- https://github.com/ChenYilong/iOSInterviewQuestions
- https://github.com/limboy/iOS-Developer-Interview-Questions
- https://draveness.me/guan-yu-xie-ios-wen-ti-de-jie-da/
-
OSI
物理层、链路层、网络层、传输层、会话层、表示层、应用层
-
TCP/IP
物理链路层(网络接口层)、网际层、传输层、应用层
UDP 和 TCP 的特点 \
-
用户数据报协议 UDP(User Datagram Protocol)是无连接的,尽最大可能交付,没有拥塞控制,面向报文(对于应用程序传下来的报文不合并也不拆分,只是添加 UDP 首部),支持一对一、一对多、多对一和多对多的交互通信。
-
传输控制协议 TCP(Transmission Control Protocol)是面向连接的,提供可靠交付,有流量控制,拥塞控制,提供全双工通信,面向字节流(把应用层传下来的报文看成字节流,把字节流组织成大小不等的数据块),每一条 TCP 连接只能是点对点的(一对一)。\
-
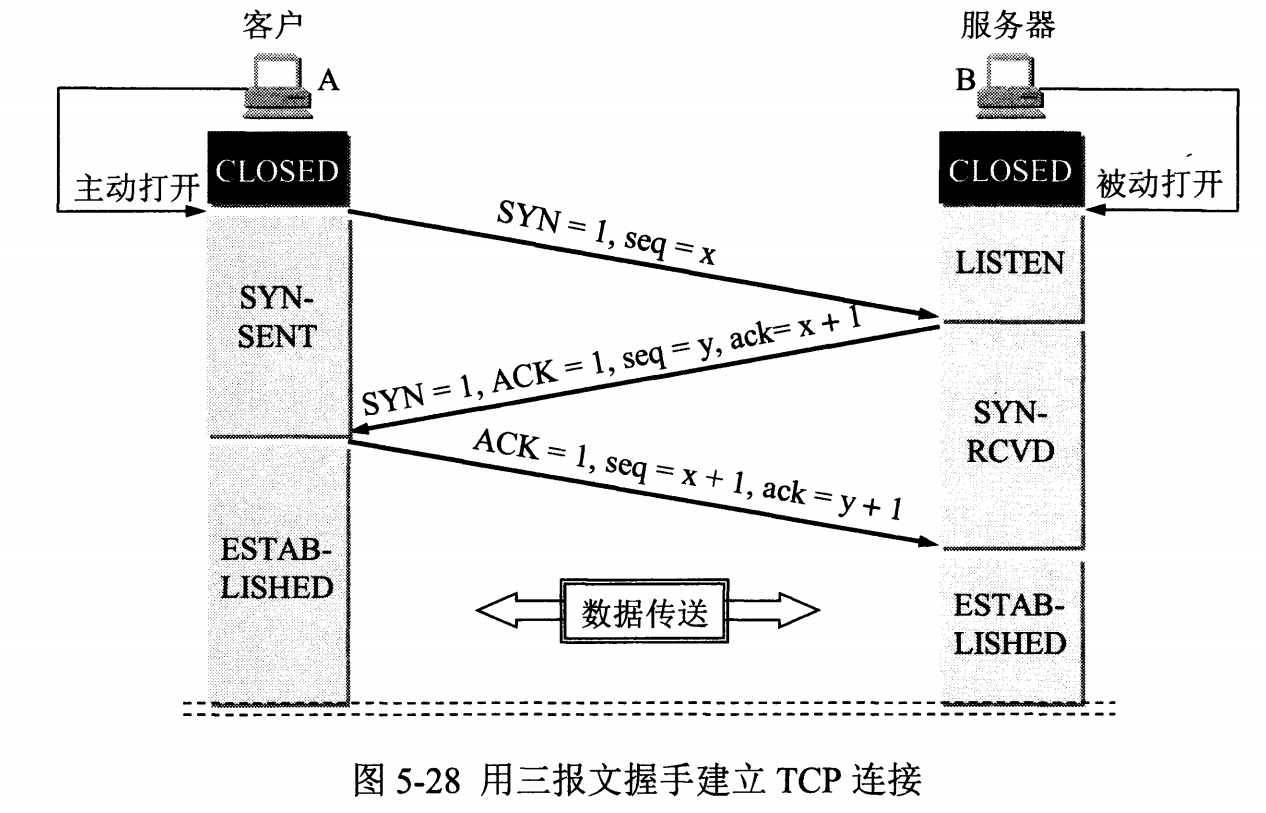
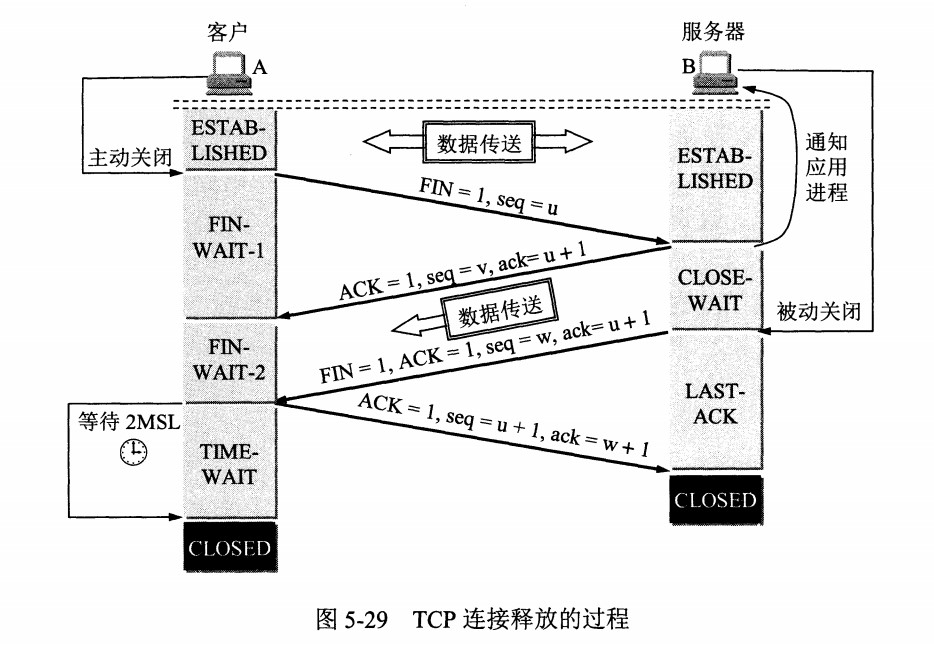
- 三次握手: ACK表示ack有效, SYN表示请求连接,FIN表示停止
- SYN = 1, ACK = 0, seq = x
- SYN = 1, ACK = 1, seq = y, ack = x + 1
- __ __ _, ACK = 1, seq = x + 1, ack = y + 1
- 四次挥手:
- ACK = 1, FIN = 1, seq = u
- ACK = 1, __ __ _, seq = v, ack = u + 1
- ACK = 1, FIN = 1, seq = w, ack = u + 1
- ACK = 1, __ __ _, seq = u + 1, ack = w + 1
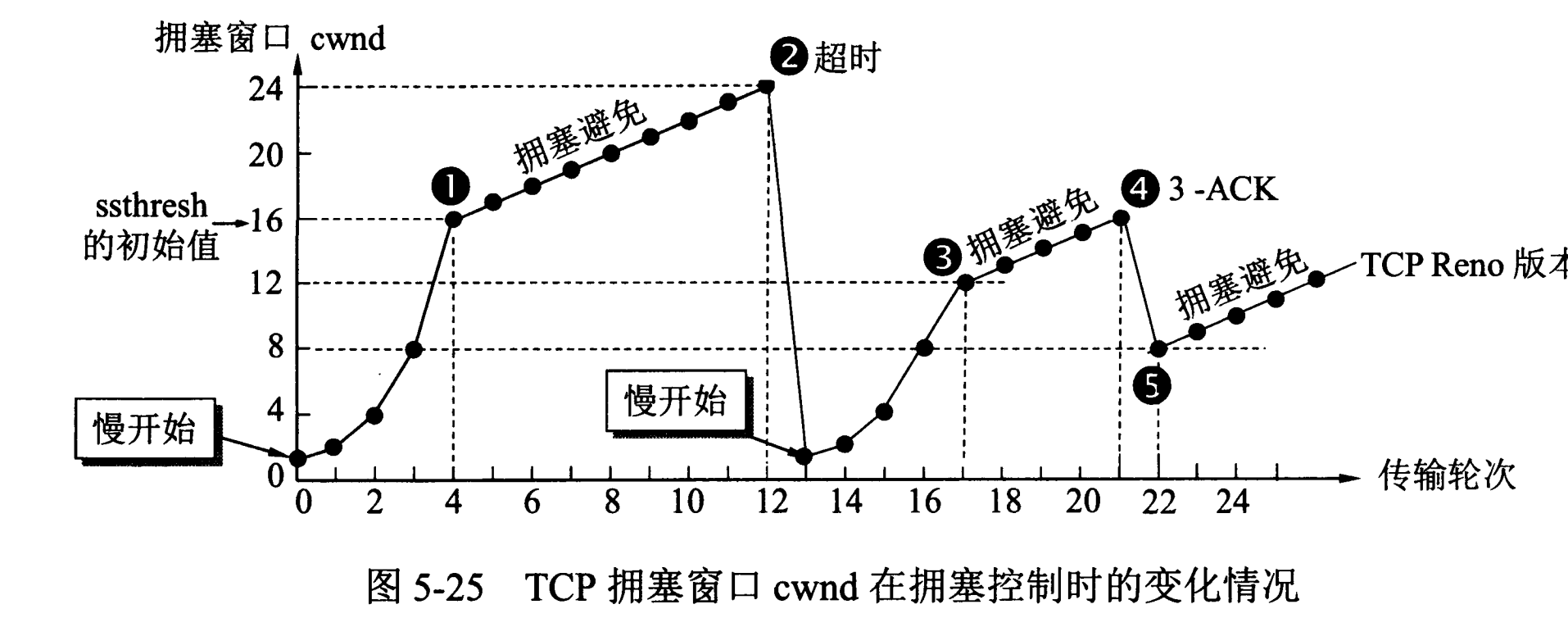
-
https / TLS
HTTPS 即 HTTP over TLS,是一种在加密信道进行 HTTP 内容传输的协议。Transport Layer Security
TLS 的完整过程需要三个算法(协议),密钥交互算法,对称加密算法,和消息认证算法 (TLS 的传输会使用 MAC(message authentication code) 进行完整性检查)。
-
SSL剥离: 通过攻击 DNS 响应,攻击者可以将自己变成中间人。https --> http
-
HSTS: 强制使用 HTTPS 进行访问,在服务器返回的响应中,加上一个特殊的头部,指示浏览器对于此网站 TTP Strict Transport Security
-
伪造证书攻击:
第一步是需要攻击 DNS 服务器。 第二步是攻击者自己的证书需要被用户信任,这一步对于用户来说是很难控制的, 需要证书颁发机构能够控制自己不滥发证书。
-
HPKP 技术是为了解决伪造证书攻击而诞生的。Public Key Pinning Extension for HTTP)在 HSTS 上更进一步, HPKP 直接在返回头中存储服务器的公钥指纹信息,一旦发现指纹和实际接受到的公钥有差异,浏览器就可以认为正在被攻击
-
断点续传 1.断点续传需要在下载过程中记录每条线程的下载进度; 2.每次下载开始之前先读取数据库,查询是否有未完成的记录,有就继续下载,没有则创建新记录插入数据库; 3.在每次向文件中写入数据之后,在数据库中更新下载进度; 4.下载完成之后删除数据库中下载记录。
分片上传: 分片上传,就是将所要上传的文件,按照一定的大小,将整个文件分隔成多个数据块(Part)来进行分片上传
-
多路io
- select 实现多路复用的方式是,将已连接的 Socket 都放到一个文件描述符集合, 然后调用 select 函数将文件描述符集合拷贝到内核里, 让内核来检查是否有网络事件产生,检查的方式很粗暴,就是通过遍历文件描述符集合的方式, 当检查到有事件产生后,将此 Socket 标记为可读或可写, 接着再把整个文件描述符集合拷贝回用户态里,然后用户态还需要再通过遍历的方法找到可读或可写的 Socket,然后再对其处理。 select 使用固定长度的 BitsMap,表示文件描述符集合,而且所支持的文件描述符的个数是有限制的, 在 Linux 系统中,由内核中的 FD_SETSIZE 限制, 默认最大值为 1024,只能监听 0~1023 的文件描述符。
-
poll
不再用 BitsMap 来存储所关注的文件描述符,取而代之用动态数组, 以链表形式来组织,突破了 select 的文件描述符个数限制,当然还会受到系统文件描述符限制。 --
-
epoll
第一点,epoll 在内核里使用红黑树来跟踪进程所有待检测的文件描述字 第二点,epoll 使用事件驱动的机制,内核里维护了一个链表来记录就绪事件, 当某个 socket 有事件发生时,通过回调函数内核会将其加入到这个就绪事件列表中
-
rpc: RPC(Remote Procedure Call),
又叫做远程过程调用。它本身并不是一个具体的协议,而是一种调用方式。
值得注意的是,虽然大部分 RPC 协议底层使用 TCP,但实际上它们不一定非得使用 TCP,改用 UDP 或者 HTTP,其实也可以做到类似的功能。
RPC 就开始退居幕后,一般用于公司内部集群里,各个微服务之间的通讯。
RPC,因为它定制化程度更高,可以采用体积更小的 Protobuf 或其他序列化协议去保存结构体数据 -
websocket 游戏场景长连接,
- 单例
+ (instancetype)sharedInstance
{
static dispatch_once_t once;
static id sharedInstance;
dispatch_once(&once, ^
{
sharedInstance = [self new];
});
return sharedInstance;
}-
OC Runtime, 垃圾回收
-
KVO & KVC: https://objccn.io/issue-7-3/
-
Apple FrameWorks
-
Framework
Framework 可以通俗的理解为封装了共享资源的具有层次结构的文件夹。 共享资源可以是 nib文件、国际化字符串文件、头文件、库文件等等。 它同时也是个 Bundle,里面的内容可以通过 Bundle 相关 API 来访问。 Framework 可以是 static framework 或 dynamic framework。 在 iOS App 打包完成后,如果 Framework 包含了模拟器指令集(x86_64 或 i386), 那么用 Xcode 发布 App 的时候,会报 unsupported architectures 的错误,所以需要我们手动或脚本去移除。 -
XCFramework
XCFramework是为了取代之前的.framework的 XCFramework 是由 Xcode 创建的一个可分发的二进制包,它包含了 framework 或 library 的一个或多个变体, 因此可以在多个平台(iOS、macOS、tvOS、watchOS) 上使用,包括模拟器。 XCFramework 可以是静态的,也可以是动态的。xcframework 的好处就是用 Xcode 发布的时候, Xcode 会自动选用正确的指令集 Frameworks,省去了手动移除动态库中的模拟器指令集的工作。 不过值得注意的是,Xcode 11 才引入 XCFramework 。
-
- +load() 方法的调用是在 main() 函数之前,并且不需要主动调用, 程序启动会把所有的文件加载,文件如果重写了 +load() 方法,主类、子类、分类都会加载调用 +load() 方法;
- 主类与分类的加载顺序是: 主类优先于分类加载,无关编译顺序;
- 分类间的加载顺序取决于编译的顺序: 先编译先加载,后编译则后加载;
- 优先顺序: (父类 > 子类 > 分类);
- 因为 +load() 是在 main() 函数之前调用,所以在这个方法里面不要作耗时操作或者阻塞的操作,会影响启动速度;
- 不要做对象的初始化操作,因为在 main() 函数之前自动调用,
- +load() 方法调用的时候使用者根本就不能确定自己要使用的对象是否已经加载进来了,所以千万不能在这里初始化对象; 可以根据业务需求,在 +load() 方法中进行 Method Swizzle 操作,交换方法。
- 父类的 + initialize() 方法会比子类先执行;
- 当子类未实现 + initialize() 方法时,会调用父类 + initialize() 方法, 子类实现 + initialize() 方法时,会覆盖父类 + initialize() 方法;
- 当有多个 Category 都实现了 + initialize() 方法,会覆盖类中的方法, 只执行一个(会执行Compile Sources 列表中最后一个 Category 的 + initialize() 方法)。
- +load() 和 +initialize() 都会在实例化对象之前调用,前者是在 main() 函数之前,后者是在 main() 函数之后;
- +load() 和 +initialize() 方法都不会显式的调用父类的方法而是自动调用, 即使子类没有 +initialize() 方法也会调用父类的方法,+load() 方法不会调用父类;
- +load() 和 +initialize() 方法内部使用了锁,因此他们是线程安全的,实现时要尽可能简单,避免线程阻塞,不要再次使用锁;
- +load() 方法常用来 method swizzle,+initialize() 常常用于初始化全局变量和静态变量。
@implementation SubPerson
-(void)test{
NSLog(@"%@",[self class]); // SubPerson
NSLog(@"%@",[self superclass]); // Person
NSLog(@"%@",[super class]); // SubPerson
NSLog(@"%@",[super superclass]); //Person
}
bundle exec jekyll build -d docs