HDFS应用实战——基于Python爬虫和HDFS的招聘信息采集与存储系统
在本次实验主要完成了一个基于Python爬虫和HDFS的招聘信息采集与存储系统,通过自学爬虫的相关知识,使用Python爬取全国最大的互联网招聘网站拉勾网的相关招聘信息,并将爬取的内容用csv格式以日期为单位保存在本地。然后,基于HDFS使用JavaWeb MVC、BootStrap和MySQL数据库开发了一个功能较为完善的招聘信息存储系统,通过该系统用户可以将爬虫采集得到的数据与HDFS直接进行交互和维护。
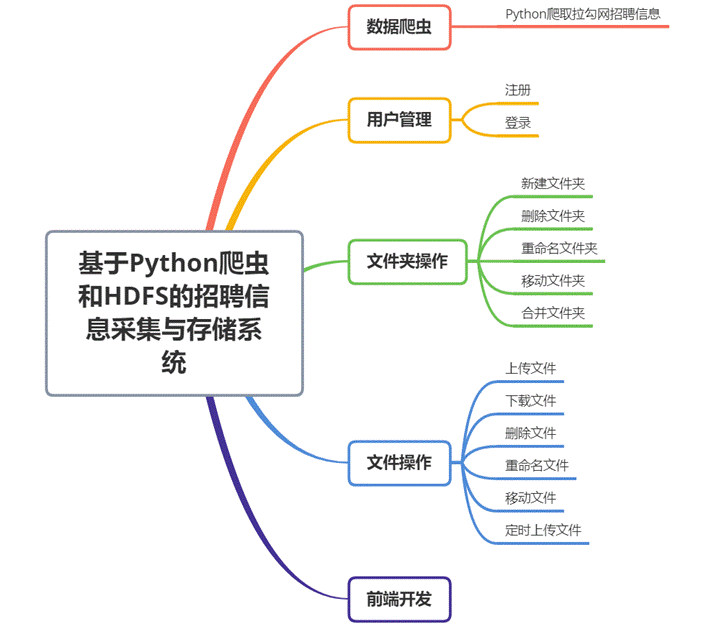
该系统的主要功能包括用户注册、用户登录、新建文件夹、删除文件夹、重命名文件夹、移动文件夹、合并文件夹中的文件、上传文件、下载文件、删除文件、重命名文件、移动文件、定时上传文件等,其中定时上传文件是每隔24小时将前一天爬取到的数据定时上传至HDFS的指定目录下。
通过学习Hadoop、HDFS、MapReduce和Yarn的基本架构和原理,能够熟练地利用Java中提供的相关API对Hadoop和HDFS进行操控,同时进一步掌握对Linux操作系统的使用,为今后的学习和工作打下坚实的基础。
网络爬虫,是一种按照一定规则,自动抓取互联网信息的程序或者脚本。由于互联数据的多样性和资源的有限性,根据用户需求定向抓取网页并分析已成为如今主流的爬取策略。爬虫的本质是模拟浏览器打开网页,获取网页中我们想要的那部分数据。
网络爬虫分为通用网络爬虫和聚焦网络爬虫。通用网络爬虫常应用于搜索引擎中,爬取的目标是在整个互联网中,以下是搜索引擎的原理图。
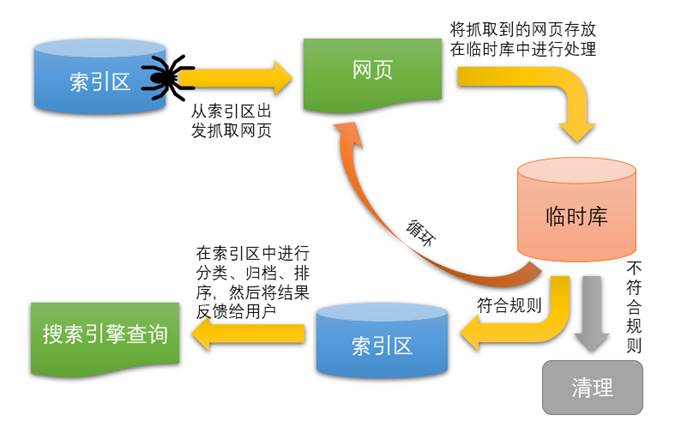
聚焦网络爬虫是指按照预先定义好的主题有选择地进行网页爬取的一种爬虫,主要应用再对特定信息的抓取中,本次实验采用的就是聚焦网络爬虫。具体流程为

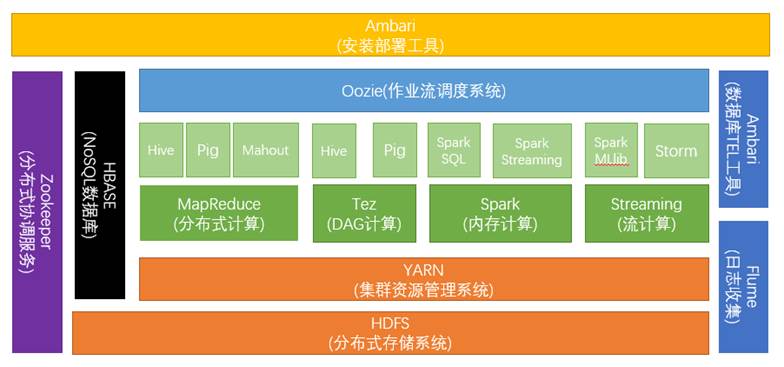
Apache Hadoop是一款支持数据密集型分布式应用程序并以Apache 2.0许可协议发布的开源软件框架。它支持在商用硬件构建的大型集群上运行的应用程序。Hadoop是根据谷歌公司发表的MapReduce和Google文件系统的论文自行实现而成。所有的Hadoop模块都有一个基本假设,即硬件故障是常见情况,应该由框架自动处理。Hadoop框架透明地为应用提供可靠性和数据移动。它实现了名为MapReduce的编程范型:应用程序被分割成许多小部分,而每个部分都能在集群中的任意节点上运行或重新运行。此外,Hadoop还提供了分布式文件系统,用以存储所有计算节点的数据,这为整个集群带来了非常高的带宽。下图为Hadoop的生态系统。
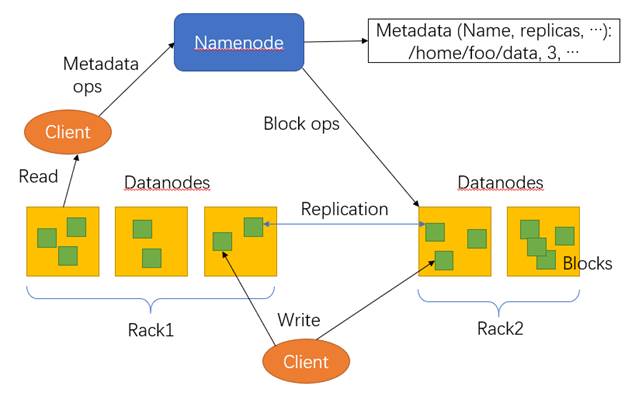
HDFS,作为Google File System(GFS)的实现,是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集的应用处理带来了很多便利。适用、不适用的场景HDFS特点:高容错性、可构建在廉价机器上适合批处理适合大数据处理流式文件访问HDFS局限:不支持低延迟访问不适合小文件存储不支持并发写入不支持修改HDFS架构HDFS由四部分组成,HDFS Client、NameNode、DataNode和Secondary NameNode。HDFS是一个主/从(Mater/Slave)体系结构,HDFS集群拥有一个NameNode和一些DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。下图为HDFS的框架示意图。
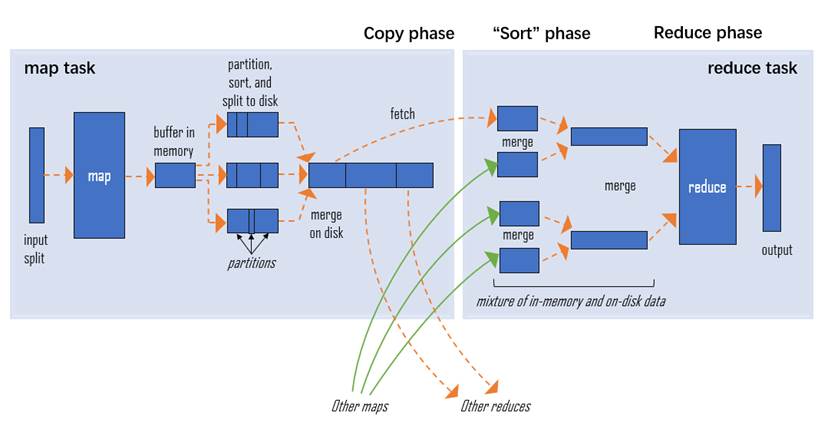
MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于Hadoop 的数据分析应用”的核心框架。MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的 分布式运算程序,并发运行在一个 Hadoop集群上。MapReduce的有优点包括:易于编程、良好的扩展性、高容错性和适合PB 级以上海量数据的离线处理。缺点包括不擅长实时计算、不擅长流式计算、不擅长DAG(有向无环图)计算。
MapReduce可以拆分为map和reduce两部分,可以简单理解为分久必合。Map:拆分数据先在input split过滤一些没用的东西,剩下的传到Map中,在Map中数据被拆分为一块块,在partition sort 将数据进行排序,然后将所有单元处理好的再简单的合并成一个整体,再将这个整体发送到Reduce。Reduce:合并数据Reduce来计算合并数据,将Map中传过来的相同类型的数据进行一个完整的合并如下图merge,最后输出完整的数据。
YARN是Hadoop 2.0中的资源管理系统,它的基本设计思想是将MRv1中的JobTracker拆分成了两个独立的服务:一个全局的资源管理器ResourceManager和每个应用程序特有的ApplicationMaster。其中ResourceManager负责整个系统的资源管理和分配,而ApplicationMaster负责单个应用程序的管理。YARN总体上仍然是Master/Slave结构,在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave,ResourceManager负责对各个NodeManager上的资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的ApplicationMaster,它负责向ResourceManager申请资源,并要求NodeManger启动可以占用一定资源的任务。由于不同的ApplicationMaster被分布到不同的节点上,因此它们之间不会相互影响,以下是YARN的基础架构示意图。
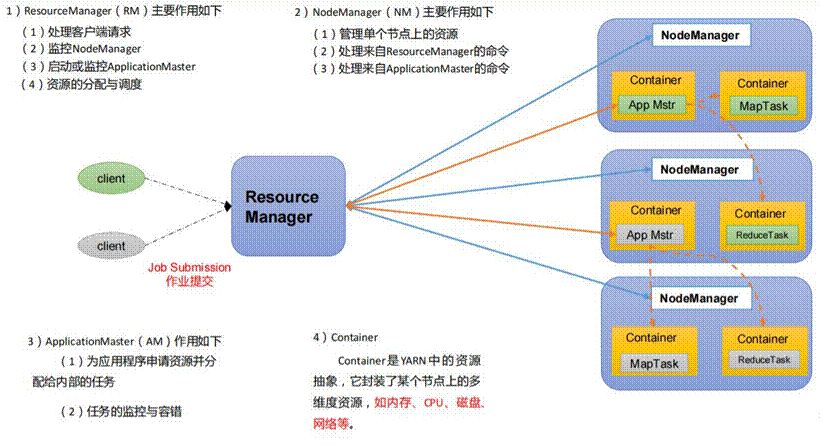
MVC 模式(Model–View–Controller)是软件工程中的一种软件架构模式,它把软件系统分为三个基本部分:模型(Model)、视图(View)和控制器(Controller)。MVC 模式的目的是实现一种动态的程序设计,简化后续对程序的修改和扩展,并且使程序某一部分的重复利用成为可能。除此之外,MVC 模式通过对复杂度的简化,使程序的结构更加直观。软件系统在分离了自身的基本部分的同时,也赋予了各个基本部分应有的功能,以下是MVC模式示意图。
Bootstrap是美国Twitter公司的设计师Mark Otto和Jacob Thornton合作基于HTML、CSS、JavaScript 开发的简洁、直观、强悍的前端开发框架,使得 Web 开发更加快捷。Bootstrap提供了优雅的HTML和CSS规范,它即是由动态CSS语言Less写成。Bootstrap一经推出后颇受欢迎,一直是GitHub上的热门开源项目,包括NASA的MSNBC(微软全国广播公司)的Breaking News都使用了该项目。国内一些移动开发者较为熟悉的框架,如WeX5前端开源框架等,也是基于Bootstrap源码进行性能优化而来。
操作系统:Windows 10
Python编译器:Jupyter Notebook 6.4.0
Python版本:3.9.6
相关模块:pandas 1.3.0、requests 2.25.1
Web开发工具:IntelliJ IDEA 2021.2 (Ultimate Edition)
数据库管理工具:Navicat Premium 15.0.12
MySQL版本:8.0.23
JDK环境:JDK 1.8.0_271
Web服务器:Tomcat 9.0.38
浏览器:Google Chrome 浏览器
为了方便用户与本系统进行交互,在本次实验中还完成了前端页面的开发,用户可以通过该系统完成的操作包括用户注册、用户登录、新建文件夹、删除文件夹、重命名文件夹、移动文件夹、合并文件夹中的文件、上传文件、下载文件、删除文件、重命名文件、移动文件、定时上传文件等,具体功能如以下思维导图所示。
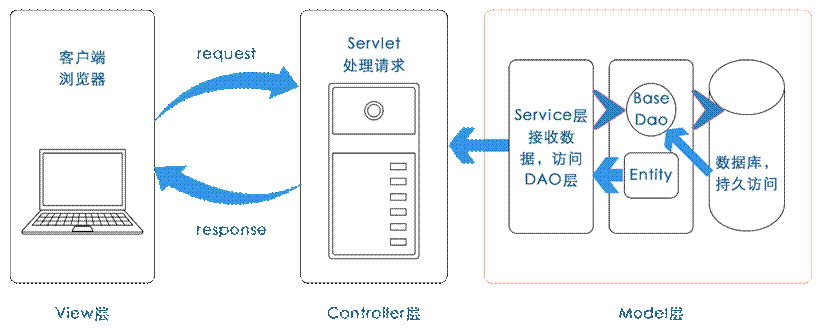
在本系统中,使用的架构设计思想是传统的三层架构,分别为表现层、业务逻辑层和数据访问层,符合“高内聚、低耦合”的思想,各层之间通过接口进行相互访问,不同的对象类对应于数据库的不同表。表现层:该层中主要使用JSP页面与用户进行交互,使用Layui框架进行开发,包括所有的登录注册页面以及HDFS操作页面,向用户展现信息并且获取用户的操作,从而将数据传输给业务逻辑层。业务逻辑层:该层主要负责对于具体问题的逻辑判断和操作,表现层 Controller封装为产品对象后调用Service,在Service层连接数据访问层并调用数据访问层的方法,使用恰当的SQL语句和HDFS的API操作完成对数据库和HDFS的操作。并且该层也接收来自数据访问层的反馈数据。数据访问层:该层主要完成对数据具体的操作,包括对数据库和HDFS的操作。以下是三层架构示意图。
本机的Hadoop运行模式采用的是完全分布式运行模式,一共有3台客户机,名称分别为hadoop102、hadoop103、hadoop104。其中,NameNode部署在hadoop02上,SecondaryNameNode部署在hadoop04上,ResourceManager部署在hadoop03上。总体部署情况如下表表 1所示。
表1 集群部署情况| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HDFS | Namemode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
虚拟机环境:VMware Workstation 16 Pro
Linux系统:CentOS 7.5
远程连接工具:Xshell 7、Xftp 7
JDK环境:JDK 1.8.0_212
Hadoop版本: 3.1.3
本实验的主要步骤如下:
(1) 使用Python爬取拉勾网数据
(2) 搭建完全分布式模式环境
(3) 完成本机数据库设计
(4) 使用Java语言连接数据库
(5) 使用Java语言连接Hadoop
(6) 使用Java语言实现用户管理相关功能(注册、登录)
(7) 使用Java语言实现文件上传功能
(8) 使用Java语言实现文件下载功能
(9) 使用Java语言实现新建文件夹功能
(10) 使用Java语言实现文件和文件夹的删除功能
(11) 使用Java语言实现文件和文件夹的重命名功能
(12) 使用Java语言实现文件和文件夹的移动功能
(13) 使用Java语言实现合并文件夹中的文件的功能
(14) 完善、美化前端页面
遵循上文所述的Java EE三层架构思想,本系统的项目结构如下所示
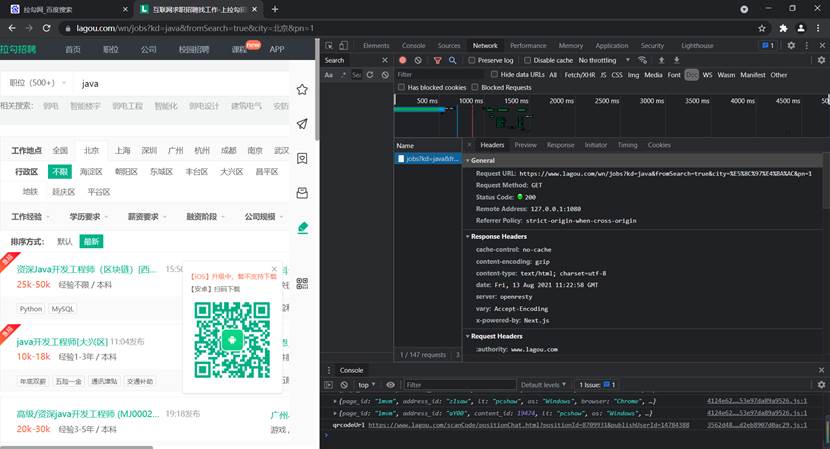
首先,为了进行获取网页相应,不被认为是恶意操作,注册拉勾网账户并进行登录。然后使用Google Chrome 浏览器的检查功能,查看Network基本信息。在网页输入框中输入想要爬取的岗位相关信息,进行搜索,观察右侧窗口的变化,发现出现一条请求,点击该请求,查看Header相关信息,如图11所示。
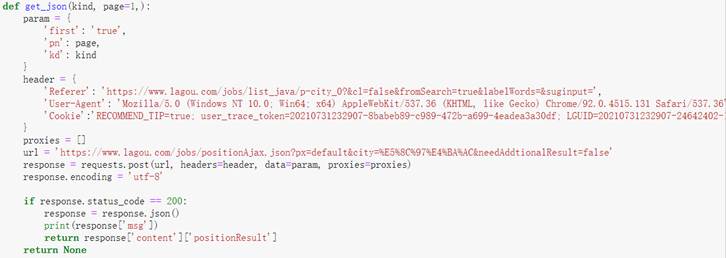
从Header中找到请求的Referer、User-Agent、Cookie等相关信息,设置代理IP,设置代理的目的是为了应对反爬虫策略,然后编写get_json函数,使用requests的post函数,初入url、headers、data、proxies等参数,然后获取response响应对象,将其转化为json格式,最后返回response[‘content’][‘positionResult’]信息。相关代码如图12所示。
然后编写主函数逐页遍历get_json得到的招聘信息,从json数据解析companyFullName、companyShortName等相关参数并进行保存,在进行遍历网页的时候为了防止频繁访问而被认为是恶意访问从而被拉黑,需要在每次爬取之后使用time的sleep函数暂定一段时间。整个任务完成后将数据转化为DataFrame的格式,最后以csv格式文件保存在本地。主函数的具体代码如图13所示。
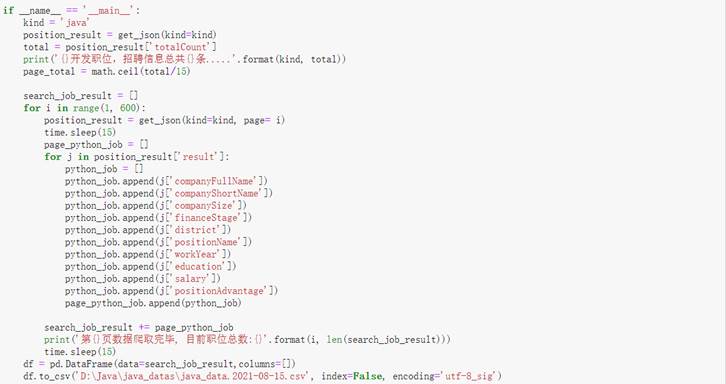
因为实验中搭建的是一个完全分布式的环境,因此首先在虚拟机中搭建一个GHOME版的模板主机,该主机的Linux版本 Centos 7.5,将该虚拟机命名为hadoop100,该虚拟机相关的配置如图14所示。
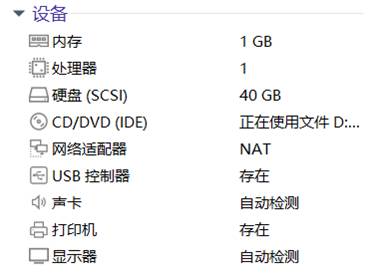
接下来关闭防火墙,修改虚拟机的静态IP和本地主机相关网络设置。以及主机名,实现虚拟机可以连接网络。修改etc/sysconfig/network-scripts/ifcfg-ens33中的内容如图15所示
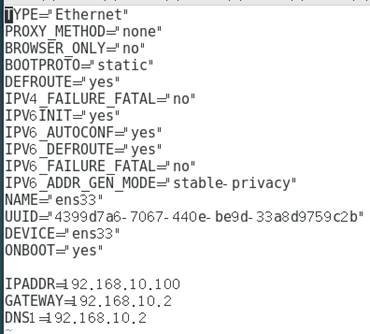
接下来配置 当前用户具有 root 权限,方便后期加 sudo 执行 root 权限的命令,然后卸载本机自带的JDK。在opt目录下添加module和software 两个文件夹,用于后续环境配置。
因为要配置三台虚拟机,为了保证三台虚拟机的相关配置一致且方便操作,使用VMware的虚拟机克隆功能,克隆出三台虚拟机,并且分别命名为hadoop102、hadoop103和hadoop104,将这三台虚拟机按照hadoop100的方法分别配置静态IP、主机名称。
之后为了可以使用,修改 windows 的主机映射文件(hosts 文件),具体方法为进入 C:\Windows\System32\drivers\etc 路径打开hosts文件并添加IP地址与主机名的映射内容。
在确保删除虚拟机自带的JDK后,使用XShell工具拷贝JDK和Hadoop的安装包到opt的software目录下,分别进行解压到module目录下,新建/etc/profile.d/my_env.sh文件并配置相关环境变量,如图16所示。
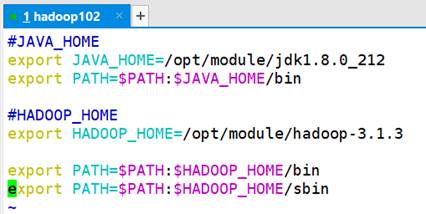
然后使用source /etc/profile命令使得修改生效,经过查看是否安装成功,最后重启hadoop102虚拟机从而完成JDK和Hadoop的完整安装。
首先,为了配置hadoop103和hadoop104的JDK和Hadoop,使用scp将hadoop102的/opt/module/jdk1.8.0_212目录和/opt/module/hadoop-3.1.3目录拷贝到hadoop103和hadoop104上。接下来为了方便每次集群的启动,在本机中为这三个项目配置了集群的群起。在/home/gift_oys/bin目录下创建一个集群分发脚本,命名为xsync。代码如下图17所示:
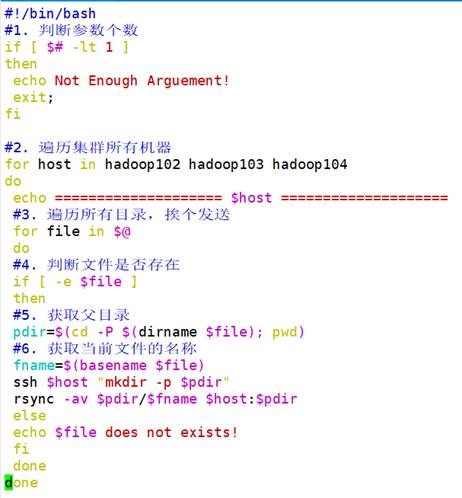
然后使用chmod +x xsync使得该文件具有执行权限,使用sudo ./bin/xsync /etc/profile.d/my_env.sh将环境变量分发到hadoop103和hadoop104,然后分别在两台虚拟机上使用source /etc/profile命令,完成最终的JDK与Hadoop安装。
为了保证一台Linux主机的安全,往往需要为这台主机设置账号密码,但是有时需要在很多太不同主机上完成操作时这就需要浪费大量的时间,因此需要设置SSH免密码登录。
首先进入hadoop102的/home/atguigu/.ssh,使用ssh-keygen -t rsa命令,连敲三个回车,就会生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥),然后使用ssh-copy-id将公钥拷贝到要免密登录的目标机器上,命令如下:
[gift_oys@hadoop102 .ssh]$ ssh-copy-id hadoop102
[gift_oys @hadoop102 .ssh]$ ssh-copy-id hadoop103
[gift_oys @hadoop102 .ssh]$ ssh-copy-id hadoop104
然后hadoop102上采用root账号,配置一下无密登录到hadoop102、hadoop103、hadoop104,在hadoop103上采用ch账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
表2是对.ssh文件夹下(~/.ssh)的文件功能解释。
表2 .ssh文件夹下文件解释| authorized_keys | 存放授权过得无密登录服务器公钥 |
|---|---|
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
对于集群的整体配置规划情况见表1,这里不再赘述。在进行配置Hadoop时一共有两类配置文件,一类是默认配置文件,另一类是自定义配置文件,默认配置文件所在的位置如表3所示,在本次实验中主要配置自定的配置文件。
表3 默认配置文件相关信息| 要获取的默认文件 | 文件存放在 Hadoop 的 jar 包中的位置 |
|---|---|
| [core-default.xml] | hadoop-common-3.1.3.jar/core-default.xml |
| [hdfs-default.xml] | hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| [yarn-default.xml] | hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| [mapred-default.xml] | hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
接下来分别对四个自定义配置文core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml进行配置。
(1)core-site.xml
路径:/opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
修改后的配置文件内容:
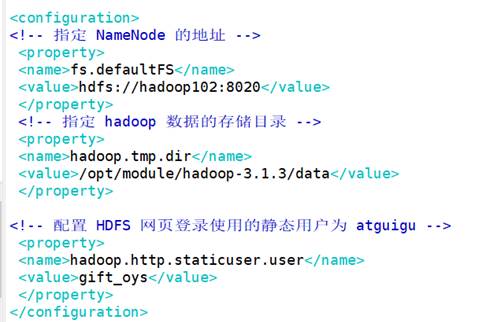
(2)hdfs-site.xml
路径:/opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
修改后的配置文件内容:

(3)yarn-site.xml
路径:/opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
修改后的配置文件内容:

(4)mapred -site.xml
路径:/opt/module/hadoop-3.1.3/etc/hadoop/ mapred -site.xml
修改后的配置文件内容:

最后使用xsync /opt/module/hadoop-3.1.3/etc/hadoop命令将配置好的Hadoop文件分发出去。
首先,为了能够实现群起,需要在/opt/module/hadoop-3.1.3/etc/hadoop/workers中同步所有节点,即在workers文件中添加每个主机的名称,如图22所示。
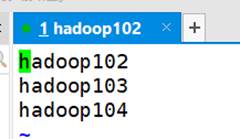
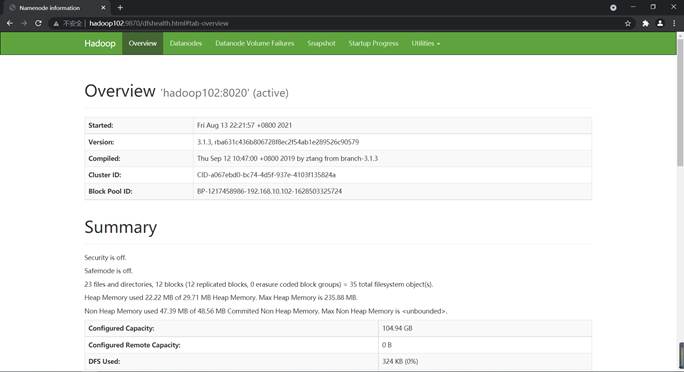
然后使用xsync /opt/module/hadoop-3.1.3/etc命令进行分发同步出去。接下来就可以实现群起了。由于集群是第一次启动,需要在hadoop102节点使用hdfs namenode -format命令格式化NameNode,然后再在hadoop102和hadoop103上使用以下命令启动集群。
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
通过Web查看启动结果如图23和图24所示。
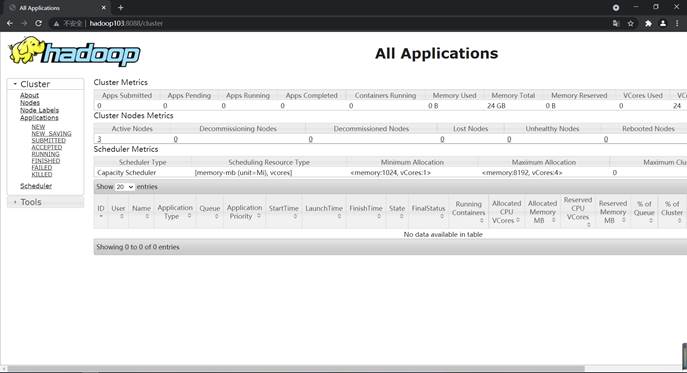
在本次实验中需要完成用户的注册、登录功能,用户各自的文件信息保存在HDFS上,而用户的个人信息是通过MySQL数据库保存在本地的,因此在本地进行了数据库设计,数据库中只有一个数据库表user,表的具体设计如图25所示。
为了实现通过Java连接Hadoop,需要在webapp/WEB-INF下创建bin目录,然后导入相关jar包,然后将jar包添加到项目依赖中,与连接MySQL有关的jar包如图26所示。

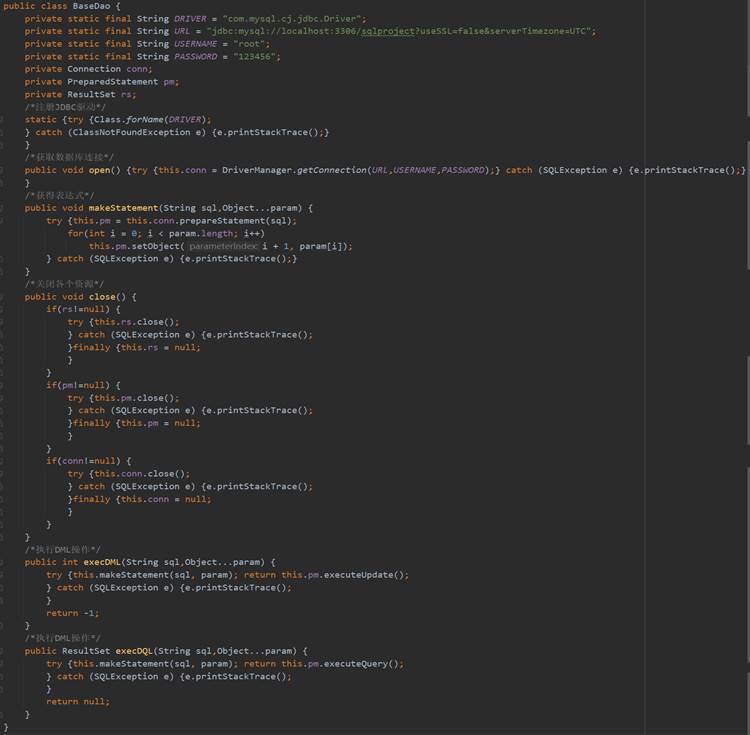
由于在实现用户注册、登录时需要连接数据库,因此在数据访问层编写了BaseDao的类,当用户在进行注册或者登录需要访问数据库时可以直接调用BaseDao,相关代码如图27所示:
为了实现通过Java连接Hadoop,需要在webapp/WEB-INF的bin目录下导入相关jar包,然后将jar包添加到项目依赖中,与连接Hadoop有关的jar包如图28所示。
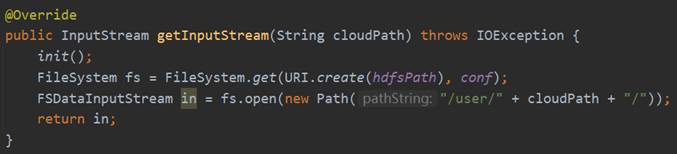
当用户希望对HDFS进行操作的时候需要通过HdfsDao来连接Hadoop,因此连接Hadoop的相关操作存放在HdfsDao。
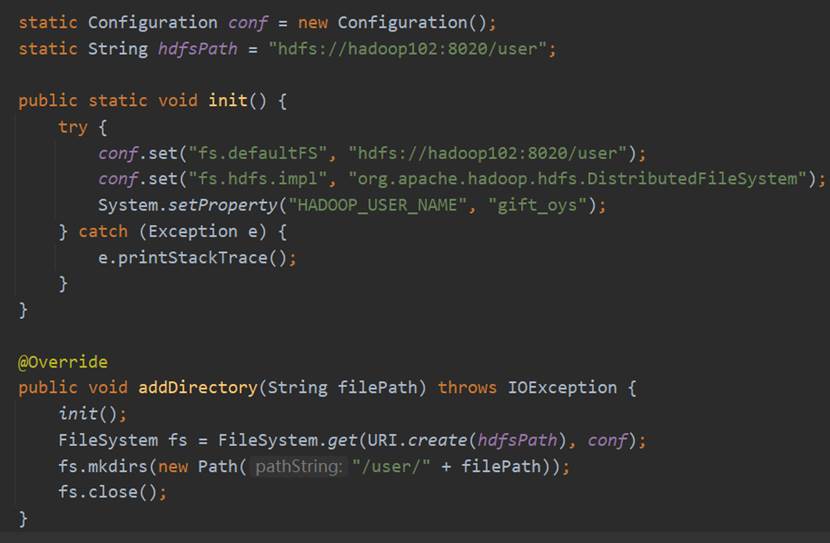
在该类中,首先声明Configuration和HDFS路径的静态对象,及init()的静态方法,在该静态方法中首先为Configuration设置fs.defaultFS参数和fs.hdfs.impl参数赋值,其中,为了区别不同用户对于HDFS的操作,因此实现已经在HDFS主目录下新建了user文件夹,用户存放不同用户的数据。然后为了获取对于HDFS的访问权限,通过System.setProperty设置了HADOOP_USER_NAME为了gift_oys(因为我的hadoop的名称都设置为了gift_oys)。
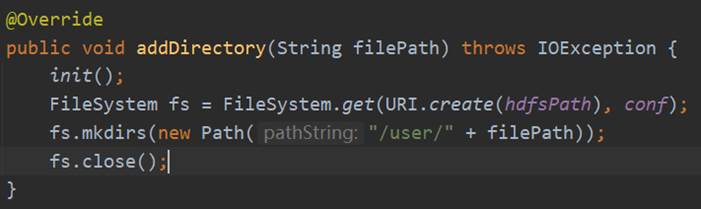
下图以addDirectory方法为例,介绍连接Hadoop的过程:首先执行init()方法,然后通过FileSystem的get方法传入uri和configuration获取FileSystem对象即可。在执行HDFS操作完成之后使用fs.close就可以关闭FileSystem。
首先,用户在注册登录界面login.jsp输入要注册的用户名和密码,通过form表单的形式将username、password1、password2传给Controller层的RegisterServlet,完成表现层向控制器层的数据请求。图30注册时提交的form表单。
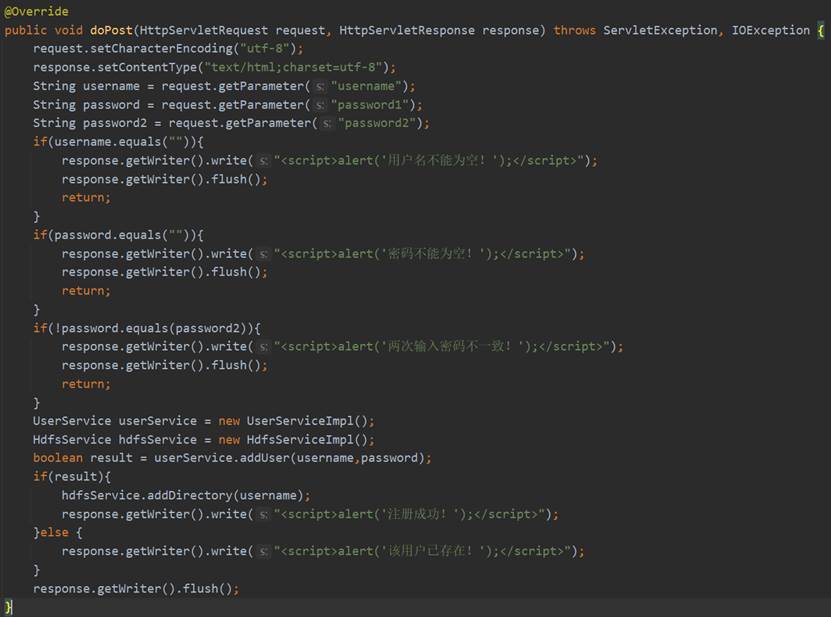
在RegisterServlet的doPost方法中首先设置请求的编码格式和相应的网页格式,然后通过request.getParameter获取前端发来的username、password1和password2,然后判断用户名和密码是否为空以及两次输入的密码是否一致,如果为空或者不一致的话直接向前端返回响应的提示信息。如果不为空且一致的话,就调用Service层的UserService和HdfsService,将用户信息用userService的addUser将用户信息存入数据库,用HDFSService的addDirectory在HDFS中为该用户添加属于他的文件夹。RegisterServlet的相关代码如图31所示。
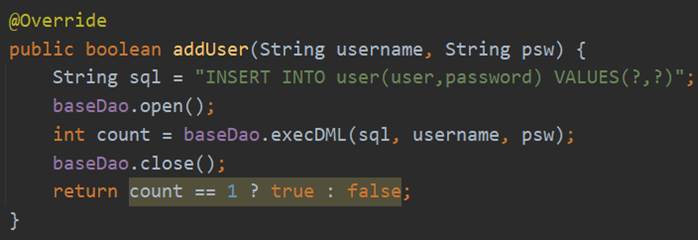
userService接口的addUser的具体实现是调用DAO层UserDao的addUser方法,而addUser具体的实现过程是首先创建数据库连接的基础类BaseDao的实体,然后调用execDML方法传入SQL语句,获取数据库变化的条数count,根据count判断是否插入成功,具体实现过程如图32所示。
HdfsService接口的addDirectory的具体实现是调用DAO层HdfsDao的addDirectory方法,而addDirectory具体的实现过程是连接Hadoop,获取FileSystem实体,然后调用它的mkdirs方法,在user目录下创建以该用户名为文件夹名的目录,最后关闭FilSystem,具体实现过程如图33所示。
下面对用户注册功能进行测试:
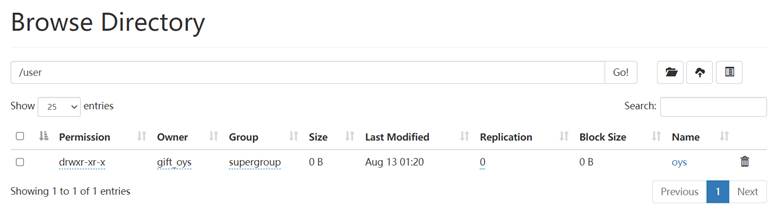
以下是未注册时的数据库表和HDFS的user下的目录:

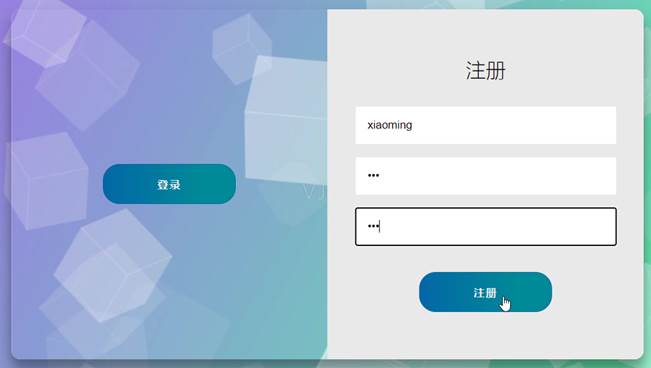
在注册页面输入注册的相关信息,并点击“注册”:
重新查看数据库表和HDFS的user目录:
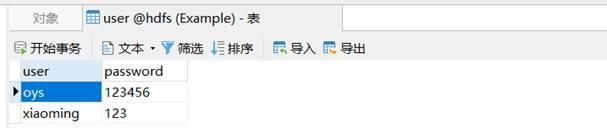
可以看到已经注册成功。
首先,用户在注册登录界面login.jsp输入要用户名和密码,通过form表单的形式将username、password传给Controller层的LoginServlet,完成表现层向控制器层的数据请求。图39为用户登录时提交的form表单。
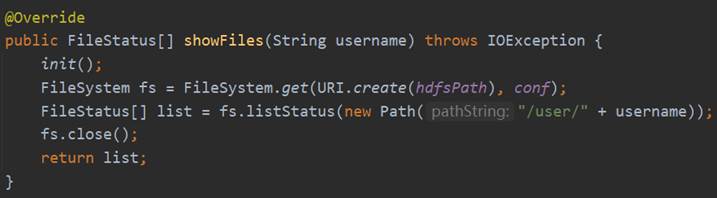
在LoginServlet的doPost方法中首先设置请求的编码格式和相应的网页格式,然后通过request.getParameter获取前端发来的username、password,调用Service层的UserService和HdfsService,使用userService的findUser从数据库中查找该用户名的信息,如果返回null的话就说明不存在该用户,向前端返回相关信息,如果返回的User实体不为null的话将该实体的password与前端传来的password进行比对,密码正确的话则在Session中设置username属性,并通过hdfs的showFiles方法获取该用户的文件信息,然后请求转发值index.jsp页面。LoginServlet的相关代码如图40所示。
userService接口的findUser的具体实现是调用DAO层UserDao的findUser方法,而findUser具体的实现过程是首先创建数据库连接的基础类BaseDao的实体,然后调用execDQL方法传入SQL语句,在ResultSet中获取查到的用户信息,具体实现过程如图41所示。
HdfsService接口的showFiles的具体实现是调用DAO层HdfsDao的showFiles方法,而showFiles具体的实现过程是连接Hadoop,获取FileSystem实体,然后调用它的listStatus方法,获取该用户名目录下的FileStatus数组并进行返回,具体实现过程如图42所示。
下面对用户登录功能进行测试:
在登录页面输入用户名和密码,点击“登录”:
然后就跳转到了主页面,页面中展示了该用户的所有文件信息:
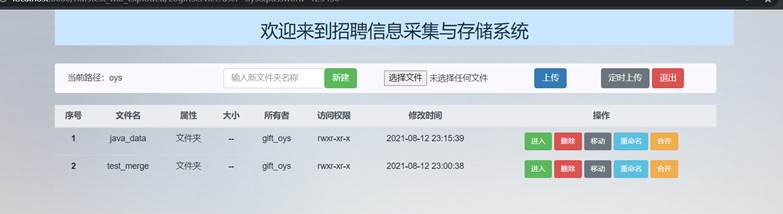
可以看到已经登录成功。
首先,用户在主界面index.jsp选择本地的文件,通过点击“上传”以form表单的形式将upFile和thisPath传给Controller层的UploadServlet,完成表现层向控制器层的数据请求。图45为上传时提交的form表单。

在UploadServlet的doPost方法中首先设置请求的编码格式和相应的网页格式,然后通过request.getParameter获取前端发来的upFile和thisPath,使用Part的getHeader方法获取文件信息和输入流,然后调用Service层HdfsService的upload方法,传入文件Part和输入流,完成上传操作。然后如果当前thisPath与Session中的username相同的话就通过HdfsService的showFiles获取文件文件列表之后重定向到index.jsp,否则跳转至上一个页面。UploadServlet的相关代码如图46所示。
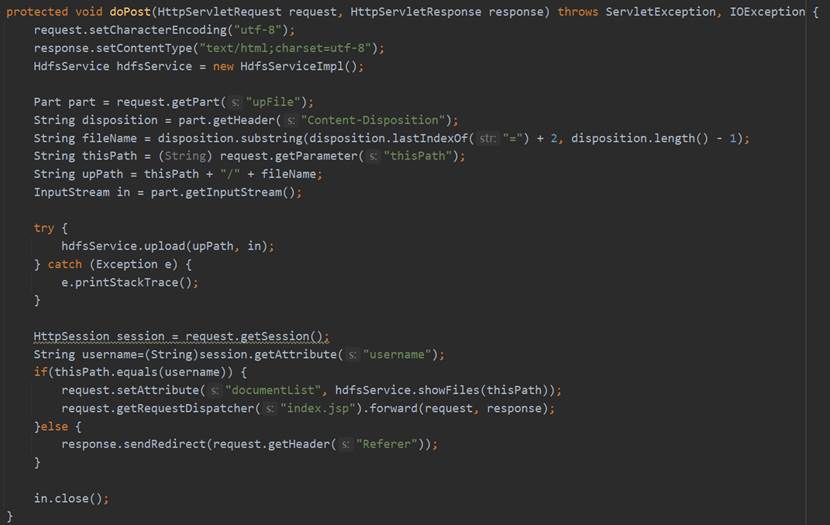
HdfsService接口的upload的具体实现是调用DAO层HdfsDao的upload方法,而upload具体的实现过程是连接Hadoop,获取FileSystem实体,然后使用fs的create方法得到FSDataOutputStream的实体,使用org.apache.hadoop.io.IOUtils的copyBytes函数来将本地的文件上传至HDFS,最后关闭FileSystem。具体实现过程如图47所示。
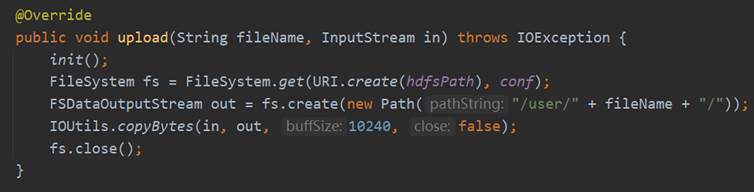
下面对上传文件功能进行测试:
上传文件前主界面文件列表如下所示:
浏览本地文件进行上传:
上传后可以发现主界面文件列表和HDFS的文件列表中出现了刚刚上传的文件:
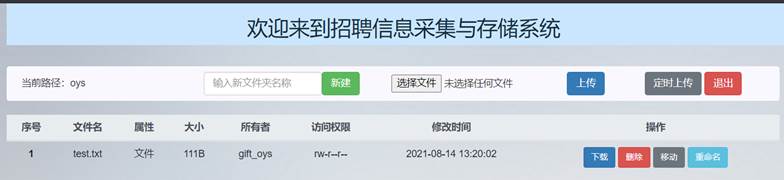
因此成功完成了文件上传功能。
首先,用户在主界面index.jsp的每条文件文件夹信息的操作列中添加“下载”按钮,当点击该文件条目的“下载”按钮时会将文件目录信息和文件名fileName传给Controller层的DownloadServlet,完成表现层向控制器层的数据请求。图52为“下载”按钮的相关前端代码。

在DownloadServlet的doPost方法中首先设置请求的编码格式和相应的网页格式,然后通过request.getParameter获取前端发来的fileName和result,调用Service层HdfsService的getInputStream方法通过文件路径获得输入流对象,然后使用read方法按字节写入文件信息,并使用ServletOutputStream对象的write方法读出数据,关闭ServletOutputStream对象之后完成下载文件的操作。之后再使用和前面功能相同的操作重定向到index.jsp或跳转至上一个页面。DownloadServlet的相关代码如图53所示。
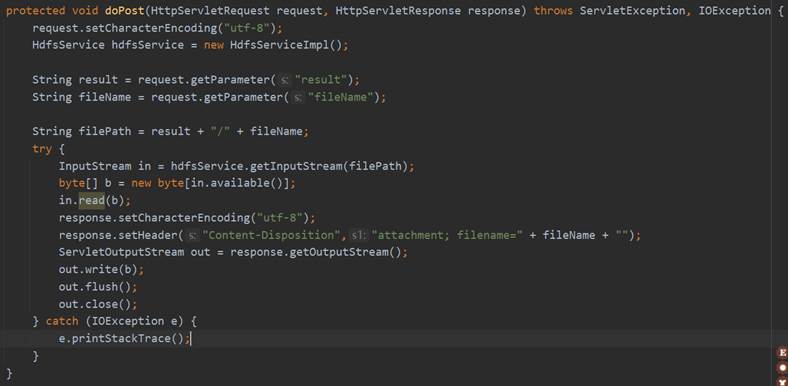
HdfsService接口的getInputStream的具体实现是调用DAO层HdfsDao的getInputStream方法,而getInputStream具体的实现过程是连接Hadoop,获取FileSystem实体,然后使用fs的open方法得到FSDataInputStream的对象,将其进行返回。具体实现过程如图54所示。
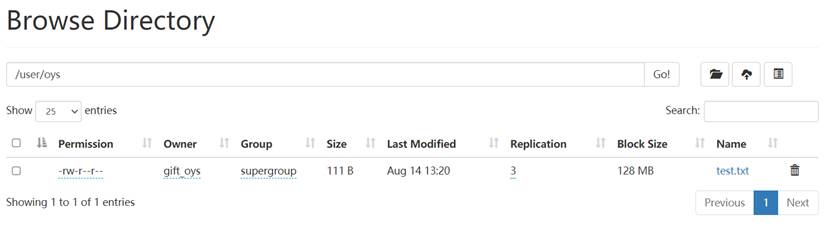
下面对文件下载功能进行测试:
文件下载前桌面上test2文件夹为空:
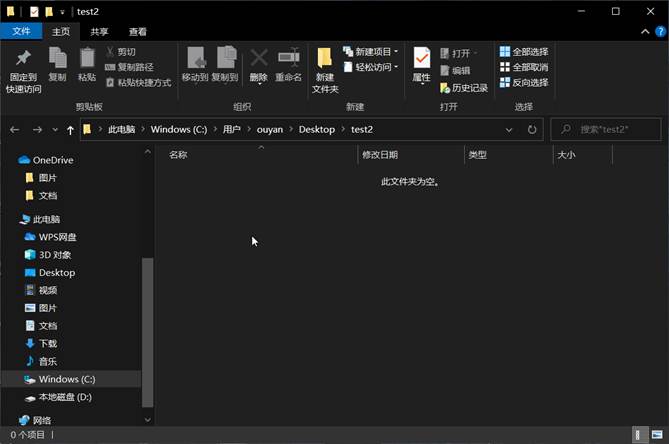
点击test.txt的“下载”按钮,将文件下载至桌面test2文件中:
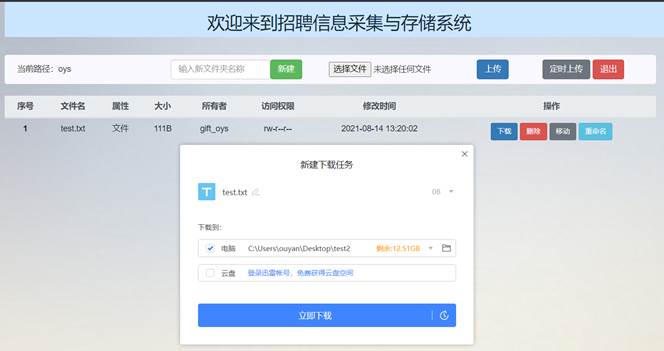
桌面test2文件中出现了test.txt文件:
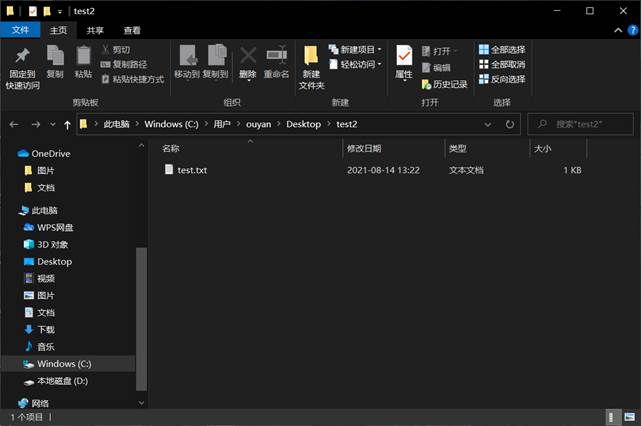
因此成功完成了文件下载功能。
首先,用户在主界面index.jsp输入要新建的文件夹名称,通过form表单的形式将dirName和thisPath传给Controller层的AddDirectoryServlet,完成表现层向控制器层的数据请求。图58为新建文件夹时提交的form表单。

在AddDirectoryServlet的doPost方法中首先设置请求的编码格式和相应的网页格式,然后通过request.getParameter获取前端发来的dirName和thisPath,调用Service层HdfsService的addDirectory方法,传入要新建的文件夹路径。之后再使用和前面功能相同的操作重定向到index.jsp或跳转至上一个页面。AddDirectoryServlet的相关代码如图59所示。
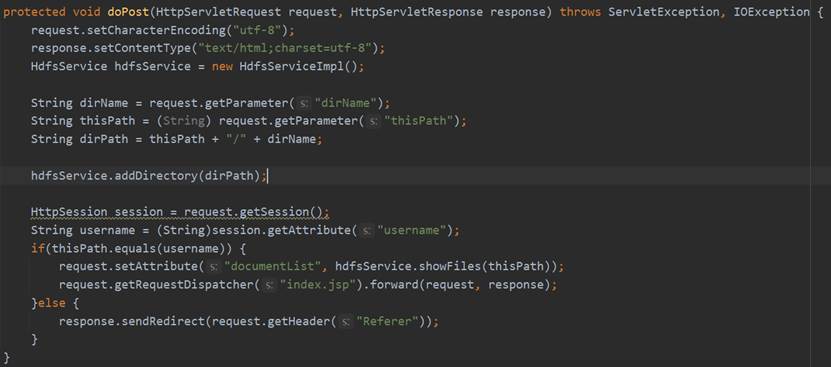
HdfsService的addDirectory方法与用户注册时的addDirectory操作完全一致,这里不再赘述。
下面对新建文件夹功能进行测试:
在新建文件夹输入框中输入要新建的文件夹名称newDir,点击“新建”:
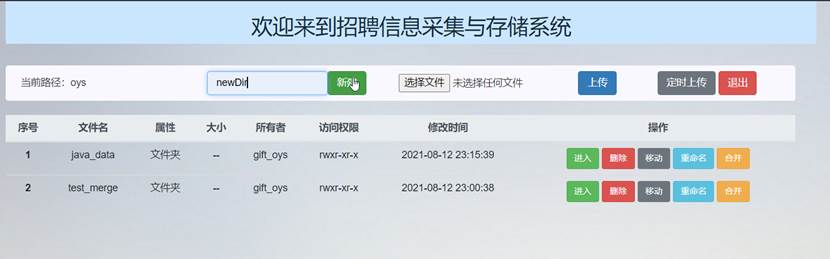
可以看到文件列表中出现了新添加的文件夹newDir:
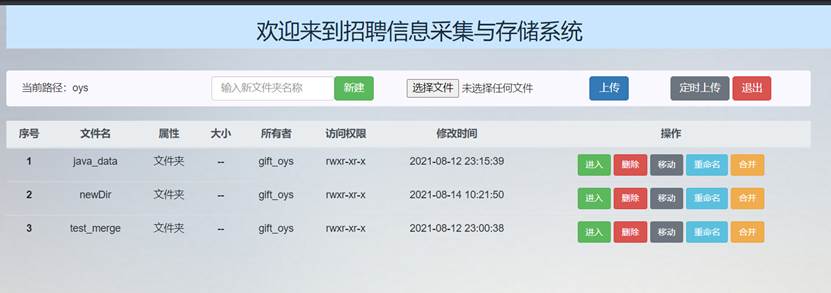
在HDFS的Web页面中该目录下也出现了新建的newDir文件夹:
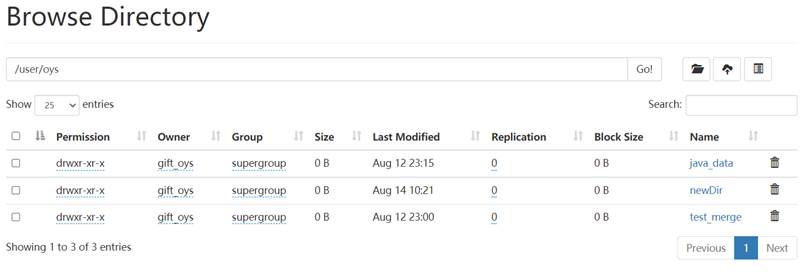
因此成功完成了新建文件夹功能。
首先,用户在主界面index.jsp的每条文件(文件夹)信息的操作列中添加“删除”按钮,当点击该文件条目的“删除”按钮时会将thisPath、该文件(文件夹)的名称fileName传给Controller层的DeleteServlet,完成表现层向控制器层的数据请求。图63为“删除”按钮的相关前端代码。

在DeleteServlet的doGet方法中首先设置请求的编码格式和相应的网页格式,然后通过request.getParameter获取前端发来的fileName和thisPath,调用Service层HdfsService的deleteFile方法,传入要删除的文件(文件夹)路径。之后再使用和前面功能相同的操作重定向到index.jsp或跳转至上一个页面。DeleteServlet的相关代码如图64所示。
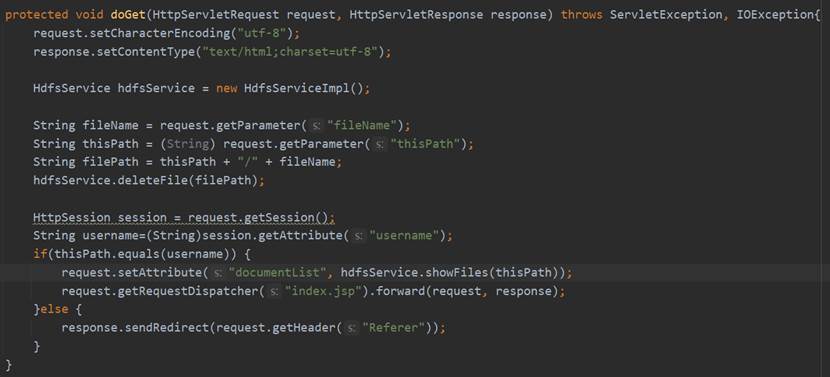
HdfsService接口的deleteFile的具体实现是调用DAO层HdfsDao的deleteFile方法,而deleteFile具体的实现过程是连接Hadoop,获取FileSystem实体,然后调用它的deleteOnExit方法,传入要删除的文件(文件夹)路径,最后关闭FilSystem。具体实现过程如图65所示。
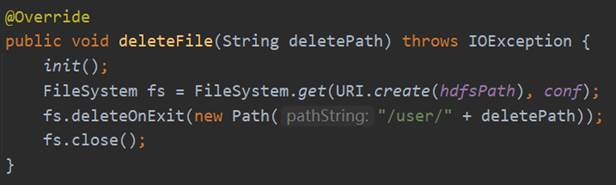
下面对删除文件和文件夹功能进行测试:
删除前文件主界面文件列表如下所示:
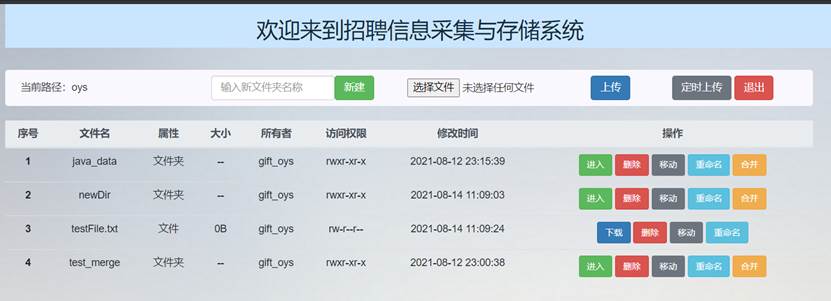
依次点击要newDir和testFile.txt操作列的“删除”按钮,可以看到主界面文件列表和HDFS中文件列表中这两条文件信息就已经消失了:
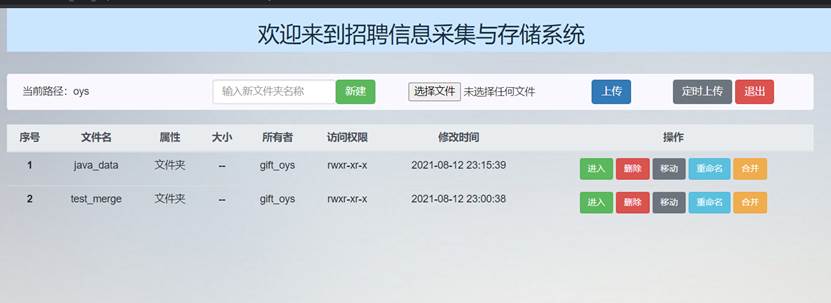
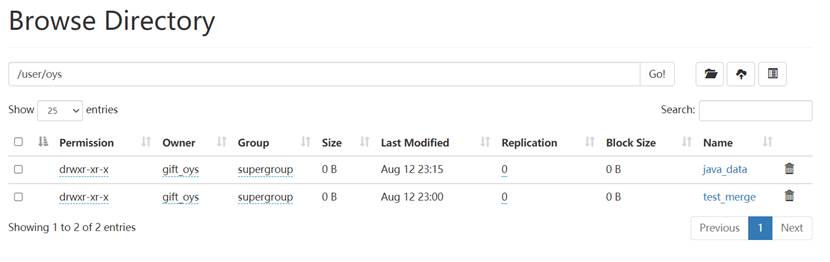
因此成功完成了删除文件和文件夹功能。
首先,用户在主界面index.jsp的每条文件(文件夹)信息的操作列中“重命名”按钮,当点击该文件条目的“重命名”按钮时会弹出模态框,用于输入新的文件(文件夹)名称,点击模态框的修改按钮后会将thisPath、该文件(文件夹)的原名称fileName和新名称newName传给Controller层的RenameServlet,完成表现层向控制器层的数据请求。图69和图70为“重命名”按钮和模态框的相关前端代码。

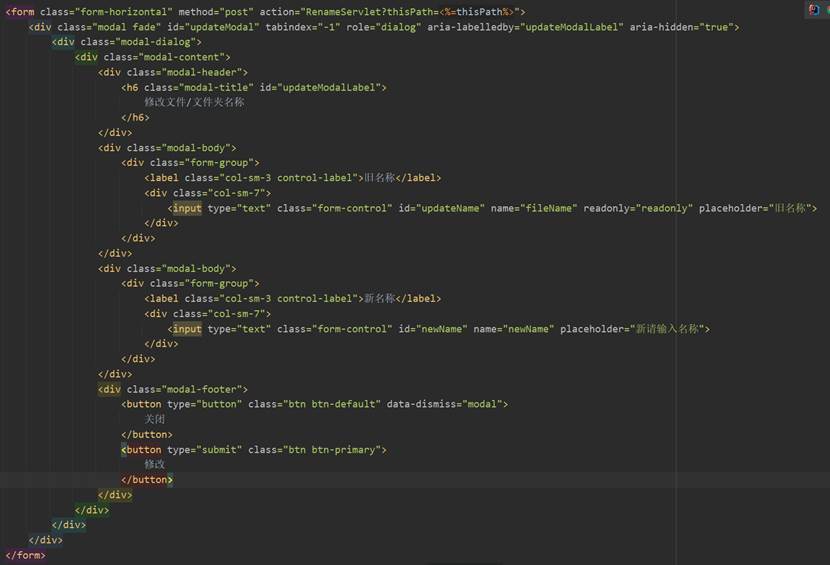
在RenameServlet的doGet方法中首先设置请求的编码格式和相应的网页格式,然后通过request.getParameter获取前端发来的fileName、newName和thisPath,调用Service层HdfsService的reName方法,传入要重命名的文件(文件夹)原路径和新路径。之后再使用和前面功能相同的操作重定向到index.jsp或跳转至上一个页面。RenameServlet的相关代码如图71所示。
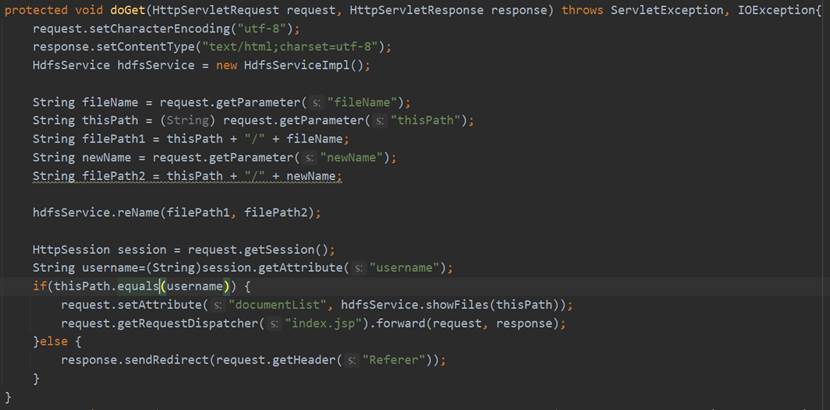
HdfsService接口的reName的具体实现是调用DAO层HdfsDao的reName方法,而reName具体的实现过程是连接Hadoop,获取FileSystem实体,然后调用它的rename方法,传入要重命名的原路径和新路径,最后关闭FilSystem。具体实现过程如图72所示。
下面对重命名文件和文件夹功能进行测试:
重命名前文件主界面文件列表如图73所示:
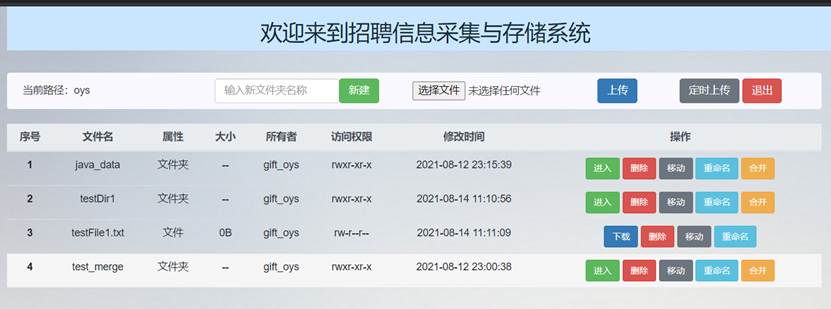
依次点击要testDir1和testFile1.txt操作列的“重命名”按钮,分别输入新名称:
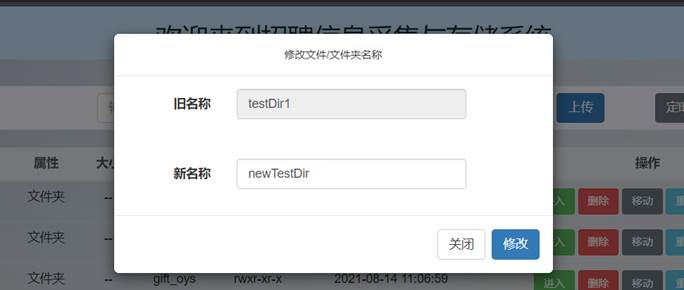
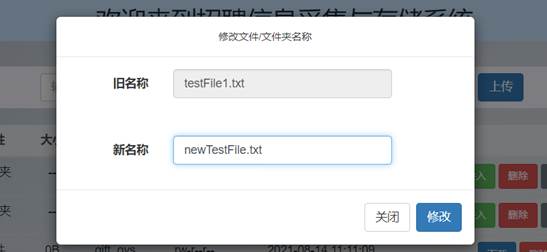
可以看到主界面文件列表和HDFS中文件列表中这两条文件的名称就已经更改了:
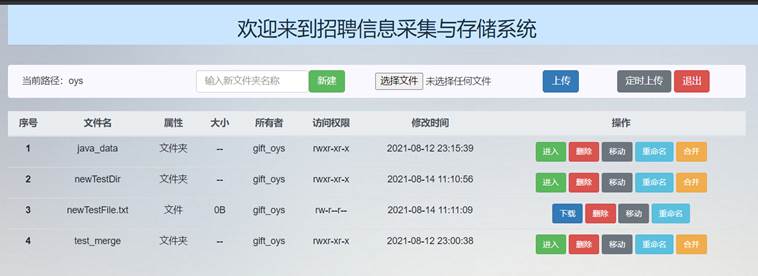
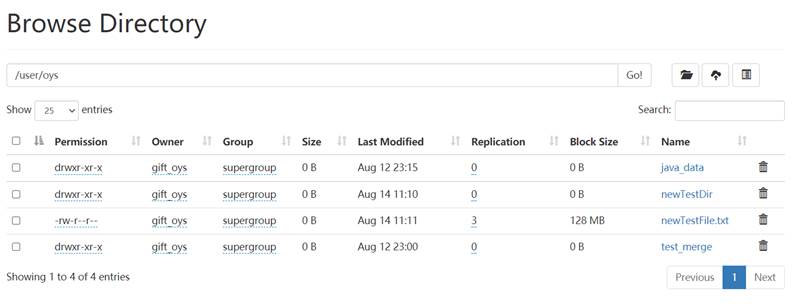
因此成功完成了重命名文件和文件夹功能。
首先,用户在主界面index.jsp的每条文件(文件夹)信息的操作列中“移动”按钮,当点击该文件条目的“移动”按钮时会弹出模态框,用于输入新的文件(文件夹)路径,点击模态框的“移动”按钮后会将thisPath、该文件(文件夹)的原路径fileName和新名称newPath传给Controller层的MoveServlet,完成表现层向控制器层的数据请求。图78、图79为“移动”按钮和模态框相关前端代码。

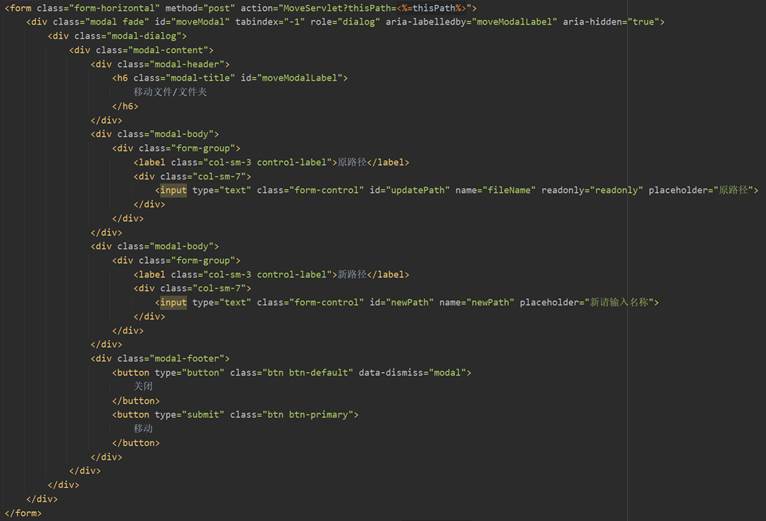
在MoveServlet的具体实现过程与RenameServlet基本一致,只是在调用HdfsService的reName方法时将文件(文件夹)的原名称换成原路径,同样使用和前面功能相同的操作重定向到index.jsp或跳转至上一个页面。具体的代码实现这里不再赘述。
下面对移动文件和文件夹功能进行测试:
移动前文件主界面文件列表如下所示,其中,merge文件夹为空:
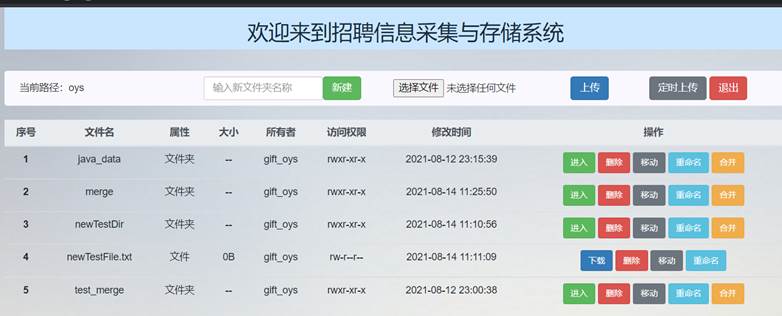
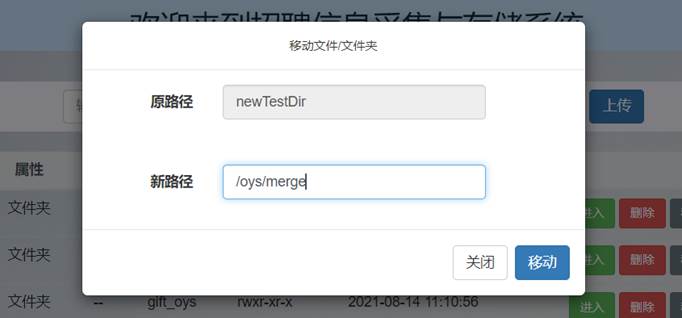
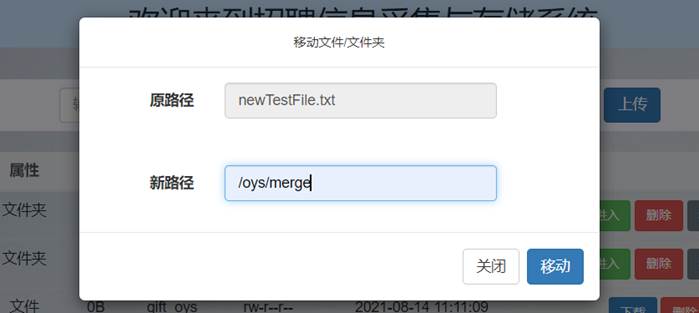
依次点击要newTestDir和newTestFile.txt操作列的“移动”按钮,分别输入要移动到的路径:
可以看到主界面merge文件夹中出现了这两个文件和文件夹,HDFS文件列表中原路径的文件不见了:
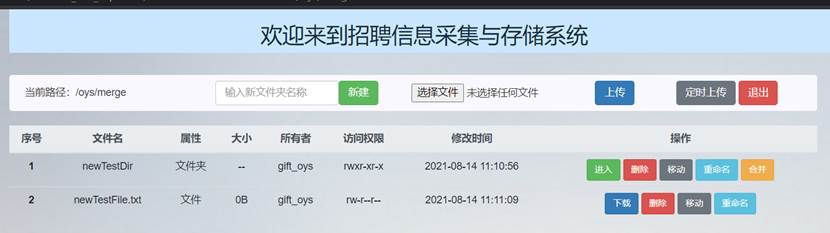
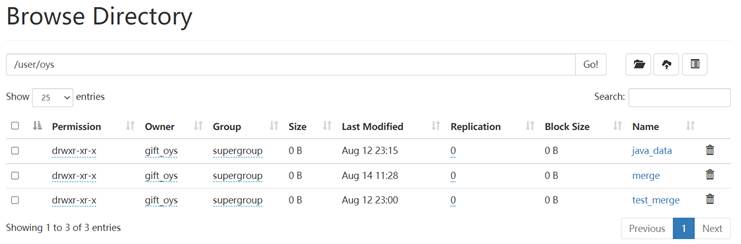
因此成功完成了移动文件和文件夹功能。
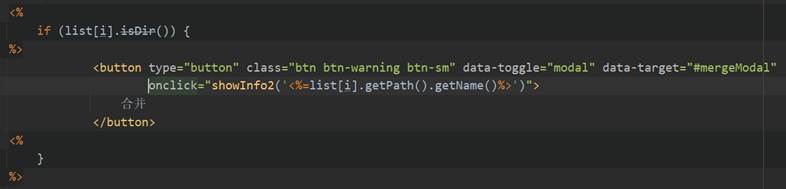
首先,用户在主界面index.jsp的每条文件夹信息的操作列中“合并”按钮,当点击该文件夹条目的“合并”按钮时会弹出模态框,用于输入合并之后的文件名称,点击模态框的“合并”按钮后会将thisPath、该文件夹的名称dirName和新文件名称newMergePath传给Controller层的MergeServlet,完成表现层向控制器层的数据请求。图85、图86为“合并”按钮和模态框的相关前端代码。
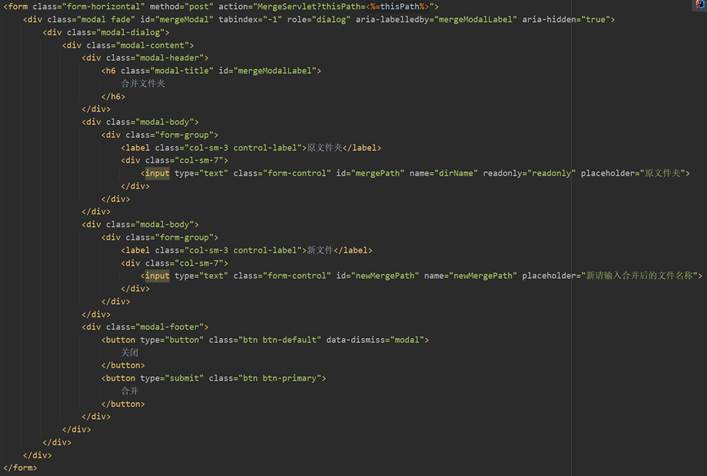
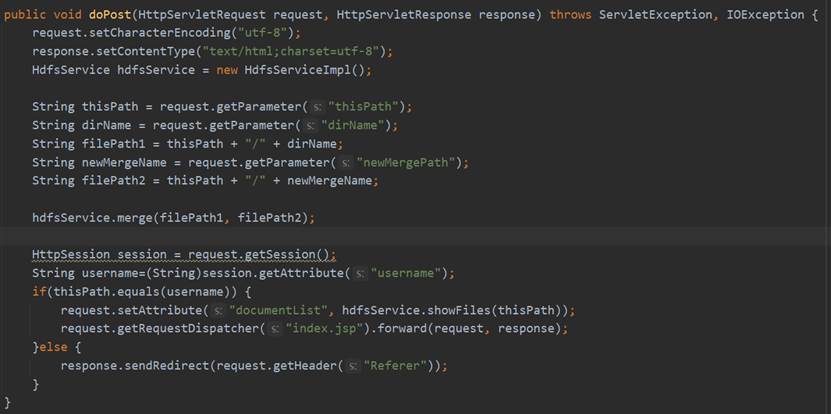
在MergeServlet的doGet方法中首先设置请求的编码格式和相应的网页格式,然后通过request.getParameter获取前端发来的fileName、dirName和newMergePath,调用Service层HdfsService的merge方法,传入要合并的文件夹原路径和合并后的新路径。之后再使用和前面功能相同的操作重定向到index.jsp或跳转至上一个页面。MergeServlet的相关代码如图87所示。
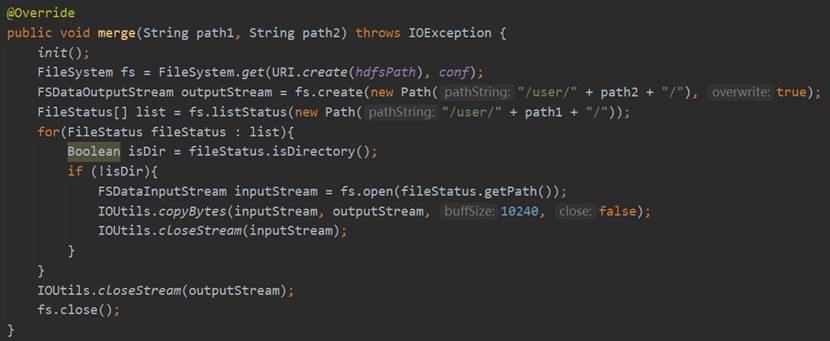
HdfsService接口的merge的具体实现是调用DAO层HdfsDao的merge方法,而merge具体的实现过程是连接Hadoop,获取FileSystem实体,然后通过合并后的文件路径获取FSDataOutputStream对象,通过fs.listStatus获取原文件夹目录下的文件FileStatus数组,再遍历数组,获取每个文件的FSDataInputStream对象并使用org.apache.hadoop.io.IOUtils的copyBytes方法进行合并操作,最后关闭IOUtils和FileSystem。具体实现过程如下所示。
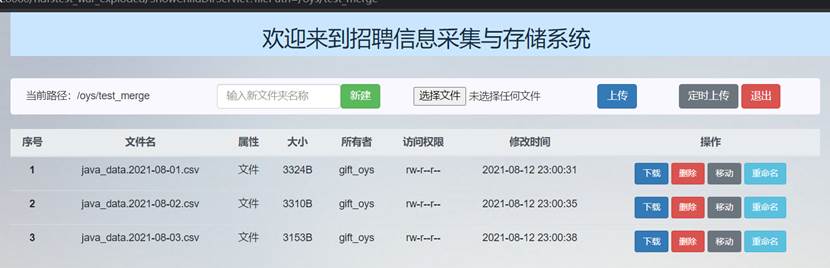
下面对合并文件夹中为文件功能进行测试:
合并前merge_test文件夹中的文件如下所示,三个文件的大小分别为3324B、3310B和3153B:
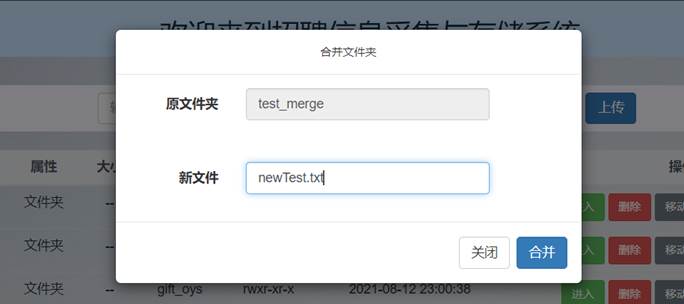
点击merge_test文件夹的“合并”按钮,输入合并后新文件的名称newTest.txt:
可以看到主界面文件列表和HDFS中文件列表中出现了合并后的newTest.txt文件,大小为9787B:
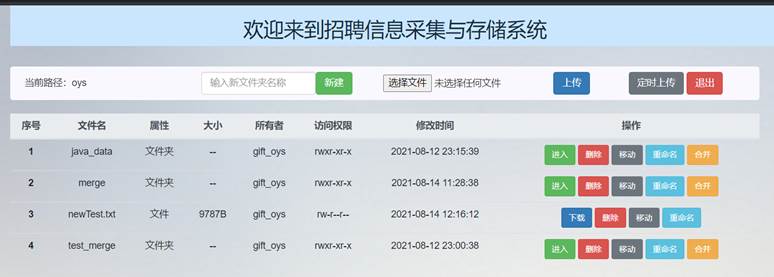
图91 合并后的主界面
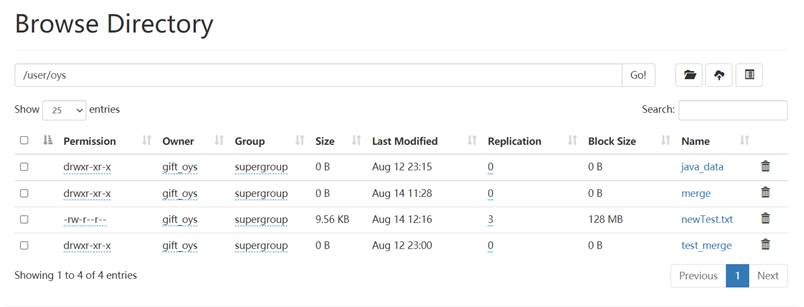
因此成功完成了合并文件夹中的文件功能。
用户在主界面index.jsp点击“定时上传”按钮,就会触发定时上传文件的功能,将thisPath传给Controller层的TimerUploadServlet,完成表现层向控制器层的数据请求。图93为定时上传时提交的form表单。

在TimerUploadServlet的doGet方法中首先设置请求的编码格式和相应的网页格式,然后通过request.getParameter获取前端发来的thisPath,调用Service层HdfsService的timerUpload方法来实现定时上传操作。之后再使用和前面功能相同的操作重定向到index.jsp或跳转至上一个页面。TimerUploadServlet的相关代码如图94所示。
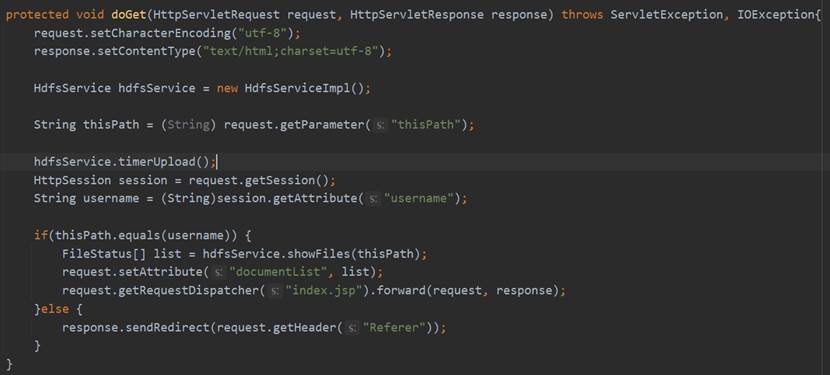
HdfsService接口的timerUpload的具体实现是先创建一个Timer定时器对象和一个自定义的UploadFile对象,然后调用timer的schedule方法传入uploadFile对象,并设置每次的运行时间间隔为24小时。具体实现过程如图95所示。
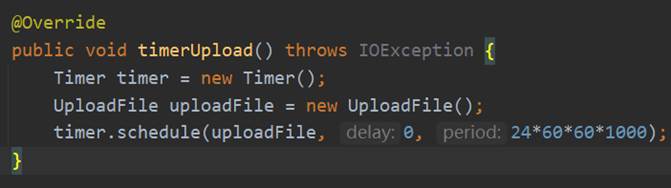
UploadFile作为一个工具类,它实现了TimerTask接口,在重载的run方法中首先获取到当前时间,然后找到指定目录下文件名称的日期部分为当日的文件,如果文件不存在的话给出提示,存在的话则传入时间和文件,执行另一个自定义的方法upload以上相关代码如图96所示。
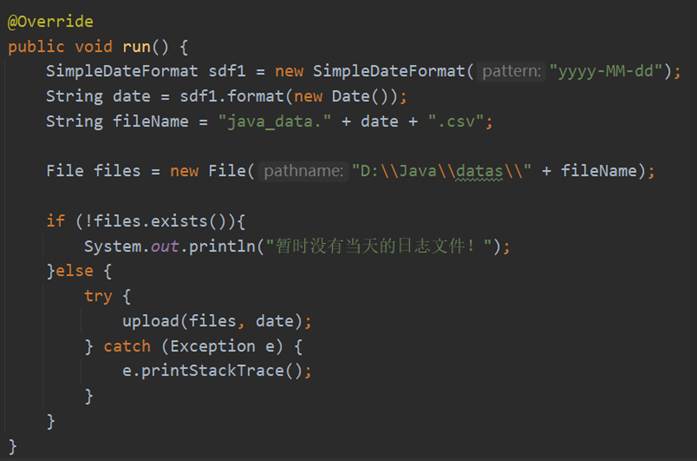
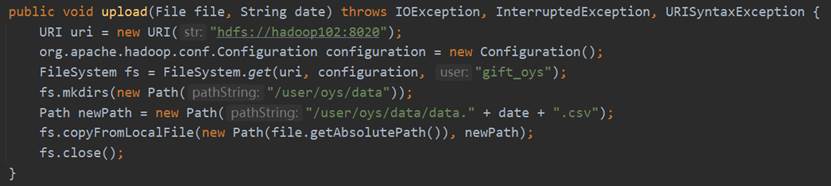
upload方法的实现过程是根据URI和Configuration得到FileSystem对象,调用其mkdirs方法在该用户的目录下创建data文件,然后使用copyFromLocalFile方法将文件上传至HDFS中,最后关闭FileSystem,相关代码如图97所示。
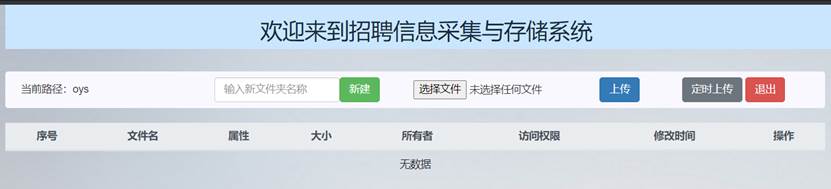
下面定时上传文件功能进行测试:
今日是8月14日,可以看到此时oys文件夹中无数据:
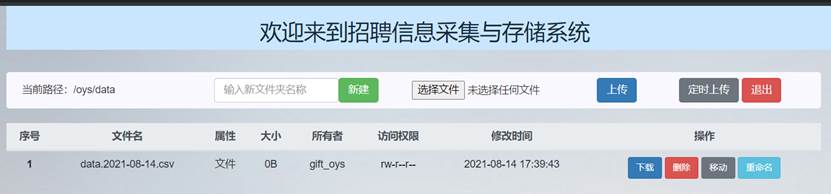
点击“定时上传”后将本地今日爬取的招聘信息文件上传至HDFS,可以看到在主页面文件列表和HDFS文件列表中上传了今日的文件:
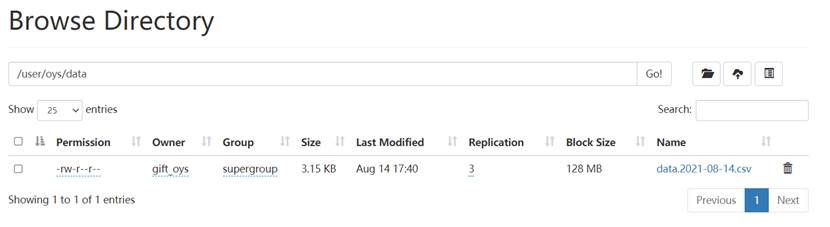
因此成功完成了定时上传文件功能。
在本次实验中前端是使用BootStrap进行编写的,共包括两个页面login.jsp和index.jsp。
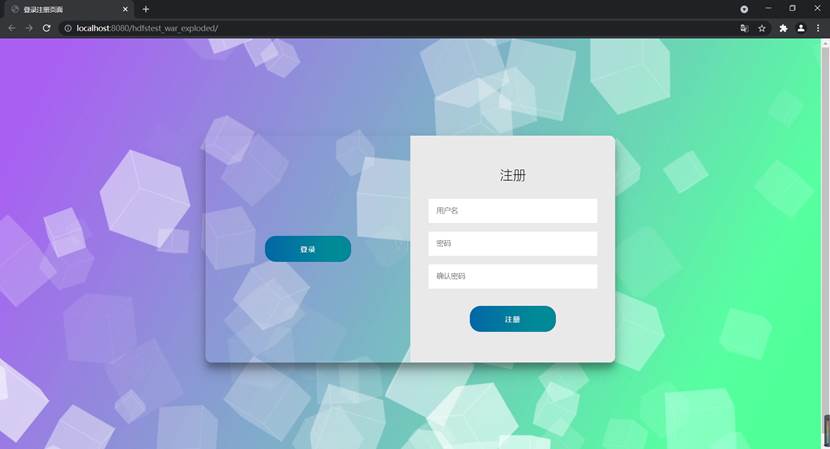
login.jsp是项目启动之后的初始页面,在引用了相关CSS以及JS组件之后,在前面注册、登录的基础上添加了动画效果,即在点击“注册”和“登录”按钮之后两个输入界面会进行左右交互,便于用户操作、给用户带来清爽的使用体验。完善后的登录注册页面如图101所示。
index.jsp实现的是系统的主页面,所有除登录、注册外的功能以及结果显示都在这个页面进行。在进行样式布局设计之前首先引入BootStrap相关的资源,如图102所示,然后在具体设计组件的时候根据情况使用相关的样式。

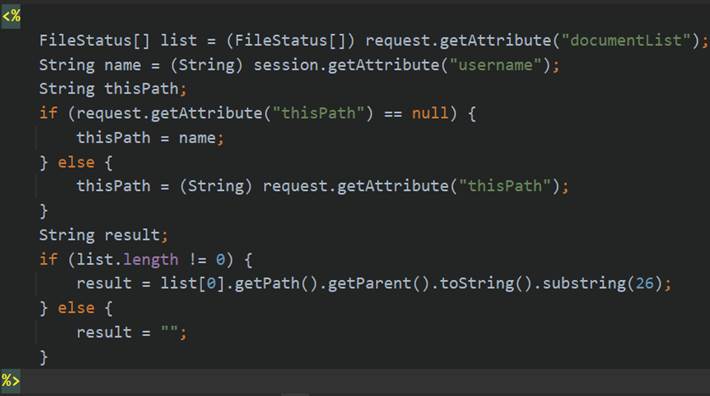
接下来使用JSTL、EL表达式获取Session和Request中的相关参数,用于页面内容的显示,其中list为当前请求中的documentList参数的FileStatus数组,thisPath是当前显示页面的路径,而在主页面是thisPath只是该用户的用户名,result也是当前路径,但当用户的下一级文件夹内容为空时该值取值为空,thisPath和result分别进行操作执行后转发的目的页面以及进入下一级目录和下载时起到不同的作用,以下是index.jsp对于这几个变量的取值过程。
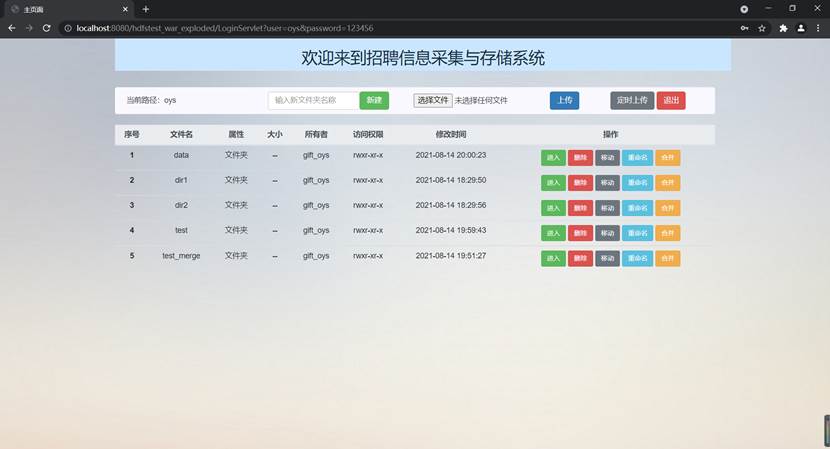
最终完善后的主界面如下所示:
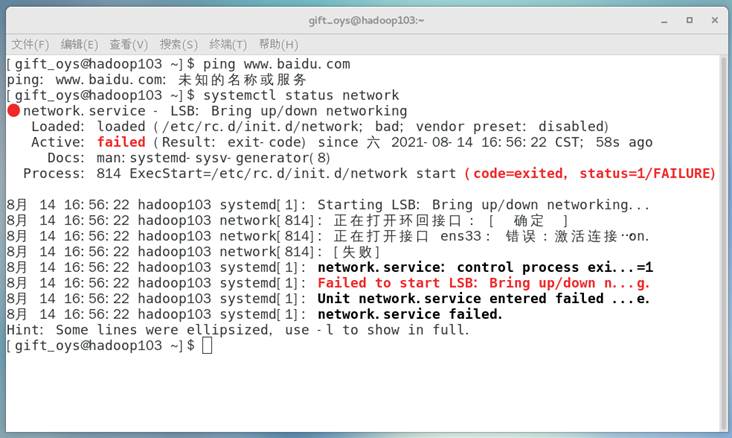
(1)在配置好虚拟机网络环境之后连接网络正常,而过了一段时间之后,没有进行非法操作但网络连接失败,通过systemctl status network查看网络配置时报错Failed to start LSB: Bring up/down n…g.如图105所示:
解决方法:进入root用户,使用mv /var/lib/NetworkManager /var/lib/NetworkManager.bak操作直接修改NetworkManager文件夹为备份文件夹,然后重启虚拟机即可。因为每次启动网络是由NetworkMannger会进行管理,给它添加.bak,可以让它初始化,reboot之后网络正常连接,会重新生成 Networkmanager。
(2)在配置的时候不能识别主机名称,报java.net.UnknownHostException错误。
分析原因:未将IP地址映射到主机名上或者主机名使用了特殊单词
解决方法:检查主机名称是否起了hadoop等特殊名称,并在/etc/hosts 文件中添加 192.168.10.102 hadoop102。
(3)在实现下载文件的时候提示FileSystem已关闭,无法下载。
分析原因:在HdfsDao的实现类中getInputStream在获取到FSDataInputStream对象之后关闭了FileSystem对象,导致报错。
解决方法:在getInputStream方法中最后不关闭FileSystem。