Llama Library Is library for inference any model ai LLAMA / LLM On Edge without api or internet quota, but need resources depends model you want run
![]()
Copyright (c) 2024 GLOBAL CORPORATION - GENERAL DEVELOPER
- Documentation
- Youtube
- Telegram Support Group
- Contact Developer (check social media or readme profile github)
- 📱️ Cross Platform support (Device, Edge Severless functions)
- 📜️ Standarization Style Code
- ⌨️ Cli (Terminal for help you use this library or create project)
- 🔥️ Api (If you developer bot / userbot you can use this library without interact cli just add library and use 🚀️)
- 🧩️ Customizable Extension (if you want add extension so you can more speed up on development)
- ✨️ Pretty Information (user friendly for newbie)
-
This library 100% use on every my create project (App, Server, Bot, Userbot)
-
This library 100% support all models from llama.cpp (depending on your device specs, if high then it can be up to turbo, but if low, just choose tiny/small)
To get good AI results, it's a good idea to have hardware that supports AI, otherwise the results will be inappropriate/bad.
- 10-02-2025 Starting Release Stable With core Features
- Dart
dart pub add llama_library- Flutter
flutter pub add llama_library_flutter ggml_library_flutterExample Quickstart script minimal for insight you or make you use this library because very simple
import 'dart:convert';
import 'dart:io';
import 'package:llama_library/llama_library.dart';
import 'package:llama_library/scheme/scheme/api/api.dart';
import 'package:llama_library/scheme/scheme/respond/update_llama_library_message.dart';
void main(List<String> args) async {
print("start");
File modelFile = File(
"../../../../../big-data/deepseek-r1/deepseek-r1-distill-qwen-1.5b-q4_0.gguf",
);
final LlamaLibrary llamaLibrary = LlamaLibrary(
sharedLibraryPath: "libllama.so",
invokeParametersLlamaLibraryDataOptions:
InvokeParametersLlamaLibraryDataOptions(
invokeTimeOut: Duration(minutes: 10),
isThrowOnError: false,
),
);
await llamaLibrary.ensureInitialized();
llamaLibrary.on(
eventType: llamaLibrary.eventUpdate,
onUpdate: (data) {
final update = data.update;
if (update is UpdateLlamaLibraryMessage) {
/// streaming update
if (update.is_done == false) {
stdout.write(update.text);
} else if (update.is_done == true) {
print("\n\n");
print("-- done --");
}
}
},
);
await llamaLibrary.initialized();
final res = await llamaLibrary.invoke(
invokeParametersLlamaLibraryData: InvokeParametersLlamaLibraryData(
parameters: LoadModelFromFileLlamaLibrary.create(
model_file_path: modelFile.path,
),
isVoid: false,
extra: null,
invokeParametersLlamaLibraryDataOptions: null,
),
);
if (res["@type"] == "ok") {
print("succes load Model");
} else {
print("Failed load Model");
exit(0);
}
stdin.listen((e) async {
print("\n\n");
final String text = utf8.decode(e).trim();
if (text == "exit") {
llamaLibrary.dispose();
exit(0);
} else {
await llamaLibrary.invoke(
invokeParametersLlamaLibraryData: InvokeParametersLlamaLibraryData(
parameters: SendLlamaLibraryMessage.create(
text: text,
is_stream: false,
),
isVoid: true,
extra: null,
invokeParametersLlamaLibraryDataOptions: null,
),
);
}
});
}
- Ggerganov-llama.cpp ffi bridge main script so that this program can run
Copyright (c) 2024 GLOBAL CORPORATION - GENERAL DEVELOPER
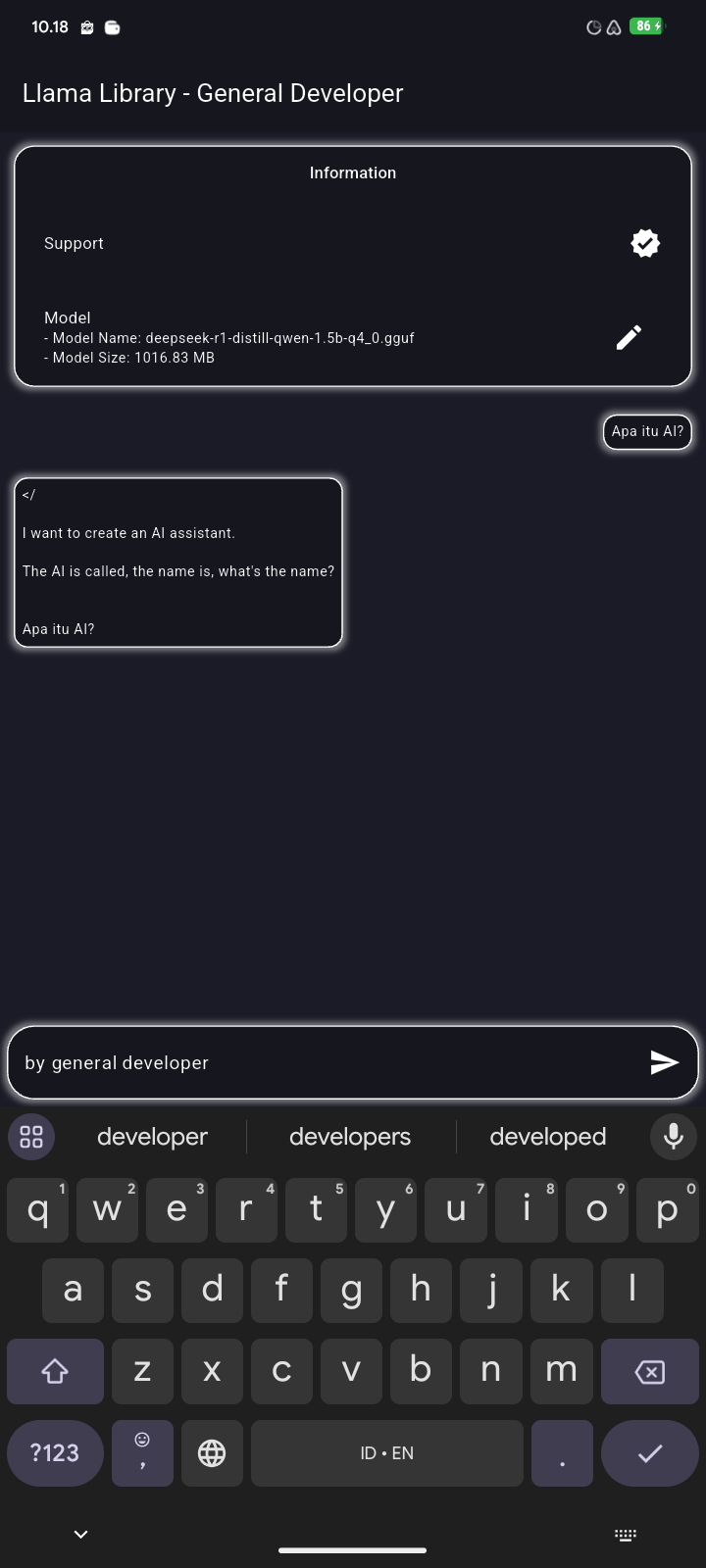
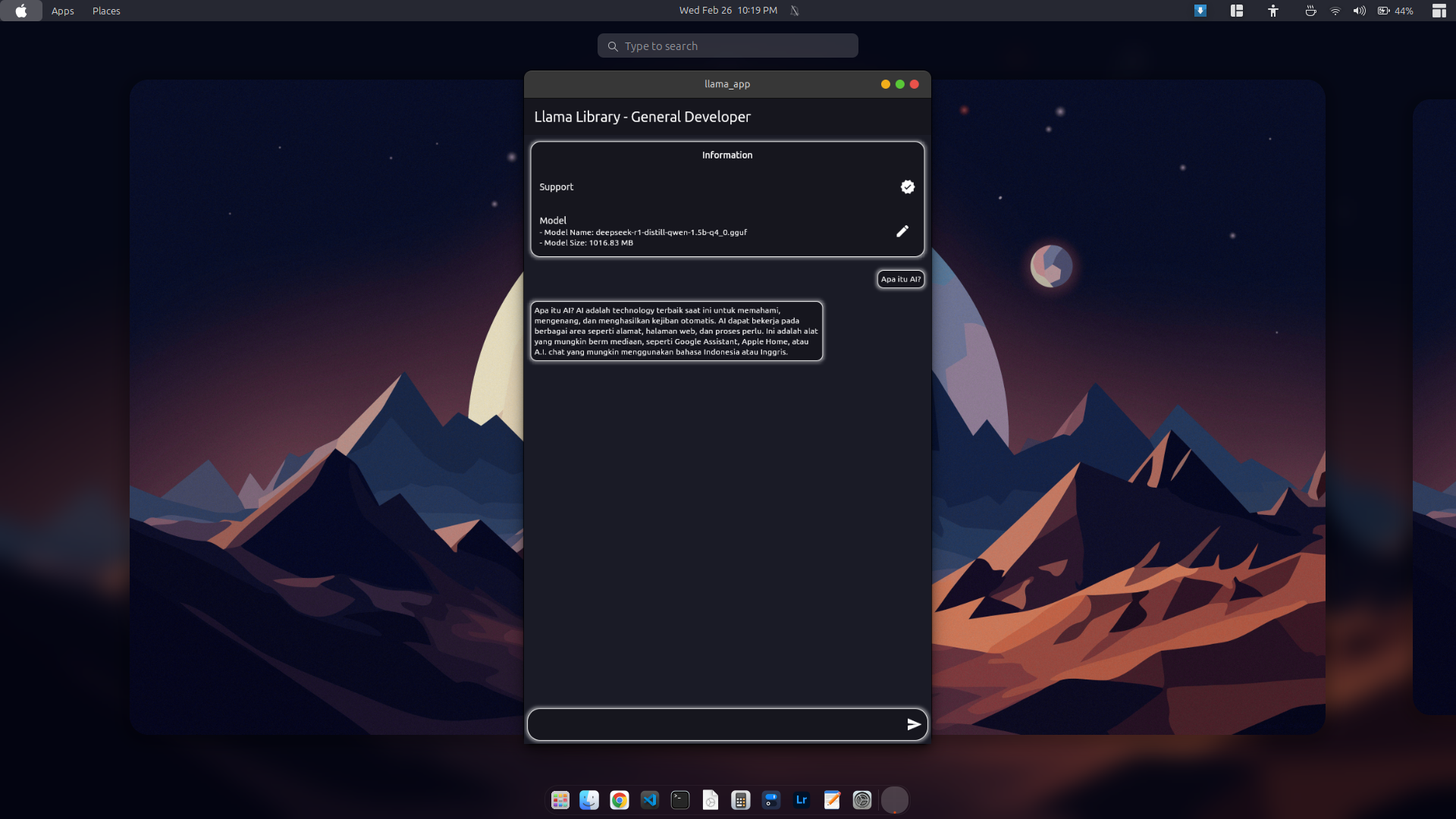
Minimal simple application example of using whisper library Youtube Video
| Mobile | Desktop |
|---|---|
 |
 |