rss-bridge is a php script capable of generating ATOM feed for specific pages which don't have one.
FlickrExplore: Latest interesting images from Flickr.GoogleSearch: Most recent results from Google Search.Twitter: Twitter. Can return keyword/hashtag search or user timeline.Identi.ca: Identita user timeline (Should be compatible with other Pump.io instances).YouTube: YouTube user channel feed.Cryptome: Returns the most recent documents from Cryptome.org.LeBonCoin: Search product on 'leboncoin.fr'.
Output format can take several forms:
Atom: ATOM Feed, for use in RSS/Feed readersJson: Json, for consumption by other applications.Html: Simple html page.Plaintext: raw text (php object, as returned by print_r)
Welcome screen:

Minecraft hashtag (#Minecraft) search on Twitter, in ATOM format (as displayed by Firefox):
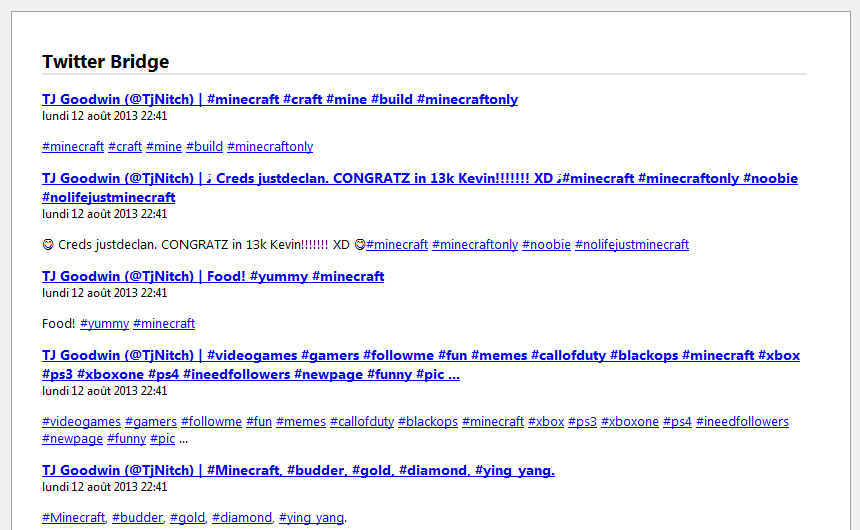
- php 5.3 or higher
- composer.phar for installation (actually is installed PHP Simple HTML DOM Parser)
- (recommended) Ssl lib activated in PHP config
Note : you can change DEBUG to true in 'app/autoload.php' and go in 'web/check_server.php' to check if you server configuration support what's necessary.
- 1 : download composer : http://getcomposer.org/download/ in a directory
- 2 : create a clone of this project by :
git clone https://github.com/Draeli/rss-bridge.git rss-bridge- 3 : install project by :
php composer.phar install- 4 : no more :)
You can try to do all in one by :
php -r "eval('?>'.file_get_contents('https://getcomposer.org/installer'));" && git clone https://github.com/Draeli/rss-bridge.git rss-bridge && cd rss-bridge && php ../composer.phar installYves ASTIER (Draeli) : PHP refactoring, optimizations, fixes, dynamic brigde/format list with all stuff behind and extend cache system. Documentation and some bridges. Mail : contact@yves-astier.com
I'm sebsauvage, webmaster of sebsauvage.net, author of Shaarli and ZeroBin.
Patch :
- Mitsukarenai : Initial inspiration, TwitterBridge, IdenticaBridge, YoutubeBridge.
- ArthurHoaro
- BoboTiG
MIT License. Only limit is to keep original author.
- There is a cache so that source services won't ban you even if you hammer the rss-bridge with requests. Each bridge has a different duration for the cache. The
cachesubdirectory will be automatically created. You can purge it whenever you want. - To implement a new rss-bridge, create a new class in
bridgessubdirectory. Look at existing bridges for examples. For items you generate in$this->items, onlyuriandtitleare mandatory in each item.timestampandcontentare optional but recommended. Any additional key will be ignored by ATOM feed (but outputed to jSon).
- Each bridge come with its own implementation. Rss-bridge library provides easy tools to perform implementation. That means you need only to follow these steps :
1 : Go in 'src/Draeli/RssBridge/Adapter/Bridge' directory and create a file named under convention [Name]Bridge.php where 'Name' begin at least by one alphabetic character follow or not by one or more alphanumeric characters included dash.
2 : Open this file and copy this :
namespace Draeli\RssBridge\Adapter\Bridge;
use Draeli\RssBridge\Html,
Draeli\RssBridge\Item;
class NameBridge extends \Draeli\RssBridge\BridgeAbstract{
/* here your implementation */
}Don't forget to change 'Name' in order to have the same your declare as file name.
3 : Now you have your class, you need at least to implement defined methods in 'BridgeInterface', actually there are :
- getName : human bridge name
- getURI : URI reference for the bridge
- getCacheDuration : cache duration supposed to be the bridge. (optional, by default duration is 1 hour)
- collectData : to recover informations (see next step for details)
4 : 'collectData' is the most important method, it's important to read this before begin your first bridge !!!
- First to know, method receives only one parameter which is (and must be) an array with all stuff you are supposed to use (if you use the default index.php, you don't need to know more about now).
- At least, you want to call an URL, for making this, use 'Html::getFromUrl' method with your URL as first and only one argument. Then, the method will send you an object which represents a code source returnable by your call (it's important that the page you're calling use derived language from XML, for example : HTML4, XHTML, HTML5, XML, SVG, XSLT, RSS, ...).
- Now you have your object, you need to walk through him, don't be afraid, it's easy to provide by some methods. To see details, refer to the library we use : http://simplehtmldom.sourceforge.net/manual.htm .
- Each element you catch must use an 'new Item()' and you must bind all details of your elements to this 'Item' and when you would finish to create the Item, you will need to add it to the bridge by '$this->addItem($yourItemObject)'. To bind a value on Item, you need only to do :
$yourItemObject->theKeyName = $yourValue;Some "keyName" are reserved for specific usage like 'title', 'content', 'uri'.
5 : at this point, you can stop doing the code, now if you want your bridge appears in global list (web/index.php), you must defined some Annotations to your class. For example :
/**
* @name The human name here (use the same you use in getName method)
* @description A quick description
* @use1(q="keyword",q2="keyword 2")
* @use2(other="something",another="what else ...")
*/@name Return name bridge
@description Return the discription of your bridge
@useN(keyName="key description") For each use, if there is expected parameters, only put the key name and a little description and separates parameters by a comma. If your bridge doesn't use parameters, don't declare @use annotation.
6 : At this point, all is suppose to be good, you need only to open the main entrance page (web/index.php) and check if your bridge appears. To learn and understand details, don't hesitate to read existing bridges and after, when all will be fine, don't forget to share :)
Dear so-called "social" websites.
Your catchword is �share�, but you don't want us to share. You want to keep us within your walled gardens. That's why you've been removing RSS links from webpages, hiding them deep on your website, or removed RSS entirely, replacing it with crippled or demented proprietary API. FUCK YOU.
You're not social when you hamper sharing by removing RSS. You're happy to have customers create content for your ecosystem, but you don't want this content out - a content you do not even own. Google Takeout is just a gimmick. We want our data to flow, we want RSS.
We want to share with friends, using open protocols: RSS, XMPP, whatever. Because no one wants to have your service with your applications using your API forced-feeded to them. Friends must be free to choose whatever software and service they want.
We are rebuilding bridges your have wilfully destroyed.
Get your shit together: Put RSS back in.