A Python natural language processing program for identifying key words and phrases in conservation management plans.
- Can we identify common themes / conservation measures among management plans?
- Can we capture values and interests of plans’ authors?
The PdfScrape program processes PDFs hosted online into various analysis ready data, and performs some initial, exploratory visualizations of common words and their connections.
Initial development focused on coastal management plans for the state of Washington.
Contained within this repository are:
-
A complied list of URLs for the management plans.
-
Various analysis ready versions of Fish & Wildlife Species Recovery Plans PDFs
-
Exploratory visualizations of common words and their connections (see below)
-
The PdfScrape program &
explaining how to use the program for your own list of PDF URLs.
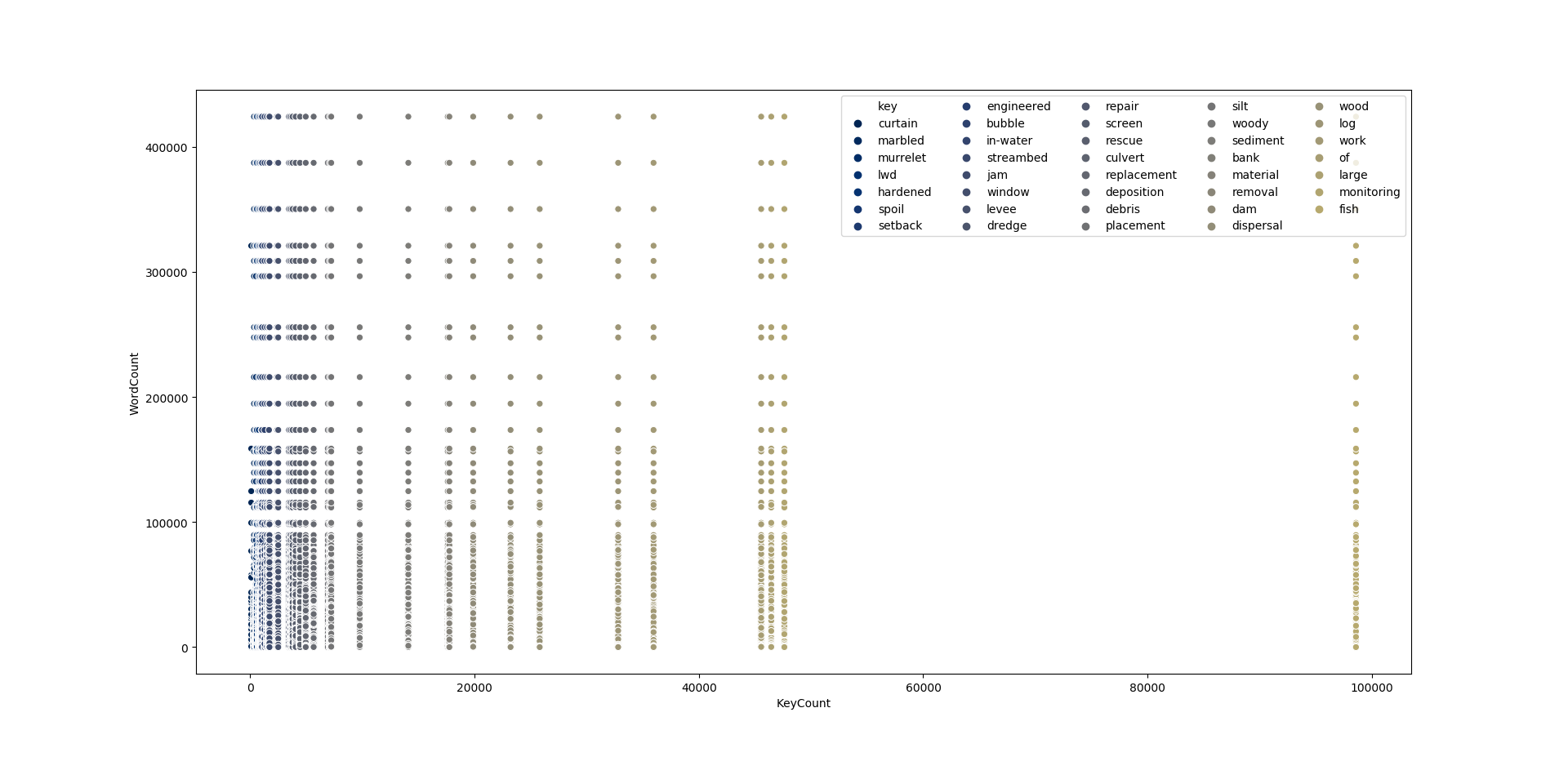
For user-specified key words, the pseudo-clustering plot shows the relationship between the word count for each key word (KeyCount) and the word count for the words surrounding / co-occurring with the key word (WordCount). Further details provided in the PdfScrape README
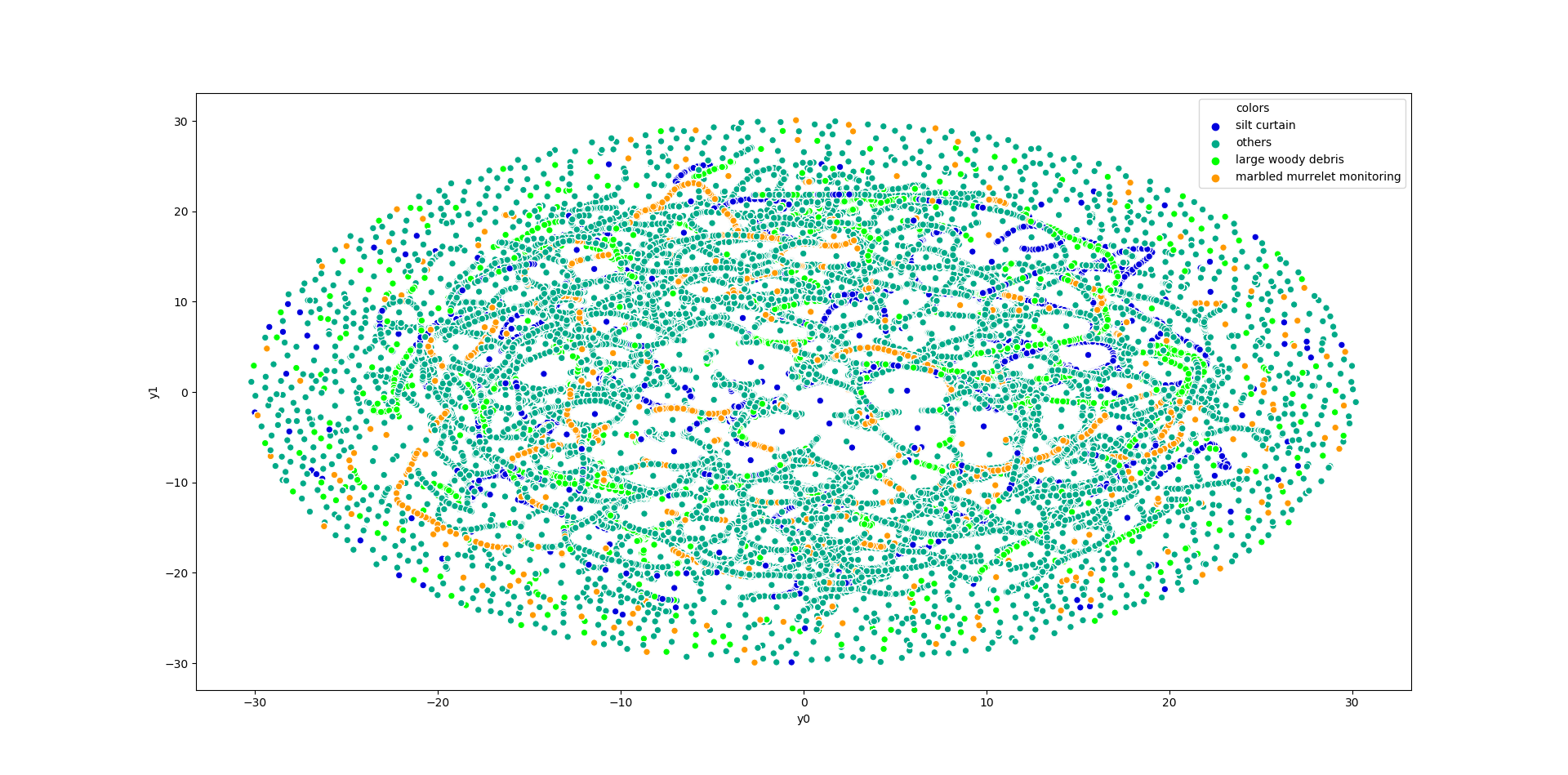
Visually analyze text clustering patterns from the input PDFs