-
Notifications
You must be signed in to change notification settings - Fork 11
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Merge pull request #6 from vynpt/main
Final Code with Documentation and Deployment
- Loading branch information
Showing
29 changed files
with
128,660 additions
and
4 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,33 @@ | ||
| { | ||
| "name": "Python 3", | ||
| // Or use a Dockerfile or Docker Compose file. More info: https://containers.dev/guide/dockerfile | ||
| "image": "mcr.microsoft.com/devcontainers/python:1-3.11-bullseye", | ||
| "customizations": { | ||
| "codespaces": { | ||
| "openFiles": [ | ||
| "README.md", | ||
| "demoapp/app.py" | ||
| ] | ||
| }, | ||
| "vscode": { | ||
| "settings": {}, | ||
| "extensions": [ | ||
| "ms-python.python", | ||
| "ms-python.vscode-pylance" | ||
| ] | ||
| } | ||
| }, | ||
| "updateContentCommand": "[ -f packages.txt ] && sudo apt update && sudo apt upgrade -y && sudo xargs apt install -y <packages.txt; [ -f requirements.txt ] && pip3 install --user -r requirements.txt; pip3 install --user streamlit; echo '✅ Packages installed and Requirements met'", | ||
| "postAttachCommand": { | ||
| "server": "streamlit run demoapp/app.py --server.enableCORS false --server.enableXsrfProtection false" | ||
| }, | ||
| "portsAttributes": { | ||
| "8501": { | ||
| "label": "Application", | ||
| "onAutoForward": "openPreview" | ||
| } | ||
| }, | ||
| "forwardPorts": [ | ||
| 8501 | ||
| ] | ||
| } |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,4 @@ | ||
| Vy Nguyen - Github Username: vynpt | ||
| Andy Yang - Github Username: ayang903 | ||
| Gauri Bhandarwar - Github Username: gbhandarwar | ||
| Weining Mai - Github Username: weibb123 |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1 @@ | ||
| Demo app: https://maple-billsummarization.streamlit.app/ |
Binary file not shown.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,97 @@ | ||
| # Research MAPLE | ||
|
|
||
| **Research Methods (MAPLE Project)** | ||
|
|
||
| **Team members:** Andy Yang, Gauri Bhandarwar, Weining Mai, Vy Nguyen | ||
|
|
||
| 1. **Overview** | ||
|
|
||
| This paper goes over the methods for summarization and tagging of Massachusetts bills for the MAPLE Platform. The goal is to simplify the legal language and content to make it comprehensible for a broader audience (9th-grade comprehension level). This summarization has to be done while still retaining the key information about the bills and maintaining full accuracy. This involves utilizing Large Language Models (LLMs) to summarize and categorize the content effectively. This paper will summarize some of the methods, processes, considerations, and evaluation metrics used during our research process of finding the most suitable method to execute the project. | ||
|
|
||
| 1. **Preliminary Research on LLMs and Performance Criteria Definition** | ||
|
|
||
| Before we dive into our research of LLMs we have defined a few criteria that will help us evaluate the models we are potentially using. These criteria and metrics are listed below: | ||
|
|
||
| - **Comprehensibility: Model's ability to generate text that is comprehensible (9th grade level)** | ||
| - **Content Accuracy: The model's ability to retain critical legal details and nuances in the summarization process.** | ||
| - **Scalability: The ability of the model to handle a large number of documents efficiently.** | ||
| - **Customizability: The ease with which the model can be fine-tuned or adapted to specific requirements of the task such as focusing on certain aspects of legal bills.** | ||
| - **Cost Efficiency: Considers the full expense of using the model including : training, fine-tuning, and runtime inference costs.** | ||
| - **Overall Suitability: A general suitability measure for the model, considering all the factors above.** | ||
|
|
||
| Based on these criteria and reading up on the various LLMs from different sites and papers (refer to sources), we have come up with a general table which contains all the models to whom we have assigned a high, medium or low grade for each of the criteria. | ||
|
|
||
|  | ||
|
|
||
| **Figure 1** : Comparison of LLMs and methods based on key evaluation metrics | ||
|
|
||
| Above we have provided a succinct table generalizing the use-cases for each LLM / method based on criteria such as Comprehensibility, Content Accuracy, Scalability, Cost Efficiency, and given them a final sum of scores based on the factors that are most important for this project. These metrics will help us choose the best model for our application needs. Content Accuracy is one of the most important factors as we are dealing with legislation. This need for accuracy was also highlighted by the client as it is imperative for the summaries to be accurate to maintain the trustworthiness of the MAPLE platform. | ||
|
|
||
| In addition to that, comprehensibility is a close second however not as important because we can hopefully tune each model to summarize in a more simple manner. Due to the fact that cost is also another consideration, we have given High scores to BERT, T5, and GPT-3.5. However, we have not tested how far tuning some models like LLAMA and customized transformers can go yet. Regarding the Customizability criteria, LLAMA, T5, and Customer Training with Transformation models seem to offer high customizability as they can be fine-tuned for specific tasks and domains. Moreover, GPT-3.5, LLAMA, and T5 are moderately cost-efficient, considering their performance while XLNet, BERT, and Customer Training with Transformation might be costlier due to resource-intensive fine-tuning and training processes. We will also aditionally explore using GPT-4 and GPT-3.5 Turbo given the new OpenAI updates. | ||
|
|
||
| Overall, LLAMA, T5, and Customer Training with Transformer models appear to be the most suitable choices for simplifying Massachusetts bills since they excel in comprehensibility, content accuracy, customizability, and overall performance. Hence, we will put more emphasis on these models while conducting performance tests and cost analysis. | ||
|
|
||
| 1. **Preliminary Testing** | ||
|
|
||
| 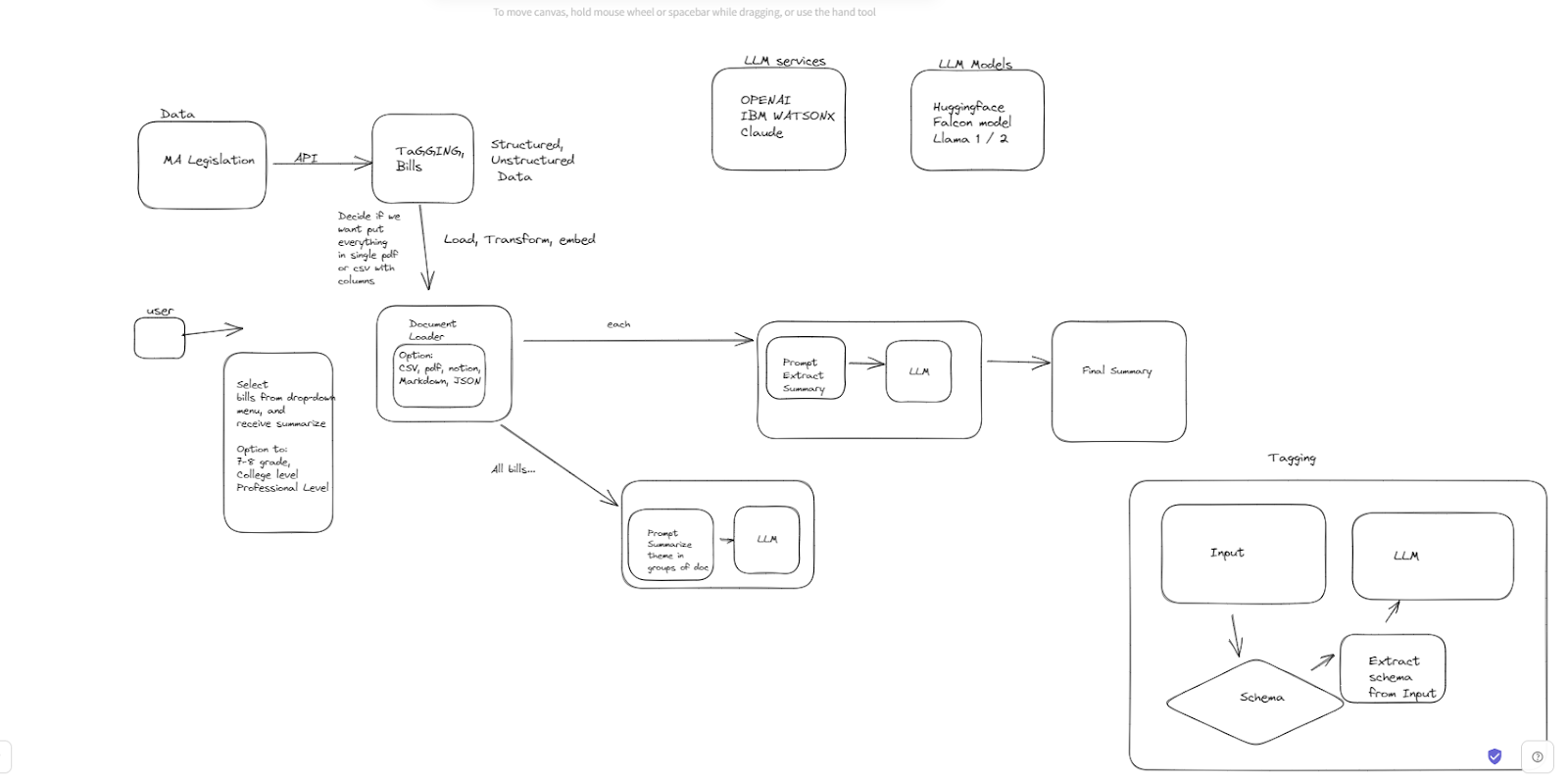 | ||
|
|
||
| **Figure 2:** Rough Sketch of Development Process | ||
|
|
||
| 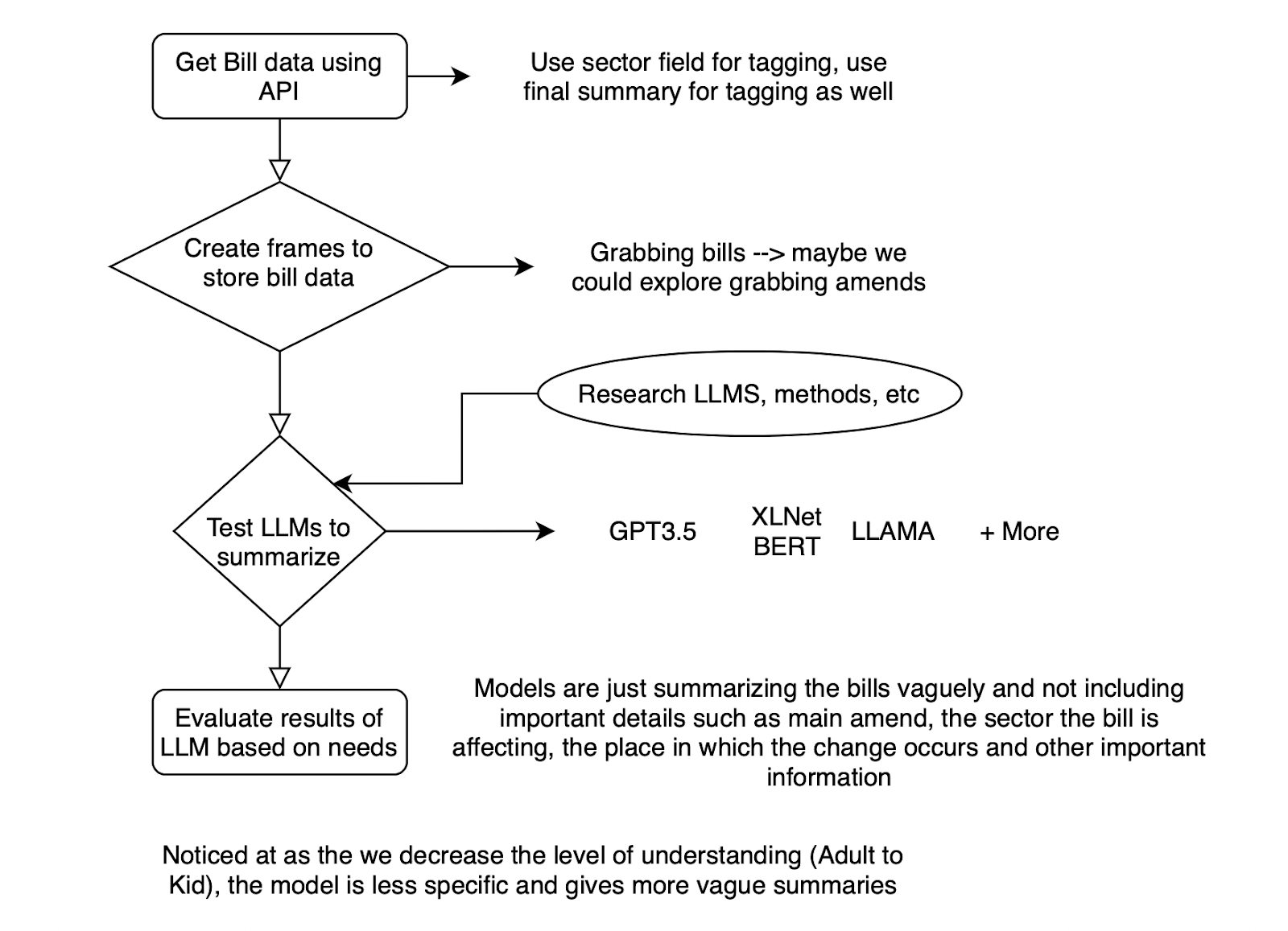 | ||
|
|
||
| **Figure 3** : Scraping, Summarizing and tagging bills with a sample set of 10 bills | ||
|
|
||
| We were able to successfully use the API to retrieve key data for ten bills including the : Title, Bill Number, Docket Number, General Court Number and Document Text. We mainly used the document text and title, feeding it through GPT-3.5 to create a Web-app (see Appendix) to demonstrate the summaries that were outputted. We generated summaries based on their degree of comprehensibility – Kid level, College level and Professional (legal) level. For each bill in our sample set, we generated 3 types of summaries and evaluated them. | ||
|
|
||
| Right now we’re using ten bills for testing. We can pull all 6.5k bills using the /Documents endpoint, then passing each BillNumber into the /Documents/{document_number} endpoint. The final goal here would be a csv of bills, with different features so that we can do EDA and eventually use to feed into our models. | ||
|
|
||
|
|
||
| We noticed that in most of the bills the models were just summarizing the bills vaguely and not including important details such as the main amendment the bill was making, the sector the bill was affecting (ex:Automotive industry, Home, etc), the city or town the bill is affecting and other important information. In addition to that, we noticed that as we decreased the degree (College level to Kid level), the model got less specific and gave more vague summaries that did not relate to the specific key point of the bill but talked more about the general issue that it was tackling. As to improve, we will experiment with more prompts making sure summaries can capture main ideas. For example, we can give a large language model a persona or a role such as attorney and be specific on the requirements. | ||
|
|
||
| 1. **Research Methods/tools for Improvement and Evaluation of Summaries** | ||
|
|
||
| We have included the summary of one interesting research paper that has to deal with the evaluation of the quality of summaries based on a method that relies on reference summaries created by humans. | ||
|
|
||
| **"ROUGE: A Package for Automatic Evaluation of Summaries" by Chin-Yew Lin:** | ||
|
|
||
| Link : [https://aclanthology.org/W04-1013.pdf](https://aclanthology.org/W04-1013.pdf) | ||
|
|
||
| (Summary of Paper Generated by SciSummary Tool) | ||
|
|
||
| This paper introduces ROUGE (Recall-Oriented Understudy for Gisting Evaluation), a toolkit used for the evaluation of automatic summarization and machine translation software. The focus of ROUGE is to determine the quality of summaries by comparing them to reference summaries created by humans (usually professional abstractors). The paper emphasizes the importance of recall in summary evaluation, considering the coverage of information as critical. | ||
|
|
||
| ROUGE employs various metrics, including ROUGE-N (overlap of N-grams between the system and reference summaries), ROUGE-L (longest common subsequence), ROUGE-W (weighted longest common subsequence), and others. These metrics provide different perspectives for assessing the content similarity between generated and reference summaries. Experiments using ROUGE on different summarization tasks have demonstrated its efficacy and correlation with human judgments, validating its utility as an automatic evaluation method for various kinds of summaries (extractive, abstractive, single-document, or multi-document). The paper concludes that ROUGE is a valuable, scalable, and reliable tool in the development and assessment cycle of automatic summarization systems. | ||
|
|
||
| **V. Conclusion** | ||
|
|
||
| Based off of our current findings and knowledge, we have one major takeaway which is to drive focus towards generating summaries that have the key important details such as the main amend the bill was making, the sector the bill was affecting (ex:Automotive industry, Home, etc), the city or town the bill is affecting and other important information. We hope to research more evaluation methods and techniques that will help us achieve this goal in the context of legal documents. | ||
|
|
||
| **Works Cited / Sources / Appendix** | ||
|
|
||
| **Sources for :** Figure 1 : Comparison of LLMs and methods based on key evaluation metrics (Numbered 1-11 as shown on Figure 1) | ||
|
|
||
| 1. Brown, T. B., et al. (2020). Language Models are Few-Shot Learners. OpenAI Blog. Link: [https://arxiv.org/abs/2005.14165](https://arxiv.org/abs/2005.14165) | ||
| 2. OpenAI API Documentation. Link: [https://beta.openai.com/docs/](https://beta.openai.com/docs/) | ||
| 3. Yang, Z., et al. (2019). XLNet: Generalized Autoregressive Pretraining for Language Understanding. Link: [https://arxiv.org/abs/1906.08237](https://arxiv.org/abs/1906.08237) | ||
| 4. XLNet Documentation, Hugging Face. Link: [https://huggingface.co/transformers/model_doc/xlnet.html](https://huggingface.co/transformers/model_doc/xlnet.html) | ||
| 5. LLAMA: A Multi-Task Meta Learning Approach for Few-Shot Classification, 2021. Link: [https://arxiv.org/abs/2112.01547](https://arxiv.org/abs/2112.01547) | ||
| 6. Devlin, J., et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Link: [https://arxiv.org/abs/1810.04805](https://arxiv.org/abs/1810.04805) | ||
| 7. BERT Documentation, Hugging Face. Link: [https://huggingface.co/transformers/model_doc/bert.html](https://huggingface.co/transformers/model_doc/bert.html) | ||
| 8. Raffel, C., et al. (2019). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Link: [https://arxiv.org/abs/1910.10683](https://arxiv.org/abs/1910.10683) | ||
| 9. T5 Documentation, Hugging Face. Link: [https://huggingface.co/transformers/model_doc/t5.html](https://huggingface.co/transformers/model_doc/t5.html) | ||
| 10. Vaswani, A., et al. (2017). Attention Is All You Need. Link: [https://arxiv.org/abs/1706.03762](https://arxiv.org/abs/1706.03762) | ||
| 11. Custom Training of Transformers, Hugging Face. Link:[https://huggingface.co/transformers/custom_datasets.html](https://huggingface.co/transformers/custom_datasets.html) | ||
|
|
||
| **More Article Sources for LLMs + Implementation methods:** | ||
|
|
||
| [https://medium.com/analytics-vidhya/text-summarization-using-bert-gpt2-xlnet-5ee80608e961](https://medium.com/analytics-vidhya/text-summarization-using-bert-gpt2-xlnet-5ee80608e961) | ||
|
|
||
| [https://medium.com/@ps.augereau/the-power-of-named-entity-recognition-ner-with-llm-2ff413360c5#:~:text=It%20refers%20to%20the%20method,understanding%20and%20analyzing%20text%20data](https://medium.com/@ps.augereau/the-power-of-named-entity-recognition-ner-with-llm-2ff413360c5#:~:text=It%20refers%20to%20the%20method,understanding%20and%20analyzing%20text%20data). | ||
|
|
||
| **Appendix** | ||
|
|
||
| GPT 3.5 Web app Demo screenshot | ||
|
|
||
| 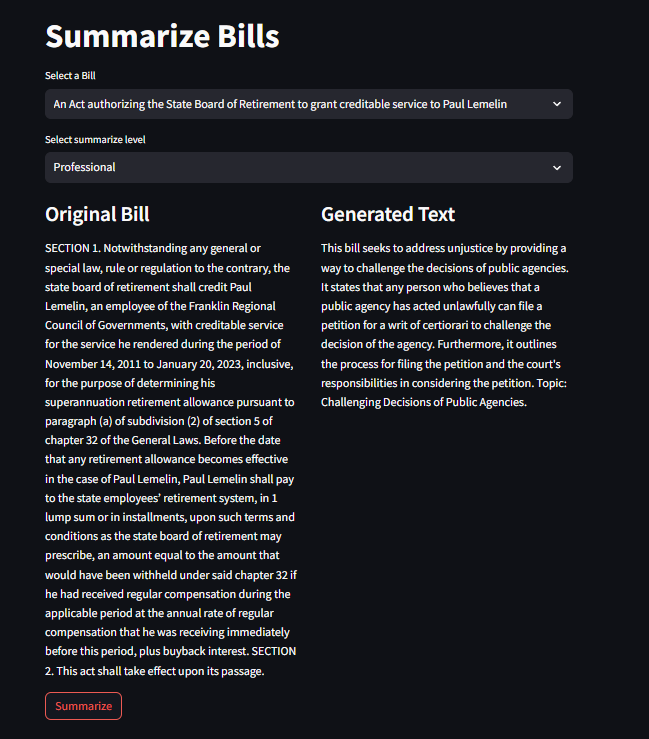 | ||
|
|
||
| 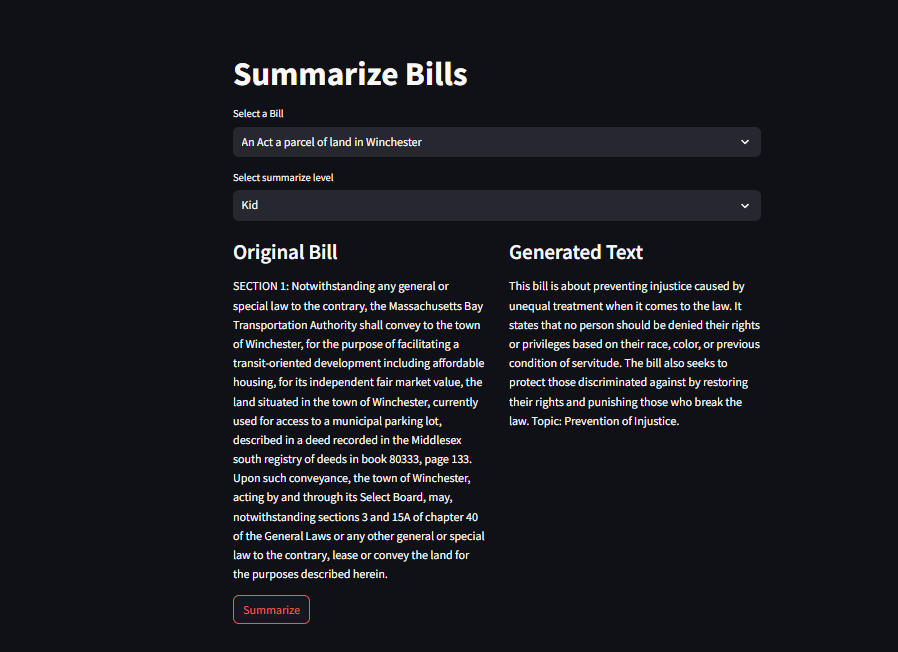 |
Oops, something went wrong.