

The Purpose of this repo is for it to act as a central source of truth for schemas, best practices, and other ad auris engineering relevant documentation. This documentation is to be use by newcomers in onboarding or refreshers for existing members as these are a growing and dynamic set of documents.

- ➤ Engineering Best Practices
- ➤ UX and Engineering
- ➤ Apps
- ➤ Architecture
- ➤ Databases
- ➤ Data Culture and Best Practices
- ➤ Agile Methodology
- ➤ Tools
- ➤ Environment Setup
- ➤ Branching Strategy
- ➤ Resources
- ➤ Glossary
- Technical Values
- Technical Priorities
- Process Priorities
- Architectural Priorities
- System Architecture
- Coding Guidelines
- Key Protocols
KISS - Keep It Simple Stupid - Complexity is our enemy. We need to solve the complexity inherent in the problems we face using simple solutions, and avoid introducing complexity that isn't inherent. Solution complexity is rejected, rather than dealt with. We ask 5 whys about complexity. What can be relaxed or changed to make the complexity go away?
YAGNI - You Ain't Gonna Need It - This is the answer to much introduced complexity. We force complexity upon ourselves by being so good at asking "But what if...?" Instead, we build for the problems we have today, not for the problems we think we might have someday. None of us are fortune tellers. We're mostly wrong.
No Punting - No one owns an app, a system a section of code, or a problem. We don’t punt issues off to others just because we weren't involved in the inception. Everyone works on, and fixes everything. Not knowing how something works doesn't mean you don’t work on it or fix it, it means the opposite! We seek out every opportunity to work on things we don't know about (and we fill in any missing documentation as we learn). Everyone on the team is full-stack. No specialists.
- Simple & DRY with a single responsibility
- Simple - see KISS and YAGNI above.
- DRY - Don't Repeat Yourself - there's no place for copy and paste. It inevitably bites you in the ass.
- Single Responsibility - units of software do 1 thing well, and only 1 thing. This is fractal and applies to lines of code, functions, classes, services, systems, and apps.
- Transparent & manageable - logs, analytics, error reporting, separation of config from code, and real-time adjustments are good
By following these 2 top technical priorities, we get two important emergent properties: robustness and scalability while being able to maintian speed of shipping 🛳️
Our full set of technical priorities, in order:
- Speed to Market
- Simple & DRY with a single responsibility
- Transparent & manageable
- Consistent
- Documented
- Tested
Developers are held accountable to these technical priorities. Code reviews are structured around these technical priorities.
Living these priorities requires hard thinking about the technical problems we face. Code that works is not the goal. Code that works by embodying these priorities, and the appropriate trade-offs between them, is the goal.
Production code gets tested. Tests run in continuous integration (CI). Not all code needs all kinds of tests (unit, integration, system, acceptance, ...). Pragmatism still rules and strict test-driven development (TDD) is not important to us (we prefer our own acronym of TDD, thinking-driven development), but automated test development is a core skill of all our developers and test automation is a key consideration in code reviews.
All services do their best to trap and report errors. Error handling and alerting is a key consideration in code reviews.
Deployment is automated. It's not done until it ships with automated deployment. It ships as soon as possible. Risk is mitigated by shipping small changes incrementally.
All developers write documentation. Documentation is part of code review: did the appropriate docs get created and updated for the addition/change?
Documentation is well-organized. Even when good docs exist, if the person that needs them doesn't know where they are or that they exist, they do no good.
Code is documented. Comments are good! It can be good to comment on why this code is doing what it's doing but writing code that is clear and talks for itself is BETTER . It’s also important to comment on what the code is doing, when that's not completely obvious.
We build services, not monoliths. Services compose in architecturally sound ways to deliver services to layers higher up the stack.
Libraries are better than micro-frameworks, which are better than monolithic frameworks.
Observers are better than Pub/Sub, which is better than Queued Data Pipelines, which are better than Synchronous Services. Observers and queues are more robust than synchronous services (e.g. HTTP) and should be preferred where appropriate.
We use the right language for the job. We are a polyglot team. We prefer polyglot developers who have learned how to efficiently learn new things.
The right language for the job is generally obvious due to a language feature or library implemented in the language that makes the job a much easier match for our technical priorities. The job becomes much simpler, or more robust, or easier to test, etc.
If the job is general purpose utility computing with no language feature or library advantages, we use JavaScript as our default.
We're much more interested in ensuring code follows the values and priorities described above than that it follows any particular coding standard. Code formatting is just the small tip of a very large iceberg; poorly formatted code can be programmatically tidied, but poorly done thinking can't be programmatically rethought. That being said, here are some code guidelines we look for:
- Do your best to conform to the coding style that's already there in the repository... That means we like it.
- Use 2 soft spaces for indentation for white space irrelevant code/data. Use 4 soft spaces for white space relevant code/data.
- Don't leave trailing spaces after lines.
- Don't leave trailing new lines at the end of files.
- Write clean code. Clean code means less comments. And comments lie. Clean code is good.
- Write tests. Tests are good.
- Don't submit über pull requests, keep your changes focused and atomic. They should be representative of a Jira Ticket.
- Submit pull requests to the
mainlinebranch of repos. - Have fun!
The purpose of the pull request process is to ensure code and product quality. The reviewer has 2 important responsibilities: code quality via code review, and product quality via QA of the change, ensuring both that the new functionality or fix works as expected and that other related parts of the product haven't regressed.
- The creator of the pull request is responsible for adequately describing the change being made. The main components of the description are what changed, how it changed, and why it changed, and what steps were taken to fully QA the change.
- The creator of the pull request marks them-self as the assignee, which signifies they are the primary submitter of the change and will be the one to respond to reviewer's question, comments and requests for changes. If at some point another developer becomes the primary contributor of the change, the assignee is changed.
- At this point though, the PR is not yet ready for review, it may still be in progress. Once it is ready to be reviewed, the assignee adds the label "ready for review". In the unusual case that the assignee wants the PR reviewed by a specific developer, they can also assign that developer with the reviewer field. NB: This is not usually done and you need a good reason to want a specific reviewer.
- At this point, any other developer that sees the PR should do the review, assigning themself with the reviewer field, removing the "ready for review" label, and labeling it with "reviewing". The reviewer reviews the code and performs QA, repeating the steps provided in the PR description and thinking critically about what additional QA steps may have been missed by the assignee.
- Now the usual back and forth commences between the assignee and the reviewer consisting of questions, comments, ideas, requests, suggestions and changes. NB: Reviews are about the code, not about the people, as an assignee, try to remain objective and not take anything from the reviewer personally, and as a reviewer, be kind and stay focused on the code.
- Once the code is in a place that both the assignee and reviewer are happy with it, it is the assignees responsibility to merge the PR and get the code deployed into production. Any special notes on deployment steps or dependencies should be included in the PR for the reviewer.
👨🏭 Self QA Protocol
This section applies to when you work with enterprise customizations or any services that directly affects text ingestion or audio output.
This section is intended to communicate the self-QA process client custom requests and to reduce narration related bugs.
These tests are E2E in nature and will require some manual testing but regression tests are highly encouraged as bugs or idiosyncracies are found.
- Initial Filtering for issues as a foundation
- After receiving a Jira card, first and foremost it’s important we can communicate any expected (or suspected) issues and/or high effort/time required for the request.
- If issue suspected, etc., communicate that on the Jira card and to the relevant stakeholder
- After receiving a Jira card, first and foremost it’s important we can communicate any expected (or suspected) issues and/or high effort/time required for the request.
- Using multiple articles to test with
- After coding up required specs, test with multiple articles (a large enough sample size at your discretion).
- While we have encountered edge cases on many of the requests, at the very least we both record what those are, and communicate it on the Jira card and to relevant stakeholder.
- Record the # of articles tested as well as the associated URLS
- After coding up required specs, test with multiple articles (a large enough sample size at your discretion).
- Listen to the article and follow along the article
- Ensure the audio matches both the article and the required specs.
- E2E tests (Emulating User Behavior)
- it’s important that we test beyond postman and instant, we should be testing with the aforementioned and as well as RSS of course.
- Record any abnormal behavior on Jira card.
- Repairing Narrations
- Ensure that the affected narration(s) are re-narrated if there was an issue due to a bug. Refresh the a given publication’s narrations by at least 24 hours.
- We have a script in RSS service or use the Internal tool to refresh a given publication's narrations.
- Confirmation of completion
- when pushed (or card moved to done) communicate final QA results and readiness to relevant stakeholder.
-
Communicate effort/time of a customization
-
Use multiple articles to test with
-
listen the narration and follow along article
-
E2E tests (Emulating User behavior)
-
Repairing narrations (re-narrate)
-
Confirm completion
At a high level
-
No ad-hoc pushing straight to master/main (usually locked)
-
Merges done develop/staging branch
-
Some Tests must be written for the new code unless otherwise specified
-
CodeShip will block pushes to master/main that have tests that fail
-
Pushes to master/main requires PR by someone on the team.
At Ad Auris, if you're a frontend dev or even a full-stakc dev and you're working on some frontend related task, inherently, you adopt the responsibilities of a UX Engineering. Those responsibilities being:
- Transform the design language into a component library, coded in a framework or library
- Promote the adoption of the design system throughout the organization
- Turn low-fidelity designs into high-fidelity prototypes using the component library
- Improve communication and collaboration between the engineering and design team
A few rules of thumb for both designers and engineers (UX, FE):
- Designers need to think beyond just delivering the design itself.
- Designers should spend more one-on-one time with engineers.
- Engineers should be familiar with basic fundamentals of designs.

As you can see here, as a front-end dev you must go beyond the code and be hyper aware about the true objectives and requirements of any frontend project. This is typically represented by the responsibilties a front end dev has with UX engineering, and that is where the collaboration overlap rests with the UX designer.
From business requirements to release.
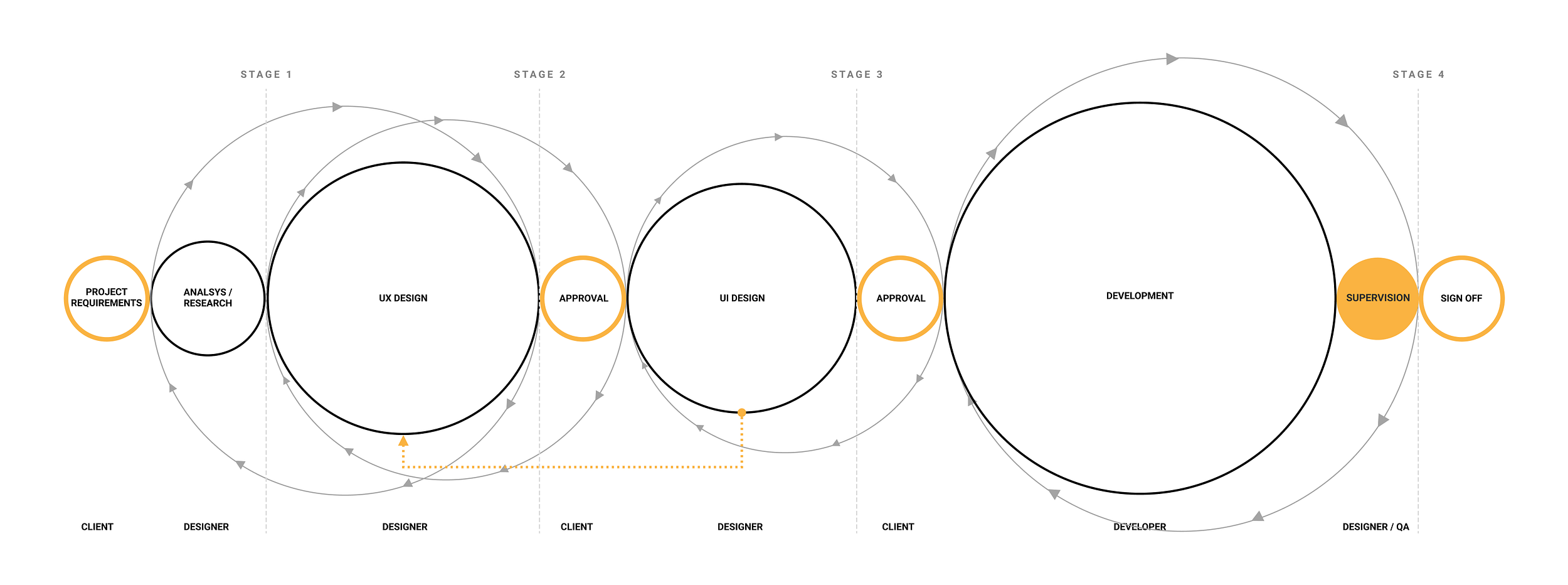
THe main point of this chart is to show how there are multiple iterative steps along the development process where key communication and wokrflow points exist for design and eng teams.
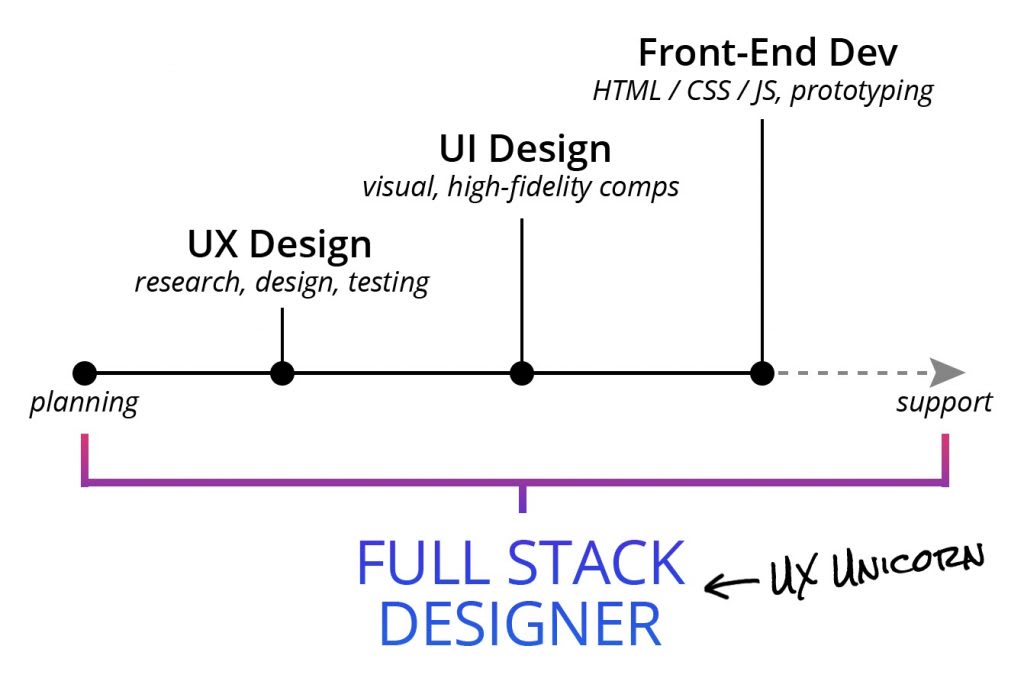
At Ad Auris, wheather you're a front end dev, or a full-stack dev on a frontend project, we inherently must become UX Unicorn, or rather a full-stack designer. That means having the sufficient understanding of the given projects UX design, UI design, and of course the dev implementation. By being a UX unicorn it means you can better iterate on projects, address user pain points with much more finesse, and an overall more robust peice of shipped software.
(Client or Sales Facing)
Ad Auris uses a distributed & serverless microservices architecture. Many services provide access to themselves via HTTPS. Others provide their services through the Cloud Scheduler/Cron Jobs. Endpoints are not authenticated at this time so don't worry about JWT request tokens.
.jpg)
- Business Logic Layer (🔑 Key Schema)
- Microservices Layer (🔑 Key Schema)
- Play App Wireframe
- Global Company (and legacy) Wireframe
- Pipeline Revamp Wireframe
SQL - Operational DB (🔑 key DB)
Mongo - Events Database (🔑 key DB)
Firestore - Stripe and Admin Database
Segment - Customer Data Platform (CDP) (Not active yet)- SQL Schema (🔑 Key Schema) (password is adauris2021)
- MongoDB Wireframe
- Firestore
- Segment
- Data Tracking Sheet (🔑 Key Schema)
At its core, Data Governance is a schema or robust set of instructions for capturing high-quality data and ensuring standards are maintained across the collection and the cleaning of data.
To succeed with data governance, teams must ensure data across all your business units and products stay clean and consistent.
A properly executed Data Governance strategy prevents the inconsistent and unactionable data issues we talked about in previous lessons!
Three core aspects: Quality, Access, and Data Control.
Establish and enforce standards (such as naming conventions) for all incoming data. Do this by creating a Tracking Plan, sharing it with other teams, and getting buy-in for it from around your organization.
Limit who can modify your data (for example, a member of your team might only need read-only access to your data).
Map out which data goes to which downstream tools, to prevent any duplication or data clutter.
With one or more of these facets missing, a company faces something called the Data Wheel of Death. While companies of all types face this, startups must pay special care as they build their data from the ground up and it can result in delayed projects, bad business and product decisions, and once the wheel gains enough inertia, it can become very difficult to spin out of, which ultimately leads to death (death of data or death of features/product)
.png)
-
Due to no schema standards or restrictions in Mongo, we have a lot of unusable documents
-
Due to ill-configured implementation on narration creation date collection, that data is deeply flawed (represents attempts of creation no true success) that it’s become totally unusable on Mongo side.
-
The IsReturned data point in Mongo is quite off and there are 10s of thousands of documents with this deeply flawed data point
-
One dev did not push the charCounter data collection metric causing a no data scenario in the ttsCharDB, no data governance structure meant this slipped right past us as no clear protocol of tracking.
-
The inconsistent naming convention among SQL, Mongo, Firestore, and GA makes it a very difficult task of creating true user data personas (pub user and end listener) and the ability to connect data across the different databases. Even with Segment, without unified naming conventions and standards, nothing can save us here depending on severity.
-
On the business side, without a lack of clear business use cases, or data points tied to OKRs, the wrong or incomplete data is collected sometimes as well.
At Ad Auris, we adopt the best practices of agile methodology to develop and iterate on our product.
Generally, this is a multi stage process that requires multiple stakeholders at one point or another, be it tech, product, design, and data.
Sprints are a staple of development, and our unifiying work stream.
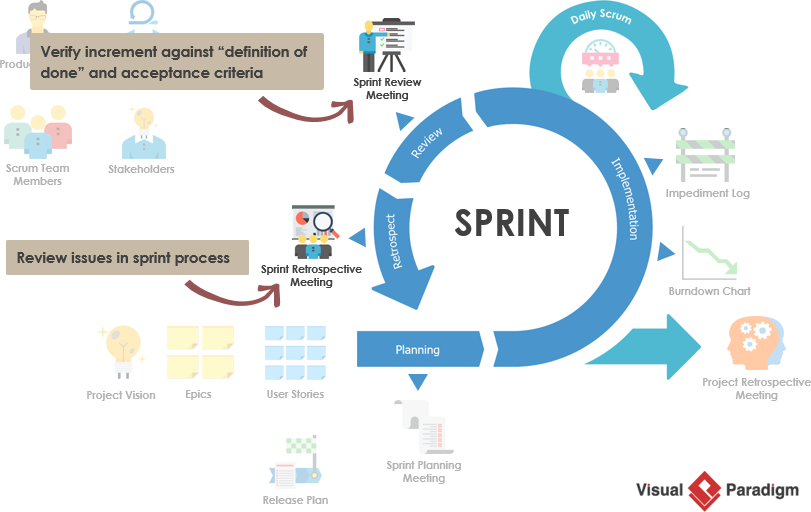
- Research
- This can be from product, tech, sales, etc. where we discover areas of opportunity for growth, addressing user pain points, or improving our software.
- Ideation & Prioritization
- Before a sprint can start there is an ideation and prioriization phase where we ensure this endeavor will bring us closer to 1 or more of our 3 mission critical objectives. Those being:
- Most Engaging Audio
- Furthest Distribution
- Ease of Integration
- Product and Business Requirement scoping
- This is where the business side sets the overall scoping, and the problems we are to solve without biasing on implementation as much as possible
- Initial Technical Specification Scoping
- A foundational layer for scoping the specs, solutions, pathways, etc are developed.
- Engineering Team Brainstorm
- Eng then brainstorms and iterates on the inital tech scoping to find the most optimal path for success given the business and technical constraints/requirements.
- Final Tech Spec Sheet is written up
- Breakdown of Tasks
- We as a team parse through the spec sheet and break down tasks on an aggregate and indiviual level.
- Tickets issued on Jira (Epics, stories, tasks)
- Estimation of Development
- Once tasks are set we as a team and individually we scope and set estimation for deliverables.
- Sprint Kickoff
- Team rallys during the Sprint kickoff and we do final prioritization and selection of sprint tickets
- Hit the ground
- This when the coding actually begins and the development period is set
- Feedback Loop
- During the sprint it's key we get feedback on what we're building.
- We'll give half developed demos to product for their feedback
- Feedback on the code itself (via PRs or informal dicussions)
- Challenge assumptions and micro-pivot on implementation if a new and better pathway is found
- During the sprint it's key we get feedback on what we're building.
- QA & Testing
- We'll self-Quality Assure our own tasks as we go but the team will also be providing peer QA where necessary.
- We ensure we try to follow some form of testing framework, generally TDD but read Engineering Best Practices on more on this.
- Final Merge to production
- Product Develivered
- Sprint Retro
- Here we discover what went well, what needs improvement, and iterate on the process all together. Each sprint is different as we improve.

As you can see with the agile development framework, it cyclically flows in line with the sprint framework. Infact, one can argue that sprints are really developed around its heart which is agile development.
We are startup of self-organizing teams. This is critical❗ 

- Mangers are servent leaders
- Customer Driven
- Decentralization when possible is preferred under the guise of a unified goal
- Continuous improvement
At Ad Auris, we use a t-shirt size system and correlate them to rough story points in the form of fibonaci sizing. We equate to story points for high fidelity of work tracking data on Jira. The most important aspect here is understanding the t-shirt sizes.
- XXS = 10 min - 1 hour = 0.5 points
- XS = Couple of hours = 1 point
- S = ~1 day = 2 points
- M = ~2-3 days = 3-5 points
- L = ~4-5 days = 6-7 points
- XL = ~1 week+ (6-7 days) = 10+ points
- XXL = ~1.5 weeks = 14+ points
- XXXL = ~2 weeks = 18+ points
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
As we are a fast moving team we use set of tools that enables to communicate sync and async where appropiate.
- We have a very responsive team and have various lines of communication.
- Overall, a healthy combination of asynchronous and direct communication
- Slack is our primary source of P2P comms and everyone can expect a pretty fast and meaningful response from anyone on the team.
- Asynchronously, we communicate via Confluence docs, Jira Tickets (comments), PRs, and API interfaces.
- We have engineering daily scrums
- Everyone occasionally puts together a presentation and teaches the team something or present something relevant to the current build
- Optional 1 - 2 days a week we'll work together in person at WeWork
- Slack (Direct Comms)
- If Slack goes down we'll hop over to Discord
- Google Meets + Zoom (Zooms are for all hands usually)
- Jira (For Ticketing tasks)
- Confluence + Notion (Documentation and Company/Product Sheets)
- dbdiagram (SQL Schmea Designing)
- draw.io || Lucid (for database schema and architecture designing)
- PRs of course and PR code comment threads
Currently, each service has it's own environment set up but there are a few major environment set up patterns. These environment patterns are:
- Localized Node JS (or with React)
- Dockerized Node or Python Applications
- Herokuized Applications
Other than heroku, our serverless microservices generally sit atop GCP Cloud Functions & Cloud Run where we iteract with development and production environments via a cloubuild.yaml and/or a Dockerfile.
The purpose of this section is to outline Ad Auris's git branching strategy for optimized continuous delivery of code. At a high leve we follow an environment branching strategy. We also fluidly follow these practices of branch naming convetions
We avoid commiting directly to our environment branches and we merge our feature & other development branches into the environment branches.
-
Production Branches:
- main/master
- (if greenfield project default to main)
- Pushes to main/master will typically redploy the production service
-
Staging Branch:
- Staging
- Pushes to staging will typically redploy the staging version of the service
- This is used for final QA of a service's new changes, post-PR Approval
-
Develop Branches:
- For our microservices in particular We typically don't use a trunk develop branch but we branch off staging to create a dev specific development branch
- naming convention should follow:
- feature/XYZ
- E.G: feature/integrate-rssparser
- For our Full Stack Apps such as the Dashboard, Play App, Narration Widget, and Internal Tool the develop branch plays a key role.
- Devs should be branching off from develop, creating feature branches, and PR back into Develop.
- Dev Branches off develop
- Dev Creates feature/podcast-page-update
- Dev finishes task and creates a PR back into Develop
- Pending Approval, code is merged into develop
- For QA of final project/update etc, we do a final project QA off of "staging" branch.
- Bug is identified in QA so then Dev creates a branch called bugfix/XYZ off of develop
- Pending Approval, code is remerged again into staging
- Finally, the production environment branch is updated and feature is live & in production!
- https://sairamkrish.medium.com/git-branching-strategy-for-true-continuous-delivery-eade4435b57e
- https://dev.to/couchcamote/git-branching-name-convention-cch
Some of Ad Auris' Engineers' favorite books that will help guide you in our development process and for overall success.
- Web scalability for startup engineers - tips & techniques for scaling your Web application
- A Handbook of Agile Software Craftsmanship By Robert C Martin
- Web Dev Skills Map
- Came across a particular concept you don't quite understand or need a refresher? At a high level this covers most of what you'll need to know as a web dev.
A Log of commonly used terms and acronyms at Ad Auris
- CT = Customization Template
- Sprint = Focused Build Period
- GAM = Google Ad Manager
- GCP = Google Cloud Platform
- AWS = Amazon Web Services
- DO = Digital Ocean
- PR = Pull Request
- C-Suite = executive team
- SRP = Single Responsbility Principle
- DRY = Don't Repeat Yourself
- end users = listeners, indirect users who listent to our produced audio
- users = the actual direct users such as publications and journalists
- business requirements sheet = the document which the product and technical specifications are developed from
- spec sheet = technical specification doc
- OKRs = Objectives and Key Results
- KPIs = Key Performance Indicators