In recent few months, the Large Language Models(LLMs) --- in particular ChatGPT --- have swept the world by causing a huge influence on numerous domains. Assisted by the WebUI, open-source models, APIs, or the ecosystem Plugins, these LLMs successfully immerse into everyone's life, worldwide.
This success of LLMs is truly unprecedented. However, at the current stage, LLMs are not perfect and pose numerous potential risks, including difficulties in identifying noisy inputs. These risks, particularly challenging in large-scale applications and deployments, urgently require evaluation. Additionally, the massive and unknown training data of LLMs present a pressing issue in selecting trustworthy evaluation data.
Driven by the above two points, we introduce this automated framework to conduct a systematic evaluation of LLMs and the data. We hope this can be helpful to build a more reliable evaluation system.
- Motivation
- Repo Structure
- Installation
- Data Format
- Evaluation on Benchmarks
- Benchmarks
- Contribution
- Paper
- Citation
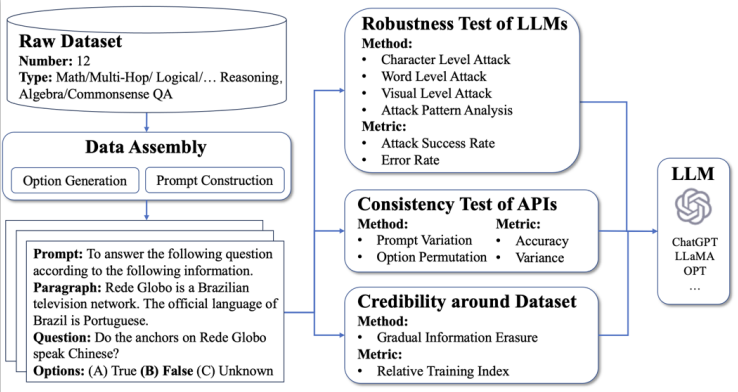
We open-source this tool and framework to assess LLM's performance and identify potential limitations. Our works cover three new terms of Robustness, Consistency, and Credibility.
- Robustness focuses on examining LLMs' ability to handle adversarial examples, aligning with real-world deployment scenarios.
- Consistency aims to measure the distinction in LLMs' responses to semantically similar inputs.
-
$\textsf{RTI}$ (Credibility) provides insights into the datasets used to train LLMs. This score reflects the relative probability that the datasets have been memorized by LLMs.
More details are shown in our paper.
- Analysor: scripts for pattern analysis of attacked samples
|- analysis_dep_tag.py
|- analysis_pos_parser.py
- API: script to fetch responses from the ChatGPT API in bulk
|- api.py
- Components
|- attacker.py
|- converter.py
|- generator.py
|- interpreter.py
- DA
|- eda.py
|- token_level_attack.py
|- visual_letter_map.json
- Datasets: benchmark datasets
|- Attacker_out : attacked data primitives benchmark
|- Generator_out : data primitives benchmarks
|- Raw_Data
|- prompt_template.json : standard prompts for consistency evaluation
- Evals: scripts for evaluting from different aspects
|- conEval.py
|- creEval.py
|- get_path.py
|- robEval.py
- Preprocess: scripts for pre-processing the benchmark datasets
|- ecqa.py
|- esnli.py
|- format.py
|- gsm8k_clean.py
|- noah_clean.py
|- qasc.py
|- qed.py
|- senmaking.py
- eval.py: script for evaluation of the output responses of the LLMs
- processor.py: script for generating a questions list as the input of the LLMs
To install our tool, simply run this command:
pip install -e .All code has been successfully tested in the Python 3.10.9 environment.
If you want to evaluate models on our custom dataset, please read this section carefully, otherwise you may choose to skip it.
To facilitate auto-interpretation and auto-evaluation, we define a unified data format --- data primitive (see paper for more details): $$ D=\lbrace\mathbf{x}\rbrace=\lbrace(\mathbf{prompt},\mathbf{p},q,o,a)\rbrace $$ An example is as follows:
{
"id" : {
"passage" : "...",
"sub-qa" : [
{
"question" : "...",
"answer" : "...",
"options" : [
{
"option_type": "...",
"option_describe": "..."
}
]
}
]
}
}where passage denotes the conditions, and sub-qa denotes the sub-questions and corresponding answers connected to the passage.
For datasets withouts options provided, remove the options field.
All the datasets in this repository have been converted to this format. If you need to evaluate models on your custom dataset, please convert your dataset to the above format. You can refer to converter.py for converting raw dataset to the data primitive format (take GSM8K dataset as the example here) :
python converter.py
To evaluate on our benchmarks, first obtain a list of questions using the following command. (change dataset parameter according to different benchmarks) :
-
Robustness or credibility
python processor.py --type robustness credibility -
Consistency
python processor.py --type consistency \ --prompt_dir 'Datasets\prompt_template.json'
Then, feed the question list into a language model, which can be your own model or any publicly available model. And, you need to format the reponse of model as a list:
[['response to Q1 of sample1', 'response to Q2 of sample1', ...], ['response to Q1 of sample2', ...], ...]Also, ChatGPT inference is provided for direct evaluation :
python processor.py --useChatGPT --api_key ['', '']
# provide multiple keys `api_key` to speed up the evaluation processNext, evaluate model outputs (formated) using the following command:
python eval.py \
--response_dir '' \ # the path of the formated reponse list
--file_path '' \ # the path of the data primitive format file.Datasets/* directory stores all datasets as benchmarks tests :
Raw_Data: Raw format datasets;Generator_out: Data primitives format datasets;Attacker_out: Attacked data primitives format datasets;
Related repos:
- API: Reverse engineered ChatGPT API
- Datasets: AQuA | creak | NoahQA | GSM8K | bAbI-tasks | Sen-Making | strategyqa | QASC | e-SNLI | ECQA | QED
- Data augment: eda_nlp | HanLP
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
More details and benchmark results are shown in the paper "Assessing Hidden Risks of LLMs: An Empirical Study on Robustness, Consistency, and Credibility".
Please use the below BibTeX entry to cite this dataset:
@misc{ye2023assessing,
title={Assessing Hidden Risks of LLMs: An Empirical Study on Robustness, Consistency, and Credibility},
author={Wentao Ye and Mingfeng Ou and Tianyi Li and Yipeng chen and Xuetao Ma and Yifan Yanggong and Sai Wu and Jie Fu and Gang Chen and Haobo Wang and Junbo Zhao},
year={2023},
eprint={2305.10235},
archivePrefix={arXiv},
primaryClass={cs.LG}
}