diff --git a/CITATION.cff b/CITATION.cff
index 62b75a422a..3e0106f767 100644
--- a/CITATION.cff
+++ b/CITATION.cff
@@ -1,8 +1,8 @@
-cff-version: 1.2.0
-message: "If you use this software, please cite it as below."
-authors:
- - name: "MMPose Contributors"
-title: "OpenMMLab Pose Estimation Toolbox and Benchmark"
-date-released: 2020-08-31
-url: "https://github.com/open-mmlab/mmpose"
-license: Apache-2.0
+cff-version: 1.2.0
+message: "If you use this software, please cite it as below."
+authors:
+ - name: "MMPose Contributors"
+title: "OpenMMLab Pose Estimation Toolbox and Benchmark"
+date-released: 2020-08-31
+url: "https://github.com/open-mmlab/mmpose"
+license: Apache-2.0
diff --git a/LICENSE b/LICENSE
index b712427afe..a17f705f20 100644
--- a/LICENSE
+++ b/LICENSE
@@ -1,203 +1,203 @@
-Copyright 2018-2020 Open-MMLab. All rights reserved.
-
- Apache License
- Version 2.0, January 2004
- http://www.apache.org/licenses/
-
- TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
-
- 1. Definitions.
-
- "License" shall mean the terms and conditions for use, reproduction,
- and distribution as defined by Sections 1 through 9 of this document.
-
- "Licensor" shall mean the copyright owner or entity authorized by
- the copyright owner that is granting the License.
-
- "Legal Entity" shall mean the union of the acting entity and all
- other entities that control, are controlled by, or are under common
- control with that entity. For the purposes of this definition,
- "control" means (i) the power, direct or indirect, to cause the
- direction or management of such entity, whether by contract or
- otherwise, or (ii) ownership of fifty percent (50%) or more of the
- outstanding shares, or (iii) beneficial ownership of such entity.
-
- "You" (or "Your") shall mean an individual or Legal Entity
- exercising permissions granted by this License.
-
- "Source" form shall mean the preferred form for making modifications,
- including but not limited to software source code, documentation
- source, and configuration files.
-
- "Object" form shall mean any form resulting from mechanical
- transformation or translation of a Source form, including but
- not limited to compiled object code, generated documentation,
- and conversions to other media types.
-
- "Work" shall mean the work of authorship, whether in Source or
- Object form, made available under the License, as indicated by a
- copyright notice that is included in or attached to the work
- (an example is provided in the Appendix below).
-
- "Derivative Works" shall mean any work, whether in Source or Object
- form, that is based on (or derived from) the Work and for which the
- editorial revisions, annotations, elaborations, or other modifications
- represent, as a whole, an original work of authorship. For the purposes
- of this License, Derivative Works shall not include works that remain
- separable from, or merely link (or bind by name) to the interfaces of,
- the Work and Derivative Works thereof.
-
- "Contribution" shall mean any work of authorship, including
- the original version of the Work and any modifications or additions
- to that Work or Derivative Works thereof, that is intentionally
- submitted to Licensor for inclusion in the Work by the copyright owner
- or by an individual or Legal Entity authorized to submit on behalf of
- the copyright owner. For the purposes of this definition, "submitted"
- means any form of electronic, verbal, or written communication sent
- to the Licensor or its representatives, including but not limited to
- communication on electronic mailing lists, source code control systems,
- and issue tracking systems that are managed by, or on behalf of, the
- Licensor for the purpose of discussing and improving the Work, but
- excluding communication that is conspicuously marked or otherwise
- designated in writing by the copyright owner as "Not a Contribution."
-
- "Contributor" shall mean Licensor and any individual or Legal Entity
- on behalf of whom a Contribution has been received by Licensor and
- subsequently incorporated within the Work.
-
- 2. Grant of Copyright License. Subject to the terms and conditions of
- this License, each Contributor hereby grants to You a perpetual,
- worldwide, non-exclusive, no-charge, royalty-free, irrevocable
- copyright license to reproduce, prepare Derivative Works of,
- publicly display, publicly perform, sublicense, and distribute the
- Work and such Derivative Works in Source or Object form.
-
- 3. Grant of Patent License. Subject to the terms and conditions of
- this License, each Contributor hereby grants to You a perpetual,
- worldwide, non-exclusive, no-charge, royalty-free, irrevocable
- (except as stated in this section) patent license to make, have made,
- use, offer to sell, sell, import, and otherwise transfer the Work,
- where such license applies only to those patent claims licensable
- by such Contributor that are necessarily infringed by their
- Contribution(s) alone or by combination of their Contribution(s)
- with the Work to which such Contribution(s) was submitted. If You
- institute patent litigation against any entity (including a
- cross-claim or counterclaim in a lawsuit) alleging that the Work
- or a Contribution incorporated within the Work constitutes direct
- or contributory patent infringement, then any patent licenses
- granted to You under this License for that Work shall terminate
- as of the date such litigation is filed.
-
- 4. Redistribution. You may reproduce and distribute copies of the
- Work or Derivative Works thereof in any medium, with or without
- modifications, and in Source or Object form, provided that You
- meet the following conditions:
-
- (a) You must give any other recipients of the Work or
- Derivative Works a copy of this License; and
-
- (b) You must cause any modified files to carry prominent notices
- stating that You changed the files; and
-
- (c) You must retain, in the Source form of any Derivative Works
- that You distribute, all copyright, patent, trademark, and
- attribution notices from the Source form of the Work,
- excluding those notices that do not pertain to any part of
- the Derivative Works; and
-
- (d) If the Work includes a "NOTICE" text file as part of its
- distribution, then any Derivative Works that You distribute must
- include a readable copy of the attribution notices contained
- within such NOTICE file, excluding those notices that do not
- pertain to any part of the Derivative Works, in at least one
- of the following places: within a NOTICE text file distributed
- as part of the Derivative Works; within the Source form or
- documentation, if provided along with the Derivative Works; or,
- within a display generated by the Derivative Works, if and
- wherever such third-party notices normally appear. The contents
- of the NOTICE file are for informational purposes only and
- do not modify the License. You may add Your own attribution
- notices within Derivative Works that You distribute, alongside
- or as an addendum to the NOTICE text from the Work, provided
- that such additional attribution notices cannot be construed
- as modifying the License.
-
- You may add Your own copyright statement to Your modifications and
- may provide additional or different license terms and conditions
- for use, reproduction, or distribution of Your modifications, or
- for any such Derivative Works as a whole, provided Your use,
- reproduction, and distribution of the Work otherwise complies with
- the conditions stated in this License.
-
- 5. Submission of Contributions. Unless You explicitly state otherwise,
- any Contribution intentionally submitted for inclusion in the Work
- by You to the Licensor shall be under the terms and conditions of
- this License, without any additional terms or conditions.
- Notwithstanding the above, nothing herein shall supersede or modify
- the terms of any separate license agreement you may have executed
- with Licensor regarding such Contributions.
-
- 6. Trademarks. This License does not grant permission to use the trade
- names, trademarks, service marks, or product names of the Licensor,
- except as required for reasonable and customary use in describing the
- origin of the Work and reproducing the content of the NOTICE file.
-
- 7. Disclaimer of Warranty. Unless required by applicable law or
- agreed to in writing, Licensor provides the Work (and each
- Contributor provides its Contributions) on an "AS IS" BASIS,
- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
- implied, including, without limitation, any warranties or conditions
- of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
- PARTICULAR PURPOSE. You are solely responsible for determining the
- appropriateness of using or redistributing the Work and assume any
- risks associated with Your exercise of permissions under this License.
-
- 8. Limitation of Liability. In no event and under no legal theory,
- whether in tort (including negligence), contract, or otherwise,
- unless required by applicable law (such as deliberate and grossly
- negligent acts) or agreed to in writing, shall any Contributor be
- liable to You for damages, including any direct, indirect, special,
- incidental, or consequential damages of any character arising as a
- result of this License or out of the use or inability to use the
- Work (including but not limited to damages for loss of goodwill,
- work stoppage, computer failure or malfunction, or any and all
- other commercial damages or losses), even if such Contributor
- has been advised of the possibility of such damages.
-
- 9. Accepting Warranty or Additional Liability. While redistributing
- the Work or Derivative Works thereof, You may choose to offer,
- and charge a fee for, acceptance of support, warranty, indemnity,
- or other liability obligations and/or rights consistent with this
- License. However, in accepting such obligations, You may act only
- on Your own behalf and on Your sole responsibility, not on behalf
- of any other Contributor, and only if You agree to indemnify,
- defend, and hold each Contributor harmless for any liability
- incurred by, or claims asserted against, such Contributor by reason
- of your accepting any such warranty or additional liability.
-
- END OF TERMS AND CONDITIONS
-
- APPENDIX: How to apply the Apache License to your work.
-
- To apply the Apache License to your work, attach the following
- boilerplate notice, with the fields enclosed by brackets "[]"
- replaced with your own identifying information. (Don't include
- the brackets!) The text should be enclosed in the appropriate
- comment syntax for the file format. We also recommend that a
- file or class name and description of purpose be included on the
- same "printed page" as the copyright notice for easier
- identification within third-party archives.
-
- Copyright 2018-2020 Open-MMLab.
-
- Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License.
- You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software
- distributed under the License is distributed on an "AS IS" BASIS,
- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- See the License for the specific language governing permissions and
- limitations under the License.
+Copyright 2018-2020 Open-MMLab. All rights reserved.
+
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright 2018-2020 Open-MMLab.
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/MANIFEST.in b/MANIFEST.in
index c6d3090b1c..317437fc9c 100644
--- a/MANIFEST.in
+++ b/MANIFEST.in
@@ -1,6 +1,6 @@
-include requirements/*.txt
-include mmpose/.mim/model-index.yml
-include mmpose/.mim/dataset-index.yml
-recursive-include mmpose/.mim/configs *.py *.yml
-recursive-include mmpose/.mim/tools *.py *.sh
-recursive-include mmpose/.mim/demo *.py
+include requirements/*.txt
+include mmpose/.mim/model-index.yml
+include mmpose/.mim/dataset-index.yml
+recursive-include mmpose/.mim/configs *.py *.yml
+recursive-include mmpose/.mim/tools *.py *.sh
+recursive-include mmpose/.mim/demo *.py
diff --git a/MYREADME.md b/MYREADME.md
new file mode 100644
index 0000000000..632fb6317b
--- /dev/null
+++ b/MYREADME.md
@@ -0,0 +1,38 @@
+# OCTSB1
+```
+11/23 03:46:19 - mmengine - INFO - Epoch(train) [1258][100/163] lr: 1.000000e-05 eta: 0:03:22 time: 0.520031 data_time: 0.012644 memory: 14376 loss: 0.000183 loss/heatmap: 0.000112 loss/displacement: 0.000071
+11/23 03:46:23 - mmengine - INFO - Exp name: dekr_testmodel-w32_8xb10-140e_octsegflat-512x512_20231121_182822
+11/23 03:46:45 - mmengine - INFO - Epoch(train) [1258][150/163] lr: 1.000000e-05 eta: 0:02:56 time: 0.521060 data_time: 0.012762 memory: 14376 loss: 0.000178 loss/heatmap: 0.000116 loss/displacement: 0.000062
+11/23 03:46:51 - mmengine - INFO - Exp name: dekr_testmodel-w32_8xb10-140e_octsegflat-512x512_20231121_182822
+11/23 03:47:17 - mmengine - INFO - Epoch(train) [1259][ 50/163] lr: 1.000000e-05 eta: 0:02:23 time: 0.523196 data_time: 0.016144 memory: 14376 loss: 0.000186 loss/heatmap: 0.000123 loss/displacement: 0.000063
+11/23 03:47:44 - mmengine - INFO - Epoch(train) [1259][100/163] lr: 1.000000e-05 eta: 0:01:57 time: 0.523867 data_time: 0.016063 memory: 14376 loss: 0.000195 loss/heatmap: 0.000125 loss/displacement: 0.000071
+11/23 03:48:10 - mmengine - INFO - Epoch(train) [1259][150/163] lr: 1.000000e-05 eta: 0:01:31 time: 0.520021 data_time: 0.012742 memory: 14376 loss: 0.000180 loss/heatmap: 0.000116 loss/displacement: 0.000064
+11/23 03:48:16 - mmengine - INFO - Exp name: dekr_testmodel-w32_8xb10-140e_octsegflat-512x512_20231121_182822
+11/23 03:48:42 - mmengine - INFO - Epoch(train) [1260][ 50/163] lr: 1.000000e-05 eta: 0:00:58 time: 0.521599 data_time: 0.015162 memory: 14376 loss: 0.000178 loss/heatmap: 0.000114 loss/displacement: 0.000064
+11/23 03:49:08 - mmengine - INFO - Epoch(train) [1260][100/163] lr: 1.000000e-05 eta: 0:00:32 time: 0.521193 data_time: 0.013141 memory: 14376 loss: 0.000211 loss/heatmap: 0.000133 loss/displacement: 0.000078
+11/23 03:49:35 - mmengine - INFO - Epoch(train) [1260][150/163] lr: 1.000000e-05 eta: 0:00:06 time: 0.522587 data_time: 0.013465 memory: 14376 loss: 0.000189 loss/heatmap: 0.000120 loss/displacement: 0.000068
+
+...
+
+
+Loading and preparing results...
+DONE (t=2.05s)
+creating index...
+index created!
+Running per image evaluation...
+Evaluate annotation type *keypoints*
+DONE (t=1.41s).
+Accumulating evaluation results...
+DONE (t=0.22s).
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.645
+ Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.650
+ Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.650
+ Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = -1.000
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.933
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.998
+ Average Recall (AR) @[ IoU=0.50 | area= all | maxDets= 20 ] = 1.000
+ Average Recall (AR) @[ IoU=0.75 | area= all | maxDets= 20 ] = 1.000
+ Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = -1.000
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.998
+11/23 04:00:28 - mmengine - INFO - Epoch(val) [1260][5715/5715] coco/AP: 0.645355 coco/AP .5: 0.650285 coco/AP .75: 0.650285 coco/AP (M): -1.000000 coco/AP (L): 0.932906 coco/AR: 0.998463 coco/AR .5: 1.000000 coco/AR .75: 1.000000 coco/AR (M): -1.000000 coco/AR (L): 0.998463 data_time: 0.000598 time: 0.110494
+```
\ No newline at end of file
diff --git a/README.md b/README.md
index b250d570b3..1c5f9d131f 100644
--- a/README.md
+++ b/README.md
@@ -1,368 +1,368 @@
-
-
-## Introduction
-
-English | [简体中文](README_CN.md)
-
-MMPose is an open-source toolbox for pose estimation based on PyTorch.
-It is a part of the [OpenMMLab project](https://github.com/open-mmlab).
-
-The main branch works with **PyTorch 1.8+**.
-
-https://user-images.githubusercontent.com/15977946/124654387-0fd3c500-ded1-11eb-84f6-24eeddbf4d91.mp4
-
-
-
-
-Major Features
-
-- **Support diverse tasks**
-
- We support a wide spectrum of mainstream pose analysis tasks in current research community, including 2d multi-person human pose estimation, 2d hand pose estimation, 2d face landmark detection, 133 keypoint whole-body human pose estimation, 3d human mesh recovery, fashion landmark detection and animal pose estimation.
- See [Demo](demo/docs/en) for more information.
-
-- **Higher efficiency and higher accuracy**
-
- MMPose implements multiple state-of-the-art (SOTA) deep learning models, including both top-down & bottom-up approaches. We achieve faster training speed and higher accuracy than other popular codebases, such as [HRNet](https://github.com/leoxiaobin/deep-high-resolution-net.pytorch).
- See [benchmark.md](docs/en/notes/benchmark.md) for more information.
-
-- **Support for various datasets**
-
- The toolbox directly supports multiple popular and representative datasets, COCO, AIC, MPII, MPII-TRB, OCHuman etc.
- See [dataset_zoo](docs/en/dataset_zoo) for more information.
-
-- **Well designed, tested and documented**
-
- We decompose MMPose into different components and one can easily construct a customized
- pose estimation framework by combining different modules.
- We provide detailed documentation and API reference, as well as unittests.
-
-
-
-## What's New
-
-- We are glad to support 3 new datasets:
- - (CVPR 2023) [Human-Art](https://github.com/IDEA-Research/HumanArt)
- - (CVPR 2022) [Animal Kingdom](https://github.com/sutdcv/Animal-Kingdom)
- - (AAAI 2020) [LaPa](https://github.com/JDAI-CV/lapa-dataset/)
-
-
-
-- Welcome to [*projects of MMPose*](/projects/README.md), where you can access to the latest features of MMPose, and share your ideas and codes with the community at once. Contribution to MMPose will be simple and smooth:
-
- - Provide an easy and agile way to integrate algorithms, features and applications into MMPose
- - Allow flexible code structure and style; only need a short code review process
- - Build individual projects with full power of MMPose but not bound up with heavy frameworks
- - Checkout new projects:
- - [RTMPose](/projects/rtmpose/)
- - [YOLOX-Pose](/projects/yolox_pose/)
- - [MMPose4AIGC](/projects/mmpose4aigc/)
- - [Simple Keypoints](/projects/skps/)
- - Become a contributors and make MMPose greater. Start your journey from the [example project](/projects/example_project/)
-
-
-
-- 2023-07-04: MMPose [v1.1.0](https://github.com/open-mmlab/mmpose/releases/tag/v1.1.0) is officially released, with the main updates including:
-
- - Support new datasets: Human-Art, Animal Kingdom and LaPa.
- - Support new config type that is more user-friendly and flexible.
- - Improve RTMPose with better performance.
- - Migrate 3D pose estimation models on h36m.
- - Inference speedup and webcam inference with all demo scripts.
-
- Please refer to the [release notes](https://github.com/open-mmlab/mmpose/releases/tag/v1.1.0) for more updates brought by MMPose v1.1.0!
-
-## 0.x / 1.x Migration
-
-MMPose v1.0.0 is a major update, including many API and config file changes. Currently, a part of the algorithms have been migrated to v1.0.0, and the remaining algorithms will be completed in subsequent versions. We will show the migration progress in the following list.
-
-
-Migration Progress
-
-| Algorithm | Status |
-| :-------------------------------- | :---------: |
-| MTUT (CVPR 2019) | |
-| MSPN (ArXiv 2019) | done |
-| InterNet (ECCV 2020) | |
-| DEKR (CVPR 2021) | done |
-| HigherHRNet (CVPR 2020) | |
-| DeepPose (CVPR 2014) | done |
-| RLE (ICCV 2021) | done |
-| SoftWingloss (TIP 2021) | done |
-| VideoPose3D (CVPR 2019) | done |
-| Hourglass (ECCV 2016) | done |
-| LiteHRNet (CVPR 2021) | done |
-| AdaptiveWingloss (ICCV 2019) | done |
-| SimpleBaseline2D (ECCV 2018) | done |
-| PoseWarper (NeurIPS 2019) | |
-| SimpleBaseline3D (ICCV 2017) | done |
-| HMR (CVPR 2018) | |
-| UDP (CVPR 2020) | done |
-| VIPNAS (CVPR 2021) | done |
-| Wingloss (CVPR 2018) | done |
-| DarkPose (CVPR 2020) | done |
-| Associative Embedding (NIPS 2017) | in progress |
-| VoxelPose (ECCV 2020) | |
-| RSN (ECCV 2020) | done |
-| CID (CVPR 2022) | done |
-| CPM (CVPR 2016) | done |
-| HRNet (CVPR 2019) | done |
-| HRNetv2 (TPAMI 2019) | done |
-| SCNet (CVPR 2020) | done |
-
-
-
-If your algorithm has not been migrated, you can continue to use the [0.x branch](https://github.com/open-mmlab/mmpose/tree/0.x) and [old documentation](https://mmpose.readthedocs.io/en/0.x/).
-
-## Installation
-
-Please refer to [installation.md](https://mmpose.readthedocs.io/en/latest/installation.html) for more detailed installation and dataset preparation.
-
-## Getting Started
-
-We provided a series of tutorials about the basic usage of MMPose for new users:
-
-1. For the basic usage of MMPose:
-
- - [A 20-minute Tour to MMPose](https://mmpose.readthedocs.io/en/latest/guide_to_framework.html)
- - [Demos](https://mmpose.readthedocs.io/en/latest/demos.html)
- - [Inference](https://mmpose.readthedocs.io/en/latest/user_guides/inference.html)
- - [Configs](https://mmpose.readthedocs.io/en/latest/user_guides/configs.html)
- - [Prepare Datasets](https://mmpose.readthedocs.io/en/latest/user_guides/prepare_datasets.html)
- - [Train and Test](https://mmpose.readthedocs.io/en/latest/user_guides/train_and_test.html)
-
-2. For developers who wish to develop based on MMPose:
-
- - [Learn about Codecs](https://mmpose.readthedocs.io/en/latest/advanced_guides/codecs.html)
- - [Dataflow in MMPose](https://mmpose.readthedocs.io/en/latest/advanced_guides/dataflow.html)
- - [Implement New Models](https://mmpose.readthedocs.io/en/latest/advanced_guides/implement_new_models.html)
- - [Customize Datasets](https://mmpose.readthedocs.io/en/latest/advanced_guides/customize_datasets.html)
- - [Customize Data Transforms](https://mmpose.readthedocs.io/en/latest/advanced_guides/customize_transforms.html)
- - [Customize Optimizer](https://mmpose.readthedocs.io/en/latest/advanced_guides/customize_optimizer.html)
- - [Customize Logging](https://mmpose.readthedocs.io/en/latest/advanced_guides/customize_logging.html)
- - [How to Deploy](https://mmpose.readthedocs.io/en/latest/advanced_guides/how_to_deploy.html)
- - [Model Analysis](https://mmpose.readthedocs.io/en/latest/advanced_guides/model_analysis.html)
- - [Migration Guide](https://mmpose.readthedocs.io/en/latest/migration.html)
-
-3. For researchers and developers who are willing to contribute to MMPose:
-
- - [Contribution Guide](https://mmpose.readthedocs.io/en/latest/contribution_guide.html)
-
-4. For some common issues, we provide a FAQ list:
-
- - [FAQ](https://mmpose.readthedocs.io/en/latest/faq.html)
-
-## Model Zoo
-
-Results and models are available in the **README.md** of each method's config directory.
-A summary can be found in the [Model Zoo](https://mmpose.readthedocs.io/en/latest/model_zoo.html) page.
-
-
-Supported algorithms:
-
-- [x] [DeepPose](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#deeppose-cvpr-2014) (CVPR'2014)
-- [x] [CPM](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#cpm-cvpr-2016) (CVPR'2016)
-- [x] [Hourglass](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#hourglass-eccv-2016) (ECCV'2016)
-- [x] [SimpleBaseline3D](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#simplebaseline3d-iccv-2017) (ICCV'2017)
-- [ ] [Associative Embedding](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#associative-embedding-nips-2017) (NeurIPS'2017)
-- [x] [SimpleBaseline2D](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#simplebaseline2d-eccv-2018) (ECCV'2018)
-- [x] [DSNT](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#dsnt-2018) (ArXiv'2021)
-- [x] [HRNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#hrnet-cvpr-2019) (CVPR'2019)
-- [x] [IPR](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#ipr-eccv-2018) (ECCV'2018)
-- [x] [VideoPose3D](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#videopose3d-cvpr-2019) (CVPR'2019)
-- [x] [HRNetv2](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#hrnetv2-tpami-2019) (TPAMI'2019)
-- [x] [MSPN](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#mspn-arxiv-2019) (ArXiv'2019)
-- [x] [SCNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#scnet-cvpr-2020) (CVPR'2020)
-- [ ] [HigherHRNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#higherhrnet-cvpr-2020) (CVPR'2020)
-- [x] [RSN](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#rsn-eccv-2020) (ECCV'2020)
-- [ ] [InterNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#internet-eccv-2020) (ECCV'2020)
-- [ ] [VoxelPose](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#voxelpose-eccv-2020) (ECCV'2020)
-- [x] [LiteHRNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#litehrnet-cvpr-2021) (CVPR'2021)
-- [x] [ViPNAS](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#vipnas-cvpr-2021) (CVPR'2021)
-- [x] [Debias-IPR](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#debias-ipr-iccv-2021) (ICCV'2021)
-- [x] [SimCC](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#simcc-eccv-2022) (ECCV'2022)
-
-
-
-
-Supported techniques:
-
-- [x] [FPN](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/techniques.html#fpn-cvpr-2017) (CVPR'2017)
-- [x] [FP16](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/techniques.html#fp16-arxiv-2017) (ArXiv'2017)
-- [x] [Wingloss](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/techniques.html#wingloss-cvpr-2018) (CVPR'2018)
-- [x] [AdaptiveWingloss](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/techniques.html#adaptivewingloss-iccv-2019) (ICCV'2019)
-- [x] [DarkPose](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/techniques.html#darkpose-cvpr-2020) (CVPR'2020)
-- [x] [UDP](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/techniques.html#udp-cvpr-2020) (CVPR'2020)
-- [x] [Albumentations](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/techniques.html#albumentations-information-2020) (Information'2020)
-- [x] [SoftWingloss](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/techniques.html#softwingloss-tip-2021) (TIP'2021)
-- [x] [RLE](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/techniques.html#rle-iccv-2021) (ICCV'2021)
-
-
-
-
-Supported datasets:
-
-- [x] [AFLW](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#aflw-iccvw-2011) \[[homepage](https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/aflw/)\] (ICCVW'2011)
-- [x] [sub-JHMDB](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#jhmdb-iccv-2013) \[[homepage](http://jhmdb.is.tue.mpg.de/dataset)\] (ICCV'2013)
-- [x] [COFW](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#cofw-iccv-2013) \[[homepage](http://www.vision.caltech.edu/xpburgos/ICCV13/)\] (ICCV'2013)
-- [x] [MPII](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#mpii-cvpr-2014) \[[homepage](http://human-pose.mpi-inf.mpg.de/)\] (CVPR'2014)
-- [x] [Human3.6M](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#human3-6m-tpami-2014) \[[homepage](http://vision.imar.ro/human3.6m/description.php)\] (TPAMI'2014)
-- [x] [COCO](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#coco-eccv-2014) \[[homepage](http://cocodataset.org/)\] (ECCV'2014)
-- [x] [CMU Panoptic](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#cmu-panoptic-iccv-2015) \[[homepage](http://domedb.perception.cs.cmu.edu/)\] (ICCV'2015)
-- [x] [DeepFashion](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#deepfashion-cvpr-2016) \[[homepage](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/LandmarkDetection.html)\] (CVPR'2016)
-- [x] [300W](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#300w-imavis-2016) \[[homepage](https://ibug.doc.ic.ac.uk/resources/300-W/)\] (IMAVIS'2016)
-- [x] [RHD](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#rhd-iccv-2017) \[[homepage](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html)\] (ICCV'2017)
-- [x] [CMU Panoptic HandDB](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#cmu-panoptic-handdb-cvpr-2017) \[[homepage](http://domedb.perception.cs.cmu.edu/handdb.html)\] (CVPR'2017)
-- [x] [AI Challenger](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#ai-challenger-arxiv-2017) \[[homepage](https://github.com/AIChallenger/AI_Challenger_2017)\] (ArXiv'2017)
-- [x] [MHP](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#mhp-acm-mm-2018) \[[homepage](https://lv-mhp.github.io/dataset)\] (ACM MM'2018)
-- [x] [WFLW](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#wflw-cvpr-2018) \[[homepage](https://wywu.github.io/projects/LAB/WFLW.html)\] (CVPR'2018)
-- [x] [PoseTrack18](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#posetrack18-cvpr-2018) \[[homepage](https://posetrack.net/users/download.php)\] (CVPR'2018)
-- [x] [OCHuman](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#ochuman-cvpr-2019) \[[homepage](https://github.com/liruilong940607/OCHumanApi)\] (CVPR'2019)
-- [x] [CrowdPose](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#crowdpose-cvpr-2019) \[[homepage](https://github.com/Jeff-sjtu/CrowdPose)\] (CVPR'2019)
-- [x] [MPII-TRB](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#mpii-trb-iccv-2019) \[[homepage](https://github.com/kennymckormick/Triplet-Representation-of-human-Body)\] (ICCV'2019)
-- [x] [FreiHand](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#freihand-iccv-2019) \[[homepage](https://lmb.informatik.uni-freiburg.de/projects/freihand/)\] (ICCV'2019)
-- [x] [Animal-Pose](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#animal-pose-iccv-2019) \[[homepage](https://sites.google.com/view/animal-pose/)\] (ICCV'2019)
-- [x] [OneHand10K](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#onehand10k-tcsvt-2019) \[[homepage](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html)\] (TCSVT'2019)
-- [x] [Vinegar Fly](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#vinegar-fly-nature-methods-2019) \[[homepage](https://github.com/jgraving/DeepPoseKit-Data)\] (Nature Methods'2019)
-- [x] [Desert Locust](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#desert-locust-elife-2019) \[[homepage](https://github.com/jgraving/DeepPoseKit-Data)\] (Elife'2019)
-- [x] [Grévy’s Zebra](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#grevys-zebra-elife-2019) \[[homepage](https://github.com/jgraving/DeepPoseKit-Data)\] (Elife'2019)
-- [x] [ATRW](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#atrw-acm-mm-2020) \[[homepage](https://cvwc2019.github.io/challenge.html)\] (ACM MM'2020)
-- [x] [Halpe](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#halpe-cvpr-2020) \[[homepage](https://github.com/Fang-Haoshu/Halpe-FullBody/)\] (CVPR'2020)
-- [x] [COCO-WholeBody](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#coco-wholebody-eccv-2020) \[[homepage](https://github.com/jin-s13/COCO-WholeBody/)\] (ECCV'2020)
-- [x] [MacaquePose](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#macaquepose-biorxiv-2020) \[[homepage](http://www.pri.kyoto-u.ac.jp/datasets/macaquepose/index.html)\] (bioRxiv'2020)
-- [x] [InterHand2.6M](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#interhand2-6m-eccv-2020) \[[homepage](https://mks0601.github.io/InterHand2.6M/)\] (ECCV'2020)
-- [x] [AP-10K](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#ap-10k-neurips-2021) \[[homepage](https://github.com/AlexTheBad/AP-10K)\] (NeurIPS'2021)
-- [x] [Horse-10](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#horse-10-wacv-2021) \[[homepage](http://www.mackenziemathislab.org/horse10)\] (WACV'2021)
-- [x] [Human-Art](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#human-art-cvpr-2023) \[[homepage](https://idea-research.github.io/HumanArt/)\] (CVPR'2023)
-- [x] [LaPa](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#lapa-aaai-2020) \[[homepage](https://github.com/JDAI-CV/lapa-dataset)\] (AAAI'2020)
-
-
-
-
-Supported backbones:
-
-- [x] [AlexNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#alexnet-neurips-2012) (NeurIPS'2012)
-- [x] [VGG](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#vgg-iclr-2015) (ICLR'2015)
-- [x] [ResNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#resnet-cvpr-2016) (CVPR'2016)
-- [x] [ResNext](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#resnext-cvpr-2017) (CVPR'2017)
-- [x] [SEResNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#seresnet-cvpr-2018) (CVPR'2018)
-- [x] [ShufflenetV1](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#shufflenetv1-cvpr-2018) (CVPR'2018)
-- [x] [ShufflenetV2](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#shufflenetv2-eccv-2018) (ECCV'2018)
-- [x] [MobilenetV2](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#mobilenetv2-cvpr-2018) (CVPR'2018)
-- [x] [ResNetV1D](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#resnetv1d-cvpr-2019) (CVPR'2019)
-- [x] [ResNeSt](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#resnest-arxiv-2020) (ArXiv'2020)
-- [x] [Swin](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#swin-cvpr-2021) (CVPR'2021)
-- [x] [HRFormer](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#hrformer-nips-2021) (NIPS'2021)
-- [x] [PVT](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#pvt-iccv-2021) (ICCV'2021)
-- [x] [PVTV2](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#pvtv2-cvmj-2022) (CVMJ'2022)
-
-
-
-### Model Request
-
-We will keep up with the latest progress of the community, and support more popular algorithms and frameworks. If you have any feature requests, please feel free to leave a comment in [MMPose Roadmap](https://github.com/open-mmlab/mmpose/issues/2258).
-
-## Contributing
-
-We appreciate all contributions to improve MMPose. Please refer to [CONTRIBUTING.md](https://mmpose.readthedocs.io/en/latest/contribution_guide.html) for the contributing guideline.
-
-## Acknowledgement
-
-MMPose is an open source project that is contributed by researchers and engineers from various colleges and companies.
-We appreciate all the contributors who implement their methods or add new features, as well as users who give valuable feedbacks.
-We wish that the toolbox and benchmark could serve the growing research community by providing a flexible toolkit to reimplement existing methods and develop their own new models.
-
-## Citation
-
-If you find this project useful in your research, please consider cite:
-
-```bibtex
-@misc{mmpose2020,
- title={OpenMMLab Pose Estimation Toolbox and Benchmark},
- author={MMPose Contributors},
- howpublished = {\url{https://github.com/open-mmlab/mmpose}},
- year={2020}
-}
-```
-
-## License
-
-This project is released under the [Apache 2.0 license](LICENSE).
-
-## Projects in OpenMMLab
-
-- [MMEngine](https://github.com/open-mmlab/mmengine): OpenMMLab foundational library for training deep learning models.
-- [MMCV](https://github.com/open-mmlab/mmcv): OpenMMLab foundational library for computer vision.
-- [MMPreTrain](https://github.com/open-mmlab/mmpretrain): OpenMMLab pre-training toolbox and benchmark.
-- [MMagic](https://github.com/open-mmlab/mmagic): Open**MM**Lab **A**dvanced, **G**enerative and **I**ntelligent **C**reation toolbox.
-- [MMDetection](https://github.com/open-mmlab/mmdetection): OpenMMLab detection toolbox and benchmark.
-- [MMDetection3D](https://github.com/open-mmlab/mmdetection3d): OpenMMLab's next-generation platform for general 3D object detection.
-- [MMRotate](https://github.com/open-mmlab/mmrotate): OpenMMLab rotated object detection toolbox and benchmark.
-- [MMTracking](https://github.com/open-mmlab/mmtracking): OpenMMLab video perception toolbox and benchmark.
-- [MMSegmentation](https://github.com/open-mmlab/mmsegmentation): OpenMMLab semantic segmentation toolbox and benchmark.
-- [MMOCR](https://github.com/open-mmlab/mmocr): OpenMMLab text detection, recognition, and understanding toolbox.
-- [MMPose](https://github.com/open-mmlab/mmpose): OpenMMLab pose estimation toolbox and benchmark.
-- [MMHuman3D](https://github.com/open-mmlab/mmhuman3d): OpenMMLab 3D human parametric model toolbox and benchmark.
-- [MMFewShot](https://github.com/open-mmlab/mmfewshot): OpenMMLab fewshot learning toolbox and benchmark.
-- [MMAction2](https://github.com/open-mmlab/mmaction2): OpenMMLab's next-generation action understanding toolbox and benchmark.
-- [MMFlow](https://github.com/open-mmlab/mmflow): OpenMMLab optical flow toolbox and benchmark.
-- [MMDeploy](https://github.com/open-mmlab/mmdeploy): OpenMMLab Model Deployment Framework.
-- [MMRazor](https://github.com/open-mmlab/mmrazor): OpenMMLab model compression toolbox and benchmark.
-- [MIM](https://github.com/open-mmlab/mim): MIM installs OpenMMLab packages.
-- [Playground](https://github.com/open-mmlab/playground): A central hub for gathering and showcasing amazing projects built upon OpenMMLab.
+
+
+## Introduction
+
+English | [简体中文](README_CN.md)
+
+MMPose is an open-source toolbox for pose estimation based on PyTorch.
+It is a part of the [OpenMMLab project](https://github.com/open-mmlab).
+
+The main branch works with **PyTorch 1.8+**.
+
+https://user-images.githubusercontent.com/15977946/124654387-0fd3c500-ded1-11eb-84f6-24eeddbf4d91.mp4
+
+
+
+
+Major Features
+
+- **Support diverse tasks**
+
+ We support a wide spectrum of mainstream pose analysis tasks in current research community, including 2d multi-person human pose estimation, 2d hand pose estimation, 2d face landmark detection, 133 keypoint whole-body human pose estimation, 3d human mesh recovery, fashion landmark detection and animal pose estimation.
+ See [Demo](demo/docs/en) for more information.
+
+- **Higher efficiency and higher accuracy**
+
+ MMPose implements multiple state-of-the-art (SOTA) deep learning models, including both top-down & bottom-up approaches. We achieve faster training speed and higher accuracy than other popular codebases, such as [HRNet](https://github.com/leoxiaobin/deep-high-resolution-net.pytorch).
+ See [benchmark.md](docs/en/notes/benchmark.md) for more information.
+
+- **Support for various datasets**
+
+ The toolbox directly supports multiple popular and representative datasets, COCO, AIC, MPII, MPII-TRB, OCHuman etc.
+ See [dataset_zoo](docs/en/dataset_zoo) for more information.
+
+- **Well designed, tested and documented**
+
+ We decompose MMPose into different components and one can easily construct a customized
+ pose estimation framework by combining different modules.
+ We provide detailed documentation and API reference, as well as unittests.
+
+
+
+## What's New
+
+- We are glad to support 3 new datasets:
+ - (CVPR 2023) [Human-Art](https://github.com/IDEA-Research/HumanArt)
+ - (CVPR 2022) [Animal Kingdom](https://github.com/sutdcv/Animal-Kingdom)
+ - (AAAI 2020) [LaPa](https://github.com/JDAI-CV/lapa-dataset/)
+
+
+
+- Welcome to [*projects of MMPose*](/projects/README.md), where you can access to the latest features of MMPose, and share your ideas and codes with the community at once. Contribution to MMPose will be simple and smooth:
+
+ - Provide an easy and agile way to integrate algorithms, features and applications into MMPose
+ - Allow flexible code structure and style; only need a short code review process
+ - Build individual projects with full power of MMPose but not bound up with heavy frameworks
+ - Checkout new projects:
+ - [RTMPose](/projects/rtmpose/)
+ - [YOLOX-Pose](/projects/yolox_pose/)
+ - [MMPose4AIGC](/projects/mmpose4aigc/)
+ - [Simple Keypoints](/projects/skps/)
+ - Become a contributors and make MMPose greater. Start your journey from the [example project](/projects/example_project/)
+
+
+
+- 2023-07-04: MMPose [v1.1.0](https://github.com/open-mmlab/mmpose/releases/tag/v1.1.0) is officially released, with the main updates including:
+
+ - Support new datasets: Human-Art, Animal Kingdom and LaPa.
+ - Support new config type that is more user-friendly and flexible.
+ - Improve RTMPose with better performance.
+ - Migrate 3D pose estimation models on h36m.
+ - Inference speedup and webcam inference with all demo scripts.
+
+ Please refer to the [release notes](https://github.com/open-mmlab/mmpose/releases/tag/v1.1.0) for more updates brought by MMPose v1.1.0!
+
+## 0.x / 1.x Migration
+
+MMPose v1.0.0 is a major update, including many API and config file changes. Currently, a part of the algorithms have been migrated to v1.0.0, and the remaining algorithms will be completed in subsequent versions. We will show the migration progress in the following list.
+
+
+Migration Progress
+
+| Algorithm | Status |
+| :-------------------------------- | :---------: |
+| MTUT (CVPR 2019) | |
+| MSPN (ArXiv 2019) | done |
+| InterNet (ECCV 2020) | |
+| DEKR (CVPR 2021) | done |
+| HigherHRNet (CVPR 2020) | |
+| DeepPose (CVPR 2014) | done |
+| RLE (ICCV 2021) | done |
+| SoftWingloss (TIP 2021) | done |
+| VideoPose3D (CVPR 2019) | done |
+| Hourglass (ECCV 2016) | done |
+| LiteHRNet (CVPR 2021) | done |
+| AdaptiveWingloss (ICCV 2019) | done |
+| SimpleBaseline2D (ECCV 2018) | done |
+| PoseWarper (NeurIPS 2019) | |
+| SimpleBaseline3D (ICCV 2017) | done |
+| HMR (CVPR 2018) | |
+| UDP (CVPR 2020) | done |
+| VIPNAS (CVPR 2021) | done |
+| Wingloss (CVPR 2018) | done |
+| DarkPose (CVPR 2020) | done |
+| Associative Embedding (NIPS 2017) | in progress |
+| VoxelPose (ECCV 2020) | |
+| RSN (ECCV 2020) | done |
+| CID (CVPR 2022) | done |
+| CPM (CVPR 2016) | done |
+| HRNet (CVPR 2019) | done |
+| HRNetv2 (TPAMI 2019) | done |
+| SCNet (CVPR 2020) | done |
+
+
+
+If your algorithm has not been migrated, you can continue to use the [0.x branch](https://github.com/open-mmlab/mmpose/tree/0.x) and [old documentation](https://mmpose.readthedocs.io/en/0.x/).
+
+## Installation
+
+Please refer to [installation.md](https://mmpose.readthedocs.io/en/latest/installation.html) for more detailed installation and dataset preparation.
+
+## Getting Started
+
+We provided a series of tutorials about the basic usage of MMPose for new users:
+
+1. For the basic usage of MMPose:
+
+ - [A 20-minute Tour to MMPose](https://mmpose.readthedocs.io/en/latest/guide_to_framework.html)
+ - [Demos](https://mmpose.readthedocs.io/en/latest/demos.html)
+ - [Inference](https://mmpose.readthedocs.io/en/latest/user_guides/inference.html)
+ - [Configs](https://mmpose.readthedocs.io/en/latest/user_guides/configs.html)
+ - [Prepare Datasets](https://mmpose.readthedocs.io/en/latest/user_guides/prepare_datasets.html)
+ - [Train and Test](https://mmpose.readthedocs.io/en/latest/user_guides/train_and_test.html)
+
+2. For developers who wish to develop based on MMPose:
+
+ - [Learn about Codecs](https://mmpose.readthedocs.io/en/latest/advanced_guides/codecs.html)
+ - [Dataflow in MMPose](https://mmpose.readthedocs.io/en/latest/advanced_guides/dataflow.html)
+ - [Implement New Models](https://mmpose.readthedocs.io/en/latest/advanced_guides/implement_new_models.html)
+ - [Customize Datasets](https://mmpose.readthedocs.io/en/latest/advanced_guides/customize_datasets.html)
+ - [Customize Data Transforms](https://mmpose.readthedocs.io/en/latest/advanced_guides/customize_transforms.html)
+ - [Customize Optimizer](https://mmpose.readthedocs.io/en/latest/advanced_guides/customize_optimizer.html)
+ - [Customize Logging](https://mmpose.readthedocs.io/en/latest/advanced_guides/customize_logging.html)
+ - [How to Deploy](https://mmpose.readthedocs.io/en/latest/advanced_guides/how_to_deploy.html)
+ - [Model Analysis](https://mmpose.readthedocs.io/en/latest/advanced_guides/model_analysis.html)
+ - [Migration Guide](https://mmpose.readthedocs.io/en/latest/migration.html)
+
+3. For researchers and developers who are willing to contribute to MMPose:
+
+ - [Contribution Guide](https://mmpose.readthedocs.io/en/latest/contribution_guide.html)
+
+4. For some common issues, we provide a FAQ list:
+
+ - [FAQ](https://mmpose.readthedocs.io/en/latest/faq.html)
+
+## Model Zoo
+
+Results and models are available in the **README.md** of each method's config directory.
+A summary can be found in the [Model Zoo](https://mmpose.readthedocs.io/en/latest/model_zoo.html) page.
+
+
+Supported algorithms:
+
+- [x] [DeepPose](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#deeppose-cvpr-2014) (CVPR'2014)
+- [x] [CPM](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#cpm-cvpr-2016) (CVPR'2016)
+- [x] [Hourglass](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#hourglass-eccv-2016) (ECCV'2016)
+- [x] [SimpleBaseline3D](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#simplebaseline3d-iccv-2017) (ICCV'2017)
+- [ ] [Associative Embedding](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#associative-embedding-nips-2017) (NeurIPS'2017)
+- [x] [SimpleBaseline2D](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#simplebaseline2d-eccv-2018) (ECCV'2018)
+- [x] [DSNT](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#dsnt-2018) (ArXiv'2021)
+- [x] [HRNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#hrnet-cvpr-2019) (CVPR'2019)
+- [x] [IPR](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#ipr-eccv-2018) (ECCV'2018)
+- [x] [VideoPose3D](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#videopose3d-cvpr-2019) (CVPR'2019)
+- [x] [HRNetv2](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#hrnetv2-tpami-2019) (TPAMI'2019)
+- [x] [MSPN](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#mspn-arxiv-2019) (ArXiv'2019)
+- [x] [SCNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#scnet-cvpr-2020) (CVPR'2020)
+- [ ] [HigherHRNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#higherhrnet-cvpr-2020) (CVPR'2020)
+- [x] [RSN](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#rsn-eccv-2020) (ECCV'2020)
+- [ ] [InterNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#internet-eccv-2020) (ECCV'2020)
+- [ ] [VoxelPose](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#voxelpose-eccv-2020) (ECCV'2020)
+- [x] [LiteHRNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#litehrnet-cvpr-2021) (CVPR'2021)
+- [x] [ViPNAS](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#vipnas-cvpr-2021) (CVPR'2021)
+- [x] [Debias-IPR](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#debias-ipr-iccv-2021) (ICCV'2021)
+- [x] [SimCC](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#simcc-eccv-2022) (ECCV'2022)
+
+
+
+
+Supported techniques:
+
+- [x] [FPN](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/techniques.html#fpn-cvpr-2017) (CVPR'2017)
+- [x] [FP16](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/techniques.html#fp16-arxiv-2017) (ArXiv'2017)
+- [x] [Wingloss](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/techniques.html#wingloss-cvpr-2018) (CVPR'2018)
+- [x] [AdaptiveWingloss](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/techniques.html#adaptivewingloss-iccv-2019) (ICCV'2019)
+- [x] [DarkPose](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/techniques.html#darkpose-cvpr-2020) (CVPR'2020)
+- [x] [UDP](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/techniques.html#udp-cvpr-2020) (CVPR'2020)
+- [x] [Albumentations](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/techniques.html#albumentations-information-2020) (Information'2020)
+- [x] [SoftWingloss](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/techniques.html#softwingloss-tip-2021) (TIP'2021)
+- [x] [RLE](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/techniques.html#rle-iccv-2021) (ICCV'2021)
+
+
+
+
+Supported datasets:
+
+- [x] [AFLW](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#aflw-iccvw-2011) \[[homepage](https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/aflw/)\] (ICCVW'2011)
+- [x] [sub-JHMDB](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#jhmdb-iccv-2013) \[[homepage](http://jhmdb.is.tue.mpg.de/dataset)\] (ICCV'2013)
+- [x] [COFW](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#cofw-iccv-2013) \[[homepage](http://www.vision.caltech.edu/xpburgos/ICCV13/)\] (ICCV'2013)
+- [x] [MPII](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#mpii-cvpr-2014) \[[homepage](http://human-pose.mpi-inf.mpg.de/)\] (CVPR'2014)
+- [x] [Human3.6M](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#human3-6m-tpami-2014) \[[homepage](http://vision.imar.ro/human3.6m/description.php)\] (TPAMI'2014)
+- [x] [COCO](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#coco-eccv-2014) \[[homepage](http://cocodataset.org/)\] (ECCV'2014)
+- [x] [CMU Panoptic](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#cmu-panoptic-iccv-2015) \[[homepage](http://domedb.perception.cs.cmu.edu/)\] (ICCV'2015)
+- [x] [DeepFashion](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#deepfashion-cvpr-2016) \[[homepage](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/LandmarkDetection.html)\] (CVPR'2016)
+- [x] [300W](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#300w-imavis-2016) \[[homepage](https://ibug.doc.ic.ac.uk/resources/300-W/)\] (IMAVIS'2016)
+- [x] [RHD](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#rhd-iccv-2017) \[[homepage](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html)\] (ICCV'2017)
+- [x] [CMU Panoptic HandDB](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#cmu-panoptic-handdb-cvpr-2017) \[[homepage](http://domedb.perception.cs.cmu.edu/handdb.html)\] (CVPR'2017)
+- [x] [AI Challenger](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#ai-challenger-arxiv-2017) \[[homepage](https://github.com/AIChallenger/AI_Challenger_2017)\] (ArXiv'2017)
+- [x] [MHP](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#mhp-acm-mm-2018) \[[homepage](https://lv-mhp.github.io/dataset)\] (ACM MM'2018)
+- [x] [WFLW](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#wflw-cvpr-2018) \[[homepage](https://wywu.github.io/projects/LAB/WFLW.html)\] (CVPR'2018)
+- [x] [PoseTrack18](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#posetrack18-cvpr-2018) \[[homepage](https://posetrack.net/users/download.php)\] (CVPR'2018)
+- [x] [OCHuman](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#ochuman-cvpr-2019) \[[homepage](https://github.com/liruilong940607/OCHumanApi)\] (CVPR'2019)
+- [x] [CrowdPose](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#crowdpose-cvpr-2019) \[[homepage](https://github.com/Jeff-sjtu/CrowdPose)\] (CVPR'2019)
+- [x] [MPII-TRB](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#mpii-trb-iccv-2019) \[[homepage](https://github.com/kennymckormick/Triplet-Representation-of-human-Body)\] (ICCV'2019)
+- [x] [FreiHand](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#freihand-iccv-2019) \[[homepage](https://lmb.informatik.uni-freiburg.de/projects/freihand/)\] (ICCV'2019)
+- [x] [Animal-Pose](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#animal-pose-iccv-2019) \[[homepage](https://sites.google.com/view/animal-pose/)\] (ICCV'2019)
+- [x] [OneHand10K](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#onehand10k-tcsvt-2019) \[[homepage](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html)\] (TCSVT'2019)
+- [x] [Vinegar Fly](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#vinegar-fly-nature-methods-2019) \[[homepage](https://github.com/jgraving/DeepPoseKit-Data)\] (Nature Methods'2019)
+- [x] [Desert Locust](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#desert-locust-elife-2019) \[[homepage](https://github.com/jgraving/DeepPoseKit-Data)\] (Elife'2019)
+- [x] [Grévy’s Zebra](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#grevys-zebra-elife-2019) \[[homepage](https://github.com/jgraving/DeepPoseKit-Data)\] (Elife'2019)
+- [x] [ATRW](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#atrw-acm-mm-2020) \[[homepage](https://cvwc2019.github.io/challenge.html)\] (ACM MM'2020)
+- [x] [Halpe](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#halpe-cvpr-2020) \[[homepage](https://github.com/Fang-Haoshu/Halpe-FullBody/)\] (CVPR'2020)
+- [x] [COCO-WholeBody](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#coco-wholebody-eccv-2020) \[[homepage](https://github.com/jin-s13/COCO-WholeBody/)\] (ECCV'2020)
+- [x] [MacaquePose](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#macaquepose-biorxiv-2020) \[[homepage](http://www.pri.kyoto-u.ac.jp/datasets/macaquepose/index.html)\] (bioRxiv'2020)
+- [x] [InterHand2.6M](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#interhand2-6m-eccv-2020) \[[homepage](https://mks0601.github.io/InterHand2.6M/)\] (ECCV'2020)
+- [x] [AP-10K](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#ap-10k-neurips-2021) \[[homepage](https://github.com/AlexTheBad/AP-10K)\] (NeurIPS'2021)
+- [x] [Horse-10](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#horse-10-wacv-2021) \[[homepage](http://www.mackenziemathislab.org/horse10)\] (WACV'2021)
+- [x] [Human-Art](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#human-art-cvpr-2023) \[[homepage](https://idea-research.github.io/HumanArt/)\] (CVPR'2023)
+- [x] [LaPa](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#lapa-aaai-2020) \[[homepage](https://github.com/JDAI-CV/lapa-dataset)\] (AAAI'2020)
+
+
+
+
+Supported backbones:
+
+- [x] [AlexNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#alexnet-neurips-2012) (NeurIPS'2012)
+- [x] [VGG](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#vgg-iclr-2015) (ICLR'2015)
+- [x] [ResNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#resnet-cvpr-2016) (CVPR'2016)
+- [x] [ResNext](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#resnext-cvpr-2017) (CVPR'2017)
+- [x] [SEResNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#seresnet-cvpr-2018) (CVPR'2018)
+- [x] [ShufflenetV1](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#shufflenetv1-cvpr-2018) (CVPR'2018)
+- [x] [ShufflenetV2](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#shufflenetv2-eccv-2018) (ECCV'2018)
+- [x] [MobilenetV2](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#mobilenetv2-cvpr-2018) (CVPR'2018)
+- [x] [ResNetV1D](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#resnetv1d-cvpr-2019) (CVPR'2019)
+- [x] [ResNeSt](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#resnest-arxiv-2020) (ArXiv'2020)
+- [x] [Swin](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#swin-cvpr-2021) (CVPR'2021)
+- [x] [HRFormer](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#hrformer-nips-2021) (NIPS'2021)
+- [x] [PVT](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#pvt-iccv-2021) (ICCV'2021)
+- [x] [PVTV2](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#pvtv2-cvmj-2022) (CVMJ'2022)
+
+
+
+### Model Request
+
+We will keep up with the latest progress of the community, and support more popular algorithms and frameworks. If you have any feature requests, please feel free to leave a comment in [MMPose Roadmap](https://github.com/open-mmlab/mmpose/issues/2258).
+
+## Contributing
+
+We appreciate all contributions to improve MMPose. Please refer to [CONTRIBUTING.md](https://mmpose.readthedocs.io/en/latest/contribution_guide.html) for the contributing guideline.
+
+## Acknowledgement
+
+MMPose is an open source project that is contributed by researchers and engineers from various colleges and companies.
+We appreciate all the contributors who implement their methods or add new features, as well as users who give valuable feedbacks.
+We wish that the toolbox and benchmark could serve the growing research community by providing a flexible toolkit to reimplement existing methods and develop their own new models.
+
+## Citation
+
+If you find this project useful in your research, please consider cite:
+
+```bibtex
+@misc{mmpose2020,
+ title={OpenMMLab Pose Estimation Toolbox and Benchmark},
+ author={MMPose Contributors},
+ howpublished = {\url{https://github.com/open-mmlab/mmpose}},
+ year={2020}
+}
+```
+
+## License
+
+This project is released under the [Apache 2.0 license](LICENSE).
+
+## Projects in OpenMMLab
+
+- [MMEngine](https://github.com/open-mmlab/mmengine): OpenMMLab foundational library for training deep learning models.
+- [MMCV](https://github.com/open-mmlab/mmcv): OpenMMLab foundational library for computer vision.
+- [MMPreTrain](https://github.com/open-mmlab/mmpretrain): OpenMMLab pre-training toolbox and benchmark.
+- [MMagic](https://github.com/open-mmlab/mmagic): Open**MM**Lab **A**dvanced, **G**enerative and **I**ntelligent **C**reation toolbox.
+- [MMDetection](https://github.com/open-mmlab/mmdetection): OpenMMLab detection toolbox and benchmark.
+- [MMDetection3D](https://github.com/open-mmlab/mmdetection3d): OpenMMLab's next-generation platform for general 3D object detection.
+- [MMRotate](https://github.com/open-mmlab/mmrotate): OpenMMLab rotated object detection toolbox and benchmark.
+- [MMTracking](https://github.com/open-mmlab/mmtracking): OpenMMLab video perception toolbox and benchmark.
+- [MMSegmentation](https://github.com/open-mmlab/mmsegmentation): OpenMMLab semantic segmentation toolbox and benchmark.
+- [MMOCR](https://github.com/open-mmlab/mmocr): OpenMMLab text detection, recognition, and understanding toolbox.
+- [MMPose](https://github.com/open-mmlab/mmpose): OpenMMLab pose estimation toolbox and benchmark.
+- [MMHuman3D](https://github.com/open-mmlab/mmhuman3d): OpenMMLab 3D human parametric model toolbox and benchmark.
+- [MMFewShot](https://github.com/open-mmlab/mmfewshot): OpenMMLab fewshot learning toolbox and benchmark.
+- [MMAction2](https://github.com/open-mmlab/mmaction2): OpenMMLab's next-generation action understanding toolbox and benchmark.
+- [MMFlow](https://github.com/open-mmlab/mmflow): OpenMMLab optical flow toolbox and benchmark.
+- [MMDeploy](https://github.com/open-mmlab/mmdeploy): OpenMMLab Model Deployment Framework.
+- [MMRazor](https://github.com/open-mmlab/mmrazor): OpenMMLab model compression toolbox and benchmark.
+- [MIM](https://github.com/open-mmlab/mim): MIM installs OpenMMLab packages.
+- [Playground](https://github.com/open-mmlab/playground): A central hub for gathering and showcasing amazing projects built upon OpenMMLab.
diff --git a/README_CN.md b/README_CN.md
index 48672c2a88..f0649d2c37 100644
--- a/README_CN.md
+++ b/README_CN.md
@@ -1,384 +1,384 @@
-
+# Human Body 2D Pose Estimation
+
+Multi-person human pose estimation is defined as the task of detecting the poses (or keypoints) of all people from an input image.
+
+Existing approaches can be categorized into top-down and bottom-up approaches.
+
+Top-down methods (e.g. DeepPose) divide the task into two stages: human detection and pose estimation. They perform human detection first, followed by single-person pose estimation given human bounding boxes.
+
+Bottom-up approaches (e.g. Associative Embedding) first detect all the keypoints and then group/associate them into person instances.
+
+## Data preparation
+
+Please follow [DATA Preparation](/docs/en/dataset_zoo/2d_body_keypoint.md) to prepare data.
+
+## Demo
+
+Please follow [Demo](/demo/docs/en/2d_human_pose_demo.md#2d-human-pose-demo) to run demos.
+
+
+
+
diff --git a/configs/body_2d_keypoint/associative_embedding/README.md b/configs/body_2d_keypoint/associative_embedding/README.md
index 7f5fa8ea17..5592374d2f 100644
--- a/configs/body_2d_keypoint/associative_embedding/README.md
+++ b/configs/body_2d_keypoint/associative_embedding/README.md
@@ -1,9 +1,9 @@
-# Associative embedding: End-to-end learning for joint detection and grouping (AE)
-
-Associative Embedding is one of the most popular 2D bottom-up pose estimation approaches, that first detect all the keypoints and then group/associate them into person instances.
-
-In order to group all the predicted keypoints to individuals, a tag is also predicted for each detected keypoint. Tags of the same person are similar, while tags of different people are different. Thus the keypoints can be grouped according to the tags.
-
-
-
-
+# Associative embedding: End-to-end learning for joint detection and grouping (AE)
+
+Associative Embedding is one of the most popular 2D bottom-up pose estimation approaches, that first detect all the keypoints and then group/associate them into person instances.
+
+In order to group all the predicted keypoints to individuals, a tag is also predicted for each detected keypoint. Tags of the same person are similar, while tags of different people are different. Thus the keypoints can be grouped according to the tags.
+
+
-
-## Results and Models
-
-### COCO Dataset
-
-Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
-
-| Model | Input Size | AP | AR | Details and Download |
-| :---------------------------: | :--------: | :---: | :---: | :-----------------------------------------------: |
-| ResNet-50+SimCC | 384x288 | 0.735 | 0.790 | [resnet_coco.md](./coco/resnet_coco.md) |
-| ResNet-50+SimCC | 256x192 | 0.721 | 0.781 | [resnet_coco.md](./coco/resnet_coco.md) |
-| S-ViPNAS-MobileNet-V3+SimCC | 256x192 | 0.695 | 0.755 | [vipnas_coco.md](./coco/vipnas_coco.md) |
-| MobileNet-V2+SimCC(wo/deconv) | 256x192 | 0.620 | 0.678 | [mobilenetv2_coco.md](./coco/mobilenetv2_coco.md) |
+# Top-down SimCC-based pose estimation
+
+Top-down methods divide the task into two stages: object detection, followed by single-object pose estimation given object bounding boxes. At the 2nd stage, SimCC based methods reformulate human pose estimation as two classification tasks for horizontal and vertical coordinates, and uniformly divide each pixel into several bins, thus obtain the keypoint coordinates given the features extracted from the bounding box area, following the paradigm introduced in [SimCC: a Simple Coordinate Classification Perspective for Human Pose Estimation](https://arxiv.org/abs/2107.03332).
+
+
', '', f'## {titlecase(dataset)} Dataset',
- ''
- ]
-
- for keywords, doc in keywords_dict.items():
- keyword_strs = [
- titlecase(x.replace('_', ' ')) for x in keywords
- ]
- dataset_str = titlecase(dataset)
- if dataset_str in keyword_strs:
- keyword_strs.remove(dataset_str)
-
- lines += [
- ' ', '',
- (f'### {" + ".join(keyword_strs)}'
- f' on {dataset_str}'), '', doc['content'], ''
- ]
-
- fn = osp.join('model_zoo', f'{task.replace(" ", "_").lower()}.md')
- with open(fn, 'w', encoding='utf-8') as f:
- f.write('\n'.join(lines))
-
- # Write files by paper
- paper_refs = _get_paper_refs()
-
- for paper_cat, paper_list in paper_refs.items():
- lines = []
- for paper_fn in paper_list:
- paper_name, indicator = _parse_paper_ref(paper_fn)
- paperlines = []
- for task, dataset_dict in model_docs.items():
- for dataset, keywords_dict in dataset_dict.items():
- for keywords, doc_info in keywords_dict.items():
-
- if indicator not in doc_info['content']:
- continue
-
- keyword_strs = [
- titlecase(x.replace('_', ' ')) for x in keywords
- ]
-
- dataset_str = titlecase(dataset)
- if dataset_str in keyword_strs:
- keyword_strs.remove(dataset_str)
- paperlines += [
- ' ', '',
- (f'### {" + ".join(keyword_strs)}'
- f' on {dataset_str}'), '', doc_info['content'], ''
- ]
- if paperlines:
- lines += ['', '
', '', f'## {paper_name}', '']
- lines += paperlines
-
- if lines:
- lines = [f'# {titlecase(paper_cat)}', ''] + lines
- with open(
- osp.join('model_zoo_papers', f'{paper_cat.lower()}.md'),
- 'w',
- encoding='utf-8') as f:
- f.write('\n'.join(lines))
-
-
-if __name__ == '__main__':
- print('collect model zoo documents')
- main()
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import os.path as osp
+import re
+from collections import defaultdict
+from glob import glob
+
+from addict import Addict
+from titlecase import titlecase
+
+
+def _get_model_docs():
+ """Get all model document files.
+
+ Returns:
+ list[str]: file paths
+ """
+ config_root = osp.join('..', '..', 'configs')
+ pattern = osp.sep.join(['*'] * 4) + '.md'
+ docs = glob(osp.join(config_root, pattern))
+ docs = [doc for doc in docs if '_base_' not in doc]
+ return docs
+
+
+def _parse_model_doc_path(path):
+ """Parse doc file path.
+
+ Typical path would be like:
+
+ configs////.md
+
+ An example is:
+
+ "configs/animal_2d_keypoint/topdown_heatmap/
+ animalpose/resnet_animalpose.md"
+
+ Returns:
+ tuple:
+ - task (str): e.g. ``'Animal 2D Keypoint'``
+ - dataset (str): e.g. ``'animalpose'``
+ - keywords (tuple): e.g. ``('topdown heatmap', 'resnet')``
+ """
+ _path = path.split(osp.sep)
+ _rel_path = _path[_path.index('configs'):]
+
+ # get task
+ def _titlecase_callback(word, **kwargs):
+ if word == '2d':
+ return '2D'
+ if word == '3d':
+ return '3D'
+
+ task = titlecase(
+ _rel_path[1].replace('_', ' '), callback=_titlecase_callback)
+
+ # get dataset
+ dataset = _rel_path[3]
+
+ # get keywords
+ keywords_algo = (_rel_path[2], )
+ keywords_setting = tuple(_rel_path[4][:-3].split('_'))
+ keywords = keywords_algo + keywords_setting
+
+ return task, dataset, keywords
+
+
+def _get_paper_refs():
+ """Get all paper references.
+
+ Returns:
+ Dict[str, List[str]]: keys are paper categories and values are lists
+ of paper paths.
+ """
+ papers = glob('../src/papers/*/*.md')
+ paper_refs = defaultdict(list)
+ for fn in papers:
+ category = fn.split(osp.sep)[3]
+ paper_refs[category].append(fn)
+
+ return paper_refs
+
+
+def _parse_paper_ref(fn):
+ """Get paper name and indicator pattern from a paper reference file.
+
+ Returns:
+ tuple:
+ - paper_name (str)
+ - paper_indicator (str)
+ """
+ indicator = None
+ with open(fn, 'r', encoding='utf-8') as f:
+ for line in f.readlines():
+ if line.startswith('', '', indicator).strip()
+ return paper_name, indicator
+
+
+def main():
+
+ # Build output folders
+ os.makedirs('model_zoo', exist_ok=True)
+ os.makedirs('model_zoo_papers', exist_ok=True)
+
+ # Collect all document contents
+ model_doc_list = _get_model_docs()
+ model_docs = Addict()
+
+ for path in model_doc_list:
+ task, dataset, keywords = _parse_model_doc_path(path)
+ with open(path, 'r', encoding='utf-8') as f:
+ doc = {
+ 'task': task,
+ 'dataset': dataset,
+ 'keywords': keywords,
+ 'path': path,
+ 'content': f.read()
+ }
+ model_docs[task][dataset][keywords] = doc
+
+ # Write files by task
+ for task, dataset_dict in model_docs.items():
+ lines = [f'# {task}', '']
+ for dataset, keywords_dict in dataset_dict.items():
+ lines += [
+ '', '
', '', f'## {titlecase(dataset)} Dataset',
+ ''
+ ]
+
+ for keywords, doc in keywords_dict.items():
+ keyword_strs = [
+ titlecase(x.replace('_', ' ')) for x in keywords
+ ]
+ dataset_str = titlecase(dataset)
+ if dataset_str in keyword_strs:
+ keyword_strs.remove(dataset_str)
+
+ lines += [
+ ' ', '',
+ (f'### {" + ".join(keyword_strs)}'
+ f' on {dataset_str}'), '', doc['content'], ''
+ ]
+
+ fn = osp.join('model_zoo', f'{task.replace(" ", "_").lower()}.md')
+ with open(fn, 'w', encoding='utf-8') as f:
+ f.write('\n'.join(lines))
+
+ # Write files by paper
+ paper_refs = _get_paper_refs()
+
+ for paper_cat, paper_list in paper_refs.items():
+ lines = []
+ for paper_fn in paper_list:
+ paper_name, indicator = _parse_paper_ref(paper_fn)
+ paperlines = []
+ for task, dataset_dict in model_docs.items():
+ for dataset, keywords_dict in dataset_dict.items():
+ for keywords, doc_info in keywords_dict.items():
+
+ if indicator not in doc_info['content']:
+ continue
+
+ keyword_strs = [
+ titlecase(x.replace('_', ' ')) for x in keywords
+ ]
+
+ dataset_str = titlecase(dataset)
+ if dataset_str in keyword_strs:
+ keyword_strs.remove(dataset_str)
+ paperlines += [
+ ' ', '',
+ (f'### {" + ".join(keyword_strs)}'
+ f' on {dataset_str}'), '', doc_info['content'], ''
+ ]
+ if paperlines:
+ lines += ['', '
', '', f'## {paper_name}', '']
+ lines += paperlines
+
+ if lines:
+ lines = [f'# {titlecase(paper_cat)}', ''] + lines
+ with open(
+ osp.join('model_zoo_papers', f'{paper_cat.lower()}.md'),
+ 'w',
+ encoding='utf-8') as f:
+ f.write('\n'.join(lines))
+
+
+if __name__ == '__main__':
+ print('collect model zoo documents')
+ main()
diff --git a/docs/en/collect_projects.py b/docs/en/collect_projects.py
index 29c0449862..971e21cf66 100644
--- a/docs/en/collect_projects.py
+++ b/docs/en/collect_projects.py
@@ -1,116 +1,116 @@
-#!/usr/bin/env python
-# Copyright (c) OpenMMLab. All rights reserved.
-import os
-import os.path as osp
-import re
-from glob import glob
-
-
-def _get_project_docs():
- """Get all project document files.
-
- Returns:
- list[str]: file paths
- """
- project_root = osp.join('..', '..', 'projects')
- pattern = osp.sep.join(['*'] * 2) + '.md'
- docs = glob(osp.join(project_root, pattern))
- docs = [
- doc for doc in docs
- if 'example_project' not in doc and '_CN' not in doc
- ]
- return docs
-
-
-def _parse_project_doc_path(fn):
- """Get project name and banner from a project reference file.
-
- Returns:
- tuple:
- - project_name (str)
- - project_banner (str)
- """
- project_banner, project_name = None, None
- with open(fn, 'r', encoding='utf-8') as f:
- for line in f.readlines():
- if re.match('^( )*', ' ' + banner, '', ' ', ''
- ]
-
- project_intro_doc = _get_project_intro_doc()
- faq_doc = _get_faq_doc()
-
- with open(
- osp.join('projects', 'community_projects.md'), 'w',
- encoding='utf-8') as f:
- f.write('# Projects from Community Contributors\n')
- f.write(''.join(project_intro_doc))
- f.write('\n'.join(project_lines))
- f.write(''.join(faq_doc))
-
-
-if __name__ == '__main__':
- print('collect project documents')
- main()
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import os.path as osp
+import re
+from glob import glob
+
+
+def _get_project_docs():
+ """Get all project document files.
+
+ Returns:
+ list[str]: file paths
+ """
+ project_root = osp.join('..', '..', 'projects')
+ pattern = osp.sep.join(['*'] * 2) + '.md'
+ docs = glob(osp.join(project_root, pattern))
+ docs = [
+ doc for doc in docs
+ if 'example_project' not in doc and '_CN' not in doc
+ ]
+ return docs
+
+
+def _parse_project_doc_path(fn):
+ """Get project name and banner from a project reference file.
+
+ Returns:
+ tuple:
+ - project_name (str)
+ - project_banner (str)
+ """
+ project_banner, project_name = None, None
+ with open(fn, 'r', encoding='utf-8') as f:
+ for line in f.readlines():
+ if re.match('^( )*', ' ' + banner, '', ' ', ''
+ ]
+
+ project_intro_doc = _get_project_intro_doc()
+ faq_doc = _get_faq_doc()
+
+ with open(
+ osp.join('projects', 'community_projects.md'), 'w',
+ encoding='utf-8') as f:
+ f.write('# Projects from Community Contributors\n')
+ f.write(''.join(project_intro_doc))
+ f.write('\n'.join(project_lines))
+ f.write(''.join(faq_doc))
+
+
+if __name__ == '__main__':
+ print('collect project documents')
+ main()
diff --git a/docs/en/conf.py b/docs/en/conf.py
index 4359aa46e9..90bf66d0dd 100644
--- a/docs/en/conf.py
+++ b/docs/en/conf.py
@@ -1,111 +1,111 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-# Configuration file for the Sphinx documentation builder.
-#
-# This file only contains a selection of the most common options. For a full
-# list see the documentation:
-# https://www.sphinx-doc.org/en/master/usage/configuration.html
-
-# -- Path setup --------------------------------------------------------------
-
-# If extensions (or modules to document with autodoc) are in another directory,
-# add these directories to sys.path here. If the directory is relative to the
-# documentation root, use os.path.abspath to make it absolute, like shown here.
-
-import os
-import subprocess
-import sys
-
-import pytorch_sphinx_theme
-
-sys.path.insert(0, os.path.abspath('../..'))
-
-# -- Project information -----------------------------------------------------
-
-project = 'MMPose'
-copyright = '2020-2021, OpenMMLab'
-author = 'MMPose Authors'
-
-# The full version, including alpha/beta/rc tags
-version_file = '../../mmpose/version.py'
-
-
-def get_version():
- with open(version_file, 'r') as f:
- exec(compile(f.read(), version_file, 'exec'))
- return locals()['__version__']
-
-
-release = get_version()
-
-# -- General configuration ---------------------------------------------------
-
-# Add any Sphinx extension module names here, as strings. They can be
-# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
-# ones.
-extensions = [
- 'sphinx.ext.autodoc', 'sphinx.ext.napoleon', 'sphinx.ext.viewcode',
- 'sphinx_markdown_tables', 'sphinx_copybutton', 'myst_parser',
- 'sphinx.ext.autosummary'
-]
-
-autodoc_mock_imports = ['json_tricks', 'mmpose.version']
-
-# Ignore >>> when copying code
-copybutton_prompt_text = r'>>> |\.\.\. '
-copybutton_prompt_is_regexp = True
-
-# Add any paths that contain templates here, relative to this directory.
-templates_path = ['_templates']
-
-# List of patterns, relative to source directory, that match files and
-# directories to ignore when looking for source files.
-# This pattern also affects html_static_path and html_extra_path.
-exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
-
-# -- Options for HTML output -------------------------------------------------
-source_suffix = {
- '.rst': 'restructuredtext',
- '.md': 'markdown',
-}
-
-# The theme to use for HTML and HTML Help pages. See the documentation for
-# a list of builtin themes.
-#
-html_theme = 'pytorch_sphinx_theme'
-html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
-html_theme_options = {
- 'menu': [
- {
- 'name': 'GitHub',
- 'url': 'https://github.com/open-mmlab/mmpose/tree/main'
- },
- ],
- # Specify the language of the shared menu
- 'menu_lang':
- 'en'
-}
-
-# Add any paths that contain custom static files (such as style sheets) here,
-# relative to this directory. They are copied after the builtin static files,
-# so a file named "default.css" will overwrite the builtin "default.css".
-
-language = 'en'
-
-html_static_path = ['_static']
-html_css_files = ['css/readthedocs.css']
-
-# Enable ::: for my_st
-myst_enable_extensions = ['colon_fence']
-
-master_doc = 'index'
-
-
-def builder_inited_handler(app):
- subprocess.run(['python', './collect_modelzoo.py'])
- subprocess.run(['python', './collect_projects.py'])
- subprocess.run(['sh', './merge_docs.sh'])
- subprocess.run(['python', './stats.py'])
-
-
-def setup(app):
- app.connect('builder-inited', builder_inited_handler)
+# Copyright (c) OpenMMLab. All rights reserved.
+# Configuration file for the Sphinx documentation builder.
+#
+# This file only contains a selection of the most common options. For a full
+# list see the documentation:
+# https://www.sphinx-doc.org/en/master/usage/configuration.html
+
+# -- Path setup --------------------------------------------------------------
+
+# If extensions (or modules to document with autodoc) are in another directory,
+# add these directories to sys.path here. If the directory is relative to the
+# documentation root, use os.path.abspath to make it absolute, like shown here.
+
+import os
+import subprocess
+import sys
+
+import pytorch_sphinx_theme
+
+sys.path.insert(0, os.path.abspath('../..'))
+
+# -- Project information -----------------------------------------------------
+
+project = 'MMPose'
+copyright = '2020-2021, OpenMMLab'
+author = 'MMPose Authors'
+
+# The full version, including alpha/beta/rc tags
+version_file = '../../mmpose/version.py'
+
+
+def get_version():
+ with open(version_file, 'r') as f:
+ exec(compile(f.read(), version_file, 'exec'))
+ return locals()['__version__']
+
+
+release = get_version()
+
+# -- General configuration ---------------------------------------------------
+
+# Add any Sphinx extension module names here, as strings. They can be
+# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
+# ones.
+extensions = [
+ 'sphinx.ext.autodoc', 'sphinx.ext.napoleon', 'sphinx.ext.viewcode',
+ 'sphinx_markdown_tables', 'sphinx_copybutton', 'myst_parser',
+ 'sphinx.ext.autosummary'
+]
+
+autodoc_mock_imports = ['json_tricks', 'mmpose.version']
+
+# Ignore >>> when copying code
+copybutton_prompt_text = r'>>> |\.\.\. '
+copybutton_prompt_is_regexp = True
+
+# Add any paths that contain templates here, relative to this directory.
+templates_path = ['_templates']
+
+# List of patterns, relative to source directory, that match files and
+# directories to ignore when looking for source files.
+# This pattern also affects html_static_path and html_extra_path.
+exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
+
+# -- Options for HTML output -------------------------------------------------
+source_suffix = {
+ '.rst': 'restructuredtext',
+ '.md': 'markdown',
+}
+
+# The theme to use for HTML and HTML Help pages. See the documentation for
+# a list of builtin themes.
+#
+html_theme = 'pytorch_sphinx_theme'
+html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
+html_theme_options = {
+ 'menu': [
+ {
+ 'name': 'GitHub',
+ 'url': 'https://github.com/open-mmlab/mmpose/tree/main'
+ },
+ ],
+ # Specify the language of the shared menu
+ 'menu_lang':
+ 'en'
+}
+
+# Add any paths that contain custom static files (such as style sheets) here,
+# relative to this directory. They are copied after the builtin static files,
+# so a file named "default.css" will overwrite the builtin "default.css".
+
+language = 'en'
+
+html_static_path = ['_static']
+html_css_files = ['css/readthedocs.css']
+
+# Enable ::: for my_st
+myst_enable_extensions = ['colon_fence']
+
+master_doc = 'index'
+
+
+def builder_inited_handler(app):
+ subprocess.run(['python', './collect_modelzoo.py'])
+ subprocess.run(['python', './collect_projects.py'])
+ subprocess.run(['sh', './merge_docs.sh'])
+ subprocess.run(['python', './stats.py'])
+
+
+def setup(app):
+ app.connect('builder-inited', builder_inited_handler)
diff --git a/docs/en/contribution_guide.md b/docs/en/contribution_guide.md
index 525ca9a7e1..60ecd37ce3 100644
--- a/docs/en/contribution_guide.md
+++ b/docs/en/contribution_guide.md
@@ -1,191 +1,191 @@
-# How to Contribute to MMPose
-
-Welcome to join the MMPose community, we are committed to building cutting-edge computer vision foundational library. All kinds of contributions are welcomed, including but not limited to:
-
-- **Fix bugs**
- 1. If the modification involves significant changes, it's recommended to create an issue first that describes the error information and how to trigger the bug. Other developers will discuss it with you and propose a proper solution.
- 2. Fix the bug and add the corresponding unit test, submit the PR.
-- **Add new features or components**
- 1. If the new feature or module involves a large amount of code changes, we suggest you to submit an issue first, and we will confirm the necessity of the function with you.
- 2. Implement the new feature and add unit tests, submit the PR.
-- **Improve documentation or translation**
- - If you find errors or incomplete documentation, please submit a PR directly.
-
-```{note}
-- If you hope to contribute to MMPose 1.0, please create a new branch from dev-1.x and submit a PR to the dev-1.x branch.
-- If you are the author of papers in this field and would like to include your work to MMPose, please contact us. We will much appreciate your contribution.
-- If you hope to share your MMPose-based projects with the community at once, consider creating a PR to `Projects` directory, which will simplify the review process and bring in the projects as soon as possible. Checkout our [example project](/projects/example_project)
-- If you wish to join the MMPose developers, please feel free to contact us and we will invite you to join the MMPose developers group.
-```
-
-## Preparation
-
-The commands for processing pull requests are implemented using Git, and this chapter details Git Configuration and associated GitHub.
-
-### Git Configuration
-
-First, you need to install Git and configure your Git username and email.
-
-```shell
-# view the Git version
-git --version
-```
-
-Second, check your Git config and ensure that `user.name` and `user.email` are properly configured.
-
-```shell
-# view the Git config
-git config --global --list
-# configure the user name and email
-git config --global user.name "Change your user name here"
-git config --global user.email "Change your user email here"
-```
-
-## Pull Request Workflow
-
-If you’re not familiar with Pull Request, don’t worry! The following guidance will tell you how to create a Pull Request step by step. If you want to dive into the development mode of Pull Request, you can refer to the [official documents](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests).
-
-### 1. Fork and Clone
-
-If you are posting a pull request for the first time, you should fork the OpenMMLab repositories by clicking the **Fork** button in the top right corner of the GitHub page, and the forked repositories will appear under your GitHub profile.
-
-
-
-Then you need to clone the forked repository to your local machine.
-
-```shell
-# clone the forked repository
-git clone https://github.com/username/mmpose.git
-
-# Add official repository as upstream remote
-cd mmpose
-git remote add upstream https://github.com/open-mmlab/mmpose.git
-```
-
-Enter the following command in the terminal to see if the remote repository was successfully added.
-
-```shell
-git remote -v
-```
-
-If the following message appears, you have successfully added a remote repository.
-
-```Shell
-origin https://github.com/{username}/mmpose.git (fetch)
-origin https://github.com/{username}/mmpose.git (push)
-upstream https://github.com/open-mmlab/mmpose.git (fetch)
-upstream https://github.com/open-mmlab/mmpose.git (push)
-```
-
-```{note}
-Here’s a brief introduction to the origin and upstream. When we use “git clone”, we create an “origin” remote by default, which points to the repository cloned from. As for “upstream”, we add it ourselves to point to the target repository. Of course, if you don’t like the name “upstream”, you could name it as you wish. Usually, we’ll push the code to “origin”. If the pushed code conflicts with the latest code in official(“upstream”), we should pull the latest code from upstream to resolve the conflicts, and then push to “origin” again. The posted Pull Request will be updated automatically.
-```
-
-### 2. Configure pre-commit
-
-You should configure pre-commit in the local development environment to make sure the code style matches that of OpenMMLab. Note: The following code should be executed under the MMPOSE directory.
-
-```Shell
-pip install -U pre-commit
-pre-commit install
-```
-
-Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
-
-```Shell
-pre-commit run --all-files
-```
-
-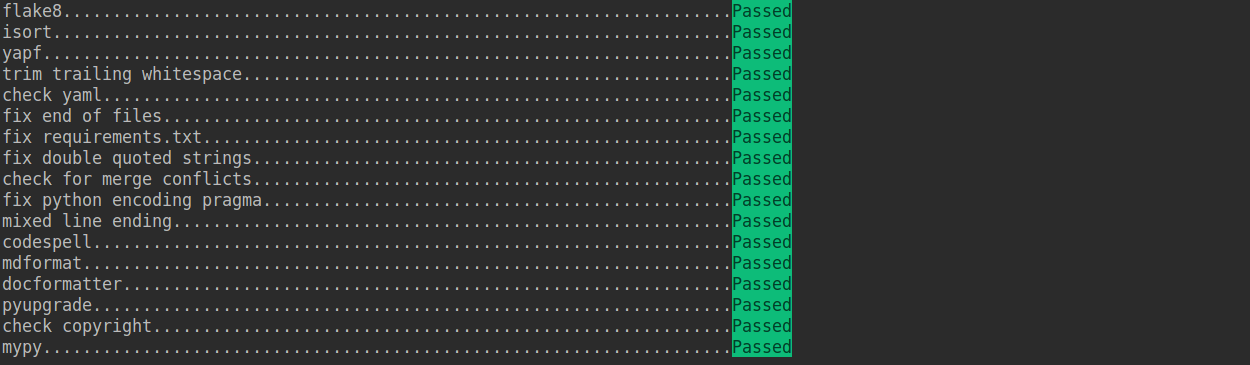
-
-```{note}
-Chinese users may fail to download the pre-commit hooks due to the network issue. In this case, you could download these hooks from:
-
-pip install -U pre-commit -i https://pypi.tuna.tsinghua.edu.cn/simple
-
-or:
-
-pip install -U pre-commit -i https://pypi.mirrors.ustc.edu.cn/simple
-```
-
-If the installation process is interrupted, you can repeatedly run `pre-commit run ...` to continue the installation.
-
-If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
-
-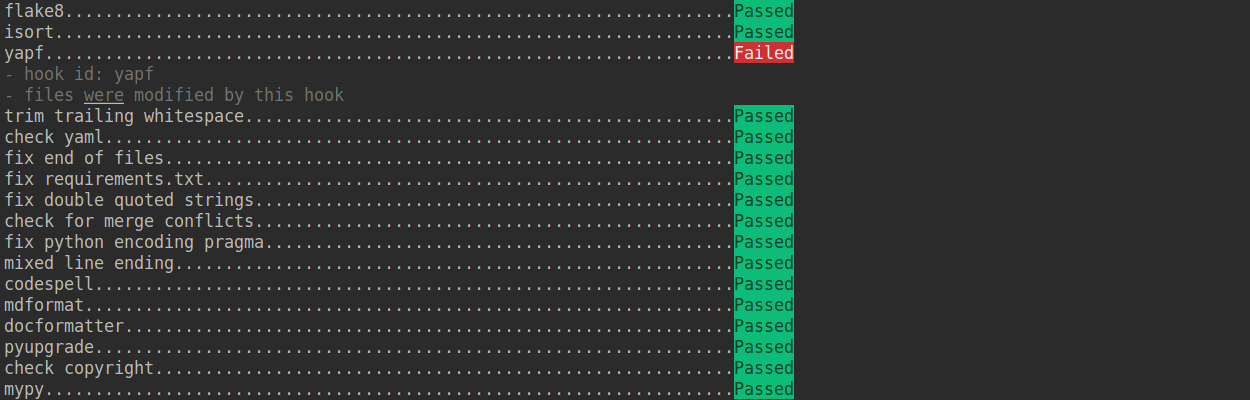
-
-### 3. Create a development branch
-
-After configuring the pre-commit, we should create a branch based on the dev branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`.
-
-```Shell
-git checkout -b username/refactor_contributing_doc
-```
-
-In subsequent development, if the dev branch of the local repository lags behind the dev branch of the official repository, you need to pull the upstream dev branch first and then rebase it to the local development branch.
-
-```Shell
-git checkout username/refactor_contributing_doc
-git fetch upstream
-git rebase upstream/dev-1.x
-```
-
-When rebasing, if a conflict arises, you need to resolve the conflict manually, then execute the `git add` command, and then execute the `git rebase --continue` command until the rebase is complete.
-
-### 4. Commit the code and pass the unit test
-
-After the local development is done, we need to pass the unit tests locally and then commit the code.
-
-```shell
-# run unit test
-pytest tests/
-
-# commit the code
-git add .
-git commit -m "commit message"
-```
-
-### 5. Push the code to the remote repository
-
-After the local development is done, we need to push the code to the remote repository.
-
-```Shell
-git push origin username/refactor_contributing_doc
-```
-
-### 6. Create a Pull Request
-
-#### (1) Create a Pull Request on GitHub
-
-
-
-#### (2) Fill in the Pull Request template
-
-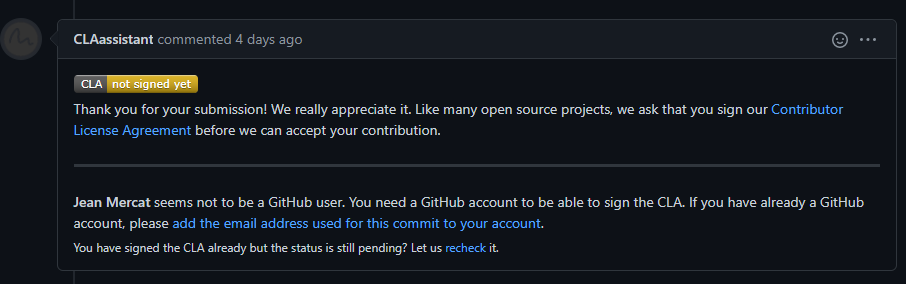
-
-## Code Style
-
-### Python
-
-We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style, and use the following tools for linting and formatting:
-
-- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
-- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
-- [yapf](https://github.com/google/yapf): A formatter for Python files.
-- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
-- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
-- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
-
-Style configurations of yapf and isort can be found in [setup.cfg](/setup.cfg).
-
-We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
-fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
-The config for a pre-commit hook is stored in [.pre-commit-config](/.pre-commit-config.yaml).
-
-```{note}
-Before you create a PR, make sure that your code lints and is formatted by yapf.
-```
-
-### C++ and CUDA
-
-We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
+# How to Contribute to MMPose
+
+Welcome to join the MMPose community, we are committed to building cutting-edge computer vision foundational library. All kinds of contributions are welcomed, including but not limited to:
+
+- **Fix bugs**
+ 1. If the modification involves significant changes, it's recommended to create an issue first that describes the error information and how to trigger the bug. Other developers will discuss it with you and propose a proper solution.
+ 2. Fix the bug and add the corresponding unit test, submit the PR.
+- **Add new features or components**
+ 1. If the new feature or module involves a large amount of code changes, we suggest you to submit an issue first, and we will confirm the necessity of the function with you.
+ 2. Implement the new feature and add unit tests, submit the PR.
+- **Improve documentation or translation**
+ - If you find errors or incomplete documentation, please submit a PR directly.
+
+```{note}
+- If you hope to contribute to MMPose 1.0, please create a new branch from dev-1.x and submit a PR to the dev-1.x branch.
+- If you are the author of papers in this field and would like to include your work to MMPose, please contact us. We will much appreciate your contribution.
+- If you hope to share your MMPose-based projects with the community at once, consider creating a PR to `Projects` directory, which will simplify the review process and bring in the projects as soon as possible. Checkout our [example project](/projects/example_project)
+- If you wish to join the MMPose developers, please feel free to contact us and we will invite you to join the MMPose developers group.
+```
+
+## Preparation
+
+The commands for processing pull requests are implemented using Git, and this chapter details Git Configuration and associated GitHub.
+
+### Git Configuration
+
+First, you need to install Git and configure your Git username and email.
+
+```shell
+# view the Git version
+git --version
+```
+
+Second, check your Git config and ensure that `user.name` and `user.email` are properly configured.
+
+```shell
+# view the Git config
+git config --global --list
+# configure the user name and email
+git config --global user.name "Change your user name here"
+git config --global user.email "Change your user email here"
+```
+
+## Pull Request Workflow
+
+If you’re not familiar with Pull Request, don’t worry! The following guidance will tell you how to create a Pull Request step by step. If you want to dive into the development mode of Pull Request, you can refer to the [official documents](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests).
+
+### 1. Fork and Clone
+
+If you are posting a pull request for the first time, you should fork the OpenMMLab repositories by clicking the **Fork** button in the top right corner of the GitHub page, and the forked repositories will appear under your GitHub profile.
+
+
+
+Then you need to clone the forked repository to your local machine.
+
+```shell
+# clone the forked repository
+git clone https://github.com/username/mmpose.git
+
+# Add official repository as upstream remote
+cd mmpose
+git remote add upstream https://github.com/open-mmlab/mmpose.git
+```
+
+Enter the following command in the terminal to see if the remote repository was successfully added.
+
+```shell
+git remote -v
+```
+
+If the following message appears, you have successfully added a remote repository.
+
+```Shell
+origin https://github.com/{username}/mmpose.git (fetch)
+origin https://github.com/{username}/mmpose.git (push)
+upstream https://github.com/open-mmlab/mmpose.git (fetch)
+upstream https://github.com/open-mmlab/mmpose.git (push)
+```
+
+```{note}
+Here’s a brief introduction to the origin and upstream. When we use “git clone”, we create an “origin” remote by default, which points to the repository cloned from. As for “upstream”, we add it ourselves to point to the target repository. Of course, if you don’t like the name “upstream”, you could name it as you wish. Usually, we’ll push the code to “origin”. If the pushed code conflicts with the latest code in official(“upstream”), we should pull the latest code from upstream to resolve the conflicts, and then push to “origin” again. The posted Pull Request will be updated automatically.
+```
+
+### 2. Configure pre-commit
+
+You should configure pre-commit in the local development environment to make sure the code style matches that of OpenMMLab. Note: The following code should be executed under the MMPOSE directory.
+
+```Shell
+pip install -U pre-commit
+pre-commit install
+```
+
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```Shell
+pre-commit run --all-files
+```
+
+
+
+```{note}
+Chinese users may fail to download the pre-commit hooks due to the network issue. In this case, you could download these hooks from:
+
+pip install -U pre-commit -i https://pypi.tuna.tsinghua.edu.cn/simple
+
+or:
+
+pip install -U pre-commit -i https://pypi.mirrors.ustc.edu.cn/simple
+```
+
+If the installation process is interrupted, you can repeatedly run `pre-commit run ...` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+
+
+### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the dev branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`.
+
+```Shell
+git checkout -b username/refactor_contributing_doc
+```
+
+In subsequent development, if the dev branch of the local repository lags behind the dev branch of the official repository, you need to pull the upstream dev branch first and then rebase it to the local development branch.
+
+```Shell
+git checkout username/refactor_contributing_doc
+git fetch upstream
+git rebase upstream/dev-1.x
+```
+
+When rebasing, if a conflict arises, you need to resolve the conflict manually, then execute the `git add` command, and then execute the `git rebase --continue` command until the rebase is complete.
+
+### 4. Commit the code and pass the unit test
+
+After the local development is done, we need to pass the unit tests locally and then commit the code.
+
+```shell
+# run unit test
+pytest tests/
+
+# commit the code
+git add .
+git commit -m "commit message"
+```
+
+### 5. Push the code to the remote repository
+
+After the local development is done, we need to push the code to the remote repository.
+
+```Shell
+git push origin username/refactor_contributing_doc
+```
+
+### 6. Create a Pull Request
+
+#### (1) Create a Pull Request on GitHub
+
+
+
+#### (2) Fill in the Pull Request template
+
+
+
+## Code Style
+
+### Python
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style, and use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](/setup.cfg).
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](/.pre-commit-config.yaml).
+
+```{note}
+Before you create a PR, make sure that your code lints and is formatted by yapf.
+```
+
+### C++ and CUDA
+
+We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
diff --git a/docs/en/dataset_zoo/2d_animal_keypoint.md b/docs/en/dataset_zoo/2d_animal_keypoint.md
index 9ef6022ecc..1263f1bed8 100644
--- a/docs/en/dataset_zoo/2d_animal_keypoint.md
+++ b/docs/en/dataset_zoo/2d_animal_keypoint.md
@@ -1,535 +1,535 @@
-# 2D Animal Keypoint Dataset
-
-It is recommended to symlink the dataset root to `$MMPOSE/data`.
-If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMPose supported datasets:
-
-- [Animal-Pose](#animal-pose) \[ [Homepage](https://sites.google.com/view/animal-pose/) \]
-- [AP-10K](#ap-10k) \[ [Homepage](https://github.com/AlexTheBad/AP-10K/) \]
-- [Horse-10](#horse-10) \[ [Homepage](http://www.mackenziemathislab.org/horse10) \]
-- [MacaquePose](#macaquepose) \[ [Homepage](http://pri.ehub.kyoto-u.ac.jp/datasets/macaquepose/index.html) \]
-- [Vinegar Fly](#vinegar-fly) \[ [Homepage](https://github.com/jgraving/DeepPoseKit-Data) \]
-- [Desert Locust](#desert-locust) \[ [Homepage](https://github.com/jgraving/DeepPoseKit-Data) \]
-- [Grévy’s Zebra](#grvys-zebra) \[ [Homepage](https://github.com/jgraving/DeepPoseKit-Data) \]
-- [ATRW](#atrw) \[ [Homepage](https://cvwc2019.github.io/challenge.html) \]
-- [Animal Kingdom](#Animal-Kindom) \[ [Homepage](https://openaccess.thecvf.com/content/CVPR2022/html/Ng_Animal_Kingdom_A_Large_and_Diverse_Dataset_for_Animal_Behavior_CVPR_2022_paper.html) \]
-
-## Animal-Pose
-
-
-
-
-Animal-Pose (ICCV'2019)
-
-```bibtex
-@InProceedings{Cao_2019_ICCV,
- author = {Cao, Jinkun and Tang, Hongyang and Fang, Hao-Shu and Shen, Xiaoyong and Lu, Cewu and Tai, Yu-Wing},
- title = {Cross-Domain Adaptation for Animal Pose Estimation},
- booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
- month = {October},
- year = {2019}
-}
-```
-
-
-
-
-
-
-
-For [Animal-Pose](https://sites.google.com/view/animal-pose/) dataset, we prepare the dataset as follows:
-
-1. Download the images of [PASCAL VOC2012](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/#data), especially the five categories (dog, cat, sheep, cow, horse), which we use as trainval dataset.
-2. Download the [test-set](https://drive.google.com/drive/folders/1DwhQobZlGntOXxdm7vQsE4bqbFmN3b9y?usp=sharing) images with raw annotations (1000 images, 5 categories).
-3. We have pre-processed the annotations to make it compatible with MMPose. Please download the annotation files from [annotations](https://download.openmmlab.com/mmpose/datasets/animalpose_annotations.tar). If you would like to generate the annotations by yourself, please check our dataset parsing [codes](/tools/dataset_converters/parse_animalpose_dataset.py).
-
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── animalpose
- │
- │-- VOC2012
- │ │-- Annotations
- │ │-- ImageSets
- │ │-- JPEGImages
- │ │-- SegmentationClass
- │ │-- SegmentationObject
- │
- │-- animalpose_image_part2
- │ │-- cat
- │ │-- cow
- │ │-- dog
- │ │-- horse
- │ │-- sheep
- │
- │-- annotations
- │ │-- animalpose_train.json
- │ |-- animalpose_val.json
- │ |-- animalpose_trainval.json
- │ │-- animalpose_test.json
- │
- │-- PASCAL2011_animal_annotation
- │ │-- cat
- │ │ |-- 2007_000528_1.xml
- │ │ |-- 2007_000549_1.xml
- │ │ │-- ...
- │ │-- cow
- │ │-- dog
- │ │-- horse
- │ │-- sheep
- │
- │-- annimalpose_anno2
- │ │-- cat
- │ │ |-- ca1.xml
- │ │ |-- ca2.xml
- │ │ │-- ...
- │ │-- cow
- │ │-- dog
- │ │-- horse
- │ │-- sheep
-```
-
-The official dataset does not provide the official train/val/test set split.
-We choose the images from PascalVOC for train & val. In total, we have 3608 images and 5117 annotations for train+val, where
-2798 images with 4000 annotations are used for training, and 810 images with 1117 annotations are used for validation.
-Those images from other sources (1000 images with 1000 annotations) are used for testing.
-
-## AP-10K
-
-
-
-
-AP-10K (NeurIPS'2021)
-
-```bibtex
-@misc{yu2021ap10k,
- title={AP-10K: A Benchmark for Animal Pose Estimation in the Wild},
- author={Hang Yu and Yufei Xu and Jing Zhang and Wei Zhao and Ziyu Guan and Dacheng Tao},
- year={2021},
- eprint={2108.12617},
- archivePrefix={arXiv},
- primaryClass={cs.CV}
-}
-```
-
-
-
-
-
-
-
-For [AP-10K](https://github.com/AlexTheBad/AP-10K/) dataset, images and annotations can be downloaded from [download](https://drive.google.com/file/d/1-FNNGcdtAQRehYYkGY1y4wzFNg4iWNad/view?usp=sharing).
-Note, this data and annotation data is for non-commercial use only.
-
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── ap10k
- │-- annotations
- │ │-- ap10k-train-split1.json
- │ |-- ap10k-train-split2.json
- │ |-- ap10k-train-split3.json
- │ │-- ap10k-val-split1.json
- │ |-- ap10k-val-split2.json
- │ |-- ap10k-val-split3.json
- │ |-- ap10k-test-split1.json
- │ |-- ap10k-test-split2.json
- │ |-- ap10k-test-split3.json
- │-- data
- │ │-- 000000000001.jpg
- │ │-- 000000000002.jpg
- │ │-- ...
-```
-
-The annotation files in 'annotation' folder contains 50 labeled animal species. There are total 10,015 labeled images with 13,028 instances in the AP-10K dataset. We randonly split them into train, val, and test set following the ratio of 7:1:2.
-
-## Horse-10
-
-
-
-
-Horse-10 (WACV'2021)
-
-```bibtex
-@inproceedings{mathis2021pretraining,
- title={Pretraining boosts out-of-domain robustness for pose estimation},
- author={Mathis, Alexander and Biasi, Thomas and Schneider, Steffen and Yuksekgonul, Mert and Rogers, Byron and Bethge, Matthias and Mathis, Mackenzie W},
- booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
- pages={1859--1868},
- year={2021}
-}
-```
-
-
-
-
-
-
-
-For [Horse-10](http://www.mackenziemathislab.org/horse10) dataset, images can be downloaded from [download](http://www.mackenziemathislab.org/horse10).
-Please download the annotation files from [horse10_annotations](https://download.openmmlab.com/mmpose/datasets/horse10_annotations.tar). Note, this data and annotation data is for non-commercial use only, per the authors (see http://horse10.deeplabcut.org for more information).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── horse10
- │-- annotations
- │ │-- horse10-train-split1.json
- │ |-- horse10-train-split2.json
- │ |-- horse10-train-split3.json
- │ │-- horse10-test-split1.json
- │ |-- horse10-test-split2.json
- │ |-- horse10-test-split3.json
- │-- labeled-data
- │ │-- BrownHorseinShadow
- │ │-- BrownHorseintoshadow
- │ │-- ...
-```
-
-## MacaquePose
-
-
-
-
-MacaquePose (bioRxiv'2020)
-
-```bibtex
-@article{labuguen2020macaquepose,
- title={MacaquePose: A novel ‘in the wild’macaque monkey pose dataset for markerless motion capture},
- author={Labuguen, Rollyn and Matsumoto, Jumpei and Negrete, Salvador and Nishimaru, Hiroshi and Nishijo, Hisao and Takada, Masahiko and Go, Yasuhiro and Inoue, Ken-ichi and Shibata, Tomohiro},
- journal={bioRxiv},
- year={2020},
- publisher={Cold Spring Harbor Laboratory}
-}
-```
-
-
-
-
-
-
-
-For [MacaquePose](http://pri.ehub.kyoto-u.ac.jp/datasets/macaquepose/index.html) dataset, images can be downloaded from [download](http://pri.ehub.kyoto-u.ac.jp/datasets/macaquepose/download.php).
-Please download the annotation files from [macaque_annotations](https://download.openmmlab.com/mmpose/datasets/macaque_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── macaque
- │-- annotations
- │ │-- macaque_train.json
- │ |-- macaque_test.json
- │-- images
- │ │-- 01418849d54b3005.jpg
- │ │-- 0142d1d1a6904a70.jpg
- │ │-- 01ef2c4c260321b7.jpg
- │ │-- 020a1c75c8c85238.jpg
- │ │-- 020b1506eef2557d.jpg
- │ │-- ...
-```
-
-Since the official dataset does not provide the test set, we randomly select 12500 images for training, and the rest for evaluation (see [code](/tools/dataset/parse_macaquepose_dataset.py)).
-
-## Vinegar Fly
-
-
-
-
-Vinegar Fly (Nature Methods'2019)
-
-```bibtex
-@article{pereira2019fast,
- title={Fast animal pose estimation using deep neural networks},
- author={Pereira, Talmo D and Aldarondo, Diego E and Willmore, Lindsay and Kislin, Mikhail and Wang, Samuel S-H and Murthy, Mala and Shaevitz, Joshua W},
- journal={Nature methods},
- volume={16},
- number={1},
- pages={117--125},
- year={2019},
- publisher={Nature Publishing Group}
-}
-```
-
-
-
-
-
-
-
-For [Vinegar Fly](https://github.com/jgraving/DeepPoseKit-Data) dataset, images can be downloaded from [vinegar_fly_images](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_images.tar).
-Please download the annotation files from [vinegar_fly_annotations](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── fly
- │-- annotations
- │ │-- fly_train.json
- │ |-- fly_test.json
- │-- images
- │ │-- 0.jpg
- │ │-- 1.jpg
- │ │-- 2.jpg
- │ │-- 3.jpg
- │ │-- ...
-```
-
-Since the official dataset does not provide the test set, we randomly select 90% images for training, and the rest (10%) for evaluation (see [code](/tools/dataset_converters/parse_deepposekit_dataset.py)).
-
-## Desert Locust
-
-
-
-
-Desert Locust (Elife'2019)
-
-```bibtex
-@article{graving2019deepposekit,
- title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning},
- author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D},
- journal={Elife},
- volume={8},
- pages={e47994},
- year={2019},
- publisher={eLife Sciences Publications Limited}
-}
-```
-
-
-
-
-
-
-
-For [Desert Locust](https://github.com/jgraving/DeepPoseKit-Data) dataset, images can be downloaded from [locust_images](https://download.openmmlab.com/mmpose/datasets/locust_images.tar).
-Please download the annotation files from [locust_annotations](https://download.openmmlab.com/mmpose/datasets/locust_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── locust
- │-- annotations
- │ │-- locust_train.json
- │ |-- locust_test.json
- │-- images
- │ │-- 0.jpg
- │ │-- 1.jpg
- │ │-- 2.jpg
- │ │-- 3.jpg
- │ │-- ...
-```
-
-Since the official dataset does not provide the test set, we randomly select 90% images for training, and the rest (10%) for evaluation (see [code](/tools/dataset_converters/parse_deepposekit_dataset.py)).
-
-## Grévy’s Zebra
-
-
-
-
-Grévy’s Zebra (Elife'2019)
-
-```bibtex
-@article{graving2019deepposekit,
- title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning},
- author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D},
- journal={Elife},
- volume={8},
- pages={e47994},
- year={2019},
- publisher={eLife Sciences Publications Limited}
-}
-```
-
-
-
-
-
-
-For [Grévy’s Zebra](https://github.com/jgraving/DeepPoseKit-Data) dataset, images can be downloaded from [zebra_images](https://download.openmmlab.com/mmpose/datasets/zebra_images.tar).
-Please download the annotation files from [zebra_annotations](https://download.openmmlab.com/mmpose/datasets/zebra_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── zebra
- │-- annotations
- │ │-- zebra_train.json
- │ |-- zebra_test.json
- │-- images
- │ │-- 0.jpg
- │ │-- 1.jpg
- │ │-- 2.jpg
- │ │-- 3.jpg
- │ │-- ...
-```
-
-Since the official dataset does not provide the test set, we randomly select 90% images for training, and the rest (10%) for evaluation (see [code](/tools/dataset_converters/parse_deepposekit_dataset.py)).
-
-## ATRW
-
-
-
-
-ATRW (ACM MM'2020)
-
-```bibtex
-@inproceedings{li2020atrw,
- title={ATRW: A Benchmark for Amur Tiger Re-identification in the Wild},
- author={Li, Shuyuan and Li, Jianguo and Tang, Hanlin and Qian, Rui and Lin, Weiyao},
- booktitle={Proceedings of the 28th ACM International Conference on Multimedia},
- pages={2590--2598},
- year={2020}
-}
-```
-
-
-
-
-
-
-ATRW captures images of the Amur tiger (also known as Siberian tiger, Northeast-China tiger) in the wild.
-For [ATRW](https://cvwc2019.github.io/challenge.html) dataset, please download images from
-[Pose_train](https://lilablobssc.blob.core.windows.net/cvwc2019/train/atrw_pose_train.tar.gz),
-[Pose_val](https://lilablobssc.blob.core.windows.net/cvwc2019/train/atrw_pose_val.tar.gz), and
-[Pose_test](https://lilablobssc.blob.core.windows.net/cvwc2019/test/atrw_pose_test.tar.gz).
-Note that in the ATRW official annotation files, the key "file_name" is written as "filename". To make it compatible with
-other coco-type json files, we have modified this key.
-Please download the modified annotation files from [atrw_annotations](https://download.openmmlab.com/mmpose/datasets/atrw_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── atrw
- │-- annotations
- │ │-- keypoint_train.json
- │ │-- keypoint_val.json
- │ │-- keypoint_trainval.json
- │-- images
- │ │-- train
- │ │ │-- 000002.jpg
- │ │ │-- 000003.jpg
- │ │ │-- ...
- │ │-- val
- │ │ │-- 000001.jpg
- │ │ │-- 000013.jpg
- │ │ │-- ...
- │ │-- test
- │ │ │-- 000000.jpg
- │ │ │-- 000004.jpg
- │ │ │-- ...
-```
-
-## Animal Kingdom
-
-
-Animal Kingdom (CVPR'2022)
-
-
-
-
-
-```bibtex
-@inproceedings{Ng_2022_CVPR,
- author = {Ng, Xun Long and Ong, Kian Eng and Zheng, Qichen and Ni, Yun and Yeo, Si Yong and Liu, Jun},
- title = {Animal Kingdom: A Large and Diverse Dataset for Animal Behavior Understanding},
- booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
- month = {June},
- year = {2022},
- pages = {19023-19034}
- }
-```
-
-For [Animal Kingdom](https://github.com/sutdcv/Animal-Kingdom) dataset, images can be downloaded from [here](https://forms.office.com/pages/responsepage.aspx?id=drd2NJDpck-5UGJImDFiPVRYpnTEMixKqPJ1FxwK6VZUQkNTSkRISTNORUI2TDBWMUpZTlQ5WUlaSyQlQCN0PWcu).
-Please Extract dataset under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── ak
- |--annotations
- │ │-- ak_P1
- │ │ │-- train.json
- │ │ │-- test.json
- │ │-- ak_P2
- │ │ │-- train.json
- │ │ │-- test.json
- │ │-- ak_P3_amphibian
- │ │ │-- train.json
- │ │ │-- test.json
- │ │-- ak_P3_bird
- │ │ │-- train.json
- │ │ │-- test.json
- │ │-- ak_P3_fish
- │ │ │-- train.json
- │ │ │-- test.json
- │ │-- ak_P3_mammal
- │ │ │-- train.json
- │ │ │-- test.json
- │ │-- ak_P3_reptile
- │ │-- train.json
- │ │-- test.json
- │-- images
- │ │-- AAACXZTV
- │ │ │--AAACXZTV_f000059.jpg
- │ │ │--...
- │ │-- AAAUILHH
- │ │ │--AAAUILHH_f000098.jpg
- │ │ │--...
- │ │-- ...
-```
+# 2D Animal Keypoint Dataset
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [Animal-Pose](#animal-pose) \[ [Homepage](https://sites.google.com/view/animal-pose/) \]
+- [AP-10K](#ap-10k) \[ [Homepage](https://github.com/AlexTheBad/AP-10K/) \]
+- [Horse-10](#horse-10) \[ [Homepage](http://www.mackenziemathislab.org/horse10) \]
+- [MacaquePose](#macaquepose) \[ [Homepage](http://pri.ehub.kyoto-u.ac.jp/datasets/macaquepose/index.html) \]
+- [Vinegar Fly](#vinegar-fly) \[ [Homepage](https://github.com/jgraving/DeepPoseKit-Data) \]
+- [Desert Locust](#desert-locust) \[ [Homepage](https://github.com/jgraving/DeepPoseKit-Data) \]
+- [Grévy’s Zebra](#grvys-zebra) \[ [Homepage](https://github.com/jgraving/DeepPoseKit-Data) \]
+- [ATRW](#atrw) \[ [Homepage](https://cvwc2019.github.io/challenge.html) \]
+- [Animal Kingdom](#Animal-Kindom) \[ [Homepage](https://openaccess.thecvf.com/content/CVPR2022/html/Ng_Animal_Kingdom_A_Large_and_Diverse_Dataset_for_Animal_Behavior_CVPR_2022_paper.html) \]
+
+## Animal-Pose
+
+
+
+
+Animal-Pose (ICCV'2019)
+
+```bibtex
+@InProceedings{Cao_2019_ICCV,
+ author = {Cao, Jinkun and Tang, Hongyang and Fang, Hao-Shu and Shen, Xiaoyong and Lu, Cewu and Tai, Yu-Wing},
+ title = {Cross-Domain Adaptation for Animal Pose Estimation},
+ booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
+ month = {October},
+ year = {2019}
+}
+```
+
+
+
+
+
+
+
+For [Animal-Pose](https://sites.google.com/view/animal-pose/) dataset, we prepare the dataset as follows:
+
+1. Download the images of [PASCAL VOC2012](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/#data), especially the five categories (dog, cat, sheep, cow, horse), which we use as trainval dataset.
+2. Download the [test-set](https://drive.google.com/drive/folders/1DwhQobZlGntOXxdm7vQsE4bqbFmN3b9y?usp=sharing) images with raw annotations (1000 images, 5 categories).
+3. We have pre-processed the annotations to make it compatible with MMPose. Please download the annotation files from [annotations](https://download.openmmlab.com/mmpose/datasets/animalpose_annotations.tar). If you would like to generate the annotations by yourself, please check our dataset parsing [codes](/tools/dataset_converters/parse_animalpose_dataset.py).
+
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── animalpose
+ │
+ │-- VOC2012
+ │ │-- Annotations
+ │ │-- ImageSets
+ │ │-- JPEGImages
+ │ │-- SegmentationClass
+ │ │-- SegmentationObject
+ │
+ │-- animalpose_image_part2
+ │ │-- cat
+ │ │-- cow
+ │ │-- dog
+ │ │-- horse
+ │ │-- sheep
+ │
+ │-- annotations
+ │ │-- animalpose_train.json
+ │ |-- animalpose_val.json
+ │ |-- animalpose_trainval.json
+ │ │-- animalpose_test.json
+ │
+ │-- PASCAL2011_animal_annotation
+ │ │-- cat
+ │ │ |-- 2007_000528_1.xml
+ │ │ |-- 2007_000549_1.xml
+ │ │ │-- ...
+ │ │-- cow
+ │ │-- dog
+ │ │-- horse
+ │ │-- sheep
+ │
+ │-- annimalpose_anno2
+ │ │-- cat
+ │ │ |-- ca1.xml
+ │ │ |-- ca2.xml
+ │ │ │-- ...
+ │ │-- cow
+ │ │-- dog
+ │ │-- horse
+ │ │-- sheep
+```
+
+The official dataset does not provide the official train/val/test set split.
+We choose the images from PascalVOC for train & val. In total, we have 3608 images and 5117 annotations for train+val, where
+2798 images with 4000 annotations are used for training, and 810 images with 1117 annotations are used for validation.
+Those images from other sources (1000 images with 1000 annotations) are used for testing.
+
+## AP-10K
+
+
+
+
+AP-10K (NeurIPS'2021)
+
+```bibtex
+@misc{yu2021ap10k,
+ title={AP-10K: A Benchmark for Animal Pose Estimation in the Wild},
+ author={Hang Yu and Yufei Xu and Jing Zhang and Wei Zhao and Ziyu Guan and Dacheng Tao},
+ year={2021},
+ eprint={2108.12617},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+}
+```
+
+
+
+
+
+
+
+For [AP-10K](https://github.com/AlexTheBad/AP-10K/) dataset, images and annotations can be downloaded from [download](https://drive.google.com/file/d/1-FNNGcdtAQRehYYkGY1y4wzFNg4iWNad/view?usp=sharing).
+Note, this data and annotation data is for non-commercial use only.
+
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── ap10k
+ │-- annotations
+ │ │-- ap10k-train-split1.json
+ │ |-- ap10k-train-split2.json
+ │ |-- ap10k-train-split3.json
+ │ │-- ap10k-val-split1.json
+ │ |-- ap10k-val-split2.json
+ │ |-- ap10k-val-split3.json
+ │ |-- ap10k-test-split1.json
+ │ |-- ap10k-test-split2.json
+ │ |-- ap10k-test-split3.json
+ │-- data
+ │ │-- 000000000001.jpg
+ │ │-- 000000000002.jpg
+ │ │-- ...
+```
+
+The annotation files in 'annotation' folder contains 50 labeled animal species. There are total 10,015 labeled images with 13,028 instances in the AP-10K dataset. We randonly split them into train, val, and test set following the ratio of 7:1:2.
+
+## Horse-10
+
+
+
+
+Horse-10 (WACV'2021)
+
+```bibtex
+@inproceedings{mathis2021pretraining,
+ title={Pretraining boosts out-of-domain robustness for pose estimation},
+ author={Mathis, Alexander and Biasi, Thomas and Schneider, Steffen and Yuksekgonul, Mert and Rogers, Byron and Bethge, Matthias and Mathis, Mackenzie W},
+ booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
+ pages={1859--1868},
+ year={2021}
+}
+```
+
+
+
+
+
+
+
+For [Horse-10](http://www.mackenziemathislab.org/horse10) dataset, images can be downloaded from [download](http://www.mackenziemathislab.org/horse10).
+Please download the annotation files from [horse10_annotations](https://download.openmmlab.com/mmpose/datasets/horse10_annotations.tar). Note, this data and annotation data is for non-commercial use only, per the authors (see http://horse10.deeplabcut.org for more information).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── horse10
+ │-- annotations
+ │ │-- horse10-train-split1.json
+ │ |-- horse10-train-split2.json
+ │ |-- horse10-train-split3.json
+ │ │-- horse10-test-split1.json
+ │ |-- horse10-test-split2.json
+ │ |-- horse10-test-split3.json
+ │-- labeled-data
+ │ │-- BrownHorseinShadow
+ │ │-- BrownHorseintoshadow
+ │ │-- ...
+```
+
+## MacaquePose
+
+
+
+
+MacaquePose (bioRxiv'2020)
+
+```bibtex
+@article{labuguen2020macaquepose,
+ title={MacaquePose: A novel ‘in the wild’macaque monkey pose dataset for markerless motion capture},
+ author={Labuguen, Rollyn and Matsumoto, Jumpei and Negrete, Salvador and Nishimaru, Hiroshi and Nishijo, Hisao and Takada, Masahiko and Go, Yasuhiro and Inoue, Ken-ichi and Shibata, Tomohiro},
+ journal={bioRxiv},
+ year={2020},
+ publisher={Cold Spring Harbor Laboratory}
+}
+```
+
+
+
+
+
+
+
+For [MacaquePose](http://pri.ehub.kyoto-u.ac.jp/datasets/macaquepose/index.html) dataset, images can be downloaded from [download](http://pri.ehub.kyoto-u.ac.jp/datasets/macaquepose/download.php).
+Please download the annotation files from [macaque_annotations](https://download.openmmlab.com/mmpose/datasets/macaque_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── macaque
+ │-- annotations
+ │ │-- macaque_train.json
+ │ |-- macaque_test.json
+ │-- images
+ │ │-- 01418849d54b3005.jpg
+ │ │-- 0142d1d1a6904a70.jpg
+ │ │-- 01ef2c4c260321b7.jpg
+ │ │-- 020a1c75c8c85238.jpg
+ │ │-- 020b1506eef2557d.jpg
+ │ │-- ...
+```
+
+Since the official dataset does not provide the test set, we randomly select 12500 images for training, and the rest for evaluation (see [code](/tools/dataset/parse_macaquepose_dataset.py)).
+
+## Vinegar Fly
+
+
+
+
+Vinegar Fly (Nature Methods'2019)
+
+```bibtex
+@article{pereira2019fast,
+ title={Fast animal pose estimation using deep neural networks},
+ author={Pereira, Talmo D and Aldarondo, Diego E and Willmore, Lindsay and Kislin, Mikhail and Wang, Samuel S-H and Murthy, Mala and Shaevitz, Joshua W},
+ journal={Nature methods},
+ volume={16},
+ number={1},
+ pages={117--125},
+ year={2019},
+ publisher={Nature Publishing Group}
+}
+```
+
+
+
+
+
+
+
+For [Vinegar Fly](https://github.com/jgraving/DeepPoseKit-Data) dataset, images can be downloaded from [vinegar_fly_images](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_images.tar).
+Please download the annotation files from [vinegar_fly_annotations](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── fly
+ │-- annotations
+ │ │-- fly_train.json
+ │ |-- fly_test.json
+ │-- images
+ │ │-- 0.jpg
+ │ │-- 1.jpg
+ │ │-- 2.jpg
+ │ │-- 3.jpg
+ │ │-- ...
+```
+
+Since the official dataset does not provide the test set, we randomly select 90% images for training, and the rest (10%) for evaluation (see [code](/tools/dataset_converters/parse_deepposekit_dataset.py)).
+
+## Desert Locust
+
+
+
+
+Desert Locust (Elife'2019)
+
+```bibtex
+@article{graving2019deepposekit,
+ title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning},
+ author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D},
+ journal={Elife},
+ volume={8},
+ pages={e47994},
+ year={2019},
+ publisher={eLife Sciences Publications Limited}
+}
+```
+
+
+
+
+
+
+
+For [Desert Locust](https://github.com/jgraving/DeepPoseKit-Data) dataset, images can be downloaded from [locust_images](https://download.openmmlab.com/mmpose/datasets/locust_images.tar).
+Please download the annotation files from [locust_annotations](https://download.openmmlab.com/mmpose/datasets/locust_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── locust
+ │-- annotations
+ │ │-- locust_train.json
+ │ |-- locust_test.json
+ │-- images
+ │ │-- 0.jpg
+ │ │-- 1.jpg
+ │ │-- 2.jpg
+ │ │-- 3.jpg
+ │ │-- ...
+```
+
+Since the official dataset does not provide the test set, we randomly select 90% images for training, and the rest (10%) for evaluation (see [code](/tools/dataset_converters/parse_deepposekit_dataset.py)).
+
+## Grévy’s Zebra
+
+
+
+
+Grévy’s Zebra (Elife'2019)
+
+```bibtex
+@article{graving2019deepposekit,
+ title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning},
+ author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D},
+ journal={Elife},
+ volume={8},
+ pages={e47994},
+ year={2019},
+ publisher={eLife Sciences Publications Limited}
+}
+```
+
+
+
+
+
+
+For [Grévy’s Zebra](https://github.com/jgraving/DeepPoseKit-Data) dataset, images can be downloaded from [zebra_images](https://download.openmmlab.com/mmpose/datasets/zebra_images.tar).
+Please download the annotation files from [zebra_annotations](https://download.openmmlab.com/mmpose/datasets/zebra_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── zebra
+ │-- annotations
+ │ │-- zebra_train.json
+ │ |-- zebra_test.json
+ │-- images
+ │ │-- 0.jpg
+ │ │-- 1.jpg
+ │ │-- 2.jpg
+ │ │-- 3.jpg
+ │ │-- ...
+```
+
+Since the official dataset does not provide the test set, we randomly select 90% images for training, and the rest (10%) for evaluation (see [code](/tools/dataset_converters/parse_deepposekit_dataset.py)).
+
+## ATRW
+
+
+
+
+ATRW (ACM MM'2020)
+
+```bibtex
+@inproceedings{li2020atrw,
+ title={ATRW: A Benchmark for Amur Tiger Re-identification in the Wild},
+ author={Li, Shuyuan and Li, Jianguo and Tang, Hanlin and Qian, Rui and Lin, Weiyao},
+ booktitle={Proceedings of the 28th ACM International Conference on Multimedia},
+ pages={2590--2598},
+ year={2020}
+}
+```
+
+
+
+
+
+
+ATRW captures images of the Amur tiger (also known as Siberian tiger, Northeast-China tiger) in the wild.
+For [ATRW](https://cvwc2019.github.io/challenge.html) dataset, please download images from
+[Pose_train](https://lilablobssc.blob.core.windows.net/cvwc2019/train/atrw_pose_train.tar.gz),
+[Pose_val](https://lilablobssc.blob.core.windows.net/cvwc2019/train/atrw_pose_val.tar.gz), and
+[Pose_test](https://lilablobssc.blob.core.windows.net/cvwc2019/test/atrw_pose_test.tar.gz).
+Note that in the ATRW official annotation files, the key "file_name" is written as "filename". To make it compatible with
+other coco-type json files, we have modified this key.
+Please download the modified annotation files from [atrw_annotations](https://download.openmmlab.com/mmpose/datasets/atrw_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── atrw
+ │-- annotations
+ │ │-- keypoint_train.json
+ │ │-- keypoint_val.json
+ │ │-- keypoint_trainval.json
+ │-- images
+ │ │-- train
+ │ │ │-- 000002.jpg
+ │ │ │-- 000003.jpg
+ │ │ │-- ...
+ │ │-- val
+ │ │ │-- 000001.jpg
+ │ │ │-- 000013.jpg
+ │ │ │-- ...
+ │ │-- test
+ │ │ │-- 000000.jpg
+ │ │ │-- 000004.jpg
+ │ │ │-- ...
+```
+
+## Animal Kingdom
+
+
+Animal Kingdom (CVPR'2022)
+
+
+
+
+
+```bibtex
+@inproceedings{Ng_2022_CVPR,
+ author = {Ng, Xun Long and Ong, Kian Eng and Zheng, Qichen and Ni, Yun and Yeo, Si Yong and Liu, Jun},
+ title = {Animal Kingdom: A Large and Diverse Dataset for Animal Behavior Understanding},
+ booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ month = {June},
+ year = {2022},
+ pages = {19023-19034}
+ }
+```
+
+For [Animal Kingdom](https://github.com/sutdcv/Animal-Kingdom) dataset, images can be downloaded from [here](https://forms.office.com/pages/responsepage.aspx?id=drd2NJDpck-5UGJImDFiPVRYpnTEMixKqPJ1FxwK6VZUQkNTSkRISTNORUI2TDBWMUpZTlQ5WUlaSyQlQCN0PWcu).
+Please Extract dataset under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── ak
+ |--annotations
+ │ │-- ak_P1
+ │ │ │-- train.json
+ │ │ │-- test.json
+ │ │-- ak_P2
+ │ │ │-- train.json
+ │ │ │-- test.json
+ │ │-- ak_P3_amphibian
+ │ │ │-- train.json
+ │ │ │-- test.json
+ │ │-- ak_P3_bird
+ │ │ │-- train.json
+ │ │ │-- test.json
+ │ │-- ak_P3_fish
+ │ │ │-- train.json
+ │ │ │-- test.json
+ │ │-- ak_P3_mammal
+ │ │ │-- train.json
+ │ │ │-- test.json
+ │ │-- ak_P3_reptile
+ │ │-- train.json
+ │ │-- test.json
+ │-- images
+ │ │-- AAACXZTV
+ │ │ │--AAACXZTV_f000059.jpg
+ │ │ │--...
+ │ │-- AAAUILHH
+ │ │ │--AAAUILHH_f000098.jpg
+ │ │ │--...
+ │ │-- ...
+```
diff --git a/docs/en/dataset_zoo/2d_body_keypoint.md b/docs/en/dataset_zoo/2d_body_keypoint.md
index 4448ebe8f4..3c68b1affc 100644
--- a/docs/en/dataset_zoo/2d_body_keypoint.md
+++ b/docs/en/dataset_zoo/2d_body_keypoint.md
@@ -1,588 +1,588 @@
-# 2D Body Keypoint Datasets
-
-It is recommended to symlink the dataset root to `$MMPOSE/data`.
-If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMPose supported datasets:
-
-- Images
- - [COCO](#coco) \[ [Homepage](http://cocodataset.org/) \]
- - [MPII](#mpii) \[ [Homepage](http://human-pose.mpi-inf.mpg.de/) \]
- - [MPII-TRB](#mpii-trb) \[ [Homepage](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) \]
- - [AI Challenger](#aic) \[ [Homepage](https://github.com/AIChallenger/AI_Challenger_2017) \]
- - [CrowdPose](#crowdpose) \[ [Homepage](https://github.com/Jeff-sjtu/CrowdPose) \]
- - [OCHuman](#ochuman) \[ [Homepage](https://github.com/liruilong940607/OCHumanApi) \]
- - [MHP](#mhp) \[ [Homepage](https://lv-mhp.github.io/dataset) \]
- - [Human-Art](#humanart) \[ [Homepage](https://idea-research.github.io/HumanArt/) \]
-- Videos
- - [PoseTrack18](#posetrack18) \[ [Homepage](https://posetrack.net/users/download.php) \]
- - [sub-JHMDB](#sub-jhmdb-dataset) \[ [Homepage](http://jhmdb.is.tue.mpg.de/dataset) \]
-
-## COCO
-
-
-
-
-COCO (ECCV'2014)
-
-```bibtex
-@inproceedings{lin2014microsoft,
- title={Microsoft coco: Common objects in context},
- author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence},
- booktitle={European conference on computer vision},
- pages={740--755},
- year={2014},
- organization={Springer}
-}
-```
-
-
-
-
-
-
-
-For [COCO](http://cocodataset.org/) data, please download from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
-[HRNet-Human-Pose-Estimation](https://github.com/HRNet/HRNet-Human-Pose-Estimation) provides person detection result of COCO val2017 to reproduce our multi-person pose estimation results.
-Please download from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
-Optionally, to evaluate on COCO'2017 test-dev, please download the [image-info](https://download.openmmlab.com/mmpose/datasets/person_keypoints_test-dev-2017.json).
-Download and extract them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── coco
- │-- annotations
- │ │-- person_keypoints_train2017.json
- │ |-- person_keypoints_val2017.json
- │ |-- person_keypoints_test-dev-2017.json
- |-- person_detection_results
- | |-- COCO_val2017_detections_AP_H_56_person.json
- | |-- COCO_test-dev2017_detections_AP_H_609_person.json
- │-- train2017
- │ │-- 000000000009.jpg
- │ │-- 000000000025.jpg
- │ │-- 000000000030.jpg
- │ │-- ...
- `-- val2017
- │-- 000000000139.jpg
- │-- 000000000285.jpg
- │-- 000000000632.jpg
- │-- ...
-
-```
-
-## MPII
-
-
-
-
-MPII (CVPR'2014)
-
-```bibtex
-@inproceedings{andriluka14cvpr,
- author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt},
- title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = {2014},
- month = {June}
-}
-```
-
-
-
-
-
-
-
-For [MPII](http://human-pose.mpi-inf.mpg.de/) data, please download from [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/).
-We have converted the original annotation files into json format, please download them from [mpii_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── mpii
- |── annotations
- | |── mpii_gt_val.mat
- | |── mpii_test.json
- | |── mpii_train.json
- | |── mpii_trainval.json
- | `── mpii_val.json
- `── images
- |── 000001163.jpg
- |── 000003072.jpg
-
-```
-
-During training and inference, the prediction result will be saved as '.mat' format by default. We also provide a tool to convert this '.mat' to more readable '.json' format.
-
-```shell
-python tools/dataset/mat2json ${PRED_MAT_FILE} ${GT_JSON_FILE} ${OUTPUT_PRED_JSON_FILE}
-```
-
-For example,
-
-```shell
-python tools/dataset/mat2json work_dirs/res50_mpii_256x256/pred.mat data/mpii/annotations/mpii_val.json pred.json
-```
-
-## MPII-TRB
-
-
-
-
-MPII-TRB (ICCV'2019)
-
-```bibtex
-@inproceedings{duan2019trb,
- title={TRB: A Novel Triplet Representation for Understanding 2D Human Body},
- author={Duan, Haodong and Lin, Kwan-Yee and Jin, Sheng and Liu, Wentao and Qian, Chen and Ouyang, Wanli},
- booktitle={Proceedings of the IEEE International Conference on Computer Vision},
- pages={9479--9488},
- year={2019}
-}
-```
-
-
-
-
-
-
-
-For [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) data, please download from [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/).
-Please download the annotation files from [mpii_trb_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_trb_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── mpii
- |── annotations
- | |── mpii_trb_train.json
- | |── mpii_trb_val.json
- `── images
- |── 000001163.jpg
- |── 000003072.jpg
-
-```
-
-## AIC
-
-
-
-
-AI Challenger (ArXiv'2017)
-
-```bibtex
-@article{wu2017ai,
- title={Ai challenger: A large-scale dataset for going deeper in image understanding},
- author={Wu, Jiahong and Zheng, He and Zhao, Bo and Li, Yixin and Yan, Baoming and Liang, Rui and Wang, Wenjia and Zhou, Shipei and Lin, Guosen and Fu, Yanwei and others},
- journal={arXiv preprint arXiv:1711.06475},
- year={2017}
-}
-```
-
-
-
-
-
-
-
-For [AIC](https://github.com/AIChallenger/AI_Challenger_2017) data, please download from [AI Challenger 2017](https://github.com/AIChallenger/AI_Challenger_2017), 2017 Train/Val is needed for keypoints training and validation.
-Please download the annotation files from [aic_annotations](https://download.openmmlab.com/mmpose/datasets/aic_annotations.tar).
-Download and extract them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── aic
- │-- annotations
- │ │-- aic_train.json
- │ |-- aic_val.json
- │-- ai_challenger_keypoint_train_20170902
- │ │-- keypoint_train_images_20170902
- │ │ │-- 0000252aea98840a550dac9a78c476ecb9f47ffa.jpg
- │ │ │-- 000050f770985ac9653198495ef9b5c82435d49c.jpg
- │ │ │-- ...
- `-- ai_challenger_keypoint_validation_20170911
- │-- keypoint_validation_images_20170911
- │-- 0002605c53fb92109a3f2de4fc3ce06425c3b61f.jpg
- │-- 0003b55a2c991223e6d8b4b820045bd49507bf6d.jpg
- │-- ...
-```
-
-## CrowdPose
-
-
-
-
-CrowdPose (CVPR'2019)
-
-```bibtex
-@article{li2018crowdpose,
- title={CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark},
- author={Li, Jiefeng and Wang, Can and Zhu, Hao and Mao, Yihuan and Fang, Hao-Shu and Lu, Cewu},
- journal={arXiv preprint arXiv:1812.00324},
- year={2018}
-}
-```
-
-
-
-
-
-
-
-For [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose) data, please download from [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose).
-Please download the annotation files and human detection results from [crowdpose_annotations](https://download.openmmlab.com/mmpose/datasets/crowdpose_annotations.tar).
-For top-down approaches, we follow [CrowdPose](https://arxiv.org/abs/1812.00324) to use the [pre-trained weights](https://pjreddie.com/media/files/yolov3.weights) of [YOLOv3](https://github.com/eriklindernoren/PyTorch-YOLOv3) to generate the detected human bounding boxes.
-For model training, we follow [HigherHRNet](https://github.com/HRNet/HigherHRNet-Human-Pose-Estimation) to train models on CrowdPose train/val dataset, and evaluate models on CrowdPose test dataset.
-Download and extract them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── crowdpose
- │-- annotations
- │ │-- mmpose_crowdpose_train.json
- │ │-- mmpose_crowdpose_val.json
- │ │-- mmpose_crowdpose_trainval.json
- │ │-- mmpose_crowdpose_test.json
- │ │-- det_for_crowd_test_0.1_0.5.json
- │-- images
- │-- 100000.jpg
- │-- 100001.jpg
- │-- 100002.jpg
- │-- ...
-```
-
-## OCHuman
-
-
-
-
-OCHuman (CVPR'2019)
-
-```bibtex
-@inproceedings{zhang2019pose2seg,
- title={Pose2seg: Detection free human instance segmentation},
- author={Zhang, Song-Hai and Li, Ruilong and Dong, Xin and Rosin, Paul and Cai, Zixi and Han, Xi and Yang, Dingcheng and Huang, Haozhi and Hu, Shi-Min},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- pages={889--898},
- year={2019}
-}
-```
-
-
-
-
-
-
-
-For [OCHuman](https://github.com/liruilong940607/OCHumanApi) data, please download the images and annotations from [OCHuman](https://github.com/liruilong940607/OCHumanApi),
-Move them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── ochuman
- │-- annotations
- │ │-- ochuman_coco_format_val_range_0.00_1.00.json
- │ |-- ochuman_coco_format_test_range_0.00_1.00.json
- |-- images
- │-- 000001.jpg
- │-- 000002.jpg
- │-- 000003.jpg
- │-- ...
-
-```
-
-## MHP
-
-
-
-
-MHP (ACM MM'2018)
-
-```bibtex
-@inproceedings{zhao2018understanding,
- title={Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing},
- author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
- booktitle={Proceedings of the 26th ACM international conference on Multimedia},
- pages={792--800},
- year={2018}
-}
-```
-
-
-
-
-
-
-
-For [MHP](https://lv-mhp.github.io/dataset) data, please download from [MHP](https://lv-mhp.github.io/dataset).
-Please download the annotation files from [mhp_annotations](https://download.openmmlab.com/mmpose/datasets/mhp_annotations.tar.gz).
-Please download and extract them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── mhp
- │-- annotations
- │ │-- mhp_train.json
- │ │-- mhp_val.json
- │
- `-- train
- │ │-- images
- │ │ │-- 1004.jpg
- │ │ │-- 10050.jpg
- │ │ │-- ...
- │
- `-- val
- │ │-- images
- │ │ │-- 10059.jpg
- │ │ │-- 10068.jpg
- │ │ │-- ...
- │
- `-- test
- │ │-- images
- │ │ │-- 1005.jpg
- │ │ │-- 10052.jpg
- │ │ │-- ...~~~~
-```
-
-## Human-Art dataset
-
-
-
-
-Human-Art (CVPR'2023)
-
-```bibtex
-@inproceedings{ju2023humanart,
- title={Human-Art: A Versatile Human-Centric Dataset Bridging Natural and Artificial Scenes},
- author={Ju, Xuan and Zeng, Ailing and Jianan, Wang and Qiang, Xu and Lei, Zhang},
- booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
- year={2023}}
-```
-
-
-
-
-
-
-
-For [Human-Art](https://idea-research.github.io/HumanArt/) data, please download the images and annotation files from [its website](https://idea-research.github.io/HumanArt/). You need to fill in the [data form](https://docs.google.com/forms/d/e/1FAIpQLScroT_jvw6B9U2Qca1_cl5Kmmu1ceKtlh6DJNmWLte8xNEhEw/viewform) to get access to the data.
-Move them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-|── data
- │── HumanArt
- │-- images
- │ │-- 2D_virtual_human
- │ │ |-- cartoon
- │ │ | |-- 000000000000.jpg
- │ │ | |-- ...
- │ │ |-- digital_art
- │ │ |-- ...
- │ |-- 3D_virtual_human
- │ |-- real_human
- |-- annotations
- │ │-- validation_humanart.json
- │ │-- training_humanart_coco.json
- |-- person_detection_results
- │ │-- HumanArt_validation_detections_AP_H_56_person.json
-```
-
-You can choose whether to download other annotation files in Human-Art. If you want to use additional annotation files (e.g. validation set of cartoon), you need to edit the corresponding code in config file.
-
-## PoseTrack18
-
-
-
-
-PoseTrack18 (CVPR'2018)
-
-```bibtex
-@inproceedings{andriluka2018posetrack,
- title={Posetrack: A benchmark for human pose estimation and tracking},
- author={Andriluka, Mykhaylo and Iqbal, Umar and Insafutdinov, Eldar and Pishchulin, Leonid and Milan, Anton and Gall, Juergen and Schiele, Bernt},
- booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
- pages={5167--5176},
- year={2018}
-}
-```
-
-
-
-
-
-
-
-For [PoseTrack18](https://posetrack.net/users/download.php) data, please download from [PoseTrack18](https://posetrack.net/users/download.php).
-Please download the annotation files from [posetrack18_annotations](https://download.openmmlab.com/mmpose/datasets/posetrack18_annotations.tar).
-We have merged the video-wise separated official annotation files into two json files (posetrack18_train & posetrack18_val.json). We also generate the [mask files](https://download.openmmlab.com/mmpose/datasets/posetrack18_mask.tar) to speed up training.
-For top-down approaches, we use [MMDetection](https://github.com/open-mmlab/mmdetection) pre-trained [Cascade R-CNN](https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_rcnn_x101_64x4d_fpn_20e_coco/cascade_rcnn_x101_64x4d_fpn_20e_coco_20200509_224357-051557b1.pth) (X-101-64x4d-FPN) to generate the detected human bounding boxes.
-Please download and extract them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── posetrack18
- │-- annotations
- │ │-- posetrack18_train.json
- │ │-- posetrack18_val.json
- │ │-- posetrack18_val_human_detections.json
- │ │-- train
- │ │ │-- 000001_bonn_train.json
- │ │ │-- 000002_bonn_train.json
- │ │ │-- ...
- │ │-- val
- │ │ │-- 000342_mpii_test.json
- │ │ │-- 000522_mpii_test.json
- │ │ │-- ...
- │ `-- test
- │ │-- 000001_mpiinew_test.json
- │ │-- 000002_mpiinew_test.json
- │ │-- ...
- │
- `-- images
- │ │-- train
- │ │ │-- 000001_bonn_train
- │ │ │ │-- 000000.jpg
- │ │ │ │-- 000001.jpg
- │ │ │ │-- ...
- │ │ │-- ...
- │ │-- val
- │ │ │-- 000342_mpii_test
- │ │ │ │-- 000000.jpg
- │ │ │ │-- 000001.jpg
- │ │ │ │-- ...
- │ │ │-- ...
- │ `-- test
- │ │-- 000001_mpiinew_test
- │ │ │-- 000000.jpg
- │ │ │-- 000001.jpg
- │ │ │-- ...
- │ │-- ...
- `-- mask
- │-- train
- │ │-- 000002_bonn_train
- │ │ │-- 000000.jpg
- │ │ │-- 000001.jpg
- │ │ │-- ...
- │ │-- ...
- `-- val
- │-- 000522_mpii_test
- │ │-- 000000.jpg
- │ │-- 000001.jpg
- │ │-- ...
- │-- ...
-```
-
-The official evaluation tool for PoseTrack should be installed from GitHub.
-
-```shell
-pip install git+https://github.com/svenkreiss/poseval.git
-```
-
-## sub-JHMDB dataset
-
-
-
-
-RSN (ECCV'2020)
-
-```bibtex
-@misc{cai2020learning,
- title={Learning Delicate Local Representations for Multi-Person Pose Estimation},
- author={Yuanhao Cai and Zhicheng Wang and Zhengxiong Luo and Binyi Yin and Angang Du and Haoqian Wang and Xinyu Zhou and Erjin Zhou and Xiangyu Zhang and Jian Sun},
- year={2020},
- eprint={2003.04030},
- archivePrefix={arXiv},
- primaryClass={cs.CV}
-}
-```
-
-
-
-
-
-
-
-For [sub-JHMDB](http://jhmdb.is.tue.mpg.de/dataset) data, please download the [images](<(http://files.is.tue.mpg.de/jhmdb/Rename_Images.tar.gz)>) from [JHMDB](http://jhmdb.is.tue.mpg.de/dataset),
-Please download the annotation files from [jhmdb_annotations](https://download.openmmlab.com/mmpose/datasets/jhmdb_annotations.tar).
-Move them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── jhmdb
- │-- annotations
- │ │-- Sub1_train.json
- │ |-- Sub1_test.json
- │ │-- Sub2_train.json
- │ |-- Sub2_test.json
- │ │-- Sub3_train.json
- │ |-- Sub3_test.json
- |-- Rename_Images
- │-- brush_hair
- │ │--April_09_brush_hair_u_nm_np1_ba_goo_0
- | │ │--00001.png
- | │ │--00002.png
- │-- catch
- │-- ...
-
-```
+# 2D Body Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- Images
+ - [COCO](#coco) \[ [Homepage](http://cocodataset.org/) \]
+ - [MPII](#mpii) \[ [Homepage](http://human-pose.mpi-inf.mpg.de/) \]
+ - [MPII-TRB](#mpii-trb) \[ [Homepage](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) \]
+ - [AI Challenger](#aic) \[ [Homepage](https://github.com/AIChallenger/AI_Challenger_2017) \]
+ - [CrowdPose](#crowdpose) \[ [Homepage](https://github.com/Jeff-sjtu/CrowdPose) \]
+ - [OCHuman](#ochuman) \[ [Homepage](https://github.com/liruilong940607/OCHumanApi) \]
+ - [MHP](#mhp) \[ [Homepage](https://lv-mhp.github.io/dataset) \]
+ - [Human-Art](#humanart) \[ [Homepage](https://idea-research.github.io/HumanArt/) \]
+- Videos
+ - [PoseTrack18](#posetrack18) \[ [Homepage](https://posetrack.net/users/download.php) \]
+ - [sub-JHMDB](#sub-jhmdb-dataset) \[ [Homepage](http://jhmdb.is.tue.mpg.de/dataset) \]
+
+## COCO
+
+
+
+
+COCO (ECCV'2014)
+
+```bibtex
+@inproceedings{lin2014microsoft,
+ title={Microsoft coco: Common objects in context},
+ author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence},
+ booktitle={European conference on computer vision},
+ pages={740--755},
+ year={2014},
+ organization={Springer}
+}
+```
+
+
+
+
+
+
+
+For [COCO](http://cocodataset.org/) data, please download from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
+[HRNet-Human-Pose-Estimation](https://github.com/HRNet/HRNet-Human-Pose-Estimation) provides person detection result of COCO val2017 to reproduce our multi-person pose estimation results.
+Please download from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Optionally, to evaluate on COCO'2017 test-dev, please download the [image-info](https://download.openmmlab.com/mmpose/datasets/person_keypoints_test-dev-2017.json).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── coco
+ │-- annotations
+ │ │-- person_keypoints_train2017.json
+ │ |-- person_keypoints_val2017.json
+ │ |-- person_keypoints_test-dev-2017.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ | |-- COCO_test-dev2017_detections_AP_H_609_person.json
+ │-- train2017
+ │ │-- 000000000009.jpg
+ │ │-- 000000000025.jpg
+ │ │-- 000000000030.jpg
+ │ │-- ...
+ `-- val2017
+ │-- 000000000139.jpg
+ │-- 000000000285.jpg
+ │-- 000000000632.jpg
+ │-- ...
+
+```
+
+## MPII
+
+
+
+
+MPII (CVPR'2014)
+
+```bibtex
+@inproceedings{andriluka14cvpr,
+ author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt},
+ title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis},
+ booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year = {2014},
+ month = {June}
+}
+```
+
+
+
+
+
+
+
+For [MPII](http://human-pose.mpi-inf.mpg.de/) data, please download from [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/).
+We have converted the original annotation files into json format, please download them from [mpii_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── mpii
+ |── annotations
+ | |── mpii_gt_val.mat
+ | |── mpii_test.json
+ | |── mpii_train.json
+ | |── mpii_trainval.json
+ | `── mpii_val.json
+ `── images
+ |── 000001163.jpg
+ |── 000003072.jpg
+
+```
+
+During training and inference, the prediction result will be saved as '.mat' format by default. We also provide a tool to convert this '.mat' to more readable '.json' format.
+
+```shell
+python tools/dataset/mat2json ${PRED_MAT_FILE} ${GT_JSON_FILE} ${OUTPUT_PRED_JSON_FILE}
+```
+
+For example,
+
+```shell
+python tools/dataset/mat2json work_dirs/res50_mpii_256x256/pred.mat data/mpii/annotations/mpii_val.json pred.json
+```
+
+## MPII-TRB
+
+
+
+
+MPII-TRB (ICCV'2019)
+
+```bibtex
+@inproceedings{duan2019trb,
+ title={TRB: A Novel Triplet Representation for Understanding 2D Human Body},
+ author={Duan, Haodong and Lin, Kwan-Yee and Jin, Sheng and Liu, Wentao and Qian, Chen and Ouyang, Wanli},
+ booktitle={Proceedings of the IEEE International Conference on Computer Vision},
+ pages={9479--9488},
+ year={2019}
+}
+```
+
+
+
+
+
+
+
+For [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) data, please download from [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/).
+Please download the annotation files from [mpii_trb_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_trb_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── mpii
+ |── annotations
+ | |── mpii_trb_train.json
+ | |── mpii_trb_val.json
+ `── images
+ |── 000001163.jpg
+ |── 000003072.jpg
+
+```
+
+## AIC
+
+
+
+
+AI Challenger (ArXiv'2017)
+
+```bibtex
+@article{wu2017ai,
+ title={Ai challenger: A large-scale dataset for going deeper in image understanding},
+ author={Wu, Jiahong and Zheng, He and Zhao, Bo and Li, Yixin and Yan, Baoming and Liang, Rui and Wang, Wenjia and Zhou, Shipei and Lin, Guosen and Fu, Yanwei and others},
+ journal={arXiv preprint arXiv:1711.06475},
+ year={2017}
+}
+```
+
+
+
+
+
+
+
+For [AIC](https://github.com/AIChallenger/AI_Challenger_2017) data, please download from [AI Challenger 2017](https://github.com/AIChallenger/AI_Challenger_2017), 2017 Train/Val is needed for keypoints training and validation.
+Please download the annotation files from [aic_annotations](https://download.openmmlab.com/mmpose/datasets/aic_annotations.tar).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── aic
+ │-- annotations
+ │ │-- aic_train.json
+ │ |-- aic_val.json
+ │-- ai_challenger_keypoint_train_20170902
+ │ │-- keypoint_train_images_20170902
+ │ │ │-- 0000252aea98840a550dac9a78c476ecb9f47ffa.jpg
+ │ │ │-- 000050f770985ac9653198495ef9b5c82435d49c.jpg
+ │ │ │-- ...
+ `-- ai_challenger_keypoint_validation_20170911
+ │-- keypoint_validation_images_20170911
+ │-- 0002605c53fb92109a3f2de4fc3ce06425c3b61f.jpg
+ │-- 0003b55a2c991223e6d8b4b820045bd49507bf6d.jpg
+ │-- ...
+```
+
+## CrowdPose
+
+
+
+
+CrowdPose (CVPR'2019)
+
+```bibtex
+@article{li2018crowdpose,
+ title={CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark},
+ author={Li, Jiefeng and Wang, Can and Zhu, Hao and Mao, Yihuan and Fang, Hao-Shu and Lu, Cewu},
+ journal={arXiv preprint arXiv:1812.00324},
+ year={2018}
+}
+```
+
+
+
+
+
+
+
+For [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose) data, please download from [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose).
+Please download the annotation files and human detection results from [crowdpose_annotations](https://download.openmmlab.com/mmpose/datasets/crowdpose_annotations.tar).
+For top-down approaches, we follow [CrowdPose](https://arxiv.org/abs/1812.00324) to use the [pre-trained weights](https://pjreddie.com/media/files/yolov3.weights) of [YOLOv3](https://github.com/eriklindernoren/PyTorch-YOLOv3) to generate the detected human bounding boxes.
+For model training, we follow [HigherHRNet](https://github.com/HRNet/HigherHRNet-Human-Pose-Estimation) to train models on CrowdPose train/val dataset, and evaluate models on CrowdPose test dataset.
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── crowdpose
+ │-- annotations
+ │ │-- mmpose_crowdpose_train.json
+ │ │-- mmpose_crowdpose_val.json
+ │ │-- mmpose_crowdpose_trainval.json
+ │ │-- mmpose_crowdpose_test.json
+ │ │-- det_for_crowd_test_0.1_0.5.json
+ │-- images
+ │-- 100000.jpg
+ │-- 100001.jpg
+ │-- 100002.jpg
+ │-- ...
+```
+
+## OCHuman
+
+
+
+
+OCHuman (CVPR'2019)
+
+```bibtex
+@inproceedings{zhang2019pose2seg,
+ title={Pose2seg: Detection free human instance segmentation},
+ author={Zhang, Song-Hai and Li, Ruilong and Dong, Xin and Rosin, Paul and Cai, Zixi and Han, Xi and Yang, Dingcheng and Huang, Haozhi and Hu, Shi-Min},
+ booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
+ pages={889--898},
+ year={2019}
+}
+```
+
+
+
+
+
+
+
+For [OCHuman](https://github.com/liruilong940607/OCHumanApi) data, please download the images and annotations from [OCHuman](https://github.com/liruilong940607/OCHumanApi),
+Move them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── ochuman
+ │-- annotations
+ │ │-- ochuman_coco_format_val_range_0.00_1.00.json
+ │ |-- ochuman_coco_format_test_range_0.00_1.00.json
+ |-- images
+ │-- 000001.jpg
+ │-- 000002.jpg
+ │-- 000003.jpg
+ │-- ...
+
+```
+
+## MHP
+
+
+
+
+MHP (ACM MM'2018)
+
+```bibtex
+@inproceedings{zhao2018understanding,
+ title={Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing},
+ author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
+ booktitle={Proceedings of the 26th ACM international conference on Multimedia},
+ pages={792--800},
+ year={2018}
+}
+```
+
+
+
+
+
+
+
+For [MHP](https://lv-mhp.github.io/dataset) data, please download from [MHP](https://lv-mhp.github.io/dataset).
+Please download the annotation files from [mhp_annotations](https://download.openmmlab.com/mmpose/datasets/mhp_annotations.tar.gz).
+Please download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── mhp
+ │-- annotations
+ │ │-- mhp_train.json
+ │ │-- mhp_val.json
+ │
+ `-- train
+ │ │-- images
+ │ │ │-- 1004.jpg
+ │ │ │-- 10050.jpg
+ │ │ │-- ...
+ │
+ `-- val
+ │ │-- images
+ │ │ │-- 10059.jpg
+ │ │ │-- 10068.jpg
+ │ │ │-- ...
+ │
+ `-- test
+ │ │-- images
+ │ │ │-- 1005.jpg
+ │ │ │-- 10052.jpg
+ │ │ │-- ...~~~~
+```
+
+## Human-Art dataset
+
+
+
+
+Human-Art (CVPR'2023)
+
+```bibtex
+@inproceedings{ju2023humanart,
+ title={Human-Art: A Versatile Human-Centric Dataset Bridging Natural and Artificial Scenes},
+ author={Ju, Xuan and Zeng, Ailing and Jianan, Wang and Qiang, Xu and Lei, Zhang},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
+ year={2023}}
+```
+
+
+
+
+
+
+
+For [Human-Art](https://idea-research.github.io/HumanArt/) data, please download the images and annotation files from [its website](https://idea-research.github.io/HumanArt/). You need to fill in the [data form](https://docs.google.com/forms/d/e/1FAIpQLScroT_jvw6B9U2Qca1_cl5Kmmu1ceKtlh6DJNmWLte8xNEhEw/viewform) to get access to the data.
+Move them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+|── data
+ │── HumanArt
+ │-- images
+ │ │-- 2D_virtual_human
+ │ │ |-- cartoon
+ │ │ | |-- 000000000000.jpg
+ │ │ | |-- ...
+ │ │ |-- digital_art
+ │ │ |-- ...
+ │ |-- 3D_virtual_human
+ │ |-- real_human
+ |-- annotations
+ │ │-- validation_humanart.json
+ │ │-- training_humanart_coco.json
+ |-- person_detection_results
+ │ │-- HumanArt_validation_detections_AP_H_56_person.json
+```
+
+You can choose whether to download other annotation files in Human-Art. If you want to use additional annotation files (e.g. validation set of cartoon), you need to edit the corresponding code in config file.
+
+## PoseTrack18
+
+
+
+
+PoseTrack18 (CVPR'2018)
+
+```bibtex
+@inproceedings{andriluka2018posetrack,
+ title={Posetrack: A benchmark for human pose estimation and tracking},
+ author={Andriluka, Mykhaylo and Iqbal, Umar and Insafutdinov, Eldar and Pishchulin, Leonid and Milan, Anton and Gall, Juergen and Schiele, Bernt},
+ booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={5167--5176},
+ year={2018}
+}
+```
+
+
+
+
+
+
+
+For [PoseTrack18](https://posetrack.net/users/download.php) data, please download from [PoseTrack18](https://posetrack.net/users/download.php).
+Please download the annotation files from [posetrack18_annotations](https://download.openmmlab.com/mmpose/datasets/posetrack18_annotations.tar).
+We have merged the video-wise separated official annotation files into two json files (posetrack18_train & posetrack18_val.json). We also generate the [mask files](https://download.openmmlab.com/mmpose/datasets/posetrack18_mask.tar) to speed up training.
+For top-down approaches, we use [MMDetection](https://github.com/open-mmlab/mmdetection) pre-trained [Cascade R-CNN](https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_rcnn_x101_64x4d_fpn_20e_coco/cascade_rcnn_x101_64x4d_fpn_20e_coco_20200509_224357-051557b1.pth) (X-101-64x4d-FPN) to generate the detected human bounding boxes.
+Please download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── posetrack18
+ │-- annotations
+ │ │-- posetrack18_train.json
+ │ │-- posetrack18_val.json
+ │ │-- posetrack18_val_human_detections.json
+ │ │-- train
+ │ │ │-- 000001_bonn_train.json
+ │ │ │-- 000002_bonn_train.json
+ │ │ │-- ...
+ │ │-- val
+ │ │ │-- 000342_mpii_test.json
+ │ │ │-- 000522_mpii_test.json
+ │ │ │-- ...
+ │ `-- test
+ │ │-- 000001_mpiinew_test.json
+ │ │-- 000002_mpiinew_test.json
+ │ │-- ...
+ │
+ `-- images
+ │ │-- train
+ │ │ │-- 000001_bonn_train
+ │ │ │ │-- 000000.jpg
+ │ │ │ │-- 000001.jpg
+ │ │ │ │-- ...
+ │ │ │-- ...
+ │ │-- val
+ │ │ │-- 000342_mpii_test
+ │ │ │ │-- 000000.jpg
+ │ │ │ │-- 000001.jpg
+ │ │ │ │-- ...
+ │ │ │-- ...
+ │ `-- test
+ │ │-- 000001_mpiinew_test
+ │ │ │-- 000000.jpg
+ │ │ │-- 000001.jpg
+ │ │ │-- ...
+ │ │-- ...
+ `-- mask
+ │-- train
+ │ │-- 000002_bonn_train
+ │ │ │-- 000000.jpg
+ │ │ │-- 000001.jpg
+ │ │ │-- ...
+ │ │-- ...
+ `-- val
+ │-- 000522_mpii_test
+ │ │-- 000000.jpg
+ │ │-- 000001.jpg
+ │ │-- ...
+ │-- ...
+```
+
+The official evaluation tool for PoseTrack should be installed from GitHub.
+
+```shell
+pip install git+https://github.com/svenkreiss/poseval.git
+```
+
+## sub-JHMDB dataset
+
+
+
+
+RSN (ECCV'2020)
+
+```bibtex
+@misc{cai2020learning,
+ title={Learning Delicate Local Representations for Multi-Person Pose Estimation},
+ author={Yuanhao Cai and Zhicheng Wang and Zhengxiong Luo and Binyi Yin and Angang Du and Haoqian Wang and Xinyu Zhou and Erjin Zhou and Xiangyu Zhang and Jian Sun},
+ year={2020},
+ eprint={2003.04030},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+}
+```
+
+
+
+
+
+
+
+For [sub-JHMDB](http://jhmdb.is.tue.mpg.de/dataset) data, please download the [images](<(http://files.is.tue.mpg.de/jhmdb/Rename_Images.tar.gz)>) from [JHMDB](http://jhmdb.is.tue.mpg.de/dataset),
+Please download the annotation files from [jhmdb_annotations](https://download.openmmlab.com/mmpose/datasets/jhmdb_annotations.tar).
+Move them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── jhmdb
+ │-- annotations
+ │ │-- Sub1_train.json
+ │ |-- Sub1_test.json
+ │ │-- Sub2_train.json
+ │ |-- Sub2_test.json
+ │ │-- Sub3_train.json
+ │ |-- Sub3_test.json
+ |-- Rename_Images
+ │-- brush_hair
+ │ │--April_09_brush_hair_u_nm_np1_ba_goo_0
+ | │ │--00001.png
+ | │ │--00002.png
+ │-- catch
+ │-- ...
+
+```
diff --git a/docs/en/dataset_zoo/2d_face_keypoint.md b/docs/en/dataset_zoo/2d_face_keypoint.md
index 62f66bd82b..13bbb5dec4 100644
--- a/docs/en/dataset_zoo/2d_face_keypoint.md
+++ b/docs/en/dataset_zoo/2d_face_keypoint.md
@@ -1,384 +1,384 @@
-# 2D Face Keypoint Datasets
-
-It is recommended to symlink the dataset root to `$MMPOSE/data`.
-If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMPose supported datasets:
-
-- [300W](#300w-dataset) \[ [Homepage](https://ibug.doc.ic.ac.uk/resources/300-W/) \]
-- [WFLW](#wflw-dataset) \[ [Homepage](https://wywu.github.io/projects/LAB/WFLW.html) \]
-- [AFLW](#aflw-dataset) \[ [Homepage](https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/aflw/) \]
-- [COFW](#cofw-dataset) \[ [Homepage](http://www.vision.caltech.edu/xpburgos/ICCV13/) \]
-- [COCO-WholeBody-Face](#coco-wholebody-face) \[ [Homepage](https://github.com/jin-s13/COCO-WholeBody/) \]
-- [LaPa](#lapa-dataset) \[ [Homepage](https://github.com/JDAI-CV/lapa-dataset) \]
-
-## 300W Dataset
-
-
-
-
-300W (IMAVIS'2016)
-
-```bibtex
-@article{sagonas2016300,
- title={300 faces in-the-wild challenge: Database and results},
- author={Sagonas, Christos and Antonakos, Epameinondas and Tzimiropoulos, Georgios and Zafeiriou, Stefanos and Pantic, Maja},
- journal={Image and vision computing},
- volume={47},
- pages={3--18},
- year={2016},
- publisher={Elsevier}
-}
-```
-
-
-
-
+
+For WFLW data, please download images from [WFLW Dataset](https://wywu.github.io/projects/LAB/WFLW.html).
+Please download the annotation files from [wflw_annotations](https://download.openmmlab.com/mmpose/datasets/wflw_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── wflw
+ |── annotations
+ | |── face_landmarks_wflw_train.json
+ | |── face_landmarks_wflw_test.json
+ | |── face_landmarks_wflw_test_blur.json
+ | |── face_landmarks_wflw_test_occlusion.json
+ | |── face_landmarks_wflw_test_expression.json
+ | |── face_landmarks_wflw_test_largepose.json
+ | |── face_landmarks_wflw_test_illumination.json
+ | |── face_landmarks_wflw_test_makeup.json
+ |
+ `── images
+ |── 0--Parade
+ | |── 0_Parade_marchingband_1_1015.jpg
+ | |── 0_Parade_marchingband_1_1031.jpg
+ | ...
+ |── 1--Handshaking
+ | |── 1_Handshaking_Handshaking_1_105.jpg
+ | |── 1_Handshaking_Handshaking_1_107.jpg
+ | ...
+ ...
+```
+
+## AFLW Dataset
+
+
+
+
+AFLW (ICCVW'2011)
+
+```bibtex
+@inproceedings{koestinger2011annotated,
+ title={Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization},
+ author={Koestinger, Martin and Wohlhart, Paul and Roth, Peter M and Bischof, Horst},
+ booktitle={2011 IEEE international conference on computer vision workshops (ICCV workshops)},
+ pages={2144--2151},
+ year={2011},
+ organization={IEEE}
+}
+```
+
+
+
+For AFLW data, please download images from [AFLW Dataset](https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/aflw/).
+Please download the annotation files from [aflw_annotations](https://download.openmmlab.com/mmpose/datasets/aflw_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── aflw
+ |── annotations
+ | |── face_landmarks_aflw_train.json
+ | |── face_landmarks_aflw_test_frontal.json
+ | |── face_landmarks_aflw_test.json
+ `── images
+ |── flickr
+ |── 0
+ | |── image00002.jpg
+ | |── image00013.jpg
+ | ...
+ |── 2
+ | |── image00004.jpg
+ | |── image00006.jpg
+ | ...
+ `── 3
+ |── image00032.jpg
+ |── image00035.jpg
+ ...
+```
+
+## COFW Dataset
+
+
+
+
+COFW (ICCV'2013)
+
+```bibtex
+@inproceedings{burgos2013robust,
+ title={Robust face landmark estimation under occlusion},
+ author={Burgos-Artizzu, Xavier P and Perona, Pietro and Doll{\'a}r, Piotr},
+ booktitle={Proceedings of the IEEE international conference on computer vision},
+ pages={1513--1520},
+ year={2013}
+}
+```
+
+
+
+
+
+
+
+For COFW data, please download from [COFW Dataset (Color Images)](http://www.vision.caltech.edu/xpburgos/ICCV13/Data/COFW_color.zip).
+Move `COFW_train_color.mat` and `COFW_test_color.mat` to `data/cofw/` and make them look like:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── cofw
+ |── COFW_train_color.mat
+ |── COFW_test_color.mat
+```
+
+Run the following script under `{MMPose}/data`
+
+`python tools/dataset_converters/parse_cofw_dataset.py`
+
+And you will get
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── cofw
+ |── COFW_train_color.mat
+ |── COFW_test_color.mat
+ |── annotations
+ | |── cofw_train.json
+ | |── cofw_test.json
+ |── images
+ |── 000001.jpg
+ |── 000002.jpg
+```
+
+## COCO-WholeBody (Face)
+
+
+
+
+COCO-WholeBody-Face (ECCV'2020)
+
+```bibtex
+@inproceedings{jin2020whole,
+ title={Whole-Body Human Pose Estimation in the Wild},
+ author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping},
+ booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
+ year={2020}
+}
+```
+
+
+
+
+
+
+
+For [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/) dataset, images can be downloaded from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
+Download COCO-WholeBody annotations for COCO-WholeBody annotations for [Train](https://drive.google.com/file/d/1thErEToRbmM9uLNi1JXXfOsaS5VK2FXf/view?usp=sharing) / [Validation](https://drive.google.com/file/d/1N6VgwKnj8DeyGXCvp1eYgNbRmw6jdfrb/view?usp=sharing) (Google Drive).
+Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── coco
+ │-- annotations
+ │ │-- coco_wholebody_train_v1.0.json
+ │ |-- coco_wholebody_val_v1.0.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ │-- train2017
+ │ │-- 000000000009.jpg
+ │ │-- 000000000025.jpg
+ │ │-- 000000000030.jpg
+ │ │-- ...
+ `-- val2017
+ │-- 000000000139.jpg
+ │-- 000000000285.jpg
+ │-- 000000000632.jpg
+ │-- ...
+
+```
+
+Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) to support COCO-WholeBody evaluation:
+
+`pip install xtcocotools`
+
+## LaPa
+
+
+
+
+LaPa (AAAI'2020)
+
+```bibtex
+@inproceedings{liu2020new,
+ title={A New Dataset and Boundary-Attention Semantic Segmentation for Face Parsing.},
+ author={Liu, Yinglu and Shi, Hailin and Shen, Hao and Si, Yue and Wang, Xiaobo and Mei, Tao},
+ booktitle={AAAI},
+ pages={11637--11644},
+ year={2020}
+}
+```
+
+
+
+
+
+
+
+For [LaPa](https://github.com/JDAI-CV/lapa-dataset) dataset, images can be downloaded from [their github page](https://github.com/JDAI-CV/lapa-dataset).
+
+Download and extract them under $MMPOSE/data, and use our `tools/dataset_converters/lapa2coco.py` to make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── LaPa
+ │-- annotations
+ │ │-- lapa_train.json
+ │ |-- lapa_val.json
+ │ |-- lapa_test.json
+ | |-- lapa_trainval.json
+ │-- train
+ │ │-- images
+ │ │-- labels
+ │ │-- landmarks
+ │-- val
+ │ │-- images
+ │ │-- labels
+ │ │-- landmarks
+ `-- test
+ │ │-- images
+ │ │-- labels
+ │ │-- landmarks
+
+```
diff --git a/docs/en/dataset_zoo/2d_fashion_landmark.md b/docs/en/dataset_zoo/2d_fashion_landmark.md
index b1146b47b6..c13ee0308d 100644
--- a/docs/en/dataset_zoo/2d_fashion_landmark.md
+++ b/docs/en/dataset_zoo/2d_fashion_landmark.md
@@ -1,142 +1,142 @@
-# 2D Fashion Landmark Dataset
-
-It is recommended to symlink the dataset root to `$MMPOSE/data`.
-If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMPose supported datasets:
-
-- [DeepFashion](#deepfashion) \[ [Homepage](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/LandmarkDetection.html) \]
-- [DeepFashion2](#deepfashion2) \[ [Homepage](https://github.com/switchablenorms/DeepFashion2) \]
-
-## DeepFashion (Fashion Landmark Detection, FLD)
-
-
-
-
-DeepFashion (CVPR'2016)
-
-```bibtex
-@inproceedings{liuLQWTcvpr16DeepFashion,
- author = {Liu, Ziwei and Luo, Ping and Qiu, Shi and Wang, Xiaogang and Tang, Xiaoou},
- title = {DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations},
- booktitle = {Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- month = {June},
- year = {2016}
-}
-```
-
-
-
-
-
-
-DeepFashion (ECCV'2016)
-
-```bibtex
-@inproceedings{liuYLWTeccv16FashionLandmark,
- author = {Liu, Ziwei and Yan, Sijie and Luo, Ping and Wang, Xiaogang and Tang, Xiaoou},
- title = {Fashion Landmark Detection in the Wild},
- booktitle = {European Conference on Computer Vision (ECCV)},
- month = {October},
- year = {2016}
- }
-```
-
-
-
-
-
-
-
-For [DeepFashion](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/LandmarkDetection.html) dataset, images can be downloaded from [download](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/LandmarkDetection.html).
-Please download the annotation files from [fld_annotations](https://download.openmmlab.com/mmpose/datasets/fld_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── fld
- │-- annotations
- │ │-- fld_upper_train.json
- │ |-- fld_upper_val.json
- │ |-- fld_upper_test.json
- │ │-- fld_lower_train.json
- │ |-- fld_lower_val.json
- │ |-- fld_lower_test.json
- │ │-- fld_full_train.json
- │ |-- fld_full_val.json
- │ |-- fld_full_test.json
- │-- img
- │ │-- img_00000001.jpg
- │ │-- img_00000002.jpg
- │ │-- img_00000003.jpg
- │ │-- img_00000004.jpg
- │ │-- img_00000005.jpg
- │ │-- ...
-```
-
-## DeepFashion2
-
-
-
-
-DeepFashion2 (CVPR'2019)
-
-```bibtex
-@article{DeepFashion2,
- author = {Yuying Ge and Ruimao Zhang and Lingyun Wu and Xiaogang Wang and Xiaoou Tang and Ping Luo},
- title={A Versatile Benchmark for Detection, Pose Estimation, Segmentation and Re-Identification of Clothing Images},
- journal={CVPR},
- year={2019}
-}
-```
-
-
-
-
-
-For [DeepFashion2](https://github.com/switchablenorms/DeepFashion2) dataset, images can be downloaded from [download](https://drive.google.com/drive/folders/125F48fsMBz2EF0Cpqk6aaHet5VH399Ok?usp=sharing).
-Please download the [annotation files](https://drive.google.com/file/d/1RM9l9EaB9ULRXhoCS72PkCXtJ4Cn4i6O/view?usp=share_link). These annotation files are converted by [deepfashion2_to_coco.py](https://github.com/switchablenorms/DeepFashion2/blob/master/evaluation/deepfashion2_to_coco.py).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── deepfashion2
- │── train
- │-- deepfashion2_short_sleeved_outwear_train.json
- │-- deepfashion2_short_sleeved_dress_train.json
- │-- deepfashion2_skirt_train.json
- │-- deepfashion2_sling_dress_train.json
- │-- ...
- │-- image
- │ │-- 000001.jpg
- │ │-- 000002.jpg
- │ │-- 000003.jpg
- │ │-- 000004.jpg
- │ │-- 000005.jpg
- │ │-- ...
- │── validation
- │-- deepfashion2_short_sleeved_dress_validation.json
- │-- deepfashion2_long_sleeved_shirt_validation.json
- │-- deepfashion2_trousers_validation.json
- │-- deepfashion2_skirt_validation.json
- │-- ...
- │-- image
- │ │-- 000001.jpg
- │ │-- 000002.jpg
- │ │-- 000003.jpg
- │ │-- 000004.jpg
- │ │-- 000005.jpg
- │ │-- ...
-```
+# 2D Fashion Landmark Dataset
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [DeepFashion](#deepfashion) \[ [Homepage](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/LandmarkDetection.html) \]
+- [DeepFashion2](#deepfashion2) \[ [Homepage](https://github.com/switchablenorms/DeepFashion2) \]
+
+## DeepFashion (Fashion Landmark Detection, FLD)
+
+
+
+
+DeepFashion (CVPR'2016)
+
+```bibtex
+@inproceedings{liuLQWTcvpr16DeepFashion,
+ author = {Liu, Ziwei and Luo, Ping and Qiu, Shi and Wang, Xiaogang and Tang, Xiaoou},
+ title = {DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations},
+ booktitle = {Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
+ month = {June},
+ year = {2016}
+}
+```
+
+
+
+
+
+
+DeepFashion (ECCV'2016)
+
+```bibtex
+@inproceedings{liuYLWTeccv16FashionLandmark,
+ author = {Liu, Ziwei and Yan, Sijie and Luo, Ping and Wang, Xiaogang and Tang, Xiaoou},
+ title = {Fashion Landmark Detection in the Wild},
+ booktitle = {European Conference on Computer Vision (ECCV)},
+ month = {October},
+ year = {2016}
+ }
+```
+
+
+
+
+
+
+
+For [DeepFashion](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/LandmarkDetection.html) dataset, images can be downloaded from [download](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/LandmarkDetection.html).
+Please download the annotation files from [fld_annotations](https://download.openmmlab.com/mmpose/datasets/fld_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── fld
+ │-- annotations
+ │ │-- fld_upper_train.json
+ │ |-- fld_upper_val.json
+ │ |-- fld_upper_test.json
+ │ │-- fld_lower_train.json
+ │ |-- fld_lower_val.json
+ │ |-- fld_lower_test.json
+ │ │-- fld_full_train.json
+ │ |-- fld_full_val.json
+ │ |-- fld_full_test.json
+ │-- img
+ │ │-- img_00000001.jpg
+ │ │-- img_00000002.jpg
+ │ │-- img_00000003.jpg
+ │ │-- img_00000004.jpg
+ │ │-- img_00000005.jpg
+ │ │-- ...
+```
+
+## DeepFashion2
+
+
+
+
+DeepFashion2 (CVPR'2019)
+
+```bibtex
+@article{DeepFashion2,
+ author = {Yuying Ge and Ruimao Zhang and Lingyun Wu and Xiaogang Wang and Xiaoou Tang and Ping Luo},
+ title={A Versatile Benchmark for Detection, Pose Estimation, Segmentation and Re-Identification of Clothing Images},
+ journal={CVPR},
+ year={2019}
+}
+```
+
+
+
+
+
+For [DeepFashion2](https://github.com/switchablenorms/DeepFashion2) dataset, images can be downloaded from [download](https://drive.google.com/drive/folders/125F48fsMBz2EF0Cpqk6aaHet5VH399Ok?usp=sharing).
+Please download the [annotation files](https://drive.google.com/file/d/1RM9l9EaB9ULRXhoCS72PkCXtJ4Cn4i6O/view?usp=share_link). These annotation files are converted by [deepfashion2_to_coco.py](https://github.com/switchablenorms/DeepFashion2/blob/master/evaluation/deepfashion2_to_coco.py).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── deepfashion2
+ │── train
+ │-- deepfashion2_short_sleeved_outwear_train.json
+ │-- deepfashion2_short_sleeved_dress_train.json
+ │-- deepfashion2_skirt_train.json
+ │-- deepfashion2_sling_dress_train.json
+ │-- ...
+ │-- image
+ │ │-- 000001.jpg
+ │ │-- 000002.jpg
+ │ │-- 000003.jpg
+ │ │-- 000004.jpg
+ │ │-- 000005.jpg
+ │ │-- ...
+ │── validation
+ │-- deepfashion2_short_sleeved_dress_validation.json
+ │-- deepfashion2_long_sleeved_shirt_validation.json
+ │-- deepfashion2_trousers_validation.json
+ │-- deepfashion2_skirt_validation.json
+ │-- ...
+ │-- image
+ │ │-- 000001.jpg
+ │ │-- 000002.jpg
+ │ │-- 000003.jpg
+ │ │-- 000004.jpg
+ │ │-- 000005.jpg
+ │ │-- ...
+```
diff --git a/docs/en/dataset_zoo/2d_hand_keypoint.md b/docs/en/dataset_zoo/2d_hand_keypoint.md
index d641bc311d..6c7cd0d43b 100644
--- a/docs/en/dataset_zoo/2d_hand_keypoint.md
+++ b/docs/en/dataset_zoo/2d_hand_keypoint.md
@@ -1,348 +1,348 @@
-# 2D Hand Keypoint Datasets
-
-It is recommended to symlink the dataset root to `$MMPOSE/data`.
-If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMPose supported datasets:
-
-- [OneHand10K](#onehand10k) \[ [Homepage](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html) \]
-- [FreiHand](#freihand-dataset) \[ [Homepage](https://lmb.informatik.uni-freiburg.de/projects/freihand/) \]
-- [CMU Panoptic HandDB](#cmu-panoptic-handdb) \[ [Homepage](http://domedb.perception.cs.cmu.edu/handdb.html) \]
-- [InterHand2.6M](#interhand26m) \[ [Homepage](https://mks0601.github.io/InterHand2.6M/) \]
-- [RHD](#rhd-dataset) \[ [Homepage](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html) \]
-- [COCO-WholeBody-Hand](#coco-wholebody-hand) \[ [Homepage](https://github.com/jin-s13/COCO-WholeBody/) \]
-
-## OneHand10K
-
-
-
-
-OneHand10K (TCSVT'2019)
-
-```bibtex
-@article{wang2018mask,
- title={Mask-pose cascaded cnn for 2d hand pose estimation from single color image},
- author={Wang, Yangang and Peng, Cong and Liu, Yebin},
- journal={IEEE Transactions on Circuits and Systems for Video Technology},
- volume={29},
- number={11},
- pages={3258--3268},
- year={2018},
- publisher={IEEE}
-}
-```
-
-
-
-
-
-
-
-For [OneHand10K](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html) data, please download from [OneHand10K Dataset](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html).
-Please download the annotation files from [onehand10k_annotations](https://download.openmmlab.com/mmpose/datasets/onehand10k_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── onehand10k
- |── annotations
- | |── onehand10k_train.json
- | |── onehand10k_test.json
- `── Train
- | |── source
- | |── 0.jpg
- | |── 1.jpg
- | ...
- `── Test
- |── source
- |── 0.jpg
- |── 1.jpg
-
-```
-
-## FreiHAND Dataset
-
-
-
-
-FreiHand (ICCV'2019)
-
-```bibtex
-@inproceedings{zimmermann2019freihand,
- title={Freihand: A dataset for markerless capture of hand pose and shape from single rgb images},
- author={Zimmermann, Christian and Ceylan, Duygu and Yang, Jimei and Russell, Bryan and Argus, Max and Brox, Thomas},
- booktitle={Proceedings of the IEEE International Conference on Computer Vision},
- pages={813--822},
- year={2019}
-}
-```
-
-
-
-
-
-
-
-For [FreiHAND](https://lmb.informatik.uni-freiburg.de/projects/freihand/) data, please download from [FreiHand Dataset](https://lmb.informatik.uni-freiburg.de/resources/datasets/FreihandDataset.en.html).
-Since the official dataset does not provide validation set, we randomly split the training data into 8:1:1 for train/val/test.
-Please download the annotation files from [freihand_annotations](https://download.openmmlab.com/mmpose/datasets/frei_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── freihand
- |── annotations
- | |── freihand_train.json
- | |── freihand_val.json
- | |── freihand_test.json
- `── training
- |── rgb
- | |── 00000000.jpg
- | |── 00000001.jpg
- | ...
- |── mask
- |── 00000000.jpg
- |── 00000001.jpg
- ...
-```
-
-## CMU Panoptic HandDB
-
-
-
-
-CMU Panoptic HandDB (CVPR'2017)
-
-```bibtex
-@inproceedings{simon2017hand,
- title={Hand keypoint detection in single images using multiview bootstrapping},
- author={Simon, Tomas and Joo, Hanbyul and Matthews, Iain and Sheikh, Yaser},
- booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition},
- pages={1145--1153},
- year={2017}
-}
-```
-
-
-
-
-
-
-
-For [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html), please download from [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html).
-Following [Simon et al](https://arxiv.org/abs/1704.07809), panoptic images (hand143_panopticdb) and MPII & NZSL training sets (manual_train) are used for training, while MPII & NZSL test set (manual_test) for testing.
-Please download the annotation files from [panoptic_annotations](https://download.openmmlab.com/mmpose/datasets/panoptic_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── panoptic
- |── annotations
- | |── panoptic_train.json
- | |── panoptic_test.json
- |
- `── hand143_panopticdb
- | |── imgs
- | | |── 00000000.jpg
- | | |── 00000001.jpg
- | | ...
- |
- `── hand_labels
- |── manual_train
- | |── 000015774_01_l.jpg
- | |── 000015774_01_r.jpg
- | ...
- |
- `── manual_test
- |── 000648952_02_l.jpg
- |── 000835470_01_l.jpg
- ...
-```
-
-## InterHand2.6M
-
-
-
-
-InterHand2.6M (ECCV'2020)
-
-```bibtex
-@InProceedings{Moon_2020_ECCV_InterHand2.6M,
-author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu},
-title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image},
-booktitle = {European Conference on Computer Vision (ECCV)},
-year = {2020}
-}
-```
-
-
-
-
-
-
-
-For [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/), please download from [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/).
-Please download the annotation files from [annotations](https://download.openmmlab.com/mmpose/datasets/interhand2.6m_annotations.zip).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── interhand2.6m
- |── annotations
- | |── all
- | |── human_annot
- | |── machine_annot
- | |── skeleton.txt
- | |── subject.txt
- |
- `── images
- | |── train
- | | |-- Capture0 ~ Capture26
- | |── val
- | | |-- Capture0
- | |── test
- | | |-- Capture0 ~ Capture7
-```
-
-## RHD Dataset
-
-
-
-
-RHD (ICCV'2017)
-
-```bibtex
-@TechReport{zb2017hand,
- author={Christian Zimmermann and Thomas Brox},
- title={Learning to Estimate 3D Hand Pose from Single RGB Images},
- institution={arXiv:1705.01389},
- year={2017},
- note="https://arxiv.org/abs/1705.01389",
- url="https://lmb.informatik.uni-freiburg.de/projects/hand3d/"
-}
-```
-
-
-
-
-
-
-
-For [RHD Dataset](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html), please download from [RHD Dataset](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html).
-Please download the annotation files from [rhd_annotations](https://download.openmmlab.com/mmpose/datasets/rhd_annotations.zip).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── rhd
- |── annotations
- | |── rhd_train.json
- | |── rhd_test.json
- `── training
- | |── color
- | | |── 00000.jpg
- | | |── 00001.jpg
- | |── depth
- | | |── 00000.jpg
- | | |── 00001.jpg
- | |── mask
- | | |── 00000.jpg
- | | |── 00001.jpg
- `── evaluation
- | |── color
- | | |── 00000.jpg
- | | |── 00001.jpg
- | |── depth
- | | |── 00000.jpg
- | | |── 00001.jpg
- | |── mask
- | | |── 00000.jpg
- | | |── 00001.jpg
-```
-
-## COCO-WholeBody (Hand)
-
-
-
-
-COCO-WholeBody-Hand (ECCV'2020)
-
-```bibtex
-@inproceedings{jin2020whole,
- title={Whole-Body Human Pose Estimation in the Wild},
- author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping},
- booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
- year={2020}
-}
-```
-
-
-
-
-
-
-
-For [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/) dataset, images can be downloaded from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
-Download COCO-WholeBody annotations for COCO-WholeBody annotations for [Train](https://drive.google.com/file/d/1thErEToRbmM9uLNi1JXXfOsaS5VK2FXf/view?usp=sharing) / [Validation](https://drive.google.com/file/d/1N6VgwKnj8DeyGXCvp1eYgNbRmw6jdfrb/view?usp=sharing) (Google Drive).
-Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
-Download and extract them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── coco
- │-- annotations
- │ │-- coco_wholebody_train_v1.0.json
- │ |-- coco_wholebody_val_v1.0.json
- |-- person_detection_results
- | |-- COCO_val2017_detections_AP_H_56_person.json
- │-- train2017
- │ │-- 000000000009.jpg
- │ │-- 000000000025.jpg
- │ │-- 000000000030.jpg
- │ │-- ...
- `-- val2017
- │-- 000000000139.jpg
- │-- 000000000285.jpg
- │-- 000000000632.jpg
- │-- ...
-```
-
-Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) to support COCO-WholeBody evaluation:
-
-`pip install xtcocotools`
+# 2D Hand Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [OneHand10K](#onehand10k) \[ [Homepage](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html) \]
+- [FreiHand](#freihand-dataset) \[ [Homepage](https://lmb.informatik.uni-freiburg.de/projects/freihand/) \]
+- [CMU Panoptic HandDB](#cmu-panoptic-handdb) \[ [Homepage](http://domedb.perception.cs.cmu.edu/handdb.html) \]
+- [InterHand2.6M](#interhand26m) \[ [Homepage](https://mks0601.github.io/InterHand2.6M/) \]
+- [RHD](#rhd-dataset) \[ [Homepage](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html) \]
+- [COCO-WholeBody-Hand](#coco-wholebody-hand) \[ [Homepage](https://github.com/jin-s13/COCO-WholeBody/) \]
+
+## OneHand10K
+
+
+
+
+OneHand10K (TCSVT'2019)
+
+```bibtex
+@article{wang2018mask,
+ title={Mask-pose cascaded cnn for 2d hand pose estimation from single color image},
+ author={Wang, Yangang and Peng, Cong and Liu, Yebin},
+ journal={IEEE Transactions on Circuits and Systems for Video Technology},
+ volume={29},
+ number={11},
+ pages={3258--3268},
+ year={2018},
+ publisher={IEEE}
+}
+```
+
+
+
+
+
+
+
+For [OneHand10K](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html) data, please download from [OneHand10K Dataset](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html).
+Please download the annotation files from [onehand10k_annotations](https://download.openmmlab.com/mmpose/datasets/onehand10k_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── onehand10k
+ |── annotations
+ | |── onehand10k_train.json
+ | |── onehand10k_test.json
+ `── Train
+ | |── source
+ | |── 0.jpg
+ | |── 1.jpg
+ | ...
+ `── Test
+ |── source
+ |── 0.jpg
+ |── 1.jpg
+
+```
+
+## FreiHAND Dataset
+
+
+
+
+FreiHand (ICCV'2019)
+
+```bibtex
+@inproceedings{zimmermann2019freihand,
+ title={Freihand: A dataset for markerless capture of hand pose and shape from single rgb images},
+ author={Zimmermann, Christian and Ceylan, Duygu and Yang, Jimei and Russell, Bryan and Argus, Max and Brox, Thomas},
+ booktitle={Proceedings of the IEEE International Conference on Computer Vision},
+ pages={813--822},
+ year={2019}
+}
+```
+
+
+
+
+
+
+
+For [FreiHAND](https://lmb.informatik.uni-freiburg.de/projects/freihand/) data, please download from [FreiHand Dataset](https://lmb.informatik.uni-freiburg.de/resources/datasets/FreihandDataset.en.html).
+Since the official dataset does not provide validation set, we randomly split the training data into 8:1:1 for train/val/test.
+Please download the annotation files from [freihand_annotations](https://download.openmmlab.com/mmpose/datasets/frei_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── freihand
+ |── annotations
+ | |── freihand_train.json
+ | |── freihand_val.json
+ | |── freihand_test.json
+ `── training
+ |── rgb
+ | |── 00000000.jpg
+ | |── 00000001.jpg
+ | ...
+ |── mask
+ |── 00000000.jpg
+ |── 00000001.jpg
+ ...
+```
+
+## CMU Panoptic HandDB
+
+
+
+
+CMU Panoptic HandDB (CVPR'2017)
+
+```bibtex
+@inproceedings{simon2017hand,
+ title={Hand keypoint detection in single images using multiview bootstrapping},
+ author={Simon, Tomas and Joo, Hanbyul and Matthews, Iain and Sheikh, Yaser},
+ booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition},
+ pages={1145--1153},
+ year={2017}
+}
+```
+
+
+
+
+
+
+
+For [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html), please download from [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html).
+Following [Simon et al](https://arxiv.org/abs/1704.07809), panoptic images (hand143_panopticdb) and MPII & NZSL training sets (manual_train) are used for training, while MPII & NZSL test set (manual_test) for testing.
+Please download the annotation files from [panoptic_annotations](https://download.openmmlab.com/mmpose/datasets/panoptic_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── panoptic
+ |── annotations
+ | |── panoptic_train.json
+ | |── panoptic_test.json
+ |
+ `── hand143_panopticdb
+ | |── imgs
+ | | |── 00000000.jpg
+ | | |── 00000001.jpg
+ | | ...
+ |
+ `── hand_labels
+ |── manual_train
+ | |── 000015774_01_l.jpg
+ | |── 000015774_01_r.jpg
+ | ...
+ |
+ `── manual_test
+ |── 000648952_02_l.jpg
+ |── 000835470_01_l.jpg
+ ...
+```
+
+## InterHand2.6M
+
+
+
+
+InterHand2.6M (ECCV'2020)
+
+```bibtex
+@InProceedings{Moon_2020_ECCV_InterHand2.6M,
+author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu},
+title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image},
+booktitle = {European Conference on Computer Vision (ECCV)},
+year = {2020}
+}
+```
+
+
+
+
+
+
+
+For [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/), please download from [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/).
+Please download the annotation files from [annotations](https://download.openmmlab.com/mmpose/datasets/interhand2.6m_annotations.zip).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── interhand2.6m
+ |── annotations
+ | |── all
+ | |── human_annot
+ | |── machine_annot
+ | |── skeleton.txt
+ | |── subject.txt
+ |
+ `── images
+ | |── train
+ | | |-- Capture0 ~ Capture26
+ | |── val
+ | | |-- Capture0
+ | |── test
+ | | |-- Capture0 ~ Capture7
+```
+
+## RHD Dataset
+
+
+
+
+RHD (ICCV'2017)
+
+```bibtex
+@TechReport{zb2017hand,
+ author={Christian Zimmermann and Thomas Brox},
+ title={Learning to Estimate 3D Hand Pose from Single RGB Images},
+ institution={arXiv:1705.01389},
+ year={2017},
+ note="https://arxiv.org/abs/1705.01389",
+ url="https://lmb.informatik.uni-freiburg.de/projects/hand3d/"
+}
+```
+
+
+
+
+
+
+
+For [RHD Dataset](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html), please download from [RHD Dataset](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html).
+Please download the annotation files from [rhd_annotations](https://download.openmmlab.com/mmpose/datasets/rhd_annotations.zip).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── rhd
+ |── annotations
+ | |── rhd_train.json
+ | |── rhd_test.json
+ `── training
+ | |── color
+ | | |── 00000.jpg
+ | | |── 00001.jpg
+ | |── depth
+ | | |── 00000.jpg
+ | | |── 00001.jpg
+ | |── mask
+ | | |── 00000.jpg
+ | | |── 00001.jpg
+ `── evaluation
+ | |── color
+ | | |── 00000.jpg
+ | | |── 00001.jpg
+ | |── depth
+ | | |── 00000.jpg
+ | | |── 00001.jpg
+ | |── mask
+ | | |── 00000.jpg
+ | | |── 00001.jpg
+```
+
+## COCO-WholeBody (Hand)
+
+
+
+
+COCO-WholeBody-Hand (ECCV'2020)
+
+```bibtex
+@inproceedings{jin2020whole,
+ title={Whole-Body Human Pose Estimation in the Wild},
+ author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping},
+ booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
+ year={2020}
+}
+```
+
+
+
+
+
+
+
+For [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/) dataset, images can be downloaded from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
+Download COCO-WholeBody annotations for COCO-WholeBody annotations for [Train](https://drive.google.com/file/d/1thErEToRbmM9uLNi1JXXfOsaS5VK2FXf/view?usp=sharing) / [Validation](https://drive.google.com/file/d/1N6VgwKnj8DeyGXCvp1eYgNbRmw6jdfrb/view?usp=sharing) (Google Drive).
+Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── coco
+ │-- annotations
+ │ │-- coco_wholebody_train_v1.0.json
+ │ |-- coco_wholebody_val_v1.0.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ │-- train2017
+ │ │-- 000000000009.jpg
+ │ │-- 000000000025.jpg
+ │ │-- 000000000030.jpg
+ │ │-- ...
+ `-- val2017
+ │-- 000000000139.jpg
+ │-- 000000000285.jpg
+ │-- 000000000632.jpg
+ │-- ...
+```
+
+Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) to support COCO-WholeBody evaluation:
+
+`pip install xtcocotools`
diff --git a/docs/en/dataset_zoo/2d_wholebody_keypoint.md b/docs/en/dataset_zoo/2d_wholebody_keypoint.md
index a082c657c6..55a76139df 100644
--- a/docs/en/dataset_zoo/2d_wholebody_keypoint.md
+++ b/docs/en/dataset_zoo/2d_wholebody_keypoint.md
@@ -1,133 +1,133 @@
-# 2D Wholebody Keypoint Datasets
-
-It is recommended to symlink the dataset root to `$MMPOSE/data`.
-If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMPose supported datasets:
-
-- [COCO-WholeBody](#coco-wholebody) \[ [Homepage](https://github.com/jin-s13/COCO-WholeBody/) \]
-- [Halpe](#halpe) \[ [Homepage](https://github.com/Fang-Haoshu/Halpe-FullBody/) \]
-
-## COCO-WholeBody
-
-
-
-
-COCO-WholeBody (ECCV'2020)
-
-```bibtex
-@inproceedings{jin2020whole,
- title={Whole-Body Human Pose Estimation in the Wild},
- author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping},
- booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
- year={2020}
-}
-```
-
-
-
-
-
-
-
-For [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/) dataset, images can be downloaded from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
-Download COCO-WholeBody annotations for COCO-WholeBody annotations for [Train](https://drive.google.com/file/d/1thErEToRbmM9uLNi1JXXfOsaS5VK2FXf/view?usp=sharing) / [Validation](https://drive.google.com/file/d/1N6VgwKnj8DeyGXCvp1eYgNbRmw6jdfrb/view?usp=sharing) (Google Drive).
-Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
-Download and extract them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── coco
- │-- annotations
- │ │-- coco_wholebody_train_v1.0.json
- │ |-- coco_wholebody_val_v1.0.json
- |-- person_detection_results
- | |-- COCO_val2017_detections_AP_H_56_person.json
- │-- train2017
- │ │-- 000000000009.jpg
- │ │-- 000000000025.jpg
- │ │-- 000000000030.jpg
- │ │-- ...
- `-- val2017
- │-- 000000000139.jpg
- │-- 000000000285.jpg
- │-- 000000000632.jpg
- │-- ...
-
-```
-
-Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) (version>=1.5) to support COCO-WholeBody evaluation:
-
-`pip install xtcocotools`
-
-## Halpe
-
-
-
-
-Halpe (CVPR'2020)
-
-```bibtex
-@inproceedings{li2020pastanet,
- title={PaStaNet: Toward Human Activity Knowledge Engine},
- author={Li, Yong-Lu and Xu, Liang and Liu, Xinpeng and Huang, Xijie and Xu, Yue and Wang, Shiyi and Fang, Hao-Shu and Ma, Ze and Chen, Mingyang and Lu, Cewu},
- booktitle={CVPR},
- year={2020}
-}
-```
-
-
-
-
-
-
-
-For [Halpe](https://github.com/Fang-Haoshu/Halpe-FullBody/) dataset, please download images and annotations from [Halpe download](https://github.com/Fang-Haoshu/Halpe-FullBody).
-The images of the training set are from [HICO-Det](https://drive.google.com/open?id=1QZcJmGVlF9f4h-XLWe9Gkmnmj2z1gSnk) and those of the validation set are from [COCO](http://images.cocodataset.org/zips/val2017.zip).
-Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
-Download and extract them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── halpe
- │-- annotations
- │ │-- halpe_train_v1.json
- │ |-- halpe_val_v1.json
- |-- person_detection_results
- | |-- COCO_val2017_detections_AP_H_56_person.json
- │-- hico_20160224_det
- │ │-- anno_bbox.mat
- │ │-- anno.mat
- │ │-- README
- │ │-- images
- │ │ │-- train2015
- │ │ │ │-- HICO_train2015_00000001.jpg
- │ │ │ │-- HICO_train2015_00000002.jpg
- │ │ │ │-- HICO_train2015_00000003.jpg
- │ │ │ │-- ...
- │ │ │-- test2015
- │ │-- tools
- │ │-- ...
- `-- val2017
- │-- 000000000139.jpg
- │-- 000000000285.jpg
- │-- 000000000632.jpg
- │-- ...
-
-```
-
-Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) (version>=1.5) to support Halpe evaluation:
-
-`pip install xtcocotools`
+# 2D Wholebody Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [COCO-WholeBody](#coco-wholebody) \[ [Homepage](https://github.com/jin-s13/COCO-WholeBody/) \]
+- [Halpe](#halpe) \[ [Homepage](https://github.com/Fang-Haoshu/Halpe-FullBody/) \]
+
+## COCO-WholeBody
+
+
+
+
+COCO-WholeBody (ECCV'2020)
+
+```bibtex
+@inproceedings{jin2020whole,
+ title={Whole-Body Human Pose Estimation in the Wild},
+ author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping},
+ booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
+ year={2020}
+}
+```
+
+
+
+
+
+
+
+For [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/) dataset, images can be downloaded from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
+Download COCO-WholeBody annotations for COCO-WholeBody annotations for [Train](https://drive.google.com/file/d/1thErEToRbmM9uLNi1JXXfOsaS5VK2FXf/view?usp=sharing) / [Validation](https://drive.google.com/file/d/1N6VgwKnj8DeyGXCvp1eYgNbRmw6jdfrb/view?usp=sharing) (Google Drive).
+Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── coco
+ │-- annotations
+ │ │-- coco_wholebody_train_v1.0.json
+ │ |-- coco_wholebody_val_v1.0.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ │-- train2017
+ │ │-- 000000000009.jpg
+ │ │-- 000000000025.jpg
+ │ │-- 000000000030.jpg
+ │ │-- ...
+ `-- val2017
+ │-- 000000000139.jpg
+ │-- 000000000285.jpg
+ │-- 000000000632.jpg
+ │-- ...
+
+```
+
+Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) (version>=1.5) to support COCO-WholeBody evaluation:
+
+`pip install xtcocotools`
+
+## Halpe
+
+
+
+
+Halpe (CVPR'2020)
+
+```bibtex
+@inproceedings{li2020pastanet,
+ title={PaStaNet: Toward Human Activity Knowledge Engine},
+ author={Li, Yong-Lu and Xu, Liang and Liu, Xinpeng and Huang, Xijie and Xu, Yue and Wang, Shiyi and Fang, Hao-Shu and Ma, Ze and Chen, Mingyang and Lu, Cewu},
+ booktitle={CVPR},
+ year={2020}
+}
+```
+
+
+
+
+
+
+
+For [Halpe](https://github.com/Fang-Haoshu/Halpe-FullBody/) dataset, please download images and annotations from [Halpe download](https://github.com/Fang-Haoshu/Halpe-FullBody).
+The images of the training set are from [HICO-Det](https://drive.google.com/open?id=1QZcJmGVlF9f4h-XLWe9Gkmnmj2z1gSnk) and those of the validation set are from [COCO](http://images.cocodataset.org/zips/val2017.zip).
+Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── halpe
+ │-- annotations
+ │ │-- halpe_train_v1.json
+ │ |-- halpe_val_v1.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ │-- hico_20160224_det
+ │ │-- anno_bbox.mat
+ │ │-- anno.mat
+ │ │-- README
+ │ │-- images
+ │ │ │-- train2015
+ │ │ │ │-- HICO_train2015_00000001.jpg
+ │ │ │ │-- HICO_train2015_00000002.jpg
+ │ │ │ │-- HICO_train2015_00000003.jpg
+ │ │ │ │-- ...
+ │ │ │-- test2015
+ │ │-- tools
+ │ │-- ...
+ `-- val2017
+ │-- 000000000139.jpg
+ │-- 000000000285.jpg
+ │-- 000000000632.jpg
+ │-- ...
+
+```
+
+Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) (version>=1.5) to support Halpe evaluation:
+
+`pip install xtcocotools`
diff --git a/docs/en/dataset_zoo/3d_body_keypoint.md b/docs/en/dataset_zoo/3d_body_keypoint.md
index 82e21010fc..25b1d8415c 100644
--- a/docs/en/dataset_zoo/3d_body_keypoint.md
+++ b/docs/en/dataset_zoo/3d_body_keypoint.md
@@ -1,199 +1,199 @@
-# 3D Body Keypoint Datasets
-
-It is recommended to symlink the dataset root to `$MMPOSE/data`.
-If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMPose supported datasets:
-
-- [Human3.6M](#human36m) \[ [Homepage](http://vision.imar.ro/human3.6m/description.php) \]
-- [CMU Panoptic](#cmu-panoptic) \[ [Homepage](http://domedb.perception.cs.cmu.edu/) \]
-- [Campus/Shelf](#campus-and-shelf) \[ [Homepage](http://campar.in.tum.de/Chair/MultiHumanPose) \]
-
-## Human3.6M
-
-
-
-
-Human3.6M (TPAMI'2014)
-
-```bibtex
-@article{h36m_pami,
- author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian},
- title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments},
- journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
- publisher = {IEEE Computer Society},
- volume = {36},
- number = {7},
- pages = {1325-1339},
- month = {jul},
- year = {2014}
-}
-```
-
-
-
-
-
-
-
-For [Human3.6M](http://vision.imar.ro/human3.6m/description.php), please download from the official website and run the [preprocessing script](/tools/dataset_converters/preprocess_h36m.py), which will extract camera parameters and pose annotations at full framerate (50 FPS) and downsampled framerate (10 FPS). The processed data should have the following structure:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- ├── h36m
- ├── annotation_body3d
- | ├── cameras.pkl
- | ├── fps50
- | | ├── h36m_test.npz
- | | ├── h36m_train.npz
- | | ├── joint2d_rel_stats.pkl
- | | ├── joint2d_stats.pkl
- | | ├── joint3d_rel_stats.pkl
- | | `── joint3d_stats.pkl
- | `── fps10
- | ├── h36m_test.npz
- | ├── h36m_train.npz
- | ├── joint2d_rel_stats.pkl
- | ├── joint2d_stats.pkl
- | ├── joint3d_rel_stats.pkl
- | `── joint3d_stats.pkl
- `── images
- ├── S1
- | ├── S1_Directions_1.54138969
- | | ├── S1_Directions_1.54138969_00001.jpg
- | | ├── S1_Directions_1.54138969_00002.jpg
- | | ├── ...
- | ├── ...
- ├── S5
- ├── S6
- ├── S7
- ├── S8
- ├── S9
- `── S11
-```
-
-## CMU Panoptic
-
-
-CMU Panoptic (ICCV'2015)
-
-```bibtex
-@Article = {joo_iccv_2015,
-author = {Hanbyul Joo, Hao Liu, Lei Tan, Lin Gui, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh},
-title = {Panoptic Studio: A Massively Multiview System for Social Motion Capture},
-booktitle = {ICCV},
-year = {2015}
-}
-```
-
-
-
-
-
-
-
-Please follow [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch) to prepare this dataset.
-
-1. Download the dataset by following the instructions in [panoptic-toolbox](https://github.com/CMU-Perceptual-Computing-Lab/panoptic-toolbox) and extract them under `$MMPOSE/data/panoptic`.
-
-2. Only download those sequences that are needed. You can also just download a subset of camera views by specifying the number of views (HD_Video_Number) and changing the camera order in `./scripts/getData.sh`. The used sequences and camera views can be found in [VoxelPose](https://arxiv.org/abs/2004.06239). Note that the sequence "160906_band3" might not be available due to errors on the server of CMU Panoptic.
-
-3. Note that we only use HD videos, calibration data, and 3D Body Keypoint in the codes. You can comment out other irrelevant codes such as downloading 3D Face data in `./scripts/getData.sh`.
-
-The directory tree should be like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- ├── panoptic
- ├── 16060224_haggling1
- | | ├── hdImgs
- | | ├── hdvideos
- | | ├── hdPose3d_stage1_coco19
- | | ├── calibration_160224_haggling1.json
- ├── 160226_haggling1
- ├── ...
-```
-
-## Campus and Shelf
-
-
-Campus and Shelf (CVPR'2014)
-
-```bibtex
-@inproceedings {belagian14multi,
- title = {{3D} Pictorial Structures for Multiple Human Pose Estimation},
- author = {Belagiannis, Vasileios and Amin, Sikandar and Andriluka, Mykhaylo and Schiele, Bernt and Navab
- Nassir and Ilic, Slobo
- booktitle = {IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = {2014},
- month = {June},
- organization={IEEE}
-}
-```
-
-
-
-
-
-
-
-Please follow [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch) to prepare these two datasets.
-
-1. Please download the datasets from the [official website](http://campar.in.tum.de/Chair/MultiHumanPose) and extract them under `$MMPOSE/data/campus` and `$MMPOSE/data/shelf`, respectively. The original data include images as well as the ground truth pose file `actorsGT.mat`.
-
-2. We directly use the processed camera parameters from [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch). You can download them from this repository and place in under `$MMPOSE/data/campus/calibration_campus.json` and `$MMPOSE/data/shelf/calibration_shelf.json`, respectively.
-
-3. Like [Voxelpose](https://github.com/microsoft/voxelpose-pytorch), due to the limited and incomplete annotations of the two datasets, we don't train the model using this dataset. Instead, we directly use the 2D pose estimator trained on COCO, and use independent 3D human poses from the CMU Panoptic dataset to train our 3D model. It lies in `${MMPOSE}/data/panoptic_training_pose.pkl`.
-
-4. Like [Voxelpose](https://github.com/microsoft/voxelpose-pytorch), for testing, we first estimate 2D poses and generate 2D heatmaps for these two datasets. You can download the predicted poses from [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch) and place them in `$MMPOSE/data/campus/pred_campus_maskrcnn_hrnet_coco.pkl` and `$MMPOSE/data/shelf/pred_shelf_maskrcnn_hrnet_coco.pkl`, respectively. You can also use the models trained on COCO dataset (like HigherHRNet) to generate 2D heatmaps directly.
-
-The directory tree should be like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- ├── panoptic_training_pose.pkl
- ├── campus
- | ├── Camera0
- | | | ├── campus4-c0-00000.png
- | | | ├── ...
- | | | ├── campus4-c0-01999.png
- | ...
- | ├── Camera2
- | | | ├── campus4-c2-00000.png
- | | | ├── ...
- | | | ├── campus4-c2-01999.png
- | ├── calibration_campus.json
- | ├── pred_campus_maskrcnn_hrnet_coco.pkl
- | ├── actorsGT.mat
- ├── shelf
- | ├── Camera0
- | | | ├── img_000000.png
- | | | ├── ...
- | | | ├── img_003199.png
- | ...
- | ├── Camera4
- | | | ├── img_000000.png
- | | | ├── ...
- | | | ├── img_003199.png
- | ├── calibration_shelf.json
- | ├── pred_shelf_maskrcnn_hrnet_coco.pkl
- | ├── actorsGT.mat
-```
+# 3D Body Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [Human3.6M](#human36m) \[ [Homepage](http://vision.imar.ro/human3.6m/description.php) \]
+- [CMU Panoptic](#cmu-panoptic) \[ [Homepage](http://domedb.perception.cs.cmu.edu/) \]
+- [Campus/Shelf](#campus-and-shelf) \[ [Homepage](http://campar.in.tum.de/Chair/MultiHumanPose) \]
+
+## Human3.6M
+
+
+
+
+Human3.6M (TPAMI'2014)
+
+```bibtex
+@article{h36m_pami,
+ author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian},
+ title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments},
+ journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
+ publisher = {IEEE Computer Society},
+ volume = {36},
+ number = {7},
+ pages = {1325-1339},
+ month = {jul},
+ year = {2014}
+}
+```
+
+
+
+
+
+
+
+For [Human3.6M](http://vision.imar.ro/human3.6m/description.php), please download from the official website and run the [preprocessing script](/tools/dataset_converters/preprocess_h36m.py), which will extract camera parameters and pose annotations at full framerate (50 FPS) and downsampled framerate (10 FPS). The processed data should have the following structure:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ ├── h36m
+ ├── annotation_body3d
+ | ├── cameras.pkl
+ | ├── fps50
+ | | ├── h36m_test.npz
+ | | ├── h36m_train.npz
+ | | ├── joint2d_rel_stats.pkl
+ | | ├── joint2d_stats.pkl
+ | | ├── joint3d_rel_stats.pkl
+ | | `── joint3d_stats.pkl
+ | `── fps10
+ | ├── h36m_test.npz
+ | ├── h36m_train.npz
+ | ├── joint2d_rel_stats.pkl
+ | ├── joint2d_stats.pkl
+ | ├── joint3d_rel_stats.pkl
+ | `── joint3d_stats.pkl
+ `── images
+ ├── S1
+ | ├── S1_Directions_1.54138969
+ | | ├── S1_Directions_1.54138969_00001.jpg
+ | | ├── S1_Directions_1.54138969_00002.jpg
+ | | ├── ...
+ | ├── ...
+ ├── S5
+ ├── S6
+ ├── S7
+ ├── S8
+ ├── S9
+ `── S11
+```
+
+## CMU Panoptic
+
+
+CMU Panoptic (ICCV'2015)
+
+```bibtex
+@Article = {joo_iccv_2015,
+author = {Hanbyul Joo, Hao Liu, Lei Tan, Lin Gui, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh},
+title = {Panoptic Studio: A Massively Multiview System for Social Motion Capture},
+booktitle = {ICCV},
+year = {2015}
+}
+```
+
+
+
+
+
+
+
+Please follow [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch) to prepare this dataset.
+
+1. Download the dataset by following the instructions in [panoptic-toolbox](https://github.com/CMU-Perceptual-Computing-Lab/panoptic-toolbox) and extract them under `$MMPOSE/data/panoptic`.
+
+2. Only download those sequences that are needed. You can also just download a subset of camera views by specifying the number of views (HD_Video_Number) and changing the camera order in `./scripts/getData.sh`. The used sequences and camera views can be found in [VoxelPose](https://arxiv.org/abs/2004.06239). Note that the sequence "160906_band3" might not be available due to errors on the server of CMU Panoptic.
+
+3. Note that we only use HD videos, calibration data, and 3D Body Keypoint in the codes. You can comment out other irrelevant codes such as downloading 3D Face data in `./scripts/getData.sh`.
+
+The directory tree should be like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ ├── panoptic
+ ├── 16060224_haggling1
+ | | ├── hdImgs
+ | | ├── hdvideos
+ | | ├── hdPose3d_stage1_coco19
+ | | ├── calibration_160224_haggling1.json
+ ├── 160226_haggling1
+ ├── ...
+```
+
+## Campus and Shelf
+
+
+Campus and Shelf (CVPR'2014)
+
+```bibtex
+@inproceedings {belagian14multi,
+ title = {{3D} Pictorial Structures for Multiple Human Pose Estimation},
+ author = {Belagiannis, Vasileios and Amin, Sikandar and Andriluka, Mykhaylo and Schiele, Bernt and Navab
+ Nassir and Ilic, Slobo
+ booktitle = {IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year = {2014},
+ month = {June},
+ organization={IEEE}
+}
+```
+
+
+
+
+
+
+
+Please follow [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch) to prepare these two datasets.
+
+1. Please download the datasets from the [official website](http://campar.in.tum.de/Chair/MultiHumanPose) and extract them under `$MMPOSE/data/campus` and `$MMPOSE/data/shelf`, respectively. The original data include images as well as the ground truth pose file `actorsGT.mat`.
+
+2. We directly use the processed camera parameters from [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch). You can download them from this repository and place in under `$MMPOSE/data/campus/calibration_campus.json` and `$MMPOSE/data/shelf/calibration_shelf.json`, respectively.
+
+3. Like [Voxelpose](https://github.com/microsoft/voxelpose-pytorch), due to the limited and incomplete annotations of the two datasets, we don't train the model using this dataset. Instead, we directly use the 2D pose estimator trained on COCO, and use independent 3D human poses from the CMU Panoptic dataset to train our 3D model. It lies in `${MMPOSE}/data/panoptic_training_pose.pkl`.
+
+4. Like [Voxelpose](https://github.com/microsoft/voxelpose-pytorch), for testing, we first estimate 2D poses and generate 2D heatmaps for these two datasets. You can download the predicted poses from [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch) and place them in `$MMPOSE/data/campus/pred_campus_maskrcnn_hrnet_coco.pkl` and `$MMPOSE/data/shelf/pred_shelf_maskrcnn_hrnet_coco.pkl`, respectively. You can also use the models trained on COCO dataset (like HigherHRNet) to generate 2D heatmaps directly.
+
+The directory tree should be like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ ├── panoptic_training_pose.pkl
+ ├── campus
+ | ├── Camera0
+ | | | ├── campus4-c0-00000.png
+ | | | ├── ...
+ | | | ├── campus4-c0-01999.png
+ | ...
+ | ├── Camera2
+ | | | ├── campus4-c2-00000.png
+ | | | ├── ...
+ | | | ├── campus4-c2-01999.png
+ | ├── calibration_campus.json
+ | ├── pred_campus_maskrcnn_hrnet_coco.pkl
+ | ├── actorsGT.mat
+ ├── shelf
+ | ├── Camera0
+ | | | ├── img_000000.png
+ | | | ├── ...
+ | | | ├── img_003199.png
+ | ...
+ | ├── Camera4
+ | | | ├── img_000000.png
+ | | | ├── ...
+ | | | ├── img_003199.png
+ | ├── calibration_shelf.json
+ | ├── pred_shelf_maskrcnn_hrnet_coco.pkl
+ | ├── actorsGT.mat
+```
diff --git a/docs/en/dataset_zoo/3d_body_mesh.md b/docs/en/dataset_zoo/3d_body_mesh.md
index aced63c802..25a08fd676 100644
--- a/docs/en/dataset_zoo/3d_body_mesh.md
+++ b/docs/en/dataset_zoo/3d_body_mesh.md
@@ -1,342 +1,342 @@
-# 3D Body Mesh Recovery Datasets
-
-It is recommended to symlink the dataset root to `$MMPOSE/data`.
-If your folder structure is different, you may need to change the corresponding paths in config files.
-
-To achieve high-quality human mesh estimation, we use multiple datasets for training.
-The following items should be prepared for human mesh training:
-
-
-
-- [3D Body Mesh Recovery Datasets](#3d-body-mesh-recovery-datasets)
- - [Notes](#notes)
- - [Annotation Files for Human Mesh Estimation](#annotation-files-for-human-mesh-estimation)
- - [SMPL Model](#smpl-model)
- - [COCO](#coco)
- - [Human3.6M](#human36m)
- - [MPI-INF-3DHP](#mpi-inf-3dhp)
- - [LSP](#lsp)
- - [LSPET](#lspet)
- - [CMU MoShed Data](#cmu-moshed-data)
-
-
-
-## Notes
-
-### Annotation Files for Human Mesh Estimation
-
-For human mesh estimation, we use multiple datasets for training.
-The annotation of different datasets are preprocessed to the same format. Please
-follow the [preprocess procedure](https://github.com/nkolot/SPIN/tree/master/datasets/preprocess)
-of SPIN to generate the annotation files or download the processed files from
-[here](https://download.openmmlab.com/mmpose/datasets/mesh_annotation_files.zip),
-and make it look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── mesh_annotation_files
- ├── coco_2014_train.npz
- ├── h36m_valid_protocol1.npz
- ├── h36m_valid_protocol2.npz
- ├── hr-lspet_train.npz
- ├── lsp_dataset_original_train.npz
- ├── mpi_inf_3dhp_train.npz
- └── mpii_train.npz
-```
-
-### SMPL Model
-
-```bibtex
-@article{loper2015smpl,
- title={SMPL: A skinned multi-person linear model},
- author={Loper, Matthew and Mahmood, Naureen and Romero, Javier and Pons-Moll, Gerard and Black, Michael J},
- journal={ACM transactions on graphics (TOG)},
- volume={34},
- number={6},
- pages={1--16},
- year={2015},
- publisher={ACM New York, NY, USA}
-}
-```
-
-For human mesh estimation, SMPL model is used to generate the human mesh.
-Please download the [gender neutral SMPL model](http://smplify.is.tue.mpg.de/),
-[joints regressor](https://download.openmmlab.com/mmpose/datasets/joints_regressor_cmr.npy)
-and [mean parameters](https://download.openmmlab.com/mmpose/datasets/smpl_mean_params.npz)
-under `$MMPOSE/models/smpl`, and make it look like this:
-
-```text
-mmpose
-├── mmpose
-├── ...
-├── models
- │── smpl
- ├── joints_regressor_cmr.npy
- ├── smpl_mean_params.npz
- └── SMPL_NEUTRAL.pkl
-```
-
-## COCO
-
-
-
-
-COCO (ECCV'2014)
-
-```bibtex
-@inproceedings{lin2014microsoft,
- title={Microsoft coco: Common objects in context},
- author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence},
- booktitle={European conference on computer vision},
- pages={740--755},
- year={2014},
- organization={Springer}
-}
-```
-
-
-
-For [COCO](http://cocodataset.org/) data, please download from [COCO download](http://cocodataset.org/#download). COCO'2014 Train is needed for human mesh estimation training.
-Download and extract them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── coco
- │-- train2014
- │ ├── COCO_train2014_000000000009.jpg
- │ ├── COCO_train2014_000000000025.jpg
- │ ├── COCO_train2014_000000000030.jpg
- | │-- ...
-
-```
-
-## Human3.6M
-
-
-
-
-Human3.6M (TPAMI'2014)
-
-```bibtex
-@article{h36m_pami,
- author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian},
- title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments},
- journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
- publisher = {IEEE Computer Society},
- volume = {36},
- number = {7},
- pages = {1325-1339},
- month = {jul},
- year = {2014}
-}
-```
-
-
-
-For [Human3.6M](http://vision.imar.ro/human3.6m/description.php), we use the MoShed data provided in [HMR](https://github.com/akanazawa/hmr) for training.
-However, due to license limitations, we are not allowed to redistribute the MoShed data.
-
-For the evaluation on Human3.6M dataset, please follow the
-[preprocess procedure](https://github.com/nkolot/SPIN/tree/master/datasets/preprocess)
-of SPIN to extract test images from
-[Human3.6M](http://vision.imar.ro/human3.6m/description.php) original videos,
-and make it look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── Human3.6M
- ├── images
- ├── S11_Directions_1.54138969_000001.jpg
- ├── S11_Directions_1.54138969_000006.jpg
- ├── S11_Directions_1.54138969_000011.jpg
- ├── ...
-```
-
-The download of Human3.6M dataset is quite difficult, you can also download the
-[zip file](https://drive.google.com/file/d/1WnRJD9FS3NUf7MllwgLRJJC-JgYFr8oi/view?usp=sharing)
-of the test images. However, due to the license limitations, we are not allowed to
-redistribute the images either. So the users need to download the original video and
-extract the images by themselves.
-
-## MPI-INF-3DHP
-
-
-
-```bibtex
-@inproceedings{mono-3dhp2017,
- author = {Mehta, Dushyant and Rhodin, Helge and Casas, Dan and Fua, Pascal and Sotnychenko, Oleksandr and Xu, Weipeng and Theobalt, Christian},
- title = {Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision},
- booktitle = {3D Vision (3DV), 2017 Fifth International Conference on},
- url = {http://gvv.mpi-inf.mpg.de/3dhp_dataset},
- year = {2017},
- organization={IEEE},
- doi={10.1109/3dv.2017.00064},
-}
-```
-
-For [MPI-INF-3DHP](http://gvv.mpi-inf.mpg.de/3dhp-dataset/), please follow the
-[preprocess procedure](https://github.com/nkolot/SPIN/tree/master/datasets/preprocess)
-of SPIN to sample images, and make them like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- ├── mpi_inf_3dhp_test_set
- │ ├── TS1
- │ ├── TS2
- │ ├── TS3
- │ ├── TS4
- │ ├── TS5
- │ └── TS6
- ├── S1
- │ ├── Seq1
- │ └── Seq2
- ├── S2
- │ ├── Seq1
- │ └── Seq2
- ├── S3
- │ ├── Seq1
- │ └── Seq2
- ├── S4
- │ ├── Seq1
- │ └── Seq2
- ├── S5
- │ ├── Seq1
- │ └── Seq2
- ├── S6
- │ ├── Seq1
- │ └── Seq2
- ├── S7
- │ ├── Seq1
- │ └── Seq2
- └── S8
- ├── Seq1
- └── Seq2
-```
-
-## LSP
-
-
-
-```bibtex
-@inproceedings{johnson2010clustered,
- title={Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation.},
- author={Johnson, Sam and Everingham, Mark},
- booktitle={bmvc},
- volume={2},
- number={4},
- pages={5},
- year={2010},
- organization={Citeseer}
-}
-```
-
-For [LSP](https://sam.johnson.io/research/lsp.html), please download the high resolution version
-[LSP dataset original](http://sam.johnson.io/research/lsp_dataset_original.zip).
-Extract them under `$MMPOSE/data`, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── lsp_dataset_original
- ├── images
- ├── im0001.jpg
- ├── im0002.jpg
- └── ...
-```
-
-## LSPET
-
-
-
-```bibtex
-@inproceedings{johnson2011learning,
- title={Learning effective human pose estimation from inaccurate annotation},
- author={Johnson, Sam and Everingham, Mark},
- booktitle={CVPR 2011},
- pages={1465--1472},
- year={2011},
- organization={IEEE}
-}
-```
-
-For [LSPET](https://sam.johnson.io/research/lspet.html), please download its high resolution form
-[HR-LSPET](http://datasets.d2.mpi-inf.mpg.de/hr-lspet/hr-lspet.zip).
-Extract them under `$MMPOSE/data`, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── lspet_dataset
- ├── images
- │ ├── im00001.jpg
- │ ├── im00002.jpg
- │ ├── im00003.jpg
- │ └── ...
- └── joints.mat
-```
-
-## CMU MoShed Data
-
-
-
-```bibtex
-@inproceedings{kanazawa2018end,
- title={End-to-end recovery of human shape and pose},
- author={Kanazawa, Angjoo and Black, Michael J and Jacobs, David W and Malik, Jitendra},
- booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
- pages={7122--7131},
- year={2018}
-}
-```
-
-Real-world SMPL parameters are used for the adversarial training in human mesh estimation.
-The MoShed data provided in [HMR](https://github.com/akanazawa/hmr) is included in this
-[zip file](https://download.openmmlab.com/mmpose/datasets/mesh_annotation_files.zip).
-Please download and extract it under `$MMPOSE/data`, and make it look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── mesh_annotation_files
- ├── CMU_mosh.npz
- └── ...
-```
+# 3D Body Mesh Recovery Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+To achieve high-quality human mesh estimation, we use multiple datasets for training.
+The following items should be prepared for human mesh training:
+
+
+
+- [3D Body Mesh Recovery Datasets](#3d-body-mesh-recovery-datasets)
+ - [Notes](#notes)
+ - [Annotation Files for Human Mesh Estimation](#annotation-files-for-human-mesh-estimation)
+ - [SMPL Model](#smpl-model)
+ - [COCO](#coco)
+ - [Human3.6M](#human36m)
+ - [MPI-INF-3DHP](#mpi-inf-3dhp)
+ - [LSP](#lsp)
+ - [LSPET](#lspet)
+ - [CMU MoShed Data](#cmu-moshed-data)
+
+
+
+## Notes
+
+### Annotation Files for Human Mesh Estimation
+
+For human mesh estimation, we use multiple datasets for training.
+The annotation of different datasets are preprocessed to the same format. Please
+follow the [preprocess procedure](https://github.com/nkolot/SPIN/tree/master/datasets/preprocess)
+of SPIN to generate the annotation files or download the processed files from
+[here](https://download.openmmlab.com/mmpose/datasets/mesh_annotation_files.zip),
+and make it look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── mesh_annotation_files
+ ├── coco_2014_train.npz
+ ├── h36m_valid_protocol1.npz
+ ├── h36m_valid_protocol2.npz
+ ├── hr-lspet_train.npz
+ ├── lsp_dataset_original_train.npz
+ ├── mpi_inf_3dhp_train.npz
+ └── mpii_train.npz
+```
+
+### SMPL Model
+
+```bibtex
+@article{loper2015smpl,
+ title={SMPL: A skinned multi-person linear model},
+ author={Loper, Matthew and Mahmood, Naureen and Romero, Javier and Pons-Moll, Gerard and Black, Michael J},
+ journal={ACM transactions on graphics (TOG)},
+ volume={34},
+ number={6},
+ pages={1--16},
+ year={2015},
+ publisher={ACM New York, NY, USA}
+}
+```
+
+For human mesh estimation, SMPL model is used to generate the human mesh.
+Please download the [gender neutral SMPL model](http://smplify.is.tue.mpg.de/),
+[joints regressor](https://download.openmmlab.com/mmpose/datasets/joints_regressor_cmr.npy)
+and [mean parameters](https://download.openmmlab.com/mmpose/datasets/smpl_mean_params.npz)
+under `$MMPOSE/models/smpl`, and make it look like this:
+
+```text
+mmpose
+├── mmpose
+├── ...
+├── models
+ │── smpl
+ ├── joints_regressor_cmr.npy
+ ├── smpl_mean_params.npz
+ └── SMPL_NEUTRAL.pkl
+```
+
+## COCO
+
+
+
+
+COCO (ECCV'2014)
+
+```bibtex
+@inproceedings{lin2014microsoft,
+ title={Microsoft coco: Common objects in context},
+ author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence},
+ booktitle={European conference on computer vision},
+ pages={740--755},
+ year={2014},
+ organization={Springer}
+}
+```
+
+
+
+For [COCO](http://cocodataset.org/) data, please download from [COCO download](http://cocodataset.org/#download). COCO'2014 Train is needed for human mesh estimation training.
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── coco
+ │-- train2014
+ │ ├── COCO_train2014_000000000009.jpg
+ │ ├── COCO_train2014_000000000025.jpg
+ │ ├── COCO_train2014_000000000030.jpg
+ | │-- ...
+
+```
+
+## Human3.6M
+
+
+
+
+Human3.6M (TPAMI'2014)
+
+```bibtex
+@article{h36m_pami,
+ author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian},
+ title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments},
+ journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
+ publisher = {IEEE Computer Society},
+ volume = {36},
+ number = {7},
+ pages = {1325-1339},
+ month = {jul},
+ year = {2014}
+}
+```
+
+
+
+For [Human3.6M](http://vision.imar.ro/human3.6m/description.php), we use the MoShed data provided in [HMR](https://github.com/akanazawa/hmr) for training.
+However, due to license limitations, we are not allowed to redistribute the MoShed data.
+
+For the evaluation on Human3.6M dataset, please follow the
+[preprocess procedure](https://github.com/nkolot/SPIN/tree/master/datasets/preprocess)
+of SPIN to extract test images from
+[Human3.6M](http://vision.imar.ro/human3.6m/description.php) original videos,
+and make it look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── Human3.6M
+ ├── images
+ ├── S11_Directions_1.54138969_000001.jpg
+ ├── S11_Directions_1.54138969_000006.jpg
+ ├── S11_Directions_1.54138969_000011.jpg
+ ├── ...
+```
+
+The download of Human3.6M dataset is quite difficult, you can also download the
+[zip file](https://drive.google.com/file/d/1WnRJD9FS3NUf7MllwgLRJJC-JgYFr8oi/view?usp=sharing)
+of the test images. However, due to the license limitations, we are not allowed to
+redistribute the images either. So the users need to download the original video and
+extract the images by themselves.
+
+## MPI-INF-3DHP
+
+
+
+```bibtex
+@inproceedings{mono-3dhp2017,
+ author = {Mehta, Dushyant and Rhodin, Helge and Casas, Dan and Fua, Pascal and Sotnychenko, Oleksandr and Xu, Weipeng and Theobalt, Christian},
+ title = {Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision},
+ booktitle = {3D Vision (3DV), 2017 Fifth International Conference on},
+ url = {http://gvv.mpi-inf.mpg.de/3dhp_dataset},
+ year = {2017},
+ organization={IEEE},
+ doi={10.1109/3dv.2017.00064},
+}
+```
+
+For [MPI-INF-3DHP](http://gvv.mpi-inf.mpg.de/3dhp-dataset/), please follow the
+[preprocess procedure](https://github.com/nkolot/SPIN/tree/master/datasets/preprocess)
+of SPIN to sample images, and make them like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ ├── mpi_inf_3dhp_test_set
+ │ ├── TS1
+ │ ├── TS2
+ │ ├── TS3
+ │ ├── TS4
+ │ ├── TS5
+ │ └── TS6
+ ├── S1
+ │ ├── Seq1
+ │ └── Seq2
+ ├── S2
+ │ ├── Seq1
+ │ └── Seq2
+ ├── S3
+ │ ├── Seq1
+ │ └── Seq2
+ ├── S4
+ │ ├── Seq1
+ │ └── Seq2
+ ├── S5
+ │ ├── Seq1
+ │ └── Seq2
+ ├── S6
+ │ ├── Seq1
+ │ └── Seq2
+ ├── S7
+ │ ├── Seq1
+ │ └── Seq2
+ └── S8
+ ├── Seq1
+ └── Seq2
+```
+
+## LSP
+
+
+
+```bibtex
+@inproceedings{johnson2010clustered,
+ title={Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation.},
+ author={Johnson, Sam and Everingham, Mark},
+ booktitle={bmvc},
+ volume={2},
+ number={4},
+ pages={5},
+ year={2010},
+ organization={Citeseer}
+}
+```
+
+For [LSP](https://sam.johnson.io/research/lsp.html), please download the high resolution version
+[LSP dataset original](http://sam.johnson.io/research/lsp_dataset_original.zip).
+Extract them under `$MMPOSE/data`, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── lsp_dataset_original
+ ├── images
+ ├── im0001.jpg
+ ├── im0002.jpg
+ └── ...
+```
+
+## LSPET
+
+
+
+```bibtex
+@inproceedings{johnson2011learning,
+ title={Learning effective human pose estimation from inaccurate annotation},
+ author={Johnson, Sam and Everingham, Mark},
+ booktitle={CVPR 2011},
+ pages={1465--1472},
+ year={2011},
+ organization={IEEE}
+}
+```
+
+For [LSPET](https://sam.johnson.io/research/lspet.html), please download its high resolution form
+[HR-LSPET](http://datasets.d2.mpi-inf.mpg.de/hr-lspet/hr-lspet.zip).
+Extract them under `$MMPOSE/data`, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── lspet_dataset
+ ├── images
+ │ ├── im00001.jpg
+ │ ├── im00002.jpg
+ │ ├── im00003.jpg
+ │ └── ...
+ └── joints.mat
+```
+
+## CMU MoShed Data
+
+
+
+```bibtex
+@inproceedings{kanazawa2018end,
+ title={End-to-end recovery of human shape and pose},
+ author={Kanazawa, Angjoo and Black, Michael J and Jacobs, David W and Malik, Jitendra},
+ booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={7122--7131},
+ year={2018}
+}
+```
+
+Real-world SMPL parameters are used for the adversarial training in human mesh estimation.
+The MoShed data provided in [HMR](https://github.com/akanazawa/hmr) is included in this
+[zip file](https://download.openmmlab.com/mmpose/datasets/mesh_annotation_files.zip).
+Please download and extract it under `$MMPOSE/data`, and make it look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── mesh_annotation_files
+ ├── CMU_mosh.npz
+ └── ...
+```
diff --git a/docs/en/dataset_zoo/3d_hand_keypoint.md b/docs/en/dataset_zoo/3d_hand_keypoint.md
index 823dc6ad64..c49594bf8e 100644
--- a/docs/en/dataset_zoo/3d_hand_keypoint.md
+++ b/docs/en/dataset_zoo/3d_hand_keypoint.md
@@ -1,59 +1,59 @@
-# 3D Hand Keypoint Datasets
-
-It is recommended to symlink the dataset root to `$MMPOSE/data`.
-If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMPose supported datasets:
-
-- [InterHand2.6M](#interhand26m) \[ [Homepage](https://mks0601.github.io/InterHand2.6M/) \]
-
-## InterHand2.6M
-
-
-
-
-InterHand2.6M (ECCV'2020)
-
-```bibtex
-@InProceedings{Moon_2020_ECCV_InterHand2.6M,
-author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu},
-title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image},
-booktitle = {European Conference on Computer Vision (ECCV)},
-year = {2020}
-}
-```
-
-
-
-
-
-
-
-For [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/), please download from [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/).
-Please download the annotation files from [annotations](https://download.openmmlab.com/mmpose/datasets/interhand2.6m_annotations.zip).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── interhand2.6m
- |── annotations
- | |── all
- | |── human_annot
- | |── machine_annot
- | |── skeleton.txt
- | |── subject.txt
- |
- `── images
- | |── train
- | | |-- Capture0 ~ Capture26
- | |── val
- | | |-- Capture0
- | |── test
- | | |-- Capture0 ~ Capture7
-```
+# 3D Hand Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [InterHand2.6M](#interhand26m) \[ [Homepage](https://mks0601.github.io/InterHand2.6M/) \]
+
+## InterHand2.6M
+
+
+
+
+InterHand2.6M (ECCV'2020)
+
+```bibtex
+@InProceedings{Moon_2020_ECCV_InterHand2.6M,
+author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu},
+title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image},
+booktitle = {European Conference on Computer Vision (ECCV)},
+year = {2020}
+}
+```
+
+
+
+
+
+
+
+For [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/), please download from [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/).
+Please download the annotation files from [annotations](https://download.openmmlab.com/mmpose/datasets/interhand2.6m_annotations.zip).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── interhand2.6m
+ |── annotations
+ | |── all
+ | |── human_annot
+ | |── machine_annot
+ | |── skeleton.txt
+ | |── subject.txt
+ |
+ `── images
+ | |── train
+ | | |-- Capture0 ~ Capture26
+ | |── val
+ | | |-- Capture0
+ | |── test
+ | | |-- Capture0 ~ Capture7
+```
diff --git a/docs/en/dataset_zoo/dataset_tools.md b/docs/en/dataset_zoo/dataset_tools.md
index 44a7c96b2b..dd05d8f2af 100644
--- a/docs/en/dataset_zoo/dataset_tools.md
+++ b/docs/en/dataset_zoo/dataset_tools.md
@@ -1,398 +1,398 @@
-# Dataset Tools
-
-## Animal Pose
-
-
-Animal-Pose (ICCV'2019)
-
-```bibtex
-@InProceedings{Cao_2019_ICCV,
- author = {Cao, Jinkun and Tang, Hongyang and Fang, Hao-Shu and Shen, Xiaoyong and Lu, Cewu and Tai, Yu-Wing},
- title = {Cross-Domain Adaptation for Animal Pose Estimation},
- booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
- month = {October},
- year = {2019}
-}
-```
-
-
-
-For [Animal-Pose](https://sites.google.com/view/animal-pose/) dataset, the images and annotations can be downloaded from [official website](https://sites.google.com/view/animal-pose/). The script `tools/dataset_converters/parse_animalpose_dataset.py` converts raw annotations into the format compatible with MMPose. The pre-processed [annotation files](https://download.openmmlab.com/mmpose/datasets/animalpose_annotations.tar) are available. If you would like to generate the annotations by yourself, please follow:
-
-1. Download the raw images and annotations and extract them under `$MMPOSE/data`. Make them look like this:
-
- ```text
- mmpose
- ├── mmpose
- ├── docs
- ├── tests
- ├── tools
- ├── configs
- `── data
- │── animalpose
- │
- │-- VOC2012
- │ │-- Annotations
- │ │-- ImageSets
- │ │-- JPEGImages
- │ │-- SegmentationClass
- │ │-- SegmentationObject
- │
- │-- animalpose_image_part2
- │ │-- cat
- │ │-- cow
- │ │-- dog
- │ │-- horse
- │ │-- sheep
- │
- │-- PASCAL2011_animal_annotation
- │ │-- cat
- │ │ |-- 2007_000528_1.xml
- │ │ |-- 2007_000549_1.xml
- │ │ │-- ...
- │ │-- cow
- │ │-- dog
- │ │-- horse
- │ │-- sheep
- │
- │-- annimalpose_anno2
- │ │-- cat
- │ │ |-- ca1.xml
- │ │ |-- ca2.xml
- │ │ │-- ...
- │ │-- cow
- │ │-- dog
- │ │-- horse
- │ │-- sheep
- ```
-
-2. Run command
-
- ```bash
- python tools/dataset_converters/parse_animalpose_dataset.py
- ```
-
- The generated annotation files are put in `$MMPOSE/data/animalpose/annotations`.
-
-The official dataset does not provide the official train/val/test set split.
-We choose the images from PascalVOC for train & val. In total, we have 3608 images and 5117 annotations for train+val, where
-2798 images with 4000 annotations are used for training, and 810 images with 1117 annotations are used for validation.
-Those images from other sources (1000 images with 1000 annotations) are used for testing.
-
-## COFW
-
-
-COFW (ICCV'2013)
-
-```bibtex
-@inproceedings{burgos2013robust,
- title={Robust face landmark estimation under occlusion},
- author={Burgos-Artizzu, Xavier P and Perona, Pietro and Doll{\'a}r, Piotr},
- booktitle={Proceedings of the IEEE international conference on computer vision},
- pages={1513--1520},
- year={2013}
-}
-```
-
-
-
-For COFW data, please download from [COFW Dataset (Color Images)](https://data.caltech.edu/records/20099).
-Move `COFW_train_color.mat` and `COFW_test_color.mat` to `$MMPOSE/data/cofw/` and make them look like:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── cofw
- |── COFW_train_color.mat
- |── COFW_test_color.mat
-```
-
-Run `pip install h5py` first to install the dependency, then run the following script under `$MMPOSE`:
-
-```bash
-python tools/dataset_converters/parse_cofw_dataset.py
-```
-
-And you will get
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── cofw
- |── COFW_train_color.mat
- |── COFW_test_color.mat
- |── annotations
- | |── cofw_train.json
- | |── cofw_test.json
- |── images
- |── 000001.jpg
- |── 000002.jpg
-```
-
-## DeepposeKit
-
-
-Desert Locust (Elife'2019)
-
-```bibtex
-@article{graving2019deepposekit,
- title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning},
- author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D},
- journal={Elife},
- volume={8},
- pages={e47994},
- year={2019},
- publisher={eLife Sciences Publications Limited}
-}
-```
-
-
-
-For [Vinegar Fly](https://github.com/jgraving/DeepPoseKit-Data), [Desert Locust](https://github.com/jgraving/DeepPoseKit-Data), and [Grévy’s Zebra](https://github.com/jgraving/DeepPoseKit-Data) dataset, the annotations files can be downloaded from [DeepPoseKit-Data](https://github.com/jgraving/DeepPoseKit-Data). The script `tools/dataset_converters/parse_deepposekit_dataset.py` converts raw annotations into the format compatible with MMPose. The pre-processed annotation files are available at [vinegar_fly_annotations](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_annotations.tar), [locust_annotations](https://download.openmmlab.com/mmpose/datasets/locust_annotations.tar), and [zebra_annotations](https://download.openmmlab.com/mmpose/datasets/zebra_annotations.tar). If you would like to generate the annotations by yourself, please follows:
-
-1. Download the raw images and annotations and extract them under `$MMPOSE/data`. Make them look like this:
-
- ```text
- mmpose
- ├── mmpose
- ├── docs
- ├── tests
- ├── tools
- ├── configs
- `── data
- |
- |── DeepPoseKit-Data
- | `── datasets
- | |── fly
- | | |── annotation_data_release.h5
- | | |── skeleton.csv
- | | |── ...
- | |
- | |── locust
- | | |── annotation_data_release.h5
- | | |── skeleton.csv
- | | |── ...
- | |
- | `── zebra
- | |── annotation_data_release.h5
- | |── skeleton.csv
- | |── ...
- |
- │── fly
- `-- images
- │-- 0.jpg
- │-- 1.jpg
- │-- ...
- ```
-
- Note that the images can be downloaded from [vinegar_fly_images](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_images.tar), [locust_images](https://download.openmmlab.com/mmpose/datasets/locust_images.tar), and [zebra_images](https://download.openmmlab.com/mmpose/datasets/zebra_images.tar).
-
-2. Run command
-
- ```bash
- python tools/dataset_converters/parse_deepposekit_dataset.py
- ```
-
- The generated annotation files are put in `$MMPOSE/data/fly/annotations`, `$MMPOSE/data/locust/annotations`, and `$MMPOSE/data/zebra/annotations`.
-
-Since the official dataset does not provide the test set, we randomly select 90% images for training, and the rest (10%) for evaluation.
-
-## Macaque
-
-
-MacaquePose (bioRxiv'2020)
-
-```bibtex
-@article{labuguen2020macaquepose,
- title={MacaquePose: A novel ‘in the wild’macaque monkey pose dataset for markerless motion capture},
- author={Labuguen, Rollyn and Matsumoto, Jumpei and Negrete, Salvador and Nishimaru, Hiroshi and Nishijo, Hisao and Takada, Masahiko and Go, Yasuhiro and Inoue, Ken-ichi and Shibata, Tomohiro},
- journal={bioRxiv},
- year={2020},
- publisher={Cold Spring Harbor Laboratory}
-}
-```
-
-
-
-For [MacaquePose](http://www2.ehub.kyoto-u.ac.jp/datasets/macaquepose/index.html) dataset, images and annotations can be downloaded from [download](http://www2.ehub.kyoto-u.ac.jp/datasets/macaquepose/index.html). The script `tools/dataset_converters/parse_macaquepose_dataset.py` converts raw annotations into the format compatible with MMPose. The pre-processed [macaque_annotations](https://download.openmmlab.com/mmpose/datasets/macaque_annotations.tar) are available. If you would like to generate the annotations by yourself, please follows:
-
-1. Download the raw images and annotations and extract them under `$MMPOSE/data`. Make them look like this:
-
- ```text
- mmpose
- ├── mmpose
- ├── docs
- ├── tests
- ├── tools
- ├── configs
- `── data
- │── macaque
- │-- annotations.csv
- │-- images
- │ │-- 01418849d54b3005.jpg
- │ │-- 0142d1d1a6904a70.jpg
- │ │-- 01ef2c4c260321b7.jpg
- │ │-- 020a1c75c8c85238.jpg
- │ │-- 020b1506eef2557d.jpg
- │ │-- ...
- ```
-
-2. Run command
-
- ```bash
- python tools/dataset_converters/parse_macaquepose_dataset.py
- ```
-
- The generated annotation files are put in `$MMPOSE/data/macaque/annotations`.
-
-Since the official dataset does not provide the test set, we randomly select 12500 images for training, and the rest for evaluation.
-
-## Human3.6M
-
-
-Human3.6M (TPAMI'2014)
-
-```bibtex
-@article{h36m_pami,
- author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian},
- title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments},
- journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
- publisher = {IEEE Computer Society},
- volume = {36},
- number = {7},
- pages = {1325-1339},
- month = {jul},
- year = {2014}
-}
-```
-
-
-
-For [Human3.6M](http://vision.imar.ro/human3.6m/description.php), please download from the official website and place the files under `$MMPOSE/data/h36m`.
-Then run the [preprocessing script](/tools/dataset_converters/preprocess_h36m.py):
-
-```bash
-python tools/dataset_converters/preprocess_h36m.py --metadata {path to metadata.xml} --original data/h36m
-```
-
-This will extract camera parameters and pose annotations at full framerate (50 FPS) and downsampled framerate (10 FPS). The processed data should have the following structure:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- ├── h36m
- ├── annotation_body3d
- | ├── cameras.pkl
- | ├── fps50
- | | ├── h36m_test.npz
- | | ├── h36m_train.npz
- | | ├── joint2d_rel_stats.pkl
- | | ├── joint2d_stats.pkl
- | | ├── joint3d_rel_stats.pkl
- | | `── joint3d_stats.pkl
- | `── fps10
- | ├── h36m_test.npz
- | ├── h36m_train.npz
- | ├── joint2d_rel_stats.pkl
- | ├── joint2d_stats.pkl
- | ├── joint3d_rel_stats.pkl
- | `── joint3d_stats.pkl
- `── images
- ├── S1
- | ├── S1_Directions_1.54138969
- | | ├── S1_Directions_1.54138969_00001.jpg
- | | ├── S1_Directions_1.54138969_00002.jpg
- | | ├── ...
- | ├── ...
- ├── S5
- ├── S6
- ├── S7
- ├── S8
- ├── S9
- `── S11
-```
-
-After that, the annotations need to be transformed into COCO format which is compatible with MMPose. Please run:
-
-```bash
-python tools/dataset_converters/h36m_to_coco.py
-```
-
-## MPII
-
-
-MPII (CVPR'2014)
-
-```bibtex
-@inproceedings{andriluka14cvpr,
- author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt},
- title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = {2014},
- month = {June}
-}
-```
-
-
-
-During training and inference for [MPII](http://human-pose.mpi-inf.mpg.de/), the prediction result will be saved as '.mat' format by default. We also provide a tool to convert this `.mat` to more readable `.json` format.
-
-```shell
-python tools/dataset_converters/mat2json ${PRED_MAT_FILE} ${GT_JSON_FILE} ${OUTPUT_PRED_JSON_FILE}
-```
-
-For example,
-
-```shell
-python tools/dataset/mat2json work_dirs/res50_mpii_256x256/pred.mat data/mpii/annotations/mpii_val.json pred.json
-```
-
-## Label Studio
-
-
-Label Studio
-
-```bibtex
-@misc{Label Studio,
- title={{Label Studio}: Data labeling software},
- url={https://github.com/heartexlabs/label-studio},
- note={Open source software available from https://github.com/heartexlabs/label-studio},
- author={
- Maxim Tkachenko and
- Mikhail Malyuk and
- Andrey Holmanyuk and
- Nikolai Liubimov},
- year={2020-2022},
-}
-```
-
-
-
-For users of [Label Studio](https://github.com/heartexlabs/label-studio/), please follow the instructions in the [Label Studio to COCO document](./label_studio.md) to annotate and export the results as a Label Studio `.json` file. And save the `Code` from the `Labeling Interface` as an `.xml` file.
-
-We provide a script to convert Label Studio `.json` annotation file to COCO `.json` format file. It can be used by running the following command:
-
-```shell
-python tools/dataset_converters/labelstudio2coco.py ${LS_JSON_FILE} ${LS_XML_FILE} ${OUTPUT_COCO_JSON_FILE}
-```
-
-For example,
-
-```shell
-python tools/dataset_converters/labelstudio2coco.py config.xml project-1-at-2023-05-13-09-22-91b53efa.json output/result.json
-```
+# Dataset Tools
+
+## Animal Pose
+
+
+Animal-Pose (ICCV'2019)
+
+```bibtex
+@InProceedings{Cao_2019_ICCV,
+ author = {Cao, Jinkun and Tang, Hongyang and Fang, Hao-Shu and Shen, Xiaoyong and Lu, Cewu and Tai, Yu-Wing},
+ title = {Cross-Domain Adaptation for Animal Pose Estimation},
+ booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
+ month = {October},
+ year = {2019}
+}
+```
+
+
+
+For [Animal-Pose](https://sites.google.com/view/animal-pose/) dataset, the images and annotations can be downloaded from [official website](https://sites.google.com/view/animal-pose/). The script `tools/dataset_converters/parse_animalpose_dataset.py` converts raw annotations into the format compatible with MMPose. The pre-processed [annotation files](https://download.openmmlab.com/mmpose/datasets/animalpose_annotations.tar) are available. If you would like to generate the annotations by yourself, please follow:
+
+1. Download the raw images and annotations and extract them under `$MMPOSE/data`. Make them look like this:
+
+ ```text
+ mmpose
+ ├── mmpose
+ ├── docs
+ ├── tests
+ ├── tools
+ ├── configs
+ `── data
+ │── animalpose
+ │
+ │-- VOC2012
+ │ │-- Annotations
+ │ │-- ImageSets
+ │ │-- JPEGImages
+ │ │-- SegmentationClass
+ │ │-- SegmentationObject
+ │
+ │-- animalpose_image_part2
+ │ │-- cat
+ │ │-- cow
+ │ │-- dog
+ │ │-- horse
+ │ │-- sheep
+ │
+ │-- PASCAL2011_animal_annotation
+ │ │-- cat
+ │ │ |-- 2007_000528_1.xml
+ │ │ |-- 2007_000549_1.xml
+ │ │ │-- ...
+ │ │-- cow
+ │ │-- dog
+ │ │-- horse
+ │ │-- sheep
+ │
+ │-- annimalpose_anno2
+ │ │-- cat
+ │ │ |-- ca1.xml
+ │ │ |-- ca2.xml
+ │ │ │-- ...
+ │ │-- cow
+ │ │-- dog
+ │ │-- horse
+ │ │-- sheep
+ ```
+
+2. Run command
+
+ ```bash
+ python tools/dataset_converters/parse_animalpose_dataset.py
+ ```
+
+ The generated annotation files are put in `$MMPOSE/data/animalpose/annotations`.
+
+The official dataset does not provide the official train/val/test set split.
+We choose the images from PascalVOC for train & val. In total, we have 3608 images and 5117 annotations for train+val, where
+2798 images with 4000 annotations are used for training, and 810 images with 1117 annotations are used for validation.
+Those images from other sources (1000 images with 1000 annotations) are used for testing.
+
+## COFW
+
+
+COFW (ICCV'2013)
+
+```bibtex
+@inproceedings{burgos2013robust,
+ title={Robust face landmark estimation under occlusion},
+ author={Burgos-Artizzu, Xavier P and Perona, Pietro and Doll{\'a}r, Piotr},
+ booktitle={Proceedings of the IEEE international conference on computer vision},
+ pages={1513--1520},
+ year={2013}
+}
+```
+
+
+
+For COFW data, please download from [COFW Dataset (Color Images)](https://data.caltech.edu/records/20099).
+Move `COFW_train_color.mat` and `COFW_test_color.mat` to `$MMPOSE/data/cofw/` and make them look like:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── cofw
+ |── COFW_train_color.mat
+ |── COFW_test_color.mat
+```
+
+Run `pip install h5py` first to install the dependency, then run the following script under `$MMPOSE`:
+
+```bash
+python tools/dataset_converters/parse_cofw_dataset.py
+```
+
+And you will get
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── cofw
+ |── COFW_train_color.mat
+ |── COFW_test_color.mat
+ |── annotations
+ | |── cofw_train.json
+ | |── cofw_test.json
+ |── images
+ |── 000001.jpg
+ |── 000002.jpg
+```
+
+## DeepposeKit
+
+
+Desert Locust (Elife'2019)
+
+```bibtex
+@article{graving2019deepposekit,
+ title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning},
+ author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D},
+ journal={Elife},
+ volume={8},
+ pages={e47994},
+ year={2019},
+ publisher={eLife Sciences Publications Limited}
+}
+```
+
+
+
+For [Vinegar Fly](https://github.com/jgraving/DeepPoseKit-Data), [Desert Locust](https://github.com/jgraving/DeepPoseKit-Data), and [Grévy’s Zebra](https://github.com/jgraving/DeepPoseKit-Data) dataset, the annotations files can be downloaded from [DeepPoseKit-Data](https://github.com/jgraving/DeepPoseKit-Data). The script `tools/dataset_converters/parse_deepposekit_dataset.py` converts raw annotations into the format compatible with MMPose. The pre-processed annotation files are available at [vinegar_fly_annotations](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_annotations.tar), [locust_annotations](https://download.openmmlab.com/mmpose/datasets/locust_annotations.tar), and [zebra_annotations](https://download.openmmlab.com/mmpose/datasets/zebra_annotations.tar). If you would like to generate the annotations by yourself, please follows:
+
+1. Download the raw images and annotations and extract them under `$MMPOSE/data`. Make them look like this:
+
+ ```text
+ mmpose
+ ├── mmpose
+ ├── docs
+ ├── tests
+ ├── tools
+ ├── configs
+ `── data
+ |
+ |── DeepPoseKit-Data
+ | `── datasets
+ | |── fly
+ | | |── annotation_data_release.h5
+ | | |── skeleton.csv
+ | | |── ...
+ | |
+ | |── locust
+ | | |── annotation_data_release.h5
+ | | |── skeleton.csv
+ | | |── ...
+ | |
+ | `── zebra
+ | |── annotation_data_release.h5
+ | |── skeleton.csv
+ | |── ...
+ |
+ │── fly
+ `-- images
+ │-- 0.jpg
+ │-- 1.jpg
+ │-- ...
+ ```
+
+ Note that the images can be downloaded from [vinegar_fly_images](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_images.tar), [locust_images](https://download.openmmlab.com/mmpose/datasets/locust_images.tar), and [zebra_images](https://download.openmmlab.com/mmpose/datasets/zebra_images.tar).
+
+2. Run command
+
+ ```bash
+ python tools/dataset_converters/parse_deepposekit_dataset.py
+ ```
+
+ The generated annotation files are put in `$MMPOSE/data/fly/annotations`, `$MMPOSE/data/locust/annotations`, and `$MMPOSE/data/zebra/annotations`.
+
+Since the official dataset does not provide the test set, we randomly select 90% images for training, and the rest (10%) for evaluation.
+
+## Macaque
+
+
+MacaquePose (bioRxiv'2020)
+
+```bibtex
+@article{labuguen2020macaquepose,
+ title={MacaquePose: A novel ‘in the wild’macaque monkey pose dataset for markerless motion capture},
+ author={Labuguen, Rollyn and Matsumoto, Jumpei and Negrete, Salvador and Nishimaru, Hiroshi and Nishijo, Hisao and Takada, Masahiko and Go, Yasuhiro and Inoue, Ken-ichi and Shibata, Tomohiro},
+ journal={bioRxiv},
+ year={2020},
+ publisher={Cold Spring Harbor Laboratory}
+}
+```
+
+
+
+For [MacaquePose](http://www2.ehub.kyoto-u.ac.jp/datasets/macaquepose/index.html) dataset, images and annotations can be downloaded from [download](http://www2.ehub.kyoto-u.ac.jp/datasets/macaquepose/index.html). The script `tools/dataset_converters/parse_macaquepose_dataset.py` converts raw annotations into the format compatible with MMPose. The pre-processed [macaque_annotations](https://download.openmmlab.com/mmpose/datasets/macaque_annotations.tar) are available. If you would like to generate the annotations by yourself, please follows:
+
+1. Download the raw images and annotations and extract them under `$MMPOSE/data`. Make them look like this:
+
+ ```text
+ mmpose
+ ├── mmpose
+ ├── docs
+ ├── tests
+ ├── tools
+ ├── configs
+ `── data
+ │── macaque
+ │-- annotations.csv
+ │-- images
+ │ │-- 01418849d54b3005.jpg
+ │ │-- 0142d1d1a6904a70.jpg
+ │ │-- 01ef2c4c260321b7.jpg
+ │ │-- 020a1c75c8c85238.jpg
+ │ │-- 020b1506eef2557d.jpg
+ │ │-- ...
+ ```
+
+2. Run command
+
+ ```bash
+ python tools/dataset_converters/parse_macaquepose_dataset.py
+ ```
+
+ The generated annotation files are put in `$MMPOSE/data/macaque/annotations`.
+
+Since the official dataset does not provide the test set, we randomly select 12500 images for training, and the rest for evaluation.
+
+## Human3.6M
+
+
+Human3.6M (TPAMI'2014)
+
+```bibtex
+@article{h36m_pami,
+ author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian},
+ title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments},
+ journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
+ publisher = {IEEE Computer Society},
+ volume = {36},
+ number = {7},
+ pages = {1325-1339},
+ month = {jul},
+ year = {2014}
+}
+```
+
+
+
+For [Human3.6M](http://vision.imar.ro/human3.6m/description.php), please download from the official website and place the files under `$MMPOSE/data/h36m`.
+Then run the [preprocessing script](/tools/dataset_converters/preprocess_h36m.py):
+
+```bash
+python tools/dataset_converters/preprocess_h36m.py --metadata {path to metadata.xml} --original data/h36m
+```
+
+This will extract camera parameters and pose annotations at full framerate (50 FPS) and downsampled framerate (10 FPS). The processed data should have the following structure:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ ├── h36m
+ ├── annotation_body3d
+ | ├── cameras.pkl
+ | ├── fps50
+ | | ├── h36m_test.npz
+ | | ├── h36m_train.npz
+ | | ├── joint2d_rel_stats.pkl
+ | | ├── joint2d_stats.pkl
+ | | ├── joint3d_rel_stats.pkl
+ | | `── joint3d_stats.pkl
+ | `── fps10
+ | ├── h36m_test.npz
+ | ├── h36m_train.npz
+ | ├── joint2d_rel_stats.pkl
+ | ├── joint2d_stats.pkl
+ | ├── joint3d_rel_stats.pkl
+ | `── joint3d_stats.pkl
+ `── images
+ ├── S1
+ | ├── S1_Directions_1.54138969
+ | | ├── S1_Directions_1.54138969_00001.jpg
+ | | ├── S1_Directions_1.54138969_00002.jpg
+ | | ├── ...
+ | ├── ...
+ ├── S5
+ ├── S6
+ ├── S7
+ ├── S8
+ ├── S9
+ `── S11
+```
+
+After that, the annotations need to be transformed into COCO format which is compatible with MMPose. Please run:
+
+```bash
+python tools/dataset_converters/h36m_to_coco.py
+```
+
+## MPII
+
+
+MPII (CVPR'2014)
+
+```bibtex
+@inproceedings{andriluka14cvpr,
+ author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt},
+ title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis},
+ booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year = {2014},
+ month = {June}
+}
+```
+
+
+
+During training and inference for [MPII](http://human-pose.mpi-inf.mpg.de/), the prediction result will be saved as '.mat' format by default. We also provide a tool to convert this `.mat` to more readable `.json` format.
+
+```shell
+python tools/dataset_converters/mat2json ${PRED_MAT_FILE} ${GT_JSON_FILE} ${OUTPUT_PRED_JSON_FILE}
+```
+
+For example,
+
+```shell
+python tools/dataset/mat2json work_dirs/res50_mpii_256x256/pred.mat data/mpii/annotations/mpii_val.json pred.json
+```
+
+## Label Studio
+
+
+Label Studio
+
+```bibtex
+@misc{Label Studio,
+ title={{Label Studio}: Data labeling software},
+ url={https://github.com/heartexlabs/label-studio},
+ note={Open source software available from https://github.com/heartexlabs/label-studio},
+ author={
+ Maxim Tkachenko and
+ Mikhail Malyuk and
+ Andrey Holmanyuk and
+ Nikolai Liubimov},
+ year={2020-2022},
+}
+```
+
+
+
+For users of [Label Studio](https://github.com/heartexlabs/label-studio/), please follow the instructions in the [Label Studio to COCO document](./label_studio.md) to annotate and export the results as a Label Studio `.json` file. And save the `Code` from the `Labeling Interface` as an `.xml` file.
+
+We provide a script to convert Label Studio `.json` annotation file to COCO `.json` format file. It can be used by running the following command:
+
+```shell
+python tools/dataset_converters/labelstudio2coco.py ${LS_JSON_FILE} ${LS_XML_FILE} ${OUTPUT_COCO_JSON_FILE}
+```
+
+For example,
+
+```shell
+python tools/dataset_converters/labelstudio2coco.py config.xml project-1-at-2023-05-13-09-22-91b53efa.json output/result.json
+```
diff --git a/docs/en/dataset_zoo/label_studio.md b/docs/en/dataset_zoo/label_studio.md
index 3b499e05c6..93978a4172 100644
--- a/docs/en/dataset_zoo/label_studio.md
+++ b/docs/en/dataset_zoo/label_studio.md
@@ -1,76 +1,76 @@
-# Label Studio Annotations to COCO Script
-
-[Label Studio](https://labelstud.io/) is a popular deep learning annotation tool that can be used for annotating various tasks. However, for keypoint annotation, Label Studio can not directly export to the COCO format required by MMPose. This article will explain how to use Label Studio to annotate keypoint data and convert it into the required COCO format using the [labelstudio2coco.py](../../../tools/dataset_converters/labelstudio2coco.py) tool.
-
-## Label Studio Annotation Requirements
-
-According to the COCO format requirements, each annotated instance needs to include information about keypoints, segmentation, and bounding box (bbox). However, Label Studio scatters this information across different instances during annotation. Therefore, certain rules need to be followed during annotation to ensure proper usage with the subsequent scripts.
-
-1. Label Interface Setup
-
-For a newly created Label Studio project, the label interface needs to be set up. There should be three types of annotations: `KeyPointLabels`, `PolygonLabels`, and `RectangleLabels`, which correspond to `keypoints`, `segmentation`, and `bbox` in the COCO format, respectively. The following is an example of a label interface. You can find the `Labeling Interface` in the project's `Settings`, click on `Code`, and paste the following example.
-
-```xml
-
-
-
-
-
-
-
-
-
-
-
-
-```
-
-2. Annotation Order
-
-Since it is necessary to combine annotations of different types into one instance, a specific order of annotation is required to determine whether the annotations belong to the same instance. Annotations should be made in the order of `KeyPointLabels` -> `PolygonLabels`/`RectangleLabels`. The order and number of `KeyPointLabels` should match the order and number of keypoints specified in the `dataset_info` in MMPose configuration file. The annotation order of `PolygonLabels` and `RectangleLabels` can be interchangeable, and only one of them needs to be annotated. The annotation should be within one instance starts with keypoints and ends with non-keypoints. The following image shows an annotation example:
-
-*Note: The bbox and area will be calculated based on the later PolygonLabels/RectangleLabels. If you annotate PolygonLabels first, the bbox will be based on the range of the later RectangleLabels, and the area will be equal to the area of the rectangle. Conversely, they will be based on the minimum bounding rectangle of the polygon and the area of the polygon.*
-
-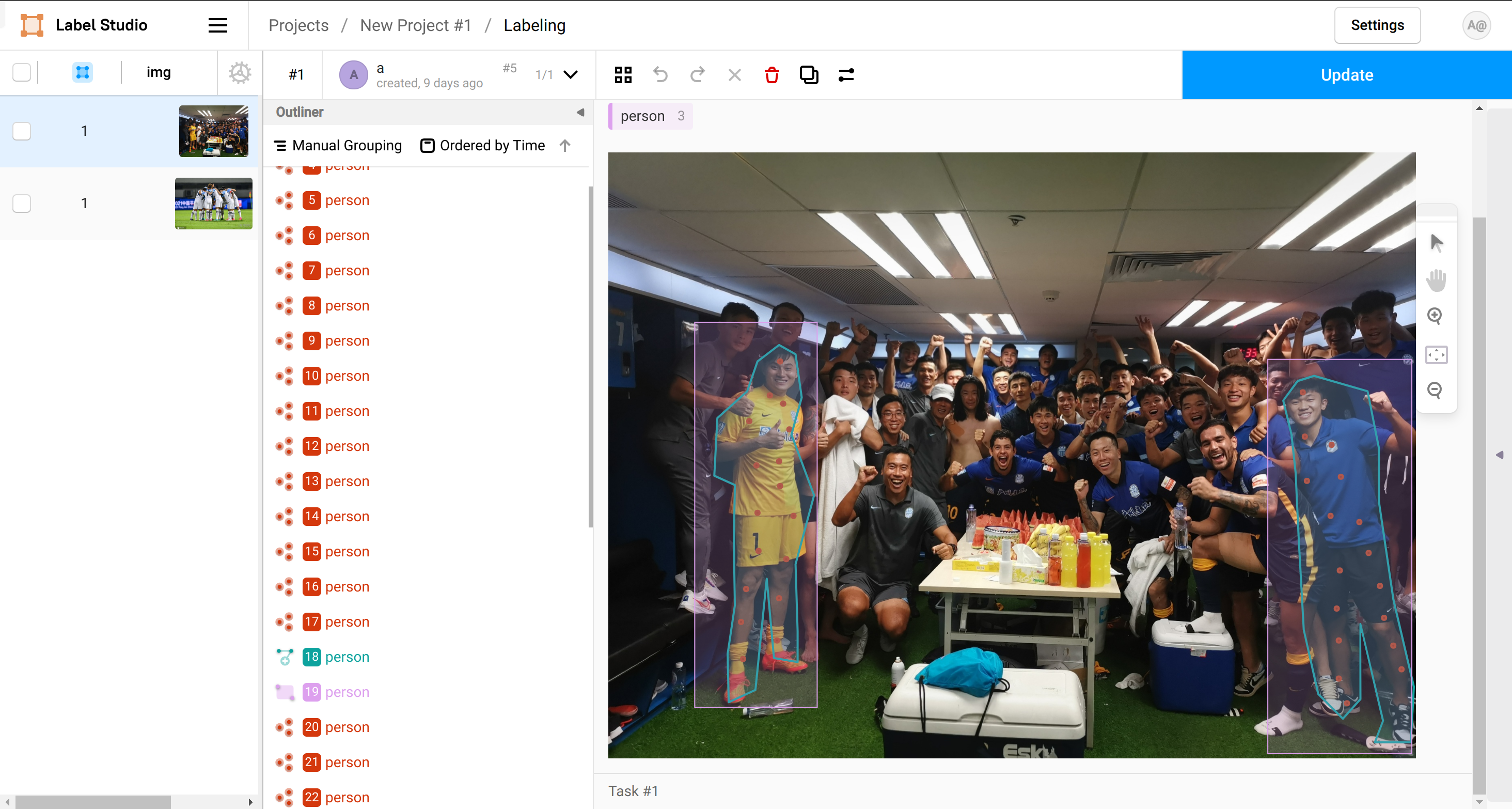
-
-3. Exporting Annotations
-
-Once the annotations are completed as described above, they need to be exported. Select the `Export` button on the project interface, choose the `JSON` format, and click `Export` to download the JSON file containing the labels.
-
-*Note: The exported file only contains the labels and does not include the original images. Therefore, the corresponding annotated images need to be provided separately. It is not recommended to use directly uploaded files because Label Studio truncates long filenames. Instead, use the export COCO format tool available in the `Export` functionality, which includes a folder with the image files within the downloaded compressed package.*
-
-
-
-## Usage of the Conversion Tool Script
-
-The conversion tool script is located at `tools/dataset_converters/labelstudio2coco.py`and can be used as follows:
-
-```bash
-python tools/dataset_converters/labelstudio2coco.py config.xml project-1-at-2023-05-13-09-22-91b53efa.json output/result.json
-```
-
-Where `config.xml` contains the code from the Labeling Interface mentioned earlier, `project-1-at-2023-05-13-09-22-91b53efa.json` is the JSON file exported from Label Studio, and `output/result.json` is the path to the resulting JSON file in COCO format. If the path does not exist, the script will create it automatically.
-
-Afterward, place the image folder in the output directory to complete the conversion of the COCO dataset. The directory structure can be as follows:
-
-```bash
-.
-├── images
-│ ├── 38b480f2.jpg
-│ └── aeb26f04.jpg
-└── result.json
-
-```
-
-If you want to use this dataset in MMPose, you can make modifications like the following example:
-
-```python
-dataset=dict(
- type=dataset_type,
- data_root=data_root,
- data_mode=data_mode,
- ann_file='result.json',
- data_prefix=dict(img='images/'),
- pipeline=train_pipeline,
-)
-```
+# Label Studio Annotations to COCO Script
+
+[Label Studio](https://labelstud.io/) is a popular deep learning annotation tool that can be used for annotating various tasks. However, for keypoint annotation, Label Studio can not directly export to the COCO format required by MMPose. This article will explain how to use Label Studio to annotate keypoint data and convert it into the required COCO format using the [labelstudio2coco.py](../../../tools/dataset_converters/labelstudio2coco.py) tool.
+
+## Label Studio Annotation Requirements
+
+According to the COCO format requirements, each annotated instance needs to include information about keypoints, segmentation, and bounding box (bbox). However, Label Studio scatters this information across different instances during annotation. Therefore, certain rules need to be followed during annotation to ensure proper usage with the subsequent scripts.
+
+1. Label Interface Setup
+
+For a newly created Label Studio project, the label interface needs to be set up. There should be three types of annotations: `KeyPointLabels`, `PolygonLabels`, and `RectangleLabels`, which correspond to `keypoints`, `segmentation`, and `bbox` in the COCO format, respectively. The following is an example of a label interface. You can find the `Labeling Interface` in the project's `Settings`, click on `Code`, and paste the following example.
+
+```xml
+
+
+
+
+
+
+
+
+
+
+
+
+```
+
+2. Annotation Order
+
+Since it is necessary to combine annotations of different types into one instance, a specific order of annotation is required to determine whether the annotations belong to the same instance. Annotations should be made in the order of `KeyPointLabels` -> `PolygonLabels`/`RectangleLabels`. The order and number of `KeyPointLabels` should match the order and number of keypoints specified in the `dataset_info` in MMPose configuration file. The annotation order of `PolygonLabels` and `RectangleLabels` can be interchangeable, and only one of them needs to be annotated. The annotation should be within one instance starts with keypoints and ends with non-keypoints. The following image shows an annotation example:
+
+*Note: The bbox and area will be calculated based on the later PolygonLabels/RectangleLabels. If you annotate PolygonLabels first, the bbox will be based on the range of the later RectangleLabels, and the area will be equal to the area of the rectangle. Conversely, they will be based on the minimum bounding rectangle of the polygon and the area of the polygon.*
+
+
+
+3. Exporting Annotations
+
+Once the annotations are completed as described above, they need to be exported. Select the `Export` button on the project interface, choose the `JSON` format, and click `Export` to download the JSON file containing the labels.
+
+*Note: The exported file only contains the labels and does not include the original images. Therefore, the corresponding annotated images need to be provided separately. It is not recommended to use directly uploaded files because Label Studio truncates long filenames. Instead, use the export COCO format tool available in the `Export` functionality, which includes a folder with the image files within the downloaded compressed package.*
+
+
+
+## Usage of the Conversion Tool Script
+
+The conversion tool script is located at `tools/dataset_converters/labelstudio2coco.py`and can be used as follows:
+
+```bash
+python tools/dataset_converters/labelstudio2coco.py config.xml project-1-at-2023-05-13-09-22-91b53efa.json output/result.json
+```
+
+Where `config.xml` contains the code from the Labeling Interface mentioned earlier, `project-1-at-2023-05-13-09-22-91b53efa.json` is the JSON file exported from Label Studio, and `output/result.json` is the path to the resulting JSON file in COCO format. If the path does not exist, the script will create it automatically.
+
+Afterward, place the image folder in the output directory to complete the conversion of the COCO dataset. The directory structure can be as follows:
+
+```bash
+.
+├── images
+│ ├── 38b480f2.jpg
+│ └── aeb26f04.jpg
+└── result.json
+
+```
+
+If you want to use this dataset in MMPose, you can make modifications like the following example:
+
+```python
+dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='result.json',
+ data_prefix=dict(img='images/'),
+ pipeline=train_pipeline,
+)
+```
diff --git a/docs/en/faq.md b/docs/en/faq.md
index 3e81a312ca..80557aac7f 100644
--- a/docs/en/faq.md
+++ b/docs/en/faq.md
@@ -1,159 +1,159 @@
-# FAQ
-
-We list some common issues faced by many users and their corresponding solutions here.
-Feel free to enrich the list if you find any frequent issues and have ways to help others to solve them.
-If the contents here do not cover your issue, please create an issue using the [provided templates](/.github/ISSUE_TEMPLATE/error-report.md) and make sure you fill in all required information in the template.
-
-## Installation
-
-Compatibility issue between MMCV and MMPose; "AssertionError: MMCV==xxx is used but incompatible. Please install mmcv>=xxx, \<=xxx."
-
-Here are the version correspondences between `mmdet`, `mmcv` and `mmpose`:
-
-- mmdet 2.x \<=> mmpose 0.x \<=> mmcv 1.x
-- mmdet 3.x \<=> mmpose 1.x \<=> mmcv 2.x
-
-Detailed compatible MMPose and MMCV versions are shown as below. Please choose the correct version of MMCV to avoid installation issues.
-
-### MMPose 1.x
-
-| MMPose version | MMCV/MMEngine version |
-| :------------: | :-----------------------------: |
-| 1.1.0 | mmcv>=2.0.1, mmengine>=0.8.0 |
-| 1.0.0 | mmcv>=2.0.0, mmengine>=0.7.0 |
-| 1.0.0rc1 | mmcv>=2.0.0rc4, mmengine>=0.6.0 |
-| 1.0.0rc0 | mmcv>=2.0.0rc0, mmengine>=0.0.1 |
-| 1.0.0b0 | mmcv>=2.0.0rc0, mmengine>=0.0.1 |
-
-### MMPose 0.x
-
-| MMPose version | MMCV version |
-| :------------: | :-----------------------: |
-| 0.x | mmcv-full>=1.3.8, \<1.8.0 |
-| 0.29.0 | mmcv-full>=1.3.8, \<1.7.0 |
-| 0.28.1 | mmcv-full>=1.3.8, \<1.7.0 |
-| 0.28.0 | mmcv-full>=1.3.8, \<1.6.0 |
-| 0.27.0 | mmcv-full>=1.3.8, \<1.6.0 |
-| 0.26.0 | mmcv-full>=1.3.8, \<1.6.0 |
-| 0.25.1 | mmcv-full>=1.3.8, \<1.6.0 |
-| 0.25.0 | mmcv-full>=1.3.8, \<1.5.0 |
-| 0.24.0 | mmcv-full>=1.3.8, \<1.5.0 |
-| 0.23.0 | mmcv-full>=1.3.8, \<1.5.0 |
-| 0.22.0 | mmcv-full>=1.3.8, \<1.5.0 |
-| 0.21.0 | mmcv-full>=1.3.8, \<1.5.0 |
-| 0.20.0 | mmcv-full>=1.3.8, \<1.4.0 |
-| 0.19.0 | mmcv-full>=1.3.8, \<1.4.0 |
-| 0.18.0 | mmcv-full>=1.3.8, \<1.4.0 |
-| 0.17.0 | mmcv-full>=1.3.8, \<1.4.0 |
-| 0.16.0 | mmcv-full>=1.3.8, \<1.4.0 |
-| 0.14.0 | mmcv-full>=1.1.3, \<1.4.0 |
-| 0.13.0 | mmcv-full>=1.1.3, \<1.4.0 |
-| 0.12.0 | mmcv-full>=1.1.3, \<1.3 |
-| 0.11.0 | mmcv-full>=1.1.3, \<1.3 |
-| 0.10.0 | mmcv-full>=1.1.3, \<1.3 |
-| 0.9.0 | mmcv-full>=1.1.3, \<1.3 |
-| 0.8.0 | mmcv-full>=1.1.1, \<1.2 |
-| 0.7.0 | mmcv-full>=1.1.1, \<1.2 |
-
-- **Unable to install xtcocotools**
-
- 1. Try to install it using pypi manually `pip install xtcocotools`.
- 2. If step1 does not work. Try to install it from [source](https://github.com/jin-s13/xtcocoapi).
-
- ```
- git clone https://github.com/jin-s13/xtcocoapi
- cd xtcocoapi
- python setup.py install
- ```
-
-- **No matching distribution found for xtcocotools>=1.6**
-
- 1. Install cython by `pip install cython`.
- 2. Install xtcocotools from [source](https://github.com/jin-s13/xtcocoapi).
-
- ```
- git clone https://github.com/jin-s13/xtcocoapi
- cd xtcocoapi
- python setup.py install
- ```
-
-- **"No module named 'mmcv.ops'"; "No module named 'mmcv.\_ext'"**
-
- 1. Uninstall existing mmcv in the environment using `pip uninstall mmcv`.
- 2. Install mmcv following [mmcv installation instruction](https://mmcv.readthedocs.io/en/2.x/get_started/installation.html).
-
-## Data
-
-- **What if my custom dataset does not have bounding box label?**
-
- We can estimate the bounding box of a person as the minimal box that tightly bounds all the keypoints.
-
-- **What is `COCO_val2017_detections_AP_H_56_person.json`? Can I train pose models without it?**
-
- "COCO_val2017_detections_AP_H_56_person.json" contains the "detected" human bounding boxes for COCO validation set, which are generated by FasterRCNN.
- One can choose to use gt bounding boxes to evaluate models, by setting `bbox_file=None` in `val_dataloader.dataset` in config. Or one can use detected boxes to evaluate
- the generalizability of models, by setting `bbox_file='COCO_val2017_detections_AP_H_56_person.json'`.
-
-## Training
-
-- **RuntimeError: Address already in use**
-
- Set the environment variables `MASTER_PORT=XXX`. For example:
-
- ```shell
- MASTER_PORT=29517 GPUS=16 GPUS_PER_NODE=8 CPUS_PER_TASK=2 ./tools/slurm_train.sh train res50 configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_8xb64-210e_coco-256x192.py work_dirs/res50_coco_256x192
- ```
-
-- **"Unexpected keys in source state dict" when loading pre-trained weights**
-
- It's normal that some layers in the pretrained model are not used in the pose model. ImageNet-pretrained classification network and the pose network may have different architectures (e.g. no classification head). So some unexpected keys in source state dict is actually expected.
-
-- **How to use trained models for backbone pre-training ?**
-
- Refer to [Migration - Step3: Model - Backbone](../migration.md).
-
- When training, the unexpected keys will be ignored.
-
-- **How to visualize the training accuracy/loss curves in real-time ?**
-
- Modify `vis_backends` in config file like:
-
- ```python
- vis_backends = [
- dict(type='LocalVisBackend'),
- dict(type='TensorboardVisBackend')
- ]
- ```
-
- You can refer to [user_guides/visualization.md](../user_guides/visualization.md).
-
-- **Log info is NOT printed**
-
- Use smaller log interval. For example, change `interval=50` to `interval=1` in the config:
-
- ```python
- # hooks
- default_hooks = dict(logger=dict(interval=1))
- ```
-
-## Evaluation
-
-- **How to evaluate on MPII test dataset?**
- Since we do not have the ground-truth for test dataset, we cannot evaluate it 'locally'.
- If you would like to evaluate the performance on test set, you have to upload the pred.mat (which is generated during testing) to the official server via email, according to [the MPII guideline](http://human-pose.mpi-inf.mpg.de/#evaluation).
-
-- **For top-down 2d pose estimation, why predicted joint coordinates can be out of the bounding box (bbox)?**
- We do not directly use the bbox to crop the image. bbox will be first transformed to center & scale, and the scale will be multiplied by a factor (1.25) to include some context. If the ratio of width/height is different from that of model input (possibly 192/256), we will adjust the bbox.
-
-## Inference
-
-- **How to run mmpose on CPU?**
-
- Run demos with `--device=cpu`.
-
-- **How to speed up inference?**
-
- A few approaches may help to improve the inference speed:
-
- 1. Set `flip_test=False` in `init_cfg` in the config file.
- 2. For top-down models, use faster human bounding box detector, see [MMDetection](https://mmdetection.readthedocs.io/en/3.x/model_zoo.html).
+# FAQ
+
+We list some common issues faced by many users and their corresponding solutions here.
+Feel free to enrich the list if you find any frequent issues and have ways to help others to solve them.
+If the contents here do not cover your issue, please create an issue using the [provided templates](/.github/ISSUE_TEMPLATE/error-report.md) and make sure you fill in all required information in the template.
+
+## Installation
+
+Compatibility issue between MMCV and MMPose; "AssertionError: MMCV==xxx is used but incompatible. Please install mmcv>=xxx, \<=xxx."
+
+Here are the version correspondences between `mmdet`, `mmcv` and `mmpose`:
+
+- mmdet 2.x \<=> mmpose 0.x \<=> mmcv 1.x
+- mmdet 3.x \<=> mmpose 1.x \<=> mmcv 2.x
+
+Detailed compatible MMPose and MMCV versions are shown as below. Please choose the correct version of MMCV to avoid installation issues.
+
+### MMPose 1.x
+
+| MMPose version | MMCV/MMEngine version |
+| :------------: | :-----------------------------: |
+| 1.1.0 | mmcv>=2.0.1, mmengine>=0.8.0 |
+| 1.0.0 | mmcv>=2.0.0, mmengine>=0.7.0 |
+| 1.0.0rc1 | mmcv>=2.0.0rc4, mmengine>=0.6.0 |
+| 1.0.0rc0 | mmcv>=2.0.0rc0, mmengine>=0.0.1 |
+| 1.0.0b0 | mmcv>=2.0.0rc0, mmengine>=0.0.1 |
+
+### MMPose 0.x
+
+| MMPose version | MMCV version |
+| :------------: | :-----------------------: |
+| 0.x | mmcv-full>=1.3.8, \<1.8.0 |
+| 0.29.0 | mmcv-full>=1.3.8, \<1.7.0 |
+| 0.28.1 | mmcv-full>=1.3.8, \<1.7.0 |
+| 0.28.0 | mmcv-full>=1.3.8, \<1.6.0 |
+| 0.27.0 | mmcv-full>=1.3.8, \<1.6.0 |
+| 0.26.0 | mmcv-full>=1.3.8, \<1.6.0 |
+| 0.25.1 | mmcv-full>=1.3.8, \<1.6.0 |
+| 0.25.0 | mmcv-full>=1.3.8, \<1.5.0 |
+| 0.24.0 | mmcv-full>=1.3.8, \<1.5.0 |
+| 0.23.0 | mmcv-full>=1.3.8, \<1.5.0 |
+| 0.22.0 | mmcv-full>=1.3.8, \<1.5.0 |
+| 0.21.0 | mmcv-full>=1.3.8, \<1.5.0 |
+| 0.20.0 | mmcv-full>=1.3.8, \<1.4.0 |
+| 0.19.0 | mmcv-full>=1.3.8, \<1.4.0 |
+| 0.18.0 | mmcv-full>=1.3.8, \<1.4.0 |
+| 0.17.0 | mmcv-full>=1.3.8, \<1.4.0 |
+| 0.16.0 | mmcv-full>=1.3.8, \<1.4.0 |
+| 0.14.0 | mmcv-full>=1.1.3, \<1.4.0 |
+| 0.13.0 | mmcv-full>=1.1.3, \<1.4.0 |
+| 0.12.0 | mmcv-full>=1.1.3, \<1.3 |
+| 0.11.0 | mmcv-full>=1.1.3, \<1.3 |
+| 0.10.0 | mmcv-full>=1.1.3, \<1.3 |
+| 0.9.0 | mmcv-full>=1.1.3, \<1.3 |
+| 0.8.0 | mmcv-full>=1.1.1, \<1.2 |
+| 0.7.0 | mmcv-full>=1.1.1, \<1.2 |
+
+- **Unable to install xtcocotools**
+
+ 1. Try to install it using pypi manually `pip install xtcocotools`.
+ 2. If step1 does not work. Try to install it from [source](https://github.com/jin-s13/xtcocoapi).
+
+ ```
+ git clone https://github.com/jin-s13/xtcocoapi
+ cd xtcocoapi
+ python setup.py install
+ ```
+
+- **No matching distribution found for xtcocotools>=1.6**
+
+ 1. Install cython by `pip install cython`.
+ 2. Install xtcocotools from [source](https://github.com/jin-s13/xtcocoapi).
+
+ ```
+ git clone https://github.com/jin-s13/xtcocoapi
+ cd xtcocoapi
+ python setup.py install
+ ```
+
+- **"No module named 'mmcv.ops'"; "No module named 'mmcv.\_ext'"**
+
+ 1. Uninstall existing mmcv in the environment using `pip uninstall mmcv`.
+ 2. Install mmcv following [mmcv installation instruction](https://mmcv.readthedocs.io/en/2.x/get_started/installation.html).
+
+## Data
+
+- **What if my custom dataset does not have bounding box label?**
+
+ We can estimate the bounding box of a person as the minimal box that tightly bounds all the keypoints.
+
+- **What is `COCO_val2017_detections_AP_H_56_person.json`? Can I train pose models without it?**
+
+ "COCO_val2017_detections_AP_H_56_person.json" contains the "detected" human bounding boxes for COCO validation set, which are generated by FasterRCNN.
+ One can choose to use gt bounding boxes to evaluate models, by setting `bbox_file=None` in `val_dataloader.dataset` in config. Or one can use detected boxes to evaluate
+ the generalizability of models, by setting `bbox_file='COCO_val2017_detections_AP_H_56_person.json'`.
+
+## Training
+
+- **RuntimeError: Address already in use**
+
+ Set the environment variables `MASTER_PORT=XXX`. For example:
+
+ ```shell
+ MASTER_PORT=29517 GPUS=16 GPUS_PER_NODE=8 CPUS_PER_TASK=2 ./tools/slurm_train.sh train res50 configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_8xb64-210e_coco-256x192.py work_dirs/res50_coco_256x192
+ ```
+
+- **"Unexpected keys in source state dict" when loading pre-trained weights**
+
+ It's normal that some layers in the pretrained model are not used in the pose model. ImageNet-pretrained classification network and the pose network may have different architectures (e.g. no classification head). So some unexpected keys in source state dict is actually expected.
+
+- **How to use trained models for backbone pre-training ?**
+
+ Refer to [Migration - Step3: Model - Backbone](../migration.md).
+
+ When training, the unexpected keys will be ignored.
+
+- **How to visualize the training accuracy/loss curves in real-time ?**
+
+ Modify `vis_backends` in config file like:
+
+ ```python
+ vis_backends = [
+ dict(type='LocalVisBackend'),
+ dict(type='TensorboardVisBackend')
+ ]
+ ```
+
+ You can refer to [user_guides/visualization.md](../user_guides/visualization.md).
+
+- **Log info is NOT printed**
+
+ Use smaller log interval. For example, change `interval=50` to `interval=1` in the config:
+
+ ```python
+ # hooks
+ default_hooks = dict(logger=dict(interval=1))
+ ```
+
+## Evaluation
+
+- **How to evaluate on MPII test dataset?**
+ Since we do not have the ground-truth for test dataset, we cannot evaluate it 'locally'.
+ If you would like to evaluate the performance on test set, you have to upload the pred.mat (which is generated during testing) to the official server via email, according to [the MPII guideline](http://human-pose.mpi-inf.mpg.de/#evaluation).
+
+- **For top-down 2d pose estimation, why predicted joint coordinates can be out of the bounding box (bbox)?**
+ We do not directly use the bbox to crop the image. bbox will be first transformed to center & scale, and the scale will be multiplied by a factor (1.25) to include some context. If the ratio of width/height is different from that of model input (possibly 192/256), we will adjust the bbox.
+
+## Inference
+
+- **How to run mmpose on CPU?**
+
+ Run demos with `--device=cpu`.
+
+- **How to speed up inference?**
+
+ A few approaches may help to improve the inference speed:
+
+ 1. Set `flip_test=False` in `init_cfg` in the config file.
+ 2. For top-down models, use faster human bounding box detector, see [MMDetection](https://mmdetection.readthedocs.io/en/3.x/model_zoo.html).
diff --git a/docs/en/guide_to_framework.md b/docs/en/guide_to_framework.md
index 1bfe7d3b59..a1300eaa31 100644
--- a/docs/en/guide_to_framework.md
+++ b/docs/en/guide_to_framework.md
@@ -1,668 +1,668 @@
-# A 20-minute Tour to MMPose
-
-MMPose 1.0 is built upon a brand-new framework. For developers with basic knowledge of deep learning, this tutorial provides a overview of MMPose 1.0 framework design. Whether you are **a user of the previous version of MMPose**, or **a beginner of MMPose wishing to start with v1.0**, this tutorial will show you how to build a project based on MMPose 1.0.
-
-```{note}
-This tutorial covers what developers will concern when using MMPose 1.0:
-
-- Overall code architecture
-
-- How to manage modules with configs
-
-- How to use my own custom datasets
-
-- How to add new modules(backbone, head, loss function, etc.)
-```
-
-The content of this tutorial is organized as follows:
-
-- [A 20 Minute Guide to MMPose Framework](#a-20-minute-guide-to-mmpose-framework)
- - [Overview](#overview)
- - [Step1: Configs](#step1-configs)
- - [Step2: Data](#step2-data)
- - [Dataset Meta Information](#dataset-meta-information)
- - [Dataset](#dataset)
- - [Pipeline](#pipeline)
- - [i. Augmentation](#i-augmentation)
- - [ii. Transformation](#ii-transformation)
- - [iii. Encoding](#iii-encoding)
- - [iv. Packing](#iv-packing)
- - [Step3: Model](#step3-model)
- - [Data Preprocessor](#data-preprocessor)
- - [Backbone](#backbone)
- - [Neck](#neck)
- - [Head](#head)
-
-## Overview
-
-
-
-Generally speaking, there are **five parts** developers will use during project development:
-
-- **General:** Environment, Hook, Checkpoint, Logger, etc.
-
-- **Data:** Dataset, Dataloader, Data Augmentation, etc.
-
-- **Training:** Optimizer, Learning Rate Scheduler, etc.
-
-- **Model:** Backbone, Neck, Head, Loss function, etc.
-
-- **Evaluation:** Metric, Evaluator, etc.
-
-Among them, modules related to **General**, **Training** and **Evaluation** are often provided by the training framework [MMEngine](https://github.com/open-mmlab/mmengine), and developers only need to call APIs and adjust the parameters. Developers mainly focus on implementing the **Data** and **Model** parts.
-
-## Step1: Configs
-
-In MMPose, we use a Python file as config for the definition and parameter management of the whole project. Therefore, we strongly recommend the developers who use MMPose for the first time to refer to [Configs](./user_guides/configs.md).
-
-Note that all new modules need to be registered using `Registry` and imported in `__init__.py` in the corresponding directory before we can create their instances from configs.
-
-## Step2: Data
-
-The organization of data in MMPose contains:
-
-- Dataset Meta Information
-
-- Dataset
-
-- Pipeline
-
-### Dataset Meta Information
-
-The meta information of a pose dataset usually includes the definition of keypoints and skeleton, symmetrical characteristic, and keypoint properties (e.g. belonging to upper or lower body, weights and sigmas). These information is important in data preprocessing, model training and evaluation. In MMpose, the dataset meta information is stored in configs files under `$MMPOSE/configs/_base_/datasets/`.
-
-To use a custom dataset in MMPose, you need to add a new config file of the dataset meta information. Take the MPII dataset (`$MMPOSE/configs/_base_/datasets/mpii.py`) as an example. Here is its dataset information:
-
-```Python
-dataset_info = dict(
- dataset_name='mpii',
- paper_info=dict(
- author='Mykhaylo Andriluka and Leonid Pishchulin and '
- 'Peter Gehler and Schiele, Bernt',
- title='2D Human Pose Estimation: New Benchmark and '
- 'State of the Art Analysis',
- container='IEEE Conference on Computer Vision and '
- 'Pattern Recognition (CVPR)',
- year='2014',
- homepage='http://human-pose.mpi-inf.mpg.de/',
- ),
- keypoint_info={
- 0:
- dict(
- name='right_ankle',
- id=0,
- color=[255, 128, 0],
- type='lower',
- swap='left_ankle'),
- ## omitted
- },
- skeleton_info={
- 0:
- dict(link=('right_ankle', 'right_knee'), id=0, color=[255, 128, 0]),
- ## omitted
- },
- joint_weights=[
- 1.5, 1.2, 1., 1., 1.2, 1.5, 1., 1., 1., 1., 1.5, 1.2, 1., 1., 1.2, 1.5
- ],
- # Adapted from COCO dataset.
- sigmas=[
- 0.089, 0.083, 0.107, 0.107, 0.083, 0.089, 0.026, 0.026, 0.026, 0.026,
- 0.062, 0.072, 0.179, 0.179, 0.072, 0.062
- ])
-```
-
-In the model config, the user needs to specify the metainfo path of the custom dataset (e.g. `$MMPOSE/configs/_base_/datasets/custom.py`) as follows:\`\`\`
-
-```python
-# dataset and dataloader settings
-dataset_type = 'MyCustomDataset' # or 'CocoDataset'
-
-train_dataloader = dict(
- batch_size=2,
- dataset=dict(
- type=dataset_type,
- data_root='root/of/your/train/data',
- ann_file='path/to/your/train/json',
- data_prefix=dict(img='path/to/your/train/img'),
- # specify the new dataset meta information config file
- metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
- ...),
- )
-
-val_dataloader = dict(
- batch_size=2,
- dataset=dict(
- type=dataset_type,
- data_root='root/of/your/val/data',
- ann_file='path/to/your/val/json',
- data_prefix=dict(img='path/to/your/val/img'),
- # specify the new dataset meta information config file
- metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
- ...),
- )
-
-test_dataloader = val_dataloader
-```
-
-### Dataset
-
-To use custom dataset in MMPose, we recommend converting the annotations into a supported format (e.g. COCO or MPII) and directly using our implementation of the corresponding dataset. If this is not applicable, you may need to implement your own dataset class.
-
-Most 2D keypoint datasets in MMPose **organize the annotations in a COCO-like style**. Thus we provide a base class [BaseCocoStyleDataset](mmpose/datasets/datasets/base/base_coco_style_dataset.py) for these datasets. We recommend that users subclass `BaseCocoStyleDataset` and override the methods as needed (usually `__init__()` and `_load_annotations()`) to extend to a new custom 2D keypoint dataset.
-
-```{note}
-Please refer to [COCO](./dataset_zoo/2d_body_keypoint.md) for more details about the COCO data format.
-```
-
-```{note}
-The bbox format in MMPose is in `xyxy` instead of `xywh`, which is consistent with the format used in other OpenMMLab projects like [MMDetection](https://github.com/open-mmlab/mmdetection). We provide useful utils for bbox format conversion, such as `bbox_xyxy2xywh`, `bbox_xywh2xyxy`, `bbox_xyxy2cs`, etc., which are defined in `$MMPOSE/mmpose/structures/bbox/transforms.py`.
-```
-
-Let's take the implementation of the MPII dataset (`$MMPOSE/mmpose/datasets/datasets/body/mpii_dataset.py`) as an example.
-
-```Python
-@DATASETS.register_module()
-class MpiiDataset(BaseCocoStyleDataset):
- METAINFO: dict = dict(from_file='configs/_base_/datasets/mpii.py')
-
- def __init__(self,
- ## omitted
- headbox_file: Optional[str] = None,
- ## omitted
- ):
-
- if headbox_file:
- if data_mode != 'topdown':
- raise ValueError(
- f'{self.__class__.__name__} is set to {data_mode}: '
- 'mode, while "headbox_file" is only '
- 'supported in topdown mode.')
-
- if not test_mode:
- raise ValueError(
- f'{self.__class__.__name__} has `test_mode==False` '
- 'while "headbox_file" is only '
- 'supported when `test_mode==True`.')
-
- headbox_file_type = headbox_file[-3:]
- allow_headbox_file_type = ['mat']
- if headbox_file_type not in allow_headbox_file_type:
- raise KeyError(
- f'The head boxes file type {headbox_file_type} is not '
- f'supported. Should be `mat` but got {headbox_file_type}.')
- self.headbox_file = headbox_file
-
- super().__init__(
- ## omitted
- )
-
- def _load_annotations(self) -> List[dict]:
- """Load data from annotations in MPII format."""
- check_file_exist(self.ann_file)
- with open(self.ann_file) as anno_file:
- anns = json.load(anno_file)
-
- if self.headbox_file:
- check_file_exist(self.headbox_file)
- headbox_dict = loadmat(self.headbox_file)
- headboxes_src = np.transpose(headbox_dict['headboxes_src'],
- [2, 0, 1])
- SC_BIAS = 0.6
-
- data_list = []
- ann_id = 0
-
- # mpii bbox scales are normalized with factor 200.
- pixel_std = 200.
-
- for idx, ann in enumerate(anns):
- center = np.array(ann['center'], dtype=np.float32)
- scale = np.array([ann['scale'], ann['scale']],
- dtype=np.float32) * pixel_std
-
- # Adjust center/scale slightly to avoid cropping limbs
- if center[0] != -1:
- center[1] = center[1] + 15. / pixel_std * scale[1]
-
- # MPII uses matlab format, index is 1-based,
- # we should first convert to 0-based index
- center = center - 1
-
- # unify shape with coco datasets
- center = center.reshape(1, -1)
- scale = scale.reshape(1, -1)
- bbox = bbox_cs2xyxy(center, scale)
-
- # load keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
- keypoints = np.array(ann['joints']).reshape(1, -1, 2)
- keypoints_visible = np.array(ann['joints_vis']).reshape(1, -1)
-
- data_info = {
- 'id': ann_id,
- 'img_id': int(ann['image'].split('.')[0]),
- 'img_path': osp.join(self.data_prefix['img'], ann['image']),
- 'bbox_center': center,
- 'bbox_scale': scale,
- 'bbox': bbox,
- 'bbox_score': np.ones(1, dtype=np.float32),
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- }
-
- if self.headbox_file:
- # calculate the diagonal length of head box as norm_factor
- headbox = headboxes_src[idx]
- head_size = np.linalg.norm(headbox[1] - headbox[0], axis=0)
- head_size *= SC_BIAS
- data_info['head_size'] = head_size.reshape(1, -1)
-
- data_list.append(data_info)
- ann_id = ann_id + 1
-
- return data_list
-```
-
-When supporting MPII dataset, since we need to use `head_size` to calculate `PCKh`, we add `headbox_file` to `__init__()` and override`_load_annotations()`.
-
-To support a dataset that is beyond the scope of `BaseCocoStyleDataset`, you may need to subclass from the `BaseDataset` provided by [MMEngine](https://github.com/open-mmlab/mmengine). Please refer to the [documents](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/basedataset.html) for details.
-
-### Pipeline
-
-Data augmentations and transformations during pre-processing are organized as a pipeline. Here is an example of typical pipelines:
-
-```Python
-# pipelines
-train_pipeline = [
- dict(type='LoadImage'),
- dict(type='GetBBoxCenterScale'),
- dict(type='RandomFlip', direction='horizontal'),
- dict(type='RandomHalfBody'),
- dict(type='RandomBBoxTransform'),
- dict(type='TopdownAffine', input_size=codec['input_size']),
- dict(type='GenerateTarget', encoder=codec),
- dict(type='PackPoseInputs')
-]
-test_pipeline = [
- dict(type='LoadImage'),
- dict(type='GetBBoxCenterScale'),
- dict(type='TopdownAffine', input_size=codec['input_size']),
- dict(type='PackPoseInputs')
-]
-```
-
-In a keypoint detection task, data will be transformed among three scale spaces:
-
-- **Original Image Space**: the space where the images are stored. The sizes of different images are not necessarily the same
-
-- **Input Image Space**: the image space used for model input. All **images** and **annotations** will be transformed into this space, such as `256x256`, `256x192`, etc.
-
-- **Output Space**: the scale space where model outputs are located, such as `64x64(Heatmap)`,`1x1(Regression)`, etc. The supervision signal is also in this space during training
-
-Here is a diagram to show the workflow of data transformation among the three scale spaces:
-
-
-
-In MMPose, the modules used for data transformation are under `$MMPOSE/mmpose/datasets/transforms`, and their workflow is shown as follows:
-
-
-
-#### i. Augmentation
-
-Commonly used transforms are defined in `$MMPOSE/mmpose/datasets/transforms/common_transforms.py`, such as `RandomFlip`, `RandomHalfBody`, etc.
-
-For top-down methods, `Shift`, `Rotate`and `Resize` are implemented by `RandomBBoxTransform`**.** For bottom-up methods, `BottomupRandomAffine` is used.
-
-```{note}
-Most data transforms depend on `bbox_center` and `bbox_scale`, which can be obtained by `GetBBoxCenterScale`.
-```
-
-#### ii. Transformation
-
-Affine transformation is used to convert images and annotations from the original image space to the input space. This is done by `TopdownAffine` for top-down methods and `BottomupRandomAffine` for bottom-up methods.
-
-#### iii. Encoding
-
-In training phase, after the data is transformed from the original image space into the input space, it is necessary to use `GenerateTarget` to obtain the training target(e.g. Gaussian Heatmaps). We name this process **Encoding**. Conversely, the process of getting the corresponding coordinates from Gaussian Heatmaps is called **Decoding**.
-
-In MMPose, we collect Encoding and Decoding processes into a **Codec**, in which `encode()` and `decode()` are implemented.
-
-Currently we support the following types of Targets.
-
-- `heatmap`: Gaussian heatmaps
-- `keypoint_label`: keypoint representation (e.g. normalized coordinates)
-- `keypoint_xy_label`: axis-wise keypoint representation
-- `heatmap+keypoint_label`: Gaussian heatmaps and keypoint representation
-- `multiscale_heatmap`: multi-scale Gaussian heatmaps
-
-and the generated targets will be packed as follows.
-
-- `heatmaps`: Gaussian heatmaps
-- `keypoint_labels`: keypoint representation (e.g. normalized coordinates)
-- `keypoint_x_labels`: keypoint x-axis representation
-- `keypoint_y_labels`: keypoint y-axis representation
-- `keypoint_weights`: keypoint visibility and weights
-
-Note that we unify the data format of top-down and bottom-up methods, which means that a new dimension is added to represent different instances from the same image, in shape:
-
-```Python
-[batch_size, num_instances, num_keypoints, dim_coordinates]
-```
-
-- top-down: `[B, 1, K, D]`
-
-- Bottom-up: `[B, N, K, D]`
-
-The provided codecs are stored under `$MMPOSE/mmpose/codecs`.
-
-```{note}
-If you wish to customize a new codec, you can refer to [Codec](./user_guides/codecs.md) for more details.
-```
-
-#### iv. Packing
-
-After the data is transformed, you need to pack it using `PackPoseInputs`.
-
-This method converts the data stored in the dictionary `results` into standard data structures in MMPose, such as `InstanceData`, `PixelData`, `PoseDataSample`, etc.
-
-Specifically, we divide the data into `gt` (ground-truth) and `pred` (prediction), each of which has the following types:
-
-- **instances**(numpy.array): instance-level raw annotations or predictions in the original scale space
-- **instance_labels**(torch.tensor): instance-level training labels (e.g. normalized coordinates, keypoint visibility) in the output scale space
-- **fields**(torch.tensor): pixel-level training labels or predictions (e.g. Gaussian Heatmaps) in the output scale space
-
-The following is an example of the implementation of `PoseDataSample` under the hood:
-
-```Python
-def get_pose_data_sample(self):
- # meta
- pose_meta = dict(
- img_shape=(600, 900), # [h, w, c]
- crop_size=(256, 192), # [h, w]
- heatmap_size=(64, 48), # [h, w]
- )
-
- # gt_instances
- gt_instances = InstanceData()
- gt_instances.bboxes = np.random.rand(1, 4)
- gt_instances.keypoints = np.random.rand(1, 17, 2)
-
- # gt_instance_labels
- gt_instance_labels = InstanceData()
- gt_instance_labels.keypoint_labels = torch.rand(1, 17, 2)
- gt_instance_labels.keypoint_weights = torch.rand(1, 17)
-
- # pred_instances
- pred_instances = InstanceData()
- pred_instances.keypoints = np.random.rand(1, 17, 2)
- pred_instances.keypoint_scores = np.random.rand(1, 17)
-
- # gt_fields
- gt_fields = PixelData()
- gt_fields.heatmaps = torch.rand(17, 64, 48)
-
- # pred_fields
- pred_fields = PixelData()
- pred_fields.heatmaps = torch.rand(17, 64, 48)
- data_sample = PoseDataSample(
- gt_instances=gt_instances,
- pred_instances=pred_instances,
- gt_fields=gt_fields,
- pred_fields=pred_fields,
- metainfo=pose_meta)
-
- return data_sample
-```
-
-## Step3: Model
-
-In MMPose 1.0, the model consists of the following components:
-
-- **Data Preprocessor**: perform data normalization and channel transposition
-
-- **Backbone**: used for feature extraction
-
-- **Neck**: GAP,FPN, etc. are optional
-
-- **Head**: used to implement the core algorithm and loss function
-
-We define a base class `BasePoseEstimator` for the model in `$MMPOSE/models/pose_estimators/base.py`. All models, e.g. `TopdownPoseEstimator`, should inherit from this base class and override the corresponding methods.
-
-Three modes are provided in `forward()` of the estimator:
-
-- `mode == 'loss'`: return the result of loss function for model training
-
-- `mode == 'predict'`: return the prediction result in the input space, used for model inference
-
-- `mode == 'tensor'`: return the model output in the output space, i.e. model forward propagation only, for model export
-
-Developers should build the components by calling the corresponding registry. Taking the top-down model as an example:
-
-```Python
-@MODELS.register_module()
-class TopdownPoseEstimator(BasePoseEstimator):
- def __init__(self,
- backbone: ConfigType,
- neck: OptConfigType = None,
- head: OptConfigType = None,
- train_cfg: OptConfigType = None,
- test_cfg: OptConfigType = None,
- data_preprocessor: OptConfigType = None,
- init_cfg: OptMultiConfig = None):
- super().__init__(data_preprocessor, init_cfg)
-
- self.backbone = MODELS.build(backbone)
-
- if neck is not None:
- self.neck = MODELS.build(neck)
-
- if head is not None:
- self.head = MODELS.build(head)
-```
-
-### Data Preprocessor
-
-Starting from MMPose 1.0, we have added a new module to the model called data preprocessor, which performs data preprocessings like image normalization and channel transposition. It can benefit from the high computing power of devices like GPU, and improve the integrity in model export and deployment.
-
-A typical `data_preprocessor` in the config is as follows:
-
-```Python
-data_preprocessor=dict(
- type='PoseDataPreprocessor',
- mean=[123.675, 116.28, 103.53],
- std=[58.395, 57.12, 57.375],
- bgr_to_rgb=True),
-```
-
-It will transpose the channel order of the input image from `bgr` to `rgb` and normalize the data according to `mean` and `std`.
-
-### Backbone
-
-MMPose provides some commonly used backbones under `$MMPOSE/mmpose/models/backbones`.
-
-In practice, developers often use pre-trained backbone weights for transfer learning, which can improve the performance of the model on small datasets.
-
-In MMPose, you can use the pre-trained weights by setting `init_cfg` in config:
-
-```Python
-init_cfg=dict(
- type='Pretrained',
- checkpoint='PATH/TO/YOUR_MODEL_WEIGHTS.pth'),
-```
-
-If you want to load a checkpoint to your backbone, you should specify the `prefix`:
-
-```Python
-init_cfg=dict(
- type='Pretrained',
- prefix='backbone.',
- checkpoint='PATH/TO/YOUR_CHECKPOINT.pth'),
-```
-
-`checkpoint` can be either a local path or a download link. Thus, if you wish to use a pre-trained model provided by Torchvision(e.g. ResNet50), you can simply use:
-
-```Python
-init_cfg=dict(
- type='Pretrained',
- checkpoint='torchvision://resnet50')
-```
-
-In addition to these commonly used backbones, you can easily use backbones from other repositories in the OpenMMLab family such as MMClassification, which all share the same config system and provide pre-trained weights.
-
-It should be emphasized that if you add a new backbone, you need to register it by doing:
-
-```Python
-@MODELS.register_module()
-class YourBackbone(BaseBackbone):
-```
-
-Besides, import it in `$MMPOSE/mmpose/models/backbones/__init__.py`, and add it to `__all__`.
-
-### Neck
-
-Neck is usually a module between Backbone and Head, which is used in some algorithms. Here are some commonly used Neck:
-
-- Global Average Pooling (GAP)
-
-- Feature Pyramid Networks (FPN)
-
-- Feature Map Processor (FMP)
-
- The `FeatureMapProcessor` is a flexible PyTorch module designed to transform the feature outputs generated by backbones into a format suitable for heads. It achieves this by utilizing non-parametric operations such as selecting, concatenating, and rescaling. Below are some examples along with their corresponding configurations:
-
- - Select operation
-
- ```python
- neck=dict(type='FeatureMapProcessor', select_index=0)
- ```
-
-
-
- - Concatenate operation
-
- ```python
- neck=dict(type='FeatureMapProcessor', concat=True)
- ```
-
-
-
- Note that all feature maps will be resized to match the shape of the first feature map (index 0) prior to concatenation.
-
- - rescale operation
-
- ```python
- neck=dict(type='FeatureMapProcessor', scale_factor=2.0)
- ```
-
-
-
-### Head
-
-Generally speaking, Head is often the core of an algorithm, which is used to make predictions and perform loss calculation.
-
-Modules related to Head in MMPose are defined under `$MMPOSE/mmpose/models/heads`, and developers need to inherit the base class `BaseHead` when customizing Head and override the following methods:
-
-- forward()
-
-- predict()
-
-- loss()
-
-Specifically, `predict()` method needs to return pose predictions in the image space, which is obtained from the model output though the decoding function provided by the codec. We implement this process in `BaseHead.decode()`.
-
-On the other hand, we will perform test-time augmentation(TTA) in `predict()`.
-
-A commonly used TTA is `flip_test`, namely, an image and its flipped version are sent into the model to inference, and the output of the flipped version will be flipped back, then average them to stabilize the prediction.
-
-Here is an example of `predict()` in `RegressionHead`:
-
-```Python
-def predict(self,
- feats: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- test_cfg: ConfigType = {}) -> Predictions:
- """Predict results from outputs."""
-
- if test_cfg.get('flip_test', False):
- # TTA: flip test -> feats = [orig, flipped]
- assert isinstance(feats, list) and len(feats) == 2
- flip_indices = batch_data_samples[0].metainfo['flip_indices']
- input_size = batch_data_samples[0].metainfo['input_size']
- _feats, _feats_flip = feats
- _batch_coords = self.forward(_feats)
- _batch_coords_flip = flip_coordinates(
- self.forward(_feats_flip),
- flip_indices=flip_indices,
- shift_coords=test_cfg.get('shift_coords', True),
- input_size=input_size)
- batch_coords = (_batch_coords + _batch_coords_flip) * 0.5
- else:
- batch_coords = self.forward(feats) # (B, K, D)
-
- batch_coords.unsqueeze_(dim=1) # (B, N, K, D)
- preds = self.decode(batch_coords)
-```
-
-The `loss()` not only performs the calculation of loss functions, but also the calculation of training-time metrics such as pose accuracy. The results are carried by a dictionary `losses`:
-
-```Python
- # calculate accuracy
-_, avg_acc, _ = keypoint_pck_accuracy(
- pred=to_numpy(pred_coords),
- gt=to_numpy(keypoint_labels),
- mask=to_numpy(keypoint_weights) > 0,
- thr=0.05,
- norm_factor=np.ones((pred_coords.size(0), 2), dtype=np.float32))
-
-acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
-losses.update(acc_pose=acc_pose)
-```
-
-The data of each batch is packaged into `batch_data_samples`. Taking the Regression-based method as an example, the normalized coordinates and keypoint weights can be obtained as follows:
-
-```Python
-keypoint_labels = torch.cat(
- [d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
-keypoint_weights = torch.cat([
- d.gt_instance_labels.keypoint_weights for d in batch_data_samples
-])
-```
-
-Here is the complete implementation of `loss()` in `RegressionHead`:
-
-```Python
-def loss(self,
- inputs: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- train_cfg: ConfigType = {}) -> dict:
- """Calculate losses from a batch of inputs and data samples."""
-
- pred_outputs = self.forward(inputs)
-
- keypoint_labels = torch.cat(
- [d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
- keypoint_weights = torch.cat([
- d.gt_instance_labels.keypoint_weights for d in batch_data_samples
- ])
-
- # calculate losses
- losses = dict()
- loss = self.loss_module(pred_outputs, keypoint_labels,
- keypoint_weights.unsqueeze(-1))
-
- if isinstance(loss, dict):
- losses.update(loss)
- else:
- losses.update(loss_kpt=loss)
-
- # calculate accuracy
- _, avg_acc, _ = keypoint_pck_accuracy(
- pred=to_numpy(pred_outputs),
- gt=to_numpy(keypoint_labels),
- mask=to_numpy(keypoint_weights) > 0,
- thr=0.05,
- norm_factor=np.ones((pred_outputs.size(0), 2), dtype=np.float32))
- acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
- losses.update(acc_pose=acc_pose)
-
- return losses
-```
+# A 20-minute Tour to MMPose
+
+MMPose 1.0 is built upon a brand-new framework. For developers with basic knowledge of deep learning, this tutorial provides a overview of MMPose 1.0 framework design. Whether you are **a user of the previous version of MMPose**, or **a beginner of MMPose wishing to start with v1.0**, this tutorial will show you how to build a project based on MMPose 1.0.
+
+```{note}
+This tutorial covers what developers will concern when using MMPose 1.0:
+
+- Overall code architecture
+
+- How to manage modules with configs
+
+- How to use my own custom datasets
+
+- How to add new modules(backbone, head, loss function, etc.)
+```
+
+The content of this tutorial is organized as follows:
+
+- [A 20 Minute Guide to MMPose Framework](#a-20-minute-guide-to-mmpose-framework)
+ - [Overview](#overview)
+ - [Step1: Configs](#step1-configs)
+ - [Step2: Data](#step2-data)
+ - [Dataset Meta Information](#dataset-meta-information)
+ - [Dataset](#dataset)
+ - [Pipeline](#pipeline)
+ - [i. Augmentation](#i-augmentation)
+ - [ii. Transformation](#ii-transformation)
+ - [iii. Encoding](#iii-encoding)
+ - [iv. Packing](#iv-packing)
+ - [Step3: Model](#step3-model)
+ - [Data Preprocessor](#data-preprocessor)
+ - [Backbone](#backbone)
+ - [Neck](#neck)
+ - [Head](#head)
+
+## Overview
+
+
+
+Generally speaking, there are **five parts** developers will use during project development:
+
+- **General:** Environment, Hook, Checkpoint, Logger, etc.
+
+- **Data:** Dataset, Dataloader, Data Augmentation, etc.
+
+- **Training:** Optimizer, Learning Rate Scheduler, etc.
+
+- **Model:** Backbone, Neck, Head, Loss function, etc.
+
+- **Evaluation:** Metric, Evaluator, etc.
+
+Among them, modules related to **General**, **Training** and **Evaluation** are often provided by the training framework [MMEngine](https://github.com/open-mmlab/mmengine), and developers only need to call APIs and adjust the parameters. Developers mainly focus on implementing the **Data** and **Model** parts.
+
+## Step1: Configs
+
+In MMPose, we use a Python file as config for the definition and parameter management of the whole project. Therefore, we strongly recommend the developers who use MMPose for the first time to refer to [Configs](./user_guides/configs.md).
+
+Note that all new modules need to be registered using `Registry` and imported in `__init__.py` in the corresponding directory before we can create their instances from configs.
+
+## Step2: Data
+
+The organization of data in MMPose contains:
+
+- Dataset Meta Information
+
+- Dataset
+
+- Pipeline
+
+### Dataset Meta Information
+
+The meta information of a pose dataset usually includes the definition of keypoints and skeleton, symmetrical characteristic, and keypoint properties (e.g. belonging to upper or lower body, weights and sigmas). These information is important in data preprocessing, model training and evaluation. In MMpose, the dataset meta information is stored in configs files under `$MMPOSE/configs/_base_/datasets/`.
+
+To use a custom dataset in MMPose, you need to add a new config file of the dataset meta information. Take the MPII dataset (`$MMPOSE/configs/_base_/datasets/mpii.py`) as an example. Here is its dataset information:
+
+```Python
+dataset_info = dict(
+ dataset_name='mpii',
+ paper_info=dict(
+ author='Mykhaylo Andriluka and Leonid Pishchulin and '
+ 'Peter Gehler and Schiele, Bernt',
+ title='2D Human Pose Estimation: New Benchmark and '
+ 'State of the Art Analysis',
+ container='IEEE Conference on Computer Vision and '
+ 'Pattern Recognition (CVPR)',
+ year='2014',
+ homepage='http://human-pose.mpi-inf.mpg.de/',
+ ),
+ keypoint_info={
+ 0:
+ dict(
+ name='right_ankle',
+ id=0,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_ankle'),
+ ## omitted
+ },
+ skeleton_info={
+ 0:
+ dict(link=('right_ankle', 'right_knee'), id=0, color=[255, 128, 0]),
+ ## omitted
+ },
+ joint_weights=[
+ 1.5, 1.2, 1., 1., 1.2, 1.5, 1., 1., 1., 1., 1.5, 1.2, 1., 1., 1.2, 1.5
+ ],
+ # Adapted from COCO dataset.
+ sigmas=[
+ 0.089, 0.083, 0.107, 0.107, 0.083, 0.089, 0.026, 0.026, 0.026, 0.026,
+ 0.062, 0.072, 0.179, 0.179, 0.072, 0.062
+ ])
+```
+
+In the model config, the user needs to specify the metainfo path of the custom dataset (e.g. `$MMPOSE/configs/_base_/datasets/custom.py`) as follows:\`\`\`
+
+```python
+# dataset and dataloader settings
+dataset_type = 'MyCustomDataset' # or 'CocoDataset'
+
+train_dataloader = dict(
+ batch_size=2,
+ dataset=dict(
+ type=dataset_type,
+ data_root='root/of/your/train/data',
+ ann_file='path/to/your/train/json',
+ data_prefix=dict(img='path/to/your/train/img'),
+ # specify the new dataset meta information config file
+ metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
+ ...),
+ )
+
+val_dataloader = dict(
+ batch_size=2,
+ dataset=dict(
+ type=dataset_type,
+ data_root='root/of/your/val/data',
+ ann_file='path/to/your/val/json',
+ data_prefix=dict(img='path/to/your/val/img'),
+ # specify the new dataset meta information config file
+ metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
+ ...),
+ )
+
+test_dataloader = val_dataloader
+```
+
+### Dataset
+
+To use custom dataset in MMPose, we recommend converting the annotations into a supported format (e.g. COCO or MPII) and directly using our implementation of the corresponding dataset. If this is not applicable, you may need to implement your own dataset class.
+
+Most 2D keypoint datasets in MMPose **organize the annotations in a COCO-like style**. Thus we provide a base class [BaseCocoStyleDataset](mmpose/datasets/datasets/base/base_coco_style_dataset.py) for these datasets. We recommend that users subclass `BaseCocoStyleDataset` and override the methods as needed (usually `__init__()` and `_load_annotations()`) to extend to a new custom 2D keypoint dataset.
+
+```{note}
+Please refer to [COCO](./dataset_zoo/2d_body_keypoint.md) for more details about the COCO data format.
+```
+
+```{note}
+The bbox format in MMPose is in `xyxy` instead of `xywh`, which is consistent with the format used in other OpenMMLab projects like [MMDetection](https://github.com/open-mmlab/mmdetection). We provide useful utils for bbox format conversion, such as `bbox_xyxy2xywh`, `bbox_xywh2xyxy`, `bbox_xyxy2cs`, etc., which are defined in `$MMPOSE/mmpose/structures/bbox/transforms.py`.
+```
+
+Let's take the implementation of the MPII dataset (`$MMPOSE/mmpose/datasets/datasets/body/mpii_dataset.py`) as an example.
+
+```Python
+@DATASETS.register_module()
+class MpiiDataset(BaseCocoStyleDataset):
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/mpii.py')
+
+ def __init__(self,
+ ## omitted
+ headbox_file: Optional[str] = None,
+ ## omitted
+ ):
+
+ if headbox_file:
+ if data_mode != 'topdown':
+ raise ValueError(
+ f'{self.__class__.__name__} is set to {data_mode}: '
+ 'mode, while "headbox_file" is only '
+ 'supported in topdown mode.')
+
+ if not test_mode:
+ raise ValueError(
+ f'{self.__class__.__name__} has `test_mode==False` '
+ 'while "headbox_file" is only '
+ 'supported when `test_mode==True`.')
+
+ headbox_file_type = headbox_file[-3:]
+ allow_headbox_file_type = ['mat']
+ if headbox_file_type not in allow_headbox_file_type:
+ raise KeyError(
+ f'The head boxes file type {headbox_file_type} is not '
+ f'supported. Should be `mat` but got {headbox_file_type}.')
+ self.headbox_file = headbox_file
+
+ super().__init__(
+ ## omitted
+ )
+
+ def _load_annotations(self) -> List[dict]:
+ """Load data from annotations in MPII format."""
+ check_file_exist(self.ann_file)
+ with open(self.ann_file) as anno_file:
+ anns = json.load(anno_file)
+
+ if self.headbox_file:
+ check_file_exist(self.headbox_file)
+ headbox_dict = loadmat(self.headbox_file)
+ headboxes_src = np.transpose(headbox_dict['headboxes_src'],
+ [2, 0, 1])
+ SC_BIAS = 0.6
+
+ data_list = []
+ ann_id = 0
+
+ # mpii bbox scales are normalized with factor 200.
+ pixel_std = 200.
+
+ for idx, ann in enumerate(anns):
+ center = np.array(ann['center'], dtype=np.float32)
+ scale = np.array([ann['scale'], ann['scale']],
+ dtype=np.float32) * pixel_std
+
+ # Adjust center/scale slightly to avoid cropping limbs
+ if center[0] != -1:
+ center[1] = center[1] + 15. / pixel_std * scale[1]
+
+ # MPII uses matlab format, index is 1-based,
+ # we should first convert to 0-based index
+ center = center - 1
+
+ # unify shape with coco datasets
+ center = center.reshape(1, -1)
+ scale = scale.reshape(1, -1)
+ bbox = bbox_cs2xyxy(center, scale)
+
+ # load keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
+ keypoints = np.array(ann['joints']).reshape(1, -1, 2)
+ keypoints_visible = np.array(ann['joints_vis']).reshape(1, -1)
+
+ data_info = {
+ 'id': ann_id,
+ 'img_id': int(ann['image'].split('.')[0]),
+ 'img_path': osp.join(self.data_prefix['img'], ann['image']),
+ 'bbox_center': center,
+ 'bbox_scale': scale,
+ 'bbox': bbox,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ }
+
+ if self.headbox_file:
+ # calculate the diagonal length of head box as norm_factor
+ headbox = headboxes_src[idx]
+ head_size = np.linalg.norm(headbox[1] - headbox[0], axis=0)
+ head_size *= SC_BIAS
+ data_info['head_size'] = head_size.reshape(1, -1)
+
+ data_list.append(data_info)
+ ann_id = ann_id + 1
+
+ return data_list
+```
+
+When supporting MPII dataset, since we need to use `head_size` to calculate `PCKh`, we add `headbox_file` to `__init__()` and override`_load_annotations()`.
+
+To support a dataset that is beyond the scope of `BaseCocoStyleDataset`, you may need to subclass from the `BaseDataset` provided by [MMEngine](https://github.com/open-mmlab/mmengine). Please refer to the [documents](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/basedataset.html) for details.
+
+### Pipeline
+
+Data augmentations and transformations during pre-processing are organized as a pipeline. Here is an example of typical pipelines:
+
+```Python
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+test_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+```
+
+In a keypoint detection task, data will be transformed among three scale spaces:
+
+- **Original Image Space**: the space where the images are stored. The sizes of different images are not necessarily the same
+
+- **Input Image Space**: the image space used for model input. All **images** and **annotations** will be transformed into this space, such as `256x256`, `256x192`, etc.
+
+- **Output Space**: the scale space where model outputs are located, such as `64x64(Heatmap)`,`1x1(Regression)`, etc. The supervision signal is also in this space during training
+
+Here is a diagram to show the workflow of data transformation among the three scale spaces:
+
+
+
+In MMPose, the modules used for data transformation are under `$MMPOSE/mmpose/datasets/transforms`, and their workflow is shown as follows:
+
+
+
+#### i. Augmentation
+
+Commonly used transforms are defined in `$MMPOSE/mmpose/datasets/transforms/common_transforms.py`, such as `RandomFlip`, `RandomHalfBody`, etc.
+
+For top-down methods, `Shift`, `Rotate`and `Resize` are implemented by `RandomBBoxTransform`**.** For bottom-up methods, `BottomupRandomAffine` is used.
+
+```{note}
+Most data transforms depend on `bbox_center` and `bbox_scale`, which can be obtained by `GetBBoxCenterScale`.
+```
+
+#### ii. Transformation
+
+Affine transformation is used to convert images and annotations from the original image space to the input space. This is done by `TopdownAffine` for top-down methods and `BottomupRandomAffine` for bottom-up methods.
+
+#### iii. Encoding
+
+In training phase, after the data is transformed from the original image space into the input space, it is necessary to use `GenerateTarget` to obtain the training target(e.g. Gaussian Heatmaps). We name this process **Encoding**. Conversely, the process of getting the corresponding coordinates from Gaussian Heatmaps is called **Decoding**.
+
+In MMPose, we collect Encoding and Decoding processes into a **Codec**, in which `encode()` and `decode()` are implemented.
+
+Currently we support the following types of Targets.
+
+- `heatmap`: Gaussian heatmaps
+- `keypoint_label`: keypoint representation (e.g. normalized coordinates)
+- `keypoint_xy_label`: axis-wise keypoint representation
+- `heatmap+keypoint_label`: Gaussian heatmaps and keypoint representation
+- `multiscale_heatmap`: multi-scale Gaussian heatmaps
+
+and the generated targets will be packed as follows.
+
+- `heatmaps`: Gaussian heatmaps
+- `keypoint_labels`: keypoint representation (e.g. normalized coordinates)
+- `keypoint_x_labels`: keypoint x-axis representation
+- `keypoint_y_labels`: keypoint y-axis representation
+- `keypoint_weights`: keypoint visibility and weights
+
+Note that we unify the data format of top-down and bottom-up methods, which means that a new dimension is added to represent different instances from the same image, in shape:
+
+```Python
+[batch_size, num_instances, num_keypoints, dim_coordinates]
+```
+
+- top-down: `[B, 1, K, D]`
+
+- Bottom-up: `[B, N, K, D]`
+
+The provided codecs are stored under `$MMPOSE/mmpose/codecs`.
+
+```{note}
+If you wish to customize a new codec, you can refer to [Codec](./user_guides/codecs.md) for more details.
+```
+
+#### iv. Packing
+
+After the data is transformed, you need to pack it using `PackPoseInputs`.
+
+This method converts the data stored in the dictionary `results` into standard data structures in MMPose, such as `InstanceData`, `PixelData`, `PoseDataSample`, etc.
+
+Specifically, we divide the data into `gt` (ground-truth) and `pred` (prediction), each of which has the following types:
+
+- **instances**(numpy.array): instance-level raw annotations or predictions in the original scale space
+- **instance_labels**(torch.tensor): instance-level training labels (e.g. normalized coordinates, keypoint visibility) in the output scale space
+- **fields**(torch.tensor): pixel-level training labels or predictions (e.g. Gaussian Heatmaps) in the output scale space
+
+The following is an example of the implementation of `PoseDataSample` under the hood:
+
+```Python
+def get_pose_data_sample(self):
+ # meta
+ pose_meta = dict(
+ img_shape=(600, 900), # [h, w, c]
+ crop_size=(256, 192), # [h, w]
+ heatmap_size=(64, 48), # [h, w]
+ )
+
+ # gt_instances
+ gt_instances = InstanceData()
+ gt_instances.bboxes = np.random.rand(1, 4)
+ gt_instances.keypoints = np.random.rand(1, 17, 2)
+
+ # gt_instance_labels
+ gt_instance_labels = InstanceData()
+ gt_instance_labels.keypoint_labels = torch.rand(1, 17, 2)
+ gt_instance_labels.keypoint_weights = torch.rand(1, 17)
+
+ # pred_instances
+ pred_instances = InstanceData()
+ pred_instances.keypoints = np.random.rand(1, 17, 2)
+ pred_instances.keypoint_scores = np.random.rand(1, 17)
+
+ # gt_fields
+ gt_fields = PixelData()
+ gt_fields.heatmaps = torch.rand(17, 64, 48)
+
+ # pred_fields
+ pred_fields = PixelData()
+ pred_fields.heatmaps = torch.rand(17, 64, 48)
+ data_sample = PoseDataSample(
+ gt_instances=gt_instances,
+ pred_instances=pred_instances,
+ gt_fields=gt_fields,
+ pred_fields=pred_fields,
+ metainfo=pose_meta)
+
+ return data_sample
+```
+
+## Step3: Model
+
+In MMPose 1.0, the model consists of the following components:
+
+- **Data Preprocessor**: perform data normalization and channel transposition
+
+- **Backbone**: used for feature extraction
+
+- **Neck**: GAP,FPN, etc. are optional
+
+- **Head**: used to implement the core algorithm and loss function
+
+We define a base class `BasePoseEstimator` for the model in `$MMPOSE/models/pose_estimators/base.py`. All models, e.g. `TopdownPoseEstimator`, should inherit from this base class and override the corresponding methods.
+
+Three modes are provided in `forward()` of the estimator:
+
+- `mode == 'loss'`: return the result of loss function for model training
+
+- `mode == 'predict'`: return the prediction result in the input space, used for model inference
+
+- `mode == 'tensor'`: return the model output in the output space, i.e. model forward propagation only, for model export
+
+Developers should build the components by calling the corresponding registry. Taking the top-down model as an example:
+
+```Python
+@MODELS.register_module()
+class TopdownPoseEstimator(BasePoseEstimator):
+ def __init__(self,
+ backbone: ConfigType,
+ neck: OptConfigType = None,
+ head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None):
+ super().__init__(data_preprocessor, init_cfg)
+
+ self.backbone = MODELS.build(backbone)
+
+ if neck is not None:
+ self.neck = MODELS.build(neck)
+
+ if head is not None:
+ self.head = MODELS.build(head)
+```
+
+### Data Preprocessor
+
+Starting from MMPose 1.0, we have added a new module to the model called data preprocessor, which performs data preprocessings like image normalization and channel transposition. It can benefit from the high computing power of devices like GPU, and improve the integrity in model export and deployment.
+
+A typical `data_preprocessor` in the config is as follows:
+
+```Python
+data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+```
+
+It will transpose the channel order of the input image from `bgr` to `rgb` and normalize the data according to `mean` and `std`.
+
+### Backbone
+
+MMPose provides some commonly used backbones under `$MMPOSE/mmpose/models/backbones`.
+
+In practice, developers often use pre-trained backbone weights for transfer learning, which can improve the performance of the model on small datasets.
+
+In MMPose, you can use the pre-trained weights by setting `init_cfg` in config:
+
+```Python
+init_cfg=dict(
+ type='Pretrained',
+ checkpoint='PATH/TO/YOUR_MODEL_WEIGHTS.pth'),
+```
+
+If you want to load a checkpoint to your backbone, you should specify the `prefix`:
+
+```Python
+init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='PATH/TO/YOUR_CHECKPOINT.pth'),
+```
+
+`checkpoint` can be either a local path or a download link. Thus, if you wish to use a pre-trained model provided by Torchvision(e.g. ResNet50), you can simply use:
+
+```Python
+init_cfg=dict(
+ type='Pretrained',
+ checkpoint='torchvision://resnet50')
+```
+
+In addition to these commonly used backbones, you can easily use backbones from other repositories in the OpenMMLab family such as MMClassification, which all share the same config system and provide pre-trained weights.
+
+It should be emphasized that if you add a new backbone, you need to register it by doing:
+
+```Python
+@MODELS.register_module()
+class YourBackbone(BaseBackbone):
+```
+
+Besides, import it in `$MMPOSE/mmpose/models/backbones/__init__.py`, and add it to `__all__`.
+
+### Neck
+
+Neck is usually a module between Backbone and Head, which is used in some algorithms. Here are some commonly used Neck:
+
+- Global Average Pooling (GAP)
+
+- Feature Pyramid Networks (FPN)
+
+- Feature Map Processor (FMP)
+
+ The `FeatureMapProcessor` is a flexible PyTorch module designed to transform the feature outputs generated by backbones into a format suitable for heads. It achieves this by utilizing non-parametric operations such as selecting, concatenating, and rescaling. Below are some examples along with their corresponding configurations:
+
+ - Select operation
+
+ ```python
+ neck=dict(type='FeatureMapProcessor', select_index=0)
+ ```
+
+
+
+ - Concatenate operation
+
+ ```python
+ neck=dict(type='FeatureMapProcessor', concat=True)
+ ```
+
+
+
+ Note that all feature maps will be resized to match the shape of the first feature map (index 0) prior to concatenation.
+
+ - rescale operation
+
+ ```python
+ neck=dict(type='FeatureMapProcessor', scale_factor=2.0)
+ ```
+
+
+
+### Head
+
+Generally speaking, Head is often the core of an algorithm, which is used to make predictions and perform loss calculation.
+
+Modules related to Head in MMPose are defined under `$MMPOSE/mmpose/models/heads`, and developers need to inherit the base class `BaseHead` when customizing Head and override the following methods:
+
+- forward()
+
+- predict()
+
+- loss()
+
+Specifically, `predict()` method needs to return pose predictions in the image space, which is obtained from the model output though the decoding function provided by the codec. We implement this process in `BaseHead.decode()`.
+
+On the other hand, we will perform test-time augmentation(TTA) in `predict()`.
+
+A commonly used TTA is `flip_test`, namely, an image and its flipped version are sent into the model to inference, and the output of the flipped version will be flipped back, then average them to stabilize the prediction.
+
+Here is an example of `predict()` in `RegressionHead`:
+
+```Python
+def predict(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ test_cfg: ConfigType = {}) -> Predictions:
+ """Predict results from outputs."""
+
+ if test_cfg.get('flip_test', False):
+ # TTA: flip test -> feats = [orig, flipped]
+ assert isinstance(feats, list) and len(feats) == 2
+ flip_indices = batch_data_samples[0].metainfo['flip_indices']
+ input_size = batch_data_samples[0].metainfo['input_size']
+ _feats, _feats_flip = feats
+ _batch_coords = self.forward(_feats)
+ _batch_coords_flip = flip_coordinates(
+ self.forward(_feats_flip),
+ flip_indices=flip_indices,
+ shift_coords=test_cfg.get('shift_coords', True),
+ input_size=input_size)
+ batch_coords = (_batch_coords + _batch_coords_flip) * 0.5
+ else:
+ batch_coords = self.forward(feats) # (B, K, D)
+
+ batch_coords.unsqueeze_(dim=1) # (B, N, K, D)
+ preds = self.decode(batch_coords)
+```
+
+The `loss()` not only performs the calculation of loss functions, but also the calculation of training-time metrics such as pose accuracy. The results are carried by a dictionary `losses`:
+
+```Python
+ # calculate accuracy
+_, avg_acc, _ = keypoint_pck_accuracy(
+ pred=to_numpy(pred_coords),
+ gt=to_numpy(keypoint_labels),
+ mask=to_numpy(keypoint_weights) > 0,
+ thr=0.05,
+ norm_factor=np.ones((pred_coords.size(0), 2), dtype=np.float32))
+
+acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
+losses.update(acc_pose=acc_pose)
+```
+
+The data of each batch is packaged into `batch_data_samples`. Taking the Regression-based method as an example, the normalized coordinates and keypoint weights can be obtained as follows:
+
+```Python
+keypoint_labels = torch.cat(
+ [d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
+keypoint_weights = torch.cat([
+ d.gt_instance_labels.keypoint_weights for d in batch_data_samples
+])
+```
+
+Here is the complete implementation of `loss()` in `RegressionHead`:
+
+```Python
+def loss(self,
+ inputs: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: ConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples."""
+
+ pred_outputs = self.forward(inputs)
+
+ keypoint_labels = torch.cat(
+ [d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
+ keypoint_weights = torch.cat([
+ d.gt_instance_labels.keypoint_weights for d in batch_data_samples
+ ])
+
+ # calculate losses
+ losses = dict()
+ loss = self.loss_module(pred_outputs, keypoint_labels,
+ keypoint_weights.unsqueeze(-1))
+
+ if isinstance(loss, dict):
+ losses.update(loss)
+ else:
+ losses.update(loss_kpt=loss)
+
+ # calculate accuracy
+ _, avg_acc, _ = keypoint_pck_accuracy(
+ pred=to_numpy(pred_outputs),
+ gt=to_numpy(keypoint_labels),
+ mask=to_numpy(keypoint_weights) > 0,
+ thr=0.05,
+ norm_factor=np.ones((pred_outputs.size(0), 2), dtype=np.float32))
+ acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
+ losses.update(acc_pose=acc_pose)
+
+ return losses
+```
diff --git a/docs/en/index.rst b/docs/en/index.rst
index 044b54be0f..fe346656ee 100644
--- a/docs/en/index.rst
+++ b/docs/en/index.rst
@@ -1,116 +1,116 @@
-Welcome to MMPose's documentation!
-==================================
-
-You can change the documentation language at the lower-left corner of the page.
-
-您可以在页面左下角切换文档语言。
-
-.. toctree::
- :maxdepth: 1
- :caption: Get Started
-
- overview.md
- installation.md
- guide_to_framework.md
- demos.md
- contribution_guide.md
- faq.md
-
-.. toctree::
- :maxdepth: 1
- :caption: User Guides
-
- user_guides/inference.md
- user_guides/configs.md
- user_guides/prepare_datasets.md
- user_guides/train_and_test.md
-
-.. toctree::
- :maxdepth: 1
- :caption: Advanced Guides
-
- advanced_guides/codecs.md
- advanced_guides/dataflow.md
- advanced_guides/implement_new_models.md
- advanced_guides/customize_datasets.md
- advanced_guides/customize_transforms.md
- advanced_guides/customize_optimizer.md
- advanced_guides/customize_logging.md
- advanced_guides/how_to_deploy.md
- advanced_guides/model_analysis.md
-
-.. toctree::
- :maxdepth: 1
- :caption: Migration
-
- migration.md
-
-.. toctree::
- :maxdepth: 2
- :caption: Model Zoo
-
- model_zoo.txt
- model_zoo/body_2d_keypoint.md
- model_zoo/body_3d_keypoint.md
- model_zoo/face_2d_keypoint.md
- model_zoo/hand_2d_keypoint.md
- model_zoo/wholebody_2d_keypoint.md
- model_zoo/animal_2d_keypoint.md
-
-.. toctree::
- :maxdepth: 2
- :caption: Model Zoo (by paper)
-
- model_zoo_papers/algorithms.md
- model_zoo_papers/backbones.md
- model_zoo_papers/techniques.md
- model_zoo_papers/datasets.md
-
-.. toctree::
- :maxdepth: 2
- :caption: Dataset Zoo
-
- dataset_zoo.md
- dataset_zoo/2d_body_keypoint.md
- dataset_zoo/2d_wholebody_keypoint.md
- dataset_zoo/2d_face_keypoint.md
- dataset_zoo/2d_hand_keypoint.md
- dataset_zoo/2d_fashion_landmark.md
- dataset_zoo/2d_animal_keypoint.md
- dataset_zoo/3d_body_keypoint.md
- dataset_zoo/3d_hand_keypoint.md
- dataset_zoo/dataset_tools.md
-
-.. toctree::
- :maxdepth: 1
- :caption: Projects
-
- projects/community_projects.md
- projects/projects.md
-
-.. toctree::
- :maxdepth: 1
- :caption: Notes
-
- notes/ecosystem.md
- notes/changelog.md
- notes/benchmark.md
- notes/pytorch_2.md
-
-.. toctree::
- :caption: API Reference
-
- api.rst
-
-.. toctree::
- :caption: Switch Language
-
- switch_language.md
-
-
-
-Indices and tables
-==================
-
-* :ref:`genindex`
-* :ref:`search`
+Welcome to MMPose's documentation!
+==================================
+
+You can change the documentation language at the lower-left corner of the page.
+
+您可以在页面左下角切换文档语言。
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Get Started
+
+ overview.md
+ installation.md
+ guide_to_framework.md
+ demos.md
+ contribution_guide.md
+ faq.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: User Guides
+
+ user_guides/inference.md
+ user_guides/configs.md
+ user_guides/prepare_datasets.md
+ user_guides/train_and_test.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Advanced Guides
+
+ advanced_guides/codecs.md
+ advanced_guides/dataflow.md
+ advanced_guides/implement_new_models.md
+ advanced_guides/customize_datasets.md
+ advanced_guides/customize_transforms.md
+ advanced_guides/customize_optimizer.md
+ advanced_guides/customize_logging.md
+ advanced_guides/how_to_deploy.md
+ advanced_guides/model_analysis.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Migration
+
+ migration.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Model Zoo
+
+ model_zoo.txt
+ model_zoo/body_2d_keypoint.md
+ model_zoo/body_3d_keypoint.md
+ model_zoo/face_2d_keypoint.md
+ model_zoo/hand_2d_keypoint.md
+ model_zoo/wholebody_2d_keypoint.md
+ model_zoo/animal_2d_keypoint.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Model Zoo (by paper)
+
+ model_zoo_papers/algorithms.md
+ model_zoo_papers/backbones.md
+ model_zoo_papers/techniques.md
+ model_zoo_papers/datasets.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Dataset Zoo
+
+ dataset_zoo.md
+ dataset_zoo/2d_body_keypoint.md
+ dataset_zoo/2d_wholebody_keypoint.md
+ dataset_zoo/2d_face_keypoint.md
+ dataset_zoo/2d_hand_keypoint.md
+ dataset_zoo/2d_fashion_landmark.md
+ dataset_zoo/2d_animal_keypoint.md
+ dataset_zoo/3d_body_keypoint.md
+ dataset_zoo/3d_hand_keypoint.md
+ dataset_zoo/dataset_tools.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Projects
+
+ projects/community_projects.md
+ projects/projects.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Notes
+
+ notes/ecosystem.md
+ notes/changelog.md
+ notes/benchmark.md
+ notes/pytorch_2.md
+
+.. toctree::
+ :caption: API Reference
+
+ api.rst
+
+.. toctree::
+ :caption: Switch Language
+
+ switch_language.md
+
+
+
+Indices and tables
+==================
+
+* :ref:`genindex`
+* :ref:`search`
diff --git a/docs/en/installation.md b/docs/en/installation.md
index 47db25bb5f..987d754929 100644
--- a/docs/en/installation.md
+++ b/docs/en/installation.md
@@ -1,245 +1,245 @@
-# Installation
-
-We recommend that users follow our best practices to install MMPose. However, the whole process is highly customizable. See [Customize Installation](#customize-installation) section for more information.
-
-- [Installation](#installation)
- - [Prerequisites](#prerequisites)
- - [Best Practices](#best-practices)
- - [Build MMPose from source](#build-mmpose-from-source)
- - [Install as a Python package](#install-as-a-python-package)
- - [Customize Installation](#customize-installation)
- - [CUDA versions](#cuda-versions)
- - [Install MMEngine without MIM](#install-mmengine-without-mim)
- - [Install MMCV without MIM](#install-mmcv-without-mim)
- - [Install on CPU-only platforms](#install-on-cpu-only-platforms)
- - [Install on Google Colab](#install-on-google-colab)
- - [Using MMPose with Docker](#using-mmpose-with-docker)
- - [Verify the installation](#verify-the-installation)
- - [Trouble shooting](#trouble-shooting)
-
-
-
-## Prerequisites
-
-In this section we demonstrate how to prepare an environment with PyTorch.
-
-MMPose works on Linux, Windows and macOS. It requires Python 3.7+, CUDA 9.2+ and PyTorch 1.8+.
-
-If you are experienced with PyTorch and have already installed it, you can skip this part and jump to the [MMPose Installation](#install-mmpose). Otherwise, you can follow these steps for the preparation.
-
-**Step 0.** Download and install Miniconda from the [official website](https://docs.conda.io/en/latest/miniconda.html).
-
-**Step 1.** Create a conda environment and activate it.
-
-```shell
-conda create --name openmmlab python=3.8 -y
-conda activate openmmlab
-```
-
-**Step 2.** Install PyTorch following [official instructions](https://pytorch.org/get-started/locally/), e.g.
-
-On GPU platforms:
-
-```shell
-conda install pytorch torchvision -c pytorch
-```
-
-```{warning}
-This command will automatically install the latest version PyTorch and cudatoolkit, please check whether they match your environment.
-```
-
-On CPU platforms:
-
-```shell
-conda install pytorch torchvision cpuonly -c pytorch
-```
-
-**Step 3.** Install [MMEngine](https://github.com/open-mmlab/mmengine) and [MMCV](https://github.com/open-mmlab/mmcv/tree/2.x) using [MIM](https://github.com/open-mmlab/mim).
-
-```shell
-pip install -U openmim
-mim install mmengine
-mim install "mmcv>=2.0.1"
-```
-
-Note that some of the demo scripts in MMPose require [MMDetection](https://github.com/open-mmlab/mmdetection) (mmdet) for human detection. If you want to run these demo scripts with mmdet, you can easily install mmdet as a dependency by running:
-
-```shell
-mim install "mmdet>=3.1.0"
-```
-
-## Best Practices
-
-### Build MMPose from source
-
-To develop and run mmpose directly, install it from source:
-
-```shell
-git clone https://github.com/open-mmlab/mmpose.git
-cd mmpose
-pip install -r requirements.txt
-pip install -v -e .
-# "-v" means verbose, or more output
-# "-e" means installing a project in editable mode,
-# thus any local modifications made to the code will take effect without reinstallation.
-```
-
-### Install as a Python package
-
-To use mmpose as a dependency or third-party package, install it with pip:
-
-```shell
-mim install "mmpose>=1.1.0"
-```
-
-## Verify the installation
-
-To verify that MMPose is installed correctly, you can run an inference demo with the following steps.
-
-**Step 1.** We need to download config and checkpoint files.
-
-```shell
-mim download mmpose --config td-hm_hrnet-w48_8xb32-210e_coco-256x192 --dest .
-```
-
-The downloading will take several seconds or more, depending on your network environment. When it is done, you will find two files `td-hm_hrnet-w48_8xb32-210e_coco-256x192.py` and `hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth` in your current folder.
-
-**Step 2.** Run the inference demo.
-
-Option (A). If you install mmpose from source, just run the following command under the folder `$MMPOSE`:
-
-```shell
-python demo/image_demo.py \
- tests/data/coco/000000000785.jpg \
- td-hm_hrnet-w48_8xb32-210e_coco-256x192.py \
- hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \
- --out-file vis_results.jpg \
- --draw-heatmap
-```
-
-If everything goes fine, you will be able to get the following visualization result from `vis_results.jpg` in your current folder, which displays the predicted keypoints and heatmaps overlaid on the person in the image.
-
-
-
-Option (B). If you install mmpose with pip, open you python interpreter and copy & paste the following codes.
-
-```python
-from mmpose.apis import inference_topdown, init_model
-from mmpose.utils import register_all_modules
-
-register_all_modules()
-
-config_file = 'td-hm_hrnet-w48_8xb32-210e_coco-256x192.py'
-checkpoint_file = 'hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth'
-model = init_model(config_file, checkpoint_file, device='cpu') # or device='cuda:0'
-
-# please prepare an image with person
-results = inference_topdown(model, 'demo.jpg')
-```
-
-The `demo.jpg` can be downloaded from [Github](https://raw.githubusercontent.com/open-mmlab/mmpose/main/tests/data/coco/000000000785.jpg).
-
-The inference results will be a list of `PoseDataSample`, and the predictions are in the `pred_instances`, indicating the detected keypoint locations and scores.
-
-## Customize Installation
-
-### CUDA versions
-
-When installing PyTorch, you need to specify the version of CUDA. If you are not clear on which to choose, follow our recommendations:
-
-- For Ampere-based NVIDIA GPUs, such as GeForce 30 series and NVIDIA A100, CUDA 11 is a must.
-- For older NVIDIA GPUs, CUDA 11 is backward compatible, but CUDA 10.2 offers better compatibility and is more lightweight.
-
-Please make sure the GPU driver satisfies the minimum version requirements. See [this table](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions) for more information.
-
-Installing CUDA runtime libraries is enough if you follow our best practices, because no CUDA code will be compiled locally. However if you hope to compile MMCV from source or develop other CUDA operators, you need to install the complete CUDA toolkit from NVIDIA's [website](https://developer.nvidia.com/cuda-downloads), and its version should match the CUDA version of PyTorch. i.e., the specified version of cudatoolkit in `conda install` command.
-
-### Install MMEngine without MIM
-
-To install MMEngine with pip instead of MIM, please follow [MMEngine installation guides](https://mmengine.readthedocs.io/zh_CN/latest/get_started/installation.html).
-
-For example, you can install MMEngine by the following command.
-
-```shell
-pip install mmengine
-```
-
-### Install MMCV without MIM
-
-MMCV contains C++ and CUDA extensions, thus depending on PyTorch in a complex way. MIM solves such dependencies automatically and makes the installation easier. However, it is not a must.
-
-To install MMCV with pip instead of MIM, please follow [MMCV installation guides](https://mmcv.readthedocs.io/en/2.x/get_started/installation.html). This requires manually specifying a find-url based on PyTorch version and its CUDA version.
-
-For example, the following command install mmcv built for PyTorch 1.10.x and CUDA 11.3.
-
-```shell
-pip install 'mmcv>=2.0.1' -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10/index.html
-```
-
-### Install on CPU-only platforms
-
-MMPose can be built for CPU only environment. In CPU mode you can train, test or inference a model.
-
-However, some functionalities are missing in this mode, usually GPU-compiled ops like `Deformable Convolution`. Most models in MMPose don't depend on these ops, but if you try to train/test/infer a model containing these ops, an error will be raised.
-
-### Install on Google Colab
-
-[Google Colab](https://colab.research.google.com/) usually has PyTorch installed,
-thus we only need to install MMEngine, MMCV and MMPose with the following commands.
-
-**Step 1.** Install [MMEngine](https://github.com/open-mmlab/mmengine) and [MMCV](https://github.com/open-mmlab/mmcv/tree/2.x) using [MIM](https://github.com/open-mmlab/mim).
-
-```shell
-!pip3 install openmim
-!mim install mmengine
-!mim install "mmcv>=2.0.1"
-```
-
-**Step 2.** Install MMPose from the source.
-
-```shell
-!git clone https://github.com/open-mmlab/mmpose.git
-%cd mmpose
-!pip install -e .
-```
-
-**Step 3.** Verification.
-
-```python
-import mmpose
-print(mmpose.__version__)
-# Example output: 1.1.0
-```
-
-```{note}
-Note that within Jupyter, the exclamation mark `!` is used to call external executables and `%cd` is a [magic command](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-cd) to change the current working directory of Python.
-```
-
-### Using MMPose with Docker
-
-We provide a [Dockerfile](https://github.com/open-mmlab/mmpose/blob/master/docker/Dockerfile) to build an image. Ensure that your [docker version](https://docs.docker.com/engine/install/) >=19.03.
-
-```shell
-# build an image with PyTorch 1.8.0, CUDA 10.1, CUDNN 7.
-# If you prefer other versions, just modified the Dockerfile
-docker build -t mmpose docker/
-```
-
-**Important:** Make sure you've installed the [nvidia-container-toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker).
-
-Run it with
-
-```shell
-docker run --gpus all --shm-size=8g -it -v {DATA_DIR}:/mmpose/data mmpose
-```
-
-`{DATA_DIR}` is your local folder containing all the datasets for mmpose.
-
-```{note}
-If you encounter the error message like `permission denied`, please add `sudo` at the start of the command and try it again.
-```
-
-## Trouble shooting
-
-If you have some issues during the installation, please first view the [FAQ](./faq.md) page.
-You may [open an issue](https://github.com/open-mmlab/mmpose/issues/new/choose) on GitHub if no solution is found.
+# Installation
+
+We recommend that users follow our best practices to install MMPose. However, the whole process is highly customizable. See [Customize Installation](#customize-installation) section for more information.
+
+- [Installation](#installation)
+ - [Prerequisites](#prerequisites)
+ - [Best Practices](#best-practices)
+ - [Build MMPose from source](#build-mmpose-from-source)
+ - [Install as a Python package](#install-as-a-python-package)
+ - [Customize Installation](#customize-installation)
+ - [CUDA versions](#cuda-versions)
+ - [Install MMEngine without MIM](#install-mmengine-without-mim)
+ - [Install MMCV without MIM](#install-mmcv-without-mim)
+ - [Install on CPU-only platforms](#install-on-cpu-only-platforms)
+ - [Install on Google Colab](#install-on-google-colab)
+ - [Using MMPose with Docker](#using-mmpose-with-docker)
+ - [Verify the installation](#verify-the-installation)
+ - [Trouble shooting](#trouble-shooting)
+
+
+
+## Prerequisites
+
+In this section we demonstrate how to prepare an environment with PyTorch.
+
+MMPose works on Linux, Windows and macOS. It requires Python 3.7+, CUDA 9.2+ and PyTorch 1.8+.
+
+If you are experienced with PyTorch and have already installed it, you can skip this part and jump to the [MMPose Installation](#install-mmpose). Otherwise, you can follow these steps for the preparation.
+
+**Step 0.** Download and install Miniconda from the [official website](https://docs.conda.io/en/latest/miniconda.html).
+
+**Step 1.** Create a conda environment and activate it.
+
+```shell
+conda create --name openmmlab python=3.8 -y
+conda activate openmmlab
+```
+
+**Step 2.** Install PyTorch following [official instructions](https://pytorch.org/get-started/locally/), e.g.
+
+On GPU platforms:
+
+```shell
+conda install pytorch torchvision -c pytorch
+```
+
+```{warning}
+This command will automatically install the latest version PyTorch and cudatoolkit, please check whether they match your environment.
+```
+
+On CPU platforms:
+
+```shell
+conda install pytorch torchvision cpuonly -c pytorch
+```
+
+**Step 3.** Install [MMEngine](https://github.com/open-mmlab/mmengine) and [MMCV](https://github.com/open-mmlab/mmcv/tree/2.x) using [MIM](https://github.com/open-mmlab/mim).
+
+```shell
+pip install -U openmim
+mim install mmengine
+mim install "mmcv>=2.0.1"
+```
+
+Note that some of the demo scripts in MMPose require [MMDetection](https://github.com/open-mmlab/mmdetection) (mmdet) for human detection. If you want to run these demo scripts with mmdet, you can easily install mmdet as a dependency by running:
+
+```shell
+mim install "mmdet>=3.1.0"
+```
+
+## Best Practices
+
+### Build MMPose from source
+
+To develop and run mmpose directly, install it from source:
+
+```shell
+git clone https://github.com/open-mmlab/mmpose.git
+cd mmpose
+pip install -r requirements.txt
+pip install -v -e .
+# "-v" means verbose, or more output
+# "-e" means installing a project in editable mode,
+# thus any local modifications made to the code will take effect without reinstallation.
+```
+
+### Install as a Python package
+
+To use mmpose as a dependency or third-party package, install it with pip:
+
+```shell
+mim install "mmpose>=1.1.0"
+```
+
+## Verify the installation
+
+To verify that MMPose is installed correctly, you can run an inference demo with the following steps.
+
+**Step 1.** We need to download config and checkpoint files.
+
+```shell
+mim download mmpose --config td-hm_hrnet-w48_8xb32-210e_coco-256x192 --dest .
+```
+
+The downloading will take several seconds or more, depending on your network environment. When it is done, you will find two files `td-hm_hrnet-w48_8xb32-210e_coco-256x192.py` and `hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth` in your current folder.
+
+**Step 2.** Run the inference demo.
+
+Option (A). If you install mmpose from source, just run the following command under the folder `$MMPOSE`:
+
+```shell
+python demo/image_demo.py \
+ tests/data/coco/000000000785.jpg \
+ td-hm_hrnet-w48_8xb32-210e_coco-256x192.py \
+ hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \
+ --out-file vis_results.jpg \
+ --draw-heatmap
+```
+
+If everything goes fine, you will be able to get the following visualization result from `vis_results.jpg` in your current folder, which displays the predicted keypoints and heatmaps overlaid on the person in the image.
+
+
+
+Option (B). If you install mmpose with pip, open you python interpreter and copy & paste the following codes.
+
+```python
+from mmpose.apis import inference_topdown, init_model
+from mmpose.utils import register_all_modules
+
+register_all_modules()
+
+config_file = 'td-hm_hrnet-w48_8xb32-210e_coco-256x192.py'
+checkpoint_file = 'hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth'
+model = init_model(config_file, checkpoint_file, device='cpu') # or device='cuda:0'
+
+# please prepare an image with person
+results = inference_topdown(model, 'demo.jpg')
+```
+
+The `demo.jpg` can be downloaded from [Github](https://raw.githubusercontent.com/open-mmlab/mmpose/main/tests/data/coco/000000000785.jpg).
+
+The inference results will be a list of `PoseDataSample`, and the predictions are in the `pred_instances`, indicating the detected keypoint locations and scores.
+
+## Customize Installation
+
+### CUDA versions
+
+When installing PyTorch, you need to specify the version of CUDA. If you are not clear on which to choose, follow our recommendations:
+
+- For Ampere-based NVIDIA GPUs, such as GeForce 30 series and NVIDIA A100, CUDA 11 is a must.
+- For older NVIDIA GPUs, CUDA 11 is backward compatible, but CUDA 10.2 offers better compatibility and is more lightweight.
+
+Please make sure the GPU driver satisfies the minimum version requirements. See [this table](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions) for more information.
+
+Installing CUDA runtime libraries is enough if you follow our best practices, because no CUDA code will be compiled locally. However if you hope to compile MMCV from source or develop other CUDA operators, you need to install the complete CUDA toolkit from NVIDIA's [website](https://developer.nvidia.com/cuda-downloads), and its version should match the CUDA version of PyTorch. i.e., the specified version of cudatoolkit in `conda install` command.
+
+### Install MMEngine without MIM
+
+To install MMEngine with pip instead of MIM, please follow [MMEngine installation guides](https://mmengine.readthedocs.io/zh_CN/latest/get_started/installation.html).
+
+For example, you can install MMEngine by the following command.
+
+```shell
+pip install mmengine
+```
+
+### Install MMCV without MIM
+
+MMCV contains C++ and CUDA extensions, thus depending on PyTorch in a complex way. MIM solves such dependencies automatically and makes the installation easier. However, it is not a must.
+
+To install MMCV with pip instead of MIM, please follow [MMCV installation guides](https://mmcv.readthedocs.io/en/2.x/get_started/installation.html). This requires manually specifying a find-url based on PyTorch version and its CUDA version.
+
+For example, the following command install mmcv built for PyTorch 1.10.x and CUDA 11.3.
+
+```shell
+pip install 'mmcv>=2.0.1' -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10/index.html
+```
+
+### Install on CPU-only platforms
+
+MMPose can be built for CPU only environment. In CPU mode you can train, test or inference a model.
+
+However, some functionalities are missing in this mode, usually GPU-compiled ops like `Deformable Convolution`. Most models in MMPose don't depend on these ops, but if you try to train/test/infer a model containing these ops, an error will be raised.
+
+### Install on Google Colab
+
+[Google Colab](https://colab.research.google.com/) usually has PyTorch installed,
+thus we only need to install MMEngine, MMCV and MMPose with the following commands.
+
+**Step 1.** Install [MMEngine](https://github.com/open-mmlab/mmengine) and [MMCV](https://github.com/open-mmlab/mmcv/tree/2.x) using [MIM](https://github.com/open-mmlab/mim).
+
+```shell
+!pip3 install openmim
+!mim install mmengine
+!mim install "mmcv>=2.0.1"
+```
+
+**Step 2.** Install MMPose from the source.
+
+```shell
+!git clone https://github.com/open-mmlab/mmpose.git
+%cd mmpose
+!pip install -e .
+```
+
+**Step 3.** Verification.
+
+```python
+import mmpose
+print(mmpose.__version__)
+# Example output: 1.1.0
+```
+
+```{note}
+Note that within Jupyter, the exclamation mark `!` is used to call external executables and `%cd` is a [magic command](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-cd) to change the current working directory of Python.
+```
+
+### Using MMPose with Docker
+
+We provide a [Dockerfile](https://github.com/open-mmlab/mmpose/blob/master/docker/Dockerfile) to build an image. Ensure that your [docker version](https://docs.docker.com/engine/install/) >=19.03.
+
+```shell
+# build an image with PyTorch 1.8.0, CUDA 10.1, CUDNN 7.
+# If you prefer other versions, just modified the Dockerfile
+docker build -t mmpose docker/
+```
+
+**Important:** Make sure you've installed the [nvidia-container-toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker).
+
+Run it with
+
+```shell
+docker run --gpus all --shm-size=8g -it -v {DATA_DIR}:/mmpose/data mmpose
+```
+
+`{DATA_DIR}` is your local folder containing all the datasets for mmpose.
+
+```{note}
+If you encounter the error message like `permission denied`, please add `sudo` at the start of the command and try it again.
+```
+
+## Trouble shooting
+
+If you have some issues during the installation, please first view the [FAQ](./faq.md) page.
+You may [open an issue](https://github.com/open-mmlab/mmpose/issues/new/choose) on GitHub if no solution is found.
diff --git a/docs/en/make.bat b/docs/en/make.bat
index 922152e96a..2119f51099 100644
--- a/docs/en/make.bat
+++ b/docs/en/make.bat
@@ -1,35 +1,35 @@
-@ECHO OFF
-
-pushd %~dp0
-
-REM Command file for Sphinx documentation
-
-if "%SPHINXBUILD%" == "" (
- set SPHINXBUILD=sphinx-build
-)
-set SOURCEDIR=.
-set BUILDDIR=_build
-
-if "%1" == "" goto help
-
-%SPHINXBUILD% >NUL 2>NUL
-if errorlevel 9009 (
- echo.
- echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
- echo.installed, then set the SPHINXBUILD environment variable to point
- echo.to the full path of the 'sphinx-build' executable. Alternatively you
- echo.may add the Sphinx directory to PATH.
- echo.
- echo.If you don't have Sphinx installed, grab it from
- echo.http://sphinx-doc.org/
- exit /b 1
-)
-
-%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
-goto end
-
-:help
-%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
-
-:end
-popd
+@ECHO OFF
+
+pushd %~dp0
+
+REM Command file for Sphinx documentation
+
+if "%SPHINXBUILD%" == "" (
+ set SPHINXBUILD=sphinx-build
+)
+set SOURCEDIR=.
+set BUILDDIR=_build
+
+if "%1" == "" goto help
+
+%SPHINXBUILD% >NUL 2>NUL
+if errorlevel 9009 (
+ echo.
+ echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
+ echo.installed, then set the SPHINXBUILD environment variable to point
+ echo.to the full path of the 'sphinx-build' executable. Alternatively you
+ echo.may add the Sphinx directory to PATH.
+ echo.
+ echo.If you don't have Sphinx installed, grab it from
+ echo.http://sphinx-doc.org/
+ exit /b 1
+)
+
+%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+goto end
+
+:help
+%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+
+:end
+popd
diff --git a/docs/en/merge_docs.sh b/docs/en/merge_docs.sh
index 23af31dd56..431b27a312 100644
--- a/docs/en/merge_docs.sh
+++ b/docs/en/merge_docs.sh
@@ -1,31 +1,31 @@
-#!/usr/bin/env bash
-# Copyright (c) OpenMMLab. All rights reserved.
-
-sed -i '$a\\n' ../../demo/docs/en/*_demo.md
-cat ../../demo/docs/en/*_demo.md | sed "s/^## 2D\(.*\)Demo/##\1Estimation/" | sed "s/md###t/html#t/g" | sed '1i\# Demos\n' | sed 's=](/docs/en/=](/=g' | sed 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' >demos.md
-
- # remove /docs/ for link used in doc site
-sed -i 's=](/docs/en/=](=g' overview.md
-sed -i 's=](/docs/en/=](=g' installation.md
-sed -i 's=](/docs/en/=](=g' quick_run.md
-sed -i 's=](/docs/en/=](=g' migration.md
-sed -i 's=](/docs/en/=](=g' ./model_zoo/*.md
-sed -i 's=](/docs/en/=](=g' ./model_zoo_papers/*.md
-sed -i 's=](/docs/en/=](=g' ./user_guides/*.md
-sed -i 's=](/docs/en/=](=g' ./advanced_guides/*.md
-sed -i 's=](/docs/en/=](=g' ./dataset_zoo/*.md
-sed -i 's=](/docs/en/=](=g' ./notes/*.md
-sed -i 's=](/docs/en/=](=g' ./projects/*.md
-
-
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' overview.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' installation.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' quick_run.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' migration.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./advanced_guides/*.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./model_zoo/*.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./model_zoo_papers/*.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./user_guides/*.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./dataset_zoo/*.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./notes/*.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./projects/*.md
+#!/usr/bin/env bash
+# Copyright (c) OpenMMLab. All rights reserved.
+
+sed -i '$a\\n' ../../demo/docs/en/*_demo.md
+cat ../../demo/docs/en/*_demo.md | sed "s/^## 2D\(.*\)Demo/##\1Estimation/" | sed "s/md###t/html#t/g" | sed '1i\# Demos\n' | sed 's=](/docs/en/=](/=g' | sed 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' >demos.md
+
+ # remove /docs/ for link used in doc site
+sed -i 's=](/docs/en/=](=g' overview.md
+sed -i 's=](/docs/en/=](=g' installation.md
+sed -i 's=](/docs/en/=](=g' quick_run.md
+sed -i 's=](/docs/en/=](=g' migration.md
+sed -i 's=](/docs/en/=](=g' ./model_zoo/*.md
+sed -i 's=](/docs/en/=](=g' ./model_zoo_papers/*.md
+sed -i 's=](/docs/en/=](=g' ./user_guides/*.md
+sed -i 's=](/docs/en/=](=g' ./advanced_guides/*.md
+sed -i 's=](/docs/en/=](=g' ./dataset_zoo/*.md
+sed -i 's=](/docs/en/=](=g' ./notes/*.md
+sed -i 's=](/docs/en/=](=g' ./projects/*.md
+
+
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' overview.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' installation.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' quick_run.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' migration.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./advanced_guides/*.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./model_zoo/*.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./model_zoo_papers/*.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./user_guides/*.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./dataset_zoo/*.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./notes/*.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./projects/*.md
diff --git a/docs/en/migration.md b/docs/en/migration.md
index 70ed0b5a52..56373b25aa 100644
--- a/docs/en/migration.md
+++ b/docs/en/migration.md
@@ -1,210 +1,210 @@
-# How to Migrate MMPose 0.x Projects to MMPose 1.0
-
-MMPose 1.0 has been refactored extensively and addressed many legacy issues. Most of the code in MMPose 1.0 will not be compatible with 0.x version.
-
-To try our best to help you migrate your code and model, here are some major changes:
-
-## Data Transformation
-
-### Translation, Rotation and Scaling
-
-The transformation methods `TopDownRandomShiftBboxCenter` and `TopDownGetRandomScaleRotation` in old version, will be merged into `RandomBBoxTransform`.
-
-```Python
-@TRANSFORMS.register_module()
-class RandomBBoxTransform(BaseTransform):
- r"""Rnadomly shift, resize and rotate the bounding boxes.
-
- Required Keys:
-
- - bbox_center
- - bbox_scale
-
- Modified Keys:
-
- - bbox_center
- - bbox_scale
-
- Added Keys:
- - bbox_rotation
-
- Args:
- shift_factor (float): Randomly shift the bbox in range
- :math:`[-dx, dx]` and :math:`[-dy, dy]` in X and Y directions,
- where :math:`dx(y) = x(y)_scale \cdot shift_factor` in pixels.
- Defaults to 0.16
- shift_prob (float): Probability of applying random shift. Defaults to
- 0.3
- scale_factor (Tuple[float, float]): Randomly resize the bbox in range
- :math:`[scale_factor[0], scale_factor[1]]`. Defaults to (0.5, 1.5)
- scale_prob (float): Probability of applying random resizing. Defaults
- to 1.0
- rotate_factor (float): Randomly rotate the bbox in
- :math:`[-rotate_factor, rotate_factor]` in degrees. Defaults
- to 80.0
- rotate_prob (float): Probability of applying random rotation. Defaults
- to 0.6
- """
-
- def __init__(self,
- shift_factor: float = 0.16,
- shift_prob: float = 0.3,
- scale_factor: Tuple[float, float] = (0.5, 1.5),
- scale_prob: float = 1.0,
- rotate_factor: float = 80.0,
- rotate_prob: float = 0.6) -> None:
-```
-
-### Target Generation
-
-The old methods like:
-
-- `TopDownGenerateTarget`
-- `TopDownGenerateTargetRegression`
-- `BottomUpGenerateHeatmapTarget`
-- `BottomUpGenerateTarget`
-
-will be merged in to `GenerateTarget`, and the actual generation methods are implemented in [Codec](./user_guides/codecs.md).
-
-```Python
-@TRANSFORMS.register_module()
-class GenerateTarget(BaseTransform):
- """Encode keypoints into Target.
-
- The generated target is usually the supervision signal of the model
- learning, e.g. heatmaps or regression labels.
-
- Required Keys:
-
- - keypoints
- - keypoints_visible
- - dataset_keypoint_weights
-
- Added Keys:
-
- - The keys of the encoded items from the codec will be updated into
- the results, e.g. ``'heatmaps'`` or ``'keypoint_weights'``. See
- the specific codec for more details.
-
- Args:
- encoder (dict | list[dict]): The codec config for keypoint encoding.
- Both single encoder and multiple encoders (given as a list) are
- supported
- multilevel (bool): Determine the method to handle multiple encoders.
- If ``multilevel==True``, generate multilevel targets from a group
- of encoders of the same type (e.g. multiple :class:`MSRAHeatmap`
- encoders with different sigma values); If ``multilevel==False``,
- generate combined targets from a group of different encoders. This
- argument will have no effect in case of single encoder. Defaults
- to ``False``
- use_dataset_keypoint_weights (bool): Whether use the keypoint weights
- from the dataset meta information. Defaults to ``False``
- """
-
- def __init__(self,
- encoder: MultiConfig,
- multilevel: bool = False,
- use_dataset_keypoint_weights: bool = False) -> None:
-```
-
-### Data Normalization
-
-The data normalization operations `NormalizeTensor` and `ToTensor` will be replaced by **DataPreprocessor** module, which will no longer be used as a preprocessing operation, but will be merged as a part of the model forward propagation.
-
-## Compatibility of Models
-
-We have performed compatibility with the model weights provided by model zoo to ensure that the same model weights can get a comparable accuracy in both version. But note that due to the large number of differences in processing details, the inference outputs can be slightly different(less than 0.05% difference in accuracy).
-
-For model weights saved by training with 0.x version, we provide a `_load_state_dict_pre_hook()` method in Head to replace the old version of the `state_dict` with the new one. If you wish to make your model compatible with MMPose 1.0, you can refer to our implementation as follows.
-
-```Python
-@MODELS.register_module()
-class YourHead(BaseHead):
-def __init__(self):
-
- ## omitted
-
- # Register the hook to automatically convert old version state dicts
- self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
-```
-
-### Heatmap-based Model
-
-For models based on `SimpleBaseline` approach, developers need to pay attention to the last convolutional layer.
-
-```Python
-def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
- **kwargs):
- version = local_meta.get('version', None)
-
- if version and version >= self._version:
- return
-
- # convert old-version state dict
- keys = list(state_dict.keys())
- for _k in keys:
- if not _k.startswith(prefix):
- continue
- v = state_dict.pop(_k)
- k = _k[len(prefix):]
- # In old version, "final_layer" includes both intermediate
- # conv layers (new "conv_layers") and final conv layers (new
- # "final_layer").
- #
- # If there is no intermediate conv layer, old "final_layer" will
- # have keys like "final_layer.xxx", which should be still
- # named "final_layer.xxx";
- #
- # If there are intermediate conv layers, old "final_layer" will
- # have keys like "final_layer.n.xxx", where the weights of the last
- # one should be renamed "final_layer.xxx", and others should be
- # renamed "conv_layers.n.xxx"
- k_parts = k.split('.')
- if k_parts[0] == 'final_layer':
- if len(k_parts) == 3:
- assert isinstance(self.conv_layers, nn.Sequential)
- idx = int(k_parts[1])
- if idx < len(self.conv_layers):
- # final_layer.n.xxx -> conv_layers.n.xxx
- k_new = 'conv_layers.' + '.'.join(k_parts[1:])
- else:
- # final_layer.n.xxx -> final_layer.xxx
- k_new = 'final_layer.' + k_parts[2]
- else:
- # final_layer.xxx remains final_layer.xxx
- k_new = k
- else:
- k_new = k
-
- state_dict[prefix + k_new] = v
-```
-
-### RLE-based Model
-
-For the RLE-based models, since the loss module is renamed to `loss_module` in MMPose 1.0, and the flow model is subsumed under the loss module, changes need to be made to the keys in `state_dict`:
-
-```Python
-def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
- **kwargs):
-
- version = local_meta.get('version', None)
-
- if version and version >= self._version:
- return
-
- # convert old-version state dict
- keys = list(state_dict.keys())
- for _k in keys:
- v = state_dict.pop(_k)
- k = _k.lstrip(prefix)
- # In old version, "loss" includes the instances of loss,
- # now it should be renamed "loss_module"
- k_parts = k.split('.')
- if k_parts[0] == 'loss':
- # loss.xxx -> loss_module.xxx
- k_new = prefix + 'loss_module.' + '.'.join(k_parts[1:])
- else:
- k_new = _k
-
- state_dict[k_new] = v
-```
+# How to Migrate MMPose 0.x Projects to MMPose 1.0
+
+MMPose 1.0 has been refactored extensively and addressed many legacy issues. Most of the code in MMPose 1.0 will not be compatible with 0.x version.
+
+To try our best to help you migrate your code and model, here are some major changes:
+
+## Data Transformation
+
+### Translation, Rotation and Scaling
+
+The transformation methods `TopDownRandomShiftBboxCenter` and `TopDownGetRandomScaleRotation` in old version, will be merged into `RandomBBoxTransform`.
+
+```Python
+@TRANSFORMS.register_module()
+class RandomBBoxTransform(BaseTransform):
+ r"""Rnadomly shift, resize and rotate the bounding boxes.
+
+ Required Keys:
+
+ - bbox_center
+ - bbox_scale
+
+ Modified Keys:
+
+ - bbox_center
+ - bbox_scale
+
+ Added Keys:
+ - bbox_rotation
+
+ Args:
+ shift_factor (float): Randomly shift the bbox in range
+ :math:`[-dx, dx]` and :math:`[-dy, dy]` in X and Y directions,
+ where :math:`dx(y) = x(y)_scale \cdot shift_factor` in pixels.
+ Defaults to 0.16
+ shift_prob (float): Probability of applying random shift. Defaults to
+ 0.3
+ scale_factor (Tuple[float, float]): Randomly resize the bbox in range
+ :math:`[scale_factor[0], scale_factor[1]]`. Defaults to (0.5, 1.5)
+ scale_prob (float): Probability of applying random resizing. Defaults
+ to 1.0
+ rotate_factor (float): Randomly rotate the bbox in
+ :math:`[-rotate_factor, rotate_factor]` in degrees. Defaults
+ to 80.0
+ rotate_prob (float): Probability of applying random rotation. Defaults
+ to 0.6
+ """
+
+ def __init__(self,
+ shift_factor: float = 0.16,
+ shift_prob: float = 0.3,
+ scale_factor: Tuple[float, float] = (0.5, 1.5),
+ scale_prob: float = 1.0,
+ rotate_factor: float = 80.0,
+ rotate_prob: float = 0.6) -> None:
+```
+
+### Target Generation
+
+The old methods like:
+
+- `TopDownGenerateTarget`
+- `TopDownGenerateTargetRegression`
+- `BottomUpGenerateHeatmapTarget`
+- `BottomUpGenerateTarget`
+
+will be merged in to `GenerateTarget`, and the actual generation methods are implemented in [Codec](./user_guides/codecs.md).
+
+```Python
+@TRANSFORMS.register_module()
+class GenerateTarget(BaseTransform):
+ """Encode keypoints into Target.
+
+ The generated target is usually the supervision signal of the model
+ learning, e.g. heatmaps or regression labels.
+
+ Required Keys:
+
+ - keypoints
+ - keypoints_visible
+ - dataset_keypoint_weights
+
+ Added Keys:
+
+ - The keys of the encoded items from the codec will be updated into
+ the results, e.g. ``'heatmaps'`` or ``'keypoint_weights'``. See
+ the specific codec for more details.
+
+ Args:
+ encoder (dict | list[dict]): The codec config for keypoint encoding.
+ Both single encoder and multiple encoders (given as a list) are
+ supported
+ multilevel (bool): Determine the method to handle multiple encoders.
+ If ``multilevel==True``, generate multilevel targets from a group
+ of encoders of the same type (e.g. multiple :class:`MSRAHeatmap`
+ encoders with different sigma values); If ``multilevel==False``,
+ generate combined targets from a group of different encoders. This
+ argument will have no effect in case of single encoder. Defaults
+ to ``False``
+ use_dataset_keypoint_weights (bool): Whether use the keypoint weights
+ from the dataset meta information. Defaults to ``False``
+ """
+
+ def __init__(self,
+ encoder: MultiConfig,
+ multilevel: bool = False,
+ use_dataset_keypoint_weights: bool = False) -> None:
+```
+
+### Data Normalization
+
+The data normalization operations `NormalizeTensor` and `ToTensor` will be replaced by **DataPreprocessor** module, which will no longer be used as a preprocessing operation, but will be merged as a part of the model forward propagation.
+
+## Compatibility of Models
+
+We have performed compatibility with the model weights provided by model zoo to ensure that the same model weights can get a comparable accuracy in both version. But note that due to the large number of differences in processing details, the inference outputs can be slightly different(less than 0.05% difference in accuracy).
+
+For model weights saved by training with 0.x version, we provide a `_load_state_dict_pre_hook()` method in Head to replace the old version of the `state_dict` with the new one. If you wish to make your model compatible with MMPose 1.0, you can refer to our implementation as follows.
+
+```Python
+@MODELS.register_module()
+class YourHead(BaseHead):
+def __init__(self):
+
+ ## omitted
+
+ # Register the hook to automatically convert old version state dicts
+ self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
+```
+
+### Heatmap-based Model
+
+For models based on `SimpleBaseline` approach, developers need to pay attention to the last convolutional layer.
+
+```Python
+def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
+ **kwargs):
+ version = local_meta.get('version', None)
+
+ if version and version >= self._version:
+ return
+
+ # convert old-version state dict
+ keys = list(state_dict.keys())
+ for _k in keys:
+ if not _k.startswith(prefix):
+ continue
+ v = state_dict.pop(_k)
+ k = _k[len(prefix):]
+ # In old version, "final_layer" includes both intermediate
+ # conv layers (new "conv_layers") and final conv layers (new
+ # "final_layer").
+ #
+ # If there is no intermediate conv layer, old "final_layer" will
+ # have keys like "final_layer.xxx", which should be still
+ # named "final_layer.xxx";
+ #
+ # If there are intermediate conv layers, old "final_layer" will
+ # have keys like "final_layer.n.xxx", where the weights of the last
+ # one should be renamed "final_layer.xxx", and others should be
+ # renamed "conv_layers.n.xxx"
+ k_parts = k.split('.')
+ if k_parts[0] == 'final_layer':
+ if len(k_parts) == 3:
+ assert isinstance(self.conv_layers, nn.Sequential)
+ idx = int(k_parts[1])
+ if idx < len(self.conv_layers):
+ # final_layer.n.xxx -> conv_layers.n.xxx
+ k_new = 'conv_layers.' + '.'.join(k_parts[1:])
+ else:
+ # final_layer.n.xxx -> final_layer.xxx
+ k_new = 'final_layer.' + k_parts[2]
+ else:
+ # final_layer.xxx remains final_layer.xxx
+ k_new = k
+ else:
+ k_new = k
+
+ state_dict[prefix + k_new] = v
+```
+
+### RLE-based Model
+
+For the RLE-based models, since the loss module is renamed to `loss_module` in MMPose 1.0, and the flow model is subsumed under the loss module, changes need to be made to the keys in `state_dict`:
+
+```Python
+def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
+ **kwargs):
+
+ version = local_meta.get('version', None)
+
+ if version and version >= self._version:
+ return
+
+ # convert old-version state dict
+ keys = list(state_dict.keys())
+ for _k in keys:
+ v = state_dict.pop(_k)
+ k = _k.lstrip(prefix)
+ # In old version, "loss" includes the instances of loss,
+ # now it should be renamed "loss_module"
+ k_parts = k.split('.')
+ if k_parts[0] == 'loss':
+ # loss.xxx -> loss_module.xxx
+ k_new = prefix + 'loss_module.' + '.'.join(k_parts[1:])
+ else:
+ k_new = _k
+
+ state_dict[k_new] = v
+```
diff --git a/docs/en/notes/benchmark.md b/docs/en/notes/benchmark.md
index 8c82383f8c..48a4d99cd6 100644
--- a/docs/en/notes/benchmark.md
+++ b/docs/en/notes/benchmark.md
@@ -1,46 +1,46 @@
-# Benchmark
-
-We compare our results with some popular frameworks and official releases in terms of speed and accuracy.
-
-## Comparison Rules
-
-Here we compare our MMPose repo with other pose estimation toolboxes in the same data and model settings.
-
-To ensure the fairness of the comparison, the comparison experiments were conducted under the same hardware environment and using the same dataset.
-For each model setting, we kept the same data pre-processing methods to make sure the same feature input.
-In addition, we also used Memcached, a distributed memory-caching system, to load the data in all the compared toolboxes.
-This minimizes the IO time during benchmark.
-
-The time we measured is the average training time for an iteration, including data processing and model training.
-The training speed is measure with s/iter. The lower, the better.
-
-### Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
-
-We demonstrate the superiority of our MMPose framework in terms of speed and accuracy on the standard COCO keypoint detection benchmark.
-The mAP (the mean average precision) is used as the evaluation metric.
-
-| Model | Input size | MMPose (s/iter) | HRNet (s/iter) | MMPose (mAP) | HRNet (mAP) |
-| :--------- | :--------: | :-------------: | :------------: | :----------: | :---------: |
-| resnet_50 | 256x192 | **0.28** | 0.64 | **0.718** | 0.704 |
-| resnet_50 | 384x288 | **0.81** | 1.24 | **0.731** | 0.722 |
-| resnet_101 | 256x192 | **0.36** | 0.84 | **0.726** | 0.714 |
-| resnet_101 | 384x288 | **0.79** | 1.53 | **0.748** | 0.736 |
-| resnet_152 | 256x192 | **0.49** | 1.00 | **0.735** | 0.720 |
-| resnet_152 | 384x288 | **0.96** | 1.65 | **0.750** | 0.743 |
-| hrnet_w32 | 256x192 | **0.54** | 1.31 | **0.746** | 0.744 |
-| hrnet_w32 | 384x288 | **0.76** | 2.00 | **0.760** | 0.758 |
-| hrnet_w48 | 256x192 | **0.66** | 1.55 | **0.756** | 0.751 |
-| hrnet_w48 | 384x288 | **1.23** | 2.20 | **0.767** | 0.763 |
-
-## Hardware
-
-- 8 NVIDIA Tesla V100 (32G) GPUs
-- Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz
-
-## Software Environment
-
-- Python 3.7
-- PyTorch 1.4
-- CUDA 10.1
-- CUDNN 7.6.03
-- NCCL 2.4.08
+# Benchmark
+
+We compare our results with some popular frameworks and official releases in terms of speed and accuracy.
+
+## Comparison Rules
+
+Here we compare our MMPose repo with other pose estimation toolboxes in the same data and model settings.
+
+To ensure the fairness of the comparison, the comparison experiments were conducted under the same hardware environment and using the same dataset.
+For each model setting, we kept the same data pre-processing methods to make sure the same feature input.
+In addition, we also used Memcached, a distributed memory-caching system, to load the data in all the compared toolboxes.
+This minimizes the IO time during benchmark.
+
+The time we measured is the average training time for an iteration, including data processing and model training.
+The training speed is measure with s/iter. The lower, the better.
+
+### Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+We demonstrate the superiority of our MMPose framework in terms of speed and accuracy on the standard COCO keypoint detection benchmark.
+The mAP (the mean average precision) is used as the evaluation metric.
+
+| Model | Input size | MMPose (s/iter) | HRNet (s/iter) | MMPose (mAP) | HRNet (mAP) |
+| :--------- | :--------: | :-------------: | :------------: | :----------: | :---------: |
+| resnet_50 | 256x192 | **0.28** | 0.64 | **0.718** | 0.704 |
+| resnet_50 | 384x288 | **0.81** | 1.24 | **0.731** | 0.722 |
+| resnet_101 | 256x192 | **0.36** | 0.84 | **0.726** | 0.714 |
+| resnet_101 | 384x288 | **0.79** | 1.53 | **0.748** | 0.736 |
+| resnet_152 | 256x192 | **0.49** | 1.00 | **0.735** | 0.720 |
+| resnet_152 | 384x288 | **0.96** | 1.65 | **0.750** | 0.743 |
+| hrnet_w32 | 256x192 | **0.54** | 1.31 | **0.746** | 0.744 |
+| hrnet_w32 | 384x288 | **0.76** | 2.00 | **0.760** | 0.758 |
+| hrnet_w48 | 256x192 | **0.66** | 1.55 | **0.756** | 0.751 |
+| hrnet_w48 | 384x288 | **1.23** | 2.20 | **0.767** | 0.763 |
+
+## Hardware
+
+- 8 NVIDIA Tesla V100 (32G) GPUs
+- Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz
+
+## Software Environment
+
+- Python 3.7
+- PyTorch 1.4
+- CUDA 10.1
+- CUDNN 7.6.03
+- NCCL 2.4.08
diff --git a/docs/en/notes/changelog.md b/docs/en/notes/changelog.md
index 1d1be738e3..72fc7b085a 100644
--- a/docs/en/notes/changelog.md
+++ b/docs/en/notes/changelog.md
@@ -1,1314 +1,1314 @@
-# Changelog
-
-## **v1.0.0rc1 (14/10/2022)**
-
-**Highlights**
-
-- Release RTMPose, a high-performance real-time pose estimation algorithm with cross-platform deployment and inference support. See details at the [project page](/projects/rtmpose/)
-- Support several new algorithms: ViTPose (arXiv'2022), CID (CVPR'2022), DEKR (CVPR'2021)
-- Add Inferencer, a convenient inference interface that perform pose estimation and visualization on images, videos and webcam streams with only one line of code
-- Introduce *Project*, a new form for rapid and easy implementation of new algorithms and features in MMPose, which is more handy for community contributors
-
-**New Features**
-
-- Support RTMPose ([#1971](https://github.com/open-mmlab/mmpose/pull/1971), [#2024](https://github.com/open-mmlab/mmpose/pull/2024), [#2028](https://github.com/open-mmlab/mmpose/pull/2028), [#2030](https://github.com/open-mmlab/mmpose/pull/2030), [#2040](https://github.com/open-mmlab/mmpose/pull/2040), [#2057](https://github.com/open-mmlab/mmpose/pull/2057))
-- Support Inferencer ([#1969](https://github.com/open-mmlab/mmpose/pull/1969))
-- Support ViTPose ([#1876](https://github.com/open-mmlab/mmpose/pull/1876), [#2056](https://github.com/open-mmlab/mmpose/pull/2056), [#2058](https://github.com/open-mmlab/mmpose/pull/2058), [#2065](https://github.com/open-mmlab/mmpose/pull/2065))
-- Support CID ([#1907](https://github.com/open-mmlab/mmpose/pull/1907))
-- Support DEKR ([#1834](https://github.com/open-mmlab/mmpose/pull/1834), [#1901](https://github.com/open-mmlab/mmpose/pull/1901))
-- Support training with multiple datasets ([#1767](https://github.com/open-mmlab/mmpose/pull/1767), [#1930](https://github.com/open-mmlab/mmpose/pull/1930), [#1938](https://github.com/open-mmlab/mmpose/pull/1938), [#2025](https://github.com/open-mmlab/mmpose/pull/2025))
-- Add *project* to allow rapid and easy implementation of new models and features ([#1914](https://github.com/open-mmlab/mmpose/pull/1914))
-
-**Improvements**
-
-- Improve documentation quality ([#1846](https://github.com/open-mmlab/mmpose/pull/1846), [#1858](https://github.com/open-mmlab/mmpose/pull/1858), [#1872](https://github.com/open-mmlab/mmpose/pull/1872), [#1899](https://github.com/open-mmlab/mmpose/pull/1899), [#1925](https://github.com/open-mmlab/mmpose/pull/1925), [#1945](https://github.com/open-mmlab/mmpose/pull/1945), [#1952](https://github.com/open-mmlab/mmpose/pull/1952), [#1990](https://github.com/open-mmlab/mmpose/pull/1990), [#2023](https://github.com/open-mmlab/mmpose/pull/2023), [#2042](https://github.com/open-mmlab/mmpose/pull/2042))
-- Support visualizing keypoint indices ([#2051](https://github.com/open-mmlab/mmpose/pull/2051))
-- Support OpenPose style visualization ([#2055](https://github.com/open-mmlab/mmpose/pull/2055))
-- Accelerate image transpose in data pipelines with tensor operation ([#1976](https://github.com/open-mmlab/mmpose/pull/1976))
-- Support auto-import modules from registry ([#1961](https://github.com/open-mmlab/mmpose/pull/1961))
-- Support keypoint partition metric ([#1944](https://github.com/open-mmlab/mmpose/pull/1944))
-- Support SimCC 1D-heatmap visualization ([#1912](https://github.com/open-mmlab/mmpose/pull/1912))
-- Support saving predictions and data metainfo in demos ([#1814](https://github.com/open-mmlab/mmpose/pull/1814), [#1879](https://github.com/open-mmlab/mmpose/pull/1879))
-- Support SimCC with DARK ([#1870](https://github.com/open-mmlab/mmpose/pull/1870))
-- Remove Gaussian blur for offset maps in UDP-regress ([#1815](https://github.com/open-mmlab/mmpose/pull/1815))
-- Refactor encoding interface of Codec for better extendibility and easier configuration ([#1781](https://github.com/open-mmlab/mmpose/pull/1781))
-- Support evaluating CocoMetric without annotation file ([#1722](https://github.com/open-mmlab/mmpose/pull/1722))
-- Improve unit tests ([#1765](https://github.com/open-mmlab/mmpose/pull/1765))
-
-**Bug Fixes**
-
-- Fix repeated warnings from different ranks ([#2053](https://github.com/open-mmlab/mmpose/pull/2053))
-- Avoid frequent scope switching when using mmdet inference api ([#2039](https://github.com/open-mmlab/mmpose/pull/2039))
-- Remove EMA parameters and message hub data when publishing model checkpoints ([#2036](https://github.com/open-mmlab/mmpose/pull/2036))
-- Fix metainfo copying in dataset class ([#2017](https://github.com/open-mmlab/mmpose/pull/2017))
-- Fix top-down demo bug when there is no object detected ([#2007](https://github.com/open-mmlab/mmpose/pull/2007))
-- Fix config errors ([#1882](https://github.com/open-mmlab/mmpose/pull/1882), [#1906](https://github.com/open-mmlab/mmpose/pull/1906), [#1995](https://github.com/open-mmlab/mmpose/pull/1995))
-- Fix image demo failure when GUI is unavailable ([#1968](https://github.com/open-mmlab/mmpose/pull/1968))
-- Fix bug in AdaptiveWingLoss ([#1953](https://github.com/open-mmlab/mmpose/pull/1953))
-- Fix incorrect importing of RepeatDataset which is deprecated ([#1943](https://github.com/open-mmlab/mmpose/pull/1943))
-- Fix bug in bottom-up datasets that ignores images without instances ([#1752](https://github.com/open-mmlab/mmpose/pull/1752), [#1936](https://github.com/open-mmlab/mmpose/pull/1936))
-- Fix upstream dependency issues ([#1867](https://github.com/open-mmlab/mmpose/pull/1867), [#1921](https://github.com/open-mmlab/mmpose/pull/1921))
-- Fix evaluation issues and update results ([#1763](https://github.com/open-mmlab/mmpose/pull/1763), [#1773](https://github.com/open-mmlab/mmpose/pull/1773), [#1780](https://github.com/open-mmlab/mmpose/pull/1780), [#1850](https://github.com/open-mmlab/mmpose/pull/1850), [#1868](https://github.com/open-mmlab/mmpose/pull/1868))
-- Fix local registry missing warnings ([#1849](https://github.com/open-mmlab/mmpose/pull/1849))
-- Remove deprecated scripts for model deployment ([#1845](https://github.com/open-mmlab/mmpose/pull/1845))
-- Fix a bug in input transformation in BaseHead ([#1843](https://github.com/open-mmlab/mmpose/pull/1843))
-- Fix an interface mismatch with MMDetection in webcam demo ([#1813](https://github.com/open-mmlab/mmpose/pull/1813))
-- Fix a bug in heatmap visualization that causes incorrect scale ([#1800](https://github.com/open-mmlab/mmpose/pull/1800))
-- Add model metafiles ([#1768](https://github.com/open-mmlab/mmpose/pull/1768))
-
-## **v1.0.0rc0 (14/10/2022)**
-
-**New Features**
-
-- Support 4 light-weight pose estimation algorithms: [SimCC](https://doi.org/10.48550/arxiv.2107.03332) (ECCV'2022), [Debias-IPR](https://openaccess.thecvf.com/content/ICCV2021/papers/Gu_Removing_the_Bias_of_Integral_Pose_Regression_ICCV_2021_paper.pdf) (ICCV'2021), [IPR](https://arxiv.org/abs/1711.08229) (ECCV'2018), and [DSNT](https://arxiv.org/abs/1801.07372v2) (ArXiv'2018) ([#1628](https://github.com/open-mmlab/mmpose/pull/1628))
-
-**Migrations**
-
-- Add Webcam API in MMPose 1.0 ([#1638](https://github.com/open-mmlab/mmpose/pull/1638), [#1662](https://github.com/open-mmlab/mmpose/pull/1662)) @Ben-Louis
-- Add codec for Associative Embedding (beta) ([#1603](https://github.com/open-mmlab/mmpose/pull/1603)) @ly015
-
-**Improvements**
-
-- Add a colab tutorial for MMPose 1.0 ([#1660](https://github.com/open-mmlab/mmpose/pull/1660)) @Tau-J
-- Add model index in config folder ([#1710](https://github.com/open-mmlab/mmpose/pull/1710), [#1709](https://github.com/open-mmlab/mmpose/pull/1709), [#1627](https://github.com/open-mmlab/mmpose/pull/1627)) @ly015, @Tau-J, @Ben-Louis
-- Update and improve documentation ([#1692](https://github.com/open-mmlab/mmpose/pull/1692), [#1656](https://github.com/open-mmlab/mmpose/pull/1656), [#1681](https://github.com/open-mmlab/mmpose/pull/1681), [#1677](https://github.com/open-mmlab/mmpose/pull/1677), [#1664](https://github.com/open-mmlab/mmpose/pull/1664), [#1659](https://github.com/open-mmlab/mmpose/pull/1659)) @Tau-J, @Ben-Louis, @liqikai9
-- Improve config structures and formats ([#1651](https://github.com/open-mmlab/mmpose/pull/1651)) @liqikai9
-
-**Bug Fixes**
-
-- Update mmengine version requirements ([#1715](https://github.com/open-mmlab/mmpose/pull/1715)) @Ben-Louis
-- Update dependencies of pre-commit hooks ([#1705](https://github.com/open-mmlab/mmpose/pull/1705)) @Ben-Louis
-- Fix mmcv version in DockerFile ([#1704](https://github.com/open-mmlab/mmpose/pull/1704))
-- Fix a bug in setting dataset metainfo in configs ([#1684](https://github.com/open-mmlab/mmpose/pull/1684)) @ly015
-- Fix a bug in UDP training ([#1682](https://github.com/open-mmlab/mmpose/pull/1682)) @liqikai9
-- Fix a bug in Dark decoding ([#1676](https://github.com/open-mmlab/mmpose/pull/1676)) @liqikai9
-- Fix bugs in visualization ([#1671](https://github.com/open-mmlab/mmpose/pull/1671), [#1668](https://github.com/open-mmlab/mmpose/pull/1668), [#1657](https://github.com/open-mmlab/mmpose/pull/1657)) @liqikai9, @Ben-Louis
-- Fix incorrect flops calculation ([#1669](https://github.com/open-mmlab/mmpose/pull/1669)) @liqikai9
-- Fix `tensor.tile` compatibility issue for pytorch 1.6 ([#1658](https://github.com/open-mmlab/mmpose/pull/1658)) @ly015
-- Fix compatibility with `MultilevelPixelData` ([#1647](https://github.com/open-mmlab/mmpose/pull/1647)) @liqikai9
-
-## **v1.0.0beta (1/09/2022)**
-
-We are excited to announce the release of MMPose 1.0.0beta.
-MMPose 1.0.0beta is the first version of MMPose 1.x, a part of the OpenMMLab 2.0 projects.
-Built upon the new [training engine](https://github.com/open-mmlab/mmengine).
-
-**Highlights**
-
-- **New engines**. MMPose 1.x is based on [MMEngine](https://github.com/open-mmlab/mmengine), which provides a general and powerful runner that allows more flexible customizations and significantly simplifies the entrypoints of high-level interfaces.
-
-- **Unified interfaces**. As a part of the OpenMMLab 2.0 projects, MMPose 1.x unifies and refactors the interfaces and internal logics of train, testing, datasets, models, evaluation, and visualization. All the OpenMMLab 2.0 projects share the same design in those interfaces and logics to allow the emergence of multi-task/modality algorithms.
-
-- **More documentation and tutorials**. We add a bunch of documentation and tutorials to help users get started more smoothly. Read it [here](https://mmpose.readthedocs.io/en/latest/).
-
-**Breaking Changes**
-
-In this release, we made lots of major refactoring and modifications. Please refer to the [migration guide](../migration.md) for details and migration instructions.
-
-## **v0.28.1 (28/07/2022)**
-
-This release is meant to fix the compatibility with the latest mmcv v1.6.1
-
-## **v0.28.0 (06/07/2022)**
-
-**Highlights**
-
-- Support [TCFormer](https://openaccess.thecvf.com/content/CVPR2022/html/Zeng_Not_All_Tokens_Are_Equal_Human-Centric_Visual_Analysis_via_Token_CVPR_2022_paper.html) backbone, CVPR'2022 ([#1447](https://github.com/open-mmlab/mmpose/pull/1447), [#1452](https://github.com/open-mmlab/mmpose/pull/1452)) @zengwang430521
-
-- Add [RLE](https://arxiv.org/abs/2107.11291) models on COCO dataset ([#1424](https://github.com/open-mmlab/mmpose/pull/1424)) @Indigo6, @Ben-Louis, @ly015
-
-- Update swin models with better performance ([#1467](https://github.com/open-mmlab/mmpose/pull/1434)) @jin-s13
-
-**New Features**
-
-- Support [TCFormer](https://openaccess.thecvf.com/content/CVPR2022/html/Zeng_Not_All_Tokens_Are_Equal_Human-Centric_Visual_Analysis_via_Token_CVPR_2022_paper.html) backbone, CVPR'2022 ([#1447](https://github.com/open-mmlab/mmpose/pull/1447), [#1452](https://github.com/open-mmlab/mmpose/pull/1452)) @zengwang430521
-
-- Add [RLE](https://arxiv.org/abs/2107.11291) models on COCO dataset ([#1424](https://github.com/open-mmlab/mmpose/pull/1424)) @Indigo6, @Ben-Louis, @ly015
-
-- Support layer decay optimizer constructor and learning rate decay optimizer constructor ([#1423](https://github.com/open-mmlab/mmpose/pull/1423)) @jin-s13
-
-**Improvements**
-
-- Improve documentation quality ([#1416](https://github.com/open-mmlab/mmpose/pull/1416), [#1421](https://github.com/open-mmlab/mmpose/pull/1421), [#1423](https://github.com/open-mmlab/mmpose/pull/1423), [#1426](https://github.com/open-mmlab/mmpose/pull/1426), [#1458](https://github.com/open-mmlab/mmpose/pull/1458), [#1463](https://github.com/open-mmlab/mmpose/pull/1463)) @ly015, @liqikai9
-
-- Support installation by [mim](https://github.com/open-mmlab/mim) ([#1425](https://github.com/open-mmlab/mmpose/pull/1425)) @liqikai9
-
-- Support PAVI logger ([#1434](https://github.com/open-mmlab/mmpose/pull/1434)) @EvelynWang-0423
-
-- Add progress bar for some demos ([#1454](https://github.com/open-mmlab/mmpose/pull/1454)) @liqikai9
-
-- Webcam API supports quick device setting in terminal commands ([#1466](https://github.com/open-mmlab/mmpose/pull/1466)) @ly015
-
-- Update swin models with better performance ([#1467](https://github.com/open-mmlab/mmpose/pull/1434)) @jin-s13
-
-**Bug Fixes**
-
-- Rename `custom_hooks_config` to `custom_hooks` in configs to align with the documentation ([#1427](https://github.com/open-mmlab/mmpose/pull/1427)) @ly015
-
-- Fix deadlock issue in Webcam API ([#1430](https://github.com/open-mmlab/mmpose/pull/1430)) @ly015
-
-- Fix smoother configs in video 3D demo ([#1457](https://github.com/open-mmlab/mmpose/pull/1457)) @ly015
-
-## **v0.27.0 (07/06/2022)**
-
-**Highlights**
-
-- Support hand gesture recognition
-
- - Try the demo for gesture recognition
- - Learn more about the algorithm, dataset and experiment results
-
-- Major upgrade to the Webcam API
-
- - Tutorials (EN|zh_CN)
- - [API Reference](https://mmpose.readthedocs.io/en/latest/api.html#mmpose-apis-webcam)
- - Demo
-
-**New Features**
-
-- Support gesture recognition algorithm [MTUT](https://openaccess.thecvf.com/content_CVPR_2019/html/Abavisani_Improving_the_Performance_of_Unimodal_Dynamic_Hand-Gesture_Recognition_With_Multimodal_CVPR_2019_paper.html) CVPR'2019 and dataset [NVGesture](https://openaccess.thecvf.com/content_cvpr_2016/html/Molchanov_Online_Detection_and_CVPR_2016_paper.html) CVPR'2016 ([#1380](https://github.com/open-mmlab/mmpose/pull/1380)) @Ben-Louis
-
-**Improvements**
-
-- Upgrade Webcam API and related documents ([#1393](https://github.com/open-mmlab/mmpose/pull/1393), [#1404](https://github.com/open-mmlab/mmpose/pull/1404), [#1413](https://github.com/open-mmlab/mmpose/pull/1413)) @ly015
-
-- Support exporting COCO inference result without the annotation file ([#1368](https://github.com/open-mmlab/mmpose/pull/1368)) @liqikai9
-
-- Replace markdownlint with mdformat in CI to avoid the dependence on ruby [#1382](https://github.com/open-mmlab/mmpose/pull/1382) @ly015
-
-- Improve documentation quality ([#1385](https://github.com/open-mmlab/mmpose/pull/1385), [#1394](https://github.com/open-mmlab/mmpose/pull/1394), [#1395](https://github.com/open-mmlab/mmpose/pull/1395), [#1408](https://github.com/open-mmlab/mmpose/pull/1408)) @chubei-oppen, @ly015, @liqikai9
-
-**Bug Fixes**
-
-- Fix xywh->xyxy bbox conversion in dataset sanity check ([#1367](https://github.com/open-mmlab/mmpose/pull/1367)) @jin-s13
-
-- Fix a bug in two-stage 3D keypoint demo ([#1373](https://github.com/open-mmlab/mmpose/pull/1373)) @ly015
-
-- Fix out-dated settings in PVT configs ([#1376](https://github.com/open-mmlab/mmpose/pull/1376)) @ly015
-
-- Fix myst settings for document compiling ([#1381](https://github.com/open-mmlab/mmpose/pull/1381)) @ly015
-
-- Fix a bug in bbox transform ([#1384](https://github.com/open-mmlab/mmpose/pull/1384)) @ly015
-
-- Fix inaccurate description of `min_keypoints` in tracking apis ([#1398](https://github.com/open-mmlab/mmpose/pull/1398)) @pallgeuer
-
-- Fix warning with `torch.meshgrid` ([#1402](https://github.com/open-mmlab/mmpose/pull/1402)) @pallgeuer
-
-- Remove redundant transformer modules from `mmpose.datasets.backbones.utils` ([#1405](https://github.com/open-mmlab/mmpose/pull/1405)) @ly015
-
-## **v0.26.0 (05/05/2022)**
-
-**Highlights**
-
-- Support [RLE (Residual Log-likelihood Estimation)](https://arxiv.org/abs/2107.11291), ICCV'2021 ([#1259](https://github.com/open-mmlab/mmpose/pull/1259)) @Indigo6, @ly015
-
-- Support [Swin Transformer](https://arxiv.org/abs/2103.14030), ICCV'2021 ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @yumendecc, @ly015
-
-- Support [PVT](https://arxiv.org/abs/2102.12122), ICCV'2021 and [PVTv2](https://arxiv.org/abs/2106.13797), CVMJ'2022 ([#1343](https://github.com/open-mmlab/mmpose/pull/1343)) @zengwang430521
-
-- Speed up inference and reduce CPU usage by optimizing the pre-processing pipeline ([#1320](https://github.com/open-mmlab/mmpose/pull/1320)) @chenxinfeng4, @liqikai9
-
-**New Features**
-
-- Support [RLE (Residual Log-likelihood Estimation)](https://arxiv.org/abs/2107.11291), ICCV'2021 ([#1259](https://github.com/open-mmlab/mmpose/pull/1259)) @Indigo6, @ly015
-
-- Support [Swin Transformer](https://arxiv.org/abs/2103.14030), ICCV'2021 ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @yumendecc, @ly015
-
-- Support [PVT](https://arxiv.org/abs/2102.12122), ICCV'2021 and [PVTv2](https://arxiv.org/abs/2106.13797), CVMJ'2022 ([#1343](https://github.com/open-mmlab/mmpose/pull/1343)) @zengwang430521
-
-- Support [FPN](https://openaccess.thecvf.com/content_cvpr_2017/html/Lin_Feature_Pyramid_Networks_CVPR_2017_paper.html), CVPR'2017 ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @yumendecc, @ly015
-
-**Improvements**
-
-- Speed up inference and reduce CPU usage by optimizing the pre-processing pipeline ([#1320](https://github.com/open-mmlab/mmpose/pull/1320)) @chenxinfeng4, @liqikai9
-
-- Video demo supports models that requires multi-frame inputs ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @liqikai9, @jin-s13
-
-- Update benchmark regression list ([#1328](https://github.com/open-mmlab/mmpose/pull/1328)) @ly015, @liqikai9
-
-- Remove unnecessary warnings in `TopDownPoseTrack18VideoDataset` ([#1335](https://github.com/open-mmlab/mmpose/pull/1335)) @liqikai9
-
-- Improve documentation quality ([#1313](https://github.com/open-mmlab/mmpose/pull/1313), [#1305](https://github.com/open-mmlab/mmpose/pull/1305)) @Ben-Louis, @ly015
-
-- Update deprecating settings in configs ([#1317](https://github.com/open-mmlab/mmpose/pull/1317)) @ly015
-
-**Bug Fixes**
-
-- Fix a bug in human skeleton grouping that may skip the matching process unexpectedly when `ignore_to_much` is True ([#1341](https://github.com/open-mmlab/mmpose/pull/1341)) @daixinghome
-
-- Fix a GPG key error that leads to CI failure ([#1354](https://github.com/open-mmlab/mmpose/pull/1354)) @ly015
-
-- Fix bugs in distributed training script ([#1338](https://github.com/open-mmlab/mmpose/pull/1338), [#1298](https://github.com/open-mmlab/mmpose/pull/1298)) @ly015
-
-- Fix an upstream bug in xtoccotools that causes incorrect AP(M) results ([#1308](https://github.com/open-mmlab/mmpose/pull/1308)) @jin-s13, @ly015
-
-- Fix indentiation errors in the colab tutorial ([#1298](https://github.com/open-mmlab/mmpose/pull/1298)) @YuanZi1501040205
-
-- Fix incompatible model weight initialization with other OpenMMLab codebases ([#1329](https://github.com/open-mmlab/mmpose/pull/1329)) @274869388
-
-- Fix HRNet FP16 checkpoints download URL ([#1309](https://github.com/open-mmlab/mmpose/pull/1309)) @YinAoXiong
-
-- Fix typos in `body3d_two_stage_video_demo.py` ([#1295](https://github.com/open-mmlab/mmpose/pull/1295)) @mucozcan
-
-**Breaking Changes**
-
-- Refactor bbox processing in datasets and pipelines ([#1311](https://github.com/open-mmlab/mmpose/pull/1311)) @ly015, @Ben-Louis
-
-- The bbox format conversion (xywh to center-scale) and random translation are moved from the dataset to the pipeline. The comparison between new and old version is as below:
-
-v0.26.0v0.25.0Dataset
-(e.g. [TopDownCOCODataset](https://github.com/open-mmlab/mmpose/blob/master/mmpose/datasets/datasets/top_down/topdown_coco_dataset.py))
-
-... # Data sample only contains bbox rec.append({ 'bbox': obj\['clean_bbox\]\[:4\], ... })
-
-
-
-
-
-... # Convert bbox from xywh to center-scale center, scale = self.\_xywh2cs(\*obj\['clean_bbox'\]\[:4\]) # Data sample contains center and scale rec.append({ 'bbox': obj\['clean_bbox\]\[:4\], 'center': center, 'scale': scale, ... })
-
-
Apply bbox random translation every epoch (instead of only applying once at the annotation loading)
-
-
-
-
-
-
-
-
-
-
-
BC Breaking
-
-
The method `_xywh2cs` of dataset base classes (e.g. [Kpt2dSviewRgbImgTopDownDataset](https://github.com/open-mmlab/mmpose/blob/master/mmpose/datasets/datasets/base/kpt_2d_sview_rgb_img_top_down_dataset.py)) will be deprecated in the future. Custom datasets will need modifications to move the bbox format conversion to pipelines.
-
-
-
-
-
-
-
-
-
-
-## **v0.25.0 (02/04/2022)**
-
-**Highlights**
-
-- Support Shelf and Campus datasets with pre-trained VoxelPose models, ["3D Pictorial Structures for Multiple Human Pose Estimation"](http://campar.in.tum.de/pub/belagiannis2014cvpr/belagiannis2014cvpr.pdf), CVPR'2014 ([#1225](https://github.com/open-mmlab/mmpose/pull/1225)) @liqikai9, @wusize
-
-- Add `Smoother` module for temporal smoothing of the pose estimation with configurable filters ([#1127](https://github.com/open-mmlab/mmpose/pull/1127)) @ailingzengzzz, @ly015
-
-- Support SmoothNet for pose smoothing, ["SmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos"](https://arxiv.org/abs/2112.13715), arXiv'2021 ([#1279](https://github.com/open-mmlab/mmpose/pull/1279)) @ailingzengzzz, @ly015
-
-- Add multiview 3D pose estimation demo ([#1270](https://github.com/open-mmlab/mmpose/pull/1270)) @wusize
-
-**New Features**
-
-- Support Shelf and Campus datasets with pre-trained VoxelPose models, ["3D Pictorial Structures for Multiple Human Pose Estimation"](http://campar.in.tum.de/pub/belagiannis2014cvpr/belagiannis2014cvpr.pdf), CVPR'2014 ([#1225](https://github.com/open-mmlab/mmpose/pull/1225)) @liqikai9, @wusize
-
-- Add `Smoother` module for temporal smoothing of the pose estimation with configurable filters ([#1127](https://github.com/open-mmlab/mmpose/pull/1127)) @ailingzengzzz, @ly015
-
-- Support SmoothNet for pose smoothing, ["SmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos"](https://arxiv.org/abs/2112.13715), arXiv'2021 ([#1279](https://github.com/open-mmlab/mmpose/pull/1279)) @ailingzengzzz, @ly015
-
-- Add multiview 3D pose estimation demo ([#1270](https://github.com/open-mmlab/mmpose/pull/1270)) @wusize
-
-- Support multi-machine distributed training ([#1248](https://github.com/open-mmlab/mmpose/pull/1248)) @ly015
-
-**Improvements**
-
-- Update HRFormer configs and checkpoints with relative position bias ([#1245](https://github.com/open-mmlab/mmpose/pull/1245)) @zengwang430521
-
-- Support using different random seed for each distributed node ([#1257](https://github.com/open-mmlab/mmpose/pull/1257), [#1229](https://github.com/open-mmlab/mmpose/pull/1229)) @ly015
-
-- Improve documentation quality ([#1275](https://github.com/open-mmlab/mmpose/pull/1275), [#1255](https://github.com/open-mmlab/mmpose/pull/1255), [#1258](https://github.com/open-mmlab/mmpose/pull/1258), [#1249](https://github.com/open-mmlab/mmpose/pull/1249), [#1247](https://github.com/open-mmlab/mmpose/pull/1247), [#1240](https://github.com/open-mmlab/mmpose/pull/1240), [#1235](https://github.com/open-mmlab/mmpose/pull/1235)) @ly015, @jin-s13, @YoniChechik
-
-**Bug Fixes**
-
-- Fix keypoint index in RHD dataset meta information ([#1265](https://github.com/open-mmlab/mmpose/pull/1265)) @liqikai9
-
-- Fix pre-commit hook unexpected behavior on Windows ([#1282](https://github.com/open-mmlab/mmpose/pull/1282)) @liqikai9
-
-- Remove python-dev installation in CI ([#1276](https://github.com/open-mmlab/mmpose/pull/1276)) @ly015
-
-- Unify hyphens in argument names in tools and demos ([#1271](https://github.com/open-mmlab/mmpose/pull/1271)) @ly015
-
-- Fix ambiguous channel size in `channel_shuffle` that may cause exporting failure (#1242) @PINTO0309
-
-- Fix a bug in Webcam API that causes single-class detectors fail ([#1239](https://github.com/open-mmlab/mmpose/pull/1239)) @674106399
-
-- Fix the issue that `custom_hook` can not be set in configs ([#1236](https://github.com/open-mmlab/mmpose/pull/1236)) @bladrome
-
-- Fix incompatible MMCV version in DockerFile ([#raykindle](https://github.com/open-mmlab/mmpose/pull/raykindle))
-
-- Skip invisible joints in visualization ([#1228](https://github.com/open-mmlab/mmpose/pull/1228)) @womeier
-
-## **v0.24.0 (07/03/2022)**
-
-**Highlights**
-
-- Support HRFormer ["HRFormer: High-Resolution Vision Transformer for Dense Predict"](https://proceedings.neurips.cc/paper/2021/hash/3bbfdde8842a5c44a0323518eec97cbe-Abstract.html), NeurIPS'2021 ([#1203](https://github.com/open-mmlab/mmpose/pull/1203)) @zengwang430521
-
-- Support Windows installation with pip ([#1213](https://github.com/open-mmlab/mmpose/pull/1213)) @jin-s13, @ly015
-
-- Add WebcamAPI documents ([#1187](https://github.com/open-mmlab/mmpose/pull/1187)) @ly015
-
-**New Features**
-
-- Support HRFormer ["HRFormer: High-Resolution Vision Transformer for Dense Predict"](https://proceedings.neurips.cc/paper/2021/hash/3bbfdde8842a5c44a0323518eec97cbe-Abstract.html), NeurIPS'2021 ([#1203](https://github.com/open-mmlab/mmpose/pull/1203)) @zengwang430521
-
-- Support Windows installation with pip ([#1213](https://github.com/open-mmlab/mmpose/pull/1213)) @jin-s13, @ly015
-
-- Support CPU training with mmcv \< v1.4.4 ([#1161](https://github.com/open-mmlab/mmpose/pull/1161)) @EasonQYS, @ly015
-
-- Add "Valentine Magic" demo with WebcamAPI ([#1189](https://github.com/open-mmlab/mmpose/pull/1189), [#1191](https://github.com/open-mmlab/mmpose/pull/1191)) @liqikai9
-
-**Improvements**
-
-- Refactor multi-view 3D pose estimation framework towards better modularization and expansibility ([#1196](https://github.com/open-mmlab/mmpose/pull/1196)) @wusize
-
-- Add WebcamAPI documents and tutorials ([#1187](https://github.com/open-mmlab/mmpose/pull/1187)) @ly015
-
-- Refactor dataset evaluation interface to align with other OpenMMLab codebases ([#1209](https://github.com/open-mmlab/mmpose/pull/1209)) @ly015
-
-- Add deprecation message for deploy tools since [MMDeploy](https://github.com/open-mmlab/mmdeploy) has supported MMPose ([#1207](https://github.com/open-mmlab/mmpose/pull/1207)) @QwQ2000
-
-- Improve documentation quality ([#1206](https://github.com/open-mmlab/mmpose/pull/1206), [#1161](https://github.com/open-mmlab/mmpose/pull/1161)) @ly015
-
-- Switch to OpenMMLab official pre-commit-hook for copyright check ([#1214](https://github.com/open-mmlab/mmpose/pull/1214)) @ly015
-
-**Bug Fixes**
-
-- Fix hard-coded data collating and scattering in inference ([#1175](https://github.com/open-mmlab/mmpose/pull/1175)) @ly015
-
-- Fix model configs on JHMDB dataset ([#1188](https://github.com/open-mmlab/mmpose/pull/1188)) @jin-s13
-
-- Fix area calculation in pose tracking inference ([#1197](https://github.com/open-mmlab/mmpose/pull/1197)) @pallgeuer
-
-- Fix registry scope conflict of module wrapper ([#1204](https://github.com/open-mmlab/mmpose/pull/1204)) @ly015
-
-- Update MMCV installation in CI and documents ([#1205](https://github.com/open-mmlab/mmpose/pull/1205))
-
-- Fix incorrect color channel order in visualization functions ([#1212](https://github.com/open-mmlab/mmpose/pull/1212)) @ly015
-
-## **v0.23.0 (11/02/2022)**
-
-**Highlights**
-
-- Add [MMPose Webcam API](https://github.com/open-mmlab/mmpose/tree/master/tools/webcam): A simple yet powerful tools to develop interactive webcam applications with MMPose functions. ([#1178](https://github.com/open-mmlab/mmpose/pull/1178), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1143](https://github.com/open-mmlab/mmpose/pull/1143), [#1094](https://github.com/open-mmlab/mmpose/pull/1094), [#1133](https://github.com/open-mmlab/mmpose/pull/1133), [#1098](https://github.com/open-mmlab/mmpose/pull/1098), [#1160](https://github.com/open-mmlab/mmpose/pull/1160)) @ly015, @jin-s13, @liqikai9, @wusize, @luminxu, @zengwang430521 @mzr1996
-
-**New Features**
-
-- Add [MMPose Webcam API](https://github.com/open-mmlab/mmpose/tree/master/tools/webcam): A simple yet powerful tools to develop interactive webcam applications with MMPose functions. ([#1178](https://github.com/open-mmlab/mmpose/pull/1178), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1143](https://github.com/open-mmlab/mmpose/pull/1143), [#1094](https://github.com/open-mmlab/mmpose/pull/1094), [#1133](https://github.com/open-mmlab/mmpose/pull/1133), [#1098](https://github.com/open-mmlab/mmpose/pull/1098), [#1160](https://github.com/open-mmlab/mmpose/pull/1160)) @ly015, @jin-s13, @liqikai9, @wusize, @luminxu, @zengwang430521 @mzr1996
-
-- Support ConcatDataset ([#1139](https://github.com/open-mmlab/mmpose/pull/1139)) @Canwang-sjtu
-
-- Support CPU training and testing ([#1157](https://github.com/open-mmlab/mmpose/pull/1157)) @ly015
-
-**Improvements**
-
-- Add multi-processing configurations to speed up distributed training and testing ([#1146](https://github.com/open-mmlab/mmpose/pull/1146)) @ly015
-
-- Add default runtime config ([#1145](https://github.com/open-mmlab/mmpose/pull/1145))
-
-- Upgrade isort in pre-commit hook ([#1179](https://github.com/open-mmlab/mmpose/pull/1179)) @liqikai9
-
-- Update README and documents ([#1171](https://github.com/open-mmlab/mmpose/pull/1171), [#1167](https://github.com/open-mmlab/mmpose/pull/1167), [#1153](https://github.com/open-mmlab/mmpose/pull/1153), [#1149](https://github.com/open-mmlab/mmpose/pull/1149), [#1148](https://github.com/open-mmlab/mmpose/pull/1148), [#1147](https://github.com/open-mmlab/mmpose/pull/1147), [#1140](https://github.com/open-mmlab/mmpose/pull/1140)) @jin-s13, @wusize, @TommyZihao, @ly015
-
-**Bug Fixes**
-
-- Fix undeterministic behavior in pre-commit hooks ([#1136](https://github.com/open-mmlab/mmpose/pull/1136)) @jin-s13
-
-- Deprecate the support for "python setup.py test" ([#1179](https://github.com/open-mmlab/mmpose/pull/1179)) @ly015
-
-- Fix incompatible settings with MMCV on HSigmoid default parameters ([#1132](https://github.com/open-mmlab/mmpose/pull/1132)) @ly015
-
-- Fix albumentation installation ([#1184](https://github.com/open-mmlab/mmpose/pull/1184)) @BIGWangYuDong
-
-## **v0.22.0 (04/01/2022)**
-
-**Highlights**
-
-- Support VoxelPose ["VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment"](https://arxiv.org/abs/2004.06239), ECCV'2020 ([#1050](https://github.com/open-mmlab/mmpose/pull/1050)) @wusize
-
-- Support Soft Wing loss ["Structure-Coherent Deep Feature Learning for Robust Face Alignment"](https://linchunze.github.io/papers/TIP21_Structure_coherent_FA.pdf), TIP'2021 ([#1077](https://github.com/open-mmlab/mmpose/pull/1077)) @jin-s13
-
-- Support Adaptive Wing loss ["Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression"](https://arxiv.org/abs/1904.07399), ICCV'2019 ([#1072](https://github.com/open-mmlab/mmpose/pull/1072)) @jin-s13
-
-**New Features**
-
-- Support VoxelPose ["VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment"](https://arxiv.org/abs/2004.06239), ECCV'2020 ([#1050](https://github.com/open-mmlab/mmpose/pull/1050)) @wusize
-
-- Support Soft Wing loss ["Structure-Coherent Deep Feature Learning for Robust Face Alignment"](https://linchunze.github.io/papers/TIP21_Structure_coherent_FA.pdf), TIP'2021 ([#1077](https://github.com/open-mmlab/mmpose/pull/1077)) @jin-s13
-
-- Support Adaptive Wing loss ["Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression"](https://arxiv.org/abs/1904.07399), ICCV'2019 ([#1072](https://github.com/open-mmlab/mmpose/pull/1072)) @jin-s13
-
-- Add LiteHRNet-18 Checkpoints trained on COCO. ([#1120](https://github.com/open-mmlab/mmpose/pull/1120)) @jin-s13
-
-**Improvements**
-
-- Improve documentation quality ([#1115](https://github.com/open-mmlab/mmpose/pull/1115), [#1111](https://github.com/open-mmlab/mmpose/pull/1111), [#1105](https://github.com/open-mmlab/mmpose/pull/1105), [#1087](https://github.com/open-mmlab/mmpose/pull/1087), [#1086](https://github.com/open-mmlab/mmpose/pull/1086), [#1085](https://github.com/open-mmlab/mmpose/pull/1085), [#1084](https://github.com/open-mmlab/mmpose/pull/1084), [#1083](https://github.com/open-mmlab/mmpose/pull/1083), [#1124](https://github.com/open-mmlab/mmpose/pull/1124), [#1070](https://github.com/open-mmlab/mmpose/pull/1070), [#1068](https://github.com/open-mmlab/mmpose/pull/1068)) @jin-s13, @liqikai9, @ly015
-
-- Support CircleCI ([#1074](https://github.com/open-mmlab/mmpose/pull/1074)) @ly015
-
-- Skip unit tests in CI when only document files were changed ([#1074](https://github.com/open-mmlab/mmpose/pull/1074), [#1041](https://github.com/open-mmlab/mmpose/pull/1041)) @QwQ2000, @ly015
-
-- Support file_client_args in LoadImageFromFile ([#1076](https://github.com/open-mmlab/mmpose/pull/1076)) @jin-s13
-
-**Bug Fixes**
-
-- Fix a bug in Dark UDP postprocessing that causes error when the channel number is large. ([#1079](https://github.com/open-mmlab/mmpose/pull/1079), [#1116](https://github.com/open-mmlab/mmpose/pull/1116)) @X00123, @jin-s13
-
-- Fix hard-coded `sigmas` in bottom-up image demo ([#1107](https://github.com/open-mmlab/mmpose/pull/1107), [#1101](https://github.com/open-mmlab/mmpose/pull/1101)) @chenxinfeng4, @liqikai9
-
-- Fix unstable checks in unit tests ([#1112](https://github.com/open-mmlab/mmpose/pull/1112)) @ly015
-
-- Do not destroy NULL windows if `args.show==False` in demo scripts ([#1104](https://github.com/open-mmlab/mmpose/pull/1104)) @bladrome
-
-## **v0.21.0 (06/12/2021)**
-
-**Highlights**
-
-- Support ["Learning Temporal Pose Estimation from Sparsely-Labeled Videos"](https://arxiv.org/abs/1906.04016), NeurIPS'2019 ([#932](https://github.com/open-mmlab/mmpose/pull/932), [#1006](https://github.com/open-mmlab/mmpose/pull/1006), [#1036](https://github.com/open-mmlab/mmpose/pull/1036), [#1060](https://github.com/open-mmlab/mmpose/pull/1060)) @liqikai9
-
-- Add ViPNAS-MobileNetV3 models ([#1025](https://github.com/open-mmlab/mmpose/pull/1025)) @luminxu, @jin-s13
-
-- Add inference speed benchmark ([#1028](https://github.com/open-mmlab/mmpose/pull/1028), [#1034](https://github.com/open-mmlab/mmpose/pull/1034), [#1044](https://github.com/open-mmlab/mmpose/pull/1044)) @liqikai9
-
-**New Features**
-
-- Support ["Learning Temporal Pose Estimation from Sparsely-Labeled Videos"](https://arxiv.org/abs/1906.04016), NeurIPS'2019 ([#932](https://github.com/open-mmlab/mmpose/pull/932), [#1006](https://github.com/open-mmlab/mmpose/pull/1006), [#1036](https://github.com/open-mmlab/mmpose/pull/1036)) @liqikai9
-
-- Add ViPNAS-MobileNetV3 models ([#1025](https://github.com/open-mmlab/mmpose/pull/1025)) @luminxu, @jin-s13
-
-- Add light-weight top-down models for whole-body keypoint detection ([#1009](https://github.com/open-mmlab/mmpose/pull/1009), [#1020](https://github.com/open-mmlab/mmpose/pull/1020), [#1055](https://github.com/open-mmlab/mmpose/pull/1055)) @luminxu, @ly015
-
-- Add HRNet checkpoints with various settings on PoseTrack18 ([#1035](https://github.com/open-mmlab/mmpose/pull/1035)) @liqikai9
-
-**Improvements**
-
-- Add inference speed benchmark ([#1028](https://github.com/open-mmlab/mmpose/pull/1028), [#1034](https://github.com/open-mmlab/mmpose/pull/1034), [#1044](https://github.com/open-mmlab/mmpose/pull/1044)) @liqikai9
-
-- Update model metafile format ([#1001](https://github.com/open-mmlab/mmpose/pull/1001)) @ly015
-
-- Support minus output feature index in mobilenet_v3 ([#1005](https://github.com/open-mmlab/mmpose/pull/1005)) @luminxu
-
-- Improve documentation quality ([#1018](https://github.com/open-mmlab/mmpose/pull/1018), [#1026](https://github.com/open-mmlab/mmpose/pull/1026), [#1027](https://github.com/open-mmlab/mmpose/pull/1027), [#1031](https://github.com/open-mmlab/mmpose/pull/1031), [#1038](https://github.com/open-mmlab/mmpose/pull/1038), [#1046](https://github.com/open-mmlab/mmpose/pull/1046), [#1056](https://github.com/open-mmlab/mmpose/pull/1056), [#1057](https://github.com/open-mmlab/mmpose/pull/1057)) @edybk, @luminxu, @ly015, @jin-s13
-
-- Set default random seed in training initialization ([#1030](https://github.com/open-mmlab/mmpose/pull/1030)) @ly015
-
-- Skip CI when only specific files changed ([#1041](https://github.com/open-mmlab/mmpose/pull/1041), [#1059](https://github.com/open-mmlab/mmpose/pull/1059)) @QwQ2000, @ly015
-
-- Automatically cancel uncompleted action runs when new commit arrives ([#1053](https://github.com/open-mmlab/mmpose/pull/1053)) @ly015
-
-**Bug Fixes**
-
-- Update pose tracking demo to be compatible with latest mmtracking ([#1014](https://github.com/open-mmlab/mmpose/pull/1014)) @jin-s13
-
-- Fix symlink creation failure when installed in Windows environments ([#1039](https://github.com/open-mmlab/mmpose/pull/1039)) @QwQ2000
-
-- Fix AP-10K dataset sigmas ([#1040](https://github.com/open-mmlab/mmpose/pull/1040)) @jin-s13
-
-## **v0.20.0 (01/11/2021)**
-
-**Highlights**
-
-- Add AP-10K dataset for animal pose estimation ([#987](https://github.com/open-mmlab/mmpose/pull/987)) @Annbless, @AlexTheBad, @jin-s13, @ly015
-
-- Support TorchServe ([#979](https://github.com/open-mmlab/mmpose/pull/979)) @ly015
-
-**New Features**
-
-- Add AP-10K dataset for animal pose estimation ([#987](https://github.com/open-mmlab/mmpose/pull/987)) @Annbless, @AlexTheBad, @jin-s13, @ly015
-
-- Add HRNetv2 checkpoints on 300W and COFW datasets ([#980](https://github.com/open-mmlab/mmpose/pull/980)) @jin-s13
-
-- Support TorchServe ([#979](https://github.com/open-mmlab/mmpose/pull/979)) @ly015
-
-**Bug Fixes**
-
-- Fix some deprecated or risky settings in configs ([#963](https://github.com/open-mmlab/mmpose/pull/963), [#976](https://github.com/open-mmlab/mmpose/pull/976), [#992](https://github.com/open-mmlab/mmpose/pull/992)) @jin-s13, @wusize
-
-- Fix issues of default arguments of training and testing scripts ([#970](https://github.com/open-mmlab/mmpose/pull/970), [#985](https://github.com/open-mmlab/mmpose/pull/985)) @liqikai9, @wusize
-
-- Fix heatmap and tag size mismatch in bottom-up with UDP ([#994](https://github.com/open-mmlab/mmpose/pull/994)) @wusize
-
-- Fix python3.9 installation in CI ([#983](https://github.com/open-mmlab/mmpose/pull/983)) @ly015
-
-- Fix model zoo document integrity issue ([#990](https://github.com/open-mmlab/mmpose/pull/990)) @jin-s13
-
-**Improvements**
-
-- Support non-square input shape for bottom-up ([#991](https://github.com/open-mmlab/mmpose/pull/991)) @wusize
-
-- Add image and video resources for demo ([#971](https://github.com/open-mmlab/mmpose/pull/971)) @liqikai9
-
-- Use CUDA docker images to accelerate CI ([#973](https://github.com/open-mmlab/mmpose/pull/973)) @ly015
-
-- Add codespell hook and fix detected typos ([#977](https://github.com/open-mmlab/mmpose/pull/977)) @ly015
-
-## **v0.19.0 (08/10/2021)**
-
-**Highlights**
-
-- Add models for Associative Embedding with Hourglass network backbone ([#906](https://github.com/open-mmlab/mmpose/pull/906), [#955](https://github.com/open-mmlab/mmpose/pull/955)) @jin-s13, @luminxu
-
-- Support COCO-Wholebody-Face and COCO-Wholebody-Hand datasets ([#813](https://github.com/open-mmlab/mmpose/pull/813)) @jin-s13, @innerlee, @luminxu
-
-- Upgrade dataset interface ([#901](https://github.com/open-mmlab/mmpose/pull/901), [#924](https://github.com/open-mmlab/mmpose/pull/924)) @jin-s13, @innerlee, @ly015, @liqikai9
-
-- New style of documentation ([#945](https://github.com/open-mmlab/mmpose/pull/945)) @ly015
-
-**New Features**
-
-- Add models for Associative Embedding with Hourglass network backbone ([#906](https://github.com/open-mmlab/mmpose/pull/906), [#955](https://github.com/open-mmlab/mmpose/pull/955)) @jin-s13, @luminxu
-
-- Support COCO-Wholebody-Face and COCO-Wholebody-Hand datasets ([#813](https://github.com/open-mmlab/mmpose/pull/813)) @jin-s13, @innerlee, @luminxu
-
-- Add pseudo-labeling tool to generate COCO style keypoint annotations with given bounding boxes ([#928](https://github.com/open-mmlab/mmpose/pull/928)) @soltkreig
-
-- New style of documentation ([#945](https://github.com/open-mmlab/mmpose/pull/945)) @ly015
-
-**Bug Fixes**
-
-- Fix segmentation parsing in Macaque dataset preprocessing ([#948](https://github.com/open-mmlab/mmpose/pull/948)) @jin-s13
-
-- Fix dependencies that may lead to CI failure in downstream projects ([#936](https://github.com/open-mmlab/mmpose/pull/936), [#953](https://github.com/open-mmlab/mmpose/pull/953)) @RangiLyu, @ly015
-
-- Fix keypoint order in Human3.6M dataset ([#940](https://github.com/open-mmlab/mmpose/pull/940)) @ttxskk
-
-- Fix unstable image loading for Interhand2.6M ([#913](https://github.com/open-mmlab/mmpose/pull/913)) @zengwang430521
-
-**Improvements**
-
-- Upgrade dataset interface ([#901](https://github.com/open-mmlab/mmpose/pull/901), [#924](https://github.com/open-mmlab/mmpose/pull/924)) @jin-s13, @innerlee, @ly015, @liqikai9
-
-- Improve demo usability and stability ([#908](https://github.com/open-mmlab/mmpose/pull/908), [#934](https://github.com/open-mmlab/mmpose/pull/934)) @ly015
-
-- Standardize model metafile format ([#941](https://github.com/open-mmlab/mmpose/pull/941)) @ly015
-
-- Support `persistent_worker` and several other arguments in configs ([#946](https://github.com/open-mmlab/mmpose/pull/946)) @jin-s13
-
-- Use MMCV root model registry to enable cross-project module building ([#935](https://github.com/open-mmlab/mmpose/pull/935)) @RangiLyu
-
-- Improve the document quality ([#916](https://github.com/open-mmlab/mmpose/pull/916), [#909](https://github.com/open-mmlab/mmpose/pull/909), [#942](https://github.com/open-mmlab/mmpose/pull/942), [#913](https://github.com/open-mmlab/mmpose/pull/913), [#956](https://github.com/open-mmlab/mmpose/pull/956)) @jin-s13, @ly015, @bit-scientist, @zengwang430521
-
-- Improve pull request template ([#952](https://github.com/open-mmlab/mmpose/pull/952), [#954](https://github.com/open-mmlab/mmpose/pull/954)) @ly015
-
-**Breaking Changes**
-
-- Upgrade dataset interface ([#901](https://github.com/open-mmlab/mmpose/pull/901)) @jin-s13, @innerlee, @ly015
-
-## **v0.18.0 (01/09/2021)**
-
-**Bug Fixes**
-
-- Fix redundant model weight loading in pytorch-to-onnx conversion ([#850](https://github.com/open-mmlab/mmpose/pull/850)) @ly015
-
-- Fix a bug in update_model_index.py that may cause pre-commit hook failure([#866](https://github.com/open-mmlab/mmpose/pull/866)) @ly015
-
-- Fix a bug in interhand_3d_head ([#890](https://github.com/open-mmlab/mmpose/pull/890)) @zengwang430521
-
-- Fix pose tracking demo failure caused by out-of-date configs ([#891](https://github.com/open-mmlab/mmpose/pull/891))
-
-**Improvements**
-
-- Add automatic benchmark regression tools ([#849](https://github.com/open-mmlab/mmpose/pull/849), [#880](https://github.com/open-mmlab/mmpose/pull/880), [#885](https://github.com/open-mmlab/mmpose/pull/885)) @liqikai9, @ly015
-
-- Add copyright information and checking hook ([#872](https://github.com/open-mmlab/mmpose/pull/872))
-
-- Add PR template ([#875](https://github.com/open-mmlab/mmpose/pull/875)) @ly015
-
-- Add citation information ([#876](https://github.com/open-mmlab/mmpose/pull/876)) @ly015
-
-- Add python3.9 in CI ([#877](https://github.com/open-mmlab/mmpose/pull/877), [#883](https://github.com/open-mmlab/mmpose/pull/883)) @ly015
-
-- Improve the quality of the documents ([#845](https://github.com/open-mmlab/mmpose/pull/845), [#845](https://github.com/open-mmlab/mmpose/pull/845), [#848](https://github.com/open-mmlab/mmpose/pull/848), [#867](https://github.com/open-mmlab/mmpose/pull/867), [#870](https://github.com/open-mmlab/mmpose/pull/870), [#873](https://github.com/open-mmlab/mmpose/pull/873), [#896](https://github.com/open-mmlab/mmpose/pull/896)) @jin-s13, @ly015, @zhiqwang
-
-## **v0.17.0 (06/08/2021)**
-
-**Highlights**
-
-1. Support ["Lite-HRNet: A Lightweight High-Resolution Network"](https://arxiv.org/abs/2104.06403) CVPR'2021 ([#733](https://github.com/open-mmlab/mmpose/pull/733),[#800](https://github.com/open-mmlab/mmpose/pull/800)) @jin-s13
-
-2. Add 3d body mesh demo ([#771](https://github.com/open-mmlab/mmpose/pull/771)) @zengwang430521
-
-3. Add Chinese documentation ([#787](https://github.com/open-mmlab/mmpose/pull/787), [#798](https://github.com/open-mmlab/mmpose/pull/798), [#799](https://github.com/open-mmlab/mmpose/pull/799), [#802](https://github.com/open-mmlab/mmpose/pull/802), [#804](https://github.com/open-mmlab/mmpose/pull/804), [#805](https://github.com/open-mmlab/mmpose/pull/805), [#815](https://github.com/open-mmlab/mmpose/pull/815), [#816](https://github.com/open-mmlab/mmpose/pull/816), [#817](https://github.com/open-mmlab/mmpose/pull/817), [#819](https://github.com/open-mmlab/mmpose/pull/819), [#839](https://github.com/open-mmlab/mmpose/pull/839)) @ly015, @luminxu, @jin-s13, @liqikai9, @zengwang430521
-
-4. Add Colab Tutorial ([#834](https://github.com/open-mmlab/mmpose/pull/834)) @ly015
-
-**New Features**
-
-- Support ["Lite-HRNet: A Lightweight High-Resolution Network"](https://arxiv.org/abs/2104.06403) CVPR'2021 ([#733](https://github.com/open-mmlab/mmpose/pull/733),[#800](https://github.com/open-mmlab/mmpose/pull/800)) @jin-s13
-
-- Add 3d body mesh demo ([#771](https://github.com/open-mmlab/mmpose/pull/771)) @zengwang430521
-
-- Add Chinese documentation ([#787](https://github.com/open-mmlab/mmpose/pull/787), [#798](https://github.com/open-mmlab/mmpose/pull/798), [#799](https://github.com/open-mmlab/mmpose/pull/799), [#802](https://github.com/open-mmlab/mmpose/pull/802), [#804](https://github.com/open-mmlab/mmpose/pull/804), [#805](https://github.com/open-mmlab/mmpose/pull/805), [#815](https://github.com/open-mmlab/mmpose/pull/815), [#816](https://github.com/open-mmlab/mmpose/pull/816), [#817](https://github.com/open-mmlab/mmpose/pull/817), [#819](https://github.com/open-mmlab/mmpose/pull/819), [#839](https://github.com/open-mmlab/mmpose/pull/839)) @ly015, @luminxu, @jin-s13, @liqikai9, @zengwang430521
-
-- Add Colab Tutorial ([#834](https://github.com/open-mmlab/mmpose/pull/834)) @ly015
-
-- Support training for InterHand v1.0 dataset ([#761](https://github.com/open-mmlab/mmpose/pull/761)) @zengwang430521
-
-**Bug Fixes**
-
-- Fix mpii pckh@0.1 index ([#773](https://github.com/open-mmlab/mmpose/pull/773)) @jin-s13
-
-- Fix multi-node distributed test ([#818](https://github.com/open-mmlab/mmpose/pull/818)) @ly015
-
-- Fix docstring and init_weights error of ShuffleNetV1 ([#814](https://github.com/open-mmlab/mmpose/pull/814)) @Junjun2016
-
-- Fix imshow_bbox error when input bboxes is empty ([#796](https://github.com/open-mmlab/mmpose/pull/796)) @ly015
-
-- Fix model zoo doc generation ([#778](https://github.com/open-mmlab/mmpose/pull/778)) @ly015
-
-- Fix typo ([#767](https://github.com/open-mmlab/mmpose/pull/767)), ([#780](https://github.com/open-mmlab/mmpose/pull/780), [#782](https://github.com/open-mmlab/mmpose/pull/782)) @ly015, @jin-s13
-
-**Breaking Changes**
-
-- Use MMCV EvalHook ([#686](https://github.com/open-mmlab/mmpose/pull/686)) @ly015
-
-**Improvements**
-
-- Add pytest.ini and fix docstring ([#812](https://github.com/open-mmlab/mmpose/pull/812)) @jin-s13
-
-- Update MSELoss ([#829](https://github.com/open-mmlab/mmpose/pull/829)) @Ezra-Yu
-
-- Move process_mmdet_results into inference.py ([#831](https://github.com/open-mmlab/mmpose/pull/831)) @ly015
-
-- Update resource limit ([#783](https://github.com/open-mmlab/mmpose/pull/783)) @jin-s13
-
-- Use COCO 2D pose model in 3D demo examples ([#785](https://github.com/open-mmlab/mmpose/pull/785)) @ly015
-
-- Change model zoo titles in the doc from center-aligned to left-aligned ([#792](https://github.com/open-mmlab/mmpose/pull/792), [#797](https://github.com/open-mmlab/mmpose/pull/797)) @ly015
-
-- Support MIM ([#706](https://github.com/open-mmlab/mmpose/pull/706), [#794](https://github.com/open-mmlab/mmpose/pull/794)) @ly015
-
-- Update out-of-date configs ([#827](https://github.com/open-mmlab/mmpose/pull/827)) @jin-s13
-
-- Remove opencv-python-headless dependency by albumentations ([#833](https://github.com/open-mmlab/mmpose/pull/833)) @ly015
-
-- Update QQ QR code in README_CN.md ([#832](https://github.com/open-mmlab/mmpose/pull/832)) @ly015
-
-## **v0.16.0 (02/07/2021)**
-
-**Highlights**
-
-1. Support ["ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search"](https://arxiv.org/abs/2105.10154) CVPR'2021 ([#742](https://github.com/open-mmlab/mmpose/pull/742),[#755](https://github.com/open-mmlab/mmpose/pull/755)).
-
-2. Support MPI-INF-3DHP dataset ([#683](https://github.com/open-mmlab/mmpose/pull/683),[#746](https://github.com/open-mmlab/mmpose/pull/746),[#751](https://github.com/open-mmlab/mmpose/pull/751)).
-
-3. Add webcam demo tool ([#729](https://github.com/open-mmlab/mmpose/pull/729))
-
-4. Add 3d body and hand pose estimation demo ([#704](https://github.com/open-mmlab/mmpose/pull/704), [#727](https://github.com/open-mmlab/mmpose/pull/727)).
-
-**New Features**
-
-- Support ["ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search"](https://arxiv.org/abs/2105.10154) CVPR'2021 ([#742](https://github.com/open-mmlab/mmpose/pull/742),[#755](https://github.com/open-mmlab/mmpose/pull/755))
-
-- Support MPI-INF-3DHP dataset ([#683](https://github.com/open-mmlab/mmpose/pull/683),[#746](https://github.com/open-mmlab/mmpose/pull/746),[#751](https://github.com/open-mmlab/mmpose/pull/751))
-
-- Support Webcam demo ([#729](https://github.com/open-mmlab/mmpose/pull/729))
-
-- Support Interhand 3d demo ([#704](https://github.com/open-mmlab/mmpose/pull/704))
-
-- Support 3d pose video demo ([#727](https://github.com/open-mmlab/mmpose/pull/727))
-
-- Support H36m dataset for 2d pose estimation ([#709](https://github.com/open-mmlab/mmpose/pull/709), [#735](https://github.com/open-mmlab/mmpose/pull/735))
-
-- Add scripts to generate mim metafile ([#749](https://github.com/open-mmlab/mmpose/pull/749))
-
-**Bug Fixes**
-
-- Fix typos ([#692](https://github.com/open-mmlab/mmpose/pull/692),[#696](https://github.com/open-mmlab/mmpose/pull/696),[#697](https://github.com/open-mmlab/mmpose/pull/697),[#698](https://github.com/open-mmlab/mmpose/pull/698),[#712](https://github.com/open-mmlab/mmpose/pull/712),[#718](https://github.com/open-mmlab/mmpose/pull/718),[#728](https://github.com/open-mmlab/mmpose/pull/728))
-
-- Change model download links from `http` to `https` ([#716](https://github.com/open-mmlab/mmpose/pull/716))
-
-**Breaking Changes**
-
-- Switch to MMCV MODEL_REGISTRY ([#669](https://github.com/open-mmlab/mmpose/pull/669))
-
-**Improvements**
-
-- Refactor MeshMixDataset ([#752](https://github.com/open-mmlab/mmpose/pull/752))
-
-- Rename 'GaussianHeatMap' to 'GaussianHeatmap' ([#745](https://github.com/open-mmlab/mmpose/pull/745))
-
-- Update out-of-date configs ([#734](https://github.com/open-mmlab/mmpose/pull/734))
-
-- Improve compatibility for breaking changes ([#731](https://github.com/open-mmlab/mmpose/pull/731))
-
-- Enable to control radius and thickness in visualization ([#722](https://github.com/open-mmlab/mmpose/pull/722))
-
-- Add regex dependency ([#720](https://github.com/open-mmlab/mmpose/pull/720))
-
-## **v0.15.0 (02/06/2021)**
-
-**Highlights**
-
-1. Support 3d video pose estimation (VideoPose3D).
-
-2. Support 3d hand pose estimation (InterNet).
-
-3. Improve presentation of modelzoo.
-
-**New Features**
-
-- Support "InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image" (ECCV‘20) ([#624](https://github.com/open-mmlab/mmpose/pull/624))
-
-- Support "3D human pose estimation in video with temporal convolutions and semi-supervised training" (CVPR'19) ([#602](https://github.com/open-mmlab/mmpose/pull/602), [#681](https://github.com/open-mmlab/mmpose/pull/681))
-
-- Support 3d pose estimation demo ([#653](https://github.com/open-mmlab/mmpose/pull/653), [#670](https://github.com/open-mmlab/mmpose/pull/670))
-
-- Support bottom-up whole-body pose estimation ([#689](https://github.com/open-mmlab/mmpose/pull/689))
-
-- Support mmcli ([#634](https://github.com/open-mmlab/mmpose/pull/634))
-
-**Bug Fixes**
-
-- Fix opencv compatibility ([#635](https://github.com/open-mmlab/mmpose/pull/635))
-
-- Fix demo with UDP ([#637](https://github.com/open-mmlab/mmpose/pull/637))
-
-- Fix bottom-up model onnx conversion ([#680](https://github.com/open-mmlab/mmpose/pull/680))
-
-- Fix `GPU_IDS` in distributed training ([#668](https://github.com/open-mmlab/mmpose/pull/668))
-
-- Fix MANIFEST.in ([#641](https://github.com/open-mmlab/mmpose/pull/641), [#657](https://github.com/open-mmlab/mmpose/pull/657))
-
-- Fix docs ([#643](https://github.com/open-mmlab/mmpose/pull/643),[#684](https://github.com/open-mmlab/mmpose/pull/684),[#688](https://github.com/open-mmlab/mmpose/pull/688),[#690](https://github.com/open-mmlab/mmpose/pull/690),[#692](https://github.com/open-mmlab/mmpose/pull/692))
-
-**Breaking Changes**
-
-- Reorganize configs by tasks, algorithms, datasets, and techniques ([#647](https://github.com/open-mmlab/mmpose/pull/647))
-
-- Rename heads and detectors ([#667](https://github.com/open-mmlab/mmpose/pull/667))
-
-**Improvements**
-
-- Add `radius` and `thickness` parameters in visualization ([#638](https://github.com/open-mmlab/mmpose/pull/638))
-
-- Add `trans_prob` parameter in `TopDownRandomTranslation` ([#650](https://github.com/open-mmlab/mmpose/pull/650))
-
-- Switch to `MMCV MODEL_REGISTRY` ([#669](https://github.com/open-mmlab/mmpose/pull/669))
-
-- Update dependencies ([#674](https://github.com/open-mmlab/mmpose/pull/674), [#676](https://github.com/open-mmlab/mmpose/pull/676))
-
-## **v0.14.0 (06/05/2021)**
-
-**Highlights**
-
-1. Support animal pose estimation with 7 popular datasets.
-
-2. Support "A simple yet effective baseline for 3d human pose estimation" (ICCV'17).
-
-**New Features**
-
-- Support "A simple yet effective baseline for 3d human pose estimation" (ICCV'17) ([#554](https://github.com/open-mmlab/mmpose/pull/554),[#558](https://github.com/open-mmlab/mmpose/pull/558),[#566](https://github.com/open-mmlab/mmpose/pull/566),[#570](https://github.com/open-mmlab/mmpose/pull/570),[#589](https://github.com/open-mmlab/mmpose/pull/589))
-
-- Support animal pose estimation ([#559](https://github.com/open-mmlab/mmpose/pull/559),[#561](https://github.com/open-mmlab/mmpose/pull/561),[#563](https://github.com/open-mmlab/mmpose/pull/563),[#571](https://github.com/open-mmlab/mmpose/pull/571),[#603](https://github.com/open-mmlab/mmpose/pull/603),[#605](https://github.com/open-mmlab/mmpose/pull/605))
-
-- Support Horse-10 dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), MacaquePose dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), Vinegar Fly dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), Desert Locust dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), Grevy's Zebra dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), ATRW dataset ([#571](https://github.com/open-mmlab/mmpose/pull/571)), and Animal-Pose dataset ([#603](https://github.com/open-mmlab/mmpose/pull/603))
-
-- Support bottom-up pose tracking demo ([#574](https://github.com/open-mmlab/mmpose/pull/574))
-
-- Support FP16 training ([#584](https://github.com/open-mmlab/mmpose/pull/584),[#616](https://github.com/open-mmlab/mmpose/pull/616),[#626](https://github.com/open-mmlab/mmpose/pull/626))
-
-- Support NMS for bottom-up ([#609](https://github.com/open-mmlab/mmpose/pull/609))
-
-**Bug Fixes**
-
-- Fix bugs in the top-down demo, when there are no people in the images ([#569](https://github.com/open-mmlab/mmpose/pull/569)).
-
-- Fix the links in the doc ([#612](https://github.com/open-mmlab/mmpose/pull/612))
-
-**Improvements**
-
-- Speed up top-down inference ([#560](https://github.com/open-mmlab/mmpose/pull/560))
-
-- Update github CI ([#562](https://github.com/open-mmlab/mmpose/pull/562), [#564](https://github.com/open-mmlab/mmpose/pull/564))
-
-- Update Readme ([#578](https://github.com/open-mmlab/mmpose/pull/578),[#579](https://github.com/open-mmlab/mmpose/pull/579),[#580](https://github.com/open-mmlab/mmpose/pull/580),[#592](https://github.com/open-mmlab/mmpose/pull/592),[#599](https://github.com/open-mmlab/mmpose/pull/599),[#600](https://github.com/open-mmlab/mmpose/pull/600),[#607](https://github.com/open-mmlab/mmpose/pull/607))
-
-- Update Faq ([#587](https://github.com/open-mmlab/mmpose/pull/587), [#610](https://github.com/open-mmlab/mmpose/pull/610))
-
-## **v0.13.0 (31/03/2021)**
-
-**Highlights**
-
-1. Support Wingloss.
-
-2. Support RHD hand dataset.
-
-**New Features**
-
-- Support Wingloss ([#482](https://github.com/open-mmlab/mmpose/pull/482))
-
-- Support RHD hand dataset ([#523](https://github.com/open-mmlab/mmpose/pull/523), [#551](https://github.com/open-mmlab/mmpose/pull/551))
-
-- Support Human3.6m dataset for 3d keypoint detection ([#518](https://github.com/open-mmlab/mmpose/pull/518), [#527](https://github.com/open-mmlab/mmpose/pull/527))
-
-- Support TCN model for 3d keypoint detection ([#521](https://github.com/open-mmlab/mmpose/pull/521), [#522](https://github.com/open-mmlab/mmpose/pull/522))
-
-- Support Interhand3D model for 3d hand detection ([#536](https://github.com/open-mmlab/mmpose/pull/536))
-
-- Support Multi-task detector ([#480](https://github.com/open-mmlab/mmpose/pull/480))
-
-**Bug Fixes**
-
-- Fix PCKh@0.1 calculation ([#516](https://github.com/open-mmlab/mmpose/pull/516))
-
-- Fix unittest ([#529](https://github.com/open-mmlab/mmpose/pull/529))
-
-- Fix circular importing ([#542](https://github.com/open-mmlab/mmpose/pull/542))
-
-- Fix bugs in bottom-up keypoint score ([#548](https://github.com/open-mmlab/mmpose/pull/548))
-
-**Improvements**
-
-- Update config & checkpoints ([#525](https://github.com/open-mmlab/mmpose/pull/525), [#546](https://github.com/open-mmlab/mmpose/pull/546))
-
-- Fix typos ([#514](https://github.com/open-mmlab/mmpose/pull/514), [#519](https://github.com/open-mmlab/mmpose/pull/519), [#532](https://github.com/open-mmlab/mmpose/pull/532), [#537](https://github.com/open-mmlab/mmpose/pull/537), )
-
-- Speed up post processing ([#535](https://github.com/open-mmlab/mmpose/pull/535))
-
-- Update mmcv version dependency ([#544](https://github.com/open-mmlab/mmpose/pull/544))
-
-## **v0.12.0 (28/02/2021)**
-
-**Highlights**
-
-1. Support DeepPose algorithm.
-
-**New Features**
-
-- Support DeepPose algorithm ([#446](https://github.com/open-mmlab/mmpose/pull/446), [#461](https://github.com/open-mmlab/mmpose/pull/461))
-
-- Support interhand3d dataset ([#468](https://github.com/open-mmlab/mmpose/pull/468))
-
-- Support Albumentation pipeline ([#469](https://github.com/open-mmlab/mmpose/pull/469))
-
-- Support PhotometricDistortion pipeline ([#485](https://github.com/open-mmlab/mmpose/pull/485))
-
-- Set seed option for training ([#493](https://github.com/open-mmlab/mmpose/pull/493))
-
-- Add demos for face keypoint detection ([#502](https://github.com/open-mmlab/mmpose/pull/502))
-
-**Bug Fixes**
-
-- Change channel order according to configs ([#504](https://github.com/open-mmlab/mmpose/pull/504))
-
-- Fix `num_factors` in UDP encoding ([#495](https://github.com/open-mmlab/mmpose/pull/495))
-
-- Fix configs ([#456](https://github.com/open-mmlab/mmpose/pull/456))
-
-**Breaking Changes**
-
-- Refactor configs for wholebody pose estimation ([#487](https://github.com/open-mmlab/mmpose/pull/487), [#491](https://github.com/open-mmlab/mmpose/pull/491))
-
-- Rename `decode` function for heads ([#481](https://github.com/open-mmlab/mmpose/pull/481))
-
-**Improvements**
-
-- Update config & checkpoints ([#453](https://github.com/open-mmlab/mmpose/pull/453),[#484](https://github.com/open-mmlab/mmpose/pull/484),[#487](https://github.com/open-mmlab/mmpose/pull/487))
-
-- Add README in Chinese ([#462](https://github.com/open-mmlab/mmpose/pull/462))
-
-- Add tutorials about configs ([#465](https://github.com/open-mmlab/mmpose/pull/465))
-
-- Add demo videos for various tasks ([#499](https://github.com/open-mmlab/mmpose/pull/499), [#503](https://github.com/open-mmlab/mmpose/pull/503))
-
-- Update docs about MMPose installation ([#467](https://github.com/open-mmlab/mmpose/pull/467), [#505](https://github.com/open-mmlab/mmpose/pull/505))
-
-- Rename `stat.py` to `stats.py` ([#483](https://github.com/open-mmlab/mmpose/pull/483))
-
-- Fix typos ([#463](https://github.com/open-mmlab/mmpose/pull/463), [#464](https://github.com/open-mmlab/mmpose/pull/464), [#477](https://github.com/open-mmlab/mmpose/pull/477), [#481](https://github.com/open-mmlab/mmpose/pull/481))
-
-- latex to bibtex ([#471](https://github.com/open-mmlab/mmpose/pull/471))
-
-- Update FAQ ([#466](https://github.com/open-mmlab/mmpose/pull/466))
-
-## **v0.11.0 (31/01/2021)**
-
-**Highlights**
-
-1. Support fashion landmark detection.
-
-2. Support face keypoint detection.
-
-3. Support pose tracking with MMTracking.
-
-**New Features**
-
-- Support fashion landmark detection (DeepFashion) ([#413](https://github.com/open-mmlab/mmpose/pull/413))
-
-- Support face keypoint detection (300W, AFLW, COFW, WFLW) ([#367](https://github.com/open-mmlab/mmpose/pull/367))
-
-- Support pose tracking demo with MMTracking ([#427](https://github.com/open-mmlab/mmpose/pull/427))
-
-- Support face demo ([#443](https://github.com/open-mmlab/mmpose/pull/443))
-
-- Support AIC dataset for bottom-up methods ([#438](https://github.com/open-mmlab/mmpose/pull/438), [#449](https://github.com/open-mmlab/mmpose/pull/449))
-
-**Bug Fixes**
-
-- Fix multi-batch training ([#434](https://github.com/open-mmlab/mmpose/pull/434))
-
-- Fix sigmas in AIC dataset ([#441](https://github.com/open-mmlab/mmpose/pull/441))
-
-- Fix config file ([#420](https://github.com/open-mmlab/mmpose/pull/420))
-
-**Breaking Changes**
-
-- Refactor Heads ([#382](https://github.com/open-mmlab/mmpose/pull/382))
-
-**Improvements**
-
-- Update readme ([#409](https://github.com/open-mmlab/mmpose/pull/409), [#412](https://github.com/open-mmlab/mmpose/pull/412), [#415](https://github.com/open-mmlab/mmpose/pull/415), [#416](https://github.com/open-mmlab/mmpose/pull/416), [#419](https://github.com/open-mmlab/mmpose/pull/419), [#421](https://github.com/open-mmlab/mmpose/pull/421), [#422](https://github.com/open-mmlab/mmpose/pull/422), [#424](https://github.com/open-mmlab/mmpose/pull/424), [#425](https://github.com/open-mmlab/mmpose/pull/425), [#435](https://github.com/open-mmlab/mmpose/pull/435), [#436](https://github.com/open-mmlab/mmpose/pull/436), [#437](https://github.com/open-mmlab/mmpose/pull/437), [#444](https://github.com/open-mmlab/mmpose/pull/444), [#445](https://github.com/open-mmlab/mmpose/pull/445))
-
-- Add GAP (global average pooling) neck ([#414](https://github.com/open-mmlab/mmpose/pull/414))
-
-- Speed up ([#411](https://github.com/open-mmlab/mmpose/pull/411), [#423](https://github.com/open-mmlab/mmpose/pull/423))
-
-- Support COCO test-dev test ([#433](https://github.com/open-mmlab/mmpose/pull/433))
-
-## **v0.10.0 (31/12/2020)**
-
-**Highlights**
-
-1. Support more human pose estimation methods.
-
- 1. [UDP](https://arxiv.org/abs/1911.07524)
-
-2. Support pose tracking.
-
-3. Support multi-batch inference.
-
-4. Add some useful tools, including `analyze_logs`, `get_flops`, `print_config`.
-
-5. Support more backbone networks.
-
- 1. [ResNest](https://arxiv.org/pdf/2004.08955.pdf)
- 2. [VGG](https://arxiv.org/abs/1409.1556)
-
-**New Features**
-
-- Support UDP ([#353](https://github.com/open-mmlab/mmpose/pull/353), [#371](https://github.com/open-mmlab/mmpose/pull/371), [#402](https://github.com/open-mmlab/mmpose/pull/402))
-
-- Support multi-batch inference ([#390](https://github.com/open-mmlab/mmpose/pull/390))
-
-- Support MHP dataset ([#386](https://github.com/open-mmlab/mmpose/pull/386))
-
-- Support pose tracking demo ([#380](https://github.com/open-mmlab/mmpose/pull/380))
-
-- Support mpii-trb demo ([#372](https://github.com/open-mmlab/mmpose/pull/372))
-
-- Support mobilenet for hand pose estimation ([#377](https://github.com/open-mmlab/mmpose/pull/377))
-
-- Support ResNest backbone ([#370](https://github.com/open-mmlab/mmpose/pull/370))
-
-- Support VGG backbone ([#370](https://github.com/open-mmlab/mmpose/pull/370))
-
-- Add some useful tools, including `analyze_logs`, `get_flops`, `print_config` ([#324](https://github.com/open-mmlab/mmpose/pull/324))
-
-**Bug Fixes**
-
-- Fix bugs in pck evaluation ([#328](https://github.com/open-mmlab/mmpose/pull/328))
-
-- Fix model download links in README ([#396](https://github.com/open-mmlab/mmpose/pull/396), [#397](https://github.com/open-mmlab/mmpose/pull/397))
-
-- Fix CrowdPose annotations and update benchmarks ([#384](https://github.com/open-mmlab/mmpose/pull/384))
-
-- Fix modelzoo stat ([#354](https://github.com/open-mmlab/mmpose/pull/354), [#360](https://github.com/open-mmlab/mmpose/pull/360), [#362](https://github.com/open-mmlab/mmpose/pull/362))
-
-- Fix config files for aic datasets ([#340](https://github.com/open-mmlab/mmpose/pull/340))
-
-**Breaking Changes**
-
-- Rename `image_thr` to `det_bbox_thr` for top-down methods.
-
-**Improvements**
-
-- Organize the readme files ([#398](https://github.com/open-mmlab/mmpose/pull/398), [#399](https://github.com/open-mmlab/mmpose/pull/399), [#400](https://github.com/open-mmlab/mmpose/pull/400))
-
-- Check linting for markdown ([#379](https://github.com/open-mmlab/mmpose/pull/379))
-
-- Add faq.md ([#350](https://github.com/open-mmlab/mmpose/pull/350))
-
-- Remove PyTorch 1.4 in CI ([#338](https://github.com/open-mmlab/mmpose/pull/338))
-
-- Add pypi badge in readme ([#329](https://github.com/open-mmlab/mmpose/pull/329))
-
-## **v0.9.0 (30/11/2020)**
-
-**Highlights**
-
-1. Support more human pose estimation methods.
-
- 1. [MSPN](https://arxiv.org/abs/1901.00148)
- 2. [RSN](https://arxiv.org/abs/2003.04030)
-
-2. Support video pose estimation datasets.
-
- 1. [sub-JHMDB](http://jhmdb.is.tue.mpg.de/dataset)
-
-3. Support Onnx model conversion.
-
-**New Features**
-
-- Support MSPN ([#278](https://github.com/open-mmlab/mmpose/pull/278))
-
-- Support RSN ([#221](https://github.com/open-mmlab/mmpose/pull/221), [#318](https://github.com/open-mmlab/mmpose/pull/318))
-
-- Support new post-processing method for MSPN & RSN ([#288](https://github.com/open-mmlab/mmpose/pull/288))
-
-- Support sub-JHMDB dataset ([#292](https://github.com/open-mmlab/mmpose/pull/292))
-
-- Support urls for pre-trained models in config files ([#232](https://github.com/open-mmlab/mmpose/pull/232))
-
-- Support Onnx ([#305](https://github.com/open-mmlab/mmpose/pull/305))
-
-**Bug Fixes**
-
-- Fix model download links in README ([#255](https://github.com/open-mmlab/mmpose/pull/255), [#315](https://github.com/open-mmlab/mmpose/pull/315))
-
-**Breaking Changes**
-
-- `post_process=True|False` and `unbiased_decoding=True|False` are deprecated, use `post_process=None|default|unbiased` etc. instead ([#288](https://github.com/open-mmlab/mmpose/pull/288))
-
-**Improvements**
-
-- Enrich the model zoo ([#256](https://github.com/open-mmlab/mmpose/pull/256), [#320](https://github.com/open-mmlab/mmpose/pull/320))
-
-- Set the default map_location as 'cpu' to reduce gpu memory cost ([#227](https://github.com/open-mmlab/mmpose/pull/227))
-
-- Support return heatmaps and backbone features for bottom-up models ([#229](https://github.com/open-mmlab/mmpose/pull/229))
-
-- Upgrade mmcv maximum & minimum version ([#269](https://github.com/open-mmlab/mmpose/pull/269), [#313](https://github.com/open-mmlab/mmpose/pull/313))
-
-- Automatically add modelzoo statistics to readthedocs ([#252](https://github.com/open-mmlab/mmpose/pull/252))
-
-- Fix Pylint issues ([#258](https://github.com/open-mmlab/mmpose/pull/258), [#259](https://github.com/open-mmlab/mmpose/pull/259), [#260](https://github.com/open-mmlab/mmpose/pull/260), [#262](https://github.com/open-mmlab/mmpose/pull/262), [#265](https://github.com/open-mmlab/mmpose/pull/265), [#267](https://github.com/open-mmlab/mmpose/pull/267), [#268](https://github.com/open-mmlab/mmpose/pull/268), [#270](https://github.com/open-mmlab/mmpose/pull/270), [#271](https://github.com/open-mmlab/mmpose/pull/271), [#272](https://github.com/open-mmlab/mmpose/pull/272), [#273](https://github.com/open-mmlab/mmpose/pull/273), [#275](https://github.com/open-mmlab/mmpose/pull/275), [#276](https://github.com/open-mmlab/mmpose/pull/276), [#283](https://github.com/open-mmlab/mmpose/pull/283), [#285](https://github.com/open-mmlab/mmpose/pull/285), [#293](https://github.com/open-mmlab/mmpose/pull/293), [#294](https://github.com/open-mmlab/mmpose/pull/294), [#295](https://github.com/open-mmlab/mmpose/pull/295))
-
-- Improve README ([#226](https://github.com/open-mmlab/mmpose/pull/226), [#257](https://github.com/open-mmlab/mmpose/pull/257), [#264](https://github.com/open-mmlab/mmpose/pull/264), [#280](https://github.com/open-mmlab/mmpose/pull/280), [#296](https://github.com/open-mmlab/mmpose/pull/296))
-
-- Support PyTorch 1.7 in CI ([#274](https://github.com/open-mmlab/mmpose/pull/274))
-
-- Add docs/tutorials for running demos ([#263](https://github.com/open-mmlab/mmpose/pull/263))
-
-## **v0.8.0 (31/10/2020)**
-
-**Highlights**
-
-1. Support more human pose estimation datasets.
-
- 1. [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose)
- 2. [PoseTrack18](https://posetrack.net/)
-
-2. Support more 2D hand keypoint estimation datasets.
-
- 1. [InterHand2.6](https://github.com/facebookresearch/InterHand2.6M)
-
-3. Support adversarial training for 3D human shape recovery.
-
-4. Support multi-stage losses.
-
-5. Support mpii demo.
-
-**New Features**
-
-- Support [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose) dataset ([#195](https://github.com/open-mmlab/mmpose/pull/195))
-
-- Support [PoseTrack18](https://posetrack.net/) dataset ([#220](https://github.com/open-mmlab/mmpose/pull/220))
-
-- Support [InterHand2.6](https://github.com/facebookresearch/InterHand2.6M) dataset ([#202](https://github.com/open-mmlab/mmpose/pull/202))
-
-- Support adversarial training for 3D human shape recovery ([#192](https://github.com/open-mmlab/mmpose/pull/192))
-
-- Support multi-stage losses ([#204](https://github.com/open-mmlab/mmpose/pull/204))
-
-**Bug Fixes**
-
-- Fix config files ([#190](https://github.com/open-mmlab/mmpose/pull/190))
-
-**Improvements**
-
-- Add mpii demo ([#216](https://github.com/open-mmlab/mmpose/pull/216))
-
-- Improve README ([#181](https://github.com/open-mmlab/mmpose/pull/181), [#183](https://github.com/open-mmlab/mmpose/pull/183), [#208](https://github.com/open-mmlab/mmpose/pull/208))
-
-- Support return heatmaps and backbone features ([#196](https://github.com/open-mmlab/mmpose/pull/196), [#212](https://github.com/open-mmlab/mmpose/pull/212))
-
-- Support different return formats of mmdetection models ([#217](https://github.com/open-mmlab/mmpose/pull/217))
-
-## **v0.7.0 (30/9/2020)**
-
-**Highlights**
-
-1. Support HMR for 3D human shape recovery.
-
-2. Support WholeBody human pose estimation.
-
- 1. [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody)
-
-3. Support more 2D hand keypoint estimation datasets.
-
- 1. [Frei-hand](https://lmb.informatik.uni-freiburg.de/projects/freihand/)
- 2. [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html)
-
-4. Add more popular backbones & enrich the [modelzoo](https://mmpose.readthedocs.io/en/latest/model_zoo.html)
-
- 1. ShuffleNetv2
-
-5. Support hand demo and whole-body demo.
-
-**New Features**
-
-- Support HMR for 3D human shape recovery ([#157](https://github.com/open-mmlab/mmpose/pull/157), [#160](https://github.com/open-mmlab/mmpose/pull/160), [#161](https://github.com/open-mmlab/mmpose/pull/161), [#162](https://github.com/open-mmlab/mmpose/pull/162))
-
-- Support [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody) dataset ([#133](https://github.com/open-mmlab/mmpose/pull/133))
-
-- Support [Frei-hand](https://lmb.informatik.uni-freiburg.de/projects/freihand/) dataset ([#125](https://github.com/open-mmlab/mmpose/pull/125))
-
-- Support [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html) dataset ([#144](https://github.com/open-mmlab/mmpose/pull/144))
-
-- Support H36M dataset ([#159](https://github.com/open-mmlab/mmpose/pull/159))
-
-- Support ShuffleNetv2 ([#139](https://github.com/open-mmlab/mmpose/pull/139))
-
-- Support saving best models based on key indicator ([#127](https://github.com/open-mmlab/mmpose/pull/127))
-
-**Bug Fixes**
-
-- Fix typos in docs ([#121](https://github.com/open-mmlab/mmpose/pull/121))
-
-- Fix assertion ([#142](https://github.com/open-mmlab/mmpose/pull/142))
-
-**Improvements**
-
-- Add tools to transform .mat format to .json format ([#126](https://github.com/open-mmlab/mmpose/pull/126))
-
-- Add hand demo ([#115](https://github.com/open-mmlab/mmpose/pull/115))
-
-- Add whole-body demo ([#163](https://github.com/open-mmlab/mmpose/pull/163))
-
-- Reuse mmcv utility function and update version files ([#135](https://github.com/open-mmlab/mmpose/pull/135), [#137](https://github.com/open-mmlab/mmpose/pull/137))
-
-- Enrich the modelzoo ([#147](https://github.com/open-mmlab/mmpose/pull/147), [#169](https://github.com/open-mmlab/mmpose/pull/169))
-
-- Improve docs ([#174](https://github.com/open-mmlab/mmpose/pull/174), [#175](https://github.com/open-mmlab/mmpose/pull/175), [#178](https://github.com/open-mmlab/mmpose/pull/178))
-
-- Improve README ([#176](https://github.com/open-mmlab/mmpose/pull/176))
-
-- Improve version.py ([#173](https://github.com/open-mmlab/mmpose/pull/173))
-
-## **v0.6.0 (31/8/2020)**
-
-**Highlights**
-
-1. Add more popular backbones & enrich the [modelzoo](https://mmpose.readthedocs.io/en/latest/model_zoo.html)
-
- 1. ResNext
- 2. SEResNet
- 3. ResNetV1D
- 4. MobileNetv2
- 5. ShuffleNetv1
- 6. CPM (Convolutional Pose Machine)
-
-2. Add more popular datasets:
-
- 1. [AIChallenger](https://arxiv.org/abs/1711.06475?context=cs.CV)
- 2. [MPII](http://human-pose.mpi-inf.mpg.de/)
- 3. [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body)
- 4. [OCHuman](http://www.liruilong.cn/projects/pose2seg/index.html)
-
-3. Support 2d hand keypoint estimation.
-
- 1. [OneHand10K](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html)
-
-4. Support bottom-up inference.
-
-**New Features**
-
-- Support [OneHand10K](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html) dataset ([#52](https://github.com/open-mmlab/mmpose/pull/52))
-
-- Support [MPII](http://human-pose.mpi-inf.mpg.de/) dataset ([#55](https://github.com/open-mmlab/mmpose/pull/55))
-
-- Support [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) dataset ([#19](https://github.com/open-mmlab/mmpose/pull/19), [#47](https://github.com/open-mmlab/mmpose/pull/47), [#48](https://github.com/open-mmlab/mmpose/pull/48))
-
-- Support [OCHuman](http://www.liruilong.cn/projects/pose2seg/index.html) dataset ([#70](https://github.com/open-mmlab/mmpose/pull/70))
-
-- Support [AIChallenger](https://arxiv.org/abs/1711.06475?context=cs.CV) dataset ([#87](https://github.com/open-mmlab/mmpose/pull/87))
-
-- Support multiple backbones ([#26](https://github.com/open-mmlab/mmpose/pull/26))
-
-- Support CPM model ([#56](https://github.com/open-mmlab/mmpose/pull/56))
-
-**Bug Fixes**
-
-- Fix configs for MPII & MPII-TRB datasets ([#93](https://github.com/open-mmlab/mmpose/pull/93))
-
-- Fix the bug of missing `test_pipeline` in configs ([#14](https://github.com/open-mmlab/mmpose/pull/14))
-
-- Fix typos ([#27](https://github.com/open-mmlab/mmpose/pull/27), [#28](https://github.com/open-mmlab/mmpose/pull/28), [#50](https://github.com/open-mmlab/mmpose/pull/50), [#53](https://github.com/open-mmlab/mmpose/pull/53), [#63](https://github.com/open-mmlab/mmpose/pull/63))
-
-**Improvements**
-
-- Update benchmark ([#93](https://github.com/open-mmlab/mmpose/pull/93))
-
-- Add Dockerfile ([#44](https://github.com/open-mmlab/mmpose/pull/44))
-
-- Improve unittest coverage and minor fix ([#18](https://github.com/open-mmlab/mmpose/pull/18))
-
-- Support CPUs for train/val/demo ([#34](https://github.com/open-mmlab/mmpose/pull/34))
-
-- Support bottom-up demo ([#69](https://github.com/open-mmlab/mmpose/pull/69))
-
-- Add tools to publish model ([#62](https://github.com/open-mmlab/mmpose/pull/62))
-
-- Enrich the modelzoo ([#64](https://github.com/open-mmlab/mmpose/pull/64), [#68](https://github.com/open-mmlab/mmpose/pull/68), [#82](https://github.com/open-mmlab/mmpose/pull/82))
-
-## **v0.5.0 (21/7/2020)**
-
-**Highlights**
-
-- MMPose is released.
-
-**Main Features**
-
-- Support both top-down and bottom-up pose estimation approaches.
-
-- Achieve higher training efficiency and higher accuracy than other popular codebases (e.g. AlphaPose, HRNet)
-
-- Support various backbone models: ResNet, HRNet, SCNet, Houglass and HigherHRNet.
+# Changelog
+
+## **v1.0.0rc1 (14/10/2022)**
+
+**Highlights**
+
+- Release RTMPose, a high-performance real-time pose estimation algorithm with cross-platform deployment and inference support. See details at the [project page](/projects/rtmpose/)
+- Support several new algorithms: ViTPose (arXiv'2022), CID (CVPR'2022), DEKR (CVPR'2021)
+- Add Inferencer, a convenient inference interface that perform pose estimation and visualization on images, videos and webcam streams with only one line of code
+- Introduce *Project*, a new form for rapid and easy implementation of new algorithms and features in MMPose, which is more handy for community contributors
+
+**New Features**
+
+- Support RTMPose ([#1971](https://github.com/open-mmlab/mmpose/pull/1971), [#2024](https://github.com/open-mmlab/mmpose/pull/2024), [#2028](https://github.com/open-mmlab/mmpose/pull/2028), [#2030](https://github.com/open-mmlab/mmpose/pull/2030), [#2040](https://github.com/open-mmlab/mmpose/pull/2040), [#2057](https://github.com/open-mmlab/mmpose/pull/2057))
+- Support Inferencer ([#1969](https://github.com/open-mmlab/mmpose/pull/1969))
+- Support ViTPose ([#1876](https://github.com/open-mmlab/mmpose/pull/1876), [#2056](https://github.com/open-mmlab/mmpose/pull/2056), [#2058](https://github.com/open-mmlab/mmpose/pull/2058), [#2065](https://github.com/open-mmlab/mmpose/pull/2065))
+- Support CID ([#1907](https://github.com/open-mmlab/mmpose/pull/1907))
+- Support DEKR ([#1834](https://github.com/open-mmlab/mmpose/pull/1834), [#1901](https://github.com/open-mmlab/mmpose/pull/1901))
+- Support training with multiple datasets ([#1767](https://github.com/open-mmlab/mmpose/pull/1767), [#1930](https://github.com/open-mmlab/mmpose/pull/1930), [#1938](https://github.com/open-mmlab/mmpose/pull/1938), [#2025](https://github.com/open-mmlab/mmpose/pull/2025))
+- Add *project* to allow rapid and easy implementation of new models and features ([#1914](https://github.com/open-mmlab/mmpose/pull/1914))
+
+**Improvements**
+
+- Improve documentation quality ([#1846](https://github.com/open-mmlab/mmpose/pull/1846), [#1858](https://github.com/open-mmlab/mmpose/pull/1858), [#1872](https://github.com/open-mmlab/mmpose/pull/1872), [#1899](https://github.com/open-mmlab/mmpose/pull/1899), [#1925](https://github.com/open-mmlab/mmpose/pull/1925), [#1945](https://github.com/open-mmlab/mmpose/pull/1945), [#1952](https://github.com/open-mmlab/mmpose/pull/1952), [#1990](https://github.com/open-mmlab/mmpose/pull/1990), [#2023](https://github.com/open-mmlab/mmpose/pull/2023), [#2042](https://github.com/open-mmlab/mmpose/pull/2042))
+- Support visualizing keypoint indices ([#2051](https://github.com/open-mmlab/mmpose/pull/2051))
+- Support OpenPose style visualization ([#2055](https://github.com/open-mmlab/mmpose/pull/2055))
+- Accelerate image transpose in data pipelines with tensor operation ([#1976](https://github.com/open-mmlab/mmpose/pull/1976))
+- Support auto-import modules from registry ([#1961](https://github.com/open-mmlab/mmpose/pull/1961))
+- Support keypoint partition metric ([#1944](https://github.com/open-mmlab/mmpose/pull/1944))
+- Support SimCC 1D-heatmap visualization ([#1912](https://github.com/open-mmlab/mmpose/pull/1912))
+- Support saving predictions and data metainfo in demos ([#1814](https://github.com/open-mmlab/mmpose/pull/1814), [#1879](https://github.com/open-mmlab/mmpose/pull/1879))
+- Support SimCC with DARK ([#1870](https://github.com/open-mmlab/mmpose/pull/1870))
+- Remove Gaussian blur for offset maps in UDP-regress ([#1815](https://github.com/open-mmlab/mmpose/pull/1815))
+- Refactor encoding interface of Codec for better extendibility and easier configuration ([#1781](https://github.com/open-mmlab/mmpose/pull/1781))
+- Support evaluating CocoMetric without annotation file ([#1722](https://github.com/open-mmlab/mmpose/pull/1722))
+- Improve unit tests ([#1765](https://github.com/open-mmlab/mmpose/pull/1765))
+
+**Bug Fixes**
+
+- Fix repeated warnings from different ranks ([#2053](https://github.com/open-mmlab/mmpose/pull/2053))
+- Avoid frequent scope switching when using mmdet inference api ([#2039](https://github.com/open-mmlab/mmpose/pull/2039))
+- Remove EMA parameters and message hub data when publishing model checkpoints ([#2036](https://github.com/open-mmlab/mmpose/pull/2036))
+- Fix metainfo copying in dataset class ([#2017](https://github.com/open-mmlab/mmpose/pull/2017))
+- Fix top-down demo bug when there is no object detected ([#2007](https://github.com/open-mmlab/mmpose/pull/2007))
+- Fix config errors ([#1882](https://github.com/open-mmlab/mmpose/pull/1882), [#1906](https://github.com/open-mmlab/mmpose/pull/1906), [#1995](https://github.com/open-mmlab/mmpose/pull/1995))
+- Fix image demo failure when GUI is unavailable ([#1968](https://github.com/open-mmlab/mmpose/pull/1968))
+- Fix bug in AdaptiveWingLoss ([#1953](https://github.com/open-mmlab/mmpose/pull/1953))
+- Fix incorrect importing of RepeatDataset which is deprecated ([#1943](https://github.com/open-mmlab/mmpose/pull/1943))
+- Fix bug in bottom-up datasets that ignores images without instances ([#1752](https://github.com/open-mmlab/mmpose/pull/1752), [#1936](https://github.com/open-mmlab/mmpose/pull/1936))
+- Fix upstream dependency issues ([#1867](https://github.com/open-mmlab/mmpose/pull/1867), [#1921](https://github.com/open-mmlab/mmpose/pull/1921))
+- Fix evaluation issues and update results ([#1763](https://github.com/open-mmlab/mmpose/pull/1763), [#1773](https://github.com/open-mmlab/mmpose/pull/1773), [#1780](https://github.com/open-mmlab/mmpose/pull/1780), [#1850](https://github.com/open-mmlab/mmpose/pull/1850), [#1868](https://github.com/open-mmlab/mmpose/pull/1868))
+- Fix local registry missing warnings ([#1849](https://github.com/open-mmlab/mmpose/pull/1849))
+- Remove deprecated scripts for model deployment ([#1845](https://github.com/open-mmlab/mmpose/pull/1845))
+- Fix a bug in input transformation in BaseHead ([#1843](https://github.com/open-mmlab/mmpose/pull/1843))
+- Fix an interface mismatch with MMDetection in webcam demo ([#1813](https://github.com/open-mmlab/mmpose/pull/1813))
+- Fix a bug in heatmap visualization that causes incorrect scale ([#1800](https://github.com/open-mmlab/mmpose/pull/1800))
+- Add model metafiles ([#1768](https://github.com/open-mmlab/mmpose/pull/1768))
+
+## **v1.0.0rc0 (14/10/2022)**
+
+**New Features**
+
+- Support 4 light-weight pose estimation algorithms: [SimCC](https://doi.org/10.48550/arxiv.2107.03332) (ECCV'2022), [Debias-IPR](https://openaccess.thecvf.com/content/ICCV2021/papers/Gu_Removing_the_Bias_of_Integral_Pose_Regression_ICCV_2021_paper.pdf) (ICCV'2021), [IPR](https://arxiv.org/abs/1711.08229) (ECCV'2018), and [DSNT](https://arxiv.org/abs/1801.07372v2) (ArXiv'2018) ([#1628](https://github.com/open-mmlab/mmpose/pull/1628))
+
+**Migrations**
+
+- Add Webcam API in MMPose 1.0 ([#1638](https://github.com/open-mmlab/mmpose/pull/1638), [#1662](https://github.com/open-mmlab/mmpose/pull/1662)) @Ben-Louis
+- Add codec for Associative Embedding (beta) ([#1603](https://github.com/open-mmlab/mmpose/pull/1603)) @ly015
+
+**Improvements**
+
+- Add a colab tutorial for MMPose 1.0 ([#1660](https://github.com/open-mmlab/mmpose/pull/1660)) @Tau-J
+- Add model index in config folder ([#1710](https://github.com/open-mmlab/mmpose/pull/1710), [#1709](https://github.com/open-mmlab/mmpose/pull/1709), [#1627](https://github.com/open-mmlab/mmpose/pull/1627)) @ly015, @Tau-J, @Ben-Louis
+- Update and improve documentation ([#1692](https://github.com/open-mmlab/mmpose/pull/1692), [#1656](https://github.com/open-mmlab/mmpose/pull/1656), [#1681](https://github.com/open-mmlab/mmpose/pull/1681), [#1677](https://github.com/open-mmlab/mmpose/pull/1677), [#1664](https://github.com/open-mmlab/mmpose/pull/1664), [#1659](https://github.com/open-mmlab/mmpose/pull/1659)) @Tau-J, @Ben-Louis, @liqikai9
+- Improve config structures and formats ([#1651](https://github.com/open-mmlab/mmpose/pull/1651)) @liqikai9
+
+**Bug Fixes**
+
+- Update mmengine version requirements ([#1715](https://github.com/open-mmlab/mmpose/pull/1715)) @Ben-Louis
+- Update dependencies of pre-commit hooks ([#1705](https://github.com/open-mmlab/mmpose/pull/1705)) @Ben-Louis
+- Fix mmcv version in DockerFile ([#1704](https://github.com/open-mmlab/mmpose/pull/1704))
+- Fix a bug in setting dataset metainfo in configs ([#1684](https://github.com/open-mmlab/mmpose/pull/1684)) @ly015
+- Fix a bug in UDP training ([#1682](https://github.com/open-mmlab/mmpose/pull/1682)) @liqikai9
+- Fix a bug in Dark decoding ([#1676](https://github.com/open-mmlab/mmpose/pull/1676)) @liqikai9
+- Fix bugs in visualization ([#1671](https://github.com/open-mmlab/mmpose/pull/1671), [#1668](https://github.com/open-mmlab/mmpose/pull/1668), [#1657](https://github.com/open-mmlab/mmpose/pull/1657)) @liqikai9, @Ben-Louis
+- Fix incorrect flops calculation ([#1669](https://github.com/open-mmlab/mmpose/pull/1669)) @liqikai9
+- Fix `tensor.tile` compatibility issue for pytorch 1.6 ([#1658](https://github.com/open-mmlab/mmpose/pull/1658)) @ly015
+- Fix compatibility with `MultilevelPixelData` ([#1647](https://github.com/open-mmlab/mmpose/pull/1647)) @liqikai9
+
+## **v1.0.0beta (1/09/2022)**
+
+We are excited to announce the release of MMPose 1.0.0beta.
+MMPose 1.0.0beta is the first version of MMPose 1.x, a part of the OpenMMLab 2.0 projects.
+Built upon the new [training engine](https://github.com/open-mmlab/mmengine).
+
+**Highlights**
+
+- **New engines**. MMPose 1.x is based on [MMEngine](https://github.com/open-mmlab/mmengine), which provides a general and powerful runner that allows more flexible customizations and significantly simplifies the entrypoints of high-level interfaces.
+
+- **Unified interfaces**. As a part of the OpenMMLab 2.0 projects, MMPose 1.x unifies and refactors the interfaces and internal logics of train, testing, datasets, models, evaluation, and visualization. All the OpenMMLab 2.0 projects share the same design in those interfaces and logics to allow the emergence of multi-task/modality algorithms.
+
+- **More documentation and tutorials**. We add a bunch of documentation and tutorials to help users get started more smoothly. Read it [here](https://mmpose.readthedocs.io/en/latest/).
+
+**Breaking Changes**
+
+In this release, we made lots of major refactoring and modifications. Please refer to the [migration guide](../migration.md) for details and migration instructions.
+
+## **v0.28.1 (28/07/2022)**
+
+This release is meant to fix the compatibility with the latest mmcv v1.6.1
+
+## **v0.28.0 (06/07/2022)**
+
+**Highlights**
+
+- Support [TCFormer](https://openaccess.thecvf.com/content/CVPR2022/html/Zeng_Not_All_Tokens_Are_Equal_Human-Centric_Visual_Analysis_via_Token_CVPR_2022_paper.html) backbone, CVPR'2022 ([#1447](https://github.com/open-mmlab/mmpose/pull/1447), [#1452](https://github.com/open-mmlab/mmpose/pull/1452)) @zengwang430521
+
+- Add [RLE](https://arxiv.org/abs/2107.11291) models on COCO dataset ([#1424](https://github.com/open-mmlab/mmpose/pull/1424)) @Indigo6, @Ben-Louis, @ly015
+
+- Update swin models with better performance ([#1467](https://github.com/open-mmlab/mmpose/pull/1434)) @jin-s13
+
+**New Features**
+
+- Support [TCFormer](https://openaccess.thecvf.com/content/CVPR2022/html/Zeng_Not_All_Tokens_Are_Equal_Human-Centric_Visual_Analysis_via_Token_CVPR_2022_paper.html) backbone, CVPR'2022 ([#1447](https://github.com/open-mmlab/mmpose/pull/1447), [#1452](https://github.com/open-mmlab/mmpose/pull/1452)) @zengwang430521
+
+- Add [RLE](https://arxiv.org/abs/2107.11291) models on COCO dataset ([#1424](https://github.com/open-mmlab/mmpose/pull/1424)) @Indigo6, @Ben-Louis, @ly015
+
+- Support layer decay optimizer constructor and learning rate decay optimizer constructor ([#1423](https://github.com/open-mmlab/mmpose/pull/1423)) @jin-s13
+
+**Improvements**
+
+- Improve documentation quality ([#1416](https://github.com/open-mmlab/mmpose/pull/1416), [#1421](https://github.com/open-mmlab/mmpose/pull/1421), [#1423](https://github.com/open-mmlab/mmpose/pull/1423), [#1426](https://github.com/open-mmlab/mmpose/pull/1426), [#1458](https://github.com/open-mmlab/mmpose/pull/1458), [#1463](https://github.com/open-mmlab/mmpose/pull/1463)) @ly015, @liqikai9
+
+- Support installation by [mim](https://github.com/open-mmlab/mim) ([#1425](https://github.com/open-mmlab/mmpose/pull/1425)) @liqikai9
+
+- Support PAVI logger ([#1434](https://github.com/open-mmlab/mmpose/pull/1434)) @EvelynWang-0423
+
+- Add progress bar for some demos ([#1454](https://github.com/open-mmlab/mmpose/pull/1454)) @liqikai9
+
+- Webcam API supports quick device setting in terminal commands ([#1466](https://github.com/open-mmlab/mmpose/pull/1466)) @ly015
+
+- Update swin models with better performance ([#1467](https://github.com/open-mmlab/mmpose/pull/1434)) @jin-s13
+
+**Bug Fixes**
+
+- Rename `custom_hooks_config` to `custom_hooks` in configs to align with the documentation ([#1427](https://github.com/open-mmlab/mmpose/pull/1427)) @ly015
+
+- Fix deadlock issue in Webcam API ([#1430](https://github.com/open-mmlab/mmpose/pull/1430)) @ly015
+
+- Fix smoother configs in video 3D demo ([#1457](https://github.com/open-mmlab/mmpose/pull/1457)) @ly015
+
+## **v0.27.0 (07/06/2022)**
+
+**Highlights**
+
+- Support hand gesture recognition
+
+ - Try the demo for gesture recognition
+ - Learn more about the algorithm, dataset and experiment results
+
+- Major upgrade to the Webcam API
+
+ - Tutorials (EN|zh_CN)
+ - [API Reference](https://mmpose.readthedocs.io/en/latest/api.html#mmpose-apis-webcam)
+ - Demo
+
+**New Features**
+
+- Support gesture recognition algorithm [MTUT](https://openaccess.thecvf.com/content_CVPR_2019/html/Abavisani_Improving_the_Performance_of_Unimodal_Dynamic_Hand-Gesture_Recognition_With_Multimodal_CVPR_2019_paper.html) CVPR'2019 and dataset [NVGesture](https://openaccess.thecvf.com/content_cvpr_2016/html/Molchanov_Online_Detection_and_CVPR_2016_paper.html) CVPR'2016 ([#1380](https://github.com/open-mmlab/mmpose/pull/1380)) @Ben-Louis
+
+**Improvements**
+
+- Upgrade Webcam API and related documents ([#1393](https://github.com/open-mmlab/mmpose/pull/1393), [#1404](https://github.com/open-mmlab/mmpose/pull/1404), [#1413](https://github.com/open-mmlab/mmpose/pull/1413)) @ly015
+
+- Support exporting COCO inference result without the annotation file ([#1368](https://github.com/open-mmlab/mmpose/pull/1368)) @liqikai9
+
+- Replace markdownlint with mdformat in CI to avoid the dependence on ruby [#1382](https://github.com/open-mmlab/mmpose/pull/1382) @ly015
+
+- Improve documentation quality ([#1385](https://github.com/open-mmlab/mmpose/pull/1385), [#1394](https://github.com/open-mmlab/mmpose/pull/1394), [#1395](https://github.com/open-mmlab/mmpose/pull/1395), [#1408](https://github.com/open-mmlab/mmpose/pull/1408)) @chubei-oppen, @ly015, @liqikai9
+
+**Bug Fixes**
+
+- Fix xywh->xyxy bbox conversion in dataset sanity check ([#1367](https://github.com/open-mmlab/mmpose/pull/1367)) @jin-s13
+
+- Fix a bug in two-stage 3D keypoint demo ([#1373](https://github.com/open-mmlab/mmpose/pull/1373)) @ly015
+
+- Fix out-dated settings in PVT configs ([#1376](https://github.com/open-mmlab/mmpose/pull/1376)) @ly015
+
+- Fix myst settings for document compiling ([#1381](https://github.com/open-mmlab/mmpose/pull/1381)) @ly015
+
+- Fix a bug in bbox transform ([#1384](https://github.com/open-mmlab/mmpose/pull/1384)) @ly015
+
+- Fix inaccurate description of `min_keypoints` in tracking apis ([#1398](https://github.com/open-mmlab/mmpose/pull/1398)) @pallgeuer
+
+- Fix warning with `torch.meshgrid` ([#1402](https://github.com/open-mmlab/mmpose/pull/1402)) @pallgeuer
+
+- Remove redundant transformer modules from `mmpose.datasets.backbones.utils` ([#1405](https://github.com/open-mmlab/mmpose/pull/1405)) @ly015
+
+## **v0.26.0 (05/05/2022)**
+
+**Highlights**
+
+- Support [RLE (Residual Log-likelihood Estimation)](https://arxiv.org/abs/2107.11291), ICCV'2021 ([#1259](https://github.com/open-mmlab/mmpose/pull/1259)) @Indigo6, @ly015
+
+- Support [Swin Transformer](https://arxiv.org/abs/2103.14030), ICCV'2021 ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @yumendecc, @ly015
+
+- Support [PVT](https://arxiv.org/abs/2102.12122), ICCV'2021 and [PVTv2](https://arxiv.org/abs/2106.13797), CVMJ'2022 ([#1343](https://github.com/open-mmlab/mmpose/pull/1343)) @zengwang430521
+
+- Speed up inference and reduce CPU usage by optimizing the pre-processing pipeline ([#1320](https://github.com/open-mmlab/mmpose/pull/1320)) @chenxinfeng4, @liqikai9
+
+**New Features**
+
+- Support [RLE (Residual Log-likelihood Estimation)](https://arxiv.org/abs/2107.11291), ICCV'2021 ([#1259](https://github.com/open-mmlab/mmpose/pull/1259)) @Indigo6, @ly015
+
+- Support [Swin Transformer](https://arxiv.org/abs/2103.14030), ICCV'2021 ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @yumendecc, @ly015
+
+- Support [PVT](https://arxiv.org/abs/2102.12122), ICCV'2021 and [PVTv2](https://arxiv.org/abs/2106.13797), CVMJ'2022 ([#1343](https://github.com/open-mmlab/mmpose/pull/1343)) @zengwang430521
+
+- Support [FPN](https://openaccess.thecvf.com/content_cvpr_2017/html/Lin_Feature_Pyramid_Networks_CVPR_2017_paper.html), CVPR'2017 ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @yumendecc, @ly015
+
+**Improvements**
+
+- Speed up inference and reduce CPU usage by optimizing the pre-processing pipeline ([#1320](https://github.com/open-mmlab/mmpose/pull/1320)) @chenxinfeng4, @liqikai9
+
+- Video demo supports models that requires multi-frame inputs ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @liqikai9, @jin-s13
+
+- Update benchmark regression list ([#1328](https://github.com/open-mmlab/mmpose/pull/1328)) @ly015, @liqikai9
+
+- Remove unnecessary warnings in `TopDownPoseTrack18VideoDataset` ([#1335](https://github.com/open-mmlab/mmpose/pull/1335)) @liqikai9
+
+- Improve documentation quality ([#1313](https://github.com/open-mmlab/mmpose/pull/1313), [#1305](https://github.com/open-mmlab/mmpose/pull/1305)) @Ben-Louis, @ly015
+
+- Update deprecating settings in configs ([#1317](https://github.com/open-mmlab/mmpose/pull/1317)) @ly015
+
+**Bug Fixes**
+
+- Fix a bug in human skeleton grouping that may skip the matching process unexpectedly when `ignore_to_much` is True ([#1341](https://github.com/open-mmlab/mmpose/pull/1341)) @daixinghome
+
+- Fix a GPG key error that leads to CI failure ([#1354](https://github.com/open-mmlab/mmpose/pull/1354)) @ly015
+
+- Fix bugs in distributed training script ([#1338](https://github.com/open-mmlab/mmpose/pull/1338), [#1298](https://github.com/open-mmlab/mmpose/pull/1298)) @ly015
+
+- Fix an upstream bug in xtoccotools that causes incorrect AP(M) results ([#1308](https://github.com/open-mmlab/mmpose/pull/1308)) @jin-s13, @ly015
+
+- Fix indentiation errors in the colab tutorial ([#1298](https://github.com/open-mmlab/mmpose/pull/1298)) @YuanZi1501040205
+
+- Fix incompatible model weight initialization with other OpenMMLab codebases ([#1329](https://github.com/open-mmlab/mmpose/pull/1329)) @274869388
+
+- Fix HRNet FP16 checkpoints download URL ([#1309](https://github.com/open-mmlab/mmpose/pull/1309)) @YinAoXiong
+
+- Fix typos in `body3d_two_stage_video_demo.py` ([#1295](https://github.com/open-mmlab/mmpose/pull/1295)) @mucozcan
+
+**Breaking Changes**
+
+- Refactor bbox processing in datasets and pipelines ([#1311](https://github.com/open-mmlab/mmpose/pull/1311)) @ly015, @Ben-Louis
+
+- The bbox format conversion (xywh to center-scale) and random translation are moved from the dataset to the pipeline. The comparison between new and old version is as below:
+
+v0.26.0v0.25.0Dataset
+(e.g. [TopDownCOCODataset](https://github.com/open-mmlab/mmpose/blob/master/mmpose/datasets/datasets/top_down/topdown_coco_dataset.py))
+
+... # Data sample only contains bbox rec.append({ 'bbox': obj\['clean_bbox\]\[:4\], ... })
+
+
+
+
+
+... # Convert bbox from xywh to center-scale center, scale = self.\_xywh2cs(\*obj\['clean_bbox'\]\[:4\]) # Data sample contains center and scale rec.append({ 'bbox': obj\['clean_bbox\]\[:4\], 'center': center, 'scale': scale, ... })
+
+
Apply bbox random translation every epoch (instead of only applying once at the annotation loading)
+
+
+
+
-
+
+
+
+
+
+
BC Breaking
+
+
The method `_xywh2cs` of dataset base classes (e.g. [Kpt2dSviewRgbImgTopDownDataset](https://github.com/open-mmlab/mmpose/blob/master/mmpose/datasets/datasets/base/kpt_2d_sview_rgb_img_top_down_dataset.py)) will be deprecated in the future. Custom datasets will need modifications to move the bbox format conversion to pipelines.
+
+
-
+
+
+
+
+
+
+
+## **v0.25.0 (02/04/2022)**
+
+**Highlights**
+
+- Support Shelf and Campus datasets with pre-trained VoxelPose models, ["3D Pictorial Structures for Multiple Human Pose Estimation"](http://campar.in.tum.de/pub/belagiannis2014cvpr/belagiannis2014cvpr.pdf), CVPR'2014 ([#1225](https://github.com/open-mmlab/mmpose/pull/1225)) @liqikai9, @wusize
+
+- Add `Smoother` module for temporal smoothing of the pose estimation with configurable filters ([#1127](https://github.com/open-mmlab/mmpose/pull/1127)) @ailingzengzzz, @ly015
+
+- Support SmoothNet for pose smoothing, ["SmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos"](https://arxiv.org/abs/2112.13715), arXiv'2021 ([#1279](https://github.com/open-mmlab/mmpose/pull/1279)) @ailingzengzzz, @ly015
+
+- Add multiview 3D pose estimation demo ([#1270](https://github.com/open-mmlab/mmpose/pull/1270)) @wusize
+
+**New Features**
+
+- Support Shelf and Campus datasets with pre-trained VoxelPose models, ["3D Pictorial Structures for Multiple Human Pose Estimation"](http://campar.in.tum.de/pub/belagiannis2014cvpr/belagiannis2014cvpr.pdf), CVPR'2014 ([#1225](https://github.com/open-mmlab/mmpose/pull/1225)) @liqikai9, @wusize
+
+- Add `Smoother` module for temporal smoothing of the pose estimation with configurable filters ([#1127](https://github.com/open-mmlab/mmpose/pull/1127)) @ailingzengzzz, @ly015
+
+- Support SmoothNet for pose smoothing, ["SmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos"](https://arxiv.org/abs/2112.13715), arXiv'2021 ([#1279](https://github.com/open-mmlab/mmpose/pull/1279)) @ailingzengzzz, @ly015
+
+- Add multiview 3D pose estimation demo ([#1270](https://github.com/open-mmlab/mmpose/pull/1270)) @wusize
+
+- Support multi-machine distributed training ([#1248](https://github.com/open-mmlab/mmpose/pull/1248)) @ly015
+
+**Improvements**
+
+- Update HRFormer configs and checkpoints with relative position bias ([#1245](https://github.com/open-mmlab/mmpose/pull/1245)) @zengwang430521
+
+- Support using different random seed for each distributed node ([#1257](https://github.com/open-mmlab/mmpose/pull/1257), [#1229](https://github.com/open-mmlab/mmpose/pull/1229)) @ly015
+
+- Improve documentation quality ([#1275](https://github.com/open-mmlab/mmpose/pull/1275), [#1255](https://github.com/open-mmlab/mmpose/pull/1255), [#1258](https://github.com/open-mmlab/mmpose/pull/1258), [#1249](https://github.com/open-mmlab/mmpose/pull/1249), [#1247](https://github.com/open-mmlab/mmpose/pull/1247), [#1240](https://github.com/open-mmlab/mmpose/pull/1240), [#1235](https://github.com/open-mmlab/mmpose/pull/1235)) @ly015, @jin-s13, @YoniChechik
+
+**Bug Fixes**
+
+- Fix keypoint index in RHD dataset meta information ([#1265](https://github.com/open-mmlab/mmpose/pull/1265)) @liqikai9
+
+- Fix pre-commit hook unexpected behavior on Windows ([#1282](https://github.com/open-mmlab/mmpose/pull/1282)) @liqikai9
+
+- Remove python-dev installation in CI ([#1276](https://github.com/open-mmlab/mmpose/pull/1276)) @ly015
+
+- Unify hyphens in argument names in tools and demos ([#1271](https://github.com/open-mmlab/mmpose/pull/1271)) @ly015
+
+- Fix ambiguous channel size in `channel_shuffle` that may cause exporting failure (#1242) @PINTO0309
+
+- Fix a bug in Webcam API that causes single-class detectors fail ([#1239](https://github.com/open-mmlab/mmpose/pull/1239)) @674106399
+
+- Fix the issue that `custom_hook` can not be set in configs ([#1236](https://github.com/open-mmlab/mmpose/pull/1236)) @bladrome
+
+- Fix incompatible MMCV version in DockerFile ([#raykindle](https://github.com/open-mmlab/mmpose/pull/raykindle))
+
+- Skip invisible joints in visualization ([#1228](https://github.com/open-mmlab/mmpose/pull/1228)) @womeier
+
+## **v0.24.0 (07/03/2022)**
+
+**Highlights**
+
+- Support HRFormer ["HRFormer: High-Resolution Vision Transformer for Dense Predict"](https://proceedings.neurips.cc/paper/2021/hash/3bbfdde8842a5c44a0323518eec97cbe-Abstract.html), NeurIPS'2021 ([#1203](https://github.com/open-mmlab/mmpose/pull/1203)) @zengwang430521
+
+- Support Windows installation with pip ([#1213](https://github.com/open-mmlab/mmpose/pull/1213)) @jin-s13, @ly015
+
+- Add WebcamAPI documents ([#1187](https://github.com/open-mmlab/mmpose/pull/1187)) @ly015
+
+**New Features**
+
+- Support HRFormer ["HRFormer: High-Resolution Vision Transformer for Dense Predict"](https://proceedings.neurips.cc/paper/2021/hash/3bbfdde8842a5c44a0323518eec97cbe-Abstract.html), NeurIPS'2021 ([#1203](https://github.com/open-mmlab/mmpose/pull/1203)) @zengwang430521
+
+- Support Windows installation with pip ([#1213](https://github.com/open-mmlab/mmpose/pull/1213)) @jin-s13, @ly015
+
+- Support CPU training with mmcv \< v1.4.4 ([#1161](https://github.com/open-mmlab/mmpose/pull/1161)) @EasonQYS, @ly015
+
+- Add "Valentine Magic" demo with WebcamAPI ([#1189](https://github.com/open-mmlab/mmpose/pull/1189), [#1191](https://github.com/open-mmlab/mmpose/pull/1191)) @liqikai9
+
+**Improvements**
+
+- Refactor multi-view 3D pose estimation framework towards better modularization and expansibility ([#1196](https://github.com/open-mmlab/mmpose/pull/1196)) @wusize
+
+- Add WebcamAPI documents and tutorials ([#1187](https://github.com/open-mmlab/mmpose/pull/1187)) @ly015
+
+- Refactor dataset evaluation interface to align with other OpenMMLab codebases ([#1209](https://github.com/open-mmlab/mmpose/pull/1209)) @ly015
+
+- Add deprecation message for deploy tools since [MMDeploy](https://github.com/open-mmlab/mmdeploy) has supported MMPose ([#1207](https://github.com/open-mmlab/mmpose/pull/1207)) @QwQ2000
+
+- Improve documentation quality ([#1206](https://github.com/open-mmlab/mmpose/pull/1206), [#1161](https://github.com/open-mmlab/mmpose/pull/1161)) @ly015
+
+- Switch to OpenMMLab official pre-commit-hook for copyright check ([#1214](https://github.com/open-mmlab/mmpose/pull/1214)) @ly015
+
+**Bug Fixes**
+
+- Fix hard-coded data collating and scattering in inference ([#1175](https://github.com/open-mmlab/mmpose/pull/1175)) @ly015
+
+- Fix model configs on JHMDB dataset ([#1188](https://github.com/open-mmlab/mmpose/pull/1188)) @jin-s13
+
+- Fix area calculation in pose tracking inference ([#1197](https://github.com/open-mmlab/mmpose/pull/1197)) @pallgeuer
+
+- Fix registry scope conflict of module wrapper ([#1204](https://github.com/open-mmlab/mmpose/pull/1204)) @ly015
+
+- Update MMCV installation in CI and documents ([#1205](https://github.com/open-mmlab/mmpose/pull/1205))
+
+- Fix incorrect color channel order in visualization functions ([#1212](https://github.com/open-mmlab/mmpose/pull/1212)) @ly015
+
+## **v0.23.0 (11/02/2022)**
+
+**Highlights**
+
+- Add [MMPose Webcam API](https://github.com/open-mmlab/mmpose/tree/master/tools/webcam): A simple yet powerful tools to develop interactive webcam applications with MMPose functions. ([#1178](https://github.com/open-mmlab/mmpose/pull/1178), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1143](https://github.com/open-mmlab/mmpose/pull/1143), [#1094](https://github.com/open-mmlab/mmpose/pull/1094), [#1133](https://github.com/open-mmlab/mmpose/pull/1133), [#1098](https://github.com/open-mmlab/mmpose/pull/1098), [#1160](https://github.com/open-mmlab/mmpose/pull/1160)) @ly015, @jin-s13, @liqikai9, @wusize, @luminxu, @zengwang430521 @mzr1996
+
+**New Features**
+
+- Add [MMPose Webcam API](https://github.com/open-mmlab/mmpose/tree/master/tools/webcam): A simple yet powerful tools to develop interactive webcam applications with MMPose functions. ([#1178](https://github.com/open-mmlab/mmpose/pull/1178), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1143](https://github.com/open-mmlab/mmpose/pull/1143), [#1094](https://github.com/open-mmlab/mmpose/pull/1094), [#1133](https://github.com/open-mmlab/mmpose/pull/1133), [#1098](https://github.com/open-mmlab/mmpose/pull/1098), [#1160](https://github.com/open-mmlab/mmpose/pull/1160)) @ly015, @jin-s13, @liqikai9, @wusize, @luminxu, @zengwang430521 @mzr1996
+
+- Support ConcatDataset ([#1139](https://github.com/open-mmlab/mmpose/pull/1139)) @Canwang-sjtu
+
+- Support CPU training and testing ([#1157](https://github.com/open-mmlab/mmpose/pull/1157)) @ly015
+
+**Improvements**
+
+- Add multi-processing configurations to speed up distributed training and testing ([#1146](https://github.com/open-mmlab/mmpose/pull/1146)) @ly015
+
+- Add default runtime config ([#1145](https://github.com/open-mmlab/mmpose/pull/1145))
+
+- Upgrade isort in pre-commit hook ([#1179](https://github.com/open-mmlab/mmpose/pull/1179)) @liqikai9
+
+- Update README and documents ([#1171](https://github.com/open-mmlab/mmpose/pull/1171), [#1167](https://github.com/open-mmlab/mmpose/pull/1167), [#1153](https://github.com/open-mmlab/mmpose/pull/1153), [#1149](https://github.com/open-mmlab/mmpose/pull/1149), [#1148](https://github.com/open-mmlab/mmpose/pull/1148), [#1147](https://github.com/open-mmlab/mmpose/pull/1147), [#1140](https://github.com/open-mmlab/mmpose/pull/1140)) @jin-s13, @wusize, @TommyZihao, @ly015
+
+**Bug Fixes**
+
+- Fix undeterministic behavior in pre-commit hooks ([#1136](https://github.com/open-mmlab/mmpose/pull/1136)) @jin-s13
+
+- Deprecate the support for "python setup.py test" ([#1179](https://github.com/open-mmlab/mmpose/pull/1179)) @ly015
+
+- Fix incompatible settings with MMCV on HSigmoid default parameters ([#1132](https://github.com/open-mmlab/mmpose/pull/1132)) @ly015
+
+- Fix albumentation installation ([#1184](https://github.com/open-mmlab/mmpose/pull/1184)) @BIGWangYuDong
+
+## **v0.22.0 (04/01/2022)**
+
+**Highlights**
+
+- Support VoxelPose ["VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment"](https://arxiv.org/abs/2004.06239), ECCV'2020 ([#1050](https://github.com/open-mmlab/mmpose/pull/1050)) @wusize
+
+- Support Soft Wing loss ["Structure-Coherent Deep Feature Learning for Robust Face Alignment"](https://linchunze.github.io/papers/TIP21_Structure_coherent_FA.pdf), TIP'2021 ([#1077](https://github.com/open-mmlab/mmpose/pull/1077)) @jin-s13
+
+- Support Adaptive Wing loss ["Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression"](https://arxiv.org/abs/1904.07399), ICCV'2019 ([#1072](https://github.com/open-mmlab/mmpose/pull/1072)) @jin-s13
+
+**New Features**
+
+- Support VoxelPose ["VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment"](https://arxiv.org/abs/2004.06239), ECCV'2020 ([#1050](https://github.com/open-mmlab/mmpose/pull/1050)) @wusize
+
+- Support Soft Wing loss ["Structure-Coherent Deep Feature Learning for Robust Face Alignment"](https://linchunze.github.io/papers/TIP21_Structure_coherent_FA.pdf), TIP'2021 ([#1077](https://github.com/open-mmlab/mmpose/pull/1077)) @jin-s13
+
+- Support Adaptive Wing loss ["Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression"](https://arxiv.org/abs/1904.07399), ICCV'2019 ([#1072](https://github.com/open-mmlab/mmpose/pull/1072)) @jin-s13
+
+- Add LiteHRNet-18 Checkpoints trained on COCO. ([#1120](https://github.com/open-mmlab/mmpose/pull/1120)) @jin-s13
+
+**Improvements**
+
+- Improve documentation quality ([#1115](https://github.com/open-mmlab/mmpose/pull/1115), [#1111](https://github.com/open-mmlab/mmpose/pull/1111), [#1105](https://github.com/open-mmlab/mmpose/pull/1105), [#1087](https://github.com/open-mmlab/mmpose/pull/1087), [#1086](https://github.com/open-mmlab/mmpose/pull/1086), [#1085](https://github.com/open-mmlab/mmpose/pull/1085), [#1084](https://github.com/open-mmlab/mmpose/pull/1084), [#1083](https://github.com/open-mmlab/mmpose/pull/1083), [#1124](https://github.com/open-mmlab/mmpose/pull/1124), [#1070](https://github.com/open-mmlab/mmpose/pull/1070), [#1068](https://github.com/open-mmlab/mmpose/pull/1068)) @jin-s13, @liqikai9, @ly015
+
+- Support CircleCI ([#1074](https://github.com/open-mmlab/mmpose/pull/1074)) @ly015
+
+- Skip unit tests in CI when only document files were changed ([#1074](https://github.com/open-mmlab/mmpose/pull/1074), [#1041](https://github.com/open-mmlab/mmpose/pull/1041)) @QwQ2000, @ly015
+
+- Support file_client_args in LoadImageFromFile ([#1076](https://github.com/open-mmlab/mmpose/pull/1076)) @jin-s13
+
+**Bug Fixes**
+
+- Fix a bug in Dark UDP postprocessing that causes error when the channel number is large. ([#1079](https://github.com/open-mmlab/mmpose/pull/1079), [#1116](https://github.com/open-mmlab/mmpose/pull/1116)) @X00123, @jin-s13
+
+- Fix hard-coded `sigmas` in bottom-up image demo ([#1107](https://github.com/open-mmlab/mmpose/pull/1107), [#1101](https://github.com/open-mmlab/mmpose/pull/1101)) @chenxinfeng4, @liqikai9
+
+- Fix unstable checks in unit tests ([#1112](https://github.com/open-mmlab/mmpose/pull/1112)) @ly015
+
+- Do not destroy NULL windows if `args.show==False` in demo scripts ([#1104](https://github.com/open-mmlab/mmpose/pull/1104)) @bladrome
+
+## **v0.21.0 (06/12/2021)**
+
+**Highlights**
+
+- Support ["Learning Temporal Pose Estimation from Sparsely-Labeled Videos"](https://arxiv.org/abs/1906.04016), NeurIPS'2019 ([#932](https://github.com/open-mmlab/mmpose/pull/932), [#1006](https://github.com/open-mmlab/mmpose/pull/1006), [#1036](https://github.com/open-mmlab/mmpose/pull/1036), [#1060](https://github.com/open-mmlab/mmpose/pull/1060)) @liqikai9
+
+- Add ViPNAS-MobileNetV3 models ([#1025](https://github.com/open-mmlab/mmpose/pull/1025)) @luminxu, @jin-s13
+
+- Add inference speed benchmark ([#1028](https://github.com/open-mmlab/mmpose/pull/1028), [#1034](https://github.com/open-mmlab/mmpose/pull/1034), [#1044](https://github.com/open-mmlab/mmpose/pull/1044)) @liqikai9
+
+**New Features**
+
+- Support ["Learning Temporal Pose Estimation from Sparsely-Labeled Videos"](https://arxiv.org/abs/1906.04016), NeurIPS'2019 ([#932](https://github.com/open-mmlab/mmpose/pull/932), [#1006](https://github.com/open-mmlab/mmpose/pull/1006), [#1036](https://github.com/open-mmlab/mmpose/pull/1036)) @liqikai9
+
+- Add ViPNAS-MobileNetV3 models ([#1025](https://github.com/open-mmlab/mmpose/pull/1025)) @luminxu, @jin-s13
+
+- Add light-weight top-down models for whole-body keypoint detection ([#1009](https://github.com/open-mmlab/mmpose/pull/1009), [#1020](https://github.com/open-mmlab/mmpose/pull/1020), [#1055](https://github.com/open-mmlab/mmpose/pull/1055)) @luminxu, @ly015
+
+- Add HRNet checkpoints with various settings on PoseTrack18 ([#1035](https://github.com/open-mmlab/mmpose/pull/1035)) @liqikai9
+
+**Improvements**
+
+- Add inference speed benchmark ([#1028](https://github.com/open-mmlab/mmpose/pull/1028), [#1034](https://github.com/open-mmlab/mmpose/pull/1034), [#1044](https://github.com/open-mmlab/mmpose/pull/1044)) @liqikai9
+
+- Update model metafile format ([#1001](https://github.com/open-mmlab/mmpose/pull/1001)) @ly015
+
+- Support minus output feature index in mobilenet_v3 ([#1005](https://github.com/open-mmlab/mmpose/pull/1005)) @luminxu
+
+- Improve documentation quality ([#1018](https://github.com/open-mmlab/mmpose/pull/1018), [#1026](https://github.com/open-mmlab/mmpose/pull/1026), [#1027](https://github.com/open-mmlab/mmpose/pull/1027), [#1031](https://github.com/open-mmlab/mmpose/pull/1031), [#1038](https://github.com/open-mmlab/mmpose/pull/1038), [#1046](https://github.com/open-mmlab/mmpose/pull/1046), [#1056](https://github.com/open-mmlab/mmpose/pull/1056), [#1057](https://github.com/open-mmlab/mmpose/pull/1057)) @edybk, @luminxu, @ly015, @jin-s13
+
+- Set default random seed in training initialization ([#1030](https://github.com/open-mmlab/mmpose/pull/1030)) @ly015
+
+- Skip CI when only specific files changed ([#1041](https://github.com/open-mmlab/mmpose/pull/1041), [#1059](https://github.com/open-mmlab/mmpose/pull/1059)) @QwQ2000, @ly015
+
+- Automatically cancel uncompleted action runs when new commit arrives ([#1053](https://github.com/open-mmlab/mmpose/pull/1053)) @ly015
+
+**Bug Fixes**
+
+- Update pose tracking demo to be compatible with latest mmtracking ([#1014](https://github.com/open-mmlab/mmpose/pull/1014)) @jin-s13
+
+- Fix symlink creation failure when installed in Windows environments ([#1039](https://github.com/open-mmlab/mmpose/pull/1039)) @QwQ2000
+
+- Fix AP-10K dataset sigmas ([#1040](https://github.com/open-mmlab/mmpose/pull/1040)) @jin-s13
+
+## **v0.20.0 (01/11/2021)**
+
+**Highlights**
+
+- Add AP-10K dataset for animal pose estimation ([#987](https://github.com/open-mmlab/mmpose/pull/987)) @Annbless, @AlexTheBad, @jin-s13, @ly015
+
+- Support TorchServe ([#979](https://github.com/open-mmlab/mmpose/pull/979)) @ly015
+
+**New Features**
+
+- Add AP-10K dataset for animal pose estimation ([#987](https://github.com/open-mmlab/mmpose/pull/987)) @Annbless, @AlexTheBad, @jin-s13, @ly015
+
+- Add HRNetv2 checkpoints on 300W and COFW datasets ([#980](https://github.com/open-mmlab/mmpose/pull/980)) @jin-s13
+
+- Support TorchServe ([#979](https://github.com/open-mmlab/mmpose/pull/979)) @ly015
+
+**Bug Fixes**
+
+- Fix some deprecated or risky settings in configs ([#963](https://github.com/open-mmlab/mmpose/pull/963), [#976](https://github.com/open-mmlab/mmpose/pull/976), [#992](https://github.com/open-mmlab/mmpose/pull/992)) @jin-s13, @wusize
+
+- Fix issues of default arguments of training and testing scripts ([#970](https://github.com/open-mmlab/mmpose/pull/970), [#985](https://github.com/open-mmlab/mmpose/pull/985)) @liqikai9, @wusize
+
+- Fix heatmap and tag size mismatch in bottom-up with UDP ([#994](https://github.com/open-mmlab/mmpose/pull/994)) @wusize
+
+- Fix python3.9 installation in CI ([#983](https://github.com/open-mmlab/mmpose/pull/983)) @ly015
+
+- Fix model zoo document integrity issue ([#990](https://github.com/open-mmlab/mmpose/pull/990)) @jin-s13
+
+**Improvements**
+
+- Support non-square input shape for bottom-up ([#991](https://github.com/open-mmlab/mmpose/pull/991)) @wusize
+
+- Add image and video resources for demo ([#971](https://github.com/open-mmlab/mmpose/pull/971)) @liqikai9
+
+- Use CUDA docker images to accelerate CI ([#973](https://github.com/open-mmlab/mmpose/pull/973)) @ly015
+
+- Add codespell hook and fix detected typos ([#977](https://github.com/open-mmlab/mmpose/pull/977)) @ly015
+
+## **v0.19.0 (08/10/2021)**
+
+**Highlights**
+
+- Add models for Associative Embedding with Hourglass network backbone ([#906](https://github.com/open-mmlab/mmpose/pull/906), [#955](https://github.com/open-mmlab/mmpose/pull/955)) @jin-s13, @luminxu
+
+- Support COCO-Wholebody-Face and COCO-Wholebody-Hand datasets ([#813](https://github.com/open-mmlab/mmpose/pull/813)) @jin-s13, @innerlee, @luminxu
+
+- Upgrade dataset interface ([#901](https://github.com/open-mmlab/mmpose/pull/901), [#924](https://github.com/open-mmlab/mmpose/pull/924)) @jin-s13, @innerlee, @ly015, @liqikai9
+
+- New style of documentation ([#945](https://github.com/open-mmlab/mmpose/pull/945)) @ly015
+
+**New Features**
+
+- Add models for Associative Embedding with Hourglass network backbone ([#906](https://github.com/open-mmlab/mmpose/pull/906), [#955](https://github.com/open-mmlab/mmpose/pull/955)) @jin-s13, @luminxu
+
+- Support COCO-Wholebody-Face and COCO-Wholebody-Hand datasets ([#813](https://github.com/open-mmlab/mmpose/pull/813)) @jin-s13, @innerlee, @luminxu
+
+- Add pseudo-labeling tool to generate COCO style keypoint annotations with given bounding boxes ([#928](https://github.com/open-mmlab/mmpose/pull/928)) @soltkreig
+
+- New style of documentation ([#945](https://github.com/open-mmlab/mmpose/pull/945)) @ly015
+
+**Bug Fixes**
+
+- Fix segmentation parsing in Macaque dataset preprocessing ([#948](https://github.com/open-mmlab/mmpose/pull/948)) @jin-s13
+
+- Fix dependencies that may lead to CI failure in downstream projects ([#936](https://github.com/open-mmlab/mmpose/pull/936), [#953](https://github.com/open-mmlab/mmpose/pull/953)) @RangiLyu, @ly015
+
+- Fix keypoint order in Human3.6M dataset ([#940](https://github.com/open-mmlab/mmpose/pull/940)) @ttxskk
+
+- Fix unstable image loading for Interhand2.6M ([#913](https://github.com/open-mmlab/mmpose/pull/913)) @zengwang430521
+
+**Improvements**
+
+- Upgrade dataset interface ([#901](https://github.com/open-mmlab/mmpose/pull/901), [#924](https://github.com/open-mmlab/mmpose/pull/924)) @jin-s13, @innerlee, @ly015, @liqikai9
+
+- Improve demo usability and stability ([#908](https://github.com/open-mmlab/mmpose/pull/908), [#934](https://github.com/open-mmlab/mmpose/pull/934)) @ly015
+
+- Standardize model metafile format ([#941](https://github.com/open-mmlab/mmpose/pull/941)) @ly015
+
+- Support `persistent_worker` and several other arguments in configs ([#946](https://github.com/open-mmlab/mmpose/pull/946)) @jin-s13
+
+- Use MMCV root model registry to enable cross-project module building ([#935](https://github.com/open-mmlab/mmpose/pull/935)) @RangiLyu
+
+- Improve the document quality ([#916](https://github.com/open-mmlab/mmpose/pull/916), [#909](https://github.com/open-mmlab/mmpose/pull/909), [#942](https://github.com/open-mmlab/mmpose/pull/942), [#913](https://github.com/open-mmlab/mmpose/pull/913), [#956](https://github.com/open-mmlab/mmpose/pull/956)) @jin-s13, @ly015, @bit-scientist, @zengwang430521
+
+- Improve pull request template ([#952](https://github.com/open-mmlab/mmpose/pull/952), [#954](https://github.com/open-mmlab/mmpose/pull/954)) @ly015
+
+**Breaking Changes**
+
+- Upgrade dataset interface ([#901](https://github.com/open-mmlab/mmpose/pull/901)) @jin-s13, @innerlee, @ly015
+
+## **v0.18.0 (01/09/2021)**
+
+**Bug Fixes**
+
+- Fix redundant model weight loading in pytorch-to-onnx conversion ([#850](https://github.com/open-mmlab/mmpose/pull/850)) @ly015
+
+- Fix a bug in update_model_index.py that may cause pre-commit hook failure([#866](https://github.com/open-mmlab/mmpose/pull/866)) @ly015
+
+- Fix a bug in interhand_3d_head ([#890](https://github.com/open-mmlab/mmpose/pull/890)) @zengwang430521
+
+- Fix pose tracking demo failure caused by out-of-date configs ([#891](https://github.com/open-mmlab/mmpose/pull/891))
+
+**Improvements**
+
+- Add automatic benchmark regression tools ([#849](https://github.com/open-mmlab/mmpose/pull/849), [#880](https://github.com/open-mmlab/mmpose/pull/880), [#885](https://github.com/open-mmlab/mmpose/pull/885)) @liqikai9, @ly015
+
+- Add copyright information and checking hook ([#872](https://github.com/open-mmlab/mmpose/pull/872))
+
+- Add PR template ([#875](https://github.com/open-mmlab/mmpose/pull/875)) @ly015
+
+- Add citation information ([#876](https://github.com/open-mmlab/mmpose/pull/876)) @ly015
+
+- Add python3.9 in CI ([#877](https://github.com/open-mmlab/mmpose/pull/877), [#883](https://github.com/open-mmlab/mmpose/pull/883)) @ly015
+
+- Improve the quality of the documents ([#845](https://github.com/open-mmlab/mmpose/pull/845), [#845](https://github.com/open-mmlab/mmpose/pull/845), [#848](https://github.com/open-mmlab/mmpose/pull/848), [#867](https://github.com/open-mmlab/mmpose/pull/867), [#870](https://github.com/open-mmlab/mmpose/pull/870), [#873](https://github.com/open-mmlab/mmpose/pull/873), [#896](https://github.com/open-mmlab/mmpose/pull/896)) @jin-s13, @ly015, @zhiqwang
+
+## **v0.17.0 (06/08/2021)**
+
+**Highlights**
+
+1. Support ["Lite-HRNet: A Lightweight High-Resolution Network"](https://arxiv.org/abs/2104.06403) CVPR'2021 ([#733](https://github.com/open-mmlab/mmpose/pull/733),[#800](https://github.com/open-mmlab/mmpose/pull/800)) @jin-s13
+
+2. Add 3d body mesh demo ([#771](https://github.com/open-mmlab/mmpose/pull/771)) @zengwang430521
+
+3. Add Chinese documentation ([#787](https://github.com/open-mmlab/mmpose/pull/787), [#798](https://github.com/open-mmlab/mmpose/pull/798), [#799](https://github.com/open-mmlab/mmpose/pull/799), [#802](https://github.com/open-mmlab/mmpose/pull/802), [#804](https://github.com/open-mmlab/mmpose/pull/804), [#805](https://github.com/open-mmlab/mmpose/pull/805), [#815](https://github.com/open-mmlab/mmpose/pull/815), [#816](https://github.com/open-mmlab/mmpose/pull/816), [#817](https://github.com/open-mmlab/mmpose/pull/817), [#819](https://github.com/open-mmlab/mmpose/pull/819), [#839](https://github.com/open-mmlab/mmpose/pull/839)) @ly015, @luminxu, @jin-s13, @liqikai9, @zengwang430521
+
+4. Add Colab Tutorial ([#834](https://github.com/open-mmlab/mmpose/pull/834)) @ly015
+
+**New Features**
+
+- Support ["Lite-HRNet: A Lightweight High-Resolution Network"](https://arxiv.org/abs/2104.06403) CVPR'2021 ([#733](https://github.com/open-mmlab/mmpose/pull/733),[#800](https://github.com/open-mmlab/mmpose/pull/800)) @jin-s13
+
+- Add 3d body mesh demo ([#771](https://github.com/open-mmlab/mmpose/pull/771)) @zengwang430521
+
+- Add Chinese documentation ([#787](https://github.com/open-mmlab/mmpose/pull/787), [#798](https://github.com/open-mmlab/mmpose/pull/798), [#799](https://github.com/open-mmlab/mmpose/pull/799), [#802](https://github.com/open-mmlab/mmpose/pull/802), [#804](https://github.com/open-mmlab/mmpose/pull/804), [#805](https://github.com/open-mmlab/mmpose/pull/805), [#815](https://github.com/open-mmlab/mmpose/pull/815), [#816](https://github.com/open-mmlab/mmpose/pull/816), [#817](https://github.com/open-mmlab/mmpose/pull/817), [#819](https://github.com/open-mmlab/mmpose/pull/819), [#839](https://github.com/open-mmlab/mmpose/pull/839)) @ly015, @luminxu, @jin-s13, @liqikai9, @zengwang430521
+
+- Add Colab Tutorial ([#834](https://github.com/open-mmlab/mmpose/pull/834)) @ly015
+
+- Support training for InterHand v1.0 dataset ([#761](https://github.com/open-mmlab/mmpose/pull/761)) @zengwang430521
+
+**Bug Fixes**
+
+- Fix mpii pckh@0.1 index ([#773](https://github.com/open-mmlab/mmpose/pull/773)) @jin-s13
+
+- Fix multi-node distributed test ([#818](https://github.com/open-mmlab/mmpose/pull/818)) @ly015
+
+- Fix docstring and init_weights error of ShuffleNetV1 ([#814](https://github.com/open-mmlab/mmpose/pull/814)) @Junjun2016
+
+- Fix imshow_bbox error when input bboxes is empty ([#796](https://github.com/open-mmlab/mmpose/pull/796)) @ly015
+
+- Fix model zoo doc generation ([#778](https://github.com/open-mmlab/mmpose/pull/778)) @ly015
+
+- Fix typo ([#767](https://github.com/open-mmlab/mmpose/pull/767)), ([#780](https://github.com/open-mmlab/mmpose/pull/780), [#782](https://github.com/open-mmlab/mmpose/pull/782)) @ly015, @jin-s13
+
+**Breaking Changes**
+
+- Use MMCV EvalHook ([#686](https://github.com/open-mmlab/mmpose/pull/686)) @ly015
+
+**Improvements**
+
+- Add pytest.ini and fix docstring ([#812](https://github.com/open-mmlab/mmpose/pull/812)) @jin-s13
+
+- Update MSELoss ([#829](https://github.com/open-mmlab/mmpose/pull/829)) @Ezra-Yu
+
+- Move process_mmdet_results into inference.py ([#831](https://github.com/open-mmlab/mmpose/pull/831)) @ly015
+
+- Update resource limit ([#783](https://github.com/open-mmlab/mmpose/pull/783)) @jin-s13
+
+- Use COCO 2D pose model in 3D demo examples ([#785](https://github.com/open-mmlab/mmpose/pull/785)) @ly015
+
+- Change model zoo titles in the doc from center-aligned to left-aligned ([#792](https://github.com/open-mmlab/mmpose/pull/792), [#797](https://github.com/open-mmlab/mmpose/pull/797)) @ly015
+
+- Support MIM ([#706](https://github.com/open-mmlab/mmpose/pull/706), [#794](https://github.com/open-mmlab/mmpose/pull/794)) @ly015
+
+- Update out-of-date configs ([#827](https://github.com/open-mmlab/mmpose/pull/827)) @jin-s13
+
+- Remove opencv-python-headless dependency by albumentations ([#833](https://github.com/open-mmlab/mmpose/pull/833)) @ly015
+
+- Update QQ QR code in README_CN.md ([#832](https://github.com/open-mmlab/mmpose/pull/832)) @ly015
+
+## **v0.16.0 (02/07/2021)**
+
+**Highlights**
+
+1. Support ["ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search"](https://arxiv.org/abs/2105.10154) CVPR'2021 ([#742](https://github.com/open-mmlab/mmpose/pull/742),[#755](https://github.com/open-mmlab/mmpose/pull/755)).
+
+2. Support MPI-INF-3DHP dataset ([#683](https://github.com/open-mmlab/mmpose/pull/683),[#746](https://github.com/open-mmlab/mmpose/pull/746),[#751](https://github.com/open-mmlab/mmpose/pull/751)).
+
+3. Add webcam demo tool ([#729](https://github.com/open-mmlab/mmpose/pull/729))
+
+4. Add 3d body and hand pose estimation demo ([#704](https://github.com/open-mmlab/mmpose/pull/704), [#727](https://github.com/open-mmlab/mmpose/pull/727)).
+
+**New Features**
+
+- Support ["ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search"](https://arxiv.org/abs/2105.10154) CVPR'2021 ([#742](https://github.com/open-mmlab/mmpose/pull/742),[#755](https://github.com/open-mmlab/mmpose/pull/755))
+
+- Support MPI-INF-3DHP dataset ([#683](https://github.com/open-mmlab/mmpose/pull/683),[#746](https://github.com/open-mmlab/mmpose/pull/746),[#751](https://github.com/open-mmlab/mmpose/pull/751))
+
+- Support Webcam demo ([#729](https://github.com/open-mmlab/mmpose/pull/729))
+
+- Support Interhand 3d demo ([#704](https://github.com/open-mmlab/mmpose/pull/704))
+
+- Support 3d pose video demo ([#727](https://github.com/open-mmlab/mmpose/pull/727))
+
+- Support H36m dataset for 2d pose estimation ([#709](https://github.com/open-mmlab/mmpose/pull/709), [#735](https://github.com/open-mmlab/mmpose/pull/735))
+
+- Add scripts to generate mim metafile ([#749](https://github.com/open-mmlab/mmpose/pull/749))
+
+**Bug Fixes**
+
+- Fix typos ([#692](https://github.com/open-mmlab/mmpose/pull/692),[#696](https://github.com/open-mmlab/mmpose/pull/696),[#697](https://github.com/open-mmlab/mmpose/pull/697),[#698](https://github.com/open-mmlab/mmpose/pull/698),[#712](https://github.com/open-mmlab/mmpose/pull/712),[#718](https://github.com/open-mmlab/mmpose/pull/718),[#728](https://github.com/open-mmlab/mmpose/pull/728))
+
+- Change model download links from `http` to `https` ([#716](https://github.com/open-mmlab/mmpose/pull/716))
+
+**Breaking Changes**
+
+- Switch to MMCV MODEL_REGISTRY ([#669](https://github.com/open-mmlab/mmpose/pull/669))
+
+**Improvements**
+
+- Refactor MeshMixDataset ([#752](https://github.com/open-mmlab/mmpose/pull/752))
+
+- Rename 'GaussianHeatMap' to 'GaussianHeatmap' ([#745](https://github.com/open-mmlab/mmpose/pull/745))
+
+- Update out-of-date configs ([#734](https://github.com/open-mmlab/mmpose/pull/734))
+
+- Improve compatibility for breaking changes ([#731](https://github.com/open-mmlab/mmpose/pull/731))
+
+- Enable to control radius and thickness in visualization ([#722](https://github.com/open-mmlab/mmpose/pull/722))
+
+- Add regex dependency ([#720](https://github.com/open-mmlab/mmpose/pull/720))
+
+## **v0.15.0 (02/06/2021)**
+
+**Highlights**
+
+1. Support 3d video pose estimation (VideoPose3D).
+
+2. Support 3d hand pose estimation (InterNet).
+
+3. Improve presentation of modelzoo.
+
+**New Features**
+
+- Support "InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image" (ECCV‘20) ([#624](https://github.com/open-mmlab/mmpose/pull/624))
+
+- Support "3D human pose estimation in video with temporal convolutions and semi-supervised training" (CVPR'19) ([#602](https://github.com/open-mmlab/mmpose/pull/602), [#681](https://github.com/open-mmlab/mmpose/pull/681))
+
+- Support 3d pose estimation demo ([#653](https://github.com/open-mmlab/mmpose/pull/653), [#670](https://github.com/open-mmlab/mmpose/pull/670))
+
+- Support bottom-up whole-body pose estimation ([#689](https://github.com/open-mmlab/mmpose/pull/689))
+
+- Support mmcli ([#634](https://github.com/open-mmlab/mmpose/pull/634))
+
+**Bug Fixes**
+
+- Fix opencv compatibility ([#635](https://github.com/open-mmlab/mmpose/pull/635))
+
+- Fix demo with UDP ([#637](https://github.com/open-mmlab/mmpose/pull/637))
+
+- Fix bottom-up model onnx conversion ([#680](https://github.com/open-mmlab/mmpose/pull/680))
+
+- Fix `GPU_IDS` in distributed training ([#668](https://github.com/open-mmlab/mmpose/pull/668))
+
+- Fix MANIFEST.in ([#641](https://github.com/open-mmlab/mmpose/pull/641), [#657](https://github.com/open-mmlab/mmpose/pull/657))
+
+- Fix docs ([#643](https://github.com/open-mmlab/mmpose/pull/643),[#684](https://github.com/open-mmlab/mmpose/pull/684),[#688](https://github.com/open-mmlab/mmpose/pull/688),[#690](https://github.com/open-mmlab/mmpose/pull/690),[#692](https://github.com/open-mmlab/mmpose/pull/692))
+
+**Breaking Changes**
+
+- Reorganize configs by tasks, algorithms, datasets, and techniques ([#647](https://github.com/open-mmlab/mmpose/pull/647))
+
+- Rename heads and detectors ([#667](https://github.com/open-mmlab/mmpose/pull/667))
+
+**Improvements**
+
+- Add `radius` and `thickness` parameters in visualization ([#638](https://github.com/open-mmlab/mmpose/pull/638))
+
+- Add `trans_prob` parameter in `TopDownRandomTranslation` ([#650](https://github.com/open-mmlab/mmpose/pull/650))
+
+- Switch to `MMCV MODEL_REGISTRY` ([#669](https://github.com/open-mmlab/mmpose/pull/669))
+
+- Update dependencies ([#674](https://github.com/open-mmlab/mmpose/pull/674), [#676](https://github.com/open-mmlab/mmpose/pull/676))
+
+## **v0.14.0 (06/05/2021)**
+
+**Highlights**
+
+1. Support animal pose estimation with 7 popular datasets.
+
+2. Support "A simple yet effective baseline for 3d human pose estimation" (ICCV'17).
+
+**New Features**
+
+- Support "A simple yet effective baseline for 3d human pose estimation" (ICCV'17) ([#554](https://github.com/open-mmlab/mmpose/pull/554),[#558](https://github.com/open-mmlab/mmpose/pull/558),[#566](https://github.com/open-mmlab/mmpose/pull/566),[#570](https://github.com/open-mmlab/mmpose/pull/570),[#589](https://github.com/open-mmlab/mmpose/pull/589))
+
+- Support animal pose estimation ([#559](https://github.com/open-mmlab/mmpose/pull/559),[#561](https://github.com/open-mmlab/mmpose/pull/561),[#563](https://github.com/open-mmlab/mmpose/pull/563),[#571](https://github.com/open-mmlab/mmpose/pull/571),[#603](https://github.com/open-mmlab/mmpose/pull/603),[#605](https://github.com/open-mmlab/mmpose/pull/605))
+
+- Support Horse-10 dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), MacaquePose dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), Vinegar Fly dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), Desert Locust dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), Grevy's Zebra dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), ATRW dataset ([#571](https://github.com/open-mmlab/mmpose/pull/571)), and Animal-Pose dataset ([#603](https://github.com/open-mmlab/mmpose/pull/603))
+
+- Support bottom-up pose tracking demo ([#574](https://github.com/open-mmlab/mmpose/pull/574))
+
+- Support FP16 training ([#584](https://github.com/open-mmlab/mmpose/pull/584),[#616](https://github.com/open-mmlab/mmpose/pull/616),[#626](https://github.com/open-mmlab/mmpose/pull/626))
+
+- Support NMS for bottom-up ([#609](https://github.com/open-mmlab/mmpose/pull/609))
+
+**Bug Fixes**
+
+- Fix bugs in the top-down demo, when there are no people in the images ([#569](https://github.com/open-mmlab/mmpose/pull/569)).
+
+- Fix the links in the doc ([#612](https://github.com/open-mmlab/mmpose/pull/612))
+
+**Improvements**
+
+- Speed up top-down inference ([#560](https://github.com/open-mmlab/mmpose/pull/560))
+
+- Update github CI ([#562](https://github.com/open-mmlab/mmpose/pull/562), [#564](https://github.com/open-mmlab/mmpose/pull/564))
+
+- Update Readme ([#578](https://github.com/open-mmlab/mmpose/pull/578),[#579](https://github.com/open-mmlab/mmpose/pull/579),[#580](https://github.com/open-mmlab/mmpose/pull/580),[#592](https://github.com/open-mmlab/mmpose/pull/592),[#599](https://github.com/open-mmlab/mmpose/pull/599),[#600](https://github.com/open-mmlab/mmpose/pull/600),[#607](https://github.com/open-mmlab/mmpose/pull/607))
+
+- Update Faq ([#587](https://github.com/open-mmlab/mmpose/pull/587), [#610](https://github.com/open-mmlab/mmpose/pull/610))
+
+## **v0.13.0 (31/03/2021)**
+
+**Highlights**
+
+1. Support Wingloss.
+
+2. Support RHD hand dataset.
+
+**New Features**
+
+- Support Wingloss ([#482](https://github.com/open-mmlab/mmpose/pull/482))
+
+- Support RHD hand dataset ([#523](https://github.com/open-mmlab/mmpose/pull/523), [#551](https://github.com/open-mmlab/mmpose/pull/551))
+
+- Support Human3.6m dataset for 3d keypoint detection ([#518](https://github.com/open-mmlab/mmpose/pull/518), [#527](https://github.com/open-mmlab/mmpose/pull/527))
+
+- Support TCN model for 3d keypoint detection ([#521](https://github.com/open-mmlab/mmpose/pull/521), [#522](https://github.com/open-mmlab/mmpose/pull/522))
+
+- Support Interhand3D model for 3d hand detection ([#536](https://github.com/open-mmlab/mmpose/pull/536))
+
+- Support Multi-task detector ([#480](https://github.com/open-mmlab/mmpose/pull/480))
+
+**Bug Fixes**
+
+- Fix PCKh@0.1 calculation ([#516](https://github.com/open-mmlab/mmpose/pull/516))
+
+- Fix unittest ([#529](https://github.com/open-mmlab/mmpose/pull/529))
+
+- Fix circular importing ([#542](https://github.com/open-mmlab/mmpose/pull/542))
+
+- Fix bugs in bottom-up keypoint score ([#548](https://github.com/open-mmlab/mmpose/pull/548))
+
+**Improvements**
+
+- Update config & checkpoints ([#525](https://github.com/open-mmlab/mmpose/pull/525), [#546](https://github.com/open-mmlab/mmpose/pull/546))
+
+- Fix typos ([#514](https://github.com/open-mmlab/mmpose/pull/514), [#519](https://github.com/open-mmlab/mmpose/pull/519), [#532](https://github.com/open-mmlab/mmpose/pull/532), [#537](https://github.com/open-mmlab/mmpose/pull/537), )
+
+- Speed up post processing ([#535](https://github.com/open-mmlab/mmpose/pull/535))
+
+- Update mmcv version dependency ([#544](https://github.com/open-mmlab/mmpose/pull/544))
+
+## **v0.12.0 (28/02/2021)**
+
+**Highlights**
+
+1. Support DeepPose algorithm.
+
+**New Features**
+
+- Support DeepPose algorithm ([#446](https://github.com/open-mmlab/mmpose/pull/446), [#461](https://github.com/open-mmlab/mmpose/pull/461))
+
+- Support interhand3d dataset ([#468](https://github.com/open-mmlab/mmpose/pull/468))
+
+- Support Albumentation pipeline ([#469](https://github.com/open-mmlab/mmpose/pull/469))
+
+- Support PhotometricDistortion pipeline ([#485](https://github.com/open-mmlab/mmpose/pull/485))
+
+- Set seed option for training ([#493](https://github.com/open-mmlab/mmpose/pull/493))
+
+- Add demos for face keypoint detection ([#502](https://github.com/open-mmlab/mmpose/pull/502))
+
+**Bug Fixes**
+
+- Change channel order according to configs ([#504](https://github.com/open-mmlab/mmpose/pull/504))
+
+- Fix `num_factors` in UDP encoding ([#495](https://github.com/open-mmlab/mmpose/pull/495))
+
+- Fix configs ([#456](https://github.com/open-mmlab/mmpose/pull/456))
+
+**Breaking Changes**
+
+- Refactor configs for wholebody pose estimation ([#487](https://github.com/open-mmlab/mmpose/pull/487), [#491](https://github.com/open-mmlab/mmpose/pull/491))
+
+- Rename `decode` function for heads ([#481](https://github.com/open-mmlab/mmpose/pull/481))
+
+**Improvements**
+
+- Update config & checkpoints ([#453](https://github.com/open-mmlab/mmpose/pull/453),[#484](https://github.com/open-mmlab/mmpose/pull/484),[#487](https://github.com/open-mmlab/mmpose/pull/487))
+
+- Add README in Chinese ([#462](https://github.com/open-mmlab/mmpose/pull/462))
+
+- Add tutorials about configs ([#465](https://github.com/open-mmlab/mmpose/pull/465))
+
+- Add demo videos for various tasks ([#499](https://github.com/open-mmlab/mmpose/pull/499), [#503](https://github.com/open-mmlab/mmpose/pull/503))
+
+- Update docs about MMPose installation ([#467](https://github.com/open-mmlab/mmpose/pull/467), [#505](https://github.com/open-mmlab/mmpose/pull/505))
+
+- Rename `stat.py` to `stats.py` ([#483](https://github.com/open-mmlab/mmpose/pull/483))
+
+- Fix typos ([#463](https://github.com/open-mmlab/mmpose/pull/463), [#464](https://github.com/open-mmlab/mmpose/pull/464), [#477](https://github.com/open-mmlab/mmpose/pull/477), [#481](https://github.com/open-mmlab/mmpose/pull/481))
+
+- latex to bibtex ([#471](https://github.com/open-mmlab/mmpose/pull/471))
+
+- Update FAQ ([#466](https://github.com/open-mmlab/mmpose/pull/466))
+
+## **v0.11.0 (31/01/2021)**
+
+**Highlights**
+
+1. Support fashion landmark detection.
+
+2. Support face keypoint detection.
+
+3. Support pose tracking with MMTracking.
+
+**New Features**
+
+- Support fashion landmark detection (DeepFashion) ([#413](https://github.com/open-mmlab/mmpose/pull/413))
+
+- Support face keypoint detection (300W, AFLW, COFW, WFLW) ([#367](https://github.com/open-mmlab/mmpose/pull/367))
+
+- Support pose tracking demo with MMTracking ([#427](https://github.com/open-mmlab/mmpose/pull/427))
+
+- Support face demo ([#443](https://github.com/open-mmlab/mmpose/pull/443))
+
+- Support AIC dataset for bottom-up methods ([#438](https://github.com/open-mmlab/mmpose/pull/438), [#449](https://github.com/open-mmlab/mmpose/pull/449))
+
+**Bug Fixes**
+
+- Fix multi-batch training ([#434](https://github.com/open-mmlab/mmpose/pull/434))
+
+- Fix sigmas in AIC dataset ([#441](https://github.com/open-mmlab/mmpose/pull/441))
+
+- Fix config file ([#420](https://github.com/open-mmlab/mmpose/pull/420))
+
+**Breaking Changes**
+
+- Refactor Heads ([#382](https://github.com/open-mmlab/mmpose/pull/382))
+
+**Improvements**
+
+- Update readme ([#409](https://github.com/open-mmlab/mmpose/pull/409), [#412](https://github.com/open-mmlab/mmpose/pull/412), [#415](https://github.com/open-mmlab/mmpose/pull/415), [#416](https://github.com/open-mmlab/mmpose/pull/416), [#419](https://github.com/open-mmlab/mmpose/pull/419), [#421](https://github.com/open-mmlab/mmpose/pull/421), [#422](https://github.com/open-mmlab/mmpose/pull/422), [#424](https://github.com/open-mmlab/mmpose/pull/424), [#425](https://github.com/open-mmlab/mmpose/pull/425), [#435](https://github.com/open-mmlab/mmpose/pull/435), [#436](https://github.com/open-mmlab/mmpose/pull/436), [#437](https://github.com/open-mmlab/mmpose/pull/437), [#444](https://github.com/open-mmlab/mmpose/pull/444), [#445](https://github.com/open-mmlab/mmpose/pull/445))
+
+- Add GAP (global average pooling) neck ([#414](https://github.com/open-mmlab/mmpose/pull/414))
+
+- Speed up ([#411](https://github.com/open-mmlab/mmpose/pull/411), [#423](https://github.com/open-mmlab/mmpose/pull/423))
+
+- Support COCO test-dev test ([#433](https://github.com/open-mmlab/mmpose/pull/433))
+
+## **v0.10.0 (31/12/2020)**
+
+**Highlights**
+
+1. Support more human pose estimation methods.
+
+ 1. [UDP](https://arxiv.org/abs/1911.07524)
+
+2. Support pose tracking.
+
+3. Support multi-batch inference.
+
+4. Add some useful tools, including `analyze_logs`, `get_flops`, `print_config`.
+
+5. Support more backbone networks.
+
+ 1. [ResNest](https://arxiv.org/pdf/2004.08955.pdf)
+ 2. [VGG](https://arxiv.org/abs/1409.1556)
+
+**New Features**
+
+- Support UDP ([#353](https://github.com/open-mmlab/mmpose/pull/353), [#371](https://github.com/open-mmlab/mmpose/pull/371), [#402](https://github.com/open-mmlab/mmpose/pull/402))
+
+- Support multi-batch inference ([#390](https://github.com/open-mmlab/mmpose/pull/390))
+
+- Support MHP dataset ([#386](https://github.com/open-mmlab/mmpose/pull/386))
+
+- Support pose tracking demo ([#380](https://github.com/open-mmlab/mmpose/pull/380))
+
+- Support mpii-trb demo ([#372](https://github.com/open-mmlab/mmpose/pull/372))
+
+- Support mobilenet for hand pose estimation ([#377](https://github.com/open-mmlab/mmpose/pull/377))
+
+- Support ResNest backbone ([#370](https://github.com/open-mmlab/mmpose/pull/370))
+
+- Support VGG backbone ([#370](https://github.com/open-mmlab/mmpose/pull/370))
+
+- Add some useful tools, including `analyze_logs`, `get_flops`, `print_config` ([#324](https://github.com/open-mmlab/mmpose/pull/324))
+
+**Bug Fixes**
+
+- Fix bugs in pck evaluation ([#328](https://github.com/open-mmlab/mmpose/pull/328))
+
+- Fix model download links in README ([#396](https://github.com/open-mmlab/mmpose/pull/396), [#397](https://github.com/open-mmlab/mmpose/pull/397))
+
+- Fix CrowdPose annotations and update benchmarks ([#384](https://github.com/open-mmlab/mmpose/pull/384))
+
+- Fix modelzoo stat ([#354](https://github.com/open-mmlab/mmpose/pull/354), [#360](https://github.com/open-mmlab/mmpose/pull/360), [#362](https://github.com/open-mmlab/mmpose/pull/362))
+
+- Fix config files for aic datasets ([#340](https://github.com/open-mmlab/mmpose/pull/340))
+
+**Breaking Changes**
+
+- Rename `image_thr` to `det_bbox_thr` for top-down methods.
+
+**Improvements**
+
+- Organize the readme files ([#398](https://github.com/open-mmlab/mmpose/pull/398), [#399](https://github.com/open-mmlab/mmpose/pull/399), [#400](https://github.com/open-mmlab/mmpose/pull/400))
+
+- Check linting for markdown ([#379](https://github.com/open-mmlab/mmpose/pull/379))
+
+- Add faq.md ([#350](https://github.com/open-mmlab/mmpose/pull/350))
+
+- Remove PyTorch 1.4 in CI ([#338](https://github.com/open-mmlab/mmpose/pull/338))
+
+- Add pypi badge in readme ([#329](https://github.com/open-mmlab/mmpose/pull/329))
+
+## **v0.9.0 (30/11/2020)**
+
+**Highlights**
+
+1. Support more human pose estimation methods.
+
+ 1. [MSPN](https://arxiv.org/abs/1901.00148)
+ 2. [RSN](https://arxiv.org/abs/2003.04030)
+
+2. Support video pose estimation datasets.
+
+ 1. [sub-JHMDB](http://jhmdb.is.tue.mpg.de/dataset)
+
+3. Support Onnx model conversion.
+
+**New Features**
+
+- Support MSPN ([#278](https://github.com/open-mmlab/mmpose/pull/278))
+
+- Support RSN ([#221](https://github.com/open-mmlab/mmpose/pull/221), [#318](https://github.com/open-mmlab/mmpose/pull/318))
+
+- Support new post-processing method for MSPN & RSN ([#288](https://github.com/open-mmlab/mmpose/pull/288))
+
+- Support sub-JHMDB dataset ([#292](https://github.com/open-mmlab/mmpose/pull/292))
+
+- Support urls for pre-trained models in config files ([#232](https://github.com/open-mmlab/mmpose/pull/232))
+
+- Support Onnx ([#305](https://github.com/open-mmlab/mmpose/pull/305))
+
+**Bug Fixes**
+
+- Fix model download links in README ([#255](https://github.com/open-mmlab/mmpose/pull/255), [#315](https://github.com/open-mmlab/mmpose/pull/315))
+
+**Breaking Changes**
+
+- `post_process=True|False` and `unbiased_decoding=True|False` are deprecated, use `post_process=None|default|unbiased` etc. instead ([#288](https://github.com/open-mmlab/mmpose/pull/288))
+
+**Improvements**
+
+- Enrich the model zoo ([#256](https://github.com/open-mmlab/mmpose/pull/256), [#320](https://github.com/open-mmlab/mmpose/pull/320))
+
+- Set the default map_location as 'cpu' to reduce gpu memory cost ([#227](https://github.com/open-mmlab/mmpose/pull/227))
+
+- Support return heatmaps and backbone features for bottom-up models ([#229](https://github.com/open-mmlab/mmpose/pull/229))
+
+- Upgrade mmcv maximum & minimum version ([#269](https://github.com/open-mmlab/mmpose/pull/269), [#313](https://github.com/open-mmlab/mmpose/pull/313))
+
+- Automatically add modelzoo statistics to readthedocs ([#252](https://github.com/open-mmlab/mmpose/pull/252))
+
+- Fix Pylint issues ([#258](https://github.com/open-mmlab/mmpose/pull/258), [#259](https://github.com/open-mmlab/mmpose/pull/259), [#260](https://github.com/open-mmlab/mmpose/pull/260), [#262](https://github.com/open-mmlab/mmpose/pull/262), [#265](https://github.com/open-mmlab/mmpose/pull/265), [#267](https://github.com/open-mmlab/mmpose/pull/267), [#268](https://github.com/open-mmlab/mmpose/pull/268), [#270](https://github.com/open-mmlab/mmpose/pull/270), [#271](https://github.com/open-mmlab/mmpose/pull/271), [#272](https://github.com/open-mmlab/mmpose/pull/272), [#273](https://github.com/open-mmlab/mmpose/pull/273), [#275](https://github.com/open-mmlab/mmpose/pull/275), [#276](https://github.com/open-mmlab/mmpose/pull/276), [#283](https://github.com/open-mmlab/mmpose/pull/283), [#285](https://github.com/open-mmlab/mmpose/pull/285), [#293](https://github.com/open-mmlab/mmpose/pull/293), [#294](https://github.com/open-mmlab/mmpose/pull/294), [#295](https://github.com/open-mmlab/mmpose/pull/295))
+
+- Improve README ([#226](https://github.com/open-mmlab/mmpose/pull/226), [#257](https://github.com/open-mmlab/mmpose/pull/257), [#264](https://github.com/open-mmlab/mmpose/pull/264), [#280](https://github.com/open-mmlab/mmpose/pull/280), [#296](https://github.com/open-mmlab/mmpose/pull/296))
+
+- Support PyTorch 1.7 in CI ([#274](https://github.com/open-mmlab/mmpose/pull/274))
+
+- Add docs/tutorials for running demos ([#263](https://github.com/open-mmlab/mmpose/pull/263))
+
+## **v0.8.0 (31/10/2020)**
+
+**Highlights**
+
+1. Support more human pose estimation datasets.
+
+ 1. [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose)
+ 2. [PoseTrack18](https://posetrack.net/)
+
+2. Support more 2D hand keypoint estimation datasets.
+
+ 1. [InterHand2.6](https://github.com/facebookresearch/InterHand2.6M)
+
+3. Support adversarial training for 3D human shape recovery.
+
+4. Support multi-stage losses.
+
+5. Support mpii demo.
+
+**New Features**
+
+- Support [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose) dataset ([#195](https://github.com/open-mmlab/mmpose/pull/195))
+
+- Support [PoseTrack18](https://posetrack.net/) dataset ([#220](https://github.com/open-mmlab/mmpose/pull/220))
+
+- Support [InterHand2.6](https://github.com/facebookresearch/InterHand2.6M) dataset ([#202](https://github.com/open-mmlab/mmpose/pull/202))
+
+- Support adversarial training for 3D human shape recovery ([#192](https://github.com/open-mmlab/mmpose/pull/192))
+
+- Support multi-stage losses ([#204](https://github.com/open-mmlab/mmpose/pull/204))
+
+**Bug Fixes**
+
+- Fix config files ([#190](https://github.com/open-mmlab/mmpose/pull/190))
+
+**Improvements**
+
+- Add mpii demo ([#216](https://github.com/open-mmlab/mmpose/pull/216))
+
+- Improve README ([#181](https://github.com/open-mmlab/mmpose/pull/181), [#183](https://github.com/open-mmlab/mmpose/pull/183), [#208](https://github.com/open-mmlab/mmpose/pull/208))
+
+- Support return heatmaps and backbone features ([#196](https://github.com/open-mmlab/mmpose/pull/196), [#212](https://github.com/open-mmlab/mmpose/pull/212))
+
+- Support different return formats of mmdetection models ([#217](https://github.com/open-mmlab/mmpose/pull/217))
+
+## **v0.7.0 (30/9/2020)**
+
+**Highlights**
+
+1. Support HMR for 3D human shape recovery.
+
+2. Support WholeBody human pose estimation.
+
+ 1. [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody)
+
+3. Support more 2D hand keypoint estimation datasets.
+
+ 1. [Frei-hand](https://lmb.informatik.uni-freiburg.de/projects/freihand/)
+ 2. [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html)
+
+4. Add more popular backbones & enrich the [modelzoo](https://mmpose.readthedocs.io/en/latest/model_zoo.html)
+
+ 1. ShuffleNetv2
+
+5. Support hand demo and whole-body demo.
+
+**New Features**
+
+- Support HMR for 3D human shape recovery ([#157](https://github.com/open-mmlab/mmpose/pull/157), [#160](https://github.com/open-mmlab/mmpose/pull/160), [#161](https://github.com/open-mmlab/mmpose/pull/161), [#162](https://github.com/open-mmlab/mmpose/pull/162))
+
+- Support [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody) dataset ([#133](https://github.com/open-mmlab/mmpose/pull/133))
+
+- Support [Frei-hand](https://lmb.informatik.uni-freiburg.de/projects/freihand/) dataset ([#125](https://github.com/open-mmlab/mmpose/pull/125))
+
+- Support [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html) dataset ([#144](https://github.com/open-mmlab/mmpose/pull/144))
+
+- Support H36M dataset ([#159](https://github.com/open-mmlab/mmpose/pull/159))
+
+- Support ShuffleNetv2 ([#139](https://github.com/open-mmlab/mmpose/pull/139))
+
+- Support saving best models based on key indicator ([#127](https://github.com/open-mmlab/mmpose/pull/127))
+
+**Bug Fixes**
+
+- Fix typos in docs ([#121](https://github.com/open-mmlab/mmpose/pull/121))
+
+- Fix assertion ([#142](https://github.com/open-mmlab/mmpose/pull/142))
+
+**Improvements**
+
+- Add tools to transform .mat format to .json format ([#126](https://github.com/open-mmlab/mmpose/pull/126))
+
+- Add hand demo ([#115](https://github.com/open-mmlab/mmpose/pull/115))
+
+- Add whole-body demo ([#163](https://github.com/open-mmlab/mmpose/pull/163))
+
+- Reuse mmcv utility function and update version files ([#135](https://github.com/open-mmlab/mmpose/pull/135), [#137](https://github.com/open-mmlab/mmpose/pull/137))
+
+- Enrich the modelzoo ([#147](https://github.com/open-mmlab/mmpose/pull/147), [#169](https://github.com/open-mmlab/mmpose/pull/169))
+
+- Improve docs ([#174](https://github.com/open-mmlab/mmpose/pull/174), [#175](https://github.com/open-mmlab/mmpose/pull/175), [#178](https://github.com/open-mmlab/mmpose/pull/178))
+
+- Improve README ([#176](https://github.com/open-mmlab/mmpose/pull/176))
+
+- Improve version.py ([#173](https://github.com/open-mmlab/mmpose/pull/173))
+
+## **v0.6.0 (31/8/2020)**
+
+**Highlights**
+
+1. Add more popular backbones & enrich the [modelzoo](https://mmpose.readthedocs.io/en/latest/model_zoo.html)
+
+ 1. ResNext
+ 2. SEResNet
+ 3. ResNetV1D
+ 4. MobileNetv2
+ 5. ShuffleNetv1
+ 6. CPM (Convolutional Pose Machine)
+
+2. Add more popular datasets:
+
+ 1. [AIChallenger](https://arxiv.org/abs/1711.06475?context=cs.CV)
+ 2. [MPII](http://human-pose.mpi-inf.mpg.de/)
+ 3. [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body)
+ 4. [OCHuman](http://www.liruilong.cn/projects/pose2seg/index.html)
+
+3. Support 2d hand keypoint estimation.
+
+ 1. [OneHand10K](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html)
+
+4. Support bottom-up inference.
+
+**New Features**
+
+- Support [OneHand10K](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html) dataset ([#52](https://github.com/open-mmlab/mmpose/pull/52))
+
+- Support [MPII](http://human-pose.mpi-inf.mpg.de/) dataset ([#55](https://github.com/open-mmlab/mmpose/pull/55))
+
+- Support [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) dataset ([#19](https://github.com/open-mmlab/mmpose/pull/19), [#47](https://github.com/open-mmlab/mmpose/pull/47), [#48](https://github.com/open-mmlab/mmpose/pull/48))
+
+- Support [OCHuman](http://www.liruilong.cn/projects/pose2seg/index.html) dataset ([#70](https://github.com/open-mmlab/mmpose/pull/70))
+
+- Support [AIChallenger](https://arxiv.org/abs/1711.06475?context=cs.CV) dataset ([#87](https://github.com/open-mmlab/mmpose/pull/87))
+
+- Support multiple backbones ([#26](https://github.com/open-mmlab/mmpose/pull/26))
+
+- Support CPM model ([#56](https://github.com/open-mmlab/mmpose/pull/56))
+
+**Bug Fixes**
+
+- Fix configs for MPII & MPII-TRB datasets ([#93](https://github.com/open-mmlab/mmpose/pull/93))
+
+- Fix the bug of missing `test_pipeline` in configs ([#14](https://github.com/open-mmlab/mmpose/pull/14))
+
+- Fix typos ([#27](https://github.com/open-mmlab/mmpose/pull/27), [#28](https://github.com/open-mmlab/mmpose/pull/28), [#50](https://github.com/open-mmlab/mmpose/pull/50), [#53](https://github.com/open-mmlab/mmpose/pull/53), [#63](https://github.com/open-mmlab/mmpose/pull/63))
+
+**Improvements**
+
+- Update benchmark ([#93](https://github.com/open-mmlab/mmpose/pull/93))
+
+- Add Dockerfile ([#44](https://github.com/open-mmlab/mmpose/pull/44))
+
+- Improve unittest coverage and minor fix ([#18](https://github.com/open-mmlab/mmpose/pull/18))
+
+- Support CPUs for train/val/demo ([#34](https://github.com/open-mmlab/mmpose/pull/34))
+
+- Support bottom-up demo ([#69](https://github.com/open-mmlab/mmpose/pull/69))
+
+- Add tools to publish model ([#62](https://github.com/open-mmlab/mmpose/pull/62))
+
+- Enrich the modelzoo ([#64](https://github.com/open-mmlab/mmpose/pull/64), [#68](https://github.com/open-mmlab/mmpose/pull/68), [#82](https://github.com/open-mmlab/mmpose/pull/82))
+
+## **v0.5.0 (21/7/2020)**
+
+**Highlights**
+
+- MMPose is released.
+
+**Main Features**
+
+- Support both top-down and bottom-up pose estimation approaches.
+
+- Achieve higher training efficiency and higher accuracy than other popular codebases (e.g. AlphaPose, HRNet)
+
+- Support various backbone models: ResNet, HRNet, SCNet, Houglass and HigherHRNet.
diff --git a/docs/en/notes/ecosystem.md b/docs/en/notes/ecosystem.md
index b0027cfa53..6ae3dd5aa6 100644
--- a/docs/en/notes/ecosystem.md
+++ b/docs/en/notes/ecosystem.md
@@ -1,3 +1,3 @@
-# Ecosystem
-
-Coming soon.
+# Ecosystem
+
+Coming soon.
diff --git a/docs/en/notes/pytorch_2.md b/docs/en/notes/pytorch_2.md
index 4892e554a5..932f9b0734 100644
--- a/docs/en/notes/pytorch_2.md
+++ b/docs/en/notes/pytorch_2.md
@@ -1,14 +1,14 @@
-# PyTorch 2.0 Compatibility and Benchmarks
-
-MMPose 1.0.0 is now compatible with PyTorch 2.0, ensuring that users can leverage the latest features and performance improvements offered by the PyTorch 2.0 framework when using MMPose. With the integration of inductor, users can expect faster model speeds. The table below shows several example models:
-
-| Model | Training Speed | Memory |
-| :-------- | :---------------------: | :-----------: |
-| ViTPose-B | 29.6% ↑ (0.931 → 0.655) | 10586 → 10663 |
-| ViTPose-S | 33.7% ↑ (0.563 → 0.373) | 6091 → 6170 |
-| HRNet-w32 | 12.8% ↑ (0.553 → 0.482) | 9849 → 10145 |
-| HRNet-w48 | 37.1% ↑ (0.437 → 0.275) | 7319 → 7394 |
-| RTMPose-t | 6.3% ↑ (1.533 → 1.437) | 6292 → 6489 |
-| RTMPose-s | 13.1% ↑ (1.645 → 1.430) | 9013 → 9208 |
-
-- Pytorch 2.0 test, add projects doc and refactor by @LareinaM in [PR#2136](https://github.com/open-mmlab/mmpose/pull/2136)
+# PyTorch 2.0 Compatibility and Benchmarks
+
+MMPose 1.0.0 is now compatible with PyTorch 2.0, ensuring that users can leverage the latest features and performance improvements offered by the PyTorch 2.0 framework when using MMPose. With the integration of inductor, users can expect faster model speeds. The table below shows several example models:
+
+| Model | Training Speed | Memory |
+| :-------- | :---------------------: | :-----------: |
+| ViTPose-B | 29.6% ↑ (0.931 → 0.655) | 10586 → 10663 |
+| ViTPose-S | 33.7% ↑ (0.563 → 0.373) | 6091 → 6170 |
+| HRNet-w32 | 12.8% ↑ (0.553 → 0.482) | 9849 → 10145 |
+| HRNet-w48 | 37.1% ↑ (0.437 → 0.275) | 7319 → 7394 |
+| RTMPose-t | 6.3% ↑ (1.533 → 1.437) | 6292 → 6489 |
+| RTMPose-s | 13.1% ↑ (1.645 → 1.430) | 9013 → 9208 |
+
+- Pytorch 2.0 test, add projects doc and refactor by @LareinaM in [PR#2136](https://github.com/open-mmlab/mmpose/pull/2136)
diff --git a/docs/en/overview.md b/docs/en/overview.md
index b6e31dd239..ff56d162bd 100644
--- a/docs/en/overview.md
+++ b/docs/en/overview.md
@@ -1,66 +1,66 @@
-# Overview
-
-This chapter will introduce you to the overall framework of MMPose and provide links to detailed tutorials.
-
-## What is MMPose
-
-
-
-MMPose is a Pytorch-based pose estimation open-source toolkit, a member of the [OpenMMLab Project](https://github.com/open-mmlab). It contains a rich set of algorithms for 2d multi-person human pose estimation, 2d hand pose estimation, 2d face landmark detection, 133 keypoint whole-body human pose estimation, fashion landmark detection and animal pose estimation as well as related components and modules, below is its overall framework.
-
-MMPose consists of **8** main components:
-
-- **apis** provides high-level APIs for model inference
-- **structures** provides data structures like bbox, keypoint and PoseDataSample
-- **datasets** supports various datasets for pose estimation
- - **transforms** contains a lot of useful data augmentation transforms
-- **codecs** provides pose encoders and decoders: an encoder encodes poses (mostly keypoints) into learning targets (e.g. heatmaps), and a decoder decodes model outputs into pose predictions
-- **models** provides all components of pose estimation models in a modular structure
- - **pose_estimators** defines all pose estimation model classes
- - **data_preprocessors** is for preprocessing the input data of the model
- - **backbones** provides a collection of backbone networks
- - **necks** contains various neck modules
- - **heads** contains various prediction heads that perform pose estimation
- - **losses** contains various loss functions
-- **engine** provides runtime components related to pose estimation
- - **hooks** provides various hooks of the runner
-- **evaluation** provides metrics for evaluating model performance
-- **visualization** is for visualizing skeletons, heatmaps and other information
-
-## How to Use this Guide
-
-We have prepared detailed guidelines for all types of users:
-
-1. For installation instrunctions:
-
- - [Installation](./installation.md)
-
-2. For the basic usage of MMPose:
-
- - [A 20-minute Tour to MMPose](./guide_to_framework.md)
- - [Demos](./demos.md)
- - [Inference](./user_guides/inference.md)
- - [Configs](./user_guides/configs.md)
- - [Prepare Datasets](./user_guides/prepare_datasets.md)
- - [Train and Test](./user_guides/train_and_test.md)
-
-3. For developers who wish to develop based on MMPose:
-
- - [Learn about Codecs](./advanced_guides/codecs.md)
- - [Dataflow in MMPose](./advanced_guides/dataflow.md)
- - [Implement New Models](./advanced_guides/implement_new_models.md)
- - [Customize Datasets](./advanced_guides/customize_datasets.md)
- - [Customize Data Transforms](./advanced_guides/customize_transforms.md)
- - [Customize Optimizer](./advanced_guides/customize_optimizer.md)
- - [Customize Logging](./advanced_guides/customize_logging.md)
- - [How to Deploy](./advanced_guides/how_to_deploy.md)
- - [Model Analysis](./advanced_guides/model_analysis.md)
- - [Migration Guide](./migration.md)
-
-4. For researchers and developers who are willing to contribute to MMPose:
-
- - [Contribution Guide](./contribution_guide.md)
-
-5. For some common issues, we provide a FAQ list:
-
- - [FAQ](./faq.md)
+# Overview
+
+This chapter will introduce you to the overall framework of MMPose and provide links to detailed tutorials.
+
+## What is MMPose
+
+
+
+MMPose is a Pytorch-based pose estimation open-source toolkit, a member of the [OpenMMLab Project](https://github.com/open-mmlab). It contains a rich set of algorithms for 2d multi-person human pose estimation, 2d hand pose estimation, 2d face landmark detection, 133 keypoint whole-body human pose estimation, fashion landmark detection and animal pose estimation as well as related components and modules, below is its overall framework.
+
+MMPose consists of **8** main components:
+
+- **apis** provides high-level APIs for model inference
+- **structures** provides data structures like bbox, keypoint and PoseDataSample
+- **datasets** supports various datasets for pose estimation
+ - **transforms** contains a lot of useful data augmentation transforms
+- **codecs** provides pose encoders and decoders: an encoder encodes poses (mostly keypoints) into learning targets (e.g. heatmaps), and a decoder decodes model outputs into pose predictions
+- **models** provides all components of pose estimation models in a modular structure
+ - **pose_estimators** defines all pose estimation model classes
+ - **data_preprocessors** is for preprocessing the input data of the model
+ - **backbones** provides a collection of backbone networks
+ - **necks** contains various neck modules
+ - **heads** contains various prediction heads that perform pose estimation
+ - **losses** contains various loss functions
+- **engine** provides runtime components related to pose estimation
+ - **hooks** provides various hooks of the runner
+- **evaluation** provides metrics for evaluating model performance
+- **visualization** is for visualizing skeletons, heatmaps and other information
+
+## How to Use this Guide
+
+We have prepared detailed guidelines for all types of users:
+
+1. For installation instrunctions:
+
+ - [Installation](./installation.md)
+
+2. For the basic usage of MMPose:
+
+ - [A 20-minute Tour to MMPose](./guide_to_framework.md)
+ - [Demos](./demos.md)
+ - [Inference](./user_guides/inference.md)
+ - [Configs](./user_guides/configs.md)
+ - [Prepare Datasets](./user_guides/prepare_datasets.md)
+ - [Train and Test](./user_guides/train_and_test.md)
+
+3. For developers who wish to develop based on MMPose:
+
+ - [Learn about Codecs](./advanced_guides/codecs.md)
+ - [Dataflow in MMPose](./advanced_guides/dataflow.md)
+ - [Implement New Models](./advanced_guides/implement_new_models.md)
+ - [Customize Datasets](./advanced_guides/customize_datasets.md)
+ - [Customize Data Transforms](./advanced_guides/customize_transforms.md)
+ - [Customize Optimizer](./advanced_guides/customize_optimizer.md)
+ - [Customize Logging](./advanced_guides/customize_logging.md)
+ - [How to Deploy](./advanced_guides/how_to_deploy.md)
+ - [Model Analysis](./advanced_guides/model_analysis.md)
+ - [Migration Guide](./migration.md)
+
+4. For researchers and developers who are willing to contribute to MMPose:
+
+ - [Contribution Guide](./contribution_guide.md)
+
+5. For some common issues, we provide a FAQ list:
+
+ - [FAQ](./faq.md)
diff --git a/docs/en/projects/projects.md b/docs/en/projects/projects.md
index 460d8583bd..599c54055f 100644
--- a/docs/en/projects/projects.md
+++ b/docs/en/projects/projects.md
@@ -1,20 +1,20 @@
-# Projects based on MMPose
-
-There are many projects built upon MMPose. We list some of them as examples of how to extend MMPose for your own projects. As the page might not be completed, please feel free to create a PR to update this page.
-
-## Projects as an extension
-
-Some projects extend the boundary of MMPose for deployment or other research fields. They reveal the potential of what MMPose can do. We list several of them as below.
-
-- [Anime Face Detector](https://github.com/hysts/anime-face-detector): An anime face landmark detection toolbox.
-- [PosePipeline](https://github.com/peabody124/PosePipeline): Open-Source Human Pose Estimation Pipeline for Clinical Research
-
-## Projects of papers
-
-There are also projects released with papers. Some of the papers are published in top-tier conferences (CVPR, ICCV, and ECCV), the others are also highly influential. We list some of these works as a reference for the community to develop and compare new pose estimation algorithms. Methods already supported and maintained by MMPose are not listed.
-
-- Pose for Everything: Towards Category-Agnostic Pose Estimation, ECCV 2022. [\[paper\]](https://arxiv.org/abs/2207.10387)[\[github\]](https://github.com/luminxu/Pose-for-Everything)
-- UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning, ICLR 2022. [\[paper\]](https://arxiv.org/abs/2201.04676)[\[github\]](https://github.com/Sense-X/UniFormer)
-- Poseur:Direct Human Pose Regression with Transformers, ECCV 2022. [\[paper\]](https://arxiv.org/abs/2201.07412)[\[github\]](https://github.com/aim-uofa/Poseur)
-- ViTAEv2: Vision Transformer Advanced by Exploring Inductive Bias for Image Recognition and Beyond, NeurIPS 2022. [\[paper\]](https://arxiv.org/abs/2106.03348)[\[github\]](https://github.com/ViTAE-Transformer/ViTAE-Transformer)
-- Dite-HRNet:Dynamic Lightweight High-Resolution Network for Human Pose Estimation, IJCAI-ECAI 2021. [\[paper\]](https://arxiv.org/abs/2204.10762)[\[github\]](https://github.com/ZiyiZhang27/Dite-HRNet)
+# Projects based on MMPose
+
+There are many projects built upon MMPose. We list some of them as examples of how to extend MMPose for your own projects. As the page might not be completed, please feel free to create a PR to update this page.
+
+## Projects as an extension
+
+Some projects extend the boundary of MMPose for deployment or other research fields. They reveal the potential of what MMPose can do. We list several of them as below.
+
+- [Anime Face Detector](https://github.com/hysts/anime-face-detector): An anime face landmark detection toolbox.
+- [PosePipeline](https://github.com/peabody124/PosePipeline): Open-Source Human Pose Estimation Pipeline for Clinical Research
+
+## Projects of papers
+
+There are also projects released with papers. Some of the papers are published in top-tier conferences (CVPR, ICCV, and ECCV), the others are also highly influential. We list some of these works as a reference for the community to develop and compare new pose estimation algorithms. Methods already supported and maintained by MMPose are not listed.
+
+- Pose for Everything: Towards Category-Agnostic Pose Estimation, ECCV 2022. [\[paper\]](https://arxiv.org/abs/2207.10387)[\[github\]](https://github.com/luminxu/Pose-for-Everything)
+- UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning, ICLR 2022. [\[paper\]](https://arxiv.org/abs/2201.04676)[\[github\]](https://github.com/Sense-X/UniFormer)
+- Poseur:Direct Human Pose Regression with Transformers, ECCV 2022. [\[paper\]](https://arxiv.org/abs/2201.07412)[\[github\]](https://github.com/aim-uofa/Poseur)
+- ViTAEv2: Vision Transformer Advanced by Exploring Inductive Bias for Image Recognition and Beyond, NeurIPS 2022. [\[paper\]](https://arxiv.org/abs/2106.03348)[\[github\]](https://github.com/ViTAE-Transformer/ViTAE-Transformer)
+- Dite-HRNet:Dynamic Lightweight High-Resolution Network for Human Pose Estimation, IJCAI-ECAI 2021. [\[paper\]](https://arxiv.org/abs/2204.10762)[\[github\]](https://github.com/ZiyiZhang27/Dite-HRNet)
diff --git a/docs/en/quick_run.md b/docs/en/quick_run.md
index 51aabfc967..5a208dce76 100644
--- a/docs/en/quick_run.md
+++ b/docs/en/quick_run.md
@@ -1,190 +1,190 @@
-# Quick Run
-
-This page provides a basic tutorial about the usage of MMPose.
-
-We will walk you through the 7 key steps of a typical MMPose workflow by training a top-down residual log-likelihood algorithm based on resnet50 on COCO dataset:
-
-1. Inference with a pretrained model
-2. Prepare the dataset
-3. Prepare a config
-4. Browse the transformed images
-5. Training
-6. Testing
-7. Visualization
-
-## Installation
-
-For installation instructions, please refer to [Installation](./installation.md).
-
-## Get Started
-
-### Inference with a pretrained model
-
-We provide a useful script to perform pose estimation with a pretrained model:
-
-```Bash
-python demo/image_demo.py \
- tests/data/coco/000000000785.jpg \
- configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py \
- https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res50_coco_256x192_rle-2ea9bb4a_20220616.pth
-```
-
-If MMPose is properly installed, you will get the visualized result as follows:
-
-
-
-```{note}
-More demo and full instructions can be found in [Inference](./user_guides/inference.md).
-```
-
-### Prepare the dataset
-
-MMPose supports multiple tasks. We provide the corresponding guidelines for data preparation.
-
-- [2D Body Keypoint Detection](./dataset_zoo/2d_body_keypoint.md)
-
-- [3D Body Keypoint Detection](./dataset_zoo/3d_body_keypoint.md)
-
-- [2D Hand Keypoint Detection](./dataset_zoo/2d_hand_keypoint.md)
-
-- [3D Hand Keypoint Detection](./dataset_zoo/3d_hand_keypoint.md)
-
-- [2D Face Keypoint Detection](./dataset_zoo/2d_face_keypoint.md)
-
-- [2D WholeBody Keypoint Detection](./dataset_zoo/2d_wholebody_keypoint.md)
-
-- [2D Fashion Landmark Detection](./dataset_zoo/2d_fashion_landmark.md)
-
-- [2D Animal Keypoint Detection](./dataset_zoo/2d_animal_keypoint.md)
-
-You can refer to \[2D Body Keypoint Detection\] > \[COCO\] for COCO dataset preparation.
-
-```{note}
-In MMPose, we suggest placing the data under `$MMPOSE/data`.
-```
-
-### Prepare a config
-
-MMPose is equipped with a powerful config system to conduct various experiments conveniently. A config file organizes the settings of:
-
-- **General**: basic configurations non-related to training or testing, such as Timer, Logger, Visualizer and other Hooks, as well as distributed-related environment settings
-
-- **Data**: dataset, dataloader and data augmentation
-
-- **Training**: resume, weights loading, optimizer, learning rate scheduling, epochs and valid interval etc.
-
-- **Model**: structure, module and loss function etc.
-
-- **Evaluation**: metrics
-
-We provide a bunch of well-prepared configs under `$MMPOSE/configs` so that you can directly use or modify.
-
-Going back to our example, we will use the prepared config:
-
-```Bash
-$MMPOSE/configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py
-```
-
-You can set the path of the COCO dataset by modifying `data_root` in the config:
-
-```Python
-data_root = 'data/coco'
-```
-
-```{note}
-If you wish to learn more about our config system, please refer to [Configs](./user_guides/configs.md).
-```
-
-### Browse the transformed images
-
-Before training, we can browse the transformed training data to check if the images are augmented properly:
-
-```Bash
-python tools/misc/browse_dastaset.py \
- configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py \
- --mode transformed
-```
-
-
-
-### Training
-
-Use the following command to train with a single GPU:
-
-```Bash
-python tools/train.py configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py
-```
-
-```{note}
-MMPose automates many useful training tricks and functions including:
-
-- Learning rate warmup and scheduling
-
-- ImageNet pretrained models
-
-- Automatic learning rate scaling
-
-- Multi-GPU and Multi-Node training support
-
-- Various Data backend support, e.g. HardDisk, LMDB, Petrel, HTTP etc.
-
-- Mixed precision training support
-
-- TensorBoard
-```
-
-### Testing
-
-Checkpoints and logs will be saved under `$MMPOSE/work_dirs` by default. The best model is under `$MMPOSE/work_dir/best_coco`.
-
-Use the following command to evaluate the model on COCO dataset:
-
-```Bash
-python tools/test.py \
- configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py \
- work_dir/best_coco/AP_epoch_20.pth
-```
-
-Here is an example of evaluation results:
-
-```Bash
- Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.704
- Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.883
- Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.777
- Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.667
- Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.769
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.751
- Average Recall (AR) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.920
- Average Recall (AR) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.815
- Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.709
- Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.811
-08/23 12:04:42 - mmengine - INFO - Epoch(test) [3254/3254] coco/AP: 0.704168 coco/AP .5: 0.883134 coco/AP .75: 0.777015 coco/AP (M): 0.667207 coco/AP (L): 0.768644 coco/AR: 0.750913 coco/AR .5: 0.919710 coco/AR .75: 0.815334 coco/AR (M): 0.709232 coco/AR (L): 0.811334
-```
-
-```{note}
-If you want to perform evaluation on other datasets, please refer to [Train & Test](./user_guides/train_and_test.md).
-```
-
-### Visualization
-
-In addition to the visualization of the keypoint skeleton, MMPose also supports the visualization of Heatmaps by setting `output_heatmap=True` in confg:
-
-```Python
-model = dict(
- ## omitted
- test_cfg = dict(
- ## omitted
- output_heatmaps=True
- )
-)
-```
-
-or add `--cfg-options='model.test_cfg.output_heatmaps=True'` at the end of your command.
-
-Visualization result (top: decoded keypoints; bottom: predicted heatmap):
-
-
-
-```{note}
-If you wish to apply MMPose to your own projects, we have prepared a detailed [Migration guide](./migration.md).
-```
+# Quick Run
+
+This page provides a basic tutorial about the usage of MMPose.
+
+We will walk you through the 7 key steps of a typical MMPose workflow by training a top-down residual log-likelihood algorithm based on resnet50 on COCO dataset:
+
+1. Inference with a pretrained model
+2. Prepare the dataset
+3. Prepare a config
+4. Browse the transformed images
+5. Training
+6. Testing
+7. Visualization
+
+## Installation
+
+For installation instructions, please refer to [Installation](./installation.md).
+
+## Get Started
+
+### Inference with a pretrained model
+
+We provide a useful script to perform pose estimation with a pretrained model:
+
+```Bash
+python demo/image_demo.py \
+ tests/data/coco/000000000785.jpg \
+ configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py \
+ https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res50_coco_256x192_rle-2ea9bb4a_20220616.pth
+```
+
+If MMPose is properly installed, you will get the visualized result as follows:
+
+
+
+```{note}
+More demo and full instructions can be found in [Inference](./user_guides/inference.md).
+```
+
+### Prepare the dataset
+
+MMPose supports multiple tasks. We provide the corresponding guidelines for data preparation.
+
+- [2D Body Keypoint Detection](./dataset_zoo/2d_body_keypoint.md)
+
+- [3D Body Keypoint Detection](./dataset_zoo/3d_body_keypoint.md)
+
+- [2D Hand Keypoint Detection](./dataset_zoo/2d_hand_keypoint.md)
+
+- [3D Hand Keypoint Detection](./dataset_zoo/3d_hand_keypoint.md)
+
+- [2D Face Keypoint Detection](./dataset_zoo/2d_face_keypoint.md)
+
+- [2D WholeBody Keypoint Detection](./dataset_zoo/2d_wholebody_keypoint.md)
+
+- [2D Fashion Landmark Detection](./dataset_zoo/2d_fashion_landmark.md)
+
+- [2D Animal Keypoint Detection](./dataset_zoo/2d_animal_keypoint.md)
+
+You can refer to \[2D Body Keypoint Detection\] > \[COCO\] for COCO dataset preparation.
+
+```{note}
+In MMPose, we suggest placing the data under `$MMPOSE/data`.
+```
+
+### Prepare a config
+
+MMPose is equipped with a powerful config system to conduct various experiments conveniently. A config file organizes the settings of:
+
+- **General**: basic configurations non-related to training or testing, such as Timer, Logger, Visualizer and other Hooks, as well as distributed-related environment settings
+
+- **Data**: dataset, dataloader and data augmentation
+
+- **Training**: resume, weights loading, optimizer, learning rate scheduling, epochs and valid interval etc.
+
+- **Model**: structure, module and loss function etc.
+
+- **Evaluation**: metrics
+
+We provide a bunch of well-prepared configs under `$MMPOSE/configs` so that you can directly use or modify.
+
+Going back to our example, we will use the prepared config:
+
+```Bash
+$MMPOSE/configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py
+```
+
+You can set the path of the COCO dataset by modifying `data_root` in the config:
+
+```Python
+data_root = 'data/coco'
+```
+
+```{note}
+If you wish to learn more about our config system, please refer to [Configs](./user_guides/configs.md).
+```
+
+### Browse the transformed images
+
+Before training, we can browse the transformed training data to check if the images are augmented properly:
+
+```Bash
+python tools/misc/browse_dastaset.py \
+ configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py \
+ --mode transformed
+```
+
+
+
+### Training
+
+Use the following command to train with a single GPU:
+
+```Bash
+python tools/train.py configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py
+```
+
+```{note}
+MMPose automates many useful training tricks and functions including:
+
+- Learning rate warmup and scheduling
+
+- ImageNet pretrained models
+
+- Automatic learning rate scaling
+
+- Multi-GPU and Multi-Node training support
+
+- Various Data backend support, e.g. HardDisk, LMDB, Petrel, HTTP etc.
+
+- Mixed precision training support
+
+- TensorBoard
+```
+
+### Testing
+
+Checkpoints and logs will be saved under `$MMPOSE/work_dirs` by default. The best model is under `$MMPOSE/work_dir/best_coco`.
+
+Use the following command to evaluate the model on COCO dataset:
+
+```Bash
+python tools/test.py \
+ configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py \
+ work_dir/best_coco/AP_epoch_20.pth
+```
+
+Here is an example of evaluation results:
+
+```Bash
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.704
+ Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.883
+ Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.777
+ Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.667
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.769
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.751
+ Average Recall (AR) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.920
+ Average Recall (AR) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.815
+ Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.709
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.811
+08/23 12:04:42 - mmengine - INFO - Epoch(test) [3254/3254] coco/AP: 0.704168 coco/AP .5: 0.883134 coco/AP .75: 0.777015 coco/AP (M): 0.667207 coco/AP (L): 0.768644 coco/AR: 0.750913 coco/AR .5: 0.919710 coco/AR .75: 0.815334 coco/AR (M): 0.709232 coco/AR (L): 0.811334
+```
+
+```{note}
+If you want to perform evaluation on other datasets, please refer to [Train & Test](./user_guides/train_and_test.md).
+```
+
+### Visualization
+
+In addition to the visualization of the keypoint skeleton, MMPose also supports the visualization of Heatmaps by setting `output_heatmap=True` in confg:
+
+```Python
+model = dict(
+ ## omitted
+ test_cfg = dict(
+ ## omitted
+ output_heatmaps=True
+ )
+)
+```
+
+or add `--cfg-options='model.test_cfg.output_heatmaps=True'` at the end of your command.
+
+Visualization result (top: decoded keypoints; bottom: predicted heatmap):
+
+
+
+```{note}
+If you wish to apply MMPose to your own projects, we have prepared a detailed [Migration guide](./migration.md).
+```
diff --git a/docs/en/stats.py b/docs/en/stats.py
index 6d92d744ea..e5bc46d0df 100644
--- a/docs/en/stats.py
+++ b/docs/en/stats.py
@@ -1,176 +1,176 @@
-#!/usr/bin/env python
-# Copyright (c) OpenMMLab. All rights reserved.
-import functools as func
-import glob
-import re
-from os.path import basename, splitext
-
-import numpy as np
-import titlecase
-
-
-def anchor(name):
- return re.sub(r'-+', '-', re.sub(r'[^a-zA-Z0-9]', '-',
- name.strip().lower())).strip('-')
-
-
-# Count algorithms
-
-files = sorted(glob.glob('model_zoo/*.md'))
-
-stats = []
-
-for f in files:
- with open(f, 'r') as content_file:
- content = content_file.read()
-
- # title
- title = content.split('\n')[0].replace('#', '')
-
- # count papers
- papers = set(
- (papertype, titlecase.titlecase(paper.lower().strip()))
- for (papertype, paper) in re.findall(
- r'\s*\n.*?\btitle\s*=\s*{(.*?)}',
- content, re.DOTALL))
- # paper links
- revcontent = '\n'.join(list(reversed(content.splitlines())))
- paperlinks = {}
- for _, p in papers:
- # print(p)
- paperlinks[p] = ', '.join(
- ((f'[{paperlink} ⇨]'
- f'(model_zoo/{splitext(basename(f))[0]}.html#'
- f'{anchor(paperlink)})') for paperlink in re.findall(
- rf'\btitle\s*=\s*{{\s*{p}\s*}}.*?\n### (.*?)\s*[,;]?\s*\n',
- revcontent, re.DOTALL | re.IGNORECASE)))
- # print(' ', paperlinks[p])
- paperlist = '\n'.join(
- sorted(f' - [{t}] {x} ({paperlinks[x]})' for t, x in papers))
- # count configs
- configs = set(x.lower().strip()
- for x in re.findall(r'.*configs/.*\.py', content))
-
- # count ckpts
- ckpts = set(x.lower().strip()
- for x in re.findall(r'https://download.*\.pth', content)
- if 'mmpose' in x)
-
- statsmsg = f"""
-## [{title}]({f})
-
-* Number of checkpoints: {len(ckpts)}
-* Number of configs: {len(configs)}
-* Number of papers: {len(papers)}
-{paperlist}
-
- """
-
- stats.append((papers, configs, ckpts, statsmsg))
-
-allpapers = func.reduce(lambda a, b: a.union(b), [p for p, _, _, _ in stats])
-allconfigs = func.reduce(lambda a, b: a.union(b), [c for _, c, _, _ in stats])
-allckpts = func.reduce(lambda a, b: a.union(b), [c for _, _, c, _ in stats])
-
-# Summarize
-
-msglist = '\n'.join(x for _, _, _, x in stats)
-papertypes, papercounts = np.unique([t for t, _ in allpapers],
- return_counts=True)
-countstr = '\n'.join(
- [f' - {t}: {c}' for t, c in zip(papertypes, papercounts)])
-
-modelzoo = f"""
-# Overview
-
-* Number of checkpoints: {len(allckpts)}
-* Number of configs: {len(allconfigs)}
-* Number of papers: {len(allpapers)}
-{countstr}
-
-For supported datasets, see [datasets overview](dataset_zoo.md).
-
-{msglist}
-
-"""
-
-with open('model_zoo.md', 'w') as f:
- f.write(modelzoo)
-
-# Count datasets
-
-files = sorted(glob.glob('model_zoo/*.md'))
-# files = sorted(glob.glob('docs/tasks/*.md'))
-
-datastats = []
-
-for f in files:
- with open(f, 'r') as content_file:
- content = content_file.read()
-
- # title
- title = content.split('\n')[0].replace('#', '')
-
- # count papers
- papers = set(
- (papertype, titlecase.titlecase(paper.lower().strip()))
- for (papertype, paper) in re.findall(
- r'\s*\n.*?\btitle\s*=\s*{(.*?)}',
- content, re.DOTALL))
- # paper links
- revcontent = '\n'.join(list(reversed(content.splitlines())))
- paperlinks = {}
- for _, p in papers:
- # print(p)
- paperlinks[p] = ', '.join(
- (f'[{p} ⇨](model_zoo/{splitext(basename(f))[0]}.html#'
- f'{anchor(p)})' for p in re.findall(
- rf'\btitle\s*=\s*{{\s*{p}\s*}}.*?\n## (.*?)\s*[,;]?\s*\n',
- revcontent, re.DOTALL | re.IGNORECASE)))
- # print(' ', paperlinks[p])
- paperlist = '\n'.join(
- sorted(f' - [{t}] {x} ({paperlinks[x]})' for t, x in papers))
- # count configs
- configs = set(x.lower().strip()
- for x in re.findall(r'https.*configs/.*\.py', content))
-
- # count ckpts
- ckpts = set(x.lower().strip()
- for x in re.findall(r'https://download.*\.pth', content)
- if 'mmpose' in x)
-
- statsmsg = f"""
-## [{title}]({f})
-
-* Number of papers: {len(papers)}
-{paperlist}
-
- """
-
- datastats.append((papers, configs, ckpts, statsmsg))
-
-alldatapapers = func.reduce(lambda a, b: a.union(b),
- [p for p, _, _, _ in datastats])
-
-# Summarize
-
-msglist = '\n'.join(x for _, _, _, x in stats)
-datamsglist = '\n'.join(x for _, _, _, x in datastats)
-papertypes, papercounts = np.unique([t for t, _ in alldatapapers],
- return_counts=True)
-countstr = '\n'.join(
- [f' - {t}: {c}' for t, c in zip(papertypes, papercounts)])
-
-dataset_zoo = f"""
-# Overview
-
-* Number of papers: {len(alldatapapers)}
-{countstr}
-
-For supported pose algorithms, see [modelzoo overview](model_zoo.md).
-
-{datamsglist}
-"""
-
-with open('dataset_zoo.md', 'w') as f:
- f.write(dataset_zoo)
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import functools as func
+import glob
+import re
+from os.path import basename, splitext
+
+import numpy as np
+import titlecase
+
+
+def anchor(name):
+ return re.sub(r'-+', '-', re.sub(r'[^a-zA-Z0-9]', '-',
+ name.strip().lower())).strip('-')
+
+
+# Count algorithms
+
+files = sorted(glob.glob('model_zoo/*.md'))
+
+stats = []
+
+for f in files:
+ with open(f, 'r') as content_file:
+ content = content_file.read()
+
+ # title
+ title = content.split('\n')[0].replace('#', '')
+
+ # count papers
+ papers = set(
+ (papertype, titlecase.titlecase(paper.lower().strip()))
+ for (papertype, paper) in re.findall(
+ r'\s*\n.*?\btitle\s*=\s*{(.*?)}',
+ content, re.DOTALL))
+ # paper links
+ revcontent = '\n'.join(list(reversed(content.splitlines())))
+ paperlinks = {}
+ for _, p in papers:
+ # print(p)
+ paperlinks[p] = ', '.join(
+ ((f'[{paperlink} ⇨]'
+ f'(model_zoo/{splitext(basename(f))[0]}.html#'
+ f'{anchor(paperlink)})') for paperlink in re.findall(
+ rf'\btitle\s*=\s*{{\s*{p}\s*}}.*?\n### (.*?)\s*[,;]?\s*\n',
+ revcontent, re.DOTALL | re.IGNORECASE)))
+ # print(' ', paperlinks[p])
+ paperlist = '\n'.join(
+ sorted(f' - [{t}] {x} ({paperlinks[x]})' for t, x in papers))
+ # count configs
+ configs = set(x.lower().strip()
+ for x in re.findall(r'.*configs/.*\.py', content))
+
+ # count ckpts
+ ckpts = set(x.lower().strip()
+ for x in re.findall(r'https://download.*\.pth', content)
+ if 'mmpose' in x)
+
+ statsmsg = f"""
+## [{title}]({f})
+
+* Number of checkpoints: {len(ckpts)}
+* Number of configs: {len(configs)}
+* Number of papers: {len(papers)}
+{paperlist}
+
+ """
+
+ stats.append((papers, configs, ckpts, statsmsg))
+
+allpapers = func.reduce(lambda a, b: a.union(b), [p for p, _, _, _ in stats])
+allconfigs = func.reduce(lambda a, b: a.union(b), [c for _, c, _, _ in stats])
+allckpts = func.reduce(lambda a, b: a.union(b), [c for _, _, c, _ in stats])
+
+# Summarize
+
+msglist = '\n'.join(x for _, _, _, x in stats)
+papertypes, papercounts = np.unique([t for t, _ in allpapers],
+ return_counts=True)
+countstr = '\n'.join(
+ [f' - {t}: {c}' for t, c in zip(papertypes, papercounts)])
+
+modelzoo = f"""
+# Overview
+
+* Number of checkpoints: {len(allckpts)}
+* Number of configs: {len(allconfigs)}
+* Number of papers: {len(allpapers)}
+{countstr}
+
+For supported datasets, see [datasets overview](dataset_zoo.md).
+
+{msglist}
+
+"""
+
+with open('model_zoo.md', 'w') as f:
+ f.write(modelzoo)
+
+# Count datasets
+
+files = sorted(glob.glob('model_zoo/*.md'))
+# files = sorted(glob.glob('docs/tasks/*.md'))
+
+datastats = []
+
+for f in files:
+ with open(f, 'r') as content_file:
+ content = content_file.read()
+
+ # title
+ title = content.split('\n')[0].replace('#', '')
+
+ # count papers
+ papers = set(
+ (papertype, titlecase.titlecase(paper.lower().strip()))
+ for (papertype, paper) in re.findall(
+ r'\s*\n.*?\btitle\s*=\s*{(.*?)}',
+ content, re.DOTALL))
+ # paper links
+ revcontent = '\n'.join(list(reversed(content.splitlines())))
+ paperlinks = {}
+ for _, p in papers:
+ # print(p)
+ paperlinks[p] = ', '.join(
+ (f'[{p} ⇨](model_zoo/{splitext(basename(f))[0]}.html#'
+ f'{anchor(p)})' for p in re.findall(
+ rf'\btitle\s*=\s*{{\s*{p}\s*}}.*?\n## (.*?)\s*[,;]?\s*\n',
+ revcontent, re.DOTALL | re.IGNORECASE)))
+ # print(' ', paperlinks[p])
+ paperlist = '\n'.join(
+ sorted(f' - [{t}] {x} ({paperlinks[x]})' for t, x in papers))
+ # count configs
+ configs = set(x.lower().strip()
+ for x in re.findall(r'https.*configs/.*\.py', content))
+
+ # count ckpts
+ ckpts = set(x.lower().strip()
+ for x in re.findall(r'https://download.*\.pth', content)
+ if 'mmpose' in x)
+
+ statsmsg = f"""
+## [{title}]({f})
+
+* Number of papers: {len(papers)}
+{paperlist}
+
+ """
+
+ datastats.append((papers, configs, ckpts, statsmsg))
+
+alldatapapers = func.reduce(lambda a, b: a.union(b),
+ [p for p, _, _, _ in datastats])
+
+# Summarize
+
+msglist = '\n'.join(x for _, _, _, x in stats)
+datamsglist = '\n'.join(x for _, _, _, x in datastats)
+papertypes, papercounts = np.unique([t for t, _ in alldatapapers],
+ return_counts=True)
+countstr = '\n'.join(
+ [f' - {t}: {c}' for t, c in zip(papertypes, papercounts)])
+
+dataset_zoo = f"""
+# Overview
+
+* Number of papers: {len(alldatapapers)}
+{countstr}
+
+For supported pose algorithms, see [modelzoo overview](model_zoo.md).
+
+{datamsglist}
+"""
+
+with open('dataset_zoo.md', 'w') as f:
+ f.write(dataset_zoo)
diff --git a/docs/en/switch_language.md b/docs/en/switch_language.md
index a0a6259bee..c0f410d59d 100644
--- a/docs/en/switch_language.md
+++ b/docs/en/switch_language.md
@@ -1,3 +1,3 @@
-## English
-
-## 简体中文
+## English
+
+## 简体中文
diff --git a/docs/en/user_guides/configs.md b/docs/en/user_guides/configs.md
index 9d2c44f7ff..c441064a9c 100644
--- a/docs/en/user_guides/configs.md
+++ b/docs/en/user_guides/configs.md
@@ -1,462 +1,462 @@
-# Configs
-
-We use python files as configs and incorporate modular and inheritance design into our config system, which is convenient to conduct various experiments.
-
-## Introduction
-
-MMPose is equipped with a powerful config system. Cooperating with Registry, a config file can organize all the configurations in the form of python dictionaries and create instances of the corresponding modules.
-
-Here is a simple example of vanilla Pytorch module definition to show how the config system works:
-
-```Python
-# Definition of Loss_A in loss_a.py
-Class Loss_A(nn.Module):
- def __init__(self, param1, param2):
- self.param1 = param1
- self.param2 = param2
- def forward(self, x):
- return x
-
-# Init the module
-loss = Loss_A(param1=1.0, param2=True)
-```
-
-All you need to do is just to register the module to the pre-defined Registry `MODELS`:
-
-```Python
-# Definition of Loss_A in loss_a.py
-from mmpose.registry import MODELS
-
-@MODELS.register_module() # register the module to MODELS
-Class Loss_A(nn.Module):
- def __init__(self, param1, param2):
- self.param1 = param1
- self.param2 = param2
- def forward(self, x):
- return x
-```
-
-And import the new module in `__init__.py` in the corresponding directory:
-
-```Python
-# __init__.py of mmpose/models/losses
-from .loss_a.py import Loss_A
-
-__all__ = ['Loss_A']
-```
-
-Then you can define the module anywhere you want:
-
-```Python
-# config_file.py
-loss_cfg = dict(
- type='Loss_A', # specify your registered module via `type`
- param1=1.0, # pass parameters to __init__() of the module
- param2=True
-)
-
-# Init the module
-loss = MODELS.build(loss_cfg) # equals to `loss = Loss_A(param1=1.0, param2=True)`
-```
-
-```{note}
-Note that all new modules need to be registered using `Registry` and imported in `__init__.py` in the corresponding directory before we can create their instances from configs.
-```
-
-Here is a list of pre-defined registries in MMPose:
-
-- `DATASETS`: data-related modules
-- `TRANSFORMS`: data transformations
-- `MODELS`: all kinds of modules inheriting `nn.Module` (Backbone, Neck, Head, Loss, etc.)
-- `VISUALIZERS`: visualization tools
-- `VISBACKENDS`: visualizer backend
-- `METRICS`: all kinds of evaluation metrics
-- `KEYPOINT_CODECS`: keypoint encoder/decoder
-- `HOOKS`: all kinds of hooks like `CheckpointHook`
-
-All registries are defined in `$MMPOSE/mmpose/registry.py`.
-
-## Config System
-
-It is best practice to layer your configs in five sections:
-
-- **General**: basic configurations non-related to training or testing, such as Timer, Logger, Visualizer and other Hooks, as well as distributed-related environment settings
-
-- **Data**: dataset, dataloader and data augmentation
-
-- **Training**: resume, weights loading, optimizer, learning rate scheduling, epochs and valid interval etc.
-
-- **Model**: structure, module and loss function etc.
-
-- **Evaluation**: metrics
-
-You can find all the provided configs under `$MMPOSE/configs`. A config can inherit contents from another config.To keep a config file simple and easy to read, we store some necessary but unremarkable configurations to `$MMPOSE/configs/_base_`.You can inspect the complete configurations by:
-
-```Bash
-python tools/analysis/print_config.py /PATH/TO/CONFIG
-```
-
-### General
-
-General configuration refers to the necessary configuration non-related to training or testing, mainly including:
-
-- **Default Hooks**: time statistics, training logs, checkpoints etc.
-
-- **Environment**: distributed backend, cudnn, multi-processing etc.
-
-- **Visualizer**: visualization backend and strategy
-
-- **Log**: log level, format, printing and recording interval etc.
-
-Here is the description of General configuration:
-
-```Python
-# General
-default_scope = 'mmpose'
-default_hooks = dict(
- timer=dict(type='IterTimerHook'), # time the data processing and model inference
- logger=dict(type='LoggerHook', interval=50), # interval to print logs
- param_scheduler=dict(type='ParamSchedulerHook'), # update lr
- checkpoint=dict(
- type='CheckpointHook', interval=1, save_best='coco/AP', # interval to save ckpt
- rule='greater'), # rule to judge the metric
- sampler_seed=dict(type='DistSamplerSeedHook')) # set the distributed seed
-env_cfg = dict(
- cudnn_benchmark=False, # cudnn benchmark flag
- mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0), # num of opencv threads
- dist_cfg=dict(backend='nccl')) # distributed training backend
-vis_backends = [dict(type='LocalVisBackend')] # visualizer backend
-visualizer = dict( # Config of visualizer
- type='PoseLocalVisualizer',
- vis_backends=[dict(type='LocalVisBackend')],
- name='visualizer')
-log_processor = dict( # Format, interval to log
- type='LogProcessor', window_size=50, by_epoch=True, num_digits=6)
-log_level = 'INFO' # The level of logging
-```
-
-General configuration is stored alone in the `$MMPOSE/configs/_base_`, and inherited by doing:
-
-```Python
-_base_ = ['../../../_base_/default_runtime.py'] # take the config file as the starting point of the relative path
-```
-
-```{note}
-CheckpointHook:
-
-- save_best: `'coco/AP'` for `CocoMetric`, `'PCK'` for `PCKAccuracy`
-- max_keep_ckpts: the maximum checkpoints to keep. Defaults to -1, which means unlimited.
-
-Example:
-
-`default_hooks = dict(checkpoint=dict(save_best='PCK', rule='greater', max_keep_ckpts=1))`
-```
-
-### Data
-
-Data configuration refers to the data processing related settings, mainly including:
-
-- **File Client**: data storage backend, default is `disk`, we also support `LMDB`, `S3 Bucket` etc.
-
-- **Dataset**: image and annotation file path
-
-- **Dataloader**: loading configuration, batch size etc.
-
-- **Pipeline**: data augmentation
-
-- **Input Encoder**: encoding the annotation into specific form of target
-
-Here is the description of Data configuration:
-
-```Python
-backend_args = dict(backend='local') # data storage backend
-dataset_type = 'CocoDataset' # name of dataset
-data_mode = 'topdown' # type of the model
-data_root = 'data/coco/' # root of the dataset
- # config of codec,to generate targets and decode preds into coordinates
-codec = dict(
- type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
-train_pipeline = [ # data aug in training
- dict(type='LoadImage', backend_args=backend_args, # image loading
- dict(type='GetBBoxCenterScale'), # calculate center and scale of bbox
- dict(type='RandomBBoxTransform'), # config of scaling, rotation and shifing
- dict(type='RandomFlip', direction='horizontal'), # config of random flipping
- dict(type='RandomHalfBody'), # config of half-body aug
- dict(type='TopdownAffine', input_size=codec['input_size']), # update inputs via transform matrix
- dict(
- type='GenerateTarget', # generate targets via transformed inputs
- # typeof targets
- encoder=codec, # get encoder from codec
- dict(type='PackPoseInputs') # pack targets
-]
-test_pipeline = [ # data aug in testing
- dict(type='LoadImage', backend_args=backend_args), # image loading
- dict(type='GetBBoxCenterScale'), # calculate center and scale of bbox
- dict(type='TopdownAffine', input_size=codec['input_size']), # update inputs via transform matrix
- dict(type='PackPoseInputs') # pack targets
-]
-train_dataloader = dict(
- batch_size=64, # batch size of each single GPU during training
- num_workers=2, # workers to pre-fetch data for each single GPU
- persistent_workers=True, # workers will stay around (with their state) waiting for another call into that dataloader.
- sampler=dict(type='DefaultSampler', shuffle=True), # data sampler, shuffle in traning
- dataset=dict(
- type=dataset_type , # name of dataset
- data_root=data_root, # root of dataset
- data_mode=data_mode, # type of the model
- ann_file='annotations/person_keypoints_train2017.json', # path to annotation file
- data_prefix=dict(img='train2017/'), # path to images
- pipeline=train_pipeline
- ))
-val_dataloader = dict(
- batch_size=32, # batch size of each single GPU during validation
- num_workers=2, # workers to pre-fetch data for each single GPU
- persistent_workers=True, # workers will stay around (with their state) waiting for another call into that dataloader.
- drop_last=False,
- sampler=dict(type='DefaultSampler', shuffle=False), # data sampler
- dataset=dict(
- type=dataset_type , # name of dataset
- data_root=data_root, # root of dataset
- data_mode=data_mode, # type of the model
- ann_file='annotations/person_keypoints_val2017.json', # path to annotation file
- bbox_file=
- 'data/coco/person_detection_results/COCO_val2017_detections_AP_H_56_person.json', # bbox file use for evaluation
- data_prefix=dict(img='val2017/'), # path to images
- test_mode=True,
- pipeline=test_pipeline
- ))
-test_dataloader = val_dataloader # use val as test by default
-```
-
-```{note}
-Common Usages:
-- [Resume training](../common_usages/resume_training.md)
-- [Automatic mixed precision (AMP) training](../common_usages/amp_training.md)
-- [Set the random seed](../common_usages/set_random_seed.md)
-
-```
-
-### Training
-
-Training configuration refers to the training related settings including:
-
-- Resume training
-
-- Model weights loading
-
-- Epochs of training and interval to validate
-
-- Learning rate adjustment strategies like warm-up, scheduling etc.
-
-- Optimizer and initial learning rate
-
-- Advanced tricks like auto learning rate scaling
-
-Here is the description of Training configuration:
-
-```Python
-resume = False # resume checkpoints from a given path, the training will be resumed from the epoch when the checkpoint's is saved
-load_from = None # load models as a pre-trained model from a given path
-train_cfg = dict(by_epoch=True, max_epochs=210, val_interval=10) # max epochs of training, interval to validate
-param_scheduler = [
- dict( # warmup strategy
- type='LinearLR', begin=0, end=500, start_factor=0.001, by_epoch=False),
- dict( # scheduler
- type='MultiStepLR',
- begin=0,
- end=210,
- milestones=[170, 200],
- gamma=0.1,
- by_epoch=True)
-]
-optim_wrapper = dict(optimizer=dict(type='Adam', lr=0.0005)) # optimizer and initial lr
-auto_scale_lr = dict(base_batch_size=512) # auto scale the lr according to batch size
-```
-
-### Model
-
-Model configuration refers to model training and inference related settings including:
-
-- Model Structure
-
-- Loss Function
-
-- Output Decoding
-
-- Test-time augmentation
-
-Here is the description of Model configuration, which defines a Top-down Heatmap-based HRNetx32:
-
-```Python
-# config of codec, if already defined in data configuration section, no need to define again
-codec = dict(
- type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
-
-model = dict(
- type='TopdownPoseEstimator', # Macro model structure
- data_preprocessor=dict( # data normalization and channel transposition
- type='PoseDataPreprocessor',
- mean=[123.675, 116.28, 103.53],
- std=[58.395, 57.12, 57.375],
- bgr_to_rgb=True),
- backbone=dict( # config of backbone
- type='HRNet',
- in_channels=3,
- extra=dict(
- stage1=dict(
- num_modules=1,
- num_branches=1,
- block='BOTTLENECK',
- num_blocks=(4, ),
- num_channels=(64, )),
- stage2=dict(
- num_modules=1,
- num_branches=2,
- block='BASIC',
- num_blocks=(4, 4),
- num_channels=(32, 64)),
- stage3=dict(
- num_modules=4,
- num_branches=3,
- block='BASIC',
- num_blocks=(4, 4, 4),
- num_channels=(32, 64, 128)),
- stage4=dict(
- num_modules=3,
- num_branches=4,
- block='BASIC',
- num_blocks=(4, 4, 4, 4),
- num_channels=(32, 64, 128, 256))),
- init_cfg=dict(
- type='Pretrained', # load pretrained weights to backbone
- checkpoint='https://download.openmmlab.com/mmpose'
- '/pretrain_models/hrnet_w32-36af842e.pth'),
- ),
- head=dict( # config of head
- type='HeatmapHead',
- in_channels=32,
- out_channels=17,
- deconv_out_channels=None,
- loss=dict(type='KeypointMSELoss', use_target_weight=True), # config of loss function
- decoder=codec), # get decoder from codec
- test_cfg=dict(
- flip_test=True, # flag of flip test
- flip_mode='heatmap', # heatmap flipping
- shift_heatmap=True, # shift the flipped heatmap several pixels to get a better performance
- ))
-```
-
-### Evaluation
-
-Evaluation configuration refers to metrics commonly used by public datasets for keypoint detection tasks, mainly including:
-
-- AR, AP and mAP
-
-- PCK, PCKh, tPCK
-
-- AUC
-
-- EPE
-
-- NME
-
-Here is the description of Evaluation configuration, which defines a COCO metric evaluator:
-
-```Python
-val_evaluator = dict(
- type='CocoMetric', # coco AP
- ann_file=data_root + 'annotations/person_keypoints_val2017.json') # path to annotation file
-test_evaluator = val_evaluator # use val as test by default
-```
-
-## Config File Naming Convention
-
-MMPose follow the style below to name config files:
-
-```Python
-{{algorithm info}}_{{module info}}_{{training info}}_{{data info}}.py
-```
-
-The filename is divided into four parts:
-
-- **Algorithm Information**: the name of algorithm, such as `topdown-heatmap`, `topdown-rle`
-
-- **Module Information**: list of intermediate modules in the forward order, such as `res101`, `hrnet-w48`
-
-- **Training Information**: settings of training(e.g. `batch_size`, `scheduler`), such as `8xb64-210e`
-
-- **Data Information**: the name of dataset, the reshape of input data, such as `ap10k-256x256`, `zebra-160x160`
-
-Words between different parts are connected by `'_'`, and those from the same part are connected by `'-'`.
-
-To avoid a too long filename, some strong related modules in `{{module info}}` will be omitted, such as `gap` in `RLE` algorithm, `deconv` in `Heatmap-based` algorithm
-
-Contributors are advised to follow the same style.
-
-## Common Usage
-
-### Inheritance
-
-This is often used to inherit configurations from other config files. Let's assume two configs like:
-
-`optimizer_cfg.py`:
-
-```Python
-optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
-```
-
-`resnet50.py`:
-
-```Python
-_base_ = ['optimizer_cfg.py']
-model = dict(type='ResNet', depth=50)
-```
-
-Although we did not define `optimizer` in `resnet50.py`, all configurations in `optimizer.py` will be inherited by setting `_base_ = ['optimizer_cfg.py']`
-
-```Python
-cfg = Config.fromfile('resnet50.py')
-cfg.optimizer # ConfigDict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
-```
-
-### Modification
-
-For configurations already set in previous configs, you can directly modify arguments specific to that module.
-
-`resnet50_lr0.01.py`:
-
-```Python
-_base_ = ['optimizer_cfg.py']
-model = dict(type='ResNet', depth=50)
-optimizer = dict(lr=0.01) # modify specific filed
-```
-
-Now only `lr` is modified:
-
-```Python
-cfg = Config.fromfile('resnet50_lr0.01.py')
-cfg.optimizer # ConfigDict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
-```
-
-### Delete
-
-For configurations already set in previous configs, if you wish to modify some specific argument and delete the remainders(in other words, discard the previous and redefine the module), you can set `_delete_=True`.
-
-`resnet50.py`:
-
-```Python
-_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
-model = dict(type='ResNet', depth=50)
-optimizer = dict(_delete_=True, type='SGD', lr=0.01) # discard the previous and redefine the module
-```
-
-Now only `type` and `lr` are kept:
-
-```Python
-cfg = Config.fromfile('resnet50_lr0.01.py')
-cfg.optimizer # ConfigDict(type='SGD', lr=0.01)
-```
-
-```{note}
-If you wish to learn more about advanced usages of the config system, please refer to [MMEngine Config](https://mmengine.readthedocs.io/en/latest/tutorials/config.html).
-```
+# Configs
+
+We use python files as configs and incorporate modular and inheritance design into our config system, which is convenient to conduct various experiments.
+
+## Introduction
+
+MMPose is equipped with a powerful config system. Cooperating with Registry, a config file can organize all the configurations in the form of python dictionaries and create instances of the corresponding modules.
+
+Here is a simple example of vanilla Pytorch module definition to show how the config system works:
+
+```Python
+# Definition of Loss_A in loss_a.py
+Class Loss_A(nn.Module):
+ def __init__(self, param1, param2):
+ self.param1 = param1
+ self.param2 = param2
+ def forward(self, x):
+ return x
+
+# Init the module
+loss = Loss_A(param1=1.0, param2=True)
+```
+
+All you need to do is just to register the module to the pre-defined Registry `MODELS`:
+
+```Python
+# Definition of Loss_A in loss_a.py
+from mmpose.registry import MODELS
+
+@MODELS.register_module() # register the module to MODELS
+Class Loss_A(nn.Module):
+ def __init__(self, param1, param2):
+ self.param1 = param1
+ self.param2 = param2
+ def forward(self, x):
+ return x
+```
+
+And import the new module in `__init__.py` in the corresponding directory:
+
+```Python
+# __init__.py of mmpose/models/losses
+from .loss_a.py import Loss_A
+
+__all__ = ['Loss_A']
+```
+
+Then you can define the module anywhere you want:
+
+```Python
+# config_file.py
+loss_cfg = dict(
+ type='Loss_A', # specify your registered module via `type`
+ param1=1.0, # pass parameters to __init__() of the module
+ param2=True
+)
+
+# Init the module
+loss = MODELS.build(loss_cfg) # equals to `loss = Loss_A(param1=1.0, param2=True)`
+```
+
+```{note}
+Note that all new modules need to be registered using `Registry` and imported in `__init__.py` in the corresponding directory before we can create their instances from configs.
+```
+
+Here is a list of pre-defined registries in MMPose:
+
+- `DATASETS`: data-related modules
+- `TRANSFORMS`: data transformations
+- `MODELS`: all kinds of modules inheriting `nn.Module` (Backbone, Neck, Head, Loss, etc.)
+- `VISUALIZERS`: visualization tools
+- `VISBACKENDS`: visualizer backend
+- `METRICS`: all kinds of evaluation metrics
+- `KEYPOINT_CODECS`: keypoint encoder/decoder
+- `HOOKS`: all kinds of hooks like `CheckpointHook`
+
+All registries are defined in `$MMPOSE/mmpose/registry.py`.
+
+## Config System
+
+It is best practice to layer your configs in five sections:
+
+- **General**: basic configurations non-related to training or testing, such as Timer, Logger, Visualizer and other Hooks, as well as distributed-related environment settings
+
+- **Data**: dataset, dataloader and data augmentation
+
+- **Training**: resume, weights loading, optimizer, learning rate scheduling, epochs and valid interval etc.
+
+- **Model**: structure, module and loss function etc.
+
+- **Evaluation**: metrics
+
+You can find all the provided configs under `$MMPOSE/configs`. A config can inherit contents from another config.To keep a config file simple and easy to read, we store some necessary but unremarkable configurations to `$MMPOSE/configs/_base_`.You can inspect the complete configurations by:
+
+```Bash
+python tools/analysis/print_config.py /PATH/TO/CONFIG
+```
+
+### General
+
+General configuration refers to the necessary configuration non-related to training or testing, mainly including:
+
+- **Default Hooks**: time statistics, training logs, checkpoints etc.
+
+- **Environment**: distributed backend, cudnn, multi-processing etc.
+
+- **Visualizer**: visualization backend and strategy
+
+- **Log**: log level, format, printing and recording interval etc.
+
+Here is the description of General configuration:
+
+```Python
+# General
+default_scope = 'mmpose'
+default_hooks = dict(
+ timer=dict(type='IterTimerHook'), # time the data processing and model inference
+ logger=dict(type='LoggerHook', interval=50), # interval to print logs
+ param_scheduler=dict(type='ParamSchedulerHook'), # update lr
+ checkpoint=dict(
+ type='CheckpointHook', interval=1, save_best='coco/AP', # interval to save ckpt
+ rule='greater'), # rule to judge the metric
+ sampler_seed=dict(type='DistSamplerSeedHook')) # set the distributed seed
+env_cfg = dict(
+ cudnn_benchmark=False, # cudnn benchmark flag
+ mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0), # num of opencv threads
+ dist_cfg=dict(backend='nccl')) # distributed training backend
+vis_backends = [dict(type='LocalVisBackend')] # visualizer backend
+visualizer = dict( # Config of visualizer
+ type='PoseLocalVisualizer',
+ vis_backends=[dict(type='LocalVisBackend')],
+ name='visualizer')
+log_processor = dict( # Format, interval to log
+ type='LogProcessor', window_size=50, by_epoch=True, num_digits=6)
+log_level = 'INFO' # The level of logging
+```
+
+General configuration is stored alone in the `$MMPOSE/configs/_base_`, and inherited by doing:
+
+```Python
+_base_ = ['../../../_base_/default_runtime.py'] # take the config file as the starting point of the relative path
+```
+
+```{note}
+CheckpointHook:
+
+- save_best: `'coco/AP'` for `CocoMetric`, `'PCK'` for `PCKAccuracy`
+- max_keep_ckpts: the maximum checkpoints to keep. Defaults to -1, which means unlimited.
+
+Example:
+
+`default_hooks = dict(checkpoint=dict(save_best='PCK', rule='greater', max_keep_ckpts=1))`
+```
+
+### Data
+
+Data configuration refers to the data processing related settings, mainly including:
+
+- **File Client**: data storage backend, default is `disk`, we also support `LMDB`, `S3 Bucket` etc.
+
+- **Dataset**: image and annotation file path
+
+- **Dataloader**: loading configuration, batch size etc.
+
+- **Pipeline**: data augmentation
+
+- **Input Encoder**: encoding the annotation into specific form of target
+
+Here is the description of Data configuration:
+
+```Python
+backend_args = dict(backend='local') # data storage backend
+dataset_type = 'CocoDataset' # name of dataset
+data_mode = 'topdown' # type of the model
+data_root = 'data/coco/' # root of the dataset
+ # config of codec,to generate targets and decode preds into coordinates
+codec = dict(
+ type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+train_pipeline = [ # data aug in training
+ dict(type='LoadImage', backend_args=backend_args, # image loading
+ dict(type='GetBBoxCenterScale'), # calculate center and scale of bbox
+ dict(type='RandomBBoxTransform'), # config of scaling, rotation and shifing
+ dict(type='RandomFlip', direction='horizontal'), # config of random flipping
+ dict(type='RandomHalfBody'), # config of half-body aug
+ dict(type='TopdownAffine', input_size=codec['input_size']), # update inputs via transform matrix
+ dict(
+ type='GenerateTarget', # generate targets via transformed inputs
+ # typeof targets
+ encoder=codec, # get encoder from codec
+ dict(type='PackPoseInputs') # pack targets
+]
+test_pipeline = [ # data aug in testing
+ dict(type='LoadImage', backend_args=backend_args), # image loading
+ dict(type='GetBBoxCenterScale'), # calculate center and scale of bbox
+ dict(type='TopdownAffine', input_size=codec['input_size']), # update inputs via transform matrix
+ dict(type='PackPoseInputs') # pack targets
+]
+train_dataloader = dict(
+ batch_size=64, # batch size of each single GPU during training
+ num_workers=2, # workers to pre-fetch data for each single GPU
+ persistent_workers=True, # workers will stay around (with their state) waiting for another call into that dataloader.
+ sampler=dict(type='DefaultSampler', shuffle=True), # data sampler, shuffle in traning
+ dataset=dict(
+ type=dataset_type , # name of dataset
+ data_root=data_root, # root of dataset
+ data_mode=data_mode, # type of the model
+ ann_file='annotations/person_keypoints_train2017.json', # path to annotation file
+ data_prefix=dict(img='train2017/'), # path to images
+ pipeline=train_pipeline
+ ))
+val_dataloader = dict(
+ batch_size=32, # batch size of each single GPU during validation
+ num_workers=2, # workers to pre-fetch data for each single GPU
+ persistent_workers=True, # workers will stay around (with their state) waiting for another call into that dataloader.
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False), # data sampler
+ dataset=dict(
+ type=dataset_type , # name of dataset
+ data_root=data_root, # root of dataset
+ data_mode=data_mode, # type of the model
+ ann_file='annotations/person_keypoints_val2017.json', # path to annotation file
+ bbox_file=
+ 'data/coco/person_detection_results/COCO_val2017_detections_AP_H_56_person.json', # bbox file use for evaluation
+ data_prefix=dict(img='val2017/'), # path to images
+ test_mode=True,
+ pipeline=test_pipeline
+ ))
+test_dataloader = val_dataloader # use val as test by default
+```
+
+```{note}
+Common Usages:
+- [Resume training](../common_usages/resume_training.md)
+- [Automatic mixed precision (AMP) training](../common_usages/amp_training.md)
+- [Set the random seed](../common_usages/set_random_seed.md)
+
+```
+
+### Training
+
+Training configuration refers to the training related settings including:
+
+- Resume training
+
+- Model weights loading
+
+- Epochs of training and interval to validate
+
+- Learning rate adjustment strategies like warm-up, scheduling etc.
+
+- Optimizer and initial learning rate
+
+- Advanced tricks like auto learning rate scaling
+
+Here is the description of Training configuration:
+
+```Python
+resume = False # resume checkpoints from a given path, the training will be resumed from the epoch when the checkpoint's is saved
+load_from = None # load models as a pre-trained model from a given path
+train_cfg = dict(by_epoch=True, max_epochs=210, val_interval=10) # max epochs of training, interval to validate
+param_scheduler = [
+ dict( # warmup strategy
+ type='LinearLR', begin=0, end=500, start_factor=0.001, by_epoch=False),
+ dict( # scheduler
+ type='MultiStepLR',
+ begin=0,
+ end=210,
+ milestones=[170, 200],
+ gamma=0.1,
+ by_epoch=True)
+]
+optim_wrapper = dict(optimizer=dict(type='Adam', lr=0.0005)) # optimizer and initial lr
+auto_scale_lr = dict(base_batch_size=512) # auto scale the lr according to batch size
+```
+
+### Model
+
+Model configuration refers to model training and inference related settings including:
+
+- Model Structure
+
+- Loss Function
+
+- Output Decoding
+
+- Test-time augmentation
+
+Here is the description of Model configuration, which defines a Top-down Heatmap-based HRNetx32:
+
+```Python
+# config of codec, if already defined in data configuration section, no need to define again
+codec = dict(
+ type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+model = dict(
+ type='TopdownPoseEstimator', # Macro model structure
+ data_preprocessor=dict( # data normalization and channel transposition
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict( # config of backbone
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ init_cfg=dict(
+ type='Pretrained', # load pretrained weights to backbone
+ checkpoint='https://download.openmmlab.com/mmpose'
+ '/pretrain_models/hrnet_w32-36af842e.pth'),
+ ),
+ head=dict( # config of head
+ type='HeatmapHead',
+ in_channels=32,
+ out_channels=17,
+ deconv_out_channels=None,
+ loss=dict(type='KeypointMSELoss', use_target_weight=True), # config of loss function
+ decoder=codec), # get decoder from codec
+ test_cfg=dict(
+ flip_test=True, # flag of flip test
+ flip_mode='heatmap', # heatmap flipping
+ shift_heatmap=True, # shift the flipped heatmap several pixels to get a better performance
+ ))
+```
+
+### Evaluation
+
+Evaluation configuration refers to metrics commonly used by public datasets for keypoint detection tasks, mainly including:
+
+- AR, AP and mAP
+
+- PCK, PCKh, tPCK
+
+- AUC
+
+- EPE
+
+- NME
+
+Here is the description of Evaluation configuration, which defines a COCO metric evaluator:
+
+```Python
+val_evaluator = dict(
+ type='CocoMetric', # coco AP
+ ann_file=data_root + 'annotations/person_keypoints_val2017.json') # path to annotation file
+test_evaluator = val_evaluator # use val as test by default
+```
+
+## Config File Naming Convention
+
+MMPose follow the style below to name config files:
+
+```Python
+{{algorithm info}}_{{module info}}_{{training info}}_{{data info}}.py
+```
+
+The filename is divided into four parts:
+
+- **Algorithm Information**: the name of algorithm, such as `topdown-heatmap`, `topdown-rle`
+
+- **Module Information**: list of intermediate modules in the forward order, such as `res101`, `hrnet-w48`
+
+- **Training Information**: settings of training(e.g. `batch_size`, `scheduler`), such as `8xb64-210e`
+
+- **Data Information**: the name of dataset, the reshape of input data, such as `ap10k-256x256`, `zebra-160x160`
+
+Words between different parts are connected by `'_'`, and those from the same part are connected by `'-'`.
+
+To avoid a too long filename, some strong related modules in `{{module info}}` will be omitted, such as `gap` in `RLE` algorithm, `deconv` in `Heatmap-based` algorithm
+
+Contributors are advised to follow the same style.
+
+## Common Usage
+
+### Inheritance
+
+This is often used to inherit configurations from other config files. Let's assume two configs like:
+
+`optimizer_cfg.py`:
+
+```Python
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+`resnet50.py`:
+
+```Python
+_base_ = ['optimizer_cfg.py']
+model = dict(type='ResNet', depth=50)
+```
+
+Although we did not define `optimizer` in `resnet50.py`, all configurations in `optimizer.py` will be inherited by setting `_base_ = ['optimizer_cfg.py']`
+
+```Python
+cfg = Config.fromfile('resnet50.py')
+cfg.optimizer # ConfigDict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+### Modification
+
+For configurations already set in previous configs, you can directly modify arguments specific to that module.
+
+`resnet50_lr0.01.py`:
+
+```Python
+_base_ = ['optimizer_cfg.py']
+model = dict(type='ResNet', depth=50)
+optimizer = dict(lr=0.01) # modify specific filed
+```
+
+Now only `lr` is modified:
+
+```Python
+cfg = Config.fromfile('resnet50_lr0.01.py')
+cfg.optimizer # ConfigDict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
+```
+
+### Delete
+
+For configurations already set in previous configs, if you wish to modify some specific argument and delete the remainders(in other words, discard the previous and redefine the module), you can set `_delete_=True`.
+
+`resnet50.py`:
+
+```Python
+_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
+model = dict(type='ResNet', depth=50)
+optimizer = dict(_delete_=True, type='SGD', lr=0.01) # discard the previous and redefine the module
+```
+
+Now only `type` and `lr` are kept:
+
+```Python
+cfg = Config.fromfile('resnet50_lr0.01.py')
+cfg.optimizer # ConfigDict(type='SGD', lr=0.01)
+```
+
+```{note}
+If you wish to learn more about advanced usages of the config system, please refer to [MMEngine Config](https://mmengine.readthedocs.io/en/latest/tutorials/config.html).
+```
diff --git a/docs/en/user_guides/inference.md b/docs/en/user_guides/inference.md
index fa51aa20fa..a42465d088 100644
--- a/docs/en/user_guides/inference.md
+++ b/docs/en/user_guides/inference.md
@@ -1,285 +1,285 @@
-# Inference with existing models
-
-MMPose provides a wide variety of pre-trained models for pose estimation, which can be found in the [Model Zoo](https://mmpose.readthedocs.io/en/latest/model_zoo.html).
-This guide will demonstrate **how to perform inference**, or running pose estimation on provided images or videos using trained models.
-
-For instructions on testing existing models on standard datasets, refer to this [guide](./train_and_test.md#test).
-
-In MMPose, a model is defined by a configuration file, while its pre-existing parameters are stored in a checkpoint file. You can find the model configuration files and corresponding checkpoint URLs in the [Model Zoo](https://mmpose.readthedocs.io/en/latest/modelzoo.html). We recommend starting with the HRNet model, using [this configuration file](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py) and [this checkpoint file](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192-81c58e40_20220909.pth).
-
-## Inferencer: a Unified Inference Interface
-
-MMPose offers a comprehensive API for inference, known as `MMPoseInferencer`. This API enables users to perform inference on both images and videos using all the models supported by MMPose. Furthermore, the API provides automatic visualization of inference results and allows for the convenient saving of predictions.
-
-### Basic Usage
-
-The `MMPoseInferencer` can be used in any Python program to perform pose estimation. Below is an example of inference on a given image using the pre-trained human pose estimator within the Python shell.
-
-```python
-from mmpose.apis import MMPoseInferencer
-
-img_path = 'tests/data/coco/000000000785.jpg' # replace this with your own image path
-
-# instantiate the inferencer using the model alias
-inferencer = MMPoseInferencer('human')
-
-# The MMPoseInferencer API employs a lazy inference approach,
-# creating a prediction generator when given input
-result_generator = inferencer(img_path, show=True)
-result = next(result_generator)
-```
-
-If everything works fine, you will see the following image in a new window:
-
-
-The `result` variable is a dictionary comprising two keys, `'visualization'` and `'predictions'`.
-
-- `'visualization'` holds a list which:
-
- - contains visualization results, such as the input image, markers of the estimated poses, and optional predicted heatmaps.
- - remains empty if the `return_vis` argument is not specified.
-
-- `'predictions'` stores:
-
- - a list of estimated keypoints for each identified instance.
-
-The structure of the `result` dictionary is as follows:
-
-```python
-result = {
- 'visualization': [
- # number of elements: batch_size (defaults to 1)
- vis_image_1,
- ...
- ],
- 'predictions': [
- # pose estimation result of each image
- # number of elements: batch_size (defaults to 1)
- [
- # pose information of each detected instance
- # number of elements: number of detected instances
- {'keypoints': ..., # instance 1
- 'keypoint_scores': ...,
- ...
- },
- {'keypoints': ..., # instance 2
- 'keypoint_scores': ...,
- ...
- },
- ]
- ...
- ]
-}
-
-```
-
-A **command-line interface (CLI)** tool for the inferencer is also available: `demo/inferencer_demo.py`. This tool allows users to perform inference using the same model and inputs with the following command:
-
-```bash
-python demo/inferencer_demo.py 'tests/data/coco/000000000785.jpg' \
- --pose2d 'human' --show --pred-out-dir 'predictions'
-```
-
-The predictions will be save in `predictions/000000000785.json`. The argument names correspond with the `MMPoseInferencer`, which serves as an API.
-
-The inferencer is capable of processing a range of input types, which includes the following:
-
-- A path to an image
-- A path to a video
-- A path to a folder (which will cause all images in that folder to be inferred)
-- An image array (NA for CLI tool)
-- A list of image arrays (NA for CLI tool)
-- A webcam (in which case the `input` parameter should be set to either `'webcam'` or `'webcam:{CAMERA_ID}'`)
-
-Please note that when the input corresponds to multiple images, such as when the input is a video or a folder path, the inference process needs to iterate over the results generator in order to perform inference on all the frames or images within the folder. Here's an example in Python:
-
-```python
-folder_path = 'tests/data/coco'
-
-result_generator = inferencer(folder_path, show=True)
-results = [result for result in result_generator]
-```
-
-In this example, the `inferencer` takes the `folder_path` as input and returns a generator object (`result_generator`) that produces inference results. By iterating over the `result_generator` and storing each result in the `results` list, you can obtain the inference results for all the frames or images within the folder.
-
-### Custom Pose Estimation Models
-
-The inferencer provides several methods that can be used to customize the models employed:
-
-```python
-
-# build the inferencer with model alias
-inferencer = MMPoseInferencer('human')
-
-# build the inferencer with model config name
-inferencer = MMPoseInferencer('td-hm_hrnet-w32_8xb64-210e_coco-256x192')
-
-# build the inferencer with model config path and checkpoint path/URL
-inferencer = MMPoseInferencer(
- pose2d='configs/body_2d_keypoint/topdown_heatmap/coco/' \
- 'td-hm_hrnet-w32_8xb64-210e_coco-256x192.py',
- pose2d_weights='https://download.openmmlab.com/mmpose/top_down/' \
- 'hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth'
-)
-```
-
-The complere list of model alias can be found in the [Model Alias](#model-alias) section.
-
-**Custom Object Detector for Top-down Pose Estimation Models**
-
-In addition, top-down pose estimators also require an object detection model. The inferencer is capable of inferring the instance type for models trained with datasets supported in MMPose, and subsequently constructing the necessary object detection model. Alternatively, users may also manually specify the detection model using the following methods:
-
-```python
-
-# specify detection model by alias
-# the available aliases include 'human', 'hand', 'face', 'animal',
-# as well as any additional aliases defined in mmdet
-inferencer = MMPoseInferencer(
- # suppose the pose estimator is trained on custom dataset
- pose2d='custom_human_pose_estimator.py',
- pose2d_weights='custom_human_pose_estimator.pth',
- det_model='human'
-)
-
-# specify detection model with model config name
-inferencer = MMPoseInferencer(
- pose2d='human',
- det_model='yolox_l_8x8_300e_coco',
- det_cat_ids=[0], # the category id of 'human' class
-)
-
-# specify detection model with config path and checkpoint path/URL
-inferencer = MMPoseInferencer(
- pose2d='human',
- det_model=f'{PATH_TO_MMDET}/configs/yolox/yolox_l_8x8_300e_coco.py',
- det_weights='https://download.openmmlab.com/mmdetection/v2.0/' \
- 'yolox/yolox_l_8x8_300e_coco/' \
- 'yolox_l_8x8_300e_coco_20211126_140236-d3bd2b23.pth',
- det_cat_ids=[0], # the category id of 'human' class
-)
-```
-
-To perform top-down pose estimation on cropped images containing a single object, users can set `det_model='whole_image'`. This bypasses the object detector initialization, creating a bounding box that matches the input image size and directly sending the entire image to the top-down pose estimator.
-
-### Dump Results
-
-After performing pose estimation, you might want to save the results for further analysis or processing. This section will guide you through saving the predicted keypoints and visualizations to your local machine.
-
-To save the predictions in a JSON file, use the `pred_out_dir` argument when running the inferencer:
-
-```python
-result_generator = inferencer(img_path, pred_out_dir='predictions')
-result = next(result_generator)
-```
-
-The predictions will be saved in the `predictions/` folder in JSON format, with each file named after the corresponding input image or video.
-
-For more advanced scenarios, you can also access the predictions directly from the `result` dictionary returned by the inferencer. The key `'predictions'` contains a list of predicted keypoints for each individual instance in the input image or video. You can then manipulate or store these results using your preferred method.
-
-Keep in mind that if you want to save both the visualization images and the prediction files in a single folder, you can use the `out_dir` argument:
-
-```python
-result_generator = inferencer(img_path, out_dir='output')
-result = next(result_generator)
-```
-
-In this case, the visualization images will be saved in the `output/visualization/` folder, while the predictions will be stored in the `output/predictions/` folder.
-
-### Visualization
-
-The inferencer can automatically draw predictions on input images or videos. Visualization results can be displayed in a new window and saved locally.
-
-To view the visualization results in a new window, use the following code:
-
-```python
-result_generator = inferencer(img_path, show=True)
-result = next(result_generator)
-```
-
-Notice that:
-
-- If the input video comes from a webcam, displaying the visualization results in a new window will be enabled by default, allowing users to see the inputs.
-- If there is no GUI on the platform, this step may become stuck.
-
-To save the visualization results locally, specify the `vis_out_dir` argument like this:
-
-```python
-result_generator = inferencer(img_path, vis_out_dir='vis_results')
-result = next(result_generator)
-```
-
-The input images or videos with predicted poses will be saved in the `vis_results/` folder.
-
-As seen in the above image, the visualization of estimated poses consists of keypoints (depicted by solid circles) and skeletons (represented by lines). The default size of these visual elements might not produce satisfactory results. Users can adjust the circle size and line thickness using the `radius` and `thickness` arguments, as shown below:
-
-```python
-result_generator = inferencer(img_path, show=True, radius=4, thickness=2)
-result = next(result_generator)
-```
-
-### Arguments of Inferencer
-
-The `MMPoseInferencer` offers a variety of arguments for customizing pose estimation, visualization, and saving predictions. Below is a list of the arguments available when initializing the inferencer and their descriptions:
-
-| Argument | Description |
-| ---------------- | ---------------------------------------------------------------------------------------------------------------- |
-| `pose2d` | Specifies the model alias, configuration file name, or configuration file path for the 2D pose estimation model. |
-| `pose2d_weights` | Specifies the URL or local path to the 2D pose estimation model's checkpoint file. |
-| `pose3d` | Specifies the model alias, configuration file name, or configuration file path for the 3D pose estimation model. |
-| `pose3d_weights` | Specifies the URL or local path to the 3D pose estimation model's checkpoint file. |
-| `det_model` | Specifies the model alias, configuration file name, or configuration file path for the object detection model. |
-| `det_weights` | Specifies the URL or local path to the object detection model's checkpoint file. |
-| `det_cat_ids` | Specifies the list of category IDs corresponding to the object classes to be detected. |
-| `device` | The device to perform the inference. If left `None`, the Inferencer will select the most suitable one. |
-| `scope` | The namespace where the model modules are defined. |
-
-The inferencer is designed for both visualization and saving predictions. The table below presents the list of arguments available when using the `MMPoseInferencer` for inference, along with their compatibility with 2D and 3D inferencing:
-
-| Argument | Description | 2D | 3D |
-| ------------------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------------- | --- | --- |
-| `show` | Controls the display of the image or video in a pop-up window. | ✔️ | ✔️ |
-| `radius` | Sets the visualization keypoint radius. | ✔️ | ✔️ |
-| `thickness` | Determines the link thickness for visualization. | ✔️ | ✔️ |
-| `kpt_thr` | Sets the keypoint score threshold. Keypoints with scores exceeding this threshold will be displayed. | ✔️ | ✔️ |
-| `draw_bbox` | Decides whether to display the bounding boxes of instances. | ✔️ | ✔️ |
-| `draw_heatmap` | Decides if the predicted heatmaps should be drawn. | ✔️ | ❌ |
-| `black_background` | Decides whether the estimated poses should be displayed on a black background. | ✔️ | ❌ |
-| `skeleton_style` | Sets the skeleton style. Options include 'mmpose' (default) and 'openpose'. | ✔️ | ❌ |
-| `use_oks_tracking` | Decides whether to use OKS as a similarity measure in tracking. | ❌ | ✔️ |
-| `tracking_thr` | Sets the similarity threshold for tracking. | ❌ | ✔️ |
-| `norm_pose_2d` | Decides whether to scale the bounding box to the dataset's average bounding box scale and relocate the bounding box to the dataset's average bounding box center. | ❌ | ✔️ |
-| `rebase_keypoint_height` | Decides whether to set the lowest keypoint with height 0. | ❌ | ✔️ |
-| `return_vis` | Decides whether to include visualization images in the results. | ✔️ | ✔️ |
-| `vis_out_dir` | Defines the folder path to save the visualization images. If unset, the visualization images will not be saved. | ✔️ | ✔️ |
-| `return_datasample` | Determines if the prediction should be returned in the `PoseDataSample` format. | ✔️ | ✔️ |
-| `pred_out_dir` | Specifies the folder path to save the predictions. If unset, the predictions will not be saved. | ✔️ | ✔️ |
-| `out_dir` | If `vis_out_dir` or `pred_out_dir` is unset, these will be set to `f'{out_dir}/visualization'` or `f'{out_dir}/predictions'`, respectively. | ✔️ | ✔️ |
-
-### Model Alias
-
-The MMPose library has predefined aliases for several frequently used models. These aliases can be utilized as a shortcut when initializing the `MMPoseInferencer`, as an alternative to providing the full model configuration name. Here are the available 2D model aliases and their corresponding configuration names:
-
-| Alias | Configuration Name | Task | Pose Estimator | Detector |
-| --------- | -------------------------------------------------- | ------------------------------- | -------------- | ------------------- |
-| animal | rtmpose-m_8xb64-210e_ap10k-256x256 | Animal pose estimation | RTMPose-m | RTMDet-m |
-| human | rtmpose-m_8xb256-420e_aic-coco-256x192 | Human pose estimation | RTMPose-m | RTMDet-m |
-| face | rtmpose-m_8xb64-60e_wflw-256x256 | Face keypoint detection | RTMPose-m | yolox-s |
-| hand | rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256 | Hand keypoint detection | RTMPose-m | ssdlite_mobilenetv2 |
-| wholebody | rtmpose-m_8xb64-270e_coco-wholebody-256x192 | Human wholebody pose estimation | RTMPose-m | RTMDet-m |
-| vitpose | td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-base | RTMDet-m |
-| vitpose-s | td-hm_ViTPose-small-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-small | RTMDet-m |
-| vitpose-b | td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-base | RTMDet-m |
-| vitpose-l | td-hm_ViTPose-large-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-large | RTMDet-m |
-| vitpose-h | td-hm_ViTPose-huge-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-huge | RTMDet-m |
-
-The following table lists the available 3D model aliases and their corresponding configuration names:
-
-| Alias | Configuration Name | Task | 3D Pose Estimator | 2D Pose Estimator | Detector |
-| ------- | --------------------------------------------------------- | ------------------------ | ----------------- | ----------------- | -------- |
-| human3d | pose-lift_videopose3d-243frm-supv-cpn-ft_8xb128-200e_h36m | Human 3D pose estimation | VideoPose3D | RTMPose-m | RTMDet-m |
-
-In addition, users can utilize the CLI tool to display all available aliases with the following command:
-
-```shell
-python demo/inferencer_demo.py --show-alias
-```
+# Inference with existing models
+
+MMPose provides a wide variety of pre-trained models for pose estimation, which can be found in the [Model Zoo](https://mmpose.readthedocs.io/en/latest/model_zoo.html).
+This guide will demonstrate **how to perform inference**, or running pose estimation on provided images or videos using trained models.
+
+For instructions on testing existing models on standard datasets, refer to this [guide](./train_and_test.md#test).
+
+In MMPose, a model is defined by a configuration file, while its pre-existing parameters are stored in a checkpoint file. You can find the model configuration files and corresponding checkpoint URLs in the [Model Zoo](https://mmpose.readthedocs.io/en/latest/modelzoo.html). We recommend starting with the HRNet model, using [this configuration file](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py) and [this checkpoint file](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192-81c58e40_20220909.pth).
+
+## Inferencer: a Unified Inference Interface
+
+MMPose offers a comprehensive API for inference, known as `MMPoseInferencer`. This API enables users to perform inference on both images and videos using all the models supported by MMPose. Furthermore, the API provides automatic visualization of inference results and allows for the convenient saving of predictions.
+
+### Basic Usage
+
+The `MMPoseInferencer` can be used in any Python program to perform pose estimation. Below is an example of inference on a given image using the pre-trained human pose estimator within the Python shell.
+
+```python
+from mmpose.apis import MMPoseInferencer
+
+img_path = 'tests/data/coco/000000000785.jpg' # replace this with your own image path
+
+# instantiate the inferencer using the model alias
+inferencer = MMPoseInferencer('human')
+
+# The MMPoseInferencer API employs a lazy inference approach,
+# creating a prediction generator when given input
+result_generator = inferencer(img_path, show=True)
+result = next(result_generator)
+```
+
+If everything works fine, you will see the following image in a new window:
+
+
+The `result` variable is a dictionary comprising two keys, `'visualization'` and `'predictions'`.
+
+- `'visualization'` holds a list which:
+
+ - contains visualization results, such as the input image, markers of the estimated poses, and optional predicted heatmaps.
+ - remains empty if the `return_vis` argument is not specified.
+
+- `'predictions'` stores:
+
+ - a list of estimated keypoints for each identified instance.
+
+The structure of the `result` dictionary is as follows:
+
+```python
+result = {
+ 'visualization': [
+ # number of elements: batch_size (defaults to 1)
+ vis_image_1,
+ ...
+ ],
+ 'predictions': [
+ # pose estimation result of each image
+ # number of elements: batch_size (defaults to 1)
+ [
+ # pose information of each detected instance
+ # number of elements: number of detected instances
+ {'keypoints': ..., # instance 1
+ 'keypoint_scores': ...,
+ ...
+ },
+ {'keypoints': ..., # instance 2
+ 'keypoint_scores': ...,
+ ...
+ },
+ ]
+ ...
+ ]
+}
+
+```
+
+A **command-line interface (CLI)** tool for the inferencer is also available: `demo/inferencer_demo.py`. This tool allows users to perform inference using the same model and inputs with the following command:
+
+```bash
+python demo/inferencer_demo.py 'tests/data/coco/000000000785.jpg' \
+ --pose2d 'human' --show --pred-out-dir 'predictions'
+```
+
+The predictions will be save in `predictions/000000000785.json`. The argument names correspond with the `MMPoseInferencer`, which serves as an API.
+
+The inferencer is capable of processing a range of input types, which includes the following:
+
+- A path to an image
+- A path to a video
+- A path to a folder (which will cause all images in that folder to be inferred)
+- An image array (NA for CLI tool)
+- A list of image arrays (NA for CLI tool)
+- A webcam (in which case the `input` parameter should be set to either `'webcam'` or `'webcam:{CAMERA_ID}'`)
+
+Please note that when the input corresponds to multiple images, such as when the input is a video or a folder path, the inference process needs to iterate over the results generator in order to perform inference on all the frames or images within the folder. Here's an example in Python:
+
+```python
+folder_path = 'tests/data/coco'
+
+result_generator = inferencer(folder_path, show=True)
+results = [result for result in result_generator]
+```
+
+In this example, the `inferencer` takes the `folder_path` as input and returns a generator object (`result_generator`) that produces inference results. By iterating over the `result_generator` and storing each result in the `results` list, you can obtain the inference results for all the frames or images within the folder.
+
+### Custom Pose Estimation Models
+
+The inferencer provides several methods that can be used to customize the models employed:
+
+```python
+
+# build the inferencer with model alias
+inferencer = MMPoseInferencer('human')
+
+# build the inferencer with model config name
+inferencer = MMPoseInferencer('td-hm_hrnet-w32_8xb64-210e_coco-256x192')
+
+# build the inferencer with model config path and checkpoint path/URL
+inferencer = MMPoseInferencer(
+ pose2d='configs/body_2d_keypoint/topdown_heatmap/coco/' \
+ 'td-hm_hrnet-w32_8xb64-210e_coco-256x192.py',
+ pose2d_weights='https://download.openmmlab.com/mmpose/top_down/' \
+ 'hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth'
+)
+```
+
+The complere list of model alias can be found in the [Model Alias](#model-alias) section.
+
+**Custom Object Detector for Top-down Pose Estimation Models**
+
+In addition, top-down pose estimators also require an object detection model. The inferencer is capable of inferring the instance type for models trained with datasets supported in MMPose, and subsequently constructing the necessary object detection model. Alternatively, users may also manually specify the detection model using the following methods:
+
+```python
+
+# specify detection model by alias
+# the available aliases include 'human', 'hand', 'face', 'animal',
+# as well as any additional aliases defined in mmdet
+inferencer = MMPoseInferencer(
+ # suppose the pose estimator is trained on custom dataset
+ pose2d='custom_human_pose_estimator.py',
+ pose2d_weights='custom_human_pose_estimator.pth',
+ det_model='human'
+)
+
+# specify detection model with model config name
+inferencer = MMPoseInferencer(
+ pose2d='human',
+ det_model='yolox_l_8x8_300e_coco',
+ det_cat_ids=[0], # the category id of 'human' class
+)
+
+# specify detection model with config path and checkpoint path/URL
+inferencer = MMPoseInferencer(
+ pose2d='human',
+ det_model=f'{PATH_TO_MMDET}/configs/yolox/yolox_l_8x8_300e_coco.py',
+ det_weights='https://download.openmmlab.com/mmdetection/v2.0/' \
+ 'yolox/yolox_l_8x8_300e_coco/' \
+ 'yolox_l_8x8_300e_coco_20211126_140236-d3bd2b23.pth',
+ det_cat_ids=[0], # the category id of 'human' class
+)
+```
+
+To perform top-down pose estimation on cropped images containing a single object, users can set `det_model='whole_image'`. This bypasses the object detector initialization, creating a bounding box that matches the input image size and directly sending the entire image to the top-down pose estimator.
+
+### Dump Results
+
+After performing pose estimation, you might want to save the results for further analysis or processing. This section will guide you through saving the predicted keypoints and visualizations to your local machine.
+
+To save the predictions in a JSON file, use the `pred_out_dir` argument when running the inferencer:
+
+```python
+result_generator = inferencer(img_path, pred_out_dir='predictions')
+result = next(result_generator)
+```
+
+The predictions will be saved in the `predictions/` folder in JSON format, with each file named after the corresponding input image or video.
+
+For more advanced scenarios, you can also access the predictions directly from the `result` dictionary returned by the inferencer. The key `'predictions'` contains a list of predicted keypoints for each individual instance in the input image or video. You can then manipulate or store these results using your preferred method.
+
+Keep in mind that if you want to save both the visualization images and the prediction files in a single folder, you can use the `out_dir` argument:
+
+```python
+result_generator = inferencer(img_path, out_dir='output')
+result = next(result_generator)
+```
+
+In this case, the visualization images will be saved in the `output/visualization/` folder, while the predictions will be stored in the `output/predictions/` folder.
+
+### Visualization
+
+The inferencer can automatically draw predictions on input images or videos. Visualization results can be displayed in a new window and saved locally.
+
+To view the visualization results in a new window, use the following code:
+
+```python
+result_generator = inferencer(img_path, show=True)
+result = next(result_generator)
+```
+
+Notice that:
+
+- If the input video comes from a webcam, displaying the visualization results in a new window will be enabled by default, allowing users to see the inputs.
+- If there is no GUI on the platform, this step may become stuck.
+
+To save the visualization results locally, specify the `vis_out_dir` argument like this:
+
+```python
+result_generator = inferencer(img_path, vis_out_dir='vis_results')
+result = next(result_generator)
+```
+
+The input images or videos with predicted poses will be saved in the `vis_results/` folder.
+
+As seen in the above image, the visualization of estimated poses consists of keypoints (depicted by solid circles) and skeletons (represented by lines). The default size of these visual elements might not produce satisfactory results. Users can adjust the circle size and line thickness using the `radius` and `thickness` arguments, as shown below:
+
+```python
+result_generator = inferencer(img_path, show=True, radius=4, thickness=2)
+result = next(result_generator)
+```
+
+### Arguments of Inferencer
+
+The `MMPoseInferencer` offers a variety of arguments for customizing pose estimation, visualization, and saving predictions. Below is a list of the arguments available when initializing the inferencer and their descriptions:
+
+| Argument | Description |
+| ---------------- | ---------------------------------------------------------------------------------------------------------------- |
+| `pose2d` | Specifies the model alias, configuration file name, or configuration file path for the 2D pose estimation model. |
+| `pose2d_weights` | Specifies the URL or local path to the 2D pose estimation model's checkpoint file. |
+| `pose3d` | Specifies the model alias, configuration file name, or configuration file path for the 3D pose estimation model. |
+| `pose3d_weights` | Specifies the URL or local path to the 3D pose estimation model's checkpoint file. |
+| `det_model` | Specifies the model alias, configuration file name, or configuration file path for the object detection model. |
+| `det_weights` | Specifies the URL or local path to the object detection model's checkpoint file. |
+| `det_cat_ids` | Specifies the list of category IDs corresponding to the object classes to be detected. |
+| `device` | The device to perform the inference. If left `None`, the Inferencer will select the most suitable one. |
+| `scope` | The namespace where the model modules are defined. |
+
+The inferencer is designed for both visualization and saving predictions. The table below presents the list of arguments available when using the `MMPoseInferencer` for inference, along with their compatibility with 2D and 3D inferencing:
+
+| Argument | Description | 2D | 3D |
+| ------------------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------------- | --- | --- |
+| `show` | Controls the display of the image or video in a pop-up window. | ✔️ | ✔️ |
+| `radius` | Sets the visualization keypoint radius. | ✔️ | ✔️ |
+| `thickness` | Determines the link thickness for visualization. | ✔️ | ✔️ |
+| `kpt_thr` | Sets the keypoint score threshold. Keypoints with scores exceeding this threshold will be displayed. | ✔️ | ✔️ |
+| `draw_bbox` | Decides whether to display the bounding boxes of instances. | ✔️ | ✔️ |
+| `draw_heatmap` | Decides if the predicted heatmaps should be drawn. | ✔️ | ❌ |
+| `black_background` | Decides whether the estimated poses should be displayed on a black background. | ✔️ | ❌ |
+| `skeleton_style` | Sets the skeleton style. Options include 'mmpose' (default) and 'openpose'. | ✔️ | ❌ |
+| `use_oks_tracking` | Decides whether to use OKS as a similarity measure in tracking. | ❌ | ✔️ |
+| `tracking_thr` | Sets the similarity threshold for tracking. | ❌ | ✔️ |
+| `norm_pose_2d` | Decides whether to scale the bounding box to the dataset's average bounding box scale and relocate the bounding box to the dataset's average bounding box center. | ❌ | ✔️ |
+| `rebase_keypoint_height` | Decides whether to set the lowest keypoint with height 0. | ❌ | ✔️ |
+| `return_vis` | Decides whether to include visualization images in the results. | ✔️ | ✔️ |
+| `vis_out_dir` | Defines the folder path to save the visualization images. If unset, the visualization images will not be saved. | ✔️ | ✔️ |
+| `return_datasample` | Determines if the prediction should be returned in the `PoseDataSample` format. | ✔️ | ✔️ |
+| `pred_out_dir` | Specifies the folder path to save the predictions. If unset, the predictions will not be saved. | ✔️ | ✔️ |
+| `out_dir` | If `vis_out_dir` or `pred_out_dir` is unset, these will be set to `f'{out_dir}/visualization'` or `f'{out_dir}/predictions'`, respectively. | ✔️ | ✔️ |
+
+### Model Alias
+
+The MMPose library has predefined aliases for several frequently used models. These aliases can be utilized as a shortcut when initializing the `MMPoseInferencer`, as an alternative to providing the full model configuration name. Here are the available 2D model aliases and their corresponding configuration names:
+
+| Alias | Configuration Name | Task | Pose Estimator | Detector |
+| --------- | -------------------------------------------------- | ------------------------------- | -------------- | ------------------- |
+| animal | rtmpose-m_8xb64-210e_ap10k-256x256 | Animal pose estimation | RTMPose-m | RTMDet-m |
+| human | rtmpose-m_8xb256-420e_aic-coco-256x192 | Human pose estimation | RTMPose-m | RTMDet-m |
+| face | rtmpose-m_8xb64-60e_wflw-256x256 | Face keypoint detection | RTMPose-m | yolox-s |
+| hand | rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256 | Hand keypoint detection | RTMPose-m | ssdlite_mobilenetv2 |
+| wholebody | rtmpose-m_8xb64-270e_coco-wholebody-256x192 | Human wholebody pose estimation | RTMPose-m | RTMDet-m |
+| vitpose | td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-base | RTMDet-m |
+| vitpose-s | td-hm_ViTPose-small-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-small | RTMDet-m |
+| vitpose-b | td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-base | RTMDet-m |
+| vitpose-l | td-hm_ViTPose-large-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-large | RTMDet-m |
+| vitpose-h | td-hm_ViTPose-huge-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-huge | RTMDet-m |
+
+The following table lists the available 3D model aliases and their corresponding configuration names:
+
+| Alias | Configuration Name | Task | 3D Pose Estimator | 2D Pose Estimator | Detector |
+| ------- | --------------------------------------------------------- | ------------------------ | ----------------- | ----------------- | -------- |
+| human3d | pose-lift_videopose3d-243frm-supv-cpn-ft_8xb128-200e_h36m | Human 3D pose estimation | VideoPose3D | RTMPose-m | RTMDet-m |
+
+In addition, users can utilize the CLI tool to display all available aliases with the following command:
+
+```shell
+python demo/inferencer_demo.py --show-alias
+```
diff --git a/docs/en/user_guides/mixed_datasets.md b/docs/en/user_guides/mixed_datasets.md
index f9bcc93e15..aa18b5e539 100644
--- a/docs/en/user_guides/mixed_datasets.md
+++ b/docs/en/user_guides/mixed_datasets.md
@@ -1,159 +1,159 @@
-# Use Mixed Datasets for Training
-
-MMPose offers a convenient and versatile solution for training with mixed datasets through its `CombinedDataset` tool. Acting as a wrapper, it allows for the inclusion of multiple datasets and seamlessly reads and converts data from varying sources into a unified format for model training. The data processing pipeline utilizing `CombinedDataset` is illustrated in the following figure.
-
-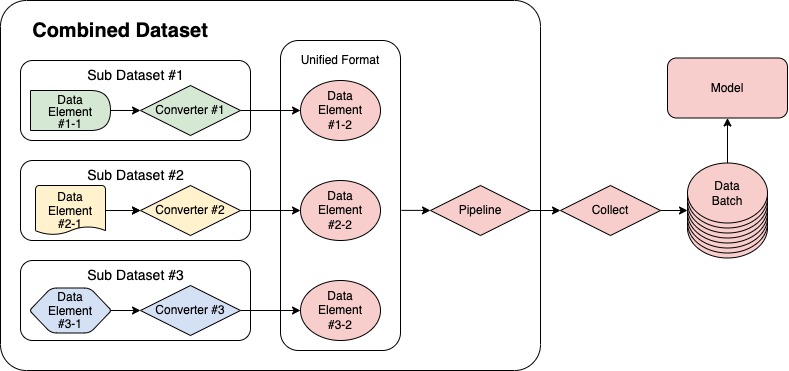
-
-The following section will provide a detailed description of how to configure `CombinedDataset` with an example that combines the COCO and AI Challenger (AIC) datasets.
-
-## COCO & AIC example
-
-The COCO and AIC datasets are both human 2D pose datasets, but they differ in the number and order of keypoints. Here are two instances from the respective datasets.
-
-
-
-Some keypoints, such as "left hand", are defined in both datasets, but they have different indices. Specifically, the index for the "left hand" keypoint is 9 in the COCO dataset and 5 in the AIC dataset. Furthermore, each dataset contains unique keypoints that are not present in the counterpart dataset. For instance, the facial keypoints (with indices 0~4) are only defined in the COCO dataset, whereas the "head top" (with index 12) and "neck" (with index 13) keypoints are exclusive to the AIC dataset. The relationship between the keypoints in both datasets is illustrated in the following Venn diagram.
-
-
-
-Next, we will discuss two methods of mixing datasets.
-
-- [Merge](#merge-aic-into-coco)
-- [Combine](#combine-aic-and-coco)
-
-### Merge AIC into COCO
-
-If users aim to enhance their model's performance on the COCO dataset or other similar datasets, they can use the AIC dataset as an auxiliary source. To do so, they should select only the keypoints in AIC dataset that are shared with COCO datasets and ignore the rest. Moreover, the indices of these chosen keypoints in the AIC dataset should be transformed to match the corresponding indices in the COCO dataset.
-
-
-
-In this scenario, no data conversion is required for the elements from the COCO dataset. To configure the COCO dataset, use the following code:
-
-```python
-dataset_coco = dict(
- type='CocoDataset',
- data_root='data/coco/',
- ann_file='annotations/person_keypoints_train2017.json',
- data_prefix=dict(img='train2017/'),
- pipeline=[], # Leave the `pipeline` empty, as no conversion is needed
-)
-```
-
-For AIC dataset, the order of the keypoints needs to be transformed. MMPose provides a `KeypointConverter` transform to achieve this. Here's an example of how to configure the AIC sub dataset:
-
-```python
-dataset_aic = dict(
- type='AicDataset',
- data_root='data/aic/',
- ann_file='annotations/aic_train.json',
- data_prefix=dict(img='ai_challenger_keypoint_train_20170902/'
- 'keypoint_train_images_20170902/'),
- pipeline=[
- dict(
- type='KeypointConverter',
- num_keypoints=17, # same as COCO dataset
- mapping=[ # includes index pairs for corresponding keypoints
- (0, 6), # index 0 (in AIC) -> index 6 (in COCO)
- (1, 8),
- (2, 10),
- (3, 5),
- (4, 7),
- (5, 9),
- (6, 12),
- (7, 14),
- (8, 16),
- (9, 11),
- (10, 13),
- (11, 15),
- ])
- ],
-)
-```
-
-By using the `KeypointConverter`, the indices of keypoints with indices 0 to 11 will be transformed to corresponding indices among 5 to 16. Meanwhile, the keypoints with indices 12 and 13 will be removed. For the target keypoints with indices 0 to 4, which are not defined in the `mapping` argument, they will be set as invisible and won't be used in training.
-
-Once the sub datasets are configured, the `CombinedDataset` wrapper can be defined as follows:
-
-```python
-dataset = dict(
- type='CombinedDataset',
- # Since the combined dataset has the same data format as COCO,
- # it should use the same meta information for the dataset
- metainfo=dict(from_file='configs/_base_/datasets/coco.py'),
- datasets=[dataset_coco, dataset_aic],
- # The pipeline includes typical transforms, such as loading the
- # image and data augmentation
- pipeline=train_pipeline,
-)
-```
-
-A complete, ready-to-use [config file](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-merge.py) that merges the AIC dataset into the COCO dataset is also available. Users can refer to it for more details and use it as a template to build their own custom dataset.
-
-### Combine AIC and COCO
-
-The previously mentioned method discards some annotations in the AIC dataset. If users want to use all the information from both datasets, they can combine the two datasets. This means taking the union set of keypoints in both datasets.
-
-
-
-In this scenario, both COCO and AIC datasets need to adjust the keypoint indices using `KeypointConverter`:
-
-```python
-dataset_coco = dict(
- type='CocoDataset',
- data_root='data/coco/',
- ann_file='annotations/person_keypoints_train2017.json',
- data_prefix=dict(img='train2017/'),
- pipeline=[
- dict(
- type='KeypointConverter',
- num_keypoints=19, # the size of union keypoint set
- mapping=[
- (0, 0),
- (1, 1),
- # omitted
- (16, 16),
- ])
- ])
-
-dataset_aic = dict(
- type='AicDataset',
- data_root='data/aic/',
- ann_file='annotations/aic_train.json',
- data_prefix=dict(img='ai_challenger_keypoint_train_20170902/'
- 'keypoint_train_images_20170902/'),
- pipeline=[
- dict(
- type='KeypointConverter',
- num_keypoints=19, # the size of union keypoint set
- mapping=[
- (0, 6),
- # omitted
- (12, 17),
- (13, 18),
- ])
- ],
-)
-```
-
-To account for the fact that the combined dataset has 19 keypoints, which is different from either COCO or AIC dataset, a new dataset meta information file is needed to describe the new dataset. An example of such a file is [coco_aic.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/_base_/datasets/coco_aic.py), which is based on [coco.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/_base_/datasets/coco.py) but includes several updates:
-
-- The paper information of AIC dataset has been added.
-- The 'head_top' and 'neck' keypoints, which are unique in AIC, have been added to the `keypoint_info`.
-- A skeleton link between 'head_top' and 'neck' has been added.
-- The `joint_weights` and `sigmas` have been extended for the newly added keypoints.
-
-Finally, the combined dataset can be configured as:
-
-```python
-dataset = dict(
- type='CombinedDataset',
- # using new dataset meta information file
- metainfo=dict(from_file='configs/_base_/datasets/coco_aic.py'),
- datasets=[dataset_coco, dataset_aic],
- # The pipeline includes typical transforms, such as loading the
- # image and data augmentation
- pipeline=train_pipeline,
-)
-```
-
-Additionally, the output channel number of the model should be adjusted as the number of keypoints changes. If the users aim to evaluate the model on the COCO dataset, a subset of model outputs must be chosen. This subset can be customized using the `output_keypoint_indices` argument in `test_cfg`. Users can refer to the [config file](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-combine.py), which combines the COCO and AIC dataset, for more details and use it as a template to create their custom dataset.
+# Use Mixed Datasets for Training
+
+MMPose offers a convenient and versatile solution for training with mixed datasets through its `CombinedDataset` tool. Acting as a wrapper, it allows for the inclusion of multiple datasets and seamlessly reads and converts data from varying sources into a unified format for model training. The data processing pipeline utilizing `CombinedDataset` is illustrated in the following figure.
+
+
+
+The following section will provide a detailed description of how to configure `CombinedDataset` with an example that combines the COCO and AI Challenger (AIC) datasets.
+
+## COCO & AIC example
+
+The COCO and AIC datasets are both human 2D pose datasets, but they differ in the number and order of keypoints. Here are two instances from the respective datasets.
+
+
+
+Some keypoints, such as "left hand", are defined in both datasets, but they have different indices. Specifically, the index for the "left hand" keypoint is 9 in the COCO dataset and 5 in the AIC dataset. Furthermore, each dataset contains unique keypoints that are not present in the counterpart dataset. For instance, the facial keypoints (with indices 0~4) are only defined in the COCO dataset, whereas the "head top" (with index 12) and "neck" (with index 13) keypoints are exclusive to the AIC dataset. The relationship between the keypoints in both datasets is illustrated in the following Venn diagram.
+
+
+
+Next, we will discuss two methods of mixing datasets.
+
+- [Merge](#merge-aic-into-coco)
+- [Combine](#combine-aic-and-coco)
+
+### Merge AIC into COCO
+
+If users aim to enhance their model's performance on the COCO dataset or other similar datasets, they can use the AIC dataset as an auxiliary source. To do so, they should select only the keypoints in AIC dataset that are shared with COCO datasets and ignore the rest. Moreover, the indices of these chosen keypoints in the AIC dataset should be transformed to match the corresponding indices in the COCO dataset.
+
+
+
+In this scenario, no data conversion is required for the elements from the COCO dataset. To configure the COCO dataset, use the following code:
+
+```python
+dataset_coco = dict(
+ type='CocoDataset',
+ data_root='data/coco/',
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=[], # Leave the `pipeline` empty, as no conversion is needed
+)
+```
+
+For AIC dataset, the order of the keypoints needs to be transformed. MMPose provides a `KeypointConverter` transform to achieve this. Here's an example of how to configure the AIC sub dataset:
+
+```python
+dataset_aic = dict(
+ type='AicDataset',
+ data_root='data/aic/',
+ ann_file='annotations/aic_train.json',
+ data_prefix=dict(img='ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=17, # same as COCO dataset
+ mapping=[ # includes index pairs for corresponding keypoints
+ (0, 6), # index 0 (in AIC) -> index 6 (in COCO)
+ (1, 8),
+ (2, 10),
+ (3, 5),
+ (4, 7),
+ (5, 9),
+ (6, 12),
+ (7, 14),
+ (8, 16),
+ (9, 11),
+ (10, 13),
+ (11, 15),
+ ])
+ ],
+)
+```
+
+By using the `KeypointConverter`, the indices of keypoints with indices 0 to 11 will be transformed to corresponding indices among 5 to 16. Meanwhile, the keypoints with indices 12 and 13 will be removed. For the target keypoints with indices 0 to 4, which are not defined in the `mapping` argument, they will be set as invisible and won't be used in training.
+
+Once the sub datasets are configured, the `CombinedDataset` wrapper can be defined as follows:
+
+```python
+dataset = dict(
+ type='CombinedDataset',
+ # Since the combined dataset has the same data format as COCO,
+ # it should use the same meta information for the dataset
+ metainfo=dict(from_file='configs/_base_/datasets/coco.py'),
+ datasets=[dataset_coco, dataset_aic],
+ # The pipeline includes typical transforms, such as loading the
+ # image and data augmentation
+ pipeline=train_pipeline,
+)
+```
+
+A complete, ready-to-use [config file](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-merge.py) that merges the AIC dataset into the COCO dataset is also available. Users can refer to it for more details and use it as a template to build their own custom dataset.
+
+### Combine AIC and COCO
+
+The previously mentioned method discards some annotations in the AIC dataset. If users want to use all the information from both datasets, they can combine the two datasets. This means taking the union set of keypoints in both datasets.
+
+
+
+In this scenario, both COCO and AIC datasets need to adjust the keypoint indices using `KeypointConverter`:
+
+```python
+dataset_coco = dict(
+ type='CocoDataset',
+ data_root='data/coco/',
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=19, # the size of union keypoint set
+ mapping=[
+ (0, 0),
+ (1, 1),
+ # omitted
+ (16, 16),
+ ])
+ ])
+
+dataset_aic = dict(
+ type='AicDataset',
+ data_root='data/aic/',
+ ann_file='annotations/aic_train.json',
+ data_prefix=dict(img='ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=19, # the size of union keypoint set
+ mapping=[
+ (0, 6),
+ # omitted
+ (12, 17),
+ (13, 18),
+ ])
+ ],
+)
+```
+
+To account for the fact that the combined dataset has 19 keypoints, which is different from either COCO or AIC dataset, a new dataset meta information file is needed to describe the new dataset. An example of such a file is [coco_aic.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/_base_/datasets/coco_aic.py), which is based on [coco.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/_base_/datasets/coco.py) but includes several updates:
+
+- The paper information of AIC dataset has been added.
+- The 'head_top' and 'neck' keypoints, which are unique in AIC, have been added to the `keypoint_info`.
+- A skeleton link between 'head_top' and 'neck' has been added.
+- The `joint_weights` and `sigmas` have been extended for the newly added keypoints.
+
+Finally, the combined dataset can be configured as:
+
+```python
+dataset = dict(
+ type='CombinedDataset',
+ # using new dataset meta information file
+ metainfo=dict(from_file='configs/_base_/datasets/coco_aic.py'),
+ datasets=[dataset_coco, dataset_aic],
+ # The pipeline includes typical transforms, such as loading the
+ # image and data augmentation
+ pipeline=train_pipeline,
+)
+```
+
+Additionally, the output channel number of the model should be adjusted as the number of keypoints changes. If the users aim to evaluate the model on the COCO dataset, a subset of model outputs must be chosen. This subset can be customized using the `output_keypoint_indices` argument in `test_cfg`. Users can refer to the [config file](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-combine.py), which combines the COCO and AIC dataset, for more details and use it as a template to create their custom dataset.
diff --git a/docs/en/user_guides/prepare_datasets.md b/docs/en/user_guides/prepare_datasets.md
index 2f8ddcbc32..e3f91f0504 100644
--- a/docs/en/user_guides/prepare_datasets.md
+++ b/docs/en/user_guides/prepare_datasets.md
@@ -1,221 +1,221 @@
-# Prepare Datasets
-
-In this document, we will give a guide on the process of preparing datasets for the MMPose. Various aspects of dataset preparation will be discussed, including using built-in datasets, creating custom datasets, combining datasets for training, browsing and downloading the datasets.
-
-## Use built-in datasets
-
-**Step 1**: Prepare Data
-
-MMPose supports multiple tasks and corresponding datasets. You can find them in [dataset zoo](https://mmpose.readthedocs.io/en/latest/dataset_zoo.html). To properly prepare your data, please follow the guidelines associated with your chosen dataset.
-
-**Step 2**: Configure Dataset Settings in the Config File
-
-Before training or evaluating models, you must configure the dataset settings. Take [`td-hm_hrnet-w32_8xb64-210e_coco-256x192.py`](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py) for example, which can be used to train or evaluate the HRNet pose estimator on COCO dataset. We will go through the dataset configuration.
-
-- Basic Dataset Arguments
-
- ```python
- # base dataset settings
- dataset_type = 'CocoDataset'
- data_mode = 'topdown'
- data_root = 'data/coco/'
- ```
-
- - `dataset_type` specifies the class name of the dataset. Users can refer to [Datasets APIs](https://mmpose.readthedocs.io/en/latest/api.html#datasets) to find the class name of their desired dataset.
- - `data_mode` determines the output format of the dataset, with two options available: `'topdown'` and `'bottomup'`. If `data_mode='topdown'`, the data element represents a single instance with its pose; otherwise, the data element is an entire image containing multiple instances and poses.
- - `data_root` designates the root directory of the dataset.
-
-- Data Processing Pipelines
-
- ```python
- # pipelines
- train_pipeline = [
- dict(type='LoadImage'),
- dict(type='GetBBoxCenterScale'),
- dict(type='RandomFlip', direction='horizontal'),
- dict(type='RandomHalfBody'),
- dict(type='RandomBBoxTransform'),
- dict(type='TopdownAffine', input_size=codec['input_size']),
- dict(type='GenerateTarget', encoder=codec),
- dict(type='PackPoseInputs')
- ]
- val_pipeline = [
- dict(type='LoadImage'),
- dict(type='GetBBoxCenterScale'),
- dict(type='TopdownAffine', input_size=codec['input_size']),
- dict(type='PackPoseInputs')
- ]
- ```
-
- The `train_pipeline` and `val_pipeline` define the steps to process data elements during the training and evaluation phases, respectively. In addition to loading images and packing inputs, the `train_pipeline` primarily consists of data augmentation techniques and target generator, while the `val_pipeline` focuses on transforming data elements into a unified format.
-
-- Data Loaders
-
- ```python
- # data loaders
- train_dataloader = dict(
- batch_size=64,
- num_workers=2,
- persistent_workers=True,
- sampler=dict(type='DefaultSampler', shuffle=True),
- dataset=dict(
- type=dataset_type,
- data_root=data_root,
- data_mode=data_mode,
- ann_file='annotations/person_keypoints_train2017.json',
- data_prefix=dict(img='train2017/'),
- pipeline=train_pipeline,
- ))
- val_dataloader = dict(
- batch_size=32,
- num_workers=2,
- persistent_workers=True,
- drop_last=False,
- sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
- dataset=dict(
- type=dataset_type,
- data_root=data_root,
- data_mode=data_mode,
- ann_file='annotations/person_keypoints_val2017.json',
- bbox_file='data/coco/person_detection_results/'
- 'COCO_val2017_detections_AP_H_56_person.json',
- data_prefix=dict(img='val2017/'),
- test_mode=True,
- pipeline=val_pipeline,
- ))
- test_dataloader = val_dataloader
- ```
-
- This section is crucial for configuring the dataset in the config file. In addition to the basic dataset arguments and pipelines discussed earlier, other important parameters are defined here. The `batch_size` determines the batch size per GPU; the `ann_file` indicates the annotation file for the dataset; and `data_prefix` specifies the image folder. The `bbox_file`, which supplies detected bounding box information, is only used in the val/test data loader for top-down datasets.
-
-We recommend copying the dataset configuration from provided config files that use the same dataset, rather than writing it from scratch, in order to minimize potential errors. By doing so, users can simply make the necessary modifications as needed, ensuring a more reliable and efficient setup process.
-
-## Use a custom dataset
-
-The [Customize Datasets](../advanced_guides/customize_datasets.md) guide provides detailed information on how to build a custom dataset. In this section, we will highlight some key tips for using and configuring custom datasets.
-
-- Determine the dataset class name. If you reorganize your dataset into the COCO format, you can simply use `CocoDataset` as the value for `dataset_type`. Otherwise, you will need to use the name of the custom dataset class you added.
-
-- Specify the meta information config file. MMPose 1.x employs a different strategy for specifying meta information compared to MMPose 0.x. In MMPose 1.x, users can specify the meta information config file as follows:
-
- ```python
- train_dataloader = dict(
- ...
- dataset=dict(
- type=dataset_type,
- data_root='root/of/your/train/data',
- ann_file='path/to/your/train/json',
- data_prefix=dict(img='path/to/your/train/img'),
- # specify dataset meta information
- metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
- ...),
- )
- ```
-
- Note that the argument `metainfo` must be specified in the val/test data loaders as well.
-
-## Use mixed datasets for training
-
-MMPose offers a convenient and versatile solution for training with mixed datasets. Please refer to [Use Mixed Datasets for Training](./mixed_datasets.md).
-
-## Browse dataset
-
-`tools/analysis_tools/browse_dataset.py` helps the user to browse a pose dataset visually, or save the image to a designated directory.
-
-```shell
-python tools/misc/browse_dataset.py ${CONFIG} [-h] [--output-dir ${OUTPUT_DIR}] [--not-show] [--phase ${PHASE}] [--mode ${MODE}] [--show-interval ${SHOW_INTERVAL}]
-```
-
-| ARGS | Description |
-| -------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------- |
-| `CONFIG` | The path to the config file. |
-| `--output-dir OUTPUT_DIR` | The target folder to save visualization results. If not specified, the visualization results will not be saved. |
-| `--not-show` | Do not show the visualization results in an external window. |
-| `--phase {train, val, test}` | Options for dataset. |
-| `--mode {original, transformed}` | Specify the type of visualized images. `original` means to show images without pre-processing; `transformed` means to show images are pre-processed. |
-| `--show-interval SHOW_INTERVAL` | Time interval between visualizing two images. |
-
-For instance, users who want to visualize images and annotations in COCO dataset use:
-
-```shell
-python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-e210_coco-256x192.py --mode original
-```
-
-The bounding boxes and keypoints will be plotted on the original image. Following is an example:
-
-
-The original images need to be processed before being fed into models. To visualize pre-processed images and annotations, users need to modify the argument `mode` to `transformed`. For example:
-
-```shell
-python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-e210_coco-256x192.py --mode transformed
-```
-
-Here is a processed sample
-
-
-
-The heatmap target will be visualized together if it is generated in the pipeline.
-
-## Download dataset via MIM
-
-By using [OpenDataLab](https://opendatalab.com/), you can obtain free formatted datasets in various fields. Through the search function of the platform, you may address the dataset they look for quickly and easily. Using the formatted datasets from the platform, you can efficiently conduct tasks across datasets.
-
-If you use MIM to download, make sure that the version is greater than v0.3.8. You can use the following command to update, install, login and download the dataset:
-
-```shell
-# upgrade your MIM
-pip install -U openmim
-
-# install OpenDataLab CLI tools
-pip install -U opendatalab
-# log in OpenDataLab, registry
-odl login
-
-# download coco2017 and preprocess by MIM
-mim download mmpose --dataset coco2017
-```
-
-### Supported datasets
-
-Here is the list of supported datasets, we will continue to update it in the future.
-
-#### Body
-
-| Dataset name | Download command |
-| ------------- | ----------------------------------------- |
-| COCO 2017 | `mim download mmpose --dataset coco2017` |
-| MPII | `mim download mmpose --dataset mpii` |
-| AI Challenger | `mim download mmpose --dataset aic` |
-| CrowdPose | `mim download mmpose --dataset crowdpose` |
-
-#### Face
-
-| Dataset name | Download command |
-| ------------ | ------------------------------------ |
-| LaPa | `mim download mmpose --dataset lapa` |
-| 300W | `mim download mmpose --dataset 300w` |
-| WFLW | `mim download mmpose --dataset wflw` |
-
-#### Hand
-
-| Dataset name | Download command |
-| ------------ | ------------------------------------------ |
-| OneHand10K | `mim download mmpose --dataset onehand10k` |
-| FreiHand | `mim download mmpose --dataset freihand` |
-| HaGRID | `mim download mmpose --dataset hagrid` |
-
-#### Whole Body
-
-| Dataset name | Download command |
-| ------------ | ------------------------------------- |
-| Halpe | `mim download mmpose --dataset halpe` |
-
-#### Animal
-
-| Dataset name | Download command |
-| ------------ | ------------------------------------- |
-| AP-10K | `mim download mmpose --dataset ap10k` |
-
-#### Fashion
-
-Coming Soon
+# Prepare Datasets
+
+In this document, we will give a guide on the process of preparing datasets for the MMPose. Various aspects of dataset preparation will be discussed, including using built-in datasets, creating custom datasets, combining datasets for training, browsing and downloading the datasets.
+
+## Use built-in datasets
+
+**Step 1**: Prepare Data
+
+MMPose supports multiple tasks and corresponding datasets. You can find them in [dataset zoo](https://mmpose.readthedocs.io/en/latest/dataset_zoo.html). To properly prepare your data, please follow the guidelines associated with your chosen dataset.
+
+**Step 2**: Configure Dataset Settings in the Config File
+
+Before training or evaluating models, you must configure the dataset settings. Take [`td-hm_hrnet-w32_8xb64-210e_coco-256x192.py`](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py) for example, which can be used to train or evaluate the HRNet pose estimator on COCO dataset. We will go through the dataset configuration.
+
+- Basic Dataset Arguments
+
+ ```python
+ # base dataset settings
+ dataset_type = 'CocoDataset'
+ data_mode = 'topdown'
+ data_root = 'data/coco/'
+ ```
+
+ - `dataset_type` specifies the class name of the dataset. Users can refer to [Datasets APIs](https://mmpose.readthedocs.io/en/latest/api.html#datasets) to find the class name of their desired dataset.
+ - `data_mode` determines the output format of the dataset, with two options available: `'topdown'` and `'bottomup'`. If `data_mode='topdown'`, the data element represents a single instance with its pose; otherwise, the data element is an entire image containing multiple instances and poses.
+ - `data_root` designates the root directory of the dataset.
+
+- Data Processing Pipelines
+
+ ```python
+ # pipelines
+ train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+ ]
+ val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+ ]
+ ```
+
+ The `train_pipeline` and `val_pipeline` define the steps to process data elements during the training and evaluation phases, respectively. In addition to loading images and packing inputs, the `train_pipeline` primarily consists of data augmentation techniques and target generator, while the `val_pipeline` focuses on transforming data elements into a unified format.
+
+- Data Loaders
+
+ ```python
+ # data loaders
+ train_dataloader = dict(
+ batch_size=64,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+ val_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_val2017.json',
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+ test_dataloader = val_dataloader
+ ```
+
+ This section is crucial for configuring the dataset in the config file. In addition to the basic dataset arguments and pipelines discussed earlier, other important parameters are defined here. The `batch_size` determines the batch size per GPU; the `ann_file` indicates the annotation file for the dataset; and `data_prefix` specifies the image folder. The `bbox_file`, which supplies detected bounding box information, is only used in the val/test data loader for top-down datasets.
+
+We recommend copying the dataset configuration from provided config files that use the same dataset, rather than writing it from scratch, in order to minimize potential errors. By doing so, users can simply make the necessary modifications as needed, ensuring a more reliable and efficient setup process.
+
+## Use a custom dataset
+
+The [Customize Datasets](../advanced_guides/customize_datasets.md) guide provides detailed information on how to build a custom dataset. In this section, we will highlight some key tips for using and configuring custom datasets.
+
+- Determine the dataset class name. If you reorganize your dataset into the COCO format, you can simply use `CocoDataset` as the value for `dataset_type`. Otherwise, you will need to use the name of the custom dataset class you added.
+
+- Specify the meta information config file. MMPose 1.x employs a different strategy for specifying meta information compared to MMPose 0.x. In MMPose 1.x, users can specify the meta information config file as follows:
+
+ ```python
+ train_dataloader = dict(
+ ...
+ dataset=dict(
+ type=dataset_type,
+ data_root='root/of/your/train/data',
+ ann_file='path/to/your/train/json',
+ data_prefix=dict(img='path/to/your/train/img'),
+ # specify dataset meta information
+ metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
+ ...),
+ )
+ ```
+
+ Note that the argument `metainfo` must be specified in the val/test data loaders as well.
+
+## Use mixed datasets for training
+
+MMPose offers a convenient and versatile solution for training with mixed datasets. Please refer to [Use Mixed Datasets for Training](./mixed_datasets.md).
+
+## Browse dataset
+
+`tools/analysis_tools/browse_dataset.py` helps the user to browse a pose dataset visually, or save the image to a designated directory.
+
+```shell
+python tools/misc/browse_dataset.py ${CONFIG} [-h] [--output-dir ${OUTPUT_DIR}] [--not-show] [--phase ${PHASE}] [--mode ${MODE}] [--show-interval ${SHOW_INTERVAL}]
+```
+
+| ARGS | Description |
+| -------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `CONFIG` | The path to the config file. |
+| `--output-dir OUTPUT_DIR` | The target folder to save visualization results. If not specified, the visualization results will not be saved. |
+| `--not-show` | Do not show the visualization results in an external window. |
+| `--phase {train, val, test}` | Options for dataset. |
+| `--mode {original, transformed}` | Specify the type of visualized images. `original` means to show images without pre-processing; `transformed` means to show images are pre-processed. |
+| `--show-interval SHOW_INTERVAL` | Time interval between visualizing two images. |
+
+For instance, users who want to visualize images and annotations in COCO dataset use:
+
+```shell
+python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-e210_coco-256x192.py --mode original
+```
+
+The bounding boxes and keypoints will be plotted on the original image. Following is an example:
+
+
+The original images need to be processed before being fed into models. To visualize pre-processed images and annotations, users need to modify the argument `mode` to `transformed`. For example:
+
+```shell
+python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-e210_coco-256x192.py --mode transformed
+```
+
+Here is a processed sample
+
+
+
+The heatmap target will be visualized together if it is generated in the pipeline.
+
+## Download dataset via MIM
+
+By using [OpenDataLab](https://opendatalab.com/), you can obtain free formatted datasets in various fields. Through the search function of the platform, you may address the dataset they look for quickly and easily. Using the formatted datasets from the platform, you can efficiently conduct tasks across datasets.
+
+If you use MIM to download, make sure that the version is greater than v0.3.8. You can use the following command to update, install, login and download the dataset:
+
+```shell
+# upgrade your MIM
+pip install -U openmim
+
+# install OpenDataLab CLI tools
+pip install -U opendatalab
+# log in OpenDataLab, registry
+odl login
+
+# download coco2017 and preprocess by MIM
+mim download mmpose --dataset coco2017
+```
+
+### Supported datasets
+
+Here is the list of supported datasets, we will continue to update it in the future.
+
+#### Body
+
+| Dataset name | Download command |
+| ------------- | ----------------------------------------- |
+| COCO 2017 | `mim download mmpose --dataset coco2017` |
+| MPII | `mim download mmpose --dataset mpii` |
+| AI Challenger | `mim download mmpose --dataset aic` |
+| CrowdPose | `mim download mmpose --dataset crowdpose` |
+
+#### Face
+
+| Dataset name | Download command |
+| ------------ | ------------------------------------ |
+| LaPa | `mim download mmpose --dataset lapa` |
+| 300W | `mim download mmpose --dataset 300w` |
+| WFLW | `mim download mmpose --dataset wflw` |
+
+#### Hand
+
+| Dataset name | Download command |
+| ------------ | ------------------------------------------ |
+| OneHand10K | `mim download mmpose --dataset onehand10k` |
+| FreiHand | `mim download mmpose --dataset freihand` |
+| HaGRID | `mim download mmpose --dataset hagrid` |
+
+#### Whole Body
+
+| Dataset name | Download command |
+| ------------ | ------------------------------------- |
+| Halpe | `mim download mmpose --dataset halpe` |
+
+#### Animal
+
+| Dataset name | Download command |
+| ------------ | ------------------------------------- |
+| AP-10K | `mim download mmpose --dataset ap10k` |
+
+#### Fashion
+
+Coming Soon
diff --git a/docs/en/user_guides/train_and_test.md b/docs/en/user_guides/train_and_test.md
index 6bcc88fc3b..ef317ae321 100644
--- a/docs/en/user_guides/train_and_test.md
+++ b/docs/en/user_guides/train_and_test.md
@@ -1,369 +1,369 @@
-# Training and Testing
-
-## Launch training
-
-### Train with your PC
-
-You can use `tools/train.py` to train a model on a single machine with a CPU and optionally a GPU.
-
-Here is the full usage of the script:
-
-```shell
-python tools/train.py ${CONFIG_FILE} [ARGS]
-```
-
-```{note}
-By default, MMPose prefers GPU to CPU. If you want to train a model on CPU, please empty `CUDA_VISIBLE_DEVICES` or set it to -1 to make GPU invisible to the program.
-
-```
-
-```shell
-CUDA_VISIBLE_DEVICES=-1 python tools/train.py ${CONFIG_FILE} [ARGS]
-```
-
-| ARGS | Description |
-| ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
-| `CONFIG_FILE` | The path to the config file. |
-| `--work-dir WORK_DIR` | The target folder to save logs and checkpoints. Defaults to a folder with the same name as the config file under `./work_dirs`. |
-| `--resume [RESUME]` | Resume training. If specify a path, resume from it, while if not specify, try to auto resume from the latest checkpoint. |
-| `--amp` | Enable automatic-mixed-precision training. |
-| `--no-validate` | **Not suggested**. Disable checkpoint evaluation during training. |
-| `--auto-scale-lr` | Automatically rescale the learning rate according to the actual batch size and the original batch size. |
-| `--cfg-options CFG_OPTIONS` | Override some settings in the used config, the key-value pair in xxx=yyy format will be merged into the config file. If the value to be overwritten is a list, it should be of the form of either `key="[a,b]"` or `key=a,b`. The argument also allows nested list/tuple values, e.g. `key="[(a,b),(c,d)]"`. Note that quotation marks are necessary and that **no white space is allowed**. |
-| `--show-dir SHOW_DIR` | The directory to save the result visualization images generated during validation. |
-| `--show` | Visualize the prediction result in a window. |
-| `--interval INTERVAL` | The interval of samples to visualize. |
-| `--wait-time WAIT_TIME` | The display time of every window (in seconds). Defaults to 1. |
-| `--launcher {none,pytorch,slurm,mpi}` | Options for job launcher. |
-
-### Train with multiple GPUs
-
-We provide a shell script to start a multi-GPUs task with `torch.distributed.launch`.
-
-```shell
-bash ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS]
-```
-
-| ARGS | Description |
-| ------------- | ---------------------------------------------------------------------------------- |
-| `CONFIG_FILE` | The path to the config file. |
-| `GPU_NUM` | The number of GPUs to be used. |
-| `[PYARGS]` | The other optional arguments of `tools/train.py`, see [here](#train-with-your-pc). |
-
-You can also specify extra arguments of the launcher by environment variables. For example, change the
-communication port of the launcher to 29666 by the below command:
-
-```shell
-PORT=29666 bash ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS]
-```
-
-If you want to startup multiple training jobs and use different GPUs, you can launch them by specifying
-different port and visible devices.
-
-```shell
-CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 bash ./tools/dist_train.sh ${CONFIG_FILE1} 4 [PY_ARGS]
-CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=29501 bash ./tools/dist_train.sh ${CONFIG_FILE2} 4 [PY_ARGS]
-```
-
-### Train with multiple machines
-
-#### Multiple machines in the same network
-
-If you launch a training job with multiple machines connected with ethernet, you can run the following commands:
-
-On the first machine:
-
-```shell
-NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_train.sh $CONFIG $GPUS
-```
-
-On the second machine:
-
-```shell
-NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_train.sh $CONFIG $GPUS
-```
-
-Compared with multi-GPUs in a single machine, you need to specify some extra environment variables:
-
-| ENV_VARS | Description |
-| ------------- | ---------------------------------------------------------------------------- |
-| `NNODES` | The total number of machines. |
-| `NODE_RANK` | The index of the local machine. |
-| `PORT` | The communication port, it should be the same in all machines. |
-| `MASTER_ADDR` | The IP address of the master machine, it should be the same in all machines. |
-
-Usually, it is slow if you do not have high-speed networking like InfiniBand.
-
-#### Multiple machines managed with slurm
-
-If you run MMPose on a cluster managed with [slurm](https://slurm.schedmd.com/), you can use the script `slurm_train.sh`.
-
-```shell
-[ENV_VARS] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR} [PY_ARGS]
-```
-
-Here are the arguments description of the script.
-
-| ARGS | Description |
-| ------------- | ---------------------------------------------------------------------------------- |
-| `PARTITION` | The partition to use in your cluster. |
-| `JOB_NAME` | The name of your job, you can name it as you like. |
-| `CONFIG_FILE` | The path to the config file. |
-| `WORK_DIR` | The target folder to save logs and checkpoints. |
-| `[PYARGS]` | The other optional arguments of `tools/train.py`, see [here](#train-with-your-pc). |
-
-Here are the environment variables that can be used to configure the slurm job.
-
-| ENV_VARS | Description |
-| --------------- | ---------------------------------------------------------------------------------------------------------- |
-| `GPUS` | The total number of GPUs to be used. Defaults to 8. |
-| `GPUS_PER_NODE` | The number of GPUs to be allocated per node. Defaults to 8. |
-| `CPUS_PER_TASK` | The number of CPUs to be allocated per task (Usually one GPU corresponds to one task). Defaults to 5. |
-| `SRUN_ARGS` | The other arguments of `srun`. Available options can be found [here](https://slurm.schedmd.com/srun.html). |
-
-## Resume training
-
-Resume training means to continue training from the state saved from one of the previous trainings, where the state includes the model weights, the state of the optimizer and the optimizer parameter adjustment strategy.
-
-### Automatically resume training
-
-Users can add `--resume` to the end of the training command to resume training. The program will automatically load the latest weight file from `work_dirs` to resume training. If there is a latest `checkpoint` in `work_dirs` (e.g. the training was interrupted during the previous training), the training will be resumed from the `checkpoint`. Otherwise (e.g. the previous training did not save `checkpoint` in time or a new training task was started), the training will be restarted.
-
-Here is an example of resuming training:
-
-```shell
-python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py --resume
-```
-
-### Specify the checkpoint to resume training
-
-You can also specify the `checkpoint` path for `--resume`. MMPose will automatically read the `checkpoint` and resume training from it. The command is as follows:
-
-```shell
-python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py \
- --resume work_dirs/td-hm_res50_8xb64-210e_coco-256x192/latest.pth
-```
-
-If you hope to manually specify the `checkpoint` path in the config file, in addition to setting `resume=True`, you also need to set the `load_from`.
-
-It should be noted that if only `load_from` is set without setting `resume=True`, only the weights in the `checkpoint` will be loaded and the training will be restarted from scratch, instead of continuing from the previous state.
-
-The following example is equivalent to the example above that specifies the `--resume` parameter:
-
-```python
-resume = True
-load_from = 'work_dirs/td-hm_res50_8xb64-210e_coco-256x192/latest.pth'
-# model settings
-model = dict(
- ## omitted ##
- )
-```
-
-## Freeze partial parameters during training
-
-In some scenarios, it might be desirable to freeze certain parameters of a model during training to fine-tune specific parts or to prevent overfitting. In MMPose, you can set different hyperparameters for any module in the model by setting custom_keys in `paramwise_cfg`. This allows you to control the learning rate and decay coefficient for specific parts of the model.
-
-For example, if you want to freeze the parameters in `backbone.layer0` and `backbone.layer1`, you can modify the optimizer wrapper in the config file as:
-
-```python
-optim_wrapper = dict(
- optimizer=dict(...),
- paramwise_cfg=dict(
- custom_keys={
- 'backbone.layer0': dict(lr_mult=0, decay_mult=0),
- 'backbone.layer0': dict(lr_mult=0, decay_mult=0),
- }))
-```
-
-This configuration will freeze the parameters in `backbone.layer0` and `backbone.layer1` by setting their learning rate and decay coefficient to 0. By using this approach, you can effectively control the training process and fine-tune specific parts of your model as needed.
-
-## Automatic Mixed Precision (AMP) training
-
-Mixed precision training can reduce training time and storage requirements without changing the model or reducing the model training accuracy, thus supporting larger batch sizes, larger models, and larger input sizes.
-
-To enable Automatic Mixing Precision (AMP) training, add `--amp` to the end of the training command, which is as follows:
-
-```shell
-python tools/train.py ${CONFIG_FILE} --amp
-```
-
-Specific examples are as follows:
-
-```shell
-python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py --amp
-```
-
-## Set the random seed
-
-If you want to specify the random seed during training, you can use the following command:
-
-```shell
-python ./tools/train.py \
- ${CONFIG} \ # config file
- --cfg-options randomness.seed=2023 \ # set the random seed = 2023
- [randomness.diff_rank_seed=True] \ # Set different seeds according to rank.
- [randomness.deterministic=True] # Set the cuDNN backend deterministic option to True
-# `[]` stands for optional parameters, when actually entering the command line, you do not need to enter `[]`
-```
-
-`randomness` has three parameters that can be set, with the following meanings.
-
-- `randomness.seed=2023`, set the random seed to `2023`.
-
-- `randomness.diff_rank_seed=True`, set different seeds according to global `rank`. Defaults to `False`.
-
-- `randomness.deterministic=True`, set the deterministic option for `cuDNN` backend, i.e., set `torch.backends.cudnn.deterministic` to `True` and `torch.backends.cudnn.benchmark` to `False`. Defaults to `False`. See [Pytorch Randomness](https://pytorch.org/docs/stable/notes/randomness.html) for more details.
-
-## Visualize training process
-
-Monitoring the training process is essential for understanding the performance of your model and making necessary adjustments. In this section, we will introduce two methods to visualize the training process of your MMPose model: TensorBoard and the MMEngine Visualizer.
-
-### TensorBoard
-
-TensorBoard is a powerful tool that allows you to visualize the changes in losses during training. To enable TensorBoard visualization, you may need to:
-
-1. Install TensorBoard environment
-
- ```shell
- pip install tensorboard
- ```
-
-2. Enable TensorBoard in the config file
-
- ```python
- visualizer = dict(vis_backends=[
- dict(type='LocalVisBackend'),
- dict(type='TensorboardVisBackend'),
- ])
- ```
-
-The event file generated by TensorBoard will be save under the experiment log folder `${WORK_DIR}`, which defaults to `work_dir/${CONFIG}` or can be specified using the `--work-dir` option. To visualize the training process, use the following command:
-
-```shell
-tensorboard --logdir ${WORK_DIR}/${TIMESTAMP}/vis_data
-```
-
-### MMEngine visualizer
-
-MMPose also supports visualizing model inference results during validation. To activate this function, please use the `--show` option or set `--show-dir` when launching training. This feature provides an effective way to analyze the model's performance on specific examples and make any necessary adjustments.
-
-## Test your model
-
-### Test with your PC
-
-You can use `tools/test.py` to test a model on a single machine with a CPU and optionally a GPU.
-
-Here is the full usage of the script:
-
-```shell
-python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS]
-```
-
-```{note}
-By default, MMPose prefers GPU to CPU. If you want to test a model on CPU, please empty `CUDA_VISIBLE_DEVICES` or set it to -1 to make GPU invisible to the program.
-
-```
-
-```shell
-CUDA_VISIBLE_DEVICES=-1 python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS]
-```
-
-| ARGS | Description |
-| ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
-| `CONFIG_FILE` | The path to the config file. |
-| `CHECKPOINT_FILE` | The path to the checkpoint file (It can be a http link, and you can find checkpoints [here](https://MMPose.readthedocs.io/en/latest/model_zoo.html)). |
-| `--work-dir WORK_DIR` | The directory to save the file containing evaluation metrics. |
-| `--out OUT` | The path to save the file containing evaluation metrics. |
-| `--dump DUMP` | The path to dump all outputs of the model for offline evaluation. |
-| `--cfg-options CFG_OPTIONS` | Override some settings in the used config, the key-value pair in xxx=yyy format will be merged into the config file. If the value to be overwritten is a list, it should be of the form of either `key="[a,b]"` or `key=a,b`. The argument also allows nested list/tuple values, e.g. `key="[(a,b),(c,d)]"`. Note that quotation marks are necessary and that no white space is allowed. |
-| `--show-dir SHOW_DIR` | The directory to save the result visualization images. |
-| `--show` | Visualize the prediction result in a window. |
-| `--interval INTERVAL` | The interval of samples to visualize. |
-| `--wait-time WAIT_TIME` | The display time of every window (in seconds). Defaults to 1. |
-| `--launcher {none,pytorch,slurm,mpi}` | Options for job launcher. |
-
-### Test with multiple GPUs
-
-We provide a shell script to start a multi-GPUs task with `torch.distributed.launch`.
-
-```shell
-bash ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS]
-```
-
-| ARGS | Description |
-| ----------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
-| `CONFIG_FILE` | The path to the config file. |
-| `CHECKPOINT_FILE` | The path to the checkpoint file (It can be a http link, and you can find checkpoints [here](https://mmpose.readthedocs.io/en/latest/model_zoo.html)). |
-| `GPU_NUM` | The number of GPUs to be used. |
-| `[PYARGS]` | The other optional arguments of `tools/test.py`, see [here](#test-with-your-pc). |
-
-You can also specify extra arguments of the launcher by environment variables. For example, change the
-communication port of the launcher to 29666 by the below command:
-
-```shell
-PORT=29666 bash ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS]
-```
-
-If you want to startup multiple test jobs and use different GPUs, you can launch them by specifying
-different port and visible devices.
-
-```shell
-CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 bash ./tools/dist_test.sh ${CONFIG_FILE1} ${CHECKPOINT_FILE} 4 [PY_ARGS]
-CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 bash ./tools/dist_test.sh ${CONFIG_FILE2} ${CHECKPOINT_FILE} 4 [PY_ARGS]
-```
-
-### Test with multiple machines
-
-#### Multiple machines in the same network
-
-If you launch a test job with multiple machines connected with ethernet, you can run the following commands:
-
-On the first machine:
-
-```shell
-NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_test.sh $CONFIG $CHECKPOINT_FILE $GPUS
-```
-
-On the second machine:
-
-```shell
-NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_test.sh $CONFIG $CHECKPOINT_FILE $GPUS
-```
-
-Compared with multi-GPUs in a single machine, you need to specify some extra environment variables:
-
-| ENV_VARS | Description |
-| ------------- | ---------------------------------------------------------------------------- |
-| `NNODES` | The total number of machines. |
-| `NODE_RANK` | The index of the local machine. |
-| `PORT` | The communication port, it should be the same in all machines. |
-| `MASTER_ADDR` | The IP address of the master machine, it should be the same in all machines. |
-
-Usually, it is slow if you do not have high-speed networking like InfiniBand.
-
-#### Multiple machines managed with slurm
-
-If you run MMPose on a cluster managed with [slurm](https://slurm.schedmd.com/), you can use the script `slurm_test.sh`.
-
-```shell
-[ENV_VARS] ./tools/slurm_test.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${CHECKPOINT_FILE} [PY_ARGS]
-```
-
-Here are the argument descriptions of the script.
-
-| ARGS | Description |
-| ----------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
-| `PARTITION` | The partition to use in your cluster. |
-| `JOB_NAME` | The name of your job, you can name it as you like. |
-| `CONFIG_FILE` | The path to the config file. |
-| `CHECKPOINT_FILE` | The path to the checkpoint file (It can be a http link, and you can find checkpoints [here](https://MMPose.readthedocs.io/en/latest/model_zoo.html)). |
-| `[PYARGS]` | The other optional arguments of `tools/test.py`, see [here](#test-with-your-pc). |
-
-Here are the environment variables that can be used to configure the slurm job.
-
-| ENV_VARS | Description |
-| --------------- | ---------------------------------------------------------------------------------------------------------- |
-| `GPUS` | The total number of GPUs to be used. Defaults to 8. |
-| `GPUS_PER_NODE` | The number of GPUs to be allocated per node. Defaults to 8. |
-| `CPUS_PER_TASK` | The number of CPUs to be allocated per task (Usually one GPU corresponds to one task). Defaults to 5. |
-| `SRUN_ARGS` | The other arguments of `srun`. Available options can be found [here](https://slurm.schedmd.com/srun.html). |
+# Training and Testing
+
+## Launch training
+
+### Train with your PC
+
+You can use `tools/train.py` to train a model on a single machine with a CPU and optionally a GPU.
+
+Here is the full usage of the script:
+
+```shell
+python tools/train.py ${CONFIG_FILE} [ARGS]
+```
+
+```{note}
+By default, MMPose prefers GPU to CPU. If you want to train a model on CPU, please empty `CUDA_VISIBLE_DEVICES` or set it to -1 to make GPU invisible to the program.
+
+```
+
+```shell
+CUDA_VISIBLE_DEVICES=-1 python tools/train.py ${CONFIG_FILE} [ARGS]
+```
+
+| ARGS | Description |
+| ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `CONFIG_FILE` | The path to the config file. |
+| `--work-dir WORK_DIR` | The target folder to save logs and checkpoints. Defaults to a folder with the same name as the config file under `./work_dirs`. |
+| `--resume [RESUME]` | Resume training. If specify a path, resume from it, while if not specify, try to auto resume from the latest checkpoint. |
+| `--amp` | Enable automatic-mixed-precision training. |
+| `--no-validate` | **Not suggested**. Disable checkpoint evaluation during training. |
+| `--auto-scale-lr` | Automatically rescale the learning rate according to the actual batch size and the original batch size. |
+| `--cfg-options CFG_OPTIONS` | Override some settings in the used config, the key-value pair in xxx=yyy format will be merged into the config file. If the value to be overwritten is a list, it should be of the form of either `key="[a,b]"` or `key=a,b`. The argument also allows nested list/tuple values, e.g. `key="[(a,b),(c,d)]"`. Note that quotation marks are necessary and that **no white space is allowed**. |
+| `--show-dir SHOW_DIR` | The directory to save the result visualization images generated during validation. |
+| `--show` | Visualize the prediction result in a window. |
+| `--interval INTERVAL` | The interval of samples to visualize. |
+| `--wait-time WAIT_TIME` | The display time of every window (in seconds). Defaults to 1. |
+| `--launcher {none,pytorch,slurm,mpi}` | Options for job launcher. |
+
+### Train with multiple GPUs
+
+We provide a shell script to start a multi-GPUs task with `torch.distributed.launch`.
+
+```shell
+bash ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+| ARGS | Description |
+| ------------- | ---------------------------------------------------------------------------------- |
+| `CONFIG_FILE` | The path to the config file. |
+| `GPU_NUM` | The number of GPUs to be used. |
+| `[PYARGS]` | The other optional arguments of `tools/train.py`, see [here](#train-with-your-pc). |
+
+You can also specify extra arguments of the launcher by environment variables. For example, change the
+communication port of the launcher to 29666 by the below command:
+
+```shell
+PORT=29666 bash ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+If you want to startup multiple training jobs and use different GPUs, you can launch them by specifying
+different port and visible devices.
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 bash ./tools/dist_train.sh ${CONFIG_FILE1} 4 [PY_ARGS]
+CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=29501 bash ./tools/dist_train.sh ${CONFIG_FILE2} 4 [PY_ARGS]
+```
+
+### Train with multiple machines
+
+#### Multiple machines in the same network
+
+If you launch a training job with multiple machines connected with ethernet, you can run the following commands:
+
+On the first machine:
+
+```shell
+NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_train.sh $CONFIG $GPUS
+```
+
+On the second machine:
+
+```shell
+NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_train.sh $CONFIG $GPUS
+```
+
+Compared with multi-GPUs in a single machine, you need to specify some extra environment variables:
+
+| ENV_VARS | Description |
+| ------------- | ---------------------------------------------------------------------------- |
+| `NNODES` | The total number of machines. |
+| `NODE_RANK` | The index of the local machine. |
+| `PORT` | The communication port, it should be the same in all machines. |
+| `MASTER_ADDR` | The IP address of the master machine, it should be the same in all machines. |
+
+Usually, it is slow if you do not have high-speed networking like InfiniBand.
+
+#### Multiple machines managed with slurm
+
+If you run MMPose on a cluster managed with [slurm](https://slurm.schedmd.com/), you can use the script `slurm_train.sh`.
+
+```shell
+[ENV_VARS] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR} [PY_ARGS]
+```
+
+Here are the arguments description of the script.
+
+| ARGS | Description |
+| ------------- | ---------------------------------------------------------------------------------- |
+| `PARTITION` | The partition to use in your cluster. |
+| `JOB_NAME` | The name of your job, you can name it as you like. |
+| `CONFIG_FILE` | The path to the config file. |
+| `WORK_DIR` | The target folder to save logs and checkpoints. |
+| `[PYARGS]` | The other optional arguments of `tools/train.py`, see [here](#train-with-your-pc). |
+
+Here are the environment variables that can be used to configure the slurm job.
+
+| ENV_VARS | Description |
+| --------------- | ---------------------------------------------------------------------------------------------------------- |
+| `GPUS` | The total number of GPUs to be used. Defaults to 8. |
+| `GPUS_PER_NODE` | The number of GPUs to be allocated per node. Defaults to 8. |
+| `CPUS_PER_TASK` | The number of CPUs to be allocated per task (Usually one GPU corresponds to one task). Defaults to 5. |
+| `SRUN_ARGS` | The other arguments of `srun`. Available options can be found [here](https://slurm.schedmd.com/srun.html). |
+
+## Resume training
+
+Resume training means to continue training from the state saved from one of the previous trainings, where the state includes the model weights, the state of the optimizer and the optimizer parameter adjustment strategy.
+
+### Automatically resume training
+
+Users can add `--resume` to the end of the training command to resume training. The program will automatically load the latest weight file from `work_dirs` to resume training. If there is a latest `checkpoint` in `work_dirs` (e.g. the training was interrupted during the previous training), the training will be resumed from the `checkpoint`. Otherwise (e.g. the previous training did not save `checkpoint` in time or a new training task was started), the training will be restarted.
+
+Here is an example of resuming training:
+
+```shell
+python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py --resume
+```
+
+### Specify the checkpoint to resume training
+
+You can also specify the `checkpoint` path for `--resume`. MMPose will automatically read the `checkpoint` and resume training from it. The command is as follows:
+
+```shell
+python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py \
+ --resume work_dirs/td-hm_res50_8xb64-210e_coco-256x192/latest.pth
+```
+
+If you hope to manually specify the `checkpoint` path in the config file, in addition to setting `resume=True`, you also need to set the `load_from`.
+
+It should be noted that if only `load_from` is set without setting `resume=True`, only the weights in the `checkpoint` will be loaded and the training will be restarted from scratch, instead of continuing from the previous state.
+
+The following example is equivalent to the example above that specifies the `--resume` parameter:
+
+```python
+resume = True
+load_from = 'work_dirs/td-hm_res50_8xb64-210e_coco-256x192/latest.pth'
+# model settings
+model = dict(
+ ## omitted ##
+ )
+```
+
+## Freeze partial parameters during training
+
+In some scenarios, it might be desirable to freeze certain parameters of a model during training to fine-tune specific parts or to prevent overfitting. In MMPose, you can set different hyperparameters for any module in the model by setting custom_keys in `paramwise_cfg`. This allows you to control the learning rate and decay coefficient for specific parts of the model.
+
+For example, if you want to freeze the parameters in `backbone.layer0` and `backbone.layer1`, you can modify the optimizer wrapper in the config file as:
+
+```python
+optim_wrapper = dict(
+ optimizer=dict(...),
+ paramwise_cfg=dict(
+ custom_keys={
+ 'backbone.layer0': dict(lr_mult=0, decay_mult=0),
+ 'backbone.layer0': dict(lr_mult=0, decay_mult=0),
+ }))
+```
+
+This configuration will freeze the parameters in `backbone.layer0` and `backbone.layer1` by setting their learning rate and decay coefficient to 0. By using this approach, you can effectively control the training process and fine-tune specific parts of your model as needed.
+
+## Automatic Mixed Precision (AMP) training
+
+Mixed precision training can reduce training time and storage requirements without changing the model or reducing the model training accuracy, thus supporting larger batch sizes, larger models, and larger input sizes.
+
+To enable Automatic Mixing Precision (AMP) training, add `--amp` to the end of the training command, which is as follows:
+
+```shell
+python tools/train.py ${CONFIG_FILE} --amp
+```
+
+Specific examples are as follows:
+
+```shell
+python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py --amp
+```
+
+## Set the random seed
+
+If you want to specify the random seed during training, you can use the following command:
+
+```shell
+python ./tools/train.py \
+ ${CONFIG} \ # config file
+ --cfg-options randomness.seed=2023 \ # set the random seed = 2023
+ [randomness.diff_rank_seed=True] \ # Set different seeds according to rank.
+ [randomness.deterministic=True] # Set the cuDNN backend deterministic option to True
+# `[]` stands for optional parameters, when actually entering the command line, you do not need to enter `[]`
+```
+
+`randomness` has three parameters that can be set, with the following meanings.
+
+- `randomness.seed=2023`, set the random seed to `2023`.
+
+- `randomness.diff_rank_seed=True`, set different seeds according to global `rank`. Defaults to `False`.
+
+- `randomness.deterministic=True`, set the deterministic option for `cuDNN` backend, i.e., set `torch.backends.cudnn.deterministic` to `True` and `torch.backends.cudnn.benchmark` to `False`. Defaults to `False`. See [Pytorch Randomness](https://pytorch.org/docs/stable/notes/randomness.html) for more details.
+
+## Visualize training process
+
+Monitoring the training process is essential for understanding the performance of your model and making necessary adjustments. In this section, we will introduce two methods to visualize the training process of your MMPose model: TensorBoard and the MMEngine Visualizer.
+
+### TensorBoard
+
+TensorBoard is a powerful tool that allows you to visualize the changes in losses during training. To enable TensorBoard visualization, you may need to:
+
+1. Install TensorBoard environment
+
+ ```shell
+ pip install tensorboard
+ ```
+
+2. Enable TensorBoard in the config file
+
+ ```python
+ visualizer = dict(vis_backends=[
+ dict(type='LocalVisBackend'),
+ dict(type='TensorboardVisBackend'),
+ ])
+ ```
+
+The event file generated by TensorBoard will be save under the experiment log folder `${WORK_DIR}`, which defaults to `work_dir/${CONFIG}` or can be specified using the `--work-dir` option. To visualize the training process, use the following command:
+
+```shell
+tensorboard --logdir ${WORK_DIR}/${TIMESTAMP}/vis_data
+```
+
+### MMEngine visualizer
+
+MMPose also supports visualizing model inference results during validation. To activate this function, please use the `--show` option or set `--show-dir` when launching training. This feature provides an effective way to analyze the model's performance on specific examples and make any necessary adjustments.
+
+## Test your model
+
+### Test with your PC
+
+You can use `tools/test.py` to test a model on a single machine with a CPU and optionally a GPU.
+
+Here is the full usage of the script:
+
+```shell
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS]
+```
+
+```{note}
+By default, MMPose prefers GPU to CPU. If you want to test a model on CPU, please empty `CUDA_VISIBLE_DEVICES` or set it to -1 to make GPU invisible to the program.
+
+```
+
+```shell
+CUDA_VISIBLE_DEVICES=-1 python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS]
+```
+
+| ARGS | Description |
+| ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `CONFIG_FILE` | The path to the config file. |
+| `CHECKPOINT_FILE` | The path to the checkpoint file (It can be a http link, and you can find checkpoints [here](https://MMPose.readthedocs.io/en/latest/model_zoo.html)). |
+| `--work-dir WORK_DIR` | The directory to save the file containing evaluation metrics. |
+| `--out OUT` | The path to save the file containing evaluation metrics. |
+| `--dump DUMP` | The path to dump all outputs of the model for offline evaluation. |
+| `--cfg-options CFG_OPTIONS` | Override some settings in the used config, the key-value pair in xxx=yyy format will be merged into the config file. If the value to be overwritten is a list, it should be of the form of either `key="[a,b]"` or `key=a,b`. The argument also allows nested list/tuple values, e.g. `key="[(a,b),(c,d)]"`. Note that quotation marks are necessary and that no white space is allowed. |
+| `--show-dir SHOW_DIR` | The directory to save the result visualization images. |
+| `--show` | Visualize the prediction result in a window. |
+| `--interval INTERVAL` | The interval of samples to visualize. |
+| `--wait-time WAIT_TIME` | The display time of every window (in seconds). Defaults to 1. |
+| `--launcher {none,pytorch,slurm,mpi}` | Options for job launcher. |
+
+### Test with multiple GPUs
+
+We provide a shell script to start a multi-GPUs task with `torch.distributed.launch`.
+
+```shell
+bash ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+| ARGS | Description |
+| ----------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `CONFIG_FILE` | The path to the config file. |
+| `CHECKPOINT_FILE` | The path to the checkpoint file (It can be a http link, and you can find checkpoints [here](https://mmpose.readthedocs.io/en/latest/model_zoo.html)). |
+| `GPU_NUM` | The number of GPUs to be used. |
+| `[PYARGS]` | The other optional arguments of `tools/test.py`, see [here](#test-with-your-pc). |
+
+You can also specify extra arguments of the launcher by environment variables. For example, change the
+communication port of the launcher to 29666 by the below command:
+
+```shell
+PORT=29666 bash ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+If you want to startup multiple test jobs and use different GPUs, you can launch them by specifying
+different port and visible devices.
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 bash ./tools/dist_test.sh ${CONFIG_FILE1} ${CHECKPOINT_FILE} 4 [PY_ARGS]
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 bash ./tools/dist_test.sh ${CONFIG_FILE2} ${CHECKPOINT_FILE} 4 [PY_ARGS]
+```
+
+### Test with multiple machines
+
+#### Multiple machines in the same network
+
+If you launch a test job with multiple machines connected with ethernet, you can run the following commands:
+
+On the first machine:
+
+```shell
+NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_test.sh $CONFIG $CHECKPOINT_FILE $GPUS
+```
+
+On the second machine:
+
+```shell
+NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_test.sh $CONFIG $CHECKPOINT_FILE $GPUS
+```
+
+Compared with multi-GPUs in a single machine, you need to specify some extra environment variables:
+
+| ENV_VARS | Description |
+| ------------- | ---------------------------------------------------------------------------- |
+| `NNODES` | The total number of machines. |
+| `NODE_RANK` | The index of the local machine. |
+| `PORT` | The communication port, it should be the same in all machines. |
+| `MASTER_ADDR` | The IP address of the master machine, it should be the same in all machines. |
+
+Usually, it is slow if you do not have high-speed networking like InfiniBand.
+
+#### Multiple machines managed with slurm
+
+If you run MMPose on a cluster managed with [slurm](https://slurm.schedmd.com/), you can use the script `slurm_test.sh`.
+
+```shell
+[ENV_VARS] ./tools/slurm_test.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${CHECKPOINT_FILE} [PY_ARGS]
+```
+
+Here are the argument descriptions of the script.
+
+| ARGS | Description |
+| ----------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `PARTITION` | The partition to use in your cluster. |
+| `JOB_NAME` | The name of your job, you can name it as you like. |
+| `CONFIG_FILE` | The path to the config file. |
+| `CHECKPOINT_FILE` | The path to the checkpoint file (It can be a http link, and you can find checkpoints [here](https://MMPose.readthedocs.io/en/latest/model_zoo.html)). |
+| `[PYARGS]` | The other optional arguments of `tools/test.py`, see [here](#test-with-your-pc). |
+
+Here are the environment variables that can be used to configure the slurm job.
+
+| ENV_VARS | Description |
+| --------------- | ---------------------------------------------------------------------------------------------------------- |
+| `GPUS` | The total number of GPUs to be used. Defaults to 8. |
+| `GPUS_PER_NODE` | The number of GPUs to be allocated per node. Defaults to 8. |
+| `CPUS_PER_TASK` | The number of CPUs to be allocated per task (Usually one GPU corresponds to one task). Defaults to 5. |
+| `SRUN_ARGS` | The other arguments of `srun`. Available options can be found [here](https://slurm.schedmd.com/srun.html). |
diff --git a/docs/en/visualization.md b/docs/en/visualization.md
index 2dd39c6f65..a5448ae975 100644
--- a/docs/en/visualization.md
+++ b/docs/en/visualization.md
@@ -1,103 +1,103 @@
-# Visualization
-
-- [Single Image](#single-image)
-- [Browse Dataset](#browse-dataset)
-- [Visualizer Hook](#visualizer-hook)
-
-## Single Image
-
-`demo/image_demo.py` helps the user to visualize the prediction result of a single image, including the skeleton and heatmaps.
-
-```shell
-python demo/image_demo.py ${IMG} ${CONFIG} ${CHECKPOINT} [-h] [--out-file OUT_FILE] [--device DEVICE] [--draw-heatmap]
-```
-
-| ARGS | Description |
-| --------------------- | -------------------------------- |
-| `IMG` | The path to the test image. |
-| `CONFIG` | The path to the config file. |
-| `CHECKPOINT` | The path to the checkpoint file. |
-| `--out-file OUT_FILE` | Path to output file. |
-| `--device DEVICE` | Device used for inference. |
-| `--draw-heatmap` | Visualize the predicted heatmap. |
-
-Here is an example of Heatmap visualization:
-
-
-
-## Browse Dataset
-
-`tools/analysis_tools/browse_dataset.py` helps the user to browse a pose dataset visually, or save the image to a designated directory.
-
-```shell
-python tools/misc/browse_dataset.py ${CONFIG} [-h] [--output-dir ${OUTPUT_DIR}] [--not-show] [--phase ${PHASE}] [--mode ${MODE}] [--show-interval ${SHOW_INTERVAL}]
-```
-
-| ARGS | Description |
-| -------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------- |
-| `CONFIG` | The path to the config file. |
-| `--output-dir OUTPUT_DIR` | The target folder to save visualization results. If not specified, the visualization results will not be saved. |
-| `--not-show` | Do not show the visualization results in an external window. |
-| `--phase {train, val, test}` | Options for dataset. |
-| `--mode {original, transformed}` | Specify the type of visualized images. `original` means to show images without pre-processing; `transformed` means to show images are pre-processed. |
-| `--show-interval SHOW_INTERVAL` | Time interval between visualizing two images. |
-
-For instance, users who want to visualize images and annotations in COCO dataset use:
-
-```shell
-python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-e210_coco-256x192.py --mode original
-```
-
-The bounding boxes and keypoints will be plotted on the original image. Following is an example:
-
-
-The original images need to be processed before being fed into models. To visualize pre-processed images and annotations, users need to modify the argument `mode` to `transformed`. For example:
-
-```shell
-python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-e210_coco-256x192.py --mode transformed
-```
-
-Here is a processed sample
-
-
-
-The heatmap target will be visualized together if it is generated in the pipeline.
-
-## Visualizer Hook
-
-During validation and testing, users can specify certain arguments to visualize the output of trained models.
-
-To visualize in external window during testing:
-
-```shell
-python tools/test.py ${CONFIG} ${CHECKPOINT} --show
-```
-
-During validation:
-
-```shell
-python tools/train.py ${CONFIG} --work-dir ${WORK_DIR} --show --interval ${INTERVAL}
-```
-
-It is suggested to use large `INTERVAL` (e.g., 50) if users want to visualize during validation, since the wait time for each visualized instance will make the validation process very slow.
-
-To save visualization results in `SHOW_DIR` during testing:
-
-```shell
-python tools/test.py ${CONFIG} ${CHECKPOINT} --show-dir=${SHOW_DIR}
-```
-
-During validation:
-
-```shell
-python tools/train.py ${CONFIG} --work-dir ${WORK_DIR} --show-dir=${SHOW_DIR}
-```
-
-More details about visualization arguments can be found in [train_and_test](./train_and_test.md).
-
-If you use a heatmap-based method and want to visualize predicted heatmaps, you can manually specify `output_heatmaps=True` for `model.test_cfg` in config file. Another way is to add `--cfg-options='model.test_cfg.output_heatmaps=True'` at the end of your command.
-
-Visualization example (top: decoded keypoints; bottom: predicted heatmap):
-
-
-For top-down models, each sample only contains one instance. So there will be multiple visualization results for each image.
+# Visualization
+
+- [Single Image](#single-image)
+- [Browse Dataset](#browse-dataset)
+- [Visualizer Hook](#visualizer-hook)
+
+## Single Image
+
+`demo/image_demo.py` helps the user to visualize the prediction result of a single image, including the skeleton and heatmaps.
+
+```shell
+python demo/image_demo.py ${IMG} ${CONFIG} ${CHECKPOINT} [-h] [--out-file OUT_FILE] [--device DEVICE] [--draw-heatmap]
+```
+
+| ARGS | Description |
+| --------------------- | -------------------------------- |
+| `IMG` | The path to the test image. |
+| `CONFIG` | The path to the config file. |
+| `CHECKPOINT` | The path to the checkpoint file. |
+| `--out-file OUT_FILE` | Path to output file. |
+| `--device DEVICE` | Device used for inference. |
+| `--draw-heatmap` | Visualize the predicted heatmap. |
+
+Here is an example of Heatmap visualization:
+
+
+
+## Browse Dataset
+
+`tools/analysis_tools/browse_dataset.py` helps the user to browse a pose dataset visually, or save the image to a designated directory.
+
+```shell
+python tools/misc/browse_dataset.py ${CONFIG} [-h] [--output-dir ${OUTPUT_DIR}] [--not-show] [--phase ${PHASE}] [--mode ${MODE}] [--show-interval ${SHOW_INTERVAL}]
+```
+
+| ARGS | Description |
+| -------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `CONFIG` | The path to the config file. |
+| `--output-dir OUTPUT_DIR` | The target folder to save visualization results. If not specified, the visualization results will not be saved. |
+| `--not-show` | Do not show the visualization results in an external window. |
+| `--phase {train, val, test}` | Options for dataset. |
+| `--mode {original, transformed}` | Specify the type of visualized images. `original` means to show images without pre-processing; `transformed` means to show images are pre-processed. |
+| `--show-interval SHOW_INTERVAL` | Time interval between visualizing two images. |
+
+For instance, users who want to visualize images and annotations in COCO dataset use:
+
+```shell
+python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-e210_coco-256x192.py --mode original
+```
+
+The bounding boxes and keypoints will be plotted on the original image. Following is an example:
+
+
+The original images need to be processed before being fed into models. To visualize pre-processed images and annotations, users need to modify the argument `mode` to `transformed`. For example:
+
+```shell
+python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-e210_coco-256x192.py --mode transformed
+```
+
+Here is a processed sample
+
+
+
+The heatmap target will be visualized together if it is generated in the pipeline.
+
+## Visualizer Hook
+
+During validation and testing, users can specify certain arguments to visualize the output of trained models.
+
+To visualize in external window during testing:
+
+```shell
+python tools/test.py ${CONFIG} ${CHECKPOINT} --show
+```
+
+During validation:
+
+```shell
+python tools/train.py ${CONFIG} --work-dir ${WORK_DIR} --show --interval ${INTERVAL}
+```
+
+It is suggested to use large `INTERVAL` (e.g., 50) if users want to visualize during validation, since the wait time for each visualized instance will make the validation process very slow.
+
+To save visualization results in `SHOW_DIR` during testing:
+
+```shell
+python tools/test.py ${CONFIG} ${CHECKPOINT} --show-dir=${SHOW_DIR}
+```
+
+During validation:
+
+```shell
+python tools/train.py ${CONFIG} --work-dir ${WORK_DIR} --show-dir=${SHOW_DIR}
+```
+
+More details about visualization arguments can be found in [train_and_test](./train_and_test.md).
+
+If you use a heatmap-based method and want to visualize predicted heatmaps, you can manually specify `output_heatmaps=True` for `model.test_cfg` in config file. Another way is to add `--cfg-options='model.test_cfg.output_heatmaps=True'` at the end of your command.
+
+Visualization example (top: decoded keypoints; bottom: predicted heatmap):
+
+
+For top-down models, each sample only contains one instance. So there will be multiple visualization results for each image.
diff --git a/docs/src/papers/algorithms/associative_embedding.md b/docs/src/papers/algorithms/associative_embedding.md
index 3a27267ae9..b545b7aa65 100644
--- a/docs/src/papers/algorithms/associative_embedding.md
+++ b/docs/src/papers/algorithms/associative_embedding.md
@@ -1,30 +1,30 @@
-# Associative embedding: End-to-end learning for joint detection and grouping (AE)
-
-
-
-
-Associative Embedding (NIPS'2017)
-
-```bibtex
-@inproceedings{newell2017associative,
- title={Associative embedding: End-to-end learning for joint detection and grouping},
- author={Newell, Alejandro and Huang, Zhiao and Deng, Jia},
- booktitle={Advances in neural information processing systems},
- pages={2277--2287},
- year={2017}
-}
-```
-
-
-
-## Abstract
-
-
-
-We introduce associative embedding, a novel method for supervising convolutional neural networks for the task of detection and grouping. A number of computer vision problems can be framed in this manner including multi-person pose estimation, instance segmentation, and multi-object tracking. Usually the grouping of detections is achieved with multi-stage pipelines, instead we propose an approach that teaches a network to simultaneously output detections and group assignments. This technique can be easily integrated into any state-of-the-art network architecture that produces pixel-wise predictions. We show how to apply this method to both multi-person pose estimation and instance segmentation and report state-of-the-art performance for multi-person pose on the MPII and MS-COCO datasets.
-
-
-
-
-
-
+# Associative embedding: End-to-end learning for joint detection and grouping (AE)
+
+
+
+
+Associative Embedding (NIPS'2017)
+
+```bibtex
+@inproceedings{newell2017associative,
+ title={Associative embedding: End-to-end learning for joint detection and grouping},
+ author={Newell, Alejandro and Huang, Zhiao and Deng, Jia},
+ booktitle={Advances in neural information processing systems},
+ pages={2277--2287},
+ year={2017}
+}
+```
+
+
+
+## Abstract
+
+
+
+We introduce associative embedding, a novel method for supervising convolutional neural networks for the task of detection and grouping. A number of computer vision problems can be framed in this manner including multi-person pose estimation, instance segmentation, and multi-object tracking. Usually the grouping of detections is achieved with multi-stage pipelines, instead we propose an approach that teaches a network to simultaneously output detections and group assignments. This technique can be easily integrated into any state-of-the-art network architecture that produces pixel-wise predictions. We show how to apply this method to both multi-person pose estimation and instance segmentation and report state-of-the-art performance for multi-person pose on the MPII and MS-COCO datasets.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/awingloss.md b/docs/src/papers/algorithms/awingloss.md
index 4d4b93a87c..4633e32581 100644
--- a/docs/src/papers/algorithms/awingloss.md
+++ b/docs/src/papers/algorithms/awingloss.md
@@ -1,31 +1,31 @@
-# Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression
-
-
-
-
-AdaptiveWingloss (ICCV'2019)
-
-```bibtex
-@inproceedings{wang2019adaptive,
- title={Adaptive wing loss for robust face alignment via heatmap regression},
- author={Wang, Xinyao and Bo, Liefeng and Fuxin, Li},
- booktitle={Proceedings of the IEEE/CVF international conference on computer vision},
- pages={6971--6981},
- year={2019}
-}
-```
-
-
-
-## Abstract
-
-
-
-Heatmap regression with a deep network has become one of the mainstream approaches to localize facial landmarks. However, the loss function for heatmap regression is rarely studied. In this paper, we analyze the ideal loss function properties for heatmap regression in face alignment problems. Then we propose a novel loss function, named Adaptive Wing loss, that is able to adapt its shape to different types of ground truth heatmap pixels. This adaptability penalizes loss more on foreground pixels while less on background pixels. To address the imbalance between foreground and background pixels, we also propose Weighted Loss Map, which assigns high weights on foreground and difficult background pixels to help training process focus more on pixels that are crucial to landmark localization. To further improve face alignment accuracy, we introduce boundary prediction and CoordConv with boundary coordinates. Extensive experiments on different benchmarks, including COFW, 300W and WFLW, show our approach outperforms the state-of-the-art by a significant margin on
-various evaluation metrics. Besides, the Adaptive Wing loss also helps other heatmap regression tasks.
-
-
-
-
-
-
+# Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression
+
+
+
+
+AdaptiveWingloss (ICCV'2019)
+
+```bibtex
+@inproceedings{wang2019adaptive,
+ title={Adaptive wing loss for robust face alignment via heatmap regression},
+ author={Wang, Xinyao and Bo, Liefeng and Fuxin, Li},
+ booktitle={Proceedings of the IEEE/CVF international conference on computer vision},
+ pages={6971--6981},
+ year={2019}
+}
+```
+
+
+
+## Abstract
+
+
+
+Heatmap regression with a deep network has become one of the mainstream approaches to localize facial landmarks. However, the loss function for heatmap regression is rarely studied. In this paper, we analyze the ideal loss function properties for heatmap regression in face alignment problems. Then we propose a novel loss function, named Adaptive Wing loss, that is able to adapt its shape to different types of ground truth heatmap pixels. This adaptability penalizes loss more on foreground pixels while less on background pixels. To address the imbalance between foreground and background pixels, we also propose Weighted Loss Map, which assigns high weights on foreground and difficult background pixels to help training process focus more on pixels that are crucial to landmark localization. To further improve face alignment accuracy, we introduce boundary prediction and CoordConv with boundary coordinates. Extensive experiments on different benchmarks, including COFW, 300W and WFLW, show our approach outperforms the state-of-the-art by a significant margin on
+various evaluation metrics. Besides, the Adaptive Wing loss also helps other heatmap regression tasks.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/cid.md b/docs/src/papers/algorithms/cid.md
index 4366f95504..10b76ce2f5 100644
--- a/docs/src/papers/algorithms/cid.md
+++ b/docs/src/papers/algorithms/cid.md
@@ -1,31 +1,31 @@
-# Contextual Instance Decoupling for Robust Multi-Person Pose Estimation
-
-
-
-
-CID (CVPR'2022)
-
-```bibtex
-@InProceedings{Wang_2022_CVPR,
- author = {Wang, Dongkai and Zhang, Shiliang},
- title = {Contextual Instance Decoupling for Robust Multi-Person Pose Estimation},
- booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
- month = {June},
- year = {2022},
- pages = {11060-11068}
-}
-```
-
-
-
-## Abstract
-
-
-
-Crowded scenes make it challenging to differentiate persons and locate their pose keypoints. This paper proposes the Contextual Instance Decoupling (CID), which presents a new pipeline for multi-person pose estimation. Instead of relying on person bounding boxes to spatially differentiate persons, CID decouples persons in an image into multiple instance-aware feature maps. Each of those feature maps is hence adopted to infer keypoints for a specific person. Compared with bounding box detection, CID is differentiable and robust to detection errors. Decoupling persons into different feature maps allows to isolate distractions from other persons, and explore context cues at scales larger than the bounding box size. Experiments show that CID outperforms previous multi-person pose estimation pipelines on crowded scenes pose estimation benchmarks in both accuracy and efficiency. For instance, it achieves 71.3% AP on CrowdPose, outperforming the recent single-stage DEKR by 5.6%, the bottom-up CenterAttention by 3.7%, and the top-down JCSPPE by 5.3%. This advantage sustains on the commonly used COCO benchmark.
-
-
-
-
-
-
+# Contextual Instance Decoupling for Robust Multi-Person Pose Estimation
+
+
+
+
+CID (CVPR'2022)
+
+```bibtex
+@InProceedings{Wang_2022_CVPR,
+ author = {Wang, Dongkai and Zhang, Shiliang},
+ title = {Contextual Instance Decoupling for Robust Multi-Person Pose Estimation},
+ booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ month = {June},
+ year = {2022},
+ pages = {11060-11068}
+}
+```
+
+
+
+## Abstract
+
+
+
+Crowded scenes make it challenging to differentiate persons and locate their pose keypoints. This paper proposes the Contextual Instance Decoupling (CID), which presents a new pipeline for multi-person pose estimation. Instead of relying on person bounding boxes to spatially differentiate persons, CID decouples persons in an image into multiple instance-aware feature maps. Each of those feature maps is hence adopted to infer keypoints for a specific person. Compared with bounding box detection, CID is differentiable and robust to detection errors. Decoupling persons into different feature maps allows to isolate distractions from other persons, and explore context cues at scales larger than the bounding box size. Experiments show that CID outperforms previous multi-person pose estimation pipelines on crowded scenes pose estimation benchmarks in both accuracy and efficiency. For instance, it achieves 71.3% AP on CrowdPose, outperforming the recent single-stage DEKR by 5.6%, the bottom-up CenterAttention by 3.7%, and the top-down JCSPPE by 5.3%. This advantage sustains on the commonly used COCO benchmark.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/cpm.md b/docs/src/papers/algorithms/cpm.md
index fb5dbfacec..ea2ac7f73a 100644
--- a/docs/src/papers/algorithms/cpm.md
+++ b/docs/src/papers/algorithms/cpm.md
@@ -1,30 +1,30 @@
-# Convolutional pose machines
-
-
-
-
-CPM (CVPR'2016)
-
-```bibtex
-@inproceedings{wei2016convolutional,
- title={Convolutional pose machines},
- author={Wei, Shih-En and Ramakrishna, Varun and Kanade, Takeo and Sheikh, Yaser},
- booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition},
- pages={4724--4732},
- year={2016}
-}
-```
-
-
-
-## Abstract
-
-
-
-We introduce associative embedding, a novel method for supervising convolutional neural networks for the task of detection and grouping. A number of computer vision problems can be framed in this manner including multi-person pose estimation, instance segmentation, and multi-object tracking. Usually the grouping of detections is achieved with multi-stage pipelines, instead we propose an approach that teaches a network to simultaneously output detections and group assignments. This technique can be easily integrated into any state-of-the-art network architecture that produces pixel-wise predictions. We show how to apply this method to both multi-person pose estimation and instance segmentation and report state-of-the-art performance for multi-person pose on the MPII and MS-COCO datasets.
-
-
-
-
-
-
+# Convolutional pose machines
+
+
+
+
+CPM (CVPR'2016)
+
+```bibtex
+@inproceedings{wei2016convolutional,
+ title={Convolutional pose machines},
+ author={Wei, Shih-En and Ramakrishna, Varun and Kanade, Takeo and Sheikh, Yaser},
+ booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition},
+ pages={4724--4732},
+ year={2016}
+}
+```
+
+
+
+## Abstract
+
+
+
+We introduce associative embedding, a novel method for supervising convolutional neural networks for the task of detection and grouping. A number of computer vision problems can be framed in this manner including multi-person pose estimation, instance segmentation, and multi-object tracking. Usually the grouping of detections is achieved with multi-stage pipelines, instead we propose an approach that teaches a network to simultaneously output detections and group assignments. This technique can be easily integrated into any state-of-the-art network architecture that produces pixel-wise predictions. We show how to apply this method to both multi-person pose estimation and instance segmentation and report state-of-the-art performance for multi-person pose on the MPII and MS-COCO datasets.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/dark.md b/docs/src/papers/algorithms/dark.md
index 083b7596ab..94da433e29 100644
--- a/docs/src/papers/algorithms/dark.md
+++ b/docs/src/papers/algorithms/dark.md
@@ -1,30 +1,30 @@
-# Distribution-aware coordinate representation for human pose estimation
-
-
-
-
-DarkPose (CVPR'2020)
-
-```bibtex
-@inproceedings{zhang2020distribution,
- title={Distribution-aware coordinate representation for human pose estimation},
- author={Zhang, Feng and Zhu, Xiatian and Dai, Hanbin and Ye, Mao and Zhu, Ce},
- booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
- pages={7093--7102},
- year={2020}
-}
-```
-
-
-
-## Abstract
-
-
-
-While being the de facto standard coordinate representation for human pose estimation, heatmap has not been investigated in-depth. This work fills this gap. For the first time, we find that the process of decoding the predicted heatmaps into the final joint coordinates in the original image space is surprisingly significant for the performance. We further probe the design limitations of the standard coordinate decoding method, and propose a more principled distributionaware decoding method. Also, we improve the standard coordinate encoding process (i.e. transforming ground-truth coordinates to heatmaps) by generating unbiased/accurate heatmaps. Taking the two together, we formulate a novel Distribution-Aware coordinate Representation of Keypoints (DARK) method. Serving as a model-agnostic plug-in, DARK brings about significant performance boost to existing human pose estimation models. Extensive experiments show that DARK yields the best results on two common benchmarks, MPII and COCO. Besides, DARK achieves the 2nd place entry in the ICCV 2019 COCO Keypoints Challenge. The code is available online.
-
-
-
-
-
-
+# Distribution-aware coordinate representation for human pose estimation
+
+
+
+
+DarkPose (CVPR'2020)
+
+```bibtex
+@inproceedings{zhang2020distribution,
+ title={Distribution-aware coordinate representation for human pose estimation},
+ author={Zhang, Feng and Zhu, Xiatian and Dai, Hanbin and Ye, Mao and Zhu, Ce},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={7093--7102},
+ year={2020}
+}
+```
+
+
+
+## Abstract
+
+
+
+While being the de facto standard coordinate representation for human pose estimation, heatmap has not been investigated in-depth. This work fills this gap. For the first time, we find that the process of decoding the predicted heatmaps into the final joint coordinates in the original image space is surprisingly significant for the performance. We further probe the design limitations of the standard coordinate decoding method, and propose a more principled distributionaware decoding method. Also, we improve the standard coordinate encoding process (i.e. transforming ground-truth coordinates to heatmaps) by generating unbiased/accurate heatmaps. Taking the two together, we formulate a novel Distribution-Aware coordinate Representation of Keypoints (DARK) method. Serving as a model-agnostic plug-in, DARK brings about significant performance boost to existing human pose estimation models. Extensive experiments show that DARK yields the best results on two common benchmarks, MPII and COCO. Besides, DARK achieves the 2nd place entry in the ICCV 2019 COCO Keypoints Challenge. The code is available online.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/debias_ipr.md b/docs/src/papers/algorithms/debias_ipr.md
index 8d77c84c09..b02e58ecdf 100644
--- a/docs/src/papers/algorithms/debias_ipr.md
+++ b/docs/src/papers/algorithms/debias_ipr.md
@@ -1,30 +1,30 @@
-# Removing the Bias of Integral Pose Regression
-
-
-
-
-Debias IPR (ICCV'2021)
-
-```bibtex
-@inproceedings{gu2021removing,
- title={Removing the Bias of Integral Pose Regression},
- author={Gu, Kerui and Yang, Linlin and Yao, Angela},
- booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
- pages={11067--11076},
- year={2021}
- }
-```
-
-
-
-## Abstract
-
-
-
-Heatmap-based detection methods are dominant for 2D human pose estimation even though regression is more intuitive. The introduction of the integral regression method, which, architecture-wise uses an implicit heatmap, brings the two approaches even closer together. This begs the question -- does detection really outperform regression? In this paper, we investigate the difference in supervision between the heatmap-based detection and integral regression, as this is the key remaining difference between the two approaches. In the process, we discover an underlying bias behind integral pose regression that arises from taking the expectation after the softmax function. To counter the bias, we present a compensation method which we find to improve integral regression accuracy on all 2D pose estimation benchmarks. We further propose a simple combined detection and bias-compensated regression method that considerably outperforms state-of-the-art baselines with few added components.
-
-
-
-
-
-
+# Removing the Bias of Integral Pose Regression
+
+
+
+
+Debias IPR (ICCV'2021)
+
+```bibtex
+@inproceedings{gu2021removing,
+ title={Removing the Bias of Integral Pose Regression},
+ author={Gu, Kerui and Yang, Linlin and Yao, Angela},
+ booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
+ pages={11067--11076},
+ year={2021}
+ }
+```
+
+
+
+## Abstract
+
+
+
+Heatmap-based detection methods are dominant for 2D human pose estimation even though regression is more intuitive. The introduction of the integral regression method, which, architecture-wise uses an implicit heatmap, brings the two approaches even closer together. This begs the question -- does detection really outperform regression? In this paper, we investigate the difference in supervision between the heatmap-based detection and integral regression, as this is the key remaining difference between the two approaches. In the process, we discover an underlying bias behind integral pose regression that arises from taking the expectation after the softmax function. To counter the bias, we present a compensation method which we find to improve integral regression accuracy on all 2D pose estimation benchmarks. We further propose a simple combined detection and bias-compensated regression method that considerably outperforms state-of-the-art baselines with few added components.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/deeppose.md b/docs/src/papers/algorithms/deeppose.md
index 24778ba9db..a6e96f5106 100644
--- a/docs/src/papers/algorithms/deeppose.md
+++ b/docs/src/papers/algorithms/deeppose.md
@@ -1,30 +1,30 @@
-# DeepPose: Human pose estimation via deep neural networks
-
-
-
-
-DeepPose (CVPR'2014)
-
-```bibtex
-@inproceedings{toshev2014deeppose,
- title={Deeppose: Human pose estimation via deep neural networks},
- author={Toshev, Alexander and Szegedy, Christian},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- pages={1653--1660},
- year={2014}
-}
-```
-
-
-
-## Abstract
-
-
-
-We propose a method for human pose estimation based on Deep Neural Networks (DNNs). The pose estimation is formulated as a DNN-based regression problem towards body joints. We present a cascade of such DNN regressors which results in high precision pose estimates. The approach has the advantage of reasoning about pose in a holistic fashion and has a simple but yet powerful formulation which capitalizes on recent advances in Deep Learning. We present a detailed empirical analysis with state-of-art or better performance on four academic benchmarks of diverse real-world images.
-
-
-
-
-
-
+# DeepPose: Human pose estimation via deep neural networks
+
+
+
+
+DeepPose (CVPR'2014)
+
+```bibtex
+@inproceedings{toshev2014deeppose,
+ title={Deeppose: Human pose estimation via deep neural networks},
+ author={Toshev, Alexander and Szegedy, Christian},
+ booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
+ pages={1653--1660},
+ year={2014}
+}
+```
+
+
+
+## Abstract
+
+
+
+We propose a method for human pose estimation based on Deep Neural Networks (DNNs). The pose estimation is formulated as a DNN-based regression problem towards body joints. We present a cascade of such DNN regressors which results in high precision pose estimates. The approach has the advantage of reasoning about pose in a holistic fashion and has a simple but yet powerful formulation which capitalizes on recent advances in Deep Learning. We present a detailed empirical analysis with state-of-art or better performance on four academic benchmarks of diverse real-world images.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/dekr.md b/docs/src/papers/algorithms/dekr.md
index ee19a3315b..605035d6ec 100644
--- a/docs/src/papers/algorithms/dekr.md
+++ b/docs/src/papers/algorithms/dekr.md
@@ -1,31 +1,31 @@
-# Bottom-up Human Pose Estimation via Disentangled Keypoint Regression
-
-
-
-
-DEKR (CVPR'2021)
-
-```bibtex
-@inproceedings{geng2021bottom,
- title={Bottom-up human pose estimation via disentangled keypoint regression},
- author={Geng, Zigang and Sun, Ke and Xiao, Bin and Zhang, Zhaoxiang and Wang, Jingdong},
- booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
- pages={14676--14686},
- year={2021}
-}
-```
-
-
-
-## Abstract
-
-
-
-In this paper, we are interested in the bottom-up paradigm of estimating human poses from an image. We study the dense keypoint regression framework that is previously inferior to the keypoint detection and grouping framework. Our motivation is that regressing keypoint positions accurately needs to learn representations that focus on the keypoint regions.
-We present a simple yet effective approach, named disentangled keypoint regression (DEKR). We adopt adaptive convolutions through pixel-wise spatial transformer to activate the pixels in the keypoint regions and accordingly learn representations from them. We use a multi-branch structure for separate regression: each branch learns a representation with dedicated adaptive convolutions and regresses one keypoint. The resulting disentangled representations are able to attend to the keypoint regions, respectively, and thus the keypoint regression is spatially more accurate. We empirically show that the proposed direct regression method outperforms keypoint detection and grouping methods and achieves superior bottom-up pose estimation results on two benchmark datasets, COCO and CrowdPose. The code and models are available at [this https URL](https://github.com/HRNet/DEKR).
-
-
-
-
-
-
+# Bottom-up Human Pose Estimation via Disentangled Keypoint Regression
+
+
+
+
+DEKR (CVPR'2021)
+
+```bibtex
+@inproceedings{geng2021bottom,
+ title={Bottom-up human pose estimation via disentangled keypoint regression},
+ author={Geng, Zigang and Sun, Ke and Xiao, Bin and Zhang, Zhaoxiang and Wang, Jingdong},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={14676--14686},
+ year={2021}
+}
+```
+
+
+
+## Abstract
+
+
+
+In this paper, we are interested in the bottom-up paradigm of estimating human poses from an image. We study the dense keypoint regression framework that is previously inferior to the keypoint detection and grouping framework. Our motivation is that regressing keypoint positions accurately needs to learn representations that focus on the keypoint regions.
+We present a simple yet effective approach, named disentangled keypoint regression (DEKR). We adopt adaptive convolutions through pixel-wise spatial transformer to activate the pixels in the keypoint regions and accordingly learn representations from them. We use a multi-branch structure for separate regression: each branch learns a representation with dedicated adaptive convolutions and regresses one keypoint. The resulting disentangled representations are able to attend to the keypoint regions, respectively, and thus the keypoint regression is spatially more accurate. We empirically show that the proposed direct regression method outperforms keypoint detection and grouping methods and achieves superior bottom-up pose estimation results on two benchmark datasets, COCO and CrowdPose. The code and models are available at [this https URL](https://github.com/HRNet/DEKR).
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/dsnt.md b/docs/src/papers/algorithms/dsnt.md
index 6a526429d6..dd187391af 100644
--- a/docs/src/papers/algorithms/dsnt.md
+++ b/docs/src/papers/algorithms/dsnt.md
@@ -1,29 +1,29 @@
-# Numerical Coordinate Regression with Convolutional Neural Networks
-
-
-
-
-DSNT (2018)
-
-```bibtex
-@article{nibali2018numerical,
- title={Numerical Coordinate Regression with Convolutional Neural Networks},
- author={Nibali, Aiden and He, Zhen and Morgan, Stuart and Prendergast, Luke},
- journal={arXiv preprint arXiv:1801.07372},
- year={2018}
-}
-```
-
-
-
-## Abstract
-
-
-
-We study deep learning approaches to inferring numerical coordinates for points of interest in an input image. Existing convolutional neural network-based solutions to this problem either take a heatmap matching approach or regress to coordinates with a fully connected output layer. Neither of these approaches is ideal, since the former is not entirely differentiable, and the latter lacks inherent spatial generalization. We propose our differentiable spatial to numerical transform (DSNT) to fill this gap. The DSNT layer adds no trainable parameters, is fully differentiable, and exhibits good spatial generalization. Unlike heatmap matching, DSNT works well with low heatmap resolutions, so it can be dropped in as an output layer for a wide range of existing fully convolutional architectures. Consequently, DSNT offers a better trade-off between inference speed and prediction accuracy compared to existing techniques. When used to replace the popular heatmap matching approach used in almost all state-of-the-art methods for pose estimation, DSNT gives better prediction accuracy for all model architectures tested.
-
-
-
-
-
-
+# Numerical Coordinate Regression with Convolutional Neural Networks
+
+
+
+
+DSNT (2018)
+
+```bibtex
+@article{nibali2018numerical,
+ title={Numerical Coordinate Regression with Convolutional Neural Networks},
+ author={Nibali, Aiden and He, Zhen and Morgan, Stuart and Prendergast, Luke},
+ journal={arXiv preprint arXiv:1801.07372},
+ year={2018}
+}
+```
+
+
+
+## Abstract
+
+
+
+We study deep learning approaches to inferring numerical coordinates for points of interest in an input image. Existing convolutional neural network-based solutions to this problem either take a heatmap matching approach or regress to coordinates with a fully connected output layer. Neither of these approaches is ideal, since the former is not entirely differentiable, and the latter lacks inherent spatial generalization. We propose our differentiable spatial to numerical transform (DSNT) to fill this gap. The DSNT layer adds no trainable parameters, is fully differentiable, and exhibits good spatial generalization. Unlike heatmap matching, DSNT works well with low heatmap resolutions, so it can be dropped in as an output layer for a wide range of existing fully convolutional architectures. Consequently, DSNT offers a better trade-off between inference speed and prediction accuracy compared to existing techniques. When used to replace the popular heatmap matching approach used in almost all state-of-the-art methods for pose estimation, DSNT gives better prediction accuracy for all model architectures tested.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/higherhrnet.md b/docs/src/papers/algorithms/higherhrnet.md
index c1d61c992a..feed6ea06d 100644
--- a/docs/src/papers/algorithms/higherhrnet.md
+++ b/docs/src/papers/algorithms/higherhrnet.md
@@ -1,30 +1,30 @@
-# HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation
-
-
-
-
-HigherHRNet (CVPR'2020)
-
-```bibtex
-@inproceedings{cheng2020higherhrnet,
- title={HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation},
- author={Cheng, Bowen and Xiao, Bin and Wang, Jingdong and Shi, Honghui and Huang, Thomas S and Zhang, Lei},
- booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
- pages={5386--5395},
- year={2020}
-}
-```
-
-
-
-## Abstract
-
-
-
-Bottom-up human pose estimation methods have difficulties in predicting the correct pose for small persons due to challenges in scale variation. In this paper, we present HigherHRNet: a novel bottom-up human pose estimation method for learning scale-aware representations using high-resolution feature pyramids. Equipped with multi-resolution supervision for training and multi-resolution aggregation for inference, the proposed approach is able to solve the scale variation challenge in bottom-up multi-person pose estimation and localize keypoints more precisely, especially for small person. The feature pyramid in HigherHRNet consists of feature map outputs from HRNet and upsampled higher-resolution outputs through a transposed convolution. HigherHRNet outperforms the previous best bottom-up method by 2.5% AP for medium person on COCO test-dev, showing its effectiveness in handling scale variation. Furthermore, HigherHRNet achieves new state-of-the-art result on COCO test-dev (70.5% AP) without using refinement or other post-processing techniques, surpassing all existing bottom-up methods. HigherHRNet even surpasses all top-down methods on CrowdPose test (67.6% AP), suggesting its robustness in crowded scene.
-
-
-
-
-
-
+# HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation
+
+
+
+
+HigherHRNet (CVPR'2020)
+
+```bibtex
+@inproceedings{cheng2020higherhrnet,
+ title={HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation},
+ author={Cheng, Bowen and Xiao, Bin and Wang, Jingdong and Shi, Honghui and Huang, Thomas S and Zhang, Lei},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={5386--5395},
+ year={2020}
+}
+```
+
+
+
+## Abstract
+
+
+
+Bottom-up human pose estimation methods have difficulties in predicting the correct pose for small persons due to challenges in scale variation. In this paper, we present HigherHRNet: a novel bottom-up human pose estimation method for learning scale-aware representations using high-resolution feature pyramids. Equipped with multi-resolution supervision for training and multi-resolution aggregation for inference, the proposed approach is able to solve the scale variation challenge in bottom-up multi-person pose estimation and localize keypoints more precisely, especially for small person. The feature pyramid in HigherHRNet consists of feature map outputs from HRNet and upsampled higher-resolution outputs through a transposed convolution. HigherHRNet outperforms the previous best bottom-up method by 2.5% AP for medium person on COCO test-dev, showing its effectiveness in handling scale variation. Furthermore, HigherHRNet achieves new state-of-the-art result on COCO test-dev (70.5% AP) without using refinement or other post-processing techniques, surpassing all existing bottom-up methods. HigherHRNet even surpasses all top-down methods on CrowdPose test (67.6% AP), suggesting its robustness in crowded scene.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/hmr.md b/docs/src/papers/algorithms/hmr.md
index 5c90aa4521..3cdc9dba52 100644
--- a/docs/src/papers/algorithms/hmr.md
+++ b/docs/src/papers/algorithms/hmr.md
@@ -1,32 +1,32 @@
-# End-to-end Recovery of Human Shape and Pose
-
-
-
-
-HMR (CVPR'2018)
-
-```bibtex
-@inProceedings{kanazawaHMR18,
- title={End-to-end Recovery of Human Shape and Pose},
- author = {Angjoo Kanazawa
- and Michael J. Black
- and David W. Jacobs
- and Jitendra Malik},
- booktitle={Computer Vision and Pattern Recognition (CVPR)},
- year={2018}
-}
-```
-
-
-
-## Abstract
-
-
-
-We describe Human Mesh Recovery (HMR), an end-to-end framework for reconstructing a full 3D mesh of a human body from a single RGB image. In contrast to most current methods that compute 2D or 3D joint locations, we produce a richer and more useful mesh representation that is parameterized by shape and 3D joint angles. The main objective is to minimize the reprojection loss of keypoints, which allows our model to be trained using in-the-wild images that only have ground truth 2D annotations. However, the reprojection loss alone is highly underconstrained. In this work we address this problem by introducing an adversary trained to tell whether human body shape and pose are real or not using a large database of 3D human meshes. We show that HMR can be trained with and without using any paired 2D-to-3D supervision. We do not rely on intermediate 2D keypoint detections and infer 3D pose and shape parameters directly from image pixels. Our model runs in real-time given a bounding box containing the person. We demonstrate our approach on various images in-the-wild and out-perform previous optimization-based methods that output 3D meshes and show competitive results on tasks such as 3D joint location estimation and part segmentation.
-
-
-
-
-
-
+# End-to-end Recovery of Human Shape and Pose
+
+
+
+
+HMR (CVPR'2018)
+
+```bibtex
+@inProceedings{kanazawaHMR18,
+ title={End-to-end Recovery of Human Shape and Pose},
+ author = {Angjoo Kanazawa
+ and Michael J. Black
+ and David W. Jacobs
+ and Jitendra Malik},
+ booktitle={Computer Vision and Pattern Recognition (CVPR)},
+ year={2018}
+}
+```
+
+
+
+## Abstract
+
+
+
+We describe Human Mesh Recovery (HMR), an end-to-end framework for reconstructing a full 3D mesh of a human body from a single RGB image. In contrast to most current methods that compute 2D or 3D joint locations, we produce a richer and more useful mesh representation that is parameterized by shape and 3D joint angles. The main objective is to minimize the reprojection loss of keypoints, which allows our model to be trained using in-the-wild images that only have ground truth 2D annotations. However, the reprojection loss alone is highly underconstrained. In this work we address this problem by introducing an adversary trained to tell whether human body shape and pose are real or not using a large database of 3D human meshes. We show that HMR can be trained with and without using any paired 2D-to-3D supervision. We do not rely on intermediate 2D keypoint detections and infer 3D pose and shape parameters directly from image pixels. Our model runs in real-time given a bounding box containing the person. We demonstrate our approach on various images in-the-wild and out-perform previous optimization-based methods that output 3D meshes and show competitive results on tasks such as 3D joint location estimation and part segmentation.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/hourglass.md b/docs/src/papers/algorithms/hourglass.md
index 15f4d4d3c6..c6c7e51592 100644
--- a/docs/src/papers/algorithms/hourglass.md
+++ b/docs/src/papers/algorithms/hourglass.md
@@ -1,31 +1,31 @@
-# Stacked hourglass networks for human pose estimation
-
-
-
-
-Hourglass (ECCV'2016)
-
-```bibtex
-@inproceedings{newell2016stacked,
- title={Stacked hourglass networks for human pose estimation},
- author={Newell, Alejandro and Yang, Kaiyu and Deng, Jia},
- booktitle={European conference on computer vision},
- pages={483--499},
- year={2016},
- organization={Springer}
-}
-```
-
-
-
-## Abstract
-
-
-
-This work introduces a novel convolutional network architecture for the task of human pose estimation. Features are processed across all scales and consolidated to best capture the various spatial relationships associated with the body. We show how repeated bottom-up, top-down processing used in conjunction with intermediate supervision is critical to improving the performance of the network. We refer to the architecture as a "stacked hourglass" network based on the successive steps of pooling and upsampling that are done to produce a final set of predictions. State-of-the-art results are achieved on the FLIC and MPII benchmarks outcompeting all recent methods.
-
-
-
-
-
-
+# Stacked hourglass networks for human pose estimation
+
+
+
+
+Hourglass (ECCV'2016)
+
+```bibtex
+@inproceedings{newell2016stacked,
+ title={Stacked hourglass networks for human pose estimation},
+ author={Newell, Alejandro and Yang, Kaiyu and Deng, Jia},
+ booktitle={European conference on computer vision},
+ pages={483--499},
+ year={2016},
+ organization={Springer}
+}
+```
+
+
+
+## Abstract
+
+
+
+This work introduces a novel convolutional network architecture for the task of human pose estimation. Features are processed across all scales and consolidated to best capture the various spatial relationships associated with the body. We show how repeated bottom-up, top-down processing used in conjunction with intermediate supervision is critical to improving the performance of the network. We refer to the architecture as a "stacked hourglass" network based on the successive steps of pooling and upsampling that are done to produce a final set of predictions. State-of-the-art results are achieved on the FLIC and MPII benchmarks outcompeting all recent methods.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/hrnet.md b/docs/src/papers/algorithms/hrnet.md
index 05a46f543e..e1fba7b601 100644
--- a/docs/src/papers/algorithms/hrnet.md
+++ b/docs/src/papers/algorithms/hrnet.md
@@ -1,32 +1,32 @@
-# Deep high-resolution representation learning for human pose estimation
-
-
-
-
-HRNet (CVPR'2019)
-
-```bibtex
-@inproceedings{sun2019deep,
- title={Deep high-resolution representation learning for human pose estimation},
- author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- pages={5693--5703},
- year={2019}
-}
-```
-
-
-
-## Abstract
-
-
-
-In this paper, we are interested in the human pose estimation problem with a focus on learning reliable highresolution representations. Most existing methods recover high-resolution representations from low-resolution representations produced by a high-to-low resolution network. Instead, our proposed network maintains high-resolution representations through the whole process. We start from a high-resolution subnetwork as the first stage, gradually add high-to-low resolution subnetworks one by one to form more stages, and connect the mutliresolution subnetworks in parallel. We conduct repeated multi-scale fusions such that each of the high-to-low resolution representations receives information from other parallel representations over and over, leading to rich highresolution representations. As a result, the predicted keypoint heatmap is potentially more accurate and spatially more precise. We empirically demonstrate the effectiveness
-of our network through the superior pose estimation results over two benchmark datasets: the COCO keypoint detection
-dataset and the MPII Human Pose dataset. In addition, we show the superiority of our network in pose tracking on the PoseTrack dataset.
-
-
-
-
-
-
+# Deep high-resolution representation learning for human pose estimation
+
+
+
+
+HRNet (CVPR'2019)
+
+```bibtex
+@inproceedings{sun2019deep,
+ title={Deep high-resolution representation learning for human pose estimation},
+ author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong},
+ booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
+ pages={5693--5703},
+ year={2019}
+}
+```
+
+
+
+## Abstract
+
+
+
+In this paper, we are interested in the human pose estimation problem with a focus on learning reliable highresolution representations. Most existing methods recover high-resolution representations from low-resolution representations produced by a high-to-low resolution network. Instead, our proposed network maintains high-resolution representations through the whole process. We start from a high-resolution subnetwork as the first stage, gradually add high-to-low resolution subnetworks one by one to form more stages, and connect the mutliresolution subnetworks in parallel. We conduct repeated multi-scale fusions such that each of the high-to-low resolution representations receives information from other parallel representations over and over, leading to rich highresolution representations. As a result, the predicted keypoint heatmap is potentially more accurate and spatially more precise. We empirically demonstrate the effectiveness
+of our network through the superior pose estimation results over two benchmark datasets: the COCO keypoint detection
+dataset and the MPII Human Pose dataset. In addition, we show the superiority of our network in pose tracking on the PoseTrack dataset.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/hrnetv2.md b/docs/src/papers/algorithms/hrnetv2.md
index f2ed2a9c0c..f764d61def 100644
--- a/docs/src/papers/algorithms/hrnetv2.md
+++ b/docs/src/papers/algorithms/hrnetv2.md
@@ -1,31 +1,31 @@
-# Deep high-resolution representation learning for visual recognition
-
-
-
-
-HRNetv2 (TPAMI'2019)
-
-```bibtex
-@article{WangSCJDZLMTWLX19,
- title={Deep High-Resolution Representation Learning for Visual Recognition},
- author={Jingdong Wang and Ke Sun and Tianheng Cheng and
- Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and
- Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao},
- journal={TPAMI},
- year={2019}
-}
-```
-
-
-
-## Abstract
-
-
-
-High-resolution representations are essential for position-sensitive vision problems, such as human pose estimation, semantic segmentation, and object detection. Existing state-of-the-art frameworks first encode the input image as a low-resolution representation through a subnetwork that is formed by connecting high-to-low resolution convolutions in series (e.g., ResNet, VGGNet), and then recover the high-resolution representation from the encoded low-resolution representation. Instead, our proposed network, named as High-Resolution Network (HRNet), maintains high-resolution representations through the whole process. There are two key characteristics: (i) Connect the high-to-low resolution convolution streams in parallel and (ii) repeatedly exchange the information across resolutions. The benefit is that the resulting representation is semantically richer and spatially more precise. We show the superiority of the proposed HRNet in a wide range of applications, including human pose estimation, semantic segmentation, and object detection, suggesting that the HRNet is a stronger backbone for computer vision problems.
-
-
-
-
-
-
+# Deep high-resolution representation learning for visual recognition
+
+
+
+
+HRNetv2 (TPAMI'2019)
+
+```bibtex
+@article{WangSCJDZLMTWLX19,
+ title={Deep High-Resolution Representation Learning for Visual Recognition},
+ author={Jingdong Wang and Ke Sun and Tianheng Cheng and
+ Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and
+ Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao},
+ journal={TPAMI},
+ year={2019}
+}
+```
+
+
+
+## Abstract
+
+
+
+High-resolution representations are essential for position-sensitive vision problems, such as human pose estimation, semantic segmentation, and object detection. Existing state-of-the-art frameworks first encode the input image as a low-resolution representation through a subnetwork that is formed by connecting high-to-low resolution convolutions in series (e.g., ResNet, VGGNet), and then recover the high-resolution representation from the encoded low-resolution representation. Instead, our proposed network, named as High-Resolution Network (HRNet), maintains high-resolution representations through the whole process. There are two key characteristics: (i) Connect the high-to-low resolution convolution streams in parallel and (ii) repeatedly exchange the information across resolutions. The benefit is that the resulting representation is semantically richer and spatially more precise. We show the superiority of the proposed HRNet in a wide range of applications, including human pose estimation, semantic segmentation, and object detection, suggesting that the HRNet is a stronger backbone for computer vision problems.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/internet.md b/docs/src/papers/algorithms/internet.md
index e37ea72cea..3c9ad7013a 100644
--- a/docs/src/papers/algorithms/internet.md
+++ b/docs/src/papers/algorithms/internet.md
@@ -1,29 +1,29 @@
-# InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image
-
-
-
-
-InterNet (ECCV'2020)
-
-```bibtex
-@InProceedings{Moon_2020_ECCV_InterHand2.6M,
-author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu},
-title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image},
-booktitle = {European Conference on Computer Vision (ECCV)},
-year = {2020}
-}
-```
-
-
-
-## Abstract
-
-
-
-Analysis of hand-hand interactions is a crucial step towards better understanding human behavior. However, most researches in 3D hand pose estimation have focused on the isolated single hand case. Therefore, we firstly propose (1) a large-scale dataset, InterHand2.6M, and (2) a baseline network, InterNet, for 3D interacting hand pose estimation from a single RGB image. The proposed InterHand2.6M consists of 2.6 M labeled single and interacting hand frames under various poses from multiple subjects. Our InterNet simultaneously performs 3D single and interacting hand pose estimation. In our experiments, we demonstrate big gains in 3D interacting hand pose estimation accuracy when leveraging the interacting hand data in InterHand2.6M. We also report the accuracy of InterNet on InterHand2.6M, which serves as a strong baseline for this new dataset. Finally, we show 3D interacting hand pose estimation results from general images.
-
-
-
-
-
-
+# InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image
+
+
+
+
+InterNet (ECCV'2020)
+
+```bibtex
+@InProceedings{Moon_2020_ECCV_InterHand2.6M,
+author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu},
+title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image},
+booktitle = {European Conference on Computer Vision (ECCV)},
+year = {2020}
+}
+```
+
+
+
+## Abstract
+
+
+
+Analysis of hand-hand interactions is a crucial step towards better understanding human behavior. However, most researches in 3D hand pose estimation have focused on the isolated single hand case. Therefore, we firstly propose (1) a large-scale dataset, InterHand2.6M, and (2) a baseline network, InterNet, for 3D interacting hand pose estimation from a single RGB image. The proposed InterHand2.6M consists of 2.6 M labeled single and interacting hand frames under various poses from multiple subjects. Our InterNet simultaneously performs 3D single and interacting hand pose estimation. In our experiments, we demonstrate big gains in 3D interacting hand pose estimation accuracy when leveraging the interacting hand data in InterHand2.6M. We also report the accuracy of InterNet on InterHand2.6M, which serves as a strong baseline for this new dataset. Finally, we show 3D interacting hand pose estimation results from general images.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/ipr.md b/docs/src/papers/algorithms/ipr.md
index fca06b986a..859b36a89b 100644
--- a/docs/src/papers/algorithms/ipr.md
+++ b/docs/src/papers/algorithms/ipr.md
@@ -1,30 +1,30 @@
-# Integral Human Pose Regression
-
-
-
-
-IPR (ECCV'2018)
-
-```bibtex
-@inproceedings{sun2018integral,
- title={Integral human pose regression},
- author={Sun, Xiao and Xiao, Bin and Wei, Fangyin and Liang, Shuang and Wei, Yichen},
- booktitle={Proceedings of the European conference on computer vision (ECCV)},
- pages={529--545},
- year={2018}
-}
-```
-
-
-
-## Abstract
-
-
-
-State-of-the-art human pose estimation methods are based on heat map representation. In spite of the good performance, the representation has a few issues in nature, such as not differentiable and quantization error. This work shows that a simple integral operation relates and unifies the heat map representation and joint regression, thus avoiding the above issues. It is differentiable, efficient, and compatible with any heat map based methods. Its effectiveness is convincingly validated via comprehensive ablation experiments under various settings, specifically on 3D pose estimation, for the first time.
-
-
-
-
-
-
+# Integral Human Pose Regression
+
+
+
+
+IPR (ECCV'2018)
+
+```bibtex
+@inproceedings{sun2018integral,
+ title={Integral human pose regression},
+ author={Sun, Xiao and Xiao, Bin and Wei, Fangyin and Liang, Shuang and Wei, Yichen},
+ booktitle={Proceedings of the European conference on computer vision (ECCV)},
+ pages={529--545},
+ year={2018}
+}
+```
+
+
+
+## Abstract
+
+
+
+State-of-the-art human pose estimation methods are based on heat map representation. In spite of the good performance, the representation has a few issues in nature, such as not differentiable and quantization error. This work shows that a simple integral operation relates and unifies the heat map representation and joint regression, thus avoiding the above issues. It is differentiable, efficient, and compatible with any heat map based methods. Its effectiveness is convincingly validated via comprehensive ablation experiments under various settings, specifically on 3D pose estimation, for the first time.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/litehrnet.md b/docs/src/papers/algorithms/litehrnet.md
index f446062caf..06c0077640 100644
--- a/docs/src/papers/algorithms/litehrnet.md
+++ b/docs/src/papers/algorithms/litehrnet.md
@@ -1,30 +1,30 @@
-# Lite-HRNet: A Lightweight High-Resolution Network
-
-
-
-
-LiteHRNet (CVPR'2021)
-
-```bibtex
-@inproceedings{Yulitehrnet21,
- title={Lite-HRNet: A Lightweight High-Resolution Network},
- author={Yu, Changqian and Xiao, Bin and Gao, Changxin and Yuan, Lu and Zhang, Lei and Sang, Nong and Wang, Jingdong},
- booktitle={CVPR},
- year={2021}
-}
-```
-
-
-
-## Abstract
-
-
-
-We present an efficient high-resolution network, Lite-HRNet, for human pose estimation. We start by simply applying the efficient shuffle block in ShuffleNet to HRNet (high-resolution network), yielding stronger performance over popular lightweight networks, such as MobileNet, ShuffleNet, and Small HRNet.
-We find that the heavily-used pointwise (1x1) convolutions in shuffle blocks become the computational bottleneck. We introduce a lightweight unit, conditional channel weighting, to replace costly pointwise (1x1) convolutions in shuffle blocks. The complexity of channel weighting is linear w.r.t the number of channels and lower than the quadratic time complexity for pointwise convolutions. Our solution learns the weights from all the channels and over multiple resolutions that are readily available in the parallel branches in HRNet. It uses the weights as the bridge to exchange information across channels and resolutions, compensating the role played by the pointwise (1x1) convolution. Lite-HRNet demonstrates superior results on human pose estimation over popular lightweight networks. Moreover, Lite-HRNet can be easily applied to semantic segmentation task in the same lightweight manner.
-
-
-
-
-
-
+# Lite-HRNet: A Lightweight High-Resolution Network
+
+
+
+
+LiteHRNet (CVPR'2021)
+
+```bibtex
+@inproceedings{Yulitehrnet21,
+ title={Lite-HRNet: A Lightweight High-Resolution Network},
+ author={Yu, Changqian and Xiao, Bin and Gao, Changxin and Yuan, Lu and Zhang, Lei and Sang, Nong and Wang, Jingdong},
+ booktitle={CVPR},
+ year={2021}
+}
+```
+
+
+
+## Abstract
+
+
+
+We present an efficient high-resolution network, Lite-HRNet, for human pose estimation. We start by simply applying the efficient shuffle block in ShuffleNet to HRNet (high-resolution network), yielding stronger performance over popular lightweight networks, such as MobileNet, ShuffleNet, and Small HRNet.
+We find that the heavily-used pointwise (1x1) convolutions in shuffle blocks become the computational bottleneck. We introduce a lightweight unit, conditional channel weighting, to replace costly pointwise (1x1) convolutions in shuffle blocks. The complexity of channel weighting is linear w.r.t the number of channels and lower than the quadratic time complexity for pointwise convolutions. Our solution learns the weights from all the channels and over multiple resolutions that are readily available in the parallel branches in HRNet. It uses the weights as the bridge to exchange information across channels and resolutions, compensating the role played by the pointwise (1x1) convolution. Lite-HRNet demonstrates superior results on human pose estimation over popular lightweight networks. Moreover, Lite-HRNet can be easily applied to semantic segmentation task in the same lightweight manner.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/mspn.md b/docs/src/papers/algorithms/mspn.md
index 1915cd3915..5824221603 100644
--- a/docs/src/papers/algorithms/mspn.md
+++ b/docs/src/papers/algorithms/mspn.md
@@ -1,29 +1,29 @@
-# Rethinking on multi-stage networks for human pose estimation
-
-
-
-
-MSPN (ArXiv'2019)
-
-```bibtex
-@article{li2019rethinking,
- title={Rethinking on Multi-Stage Networks for Human Pose Estimation},
- author={Li, Wenbo and Wang, Zhicheng and Yin, Binyi and Peng, Qixiang and Du, Yuming and Xiao, Tianzi and Yu, Gang and Lu, Hongtao and Wei, Yichen and Sun, Jian},
- journal={arXiv preprint arXiv:1901.00148},
- year={2019}
-}
-```
-
-
-
-## Abstract
-
-
-
-Existing pose estimation approaches fall into two categories: single-stage and multi-stage methods. While multi-stage methods are seemingly more suited for the task, their performance in current practice is not as good as single-stage methods. This work studies this issue. We argue that the current multi-stage methods' unsatisfactory performance comes from the insufficiency in various design choices. We propose several improvements, including the single-stage module design, cross stage feature aggregation, and coarse-to-fine supervision. The resulting method establishes the new state-of-the-art on both MS COCO and MPII Human Pose dataset, justifying the effectiveness of a multi-stage architecture. The source code is publicly available for further research.
-
-
-
-
-
-
+# Rethinking on multi-stage networks for human pose estimation
+
+
+
+
+MSPN (ArXiv'2019)
+
+```bibtex
+@article{li2019rethinking,
+ title={Rethinking on Multi-Stage Networks for Human Pose Estimation},
+ author={Li, Wenbo and Wang, Zhicheng and Yin, Binyi and Peng, Qixiang and Du, Yuming and Xiao, Tianzi and Yu, Gang and Lu, Hongtao and Wei, Yichen and Sun, Jian},
+ journal={arXiv preprint arXiv:1901.00148},
+ year={2019}
+}
+```
+
+
+
+## Abstract
+
+
+
+Existing pose estimation approaches fall into two categories: single-stage and multi-stage methods. While multi-stage methods are seemingly more suited for the task, their performance in current practice is not as good as single-stage methods. This work studies this issue. We argue that the current multi-stage methods' unsatisfactory performance comes from the insufficiency in various design choices. We propose several improvements, including the single-stage module design, cross stage feature aggregation, and coarse-to-fine supervision. The resulting method establishes the new state-of-the-art on both MS COCO and MPII Human Pose dataset, justifying the effectiveness of a multi-stage architecture. The source code is publicly available for further research.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/posewarper.md b/docs/src/papers/algorithms/posewarper.md
index 285a36c582..973b298049 100644
--- a/docs/src/papers/algorithms/posewarper.md
+++ b/docs/src/papers/algorithms/posewarper.md
@@ -1,29 +1,29 @@
-# Learning Temporal Pose Estimation from Sparsely-Labeled Videos
-
-
-
-
-PoseWarper (NeurIPS'2019)
-
-```bibtex
-@inproceedings{NIPS2019_gberta,
-title = {Learning Temporal Pose Estimation from Sparsely Labeled Videos},
-author = {Bertasius, Gedas and Feichtenhofer, Christoph, and Tran, Du and Shi, Jianbo, and Torresani, Lorenzo},
-booktitle = {Advances in Neural Information Processing Systems 33},
-year = {2019},
-}
-```
-
-
-
-## Abstract
-
-
-
-Modern approaches for multi-person pose estimation in video require large amounts of dense annotations. However, labeling every frame in a video is costly and labor intensive. To reduce the need for dense annotations, we propose a PoseWarper network that leverages training videos with sparse annotations (every k frames) to learn to perform dense temporal pose propagation and estimation. Given a pair of video frames---a labeled Frame A and an unlabeled Frame B---we train our model to predict human pose in Frame A using the features from Frame B by means of deformable convolutions to implicitly learn the pose warping between A and B. We demonstrate that we can leverage our trained PoseWarper for several applications. First, at inference time we can reverse the application direction of our network in order to propagate pose information from manually annotated frames to unlabeled frames. This makes it possible to generate pose annotations for the entire video given only a few manually-labeled frames. Compared to modern label propagation methods based on optical flow, our warping mechanism is much more compact (6M vs 39M parameters), and also more accurate (88.7% mAP vs 83.8% mAP). We also show that we can improve the accuracy of a pose estimator by training it on an augmented dataset obtained by adding our propagated poses to the original manual labels. Lastly, we can use our PoseWarper to aggregate temporal pose information from neighboring frames during inference. This allows our system to achieve state-of-the-art pose detection results on the PoseTrack2017 and PoseTrack2018 datasets.
-
-
-
-
-
-
+# Learning Temporal Pose Estimation from Sparsely-Labeled Videos
+
+
+
+
+PoseWarper (NeurIPS'2019)
+
+```bibtex
+@inproceedings{NIPS2019_gberta,
+title = {Learning Temporal Pose Estimation from Sparsely Labeled Videos},
+author = {Bertasius, Gedas and Feichtenhofer, Christoph, and Tran, Du and Shi, Jianbo, and Torresani, Lorenzo},
+booktitle = {Advances in Neural Information Processing Systems 33},
+year = {2019},
+}
+```
+
+
+
+## Abstract
+
+
+
+Modern approaches for multi-person pose estimation in video require large amounts of dense annotations. However, labeling every frame in a video is costly and labor intensive. To reduce the need for dense annotations, we propose a PoseWarper network that leverages training videos with sparse annotations (every k frames) to learn to perform dense temporal pose propagation and estimation. Given a pair of video frames---a labeled Frame A and an unlabeled Frame B---we train our model to predict human pose in Frame A using the features from Frame B by means of deformable convolutions to implicitly learn the pose warping between A and B. We demonstrate that we can leverage our trained PoseWarper for several applications. First, at inference time we can reverse the application direction of our network in order to propagate pose information from manually annotated frames to unlabeled frames. This makes it possible to generate pose annotations for the entire video given only a few manually-labeled frames. Compared to modern label propagation methods based on optical flow, our warping mechanism is much more compact (6M vs 39M parameters), and also more accurate (88.7% mAP vs 83.8% mAP). We also show that we can improve the accuracy of a pose estimator by training it on an augmented dataset obtained by adding our propagated poses to the original manual labels. Lastly, we can use our PoseWarper to aggregate temporal pose information from neighboring frames during inference. This allows our system to achieve state-of-the-art pose detection results on the PoseTrack2017 and PoseTrack2018 datasets.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/rle.md b/docs/src/papers/algorithms/rle.md
index cdc59d57ec..7734ca3d44 100644
--- a/docs/src/papers/algorithms/rle.md
+++ b/docs/src/papers/algorithms/rle.md
@@ -1,30 +1,30 @@
-# Human pose regression with residual log-likelihood estimation
-
-
-
-
-RLE (ICCV'2021)
-
-```bibtex
-@inproceedings{li2021human,
- title={Human pose regression with residual log-likelihood estimation},
- author={Li, Jiefeng and Bian, Siyuan and Zeng, Ailing and Wang, Can and Pang, Bo and Liu, Wentao and Lu, Cewu},
- booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
- pages={11025--11034},
- year={2021}
-}
-```
-
-
-
-## Abstract
-
-
-
-Heatmap-based methods dominate in the field of human pose estimation by modelling the output distribution through likelihood heatmaps. In contrast, regressionbased methods are more efficient but suffer from inferior performance. In this work, we explore maximum likelihood estimation (MLE) to develop an efficient and effective regression-based methods. From the perspective of MLE, adopting different regression losses is making different assumptions about the output density function. A density function closer to the true distribution leads to a better regression performance. In light of this, we propose a novel regression paradigm with Residual Log-likelihood Estimation (RLE) to capture the underlying output distribution. Concretely, RLE learns the change of the distribution instead of the unreferenced underlying distribution to facilitate the training process. With the proposed reparameterization design, our method is compatible with offthe-shelf flow models. The proposed method is effective, efficient and flexible. We show its potential in various human pose estimation tasks with comprehensive experiments. Compared to the conventional regression paradigm, regression with RLE bring 12.4 mAP improvement on MSCOCO without any test-time overhead. Moreover, for the first time, especially on multi-person pose estimation, our regression method is superior to the heatmap-based methods.
-
-
-
-
-
-
+# Human pose regression with residual log-likelihood estimation
+
+
+
+
+RLE (ICCV'2021)
+
+```bibtex
+@inproceedings{li2021human,
+ title={Human pose regression with residual log-likelihood estimation},
+ author={Li, Jiefeng and Bian, Siyuan and Zeng, Ailing and Wang, Can and Pang, Bo and Liu, Wentao and Lu, Cewu},
+ booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
+ pages={11025--11034},
+ year={2021}
+}
+```
+
+
+
+## Abstract
+
+
+
+Heatmap-based methods dominate in the field of human pose estimation by modelling the output distribution through likelihood heatmaps. In contrast, regressionbased methods are more efficient but suffer from inferior performance. In this work, we explore maximum likelihood estimation (MLE) to develop an efficient and effective regression-based methods. From the perspective of MLE, adopting different regression losses is making different assumptions about the output density function. A density function closer to the true distribution leads to a better regression performance. In light of this, we propose a novel regression paradigm with Residual Log-likelihood Estimation (RLE) to capture the underlying output distribution. Concretely, RLE learns the change of the distribution instead of the unreferenced underlying distribution to facilitate the training process. With the proposed reparameterization design, our method is compatible with offthe-shelf flow models. The proposed method is effective, efficient and flexible. We show its potential in various human pose estimation tasks with comprehensive experiments. Compared to the conventional regression paradigm, regression with RLE bring 12.4 mAP improvement on MSCOCO without any test-time overhead. Moreover, for the first time, especially on multi-person pose estimation, our regression method is superior to the heatmap-based methods.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/rsn.md b/docs/src/papers/algorithms/rsn.md
index b1fb1ea913..d8af907926 100644
--- a/docs/src/papers/algorithms/rsn.md
+++ b/docs/src/papers/algorithms/rsn.md
@@ -1,31 +1,31 @@
-# Learning delicate local representations for multi-person pose estimation
-
-
-
-
-RSN (ECCV'2020)
-
-```bibtex
-@misc{cai2020learning,
- title={Learning Delicate Local Representations for Multi-Person Pose Estimation},
- author={Yuanhao Cai and Zhicheng Wang and Zhengxiong Luo and Binyi Yin and Angang Du and Haoqian Wang and Xinyu Zhou and Erjin Zhou and Xiangyu Zhang and Jian Sun},
- year={2020},
- eprint={2003.04030},
- archivePrefix={arXiv},
- primaryClass={cs.CV}
-}
-```
-
-
-
-## Abstract
-
-
-
-In this paper, we propose a novel method called Residual Steps Network (RSN). RSN aggregates features with the same spatial size (Intra-level features) efficiently to obtain delicate local representations, which retain rich low-level spatial information and result in precise keypoint localization. Additionally, we observe the output features contribute differently to final performance. To tackle this problem, we propose an efficient attention mechanism - Pose Refine Machine (PRM) to make a trade-off between local and global representations in output features and further refine the keypoint locations. Our approach won the 1st place of COCO Keypoint Challenge 2019 and achieves state-of-the-art results on both COCO and MPII benchmarks, without using extra training data and pretrained model. Our single model achieves 78.6 on COCO test-dev, 93.0 on MPII test dataset. Ensembled models achieve 79.2 on COCO test-dev, 77.1 on COCO test-challenge dataset.
-
-
-
-
-
-
+# Learning delicate local representations for multi-person pose estimation
+
+
+
+
+RSN (ECCV'2020)
+
+```bibtex
+@misc{cai2020learning,
+ title={Learning Delicate Local Representations for Multi-Person Pose Estimation},
+ author={Yuanhao Cai and Zhicheng Wang and Zhengxiong Luo and Binyi Yin and Angang Du and Haoqian Wang and Xinyu Zhou and Erjin Zhou and Xiangyu Zhang and Jian Sun},
+ year={2020},
+ eprint={2003.04030},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+}
+```
+
+
+
+## Abstract
+
+
+
+In this paper, we propose a novel method called Residual Steps Network (RSN). RSN aggregates features with the same spatial size (Intra-level features) efficiently to obtain delicate local representations, which retain rich low-level spatial information and result in precise keypoint localization. Additionally, we observe the output features contribute differently to final performance. To tackle this problem, we propose an efficient attention mechanism - Pose Refine Machine (PRM) to make a trade-off between local and global representations in output features and further refine the keypoint locations. Our approach won the 1st place of COCO Keypoint Challenge 2019 and achieves state-of-the-art results on both COCO and MPII benchmarks, without using extra training data and pretrained model. Our single model achieves 78.6 on COCO test-dev, 93.0 on MPII test dataset. Ensembled models achieve 79.2 on COCO test-dev, 77.1 on COCO test-challenge dataset.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/rtmpose.md b/docs/src/papers/algorithms/rtmpose.md
index 04a3fb0a22..ff8ddd6411 100644
--- a/docs/src/papers/algorithms/rtmpose.md
+++ b/docs/src/papers/algorithms/rtmpose.md
@@ -1,34 +1,34 @@
-# RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose
-
-
-
-
-RTMPose (arXiv'2023)
-
-```bibtex
-@misc{https://doi.org/10.48550/arxiv.2303.07399,
- doi = {10.48550/ARXIV.2303.07399},
- url = {https://arxiv.org/abs/2303.07399},
- author = {Jiang, Tao and Lu, Peng and Zhang, Li and Ma, Ningsheng and Han, Rui and Lyu, Chengqi and Li, Yining and Chen, Kai},
- keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
- title = {RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose},
- publisher = {arXiv},
- year = {2023},
- copyright = {Creative Commons Attribution 4.0 International}
-}
-
-```
-
-
-
-## Abstract
-
-
-
-Recent studies on 2D pose estimation have achieved excellent performance on public benchmarks, yet its application in the industrial community still suffers from heavy model parameters and high latency. In order to bridge this gap, we empirically explore key factors in pose estimation including paradigm, model architecture, training strategy, and deployment, and present a high-performance real-time multi-person pose estimation framework, RTMPose, based on MMPose. Our RTMPose-m achieves 75.8% AP on COCO with 90+ FPS on an Intel i7-11700 CPU and 430+ FPS on an NVIDIA GTX 1660 Ti GPU, and RTMPose-l achieves 67.0% AP on COCO-WholeBody with 130+ FPS. To further evaluate RTMPose’s capability in critical real-time applications, we also report the performance after deploying on the mobile device. Our RTMPoses achieves 72.2% AP on COCO with 70+ FPS on a Snapdragon 865 chip, outperforming existing open-source libraries. Code and models are released at https://github.com/open-mmlab/mmpose/tree/main/projects/rtmpose.
-
-
-
-
-
-
+# RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose
+
+
+
+
+RTMPose (arXiv'2023)
+
+```bibtex
+@misc{https://doi.org/10.48550/arxiv.2303.07399,
+ doi = {10.48550/ARXIV.2303.07399},
+ url = {https://arxiv.org/abs/2303.07399},
+ author = {Jiang, Tao and Lu, Peng and Zhang, Li and Ma, Ningsheng and Han, Rui and Lyu, Chengqi and Li, Yining and Chen, Kai},
+ keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
+ title = {RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose},
+ publisher = {arXiv},
+ year = {2023},
+ copyright = {Creative Commons Attribution 4.0 International}
+}
+
+```
+
+
+
+## Abstract
+
+
+
+Recent studies on 2D pose estimation have achieved excellent performance on public benchmarks, yet its application in the industrial community still suffers from heavy model parameters and high latency. In order to bridge this gap, we empirically explore key factors in pose estimation including paradigm, model architecture, training strategy, and deployment, and present a high-performance real-time multi-person pose estimation framework, RTMPose, based on MMPose. Our RTMPose-m achieves 75.8% AP on COCO with 90+ FPS on an Intel i7-11700 CPU and 430+ FPS on an NVIDIA GTX 1660 Ti GPU, and RTMPose-l achieves 67.0% AP on COCO-WholeBody with 130+ FPS. To further evaluate RTMPose’s capability in critical real-time applications, we also report the performance after deploying on the mobile device. Our RTMPoses achieves 72.2% AP on COCO with 70+ FPS on a Snapdragon 865 chip, outperforming existing open-source libraries. Code and models are released at https://github.com/open-mmlab/mmpose/tree/main/projects/rtmpose.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/scnet.md b/docs/src/papers/algorithms/scnet.md
index 043c144111..24f13e82b8 100644
--- a/docs/src/papers/algorithms/scnet.md
+++ b/docs/src/papers/algorithms/scnet.md
@@ -1,30 +1,30 @@
-# Improving Convolutional Networks with Self-Calibrated Convolutions
-
-
-
-
-SCNet (CVPR'2020)
-
-```bibtex
-@inproceedings{liu2020improving,
- title={Improving Convolutional Networks with Self-Calibrated Convolutions},
- author={Liu, Jiang-Jiang and Hou, Qibin and Cheng, Ming-Ming and Wang, Changhu and Feng, Jiashi},
- booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
- pages={10096--10105},
- year={2020}
-}
-```
-
-
-
-## Abstract
-
-
-
-Recent advances on CNNs are mostly devoted to designing more complex architectures to enhance their representation learning capacity. In this paper, we consider how to improve the basic convolutional feature transformation process of CNNs without tuning the model architectures. To this end, we present a novel self-calibrated convolutions that explicitly expand fields-of-view of each convolutional layers through internal communications and hence enrich the output features. In particular, unlike the standard convolutions that fuse spatial and channel-wise information using small kernels (e.g., 3x3), self-calibrated convolutions adaptively build long-range spatial and inter-channel dependencies around each spatial location through a novel self-calibration operation. Thus, it can help CNNs generate more discriminative representations by explicitly incorporating richer information. Our self-calibrated convolution design is simple and generic, and can be easily applied to augment standard convolutional layers without introducing extra parameters and complexity. Extensive experiments demonstrate that when applying self-calibrated convolutions into different backbones, our networks can significantly improve the baseline models in a variety of vision tasks, including image recognition, object detection, instance segmentation, and keypoint detection, with no need to change the network architectures. We hope this work could provide a promising way for future research in designing novel convolutional feature transformations for improving convolutional networks. Code is available on the project page.
-
-
-
-
-
-
+# Improving Convolutional Networks with Self-Calibrated Convolutions
+
+
+
+
+SCNet (CVPR'2020)
+
+```bibtex
+@inproceedings{liu2020improving,
+ title={Improving Convolutional Networks with Self-Calibrated Convolutions},
+ author={Liu, Jiang-Jiang and Hou, Qibin and Cheng, Ming-Ming and Wang, Changhu and Feng, Jiashi},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={10096--10105},
+ year={2020}
+}
+```
+
+
+
+## Abstract
+
+
+
+Recent advances on CNNs are mostly devoted to designing more complex architectures to enhance their representation learning capacity. In this paper, we consider how to improve the basic convolutional feature transformation process of CNNs without tuning the model architectures. To this end, we present a novel self-calibrated convolutions that explicitly expand fields-of-view of each convolutional layers through internal communications and hence enrich the output features. In particular, unlike the standard convolutions that fuse spatial and channel-wise information using small kernels (e.g., 3x3), self-calibrated convolutions adaptively build long-range spatial and inter-channel dependencies around each spatial location through a novel self-calibration operation. Thus, it can help CNNs generate more discriminative representations by explicitly incorporating richer information. Our self-calibrated convolution design is simple and generic, and can be easily applied to augment standard convolutional layers without introducing extra parameters and complexity. Extensive experiments demonstrate that when applying self-calibrated convolutions into different backbones, our networks can significantly improve the baseline models in a variety of vision tasks, including image recognition, object detection, instance segmentation, and keypoint detection, with no need to change the network architectures. We hope this work could provide a promising way for future research in designing novel convolutional feature transformations for improving convolutional networks. Code is available on the project page.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/simcc.md b/docs/src/papers/algorithms/simcc.md
index 9a00d229f3..0d9fb89515 100644
--- a/docs/src/papers/algorithms/simcc.md
+++ b/docs/src/papers/algorithms/simcc.md
@@ -1,28 +1,28 @@
-# SimCC: a Simple Coordinate Classification Perspective for Human Pose Estimation
-
-
-
-
-SimCC (ECCV'2022)
-
-```bibtex
-@misc{https://doi.org/10.48550/arxiv.2107.03332,
- title={SimCC: a Simple Coordinate Classification Perspective for Human Pose Estimation},
- author={Li, Yanjie and Yang, Sen and Liu, Peidong and Zhang, Shoukui and Wang, Yunxiao and Wang, Zhicheng and Yang, Wankou and Xia, Shu-Tao},
- year={2021}
-}
-```
-
-
-
-## Abstract
-
-
-
-The 2D heatmap-based approaches have dominated Human Pose Estimation (HPE) for years due to high performance. However, the long-standing quantization error problem in the 2D heatmap-based methods leads to several well-known drawbacks: 1) The performance for the low-resolution inputs is limited; 2) To improve the feature map resolution for higher localization precision, multiple costly upsampling layers are required; 3) Extra post-processing is adopted to reduce the quantization error. To address these issues, we aim to explore a brand new scheme, called \\textit{SimCC}, which reformulates HPE as two classification tasks for horizontal and vertical coordinates. The proposed SimCC uniformly divides each pixel into several bins, thus achieving \\emph{sub-pixel} localization precision and low quantization error. Benefiting from that, SimCC can omit additional refinement post-processing and exclude upsampling layers under certain settings, resulting in a more simple and effective pipeline for HPE. Extensive experiments conducted over COCO, CrowdPose, and MPII datasets show that SimCC outperforms heatmap-based counterparts, especially in low-resolution settings by a large margin.
-
-
-
-
-
-
+# SimCC: a Simple Coordinate Classification Perspective for Human Pose Estimation
+
+
+
+
+SimCC (ECCV'2022)
+
+```bibtex
+@misc{https://doi.org/10.48550/arxiv.2107.03332,
+ title={SimCC: a Simple Coordinate Classification Perspective for Human Pose Estimation},
+ author={Li, Yanjie and Yang, Sen and Liu, Peidong and Zhang, Shoukui and Wang, Yunxiao and Wang, Zhicheng and Yang, Wankou and Xia, Shu-Tao},
+ year={2021}
+}
+```
+
+
+
+## Abstract
+
+
+
+The 2D heatmap-based approaches have dominated Human Pose Estimation (HPE) for years due to high performance. However, the long-standing quantization error problem in the 2D heatmap-based methods leads to several well-known drawbacks: 1) The performance for the low-resolution inputs is limited; 2) To improve the feature map resolution for higher localization precision, multiple costly upsampling layers are required; 3) Extra post-processing is adopted to reduce the quantization error. To address these issues, we aim to explore a brand new scheme, called \\textit{SimCC}, which reformulates HPE as two classification tasks for horizontal and vertical coordinates. The proposed SimCC uniformly divides each pixel into several bins, thus achieving \\emph{sub-pixel} localization precision and low quantization error. Benefiting from that, SimCC can omit additional refinement post-processing and exclude upsampling layers under certain settings, resulting in a more simple and effective pipeline for HPE. Extensive experiments conducted over COCO, CrowdPose, and MPII datasets show that SimCC outperforms heatmap-based counterparts, especially in low-resolution settings by a large margin.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/simplebaseline2d.md b/docs/src/papers/algorithms/simplebaseline2d.md
index 3eca224da1..b2d7f69e92 100644
--- a/docs/src/papers/algorithms/simplebaseline2d.md
+++ b/docs/src/papers/algorithms/simplebaseline2d.md
@@ -1,30 +1,30 @@
-# Simple baselines for human pose estimation and tracking
-
-
-
-
-SimpleBaseline2D (ECCV'2018)
-
-```bibtex
-@inproceedings{xiao2018simple,
- title={Simple baselines for human pose estimation and tracking},
- author={Xiao, Bin and Wu, Haiping and Wei, Yichen},
- booktitle={Proceedings of the European conference on computer vision (ECCV)},
- pages={466--481},
- year={2018}
-}
-```
-
-
-
-## Abstract
-
-
-
-There has been significant progress on pose estimation and increasing interests on pose tracking in recent years. At the same time, the overall algorithm and system complexity increases as well, making the algorithm analysis and comparison more difficult. This work provides simple and effective baseline methods. They are helpful for inspiring and evaluating new ideas for the field. State-of-the-art results are achieved on challenging benchmarks.
-
-
-
-
-
-
+# Simple baselines for human pose estimation and tracking
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+
+```bibtex
+@inproceedings{xiao2018simple,
+ title={Simple baselines for human pose estimation and tracking},
+ author={Xiao, Bin and Wu, Haiping and Wei, Yichen},
+ booktitle={Proceedings of the European conference on computer vision (ECCV)},
+ pages={466--481},
+ year={2018}
+}
+```
+
+
+
+## Abstract
+
+
+
+There has been significant progress on pose estimation and increasing interests on pose tracking in recent years. At the same time, the overall algorithm and system complexity increases as well, making the algorithm analysis and comparison more difficult. This work provides simple and effective baseline methods. They are helpful for inspiring and evaluating new ideas for the field. State-of-the-art results are achieved on challenging benchmarks.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/simplebaseline3d.md b/docs/src/papers/algorithms/simplebaseline3d.md
index ee3c58368a..c11497ca5e 100644
--- a/docs/src/papers/algorithms/simplebaseline3d.md
+++ b/docs/src/papers/algorithms/simplebaseline3d.md
@@ -1,29 +1,29 @@
-# A simple yet effective baseline for 3d human pose estimation
-
-
-
-
-SimpleBaseline3D (ICCV'2017)
-
-```bibtex
-@inproceedings{martinez_2017_3dbaseline,
- title={A simple yet effective baseline for 3d human pose estimation},
- author={Martinez, Julieta and Hossain, Rayat and Romero, Javier and Little, James J.},
- booktitle={ICCV},
- year={2017}
-}
-```
-
-
-
-## Abstract
-
-
-
-Following the success of deep convolutional networks, state-of-the-art methods for 3d human pose estimation have focused on deep end-to-end systems that predict 3d joint locations given raw image pixels. Despite their excellent performance, it is often not easy to understand whether their remaining error stems from a limited 2d pose (visual) understanding, or from a failure to map 2d poses into 3-dimensional positions. With the goal of understanding these sources of error, we set out to build a system that given 2d joint locations predicts 3d positions. Much to our surprise, we have found that, with current technology, "lifting" ground truth 2d joint locations to 3d space is a task that can be solved with a remarkably low error rate: a relatively simple deep feed-forward network outperforms the best reported result by about 30% on Human3.6M, the largest publicly available 3d pose estimation benchmark. Furthermore, training our system on the output of an off-the-shelf state-of-the-art 2d detector (i.e., using images as input) yields state of the art results -- this includes an array of systems that have been trained end-to-end specifically for this task. Our results indicate that a large portion of the error of modern deep 3d pose estimation systems stems from their visual analysis, and suggests directions to further advance the state of the art in 3d human pose estimation.
-
-
-
-
-
-
+# A simple yet effective baseline for 3d human pose estimation
+
+
+
+
+SimpleBaseline3D (ICCV'2017)
+
+```bibtex
+@inproceedings{martinez_2017_3dbaseline,
+ title={A simple yet effective baseline for 3d human pose estimation},
+ author={Martinez, Julieta and Hossain, Rayat and Romero, Javier and Little, James J.},
+ booktitle={ICCV},
+ year={2017}
+}
+```
+
+
+
+## Abstract
+
+
+
+Following the success of deep convolutional networks, state-of-the-art methods for 3d human pose estimation have focused on deep end-to-end systems that predict 3d joint locations given raw image pixels. Despite their excellent performance, it is often not easy to understand whether their remaining error stems from a limited 2d pose (visual) understanding, or from a failure to map 2d poses into 3-dimensional positions. With the goal of understanding these sources of error, we set out to build a system that given 2d joint locations predicts 3d positions. Much to our surprise, we have found that, with current technology, "lifting" ground truth 2d joint locations to 3d space is a task that can be solved with a remarkably low error rate: a relatively simple deep feed-forward network outperforms the best reported result by about 30% on Human3.6M, the largest publicly available 3d pose estimation benchmark. Furthermore, training our system on the output of an off-the-shelf state-of-the-art 2d detector (i.e., using images as input) yields state of the art results -- this includes an array of systems that have been trained end-to-end specifically for this task. Our results indicate that a large portion of the error of modern deep 3d pose estimation systems stems from their visual analysis, and suggests directions to further advance the state of the art in 3d human pose estimation.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/softwingloss.md b/docs/src/papers/algorithms/softwingloss.md
index 524a6089ff..d638109270 100644
--- a/docs/src/papers/algorithms/softwingloss.md
+++ b/docs/src/papers/algorithms/softwingloss.md
@@ -1,30 +1,30 @@
-# Structure-Coherent Deep Feature Learning for Robust Face Alignment
-
-
-
-
-SoftWingloss (TIP'2021)
-
-```bibtex
-@article{lin2021structure,
- title={Structure-Coherent Deep Feature Learning for Robust Face Alignment},
- author={Lin, Chunze and Zhu, Beier and Wang, Quan and Liao, Renjie and Qian, Chen and Lu, Jiwen and Zhou, Jie},
- journal={IEEE Transactions on Image Processing},
- year={2021},
- publisher={IEEE}
-}
-```
-
-
-
-## Abstract
-
-
-
-In this paper, we propose a structure-coherent deep feature learning method for face alignment. Unlike most existing face alignment methods which overlook the facial structure cues, we explicitly exploit the relation among facial landmarks to make the detector robust to hard cases such as occlusion and large pose. Specifically, we leverage a landmark-graph relational network to enforce the structural relationships among landmarks. We consider the facial landmarks as structural graph nodes and carefully design the neighborhood to passing features among the most related nodes. Our method dynamically adapts the weights of node neighborhood to eliminate distracted information from noisy nodes, such as occluded landmark point. Moreover, different from most previous works which only tend to penalize the landmarks absolute position during the training, we propose a relative location loss to enhance the information of relative location of landmarks. This relative location supervision further regularizes the facial structure. Our approach considers the interactions among facial landmarks and can be easily implemented on top of any convolutional backbone to boost the performance. Extensive experiments on three popular benchmarks, including WFLW, COFW and 300W, demonstrate the effectiveness of the proposed method. In particular, due to explicit structure modeling, our approach is especially robust to challenging cases resulting in impressive low failure rate on COFW and WFLW datasets.
-
-
-
-
-
-
+# Structure-Coherent Deep Feature Learning for Robust Face Alignment
+
+
+
+
+SoftWingloss (TIP'2021)
+
+```bibtex
+@article{lin2021structure,
+ title={Structure-Coherent Deep Feature Learning for Robust Face Alignment},
+ author={Lin, Chunze and Zhu, Beier and Wang, Quan and Liao, Renjie and Qian, Chen and Lu, Jiwen and Zhou, Jie},
+ journal={IEEE Transactions on Image Processing},
+ year={2021},
+ publisher={IEEE}
+}
+```
+
+
+
+## Abstract
+
+
+
+In this paper, we propose a structure-coherent deep feature learning method for face alignment. Unlike most existing face alignment methods which overlook the facial structure cues, we explicitly exploit the relation among facial landmarks to make the detector robust to hard cases such as occlusion and large pose. Specifically, we leverage a landmark-graph relational network to enforce the structural relationships among landmarks. We consider the facial landmarks as structural graph nodes and carefully design the neighborhood to passing features among the most related nodes. Our method dynamically adapts the weights of node neighborhood to eliminate distracted information from noisy nodes, such as occluded landmark point. Moreover, different from most previous works which only tend to penalize the landmarks absolute position during the training, we propose a relative location loss to enhance the information of relative location of landmarks. This relative location supervision further regularizes the facial structure. Our approach considers the interactions among facial landmarks and can be easily implemented on top of any convolutional backbone to boost the performance. Extensive experiments on three popular benchmarks, including WFLW, COFW and 300W, demonstrate the effectiveness of the proposed method. In particular, due to explicit structure modeling, our approach is especially robust to challenging cases resulting in impressive low failure rate on COFW and WFLW datasets.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/udp.md b/docs/src/papers/algorithms/udp.md
index bb4acebfbc..00604fc5ce 100644
--- a/docs/src/papers/algorithms/udp.md
+++ b/docs/src/papers/algorithms/udp.md
@@ -1,30 +1,30 @@
-# The Devil is in the Details: Delving into Unbiased Data Processing for Human Pose Estimation
-
-
-
-
-UDP (CVPR'2020)
-
-```bibtex
-@InProceedings{Huang_2020_CVPR,
- author = {Huang, Junjie and Zhu, Zheng and Guo, Feng and Huang, Guan},
- title = {The Devil Is in the Details: Delving Into Unbiased Data Processing for Human Pose Estimation},
- booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
- month = {June},
- year = {2020}
-}
-```
-
-
-
-## Abstract
-
-
-
-Recently, the leading performance of human pose estimation is dominated by top-down methods. Being a fundamental component in training and inference, data processing has not been systematically considered in pose estimation community, to the best of our knowledge. In this paper, we focus on this problem and find that the devil of top-down pose estimator is in the biased data processing. Specifically, by investigating the standard data processing in state-of-the-art approaches mainly including data transformation and encoding-decoding, we find that the results obtained by common flipping strategy are unaligned with the original ones in inference. Moreover, there is statistical error in standard encoding-decoding during both training and inference. Two problems couple together and significantly degrade the pose estimation performance. Based on quantitative analyses, we then formulate a principled way to tackle this dilemma. Data is processed in continuous space based on unit length (the intervals between pixels) instead of in discrete space with pixel, and a combined classification and regression approach is adopted to perform encoding-decoding. The Unbiased Data Processing (UDP) for human pose estimation can be achieved by combining the two together. UDP not only boosts the performance of existing methods by a large margin but also plays a important role in result reproducing and future exploration. As a model-agnostic approach, UDP promotes SimpleBaseline-ResNet50-256x192 by 1.5 AP (70.2 to 71.7) and HRNet-W32-256x192 by 1.7 AP (73.5 to 75.2) on COCO test-dev set. The HRNet-W48-384x288 equipped with UDP achieves 76.5 AP and sets a new state-of-the-art for human pose estimation. The source code is publicly available for further research.
-
-
-
-
-
-
+# The Devil is in the Details: Delving into Unbiased Data Processing for Human Pose Estimation
+
+
+
+
+UDP (CVPR'2020)
+
+```bibtex
+@InProceedings{Huang_2020_CVPR,
+ author = {Huang, Junjie and Zhu, Zheng and Guo, Feng and Huang, Guan},
+ title = {The Devil Is in the Details: Delving Into Unbiased Data Processing for Human Pose Estimation},
+ booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ month = {June},
+ year = {2020}
+}
+```
+
+
+
+## Abstract
+
+
+
+Recently, the leading performance of human pose estimation is dominated by top-down methods. Being a fundamental component in training and inference, data processing has not been systematically considered in pose estimation community, to the best of our knowledge. In this paper, we focus on this problem and find that the devil of top-down pose estimator is in the biased data processing. Specifically, by investigating the standard data processing in state-of-the-art approaches mainly including data transformation and encoding-decoding, we find that the results obtained by common flipping strategy are unaligned with the original ones in inference. Moreover, there is statistical error in standard encoding-decoding during both training and inference. Two problems couple together and significantly degrade the pose estimation performance. Based on quantitative analyses, we then formulate a principled way to tackle this dilemma. Data is processed in continuous space based on unit length (the intervals between pixels) instead of in discrete space with pixel, and a combined classification and regression approach is adopted to perform encoding-decoding. The Unbiased Data Processing (UDP) for human pose estimation can be achieved by combining the two together. UDP not only boosts the performance of existing methods by a large margin but also plays a important role in result reproducing and future exploration. As a model-agnostic approach, UDP promotes SimpleBaseline-ResNet50-256x192 by 1.5 AP (70.2 to 71.7) and HRNet-W32-256x192 by 1.7 AP (73.5 to 75.2) on COCO test-dev set. The HRNet-W48-384x288 equipped with UDP achieves 76.5 AP and sets a new state-of-the-art for human pose estimation. The source code is publicly available for further research.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/videopose3d.md b/docs/src/papers/algorithms/videopose3d.md
index f8647e0ee8..fc427346ee 100644
--- a/docs/src/papers/algorithms/videopose3d.md
+++ b/docs/src/papers/algorithms/videopose3d.md
@@ -1,30 +1,30 @@
-# 3D human pose estimation in video with temporal convolutions and semi-supervised training
-
-
-
-
-VideoPose3D (CVPR'2019)
-
-```bibtex
-@inproceedings{pavllo20193d,
- title={3d human pose estimation in video with temporal convolutions and semi-supervised training},
- author={Pavllo, Dario and Feichtenhofer, Christoph and Grangier, David and Auli, Michael},
- booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
- pages={7753--7762},
- year={2019}
-}
-```
-
-
-
-## Abstract
-
-
-
-In this work, we demonstrate that 3D poses in video can be effectively estimated with a fully convolutional model based on dilated temporal convolutions over 2D keypoints. We also introduce back-projection, a simple and effective semi-supervised training method that leverages unlabeled video data. We start with predicted 2D keypoints for unlabeled video, then estimate 3D poses and finally back-project to the input 2D keypoints. In the supervised setting, our fully-convolutional model outperforms the previous best result from the literature by 6 mm mean per-joint position error on Human3.6M, corresponding to an error reduction of 11%, and the model also shows significant improvements on HumanEva-I. Moreover, experiments with back-projection show that it comfortably outperforms previous state-of-the-art results in semi-supervised settings where labeled data is scarce.
-
-
-
-
-
-
+# 3D human pose estimation in video with temporal convolutions and semi-supervised training
+
+
+
+
+VideoPose3D (CVPR'2019)
+
+```bibtex
+@inproceedings{pavllo20193d,
+ title={3d human pose estimation in video with temporal convolutions and semi-supervised training},
+ author={Pavllo, Dario and Feichtenhofer, Christoph and Grangier, David and Auli, Michael},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={7753--7762},
+ year={2019}
+}
+```
+
+
+
+## Abstract
+
+
+
+In this work, we demonstrate that 3D poses in video can be effectively estimated with a fully convolutional model based on dilated temporal convolutions over 2D keypoints. We also introduce back-projection, a simple and effective semi-supervised training method that leverages unlabeled video data. We start with predicted 2D keypoints for unlabeled video, then estimate 3D poses and finally back-project to the input 2D keypoints. In the supervised setting, our fully-convolutional model outperforms the previous best result from the literature by 6 mm mean per-joint position error on Human3.6M, corresponding to an error reduction of 11%, and the model also shows significant improvements on HumanEva-I. Moreover, experiments with back-projection show that it comfortably outperforms previous state-of-the-art results in semi-supervised settings where labeled data is scarce.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/vipnas.md b/docs/src/papers/algorithms/vipnas.md
index 5f52a8cac0..53058bf7bb 100644
--- a/docs/src/papers/algorithms/vipnas.md
+++ b/docs/src/papers/algorithms/vipnas.md
@@ -1,29 +1,29 @@
-# ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search
-
-
-
-
-ViPNAS (CVPR'2021)
-
-```bibtex
-@article{xu2021vipnas,
- title={ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search},
- author={Xu, Lumin and Guan, Yingda and Jin, Sheng and Liu, Wentao and Qian, Chen and Luo, Ping and Ouyang, Wanli and Wang, Xiaogang},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- year={2021}
-}
-```
-
-
-
-## Abstract
-
-
-
-Human pose estimation has achieved significant progress in recent years. However, most of the recent methods focus on improving accuracy using complicated models and ignoring real-time efficiency. To achieve a better trade-off between accuracy and efficiency, we propose a novel neural architecture search (NAS) method, termed ViPNAS, to search networks in both spatial and temporal levels for fast online video pose estimation. In the spatial level, we carefully design the search space with five different dimensions including network depth, width, kernel size, group number, and attentions. In the temporal level, we search from a series of temporal feature fusions to optimize the total accuracy and speed across multiple video frames. To the best of our knowledge, we are the first to search for the temporal feature fusion and automatic computation allocation in videos. Extensive experiments demonstrate the effectiveness of our approach on the challenging COCO2017 and PoseTrack2018 datasets. Our discovered model family, S-ViPNAS and T-ViPNAS, achieve significantly higher inference speed (CPU real-time) without sacrificing the accuracy compared to the previous state-of-the-art methods.
-
-
-
-
-
-
+# ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search
+
+
+
+
+ViPNAS (CVPR'2021)
+
+```bibtex
+@article{xu2021vipnas,
+ title={ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search},
+ author={Xu, Lumin and Guan, Yingda and Jin, Sheng and Liu, Wentao and Qian, Chen and Luo, Ping and Ouyang, Wanli and Wang, Xiaogang},
+ booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
+ year={2021}
+}
+```
+
+
+
+## Abstract
+
+
+
+Human pose estimation has achieved significant progress in recent years. However, most of the recent methods focus on improving accuracy using complicated models and ignoring real-time efficiency. To achieve a better trade-off between accuracy and efficiency, we propose a novel neural architecture search (NAS) method, termed ViPNAS, to search networks in both spatial and temporal levels for fast online video pose estimation. In the spatial level, we carefully design the search space with five different dimensions including network depth, width, kernel size, group number, and attentions. In the temporal level, we search from a series of temporal feature fusions to optimize the total accuracy and speed across multiple video frames. To the best of our knowledge, we are the first to search for the temporal feature fusion and automatic computation allocation in videos. Extensive experiments demonstrate the effectiveness of our approach on the challenging COCO2017 and PoseTrack2018 datasets. Our discovered model family, S-ViPNAS and T-ViPNAS, achieve significantly higher inference speed (CPU real-time) without sacrificing the accuracy compared to the previous state-of-the-art methods.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/vitpose.md b/docs/src/papers/algorithms/vitpose.md
index dd218a5f98..334df15d13 100644
--- a/docs/src/papers/algorithms/vitpose.md
+++ b/docs/src/papers/algorithms/vitpose.md
@@ -1,30 +1,30 @@
-# ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
-
-
-
-
-ViTPose (NeurIPS'2022)
-
-```bibtex
-@inproceedings{
- xu2022vitpose,
- title={ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation},
- author={Yufei Xu and Jing Zhang and Qiming Zhang and Dacheng Tao},
- booktitle={Advances in Neural Information Processing Systems},
- year={2022},
-}
-```
-
-
-
-## Abstract
-
-
-
-Although no specific domain knowledge is considered in the design, plain vision transformers have shown excellent performance in visual recognition tasks. However, little effort has been made to reveal the potential of such simple structures for pose estimation tasks. In this paper, we show the surprisingly good capabilities of plain vision transformers for pose estimation from various aspects, namely simplicity in model structure, scalability in model size, flexibility in training paradigm, and transferability of knowledge between models, through a simple baseline model called ViTPose. Specifically, ViTPose employs plain and non-hierarchical vision transformers as backbones to extract features for a given person instance and a lightweight decoder for pose estimation. It can be scaled up from 100M to 1B parameters by taking the advantages of the scalable model capacity and high parallelism of transformers, setting a new Pareto front between throughput and performance. Besides, ViTPose is very flexible regarding the attention type, input resolution, pre-training and finetuning strategy, as well as dealing with multiple pose tasks. We also empirically demonstrate that the knowledge of large ViTPose models can be easily transferred to small ones via a simple knowledge token. Experimental results show that our basic ViTPose model outperforms representative methods on the challenging MS COCO Keypoint Detection benchmark, while the largest model sets a new state-of-the-art.
-
-
-
-
-
-
+# ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
+
+
+
+
+ViTPose (NeurIPS'2022)
+
+```bibtex
+@inproceedings{
+ xu2022vitpose,
+ title={ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation},
+ author={Yufei Xu and Jing Zhang and Qiming Zhang and Dacheng Tao},
+ booktitle={Advances in Neural Information Processing Systems},
+ year={2022},
+}
+```
+
+
+
+## Abstract
+
+
+
+Although no specific domain knowledge is considered in the design, plain vision transformers have shown excellent performance in visual recognition tasks. However, little effort has been made to reveal the potential of such simple structures for pose estimation tasks. In this paper, we show the surprisingly good capabilities of plain vision transformers for pose estimation from various aspects, namely simplicity in model structure, scalability in model size, flexibility in training paradigm, and transferability of knowledge between models, through a simple baseline model called ViTPose. Specifically, ViTPose employs plain and non-hierarchical vision transformers as backbones to extract features for a given person instance and a lightweight decoder for pose estimation. It can be scaled up from 100M to 1B parameters by taking the advantages of the scalable model capacity and high parallelism of transformers, setting a new Pareto front between throughput and performance. Besides, ViTPose is very flexible regarding the attention type, input resolution, pre-training and finetuning strategy, as well as dealing with multiple pose tasks. We also empirically demonstrate that the knowledge of large ViTPose models can be easily transferred to small ones via a simple knowledge token. Experimental results show that our basic ViTPose model outperforms representative methods on the challenging MS COCO Keypoint Detection benchmark, while the largest model sets a new state-of-the-art.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/voxelpose.md b/docs/src/papers/algorithms/voxelpose.md
index 384f4ca1e5..421d49f896 100644
--- a/docs/src/papers/algorithms/voxelpose.md
+++ b/docs/src/papers/algorithms/voxelpose.md
@@ -1,29 +1,29 @@
-# VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment
-
-
-
-
-VoxelPose (ECCV'2020)
-
-```bibtex
-@inproceedings{tumultipose,
- title={VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment},
- author={Tu, Hanyue and Wang, Chunyu and Zeng, Wenjun},
- booktitle={ECCV},
- year={2020}
-}
-```
-
-
-
-## Abstract
-
-
-
-We present VoxelPose to estimate 3D poses of multiple people from multiple camera views. In contrast to the previous efforts which require to establish cross-view correspondence based on noisy and incomplete 2D pose estimates, VoxelPose directly operates in the 3D space therefore avoids making incorrect decisions in each camera view. To achieve this goal, features in all camera views are aggregated in the 3D voxel space and fed into Cuboid Proposal Network (CPN) to localize all people. Then we propose Pose Regression Network (PRN) to estimate a detailed 3D pose for each proposal. The approach is robust to occlusion which occurs frequently in practice. Without bells and whistles, it outperforms the previous methods on several public datasets.
-
-
-
-
-
-
+# VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment
+
+
+
+
+VoxelPose (ECCV'2020)
+
+```bibtex
+@inproceedings{tumultipose,
+ title={VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment},
+ author={Tu, Hanyue and Wang, Chunyu and Zeng, Wenjun},
+ booktitle={ECCV},
+ year={2020}
+}
+```
+
+
+
+## Abstract
+
+
+
+We present VoxelPose to estimate 3D poses of multiple people from multiple camera views. In contrast to the previous efforts which require to establish cross-view correspondence based on noisy and incomplete 2D pose estimates, VoxelPose directly operates in the 3D space therefore avoids making incorrect decisions in each camera view. To achieve this goal, features in all camera views are aggregated in the 3D voxel space and fed into Cuboid Proposal Network (CPN) to localize all people. Then we propose Pose Regression Network (PRN) to estimate a detailed 3D pose for each proposal. The approach is robust to occlusion which occurs frequently in practice. Without bells and whistles, it outperforms the previous methods on several public datasets.
+
+
+
+
+
+
diff --git a/docs/src/papers/algorithms/wingloss.md b/docs/src/papers/algorithms/wingloss.md
index 2aaa05722e..a0f0a35cfb 100644
--- a/docs/src/papers/algorithms/wingloss.md
+++ b/docs/src/papers/algorithms/wingloss.md
@@ -1,31 +1,31 @@
-# Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks
-
-
-
-
-Wingloss (CVPR'2018)
-
-```bibtex
-@inproceedings{feng2018wing,
- title={Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks},
- author={Feng, Zhen-Hua and Kittler, Josef and Awais, Muhammad and Huber, Patrik and Wu, Xiao-Jun},
- booktitle={Computer Vision and Pattern Recognition (CVPR), 2018 IEEE Conference on},
- year={2018},
- pages ={2235-2245},
- organization={IEEE}
-}
-```
-
-
-
-## Abstract
-
-
-
-We present a new loss function, namely Wing loss, for robust facial landmark localisation with Convolutional Neural Networks (CNNs). We first compare and analyse different loss functions including L2, L1 and smooth L1. The analysis of these loss functions suggests that, for the training of a CNN-based localisation model, more attention should be paid to small and medium range errors. To this end, we design a piece-wise loss function. The new loss amplifies the impact of errors from the interval (-w, w) by switching from L1 loss to a modified logarithm function. To address the problem of under-representation of samples with large out-of-plane head rotations in the training set, we propose a simple but effective boosting strategy, referred to as pose-based data balancing. In particular, we deal with the data imbalance problem by duplicating the minority training samples and perturbing them by injecting random image rotation, bounding box translation and other data augmentation approaches. Last, the proposed approach is extended to create a two-stage framework for robust facial landmark localisation. The experimental results obtained on AFLW and 300W demonstrate the merits of the Wing loss function, and prove the superiority of the proposed method over the state-of-the-art approaches.
-
-
-
-
-
-
+# Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks
+
+
+
+
+Wingloss (CVPR'2018)
+
+```bibtex
+@inproceedings{feng2018wing,
+ title={Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks},
+ author={Feng, Zhen-Hua and Kittler, Josef and Awais, Muhammad and Huber, Patrik and Wu, Xiao-Jun},
+ booktitle={Computer Vision and Pattern Recognition (CVPR), 2018 IEEE Conference on},
+ year={2018},
+ pages ={2235-2245},
+ organization={IEEE}
+}
+```
+
+
+
+## Abstract
+
+
+
+We present a new loss function, namely Wing loss, for robust facial landmark localisation with Convolutional Neural Networks (CNNs). We first compare and analyse different loss functions including L2, L1 and smooth L1. The analysis of these loss functions suggests that, for the training of a CNN-based localisation model, more attention should be paid to small and medium range errors. To this end, we design a piece-wise loss function. The new loss amplifies the impact of errors from the interval (-w, w) by switching from L1 loss to a modified logarithm function. To address the problem of under-representation of samples with large out-of-plane head rotations in the training set, we propose a simple but effective boosting strategy, referred to as pose-based data balancing. In particular, we deal with the data imbalance problem by duplicating the minority training samples and perturbing them by injecting random image rotation, bounding box translation and other data augmentation approaches. Last, the proposed approach is extended to create a two-stage framework for robust facial landmark localisation. The experimental results obtained on AFLW and 300W demonstrate the merits of the Wing loss function, and prove the superiority of the proposed method over the state-of-the-art approaches.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/alexnet.md b/docs/src/papers/backbones/alexnet.md
index d1ea753119..6b6c6a65db 100644
--- a/docs/src/papers/backbones/alexnet.md
+++ b/docs/src/papers/backbones/alexnet.md
@@ -1,30 +1,30 @@
-# Imagenet classification with deep convolutional neural networks
-
-
-
-
-AlexNet (NeurIPS'2012)
-
-```bibtex
-@inproceedings{krizhevsky2012imagenet,
- title={Imagenet classification with deep convolutional neural networks},
- author={Krizhevsky, Alex and Sutskever, Ilya and Hinton, Geoffrey E},
- booktitle={Advances in neural information processing systems},
- pages={1097--1105},
- year={2012}
-}
-```
-
-
-
-## Abstract
-
-
-
-We trained a large, deep convolutional neural network to classify the 1.2 million high-resolution images in the ImageNet LSVRC-2010 contest into the 1000 different classes. On the test data, we achieved top-1 and top-5 error rates of 37.5% and 17.0% which is considerably better than the previous state-of-the-art. The neural network, which has 60 million parameters and 650,000 neurons, consists of five convolutional layers, some of which are followed by max-pooling layers, and three fully-connected layers with a final 1000-way softmax. To make training faster, we used non-saturating neurons and a very efficient GPU implementation of the convolution operation. To reduce overfitting in the fully-connected layers we employed a recently-developed regularization method called "dropout" that proved to be very effective. We also entered a variant of this model in the ILSVRC-2012 competition and achieved a winning top-5 test error rate of 15.3%, compared to 26.2% achieved by the second-best entry
-
-
-
-
-
-
+# Imagenet classification with deep convolutional neural networks
+
+
+
+
+AlexNet (NeurIPS'2012)
+
+```bibtex
+@inproceedings{krizhevsky2012imagenet,
+ title={Imagenet classification with deep convolutional neural networks},
+ author={Krizhevsky, Alex and Sutskever, Ilya and Hinton, Geoffrey E},
+ booktitle={Advances in neural information processing systems},
+ pages={1097--1105},
+ year={2012}
+}
+```
+
+
+
+## Abstract
+
+
+
+We trained a large, deep convolutional neural network to classify the 1.2 million high-resolution images in the ImageNet LSVRC-2010 contest into the 1000 different classes. On the test data, we achieved top-1 and top-5 error rates of 37.5% and 17.0% which is considerably better than the previous state-of-the-art. The neural network, which has 60 million parameters and 650,000 neurons, consists of five convolutional layers, some of which are followed by max-pooling layers, and three fully-connected layers with a final 1000-way softmax. To make training faster, we used non-saturating neurons and a very efficient GPU implementation of the convolution operation. To reduce overfitting in the fully-connected layers we employed a recently-developed regularization method called "dropout" that proved to be very effective. We also entered a variant of this model in the ILSVRC-2012 competition and achieved a winning top-5 test error rate of 15.3%, compared to 26.2% achieved by the second-best entry
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/cpm.md b/docs/src/papers/backbones/cpm.md
index fb5dbfacec..ea2ac7f73a 100644
--- a/docs/src/papers/backbones/cpm.md
+++ b/docs/src/papers/backbones/cpm.md
@@ -1,30 +1,30 @@
-# Convolutional pose machines
-
-
-
-
-CPM (CVPR'2016)
-
-```bibtex
-@inproceedings{wei2016convolutional,
- title={Convolutional pose machines},
- author={Wei, Shih-En and Ramakrishna, Varun and Kanade, Takeo and Sheikh, Yaser},
- booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition},
- pages={4724--4732},
- year={2016}
-}
-```
-
-
-
-## Abstract
-
-
-
-We introduce associative embedding, a novel method for supervising convolutional neural networks for the task of detection and grouping. A number of computer vision problems can be framed in this manner including multi-person pose estimation, instance segmentation, and multi-object tracking. Usually the grouping of detections is achieved with multi-stage pipelines, instead we propose an approach that teaches a network to simultaneously output detections and group assignments. This technique can be easily integrated into any state-of-the-art network architecture that produces pixel-wise predictions. We show how to apply this method to both multi-person pose estimation and instance segmentation and report state-of-the-art performance for multi-person pose on the MPII and MS-COCO datasets.
-
-
-
-
-
-
+# Convolutional pose machines
+
+
+
+
+CPM (CVPR'2016)
+
+```bibtex
+@inproceedings{wei2016convolutional,
+ title={Convolutional pose machines},
+ author={Wei, Shih-En and Ramakrishna, Varun and Kanade, Takeo and Sheikh, Yaser},
+ booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition},
+ pages={4724--4732},
+ year={2016}
+}
+```
+
+
+
+## Abstract
+
+
+
+We introduce associative embedding, a novel method for supervising convolutional neural networks for the task of detection and grouping. A number of computer vision problems can be framed in this manner including multi-person pose estimation, instance segmentation, and multi-object tracking. Usually the grouping of detections is achieved with multi-stage pipelines, instead we propose an approach that teaches a network to simultaneously output detections and group assignments. This technique can be easily integrated into any state-of-the-art network architecture that produces pixel-wise predictions. We show how to apply this method to both multi-person pose estimation and instance segmentation and report state-of-the-art performance for multi-person pose on the MPII and MS-COCO datasets.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/higherhrnet.md b/docs/src/papers/backbones/higherhrnet.md
index c1d61c992a..feed6ea06d 100644
--- a/docs/src/papers/backbones/higherhrnet.md
+++ b/docs/src/papers/backbones/higherhrnet.md
@@ -1,30 +1,30 @@
-# HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation
-
-
-
-
-HigherHRNet (CVPR'2020)
-
-```bibtex
-@inproceedings{cheng2020higherhrnet,
- title={HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation},
- author={Cheng, Bowen and Xiao, Bin and Wang, Jingdong and Shi, Honghui and Huang, Thomas S and Zhang, Lei},
- booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
- pages={5386--5395},
- year={2020}
-}
-```
-
-
-
-## Abstract
-
-
-
-Bottom-up human pose estimation methods have difficulties in predicting the correct pose for small persons due to challenges in scale variation. In this paper, we present HigherHRNet: a novel bottom-up human pose estimation method for learning scale-aware representations using high-resolution feature pyramids. Equipped with multi-resolution supervision for training and multi-resolution aggregation for inference, the proposed approach is able to solve the scale variation challenge in bottom-up multi-person pose estimation and localize keypoints more precisely, especially for small person. The feature pyramid in HigherHRNet consists of feature map outputs from HRNet and upsampled higher-resolution outputs through a transposed convolution. HigherHRNet outperforms the previous best bottom-up method by 2.5% AP for medium person on COCO test-dev, showing its effectiveness in handling scale variation. Furthermore, HigherHRNet achieves new state-of-the-art result on COCO test-dev (70.5% AP) without using refinement or other post-processing techniques, surpassing all existing bottom-up methods. HigherHRNet even surpasses all top-down methods on CrowdPose test (67.6% AP), suggesting its robustness in crowded scene.
-
-
-
-
-
-
+# HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation
+
+
+
+
+HigherHRNet (CVPR'2020)
+
+```bibtex
+@inproceedings{cheng2020higherhrnet,
+ title={HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation},
+ author={Cheng, Bowen and Xiao, Bin and Wang, Jingdong and Shi, Honghui and Huang, Thomas S and Zhang, Lei},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={5386--5395},
+ year={2020}
+}
+```
+
+
+
+## Abstract
+
+
+
+Bottom-up human pose estimation methods have difficulties in predicting the correct pose for small persons due to challenges in scale variation. In this paper, we present HigherHRNet: a novel bottom-up human pose estimation method for learning scale-aware representations using high-resolution feature pyramids. Equipped with multi-resolution supervision for training and multi-resolution aggregation for inference, the proposed approach is able to solve the scale variation challenge in bottom-up multi-person pose estimation and localize keypoints more precisely, especially for small person. The feature pyramid in HigherHRNet consists of feature map outputs from HRNet and upsampled higher-resolution outputs through a transposed convolution. HigherHRNet outperforms the previous best bottom-up method by 2.5% AP for medium person on COCO test-dev, showing its effectiveness in handling scale variation. Furthermore, HigherHRNet achieves new state-of-the-art result on COCO test-dev (70.5% AP) without using refinement or other post-processing techniques, surpassing all existing bottom-up methods. HigherHRNet even surpasses all top-down methods on CrowdPose test (67.6% AP), suggesting its robustness in crowded scene.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/hourglass.md b/docs/src/papers/backbones/hourglass.md
index 15f4d4d3c6..c6c7e51592 100644
--- a/docs/src/papers/backbones/hourglass.md
+++ b/docs/src/papers/backbones/hourglass.md
@@ -1,31 +1,31 @@
-# Stacked hourglass networks for human pose estimation
-
-
-
-
-Hourglass (ECCV'2016)
-
-```bibtex
-@inproceedings{newell2016stacked,
- title={Stacked hourglass networks for human pose estimation},
- author={Newell, Alejandro and Yang, Kaiyu and Deng, Jia},
- booktitle={European conference on computer vision},
- pages={483--499},
- year={2016},
- organization={Springer}
-}
-```
-
-
-
-## Abstract
-
-
-
-This work introduces a novel convolutional network architecture for the task of human pose estimation. Features are processed across all scales and consolidated to best capture the various spatial relationships associated with the body. We show how repeated bottom-up, top-down processing used in conjunction with intermediate supervision is critical to improving the performance of the network. We refer to the architecture as a "stacked hourglass" network based on the successive steps of pooling and upsampling that are done to produce a final set of predictions. State-of-the-art results are achieved on the FLIC and MPII benchmarks outcompeting all recent methods.
-
-
-
-
-
-
+# Stacked hourglass networks for human pose estimation
+
+
+
+
+Hourglass (ECCV'2016)
+
+```bibtex
+@inproceedings{newell2016stacked,
+ title={Stacked hourglass networks for human pose estimation},
+ author={Newell, Alejandro and Yang, Kaiyu and Deng, Jia},
+ booktitle={European conference on computer vision},
+ pages={483--499},
+ year={2016},
+ organization={Springer}
+}
+```
+
+
+
+## Abstract
+
+
+
+This work introduces a novel convolutional network architecture for the task of human pose estimation. Features are processed across all scales and consolidated to best capture the various spatial relationships associated with the body. We show how repeated bottom-up, top-down processing used in conjunction with intermediate supervision is critical to improving the performance of the network. We refer to the architecture as a "stacked hourglass" network based on the successive steps of pooling and upsampling that are done to produce a final set of predictions. State-of-the-art results are achieved on the FLIC and MPII benchmarks outcompeting all recent methods.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/hrformer.md b/docs/src/papers/backbones/hrformer.md
index dfa7a13f6b..dd00bfea1f 100644
--- a/docs/src/papers/backbones/hrformer.md
+++ b/docs/src/papers/backbones/hrformer.md
@@ -1,39 +1,39 @@
-# HRFormer: High-Resolution Vision Transformer for Dense Predict
-
-
-
-
-HRFormer (NIPS'2021)
-
-```bibtex
-@article{yuan2021hrformer,
- title={HRFormer: High-Resolution Vision Transformer for Dense Predict},
- author={Yuan, Yuhui and Fu, Rao and Huang, Lang and Lin, Weihong and Zhang, Chao and Chen, Xilin and Wang, Jingdong},
- journal={Advances in Neural Information Processing Systems},
- volume={34},
- year={2021}
-}
-```
-
-
-
-## Abstract
-
-
-
-We present a High-Resolution Transformer (HRFormer) that learns high-resolution representations for dense
-prediction tasks, in contrast to the original Vision Transformer that produces low-resolution representations
-and has high memory and computational cost. We take advantage of the multi-resolution parallel design
-introduced in high-resolution convolutional networks (HRNet), along with local-window self-attention
-that performs self-attention over small non-overlapping image windows, for improving the memory and
-computation efficiency. In addition, we introduce a convolution into the FFN to exchange information
-across the disconnected image windows. We demonstrate the effectiveness of the HighResolution Transformer
-on both human pose estimation and semantic segmentation tasks, e.g., HRFormer outperforms Swin
-transformer by 1.3 AP on COCO pose estimation with 50% fewer parameters and 30% fewer FLOPs.
-Code is available at: https://github.com/HRNet/HRFormer
-
-
-
-
-
-
+# HRFormer: High-Resolution Vision Transformer for Dense Predict
+
+
+
+
+HRFormer (NIPS'2021)
+
+```bibtex
+@article{yuan2021hrformer,
+ title={HRFormer: High-Resolution Vision Transformer for Dense Predict},
+ author={Yuan, Yuhui and Fu, Rao and Huang, Lang and Lin, Weihong and Zhang, Chao and Chen, Xilin and Wang, Jingdong},
+ journal={Advances in Neural Information Processing Systems},
+ volume={34},
+ year={2021}
+}
+```
+
+
+
+## Abstract
+
+
+
+We present a High-Resolution Transformer (HRFormer) that learns high-resolution representations for dense
+prediction tasks, in contrast to the original Vision Transformer that produces low-resolution representations
+and has high memory and computational cost. We take advantage of the multi-resolution parallel design
+introduced in high-resolution convolutional networks (HRNet), along with local-window self-attention
+that performs self-attention over small non-overlapping image windows, for improving the memory and
+computation efficiency. In addition, we introduce a convolution into the FFN to exchange information
+across the disconnected image windows. We demonstrate the effectiveness of the HighResolution Transformer
+on both human pose estimation and semantic segmentation tasks, e.g., HRFormer outperforms Swin
+transformer by 1.3 AP on COCO pose estimation with 50% fewer parameters and 30% fewer FLOPs.
+Code is available at: https://github.com/HRNet/HRFormer
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/hrnet.md b/docs/src/papers/backbones/hrnet.md
index 05a46f543e..e1fba7b601 100644
--- a/docs/src/papers/backbones/hrnet.md
+++ b/docs/src/papers/backbones/hrnet.md
@@ -1,32 +1,32 @@
-# Deep high-resolution representation learning for human pose estimation
-
-
-
-
-HRNet (CVPR'2019)
-
-```bibtex
-@inproceedings{sun2019deep,
- title={Deep high-resolution representation learning for human pose estimation},
- author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- pages={5693--5703},
- year={2019}
-}
-```
-
-
-
-## Abstract
-
-
-
-In this paper, we are interested in the human pose estimation problem with a focus on learning reliable highresolution representations. Most existing methods recover high-resolution representations from low-resolution representations produced by a high-to-low resolution network. Instead, our proposed network maintains high-resolution representations through the whole process. We start from a high-resolution subnetwork as the first stage, gradually add high-to-low resolution subnetworks one by one to form more stages, and connect the mutliresolution subnetworks in parallel. We conduct repeated multi-scale fusions such that each of the high-to-low resolution representations receives information from other parallel representations over and over, leading to rich highresolution representations. As a result, the predicted keypoint heatmap is potentially more accurate and spatially more precise. We empirically demonstrate the effectiveness
-of our network through the superior pose estimation results over two benchmark datasets: the COCO keypoint detection
-dataset and the MPII Human Pose dataset. In addition, we show the superiority of our network in pose tracking on the PoseTrack dataset.
-
-
-
-
-
-
+# Deep high-resolution representation learning for human pose estimation
+
+
+
+
+HRNet (CVPR'2019)
+
+```bibtex
+@inproceedings{sun2019deep,
+ title={Deep high-resolution representation learning for human pose estimation},
+ author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong},
+ booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
+ pages={5693--5703},
+ year={2019}
+}
+```
+
+
+
+## Abstract
+
+
+
+In this paper, we are interested in the human pose estimation problem with a focus on learning reliable highresolution representations. Most existing methods recover high-resolution representations from low-resolution representations produced by a high-to-low resolution network. Instead, our proposed network maintains high-resolution representations through the whole process. We start from a high-resolution subnetwork as the first stage, gradually add high-to-low resolution subnetworks one by one to form more stages, and connect the mutliresolution subnetworks in parallel. We conduct repeated multi-scale fusions such that each of the high-to-low resolution representations receives information from other parallel representations over and over, leading to rich highresolution representations. As a result, the predicted keypoint heatmap is potentially more accurate and spatially more precise. We empirically demonstrate the effectiveness
+of our network through the superior pose estimation results over two benchmark datasets: the COCO keypoint detection
+dataset and the MPII Human Pose dataset. In addition, we show the superiority of our network in pose tracking on the PoseTrack dataset.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/hrnetv2.md b/docs/src/papers/backbones/hrnetv2.md
index f2ed2a9c0c..f764d61def 100644
--- a/docs/src/papers/backbones/hrnetv2.md
+++ b/docs/src/papers/backbones/hrnetv2.md
@@ -1,31 +1,31 @@
-# Deep high-resolution representation learning for visual recognition
-
-
-
-
-HRNetv2 (TPAMI'2019)
-
-```bibtex
-@article{WangSCJDZLMTWLX19,
- title={Deep High-Resolution Representation Learning for Visual Recognition},
- author={Jingdong Wang and Ke Sun and Tianheng Cheng and
- Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and
- Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao},
- journal={TPAMI},
- year={2019}
-}
-```
-
-
-
-## Abstract
-
-
-
-High-resolution representations are essential for position-sensitive vision problems, such as human pose estimation, semantic segmentation, and object detection. Existing state-of-the-art frameworks first encode the input image as a low-resolution representation through a subnetwork that is formed by connecting high-to-low resolution convolutions in series (e.g., ResNet, VGGNet), and then recover the high-resolution representation from the encoded low-resolution representation. Instead, our proposed network, named as High-Resolution Network (HRNet), maintains high-resolution representations through the whole process. There are two key characteristics: (i) Connect the high-to-low resolution convolution streams in parallel and (ii) repeatedly exchange the information across resolutions. The benefit is that the resulting representation is semantically richer and spatially more precise. We show the superiority of the proposed HRNet in a wide range of applications, including human pose estimation, semantic segmentation, and object detection, suggesting that the HRNet is a stronger backbone for computer vision problems.
-
-
-
-
-
-
+# Deep high-resolution representation learning for visual recognition
+
+
+
+
+HRNetv2 (TPAMI'2019)
+
+```bibtex
+@article{WangSCJDZLMTWLX19,
+ title={Deep High-Resolution Representation Learning for Visual Recognition},
+ author={Jingdong Wang and Ke Sun and Tianheng Cheng and
+ Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and
+ Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao},
+ journal={TPAMI},
+ year={2019}
+}
+```
+
+
+
+## Abstract
+
+
+
+High-resolution representations are essential for position-sensitive vision problems, such as human pose estimation, semantic segmentation, and object detection. Existing state-of-the-art frameworks first encode the input image as a low-resolution representation through a subnetwork that is formed by connecting high-to-low resolution convolutions in series (e.g., ResNet, VGGNet), and then recover the high-resolution representation from the encoded low-resolution representation. Instead, our proposed network, named as High-Resolution Network (HRNet), maintains high-resolution representations through the whole process. There are two key characteristics: (i) Connect the high-to-low resolution convolution streams in parallel and (ii) repeatedly exchange the information across resolutions. The benefit is that the resulting representation is semantically richer and spatially more precise. We show the superiority of the proposed HRNet in a wide range of applications, including human pose estimation, semantic segmentation, and object detection, suggesting that the HRNet is a stronger backbone for computer vision problems.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/litehrnet.md b/docs/src/papers/backbones/litehrnet.md
index f446062caf..06c0077640 100644
--- a/docs/src/papers/backbones/litehrnet.md
+++ b/docs/src/papers/backbones/litehrnet.md
@@ -1,30 +1,30 @@
-# Lite-HRNet: A Lightweight High-Resolution Network
-
-
-
-
-LiteHRNet (CVPR'2021)
-
-```bibtex
-@inproceedings{Yulitehrnet21,
- title={Lite-HRNet: A Lightweight High-Resolution Network},
- author={Yu, Changqian and Xiao, Bin and Gao, Changxin and Yuan, Lu and Zhang, Lei and Sang, Nong and Wang, Jingdong},
- booktitle={CVPR},
- year={2021}
-}
-```
-
-
-
-## Abstract
-
-
-
-We present an efficient high-resolution network, Lite-HRNet, for human pose estimation. We start by simply applying the efficient shuffle block in ShuffleNet to HRNet (high-resolution network), yielding stronger performance over popular lightweight networks, such as MobileNet, ShuffleNet, and Small HRNet.
-We find that the heavily-used pointwise (1x1) convolutions in shuffle blocks become the computational bottleneck. We introduce a lightweight unit, conditional channel weighting, to replace costly pointwise (1x1) convolutions in shuffle blocks. The complexity of channel weighting is linear w.r.t the number of channels and lower than the quadratic time complexity for pointwise convolutions. Our solution learns the weights from all the channels and over multiple resolutions that are readily available in the parallel branches in HRNet. It uses the weights as the bridge to exchange information across channels and resolutions, compensating the role played by the pointwise (1x1) convolution. Lite-HRNet demonstrates superior results on human pose estimation over popular lightweight networks. Moreover, Lite-HRNet can be easily applied to semantic segmentation task in the same lightweight manner.
-
-
-
-
-
-
+# Lite-HRNet: A Lightweight High-Resolution Network
+
+
+
+
+LiteHRNet (CVPR'2021)
+
+```bibtex
+@inproceedings{Yulitehrnet21,
+ title={Lite-HRNet: A Lightweight High-Resolution Network},
+ author={Yu, Changqian and Xiao, Bin and Gao, Changxin and Yuan, Lu and Zhang, Lei and Sang, Nong and Wang, Jingdong},
+ booktitle={CVPR},
+ year={2021}
+}
+```
+
+
+
+## Abstract
+
+
+
+We present an efficient high-resolution network, Lite-HRNet, for human pose estimation. We start by simply applying the efficient shuffle block in ShuffleNet to HRNet (high-resolution network), yielding stronger performance over popular lightweight networks, such as MobileNet, ShuffleNet, and Small HRNet.
+We find that the heavily-used pointwise (1x1) convolutions in shuffle blocks become the computational bottleneck. We introduce a lightweight unit, conditional channel weighting, to replace costly pointwise (1x1) convolutions in shuffle blocks. The complexity of channel weighting is linear w.r.t the number of channels and lower than the quadratic time complexity for pointwise convolutions. Our solution learns the weights from all the channels and over multiple resolutions that are readily available in the parallel branches in HRNet. It uses the weights as the bridge to exchange information across channels and resolutions, compensating the role played by the pointwise (1x1) convolution. Lite-HRNet demonstrates superior results on human pose estimation over popular lightweight networks. Moreover, Lite-HRNet can be easily applied to semantic segmentation task in the same lightweight manner.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/mobilenetv2.md b/docs/src/papers/backbones/mobilenetv2.md
index 9456520d46..2e1677a52d 100644
--- a/docs/src/papers/backbones/mobilenetv2.md
+++ b/docs/src/papers/backbones/mobilenetv2.md
@@ -1,30 +1,30 @@
-# Mobilenetv2: Inverted residuals and linear bottlenecks
-
-
-
-
-MobilenetV2 (CVPR'2018)
-
-```bibtex
-@inproceedings{sandler2018mobilenetv2,
- title={Mobilenetv2: Inverted residuals and linear bottlenecks},
- author={Sandler, Mark and Howard, Andrew and Zhu, Menglong and Zhmoginov, Andrey and Chen, Liang-Chieh},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- pages={4510--4520},
- year={2018}
-}
-```
-
-
-
-## Abstract
-
-
-
-In this paper we describe a new mobile architecture, mbox{MobileNetV2}, that improves the state of the art performance of mobile models on multiple tasks and benchmarks as well as across a spectrum of different model sizes. We also describe efficient ways of applying these mobile models to object detection in a novel framework we call mbox{SSDLite}. Additionally, we demonstrate how to build mobile semantic segmentation models through a reduced form of mbox{DeepLabv3} which we call Mobile mbox{DeepLabv3}. is based on an inverted residual structure where the shortcut connections are between the thin bottleneck layers. The intermediate expansion layer uses lightweight depthwise convolutions to filter features as a source of non-linearity. Additionally, we find that it is important to remove non-linearities in the narrow layers in order to maintain representational power. We demonstrate that this improves performance and provide an intuition that led to this design. Finally, our approach allows decoupling of the input/output domains from the expressiveness of the transformation, which provides a convenient framework for further analysis. We measure our performance on mbox{ImageNet}~cite{Russakovsky:2015:ILS:2846547.2846559} classification, COCO object detection cite{COCO}, VOC image segmentation cite{PASCAL}. We evaluate the trade-offs between accuracy, and number of operations measured by multiply-adds (MAdd), as well as actual latency, and the number of parameters.
-
-
-
-
-
-
+# Mobilenetv2: Inverted residuals and linear bottlenecks
+
+
+
+
+MobilenetV2 (CVPR'2018)
+
+```bibtex
+@inproceedings{sandler2018mobilenetv2,
+ title={Mobilenetv2: Inverted residuals and linear bottlenecks},
+ author={Sandler, Mark and Howard, Andrew and Zhu, Menglong and Zhmoginov, Andrey and Chen, Liang-Chieh},
+ booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
+ pages={4510--4520},
+ year={2018}
+}
+```
+
+
+
+## Abstract
+
+
+
+In this paper we describe a new mobile architecture, mbox{MobileNetV2}, that improves the state of the art performance of mobile models on multiple tasks and benchmarks as well as across a spectrum of different model sizes. We also describe efficient ways of applying these mobile models to object detection in a novel framework we call mbox{SSDLite}. Additionally, we demonstrate how to build mobile semantic segmentation models through a reduced form of mbox{DeepLabv3} which we call Mobile mbox{DeepLabv3}. is based on an inverted residual structure where the shortcut connections are between the thin bottleneck layers. The intermediate expansion layer uses lightweight depthwise convolutions to filter features as a source of non-linearity. Additionally, we find that it is important to remove non-linearities in the narrow layers in order to maintain representational power. We demonstrate that this improves performance and provide an intuition that led to this design. Finally, our approach allows decoupling of the input/output domains from the expressiveness of the transformation, which provides a convenient framework for further analysis. We measure our performance on mbox{ImageNet}~cite{Russakovsky:2015:ILS:2846547.2846559} classification, COCO object detection cite{COCO}, VOC image segmentation cite{PASCAL}. We evaluate the trade-offs between accuracy, and number of operations measured by multiply-adds (MAdd), as well as actual latency, and the number of parameters.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/mspn.md b/docs/src/papers/backbones/mspn.md
index 1915cd3915..5824221603 100644
--- a/docs/src/papers/backbones/mspn.md
+++ b/docs/src/papers/backbones/mspn.md
@@ -1,29 +1,29 @@
-# Rethinking on multi-stage networks for human pose estimation
-
-
-
-
-MSPN (ArXiv'2019)
-
-```bibtex
-@article{li2019rethinking,
- title={Rethinking on Multi-Stage Networks for Human Pose Estimation},
- author={Li, Wenbo and Wang, Zhicheng and Yin, Binyi and Peng, Qixiang and Du, Yuming and Xiao, Tianzi and Yu, Gang and Lu, Hongtao and Wei, Yichen and Sun, Jian},
- journal={arXiv preprint arXiv:1901.00148},
- year={2019}
-}
-```
-
-
-
-## Abstract
-
-
-
-Existing pose estimation approaches fall into two categories: single-stage and multi-stage methods. While multi-stage methods are seemingly more suited for the task, their performance in current practice is not as good as single-stage methods. This work studies this issue. We argue that the current multi-stage methods' unsatisfactory performance comes from the insufficiency in various design choices. We propose several improvements, including the single-stage module design, cross stage feature aggregation, and coarse-to-fine supervision. The resulting method establishes the new state-of-the-art on both MS COCO and MPII Human Pose dataset, justifying the effectiveness of a multi-stage architecture. The source code is publicly available for further research.
-
-
-
-
-
-
+# Rethinking on multi-stage networks for human pose estimation
+
+
+
+
+MSPN (ArXiv'2019)
+
+```bibtex
+@article{li2019rethinking,
+ title={Rethinking on Multi-Stage Networks for Human Pose Estimation},
+ author={Li, Wenbo and Wang, Zhicheng and Yin, Binyi and Peng, Qixiang and Du, Yuming and Xiao, Tianzi and Yu, Gang and Lu, Hongtao and Wei, Yichen and Sun, Jian},
+ journal={arXiv preprint arXiv:1901.00148},
+ year={2019}
+}
+```
+
+
+
+## Abstract
+
+
+
+Existing pose estimation approaches fall into two categories: single-stage and multi-stage methods. While multi-stage methods are seemingly more suited for the task, their performance in current practice is not as good as single-stage methods. This work studies this issue. We argue that the current multi-stage methods' unsatisfactory performance comes from the insufficiency in various design choices. We propose several improvements, including the single-stage module design, cross stage feature aggregation, and coarse-to-fine supervision. The resulting method establishes the new state-of-the-art on both MS COCO and MPII Human Pose dataset, justifying the effectiveness of a multi-stage architecture. The source code is publicly available for further research.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/pvt.md b/docs/src/papers/backbones/pvt.md
index 303a126912..f4a5a6a85d 100644
--- a/docs/src/papers/backbones/pvt.md
+++ b/docs/src/papers/backbones/pvt.md
@@ -1,49 +1,49 @@
-# Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
-
-
-
-
-PVT (ICCV'2021)
-
-```bibtex
-@inproceedings{wang2021pyramid,
- title={Pyramid vision transformer: A versatile backbone for dense prediction without convolutions},
- author={Wang, Wenhai and Xie, Enze and Li, Xiang and Fan, Deng-Ping and Song, Kaitao and Liang, Ding and Lu, Tong and Luo, Ping and Shao, Ling},
- booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
- pages={568--578},
- year={2021}
-}
-```
-
-
-
-## Abstract
-
-
-
-Although using convolutional neural networks (CNNs) as backbones achieves great
-successes in computer vision, this work investigates a simple backbone network
-useful for many dense prediction tasks without convolutions. Unlike the
-recently-proposed Transformer model (e.g., ViT) that is specially designed for
-image classification, we propose Pyramid Vision Transformer~(PVT), which overcomes
-the difficulties of porting Transformer to various dense prediction tasks.
-PVT has several merits compared to prior arts. (1) Different from ViT that
-typically has low-resolution outputs and high computational and memory cost,
-PVT can be not only trained on dense partitions of the image to achieve high
-output resolution, which is important for dense predictions but also using a
-progressive shrinking pyramid to reduce computations of large feature maps.
-(2) PVT inherits the advantages from both CNN and Transformer, making it a
-unified backbone in various vision tasks without convolutions by simply replacing
-CNN backbones. (3) We validate PVT by conducting extensive experiments, showing
-that it boosts the performance of many downstream tasks, e.g., object detection,
-semantic, and instance segmentation. For example, with a comparable number of
-parameters, RetinaNet+PVT achieves 40.4 AP on the COCO dataset, surpassing
-RetinNet+ResNet50 (36.3 AP) by 4.1 absolute AP. We hope PVT could serve as an
-alternative and useful backbone for pixel-level predictions and facilitate future
-researches. Code is available at https://github.com/whai362/PVT .
-
-
-
-
-
-
+# Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
+
+
+
+
+PVT (ICCV'2021)
+
+```bibtex
+@inproceedings{wang2021pyramid,
+ title={Pyramid vision transformer: A versatile backbone for dense prediction without convolutions},
+ author={Wang, Wenhai and Xie, Enze and Li, Xiang and Fan, Deng-Ping and Song, Kaitao and Liang, Ding and Lu, Tong and Luo, Ping and Shao, Ling},
+ booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
+ pages={568--578},
+ year={2021}
+}
+```
+
+
+
+## Abstract
+
+
+
+Although using convolutional neural networks (CNNs) as backbones achieves great
+successes in computer vision, this work investigates a simple backbone network
+useful for many dense prediction tasks without convolutions. Unlike the
+recently-proposed Transformer model (e.g., ViT) that is specially designed for
+image classification, we propose Pyramid Vision Transformer~(PVT), which overcomes
+the difficulties of porting Transformer to various dense prediction tasks.
+PVT has several merits compared to prior arts. (1) Different from ViT that
+typically has low-resolution outputs and high computational and memory cost,
+PVT can be not only trained on dense partitions of the image to achieve high
+output resolution, which is important for dense predictions but also using a
+progressive shrinking pyramid to reduce computations of large feature maps.
+(2) PVT inherits the advantages from both CNN and Transformer, making it a
+unified backbone in various vision tasks without convolutions by simply replacing
+CNN backbones. (3) We validate PVT by conducting extensive experiments, showing
+that it boosts the performance of many downstream tasks, e.g., object detection,
+semantic, and instance segmentation. For example, with a comparable number of
+parameters, RetinaNet+PVT achieves 40.4 AP on the COCO dataset, surpassing
+RetinNet+ResNet50 (36.3 AP) by 4.1 absolute AP. We hope PVT could serve as an
+alternative and useful backbone for pixel-level predictions and facilitate future
+researches. Code is available at https://github.com/whai362/PVT .
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/pvtv2.md b/docs/src/papers/backbones/pvtv2.md
index 43657d8fb9..0d48709d5f 100644
--- a/docs/src/papers/backbones/pvtv2.md
+++ b/docs/src/papers/backbones/pvtv2.md
@@ -1,35 +1,35 @@
-# PVTv2: Improved Baselines with Pyramid Vision Transformer
-
-
-
-
-PVTV2 (CVMJ'2022)
-
-```bibtex
-@article{wang2022pvt,
- title={PVT v2: Improved baselines with Pyramid Vision Transformer},
- author={Wang, Wenhai and Xie, Enze and Li, Xiang and Fan, Deng-Ping and Song, Kaitao and Liang, Ding and Lu, Tong and Luo, Ping and Shao, Ling},
- journal={Computational Visual Media},
- pages={1--10},
- year={2022},
- publisher={Springer}
-}
-```
-
-
-
-## Abstract
-
-
-
-Transformer recently has presented encouraging progress in computer vision.
-In this work, we present new baselines by improving the original Pyramid
-Vision Transformer (PVTv1) by adding three designs, including (1) linear
-complexity attention layer, (2) overlapping patch embedding, and (3)
-convolutional feed-forward network. With these modifications, PVTv2 reduces
-the computational complexity of PVTv1 to linear and achieves significant
-improvements on fundamental vision tasks such as classification, detection,
-and segmentation. Notably, the proposed PVTv2 achieves comparable or better
-performances than recent works such as Swin Transformer. We hope this work
-will facilitate state-of-the-art Transformer researches in computer vision.
-Code is available at https://github.com/whai362/PVT .
+# PVTv2: Improved Baselines with Pyramid Vision Transformer
+
+
+
+
+PVTV2 (CVMJ'2022)
+
+```bibtex
+@article{wang2022pvt,
+ title={PVT v2: Improved baselines with Pyramid Vision Transformer},
+ author={Wang, Wenhai and Xie, Enze and Li, Xiang and Fan, Deng-Ping and Song, Kaitao and Liang, Ding and Lu, Tong and Luo, Ping and Shao, Ling},
+ journal={Computational Visual Media},
+ pages={1--10},
+ year={2022},
+ publisher={Springer}
+}
+```
+
+
+
+## Abstract
+
+
+
+Transformer recently has presented encouraging progress in computer vision.
+In this work, we present new baselines by improving the original Pyramid
+Vision Transformer (PVTv1) by adding three designs, including (1) linear
+complexity attention layer, (2) overlapping patch embedding, and (3)
+convolutional feed-forward network. With these modifications, PVTv2 reduces
+the computational complexity of PVTv1 to linear and achieves significant
+improvements on fundamental vision tasks such as classification, detection,
+and segmentation. Notably, the proposed PVTv2 achieves comparable or better
+performances than recent works such as Swin Transformer. We hope this work
+will facilitate state-of-the-art Transformer researches in computer vision.
+Code is available at https://github.com/whai362/PVT .
diff --git a/docs/src/papers/backbones/resnest.md b/docs/src/papers/backbones/resnest.md
index 748c94737a..ecd5c1b12d 100644
--- a/docs/src/papers/backbones/resnest.md
+++ b/docs/src/papers/backbones/resnest.md
@@ -1,29 +1,29 @@
-# ResNeSt: Split-Attention Networks
-
-
-
-
-ResNeSt (ArXiv'2020)
-
-```bibtex
-@article{zhang2020resnest,
- title={ResNeSt: Split-Attention Networks},
- author={Zhang, Hang and Wu, Chongruo and Zhang, Zhongyue and Zhu, Yi and Zhang, Zhi and Lin, Haibin and Sun, Yue and He, Tong and Muller, Jonas and Manmatha, R. and Li, Mu and Smola, Alexander},
- journal={arXiv preprint arXiv:2004.08955},
- year={2020}
-}
-```
-
-
-
-## Abstract
-
-
-
-It is well known that featuremap attention and multi-path representation are important for visual recognition. In this paper, we present a modularized architecture, which applies the channel-wise attention on different network branches to leverage their success in capturing cross-feature interactions and learning diverse representations. Our design results in a simple and unified computation block, which can be parameterized using only a few variables. Our model, named ResNeSt, outperforms EfficientNet in accuracy and latency trade-off on image classification. In addition, ResNeSt has achieved superior transfer learning results on several public benchmarks serving as the backbone, and has been adopted by the winning entries of COCO-LVIS challenge. The source code for complete system and pretrained models are publicly available.
-
-
-
-
-
-
+# ResNeSt: Split-Attention Networks
+
+
+
+
+ResNeSt (ArXiv'2020)
+
+```bibtex
+@article{zhang2020resnest,
+ title={ResNeSt: Split-Attention Networks},
+ author={Zhang, Hang and Wu, Chongruo and Zhang, Zhongyue and Zhu, Yi and Zhang, Zhi and Lin, Haibin and Sun, Yue and He, Tong and Muller, Jonas and Manmatha, R. and Li, Mu and Smola, Alexander},
+ journal={arXiv preprint arXiv:2004.08955},
+ year={2020}
+}
+```
+
+
+
+## Abstract
+
+
+
+It is well known that featuremap attention and multi-path representation are important for visual recognition. In this paper, we present a modularized architecture, which applies the channel-wise attention on different network branches to leverage their success in capturing cross-feature interactions and learning diverse representations. Our design results in a simple and unified computation block, which can be parameterized using only a few variables. Our model, named ResNeSt, outperforms EfficientNet in accuracy and latency trade-off on image classification. In addition, ResNeSt has achieved superior transfer learning results on several public benchmarks serving as the backbone, and has been adopted by the winning entries of COCO-LVIS challenge. The source code for complete system and pretrained models are publicly available.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/resnet.md b/docs/src/papers/backbones/resnet.md
index 86b91ffc38..875ec8c7a6 100644
--- a/docs/src/papers/backbones/resnet.md
+++ b/docs/src/papers/backbones/resnet.md
@@ -1,32 +1,32 @@
-# Deep residual learning for image recognition
-
-
-
-
-ResNet (CVPR'2016)
-
-```bibtex
-@inproceedings{he2016deep,
- title={Deep residual learning for image recognition},
- author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- pages={770--778},
- year={2016}
-}
-```
-
-
-
-## Abstract
-
-
-
-Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from
-considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers—8× deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers. The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC
-& COCO 2015 competitions1 , where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
-
-
-
-
-
-
+# Deep residual learning for image recognition
+
+
+
+
+ResNet (CVPR'2016)
+
+```bibtex
+@inproceedings{he2016deep,
+ title={Deep residual learning for image recognition},
+ author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian},
+ booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
+ pages={770--778},
+ year={2016}
+}
+```
+
+
+
+## Abstract
+
+
+
+Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from
+considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers—8× deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers. The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC
+& COCO 2015 competitions1 , where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/resnetv1d.md b/docs/src/papers/backbones/resnetv1d.md
index ebde55454e..d64141e47d 100644
--- a/docs/src/papers/backbones/resnetv1d.md
+++ b/docs/src/papers/backbones/resnetv1d.md
@@ -1,31 +1,31 @@
-# Bag of tricks for image classification with convolutional neural networks
-
-
-
-
-ResNetV1D (CVPR'2019)
-
-```bibtex
-@inproceedings{he2019bag,
- title={Bag of tricks for image classification with convolutional neural networks},
- author={He, Tong and Zhang, Zhi and Zhang, Hang and Zhang, Zhongyue and Xie, Junyuan and Li, Mu},
- booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
- pages={558--567},
- year={2019}
-}
-```
-
-
-
-## Abstract
-
-
-
-Much of the recent progress made in image classification research can be credited to training procedure refinements, such as changes in data augmentations and optimization methods. In the literature, however, most refinements are either briefly mentioned as implementation details or only visible in source code. In this paper, we will examine a collection of such refinements and empirically evaluate their impact on the final model accuracy through ablation study. We will show that, by combining these refinements together, we are able to improve various CNN models significantly. For example, we raise ResNet-50’s top-1 validation accuracy from 75.3% to 79.29% on ImageNet. We will also demonstrate that improvement on image classification accuracy leads to better transfer learning performance in other application domains such as object detection and semantic
-segmentation.
-
-
-
-
-
-
+# Bag of tricks for image classification with convolutional neural networks
+
+
+
+
+ResNetV1D (CVPR'2019)
+
+```bibtex
+@inproceedings{he2019bag,
+ title={Bag of tricks for image classification with convolutional neural networks},
+ author={He, Tong and Zhang, Zhi and Zhang, Hang and Zhang, Zhongyue and Xie, Junyuan and Li, Mu},
+ booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={558--567},
+ year={2019}
+}
+```
+
+
+
+## Abstract
+
+
+
+Much of the recent progress made in image classification research can be credited to training procedure refinements, such as changes in data augmentations and optimization methods. In the literature, however, most refinements are either briefly mentioned as implementation details or only visible in source code. In this paper, we will examine a collection of such refinements and empirically evaluate their impact on the final model accuracy through ablation study. We will show that, by combining these refinements together, we are able to improve various CNN models significantly. For example, we raise ResNet-50’s top-1 validation accuracy from 75.3% to 79.29% on ImageNet. We will also demonstrate that improvement on image classification accuracy leads to better transfer learning performance in other application domains such as object detection and semantic
+segmentation.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/resnext.md b/docs/src/papers/backbones/resnext.md
index 9803ee9bcd..6703c4c89a 100644
--- a/docs/src/papers/backbones/resnext.md
+++ b/docs/src/papers/backbones/resnext.md
@@ -1,30 +1,30 @@
-# Aggregated residual transformations for deep neural networks
-
-
-
-
-ResNext (CVPR'2017)
-
-```bibtex
-@inproceedings{xie2017aggregated,
- title={Aggregated residual transformations for deep neural networks},
- author={Xie, Saining and Girshick, Ross and Doll{\'a}r, Piotr and Tu, Zhuowen and He, Kaiming},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- pages={1492--1500},
- year={2017}
-}
-```
-
-
-
-## Abstract
-
-
-
-We present a simple, highly modularized network architecture for image classification. Our network is constructed by repeating a building block that aggregates a set of transformations with the same topology. Our simple design results in a homogeneous, multi-branch architecture that has only a few hyper-parameters to set. This strategy exposes a new dimension, which we call "cardinality" (the size of the set of transformations), as an essential factor in addition to the dimensions of depth and width. On the ImageNet-1K dataset, we empirically show that even under the restricted condition of maintaining complexity, increasing cardinality is able to improve classification accuracy. Moreover, increasing cardinality is more effective than going deeper or wider when we increase the capacity. Our models, named ResNeXt, are the foundations of our entry to the ILSVRC 2016 classification task in which we secured 2nd place. We further investigate ResNeXt on an ImageNet-5K set and the COCO detection set, also showing better results than its ResNet counterpart. The code and models are publicly available online.
-
-
-
-
-
-
+# Aggregated residual transformations for deep neural networks
+
+
+
+
+ResNext (CVPR'2017)
+
+```bibtex
+@inproceedings{xie2017aggregated,
+ title={Aggregated residual transformations for deep neural networks},
+ author={Xie, Saining and Girshick, Ross and Doll{\'a}r, Piotr and Tu, Zhuowen and He, Kaiming},
+ booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
+ pages={1492--1500},
+ year={2017}
+}
+```
+
+
+
+## Abstract
+
+
+
+We present a simple, highly modularized network architecture for image classification. Our network is constructed by repeating a building block that aggregates a set of transformations with the same topology. Our simple design results in a homogeneous, multi-branch architecture that has only a few hyper-parameters to set. This strategy exposes a new dimension, which we call "cardinality" (the size of the set of transformations), as an essential factor in addition to the dimensions of depth and width. On the ImageNet-1K dataset, we empirically show that even under the restricted condition of maintaining complexity, increasing cardinality is able to improve classification accuracy. Moreover, increasing cardinality is more effective than going deeper or wider when we increase the capacity. Our models, named ResNeXt, are the foundations of our entry to the ILSVRC 2016 classification task in which we secured 2nd place. We further investigate ResNeXt on an ImageNet-5K set and the COCO detection set, also showing better results than its ResNet counterpart. The code and models are publicly available online.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/rsn.md b/docs/src/papers/backbones/rsn.md
index b1fb1ea913..d8af907926 100644
--- a/docs/src/papers/backbones/rsn.md
+++ b/docs/src/papers/backbones/rsn.md
@@ -1,31 +1,31 @@
-# Learning delicate local representations for multi-person pose estimation
-
-
-
-
-RSN (ECCV'2020)
-
-```bibtex
-@misc{cai2020learning,
- title={Learning Delicate Local Representations for Multi-Person Pose Estimation},
- author={Yuanhao Cai and Zhicheng Wang and Zhengxiong Luo and Binyi Yin and Angang Du and Haoqian Wang and Xinyu Zhou and Erjin Zhou and Xiangyu Zhang and Jian Sun},
- year={2020},
- eprint={2003.04030},
- archivePrefix={arXiv},
- primaryClass={cs.CV}
-}
-```
-
-
-
-## Abstract
-
-
-
-In this paper, we propose a novel method called Residual Steps Network (RSN). RSN aggregates features with the same spatial size (Intra-level features) efficiently to obtain delicate local representations, which retain rich low-level spatial information and result in precise keypoint localization. Additionally, we observe the output features contribute differently to final performance. To tackle this problem, we propose an efficient attention mechanism - Pose Refine Machine (PRM) to make a trade-off between local and global representations in output features and further refine the keypoint locations. Our approach won the 1st place of COCO Keypoint Challenge 2019 and achieves state-of-the-art results on both COCO and MPII benchmarks, without using extra training data and pretrained model. Our single model achieves 78.6 on COCO test-dev, 93.0 on MPII test dataset. Ensembled models achieve 79.2 on COCO test-dev, 77.1 on COCO test-challenge dataset.
-
-
-
-
-
-
+# Learning delicate local representations for multi-person pose estimation
+
+
+
+
+RSN (ECCV'2020)
+
+```bibtex
+@misc{cai2020learning,
+ title={Learning Delicate Local Representations for Multi-Person Pose Estimation},
+ author={Yuanhao Cai and Zhicheng Wang and Zhengxiong Luo and Binyi Yin and Angang Du and Haoqian Wang and Xinyu Zhou and Erjin Zhou and Xiangyu Zhang and Jian Sun},
+ year={2020},
+ eprint={2003.04030},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+}
+```
+
+
+
+## Abstract
+
+
+
+In this paper, we propose a novel method called Residual Steps Network (RSN). RSN aggregates features with the same spatial size (Intra-level features) efficiently to obtain delicate local representations, which retain rich low-level spatial information and result in precise keypoint localization. Additionally, we observe the output features contribute differently to final performance. To tackle this problem, we propose an efficient attention mechanism - Pose Refine Machine (PRM) to make a trade-off between local and global representations in output features and further refine the keypoint locations. Our approach won the 1st place of COCO Keypoint Challenge 2019 and achieves state-of-the-art results on both COCO and MPII benchmarks, without using extra training data and pretrained model. Our single model achieves 78.6 on COCO test-dev, 93.0 on MPII test dataset. Ensembled models achieve 79.2 on COCO test-dev, 77.1 on COCO test-challenge dataset.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/scnet.md b/docs/src/papers/backbones/scnet.md
index 043c144111..24f13e82b8 100644
--- a/docs/src/papers/backbones/scnet.md
+++ b/docs/src/papers/backbones/scnet.md
@@ -1,30 +1,30 @@
-# Improving Convolutional Networks with Self-Calibrated Convolutions
-
-
-
-
-SCNet (CVPR'2020)
-
-```bibtex
-@inproceedings{liu2020improving,
- title={Improving Convolutional Networks with Self-Calibrated Convolutions},
- author={Liu, Jiang-Jiang and Hou, Qibin and Cheng, Ming-Ming and Wang, Changhu and Feng, Jiashi},
- booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
- pages={10096--10105},
- year={2020}
-}
-```
-
-
-
-## Abstract
-
-
-
-Recent advances on CNNs are mostly devoted to designing more complex architectures to enhance their representation learning capacity. In this paper, we consider how to improve the basic convolutional feature transformation process of CNNs without tuning the model architectures. To this end, we present a novel self-calibrated convolutions that explicitly expand fields-of-view of each convolutional layers through internal communications and hence enrich the output features. In particular, unlike the standard convolutions that fuse spatial and channel-wise information using small kernels (e.g., 3x3), self-calibrated convolutions adaptively build long-range spatial and inter-channel dependencies around each spatial location through a novel self-calibration operation. Thus, it can help CNNs generate more discriminative representations by explicitly incorporating richer information. Our self-calibrated convolution design is simple and generic, and can be easily applied to augment standard convolutional layers without introducing extra parameters and complexity. Extensive experiments demonstrate that when applying self-calibrated convolutions into different backbones, our networks can significantly improve the baseline models in a variety of vision tasks, including image recognition, object detection, instance segmentation, and keypoint detection, with no need to change the network architectures. We hope this work could provide a promising way for future research in designing novel convolutional feature transformations for improving convolutional networks. Code is available on the project page.
-
-
-
-
-
-
+# Improving Convolutional Networks with Self-Calibrated Convolutions
+
+
+
+
+SCNet (CVPR'2020)
+
+```bibtex
+@inproceedings{liu2020improving,
+ title={Improving Convolutional Networks with Self-Calibrated Convolutions},
+ author={Liu, Jiang-Jiang and Hou, Qibin and Cheng, Ming-Ming and Wang, Changhu and Feng, Jiashi},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={10096--10105},
+ year={2020}
+}
+```
+
+
+
+## Abstract
+
+
+
+Recent advances on CNNs are mostly devoted to designing more complex architectures to enhance their representation learning capacity. In this paper, we consider how to improve the basic convolutional feature transformation process of CNNs without tuning the model architectures. To this end, we present a novel self-calibrated convolutions that explicitly expand fields-of-view of each convolutional layers through internal communications and hence enrich the output features. In particular, unlike the standard convolutions that fuse spatial and channel-wise information using small kernels (e.g., 3x3), self-calibrated convolutions adaptively build long-range spatial and inter-channel dependencies around each spatial location through a novel self-calibration operation. Thus, it can help CNNs generate more discriminative representations by explicitly incorporating richer information. Our self-calibrated convolution design is simple and generic, and can be easily applied to augment standard convolutional layers without introducing extra parameters and complexity. Extensive experiments demonstrate that when applying self-calibrated convolutions into different backbones, our networks can significantly improve the baseline models in a variety of vision tasks, including image recognition, object detection, instance segmentation, and keypoint detection, with no need to change the network architectures. We hope this work could provide a promising way for future research in designing novel convolutional feature transformations for improving convolutional networks. Code is available on the project page.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/seresnet.md b/docs/src/papers/backbones/seresnet.md
index 32295324d3..fcf1db99a8 100644
--- a/docs/src/papers/backbones/seresnet.md
+++ b/docs/src/papers/backbones/seresnet.md
@@ -1,30 +1,30 @@
-# Squeeze-and-excitation networks
-
-
-
-
-SEResNet (CVPR'2018)
-
-```bibtex
-@inproceedings{hu2018squeeze,
- title={Squeeze-and-excitation networks},
- author={Hu, Jie and Shen, Li and Sun, Gang},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- pages={7132--7141},
- year={2018}
-}
-```
-
-
-
-## Abstract
-
-
-
-Convolutional neural networks are built upon the convolution operation, which extracts informative features by fusing spatial and channel-wise information together within local receptive fields. In order to boost the representational power of a network, several recent approaches have shown the benefit of enhancing spatial encoding. In this work, we focus on the channel relationship and propose a novel architectural unit, which we term the "Squeeze-and-Excitation" (SE) block, that adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels. We demonstrate that by stacking these blocks together, we can construct SENet architectures that generalise extremely well across challenging datasets. Crucially, we find that SE blocks produce significant performance improvements for existing state-of-the-art deep architectures at minimal additional computational cost. SENets formed the foundation of our ILSVRC 2017 classification submission which won first place and significantly reduced the top-5 error to 2.251%, achieving a ∼25% relative improvement over the winning entry of 2016. Code and models are available at https: //github.com/hujie-frank/SENet.
-
-
-
-
-
-
+# Squeeze-and-excitation networks
+
+
+
+
+SEResNet (CVPR'2018)
+
+```bibtex
+@inproceedings{hu2018squeeze,
+ title={Squeeze-and-excitation networks},
+ author={Hu, Jie and Shen, Li and Sun, Gang},
+ booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
+ pages={7132--7141},
+ year={2018}
+}
+```
+
+
+
+## Abstract
+
+
+
+Convolutional neural networks are built upon the convolution operation, which extracts informative features by fusing spatial and channel-wise information together within local receptive fields. In order to boost the representational power of a network, several recent approaches have shown the benefit of enhancing spatial encoding. In this work, we focus on the channel relationship and propose a novel architectural unit, which we term the "Squeeze-and-Excitation" (SE) block, that adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels. We demonstrate that by stacking these blocks together, we can construct SENet architectures that generalise extremely well across challenging datasets. Crucially, we find that SE blocks produce significant performance improvements for existing state-of-the-art deep architectures at minimal additional computational cost. SENets formed the foundation of our ILSVRC 2017 classification submission which won first place and significantly reduced the top-5 error to 2.251%, achieving a ∼25% relative improvement over the winning entry of 2016. Code and models are available at https: //github.com/hujie-frank/SENet.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/shufflenetv1.md b/docs/src/papers/backbones/shufflenetv1.md
index a314c9b709..d60a1af890 100644
--- a/docs/src/papers/backbones/shufflenetv1.md
+++ b/docs/src/papers/backbones/shufflenetv1.md
@@ -1,30 +1,30 @@
-# Shufflenet: An extremely efficient convolutional neural network for mobile devices
-
-
-
-
-ShufflenetV1 (CVPR'2018)
-
-```bibtex
-@inproceedings{zhang2018shufflenet,
- title={Shufflenet: An extremely efficient convolutional neural network for mobile devices},
- author={Zhang, Xiangyu and Zhou, Xinyu and Lin, Mengxiao and Sun, Jian},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- pages={6848--6856},
- year={2018}
-}
-```
-
-
-
-## Abstract
-
-
-
-We introduce an extremely computation-efficient CNN architecture named ShuffleNet, which is designed specially for mobile devices with very limited computing power (e.g., 10-150 MFLOPs). The new architecture utilizes two new operations, pointwise group convolution and channel shuffle, to greatly reduce computation cost while maintaining accuracy. Experiments on ImageNet classification and MS COCO object detection demonstrate the superior performance of ShuffleNet over other structures, e.g. lower top-1 error (absolute 7.8%) than recent MobileNet~cite{howard2017mobilenets} on ImageNet classification task, under the computation budget of 40 MFLOPs. On an ARM-based mobile device, ShuffleNet achieves $sim$13$ imes$ actual speedup over AlexNet while maintaining comparable accuracy.
-
-
-
-
-
-
+# Shufflenet: An extremely efficient convolutional neural network for mobile devices
+
+
+
+
+ShufflenetV1 (CVPR'2018)
+
+```bibtex
+@inproceedings{zhang2018shufflenet,
+ title={Shufflenet: An extremely efficient convolutional neural network for mobile devices},
+ author={Zhang, Xiangyu and Zhou, Xinyu and Lin, Mengxiao and Sun, Jian},
+ booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
+ pages={6848--6856},
+ year={2018}
+}
+```
+
+
+
+## Abstract
+
+
+
+We introduce an extremely computation-efficient CNN architecture named ShuffleNet, which is designed specially for mobile devices with very limited computing power (e.g., 10-150 MFLOPs). The new architecture utilizes two new operations, pointwise group convolution and channel shuffle, to greatly reduce computation cost while maintaining accuracy. Experiments on ImageNet classification and MS COCO object detection demonstrate the superior performance of ShuffleNet over other structures, e.g. lower top-1 error (absolute 7.8%) than recent MobileNet~cite{howard2017mobilenets} on ImageNet classification task, under the computation budget of 40 MFLOPs. On an ARM-based mobile device, ShuffleNet achieves $sim$13$ imes$ actual speedup over AlexNet while maintaining comparable accuracy.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/shufflenetv2.md b/docs/src/papers/backbones/shufflenetv2.md
index 834ee38bc0..5ecf6ac785 100644
--- a/docs/src/papers/backbones/shufflenetv2.md
+++ b/docs/src/papers/backbones/shufflenetv2.md
@@ -1,30 +1,30 @@
-# Shufflenet v2: Practical guidelines for efficient cnn architecture design
-
-
-
-
-ShufflenetV2 (ECCV'2018)
-
-```bibtex
-@inproceedings{ma2018shufflenet,
- title={Shufflenet v2: Practical guidelines for efficient cnn architecture design},
- author={Ma, Ningning and Zhang, Xiangyu and Zheng, Hai-Tao and Sun, Jian},
- booktitle={Proceedings of the European conference on computer vision (ECCV)},
- pages={116--131},
- year={2018}
-}
-```
-
-
-
-## Abstract
-
-
-
-Current network architecture design is mostly guided by the indirect metric of computation complexity, i.e., FLOPs. However, the direct metric, such as speed, also depends on the other factors such as memory access cost and platform characterics. Taking these factors into account, this work proposes practical guidelines for efficient network de- sign. Accordingly, a new architecture called ShuffleNet V2 is presented. Comprehensive experiments verify that it is the state-of-the-art in both speed and accuracy.
-
-
-
-
-
-
+# Shufflenet v2: Practical guidelines for efficient cnn architecture design
+
+
+
+
+ShufflenetV2 (ECCV'2018)
+
+```bibtex
+@inproceedings{ma2018shufflenet,
+ title={Shufflenet v2: Practical guidelines for efficient cnn architecture design},
+ author={Ma, Ningning and Zhang, Xiangyu and Zheng, Hai-Tao and Sun, Jian},
+ booktitle={Proceedings of the European conference on computer vision (ECCV)},
+ pages={116--131},
+ year={2018}
+}
+```
+
+
+
+## Abstract
+
+
+
+Current network architecture design is mostly guided by the indirect metric of computation complexity, i.e., FLOPs. However, the direct metric, such as speed, also depends on the other factors such as memory access cost and platform characterics. Taking these factors into account, this work proposes practical guidelines for efficient network de- sign. Accordingly, a new architecture called ShuffleNet V2 is presented. Comprehensive experiments verify that it is the state-of-the-art in both speed and accuracy.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/swin.md b/docs/src/papers/backbones/swin.md
index a2c04c0cf2..663e99fb62 100644
--- a/docs/src/papers/backbones/swin.md
+++ b/docs/src/papers/backbones/swin.md
@@ -1,30 +1,30 @@
-# Swin transformer: Hierarchical vision transformer using shifted windows
-
-
-
-
-Swin (ICCV'2021)
-
-```bibtex
-@inproceedings{liu2021swin,
- title={Swin transformer: Hierarchical vision transformer using shifted windows},
- author={Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining},
- booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
- pages={10012--10022},
- year={2021}
-}
-```
-
-
-
-## Abstract
-
-
-
-This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text. To address these differences, we propose a hierarchical Transformer whose representation is computed with Shifted windows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO testdev) and semantic segmentation (53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-theart by a large margin of +2.7 box AP and +2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones. The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures.
-
-
-
-
-
-
+# Swin transformer: Hierarchical vision transformer using shifted windows
+
+
+
+
+Swin (ICCV'2021)
+
+```bibtex
+@inproceedings{liu2021swin,
+ title={Swin transformer: Hierarchical vision transformer using shifted windows},
+ author={Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining},
+ booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
+ pages={10012--10022},
+ year={2021}
+}
+```
+
+
+
+## Abstract
+
+
+
+This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text. To address these differences, we propose a hierarchical Transformer whose representation is computed with Shifted windows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO testdev) and semantic segmentation (53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-theart by a large margin of +2.7 box AP and +2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones. The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/vgg.md b/docs/src/papers/backbones/vgg.md
index 3a92a46b98..8f9e9069c7 100644
--- a/docs/src/papers/backbones/vgg.md
+++ b/docs/src/papers/backbones/vgg.md
@@ -1,29 +1,29 @@
-# Very Deep Convolutional Networks for Large-Scale Image Recognition
-
-
-
-
-VGG (ICLR'2015)
-
-```bibtex
-@article{simonyan2014very,
- title={Very deep convolutional networks for large-scale image recognition},
- author={Simonyan, Karen and Zisserman, Andrew},
- journal={arXiv preprint arXiv:1409.1556},
- year={2014}
-}
-```
-
-
-
-## Abstract
-
-
-
-In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3x3) convolution filters, which shows that a significant improvement on the prior-art configurations can be achieved by pushing the depth to 16-19 weight layers. These findings were the basis of our ImageNet Challenge 2014 submission, where our team secured the first and the second places in the localisation and classification tracks respectively. We also show that our representations generalise well to other datasets, where they achieve state-of-the-art results. We have made our two best-performing ConvNet models publicly available to facilitate further research on the use of deep visual representations in computer vision.
-
-
-
-
-
-
+# Very Deep Convolutional Networks for Large-Scale Image Recognition
+
+
+
+
+VGG (ICLR'2015)
+
+```bibtex
+@article{simonyan2014very,
+ title={Very deep convolutional networks for large-scale image recognition},
+ author={Simonyan, Karen and Zisserman, Andrew},
+ journal={arXiv preprint arXiv:1409.1556},
+ year={2014}
+}
+```
+
+
+
+## Abstract
+
+
+
+In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3x3) convolution filters, which shows that a significant improvement on the prior-art configurations can be achieved by pushing the depth to 16-19 weight layers. These findings were the basis of our ImageNet Challenge 2014 submission, where our team secured the first and the second places in the localisation and classification tracks respectively. We also show that our representations generalise well to other datasets, where they achieve state-of-the-art results. We have made our two best-performing ConvNet models publicly available to facilitate further research on the use of deep visual representations in computer vision.
+
+
+
+
+
+
diff --git a/docs/src/papers/backbones/vipnas.md b/docs/src/papers/backbones/vipnas.md
index 5f52a8cac0..53058bf7bb 100644
--- a/docs/src/papers/backbones/vipnas.md
+++ b/docs/src/papers/backbones/vipnas.md
@@ -1,29 +1,29 @@
-# ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search
-
-
-
-
-ViPNAS (CVPR'2021)
-
-```bibtex
-@article{xu2021vipnas,
- title={ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search},
- author={Xu, Lumin and Guan, Yingda and Jin, Sheng and Liu, Wentao and Qian, Chen and Luo, Ping and Ouyang, Wanli and Wang, Xiaogang},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- year={2021}
-}
-```
-
-
-
-## Abstract
-
-
-
-Human pose estimation has achieved significant progress in recent years. However, most of the recent methods focus on improving accuracy using complicated models and ignoring real-time efficiency. To achieve a better trade-off between accuracy and efficiency, we propose a novel neural architecture search (NAS) method, termed ViPNAS, to search networks in both spatial and temporal levels for fast online video pose estimation. In the spatial level, we carefully design the search space with five different dimensions including network depth, width, kernel size, group number, and attentions. In the temporal level, we search from a series of temporal feature fusions to optimize the total accuracy and speed across multiple video frames. To the best of our knowledge, we are the first to search for the temporal feature fusion and automatic computation allocation in videos. Extensive experiments demonstrate the effectiveness of our approach on the challenging COCO2017 and PoseTrack2018 datasets. Our discovered model family, S-ViPNAS and T-ViPNAS, achieve significantly higher inference speed (CPU real-time) without sacrificing the accuracy compared to the previous state-of-the-art methods.
-
-
-
-
-
-
+# ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search
+
+
+
+
+ViPNAS (CVPR'2021)
+
+```bibtex
+@article{xu2021vipnas,
+ title={ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search},
+ author={Xu, Lumin and Guan, Yingda and Jin, Sheng and Liu, Wentao and Qian, Chen and Luo, Ping and Ouyang, Wanli and Wang, Xiaogang},
+ booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
+ year={2021}
+}
+```
+
+
+
+## Abstract
+
+
+
+Human pose estimation has achieved significant progress in recent years. However, most of the recent methods focus on improving accuracy using complicated models and ignoring real-time efficiency. To achieve a better trade-off between accuracy and efficiency, we propose a novel neural architecture search (NAS) method, termed ViPNAS, to search networks in both spatial and temporal levels for fast online video pose estimation. In the spatial level, we carefully design the search space with five different dimensions including network depth, width, kernel size, group number, and attentions. In the temporal level, we search from a series of temporal feature fusions to optimize the total accuracy and speed across multiple video frames. To the best of our knowledge, we are the first to search for the temporal feature fusion and automatic computation allocation in videos. Extensive experiments demonstrate the effectiveness of our approach on the challenging COCO2017 and PoseTrack2018 datasets. Our discovered model family, S-ViPNAS and T-ViPNAS, achieve significantly higher inference speed (CPU real-time) without sacrificing the accuracy compared to the previous state-of-the-art methods.
+
+
+
+
+
+
diff --git a/docs/src/papers/datasets/300w.md b/docs/src/papers/datasets/300w.md
index 7af778ee6d..b0cba72bae 100644
--- a/docs/src/papers/datasets/300w.md
+++ b/docs/src/papers/datasets/300w.md
@@ -1,20 +1,20 @@
-# 300 faces in-the-wild challenge: Database and results
-
-
-
-
-300W (IMAVIS'2016)
-
-```bibtex
-@article{sagonas2016300,
- title={300 faces in-the-wild challenge: Database and results},
- author={Sagonas, Christos and Antonakos, Epameinondas and Tzimiropoulos, Georgios and Zafeiriou, Stefanos and Pantic, Maja},
- journal={Image and vision computing},
- volume={47},
- pages={3--18},
- year={2016},
- publisher={Elsevier}
-}
-```
-
-
+# 300 faces in-the-wild challenge: Database and results
+
+
+
+
+300W (IMAVIS'2016)
+
+```bibtex
+@article{sagonas2016300,
+ title={300 faces in-the-wild challenge: Database and results},
+ author={Sagonas, Christos and Antonakos, Epameinondas and Tzimiropoulos, Georgios and Zafeiriou, Stefanos and Pantic, Maja},
+ journal={Image and vision computing},
+ volume={47},
+ pages={3--18},
+ year={2016},
+ publisher={Elsevier}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/aflw.md b/docs/src/papers/datasets/aflw.md
index f04f265c83..d5ee4a8820 100644
--- a/docs/src/papers/datasets/aflw.md
+++ b/docs/src/papers/datasets/aflw.md
@@ -1,19 +1,19 @@
-# Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization
-
-
-
-
-AFLW (ICCVW'2011)
-
-```bibtex
-@inproceedings{koestinger2011annotated,
- title={Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization},
- author={Koestinger, Martin and Wohlhart, Paul and Roth, Peter M and Bischof, Horst},
- booktitle={2011 IEEE international conference on computer vision workshops (ICCV workshops)},
- pages={2144--2151},
- year={2011},
- organization={IEEE}
-}
-```
-
-
+# Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization
+
+
+
+
+AFLW (ICCVW'2011)
+
+```bibtex
+@inproceedings{koestinger2011annotated,
+ title={Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization},
+ author={Koestinger, Martin and Wohlhart, Paul and Roth, Peter M and Bischof, Horst},
+ booktitle={2011 IEEE international conference on computer vision workshops (ICCV workshops)},
+ pages={2144--2151},
+ year={2011},
+ organization={IEEE}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/aic.md b/docs/src/papers/datasets/aic.md
index 5054609a39..8e79f814f8 100644
--- a/docs/src/papers/datasets/aic.md
+++ b/docs/src/papers/datasets/aic.md
@@ -1,17 +1,17 @@
-# Ai challenger: A large-scale dataset for going deeper in image understanding
-
-
-
-
-AI Challenger (ArXiv'2017)
-
-```bibtex
-@article{wu2017ai,
- title={Ai challenger: A large-scale dataset for going deeper in image understanding},
- author={Wu, Jiahong and Zheng, He and Zhao, Bo and Li, Yixin and Yan, Baoming and Liang, Rui and Wang, Wenjia and Zhou, Shipei and Lin, Guosen and Fu, Yanwei and others},
- journal={arXiv preprint arXiv:1711.06475},
- year={2017}
-}
-```
-
-
+# Ai challenger: A large-scale dataset for going deeper in image understanding
+
+
+
+
+AI Challenger (ArXiv'2017)
+
+```bibtex
+@article{wu2017ai,
+ title={Ai challenger: A large-scale dataset for going deeper in image understanding},
+ author={Wu, Jiahong and Zheng, He and Zhao, Bo and Li, Yixin and Yan, Baoming and Liang, Rui and Wang, Wenjia and Zhou, Shipei and Lin, Guosen and Fu, Yanwei and others},
+ journal={arXiv preprint arXiv:1711.06475},
+ year={2017}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/animalkingdom.md b/docs/src/papers/datasets/animalkingdom.md
index 64b5fe375a..815fa71e89 100644
--- a/docs/src/papers/datasets/animalkingdom.md
+++ b/docs/src/papers/datasets/animalkingdom.md
@@ -1,19 +1,19 @@
-# Animal Kingdom: A Large and Diverse Dataset for Animal Behavior Understanding
-
-
-
-
-Animal Kingdom (CVPR'2022)
-
-```bibtex
-@InProceedings{Ng_2022_CVPR,
- author = {Ng, Xun Long and Ong, Kian Eng and Zheng, Qichen and Ni, Yun and Yeo, Si Yong and Liu, Jun},
- title = {Animal Kingdom: A Large and Diverse Dataset for Animal Behavior Understanding},
- booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
- month = {June},
- year = {2022},
- pages = {19023-19034}
- }
-```
-
-
+# Animal Kingdom: A Large and Diverse Dataset for Animal Behavior Understanding
+
+
+
+
+Animal Kingdom (CVPR'2022)
+
+```bibtex
+@InProceedings{Ng_2022_CVPR,
+ author = {Ng, Xun Long and Ong, Kian Eng and Zheng, Qichen and Ni, Yun and Yeo, Si Yong and Liu, Jun},
+ title = {Animal Kingdom: A Large and Diverse Dataset for Animal Behavior Understanding},
+ booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ month = {June},
+ year = {2022},
+ pages = {19023-19034}
+ }
+```
+
+
diff --git a/docs/src/papers/datasets/animalpose.md b/docs/src/papers/datasets/animalpose.md
index 58303b8ee2..ab55c87895 100644
--- a/docs/src/papers/datasets/animalpose.md
+++ b/docs/src/papers/datasets/animalpose.md
@@ -1,18 +1,18 @@
-# Cross-Domain Adaptation for Animal Pose Estimation
-
-
-
-
-Animal-Pose (ICCV'2019)
-
-```bibtex
-@InProceedings{Cao_2019_ICCV,
- author = {Cao, Jinkun and Tang, Hongyang and Fang, Hao-Shu and Shen, Xiaoyong and Lu, Cewu and Tai, Yu-Wing},
- title = {Cross-Domain Adaptation for Animal Pose Estimation},
- booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
- month = {October},
- year = {2019}
-}
-```
-
-
+# Cross-Domain Adaptation for Animal Pose Estimation
+
+
+
+
+Animal-Pose (ICCV'2019)
+
+```bibtex
+@InProceedings{Cao_2019_ICCV,
+ author = {Cao, Jinkun and Tang, Hongyang and Fang, Hao-Shu and Shen, Xiaoyong and Lu, Cewu and Tai, Yu-Wing},
+ title = {Cross-Domain Adaptation for Animal Pose Estimation},
+ booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
+ month = {October},
+ year = {2019}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/ap10k.md b/docs/src/papers/datasets/ap10k.md
index e36988d833..73041fea55 100644
--- a/docs/src/papers/datasets/ap10k.md
+++ b/docs/src/papers/datasets/ap10k.md
@@ -1,19 +1,19 @@
-# AP-10K: A Benchmark for Animal Pose Estimation in the Wild
-
-
-
-
-AP-10K (NeurIPS'2021)
-
-```bibtex
-@misc{yu2021ap10k,
- title={AP-10K: A Benchmark for Animal Pose Estimation in the Wild},
- author={Hang Yu and Yufei Xu and Jing Zhang and Wei Zhao and Ziyu Guan and Dacheng Tao},
- year={2021},
- eprint={2108.12617},
- archivePrefix={arXiv},
- primaryClass={cs.CV}
-}
-```
-
-
+# AP-10K: A Benchmark for Animal Pose Estimation in the Wild
+
+
+
+
+AP-10K (NeurIPS'2021)
+
+```bibtex
+@misc{yu2021ap10k,
+ title={AP-10K: A Benchmark for Animal Pose Estimation in the Wild},
+ author={Hang Yu and Yufei Xu and Jing Zhang and Wei Zhao and Ziyu Guan and Dacheng Tao},
+ year={2021},
+ eprint={2108.12617},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/atrw.md b/docs/src/papers/datasets/atrw.md
index fe83ac0e94..4fed4ccd26 100644
--- a/docs/src/papers/datasets/atrw.md
+++ b/docs/src/papers/datasets/atrw.md
@@ -1,18 +1,18 @@
-# ATRW: A Benchmark for Amur Tiger Re-identification in the Wild
-
-
-
-
-ATRW (ACM MM'2020)
-
-```bibtex
-@inproceedings{li2020atrw,
- title={ATRW: A Benchmark for Amur Tiger Re-identification in the Wild},
- author={Li, Shuyuan and Li, Jianguo and Tang, Hanlin and Qian, Rui and Lin, Weiyao},
- booktitle={Proceedings of the 28th ACM International Conference on Multimedia},
- pages={2590--2598},
- year={2020}
-}
-```
-
-
+# ATRW: A Benchmark for Amur Tiger Re-identification in the Wild
+
+
+
+
+ATRW (ACM MM'2020)
+
+```bibtex
+@inproceedings{li2020atrw,
+ title={ATRW: A Benchmark for Amur Tiger Re-identification in the Wild},
+ author={Li, Shuyuan and Li, Jianguo and Tang, Hanlin and Qian, Rui and Lin, Weiyao},
+ booktitle={Proceedings of the 28th ACM International Conference on Multimedia},
+ pages={2590--2598},
+ year={2020}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/campus_and_shelf.md b/docs/src/papers/datasets/campus_and_shelf.md
index 8748be137e..4b7babe038 100644
--- a/docs/src/papers/datasets/campus_and_shelf.md
+++ b/docs/src/papers/datasets/campus_and_shelf.md
@@ -1,20 +1,20 @@
-# 3D Pictorial Structures for Multiple Human Pose Estimation
-
-
-
-
-Campus and Shelf (CVPR'2014)
-
-```bibtex
-@inproceedings {belagian14multi,
- title = {{3D} Pictorial Structures for Multiple Human Pose Estimation},
- author = {Belagiannis, Vasileios and Amin, Sikandar and Andriluka, Mykhaylo and Schiele, Bernt and Navab
- Nassir and Ilic, Slobodan},
- booktitle = {IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = {2014},
- month = {June},
- organization={IEEE}
-}
-```
-
-
+# 3D Pictorial Structures for Multiple Human Pose Estimation
+
+
+
+
+Campus and Shelf (CVPR'2014)
+
+```bibtex
+@inproceedings {belagian14multi,
+ title = {{3D} Pictorial Structures for Multiple Human Pose Estimation},
+ author = {Belagiannis, Vasileios and Amin, Sikandar and Andriluka, Mykhaylo and Schiele, Bernt and Navab
+ Nassir and Ilic, Slobodan},
+ booktitle = {IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year = {2014},
+ month = {June},
+ organization={IEEE}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/coco.md b/docs/src/papers/datasets/coco.md
index 8051dc756b..c595c38403 100644
--- a/docs/src/papers/datasets/coco.md
+++ b/docs/src/papers/datasets/coco.md
@@ -1,19 +1,19 @@
-# Microsoft coco: Common objects in context
-
-
-
-
-COCO (ECCV'2014)
-
-```bibtex
-@inproceedings{lin2014microsoft,
- title={Microsoft coco: Common objects in context},
- author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence},
- booktitle={European conference on computer vision},
- pages={740--755},
- year={2014},
- organization={Springer}
-}
-```
-
-
+# Microsoft coco: Common objects in context
+
+
+
+
+COCO (ECCV'2014)
+
+```bibtex
+@inproceedings{lin2014microsoft,
+ title={Microsoft coco: Common objects in context},
+ author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence},
+ booktitle={European conference on computer vision},
+ pages={740--755},
+ year={2014},
+ organization={Springer}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/coco_wholebody.md b/docs/src/papers/datasets/coco_wholebody.md
index 69cb2b98d1..0717a78f56 100644
--- a/docs/src/papers/datasets/coco_wholebody.md
+++ b/docs/src/papers/datasets/coco_wholebody.md
@@ -1,17 +1,17 @@
-# Whole-Body Human Pose Estimation in the Wild
-
-
-
-
-COCO-WholeBody (ECCV'2020)
-
-```bibtex
-@inproceedings{jin2020whole,
- title={Whole-Body Human Pose Estimation in the Wild},
- author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping},
- booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
- year={2020}
-}
-```
-
-
+# Whole-Body Human Pose Estimation in the Wild
+
+
+
+
+COCO-WholeBody (ECCV'2020)
+
+```bibtex
+@inproceedings{jin2020whole,
+ title={Whole-Body Human Pose Estimation in the Wild},
+ author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping},
+ booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
+ year={2020}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/coco_wholebody_face.md b/docs/src/papers/datasets/coco_wholebody_face.md
index 3e1d3d4501..9b48922d54 100644
--- a/docs/src/papers/datasets/coco_wholebody_face.md
+++ b/docs/src/papers/datasets/coco_wholebody_face.md
@@ -1,17 +1,17 @@
-# Whole-Body Human Pose Estimation in the Wild
-
-
-
-
-COCO-WholeBody-Face (ECCV'2020)
-
-```bibtex
-@inproceedings{jin2020whole,
- title={Whole-Body Human Pose Estimation in the Wild},
- author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping},
- booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
- year={2020}
-}
-```
-
-
+# Whole-Body Human Pose Estimation in the Wild
+
+
+
+
+COCO-WholeBody-Face (ECCV'2020)
+
+```bibtex
+@inproceedings{jin2020whole,
+ title={Whole-Body Human Pose Estimation in the Wild},
+ author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping},
+ booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
+ year={2020}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/coco_wholebody_hand.md b/docs/src/papers/datasets/coco_wholebody_hand.md
index 51e2169363..c2b2bb7c9d 100644
--- a/docs/src/papers/datasets/coco_wholebody_hand.md
+++ b/docs/src/papers/datasets/coco_wholebody_hand.md
@@ -1,17 +1,17 @@
-# Whole-Body Human Pose Estimation in the Wild
-
-
-
-
-COCO-WholeBody-Hand (ECCV'2020)
-
-```bibtex
-@inproceedings{jin2020whole,
- title={Whole-Body Human Pose Estimation in the Wild},
- author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping},
- booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
- year={2020}
-}
-```
-
-
+# Whole-Body Human Pose Estimation in the Wild
+
+
+
+
+COCO-WholeBody-Hand (ECCV'2020)
+
+```bibtex
+@inproceedings{jin2020whole,
+ title={Whole-Body Human Pose Estimation in the Wild},
+ author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping},
+ booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
+ year={2020}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/cofw.md b/docs/src/papers/datasets/cofw.md
index 20d29acdc7..3b712e7682 100644
--- a/docs/src/papers/datasets/cofw.md
+++ b/docs/src/papers/datasets/cofw.md
@@ -1,18 +1,18 @@
-# Robust face landmark estimation under occlusion
-
-
-
-
-COFW (ICCV'2013)
-
-```bibtex
-@inproceedings{burgos2013robust,
- title={Robust face landmark estimation under occlusion},
- author={Burgos-Artizzu, Xavier P and Perona, Pietro and Doll{\'a}r, Piotr},
- booktitle={Proceedings of the IEEE international conference on computer vision},
- pages={1513--1520},
- year={2013}
-}
-```
-
-
+# Robust face landmark estimation under occlusion
+
+
+
+
+COFW (ICCV'2013)
+
+```bibtex
+@inproceedings{burgos2013robust,
+ title={Robust face landmark estimation under occlusion},
+ author={Burgos-Artizzu, Xavier P and Perona, Pietro and Doll{\'a}r, Piotr},
+ booktitle={Proceedings of the IEEE international conference on computer vision},
+ pages={1513--1520},
+ year={2013}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/crowdpose.md b/docs/src/papers/datasets/crowdpose.md
index ee678aa74f..c5bce3a13b 100644
--- a/docs/src/papers/datasets/crowdpose.md
+++ b/docs/src/papers/datasets/crowdpose.md
@@ -1,17 +1,17 @@
-# CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark
-
-
-
-
-CrowdPose (CVPR'2019)
-
-```bibtex
-@article{li2018crowdpose,
- title={CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark},
- author={Li, Jiefeng and Wang, Can and Zhu, Hao and Mao, Yihuan and Fang, Hao-Shu and Lu, Cewu},
- journal={arXiv preprint arXiv:1812.00324},
- year={2018}
-}
-```
-
-
+# CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark
+
+
+
+
+CrowdPose (CVPR'2019)
+
+```bibtex
+@article{li2018crowdpose,
+ title={CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark},
+ author={Li, Jiefeng and Wang, Can and Zhu, Hao and Mao, Yihuan and Fang, Hao-Shu and Lu, Cewu},
+ journal={arXiv preprint arXiv:1812.00324},
+ year={2018}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/deepfashion.md b/docs/src/papers/datasets/deepfashion.md
index 3955cf3092..f661e8680f 100644
--- a/docs/src/papers/datasets/deepfashion.md
+++ b/docs/src/papers/datasets/deepfashion.md
@@ -1,35 +1,35 @@
-# DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations
-
-
-
-
-DeepFashion (CVPR'2016)
-
-```bibtex
-@inproceedings{liuLQWTcvpr16DeepFashion,
- author = {Liu, Ziwei and Luo, Ping and Qiu, Shi and Wang, Xiaogang and Tang, Xiaoou},
- title = {DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations},
- booktitle = {Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- month = {June},
- year = {2016}
-}
-```
-
-
-
-
-
-
-DeepFashion (ECCV'2016)
-
-```bibtex
-@inproceedings{liuYLWTeccv16FashionLandmark,
- author = {Liu, Ziwei and Yan, Sijie and Luo, Ping and Wang, Xiaogang and Tang, Xiaoou},
- title = {Fashion Landmark Detection in the Wild},
- booktitle = {European Conference on Computer Vision (ECCV)},
- month = {October},
- year = {2016}
- }
-```
-
-
+# DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations
+
+
+
+
+DeepFashion (CVPR'2016)
+
+```bibtex
+@inproceedings{liuLQWTcvpr16DeepFashion,
+ author = {Liu, Ziwei and Luo, Ping and Qiu, Shi and Wang, Xiaogang and Tang, Xiaoou},
+ title = {DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations},
+ booktitle = {Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
+ month = {June},
+ year = {2016}
+}
+```
+
+
+
+
+
+
+DeepFashion (ECCV'2016)
+
+```bibtex
+@inproceedings{liuYLWTeccv16FashionLandmark,
+ author = {Liu, Ziwei and Yan, Sijie and Luo, Ping and Wang, Xiaogang and Tang, Xiaoou},
+ title = {Fashion Landmark Detection in the Wild},
+ booktitle = {European Conference on Computer Vision (ECCV)},
+ month = {October},
+ year = {2016}
+ }
+```
+
+
diff --git a/docs/src/papers/datasets/fly.md b/docs/src/papers/datasets/fly.md
index ed1a9c148e..31071727c9 100644
--- a/docs/src/papers/datasets/fly.md
+++ b/docs/src/papers/datasets/fly.md
@@ -1,21 +1,21 @@
-# Fast animal pose estimation using deep neural networks
-
-
-
-
-Vinegar Fly (Nature Methods'2019)
-
-```bibtex
-@article{pereira2019fast,
- title={Fast animal pose estimation using deep neural networks},
- author={Pereira, Talmo D and Aldarondo, Diego E and Willmore, Lindsay and Kislin, Mikhail and Wang, Samuel S-H and Murthy, Mala and Shaevitz, Joshua W},
- journal={Nature methods},
- volume={16},
- number={1},
- pages={117--125},
- year={2019},
- publisher={Nature Publishing Group}
-}
-```
-
-
+# Fast animal pose estimation using deep neural networks
+
+
+
+
+Vinegar Fly (Nature Methods'2019)
+
+```bibtex
+@article{pereira2019fast,
+ title={Fast animal pose estimation using deep neural networks},
+ author={Pereira, Talmo D and Aldarondo, Diego E and Willmore, Lindsay and Kislin, Mikhail and Wang, Samuel S-H and Murthy, Mala and Shaevitz, Joshua W},
+ journal={Nature methods},
+ volume={16},
+ number={1},
+ pages={117--125},
+ year={2019},
+ publisher={Nature Publishing Group}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/freihand.md b/docs/src/papers/datasets/freihand.md
index ee08602069..3090989cb6 100644
--- a/docs/src/papers/datasets/freihand.md
+++ b/docs/src/papers/datasets/freihand.md
@@ -1,18 +1,18 @@
-# Freihand: A dataset for markerless capture of hand pose and shape from single rgb images
-
-
-
-
-FreiHand (ICCV'2019)
-
-```bibtex
-@inproceedings{zimmermann2019freihand,
- title={Freihand: A dataset for markerless capture of hand pose and shape from single rgb images},
- author={Zimmermann, Christian and Ceylan, Duygu and Yang, Jimei and Russell, Bryan and Argus, Max and Brox, Thomas},
- booktitle={Proceedings of the IEEE International Conference on Computer Vision},
- pages={813--822},
- year={2019}
-}
-```
-
-
+# Freihand: A dataset for markerless capture of hand pose and shape from single rgb images
+
+
+
+
+FreiHand (ICCV'2019)
+
+```bibtex
+@inproceedings{zimmermann2019freihand,
+ title={Freihand: A dataset for markerless capture of hand pose and shape from single rgb images},
+ author={Zimmermann, Christian and Ceylan, Duygu and Yang, Jimei and Russell, Bryan and Argus, Max and Brox, Thomas},
+ booktitle={Proceedings of the IEEE International Conference on Computer Vision},
+ pages={813--822},
+ year={2019}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/h36m.md b/docs/src/papers/datasets/h36m.md
index 143e15417c..c71de56fe9 100644
--- a/docs/src/papers/datasets/h36m.md
+++ b/docs/src/papers/datasets/h36m.md
@@ -1,22 +1,22 @@
-# Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments
-
-
-
-
-Human3.6M (TPAMI'2014)
-
-```bibtex
-@article{h36m_pami,
- author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian},
- title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments},
- journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
- publisher = {IEEE Computer Society},
- volume = {36},
- number = {7},
- pages = {1325-1339},
- month = {jul},
- year = {2014}
-}
-```
-
-
+# Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments
+
+
+
+
+Human3.6M (TPAMI'2014)
+
+```bibtex
+@article{h36m_pami,
+ author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian},
+ title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments},
+ journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
+ publisher = {IEEE Computer Society},
+ volume = {36},
+ number = {7},
+ pages = {1325-1339},
+ month = {jul},
+ year = {2014}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/halpe.md b/docs/src/papers/datasets/halpe.md
index f71793fdbd..ccd8dea010 100644
--- a/docs/src/papers/datasets/halpe.md
+++ b/docs/src/papers/datasets/halpe.md
@@ -1,17 +1,17 @@
-# PaStaNet: Toward Human Activity Knowledge Engine
-
-
-
-
-Halpe (CVPR'2020)
-
-```bibtex
-@inproceedings{li2020pastanet,
- title={PaStaNet: Toward Human Activity Knowledge Engine},
- author={Li, Yong-Lu and Xu, Liang and Liu, Xinpeng and Huang, Xijie and Xu, Yue and Wang, Shiyi and Fang, Hao-Shu and Ma, Ze and Chen, Mingyang and Lu, Cewu},
- booktitle={CVPR},
- year={2020}
-}
-```
-
-
+# PaStaNet: Toward Human Activity Knowledge Engine
+
+
+
+
+Halpe (CVPR'2020)
+
+```bibtex
+@inproceedings{li2020pastanet,
+ title={PaStaNet: Toward Human Activity Knowledge Engine},
+ author={Li, Yong-Lu and Xu, Liang and Liu, Xinpeng and Huang, Xijie and Xu, Yue and Wang, Shiyi and Fang, Hao-Shu and Ma, Ze and Chen, Mingyang and Lu, Cewu},
+ booktitle={CVPR},
+ year={2020}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/horse10.md b/docs/src/papers/datasets/horse10.md
index 94e559db51..e361810d68 100644
--- a/docs/src/papers/datasets/horse10.md
+++ b/docs/src/papers/datasets/horse10.md
@@ -1,18 +1,18 @@
-# Pretraining boosts out-of-domain robustness for pose estimation
-
-
-
-
-Horse-10 (WACV'2021)
-
-```bibtex
-@inproceedings{mathis2021pretraining,
- title={Pretraining boosts out-of-domain robustness for pose estimation},
- author={Mathis, Alexander and Biasi, Thomas and Schneider, Steffen and Yuksekgonul, Mert and Rogers, Byron and Bethge, Matthias and Mathis, Mackenzie W},
- booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
- pages={1859--1868},
- year={2021}
-}
-```
-
-
+# Pretraining boosts out-of-domain robustness for pose estimation
+
+
+
+
+Horse-10 (WACV'2021)
+
+```bibtex
+@inproceedings{mathis2021pretraining,
+ title={Pretraining boosts out-of-domain robustness for pose estimation},
+ author={Mathis, Alexander and Biasi, Thomas and Schneider, Steffen and Yuksekgonul, Mert and Rogers, Byron and Bethge, Matthias and Mathis, Mackenzie W},
+ booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
+ pages={1859--1868},
+ year={2021}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/human_art.md b/docs/src/papers/datasets/human_art.md
index dc39dabbad..f95416735a 100644
--- a/docs/src/papers/datasets/human_art.md
+++ b/docs/src/papers/datasets/human_art.md
@@ -1,16 +1,16 @@
-# Human-Art: A Versatile Human-Centric Dataset Bridging Natural and Artificial Scenes
-
-
-
-
-Human-Art (CVPR'2023)
-
-```bibtex
-@inproceedings{ju2023humanart,
- title={Human-Art: A Versatile Human-Centric Dataset Bridging Natural and Artificial Scenes},
- author={Ju, Xuan and Zeng, Ailing and Jianan, Wang and Qiang, Xu and Lei, Zhang},
- booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
- year={2023}}
-```
-
-
+# Human-Art: A Versatile Human-Centric Dataset Bridging Natural and Artificial Scenes
+
+
+
+
+Human-Art (CVPR'2023)
+
+```bibtex
+@inproceedings{ju2023humanart,
+ title={Human-Art: A Versatile Human-Centric Dataset Bridging Natural and Artificial Scenes},
+ author={Ju, Xuan and Zeng, Ailing and Jianan, Wang and Qiang, Xu and Lei, Zhang},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
+ year={2023}}
+```
+
+
diff --git a/docs/src/papers/datasets/interhand.md b/docs/src/papers/datasets/interhand.md
index 6b4458a01e..218a6bc82f 100644
--- a/docs/src/papers/datasets/interhand.md
+++ b/docs/src/papers/datasets/interhand.md
@@ -1,18 +1,18 @@
-# InterHand2.6M: A dataset and baseline for 3D interacting hand pose estimation from a single RGB image
-
-
-
-
-InterHand2.6M (ECCV'2020)
-
-```bibtex
-@article{moon2020interhand2,
- title={InterHand2.6M: A dataset and baseline for 3D interacting hand pose estimation from a single RGB image},
- author={Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu},
- journal={arXiv preprint arXiv:2008.09309},
- year={2020},
- publisher={Springer}
-}
-```
-
-
+# InterHand2.6M: A dataset and baseline for 3D interacting hand pose estimation from a single RGB image
+
+
+
+
+InterHand2.6M (ECCV'2020)
+
+```bibtex
+@article{moon2020interhand2,
+ title={InterHand2.6M: A dataset and baseline for 3D interacting hand pose estimation from a single RGB image},
+ author={Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu},
+ journal={arXiv preprint arXiv:2008.09309},
+ year={2020},
+ publisher={Springer}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/jhmdb.md b/docs/src/papers/datasets/jhmdb.md
index 890d788ab2..f589d83483 100644
--- a/docs/src/papers/datasets/jhmdb.md
+++ b/docs/src/papers/datasets/jhmdb.md
@@ -1,19 +1,19 @@
-# Towards understanding action recognition
-
-
-
-
-JHMDB (ICCV'2013)
-
-```bibtex
-@inproceedings{Jhuang:ICCV:2013,
- title = {Towards understanding action recognition},
- author = {H. Jhuang and J. Gall and S. Zuffi and C. Schmid and M. J. Black},
- booktitle = {International Conf. on Computer Vision (ICCV)},
- month = Dec,
- pages = {3192-3199},
- year = {2013}
-}
-```
-
-
+# Towards understanding action recognition
+
+
+
+
+JHMDB (ICCV'2013)
+
+```bibtex
+@inproceedings{Jhuang:ICCV:2013,
+ title = {Towards understanding action recognition},
+ author = {H. Jhuang and J. Gall and S. Zuffi and C. Schmid and M. J. Black},
+ booktitle = {International Conf. on Computer Vision (ICCV)},
+ month = Dec,
+ pages = {3192-3199},
+ year = {2013}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/lapa.md b/docs/src/papers/datasets/lapa.md
index f82c50ca22..183ef6f96b 100644
--- a/docs/src/papers/datasets/lapa.md
+++ b/docs/src/papers/datasets/lapa.md
@@ -1,18 +1,18 @@
-# A New Dataset and Boundary-Attention Semantic Segmentation for Face Parsing
-
-
-
-
-LaPa (AAAI'2020)
-
-```bibtex
-@inproceedings{liu2020new,
- title={A New Dataset and Boundary-Attention Semantic Segmentation for Face Parsing.},
- author={Liu, Yinglu and Shi, Hailin and Shen, Hao and Si, Yue and Wang, Xiaobo and Mei, Tao},
- booktitle={AAAI},
- pages={11637--11644},
- year={2020}
-}
-```
-
-
+# A New Dataset and Boundary-Attention Semantic Segmentation for Face Parsing
+
+
+
+
+LaPa (AAAI'2020)
+
+```bibtex
+@inproceedings{liu2020new,
+ title={A New Dataset and Boundary-Attention Semantic Segmentation for Face Parsing.},
+ author={Liu, Yinglu and Shi, Hailin and Shen, Hao and Si, Yue and Wang, Xiaobo and Mei, Tao},
+ booktitle={AAAI},
+ pages={11637--11644},
+ year={2020}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/locust.md b/docs/src/papers/datasets/locust.md
index 896ee03b83..f58316f3b7 100644
--- a/docs/src/papers/datasets/locust.md
+++ b/docs/src/papers/datasets/locust.md
@@ -1,20 +1,20 @@
-# DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning
-
-
-
-
-Desert Locust (Elife'2019)
-
-```bibtex
-@article{graving2019deepposekit,
- title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning},
- author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D},
- journal={Elife},
- volume={8},
- pages={e47994},
- year={2019},
- publisher={eLife Sciences Publications Limited}
-}
-```
-
-
+# DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning
+
+
+
+
+Desert Locust (Elife'2019)
+
+```bibtex
+@article{graving2019deepposekit,
+ title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning},
+ author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D},
+ journal={Elife},
+ volume={8},
+ pages={e47994},
+ year={2019},
+ publisher={eLife Sciences Publications Limited}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/macaque.md b/docs/src/papers/datasets/macaque.md
index be4bec1131..c913d6cd8d 100644
--- a/docs/src/papers/datasets/macaque.md
+++ b/docs/src/papers/datasets/macaque.md
@@ -1,18 +1,18 @@
-# MacaquePose: A novel ‘in the wild’macaque monkey pose dataset for markerless motion capture
-
-
-
-
-MacaquePose (bioRxiv'2020)
-
-```bibtex
-@article{labuguen2020macaquepose,
- title={MacaquePose: A novel ‘in the wild’macaque monkey pose dataset for markerless motion capture},
- author={Labuguen, Rollyn and Matsumoto, Jumpei and Negrete, Salvador and Nishimaru, Hiroshi and Nishijo, Hisao and Takada, Masahiko and Go, Yasuhiro and Inoue, Ken-ichi and Shibata, Tomohiro},
- journal={bioRxiv},
- year={2020},
- publisher={Cold Spring Harbor Laboratory}
-}
-```
-
-
+# MacaquePose: A novel ‘in the wild’macaque monkey pose dataset for markerless motion capture
+
+
+
+
+MacaquePose (bioRxiv'2020)
+
+```bibtex
+@article{labuguen2020macaquepose,
+ title={MacaquePose: A novel ‘in the wild’macaque monkey pose dataset for markerless motion capture},
+ author={Labuguen, Rollyn and Matsumoto, Jumpei and Negrete, Salvador and Nishimaru, Hiroshi and Nishijo, Hisao and Takada, Masahiko and Go, Yasuhiro and Inoue, Ken-ichi and Shibata, Tomohiro},
+ journal={bioRxiv},
+ year={2020},
+ publisher={Cold Spring Harbor Laboratory}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/mhp.md b/docs/src/papers/datasets/mhp.md
index 6dc5b17ccc..518d9fa003 100644
--- a/docs/src/papers/datasets/mhp.md
+++ b/docs/src/papers/datasets/mhp.md
@@ -1,18 +1,18 @@
-# Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing
-
-
-
-
-MHP (ACM MM'2018)
-
-```bibtex
-@inproceedings{zhao2018understanding,
- title={Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing},
- author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
- booktitle={Proceedings of the 26th ACM international conference on Multimedia},
- pages={792--800},
- year={2018}
-}
-```
-
-
+# Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing
+
+
+
+
+MHP (ACM MM'2018)
+
+```bibtex
+@inproceedings{zhao2018understanding,
+ title={Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing},
+ author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
+ booktitle={Proceedings of the 26th ACM international conference on Multimedia},
+ pages={792--800},
+ year={2018}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/mpi_inf_3dhp.md b/docs/src/papers/datasets/mpi_inf_3dhp.md
index 3a26d49fd5..4e93e83785 100644
--- a/docs/src/papers/datasets/mpi_inf_3dhp.md
+++ b/docs/src/papers/datasets/mpi_inf_3dhp.md
@@ -1,20 +1,20 @@
-# Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision
-
-
-
-
-MPI-INF-3DHP (3DV'2017)
-
-```bibtex
-@inproceedings{mono-3dhp2017,
- author = {Mehta, Dushyant and Rhodin, Helge and Casas, Dan and Fua, Pascal and Sotnychenko, Oleksandr and Xu, Weipeng and Theobalt, Christian},
- title = {Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision},
- booktitle = {3D Vision (3DV), 2017 Fifth International Conference on},
- url = {http://gvv.mpi-inf.mpg.de/3dhp_dataset},
- year = {2017},
- organization={IEEE},
- doi={10.1109/3dv.2017.00064},
-}
-```
-
-
+# Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision
+
+
+
+
+MPI-INF-3DHP (3DV'2017)
+
+```bibtex
+@inproceedings{mono-3dhp2017,
+ author = {Mehta, Dushyant and Rhodin, Helge and Casas, Dan and Fua, Pascal and Sotnychenko, Oleksandr and Xu, Weipeng and Theobalt, Christian},
+ title = {Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision},
+ booktitle = {3D Vision (3DV), 2017 Fifth International Conference on},
+ url = {http://gvv.mpi-inf.mpg.de/3dhp_dataset},
+ year = {2017},
+ organization={IEEE},
+ doi={10.1109/3dv.2017.00064},
+}
+```
+
+
diff --git a/docs/src/papers/datasets/mpii.md b/docs/src/papers/datasets/mpii.md
index e2df7cfd7d..f914f957f0 100644
--- a/docs/src/papers/datasets/mpii.md
+++ b/docs/src/papers/datasets/mpii.md
@@ -1,18 +1,18 @@
-# 2D Human Pose Estimation: New Benchmark and State of the Art Analysis
-
-
-
-
-MPII (CVPR'2014)
-
-```bibtex
-@inproceedings{andriluka14cvpr,
- author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt},
- title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = {2014},
- month = {June}
-}
-```
-
-
+# 2D Human Pose Estimation: New Benchmark and State of the Art Analysis
+
+
+
+
+MPII (CVPR'2014)
+
+```bibtex
+@inproceedings{andriluka14cvpr,
+ author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt},
+ title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis},
+ booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year = {2014},
+ month = {June}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/mpii_trb.md b/docs/src/papers/datasets/mpii_trb.md
index b3e96a77d2..0395c62f82 100644
--- a/docs/src/papers/datasets/mpii_trb.md
+++ b/docs/src/papers/datasets/mpii_trb.md
@@ -1,18 +1,18 @@
-# TRB: A Novel Triplet Representation for Understanding 2D Human Body
-
-
-
-
-MPII-TRB (ICCV'2019)
-
-```bibtex
-@inproceedings{duan2019trb,
- title={TRB: A Novel Triplet Representation for Understanding 2D Human Body},
- author={Duan, Haodong and Lin, Kwan-Yee and Jin, Sheng and Liu, Wentao and Qian, Chen and Ouyang, Wanli},
- booktitle={Proceedings of the IEEE International Conference on Computer Vision},
- pages={9479--9488},
- year={2019}
-}
-```
-
-
+# TRB: A Novel Triplet Representation for Understanding 2D Human Body
+
+
+
+
+MPII-TRB (ICCV'2019)
+
+```bibtex
+@inproceedings{duan2019trb,
+ title={TRB: A Novel Triplet Representation for Understanding 2D Human Body},
+ author={Duan, Haodong and Lin, Kwan-Yee and Jin, Sheng and Liu, Wentao and Qian, Chen and Ouyang, Wanli},
+ booktitle={Proceedings of the IEEE International Conference on Computer Vision},
+ pages={9479--9488},
+ year={2019}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/ochuman.md b/docs/src/papers/datasets/ochuman.md
index 5211c341e4..345a503613 100644
--- a/docs/src/papers/datasets/ochuman.md
+++ b/docs/src/papers/datasets/ochuman.md
@@ -1,18 +1,18 @@
-# Pose2seg: Detection free human instance segmentation
-
-
-
-
-OCHuman (CVPR'2019)
-
-```bibtex
-@inproceedings{zhang2019pose2seg,
- title={Pose2seg: Detection free human instance segmentation},
- author={Zhang, Song-Hai and Li, Ruilong and Dong, Xin and Rosin, Paul and Cai, Zixi and Han, Xi and Yang, Dingcheng and Huang, Haozhi and Hu, Shi-Min},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- pages={889--898},
- year={2019}
-}
-```
-
-
+# Pose2seg: Detection free human instance segmentation
+
+
+
+
+OCHuman (CVPR'2019)
+
+```bibtex
+@inproceedings{zhang2019pose2seg,
+ title={Pose2seg: Detection free human instance segmentation},
+ author={Zhang, Song-Hai and Li, Ruilong and Dong, Xin and Rosin, Paul and Cai, Zixi and Han, Xi and Yang, Dingcheng and Huang, Haozhi and Hu, Shi-Min},
+ booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
+ pages={889--898},
+ year={2019}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/onehand10k.md b/docs/src/papers/datasets/onehand10k.md
index 5710fda477..48b2e67f75 100644
--- a/docs/src/papers/datasets/onehand10k.md
+++ b/docs/src/papers/datasets/onehand10k.md
@@ -1,21 +1,21 @@
-# Mask-pose cascaded cnn for 2d hand pose estimation from single color image
-
-
-
-
-OneHand10K (TCSVT'2019)
-
-```bibtex
-@article{wang2018mask,
- title={Mask-pose cascaded cnn for 2d hand pose estimation from single color image},
- author={Wang, Yangang and Peng, Cong and Liu, Yebin},
- journal={IEEE Transactions on Circuits and Systems for Video Technology},
- volume={29},
- number={11},
- pages={3258--3268},
- year={2018},
- publisher={IEEE}
-}
-```
-
-
+# Mask-pose cascaded cnn for 2d hand pose estimation from single color image
+
+
+
+
+OneHand10K (TCSVT'2019)
+
+```bibtex
+@article{wang2018mask,
+ title={Mask-pose cascaded cnn for 2d hand pose estimation from single color image},
+ author={Wang, Yangang and Peng, Cong and Liu, Yebin},
+ journal={IEEE Transactions on Circuits and Systems for Video Technology},
+ volume={29},
+ number={11},
+ pages={3258--3268},
+ year={2018},
+ publisher={IEEE}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/panoptic.md b/docs/src/papers/datasets/panoptic.md
index 60719c4df9..b7ce0585b0 100644
--- a/docs/src/papers/datasets/panoptic.md
+++ b/docs/src/papers/datasets/panoptic.md
@@ -1,18 +1,18 @@
-# Hand keypoint detection in single images using multiview bootstrapping
-
-
-
-
-CMU Panoptic HandDB (CVPR'2017)
-
-```bibtex
-@inproceedings{simon2017hand,
- title={Hand keypoint detection in single images using multiview bootstrapping},
- author={Simon, Tomas and Joo, Hanbyul and Matthews, Iain and Sheikh, Yaser},
- booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition},
- pages={1145--1153},
- year={2017}
-}
-```
-
-
+# Hand keypoint detection in single images using multiview bootstrapping
+
+
+
+
+CMU Panoptic HandDB (CVPR'2017)
+
+```bibtex
+@inproceedings{simon2017hand,
+ title={Hand keypoint detection in single images using multiview bootstrapping},
+ author={Simon, Tomas and Joo, Hanbyul and Matthews, Iain and Sheikh, Yaser},
+ booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition},
+ pages={1145--1153},
+ year={2017}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/panoptic_body3d.md b/docs/src/papers/datasets/panoptic_body3d.md
index b7f45c8beb..3e7cfec289 100644
--- a/docs/src/papers/datasets/panoptic_body3d.md
+++ b/docs/src/papers/datasets/panoptic_body3d.md
@@ -1,17 +1,17 @@
-# Panoptic Studio: A Massively Multiview System for Social Motion Capture
-
-
-
-
-CMU Panoptic (ICCV'2015)
-
-```bibtex
-@Article = {joo_iccv_2015,
-author = {Hanbyul Joo, Hao Liu, Lei Tan, Lin Gui, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh},
-title = {Panoptic Studio: A Massively Multiview System for Social Motion Capture},
-booktitle = {ICCV},
-year = {2015}
-}
-```
-
-
+# Panoptic Studio: A Massively Multiview System for Social Motion Capture
+
+
+
+
+CMU Panoptic (ICCV'2015)
+
+```bibtex
+@Article = {joo_iccv_2015,
+author = {Hanbyul Joo, Hao Liu, Lei Tan, Lin Gui, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh},
+title = {Panoptic Studio: A Massively Multiview System for Social Motion Capture},
+booktitle = {ICCV},
+year = {2015}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/posetrack18.md b/docs/src/papers/datasets/posetrack18.md
index 90cfcb54f8..bc5a4f984e 100644
--- a/docs/src/papers/datasets/posetrack18.md
+++ b/docs/src/papers/datasets/posetrack18.md
@@ -1,18 +1,18 @@
-# Posetrack: A benchmark for human pose estimation and tracking
-
-
-
-
-PoseTrack18 (CVPR'2018)
-
-```bibtex
-@inproceedings{andriluka2018posetrack,
- title={Posetrack: A benchmark for human pose estimation and tracking},
- author={Andriluka, Mykhaylo and Iqbal, Umar and Insafutdinov, Eldar and Pishchulin, Leonid and Milan, Anton and Gall, Juergen and Schiele, Bernt},
- booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
- pages={5167--5176},
- year={2018}
-}
-```
-
-
+# Posetrack: A benchmark for human pose estimation and tracking
+
+
+
+
+PoseTrack18 (CVPR'2018)
+
+```bibtex
+@inproceedings{andriluka2018posetrack,
+ title={Posetrack: A benchmark for human pose estimation and tracking},
+ author={Andriluka, Mykhaylo and Iqbal, Umar and Insafutdinov, Eldar and Pishchulin, Leonid and Milan, Anton and Gall, Juergen and Schiele, Bernt},
+ booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={5167--5176},
+ year={2018}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/rhd.md b/docs/src/papers/datasets/rhd.md
index 1855037bdc..2e553497b9 100644
--- a/docs/src/papers/datasets/rhd.md
+++ b/docs/src/papers/datasets/rhd.md
@@ -1,19 +1,19 @@
-# Learning to Estimate 3D Hand Pose from Single RGB Images
-
-
-
-
-RHD (ICCV'2017)
-
-```bibtex
-@TechReport{zb2017hand,
- author={Christian Zimmermann and Thomas Brox},
- title={Learning to Estimate 3D Hand Pose from Single RGB Images},
- institution={arXiv:1705.01389},
- year={2017},
- note="https://arxiv.org/abs/1705.01389",
- url="https://lmb.informatik.uni-freiburg.de/projects/hand3d/"
-}
-```
-
-
+# Learning to Estimate 3D Hand Pose from Single RGB Images
+
+
+
+
+RHD (ICCV'2017)
+
+```bibtex
+@TechReport{zb2017hand,
+ author={Christian Zimmermann and Thomas Brox},
+ title={Learning to Estimate 3D Hand Pose from Single RGB Images},
+ institution={arXiv:1705.01389},
+ year={2017},
+ note="https://arxiv.org/abs/1705.01389",
+ url="https://lmb.informatik.uni-freiburg.de/projects/hand3d/"
+}
+```
+
+
diff --git a/docs/src/papers/datasets/wflw.md b/docs/src/papers/datasets/wflw.md
index 08c3ccced3..8ab9678437 100644
--- a/docs/src/papers/datasets/wflw.md
+++ b/docs/src/papers/datasets/wflw.md
@@ -1,18 +1,18 @@
-# Look at boundary: A boundary-aware face alignment algorithm
-
-
-
-
-WFLW (CVPR'2018)
-
-```bibtex
-@inproceedings{wu2018look,
- title={Look at boundary: A boundary-aware face alignment algorithm},
- author={Wu, Wayne and Qian, Chen and Yang, Shuo and Wang, Quan and Cai, Yici and Zhou, Qiang},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- pages={2129--2138},
- year={2018}
-}
-```
-
-
+# Look at boundary: A boundary-aware face alignment algorithm
+
+
+
+
+WFLW (CVPR'2018)
+
+```bibtex
+@inproceedings{wu2018look,
+ title={Look at boundary: A boundary-aware face alignment algorithm},
+ author={Wu, Wayne and Qian, Chen and Yang, Shuo and Wang, Quan and Cai, Yici and Zhou, Qiang},
+ booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
+ pages={2129--2138},
+ year={2018}
+}
+```
+
+
diff --git a/docs/src/papers/datasets/zebra.md b/docs/src/papers/datasets/zebra.md
index 2727e595fc..603c23a5bd 100644
--- a/docs/src/papers/datasets/zebra.md
+++ b/docs/src/papers/datasets/zebra.md
@@ -1,20 +1,20 @@
-# DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning
-
-
-
-
-Grévy’s Zebra (Elife'2019)
-
-```bibtex
-@article{graving2019deepposekit,
- title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning},
- author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D},
- journal={Elife},
- volume={8},
- pages={e47994},
- year={2019},
- publisher={eLife Sciences Publications Limited}
-}
-```
-
-
+# DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning
+
+
+
+
+Grévy’s Zebra (Elife'2019)
+
+```bibtex
+@article{graving2019deepposekit,
+ title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning},
+ author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D},
+ journal={Elife},
+ volume={8},
+ pages={e47994},
+ year={2019},
+ publisher={eLife Sciences Publications Limited}
+}
+```
+
+
diff --git a/docs/src/papers/techniques/albumentations.md b/docs/src/papers/techniques/albumentations.md
index 9d09a7a344..e78962433e 100644
--- a/docs/src/papers/techniques/albumentations.md
+++ b/docs/src/papers/techniques/albumentations.md
@@ -1,21 +1,21 @@
-# Albumentations: fast and flexible image augmentations
-
-
-
-
-Albumentations (Information'2020)
-
-```bibtex
-@article{buslaev2020albumentations,
- title={Albumentations: fast and flexible image augmentations},
- author={Buslaev, Alexander and Iglovikov, Vladimir I and Khvedchenya, Eugene and Parinov, Alex and Druzhinin, Mikhail and Kalinin, Alexandr A},
- journal={Information},
- volume={11},
- number={2},
- pages={125},
- year={2020},
- publisher={Multidisciplinary Digital Publishing Institute}
-}
-```
-
-
+# Albumentations: fast and flexible image augmentations
+
+
+
+
+Albumentations (Information'2020)
+
+```bibtex
+@article{buslaev2020albumentations,
+ title={Albumentations: fast and flexible image augmentations},
+ author={Buslaev, Alexander and Iglovikov, Vladimir I and Khvedchenya, Eugene and Parinov, Alex and Druzhinin, Mikhail and Kalinin, Alexandr A},
+ journal={Information},
+ volume={11},
+ number={2},
+ pages={125},
+ year={2020},
+ publisher={Multidisciplinary Digital Publishing Institute}
+}
+```
+
+
diff --git a/docs/src/papers/techniques/awingloss.md b/docs/src/papers/techniques/awingloss.md
index 4d4b93a87c..4633e32581 100644
--- a/docs/src/papers/techniques/awingloss.md
+++ b/docs/src/papers/techniques/awingloss.md
@@ -1,31 +1,31 @@
-# Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression
-
-
-
-
-AdaptiveWingloss (ICCV'2019)
-
-```bibtex
-@inproceedings{wang2019adaptive,
- title={Adaptive wing loss for robust face alignment via heatmap regression},
- author={Wang, Xinyao and Bo, Liefeng and Fuxin, Li},
- booktitle={Proceedings of the IEEE/CVF international conference on computer vision},
- pages={6971--6981},
- year={2019}
-}
-```
-
-
-
-## Abstract
-
-
-
-Heatmap regression with a deep network has become one of the mainstream approaches to localize facial landmarks. However, the loss function for heatmap regression is rarely studied. In this paper, we analyze the ideal loss function properties for heatmap regression in face alignment problems. Then we propose a novel loss function, named Adaptive Wing loss, that is able to adapt its shape to different types of ground truth heatmap pixels. This adaptability penalizes loss more on foreground pixels while less on background pixels. To address the imbalance between foreground and background pixels, we also propose Weighted Loss Map, which assigns high weights on foreground and difficult background pixels to help training process focus more on pixels that are crucial to landmark localization. To further improve face alignment accuracy, we introduce boundary prediction and CoordConv with boundary coordinates. Extensive experiments on different benchmarks, including COFW, 300W and WFLW, show our approach outperforms the state-of-the-art by a significant margin on
-various evaluation metrics. Besides, the Adaptive Wing loss also helps other heatmap regression tasks.
-
-
-
-
-
-
+# Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression
+
+
+
+
+AdaptiveWingloss (ICCV'2019)
+
+```bibtex
+@inproceedings{wang2019adaptive,
+ title={Adaptive wing loss for robust face alignment via heatmap regression},
+ author={Wang, Xinyao and Bo, Liefeng and Fuxin, Li},
+ booktitle={Proceedings of the IEEE/CVF international conference on computer vision},
+ pages={6971--6981},
+ year={2019}
+}
+```
+
+
+
+## Abstract
+
+
+
+Heatmap regression with a deep network has become one of the mainstream approaches to localize facial landmarks. However, the loss function for heatmap regression is rarely studied. In this paper, we analyze the ideal loss function properties for heatmap regression in face alignment problems. Then we propose a novel loss function, named Adaptive Wing loss, that is able to adapt its shape to different types of ground truth heatmap pixels. This adaptability penalizes loss more on foreground pixels while less on background pixels. To address the imbalance between foreground and background pixels, we also propose Weighted Loss Map, which assigns high weights on foreground and difficult background pixels to help training process focus more on pixels that are crucial to landmark localization. To further improve face alignment accuracy, we introduce boundary prediction and CoordConv with boundary coordinates. Extensive experiments on different benchmarks, including COFW, 300W and WFLW, show our approach outperforms the state-of-the-art by a significant margin on
+various evaluation metrics. Besides, the Adaptive Wing loss also helps other heatmap regression tasks.
+
+
+
+
+
+
diff --git a/docs/src/papers/techniques/dark.md b/docs/src/papers/techniques/dark.md
index 083b7596ab..94da433e29 100644
--- a/docs/src/papers/techniques/dark.md
+++ b/docs/src/papers/techniques/dark.md
@@ -1,30 +1,30 @@
-# Distribution-aware coordinate representation for human pose estimation
-
-
-
-
-DarkPose (CVPR'2020)
-
-```bibtex
-@inproceedings{zhang2020distribution,
- title={Distribution-aware coordinate representation for human pose estimation},
- author={Zhang, Feng and Zhu, Xiatian and Dai, Hanbin and Ye, Mao and Zhu, Ce},
- booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
- pages={7093--7102},
- year={2020}
-}
-```
-
-
-
-## Abstract
-
-
-
-While being the de facto standard coordinate representation for human pose estimation, heatmap has not been investigated in-depth. This work fills this gap. For the first time, we find that the process of decoding the predicted heatmaps into the final joint coordinates in the original image space is surprisingly significant for the performance. We further probe the design limitations of the standard coordinate decoding method, and propose a more principled distributionaware decoding method. Also, we improve the standard coordinate encoding process (i.e. transforming ground-truth coordinates to heatmaps) by generating unbiased/accurate heatmaps. Taking the two together, we formulate a novel Distribution-Aware coordinate Representation of Keypoints (DARK) method. Serving as a model-agnostic plug-in, DARK brings about significant performance boost to existing human pose estimation models. Extensive experiments show that DARK yields the best results on two common benchmarks, MPII and COCO. Besides, DARK achieves the 2nd place entry in the ICCV 2019 COCO Keypoints Challenge. The code is available online.
-
-
-
-
-
-
+# Distribution-aware coordinate representation for human pose estimation
+
+
+
+
+DarkPose (CVPR'2020)
+
+```bibtex
+@inproceedings{zhang2020distribution,
+ title={Distribution-aware coordinate representation for human pose estimation},
+ author={Zhang, Feng and Zhu, Xiatian and Dai, Hanbin and Ye, Mao and Zhu, Ce},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={7093--7102},
+ year={2020}
+}
+```
+
+
+
+## Abstract
+
+
+
+While being the de facto standard coordinate representation for human pose estimation, heatmap has not been investigated in-depth. This work fills this gap. For the first time, we find that the process of decoding the predicted heatmaps into the final joint coordinates in the original image space is surprisingly significant for the performance. We further probe the design limitations of the standard coordinate decoding method, and propose a more principled distributionaware decoding method. Also, we improve the standard coordinate encoding process (i.e. transforming ground-truth coordinates to heatmaps) by generating unbiased/accurate heatmaps. Taking the two together, we formulate a novel Distribution-Aware coordinate Representation of Keypoints (DARK) method. Serving as a model-agnostic plug-in, DARK brings about significant performance boost to existing human pose estimation models. Extensive experiments show that DARK yields the best results on two common benchmarks, MPII and COCO. Besides, DARK achieves the 2nd place entry in the ICCV 2019 COCO Keypoints Challenge. The code is available online.
+
+
+
+
+
+
diff --git a/docs/src/papers/techniques/fp16.md b/docs/src/papers/techniques/fp16.md
index 7fd7ee0011..bbc7b567c2 100644
--- a/docs/src/papers/techniques/fp16.md
+++ b/docs/src/papers/techniques/fp16.md
@@ -1,17 +1,17 @@
-# Mixed Precision Training
-
-
-
-
-FP16 (ArXiv'2017)
-
-```bibtex
-@article{micikevicius2017mixed,
- title={Mixed precision training},
- author={Micikevicius, Paulius and Narang, Sharan and Alben, Jonah and Diamos, Gregory and Elsen, Erich and Garcia, David and Ginsburg, Boris and Houston, Michael and Kuchaiev, Oleksii and Venkatesh, Ganesh and others},
- journal={arXiv preprint arXiv:1710.03740},
- year={2017}
-}
-```
-
-
+# Mixed Precision Training
+
+
+
+
+FP16 (ArXiv'2017)
+
+```bibtex
+@article{micikevicius2017mixed,
+ title={Mixed precision training},
+ author={Micikevicius, Paulius and Narang, Sharan and Alben, Jonah and Diamos, Gregory and Elsen, Erich and Garcia, David and Ginsburg, Boris and Houston, Michael and Kuchaiev, Oleksii and Venkatesh, Ganesh and others},
+ journal={arXiv preprint arXiv:1710.03740},
+ year={2017}
+}
+```
+
+
diff --git a/docs/src/papers/techniques/fpn.md b/docs/src/papers/techniques/fpn.md
index 0de33f4866..1faf5103d8 100644
--- a/docs/src/papers/techniques/fpn.md
+++ b/docs/src/papers/techniques/fpn.md
@@ -1,30 +1,30 @@
-# Feature pyramid networks for object detection
-
-
-
-
-FPN (CVPR'2017)
-
-```bibtex
-@inproceedings{lin2017feature,
- title={Feature pyramid networks for object detection},
- author={Lin, Tsung-Yi and Doll{\'a}r, Piotr and Girshick, Ross and He, Kaiming and Hariharan, Bharath and Belongie, Serge},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- pages={2117--2125},
- year={2017}
-}
-```
-
-
-
-## Abstract
-
-
-
-Feature pyramids are a basic component in recognition systems for detecting objects at different scales. But recent deep learning object detectors have avoided pyramid representations, in part because they are compute and memory intensive. In this paper, we exploit the inherent multi-scale, pyramidal hierarchy of deep convolutional networks to construct feature pyramids with marginal extra cost. A topdown architecture with lateral connections is developed for building high-level semantic feature maps at all scales. This architecture, called a Feature Pyramid Network (FPN), shows significant improvement as a generic feature extractor in several applications. Using FPN in a basic Faster R-CNN system, our method achieves state-of-the-art singlemodel results on the COCO detection benchmark without bells and whistles, surpassing all existing single-model entries including those from the COCO 2016 challenge winners. In addition, our method can run at 6 FPS on a GPU and thus is a practical and accurate solution to multi-scale object detection. Code will be made publicly available.
-
-
-
-
-
-
+# Feature pyramid networks for object detection
+
+
+
+
+FPN (CVPR'2017)
+
+```bibtex
+@inproceedings{lin2017feature,
+ title={Feature pyramid networks for object detection},
+ author={Lin, Tsung-Yi and Doll{\'a}r, Piotr and Girshick, Ross and He, Kaiming and Hariharan, Bharath and Belongie, Serge},
+ booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
+ pages={2117--2125},
+ year={2017}
+}
+```
+
+
+
+## Abstract
+
+
+
+Feature pyramids are a basic component in recognition systems for detecting objects at different scales. But recent deep learning object detectors have avoided pyramid representations, in part because they are compute and memory intensive. In this paper, we exploit the inherent multi-scale, pyramidal hierarchy of deep convolutional networks to construct feature pyramids with marginal extra cost. A topdown architecture with lateral connections is developed for building high-level semantic feature maps at all scales. This architecture, called a Feature Pyramid Network (FPN), shows significant improvement as a generic feature extractor in several applications. Using FPN in a basic Faster R-CNN system, our method achieves state-of-the-art singlemodel results on the COCO detection benchmark without bells and whistles, surpassing all existing single-model entries including those from the COCO 2016 challenge winners. In addition, our method can run at 6 FPS on a GPU and thus is a practical and accurate solution to multi-scale object detection. Code will be made publicly available.
+
+
+
+
+
+
diff --git a/docs/src/papers/techniques/rle.md b/docs/src/papers/techniques/rle.md
index cdc59d57ec..7734ca3d44 100644
--- a/docs/src/papers/techniques/rle.md
+++ b/docs/src/papers/techniques/rle.md
@@ -1,30 +1,30 @@
-# Human pose regression with residual log-likelihood estimation
-
-
-
-
-RLE (ICCV'2021)
-
-```bibtex
-@inproceedings{li2021human,
- title={Human pose regression with residual log-likelihood estimation},
- author={Li, Jiefeng and Bian, Siyuan and Zeng, Ailing and Wang, Can and Pang, Bo and Liu, Wentao and Lu, Cewu},
- booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
- pages={11025--11034},
- year={2021}
-}
-```
-
-
-
-## Abstract
-
-
-
-Heatmap-based methods dominate in the field of human pose estimation by modelling the output distribution through likelihood heatmaps. In contrast, regressionbased methods are more efficient but suffer from inferior performance. In this work, we explore maximum likelihood estimation (MLE) to develop an efficient and effective regression-based methods. From the perspective of MLE, adopting different regression losses is making different assumptions about the output density function. A density function closer to the true distribution leads to a better regression performance. In light of this, we propose a novel regression paradigm with Residual Log-likelihood Estimation (RLE) to capture the underlying output distribution. Concretely, RLE learns the change of the distribution instead of the unreferenced underlying distribution to facilitate the training process. With the proposed reparameterization design, our method is compatible with offthe-shelf flow models. The proposed method is effective, efficient and flexible. We show its potential in various human pose estimation tasks with comprehensive experiments. Compared to the conventional regression paradigm, regression with RLE bring 12.4 mAP improvement on MSCOCO without any test-time overhead. Moreover, for the first time, especially on multi-person pose estimation, our regression method is superior to the heatmap-based methods.
-
-
-
-
-
-
+# Human pose regression with residual log-likelihood estimation
+
+
+
+
+RLE (ICCV'2021)
+
+```bibtex
+@inproceedings{li2021human,
+ title={Human pose regression with residual log-likelihood estimation},
+ author={Li, Jiefeng and Bian, Siyuan and Zeng, Ailing and Wang, Can and Pang, Bo and Liu, Wentao and Lu, Cewu},
+ booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
+ pages={11025--11034},
+ year={2021}
+}
+```
+
+
+
+## Abstract
+
+
+
+Heatmap-based methods dominate in the field of human pose estimation by modelling the output distribution through likelihood heatmaps. In contrast, regressionbased methods are more efficient but suffer from inferior performance. In this work, we explore maximum likelihood estimation (MLE) to develop an efficient and effective regression-based methods. From the perspective of MLE, adopting different regression losses is making different assumptions about the output density function. A density function closer to the true distribution leads to a better regression performance. In light of this, we propose a novel regression paradigm with Residual Log-likelihood Estimation (RLE) to capture the underlying output distribution. Concretely, RLE learns the change of the distribution instead of the unreferenced underlying distribution to facilitate the training process. With the proposed reparameterization design, our method is compatible with offthe-shelf flow models. The proposed method is effective, efficient and flexible. We show its potential in various human pose estimation tasks with comprehensive experiments. Compared to the conventional regression paradigm, regression with RLE bring 12.4 mAP improvement on MSCOCO without any test-time overhead. Moreover, for the first time, especially on multi-person pose estimation, our regression method is superior to the heatmap-based methods.
+
+
+
+
+
+
diff --git a/docs/src/papers/techniques/smoothnet.md b/docs/src/papers/techniques/smoothnet.md
index b09988ce44..f452299258 100644
--- a/docs/src/papers/techniques/smoothnet.md
+++ b/docs/src/papers/techniques/smoothnet.md
@@ -1,29 +1,29 @@
-# SmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos
-
-
-
-
-SmoothNet (arXiv'2021)
-
-```bibtex
-@article{zeng2021smoothnet,
- title={SmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos},
- author={Zeng, Ailing and Yang, Lei and Ju, Xuan and Li, Jiefeng and Wang, Jianyi and Xu, Qiang},
- journal={arXiv preprint arXiv:2112.13715},
- year={2021}
-}
-```
-
-
-
-## Abstract
-
-
-
-When analyzing human motion videos, the output jitters from existing pose estimators are highly-unbalanced. Most frames only suffer from slight jitters, while significant jitters occur in those frames with occlusion or poor image quality. Such complex poses often persist in videos, leading to consecutive frames with poor estimation results and large jitters. Existing pose smoothing solutions based on temporal convolutional networks, recurrent neural networks, or low-pass filters cannot deal with such a long-term jitter problem without considering the significant and persistent errors within the jittering video segment. Motivated by the above observation, we propose a novel plug-and-play refinement network, namely SMOOTHNET, which can be attached to any existing pose estimators to improve its temporal smoothness and enhance its per-frame precision simultaneously. Especially, SMOOTHNET is a simple yet effective data-driven fully-connected network with large receptive fields, effectively mitigating the impact of long-term jitters with unreliable estimation results. We conduct extensive experiments on twelve backbone networks with seven datasets across 2D and 3D pose estimation, body recovery, and downstream tasks. Our results demonstrate that the proposed SMOOTHNET consistently outperforms existing solutions, especially on those clips with high errors and long-term jitters.
-
-
-
-
-
-
+# SmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos
+
+
+
+
+SmoothNet (arXiv'2021)
+
+```bibtex
+@article{zeng2021smoothnet,
+ title={SmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos},
+ author={Zeng, Ailing and Yang, Lei and Ju, Xuan and Li, Jiefeng and Wang, Jianyi and Xu, Qiang},
+ journal={arXiv preprint arXiv:2112.13715},
+ year={2021}
+}
+```
+
+
+
+## Abstract
+
+
+
+When analyzing human motion videos, the output jitters from existing pose estimators are highly-unbalanced. Most frames only suffer from slight jitters, while significant jitters occur in those frames with occlusion or poor image quality. Such complex poses often persist in videos, leading to consecutive frames with poor estimation results and large jitters. Existing pose smoothing solutions based on temporal convolutional networks, recurrent neural networks, or low-pass filters cannot deal with such a long-term jitter problem without considering the significant and persistent errors within the jittering video segment. Motivated by the above observation, we propose a novel plug-and-play refinement network, namely SMOOTHNET, which can be attached to any existing pose estimators to improve its temporal smoothness and enhance its per-frame precision simultaneously. Especially, SMOOTHNET is a simple yet effective data-driven fully-connected network with large receptive fields, effectively mitigating the impact of long-term jitters with unreliable estimation results. We conduct extensive experiments on twelve backbone networks with seven datasets across 2D and 3D pose estimation, body recovery, and downstream tasks. Our results demonstrate that the proposed SMOOTHNET consistently outperforms existing solutions, especially on those clips with high errors and long-term jitters.
+
+
+
+
+
+
diff --git a/docs/src/papers/techniques/softwingloss.md b/docs/src/papers/techniques/softwingloss.md
index 524a6089ff..d638109270 100644
--- a/docs/src/papers/techniques/softwingloss.md
+++ b/docs/src/papers/techniques/softwingloss.md
@@ -1,30 +1,30 @@
-# Structure-Coherent Deep Feature Learning for Robust Face Alignment
-
-
-
-
-SoftWingloss (TIP'2021)
-
-```bibtex
-@article{lin2021structure,
- title={Structure-Coherent Deep Feature Learning for Robust Face Alignment},
- author={Lin, Chunze and Zhu, Beier and Wang, Quan and Liao, Renjie and Qian, Chen and Lu, Jiwen and Zhou, Jie},
- journal={IEEE Transactions on Image Processing},
- year={2021},
- publisher={IEEE}
-}
-```
-
-
-
-## Abstract
-
-
-
-In this paper, we propose a structure-coherent deep feature learning method for face alignment. Unlike most existing face alignment methods which overlook the facial structure cues, we explicitly exploit the relation among facial landmarks to make the detector robust to hard cases such as occlusion and large pose. Specifically, we leverage a landmark-graph relational network to enforce the structural relationships among landmarks. We consider the facial landmarks as structural graph nodes and carefully design the neighborhood to passing features among the most related nodes. Our method dynamically adapts the weights of node neighborhood to eliminate distracted information from noisy nodes, such as occluded landmark point. Moreover, different from most previous works which only tend to penalize the landmarks absolute position during the training, we propose a relative location loss to enhance the information of relative location of landmarks. This relative location supervision further regularizes the facial structure. Our approach considers the interactions among facial landmarks and can be easily implemented on top of any convolutional backbone to boost the performance. Extensive experiments on three popular benchmarks, including WFLW, COFW and 300W, demonstrate the effectiveness of the proposed method. In particular, due to explicit structure modeling, our approach is especially robust to challenging cases resulting in impressive low failure rate on COFW and WFLW datasets.
-
-
-
-
-
-
+# Structure-Coherent Deep Feature Learning for Robust Face Alignment
+
+
+
+
+SoftWingloss (TIP'2021)
+
+```bibtex
+@article{lin2021structure,
+ title={Structure-Coherent Deep Feature Learning for Robust Face Alignment},
+ author={Lin, Chunze and Zhu, Beier and Wang, Quan and Liao, Renjie and Qian, Chen and Lu, Jiwen and Zhou, Jie},
+ journal={IEEE Transactions on Image Processing},
+ year={2021},
+ publisher={IEEE}
+}
+```
+
+
+
+## Abstract
+
+
+
+In this paper, we propose a structure-coherent deep feature learning method for face alignment. Unlike most existing face alignment methods which overlook the facial structure cues, we explicitly exploit the relation among facial landmarks to make the detector robust to hard cases such as occlusion and large pose. Specifically, we leverage a landmark-graph relational network to enforce the structural relationships among landmarks. We consider the facial landmarks as structural graph nodes and carefully design the neighborhood to passing features among the most related nodes. Our method dynamically adapts the weights of node neighborhood to eliminate distracted information from noisy nodes, such as occluded landmark point. Moreover, different from most previous works which only tend to penalize the landmarks absolute position during the training, we propose a relative location loss to enhance the information of relative location of landmarks. This relative location supervision further regularizes the facial structure. Our approach considers the interactions among facial landmarks and can be easily implemented on top of any convolutional backbone to boost the performance. Extensive experiments on three popular benchmarks, including WFLW, COFW and 300W, demonstrate the effectiveness of the proposed method. In particular, due to explicit structure modeling, our approach is especially robust to challenging cases resulting in impressive low failure rate on COFW and WFLW datasets.
+
+
+
+
+
+
diff --git a/docs/src/papers/techniques/udp.md b/docs/src/papers/techniques/udp.md
index bb4acebfbc..00604fc5ce 100644
--- a/docs/src/papers/techniques/udp.md
+++ b/docs/src/papers/techniques/udp.md
@@ -1,30 +1,30 @@
-# The Devil is in the Details: Delving into Unbiased Data Processing for Human Pose Estimation
-
-
-
-
-UDP (CVPR'2020)
-
-```bibtex
-@InProceedings{Huang_2020_CVPR,
- author = {Huang, Junjie and Zhu, Zheng and Guo, Feng and Huang, Guan},
- title = {The Devil Is in the Details: Delving Into Unbiased Data Processing for Human Pose Estimation},
- booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
- month = {June},
- year = {2020}
-}
-```
-
-
-
-## Abstract
-
-
-
-Recently, the leading performance of human pose estimation is dominated by top-down methods. Being a fundamental component in training and inference, data processing has not been systematically considered in pose estimation community, to the best of our knowledge. In this paper, we focus on this problem and find that the devil of top-down pose estimator is in the biased data processing. Specifically, by investigating the standard data processing in state-of-the-art approaches mainly including data transformation and encoding-decoding, we find that the results obtained by common flipping strategy are unaligned with the original ones in inference. Moreover, there is statistical error in standard encoding-decoding during both training and inference. Two problems couple together and significantly degrade the pose estimation performance. Based on quantitative analyses, we then formulate a principled way to tackle this dilemma. Data is processed in continuous space based on unit length (the intervals between pixels) instead of in discrete space with pixel, and a combined classification and regression approach is adopted to perform encoding-decoding. The Unbiased Data Processing (UDP) for human pose estimation can be achieved by combining the two together. UDP not only boosts the performance of existing methods by a large margin but also plays a important role in result reproducing and future exploration. As a model-agnostic approach, UDP promotes SimpleBaseline-ResNet50-256x192 by 1.5 AP (70.2 to 71.7) and HRNet-W32-256x192 by 1.7 AP (73.5 to 75.2) on COCO test-dev set. The HRNet-W48-384x288 equipped with UDP achieves 76.5 AP and sets a new state-of-the-art for human pose estimation. The source code is publicly available for further research.
-
-
-
-
-
-
+# The Devil is in the Details: Delving into Unbiased Data Processing for Human Pose Estimation
+
+
+
+
+UDP (CVPR'2020)
+
+```bibtex
+@InProceedings{Huang_2020_CVPR,
+ author = {Huang, Junjie and Zhu, Zheng and Guo, Feng and Huang, Guan},
+ title = {The Devil Is in the Details: Delving Into Unbiased Data Processing for Human Pose Estimation},
+ booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ month = {June},
+ year = {2020}
+}
+```
+
+
+
+## Abstract
+
+
+
+Recently, the leading performance of human pose estimation is dominated by top-down methods. Being a fundamental component in training and inference, data processing has not been systematically considered in pose estimation community, to the best of our knowledge. In this paper, we focus on this problem and find that the devil of top-down pose estimator is in the biased data processing. Specifically, by investigating the standard data processing in state-of-the-art approaches mainly including data transformation and encoding-decoding, we find that the results obtained by common flipping strategy are unaligned with the original ones in inference. Moreover, there is statistical error in standard encoding-decoding during both training and inference. Two problems couple together and significantly degrade the pose estimation performance. Based on quantitative analyses, we then formulate a principled way to tackle this dilemma. Data is processed in continuous space based on unit length (the intervals between pixels) instead of in discrete space with pixel, and a combined classification and regression approach is adopted to perform encoding-decoding. The Unbiased Data Processing (UDP) for human pose estimation can be achieved by combining the two together. UDP not only boosts the performance of existing methods by a large margin but also plays a important role in result reproducing and future exploration. As a model-agnostic approach, UDP promotes SimpleBaseline-ResNet50-256x192 by 1.5 AP (70.2 to 71.7) and HRNet-W32-256x192 by 1.7 AP (73.5 to 75.2) on COCO test-dev set. The HRNet-W48-384x288 equipped with UDP achieves 76.5 AP and sets a new state-of-the-art for human pose estimation. The source code is publicly available for further research.
+
+
+
+
+
+
diff --git a/docs/src/papers/techniques/wingloss.md b/docs/src/papers/techniques/wingloss.md
index 2aaa05722e..a0f0a35cfb 100644
--- a/docs/src/papers/techniques/wingloss.md
+++ b/docs/src/papers/techniques/wingloss.md
@@ -1,31 +1,31 @@
-# Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks
-
-
-
-
-Wingloss (CVPR'2018)
-
-```bibtex
-@inproceedings{feng2018wing,
- title={Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks},
- author={Feng, Zhen-Hua and Kittler, Josef and Awais, Muhammad and Huber, Patrik and Wu, Xiao-Jun},
- booktitle={Computer Vision and Pattern Recognition (CVPR), 2018 IEEE Conference on},
- year={2018},
- pages ={2235-2245},
- organization={IEEE}
-}
-```
-
-
-
-## Abstract
-
-
-
-We present a new loss function, namely Wing loss, for robust facial landmark localisation with Convolutional Neural Networks (CNNs). We first compare and analyse different loss functions including L2, L1 and smooth L1. The analysis of these loss functions suggests that, for the training of a CNN-based localisation model, more attention should be paid to small and medium range errors. To this end, we design a piece-wise loss function. The new loss amplifies the impact of errors from the interval (-w, w) by switching from L1 loss to a modified logarithm function. To address the problem of under-representation of samples with large out-of-plane head rotations in the training set, we propose a simple but effective boosting strategy, referred to as pose-based data balancing. In particular, we deal with the data imbalance problem by duplicating the minority training samples and perturbing them by injecting random image rotation, bounding box translation and other data augmentation approaches. Last, the proposed approach is extended to create a two-stage framework for robust facial landmark localisation. The experimental results obtained on AFLW and 300W demonstrate the merits of the Wing loss function, and prove the superiority of the proposed method over the state-of-the-art approaches.
-
-
-
-
-
-
+# Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks
+
+
+
+
+Wingloss (CVPR'2018)
+
+```bibtex
+@inproceedings{feng2018wing,
+ title={Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks},
+ author={Feng, Zhen-Hua and Kittler, Josef and Awais, Muhammad and Huber, Patrik and Wu, Xiao-Jun},
+ booktitle={Computer Vision and Pattern Recognition (CVPR), 2018 IEEE Conference on},
+ year={2018},
+ pages ={2235-2245},
+ organization={IEEE}
+}
+```
+
+
+
+## Abstract
+
+
+
+We present a new loss function, namely Wing loss, for robust facial landmark localisation with Convolutional Neural Networks (CNNs). We first compare and analyse different loss functions including L2, L1 and smooth L1. The analysis of these loss functions suggests that, for the training of a CNN-based localisation model, more attention should be paid to small and medium range errors. To this end, we design a piece-wise loss function. The new loss amplifies the impact of errors from the interval (-w, w) by switching from L1 loss to a modified logarithm function. To address the problem of under-representation of samples with large out-of-plane head rotations in the training set, we propose a simple but effective boosting strategy, referred to as pose-based data balancing. In particular, we deal with the data imbalance problem by duplicating the minority training samples and perturbing them by injecting random image rotation, bounding box translation and other data augmentation approaches. Last, the proposed approach is extended to create a two-stage framework for robust facial landmark localisation. The experimental results obtained on AFLW and 300W demonstrate the merits of the Wing loss function, and prove the superiority of the proposed method over the state-of-the-art approaches.
+
+
+
+
', '', f'## {titlecase(dataset)} Dataset',
- ''
- ]
-
- for keywords, doc in keywords_dict.items():
- keyword_strs = [
- titlecase(x.replace('_', ' ')) for x in keywords
- ]
- dataset_str = titlecase(dataset)
- if dataset_str in keyword_strs:
- keyword_strs.remove(dataset_str)
-
- lines += [
- ' ', '',
- (f'### {" + ".join(keyword_strs)}'
- f' on {dataset_str}'), '', doc['content'], ''
- ]
-
- fn = osp.join('model_zoo', f'{task.replace(" ", "_").lower()}.md')
- with open(fn, 'w', encoding='utf-8') as f:
- f.write('\n'.join(lines))
-
- # Write files by paper
- paper_refs = _get_paper_refs()
-
- for paper_cat, paper_list in paper_refs.items():
- lines = []
- for paper_fn in paper_list:
- paper_name, indicator = _parse_paper_ref(paper_fn)
- paperlines = []
- for task, dataset_dict in model_docs.items():
- for dataset, keywords_dict in dataset_dict.items():
- for keywords, doc_info in keywords_dict.items():
-
- if indicator not in doc_info['content']:
- continue
-
- keyword_strs = [
- titlecase(x.replace('_', ' ')) for x in keywords
- ]
-
- dataset_str = titlecase(dataset)
- if dataset_str in keyword_strs:
- keyword_strs.remove(dataset_str)
- paperlines += [
- ' ', '',
- (f'### {" + ".join(keyword_strs)}'
- f' on {dataset_str}'), '', doc_info['content'], ''
- ]
- if paperlines:
- lines += ['', '
', '', f'## {paper_name}', '']
- lines += paperlines
-
- if lines:
- lines = [f'# {titlecase(paper_cat)}', ''] + lines
- with open(
- osp.join('model_zoo_papers', f'{paper_cat.lower()}.md'),
- 'w',
- encoding='utf-8') as f:
- f.write('\n'.join(lines))
-
-
-if __name__ == '__main__':
- print('collect model zoo documents')
- main()
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import os.path as osp
+import re
+from collections import defaultdict
+from glob import glob
+
+from addict import Addict
+from titlecase import titlecase
+
+
+def _get_model_docs():
+ """Get all model document files.
+
+ Returns:
+ list[str]: file paths
+ """
+ config_root = osp.join('..', '..', 'configs')
+ pattern = osp.sep.join(['*'] * 4) + '.md'
+ docs = glob(osp.join(config_root, pattern))
+ docs = [doc for doc in docs if '_base_' not in doc]
+ return docs
+
+
+def _parse_model_doc_path(path):
+ """Parse doc file path.
+
+ Typical path would be like:
+
+ configs////.md
+
+ An example is:
+
+ "configs/animal_2d_keypoint/topdown_heatmap/
+ animalpose/resnet_animalpose.md"
+
+ Returns:
+ tuple:
+ - task (str): e.g. ``'Animal 2D Keypoint'``
+ - dataset (str): e.g. ``'animalpose'``
+ - keywords (tuple): e.g. ``('topdown heatmap', 'resnet')``
+ """
+ _path = path.split(osp.sep)
+ _rel_path = _path[_path.index('configs'):]
+
+ # get task
+ def _titlecase_callback(word, **kwargs):
+ if word == '2d':
+ return '2D'
+ if word == '3d':
+ return '3D'
+
+ task = titlecase(
+ _rel_path[1].replace('_', ' '), callback=_titlecase_callback)
+
+ # get dataset
+ dataset = _rel_path[3]
+
+ # get keywords
+ keywords_algo = (_rel_path[2], )
+ keywords_setting = tuple(_rel_path[4][:-3].split('_'))
+ keywords = keywords_algo + keywords_setting
+
+ return task, dataset, keywords
+
+
+def _get_paper_refs():
+ """Get all paper references.
+
+ Returns:
+ Dict[str, List[str]]: keys are paper categories and values are lists
+ of paper paths.
+ """
+ papers = glob('../src/papers/*/*.md')
+ paper_refs = defaultdict(list)
+ for fn in papers:
+ category = fn.split(osp.sep)[3]
+ paper_refs[category].append(fn)
+
+ return paper_refs
+
+
+def _parse_paper_ref(fn):
+ """Get paper name and indicator pattern from a paper reference file.
+
+ Returns:
+ tuple:
+ - paper_name (str)
+ - paper_indicator (str)
+ """
+ indicator = None
+ with open(fn, 'r', encoding='utf-8') as f:
+ for line in f.readlines():
+ if line.startswith('', '', indicator).strip()
+ return paper_name, indicator
+
+
+def main():
+
+ # Build output folders
+ os.makedirs('model_zoo', exist_ok=True)
+ os.makedirs('model_zoo_papers', exist_ok=True)
+
+ # Collect all document contents
+ model_doc_list = _get_model_docs()
+ model_docs = Addict()
+
+ for path in model_doc_list:
+ task, dataset, keywords = _parse_model_doc_path(path)
+ with open(path, 'r', encoding='utf-8') as f:
+ doc = {
+ 'task': task,
+ 'dataset': dataset,
+ 'keywords': keywords,
+ 'path': path,
+ 'content': f.read()
+ }
+ model_docs[task][dataset][keywords] = doc
+
+ # Write files by task
+ for task, dataset_dict in model_docs.items():
+ lines = [f'# {task}', '']
+ for dataset, keywords_dict in dataset_dict.items():
+ lines += [
+ '', '
', '', f'## {titlecase(dataset)} Dataset',
+ ''
+ ]
+
+ for keywords, doc in keywords_dict.items():
+ keyword_strs = [
+ titlecase(x.replace('_', ' ')) for x in keywords
+ ]
+ dataset_str = titlecase(dataset)
+ if dataset_str in keyword_strs:
+ keyword_strs.remove(dataset_str)
+
+ lines += [
+ ' ', '',
+ (f'### {" + ".join(keyword_strs)}'
+ f' on {dataset_str}'), '', doc['content'], ''
+ ]
+
+ fn = osp.join('model_zoo', f'{task.replace(" ", "_").lower()}.md')
+ with open(fn, 'w', encoding='utf-8') as f:
+ f.write('\n'.join(lines))
+
+ # Write files by paper
+ paper_refs = _get_paper_refs()
+
+ for paper_cat, paper_list in paper_refs.items():
+ lines = []
+ for paper_fn in paper_list:
+ paper_name, indicator = _parse_paper_ref(paper_fn)
+ paperlines = []
+ for task, dataset_dict in model_docs.items():
+ for dataset, keywords_dict in dataset_dict.items():
+ for keywords, doc_info in keywords_dict.items():
+
+ if indicator not in doc_info['content']:
+ continue
+
+ keyword_strs = [
+ titlecase(x.replace('_', ' ')) for x in keywords
+ ]
+
+ dataset_str = titlecase(dataset)
+ if dataset_str in keyword_strs:
+ keyword_strs.remove(dataset_str)
+ paperlines += [
+ ' ', '',
+ (f'### {" + ".join(keyword_strs)}'
+ f' on {dataset_str}'), '', doc_info['content'], ''
+ ]
+ if paperlines:
+ lines += ['', '
', '', f'## {paper_name}', '']
+ lines += paperlines
+
+ if lines:
+ lines = [f'# {titlecase(paper_cat)}', ''] + lines
+ with open(
+ osp.join('model_zoo_papers', f'{paper_cat.lower()}.md'),
+ 'w',
+ encoding='utf-8') as f:
+ f.write('\n'.join(lines))
+
+
+if __name__ == '__main__':
+ print('collect model zoo documents')
+ main()
diff --git a/docs/zh_cn/collect_projects.py b/docs/zh_cn/collect_projects.py
index 93562cb4b2..e9e4ee3d18 100644
--- a/docs/zh_cn/collect_projects.py
+++ b/docs/zh_cn/collect_projects.py
@@ -1,119 +1,119 @@
-#!/usr/bin/env python
-# Copyright (c) OpenMMLab. All rights reserved.
-import os
-import os.path as osp
-import re
-from glob import glob
-
-
-def _get_project_docs():
- """Get all project document files.
-
- Returns:
- list[str]: file paths
- """
- project_root = osp.join('..', '..', 'projects')
- pattern = osp.sep.join(['*'] * 2) + '.md'
- docs = glob(osp.join(project_root, pattern))
- docs = [
- doc for doc in docs
- if 'example_project' not in doc and '_CN' not in doc
- ]
- return docs
-
-
-def _parse_project_doc_path(fn):
- """Get project name and banner from a project reference file.
-
- Returns:
- tuple:
- - project_name (str)
- - project_banner (str)
- """
- project_banner, project_name = None, None
- with open(fn, 'r', encoding='utf-8') as f:
- for line in f.readlines():
- if re.match('^( )*#', line)
- faq_doc.append(line)
- return faq_doc
-
-
-def main():
-
- # Build output folders
- os.makedirs('projects', exist_ok=True)
-
- # Collect all document contents
- project_doc_list = _get_project_docs()
-
- project_lines = []
- for path in project_doc_list:
- name, banner = _parse_project_doc_path(path)
- _path = path.split(osp.sep)
- _rel_path = _path[_path.index('projects'):-1]
- url = 'https://github.com/open-mmlab/mmpose/blob/dev-1.x/' + '/'.join(
- _rel_path)
- _name = name.split(':', 1)
- name, description = _name[0], '' if len(
- _name) < 2 else f': {_name[-1]}'
- project_lines += [
- f'- **{name}**{description} [\\[github\\]]({url})', '',
- '
', ' ' + banner, '
', ' ', ''
- ]
-
- project_intro_doc = _get_project_intro_doc()
- faq_doc = _get_faq_doc()
-
- with open(
- osp.join('projects', 'community_projects.md'), 'w',
- encoding='utf-8') as f:
- f.write('# Projects of MMPose from Community Contributors\n')
- f.write(''.join(project_intro_doc))
- f.write('\n'.join(project_lines))
- f.write(''.join(faq_doc))
-
-
-if __name__ == '__main__':
- print('collect project documents')
- main()
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import os.path as osp
+import re
+from glob import glob
+
+
+def _get_project_docs():
+ """Get all project document files.
+
+ Returns:
+ list[str]: file paths
+ """
+ project_root = osp.join('..', '..', 'projects')
+ pattern = osp.sep.join(['*'] * 2) + '.md'
+ docs = glob(osp.join(project_root, pattern))
+ docs = [
+ doc for doc in docs
+ if 'example_project' not in doc and '_CN' not in doc
+ ]
+ return docs
+
+
+def _parse_project_doc_path(fn):
+ """Get project name and banner from a project reference file.
+
+ Returns:
+ tuple:
+ - project_name (str)
+ - project_banner (str)
+ """
+ project_banner, project_name = None, None
+ with open(fn, 'r', encoding='utf-8') as f:
+ for line in f.readlines():
+ if re.match('^( )*#', line)
+ faq_doc.append(line)
+ return faq_doc
+
+
+def main():
+
+ # Build output folders
+ os.makedirs('projects', exist_ok=True)
+
+ # Collect all document contents
+ project_doc_list = _get_project_docs()
+
+ project_lines = []
+ for path in project_doc_list:
+ name, banner = _parse_project_doc_path(path)
+ _path = path.split(osp.sep)
+ _rel_path = _path[_path.index('projects'):-1]
+ url = 'https://github.com/open-mmlab/mmpose/blob/dev-1.x/' + '/'.join(
+ _rel_path)
+ _name = name.split(':', 1)
+ name, description = _name[0], '' if len(
+ _name) < 2 else f': {_name[-1]}'
+ project_lines += [
+ f'- **{name}**{description} [\\[github\\]]({url})', '',
+ '
', ' ' + banner, '
', ' ', ''
+ ]
+
+ project_intro_doc = _get_project_intro_doc()
+ faq_doc = _get_faq_doc()
+
+ with open(
+ osp.join('projects', 'community_projects.md'), 'w',
+ encoding='utf-8') as f:
+ f.write('# Projects of MMPose from Community Contributors\n')
+ f.write(''.join(project_intro_doc))
+ f.write('\n'.join(project_lines))
+ f.write(''.join(faq_doc))
+
+
+if __name__ == '__main__':
+ print('collect project documents')
+ main()
diff --git a/docs/zh_cn/conf.py b/docs/zh_cn/conf.py
index c82b9edc04..fd2df51ab6 100644
--- a/docs/zh_cn/conf.py
+++ b/docs/zh_cn/conf.py
@@ -1,108 +1,108 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-# Configuration file for the Sphinx documentation builder.
-#
-# This file only contains a selection of the most common options. For a full
-# list see the documentation:
-# https://www.sphinx-doc.org/en/master/usage/configuration.html
-
-# -- Path setup --------------------------------------------------------------
-
-# If extensions (or modules to document with autodoc) are in another directory,
-# add these directories to sys.path here. If the directory is relative to the
-# documentation root, use os.path.abspath to make it absolute, like shown here.
-
-import os
-import subprocess
-import sys
-
-import pytorch_sphinx_theme
-
-sys.path.insert(0, os.path.abspath('../..'))
-
-# -- Project information -----------------------------------------------------
-
-project = 'MMPose'
-copyright = '2020-2021, OpenMMLab'
-author = 'MMPose Authors'
-
-# The full version, including alpha/beta/rc tags
-version_file = '../../mmpose/version.py'
-
-
-def get_version():
- with open(version_file, 'r') as f:
- exec(compile(f.read(), version_file, 'exec'))
- return locals()['__version__']
-
-
-release = get_version()
-
-# -- General configuration ---------------------------------------------------
-
-# Add any Sphinx extension module names here, as strings. They can be
-# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
-# ones.
-extensions = [
- 'sphinx.ext.autodoc', 'sphinx.ext.napoleon', 'sphinx.ext.viewcode',
- 'sphinx_markdown_tables', 'sphinx_copybutton', 'myst_parser',
- 'sphinx.ext.autosummary'
-]
-
-autodoc_mock_imports = ['json_tricks', 'mmpose.version']
-
-# Ignore >>> when copying code
-copybutton_prompt_text = r'>>> |\.\.\. '
-copybutton_prompt_is_regexp = True
-
-# Add any paths that contain templates here, relative to this directory.
-templates_path = ['_templates']
-
-# List of patterns, relative to source directory, that match files and
-# directories to ignore when looking for source files.
-# This pattern also affects html_static_path and html_extra_path.
-exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
-
-# -- Options for HTML output -------------------------------------------------
-source_suffix = {
- '.rst': 'restructuredtext',
- '.md': 'markdown',
-}
-
-# The theme to use for HTML and HTML Help pages. See the documentation for
-# a list of builtin themes.
-#
-html_theme = 'pytorch_sphinx_theme'
-html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
-html_theme_options = {
- 'menu': [{
- 'name': 'GitHub',
- 'url': 'https://github.com/open-mmlab/mmpose'
- }],
- # Specify the language of the shared menu
- 'menu_lang': 'cn'
-}
-
-# Add any paths that contain custom static files (such as style sheets) here,
-# relative to this directory. They are copied after the builtin static files,
-# so a file named "default.css" will overwrite the builtin "default.css".
-
-language = 'zh_CN'
-
-html_static_path = ['_static']
-html_css_files = ['css/readthedocs.css']
-
-# Enable ::: for my_st
-myst_enable_extensions = ['colon_fence']
-
-master_doc = 'index'
-
-
-def builder_inited_handler(app):
- subprocess.run(['python', './collect_modelzoo.py'])
- subprocess.run(['python', './collect_projects.py'])
- subprocess.run(['sh', './merge_docs.sh'])
- subprocess.run(['python', './stats.py'])
-
-
-def setup(app):
- app.connect('builder-inited', builder_inited_handler)
+# Copyright (c) OpenMMLab. All rights reserved.
+# Configuration file for the Sphinx documentation builder.
+#
+# This file only contains a selection of the most common options. For a full
+# list see the documentation:
+# https://www.sphinx-doc.org/en/master/usage/configuration.html
+
+# -- Path setup --------------------------------------------------------------
+
+# If extensions (or modules to document with autodoc) are in another directory,
+# add these directories to sys.path here. If the directory is relative to the
+# documentation root, use os.path.abspath to make it absolute, like shown here.
+
+import os
+import subprocess
+import sys
+
+import pytorch_sphinx_theme
+
+sys.path.insert(0, os.path.abspath('../..'))
+
+# -- Project information -----------------------------------------------------
+
+project = 'MMPose'
+copyright = '2020-2021, OpenMMLab'
+author = 'MMPose Authors'
+
+# The full version, including alpha/beta/rc tags
+version_file = '../../mmpose/version.py'
+
+
+def get_version():
+ with open(version_file, 'r') as f:
+ exec(compile(f.read(), version_file, 'exec'))
+ return locals()['__version__']
+
+
+release = get_version()
+
+# -- General configuration ---------------------------------------------------
+
+# Add any Sphinx extension module names here, as strings. They can be
+# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
+# ones.
+extensions = [
+ 'sphinx.ext.autodoc', 'sphinx.ext.napoleon', 'sphinx.ext.viewcode',
+ 'sphinx_markdown_tables', 'sphinx_copybutton', 'myst_parser',
+ 'sphinx.ext.autosummary'
+]
+
+autodoc_mock_imports = ['json_tricks', 'mmpose.version']
+
+# Ignore >>> when copying code
+copybutton_prompt_text = r'>>> |\.\.\. '
+copybutton_prompt_is_regexp = True
+
+# Add any paths that contain templates here, relative to this directory.
+templates_path = ['_templates']
+
+# List of patterns, relative to source directory, that match files and
+# directories to ignore when looking for source files.
+# This pattern also affects html_static_path and html_extra_path.
+exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
+
+# -- Options for HTML output -------------------------------------------------
+source_suffix = {
+ '.rst': 'restructuredtext',
+ '.md': 'markdown',
+}
+
+# The theme to use for HTML and HTML Help pages. See the documentation for
+# a list of builtin themes.
+#
+html_theme = 'pytorch_sphinx_theme'
+html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
+html_theme_options = {
+ 'menu': [{
+ 'name': 'GitHub',
+ 'url': 'https://github.com/open-mmlab/mmpose'
+ }],
+ # Specify the language of the shared menu
+ 'menu_lang': 'cn'
+}
+
+# Add any paths that contain custom static files (such as style sheets) here,
+# relative to this directory. They are copied after the builtin static files,
+# so a file named "default.css" will overwrite the builtin "default.css".
+
+language = 'zh_CN'
+
+html_static_path = ['_static']
+html_css_files = ['css/readthedocs.css']
+
+# Enable ::: for my_st
+myst_enable_extensions = ['colon_fence']
+
+master_doc = 'index'
+
+
+def builder_inited_handler(app):
+ subprocess.run(['python', './collect_modelzoo.py'])
+ subprocess.run(['python', './collect_projects.py'])
+ subprocess.run(['sh', './merge_docs.sh'])
+ subprocess.run(['python', './stats.py'])
+
+
+def setup(app):
+ app.connect('builder-inited', builder_inited_handler)
diff --git a/docs/zh_cn/contribution_guide.md b/docs/zh_cn/contribution_guide.md
index 96be7d1723..50ae265566 100644
--- a/docs/zh_cn/contribution_guide.md
+++ b/docs/zh_cn/contribution_guide.md
@@ -1,207 +1,207 @@
-# 如何给 MMPose 贡献代码
-
-欢迎加入 MMPose 社区,我们致力于打造最前沿的计算机视觉基础库,我们欢迎任何形式的贡献,包括但不限于:
-
-- **修复错误**
- 1. 如果提交的代码改动较大,我们鼓励你先开一个 issue 并正确描述现象、原因和复现方式,讨论后确认修复方案。
- 2. 修复错误并补充相应的单元测试,提交 PR 。
-- **新增功能或组件**
- 1. 如果新功能或模块涉及较大的代码改动,我们建议先提交 issue,与我们确认功能的必要性。
- 2. 实现新增功能并添加单元测试,提交 PR 。
-- **文档补充或翻译**
- - 如果发现文档有错误或不完善的地方,欢迎直接提交 PR 。
-
-```{note}
-- 如果你希望向 MMPose 1.0 贡献代码,请从 dev-1.x 上创建新分支,并提交 PR 到 dev-1.x 分支上。
-- 如果你是论文作者,并希望将你的方法加入到 MMPose 中,欢迎联系我们,我们将非常感谢你的贡献。
-- 如果你希望尽快将你的项目分享到 MMPose 开源社区,欢迎将 PR 提到 Projects 目录下,该目录下的项目将简化 Review 流程并尽快合入。
-- 如果你希望加入 MMPose 的维护者,欢迎联系我们,我们将邀请你加入 MMPose 的维护者群。
-```
-
-## 准备工作
-
-PR 操作所使用的命令都是用 Git 去实现的,该章节将介绍如何进行 Git 配置与 GitHub 绑定。
-
-### Git 配置
-
-首先,你需要在本地安装 Git,然后配置你的 Git 用户名和邮箱:
-
-```Shell
-# 在命令提示符(cmd)或终端(terminal)中输入以下命令,查看 Git 版本
-git --version
-```
-
-然后,你需要检查自己的 Git Config 是否正确配置,如果 `user.name` 和 `user.email` 为空,你需要配置你的 Git 用户名和邮箱:
-
-```Shell
-# 在命令提示符(cmd)或终端(terminal)中输入以下命令,查看 Git 配置
-git config --global --list
-# 设置 Git 用户名和邮箱
-git config --global user.name "这里填入你的用户名"
-git config --global user.email "这里填入你的邮箱"
-```
-
-## PR 流程
-
-如果你对 PR 流程不熟悉,接下来将会从零开始,一步一步地教你如何提交 PR。如果你想深入了解 PR 开发模式,可以参考 [GitHub 官方文档](https://docs.github.com/cn/github/collaborating-with-issues-and-pull-requests/about-pull-requests)。
-
-### 1. Fork 项目
-
-当你第一次提交 PR 时,需要先 Fork 项目到自己的 GitHub 账号下。点击项目右上角的 Fork 按钮,将项目 Fork 到自己的 GitHub 账号下。
-
-
-
-接着,你需要将你的 Fork 仓库 Clone 到本地,然后添加官方仓库作为远程仓库:
-
-```Shell
-
-# Clone 你的 Fork 仓库到本地
-git clone https://github.com/username/mmpose.git
-
-# 添加官方仓库作为远程仓库
-cd mmpose
-git remote add upstream https://github.com/open-mmlab/mmpose.git
-```
-
-在终端中输入以下命令,查看远程仓库是否成功添加:
-
-```Shell
-git remote -v
-```
-
-如果出现以下信息,说明你已经成功添加了远程仓库:
-
-```Shell
-origin https://github.com/{username}/mmpose.git (fetch)
-origin https://github.com/{username}/mmpose.git (push)
-upstream https://github.com/open-mmlab/mmpose.git (fetch)
-upstream https://github.com/open-mmlab/mmpose.git (push)
-```
-
-```{note}
-这里对 origin 和 upstream 进行一个简单的介绍,当我们使用 git clone 来克隆代码时,会默认创建一个 origin 的 remote,它指向我们克隆的代码库地址,而 upstream 则是我们自己添加的,用来指向原始代码库地址。当然如果你不喜欢他叫 upstream,也可以自己修改,比如叫 open-mmlab。我们通常向 origin 提交代码(即 fork 下来的远程仓库),然后向 upstream 提交一个 pull request。如果提交的代码和最新的代码发生冲突,再从 upstream 拉取最新的代码,和本地分支解决冲突,再提交到 origin。
-```
-
-### 2. 配置 pre-commit
-
-在本地开发环境中,我们使用 pre-commit 来检查代码风格,以确保代码风格的统一。在提交代码前,你需要先安装 pre-commit:
-
-```Shell
-pip install -U pre-commit
-
-# 在 mmpose 根目录下安装 pre-commit
-pre-commit install
-```
-
-检查 pre-commit 是否配置成功,并安装 `.pre-commit-config.yaml` 中的钩子:
-
-```Shell
-pre-commit run --all-files
-```
-
-
-
-```{note}
-如果你是中国大陆用户,由于网络原因,可能会出现 pre-commit 安装失败的情况。
-
-这时你可以使用清华源来安装 pre-commit:
-pip install -U pre-commit -i https://pypi.tuna.tsinghua.edu.cn/simple
-
-或者使用国内镜像来安装 pre-commit:
-pip install -U pre-commit -i https://pypi.mirrors.ustc.edu.cn/simple
-```
-
-如果安装过程被中断,可以重复执行上述命令,直到安装成功。
-
-如果你提交的代码中有不符合规范的地方,pre-commit 会发出警告,并自动修复部分错误。
-
-
-
-### 3. 创建开发分支
-
-安装完 pre-commit 之后,我们需要基于 dev 分支创建一个新的开发分支,建议以 `username/pr_name` 的形式命名,例如:
-
-```Shell
-git checkout -b username/refactor_contributing_doc
-```
-
-在后续的开发中,如果本地仓库的 dev 分支落后于官方仓库的 dev 分支,需要先拉取 upstream 的 dev 分支,然后 rebase 到本地的开发分支上:
-
-```Shell
-git checkout username/refactor_contributing_doc
-git fetch upstream
-git rebase upstream/dev-1.x
-```
-
-在 rebase 时,如果出现冲突,需要手动解决冲突,然后执行 `git add` 命令,再执行 `git rebase --continue` 命令,直到 rebase 完成。
-
-### 4. 提交代码并在本地通过单元测试
-
-在本地开发完成后,我们需要在本地通过单元测试,然后提交代码。
-
-```shell
-# 运行单元测试
-pytest tests/
-
-# 提交代码
-git add .
-git commit -m "commit message"
-```
-
-### 5. 推送代码到远程仓库
-
-在本地开发完成后,我们需要将代码推送到远程仓库。
-
-```Shell
-git push origin username/refactor_contributing_doc
-```
-
-### 6. 提交 Pull Request (PR)
-
-#### (1) 在 GitHub 上创建 PR
-
-
-
-#### (2) 在 PR 中根据指引修改描述,添加必要的信息
-
-
-
-```{note}
-- 在 PR branch 左侧选择 `dev` 分支,否则 PR 会被拒绝。
-- 如果你是第一次向 OpenMMLab 提交 PR,需要签署 CLA。
-```
-
-
-
-## 代码风格
-
-### Python
-
-我们采用[PEP8](https://www.python.org/dev/peps/pep-0008/)作为代码风格。
-
-使用下面的工具来对代码进行整理和格式化:
-
-- [flake8](http://flake8.pycqa.org/en/latest/):代码提示
-- [isort](https://github.com/timothycrosley/isort):import 排序
-- [yapf](https://github.com/google/yapf):格式化工具
-- [codespell](https://github.com/codespell-project/codespell): 单词拼写检查
-- [mdformat](https://github.com/executablebooks/mdformat): markdown 文件格式化工具
-- [docformatter](https://github.com/myint/docformatter): docstring 格式化工具
-
-`yapf`和`isort`的样式配置可以在[setup.cfg](/setup.cfg)中找到。
-
-我们使用[pre-commit hook](https://pre-commit.com/)来:
-
-- 检查和格式化 `flake8`、`yapf`、`isort`、`trailing whitespaces`
-- 修复 `end-of-files`
-- 在每次提交时自动排序 `requirments.txt`
-
-`pre-commit`的配置存储在[.pre-commit-config](/.pre-commit-config.yaml)中。
-
-```{note}
-在你创建PR之前,请确保你的代码格式符合规范,且经过了 yapf 格式化。
-```
-
-### C++与CUDA
-
-遵循[Google C++风格指南](https://google.github.io/styleguide/cppguide.html)
+# 如何给 MMPose 贡献代码
+
+欢迎加入 MMPose 社区,我们致力于打造最前沿的计算机视觉基础库,我们欢迎任何形式的贡献,包括但不限于:
+
+- **修复错误**
+ 1. 如果提交的代码改动较大,我们鼓励你先开一个 issue 并正确描述现象、原因和复现方式,讨论后确认修复方案。
+ 2. 修复错误并补充相应的单元测试,提交 PR 。
+- **新增功能或组件**
+ 1. 如果新功能或模块涉及较大的代码改动,我们建议先提交 issue,与我们确认功能的必要性。
+ 2. 实现新增功能并添加单元测试,提交 PR 。
+- **文档补充或翻译**
+ - 如果发现文档有错误或不完善的地方,欢迎直接提交 PR 。
+
+```{note}
+- 如果你希望向 MMPose 1.0 贡献代码,请从 dev-1.x 上创建新分支,并提交 PR 到 dev-1.x 分支上。
+- 如果你是论文作者,并希望将你的方法加入到 MMPose 中,欢迎联系我们,我们将非常感谢你的贡献。
+- 如果你希望尽快将你的项目分享到 MMPose 开源社区,欢迎将 PR 提到 Projects 目录下,该目录下的项目将简化 Review 流程并尽快合入。
+- 如果你希望加入 MMPose 的维护者,欢迎联系我们,我们将邀请你加入 MMPose 的维护者群。
+```
+
+## 准备工作
+
+PR 操作所使用的命令都是用 Git 去实现的,该章节将介绍如何进行 Git 配置与 GitHub 绑定。
+
+### Git 配置
+
+首先,你需要在本地安装 Git,然后配置你的 Git 用户名和邮箱:
+
+```Shell
+# 在命令提示符(cmd)或终端(terminal)中输入以下命令,查看 Git 版本
+git --version
+```
+
+然后,你需要检查自己的 Git Config 是否正确配置,如果 `user.name` 和 `user.email` 为空,你需要配置你的 Git 用户名和邮箱:
+
+```Shell
+# 在命令提示符(cmd)或终端(terminal)中输入以下命令,查看 Git 配置
+git config --global --list
+# 设置 Git 用户名和邮箱
+git config --global user.name "这里填入你的用户名"
+git config --global user.email "这里填入你的邮箱"
+```
+
+## PR 流程
+
+如果你对 PR 流程不熟悉,接下来将会从零开始,一步一步地教你如何提交 PR。如果你想深入了解 PR 开发模式,可以参考 [GitHub 官方文档](https://docs.github.com/cn/github/collaborating-with-issues-and-pull-requests/about-pull-requests)。
+
+### 1. Fork 项目
+
+当你第一次提交 PR 时,需要先 Fork 项目到自己的 GitHub 账号下。点击项目右上角的 Fork 按钮,将项目 Fork 到自己的 GitHub 账号下。
+
+
+
+接着,你需要将你的 Fork 仓库 Clone 到本地,然后添加官方仓库作为远程仓库:
+
+```Shell
+
+# Clone 你的 Fork 仓库到本地
+git clone https://github.com/username/mmpose.git
+
+# 添加官方仓库作为远程仓库
+cd mmpose
+git remote add upstream https://github.com/open-mmlab/mmpose.git
+```
+
+在终端中输入以下命令,查看远程仓库是否成功添加:
+
+```Shell
+git remote -v
+```
+
+如果出现以下信息,说明你已经成功添加了远程仓库:
+
+```Shell
+origin https://github.com/{username}/mmpose.git (fetch)
+origin https://github.com/{username}/mmpose.git (push)
+upstream https://github.com/open-mmlab/mmpose.git (fetch)
+upstream https://github.com/open-mmlab/mmpose.git (push)
+```
+
+```{note}
+这里对 origin 和 upstream 进行一个简单的介绍,当我们使用 git clone 来克隆代码时,会默认创建一个 origin 的 remote,它指向我们克隆的代码库地址,而 upstream 则是我们自己添加的,用来指向原始代码库地址。当然如果你不喜欢他叫 upstream,也可以自己修改,比如叫 open-mmlab。我们通常向 origin 提交代码(即 fork 下来的远程仓库),然后向 upstream 提交一个 pull request。如果提交的代码和最新的代码发生冲突,再从 upstream 拉取最新的代码,和本地分支解决冲突,再提交到 origin。
+```
+
+### 2. 配置 pre-commit
+
+在本地开发环境中,我们使用 pre-commit 来检查代码风格,以确保代码风格的统一。在提交代码前,你需要先安装 pre-commit:
+
+```Shell
+pip install -U pre-commit
+
+# 在 mmpose 根目录下安装 pre-commit
+pre-commit install
+```
+
+检查 pre-commit 是否配置成功,并安装 `.pre-commit-config.yaml` 中的钩子:
+
+```Shell
+pre-commit run --all-files
+```
+
+
+
+```{note}
+如果你是中国大陆用户,由于网络原因,可能会出现 pre-commit 安装失败的情况。
+
+这时你可以使用清华源来安装 pre-commit:
+pip install -U pre-commit -i https://pypi.tuna.tsinghua.edu.cn/simple
+
+或者使用国内镜像来安装 pre-commit:
+pip install -U pre-commit -i https://pypi.mirrors.ustc.edu.cn/simple
+```
+
+如果安装过程被中断,可以重复执行上述命令,直到安装成功。
+
+如果你提交的代码中有不符合规范的地方,pre-commit 会发出警告,并自动修复部分错误。
+
+
+
+### 3. 创建开发分支
+
+安装完 pre-commit 之后,我们需要基于 dev 分支创建一个新的开发分支,建议以 `username/pr_name` 的形式命名,例如:
+
+```Shell
+git checkout -b username/refactor_contributing_doc
+```
+
+在后续的开发中,如果本地仓库的 dev 分支落后于官方仓库的 dev 分支,需要先拉取 upstream 的 dev 分支,然后 rebase 到本地的开发分支上:
+
+```Shell
+git checkout username/refactor_contributing_doc
+git fetch upstream
+git rebase upstream/dev-1.x
+```
+
+在 rebase 时,如果出现冲突,需要手动解决冲突,然后执行 `git add` 命令,再执行 `git rebase --continue` 命令,直到 rebase 完成。
+
+### 4. 提交代码并在本地通过单元测试
+
+在本地开发完成后,我们需要在本地通过单元测试,然后提交代码。
+
+```shell
+# 运行单元测试
+pytest tests/
+
+# 提交代码
+git add .
+git commit -m "commit message"
+```
+
+### 5. 推送代码到远程仓库
+
+在本地开发完成后,我们需要将代码推送到远程仓库。
+
+```Shell
+git push origin username/refactor_contributing_doc
+```
+
+### 6. 提交 Pull Request (PR)
+
+#### (1) 在 GitHub 上创建 PR
+
+
+
+#### (2) 在 PR 中根据指引修改描述,添加必要的信息
+
+
+
+```{note}
+- 在 PR branch 左侧选择 `dev` 分支,否则 PR 会被拒绝。
+- 如果你是第一次向 OpenMMLab 提交 PR,需要签署 CLA。
+```
+
+
+
+## 代码风格
+
+### Python
+
+我们采用[PEP8](https://www.python.org/dev/peps/pep-0008/)作为代码风格。
+
+使用下面的工具来对代码进行整理和格式化:
+
+- [flake8](http://flake8.pycqa.org/en/latest/):代码提示
+- [isort](https://github.com/timothycrosley/isort):import 排序
+- [yapf](https://github.com/google/yapf):格式化工具
+- [codespell](https://github.com/codespell-project/codespell): 单词拼写检查
+- [mdformat](https://github.com/executablebooks/mdformat): markdown 文件格式化工具
+- [docformatter](https://github.com/myint/docformatter): docstring 格式化工具
+
+`yapf`和`isort`的样式配置可以在[setup.cfg](/setup.cfg)中找到。
+
+我们使用[pre-commit hook](https://pre-commit.com/)来:
+
+- 检查和格式化 `flake8`、`yapf`、`isort`、`trailing whitespaces`
+- 修复 `end-of-files`
+- 在每次提交时自动排序 `requirments.txt`
+
+`pre-commit`的配置存储在[.pre-commit-config](/.pre-commit-config.yaml)中。
+
+```{note}
+在你创建PR之前,请确保你的代码格式符合规范,且经过了 yapf 格式化。
+```
+
+### C++与CUDA
+
+遵循[Google C++风格指南](https://google.github.io/styleguide/cppguide.html)
diff --git a/docs/zh_cn/dataset_zoo/2d_animal_keypoint.md b/docs/zh_cn/dataset_zoo/2d_animal_keypoint.md
index 28b0b726b4..5e9ca92a71 100644
--- a/docs/zh_cn/dataset_zoo/2d_animal_keypoint.md
+++ b/docs/zh_cn/dataset_zoo/2d_animal_keypoint.md
@@ -1,545 +1,545 @@
-# 2D Animal Keypoint Dataset
-
-It is recommended to symlink the dataset root to `$MMPOSE/data`.
-If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMPose supported datasets:
-
-- [Animal-Pose](#animal-pose) \[ [Homepage](https://sites.google.com/view/animal-pose/) \]
-- [AP-10K](#ap-10k) \[ [Homepage](https://github.com/AlexTheBad/AP-10K/) \]
-- [Horse-10](#horse-10) \[ [Homepage](http://www.mackenziemathislab.org/horse10) \]
-- [MacaquePose](#macaquepose) \[ [Homepage](http://www.pri.kyoto-u.ac.jp/datasets/macaquepose/index.html) \]
-- [Vinegar Fly](#vinegar-fly) \[ [Homepage](https://github.com/jgraving/DeepPoseKit-Data) \]
-- [Desert Locust](#desert-locust) \[ [Homepage](https://github.com/jgraving/DeepPoseKit-Data) \]
-- [Grévy’s Zebra](#grvys-zebra) \[ [Homepage](https://github.com/jgraving/DeepPoseKit-Data) \]
-- [ATRW](#atrw) \[ [Homepage](https://cvwc2019.github.io/challenge.html) \]
-- [Animal Kingdom](#Animal-Kindom) \[ [Homepage](https://openaccess.thecvf.com/content/CVPR2022/html/Ng_Animal_Kingdom_A_Large_and_Diverse_Dataset_for_Animal_Behavior_CVPR_2022_paper.html) \]
-
-## Animal-Pose
-
-
-
-
-Animal-Pose (ICCV'2019)
-
-```bibtex
-@InProceedings{Cao_2019_ICCV,
- author = {Cao, Jinkun and Tang, Hongyang and Fang, Hao-Shu and Shen, Xiaoyong and Lu, Cewu and Tai, Yu-Wing},
- title = {Cross-Domain Adaptation for Animal Pose Estimation},
- booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
- month = {October},
- year = {2019}
-}
-```
-
-
-
-
-
-
-
-For [Animal-Pose](https://sites.google.com/view/animal-pose/) dataset, we prepare the dataset as follows:
-
-1. Download the images of [PASCAL VOC2012](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/#data), especially the five categories (dog, cat, sheep, cow, horse), which we use as trainval dataset.
-2. Download the [test-set](https://drive.google.com/drive/folders/1DwhQobZlGntOXxdm7vQsE4bqbFmN3b9y?usp=sharing) images with raw annotations (1000 images, 5 categories).
-3. We have pre-processed the annotations to make it compatible with MMPose. Please download the annotation files from [annotations](https://download.openmmlab.com/mmpose/datasets/animalpose_annotations.tar). If you would like to generate the annotations by yourself, please check our dataset parsing [codes](/tools/dataset_converters/parse_animalpose_dataset.py).
-
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── animalpose
- │
- │-- VOC2012
- │ │-- Annotations
- │ │-- ImageSets
- │ │-- JPEGImages
- │ │-- SegmentationClass
- │ │-- SegmentationObject
- │
- │-- animalpose_image_part2
- │ │-- cat
- │ │-- cow
- │ │-- dog
- │ │-- horse
- │ │-- sheep
- │
- │-- annotations
- │ │-- animalpose_train.json
- │ |-- animalpose_val.json
- │ |-- animalpose_trainval.json
- │ │-- animalpose_test.json
- │
- │-- PASCAL2011_animal_annotation
- │ │-- cat
- │ │ |-- 2007_000528_1.xml
- │ │ |-- 2007_000549_1.xml
- │ │ │-- ...
- │ │-- cow
- │ │-- dog
- │ │-- horse
- │ │-- sheep
- │
- │-- annimalpose_anno2
- │ │-- cat
- │ │ |-- ca1.xml
- │ │ |-- ca2.xml
- │ │ │-- ...
- │ │-- cow
- │ │-- dog
- │ │-- horse
- │ │-- sheep
-
-```
-
-The official dataset does not provide the official train/val/test set split.
-We choose the images from PascalVOC for train & val. In total, we have 3608 images and 5117 annotations for train+val, where
-2798 images with 4000 annotations are used for training, and 810 images with 1117 annotations are used for validation.
-Those images from other sources (1000 images with 1000 annotations) are used for testing.
-
-## AP-10K
-
-
-
-
-AP-10K (NeurIPS'2021)
-
-```bibtex
-@misc{yu2021ap10k,
- title={AP-10K: A Benchmark for Animal Pose Estimation in the Wild},
- author={Hang Yu and Yufei Xu and Jing Zhang and Wei Zhao and Ziyu Guan and Dacheng Tao},
- year={2021},
- eprint={2108.12617},
- archivePrefix={arXiv},
- primaryClass={cs.CV}
-}
-```
-
-
-
-
-
-
-
-For [AP-10K](https://github.com/AlexTheBad/AP-10K/) dataset, images and annotations can be downloaded from [download](https://drive.google.com/file/d/1-FNNGcdtAQRehYYkGY1y4wzFNg4iWNad/view?usp=sharing).
-Note, this data and annotation data is for non-commercial use only.
-
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── ap10k
- │-- annotations
- │ │-- ap10k-train-split1.json
- │ |-- ap10k-train-split2.json
- │ |-- ap10k-train-split3.json
- │ │-- ap10k-val-split1.json
- │ |-- ap10k-val-split2.json
- │ |-- ap10k-val-split3.json
- │ |-- ap10k-test-split1.json
- │ |-- ap10k-test-split2.json
- │ |-- ap10k-test-split3.json
- │-- data
- │ │-- 000000000001.jpg
- │ │-- 000000000002.jpg
- │ │-- ...
-
-```
-
-The annotation files in 'annotation' folder contains 50 labeled animal species. There are total 10,015 labeled images with 13,028 instances in the AP-10K dataset. We randonly split them into train, val, and test set following the ratio of 7:1:2.
-
-## Horse-10
-
-
-
-
-Horse-10 (WACV'2021)
-
-```bibtex
-@inproceedings{mathis2021pretraining,
- title={Pretraining boosts out-of-domain robustness for pose estimation},
- author={Mathis, Alexander and Biasi, Thomas and Schneider, Steffen and Yuksekgonul, Mert and Rogers, Byron and Bethge, Matthias and Mathis, Mackenzie W},
- booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
- pages={1859--1868},
- year={2021}
-}
-```
-
-
-
-
-
-
-
-For [Horse-10](http://www.mackenziemathislab.org/horse10) dataset, images can be downloaded from [download](http://www.mackenziemathislab.org/horse10).
-Please download the annotation files from [horse10_annotations](https://download.openmmlab.com/mmpose/datasets/horse10_annotations.tar). Note, this data and annotation data is for non-commercial use only, per the authors (see http://horse10.deeplabcut.org for more information).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── horse10
- │-- annotations
- │ │-- horse10-train-split1.json
- │ |-- horse10-train-split2.json
- │ |-- horse10-train-split3.json
- │ │-- horse10-test-split1.json
- │ |-- horse10-test-split2.json
- │ |-- horse10-test-split3.json
- │-- labeled-data
- │ │-- BrownHorseinShadow
- │ │-- BrownHorseintoshadow
- │ │-- ...
-
-```
-
-## MacaquePose
-
-
-
-
-MacaquePose (bioRxiv'2020)
-
-```bibtex
-@article{labuguen2020macaquepose,
- title={MacaquePose: A novel ‘in the wild’macaque monkey pose dataset for markerless motion capture},
- author={Labuguen, Rollyn and Matsumoto, Jumpei and Negrete, Salvador and Nishimaru, Hiroshi and Nishijo, Hisao and Takada, Masahiko and Go, Yasuhiro and Inoue, Ken-ichi and Shibata, Tomohiro},
- journal={bioRxiv},
- year={2020},
- publisher={Cold Spring Harbor Laboratory}
-}
-```
-
-
-
-
-
-
-
-For [MacaquePose](http://www.pri.kyoto-u.ac.jp/datasets/macaquepose/index.html) dataset, images can be downloaded from [download](http://www.pri.kyoto-u.ac.jp/datasets/macaquepose/index.html).
-Please download the annotation files from [macaque_annotations](https://download.openmmlab.com/mmpose/datasets/macaque_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── macaque
- │-- annotations
- │ │-- macaque_train.json
- │ |-- macaque_test.json
- │-- images
- │ │-- 01418849d54b3005.jpg
- │ │-- 0142d1d1a6904a70.jpg
- │ │-- 01ef2c4c260321b7.jpg
- │ │-- 020a1c75c8c85238.jpg
- │ │-- 020b1506eef2557d.jpg
- │ │-- ...
-
-```
-
-Since the official dataset does not provide the test set, we randomly select 12500 images for training, and the rest for evaluation (see [code](/tools/dataset/parse_macaquepose_dataset.py)).
-
-## Vinegar Fly
-
-
-
-
-Vinegar Fly (Nature Methods'2019)
-
-```bibtex
-@article{pereira2019fast,
- title={Fast animal pose estimation using deep neural networks},
- author={Pereira, Talmo D and Aldarondo, Diego E and Willmore, Lindsay and Kislin, Mikhail and Wang, Samuel S-H and Murthy, Mala and Shaevitz, Joshua W},
- journal={Nature methods},
- volume={16},
- number={1},
- pages={117--125},
- year={2019},
- publisher={Nature Publishing Group}
-}
-```
-
-
-
-
-
-
-
-For [Vinegar Fly](https://github.com/jgraving/DeepPoseKit-Data) dataset, images can be downloaded from [vinegar_fly_images](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_images.tar).
-Please download the annotation files from [vinegar_fly_annotations](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── fly
- │-- annotations
- │ │-- fly_train.json
- │ |-- fly_test.json
- │-- images
- │ │-- 0.jpg
- │ │-- 1.jpg
- │ │-- 2.jpg
- │ │-- 3.jpg
- │ │-- ...
-
-```
-
-Since the official dataset does not provide the test set, we randomly select 90% images for training, and the rest (10%) for evaluation (see [code](/tools/dataset_converters/parse_deepposekit_dataset.py)).
-
-## Desert Locust
-
-
-
-
-Desert Locust (Elife'2019)
-
-```bibtex
-@article{graving2019deepposekit,
- title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning},
- author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D},
- journal={Elife},
- volume={8},
- pages={e47994},
- year={2019},
- publisher={eLife Sciences Publications Limited}
-}
-```
-
-
-
-
-
-
-
-For [Desert Locust](https://github.com/jgraving/DeepPoseKit-Data) dataset, images can be downloaded from [locust_images](https://download.openmmlab.com/mmpose/datasets/locust_images.tar).
-Please download the annotation files from [locust_annotations](https://download.openmmlab.com/mmpose/datasets/locust_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── locust
- │-- annotations
- │ │-- locust_train.json
- │ |-- locust_test.json
- │-- images
- │ │-- 0.jpg
- │ │-- 1.jpg
- │ │-- 2.jpg
- │ │-- 3.jpg
- │ │-- ...
-
-```
-
-Since the official dataset does not provide the test set, we randomly select 90% images for training, and the rest (10%) for evaluation (see [code](/tools/dataset_converters/parse_deepposekit_dataset.py)).
-
-## Grévy’s Zebra
-
-
-
-
-Grévy’s Zebra (Elife'2019)
-
-```bibtex
-@article{graving2019deepposekit,
- title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning},
- author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D},
- journal={Elife},
- volume={8},
- pages={e47994},
- year={2019},
- publisher={eLife Sciences Publications Limited}
-}
-```
-
-
-
-
-
-
-
-For [Grévy’s Zebra](https://github.com/jgraving/DeepPoseKit-Data) dataset, images can be downloaded from [zebra_images](https://download.openmmlab.com/mmpose/datasets/zebra_images.tar).
-Please download the annotation files from [zebra_annotations](https://download.openmmlab.com/mmpose/datasets/zebra_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── zebra
- │-- annotations
- │ │-- zebra_train.json
- │ |-- zebra_test.json
- │-- images
- │ │-- 0.jpg
- │ │-- 1.jpg
- │ │-- 2.jpg
- │ │-- 3.jpg
- │ │-- ...
-
-```
-
-Since the official dataset does not provide the test set, we randomly select 90% images for training, and the rest (10%) for evaluation (see [code](/tools/dataset_converters/parse_deepposekit_dataset.py)).
-
-## ATRW
-
-
-
-
-ATRW (ACM MM'2020)
-
-```bibtex
-@inproceedings{li2020atrw,
- title={ATRW: A Benchmark for Amur Tiger Re-identification in the Wild},
- author={Li, Shuyuan and Li, Jianguo and Tang, Hanlin and Qian, Rui and Lin, Weiyao},
- booktitle={Proceedings of the 28th ACM International Conference on Multimedia},
- pages={2590--2598},
- year={2020}
-}
-```
-
-
-
-
-
-
-
-ATRW captures images of the Amur tiger (also known as Siberian tiger, Northeast-China tiger) in the wild.
-For [ATRW](https://cvwc2019.github.io/challenge.html) dataset, please download images from
-[Pose_train](https://lilablobssc.blob.core.windows.net/cvwc2019/train/atrw_pose_train.tar.gz),
-[Pose_val](https://lilablobssc.blob.core.windows.net/cvwc2019/train/atrw_pose_val.tar.gz), and
-[Pose_test](https://lilablobssc.blob.core.windows.net/cvwc2019/test/atrw_pose_test.tar.gz).
-Note that in the ATRW official annotation files, the key "file_name" is written as "filename". To make it compatible with
-other coco-type json files, we have modified this key.
-Please download the modified annotation files from [atrw_annotations](https://download.openmmlab.com/mmpose/datasets/atrw_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── atrw
- │-- annotations
- │ │-- keypoint_train.json
- │ │-- keypoint_val.json
- │ │-- keypoint_trainval.json
- │-- images
- │ │-- train
- │ │ │-- 000002.jpg
- │ │ │-- 000003.jpg
- │ │ │-- ...
- │ │-- val
- │ │ │-- 000001.jpg
- │ │ │-- 000013.jpg
- │ │ │-- ...
- │ │-- test
- │ │ │-- 000000.jpg
- │ │ │-- 000004.jpg
- │ │ │-- ...
-
-```
-
-## Animal Kingdom
-
-
-Animal Kingdom (CVPR'2022)
-
-
-
-
-
-```bibtex
-@inproceedings{Ng_2022_CVPR,
- author = {Ng, Xun Long and Ong, Kian Eng and Zheng, Qichen and Ni, Yun and Yeo, Si Yong and Liu, Jun},
- title = {Animal Kingdom: A Large and Diverse Dataset for Animal Behavior Understanding},
- booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
- month = {June},
- year = {2022},
- pages = {19023-19034}
- }
-```
-
-For [Animal Kingdom](https://github.com/sutdcv/Animal-Kingdom) dataset, images can be downloaded from [here](https://forms.office.com/pages/responsepage.aspx?id=drd2NJDpck-5UGJImDFiPVRYpnTEMixKqPJ1FxwK6VZUQkNTSkRISTNORUI2TDBWMUpZTlQ5WUlaSyQlQCN0PWcu).
-Please Extract dataset under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── ak
- |--annotations
- │ │-- ak_P1
- │ │ │-- train.json
- │ │ │-- test.json
- │ │-- ak_P2
- │ │ │-- train.json
- │ │ │-- test.json
- │ │-- ak_P3_amphibian
- │ │ │-- train.json
- │ │ │-- test.json
- │ │-- ak_P3_bird
- │ │ │-- train.json
- │ │ │-- test.json
- │ │-- ak_P3_fish
- │ │ │-- train.json
- │ │ │-- test.json
- │ │-- ak_P3_mammal
- │ │ │-- train.json
- │ │ │-- test.json
- │ │-- ak_P3_reptile
- │ │-- train.json
- │ │-- test.json
- │-- images
- │ │-- AAACXZTV
- │ │ │--AAACXZTV_f000059.jpg
- │ │ │--...
- │ │-- AAAUILHH
- │ │ │--AAAUILHH_f000098.jpg
- │ │ │--...
- │ │-- ...
-```
+# 2D Animal Keypoint Dataset
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [Animal-Pose](#animal-pose) \[ [Homepage](https://sites.google.com/view/animal-pose/) \]
+- [AP-10K](#ap-10k) \[ [Homepage](https://github.com/AlexTheBad/AP-10K/) \]
+- [Horse-10](#horse-10) \[ [Homepage](http://www.mackenziemathislab.org/horse10) \]
+- [MacaquePose](#macaquepose) \[ [Homepage](http://www.pri.kyoto-u.ac.jp/datasets/macaquepose/index.html) \]
+- [Vinegar Fly](#vinegar-fly) \[ [Homepage](https://github.com/jgraving/DeepPoseKit-Data) \]
+- [Desert Locust](#desert-locust) \[ [Homepage](https://github.com/jgraving/DeepPoseKit-Data) \]
+- [Grévy’s Zebra](#grvys-zebra) \[ [Homepage](https://github.com/jgraving/DeepPoseKit-Data) \]
+- [ATRW](#atrw) \[ [Homepage](https://cvwc2019.github.io/challenge.html) \]
+- [Animal Kingdom](#Animal-Kindom) \[ [Homepage](https://openaccess.thecvf.com/content/CVPR2022/html/Ng_Animal_Kingdom_A_Large_and_Diverse_Dataset_for_Animal_Behavior_CVPR_2022_paper.html) \]
+
+## Animal-Pose
+
+
+
+
+Animal-Pose (ICCV'2019)
+
+```bibtex
+@InProceedings{Cao_2019_ICCV,
+ author = {Cao, Jinkun and Tang, Hongyang and Fang, Hao-Shu and Shen, Xiaoyong and Lu, Cewu and Tai, Yu-Wing},
+ title = {Cross-Domain Adaptation for Animal Pose Estimation},
+ booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
+ month = {October},
+ year = {2019}
+}
+```
+
+
+
+
+
+
+
+For [Animal-Pose](https://sites.google.com/view/animal-pose/) dataset, we prepare the dataset as follows:
+
+1. Download the images of [PASCAL VOC2012](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/#data), especially the five categories (dog, cat, sheep, cow, horse), which we use as trainval dataset.
+2. Download the [test-set](https://drive.google.com/drive/folders/1DwhQobZlGntOXxdm7vQsE4bqbFmN3b9y?usp=sharing) images with raw annotations (1000 images, 5 categories).
+3. We have pre-processed the annotations to make it compatible with MMPose. Please download the annotation files from [annotations](https://download.openmmlab.com/mmpose/datasets/animalpose_annotations.tar). If you would like to generate the annotations by yourself, please check our dataset parsing [codes](/tools/dataset_converters/parse_animalpose_dataset.py).
+
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── animalpose
+ │
+ │-- VOC2012
+ │ │-- Annotations
+ │ │-- ImageSets
+ │ │-- JPEGImages
+ │ │-- SegmentationClass
+ │ │-- SegmentationObject
+ │
+ │-- animalpose_image_part2
+ │ │-- cat
+ │ │-- cow
+ │ │-- dog
+ │ │-- horse
+ │ │-- sheep
+ │
+ │-- annotations
+ │ │-- animalpose_train.json
+ │ |-- animalpose_val.json
+ │ |-- animalpose_trainval.json
+ │ │-- animalpose_test.json
+ │
+ │-- PASCAL2011_animal_annotation
+ │ │-- cat
+ │ │ |-- 2007_000528_1.xml
+ │ │ |-- 2007_000549_1.xml
+ │ │ │-- ...
+ │ │-- cow
+ │ │-- dog
+ │ │-- horse
+ │ │-- sheep
+ │
+ │-- annimalpose_anno2
+ │ │-- cat
+ │ │ |-- ca1.xml
+ │ │ |-- ca2.xml
+ │ │ │-- ...
+ │ │-- cow
+ │ │-- dog
+ │ │-- horse
+ │ │-- sheep
+
+```
+
+The official dataset does not provide the official train/val/test set split.
+We choose the images from PascalVOC for train & val. In total, we have 3608 images and 5117 annotations for train+val, where
+2798 images with 4000 annotations are used for training, and 810 images with 1117 annotations are used for validation.
+Those images from other sources (1000 images with 1000 annotations) are used for testing.
+
+## AP-10K
+
+
+
+
+AP-10K (NeurIPS'2021)
+
+```bibtex
+@misc{yu2021ap10k,
+ title={AP-10K: A Benchmark for Animal Pose Estimation in the Wild},
+ author={Hang Yu and Yufei Xu and Jing Zhang and Wei Zhao and Ziyu Guan and Dacheng Tao},
+ year={2021},
+ eprint={2108.12617},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+}
+```
+
+
+
+
+
+
+
+For [AP-10K](https://github.com/AlexTheBad/AP-10K/) dataset, images and annotations can be downloaded from [download](https://drive.google.com/file/d/1-FNNGcdtAQRehYYkGY1y4wzFNg4iWNad/view?usp=sharing).
+Note, this data and annotation data is for non-commercial use only.
+
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── ap10k
+ │-- annotations
+ │ │-- ap10k-train-split1.json
+ │ |-- ap10k-train-split2.json
+ │ |-- ap10k-train-split3.json
+ │ │-- ap10k-val-split1.json
+ │ |-- ap10k-val-split2.json
+ │ |-- ap10k-val-split3.json
+ │ |-- ap10k-test-split1.json
+ │ |-- ap10k-test-split2.json
+ │ |-- ap10k-test-split3.json
+ │-- data
+ │ │-- 000000000001.jpg
+ │ │-- 000000000002.jpg
+ │ │-- ...
+
+```
+
+The annotation files in 'annotation' folder contains 50 labeled animal species. There are total 10,015 labeled images with 13,028 instances in the AP-10K dataset. We randonly split them into train, val, and test set following the ratio of 7:1:2.
+
+## Horse-10
+
+
+
+
+Horse-10 (WACV'2021)
+
+```bibtex
+@inproceedings{mathis2021pretraining,
+ title={Pretraining boosts out-of-domain robustness for pose estimation},
+ author={Mathis, Alexander and Biasi, Thomas and Schneider, Steffen and Yuksekgonul, Mert and Rogers, Byron and Bethge, Matthias and Mathis, Mackenzie W},
+ booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
+ pages={1859--1868},
+ year={2021}
+}
+```
+
+
+
+
+
+
+
+For [Horse-10](http://www.mackenziemathislab.org/horse10) dataset, images can be downloaded from [download](http://www.mackenziemathislab.org/horse10).
+Please download the annotation files from [horse10_annotations](https://download.openmmlab.com/mmpose/datasets/horse10_annotations.tar). Note, this data and annotation data is for non-commercial use only, per the authors (see http://horse10.deeplabcut.org for more information).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── horse10
+ │-- annotations
+ │ │-- horse10-train-split1.json
+ │ |-- horse10-train-split2.json
+ │ |-- horse10-train-split3.json
+ │ │-- horse10-test-split1.json
+ │ |-- horse10-test-split2.json
+ │ |-- horse10-test-split3.json
+ │-- labeled-data
+ │ │-- BrownHorseinShadow
+ │ │-- BrownHorseintoshadow
+ │ │-- ...
+
+```
+
+## MacaquePose
+
+
+
+
+MacaquePose (bioRxiv'2020)
+
+```bibtex
+@article{labuguen2020macaquepose,
+ title={MacaquePose: A novel ‘in the wild’macaque monkey pose dataset for markerless motion capture},
+ author={Labuguen, Rollyn and Matsumoto, Jumpei and Negrete, Salvador and Nishimaru, Hiroshi and Nishijo, Hisao and Takada, Masahiko and Go, Yasuhiro and Inoue, Ken-ichi and Shibata, Tomohiro},
+ journal={bioRxiv},
+ year={2020},
+ publisher={Cold Spring Harbor Laboratory}
+}
+```
+
+
+
+
+
+
+
+For [MacaquePose](http://www.pri.kyoto-u.ac.jp/datasets/macaquepose/index.html) dataset, images can be downloaded from [download](http://www.pri.kyoto-u.ac.jp/datasets/macaquepose/index.html).
+Please download the annotation files from [macaque_annotations](https://download.openmmlab.com/mmpose/datasets/macaque_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── macaque
+ │-- annotations
+ │ │-- macaque_train.json
+ │ |-- macaque_test.json
+ │-- images
+ │ │-- 01418849d54b3005.jpg
+ │ │-- 0142d1d1a6904a70.jpg
+ │ │-- 01ef2c4c260321b7.jpg
+ │ │-- 020a1c75c8c85238.jpg
+ │ │-- 020b1506eef2557d.jpg
+ │ │-- ...
+
+```
+
+Since the official dataset does not provide the test set, we randomly select 12500 images for training, and the rest for evaluation (see [code](/tools/dataset/parse_macaquepose_dataset.py)).
+
+## Vinegar Fly
+
+
+
+
+Vinegar Fly (Nature Methods'2019)
+
+```bibtex
+@article{pereira2019fast,
+ title={Fast animal pose estimation using deep neural networks},
+ author={Pereira, Talmo D and Aldarondo, Diego E and Willmore, Lindsay and Kislin, Mikhail and Wang, Samuel S-H and Murthy, Mala and Shaevitz, Joshua W},
+ journal={Nature methods},
+ volume={16},
+ number={1},
+ pages={117--125},
+ year={2019},
+ publisher={Nature Publishing Group}
+}
+```
+
+
+
+
+
+
+
+For [Vinegar Fly](https://github.com/jgraving/DeepPoseKit-Data) dataset, images can be downloaded from [vinegar_fly_images](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_images.tar).
+Please download the annotation files from [vinegar_fly_annotations](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── fly
+ │-- annotations
+ │ │-- fly_train.json
+ │ |-- fly_test.json
+ │-- images
+ │ │-- 0.jpg
+ │ │-- 1.jpg
+ │ │-- 2.jpg
+ │ │-- 3.jpg
+ │ │-- ...
+
+```
+
+Since the official dataset does not provide the test set, we randomly select 90% images for training, and the rest (10%) for evaluation (see [code](/tools/dataset_converters/parse_deepposekit_dataset.py)).
+
+## Desert Locust
+
+
+
+
+Desert Locust (Elife'2019)
+
+```bibtex
+@article{graving2019deepposekit,
+ title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning},
+ author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D},
+ journal={Elife},
+ volume={8},
+ pages={e47994},
+ year={2019},
+ publisher={eLife Sciences Publications Limited}
+}
+```
+
+
+
+
+
+
+
+For [Desert Locust](https://github.com/jgraving/DeepPoseKit-Data) dataset, images can be downloaded from [locust_images](https://download.openmmlab.com/mmpose/datasets/locust_images.tar).
+Please download the annotation files from [locust_annotations](https://download.openmmlab.com/mmpose/datasets/locust_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── locust
+ │-- annotations
+ │ │-- locust_train.json
+ │ |-- locust_test.json
+ │-- images
+ │ │-- 0.jpg
+ │ │-- 1.jpg
+ │ │-- 2.jpg
+ │ │-- 3.jpg
+ │ │-- ...
+
+```
+
+Since the official dataset does not provide the test set, we randomly select 90% images for training, and the rest (10%) for evaluation (see [code](/tools/dataset_converters/parse_deepposekit_dataset.py)).
+
+## Grévy’s Zebra
+
+
+
+
+Grévy’s Zebra (Elife'2019)
+
+```bibtex
+@article{graving2019deepposekit,
+ title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning},
+ author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D},
+ journal={Elife},
+ volume={8},
+ pages={e47994},
+ year={2019},
+ publisher={eLife Sciences Publications Limited}
+}
+```
+
+
+
+
+
+
+
+For [Grévy’s Zebra](https://github.com/jgraving/DeepPoseKit-Data) dataset, images can be downloaded from [zebra_images](https://download.openmmlab.com/mmpose/datasets/zebra_images.tar).
+Please download the annotation files from [zebra_annotations](https://download.openmmlab.com/mmpose/datasets/zebra_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── zebra
+ │-- annotations
+ │ │-- zebra_train.json
+ │ |-- zebra_test.json
+ │-- images
+ │ │-- 0.jpg
+ │ │-- 1.jpg
+ │ │-- 2.jpg
+ │ │-- 3.jpg
+ │ │-- ...
+
+```
+
+Since the official dataset does not provide the test set, we randomly select 90% images for training, and the rest (10%) for evaluation (see [code](/tools/dataset_converters/parse_deepposekit_dataset.py)).
+
+## ATRW
+
+
+
+
+ATRW (ACM MM'2020)
+
+```bibtex
+@inproceedings{li2020atrw,
+ title={ATRW: A Benchmark for Amur Tiger Re-identification in the Wild},
+ author={Li, Shuyuan and Li, Jianguo and Tang, Hanlin and Qian, Rui and Lin, Weiyao},
+ booktitle={Proceedings of the 28th ACM International Conference on Multimedia},
+ pages={2590--2598},
+ year={2020}
+}
+```
+
+
+
+
+
+
+
+ATRW captures images of the Amur tiger (also known as Siberian tiger, Northeast-China tiger) in the wild.
+For [ATRW](https://cvwc2019.github.io/challenge.html) dataset, please download images from
+[Pose_train](https://lilablobssc.blob.core.windows.net/cvwc2019/train/atrw_pose_train.tar.gz),
+[Pose_val](https://lilablobssc.blob.core.windows.net/cvwc2019/train/atrw_pose_val.tar.gz), and
+[Pose_test](https://lilablobssc.blob.core.windows.net/cvwc2019/test/atrw_pose_test.tar.gz).
+Note that in the ATRW official annotation files, the key "file_name" is written as "filename". To make it compatible with
+other coco-type json files, we have modified this key.
+Please download the modified annotation files from [atrw_annotations](https://download.openmmlab.com/mmpose/datasets/atrw_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── atrw
+ │-- annotations
+ │ │-- keypoint_train.json
+ │ │-- keypoint_val.json
+ │ │-- keypoint_trainval.json
+ │-- images
+ │ │-- train
+ │ │ │-- 000002.jpg
+ │ │ │-- 000003.jpg
+ │ │ │-- ...
+ │ │-- val
+ │ │ │-- 000001.jpg
+ │ │ │-- 000013.jpg
+ │ │ │-- ...
+ │ │-- test
+ │ │ │-- 000000.jpg
+ │ │ │-- 000004.jpg
+ │ │ │-- ...
+
+```
+
+## Animal Kingdom
+
+
+Animal Kingdom (CVPR'2022)
+
+
+
+
+
+```bibtex
+@inproceedings{Ng_2022_CVPR,
+ author = {Ng, Xun Long and Ong, Kian Eng and Zheng, Qichen and Ni, Yun and Yeo, Si Yong and Liu, Jun},
+ title = {Animal Kingdom: A Large and Diverse Dataset for Animal Behavior Understanding},
+ booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ month = {June},
+ year = {2022},
+ pages = {19023-19034}
+ }
+```
+
+For [Animal Kingdom](https://github.com/sutdcv/Animal-Kingdom) dataset, images can be downloaded from [here](https://forms.office.com/pages/responsepage.aspx?id=drd2NJDpck-5UGJImDFiPVRYpnTEMixKqPJ1FxwK6VZUQkNTSkRISTNORUI2TDBWMUpZTlQ5WUlaSyQlQCN0PWcu).
+Please Extract dataset under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── ak
+ |--annotations
+ │ │-- ak_P1
+ │ │ │-- train.json
+ │ │ │-- test.json
+ │ │-- ak_P2
+ │ │ │-- train.json
+ │ │ │-- test.json
+ │ │-- ak_P3_amphibian
+ │ │ │-- train.json
+ │ │ │-- test.json
+ │ │-- ak_P3_bird
+ │ │ │-- train.json
+ │ │ │-- test.json
+ │ │-- ak_P3_fish
+ │ │ │-- train.json
+ │ │ │-- test.json
+ │ │-- ak_P3_mammal
+ │ │ │-- train.json
+ │ │ │-- test.json
+ │ │-- ak_P3_reptile
+ │ │-- train.json
+ │ │-- test.json
+ │-- images
+ │ │-- AAACXZTV
+ │ │ │--AAACXZTV_f000059.jpg
+ │ │ │--...
+ │ │-- AAAUILHH
+ │ │ │--AAAUILHH_f000098.jpg
+ │ │ │--...
+ │ │-- ...
+```
diff --git a/docs/zh_cn/dataset_zoo/2d_body_keypoint.md b/docs/zh_cn/dataset_zoo/2d_body_keypoint.md
index 4448ebe8f4..3c68b1affc 100644
--- a/docs/zh_cn/dataset_zoo/2d_body_keypoint.md
+++ b/docs/zh_cn/dataset_zoo/2d_body_keypoint.md
@@ -1,588 +1,588 @@
-# 2D Body Keypoint Datasets
-
-It is recommended to symlink the dataset root to `$MMPOSE/data`.
-If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMPose supported datasets:
-
-- Images
- - [COCO](#coco) \[ [Homepage](http://cocodataset.org/) \]
- - [MPII](#mpii) \[ [Homepage](http://human-pose.mpi-inf.mpg.de/) \]
- - [MPII-TRB](#mpii-trb) \[ [Homepage](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) \]
- - [AI Challenger](#aic) \[ [Homepage](https://github.com/AIChallenger/AI_Challenger_2017) \]
- - [CrowdPose](#crowdpose) \[ [Homepage](https://github.com/Jeff-sjtu/CrowdPose) \]
- - [OCHuman](#ochuman) \[ [Homepage](https://github.com/liruilong940607/OCHumanApi) \]
- - [MHP](#mhp) \[ [Homepage](https://lv-mhp.github.io/dataset) \]
- - [Human-Art](#humanart) \[ [Homepage](https://idea-research.github.io/HumanArt/) \]
-- Videos
- - [PoseTrack18](#posetrack18) \[ [Homepage](https://posetrack.net/users/download.php) \]
- - [sub-JHMDB](#sub-jhmdb-dataset) \[ [Homepage](http://jhmdb.is.tue.mpg.de/dataset) \]
-
-## COCO
-
-
-
-
-COCO (ECCV'2014)
-
-```bibtex
-@inproceedings{lin2014microsoft,
- title={Microsoft coco: Common objects in context},
- author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence},
- booktitle={European conference on computer vision},
- pages={740--755},
- year={2014},
- organization={Springer}
-}
-```
-
-
-
-
-
-
-
-For [COCO](http://cocodataset.org/) data, please download from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
-[HRNet-Human-Pose-Estimation](https://github.com/HRNet/HRNet-Human-Pose-Estimation) provides person detection result of COCO val2017 to reproduce our multi-person pose estimation results.
-Please download from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
-Optionally, to evaluate on COCO'2017 test-dev, please download the [image-info](https://download.openmmlab.com/mmpose/datasets/person_keypoints_test-dev-2017.json).
-Download and extract them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── coco
- │-- annotations
- │ │-- person_keypoints_train2017.json
- │ |-- person_keypoints_val2017.json
- │ |-- person_keypoints_test-dev-2017.json
- |-- person_detection_results
- | |-- COCO_val2017_detections_AP_H_56_person.json
- | |-- COCO_test-dev2017_detections_AP_H_609_person.json
- │-- train2017
- │ │-- 000000000009.jpg
- │ │-- 000000000025.jpg
- │ │-- 000000000030.jpg
- │ │-- ...
- `-- val2017
- │-- 000000000139.jpg
- │-- 000000000285.jpg
- │-- 000000000632.jpg
- │-- ...
-
-```
-
-## MPII
-
-
-
-
-MPII (CVPR'2014)
-
-```bibtex
-@inproceedings{andriluka14cvpr,
- author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt},
- title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = {2014},
- month = {June}
-}
-```
-
-
-
-
-
-
-
-For [MPII](http://human-pose.mpi-inf.mpg.de/) data, please download from [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/).
-We have converted the original annotation files into json format, please download them from [mpii_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── mpii
- |── annotations
- | |── mpii_gt_val.mat
- | |── mpii_test.json
- | |── mpii_train.json
- | |── mpii_trainval.json
- | `── mpii_val.json
- `── images
- |── 000001163.jpg
- |── 000003072.jpg
-
-```
-
-During training and inference, the prediction result will be saved as '.mat' format by default. We also provide a tool to convert this '.mat' to more readable '.json' format.
-
-```shell
-python tools/dataset/mat2json ${PRED_MAT_FILE} ${GT_JSON_FILE} ${OUTPUT_PRED_JSON_FILE}
-```
-
-For example,
-
-```shell
-python tools/dataset/mat2json work_dirs/res50_mpii_256x256/pred.mat data/mpii/annotations/mpii_val.json pred.json
-```
-
-## MPII-TRB
-
-
-
-
-MPII-TRB (ICCV'2019)
-
-```bibtex
-@inproceedings{duan2019trb,
- title={TRB: A Novel Triplet Representation for Understanding 2D Human Body},
- author={Duan, Haodong and Lin, Kwan-Yee and Jin, Sheng and Liu, Wentao and Qian, Chen and Ouyang, Wanli},
- booktitle={Proceedings of the IEEE International Conference on Computer Vision},
- pages={9479--9488},
- year={2019}
-}
-```
-
-
-
-
-
-
-
-For [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) data, please download from [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/).
-Please download the annotation files from [mpii_trb_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_trb_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── mpii
- |── annotations
- | |── mpii_trb_train.json
- | |── mpii_trb_val.json
- `── images
- |── 000001163.jpg
- |── 000003072.jpg
-
-```
-
-## AIC
-
-
-
-
-AI Challenger (ArXiv'2017)
-
-```bibtex
-@article{wu2017ai,
- title={Ai challenger: A large-scale dataset for going deeper in image understanding},
- author={Wu, Jiahong and Zheng, He and Zhao, Bo and Li, Yixin and Yan, Baoming and Liang, Rui and Wang, Wenjia and Zhou, Shipei and Lin, Guosen and Fu, Yanwei and others},
- journal={arXiv preprint arXiv:1711.06475},
- year={2017}
-}
-```
-
-
-
-
-
-
-
-For [AIC](https://github.com/AIChallenger/AI_Challenger_2017) data, please download from [AI Challenger 2017](https://github.com/AIChallenger/AI_Challenger_2017), 2017 Train/Val is needed for keypoints training and validation.
-Please download the annotation files from [aic_annotations](https://download.openmmlab.com/mmpose/datasets/aic_annotations.tar).
-Download and extract them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── aic
- │-- annotations
- │ │-- aic_train.json
- │ |-- aic_val.json
- │-- ai_challenger_keypoint_train_20170902
- │ │-- keypoint_train_images_20170902
- │ │ │-- 0000252aea98840a550dac9a78c476ecb9f47ffa.jpg
- │ │ │-- 000050f770985ac9653198495ef9b5c82435d49c.jpg
- │ │ │-- ...
- `-- ai_challenger_keypoint_validation_20170911
- │-- keypoint_validation_images_20170911
- │-- 0002605c53fb92109a3f2de4fc3ce06425c3b61f.jpg
- │-- 0003b55a2c991223e6d8b4b820045bd49507bf6d.jpg
- │-- ...
-```
-
-## CrowdPose
-
-
-
-
-CrowdPose (CVPR'2019)
-
-```bibtex
-@article{li2018crowdpose,
- title={CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark},
- author={Li, Jiefeng and Wang, Can and Zhu, Hao and Mao, Yihuan and Fang, Hao-Shu and Lu, Cewu},
- journal={arXiv preprint arXiv:1812.00324},
- year={2018}
-}
-```
-
-
-
-
-
-
-
-For [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose) data, please download from [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose).
-Please download the annotation files and human detection results from [crowdpose_annotations](https://download.openmmlab.com/mmpose/datasets/crowdpose_annotations.tar).
-For top-down approaches, we follow [CrowdPose](https://arxiv.org/abs/1812.00324) to use the [pre-trained weights](https://pjreddie.com/media/files/yolov3.weights) of [YOLOv3](https://github.com/eriklindernoren/PyTorch-YOLOv3) to generate the detected human bounding boxes.
-For model training, we follow [HigherHRNet](https://github.com/HRNet/HigherHRNet-Human-Pose-Estimation) to train models on CrowdPose train/val dataset, and evaluate models on CrowdPose test dataset.
-Download and extract them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── crowdpose
- │-- annotations
- │ │-- mmpose_crowdpose_train.json
- │ │-- mmpose_crowdpose_val.json
- │ │-- mmpose_crowdpose_trainval.json
- │ │-- mmpose_crowdpose_test.json
- │ │-- det_for_crowd_test_0.1_0.5.json
- │-- images
- │-- 100000.jpg
- │-- 100001.jpg
- │-- 100002.jpg
- │-- ...
-```
-
-## OCHuman
-
-
-
-
-OCHuman (CVPR'2019)
-
-```bibtex
-@inproceedings{zhang2019pose2seg,
- title={Pose2seg: Detection free human instance segmentation},
- author={Zhang, Song-Hai and Li, Ruilong and Dong, Xin and Rosin, Paul and Cai, Zixi and Han, Xi and Yang, Dingcheng and Huang, Haozhi and Hu, Shi-Min},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- pages={889--898},
- year={2019}
-}
-```
-
-
-
-
-
-
-
-For [OCHuman](https://github.com/liruilong940607/OCHumanApi) data, please download the images and annotations from [OCHuman](https://github.com/liruilong940607/OCHumanApi),
-Move them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── ochuman
- │-- annotations
- │ │-- ochuman_coco_format_val_range_0.00_1.00.json
- │ |-- ochuman_coco_format_test_range_0.00_1.00.json
- |-- images
- │-- 000001.jpg
- │-- 000002.jpg
- │-- 000003.jpg
- │-- ...
-
-```
-
-## MHP
-
-
-
-
-MHP (ACM MM'2018)
-
-```bibtex
-@inproceedings{zhao2018understanding,
- title={Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing},
- author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
- booktitle={Proceedings of the 26th ACM international conference on Multimedia},
- pages={792--800},
- year={2018}
-}
-```
-
-
-
-
-
-
-
-For [MHP](https://lv-mhp.github.io/dataset) data, please download from [MHP](https://lv-mhp.github.io/dataset).
-Please download the annotation files from [mhp_annotations](https://download.openmmlab.com/mmpose/datasets/mhp_annotations.tar.gz).
-Please download and extract them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── mhp
- │-- annotations
- │ │-- mhp_train.json
- │ │-- mhp_val.json
- │
- `-- train
- │ │-- images
- │ │ │-- 1004.jpg
- │ │ │-- 10050.jpg
- │ │ │-- ...
- │
- `-- val
- │ │-- images
- │ │ │-- 10059.jpg
- │ │ │-- 10068.jpg
- │ │ │-- ...
- │
- `-- test
- │ │-- images
- │ │ │-- 1005.jpg
- │ │ │-- 10052.jpg
- │ │ │-- ...~~~~
-```
-
-## Human-Art dataset
-
-
-
-
-Human-Art (CVPR'2023)
-
-```bibtex
-@inproceedings{ju2023humanart,
- title={Human-Art: A Versatile Human-Centric Dataset Bridging Natural and Artificial Scenes},
- author={Ju, Xuan and Zeng, Ailing and Jianan, Wang and Qiang, Xu and Lei, Zhang},
- booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
- year={2023}}
-```
-
-
-
-
-
-
-
-For [Human-Art](https://idea-research.github.io/HumanArt/) data, please download the images and annotation files from [its website](https://idea-research.github.io/HumanArt/). You need to fill in the [data form](https://docs.google.com/forms/d/e/1FAIpQLScroT_jvw6B9U2Qca1_cl5Kmmu1ceKtlh6DJNmWLte8xNEhEw/viewform) to get access to the data.
-Move them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-|── data
- │── HumanArt
- │-- images
- │ │-- 2D_virtual_human
- │ │ |-- cartoon
- │ │ | |-- 000000000000.jpg
- │ │ | |-- ...
- │ │ |-- digital_art
- │ │ |-- ...
- │ |-- 3D_virtual_human
- │ |-- real_human
- |-- annotations
- │ │-- validation_humanart.json
- │ │-- training_humanart_coco.json
- |-- person_detection_results
- │ │-- HumanArt_validation_detections_AP_H_56_person.json
-```
-
-You can choose whether to download other annotation files in Human-Art. If you want to use additional annotation files (e.g. validation set of cartoon), you need to edit the corresponding code in config file.
-
-## PoseTrack18
-
-
-
-
-PoseTrack18 (CVPR'2018)
-
-```bibtex
-@inproceedings{andriluka2018posetrack,
- title={Posetrack: A benchmark for human pose estimation and tracking},
- author={Andriluka, Mykhaylo and Iqbal, Umar and Insafutdinov, Eldar and Pishchulin, Leonid and Milan, Anton and Gall, Juergen and Schiele, Bernt},
- booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
- pages={5167--5176},
- year={2018}
-}
-```
-
-
-
-
-
-
-
-For [PoseTrack18](https://posetrack.net/users/download.php) data, please download from [PoseTrack18](https://posetrack.net/users/download.php).
-Please download the annotation files from [posetrack18_annotations](https://download.openmmlab.com/mmpose/datasets/posetrack18_annotations.tar).
-We have merged the video-wise separated official annotation files into two json files (posetrack18_train & posetrack18_val.json). We also generate the [mask files](https://download.openmmlab.com/mmpose/datasets/posetrack18_mask.tar) to speed up training.
-For top-down approaches, we use [MMDetection](https://github.com/open-mmlab/mmdetection) pre-trained [Cascade R-CNN](https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_rcnn_x101_64x4d_fpn_20e_coco/cascade_rcnn_x101_64x4d_fpn_20e_coco_20200509_224357-051557b1.pth) (X-101-64x4d-FPN) to generate the detected human bounding boxes.
-Please download and extract them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── posetrack18
- │-- annotations
- │ │-- posetrack18_train.json
- │ │-- posetrack18_val.json
- │ │-- posetrack18_val_human_detections.json
- │ │-- train
- │ │ │-- 000001_bonn_train.json
- │ │ │-- 000002_bonn_train.json
- │ │ │-- ...
- │ │-- val
- │ │ │-- 000342_mpii_test.json
- │ │ │-- 000522_mpii_test.json
- │ │ │-- ...
- │ `-- test
- │ │-- 000001_mpiinew_test.json
- │ │-- 000002_mpiinew_test.json
- │ │-- ...
- │
- `-- images
- │ │-- train
- │ │ │-- 000001_bonn_train
- │ │ │ │-- 000000.jpg
- │ │ │ │-- 000001.jpg
- │ │ │ │-- ...
- │ │ │-- ...
- │ │-- val
- │ │ │-- 000342_mpii_test
- │ │ │ │-- 000000.jpg
- │ │ │ │-- 000001.jpg
- │ │ │ │-- ...
- │ │ │-- ...
- │ `-- test
- │ │-- 000001_mpiinew_test
- │ │ │-- 000000.jpg
- │ │ │-- 000001.jpg
- │ │ │-- ...
- │ │-- ...
- `-- mask
- │-- train
- │ │-- 000002_bonn_train
- │ │ │-- 000000.jpg
- │ │ │-- 000001.jpg
- │ │ │-- ...
- │ │-- ...
- `-- val
- │-- 000522_mpii_test
- │ │-- 000000.jpg
- │ │-- 000001.jpg
- │ │-- ...
- │-- ...
-```
-
-The official evaluation tool for PoseTrack should be installed from GitHub.
-
-```shell
-pip install git+https://github.com/svenkreiss/poseval.git
-```
-
-## sub-JHMDB dataset
-
-
-
-
-RSN (ECCV'2020)
-
-```bibtex
-@misc{cai2020learning,
- title={Learning Delicate Local Representations for Multi-Person Pose Estimation},
- author={Yuanhao Cai and Zhicheng Wang and Zhengxiong Luo and Binyi Yin and Angang Du and Haoqian Wang and Xinyu Zhou and Erjin Zhou and Xiangyu Zhang and Jian Sun},
- year={2020},
- eprint={2003.04030},
- archivePrefix={arXiv},
- primaryClass={cs.CV}
-}
-```
-
-
-
-
-
-
-
-For [sub-JHMDB](http://jhmdb.is.tue.mpg.de/dataset) data, please download the [images](<(http://files.is.tue.mpg.de/jhmdb/Rename_Images.tar.gz)>) from [JHMDB](http://jhmdb.is.tue.mpg.de/dataset),
-Please download the annotation files from [jhmdb_annotations](https://download.openmmlab.com/mmpose/datasets/jhmdb_annotations.tar).
-Move them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── jhmdb
- │-- annotations
- │ │-- Sub1_train.json
- │ |-- Sub1_test.json
- │ │-- Sub2_train.json
- │ |-- Sub2_test.json
- │ │-- Sub3_train.json
- │ |-- Sub3_test.json
- |-- Rename_Images
- │-- brush_hair
- │ │--April_09_brush_hair_u_nm_np1_ba_goo_0
- | │ │--00001.png
- | │ │--00002.png
- │-- catch
- │-- ...
-
-```
+# 2D Body Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- Images
+ - [COCO](#coco) \[ [Homepage](http://cocodataset.org/) \]
+ - [MPII](#mpii) \[ [Homepage](http://human-pose.mpi-inf.mpg.de/) \]
+ - [MPII-TRB](#mpii-trb) \[ [Homepage](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) \]
+ - [AI Challenger](#aic) \[ [Homepage](https://github.com/AIChallenger/AI_Challenger_2017) \]
+ - [CrowdPose](#crowdpose) \[ [Homepage](https://github.com/Jeff-sjtu/CrowdPose) \]
+ - [OCHuman](#ochuman) \[ [Homepage](https://github.com/liruilong940607/OCHumanApi) \]
+ - [MHP](#mhp) \[ [Homepage](https://lv-mhp.github.io/dataset) \]
+ - [Human-Art](#humanart) \[ [Homepage](https://idea-research.github.io/HumanArt/) \]
+- Videos
+ - [PoseTrack18](#posetrack18) \[ [Homepage](https://posetrack.net/users/download.php) \]
+ - [sub-JHMDB](#sub-jhmdb-dataset) \[ [Homepage](http://jhmdb.is.tue.mpg.de/dataset) \]
+
+## COCO
+
+
+
+
+COCO (ECCV'2014)
+
+```bibtex
+@inproceedings{lin2014microsoft,
+ title={Microsoft coco: Common objects in context},
+ author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence},
+ booktitle={European conference on computer vision},
+ pages={740--755},
+ year={2014},
+ organization={Springer}
+}
+```
+
+
+
+
+
+
+
+For [COCO](http://cocodataset.org/) data, please download from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
+[HRNet-Human-Pose-Estimation](https://github.com/HRNet/HRNet-Human-Pose-Estimation) provides person detection result of COCO val2017 to reproduce our multi-person pose estimation results.
+Please download from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Optionally, to evaluate on COCO'2017 test-dev, please download the [image-info](https://download.openmmlab.com/mmpose/datasets/person_keypoints_test-dev-2017.json).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── coco
+ │-- annotations
+ │ │-- person_keypoints_train2017.json
+ │ |-- person_keypoints_val2017.json
+ │ |-- person_keypoints_test-dev-2017.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ | |-- COCO_test-dev2017_detections_AP_H_609_person.json
+ │-- train2017
+ │ │-- 000000000009.jpg
+ │ │-- 000000000025.jpg
+ │ │-- 000000000030.jpg
+ │ │-- ...
+ `-- val2017
+ │-- 000000000139.jpg
+ │-- 000000000285.jpg
+ │-- 000000000632.jpg
+ │-- ...
+
+```
+
+## MPII
+
+
+
+
+MPII (CVPR'2014)
+
+```bibtex
+@inproceedings{andriluka14cvpr,
+ author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt},
+ title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis},
+ booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year = {2014},
+ month = {June}
+}
+```
+
+
+
+
+
+
+
+For [MPII](http://human-pose.mpi-inf.mpg.de/) data, please download from [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/).
+We have converted the original annotation files into json format, please download them from [mpii_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── mpii
+ |── annotations
+ | |── mpii_gt_val.mat
+ | |── mpii_test.json
+ | |── mpii_train.json
+ | |── mpii_trainval.json
+ | `── mpii_val.json
+ `── images
+ |── 000001163.jpg
+ |── 000003072.jpg
+
+```
+
+During training and inference, the prediction result will be saved as '.mat' format by default. We also provide a tool to convert this '.mat' to more readable '.json' format.
+
+```shell
+python tools/dataset/mat2json ${PRED_MAT_FILE} ${GT_JSON_FILE} ${OUTPUT_PRED_JSON_FILE}
+```
+
+For example,
+
+```shell
+python tools/dataset/mat2json work_dirs/res50_mpii_256x256/pred.mat data/mpii/annotations/mpii_val.json pred.json
+```
+
+## MPII-TRB
+
+
+
+
+MPII-TRB (ICCV'2019)
+
+```bibtex
+@inproceedings{duan2019trb,
+ title={TRB: A Novel Triplet Representation for Understanding 2D Human Body},
+ author={Duan, Haodong and Lin, Kwan-Yee and Jin, Sheng and Liu, Wentao and Qian, Chen and Ouyang, Wanli},
+ booktitle={Proceedings of the IEEE International Conference on Computer Vision},
+ pages={9479--9488},
+ year={2019}
+}
+```
+
+
+
+
+
+
+
+For [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) data, please download from [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/).
+Please download the annotation files from [mpii_trb_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_trb_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── mpii
+ |── annotations
+ | |── mpii_trb_train.json
+ | |── mpii_trb_val.json
+ `── images
+ |── 000001163.jpg
+ |── 000003072.jpg
+
+```
+
+## AIC
+
+
+
+
+AI Challenger (ArXiv'2017)
+
+```bibtex
+@article{wu2017ai,
+ title={Ai challenger: A large-scale dataset for going deeper in image understanding},
+ author={Wu, Jiahong and Zheng, He and Zhao, Bo and Li, Yixin and Yan, Baoming and Liang, Rui and Wang, Wenjia and Zhou, Shipei and Lin, Guosen and Fu, Yanwei and others},
+ journal={arXiv preprint arXiv:1711.06475},
+ year={2017}
+}
+```
+
+
+
+
+
+
+
+For [AIC](https://github.com/AIChallenger/AI_Challenger_2017) data, please download from [AI Challenger 2017](https://github.com/AIChallenger/AI_Challenger_2017), 2017 Train/Val is needed for keypoints training and validation.
+Please download the annotation files from [aic_annotations](https://download.openmmlab.com/mmpose/datasets/aic_annotations.tar).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── aic
+ │-- annotations
+ │ │-- aic_train.json
+ │ |-- aic_val.json
+ │-- ai_challenger_keypoint_train_20170902
+ │ │-- keypoint_train_images_20170902
+ │ │ │-- 0000252aea98840a550dac9a78c476ecb9f47ffa.jpg
+ │ │ │-- 000050f770985ac9653198495ef9b5c82435d49c.jpg
+ │ │ │-- ...
+ `-- ai_challenger_keypoint_validation_20170911
+ │-- keypoint_validation_images_20170911
+ │-- 0002605c53fb92109a3f2de4fc3ce06425c3b61f.jpg
+ │-- 0003b55a2c991223e6d8b4b820045bd49507bf6d.jpg
+ │-- ...
+```
+
+## CrowdPose
+
+
+
+
+CrowdPose (CVPR'2019)
+
+```bibtex
+@article{li2018crowdpose,
+ title={CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark},
+ author={Li, Jiefeng and Wang, Can and Zhu, Hao and Mao, Yihuan and Fang, Hao-Shu and Lu, Cewu},
+ journal={arXiv preprint arXiv:1812.00324},
+ year={2018}
+}
+```
+
+
+
+
+
+
+
+For [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose) data, please download from [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose).
+Please download the annotation files and human detection results from [crowdpose_annotations](https://download.openmmlab.com/mmpose/datasets/crowdpose_annotations.tar).
+For top-down approaches, we follow [CrowdPose](https://arxiv.org/abs/1812.00324) to use the [pre-trained weights](https://pjreddie.com/media/files/yolov3.weights) of [YOLOv3](https://github.com/eriklindernoren/PyTorch-YOLOv3) to generate the detected human bounding boxes.
+For model training, we follow [HigherHRNet](https://github.com/HRNet/HigherHRNet-Human-Pose-Estimation) to train models on CrowdPose train/val dataset, and evaluate models on CrowdPose test dataset.
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── crowdpose
+ │-- annotations
+ │ │-- mmpose_crowdpose_train.json
+ │ │-- mmpose_crowdpose_val.json
+ │ │-- mmpose_crowdpose_trainval.json
+ │ │-- mmpose_crowdpose_test.json
+ │ │-- det_for_crowd_test_0.1_0.5.json
+ │-- images
+ │-- 100000.jpg
+ │-- 100001.jpg
+ │-- 100002.jpg
+ │-- ...
+```
+
+## OCHuman
+
+
+
+
+OCHuman (CVPR'2019)
+
+```bibtex
+@inproceedings{zhang2019pose2seg,
+ title={Pose2seg: Detection free human instance segmentation},
+ author={Zhang, Song-Hai and Li, Ruilong and Dong, Xin and Rosin, Paul and Cai, Zixi and Han, Xi and Yang, Dingcheng and Huang, Haozhi and Hu, Shi-Min},
+ booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
+ pages={889--898},
+ year={2019}
+}
+```
+
+
+
+
+
+
+
+For [OCHuman](https://github.com/liruilong940607/OCHumanApi) data, please download the images and annotations from [OCHuman](https://github.com/liruilong940607/OCHumanApi),
+Move them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── ochuman
+ │-- annotations
+ │ │-- ochuman_coco_format_val_range_0.00_1.00.json
+ │ |-- ochuman_coco_format_test_range_0.00_1.00.json
+ |-- images
+ │-- 000001.jpg
+ │-- 000002.jpg
+ │-- 000003.jpg
+ │-- ...
+
+```
+
+## MHP
+
+
+
+
+MHP (ACM MM'2018)
+
+```bibtex
+@inproceedings{zhao2018understanding,
+ title={Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing},
+ author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
+ booktitle={Proceedings of the 26th ACM international conference on Multimedia},
+ pages={792--800},
+ year={2018}
+}
+```
+
+
+
+
+
+
+
+For [MHP](https://lv-mhp.github.io/dataset) data, please download from [MHP](https://lv-mhp.github.io/dataset).
+Please download the annotation files from [mhp_annotations](https://download.openmmlab.com/mmpose/datasets/mhp_annotations.tar.gz).
+Please download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── mhp
+ │-- annotations
+ │ │-- mhp_train.json
+ │ │-- mhp_val.json
+ │
+ `-- train
+ │ │-- images
+ │ │ │-- 1004.jpg
+ │ │ │-- 10050.jpg
+ │ │ │-- ...
+ │
+ `-- val
+ │ │-- images
+ │ │ │-- 10059.jpg
+ │ │ │-- 10068.jpg
+ │ │ │-- ...
+ │
+ `-- test
+ │ │-- images
+ │ │ │-- 1005.jpg
+ │ │ │-- 10052.jpg
+ │ │ │-- ...~~~~
+```
+
+## Human-Art dataset
+
+
+
+
+Human-Art (CVPR'2023)
+
+```bibtex
+@inproceedings{ju2023humanart,
+ title={Human-Art: A Versatile Human-Centric Dataset Bridging Natural and Artificial Scenes},
+ author={Ju, Xuan and Zeng, Ailing and Jianan, Wang and Qiang, Xu and Lei, Zhang},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
+ year={2023}}
+```
+
+
+
+
+
+
+
+For [Human-Art](https://idea-research.github.io/HumanArt/) data, please download the images and annotation files from [its website](https://idea-research.github.io/HumanArt/). You need to fill in the [data form](https://docs.google.com/forms/d/e/1FAIpQLScroT_jvw6B9U2Qca1_cl5Kmmu1ceKtlh6DJNmWLte8xNEhEw/viewform) to get access to the data.
+Move them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+|── data
+ │── HumanArt
+ │-- images
+ │ │-- 2D_virtual_human
+ │ │ |-- cartoon
+ │ │ | |-- 000000000000.jpg
+ │ │ | |-- ...
+ │ │ |-- digital_art
+ │ │ |-- ...
+ │ |-- 3D_virtual_human
+ │ |-- real_human
+ |-- annotations
+ │ │-- validation_humanart.json
+ │ │-- training_humanart_coco.json
+ |-- person_detection_results
+ │ │-- HumanArt_validation_detections_AP_H_56_person.json
+```
+
+You can choose whether to download other annotation files in Human-Art. If you want to use additional annotation files (e.g. validation set of cartoon), you need to edit the corresponding code in config file.
+
+## PoseTrack18
+
+
+
+
+PoseTrack18 (CVPR'2018)
+
+```bibtex
+@inproceedings{andriluka2018posetrack,
+ title={Posetrack: A benchmark for human pose estimation and tracking},
+ author={Andriluka, Mykhaylo and Iqbal, Umar and Insafutdinov, Eldar and Pishchulin, Leonid and Milan, Anton and Gall, Juergen and Schiele, Bernt},
+ booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={5167--5176},
+ year={2018}
+}
+```
+
+
+
+
+
+
+
+For [PoseTrack18](https://posetrack.net/users/download.php) data, please download from [PoseTrack18](https://posetrack.net/users/download.php).
+Please download the annotation files from [posetrack18_annotations](https://download.openmmlab.com/mmpose/datasets/posetrack18_annotations.tar).
+We have merged the video-wise separated official annotation files into two json files (posetrack18_train & posetrack18_val.json). We also generate the [mask files](https://download.openmmlab.com/mmpose/datasets/posetrack18_mask.tar) to speed up training.
+For top-down approaches, we use [MMDetection](https://github.com/open-mmlab/mmdetection) pre-trained [Cascade R-CNN](https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_rcnn_x101_64x4d_fpn_20e_coco/cascade_rcnn_x101_64x4d_fpn_20e_coco_20200509_224357-051557b1.pth) (X-101-64x4d-FPN) to generate the detected human bounding boxes.
+Please download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── posetrack18
+ │-- annotations
+ │ │-- posetrack18_train.json
+ │ │-- posetrack18_val.json
+ │ │-- posetrack18_val_human_detections.json
+ │ │-- train
+ │ │ │-- 000001_bonn_train.json
+ │ │ │-- 000002_bonn_train.json
+ │ │ │-- ...
+ │ │-- val
+ │ │ │-- 000342_mpii_test.json
+ │ │ │-- 000522_mpii_test.json
+ │ │ │-- ...
+ │ `-- test
+ │ │-- 000001_mpiinew_test.json
+ │ │-- 000002_mpiinew_test.json
+ │ │-- ...
+ │
+ `-- images
+ │ │-- train
+ │ │ │-- 000001_bonn_train
+ │ │ │ │-- 000000.jpg
+ │ │ │ │-- 000001.jpg
+ │ │ │ │-- ...
+ │ │ │-- ...
+ │ │-- val
+ │ │ │-- 000342_mpii_test
+ │ │ │ │-- 000000.jpg
+ │ │ │ │-- 000001.jpg
+ │ │ │ │-- ...
+ │ │ │-- ...
+ │ `-- test
+ │ │-- 000001_mpiinew_test
+ │ │ │-- 000000.jpg
+ │ │ │-- 000001.jpg
+ │ │ │-- ...
+ │ │-- ...
+ `-- mask
+ │-- train
+ │ │-- 000002_bonn_train
+ │ │ │-- 000000.jpg
+ │ │ │-- 000001.jpg
+ │ │ │-- ...
+ │ │-- ...
+ `-- val
+ │-- 000522_mpii_test
+ │ │-- 000000.jpg
+ │ │-- 000001.jpg
+ │ │-- ...
+ │-- ...
+```
+
+The official evaluation tool for PoseTrack should be installed from GitHub.
+
+```shell
+pip install git+https://github.com/svenkreiss/poseval.git
+```
+
+## sub-JHMDB dataset
+
+
+
+
+RSN (ECCV'2020)
+
+```bibtex
+@misc{cai2020learning,
+ title={Learning Delicate Local Representations for Multi-Person Pose Estimation},
+ author={Yuanhao Cai and Zhicheng Wang and Zhengxiong Luo and Binyi Yin and Angang Du and Haoqian Wang and Xinyu Zhou and Erjin Zhou and Xiangyu Zhang and Jian Sun},
+ year={2020},
+ eprint={2003.04030},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+}
+```
+
+
+
+
+
+
+
+For [sub-JHMDB](http://jhmdb.is.tue.mpg.de/dataset) data, please download the [images](<(http://files.is.tue.mpg.de/jhmdb/Rename_Images.tar.gz)>) from [JHMDB](http://jhmdb.is.tue.mpg.de/dataset),
+Please download the annotation files from [jhmdb_annotations](https://download.openmmlab.com/mmpose/datasets/jhmdb_annotations.tar).
+Move them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── jhmdb
+ │-- annotations
+ │ │-- Sub1_train.json
+ │ |-- Sub1_test.json
+ │ │-- Sub2_train.json
+ │ |-- Sub2_test.json
+ │ │-- Sub3_train.json
+ │ |-- Sub3_test.json
+ |-- Rename_Images
+ │-- brush_hair
+ │ │--April_09_brush_hair_u_nm_np1_ba_goo_0
+ | │ │--00001.png
+ | │ │--00002.png
+ │-- catch
+ │-- ...
+
+```
diff --git a/docs/zh_cn/dataset_zoo/2d_face_keypoint.md b/docs/zh_cn/dataset_zoo/2d_face_keypoint.md
index 62f66bd82b..13bbb5dec4 100644
--- a/docs/zh_cn/dataset_zoo/2d_face_keypoint.md
+++ b/docs/zh_cn/dataset_zoo/2d_face_keypoint.md
@@ -1,384 +1,384 @@
-# 2D Face Keypoint Datasets
-
-It is recommended to symlink the dataset root to `$MMPOSE/data`.
-If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMPose supported datasets:
-
-- [300W](#300w-dataset) \[ [Homepage](https://ibug.doc.ic.ac.uk/resources/300-W/) \]
-- [WFLW](#wflw-dataset) \[ [Homepage](https://wywu.github.io/projects/LAB/WFLW.html) \]
-- [AFLW](#aflw-dataset) \[ [Homepage](https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/aflw/) \]
-- [COFW](#cofw-dataset) \[ [Homepage](http://www.vision.caltech.edu/xpburgos/ICCV13/) \]
-- [COCO-WholeBody-Face](#coco-wholebody-face) \[ [Homepage](https://github.com/jin-s13/COCO-WholeBody/) \]
-- [LaPa](#lapa-dataset) \[ [Homepage](https://github.com/JDAI-CV/lapa-dataset) \]
-
-## 300W Dataset
-
-
-
-
-300W (IMAVIS'2016)
-
-```bibtex
-@article{sagonas2016300,
- title={300 faces in-the-wild challenge: Database and results},
- author={Sagonas, Christos and Antonakos, Epameinondas and Tzimiropoulos, Georgios and Zafeiriou, Stefanos and Pantic, Maja},
- journal={Image and vision computing},
- volume={47},
- pages={3--18},
- year={2016},
- publisher={Elsevier}
-}
-```
-
-
-
-
+
+For WFLW data, please download images from [WFLW Dataset](https://wywu.github.io/projects/LAB/WFLW.html).
+Please download the annotation files from [wflw_annotations](https://download.openmmlab.com/mmpose/datasets/wflw_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── wflw
+ |── annotations
+ | |── face_landmarks_wflw_train.json
+ | |── face_landmarks_wflw_test.json
+ | |── face_landmarks_wflw_test_blur.json
+ | |── face_landmarks_wflw_test_occlusion.json
+ | |── face_landmarks_wflw_test_expression.json
+ | |── face_landmarks_wflw_test_largepose.json
+ | |── face_landmarks_wflw_test_illumination.json
+ | |── face_landmarks_wflw_test_makeup.json
+ |
+ `── images
+ |── 0--Parade
+ | |── 0_Parade_marchingband_1_1015.jpg
+ | |── 0_Parade_marchingband_1_1031.jpg
+ | ...
+ |── 1--Handshaking
+ | |── 1_Handshaking_Handshaking_1_105.jpg
+ | |── 1_Handshaking_Handshaking_1_107.jpg
+ | ...
+ ...
+```
+
+## AFLW Dataset
+
+
+
+
+AFLW (ICCVW'2011)
+
+```bibtex
+@inproceedings{koestinger2011annotated,
+ title={Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization},
+ author={Koestinger, Martin and Wohlhart, Paul and Roth, Peter M and Bischof, Horst},
+ booktitle={2011 IEEE international conference on computer vision workshops (ICCV workshops)},
+ pages={2144--2151},
+ year={2011},
+ organization={IEEE}
+}
+```
+
+
+
+For AFLW data, please download images from [AFLW Dataset](https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/aflw/).
+Please download the annotation files from [aflw_annotations](https://download.openmmlab.com/mmpose/datasets/aflw_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── aflw
+ |── annotations
+ | |── face_landmarks_aflw_train.json
+ | |── face_landmarks_aflw_test_frontal.json
+ | |── face_landmarks_aflw_test.json
+ `── images
+ |── flickr
+ |── 0
+ | |── image00002.jpg
+ | |── image00013.jpg
+ | ...
+ |── 2
+ | |── image00004.jpg
+ | |── image00006.jpg
+ | ...
+ `── 3
+ |── image00032.jpg
+ |── image00035.jpg
+ ...
+```
+
+## COFW Dataset
+
+
+
+
+COFW (ICCV'2013)
+
+```bibtex
+@inproceedings{burgos2013robust,
+ title={Robust face landmark estimation under occlusion},
+ author={Burgos-Artizzu, Xavier P and Perona, Pietro and Doll{\'a}r, Piotr},
+ booktitle={Proceedings of the IEEE international conference on computer vision},
+ pages={1513--1520},
+ year={2013}
+}
+```
+
+
+
+
+
+
+
+For COFW data, please download from [COFW Dataset (Color Images)](http://www.vision.caltech.edu/xpburgos/ICCV13/Data/COFW_color.zip).
+Move `COFW_train_color.mat` and `COFW_test_color.mat` to `data/cofw/` and make them look like:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── cofw
+ |── COFW_train_color.mat
+ |── COFW_test_color.mat
+```
+
+Run the following script under `{MMPose}/data`
+
+`python tools/dataset_converters/parse_cofw_dataset.py`
+
+And you will get
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── cofw
+ |── COFW_train_color.mat
+ |── COFW_test_color.mat
+ |── annotations
+ | |── cofw_train.json
+ | |── cofw_test.json
+ |── images
+ |── 000001.jpg
+ |── 000002.jpg
+```
+
+## COCO-WholeBody (Face)
+
+
+
+
+COCO-WholeBody-Face (ECCV'2020)
+
+```bibtex
+@inproceedings{jin2020whole,
+ title={Whole-Body Human Pose Estimation in the Wild},
+ author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping},
+ booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
+ year={2020}
+}
+```
+
+
+
+
+
+
+
+For [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/) dataset, images can be downloaded from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
+Download COCO-WholeBody annotations for COCO-WholeBody annotations for [Train](https://drive.google.com/file/d/1thErEToRbmM9uLNi1JXXfOsaS5VK2FXf/view?usp=sharing) / [Validation](https://drive.google.com/file/d/1N6VgwKnj8DeyGXCvp1eYgNbRmw6jdfrb/view?usp=sharing) (Google Drive).
+Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── coco
+ │-- annotations
+ │ │-- coco_wholebody_train_v1.0.json
+ │ |-- coco_wholebody_val_v1.0.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ │-- train2017
+ │ │-- 000000000009.jpg
+ │ │-- 000000000025.jpg
+ │ │-- 000000000030.jpg
+ │ │-- ...
+ `-- val2017
+ │-- 000000000139.jpg
+ │-- 000000000285.jpg
+ │-- 000000000632.jpg
+ │-- ...
+
+```
+
+Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) to support COCO-WholeBody evaluation:
+
+`pip install xtcocotools`
+
+## LaPa
+
+
+
+
+LaPa (AAAI'2020)
+
+```bibtex
+@inproceedings{liu2020new,
+ title={A New Dataset and Boundary-Attention Semantic Segmentation for Face Parsing.},
+ author={Liu, Yinglu and Shi, Hailin and Shen, Hao and Si, Yue and Wang, Xiaobo and Mei, Tao},
+ booktitle={AAAI},
+ pages={11637--11644},
+ year={2020}
+}
+```
+
+
+
+
+
+
+
+For [LaPa](https://github.com/JDAI-CV/lapa-dataset) dataset, images can be downloaded from [their github page](https://github.com/JDAI-CV/lapa-dataset).
+
+Download and extract them under $MMPOSE/data, and use our `tools/dataset_converters/lapa2coco.py` to make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── LaPa
+ │-- annotations
+ │ │-- lapa_train.json
+ │ |-- lapa_val.json
+ │ |-- lapa_test.json
+ | |-- lapa_trainval.json
+ │-- train
+ │ │-- images
+ │ │-- labels
+ │ │-- landmarks
+ │-- val
+ │ │-- images
+ │ │-- labels
+ │ │-- landmarks
+ `-- test
+ │ │-- images
+ │ │-- labels
+ │ │-- landmarks
+
+```
diff --git a/docs/zh_cn/dataset_zoo/2d_fashion_landmark.md b/docs/zh_cn/dataset_zoo/2d_fashion_landmark.md
index 25b7fd7c64..bae782e515 100644
--- a/docs/zh_cn/dataset_zoo/2d_fashion_landmark.md
+++ b/docs/zh_cn/dataset_zoo/2d_fashion_landmark.md
@@ -1,3 +1,3 @@
-# 2D服装关键点数据集
-
-内容建设中……
+# 2D服装关键点数据集
+
+内容建设中……
diff --git a/docs/zh_cn/dataset_zoo/2d_hand_keypoint.md b/docs/zh_cn/dataset_zoo/2d_hand_keypoint.md
index aade35850c..825fe87742 100644
--- a/docs/zh_cn/dataset_zoo/2d_hand_keypoint.md
+++ b/docs/zh_cn/dataset_zoo/2d_hand_keypoint.md
@@ -1,348 +1,348 @@
-# 2D Hand Keypoint Datasets
-
-It is recommended to symlink the dataset root to `$MMPOSE/data`.
-If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMPose supported datasets:
-
-- [OneHand10K](#onehand10k) \[ [Homepage](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html) \]
-- [FreiHand](#freihand-dataset) \[ [Homepage](https://lmb.informatik.uni-freiburg.de/projects/freihand/) \]
-- [CMU Panoptic HandDB](#cmu-panoptic-handdb) \[ [Homepage](http://domedb.perception.cs.cmu.edu/handdb.html) \]
-- [InterHand2.6M](#interhand26m) \[ [Homepage](https://mks0601.github.io/InterHand2.6M/) \]
-- [RHD](#rhd-dataset) \[ [Homepage](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html) \]
-- [COCO-WholeBody-Hand](#coco-wholebody-hand) \[ [Homepage](https://github.com/jin-s13/COCO-WholeBody/) \]
-
-## OneHand10K
-
-
-
-
-OneHand10K (TCSVT'2019)
-
-```bibtex
-@article{wang2018mask,
- title={Mask-pose cascaded cnn for 2d hand pose estimation from single color image},
- author={Wang, Yangang and Peng, Cong and Liu, Yebin},
- journal={IEEE Transactions on Circuits and Systems for Video Technology},
- volume={29},
- number={11},
- pages={3258--3268},
- year={2018},
- publisher={IEEE}
-}
-```
-
-
-
-
-
-
-
-For [OneHand10K](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html) data, please download from [OneHand10K Dataset](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html).
-Please download the annotation files from [onehand10k_annotations](https://download.openmmlab.com/mmpose/datasets/onehand10k_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── onehand10k
- |── annotations
- | |── onehand10k_train.json
- | |── onehand10k_test.json
- `── Train
- | |── source
- | |── 0.jpg
- | |── 1.jpg
- | ...
- `── Test
- |── source
- |── 0.jpg
- |── 1.jpg
-
-```
-
-## FreiHAND Dataset
-
-
-
-
-FreiHand (ICCV'2019)
-
-```bibtex
-@inproceedings{zimmermann2019freihand,
- title={Freihand: A dataset for markerless capture of hand pose and shape from single rgb images},
- author={Zimmermann, Christian and Ceylan, Duygu and Yang, Jimei and Russell, Bryan and Argus, Max and Brox, Thomas},
- booktitle={Proceedings of the IEEE International Conference on Computer Vision},
- pages={813--822},
- year={2019}
-}
-```
-
-
-
-
-
-
-
-For [FreiHAND](https://lmb.informatik.uni-freiburg.de/projects/freihand/) data, please download from [FreiHand Dataset](https://lmb.informatik.uni-freiburg.de/resources/datasets/FreihandDataset.en.html).
-Since the official dataset does not provide validation set, we randomly split the training data into 8:1:1 for train/val/test.
-Please download the annotation files from [freihand_annotations](https://download.openmmlab.com/mmpose/datasets/frei_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── freihand
- |── annotations
- | |── freihand_train.json
- | |── freihand_val.json
- | |── freihand_test.json
- `── training
- |── rgb
- | |── 00000000.jpg
- | |── 00000001.jpg
- | ...
- |── mask
- |── 00000000.jpg
- |── 00000001.jpg
- ...
-```
-
-## CMU Panoptic HandDB
-
-
-
-
-CMU Panoptic HandDB (CVPR'2017)
-
-```bibtex
-@inproceedings{simon2017hand,
- title={Hand keypoint detection in single images using multiview bootstrapping},
- author={Simon, Tomas and Joo, Hanbyul and Matthews, Iain and Sheikh, Yaser},
- booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition},
- pages={1145--1153},
- year={2017}
-}
-```
-
-
-
-
-
-
-
-For [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html), please download from [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html).
-Following [Simon et al](https://arxiv.org/abs/1704.07809), panoptic images (hand143_panopticdb) and MPII & NZSL training sets (manual_train) are used for training, while MPII & NZSL test set (manual_test) for testing.
-Please download the annotation files from [panoptic_annotations](https://download.openmmlab.com/mmpose/datasets/panoptic_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── panoptic
- |── annotations
- | |── panoptic_train.json
- | |── panoptic_test.json
- |
- `── hand143_panopticdb
- | |── imgs
- | | |── 00000000.jpg
- | | |── 00000001.jpg
- | | ...
- |
- `── hand_labels
- |── manual_train
- | |── 000015774_01_l.jpg
- | |── 000015774_01_r.jpg
- | ...
- |
- `── manual_test
- |── 000648952_02_l.jpg
- |── 000835470_01_l.jpg
- ...
-```
-
-## InterHand2.6M
-
-
-
-
-InterHand2.6M (ECCV'2020)
-
-```bibtex
-@InProceedings{Moon_2020_ECCV_InterHand2.6M,
-author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu},
-title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image},
-booktitle = {European Conference on Computer Vision (ECCV)},
-year = {2020}
-}
-```
-
-
-
-
-
-
-
-For [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/), please download from [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/).
-Please download the annotation files from [annotations](https://drive.google.com/drive/folders/1pWXhdfaka-J0fSAze0MsajN0VpZ8e8tO).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── interhand2.6m
- |── annotations
- | |── all
- | |── human_annot
- | |── machine_annot
- | |── skeleton.txt
- | |── subject.txt
- |
- `── images
- | |── train
- | | |-- Capture0 ~ Capture26
- | |── val
- | | |-- Capture0
- | |── test
- | | |-- Capture0 ~ Capture7
-```
-
-## RHD Dataset
-
-
-
-
-RHD (ICCV'2017)
-
-```bibtex
-@TechReport{zb2017hand,
- author={Christian Zimmermann and Thomas Brox},
- title={Learning to Estimate 3D Hand Pose from Single RGB Images},
- institution={arXiv:1705.01389},
- year={2017},
- note="https://arxiv.org/abs/1705.01389",
- url="https://lmb.informatik.uni-freiburg.de/projects/hand3d/"
-}
-```
-
-
-
-
-
-
-
-For [RHD Dataset](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html), please download from [RHD Dataset](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html).
-Please download the annotation files from [rhd_annotations](https://download.openmmlab.com/mmpose/datasets/rhd_annotations.zip).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── rhd
- |── annotations
- | |── rhd_train.json
- | |── rhd_test.json
- `── training
- | |── color
- | | |── 00000.jpg
- | | |── 00001.jpg
- | |── depth
- | | |── 00000.jpg
- | | |── 00001.jpg
- | |── mask
- | | |── 00000.jpg
- | | |── 00001.jpg
- `── evaluation
- | |── color
- | | |── 00000.jpg
- | | |── 00001.jpg
- | |── depth
- | | |── 00000.jpg
- | | |── 00001.jpg
- | |── mask
- | | |── 00000.jpg
- | | |── 00001.jpg
-```
-
-## COCO-WholeBody (Hand)
-
-
-
-
-COCO-WholeBody-Hand (ECCV'2020)
-
-```bibtex
-@inproceedings{jin2020whole,
- title={Whole-Body Human Pose Estimation in the Wild},
- author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping},
- booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
- year={2020}
-}
-```
-
-
-
-
-
-
-
-For [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/) dataset, images can be downloaded from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
-Download COCO-WholeBody annotations for COCO-WholeBody annotations for [Train](https://drive.google.com/file/d/1thErEToRbmM9uLNi1JXXfOsaS5VK2FXf/view?usp=sharing) / [Validation](https://drive.google.com/file/d/1N6VgwKnj8DeyGXCvp1eYgNbRmw6jdfrb/view?usp=sharing) (Google Drive).
-Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
-Download and extract them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── coco
- │-- annotations
- │ │-- coco_wholebody_train_v1.0.json
- │ |-- coco_wholebody_val_v1.0.json
- |-- person_detection_results
- | |-- COCO_val2017_detections_AP_H_56_person.json
- │-- train2017
- │ │-- 000000000009.jpg
- │ │-- 000000000025.jpg
- │ │-- 000000000030.jpg
- │ │-- ...
- `-- val2017
- │-- 000000000139.jpg
- │-- 000000000285.jpg
- │-- 000000000632.jpg
- │-- ...
-```
-
-Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) to support COCO-WholeBody evaluation:
-
-`pip install xtcocotools`
+# 2D Hand Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [OneHand10K](#onehand10k) \[ [Homepage](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html) \]
+- [FreiHand](#freihand-dataset) \[ [Homepage](https://lmb.informatik.uni-freiburg.de/projects/freihand/) \]
+- [CMU Panoptic HandDB](#cmu-panoptic-handdb) \[ [Homepage](http://domedb.perception.cs.cmu.edu/handdb.html) \]
+- [InterHand2.6M](#interhand26m) \[ [Homepage](https://mks0601.github.io/InterHand2.6M/) \]
+- [RHD](#rhd-dataset) \[ [Homepage](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html) \]
+- [COCO-WholeBody-Hand](#coco-wholebody-hand) \[ [Homepage](https://github.com/jin-s13/COCO-WholeBody/) \]
+
+## OneHand10K
+
+
+
+
+OneHand10K (TCSVT'2019)
+
+```bibtex
+@article{wang2018mask,
+ title={Mask-pose cascaded cnn for 2d hand pose estimation from single color image},
+ author={Wang, Yangang and Peng, Cong and Liu, Yebin},
+ journal={IEEE Transactions on Circuits and Systems for Video Technology},
+ volume={29},
+ number={11},
+ pages={3258--3268},
+ year={2018},
+ publisher={IEEE}
+}
+```
+
+
+
+
+
+
+
+For [OneHand10K](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html) data, please download from [OneHand10K Dataset](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html).
+Please download the annotation files from [onehand10k_annotations](https://download.openmmlab.com/mmpose/datasets/onehand10k_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── onehand10k
+ |── annotations
+ | |── onehand10k_train.json
+ | |── onehand10k_test.json
+ `── Train
+ | |── source
+ | |── 0.jpg
+ | |── 1.jpg
+ | ...
+ `── Test
+ |── source
+ |── 0.jpg
+ |── 1.jpg
+
+```
+
+## FreiHAND Dataset
+
+
+
+
+FreiHand (ICCV'2019)
+
+```bibtex
+@inproceedings{zimmermann2019freihand,
+ title={Freihand: A dataset for markerless capture of hand pose and shape from single rgb images},
+ author={Zimmermann, Christian and Ceylan, Duygu and Yang, Jimei and Russell, Bryan and Argus, Max and Brox, Thomas},
+ booktitle={Proceedings of the IEEE International Conference on Computer Vision},
+ pages={813--822},
+ year={2019}
+}
+```
+
+
+
+
+
+
+
+For [FreiHAND](https://lmb.informatik.uni-freiburg.de/projects/freihand/) data, please download from [FreiHand Dataset](https://lmb.informatik.uni-freiburg.de/resources/datasets/FreihandDataset.en.html).
+Since the official dataset does not provide validation set, we randomly split the training data into 8:1:1 for train/val/test.
+Please download the annotation files from [freihand_annotations](https://download.openmmlab.com/mmpose/datasets/frei_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── freihand
+ |── annotations
+ | |── freihand_train.json
+ | |── freihand_val.json
+ | |── freihand_test.json
+ `── training
+ |── rgb
+ | |── 00000000.jpg
+ | |── 00000001.jpg
+ | ...
+ |── mask
+ |── 00000000.jpg
+ |── 00000001.jpg
+ ...
+```
+
+## CMU Panoptic HandDB
+
+
+
+
+CMU Panoptic HandDB (CVPR'2017)
+
+```bibtex
+@inproceedings{simon2017hand,
+ title={Hand keypoint detection in single images using multiview bootstrapping},
+ author={Simon, Tomas and Joo, Hanbyul and Matthews, Iain and Sheikh, Yaser},
+ booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition},
+ pages={1145--1153},
+ year={2017}
+}
+```
+
+
+
+
+
+
+
+For [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html), please download from [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html).
+Following [Simon et al](https://arxiv.org/abs/1704.07809), panoptic images (hand143_panopticdb) and MPII & NZSL training sets (manual_train) are used for training, while MPII & NZSL test set (manual_test) for testing.
+Please download the annotation files from [panoptic_annotations](https://download.openmmlab.com/mmpose/datasets/panoptic_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── panoptic
+ |── annotations
+ | |── panoptic_train.json
+ | |── panoptic_test.json
+ |
+ `── hand143_panopticdb
+ | |── imgs
+ | | |── 00000000.jpg
+ | | |── 00000001.jpg
+ | | ...
+ |
+ `── hand_labels
+ |── manual_train
+ | |── 000015774_01_l.jpg
+ | |── 000015774_01_r.jpg
+ | ...
+ |
+ `── manual_test
+ |── 000648952_02_l.jpg
+ |── 000835470_01_l.jpg
+ ...
+```
+
+## InterHand2.6M
+
+
+
+
+InterHand2.6M (ECCV'2020)
+
+```bibtex
+@InProceedings{Moon_2020_ECCV_InterHand2.6M,
+author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu},
+title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image},
+booktitle = {European Conference on Computer Vision (ECCV)},
+year = {2020}
+}
+```
+
+
+
+
+
+
+
+For [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/), please download from [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/).
+Please download the annotation files from [annotations](https://drive.google.com/drive/folders/1pWXhdfaka-J0fSAze0MsajN0VpZ8e8tO).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── interhand2.6m
+ |── annotations
+ | |── all
+ | |── human_annot
+ | |── machine_annot
+ | |── skeleton.txt
+ | |── subject.txt
+ |
+ `── images
+ | |── train
+ | | |-- Capture0 ~ Capture26
+ | |── val
+ | | |-- Capture0
+ | |── test
+ | | |-- Capture0 ~ Capture7
+```
+
+## RHD Dataset
+
+
+
+
+RHD (ICCV'2017)
+
+```bibtex
+@TechReport{zb2017hand,
+ author={Christian Zimmermann and Thomas Brox},
+ title={Learning to Estimate 3D Hand Pose from Single RGB Images},
+ institution={arXiv:1705.01389},
+ year={2017},
+ note="https://arxiv.org/abs/1705.01389",
+ url="https://lmb.informatik.uni-freiburg.de/projects/hand3d/"
+}
+```
+
+
+
+
+
+
+
+For [RHD Dataset](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html), please download from [RHD Dataset](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html).
+Please download the annotation files from [rhd_annotations](https://download.openmmlab.com/mmpose/datasets/rhd_annotations.zip).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── rhd
+ |── annotations
+ | |── rhd_train.json
+ | |── rhd_test.json
+ `── training
+ | |── color
+ | | |── 00000.jpg
+ | | |── 00001.jpg
+ | |── depth
+ | | |── 00000.jpg
+ | | |── 00001.jpg
+ | |── mask
+ | | |── 00000.jpg
+ | | |── 00001.jpg
+ `── evaluation
+ | |── color
+ | | |── 00000.jpg
+ | | |── 00001.jpg
+ | |── depth
+ | | |── 00000.jpg
+ | | |── 00001.jpg
+ | |── mask
+ | | |── 00000.jpg
+ | | |── 00001.jpg
+```
+
+## COCO-WholeBody (Hand)
+
+
+
+
+COCO-WholeBody-Hand (ECCV'2020)
+
+```bibtex
+@inproceedings{jin2020whole,
+ title={Whole-Body Human Pose Estimation in the Wild},
+ author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping},
+ booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
+ year={2020}
+}
+```
+
+
+
+
+
+
+
+For [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/) dataset, images can be downloaded from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
+Download COCO-WholeBody annotations for COCO-WholeBody annotations for [Train](https://drive.google.com/file/d/1thErEToRbmM9uLNi1JXXfOsaS5VK2FXf/view?usp=sharing) / [Validation](https://drive.google.com/file/d/1N6VgwKnj8DeyGXCvp1eYgNbRmw6jdfrb/view?usp=sharing) (Google Drive).
+Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── coco
+ │-- annotations
+ │ │-- coco_wholebody_train_v1.0.json
+ │ |-- coco_wholebody_val_v1.0.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ │-- train2017
+ │ │-- 000000000009.jpg
+ │ │-- 000000000025.jpg
+ │ │-- 000000000030.jpg
+ │ │-- ...
+ `-- val2017
+ │-- 000000000139.jpg
+ │-- 000000000285.jpg
+ │-- 000000000632.jpg
+ │-- ...
+```
+
+Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) to support COCO-WholeBody evaluation:
+
+`pip install xtcocotools`
diff --git a/docs/zh_cn/dataset_zoo/2d_wholebody_keypoint.md b/docs/zh_cn/dataset_zoo/2d_wholebody_keypoint.md
index a082c657c6..55a76139df 100644
--- a/docs/zh_cn/dataset_zoo/2d_wholebody_keypoint.md
+++ b/docs/zh_cn/dataset_zoo/2d_wholebody_keypoint.md
@@ -1,133 +1,133 @@
-# 2D Wholebody Keypoint Datasets
-
-It is recommended to symlink the dataset root to `$MMPOSE/data`.
-If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMPose supported datasets:
-
-- [COCO-WholeBody](#coco-wholebody) \[ [Homepage](https://github.com/jin-s13/COCO-WholeBody/) \]
-- [Halpe](#halpe) \[ [Homepage](https://github.com/Fang-Haoshu/Halpe-FullBody/) \]
-
-## COCO-WholeBody
-
-
-
-
-COCO-WholeBody (ECCV'2020)
-
-```bibtex
-@inproceedings{jin2020whole,
- title={Whole-Body Human Pose Estimation in the Wild},
- author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping},
- booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
- year={2020}
-}
-```
-
-
-
-
-
-
-
-For [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/) dataset, images can be downloaded from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
-Download COCO-WholeBody annotations for COCO-WholeBody annotations for [Train](https://drive.google.com/file/d/1thErEToRbmM9uLNi1JXXfOsaS5VK2FXf/view?usp=sharing) / [Validation](https://drive.google.com/file/d/1N6VgwKnj8DeyGXCvp1eYgNbRmw6jdfrb/view?usp=sharing) (Google Drive).
-Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
-Download and extract them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── coco
- │-- annotations
- │ │-- coco_wholebody_train_v1.0.json
- │ |-- coco_wholebody_val_v1.0.json
- |-- person_detection_results
- | |-- COCO_val2017_detections_AP_H_56_person.json
- │-- train2017
- │ │-- 000000000009.jpg
- │ │-- 000000000025.jpg
- │ │-- 000000000030.jpg
- │ │-- ...
- `-- val2017
- │-- 000000000139.jpg
- │-- 000000000285.jpg
- │-- 000000000632.jpg
- │-- ...
-
-```
-
-Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) (version>=1.5) to support COCO-WholeBody evaluation:
-
-`pip install xtcocotools`
-
-## Halpe
-
-
-
-
-Halpe (CVPR'2020)
-
-```bibtex
-@inproceedings{li2020pastanet,
- title={PaStaNet: Toward Human Activity Knowledge Engine},
- author={Li, Yong-Lu and Xu, Liang and Liu, Xinpeng and Huang, Xijie and Xu, Yue and Wang, Shiyi and Fang, Hao-Shu and Ma, Ze and Chen, Mingyang and Lu, Cewu},
- booktitle={CVPR},
- year={2020}
-}
-```
-
-
-
-
-
-
-
-For [Halpe](https://github.com/Fang-Haoshu/Halpe-FullBody/) dataset, please download images and annotations from [Halpe download](https://github.com/Fang-Haoshu/Halpe-FullBody).
-The images of the training set are from [HICO-Det](https://drive.google.com/open?id=1QZcJmGVlF9f4h-XLWe9Gkmnmj2z1gSnk) and those of the validation set are from [COCO](http://images.cocodataset.org/zips/val2017.zip).
-Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
-Download and extract them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── halpe
- │-- annotations
- │ │-- halpe_train_v1.json
- │ |-- halpe_val_v1.json
- |-- person_detection_results
- | |-- COCO_val2017_detections_AP_H_56_person.json
- │-- hico_20160224_det
- │ │-- anno_bbox.mat
- │ │-- anno.mat
- │ │-- README
- │ │-- images
- │ │ │-- train2015
- │ │ │ │-- HICO_train2015_00000001.jpg
- │ │ │ │-- HICO_train2015_00000002.jpg
- │ │ │ │-- HICO_train2015_00000003.jpg
- │ │ │ │-- ...
- │ │ │-- test2015
- │ │-- tools
- │ │-- ...
- `-- val2017
- │-- 000000000139.jpg
- │-- 000000000285.jpg
- │-- 000000000632.jpg
- │-- ...
-
-```
-
-Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) (version>=1.5) to support Halpe evaluation:
-
-`pip install xtcocotools`
+# 2D Wholebody Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [COCO-WholeBody](#coco-wholebody) \[ [Homepage](https://github.com/jin-s13/COCO-WholeBody/) \]
+- [Halpe](#halpe) \[ [Homepage](https://github.com/Fang-Haoshu/Halpe-FullBody/) \]
+
+## COCO-WholeBody
+
+
+
+
+COCO-WholeBody (ECCV'2020)
+
+```bibtex
+@inproceedings{jin2020whole,
+ title={Whole-Body Human Pose Estimation in the Wild},
+ author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping},
+ booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
+ year={2020}
+}
+```
+
+
+
+
+
+
+
+For [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/) dataset, images can be downloaded from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
+Download COCO-WholeBody annotations for COCO-WholeBody annotations for [Train](https://drive.google.com/file/d/1thErEToRbmM9uLNi1JXXfOsaS5VK2FXf/view?usp=sharing) / [Validation](https://drive.google.com/file/d/1N6VgwKnj8DeyGXCvp1eYgNbRmw6jdfrb/view?usp=sharing) (Google Drive).
+Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── coco
+ │-- annotations
+ │ │-- coco_wholebody_train_v1.0.json
+ │ |-- coco_wholebody_val_v1.0.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ │-- train2017
+ │ │-- 000000000009.jpg
+ │ │-- 000000000025.jpg
+ │ │-- 000000000030.jpg
+ │ │-- ...
+ `-- val2017
+ │-- 000000000139.jpg
+ │-- 000000000285.jpg
+ │-- 000000000632.jpg
+ │-- ...
+
+```
+
+Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) (version>=1.5) to support COCO-WholeBody evaluation:
+
+`pip install xtcocotools`
+
+## Halpe
+
+
+
+
+Halpe (CVPR'2020)
+
+```bibtex
+@inproceedings{li2020pastanet,
+ title={PaStaNet: Toward Human Activity Knowledge Engine},
+ author={Li, Yong-Lu and Xu, Liang and Liu, Xinpeng and Huang, Xijie and Xu, Yue and Wang, Shiyi and Fang, Hao-Shu and Ma, Ze and Chen, Mingyang and Lu, Cewu},
+ booktitle={CVPR},
+ year={2020}
+}
+```
+
+
+
+
+
+
+
+For [Halpe](https://github.com/Fang-Haoshu/Halpe-FullBody/) dataset, please download images and annotations from [Halpe download](https://github.com/Fang-Haoshu/Halpe-FullBody).
+The images of the training set are from [HICO-Det](https://drive.google.com/open?id=1QZcJmGVlF9f4h-XLWe9Gkmnmj2z1gSnk) and those of the validation set are from [COCO](http://images.cocodataset.org/zips/val2017.zip).
+Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── halpe
+ │-- annotations
+ │ │-- halpe_train_v1.json
+ │ |-- halpe_val_v1.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ │-- hico_20160224_det
+ │ │-- anno_bbox.mat
+ │ │-- anno.mat
+ │ │-- README
+ │ │-- images
+ │ │ │-- train2015
+ │ │ │ │-- HICO_train2015_00000001.jpg
+ │ │ │ │-- HICO_train2015_00000002.jpg
+ │ │ │ │-- HICO_train2015_00000003.jpg
+ │ │ │ │-- ...
+ │ │ │-- test2015
+ │ │-- tools
+ │ │-- ...
+ `-- val2017
+ │-- 000000000139.jpg
+ │-- 000000000285.jpg
+ │-- 000000000632.jpg
+ │-- ...
+
+```
+
+Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) (version>=1.5) to support Halpe evaluation:
+
+`pip install xtcocotools`
diff --git a/docs/zh_cn/dataset_zoo/3d_body_keypoint.md b/docs/zh_cn/dataset_zoo/3d_body_keypoint.md
index 82e21010fc..25b1d8415c 100644
--- a/docs/zh_cn/dataset_zoo/3d_body_keypoint.md
+++ b/docs/zh_cn/dataset_zoo/3d_body_keypoint.md
@@ -1,199 +1,199 @@
-# 3D Body Keypoint Datasets
-
-It is recommended to symlink the dataset root to `$MMPOSE/data`.
-If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMPose supported datasets:
-
-- [Human3.6M](#human36m) \[ [Homepage](http://vision.imar.ro/human3.6m/description.php) \]
-- [CMU Panoptic](#cmu-panoptic) \[ [Homepage](http://domedb.perception.cs.cmu.edu/) \]
-- [Campus/Shelf](#campus-and-shelf) \[ [Homepage](http://campar.in.tum.de/Chair/MultiHumanPose) \]
-
-## Human3.6M
-
-
-
-
-Human3.6M (TPAMI'2014)
-
-```bibtex
-@article{h36m_pami,
- author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian},
- title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments},
- journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
- publisher = {IEEE Computer Society},
- volume = {36},
- number = {7},
- pages = {1325-1339},
- month = {jul},
- year = {2014}
-}
-```
-
-
-
-
-
-
-
-For [Human3.6M](http://vision.imar.ro/human3.6m/description.php), please download from the official website and run the [preprocessing script](/tools/dataset_converters/preprocess_h36m.py), which will extract camera parameters and pose annotations at full framerate (50 FPS) and downsampled framerate (10 FPS). The processed data should have the following structure:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- ├── h36m
- ├── annotation_body3d
- | ├── cameras.pkl
- | ├── fps50
- | | ├── h36m_test.npz
- | | ├── h36m_train.npz
- | | ├── joint2d_rel_stats.pkl
- | | ├── joint2d_stats.pkl
- | | ├── joint3d_rel_stats.pkl
- | | `── joint3d_stats.pkl
- | `── fps10
- | ├── h36m_test.npz
- | ├── h36m_train.npz
- | ├── joint2d_rel_stats.pkl
- | ├── joint2d_stats.pkl
- | ├── joint3d_rel_stats.pkl
- | `── joint3d_stats.pkl
- `── images
- ├── S1
- | ├── S1_Directions_1.54138969
- | | ├── S1_Directions_1.54138969_00001.jpg
- | | ├── S1_Directions_1.54138969_00002.jpg
- | | ├── ...
- | ├── ...
- ├── S5
- ├── S6
- ├── S7
- ├── S8
- ├── S9
- `── S11
-```
-
-## CMU Panoptic
-
-
-CMU Panoptic (ICCV'2015)
-
-```bibtex
-@Article = {joo_iccv_2015,
-author = {Hanbyul Joo, Hao Liu, Lei Tan, Lin Gui, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh},
-title = {Panoptic Studio: A Massively Multiview System for Social Motion Capture},
-booktitle = {ICCV},
-year = {2015}
-}
-```
-
-
-
-
-
-
-
-Please follow [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch) to prepare this dataset.
-
-1. Download the dataset by following the instructions in [panoptic-toolbox](https://github.com/CMU-Perceptual-Computing-Lab/panoptic-toolbox) and extract them under `$MMPOSE/data/panoptic`.
-
-2. Only download those sequences that are needed. You can also just download a subset of camera views by specifying the number of views (HD_Video_Number) and changing the camera order in `./scripts/getData.sh`. The used sequences and camera views can be found in [VoxelPose](https://arxiv.org/abs/2004.06239). Note that the sequence "160906_band3" might not be available due to errors on the server of CMU Panoptic.
-
-3. Note that we only use HD videos, calibration data, and 3D Body Keypoint in the codes. You can comment out other irrelevant codes such as downloading 3D Face data in `./scripts/getData.sh`.
-
-The directory tree should be like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- ├── panoptic
- ├── 16060224_haggling1
- | | ├── hdImgs
- | | ├── hdvideos
- | | ├── hdPose3d_stage1_coco19
- | | ├── calibration_160224_haggling1.json
- ├── 160226_haggling1
- ├── ...
-```
-
-## Campus and Shelf
-
-
-Campus and Shelf (CVPR'2014)
-
-```bibtex
-@inproceedings {belagian14multi,
- title = {{3D} Pictorial Structures for Multiple Human Pose Estimation},
- author = {Belagiannis, Vasileios and Amin, Sikandar and Andriluka, Mykhaylo and Schiele, Bernt and Navab
- Nassir and Ilic, Slobo
- booktitle = {IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = {2014},
- month = {June},
- organization={IEEE}
-}
-```
-
-
-
-
-
-
-
-Please follow [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch) to prepare these two datasets.
-
-1. Please download the datasets from the [official website](http://campar.in.tum.de/Chair/MultiHumanPose) and extract them under `$MMPOSE/data/campus` and `$MMPOSE/data/shelf`, respectively. The original data include images as well as the ground truth pose file `actorsGT.mat`.
-
-2. We directly use the processed camera parameters from [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch). You can download them from this repository and place in under `$MMPOSE/data/campus/calibration_campus.json` and `$MMPOSE/data/shelf/calibration_shelf.json`, respectively.
-
-3. Like [Voxelpose](https://github.com/microsoft/voxelpose-pytorch), due to the limited and incomplete annotations of the two datasets, we don't train the model using this dataset. Instead, we directly use the 2D pose estimator trained on COCO, and use independent 3D human poses from the CMU Panoptic dataset to train our 3D model. It lies in `${MMPOSE}/data/panoptic_training_pose.pkl`.
-
-4. Like [Voxelpose](https://github.com/microsoft/voxelpose-pytorch), for testing, we first estimate 2D poses and generate 2D heatmaps for these two datasets. You can download the predicted poses from [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch) and place them in `$MMPOSE/data/campus/pred_campus_maskrcnn_hrnet_coco.pkl` and `$MMPOSE/data/shelf/pred_shelf_maskrcnn_hrnet_coco.pkl`, respectively. You can also use the models trained on COCO dataset (like HigherHRNet) to generate 2D heatmaps directly.
-
-The directory tree should be like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- ├── panoptic_training_pose.pkl
- ├── campus
- | ├── Camera0
- | | | ├── campus4-c0-00000.png
- | | | ├── ...
- | | | ├── campus4-c0-01999.png
- | ...
- | ├── Camera2
- | | | ├── campus4-c2-00000.png
- | | | ├── ...
- | | | ├── campus4-c2-01999.png
- | ├── calibration_campus.json
- | ├── pred_campus_maskrcnn_hrnet_coco.pkl
- | ├── actorsGT.mat
- ├── shelf
- | ├── Camera0
- | | | ├── img_000000.png
- | | | ├── ...
- | | | ├── img_003199.png
- | ...
- | ├── Camera4
- | | | ├── img_000000.png
- | | | ├── ...
- | | | ├── img_003199.png
- | ├── calibration_shelf.json
- | ├── pred_shelf_maskrcnn_hrnet_coco.pkl
- | ├── actorsGT.mat
-```
+# 3D Body Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [Human3.6M](#human36m) \[ [Homepage](http://vision.imar.ro/human3.6m/description.php) \]
+- [CMU Panoptic](#cmu-panoptic) \[ [Homepage](http://domedb.perception.cs.cmu.edu/) \]
+- [Campus/Shelf](#campus-and-shelf) \[ [Homepage](http://campar.in.tum.de/Chair/MultiHumanPose) \]
+
+## Human3.6M
+
+
+
+
+Human3.6M (TPAMI'2014)
+
+```bibtex
+@article{h36m_pami,
+ author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian},
+ title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments},
+ journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
+ publisher = {IEEE Computer Society},
+ volume = {36},
+ number = {7},
+ pages = {1325-1339},
+ month = {jul},
+ year = {2014}
+}
+```
+
+
+
+
+
+
+
+For [Human3.6M](http://vision.imar.ro/human3.6m/description.php), please download from the official website and run the [preprocessing script](/tools/dataset_converters/preprocess_h36m.py), which will extract camera parameters and pose annotations at full framerate (50 FPS) and downsampled framerate (10 FPS). The processed data should have the following structure:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ ├── h36m
+ ├── annotation_body3d
+ | ├── cameras.pkl
+ | ├── fps50
+ | | ├── h36m_test.npz
+ | | ├── h36m_train.npz
+ | | ├── joint2d_rel_stats.pkl
+ | | ├── joint2d_stats.pkl
+ | | ├── joint3d_rel_stats.pkl
+ | | `── joint3d_stats.pkl
+ | `── fps10
+ | ├── h36m_test.npz
+ | ├── h36m_train.npz
+ | ├── joint2d_rel_stats.pkl
+ | ├── joint2d_stats.pkl
+ | ├── joint3d_rel_stats.pkl
+ | `── joint3d_stats.pkl
+ `── images
+ ├── S1
+ | ├── S1_Directions_1.54138969
+ | | ├── S1_Directions_1.54138969_00001.jpg
+ | | ├── S1_Directions_1.54138969_00002.jpg
+ | | ├── ...
+ | ├── ...
+ ├── S5
+ ├── S6
+ ├── S7
+ ├── S8
+ ├── S9
+ `── S11
+```
+
+## CMU Panoptic
+
+
+CMU Panoptic (ICCV'2015)
+
+```bibtex
+@Article = {joo_iccv_2015,
+author = {Hanbyul Joo, Hao Liu, Lei Tan, Lin Gui, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh},
+title = {Panoptic Studio: A Massively Multiview System for Social Motion Capture},
+booktitle = {ICCV},
+year = {2015}
+}
+```
+
+
+
+
+
+
+
+Please follow [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch) to prepare this dataset.
+
+1. Download the dataset by following the instructions in [panoptic-toolbox](https://github.com/CMU-Perceptual-Computing-Lab/panoptic-toolbox) and extract them under `$MMPOSE/data/panoptic`.
+
+2. Only download those sequences that are needed. You can also just download a subset of camera views by specifying the number of views (HD_Video_Number) and changing the camera order in `./scripts/getData.sh`. The used sequences and camera views can be found in [VoxelPose](https://arxiv.org/abs/2004.06239). Note that the sequence "160906_band3" might not be available due to errors on the server of CMU Panoptic.
+
+3. Note that we only use HD videos, calibration data, and 3D Body Keypoint in the codes. You can comment out other irrelevant codes such as downloading 3D Face data in `./scripts/getData.sh`.
+
+The directory tree should be like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ ├── panoptic
+ ├── 16060224_haggling1
+ | | ├── hdImgs
+ | | ├── hdvideos
+ | | ├── hdPose3d_stage1_coco19
+ | | ├── calibration_160224_haggling1.json
+ ├── 160226_haggling1
+ ├── ...
+```
+
+## Campus and Shelf
+
+
+Campus and Shelf (CVPR'2014)
+
+```bibtex
+@inproceedings {belagian14multi,
+ title = {{3D} Pictorial Structures for Multiple Human Pose Estimation},
+ author = {Belagiannis, Vasileios and Amin, Sikandar and Andriluka, Mykhaylo and Schiele, Bernt and Navab
+ Nassir and Ilic, Slobo
+ booktitle = {IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year = {2014},
+ month = {June},
+ organization={IEEE}
+}
+```
+
+
+
+
+
+
+
+Please follow [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch) to prepare these two datasets.
+
+1. Please download the datasets from the [official website](http://campar.in.tum.de/Chair/MultiHumanPose) and extract them under `$MMPOSE/data/campus` and `$MMPOSE/data/shelf`, respectively. The original data include images as well as the ground truth pose file `actorsGT.mat`.
+
+2. We directly use the processed camera parameters from [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch). You can download them from this repository and place in under `$MMPOSE/data/campus/calibration_campus.json` and `$MMPOSE/data/shelf/calibration_shelf.json`, respectively.
+
+3. Like [Voxelpose](https://github.com/microsoft/voxelpose-pytorch), due to the limited and incomplete annotations of the two datasets, we don't train the model using this dataset. Instead, we directly use the 2D pose estimator trained on COCO, and use independent 3D human poses from the CMU Panoptic dataset to train our 3D model. It lies in `${MMPOSE}/data/panoptic_training_pose.pkl`.
+
+4. Like [Voxelpose](https://github.com/microsoft/voxelpose-pytorch), for testing, we first estimate 2D poses and generate 2D heatmaps for these two datasets. You can download the predicted poses from [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch) and place them in `$MMPOSE/data/campus/pred_campus_maskrcnn_hrnet_coco.pkl` and `$MMPOSE/data/shelf/pred_shelf_maskrcnn_hrnet_coco.pkl`, respectively. You can also use the models trained on COCO dataset (like HigherHRNet) to generate 2D heatmaps directly.
+
+The directory tree should be like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ ├── panoptic_training_pose.pkl
+ ├── campus
+ | ├── Camera0
+ | | | ├── campus4-c0-00000.png
+ | | | ├── ...
+ | | | ├── campus4-c0-01999.png
+ | ...
+ | ├── Camera2
+ | | | ├── campus4-c2-00000.png
+ | | | ├── ...
+ | | | ├── campus4-c2-01999.png
+ | ├── calibration_campus.json
+ | ├── pred_campus_maskrcnn_hrnet_coco.pkl
+ | ├── actorsGT.mat
+ ├── shelf
+ | ├── Camera0
+ | | | ├── img_000000.png
+ | | | ├── ...
+ | | | ├── img_003199.png
+ | ...
+ | ├── Camera4
+ | | | ├── img_000000.png
+ | | | ├── ...
+ | | | ├── img_003199.png
+ | ├── calibration_shelf.json
+ | ├── pred_shelf_maskrcnn_hrnet_coco.pkl
+ | ├── actorsGT.mat
+```
diff --git a/docs/zh_cn/dataset_zoo/3d_body_mesh.md b/docs/zh_cn/dataset_zoo/3d_body_mesh.md
index aced63c802..25a08fd676 100644
--- a/docs/zh_cn/dataset_zoo/3d_body_mesh.md
+++ b/docs/zh_cn/dataset_zoo/3d_body_mesh.md
@@ -1,342 +1,342 @@
-# 3D Body Mesh Recovery Datasets
-
-It is recommended to symlink the dataset root to `$MMPOSE/data`.
-If your folder structure is different, you may need to change the corresponding paths in config files.
-
-To achieve high-quality human mesh estimation, we use multiple datasets for training.
-The following items should be prepared for human mesh training:
-
-
-
-- [3D Body Mesh Recovery Datasets](#3d-body-mesh-recovery-datasets)
- - [Notes](#notes)
- - [Annotation Files for Human Mesh Estimation](#annotation-files-for-human-mesh-estimation)
- - [SMPL Model](#smpl-model)
- - [COCO](#coco)
- - [Human3.6M](#human36m)
- - [MPI-INF-3DHP](#mpi-inf-3dhp)
- - [LSP](#lsp)
- - [LSPET](#lspet)
- - [CMU MoShed Data](#cmu-moshed-data)
-
-
-
-## Notes
-
-### Annotation Files for Human Mesh Estimation
-
-For human mesh estimation, we use multiple datasets for training.
-The annotation of different datasets are preprocessed to the same format. Please
-follow the [preprocess procedure](https://github.com/nkolot/SPIN/tree/master/datasets/preprocess)
-of SPIN to generate the annotation files or download the processed files from
-[here](https://download.openmmlab.com/mmpose/datasets/mesh_annotation_files.zip),
-and make it look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── mesh_annotation_files
- ├── coco_2014_train.npz
- ├── h36m_valid_protocol1.npz
- ├── h36m_valid_protocol2.npz
- ├── hr-lspet_train.npz
- ├── lsp_dataset_original_train.npz
- ├── mpi_inf_3dhp_train.npz
- └── mpii_train.npz
-```
-
-### SMPL Model
-
-```bibtex
-@article{loper2015smpl,
- title={SMPL: A skinned multi-person linear model},
- author={Loper, Matthew and Mahmood, Naureen and Romero, Javier and Pons-Moll, Gerard and Black, Michael J},
- journal={ACM transactions on graphics (TOG)},
- volume={34},
- number={6},
- pages={1--16},
- year={2015},
- publisher={ACM New York, NY, USA}
-}
-```
-
-For human mesh estimation, SMPL model is used to generate the human mesh.
-Please download the [gender neutral SMPL model](http://smplify.is.tue.mpg.de/),
-[joints regressor](https://download.openmmlab.com/mmpose/datasets/joints_regressor_cmr.npy)
-and [mean parameters](https://download.openmmlab.com/mmpose/datasets/smpl_mean_params.npz)
-under `$MMPOSE/models/smpl`, and make it look like this:
-
-```text
-mmpose
-├── mmpose
-├── ...
-├── models
- │── smpl
- ├── joints_regressor_cmr.npy
- ├── smpl_mean_params.npz
- └── SMPL_NEUTRAL.pkl
-```
-
-## COCO
-
-
-
-
-COCO (ECCV'2014)
-
-```bibtex
-@inproceedings{lin2014microsoft,
- title={Microsoft coco: Common objects in context},
- author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence},
- booktitle={European conference on computer vision},
- pages={740--755},
- year={2014},
- organization={Springer}
-}
-```
-
-
-
-For [COCO](http://cocodataset.org/) data, please download from [COCO download](http://cocodataset.org/#download). COCO'2014 Train is needed for human mesh estimation training.
-Download and extract them under $MMPOSE/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── coco
- │-- train2014
- │ ├── COCO_train2014_000000000009.jpg
- │ ├── COCO_train2014_000000000025.jpg
- │ ├── COCO_train2014_000000000030.jpg
- | │-- ...
-
-```
-
-## Human3.6M
-
-
-
-
-Human3.6M (TPAMI'2014)
-
-```bibtex
-@article{h36m_pami,
- author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian},
- title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments},
- journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
- publisher = {IEEE Computer Society},
- volume = {36},
- number = {7},
- pages = {1325-1339},
- month = {jul},
- year = {2014}
-}
-```
-
-
-
-For [Human3.6M](http://vision.imar.ro/human3.6m/description.php), we use the MoShed data provided in [HMR](https://github.com/akanazawa/hmr) for training.
-However, due to license limitations, we are not allowed to redistribute the MoShed data.
-
-For the evaluation on Human3.6M dataset, please follow the
-[preprocess procedure](https://github.com/nkolot/SPIN/tree/master/datasets/preprocess)
-of SPIN to extract test images from
-[Human3.6M](http://vision.imar.ro/human3.6m/description.php) original videos,
-and make it look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── Human3.6M
- ├── images
- ├── S11_Directions_1.54138969_000001.jpg
- ├── S11_Directions_1.54138969_000006.jpg
- ├── S11_Directions_1.54138969_000011.jpg
- ├── ...
-```
-
-The download of Human3.6M dataset is quite difficult, you can also download the
-[zip file](https://drive.google.com/file/d/1WnRJD9FS3NUf7MllwgLRJJC-JgYFr8oi/view?usp=sharing)
-of the test images. However, due to the license limitations, we are not allowed to
-redistribute the images either. So the users need to download the original video and
-extract the images by themselves.
-
-## MPI-INF-3DHP
-
-
-
-```bibtex
-@inproceedings{mono-3dhp2017,
- author = {Mehta, Dushyant and Rhodin, Helge and Casas, Dan and Fua, Pascal and Sotnychenko, Oleksandr and Xu, Weipeng and Theobalt, Christian},
- title = {Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision},
- booktitle = {3D Vision (3DV), 2017 Fifth International Conference on},
- url = {http://gvv.mpi-inf.mpg.de/3dhp_dataset},
- year = {2017},
- organization={IEEE},
- doi={10.1109/3dv.2017.00064},
-}
-```
-
-For [MPI-INF-3DHP](http://gvv.mpi-inf.mpg.de/3dhp-dataset/), please follow the
-[preprocess procedure](https://github.com/nkolot/SPIN/tree/master/datasets/preprocess)
-of SPIN to sample images, and make them like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- ├── mpi_inf_3dhp_test_set
- │ ├── TS1
- │ ├── TS2
- │ ├── TS3
- │ ├── TS4
- │ ├── TS5
- │ └── TS6
- ├── S1
- │ ├── Seq1
- │ └── Seq2
- ├── S2
- │ ├── Seq1
- │ └── Seq2
- ├── S3
- │ ├── Seq1
- │ └── Seq2
- ├── S4
- │ ├── Seq1
- │ └── Seq2
- ├── S5
- │ ├── Seq1
- │ └── Seq2
- ├── S6
- │ ├── Seq1
- │ └── Seq2
- ├── S7
- │ ├── Seq1
- │ └── Seq2
- └── S8
- ├── Seq1
- └── Seq2
-```
-
-## LSP
-
-
-
-```bibtex
-@inproceedings{johnson2010clustered,
- title={Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation.},
- author={Johnson, Sam and Everingham, Mark},
- booktitle={bmvc},
- volume={2},
- number={4},
- pages={5},
- year={2010},
- organization={Citeseer}
-}
-```
-
-For [LSP](https://sam.johnson.io/research/lsp.html), please download the high resolution version
-[LSP dataset original](http://sam.johnson.io/research/lsp_dataset_original.zip).
-Extract them under `$MMPOSE/data`, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── lsp_dataset_original
- ├── images
- ├── im0001.jpg
- ├── im0002.jpg
- └── ...
-```
-
-## LSPET
-
-
-
-```bibtex
-@inproceedings{johnson2011learning,
- title={Learning effective human pose estimation from inaccurate annotation},
- author={Johnson, Sam and Everingham, Mark},
- booktitle={CVPR 2011},
- pages={1465--1472},
- year={2011},
- organization={IEEE}
-}
-```
-
-For [LSPET](https://sam.johnson.io/research/lspet.html), please download its high resolution form
-[HR-LSPET](http://datasets.d2.mpi-inf.mpg.de/hr-lspet/hr-lspet.zip).
-Extract them under `$MMPOSE/data`, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── lspet_dataset
- ├── images
- │ ├── im00001.jpg
- │ ├── im00002.jpg
- │ ├── im00003.jpg
- │ └── ...
- └── joints.mat
-```
-
-## CMU MoShed Data
-
-
-
-```bibtex
-@inproceedings{kanazawa2018end,
- title={End-to-end recovery of human shape and pose},
- author={Kanazawa, Angjoo and Black, Michael J and Jacobs, David W and Malik, Jitendra},
- booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
- pages={7122--7131},
- year={2018}
-}
-```
-
-Real-world SMPL parameters are used for the adversarial training in human mesh estimation.
-The MoShed data provided in [HMR](https://github.com/akanazawa/hmr) is included in this
-[zip file](https://download.openmmlab.com/mmpose/datasets/mesh_annotation_files.zip).
-Please download and extract it under `$MMPOSE/data`, and make it look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── mesh_annotation_files
- ├── CMU_mosh.npz
- └── ...
-```
+# 3D Body Mesh Recovery Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+To achieve high-quality human mesh estimation, we use multiple datasets for training.
+The following items should be prepared for human mesh training:
+
+
+
+- [3D Body Mesh Recovery Datasets](#3d-body-mesh-recovery-datasets)
+ - [Notes](#notes)
+ - [Annotation Files for Human Mesh Estimation](#annotation-files-for-human-mesh-estimation)
+ - [SMPL Model](#smpl-model)
+ - [COCO](#coco)
+ - [Human3.6M](#human36m)
+ - [MPI-INF-3DHP](#mpi-inf-3dhp)
+ - [LSP](#lsp)
+ - [LSPET](#lspet)
+ - [CMU MoShed Data](#cmu-moshed-data)
+
+
+
+## Notes
+
+### Annotation Files for Human Mesh Estimation
+
+For human mesh estimation, we use multiple datasets for training.
+The annotation of different datasets are preprocessed to the same format. Please
+follow the [preprocess procedure](https://github.com/nkolot/SPIN/tree/master/datasets/preprocess)
+of SPIN to generate the annotation files or download the processed files from
+[here](https://download.openmmlab.com/mmpose/datasets/mesh_annotation_files.zip),
+and make it look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── mesh_annotation_files
+ ├── coco_2014_train.npz
+ ├── h36m_valid_protocol1.npz
+ ├── h36m_valid_protocol2.npz
+ ├── hr-lspet_train.npz
+ ├── lsp_dataset_original_train.npz
+ ├── mpi_inf_3dhp_train.npz
+ └── mpii_train.npz
+```
+
+### SMPL Model
+
+```bibtex
+@article{loper2015smpl,
+ title={SMPL: A skinned multi-person linear model},
+ author={Loper, Matthew and Mahmood, Naureen and Romero, Javier and Pons-Moll, Gerard and Black, Michael J},
+ journal={ACM transactions on graphics (TOG)},
+ volume={34},
+ number={6},
+ pages={1--16},
+ year={2015},
+ publisher={ACM New York, NY, USA}
+}
+```
+
+For human mesh estimation, SMPL model is used to generate the human mesh.
+Please download the [gender neutral SMPL model](http://smplify.is.tue.mpg.de/),
+[joints regressor](https://download.openmmlab.com/mmpose/datasets/joints_regressor_cmr.npy)
+and [mean parameters](https://download.openmmlab.com/mmpose/datasets/smpl_mean_params.npz)
+under `$MMPOSE/models/smpl`, and make it look like this:
+
+```text
+mmpose
+├── mmpose
+├── ...
+├── models
+ │── smpl
+ ├── joints_regressor_cmr.npy
+ ├── smpl_mean_params.npz
+ └── SMPL_NEUTRAL.pkl
+```
+
+## COCO
+
+
+
+
+COCO (ECCV'2014)
+
+```bibtex
+@inproceedings{lin2014microsoft,
+ title={Microsoft coco: Common objects in context},
+ author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence},
+ booktitle={European conference on computer vision},
+ pages={740--755},
+ year={2014},
+ organization={Springer}
+}
+```
+
+
+
+For [COCO](http://cocodataset.org/) data, please download from [COCO download](http://cocodataset.org/#download). COCO'2014 Train is needed for human mesh estimation training.
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── coco
+ │-- train2014
+ │ ├── COCO_train2014_000000000009.jpg
+ │ ├── COCO_train2014_000000000025.jpg
+ │ ├── COCO_train2014_000000000030.jpg
+ | │-- ...
+
+```
+
+## Human3.6M
+
+
+
+
+Human3.6M (TPAMI'2014)
+
+```bibtex
+@article{h36m_pami,
+ author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian},
+ title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments},
+ journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
+ publisher = {IEEE Computer Society},
+ volume = {36},
+ number = {7},
+ pages = {1325-1339},
+ month = {jul},
+ year = {2014}
+}
+```
+
+
+
+For [Human3.6M](http://vision.imar.ro/human3.6m/description.php), we use the MoShed data provided in [HMR](https://github.com/akanazawa/hmr) for training.
+However, due to license limitations, we are not allowed to redistribute the MoShed data.
+
+For the evaluation on Human3.6M dataset, please follow the
+[preprocess procedure](https://github.com/nkolot/SPIN/tree/master/datasets/preprocess)
+of SPIN to extract test images from
+[Human3.6M](http://vision.imar.ro/human3.6m/description.php) original videos,
+and make it look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── Human3.6M
+ ├── images
+ ├── S11_Directions_1.54138969_000001.jpg
+ ├── S11_Directions_1.54138969_000006.jpg
+ ├── S11_Directions_1.54138969_000011.jpg
+ ├── ...
+```
+
+The download of Human3.6M dataset is quite difficult, you can also download the
+[zip file](https://drive.google.com/file/d/1WnRJD9FS3NUf7MllwgLRJJC-JgYFr8oi/view?usp=sharing)
+of the test images. However, due to the license limitations, we are not allowed to
+redistribute the images either. So the users need to download the original video and
+extract the images by themselves.
+
+## MPI-INF-3DHP
+
+
+
+```bibtex
+@inproceedings{mono-3dhp2017,
+ author = {Mehta, Dushyant and Rhodin, Helge and Casas, Dan and Fua, Pascal and Sotnychenko, Oleksandr and Xu, Weipeng and Theobalt, Christian},
+ title = {Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision},
+ booktitle = {3D Vision (3DV), 2017 Fifth International Conference on},
+ url = {http://gvv.mpi-inf.mpg.de/3dhp_dataset},
+ year = {2017},
+ organization={IEEE},
+ doi={10.1109/3dv.2017.00064},
+}
+```
+
+For [MPI-INF-3DHP](http://gvv.mpi-inf.mpg.de/3dhp-dataset/), please follow the
+[preprocess procedure](https://github.com/nkolot/SPIN/tree/master/datasets/preprocess)
+of SPIN to sample images, and make them like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ ├── mpi_inf_3dhp_test_set
+ │ ├── TS1
+ │ ├── TS2
+ │ ├── TS3
+ │ ├── TS4
+ │ ├── TS5
+ │ └── TS6
+ ├── S1
+ │ ├── Seq1
+ │ └── Seq2
+ ├── S2
+ │ ├── Seq1
+ │ └── Seq2
+ ├── S3
+ │ ├── Seq1
+ │ └── Seq2
+ ├── S4
+ │ ├── Seq1
+ │ └── Seq2
+ ├── S5
+ │ ├── Seq1
+ │ └── Seq2
+ ├── S6
+ │ ├── Seq1
+ │ └── Seq2
+ ├── S7
+ │ ├── Seq1
+ │ └── Seq2
+ └── S8
+ ├── Seq1
+ └── Seq2
+```
+
+## LSP
+
+
+
+```bibtex
+@inproceedings{johnson2010clustered,
+ title={Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation.},
+ author={Johnson, Sam and Everingham, Mark},
+ booktitle={bmvc},
+ volume={2},
+ number={4},
+ pages={5},
+ year={2010},
+ organization={Citeseer}
+}
+```
+
+For [LSP](https://sam.johnson.io/research/lsp.html), please download the high resolution version
+[LSP dataset original](http://sam.johnson.io/research/lsp_dataset_original.zip).
+Extract them under `$MMPOSE/data`, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── lsp_dataset_original
+ ├── images
+ ├── im0001.jpg
+ ├── im0002.jpg
+ └── ...
+```
+
+## LSPET
+
+
+
+```bibtex
+@inproceedings{johnson2011learning,
+ title={Learning effective human pose estimation from inaccurate annotation},
+ author={Johnson, Sam and Everingham, Mark},
+ booktitle={CVPR 2011},
+ pages={1465--1472},
+ year={2011},
+ organization={IEEE}
+}
+```
+
+For [LSPET](https://sam.johnson.io/research/lspet.html), please download its high resolution form
+[HR-LSPET](http://datasets.d2.mpi-inf.mpg.de/hr-lspet/hr-lspet.zip).
+Extract them under `$MMPOSE/data`, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── lspet_dataset
+ ├── images
+ │ ├── im00001.jpg
+ │ ├── im00002.jpg
+ │ ├── im00003.jpg
+ │ └── ...
+ └── joints.mat
+```
+
+## CMU MoShed Data
+
+
+
+```bibtex
+@inproceedings{kanazawa2018end,
+ title={End-to-end recovery of human shape and pose},
+ author={Kanazawa, Angjoo and Black, Michael J and Jacobs, David W and Malik, Jitendra},
+ booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={7122--7131},
+ year={2018}
+}
+```
+
+Real-world SMPL parameters are used for the adversarial training in human mesh estimation.
+The MoShed data provided in [HMR](https://github.com/akanazawa/hmr) is included in this
+[zip file](https://download.openmmlab.com/mmpose/datasets/mesh_annotation_files.zip).
+Please download and extract it under `$MMPOSE/data`, and make it look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── mesh_annotation_files
+ ├── CMU_mosh.npz
+ └── ...
+```
diff --git a/docs/zh_cn/dataset_zoo/3d_hand_keypoint.md b/docs/zh_cn/dataset_zoo/3d_hand_keypoint.md
index 2b1f4d3923..8a3c398c04 100644
--- a/docs/zh_cn/dataset_zoo/3d_hand_keypoint.md
+++ b/docs/zh_cn/dataset_zoo/3d_hand_keypoint.md
@@ -1,59 +1,59 @@
-# 3D Hand Keypoint Datasets
-
-It is recommended to symlink the dataset root to `$MMPOSE/data`.
-If your folder structure is different, you may need to change the corresponding paths in config files.
-
-MMPose supported datasets:
-
-- [InterHand2.6M](#interhand26m) \[ [Homepage](https://mks0601.github.io/InterHand2.6M/) \]
-
-## InterHand2.6M
-
-
-
-
-InterHand2.6M (ECCV'2020)
-
-```bibtex
-@InProceedings{Moon_2020_ECCV_InterHand2.6M,
-author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu},
-title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image},
-booktitle = {European Conference on Computer Vision (ECCV)},
-year = {2020}
-}
-```
-
-
-
-
-
-
-
-For [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/), please download from [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/).
-Please download the annotation files from [annotations](https://drive.google.com/drive/folders/1pWXhdfaka-J0fSAze0MsajN0VpZ8e8tO).
-Extract them under {MMPose}/data, and make them look like this:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── interhand2.6m
- |── annotations
- | |── all
- | |── human_annot
- | |── machine_annot
- | |── skeleton.txt
- | |── subject.txt
- |
- `── images
- | |── train
- | | |-- Capture0 ~ Capture26
- | |── val
- | | |-- Capture0
- | |── test
- | | |-- Capture0 ~ Capture7
-```
+# 3D Hand Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [InterHand2.6M](#interhand26m) \[ [Homepage](https://mks0601.github.io/InterHand2.6M/) \]
+
+## InterHand2.6M
+
+
+
+
+InterHand2.6M (ECCV'2020)
+
+```bibtex
+@InProceedings{Moon_2020_ECCV_InterHand2.6M,
+author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu},
+title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image},
+booktitle = {European Conference on Computer Vision (ECCV)},
+year = {2020}
+}
+```
+
+
+
+
+
+
+
+For [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/), please download from [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/).
+Please download the annotation files from [annotations](https://drive.google.com/drive/folders/1pWXhdfaka-J0fSAze0MsajN0VpZ8e8tO).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── interhand2.6m
+ |── annotations
+ | |── all
+ | |── human_annot
+ | |── machine_annot
+ | |── skeleton.txt
+ | |── subject.txt
+ |
+ `── images
+ | |── train
+ | | |-- Capture0 ~ Capture26
+ | |── val
+ | | |-- Capture0
+ | |── test
+ | | |-- Capture0 ~ Capture7
+```
diff --git a/docs/zh_cn/dataset_zoo/dataset_tools.md b/docs/zh_cn/dataset_zoo/dataset_tools.md
index a2e6d01d97..358f0788e3 100644
--- a/docs/zh_cn/dataset_zoo/dataset_tools.md
+++ b/docs/zh_cn/dataset_zoo/dataset_tools.md
@@ -1,413 +1,413 @@
-# 数据集格式转换脚本
-
-MMPose 提供了一些工具来帮助用户处理数据集。
-
-## Animal Pose 数据集
-
-
-Animal-Pose (ICCV'2019)
-
-```bibtex
-@InProceedings{Cao_2019_ICCV,
- author = {Cao, Jinkun and Tang, Hongyang and Fang, Hao-Shu and Shen, Xiaoyong and Lu, Cewu and Tai, Yu-Wing},
- title = {Cross-Domain Adaptation for Animal Pose Estimation},
- booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
- month = {October},
- year = {2019}
-}
-```
-
-
-
-对于 [Animal-Pose](https://sites.google.com/view/animal-pose/),可以从[官方网站](https://sites.google.com/view/animal-pose/)下载图像和标注。脚本 `tools/dataset_converters/parse_animalpose_dataset.py` 将原始标注转换为 MMPose 兼容的格式。预处理的[标注文件](https://download.openmmlab.com/mmpose/datasets/animalpose_annotations.tar)可用。如果您想自己生成标注,请按照以下步骤操作:
-
-1. 下载图片与标注信息并解压到 `$MMPOSE/data`,按照以下格式组织:
-
- ```text
- mmpose
- ├── mmpose
- ├── docs
- ├── tests
- ├── tools
- ├── configs
- `── data
- │── animalpose
- │
- │-- VOC2012
- │ │-- Annotations
- │ │-- ImageSets
- │ │-- JPEGImages
- │ │-- SegmentationClass
- │ │-- SegmentationObject
- │
- │-- animalpose_image_part2
- │ │-- cat
- │ │-- cow
- │ │-- dog
- │ │-- horse
- │ │-- sheep
- │
- │-- PASCAL2011_animal_annotation
- │ │-- cat
- │ │ |-- 2007_000528_1.xml
- │ │ |-- 2007_000549_1.xml
- │ │ │-- ...
- │ │-- cow
- │ │-- dog
- │ │-- horse
- │ │-- sheep
- │
- │-- annimalpose_anno2
- │ │-- cat
- │ │ |-- ca1.xml
- │ │ |-- ca2.xml
- │ │ │-- ...
- │ │-- cow
- │ │-- dog
- │ │-- horse
- │ │-- sheep
- ```
-
-2. 运行脚本
-
- ```bash
- python tools/dataset_converters/parse_animalpose_dataset.py
- ```
-
- 生成的标注文件将保存在 `$MMPOSE/data/animalpose/annotations` 中。
-
-开源作者没有提供官方的 train/val/test 划分,我们选择来自 PascalVOC 的图片作为 train & val,train+val 一共 3600 张图片,5117 个标注。其中 2798 张图片,4000 个标注用于训练,810 张图片,1117 个标注用于验证。测试集包含 1000 张图片,1000 个标注用于评估。
-
-## COFW 数据集
-
-
-COFW (ICCV'2013)
-
-```bibtex
-@inproceedings{burgos2013robust,
- title={Robust face landmark estimation under occlusion},
- author={Burgos-Artizzu, Xavier P and Perona, Pietro and Doll{\'a}r, Piotr},
- booktitle={Proceedings of the IEEE international conference on computer vision},
- pages={1513--1520},
- year={2013}
-}
-```
-
-
-
-对于 COFW 数据集,请从 [COFW Dataset (Color Images)](https://data.caltech.edu/records/20099) 进行下载。
-
-将 `COFW_train_color.mat` 和 `COFW_test_color.mat` 移动到 `$MMPOSE/data/cofw/`,确保它们按照以下格式组织:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── cofw
- |── COFW_train_color.mat
- |── COFW_test_color.mat
-```
-
-运行 `pip install h5py` 安装依赖,然后在 `$MMPOSE` 下运行脚本:
-
-```bash
-python tools/dataset_converters/parse_cofw_dataset.py
-```
-
-最终结果为:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- │── cofw
- |── COFW_train_color.mat
- |── COFW_test_color.mat
- |── annotations
- | |── cofw_train.json
- | |── cofw_test.json
- |── images
- |── 000001.jpg
- |── 000002.jpg
-```
-
-## DeepposeKit 数据集
-
-
-Desert Locust (Elife'2019)
-
-```bibtex
-@article{graving2019deepposekit,
- title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning},
- author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D},
- journal={Elife},
- volume={8},
- pages={e47994},
- year={2019},
- publisher={eLife Sciences Publications Limited}
-}
-```
-
-
-
-对于 [Vinegar Fly](https://github.com/jgraving/DeepPoseKit-Data),[Desert Locust](https://github.com/jgraving/DeepPoseKit-Data), 和 [Grévy’s Zebra](https://github.com/jgraving/DeepPoseKit-Data) 数据集,请从 [DeepPoseKit-Data](https://github.com/jgraving/DeepPoseKit-Data) 下载数据。
-
-`tools/dataset_converters/parse_deepposekit_dataset.py` 脚本可以将原始标注转换为 MMPose 支持的格式。我们已经转换好的标注文件可以在这里下载:
-
-- [vinegar_fly_annotations](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_annotations.tar)
-- [locust_annotations](https://download.openmmlab.com/mmpose/datasets/locust_annotations.tar)
-- [zebra_annotations](https://download.openmmlab.com/mmpose/datasets/zebra_annotations.tar)
-
-如果你希望自己转换数据,请按照以下步骤操作:
-
-1. 下载原始图片和标注,并解压到 `$MMPOSE/data`,将它们按照以下格式组织:
-
- ```text
- mmpose
- ├── mmpose
- ├── docs
- ├── tests
- ├── tools
- ├── configs
- `── data
- |
- |── DeepPoseKit-Data
- | `── datasets
- | |── fly
- | | |── annotation_data_release.h5
- | | |── skeleton.csv
- | | |── ...
- | |
- | |── locust
- | | |── annotation_data_release.h5
- | | |── skeleton.csv
- | | |── ...
- | |
- | `── zebra
- | |── annotation_data_release.h5
- | |── skeleton.csv
- | |── ...
- |
- │── fly
- `-- images
- │-- 0.jpg
- │-- 1.jpg
- │-- ...
- ```
-
- 图片也可以在 [vinegar_fly_images](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_images.tar),[locust_images](https://download.openmmlab.com/mmpose/datasets/locust_images.tar) 和[zebra_images](https://download.openmmlab.com/mmpose/datasets/zebra_images.tar) 下载。
-
-2. 运行脚本:
-
- ```bash
- python tools/dataset_converters/parse_deepposekit_dataset.py
- ```
-
- 生成的标注文件将保存在 $MMPOSE/data/fly/annotations`,`$MMPOSE/data/locust/annotations`和`$MMPOSE/data/zebra/annotations\` 中。
-
-由于官方数据集中没有提供测试集,我们随机选择了 90% 的图片用于训练,剩下的 10% 用于测试。
-
-## Macaque 数据集
-
-
-MacaquePose (bioRxiv'2020)
-
-```bibtex
-@article{labuguen2020macaquepose,
- title={MacaquePose: A novel ‘in the wild’macaque monkey pose dataset for markerless motion capture},
- author={Labuguen, Rollyn and Matsumoto, Jumpei and Negrete, Salvador and Nishimaru, Hiroshi and Nishijo, Hisao and Takada, Masahiko and Go, Yasuhiro and Inoue, Ken-ichi and Shibata, Tomohiro},
- journal={bioRxiv},
- year={2020},
- publisher={Cold Spring Harbor Laboratory}
-}
-```
-
-
-
-对于 [MacaquePose](http://www2.ehub.kyoto-u.ac.jp/datasets/macaquepose/index.html) 数据集,请从 [这里](http://www2.ehub.kyoto-u.ac.jp/datasets/macaquepose/index.html) 下载数据。
-
-`tools/dataset_converters/parse_macaquepose_dataset.py` 脚本可以将原始标注转换为 MMPose 支持的格式。我们已经转换好的标注文件可以在 [这里](https://download.openmmlab.com/mmpose/datasets/macaque_annotations.tar) 下载。
-
-如果你希望自己转换数据,请按照以下步骤操作:
-
-1. 下载原始图片和标注,并解压到 `$MMPOSE/data`,将它们按照以下格式组织:
-
- ```text
- mmpose
- ├── mmpose
- ├── docs
- ├── tests
- ├── tools
- ├── configs
- `── data
- │── macaque
- │-- annotations.csv
- │-- images
- │ │-- 01418849d54b3005.jpg
- │ │-- 0142d1d1a6904a70.jpg
- │ │-- 01ef2c4c260321b7.jpg
- │ │-- 020a1c75c8c85238.jpg
- │ │-- 020b1506eef2557d.jpg
- │ │-- ...
- ```
-
-2. 运行脚本:
-
- ```bash
- python tools/dataset_converters/parse_macaquepose_dataset.py
- ```
-
- 生成的标注文件将保存在 `$MMPOSE/data/macaque/annotations` 中。
-
-由于官方数据集中没有提供测试集,我们随机选择了 90% 的图片用于训练,剩下的 10% 用于测试。
-
-## Human3.6M 数据集
-
-
-Human3.6M (TPAMI'2014)
-
-```bibtex
-@article{h36m_pami,
- author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian},
- title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments},
- journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
- publisher = {IEEE Computer Society},
- volume = {36},
- number = {7},
- pages = {1325-1339},
- month = {jul},
- year = {2014}
-}
-```
-
-
-
-对于 [Human3.6M](http://vision.imar.ro/human3.6m/description.php) 数据集,请从官网下载数据,放置到 `$MMPOSE/data/h36m` 下。
-
-然后执行 [预处理脚本](/tools/dataset_converters/preprocess_h36m.py)。
-
-```bash
-python tools/dataset_converters/preprocess_h36m.py --metadata {path to metadata.xml} --original data/h36m
-```
-
-这将在全帧率(50 FPS)和降频帧率(10 FPS)下提取相机参数和姿势注释。处理后的数据应具有以下结构:
-
-```text
-mmpose
-├── mmpose
-├── docs
-├── tests
-├── tools
-├── configs
-`── data
- ├── h36m
- ├── annotation_body3d
- | ├── cameras.pkl
- | ├── fps50
- | | ├── h36m_test.npz
- | | ├── h36m_train.npz
- | | ├── joint2d_rel_stats.pkl
- | | ├── joint2d_stats.pkl
- | | ├── joint3d_rel_stats.pkl
- | | `── joint3d_stats.pkl
- | `── fps10
- | ├── h36m_test.npz
- | ├── h36m_train.npz
- | ├── joint2d_rel_stats.pkl
- | ├── joint2d_stats.pkl
- | ├── joint3d_rel_stats.pkl
- | `── joint3d_stats.pkl
- `── images
- ├── S1
- | ├── S1_Directions_1.54138969
- | | ├── S1_Directions_1.54138969_00001.jpg
- | | ├── S1_Directions_1.54138969_00002.jpg
- | | ├── ...
- | ├── ...
- ├── S5
- ├── S6
- ├── S7
- ├── S8
- ├── S9
- `── S11
-```
-
-然后,标注信息需要转换为 MMPose 支持的 COCO 格式。这可以通过运行以下命令完成:
-
-```bash
-python tools/dataset_converters/h36m_to_coco.py
-```
-
-## MPII 数据集
-
-
-MPII (CVPR'2014)
-
-```bibtex
-@inproceedings{andriluka14cvpr,
- author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt},
- title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = {2014},
- month = {June}
-}
-```
-
-
-
-对于 [MPII](http://human-pose.mpi-inf.mpg.de/) 数据集,请从官网下载数据,放置到 `$MMPOSE/data/mpii` 下。
-
-我们提供了一个脚本来将 `.mat` 格式的标注文件转换为 `.json` 格式。这可以通过运行以下命令完成:
-
-```shell
-python tools/dataset_converters/mat2json ${PRED_MAT_FILE} ${GT_JSON_FILE} ${OUTPUT_PRED_JSON_FILE}
-```
-
-例如:
-
-```shell
-python tools/dataset/mat2json work_dirs/res50_mpii_256x256/pred.mat data/mpii/annotations/mpii_val.json pred.json
-```
-
-## Label Studio 数据集
-
-
-Label Studio
-
-```bibtex
-@misc{Label Studio,
- title={{Label Studio}: Data labeling software},
- url={https://github.com/heartexlabs/label-studio},
- note={Open source software available from https://github.com/heartexlabs/label-studio},
- author={
- Maxim Tkachenko and
- Mikhail Malyuk and
- Andrey Holmanyuk and
- Nikolai Liubimov},
- year={2020-2022},
-}
-```
-
-
-
-对于 [Label Studio](https://github.com/heartexlabs/label-studio/) 用户,请依照 [Label Studio 转换工具文档](./label_studio.md) 中的方法进行标注,并将结果导出为 Label Studio 标准的 `.json` 文件,将 `Labeling Interface` 中的 `Code` 保存为 `.xml` 文件。
-
-我们提供了一个脚本来将 Label Studio 标准的 `.json` 格式标注文件转换为 COCO 标准的 `.json` 格式。这可以通过运行以下命令完成:
-
-```shell
-python tools/dataset_converters/labelstudio2coco.py ${LS_JSON_FILE} ${LS_XML_FILE} ${OUTPUT_COCO_JSON_FILE}
-```
-
-例如:
-
-```shell
-python tools/dataset_converters/labelstudio2coco.py config.xml project-1-at-2023-05-13-09-22-91b53efa.json output/result.json
-```
+# 数据集格式转换脚本
+
+MMPose 提供了一些工具来帮助用户处理数据集。
+
+## Animal Pose 数据集
+
+
+Animal-Pose (ICCV'2019)
+
+```bibtex
+@InProceedings{Cao_2019_ICCV,
+ author = {Cao, Jinkun and Tang, Hongyang and Fang, Hao-Shu and Shen, Xiaoyong and Lu, Cewu and Tai, Yu-Wing},
+ title = {Cross-Domain Adaptation for Animal Pose Estimation},
+ booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
+ month = {October},
+ year = {2019}
+}
+```
+
+
+
+对于 [Animal-Pose](https://sites.google.com/view/animal-pose/),可以从[官方网站](https://sites.google.com/view/animal-pose/)下载图像和标注。脚本 `tools/dataset_converters/parse_animalpose_dataset.py` 将原始标注转换为 MMPose 兼容的格式。预处理的[标注文件](https://download.openmmlab.com/mmpose/datasets/animalpose_annotations.tar)可用。如果您想自己生成标注,请按照以下步骤操作:
+
+1. 下载图片与标注信息并解压到 `$MMPOSE/data`,按照以下格式组织:
+
+ ```text
+ mmpose
+ ├── mmpose
+ ├── docs
+ ├── tests
+ ├── tools
+ ├── configs
+ `── data
+ │── animalpose
+ │
+ │-- VOC2012
+ │ │-- Annotations
+ │ │-- ImageSets
+ │ │-- JPEGImages
+ │ │-- SegmentationClass
+ │ │-- SegmentationObject
+ │
+ │-- animalpose_image_part2
+ │ │-- cat
+ │ │-- cow
+ │ │-- dog
+ │ │-- horse
+ │ │-- sheep
+ │
+ │-- PASCAL2011_animal_annotation
+ │ │-- cat
+ │ │ |-- 2007_000528_1.xml
+ │ │ |-- 2007_000549_1.xml
+ │ │ │-- ...
+ │ │-- cow
+ │ │-- dog
+ │ │-- horse
+ │ │-- sheep
+ │
+ │-- annimalpose_anno2
+ │ │-- cat
+ │ │ |-- ca1.xml
+ │ │ |-- ca2.xml
+ │ │ │-- ...
+ │ │-- cow
+ │ │-- dog
+ │ │-- horse
+ │ │-- sheep
+ ```
+
+2. 运行脚本
+
+ ```bash
+ python tools/dataset_converters/parse_animalpose_dataset.py
+ ```
+
+ 生成的标注文件将保存在 `$MMPOSE/data/animalpose/annotations` 中。
+
+开源作者没有提供官方的 train/val/test 划分,我们选择来自 PascalVOC 的图片作为 train & val,train+val 一共 3600 张图片,5117 个标注。其中 2798 张图片,4000 个标注用于训练,810 张图片,1117 个标注用于验证。测试集包含 1000 张图片,1000 个标注用于评估。
+
+## COFW 数据集
+
+
+COFW (ICCV'2013)
+
+```bibtex
+@inproceedings{burgos2013robust,
+ title={Robust face landmark estimation under occlusion},
+ author={Burgos-Artizzu, Xavier P and Perona, Pietro and Doll{\'a}r, Piotr},
+ booktitle={Proceedings of the IEEE international conference on computer vision},
+ pages={1513--1520},
+ year={2013}
+}
+```
+
+
+
+对于 COFW 数据集,请从 [COFW Dataset (Color Images)](https://data.caltech.edu/records/20099) 进行下载。
+
+将 `COFW_train_color.mat` 和 `COFW_test_color.mat` 移动到 `$MMPOSE/data/cofw/`,确保它们按照以下格式组织:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── cofw
+ |── COFW_train_color.mat
+ |── COFW_test_color.mat
+```
+
+运行 `pip install h5py` 安装依赖,然后在 `$MMPOSE` 下运行脚本:
+
+```bash
+python tools/dataset_converters/parse_cofw_dataset.py
+```
+
+最终结果为:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── cofw
+ |── COFW_train_color.mat
+ |── COFW_test_color.mat
+ |── annotations
+ | |── cofw_train.json
+ | |── cofw_test.json
+ |── images
+ |── 000001.jpg
+ |── 000002.jpg
+```
+
+## DeepposeKit 数据集
+
+
+Desert Locust (Elife'2019)
+
+```bibtex
+@article{graving2019deepposekit,
+ title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning},
+ author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D},
+ journal={Elife},
+ volume={8},
+ pages={e47994},
+ year={2019},
+ publisher={eLife Sciences Publications Limited}
+}
+```
+
+
+
+对于 [Vinegar Fly](https://github.com/jgraving/DeepPoseKit-Data),[Desert Locust](https://github.com/jgraving/DeepPoseKit-Data), 和 [Grévy’s Zebra](https://github.com/jgraving/DeepPoseKit-Data) 数据集,请从 [DeepPoseKit-Data](https://github.com/jgraving/DeepPoseKit-Data) 下载数据。
+
+`tools/dataset_converters/parse_deepposekit_dataset.py` 脚本可以将原始标注转换为 MMPose 支持的格式。我们已经转换好的标注文件可以在这里下载:
+
+- [vinegar_fly_annotations](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_annotations.tar)
+- [locust_annotations](https://download.openmmlab.com/mmpose/datasets/locust_annotations.tar)
+- [zebra_annotations](https://download.openmmlab.com/mmpose/datasets/zebra_annotations.tar)
+
+如果你希望自己转换数据,请按照以下步骤操作:
+
+1. 下载原始图片和标注,并解压到 `$MMPOSE/data`,将它们按照以下格式组织:
+
+ ```text
+ mmpose
+ ├── mmpose
+ ├── docs
+ ├── tests
+ ├── tools
+ ├── configs
+ `── data
+ |
+ |── DeepPoseKit-Data
+ | `── datasets
+ | |── fly
+ | | |── annotation_data_release.h5
+ | | |── skeleton.csv
+ | | |── ...
+ | |
+ | |── locust
+ | | |── annotation_data_release.h5
+ | | |── skeleton.csv
+ | | |── ...
+ | |
+ | `── zebra
+ | |── annotation_data_release.h5
+ | |── skeleton.csv
+ | |── ...
+ |
+ │── fly
+ `-- images
+ │-- 0.jpg
+ │-- 1.jpg
+ │-- ...
+ ```
+
+ 图片也可以在 [vinegar_fly_images](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_images.tar),[locust_images](https://download.openmmlab.com/mmpose/datasets/locust_images.tar) 和[zebra_images](https://download.openmmlab.com/mmpose/datasets/zebra_images.tar) 下载。
+
+2. 运行脚本:
+
+ ```bash
+ python tools/dataset_converters/parse_deepposekit_dataset.py
+ ```
+
+ 生成的标注文件将保存在 $MMPOSE/data/fly/annotations`,`$MMPOSE/data/locust/annotations`和`$MMPOSE/data/zebra/annotations\` 中。
+
+由于官方数据集中没有提供测试集,我们随机选择了 90% 的图片用于训练,剩下的 10% 用于测试。
+
+## Macaque 数据集
+
+
+MacaquePose (bioRxiv'2020)
+
+```bibtex
+@article{labuguen2020macaquepose,
+ title={MacaquePose: A novel ‘in the wild’macaque monkey pose dataset for markerless motion capture},
+ author={Labuguen, Rollyn and Matsumoto, Jumpei and Negrete, Salvador and Nishimaru, Hiroshi and Nishijo, Hisao and Takada, Masahiko and Go, Yasuhiro and Inoue, Ken-ichi and Shibata, Tomohiro},
+ journal={bioRxiv},
+ year={2020},
+ publisher={Cold Spring Harbor Laboratory}
+}
+```
+
+
+
+对于 [MacaquePose](http://www2.ehub.kyoto-u.ac.jp/datasets/macaquepose/index.html) 数据集,请从 [这里](http://www2.ehub.kyoto-u.ac.jp/datasets/macaquepose/index.html) 下载数据。
+
+`tools/dataset_converters/parse_macaquepose_dataset.py` 脚本可以将原始标注转换为 MMPose 支持的格式。我们已经转换好的标注文件可以在 [这里](https://download.openmmlab.com/mmpose/datasets/macaque_annotations.tar) 下载。
+
+如果你希望自己转换数据,请按照以下步骤操作:
+
+1. 下载原始图片和标注,并解压到 `$MMPOSE/data`,将它们按照以下格式组织:
+
+ ```text
+ mmpose
+ ├── mmpose
+ ├── docs
+ ├── tests
+ ├── tools
+ ├── configs
+ `── data
+ │── macaque
+ │-- annotations.csv
+ │-- images
+ │ │-- 01418849d54b3005.jpg
+ │ │-- 0142d1d1a6904a70.jpg
+ │ │-- 01ef2c4c260321b7.jpg
+ │ │-- 020a1c75c8c85238.jpg
+ │ │-- 020b1506eef2557d.jpg
+ │ │-- ...
+ ```
+
+2. 运行脚本:
+
+ ```bash
+ python tools/dataset_converters/parse_macaquepose_dataset.py
+ ```
+
+ 生成的标注文件将保存在 `$MMPOSE/data/macaque/annotations` 中。
+
+由于官方数据集中没有提供测试集,我们随机选择了 90% 的图片用于训练,剩下的 10% 用于测试。
+
+## Human3.6M 数据集
+
+
+Human3.6M (TPAMI'2014)
+
+```bibtex
+@article{h36m_pami,
+ author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian},
+ title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments},
+ journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
+ publisher = {IEEE Computer Society},
+ volume = {36},
+ number = {7},
+ pages = {1325-1339},
+ month = {jul},
+ year = {2014}
+}
+```
+
+
+
+对于 [Human3.6M](http://vision.imar.ro/human3.6m/description.php) 数据集,请从官网下载数据,放置到 `$MMPOSE/data/h36m` 下。
+
+然后执行 [预处理脚本](/tools/dataset_converters/preprocess_h36m.py)。
+
+```bash
+python tools/dataset_converters/preprocess_h36m.py --metadata {path to metadata.xml} --original data/h36m
+```
+
+这将在全帧率(50 FPS)和降频帧率(10 FPS)下提取相机参数和姿势注释。处理后的数据应具有以下结构:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ ├── h36m
+ ├── annotation_body3d
+ | ├── cameras.pkl
+ | ├── fps50
+ | | ├── h36m_test.npz
+ | | ├── h36m_train.npz
+ | | ├── joint2d_rel_stats.pkl
+ | | ├── joint2d_stats.pkl
+ | | ├── joint3d_rel_stats.pkl
+ | | `── joint3d_stats.pkl
+ | `── fps10
+ | ├── h36m_test.npz
+ | ├── h36m_train.npz
+ | ├── joint2d_rel_stats.pkl
+ | ├── joint2d_stats.pkl
+ | ├── joint3d_rel_stats.pkl
+ | `── joint3d_stats.pkl
+ `── images
+ ├── S1
+ | ├── S1_Directions_1.54138969
+ | | ├── S1_Directions_1.54138969_00001.jpg
+ | | ├── S1_Directions_1.54138969_00002.jpg
+ | | ├── ...
+ | ├── ...
+ ├── S5
+ ├── S6
+ ├── S7
+ ├── S8
+ ├── S9
+ `── S11
+```
+
+然后,标注信息需要转换为 MMPose 支持的 COCO 格式。这可以通过运行以下命令完成:
+
+```bash
+python tools/dataset_converters/h36m_to_coco.py
+```
+
+## MPII 数据集
+
+
+MPII (CVPR'2014)
+
+```bibtex
+@inproceedings{andriluka14cvpr,
+ author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt},
+ title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis},
+ booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year = {2014},
+ month = {June}
+}
+```
+
+
+
+对于 [MPII](http://human-pose.mpi-inf.mpg.de/) 数据集,请从官网下载数据,放置到 `$MMPOSE/data/mpii` 下。
+
+我们提供了一个脚本来将 `.mat` 格式的标注文件转换为 `.json` 格式。这可以通过运行以下命令完成:
+
+```shell
+python tools/dataset_converters/mat2json ${PRED_MAT_FILE} ${GT_JSON_FILE} ${OUTPUT_PRED_JSON_FILE}
+```
+
+例如:
+
+```shell
+python tools/dataset/mat2json work_dirs/res50_mpii_256x256/pred.mat data/mpii/annotations/mpii_val.json pred.json
+```
+
+## Label Studio 数据集
+
+
+Label Studio
+
+```bibtex
+@misc{Label Studio,
+ title={{Label Studio}: Data labeling software},
+ url={https://github.com/heartexlabs/label-studio},
+ note={Open source software available from https://github.com/heartexlabs/label-studio},
+ author={
+ Maxim Tkachenko and
+ Mikhail Malyuk and
+ Andrey Holmanyuk and
+ Nikolai Liubimov},
+ year={2020-2022},
+}
+```
+
+
+
+对于 [Label Studio](https://github.com/heartexlabs/label-studio/) 用户,请依照 [Label Studio 转换工具文档](./label_studio.md) 中的方法进行标注,并将结果导出为 Label Studio 标准的 `.json` 文件,将 `Labeling Interface` 中的 `Code` 保存为 `.xml` 文件。
+
+我们提供了一个脚本来将 Label Studio 标准的 `.json` 格式标注文件转换为 COCO 标准的 `.json` 格式。这可以通过运行以下命令完成:
+
+```shell
+python tools/dataset_converters/labelstudio2coco.py ${LS_JSON_FILE} ${LS_XML_FILE} ${OUTPUT_COCO_JSON_FILE}
+```
+
+例如:
+
+```shell
+python tools/dataset_converters/labelstudio2coco.py config.xml project-1-at-2023-05-13-09-22-91b53efa.json output/result.json
+```
diff --git a/docs/zh_cn/dataset_zoo/label_studio.md b/docs/zh_cn/dataset_zoo/label_studio.md
index 94cbd6418c..8ae69a9c51 100644
--- a/docs/zh_cn/dataset_zoo/label_studio.md
+++ b/docs/zh_cn/dataset_zoo/label_studio.md
@@ -1,76 +1,76 @@
-# Label Studio 标注工具转COCO脚本
-
-[Label Studio](https://labelstud.io/) 是一款广受欢迎的深度学习标注工具,可以对多种任务进行标注,然而对于关键点标注,Label Studio 无法直接导出成 MMPose 所需要的 COCO 格式。本文将介绍如何使用Label Studio 标注关键点数据,并利用 [labelstudio2coco.py](../../../tools/dataset_converters/labelstudio2coco.py) 工具将其转换为训练所需的格式。
-
-## Label Studio 标注要求
-
-根据 COCO 格式的要求,每个标注的实例中都需要包含关键点、分割和 bbox 的信息,然而 Label Studio 在标注时会将这些信息分散在不同的实例中,因此需要按一定规则进行标注,才能正常使用后续的脚本。
-
-1. 标签接口设置
-
-对于一个新建的 Label Studio 项目,首先要设置它的标签接口。这里需要有三种类型的标注:`KeyPointLabels`、`PolygonLabels`、`RectangleLabels`,分别对应 COCO 格式中的`keypoints`、`segmentation`、`bbox`。以下是一个标签接口的示例,可以在项目的`Settings`中找到`Labeling Interface`,点击`Code`,粘贴使用该示例。
-
-```xml
-
-
-
-
-
-
-
-
-
-
-
-
-```
-
-2. 标注顺序
-
-由于需要将多个标注实例中的不同类型标注组合到一个实例中,因此采取了按特定顺序标注的方式,以此来判断各标注是否位于同一个实例。标注时须按照 **KeyPointLabels -> PolygonLabels/RectangleLabels** 的顺序标注,其中 KeyPointLabels 的顺序和数量要与 MMPose 配置文件中的`dataset_info`的关键点顺序和数量一致, PolygonLabels 和 RectangleLabels 的标注顺序可以互换,且可以只标注其中一个,只要保证一个实例的标注中,以关键点开始,以非关键点结束即可。下图为标注的示例:
-
-*注:bbox 和 area 会根据靠后的 PolygonLabels/RectangleLabels 来计算,如若先标 PolygonLabels,那么bbox会是靠后的 RectangleLabels 的范围,面积为矩形的面积,反之则是多边形外接矩形和多边形的面积*
-
-
-
-3. 导出标注
-
-上述标注完成后,需要将标注进行导出。选择项目界面的`Export`按钮,选择`JSON`格式,再点击`Export`即可下载包含标签的 JSON 格式文件。
-
-*注:上述文件中仅仅包含标签,不包含原始图片,因此需要额外提供标注对应的图片。由于 Label Studio 会对过长的文件名进行截断,因此不建议直接使用上传的文件,而是使用`Export`功能中的导出 COCO 格式工具,使用压缩包内的图片文件夹。*
-
-
-
-## 转换工具脚本的使用
-
-转换工具脚本位于`tools/dataset_converters/labelstudio2coco.py`,使用方式如下:
-
-```bash
-python tools/dataset_converters/labelstudio2coco.py config.xml project-1-at-2023-05-13-09-22-91b53efa.json output/result.json
-```
-
-其中`config.xml`的内容为标签接口设置中提到的`Labeling Interface`中的`Code`,`project-1-at-2023-05-13-09-22-91b53efa.json`即为导出标注时导出的 Label Studio 格式的 JSON 文件,`output/result.json`为转换后得到的 COCO 格式的 JSON 文件路径,若路径不存在,该脚本会自动创建路径。
-
-随后,将图片的文件夹放置在输出目录下,即可完成 COCO 数据集的转换。目录结构示例如下:
-
-```bash
-.
-├── images
-│ ├── 38b480f2.jpg
-│ └── aeb26f04.jpg
-└── result.json
-
-```
-
-若想在 MMPose 中使用该数据集,可以进行类似如下的修改:
-
-```python
-dataset=dict(
- type=dataset_type,
- data_root=data_root,
- data_mode=data_mode,
- ann_file='result.json',
- data_prefix=dict(img='images/'),
- pipeline=train_pipeline,
-)
-```
+# Label Studio 标注工具转COCO脚本
+
+[Label Studio](https://labelstud.io/) 是一款广受欢迎的深度学习标注工具,可以对多种任务进行标注,然而对于关键点标注,Label Studio 无法直接导出成 MMPose 所需要的 COCO 格式。本文将介绍如何使用Label Studio 标注关键点数据,并利用 [labelstudio2coco.py](../../../tools/dataset_converters/labelstudio2coco.py) 工具将其转换为训练所需的格式。
+
+## Label Studio 标注要求
+
+根据 COCO 格式的要求,每个标注的实例中都需要包含关键点、分割和 bbox 的信息,然而 Label Studio 在标注时会将这些信息分散在不同的实例中,因此需要按一定规则进行标注,才能正常使用后续的脚本。
+
+1. 标签接口设置
+
+对于一个新建的 Label Studio 项目,首先要设置它的标签接口。这里需要有三种类型的标注:`KeyPointLabels`、`PolygonLabels`、`RectangleLabels`,分别对应 COCO 格式中的`keypoints`、`segmentation`、`bbox`。以下是一个标签接口的示例,可以在项目的`Settings`中找到`Labeling Interface`,点击`Code`,粘贴使用该示例。
+
+```xml
+
+
+
+
+
+
+
+
+
+
+
+
+```
+
+2. 标注顺序
+
+由于需要将多个标注实例中的不同类型标注组合到一个实例中,因此采取了按特定顺序标注的方式,以此来判断各标注是否位于同一个实例。标注时须按照 **KeyPointLabels -> PolygonLabels/RectangleLabels** 的顺序标注,其中 KeyPointLabels 的顺序和数量要与 MMPose 配置文件中的`dataset_info`的关键点顺序和数量一致, PolygonLabels 和 RectangleLabels 的标注顺序可以互换,且可以只标注其中一个,只要保证一个实例的标注中,以关键点开始,以非关键点结束即可。下图为标注的示例:
+
+*注:bbox 和 area 会根据靠后的 PolygonLabels/RectangleLabels 来计算,如若先标 PolygonLabels,那么bbox会是靠后的 RectangleLabels 的范围,面积为矩形的面积,反之则是多边形外接矩形和多边形的面积*
+
+
+
+3. 导出标注
+
+上述标注完成后,需要将标注进行导出。选择项目界面的`Export`按钮,选择`JSON`格式,再点击`Export`即可下载包含标签的 JSON 格式文件。
+
+*注:上述文件中仅仅包含标签,不包含原始图片,因此需要额外提供标注对应的图片。由于 Label Studio 会对过长的文件名进行截断,因此不建议直接使用上传的文件,而是使用`Export`功能中的导出 COCO 格式工具,使用压缩包内的图片文件夹。*
+
+
+
+## 转换工具脚本的使用
+
+转换工具脚本位于`tools/dataset_converters/labelstudio2coco.py`,使用方式如下:
+
+```bash
+python tools/dataset_converters/labelstudio2coco.py config.xml project-1-at-2023-05-13-09-22-91b53efa.json output/result.json
+```
+
+其中`config.xml`的内容为标签接口设置中提到的`Labeling Interface`中的`Code`,`project-1-at-2023-05-13-09-22-91b53efa.json`即为导出标注时导出的 Label Studio 格式的 JSON 文件,`output/result.json`为转换后得到的 COCO 格式的 JSON 文件路径,若路径不存在,该脚本会自动创建路径。
+
+随后,将图片的文件夹放置在输出目录下,即可完成 COCO 数据集的转换。目录结构示例如下:
+
+```bash
+.
+├── images
+│ ├── 38b480f2.jpg
+│ └── aeb26f04.jpg
+└── result.json
+
+```
+
+若想在 MMPose 中使用该数据集,可以进行类似如下的修改:
+
+```python
+dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='result.json',
+ data_prefix=dict(img='images/'),
+ pipeline=train_pipeline,
+)
+```
diff --git a/docs/zh_cn/faq.md b/docs/zh_cn/faq.md
index b1e6998396..c87ec2de6f 100644
--- a/docs/zh_cn/faq.md
+++ b/docs/zh_cn/faq.md
@@ -1,148 +1,148 @@
-# FAQ
-
-We list some common issues faced by many users and their corresponding solutions here.
-Feel free to enrich the list if you find any frequent issues and have ways to help others to solve them.
-If the contents here do not cover your issue, please create an issue using the [provided templates](/.github/ISSUE_TEMPLATE/error-report.md) and make sure you fill in all required information in the template.
-
-## Installation
-
-Compatibility issue between MMCV and MMPose; "AssertionError: MMCV==xxx is used but incompatible. Please install mmcv>=xxx, \<=xxx."
-
-Here are the version correspondences between `mmdet`, `mmcv` and `mmpose`:
-
-- mmdet 2.x \<=> mmpose 0.x \<=> mmcv 1.x
-- mmdet 3.x \<=> mmpose 1.x \<=> mmcv 2.x
-
-Detailed compatible MMPose and MMCV versions are shown as below. Please choose the correct version of MMCV to avoid installation issues.
-
-### MMPose 1.x
-
-| MMPose version | MMCV/MMEngine version |
-| :------------: | :-----------------------------: |
-| 1.1.0 | mmcv>=2.0.1, mmengine>=0.8.0 |
-| 1.0.0 | mmcv>=2.0.0, mmengine>=0.7.0 |
-| 1.0.0rc1 | mmcv>=2.0.0rc4, mmengine>=0.6.0 |
-| 1.0.0rc0 | mmcv>=2.0.0rc0, mmengine>=0.0.1 |
-| 1.0.0b0 | mmcv>=2.0.0rc0, mmengine>=0.0.1 |
-
-### MMPose 0.x
-
-| MMPose version | MMCV version |
-| :------------: | :-----------------------: |
-| 0.x | mmcv-full>=1.3.8, \<1.8.0 |
-| 0.29.0 | mmcv-full>=1.3.8, \<1.7.0 |
-| 0.28.1 | mmcv-full>=1.3.8, \<1.7.0 |
-| 0.28.0 | mmcv-full>=1.3.8, \<1.6.0 |
-| 0.27.0 | mmcv-full>=1.3.8, \<1.6.0 |
-| 0.26.0 | mmcv-full>=1.3.8, \<1.6.0 |
-| 0.25.1 | mmcv-full>=1.3.8, \<1.6.0 |
-| 0.25.0 | mmcv-full>=1.3.8, \<1.5.0 |
-| 0.24.0 | mmcv-full>=1.3.8, \<1.5.0 |
-| 0.23.0 | mmcv-full>=1.3.8, \<1.5.0 |
-| 0.22.0 | mmcv-full>=1.3.8, \<1.5.0 |
-| 0.21.0 | mmcv-full>=1.3.8, \<1.5.0 |
-| 0.20.0 | mmcv-full>=1.3.8, \<1.4.0 |
-| 0.19.0 | mmcv-full>=1.3.8, \<1.4.0 |
-| 0.18.0 | mmcv-full>=1.3.8, \<1.4.0 |
-| 0.17.0 | mmcv-full>=1.3.8, \<1.4.0 |
-| 0.16.0 | mmcv-full>=1.3.8, \<1.4.0 |
-| 0.14.0 | mmcv-full>=1.1.3, \<1.4.0 |
-| 0.13.0 | mmcv-full>=1.1.3, \<1.4.0 |
-| 0.12.0 | mmcv-full>=1.1.3, \<1.3 |
-| 0.11.0 | mmcv-full>=1.1.3, \<1.3 |
-| 0.10.0 | mmcv-full>=1.1.3, \<1.3 |
-| 0.9.0 | mmcv-full>=1.1.3, \<1.3 |
-| 0.8.0 | mmcv-full>=1.1.1, \<1.2 |
-| 0.7.0 | mmcv-full>=1.1.1, \<1.2 |
-
-- **Unable to install xtcocotools**
-
- 1. Try to install it using pypi manually `pip install xtcocotools`.
- 2. If step1 does not work. Try to install it from [source](https://github.com/jin-s13/xtcocoapi).
-
- ```
- git clone https://github.com/jin-s13/xtcocoapi
- cd xtcocoapi
- python setup.py install
- ```
-
-- **No matching distribution found for xtcocotools>=1.6**
-
- 1. Install cython by `pip install cython`.
- 2. Install xtcocotools from [source](https://github.com/jin-s13/xtcocoapi).
-
- ```
- git clone https://github.com/jin-s13/xtcocoapi
- cd xtcocoapi
- python setup.py install
- ```
-
-- **"No module named 'mmcv.ops'"; "No module named 'mmcv.\_ext'"**
-
- 1. Uninstall existing mmcv in the environment using `pip uninstall mmcv`.
- 2. Install mmcv-full following the [installation instruction](https://mmcv.readthedocs.io/en/latest/#installation).
-
-## Data
-
-- **What if my custom dataset does not have bounding box label?**
-
- We can estimate the bounding box of a person as the minimal box that tightly bounds all the keypoints.
-
-- **What is `COCO_val2017_detections_AP_H_56_person.json`? Can I train pose models without it?**
-
- "COCO_val2017_detections_AP_H_56_person.json" contains the "detected" human bounding boxes for COCO validation set, which are generated by FasterRCNN.
- One can choose to use gt bounding boxes to evaluate models, by setting `bbox_file=None''` in `val_dataloader.dataset` in config. Or one can use detected boxes to evaluate
- the generalizability of models, by setting `bbox_file='COCO_val2017_detections_AP_H_56_person.json'`.
-
-## Training
-
-- **RuntimeError: Address already in use**
-
- Set the environment variables `MASTER_PORT=XXX`. For example,
- `MASTER_PORT=29517 GPUS=16 GPUS_PER_NODE=8 CPUS_PER_TASK=2 ./tools/slurm_train.sh Test res50 configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_8xb64-210e_coco-256x192.py work_dirs/res50_coco_256x192`
-
-- **"Unexpected keys in source state dict" when loading pre-trained weights**
-
- It's normal that some layers in the pretrained model are not used in the pose model. ImageNet-pretrained classification network and the pose network may have different architectures (e.g. no classification head). So some unexpected keys in source state dict is actually expected.
-
-- **How to use trained models for backbone pre-training ?**
-
- Refer to [Migration - Step3: Model - Backbone](../migration.md).
-
- When training, the unexpected keys will be ignored.
-
-- **How to visualize the training accuracy/loss curves in real-time ?**
-
- Use `TensorboardLoggerHook` in `log_config` like
-
- ```python
- log_config=dict(interval=20, hooks=[dict(type='TensorboardLoggerHook')])
- ```
-
- You can refer to [user_guides/visualization.md](../user_guides/visualization.md).
-
-- **Log info is NOT printed**
-
- Use smaller log interval. For example, change `interval=50` to `interval=1` in the config.
-
-## Evaluation
-
-- **How to evaluate on MPII test dataset?**
- Since we do not have the ground-truth for test dataset, we cannot evaluate it 'locally'.
- If you would like to evaluate the performance on test set, you have to upload the pred.mat (which is generated during testing) to the official server via email, according to [the MPII guideline](http://human-pose.mpi-inf.mpg.de/#evaluation).
-
-- **For top-down 2d pose estimation, why predicted joint coordinates can be out of the bounding box (bbox)?**
- We do not directly use the bbox to crop the image. bbox will be first transformed to center & scale, and the scale will be multiplied by a factor (1.25) to include some context. If the ratio of width/height is different from that of model input (possibly 192/256), we will adjust the bbox.
-
-## Inference
-
-- **How to run mmpose on CPU?**
-
- Run demos with `--device=cpu`.
-
-- **How to speed up inference?**
-
- For top-down models, try to edit the config file. For example,
-
- 1. set `flip_test=False` in `init_cfg` in the config file.
- 2. use faster human bounding box detector, see [MMDetection](https://mmdetection.readthedocs.io/zh_CN/3.x/model_zoo.html).
+# FAQ
+
+We list some common issues faced by many users and their corresponding solutions here.
+Feel free to enrich the list if you find any frequent issues and have ways to help others to solve them.
+If the contents here do not cover your issue, please create an issue using the [provided templates](/.github/ISSUE_TEMPLATE/error-report.md) and make sure you fill in all required information in the template.
+
+## Installation
+
+Compatibility issue between MMCV and MMPose; "AssertionError: MMCV==xxx is used but incompatible. Please install mmcv>=xxx, \<=xxx."
+
+Here are the version correspondences between `mmdet`, `mmcv` and `mmpose`:
+
+- mmdet 2.x \<=> mmpose 0.x \<=> mmcv 1.x
+- mmdet 3.x \<=> mmpose 1.x \<=> mmcv 2.x
+
+Detailed compatible MMPose and MMCV versions are shown as below. Please choose the correct version of MMCV to avoid installation issues.
+
+### MMPose 1.x
+
+| MMPose version | MMCV/MMEngine version |
+| :------------: | :-----------------------------: |
+| 1.1.0 | mmcv>=2.0.1, mmengine>=0.8.0 |
+| 1.0.0 | mmcv>=2.0.0, mmengine>=0.7.0 |
+| 1.0.0rc1 | mmcv>=2.0.0rc4, mmengine>=0.6.0 |
+| 1.0.0rc0 | mmcv>=2.0.0rc0, mmengine>=0.0.1 |
+| 1.0.0b0 | mmcv>=2.0.0rc0, mmengine>=0.0.1 |
+
+### MMPose 0.x
+
+| MMPose version | MMCV version |
+| :------------: | :-----------------------: |
+| 0.x | mmcv-full>=1.3.8, \<1.8.0 |
+| 0.29.0 | mmcv-full>=1.3.8, \<1.7.0 |
+| 0.28.1 | mmcv-full>=1.3.8, \<1.7.0 |
+| 0.28.0 | mmcv-full>=1.3.8, \<1.6.0 |
+| 0.27.0 | mmcv-full>=1.3.8, \<1.6.0 |
+| 0.26.0 | mmcv-full>=1.3.8, \<1.6.0 |
+| 0.25.1 | mmcv-full>=1.3.8, \<1.6.0 |
+| 0.25.0 | mmcv-full>=1.3.8, \<1.5.0 |
+| 0.24.0 | mmcv-full>=1.3.8, \<1.5.0 |
+| 0.23.0 | mmcv-full>=1.3.8, \<1.5.0 |
+| 0.22.0 | mmcv-full>=1.3.8, \<1.5.0 |
+| 0.21.0 | mmcv-full>=1.3.8, \<1.5.0 |
+| 0.20.0 | mmcv-full>=1.3.8, \<1.4.0 |
+| 0.19.0 | mmcv-full>=1.3.8, \<1.4.0 |
+| 0.18.0 | mmcv-full>=1.3.8, \<1.4.0 |
+| 0.17.0 | mmcv-full>=1.3.8, \<1.4.0 |
+| 0.16.0 | mmcv-full>=1.3.8, \<1.4.0 |
+| 0.14.0 | mmcv-full>=1.1.3, \<1.4.0 |
+| 0.13.0 | mmcv-full>=1.1.3, \<1.4.0 |
+| 0.12.0 | mmcv-full>=1.1.3, \<1.3 |
+| 0.11.0 | mmcv-full>=1.1.3, \<1.3 |
+| 0.10.0 | mmcv-full>=1.1.3, \<1.3 |
+| 0.9.0 | mmcv-full>=1.1.3, \<1.3 |
+| 0.8.0 | mmcv-full>=1.1.1, \<1.2 |
+| 0.7.0 | mmcv-full>=1.1.1, \<1.2 |
+
+- **Unable to install xtcocotools**
+
+ 1. Try to install it using pypi manually `pip install xtcocotools`.
+ 2. If step1 does not work. Try to install it from [source](https://github.com/jin-s13/xtcocoapi).
+
+ ```
+ git clone https://github.com/jin-s13/xtcocoapi
+ cd xtcocoapi
+ python setup.py install
+ ```
+
+- **No matching distribution found for xtcocotools>=1.6**
+
+ 1. Install cython by `pip install cython`.
+ 2. Install xtcocotools from [source](https://github.com/jin-s13/xtcocoapi).
+
+ ```
+ git clone https://github.com/jin-s13/xtcocoapi
+ cd xtcocoapi
+ python setup.py install
+ ```
+
+- **"No module named 'mmcv.ops'"; "No module named 'mmcv.\_ext'"**
+
+ 1. Uninstall existing mmcv in the environment using `pip uninstall mmcv`.
+ 2. Install mmcv-full following the [installation instruction](https://mmcv.readthedocs.io/en/latest/#installation).
+
+## Data
+
+- **What if my custom dataset does not have bounding box label?**
+
+ We can estimate the bounding box of a person as the minimal box that tightly bounds all the keypoints.
+
+- **What is `COCO_val2017_detections_AP_H_56_person.json`? Can I train pose models without it?**
+
+ "COCO_val2017_detections_AP_H_56_person.json" contains the "detected" human bounding boxes for COCO validation set, which are generated by FasterRCNN.
+ One can choose to use gt bounding boxes to evaluate models, by setting `bbox_file=None''` in `val_dataloader.dataset` in config. Or one can use detected boxes to evaluate
+ the generalizability of models, by setting `bbox_file='COCO_val2017_detections_AP_H_56_person.json'`.
+
+## Training
+
+- **RuntimeError: Address already in use**
+
+ Set the environment variables `MASTER_PORT=XXX`. For example,
+ `MASTER_PORT=29517 GPUS=16 GPUS_PER_NODE=8 CPUS_PER_TASK=2 ./tools/slurm_train.sh Test res50 configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_8xb64-210e_coco-256x192.py work_dirs/res50_coco_256x192`
+
+- **"Unexpected keys in source state dict" when loading pre-trained weights**
+
+ It's normal that some layers in the pretrained model are not used in the pose model. ImageNet-pretrained classification network and the pose network may have different architectures (e.g. no classification head). So some unexpected keys in source state dict is actually expected.
+
+- **How to use trained models for backbone pre-training ?**
+
+ Refer to [Migration - Step3: Model - Backbone](../migration.md).
+
+ When training, the unexpected keys will be ignored.
+
+- **How to visualize the training accuracy/loss curves in real-time ?**
+
+ Use `TensorboardLoggerHook` in `log_config` like
+
+ ```python
+ log_config=dict(interval=20, hooks=[dict(type='TensorboardLoggerHook')])
+ ```
+
+ You can refer to [user_guides/visualization.md](../user_guides/visualization.md).
+
+- **Log info is NOT printed**
+
+ Use smaller log interval. For example, change `interval=50` to `interval=1` in the config.
+
+## Evaluation
+
+- **How to evaluate on MPII test dataset?**
+ Since we do not have the ground-truth for test dataset, we cannot evaluate it 'locally'.
+ If you would like to evaluate the performance on test set, you have to upload the pred.mat (which is generated during testing) to the official server via email, according to [the MPII guideline](http://human-pose.mpi-inf.mpg.de/#evaluation).
+
+- **For top-down 2d pose estimation, why predicted joint coordinates can be out of the bounding box (bbox)?**
+ We do not directly use the bbox to crop the image. bbox will be first transformed to center & scale, and the scale will be multiplied by a factor (1.25) to include some context. If the ratio of width/height is different from that of model input (possibly 192/256), we will adjust the bbox.
+
+## Inference
+
+- **How to run mmpose on CPU?**
+
+ Run demos with `--device=cpu`.
+
+- **How to speed up inference?**
+
+ For top-down models, try to edit the config file. For example,
+
+ 1. set `flip_test=False` in `init_cfg` in the config file.
+ 2. use faster human bounding box detector, see [MMDetection](https://mmdetection.readthedocs.io/zh_CN/3.x/model_zoo.html).
diff --git a/docs/zh_cn/guide_to_framework.md b/docs/zh_cn/guide_to_framework.md
index 349abf2358..c8184a91c5 100644
--- a/docs/zh_cn/guide_to_framework.md
+++ b/docs/zh_cn/guide_to_framework.md
@@ -1,682 +1,682 @@
-# 20 分钟了解 MMPose 架构设计
-
-MMPose 1.0 与之前的版本有较大改动,对部分模块进行了重新设计和组织,降低代码冗余度,提升运行效率,降低学习难度。
-
-MMPose 1.0 采用了全新的模块结构设计以精简代码,提升运行效率,降低学习难度。对于有一定深度学习基础的用户,本章节提供了对 MMPose 架构设计的总体介绍。不论你是**旧版 MMPose 的用户**,还是**希望直接从 MMPose 1.0 上手的新用户**,都可以通过本教程了解如何构建一个基于 MMPose 1.0 的项目。
-
-```{note}
-本教程包含了使用 MMPose 1.0 时开发者会关心的内容:
-
-- 整体代码架构与设计逻辑
-
-- 如何用config文件管理模块
-
-- 如何使用自定义数据集
-
-- 如何添加新的模块(骨干网络、模型头部、损失函数等)
-```
-
-以下是这篇教程的目录:
-
-- [20 分钟了解 MMPose 架构设计](#20-分钟了解-mmpose-架构设计)
- - [总览](#总览)
- - [Step1:配置文件](#step1配置文件)
- - [Step2:数据](#step2数据)
- - [数据集元信息](#数据集元信息)
- - [数据集](#数据集)
- - [数据流水线](#数据流水线)
- - [i. 数据增强](#i-数据增强)
- - [ii. 数据变换](#ii-数据变换)
- - [iii. 数据编码](#iii-数据编码)
- - [iv. 数据打包](#iv-数据打包)
- - [Step3: 模型](#step3-模型)
- - [前处理器(DataPreprocessor)](#前处理器datapreprocessor)
- - [主干网络(Backbone)](#主干网络backbone)
- - [颈部模块(Neck)](#颈部模块neck)
- - [预测头(Head)](#预测头head)
-
-## 总览
-
-
-
-一般来说,开发者在项目开发过程中经常接触内容的主要有**五个**方面:
-
-- **通用**:环境、钩子(Hook)、模型权重存取(Checkpoint)、日志(Logger)等
-
-- **数据**:数据集、数据读取(Dataloader)、数据增强等
-
-- **训练**:优化器、学习率调整等
-
-- **模型**:主干网络、颈部模块(Neck)、预测头模块(Head)、损失函数等
-
-- **评测**:评测指标(Metric)、评测器(Evaluator)等
-
-其中**通用**、**训练**和**评测**相关的模块往往由训练框架提供,开发者只需要调用和调整参数,不需要自行实现,开发者主要实现的是**数据**和**模型**部分。
-
-## Step1:配置文件
-
-在MMPose中,我们通常 python 格式的配置文件,用于整个项目的定义、参数管理,因此我们强烈建议第一次接触 MMPose 的开发者,查阅 [配置文件](./user_guides/configs.md) 学习配置文件的定义。
-
-需要注意的是,所有新增的模块都需要使用注册器(Registry)进行注册,并在对应目录的 `__init__.py` 中进行 `import`,以便能够使用配置文件构建其实例。
-
-## Step2:数据
-
-MMPose 数据的组织主要包含三个方面:
-
-- 数据集元信息
-
-- 数据集
-
-- 数据流水线
-
-### 数据集元信息
-
-元信息指具体标注之外的数据集信息。姿态估计数据集的元信息通常包括:关键点和骨骼连接的定义、对称性、关键点性质(如关键点权重、标注标准差、所属上下半身)等。这些信息在数据在数据处理、模型训练和测试中有重要作用。在 MMPose 中,数据集的元信息使用 python 格式的配置文件保存,位于 `$MMPOSE/configs/_base_/datasets` 目录下。
-
-在 MMPose 中使用自定义数据集时,你需要增加对应的元信息配置文件。以 MPII 数据集(`$MMPOSE/configs/_base_/datasets/mpii.py`)为例:
-
-```Python
-dataset_info = dict(
- dataset_name='mpii',
- paper_info=dict(
- author='Mykhaylo Andriluka and Leonid Pishchulin and '
- 'Peter Gehler and Schiele, Bernt',
- title='2D Human Pose Estimation: New Benchmark and '
- 'State of the Art Analysis',
- container='IEEE Conference on Computer Vision and '
- 'Pattern Recognition (CVPR)',
- year='2014',
- homepage='http://human-pose.mpi-inf.mpg.de/',
- ),
- keypoint_info={
- 0:
- dict(
- name='right_ankle',
- id=0,
- color=[255, 128, 0],
- type='lower',
- swap='left_ankle'),
- ## 内容省略
- },
- skeleton_info={
- 0:
- dict(link=('right_ankle', 'right_knee'), id=0, color=[255, 128, 0]),
- ## 内容省略
- },
- joint_weights=[
- 1.5, 1.2, 1., 1., 1.2, 1.5, 1., 1., 1., 1., 1.5, 1.2, 1., 1., 1.2, 1.5
- ],
- # 使用 COCO 数据集中提供的 sigmas 值
- sigmas=[
- 0.089, 0.083, 0.107, 0.107, 0.083, 0.089, 0.026, 0.026, 0.026, 0.026,
- 0.062, 0.072, 0.179, 0.179, 0.072, 0.062
- ])
-```
-
-在模型配置文件中,你需要为自定义数据集指定对应的元信息配置文件。假如该元信息配置文件路径为 `$MMPOSE/configs/_base_/datasets/custom.py`,指定方式如下:
-
-```python
-# dataset and dataloader settings
-dataset_type = 'MyCustomDataset' # or 'CocoDataset'
-train_dataloader = dict(
- batch_size=2,
- dataset=dict(
- type=dataset_type,
- data_root='root/of/your/train/data',
- ann_file='path/to/your/train/json',
- data_prefix=dict(img='path/to/your/train/img'),
- # 指定对应的元信息配置文件
- metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
- ...),
- )
-val_dataloader = dict(
- batch_size=2,
- dataset=dict(
- type=dataset_type,
- data_root='root/of/your/val/data',
- ann_file='path/to/your/val/json',
- data_prefix=dict(img='path/to/your/val/img'),
- # 指定对应的元信息配置文件
- metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
- ...),
- )
-test_dataloader = val_dataloader
-```
-
-### 数据集
-
-在 MMPose 中使用自定义数据集时,我们推荐将数据转化为已支持的格式(如 COCO 或 MPII),并直接使用我们提供的对应数据集实现。如果这种方式不可行,则用户需要实现自己的数据集类。
-
-MMPose 中的大部分 2D 关键点数据集**以 COCO 形式组织**,为此我们提供了基类 [BaseCocoStyleDataset](/mmpose/datasets/datasets/base/base_coco_style_dataset.py)。我们推荐用户继承该基类,并按需重写它的方法(通常是 `__init__()` 和 `_load_annotations()` 方法),以扩展到新的 2D 关键点数据集。
-
-```{note}
-关于COCO数据格式的详细说明请参考 [COCO](./dataset_zoo/2d_body_keypoint.md) 。
-```
-
-```{note}
-在 MMPose 中 bbox 的数据格式采用 `xyxy`,而不是 `xywh`,这与 [MMDetection](https://github.com/open-mmlab/mmdetection) 等其他 OpenMMLab 成员保持一致。为了实现不同 bbox 格式之间的转换,我们提供了丰富的函数:`bbox_xyxy2xywh`、`bbox_xywh2xyxy`、`bbox_xyxy2cs`等。这些函数定义在`$MMPOSE/mmpose/structures/bbox/transforms.py`。
-```
-
-下面我们以MPII数据集的实现(`$MMPOSE/mmpose/datasets/datasets/body/mpii_dataset.py`)为例:
-
-```Python
-@DATASETS.register_module()
-class MpiiDataset(BaseCocoStyleDataset):
- METAINFO: dict = dict(from_file='configs/_base_/datasets/mpii.py')
-
- def __init__(self,
- ## 内容省略
- headbox_file: Optional[str] = None,
- ## 内容省略):
-
- if headbox_file:
- if data_mode != 'topdown':
- raise ValueError(
- f'{self.__class__.__name__} is set to {data_mode}: '
- 'mode, while "headbox_file" is only '
- 'supported in topdown mode.')
-
- if not test_mode:
- raise ValueError(
- f'{self.__class__.__name__} has `test_mode==False` '
- 'while "headbox_file" is only '
- 'supported when `test_mode==True`.')
-
- headbox_file_type = headbox_file[-3:]
- allow_headbox_file_type = ['mat']
- if headbox_file_type not in allow_headbox_file_type:
- raise KeyError(
- f'The head boxes file type {headbox_file_type} is not '
- f'supported. Should be `mat` but got {headbox_file_type}.')
- self.headbox_file = headbox_file
-
- super().__init__(
- ## 内容省略
- )
-
- def _load_annotations(self) -> List[dict]:
- """Load data from annotations in MPII format."""
- check_file_exist(self.ann_file)
- with open(self.ann_file) as anno_file:
- anns = json.load(anno_file)
-
- if self.headbox_file:
- check_file_exist(self.headbox_file)
- headbox_dict = loadmat(self.headbox_file)
- headboxes_src = np.transpose(headbox_dict['headboxes_src'],
- [2, 0, 1])
- SC_BIAS = 0.6
-
- data_list = []
- ann_id = 0
-
- # mpii bbox scales are normalized with factor 200.
- pixel_std = 200.
-
- for idx, ann in enumerate(anns):
- center = np.array(ann['center'], dtype=np.float32)
- scale = np.array([ann['scale'], ann['scale']],
- dtype=np.float32) * pixel_std
-
- # Adjust center/scale slightly to avoid cropping limbs
- if center[0] != -1:
- center[1] = center[1] + 15. / pixel_std * scale[1]
-
- # MPII uses matlab format, index is 1-based,
- # we should first convert to 0-based index
- center = center - 1
-
- # unify shape with coco datasets
- center = center.reshape(1, -1)
- scale = scale.reshape(1, -1)
- bbox = bbox_cs2xyxy(center, scale)
-
- # load keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
- keypoints = np.array(ann['joints']).reshape(1, -1, 2)
- keypoints_visible = np.array(ann['joints_vis']).reshape(1, -1)
-
- data_info = {
- 'id': ann_id,
- 'img_id': int(ann['image'].split('.')[0]),
- 'img_path': osp.join(self.data_prefix['img'], ann['image']),
- 'bbox_center': center,
- 'bbox_scale': scale,
- 'bbox': bbox,
- 'bbox_score': np.ones(1, dtype=np.float32),
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- }
-
- if self.headbox_file:
- # calculate the diagonal length of head box as norm_factor
- headbox = headboxes_src[idx]
- head_size = np.linalg.norm(headbox[1] - headbox[0], axis=0)
- head_size *= SC_BIAS
- data_info['head_size'] = head_size.reshape(1, -1)
-
- data_list.append(data_info)
- ann_id = ann_id + 1
-
- return data_list
-```
-
-在对MPII数据集进行支持时,由于MPII需要读入 `head_size` 信息来计算 `PCKh`,因此我们在`__init__()`中增加了 `headbox_file`,并重载了 `_load_annotations()` 来完成数据组织。
-
-如果自定义数据集无法被 `BaseCocoStyleDataset` 支持,你需要直接继承 [MMEngine](https://github.com/open-mmlab/mmengine) 中提供的 `BaseDataset` 基类。具体方法请参考相关[文档](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/basedataset.html)。
-
-### 数据流水线
-
-一个典型的数据流水线配置如下:
-
-```Python
-# pipelines
-train_pipeline = [
- dict(type='LoadImage'),
- dict(type='GetBBoxCenterScale'),
- dict(type='RandomFlip', direction='horizontal'),
- dict(type='RandomHalfBody'),
- dict(type='RandomBBoxTransform'),
- dict(type='TopdownAffine', input_size=codec['input_size']),
- dict(type='GenerateTarget', encoder=codec),
- dict(type='PackPoseInputs')
-]
-test_pipeline = [
- dict(type='LoadImage'),
- dict(type='GetBBoxCenterScale'),
- dict(type='TopdownAffine', input_size=codec['input_size']),
- dict(type='PackPoseInputs')
-]
-```
-
-在关键点检测任务中,数据一般会在三个尺度空间中变换:
-
-- **原始图片空间**:图片存储时的原始空间,不同图片的尺寸不一定相同
-
-- **输入图片空间**:模型输入的图片尺度空间,所有**图片**和**标注**被缩放到输入尺度,如 `256x256`,`256x192` 等
-
-- **输出尺度空间**:模型输出和训练监督信息所在的尺度空间,如`64x64(热力图)`,`1x1(回归坐标值)`等
-
-数据在三个空间中变换的流程如图所示:
-
-
-
-在MMPose中,数据变换所需要的模块在`$MMPOSE/mmpose/datasets/transforms`目录下,它们的工作流程如图所示:
-
-
-
-#### i. 数据增强
-
-数据增强中常用的变换存放在 `$MMPOSE/mmpose/datasets/transforms/common_transforms.py` 中,如 `RandomFlip`、`RandomHalfBody` 等。
-
-对于 top-down 方法,`Shift`、`Rotate`、`Resize` 操作由 `RandomBBoxTransform`来实现;对于 bottom-up 方法,这些则是由 `BottomupRandomAffine` 实现。
-
-```{note}
-值得注意的是,大部分数据变换都依赖于 `bbox_center` 和 `bbox_scale`,它们可以通过 `GetBBoxCenterScale` 来得到。
-```
-
-#### ii. 数据变换
-
-我们使用仿射变换,将图像和坐标标注从原始图片空间变换到输入图片空间。这一操作在 top-down 方法中由 `TopdownAffine` 完成,在 bottom-up 方法中则由 `BottomupRandomAffine` 完成。
-
-#### iii. 数据编码
-
-在模型训练时,数据从原始空间变换到输入图片空间后,需要使用 `GenerateTarget` 来生成训练所需的监督目标(比如用坐标值生成高斯热图),我们将这一过程称为编码(Encode),反之,通过高斯热图得到对应坐标值的过程称为解码(Decode)。
-
-在 MMPose 中,我们将编码和解码过程集合成一个编解码器(Codec),在其中实现 `encode()` 和 `decode()`。
-
-目前 MMPose 支持生成以下类型的监督目标:
-
-- `heatmap`: 高斯热图
-
-- `keypoint_label`: 关键点标签(如归一化的坐标值)
-
-- `keypoint_xy_label`: 单个坐标轴关键点标签
-
-- `heatmap+keypoint_label`: 同时生成高斯热图和关键点标签
-
-- `multiscale_heatmap`: 多尺度高斯热图
-
-生成的监督目标会按以下关键字进行封装:
-
-- `heatmaps`:高斯热图
-
-- `keypoint_labels`:关键点标签(如归一化的坐标值)
-
-- `keypoint_x_labels`:x 轴关键点标签
-
-- `keypoint_y_labels`:y 轴关键点标签
-
-- `keypoint_weights`:关键点权重
-
-```Python
-@TRANSFORMS.register_module()
-class GenerateTarget(BaseTransform):
- """Encode keypoints into Target.
-
- Added Keys (depends on the args):
- - heatmaps
- - keypoint_labels
- - keypoint_x_labels
- - keypoint_y_labels
- - keypoint_weights
- """
-```
-
-值得注意的是,我们对 top-down 和 bottom-up 的数据格式进行了统一,这意味着标注信息中会新增一个维度来代表同一张图里的不同目标(如人),格式为:
-
-```Python
-[batch_size, num_instances, num_keypoints, dim_coordinates]
-```
-
-- top-down:`[B, 1, K, D]`
-
-- Bottom-up: `[B, N, K, D]`
-
-当前已经支持的编解码器定义在 `$MMPOSE/mmpose/codecs` 目录下,如果你需要自定新的编解码器,可以前往[编解码器](./user_guides/codecs.md)了解更多详情。
-
-#### iv. 数据打包
-
-数据经过前处理变换后,最终需要通过 `PackPoseInputs` 打包成数据样本。该操作定义在 `$MMPOSE/mmpose/datasets/transforms/formatting.py` 中。
-
-打包过程会将数据流水线中用字典 `results` 存储的数据转换成用 MMPose 所需的标准数据结构, 如 `InstanceData`,`PixelData`,`PoseDataSample` 等。
-
-具体而言,我们将数据样本内容分为 `gt`(标注真值) 和 `pred`(模型预测)两部分,它们都包含以下数据项:
-
-- **instances**(numpy.array):实例级别的原始标注或预测结果,属于原始尺度空间
-
-- **instance_labels**(torch.tensor):实例级别的训练标签(如归一化的坐标值、关键点可见性),属于输出尺度空间
-
-- **fields**(torch.tensor):像素级别的训练标签(如高斯热图)或预测结果,属于输出尺度空间
-
-下面是 `PoseDataSample` 底层实现的例子:
-
-```Python
-def get_pose_data_sample(self):
- # meta
- pose_meta = dict(
- img_shape=(600, 900), # [h, w, c]
- crop_size=(256, 192), # [h, w]
- heatmap_size=(64, 48), # [h, w]
- )
-
- # gt_instances
- gt_instances = InstanceData()
- gt_instances.bboxes = np.random.rand(1, 4)
- gt_instances.keypoints = np.random.rand(1, 17, 2)
-
- # gt_instance_labels
- gt_instance_labels = InstanceData()
- gt_instance_labels.keypoint_labels = torch.rand(1, 17, 2)
- gt_instance_labels.keypoint_weights = torch.rand(1, 17)
-
- # pred_instances
- pred_instances = InstanceData()
- pred_instances.keypoints = np.random.rand(1, 17, 2)
- pred_instances.keypoint_scores = np.random.rand(1, 17)
-
- # gt_fields
- gt_fields = PixelData()
- gt_fields.heatmaps = torch.rand(17, 64, 48)
-
- # pred_fields
- pred_fields = PixelData()
- pred_fields.heatmaps = torch.rand(17, 64, 48)
- data_sample = PoseDataSample(
- gt_instances=gt_instances,
- pred_instances=pred_instances,
- gt_fields=gt_fields,
- pred_fields=pred_fields,
- metainfo=pose_meta)
-
- return data_sample
-```
-
-## Step3: 模型
-
-在 MMPose 1.0中,模型由以下几部分构成:
-
-- **预处理器(DataPreprocessor)**:完成图像归一化和通道转换等前处理
-
-- **主干网络 (Backbone)**:用于特征提取
-
-- **颈部模块(Neck)**:GAP,FPN 等可选项
-
-- **预测头(Head)**:用于实现核心算法功能和损失函数定义
-
-我们在 `$MMPOSE/models/pose_estimators/base.py` 下为姿态估计模型定义了一个基类 `BasePoseEstimator`,所有的模型(如 `TopdownPoseEstimator`)都需要继承这个基类,并重载对应的方法。
-
-在模型的 `forward()` 方法中提供了三种不同的模式:
-
-- `mode == 'loss'`:返回损失函数计算的结果,用于模型训练
-
-- `mode == 'predict'`:返回输入尺度下的预测结果,用于模型推理
-
-- `mode == 'tensor'`:返回输出尺度下的模型输出,即只进行模型前向传播,用于模型导出
-
-开发者需要在 `PoseEstimator` 中按照模型结构调用对应的 `Registry` ,对模块进行实例化。以 top-down 模型为例:
-
-```Python
-@MODELS.register_module()
-class TopdownPoseEstimator(BasePoseEstimator):
- def __init__(self,
- backbone: ConfigType,
- neck: OptConfigType = None,
- head: OptConfigType = None,
- train_cfg: OptConfigType = None,
- test_cfg: OptConfigType = None,
- data_preprocessor: OptConfigType = None,
- init_cfg: OptMultiConfig = None):
- super().__init__(data_preprocessor, init_cfg)
-
- self.backbone = MODELS.build(backbone)
-
- if neck is not None:
- self.neck = MODELS.build(neck)
-
- if head is not None:
- self.head = MODELS.build(head)
-```
-
-### 前处理器(DataPreprocessor)
-
-从 MMPose 1.0 开始,我们在模型中添加了新的前处理器模块,用以完成图像归一化、通道顺序变换等操作。这样做的好处是可以利用 GPU 等设备的计算能力加快计算,并使模型在导出和部署时更具完整性。
-
-在配置文件中,一个常见的 `data_preprocessor` 如下:
-
-```Python
-data_preprocessor=dict(
- type='PoseDataPreprocessor',
- mean=[123.675, 116.28, 103.53],
- std=[58.395, 57.12, 57.375],
- bgr_to_rgb=True),
-```
-
-它会将输入图片的通道顺序从 `bgr` 转换为 `rgb`,并根据 `mean` 和 `std` 进行数据归一化。
-
-### 主干网络(Backbone)
-
-MMPose 实现的主干网络存放在 `$MMPOSE/mmpose/models/backbones` 目录下。
-
-在实际开发中,开发者经常会使用预训练的网络权重进行迁移学习,这能有效提升模型在小数据集上的性能。 在 MMPose 中,只需要在配置文件 `backbone` 的 `init_cfg` 中设置:
-
-```Python
-init_cfg=dict(
- type='Pretrained',
- checkpoint='PATH/TO/YOUR_MODEL_WEIGHTS.pth'),
-```
-
-如果你想只加载一个训练好的 checkpoint 的 backbone 部分,你需要指明一下前缀 `prefix`:
-
-```Python
-init_cfg=dict(
- type='Pretrained',
- prefix='backbone.',
- checkpoint='PATH/TO/YOUR_CHECKPOINT.pth'),
-```
-
-其中 `checkpoint` 既可以是本地路径,也可以是下载链接。因此,如果你想使用 Torchvision 提供的预训练模型(比如ResNet50),可以使用:
-
-```Python
-init_cfg=dict(
- type='Pretrained',
- checkpoint='torchvision://resnet50')
-```
-
-除了这些常用的主干网络以外,你还可以从 MMClassification 等其他 OpenMMLab 项目中方便地迁移主干网络,它们都遵循同一套配置文件格式,并提供了预训练权重可供使用。
-
-需要强调的是,如果你加入了新的主干网络,需要在模型定义时进行注册:
-
-```Python
-@MODELS.register_module()
-class YourBackbone(BaseBackbone):
-```
-
-同时在 `$MMPOSE/mmpose/models/backbones/__init__.py` 下进行 `import`,并加入到 `__all__` 中,才能被配置文件正确地调用。
-
-### 颈部模块(Neck)
-
-颈部模块通常是介于主干网络和预测头之间的模块,在部分模型算法中会用到,常见的颈部模块有:
-
-- Global Average Pooling (GAP)
-
-- Feature Pyramid Networks (FPN)
-
-- Feature Map Processor (FMP)
-
- `FeatureMapProcessor` 是一个通用的 PyTorch 模块,旨在通过选择、拼接和缩放等非参数变换将主干网络输出的特征图转换成适合预测头的格式。以下是一些操作的配置方式及效果示意图:
-
- - 选择操作
-
- ```python
- neck=dict(type='FeatureMapProcessor', select_index=0)
- ```
-
-
-
- - 拼接操作
-
- ```python
- neck=dict(type='FeatureMapProcessor', concat=True)
- ```
-
-
-
- 拼接之前,其它特征图会被缩放到和序号为 0 的特征图相同的尺寸。
-
- - 缩放操作
-
- ```python
- neck=dict(type='FeatureMapProcessor', scale_factor=2.0)
- ```
-
-
-
-### 预测头(Head)
-
-通常来说,预测头是模型算法实现的核心,用于控制模型的输出,并进行损失函数计算。
-
-MMPose 中 Head 相关的模块定义在 `$MMPOSE/mmpose/models/heads` 目录下,开发者在自定义预测头时需要继承我们提供的基类 `BaseHead`,并重载以下三个方法对应模型推理的三种模式:
-
-- forward()
-
-- predict()
-
-- loss()
-
-具体而言,`predict()` 返回的应是输入图片尺度下的结果,因此需要调用 `self.decode()` 对网络输出进行解码,这一过程实现在 `BaseHead` 中已经实现,它会调用编解码器提供的 `decode()` 方法来完成解码。
-
-另一方面,我们会在 `predict()` 中进行测试时增强。在进行预测时,一个常见的测试时增强技巧是进行翻转集成。即,将一张图片先进行一次推理,再将图片水平翻转进行一次推理,推理的结果再次水平翻转回去,对两次推理的结果进行平均。这个技巧能有效提升模型的预测稳定性。
-
-下面是在 `RegressionHead` 中定义 `predict()` 的例子:
-
-```Python
-def predict(self,
- feats: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- test_cfg: ConfigType = {}) -> Predictions:
- """Predict results from outputs."""
-
- if test_cfg.get('flip_test', False):
- # TTA: flip test -> feats = [orig, flipped]
- assert isinstance(feats, list) and len(feats) == 2
- flip_indices = batch_data_samples[0].metainfo['flip_indices']
- input_size = batch_data_samples[0].metainfo['input_size']
- _feats, _feats_flip = feats
- _batch_coords = self.forward(_feats)
- _batch_coords_flip = flip_coordinates(
- self.forward(_feats_flip),
- flip_indices=flip_indices,
- shift_coords=test_cfg.get('shift_coords', True),
- input_size=input_size)
- batch_coords = (_batch_coords + _batch_coords_flip) * 0.5
- else:
- batch_coords = self.forward(feats) # (B, K, D)
-
- batch_coords.unsqueeze_(dim=1) # (B, N, K, D)
- preds = self.decode(batch_coords)
-```
-
-`loss()`除了进行损失函数的计算,还会进行 accuracy 等训练时指标的计算,并通过一个字典 `losses` 来传递:
-
-```Python
- # calculate accuracy
-_, avg_acc, _ = keypoint_pck_accuracy(
- pred=to_numpy(pred_coords),
- gt=to_numpy(keypoint_labels),
- mask=to_numpy(keypoint_weights) > 0,
- thr=0.05,
- norm_factor=np.ones((pred_coords.size(0), 2), dtype=np.float32))
-
-acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
-losses.update(acc_pose=acc_pose)
-```
-
-每个 batch 的数据都打包成了 `batch_data_samples`。以 Regression-based 方法为例,训练所需的归一化的坐标值和关键点权重可以用如下方式获取:
-
-```Python
-keypoint_labels = torch.cat(
- [d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
-keypoint_weights = torch.cat([
- d.gt_instance_labels.keypoint_weights for d in batch_data_samples
-])
-```
-
-以下为 `RegressionHead` 中完整的 `loss()` 实现:
-
-```Python
-def loss(self,
- inputs: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- train_cfg: ConfigType = {}) -> dict:
- """Calculate losses from a batch of inputs and data samples."""
-
- pred_outputs = self.forward(inputs)
-
- keypoint_labels = torch.cat(
- [d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
- keypoint_weights = torch.cat([
- d.gt_instance_labels.keypoint_weights for d in batch_data_samples
- ])
-
- # calculate losses
- losses = dict()
- loss = self.loss_module(pred_outputs, keypoint_labels,
- keypoint_weights.unsqueeze(-1))
-
- if isinstance(loss, dict):
- losses.update(loss)
- else:
- losses.update(loss_kpt=loss)
-
- # calculate accuracy
- _, avg_acc, _ = keypoint_pck_accuracy(
- pred=to_numpy(pred_outputs),
- gt=to_numpy(keypoint_labels),
- mask=to_numpy(keypoint_weights) > 0,
- thr=0.05,
- norm_factor=np.ones((pred_outputs.size(0), 2), dtype=np.float32))
- acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
- losses.update(acc_pose=acc_pose)
-
- return losses
-```
+# 20 分钟了解 MMPose 架构设计
+
+MMPose 1.0 与之前的版本有较大改动,对部分模块进行了重新设计和组织,降低代码冗余度,提升运行效率,降低学习难度。
+
+MMPose 1.0 采用了全新的模块结构设计以精简代码,提升运行效率,降低学习难度。对于有一定深度学习基础的用户,本章节提供了对 MMPose 架构设计的总体介绍。不论你是**旧版 MMPose 的用户**,还是**希望直接从 MMPose 1.0 上手的新用户**,都可以通过本教程了解如何构建一个基于 MMPose 1.0 的项目。
+
+```{note}
+本教程包含了使用 MMPose 1.0 时开发者会关心的内容:
+
+- 整体代码架构与设计逻辑
+
+- 如何用config文件管理模块
+
+- 如何使用自定义数据集
+
+- 如何添加新的模块(骨干网络、模型头部、损失函数等)
+```
+
+以下是这篇教程的目录:
+
+- [20 分钟了解 MMPose 架构设计](#20-分钟了解-mmpose-架构设计)
+ - [总览](#总览)
+ - [Step1:配置文件](#step1配置文件)
+ - [Step2:数据](#step2数据)
+ - [数据集元信息](#数据集元信息)
+ - [数据集](#数据集)
+ - [数据流水线](#数据流水线)
+ - [i. 数据增强](#i-数据增强)
+ - [ii. 数据变换](#ii-数据变换)
+ - [iii. 数据编码](#iii-数据编码)
+ - [iv. 数据打包](#iv-数据打包)
+ - [Step3: 模型](#step3-模型)
+ - [前处理器(DataPreprocessor)](#前处理器datapreprocessor)
+ - [主干网络(Backbone)](#主干网络backbone)
+ - [颈部模块(Neck)](#颈部模块neck)
+ - [预测头(Head)](#预测头head)
+
+## 总览
+
+
+
+一般来说,开发者在项目开发过程中经常接触内容的主要有**五个**方面:
+
+- **通用**:环境、钩子(Hook)、模型权重存取(Checkpoint)、日志(Logger)等
+
+- **数据**:数据集、数据读取(Dataloader)、数据增强等
+
+- **训练**:优化器、学习率调整等
+
+- **模型**:主干网络、颈部模块(Neck)、预测头模块(Head)、损失函数等
+
+- **评测**:评测指标(Metric)、评测器(Evaluator)等
+
+其中**通用**、**训练**和**评测**相关的模块往往由训练框架提供,开发者只需要调用和调整参数,不需要自行实现,开发者主要实现的是**数据**和**模型**部分。
+
+## Step1:配置文件
+
+在MMPose中,我们通常 python 格式的配置文件,用于整个项目的定义、参数管理,因此我们强烈建议第一次接触 MMPose 的开发者,查阅 [配置文件](./user_guides/configs.md) 学习配置文件的定义。
+
+需要注意的是,所有新增的模块都需要使用注册器(Registry)进行注册,并在对应目录的 `__init__.py` 中进行 `import`,以便能够使用配置文件构建其实例。
+
+## Step2:数据
+
+MMPose 数据的组织主要包含三个方面:
+
+- 数据集元信息
+
+- 数据集
+
+- 数据流水线
+
+### 数据集元信息
+
+元信息指具体标注之外的数据集信息。姿态估计数据集的元信息通常包括:关键点和骨骼连接的定义、对称性、关键点性质(如关键点权重、标注标准差、所属上下半身)等。这些信息在数据在数据处理、模型训练和测试中有重要作用。在 MMPose 中,数据集的元信息使用 python 格式的配置文件保存,位于 `$MMPOSE/configs/_base_/datasets` 目录下。
+
+在 MMPose 中使用自定义数据集时,你需要增加对应的元信息配置文件。以 MPII 数据集(`$MMPOSE/configs/_base_/datasets/mpii.py`)为例:
+
+```Python
+dataset_info = dict(
+ dataset_name='mpii',
+ paper_info=dict(
+ author='Mykhaylo Andriluka and Leonid Pishchulin and '
+ 'Peter Gehler and Schiele, Bernt',
+ title='2D Human Pose Estimation: New Benchmark and '
+ 'State of the Art Analysis',
+ container='IEEE Conference on Computer Vision and '
+ 'Pattern Recognition (CVPR)',
+ year='2014',
+ homepage='http://human-pose.mpi-inf.mpg.de/',
+ ),
+ keypoint_info={
+ 0:
+ dict(
+ name='right_ankle',
+ id=0,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_ankle'),
+ ## 内容省略
+ },
+ skeleton_info={
+ 0:
+ dict(link=('right_ankle', 'right_knee'), id=0, color=[255, 128, 0]),
+ ## 内容省略
+ },
+ joint_weights=[
+ 1.5, 1.2, 1., 1., 1.2, 1.5, 1., 1., 1., 1., 1.5, 1.2, 1., 1., 1.2, 1.5
+ ],
+ # 使用 COCO 数据集中提供的 sigmas 值
+ sigmas=[
+ 0.089, 0.083, 0.107, 0.107, 0.083, 0.089, 0.026, 0.026, 0.026, 0.026,
+ 0.062, 0.072, 0.179, 0.179, 0.072, 0.062
+ ])
+```
+
+在模型配置文件中,你需要为自定义数据集指定对应的元信息配置文件。假如该元信息配置文件路径为 `$MMPOSE/configs/_base_/datasets/custom.py`,指定方式如下:
+
+```python
+# dataset and dataloader settings
+dataset_type = 'MyCustomDataset' # or 'CocoDataset'
+train_dataloader = dict(
+ batch_size=2,
+ dataset=dict(
+ type=dataset_type,
+ data_root='root/of/your/train/data',
+ ann_file='path/to/your/train/json',
+ data_prefix=dict(img='path/to/your/train/img'),
+ # 指定对应的元信息配置文件
+ metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
+ ...),
+ )
+val_dataloader = dict(
+ batch_size=2,
+ dataset=dict(
+ type=dataset_type,
+ data_root='root/of/your/val/data',
+ ann_file='path/to/your/val/json',
+ data_prefix=dict(img='path/to/your/val/img'),
+ # 指定对应的元信息配置文件
+ metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
+ ...),
+ )
+test_dataloader = val_dataloader
+```
+
+### 数据集
+
+在 MMPose 中使用自定义数据集时,我们推荐将数据转化为已支持的格式(如 COCO 或 MPII),并直接使用我们提供的对应数据集实现。如果这种方式不可行,则用户需要实现自己的数据集类。
+
+MMPose 中的大部分 2D 关键点数据集**以 COCO 形式组织**,为此我们提供了基类 [BaseCocoStyleDataset](/mmpose/datasets/datasets/base/base_coco_style_dataset.py)。我们推荐用户继承该基类,并按需重写它的方法(通常是 `__init__()` 和 `_load_annotations()` 方法),以扩展到新的 2D 关键点数据集。
+
+```{note}
+关于COCO数据格式的详细说明请参考 [COCO](./dataset_zoo/2d_body_keypoint.md) 。
+```
+
+```{note}
+在 MMPose 中 bbox 的数据格式采用 `xyxy`,而不是 `xywh`,这与 [MMDetection](https://github.com/open-mmlab/mmdetection) 等其他 OpenMMLab 成员保持一致。为了实现不同 bbox 格式之间的转换,我们提供了丰富的函数:`bbox_xyxy2xywh`、`bbox_xywh2xyxy`、`bbox_xyxy2cs`等。这些函数定义在`$MMPOSE/mmpose/structures/bbox/transforms.py`。
+```
+
+下面我们以MPII数据集的实现(`$MMPOSE/mmpose/datasets/datasets/body/mpii_dataset.py`)为例:
+
+```Python
+@DATASETS.register_module()
+class MpiiDataset(BaseCocoStyleDataset):
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/mpii.py')
+
+ def __init__(self,
+ ## 内容省略
+ headbox_file: Optional[str] = None,
+ ## 内容省略):
+
+ if headbox_file:
+ if data_mode != 'topdown':
+ raise ValueError(
+ f'{self.__class__.__name__} is set to {data_mode}: '
+ 'mode, while "headbox_file" is only '
+ 'supported in topdown mode.')
+
+ if not test_mode:
+ raise ValueError(
+ f'{self.__class__.__name__} has `test_mode==False` '
+ 'while "headbox_file" is only '
+ 'supported when `test_mode==True`.')
+
+ headbox_file_type = headbox_file[-3:]
+ allow_headbox_file_type = ['mat']
+ if headbox_file_type not in allow_headbox_file_type:
+ raise KeyError(
+ f'The head boxes file type {headbox_file_type} is not '
+ f'supported. Should be `mat` but got {headbox_file_type}.')
+ self.headbox_file = headbox_file
+
+ super().__init__(
+ ## 内容省略
+ )
+
+ def _load_annotations(self) -> List[dict]:
+ """Load data from annotations in MPII format."""
+ check_file_exist(self.ann_file)
+ with open(self.ann_file) as anno_file:
+ anns = json.load(anno_file)
+
+ if self.headbox_file:
+ check_file_exist(self.headbox_file)
+ headbox_dict = loadmat(self.headbox_file)
+ headboxes_src = np.transpose(headbox_dict['headboxes_src'],
+ [2, 0, 1])
+ SC_BIAS = 0.6
+
+ data_list = []
+ ann_id = 0
+
+ # mpii bbox scales are normalized with factor 200.
+ pixel_std = 200.
+
+ for idx, ann in enumerate(anns):
+ center = np.array(ann['center'], dtype=np.float32)
+ scale = np.array([ann['scale'], ann['scale']],
+ dtype=np.float32) * pixel_std
+
+ # Adjust center/scale slightly to avoid cropping limbs
+ if center[0] != -1:
+ center[1] = center[1] + 15. / pixel_std * scale[1]
+
+ # MPII uses matlab format, index is 1-based,
+ # we should first convert to 0-based index
+ center = center - 1
+
+ # unify shape with coco datasets
+ center = center.reshape(1, -1)
+ scale = scale.reshape(1, -1)
+ bbox = bbox_cs2xyxy(center, scale)
+
+ # load keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
+ keypoints = np.array(ann['joints']).reshape(1, -1, 2)
+ keypoints_visible = np.array(ann['joints_vis']).reshape(1, -1)
+
+ data_info = {
+ 'id': ann_id,
+ 'img_id': int(ann['image'].split('.')[0]),
+ 'img_path': osp.join(self.data_prefix['img'], ann['image']),
+ 'bbox_center': center,
+ 'bbox_scale': scale,
+ 'bbox': bbox,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ }
+
+ if self.headbox_file:
+ # calculate the diagonal length of head box as norm_factor
+ headbox = headboxes_src[idx]
+ head_size = np.linalg.norm(headbox[1] - headbox[0], axis=0)
+ head_size *= SC_BIAS
+ data_info['head_size'] = head_size.reshape(1, -1)
+
+ data_list.append(data_info)
+ ann_id = ann_id + 1
+
+ return data_list
+```
+
+在对MPII数据集进行支持时,由于MPII需要读入 `head_size` 信息来计算 `PCKh`,因此我们在`__init__()`中增加了 `headbox_file`,并重载了 `_load_annotations()` 来完成数据组织。
+
+如果自定义数据集无法被 `BaseCocoStyleDataset` 支持,你需要直接继承 [MMEngine](https://github.com/open-mmlab/mmengine) 中提供的 `BaseDataset` 基类。具体方法请参考相关[文档](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/basedataset.html)。
+
+### 数据流水线
+
+一个典型的数据流水线配置如下:
+
+```Python
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+test_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+```
+
+在关键点检测任务中,数据一般会在三个尺度空间中变换:
+
+- **原始图片空间**:图片存储时的原始空间,不同图片的尺寸不一定相同
+
+- **输入图片空间**:模型输入的图片尺度空间,所有**图片**和**标注**被缩放到输入尺度,如 `256x256`,`256x192` 等
+
+- **输出尺度空间**:模型输出和训练监督信息所在的尺度空间,如`64x64(热力图)`,`1x1(回归坐标值)`等
+
+数据在三个空间中变换的流程如图所示:
+
+
+
+在MMPose中,数据变换所需要的模块在`$MMPOSE/mmpose/datasets/transforms`目录下,它们的工作流程如图所示:
+
+
+
+#### i. 数据增强
+
+数据增强中常用的变换存放在 `$MMPOSE/mmpose/datasets/transforms/common_transforms.py` 中,如 `RandomFlip`、`RandomHalfBody` 等。
+
+对于 top-down 方法,`Shift`、`Rotate`、`Resize` 操作由 `RandomBBoxTransform`来实现;对于 bottom-up 方法,这些则是由 `BottomupRandomAffine` 实现。
+
+```{note}
+值得注意的是,大部分数据变换都依赖于 `bbox_center` 和 `bbox_scale`,它们可以通过 `GetBBoxCenterScale` 来得到。
+```
+
+#### ii. 数据变换
+
+我们使用仿射变换,将图像和坐标标注从原始图片空间变换到输入图片空间。这一操作在 top-down 方法中由 `TopdownAffine` 完成,在 bottom-up 方法中则由 `BottomupRandomAffine` 完成。
+
+#### iii. 数据编码
+
+在模型训练时,数据从原始空间变换到输入图片空间后,需要使用 `GenerateTarget` 来生成训练所需的监督目标(比如用坐标值生成高斯热图),我们将这一过程称为编码(Encode),反之,通过高斯热图得到对应坐标值的过程称为解码(Decode)。
+
+在 MMPose 中,我们将编码和解码过程集合成一个编解码器(Codec),在其中实现 `encode()` 和 `decode()`。
+
+目前 MMPose 支持生成以下类型的监督目标:
+
+- `heatmap`: 高斯热图
+
+- `keypoint_label`: 关键点标签(如归一化的坐标值)
+
+- `keypoint_xy_label`: 单个坐标轴关键点标签
+
+- `heatmap+keypoint_label`: 同时生成高斯热图和关键点标签
+
+- `multiscale_heatmap`: 多尺度高斯热图
+
+生成的监督目标会按以下关键字进行封装:
+
+- `heatmaps`:高斯热图
+
+- `keypoint_labels`:关键点标签(如归一化的坐标值)
+
+- `keypoint_x_labels`:x 轴关键点标签
+
+- `keypoint_y_labels`:y 轴关键点标签
+
+- `keypoint_weights`:关键点权重
+
+```Python
+@TRANSFORMS.register_module()
+class GenerateTarget(BaseTransform):
+ """Encode keypoints into Target.
+
+ Added Keys (depends on the args):
+ - heatmaps
+ - keypoint_labels
+ - keypoint_x_labels
+ - keypoint_y_labels
+ - keypoint_weights
+ """
+```
+
+值得注意的是,我们对 top-down 和 bottom-up 的数据格式进行了统一,这意味着标注信息中会新增一个维度来代表同一张图里的不同目标(如人),格式为:
+
+```Python
+[batch_size, num_instances, num_keypoints, dim_coordinates]
+```
+
+- top-down:`[B, 1, K, D]`
+
+- Bottom-up: `[B, N, K, D]`
+
+当前已经支持的编解码器定义在 `$MMPOSE/mmpose/codecs` 目录下,如果你需要自定新的编解码器,可以前往[编解码器](./user_guides/codecs.md)了解更多详情。
+
+#### iv. 数据打包
+
+数据经过前处理变换后,最终需要通过 `PackPoseInputs` 打包成数据样本。该操作定义在 `$MMPOSE/mmpose/datasets/transforms/formatting.py` 中。
+
+打包过程会将数据流水线中用字典 `results` 存储的数据转换成用 MMPose 所需的标准数据结构, 如 `InstanceData`,`PixelData`,`PoseDataSample` 等。
+
+具体而言,我们将数据样本内容分为 `gt`(标注真值) 和 `pred`(模型预测)两部分,它们都包含以下数据项:
+
+- **instances**(numpy.array):实例级别的原始标注或预测结果,属于原始尺度空间
+
+- **instance_labels**(torch.tensor):实例级别的训练标签(如归一化的坐标值、关键点可见性),属于输出尺度空间
+
+- **fields**(torch.tensor):像素级别的训练标签(如高斯热图)或预测结果,属于输出尺度空间
+
+下面是 `PoseDataSample` 底层实现的例子:
+
+```Python
+def get_pose_data_sample(self):
+ # meta
+ pose_meta = dict(
+ img_shape=(600, 900), # [h, w, c]
+ crop_size=(256, 192), # [h, w]
+ heatmap_size=(64, 48), # [h, w]
+ )
+
+ # gt_instances
+ gt_instances = InstanceData()
+ gt_instances.bboxes = np.random.rand(1, 4)
+ gt_instances.keypoints = np.random.rand(1, 17, 2)
+
+ # gt_instance_labels
+ gt_instance_labels = InstanceData()
+ gt_instance_labels.keypoint_labels = torch.rand(1, 17, 2)
+ gt_instance_labels.keypoint_weights = torch.rand(1, 17)
+
+ # pred_instances
+ pred_instances = InstanceData()
+ pred_instances.keypoints = np.random.rand(1, 17, 2)
+ pred_instances.keypoint_scores = np.random.rand(1, 17)
+
+ # gt_fields
+ gt_fields = PixelData()
+ gt_fields.heatmaps = torch.rand(17, 64, 48)
+
+ # pred_fields
+ pred_fields = PixelData()
+ pred_fields.heatmaps = torch.rand(17, 64, 48)
+ data_sample = PoseDataSample(
+ gt_instances=gt_instances,
+ pred_instances=pred_instances,
+ gt_fields=gt_fields,
+ pred_fields=pred_fields,
+ metainfo=pose_meta)
+
+ return data_sample
+```
+
+## Step3: 模型
+
+在 MMPose 1.0中,模型由以下几部分构成:
+
+- **预处理器(DataPreprocessor)**:完成图像归一化和通道转换等前处理
+
+- **主干网络 (Backbone)**:用于特征提取
+
+- **颈部模块(Neck)**:GAP,FPN 等可选项
+
+- **预测头(Head)**:用于实现核心算法功能和损失函数定义
+
+我们在 `$MMPOSE/models/pose_estimators/base.py` 下为姿态估计模型定义了一个基类 `BasePoseEstimator`,所有的模型(如 `TopdownPoseEstimator`)都需要继承这个基类,并重载对应的方法。
+
+在模型的 `forward()` 方法中提供了三种不同的模式:
+
+- `mode == 'loss'`:返回损失函数计算的结果,用于模型训练
+
+- `mode == 'predict'`:返回输入尺度下的预测结果,用于模型推理
+
+- `mode == 'tensor'`:返回输出尺度下的模型输出,即只进行模型前向传播,用于模型导出
+
+开发者需要在 `PoseEstimator` 中按照模型结构调用对应的 `Registry` ,对模块进行实例化。以 top-down 模型为例:
+
+```Python
+@MODELS.register_module()
+class TopdownPoseEstimator(BasePoseEstimator):
+ def __init__(self,
+ backbone: ConfigType,
+ neck: OptConfigType = None,
+ head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None):
+ super().__init__(data_preprocessor, init_cfg)
+
+ self.backbone = MODELS.build(backbone)
+
+ if neck is not None:
+ self.neck = MODELS.build(neck)
+
+ if head is not None:
+ self.head = MODELS.build(head)
+```
+
+### 前处理器(DataPreprocessor)
+
+从 MMPose 1.0 开始,我们在模型中添加了新的前处理器模块,用以完成图像归一化、通道顺序变换等操作。这样做的好处是可以利用 GPU 等设备的计算能力加快计算,并使模型在导出和部署时更具完整性。
+
+在配置文件中,一个常见的 `data_preprocessor` 如下:
+
+```Python
+data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+```
+
+它会将输入图片的通道顺序从 `bgr` 转换为 `rgb`,并根据 `mean` 和 `std` 进行数据归一化。
+
+### 主干网络(Backbone)
+
+MMPose 实现的主干网络存放在 `$MMPOSE/mmpose/models/backbones` 目录下。
+
+在实际开发中,开发者经常会使用预训练的网络权重进行迁移学习,这能有效提升模型在小数据集上的性能。 在 MMPose 中,只需要在配置文件 `backbone` 的 `init_cfg` 中设置:
+
+```Python
+init_cfg=dict(
+ type='Pretrained',
+ checkpoint='PATH/TO/YOUR_MODEL_WEIGHTS.pth'),
+```
+
+如果你想只加载一个训练好的 checkpoint 的 backbone 部分,你需要指明一下前缀 `prefix`:
+
+```Python
+init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='PATH/TO/YOUR_CHECKPOINT.pth'),
+```
+
+其中 `checkpoint` 既可以是本地路径,也可以是下载链接。因此,如果你想使用 Torchvision 提供的预训练模型(比如ResNet50),可以使用:
+
+```Python
+init_cfg=dict(
+ type='Pretrained',
+ checkpoint='torchvision://resnet50')
+```
+
+除了这些常用的主干网络以外,你还可以从 MMClassification 等其他 OpenMMLab 项目中方便地迁移主干网络,它们都遵循同一套配置文件格式,并提供了预训练权重可供使用。
+
+需要强调的是,如果你加入了新的主干网络,需要在模型定义时进行注册:
+
+```Python
+@MODELS.register_module()
+class YourBackbone(BaseBackbone):
+```
+
+同时在 `$MMPOSE/mmpose/models/backbones/__init__.py` 下进行 `import`,并加入到 `__all__` 中,才能被配置文件正确地调用。
+
+### 颈部模块(Neck)
+
+颈部模块通常是介于主干网络和预测头之间的模块,在部分模型算法中会用到,常见的颈部模块有:
+
+- Global Average Pooling (GAP)
+
+- Feature Pyramid Networks (FPN)
+
+- Feature Map Processor (FMP)
+
+ `FeatureMapProcessor` 是一个通用的 PyTorch 模块,旨在通过选择、拼接和缩放等非参数变换将主干网络输出的特征图转换成适合预测头的格式。以下是一些操作的配置方式及效果示意图:
+
+ - 选择操作
+
+ ```python
+ neck=dict(type='FeatureMapProcessor', select_index=0)
+ ```
+
+
+
+ - 拼接操作
+
+ ```python
+ neck=dict(type='FeatureMapProcessor', concat=True)
+ ```
+
+
+
+ 拼接之前,其它特征图会被缩放到和序号为 0 的特征图相同的尺寸。
+
+ - 缩放操作
+
+ ```python
+ neck=dict(type='FeatureMapProcessor', scale_factor=2.0)
+ ```
+
+
+
+### 预测头(Head)
+
+通常来说,预测头是模型算法实现的核心,用于控制模型的输出,并进行损失函数计算。
+
+MMPose 中 Head 相关的模块定义在 `$MMPOSE/mmpose/models/heads` 目录下,开发者在自定义预测头时需要继承我们提供的基类 `BaseHead`,并重载以下三个方法对应模型推理的三种模式:
+
+- forward()
+
+- predict()
+
+- loss()
+
+具体而言,`predict()` 返回的应是输入图片尺度下的结果,因此需要调用 `self.decode()` 对网络输出进行解码,这一过程实现在 `BaseHead` 中已经实现,它会调用编解码器提供的 `decode()` 方法来完成解码。
+
+另一方面,我们会在 `predict()` 中进行测试时增强。在进行预测时,一个常见的测试时增强技巧是进行翻转集成。即,将一张图片先进行一次推理,再将图片水平翻转进行一次推理,推理的结果再次水平翻转回去,对两次推理的结果进行平均。这个技巧能有效提升模型的预测稳定性。
+
+下面是在 `RegressionHead` 中定义 `predict()` 的例子:
+
+```Python
+def predict(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ test_cfg: ConfigType = {}) -> Predictions:
+ """Predict results from outputs."""
+
+ if test_cfg.get('flip_test', False):
+ # TTA: flip test -> feats = [orig, flipped]
+ assert isinstance(feats, list) and len(feats) == 2
+ flip_indices = batch_data_samples[0].metainfo['flip_indices']
+ input_size = batch_data_samples[0].metainfo['input_size']
+ _feats, _feats_flip = feats
+ _batch_coords = self.forward(_feats)
+ _batch_coords_flip = flip_coordinates(
+ self.forward(_feats_flip),
+ flip_indices=flip_indices,
+ shift_coords=test_cfg.get('shift_coords', True),
+ input_size=input_size)
+ batch_coords = (_batch_coords + _batch_coords_flip) * 0.5
+ else:
+ batch_coords = self.forward(feats) # (B, K, D)
+
+ batch_coords.unsqueeze_(dim=1) # (B, N, K, D)
+ preds = self.decode(batch_coords)
+```
+
+`loss()`除了进行损失函数的计算,还会进行 accuracy 等训练时指标的计算,并通过一个字典 `losses` 来传递:
+
+```Python
+ # calculate accuracy
+_, avg_acc, _ = keypoint_pck_accuracy(
+ pred=to_numpy(pred_coords),
+ gt=to_numpy(keypoint_labels),
+ mask=to_numpy(keypoint_weights) > 0,
+ thr=0.05,
+ norm_factor=np.ones((pred_coords.size(0), 2), dtype=np.float32))
+
+acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
+losses.update(acc_pose=acc_pose)
+```
+
+每个 batch 的数据都打包成了 `batch_data_samples`。以 Regression-based 方法为例,训练所需的归一化的坐标值和关键点权重可以用如下方式获取:
+
+```Python
+keypoint_labels = torch.cat(
+ [d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
+keypoint_weights = torch.cat([
+ d.gt_instance_labels.keypoint_weights for d in batch_data_samples
+])
+```
+
+以下为 `RegressionHead` 中完整的 `loss()` 实现:
+
+```Python
+def loss(self,
+ inputs: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: ConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples."""
+
+ pred_outputs = self.forward(inputs)
+
+ keypoint_labels = torch.cat(
+ [d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
+ keypoint_weights = torch.cat([
+ d.gt_instance_labels.keypoint_weights for d in batch_data_samples
+ ])
+
+ # calculate losses
+ losses = dict()
+ loss = self.loss_module(pred_outputs, keypoint_labels,
+ keypoint_weights.unsqueeze(-1))
+
+ if isinstance(loss, dict):
+ losses.update(loss)
+ else:
+ losses.update(loss_kpt=loss)
+
+ # calculate accuracy
+ _, avg_acc, _ = keypoint_pck_accuracy(
+ pred=to_numpy(pred_outputs),
+ gt=to_numpy(keypoint_labels),
+ mask=to_numpy(keypoint_weights) > 0,
+ thr=0.05,
+ norm_factor=np.ones((pred_outputs.size(0), 2), dtype=np.float32))
+ acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
+ losses.update(acc_pose=acc_pose)
+
+ return losses
+```
diff --git a/docs/zh_cn/index.rst b/docs/zh_cn/index.rst
index 2431d82e4d..67a68f732a 100644
--- a/docs/zh_cn/index.rst
+++ b/docs/zh_cn/index.rst
@@ -1,116 +1,116 @@
-欢迎来到 MMPose 中文文档!
-==================================
-
-您可以在页面左下角切换文档语言。
-
-You can change the documentation language at the lower-left corner of the page.
-
-.. toctree::
- :maxdepth: 1
- :caption: 开启 MMPose 之旅
-
- overview.md
- installation.md
- guide_to_framework.md
- demos.md
- contribution_guide.md
- faq.md
-
-.. toctree::
- :maxdepth: 1
- :caption: 用户教程
-
- user_guides/inference.md
- user_guides/configs.md
- user_guides/prepare_datasets.md
- user_guides/train_and_test.md
-
-.. toctree::
- :maxdepth: 1
- :caption: 进阶教程
-
- advanced_guides/codecs.md
- advanced_guides/dataflow.md
- advanced_guides/implement_new_models.md
- advanced_guides/customize_datasets.md
- advanced_guides/customize_transforms.md
- advanced_guides/customize_optimizer.md
- advanced_guides/customize_logging.md
- advanced_guides/how_to_deploy.md
- advanced_guides/model_analysis.md
-
-.. toctree::
- :maxdepth: 1
- :caption: 1.x 版本迁移指南
-
- migration.md
-
-.. toctree::
- :maxdepth: 2
- :caption: 模型库
-
- model_zoo.txt
- model_zoo/body_2d_keypoint.md
- model_zoo/body_3d_keypoint.md
- model_zoo/face_2d_keypoint.md
- model_zoo/hand_2d_keypoint.md
- model_zoo/wholebody_2d_keypoint.md
- model_zoo/animal_2d_keypoint.md
-
-.. toctree::
- :maxdepth: 2
- :caption: 模型库(按论文整理)
-
- model_zoo_papers/algorithms.md
- model_zoo_papers/backbones.md
- model_zoo_papers/techniques.md
- model_zoo_papers/datasets.md
-
-.. toctree::
- :maxdepth: 2
- :caption: 数据集
-
- dataset_zoo.md
- dataset_zoo/2d_body_keypoint.md
- dataset_zoo/2d_wholebody_keypoint.md
- dataset_zoo/2d_face_keypoint.md
- dataset_zoo/2d_hand_keypoint.md
- dataset_zoo/2d_fashion_landmark.md
- dataset_zoo/2d_animal_keypoint.md
- dataset_zoo/3d_body_keypoint.md
- dataset_zoo/3d_hand_keypoint.md
- dataset_zoo/dataset_tools.md
-
-.. toctree::
- :maxdepth: 1
- :caption: 相关项目
-
- projects/community_projects.md
-
-.. toctree::
- :maxdepth: 1
- :caption: 其他说明
-
- notes/ecosystem.md
- notes/changelog.md
- notes/benchmark.md
- notes/pytorch_2.md
-
-.. toctree::
- :maxdepth: 1
- :caption: API 参考文档
-
- api.rst
-
-.. toctree::
- :caption: 切换语言
-
- switch_language.md
-
-
-
-索引与表格
-==================
-
-* :ref:`genindex`
-* :ref:`search`
+欢迎来到 MMPose 中文文档!
+==================================
+
+您可以在页面左下角切换文档语言。
+
+You can change the documentation language at the lower-left corner of the page.
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 开启 MMPose 之旅
+
+ overview.md
+ installation.md
+ guide_to_framework.md
+ demos.md
+ contribution_guide.md
+ faq.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 用户教程
+
+ user_guides/inference.md
+ user_guides/configs.md
+ user_guides/prepare_datasets.md
+ user_guides/train_and_test.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 进阶教程
+
+ advanced_guides/codecs.md
+ advanced_guides/dataflow.md
+ advanced_guides/implement_new_models.md
+ advanced_guides/customize_datasets.md
+ advanced_guides/customize_transforms.md
+ advanced_guides/customize_optimizer.md
+ advanced_guides/customize_logging.md
+ advanced_guides/how_to_deploy.md
+ advanced_guides/model_analysis.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 1.x 版本迁移指南
+
+ migration.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 模型库
+
+ model_zoo.txt
+ model_zoo/body_2d_keypoint.md
+ model_zoo/body_3d_keypoint.md
+ model_zoo/face_2d_keypoint.md
+ model_zoo/hand_2d_keypoint.md
+ model_zoo/wholebody_2d_keypoint.md
+ model_zoo/animal_2d_keypoint.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 模型库(按论文整理)
+
+ model_zoo_papers/algorithms.md
+ model_zoo_papers/backbones.md
+ model_zoo_papers/techniques.md
+ model_zoo_papers/datasets.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 数据集
+
+ dataset_zoo.md
+ dataset_zoo/2d_body_keypoint.md
+ dataset_zoo/2d_wholebody_keypoint.md
+ dataset_zoo/2d_face_keypoint.md
+ dataset_zoo/2d_hand_keypoint.md
+ dataset_zoo/2d_fashion_landmark.md
+ dataset_zoo/2d_animal_keypoint.md
+ dataset_zoo/3d_body_keypoint.md
+ dataset_zoo/3d_hand_keypoint.md
+ dataset_zoo/dataset_tools.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 相关项目
+
+ projects/community_projects.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 其他说明
+
+ notes/ecosystem.md
+ notes/changelog.md
+ notes/benchmark.md
+ notes/pytorch_2.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: API 参考文档
+
+ api.rst
+
+.. toctree::
+ :caption: 切换语言
+
+ switch_language.md
+
+
+
+索引与表格
+==================
+
+* :ref:`genindex`
+* :ref:`search`
diff --git a/docs/zh_cn/installation.md b/docs/zh_cn/installation.md
index ef515c8030..9df63595a8 100644
--- a/docs/zh_cn/installation.md
+++ b/docs/zh_cn/installation.md
@@ -1,248 +1,248 @@
-# 安装
-
-我们推荐用户按照我们的最佳实践来安装 MMPose。但除此之外,如果您想根据
-您的习惯完成安装流程,也可以参见 [自定义安装](#自定义安装) 一节来获取更多信息。
-
-- [安装](#安装)
- - [依赖环境](#依赖环境)
- - [最佳实践](#最佳实践)
- - [从源码安装 MMPose](#从源码安装-mmpose)
- - [作为 Python 包安装](#作为-python-包安装)
- - [验证安装](#验证安装)
- - [自定义安装](#自定义安装)
- - [CUDA 版本](#cuda-版本)
- - [不使用 MIM 安装 MMEngine](#不使用-mim-安装-mmengine)
- - [在 CPU 环境中安装](#在-cpu-环境中安装)
- - [在 Google Colab 中安装](#在-google-colab-中安装)
- - [通过 Docker 使用 MMPose](#通过-docker-使用-mmpose)
- - [故障解决](#故障解决)
-
-## 依赖环境
-
-在本节中,我们将演示如何准备 PyTorch 相关的依赖环境。
-
-MMPose 适用于 Linux、Windows 和 macOS。它需要 Python 3.7+、CUDA 9.2+ 和 PyTorch 1.8+。
-
-如果您对配置 PyTorch 环境已经很熟悉,并且已经完成了配置,可以直接进入下一节:[安装](#安装-mmpose)。否则,请依照以下步骤完成配置。
-
-**第 1 步** 从[官网](https://docs.conda.io/en/latest/miniconda.html) 下载并安装 Miniconda。
-
-**第 2 步** 创建一个 conda 虚拟环境并激活它。
-
-```shell
-conda create --name openmmlab python=3.8 -y
-conda activate openmmlab
-```
-
-**第 3 步** 按照[官方指南](https://pytorch.org/get-started/locally/) 安装 PyTorch。例如:
-
-在 GPU 平台:
-
-```shell
-conda install pytorch torchvision -c pytorch
-```
-
-```{warning}
-以上命令会自动安装最新版的 PyTorch 与对应的 cudatoolkit,请检查它们是否与您的环境匹配。
-```
-
-在 CPU 平台:
-
-```shell
-conda install pytorch torchvision cpuonly -c pytorch
-```
-
-**第 4 步** 使用 [MIM](https://github.com/open-mmlab/mim) 安装 [MMEngine](https://github.com/open-mmlab/mmengine) 和 [MMCV](https://github.com/open-mmlab/mmcv/tree/2.x)
-
-```shell
-pip install -U openmim
-mim install mmengine
-mim install "mmcv>=2.0.1"
-```
-
-请注意,MMPose 中的一些推理示例脚本需要使用 [MMDetection](https://github.com/open-mmlab/mmdetection) (mmdet) 检测人体。如果您想运行这些示例脚本,可以通过运行以下命令安装 mmdet:
-
-```shell
-mim install "mmdet>=3.1.0"
-```
-
-## 最佳实践
-
-根据具体需求,我们支持两种安装模式: 从源码安装(推荐)和作为 Python 包安装
-
-### 从源码安装(推荐)
-
-如果基于 MMPose 框架开发自己的任务,需要添加新的功能,比如新的模型或是数据集,或者使用我们提供的各种工具。从源码按如下方式安装 mmpose:
-
-```shell
-git clone https://github.com/open-mmlab/mmpose.git
-cd mmpose
-pip install -r requirements.txt
-pip install -v -e .
-# "-v" 表示输出更多安装相关的信息
-# "-e" 表示以可编辑形式安装,这样可以在不重新安装的情况下,让本地修改直接生效
-```
-
-### 作为 Python 包安装
-
-如果只是希望调用 MMPose 的接口,或者在自己的项目中导入 MMPose 中的模块。直接使用 mim 安装即可。
-
-```shell
-mim install "mmpose>=1.1.0"
-```
-
-## 验证安装
-
-为了验证 MMPose 是否安装正确,您可以通过以下步骤运行模型推理。
-
-**第 1 步** 我们需要下载配置文件和模型权重文件
-
-```shell
-mim download mmpose --config td-hm_hrnet-w48_8xb32-210e_coco-256x192 --dest .
-```
-
-下载过程往往需要几秒或更多的时间,这取决于您的网络环境。完成之后,您会在当前目录下找到这两个文件:`td-hm_hrnet-w48_8xb32-210e_coco-256x192.py` 和 `hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth`, 分别是配置文件和对应的模型权重文件。
-
-**第 2 步** 验证推理示例
-
-如果您是**从源码安装**的 mmpose,可以直接运行以下命令进行验证:
-
-```shell
-python demo/image_demo.py \
- tests/data/coco/000000000785.jpg \
- td-hm_hrnet-w48_8xb32-210e_coco-256x192.py \
- hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \
- --out-file vis_results.jpg \
- --draw-heatmap
-```
-
-如果一切顺利,您将会得到这样的可视化结果:
-
-
-
-代码会将预测的关键点和热图绘制在图像中的人体上,并保存到当前文件夹下的 `vis_results.jpg`。
-
-如果您是**作为 Python 包安装**,可以打开您的 Python 解释器,复制并粘贴如下代码:
-
-```python
-from mmpose.apis import inference_topdown, init_model
-from mmpose.utils import register_all_modules
-
-register_all_modules()
-
-config_file = 'td-hm_hrnet-w48_8xb32-210e_coco-256x192.py'
-checkpoint_file = 'hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth'
-model = init_model(config_file, checkpoint_file, device='cpu') # or device='cuda:0'
-
-# 请准备好一张带有人体的图片
-results = inference_topdown(model, 'demo.jpg')
-```
-
-示例图片 `demo.jpg` 可以从 [Github](https://raw.githubusercontent.com/open-mmlab/mmpose/main/tests/data/coco/000000000785.jpg) 下载。
-推理结果是一个 `PoseDataSample` 列表,预测结果将会保存在 `pred_instances` 中,包括检测到的关键点位置和置信度。
-
-## 自定义安装
-
-### CUDA 版本
-
-安装 PyTorch 时,需要指定 CUDA 版本。如果您不清楚选择哪个,请遵循我们的建议:
-
-- 对于 Ampere 架构的 NVIDIA GPU,例如 GeForce 30 系列 以及 NVIDIA A100,CUDA 11 是必需的。
-- 对于更早的 NVIDIA GPU,CUDA 11 是向后兼容 (backward compatible) 的,但 CUDA 10.2 能够提供更好的兼容性,也更加轻量。
-
-请确保您的 GPU 驱动版本满足最低的版本需求,参阅[这张表](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions)。
-
-```{note}
-如果按照我们的最佳实践进行安装,CUDA 运行时库就足够了,因为我们提供相关 CUDA 代码的预编译,您不需要进行本地编译。
-但如果您希望从源码进行 MMCV 的编译,或是进行其他 CUDA 算子的开发,那么就必须安装完整的 CUDA 工具链,参见
-[NVIDIA 官网](https://developer.nvidia.com/cuda-downloads),另外还需要确保该 CUDA 工具链的版本与 PyTorch 安装时
-的配置相匹配(如用 `conda install` 安装 PyTorch 时指定的 cudatoolkit 版本)。
-```
-
-### 不使用 MIM 安装 MMEngine
-
-若不使用 mim 安装 MMEngine,请遵循 [ MMEngine 安装指南](https://mmengine.readthedocs.io/zh_CN/latest/get_started/installation.html).
-
-例如,您可以通过以下命令安装 MMEngine:
-
-```shell
-pip install mmengine
-```
-
-### 不使用 MIM 安装 MMCV
-
-MMCV 包含 C++ 和 CUDA 扩展,因此其对 PyTorch 的依赖比较复杂。MIM 会自动解析这些
-依赖,选择合适的 MMCV 预编译包,使安装更简单,但它并不是必需的。
-
-若不使用 mim 来安装 MMCV,请遵照 [MMCV 安装指南](https://mmcv.readthedocs.io/zh_CN/2.x/get_started/installation.html)。
-它需要您用指定 url 的形式手动指定对应的 PyTorch 和 CUDA 版本。
-
-举个例子,如下命令将会安装基于 PyTorch 1.10.x 和 CUDA 11.3 编译的 mmcv。
-
-```shell
-pip install 'mmcv>=2.0.1' -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10/index.html
-```
-
-### 在 CPU 环境中安装
-
-MMPose 可以仅在 CPU 环境中安装,在 CPU 模式下,您可以完成训练、测试和模型推理等所有操作。
-
-在 CPU 模式下,MMCV 的部分功能将不可用,通常是一些 GPU 编译的算子,如 `Deformable Convolution`。MMPose 中大部分的模型都不会依赖这些算子,但是如果您尝试使用包含这些算子的模型来运行训练、测试或推理,将会报错。
-
-### 在 Google Colab 中安装
-
-[Google Colab](https://colab.research.google.com/) 通常已经包含了 PyTorch 环境,因此我们只需要安装 MMEngine, MMCV 和 MMPose 即可,命令如下:
-
-**第 1 步** 使用 [MIM](https://github.com/open-mmlab/mim) 安装 [MMEngine](https://github.com/open-mmlab/mmengine) 和 [MMCV](https://github.com/open-mmlab/mmcv/tree/2.x)
-
-```shell
-!pip3 install openmim
-!mim install mmengine
-!mim install "mmcv>=2.0.1"
-```
-
-**第 2 步** 从源码安装 mmpose
-
-```shell
-!git clone https://github.com/open-mmlab/mmpose.git
-%cd mmpose
-!pip install -e .
-```
-
-**第 3 步** 验证
-
-```python
-import mmpose
-print(mmpose.__version__)
-# 预期输出: 1.1.0
-```
-
-```{note}
-在 Jupyter 中,感叹号 `!` 用于执行外部命令,而 `%cd` 是一个[魔术命令](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-cd),用于切换 Python 的工作路径。
-```
-
-### 通过 Docker 使用 MMPose
-
-MMPose 提供 [Dockerfile](https://github.com/open-mmlab/mmpose/blob/master/docker/Dockerfile)
-用于构建镜像。请确保您的 [Docker 版本](https://docs.docker.com/engine/install/) >=19.03。
-
-```shell
-# 构建默认的 PyTorch 1.8.0,CUDA 10.1 版本镜像
-# 如果您希望使用其他版本,请修改 Dockerfile
-docker build -t mmpose docker/
-```
-
-**注意**:请确保您已经安装了 [nvidia-container-toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker)。
-
-用以下命令运行 Docker 镜像:
-
-```shell
-docker run --gpus all --shm-size=8g -it -v {DATA_DIR}:/mmpose/data mmpose
-```
-
-`{DATA_DIR}` 是您本地存放用于 MMPose 训练、测试、推理等流程的数据目录。
-
-## 故障解决
-
-如果您在安装过程中遇到了什么问题,请先查阅[常见问题](faq.md)。如果没有找到解决方法,可以在 GitHub
-上[提出 issue](https://github.com/open-mmlab/mmpose/issues/new/choose)。
+# 安装
+
+我们推荐用户按照我们的最佳实践来安装 MMPose。但除此之外,如果您想根据
+您的习惯完成安装流程,也可以参见 [自定义安装](#自定义安装) 一节来获取更多信息。
+
+- [安装](#安装)
+ - [依赖环境](#依赖环境)
+ - [最佳实践](#最佳实践)
+ - [从源码安装 MMPose](#从源码安装-mmpose)
+ - [作为 Python 包安装](#作为-python-包安装)
+ - [验证安装](#验证安装)
+ - [自定义安装](#自定义安装)
+ - [CUDA 版本](#cuda-版本)
+ - [不使用 MIM 安装 MMEngine](#不使用-mim-安装-mmengine)
+ - [在 CPU 环境中安装](#在-cpu-环境中安装)
+ - [在 Google Colab 中安装](#在-google-colab-中安装)
+ - [通过 Docker 使用 MMPose](#通过-docker-使用-mmpose)
+ - [故障解决](#故障解决)
+
+## 依赖环境
+
+在本节中,我们将演示如何准备 PyTorch 相关的依赖环境。
+
+MMPose 适用于 Linux、Windows 和 macOS。它需要 Python 3.7+、CUDA 9.2+ 和 PyTorch 1.8+。
+
+如果您对配置 PyTorch 环境已经很熟悉,并且已经完成了配置,可以直接进入下一节:[安装](#安装-mmpose)。否则,请依照以下步骤完成配置。
+
+**第 1 步** 从[官网](https://docs.conda.io/en/latest/miniconda.html) 下载并安装 Miniconda。
+
+**第 2 步** 创建一个 conda 虚拟环境并激活它。
+
+```shell
+conda create --name openmmlab python=3.8 -y
+conda activate openmmlab
+```
+
+**第 3 步** 按照[官方指南](https://pytorch.org/get-started/locally/) 安装 PyTorch。例如:
+
+在 GPU 平台:
+
+```shell
+conda install pytorch torchvision -c pytorch
+```
+
+```{warning}
+以上命令会自动安装最新版的 PyTorch 与对应的 cudatoolkit,请检查它们是否与您的环境匹配。
+```
+
+在 CPU 平台:
+
+```shell
+conda install pytorch torchvision cpuonly -c pytorch
+```
+
+**第 4 步** 使用 [MIM](https://github.com/open-mmlab/mim) 安装 [MMEngine](https://github.com/open-mmlab/mmengine) 和 [MMCV](https://github.com/open-mmlab/mmcv/tree/2.x)
+
+```shell
+pip install -U openmim
+mim install mmengine
+mim install "mmcv>=2.0.1"
+```
+
+请注意,MMPose 中的一些推理示例脚本需要使用 [MMDetection](https://github.com/open-mmlab/mmdetection) (mmdet) 检测人体。如果您想运行这些示例脚本,可以通过运行以下命令安装 mmdet:
+
+```shell
+mim install "mmdet>=3.1.0"
+```
+
+## 最佳实践
+
+根据具体需求,我们支持两种安装模式: 从源码安装(推荐)和作为 Python 包安装
+
+### 从源码安装(推荐)
+
+如果基于 MMPose 框架开发自己的任务,需要添加新的功能,比如新的模型或是数据集,或者使用我们提供的各种工具。从源码按如下方式安装 mmpose:
+
+```shell
+git clone https://github.com/open-mmlab/mmpose.git
+cd mmpose
+pip install -r requirements.txt
+pip install -v -e .
+# "-v" 表示输出更多安装相关的信息
+# "-e" 表示以可编辑形式安装,这样可以在不重新安装的情况下,让本地修改直接生效
+```
+
+### 作为 Python 包安装
+
+如果只是希望调用 MMPose 的接口,或者在自己的项目中导入 MMPose 中的模块。直接使用 mim 安装即可。
+
+```shell
+mim install "mmpose>=1.1.0"
+```
+
+## 验证安装
+
+为了验证 MMPose 是否安装正确,您可以通过以下步骤运行模型推理。
+
+**第 1 步** 我们需要下载配置文件和模型权重文件
+
+```shell
+mim download mmpose --config td-hm_hrnet-w48_8xb32-210e_coco-256x192 --dest .
+```
+
+下载过程往往需要几秒或更多的时间,这取决于您的网络环境。完成之后,您会在当前目录下找到这两个文件:`td-hm_hrnet-w48_8xb32-210e_coco-256x192.py` 和 `hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth`, 分别是配置文件和对应的模型权重文件。
+
+**第 2 步** 验证推理示例
+
+如果您是**从源码安装**的 mmpose,可以直接运行以下命令进行验证:
+
+```shell
+python demo/image_demo.py \
+ tests/data/coco/000000000785.jpg \
+ td-hm_hrnet-w48_8xb32-210e_coco-256x192.py \
+ hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \
+ --out-file vis_results.jpg \
+ --draw-heatmap
+```
+
+如果一切顺利,您将会得到这样的可视化结果:
+
+
+
+代码会将预测的关键点和热图绘制在图像中的人体上,并保存到当前文件夹下的 `vis_results.jpg`。
+
+如果您是**作为 Python 包安装**,可以打开您的 Python 解释器,复制并粘贴如下代码:
+
+```python
+from mmpose.apis import inference_topdown, init_model
+from mmpose.utils import register_all_modules
+
+register_all_modules()
+
+config_file = 'td-hm_hrnet-w48_8xb32-210e_coco-256x192.py'
+checkpoint_file = 'hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth'
+model = init_model(config_file, checkpoint_file, device='cpu') # or device='cuda:0'
+
+# 请准备好一张带有人体的图片
+results = inference_topdown(model, 'demo.jpg')
+```
+
+示例图片 `demo.jpg` 可以从 [Github](https://raw.githubusercontent.com/open-mmlab/mmpose/main/tests/data/coco/000000000785.jpg) 下载。
+推理结果是一个 `PoseDataSample` 列表,预测结果将会保存在 `pred_instances` 中,包括检测到的关键点位置和置信度。
+
+## 自定义安装
+
+### CUDA 版本
+
+安装 PyTorch 时,需要指定 CUDA 版本。如果您不清楚选择哪个,请遵循我们的建议:
+
+- 对于 Ampere 架构的 NVIDIA GPU,例如 GeForce 30 系列 以及 NVIDIA A100,CUDA 11 是必需的。
+- 对于更早的 NVIDIA GPU,CUDA 11 是向后兼容 (backward compatible) 的,但 CUDA 10.2 能够提供更好的兼容性,也更加轻量。
+
+请确保您的 GPU 驱动版本满足最低的版本需求,参阅[这张表](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions)。
+
+```{note}
+如果按照我们的最佳实践进行安装,CUDA 运行时库就足够了,因为我们提供相关 CUDA 代码的预编译,您不需要进行本地编译。
+但如果您希望从源码进行 MMCV 的编译,或是进行其他 CUDA 算子的开发,那么就必须安装完整的 CUDA 工具链,参见
+[NVIDIA 官网](https://developer.nvidia.com/cuda-downloads),另外还需要确保该 CUDA 工具链的版本与 PyTorch 安装时
+的配置相匹配(如用 `conda install` 安装 PyTorch 时指定的 cudatoolkit 版本)。
+```
+
+### 不使用 MIM 安装 MMEngine
+
+若不使用 mim 安装 MMEngine,请遵循 [ MMEngine 安装指南](https://mmengine.readthedocs.io/zh_CN/latest/get_started/installation.html).
+
+例如,您可以通过以下命令安装 MMEngine:
+
+```shell
+pip install mmengine
+```
+
+### 不使用 MIM 安装 MMCV
+
+MMCV 包含 C++ 和 CUDA 扩展,因此其对 PyTorch 的依赖比较复杂。MIM 会自动解析这些
+依赖,选择合适的 MMCV 预编译包,使安装更简单,但它并不是必需的。
+
+若不使用 mim 来安装 MMCV,请遵照 [MMCV 安装指南](https://mmcv.readthedocs.io/zh_CN/2.x/get_started/installation.html)。
+它需要您用指定 url 的形式手动指定对应的 PyTorch 和 CUDA 版本。
+
+举个例子,如下命令将会安装基于 PyTorch 1.10.x 和 CUDA 11.3 编译的 mmcv。
+
+```shell
+pip install 'mmcv>=2.0.1' -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10/index.html
+```
+
+### 在 CPU 环境中安装
+
+MMPose 可以仅在 CPU 环境中安装,在 CPU 模式下,您可以完成训练、测试和模型推理等所有操作。
+
+在 CPU 模式下,MMCV 的部分功能将不可用,通常是一些 GPU 编译的算子,如 `Deformable Convolution`。MMPose 中大部分的模型都不会依赖这些算子,但是如果您尝试使用包含这些算子的模型来运行训练、测试或推理,将会报错。
+
+### 在 Google Colab 中安装
+
+[Google Colab](https://colab.research.google.com/) 通常已经包含了 PyTorch 环境,因此我们只需要安装 MMEngine, MMCV 和 MMPose 即可,命令如下:
+
+**第 1 步** 使用 [MIM](https://github.com/open-mmlab/mim) 安装 [MMEngine](https://github.com/open-mmlab/mmengine) 和 [MMCV](https://github.com/open-mmlab/mmcv/tree/2.x)
+
+```shell
+!pip3 install openmim
+!mim install mmengine
+!mim install "mmcv>=2.0.1"
+```
+
+**第 2 步** 从源码安装 mmpose
+
+```shell
+!git clone https://github.com/open-mmlab/mmpose.git
+%cd mmpose
+!pip install -e .
+```
+
+**第 3 步** 验证
+
+```python
+import mmpose
+print(mmpose.__version__)
+# 预期输出: 1.1.0
+```
+
+```{note}
+在 Jupyter 中,感叹号 `!` 用于执行外部命令,而 `%cd` 是一个[魔术命令](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-cd),用于切换 Python 的工作路径。
+```
+
+### 通过 Docker 使用 MMPose
+
+MMPose 提供 [Dockerfile](https://github.com/open-mmlab/mmpose/blob/master/docker/Dockerfile)
+用于构建镜像。请确保您的 [Docker 版本](https://docs.docker.com/engine/install/) >=19.03。
+
+```shell
+# 构建默认的 PyTorch 1.8.0,CUDA 10.1 版本镜像
+# 如果您希望使用其他版本,请修改 Dockerfile
+docker build -t mmpose docker/
+```
+
+**注意**:请确保您已经安装了 [nvidia-container-toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker)。
+
+用以下命令运行 Docker 镜像:
+
+```shell
+docker run --gpus all --shm-size=8g -it -v {DATA_DIR}:/mmpose/data mmpose
+```
+
+`{DATA_DIR}` 是您本地存放用于 MMPose 训练、测试、推理等流程的数据目录。
+
+## 故障解决
+
+如果您在安装过程中遇到了什么问题,请先查阅[常见问题](faq.md)。如果没有找到解决方法,可以在 GitHub
+上[提出 issue](https://github.com/open-mmlab/mmpose/issues/new/choose)。
diff --git a/docs/zh_cn/make.bat b/docs/zh_cn/make.bat
index 922152e96a..2119f51099 100644
--- a/docs/zh_cn/make.bat
+++ b/docs/zh_cn/make.bat
@@ -1,35 +1,35 @@
-@ECHO OFF
-
-pushd %~dp0
-
-REM Command file for Sphinx documentation
-
-if "%SPHINXBUILD%" == "" (
- set SPHINXBUILD=sphinx-build
-)
-set SOURCEDIR=.
-set BUILDDIR=_build
-
-if "%1" == "" goto help
-
-%SPHINXBUILD% >NUL 2>NUL
-if errorlevel 9009 (
- echo.
- echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
- echo.installed, then set the SPHINXBUILD environment variable to point
- echo.to the full path of the 'sphinx-build' executable. Alternatively you
- echo.may add the Sphinx directory to PATH.
- echo.
- echo.If you don't have Sphinx installed, grab it from
- echo.http://sphinx-doc.org/
- exit /b 1
-)
-
-%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
-goto end
-
-:help
-%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
-
-:end
-popd
+@ECHO OFF
+
+pushd %~dp0
+
+REM Command file for Sphinx documentation
+
+if "%SPHINXBUILD%" == "" (
+ set SPHINXBUILD=sphinx-build
+)
+set SOURCEDIR=.
+set BUILDDIR=_build
+
+if "%1" == "" goto help
+
+%SPHINXBUILD% >NUL 2>NUL
+if errorlevel 9009 (
+ echo.
+ echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
+ echo.installed, then set the SPHINXBUILD environment variable to point
+ echo.to the full path of the 'sphinx-build' executable. Alternatively you
+ echo.may add the Sphinx directory to PATH.
+ echo.
+ echo.If you don't have Sphinx installed, grab it from
+ echo.http://sphinx-doc.org/
+ exit /b 1
+)
+
+%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+goto end
+
+:help
+%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+
+:end
+popd
diff --git a/docs/zh_cn/merge_docs.sh b/docs/zh_cn/merge_docs.sh
index 258141d5f8..1f207abdbd 100644
--- a/docs/zh_cn/merge_docs.sh
+++ b/docs/zh_cn/merge_docs.sh
@@ -1,31 +1,31 @@
-#!/usr/bin/env bash
-# Copyright (c) OpenMMLab. All rights reserved.
-
-sed -i '$a\\n' ../../demo/docs/zh_cn/*_demo.md
-cat ../../demo/docs/zh_cn/*_demo.md | sed "s/^## 2D\(.*\)Demo/##\1Estimation/" | sed "s/md###t/html#t/g" | sed '1i\# Demos\n' | sed 's=](/docs/en/=](/=g' | sed 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' >demos.md
-
- # remove /docs/ for link used in doc site
-sed -i 's=](/docs/zh_cn/=](=g' overview.md
-sed -i 's=](/docs/zh_cn/=](=g' installation.md
-sed -i 's=](/docs/zh_cn/=](=g' quick_run.md
-sed -i 's=](/docs/zh_cn/=](=g' migration.md
-sed -i 's=](/docs/zh_cn/=](=g' ./model_zoo/*.md
-sed -i 's=](/docs/zh_cn/=](=g' ./model_zoo_papers/*.md
-sed -i 's=](/docs/zh_cn/=](=g' ./user_guides/*.md
-sed -i 's=](/docs/zh_cn/=](=g' ./advanced_guides/*.md
-sed -i 's=](/docs/zh_cn/=](=g' ./dataset_zoo/*.md
-sed -i 's=](/docs/zh_cn/=](=g' ./notes/*.md
-sed -i 's=](/docs/zh_cn/=](=g' ./projects/*.md
-
-
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' overview.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' installation.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' quick_run.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' migration.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./advanced_guides/*.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./model_zoo/*.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./model_zoo_papers/*.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./user_guides/*.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./dataset_zoo/*.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./notes/*.md
-sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./projects/*.md
+#!/usr/bin/env bash
+# Copyright (c) OpenMMLab. All rights reserved.
+
+sed -i '$a\\n' ../../demo/docs/zh_cn/*_demo.md
+cat ../../demo/docs/zh_cn/*_demo.md | sed "s/^## 2D\(.*\)Demo/##\1Estimation/" | sed "s/md###t/html#t/g" | sed '1i\# Demos\n' | sed 's=](/docs/en/=](/=g' | sed 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' >demos.md
+
+ # remove /docs/ for link used in doc site
+sed -i 's=](/docs/zh_cn/=](=g' overview.md
+sed -i 's=](/docs/zh_cn/=](=g' installation.md
+sed -i 's=](/docs/zh_cn/=](=g' quick_run.md
+sed -i 's=](/docs/zh_cn/=](=g' migration.md
+sed -i 's=](/docs/zh_cn/=](=g' ./model_zoo/*.md
+sed -i 's=](/docs/zh_cn/=](=g' ./model_zoo_papers/*.md
+sed -i 's=](/docs/zh_cn/=](=g' ./user_guides/*.md
+sed -i 's=](/docs/zh_cn/=](=g' ./advanced_guides/*.md
+sed -i 's=](/docs/zh_cn/=](=g' ./dataset_zoo/*.md
+sed -i 's=](/docs/zh_cn/=](=g' ./notes/*.md
+sed -i 's=](/docs/zh_cn/=](=g' ./projects/*.md
+
+
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' overview.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' installation.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' quick_run.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' migration.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./advanced_guides/*.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./model_zoo/*.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./model_zoo_papers/*.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./user_guides/*.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./dataset_zoo/*.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./notes/*.md
+sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/dev-1.x/=g' ./projects/*.md
diff --git a/docs/zh_cn/migration.md b/docs/zh_cn/migration.md
index 9a591dfcc9..934203ddb7 100644
--- a/docs/zh_cn/migration.md
+++ b/docs/zh_cn/migration.md
@@ -1,201 +1,201 @@
-# MMPose 0.X 兼容性说明
-
-MMPose 1.0 经过了大规模重构并解决了许多遗留问题,对于 0.x 版本的大部分代码 MMPose 1.0 将不兼容。
-
-## 数据变换
-
-### 平移、旋转和缩放
-
-旧版的数据变换方法 `TopDownRandomShiftBboxCenter` 和 `TopDownGetRandomScaleRotation`,将被合并为 `RandomBBoxTransform`:
-
-```Python
-@TRANSFORMS.register_module()
-class RandomBBoxTransform(BaseTransform):
- r"""Rnadomly shift, resize and rotate the bounding boxes.
-
- Required Keys:
-
- - bbox_center
- - bbox_scale
-
- Modified Keys:
-
- - bbox_center
- - bbox_scale
-
- Added Keys:
- - bbox_rotation
-
- Args:
- shift_factor (float): Randomly shift the bbox in range
- :math:`[-dx, dx]` and :math:`[-dy, dy]` in X and Y directions,
- where :math:`dx(y) = x(y)_scale \cdot shift_factor` in pixels.
- Defaults to 0.16
- shift_prob (float): Probability of applying random shift. Defaults to
- 0.3
- scale_factor (Tuple[float, float]): Randomly resize the bbox in range
- :math:`[scale_factor[0], scale_factor[1]]`. Defaults to (0.5, 1.5)
- scale_prob (float): Probability of applying random resizing. Defaults
- to 1.0
- rotate_factor (float): Randomly rotate the bbox in
- :math:`[-rotate_factor, rotate_factor]` in degrees. Defaults
- to 80.0
- rotate_prob (float): Probability of applying random rotation. Defaults
- to 0.6
- """
-
- def __init__(self,
- shift_factor: float = 0.16,
- shift_prob: float = 0.3,
- scale_factor: Tuple[float, float] = (0.5, 1.5),
- scale_prob: float = 1.0,
- rotate_factor: float = 80.0,
- rotate_prob: float = 0.6) -> None:
-```
-
-### 标签生成
-
-旧版用于训练标签生成的方法 `TopDownGenerateTarget` 、`TopDownGenerateTargetRegression`、`BottomUpGenerateHeatmapTarget`、`BottomUpGenerateTarget` 等将被合并为 `GenerateTarget`,而实际的生成方法由[编解码器](./user_guides/codecs.md) 提供:
-
-```Python
-@TRANSFORMS.register_module()
-class GenerateTarget(BaseTransform):
- """Encode keypoints into Target.
-
- The generated target is usually the supervision signal of the model
- learning, e.g. heatmaps or regression labels.
-
- Required Keys:
-
- - keypoints
- - keypoints_visible
- - dataset_keypoint_weights
-
- Added Keys:
-
- - The keys of the encoded items from the codec will be updated into
- the results, e.g. ``'heatmaps'`` or ``'keypoint_weights'``. See
- the specific codec for more details.
-
- Args:
- encoder (dict | list[dict]): The codec config for keypoint encoding.
- Both single encoder and multiple encoders (given as a list) are
- supported
- multilevel (bool): Determine the method to handle multiple encoders.
- If ``multilevel==True``, generate multilevel targets from a group
- of encoders of the same type (e.g. multiple :class:`MSRAHeatmap`
- encoders with different sigma values); If ``multilevel==False``,
- generate combined targets from a group of different encoders. This
- argument will have no effect in case of single encoder. Defaults
- to ``False``
- use_dataset_keypoint_weights (bool): Whether use the keypoint weights
- from the dataset meta information. Defaults to ``False``
- """
-
- def __init__(self,
- encoder: MultiConfig,
- multilevel: bool = False,
- use_dataset_keypoint_weights: bool = False) -> None:
-```
-
-### 数据归一化
-
-旧版的数据归一化操作 `NormalizeTensor` 和 `ToTensor` 方法将由 **DataPreprocessor** 模块替代,不再作为流水线的一部分,而是作为模块加入到模型前向传播中。
-
-## 模型兼容
-
-我们对 model zoo 提供的模型权重进行了兼容性处理,确保相同的模型权重测试精度能够与 0.x 版本保持同等水平,但由于在这两个版本中存在大量处理细节的差异,推理结果可能会产生轻微的不同(精度误差小于 0.05%)。
-
-对于使用 0.x 版本训练保存的模型权重,我们在预测头中提供了 `_load_state_dict_pre_hook()` 方法来将旧版的权重字典替换为新版,如果你希望将在旧版上开发的模型兼容到新版,可以参考我们的实现。
-
-```Python
-@MODELS.register_module()
-class YourHead(BaseHead):
-def __init__(self):
-
- ## omitted
-
- # Register the hook to automatically convert old version state dicts
- self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
-```
-
-### Heatmap-based 方法
-
-对于基于SimpleBaseline方法的模型,主要需要注意最后一层卷积层的兼容:
-
-```Python
-def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
- **kwargs):
- version = local_meta.get('version', None)
-
- if version and version >= self._version:
- return
-
- # convert old-version state dict
- keys = list(state_dict.keys())
- for _k in keys:
- if not _k.startswith(prefix):
- continue
- v = state_dict.pop(_k)
- k = _k[len(prefix):]
- # In old version, "final_layer" includes both intermediate
- # conv layers (new "conv_layers") and final conv layers (new
- # "final_layer").
- #
- # If there is no intermediate conv layer, old "final_layer" will
- # have keys like "final_layer.xxx", which should be still
- # named "final_layer.xxx";
- #
- # If there are intermediate conv layers, old "final_layer" will
- # have keys like "final_layer.n.xxx", where the weights of the last
- # one should be renamed "final_layer.xxx", and others should be
- # renamed "conv_layers.n.xxx"
- k_parts = k.split('.')
- if k_parts[0] == 'final_layer':
- if len(k_parts) == 3:
- assert isinstance(self.conv_layers, nn.Sequential)
- idx = int(k_parts[1])
- if idx < len(self.conv_layers):
- # final_layer.n.xxx -> conv_layers.n.xxx
- k_new = 'conv_layers.' + '.'.join(k_parts[1:])
- else:
- # final_layer.n.xxx -> final_layer.xxx
- k_new = 'final_layer.' + k_parts[2]
- else:
- # final_layer.xxx remains final_layer.xxx
- k_new = k
- else:
- k_new = k
-
- state_dict[prefix + k_new] = v
-```
-
-### RLE-based 方法
-
-对于基于 RLE 的模型,由于新版的 `loss` 模块更名为 `loss_module`,且 flow 模型归属在 `loss` 模块下,因此需要对权重字典中 `loss` 字段进行更改:
-
-```Python
-def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
- **kwargs):
-
- version = local_meta.get('version', None)
-
- if version and version >= self._version:
- return
-
- # convert old-version state dict
- keys = list(state_dict.keys())
- for _k in keys:
- v = state_dict.pop(_k)
- k = _k.lstrip(prefix)
- # In old version, "loss" includes the instances of loss,
- # now it should be renamed "loss_module"
- k_parts = k.split('.')
- if k_parts[0] == 'loss':
- # loss.xxx -> loss_module.xxx
- k_new = prefix + 'loss_module.' + '.'.join(k_parts[1:])
- else:
- k_new = _k
-
- state_dict[k_new] = v
-```
+# MMPose 0.X 兼容性说明
+
+MMPose 1.0 经过了大规模重构并解决了许多遗留问题,对于 0.x 版本的大部分代码 MMPose 1.0 将不兼容。
+
+## 数据变换
+
+### 平移、旋转和缩放
+
+旧版的数据变换方法 `TopDownRandomShiftBboxCenter` 和 `TopDownGetRandomScaleRotation`,将被合并为 `RandomBBoxTransform`:
+
+```Python
+@TRANSFORMS.register_module()
+class RandomBBoxTransform(BaseTransform):
+ r"""Rnadomly shift, resize and rotate the bounding boxes.
+
+ Required Keys:
+
+ - bbox_center
+ - bbox_scale
+
+ Modified Keys:
+
+ - bbox_center
+ - bbox_scale
+
+ Added Keys:
+ - bbox_rotation
+
+ Args:
+ shift_factor (float): Randomly shift the bbox in range
+ :math:`[-dx, dx]` and :math:`[-dy, dy]` in X and Y directions,
+ where :math:`dx(y) = x(y)_scale \cdot shift_factor` in pixels.
+ Defaults to 0.16
+ shift_prob (float): Probability of applying random shift. Defaults to
+ 0.3
+ scale_factor (Tuple[float, float]): Randomly resize the bbox in range
+ :math:`[scale_factor[0], scale_factor[1]]`. Defaults to (0.5, 1.5)
+ scale_prob (float): Probability of applying random resizing. Defaults
+ to 1.0
+ rotate_factor (float): Randomly rotate the bbox in
+ :math:`[-rotate_factor, rotate_factor]` in degrees. Defaults
+ to 80.0
+ rotate_prob (float): Probability of applying random rotation. Defaults
+ to 0.6
+ """
+
+ def __init__(self,
+ shift_factor: float = 0.16,
+ shift_prob: float = 0.3,
+ scale_factor: Tuple[float, float] = (0.5, 1.5),
+ scale_prob: float = 1.0,
+ rotate_factor: float = 80.0,
+ rotate_prob: float = 0.6) -> None:
+```
+
+### 标签生成
+
+旧版用于训练标签生成的方法 `TopDownGenerateTarget` 、`TopDownGenerateTargetRegression`、`BottomUpGenerateHeatmapTarget`、`BottomUpGenerateTarget` 等将被合并为 `GenerateTarget`,而实际的生成方法由[编解码器](./user_guides/codecs.md) 提供:
+
+```Python
+@TRANSFORMS.register_module()
+class GenerateTarget(BaseTransform):
+ """Encode keypoints into Target.
+
+ The generated target is usually the supervision signal of the model
+ learning, e.g. heatmaps or regression labels.
+
+ Required Keys:
+
+ - keypoints
+ - keypoints_visible
+ - dataset_keypoint_weights
+
+ Added Keys:
+
+ - The keys of the encoded items from the codec will be updated into
+ the results, e.g. ``'heatmaps'`` or ``'keypoint_weights'``. See
+ the specific codec for more details.
+
+ Args:
+ encoder (dict | list[dict]): The codec config for keypoint encoding.
+ Both single encoder and multiple encoders (given as a list) are
+ supported
+ multilevel (bool): Determine the method to handle multiple encoders.
+ If ``multilevel==True``, generate multilevel targets from a group
+ of encoders of the same type (e.g. multiple :class:`MSRAHeatmap`
+ encoders with different sigma values); If ``multilevel==False``,
+ generate combined targets from a group of different encoders. This
+ argument will have no effect in case of single encoder. Defaults
+ to ``False``
+ use_dataset_keypoint_weights (bool): Whether use the keypoint weights
+ from the dataset meta information. Defaults to ``False``
+ """
+
+ def __init__(self,
+ encoder: MultiConfig,
+ multilevel: bool = False,
+ use_dataset_keypoint_weights: bool = False) -> None:
+```
+
+### 数据归一化
+
+旧版的数据归一化操作 `NormalizeTensor` 和 `ToTensor` 方法将由 **DataPreprocessor** 模块替代,不再作为流水线的一部分,而是作为模块加入到模型前向传播中。
+
+## 模型兼容
+
+我们对 model zoo 提供的模型权重进行了兼容性处理,确保相同的模型权重测试精度能够与 0.x 版本保持同等水平,但由于在这两个版本中存在大量处理细节的差异,推理结果可能会产生轻微的不同(精度误差小于 0.05%)。
+
+对于使用 0.x 版本训练保存的模型权重,我们在预测头中提供了 `_load_state_dict_pre_hook()` 方法来将旧版的权重字典替换为新版,如果你希望将在旧版上开发的模型兼容到新版,可以参考我们的实现。
+
+```Python
+@MODELS.register_module()
+class YourHead(BaseHead):
+def __init__(self):
+
+ ## omitted
+
+ # Register the hook to automatically convert old version state dicts
+ self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
+```
+
+### Heatmap-based 方法
+
+对于基于SimpleBaseline方法的模型,主要需要注意最后一层卷积层的兼容:
+
+```Python
+def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
+ **kwargs):
+ version = local_meta.get('version', None)
+
+ if version and version >= self._version:
+ return
+
+ # convert old-version state dict
+ keys = list(state_dict.keys())
+ for _k in keys:
+ if not _k.startswith(prefix):
+ continue
+ v = state_dict.pop(_k)
+ k = _k[len(prefix):]
+ # In old version, "final_layer" includes both intermediate
+ # conv layers (new "conv_layers") and final conv layers (new
+ # "final_layer").
+ #
+ # If there is no intermediate conv layer, old "final_layer" will
+ # have keys like "final_layer.xxx", which should be still
+ # named "final_layer.xxx";
+ #
+ # If there are intermediate conv layers, old "final_layer" will
+ # have keys like "final_layer.n.xxx", where the weights of the last
+ # one should be renamed "final_layer.xxx", and others should be
+ # renamed "conv_layers.n.xxx"
+ k_parts = k.split('.')
+ if k_parts[0] == 'final_layer':
+ if len(k_parts) == 3:
+ assert isinstance(self.conv_layers, nn.Sequential)
+ idx = int(k_parts[1])
+ if idx < len(self.conv_layers):
+ # final_layer.n.xxx -> conv_layers.n.xxx
+ k_new = 'conv_layers.' + '.'.join(k_parts[1:])
+ else:
+ # final_layer.n.xxx -> final_layer.xxx
+ k_new = 'final_layer.' + k_parts[2]
+ else:
+ # final_layer.xxx remains final_layer.xxx
+ k_new = k
+ else:
+ k_new = k
+
+ state_dict[prefix + k_new] = v
+```
+
+### RLE-based 方法
+
+对于基于 RLE 的模型,由于新版的 `loss` 模块更名为 `loss_module`,且 flow 模型归属在 `loss` 模块下,因此需要对权重字典中 `loss` 字段进行更改:
+
+```Python
+def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
+ **kwargs):
+
+ version = local_meta.get('version', None)
+
+ if version and version >= self._version:
+ return
+
+ # convert old-version state dict
+ keys = list(state_dict.keys())
+ for _k in keys:
+ v = state_dict.pop(_k)
+ k = _k.lstrip(prefix)
+ # In old version, "loss" includes the instances of loss,
+ # now it should be renamed "loss_module"
+ k_parts = k.split('.')
+ if k_parts[0] == 'loss':
+ # loss.xxx -> loss_module.xxx
+ k_new = prefix + 'loss_module.' + '.'.join(k_parts[1:])
+ else:
+ k_new = _k
+
+ state_dict[k_new] = v
+```
diff --git a/docs/zh_cn/notes/changelog.md b/docs/zh_cn/notes/changelog.md
index 68beeeb069..41c58f0256 100644
--- a/docs/zh_cn/notes/changelog.md
+++ b/docs/zh_cn/notes/changelog.md
@@ -1,1316 +1,1316 @@
-# Changelog
-
-## **v1.0.0rc1 (14/10/2022)**
-
-**Highlights**
-
-- Release RTMPose, a high-performance real-time pose estimation algorithm with cross-platform deployment and inference support. See details at the [project page](/projects/rtmpose/)
-- Support several new algorithms: ViTPose (arXiv'2022), CID (CVPR'2022), DEKR (CVPR'2021)
-- Add Inferencer, a convenient inference interface that perform pose estimation and visualization on images, videos and webcam streams with only one line of code
-- Introduce *Project*, a new form for rapid and easy implementation of new algorithms and features in MMPose, which is more handy for community contributors
-
-**New Features**
-
-- Support RTMPose ([#1971](https://github.com/open-mmlab/mmpose/pull/1971), [#2024](https://github.com/open-mmlab/mmpose/pull/2024), [#2028](https://github.com/open-mmlab/mmpose/pull/2028), [#2030](https://github.com/open-mmlab/mmpose/pull/2030), [#2040](https://github.com/open-mmlab/mmpose/pull/2040), [#2057](https://github.com/open-mmlab/mmpose/pull/2057))
-- Support Inferencer ([#1969](https://github.com/open-mmlab/mmpose/pull/1969))
-- Support ViTPose ([#1876](https://github.com/open-mmlab/mmpose/pull/1876), [#2056](https://github.com/open-mmlab/mmpose/pull/2056), [#2058](https://github.com/open-mmlab/mmpose/pull/2058), [#2065](https://github.com/open-mmlab/mmpose/pull/2065))
-- Support CID ([#1907](https://github.com/open-mmlab/mmpose/pull/1907))
-- Support DEKR ([#1834](https://github.com/open-mmlab/mmpose/pull/1834), [#1901](https://github.com/open-mmlab/mmpose/pull/1901))
-- Support training with multiple datasets ([#1767](https://github.com/open-mmlab/mmpose/pull/1767), [#1930](https://github.com/open-mmlab/mmpose/pull/1930), [#1938](https://github.com/open-mmlab/mmpose/pull/1938), [#2025](https://github.com/open-mmlab/mmpose/pull/2025))
-- Add *project* to allow rapid and easy implementation of new models and features ([#1914](https://github.com/open-mmlab/mmpose/pull/1914))
-
-**Improvements**
-
-- Improve documentation quality ([#1846](https://github.com/open-mmlab/mmpose/pull/1846), [#1858](https://github.com/open-mmlab/mmpose/pull/1858), [#1872](https://github.com/open-mmlab/mmpose/pull/1872), [#1899](https://github.com/open-mmlab/mmpose/pull/1899), [#1925](https://github.com/open-mmlab/mmpose/pull/1925), [#1945](https://github.com/open-mmlab/mmpose/pull/1945), [#1952](https://github.com/open-mmlab/mmpose/pull/1952), [#1990](https://github.com/open-mmlab/mmpose/pull/1990), [#2023](https://github.com/open-mmlab/mmpose/pull/2023), [#2042](https://github.com/open-mmlab/mmpose/pull/2042))
-- Support visualizing keypoint indices ([#2051](https://github.com/open-mmlab/mmpose/pull/2051))
-- Support OpenPose style visualization ([#2055](https://github.com/open-mmlab/mmpose/pull/2055))
-- Accelerate image transpose in data pipelines with tensor operation ([#1976](https://github.com/open-mmlab/mmpose/pull/1976))
-- Support auto-import modules from registry ([#1961](https://github.com/open-mmlab/mmpose/pull/1961))
-- Support keypoint partition metric ([#1944](https://github.com/open-mmlab/mmpose/pull/1944))
-- Support SimCC 1D-heatmap visualization ([#1912](https://github.com/open-mmlab/mmpose/pull/1912))
-- Support saving predictions and data metainfo in demos ([#1814](https://github.com/open-mmlab/mmpose/pull/1814), [#1879](https://github.com/open-mmlab/mmpose/pull/1879))
-- Support SimCC with DARK ([#1870](https://github.com/open-mmlab/mmpose/pull/1870))
-- Remove Gaussian blur for offset maps in UDP-regress ([#1815](https://github.com/open-mmlab/mmpose/pull/1815))
-- Refactor encoding interface of Codec for better extendibility and easier configuration ([#1781](https://github.com/open-mmlab/mmpose/pull/1781))
-- Support evaluating CocoMetric without annotation file ([#1722](https://github.com/open-mmlab/mmpose/pull/1722))
-- Improve unit tests ([#1765](https://github.com/open-mmlab/mmpose/pull/1765))
-
-**Bug Fixes**
-
-- Fix repeated warnings from different ranks ([#2053](https://github.com/open-mmlab/mmpose/pull/2053))
-- Avoid frequent scope switching when using mmdet inference api ([#2039](https://github.com/open-mmlab/mmpose/pull/2039))
-- Remove EMA parameters and message hub data when publishing model checkpoints ([#2036](https://github.com/open-mmlab/mmpose/pull/2036))
-- Fix metainfo copying in dataset class ([#2017](https://github.com/open-mmlab/mmpose/pull/2017))
-- Fix top-down demo bug when there is no object detected ([#2007](https://github.com/open-mmlab/mmpose/pull/2007))
-- Fix config errors ([#1882](https://github.com/open-mmlab/mmpose/pull/1882), [#1906](https://github.com/open-mmlab/mmpose/pull/1906), [#1995](https://github.com/open-mmlab/mmpose/pull/1995))
-- Fix image demo failure when GUI is unavailable ([#1968](https://github.com/open-mmlab/mmpose/pull/1968))
-- Fix bug in AdaptiveWingLoss ([#1953](https://github.com/open-mmlab/mmpose/pull/1953))
-- Fix incorrect importing of RepeatDataset which is deprecated ([#1943](https://github.com/open-mmlab/mmpose/pull/1943))
-- Fix bug in bottom-up datasets that ignores images without instances ([#1752](https://github.com/open-mmlab/mmpose/pull/1752), [#1936](https://github.com/open-mmlab/mmpose/pull/1936))
-- Fix upstream dependency issues ([#1867](https://github.com/open-mmlab/mmpose/pull/1867), [#1921](https://github.com/open-mmlab/mmpose/pull/1921))
-- Fix evaluation issues and update results ([#1763](https://github.com/open-mmlab/mmpose/pull/1763), [#1773](https://github.com/open-mmlab/mmpose/pull/1773), [#1780](https://github.com/open-mmlab/mmpose/pull/1780), [#1850](https://github.com/open-mmlab/mmpose/pull/1850), [#1868](https://github.com/open-mmlab/mmpose/pull/1868))
-- Fix local registry missing warnings ([#1849](https://github.com/open-mmlab/mmpose/pull/1849))
-- Remove deprecated scripts for model deployment ([#1845](https://github.com/open-mmlab/mmpose/pull/1845))
-- Fix a bug in input transformation in BaseHead ([#1843](https://github.com/open-mmlab/mmpose/pull/1843))
-- Fix an interface mismatch with MMDetection in webcam demo ([#1813](https://github.com/open-mmlab/mmpose/pull/1813))
-- Fix a bug in heatmap visualization that causes incorrect scale ([#1800](https://github.com/open-mmlab/mmpose/pull/1800))
-- Add model metafiles ([#1768](https://github.com/open-mmlab/mmpose/pull/1768))
-
-## **v1.0.0rc0 (14/10/2022)**
-
-**New Features**
-
-- Support 4 light-weight pose estimation algorithms: [SimCC](https://doi.org/10.48550/arxiv.2107.03332) (ECCV'2022), [Debias-IPR](https://openaccess.thecvf.com/content/ICCV2021/papers/Gu_Removing_the_Bias_of_Integral_Pose_Regression_ICCV_2021_paper.pdf) (ICCV'2021), [IPR](https://arxiv.org/abs/1711.08229) (ECCV'2018), and [DSNT](https://arxiv.org/abs/1801.07372v2) (ArXiv'2018) ([#1628](https://github.com/open-mmlab/mmpose/pull/1628))
-
-**Migrations**
-
-- Add Webcam API in MMPose 1.0 ([#1638](https://github.com/open-mmlab/mmpose/pull/1638), [#1662](https://github.com/open-mmlab/mmpose/pull/1662)) @Ben-Louis
-- Add codec for Associative Embedding (beta) ([#1603](https://github.com/open-mmlab/mmpose/pull/1603)) @ly015
-
-**Improvements**
-
-- Add a colab tutorial for MMPose 1.0 ([#1660](https://github.com/open-mmlab/mmpose/pull/1660)) @Tau-J
-- Add model index in config folder ([#1710](https://github.com/open-mmlab/mmpose/pull/1710), [#1709](https://github.com/open-mmlab/mmpose/pull/1709), [#1627](https://github.com/open-mmlab/mmpose/pull/1627)) @ly015, @Tau-J, @Ben-Louis
-- Update and improve documentation ([#1692](https://github.com/open-mmlab/mmpose/pull/1692), [#1656](https://github.com/open-mmlab/mmpose/pull/1656), [#1681](https://github.com/open-mmlab/mmpose/pull/1681), [#1677](https://github.com/open-mmlab/mmpose/pull/1677), [#1664](https://github.com/open-mmlab/mmpose/pull/1664), [#1659](https://github.com/open-mmlab/mmpose/pull/1659)) @Tau-J, @Ben-Louis, @liqikai9
-- Improve config structures and formats ([#1651](https://github.com/open-mmlab/mmpose/pull/1651)) @liqikai9
-
-**Bug Fixes**
-
-- Update mmengine version requirements ([#1715](https://github.com/open-mmlab/mmpose/pull/1715)) @Ben-Louis
-- Update dependencies of pre-commit hooks ([#1705](https://github.com/open-mmlab/mmpose/pull/1705)) @Ben-Louis
-- Fix mmcv version in DockerFile ([#1704](https://github.com/open-mmlab/mmpose/pull/1704))
-- Fix a bug in setting dataset metainfo in configs ([#1684](https://github.com/open-mmlab/mmpose/pull/1684)) @ly015
-- Fix a bug in UDP training ([#1682](https://github.com/open-mmlab/mmpose/pull/1682)) @liqikai9
-- Fix a bug in Dark decoding ([#1676](https://github.com/open-mmlab/mmpose/pull/1676)) @liqikai9
-- Fix bugs in visualization ([#1671](https://github.com/open-mmlab/mmpose/pull/1671), [#1668](https://github.com/open-mmlab/mmpose/pull/1668), [#1657](https://github.com/open-mmlab/mmpose/pull/1657)) @liqikai9, @Ben-Louis
-- Fix incorrect flops calculation ([#1669](https://github.com/open-mmlab/mmpose/pull/1669)) @liqikai9
-- Fix `tensor.tile` compatibility issue for pytorch 1.6 ([#1658](https://github.com/open-mmlab/mmpose/pull/1658)) @ly015
-- Fix compatibility with `MultilevelPixelData` ([#1647](https://github.com/open-mmlab/mmpose/pull/1647)) @liqikai9
-
-## **v1.0.0beta (1/09/2022)**
-
-We are excited to announce the release of MMPose 1.0.0beta.
-MMPose 1.0.0beta is the first version of MMPose 1.x, a part of the OpenMMLab 2.0 projects.
-Built upon the new [training engine](https://github.com/open-mmlab/mmengine),
-MMPose 1.x unifies the interfaces of dataset, models, evaluation, and visualization with faster training and testing speed.
-It also provide a general semi-supervised object detection framework, and more strong baselines.
-
-**Highlights**
-
-- **New engines**. MMPose 1.x is based on [MMEngine](https://github.com/open-mmlab/mmengine), which provides a general and powerful runner that allows more flexible customizations and significantly simplifies the entrypoints of high-level interfaces.
-
-- **Unified interfaces**. As a part of the OpenMMLab 2.0 projects, MMPose 1.x unifies and refactors the interfaces and internal logics of train, testing, datasets, models, evaluation, and visualization. All the OpenMMLab 2.0 projects share the same design in those interfaces and logics to allow the emergence of multi-task/modality algorithms.
-
-- **More documentation and tutorials**. We add a bunch of documentation and tutorials to help users get started more smoothly. Read it [here](https://mmpose.readthedocs.io/en/latest/).
-
-**Breaking Changes**
-
-In this release, we made lots of major refactoring and modifications. Please refer to the [migration guide](../migration.md) for details and migration instructions.
-
-## **v0.28.1 (28/07/2022)**
-
-This release is meant to fix the compatibility with the latest mmcv v1.6.1
-
-## **v0.28.0 (06/07/2022)**
-
-**Highlights**
-
-- Support [TCFormer](https://openaccess.thecvf.com/content/CVPR2022/html/Zeng_Not_All_Tokens_Are_Equal_Human-Centric_Visual_Analysis_via_Token_CVPR_2022_paper.html) backbone, CVPR'2022 ([#1447](https://github.com/open-mmlab/mmpose/pull/1447), [#1452](https://github.com/open-mmlab/mmpose/pull/1452)) @zengwang430521
-
-- Add [RLE](https://arxiv.org/abs/2107.11291) models on COCO dataset ([#1424](https://github.com/open-mmlab/mmpose/pull/1424)) @Indigo6, @Ben-Louis, @ly015
-
-- Update swin models with better performance ([#1467](https://github.com/open-mmlab/mmpose/pull/1434)) @jin-s13
-
-**New Features**
-
-- Support [TCFormer](https://openaccess.thecvf.com/content/CVPR2022/html/Zeng_Not_All_Tokens_Are_Equal_Human-Centric_Visual_Analysis_via_Token_CVPR_2022_paper.html) backbone, CVPR'2022 ([#1447](https://github.com/open-mmlab/mmpose/pull/1447), [#1452](https://github.com/open-mmlab/mmpose/pull/1452)) @zengwang430521
-
-- Add [RLE](https://arxiv.org/abs/2107.11291) models on COCO dataset ([#1424](https://github.com/open-mmlab/mmpose/pull/1424)) @Indigo6, @Ben-Louis, @ly015
-
-- Support layer decay optimizer constructor and learning rate decay optimizer constructor ([#1423](https://github.com/open-mmlab/mmpose/pull/1423)) @jin-s13
-
-**Improvements**
-
-- Improve documentation quality ([#1416](https://github.com/open-mmlab/mmpose/pull/1416), [#1421](https://github.com/open-mmlab/mmpose/pull/1421), [#1423](https://github.com/open-mmlab/mmpose/pull/1423), [#1426](https://github.com/open-mmlab/mmpose/pull/1426), [#1458](https://github.com/open-mmlab/mmpose/pull/1458), [#1463](https://github.com/open-mmlab/mmpose/pull/1463)) @ly015, @liqikai9
-
-- Support installation by [mim](https://github.com/open-mmlab/mim) ([#1425](https://github.com/open-mmlab/mmpose/pull/1425)) @liqikai9
-
-- Support PAVI logger ([#1434](https://github.com/open-mmlab/mmpose/pull/1434)) @EvelynWang-0423
-
-- Add progress bar for some demos ([#1454](https://github.com/open-mmlab/mmpose/pull/1454)) @liqikai9
-
-- Webcam API supports quick device setting in terminal commands ([#1466](https://github.com/open-mmlab/mmpose/pull/1466)) @ly015
-
-- Update swin models with better performance ([#1467](https://github.com/open-mmlab/mmpose/pull/1434)) @jin-s13
-
-**Bug Fixes**
-
-- Rename `custom_hooks_config` to `custom_hooks` in configs to align with the documentation ([#1427](https://github.com/open-mmlab/mmpose/pull/1427)) @ly015
-
-- Fix deadlock issue in Webcam API ([#1430](https://github.com/open-mmlab/mmpose/pull/1430)) @ly015
-
-- Fix smoother configs in video 3D demo ([#1457](https://github.com/open-mmlab/mmpose/pull/1457)) @ly015
-
-## **v0.27.0 (07/06/2022)**
-
-**Highlights**
-
-- Support hand gesture recognition
-
- - Try the demo for gesture recognition
- - Learn more about the algorithm, dataset and experiment results
-
-- Major upgrade to the Webcam API
-
- - Tutorials (EN|zh_CN)
- - [API Reference](https://mmpose.readthedocs.io/en/latest/api.html#mmpose-apis-webcam)
- - Demo
-
-**New Features**
-
-- Support gesture recognition algorithm [MTUT](https://openaccess.thecvf.com/content_CVPR_2019/html/Abavisani_Improving_the_Performance_of_Unimodal_Dynamic_Hand-Gesture_Recognition_With_Multimodal_CVPR_2019_paper.html) CVPR'2019 and dataset [NVGesture](https://openaccess.thecvf.com/content_cvpr_2016/html/Molchanov_Online_Detection_and_CVPR_2016_paper.html) CVPR'2016 ([#1380](https://github.com/open-mmlab/mmpose/pull/1380)) @Ben-Louis
-
-**Improvements**
-
-- Upgrade Webcam API and related documents ([#1393](https://github.com/open-mmlab/mmpose/pull/1393), [#1404](https://github.com/open-mmlab/mmpose/pull/1404), [#1413](https://github.com/open-mmlab/mmpose/pull/1413)) @ly015
-
-- Support exporting COCO inference result without the annotation file ([#1368](https://github.com/open-mmlab/mmpose/pull/1368)) @liqikai9
-
-- Replace markdownlint with mdformat in CI to avoid the dependence on ruby [#1382](https://github.com/open-mmlab/mmpose/pull/1382) @ly015
-
-- Improve documentation quality ([#1385](https://github.com/open-mmlab/mmpose/pull/1385), [#1394](https://github.com/open-mmlab/mmpose/pull/1394), [#1395](https://github.com/open-mmlab/mmpose/pull/1395), [#1408](https://github.com/open-mmlab/mmpose/pull/1408)) @chubei-oppen, @ly015, @liqikai9
-
-**Bug Fixes**
-
-- Fix xywh->xyxy bbox conversion in dataset sanity check ([#1367](https://github.com/open-mmlab/mmpose/pull/1367)) @jin-s13
-
-- Fix a bug in two-stage 3D keypoint demo ([#1373](https://github.com/open-mmlab/mmpose/pull/1373)) @ly015
-
-- Fix out-dated settings in PVT configs ([#1376](https://github.com/open-mmlab/mmpose/pull/1376)) @ly015
-
-- Fix myst settings for document compiling ([#1381](https://github.com/open-mmlab/mmpose/pull/1381)) @ly015
-
-- Fix a bug in bbox transform ([#1384](https://github.com/open-mmlab/mmpose/pull/1384)) @ly015
-
-- Fix inaccurate description of `min_keypoints` in tracking apis ([#1398](https://github.com/open-mmlab/mmpose/pull/1398)) @pallgeuer
-
-- Fix warning with `torch.meshgrid` ([#1402](https://github.com/open-mmlab/mmpose/pull/1402)) @pallgeuer
-
-- Remove redundant transformer modules from `mmpose.datasets.backbones.utils` ([#1405](https://github.com/open-mmlab/mmpose/pull/1405)) @ly015
-
-## **v0.26.0 (05/05/2022)**
-
-**Highlights**
-
-- Support [RLE (Residual Log-likelihood Estimation)](https://arxiv.org/abs/2107.11291), ICCV'2021 ([#1259](https://github.com/open-mmlab/mmpose/pull/1259)) @Indigo6, @ly015
-
-- Support [Swin Transformer](https://arxiv.org/abs/2103.14030), ICCV'2021 ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @yumendecc, @ly015
-
-- Support [PVT](https://arxiv.org/abs/2102.12122), ICCV'2021 and [PVTv2](https://arxiv.org/abs/2106.13797), CVMJ'2022 ([#1343](https://github.com/open-mmlab/mmpose/pull/1343)) @zengwang430521
-
-- Speed up inference and reduce CPU usage by optimizing the pre-processing pipeline ([#1320](https://github.com/open-mmlab/mmpose/pull/1320)) @chenxinfeng4, @liqikai9
-
-**New Features**
-
-- Support [RLE (Residual Log-likelihood Estimation)](https://arxiv.org/abs/2107.11291), ICCV'2021 ([#1259](https://github.com/open-mmlab/mmpose/pull/1259)) @Indigo6, @ly015
-
-- Support [Swin Transformer](https://arxiv.org/abs/2103.14030), ICCV'2021 ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @yumendecc, @ly015
-
-- Support [PVT](https://arxiv.org/abs/2102.12122), ICCV'2021 and [PVTv2](https://arxiv.org/abs/2106.13797), CVMJ'2022 ([#1343](https://github.com/open-mmlab/mmpose/pull/1343)) @zengwang430521
-
-- Support [FPN](https://openaccess.thecvf.com/content_cvpr_2017/html/Lin_Feature_Pyramid_Networks_CVPR_2017_paper.html), CVPR'2017 ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @yumendecc, @ly015
-
-**Improvements**
-
-- Speed up inference and reduce CPU usage by optimizing the pre-processing pipeline ([#1320](https://github.com/open-mmlab/mmpose/pull/1320)) @chenxinfeng4, @liqikai9
-
-- Video demo supports models that requires multi-frame inputs ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @liqikai9, @jin-s13
-
-- Update benchmark regression list ([#1328](https://github.com/open-mmlab/mmpose/pull/1328)) @ly015, @liqikai9
-
-- Remove unnecessary warnings in `TopDownPoseTrack18VideoDataset` ([#1335](https://github.com/open-mmlab/mmpose/pull/1335)) @liqikai9
-
-- Improve documentation quality ([#1313](https://github.com/open-mmlab/mmpose/pull/1313), [#1305](https://github.com/open-mmlab/mmpose/pull/1305)) @Ben-Louis, @ly015
-
-- Update deprecating settings in configs ([#1317](https://github.com/open-mmlab/mmpose/pull/1317)) @ly015
-
-**Bug Fixes**
-
-- Fix a bug in human skeleton grouping that may skip the matching process unexpectedly when `ignore_to_much` is True ([#1341](https://github.com/open-mmlab/mmpose/pull/1341)) @daixinghome
-
-- Fix a GPG key error that leads to CI failure ([#1354](https://github.com/open-mmlab/mmpose/pull/1354)) @ly015
-
-- Fix bugs in distributed training script ([#1338](https://github.com/open-mmlab/mmpose/pull/1338), [#1298](https://github.com/open-mmlab/mmpose/pull/1298)) @ly015
-
-- Fix an upstream bug in xtoccotools that causes incorrect AP(M) results ([#1308](https://github.com/open-mmlab/mmpose/pull/1308)) @jin-s13, @ly015
-
-- Fix indentiation errors in the colab tutorial ([#1298](https://github.com/open-mmlab/mmpose/pull/1298)) @YuanZi1501040205
-
-- Fix incompatible model weight initialization with other OpenMMLab codebases ([#1329](https://github.com/open-mmlab/mmpose/pull/1329)) @274869388
-
-- Fix HRNet FP16 checkpoints download URL ([#1309](https://github.com/open-mmlab/mmpose/pull/1309)) @YinAoXiong
-
-- Fix typos in `body3d_two_stage_video_demo.py` ([#1295](https://github.com/open-mmlab/mmpose/pull/1295)) @mucozcan
-
-**Breaking Changes**
-
-- Refactor bbox processing in datasets and pipelines ([#1311](https://github.com/open-mmlab/mmpose/pull/1311)) @ly015, @Ben-Louis
-
-- The bbox format conversion (xywh to center-scale) and random translation are moved from the dataset to the pipeline. The comparison between new and old version is as below:
-
-v0.26.0v0.25.0Dataset
-(e.g. [TopDownCOCODataset](https://github.com/open-mmlab/mmpose/blob/master/mmpose/datasets/datasets/top_down/topdown_coco_dataset.py))
-
-... # Data sample only contains bbox rec.append({ 'bbox': obj\['clean_bbox\]\[:4\], ... })
-
-
-
-
-
-... # Convert bbox from xywh to center-scale center, scale = self.\_xywh2cs(\*obj\['clean_bbox'\]\[:4\]) # Data sample contains center and scale rec.append({ 'bbox': obj\['clean_bbox\]\[:4\], 'center': center, 'scale': scale, ... })
-
-
Apply bbox random translation every epoch (instead of only applying once at the annotation loading)
-
-
-
-
-
-
-
-
-
-
-
BC Breaking
-
-
The method `_xywh2cs` of dataset base classes (e.g. [Kpt2dSviewRgbImgTopDownDataset](https://github.com/open-mmlab/mmpose/blob/master/mmpose/datasets/datasets/base/kpt_2d_sview_rgb_img_top_down_dataset.py)) will be deprecated in the future. Custom datasets will need modifications to move the bbox format conversion to pipelines.
-
-
-
-
-
-
-
-
-
-
-## **v0.25.0 (02/04/2022)**
-
-**Highlights**
-
-- Support Shelf and Campus datasets with pre-trained VoxelPose models, ["3D Pictorial Structures for Multiple Human Pose Estimation"](http://campar.in.tum.de/pub/belagiannis2014cvpr/belagiannis2014cvpr.pdf), CVPR'2014 ([#1225](https://github.com/open-mmlab/mmpose/pull/1225)) @liqikai9, @wusize
-
-- Add `Smoother` module for temporal smoothing of the pose estimation with configurable filters ([#1127](https://github.com/open-mmlab/mmpose/pull/1127)) @ailingzengzzz, @ly015
-
-- Support SmoothNet for pose smoothing, ["SmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos"](https://arxiv.org/abs/2112.13715), arXiv'2021 ([#1279](https://github.com/open-mmlab/mmpose/pull/1279)) @ailingzengzzz, @ly015
-
-- Add multiview 3D pose estimation demo ([#1270](https://github.com/open-mmlab/mmpose/pull/1270)) @wusize
-
-**New Features**
-
-- Support Shelf and Campus datasets with pre-trained VoxelPose models, ["3D Pictorial Structures for Multiple Human Pose Estimation"](http://campar.in.tum.de/pub/belagiannis2014cvpr/belagiannis2014cvpr.pdf), CVPR'2014 ([#1225](https://github.com/open-mmlab/mmpose/pull/1225)) @liqikai9, @wusize
-
-- Add `Smoother` module for temporal smoothing of the pose estimation with configurable filters ([#1127](https://github.com/open-mmlab/mmpose/pull/1127)) @ailingzengzzz, @ly015
-
-- Support SmoothNet for pose smoothing, ["SmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos"](https://arxiv.org/abs/2112.13715), arXiv'2021 ([#1279](https://github.com/open-mmlab/mmpose/pull/1279)) @ailingzengzzz, @ly015
-
-- Add multiview 3D pose estimation demo ([#1270](https://github.com/open-mmlab/mmpose/pull/1270)) @wusize
-
-- Support multi-machine distributed training ([#1248](https://github.com/open-mmlab/mmpose/pull/1248)) @ly015
-
-**Improvements**
-
-- Update HRFormer configs and checkpoints with relative position bias ([#1245](https://github.com/open-mmlab/mmpose/pull/1245)) @zengwang430521
-
-- Support using different random seed for each distributed node ([#1257](https://github.com/open-mmlab/mmpose/pull/1257), [#1229](https://github.com/open-mmlab/mmpose/pull/1229)) @ly015
-
-- Improve documentation quality ([#1275](https://github.com/open-mmlab/mmpose/pull/1275), [#1255](https://github.com/open-mmlab/mmpose/pull/1255), [#1258](https://github.com/open-mmlab/mmpose/pull/1258), [#1249](https://github.com/open-mmlab/mmpose/pull/1249), [#1247](https://github.com/open-mmlab/mmpose/pull/1247), [#1240](https://github.com/open-mmlab/mmpose/pull/1240), [#1235](https://github.com/open-mmlab/mmpose/pull/1235)) @ly015, @jin-s13, @YoniChechik
-
-**Bug Fixes**
-
-- Fix keypoint index in RHD dataset meta information ([#1265](https://github.com/open-mmlab/mmpose/pull/1265)) @liqikai9
-
-- Fix pre-commit hook unexpected behavior on Windows ([#1282](https://github.com/open-mmlab/mmpose/pull/1282)) @liqikai9
-
-- Remove python-dev installation in CI ([#1276](https://github.com/open-mmlab/mmpose/pull/1276)) @ly015
-
-- Unify hyphens in argument names in tools and demos ([#1271](https://github.com/open-mmlab/mmpose/pull/1271)) @ly015
-
-- Fix ambiguous channel size in `channel_shuffle` that may cause exporting failure (#1242) @PINTO0309
-
-- Fix a bug in Webcam API that causes single-class detectors fail ([#1239](https://github.com/open-mmlab/mmpose/pull/1239)) @674106399
-
-- Fix the issue that `custom_hook` can not be set in configs ([#1236](https://github.com/open-mmlab/mmpose/pull/1236)) @bladrome
-
-- Fix incompatible MMCV version in DockerFile ([#raykindle](https://github.com/open-mmlab/mmpose/pull/raykindle))
-
-- Skip invisible joints in visualization ([#1228](https://github.com/open-mmlab/mmpose/pull/1228)) @womeier
-
-## **v0.24.0 (07/03/2022)**
-
-**Highlights**
-
-- Support HRFormer ["HRFormer: High-Resolution Vision Transformer for Dense Predict"](https://proceedings.neurips.cc/paper/2021/hash/3bbfdde8842a5c44a0323518eec97cbe-Abstract.html), NeurIPS'2021 ([#1203](https://github.com/open-mmlab/mmpose/pull/1203)) @zengwang430521
-
-- Support Windows installation with pip ([#1213](https://github.com/open-mmlab/mmpose/pull/1213)) @jin-s13, @ly015
-
-- Add WebcamAPI documents ([#1187](https://github.com/open-mmlab/mmpose/pull/1187)) @ly015
-
-**New Features**
-
-- Support HRFormer ["HRFormer: High-Resolution Vision Transformer for Dense Predict"](https://proceedings.neurips.cc/paper/2021/hash/3bbfdde8842a5c44a0323518eec97cbe-Abstract.html), NeurIPS'2021 ([#1203](https://github.com/open-mmlab/mmpose/pull/1203)) @zengwang430521
-
-- Support Windows installation with pip ([#1213](https://github.com/open-mmlab/mmpose/pull/1213)) @jin-s13, @ly015
-
-- Support CPU training with mmcv \< v1.4.4 ([#1161](https://github.com/open-mmlab/mmpose/pull/1161)) @EasonQYS, @ly015
-
-- Add "Valentine Magic" demo with WebcamAPI ([#1189](https://github.com/open-mmlab/mmpose/pull/1189), [#1191](https://github.com/open-mmlab/mmpose/pull/1191)) @liqikai9
-
-**Improvements**
-
-- Refactor multi-view 3D pose estimation framework towards better modularization and expansibility ([#1196](https://github.com/open-mmlab/mmpose/pull/1196)) @wusize
-
-- Add WebcamAPI documents and tutorials ([#1187](https://github.com/open-mmlab/mmpose/pull/1187)) @ly015
-
-- Refactor dataset evaluation interface to align with other OpenMMLab codebases ([#1209](https://github.com/open-mmlab/mmpose/pull/1209)) @ly015
-
-- Add deprecation message for deploy tools since [MMDeploy](https://github.com/open-mmlab/mmdeploy) has supported MMPose ([#1207](https://github.com/open-mmlab/mmpose/pull/1207)) @QwQ2000
-
-- Improve documentation quality ([#1206](https://github.com/open-mmlab/mmpose/pull/1206), [#1161](https://github.com/open-mmlab/mmpose/pull/1161)) @ly015
-
-- Switch to OpenMMLab official pre-commit-hook for copyright check ([#1214](https://github.com/open-mmlab/mmpose/pull/1214)) @ly015
-
-**Bug Fixes**
-
-- Fix hard-coded data collating and scattering in inference ([#1175](https://github.com/open-mmlab/mmpose/pull/1175)) @ly015
-
-- Fix model configs on JHMDB dataset ([#1188](https://github.com/open-mmlab/mmpose/pull/1188)) @jin-s13
-
-- Fix area calculation in pose tracking inference ([#1197](https://github.com/open-mmlab/mmpose/pull/1197)) @pallgeuer
-
-- Fix registry scope conflict of module wrapper ([#1204](https://github.com/open-mmlab/mmpose/pull/1204)) @ly015
-
-- Update MMCV installation in CI and documents ([#1205](https://github.com/open-mmlab/mmpose/pull/1205))
-
-- Fix incorrect color channel order in visualization functions ([#1212](https://github.com/open-mmlab/mmpose/pull/1212)) @ly015
-
-## **v0.23.0 (11/02/2022)**
-
-**Highlights**
-
-- Add [MMPose Webcam API](https://github.com/open-mmlab/mmpose/tree/master/tools/webcam): A simple yet powerful tools to develop interactive webcam applications with MMPose functions. ([#1178](https://github.com/open-mmlab/mmpose/pull/1178), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1143](https://github.com/open-mmlab/mmpose/pull/1143), [#1094](https://github.com/open-mmlab/mmpose/pull/1094), [#1133](https://github.com/open-mmlab/mmpose/pull/1133), [#1098](https://github.com/open-mmlab/mmpose/pull/1098), [#1160](https://github.com/open-mmlab/mmpose/pull/1160)) @ly015, @jin-s13, @liqikai9, @wusize, @luminxu, @zengwang430521 @mzr1996
-
-**New Features**
-
-- Add [MMPose Webcam API](https://github.com/open-mmlab/mmpose/tree/master/tools/webcam): A simple yet powerful tools to develop interactive webcam applications with MMPose functions. ([#1178](https://github.com/open-mmlab/mmpose/pull/1178), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1143](https://github.com/open-mmlab/mmpose/pull/1143), [#1094](https://github.com/open-mmlab/mmpose/pull/1094), [#1133](https://github.com/open-mmlab/mmpose/pull/1133), [#1098](https://github.com/open-mmlab/mmpose/pull/1098), [#1160](https://github.com/open-mmlab/mmpose/pull/1160)) @ly015, @jin-s13, @liqikai9, @wusize, @luminxu, @zengwang430521 @mzr1996
-
-- Support ConcatDataset ([#1139](https://github.com/open-mmlab/mmpose/pull/1139)) @Canwang-sjtu
-
-- Support CPU training and testing ([#1157](https://github.com/open-mmlab/mmpose/pull/1157)) @ly015
-
-**Improvements**
-
-- Add multi-processing configurations to speed up distributed training and testing ([#1146](https://github.com/open-mmlab/mmpose/pull/1146)) @ly015
-
-- Add default runtime config ([#1145](https://github.com/open-mmlab/mmpose/pull/1145))
-
-- Upgrade isort in pre-commit hook ([#1179](https://github.com/open-mmlab/mmpose/pull/1179)) @liqikai9
-
-- Update README and documents ([#1171](https://github.com/open-mmlab/mmpose/pull/1171), [#1167](https://github.com/open-mmlab/mmpose/pull/1167), [#1153](https://github.com/open-mmlab/mmpose/pull/1153), [#1149](https://github.com/open-mmlab/mmpose/pull/1149), [#1148](https://github.com/open-mmlab/mmpose/pull/1148), [#1147](https://github.com/open-mmlab/mmpose/pull/1147), [#1140](https://github.com/open-mmlab/mmpose/pull/1140)) @jin-s13, @wusize, @TommyZihao, @ly015
-
-**Bug Fixes**
-
-- Fix undeterministic behavior in pre-commit hooks ([#1136](https://github.com/open-mmlab/mmpose/pull/1136)) @jin-s13
-
-- Deprecate the support for "python setup.py test" ([#1179](https://github.com/open-mmlab/mmpose/pull/1179)) @ly015
-
-- Fix incompatible settings with MMCV on HSigmoid default parameters ([#1132](https://github.com/open-mmlab/mmpose/pull/1132)) @ly015
-
-- Fix albumentation installation ([#1184](https://github.com/open-mmlab/mmpose/pull/1184)) @BIGWangYuDong
-
-## **v0.22.0 (04/01/2022)**
-
-**Highlights**
-
-- Support VoxelPose ["VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment"](https://arxiv.org/abs/2004.06239), ECCV'2020 ([#1050](https://github.com/open-mmlab/mmpose/pull/1050)) @wusize
-
-- Support Soft Wing loss ["Structure-Coherent Deep Feature Learning for Robust Face Alignment"](https://linchunze.github.io/papers/TIP21_Structure_coherent_FA.pdf), TIP'2021 ([#1077](https://github.com/open-mmlab/mmpose/pull/1077)) @jin-s13
-
-- Support Adaptive Wing loss ["Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression"](https://arxiv.org/abs/1904.07399), ICCV'2019 ([#1072](https://github.com/open-mmlab/mmpose/pull/1072)) @jin-s13
-
-**New Features**
-
-- Support VoxelPose ["VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment"](https://arxiv.org/abs/2004.06239), ECCV'2020 ([#1050](https://github.com/open-mmlab/mmpose/pull/1050)) @wusize
-
-- Support Soft Wing loss ["Structure-Coherent Deep Feature Learning for Robust Face Alignment"](https://linchunze.github.io/papers/TIP21_Structure_coherent_FA.pdf), TIP'2021 ([#1077](https://github.com/open-mmlab/mmpose/pull/1077)) @jin-s13
-
-- Support Adaptive Wing loss ["Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression"](https://arxiv.org/abs/1904.07399), ICCV'2019 ([#1072](https://github.com/open-mmlab/mmpose/pull/1072)) @jin-s13
-
-- Add LiteHRNet-18 Checkpoints trained on COCO. ([#1120](https://github.com/open-mmlab/mmpose/pull/1120)) @jin-s13
-
-**Improvements**
-
-- Improve documentation quality ([#1115](https://github.com/open-mmlab/mmpose/pull/1115), [#1111](https://github.com/open-mmlab/mmpose/pull/1111), [#1105](https://github.com/open-mmlab/mmpose/pull/1105), [#1087](https://github.com/open-mmlab/mmpose/pull/1087), [#1086](https://github.com/open-mmlab/mmpose/pull/1086), [#1085](https://github.com/open-mmlab/mmpose/pull/1085), [#1084](https://github.com/open-mmlab/mmpose/pull/1084), [#1083](https://github.com/open-mmlab/mmpose/pull/1083), [#1124](https://github.com/open-mmlab/mmpose/pull/1124), [#1070](https://github.com/open-mmlab/mmpose/pull/1070), [#1068](https://github.com/open-mmlab/mmpose/pull/1068)) @jin-s13, @liqikai9, @ly015
-
-- Support CircleCI ([#1074](https://github.com/open-mmlab/mmpose/pull/1074)) @ly015
-
-- Skip unit tests in CI when only document files were changed ([#1074](https://github.com/open-mmlab/mmpose/pull/1074), [#1041](https://github.com/open-mmlab/mmpose/pull/1041)) @QwQ2000, @ly015
-
-- Support file_client_args in LoadImageFromFile ([#1076](https://github.com/open-mmlab/mmpose/pull/1076)) @jin-s13
-
-**Bug Fixes**
-
-- Fix a bug in Dark UDP postprocessing that causes error when the channel number is large. ([#1079](https://github.com/open-mmlab/mmpose/pull/1079), [#1116](https://github.com/open-mmlab/mmpose/pull/1116)) @X00123, @jin-s13
-
-- Fix hard-coded `sigmas` in bottom-up image demo ([#1107](https://github.com/open-mmlab/mmpose/pull/1107), [#1101](https://github.com/open-mmlab/mmpose/pull/1101)) @chenxinfeng4, @liqikai9
-
-- Fix unstable checks in unit tests ([#1112](https://github.com/open-mmlab/mmpose/pull/1112)) @ly015
-
-- Do not destroy NULL windows if `args.show==False` in demo scripts ([#1104](https://github.com/open-mmlab/mmpose/pull/1104)) @bladrome
-
-## **v0.21.0 (06/12/2021)**
-
-**Highlights**
-
-- Support ["Learning Temporal Pose Estimation from Sparsely-Labeled Videos"](https://arxiv.org/abs/1906.04016), NeurIPS'2019 ([#932](https://github.com/open-mmlab/mmpose/pull/932), [#1006](https://github.com/open-mmlab/mmpose/pull/1006), [#1036](https://github.com/open-mmlab/mmpose/pull/1036), [#1060](https://github.com/open-mmlab/mmpose/pull/1060)) @liqikai9
-
-- Add ViPNAS-MobileNetV3 models ([#1025](https://github.com/open-mmlab/mmpose/pull/1025)) @luminxu, @jin-s13
-
-- Add inference speed benchmark ([#1028](https://github.com/open-mmlab/mmpose/pull/1028), [#1034](https://github.com/open-mmlab/mmpose/pull/1034), [#1044](https://github.com/open-mmlab/mmpose/pull/1044)) @liqikai9
-
-**New Features**
-
-- Support ["Learning Temporal Pose Estimation from Sparsely-Labeled Videos"](https://arxiv.org/abs/1906.04016), NeurIPS'2019 ([#932](https://github.com/open-mmlab/mmpose/pull/932), [#1006](https://github.com/open-mmlab/mmpose/pull/1006), [#1036](https://github.com/open-mmlab/mmpose/pull/1036)) @liqikai9
-
-- Add ViPNAS-MobileNetV3 models ([#1025](https://github.com/open-mmlab/mmpose/pull/1025)) @luminxu, @jin-s13
-
-- Add light-weight top-down models for whole-body keypoint detection ([#1009](https://github.com/open-mmlab/mmpose/pull/1009), [#1020](https://github.com/open-mmlab/mmpose/pull/1020), [#1055](https://github.com/open-mmlab/mmpose/pull/1055)) @luminxu, @ly015
-
-- Add HRNet checkpoints with various settings on PoseTrack18 ([#1035](https://github.com/open-mmlab/mmpose/pull/1035)) @liqikai9
-
-**Improvements**
-
-- Add inference speed benchmark ([#1028](https://github.com/open-mmlab/mmpose/pull/1028), [#1034](https://github.com/open-mmlab/mmpose/pull/1034), [#1044](https://github.com/open-mmlab/mmpose/pull/1044)) @liqikai9
-
-- Update model metafile format ([#1001](https://github.com/open-mmlab/mmpose/pull/1001)) @ly015
-
-- Support minus output feature index in mobilenet_v3 ([#1005](https://github.com/open-mmlab/mmpose/pull/1005)) @luminxu
-
-- Improve documentation quality ([#1018](https://github.com/open-mmlab/mmpose/pull/1018), [#1026](https://github.com/open-mmlab/mmpose/pull/1026), [#1027](https://github.com/open-mmlab/mmpose/pull/1027), [#1031](https://github.com/open-mmlab/mmpose/pull/1031), [#1038](https://github.com/open-mmlab/mmpose/pull/1038), [#1046](https://github.com/open-mmlab/mmpose/pull/1046), [#1056](https://github.com/open-mmlab/mmpose/pull/1056), [#1057](https://github.com/open-mmlab/mmpose/pull/1057)) @edybk, @luminxu, @ly015, @jin-s13
-
-- Set default random seed in training initialization ([#1030](https://github.com/open-mmlab/mmpose/pull/1030)) @ly015
-
-- Skip CI when only specific files changed ([#1041](https://github.com/open-mmlab/mmpose/pull/1041), [#1059](https://github.com/open-mmlab/mmpose/pull/1059)) @QwQ2000, @ly015
-
-- Automatically cancel uncompleted action runs when new commit arrives ([#1053](https://github.com/open-mmlab/mmpose/pull/1053)) @ly015
-
-**Bug Fixes**
-
-- Update pose tracking demo to be compatible with latest mmtracking ([#1014](https://github.com/open-mmlab/mmpose/pull/1014)) @jin-s13
-
-- Fix symlink creation failure when installed in Windows environments ([#1039](https://github.com/open-mmlab/mmpose/pull/1039)) @QwQ2000
-
-- Fix AP-10K dataset sigmas ([#1040](https://github.com/open-mmlab/mmpose/pull/1040)) @jin-s13
-
-## **v0.20.0 (01/11/2021)**
-
-**Highlights**
-
-- Add AP-10K dataset for animal pose estimation ([#987](https://github.com/open-mmlab/mmpose/pull/987)) @Annbless, @AlexTheBad, @jin-s13, @ly015
-
-- Support TorchServe ([#979](https://github.com/open-mmlab/mmpose/pull/979)) @ly015
-
-**New Features**
-
-- Add AP-10K dataset for animal pose estimation ([#987](https://github.com/open-mmlab/mmpose/pull/987)) @Annbless, @AlexTheBad, @jin-s13, @ly015
-
-- Add HRNetv2 checkpoints on 300W and COFW datasets ([#980](https://github.com/open-mmlab/mmpose/pull/980)) @jin-s13
-
-- Support TorchServe ([#979](https://github.com/open-mmlab/mmpose/pull/979)) @ly015
-
-**Bug Fixes**
-
-- Fix some deprecated or risky settings in configs ([#963](https://github.com/open-mmlab/mmpose/pull/963), [#976](https://github.com/open-mmlab/mmpose/pull/976), [#992](https://github.com/open-mmlab/mmpose/pull/992)) @jin-s13, @wusize
-
-- Fix issues of default arguments of training and testing scripts ([#970](https://github.com/open-mmlab/mmpose/pull/970), [#985](https://github.com/open-mmlab/mmpose/pull/985)) @liqikai9, @wusize
-
-- Fix heatmap and tag size mismatch in bottom-up with UDP ([#994](https://github.com/open-mmlab/mmpose/pull/994)) @wusize
-
-- Fix python3.9 installation in CI ([#983](https://github.com/open-mmlab/mmpose/pull/983)) @ly015
-
-- Fix model zoo document integrity issue ([#990](https://github.com/open-mmlab/mmpose/pull/990)) @jin-s13
-
-**Improvements**
-
-- Support non-square input shape for bottom-up ([#991](https://github.com/open-mmlab/mmpose/pull/991)) @wusize
-
-- Add image and video resources for demo ([#971](https://github.com/open-mmlab/mmpose/pull/971)) @liqikai9
-
-- Use CUDA docker images to accelerate CI ([#973](https://github.com/open-mmlab/mmpose/pull/973)) @ly015
-
-- Add codespell hook and fix detected typos ([#977](https://github.com/open-mmlab/mmpose/pull/977)) @ly015
-
-## **v0.19.0 (08/10/2021)**
-
-**Highlights**
-
-- Add models for Associative Embedding with Hourglass network backbone ([#906](https://github.com/open-mmlab/mmpose/pull/906), [#955](https://github.com/open-mmlab/mmpose/pull/955)) @jin-s13, @luminxu
-
-- Support COCO-Wholebody-Face and COCO-Wholebody-Hand datasets ([#813](https://github.com/open-mmlab/mmpose/pull/813)) @jin-s13, @innerlee, @luminxu
-
-- Upgrade dataset interface ([#901](https://github.com/open-mmlab/mmpose/pull/901), [#924](https://github.com/open-mmlab/mmpose/pull/924)) @jin-s13, @innerlee, @ly015, @liqikai9
-
-- New style of documentation ([#945](https://github.com/open-mmlab/mmpose/pull/945)) @ly015
-
-**New Features**
-
-- Add models for Associative Embedding with Hourglass network backbone ([#906](https://github.com/open-mmlab/mmpose/pull/906), [#955](https://github.com/open-mmlab/mmpose/pull/955)) @jin-s13, @luminxu
-
-- Support COCO-Wholebody-Face and COCO-Wholebody-Hand datasets ([#813](https://github.com/open-mmlab/mmpose/pull/813)) @jin-s13, @innerlee, @luminxu
-
-- Add pseudo-labeling tool to generate COCO style keypoint annotations with given bounding boxes ([#928](https://github.com/open-mmlab/mmpose/pull/928)) @soltkreig
-
-- New style of documentation ([#945](https://github.com/open-mmlab/mmpose/pull/945)) @ly015
-
-**Bug Fixes**
-
-- Fix segmentation parsing in Macaque dataset preprocessing ([#948](https://github.com/open-mmlab/mmpose/pull/948)) @jin-s13
-
-- Fix dependencies that may lead to CI failure in downstream projects ([#936](https://github.com/open-mmlab/mmpose/pull/936), [#953](https://github.com/open-mmlab/mmpose/pull/953)) @RangiLyu, @ly015
-
-- Fix keypoint order in Human3.6M dataset ([#940](https://github.com/open-mmlab/mmpose/pull/940)) @ttxskk
-
-- Fix unstable image loading for Interhand2.6M ([#913](https://github.com/open-mmlab/mmpose/pull/913)) @zengwang430521
-
-**Improvements**
-
-- Upgrade dataset interface ([#901](https://github.com/open-mmlab/mmpose/pull/901), [#924](https://github.com/open-mmlab/mmpose/pull/924)) @jin-s13, @innerlee, @ly015, @liqikai9
-
-- Improve demo usability and stability ([#908](https://github.com/open-mmlab/mmpose/pull/908), [#934](https://github.com/open-mmlab/mmpose/pull/934)) @ly015
-
-- Standardize model metafile format ([#941](https://github.com/open-mmlab/mmpose/pull/941)) @ly015
-
-- Support `persistent_worker` and several other arguments in configs ([#946](https://github.com/open-mmlab/mmpose/pull/946)) @jin-s13
-
-- Use MMCV root model registry to enable cross-project module building ([#935](https://github.com/open-mmlab/mmpose/pull/935)) @RangiLyu
-
-- Improve the document quality ([#916](https://github.com/open-mmlab/mmpose/pull/916), [#909](https://github.com/open-mmlab/mmpose/pull/909), [#942](https://github.com/open-mmlab/mmpose/pull/942), [#913](https://github.com/open-mmlab/mmpose/pull/913), [#956](https://github.com/open-mmlab/mmpose/pull/956)) @jin-s13, @ly015, @bit-scientist, @zengwang430521
-
-- Improve pull request template ([#952](https://github.com/open-mmlab/mmpose/pull/952), [#954](https://github.com/open-mmlab/mmpose/pull/954)) @ly015
-
-**Breaking Changes**
-
-- Upgrade dataset interface ([#901](https://github.com/open-mmlab/mmpose/pull/901)) @jin-s13, @innerlee, @ly015
-
-## **v0.18.0 (01/09/2021)**
-
-**Bug Fixes**
-
-- Fix redundant model weight loading in pytorch-to-onnx conversion ([#850](https://github.com/open-mmlab/mmpose/pull/850)) @ly015
-
-- Fix a bug in update_model_index.py that may cause pre-commit hook failure([#866](https://github.com/open-mmlab/mmpose/pull/866)) @ly015
-
-- Fix a bug in interhand_3d_head ([#890](https://github.com/open-mmlab/mmpose/pull/890)) @zengwang430521
-
-- Fix pose tracking demo failure caused by out-of-date configs ([#891](https://github.com/open-mmlab/mmpose/pull/891))
-
-**Improvements**
-
-- Add automatic benchmark regression tools ([#849](https://github.com/open-mmlab/mmpose/pull/849), [#880](https://github.com/open-mmlab/mmpose/pull/880), [#885](https://github.com/open-mmlab/mmpose/pull/885)) @liqikai9, @ly015
-
-- Add copyright information and checking hook ([#872](https://github.com/open-mmlab/mmpose/pull/872))
-
-- Add PR template ([#875](https://github.com/open-mmlab/mmpose/pull/875)) @ly015
-
-- Add citation information ([#876](https://github.com/open-mmlab/mmpose/pull/876)) @ly015
-
-- Add python3.9 in CI ([#877](https://github.com/open-mmlab/mmpose/pull/877), [#883](https://github.com/open-mmlab/mmpose/pull/883)) @ly015
-
-- Improve the quality of the documents ([#845](https://github.com/open-mmlab/mmpose/pull/845), [#845](https://github.com/open-mmlab/mmpose/pull/845), [#848](https://github.com/open-mmlab/mmpose/pull/848), [#867](https://github.com/open-mmlab/mmpose/pull/867), [#870](https://github.com/open-mmlab/mmpose/pull/870), [#873](https://github.com/open-mmlab/mmpose/pull/873), [#896](https://github.com/open-mmlab/mmpose/pull/896)) @jin-s13, @ly015, @zhiqwang
-
-## **v0.17.0 (06/08/2021)**
-
-**Highlights**
-
-1. Support ["Lite-HRNet: A Lightweight High-Resolution Network"](https://arxiv.org/abs/2104.06403) CVPR'2021 ([#733](https://github.com/open-mmlab/mmpose/pull/733),[#800](https://github.com/open-mmlab/mmpose/pull/800)) @jin-s13
-
-2. Add 3d body mesh demo ([#771](https://github.com/open-mmlab/mmpose/pull/771)) @zengwang430521
-
-3. Add Chinese documentation ([#787](https://github.com/open-mmlab/mmpose/pull/787), [#798](https://github.com/open-mmlab/mmpose/pull/798), [#799](https://github.com/open-mmlab/mmpose/pull/799), [#802](https://github.com/open-mmlab/mmpose/pull/802), [#804](https://github.com/open-mmlab/mmpose/pull/804), [#805](https://github.com/open-mmlab/mmpose/pull/805), [#815](https://github.com/open-mmlab/mmpose/pull/815), [#816](https://github.com/open-mmlab/mmpose/pull/816), [#817](https://github.com/open-mmlab/mmpose/pull/817), [#819](https://github.com/open-mmlab/mmpose/pull/819), [#839](https://github.com/open-mmlab/mmpose/pull/839)) @ly015, @luminxu, @jin-s13, @liqikai9, @zengwang430521
-
-4. Add Colab Tutorial ([#834](https://github.com/open-mmlab/mmpose/pull/834)) @ly015
-
-**New Features**
-
-- Support ["Lite-HRNet: A Lightweight High-Resolution Network"](https://arxiv.org/abs/2104.06403) CVPR'2021 ([#733](https://github.com/open-mmlab/mmpose/pull/733),[#800](https://github.com/open-mmlab/mmpose/pull/800)) @jin-s13
-
-- Add 3d body mesh demo ([#771](https://github.com/open-mmlab/mmpose/pull/771)) @zengwang430521
-
-- Add Chinese documentation ([#787](https://github.com/open-mmlab/mmpose/pull/787), [#798](https://github.com/open-mmlab/mmpose/pull/798), [#799](https://github.com/open-mmlab/mmpose/pull/799), [#802](https://github.com/open-mmlab/mmpose/pull/802), [#804](https://github.com/open-mmlab/mmpose/pull/804), [#805](https://github.com/open-mmlab/mmpose/pull/805), [#815](https://github.com/open-mmlab/mmpose/pull/815), [#816](https://github.com/open-mmlab/mmpose/pull/816), [#817](https://github.com/open-mmlab/mmpose/pull/817), [#819](https://github.com/open-mmlab/mmpose/pull/819), [#839](https://github.com/open-mmlab/mmpose/pull/839)) @ly015, @luminxu, @jin-s13, @liqikai9, @zengwang430521
-
-- Add Colab Tutorial ([#834](https://github.com/open-mmlab/mmpose/pull/834)) @ly015
-
-- Support training for InterHand v1.0 dataset ([#761](https://github.com/open-mmlab/mmpose/pull/761)) @zengwang430521
-
-**Bug Fixes**
-
-- Fix mpii pckh@0.1 index ([#773](https://github.com/open-mmlab/mmpose/pull/773)) @jin-s13
-
-- Fix multi-node distributed test ([#818](https://github.com/open-mmlab/mmpose/pull/818)) @ly015
-
-- Fix docstring and init_weights error of ShuffleNetV1 ([#814](https://github.com/open-mmlab/mmpose/pull/814)) @Junjun2016
-
-- Fix imshow_bbox error when input bboxes is empty ([#796](https://github.com/open-mmlab/mmpose/pull/796)) @ly015
-
-- Fix model zoo doc generation ([#778](https://github.com/open-mmlab/mmpose/pull/778)) @ly015
-
-- Fix typo ([#767](https://github.com/open-mmlab/mmpose/pull/767)), ([#780](https://github.com/open-mmlab/mmpose/pull/780), [#782](https://github.com/open-mmlab/mmpose/pull/782)) @ly015, @jin-s13
-
-**Breaking Changes**
-
-- Use MMCV EvalHook ([#686](https://github.com/open-mmlab/mmpose/pull/686)) @ly015
-
-**Improvements**
-
-- Add pytest.ini and fix docstring ([#812](https://github.com/open-mmlab/mmpose/pull/812)) @jin-s13
-
-- Update MSELoss ([#829](https://github.com/open-mmlab/mmpose/pull/829)) @Ezra-Yu
-
-- Move process_mmdet_results into inference.py ([#831](https://github.com/open-mmlab/mmpose/pull/831)) @ly015
-
-- Update resource limit ([#783](https://github.com/open-mmlab/mmpose/pull/783)) @jin-s13
-
-- Use COCO 2D pose model in 3D demo examples ([#785](https://github.com/open-mmlab/mmpose/pull/785)) @ly015
-
-- Change model zoo titles in the doc from center-aligned to left-aligned ([#792](https://github.com/open-mmlab/mmpose/pull/792), [#797](https://github.com/open-mmlab/mmpose/pull/797)) @ly015
-
-- Support MIM ([#706](https://github.com/open-mmlab/mmpose/pull/706), [#794](https://github.com/open-mmlab/mmpose/pull/794)) @ly015
-
-- Update out-of-date configs ([#827](https://github.com/open-mmlab/mmpose/pull/827)) @jin-s13
-
-- Remove opencv-python-headless dependency by albumentations ([#833](https://github.com/open-mmlab/mmpose/pull/833)) @ly015
-
-- Update QQ QR code in README_CN.md ([#832](https://github.com/open-mmlab/mmpose/pull/832)) @ly015
-
-## **v0.16.0 (02/07/2021)**
-
-**Highlights**
-
-1. Support ["ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search"](https://arxiv.org/abs/2105.10154) CVPR'2021 ([#742](https://github.com/open-mmlab/mmpose/pull/742),[#755](https://github.com/open-mmlab/mmpose/pull/755)).
-
-2. Support MPI-INF-3DHP dataset ([#683](https://github.com/open-mmlab/mmpose/pull/683),[#746](https://github.com/open-mmlab/mmpose/pull/746),[#751](https://github.com/open-mmlab/mmpose/pull/751)).
-
-3. Add webcam demo tool ([#729](https://github.com/open-mmlab/mmpose/pull/729))
-
-4. Add 3d body and hand pose estimation demo ([#704](https://github.com/open-mmlab/mmpose/pull/704), [#727](https://github.com/open-mmlab/mmpose/pull/727)).
-
-**New Features**
-
-- Support ["ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search"](https://arxiv.org/abs/2105.10154) CVPR'2021 ([#742](https://github.com/open-mmlab/mmpose/pull/742),[#755](https://github.com/open-mmlab/mmpose/pull/755))
-
-- Support MPI-INF-3DHP dataset ([#683](https://github.com/open-mmlab/mmpose/pull/683),[#746](https://github.com/open-mmlab/mmpose/pull/746),[#751](https://github.com/open-mmlab/mmpose/pull/751))
-
-- Support Webcam demo ([#729](https://github.com/open-mmlab/mmpose/pull/729))
-
-- Support Interhand 3d demo ([#704](https://github.com/open-mmlab/mmpose/pull/704))
-
-- Support 3d pose video demo ([#727](https://github.com/open-mmlab/mmpose/pull/727))
-
-- Support H36m dataset for 2d pose estimation ([#709](https://github.com/open-mmlab/mmpose/pull/709), [#735](https://github.com/open-mmlab/mmpose/pull/735))
-
-- Add scripts to generate mim metafile ([#749](https://github.com/open-mmlab/mmpose/pull/749))
-
-**Bug Fixes**
-
-- Fix typos ([#692](https://github.com/open-mmlab/mmpose/pull/692),[#696](https://github.com/open-mmlab/mmpose/pull/696),[#697](https://github.com/open-mmlab/mmpose/pull/697),[#698](https://github.com/open-mmlab/mmpose/pull/698),[#712](https://github.com/open-mmlab/mmpose/pull/712),[#718](https://github.com/open-mmlab/mmpose/pull/718),[#728](https://github.com/open-mmlab/mmpose/pull/728))
-
-- Change model download links from `http` to `https` ([#716](https://github.com/open-mmlab/mmpose/pull/716))
-
-**Breaking Changes**
-
-- Switch to MMCV MODEL_REGISTRY ([#669](https://github.com/open-mmlab/mmpose/pull/669))
-
-**Improvements**
-
-- Refactor MeshMixDataset ([#752](https://github.com/open-mmlab/mmpose/pull/752))
-
-- Rename 'GaussianHeatMap' to 'GaussianHeatmap' ([#745](https://github.com/open-mmlab/mmpose/pull/745))
-
-- Update out-of-date configs ([#734](https://github.com/open-mmlab/mmpose/pull/734))
-
-- Improve compatibility for breaking changes ([#731](https://github.com/open-mmlab/mmpose/pull/731))
-
-- Enable to control radius and thickness in visualization ([#722](https://github.com/open-mmlab/mmpose/pull/722))
-
-- Add regex dependency ([#720](https://github.com/open-mmlab/mmpose/pull/720))
-
-## **v0.15.0 (02/06/2021)**
-
-**Highlights**
-
-1. Support 3d video pose estimation (VideoPose3D).
-
-2. Support 3d hand pose estimation (InterNet).
-
-3. Improve presentation of modelzoo.
-
-**New Features**
-
-- Support "InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image" (ECCV‘20) ([#624](https://github.com/open-mmlab/mmpose/pull/624))
-
-- Support "3D human pose estimation in video with temporal convolutions and semi-supervised training" (CVPR'19) ([#602](https://github.com/open-mmlab/mmpose/pull/602), [#681](https://github.com/open-mmlab/mmpose/pull/681))
-
-- Support 3d pose estimation demo ([#653](https://github.com/open-mmlab/mmpose/pull/653), [#670](https://github.com/open-mmlab/mmpose/pull/670))
-
-- Support bottom-up whole-body pose estimation ([#689](https://github.com/open-mmlab/mmpose/pull/689))
-
-- Support mmcli ([#634](https://github.com/open-mmlab/mmpose/pull/634))
-
-**Bug Fixes**
-
-- Fix opencv compatibility ([#635](https://github.com/open-mmlab/mmpose/pull/635))
-
-- Fix demo with UDP ([#637](https://github.com/open-mmlab/mmpose/pull/637))
-
-- Fix bottom-up model onnx conversion ([#680](https://github.com/open-mmlab/mmpose/pull/680))
-
-- Fix `GPU_IDS` in distributed training ([#668](https://github.com/open-mmlab/mmpose/pull/668))
-
-- Fix MANIFEST.in ([#641](https://github.com/open-mmlab/mmpose/pull/641), [#657](https://github.com/open-mmlab/mmpose/pull/657))
-
-- Fix docs ([#643](https://github.com/open-mmlab/mmpose/pull/643),[#684](https://github.com/open-mmlab/mmpose/pull/684),[#688](https://github.com/open-mmlab/mmpose/pull/688),[#690](https://github.com/open-mmlab/mmpose/pull/690),[#692](https://github.com/open-mmlab/mmpose/pull/692))
-
-**Breaking Changes**
-
-- Reorganize configs by tasks, algorithms, datasets, and techniques ([#647](https://github.com/open-mmlab/mmpose/pull/647))
-
-- Rename heads and detectors ([#667](https://github.com/open-mmlab/mmpose/pull/667))
-
-**Improvements**
-
-- Add `radius` and `thickness` parameters in visualization ([#638](https://github.com/open-mmlab/mmpose/pull/638))
-
-- Add `trans_prob` parameter in `TopDownRandomTranslation` ([#650](https://github.com/open-mmlab/mmpose/pull/650))
-
-- Switch to `MMCV MODEL_REGISTRY` ([#669](https://github.com/open-mmlab/mmpose/pull/669))
-
-- Update dependencies ([#674](https://github.com/open-mmlab/mmpose/pull/674), [#676](https://github.com/open-mmlab/mmpose/pull/676))
-
-## **v0.14.0 (06/05/2021)**
-
-**Highlights**
-
-1. Support animal pose estimation with 7 popular datasets.
-
-2. Support "A simple yet effective baseline for 3d human pose estimation" (ICCV'17).
-
-**New Features**
-
-- Support "A simple yet effective baseline for 3d human pose estimation" (ICCV'17) ([#554](https://github.com/open-mmlab/mmpose/pull/554),[#558](https://github.com/open-mmlab/mmpose/pull/558),[#566](https://github.com/open-mmlab/mmpose/pull/566),[#570](https://github.com/open-mmlab/mmpose/pull/570),[#589](https://github.com/open-mmlab/mmpose/pull/589))
-
-- Support animal pose estimation ([#559](https://github.com/open-mmlab/mmpose/pull/559),[#561](https://github.com/open-mmlab/mmpose/pull/561),[#563](https://github.com/open-mmlab/mmpose/pull/563),[#571](https://github.com/open-mmlab/mmpose/pull/571),[#603](https://github.com/open-mmlab/mmpose/pull/603),[#605](https://github.com/open-mmlab/mmpose/pull/605))
-
-- Support Horse-10 dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), MacaquePose dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), Vinegar Fly dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), Desert Locust dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), Grevy's Zebra dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), ATRW dataset ([#571](https://github.com/open-mmlab/mmpose/pull/571)), and Animal-Pose dataset ([#603](https://github.com/open-mmlab/mmpose/pull/603))
-
-- Support bottom-up pose tracking demo ([#574](https://github.com/open-mmlab/mmpose/pull/574))
-
-- Support FP16 training ([#584](https://github.com/open-mmlab/mmpose/pull/584),[#616](https://github.com/open-mmlab/mmpose/pull/616),[#626](https://github.com/open-mmlab/mmpose/pull/626))
-
-- Support NMS for bottom-up ([#609](https://github.com/open-mmlab/mmpose/pull/609))
-
-**Bug Fixes**
-
-- Fix bugs in the top-down demo, when there are no people in the images ([#569](https://github.com/open-mmlab/mmpose/pull/569)).
-
-- Fix the links in the doc ([#612](https://github.com/open-mmlab/mmpose/pull/612))
-
-**Improvements**
-
-- Speed up top-down inference ([#560](https://github.com/open-mmlab/mmpose/pull/560))
-
-- Update github CI ([#562](https://github.com/open-mmlab/mmpose/pull/562), [#564](https://github.com/open-mmlab/mmpose/pull/564))
-
-- Update Readme ([#578](https://github.com/open-mmlab/mmpose/pull/578),[#579](https://github.com/open-mmlab/mmpose/pull/579),[#580](https://github.com/open-mmlab/mmpose/pull/580),[#592](https://github.com/open-mmlab/mmpose/pull/592),[#599](https://github.com/open-mmlab/mmpose/pull/599),[#600](https://github.com/open-mmlab/mmpose/pull/600),[#607](https://github.com/open-mmlab/mmpose/pull/607))
-
-- Update Faq ([#587](https://github.com/open-mmlab/mmpose/pull/587), [#610](https://github.com/open-mmlab/mmpose/pull/610))
-
-## **v0.13.0 (31/03/2021)**
-
-**Highlights**
-
-1. Support Wingloss.
-
-2. Support RHD hand dataset.
-
-**New Features**
-
-- Support Wingloss ([#482](https://github.com/open-mmlab/mmpose/pull/482))
-
-- Support RHD hand dataset ([#523](https://github.com/open-mmlab/mmpose/pull/523), [#551](https://github.com/open-mmlab/mmpose/pull/551))
-
-- Support Human3.6m dataset for 3d keypoint detection ([#518](https://github.com/open-mmlab/mmpose/pull/518), [#527](https://github.com/open-mmlab/mmpose/pull/527))
-
-- Support TCN model for 3d keypoint detection ([#521](https://github.com/open-mmlab/mmpose/pull/521), [#522](https://github.com/open-mmlab/mmpose/pull/522))
-
-- Support Interhand3D model for 3d hand detection ([#536](https://github.com/open-mmlab/mmpose/pull/536))
-
-- Support Multi-task detector ([#480](https://github.com/open-mmlab/mmpose/pull/480))
-
-**Bug Fixes**
-
-- Fix PCKh@0.1 calculation ([#516](https://github.com/open-mmlab/mmpose/pull/516))
-
-- Fix unittest ([#529](https://github.com/open-mmlab/mmpose/pull/529))
-
-- Fix circular importing ([#542](https://github.com/open-mmlab/mmpose/pull/542))
-
-- Fix bugs in bottom-up keypoint score ([#548](https://github.com/open-mmlab/mmpose/pull/548))
-
-**Improvements**
-
-- Update config & checkpoints ([#525](https://github.com/open-mmlab/mmpose/pull/525), [#546](https://github.com/open-mmlab/mmpose/pull/546))
-
-- Fix typos ([#514](https://github.com/open-mmlab/mmpose/pull/514), [#519](https://github.com/open-mmlab/mmpose/pull/519), [#532](https://github.com/open-mmlab/mmpose/pull/532), [#537](https://github.com/open-mmlab/mmpose/pull/537), )
-
-- Speed up post processing ([#535](https://github.com/open-mmlab/mmpose/pull/535))
-
-- Update mmcv version dependency ([#544](https://github.com/open-mmlab/mmpose/pull/544))
-
-## **v0.12.0 (28/02/2021)**
-
-**Highlights**
-
-1. Support DeepPose algorithm.
-
-**New Features**
-
-- Support DeepPose algorithm ([#446](https://github.com/open-mmlab/mmpose/pull/446), [#461](https://github.com/open-mmlab/mmpose/pull/461))
-
-- Support interhand3d dataset ([#468](https://github.com/open-mmlab/mmpose/pull/468))
-
-- Support Albumentation pipeline ([#469](https://github.com/open-mmlab/mmpose/pull/469))
-
-- Support PhotometricDistortion pipeline ([#485](https://github.com/open-mmlab/mmpose/pull/485))
-
-- Set seed option for training ([#493](https://github.com/open-mmlab/mmpose/pull/493))
-
-- Add demos for face keypoint detection ([#502](https://github.com/open-mmlab/mmpose/pull/502))
-
-**Bug Fixes**
-
-- Change channel order according to configs ([#504](https://github.com/open-mmlab/mmpose/pull/504))
-
-- Fix `num_factors` in UDP encoding ([#495](https://github.com/open-mmlab/mmpose/pull/495))
-
-- Fix configs ([#456](https://github.com/open-mmlab/mmpose/pull/456))
-
-**Breaking Changes**
-
-- Refactor configs for wholebody pose estimation ([#487](https://github.com/open-mmlab/mmpose/pull/487), [#491](https://github.com/open-mmlab/mmpose/pull/491))
-
-- Rename `decode` function for heads ([#481](https://github.com/open-mmlab/mmpose/pull/481))
-
-**Improvements**
-
-- Update config & checkpoints ([#453](https://github.com/open-mmlab/mmpose/pull/453),[#484](https://github.com/open-mmlab/mmpose/pull/484),[#487](https://github.com/open-mmlab/mmpose/pull/487))
-
-- Add README in Chinese ([#462](https://github.com/open-mmlab/mmpose/pull/462))
-
-- Add tutorials about configs ([#465](https://github.com/open-mmlab/mmpose/pull/465))
-
-- Add demo videos for various tasks ([#499](https://github.com/open-mmlab/mmpose/pull/499), [#503](https://github.com/open-mmlab/mmpose/pull/503))
-
-- Update docs about MMPose installation ([#467](https://github.com/open-mmlab/mmpose/pull/467), [#505](https://github.com/open-mmlab/mmpose/pull/505))
-
-- Rename `stat.py` to `stats.py` ([#483](https://github.com/open-mmlab/mmpose/pull/483))
-
-- Fix typos ([#463](https://github.com/open-mmlab/mmpose/pull/463), [#464](https://github.com/open-mmlab/mmpose/pull/464), [#477](https://github.com/open-mmlab/mmpose/pull/477), [#481](https://github.com/open-mmlab/mmpose/pull/481))
-
-- latex to bibtex ([#471](https://github.com/open-mmlab/mmpose/pull/471))
-
-- Update FAQ ([#466](https://github.com/open-mmlab/mmpose/pull/466))
-
-## **v0.11.0 (31/01/2021)**
-
-**Highlights**
-
-1. Support fashion landmark detection.
-
-2. Support face keypoint detection.
-
-3. Support pose tracking with MMTracking.
-
-**New Features**
-
-- Support fashion landmark detection (DeepFashion) ([#413](https://github.com/open-mmlab/mmpose/pull/413))
-
-- Support face keypoint detection (300W, AFLW, COFW, WFLW) ([#367](https://github.com/open-mmlab/mmpose/pull/367))
-
-- Support pose tracking demo with MMTracking ([#427](https://github.com/open-mmlab/mmpose/pull/427))
-
-- Support face demo ([#443](https://github.com/open-mmlab/mmpose/pull/443))
-
-- Support AIC dataset for bottom-up methods ([#438](https://github.com/open-mmlab/mmpose/pull/438), [#449](https://github.com/open-mmlab/mmpose/pull/449))
-
-**Bug Fixes**
-
-- Fix multi-batch training ([#434](https://github.com/open-mmlab/mmpose/pull/434))
-
-- Fix sigmas in AIC dataset ([#441](https://github.com/open-mmlab/mmpose/pull/441))
-
-- Fix config file ([#420](https://github.com/open-mmlab/mmpose/pull/420))
-
-**Breaking Changes**
-
-- Refactor Heads ([#382](https://github.com/open-mmlab/mmpose/pull/382))
-
-**Improvements**
-
-- Update readme ([#409](https://github.com/open-mmlab/mmpose/pull/409), [#412](https://github.com/open-mmlab/mmpose/pull/412), [#415](https://github.com/open-mmlab/mmpose/pull/415), [#416](https://github.com/open-mmlab/mmpose/pull/416), [#419](https://github.com/open-mmlab/mmpose/pull/419), [#421](https://github.com/open-mmlab/mmpose/pull/421), [#422](https://github.com/open-mmlab/mmpose/pull/422), [#424](https://github.com/open-mmlab/mmpose/pull/424), [#425](https://github.com/open-mmlab/mmpose/pull/425), [#435](https://github.com/open-mmlab/mmpose/pull/435), [#436](https://github.com/open-mmlab/mmpose/pull/436), [#437](https://github.com/open-mmlab/mmpose/pull/437), [#444](https://github.com/open-mmlab/mmpose/pull/444), [#445](https://github.com/open-mmlab/mmpose/pull/445))
-
-- Add GAP (global average pooling) neck ([#414](https://github.com/open-mmlab/mmpose/pull/414))
-
-- Speed up ([#411](https://github.com/open-mmlab/mmpose/pull/411), [#423](https://github.com/open-mmlab/mmpose/pull/423))
-
-- Support COCO test-dev test ([#433](https://github.com/open-mmlab/mmpose/pull/433))
-
-## **v0.10.0 (31/12/2020)**
-
-**Highlights**
-
-1. Support more human pose estimation methods.
-
- 1. [UDP](https://arxiv.org/abs/1911.07524)
-
-2. Support pose tracking.
-
-3. Support multi-batch inference.
-
-4. Add some useful tools, including `analyze_logs`, `get_flops`, `print_config`.
-
-5. Support more backbone networks.
-
- 1. [ResNest](https://arxiv.org/pdf/2004.08955.pdf)
- 2. [VGG](https://arxiv.org/abs/1409.1556)
-
-**New Features**
-
-- Support UDP ([#353](https://github.com/open-mmlab/mmpose/pull/353), [#371](https://github.com/open-mmlab/mmpose/pull/371), [#402](https://github.com/open-mmlab/mmpose/pull/402))
-
-- Support multi-batch inference ([#390](https://github.com/open-mmlab/mmpose/pull/390))
-
-- Support MHP dataset ([#386](https://github.com/open-mmlab/mmpose/pull/386))
-
-- Support pose tracking demo ([#380](https://github.com/open-mmlab/mmpose/pull/380))
-
-- Support mpii-trb demo ([#372](https://github.com/open-mmlab/mmpose/pull/372))
-
-- Support mobilenet for hand pose estimation ([#377](https://github.com/open-mmlab/mmpose/pull/377))
-
-- Support ResNest backbone ([#370](https://github.com/open-mmlab/mmpose/pull/370))
-
-- Support VGG backbone ([#370](https://github.com/open-mmlab/mmpose/pull/370))
-
-- Add some useful tools, including `analyze_logs`, `get_flops`, `print_config` ([#324](https://github.com/open-mmlab/mmpose/pull/324))
-
-**Bug Fixes**
-
-- Fix bugs in pck evaluation ([#328](https://github.com/open-mmlab/mmpose/pull/328))
-
-- Fix model download links in README ([#396](https://github.com/open-mmlab/mmpose/pull/396), [#397](https://github.com/open-mmlab/mmpose/pull/397))
-
-- Fix CrowdPose annotations and update benchmarks ([#384](https://github.com/open-mmlab/mmpose/pull/384))
-
-- Fix modelzoo stat ([#354](https://github.com/open-mmlab/mmpose/pull/354), [#360](https://github.com/open-mmlab/mmpose/pull/360), [#362](https://github.com/open-mmlab/mmpose/pull/362))
-
-- Fix config files for aic datasets ([#340](https://github.com/open-mmlab/mmpose/pull/340))
-
-**Breaking Changes**
-
-- Rename `image_thr` to `det_bbox_thr` for top-down methods.
-
-**Improvements**
-
-- Organize the readme files ([#398](https://github.com/open-mmlab/mmpose/pull/398), [#399](https://github.com/open-mmlab/mmpose/pull/399), [#400](https://github.com/open-mmlab/mmpose/pull/400))
-
-- Check linting for markdown ([#379](https://github.com/open-mmlab/mmpose/pull/379))
-
-- Add faq.md ([#350](https://github.com/open-mmlab/mmpose/pull/350))
-
-- Remove PyTorch 1.4 in CI ([#338](https://github.com/open-mmlab/mmpose/pull/338))
-
-- Add pypi badge in readme ([#329](https://github.com/open-mmlab/mmpose/pull/329))
-
-## **v0.9.0 (30/11/2020)**
-
-**Highlights**
-
-1. Support more human pose estimation methods.
-
- 1. [MSPN](https://arxiv.org/abs/1901.00148)
- 2. [RSN](https://arxiv.org/abs/2003.04030)
-
-2. Support video pose estimation datasets.
-
- 1. [sub-JHMDB](http://jhmdb.is.tue.mpg.de/dataset)
-
-3. Support Onnx model conversion.
-
-**New Features**
-
-- Support MSPN ([#278](https://github.com/open-mmlab/mmpose/pull/278))
-
-- Support RSN ([#221](https://github.com/open-mmlab/mmpose/pull/221), [#318](https://github.com/open-mmlab/mmpose/pull/318))
-
-- Support new post-processing method for MSPN & RSN ([#288](https://github.com/open-mmlab/mmpose/pull/288))
-
-- Support sub-JHMDB dataset ([#292](https://github.com/open-mmlab/mmpose/pull/292))
-
-- Support urls for pre-trained models in config files ([#232](https://github.com/open-mmlab/mmpose/pull/232))
-
-- Support Onnx ([#305](https://github.com/open-mmlab/mmpose/pull/305))
-
-**Bug Fixes**
-
-- Fix model download links in README ([#255](https://github.com/open-mmlab/mmpose/pull/255), [#315](https://github.com/open-mmlab/mmpose/pull/315))
-
-**Breaking Changes**
-
-- `post_process=True|False` and `unbiased_decoding=True|False` are deprecated, use `post_process=None|default|unbiased` etc. instead ([#288](https://github.com/open-mmlab/mmpose/pull/288))
-
-**Improvements**
-
-- Enrich the model zoo ([#256](https://github.com/open-mmlab/mmpose/pull/256), [#320](https://github.com/open-mmlab/mmpose/pull/320))
-
-- Set the default map_location as 'cpu' to reduce gpu memory cost ([#227](https://github.com/open-mmlab/mmpose/pull/227))
-
-- Support return heatmaps and backbone features for bottom-up models ([#229](https://github.com/open-mmlab/mmpose/pull/229))
-
-- Upgrade mmcv maximum & minimum version ([#269](https://github.com/open-mmlab/mmpose/pull/269), [#313](https://github.com/open-mmlab/mmpose/pull/313))
-
-- Automatically add modelzoo statistics to readthedocs ([#252](https://github.com/open-mmlab/mmpose/pull/252))
-
-- Fix Pylint issues ([#258](https://github.com/open-mmlab/mmpose/pull/258), [#259](https://github.com/open-mmlab/mmpose/pull/259), [#260](https://github.com/open-mmlab/mmpose/pull/260), [#262](https://github.com/open-mmlab/mmpose/pull/262), [#265](https://github.com/open-mmlab/mmpose/pull/265), [#267](https://github.com/open-mmlab/mmpose/pull/267), [#268](https://github.com/open-mmlab/mmpose/pull/268), [#270](https://github.com/open-mmlab/mmpose/pull/270), [#271](https://github.com/open-mmlab/mmpose/pull/271), [#272](https://github.com/open-mmlab/mmpose/pull/272), [#273](https://github.com/open-mmlab/mmpose/pull/273), [#275](https://github.com/open-mmlab/mmpose/pull/275), [#276](https://github.com/open-mmlab/mmpose/pull/276), [#283](https://github.com/open-mmlab/mmpose/pull/283), [#285](https://github.com/open-mmlab/mmpose/pull/285), [#293](https://github.com/open-mmlab/mmpose/pull/293), [#294](https://github.com/open-mmlab/mmpose/pull/294), [#295](https://github.com/open-mmlab/mmpose/pull/295))
-
-- Improve README ([#226](https://github.com/open-mmlab/mmpose/pull/226), [#257](https://github.com/open-mmlab/mmpose/pull/257), [#264](https://github.com/open-mmlab/mmpose/pull/264), [#280](https://github.com/open-mmlab/mmpose/pull/280), [#296](https://github.com/open-mmlab/mmpose/pull/296))
-
-- Support PyTorch 1.7 in CI ([#274](https://github.com/open-mmlab/mmpose/pull/274))
-
-- Add docs/tutorials for running demos ([#263](https://github.com/open-mmlab/mmpose/pull/263))
-
-## **v0.8.0 (31/10/2020)**
-
-**Highlights**
-
-1. Support more human pose estimation datasets.
-
- 1. [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose)
- 2. [PoseTrack18](https://posetrack.net/)
-
-2. Support more 2D hand keypoint estimation datasets.
-
- 1. [InterHand2.6](https://github.com/facebookresearch/InterHand2.6M)
-
-3. Support adversarial training for 3D human shape recovery.
-
-4. Support multi-stage losses.
-
-5. Support mpii demo.
-
-**New Features**
-
-- Support [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose) dataset ([#195](https://github.com/open-mmlab/mmpose/pull/195))
-
-- Support [PoseTrack18](https://posetrack.net/) dataset ([#220](https://github.com/open-mmlab/mmpose/pull/220))
-
-- Support [InterHand2.6](https://github.com/facebookresearch/InterHand2.6M) dataset ([#202](https://github.com/open-mmlab/mmpose/pull/202))
-
-- Support adversarial training for 3D human shape recovery ([#192](https://github.com/open-mmlab/mmpose/pull/192))
-
-- Support multi-stage losses ([#204](https://github.com/open-mmlab/mmpose/pull/204))
-
-**Bug Fixes**
-
-- Fix config files ([#190](https://github.com/open-mmlab/mmpose/pull/190))
-
-**Improvements**
-
-- Add mpii demo ([#216](https://github.com/open-mmlab/mmpose/pull/216))
-
-- Improve README ([#181](https://github.com/open-mmlab/mmpose/pull/181), [#183](https://github.com/open-mmlab/mmpose/pull/183), [#208](https://github.com/open-mmlab/mmpose/pull/208))
-
-- Support return heatmaps and backbone features ([#196](https://github.com/open-mmlab/mmpose/pull/196), [#212](https://github.com/open-mmlab/mmpose/pull/212))
-
-- Support different return formats of mmdetection models ([#217](https://github.com/open-mmlab/mmpose/pull/217))
-
-## **v0.7.0 (30/9/2020)**
-
-**Highlights**
-
-1. Support HMR for 3D human shape recovery.
-
-2. Support WholeBody human pose estimation.
-
- 1. [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody)
-
-3. Support more 2D hand keypoint estimation datasets.
-
- 1. [Frei-hand](https://lmb.informatik.uni-freiburg.de/projects/freihand/)
- 2. [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html)
-
-4. Add more popular backbones & enrich the [modelzoo](https://mmpose.readthedocs.io/en/latest/model_zoo.html)
-
- 1. ShuffleNetv2
-
-5. Support hand demo and whole-body demo.
-
-**New Features**
-
-- Support HMR for 3D human shape recovery ([#157](https://github.com/open-mmlab/mmpose/pull/157), [#160](https://github.com/open-mmlab/mmpose/pull/160), [#161](https://github.com/open-mmlab/mmpose/pull/161), [#162](https://github.com/open-mmlab/mmpose/pull/162))
-
-- Support [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody) dataset ([#133](https://github.com/open-mmlab/mmpose/pull/133))
-
-- Support [Frei-hand](https://lmb.informatik.uni-freiburg.de/projects/freihand/) dataset ([#125](https://github.com/open-mmlab/mmpose/pull/125))
-
-- Support [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html) dataset ([#144](https://github.com/open-mmlab/mmpose/pull/144))
-
-- Support H36M dataset ([#159](https://github.com/open-mmlab/mmpose/pull/159))
-
-- Support ShuffleNetv2 ([#139](https://github.com/open-mmlab/mmpose/pull/139))
-
-- Support saving best models based on key indicator ([#127](https://github.com/open-mmlab/mmpose/pull/127))
-
-**Bug Fixes**
-
-- Fix typos in docs ([#121](https://github.com/open-mmlab/mmpose/pull/121))
-
-- Fix assertion ([#142](https://github.com/open-mmlab/mmpose/pull/142))
-
-**Improvements**
-
-- Add tools to transform .mat format to .json format ([#126](https://github.com/open-mmlab/mmpose/pull/126))
-
-- Add hand demo ([#115](https://github.com/open-mmlab/mmpose/pull/115))
-
-- Add whole-body demo ([#163](https://github.com/open-mmlab/mmpose/pull/163))
-
-- Reuse mmcv utility function and update version files ([#135](https://github.com/open-mmlab/mmpose/pull/135), [#137](https://github.com/open-mmlab/mmpose/pull/137))
-
-- Enrich the modelzoo ([#147](https://github.com/open-mmlab/mmpose/pull/147), [#169](https://github.com/open-mmlab/mmpose/pull/169))
-
-- Improve docs ([#174](https://github.com/open-mmlab/mmpose/pull/174), [#175](https://github.com/open-mmlab/mmpose/pull/175), [#178](https://github.com/open-mmlab/mmpose/pull/178))
-
-- Improve README ([#176](https://github.com/open-mmlab/mmpose/pull/176))
-
-- Improve version.py ([#173](https://github.com/open-mmlab/mmpose/pull/173))
-
-## **v0.6.0 (31/8/2020)**
-
-**Highlights**
-
-1. Add more popular backbones & enrich the [modelzoo](https://mmpose.readthedocs.io/en/latest/model_zoo.html)
-
- 1. ResNext
- 2. SEResNet
- 3. ResNetV1D
- 4. MobileNetv2
- 5. ShuffleNetv1
- 6. CPM (Convolutional Pose Machine)
-
-2. Add more popular datasets:
-
- 1. [AIChallenger](https://arxiv.org/abs/1711.06475?context=cs.CV)
- 2. [MPII](http://human-pose.mpi-inf.mpg.de/)
- 3. [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body)
- 4. [OCHuman](http://www.liruilong.cn/projects/pose2seg/index.html)
-
-3. Support 2d hand keypoint estimation.
-
- 1. [OneHand10K](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html)
-
-4. Support bottom-up inference.
-
-**New Features**
-
-- Support [OneHand10K](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html) dataset ([#52](https://github.com/open-mmlab/mmpose/pull/52))
-
-- Support [MPII](http://human-pose.mpi-inf.mpg.de/) dataset ([#55](https://github.com/open-mmlab/mmpose/pull/55))
-
-- Support [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) dataset ([#19](https://github.com/open-mmlab/mmpose/pull/19), [#47](https://github.com/open-mmlab/mmpose/pull/47), [#48](https://github.com/open-mmlab/mmpose/pull/48))
-
-- Support [OCHuman](http://www.liruilong.cn/projects/pose2seg/index.html) dataset ([#70](https://github.com/open-mmlab/mmpose/pull/70))
-
-- Support [AIChallenger](https://arxiv.org/abs/1711.06475?context=cs.CV) dataset ([#87](https://github.com/open-mmlab/mmpose/pull/87))
-
-- Support multiple backbones ([#26](https://github.com/open-mmlab/mmpose/pull/26))
-
-- Support CPM model ([#56](https://github.com/open-mmlab/mmpose/pull/56))
-
-**Bug Fixes**
-
-- Fix configs for MPII & MPII-TRB datasets ([#93](https://github.com/open-mmlab/mmpose/pull/93))
-
-- Fix the bug of missing `test_pipeline` in configs ([#14](https://github.com/open-mmlab/mmpose/pull/14))
-
-- Fix typos ([#27](https://github.com/open-mmlab/mmpose/pull/27), [#28](https://github.com/open-mmlab/mmpose/pull/28), [#50](https://github.com/open-mmlab/mmpose/pull/50), [#53](https://github.com/open-mmlab/mmpose/pull/53), [#63](https://github.com/open-mmlab/mmpose/pull/63))
-
-**Improvements**
-
-- Update benchmark ([#93](https://github.com/open-mmlab/mmpose/pull/93))
-
-- Add Dockerfile ([#44](https://github.com/open-mmlab/mmpose/pull/44))
-
-- Improve unittest coverage and minor fix ([#18](https://github.com/open-mmlab/mmpose/pull/18))
-
-- Support CPUs for train/val/demo ([#34](https://github.com/open-mmlab/mmpose/pull/34))
-
-- Support bottom-up demo ([#69](https://github.com/open-mmlab/mmpose/pull/69))
-
-- Add tools to publish model ([#62](https://github.com/open-mmlab/mmpose/pull/62))
-
-- Enrich the modelzoo ([#64](https://github.com/open-mmlab/mmpose/pull/64), [#68](https://github.com/open-mmlab/mmpose/pull/68), [#82](https://github.com/open-mmlab/mmpose/pull/82))
-
-## **v0.5.0 (21/7/2020)**
-
-**Highlights**
-
-- MMPose is released.
-
-**Main Features**
-
-- Support both top-down and bottom-up pose estimation approaches.
-
-- Achieve higher training efficiency and higher accuracy than other popular codebases (e.g. AlphaPose, HRNet)
-
-- Support various backbone models: ResNet, HRNet, SCNet, Houglass and HigherHRNet.
+# Changelog
+
+## **v1.0.0rc1 (14/10/2022)**
+
+**Highlights**
+
+- Release RTMPose, a high-performance real-time pose estimation algorithm with cross-platform deployment and inference support. See details at the [project page](/projects/rtmpose/)
+- Support several new algorithms: ViTPose (arXiv'2022), CID (CVPR'2022), DEKR (CVPR'2021)
+- Add Inferencer, a convenient inference interface that perform pose estimation and visualization on images, videos and webcam streams with only one line of code
+- Introduce *Project*, a new form for rapid and easy implementation of new algorithms and features in MMPose, which is more handy for community contributors
+
+**New Features**
+
+- Support RTMPose ([#1971](https://github.com/open-mmlab/mmpose/pull/1971), [#2024](https://github.com/open-mmlab/mmpose/pull/2024), [#2028](https://github.com/open-mmlab/mmpose/pull/2028), [#2030](https://github.com/open-mmlab/mmpose/pull/2030), [#2040](https://github.com/open-mmlab/mmpose/pull/2040), [#2057](https://github.com/open-mmlab/mmpose/pull/2057))
+- Support Inferencer ([#1969](https://github.com/open-mmlab/mmpose/pull/1969))
+- Support ViTPose ([#1876](https://github.com/open-mmlab/mmpose/pull/1876), [#2056](https://github.com/open-mmlab/mmpose/pull/2056), [#2058](https://github.com/open-mmlab/mmpose/pull/2058), [#2065](https://github.com/open-mmlab/mmpose/pull/2065))
+- Support CID ([#1907](https://github.com/open-mmlab/mmpose/pull/1907))
+- Support DEKR ([#1834](https://github.com/open-mmlab/mmpose/pull/1834), [#1901](https://github.com/open-mmlab/mmpose/pull/1901))
+- Support training with multiple datasets ([#1767](https://github.com/open-mmlab/mmpose/pull/1767), [#1930](https://github.com/open-mmlab/mmpose/pull/1930), [#1938](https://github.com/open-mmlab/mmpose/pull/1938), [#2025](https://github.com/open-mmlab/mmpose/pull/2025))
+- Add *project* to allow rapid and easy implementation of new models and features ([#1914](https://github.com/open-mmlab/mmpose/pull/1914))
+
+**Improvements**
+
+- Improve documentation quality ([#1846](https://github.com/open-mmlab/mmpose/pull/1846), [#1858](https://github.com/open-mmlab/mmpose/pull/1858), [#1872](https://github.com/open-mmlab/mmpose/pull/1872), [#1899](https://github.com/open-mmlab/mmpose/pull/1899), [#1925](https://github.com/open-mmlab/mmpose/pull/1925), [#1945](https://github.com/open-mmlab/mmpose/pull/1945), [#1952](https://github.com/open-mmlab/mmpose/pull/1952), [#1990](https://github.com/open-mmlab/mmpose/pull/1990), [#2023](https://github.com/open-mmlab/mmpose/pull/2023), [#2042](https://github.com/open-mmlab/mmpose/pull/2042))
+- Support visualizing keypoint indices ([#2051](https://github.com/open-mmlab/mmpose/pull/2051))
+- Support OpenPose style visualization ([#2055](https://github.com/open-mmlab/mmpose/pull/2055))
+- Accelerate image transpose in data pipelines with tensor operation ([#1976](https://github.com/open-mmlab/mmpose/pull/1976))
+- Support auto-import modules from registry ([#1961](https://github.com/open-mmlab/mmpose/pull/1961))
+- Support keypoint partition metric ([#1944](https://github.com/open-mmlab/mmpose/pull/1944))
+- Support SimCC 1D-heatmap visualization ([#1912](https://github.com/open-mmlab/mmpose/pull/1912))
+- Support saving predictions and data metainfo in demos ([#1814](https://github.com/open-mmlab/mmpose/pull/1814), [#1879](https://github.com/open-mmlab/mmpose/pull/1879))
+- Support SimCC with DARK ([#1870](https://github.com/open-mmlab/mmpose/pull/1870))
+- Remove Gaussian blur for offset maps in UDP-regress ([#1815](https://github.com/open-mmlab/mmpose/pull/1815))
+- Refactor encoding interface of Codec for better extendibility and easier configuration ([#1781](https://github.com/open-mmlab/mmpose/pull/1781))
+- Support evaluating CocoMetric without annotation file ([#1722](https://github.com/open-mmlab/mmpose/pull/1722))
+- Improve unit tests ([#1765](https://github.com/open-mmlab/mmpose/pull/1765))
+
+**Bug Fixes**
+
+- Fix repeated warnings from different ranks ([#2053](https://github.com/open-mmlab/mmpose/pull/2053))
+- Avoid frequent scope switching when using mmdet inference api ([#2039](https://github.com/open-mmlab/mmpose/pull/2039))
+- Remove EMA parameters and message hub data when publishing model checkpoints ([#2036](https://github.com/open-mmlab/mmpose/pull/2036))
+- Fix metainfo copying in dataset class ([#2017](https://github.com/open-mmlab/mmpose/pull/2017))
+- Fix top-down demo bug when there is no object detected ([#2007](https://github.com/open-mmlab/mmpose/pull/2007))
+- Fix config errors ([#1882](https://github.com/open-mmlab/mmpose/pull/1882), [#1906](https://github.com/open-mmlab/mmpose/pull/1906), [#1995](https://github.com/open-mmlab/mmpose/pull/1995))
+- Fix image demo failure when GUI is unavailable ([#1968](https://github.com/open-mmlab/mmpose/pull/1968))
+- Fix bug in AdaptiveWingLoss ([#1953](https://github.com/open-mmlab/mmpose/pull/1953))
+- Fix incorrect importing of RepeatDataset which is deprecated ([#1943](https://github.com/open-mmlab/mmpose/pull/1943))
+- Fix bug in bottom-up datasets that ignores images without instances ([#1752](https://github.com/open-mmlab/mmpose/pull/1752), [#1936](https://github.com/open-mmlab/mmpose/pull/1936))
+- Fix upstream dependency issues ([#1867](https://github.com/open-mmlab/mmpose/pull/1867), [#1921](https://github.com/open-mmlab/mmpose/pull/1921))
+- Fix evaluation issues and update results ([#1763](https://github.com/open-mmlab/mmpose/pull/1763), [#1773](https://github.com/open-mmlab/mmpose/pull/1773), [#1780](https://github.com/open-mmlab/mmpose/pull/1780), [#1850](https://github.com/open-mmlab/mmpose/pull/1850), [#1868](https://github.com/open-mmlab/mmpose/pull/1868))
+- Fix local registry missing warnings ([#1849](https://github.com/open-mmlab/mmpose/pull/1849))
+- Remove deprecated scripts for model deployment ([#1845](https://github.com/open-mmlab/mmpose/pull/1845))
+- Fix a bug in input transformation in BaseHead ([#1843](https://github.com/open-mmlab/mmpose/pull/1843))
+- Fix an interface mismatch with MMDetection in webcam demo ([#1813](https://github.com/open-mmlab/mmpose/pull/1813))
+- Fix a bug in heatmap visualization that causes incorrect scale ([#1800](https://github.com/open-mmlab/mmpose/pull/1800))
+- Add model metafiles ([#1768](https://github.com/open-mmlab/mmpose/pull/1768))
+
+## **v1.0.0rc0 (14/10/2022)**
+
+**New Features**
+
+- Support 4 light-weight pose estimation algorithms: [SimCC](https://doi.org/10.48550/arxiv.2107.03332) (ECCV'2022), [Debias-IPR](https://openaccess.thecvf.com/content/ICCV2021/papers/Gu_Removing_the_Bias_of_Integral_Pose_Regression_ICCV_2021_paper.pdf) (ICCV'2021), [IPR](https://arxiv.org/abs/1711.08229) (ECCV'2018), and [DSNT](https://arxiv.org/abs/1801.07372v2) (ArXiv'2018) ([#1628](https://github.com/open-mmlab/mmpose/pull/1628))
+
+**Migrations**
+
+- Add Webcam API in MMPose 1.0 ([#1638](https://github.com/open-mmlab/mmpose/pull/1638), [#1662](https://github.com/open-mmlab/mmpose/pull/1662)) @Ben-Louis
+- Add codec for Associative Embedding (beta) ([#1603](https://github.com/open-mmlab/mmpose/pull/1603)) @ly015
+
+**Improvements**
+
+- Add a colab tutorial for MMPose 1.0 ([#1660](https://github.com/open-mmlab/mmpose/pull/1660)) @Tau-J
+- Add model index in config folder ([#1710](https://github.com/open-mmlab/mmpose/pull/1710), [#1709](https://github.com/open-mmlab/mmpose/pull/1709), [#1627](https://github.com/open-mmlab/mmpose/pull/1627)) @ly015, @Tau-J, @Ben-Louis
+- Update and improve documentation ([#1692](https://github.com/open-mmlab/mmpose/pull/1692), [#1656](https://github.com/open-mmlab/mmpose/pull/1656), [#1681](https://github.com/open-mmlab/mmpose/pull/1681), [#1677](https://github.com/open-mmlab/mmpose/pull/1677), [#1664](https://github.com/open-mmlab/mmpose/pull/1664), [#1659](https://github.com/open-mmlab/mmpose/pull/1659)) @Tau-J, @Ben-Louis, @liqikai9
+- Improve config structures and formats ([#1651](https://github.com/open-mmlab/mmpose/pull/1651)) @liqikai9
+
+**Bug Fixes**
+
+- Update mmengine version requirements ([#1715](https://github.com/open-mmlab/mmpose/pull/1715)) @Ben-Louis
+- Update dependencies of pre-commit hooks ([#1705](https://github.com/open-mmlab/mmpose/pull/1705)) @Ben-Louis
+- Fix mmcv version in DockerFile ([#1704](https://github.com/open-mmlab/mmpose/pull/1704))
+- Fix a bug in setting dataset metainfo in configs ([#1684](https://github.com/open-mmlab/mmpose/pull/1684)) @ly015
+- Fix a bug in UDP training ([#1682](https://github.com/open-mmlab/mmpose/pull/1682)) @liqikai9
+- Fix a bug in Dark decoding ([#1676](https://github.com/open-mmlab/mmpose/pull/1676)) @liqikai9
+- Fix bugs in visualization ([#1671](https://github.com/open-mmlab/mmpose/pull/1671), [#1668](https://github.com/open-mmlab/mmpose/pull/1668), [#1657](https://github.com/open-mmlab/mmpose/pull/1657)) @liqikai9, @Ben-Louis
+- Fix incorrect flops calculation ([#1669](https://github.com/open-mmlab/mmpose/pull/1669)) @liqikai9
+- Fix `tensor.tile` compatibility issue for pytorch 1.6 ([#1658](https://github.com/open-mmlab/mmpose/pull/1658)) @ly015
+- Fix compatibility with `MultilevelPixelData` ([#1647](https://github.com/open-mmlab/mmpose/pull/1647)) @liqikai9
+
+## **v1.0.0beta (1/09/2022)**
+
+We are excited to announce the release of MMPose 1.0.0beta.
+MMPose 1.0.0beta is the first version of MMPose 1.x, a part of the OpenMMLab 2.0 projects.
+Built upon the new [training engine](https://github.com/open-mmlab/mmengine),
+MMPose 1.x unifies the interfaces of dataset, models, evaluation, and visualization with faster training and testing speed.
+It also provide a general semi-supervised object detection framework, and more strong baselines.
+
+**Highlights**
+
+- **New engines**. MMPose 1.x is based on [MMEngine](https://github.com/open-mmlab/mmengine), which provides a general and powerful runner that allows more flexible customizations and significantly simplifies the entrypoints of high-level interfaces.
+
+- **Unified interfaces**. As a part of the OpenMMLab 2.0 projects, MMPose 1.x unifies and refactors the interfaces and internal logics of train, testing, datasets, models, evaluation, and visualization. All the OpenMMLab 2.0 projects share the same design in those interfaces and logics to allow the emergence of multi-task/modality algorithms.
+
+- **More documentation and tutorials**. We add a bunch of documentation and tutorials to help users get started more smoothly. Read it [here](https://mmpose.readthedocs.io/en/latest/).
+
+**Breaking Changes**
+
+In this release, we made lots of major refactoring and modifications. Please refer to the [migration guide](../migration.md) for details and migration instructions.
+
+## **v0.28.1 (28/07/2022)**
+
+This release is meant to fix the compatibility with the latest mmcv v1.6.1
+
+## **v0.28.0 (06/07/2022)**
+
+**Highlights**
+
+- Support [TCFormer](https://openaccess.thecvf.com/content/CVPR2022/html/Zeng_Not_All_Tokens_Are_Equal_Human-Centric_Visual_Analysis_via_Token_CVPR_2022_paper.html) backbone, CVPR'2022 ([#1447](https://github.com/open-mmlab/mmpose/pull/1447), [#1452](https://github.com/open-mmlab/mmpose/pull/1452)) @zengwang430521
+
+- Add [RLE](https://arxiv.org/abs/2107.11291) models on COCO dataset ([#1424](https://github.com/open-mmlab/mmpose/pull/1424)) @Indigo6, @Ben-Louis, @ly015
+
+- Update swin models with better performance ([#1467](https://github.com/open-mmlab/mmpose/pull/1434)) @jin-s13
+
+**New Features**
+
+- Support [TCFormer](https://openaccess.thecvf.com/content/CVPR2022/html/Zeng_Not_All_Tokens_Are_Equal_Human-Centric_Visual_Analysis_via_Token_CVPR_2022_paper.html) backbone, CVPR'2022 ([#1447](https://github.com/open-mmlab/mmpose/pull/1447), [#1452](https://github.com/open-mmlab/mmpose/pull/1452)) @zengwang430521
+
+- Add [RLE](https://arxiv.org/abs/2107.11291) models on COCO dataset ([#1424](https://github.com/open-mmlab/mmpose/pull/1424)) @Indigo6, @Ben-Louis, @ly015
+
+- Support layer decay optimizer constructor and learning rate decay optimizer constructor ([#1423](https://github.com/open-mmlab/mmpose/pull/1423)) @jin-s13
+
+**Improvements**
+
+- Improve documentation quality ([#1416](https://github.com/open-mmlab/mmpose/pull/1416), [#1421](https://github.com/open-mmlab/mmpose/pull/1421), [#1423](https://github.com/open-mmlab/mmpose/pull/1423), [#1426](https://github.com/open-mmlab/mmpose/pull/1426), [#1458](https://github.com/open-mmlab/mmpose/pull/1458), [#1463](https://github.com/open-mmlab/mmpose/pull/1463)) @ly015, @liqikai9
+
+- Support installation by [mim](https://github.com/open-mmlab/mim) ([#1425](https://github.com/open-mmlab/mmpose/pull/1425)) @liqikai9
+
+- Support PAVI logger ([#1434](https://github.com/open-mmlab/mmpose/pull/1434)) @EvelynWang-0423
+
+- Add progress bar for some demos ([#1454](https://github.com/open-mmlab/mmpose/pull/1454)) @liqikai9
+
+- Webcam API supports quick device setting in terminal commands ([#1466](https://github.com/open-mmlab/mmpose/pull/1466)) @ly015
+
+- Update swin models with better performance ([#1467](https://github.com/open-mmlab/mmpose/pull/1434)) @jin-s13
+
+**Bug Fixes**
+
+- Rename `custom_hooks_config` to `custom_hooks` in configs to align with the documentation ([#1427](https://github.com/open-mmlab/mmpose/pull/1427)) @ly015
+
+- Fix deadlock issue in Webcam API ([#1430](https://github.com/open-mmlab/mmpose/pull/1430)) @ly015
+
+- Fix smoother configs in video 3D demo ([#1457](https://github.com/open-mmlab/mmpose/pull/1457)) @ly015
+
+## **v0.27.0 (07/06/2022)**
+
+**Highlights**
+
+- Support hand gesture recognition
+
+ - Try the demo for gesture recognition
+ - Learn more about the algorithm, dataset and experiment results
+
+- Major upgrade to the Webcam API
+
+ - Tutorials (EN|zh_CN)
+ - [API Reference](https://mmpose.readthedocs.io/en/latest/api.html#mmpose-apis-webcam)
+ - Demo
+
+**New Features**
+
+- Support gesture recognition algorithm [MTUT](https://openaccess.thecvf.com/content_CVPR_2019/html/Abavisani_Improving_the_Performance_of_Unimodal_Dynamic_Hand-Gesture_Recognition_With_Multimodal_CVPR_2019_paper.html) CVPR'2019 and dataset [NVGesture](https://openaccess.thecvf.com/content_cvpr_2016/html/Molchanov_Online_Detection_and_CVPR_2016_paper.html) CVPR'2016 ([#1380](https://github.com/open-mmlab/mmpose/pull/1380)) @Ben-Louis
+
+**Improvements**
+
+- Upgrade Webcam API and related documents ([#1393](https://github.com/open-mmlab/mmpose/pull/1393), [#1404](https://github.com/open-mmlab/mmpose/pull/1404), [#1413](https://github.com/open-mmlab/mmpose/pull/1413)) @ly015
+
+- Support exporting COCO inference result without the annotation file ([#1368](https://github.com/open-mmlab/mmpose/pull/1368)) @liqikai9
+
+- Replace markdownlint with mdformat in CI to avoid the dependence on ruby [#1382](https://github.com/open-mmlab/mmpose/pull/1382) @ly015
+
+- Improve documentation quality ([#1385](https://github.com/open-mmlab/mmpose/pull/1385), [#1394](https://github.com/open-mmlab/mmpose/pull/1394), [#1395](https://github.com/open-mmlab/mmpose/pull/1395), [#1408](https://github.com/open-mmlab/mmpose/pull/1408)) @chubei-oppen, @ly015, @liqikai9
+
+**Bug Fixes**
+
+- Fix xywh->xyxy bbox conversion in dataset sanity check ([#1367](https://github.com/open-mmlab/mmpose/pull/1367)) @jin-s13
+
+- Fix a bug in two-stage 3D keypoint demo ([#1373](https://github.com/open-mmlab/mmpose/pull/1373)) @ly015
+
+- Fix out-dated settings in PVT configs ([#1376](https://github.com/open-mmlab/mmpose/pull/1376)) @ly015
+
+- Fix myst settings for document compiling ([#1381](https://github.com/open-mmlab/mmpose/pull/1381)) @ly015
+
+- Fix a bug in bbox transform ([#1384](https://github.com/open-mmlab/mmpose/pull/1384)) @ly015
+
+- Fix inaccurate description of `min_keypoints` in tracking apis ([#1398](https://github.com/open-mmlab/mmpose/pull/1398)) @pallgeuer
+
+- Fix warning with `torch.meshgrid` ([#1402](https://github.com/open-mmlab/mmpose/pull/1402)) @pallgeuer
+
+- Remove redundant transformer modules from `mmpose.datasets.backbones.utils` ([#1405](https://github.com/open-mmlab/mmpose/pull/1405)) @ly015
+
+## **v0.26.0 (05/05/2022)**
+
+**Highlights**
+
+- Support [RLE (Residual Log-likelihood Estimation)](https://arxiv.org/abs/2107.11291), ICCV'2021 ([#1259](https://github.com/open-mmlab/mmpose/pull/1259)) @Indigo6, @ly015
+
+- Support [Swin Transformer](https://arxiv.org/abs/2103.14030), ICCV'2021 ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @yumendecc, @ly015
+
+- Support [PVT](https://arxiv.org/abs/2102.12122), ICCV'2021 and [PVTv2](https://arxiv.org/abs/2106.13797), CVMJ'2022 ([#1343](https://github.com/open-mmlab/mmpose/pull/1343)) @zengwang430521
+
+- Speed up inference and reduce CPU usage by optimizing the pre-processing pipeline ([#1320](https://github.com/open-mmlab/mmpose/pull/1320)) @chenxinfeng4, @liqikai9
+
+**New Features**
+
+- Support [RLE (Residual Log-likelihood Estimation)](https://arxiv.org/abs/2107.11291), ICCV'2021 ([#1259](https://github.com/open-mmlab/mmpose/pull/1259)) @Indigo6, @ly015
+
+- Support [Swin Transformer](https://arxiv.org/abs/2103.14030), ICCV'2021 ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @yumendecc, @ly015
+
+- Support [PVT](https://arxiv.org/abs/2102.12122), ICCV'2021 and [PVTv2](https://arxiv.org/abs/2106.13797), CVMJ'2022 ([#1343](https://github.com/open-mmlab/mmpose/pull/1343)) @zengwang430521
+
+- Support [FPN](https://openaccess.thecvf.com/content_cvpr_2017/html/Lin_Feature_Pyramid_Networks_CVPR_2017_paper.html), CVPR'2017 ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @yumendecc, @ly015
+
+**Improvements**
+
+- Speed up inference and reduce CPU usage by optimizing the pre-processing pipeline ([#1320](https://github.com/open-mmlab/mmpose/pull/1320)) @chenxinfeng4, @liqikai9
+
+- Video demo supports models that requires multi-frame inputs ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @liqikai9, @jin-s13
+
+- Update benchmark regression list ([#1328](https://github.com/open-mmlab/mmpose/pull/1328)) @ly015, @liqikai9
+
+- Remove unnecessary warnings in `TopDownPoseTrack18VideoDataset` ([#1335](https://github.com/open-mmlab/mmpose/pull/1335)) @liqikai9
+
+- Improve documentation quality ([#1313](https://github.com/open-mmlab/mmpose/pull/1313), [#1305](https://github.com/open-mmlab/mmpose/pull/1305)) @Ben-Louis, @ly015
+
+- Update deprecating settings in configs ([#1317](https://github.com/open-mmlab/mmpose/pull/1317)) @ly015
+
+**Bug Fixes**
+
+- Fix a bug in human skeleton grouping that may skip the matching process unexpectedly when `ignore_to_much` is True ([#1341](https://github.com/open-mmlab/mmpose/pull/1341)) @daixinghome
+
+- Fix a GPG key error that leads to CI failure ([#1354](https://github.com/open-mmlab/mmpose/pull/1354)) @ly015
+
+- Fix bugs in distributed training script ([#1338](https://github.com/open-mmlab/mmpose/pull/1338), [#1298](https://github.com/open-mmlab/mmpose/pull/1298)) @ly015
+
+- Fix an upstream bug in xtoccotools that causes incorrect AP(M) results ([#1308](https://github.com/open-mmlab/mmpose/pull/1308)) @jin-s13, @ly015
+
+- Fix indentiation errors in the colab tutorial ([#1298](https://github.com/open-mmlab/mmpose/pull/1298)) @YuanZi1501040205
+
+- Fix incompatible model weight initialization with other OpenMMLab codebases ([#1329](https://github.com/open-mmlab/mmpose/pull/1329)) @274869388
+
+- Fix HRNet FP16 checkpoints download URL ([#1309](https://github.com/open-mmlab/mmpose/pull/1309)) @YinAoXiong
+
+- Fix typos in `body3d_two_stage_video_demo.py` ([#1295](https://github.com/open-mmlab/mmpose/pull/1295)) @mucozcan
+
+**Breaking Changes**
+
+- Refactor bbox processing in datasets and pipelines ([#1311](https://github.com/open-mmlab/mmpose/pull/1311)) @ly015, @Ben-Louis
+
+- The bbox format conversion (xywh to center-scale) and random translation are moved from the dataset to the pipeline. The comparison between new and old version is as below:
+
+v0.26.0v0.25.0Dataset
+(e.g. [TopDownCOCODataset](https://github.com/open-mmlab/mmpose/blob/master/mmpose/datasets/datasets/top_down/topdown_coco_dataset.py))
+
+... # Data sample only contains bbox rec.append({ 'bbox': obj\['clean_bbox\]\[:4\], ... })
+
+
+
+
+
+... # Convert bbox from xywh to center-scale center, scale = self.\_xywh2cs(\*obj\['clean_bbox'\]\[:4\]) # Data sample contains center and scale rec.append({ 'bbox': obj\['clean_bbox\]\[:4\], 'center': center, 'scale': scale, ... })
+
+
Apply bbox random translation every epoch (instead of only applying once at the annotation loading)
+
+
+
+
-
+
+
+
+
+
+
BC Breaking
+
+
The method `_xywh2cs` of dataset base classes (e.g. [Kpt2dSviewRgbImgTopDownDataset](https://github.com/open-mmlab/mmpose/blob/master/mmpose/datasets/datasets/base/kpt_2d_sview_rgb_img_top_down_dataset.py)) will be deprecated in the future. Custom datasets will need modifications to move the bbox format conversion to pipelines.
+
+
-
+
+
+
+
+
+
+
+## **v0.25.0 (02/04/2022)**
+
+**Highlights**
+
+- Support Shelf and Campus datasets with pre-trained VoxelPose models, ["3D Pictorial Structures for Multiple Human Pose Estimation"](http://campar.in.tum.de/pub/belagiannis2014cvpr/belagiannis2014cvpr.pdf), CVPR'2014 ([#1225](https://github.com/open-mmlab/mmpose/pull/1225)) @liqikai9, @wusize
+
+- Add `Smoother` module for temporal smoothing of the pose estimation with configurable filters ([#1127](https://github.com/open-mmlab/mmpose/pull/1127)) @ailingzengzzz, @ly015
+
+- Support SmoothNet for pose smoothing, ["SmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos"](https://arxiv.org/abs/2112.13715), arXiv'2021 ([#1279](https://github.com/open-mmlab/mmpose/pull/1279)) @ailingzengzzz, @ly015
+
+- Add multiview 3D pose estimation demo ([#1270](https://github.com/open-mmlab/mmpose/pull/1270)) @wusize
+
+**New Features**
+
+- Support Shelf and Campus datasets with pre-trained VoxelPose models, ["3D Pictorial Structures for Multiple Human Pose Estimation"](http://campar.in.tum.de/pub/belagiannis2014cvpr/belagiannis2014cvpr.pdf), CVPR'2014 ([#1225](https://github.com/open-mmlab/mmpose/pull/1225)) @liqikai9, @wusize
+
+- Add `Smoother` module for temporal smoothing of the pose estimation with configurable filters ([#1127](https://github.com/open-mmlab/mmpose/pull/1127)) @ailingzengzzz, @ly015
+
+- Support SmoothNet for pose smoothing, ["SmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos"](https://arxiv.org/abs/2112.13715), arXiv'2021 ([#1279](https://github.com/open-mmlab/mmpose/pull/1279)) @ailingzengzzz, @ly015
+
+- Add multiview 3D pose estimation demo ([#1270](https://github.com/open-mmlab/mmpose/pull/1270)) @wusize
+
+- Support multi-machine distributed training ([#1248](https://github.com/open-mmlab/mmpose/pull/1248)) @ly015
+
+**Improvements**
+
+- Update HRFormer configs and checkpoints with relative position bias ([#1245](https://github.com/open-mmlab/mmpose/pull/1245)) @zengwang430521
+
+- Support using different random seed for each distributed node ([#1257](https://github.com/open-mmlab/mmpose/pull/1257), [#1229](https://github.com/open-mmlab/mmpose/pull/1229)) @ly015
+
+- Improve documentation quality ([#1275](https://github.com/open-mmlab/mmpose/pull/1275), [#1255](https://github.com/open-mmlab/mmpose/pull/1255), [#1258](https://github.com/open-mmlab/mmpose/pull/1258), [#1249](https://github.com/open-mmlab/mmpose/pull/1249), [#1247](https://github.com/open-mmlab/mmpose/pull/1247), [#1240](https://github.com/open-mmlab/mmpose/pull/1240), [#1235](https://github.com/open-mmlab/mmpose/pull/1235)) @ly015, @jin-s13, @YoniChechik
+
+**Bug Fixes**
+
+- Fix keypoint index in RHD dataset meta information ([#1265](https://github.com/open-mmlab/mmpose/pull/1265)) @liqikai9
+
+- Fix pre-commit hook unexpected behavior on Windows ([#1282](https://github.com/open-mmlab/mmpose/pull/1282)) @liqikai9
+
+- Remove python-dev installation in CI ([#1276](https://github.com/open-mmlab/mmpose/pull/1276)) @ly015
+
+- Unify hyphens in argument names in tools and demos ([#1271](https://github.com/open-mmlab/mmpose/pull/1271)) @ly015
+
+- Fix ambiguous channel size in `channel_shuffle` that may cause exporting failure (#1242) @PINTO0309
+
+- Fix a bug in Webcam API that causes single-class detectors fail ([#1239](https://github.com/open-mmlab/mmpose/pull/1239)) @674106399
+
+- Fix the issue that `custom_hook` can not be set in configs ([#1236](https://github.com/open-mmlab/mmpose/pull/1236)) @bladrome
+
+- Fix incompatible MMCV version in DockerFile ([#raykindle](https://github.com/open-mmlab/mmpose/pull/raykindle))
+
+- Skip invisible joints in visualization ([#1228](https://github.com/open-mmlab/mmpose/pull/1228)) @womeier
+
+## **v0.24.0 (07/03/2022)**
+
+**Highlights**
+
+- Support HRFormer ["HRFormer: High-Resolution Vision Transformer for Dense Predict"](https://proceedings.neurips.cc/paper/2021/hash/3bbfdde8842a5c44a0323518eec97cbe-Abstract.html), NeurIPS'2021 ([#1203](https://github.com/open-mmlab/mmpose/pull/1203)) @zengwang430521
+
+- Support Windows installation with pip ([#1213](https://github.com/open-mmlab/mmpose/pull/1213)) @jin-s13, @ly015
+
+- Add WebcamAPI documents ([#1187](https://github.com/open-mmlab/mmpose/pull/1187)) @ly015
+
+**New Features**
+
+- Support HRFormer ["HRFormer: High-Resolution Vision Transformer for Dense Predict"](https://proceedings.neurips.cc/paper/2021/hash/3bbfdde8842a5c44a0323518eec97cbe-Abstract.html), NeurIPS'2021 ([#1203](https://github.com/open-mmlab/mmpose/pull/1203)) @zengwang430521
+
+- Support Windows installation with pip ([#1213](https://github.com/open-mmlab/mmpose/pull/1213)) @jin-s13, @ly015
+
+- Support CPU training with mmcv \< v1.4.4 ([#1161](https://github.com/open-mmlab/mmpose/pull/1161)) @EasonQYS, @ly015
+
+- Add "Valentine Magic" demo with WebcamAPI ([#1189](https://github.com/open-mmlab/mmpose/pull/1189), [#1191](https://github.com/open-mmlab/mmpose/pull/1191)) @liqikai9
+
+**Improvements**
+
+- Refactor multi-view 3D pose estimation framework towards better modularization and expansibility ([#1196](https://github.com/open-mmlab/mmpose/pull/1196)) @wusize
+
+- Add WebcamAPI documents and tutorials ([#1187](https://github.com/open-mmlab/mmpose/pull/1187)) @ly015
+
+- Refactor dataset evaluation interface to align with other OpenMMLab codebases ([#1209](https://github.com/open-mmlab/mmpose/pull/1209)) @ly015
+
+- Add deprecation message for deploy tools since [MMDeploy](https://github.com/open-mmlab/mmdeploy) has supported MMPose ([#1207](https://github.com/open-mmlab/mmpose/pull/1207)) @QwQ2000
+
+- Improve documentation quality ([#1206](https://github.com/open-mmlab/mmpose/pull/1206), [#1161](https://github.com/open-mmlab/mmpose/pull/1161)) @ly015
+
+- Switch to OpenMMLab official pre-commit-hook for copyright check ([#1214](https://github.com/open-mmlab/mmpose/pull/1214)) @ly015
+
+**Bug Fixes**
+
+- Fix hard-coded data collating and scattering in inference ([#1175](https://github.com/open-mmlab/mmpose/pull/1175)) @ly015
+
+- Fix model configs on JHMDB dataset ([#1188](https://github.com/open-mmlab/mmpose/pull/1188)) @jin-s13
+
+- Fix area calculation in pose tracking inference ([#1197](https://github.com/open-mmlab/mmpose/pull/1197)) @pallgeuer
+
+- Fix registry scope conflict of module wrapper ([#1204](https://github.com/open-mmlab/mmpose/pull/1204)) @ly015
+
+- Update MMCV installation in CI and documents ([#1205](https://github.com/open-mmlab/mmpose/pull/1205))
+
+- Fix incorrect color channel order in visualization functions ([#1212](https://github.com/open-mmlab/mmpose/pull/1212)) @ly015
+
+## **v0.23.0 (11/02/2022)**
+
+**Highlights**
+
+- Add [MMPose Webcam API](https://github.com/open-mmlab/mmpose/tree/master/tools/webcam): A simple yet powerful tools to develop interactive webcam applications with MMPose functions. ([#1178](https://github.com/open-mmlab/mmpose/pull/1178), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1143](https://github.com/open-mmlab/mmpose/pull/1143), [#1094](https://github.com/open-mmlab/mmpose/pull/1094), [#1133](https://github.com/open-mmlab/mmpose/pull/1133), [#1098](https://github.com/open-mmlab/mmpose/pull/1098), [#1160](https://github.com/open-mmlab/mmpose/pull/1160)) @ly015, @jin-s13, @liqikai9, @wusize, @luminxu, @zengwang430521 @mzr1996
+
+**New Features**
+
+- Add [MMPose Webcam API](https://github.com/open-mmlab/mmpose/tree/master/tools/webcam): A simple yet powerful tools to develop interactive webcam applications with MMPose functions. ([#1178](https://github.com/open-mmlab/mmpose/pull/1178), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1143](https://github.com/open-mmlab/mmpose/pull/1143), [#1094](https://github.com/open-mmlab/mmpose/pull/1094), [#1133](https://github.com/open-mmlab/mmpose/pull/1133), [#1098](https://github.com/open-mmlab/mmpose/pull/1098), [#1160](https://github.com/open-mmlab/mmpose/pull/1160)) @ly015, @jin-s13, @liqikai9, @wusize, @luminxu, @zengwang430521 @mzr1996
+
+- Support ConcatDataset ([#1139](https://github.com/open-mmlab/mmpose/pull/1139)) @Canwang-sjtu
+
+- Support CPU training and testing ([#1157](https://github.com/open-mmlab/mmpose/pull/1157)) @ly015
+
+**Improvements**
+
+- Add multi-processing configurations to speed up distributed training and testing ([#1146](https://github.com/open-mmlab/mmpose/pull/1146)) @ly015
+
+- Add default runtime config ([#1145](https://github.com/open-mmlab/mmpose/pull/1145))
+
+- Upgrade isort in pre-commit hook ([#1179](https://github.com/open-mmlab/mmpose/pull/1179)) @liqikai9
+
+- Update README and documents ([#1171](https://github.com/open-mmlab/mmpose/pull/1171), [#1167](https://github.com/open-mmlab/mmpose/pull/1167), [#1153](https://github.com/open-mmlab/mmpose/pull/1153), [#1149](https://github.com/open-mmlab/mmpose/pull/1149), [#1148](https://github.com/open-mmlab/mmpose/pull/1148), [#1147](https://github.com/open-mmlab/mmpose/pull/1147), [#1140](https://github.com/open-mmlab/mmpose/pull/1140)) @jin-s13, @wusize, @TommyZihao, @ly015
+
+**Bug Fixes**
+
+- Fix undeterministic behavior in pre-commit hooks ([#1136](https://github.com/open-mmlab/mmpose/pull/1136)) @jin-s13
+
+- Deprecate the support for "python setup.py test" ([#1179](https://github.com/open-mmlab/mmpose/pull/1179)) @ly015
+
+- Fix incompatible settings with MMCV on HSigmoid default parameters ([#1132](https://github.com/open-mmlab/mmpose/pull/1132)) @ly015
+
+- Fix albumentation installation ([#1184](https://github.com/open-mmlab/mmpose/pull/1184)) @BIGWangYuDong
+
+## **v0.22.0 (04/01/2022)**
+
+**Highlights**
+
+- Support VoxelPose ["VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment"](https://arxiv.org/abs/2004.06239), ECCV'2020 ([#1050](https://github.com/open-mmlab/mmpose/pull/1050)) @wusize
+
+- Support Soft Wing loss ["Structure-Coherent Deep Feature Learning for Robust Face Alignment"](https://linchunze.github.io/papers/TIP21_Structure_coherent_FA.pdf), TIP'2021 ([#1077](https://github.com/open-mmlab/mmpose/pull/1077)) @jin-s13
+
+- Support Adaptive Wing loss ["Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression"](https://arxiv.org/abs/1904.07399), ICCV'2019 ([#1072](https://github.com/open-mmlab/mmpose/pull/1072)) @jin-s13
+
+**New Features**
+
+- Support VoxelPose ["VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment"](https://arxiv.org/abs/2004.06239), ECCV'2020 ([#1050](https://github.com/open-mmlab/mmpose/pull/1050)) @wusize
+
+- Support Soft Wing loss ["Structure-Coherent Deep Feature Learning for Robust Face Alignment"](https://linchunze.github.io/papers/TIP21_Structure_coherent_FA.pdf), TIP'2021 ([#1077](https://github.com/open-mmlab/mmpose/pull/1077)) @jin-s13
+
+- Support Adaptive Wing loss ["Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression"](https://arxiv.org/abs/1904.07399), ICCV'2019 ([#1072](https://github.com/open-mmlab/mmpose/pull/1072)) @jin-s13
+
+- Add LiteHRNet-18 Checkpoints trained on COCO. ([#1120](https://github.com/open-mmlab/mmpose/pull/1120)) @jin-s13
+
+**Improvements**
+
+- Improve documentation quality ([#1115](https://github.com/open-mmlab/mmpose/pull/1115), [#1111](https://github.com/open-mmlab/mmpose/pull/1111), [#1105](https://github.com/open-mmlab/mmpose/pull/1105), [#1087](https://github.com/open-mmlab/mmpose/pull/1087), [#1086](https://github.com/open-mmlab/mmpose/pull/1086), [#1085](https://github.com/open-mmlab/mmpose/pull/1085), [#1084](https://github.com/open-mmlab/mmpose/pull/1084), [#1083](https://github.com/open-mmlab/mmpose/pull/1083), [#1124](https://github.com/open-mmlab/mmpose/pull/1124), [#1070](https://github.com/open-mmlab/mmpose/pull/1070), [#1068](https://github.com/open-mmlab/mmpose/pull/1068)) @jin-s13, @liqikai9, @ly015
+
+- Support CircleCI ([#1074](https://github.com/open-mmlab/mmpose/pull/1074)) @ly015
+
+- Skip unit tests in CI when only document files were changed ([#1074](https://github.com/open-mmlab/mmpose/pull/1074), [#1041](https://github.com/open-mmlab/mmpose/pull/1041)) @QwQ2000, @ly015
+
+- Support file_client_args in LoadImageFromFile ([#1076](https://github.com/open-mmlab/mmpose/pull/1076)) @jin-s13
+
+**Bug Fixes**
+
+- Fix a bug in Dark UDP postprocessing that causes error when the channel number is large. ([#1079](https://github.com/open-mmlab/mmpose/pull/1079), [#1116](https://github.com/open-mmlab/mmpose/pull/1116)) @X00123, @jin-s13
+
+- Fix hard-coded `sigmas` in bottom-up image demo ([#1107](https://github.com/open-mmlab/mmpose/pull/1107), [#1101](https://github.com/open-mmlab/mmpose/pull/1101)) @chenxinfeng4, @liqikai9
+
+- Fix unstable checks in unit tests ([#1112](https://github.com/open-mmlab/mmpose/pull/1112)) @ly015
+
+- Do not destroy NULL windows if `args.show==False` in demo scripts ([#1104](https://github.com/open-mmlab/mmpose/pull/1104)) @bladrome
+
+## **v0.21.0 (06/12/2021)**
+
+**Highlights**
+
+- Support ["Learning Temporal Pose Estimation from Sparsely-Labeled Videos"](https://arxiv.org/abs/1906.04016), NeurIPS'2019 ([#932](https://github.com/open-mmlab/mmpose/pull/932), [#1006](https://github.com/open-mmlab/mmpose/pull/1006), [#1036](https://github.com/open-mmlab/mmpose/pull/1036), [#1060](https://github.com/open-mmlab/mmpose/pull/1060)) @liqikai9
+
+- Add ViPNAS-MobileNetV3 models ([#1025](https://github.com/open-mmlab/mmpose/pull/1025)) @luminxu, @jin-s13
+
+- Add inference speed benchmark ([#1028](https://github.com/open-mmlab/mmpose/pull/1028), [#1034](https://github.com/open-mmlab/mmpose/pull/1034), [#1044](https://github.com/open-mmlab/mmpose/pull/1044)) @liqikai9
+
+**New Features**
+
+- Support ["Learning Temporal Pose Estimation from Sparsely-Labeled Videos"](https://arxiv.org/abs/1906.04016), NeurIPS'2019 ([#932](https://github.com/open-mmlab/mmpose/pull/932), [#1006](https://github.com/open-mmlab/mmpose/pull/1006), [#1036](https://github.com/open-mmlab/mmpose/pull/1036)) @liqikai9
+
+- Add ViPNAS-MobileNetV3 models ([#1025](https://github.com/open-mmlab/mmpose/pull/1025)) @luminxu, @jin-s13
+
+- Add light-weight top-down models for whole-body keypoint detection ([#1009](https://github.com/open-mmlab/mmpose/pull/1009), [#1020](https://github.com/open-mmlab/mmpose/pull/1020), [#1055](https://github.com/open-mmlab/mmpose/pull/1055)) @luminxu, @ly015
+
+- Add HRNet checkpoints with various settings on PoseTrack18 ([#1035](https://github.com/open-mmlab/mmpose/pull/1035)) @liqikai9
+
+**Improvements**
+
+- Add inference speed benchmark ([#1028](https://github.com/open-mmlab/mmpose/pull/1028), [#1034](https://github.com/open-mmlab/mmpose/pull/1034), [#1044](https://github.com/open-mmlab/mmpose/pull/1044)) @liqikai9
+
+- Update model metafile format ([#1001](https://github.com/open-mmlab/mmpose/pull/1001)) @ly015
+
+- Support minus output feature index in mobilenet_v3 ([#1005](https://github.com/open-mmlab/mmpose/pull/1005)) @luminxu
+
+- Improve documentation quality ([#1018](https://github.com/open-mmlab/mmpose/pull/1018), [#1026](https://github.com/open-mmlab/mmpose/pull/1026), [#1027](https://github.com/open-mmlab/mmpose/pull/1027), [#1031](https://github.com/open-mmlab/mmpose/pull/1031), [#1038](https://github.com/open-mmlab/mmpose/pull/1038), [#1046](https://github.com/open-mmlab/mmpose/pull/1046), [#1056](https://github.com/open-mmlab/mmpose/pull/1056), [#1057](https://github.com/open-mmlab/mmpose/pull/1057)) @edybk, @luminxu, @ly015, @jin-s13
+
+- Set default random seed in training initialization ([#1030](https://github.com/open-mmlab/mmpose/pull/1030)) @ly015
+
+- Skip CI when only specific files changed ([#1041](https://github.com/open-mmlab/mmpose/pull/1041), [#1059](https://github.com/open-mmlab/mmpose/pull/1059)) @QwQ2000, @ly015
+
+- Automatically cancel uncompleted action runs when new commit arrives ([#1053](https://github.com/open-mmlab/mmpose/pull/1053)) @ly015
+
+**Bug Fixes**
+
+- Update pose tracking demo to be compatible with latest mmtracking ([#1014](https://github.com/open-mmlab/mmpose/pull/1014)) @jin-s13
+
+- Fix symlink creation failure when installed in Windows environments ([#1039](https://github.com/open-mmlab/mmpose/pull/1039)) @QwQ2000
+
+- Fix AP-10K dataset sigmas ([#1040](https://github.com/open-mmlab/mmpose/pull/1040)) @jin-s13
+
+## **v0.20.0 (01/11/2021)**
+
+**Highlights**
+
+- Add AP-10K dataset for animal pose estimation ([#987](https://github.com/open-mmlab/mmpose/pull/987)) @Annbless, @AlexTheBad, @jin-s13, @ly015
+
+- Support TorchServe ([#979](https://github.com/open-mmlab/mmpose/pull/979)) @ly015
+
+**New Features**
+
+- Add AP-10K dataset for animal pose estimation ([#987](https://github.com/open-mmlab/mmpose/pull/987)) @Annbless, @AlexTheBad, @jin-s13, @ly015
+
+- Add HRNetv2 checkpoints on 300W and COFW datasets ([#980](https://github.com/open-mmlab/mmpose/pull/980)) @jin-s13
+
+- Support TorchServe ([#979](https://github.com/open-mmlab/mmpose/pull/979)) @ly015
+
+**Bug Fixes**
+
+- Fix some deprecated or risky settings in configs ([#963](https://github.com/open-mmlab/mmpose/pull/963), [#976](https://github.com/open-mmlab/mmpose/pull/976), [#992](https://github.com/open-mmlab/mmpose/pull/992)) @jin-s13, @wusize
+
+- Fix issues of default arguments of training and testing scripts ([#970](https://github.com/open-mmlab/mmpose/pull/970), [#985](https://github.com/open-mmlab/mmpose/pull/985)) @liqikai9, @wusize
+
+- Fix heatmap and tag size mismatch in bottom-up with UDP ([#994](https://github.com/open-mmlab/mmpose/pull/994)) @wusize
+
+- Fix python3.9 installation in CI ([#983](https://github.com/open-mmlab/mmpose/pull/983)) @ly015
+
+- Fix model zoo document integrity issue ([#990](https://github.com/open-mmlab/mmpose/pull/990)) @jin-s13
+
+**Improvements**
+
+- Support non-square input shape for bottom-up ([#991](https://github.com/open-mmlab/mmpose/pull/991)) @wusize
+
+- Add image and video resources for demo ([#971](https://github.com/open-mmlab/mmpose/pull/971)) @liqikai9
+
+- Use CUDA docker images to accelerate CI ([#973](https://github.com/open-mmlab/mmpose/pull/973)) @ly015
+
+- Add codespell hook and fix detected typos ([#977](https://github.com/open-mmlab/mmpose/pull/977)) @ly015
+
+## **v0.19.0 (08/10/2021)**
+
+**Highlights**
+
+- Add models for Associative Embedding with Hourglass network backbone ([#906](https://github.com/open-mmlab/mmpose/pull/906), [#955](https://github.com/open-mmlab/mmpose/pull/955)) @jin-s13, @luminxu
+
+- Support COCO-Wholebody-Face and COCO-Wholebody-Hand datasets ([#813](https://github.com/open-mmlab/mmpose/pull/813)) @jin-s13, @innerlee, @luminxu
+
+- Upgrade dataset interface ([#901](https://github.com/open-mmlab/mmpose/pull/901), [#924](https://github.com/open-mmlab/mmpose/pull/924)) @jin-s13, @innerlee, @ly015, @liqikai9
+
+- New style of documentation ([#945](https://github.com/open-mmlab/mmpose/pull/945)) @ly015
+
+**New Features**
+
+- Add models for Associative Embedding with Hourglass network backbone ([#906](https://github.com/open-mmlab/mmpose/pull/906), [#955](https://github.com/open-mmlab/mmpose/pull/955)) @jin-s13, @luminxu
+
+- Support COCO-Wholebody-Face and COCO-Wholebody-Hand datasets ([#813](https://github.com/open-mmlab/mmpose/pull/813)) @jin-s13, @innerlee, @luminxu
+
+- Add pseudo-labeling tool to generate COCO style keypoint annotations with given bounding boxes ([#928](https://github.com/open-mmlab/mmpose/pull/928)) @soltkreig
+
+- New style of documentation ([#945](https://github.com/open-mmlab/mmpose/pull/945)) @ly015
+
+**Bug Fixes**
+
+- Fix segmentation parsing in Macaque dataset preprocessing ([#948](https://github.com/open-mmlab/mmpose/pull/948)) @jin-s13
+
+- Fix dependencies that may lead to CI failure in downstream projects ([#936](https://github.com/open-mmlab/mmpose/pull/936), [#953](https://github.com/open-mmlab/mmpose/pull/953)) @RangiLyu, @ly015
+
+- Fix keypoint order in Human3.6M dataset ([#940](https://github.com/open-mmlab/mmpose/pull/940)) @ttxskk
+
+- Fix unstable image loading for Interhand2.6M ([#913](https://github.com/open-mmlab/mmpose/pull/913)) @zengwang430521
+
+**Improvements**
+
+- Upgrade dataset interface ([#901](https://github.com/open-mmlab/mmpose/pull/901), [#924](https://github.com/open-mmlab/mmpose/pull/924)) @jin-s13, @innerlee, @ly015, @liqikai9
+
+- Improve demo usability and stability ([#908](https://github.com/open-mmlab/mmpose/pull/908), [#934](https://github.com/open-mmlab/mmpose/pull/934)) @ly015
+
+- Standardize model metafile format ([#941](https://github.com/open-mmlab/mmpose/pull/941)) @ly015
+
+- Support `persistent_worker` and several other arguments in configs ([#946](https://github.com/open-mmlab/mmpose/pull/946)) @jin-s13
+
+- Use MMCV root model registry to enable cross-project module building ([#935](https://github.com/open-mmlab/mmpose/pull/935)) @RangiLyu
+
+- Improve the document quality ([#916](https://github.com/open-mmlab/mmpose/pull/916), [#909](https://github.com/open-mmlab/mmpose/pull/909), [#942](https://github.com/open-mmlab/mmpose/pull/942), [#913](https://github.com/open-mmlab/mmpose/pull/913), [#956](https://github.com/open-mmlab/mmpose/pull/956)) @jin-s13, @ly015, @bit-scientist, @zengwang430521
+
+- Improve pull request template ([#952](https://github.com/open-mmlab/mmpose/pull/952), [#954](https://github.com/open-mmlab/mmpose/pull/954)) @ly015
+
+**Breaking Changes**
+
+- Upgrade dataset interface ([#901](https://github.com/open-mmlab/mmpose/pull/901)) @jin-s13, @innerlee, @ly015
+
+## **v0.18.0 (01/09/2021)**
+
+**Bug Fixes**
+
+- Fix redundant model weight loading in pytorch-to-onnx conversion ([#850](https://github.com/open-mmlab/mmpose/pull/850)) @ly015
+
+- Fix a bug in update_model_index.py that may cause pre-commit hook failure([#866](https://github.com/open-mmlab/mmpose/pull/866)) @ly015
+
+- Fix a bug in interhand_3d_head ([#890](https://github.com/open-mmlab/mmpose/pull/890)) @zengwang430521
+
+- Fix pose tracking demo failure caused by out-of-date configs ([#891](https://github.com/open-mmlab/mmpose/pull/891))
+
+**Improvements**
+
+- Add automatic benchmark regression tools ([#849](https://github.com/open-mmlab/mmpose/pull/849), [#880](https://github.com/open-mmlab/mmpose/pull/880), [#885](https://github.com/open-mmlab/mmpose/pull/885)) @liqikai9, @ly015
+
+- Add copyright information and checking hook ([#872](https://github.com/open-mmlab/mmpose/pull/872))
+
+- Add PR template ([#875](https://github.com/open-mmlab/mmpose/pull/875)) @ly015
+
+- Add citation information ([#876](https://github.com/open-mmlab/mmpose/pull/876)) @ly015
+
+- Add python3.9 in CI ([#877](https://github.com/open-mmlab/mmpose/pull/877), [#883](https://github.com/open-mmlab/mmpose/pull/883)) @ly015
+
+- Improve the quality of the documents ([#845](https://github.com/open-mmlab/mmpose/pull/845), [#845](https://github.com/open-mmlab/mmpose/pull/845), [#848](https://github.com/open-mmlab/mmpose/pull/848), [#867](https://github.com/open-mmlab/mmpose/pull/867), [#870](https://github.com/open-mmlab/mmpose/pull/870), [#873](https://github.com/open-mmlab/mmpose/pull/873), [#896](https://github.com/open-mmlab/mmpose/pull/896)) @jin-s13, @ly015, @zhiqwang
+
+## **v0.17.0 (06/08/2021)**
+
+**Highlights**
+
+1. Support ["Lite-HRNet: A Lightweight High-Resolution Network"](https://arxiv.org/abs/2104.06403) CVPR'2021 ([#733](https://github.com/open-mmlab/mmpose/pull/733),[#800](https://github.com/open-mmlab/mmpose/pull/800)) @jin-s13
+
+2. Add 3d body mesh demo ([#771](https://github.com/open-mmlab/mmpose/pull/771)) @zengwang430521
+
+3. Add Chinese documentation ([#787](https://github.com/open-mmlab/mmpose/pull/787), [#798](https://github.com/open-mmlab/mmpose/pull/798), [#799](https://github.com/open-mmlab/mmpose/pull/799), [#802](https://github.com/open-mmlab/mmpose/pull/802), [#804](https://github.com/open-mmlab/mmpose/pull/804), [#805](https://github.com/open-mmlab/mmpose/pull/805), [#815](https://github.com/open-mmlab/mmpose/pull/815), [#816](https://github.com/open-mmlab/mmpose/pull/816), [#817](https://github.com/open-mmlab/mmpose/pull/817), [#819](https://github.com/open-mmlab/mmpose/pull/819), [#839](https://github.com/open-mmlab/mmpose/pull/839)) @ly015, @luminxu, @jin-s13, @liqikai9, @zengwang430521
+
+4. Add Colab Tutorial ([#834](https://github.com/open-mmlab/mmpose/pull/834)) @ly015
+
+**New Features**
+
+- Support ["Lite-HRNet: A Lightweight High-Resolution Network"](https://arxiv.org/abs/2104.06403) CVPR'2021 ([#733](https://github.com/open-mmlab/mmpose/pull/733),[#800](https://github.com/open-mmlab/mmpose/pull/800)) @jin-s13
+
+- Add 3d body mesh demo ([#771](https://github.com/open-mmlab/mmpose/pull/771)) @zengwang430521
+
+- Add Chinese documentation ([#787](https://github.com/open-mmlab/mmpose/pull/787), [#798](https://github.com/open-mmlab/mmpose/pull/798), [#799](https://github.com/open-mmlab/mmpose/pull/799), [#802](https://github.com/open-mmlab/mmpose/pull/802), [#804](https://github.com/open-mmlab/mmpose/pull/804), [#805](https://github.com/open-mmlab/mmpose/pull/805), [#815](https://github.com/open-mmlab/mmpose/pull/815), [#816](https://github.com/open-mmlab/mmpose/pull/816), [#817](https://github.com/open-mmlab/mmpose/pull/817), [#819](https://github.com/open-mmlab/mmpose/pull/819), [#839](https://github.com/open-mmlab/mmpose/pull/839)) @ly015, @luminxu, @jin-s13, @liqikai9, @zengwang430521
+
+- Add Colab Tutorial ([#834](https://github.com/open-mmlab/mmpose/pull/834)) @ly015
+
+- Support training for InterHand v1.0 dataset ([#761](https://github.com/open-mmlab/mmpose/pull/761)) @zengwang430521
+
+**Bug Fixes**
+
+- Fix mpii pckh@0.1 index ([#773](https://github.com/open-mmlab/mmpose/pull/773)) @jin-s13
+
+- Fix multi-node distributed test ([#818](https://github.com/open-mmlab/mmpose/pull/818)) @ly015
+
+- Fix docstring and init_weights error of ShuffleNetV1 ([#814](https://github.com/open-mmlab/mmpose/pull/814)) @Junjun2016
+
+- Fix imshow_bbox error when input bboxes is empty ([#796](https://github.com/open-mmlab/mmpose/pull/796)) @ly015
+
+- Fix model zoo doc generation ([#778](https://github.com/open-mmlab/mmpose/pull/778)) @ly015
+
+- Fix typo ([#767](https://github.com/open-mmlab/mmpose/pull/767)), ([#780](https://github.com/open-mmlab/mmpose/pull/780), [#782](https://github.com/open-mmlab/mmpose/pull/782)) @ly015, @jin-s13
+
+**Breaking Changes**
+
+- Use MMCV EvalHook ([#686](https://github.com/open-mmlab/mmpose/pull/686)) @ly015
+
+**Improvements**
+
+- Add pytest.ini and fix docstring ([#812](https://github.com/open-mmlab/mmpose/pull/812)) @jin-s13
+
+- Update MSELoss ([#829](https://github.com/open-mmlab/mmpose/pull/829)) @Ezra-Yu
+
+- Move process_mmdet_results into inference.py ([#831](https://github.com/open-mmlab/mmpose/pull/831)) @ly015
+
+- Update resource limit ([#783](https://github.com/open-mmlab/mmpose/pull/783)) @jin-s13
+
+- Use COCO 2D pose model in 3D demo examples ([#785](https://github.com/open-mmlab/mmpose/pull/785)) @ly015
+
+- Change model zoo titles in the doc from center-aligned to left-aligned ([#792](https://github.com/open-mmlab/mmpose/pull/792), [#797](https://github.com/open-mmlab/mmpose/pull/797)) @ly015
+
+- Support MIM ([#706](https://github.com/open-mmlab/mmpose/pull/706), [#794](https://github.com/open-mmlab/mmpose/pull/794)) @ly015
+
+- Update out-of-date configs ([#827](https://github.com/open-mmlab/mmpose/pull/827)) @jin-s13
+
+- Remove opencv-python-headless dependency by albumentations ([#833](https://github.com/open-mmlab/mmpose/pull/833)) @ly015
+
+- Update QQ QR code in README_CN.md ([#832](https://github.com/open-mmlab/mmpose/pull/832)) @ly015
+
+## **v0.16.0 (02/07/2021)**
+
+**Highlights**
+
+1. Support ["ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search"](https://arxiv.org/abs/2105.10154) CVPR'2021 ([#742](https://github.com/open-mmlab/mmpose/pull/742),[#755](https://github.com/open-mmlab/mmpose/pull/755)).
+
+2. Support MPI-INF-3DHP dataset ([#683](https://github.com/open-mmlab/mmpose/pull/683),[#746](https://github.com/open-mmlab/mmpose/pull/746),[#751](https://github.com/open-mmlab/mmpose/pull/751)).
+
+3. Add webcam demo tool ([#729](https://github.com/open-mmlab/mmpose/pull/729))
+
+4. Add 3d body and hand pose estimation demo ([#704](https://github.com/open-mmlab/mmpose/pull/704), [#727](https://github.com/open-mmlab/mmpose/pull/727)).
+
+**New Features**
+
+- Support ["ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search"](https://arxiv.org/abs/2105.10154) CVPR'2021 ([#742](https://github.com/open-mmlab/mmpose/pull/742),[#755](https://github.com/open-mmlab/mmpose/pull/755))
+
+- Support MPI-INF-3DHP dataset ([#683](https://github.com/open-mmlab/mmpose/pull/683),[#746](https://github.com/open-mmlab/mmpose/pull/746),[#751](https://github.com/open-mmlab/mmpose/pull/751))
+
+- Support Webcam demo ([#729](https://github.com/open-mmlab/mmpose/pull/729))
+
+- Support Interhand 3d demo ([#704](https://github.com/open-mmlab/mmpose/pull/704))
+
+- Support 3d pose video demo ([#727](https://github.com/open-mmlab/mmpose/pull/727))
+
+- Support H36m dataset for 2d pose estimation ([#709](https://github.com/open-mmlab/mmpose/pull/709), [#735](https://github.com/open-mmlab/mmpose/pull/735))
+
+- Add scripts to generate mim metafile ([#749](https://github.com/open-mmlab/mmpose/pull/749))
+
+**Bug Fixes**
+
+- Fix typos ([#692](https://github.com/open-mmlab/mmpose/pull/692),[#696](https://github.com/open-mmlab/mmpose/pull/696),[#697](https://github.com/open-mmlab/mmpose/pull/697),[#698](https://github.com/open-mmlab/mmpose/pull/698),[#712](https://github.com/open-mmlab/mmpose/pull/712),[#718](https://github.com/open-mmlab/mmpose/pull/718),[#728](https://github.com/open-mmlab/mmpose/pull/728))
+
+- Change model download links from `http` to `https` ([#716](https://github.com/open-mmlab/mmpose/pull/716))
+
+**Breaking Changes**
+
+- Switch to MMCV MODEL_REGISTRY ([#669](https://github.com/open-mmlab/mmpose/pull/669))
+
+**Improvements**
+
+- Refactor MeshMixDataset ([#752](https://github.com/open-mmlab/mmpose/pull/752))
+
+- Rename 'GaussianHeatMap' to 'GaussianHeatmap' ([#745](https://github.com/open-mmlab/mmpose/pull/745))
+
+- Update out-of-date configs ([#734](https://github.com/open-mmlab/mmpose/pull/734))
+
+- Improve compatibility for breaking changes ([#731](https://github.com/open-mmlab/mmpose/pull/731))
+
+- Enable to control radius and thickness in visualization ([#722](https://github.com/open-mmlab/mmpose/pull/722))
+
+- Add regex dependency ([#720](https://github.com/open-mmlab/mmpose/pull/720))
+
+## **v0.15.0 (02/06/2021)**
+
+**Highlights**
+
+1. Support 3d video pose estimation (VideoPose3D).
+
+2. Support 3d hand pose estimation (InterNet).
+
+3. Improve presentation of modelzoo.
+
+**New Features**
+
+- Support "InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image" (ECCV‘20) ([#624](https://github.com/open-mmlab/mmpose/pull/624))
+
+- Support "3D human pose estimation in video with temporal convolutions and semi-supervised training" (CVPR'19) ([#602](https://github.com/open-mmlab/mmpose/pull/602), [#681](https://github.com/open-mmlab/mmpose/pull/681))
+
+- Support 3d pose estimation demo ([#653](https://github.com/open-mmlab/mmpose/pull/653), [#670](https://github.com/open-mmlab/mmpose/pull/670))
+
+- Support bottom-up whole-body pose estimation ([#689](https://github.com/open-mmlab/mmpose/pull/689))
+
+- Support mmcli ([#634](https://github.com/open-mmlab/mmpose/pull/634))
+
+**Bug Fixes**
+
+- Fix opencv compatibility ([#635](https://github.com/open-mmlab/mmpose/pull/635))
+
+- Fix demo with UDP ([#637](https://github.com/open-mmlab/mmpose/pull/637))
+
+- Fix bottom-up model onnx conversion ([#680](https://github.com/open-mmlab/mmpose/pull/680))
+
+- Fix `GPU_IDS` in distributed training ([#668](https://github.com/open-mmlab/mmpose/pull/668))
+
+- Fix MANIFEST.in ([#641](https://github.com/open-mmlab/mmpose/pull/641), [#657](https://github.com/open-mmlab/mmpose/pull/657))
+
+- Fix docs ([#643](https://github.com/open-mmlab/mmpose/pull/643),[#684](https://github.com/open-mmlab/mmpose/pull/684),[#688](https://github.com/open-mmlab/mmpose/pull/688),[#690](https://github.com/open-mmlab/mmpose/pull/690),[#692](https://github.com/open-mmlab/mmpose/pull/692))
+
+**Breaking Changes**
+
+- Reorganize configs by tasks, algorithms, datasets, and techniques ([#647](https://github.com/open-mmlab/mmpose/pull/647))
+
+- Rename heads and detectors ([#667](https://github.com/open-mmlab/mmpose/pull/667))
+
+**Improvements**
+
+- Add `radius` and `thickness` parameters in visualization ([#638](https://github.com/open-mmlab/mmpose/pull/638))
+
+- Add `trans_prob` parameter in `TopDownRandomTranslation` ([#650](https://github.com/open-mmlab/mmpose/pull/650))
+
+- Switch to `MMCV MODEL_REGISTRY` ([#669](https://github.com/open-mmlab/mmpose/pull/669))
+
+- Update dependencies ([#674](https://github.com/open-mmlab/mmpose/pull/674), [#676](https://github.com/open-mmlab/mmpose/pull/676))
+
+## **v0.14.0 (06/05/2021)**
+
+**Highlights**
+
+1. Support animal pose estimation with 7 popular datasets.
+
+2. Support "A simple yet effective baseline for 3d human pose estimation" (ICCV'17).
+
+**New Features**
+
+- Support "A simple yet effective baseline for 3d human pose estimation" (ICCV'17) ([#554](https://github.com/open-mmlab/mmpose/pull/554),[#558](https://github.com/open-mmlab/mmpose/pull/558),[#566](https://github.com/open-mmlab/mmpose/pull/566),[#570](https://github.com/open-mmlab/mmpose/pull/570),[#589](https://github.com/open-mmlab/mmpose/pull/589))
+
+- Support animal pose estimation ([#559](https://github.com/open-mmlab/mmpose/pull/559),[#561](https://github.com/open-mmlab/mmpose/pull/561),[#563](https://github.com/open-mmlab/mmpose/pull/563),[#571](https://github.com/open-mmlab/mmpose/pull/571),[#603](https://github.com/open-mmlab/mmpose/pull/603),[#605](https://github.com/open-mmlab/mmpose/pull/605))
+
+- Support Horse-10 dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), MacaquePose dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), Vinegar Fly dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), Desert Locust dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), Grevy's Zebra dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), ATRW dataset ([#571](https://github.com/open-mmlab/mmpose/pull/571)), and Animal-Pose dataset ([#603](https://github.com/open-mmlab/mmpose/pull/603))
+
+- Support bottom-up pose tracking demo ([#574](https://github.com/open-mmlab/mmpose/pull/574))
+
+- Support FP16 training ([#584](https://github.com/open-mmlab/mmpose/pull/584),[#616](https://github.com/open-mmlab/mmpose/pull/616),[#626](https://github.com/open-mmlab/mmpose/pull/626))
+
+- Support NMS for bottom-up ([#609](https://github.com/open-mmlab/mmpose/pull/609))
+
+**Bug Fixes**
+
+- Fix bugs in the top-down demo, when there are no people in the images ([#569](https://github.com/open-mmlab/mmpose/pull/569)).
+
+- Fix the links in the doc ([#612](https://github.com/open-mmlab/mmpose/pull/612))
+
+**Improvements**
+
+- Speed up top-down inference ([#560](https://github.com/open-mmlab/mmpose/pull/560))
+
+- Update github CI ([#562](https://github.com/open-mmlab/mmpose/pull/562), [#564](https://github.com/open-mmlab/mmpose/pull/564))
+
+- Update Readme ([#578](https://github.com/open-mmlab/mmpose/pull/578),[#579](https://github.com/open-mmlab/mmpose/pull/579),[#580](https://github.com/open-mmlab/mmpose/pull/580),[#592](https://github.com/open-mmlab/mmpose/pull/592),[#599](https://github.com/open-mmlab/mmpose/pull/599),[#600](https://github.com/open-mmlab/mmpose/pull/600),[#607](https://github.com/open-mmlab/mmpose/pull/607))
+
+- Update Faq ([#587](https://github.com/open-mmlab/mmpose/pull/587), [#610](https://github.com/open-mmlab/mmpose/pull/610))
+
+## **v0.13.0 (31/03/2021)**
+
+**Highlights**
+
+1. Support Wingloss.
+
+2. Support RHD hand dataset.
+
+**New Features**
+
+- Support Wingloss ([#482](https://github.com/open-mmlab/mmpose/pull/482))
+
+- Support RHD hand dataset ([#523](https://github.com/open-mmlab/mmpose/pull/523), [#551](https://github.com/open-mmlab/mmpose/pull/551))
+
+- Support Human3.6m dataset for 3d keypoint detection ([#518](https://github.com/open-mmlab/mmpose/pull/518), [#527](https://github.com/open-mmlab/mmpose/pull/527))
+
+- Support TCN model for 3d keypoint detection ([#521](https://github.com/open-mmlab/mmpose/pull/521), [#522](https://github.com/open-mmlab/mmpose/pull/522))
+
+- Support Interhand3D model for 3d hand detection ([#536](https://github.com/open-mmlab/mmpose/pull/536))
+
+- Support Multi-task detector ([#480](https://github.com/open-mmlab/mmpose/pull/480))
+
+**Bug Fixes**
+
+- Fix PCKh@0.1 calculation ([#516](https://github.com/open-mmlab/mmpose/pull/516))
+
+- Fix unittest ([#529](https://github.com/open-mmlab/mmpose/pull/529))
+
+- Fix circular importing ([#542](https://github.com/open-mmlab/mmpose/pull/542))
+
+- Fix bugs in bottom-up keypoint score ([#548](https://github.com/open-mmlab/mmpose/pull/548))
+
+**Improvements**
+
+- Update config & checkpoints ([#525](https://github.com/open-mmlab/mmpose/pull/525), [#546](https://github.com/open-mmlab/mmpose/pull/546))
+
+- Fix typos ([#514](https://github.com/open-mmlab/mmpose/pull/514), [#519](https://github.com/open-mmlab/mmpose/pull/519), [#532](https://github.com/open-mmlab/mmpose/pull/532), [#537](https://github.com/open-mmlab/mmpose/pull/537), )
+
+- Speed up post processing ([#535](https://github.com/open-mmlab/mmpose/pull/535))
+
+- Update mmcv version dependency ([#544](https://github.com/open-mmlab/mmpose/pull/544))
+
+## **v0.12.0 (28/02/2021)**
+
+**Highlights**
+
+1. Support DeepPose algorithm.
+
+**New Features**
+
+- Support DeepPose algorithm ([#446](https://github.com/open-mmlab/mmpose/pull/446), [#461](https://github.com/open-mmlab/mmpose/pull/461))
+
+- Support interhand3d dataset ([#468](https://github.com/open-mmlab/mmpose/pull/468))
+
+- Support Albumentation pipeline ([#469](https://github.com/open-mmlab/mmpose/pull/469))
+
+- Support PhotometricDistortion pipeline ([#485](https://github.com/open-mmlab/mmpose/pull/485))
+
+- Set seed option for training ([#493](https://github.com/open-mmlab/mmpose/pull/493))
+
+- Add demos for face keypoint detection ([#502](https://github.com/open-mmlab/mmpose/pull/502))
+
+**Bug Fixes**
+
+- Change channel order according to configs ([#504](https://github.com/open-mmlab/mmpose/pull/504))
+
+- Fix `num_factors` in UDP encoding ([#495](https://github.com/open-mmlab/mmpose/pull/495))
+
+- Fix configs ([#456](https://github.com/open-mmlab/mmpose/pull/456))
+
+**Breaking Changes**
+
+- Refactor configs for wholebody pose estimation ([#487](https://github.com/open-mmlab/mmpose/pull/487), [#491](https://github.com/open-mmlab/mmpose/pull/491))
+
+- Rename `decode` function for heads ([#481](https://github.com/open-mmlab/mmpose/pull/481))
+
+**Improvements**
+
+- Update config & checkpoints ([#453](https://github.com/open-mmlab/mmpose/pull/453),[#484](https://github.com/open-mmlab/mmpose/pull/484),[#487](https://github.com/open-mmlab/mmpose/pull/487))
+
+- Add README in Chinese ([#462](https://github.com/open-mmlab/mmpose/pull/462))
+
+- Add tutorials about configs ([#465](https://github.com/open-mmlab/mmpose/pull/465))
+
+- Add demo videos for various tasks ([#499](https://github.com/open-mmlab/mmpose/pull/499), [#503](https://github.com/open-mmlab/mmpose/pull/503))
+
+- Update docs about MMPose installation ([#467](https://github.com/open-mmlab/mmpose/pull/467), [#505](https://github.com/open-mmlab/mmpose/pull/505))
+
+- Rename `stat.py` to `stats.py` ([#483](https://github.com/open-mmlab/mmpose/pull/483))
+
+- Fix typos ([#463](https://github.com/open-mmlab/mmpose/pull/463), [#464](https://github.com/open-mmlab/mmpose/pull/464), [#477](https://github.com/open-mmlab/mmpose/pull/477), [#481](https://github.com/open-mmlab/mmpose/pull/481))
+
+- latex to bibtex ([#471](https://github.com/open-mmlab/mmpose/pull/471))
+
+- Update FAQ ([#466](https://github.com/open-mmlab/mmpose/pull/466))
+
+## **v0.11.0 (31/01/2021)**
+
+**Highlights**
+
+1. Support fashion landmark detection.
+
+2. Support face keypoint detection.
+
+3. Support pose tracking with MMTracking.
+
+**New Features**
+
+- Support fashion landmark detection (DeepFashion) ([#413](https://github.com/open-mmlab/mmpose/pull/413))
+
+- Support face keypoint detection (300W, AFLW, COFW, WFLW) ([#367](https://github.com/open-mmlab/mmpose/pull/367))
+
+- Support pose tracking demo with MMTracking ([#427](https://github.com/open-mmlab/mmpose/pull/427))
+
+- Support face demo ([#443](https://github.com/open-mmlab/mmpose/pull/443))
+
+- Support AIC dataset for bottom-up methods ([#438](https://github.com/open-mmlab/mmpose/pull/438), [#449](https://github.com/open-mmlab/mmpose/pull/449))
+
+**Bug Fixes**
+
+- Fix multi-batch training ([#434](https://github.com/open-mmlab/mmpose/pull/434))
+
+- Fix sigmas in AIC dataset ([#441](https://github.com/open-mmlab/mmpose/pull/441))
+
+- Fix config file ([#420](https://github.com/open-mmlab/mmpose/pull/420))
+
+**Breaking Changes**
+
+- Refactor Heads ([#382](https://github.com/open-mmlab/mmpose/pull/382))
+
+**Improvements**
+
+- Update readme ([#409](https://github.com/open-mmlab/mmpose/pull/409), [#412](https://github.com/open-mmlab/mmpose/pull/412), [#415](https://github.com/open-mmlab/mmpose/pull/415), [#416](https://github.com/open-mmlab/mmpose/pull/416), [#419](https://github.com/open-mmlab/mmpose/pull/419), [#421](https://github.com/open-mmlab/mmpose/pull/421), [#422](https://github.com/open-mmlab/mmpose/pull/422), [#424](https://github.com/open-mmlab/mmpose/pull/424), [#425](https://github.com/open-mmlab/mmpose/pull/425), [#435](https://github.com/open-mmlab/mmpose/pull/435), [#436](https://github.com/open-mmlab/mmpose/pull/436), [#437](https://github.com/open-mmlab/mmpose/pull/437), [#444](https://github.com/open-mmlab/mmpose/pull/444), [#445](https://github.com/open-mmlab/mmpose/pull/445))
+
+- Add GAP (global average pooling) neck ([#414](https://github.com/open-mmlab/mmpose/pull/414))
+
+- Speed up ([#411](https://github.com/open-mmlab/mmpose/pull/411), [#423](https://github.com/open-mmlab/mmpose/pull/423))
+
+- Support COCO test-dev test ([#433](https://github.com/open-mmlab/mmpose/pull/433))
+
+## **v0.10.0 (31/12/2020)**
+
+**Highlights**
+
+1. Support more human pose estimation methods.
+
+ 1. [UDP](https://arxiv.org/abs/1911.07524)
+
+2. Support pose tracking.
+
+3. Support multi-batch inference.
+
+4. Add some useful tools, including `analyze_logs`, `get_flops`, `print_config`.
+
+5. Support more backbone networks.
+
+ 1. [ResNest](https://arxiv.org/pdf/2004.08955.pdf)
+ 2. [VGG](https://arxiv.org/abs/1409.1556)
+
+**New Features**
+
+- Support UDP ([#353](https://github.com/open-mmlab/mmpose/pull/353), [#371](https://github.com/open-mmlab/mmpose/pull/371), [#402](https://github.com/open-mmlab/mmpose/pull/402))
+
+- Support multi-batch inference ([#390](https://github.com/open-mmlab/mmpose/pull/390))
+
+- Support MHP dataset ([#386](https://github.com/open-mmlab/mmpose/pull/386))
+
+- Support pose tracking demo ([#380](https://github.com/open-mmlab/mmpose/pull/380))
+
+- Support mpii-trb demo ([#372](https://github.com/open-mmlab/mmpose/pull/372))
+
+- Support mobilenet for hand pose estimation ([#377](https://github.com/open-mmlab/mmpose/pull/377))
+
+- Support ResNest backbone ([#370](https://github.com/open-mmlab/mmpose/pull/370))
+
+- Support VGG backbone ([#370](https://github.com/open-mmlab/mmpose/pull/370))
+
+- Add some useful tools, including `analyze_logs`, `get_flops`, `print_config` ([#324](https://github.com/open-mmlab/mmpose/pull/324))
+
+**Bug Fixes**
+
+- Fix bugs in pck evaluation ([#328](https://github.com/open-mmlab/mmpose/pull/328))
+
+- Fix model download links in README ([#396](https://github.com/open-mmlab/mmpose/pull/396), [#397](https://github.com/open-mmlab/mmpose/pull/397))
+
+- Fix CrowdPose annotations and update benchmarks ([#384](https://github.com/open-mmlab/mmpose/pull/384))
+
+- Fix modelzoo stat ([#354](https://github.com/open-mmlab/mmpose/pull/354), [#360](https://github.com/open-mmlab/mmpose/pull/360), [#362](https://github.com/open-mmlab/mmpose/pull/362))
+
+- Fix config files for aic datasets ([#340](https://github.com/open-mmlab/mmpose/pull/340))
+
+**Breaking Changes**
+
+- Rename `image_thr` to `det_bbox_thr` for top-down methods.
+
+**Improvements**
+
+- Organize the readme files ([#398](https://github.com/open-mmlab/mmpose/pull/398), [#399](https://github.com/open-mmlab/mmpose/pull/399), [#400](https://github.com/open-mmlab/mmpose/pull/400))
+
+- Check linting for markdown ([#379](https://github.com/open-mmlab/mmpose/pull/379))
+
+- Add faq.md ([#350](https://github.com/open-mmlab/mmpose/pull/350))
+
+- Remove PyTorch 1.4 in CI ([#338](https://github.com/open-mmlab/mmpose/pull/338))
+
+- Add pypi badge in readme ([#329](https://github.com/open-mmlab/mmpose/pull/329))
+
+## **v0.9.0 (30/11/2020)**
+
+**Highlights**
+
+1. Support more human pose estimation methods.
+
+ 1. [MSPN](https://arxiv.org/abs/1901.00148)
+ 2. [RSN](https://arxiv.org/abs/2003.04030)
+
+2. Support video pose estimation datasets.
+
+ 1. [sub-JHMDB](http://jhmdb.is.tue.mpg.de/dataset)
+
+3. Support Onnx model conversion.
+
+**New Features**
+
+- Support MSPN ([#278](https://github.com/open-mmlab/mmpose/pull/278))
+
+- Support RSN ([#221](https://github.com/open-mmlab/mmpose/pull/221), [#318](https://github.com/open-mmlab/mmpose/pull/318))
+
+- Support new post-processing method for MSPN & RSN ([#288](https://github.com/open-mmlab/mmpose/pull/288))
+
+- Support sub-JHMDB dataset ([#292](https://github.com/open-mmlab/mmpose/pull/292))
+
+- Support urls for pre-trained models in config files ([#232](https://github.com/open-mmlab/mmpose/pull/232))
+
+- Support Onnx ([#305](https://github.com/open-mmlab/mmpose/pull/305))
+
+**Bug Fixes**
+
+- Fix model download links in README ([#255](https://github.com/open-mmlab/mmpose/pull/255), [#315](https://github.com/open-mmlab/mmpose/pull/315))
+
+**Breaking Changes**
+
+- `post_process=True|False` and `unbiased_decoding=True|False` are deprecated, use `post_process=None|default|unbiased` etc. instead ([#288](https://github.com/open-mmlab/mmpose/pull/288))
+
+**Improvements**
+
+- Enrich the model zoo ([#256](https://github.com/open-mmlab/mmpose/pull/256), [#320](https://github.com/open-mmlab/mmpose/pull/320))
+
+- Set the default map_location as 'cpu' to reduce gpu memory cost ([#227](https://github.com/open-mmlab/mmpose/pull/227))
+
+- Support return heatmaps and backbone features for bottom-up models ([#229](https://github.com/open-mmlab/mmpose/pull/229))
+
+- Upgrade mmcv maximum & minimum version ([#269](https://github.com/open-mmlab/mmpose/pull/269), [#313](https://github.com/open-mmlab/mmpose/pull/313))
+
+- Automatically add modelzoo statistics to readthedocs ([#252](https://github.com/open-mmlab/mmpose/pull/252))
+
+- Fix Pylint issues ([#258](https://github.com/open-mmlab/mmpose/pull/258), [#259](https://github.com/open-mmlab/mmpose/pull/259), [#260](https://github.com/open-mmlab/mmpose/pull/260), [#262](https://github.com/open-mmlab/mmpose/pull/262), [#265](https://github.com/open-mmlab/mmpose/pull/265), [#267](https://github.com/open-mmlab/mmpose/pull/267), [#268](https://github.com/open-mmlab/mmpose/pull/268), [#270](https://github.com/open-mmlab/mmpose/pull/270), [#271](https://github.com/open-mmlab/mmpose/pull/271), [#272](https://github.com/open-mmlab/mmpose/pull/272), [#273](https://github.com/open-mmlab/mmpose/pull/273), [#275](https://github.com/open-mmlab/mmpose/pull/275), [#276](https://github.com/open-mmlab/mmpose/pull/276), [#283](https://github.com/open-mmlab/mmpose/pull/283), [#285](https://github.com/open-mmlab/mmpose/pull/285), [#293](https://github.com/open-mmlab/mmpose/pull/293), [#294](https://github.com/open-mmlab/mmpose/pull/294), [#295](https://github.com/open-mmlab/mmpose/pull/295))
+
+- Improve README ([#226](https://github.com/open-mmlab/mmpose/pull/226), [#257](https://github.com/open-mmlab/mmpose/pull/257), [#264](https://github.com/open-mmlab/mmpose/pull/264), [#280](https://github.com/open-mmlab/mmpose/pull/280), [#296](https://github.com/open-mmlab/mmpose/pull/296))
+
+- Support PyTorch 1.7 in CI ([#274](https://github.com/open-mmlab/mmpose/pull/274))
+
+- Add docs/tutorials for running demos ([#263](https://github.com/open-mmlab/mmpose/pull/263))
+
+## **v0.8.0 (31/10/2020)**
+
+**Highlights**
+
+1. Support more human pose estimation datasets.
+
+ 1. [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose)
+ 2. [PoseTrack18](https://posetrack.net/)
+
+2. Support more 2D hand keypoint estimation datasets.
+
+ 1. [InterHand2.6](https://github.com/facebookresearch/InterHand2.6M)
+
+3. Support adversarial training for 3D human shape recovery.
+
+4. Support multi-stage losses.
+
+5. Support mpii demo.
+
+**New Features**
+
+- Support [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose) dataset ([#195](https://github.com/open-mmlab/mmpose/pull/195))
+
+- Support [PoseTrack18](https://posetrack.net/) dataset ([#220](https://github.com/open-mmlab/mmpose/pull/220))
+
+- Support [InterHand2.6](https://github.com/facebookresearch/InterHand2.6M) dataset ([#202](https://github.com/open-mmlab/mmpose/pull/202))
+
+- Support adversarial training for 3D human shape recovery ([#192](https://github.com/open-mmlab/mmpose/pull/192))
+
+- Support multi-stage losses ([#204](https://github.com/open-mmlab/mmpose/pull/204))
+
+**Bug Fixes**
+
+- Fix config files ([#190](https://github.com/open-mmlab/mmpose/pull/190))
+
+**Improvements**
+
+- Add mpii demo ([#216](https://github.com/open-mmlab/mmpose/pull/216))
+
+- Improve README ([#181](https://github.com/open-mmlab/mmpose/pull/181), [#183](https://github.com/open-mmlab/mmpose/pull/183), [#208](https://github.com/open-mmlab/mmpose/pull/208))
+
+- Support return heatmaps and backbone features ([#196](https://github.com/open-mmlab/mmpose/pull/196), [#212](https://github.com/open-mmlab/mmpose/pull/212))
+
+- Support different return formats of mmdetection models ([#217](https://github.com/open-mmlab/mmpose/pull/217))
+
+## **v0.7.0 (30/9/2020)**
+
+**Highlights**
+
+1. Support HMR for 3D human shape recovery.
+
+2. Support WholeBody human pose estimation.
+
+ 1. [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody)
+
+3. Support more 2D hand keypoint estimation datasets.
+
+ 1. [Frei-hand](https://lmb.informatik.uni-freiburg.de/projects/freihand/)
+ 2. [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html)
+
+4. Add more popular backbones & enrich the [modelzoo](https://mmpose.readthedocs.io/en/latest/model_zoo.html)
+
+ 1. ShuffleNetv2
+
+5. Support hand demo and whole-body demo.
+
+**New Features**
+
+- Support HMR for 3D human shape recovery ([#157](https://github.com/open-mmlab/mmpose/pull/157), [#160](https://github.com/open-mmlab/mmpose/pull/160), [#161](https://github.com/open-mmlab/mmpose/pull/161), [#162](https://github.com/open-mmlab/mmpose/pull/162))
+
+- Support [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody) dataset ([#133](https://github.com/open-mmlab/mmpose/pull/133))
+
+- Support [Frei-hand](https://lmb.informatik.uni-freiburg.de/projects/freihand/) dataset ([#125](https://github.com/open-mmlab/mmpose/pull/125))
+
+- Support [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html) dataset ([#144](https://github.com/open-mmlab/mmpose/pull/144))
+
+- Support H36M dataset ([#159](https://github.com/open-mmlab/mmpose/pull/159))
+
+- Support ShuffleNetv2 ([#139](https://github.com/open-mmlab/mmpose/pull/139))
+
+- Support saving best models based on key indicator ([#127](https://github.com/open-mmlab/mmpose/pull/127))
+
+**Bug Fixes**
+
+- Fix typos in docs ([#121](https://github.com/open-mmlab/mmpose/pull/121))
+
+- Fix assertion ([#142](https://github.com/open-mmlab/mmpose/pull/142))
+
+**Improvements**
+
+- Add tools to transform .mat format to .json format ([#126](https://github.com/open-mmlab/mmpose/pull/126))
+
+- Add hand demo ([#115](https://github.com/open-mmlab/mmpose/pull/115))
+
+- Add whole-body demo ([#163](https://github.com/open-mmlab/mmpose/pull/163))
+
+- Reuse mmcv utility function and update version files ([#135](https://github.com/open-mmlab/mmpose/pull/135), [#137](https://github.com/open-mmlab/mmpose/pull/137))
+
+- Enrich the modelzoo ([#147](https://github.com/open-mmlab/mmpose/pull/147), [#169](https://github.com/open-mmlab/mmpose/pull/169))
+
+- Improve docs ([#174](https://github.com/open-mmlab/mmpose/pull/174), [#175](https://github.com/open-mmlab/mmpose/pull/175), [#178](https://github.com/open-mmlab/mmpose/pull/178))
+
+- Improve README ([#176](https://github.com/open-mmlab/mmpose/pull/176))
+
+- Improve version.py ([#173](https://github.com/open-mmlab/mmpose/pull/173))
+
+## **v0.6.0 (31/8/2020)**
+
+**Highlights**
+
+1. Add more popular backbones & enrich the [modelzoo](https://mmpose.readthedocs.io/en/latest/model_zoo.html)
+
+ 1. ResNext
+ 2. SEResNet
+ 3. ResNetV1D
+ 4. MobileNetv2
+ 5. ShuffleNetv1
+ 6. CPM (Convolutional Pose Machine)
+
+2. Add more popular datasets:
+
+ 1. [AIChallenger](https://arxiv.org/abs/1711.06475?context=cs.CV)
+ 2. [MPII](http://human-pose.mpi-inf.mpg.de/)
+ 3. [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body)
+ 4. [OCHuman](http://www.liruilong.cn/projects/pose2seg/index.html)
+
+3. Support 2d hand keypoint estimation.
+
+ 1. [OneHand10K](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html)
+
+4. Support bottom-up inference.
+
+**New Features**
+
+- Support [OneHand10K](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html) dataset ([#52](https://github.com/open-mmlab/mmpose/pull/52))
+
+- Support [MPII](http://human-pose.mpi-inf.mpg.de/) dataset ([#55](https://github.com/open-mmlab/mmpose/pull/55))
+
+- Support [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) dataset ([#19](https://github.com/open-mmlab/mmpose/pull/19), [#47](https://github.com/open-mmlab/mmpose/pull/47), [#48](https://github.com/open-mmlab/mmpose/pull/48))
+
+- Support [OCHuman](http://www.liruilong.cn/projects/pose2seg/index.html) dataset ([#70](https://github.com/open-mmlab/mmpose/pull/70))
+
+- Support [AIChallenger](https://arxiv.org/abs/1711.06475?context=cs.CV) dataset ([#87](https://github.com/open-mmlab/mmpose/pull/87))
+
+- Support multiple backbones ([#26](https://github.com/open-mmlab/mmpose/pull/26))
+
+- Support CPM model ([#56](https://github.com/open-mmlab/mmpose/pull/56))
+
+**Bug Fixes**
+
+- Fix configs for MPII & MPII-TRB datasets ([#93](https://github.com/open-mmlab/mmpose/pull/93))
+
+- Fix the bug of missing `test_pipeline` in configs ([#14](https://github.com/open-mmlab/mmpose/pull/14))
+
+- Fix typos ([#27](https://github.com/open-mmlab/mmpose/pull/27), [#28](https://github.com/open-mmlab/mmpose/pull/28), [#50](https://github.com/open-mmlab/mmpose/pull/50), [#53](https://github.com/open-mmlab/mmpose/pull/53), [#63](https://github.com/open-mmlab/mmpose/pull/63))
+
+**Improvements**
+
+- Update benchmark ([#93](https://github.com/open-mmlab/mmpose/pull/93))
+
+- Add Dockerfile ([#44](https://github.com/open-mmlab/mmpose/pull/44))
+
+- Improve unittest coverage and minor fix ([#18](https://github.com/open-mmlab/mmpose/pull/18))
+
+- Support CPUs for train/val/demo ([#34](https://github.com/open-mmlab/mmpose/pull/34))
+
+- Support bottom-up demo ([#69](https://github.com/open-mmlab/mmpose/pull/69))
+
+- Add tools to publish model ([#62](https://github.com/open-mmlab/mmpose/pull/62))
+
+- Enrich the modelzoo ([#64](https://github.com/open-mmlab/mmpose/pull/64), [#68](https://github.com/open-mmlab/mmpose/pull/68), [#82](https://github.com/open-mmlab/mmpose/pull/82))
+
+## **v0.5.0 (21/7/2020)**
+
+**Highlights**
+
+- MMPose is released.
+
+**Main Features**
+
+- Support both top-down and bottom-up pose estimation approaches.
+
+- Achieve higher training efficiency and higher accuracy than other popular codebases (e.g. AlphaPose, HRNet)
+
+- Support various backbone models: ResNet, HRNet, SCNet, Houglass and HigherHRNet.
diff --git a/docs/zh_cn/notes/ecosystem.md b/docs/zh_cn/notes/ecosystem.md
index b0027cfa53..6ae3dd5aa6 100644
--- a/docs/zh_cn/notes/ecosystem.md
+++ b/docs/zh_cn/notes/ecosystem.md
@@ -1,3 +1,3 @@
-# Ecosystem
-
-Coming soon.
+# Ecosystem
+
+Coming soon.
diff --git a/docs/zh_cn/notes/projects.md b/docs/zh_cn/notes/projects.md
index 460d8583bd..599c54055f 100644
--- a/docs/zh_cn/notes/projects.md
+++ b/docs/zh_cn/notes/projects.md
@@ -1,20 +1,20 @@
-# Projects based on MMPose
-
-There are many projects built upon MMPose. We list some of them as examples of how to extend MMPose for your own projects. As the page might not be completed, please feel free to create a PR to update this page.
-
-## Projects as an extension
-
-Some projects extend the boundary of MMPose for deployment or other research fields. They reveal the potential of what MMPose can do. We list several of them as below.
-
-- [Anime Face Detector](https://github.com/hysts/anime-face-detector): An anime face landmark detection toolbox.
-- [PosePipeline](https://github.com/peabody124/PosePipeline): Open-Source Human Pose Estimation Pipeline for Clinical Research
-
-## Projects of papers
-
-There are also projects released with papers. Some of the papers are published in top-tier conferences (CVPR, ICCV, and ECCV), the others are also highly influential. We list some of these works as a reference for the community to develop and compare new pose estimation algorithms. Methods already supported and maintained by MMPose are not listed.
-
-- Pose for Everything: Towards Category-Agnostic Pose Estimation, ECCV 2022. [\[paper\]](https://arxiv.org/abs/2207.10387)[\[github\]](https://github.com/luminxu/Pose-for-Everything)
-- UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning, ICLR 2022. [\[paper\]](https://arxiv.org/abs/2201.04676)[\[github\]](https://github.com/Sense-X/UniFormer)
-- Poseur:Direct Human Pose Regression with Transformers, ECCV 2022. [\[paper\]](https://arxiv.org/abs/2201.07412)[\[github\]](https://github.com/aim-uofa/Poseur)
-- ViTAEv2: Vision Transformer Advanced by Exploring Inductive Bias for Image Recognition and Beyond, NeurIPS 2022. [\[paper\]](https://arxiv.org/abs/2106.03348)[\[github\]](https://github.com/ViTAE-Transformer/ViTAE-Transformer)
-- Dite-HRNet:Dynamic Lightweight High-Resolution Network for Human Pose Estimation, IJCAI-ECAI 2021. [\[paper\]](https://arxiv.org/abs/2204.10762)[\[github\]](https://github.com/ZiyiZhang27/Dite-HRNet)
+# Projects based on MMPose
+
+There are many projects built upon MMPose. We list some of them as examples of how to extend MMPose for your own projects. As the page might not be completed, please feel free to create a PR to update this page.
+
+## Projects as an extension
+
+Some projects extend the boundary of MMPose for deployment or other research fields. They reveal the potential of what MMPose can do. We list several of them as below.
+
+- [Anime Face Detector](https://github.com/hysts/anime-face-detector): An anime face landmark detection toolbox.
+- [PosePipeline](https://github.com/peabody124/PosePipeline): Open-Source Human Pose Estimation Pipeline for Clinical Research
+
+## Projects of papers
+
+There are also projects released with papers. Some of the papers are published in top-tier conferences (CVPR, ICCV, and ECCV), the others are also highly influential. We list some of these works as a reference for the community to develop and compare new pose estimation algorithms. Methods already supported and maintained by MMPose are not listed.
+
+- Pose for Everything: Towards Category-Agnostic Pose Estimation, ECCV 2022. [\[paper\]](https://arxiv.org/abs/2207.10387)[\[github\]](https://github.com/luminxu/Pose-for-Everything)
+- UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning, ICLR 2022. [\[paper\]](https://arxiv.org/abs/2201.04676)[\[github\]](https://github.com/Sense-X/UniFormer)
+- Poseur:Direct Human Pose Regression with Transformers, ECCV 2022. [\[paper\]](https://arxiv.org/abs/2201.07412)[\[github\]](https://github.com/aim-uofa/Poseur)
+- ViTAEv2: Vision Transformer Advanced by Exploring Inductive Bias for Image Recognition and Beyond, NeurIPS 2022. [\[paper\]](https://arxiv.org/abs/2106.03348)[\[github\]](https://github.com/ViTAE-Transformer/ViTAE-Transformer)
+- Dite-HRNet:Dynamic Lightweight High-Resolution Network for Human Pose Estimation, IJCAI-ECAI 2021. [\[paper\]](https://arxiv.org/abs/2204.10762)[\[github\]](https://github.com/ZiyiZhang27/Dite-HRNet)
diff --git a/docs/zh_cn/notes/pytorch_2.md b/docs/zh_cn/notes/pytorch_2.md
index 4892e554a5..932f9b0734 100644
--- a/docs/zh_cn/notes/pytorch_2.md
+++ b/docs/zh_cn/notes/pytorch_2.md
@@ -1,14 +1,14 @@
-# PyTorch 2.0 Compatibility and Benchmarks
-
-MMPose 1.0.0 is now compatible with PyTorch 2.0, ensuring that users can leverage the latest features and performance improvements offered by the PyTorch 2.0 framework when using MMPose. With the integration of inductor, users can expect faster model speeds. The table below shows several example models:
-
-| Model | Training Speed | Memory |
-| :-------- | :---------------------: | :-----------: |
-| ViTPose-B | 29.6% ↑ (0.931 → 0.655) | 10586 → 10663 |
-| ViTPose-S | 33.7% ↑ (0.563 → 0.373) | 6091 → 6170 |
-| HRNet-w32 | 12.8% ↑ (0.553 → 0.482) | 9849 → 10145 |
-| HRNet-w48 | 37.1% ↑ (0.437 → 0.275) | 7319 → 7394 |
-| RTMPose-t | 6.3% ↑ (1.533 → 1.437) | 6292 → 6489 |
-| RTMPose-s | 13.1% ↑ (1.645 → 1.430) | 9013 → 9208 |
-
-- Pytorch 2.0 test, add projects doc and refactor by @LareinaM in [PR#2136](https://github.com/open-mmlab/mmpose/pull/2136)
+# PyTorch 2.0 Compatibility and Benchmarks
+
+MMPose 1.0.0 is now compatible with PyTorch 2.0, ensuring that users can leverage the latest features and performance improvements offered by the PyTorch 2.0 framework when using MMPose. With the integration of inductor, users can expect faster model speeds. The table below shows several example models:
+
+| Model | Training Speed | Memory |
+| :-------- | :---------------------: | :-----------: |
+| ViTPose-B | 29.6% ↑ (0.931 → 0.655) | 10586 → 10663 |
+| ViTPose-S | 33.7% ↑ (0.563 → 0.373) | 6091 → 6170 |
+| HRNet-w32 | 12.8% ↑ (0.553 → 0.482) | 9849 → 10145 |
+| HRNet-w48 | 37.1% ↑ (0.437 → 0.275) | 7319 → 7394 |
+| RTMPose-t | 6.3% ↑ (1.533 → 1.437) | 6292 → 6489 |
+| RTMPose-s | 13.1% ↑ (1.645 → 1.430) | 9013 → 9208 |
+
+- Pytorch 2.0 test, add projects doc and refactor by @LareinaM in [PR#2136](https://github.com/open-mmlab/mmpose/pull/2136)
diff --git a/docs/zh_cn/overview.md b/docs/zh_cn/overview.md
index a790cd3be2..f6b75ffd48 100644
--- a/docs/zh_cn/overview.md
+++ b/docs/zh_cn/overview.md
@@ -1,76 +1,76 @@
-# 概述
-
-本章将向你介绍 MMPose 的整体框架,并提供详细的教程链接。
-
-## 什么是 MMPose
-
-
-
-MMPose 是一款基于 Pytorch 的姿态估计开源工具箱,是 OpenMMLab 项目的成员之一,包含了丰富的 2D 多人姿态估计、2D 手部姿态估计、2D 人脸关键点检测、133关键点全身人体姿态估计、动物关键点检测、服饰关键点检测等算法以及相关的组件和模块,下面是它的整体框架:
-
-MMPose 由 **8** 个主要部分组成,apis、structures、datasets、codecs、models、engine、evaluation 和 visualization。
-
-- **apis** 提供用于模型推理的高级 API
-
-- **structures** 提供 bbox、keypoint 和 PoseDataSample 等数据结构
-
-- **datasets** 支持用于姿态估计的各种数据集
-
- - **transforms** 包含各种数据增强变换
-
-- **codecs** 提供姿态编解码器:编码器用于将姿态信息(通常为关键点坐标)编码为模型学习目标(如热力图),解码器则用于将模型输出解码为姿态估计结果
-
-- **models** 以模块化结构提供了姿态估计模型的各类组件
-
- - **pose_estimators** 定义了所有姿态估计模型类
- - **data_preprocessors** 用于预处理模型的输入数据
- - **backbones** 包含各种骨干网络
- - **necks** 包含各种模型颈部组件
- - **heads** 包含各种模型头部
- - **losses** 包含各种损失函数
-
-- **engine** 包含与姿态估计任务相关的运行时组件
-
- - **hooks** 提供运行时的各种钩子
-
-- **evaluation** 提供各种评估模型性能的指标
-
-- **visualization** 用于可视化关键点骨架和热力图等信息
-
-## 如何使用本指南
-
-针对不同类型的用户,我们准备了详细的指南:
-
-1. 安装说明:
-
- - [安装](./installation.md)
-
-2. MMPose 的基本使用方法:
-
- - [20 分钟上手教程](./guide_to_framework.md)
- - [Demos](./demos.md)
- - [模型推理](./user_guides/inference.md)
- - [配置文件](./user_guides/configs.md)
- - [准备数据集](./user_guides/prepare_datasets.md)
- - [训练与测试](./user_guides/train_and_test.md)
-
-3. 对于希望基于 MMPose 进行开发的研究者和开发者:
-
- - [编解码器](./advanced_guides/codecs.md)
- - [数据流](./advanced_guides/dataflow.md)
- - [实现新模型](./advanced_guides/implement_new_models.md)
- - [自定义数据集](./advanced_guides/customize_datasets.md)
- - [自定义数据变换](./advanced_guides/customize_transforms.md)
- - [自定义优化器](./advanced_guides/customize_optimizer.md)
- - [自定义日志](./advanced_guides/customize_logging.md)
- - [模型部署](./advanced_guides/how_to_deploy.md)
- - [模型分析工具](./advanced_guides/model_analysis.md)
- - [迁移指南](./migration.md)
-
-4. 对于希望加入开源社区,向 MMPose 贡献代码的研究者和开发者:
-
- - [参与贡献代码](./contribution_guide.md)
-
-5. 对于使用过程中的常见问题:
-
- - [FAQ](./faq.md)
+# 概述
+
+本章将向你介绍 MMPose 的整体框架,并提供详细的教程链接。
+
+## 什么是 MMPose
+
+
+
+MMPose 是一款基于 Pytorch 的姿态估计开源工具箱,是 OpenMMLab 项目的成员之一,包含了丰富的 2D 多人姿态估计、2D 手部姿态估计、2D 人脸关键点检测、133关键点全身人体姿态估计、动物关键点检测、服饰关键点检测等算法以及相关的组件和模块,下面是它的整体框架:
+
+MMPose 由 **8** 个主要部分组成,apis、structures、datasets、codecs、models、engine、evaluation 和 visualization。
+
+- **apis** 提供用于模型推理的高级 API
+
+- **structures** 提供 bbox、keypoint 和 PoseDataSample 等数据结构
+
+- **datasets** 支持用于姿态估计的各种数据集
+
+ - **transforms** 包含各种数据增强变换
+
+- **codecs** 提供姿态编解码器:编码器用于将姿态信息(通常为关键点坐标)编码为模型学习目标(如热力图),解码器则用于将模型输出解码为姿态估计结果
+
+- **models** 以模块化结构提供了姿态估计模型的各类组件
+
+ - **pose_estimators** 定义了所有姿态估计模型类
+ - **data_preprocessors** 用于预处理模型的输入数据
+ - **backbones** 包含各种骨干网络
+ - **necks** 包含各种模型颈部组件
+ - **heads** 包含各种模型头部
+ - **losses** 包含各种损失函数
+
+- **engine** 包含与姿态估计任务相关的运行时组件
+
+ - **hooks** 提供运行时的各种钩子
+
+- **evaluation** 提供各种评估模型性能的指标
+
+- **visualization** 用于可视化关键点骨架和热力图等信息
+
+## 如何使用本指南
+
+针对不同类型的用户,我们准备了详细的指南:
+
+1. 安装说明:
+
+ - [安装](./installation.md)
+
+2. MMPose 的基本使用方法:
+
+ - [20 分钟上手教程](./guide_to_framework.md)
+ - [Demos](./demos.md)
+ - [模型推理](./user_guides/inference.md)
+ - [配置文件](./user_guides/configs.md)
+ - [准备数据集](./user_guides/prepare_datasets.md)
+ - [训练与测试](./user_guides/train_and_test.md)
+
+3. 对于希望基于 MMPose 进行开发的研究者和开发者:
+
+ - [编解码器](./advanced_guides/codecs.md)
+ - [数据流](./advanced_guides/dataflow.md)
+ - [实现新模型](./advanced_guides/implement_new_models.md)
+ - [自定义数据集](./advanced_guides/customize_datasets.md)
+ - [自定义数据变换](./advanced_guides/customize_transforms.md)
+ - [自定义优化器](./advanced_guides/customize_optimizer.md)
+ - [自定义日志](./advanced_guides/customize_logging.md)
+ - [模型部署](./advanced_guides/how_to_deploy.md)
+ - [模型分析工具](./advanced_guides/model_analysis.md)
+ - [迁移指南](./migration.md)
+
+4. 对于希望加入开源社区,向 MMPose 贡献代码的研究者和开发者:
+
+ - [参与贡献代码](./contribution_guide.md)
+
+5. 对于使用过程中的常见问题:
+
+ - [FAQ](./faq.md)
diff --git a/docs/zh_cn/quick_run.md b/docs/zh_cn/quick_run.md
index 55c2d63b20..b81b3652f6 100644
--- a/docs/zh_cn/quick_run.md
+++ b/docs/zh_cn/quick_run.md
@@ -1,188 +1,188 @@
-# 快速上手
-
-在这一章里,我们将带领你走过MMPose工作流程中关键的七个步骤,帮助你快速上手:
-
-1. 使用预训练模型进行推理
-2. 准备数据集
-3. 准备配置文件
-4. 可视化训练图片
-5. 训练
-6. 测试
-7. 可视化
-
-## 安装
-
-请查看[安装指南](./installation.md),以了解完整步骤。
-
-## 快速开始
-
-### 使用预训练模型进行推理
-
-你可以通过以下命令来使用预训练模型对单张图片进行识别:
-
-```Bash
-python demo/image_demo.py \
- tests/data/coco/000000000785.jpg \
- configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py\
- https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res50_coco_256x192_rle-2ea9bb4a_20220616.pth
-```
-
-该命令中用到了测试图片、完整的配置文件、预训练模型,如果MMPose安装无误,将会弹出一个新窗口,对检测结果进行可视化显示:
-
-
-
-更多演示脚本的详细参数说明可以在 [模型推理](./user_guides/inference.md) 中找到。
-
-### 准备数据集
-
-MMPose支持各种不同的任务,我们提供了对应的数据集准备教程。
-
-- [2D人体关键点](./dataset_zoo/2d_body_keypoint.md)
-
-- [3D人体关键点](./dataset_zoo/3d_body_keypoint.md)
-
-- [2D人手关键点](./dataset_zoo/2d_hand_keypoint.md)
-
-- [3D人手关键点](./dataset_zoo/3d_hand_keypoint.md)
-
-- [2D人脸关键点](./dataset_zoo/2d_face_keypoint.md)
-
-- [2D全身人体关键点](./dataset_zoo/2d_wholebody_keypoint.md)
-
-- [2D服饰关键点](./dataset_zoo/2d_fashion_landmark.md)
-
-- [2D动物关键点](./dataset_zoo/2d_animal_keypoint.md)
-
-你可以在【2D人体关键点数据集】>【COCO】下找到COCO数据集的准备教程,并按照教程完成数据集的下载和整理。
-
-```{note}
-在MMPose中,我们建议将COCO数据集存放到新建的 `$MMPOSE/data` 目录下。
-```
-
-### 准备配置文件
-
-MMPose拥有一套强大的配置系统,用于管理训练所需的一系列必要参数:
-
-- **通用**:环境、Hook、Checkpoint、Logger、Timer等
-
-- **数据**:Dataset、Dataloader、数据增强等
-
-- **训练**:优化器、学习率调整等
-
-- **模型**:Backbone、Neck、Head、损失函数等
-
-- **评测**:Metrics
-
-在`$MMPOSE/configs`目录下,我们提供了大量前沿论文方法的配置文件,可供直接使用和参考。
-
-要在COCO数据集上训练基于ResNet50的RLE模型时,所需的配置文件为:
-
-```Bash
-$MMPOSE/configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py
-```
-
-我们需要将配置文件中的 data_root 变量修改为COCO数据集存放路径:
-
-```Python
-data_root = 'data/coco'
-```
-
-```{note}
-感兴趣的读者也可以查阅 [配置文件](./user_guides/configs.md) 来进一步学习MMPose所使用的配置系统。
-```
-
-### 可视化训练图片
-
-在开始训练之前,我们还可以对训练图片进行可视化,检查训练图片是否正确进行了数据增强。
-
-我们提供了相应的可视化脚本:
-
-```Bash
-python tools/misc/browse_dastaset.py \
- configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py \
- --mode transformed
-```
-
-
-
-### 训练
-
-确定数据无误后,运行以下命令启动训练:
-
-```Bash
-python tools/train.py configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py
-```
-
-```{note}
-MMPose中集成了大量实用训练trick和功能:
-
-- 学习率warmup和scheduling
-
-- ImageNet预训练权重
-
-- 自动学习率缩放、自动batch size缩放
-
-- CPU训练、多机多卡训练、集群训练
-
-- HardDisk、LMDB、Petrel、HTTP等不同数据后端
-
-- 混合精度浮点训练
-
-- TensorBoard
-```
-
-### 测试
-
-在不指定额外参数时,训练的权重和日志信息会默认存储到`$MMPOSE/work_dirs`目录下,最优的模型权重存放在`$MMPOSE/work_dir/best_coco`目录下。
-
-我们可以通过如下指令测试模型在COCO验证集上的精度:
-
-```Bash
-python tools/test.py \
- configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py \
- work_dir/best_coco/AP_epoch_20.pth
-```
-
-在COCO验证集上评测结果样例如下:
-
-```Bash
- Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.704
- Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.883
- Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.777
- Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.667
- Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.769
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.751
- Average Recall (AR) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.920
- Average Recall (AR) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.815
- Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.709
- Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.811
-08/23 12:04:42 - mmengine - INFO - Epoch(test) [3254/3254] coco/AP: 0.704168 coco/AP .5: 0.883134 coco/AP .75: 0.777015 coco/AP (M): 0.667207 coco/AP (L): 0.768644 coco/AR: 0.750913 coco/AR .5: 0.919710 coco/AR .75: 0.815334 coco/AR (M): 0.709232 coco/AR (L): 0.811334
-```
-
-```{note}
-如果需要测试模型在其他数据集上的表现,可以前往 [训练与测试](./user_guides/train_and_test.md) 查看。
-```
-
-### 可视化
-
-除了对关键点骨架的可视化以外,我们还支持对热度图进行可视化,你只需要在配置文件中设置`output_heatmap=True`:
-
-```Python
-model = dict(
- ## 内容省略
- test_cfg = dict(
- ## 内容省略
- output_heatmaps=True
- )
-)
-```
-
-或在命令行中添加`--cfg-options='model.test_cfg.output_heatmaps=True'`。
-
-可视化效果如下:
-
-
-
-```{note}
-如果你希望深入地学习MMPose,将其应用到自己的项目当中,我们准备了一份详细的 [迁移指南](./migration.md) 。
-```
+# 快速上手
+
+在这一章里,我们将带领你走过MMPose工作流程中关键的七个步骤,帮助你快速上手:
+
+1. 使用预训练模型进行推理
+2. 准备数据集
+3. 准备配置文件
+4. 可视化训练图片
+5. 训练
+6. 测试
+7. 可视化
+
+## 安装
+
+请查看[安装指南](./installation.md),以了解完整步骤。
+
+## 快速开始
+
+### 使用预训练模型进行推理
+
+你可以通过以下命令来使用预训练模型对单张图片进行识别:
+
+```Bash
+python demo/image_demo.py \
+ tests/data/coco/000000000785.jpg \
+ configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py\
+ https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res50_coco_256x192_rle-2ea9bb4a_20220616.pth
+```
+
+该命令中用到了测试图片、完整的配置文件、预训练模型,如果MMPose安装无误,将会弹出一个新窗口,对检测结果进行可视化显示:
+
+
+
+更多演示脚本的详细参数说明可以在 [模型推理](./user_guides/inference.md) 中找到。
+
+### 准备数据集
+
+MMPose支持各种不同的任务,我们提供了对应的数据集准备教程。
+
+- [2D人体关键点](./dataset_zoo/2d_body_keypoint.md)
+
+- [3D人体关键点](./dataset_zoo/3d_body_keypoint.md)
+
+- [2D人手关键点](./dataset_zoo/2d_hand_keypoint.md)
+
+- [3D人手关键点](./dataset_zoo/3d_hand_keypoint.md)
+
+- [2D人脸关键点](./dataset_zoo/2d_face_keypoint.md)
+
+- [2D全身人体关键点](./dataset_zoo/2d_wholebody_keypoint.md)
+
+- [2D服饰关键点](./dataset_zoo/2d_fashion_landmark.md)
+
+- [2D动物关键点](./dataset_zoo/2d_animal_keypoint.md)
+
+你可以在【2D人体关键点数据集】>【COCO】下找到COCO数据集的准备教程,并按照教程完成数据集的下载和整理。
+
+```{note}
+在MMPose中,我们建议将COCO数据集存放到新建的 `$MMPOSE/data` 目录下。
+```
+
+### 准备配置文件
+
+MMPose拥有一套强大的配置系统,用于管理训练所需的一系列必要参数:
+
+- **通用**:环境、Hook、Checkpoint、Logger、Timer等
+
+- **数据**:Dataset、Dataloader、数据增强等
+
+- **训练**:优化器、学习率调整等
+
+- **模型**:Backbone、Neck、Head、损失函数等
+
+- **评测**:Metrics
+
+在`$MMPOSE/configs`目录下,我们提供了大量前沿论文方法的配置文件,可供直接使用和参考。
+
+要在COCO数据集上训练基于ResNet50的RLE模型时,所需的配置文件为:
+
+```Bash
+$MMPOSE/configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py
+```
+
+我们需要将配置文件中的 data_root 变量修改为COCO数据集存放路径:
+
+```Python
+data_root = 'data/coco'
+```
+
+```{note}
+感兴趣的读者也可以查阅 [配置文件](./user_guides/configs.md) 来进一步学习MMPose所使用的配置系统。
+```
+
+### 可视化训练图片
+
+在开始训练之前,我们还可以对训练图片进行可视化,检查训练图片是否正确进行了数据增强。
+
+我们提供了相应的可视化脚本:
+
+```Bash
+python tools/misc/browse_dastaset.py \
+ configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py \
+ --mode transformed
+```
+
+
+
+### 训练
+
+确定数据无误后,运行以下命令启动训练:
+
+```Bash
+python tools/train.py configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py
+```
+
+```{note}
+MMPose中集成了大量实用训练trick和功能:
+
+- 学习率warmup和scheduling
+
+- ImageNet预训练权重
+
+- 自动学习率缩放、自动batch size缩放
+
+- CPU训练、多机多卡训练、集群训练
+
+- HardDisk、LMDB、Petrel、HTTP等不同数据后端
+
+- 混合精度浮点训练
+
+- TensorBoard
+```
+
+### 测试
+
+在不指定额外参数时,训练的权重和日志信息会默认存储到`$MMPOSE/work_dirs`目录下,最优的模型权重存放在`$MMPOSE/work_dir/best_coco`目录下。
+
+我们可以通过如下指令测试模型在COCO验证集上的精度:
+
+```Bash
+python tools/test.py \
+ configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py \
+ work_dir/best_coco/AP_epoch_20.pth
+```
+
+在COCO验证集上评测结果样例如下:
+
+```Bash
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.704
+ Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.883
+ Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.777
+ Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.667
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.769
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.751
+ Average Recall (AR) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.920
+ Average Recall (AR) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.815
+ Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.709
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.811
+08/23 12:04:42 - mmengine - INFO - Epoch(test) [3254/3254] coco/AP: 0.704168 coco/AP .5: 0.883134 coco/AP .75: 0.777015 coco/AP (M): 0.667207 coco/AP (L): 0.768644 coco/AR: 0.750913 coco/AR .5: 0.919710 coco/AR .75: 0.815334 coco/AR (M): 0.709232 coco/AR (L): 0.811334
+```
+
+```{note}
+如果需要测试模型在其他数据集上的表现,可以前往 [训练与测试](./user_guides/train_and_test.md) 查看。
+```
+
+### 可视化
+
+除了对关键点骨架的可视化以外,我们还支持对热度图进行可视化,你只需要在配置文件中设置`output_heatmap=True`:
+
+```Python
+model = dict(
+ ## 内容省略
+ test_cfg = dict(
+ ## 内容省略
+ output_heatmaps=True
+ )
+)
+```
+
+或在命令行中添加`--cfg-options='model.test_cfg.output_heatmaps=True'`。
+
+可视化效果如下:
+
+
+
+```{note}
+如果你希望深入地学习MMPose,将其应用到自己的项目当中,我们准备了一份详细的 [迁移指南](./migration.md) 。
+```
diff --git a/docs/zh_cn/stats.py b/docs/zh_cn/stats.py
index 218d23f5b0..5b2b4af1a0 100644
--- a/docs/zh_cn/stats.py
+++ b/docs/zh_cn/stats.py
@@ -1,176 +1,176 @@
-#!/usr/bin/env python
-# Copyright (c) OpenMMLab. All rights reserved.
-import functools as func
-import glob
-import re
-from os.path import basename, splitext
-
-import numpy as np
-import titlecase
-
-
-def anchor(name):
- return re.sub(r'-+', '-', re.sub(r'[^a-zA-Z0-9]', '-',
- name.strip().lower())).strip('-')
-
-
-# Count algorithms
-
-files = sorted(glob.glob('model_zoo/*.md'))
-
-stats = []
-
-for f in files:
- with open(f, 'r') as content_file:
- content = content_file.read()
-
- # title
- title = content.split('\n')[0].replace('#', '')
-
- # count papers
- papers = set(
- (papertype, titlecase.titlecase(paper.lower().strip()))
- for (papertype, paper) in re.findall(
- r'\s*\n.*?\btitle\s*=\s*{(.*?)}',
- content, re.DOTALL))
- # paper links
- revcontent = '\n'.join(list(reversed(content.splitlines())))
- paperlinks = {}
- for _, p in papers:
- # print(p)
- paperlinks[p] = ', '.join(
- ((f'[{paperlink} ⇨]'
- f'(model_zoo/{splitext(basename(f))[0]}.html#'
- f'{anchor(paperlink)})') for paperlink in re.findall(
- rf'\btitle\s*=\s*{{\s*{p}\s*}}.*?\n### (.*?)\s*[,;]?\s*\n',
- revcontent, re.DOTALL | re.IGNORECASE)))
- # print(' ', paperlinks[p])
- paperlist = '\n'.join(
- sorted(f' - [{t}] {x} ({paperlinks[x]})' for t, x in papers))
- # count configs
- configs = set(x.lower().strip()
- for x in re.findall(r'.*configs/.*\.py', content))
-
- # count ckpts
- ckpts = set(x.lower().strip()
- for x in re.findall(r'https://download.*\.pth', content)
- if 'mmpose' in x)
-
- statsmsg = f"""
-## [{title}]({f})
-
-* 模型权重文件数量: {len(ckpts)}
-* 配置文件数量: {len(configs)}
-* 论文数量: {len(papers)}
-{paperlist}
-
- """
-
- stats.append((papers, configs, ckpts, statsmsg))
-
-allpapers = func.reduce(lambda a, b: a.union(b), [p for p, _, _, _ in stats])
-allconfigs = func.reduce(lambda a, b: a.union(b), [c for _, c, _, _ in stats])
-allckpts = func.reduce(lambda a, b: a.union(b), [c for _, _, c, _ in stats])
-
-# Summarize
-
-msglist = '\n'.join(x for _, _, _, x in stats)
-papertypes, papercounts = np.unique([t for t, _ in allpapers],
- return_counts=True)
-countstr = '\n'.join(
- [f' - {t}: {c}' for t, c in zip(papertypes, papercounts)])
-
-modelzoo = f"""
-# 概览
-
-* 模型权重文件数量: {len(allckpts)}
-* 配置文件数量: {len(allconfigs)}
-* 论文数量: {len(allpapers)}
-{countstr}
-
-已支持的数据集详细信息请见 [数据集](dataset_zoo.md).
-
-{msglist}
-
-"""
-
-with open('model_zoo.md', 'w') as f:
- f.write(modelzoo)
-
-# Count datasets
-
-files = sorted(glob.glob('model_zoo/*.md'))
-# files = sorted(glob.glob('docs/tasks/*.md'))
-
-datastats = []
-
-for f in files:
- with open(f, 'r') as content_file:
- content = content_file.read()
-
- # title
- title = content.split('\n')[0].replace('#', '')
-
- # count papers
- papers = set(
- (papertype, titlecase.titlecase(paper.lower().strip()))
- for (papertype, paper) in re.findall(
- r'\s*\n.*?\btitle\s*=\s*{(.*?)}',
- content, re.DOTALL))
- # paper links
- revcontent = '\n'.join(list(reversed(content.splitlines())))
- paperlinks = {}
- for _, p in papers:
- # print(p)
- paperlinks[p] = ', '.join(
- (f'[{p} ⇨](model_zoo/{splitext(basename(f))[0]}.html#'
- f'{anchor(p)})' for p in re.findall(
- rf'\btitle\s*=\s*{{\s*{p}\s*}}.*?\n## (.*?)\s*[,;]?\s*\n',
- revcontent, re.DOTALL | re.IGNORECASE)))
- # print(' ', paperlinks[p])
- paperlist = '\n'.join(
- sorted(f' - [{t}] {x} ({paperlinks[x]})' for t, x in papers))
- # count configs
- configs = set(x.lower().strip()
- for x in re.findall(r'https.*configs/.*\.py', content))
-
- # count ckpts
- ckpts = set(x.lower().strip()
- for x in re.findall(r'https://download.*\.pth', content)
- if 'mmpose' in x)
-
- statsmsg = f"""
-## [{title}]({f})
-
-* 论文数量: {len(papers)}
-{paperlist}
-
- """
-
- datastats.append((papers, configs, ckpts, statsmsg))
-
-alldatapapers = func.reduce(lambda a, b: a.union(b),
- [p for p, _, _, _ in datastats])
-
-# Summarize
-
-msglist = '\n'.join(x for _, _, _, x in stats)
-datamsglist = '\n'.join(x for _, _, _, x in datastats)
-papertypes, papercounts = np.unique([t for t, _ in alldatapapers],
- return_counts=True)
-countstr = '\n'.join(
- [f' - {t}: {c}' for t, c in zip(papertypes, papercounts)])
-
-dataset_zoo = f"""
-# 概览
-
-* 论文数量: {len(alldatapapers)}
-{countstr}
-
-已支持的算法详细信息请见 [模型池](model_zoo.md).
-
-{datamsglist}
-"""
-
-with open('dataset_zoo.md', 'w') as f:
- f.write(dataset_zoo)
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import functools as func
+import glob
+import re
+from os.path import basename, splitext
+
+import numpy as np
+import titlecase
+
+
+def anchor(name):
+ return re.sub(r'-+', '-', re.sub(r'[^a-zA-Z0-9]', '-',
+ name.strip().lower())).strip('-')
+
+
+# Count algorithms
+
+files = sorted(glob.glob('model_zoo/*.md'))
+
+stats = []
+
+for f in files:
+ with open(f, 'r') as content_file:
+ content = content_file.read()
+
+ # title
+ title = content.split('\n')[0].replace('#', '')
+
+ # count papers
+ papers = set(
+ (papertype, titlecase.titlecase(paper.lower().strip()))
+ for (papertype, paper) in re.findall(
+ r'\s*\n.*?\btitle\s*=\s*{(.*?)}',
+ content, re.DOTALL))
+ # paper links
+ revcontent = '\n'.join(list(reversed(content.splitlines())))
+ paperlinks = {}
+ for _, p in papers:
+ # print(p)
+ paperlinks[p] = ', '.join(
+ ((f'[{paperlink} ⇨]'
+ f'(model_zoo/{splitext(basename(f))[0]}.html#'
+ f'{anchor(paperlink)})') for paperlink in re.findall(
+ rf'\btitle\s*=\s*{{\s*{p}\s*}}.*?\n### (.*?)\s*[,;]?\s*\n',
+ revcontent, re.DOTALL | re.IGNORECASE)))
+ # print(' ', paperlinks[p])
+ paperlist = '\n'.join(
+ sorted(f' - [{t}] {x} ({paperlinks[x]})' for t, x in papers))
+ # count configs
+ configs = set(x.lower().strip()
+ for x in re.findall(r'.*configs/.*\.py', content))
+
+ # count ckpts
+ ckpts = set(x.lower().strip()
+ for x in re.findall(r'https://download.*\.pth', content)
+ if 'mmpose' in x)
+
+ statsmsg = f"""
+## [{title}]({f})
+
+* 模型权重文件数量: {len(ckpts)}
+* 配置文件数量: {len(configs)}
+* 论文数量: {len(papers)}
+{paperlist}
+
+ """
+
+ stats.append((papers, configs, ckpts, statsmsg))
+
+allpapers = func.reduce(lambda a, b: a.union(b), [p for p, _, _, _ in stats])
+allconfigs = func.reduce(lambda a, b: a.union(b), [c for _, c, _, _ in stats])
+allckpts = func.reduce(lambda a, b: a.union(b), [c for _, _, c, _ in stats])
+
+# Summarize
+
+msglist = '\n'.join(x for _, _, _, x in stats)
+papertypes, papercounts = np.unique([t for t, _ in allpapers],
+ return_counts=True)
+countstr = '\n'.join(
+ [f' - {t}: {c}' for t, c in zip(papertypes, papercounts)])
+
+modelzoo = f"""
+# 概览
+
+* 模型权重文件数量: {len(allckpts)}
+* 配置文件数量: {len(allconfigs)}
+* 论文数量: {len(allpapers)}
+{countstr}
+
+已支持的数据集详细信息请见 [数据集](dataset_zoo.md).
+
+{msglist}
+
+"""
+
+with open('model_zoo.md', 'w') as f:
+ f.write(modelzoo)
+
+# Count datasets
+
+files = sorted(glob.glob('model_zoo/*.md'))
+# files = sorted(glob.glob('docs/tasks/*.md'))
+
+datastats = []
+
+for f in files:
+ with open(f, 'r') as content_file:
+ content = content_file.read()
+
+ # title
+ title = content.split('\n')[0].replace('#', '')
+
+ # count papers
+ papers = set(
+ (papertype, titlecase.titlecase(paper.lower().strip()))
+ for (papertype, paper) in re.findall(
+ r'\s*\n.*?\btitle\s*=\s*{(.*?)}',
+ content, re.DOTALL))
+ # paper links
+ revcontent = '\n'.join(list(reversed(content.splitlines())))
+ paperlinks = {}
+ for _, p in papers:
+ # print(p)
+ paperlinks[p] = ', '.join(
+ (f'[{p} ⇨](model_zoo/{splitext(basename(f))[0]}.html#'
+ f'{anchor(p)})' for p in re.findall(
+ rf'\btitle\s*=\s*{{\s*{p}\s*}}.*?\n## (.*?)\s*[,;]?\s*\n',
+ revcontent, re.DOTALL | re.IGNORECASE)))
+ # print(' ', paperlinks[p])
+ paperlist = '\n'.join(
+ sorted(f' - [{t}] {x} ({paperlinks[x]})' for t, x in papers))
+ # count configs
+ configs = set(x.lower().strip()
+ for x in re.findall(r'https.*configs/.*\.py', content))
+
+ # count ckpts
+ ckpts = set(x.lower().strip()
+ for x in re.findall(r'https://download.*\.pth', content)
+ if 'mmpose' in x)
+
+ statsmsg = f"""
+## [{title}]({f})
+
+* 论文数量: {len(papers)}
+{paperlist}
+
+ """
+
+ datastats.append((papers, configs, ckpts, statsmsg))
+
+alldatapapers = func.reduce(lambda a, b: a.union(b),
+ [p for p, _, _, _ in datastats])
+
+# Summarize
+
+msglist = '\n'.join(x for _, _, _, x in stats)
+datamsglist = '\n'.join(x for _, _, _, x in datastats)
+papertypes, papercounts = np.unique([t for t, _ in alldatapapers],
+ return_counts=True)
+countstr = '\n'.join(
+ [f' - {t}: {c}' for t, c in zip(papertypes, papercounts)])
+
+dataset_zoo = f"""
+# 概览
+
+* 论文数量: {len(alldatapapers)}
+{countstr}
+
+已支持的算法详细信息请见 [模型池](model_zoo.md).
+
+{datamsglist}
+"""
+
+with open('dataset_zoo.md', 'w') as f:
+ f.write(dataset_zoo)
diff --git a/docs/zh_cn/switch_language.md b/docs/zh_cn/switch_language.md
index 05688a9530..bfb2ae0d51 100644
--- a/docs/zh_cn/switch_language.md
+++ b/docs/zh_cn/switch_language.md
@@ -1,3 +1,3 @@
-## 简体中文
-
-## English
+## 简体中文
+
+## English
diff --git a/docs/zh_cn/user_guides/advanced_training.md b/docs/zh_cn/user_guides/advanced_training.md
index dd02a7661f..0e2dbb9c7d 100644
--- a/docs/zh_cn/user_guides/advanced_training.md
+++ b/docs/zh_cn/user_guides/advanced_training.md
@@ -1,104 +1,104 @@
-# 高级训练设置
-
-## 恢复训练
-
-恢复训练是指从之前某次训练保存下来的状态开始继续训练,这里的状态包括模型的权重、优化器和优化器参数调整策略的状态。
-
-### 自动恢复训练
-
-用户可以在训练命令最后加上 `--resume` 恢复训练,程序会自动从 `work_dirs` 中加载最新的权重文件恢复训练。如果 `work_dir` 中有最新的 `checkpoint`(例如该训练在上一次训练时被中断),则会从该 `checkpoint` 恢复训练,否则(例如上一次训练还没来得及保存 `checkpoint` 或者启动了新的训练任务)会重新开始训练。
-
-下面是一个恢复训练的示例:
-
-```shell
-python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py --resume
-```
-
-### 指定 Checkpoint 恢复训练
-
-你也可以对 `--resume` 指定 `checkpoint` 路径,MMPose 会自动读取该 `checkpoint` 并从中恢复训练,命令如下:
-
-```shell
-python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py \
- --resume work_dirs/td-hm_res50_8xb64-210e_coco-256x192/latest.pth
-```
-
-如果你希望手动在配置文件中指定 `checkpoint` 路径,除了设置 `resume=True`,还需要设置 `load_from` 参数。需要注意的是,如果只设置了 `load_from` 而没有设置 `resume=True`,则只会加载 `checkpoint` 中的权重并重新开始训练,而不是接着之前的状态继续训练。
-
-下面的例子与上面指定 `--resume` 参数的例子等价:
-
-```python
-resume = True
-load_from = 'work_dirs/td-hm_res50_8xb64-210e_coco-256x192/latest.pth'
-# model settings
-model = dict(
- ## 内容省略 ##
- )
-```
-
-## 自动混合精度(AMP)训练
-
-混合精度训练在不改变模型、不降低模型训练精度的前提下,可以缩短训练时间,降低存储需求,因而能支持更大的 batch size、更大模型和尺寸更大的输入的训练。
-
-如果要开启自动混合精度(AMP)训练,在训练命令最后加上 --amp 即可, 命令如下:
-
-```shell
-python tools/train.py ${CONFIG_FILE} --amp
-```
-
-具体例子如下:
-
-```shell
-python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py --amp
-```
-
-## 设置随机种子
-
-如果想要在训练时指定随机种子,可以使用以下命令:
-
-```shell
-python ./tools/train.py \
- ${CONFIG} \ # 配置文件路径
- --cfg-options randomness.seed=2023 \ # 设置随机种子为 2023
- [randomness.diff_rank_seed=True] \ # 根据 rank 来设置不同的种子。
- [randomness.deterministic=True] # 把 cuDNN 后端确定性选项设置为 True
-# [] 代表可选参数,实际输入命令行时,不用输入 []
-```
-
-randomness 有三个参数可设置,具体含义如下:
-
-- `randomness.seed=2023` ,设置随机种子为 `2023`。
-
-- `randomness.diff_rank_seed=True`,根据 `rank` 来设置不同的种子,`diff_rank_seed` 默认为 `False`。
-
-- `randomness.deterministic=True`,把 `cuDNN` 后端确定性选项设置为 `True`,即把 `torch.backends.cudnn.deterministic` 设为 `True`,把 `torch.backends.cudnn.benchmark` 设为 `False`。`deterministic` 默认为 `False`。更多细节见 [Pytorch Randomness](https://pytorch.org/docs/stable/notes/randomness.html)。
-
-如果你希望手动在配置文件中指定随机种子,可以在配置文件中设置 `random_seed` 参数,具体如下:
-
-```python
-randomness = dict(seed=2023)
-# model settings
-model = dict(
- ## 内容省略 ##
- )
-```
-
-## 使用 Tensorboard 可视化训练过程
-
-安装 Tensorboard 环境
-
-```shell
-pip install tensorboard
-```
-
-在 config 文件中添加 tensorboard 配置
-
-```python
-visualizer = dict(vis_backends=[dict(type='LocalVisBackend'),dict(type='TensorboardVisBackend')])
-```
-
-运行训练命令后,tensorboard 文件会生成在可视化文件夹 `work_dir/${CONFIG}/${TIMESTAMP}/vis_data` 下,运行下面的命令就可以在网页链接使用 tensorboard 查看 loss、学习率和精度等信息。
-
-```shell
-tensorboard --logdir work_dir/${CONFIG}/${TIMESTAMP}/vis_data
-```
+# 高级训练设置
+
+## 恢复训练
+
+恢复训练是指从之前某次训练保存下来的状态开始继续训练,这里的状态包括模型的权重、优化器和优化器参数调整策略的状态。
+
+### 自动恢复训练
+
+用户可以在训练命令最后加上 `--resume` 恢复训练,程序会自动从 `work_dirs` 中加载最新的权重文件恢复训练。如果 `work_dir` 中有最新的 `checkpoint`(例如该训练在上一次训练时被中断),则会从该 `checkpoint` 恢复训练,否则(例如上一次训练还没来得及保存 `checkpoint` 或者启动了新的训练任务)会重新开始训练。
+
+下面是一个恢复训练的示例:
+
+```shell
+python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py --resume
+```
+
+### 指定 Checkpoint 恢复训练
+
+你也可以对 `--resume` 指定 `checkpoint` 路径,MMPose 会自动读取该 `checkpoint` 并从中恢复训练,命令如下:
+
+```shell
+python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py \
+ --resume work_dirs/td-hm_res50_8xb64-210e_coco-256x192/latest.pth
+```
+
+如果你希望手动在配置文件中指定 `checkpoint` 路径,除了设置 `resume=True`,还需要设置 `load_from` 参数。需要注意的是,如果只设置了 `load_from` 而没有设置 `resume=True`,则只会加载 `checkpoint` 中的权重并重新开始训练,而不是接着之前的状态继续训练。
+
+下面的例子与上面指定 `--resume` 参数的例子等价:
+
+```python
+resume = True
+load_from = 'work_dirs/td-hm_res50_8xb64-210e_coco-256x192/latest.pth'
+# model settings
+model = dict(
+ ## 内容省略 ##
+ )
+```
+
+## 自动混合精度(AMP)训练
+
+混合精度训练在不改变模型、不降低模型训练精度的前提下,可以缩短训练时间,降低存储需求,因而能支持更大的 batch size、更大模型和尺寸更大的输入的训练。
+
+如果要开启自动混合精度(AMP)训练,在训练命令最后加上 --amp 即可, 命令如下:
+
+```shell
+python tools/train.py ${CONFIG_FILE} --amp
+```
+
+具体例子如下:
+
+```shell
+python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py --amp
+```
+
+## 设置随机种子
+
+如果想要在训练时指定随机种子,可以使用以下命令:
+
+```shell
+python ./tools/train.py \
+ ${CONFIG} \ # 配置文件路径
+ --cfg-options randomness.seed=2023 \ # 设置随机种子为 2023
+ [randomness.diff_rank_seed=True] \ # 根据 rank 来设置不同的种子。
+ [randomness.deterministic=True] # 把 cuDNN 后端确定性选项设置为 True
+# [] 代表可选参数,实际输入命令行时,不用输入 []
+```
+
+randomness 有三个参数可设置,具体含义如下:
+
+- `randomness.seed=2023` ,设置随机种子为 `2023`。
+
+- `randomness.diff_rank_seed=True`,根据 `rank` 来设置不同的种子,`diff_rank_seed` 默认为 `False`。
+
+- `randomness.deterministic=True`,把 `cuDNN` 后端确定性选项设置为 `True`,即把 `torch.backends.cudnn.deterministic` 设为 `True`,把 `torch.backends.cudnn.benchmark` 设为 `False`。`deterministic` 默认为 `False`。更多细节见 [Pytorch Randomness](https://pytorch.org/docs/stable/notes/randomness.html)。
+
+如果你希望手动在配置文件中指定随机种子,可以在配置文件中设置 `random_seed` 参数,具体如下:
+
+```python
+randomness = dict(seed=2023)
+# model settings
+model = dict(
+ ## 内容省略 ##
+ )
+```
+
+## 使用 Tensorboard 可视化训练过程
+
+安装 Tensorboard 环境
+
+```shell
+pip install tensorboard
+```
+
+在 config 文件中添加 tensorboard 配置
+
+```python
+visualizer = dict(vis_backends=[dict(type='LocalVisBackend'),dict(type='TensorboardVisBackend')])
+```
+
+运行训练命令后,tensorboard 文件会生成在可视化文件夹 `work_dir/${CONFIG}/${TIMESTAMP}/vis_data` 下,运行下面的命令就可以在网页链接使用 tensorboard 查看 loss、学习率和精度等信息。
+
+```shell
+tensorboard --logdir work_dir/${CONFIG}/${TIMESTAMP}/vis_data
+```
diff --git a/docs/zh_cn/user_guides/configs.md b/docs/zh_cn/user_guides/configs.md
index 0bcb7aa1a8..6f83b629f3 100644
--- a/docs/zh_cn/user_guides/configs.md
+++ b/docs/zh_cn/user_guides/configs.md
@@ -1,466 +1,466 @@
-# 配置文件
-
-MMPose 使用 Python 文件作为配置文件,将模块化设计和继承设计结合到配置系统中,便于进行各种实验。
-
-## 简介
-
-MMPose 拥有一套强大的配置系统,在注册器的配合下,用户可以通过一个配置文件来定义整个项目需要用到的所有内容,以 Python 字典形式组织配置信息,传递给注册器完成对应模块的实例化。
-
-下面是一个常见的 Pytorch 模块定义的例子:
-
-```Python
-# 在loss_a.py中定义Loss_A类
-Class Loss_A(nn.Module):
- def __init__(self, param1, param2):
- self.param1 = param1
- self.param2 = param2
- def forward(self, x):
- return x
-
-# 在需要的地方进行实例化
-loss = Loss_A(param1=1.0, param2=True)
-```
-
-只需要通过一行代码对这个类进行注册:
-
-```Python
-# 在loss_a.py中定义Loss_A类
-from mmpose.registry import MODELS
-
-@MODELS.register_module() # 注册该类到 MODELS 下
-Class Loss_A(nn.Module):
- def __init__(self, param1, param2):
- self.param1 = param1
- self.param2 = param2
- def forward(self, x):
- return x
-```
-
-并在对应目录下的 `__init__.py` 中进行 `import`:
-
-```Python
-# __init__.py of mmpose/models/losses
-from .loss_a.py import Loss_A
-
-__all__ = ['Loss_A']
-```
-
-我们就可以通过如下方式来从配置文件定义并进行实例化:
-
-```Python
-# 在config_file.py中定义
-loss_cfg = dict(
- type='Loss_A', # 通过type指定类名
- param1=1.0, # 传递__init__所需的参数
- param2=True
-)
-
-# 在需要的地方进行实例化
-loss = MODELS.build(loss_cfg) # 等价于 loss = Loss_A(param1=1.0, param2=True)
-```
-
-MMPose 预定义的 Registry 在 `$MMPOSE/mmpose/registry.py` 中,目前支持的有:
-
-- `DATASETS`:数据集
-
-- `TRANSFORMS`:数据变换
-
-- `MODELS`:模型模块(Backbone、Neck、Head、Loss等)
-
-- `VISUALIZERS`:可视化工具
-
-- `VISBACKENDS`:可视化后端
-
-- `METRICS`:评测指标
-
-- `KEYPOINT_CODECS`:编解码器
-
-- `HOOKS`:钩子类
-
-```{note}
-需要注意的是,所有新增的模块都需要使用注册器(Registry)进行注册,并在对应目录的 `__init__.py` 中进行 `import`,以便能够使用配置文件构建其实例。
-```
-
-## 配置系统
-
-具体而言,一个配置文件主要包含如下五个部分:
-
-- 通用配置:与训练或测试无关的通用配置,如时间统计,模型存储与加载,可视化等相关 Hook,以及一些分布式相关的环境配置
-
-- 数据配置:数据增强策略,Dataset和Dataloader相关配置
-
-- 训练配置:断点恢复、模型权重加载、优化器、学习率调整、训练轮数和测试间隔等
-
-- 模型配置:模型模块、参数、损失函数等
-
-- 评测配置:模型性能评测指标
-
-你可以在 `$MMPOSE/configs` 下找到我们提供的配置文件,配置文件之间通过继承来避免冗余。为了保持配置文件简洁易读,我们将一些必要但不常改动的配置存放到了 `$MMPOSE/configs/_base_` 目录下,如果希望查阅完整的配置信息,你可以运行如下指令:
-
-```Bash
-python tools/analysis/print_config.py /PATH/TO/CONFIG
-```
-
-### 通用配置
-
-通用配置指与训练或测试无关的必要配置,主要包括:
-
-- **默认Hook**:迭代时间统计,训练日志,参数更新,checkpoint 等
-
-- **环境配置**:分布式后端,cudnn,多进程配置等
-
-- **可视化器**:可视化后端和策略设置
-
-- **日志配置**:日志等级,格式,打印和记录间隔等
-
-下面是通用配置的样例说明:
-
-```Python
-# 通用配置
-default_scope = 'mmpose'
-default_hooks = dict(
- timer=dict(type='IterTimerHook'), # 迭代时间统计,包括数据耗时和模型耗时
- logger=dict(type='LoggerHook', interval=50), # 日志打印间隔
- param_scheduler=dict(type='ParamSchedulerHook'), # 用于调度学习率更新
- checkpoint=dict(
- type='CheckpointHook', interval=1, save_best='coco/AP', # ckpt保存间隔,最优ckpt参考指标
- rule='greater'), # 最优ckpt指标评价规则
- sampler_seed=dict(type='DistSamplerSeedHook')) # 分布式随机种子设置
-env_cfg = dict(
- cudnn_benchmark=False, # cudnn benchmark开关
- mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0), # opencv多线程配置
- dist_cfg=dict(backend='nccl')) # 分布式训练后端设置
-vis_backends = [dict(type='LocalVisBackend')] # 可视化器后端设置
-visualizer = dict( # 可视化器设置
- type='PoseLocalVisualizer',
- vis_backends=[dict(type='LocalVisBackend')],
- name='visualizer')
-log_processor = dict( # 训练日志格式、间隔
- type='LogProcessor', window_size=50, by_epoch=True, num_digits=6)
-log_level = 'INFO' # 日志记录等级
-```
-
-通用配置一般单独存放到`$MMPOSE/configs/_base_`目录下,通过如下方式进行继承:
-
-```Python
-_base_ = ['../../../_base_/default_runtime.py'] # 以运行时的config文件位置为相对路径起点
-```
-
-```{note}
-CheckpointHook:
-
-- save_best: `'coco/AP'` 用于 `CocoMetric`, `'PCK'` 用于 `PCKAccuracy`
-- max_keep_ckpts: 最大保留ckpt数量,默认为-1,代表不限制
-
-样例:
-
-`default_hooks = dict(checkpoint=dict(save_best='PCK', rule='greater', max_keep_ckpts=1))`
-```
-
-### 数据配置
-
-数据配置指数据处理相关的配置,主要包括:
-
-- **数据后端**:数据供给后端设置,默认为本地硬盘,我们也支持从 LMDB,S3 Bucket 等加载
-
-- **数据集**:图像与标注文件路径
-
-- **加载**:加载策略,批量大小等
-
-- **流水线**:数据增强策略
-
-- **编码器**:根据标注生成特定格式的监督信息
-
-下面是数据配置的样例说明:
-
-```Python
-backend_args = dict(backend='local') # 数据加载后端设置,默认从本地硬盘加载
-dataset_type = 'CocoDataset' # 数据集类名
-data_mode = 'topdown' # 算法结构类型,用于指定标注信息加载策略
-data_root = 'data/coco/' # 数据存放路径
- # 定义数据编解码器,用于生成target和对pred进行解码,同时包含了输入图片和输出heatmap尺寸等信息
-codec = dict(
- type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
-train_pipeline = [ # 训练时数据增强
- dict(type='LoadImage', backend_args=backend_args, # 加载图片
- dict(type='GetBBoxCenterScale'), # 根据bbox获取center和scale
- dict(type='RandomBBoxTransform'), # 生成随机位移、缩放、旋转变换矩阵
- dict(type='RandomFlip', direction='horizontal'), # 生成随机翻转变换矩阵
- dict(type='RandomHalfBody'), # 随机半身增强
- dict(type='TopdownAffine', input_size=codec['input_size']), # 根据变换矩阵更新目标数据
- dict(
- type='GenerateTarget', # 根据目标数据生成监督信息
- # 监督信息类型
- encoder=codec, # 传入编解码器,用于数据编码,生成特定格式的监督信息
- dict(type='PackPoseInputs') # 对target进行打包用于训练
-]
-test_pipeline = [ # 测试时数据增强
- dict(type='LoadImage', backend_args=backend_args), # 加载图片
- dict(type='GetBBoxCenterScale'), # 根据bbox获取center和scale
- dict(type='TopdownAffine', input_size=codec['input_size']), # 根据变换矩阵更新目标数据
- dict(type='PackPoseInputs') # 对target进行打包用于训练
-]
-train_dataloader = dict( # 训练数据加载
- batch_size=64, # 批次大小
- num_workers=2, # 数据加载进程数
- persistent_workers=True, # 在不活跃时维持进程不终止,避免反复启动进程的开销
- sampler=dict(type='DefaultSampler', shuffle=True), # 采样策略,打乱数据
- dataset=dict(
- type=dataset_type , # 数据集类名
- data_root=data_root, # 数据集路径
- data_mode=data_mode, # 算法类型
- ann_file='annotations/person_keypoints_train2017.json', # 标注文件路径
- data_prefix=dict(img='train2017/'), # 图像路径
- pipeline=train_pipeline # 数据流水线
- ))
-val_dataloader = dict(
- batch_size=32,
- num_workers=2,
- persistent_workers=True, # 在不活跃时维持进程不终止,避免反复启动进程的开销
- drop_last=False,
- sampler=dict(type='DefaultSampler', shuffle=False), # 采样策略,不进行打乱
- dataset=dict(
- type=dataset_type , # 数据集类名
- data_root=data_root, # 数据集路径
- data_mode=data_mode, # 算法类型
- ann_file='annotations/person_keypoints_val2017.json', # 标注文件路径
- bbox_file=
- 'data/coco/person_detection_results/COCO_val2017_detections_AP_H_56_person.json', # 检测框标注文件,topdown方法专用
- data_prefix=dict(img='val2017/'), # 图像路径
- test_mode=True, # 测试模式开关
- pipeline=test_pipeline # 数据流水线
- ))
-test_dataloader = val_dataloader # 默认情况下不区分验证集和测试集,用户根据需要来自行定义
-```
-
-```{note}
-
-常用功能可以参考以下教程:
-- [恢复训练](../common_usages/resume_training.md)
-- [自动混合精度训练](../common_usages/amp_training.md)
-- [设置随机种子](../common_usages/set_random_seed.md)
-
-```
-
-### 训练配置
-
-训练配置指训练策略相关的配置,主要包括:
-
-- 从断点恢复训练
-
-- 模型权重加载
-
-- 训练轮数和测试间隔
-
-- 学习率调整策略,如 warmup,scheduler
-
-- 优化器和学习率
-
-- 高级训练策略设置,如自动学习率缩放
-
-下面是训练配置的样例说明:
-
-```Python
-resume = False # 断点恢复
-load_from = None # 模型权重加载
-train_cfg = dict(by_epoch=True, max_epochs=210, val_interval=10) # 训练轮数,测试间隔
-param_scheduler = [
- dict( # warmup策略
- type='LinearLR', begin=0, end=500, start_factor=0.001, by_epoch=False),
- dict( # scheduler
- type='MultiStepLR',
- begin=0,
- end=210,
- milestones=[170, 200],
- gamma=0.1,
- by_epoch=True)
-]
-optim_wrapper = dict(optimizer=dict(type='Adam', lr=0.0005)) # 优化器和学习率
-auto_scale_lr = dict(base_batch_size=512) # 根据batch_size自动缩放学习率
-```
-
-### 模型配置
-
-模型配置指模型训练和推理相关的配置,主要包括:
-
-- 模型结构
-
-- 损失函数
-
-- 数据解码策略
-
-- 测试时增强策略
-
-下面是模型配置的样例说明,定义了一个基于 HRNetw32 的 Top-down Heatmap-based 模型:
-
-```Python
-# 定义数据编解码器,如果在数据配置部分已经定义过则无需重复定义
-codec = dict(
- type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
-# 模型配置
-model = dict(
- type='TopdownPoseEstimator', # 模型结构决定了算法流程
- data_preprocessor=dict( # 数据归一化和通道顺序调整,作为模型的一部分
- type='PoseDataPreprocessor',
- mean=[123.675, 116.28, 103.53],
- std=[58.395, 57.12, 57.375],
- bgr_to_rgb=True),
- backbone=dict( # 骨干网络定义
- type='HRNet',
- in_channels=3,
- extra=dict(
- stage1=dict(
- num_modules=1,
- num_branches=1,
- block='BOTTLENECK',
- num_blocks=(4, ),
- num_channels=(64, )),
- stage2=dict(
- num_modules=1,
- num_branches=2,
- block='BASIC',
- num_blocks=(4, 4),
- num_channels=(32, 64)),
- stage3=dict(
- num_modules=4,
- num_branches=3,
- block='BASIC',
- num_blocks=(4, 4, 4),
- num_channels=(32, 64, 128)),
- stage4=dict(
- num_modules=3,
- num_branches=4,
- block='BASIC',
- num_blocks=(4, 4, 4, 4),
- num_channels=(32, 64, 128, 256))),
- init_cfg=dict(
- type='Pretrained', # 预训练参数,只加载backbone权重用于迁移学习
- checkpoint='https://download.openmmlab.com/mmpose'
- '/pretrain_models/hrnet_w32-36af842e.pth'),
- ),
- head=dict( # 模型头部
- type='HeatmapHead',
- in_channels=32,
- out_channels=17,
- deconv_out_channels=None,
- loss=dict(type='KeypointMSELoss', use_target_weight=True), # 损失函数
- decoder=codec), # 解码器,将heatmap解码成坐标值
- test_cfg=dict(
- flip_test=True, # 开启测试时水平翻转集成
- flip_mode='heatmap', # 对heatmap进行翻转
- shift_heatmap=True, # 对翻转后的结果进行平移提高精度
- ))
-```
-
-### 评测配置
-
-评测配置指公开数据集中关键点检测任务常用的评测指标,主要包括:
-
-- AR, AP and mAP
-
-- PCK, PCKh, tPCK
-
-- AUC
-
-- EPE
-
-- NME
-
-下面是评测配置的样例说明,定义了一个COCO指标评测器:
-
-```Python
-val_evaluator = dict(
- type='CocoMetric', # coco 评测指标
- ann_file=data_root + 'annotations/person_keypoints_val2017.json') # 加载评测标注数据
-test_evaluator = val_evaluator # 默认情况下不区分验证集和测试集,用户根据需要来自行定义
-```
-
-## 配置文件命名规则
-
-MMPose 配置文件命名风格如下:
-
-```Python
-{{算法信息}}_{{模块信息}}_{{训练信息}}_{{数据信息}}.py
-```
-
-文件名总体分为四部分:算法信息,模块信息,训练信息和数据信息。不同部分的单词之间用下划线 `'_'` 连接,同一部分有多个单词用短横线 `'-'` 连接。
-
-- **算法信息**:算法名称,如 `topdown-heatmap`,`topdown-rle` 等
-
-- **模块信息**:按照数据流的顺序列举一些中间的模块,其内容依赖于算法任务,如 `res101`,`hrnet-w48`等
-
-- **训练信息**:训练策略的一些设置,包括 `batch size`,`schedule` 等,如 `8xb64-210e`
-
-- **数据信息**:数据集名称、模态、输入尺寸等,如 `ap10k-256x256`,`zebra-160x160` 等
-
-有时为了避免文件名过长,会省略模型信息中一些强相关的模块,只保留关键信息,如RLE-based算法中的`GAP`,Heatmap-based算法中的 `deconv` 等。
-
-如果你希望向MMPose添加新的方法,你的配置文件同样需要遵守该命名规则。
-
-## 常见用法
-
-### 配置文件的继承
-
-该用法常用于隐藏一些必要但不需要修改的配置,以提高配置文件的可读性。假如有如下两个配置文件:
-
-`optimizer_cfg.py`:
-
-```Python
-optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
-```
-
-`resnet50.py`:
-
-```Python
-_base_ = ['optimizer_cfg.py']
-model = dict(type='ResNet', depth=50)
-```
-
-虽然我们在 `resnet50.py` 中没有定义 optimizer 字段,但由于我们写了 `_base_ = ['optimizer_cfg.py']`,会使这个配置文件获得 `optimizer_cfg.py` 中的所有字段:
-
-```Python
-cfg = Config.fromfile('resnet50.py')
-cfg.optimizer # ConfigDict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
-```
-
-### 继承字段的修改
-
-对于继承过来的已经定义好的字典,可以直接指定对应字段进行修改,而不需要重新定义完整的字典:
-
-`resnet50_lr0.01.py`:
-
-```Python
-_base_ = ['optimizer_cfg.py']
-model = dict(type='ResNet', depth=50)
-optimizer = dict(lr=0.01) # 直接修改对应字段
-```
-
-这个配置文件只修改了对应字段`lr`的信息:
-
-```Python
-cfg = Config.fromfile('resnet50_lr0.01.py')
-cfg.optimizer # ConfigDict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
-```
-
-### 删除字典中的字段
-
-如果不仅是需要修改某些字段,还需要删除已定义的一些字段,需要在重新定义这个字典时指定`_delete_=True`,表示将没有在新定义中出现的字段全部删除:
-
-`resnet50.py`:
-
-```Python
-_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
-model = dict(type='ResNet', depth=50)
-optimizer = dict(_delete_=True, type='SGD', lr=0.01) # 重新定义字典
-```
-
-此时字典中除了 `type` 和 `lr` 以外的内容(`momentum`和`weight_decay`)将被全部删除:
-
-```Python
-cfg = Config.fromfile('resnet50_lr0.01.py')
-cfg.optimizer # ConfigDict(type='SGD', lr=0.01)
-```
-
-```{note}
-如果你希望更深入地了解配置系统的高级用法,可以查看 [MMEngine 教程](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/config.html)。
-```
+# 配置文件
+
+MMPose 使用 Python 文件作为配置文件,将模块化设计和继承设计结合到配置系统中,便于进行各种实验。
+
+## 简介
+
+MMPose 拥有一套强大的配置系统,在注册器的配合下,用户可以通过一个配置文件来定义整个项目需要用到的所有内容,以 Python 字典形式组织配置信息,传递给注册器完成对应模块的实例化。
+
+下面是一个常见的 Pytorch 模块定义的例子:
+
+```Python
+# 在loss_a.py中定义Loss_A类
+Class Loss_A(nn.Module):
+ def __init__(self, param1, param2):
+ self.param1 = param1
+ self.param2 = param2
+ def forward(self, x):
+ return x
+
+# 在需要的地方进行实例化
+loss = Loss_A(param1=1.0, param2=True)
+```
+
+只需要通过一行代码对这个类进行注册:
+
+```Python
+# 在loss_a.py中定义Loss_A类
+from mmpose.registry import MODELS
+
+@MODELS.register_module() # 注册该类到 MODELS 下
+Class Loss_A(nn.Module):
+ def __init__(self, param1, param2):
+ self.param1 = param1
+ self.param2 = param2
+ def forward(self, x):
+ return x
+```
+
+并在对应目录下的 `__init__.py` 中进行 `import`:
+
+```Python
+# __init__.py of mmpose/models/losses
+from .loss_a.py import Loss_A
+
+__all__ = ['Loss_A']
+```
+
+我们就可以通过如下方式来从配置文件定义并进行实例化:
+
+```Python
+# 在config_file.py中定义
+loss_cfg = dict(
+ type='Loss_A', # 通过type指定类名
+ param1=1.0, # 传递__init__所需的参数
+ param2=True
+)
+
+# 在需要的地方进行实例化
+loss = MODELS.build(loss_cfg) # 等价于 loss = Loss_A(param1=1.0, param2=True)
+```
+
+MMPose 预定义的 Registry 在 `$MMPOSE/mmpose/registry.py` 中,目前支持的有:
+
+- `DATASETS`:数据集
+
+- `TRANSFORMS`:数据变换
+
+- `MODELS`:模型模块(Backbone、Neck、Head、Loss等)
+
+- `VISUALIZERS`:可视化工具
+
+- `VISBACKENDS`:可视化后端
+
+- `METRICS`:评测指标
+
+- `KEYPOINT_CODECS`:编解码器
+
+- `HOOKS`:钩子类
+
+```{note}
+需要注意的是,所有新增的模块都需要使用注册器(Registry)进行注册,并在对应目录的 `__init__.py` 中进行 `import`,以便能够使用配置文件构建其实例。
+```
+
+## 配置系统
+
+具体而言,一个配置文件主要包含如下五个部分:
+
+- 通用配置:与训练或测试无关的通用配置,如时间统计,模型存储与加载,可视化等相关 Hook,以及一些分布式相关的环境配置
+
+- 数据配置:数据增强策略,Dataset和Dataloader相关配置
+
+- 训练配置:断点恢复、模型权重加载、优化器、学习率调整、训练轮数和测试间隔等
+
+- 模型配置:模型模块、参数、损失函数等
+
+- 评测配置:模型性能评测指标
+
+你可以在 `$MMPOSE/configs` 下找到我们提供的配置文件,配置文件之间通过继承来避免冗余。为了保持配置文件简洁易读,我们将一些必要但不常改动的配置存放到了 `$MMPOSE/configs/_base_` 目录下,如果希望查阅完整的配置信息,你可以运行如下指令:
+
+```Bash
+python tools/analysis/print_config.py /PATH/TO/CONFIG
+```
+
+### 通用配置
+
+通用配置指与训练或测试无关的必要配置,主要包括:
+
+- **默认Hook**:迭代时间统计,训练日志,参数更新,checkpoint 等
+
+- **环境配置**:分布式后端,cudnn,多进程配置等
+
+- **可视化器**:可视化后端和策略设置
+
+- **日志配置**:日志等级,格式,打印和记录间隔等
+
+下面是通用配置的样例说明:
+
+```Python
+# 通用配置
+default_scope = 'mmpose'
+default_hooks = dict(
+ timer=dict(type='IterTimerHook'), # 迭代时间统计,包括数据耗时和模型耗时
+ logger=dict(type='LoggerHook', interval=50), # 日志打印间隔
+ param_scheduler=dict(type='ParamSchedulerHook'), # 用于调度学习率更新
+ checkpoint=dict(
+ type='CheckpointHook', interval=1, save_best='coco/AP', # ckpt保存间隔,最优ckpt参考指标
+ rule='greater'), # 最优ckpt指标评价规则
+ sampler_seed=dict(type='DistSamplerSeedHook')) # 分布式随机种子设置
+env_cfg = dict(
+ cudnn_benchmark=False, # cudnn benchmark开关
+ mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0), # opencv多线程配置
+ dist_cfg=dict(backend='nccl')) # 分布式训练后端设置
+vis_backends = [dict(type='LocalVisBackend')] # 可视化器后端设置
+visualizer = dict( # 可视化器设置
+ type='PoseLocalVisualizer',
+ vis_backends=[dict(type='LocalVisBackend')],
+ name='visualizer')
+log_processor = dict( # 训练日志格式、间隔
+ type='LogProcessor', window_size=50, by_epoch=True, num_digits=6)
+log_level = 'INFO' # 日志记录等级
+```
+
+通用配置一般单独存放到`$MMPOSE/configs/_base_`目录下,通过如下方式进行继承:
+
+```Python
+_base_ = ['../../../_base_/default_runtime.py'] # 以运行时的config文件位置为相对路径起点
+```
+
+```{note}
+CheckpointHook:
+
+- save_best: `'coco/AP'` 用于 `CocoMetric`, `'PCK'` 用于 `PCKAccuracy`
+- max_keep_ckpts: 最大保留ckpt数量,默认为-1,代表不限制
+
+样例:
+
+`default_hooks = dict(checkpoint=dict(save_best='PCK', rule='greater', max_keep_ckpts=1))`
+```
+
+### 数据配置
+
+数据配置指数据处理相关的配置,主要包括:
+
+- **数据后端**:数据供给后端设置,默认为本地硬盘,我们也支持从 LMDB,S3 Bucket 等加载
+
+- **数据集**:图像与标注文件路径
+
+- **加载**:加载策略,批量大小等
+
+- **流水线**:数据增强策略
+
+- **编码器**:根据标注生成特定格式的监督信息
+
+下面是数据配置的样例说明:
+
+```Python
+backend_args = dict(backend='local') # 数据加载后端设置,默认从本地硬盘加载
+dataset_type = 'CocoDataset' # 数据集类名
+data_mode = 'topdown' # 算法结构类型,用于指定标注信息加载策略
+data_root = 'data/coco/' # 数据存放路径
+ # 定义数据编解码器,用于生成target和对pred进行解码,同时包含了输入图片和输出heatmap尺寸等信息
+codec = dict(
+ type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+train_pipeline = [ # 训练时数据增强
+ dict(type='LoadImage', backend_args=backend_args, # 加载图片
+ dict(type='GetBBoxCenterScale'), # 根据bbox获取center和scale
+ dict(type='RandomBBoxTransform'), # 生成随机位移、缩放、旋转变换矩阵
+ dict(type='RandomFlip', direction='horizontal'), # 生成随机翻转变换矩阵
+ dict(type='RandomHalfBody'), # 随机半身增强
+ dict(type='TopdownAffine', input_size=codec['input_size']), # 根据变换矩阵更新目标数据
+ dict(
+ type='GenerateTarget', # 根据目标数据生成监督信息
+ # 监督信息类型
+ encoder=codec, # 传入编解码器,用于数据编码,生成特定格式的监督信息
+ dict(type='PackPoseInputs') # 对target进行打包用于训练
+]
+test_pipeline = [ # 测试时数据增强
+ dict(type='LoadImage', backend_args=backend_args), # 加载图片
+ dict(type='GetBBoxCenterScale'), # 根据bbox获取center和scale
+ dict(type='TopdownAffine', input_size=codec['input_size']), # 根据变换矩阵更新目标数据
+ dict(type='PackPoseInputs') # 对target进行打包用于训练
+]
+train_dataloader = dict( # 训练数据加载
+ batch_size=64, # 批次大小
+ num_workers=2, # 数据加载进程数
+ persistent_workers=True, # 在不活跃时维持进程不终止,避免反复启动进程的开销
+ sampler=dict(type='DefaultSampler', shuffle=True), # 采样策略,打乱数据
+ dataset=dict(
+ type=dataset_type , # 数据集类名
+ data_root=data_root, # 数据集路径
+ data_mode=data_mode, # 算法类型
+ ann_file='annotations/person_keypoints_train2017.json', # 标注文件路径
+ data_prefix=dict(img='train2017/'), # 图像路径
+ pipeline=train_pipeline # 数据流水线
+ ))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True, # 在不活跃时维持进程不终止,避免反复启动进程的开销
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False), # 采样策略,不进行打乱
+ dataset=dict(
+ type=dataset_type , # 数据集类名
+ data_root=data_root, # 数据集路径
+ data_mode=data_mode, # 算法类型
+ ann_file='annotations/person_keypoints_val2017.json', # 标注文件路径
+ bbox_file=
+ 'data/coco/person_detection_results/COCO_val2017_detections_AP_H_56_person.json', # 检测框标注文件,topdown方法专用
+ data_prefix=dict(img='val2017/'), # 图像路径
+ test_mode=True, # 测试模式开关
+ pipeline=test_pipeline # 数据流水线
+ ))
+test_dataloader = val_dataloader # 默认情况下不区分验证集和测试集,用户根据需要来自行定义
+```
+
+```{note}
+
+常用功能可以参考以下教程:
+- [恢复训练](../common_usages/resume_training.md)
+- [自动混合精度训练](../common_usages/amp_training.md)
+- [设置随机种子](../common_usages/set_random_seed.md)
+
+```
+
+### 训练配置
+
+训练配置指训练策略相关的配置,主要包括:
+
+- 从断点恢复训练
+
+- 模型权重加载
+
+- 训练轮数和测试间隔
+
+- 学习率调整策略,如 warmup,scheduler
+
+- 优化器和学习率
+
+- 高级训练策略设置,如自动学习率缩放
+
+下面是训练配置的样例说明:
+
+```Python
+resume = False # 断点恢复
+load_from = None # 模型权重加载
+train_cfg = dict(by_epoch=True, max_epochs=210, val_interval=10) # 训练轮数,测试间隔
+param_scheduler = [
+ dict( # warmup策略
+ type='LinearLR', begin=0, end=500, start_factor=0.001, by_epoch=False),
+ dict( # scheduler
+ type='MultiStepLR',
+ begin=0,
+ end=210,
+ milestones=[170, 200],
+ gamma=0.1,
+ by_epoch=True)
+]
+optim_wrapper = dict(optimizer=dict(type='Adam', lr=0.0005)) # 优化器和学习率
+auto_scale_lr = dict(base_batch_size=512) # 根据batch_size自动缩放学习率
+```
+
+### 模型配置
+
+模型配置指模型训练和推理相关的配置,主要包括:
+
+- 模型结构
+
+- 损失函数
+
+- 数据解码策略
+
+- 测试时增强策略
+
+下面是模型配置的样例说明,定义了一个基于 HRNetw32 的 Top-down Heatmap-based 模型:
+
+```Python
+# 定义数据编解码器,如果在数据配置部分已经定义过则无需重复定义
+codec = dict(
+ type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+# 模型配置
+model = dict(
+ type='TopdownPoseEstimator', # 模型结构决定了算法流程
+ data_preprocessor=dict( # 数据归一化和通道顺序调整,作为模型的一部分
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict( # 骨干网络定义
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ init_cfg=dict(
+ type='Pretrained', # 预训练参数,只加载backbone权重用于迁移学习
+ checkpoint='https://download.openmmlab.com/mmpose'
+ '/pretrain_models/hrnet_w32-36af842e.pth'),
+ ),
+ head=dict( # 模型头部
+ type='HeatmapHead',
+ in_channels=32,
+ out_channels=17,
+ deconv_out_channels=None,
+ loss=dict(type='KeypointMSELoss', use_target_weight=True), # 损失函数
+ decoder=codec), # 解码器,将heatmap解码成坐标值
+ test_cfg=dict(
+ flip_test=True, # 开启测试时水平翻转集成
+ flip_mode='heatmap', # 对heatmap进行翻转
+ shift_heatmap=True, # 对翻转后的结果进行平移提高精度
+ ))
+```
+
+### 评测配置
+
+评测配置指公开数据集中关键点检测任务常用的评测指标,主要包括:
+
+- AR, AP and mAP
+
+- PCK, PCKh, tPCK
+
+- AUC
+
+- EPE
+
+- NME
+
+下面是评测配置的样例说明,定义了一个COCO指标评测器:
+
+```Python
+val_evaluator = dict(
+ type='CocoMetric', # coco 评测指标
+ ann_file=data_root + 'annotations/person_keypoints_val2017.json') # 加载评测标注数据
+test_evaluator = val_evaluator # 默认情况下不区分验证集和测试集,用户根据需要来自行定义
+```
+
+## 配置文件命名规则
+
+MMPose 配置文件命名风格如下:
+
+```Python
+{{算法信息}}_{{模块信息}}_{{训练信息}}_{{数据信息}}.py
+```
+
+文件名总体分为四部分:算法信息,模块信息,训练信息和数据信息。不同部分的单词之间用下划线 `'_'` 连接,同一部分有多个单词用短横线 `'-'` 连接。
+
+- **算法信息**:算法名称,如 `topdown-heatmap`,`topdown-rle` 等
+
+- **模块信息**:按照数据流的顺序列举一些中间的模块,其内容依赖于算法任务,如 `res101`,`hrnet-w48`等
+
+- **训练信息**:训练策略的一些设置,包括 `batch size`,`schedule` 等,如 `8xb64-210e`
+
+- **数据信息**:数据集名称、模态、输入尺寸等,如 `ap10k-256x256`,`zebra-160x160` 等
+
+有时为了避免文件名过长,会省略模型信息中一些强相关的模块,只保留关键信息,如RLE-based算法中的`GAP`,Heatmap-based算法中的 `deconv` 等。
+
+如果你希望向MMPose添加新的方法,你的配置文件同样需要遵守该命名规则。
+
+## 常见用法
+
+### 配置文件的继承
+
+该用法常用于隐藏一些必要但不需要修改的配置,以提高配置文件的可读性。假如有如下两个配置文件:
+
+`optimizer_cfg.py`:
+
+```Python
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+`resnet50.py`:
+
+```Python
+_base_ = ['optimizer_cfg.py']
+model = dict(type='ResNet', depth=50)
+```
+
+虽然我们在 `resnet50.py` 中没有定义 optimizer 字段,但由于我们写了 `_base_ = ['optimizer_cfg.py']`,会使这个配置文件获得 `optimizer_cfg.py` 中的所有字段:
+
+```Python
+cfg = Config.fromfile('resnet50.py')
+cfg.optimizer # ConfigDict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+### 继承字段的修改
+
+对于继承过来的已经定义好的字典,可以直接指定对应字段进行修改,而不需要重新定义完整的字典:
+
+`resnet50_lr0.01.py`:
+
+```Python
+_base_ = ['optimizer_cfg.py']
+model = dict(type='ResNet', depth=50)
+optimizer = dict(lr=0.01) # 直接修改对应字段
+```
+
+这个配置文件只修改了对应字段`lr`的信息:
+
+```Python
+cfg = Config.fromfile('resnet50_lr0.01.py')
+cfg.optimizer # ConfigDict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
+```
+
+### 删除字典中的字段
+
+如果不仅是需要修改某些字段,还需要删除已定义的一些字段,需要在重新定义这个字典时指定`_delete_=True`,表示将没有在新定义中出现的字段全部删除:
+
+`resnet50.py`:
+
+```Python
+_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
+model = dict(type='ResNet', depth=50)
+optimizer = dict(_delete_=True, type='SGD', lr=0.01) # 重新定义字典
+```
+
+此时字典中除了 `type` 和 `lr` 以外的内容(`momentum`和`weight_decay`)将被全部删除:
+
+```Python
+cfg = Config.fromfile('resnet50_lr0.01.py')
+cfg.optimizer # ConfigDict(type='SGD', lr=0.01)
+```
+
+```{note}
+如果你希望更深入地了解配置系统的高级用法,可以查看 [MMEngine 教程](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/config.html)。
+```
diff --git a/docs/zh_cn/user_guides/inference.md b/docs/zh_cn/user_guides/inference.md
index 0844bc611f..ca4ea06f7e 100644
--- a/docs/zh_cn/user_guides/inference.md
+++ b/docs/zh_cn/user_guides/inference.md
@@ -1,267 +1,267 @@
-# 使用现有模型进行推理
-
-MMPose为姿态估计提供了大量可以从[模型库](https://mmpose.readthedocs.io/en/latest/model_zoo.html)中找到的预测训练模型。本指南将演示**如何执行推理**,或使用训练过的模型对提供的图像或视频运行姿态估计。
-
-有关在标准数据集上测试现有模型的说明,请参阅本指南。
-
-在MMPose,模型由配置文件定义,而其已计算好的参数存储在权重文件(checkpoint file)中。您可以在[模型库](https://mmpose.readthedocs.io/en/latest/model_zoo.html)中找到模型配置文件和相应的权重文件的URL。我们建议从使用HRNet模型的[配置文件](https://github.com/open-mmlab/mmpose/blob/main/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py)和[权重文件](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192-81c58e40_20220909.pth)开始。
-
-## 推理器:统一的推理接口
-
-MMPose提供了一个被称为`MMPoseInferencer`的、全面的推理API。这个API使得用户得以使用所有MMPose支持的模型来对图像和视频进行模型推理。此外,该API可以完成推理结果自动化,并方便用户保存预测结果。
-
-### 基本用法
-
-`MMPoseInferencer`可以在任何Python程序中被用来执行姿态估计任务。以下是在一个在Python Shell中使用预训练的人体姿态模型对给定图像进行推理的示例。
-
-```python
-from mmpose.apis import MMPoseInferencer
-
-img_path = 'tests/data/coco/000000000785.jpg' # 将img_path替换给你自己的路径
-
-# 使用模型别名创建推断器
-inferencer = MMPoseInferencer('human')
-
-# MMPoseInferencer采用了惰性推断方法,在给定输入时创建一个预测生成器
-result_generator = inferencer(img_path, show=True)
-result = next(result_generator)
-```
-
-如果一切正常,你将在一个新窗口中看到下图:
-
-
-
-`result` 变量是一个包含两个键值 `'visualization'` 和 `'predictions'` 的字典。
-
-- `'visualization'` 键对应的值是一个列表,该列表:
- - 包含可视化结果,例如输入图像、估计姿态的标记,以及可选的预测热图。
- - 如果没有指定 `return_vis` 参数,该列表将保持为空。
-- `'predictions'` 键对应的值是:
- - 一个包含每个检测实例的预估关键点的列表。
-
-`result` 字典的结构如下所示:
-
-```python
-result = {
- 'visualization': [
- # 元素数量:batch_size(默认为1)
- vis_image_1,
- ...
- ],
- 'predictions': [
- # 每张图像的姿态估计结果
- # 元素数量:batch_size(默认为1)
- [
- # 每个检测到的实例的姿态信息
- # 元素数量:检测到的实例数
- {'keypoints': ..., # 实例 1
- 'keypoint_scores': ...,
- ...
- },
- {'keypoints': ..., # 实例 2
- 'keypoint_scores': ...,
- ...
- },
- ]
- ...
- ]
-}
-```
-
-还可以使用用于用于推断的**命令行界面工具**(CLI, command-line interface): `demo/inferencer_demo.py`。这个工具允许用户使用以下命令使用相同的模型和输入执行推理:
-
-```python
-python demo/inferencer_demo.py 'tests/data/coco/000000000785.jpg' \
- --pose2d 'human' --show --pred-out-dir 'predictions'
-```
-
-预测结果将被保存在路径`predictions/000000000785.json`。作为一个API,`inferencer_demo.py`的输入参数与`MMPoseInferencer`的相同。前者能够处理一系列输入类型,包括以下内容:
-
-- 图像路径
-
-- 视频路径
-
-- 文件夹路径(这会导致该文件夹中的所有图像都被推断出来)
-
-- 表示图像的 numpy array (在命令行界面工具中未支持)
-
-- 表示图像的 numpy array 列表 (在命令行界面工具中未支持)
-
-- 摄像头(在这种情况下,输入参数应该设置为`webcam`或`webcam:{CAMERA_ID}`)
-
-当输入对应于多个图像时,例如输入为**视频**或**文件夹**路径时,推理生成器必须被遍历,以便推理器对视频/文件夹中的所有帧/图像进行推理。以下是一个示例:
-
-```python
-folder_path = 'tests/data/coco'
-
-result_generator = inferencer(folder_path, show=True)
-results = [result for result in result_generator]
-```
-
-在这个示例中,`inferencer` 接受 `folder_path` 作为输入,并返回一个生成器对象(`result_generator`),用于生成推理结果。通过遍历 `result_generator` 并将每个结果存储在 `results` 列表中,您可以获得视频/文件夹中所有帧/图像的推理结果。
-
-### 自定义姿态估计模型
-
-`MMPoseInferencer`提供了几种可用于自定义所使用的模型的方法:
-
-```python
-# 使用模型别名构建推断器
-inferencer = MMPoseInferencer('human')
-
-# 使用模型配置名构建推断器
-inferencer = MMPoseInferencer('td-hm_hrnet-w32_8xb64-210e_coco-256x192')
-
-# 使用模型配置文件和权重文件的路径或 URL 构建推断器
-inferencer = MMPoseInferencer(
- pose2d='configs/body_2d_keypoint/topdown_heatmap/coco/' \
- 'td-hm_hrnet-w32_8xb64-210e_coco-256x192.py',
- pose2d_weights='https://download.openmmlab.com/mmpose/top_down/' \
- 'hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth'
-)
-```
-
-模型别名的完整列表可以在模型别名部分中找到。
-
-此外,自顶向下的姿态估计器还需要一个对象检测模型。`MMPoseInferencer`能够推断用MMPose支持的数据集训练的模型的实例类型,然后构建必要的对象检测模型。用户也可以通过以下方式手动指定检测模型:
-
-```python
-# 通过别名指定检测模型
-# 可用的别名包括“human”、“hand”、“face”、“animal”、
-# 以及mmdet中定义的任何其他别名
-inferencer = MMPoseInferencer(
- # 假设姿态估计器是在自定义数据集上训练的
- pose2d='custom_human_pose_estimator.py',
- pose2d_weights='custom_human_pose_estimator.pth',
- det_model='human'
-)
-
-# 使用模型配置名称指定检测模型
-inferencer = MMPoseInferencer(
- pose2d='human',
- det_model='yolox_l_8x8_300e_coco',
- det_cat_ids=[0], # 指定'human'类的类别id
-)
-
-# 使用模型配置文件和权重文件的路径或URL构建推断器
-inferencer = MMPoseInferencer(
- pose2d='human',
- det_model=f'{PATH_TO_MMDET}/configs/yolox/yolox_l_8x8_300e_coco.py',
- det_weights='https://download.openmmlab.com/mmdetection/v2.0/' \
- 'yolox/yolox_l_8x8_300e_coco/' \
- 'yolox_l_8x8_300e_coco_20211126_140236-d3bd2b23.pth',
- det_cat_ids=[0], # 指定'human'类的类别id
-)
-```
-
-### 转储结果
-
-在执行姿态估计推理任务之后,您可能希望保存结果以供进一步分析或处理。本节将指导您将预测的关键点和可视化结果保存到本地。
-
-要将预测保存在JSON文件中,在运行`MMPoseInferencer`的实例`inferencer`时使用`pred_out_dir`参数:
-
-```python
-result_generator = inferencer(img_path, pred_out_dir='predictions')
-result = next(result_generator)
-```
-
-预测结果将以JSON格式保存在`predictions/`文件夹中,每个文件以相应的输入图像或视频的名称命名。
-
-对于更高级的场景,还可以直接从`inferencer`返回的`result`字典中访问预测结果。其中,`predictions`包含输入图像或视频中每个单独实例的预测关键点列表。然后,您可以使用您喜欢的方法操作或存储这些结果。
-
-请记住,如果你想将可视化图像和预测文件保存在一个文件夹中,你可以使用`out_dir`参数:
-
-```python
-result_generator = inferencer(img_path, out_dir='output')
-result = next(result_generator)
-```
-
-在这种情况下,可视化图像将保存在`output/visualization/`文件夹中,而预测将存储在`output/forecasts/`文件夹中。
-
-### 可视化
-
-推理器`inferencer`可以自动对输入的图像或视频进行预测。可视化结果可以显示在一个新的窗口中,并保存在本地。
-
-要在新窗口中查看可视化结果,请使用以下代码:
-
-请注意:
-
-- 如果输入视频来自网络摄像头,默认情况下将在新窗口中显示可视化结果,以此让用户看到输入
-
-- 如果平台上没有GUI,这个步骤可能会卡住
-
-要将可视化结果保存在本地,可以像这样指定`vis_out_dir`参数:
-
-```python
-result_generator = inferencer(img_path, vis_out_dir='vis_results')
-result = next(result_generator)
-```
-
-输入图片或视频的可视化预测结果将保存在`vis_results/`文件夹中
-
-在开头展示的滑雪图中,姿态的可视化估计结果由关键点(用实心圆描绘)和骨架(用线条表示)组成。这些视觉元素的默认大小可能不会产生令人满意的结果。用户可以使用`radius`和`thickness`参数来调整圆的大小和线的粗细,如下所示:
-
-```python
-result_generator = inferencer(img_path, show=True, radius=4, thickness=2)
-result = next(result_generator)
-```
-
-### 推理器参数
-
-`MMPoseInferencer`提供了各种自定义姿态估计、可视化和保存预测结果的参数。下面是初始化推断器时可用的参数列表及对这些参数的描述:
-
-| Argument | Description |
-| ---------------- | ------------------------------------------------------------ |
-| `pose2d` | 指定 2D 姿态估计模型的模型别名、配置文件名称或配置文件路径。 |
-| `pose2d_weights` | 指定 2D 姿态估计模型权重文件的URL或本地路径。 |
-| `pose3d` | 指定 3D 姿态估计模型的模型别名、配置文件名称或配置文件路径。 |
-| `pose3d_weights` | 指定 3D 姿态估计模型权重文件的URL或本地路径。 |
-| `det_model` | 指定对象检测模型的模型别名、配置文件名或配置文件路径。 |
-| `det_weights` | 指定对象检测模型权重文件的 URL 或本地路径。 |
-| `det_cat_ids` | 指定与要检测的对象类对应的类别 id 列表。 |
-| `device` | 执行推理的设备。如果为 `None`,推理器将选择最合适的一个。 |
-| `scope` | 定义模型模块的名称空间 |
-
-推理器被设计用于可视化和保存预测。以下表格列出了在使用 `MMPoseInferencer` 进行推断时可用的参数列表,以及它们与 2D 和 3D 推理器的兼容性:
-
-| 参数 | 描述 | 2D | 3D |
-| ------------------------ | -------------------------------------------------------------------------------------------------------------------------- | --- | --- |
-| `show` | 控制是否在弹出窗口中显示图像或视频。 | ✔️ | ✔️ |
-| `radius` | 设置可视化关键点的半径。 | ✔️ | ✔️ |
-| `thickness` | 确定可视化链接的厚度。 | ✔️ | ✔️ |
-| `kpt_thr` | 设置关键点分数阈值。分数超过此阈值的关键点将被显示。 | ✔️ | ✔️ |
-| `draw_bbox` | 决定是否显示实例的边界框。 | ✔️ | ✔️ |
-| `draw_heatmap` | 决定是否绘制预测的热图。 | ✔️ | ❌ |
-| `black_background` | 决定是否在黑色背景上显示预估的姿势。 | ✔️ | ❌ |
-| `skeleton_style` | 设置骨架样式。可选项包括 'mmpose'(默认)和 'openpose'。 | ✔️ | ❌ |
-| `use_oks_tracking` | 决定是否在追踪中使用OKS作为相似度测量。 | ❌ | ✔️ |
-| `tracking_thr` | 设置追踪的相似度阈值。 | ❌ | ✔️ |
-| `norm_pose_2d` | 决定是否将边界框缩放至数据集的平均边界框尺寸,并将边界框移至数据集的平均边界框中心。 | ❌ | ✔️ |
-| `rebase_keypoint_height` | 决定是否将最低关键点的高度置为 0。 | ❌ | ✔️ |
-| `return_vis` | 决定是否在结果中包含可视化图像。 | ✔️ | ✔️ |
-| `vis_out_dir` | 定义保存可视化图像的文件夹路径。如果未设置,将不保存可视化图像。 | ✔️ | ✔️ |
-| `return_datasample` | 决定是否以 `PoseDataSample` 格式返回预测。 | ✔️ | ✔️ |
-| `pred_out_dir` | 指定保存预测的文件夹路径。如果未设置,将不保存预测。 | ✔️ | ✔️ |
-| `out_dir` | 如果 `vis_out_dir` 或 `pred_out_dir` 未设置,它们将分别设置为 `f'{out_dir}/visualization'` 或 `f'{out_dir}/predictions'`。 | ✔️ | ✔️ |
-
-### 模型别名
-
-MMPose为常用模型提供了一组预定义的别名。在初始化 `MMPoseInferencer` 时,这些别名可以用作简略的表达方式,而不是指定完整的模型配置名称。下面是可用的模型别名及其对应的配置名称的列表:
-
-| 别名 | 配置文件名称 | 对应任务 | 姿态估计模型 | 检测模型 |
-| --------- | -------------------------------------------------- | ------------------------------- | ------------- | ------------------- |
-| animal | rtmpose-m_8xb64-210e_ap10k-256x256 | Animal pose estimation | RTMPose-m | RTMDet-m |
-| human | rtmpose-m_8xb256-420e_aic-coco-256x192 | Human pose estimation | RTMPose-m | RTMDet-m |
-| face | rtmpose-m_8xb64-60e_wflw-256x256 | Face keypoint detection | RTMPose-m | yolox-s |
-| hand | rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256 | Hand keypoint detection | RTMPose-m | ssdlite_mobilenetv2 |
-| wholebody | rtmpose-m_8xb64-270e_coco-wholebody-256x192 | Human wholebody pose estimation | RTMPose-m | RTMDet-m |
-| vitpose | td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-base | RTMDet-m |
-| vitpose-s | td-hm_ViTPose-small-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-small | RTMDet-m |
-| vitpose-b | td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-base | RTMDet-m |
-| vitpose-l | td-hm_ViTPose-large-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-large | RTMDet-m |
-| vitpose-h | td-hm_ViTPose-huge-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-huge | RTMDet-m |
-
-此外,用户可以使用命令行界面工具显示所有可用的别名,使用以下命令:
-
-```shell
-python demo/inferencer_demo.py --show-alias
-```
+# 使用现有模型进行推理
+
+MMPose为姿态估计提供了大量可以从[模型库](https://mmpose.readthedocs.io/en/latest/model_zoo.html)中找到的预测训练模型。本指南将演示**如何执行推理**,或使用训练过的模型对提供的图像或视频运行姿态估计。
+
+有关在标准数据集上测试现有模型的说明,请参阅本指南。
+
+在MMPose,模型由配置文件定义,而其已计算好的参数存储在权重文件(checkpoint file)中。您可以在[模型库](https://mmpose.readthedocs.io/en/latest/model_zoo.html)中找到模型配置文件和相应的权重文件的URL。我们建议从使用HRNet模型的[配置文件](https://github.com/open-mmlab/mmpose/blob/main/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py)和[权重文件](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192-81c58e40_20220909.pth)开始。
+
+## 推理器:统一的推理接口
+
+MMPose提供了一个被称为`MMPoseInferencer`的、全面的推理API。这个API使得用户得以使用所有MMPose支持的模型来对图像和视频进行模型推理。此外,该API可以完成推理结果自动化,并方便用户保存预测结果。
+
+### 基本用法
+
+`MMPoseInferencer`可以在任何Python程序中被用来执行姿态估计任务。以下是在一个在Python Shell中使用预训练的人体姿态模型对给定图像进行推理的示例。
+
+```python
+from mmpose.apis import MMPoseInferencer
+
+img_path = 'tests/data/coco/000000000785.jpg' # 将img_path替换给你自己的路径
+
+# 使用模型别名创建推断器
+inferencer = MMPoseInferencer('human')
+
+# MMPoseInferencer采用了惰性推断方法,在给定输入时创建一个预测生成器
+result_generator = inferencer(img_path, show=True)
+result = next(result_generator)
+```
+
+如果一切正常,你将在一个新窗口中看到下图:
+
+
+
+`result` 变量是一个包含两个键值 `'visualization'` 和 `'predictions'` 的字典。
+
+- `'visualization'` 键对应的值是一个列表,该列表:
+ - 包含可视化结果,例如输入图像、估计姿态的标记,以及可选的预测热图。
+ - 如果没有指定 `return_vis` 参数,该列表将保持为空。
+- `'predictions'` 键对应的值是:
+ - 一个包含每个检测实例的预估关键点的列表。
+
+`result` 字典的结构如下所示:
+
+```python
+result = {
+ 'visualization': [
+ # 元素数量:batch_size(默认为1)
+ vis_image_1,
+ ...
+ ],
+ 'predictions': [
+ # 每张图像的姿态估计结果
+ # 元素数量:batch_size(默认为1)
+ [
+ # 每个检测到的实例的姿态信息
+ # 元素数量:检测到的实例数
+ {'keypoints': ..., # 实例 1
+ 'keypoint_scores': ...,
+ ...
+ },
+ {'keypoints': ..., # 实例 2
+ 'keypoint_scores': ...,
+ ...
+ },
+ ]
+ ...
+ ]
+}
+```
+
+还可以使用用于用于推断的**命令行界面工具**(CLI, command-line interface): `demo/inferencer_demo.py`。这个工具允许用户使用以下命令使用相同的模型和输入执行推理:
+
+```python
+python demo/inferencer_demo.py 'tests/data/coco/000000000785.jpg' \
+ --pose2d 'human' --show --pred-out-dir 'predictions'
+```
+
+预测结果将被保存在路径`predictions/000000000785.json`。作为一个API,`inferencer_demo.py`的输入参数与`MMPoseInferencer`的相同。前者能够处理一系列输入类型,包括以下内容:
+
+- 图像路径
+
+- 视频路径
+
+- 文件夹路径(这会导致该文件夹中的所有图像都被推断出来)
+
+- 表示图像的 numpy array (在命令行界面工具中未支持)
+
+- 表示图像的 numpy array 列表 (在命令行界面工具中未支持)
+
+- 摄像头(在这种情况下,输入参数应该设置为`webcam`或`webcam:{CAMERA_ID}`)
+
+当输入对应于多个图像时,例如输入为**视频**或**文件夹**路径时,推理生成器必须被遍历,以便推理器对视频/文件夹中的所有帧/图像进行推理。以下是一个示例:
+
+```python
+folder_path = 'tests/data/coco'
+
+result_generator = inferencer(folder_path, show=True)
+results = [result for result in result_generator]
+```
+
+在这个示例中,`inferencer` 接受 `folder_path` 作为输入,并返回一个生成器对象(`result_generator`),用于生成推理结果。通过遍历 `result_generator` 并将每个结果存储在 `results` 列表中,您可以获得视频/文件夹中所有帧/图像的推理结果。
+
+### 自定义姿态估计模型
+
+`MMPoseInferencer`提供了几种可用于自定义所使用的模型的方法:
+
+```python
+# 使用模型别名构建推断器
+inferencer = MMPoseInferencer('human')
+
+# 使用模型配置名构建推断器
+inferencer = MMPoseInferencer('td-hm_hrnet-w32_8xb64-210e_coco-256x192')
+
+# 使用模型配置文件和权重文件的路径或 URL 构建推断器
+inferencer = MMPoseInferencer(
+ pose2d='configs/body_2d_keypoint/topdown_heatmap/coco/' \
+ 'td-hm_hrnet-w32_8xb64-210e_coco-256x192.py',
+ pose2d_weights='https://download.openmmlab.com/mmpose/top_down/' \
+ 'hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth'
+)
+```
+
+模型别名的完整列表可以在模型别名部分中找到。
+
+此外,自顶向下的姿态估计器还需要一个对象检测模型。`MMPoseInferencer`能够推断用MMPose支持的数据集训练的模型的实例类型,然后构建必要的对象检测模型。用户也可以通过以下方式手动指定检测模型:
+
+```python
+# 通过别名指定检测模型
+# 可用的别名包括“human”、“hand”、“face”、“animal”、
+# 以及mmdet中定义的任何其他别名
+inferencer = MMPoseInferencer(
+ # 假设姿态估计器是在自定义数据集上训练的
+ pose2d='custom_human_pose_estimator.py',
+ pose2d_weights='custom_human_pose_estimator.pth',
+ det_model='human'
+)
+
+# 使用模型配置名称指定检测模型
+inferencer = MMPoseInferencer(
+ pose2d='human',
+ det_model='yolox_l_8x8_300e_coco',
+ det_cat_ids=[0], # 指定'human'类的类别id
+)
+
+# 使用模型配置文件和权重文件的路径或URL构建推断器
+inferencer = MMPoseInferencer(
+ pose2d='human',
+ det_model=f'{PATH_TO_MMDET}/configs/yolox/yolox_l_8x8_300e_coco.py',
+ det_weights='https://download.openmmlab.com/mmdetection/v2.0/' \
+ 'yolox/yolox_l_8x8_300e_coco/' \
+ 'yolox_l_8x8_300e_coco_20211126_140236-d3bd2b23.pth',
+ det_cat_ids=[0], # 指定'human'类的类别id
+)
+```
+
+### 转储结果
+
+在执行姿态估计推理任务之后,您可能希望保存结果以供进一步分析或处理。本节将指导您将预测的关键点和可视化结果保存到本地。
+
+要将预测保存在JSON文件中,在运行`MMPoseInferencer`的实例`inferencer`时使用`pred_out_dir`参数:
+
+```python
+result_generator = inferencer(img_path, pred_out_dir='predictions')
+result = next(result_generator)
+```
+
+预测结果将以JSON格式保存在`predictions/`文件夹中,每个文件以相应的输入图像或视频的名称命名。
+
+对于更高级的场景,还可以直接从`inferencer`返回的`result`字典中访问预测结果。其中,`predictions`包含输入图像或视频中每个单独实例的预测关键点列表。然后,您可以使用您喜欢的方法操作或存储这些结果。
+
+请记住,如果你想将可视化图像和预测文件保存在一个文件夹中,你可以使用`out_dir`参数:
+
+```python
+result_generator = inferencer(img_path, out_dir='output')
+result = next(result_generator)
+```
+
+在这种情况下,可视化图像将保存在`output/visualization/`文件夹中,而预测将存储在`output/forecasts/`文件夹中。
+
+### 可视化
+
+推理器`inferencer`可以自动对输入的图像或视频进行预测。可视化结果可以显示在一个新的窗口中,并保存在本地。
+
+要在新窗口中查看可视化结果,请使用以下代码:
+
+请注意:
+
+- 如果输入视频来自网络摄像头,默认情况下将在新窗口中显示可视化结果,以此让用户看到输入
+
+- 如果平台上没有GUI,这个步骤可能会卡住
+
+要将可视化结果保存在本地,可以像这样指定`vis_out_dir`参数:
+
+```python
+result_generator = inferencer(img_path, vis_out_dir='vis_results')
+result = next(result_generator)
+```
+
+输入图片或视频的可视化预测结果将保存在`vis_results/`文件夹中
+
+在开头展示的滑雪图中,姿态的可视化估计结果由关键点(用实心圆描绘)和骨架(用线条表示)组成。这些视觉元素的默认大小可能不会产生令人满意的结果。用户可以使用`radius`和`thickness`参数来调整圆的大小和线的粗细,如下所示:
+
+```python
+result_generator = inferencer(img_path, show=True, radius=4, thickness=2)
+result = next(result_generator)
+```
+
+### 推理器参数
+
+`MMPoseInferencer`提供了各种自定义姿态估计、可视化和保存预测结果的参数。下面是初始化推断器时可用的参数列表及对这些参数的描述:
+
+| Argument | Description |
+| ---------------- | ------------------------------------------------------------ |
+| `pose2d` | 指定 2D 姿态估计模型的模型别名、配置文件名称或配置文件路径。 |
+| `pose2d_weights` | 指定 2D 姿态估计模型权重文件的URL或本地路径。 |
+| `pose3d` | 指定 3D 姿态估计模型的模型别名、配置文件名称或配置文件路径。 |
+| `pose3d_weights` | 指定 3D 姿态估计模型权重文件的URL或本地路径。 |
+| `det_model` | 指定对象检测模型的模型别名、配置文件名或配置文件路径。 |
+| `det_weights` | 指定对象检测模型权重文件的 URL 或本地路径。 |
+| `det_cat_ids` | 指定与要检测的对象类对应的类别 id 列表。 |
+| `device` | 执行推理的设备。如果为 `None`,推理器将选择最合适的一个。 |
+| `scope` | 定义模型模块的名称空间 |
+
+推理器被设计用于可视化和保存预测。以下表格列出了在使用 `MMPoseInferencer` 进行推断时可用的参数列表,以及它们与 2D 和 3D 推理器的兼容性:
+
+| 参数 | 描述 | 2D | 3D |
+| ------------------------ | -------------------------------------------------------------------------------------------------------------------------- | --- | --- |
+| `show` | 控制是否在弹出窗口中显示图像或视频。 | ✔️ | ✔️ |
+| `radius` | 设置可视化关键点的半径。 | ✔️ | ✔️ |
+| `thickness` | 确定可视化链接的厚度。 | ✔️ | ✔️ |
+| `kpt_thr` | 设置关键点分数阈值。分数超过此阈值的关键点将被显示。 | ✔️ | ✔️ |
+| `draw_bbox` | 决定是否显示实例的边界框。 | ✔️ | ✔️ |
+| `draw_heatmap` | 决定是否绘制预测的热图。 | ✔️ | ❌ |
+| `black_background` | 决定是否在黑色背景上显示预估的姿势。 | ✔️ | ❌ |
+| `skeleton_style` | 设置骨架样式。可选项包括 'mmpose'(默认)和 'openpose'。 | ✔️ | ❌ |
+| `use_oks_tracking` | 决定是否在追踪中使用OKS作为相似度测量。 | ❌ | ✔️ |
+| `tracking_thr` | 设置追踪的相似度阈值。 | ❌ | ✔️ |
+| `norm_pose_2d` | 决定是否将边界框缩放至数据集的平均边界框尺寸,并将边界框移至数据集的平均边界框中心。 | ❌ | ✔️ |
+| `rebase_keypoint_height` | 决定是否将最低关键点的高度置为 0。 | ❌ | ✔️ |
+| `return_vis` | 决定是否在结果中包含可视化图像。 | ✔️ | ✔️ |
+| `vis_out_dir` | 定义保存可视化图像的文件夹路径。如果未设置,将不保存可视化图像。 | ✔️ | ✔️ |
+| `return_datasample` | 决定是否以 `PoseDataSample` 格式返回预测。 | ✔️ | ✔️ |
+| `pred_out_dir` | 指定保存预测的文件夹路径。如果未设置,将不保存预测。 | ✔️ | ✔️ |
+| `out_dir` | 如果 `vis_out_dir` 或 `pred_out_dir` 未设置,它们将分别设置为 `f'{out_dir}/visualization'` 或 `f'{out_dir}/predictions'`。 | ✔️ | ✔️ |
+
+### 模型别名
+
+MMPose为常用模型提供了一组预定义的别名。在初始化 `MMPoseInferencer` 时,这些别名可以用作简略的表达方式,而不是指定完整的模型配置名称。下面是可用的模型别名及其对应的配置名称的列表:
+
+| 别名 | 配置文件名称 | 对应任务 | 姿态估计模型 | 检测模型 |
+| --------- | -------------------------------------------------- | ------------------------------- | ------------- | ------------------- |
+| animal | rtmpose-m_8xb64-210e_ap10k-256x256 | Animal pose estimation | RTMPose-m | RTMDet-m |
+| human | rtmpose-m_8xb256-420e_aic-coco-256x192 | Human pose estimation | RTMPose-m | RTMDet-m |
+| face | rtmpose-m_8xb64-60e_wflw-256x256 | Face keypoint detection | RTMPose-m | yolox-s |
+| hand | rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256 | Hand keypoint detection | RTMPose-m | ssdlite_mobilenetv2 |
+| wholebody | rtmpose-m_8xb64-270e_coco-wholebody-256x192 | Human wholebody pose estimation | RTMPose-m | RTMDet-m |
+| vitpose | td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-base | RTMDet-m |
+| vitpose-s | td-hm_ViTPose-small-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-small | RTMDet-m |
+| vitpose-b | td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-base | RTMDet-m |
+| vitpose-l | td-hm_ViTPose-large-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-large | RTMDet-m |
+| vitpose-h | td-hm_ViTPose-huge-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-huge | RTMDet-m |
+
+此外,用户可以使用命令行界面工具显示所有可用的别名,使用以下命令:
+
+```shell
+python demo/inferencer_demo.py --show-alias
+```
diff --git a/docs/zh_cn/user_guides/mixed_datasets.md b/docs/zh_cn/user_guides/mixed_datasets.md
index fac38e3338..1964d33b0d 100644
--- a/docs/zh_cn/user_guides/mixed_datasets.md
+++ b/docs/zh_cn/user_guides/mixed_datasets.md
@@ -1,159 +1,159 @@
-# 混合数据集训练
-
-MMPose 提供了一个灵活、便捷的工具 `CombinedDataset` 来进行混合数据集训练。它作为一个封装器,可以包含多个子数据集,并将来自不同子数据集的数据转换成一个统一的格式,以用于模型训练。使用 `CombinedDataset` 的数据处理流程如下图所示。
-
-
-
-本篇教程的后续部分将通过一个结合 COCO 和 AI Challenger (AIC) 数据集的例子详细介绍如何配置 `CombinedDataset`。
-
-## COCO & AIC 数据集混合案例
-
-COCO 和 AIC 都是 2D 人体姿态数据集。但是,这两个数据集在关键点的数量和排列顺序上有所不同。下面是分别来自这两个数据集的图片及关键点:
-
-
-
-有些关键点(例如“左手”)在两个数据集中都有定义,但它们具有不同的序号。具体来说,“左手”关键点在 COCO 数据集中的序号为 9,在AIC数据集中的序号为 5。此外,每个数据集都包含独特的关键点,另一个数据集中不存在。例如,面部关键点(序号为0〜4)仅在 COCO 数据集中定义,而“头顶”(序号为 12)和“颈部”(序号为 13)关键点仅在 AIC 数据集中存在。以下的维恩图显示了两个数据集中关键点之间的关系。
-
-
-
-接下来,我们会介绍两种混合数据集的方式:
-
-- [将 AIC 合入 COCO 数据集](#将-aic-合入-coco-数据集)
-- [合并 AIC 和 COCO 数据集](#合并-aic-和-coco-数据集)
-
-### 将 AIC 合入 COCO 数据集
-
-如果用户想提高其模型在 COCO 或类似数据集上的性能,可以将 AIC 数据集作为辅助数据。此时应该仅选择 AIC 数据集中与 COCO 数据集共享的关键点,忽略其余关键点。此外,还需要将这些被选择的关键点在 AIC 数据集中的序号进行转换,以匹配在 COCO 数据集中对应关键点的序号。
-
-
-
-在这种情况下,来自 COCO 的数据不需要进行转换。此时 COCO 数据集可通过如下方式配置:
-
-```python
-dataset_coco = dict(
- type='CocoDataset',
- data_root='data/coco/',
- ann_file='annotations/person_keypoints_train2017.json',
- data_prefix=dict(img='train2017/'),
- pipeline=[], # `pipeline` 应为空列表,因为 COCO 数据不需要转换
-)
-```
-
-对于 AIC 数据集,需要转换关键点的顺序。MMPose 提供了一个 `KeypointConverter` 转换器来实现这一点。以下是配置 AIC 子数据集的示例:
-
-```python
-dataset_aic = dict(
- type='AicDataset',
- data_root='data/aic/',
- ann_file='annotations/aic_train.json',
- data_prefix=dict(img='ai_challenger_keypoint_train_20170902/'
- 'keypoint_train_images_20170902/'),
- pipeline=[
- dict(
- type='KeypointConverter',
- num_keypoints=17, # 与 COCO 数据集关键点数一致
- mapping=[ # 需要列出所有带转换关键点的序号
- (0, 6), # 0 (AIC 中的序号) -> 6 (COCO 中的序号)
- (1, 8),
- (2, 10),
- (3, 5),
- (4, 7),
- (5, 9),
- (6, 12),
- (7, 14),
- (8, 16),
- (9, 11),
- (10, 13),
- (11, 15),
- ])
- ],
-)
-```
-
-`KeypointConverter` 会将原序号在 0 到 11 之间的关键点的序号转换为在 5 到 16 之间的对应序号。同时,在 AIC 中序号为为 12 和 13 的关键点将被删除。另外,目标序号在 0 到 4 之间的关键点在 `mapping` 参数中没有定义,这些点将被设为不可见,并且不会在训练中使用。
-
-子数据集都完成配置后, 混合数据集 `CombinedDataset` 可以通过如下方式配置:
-
-```python
-dataset = dict(
- type='CombinedDataset',
- # 混合数据集关键点顺序和 COCO 数据集相同,
- # 所以使用 COCO 数据集的描述信息
- metainfo=dict(from_file='configs/_base_/datasets/coco.py'),
- datasets=[dataset_coco, dataset_aic],
- # `train_pipeline` 包含了常用的数据预处理,
- # 比如图片读取、数据增广等
- pipeline=train_pipeline,
-)
-```
-
-MMPose 提供了一份完整的 [配置文件](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-merge.py) 来将 AIC 合入 COCO 数据集并用于训练网络。用户可以查阅这个文件以获取更多细节,或者参考这个文件来构建新的混合数据集。
-
-### 合并 AIC 和 COCO 数据集
-
-将 AIC 合入 COCO 数据集的过程中丢弃了部分 AIC 数据集中的标注信息。如果用户想要使用两个数据集中的所有信息,可以将两个数据集合并,即在两个数据集中取关键点的并集。
-
-
-
-在这种情况下,COCO 和 AIC 数据集都需要使用 `KeypointConverter` 来调整它们关键点的顺序:
-
-```python
-dataset_coco = dict(
- type='CocoDataset',
- data_root='data/coco/',
- ann_file='annotations/person_keypoints_train2017.json',
- data_prefix=dict(img='train2017/'),
- pipeline=[
- dict(
- type='KeypointConverter',
- num_keypoints=19, # 并集中有 19 个关键点
- mapping=[
- (0, 0),
- (1, 1),
- # 省略
- (16, 16),
- ])
- ])
-
-dataset_aic = dict(
- type='AicDataset',
- data_root='data/aic/',
- ann_file='annotations/aic_train.json',
- data_prefix=dict(img='ai_challenger_keypoint_train_20170902/'
- 'keypoint_train_images_20170902/'),
- pipeline=[
- dict(
- type='KeypointConverter',
- num_keypoints=19, # 并集中有 19 个关键点
- mapping=[
- (0, 6),
- # 省略
- (12, 17),
- (13, 18),
- ])
- ],
-)
-```
-
-合并后的数据集有 19 个关键点,这与 COCO 或 AIC 数据集都不同,因此需要一个新的数据集描述信息文件。[coco_aic.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/_base_/datasets/coco_aic.py) 是一个描述信息文件的示例,它基于 [coco.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/_base_/datasets/coco.py) 并进行了以下几点修改:
-
-- 添加了 AIC 数据集的文章信息;
-- 在 `keypoint_info` 中添加了“头顶”和“颈部”这两个只在 AIC 中定义的关键点;
-- 在 `skeleton_info` 中添加了“头顶”和“颈部”间的连线;
-- 拓展 `joint_weights` 和 `sigmas` 以添加新增关键点的信息。
-
-完成以上步骤后,合并数据集 `CombinedDataset` 可以通过以下方式配置:
-
-```python
-dataset = dict(
- type='CombinedDataset',
- # 使用新的描述信息文件
- metainfo=dict(from_file='configs/_base_/datasets/coco_aic.py'),
- datasets=[dataset_coco, dataset_aic],
- # `train_pipeline` 包含了常用的数据预处理,
- # 比如图片读取、数据增广等
- pipeline=train_pipeline,
-)
-```
-
-此外,在使用混合数据集时,由于关键点数量的变化,模型的输出通道数也要做相应调整。如果用户用混合数据集训练了模型,但是要在 COCO 数据集上评估模型,就需要从模型输出的关键点中取出一个子集来匹配 COCO 中的关键点格式。可以通过 `test_cfg` 中的 `output_keypoint_indices` 参数自定义此子集。这个 [配置文件](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-combine.py) 展示了如何用 AIC 和 COCO 合并后的数据集训练模型并在 COCO 数据集上进行测试。用户可以查阅这个文件以获取更多细节,或者参考这个文件来构建新的混合数据集。
+# 混合数据集训练
+
+MMPose 提供了一个灵活、便捷的工具 `CombinedDataset` 来进行混合数据集训练。它作为一个封装器,可以包含多个子数据集,并将来自不同子数据集的数据转换成一个统一的格式,以用于模型训练。使用 `CombinedDataset` 的数据处理流程如下图所示。
+
+
+
+本篇教程的后续部分将通过一个结合 COCO 和 AI Challenger (AIC) 数据集的例子详细介绍如何配置 `CombinedDataset`。
+
+## COCO & AIC 数据集混合案例
+
+COCO 和 AIC 都是 2D 人体姿态数据集。但是,这两个数据集在关键点的数量和排列顺序上有所不同。下面是分别来自这两个数据集的图片及关键点:
+
+
+
+有些关键点(例如“左手”)在两个数据集中都有定义,但它们具有不同的序号。具体来说,“左手”关键点在 COCO 数据集中的序号为 9,在AIC数据集中的序号为 5。此外,每个数据集都包含独特的关键点,另一个数据集中不存在。例如,面部关键点(序号为0〜4)仅在 COCO 数据集中定义,而“头顶”(序号为 12)和“颈部”(序号为 13)关键点仅在 AIC 数据集中存在。以下的维恩图显示了两个数据集中关键点之间的关系。
+
+
+
+接下来,我们会介绍两种混合数据集的方式:
+
+- [将 AIC 合入 COCO 数据集](#将-aic-合入-coco-数据集)
+- [合并 AIC 和 COCO 数据集](#合并-aic-和-coco-数据集)
+
+### 将 AIC 合入 COCO 数据集
+
+如果用户想提高其模型在 COCO 或类似数据集上的性能,可以将 AIC 数据集作为辅助数据。此时应该仅选择 AIC 数据集中与 COCO 数据集共享的关键点,忽略其余关键点。此外,还需要将这些被选择的关键点在 AIC 数据集中的序号进行转换,以匹配在 COCO 数据集中对应关键点的序号。
+
+
+
+在这种情况下,来自 COCO 的数据不需要进行转换。此时 COCO 数据集可通过如下方式配置:
+
+```python
+dataset_coco = dict(
+ type='CocoDataset',
+ data_root='data/coco/',
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=[], # `pipeline` 应为空列表,因为 COCO 数据不需要转换
+)
+```
+
+对于 AIC 数据集,需要转换关键点的顺序。MMPose 提供了一个 `KeypointConverter` 转换器来实现这一点。以下是配置 AIC 子数据集的示例:
+
+```python
+dataset_aic = dict(
+ type='AicDataset',
+ data_root='data/aic/',
+ ann_file='annotations/aic_train.json',
+ data_prefix=dict(img='ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=17, # 与 COCO 数据集关键点数一致
+ mapping=[ # 需要列出所有带转换关键点的序号
+ (0, 6), # 0 (AIC 中的序号) -> 6 (COCO 中的序号)
+ (1, 8),
+ (2, 10),
+ (3, 5),
+ (4, 7),
+ (5, 9),
+ (6, 12),
+ (7, 14),
+ (8, 16),
+ (9, 11),
+ (10, 13),
+ (11, 15),
+ ])
+ ],
+)
+```
+
+`KeypointConverter` 会将原序号在 0 到 11 之间的关键点的序号转换为在 5 到 16 之间的对应序号。同时,在 AIC 中序号为为 12 和 13 的关键点将被删除。另外,目标序号在 0 到 4 之间的关键点在 `mapping` 参数中没有定义,这些点将被设为不可见,并且不会在训练中使用。
+
+子数据集都完成配置后, 混合数据集 `CombinedDataset` 可以通过如下方式配置:
+
+```python
+dataset = dict(
+ type='CombinedDataset',
+ # 混合数据集关键点顺序和 COCO 数据集相同,
+ # 所以使用 COCO 数据集的描述信息
+ metainfo=dict(from_file='configs/_base_/datasets/coco.py'),
+ datasets=[dataset_coco, dataset_aic],
+ # `train_pipeline` 包含了常用的数据预处理,
+ # 比如图片读取、数据增广等
+ pipeline=train_pipeline,
+)
+```
+
+MMPose 提供了一份完整的 [配置文件](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-merge.py) 来将 AIC 合入 COCO 数据集并用于训练网络。用户可以查阅这个文件以获取更多细节,或者参考这个文件来构建新的混合数据集。
+
+### 合并 AIC 和 COCO 数据集
+
+将 AIC 合入 COCO 数据集的过程中丢弃了部分 AIC 数据集中的标注信息。如果用户想要使用两个数据集中的所有信息,可以将两个数据集合并,即在两个数据集中取关键点的并集。
+
+
+
+在这种情况下,COCO 和 AIC 数据集都需要使用 `KeypointConverter` 来调整它们关键点的顺序:
+
+```python
+dataset_coco = dict(
+ type='CocoDataset',
+ data_root='data/coco/',
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=19, # 并集中有 19 个关键点
+ mapping=[
+ (0, 0),
+ (1, 1),
+ # 省略
+ (16, 16),
+ ])
+ ])
+
+dataset_aic = dict(
+ type='AicDataset',
+ data_root='data/aic/',
+ ann_file='annotations/aic_train.json',
+ data_prefix=dict(img='ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=19, # 并集中有 19 个关键点
+ mapping=[
+ (0, 6),
+ # 省略
+ (12, 17),
+ (13, 18),
+ ])
+ ],
+)
+```
+
+合并后的数据集有 19 个关键点,这与 COCO 或 AIC 数据集都不同,因此需要一个新的数据集描述信息文件。[coco_aic.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/_base_/datasets/coco_aic.py) 是一个描述信息文件的示例,它基于 [coco.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/_base_/datasets/coco.py) 并进行了以下几点修改:
+
+- 添加了 AIC 数据集的文章信息;
+- 在 `keypoint_info` 中添加了“头顶”和“颈部”这两个只在 AIC 中定义的关键点;
+- 在 `skeleton_info` 中添加了“头顶”和“颈部”间的连线;
+- 拓展 `joint_weights` 和 `sigmas` 以添加新增关键点的信息。
+
+完成以上步骤后,合并数据集 `CombinedDataset` 可以通过以下方式配置:
+
+```python
+dataset = dict(
+ type='CombinedDataset',
+ # 使用新的描述信息文件
+ metainfo=dict(from_file='configs/_base_/datasets/coco_aic.py'),
+ datasets=[dataset_coco, dataset_aic],
+ # `train_pipeline` 包含了常用的数据预处理,
+ # 比如图片读取、数据增广等
+ pipeline=train_pipeline,
+)
+```
+
+此外,在使用混合数据集时,由于关键点数量的变化,模型的输出通道数也要做相应调整。如果用户用混合数据集训练了模型,但是要在 COCO 数据集上评估模型,就需要从模型输出的关键点中取出一个子集来匹配 COCO 中的关键点格式。可以通过 `test_cfg` 中的 `output_keypoint_indices` 参数自定义此子集。这个 [配置文件](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-combine.py) 展示了如何用 AIC 和 COCO 合并后的数据集训练模型并在 COCO 数据集上进行测试。用户可以查阅这个文件以获取更多细节,或者参考这个文件来构建新的混合数据集。
diff --git a/docs/zh_cn/user_guides/prepare_datasets.md b/docs/zh_cn/user_guides/prepare_datasets.md
index 8b7d651e88..12c92bafd3 100644
--- a/docs/zh_cn/user_guides/prepare_datasets.md
+++ b/docs/zh_cn/user_guides/prepare_datasets.md
@@ -1,221 +1,221 @@
-# 准备数据集
-
-在这份文档将指导如何为 MMPose 准备数据集,包括使用内置数据集、创建自定义数据集、结合数据集进行训练、浏览和下载数据集。
-
-## 使用内置数据集
-
-**步骤一**: 准备数据
-
-MMPose 支持多种任务和相应的数据集。你可以在 [数据集仓库](https://mmpose.readthedocs.io/en/latest/dataset_zoo.html) 中找到它们。为了正确准备你的数据,请按照你选择的数据集的指南进行操作。
-
-**步骤二**: 在配置文件中进行数据集设置
-
-在开始训练或评估模型之前,你必须配置数据集设置。以 [`td-hm_hrnet-w32_8xb64-210e_coco-256x192.py`](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py) 为例,它可以用于在 COCO 数据集上训练或评估 HRNet 姿态估计器。下面我们浏览一下数据集配置:
-
-- 基础数据集参数
-
- ```python
- # base dataset settings
- dataset_type = 'CocoDataset'
- data_mode = 'topdown'
- data_root = 'data/coco/'
- ```
-
- - `dataset_type` 指定数据集的类名。用户可以参考 [数据集 API](https://mmpose.readthedocs.io/en/latest/api.html#datasets) 来找到他们想要的数据集的类名。
- - `data_mode` 决定了数据集的输出格式,有两个选项可用:`'topdown'` 和 `'bottomup'`。如果 `data_mode='topdown'`,数据元素表示一个实例及其姿态;否则,一个数据元素代表一张图像,包含多个实例和姿态。
- - `data_root` 指定数据集的根目录。
-
-- 数据处理流程
-
- ```python
- # pipelines
- train_pipeline = [
- dict(type='LoadImage'),
- dict(type='GetBBoxCenterScale'),
- dict(type='RandomFlip', direction='horizontal'),
- dict(type='RandomHalfBody'),
- dict(type='RandomBBoxTransform'),
- dict(type='TopdownAffine', input_size=codec['input_size']),
- dict(type='GenerateTarget', encoder=codec),
- dict(type='PackPoseInputs')
- ]
- val_pipeline = [
- dict(type='LoadImage'),
- dict(type='GetBBoxCenterScale'),
- dict(type='TopdownAffine', input_size=codec['input_size']),
- dict(type='PackPoseInputs')
- ]
- ```
-
- `train_pipeline` 和 `val_pipeline` 分别定义了训练和评估阶段处理数据元素的步骤。除了加载图像和打包输入之外,`train_pipeline` 主要包含数据增强技术和目标生成器,而 `val_pipeline` 则专注于将数据元素转换为统一的格式。
-
-- 数据加载器
-
- ```python
- # data loaders
- train_dataloader = dict(
- batch_size=64,
- num_workers=2,
- persistent_workers=True,
- sampler=dict(type='DefaultSampler', shuffle=True),
- dataset=dict(
- type=dataset_type,
- data_root=data_root,
- data_mode=data_mode,
- ann_file='annotations/person_keypoints_train2017.json',
- data_prefix=dict(img='train2017/'),
- pipeline=train_pipeline,
- ))
- val_dataloader = dict(
- batch_size=32,
- num_workers=2,
- persistent_workers=True,
- drop_last=False,
- sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
- dataset=dict(
- type=dataset_type,
- data_root=data_root,
- data_mode=data_mode,
- ann_file='annotations/person_keypoints_val2017.json',
- bbox_file='data/coco/person_detection_results/'
- 'COCO_val2017_detections_AP_H_56_person.json',
- data_prefix=dict(img='val2017/'),
- test_mode=True,
- pipeline=val_pipeline,
- ))
- test_dataloader = val_dataloader
- ```
-
- 这个部分是配置数据集的关键。除了前面讨论过的基础数据集参数和数据处理流程之外,这里还定义了其他重要的参数。`batch_size` 决定了每个 GPU 的 batch size;`ann_file` 指定了数据集的注释文件;`data_prefix` 指定了图像文件夹。`bbox_file` 仅在 top-down 数据集的 val/test 数据加载器中使用,用于提供检测到的边界框信息。
-
-我们推荐从使用相同数据集的配置文件中复制数据集配置,而不是从头开始编写,以最小化潜在的错误。通过这样做,用户可以根据需要进行必要的修改,从而确保更可靠和高效的设置过程。
-
-## 使用自定义数据集
-
-[自定义数据集](../advanced_guides/customize_datasets.md) 指南提供了如何构建自定义数据集的详细信息。在本节中,我们将强调一些使用和配置自定义数据集的关键技巧。
-
-- 确定数据集类名。如果你将数据集重组为 COCO 格式,你可以简单地使用 `CocoDataset` 作为 `dataset_type` 的值。否则,你将需要使用你添加的自定义数据集类的名称。
-
-- 指定元信息配置文件。MMPose 1.x 采用了与 MMPose 0.x 不同的策略来指定元信息。在 MMPose 1.x 中,用户可以按照以下方式指定元信息配置文件:
-
- ```python
- train_dataloader = dict(
- ...
- dataset=dict(
- type=dataset_type,
- data_root='root/of/your/train/data',
- ann_file='path/to/your/train/json',
- data_prefix=dict(img='path/to/your/train/img'),
- # specify dataset meta information
- metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
- ...),
- )
- ```
-
- 注意,`metainfo` 参数必须在 val/test 数据加载器中指定。
-
-## 使用混合数据集进行训练
-
-MMPose 提供了一个方便且多功能的解决方案,用于训练混合数据集。请参考[混合数据集训练](./mixed_datasets.md)。
-
-## 浏览数据集
-
-`tools/analysis_tools/browse_dataset.py` 帮助用户可视化地浏览姿态数据集,或将图像保存到指定的目录。
-
-```shell
-python tools/misc/browse_dataset.py ${CONFIG} [-h] [--output-dir ${OUTPUT_DIR}] [--not-show] [--phase ${PHASE}] [--mode ${MODE}] [--show-interval ${SHOW_INTERVAL}]
-```
-
-| ARGS | Description |
-| -------------------------------- | ---------------------------------------------------------------------------------------------------------- |
-| `CONFIG` | 配置文件的路径 |
-| `--output-dir OUTPUT_DIR` | 保存可视化结果的目标文件夹。如果不指定,可视化的结果将不会被保存 |
-| `--not-show` | 不适用外部窗口显示可视化的结果 |
-| `--phase {train, val, test}` | 数据集选项 |
-| `--mode {original, transformed}` | 指定可视化图片类型。 `original` 为不使用数据增强的原始图片及标注可视化; `transformed` 为经过增强后的可视化 |
-| `--show-interval SHOW_INTERVAL` | 显示图片的时间间隔 |
-
-例如,用户想要可视化 COCO 数据集中的图像和标注,可以使用:
-
-```shell
-python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-e210_coco-256x192.py --mode original
-```
-
-检测框和关键点将被绘制在原始图像上。下面是一个例子:
-
-
-原始图像在被输入模型之前需要被处理。为了可视化预处理后的图像和标注,用户需要将参数 `mode` 修改为 `transformed`。例如:
-
-```shell
-python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-e210_coco-256x192.py --mode transformed
-```
-
-这是一个处理后的样本:
-
-
-
-热图目标将与之一起可视化,如果它是在 pipeline 中生成的。
-
-## 用 MIM 下载数据集
-
-通过使用 [OpenDataLab](https://opendatalab.com/),您可以直接下载开源数据集。通过平台的搜索功能,您可以快速轻松地找到他们正在寻找的数据集。使用平台上的格式化数据集,您可以高效地跨数据集执行任务。
-
-如果您使用 MIM 下载,请确保版本大于 v0.3.8。您可以使用以下命令进行更新、安装、登录和数据集下载:
-
-```shell
-# upgrade your MIM
-pip install -U openmim
-
-# install OpenDataLab CLI tools
-pip install -U opendatalab
-# log in OpenDataLab, registry
-odl login
-
-# download coco2017 and preprocess by MIM
-mim download mmpose --dataset coco2017
-```
-
-### 已支持的数据集
-
-下面是支持的数据集列表,更多数据集将在之后持续更新:
-
-#### 人体数据集
-
-| Dataset name | Download command |
-| ------------- | ----------------------------------------- |
-| COCO 2017 | `mim download mmpose --dataset coco2017` |
-| MPII | `mim download mmpose --dataset mpii` |
-| AI Challenger | `mim download mmpose --dataset aic` |
-| CrowdPose | `mim download mmpose --dataset crowdpose` |
-
-#### 人脸数据集
-
-| Dataset name | Download command |
-| ------------ | ------------------------------------ |
-| LaPa | `mim download mmpose --dataset lapa` |
-| 300W | `mim download mmpose --dataset 300w` |
-| WFLW | `mim download mmpose --dataset wflw` |
-
-#### 手部数据集
-
-| Dataset name | Download command |
-| ------------ | ------------------------------------------ |
-| OneHand10K | `mim download mmpose --dataset onehand10k` |
-| FreiHand | `mim download mmpose --dataset freihand` |
-| HaGRID | `mim download mmpose --dataset hagrid` |
-
-#### 全身数据集
-
-| Dataset name | Download command |
-| ------------ | ------------------------------------- |
-| Halpe | `mim download mmpose --dataset halpe` |
-
-#### 动物数据集
-
-| Dataset name | Download command |
-| ------------ | ------------------------------------- |
-| AP-10K | `mim download mmpose --dataset ap10k` |
-
-#### 服装数据集
-
-Coming Soon
+# 准备数据集
+
+在这份文档将指导如何为 MMPose 准备数据集,包括使用内置数据集、创建自定义数据集、结合数据集进行训练、浏览和下载数据集。
+
+## 使用内置数据集
+
+**步骤一**: 准备数据
+
+MMPose 支持多种任务和相应的数据集。你可以在 [数据集仓库](https://mmpose.readthedocs.io/en/latest/dataset_zoo.html) 中找到它们。为了正确准备你的数据,请按照你选择的数据集的指南进行操作。
+
+**步骤二**: 在配置文件中进行数据集设置
+
+在开始训练或评估模型之前,你必须配置数据集设置。以 [`td-hm_hrnet-w32_8xb64-210e_coco-256x192.py`](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py) 为例,它可以用于在 COCO 数据集上训练或评估 HRNet 姿态估计器。下面我们浏览一下数据集配置:
+
+- 基础数据集参数
+
+ ```python
+ # base dataset settings
+ dataset_type = 'CocoDataset'
+ data_mode = 'topdown'
+ data_root = 'data/coco/'
+ ```
+
+ - `dataset_type` 指定数据集的类名。用户可以参考 [数据集 API](https://mmpose.readthedocs.io/en/latest/api.html#datasets) 来找到他们想要的数据集的类名。
+ - `data_mode` 决定了数据集的输出格式,有两个选项可用:`'topdown'` 和 `'bottomup'`。如果 `data_mode='topdown'`,数据元素表示一个实例及其姿态;否则,一个数据元素代表一张图像,包含多个实例和姿态。
+ - `data_root` 指定数据集的根目录。
+
+- 数据处理流程
+
+ ```python
+ # pipelines
+ train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+ ]
+ val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+ ]
+ ```
+
+ `train_pipeline` 和 `val_pipeline` 分别定义了训练和评估阶段处理数据元素的步骤。除了加载图像和打包输入之外,`train_pipeline` 主要包含数据增强技术和目标生成器,而 `val_pipeline` 则专注于将数据元素转换为统一的格式。
+
+- 数据加载器
+
+ ```python
+ # data loaders
+ train_dataloader = dict(
+ batch_size=64,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+ val_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_val2017.json',
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+ test_dataloader = val_dataloader
+ ```
+
+ 这个部分是配置数据集的关键。除了前面讨论过的基础数据集参数和数据处理流程之外,这里还定义了其他重要的参数。`batch_size` 决定了每个 GPU 的 batch size;`ann_file` 指定了数据集的注释文件;`data_prefix` 指定了图像文件夹。`bbox_file` 仅在 top-down 数据集的 val/test 数据加载器中使用,用于提供检测到的边界框信息。
+
+我们推荐从使用相同数据集的配置文件中复制数据集配置,而不是从头开始编写,以最小化潜在的错误。通过这样做,用户可以根据需要进行必要的修改,从而确保更可靠和高效的设置过程。
+
+## 使用自定义数据集
+
+[自定义数据集](../advanced_guides/customize_datasets.md) 指南提供了如何构建自定义数据集的详细信息。在本节中,我们将强调一些使用和配置自定义数据集的关键技巧。
+
+- 确定数据集类名。如果你将数据集重组为 COCO 格式,你可以简单地使用 `CocoDataset` 作为 `dataset_type` 的值。否则,你将需要使用你添加的自定义数据集类的名称。
+
+- 指定元信息配置文件。MMPose 1.x 采用了与 MMPose 0.x 不同的策略来指定元信息。在 MMPose 1.x 中,用户可以按照以下方式指定元信息配置文件:
+
+ ```python
+ train_dataloader = dict(
+ ...
+ dataset=dict(
+ type=dataset_type,
+ data_root='root/of/your/train/data',
+ ann_file='path/to/your/train/json',
+ data_prefix=dict(img='path/to/your/train/img'),
+ # specify dataset meta information
+ metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
+ ...),
+ )
+ ```
+
+ 注意,`metainfo` 参数必须在 val/test 数据加载器中指定。
+
+## 使用混合数据集进行训练
+
+MMPose 提供了一个方便且多功能的解决方案,用于训练混合数据集。请参考[混合数据集训练](./mixed_datasets.md)。
+
+## 浏览数据集
+
+`tools/analysis_tools/browse_dataset.py` 帮助用户可视化地浏览姿态数据集,或将图像保存到指定的目录。
+
+```shell
+python tools/misc/browse_dataset.py ${CONFIG} [-h] [--output-dir ${OUTPUT_DIR}] [--not-show] [--phase ${PHASE}] [--mode ${MODE}] [--show-interval ${SHOW_INTERVAL}]
+```
+
+| ARGS | Description |
+| -------------------------------- | ---------------------------------------------------------------------------------------------------------- |
+| `CONFIG` | 配置文件的路径 |
+| `--output-dir OUTPUT_DIR` | 保存可视化结果的目标文件夹。如果不指定,可视化的结果将不会被保存 |
+| `--not-show` | 不适用外部窗口显示可视化的结果 |
+| `--phase {train, val, test}` | 数据集选项 |
+| `--mode {original, transformed}` | 指定可视化图片类型。 `original` 为不使用数据增强的原始图片及标注可视化; `transformed` 为经过增强后的可视化 |
+| `--show-interval SHOW_INTERVAL` | 显示图片的时间间隔 |
+
+例如,用户想要可视化 COCO 数据集中的图像和标注,可以使用:
+
+```shell
+python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-e210_coco-256x192.py --mode original
+```
+
+检测框和关键点将被绘制在原始图像上。下面是一个例子:
+
+
+原始图像在被输入模型之前需要被处理。为了可视化预处理后的图像和标注,用户需要将参数 `mode` 修改为 `transformed`。例如:
+
+```shell
+python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-e210_coco-256x192.py --mode transformed
+```
+
+这是一个处理后的样本:
+
+
+
+热图目标将与之一起可视化,如果它是在 pipeline 中生成的。
+
+## 用 MIM 下载数据集
+
+通过使用 [OpenDataLab](https://opendatalab.com/),您可以直接下载开源数据集。通过平台的搜索功能,您可以快速轻松地找到他们正在寻找的数据集。使用平台上的格式化数据集,您可以高效地跨数据集执行任务。
+
+如果您使用 MIM 下载,请确保版本大于 v0.3.8。您可以使用以下命令进行更新、安装、登录和数据集下载:
+
+```shell
+# upgrade your MIM
+pip install -U openmim
+
+# install OpenDataLab CLI tools
+pip install -U opendatalab
+# log in OpenDataLab, registry
+odl login
+
+# download coco2017 and preprocess by MIM
+mim download mmpose --dataset coco2017
+```
+
+### 已支持的数据集
+
+下面是支持的数据集列表,更多数据集将在之后持续更新:
+
+#### 人体数据集
+
+| Dataset name | Download command |
+| ------------- | ----------------------------------------- |
+| COCO 2017 | `mim download mmpose --dataset coco2017` |
+| MPII | `mim download mmpose --dataset mpii` |
+| AI Challenger | `mim download mmpose --dataset aic` |
+| CrowdPose | `mim download mmpose --dataset crowdpose` |
+
+#### 人脸数据集
+
+| Dataset name | Download command |
+| ------------ | ------------------------------------ |
+| LaPa | `mim download mmpose --dataset lapa` |
+| 300W | `mim download mmpose --dataset 300w` |
+| WFLW | `mim download mmpose --dataset wflw` |
+
+#### 手部数据集
+
+| Dataset name | Download command |
+| ------------ | ------------------------------------------ |
+| OneHand10K | `mim download mmpose --dataset onehand10k` |
+| FreiHand | `mim download mmpose --dataset freihand` |
+| HaGRID | `mim download mmpose --dataset hagrid` |
+
+#### 全身数据集
+
+| Dataset name | Download command |
+| ------------ | ------------------------------------- |
+| Halpe | `mim download mmpose --dataset halpe` |
+
+#### 动物数据集
+
+| Dataset name | Download command |
+| ------------ | ------------------------------------- |
+| AP-10K | `mim download mmpose --dataset ap10k` |
+
+#### 服装数据集
+
+Coming Soon
diff --git a/docs/zh_cn/user_guides/train_and_test.md b/docs/zh_cn/user_guides/train_and_test.md
index 452eddc928..bf5729bfc9 100644
--- a/docs/zh_cn/user_guides/train_and_test.md
+++ b/docs/zh_cn/user_guides/train_and_test.md
@@ -1,5 +1,5 @@
-# 训练与测试
-
-中文内容建设中,暂时请查阅[英文版文档](../../en/user_guides/train_and_test.md)
-
-如果您愿意参与中文文档的翻译与维护,我们团队将十分感谢您的贡献!欢迎加入我们的社区群与我们取得联系,或直接按照 [如何给 MMPose 贡献代码](../contribution_guide.md) 在 GitHub 上提交 Pull Request。
+# 训练与测试
+
+中文内容建设中,暂时请查阅[英文版文档](../../en/user_guides/train_and_test.md)
+
+如果您愿意参与中文文档的翻译与维护,我们团队将十分感谢您的贡献!欢迎加入我们的社区群与我们取得联系,或直接按照 [如何给 MMPose 贡献代码](../contribution_guide.md) 在 GitHub 上提交 Pull Request。
diff --git a/docs/zh_cn/user_guides/useful_tools.md b/docs/zh_cn/user_guides/useful_tools.md
index f2ceb771b7..c93d9aebda 100644
--- a/docs/zh_cn/user_guides/useful_tools.md
+++ b/docs/zh_cn/user_guides/useful_tools.md
@@ -1,5 +1,5 @@
-# 常用工具
-
-中文内容建设中,暂时请查阅[英文版文档](../../en/user_guides/useful_tools.md)
-
-如果您愿意参与中文文档的翻译与维护,我们团队将十分感谢您的贡献!欢迎加入我们的社区群与我们取得联系,或直接按照 [如何给 MMPose 贡献代码](../contribution_guide.md) 在 GitHub 上提交 Pull Request。
+# 常用工具
+
+中文内容建设中,暂时请查阅[英文版文档](../../en/user_guides/useful_tools.md)
+
+如果您愿意参与中文文档的翻译与维护,我们团队将十分感谢您的贡献!欢迎加入我们的社区群与我们取得联系,或直接按照 [如何给 MMPose 贡献代码](../contribution_guide.md) 在 GitHub 上提交 Pull Request。
diff --git a/docs/zh_cn/user_guides/visualization.md b/docs/zh_cn/user_guides/visualization.md
index a584eb450e..7d86767e00 100644
--- a/docs/zh_cn/user_guides/visualization.md
+++ b/docs/zh_cn/user_guides/visualization.md
@@ -1,5 +1,5 @@
-# 可视化
-
-中文内容建设中,暂时请查阅[英文版文档](../../en/user_guides/visualization.md)
-
-如果您愿意参与中文文档的翻译与维护,我们团队将十分感谢您的贡献!欢迎加入我们的社区群与我们取得联系,或直接按照 [如何给 MMPose 贡献代码](../contribution_guide.md) 在 GitHub 上提交 Pull Request。
+# 可视化
+
+中文内容建设中,暂时请查阅[英文版文档](../../en/user_guides/visualization.md)
+
+如果您愿意参与中文文档的翻译与维护,我们团队将十分感谢您的贡献!欢迎加入我们的社区群与我们取得联系,或直接按照 [如何给 MMPose 贡献代码](../contribution_guide.md) 在 GitHub 上提交 Pull Request。
diff --git a/mmpose/__init__.py b/mmpose/__init__.py
index ad7946470d..e932f2e678 100644
--- a/mmpose/__init__.py
+++ b/mmpose/__init__.py
@@ -1,27 +1,27 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import mmcv
-import mmengine
-from mmengine.utils import digit_version
-
-from .version import __version__, short_version
-
-mmcv_minimum_version = '2.0.0rc4'
-mmcv_maximum_version = '2.1.0'
-mmcv_version = digit_version(mmcv.__version__)
-
-mmengine_minimum_version = '0.6.0'
-mmengine_maximum_version = '1.0.0'
-mmengine_version = digit_version(mmengine.__version__)
-
-assert (mmcv_version >= digit_version(mmcv_minimum_version)
- and mmcv_version <= digit_version(mmcv_maximum_version)), \
- f'MMCV=={mmcv.__version__} is used but incompatible. ' \
- f'Please install mmcv>={mmcv_minimum_version}, <={mmcv_maximum_version}.'
-
-assert (mmengine_version >= digit_version(mmengine_minimum_version)
- and mmengine_version <= digit_version(mmengine_maximum_version)), \
- f'MMEngine=={mmengine.__version__} is used but incompatible. ' \
- f'Please install mmengine>={mmengine_minimum_version}, ' \
- f'<={mmengine_maximum_version}.'
-
-__all__ = ['__version__', 'short_version']
+# Copyright (c) OpenMMLab. All rights reserved.
+import mmcv
+import mmengine
+from mmengine.utils import digit_version
+
+from .version import __version__, short_version
+
+mmcv_minimum_version = '2.0.0rc4'
+mmcv_maximum_version = '2.1.0'
+mmcv_version = digit_version(mmcv.__version__)
+
+mmengine_minimum_version = '0.6.0'
+mmengine_maximum_version = '1.0.0'
+mmengine_version = digit_version(mmengine.__version__)
+
+assert (mmcv_version >= digit_version(mmcv_minimum_version)
+ and mmcv_version <= digit_version(mmcv_maximum_version)), \
+ f'MMCV=={mmcv.__version__} is used but incompatible. ' \
+ f'Please install mmcv>={mmcv_minimum_version}, <={mmcv_maximum_version}.'
+
+assert (mmengine_version >= digit_version(mmengine_minimum_version)
+ and mmengine_version <= digit_version(mmengine_maximum_version)), \
+ f'MMEngine=={mmengine.__version__} is used but incompatible. ' \
+ f'Please install mmengine>={mmengine_minimum_version}, ' \
+ f'<={mmengine_maximum_version}.'
+
+__all__ = ['__version__', 'short_version']
diff --git a/mmpose/apis/__init__.py b/mmpose/apis/__init__.py
index 0c44f7a3f8..f0947da6ee 100644
--- a/mmpose/apis/__init__.py
+++ b/mmpose/apis/__init__.py
@@ -1,15 +1,15 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .inference import (collect_multi_frames, inference_bottomup,
- inference_topdown, init_model)
-from .inference_3d import (collate_pose_sequence, convert_keypoint_definition,
- extract_pose_sequence, inference_pose_lifter_model)
-from .inference_tracking import _compute_iou, _track_by_iou, _track_by_oks
-from .inferencers import MMPoseInferencer, Pose2DInferencer
-
-__all__ = [
- 'init_model', 'inference_topdown', 'inference_bottomup',
- 'collect_multi_frames', 'Pose2DInferencer', 'MMPoseInferencer',
- '_track_by_iou', '_track_by_oks', '_compute_iou',
- 'inference_pose_lifter_model', 'extract_pose_sequence',
- 'convert_keypoint_definition', 'collate_pose_sequence'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .inference import (collect_multi_frames, inference_bottomup,
+ inference_topdown, init_model)
+from .inference_3d import (collate_pose_sequence, convert_keypoint_definition,
+ extract_pose_sequence, inference_pose_lifter_model)
+from .inference_tracking import _compute_iou, _track_by_iou, _track_by_oks
+from .inferencers import MMPoseInferencer, Pose2DInferencer
+
+__all__ = [
+ 'init_model', 'inference_topdown', 'inference_bottomup',
+ 'collect_multi_frames', 'Pose2DInferencer', 'MMPoseInferencer',
+ '_track_by_iou', '_track_by_oks', '_compute_iou',
+ 'inference_pose_lifter_model', 'extract_pose_sequence',
+ 'convert_keypoint_definition', 'collate_pose_sequence'
+]
diff --git a/mmpose/apis/inference.py b/mmpose/apis/inference.py
index 772ef17b7c..370630e079 100644
--- a/mmpose/apis/inference.py
+++ b/mmpose/apis/inference.py
@@ -1,262 +1,262 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import warnings
-from pathlib import Path
-from typing import List, Optional, Union
-
-import numpy as np
-import torch
-import torch.nn as nn
-from mmengine.config import Config
-from mmengine.dataset import Compose, pseudo_collate
-from mmengine.model.utils import revert_sync_batchnorm
-from mmengine.registry import init_default_scope
-from mmengine.runner import load_checkpoint
-from PIL import Image
-
-from mmpose.datasets.datasets.utils import parse_pose_metainfo
-from mmpose.models.builder import build_pose_estimator
-from mmpose.structures import PoseDataSample
-from mmpose.structures.bbox import bbox_xywh2xyxy
-
-
-def dataset_meta_from_config(config: Config,
- dataset_mode: str = 'train') -> Optional[dict]:
- """Get dataset metainfo from the model config.
-
- Args:
- config (str, :obj:`Path`, or :obj:`mmengine.Config`): Config file path,
- :obj:`Path`, or the config object.
- dataset_mode (str): Specify the dataset of which to get the metainfo.
- Options are ``'train'``, ``'val'`` and ``'test'``. Defaults to
- ``'train'``
-
- Returns:
- dict, optional: The dataset metainfo. See
- ``mmpose.datasets.datasets.utils.parse_pose_metainfo`` for details.
- Return ``None`` if failing to get dataset metainfo from the config.
- """
- try:
- if dataset_mode == 'train':
- dataset_cfg = config.train_dataloader.dataset
- elif dataset_mode == 'val':
- dataset_cfg = config.val_dataloader.dataset
- elif dataset_mode == 'test':
- dataset_cfg = config.test_dataloader.dataset
- else:
- raise ValueError(
- f'Invalid dataset {dataset_mode} to get metainfo. '
- 'Should be one of "train", "val", or "test".')
-
- if 'metainfo' in dataset_cfg:
- metainfo = dataset_cfg.metainfo
- else:
- import mmpose.datasets.datasets # noqa: F401, F403
- from mmpose.registry import DATASETS
-
- dataset_class = DATASETS.get(dataset_cfg.type)
- metainfo = dataset_class.METAINFO
-
- metainfo = parse_pose_metainfo(metainfo)
-
- except AttributeError:
- metainfo = None
-
- return metainfo
-
-
-def init_model(config: Union[str, Path, Config],
- checkpoint: Optional[str] = None,
- device: str = 'cuda:0',
- cfg_options: Optional[dict] = None) -> nn.Module:
- """Initialize a pose estimator from a config file.
-
- Args:
- config (str, :obj:`Path`, or :obj:`mmengine.Config`): Config file path,
- :obj:`Path`, or the config object.
- checkpoint (str, optional): Checkpoint path. If left as None, the model
- will not load any weights. Defaults to ``None``
- device (str): The device where the anchors will be put on.
- Defaults to ``'cuda:0'``.
- cfg_options (dict, optional): Options to override some settings in
- the used config. Defaults to ``None``
-
- Returns:
- nn.Module: The constructed pose estimator.
- """
-
- if isinstance(config, (str, Path)):
- config = Config.fromfile(config)
- elif not isinstance(config, Config):
- raise TypeError('config must be a filename or Config object, '
- f'but got {type(config)}')
- if cfg_options is not None:
- config.merge_from_dict(cfg_options)
- elif 'init_cfg' in config.model.backbone:
- config.model.backbone.init_cfg = None
- config.model.train_cfg = None
-
- # register all modules in mmpose into the registries
- scope = config.get('default_scope', 'mmpose')
- if scope is not None:
- init_default_scope(scope)
-
- model = build_pose_estimator(config.model)
- model = revert_sync_batchnorm(model)
- # get dataset_meta in this priority: checkpoint > config > default (COCO)
- dataset_meta = None
-
- if checkpoint is not None:
- ckpt = load_checkpoint(model, checkpoint, map_location='cpu')
-
- if 'dataset_meta' in ckpt.get('meta', {}):
- # checkpoint from mmpose 1.x
- dataset_meta = ckpt['meta']['dataset_meta']
-
- if dataset_meta is None:
- dataset_meta = dataset_meta_from_config(config, dataset_mode='train')
-
- if dataset_meta is None:
- warnings.simplefilter('once')
- warnings.warn('Can not load dataset_meta from the checkpoint or the '
- 'model config. Use COCO metainfo by default.')
- dataset_meta = parse_pose_metainfo(
- dict(from_file='configs/_base_/datasets/coco.py'))
-
- model.dataset_meta = dataset_meta
-
- model.cfg = config # save the config in the model for convenience
- model.to(device)
- model.eval()
- return model
-
-
-def inference_topdown(model: nn.Module,
- img: Union[np.ndarray, str],
- bboxes: Optional[Union[List, np.ndarray]] = None,
- bbox_format: str = 'xyxy') -> List[PoseDataSample]:
- """Inference image with a top-down pose estimator.
-
- Args:
- model (nn.Module): The top-down pose estimator
- img (np.ndarray | str): The loaded image or image file to inference
- bboxes (np.ndarray, optional): The bboxes in shape (N, 4), each row
- represents a bbox. If not given, the entire image will be regarded
- as a single bbox area. Defaults to ``None``
- bbox_format (str): The bbox format indicator. Options are ``'xywh'``
- and ``'xyxy'``. Defaults to ``'xyxy'``
-
- Returns:
- List[:obj:`PoseDataSample`]: The inference results. Specifically, the
- predicted keypoints and scores are saved at
- ``data_sample.pred_instances.keypoints`` and
- ``data_sample.pred_instances.keypoint_scores``.
- """
- scope = model.cfg.get('default_scope', 'mmpose')
- if scope is not None:
- init_default_scope(scope)
- pipeline = Compose(model.cfg.test_dataloader.dataset.pipeline)
-
- if bboxes is None or len(bboxes) == 0:
- # get bbox from the image size
- if isinstance(img, str):
- w, h = Image.open(img).size
- else:
- h, w = img.shape[:2]
-
- bboxes = np.array([[0, 0, w, h]], dtype=np.float32)
- else:
- if isinstance(bboxes, list):
- bboxes = np.array(bboxes)
-
- assert bbox_format in {'xyxy', 'xywh'}, \
- f'Invalid bbox_format "{bbox_format}".'
-
- if bbox_format == 'xywh':
- bboxes = bbox_xywh2xyxy(bboxes)
-
- # construct batch data samples
- data_list = []
- for bbox in bboxes:
- if isinstance(img, str):
- data_info = dict(img_path=img)
- else:
- data_info = dict(img=img)
- data_info['bbox'] = bbox[None] # shape (1, 4)
- data_info['bbox_score'] = np.ones(1, dtype=np.float32) # shape (1,)
- data_info.update(model.dataset_meta)
- data_list.append(pipeline(data_info))
-
- if data_list:
- # collate data list into a batch, which is a dict with following keys:
- # batch['inputs']: a list of input images
- # batch['data_samples']: a list of :obj:`PoseDataSample`
- batch = pseudo_collate(data_list)
- with torch.no_grad():
- results = model.test_step(batch)
- else:
- results = []
-
- return results
-
-
-def inference_bottomup(model: nn.Module, img: Union[np.ndarray, str]):
- """Inference image with a bottom-up pose estimator.
-
- Args:
- model (nn.Module): The bottom-up pose estimator
- img (np.ndarray | str): The loaded image or image file to inference
-
- Returns:
- List[:obj:`PoseDataSample`]: The inference results. Specifically, the
- predicted keypoints and scores are saved at
- ``data_sample.pred_instances.keypoints`` and
- ``data_sample.pred_instances.keypoint_scores``.
- """
- pipeline = Compose(model.cfg.test_dataloader.dataset.pipeline)
-
- # prepare data batch
- if isinstance(img, str):
- data_info = dict(img_path=img)
- else:
- data_info = dict(img=img)
- data_info.update(model.dataset_meta)
- data = pipeline(data_info)
- batch = pseudo_collate([data])
-
- with torch.no_grad():
- results = model.test_step(batch)
-
- return results
-
-
-def collect_multi_frames(video, frame_id, indices, online=False):
- """Collect multi frames from the video.
-
- Args:
- video (mmcv.VideoReader): A VideoReader of the input video file.
- frame_id (int): index of the current frame
- indices (list(int)): index offsets of the frames to collect
- online (bool): inference mode, if set to True, can not use future
- frame information.
-
- Returns:
- list(ndarray): multi frames collected from the input video file.
- """
- num_frames = len(video)
- frames = []
- # put the current frame at first
- frames.append(video[frame_id])
- # use multi frames for inference
- for idx in indices:
- # skip current frame
- if idx == 0:
- continue
- support_idx = frame_id + idx
- # online mode, can not use future frame information
- if online:
- support_idx = np.clip(support_idx, 0, frame_id)
- else:
- support_idx = np.clip(support_idx, 0, num_frames - 1)
- frames.append(video[support_idx])
-
- return frames
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from pathlib import Path
+from typing import List, Optional, Union
+
+import numpy as np
+import torch
+import torch.nn as nn
+from mmengine.config import Config
+from mmengine.dataset import Compose, pseudo_collate
+from mmengine.model.utils import revert_sync_batchnorm
+from mmengine.registry import init_default_scope
+from mmengine.runner import load_checkpoint
+from PIL import Image
+
+from mmpose.datasets.datasets.utils import parse_pose_metainfo
+from mmpose.models.builder import build_pose_estimator
+from mmpose.structures import PoseDataSample
+from mmpose.structures.bbox import bbox_xywh2xyxy
+
+
+def dataset_meta_from_config(config: Config,
+ dataset_mode: str = 'train') -> Optional[dict]:
+ """Get dataset metainfo from the model config.
+
+ Args:
+ config (str, :obj:`Path`, or :obj:`mmengine.Config`): Config file path,
+ :obj:`Path`, or the config object.
+ dataset_mode (str): Specify the dataset of which to get the metainfo.
+ Options are ``'train'``, ``'val'`` and ``'test'``. Defaults to
+ ``'train'``
+
+ Returns:
+ dict, optional: The dataset metainfo. See
+ ``mmpose.datasets.datasets.utils.parse_pose_metainfo`` for details.
+ Return ``None`` if failing to get dataset metainfo from the config.
+ """
+ try:
+ if dataset_mode == 'train':
+ dataset_cfg = config.train_dataloader.dataset
+ elif dataset_mode == 'val':
+ dataset_cfg = config.val_dataloader.dataset
+ elif dataset_mode == 'test':
+ dataset_cfg = config.test_dataloader.dataset
+ else:
+ raise ValueError(
+ f'Invalid dataset {dataset_mode} to get metainfo. '
+ 'Should be one of "train", "val", or "test".')
+
+ if 'metainfo' in dataset_cfg:
+ metainfo = dataset_cfg.metainfo
+ else:
+ import mmpose.datasets.datasets # noqa: F401, F403
+ from mmpose.registry import DATASETS
+
+ dataset_class = DATASETS.get(dataset_cfg.type)
+ metainfo = dataset_class.METAINFO
+
+ metainfo = parse_pose_metainfo(metainfo)
+
+ except AttributeError:
+ metainfo = None
+
+ return metainfo
+
+
+def init_model(config: Union[str, Path, Config],
+ checkpoint: Optional[str] = None,
+ device: str = 'cuda:0',
+ cfg_options: Optional[dict] = None) -> nn.Module:
+ """Initialize a pose estimator from a config file.
+
+ Args:
+ config (str, :obj:`Path`, or :obj:`mmengine.Config`): Config file path,
+ :obj:`Path`, or the config object.
+ checkpoint (str, optional): Checkpoint path. If left as None, the model
+ will not load any weights. Defaults to ``None``
+ device (str): The device where the anchors will be put on.
+ Defaults to ``'cuda:0'``.
+ cfg_options (dict, optional): Options to override some settings in
+ the used config. Defaults to ``None``
+
+ Returns:
+ nn.Module: The constructed pose estimator.
+ """
+
+ if isinstance(config, (str, Path)):
+ config = Config.fromfile(config)
+ elif not isinstance(config, Config):
+ raise TypeError('config must be a filename or Config object, '
+ f'but got {type(config)}')
+ if cfg_options is not None:
+ config.merge_from_dict(cfg_options)
+ elif 'init_cfg' in config.model.backbone:
+ config.model.backbone.init_cfg = None
+ config.model.train_cfg = None
+
+ # register all modules in mmpose into the registries
+ scope = config.get('default_scope', 'mmpose')
+ if scope is not None:
+ init_default_scope(scope)
+
+ model = build_pose_estimator(config.model)
+ model = revert_sync_batchnorm(model)
+ # get dataset_meta in this priority: checkpoint > config > default (COCO)
+ dataset_meta = None
+
+ if checkpoint is not None:
+ ckpt = load_checkpoint(model, checkpoint, map_location='cpu')
+
+ if 'dataset_meta' in ckpt.get('meta', {}):
+ # checkpoint from mmpose 1.x
+ dataset_meta = ckpt['meta']['dataset_meta']
+
+ if dataset_meta is None:
+ dataset_meta = dataset_meta_from_config(config, dataset_mode='train')
+
+ if dataset_meta is None:
+ warnings.simplefilter('once')
+ warnings.warn('Can not load dataset_meta from the checkpoint or the '
+ 'model config. Use COCO metainfo by default.')
+ dataset_meta = parse_pose_metainfo(
+ dict(from_file='configs/_base_/datasets/coco.py'))
+
+ model.dataset_meta = dataset_meta
+
+ model.cfg = config # save the config in the model for convenience
+ model.to(device)
+ model.eval()
+ return model
+
+
+def inference_topdown(model: nn.Module,
+ img: Union[np.ndarray, str],
+ bboxes: Optional[Union[List, np.ndarray]] = None,
+ bbox_format: str = 'xyxy') -> List[PoseDataSample]:
+ """Inference image with a top-down pose estimator.
+
+ Args:
+ model (nn.Module): The top-down pose estimator
+ img (np.ndarray | str): The loaded image or image file to inference
+ bboxes (np.ndarray, optional): The bboxes in shape (N, 4), each row
+ represents a bbox. If not given, the entire image will be regarded
+ as a single bbox area. Defaults to ``None``
+ bbox_format (str): The bbox format indicator. Options are ``'xywh'``
+ and ``'xyxy'``. Defaults to ``'xyxy'``
+
+ Returns:
+ List[:obj:`PoseDataSample`]: The inference results. Specifically, the
+ predicted keypoints and scores are saved at
+ ``data_sample.pred_instances.keypoints`` and
+ ``data_sample.pred_instances.keypoint_scores``.
+ """
+ scope = model.cfg.get('default_scope', 'mmpose')
+ if scope is not None:
+ init_default_scope(scope)
+ pipeline = Compose(model.cfg.test_dataloader.dataset.pipeline)
+
+ if bboxes is None or len(bboxes) == 0:
+ # get bbox from the image size
+ if isinstance(img, str):
+ w, h = Image.open(img).size
+ else:
+ h, w = img.shape[:2]
+
+ bboxes = np.array([[0, 0, w, h]], dtype=np.float32)
+ else:
+ if isinstance(bboxes, list):
+ bboxes = np.array(bboxes)
+
+ assert bbox_format in {'xyxy', 'xywh'}, \
+ f'Invalid bbox_format "{bbox_format}".'
+
+ if bbox_format == 'xywh':
+ bboxes = bbox_xywh2xyxy(bboxes)
+
+ # construct batch data samples
+ data_list = []
+ for bbox in bboxes:
+ if isinstance(img, str):
+ data_info = dict(img_path=img)
+ else:
+ data_info = dict(img=img)
+ data_info['bbox'] = bbox[None] # shape (1, 4)
+ data_info['bbox_score'] = np.ones(1, dtype=np.float32) # shape (1,)
+ data_info.update(model.dataset_meta)
+ data_list.append(pipeline(data_info))
+
+ if data_list:
+ # collate data list into a batch, which is a dict with following keys:
+ # batch['inputs']: a list of input images
+ # batch['data_samples']: a list of :obj:`PoseDataSample`
+ batch = pseudo_collate(data_list)
+ with torch.no_grad():
+ results = model.test_step(batch)
+ else:
+ results = []
+
+ return results
+
+
+def inference_bottomup(model: nn.Module, img: Union[np.ndarray, str]):
+ """Inference image with a bottom-up pose estimator.
+
+ Args:
+ model (nn.Module): The bottom-up pose estimator
+ img (np.ndarray | str): The loaded image or image file to inference
+
+ Returns:
+ List[:obj:`PoseDataSample`]: The inference results. Specifically, the
+ predicted keypoints and scores are saved at
+ ``data_sample.pred_instances.keypoints`` and
+ ``data_sample.pred_instances.keypoint_scores``.
+ """
+ pipeline = Compose(model.cfg.test_dataloader.dataset.pipeline)
+
+ # prepare data batch
+ if isinstance(img, str):
+ data_info = dict(img_path=img)
+ else:
+ data_info = dict(img=img)
+ data_info.update(model.dataset_meta)
+ data = pipeline(data_info)
+ batch = pseudo_collate([data])
+
+ with torch.no_grad():
+ results = model.test_step(batch)
+
+ return results
+
+
+def collect_multi_frames(video, frame_id, indices, online=False):
+ """Collect multi frames from the video.
+
+ Args:
+ video (mmcv.VideoReader): A VideoReader of the input video file.
+ frame_id (int): index of the current frame
+ indices (list(int)): index offsets of the frames to collect
+ online (bool): inference mode, if set to True, can not use future
+ frame information.
+
+ Returns:
+ list(ndarray): multi frames collected from the input video file.
+ """
+ num_frames = len(video)
+ frames = []
+ # put the current frame at first
+ frames.append(video[frame_id])
+ # use multi frames for inference
+ for idx in indices:
+ # skip current frame
+ if idx == 0:
+ continue
+ support_idx = frame_id + idx
+ # online mode, can not use future frame information
+ if online:
+ support_idx = np.clip(support_idx, 0, frame_id)
+ else:
+ support_idx = np.clip(support_idx, 0, num_frames - 1)
+ frames.append(video[support_idx])
+
+ return frames
diff --git a/mmpose/apis/inference_3d.py b/mmpose/apis/inference_3d.py
index d5bb753945..5592c67f9f 100644
--- a/mmpose/apis/inference_3d.py
+++ b/mmpose/apis/inference_3d.py
@@ -1,339 +1,339 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import numpy as np
-import torch
-from mmengine.dataset import Compose, pseudo_collate
-from mmengine.registry import init_default_scope
-from mmengine.structures import InstanceData
-
-from mmpose.structures import PoseDataSample
-
-
-def convert_keypoint_definition(keypoints, pose_det_dataset,
- pose_lift_dataset):
- """Convert pose det dataset keypoints definition to pose lifter dataset
- keypoints definition, so that they are compatible with the definitions
- required for 3D pose lifting.
-
- Args:
- keypoints (ndarray[N, K, 2 or 3]): 2D keypoints to be transformed.
- pose_det_dataset, (str): Name of the dataset for 2D pose detector.
- pose_lift_dataset (str): Name of the dataset for pose lifter model.
-
- Returns:
- ndarray[K, 2 or 3]: the transformed 2D keypoints.
- """
- assert pose_lift_dataset in [
- 'Human36mDataset'], '`pose_lift_dataset` should be ' \
- f'`Human36mDataset`, but got {pose_lift_dataset}.'
-
- coco_style_datasets = [
- 'CocoDataset', 'PoseTrack18VideoDataset', 'PoseTrack18Dataset'
- ]
- keypoints_new = np.zeros((keypoints.shape[0], 17, keypoints.shape[2]),
- dtype=keypoints.dtype)
- if pose_lift_dataset == 'Human36mDataset':
- if pose_det_dataset in ['Human36mDataset']:
- keypoints_new = keypoints
- elif pose_det_dataset in coco_style_datasets:
- # pelvis (root) is in the middle of l_hip and r_hip
- keypoints_new[:, 0] = (keypoints[:, 11] + keypoints[:, 12]) / 2
- # thorax is in the middle of l_shoulder and r_shoulder
- keypoints_new[:, 8] = (keypoints[:, 5] + keypoints[:, 6]) / 2
- # spine is in the middle of thorax and pelvis
- keypoints_new[:,
- 7] = (keypoints_new[:, 0] + keypoints_new[:, 8]) / 2
- # in COCO, head is in the middle of l_eye and r_eye
- # in PoseTrack18, head is in the middle of head_bottom and head_top
- keypoints_new[:, 10] = (keypoints[:, 1] + keypoints[:, 2]) / 2
- # rearrange other keypoints
- keypoints_new[:, [1, 2, 3, 4, 5, 6, 9, 11, 12, 13, 14, 15, 16]] = \
- keypoints[:, [12, 14, 16, 11, 13, 15, 0, 5, 7, 9, 6, 8, 10]]
- elif pose_det_dataset in ['AicDataset']:
- # pelvis (root) is in the middle of l_hip and r_hip
- keypoints_new[:, 0] = (keypoints[:, 9] + keypoints[:, 6]) / 2
- # thorax is in the middle of l_shoulder and r_shoulder
- keypoints_new[:, 8] = (keypoints[:, 3] + keypoints[:, 0]) / 2
- # spine is in the middle of thorax and pelvis
- keypoints_new[:,
- 7] = (keypoints_new[:, 0] + keypoints_new[:, 8]) / 2
- # neck base (top end of neck) is 1/4 the way from
- # neck (bottom end of neck) to head top
- keypoints_new[:, 9] = (3 * keypoints[:, 13] + keypoints[:, 12]) / 4
- # head (spherical centre of head) is 7/12 the way from
- # neck (bottom end of neck) to head top
- keypoints_new[:, 10] = (5 * keypoints[:, 13] +
- 7 * keypoints[:, 12]) / 12
-
- keypoints_new[:, [1, 2, 3, 4, 5, 6, 11, 12, 13, 14, 15, 16]] = \
- keypoints[:, [6, 7, 8, 9, 10, 11, 3, 4, 5, 0, 1, 2]]
- elif pose_det_dataset in ['CrowdPoseDataset']:
- # pelvis (root) is in the middle of l_hip and r_hip
- keypoints_new[:, 0] = (keypoints[:, 6] + keypoints[:, 7]) / 2
- # thorax is in the middle of l_shoulder and r_shoulder
- keypoints_new[:, 8] = (keypoints[:, 0] + keypoints[:, 1]) / 2
- # spine is in the middle of thorax and pelvis
- keypoints_new[:,
- 7] = (keypoints_new[:, 0] + keypoints_new[:, 8]) / 2
- # neck base (top end of neck) is 1/4 the way from
- # neck (bottom end of neck) to head top
- keypoints_new[:, 9] = (3 * keypoints[:, 13] + keypoints[:, 12]) / 4
- # head (spherical centre of head) is 7/12 the way from
- # neck (bottom end of neck) to head top
- keypoints_new[:, 10] = (5 * keypoints[:, 13] +
- 7 * keypoints[:, 12]) / 12
-
- keypoints_new[:, [1, 2, 3, 4, 5, 6, 11, 12, 13, 14, 15, 16]] = \
- keypoints[:, [7, 9, 11, 6, 8, 10, 0, 2, 4, 1, 3, 5]]
- else:
- raise NotImplementedError(
- f'unsupported conversion between {pose_lift_dataset} and '
- f'{pose_det_dataset}')
-
- return keypoints_new
-
-
-def extract_pose_sequence(pose_results, frame_idx, causal, seq_len, step=1):
- """Extract the target frame from 2D pose results, and pad the sequence to a
- fixed length.
-
- Args:
- pose_results (List[List[:obj:`PoseDataSample`]]): Multi-frame pose
- detection results stored in a list.
- frame_idx (int): The index of the frame in the original video.
- causal (bool): If True, the target frame is the last frame in
- a sequence. Otherwise, the target frame is in the middle of
- a sequence.
- seq_len (int): The number of frames in the input sequence.
- step (int): Step size to extract frames from the video.
-
- Returns:
- List[List[:obj:`PoseDataSample`]]: Multi-frame pose detection results
- stored in a nested list with a length of seq_len.
- """
- if causal:
- frames_left = seq_len - 1
- frames_right = 0
- else:
- frames_left = (seq_len - 1) // 2
- frames_right = frames_left
- num_frames = len(pose_results)
-
- # get the padded sequence
- pad_left = max(0, frames_left - frame_idx // step)
- pad_right = max(0, frames_right - (num_frames - 1 - frame_idx) // step)
- start = max(frame_idx % step, frame_idx - frames_left * step)
- end = min(num_frames - (num_frames - 1 - frame_idx) % step,
- frame_idx + frames_right * step + 1)
- pose_results_seq = [pose_results[0]] * pad_left + \
- pose_results[start:end:step] + [pose_results[-1]] * pad_right
- return pose_results_seq
-
-
-def collate_pose_sequence(pose_results_2d,
- with_track_id=True,
- target_frame=-1):
- """Reorganize multi-frame pose detection results into individual pose
- sequences.
-
- Note:
- - The temporal length of the pose detection results: T
- - The number of the person instances: N
- - The number of the keypoints: K
- - The channel number of each keypoint: C
-
- Args:
- pose_results_2d (List[List[:obj:`PoseDataSample`]]): Multi-frame pose
- detection results stored in a nested list. Each element of the
- outer list is the pose detection results of a single frame, and
- each element of the inner list is the pose information of one
- person, which contains:
-
- - keypoints (ndarray[K, 2 or 3]): x, y, [score]
- - track_id (int): unique id of each person, required when
- ``with_track_id==True```
-
- with_track_id (bool): If True, the element in pose_results is expected
- to contain "track_id", which will be used to gather the pose
- sequence of a person from multiple frames. Otherwise, the pose
- results in each frame are expected to have a consistent number and
- order of identities. Default is True.
- target_frame (int): The index of the target frame. Default: -1.
-
- Returns:
- List[:obj:`PoseDataSample`]: Indivisual pose sequence in with length N.
- """
- T = len(pose_results_2d)
- assert T > 0
-
- target_frame = (T + target_frame) % T # convert negative index to positive
-
- N = len(
- pose_results_2d[target_frame]) # use identities in the target frame
- if N == 0:
- return []
-
- B, K, C = pose_results_2d[target_frame][0].pred_instances.keypoints.shape
-
- track_ids = None
- if with_track_id:
- track_ids = [res.track_id for res in pose_results_2d[target_frame]]
-
- pose_sequences = []
- for idx in range(N):
- pose_seq = PoseDataSample()
- gt_instances = InstanceData()
- pred_instances = InstanceData()
-
- for k in pose_results_2d[target_frame][idx].gt_instances.keys():
- gt_instances.set_field(
- pose_results_2d[target_frame][idx].gt_instances[k], k)
- for k in pose_results_2d[target_frame][idx].pred_instances.keys():
- if k != 'keypoints':
- pred_instances.set_field(
- pose_results_2d[target_frame][idx].pred_instances[k], k)
- pose_seq.pred_instances = pred_instances
- pose_seq.gt_instances = gt_instances
-
- if not with_track_id:
- pose_seq.pred_instances.keypoints = np.stack([
- frame[idx].pred_instances.keypoints
- for frame in pose_results_2d
- ],
- axis=1)
- else:
- keypoints = np.zeros((B, T, K, C), dtype=np.float32)
- keypoints[:, target_frame] = pose_results_2d[target_frame][
- idx].pred_instances.keypoints
- # find the left most frame containing track_ids[idx]
- for frame_idx in range(target_frame - 1, -1, -1):
- contains_idx = False
- for res in pose_results_2d[frame_idx]:
- if res.track_id == track_ids[idx]:
- keypoints[:, frame_idx] = res.pred_instances.keypoints
- contains_idx = True
- break
- if not contains_idx:
- # replicate the left most frame
- keypoints[:, :frame_idx + 1] = keypoints[:, frame_idx + 1]
- break
- # find the right most frame containing track_idx[idx]
- for frame_idx in range(target_frame + 1, T):
- contains_idx = False
- for res in pose_results_2d[frame_idx]:
- if res.track_id == track_ids[idx]:
- keypoints[:, frame_idx] = res.pred_instances.keypoints
- contains_idx = True
- break
- if not contains_idx:
- # replicate the right most frame
- keypoints[:, frame_idx + 1:] = keypoints[:, frame_idx]
- break
- pose_seq.pred_instances.keypoints = keypoints
- pose_sequences.append(pose_seq)
-
- return pose_sequences
-
-
-def inference_pose_lifter_model(model,
- pose_results_2d,
- with_track_id=True,
- image_size=None,
- norm_pose_2d=False):
- """Inference 3D pose from 2D pose sequences using a pose lifter model.
-
- Args:
- model (nn.Module): The loaded pose lifter model
- pose_results_2d (List[List[:obj:`PoseDataSample`]]): The 2D pose
- sequences stored in a nested list.
- with_track_id: If True, the element in pose_results_2d is expected to
- contain "track_id", which will be used to gather the pose sequence
- of a person from multiple frames. Otherwise, the pose results in
- each frame are expected to have a consistent number and order of
- identities. Default is True.
- image_size (tuple|list): image width, image height. If None, image size
- will not be contained in dict ``data``.
- norm_pose_2d (bool): If True, scale the bbox (along with the 2D
- pose) to the average bbox scale of the dataset, and move the bbox
- (along with the 2D pose) to the average bbox center of the dataset.
-
- Returns:
- List[:obj:`PoseDataSample`]: 3D pose inference results. Specifically,
- the predicted keypoints and scores are saved at
- ``data_sample.pred_instances.keypoints_3d``.
- """
- init_default_scope(model.cfg.get('default_scope', 'mmpose'))
- pipeline = Compose(model.cfg.test_dataloader.dataset.pipeline)
-
- causal = model.cfg.test_dataloader.dataset.get('causal', False)
- target_idx = -1 if causal else len(pose_results_2d) // 2
-
- dataset_info = model.dataset_meta
- if dataset_info is not None:
- if 'stats_info' in dataset_info:
- bbox_center = dataset_info['stats_info']['bbox_center']
- bbox_scale = dataset_info['stats_info']['bbox_scale']
- else:
- bbox_center = None
- bbox_scale = None
-
- for i, pose_res in enumerate(pose_results_2d):
- for j, data_sample in enumerate(pose_res):
- kpts = data_sample.pred_instances.keypoints
- bboxes = data_sample.pred_instances.bboxes
- keypoints = []
- for k in range(len(kpts)):
- kpt = kpts[k]
- if norm_pose_2d:
- bbox = bboxes[k]
- center = np.array([[(bbox[0] + bbox[2]) / 2,
- (bbox[1] + bbox[3]) / 2]])
- scale = max(bbox[2] - bbox[0], bbox[3] - bbox[1])
- keypoints.append((kpt[:, :2] - center) / scale *
- bbox_scale + bbox_center)
- else:
- keypoints.append(kpt[:, :2])
- pose_results_2d[i][j].pred_instances.keypoints = np.array(
- keypoints)
-
- pose_sequences_2d = collate_pose_sequence(pose_results_2d, with_track_id,
- target_idx)
-
- if not pose_sequences_2d:
- return []
-
- data_list = []
- for i, pose_seq in enumerate(pose_sequences_2d):
- data_info = dict()
-
- keypoints_2d = pose_seq.pred_instances.keypoints
- keypoints_2d = np.squeeze(
- keypoints_2d, axis=0) if keypoints_2d.ndim == 4 else keypoints_2d
-
- T, K, C = keypoints_2d.shape
-
- data_info['keypoints'] = keypoints_2d
- data_info['keypoints_visible'] = np.ones((
- T,
- K,
- ), dtype=np.float32)
- data_info['lifting_target'] = np.zeros((K, 3), dtype=np.float32)
- data_info['lifting_target_visible'] = np.ones((K, 1), dtype=np.float32)
-
- if image_size is not None:
- assert len(image_size) == 2
- data_info['camera_param'] = dict(w=image_size[0], h=image_size[1])
-
- data_info.update(model.dataset_meta)
- data_list.append(pipeline(data_info))
-
- if data_list:
- # collate data list into a batch, which is a dict with following keys:
- # batch['inputs']: a list of input images
- # batch['data_samples']: a list of :obj:`PoseDataSample`
- batch = pseudo_collate(data_list)
- with torch.no_grad():
- results = model.test_step(batch)
- else:
- results = []
-
- return results
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch
+from mmengine.dataset import Compose, pseudo_collate
+from mmengine.registry import init_default_scope
+from mmengine.structures import InstanceData
+
+from mmpose.structures import PoseDataSample
+
+
+def convert_keypoint_definition(keypoints, pose_det_dataset,
+ pose_lift_dataset):
+ """Convert pose det dataset keypoints definition to pose lifter dataset
+ keypoints definition, so that they are compatible with the definitions
+ required for 3D pose lifting.
+
+ Args:
+ keypoints (ndarray[N, K, 2 or 3]): 2D keypoints to be transformed.
+ pose_det_dataset, (str): Name of the dataset for 2D pose detector.
+ pose_lift_dataset (str): Name of the dataset for pose lifter model.
+
+ Returns:
+ ndarray[K, 2 or 3]: the transformed 2D keypoints.
+ """
+ assert pose_lift_dataset in [
+ 'Human36mDataset'], '`pose_lift_dataset` should be ' \
+ f'`Human36mDataset`, but got {pose_lift_dataset}.'
+
+ coco_style_datasets = [
+ 'CocoDataset', 'PoseTrack18VideoDataset', 'PoseTrack18Dataset'
+ ]
+ keypoints_new = np.zeros((keypoints.shape[0], 17, keypoints.shape[2]),
+ dtype=keypoints.dtype)
+ if pose_lift_dataset == 'Human36mDataset':
+ if pose_det_dataset in ['Human36mDataset']:
+ keypoints_new = keypoints
+ elif pose_det_dataset in coco_style_datasets:
+ # pelvis (root) is in the middle of l_hip and r_hip
+ keypoints_new[:, 0] = (keypoints[:, 11] + keypoints[:, 12]) / 2
+ # thorax is in the middle of l_shoulder and r_shoulder
+ keypoints_new[:, 8] = (keypoints[:, 5] + keypoints[:, 6]) / 2
+ # spine is in the middle of thorax and pelvis
+ keypoints_new[:,
+ 7] = (keypoints_new[:, 0] + keypoints_new[:, 8]) / 2
+ # in COCO, head is in the middle of l_eye and r_eye
+ # in PoseTrack18, head is in the middle of head_bottom and head_top
+ keypoints_new[:, 10] = (keypoints[:, 1] + keypoints[:, 2]) / 2
+ # rearrange other keypoints
+ keypoints_new[:, [1, 2, 3, 4, 5, 6, 9, 11, 12, 13, 14, 15, 16]] = \
+ keypoints[:, [12, 14, 16, 11, 13, 15, 0, 5, 7, 9, 6, 8, 10]]
+ elif pose_det_dataset in ['AicDataset']:
+ # pelvis (root) is in the middle of l_hip and r_hip
+ keypoints_new[:, 0] = (keypoints[:, 9] + keypoints[:, 6]) / 2
+ # thorax is in the middle of l_shoulder and r_shoulder
+ keypoints_new[:, 8] = (keypoints[:, 3] + keypoints[:, 0]) / 2
+ # spine is in the middle of thorax and pelvis
+ keypoints_new[:,
+ 7] = (keypoints_new[:, 0] + keypoints_new[:, 8]) / 2
+ # neck base (top end of neck) is 1/4 the way from
+ # neck (bottom end of neck) to head top
+ keypoints_new[:, 9] = (3 * keypoints[:, 13] + keypoints[:, 12]) / 4
+ # head (spherical centre of head) is 7/12 the way from
+ # neck (bottom end of neck) to head top
+ keypoints_new[:, 10] = (5 * keypoints[:, 13] +
+ 7 * keypoints[:, 12]) / 12
+
+ keypoints_new[:, [1, 2, 3, 4, 5, 6, 11, 12, 13, 14, 15, 16]] = \
+ keypoints[:, [6, 7, 8, 9, 10, 11, 3, 4, 5, 0, 1, 2]]
+ elif pose_det_dataset in ['CrowdPoseDataset']:
+ # pelvis (root) is in the middle of l_hip and r_hip
+ keypoints_new[:, 0] = (keypoints[:, 6] + keypoints[:, 7]) / 2
+ # thorax is in the middle of l_shoulder and r_shoulder
+ keypoints_new[:, 8] = (keypoints[:, 0] + keypoints[:, 1]) / 2
+ # spine is in the middle of thorax and pelvis
+ keypoints_new[:,
+ 7] = (keypoints_new[:, 0] + keypoints_new[:, 8]) / 2
+ # neck base (top end of neck) is 1/4 the way from
+ # neck (bottom end of neck) to head top
+ keypoints_new[:, 9] = (3 * keypoints[:, 13] + keypoints[:, 12]) / 4
+ # head (spherical centre of head) is 7/12 the way from
+ # neck (bottom end of neck) to head top
+ keypoints_new[:, 10] = (5 * keypoints[:, 13] +
+ 7 * keypoints[:, 12]) / 12
+
+ keypoints_new[:, [1, 2, 3, 4, 5, 6, 11, 12, 13, 14, 15, 16]] = \
+ keypoints[:, [7, 9, 11, 6, 8, 10, 0, 2, 4, 1, 3, 5]]
+ else:
+ raise NotImplementedError(
+ f'unsupported conversion between {pose_lift_dataset} and '
+ f'{pose_det_dataset}')
+
+ return keypoints_new
+
+
+def extract_pose_sequence(pose_results, frame_idx, causal, seq_len, step=1):
+ """Extract the target frame from 2D pose results, and pad the sequence to a
+ fixed length.
+
+ Args:
+ pose_results (List[List[:obj:`PoseDataSample`]]): Multi-frame pose
+ detection results stored in a list.
+ frame_idx (int): The index of the frame in the original video.
+ causal (bool): If True, the target frame is the last frame in
+ a sequence. Otherwise, the target frame is in the middle of
+ a sequence.
+ seq_len (int): The number of frames in the input sequence.
+ step (int): Step size to extract frames from the video.
+
+ Returns:
+ List[List[:obj:`PoseDataSample`]]: Multi-frame pose detection results
+ stored in a nested list with a length of seq_len.
+ """
+ if causal:
+ frames_left = seq_len - 1
+ frames_right = 0
+ else:
+ frames_left = (seq_len - 1) // 2
+ frames_right = frames_left
+ num_frames = len(pose_results)
+
+ # get the padded sequence
+ pad_left = max(0, frames_left - frame_idx // step)
+ pad_right = max(0, frames_right - (num_frames - 1 - frame_idx) // step)
+ start = max(frame_idx % step, frame_idx - frames_left * step)
+ end = min(num_frames - (num_frames - 1 - frame_idx) % step,
+ frame_idx + frames_right * step + 1)
+ pose_results_seq = [pose_results[0]] * pad_left + \
+ pose_results[start:end:step] + [pose_results[-1]] * pad_right
+ return pose_results_seq
+
+
+def collate_pose_sequence(pose_results_2d,
+ with_track_id=True,
+ target_frame=-1):
+ """Reorganize multi-frame pose detection results into individual pose
+ sequences.
+
+ Note:
+ - The temporal length of the pose detection results: T
+ - The number of the person instances: N
+ - The number of the keypoints: K
+ - The channel number of each keypoint: C
+
+ Args:
+ pose_results_2d (List[List[:obj:`PoseDataSample`]]): Multi-frame pose
+ detection results stored in a nested list. Each element of the
+ outer list is the pose detection results of a single frame, and
+ each element of the inner list is the pose information of one
+ person, which contains:
+
+ - keypoints (ndarray[K, 2 or 3]): x, y, [score]
+ - track_id (int): unique id of each person, required when
+ ``with_track_id==True```
+
+ with_track_id (bool): If True, the element in pose_results is expected
+ to contain "track_id", which will be used to gather the pose
+ sequence of a person from multiple frames. Otherwise, the pose
+ results in each frame are expected to have a consistent number and
+ order of identities. Default is True.
+ target_frame (int): The index of the target frame. Default: -1.
+
+ Returns:
+ List[:obj:`PoseDataSample`]: Indivisual pose sequence in with length N.
+ """
+ T = len(pose_results_2d)
+ assert T > 0
+
+ target_frame = (T + target_frame) % T # convert negative index to positive
+
+ N = len(
+ pose_results_2d[target_frame]) # use identities in the target frame
+ if N == 0:
+ return []
+
+ B, K, C = pose_results_2d[target_frame][0].pred_instances.keypoints.shape
+
+ track_ids = None
+ if with_track_id:
+ track_ids = [res.track_id for res in pose_results_2d[target_frame]]
+
+ pose_sequences = []
+ for idx in range(N):
+ pose_seq = PoseDataSample()
+ gt_instances = InstanceData()
+ pred_instances = InstanceData()
+
+ for k in pose_results_2d[target_frame][idx].gt_instances.keys():
+ gt_instances.set_field(
+ pose_results_2d[target_frame][idx].gt_instances[k], k)
+ for k in pose_results_2d[target_frame][idx].pred_instances.keys():
+ if k != 'keypoints':
+ pred_instances.set_field(
+ pose_results_2d[target_frame][idx].pred_instances[k], k)
+ pose_seq.pred_instances = pred_instances
+ pose_seq.gt_instances = gt_instances
+
+ if not with_track_id:
+ pose_seq.pred_instances.keypoints = np.stack([
+ frame[idx].pred_instances.keypoints
+ for frame in pose_results_2d
+ ],
+ axis=1)
+ else:
+ keypoints = np.zeros((B, T, K, C), dtype=np.float32)
+ keypoints[:, target_frame] = pose_results_2d[target_frame][
+ idx].pred_instances.keypoints
+ # find the left most frame containing track_ids[idx]
+ for frame_idx in range(target_frame - 1, -1, -1):
+ contains_idx = False
+ for res in pose_results_2d[frame_idx]:
+ if res.track_id == track_ids[idx]:
+ keypoints[:, frame_idx] = res.pred_instances.keypoints
+ contains_idx = True
+ break
+ if not contains_idx:
+ # replicate the left most frame
+ keypoints[:, :frame_idx + 1] = keypoints[:, frame_idx + 1]
+ break
+ # find the right most frame containing track_idx[idx]
+ for frame_idx in range(target_frame + 1, T):
+ contains_idx = False
+ for res in pose_results_2d[frame_idx]:
+ if res.track_id == track_ids[idx]:
+ keypoints[:, frame_idx] = res.pred_instances.keypoints
+ contains_idx = True
+ break
+ if not contains_idx:
+ # replicate the right most frame
+ keypoints[:, frame_idx + 1:] = keypoints[:, frame_idx]
+ break
+ pose_seq.pred_instances.keypoints = keypoints
+ pose_sequences.append(pose_seq)
+
+ return pose_sequences
+
+
+def inference_pose_lifter_model(model,
+ pose_results_2d,
+ with_track_id=True,
+ image_size=None,
+ norm_pose_2d=False):
+ """Inference 3D pose from 2D pose sequences using a pose lifter model.
+
+ Args:
+ model (nn.Module): The loaded pose lifter model
+ pose_results_2d (List[List[:obj:`PoseDataSample`]]): The 2D pose
+ sequences stored in a nested list.
+ with_track_id: If True, the element in pose_results_2d is expected to
+ contain "track_id", which will be used to gather the pose sequence
+ of a person from multiple frames. Otherwise, the pose results in
+ each frame are expected to have a consistent number and order of
+ identities. Default is True.
+ image_size (tuple|list): image width, image height. If None, image size
+ will not be contained in dict ``data``.
+ norm_pose_2d (bool): If True, scale the bbox (along with the 2D
+ pose) to the average bbox scale of the dataset, and move the bbox
+ (along with the 2D pose) to the average bbox center of the dataset.
+
+ Returns:
+ List[:obj:`PoseDataSample`]: 3D pose inference results. Specifically,
+ the predicted keypoints and scores are saved at
+ ``data_sample.pred_instances.keypoints_3d``.
+ """
+ init_default_scope(model.cfg.get('default_scope', 'mmpose'))
+ pipeline = Compose(model.cfg.test_dataloader.dataset.pipeline)
+
+ causal = model.cfg.test_dataloader.dataset.get('causal', False)
+ target_idx = -1 if causal else len(pose_results_2d) // 2
+
+ dataset_info = model.dataset_meta
+ if dataset_info is not None:
+ if 'stats_info' in dataset_info:
+ bbox_center = dataset_info['stats_info']['bbox_center']
+ bbox_scale = dataset_info['stats_info']['bbox_scale']
+ else:
+ bbox_center = None
+ bbox_scale = None
+
+ for i, pose_res in enumerate(pose_results_2d):
+ for j, data_sample in enumerate(pose_res):
+ kpts = data_sample.pred_instances.keypoints
+ bboxes = data_sample.pred_instances.bboxes
+ keypoints = []
+ for k in range(len(kpts)):
+ kpt = kpts[k]
+ if norm_pose_2d:
+ bbox = bboxes[k]
+ center = np.array([[(bbox[0] + bbox[2]) / 2,
+ (bbox[1] + bbox[3]) / 2]])
+ scale = max(bbox[2] - bbox[0], bbox[3] - bbox[1])
+ keypoints.append((kpt[:, :2] - center) / scale *
+ bbox_scale + bbox_center)
+ else:
+ keypoints.append(kpt[:, :2])
+ pose_results_2d[i][j].pred_instances.keypoints = np.array(
+ keypoints)
+
+ pose_sequences_2d = collate_pose_sequence(pose_results_2d, with_track_id,
+ target_idx)
+
+ if not pose_sequences_2d:
+ return []
+
+ data_list = []
+ for i, pose_seq in enumerate(pose_sequences_2d):
+ data_info = dict()
+
+ keypoints_2d = pose_seq.pred_instances.keypoints
+ keypoints_2d = np.squeeze(
+ keypoints_2d, axis=0) if keypoints_2d.ndim == 4 else keypoints_2d
+
+ T, K, C = keypoints_2d.shape
+
+ data_info['keypoints'] = keypoints_2d
+ data_info['keypoints_visible'] = np.ones((
+ T,
+ K,
+ ), dtype=np.float32)
+ data_info['lifting_target'] = np.zeros((K, 3), dtype=np.float32)
+ data_info['lifting_target_visible'] = np.ones((K, 1), dtype=np.float32)
+
+ if image_size is not None:
+ assert len(image_size) == 2
+ data_info['camera_param'] = dict(w=image_size[0], h=image_size[1])
+
+ data_info.update(model.dataset_meta)
+ data_list.append(pipeline(data_info))
+
+ if data_list:
+ # collate data list into a batch, which is a dict with following keys:
+ # batch['inputs']: a list of input images
+ # batch['data_samples']: a list of :obj:`PoseDataSample`
+ batch = pseudo_collate(data_list)
+ with torch.no_grad():
+ results = model.test_step(batch)
+ else:
+ results = []
+
+ return results
diff --git a/mmpose/apis/inference_tracking.py b/mmpose/apis/inference_tracking.py
index c823adcfc7..8e8ba5e712 100644
--- a/mmpose/apis/inference_tracking.py
+++ b/mmpose/apis/inference_tracking.py
@@ -1,103 +1,103 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import warnings
-
-import numpy as np
-
-from mmpose.evaluation.functional.nms import oks_iou
-
-
-def _compute_iou(bboxA, bboxB):
- """Compute the Intersection over Union (IoU) between two boxes .
-
- Args:
- bboxA (list): The first bbox info (left, top, right, bottom, score).
- bboxB (list): The second bbox info (left, top, right, bottom, score).
-
- Returns:
- float: The IoU value.
- """
-
- x1 = max(bboxA[0], bboxB[0])
- y1 = max(bboxA[1], bboxB[1])
- x2 = min(bboxA[2], bboxB[2])
- y2 = min(bboxA[3], bboxB[3])
-
- inter_area = max(0, x2 - x1) * max(0, y2 - y1)
-
- bboxA_area = (bboxA[2] - bboxA[0]) * (bboxA[3] - bboxA[1])
- bboxB_area = (bboxB[2] - bboxB[0]) * (bboxB[3] - bboxB[1])
- union_area = float(bboxA_area + bboxB_area - inter_area)
- if union_area == 0:
- union_area = 1e-5
- warnings.warn('union_area=0 is unexpected')
-
- iou = inter_area / union_area
-
- return iou
-
-
-def _track_by_iou(res, results_last, thr):
- """Get track id using IoU tracking greedily."""
-
- bbox = list(np.squeeze(res.pred_instances.bboxes, axis=0))
-
- max_iou_score = -1
- max_index = -1
- match_result = {}
- for index, res_last in enumerate(results_last):
- bbox_last = list(np.squeeze(res_last.pred_instances.bboxes, axis=0))
-
- iou_score = _compute_iou(bbox, bbox_last)
- if iou_score > max_iou_score:
- max_iou_score = iou_score
- max_index = index
-
- if max_iou_score > thr:
- track_id = results_last[max_index].track_id
- match_result = results_last[max_index]
- del results_last[max_index]
- else:
- track_id = -1
-
- return track_id, results_last, match_result
-
-
-def _track_by_oks(res, results_last, thr, sigmas=None):
- """Get track id using OKS tracking greedily."""
- keypoint = np.concatenate((res.pred_instances.keypoints,
- res.pred_instances.keypoint_scores[:, :, None]),
- axis=2)
- keypoint = np.squeeze(keypoint, axis=0).reshape((-1))
- area = np.squeeze(res.pred_instances.areas, axis=0)
- max_index = -1
- match_result = {}
-
- if len(results_last) == 0:
- return -1, results_last, match_result
-
- keypoints_last = np.array([
- np.squeeze(
- np.concatenate(
- (res_last.pred_instances.keypoints,
- res_last.pred_instances.keypoint_scores[:, :, None]),
- axis=2),
- axis=0).reshape((-1)) for res_last in results_last
- ])
- area_last = np.array([
- np.squeeze(res_last.pred_instances.areas, axis=0)
- for res_last in results_last
- ])
-
- oks_score = oks_iou(
- keypoint, keypoints_last, area, area_last, sigmas=sigmas)
-
- max_index = np.argmax(oks_score)
-
- if oks_score[max_index] > thr:
- track_id = results_last[max_index].track_id
- match_result = results_last[max_index]
- del results_last[max_index]
- else:
- track_id = -1
-
- return track_id, results_last, match_result
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import numpy as np
+
+from mmpose.evaluation.functional.nms import oks_iou
+
+
+def _compute_iou(bboxA, bboxB):
+ """Compute the Intersection over Union (IoU) between two boxes .
+
+ Args:
+ bboxA (list): The first bbox info (left, top, right, bottom, score).
+ bboxB (list): The second bbox info (left, top, right, bottom, score).
+
+ Returns:
+ float: The IoU value.
+ """
+
+ x1 = max(bboxA[0], bboxB[0])
+ y1 = max(bboxA[1], bboxB[1])
+ x2 = min(bboxA[2], bboxB[2])
+ y2 = min(bboxA[3], bboxB[3])
+
+ inter_area = max(0, x2 - x1) * max(0, y2 - y1)
+
+ bboxA_area = (bboxA[2] - bboxA[0]) * (bboxA[3] - bboxA[1])
+ bboxB_area = (bboxB[2] - bboxB[0]) * (bboxB[3] - bboxB[1])
+ union_area = float(bboxA_area + bboxB_area - inter_area)
+ if union_area == 0:
+ union_area = 1e-5
+ warnings.warn('union_area=0 is unexpected')
+
+ iou = inter_area / union_area
+
+ return iou
+
+
+def _track_by_iou(res, results_last, thr):
+ """Get track id using IoU tracking greedily."""
+
+ bbox = list(np.squeeze(res.pred_instances.bboxes, axis=0))
+
+ max_iou_score = -1
+ max_index = -1
+ match_result = {}
+ for index, res_last in enumerate(results_last):
+ bbox_last = list(np.squeeze(res_last.pred_instances.bboxes, axis=0))
+
+ iou_score = _compute_iou(bbox, bbox_last)
+ if iou_score > max_iou_score:
+ max_iou_score = iou_score
+ max_index = index
+
+ if max_iou_score > thr:
+ track_id = results_last[max_index].track_id
+ match_result = results_last[max_index]
+ del results_last[max_index]
+ else:
+ track_id = -1
+
+ return track_id, results_last, match_result
+
+
+def _track_by_oks(res, results_last, thr, sigmas=None):
+ """Get track id using OKS tracking greedily."""
+ keypoint = np.concatenate((res.pred_instances.keypoints,
+ res.pred_instances.keypoint_scores[:, :, None]),
+ axis=2)
+ keypoint = np.squeeze(keypoint, axis=0).reshape((-1))
+ area = np.squeeze(res.pred_instances.areas, axis=0)
+ max_index = -1
+ match_result = {}
+
+ if len(results_last) == 0:
+ return -1, results_last, match_result
+
+ keypoints_last = np.array([
+ np.squeeze(
+ np.concatenate(
+ (res_last.pred_instances.keypoints,
+ res_last.pred_instances.keypoint_scores[:, :, None]),
+ axis=2),
+ axis=0).reshape((-1)) for res_last in results_last
+ ])
+ area_last = np.array([
+ np.squeeze(res_last.pred_instances.areas, axis=0)
+ for res_last in results_last
+ ])
+
+ oks_score = oks_iou(
+ keypoint, keypoints_last, area, area_last, sigmas=sigmas)
+
+ max_index = np.argmax(oks_score)
+
+ if oks_score[max_index] > thr:
+ track_id = results_last[max_index].track_id
+ match_result = results_last[max_index]
+ del results_last[max_index]
+ else:
+ track_id = -1
+
+ return track_id, results_last, match_result
diff --git a/mmpose/apis/inferencers/__init__.py b/mmpose/apis/inferencers/__init__.py
index 5955d79da9..f42179a481 100644
--- a/mmpose/apis/inferencers/__init__.py
+++ b/mmpose/apis/inferencers/__init__.py
@@ -1,10 +1,10 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .mmpose_inferencer import MMPoseInferencer
-from .pose2d_inferencer import Pose2DInferencer
-from .pose3d_inferencer import Pose3DInferencer
-from .utils import get_model_aliases
-
-__all__ = [
- 'Pose2DInferencer', 'MMPoseInferencer', 'get_model_aliases',
- 'Pose3DInferencer'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .mmpose_inferencer import MMPoseInferencer
+from .pose2d_inferencer import Pose2DInferencer
+from .pose3d_inferencer import Pose3DInferencer
+from .utils import get_model_aliases
+
+__all__ = [
+ 'Pose2DInferencer', 'MMPoseInferencer', 'get_model_aliases',
+ 'Pose3DInferencer'
+]
diff --git a/mmpose/apis/inferencers/base_mmpose_inferencer.py b/mmpose/apis/inferencers/base_mmpose_inferencer.py
index bed28b90d7..c58f5ba5a4 100644
--- a/mmpose/apis/inferencers/base_mmpose_inferencer.py
+++ b/mmpose/apis/inferencers/base_mmpose_inferencer.py
@@ -1,469 +1,469 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import mimetypes
-import os
-import warnings
-from collections import defaultdict
-from typing import (Callable, Dict, Generator, Iterable, List, Optional,
- Sequence, Union)
-
-import cv2
-import mmcv
-import mmengine
-import numpy as np
-import torch.nn as nn
-from mmengine.config import Config, ConfigDict
-from mmengine.dataset import Compose
-from mmengine.fileio import (get_file_backend, isdir, join_path,
- list_dir_or_file)
-from mmengine.infer.infer import BaseInferencer
-from mmengine.registry import init_default_scope
-from mmengine.runner.checkpoint import _load_checkpoint_to_model
-from mmengine.structures import InstanceData
-from mmengine.utils import mkdir_or_exist
-
-from mmpose.apis.inference import dataset_meta_from_config
-from mmpose.structures import PoseDataSample, split_instances
-
-InstanceList = List[InstanceData]
-InputType = Union[str, np.ndarray]
-InputsType = Union[InputType, Sequence[InputType]]
-PredType = Union[InstanceData, InstanceList]
-ImgType = Union[np.ndarray, Sequence[np.ndarray]]
-ConfigType = Union[Config, ConfigDict]
-ResType = Union[Dict, List[Dict], InstanceData, List[InstanceData]]
-
-
-class BaseMMPoseInferencer(BaseInferencer):
- """The base class for MMPose inferencers."""
-
- preprocess_kwargs: set = {'bbox_thr', 'nms_thr', 'bboxes'}
- forward_kwargs: set = set()
- visualize_kwargs: set = {
- 'return_vis', 'show', 'wait_time', 'draw_bbox', 'radius', 'thickness',
- 'kpt_thr', 'vis_out_dir', 'black_background'
- }
- postprocess_kwargs: set = {'pred_out_dir'}
-
- def _load_weights_to_model(self, model: nn.Module,
- checkpoint: Optional[dict],
- cfg: Optional[ConfigType]) -> None:
- """Loading model weights and meta information from cfg and checkpoint.
-
- Subclasses could override this method to load extra meta information
- from ``checkpoint`` and ``cfg`` to model.
-
- Args:
- model (nn.Module): Model to load weights and meta information.
- checkpoint (dict, optional): The loaded checkpoint.
- cfg (Config or ConfigDict, optional): The loaded config.
- """
- if checkpoint is not None:
- _load_checkpoint_to_model(model, checkpoint)
- checkpoint_meta = checkpoint.get('meta', {})
- # save the dataset_meta in the model for convenience
- if 'dataset_meta' in checkpoint_meta:
- # mmpose 1.x
- model.dataset_meta = checkpoint_meta['dataset_meta']
- else:
- warnings.warn(
- 'dataset_meta are not saved in the checkpoint\'s '
- 'meta data, load via config.')
- model.dataset_meta = dataset_meta_from_config(
- cfg, dataset_mode='train')
- else:
- warnings.warn('Checkpoint is not loaded, and the inference '
- 'result is calculated by the randomly initialized '
- 'model!')
- model.dataset_meta = dataset_meta_from_config(
- cfg, dataset_mode='train')
-
- def _inputs_to_list(self, inputs: InputsType) -> Iterable:
- """Preprocess the inputs to a list.
-
- Preprocess inputs to a list according to its type:
-
- - list or tuple: return inputs
- - str:
- - Directory path: return all files in the directory
- - other cases: return a list containing the string. The string
- could be a path to file, a url or other types of string
- according to the task.
-
- Args:
- inputs (InputsType): Inputs for the inferencer.
-
- Returns:
- list: List of input for the :meth:`preprocess`.
- """
- self._video_input = False
-
- if isinstance(inputs, str):
- backend = get_file_backend(inputs)
- if hasattr(backend, 'isdir') and isdir(inputs):
- # Backends like HttpsBackend do not implement `isdir`, so only
- # those backends that implement `isdir` could accept the
- # inputs as a directory
- filepath_list = [
- join_path(inputs, fname)
- for fname in list_dir_or_file(inputs, list_dir=False)
- ]
- inputs = []
- for filepath in filepath_list:
- input_type = mimetypes.guess_type(filepath)[0].split(
- '/')[0]
- if input_type == 'image':
- inputs.append(filepath)
- inputs.sort()
- else:
- # if inputs is a path to a video file, it will be converted
- # to a list containing separated frame filenames
- input_type = mimetypes.guess_type(inputs)[0].split('/')[0]
- if input_type == 'video':
- self._video_input = True
- video = mmcv.VideoReader(inputs)
- self.video_info = dict(
- fps=video.fps,
- name=os.path.basename(inputs),
- writer=None,
- width=video.width,
- height=video.height,
- predictions=[])
- inputs = video
- elif input_type == 'image':
- inputs = [inputs]
- else:
- raise ValueError(f'Expected input to be an image, video, '
- f'or folder, but received {inputs} of '
- f'type {input_type}.')
-
- elif isinstance(inputs, np.ndarray):
- inputs = [inputs]
-
- return inputs
-
- def _get_webcam_inputs(self, inputs: str) -> Generator:
- """Sets up and returns a generator function that reads frames from a
- webcam input. The generator function returns a new frame each time it
- is iterated over.
-
- Args:
- inputs (str): A string describing the webcam input, in the format
- "webcam:id".
-
- Returns:
- A generator function that yields frames from the webcam input.
-
- Raises:
- ValueError: If the inputs string is not in the expected format.
- """
-
- # Ensure the inputs string is in the expected format.
- inputs = inputs.lower()
- assert inputs.startswith('webcam'), f'Expected input to start with ' \
- f'"webcam", but got "{inputs}"'
-
- # Parse the camera ID from the inputs string.
- inputs_ = inputs.split(':')
- if len(inputs_) == 1:
- camera_id = 0
- elif len(inputs_) == 2 and str.isdigit(inputs_[1]):
- camera_id = int(inputs_[1])
- else:
- raise ValueError(
- f'Expected webcam input to have format "webcam:id", '
- f'but got "{inputs}"')
-
- # Attempt to open the video capture object.
- vcap = cv2.VideoCapture(camera_id)
- if not vcap.isOpened():
- warnings.warn(f'Cannot open camera (ID={camera_id})')
- return []
-
- # Set video input flag and metadata.
- self._video_input = True
- (major_ver, minor_ver, subminor_ver) = (cv2.__version__).split('.')
- if int(major_ver) < 3:
- fps = vcap.get(cv2.cv.CV_CAP_PROP_FPS)
- width = vcap.get(cv2.cv.CV_CAP_PROP_FRAME_WIDTH)
- height = vcap.get(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT)
- else:
- fps = vcap.get(cv2.CAP_PROP_FPS)
- width = vcap.get(cv2.CAP_PROP_FRAME_WIDTH)
- height = vcap.get(cv2.CAP_PROP_FRAME_HEIGHT)
- self.video_info = dict(
- fps=fps,
- name='webcam.mp4',
- writer=None,
- width=width,
- height=height,
- predictions=[])
-
- def _webcam_reader() -> Generator:
- while True:
- if cv2.waitKey(5) & 0xFF == 27:
- vcap.release()
- break
-
- ret_val, frame = vcap.read()
- if not ret_val:
- break
-
- yield frame
-
- return _webcam_reader()
-
- def _init_pipeline(self, cfg: ConfigType) -> Callable:
- """Initialize the test pipeline.
-
- Args:
- cfg (ConfigType): model config path or dict
-
- Returns:
- A pipeline to handle various input data, such as ``str``,
- ``np.ndarray``. The returned pipeline will be used to process
- a single data.
- """
- scope = cfg.get('default_scope', 'mmpose')
- if scope is not None:
- init_default_scope(scope)
- return Compose(cfg.test_dataloader.dataset.pipeline)
-
- def update_model_visualizer_settings(self, **kwargs):
- """Update the settings of models and visualizer according to inference
- arguments."""
-
- pass
-
- def preprocess(self,
- inputs: InputsType,
- batch_size: int = 1,
- bboxes: Optional[List] = None,
- **kwargs):
- """Process the inputs into a model-feedable format.
-
- Args:
- inputs (InputsType): Inputs given by user.
- batch_size (int): batch size. Defaults to 1.
-
- Yields:
- Any: Data processed by the ``pipeline`` and ``collate_fn``.
- List[str or np.ndarray]: List of original inputs in the batch
- """
-
- for i, input in enumerate(inputs):
- bbox = bboxes[i] if bboxes else []
- data_infos = self.preprocess_single(
- input, index=i, bboxes=bbox, **kwargs)
- # only supports inference with batch size 1
- yield self.collate_fn(data_infos), [input]
-
- def visualize(self,
- inputs: list,
- preds: List[PoseDataSample],
- return_vis: bool = False,
- show: bool = False,
- draw_bbox: bool = False,
- wait_time: float = 0,
- radius: int = 3,
- thickness: int = 1,
- kpt_thr: float = 0.3,
- vis_out_dir: str = '',
- window_name: str = '',
- black_background: bool = False,
- **kwargs) -> List[np.ndarray]:
- """Visualize predictions.
-
- Args:
- inputs (list): Inputs preprocessed by :meth:`_inputs_to_list`.
- preds (Any): Predictions of the model.
- return_vis (bool): Whether to return images with predicted results.
- show (bool): Whether to display the image in a popup window.
- Defaults to False.
- wait_time (float): The interval of show (ms). Defaults to 0
- draw_bbox (bool): Whether to draw the bounding boxes.
- Defaults to False
- radius (int): Keypoint radius for visualization. Defaults to 3
- thickness (int): Link thickness for visualization. Defaults to 1
- kpt_thr (float): The threshold to visualize the keypoints.
- Defaults to 0.3
- vis_out_dir (str, optional): Directory to save visualization
- results w/o predictions. If left as empty, no file will
- be saved. Defaults to ''.
- window_name (str, optional): Title of display window.
- black_background (bool, optional): Whether to plot keypoints on a
- black image instead of the input image. Defaults to False.
-
- Returns:
- List[np.ndarray]: Visualization results.
- """
- if (not return_vis) and (not show) and (not vis_out_dir):
- return
-
- if getattr(self, 'visualizer', None) is None:
- raise ValueError('Visualization needs the "visualizer" term'
- 'defined in the config, but got None.')
-
- self.visualizer.radius = radius
- self.visualizer.line_width = thickness
-
- results = []
-
- for single_input, pred in zip(inputs, preds):
- if isinstance(single_input, str):
- img = mmcv.imread(single_input, channel_order='rgb')
- elif isinstance(single_input, np.ndarray):
- img = mmcv.bgr2rgb(single_input)
- else:
- raise ValueError('Unsupported input type: '
- f'{type(single_input)}')
- if black_background:
- img = img * 0
-
- img_name = os.path.basename(pred.metainfo['img_path'])
- window_name = window_name if window_name else img_name
-
- # since visualization and inference utilize the same process,
- # the wait time is reduced when a video input is utilized,
- # thereby eliminating the issue of inference getting stuck.
- wait_time = 1e-5 if self._video_input else wait_time
-
- visualization = self.visualizer.add_datasample(
- window_name,
- img,
- pred,
- draw_gt=False,
- draw_bbox=draw_bbox,
- show=show,
- wait_time=wait_time,
- kpt_thr=kpt_thr,
- **kwargs)
- results.append(visualization)
-
- if vis_out_dir:
- out_img = mmcv.rgb2bgr(visualization)
- _, file_extension = os.path.splitext(vis_out_dir)
- if file_extension:
- dir_name = os.path.dirname(vis_out_dir)
- file_name = os.path.basename(vis_out_dir)
- else:
- dir_name = vis_out_dir
- file_name = None
- mkdir_or_exist(dir_name)
-
- if self._video_input:
-
- if self.video_info['writer'] is None:
- fourcc = cv2.VideoWriter_fourcc(*'mp4v')
- if file_name is None:
- file_name = os.path.basename(
- self.video_info['name'])
- out_file = join_path(dir_name, file_name)
- self.video_info['writer'] = cv2.VideoWriter(
- out_file, fourcc, self.video_info['fps'],
- (visualization.shape[1], visualization.shape[0]))
- self.video_info['writer'].write(out_img)
-
- else:
- file_name = file_name if file_name else img_name
- out_file = join_path(dir_name, file_name)
- mmcv.imwrite(out_img, out_file)
-
- if return_vis:
- return results
- else:
- return []
-
- def postprocess(
- self,
- preds: List[PoseDataSample],
- visualization: List[np.ndarray],
- return_datasample=False,
- pred_out_dir: str = '',
- ) -> dict:
- """Process the predictions and visualization results from ``forward``
- and ``visualize``.
-
- This method should be responsible for the following tasks:
-
- 1. Convert datasamples into a json-serializable dict if needed.
- 2. Pack the predictions and visualization results and return them.
- 3. Dump or log the predictions.
-
- Args:
- preds (List[Dict]): Predictions of the model.
- visualization (np.ndarray): Visualized predictions.
- return_datasample (bool): Whether to return results as
- datasamples. Defaults to False.
- pred_out_dir (str): Directory to save the inference results w/o
- visualization. If left as empty, no file will be saved.
- Defaults to ''.
-
- Returns:
- dict: Inference and visualization results with key ``predictions``
- and ``visualization``
-
- - ``visualization (Any)``: Returned by :meth:`visualize`
- - ``predictions`` (dict or DataSample): Returned by
- :meth:`forward` and processed in :meth:`postprocess`.
- If ``return_datasample=False``, it usually should be a
- json-serializable dict containing only basic data elements such
- as strings and numbers.
- """
-
- result_dict = defaultdict(list)
-
- result_dict['visualization'] = visualization
- for pred in preds:
- if not return_datasample:
- # convert datasamples to list of instance predictions
- pred = split_instances(pred.pred_instances)
- result_dict['predictions'].append(pred)
-
- if pred_out_dir != '':
- for pred, data_sample in zip(result_dict['predictions'], preds):
- if self._video_input:
- # For video or webcam input, predictions for each frame
- # are gathered in the 'predictions' key of 'video_info'
- # dictionary. All frame predictions are then stored into
- # a single file after processing all frames.
- self.video_info['predictions'].append(pred)
- else:
- # For non-video inputs, predictions are stored in separate
- # JSON files. The filename is determined by the basename
- # of the input image path with a '.json' extension. The
- # predictions are then dumped into this file.
- fname = os.path.splitext(
- os.path.basename(
- data_sample.metainfo['img_path']))[0] + '.json'
- mmengine.dump(
- pred, join_path(pred_out_dir, fname), indent=' ')
-
- return result_dict
-
- def _finalize_video_processing(
- self,
- pred_out_dir: str = '',
- ):
- """Finalize video processing by releasing the video writer and saving
- predictions to a file.
-
- This method should be called after completing the video processing. It
- releases the video writer, if it exists, and saves the predictions to a
- JSON file if a prediction output directory is provided.
- """
-
- # Release the video writer if it exists
- if self.video_info['writer'] is not None:
- self.video_info['writer'].release()
-
- # Save predictions
- if pred_out_dir:
- fname = os.path.splitext(
- os.path.basename(self.video_info['name']))[0] + '.json'
- predictions = [
- dict(frame_id=i, instances=pred)
- for i, pred in enumerate(self.video_info['predictions'])
- ]
-
- mmengine.dump(
- predictions, join_path(pred_out_dir, fname), indent=' ')
+# Copyright (c) OpenMMLab. All rights reserved.
+import mimetypes
+import os
+import warnings
+from collections import defaultdict
+from typing import (Callable, Dict, Generator, Iterable, List, Optional,
+ Sequence, Union)
+
+import cv2
+import mmcv
+import mmengine
+import numpy as np
+import torch.nn as nn
+from mmengine.config import Config, ConfigDict
+from mmengine.dataset import Compose
+from mmengine.fileio import (get_file_backend, isdir, join_path,
+ list_dir_or_file)
+from mmengine.infer.infer import BaseInferencer
+from mmengine.registry import init_default_scope
+from mmengine.runner.checkpoint import _load_checkpoint_to_model
+from mmengine.structures import InstanceData
+from mmengine.utils import mkdir_or_exist
+
+from mmpose.apis.inference import dataset_meta_from_config
+from mmpose.structures import PoseDataSample, split_instances
+
+InstanceList = List[InstanceData]
+InputType = Union[str, np.ndarray]
+InputsType = Union[InputType, Sequence[InputType]]
+PredType = Union[InstanceData, InstanceList]
+ImgType = Union[np.ndarray, Sequence[np.ndarray]]
+ConfigType = Union[Config, ConfigDict]
+ResType = Union[Dict, List[Dict], InstanceData, List[InstanceData]]
+
+
+class BaseMMPoseInferencer(BaseInferencer):
+ """The base class for MMPose inferencers."""
+
+ preprocess_kwargs: set = {'bbox_thr', 'nms_thr', 'bboxes'}
+ forward_kwargs: set = set()
+ visualize_kwargs: set = {
+ 'return_vis', 'show', 'wait_time', 'draw_bbox', 'radius', 'thickness',
+ 'kpt_thr', 'vis_out_dir', 'black_background'
+ }
+ postprocess_kwargs: set = {'pred_out_dir'}
+
+ def _load_weights_to_model(self, model: nn.Module,
+ checkpoint: Optional[dict],
+ cfg: Optional[ConfigType]) -> None:
+ """Loading model weights and meta information from cfg and checkpoint.
+
+ Subclasses could override this method to load extra meta information
+ from ``checkpoint`` and ``cfg`` to model.
+
+ Args:
+ model (nn.Module): Model to load weights and meta information.
+ checkpoint (dict, optional): The loaded checkpoint.
+ cfg (Config or ConfigDict, optional): The loaded config.
+ """
+ if checkpoint is not None:
+ _load_checkpoint_to_model(model, checkpoint)
+ checkpoint_meta = checkpoint.get('meta', {})
+ # save the dataset_meta in the model for convenience
+ if 'dataset_meta' in checkpoint_meta:
+ # mmpose 1.x
+ model.dataset_meta = checkpoint_meta['dataset_meta']
+ else:
+ warnings.warn(
+ 'dataset_meta are not saved in the checkpoint\'s '
+ 'meta data, load via config.')
+ model.dataset_meta = dataset_meta_from_config(
+ cfg, dataset_mode='train')
+ else:
+ warnings.warn('Checkpoint is not loaded, and the inference '
+ 'result is calculated by the randomly initialized '
+ 'model!')
+ model.dataset_meta = dataset_meta_from_config(
+ cfg, dataset_mode='train')
+
+ def _inputs_to_list(self, inputs: InputsType) -> Iterable:
+ """Preprocess the inputs to a list.
+
+ Preprocess inputs to a list according to its type:
+
+ - list or tuple: return inputs
+ - str:
+ - Directory path: return all files in the directory
+ - other cases: return a list containing the string. The string
+ could be a path to file, a url or other types of string
+ according to the task.
+
+ Args:
+ inputs (InputsType): Inputs for the inferencer.
+
+ Returns:
+ list: List of input for the :meth:`preprocess`.
+ """
+ self._video_input = False
+
+ if isinstance(inputs, str):
+ backend = get_file_backend(inputs)
+ if hasattr(backend, 'isdir') and isdir(inputs):
+ # Backends like HttpsBackend do not implement `isdir`, so only
+ # those backends that implement `isdir` could accept the
+ # inputs as a directory
+ filepath_list = [
+ join_path(inputs, fname)
+ for fname in list_dir_or_file(inputs, list_dir=False)
+ ]
+ inputs = []
+ for filepath in filepath_list:
+ input_type = mimetypes.guess_type(filepath)[0].split(
+ '/')[0]
+ if input_type == 'image':
+ inputs.append(filepath)
+ inputs.sort()
+ else:
+ # if inputs is a path to a video file, it will be converted
+ # to a list containing separated frame filenames
+ input_type = mimetypes.guess_type(inputs)[0].split('/')[0]
+ if input_type == 'video':
+ self._video_input = True
+ video = mmcv.VideoReader(inputs)
+ self.video_info = dict(
+ fps=video.fps,
+ name=os.path.basename(inputs),
+ writer=None,
+ width=video.width,
+ height=video.height,
+ predictions=[])
+ inputs = video
+ elif input_type == 'image':
+ inputs = [inputs]
+ else:
+ raise ValueError(f'Expected input to be an image, video, '
+ f'or folder, but received {inputs} of '
+ f'type {input_type}.')
+
+ elif isinstance(inputs, np.ndarray):
+ inputs = [inputs]
+
+ return inputs
+
+ def _get_webcam_inputs(self, inputs: str) -> Generator:
+ """Sets up and returns a generator function that reads frames from a
+ webcam input. The generator function returns a new frame each time it
+ is iterated over.
+
+ Args:
+ inputs (str): A string describing the webcam input, in the format
+ "webcam:id".
+
+ Returns:
+ A generator function that yields frames from the webcam input.
+
+ Raises:
+ ValueError: If the inputs string is not in the expected format.
+ """
+
+ # Ensure the inputs string is in the expected format.
+ inputs = inputs.lower()
+ assert inputs.startswith('webcam'), f'Expected input to start with ' \
+ f'"webcam", but got "{inputs}"'
+
+ # Parse the camera ID from the inputs string.
+ inputs_ = inputs.split(':')
+ if len(inputs_) == 1:
+ camera_id = 0
+ elif len(inputs_) == 2 and str.isdigit(inputs_[1]):
+ camera_id = int(inputs_[1])
+ else:
+ raise ValueError(
+ f'Expected webcam input to have format "webcam:id", '
+ f'but got "{inputs}"')
+
+ # Attempt to open the video capture object.
+ vcap = cv2.VideoCapture(camera_id)
+ if not vcap.isOpened():
+ warnings.warn(f'Cannot open camera (ID={camera_id})')
+ return []
+
+ # Set video input flag and metadata.
+ self._video_input = True
+ (major_ver, minor_ver, subminor_ver) = (cv2.__version__).split('.')
+ if int(major_ver) < 3:
+ fps = vcap.get(cv2.cv.CV_CAP_PROP_FPS)
+ width = vcap.get(cv2.cv.CV_CAP_PROP_FRAME_WIDTH)
+ height = vcap.get(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT)
+ else:
+ fps = vcap.get(cv2.CAP_PROP_FPS)
+ width = vcap.get(cv2.CAP_PROP_FRAME_WIDTH)
+ height = vcap.get(cv2.CAP_PROP_FRAME_HEIGHT)
+ self.video_info = dict(
+ fps=fps,
+ name='webcam.mp4',
+ writer=None,
+ width=width,
+ height=height,
+ predictions=[])
+
+ def _webcam_reader() -> Generator:
+ while True:
+ if cv2.waitKey(5) & 0xFF == 27:
+ vcap.release()
+ break
+
+ ret_val, frame = vcap.read()
+ if not ret_val:
+ break
+
+ yield frame
+
+ return _webcam_reader()
+
+ def _init_pipeline(self, cfg: ConfigType) -> Callable:
+ """Initialize the test pipeline.
+
+ Args:
+ cfg (ConfigType): model config path or dict
+
+ Returns:
+ A pipeline to handle various input data, such as ``str``,
+ ``np.ndarray``. The returned pipeline will be used to process
+ a single data.
+ """
+ scope = cfg.get('default_scope', 'mmpose')
+ if scope is not None:
+ init_default_scope(scope)
+ return Compose(cfg.test_dataloader.dataset.pipeline)
+
+ def update_model_visualizer_settings(self, **kwargs):
+ """Update the settings of models and visualizer according to inference
+ arguments."""
+
+ pass
+
+ def preprocess(self,
+ inputs: InputsType,
+ batch_size: int = 1,
+ bboxes: Optional[List] = None,
+ **kwargs):
+ """Process the inputs into a model-feedable format.
+
+ Args:
+ inputs (InputsType): Inputs given by user.
+ batch_size (int): batch size. Defaults to 1.
+
+ Yields:
+ Any: Data processed by the ``pipeline`` and ``collate_fn``.
+ List[str or np.ndarray]: List of original inputs in the batch
+ """
+
+ for i, input in enumerate(inputs):
+ bbox = bboxes[i] if bboxes else []
+ data_infos = self.preprocess_single(
+ input, index=i, bboxes=bbox, **kwargs)
+ # only supports inference with batch size 1
+ yield self.collate_fn(data_infos), [input]
+
+ def visualize(self,
+ inputs: list,
+ preds: List[PoseDataSample],
+ return_vis: bool = False,
+ show: bool = False,
+ draw_bbox: bool = False,
+ wait_time: float = 0,
+ radius: int = 3,
+ thickness: int = 1,
+ kpt_thr: float = 0.3,
+ vis_out_dir: str = '',
+ window_name: str = '',
+ black_background: bool = False,
+ **kwargs) -> List[np.ndarray]:
+ """Visualize predictions.
+
+ Args:
+ inputs (list): Inputs preprocessed by :meth:`_inputs_to_list`.
+ preds (Any): Predictions of the model.
+ return_vis (bool): Whether to return images with predicted results.
+ show (bool): Whether to display the image in a popup window.
+ Defaults to False.
+ wait_time (float): The interval of show (ms). Defaults to 0
+ draw_bbox (bool): Whether to draw the bounding boxes.
+ Defaults to False
+ radius (int): Keypoint radius for visualization. Defaults to 3
+ thickness (int): Link thickness for visualization. Defaults to 1
+ kpt_thr (float): The threshold to visualize the keypoints.
+ Defaults to 0.3
+ vis_out_dir (str, optional): Directory to save visualization
+ results w/o predictions. If left as empty, no file will
+ be saved. Defaults to ''.
+ window_name (str, optional): Title of display window.
+ black_background (bool, optional): Whether to plot keypoints on a
+ black image instead of the input image. Defaults to False.
+
+ Returns:
+ List[np.ndarray]: Visualization results.
+ """
+ if (not return_vis) and (not show) and (not vis_out_dir):
+ return
+
+ if getattr(self, 'visualizer', None) is None:
+ raise ValueError('Visualization needs the "visualizer" term'
+ 'defined in the config, but got None.')
+
+ self.visualizer.radius = radius
+ self.visualizer.line_width = thickness
+
+ results = []
+
+ for single_input, pred in zip(inputs, preds):
+ if isinstance(single_input, str):
+ img = mmcv.imread(single_input, channel_order='rgb')
+ elif isinstance(single_input, np.ndarray):
+ img = mmcv.bgr2rgb(single_input)
+ else:
+ raise ValueError('Unsupported input type: '
+ f'{type(single_input)}')
+ if black_background:
+ img = img * 0
+
+ img_name = os.path.basename(pred.metainfo['img_path'])
+ window_name = window_name if window_name else img_name
+
+ # since visualization and inference utilize the same process,
+ # the wait time is reduced when a video input is utilized,
+ # thereby eliminating the issue of inference getting stuck.
+ wait_time = 1e-5 if self._video_input else wait_time
+
+ visualization = self.visualizer.add_datasample(
+ window_name,
+ img,
+ pred,
+ draw_gt=False,
+ draw_bbox=draw_bbox,
+ show=show,
+ wait_time=wait_time,
+ kpt_thr=kpt_thr,
+ **kwargs)
+ results.append(visualization)
+
+ if vis_out_dir:
+ out_img = mmcv.rgb2bgr(visualization)
+ _, file_extension = os.path.splitext(vis_out_dir)
+ if file_extension:
+ dir_name = os.path.dirname(vis_out_dir)
+ file_name = os.path.basename(vis_out_dir)
+ else:
+ dir_name = vis_out_dir
+ file_name = None
+ mkdir_or_exist(dir_name)
+
+ if self._video_input:
+
+ if self.video_info['writer'] is None:
+ fourcc = cv2.VideoWriter_fourcc(*'mp4v')
+ if file_name is None:
+ file_name = os.path.basename(
+ self.video_info['name'])
+ out_file = join_path(dir_name, file_name)
+ self.video_info['writer'] = cv2.VideoWriter(
+ out_file, fourcc, self.video_info['fps'],
+ (visualization.shape[1], visualization.shape[0]))
+ self.video_info['writer'].write(out_img)
+
+ else:
+ file_name = file_name if file_name else img_name
+ out_file = join_path(dir_name, file_name)
+ mmcv.imwrite(out_img, out_file)
+
+ if return_vis:
+ return results
+ else:
+ return []
+
+ def postprocess(
+ self,
+ preds: List[PoseDataSample],
+ visualization: List[np.ndarray],
+ return_datasample=False,
+ pred_out_dir: str = '',
+ ) -> dict:
+ """Process the predictions and visualization results from ``forward``
+ and ``visualize``.
+
+ This method should be responsible for the following tasks:
+
+ 1. Convert datasamples into a json-serializable dict if needed.
+ 2. Pack the predictions and visualization results and return them.
+ 3. Dump or log the predictions.
+
+ Args:
+ preds (List[Dict]): Predictions of the model.
+ visualization (np.ndarray): Visualized predictions.
+ return_datasample (bool): Whether to return results as
+ datasamples. Defaults to False.
+ pred_out_dir (str): Directory to save the inference results w/o
+ visualization. If left as empty, no file will be saved.
+ Defaults to ''.
+
+ Returns:
+ dict: Inference and visualization results with key ``predictions``
+ and ``visualization``
+
+ - ``visualization (Any)``: Returned by :meth:`visualize`
+ - ``predictions`` (dict or DataSample): Returned by
+ :meth:`forward` and processed in :meth:`postprocess`.
+ If ``return_datasample=False``, it usually should be a
+ json-serializable dict containing only basic data elements such
+ as strings and numbers.
+ """
+
+ result_dict = defaultdict(list)
+
+ result_dict['visualization'] = visualization
+ for pred in preds:
+ if not return_datasample:
+ # convert datasamples to list of instance predictions
+ pred = split_instances(pred.pred_instances)
+ result_dict['predictions'].append(pred)
+
+ if pred_out_dir != '':
+ for pred, data_sample in zip(result_dict['predictions'], preds):
+ if self._video_input:
+ # For video or webcam input, predictions for each frame
+ # are gathered in the 'predictions' key of 'video_info'
+ # dictionary. All frame predictions are then stored into
+ # a single file after processing all frames.
+ self.video_info['predictions'].append(pred)
+ else:
+ # For non-video inputs, predictions are stored in separate
+ # JSON files. The filename is determined by the basename
+ # of the input image path with a '.json' extension. The
+ # predictions are then dumped into this file.
+ fname = os.path.splitext(
+ os.path.basename(
+ data_sample.metainfo['img_path']))[0] + '.json'
+ mmengine.dump(
+ pred, join_path(pred_out_dir, fname), indent=' ')
+
+ return result_dict
+
+ def _finalize_video_processing(
+ self,
+ pred_out_dir: str = '',
+ ):
+ """Finalize video processing by releasing the video writer and saving
+ predictions to a file.
+
+ This method should be called after completing the video processing. It
+ releases the video writer, if it exists, and saves the predictions to a
+ JSON file if a prediction output directory is provided.
+ """
+
+ # Release the video writer if it exists
+ if self.video_info['writer'] is not None:
+ self.video_info['writer'].release()
+
+ # Save predictions
+ if pred_out_dir:
+ fname = os.path.splitext(
+ os.path.basename(self.video_info['name']))[0] + '.json'
+ predictions = [
+ dict(frame_id=i, instances=pred)
+ for i, pred in enumerate(self.video_info['predictions'])
+ ]
+
+ mmengine.dump(
+ predictions, join_path(pred_out_dir, fname), indent=' ')
diff --git a/mmpose/apis/inferencers/mmpose_inferencer.py b/mmpose/apis/inferencers/mmpose_inferencer.py
index b44361bba8..d774618de7 100644
--- a/mmpose/apis/inferencers/mmpose_inferencer.py
+++ b/mmpose/apis/inferencers/mmpose_inferencer.py
@@ -1,239 +1,239 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import warnings
-from typing import Dict, List, Optional, Sequence, Union
-
-import numpy as np
-import torch
-from mmengine.config import Config, ConfigDict
-from mmengine.infer.infer import ModelType
-from mmengine.structures import InstanceData
-
-from .base_mmpose_inferencer import BaseMMPoseInferencer
-from .pose2d_inferencer import Pose2DInferencer
-from .pose3d_inferencer import Pose3DInferencer
-
-InstanceList = List[InstanceData]
-InputType = Union[str, np.ndarray]
-InputsType = Union[InputType, Sequence[InputType]]
-PredType = Union[InstanceData, InstanceList]
-ImgType = Union[np.ndarray, Sequence[np.ndarray]]
-ConfigType = Union[Config, ConfigDict]
-ResType = Union[Dict, List[Dict], InstanceData, List[InstanceData]]
-
-
-class MMPoseInferencer(BaseMMPoseInferencer):
- """MMPose Inferencer. It's a unified inferencer interface for pose
- estimation task, currently including: Pose2D. and it can be used to perform
- 2D keypoint detection.
-
- Args:
- pose2d (str, optional): Pretrained 2D pose estimation algorithm.
- It's the path to the config file or the model name defined in
- metafile. For example, it could be:
-
- - model alias, e.g. ``'body'``,
- - config name, e.g. ``'simcc_res50_8xb64-210e_coco-256x192'``,
- - config path
-
- Defaults to ``None``.
- pose2d_weights (str, optional): Path to the custom checkpoint file of
- the selected pose2d model. If it is not specified and "pose2d" is
- a model name of metafile, the weights will be loaded from
- metafile. Defaults to None.
- device (str, optional): Device to run inference. If None, the
- available device will be automatically used. Defaults to None.
- scope (str, optional): The scope of the model. Defaults to "mmpose".
- det_model(str, optional): Config path or alias of detection model.
- Defaults to None.
- det_weights(str, optional): Path to the checkpoints of detection
- model. Defaults to None.
- det_cat_ids(int or list[int], optional): Category id for
- detection model. Defaults to None.
- output_heatmaps (bool, optional): Flag to visualize predicted
- heatmaps. If set to None, the default setting from the model
- config will be used. Default is None.
- """
-
- preprocess_kwargs: set = {
- 'bbox_thr', 'nms_thr', 'bboxes', 'use_oks_tracking', 'tracking_thr',
- 'norm_pose_2d'
- }
- forward_kwargs: set = {'rebase_keypoint_height'}
- visualize_kwargs: set = {
- 'return_vis', 'show', 'wait_time', 'draw_bbox', 'radius', 'thickness',
- 'kpt_thr', 'vis_out_dir', 'skeleton_style', 'draw_heatmap',
- 'black_background'
- }
- postprocess_kwargs: set = {'pred_out_dir'}
-
- def __init__(self,
- pose2d: Optional[str] = None,
- pose2d_weights: Optional[str] = None,
- pose3d: Optional[str] = None,
- pose3d_weights: Optional[str] = None,
- device: Optional[str] = None,
- scope: str = 'mmpose',
- det_model: Optional[Union[ModelType, str]] = None,
- det_weights: Optional[str] = None,
- det_cat_ids: Optional[Union[int, List]] = None) -> None:
-
- self.visualizer = None
- if pose3d is not None:
- self.inferencer = Pose3DInferencer(pose3d, pose3d_weights, pose2d,
- pose2d_weights, device, scope,
- det_model, det_weights,
- det_cat_ids)
- elif pose2d is not None:
- self.inferencer = Pose2DInferencer(pose2d, pose2d_weights, device,
- scope, det_model, det_weights,
- det_cat_ids)
- else:
- raise ValueError('Either 2d or 3d pose estimation algorithm '
- 'should be provided.')
-
- def preprocess(self, inputs: InputsType, batch_size: int = 1, **kwargs):
- """Process the inputs into a model-feedable format.
-
- Args:
- inputs (InputsType): Inputs given by user.
- batch_size (int): batch size. Defaults to 1.
-
- Yields:
- Any: Data processed by the ``pipeline`` and ``collate_fn``.
- List[str or np.ndarray]: List of original inputs in the batch
- """
-
- for i, input in enumerate(inputs):
- data_batch = {}
- data_infos = self.inferencer.preprocess_single(
- input, index=i, **kwargs)
- data_batch = self.inferencer.collate_fn(data_infos)
- # only supports inference with batch size 1
- yield data_batch, [input]
-
- @torch.no_grad()
- def forward(self, inputs: InputType, **forward_kwargs) -> PredType:
- """Forward the inputs to the model.
-
- Args:
- inputs (InputsType): The inputs to be forwarded.
-
- Returns:
- Dict: The prediction results. Possibly with keys "pose2d".
- """
- return self.inferencer.forward(inputs, **forward_kwargs)
-
- def __call__(
- self,
- inputs: InputsType,
- return_datasample: bool = False,
- batch_size: int = 1,
- out_dir: Optional[str] = None,
- **kwargs,
- ) -> dict:
- """Call the inferencer.
-
- Args:
- inputs (InputsType): Inputs for the inferencer.
- return_datasample (bool): Whether to return results as
- :obj:`BaseDataElement`. Defaults to False.
- batch_size (int): Batch size. Defaults to 1.
- out_dir (str, optional): directory to save visualization
- results and predictions. Will be overoden if vis_out_dir or
- pred_out_dir are given. Defaults to None
- **kwargs: Key words arguments passed to :meth:`preprocess`,
- :meth:`forward`, :meth:`visualize` and :meth:`postprocess`.
- Each key in kwargs should be in the corresponding set of
- ``preprocess_kwargs``, ``forward_kwargs``,
- ``visualize_kwargs`` and ``postprocess_kwargs``.
-
- Returns:
- dict: Inference and visualization results.
- """
- if out_dir is not None:
- if 'vis_out_dir' not in kwargs:
- kwargs['vis_out_dir'] = f'{out_dir}/visualizations'
- if 'pred_out_dir' not in kwargs:
- kwargs['pred_out_dir'] = f'{out_dir}/predictions'
-
- kwargs = {
- key: value
- for key, value in kwargs.items()
- if key in set.union(self.inferencer.preprocess_kwargs,
- self.inferencer.forward_kwargs,
- self.inferencer.visualize_kwargs,
- self.inferencer.postprocess_kwargs)
- }
- (
- preprocess_kwargs,
- forward_kwargs,
- visualize_kwargs,
- postprocess_kwargs,
- ) = self._dispatch_kwargs(**kwargs)
-
- self.inferencer.update_model_visualizer_settings(**kwargs)
-
- # preprocessing
- if isinstance(inputs, str) and inputs.startswith('webcam'):
- inputs = self.inferencer._get_webcam_inputs(inputs)
- batch_size = 1
- if not visualize_kwargs.get('show', False):
- warnings.warn('The display mode is closed when using webcam '
- 'input. It will be turned on automatically.')
- visualize_kwargs['show'] = True
- else:
- inputs = self.inferencer._inputs_to_list(inputs)
- self._video_input = self.inferencer._video_input
- if self._video_input:
- self.video_info = self.inferencer.video_info
-
- inputs = self.preprocess(
- inputs, batch_size=batch_size, **preprocess_kwargs)
-
- # forward
- if 'bbox_thr' in self.inferencer.forward_kwargs:
- forward_kwargs['bbox_thr'] = preprocess_kwargs.get('bbox_thr', -1)
-
- preds = []
-
- for proc_inputs, ori_inputs in inputs:
- preds = self.forward(proc_inputs, **forward_kwargs)
-
- visualization = self.visualize(ori_inputs, preds,
- **visualize_kwargs)
- results = self.postprocess(preds, visualization, return_datasample,
- **postprocess_kwargs)
- yield results
-
- if self._video_input:
- self._finalize_video_processing(
- postprocess_kwargs.get('pred_out_dir', ''))
-
- def visualize(self, inputs: InputsType, preds: PredType,
- **kwargs) -> List[np.ndarray]:
- """Visualize predictions.
-
- Args:
- inputs (list): Inputs preprocessed by :meth:`_inputs_to_list`.
- preds (Any): Predictions of the model.
- return_vis (bool): Whether to return images with predicted results.
- show (bool): Whether to display the image in a popup window.
- Defaults to False.
- show_interval (int): The interval of show (s). Defaults to 0
- radius (int): Keypoint radius for visualization. Defaults to 3
- thickness (int): Link thickness for visualization. Defaults to 1
- kpt_thr (float): The threshold to visualize the keypoints.
- Defaults to 0.3
- vis_out_dir (str, optional): directory to save visualization
- results w/o predictions. If left as empty, no file will
- be saved. Defaults to ''.
-
- Returns:
- List[np.ndarray]: Visualization results.
- """
- window_name = ''
- if self.inferencer._video_input:
- window_name = self.inferencer.video_info['name']
-
- return self.inferencer.visualize(
- inputs, preds, window_name=window_name, **kwargs)
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Dict, List, Optional, Sequence, Union
+
+import numpy as np
+import torch
+from mmengine.config import Config, ConfigDict
+from mmengine.infer.infer import ModelType
+from mmengine.structures import InstanceData
+
+from .base_mmpose_inferencer import BaseMMPoseInferencer
+from .pose2d_inferencer import Pose2DInferencer
+from .pose3d_inferencer import Pose3DInferencer
+
+InstanceList = List[InstanceData]
+InputType = Union[str, np.ndarray]
+InputsType = Union[InputType, Sequence[InputType]]
+PredType = Union[InstanceData, InstanceList]
+ImgType = Union[np.ndarray, Sequence[np.ndarray]]
+ConfigType = Union[Config, ConfigDict]
+ResType = Union[Dict, List[Dict], InstanceData, List[InstanceData]]
+
+
+class MMPoseInferencer(BaseMMPoseInferencer):
+ """MMPose Inferencer. It's a unified inferencer interface for pose
+ estimation task, currently including: Pose2D. and it can be used to perform
+ 2D keypoint detection.
+
+ Args:
+ pose2d (str, optional): Pretrained 2D pose estimation algorithm.
+ It's the path to the config file or the model name defined in
+ metafile. For example, it could be:
+
+ - model alias, e.g. ``'body'``,
+ - config name, e.g. ``'simcc_res50_8xb64-210e_coco-256x192'``,
+ - config path
+
+ Defaults to ``None``.
+ pose2d_weights (str, optional): Path to the custom checkpoint file of
+ the selected pose2d model. If it is not specified and "pose2d" is
+ a model name of metafile, the weights will be loaded from
+ metafile. Defaults to None.
+ device (str, optional): Device to run inference. If None, the
+ available device will be automatically used. Defaults to None.
+ scope (str, optional): The scope of the model. Defaults to "mmpose".
+ det_model(str, optional): Config path or alias of detection model.
+ Defaults to None.
+ det_weights(str, optional): Path to the checkpoints of detection
+ model. Defaults to None.
+ det_cat_ids(int or list[int], optional): Category id for
+ detection model. Defaults to None.
+ output_heatmaps (bool, optional): Flag to visualize predicted
+ heatmaps. If set to None, the default setting from the model
+ config will be used. Default is None.
+ """
+
+ preprocess_kwargs: set = {
+ 'bbox_thr', 'nms_thr', 'bboxes', 'use_oks_tracking', 'tracking_thr',
+ 'norm_pose_2d'
+ }
+ forward_kwargs: set = {'rebase_keypoint_height'}
+ visualize_kwargs: set = {
+ 'return_vis', 'show', 'wait_time', 'draw_bbox', 'radius', 'thickness',
+ 'kpt_thr', 'vis_out_dir', 'skeleton_style', 'draw_heatmap',
+ 'black_background'
+ }
+ postprocess_kwargs: set = {'pred_out_dir'}
+
+ def __init__(self,
+ pose2d: Optional[str] = None,
+ pose2d_weights: Optional[str] = None,
+ pose3d: Optional[str] = None,
+ pose3d_weights: Optional[str] = None,
+ device: Optional[str] = None,
+ scope: str = 'mmpose',
+ det_model: Optional[Union[ModelType, str]] = None,
+ det_weights: Optional[str] = None,
+ det_cat_ids: Optional[Union[int, List]] = None) -> None:
+
+ self.visualizer = None
+ if pose3d is not None:
+ self.inferencer = Pose3DInferencer(pose3d, pose3d_weights, pose2d,
+ pose2d_weights, device, scope,
+ det_model, det_weights,
+ det_cat_ids)
+ elif pose2d is not None:
+ self.inferencer = Pose2DInferencer(pose2d, pose2d_weights, device,
+ scope, det_model, det_weights,
+ det_cat_ids)
+ else:
+ raise ValueError('Either 2d or 3d pose estimation algorithm '
+ 'should be provided.')
+
+ def preprocess(self, inputs: InputsType, batch_size: int = 1, **kwargs):
+ """Process the inputs into a model-feedable format.
+
+ Args:
+ inputs (InputsType): Inputs given by user.
+ batch_size (int): batch size. Defaults to 1.
+
+ Yields:
+ Any: Data processed by the ``pipeline`` and ``collate_fn``.
+ List[str or np.ndarray]: List of original inputs in the batch
+ """
+
+ for i, input in enumerate(inputs):
+ data_batch = {}
+ data_infos = self.inferencer.preprocess_single(
+ input, index=i, **kwargs)
+ data_batch = self.inferencer.collate_fn(data_infos)
+ # only supports inference with batch size 1
+ yield data_batch, [input]
+
+ @torch.no_grad()
+ def forward(self, inputs: InputType, **forward_kwargs) -> PredType:
+ """Forward the inputs to the model.
+
+ Args:
+ inputs (InputsType): The inputs to be forwarded.
+
+ Returns:
+ Dict: The prediction results. Possibly with keys "pose2d".
+ """
+ return self.inferencer.forward(inputs, **forward_kwargs)
+
+ def __call__(
+ self,
+ inputs: InputsType,
+ return_datasample: bool = False,
+ batch_size: int = 1,
+ out_dir: Optional[str] = None,
+ **kwargs,
+ ) -> dict:
+ """Call the inferencer.
+
+ Args:
+ inputs (InputsType): Inputs for the inferencer.
+ return_datasample (bool): Whether to return results as
+ :obj:`BaseDataElement`. Defaults to False.
+ batch_size (int): Batch size. Defaults to 1.
+ out_dir (str, optional): directory to save visualization
+ results and predictions. Will be overoden if vis_out_dir or
+ pred_out_dir are given. Defaults to None
+ **kwargs: Key words arguments passed to :meth:`preprocess`,
+ :meth:`forward`, :meth:`visualize` and :meth:`postprocess`.
+ Each key in kwargs should be in the corresponding set of
+ ``preprocess_kwargs``, ``forward_kwargs``,
+ ``visualize_kwargs`` and ``postprocess_kwargs``.
+
+ Returns:
+ dict: Inference and visualization results.
+ """
+ if out_dir is not None:
+ if 'vis_out_dir' not in kwargs:
+ kwargs['vis_out_dir'] = f'{out_dir}/visualizations'
+ if 'pred_out_dir' not in kwargs:
+ kwargs['pred_out_dir'] = f'{out_dir}/predictions'
+
+ kwargs = {
+ key: value
+ for key, value in kwargs.items()
+ if key in set.union(self.inferencer.preprocess_kwargs,
+ self.inferencer.forward_kwargs,
+ self.inferencer.visualize_kwargs,
+ self.inferencer.postprocess_kwargs)
+ }
+ (
+ preprocess_kwargs,
+ forward_kwargs,
+ visualize_kwargs,
+ postprocess_kwargs,
+ ) = self._dispatch_kwargs(**kwargs)
+
+ self.inferencer.update_model_visualizer_settings(**kwargs)
+
+ # preprocessing
+ if isinstance(inputs, str) and inputs.startswith('webcam'):
+ inputs = self.inferencer._get_webcam_inputs(inputs)
+ batch_size = 1
+ if not visualize_kwargs.get('show', False):
+ warnings.warn('The display mode is closed when using webcam '
+ 'input. It will be turned on automatically.')
+ visualize_kwargs['show'] = True
+ else:
+ inputs = self.inferencer._inputs_to_list(inputs)
+ self._video_input = self.inferencer._video_input
+ if self._video_input:
+ self.video_info = self.inferencer.video_info
+
+ inputs = self.preprocess(
+ inputs, batch_size=batch_size, **preprocess_kwargs)
+
+ # forward
+ if 'bbox_thr' in self.inferencer.forward_kwargs:
+ forward_kwargs['bbox_thr'] = preprocess_kwargs.get('bbox_thr', -1)
+
+ preds = []
+
+ for proc_inputs, ori_inputs in inputs:
+ preds = self.forward(proc_inputs, **forward_kwargs)
+
+ visualization = self.visualize(ori_inputs, preds,
+ **visualize_kwargs)
+ results = self.postprocess(preds, visualization, return_datasample,
+ **postprocess_kwargs)
+ yield results
+
+ if self._video_input:
+ self._finalize_video_processing(
+ postprocess_kwargs.get('pred_out_dir', ''))
+
+ def visualize(self, inputs: InputsType, preds: PredType,
+ **kwargs) -> List[np.ndarray]:
+ """Visualize predictions.
+
+ Args:
+ inputs (list): Inputs preprocessed by :meth:`_inputs_to_list`.
+ preds (Any): Predictions of the model.
+ return_vis (bool): Whether to return images with predicted results.
+ show (bool): Whether to display the image in a popup window.
+ Defaults to False.
+ show_interval (int): The interval of show (s). Defaults to 0
+ radius (int): Keypoint radius for visualization. Defaults to 3
+ thickness (int): Link thickness for visualization. Defaults to 1
+ kpt_thr (float): The threshold to visualize the keypoints.
+ Defaults to 0.3
+ vis_out_dir (str, optional): directory to save visualization
+ results w/o predictions. If left as empty, no file will
+ be saved. Defaults to ''.
+
+ Returns:
+ List[np.ndarray]: Visualization results.
+ """
+ window_name = ''
+ if self.inferencer._video_input:
+ window_name = self.inferencer.video_info['name']
+
+ return self.inferencer.visualize(
+ inputs, preds, window_name=window_name, **kwargs)
diff --git a/mmpose/apis/inferencers/pose2d_inferencer.py b/mmpose/apis/inferencers/pose2d_inferencer.py
index 3f1f20fdc0..90530dbc02 100644
--- a/mmpose/apis/inferencers/pose2d_inferencer.py
+++ b/mmpose/apis/inferencers/pose2d_inferencer.py
@@ -1,327 +1,327 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os
-import warnings
-from typing import Dict, List, Optional, Sequence, Tuple, Union
-
-import mmcv
-import numpy as np
-import torch
-from mmengine.config import Config, ConfigDict
-from mmengine.infer.infer import ModelType
-from mmengine.model import revert_sync_batchnorm
-from mmengine.registry import init_default_scope
-from mmengine.structures import InstanceData
-
-from mmpose.evaluation.functional import nms
-from mmpose.registry import DATASETS, INFERENCERS
-from mmpose.structures import merge_data_samples
-from .base_mmpose_inferencer import BaseMMPoseInferencer
-from .utils import default_det_models
-
-try:
- from mmdet.apis.det_inferencer import DetInferencer
- has_mmdet = True
-except (ImportError, ModuleNotFoundError):
- has_mmdet = False
-
-InstanceList = List[InstanceData]
-InputType = Union[str, np.ndarray]
-InputsType = Union[InputType, Sequence[InputType]]
-PredType = Union[InstanceData, InstanceList]
-ImgType = Union[np.ndarray, Sequence[np.ndarray]]
-ConfigType = Union[Config, ConfigDict]
-ResType = Union[Dict, List[Dict], InstanceData, List[InstanceData]]
-
-
-@INFERENCERS.register_module(name='pose-estimation')
-@INFERENCERS.register_module()
-class Pose2DInferencer(BaseMMPoseInferencer):
- """The inferencer for 2D pose estimation.
-
- Args:
- model (str, optional): Pretrained 2D pose estimation algorithm.
- It's the path to the config file or the model name defined in
- metafile. For example, it could be:
-
- - model alias, e.g. ``'body'``,
- - config name, e.g. ``'simcc_res50_8xb64-210e_coco-256x192'``,
- - config path
-
- Defaults to ``None``.
- weights (str, optional): Path to the checkpoint. If it is not
- specified and "model" is a model name of metafile, the weights
- will be loaded from metafile. Defaults to None.
- device (str, optional): Device to run inference. If None, the
- available device will be automatically used. Defaults to None.
- scope (str, optional): The scope of the model. Defaults to "mmpose".
- det_model (str, optional): Config path or alias of detection model.
- Defaults to None.
- det_weights (str, optional): Path to the checkpoints of detection
- model. Defaults to None.
- det_cat_ids (int or list[int], optional): Category id for
- detection model. Defaults to None.
- """
-
- preprocess_kwargs: set = {'bbox_thr', 'nms_thr', 'bboxes'}
- forward_kwargs: set = {'merge_results'}
- visualize_kwargs: set = {
- 'return_vis',
- 'show',
- 'wait_time',
- 'draw_bbox',
- 'radius',
- 'thickness',
- 'kpt_thr',
- 'vis_out_dir',
- 'skeleton_style',
- 'draw_heatmap',
- 'black_background',
- }
- postprocess_kwargs: set = {'pred_out_dir'}
-
- def __init__(self,
- model: Union[ModelType, str],
- weights: Optional[str] = None,
- device: Optional[str] = None,
- scope: Optional[str] = 'mmpose',
- det_model: Optional[Union[ModelType, str]] = None,
- det_weights: Optional[str] = None,
- det_cat_ids: Optional[Union[int, Tuple]] = None) -> None:
-
- init_default_scope(scope)
- super().__init__(
- model=model, weights=weights, device=device, scope=scope)
- self.model = revert_sync_batchnorm(self.model)
-
- # assign dataset metainfo to self.visualizer
- self.visualizer.set_dataset_meta(self.model.dataset_meta)
-
- # initialize detector for top-down models
- if self.cfg.data_mode == 'topdown':
- object_type = DATASETS.get(self.cfg.dataset_type).__module__.split(
- 'datasets.')[-1].split('.')[0].lower()
-
- if det_model in ('whole_image', 'whole-image') or \
- (det_model is None and
- object_type not in default_det_models):
- self.detector = None
-
- else:
- det_scope = 'mmdet'
- if det_model is None:
- det_info = default_det_models[object_type]
- det_model, det_weights, det_cat_ids = det_info[
- 'model'], det_info['weights'], det_info['cat_ids']
- elif os.path.exists(det_model):
- det_cfg = Config.fromfile(det_model)
- det_scope = det_cfg.default_scope
-
- if has_mmdet:
- self.detector = DetInferencer(
- det_model, det_weights, device=device, scope=det_scope)
- else:
- raise RuntimeError(
- 'MMDetection (v3.0.0 or above) is required to build '
- 'inferencers for top-down pose estimation models.')
-
- if isinstance(det_cat_ids, (tuple, list)):
- self.det_cat_ids = det_cat_ids
- else:
- self.det_cat_ids = (det_cat_ids, )
-
- self._video_input = False
-
- def update_model_visualizer_settings(self,
- draw_heatmap: bool = False,
- skeleton_style: str = 'mmpose',
- **kwargs) -> None:
- """Update the settings of models and visualizer according to inference
- arguments.
-
- Args:
- draw_heatmaps (bool, optional): Flag to visualize predicted
- heatmaps. If not provided, it defaults to False.
- skeleton_style (str, optional): Skeleton style selection. Valid
- options are 'mmpose' and 'openpose'. Defaults to 'mmpose'.
- """
- self.model.test_cfg['output_heatmaps'] = draw_heatmap
-
- if skeleton_style not in ['mmpose', 'openpose']:
- raise ValueError('`skeleton_style` must be either \'mmpose\' '
- 'or \'openpose\'')
-
- if skeleton_style == 'openpose':
- self.visualizer.set_dataset_meta(self.model.dataset_meta,
- skeleton_style)
-
- def preprocess_single(self,
- input: InputType,
- index: int,
- bbox_thr: float = 0.3,
- nms_thr: float = 0.3,
- bboxes: Union[List[List], List[np.ndarray],
- np.ndarray] = []):
- """Process a single input into a model-feedable format.
-
- Args:
- input (InputType): Input given by user.
- index (int): index of the input
- bbox_thr (float): threshold for bounding box detection.
- Defaults to 0.3.
- nms_thr (float): IoU threshold for bounding box NMS.
- Defaults to 0.3.
-
- Yields:
- Any: Data processed by the ``pipeline`` and ``collate_fn``.
- """
-
- if isinstance(input, str):
- data_info = dict(img_path=input)
- else:
- data_info = dict(img=input, img_path=f'{index}.jpg'.rjust(10, '0'))
- data_info.update(self.model.dataset_meta)
-
- if self.cfg.data_mode == 'topdown':
- if self.detector is not None:
- det_results = self.detector(
- input, return_datasample=True)['predictions']
- pred_instance = det_results[0].pred_instances.cpu().numpy()
- bboxes = np.concatenate(
- (pred_instance.bboxes, pred_instance.scores[:, None]),
- axis=1)
-
- label_mask = np.zeros(len(bboxes), dtype=np.uint8)
- for cat_id in self.det_cat_ids:
- label_mask = np.logical_or(label_mask,
- pred_instance.labels == cat_id)
-
- bboxes = bboxes[np.logical_and(
- label_mask, pred_instance.scores > bbox_thr)]
- bboxes = bboxes[nms(bboxes, nms_thr)]
-
- data_infos = []
- if len(bboxes) > 0:
- for bbox in bboxes:
- inst = data_info.copy()
- inst['bbox'] = bbox[None, :4]
- inst['bbox_score'] = bbox[4:5]
- data_infos.append(self.pipeline(inst))
- else:
- inst = data_info.copy()
-
- # get bbox from the image size
- if isinstance(input, str):
- input = mmcv.imread(input)
- h, w = input.shape[:2]
-
- inst['bbox'] = np.array([[0, 0, w, h]], dtype=np.float32)
- inst['bbox_score'] = np.ones(1, dtype=np.float32)
- data_infos.append(self.pipeline(inst))
-
- else: # bottom-up
- data_infos = [self.pipeline(data_info)]
-
- return data_infos
-
- @torch.no_grad()
- def forward(self,
- inputs: Union[dict, tuple],
- merge_results: bool = True,
- bbox_thr: float = -1):
- """Performs a forward pass through the model.
-
- Args:
- inputs (Union[dict, tuple]): The input data to be processed. Can
- be either a dictionary or a tuple.
- merge_results (bool, optional): Whether to merge data samples,
- default to True. This is only applicable when the data_mode
- is 'topdown'.
- bbox_thr (float, optional): A threshold for the bounding box
- scores. Bounding boxes with scores greater than this value
- will be retained. Default value is -1 which retains all
- bounding boxes.
-
- Returns:
- A list of data samples with prediction instances.
- """
- data_samples = self.model.test_step(inputs)
- if self.cfg.data_mode == 'topdown' and merge_results:
- data_samples = [merge_data_samples(data_samples)]
- if bbox_thr > 0:
- for ds in data_samples:
- if 'bbox_scores' in ds.pred_instances:
- ds.pred_instances = ds.pred_instances[
- ds.pred_instances.bbox_scores > bbox_thr]
- return data_samples
-
- def __call__(
- self,
- inputs: InputsType,
- return_datasample: bool = False,
- batch_size: int = 1,
- out_dir: Optional[str] = None,
- **kwargs,
- ) -> dict:
- """Call the inferencer.
-
- Args:
- inputs (InputsType): Inputs for the inferencer.
- return_datasample (bool): Whether to return results as
- :obj:`BaseDataElement`. Defaults to False.
- batch_size (int): Batch size. Defaults to 1.
- out_dir (str, optional): directory to save visualization
- results and predictions. Will be overoden if vis_out_dir or
- pred_out_dir are given. Defaults to None
- **kwargs: Key words arguments passed to :meth:`preprocess`,
- :meth:`forward`, :meth:`visualize` and :meth:`postprocess`.
- Each key in kwargs should be in the corresponding set of
- ``preprocess_kwargs``, ``forward_kwargs``,
- ``visualize_kwargs`` and ``postprocess_kwargs``.
-
- Returns:
- dict: Inference and visualization results.
- """
- if out_dir is not None:
- if 'vis_out_dir' not in kwargs:
- kwargs['vis_out_dir'] = f'{out_dir}/visualizations'
- if 'pred_out_dir' not in kwargs:
- kwargs['pred_out_dir'] = f'{out_dir}/predictions'
-
- (
- preprocess_kwargs,
- forward_kwargs,
- visualize_kwargs,
- postprocess_kwargs,
- ) = self._dispatch_kwargs(**kwargs)
-
- self.update_model_visualizer_settings(**kwargs)
-
- # preprocessing
- if isinstance(inputs, str) and inputs.startswith('webcam'):
- inputs = self._get_webcam_inputs(inputs)
- batch_size = 1
- if not visualize_kwargs.get('show', False):
- warnings.warn('The display mode is closed when using webcam '
- 'input. It will be turned on automatically.')
- visualize_kwargs['show'] = True
- else:
- inputs = self._inputs_to_list(inputs)
-
- forward_kwargs['bbox_thr'] = preprocess_kwargs.get('bbox_thr', -1)
- inputs = self.preprocess(
- inputs, batch_size=batch_size, **preprocess_kwargs)
-
- preds = []
-
- for proc_inputs, ori_inputs in inputs:
- preds = self.forward(proc_inputs, **forward_kwargs)
-
- visualization = self.visualize(ori_inputs, preds,
- **visualize_kwargs)
- results = self.postprocess(preds, visualization, return_datasample,
- **postprocess_kwargs)
- yield results
-
- if self._video_input:
- self._finalize_video_processing(
- postprocess_kwargs.get('pred_out_dir', ''))
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import warnings
+from typing import Dict, List, Optional, Sequence, Tuple, Union
+
+import mmcv
+import numpy as np
+import torch
+from mmengine.config import Config, ConfigDict
+from mmengine.infer.infer import ModelType
+from mmengine.model import revert_sync_batchnorm
+from mmengine.registry import init_default_scope
+from mmengine.structures import InstanceData
+
+from mmpose.evaluation.functional import nms
+from mmpose.registry import DATASETS, INFERENCERS
+from mmpose.structures import merge_data_samples
+from .base_mmpose_inferencer import BaseMMPoseInferencer
+from .utils import default_det_models
+
+try:
+ from mmdet.apis.det_inferencer import DetInferencer
+ has_mmdet = True
+except (ImportError, ModuleNotFoundError):
+ has_mmdet = False
+
+InstanceList = List[InstanceData]
+InputType = Union[str, np.ndarray]
+InputsType = Union[InputType, Sequence[InputType]]
+PredType = Union[InstanceData, InstanceList]
+ImgType = Union[np.ndarray, Sequence[np.ndarray]]
+ConfigType = Union[Config, ConfigDict]
+ResType = Union[Dict, List[Dict], InstanceData, List[InstanceData]]
+
+
+@INFERENCERS.register_module(name='pose-estimation')
+@INFERENCERS.register_module()
+class Pose2DInferencer(BaseMMPoseInferencer):
+ """The inferencer for 2D pose estimation.
+
+ Args:
+ model (str, optional): Pretrained 2D pose estimation algorithm.
+ It's the path to the config file or the model name defined in
+ metafile. For example, it could be:
+
+ - model alias, e.g. ``'body'``,
+ - config name, e.g. ``'simcc_res50_8xb64-210e_coco-256x192'``,
+ - config path
+
+ Defaults to ``None``.
+ weights (str, optional): Path to the checkpoint. If it is not
+ specified and "model" is a model name of metafile, the weights
+ will be loaded from metafile. Defaults to None.
+ device (str, optional): Device to run inference. If None, the
+ available device will be automatically used. Defaults to None.
+ scope (str, optional): The scope of the model. Defaults to "mmpose".
+ det_model (str, optional): Config path or alias of detection model.
+ Defaults to None.
+ det_weights (str, optional): Path to the checkpoints of detection
+ model. Defaults to None.
+ det_cat_ids (int or list[int], optional): Category id for
+ detection model. Defaults to None.
+ """
+
+ preprocess_kwargs: set = {'bbox_thr', 'nms_thr', 'bboxes'}
+ forward_kwargs: set = {'merge_results'}
+ visualize_kwargs: set = {
+ 'return_vis',
+ 'show',
+ 'wait_time',
+ 'draw_bbox',
+ 'radius',
+ 'thickness',
+ 'kpt_thr',
+ 'vis_out_dir',
+ 'skeleton_style',
+ 'draw_heatmap',
+ 'black_background',
+ }
+ postprocess_kwargs: set = {'pred_out_dir'}
+
+ def __init__(self,
+ model: Union[ModelType, str],
+ weights: Optional[str] = None,
+ device: Optional[str] = None,
+ scope: Optional[str] = 'mmpose',
+ det_model: Optional[Union[ModelType, str]] = None,
+ det_weights: Optional[str] = None,
+ det_cat_ids: Optional[Union[int, Tuple]] = None) -> None:
+
+ init_default_scope(scope)
+ super().__init__(
+ model=model, weights=weights, device=device, scope=scope)
+ self.model = revert_sync_batchnorm(self.model)
+
+ # assign dataset metainfo to self.visualizer
+ self.visualizer.set_dataset_meta(self.model.dataset_meta)
+
+ # initialize detector for top-down models
+ if self.cfg.data_mode == 'topdown':
+ object_type = DATASETS.get(self.cfg.dataset_type).__module__.split(
+ 'datasets.')[-1].split('.')[0].lower()
+
+ if det_model in ('whole_image', 'whole-image') or \
+ (det_model is None and
+ object_type not in default_det_models):
+ self.detector = None
+
+ else:
+ det_scope = 'mmdet'
+ if det_model is None:
+ det_info = default_det_models[object_type]
+ det_model, det_weights, det_cat_ids = det_info[
+ 'model'], det_info['weights'], det_info['cat_ids']
+ elif os.path.exists(det_model):
+ det_cfg = Config.fromfile(det_model)
+ det_scope = det_cfg.default_scope
+
+ if has_mmdet:
+ self.detector = DetInferencer(
+ det_model, det_weights, device=device, scope=det_scope)
+ else:
+ raise RuntimeError(
+ 'MMDetection (v3.0.0 or above) is required to build '
+ 'inferencers for top-down pose estimation models.')
+
+ if isinstance(det_cat_ids, (tuple, list)):
+ self.det_cat_ids = det_cat_ids
+ else:
+ self.det_cat_ids = (det_cat_ids, )
+
+ self._video_input = False
+
+ def update_model_visualizer_settings(self,
+ draw_heatmap: bool = False,
+ skeleton_style: str = 'mmpose',
+ **kwargs) -> None:
+ """Update the settings of models and visualizer according to inference
+ arguments.
+
+ Args:
+ draw_heatmaps (bool, optional): Flag to visualize predicted
+ heatmaps. If not provided, it defaults to False.
+ skeleton_style (str, optional): Skeleton style selection. Valid
+ options are 'mmpose' and 'openpose'. Defaults to 'mmpose'.
+ """
+ self.model.test_cfg['output_heatmaps'] = draw_heatmap
+
+ if skeleton_style not in ['mmpose', 'openpose']:
+ raise ValueError('`skeleton_style` must be either \'mmpose\' '
+ 'or \'openpose\'')
+
+ if skeleton_style == 'openpose':
+ self.visualizer.set_dataset_meta(self.model.dataset_meta,
+ skeleton_style)
+
+ def preprocess_single(self,
+ input: InputType,
+ index: int,
+ bbox_thr: float = 0.3,
+ nms_thr: float = 0.3,
+ bboxes: Union[List[List], List[np.ndarray],
+ np.ndarray] = []):
+ """Process a single input into a model-feedable format.
+
+ Args:
+ input (InputType): Input given by user.
+ index (int): index of the input
+ bbox_thr (float): threshold for bounding box detection.
+ Defaults to 0.3.
+ nms_thr (float): IoU threshold for bounding box NMS.
+ Defaults to 0.3.
+
+ Yields:
+ Any: Data processed by the ``pipeline`` and ``collate_fn``.
+ """
+
+ if isinstance(input, str):
+ data_info = dict(img_path=input)
+ else:
+ data_info = dict(img=input, img_path=f'{index}.jpg'.rjust(10, '0'))
+ data_info.update(self.model.dataset_meta)
+
+ if self.cfg.data_mode == 'topdown':
+ if self.detector is not None:
+ det_results = self.detector(
+ input, return_datasample=True)['predictions']
+ pred_instance = det_results[0].pred_instances.cpu().numpy()
+ bboxes = np.concatenate(
+ (pred_instance.bboxes, pred_instance.scores[:, None]),
+ axis=1)
+
+ label_mask = np.zeros(len(bboxes), dtype=np.uint8)
+ for cat_id in self.det_cat_ids:
+ label_mask = np.logical_or(label_mask,
+ pred_instance.labels == cat_id)
+
+ bboxes = bboxes[np.logical_and(
+ label_mask, pred_instance.scores > bbox_thr)]
+ bboxes = bboxes[nms(bboxes, nms_thr)]
+
+ data_infos = []
+ if len(bboxes) > 0:
+ for bbox in bboxes:
+ inst = data_info.copy()
+ inst['bbox'] = bbox[None, :4]
+ inst['bbox_score'] = bbox[4:5]
+ data_infos.append(self.pipeline(inst))
+ else:
+ inst = data_info.copy()
+
+ # get bbox from the image size
+ if isinstance(input, str):
+ input = mmcv.imread(input)
+ h, w = input.shape[:2]
+
+ inst['bbox'] = np.array([[0, 0, w, h]], dtype=np.float32)
+ inst['bbox_score'] = np.ones(1, dtype=np.float32)
+ data_infos.append(self.pipeline(inst))
+
+ else: # bottom-up
+ data_infos = [self.pipeline(data_info)]
+
+ return data_infos
+
+ @torch.no_grad()
+ def forward(self,
+ inputs: Union[dict, tuple],
+ merge_results: bool = True,
+ bbox_thr: float = -1):
+ """Performs a forward pass through the model.
+
+ Args:
+ inputs (Union[dict, tuple]): The input data to be processed. Can
+ be either a dictionary or a tuple.
+ merge_results (bool, optional): Whether to merge data samples,
+ default to True. This is only applicable when the data_mode
+ is 'topdown'.
+ bbox_thr (float, optional): A threshold for the bounding box
+ scores. Bounding boxes with scores greater than this value
+ will be retained. Default value is -1 which retains all
+ bounding boxes.
+
+ Returns:
+ A list of data samples with prediction instances.
+ """
+ data_samples = self.model.test_step(inputs)
+ if self.cfg.data_mode == 'topdown' and merge_results:
+ data_samples = [merge_data_samples(data_samples)]
+ if bbox_thr > 0:
+ for ds in data_samples:
+ if 'bbox_scores' in ds.pred_instances:
+ ds.pred_instances = ds.pred_instances[
+ ds.pred_instances.bbox_scores > bbox_thr]
+ return data_samples
+
+ def __call__(
+ self,
+ inputs: InputsType,
+ return_datasample: bool = False,
+ batch_size: int = 1,
+ out_dir: Optional[str] = None,
+ **kwargs,
+ ) -> dict:
+ """Call the inferencer.
+
+ Args:
+ inputs (InputsType): Inputs for the inferencer.
+ return_datasample (bool): Whether to return results as
+ :obj:`BaseDataElement`. Defaults to False.
+ batch_size (int): Batch size. Defaults to 1.
+ out_dir (str, optional): directory to save visualization
+ results and predictions. Will be overoden if vis_out_dir or
+ pred_out_dir are given. Defaults to None
+ **kwargs: Key words arguments passed to :meth:`preprocess`,
+ :meth:`forward`, :meth:`visualize` and :meth:`postprocess`.
+ Each key in kwargs should be in the corresponding set of
+ ``preprocess_kwargs``, ``forward_kwargs``,
+ ``visualize_kwargs`` and ``postprocess_kwargs``.
+
+ Returns:
+ dict: Inference and visualization results.
+ """
+ if out_dir is not None:
+ if 'vis_out_dir' not in kwargs:
+ kwargs['vis_out_dir'] = f'{out_dir}/visualizations'
+ if 'pred_out_dir' not in kwargs:
+ kwargs['pred_out_dir'] = f'{out_dir}/predictions'
+
+ (
+ preprocess_kwargs,
+ forward_kwargs,
+ visualize_kwargs,
+ postprocess_kwargs,
+ ) = self._dispatch_kwargs(**kwargs)
+
+ self.update_model_visualizer_settings(**kwargs)
+
+ # preprocessing
+ if isinstance(inputs, str) and inputs.startswith('webcam'):
+ inputs = self._get_webcam_inputs(inputs)
+ batch_size = 1
+ if not visualize_kwargs.get('show', False):
+ warnings.warn('The display mode is closed when using webcam '
+ 'input. It will be turned on automatically.')
+ visualize_kwargs['show'] = True
+ else:
+ inputs = self._inputs_to_list(inputs)
+
+ forward_kwargs['bbox_thr'] = preprocess_kwargs.get('bbox_thr', -1)
+ inputs = self.preprocess(
+ inputs, batch_size=batch_size, **preprocess_kwargs)
+
+ preds = []
+
+ for proc_inputs, ori_inputs in inputs:
+ preds = self.forward(proc_inputs, **forward_kwargs)
+
+ visualization = self.visualize(ori_inputs, preds,
+ **visualize_kwargs)
+ results = self.postprocess(preds, visualization, return_datasample,
+ **postprocess_kwargs)
+ yield results
+
+ if self._video_input:
+ self._finalize_video_processing(
+ postprocess_kwargs.get('pred_out_dir', ''))
diff --git a/mmpose/apis/inferencers/pose3d_inferencer.py b/mmpose/apis/inferencers/pose3d_inferencer.py
index 0fe66ac72b..a2eb8f3935 100644
--- a/mmpose/apis/inferencers/pose3d_inferencer.py
+++ b/mmpose/apis/inferencers/pose3d_inferencer.py
@@ -1,518 +1,518 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os
-import warnings
-from collections import defaultdict
-from functools import partial
-from typing import Callable, Dict, List, Optional, Sequence, Tuple, Union
-
-import cv2
-import mmcv
-import numpy as np
-import torch
-from mmengine.config import Config, ConfigDict
-from mmengine.fileio import join_path
-from mmengine.infer.infer import ModelType
-from mmengine.model import revert_sync_batchnorm
-from mmengine.registry import init_default_scope
-from mmengine.structures import InstanceData
-from mmengine.utils import mkdir_or_exist
-
-from mmpose.apis import (_track_by_iou, _track_by_oks, collate_pose_sequence,
- convert_keypoint_definition, extract_pose_sequence)
-from mmpose.registry import INFERENCERS
-from mmpose.structures import PoseDataSample, merge_data_samples
-from .base_mmpose_inferencer import BaseMMPoseInferencer
-from .pose2d_inferencer import Pose2DInferencer
-
-InstanceList = List[InstanceData]
-InputType = Union[str, np.ndarray]
-InputsType = Union[InputType, Sequence[InputType]]
-PredType = Union[InstanceData, InstanceList]
-ImgType = Union[np.ndarray, Sequence[np.ndarray]]
-ConfigType = Union[Config, ConfigDict]
-ResType = Union[Dict, List[Dict], InstanceData, List[InstanceData]]
-
-
-@INFERENCERS.register_module(name='pose-estimation-3d')
-@INFERENCERS.register_module()
-class Pose3DInferencer(BaseMMPoseInferencer):
- """The inferencer for 3D pose estimation.
-
- Args:
- model (str, optional): Pretrained 2D pose estimation algorithm.
- It's the path to the config file or the model name defined in
- metafile. For example, it could be:
-
- - model alias, e.g. ``'body'``,
- - config name, e.g. ``'simcc_res50_8xb64-210e_coco-256x192'``,
- - config path
-
- Defaults to ``None``.
- weights (str, optional): Path to the checkpoint. If it is not
- specified and "model" is a model name of metafile, the weights
- will be loaded from metafile. Defaults to None.
- device (str, optional): Device to run inference. If None, the
- available device will be automatically used. Defaults to None.
- scope (str, optional): The scope of the model. Defaults to "mmpose".
- det_model (str, optional): Config path or alias of detection model.
- Defaults to None.
- det_weights (str, optional): Path to the checkpoints of detection
- model. Defaults to None.
- det_cat_ids (int or list[int], optional): Category id for
- detection model. Defaults to None.
- output_heatmaps (bool, optional): Flag to visualize predicted
- heatmaps. If set to None, the default setting from the model
- config will be used. Default is None.
- """
-
- preprocess_kwargs: set = {
- 'bbox_thr', 'nms_thr', 'bboxes', 'use_oks_tracking', 'tracking_thr',
- 'norm_pose_2d'
- }
- forward_kwargs: set = {'rebase_keypoint_height'}
- visualize_kwargs: set = {
- 'return_vis',
- 'show',
- 'wait_time',
- 'draw_bbox',
- 'radius',
- 'thickness',
- 'kpt_thr',
- 'vis_out_dir',
- }
- postprocess_kwargs: set = {'pred_out_dir'}
-
- def __init__(self,
- model: Union[ModelType, str],
- weights: Optional[str] = None,
- pose2d_model: Optional[Union[ModelType, str]] = None,
- pose2d_weights: Optional[str] = None,
- device: Optional[str] = None,
- scope: Optional[str] = 'mmpose',
- det_model: Optional[Union[ModelType, str]] = None,
- det_weights: Optional[str] = None,
- det_cat_ids: Optional[Union[int, Tuple]] = None) -> None:
-
- init_default_scope(scope)
- super().__init__(
- model=model, weights=weights, device=device, scope=scope)
- self.model = revert_sync_batchnorm(self.model)
-
- # assign dataset metainfo to self.visualizer
- self.visualizer.set_dataset_meta(self.model.dataset_meta)
-
- # initialize 2d pose estimator
- self.pose2d_model = Pose2DInferencer(
- pose2d_model if pose2d_model else 'human', pose2d_weights, device,
- scope, det_model, det_weights, det_cat_ids)
-
- # helper functions
- self._keypoint_converter = partial(
- convert_keypoint_definition,
- pose_det_dataset=self.pose2d_model.cfg.test_dataloader.
- dataset['type'],
- pose_lift_dataset=self.cfg.test_dataloader.dataset['type'],
- )
-
- self._pose_seq_extractor = partial(
- extract_pose_sequence,
- causal=self.cfg.test_dataloader.dataset.get('causal', False),
- seq_len=self.cfg.test_dataloader.dataset.get('seq_len', 1),
- step=self.cfg.test_dataloader.dataset.get('seq_step', 1))
-
- self._video_input = False
- self._buffer = defaultdict(list)
-
- def preprocess_single(self,
- input: InputType,
- index: int,
- bbox_thr: float = 0.3,
- nms_thr: float = 0.3,
- bboxes: Union[List[List], List[np.ndarray],
- np.ndarray] = [],
- use_oks_tracking: bool = False,
- tracking_thr: float = 0.3,
- norm_pose_2d: bool = False):
- """Process a single input into a model-feedable format.
-
- Args:
- input (InputType): The input provided by the user.
- index (int): The index of the input.
- bbox_thr (float, optional): The threshold for bounding box
- detection. Defaults to 0.3.
- nms_thr (float, optional): The Intersection over Union (IoU)
- threshold for bounding box Non-Maximum Suppression (NMS).
- Defaults to 0.3.
- bboxes (Union[List[List], List[np.ndarray], np.ndarray]):
- The bounding boxes to use. Defaults to [].
- use_oks_tracking (bool, optional): A flag that indicates
- whether OKS-based tracking should be used. Defaults to False.
- tracking_thr (float, optional): The threshold for tracking.
- Defaults to 0.3.
- norm_pose_2d (bool, optional): A flag that indicates whether 2D
- pose normalization should be used. Defaults to False.
-
- Yields:
- Any: The data processed by the pipeline and collate_fn.
-
- This method first calculates 2D keypoints using the provided
- pose2d_model. The method also performs instance matching, which
- can use either OKS-based tracking or IOU-based tracking.
- """
-
- # calculate 2d keypoints
- results_pose2d = next(
- self.pose2d_model(
- input,
- bbox_thr=bbox_thr,
- nms_thr=nms_thr,
- bboxes=bboxes,
- merge_results=False,
- return_datasample=True))['predictions']
-
- for ds in results_pose2d:
- ds.pred_instances.set_field(
- (ds.pred_instances.bboxes[..., 2:] -
- ds.pred_instances.bboxes[..., :2]).prod(-1), 'areas')
-
- if not self._video_input:
- height, width = results_pose2d[0].metainfo['ori_shape']
-
- # Clear the buffer if inputs are individual images to prevent
- # carryover effects from previous images
- self._buffer.clear()
-
- else:
- height = self.video_info['height']
- width = self.video_info['width']
- img_path = results_pose2d[0].metainfo['img_path']
-
- # instance matching
- if use_oks_tracking:
- _track = partial(_track_by_oks)
- else:
- _track = _track_by_iou
-
- for result in results_pose2d:
- track_id, self._buffer['results_pose2d_last'], _ = _track(
- result, self._buffer['results_pose2d_last'], tracking_thr)
- if track_id == -1:
- pred_instances = result.pred_instances.cpu().numpy()
- keypoints = pred_instances.keypoints
- if np.count_nonzero(keypoints[:, :, 1]) >= 3:
- next_id = self._buffer.get('next_id', 0)
- result.set_field(next_id, 'track_id')
- self._buffer['next_id'] = next_id + 1
- else:
- # If the number of keypoints detected is small,
- # delete that person instance.
- result.pred_instances.keypoints[..., 1] = -10
- result.pred_instances.bboxes *= 0
- result.set_field(-1, 'track_id')
- else:
- result.set_field(track_id, 'track_id')
- self._buffer['pose2d_results'] = merge_data_samples(results_pose2d)
-
- # convert keypoints
- results_pose2d_converted = [ds.cpu().numpy() for ds in results_pose2d]
- for ds in results_pose2d_converted:
- ds.pred_instances.keypoints = self._keypoint_converter(
- ds.pred_instances.keypoints)
- self._buffer['pose_est_results_list'].append(results_pose2d_converted)
-
- # extract and pad input pose2d sequence
- pose_results_2d = self._pose_seq_extractor(
- self._buffer['pose_est_results_list'],
- frame_idx=index if self._video_input else 0)
- causal = self.cfg.test_dataloader.dataset.get('causal', False)
- target_idx = -1 if causal else len(pose_results_2d) // 2
-
- stats_info = self.model.dataset_meta.get('stats_info', {})
- bbox_center = stats_info.get('bbox_center', None)
- bbox_scale = stats_info.get('bbox_scale', None)
-
- for i, pose_res in enumerate(pose_results_2d):
- for j, data_sample in enumerate(pose_res):
- kpts = data_sample.pred_instances.keypoints
- bboxes = data_sample.pred_instances.bboxes
- keypoints = []
- for k in range(len(kpts)):
- kpt = kpts[k]
- if norm_pose_2d:
- bbox = bboxes[k]
- center = np.array([[(bbox[0] + bbox[2]) / 2,
- (bbox[1] + bbox[3]) / 2]])
- scale = max(bbox[2] - bbox[0], bbox[3] - bbox[1])
- keypoints.append((kpt[:, :2] - center) / scale *
- bbox_scale + bbox_center)
- else:
- keypoints.append(kpt[:, :2])
- pose_results_2d[i][j].pred_instances.keypoints = np.array(
- keypoints)
- pose_sequences_2d = collate_pose_sequence(pose_results_2d, True,
- target_idx)
- if not pose_sequences_2d:
- return []
-
- data_list = []
- for i, pose_seq in enumerate(pose_sequences_2d):
- data_info = dict()
-
- keypoints_2d = pose_seq.pred_instances.keypoints
- keypoints_2d = np.squeeze(
- keypoints_2d,
- axis=0) if keypoints_2d.ndim == 4 else keypoints_2d
-
- T, K, C = keypoints_2d.shape
-
- data_info['keypoints'] = keypoints_2d
- data_info['keypoints_visible'] = np.ones((
- T,
- K,
- ),
- dtype=np.float32)
- data_info['lifting_target'] = np.zeros((K, 3), dtype=np.float32)
- data_info['lifting_target_visible'] = np.ones((K, 1),
- dtype=np.float32)
- data_info['camera_param'] = dict(w=width, h=height)
-
- data_info.update(self.model.dataset_meta)
- data_info = self.pipeline(data_info)
- data_info['data_samples'].set_field(
- img_path, 'img_path', field_type='metainfo')
- data_list.append(data_info)
-
- return data_list
-
- @torch.no_grad()
- def forward(self,
- inputs: Union[dict, tuple],
- rebase_keypoint_height: bool = False):
- """Perform forward pass through the model and process the results.
-
- Args:
- inputs (Union[dict, tuple]): The inputs for the model.
- rebase_keypoint_height (bool, optional): Flag to rebase the
- height of the keypoints (z-axis). Defaults to False.
-
- Returns:
- list: A list of data samples, each containing the model's output
- results.
- """
-
- pose_lift_results = self.model.test_step(inputs)
-
- # Post-processing of pose estimation results
- pose_est_results_converted = self._buffer['pose_est_results_list'][-1]
- for idx, pose_lift_res in enumerate(pose_lift_results):
- # Update track_id from the pose estimation results
- pose_lift_res.track_id = pose_est_results_converted[idx].get(
- 'track_id', 1e4)
-
- # Invert x and z values of the keypoints
- keypoints = pose_lift_res.pred_instances.keypoints
- keypoints = keypoints[..., [0, 2, 1]]
- keypoints[..., 0] = -keypoints[..., 0]
- keypoints[..., 2] = -keypoints[..., 2]
-
- # If rebase_keypoint_height is True, adjust z-axis values
- if rebase_keypoint_height:
- keypoints[..., 2] -= np.min(
- keypoints[..., 2], axis=-1, keepdims=True)
-
- pose_lift_results[idx].pred_instances.keypoints = keypoints
-
- pose_lift_results = sorted(
- pose_lift_results, key=lambda x: x.get('track_id', 1e4))
-
- data_samples = [merge_data_samples(pose_lift_results)]
- return data_samples
-
- def __call__(
- self,
- inputs: InputsType,
- return_datasample: bool = False,
- batch_size: int = 1,
- out_dir: Optional[str] = None,
- **kwargs,
- ) -> dict:
- """Call the inferencer.
-
- Args:
- inputs (InputsType): Inputs for the inferencer.
- return_datasample (bool): Whether to return results as
- :obj:`BaseDataElement`. Defaults to False.
- batch_size (int): Batch size. Defaults to 1.
- out_dir (str, optional): directory to save visualization
- results and predictions. Will be overoden if vis_out_dir or
- pred_out_dir are given. Defaults to None
- **kwargs: Key words arguments passed to :meth:`preprocess`,
- :meth:`forward`, :meth:`visualize` and :meth:`postprocess`.
- Each key in kwargs should be in the corresponding set of
- ``preprocess_kwargs``, ``forward_kwargs``,
- ``visualize_kwargs`` and ``postprocess_kwargs``.
-
- Returns:
- dict: Inference and visualization results.
- """
- if out_dir is not None:
- if 'vis_out_dir' not in kwargs:
- kwargs['vis_out_dir'] = f'{out_dir}/visualizations'
- if 'pred_out_dir' not in kwargs:
- kwargs['pred_out_dir'] = f'{out_dir}/predictions'
-
- (
- preprocess_kwargs,
- forward_kwargs,
- visualize_kwargs,
- postprocess_kwargs,
- ) = self._dispatch_kwargs(**kwargs)
-
- self.update_model_visualizer_settings(**kwargs)
-
- # preprocessing
- if isinstance(inputs, str) and inputs.startswith('webcam'):
- inputs = self._get_webcam_inputs(inputs)
- batch_size = 1
- if not visualize_kwargs.get('show', False):
- warnings.warn('The display mode is closed when using webcam '
- 'input. It will be turned on automatically.')
- visualize_kwargs['show'] = True
- else:
- inputs = self._inputs_to_list(inputs)
-
- inputs = self.preprocess(
- inputs, batch_size=batch_size, **preprocess_kwargs)
-
- preds = []
-
- for proc_inputs, ori_inputs in inputs:
- preds = self.forward(proc_inputs, **forward_kwargs)
-
- visualization = self.visualize(ori_inputs, preds,
- **visualize_kwargs)
- results = self.postprocess(preds, visualization, return_datasample,
- **postprocess_kwargs)
- yield results
-
- if self._video_input:
- self._finalize_video_processing(
- postprocess_kwargs.get('pred_out_dir', ''))
- self._buffer.clear()
-
- def visualize(self,
- inputs: list,
- preds: List[PoseDataSample],
- return_vis: bool = False,
- show: bool = False,
- draw_bbox: bool = False,
- wait_time: float = 0,
- radius: int = 3,
- thickness: int = 1,
- kpt_thr: float = 0.3,
- vis_out_dir: str = '',
- window_name: str = '',
- window_close_event_handler: Optional[Callable] = None
- ) -> List[np.ndarray]:
- """Visualize predictions.
-
- Args:
- inputs (list): Inputs preprocessed by :meth:`_inputs_to_list`.
- preds (Any): Predictions of the model.
- return_vis (bool): Whether to return images with predicted results.
- show (bool): Whether to display the image in a popup window.
- Defaults to False.
- wait_time (float): The interval of show (ms). Defaults to 0
- draw_bbox (bool): Whether to draw the bounding boxes.
- Defaults to False
- radius (int): Keypoint radius for visualization. Defaults to 3
- thickness (int): Link thickness for visualization. Defaults to 1
- kpt_thr (float): The threshold to visualize the keypoints.
- Defaults to 0.3
- vis_out_dir (str, optional): Directory to save visualization
- results w/o predictions. If left as empty, no file will
- be saved. Defaults to ''.
- window_name (str, optional): Title of display window.
- window_close_event_handler (callable, optional):
-
- Returns:
- List[np.ndarray]: Visualization results.
- """
- if (not return_vis) and (not show) and (not vis_out_dir):
- return
-
- if getattr(self, 'visualizer', None) is None:
- raise ValueError('Visualization needs the "visualizer" term'
- 'defined in the config, but got None.')
-
- self.visualizer.radius = radius
- self.visualizer.line_width = thickness
- det_kpt_color = self.pose2d_model.visualizer.kpt_color
- det_dataset_skeleton = self.pose2d_model.visualizer.skeleton
- det_dataset_link_color = self.pose2d_model.visualizer.link_color
- self.visualizer.det_kpt_color = det_kpt_color
- self.visualizer.det_dataset_skeleton = det_dataset_skeleton
- self.visualizer.det_dataset_link_color = det_dataset_link_color
-
- results = []
-
- for single_input, pred in zip(inputs, preds):
- if isinstance(single_input, str):
- img = mmcv.imread(single_input, channel_order='rgb')
- elif isinstance(single_input, np.ndarray):
- img = mmcv.bgr2rgb(single_input)
- else:
- raise ValueError('Unsupported input type: '
- f'{type(single_input)}')
-
- # since visualization and inference utilize the same process,
- # the wait time is reduced when a video input is utilized,
- # thereby eliminating the issue of inference getting stuck.
- wait_time = 1e-5 if self._video_input else wait_time
-
- visualization = self.visualizer.add_datasample(
- window_name,
- img,
- data_sample=pred,
- det_data_sample=self._buffer['pose2d_results'],
- draw_gt=False,
- draw_bbox=draw_bbox,
- show=show,
- wait_time=wait_time,
- kpt_thr=kpt_thr)
- results.append(visualization)
-
- if vis_out_dir:
- out_img = mmcv.rgb2bgr(visualization)
- _, file_extension = os.path.splitext(vis_out_dir)
- if file_extension:
- dir_name = os.path.dirname(vis_out_dir)
- file_name = os.path.basename(vis_out_dir)
- else:
- dir_name = vis_out_dir
- file_name = None
- mkdir_or_exist(dir_name)
-
- if self._video_input:
-
- if self.video_info['writer'] is None:
- fourcc = cv2.VideoWriter_fourcc(*'mp4v')
- if file_name is None:
- file_name = os.path.basename(
- self.video_info['name'])
- out_file = join_path(dir_name, file_name)
- self.video_info['writer'] = cv2.VideoWriter(
- out_file, fourcc, self.video_info['fps'],
- (visualization.shape[1], visualization.shape[0]))
- self.video_info['writer'].write(out_img)
-
- else:
- img_name = os.path.basename(pred.metainfo['img_path'])
- file_name = file_name if file_name else img_name
- out_file = join_path(dir_name, file_name)
- mmcv.imwrite(out_img, out_file)
-
- if return_vis:
- return results
- else:
- return []
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import warnings
+from collections import defaultdict
+from functools import partial
+from typing import Callable, Dict, List, Optional, Sequence, Tuple, Union
+
+import cv2
+import mmcv
+import numpy as np
+import torch
+from mmengine.config import Config, ConfigDict
+from mmengine.fileio import join_path
+from mmengine.infer.infer import ModelType
+from mmengine.model import revert_sync_batchnorm
+from mmengine.registry import init_default_scope
+from mmengine.structures import InstanceData
+from mmengine.utils import mkdir_or_exist
+
+from mmpose.apis import (_track_by_iou, _track_by_oks, collate_pose_sequence,
+ convert_keypoint_definition, extract_pose_sequence)
+from mmpose.registry import INFERENCERS
+from mmpose.structures import PoseDataSample, merge_data_samples
+from .base_mmpose_inferencer import BaseMMPoseInferencer
+from .pose2d_inferencer import Pose2DInferencer
+
+InstanceList = List[InstanceData]
+InputType = Union[str, np.ndarray]
+InputsType = Union[InputType, Sequence[InputType]]
+PredType = Union[InstanceData, InstanceList]
+ImgType = Union[np.ndarray, Sequence[np.ndarray]]
+ConfigType = Union[Config, ConfigDict]
+ResType = Union[Dict, List[Dict], InstanceData, List[InstanceData]]
+
+
+@INFERENCERS.register_module(name='pose-estimation-3d')
+@INFERENCERS.register_module()
+class Pose3DInferencer(BaseMMPoseInferencer):
+ """The inferencer for 3D pose estimation.
+
+ Args:
+ model (str, optional): Pretrained 2D pose estimation algorithm.
+ It's the path to the config file or the model name defined in
+ metafile. For example, it could be:
+
+ - model alias, e.g. ``'body'``,
+ - config name, e.g. ``'simcc_res50_8xb64-210e_coco-256x192'``,
+ - config path
+
+ Defaults to ``None``.
+ weights (str, optional): Path to the checkpoint. If it is not
+ specified and "model" is a model name of metafile, the weights
+ will be loaded from metafile. Defaults to None.
+ device (str, optional): Device to run inference. If None, the
+ available device will be automatically used. Defaults to None.
+ scope (str, optional): The scope of the model. Defaults to "mmpose".
+ det_model (str, optional): Config path or alias of detection model.
+ Defaults to None.
+ det_weights (str, optional): Path to the checkpoints of detection
+ model. Defaults to None.
+ det_cat_ids (int or list[int], optional): Category id for
+ detection model. Defaults to None.
+ output_heatmaps (bool, optional): Flag to visualize predicted
+ heatmaps. If set to None, the default setting from the model
+ config will be used. Default is None.
+ """
+
+ preprocess_kwargs: set = {
+ 'bbox_thr', 'nms_thr', 'bboxes', 'use_oks_tracking', 'tracking_thr',
+ 'norm_pose_2d'
+ }
+ forward_kwargs: set = {'rebase_keypoint_height'}
+ visualize_kwargs: set = {
+ 'return_vis',
+ 'show',
+ 'wait_time',
+ 'draw_bbox',
+ 'radius',
+ 'thickness',
+ 'kpt_thr',
+ 'vis_out_dir',
+ }
+ postprocess_kwargs: set = {'pred_out_dir'}
+
+ def __init__(self,
+ model: Union[ModelType, str],
+ weights: Optional[str] = None,
+ pose2d_model: Optional[Union[ModelType, str]] = None,
+ pose2d_weights: Optional[str] = None,
+ device: Optional[str] = None,
+ scope: Optional[str] = 'mmpose',
+ det_model: Optional[Union[ModelType, str]] = None,
+ det_weights: Optional[str] = None,
+ det_cat_ids: Optional[Union[int, Tuple]] = None) -> None:
+
+ init_default_scope(scope)
+ super().__init__(
+ model=model, weights=weights, device=device, scope=scope)
+ self.model = revert_sync_batchnorm(self.model)
+
+ # assign dataset metainfo to self.visualizer
+ self.visualizer.set_dataset_meta(self.model.dataset_meta)
+
+ # initialize 2d pose estimator
+ self.pose2d_model = Pose2DInferencer(
+ pose2d_model if pose2d_model else 'human', pose2d_weights, device,
+ scope, det_model, det_weights, det_cat_ids)
+
+ # helper functions
+ self._keypoint_converter = partial(
+ convert_keypoint_definition,
+ pose_det_dataset=self.pose2d_model.cfg.test_dataloader.
+ dataset['type'],
+ pose_lift_dataset=self.cfg.test_dataloader.dataset['type'],
+ )
+
+ self._pose_seq_extractor = partial(
+ extract_pose_sequence,
+ causal=self.cfg.test_dataloader.dataset.get('causal', False),
+ seq_len=self.cfg.test_dataloader.dataset.get('seq_len', 1),
+ step=self.cfg.test_dataloader.dataset.get('seq_step', 1))
+
+ self._video_input = False
+ self._buffer = defaultdict(list)
+
+ def preprocess_single(self,
+ input: InputType,
+ index: int,
+ bbox_thr: float = 0.3,
+ nms_thr: float = 0.3,
+ bboxes: Union[List[List], List[np.ndarray],
+ np.ndarray] = [],
+ use_oks_tracking: bool = False,
+ tracking_thr: float = 0.3,
+ norm_pose_2d: bool = False):
+ """Process a single input into a model-feedable format.
+
+ Args:
+ input (InputType): The input provided by the user.
+ index (int): The index of the input.
+ bbox_thr (float, optional): The threshold for bounding box
+ detection. Defaults to 0.3.
+ nms_thr (float, optional): The Intersection over Union (IoU)
+ threshold for bounding box Non-Maximum Suppression (NMS).
+ Defaults to 0.3.
+ bboxes (Union[List[List], List[np.ndarray], np.ndarray]):
+ The bounding boxes to use. Defaults to [].
+ use_oks_tracking (bool, optional): A flag that indicates
+ whether OKS-based tracking should be used. Defaults to False.
+ tracking_thr (float, optional): The threshold for tracking.
+ Defaults to 0.3.
+ norm_pose_2d (bool, optional): A flag that indicates whether 2D
+ pose normalization should be used. Defaults to False.
+
+ Yields:
+ Any: The data processed by the pipeline and collate_fn.
+
+ This method first calculates 2D keypoints using the provided
+ pose2d_model. The method also performs instance matching, which
+ can use either OKS-based tracking or IOU-based tracking.
+ """
+
+ # calculate 2d keypoints
+ results_pose2d = next(
+ self.pose2d_model(
+ input,
+ bbox_thr=bbox_thr,
+ nms_thr=nms_thr,
+ bboxes=bboxes,
+ merge_results=False,
+ return_datasample=True))['predictions']
+
+ for ds in results_pose2d:
+ ds.pred_instances.set_field(
+ (ds.pred_instances.bboxes[..., 2:] -
+ ds.pred_instances.bboxes[..., :2]).prod(-1), 'areas')
+
+ if not self._video_input:
+ height, width = results_pose2d[0].metainfo['ori_shape']
+
+ # Clear the buffer if inputs are individual images to prevent
+ # carryover effects from previous images
+ self._buffer.clear()
+
+ else:
+ height = self.video_info['height']
+ width = self.video_info['width']
+ img_path = results_pose2d[0].metainfo['img_path']
+
+ # instance matching
+ if use_oks_tracking:
+ _track = partial(_track_by_oks)
+ else:
+ _track = _track_by_iou
+
+ for result in results_pose2d:
+ track_id, self._buffer['results_pose2d_last'], _ = _track(
+ result, self._buffer['results_pose2d_last'], tracking_thr)
+ if track_id == -1:
+ pred_instances = result.pred_instances.cpu().numpy()
+ keypoints = pred_instances.keypoints
+ if np.count_nonzero(keypoints[:, :, 1]) >= 3:
+ next_id = self._buffer.get('next_id', 0)
+ result.set_field(next_id, 'track_id')
+ self._buffer['next_id'] = next_id + 1
+ else:
+ # If the number of keypoints detected is small,
+ # delete that person instance.
+ result.pred_instances.keypoints[..., 1] = -10
+ result.pred_instances.bboxes *= 0
+ result.set_field(-1, 'track_id')
+ else:
+ result.set_field(track_id, 'track_id')
+ self._buffer['pose2d_results'] = merge_data_samples(results_pose2d)
+
+ # convert keypoints
+ results_pose2d_converted = [ds.cpu().numpy() for ds in results_pose2d]
+ for ds in results_pose2d_converted:
+ ds.pred_instances.keypoints = self._keypoint_converter(
+ ds.pred_instances.keypoints)
+ self._buffer['pose_est_results_list'].append(results_pose2d_converted)
+
+ # extract and pad input pose2d sequence
+ pose_results_2d = self._pose_seq_extractor(
+ self._buffer['pose_est_results_list'],
+ frame_idx=index if self._video_input else 0)
+ causal = self.cfg.test_dataloader.dataset.get('causal', False)
+ target_idx = -1 if causal else len(pose_results_2d) // 2
+
+ stats_info = self.model.dataset_meta.get('stats_info', {})
+ bbox_center = stats_info.get('bbox_center', None)
+ bbox_scale = stats_info.get('bbox_scale', None)
+
+ for i, pose_res in enumerate(pose_results_2d):
+ for j, data_sample in enumerate(pose_res):
+ kpts = data_sample.pred_instances.keypoints
+ bboxes = data_sample.pred_instances.bboxes
+ keypoints = []
+ for k in range(len(kpts)):
+ kpt = kpts[k]
+ if norm_pose_2d:
+ bbox = bboxes[k]
+ center = np.array([[(bbox[0] + bbox[2]) / 2,
+ (bbox[1] + bbox[3]) / 2]])
+ scale = max(bbox[2] - bbox[0], bbox[3] - bbox[1])
+ keypoints.append((kpt[:, :2] - center) / scale *
+ bbox_scale + bbox_center)
+ else:
+ keypoints.append(kpt[:, :2])
+ pose_results_2d[i][j].pred_instances.keypoints = np.array(
+ keypoints)
+ pose_sequences_2d = collate_pose_sequence(pose_results_2d, True,
+ target_idx)
+ if not pose_sequences_2d:
+ return []
+
+ data_list = []
+ for i, pose_seq in enumerate(pose_sequences_2d):
+ data_info = dict()
+
+ keypoints_2d = pose_seq.pred_instances.keypoints
+ keypoints_2d = np.squeeze(
+ keypoints_2d,
+ axis=0) if keypoints_2d.ndim == 4 else keypoints_2d
+
+ T, K, C = keypoints_2d.shape
+
+ data_info['keypoints'] = keypoints_2d
+ data_info['keypoints_visible'] = np.ones((
+ T,
+ K,
+ ),
+ dtype=np.float32)
+ data_info['lifting_target'] = np.zeros((K, 3), dtype=np.float32)
+ data_info['lifting_target_visible'] = np.ones((K, 1),
+ dtype=np.float32)
+ data_info['camera_param'] = dict(w=width, h=height)
+
+ data_info.update(self.model.dataset_meta)
+ data_info = self.pipeline(data_info)
+ data_info['data_samples'].set_field(
+ img_path, 'img_path', field_type='metainfo')
+ data_list.append(data_info)
+
+ return data_list
+
+ @torch.no_grad()
+ def forward(self,
+ inputs: Union[dict, tuple],
+ rebase_keypoint_height: bool = False):
+ """Perform forward pass through the model and process the results.
+
+ Args:
+ inputs (Union[dict, tuple]): The inputs for the model.
+ rebase_keypoint_height (bool, optional): Flag to rebase the
+ height of the keypoints (z-axis). Defaults to False.
+
+ Returns:
+ list: A list of data samples, each containing the model's output
+ results.
+ """
+
+ pose_lift_results = self.model.test_step(inputs)
+
+ # Post-processing of pose estimation results
+ pose_est_results_converted = self._buffer['pose_est_results_list'][-1]
+ for idx, pose_lift_res in enumerate(pose_lift_results):
+ # Update track_id from the pose estimation results
+ pose_lift_res.track_id = pose_est_results_converted[idx].get(
+ 'track_id', 1e4)
+
+ # Invert x and z values of the keypoints
+ keypoints = pose_lift_res.pred_instances.keypoints
+ keypoints = keypoints[..., [0, 2, 1]]
+ keypoints[..., 0] = -keypoints[..., 0]
+ keypoints[..., 2] = -keypoints[..., 2]
+
+ # If rebase_keypoint_height is True, adjust z-axis values
+ if rebase_keypoint_height:
+ keypoints[..., 2] -= np.min(
+ keypoints[..., 2], axis=-1, keepdims=True)
+
+ pose_lift_results[idx].pred_instances.keypoints = keypoints
+
+ pose_lift_results = sorted(
+ pose_lift_results, key=lambda x: x.get('track_id', 1e4))
+
+ data_samples = [merge_data_samples(pose_lift_results)]
+ return data_samples
+
+ def __call__(
+ self,
+ inputs: InputsType,
+ return_datasample: bool = False,
+ batch_size: int = 1,
+ out_dir: Optional[str] = None,
+ **kwargs,
+ ) -> dict:
+ """Call the inferencer.
+
+ Args:
+ inputs (InputsType): Inputs for the inferencer.
+ return_datasample (bool): Whether to return results as
+ :obj:`BaseDataElement`. Defaults to False.
+ batch_size (int): Batch size. Defaults to 1.
+ out_dir (str, optional): directory to save visualization
+ results and predictions. Will be overoden if vis_out_dir or
+ pred_out_dir are given. Defaults to None
+ **kwargs: Key words arguments passed to :meth:`preprocess`,
+ :meth:`forward`, :meth:`visualize` and :meth:`postprocess`.
+ Each key in kwargs should be in the corresponding set of
+ ``preprocess_kwargs``, ``forward_kwargs``,
+ ``visualize_kwargs`` and ``postprocess_kwargs``.
+
+ Returns:
+ dict: Inference and visualization results.
+ """
+ if out_dir is not None:
+ if 'vis_out_dir' not in kwargs:
+ kwargs['vis_out_dir'] = f'{out_dir}/visualizations'
+ if 'pred_out_dir' not in kwargs:
+ kwargs['pred_out_dir'] = f'{out_dir}/predictions'
+
+ (
+ preprocess_kwargs,
+ forward_kwargs,
+ visualize_kwargs,
+ postprocess_kwargs,
+ ) = self._dispatch_kwargs(**kwargs)
+
+ self.update_model_visualizer_settings(**kwargs)
+
+ # preprocessing
+ if isinstance(inputs, str) and inputs.startswith('webcam'):
+ inputs = self._get_webcam_inputs(inputs)
+ batch_size = 1
+ if not visualize_kwargs.get('show', False):
+ warnings.warn('The display mode is closed when using webcam '
+ 'input. It will be turned on automatically.')
+ visualize_kwargs['show'] = True
+ else:
+ inputs = self._inputs_to_list(inputs)
+
+ inputs = self.preprocess(
+ inputs, batch_size=batch_size, **preprocess_kwargs)
+
+ preds = []
+
+ for proc_inputs, ori_inputs in inputs:
+ preds = self.forward(proc_inputs, **forward_kwargs)
+
+ visualization = self.visualize(ori_inputs, preds,
+ **visualize_kwargs)
+ results = self.postprocess(preds, visualization, return_datasample,
+ **postprocess_kwargs)
+ yield results
+
+ if self._video_input:
+ self._finalize_video_processing(
+ postprocess_kwargs.get('pred_out_dir', ''))
+ self._buffer.clear()
+
+ def visualize(self,
+ inputs: list,
+ preds: List[PoseDataSample],
+ return_vis: bool = False,
+ show: bool = False,
+ draw_bbox: bool = False,
+ wait_time: float = 0,
+ radius: int = 3,
+ thickness: int = 1,
+ kpt_thr: float = 0.3,
+ vis_out_dir: str = '',
+ window_name: str = '',
+ window_close_event_handler: Optional[Callable] = None
+ ) -> List[np.ndarray]:
+ """Visualize predictions.
+
+ Args:
+ inputs (list): Inputs preprocessed by :meth:`_inputs_to_list`.
+ preds (Any): Predictions of the model.
+ return_vis (bool): Whether to return images with predicted results.
+ show (bool): Whether to display the image in a popup window.
+ Defaults to False.
+ wait_time (float): The interval of show (ms). Defaults to 0
+ draw_bbox (bool): Whether to draw the bounding boxes.
+ Defaults to False
+ radius (int): Keypoint radius for visualization. Defaults to 3
+ thickness (int): Link thickness for visualization. Defaults to 1
+ kpt_thr (float): The threshold to visualize the keypoints.
+ Defaults to 0.3
+ vis_out_dir (str, optional): Directory to save visualization
+ results w/o predictions. If left as empty, no file will
+ be saved. Defaults to ''.
+ window_name (str, optional): Title of display window.
+ window_close_event_handler (callable, optional):
+
+ Returns:
+ List[np.ndarray]: Visualization results.
+ """
+ if (not return_vis) and (not show) and (not vis_out_dir):
+ return
+
+ if getattr(self, 'visualizer', None) is None:
+ raise ValueError('Visualization needs the "visualizer" term'
+ 'defined in the config, but got None.')
+
+ self.visualizer.radius = radius
+ self.visualizer.line_width = thickness
+ det_kpt_color = self.pose2d_model.visualizer.kpt_color
+ det_dataset_skeleton = self.pose2d_model.visualizer.skeleton
+ det_dataset_link_color = self.pose2d_model.visualizer.link_color
+ self.visualizer.det_kpt_color = det_kpt_color
+ self.visualizer.det_dataset_skeleton = det_dataset_skeleton
+ self.visualizer.det_dataset_link_color = det_dataset_link_color
+
+ results = []
+
+ for single_input, pred in zip(inputs, preds):
+ if isinstance(single_input, str):
+ img = mmcv.imread(single_input, channel_order='rgb')
+ elif isinstance(single_input, np.ndarray):
+ img = mmcv.bgr2rgb(single_input)
+ else:
+ raise ValueError('Unsupported input type: '
+ f'{type(single_input)}')
+
+ # since visualization and inference utilize the same process,
+ # the wait time is reduced when a video input is utilized,
+ # thereby eliminating the issue of inference getting stuck.
+ wait_time = 1e-5 if self._video_input else wait_time
+
+ visualization = self.visualizer.add_datasample(
+ window_name,
+ img,
+ data_sample=pred,
+ det_data_sample=self._buffer['pose2d_results'],
+ draw_gt=False,
+ draw_bbox=draw_bbox,
+ show=show,
+ wait_time=wait_time,
+ kpt_thr=kpt_thr)
+ results.append(visualization)
+
+ if vis_out_dir:
+ out_img = mmcv.rgb2bgr(visualization)
+ _, file_extension = os.path.splitext(vis_out_dir)
+ if file_extension:
+ dir_name = os.path.dirname(vis_out_dir)
+ file_name = os.path.basename(vis_out_dir)
+ else:
+ dir_name = vis_out_dir
+ file_name = None
+ mkdir_or_exist(dir_name)
+
+ if self._video_input:
+
+ if self.video_info['writer'] is None:
+ fourcc = cv2.VideoWriter_fourcc(*'mp4v')
+ if file_name is None:
+ file_name = os.path.basename(
+ self.video_info['name'])
+ out_file = join_path(dir_name, file_name)
+ self.video_info['writer'] = cv2.VideoWriter(
+ out_file, fourcc, self.video_info['fps'],
+ (visualization.shape[1], visualization.shape[0]))
+ self.video_info['writer'].write(out_img)
+
+ else:
+ img_name = os.path.basename(pred.metainfo['img_path'])
+ file_name = file_name if file_name else img_name
+ out_file = join_path(dir_name, file_name)
+ mmcv.imwrite(out_img, out_file)
+
+ if return_vis:
+ return results
+ else:
+ return []
diff --git a/mmpose/apis/inferencers/utils/__init__.py b/mmpose/apis/inferencers/utils/__init__.py
index 5cc40535b0..654685dbd0 100644
--- a/mmpose/apis/inferencers/utils/__init__.py
+++ b/mmpose/apis/inferencers/utils/__init__.py
@@ -1,5 +1,5 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .default_det_models import default_det_models
-from .get_model_alias import get_model_aliases
-
-__all__ = ['default_det_models', 'get_model_aliases']
+# Copyright (c) OpenMMLab. All rights reserved.
+from .default_det_models import default_det_models
+from .get_model_alias import get_model_aliases
+
+__all__ = ['default_det_models', 'get_model_aliases']
diff --git a/mmpose/apis/inferencers/utils/default_det_models.py b/mmpose/apis/inferencers/utils/default_det_models.py
index 93b759c879..b7749318cf 100644
--- a/mmpose/apis/inferencers/utils/default_det_models.py
+++ b/mmpose/apis/inferencers/utils/default_det_models.py
@@ -1,31 +1,31 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os.path as osp
-
-from mmengine.config.utils import MODULE2PACKAGE
-from mmengine.utils import get_installed_path
-
-mmpose_path = get_installed_path(MODULE2PACKAGE['mmpose'])
-
-default_det_models = dict(
- human=dict(model='rtmdet-m', weights=None, cat_ids=(0, )),
- face=dict(
- model=osp.join(mmpose_path, '.mim',
- 'demo/mmdetection_cfg/yolox-s_8xb8-300e_coco-face.py'),
- weights='https://download.openmmlab.com/mmpose/mmdet_pretrained/'
- 'yolo-x_8xb8-300e_coco-face_13274d7c.pth',
- cat_ids=(0, )),
- hand=dict(
- model=osp.join(
- mmpose_path, '.mim', 'demo/mmdetection_cfg/'
- 'ssdlite_mobilenetv2_scratch_600e_onehand.py'),
- weights='https://download.openmmlab.com/mmpose/mmdet_pretrained/'
- 'ssdlite_mobilenetv2_scratch_600e_onehand-4f9f8686_20220523.pth',
- cat_ids=(0, )),
- animal=dict(
- model='rtmdet-m',
- weights=None,
- cat_ids=(15, 16, 17, 18, 19, 20, 21, 22, 23)),
-)
-
-default_det_models['body'] = default_det_models['human']
-default_det_models['wholebody'] = default_det_models['human']
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+from mmengine.config.utils import MODULE2PACKAGE
+from mmengine.utils import get_installed_path
+
+mmpose_path = get_installed_path(MODULE2PACKAGE['mmpose'])
+
+default_det_models = dict(
+ human=dict(model='rtmdet-m', weights=None, cat_ids=(0, )),
+ face=dict(
+ model=osp.join(mmpose_path, '.mim',
+ 'demo/mmdetection_cfg/yolox-s_8xb8-300e_coco-face.py'),
+ weights='https://download.openmmlab.com/mmpose/mmdet_pretrained/'
+ 'yolo-x_8xb8-300e_coco-face_13274d7c.pth',
+ cat_ids=(0, )),
+ hand=dict(
+ model=osp.join(
+ mmpose_path, '.mim', 'demo/mmdetection_cfg/'
+ 'ssdlite_mobilenetv2_scratch_600e_onehand.py'),
+ weights='https://download.openmmlab.com/mmpose/mmdet_pretrained/'
+ 'ssdlite_mobilenetv2_scratch_600e_onehand-4f9f8686_20220523.pth',
+ cat_ids=(0, )),
+ animal=dict(
+ model='rtmdet-m',
+ weights=None,
+ cat_ids=(15, 16, 17, 18, 19, 20, 21, 22, 23)),
+)
+
+default_det_models['body'] = default_det_models['human']
+default_det_models['wholebody'] = default_det_models['human']
diff --git a/mmpose/apis/inferencers/utils/get_model_alias.py b/mmpose/apis/inferencers/utils/get_model_alias.py
index 49de6528d6..9a27cee54c 100644
--- a/mmpose/apis/inferencers/utils/get_model_alias.py
+++ b/mmpose/apis/inferencers/utils/get_model_alias.py
@@ -1,37 +1,37 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Dict
-
-from mmengine.infer import BaseInferencer
-
-
-def get_model_aliases(scope: str = 'mmpose') -> Dict[str, str]:
- """Retrieve model aliases and their corresponding configuration names.
-
- Args:
- scope (str, optional): The scope for the model aliases. Defaults
- to 'mmpose'.
-
- Returns:
- Dict[str, str]: A dictionary containing model aliases as keys and
- their corresponding configuration names as values.
- """
-
- # Get a list of model configurations from the metafile
- repo_or_mim_dir = BaseInferencer._get_repo_or_mim_dir(scope)
- model_cfgs = BaseInferencer._get_models_from_metafile(repo_or_mim_dir)
-
- model_alias_dict = dict()
- for model_cfg in model_cfgs:
- if 'Alias' in model_cfg:
- if isinstance(model_cfg['Alias'], str):
- model_alias_dict[model_cfg['Alias']] = model_cfg['Name']
- elif isinstance(model_cfg['Alias'], list):
- for alias in model_cfg['Alias']:
- model_alias_dict[alias] = model_cfg['Name']
- else:
- raise ValueError(
- 'encounter an unexpected alias type. Please raise an '
- 'issue at https://github.com/open-mmlab/mmpose/issues '
- 'to announce us')
-
- return model_alias_dict
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict
+
+from mmengine.infer import BaseInferencer
+
+
+def get_model_aliases(scope: str = 'mmpose') -> Dict[str, str]:
+ """Retrieve model aliases and their corresponding configuration names.
+
+ Args:
+ scope (str, optional): The scope for the model aliases. Defaults
+ to 'mmpose'.
+
+ Returns:
+ Dict[str, str]: A dictionary containing model aliases as keys and
+ their corresponding configuration names as values.
+ """
+
+ # Get a list of model configurations from the metafile
+ repo_or_mim_dir = BaseInferencer._get_repo_or_mim_dir(scope)
+ model_cfgs = BaseInferencer._get_models_from_metafile(repo_or_mim_dir)
+
+ model_alias_dict = dict()
+ for model_cfg in model_cfgs:
+ if 'Alias' in model_cfg:
+ if isinstance(model_cfg['Alias'], str):
+ model_alias_dict[model_cfg['Alias']] = model_cfg['Name']
+ elif isinstance(model_cfg['Alias'], list):
+ for alias in model_cfg['Alias']:
+ model_alias_dict[alias] = model_cfg['Name']
+ else:
+ raise ValueError(
+ 'encounter an unexpected alias type. Please raise an '
+ 'issue at https://github.com/open-mmlab/mmpose/issues '
+ 'to announce us')
+
+ return model_alias_dict
diff --git a/mmpose/codecs/__init__.py b/mmpose/codecs/__init__.py
index cdbd8feb0c..16f3924a7d 100644
--- a/mmpose/codecs/__init__.py
+++ b/mmpose/codecs/__init__.py
@@ -1,18 +1,18 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .associative_embedding import AssociativeEmbedding
-from .decoupled_heatmap import DecoupledHeatmap
-from .image_pose_lifting import ImagePoseLifting
-from .integral_regression_label import IntegralRegressionLabel
-from .megvii_heatmap import MegviiHeatmap
-from .msra_heatmap import MSRAHeatmap
-from .regression_label import RegressionLabel
-from .simcc_label import SimCCLabel
-from .spr import SPR
-from .udp_heatmap import UDPHeatmap
-from .video_pose_lifting import VideoPoseLifting
-
-__all__ = [
- 'MSRAHeatmap', 'MegviiHeatmap', 'UDPHeatmap', 'RegressionLabel',
- 'SimCCLabel', 'IntegralRegressionLabel', 'AssociativeEmbedding', 'SPR',
- 'DecoupledHeatmap', 'VideoPoseLifting', 'ImagePoseLifting'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .associative_embedding import AssociativeEmbedding
+from .decoupled_heatmap import DecoupledHeatmap
+from .image_pose_lifting import ImagePoseLifting
+from .integral_regression_label import IntegralRegressionLabel
+from .megvii_heatmap import MegviiHeatmap
+from .msra_heatmap import MSRAHeatmap
+from .regression_label import RegressionLabel
+from .simcc_label import SimCCLabel
+from .spr import SPR
+from .udp_heatmap import UDPHeatmap
+from .video_pose_lifting import VideoPoseLifting
+
+__all__ = [
+ 'MSRAHeatmap', 'MegviiHeatmap', 'UDPHeatmap', 'RegressionLabel',
+ 'SimCCLabel', 'IntegralRegressionLabel', 'AssociativeEmbedding', 'SPR',
+ 'DecoupledHeatmap', 'VideoPoseLifting', 'ImagePoseLifting'
+]
diff --git a/mmpose/codecs/associative_embedding.py b/mmpose/codecs/associative_embedding.py
index 7e080f1657..f9f6e5da8a 100644
--- a/mmpose/codecs/associative_embedding.py
+++ b/mmpose/codecs/associative_embedding.py
@@ -1,512 +1,512 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from collections import namedtuple
-from itertools import product
-from typing import Any, List, Optional, Tuple
-
-import numpy as np
-import torch
-from munkres import Munkres
-from torch import Tensor
-
-from mmpose.registry import KEYPOINT_CODECS
-from mmpose.utils.tensor_utils import to_numpy
-from .base import BaseKeypointCodec
-from .utils import (batch_heatmap_nms, generate_gaussian_heatmaps,
- generate_udp_gaussian_heatmaps, refine_keypoints,
- refine_keypoints_dark_udp)
-
-
-def _group_keypoints_by_tags(vals: np.ndarray,
- tags: np.ndarray,
- locs: np.ndarray,
- keypoint_order: List[int],
- val_thr: float,
- tag_thr: float = 1.0,
- max_groups: Optional[int] = None) -> np.ndarray:
- """Group the keypoints by tags using Munkres algorithm.
-
- Note:
-
- - keypoint number: K
- - candidate number: M
- - tag dimenssion: L
- - coordinate dimension: D
- - group number: G
-
- Args:
- vals (np.ndarray): The heatmap response values of keypoints in shape
- (K, M)
- tags (np.ndarray): The tags of the keypoint candidates in shape
- (K, M, L)
- locs (np.ndarray): The locations of the keypoint candidates in shape
- (K, M, D)
- keypoint_order (List[int]): The grouping order of the keypoints.
- The groupping usually starts from a keypoints around the head and
- torso, and gruadually moves out to the limbs
- val_thr (float): The threshold of the keypoint response value
- tag_thr (float): The maximum allowed tag distance when matching a
- keypoint to a group. A keypoint with larger tag distance to any
- of the existing groups will initializes a new group
- max_groups (int, optional): The maximum group number. ``None`` means
- no limitation. Defaults to ``None``
-
- Returns:
- np.ndarray: grouped keypoints in shape (G, K, D+1), where the last
- dimenssion is the concatenated keypoint coordinates and scores.
- """
- K, M, D = locs.shape
- assert vals.shape == tags.shape[:2] == (K, M)
- assert len(keypoint_order) == K
-
- # Build Munkres instance
- munkres = Munkres()
-
- # Build a group pool, each group contains the keypoints of an instance
- groups = []
-
- Group = namedtuple('Group', field_names=['kpts', 'scores', 'tag_list'])
-
- def _init_group():
- """Initialize a group, which is composed of the keypoints, keypoint
- scores and the tag of each keypoint."""
- _group = Group(
- kpts=np.zeros((K, D), dtype=np.float32),
- scores=np.zeros(K, dtype=np.float32),
- tag_list=[])
- return _group
-
- for i in keypoint_order:
- # Get all valid candidate of the i-th keypoints
- valid = vals[i] > val_thr
- if not valid.any():
- continue
-
- tags_i = tags[i, valid] # (M', L)
- vals_i = vals[i, valid] # (M',)
- locs_i = locs[i, valid] # (M', D)
-
- if len(groups) == 0: # Initialize the group pool
- for tag, val, loc in zip(tags_i, vals_i, locs_i):
- group = _init_group()
- group.kpts[i] = loc
- group.scores[i] = val
- group.tag_list.append(tag)
-
- groups.append(group)
-
- else: # Match keypoints to existing groups
- groups = groups[:max_groups]
- group_tags = [np.mean(g.tag_list, axis=0) for g in groups]
-
- # Calculate distance matrix between group tags and tag candidates
- # of the i-th keypoint
- # Shape: (M', 1, L) , (1, G, L) -> (M', G, L)
- diff = tags_i[:, None] - np.array(group_tags)[None]
- dists = np.linalg.norm(diff, ord=2, axis=2)
- num_kpts, num_groups = dists.shape[:2]
-
- # Experimental cost function for keypoint-group matching
- costs = np.round(dists) * 100 - vals_i[..., None]
- if num_kpts > num_groups:
- padding = np.full((num_kpts, num_kpts - num_groups),
- 1e10,
- dtype=np.float32)
- costs = np.concatenate((costs, padding), axis=1)
-
- # Match keypoints and groups by Munkres algorithm
- matches = munkres.compute(costs)
- for kpt_idx, group_idx in matches:
- if group_idx < num_groups and dists[kpt_idx,
- group_idx] < tag_thr:
- # Add the keypoint to the matched group
- group = groups[group_idx]
- else:
- # Initialize a new group with unmatched keypoint
- group = _init_group()
- groups.append(group)
-
- group.kpts[i] = locs_i[kpt_idx]
- group.scores[i] = vals_i[kpt_idx]
- group.tag_list.append(tags_i[kpt_idx])
-
- groups = groups[:max_groups]
- if groups:
- grouped_keypoints = np.stack(
- [np.r_['1', g.kpts, g.scores[:, None]] for g in groups])
- else:
- grouped_keypoints = np.empty((0, K, D + 1))
-
- return grouped_keypoints
-
-
-@KEYPOINT_CODECS.register_module()
-class AssociativeEmbedding(BaseKeypointCodec):
- """Encode/decode keypoints with the method introduced in "Associative
- Embedding". This is an asymmetric codec, where the keypoints are
- represented as gaussian heatmaps and position indices during encoding, and
- restored from predicted heatmaps and group tags.
-
- See the paper `Associative Embedding: End-to-End Learning for Joint
- Detection and Grouping`_ by Newell et al (2017) for details
-
- Note:
-
- - instance number: N
- - keypoint number: K
- - keypoint dimension: D
- - embedding tag dimension: L
- - image size: [w, h]
- - heatmap size: [W, H]
-
- Encoded:
-
- - heatmaps (np.ndarray): The generated heatmap in shape (K, H, W)
- where [W, H] is the `heatmap_size`
- - keypoint_indices (np.ndarray): The keypoint position indices in shape
- (N, K, 2). Each keypoint's index is [i, v], where i is the position
- index in the heatmap (:math:`i=y*w+x`) and v is the visibility
- - keypoint_weights (np.ndarray): The target weights in shape (N, K)
-
- Args:
- input_size (tuple): Image size in [w, h]
- heatmap_size (tuple): Heatmap size in [W, H]
- sigma (float): The sigma value of the Gaussian heatmap
- use_udp (bool): Whether use unbiased data processing. See
- `UDP (CVPR 2020)`_ for details. Defaults to ``False``
- decode_keypoint_order (List[int]): The grouping order of the
- keypoint indices. The groupping usually starts from a keypoints
- around the head and torso, and gruadually moves out to the limbs
- decode_keypoint_thr (float): The threshold of keypoint response value
- in heatmaps. Defaults to 0.1
- decode_tag_thr (float): The maximum allowed tag distance when matching
- a keypoint to a group. A keypoint with larger tag distance to any
- of the existing groups will initializes a new group. Defaults to
- 1.0
- decode_nms_kernel (int): The kernel size of the NMS during decoding,
- which should be an odd integer. Defaults to 5
- decode_gaussian_kernel (int): The kernel size of the Gaussian blur
- during decoding, which should be an odd integer. It is only used
- when ``self.use_udp==True``. Defaults to 3
- decode_topk (int): The number top-k candidates of each keypoints that
- will be retrieved from the heatmaps during dedocding. Defaults to
- 20
- decode_max_instances (int, optional): The maximum number of instances
- to decode. ``None`` means no limitation to the instance number.
- Defaults to ``None``
-
- .. _`Associative Embedding: End-to-End Learning for Joint Detection and
- Grouping`: https://arxiv.org/abs/1611.05424
- .. _`UDP (CVPR 2020)`: https://arxiv.org/abs/1911.07524
- """
-
- def __init__(
- self,
- input_size: Tuple[int, int],
- heatmap_size: Tuple[int, int],
- sigma: Optional[float] = None,
- use_udp: bool = False,
- decode_keypoint_order: List[int] = [],
- decode_nms_kernel: int = 5,
- decode_gaussian_kernel: int = 3,
- decode_keypoint_thr: float = 0.1,
- decode_tag_thr: float = 1.0,
- decode_topk: int = 20,
- decode_max_instances: Optional[int] = None,
- ) -> None:
- super().__init__()
- self.input_size = input_size
- self.heatmap_size = heatmap_size
- self.use_udp = use_udp
- self.decode_nms_kernel = decode_nms_kernel
- self.decode_gaussian_kernel = decode_gaussian_kernel
- self.decode_keypoint_thr = decode_keypoint_thr
- self.decode_tag_thr = decode_tag_thr
- self.decode_topk = decode_topk
- self.decode_max_instances = decode_max_instances
- self.dedecode_keypoint_order = decode_keypoint_order.copy()
-
- if self.use_udp:
- self.scale_factor = ((np.array(input_size) - 1) /
- (np.array(heatmap_size) - 1)).astype(
- np.float32)
- else:
- self.scale_factor = (np.array(input_size) /
- heatmap_size).astype(np.float32)
-
- if sigma is None:
- sigma = (heatmap_size[0] * heatmap_size[1])**0.5 / 64
- self.sigma = sigma
-
- def encode(
- self,
- keypoints: np.ndarray,
- keypoints_visible: Optional[np.ndarray] = None
- ) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
- """Encode keypoints into heatmaps and position indices. Note that the
- original keypoint coordinates should be in the input image space.
-
- Args:
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
- keypoints_visible (np.ndarray): Keypoint visibilities in shape
- (N, K)
-
- Returns:
- dict:
- - heatmaps (np.ndarray): The generated heatmap in shape
- (K, H, W) where [W, H] is the `heatmap_size`
- - keypoint_indices (np.ndarray): The keypoint position indices
- in shape (N, K, 2). Each keypoint's index is [i, v], where i
- is the position index in the heatmap (:math:`i=y*w+x`) and v
- is the visibility
- - keypoint_weights (np.ndarray): The target weights in shape
- (N, K)
- """
-
- if keypoints_visible is None:
- keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
-
- # keypoint coordinates in heatmap
- _keypoints = keypoints / self.scale_factor
-
- if self.use_udp:
- heatmaps, keypoint_weights = generate_udp_gaussian_heatmaps(
- heatmap_size=self.heatmap_size,
- keypoints=_keypoints,
- keypoints_visible=keypoints_visible,
- sigma=self.sigma)
- else:
- heatmaps, keypoint_weights = generate_gaussian_heatmaps(
- heatmap_size=self.heatmap_size,
- keypoints=_keypoints,
- keypoints_visible=keypoints_visible,
- sigma=self.sigma)
-
- keypoint_indices = self._encode_keypoint_indices(
- heatmap_size=self.heatmap_size,
- keypoints=_keypoints,
- keypoints_visible=keypoints_visible)
-
- encoded = dict(
- heatmaps=heatmaps,
- keypoint_indices=keypoint_indices,
- keypoint_weights=keypoint_weights)
-
- return encoded
-
- def _encode_keypoint_indices(self, heatmap_size: Tuple[int, int],
- keypoints: np.ndarray,
- keypoints_visible: np.ndarray) -> np.ndarray:
- w, h = heatmap_size
- N, K, _ = keypoints.shape
- keypoint_indices = np.zeros((N, K, 2), dtype=np.int64)
-
- for n, k in product(range(N), range(K)):
- x, y = (keypoints[n, k] + 0.5).astype(np.int64)
- index = y * w + x
- vis = (keypoints_visible[n, k] > 0.5 and 0 <= x < w and 0 <= y < h)
- keypoint_indices[n, k] = [index, vis]
-
- return keypoint_indices
-
- def decode(self, encoded: Any) -> Tuple[np.ndarray, np.ndarray]:
- raise NotImplementedError()
-
- def _get_batch_topk(self, batch_heatmaps: Tensor, batch_tags: Tensor,
- k: int):
- """Get top-k response values from the heatmaps and corresponding tag
- values from the tagging heatmaps.
-
- Args:
- batch_heatmaps (Tensor): Keypoint detection heatmaps in shape
- (B, K, H, W)
- batch_tags (Tensor): Tagging heatmaps in shape (B, C, H, W), where
- the tag dim C is 2*K when using flip testing, or K otherwise
- k (int): The number of top responses to get
-
- Returns:
- tuple:
- - topk_vals (Tensor): Top-k response values of each heatmap in
- shape (B, K, Topk)
- - topk_tags (Tensor): The corresponding embedding tags of the
- top-k responses, in shape (B, K, Topk, L)
- - topk_locs (Tensor): The location of the top-k responses in each
- heatmap, in shape (B, K, Topk, 2) where last dimension
- represents x and y coordinates
- """
- B, K, H, W = batch_heatmaps.shape
- L = batch_tags.shape[1] // K
-
- # shape of topk_val, top_indices: (B, K, TopK)
- topk_vals, topk_indices = batch_heatmaps.flatten(-2, -1).topk(
- k, dim=-1)
-
- topk_tags_per_kpts = [
- torch.gather(_tag, dim=2, index=topk_indices)
- for _tag in torch.unbind(batch_tags.view(B, L, K, H * W), dim=1)
- ]
-
- topk_tags = torch.stack(topk_tags_per_kpts, dim=-1) # (B, K, TopK, L)
- topk_locs = torch.stack([topk_indices % W, topk_indices // W],
- dim=-1) # (B, K, TopK, 2)
-
- return topk_vals, topk_tags, topk_locs
-
- def _group_keypoints(self, batch_vals: np.ndarray, batch_tags: np.ndarray,
- batch_locs: np.ndarray):
- """Group keypoints into groups (each represents an instance) by tags.
-
- Args:
- batch_vals (Tensor): Heatmap response values of keypoint
- candidates in shape (B, K, Topk)
- batch_tags (Tensor): Tags of keypoint candidates in shape
- (B, K, Topk, L)
- batch_locs (Tensor): Locations of keypoint candidates in shape
- (B, K, Topk, 2)
-
- Returns:
- List[np.ndarray]: Grouping results of a batch, each element is a
- np.ndarray (in shape [N, K, D+1]) that contains the groups
- detected in an image, including both keypoint coordinates and
- scores.
- """
-
- def _group_func(inputs: Tuple):
- vals, tags, locs = inputs
- return _group_keypoints_by_tags(
- vals,
- tags,
- locs,
- keypoint_order=self.dedecode_keypoint_order,
- val_thr=self.decode_keypoint_thr,
- tag_thr=self.decode_tag_thr,
- max_groups=self.decode_max_instances)
-
- _results = map(_group_func, zip(batch_vals, batch_tags, batch_locs))
- results = list(_results)
- return results
-
- def _fill_missing_keypoints(self, keypoints: np.ndarray,
- keypoint_scores: np.ndarray,
- heatmaps: np.ndarray, tags: np.ndarray):
- """Fill the missing keypoints in the initial predictions.
-
- Args:
- keypoints (np.ndarray): Keypoint predictions in shape (N, K, D)
- keypoint_scores (np.ndarray): Keypint score predictions in shape
- (N, K), in which 0 means the corresponding keypoint is
- missing in the initial prediction
- heatmaps (np.ndarry): Heatmaps in shape (K, H, W)
- tags (np.ndarray): Tagging heatmaps in shape (C, H, W) where
- C=L*K
-
- Returns:
- tuple:
- - keypoints (np.ndarray): Keypoint predictions with missing
- ones filled
- - keypoint_scores (np.ndarray): Keypoint score predictions with
- missing ones filled
- """
-
- N, K = keypoints.shape[:2]
- H, W = heatmaps.shape[1:]
- L = tags.shape[0] // K
- keypoint_tags = [tags[k::K] for k in range(K)]
-
- for n in range(N):
- # Calculate the instance tag (mean tag of detected keypoints)
- _tag = []
- for k in range(K):
- if keypoint_scores[n, k] > 0:
- x, y = keypoints[n, k, :2].astype(np.int64)
- x = np.clip(x, 0, W - 1)
- y = np.clip(y, 0, H - 1)
- _tag.append(keypoint_tags[k][:, y, x])
-
- tag = np.mean(_tag, axis=0)
- tag = tag.reshape(L, 1, 1)
- # Search maximum response of the missing keypoints
- for k in range(K):
- if keypoint_scores[n, k] > 0:
- continue
- dist_map = np.linalg.norm(
- keypoint_tags[k] - tag, ord=2, axis=0)
- cost_map = np.round(dist_map) * 100 - heatmaps[k] # H, W
- y, x = np.unravel_index(np.argmin(cost_map), shape=(H, W))
- keypoints[n, k] = [x, y]
- keypoint_scores[n, k] = heatmaps[k, y, x]
-
- return keypoints, keypoint_scores
-
- def batch_decode(self, batch_heatmaps: Tensor, batch_tags: Tensor
- ) -> Tuple[List[np.ndarray], List[np.ndarray]]:
- """Decode the keypoint coordinates from a batch of heatmaps and tagging
- heatmaps. The decoded keypoint coordinates are in the input image
- space.
-
- Args:
- batch_heatmaps (Tensor): Keypoint detection heatmaps in shape
- (B, K, H, W)
- batch_tags (Tensor): Tagging heatmaps in shape (B, C, H, W), where
- :math:`C=L*K`
-
- Returns:
- tuple:
- - batch_keypoints (List[np.ndarray]): Decoded keypoint coordinates
- of the batch, each is in shape (N, K, D)
- - batch_scores (List[np.ndarray]): Decoded keypoint scores of the
- batch, each is in shape (N, K). It usually represents the
- confidience of the keypoint prediction
- """
- B, _, H, W = batch_heatmaps.shape
- assert batch_tags.shape[0] == B and batch_tags.shape[2:4] == (H, W), (
- f'Mismatched shapes of heatmap ({batch_heatmaps.shape}) and '
- f'tagging map ({batch_tags.shape})')
-
- # Heatmap NMS
- batch_heatmaps = batch_heatmap_nms(batch_heatmaps,
- self.decode_nms_kernel)
-
- # Get top-k in each heatmap and and convert to numpy
- batch_topk_vals, batch_topk_tags, batch_topk_locs = to_numpy(
- self._get_batch_topk(
- batch_heatmaps, batch_tags, k=self.decode_topk))
-
- # Group keypoint candidates into groups (instances)
- batch_groups = self._group_keypoints(batch_topk_vals, batch_topk_tags,
- batch_topk_locs)
-
- # Convert to numpy
- batch_heatmaps_np = to_numpy(batch_heatmaps)
- batch_tags_np = to_numpy(batch_tags)
-
- # Refine the keypoint prediction
- batch_keypoints = []
- batch_keypoint_scores = []
- for i, (groups, heatmaps, tags) in enumerate(
- zip(batch_groups, batch_heatmaps_np, batch_tags_np)):
-
- keypoints, scores = groups[..., :-1], groups[..., -1]
-
- if keypoints.size > 0:
- # identify missing keypoints
- keypoints, scores = self._fill_missing_keypoints(
- keypoints, scores, heatmaps, tags)
-
- # refine keypoint coordinates according to heatmap distribution
- if self.use_udp:
- keypoints = refine_keypoints_dark_udp(
- keypoints,
- heatmaps,
- blur_kernel_size=self.decode_gaussian_kernel)
- else:
- keypoints = refine_keypoints(keypoints, heatmaps)
-
- batch_keypoints.append(keypoints)
- batch_keypoint_scores.append(scores)
-
- # restore keypoint scale
- batch_keypoints = [
- kpts * self.scale_factor for kpts in batch_keypoints
- ]
-
- return batch_keypoints, batch_keypoint_scores
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections import namedtuple
+from itertools import product
+from typing import Any, List, Optional, Tuple
+
+import numpy as np
+import torch
+from munkres import Munkres
+from torch import Tensor
+
+from mmpose.registry import KEYPOINT_CODECS
+from mmpose.utils.tensor_utils import to_numpy
+from .base import BaseKeypointCodec
+from .utils import (batch_heatmap_nms, generate_gaussian_heatmaps,
+ generate_udp_gaussian_heatmaps, refine_keypoints,
+ refine_keypoints_dark_udp)
+
+
+def _group_keypoints_by_tags(vals: np.ndarray,
+ tags: np.ndarray,
+ locs: np.ndarray,
+ keypoint_order: List[int],
+ val_thr: float,
+ tag_thr: float = 1.0,
+ max_groups: Optional[int] = None) -> np.ndarray:
+ """Group the keypoints by tags using Munkres algorithm.
+
+ Note:
+
+ - keypoint number: K
+ - candidate number: M
+ - tag dimenssion: L
+ - coordinate dimension: D
+ - group number: G
+
+ Args:
+ vals (np.ndarray): The heatmap response values of keypoints in shape
+ (K, M)
+ tags (np.ndarray): The tags of the keypoint candidates in shape
+ (K, M, L)
+ locs (np.ndarray): The locations of the keypoint candidates in shape
+ (K, M, D)
+ keypoint_order (List[int]): The grouping order of the keypoints.
+ The groupping usually starts from a keypoints around the head and
+ torso, and gruadually moves out to the limbs
+ val_thr (float): The threshold of the keypoint response value
+ tag_thr (float): The maximum allowed tag distance when matching a
+ keypoint to a group. A keypoint with larger tag distance to any
+ of the existing groups will initializes a new group
+ max_groups (int, optional): The maximum group number. ``None`` means
+ no limitation. Defaults to ``None``
+
+ Returns:
+ np.ndarray: grouped keypoints in shape (G, K, D+1), where the last
+ dimenssion is the concatenated keypoint coordinates and scores.
+ """
+ K, M, D = locs.shape
+ assert vals.shape == tags.shape[:2] == (K, M)
+ assert len(keypoint_order) == K
+
+ # Build Munkres instance
+ munkres = Munkres()
+
+ # Build a group pool, each group contains the keypoints of an instance
+ groups = []
+
+ Group = namedtuple('Group', field_names=['kpts', 'scores', 'tag_list'])
+
+ def _init_group():
+ """Initialize a group, which is composed of the keypoints, keypoint
+ scores and the tag of each keypoint."""
+ _group = Group(
+ kpts=np.zeros((K, D), dtype=np.float32),
+ scores=np.zeros(K, dtype=np.float32),
+ tag_list=[])
+ return _group
+
+ for i in keypoint_order:
+ # Get all valid candidate of the i-th keypoints
+ valid = vals[i] > val_thr
+ if not valid.any():
+ continue
+
+ tags_i = tags[i, valid] # (M', L)
+ vals_i = vals[i, valid] # (M',)
+ locs_i = locs[i, valid] # (M', D)
+
+ if len(groups) == 0: # Initialize the group pool
+ for tag, val, loc in zip(tags_i, vals_i, locs_i):
+ group = _init_group()
+ group.kpts[i] = loc
+ group.scores[i] = val
+ group.tag_list.append(tag)
+
+ groups.append(group)
+
+ else: # Match keypoints to existing groups
+ groups = groups[:max_groups]
+ group_tags = [np.mean(g.tag_list, axis=0) for g in groups]
+
+ # Calculate distance matrix between group tags and tag candidates
+ # of the i-th keypoint
+ # Shape: (M', 1, L) , (1, G, L) -> (M', G, L)
+ diff = tags_i[:, None] - np.array(group_tags)[None]
+ dists = np.linalg.norm(diff, ord=2, axis=2)
+ num_kpts, num_groups = dists.shape[:2]
+
+ # Experimental cost function for keypoint-group matching
+ costs = np.round(dists) * 100 - vals_i[..., None]
+ if num_kpts > num_groups:
+ padding = np.full((num_kpts, num_kpts - num_groups),
+ 1e10,
+ dtype=np.float32)
+ costs = np.concatenate((costs, padding), axis=1)
+
+ # Match keypoints and groups by Munkres algorithm
+ matches = munkres.compute(costs)
+ for kpt_idx, group_idx in matches:
+ if group_idx < num_groups and dists[kpt_idx,
+ group_idx] < tag_thr:
+ # Add the keypoint to the matched group
+ group = groups[group_idx]
+ else:
+ # Initialize a new group with unmatched keypoint
+ group = _init_group()
+ groups.append(group)
+
+ group.kpts[i] = locs_i[kpt_idx]
+ group.scores[i] = vals_i[kpt_idx]
+ group.tag_list.append(tags_i[kpt_idx])
+
+ groups = groups[:max_groups]
+ if groups:
+ grouped_keypoints = np.stack(
+ [np.r_['1', g.kpts, g.scores[:, None]] for g in groups])
+ else:
+ grouped_keypoints = np.empty((0, K, D + 1))
+
+ return grouped_keypoints
+
+
+@KEYPOINT_CODECS.register_module()
+class AssociativeEmbedding(BaseKeypointCodec):
+ """Encode/decode keypoints with the method introduced in "Associative
+ Embedding". This is an asymmetric codec, where the keypoints are
+ represented as gaussian heatmaps and position indices during encoding, and
+ restored from predicted heatmaps and group tags.
+
+ See the paper `Associative Embedding: End-to-End Learning for Joint
+ Detection and Grouping`_ by Newell et al (2017) for details
+
+ Note:
+
+ - instance number: N
+ - keypoint number: K
+ - keypoint dimension: D
+ - embedding tag dimension: L
+ - image size: [w, h]
+ - heatmap size: [W, H]
+
+ Encoded:
+
+ - heatmaps (np.ndarray): The generated heatmap in shape (K, H, W)
+ where [W, H] is the `heatmap_size`
+ - keypoint_indices (np.ndarray): The keypoint position indices in shape
+ (N, K, 2). Each keypoint's index is [i, v], where i is the position
+ index in the heatmap (:math:`i=y*w+x`) and v is the visibility
+ - keypoint_weights (np.ndarray): The target weights in shape (N, K)
+
+ Args:
+ input_size (tuple): Image size in [w, h]
+ heatmap_size (tuple): Heatmap size in [W, H]
+ sigma (float): The sigma value of the Gaussian heatmap
+ use_udp (bool): Whether use unbiased data processing. See
+ `UDP (CVPR 2020)`_ for details. Defaults to ``False``
+ decode_keypoint_order (List[int]): The grouping order of the
+ keypoint indices. The groupping usually starts from a keypoints
+ around the head and torso, and gruadually moves out to the limbs
+ decode_keypoint_thr (float): The threshold of keypoint response value
+ in heatmaps. Defaults to 0.1
+ decode_tag_thr (float): The maximum allowed tag distance when matching
+ a keypoint to a group. A keypoint with larger tag distance to any
+ of the existing groups will initializes a new group. Defaults to
+ 1.0
+ decode_nms_kernel (int): The kernel size of the NMS during decoding,
+ which should be an odd integer. Defaults to 5
+ decode_gaussian_kernel (int): The kernel size of the Gaussian blur
+ during decoding, which should be an odd integer. It is only used
+ when ``self.use_udp==True``. Defaults to 3
+ decode_topk (int): The number top-k candidates of each keypoints that
+ will be retrieved from the heatmaps during dedocding. Defaults to
+ 20
+ decode_max_instances (int, optional): The maximum number of instances
+ to decode. ``None`` means no limitation to the instance number.
+ Defaults to ``None``
+
+ .. _`Associative Embedding: End-to-End Learning for Joint Detection and
+ Grouping`: https://arxiv.org/abs/1611.05424
+ .. _`UDP (CVPR 2020)`: https://arxiv.org/abs/1911.07524
+ """
+
+ def __init__(
+ self,
+ input_size: Tuple[int, int],
+ heatmap_size: Tuple[int, int],
+ sigma: Optional[float] = None,
+ use_udp: bool = False,
+ decode_keypoint_order: List[int] = [],
+ decode_nms_kernel: int = 5,
+ decode_gaussian_kernel: int = 3,
+ decode_keypoint_thr: float = 0.1,
+ decode_tag_thr: float = 1.0,
+ decode_topk: int = 20,
+ decode_max_instances: Optional[int] = None,
+ ) -> None:
+ super().__init__()
+ self.input_size = input_size
+ self.heatmap_size = heatmap_size
+ self.use_udp = use_udp
+ self.decode_nms_kernel = decode_nms_kernel
+ self.decode_gaussian_kernel = decode_gaussian_kernel
+ self.decode_keypoint_thr = decode_keypoint_thr
+ self.decode_tag_thr = decode_tag_thr
+ self.decode_topk = decode_topk
+ self.decode_max_instances = decode_max_instances
+ self.dedecode_keypoint_order = decode_keypoint_order.copy()
+
+ if self.use_udp:
+ self.scale_factor = ((np.array(input_size) - 1) /
+ (np.array(heatmap_size) - 1)).astype(
+ np.float32)
+ else:
+ self.scale_factor = (np.array(input_size) /
+ heatmap_size).astype(np.float32)
+
+ if sigma is None:
+ sigma = (heatmap_size[0] * heatmap_size[1])**0.5 / 64
+ self.sigma = sigma
+
+ def encode(
+ self,
+ keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray] = None
+ ) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
+ """Encode keypoints into heatmaps and position indices. Note that the
+ original keypoint coordinates should be in the input image space.
+
+ Args:
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ keypoints_visible (np.ndarray): Keypoint visibilities in shape
+ (N, K)
+
+ Returns:
+ dict:
+ - heatmaps (np.ndarray): The generated heatmap in shape
+ (K, H, W) where [W, H] is the `heatmap_size`
+ - keypoint_indices (np.ndarray): The keypoint position indices
+ in shape (N, K, 2). Each keypoint's index is [i, v], where i
+ is the position index in the heatmap (:math:`i=y*w+x`) and v
+ is the visibility
+ - keypoint_weights (np.ndarray): The target weights in shape
+ (N, K)
+ """
+
+ if keypoints_visible is None:
+ keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
+
+ # keypoint coordinates in heatmap
+ _keypoints = keypoints / self.scale_factor
+
+ if self.use_udp:
+ heatmaps, keypoint_weights = generate_udp_gaussian_heatmaps(
+ heatmap_size=self.heatmap_size,
+ keypoints=_keypoints,
+ keypoints_visible=keypoints_visible,
+ sigma=self.sigma)
+ else:
+ heatmaps, keypoint_weights = generate_gaussian_heatmaps(
+ heatmap_size=self.heatmap_size,
+ keypoints=_keypoints,
+ keypoints_visible=keypoints_visible,
+ sigma=self.sigma)
+
+ keypoint_indices = self._encode_keypoint_indices(
+ heatmap_size=self.heatmap_size,
+ keypoints=_keypoints,
+ keypoints_visible=keypoints_visible)
+
+ encoded = dict(
+ heatmaps=heatmaps,
+ keypoint_indices=keypoint_indices,
+ keypoint_weights=keypoint_weights)
+
+ return encoded
+
+ def _encode_keypoint_indices(self, heatmap_size: Tuple[int, int],
+ keypoints: np.ndarray,
+ keypoints_visible: np.ndarray) -> np.ndarray:
+ w, h = heatmap_size
+ N, K, _ = keypoints.shape
+ keypoint_indices = np.zeros((N, K, 2), dtype=np.int64)
+
+ for n, k in product(range(N), range(K)):
+ x, y = (keypoints[n, k] + 0.5).astype(np.int64)
+ index = y * w + x
+ vis = (keypoints_visible[n, k] > 0.5 and 0 <= x < w and 0 <= y < h)
+ keypoint_indices[n, k] = [index, vis]
+
+ return keypoint_indices
+
+ def decode(self, encoded: Any) -> Tuple[np.ndarray, np.ndarray]:
+ raise NotImplementedError()
+
+ def _get_batch_topk(self, batch_heatmaps: Tensor, batch_tags: Tensor,
+ k: int):
+ """Get top-k response values from the heatmaps and corresponding tag
+ values from the tagging heatmaps.
+
+ Args:
+ batch_heatmaps (Tensor): Keypoint detection heatmaps in shape
+ (B, K, H, W)
+ batch_tags (Tensor): Tagging heatmaps in shape (B, C, H, W), where
+ the tag dim C is 2*K when using flip testing, or K otherwise
+ k (int): The number of top responses to get
+
+ Returns:
+ tuple:
+ - topk_vals (Tensor): Top-k response values of each heatmap in
+ shape (B, K, Topk)
+ - topk_tags (Tensor): The corresponding embedding tags of the
+ top-k responses, in shape (B, K, Topk, L)
+ - topk_locs (Tensor): The location of the top-k responses in each
+ heatmap, in shape (B, K, Topk, 2) where last dimension
+ represents x and y coordinates
+ """
+ B, K, H, W = batch_heatmaps.shape
+ L = batch_tags.shape[1] // K
+
+ # shape of topk_val, top_indices: (B, K, TopK)
+ topk_vals, topk_indices = batch_heatmaps.flatten(-2, -1).topk(
+ k, dim=-1)
+
+ topk_tags_per_kpts = [
+ torch.gather(_tag, dim=2, index=topk_indices)
+ for _tag in torch.unbind(batch_tags.view(B, L, K, H * W), dim=1)
+ ]
+
+ topk_tags = torch.stack(topk_tags_per_kpts, dim=-1) # (B, K, TopK, L)
+ topk_locs = torch.stack([topk_indices % W, topk_indices // W],
+ dim=-1) # (B, K, TopK, 2)
+
+ return topk_vals, topk_tags, topk_locs
+
+ def _group_keypoints(self, batch_vals: np.ndarray, batch_tags: np.ndarray,
+ batch_locs: np.ndarray):
+ """Group keypoints into groups (each represents an instance) by tags.
+
+ Args:
+ batch_vals (Tensor): Heatmap response values of keypoint
+ candidates in shape (B, K, Topk)
+ batch_tags (Tensor): Tags of keypoint candidates in shape
+ (B, K, Topk, L)
+ batch_locs (Tensor): Locations of keypoint candidates in shape
+ (B, K, Topk, 2)
+
+ Returns:
+ List[np.ndarray]: Grouping results of a batch, each element is a
+ np.ndarray (in shape [N, K, D+1]) that contains the groups
+ detected in an image, including both keypoint coordinates and
+ scores.
+ """
+
+ def _group_func(inputs: Tuple):
+ vals, tags, locs = inputs
+ return _group_keypoints_by_tags(
+ vals,
+ tags,
+ locs,
+ keypoint_order=self.dedecode_keypoint_order,
+ val_thr=self.decode_keypoint_thr,
+ tag_thr=self.decode_tag_thr,
+ max_groups=self.decode_max_instances)
+
+ _results = map(_group_func, zip(batch_vals, batch_tags, batch_locs))
+ results = list(_results)
+ return results
+
+ def _fill_missing_keypoints(self, keypoints: np.ndarray,
+ keypoint_scores: np.ndarray,
+ heatmaps: np.ndarray, tags: np.ndarray):
+ """Fill the missing keypoints in the initial predictions.
+
+ Args:
+ keypoints (np.ndarray): Keypoint predictions in shape (N, K, D)
+ keypoint_scores (np.ndarray): Keypint score predictions in shape
+ (N, K), in which 0 means the corresponding keypoint is
+ missing in the initial prediction
+ heatmaps (np.ndarry): Heatmaps in shape (K, H, W)
+ tags (np.ndarray): Tagging heatmaps in shape (C, H, W) where
+ C=L*K
+
+ Returns:
+ tuple:
+ - keypoints (np.ndarray): Keypoint predictions with missing
+ ones filled
+ - keypoint_scores (np.ndarray): Keypoint score predictions with
+ missing ones filled
+ """
+
+ N, K = keypoints.shape[:2]
+ H, W = heatmaps.shape[1:]
+ L = tags.shape[0] // K
+ keypoint_tags = [tags[k::K] for k in range(K)]
+
+ for n in range(N):
+ # Calculate the instance tag (mean tag of detected keypoints)
+ _tag = []
+ for k in range(K):
+ if keypoint_scores[n, k] > 0:
+ x, y = keypoints[n, k, :2].astype(np.int64)
+ x = np.clip(x, 0, W - 1)
+ y = np.clip(y, 0, H - 1)
+ _tag.append(keypoint_tags[k][:, y, x])
+
+ tag = np.mean(_tag, axis=0)
+ tag = tag.reshape(L, 1, 1)
+ # Search maximum response of the missing keypoints
+ for k in range(K):
+ if keypoint_scores[n, k] > 0:
+ continue
+ dist_map = np.linalg.norm(
+ keypoint_tags[k] - tag, ord=2, axis=0)
+ cost_map = np.round(dist_map) * 100 - heatmaps[k] # H, W
+ y, x = np.unravel_index(np.argmin(cost_map), shape=(H, W))
+ keypoints[n, k] = [x, y]
+ keypoint_scores[n, k] = heatmaps[k, y, x]
+
+ return keypoints, keypoint_scores
+
+ def batch_decode(self, batch_heatmaps: Tensor, batch_tags: Tensor
+ ) -> Tuple[List[np.ndarray], List[np.ndarray]]:
+ """Decode the keypoint coordinates from a batch of heatmaps and tagging
+ heatmaps. The decoded keypoint coordinates are in the input image
+ space.
+
+ Args:
+ batch_heatmaps (Tensor): Keypoint detection heatmaps in shape
+ (B, K, H, W)
+ batch_tags (Tensor): Tagging heatmaps in shape (B, C, H, W), where
+ :math:`C=L*K`
+
+ Returns:
+ tuple:
+ - batch_keypoints (List[np.ndarray]): Decoded keypoint coordinates
+ of the batch, each is in shape (N, K, D)
+ - batch_scores (List[np.ndarray]): Decoded keypoint scores of the
+ batch, each is in shape (N, K). It usually represents the
+ confidience of the keypoint prediction
+ """
+ B, _, H, W = batch_heatmaps.shape
+ assert batch_tags.shape[0] == B and batch_tags.shape[2:4] == (H, W), (
+ f'Mismatched shapes of heatmap ({batch_heatmaps.shape}) and '
+ f'tagging map ({batch_tags.shape})')
+
+ # Heatmap NMS
+ batch_heatmaps = batch_heatmap_nms(batch_heatmaps,
+ self.decode_nms_kernel)
+
+ # Get top-k in each heatmap and and convert to numpy
+ batch_topk_vals, batch_topk_tags, batch_topk_locs = to_numpy(
+ self._get_batch_topk(
+ batch_heatmaps, batch_tags, k=self.decode_topk))
+
+ # Group keypoint candidates into groups (instances)
+ batch_groups = self._group_keypoints(batch_topk_vals, batch_topk_tags,
+ batch_topk_locs)
+
+ # Convert to numpy
+ batch_heatmaps_np = to_numpy(batch_heatmaps)
+ batch_tags_np = to_numpy(batch_tags)
+
+ # Refine the keypoint prediction
+ batch_keypoints = []
+ batch_keypoint_scores = []
+ for i, (groups, heatmaps, tags) in enumerate(
+ zip(batch_groups, batch_heatmaps_np, batch_tags_np)):
+
+ keypoints, scores = groups[..., :-1], groups[..., -1]
+
+ if keypoints.size > 0:
+ # identify missing keypoints
+ keypoints, scores = self._fill_missing_keypoints(
+ keypoints, scores, heatmaps, tags)
+
+ # refine keypoint coordinates according to heatmap distribution
+ if self.use_udp:
+ keypoints = refine_keypoints_dark_udp(
+ keypoints,
+ heatmaps,
+ blur_kernel_size=self.decode_gaussian_kernel)
+ else:
+ keypoints = refine_keypoints(keypoints, heatmaps)
+
+ batch_keypoints.append(keypoints)
+ batch_keypoint_scores.append(scores)
+
+ # restore keypoint scale
+ batch_keypoints = [
+ kpts * self.scale_factor for kpts in batch_keypoints
+ ]
+
+ return batch_keypoints, batch_keypoint_scores
diff --git a/mmpose/codecs/base.py b/mmpose/codecs/base.py
index d8479fdf1e..945c957cfe 100644
--- a/mmpose/codecs/base.py
+++ b/mmpose/codecs/base.py
@@ -1,77 +1,77 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from abc import ABCMeta, abstractmethod
-from typing import Any, List, Optional, Tuple
-
-import numpy as np
-from mmengine.utils import is_method_overridden
-
-
-class BaseKeypointCodec(metaclass=ABCMeta):
- """The base class of the keypoint codec.
-
- A keypoint codec is a module to encode keypoint coordinates to specific
- representation (e.g. heatmap) and vice versa. A subclass should implement
- the methods :meth:`encode` and :meth:`decode`.
- """
-
- # pass additional encoding arguments to the `encode` method, beyond the
- # mandatory `keypoints` and `keypoints_visible` arguments.
- auxiliary_encode_keys = set()
-
- @abstractmethod
- def encode(self,
- keypoints: np.ndarray,
- keypoints_visible: Optional[np.ndarray] = None) -> dict:
- """Encode keypoints.
-
- Note:
-
- - instance number: N
- - keypoint number: K
- - keypoint dimension: D
-
- Args:
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
- keypoints_visible (np.ndarray): Keypoint visibility in shape
- (N, K, D)
-
- Returns:
- dict: Encoded items.
- """
-
- @abstractmethod
- def decode(self, encoded: Any) -> Tuple[np.ndarray, np.ndarray]:
- """Decode keypoints.
-
- Args:
- encoded (any): Encoded keypoint representation using the codec
-
- Returns:
- tuple:
- - keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
- - keypoints_visible (np.ndarray): Keypoint visibility in shape
- (N, K, D)
- """
-
- def batch_decode(self, batch_encoded: Any
- ) -> Tuple[List[np.ndarray], List[np.ndarray]]:
- """Decode keypoints.
-
- Args:
- batch_encoded (any): A batch of encoded keypoint
- representations
-
- Returns:
- tuple:
- - batch_keypoints (List[np.ndarray]): Each element is keypoint
- coordinates in shape (N, K, D)
- - batch_keypoints (List[np.ndarray]): Each element is keypoint
- visibility in shape (N, K)
- """
- raise NotImplementedError()
-
- @property
- def support_batch_decoding(self) -> bool:
- """Return whether the codec support decoding from batch data."""
- return is_method_overridden('batch_decode', BaseKeypointCodec,
- self.__class__)
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+from typing import Any, List, Optional, Tuple
+
+import numpy as np
+from mmengine.utils import is_method_overridden
+
+
+class BaseKeypointCodec(metaclass=ABCMeta):
+ """The base class of the keypoint codec.
+
+ A keypoint codec is a module to encode keypoint coordinates to specific
+ representation (e.g. heatmap) and vice versa. A subclass should implement
+ the methods :meth:`encode` and :meth:`decode`.
+ """
+
+ # pass additional encoding arguments to the `encode` method, beyond the
+ # mandatory `keypoints` and `keypoints_visible` arguments.
+ auxiliary_encode_keys = set()
+
+ @abstractmethod
+ def encode(self,
+ keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray] = None) -> dict:
+ """Encode keypoints.
+
+ Note:
+
+ - instance number: N
+ - keypoint number: K
+ - keypoint dimension: D
+
+ Args:
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ keypoints_visible (np.ndarray): Keypoint visibility in shape
+ (N, K, D)
+
+ Returns:
+ dict: Encoded items.
+ """
+
+ @abstractmethod
+ def decode(self, encoded: Any) -> Tuple[np.ndarray, np.ndarray]:
+ """Decode keypoints.
+
+ Args:
+ encoded (any): Encoded keypoint representation using the codec
+
+ Returns:
+ tuple:
+ - keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ - keypoints_visible (np.ndarray): Keypoint visibility in shape
+ (N, K, D)
+ """
+
+ def batch_decode(self, batch_encoded: Any
+ ) -> Tuple[List[np.ndarray], List[np.ndarray]]:
+ """Decode keypoints.
+
+ Args:
+ batch_encoded (any): A batch of encoded keypoint
+ representations
+
+ Returns:
+ tuple:
+ - batch_keypoints (List[np.ndarray]): Each element is keypoint
+ coordinates in shape (N, K, D)
+ - batch_keypoints (List[np.ndarray]): Each element is keypoint
+ visibility in shape (N, K)
+ """
+ raise NotImplementedError()
+
+ @property
+ def support_batch_decoding(self) -> bool:
+ """Return whether the codec support decoding from batch data."""
+ return is_method_overridden('batch_decode', BaseKeypointCodec,
+ self.__class__)
diff --git a/mmpose/codecs/decoupled_heatmap.py b/mmpose/codecs/decoupled_heatmap.py
index da38a4ce2c..721f71ab58 100644
--- a/mmpose/codecs/decoupled_heatmap.py
+++ b/mmpose/codecs/decoupled_heatmap.py
@@ -1,265 +1,265 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import random
-from typing import Optional, Tuple
-
-import numpy as np
-
-from mmpose.registry import KEYPOINT_CODECS
-from .base import BaseKeypointCodec
-from .utils import (generate_gaussian_heatmaps, get_diagonal_lengths,
- get_instance_bbox, get_instance_root)
-from .utils.post_processing import get_heatmap_maximum
-from .utils.refinement import refine_keypoints
-
-
-@KEYPOINT_CODECS.register_module()
-class DecoupledHeatmap(BaseKeypointCodec):
- """Encode/decode keypoints with the method introduced in the paper CID.
-
- See the paper Contextual Instance Decoupling for Robust Multi-Person
- Pose Estimation`_ by Wang et al (2022) for details
-
- Note:
-
- - instance number: N
- - keypoint number: K
- - keypoint dimension: D
- - image size: [w, h]
- - heatmap size: [W, H]
-
- Encoded:
- - heatmaps (np.ndarray): The coupled heatmap in shape
- (1+K, H, W) where [W, H] is the `heatmap_size`.
- - instance_heatmaps (np.ndarray): The decoupled heatmap in shape
- (M*K, H, W) where M is the number of instances.
- - keypoint_weights (np.ndarray): The weight for heatmaps in shape
- (M*K).
- - instance_coords (np.ndarray): The coordinates of instance roots
- in shape (M, 2)
-
- Args:
- input_size (tuple): Image size in [w, h]
- heatmap_size (tuple): Heatmap size in [W, H]
- root_type (str): The method to generate the instance root. Options
- are:
-
- - ``'kpt_center'``: Average coordinate of all visible keypoints.
- - ``'bbox_center'``: Center point of bounding boxes outlined by
- all visible keypoints.
-
- Defaults to ``'kpt_center'``
-
- heatmap_min_overlap (float): Minimum overlap rate among instances.
- Used when calculating sigmas for instances. Defaults to 0.7
- background_weight (float): Loss weight of background pixels.
- Defaults to 0.1
- encode_max_instances (int): The maximum number of instances
- to encode for each sample. Defaults to 30
-
- .. _`CID`: https://openaccess.thecvf.com/content/CVPR2022/html/Wang_
- Contextual_Instance_Decoupling_for_Robust_Multi-Person_Pose_Estimation_
- CVPR_2022_paper.html
- """
-
- # DecoupledHeatmap requires bounding boxes to determine the size of each
- # instance, so that it can assign varying sigmas based on their size
- auxiliary_encode_keys = {'bbox'}
-
- def __init__(
- self,
- input_size: Tuple[int, int],
- heatmap_size: Tuple[int, int],
- root_type: str = 'kpt_center',
- heatmap_min_overlap: float = 0.7,
- encode_max_instances: int = 30,
- ):
- super().__init__()
-
- self.input_size = input_size
- self.heatmap_size = heatmap_size
- self.root_type = root_type
- self.encode_max_instances = encode_max_instances
- self.heatmap_min_overlap = heatmap_min_overlap
-
- self.scale_factor = (np.array(input_size) /
- heatmap_size).astype(np.float32)
-
- def _get_instance_wise_sigmas(
- self,
- bbox: np.ndarray,
- ) -> np.ndarray:
- """Get sigma values for each instance according to their size.
-
- Args:
- bbox (np.ndarray): Bounding box in shape (N, 4, 2)
-
- Returns:
- np.ndarray: Array containing the sigma values for each instance.
- """
- sigmas = np.zeros((bbox.shape[0], ), dtype=np.float32)
-
- heights = np.sqrt(np.power(bbox[:, 0] - bbox[:, 1], 2).sum(axis=-1))
- widths = np.sqrt(np.power(bbox[:, 0] - bbox[:, 2], 2).sum(axis=-1))
-
- for i in range(bbox.shape[0]):
- h, w = heights[i], widths[i]
-
- # compute sigma for each instance
- # condition 1
- a1, b1 = 1, h + w
- c1 = w * h * (1 - self.heatmap_min_overlap) / (
- 1 + self.heatmap_min_overlap)
- sq1 = np.sqrt(b1**2 - 4 * a1 * c1)
- r1 = (b1 + sq1) / 2
-
- # condition 2
- a2 = 4
- b2 = 2 * (h + w)
- c2 = (1 - self.heatmap_min_overlap) * w * h
- sq2 = np.sqrt(b2**2 - 4 * a2 * c2)
- r2 = (b2 + sq2) / 2
-
- # condition 3
- a3 = 4 * self.heatmap_min_overlap
- b3 = -2 * self.heatmap_min_overlap * (h + w)
- c3 = (self.heatmap_min_overlap - 1) * w * h
- sq3 = np.sqrt(b3**2 - 4 * a3 * c3)
- r3 = (b3 + sq3) / 2
-
- sigmas[i] = min(r1, r2, r3) / 3
-
- return sigmas
-
- def encode(self,
- keypoints: np.ndarray,
- keypoints_visible: Optional[np.ndarray] = None,
- bbox: Optional[np.ndarray] = None) -> dict:
- """Encode keypoints into heatmaps.
-
- Args:
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
- keypoints_visible (np.ndarray): Keypoint visibilities in shape
- (N, K)
- bbox (np.ndarray): Bounding box in shape (N, 8) which includes
- coordinates of 4 corners.
-
- Returns:
- dict:
- - heatmaps (np.ndarray): The coupled heatmap in shape
- (1+K, H, W) where [W, H] is the `heatmap_size`.
- - instance_heatmaps (np.ndarray): The decoupled heatmap in shape
- (N*K, H, W) where M is the number of instances.
- - keypoint_weights (np.ndarray): The weight for heatmaps in shape
- (N*K).
- - instance_coords (np.ndarray): The coordinates of instance roots
- in shape (N, 2)
- """
-
- if keypoints_visible is None:
- keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
- if bbox is None:
- # generate pseudo bbox via visible keypoints
- bbox = get_instance_bbox(keypoints, keypoints_visible)
- bbox = np.tile(bbox, 2).reshape(-1, 4, 2)
- # corner order: left_top, left_bottom, right_top, right_bottom
- bbox[:, 1:3, 0] = bbox[:, 0:2, 0]
-
- # keypoint coordinates in heatmap
- _keypoints = keypoints / self.scale_factor
- _bbox = bbox.reshape(-1, 4, 2) / self.scale_factor
-
- # compute the root and scale of each instance
- roots, roots_visible = get_instance_root(_keypoints, keypoints_visible,
- self.root_type)
-
- sigmas = self._get_instance_wise_sigmas(_bbox)
-
- # generate global heatmaps
- heatmaps, keypoint_weights = generate_gaussian_heatmaps(
- heatmap_size=self.heatmap_size,
- keypoints=np.concatenate((_keypoints, roots[:, None]), axis=1),
- keypoints_visible=np.concatenate(
- (keypoints_visible, roots_visible[:, None]), axis=1),
- sigma=sigmas)
- roots_visible = keypoint_weights[:, -1]
-
- # select instances
- inst_roots, inst_indices = [], []
- diagonal_lengths = get_diagonal_lengths(_keypoints, keypoints_visible)
- for i in np.argsort(diagonal_lengths):
- if roots_visible[i] < 1:
- continue
- # rand root point in 3x3 grid
- x, y = roots[i] + np.random.randint(-1, 2, (2, ))
- x = max(0, min(x, self.heatmap_size[0] - 1))
- y = max(0, min(y, self.heatmap_size[1] - 1))
- if (x, y) not in inst_roots:
- inst_roots.append((x, y))
- inst_indices.append(i)
- if len(inst_indices) > self.encode_max_instances:
- rand_indices = random.sample(
- range(len(inst_indices)), self.encode_max_instances)
- inst_roots = [inst_roots[i] for i in rand_indices]
- inst_indices = [inst_indices[i] for i in rand_indices]
-
- # generate instance-wise heatmaps
- inst_heatmaps, inst_heatmap_weights = [], []
- for i in inst_indices:
- inst_heatmap, inst_heatmap_weight = generate_gaussian_heatmaps(
- heatmap_size=self.heatmap_size,
- keypoints=_keypoints[i:i + 1],
- keypoints_visible=keypoints_visible[i:i + 1],
- sigma=sigmas[i].item())
- inst_heatmaps.append(inst_heatmap)
- inst_heatmap_weights.append(inst_heatmap_weight)
-
- if len(inst_indices) > 0:
- inst_heatmaps = np.concatenate(inst_heatmaps)
- inst_heatmap_weights = np.concatenate(inst_heatmap_weights)
- inst_roots = np.array(inst_roots, dtype=np.int32)
- else:
- inst_heatmaps = np.empty((0, *self.heatmap_size[::-1]))
- inst_heatmap_weights = np.empty((0, ))
- inst_roots = np.empty((0, 2), dtype=np.int32)
-
- encoded = dict(
- heatmaps=heatmaps,
- instance_heatmaps=inst_heatmaps,
- keypoint_weights=inst_heatmap_weights,
- instance_coords=inst_roots)
-
- return encoded
-
- def decode(self, instance_heatmaps: np.ndarray,
- instance_scores: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
- """Decode keypoint coordinates from decoupled heatmaps. The decoded
- keypoint coordinates are in the input image space.
-
- Args:
- instance_heatmaps (np.ndarray): Heatmaps in shape (N, K, H, W)
- instance_scores (np.ndarray): Confidence of instance roots
- prediction in shape (N, 1)
-
- Returns:
- tuple:
- - keypoints (np.ndarray): Decoded keypoint coordinates in shape
- (N, K, D)
- - scores (np.ndarray): The keypoint scores in shape (N, K). It
- usually represents the confidence of the keypoint prediction
- """
- keypoints, keypoint_scores = [], []
-
- for i in range(instance_heatmaps.shape[0]):
- heatmaps = instance_heatmaps[i].copy()
- kpts, scores = get_heatmap_maximum(heatmaps)
- keypoints.append(refine_keypoints(kpts[None], heatmaps))
- keypoint_scores.append(scores[None])
-
- keypoints = np.concatenate(keypoints)
- # Restore the keypoint scale
- keypoints = keypoints * self.scale_factor
-
- keypoint_scores = np.concatenate(keypoint_scores)
- keypoint_scores *= instance_scores
-
- return keypoints, keypoint_scores
+# Copyright (c) OpenMMLab. All rights reserved.
+import random
+from typing import Optional, Tuple
+
+import numpy as np
+
+from mmpose.registry import KEYPOINT_CODECS
+from .base import BaseKeypointCodec
+from .utils import (generate_gaussian_heatmaps, get_diagonal_lengths,
+ get_instance_bbox, get_instance_root)
+from .utils.post_processing import get_heatmap_maximum
+from .utils.refinement import refine_keypoints
+
+
+@KEYPOINT_CODECS.register_module()
+class DecoupledHeatmap(BaseKeypointCodec):
+ """Encode/decode keypoints with the method introduced in the paper CID.
+
+ See the paper Contextual Instance Decoupling for Robust Multi-Person
+ Pose Estimation`_ by Wang et al (2022) for details
+
+ Note:
+
+ - instance number: N
+ - keypoint number: K
+ - keypoint dimension: D
+ - image size: [w, h]
+ - heatmap size: [W, H]
+
+ Encoded:
+ - heatmaps (np.ndarray): The coupled heatmap in shape
+ (1+K, H, W) where [W, H] is the `heatmap_size`.
+ - instance_heatmaps (np.ndarray): The decoupled heatmap in shape
+ (M*K, H, W) where M is the number of instances.
+ - keypoint_weights (np.ndarray): The weight for heatmaps in shape
+ (M*K).
+ - instance_coords (np.ndarray): The coordinates of instance roots
+ in shape (M, 2)
+
+ Args:
+ input_size (tuple): Image size in [w, h]
+ heatmap_size (tuple): Heatmap size in [W, H]
+ root_type (str): The method to generate the instance root. Options
+ are:
+
+ - ``'kpt_center'``: Average coordinate of all visible keypoints.
+ - ``'bbox_center'``: Center point of bounding boxes outlined by
+ all visible keypoints.
+
+ Defaults to ``'kpt_center'``
+
+ heatmap_min_overlap (float): Minimum overlap rate among instances.
+ Used when calculating sigmas for instances. Defaults to 0.7
+ background_weight (float): Loss weight of background pixels.
+ Defaults to 0.1
+ encode_max_instances (int): The maximum number of instances
+ to encode for each sample. Defaults to 30
+
+ .. _`CID`: https://openaccess.thecvf.com/content/CVPR2022/html/Wang_
+ Contextual_Instance_Decoupling_for_Robust_Multi-Person_Pose_Estimation_
+ CVPR_2022_paper.html
+ """
+
+ # DecoupledHeatmap requires bounding boxes to determine the size of each
+ # instance, so that it can assign varying sigmas based on their size
+ auxiliary_encode_keys = {'bbox'}
+
+ def __init__(
+ self,
+ input_size: Tuple[int, int],
+ heatmap_size: Tuple[int, int],
+ root_type: str = 'kpt_center',
+ heatmap_min_overlap: float = 0.7,
+ encode_max_instances: int = 30,
+ ):
+ super().__init__()
+
+ self.input_size = input_size
+ self.heatmap_size = heatmap_size
+ self.root_type = root_type
+ self.encode_max_instances = encode_max_instances
+ self.heatmap_min_overlap = heatmap_min_overlap
+
+ self.scale_factor = (np.array(input_size) /
+ heatmap_size).astype(np.float32)
+
+ def _get_instance_wise_sigmas(
+ self,
+ bbox: np.ndarray,
+ ) -> np.ndarray:
+ """Get sigma values for each instance according to their size.
+
+ Args:
+ bbox (np.ndarray): Bounding box in shape (N, 4, 2)
+
+ Returns:
+ np.ndarray: Array containing the sigma values for each instance.
+ """
+ sigmas = np.zeros((bbox.shape[0], ), dtype=np.float32)
+
+ heights = np.sqrt(np.power(bbox[:, 0] - bbox[:, 1], 2).sum(axis=-1))
+ widths = np.sqrt(np.power(bbox[:, 0] - bbox[:, 2], 2).sum(axis=-1))
+
+ for i in range(bbox.shape[0]):
+ h, w = heights[i], widths[i]
+
+ # compute sigma for each instance
+ # condition 1
+ a1, b1 = 1, h + w
+ c1 = w * h * (1 - self.heatmap_min_overlap) / (
+ 1 + self.heatmap_min_overlap)
+ sq1 = np.sqrt(b1**2 - 4 * a1 * c1)
+ r1 = (b1 + sq1) / 2
+
+ # condition 2
+ a2 = 4
+ b2 = 2 * (h + w)
+ c2 = (1 - self.heatmap_min_overlap) * w * h
+ sq2 = np.sqrt(b2**2 - 4 * a2 * c2)
+ r2 = (b2 + sq2) / 2
+
+ # condition 3
+ a3 = 4 * self.heatmap_min_overlap
+ b3 = -2 * self.heatmap_min_overlap * (h + w)
+ c3 = (self.heatmap_min_overlap - 1) * w * h
+ sq3 = np.sqrt(b3**2 - 4 * a3 * c3)
+ r3 = (b3 + sq3) / 2
+
+ sigmas[i] = min(r1, r2, r3) / 3
+
+ return sigmas
+
+ def encode(self,
+ keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray] = None,
+ bbox: Optional[np.ndarray] = None) -> dict:
+ """Encode keypoints into heatmaps.
+
+ Args:
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ keypoints_visible (np.ndarray): Keypoint visibilities in shape
+ (N, K)
+ bbox (np.ndarray): Bounding box in shape (N, 8) which includes
+ coordinates of 4 corners.
+
+ Returns:
+ dict:
+ - heatmaps (np.ndarray): The coupled heatmap in shape
+ (1+K, H, W) where [W, H] is the `heatmap_size`.
+ - instance_heatmaps (np.ndarray): The decoupled heatmap in shape
+ (N*K, H, W) where M is the number of instances.
+ - keypoint_weights (np.ndarray): The weight for heatmaps in shape
+ (N*K).
+ - instance_coords (np.ndarray): The coordinates of instance roots
+ in shape (N, 2)
+ """
+
+ if keypoints_visible is None:
+ keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
+ if bbox is None:
+ # generate pseudo bbox via visible keypoints
+ bbox = get_instance_bbox(keypoints, keypoints_visible)
+ bbox = np.tile(bbox, 2).reshape(-1, 4, 2)
+ # corner order: left_top, left_bottom, right_top, right_bottom
+ bbox[:, 1:3, 0] = bbox[:, 0:2, 0]
+
+ # keypoint coordinates in heatmap
+ _keypoints = keypoints / self.scale_factor
+ _bbox = bbox.reshape(-1, 4, 2) / self.scale_factor
+
+ # compute the root and scale of each instance
+ roots, roots_visible = get_instance_root(_keypoints, keypoints_visible,
+ self.root_type)
+
+ sigmas = self._get_instance_wise_sigmas(_bbox)
+
+ # generate global heatmaps
+ heatmaps, keypoint_weights = generate_gaussian_heatmaps(
+ heatmap_size=self.heatmap_size,
+ keypoints=np.concatenate((_keypoints, roots[:, None]), axis=1),
+ keypoints_visible=np.concatenate(
+ (keypoints_visible, roots_visible[:, None]), axis=1),
+ sigma=sigmas)
+ roots_visible = keypoint_weights[:, -1]
+
+ # select instances
+ inst_roots, inst_indices = [], []
+ diagonal_lengths = get_diagonal_lengths(_keypoints, keypoints_visible)
+ for i in np.argsort(diagonal_lengths):
+ if roots_visible[i] < 1:
+ continue
+ # rand root point in 3x3 grid
+ x, y = roots[i] + np.random.randint(-1, 2, (2, ))
+ x = max(0, min(x, self.heatmap_size[0] - 1))
+ y = max(0, min(y, self.heatmap_size[1] - 1))
+ if (x, y) not in inst_roots:
+ inst_roots.append((x, y))
+ inst_indices.append(i)
+ if len(inst_indices) > self.encode_max_instances:
+ rand_indices = random.sample(
+ range(len(inst_indices)), self.encode_max_instances)
+ inst_roots = [inst_roots[i] for i in rand_indices]
+ inst_indices = [inst_indices[i] for i in rand_indices]
+
+ # generate instance-wise heatmaps
+ inst_heatmaps, inst_heatmap_weights = [], []
+ for i in inst_indices:
+ inst_heatmap, inst_heatmap_weight = generate_gaussian_heatmaps(
+ heatmap_size=self.heatmap_size,
+ keypoints=_keypoints[i:i + 1],
+ keypoints_visible=keypoints_visible[i:i + 1],
+ sigma=sigmas[i].item())
+ inst_heatmaps.append(inst_heatmap)
+ inst_heatmap_weights.append(inst_heatmap_weight)
+
+ if len(inst_indices) > 0:
+ inst_heatmaps = np.concatenate(inst_heatmaps)
+ inst_heatmap_weights = np.concatenate(inst_heatmap_weights)
+ inst_roots = np.array(inst_roots, dtype=np.int32)
+ else:
+ inst_heatmaps = np.empty((0, *self.heatmap_size[::-1]))
+ inst_heatmap_weights = np.empty((0, ))
+ inst_roots = np.empty((0, 2), dtype=np.int32)
+
+ encoded = dict(
+ heatmaps=heatmaps,
+ instance_heatmaps=inst_heatmaps,
+ keypoint_weights=inst_heatmap_weights,
+ instance_coords=inst_roots)
+
+ return encoded
+
+ def decode(self, instance_heatmaps: np.ndarray,
+ instance_scores: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ """Decode keypoint coordinates from decoupled heatmaps. The decoded
+ keypoint coordinates are in the input image space.
+
+ Args:
+ instance_heatmaps (np.ndarray): Heatmaps in shape (N, K, H, W)
+ instance_scores (np.ndarray): Confidence of instance roots
+ prediction in shape (N, 1)
+
+ Returns:
+ tuple:
+ - keypoints (np.ndarray): Decoded keypoint coordinates in shape
+ (N, K, D)
+ - scores (np.ndarray): The keypoint scores in shape (N, K). It
+ usually represents the confidence of the keypoint prediction
+ """
+ keypoints, keypoint_scores = [], []
+
+ for i in range(instance_heatmaps.shape[0]):
+ heatmaps = instance_heatmaps[i].copy()
+ kpts, scores = get_heatmap_maximum(heatmaps)
+ keypoints.append(refine_keypoints(kpts[None], heatmaps))
+ keypoint_scores.append(scores[None])
+
+ keypoints = np.concatenate(keypoints)
+ # Restore the keypoint scale
+ keypoints = keypoints * self.scale_factor
+
+ keypoint_scores = np.concatenate(keypoint_scores)
+ keypoint_scores *= instance_scores
+
+ return keypoints, keypoint_scores
diff --git a/mmpose/codecs/image_pose_lifting.py b/mmpose/codecs/image_pose_lifting.py
index 64bf925997..e43d9abb9f 100644
--- a/mmpose/codecs/image_pose_lifting.py
+++ b/mmpose/codecs/image_pose_lifting.py
@@ -1,203 +1,203 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional, Tuple
-
-import numpy as np
-
-from mmpose.registry import KEYPOINT_CODECS
-from .base import BaseKeypointCodec
-
-
-@KEYPOINT_CODECS.register_module()
-class ImagePoseLifting(BaseKeypointCodec):
- r"""Generate keypoint coordinates for pose lifter.
-
- Note:
-
- - instance number: N
- - keypoint number: K
- - keypoint dimension: D
- - pose-lifitng target dimension: C
-
- Args:
- num_keypoints (int): The number of keypoints in the dataset.
- root_index (int): Root keypoint index in the pose.
- remove_root (bool): If true, remove the root keypoint from the pose.
- Default: ``False``.
- save_index (bool): If true, store the root position separated from the
- original pose. Default: ``False``.
- keypoints_mean (np.ndarray, optional): Mean values of keypoints
- coordinates in shape (K, D).
- keypoints_std (np.ndarray, optional): Std values of keypoints
- coordinates in shape (K, D).
- target_mean (np.ndarray, optional): Mean values of pose-lifitng target
- coordinates in shape (K, C).
- target_std (np.ndarray, optional): Std values of pose-lifitng target
- coordinates in shape (K, C).
- """
-
- auxiliary_encode_keys = {'lifting_target', 'lifting_target_visible'}
-
- def __init__(self,
- num_keypoints: int,
- root_index: int,
- remove_root: bool = False,
- save_index: bool = False,
- keypoints_mean: Optional[np.ndarray] = None,
- keypoints_std: Optional[np.ndarray] = None,
- target_mean: Optional[np.ndarray] = None,
- target_std: Optional[np.ndarray] = None):
- super().__init__()
-
- self.num_keypoints = num_keypoints
- self.root_index = root_index
- self.remove_root = remove_root
- self.save_index = save_index
- if keypoints_mean is not None and keypoints_std is not None:
- assert keypoints_mean.shape == keypoints_std.shape
- if target_mean is not None and target_std is not None:
- assert target_mean.shape == target_std.shape
- self.keypoints_mean = keypoints_mean
- self.keypoints_std = keypoints_std
- self.target_mean = target_mean
- self.target_std = target_std
-
- def encode(self,
- keypoints: np.ndarray,
- keypoints_visible: Optional[np.ndarray] = None,
- lifting_target: Optional[np.ndarray] = None,
- lifting_target_visible: Optional[np.ndarray] = None) -> dict:
- """Encoding keypoints from input image space to normalized space.
-
- Args:
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D).
- keypoints_visible (np.ndarray, optional): Keypoint visibilities in
- shape (N, K).
- lifting_target (np.ndarray, optional): 3d target coordinate in
- shape (K, C).
- lifting_target_visible (np.ndarray, optional): Target coordinate in
- shape (K, ).
-
- Returns:
- encoded (dict): Contains the following items:
-
- - keypoint_labels (np.ndarray): The processed keypoints in
- shape (K * D, N) where D is 2 for 2d coordinates.
- - lifting_target_label: The processed target coordinate in
- shape (K, C) or (K-1, C).
- - lifting_target_weights (np.ndarray): The target weights in
- shape (K, ) or (K-1, ).
- - trajectory_weights (np.ndarray): The trajectory weights in
- shape (K, ).
- - target_root (np.ndarray): The root coordinate of target in
- shape (C, ).
-
- In addition, there are some optional items it may contain:
-
- - target_root_removed (bool): Indicate whether the root of
- pose lifting target is removed. Added if ``self.remove_root``
- is ``True``.
- - target_root_index (int): An integer indicating the index of
- root. Added if ``self.remove_root`` and ``self.save_index``
- are ``True``.
- """
- if keypoints_visible is None:
- keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
-
- if lifting_target is None:
- lifting_target = keypoints[0]
-
- # set initial value for `lifting_target_weights`
- # and `trajectory_weights`
- if lifting_target_visible is None:
- lifting_target_visible = np.ones(
- lifting_target.shape[:-1], dtype=np.float32)
- lifting_target_weights = lifting_target_visible
- trajectory_weights = (1 / lifting_target[:, 2])
- else:
- valid = lifting_target_visible > 0.5
- lifting_target_weights = np.where(valid, 1., 0.).astype(np.float32)
- trajectory_weights = lifting_target_weights
-
- encoded = dict()
-
- # Zero-center the target pose around a given root keypoint
- assert (lifting_target.ndim >= 2 and
- lifting_target.shape[-2] > self.root_index), \
- f'Got invalid joint shape {lifting_target.shape}'
-
- root = lifting_target[..., self.root_index, :]
- lifting_target_label = lifting_target - root
-
- if self.remove_root:
- lifting_target_label = np.delete(
- lifting_target_label, self.root_index, axis=-2)
- assert lifting_target_weights.ndim in {1, 2}
- axis_to_remove = -2 if lifting_target_weights.ndim == 2 else -1
- lifting_target_weights = np.delete(
- lifting_target_weights, self.root_index, axis=axis_to_remove)
- # Add a flag to avoid latter transforms that rely on the root
- # joint or the original joint index
- encoded['target_root_removed'] = True
-
- # Save the root index which is necessary to restore the global pose
- if self.save_index:
- encoded['target_root_index'] = self.root_index
-
- # Normalize the 2D keypoint coordinate with mean and std
- keypoint_labels = keypoints.copy()
- if self.keypoints_mean is not None and self.keypoints_std is not None:
- keypoints_shape = keypoints.shape
- assert self.keypoints_mean.shape == keypoints_shape[1:]
-
- keypoint_labels = (keypoint_labels -
- self.keypoints_mean) / self.keypoints_std
- if self.target_mean is not None and self.target_std is not None:
- target_shape = lifting_target_label.shape
- assert self.target_mean.shape == target_shape
-
- lifting_target_label = (lifting_target_label -
- self.target_mean) / self.target_std
-
- # Generate reshaped keypoint coordinates
- assert keypoint_labels.ndim in {2, 3}
- if keypoint_labels.ndim == 2:
- keypoint_labels = keypoint_labels[None, ...]
-
- encoded['keypoint_labels'] = keypoint_labels
- encoded['lifting_target_label'] = lifting_target_label
- encoded['lifting_target_weights'] = lifting_target_weights
- encoded['trajectory_weights'] = trajectory_weights
- encoded['target_root'] = root
-
- return encoded
-
- def decode(self,
- encoded: np.ndarray,
- target_root: Optional[np.ndarray] = None
- ) -> Tuple[np.ndarray, np.ndarray]:
- """Decode keypoint coordinates from normalized space to input image
- space.
-
- Args:
- encoded (np.ndarray): Coordinates in shape (N, K, C).
- target_root (np.ndarray, optional): The target root coordinate.
- Default: ``None``.
-
- Returns:
- keypoints (np.ndarray): Decoded coordinates in shape (N, K, C).
- scores (np.ndarray): The keypoint scores in shape (N, K).
- """
- keypoints = encoded.copy()
-
- if self.target_mean is not None and self.target_std is not None:
- assert self.target_mean.shape == keypoints.shape[1:]
- keypoints = keypoints * self.target_std + self.target_mean
-
- if target_root.size > 0:
- keypoints = keypoints + np.expand_dims(target_root, axis=0)
- if self.remove_root:
- keypoints = np.insert(
- keypoints, self.root_index, target_root, axis=1)
- scores = np.ones(keypoints.shape[:-1], dtype=np.float32)
-
- return keypoints, scores
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import numpy as np
+
+from mmpose.registry import KEYPOINT_CODECS
+from .base import BaseKeypointCodec
+
+
+@KEYPOINT_CODECS.register_module()
+class ImagePoseLifting(BaseKeypointCodec):
+ r"""Generate keypoint coordinates for pose lifter.
+
+ Note:
+
+ - instance number: N
+ - keypoint number: K
+ - keypoint dimension: D
+ - pose-lifitng target dimension: C
+
+ Args:
+ num_keypoints (int): The number of keypoints in the dataset.
+ root_index (int): Root keypoint index in the pose.
+ remove_root (bool): If true, remove the root keypoint from the pose.
+ Default: ``False``.
+ save_index (bool): If true, store the root position separated from the
+ original pose. Default: ``False``.
+ keypoints_mean (np.ndarray, optional): Mean values of keypoints
+ coordinates in shape (K, D).
+ keypoints_std (np.ndarray, optional): Std values of keypoints
+ coordinates in shape (K, D).
+ target_mean (np.ndarray, optional): Mean values of pose-lifitng target
+ coordinates in shape (K, C).
+ target_std (np.ndarray, optional): Std values of pose-lifitng target
+ coordinates in shape (K, C).
+ """
+
+ auxiliary_encode_keys = {'lifting_target', 'lifting_target_visible'}
+
+ def __init__(self,
+ num_keypoints: int,
+ root_index: int,
+ remove_root: bool = False,
+ save_index: bool = False,
+ keypoints_mean: Optional[np.ndarray] = None,
+ keypoints_std: Optional[np.ndarray] = None,
+ target_mean: Optional[np.ndarray] = None,
+ target_std: Optional[np.ndarray] = None):
+ super().__init__()
+
+ self.num_keypoints = num_keypoints
+ self.root_index = root_index
+ self.remove_root = remove_root
+ self.save_index = save_index
+ if keypoints_mean is not None and keypoints_std is not None:
+ assert keypoints_mean.shape == keypoints_std.shape
+ if target_mean is not None and target_std is not None:
+ assert target_mean.shape == target_std.shape
+ self.keypoints_mean = keypoints_mean
+ self.keypoints_std = keypoints_std
+ self.target_mean = target_mean
+ self.target_std = target_std
+
+ def encode(self,
+ keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray] = None,
+ lifting_target: Optional[np.ndarray] = None,
+ lifting_target_visible: Optional[np.ndarray] = None) -> dict:
+ """Encoding keypoints from input image space to normalized space.
+
+ Args:
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D).
+ keypoints_visible (np.ndarray, optional): Keypoint visibilities in
+ shape (N, K).
+ lifting_target (np.ndarray, optional): 3d target coordinate in
+ shape (K, C).
+ lifting_target_visible (np.ndarray, optional): Target coordinate in
+ shape (K, ).
+
+ Returns:
+ encoded (dict): Contains the following items:
+
+ - keypoint_labels (np.ndarray): The processed keypoints in
+ shape (K * D, N) where D is 2 for 2d coordinates.
+ - lifting_target_label: The processed target coordinate in
+ shape (K, C) or (K-1, C).
+ - lifting_target_weights (np.ndarray): The target weights in
+ shape (K, ) or (K-1, ).
+ - trajectory_weights (np.ndarray): The trajectory weights in
+ shape (K, ).
+ - target_root (np.ndarray): The root coordinate of target in
+ shape (C, ).
+
+ In addition, there are some optional items it may contain:
+
+ - target_root_removed (bool): Indicate whether the root of
+ pose lifting target is removed. Added if ``self.remove_root``
+ is ``True``.
+ - target_root_index (int): An integer indicating the index of
+ root. Added if ``self.remove_root`` and ``self.save_index``
+ are ``True``.
+ """
+ if keypoints_visible is None:
+ keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
+
+ if lifting_target is None:
+ lifting_target = keypoints[0]
+
+ # set initial value for `lifting_target_weights`
+ # and `trajectory_weights`
+ if lifting_target_visible is None:
+ lifting_target_visible = np.ones(
+ lifting_target.shape[:-1], dtype=np.float32)
+ lifting_target_weights = lifting_target_visible
+ trajectory_weights = (1 / lifting_target[:, 2])
+ else:
+ valid = lifting_target_visible > 0.5
+ lifting_target_weights = np.where(valid, 1., 0.).astype(np.float32)
+ trajectory_weights = lifting_target_weights
+
+ encoded = dict()
+
+ # Zero-center the target pose around a given root keypoint
+ assert (lifting_target.ndim >= 2 and
+ lifting_target.shape[-2] > self.root_index), \
+ f'Got invalid joint shape {lifting_target.shape}'
+
+ root = lifting_target[..., self.root_index, :]
+ lifting_target_label = lifting_target - root
+
+ if self.remove_root:
+ lifting_target_label = np.delete(
+ lifting_target_label, self.root_index, axis=-2)
+ assert lifting_target_weights.ndim in {1, 2}
+ axis_to_remove = -2 if lifting_target_weights.ndim == 2 else -1
+ lifting_target_weights = np.delete(
+ lifting_target_weights, self.root_index, axis=axis_to_remove)
+ # Add a flag to avoid latter transforms that rely on the root
+ # joint or the original joint index
+ encoded['target_root_removed'] = True
+
+ # Save the root index which is necessary to restore the global pose
+ if self.save_index:
+ encoded['target_root_index'] = self.root_index
+
+ # Normalize the 2D keypoint coordinate with mean and std
+ keypoint_labels = keypoints.copy()
+ if self.keypoints_mean is not None and self.keypoints_std is not None:
+ keypoints_shape = keypoints.shape
+ assert self.keypoints_mean.shape == keypoints_shape[1:]
+
+ keypoint_labels = (keypoint_labels -
+ self.keypoints_mean) / self.keypoints_std
+ if self.target_mean is not None and self.target_std is not None:
+ target_shape = lifting_target_label.shape
+ assert self.target_mean.shape == target_shape
+
+ lifting_target_label = (lifting_target_label -
+ self.target_mean) / self.target_std
+
+ # Generate reshaped keypoint coordinates
+ assert keypoint_labels.ndim in {2, 3}
+ if keypoint_labels.ndim == 2:
+ keypoint_labels = keypoint_labels[None, ...]
+
+ encoded['keypoint_labels'] = keypoint_labels
+ encoded['lifting_target_label'] = lifting_target_label
+ encoded['lifting_target_weights'] = lifting_target_weights
+ encoded['trajectory_weights'] = trajectory_weights
+ encoded['target_root'] = root
+
+ return encoded
+
+ def decode(self,
+ encoded: np.ndarray,
+ target_root: Optional[np.ndarray] = None
+ ) -> Tuple[np.ndarray, np.ndarray]:
+ """Decode keypoint coordinates from normalized space to input image
+ space.
+
+ Args:
+ encoded (np.ndarray): Coordinates in shape (N, K, C).
+ target_root (np.ndarray, optional): The target root coordinate.
+ Default: ``None``.
+
+ Returns:
+ keypoints (np.ndarray): Decoded coordinates in shape (N, K, C).
+ scores (np.ndarray): The keypoint scores in shape (N, K).
+ """
+ keypoints = encoded.copy()
+
+ if self.target_mean is not None and self.target_std is not None:
+ assert self.target_mean.shape == keypoints.shape[1:]
+ keypoints = keypoints * self.target_std + self.target_mean
+
+ if target_root.size > 0:
+ keypoints = keypoints + np.expand_dims(target_root, axis=0)
+ if self.remove_root:
+ keypoints = np.insert(
+ keypoints, self.root_index, target_root, axis=1)
+ scores = np.ones(keypoints.shape[:-1], dtype=np.float32)
+
+ return keypoints, scores
diff --git a/mmpose/codecs/integral_regression_label.py b/mmpose/codecs/integral_regression_label.py
index ed8e72cb10..08f93f91c8 100644
--- a/mmpose/codecs/integral_regression_label.py
+++ b/mmpose/codecs/integral_regression_label.py
@@ -1,115 +1,115 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-
-from typing import Optional, Tuple
-
-import numpy as np
-
-from mmpose.registry import KEYPOINT_CODECS
-from .base import BaseKeypointCodec
-from .msra_heatmap import MSRAHeatmap
-from .regression_label import RegressionLabel
-
-
-@KEYPOINT_CODECS.register_module()
-class IntegralRegressionLabel(BaseKeypointCodec):
- """Generate keypoint coordinates and normalized heatmaps. See the paper:
- `DSNT`_ by Nibali et al(2018).
-
- Note:
-
- - instance number: N
- - keypoint number: K
- - keypoint dimension: D
- - image size: [w, h]
-
- Encoded:
-
- - keypoint_labels (np.ndarray): The normalized regression labels in
- shape (N, K, D) where D is 2 for 2d coordinates
- - heatmaps (np.ndarray): The generated heatmap in shape (K, H, W) where
- [W, H] is the `heatmap_size`
- - keypoint_weights (np.ndarray): The target weights in shape (N, K)
-
- Args:
- input_size (tuple): Input image size in [w, h]
- heatmap_size (tuple): Heatmap size in [W, H]
- sigma (float): The sigma value of the Gaussian heatmap
- unbiased (bool): Whether use unbiased method (DarkPose) in ``'msra'``
- encoding. See `Dark Pose`_ for details. Defaults to ``False``
- blur_kernel_size (int): The Gaussian blur kernel size of the heatmap
- modulation in DarkPose. The kernel size and sigma should follow
- the expirical formula :math:`sigma = 0.3*((ks-1)*0.5-1)+0.8`.
- Defaults to 11
- normalize (bool): Whether to normalize the heatmaps. Defaults to True.
-
- .. _`DSNT`: https://arxiv.org/abs/1801.07372
- """
-
- def __init__(self,
- input_size: Tuple[int, int],
- heatmap_size: Tuple[int, int],
- sigma: float,
- unbiased: bool = False,
- blur_kernel_size: int = 11,
- normalize: bool = True) -> None:
- super().__init__()
-
- self.heatmap_codec = MSRAHeatmap(input_size, heatmap_size, sigma,
- unbiased, blur_kernel_size)
- self.keypoint_codec = RegressionLabel(input_size)
- self.normalize = normalize
-
- def encode(self,
- keypoints: np.ndarray,
- keypoints_visible: Optional[np.ndarray] = None) -> dict:
- """Encoding keypoints to regression labels and heatmaps.
-
- Args:
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
- keypoints_visible (np.ndarray): Keypoint visibilities in shape
- (N, K)
-
- Returns:
- dict:
- - keypoint_labels (np.ndarray): The normalized regression labels in
- shape (N, K, D) where D is 2 for 2d coordinates
- - heatmaps (np.ndarray): The generated heatmap in shape
- (K, H, W) where [W, H] is the `heatmap_size`
- - keypoint_weights (np.ndarray): The target weights in shape
- (N, K)
- """
- encoded_hm = self.heatmap_codec.encode(keypoints, keypoints_visible)
- encoded_kp = self.keypoint_codec.encode(keypoints, keypoints_visible)
-
- heatmaps = encoded_hm['heatmaps']
- keypoint_labels = encoded_kp['keypoint_labels']
- keypoint_weights = encoded_kp['keypoint_weights']
-
- if self.normalize:
- val_sum = heatmaps.sum(axis=(-1, -2)).reshape(-1, 1, 1) + 1e-24
- heatmaps = heatmaps / val_sum
-
- encoded = dict(
- keypoint_labels=keypoint_labels,
- heatmaps=heatmaps,
- keypoint_weights=keypoint_weights)
-
- return encoded
-
- def decode(self, encoded: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
- """Decode keypoint coordinates from normalized space to input image
- space.
-
- Args:
- encoded (np.ndarray): Coordinates in shape (N, K, D)
-
- Returns:
- tuple:
- - keypoints (np.ndarray): Decoded coordinates in shape (N, K, D)
- - socres (np.ndarray): The keypoint scores in shape (N, K).
- It usually represents the confidence of the keypoint prediction
- """
-
- keypoints, scores = self.keypoint_codec.decode(encoded)
-
- return keypoints, scores
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from typing import Optional, Tuple
+
+import numpy as np
+
+from mmpose.registry import KEYPOINT_CODECS
+from .base import BaseKeypointCodec
+from .msra_heatmap import MSRAHeatmap
+from .regression_label import RegressionLabel
+
+
+@KEYPOINT_CODECS.register_module()
+class IntegralRegressionLabel(BaseKeypointCodec):
+ """Generate keypoint coordinates and normalized heatmaps. See the paper:
+ `DSNT`_ by Nibali et al(2018).
+
+ Note:
+
+ - instance number: N
+ - keypoint number: K
+ - keypoint dimension: D
+ - image size: [w, h]
+
+ Encoded:
+
+ - keypoint_labels (np.ndarray): The normalized regression labels in
+ shape (N, K, D) where D is 2 for 2d coordinates
+ - heatmaps (np.ndarray): The generated heatmap in shape (K, H, W) where
+ [W, H] is the `heatmap_size`
+ - keypoint_weights (np.ndarray): The target weights in shape (N, K)
+
+ Args:
+ input_size (tuple): Input image size in [w, h]
+ heatmap_size (tuple): Heatmap size in [W, H]
+ sigma (float): The sigma value of the Gaussian heatmap
+ unbiased (bool): Whether use unbiased method (DarkPose) in ``'msra'``
+ encoding. See `Dark Pose`_ for details. Defaults to ``False``
+ blur_kernel_size (int): The Gaussian blur kernel size of the heatmap
+ modulation in DarkPose. The kernel size and sigma should follow
+ the expirical formula :math:`sigma = 0.3*((ks-1)*0.5-1)+0.8`.
+ Defaults to 11
+ normalize (bool): Whether to normalize the heatmaps. Defaults to True.
+
+ .. _`DSNT`: https://arxiv.org/abs/1801.07372
+ """
+
+ def __init__(self,
+ input_size: Tuple[int, int],
+ heatmap_size: Tuple[int, int],
+ sigma: float,
+ unbiased: bool = False,
+ blur_kernel_size: int = 11,
+ normalize: bool = True) -> None:
+ super().__init__()
+
+ self.heatmap_codec = MSRAHeatmap(input_size, heatmap_size, sigma,
+ unbiased, blur_kernel_size)
+ self.keypoint_codec = RegressionLabel(input_size)
+ self.normalize = normalize
+
+ def encode(self,
+ keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray] = None) -> dict:
+ """Encoding keypoints to regression labels and heatmaps.
+
+ Args:
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ keypoints_visible (np.ndarray): Keypoint visibilities in shape
+ (N, K)
+
+ Returns:
+ dict:
+ - keypoint_labels (np.ndarray): The normalized regression labels in
+ shape (N, K, D) where D is 2 for 2d coordinates
+ - heatmaps (np.ndarray): The generated heatmap in shape
+ (K, H, W) where [W, H] is the `heatmap_size`
+ - keypoint_weights (np.ndarray): The target weights in shape
+ (N, K)
+ """
+ encoded_hm = self.heatmap_codec.encode(keypoints, keypoints_visible)
+ encoded_kp = self.keypoint_codec.encode(keypoints, keypoints_visible)
+
+ heatmaps = encoded_hm['heatmaps']
+ keypoint_labels = encoded_kp['keypoint_labels']
+ keypoint_weights = encoded_kp['keypoint_weights']
+
+ if self.normalize:
+ val_sum = heatmaps.sum(axis=(-1, -2)).reshape(-1, 1, 1) + 1e-24
+ heatmaps = heatmaps / val_sum
+
+ encoded = dict(
+ keypoint_labels=keypoint_labels,
+ heatmaps=heatmaps,
+ keypoint_weights=keypoint_weights)
+
+ return encoded
+
+ def decode(self, encoded: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ """Decode keypoint coordinates from normalized space to input image
+ space.
+
+ Args:
+ encoded (np.ndarray): Coordinates in shape (N, K, D)
+
+ Returns:
+ tuple:
+ - keypoints (np.ndarray): Decoded coordinates in shape (N, K, D)
+ - socres (np.ndarray): The keypoint scores in shape (N, K).
+ It usually represents the confidence of the keypoint prediction
+ """
+
+ keypoints, scores = self.keypoint_codec.decode(encoded)
+
+ return keypoints, scores
diff --git a/mmpose/codecs/megvii_heatmap.py b/mmpose/codecs/megvii_heatmap.py
index e898004637..946bcb5e32 100644
--- a/mmpose/codecs/megvii_heatmap.py
+++ b/mmpose/codecs/megvii_heatmap.py
@@ -1,144 +1,144 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from itertools import product
-from typing import Optional, Tuple
-
-import cv2
-import numpy as np
-
-from mmpose.registry import KEYPOINT_CODECS
-from .base import BaseKeypointCodec
-from .utils import gaussian_blur, get_heatmap_maximum
-
-
-@KEYPOINT_CODECS.register_module()
-class MegviiHeatmap(BaseKeypointCodec):
- """Represent keypoints as heatmaps via "Megvii" approach. See `MSPN`_
- (2019) and `CPN`_ (2018) for details.
-
- Note:
-
- - instance number: N
- - keypoint number: K
- - keypoint dimension: D
- - image size: [w, h]
- - heatmap size: [W, H]
-
- Encoded:
-
- - heatmaps (np.ndarray): The generated heatmap in shape (K, H, W)
- where [W, H] is the `heatmap_size`
- - keypoint_weights (np.ndarray): The target weights in shape (N, K)
-
- Args:
- input_size (tuple): Image size in [w, h]
- heatmap_size (tuple): Heatmap size in [W, H]
- kernel_size (tuple): The kernel size of the heatmap gaussian in
- [ks_x, ks_y]
-
- .. _`MSPN`: https://arxiv.org/abs/1901.00148
- .. _`CPN`: https://arxiv.org/abs/1711.07319
- """
-
- def __init__(
- self,
- input_size: Tuple[int, int],
- heatmap_size: Tuple[int, int],
- kernel_size: int,
- ) -> None:
-
- super().__init__()
- self.input_size = input_size
- self.heatmap_size = heatmap_size
- self.kernel_size = kernel_size
- self.scale_factor = (np.array(input_size) /
- heatmap_size).astype(np.float32)
-
- def encode(self,
- keypoints: np.ndarray,
- keypoints_visible: Optional[np.ndarray] = None) -> dict:
- """Encode keypoints into heatmaps. Note that the original keypoint
- coordinates should be in the input image space.
-
- Args:
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
- keypoints_visible (np.ndarray): Keypoint visibilities in shape
- (N, K)
-
- Returns:
- dict:
- - heatmaps (np.ndarray): The generated heatmap in shape
- (K, H, W) where [W, H] is the `heatmap_size`
- - keypoint_weights (np.ndarray): The target weights in shape
- (N, K)
- """
-
- N, K, _ = keypoints.shape
- W, H = self.heatmap_size
-
- assert N == 1, (
- f'{self.__class__.__name__} only support single-instance '
- 'keypoint encoding')
-
- heatmaps = np.zeros((K, H, W), dtype=np.float32)
- keypoint_weights = keypoints_visible.copy()
-
- for n, k in product(range(N), range(K)):
- # skip unlabled keypoints
- if keypoints_visible[n, k] < 0.5:
- continue
-
- # get center coordinates
- kx, ky = (keypoints[n, k] / self.scale_factor).astype(np.int64)
- if kx < 0 or kx >= W or ky < 0 or ky >= H:
- keypoint_weights[n, k] = 0
- continue
-
- heatmaps[k, ky, kx] = 1.
- kernel_size = (self.kernel_size, self.kernel_size)
- heatmaps[k] = cv2.GaussianBlur(heatmaps[k], kernel_size, 0)
-
- # normalize the heatmap
- heatmaps[k] = heatmaps[k] / heatmaps[k, ky, kx] * 255.
-
- encoded = dict(heatmaps=heatmaps, keypoint_weights=keypoint_weights)
-
- return encoded
-
- def decode(self, encoded: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
- """Decode keypoint coordinates from heatmaps. The decoded keypoint
- coordinates are in the input image space.
-
- Args:
- encoded (np.ndarray): Heatmaps in shape (K, H, W)
-
- Returns:
- tuple:
- - keypoints (np.ndarray): Decoded keypoint coordinates in shape
- (K, D)
- - scores (np.ndarray): The keypoint scores in shape (K,). It
- usually represents the confidence of the keypoint prediction
- """
- heatmaps = gaussian_blur(encoded.copy(), self.kernel_size)
- K, H, W = heatmaps.shape
-
- keypoints, scores = get_heatmap_maximum(heatmaps)
-
- for k in range(K):
- heatmap = heatmaps[k]
- px = int(keypoints[k, 0])
- py = int(keypoints[k, 1])
- if 1 < px < W - 1 and 1 < py < H - 1:
- diff = np.array([
- heatmap[py][px + 1] - heatmap[py][px - 1],
- heatmap[py + 1][px] - heatmap[py - 1][px]
- ])
- keypoints[k] += (np.sign(diff) * 0.25 + 0.5)
-
- scores = scores / 255.0 + 0.5
-
- # Unsqueeze the instance dimension for single-instance results
- # and restore the keypoint scales
- keypoints = keypoints[None] * self.scale_factor
- scores = scores[None]
-
- return keypoints, scores
+# Copyright (c) OpenMMLab. All rights reserved.
+from itertools import product
+from typing import Optional, Tuple
+
+import cv2
+import numpy as np
+
+from mmpose.registry import KEYPOINT_CODECS
+from .base import BaseKeypointCodec
+from .utils import gaussian_blur, get_heatmap_maximum
+
+
+@KEYPOINT_CODECS.register_module()
+class MegviiHeatmap(BaseKeypointCodec):
+ """Represent keypoints as heatmaps via "Megvii" approach. See `MSPN`_
+ (2019) and `CPN`_ (2018) for details.
+
+ Note:
+
+ - instance number: N
+ - keypoint number: K
+ - keypoint dimension: D
+ - image size: [w, h]
+ - heatmap size: [W, H]
+
+ Encoded:
+
+ - heatmaps (np.ndarray): The generated heatmap in shape (K, H, W)
+ where [W, H] is the `heatmap_size`
+ - keypoint_weights (np.ndarray): The target weights in shape (N, K)
+
+ Args:
+ input_size (tuple): Image size in [w, h]
+ heatmap_size (tuple): Heatmap size in [W, H]
+ kernel_size (tuple): The kernel size of the heatmap gaussian in
+ [ks_x, ks_y]
+
+ .. _`MSPN`: https://arxiv.org/abs/1901.00148
+ .. _`CPN`: https://arxiv.org/abs/1711.07319
+ """
+
+ def __init__(
+ self,
+ input_size: Tuple[int, int],
+ heatmap_size: Tuple[int, int],
+ kernel_size: int,
+ ) -> None:
+
+ super().__init__()
+ self.input_size = input_size
+ self.heatmap_size = heatmap_size
+ self.kernel_size = kernel_size
+ self.scale_factor = (np.array(input_size) /
+ heatmap_size).astype(np.float32)
+
+ def encode(self,
+ keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray] = None) -> dict:
+ """Encode keypoints into heatmaps. Note that the original keypoint
+ coordinates should be in the input image space.
+
+ Args:
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ keypoints_visible (np.ndarray): Keypoint visibilities in shape
+ (N, K)
+
+ Returns:
+ dict:
+ - heatmaps (np.ndarray): The generated heatmap in shape
+ (K, H, W) where [W, H] is the `heatmap_size`
+ - keypoint_weights (np.ndarray): The target weights in shape
+ (N, K)
+ """
+
+ N, K, _ = keypoints.shape
+ W, H = self.heatmap_size
+
+ assert N == 1, (
+ f'{self.__class__.__name__} only support single-instance '
+ 'keypoint encoding')
+
+ heatmaps = np.zeros((K, H, W), dtype=np.float32)
+ keypoint_weights = keypoints_visible.copy()
+
+ for n, k in product(range(N), range(K)):
+ # skip unlabled keypoints
+ if keypoints_visible[n, k] < 0.5:
+ continue
+
+ # get center coordinates
+ kx, ky = (keypoints[n, k] / self.scale_factor).astype(np.int64)
+ if kx < 0 or kx >= W or ky < 0 or ky >= H:
+ keypoint_weights[n, k] = 0
+ continue
+
+ heatmaps[k, ky, kx] = 1.
+ kernel_size = (self.kernel_size, self.kernel_size)
+ heatmaps[k] = cv2.GaussianBlur(heatmaps[k], kernel_size, 0)
+
+ # normalize the heatmap
+ heatmaps[k] = heatmaps[k] / heatmaps[k, ky, kx] * 255.
+
+ encoded = dict(heatmaps=heatmaps, keypoint_weights=keypoint_weights)
+
+ return encoded
+
+ def decode(self, encoded: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ """Decode keypoint coordinates from heatmaps. The decoded keypoint
+ coordinates are in the input image space.
+
+ Args:
+ encoded (np.ndarray): Heatmaps in shape (K, H, W)
+
+ Returns:
+ tuple:
+ - keypoints (np.ndarray): Decoded keypoint coordinates in shape
+ (K, D)
+ - scores (np.ndarray): The keypoint scores in shape (K,). It
+ usually represents the confidence of the keypoint prediction
+ """
+ heatmaps = gaussian_blur(encoded.copy(), self.kernel_size)
+ K, H, W = heatmaps.shape
+
+ keypoints, scores = get_heatmap_maximum(heatmaps)
+
+ for k in range(K):
+ heatmap = heatmaps[k]
+ px = int(keypoints[k, 0])
+ py = int(keypoints[k, 1])
+ if 1 < px < W - 1 and 1 < py < H - 1:
+ diff = np.array([
+ heatmap[py][px + 1] - heatmap[py][px - 1],
+ heatmap[py + 1][px] - heatmap[py - 1][px]
+ ])
+ keypoints[k] += (np.sign(diff) * 0.25 + 0.5)
+
+ scores = scores / 255.0 + 0.5
+
+ # Unsqueeze the instance dimension for single-instance results
+ # and restore the keypoint scales
+ keypoints = keypoints[None] * self.scale_factor
+ scores = scores[None]
+
+ return keypoints, scores
diff --git a/mmpose/codecs/msra_heatmap.py b/mmpose/codecs/msra_heatmap.py
index 63ba292e4d..69071f779e 100644
--- a/mmpose/codecs/msra_heatmap.py
+++ b/mmpose/codecs/msra_heatmap.py
@@ -1,150 +1,150 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional, Tuple
-
-import numpy as np
-
-from mmpose.registry import KEYPOINT_CODECS
-from .base import BaseKeypointCodec
-from .utils.gaussian_heatmap import (generate_gaussian_heatmaps,
- generate_unbiased_gaussian_heatmaps)
-from .utils.post_processing import get_heatmap_maximum
-from .utils.refinement import refine_keypoints, refine_keypoints_dark
-
-
-@KEYPOINT_CODECS.register_module()
-class MSRAHeatmap(BaseKeypointCodec):
- """Represent keypoints as heatmaps via "MSRA" approach. See the paper:
- `Simple Baselines for Human Pose Estimation and Tracking`_ by Xiao et al
- (2018) for details.
-
- Note:
-
- - instance number: N
- - keypoint number: K
- - keypoint dimension: D
- - image size: [w, h]
- - heatmap size: [W, H]
-
- Encoded:
-
- - heatmaps (np.ndarray): The generated heatmap in shape (K, H, W)
- where [W, H] is the `heatmap_size`
- - keypoint_weights (np.ndarray): The target weights in shape (N, K)
-
- Args:
- input_size (tuple): Image size in [w, h]
- heatmap_size (tuple): Heatmap size in [W, H]
- sigma (float): The sigma value of the Gaussian heatmap
- unbiased (bool): Whether use unbiased method (DarkPose) in ``'msra'``
- encoding. See `Dark Pose`_ for details. Defaults to ``False``
- blur_kernel_size (int): The Gaussian blur kernel size of the heatmap
- modulation in DarkPose. The kernel size and sigma should follow
- the expirical formula :math:`sigma = 0.3*((ks-1)*0.5-1)+0.8`.
- Defaults to 11
-
- .. _`Simple Baselines for Human Pose Estimation and Tracking`:
- https://arxiv.org/abs/1804.06208
- .. _`Dark Pose`: https://arxiv.org/abs/1910.06278
- """
-
- def __init__(self,
- input_size: Tuple[int, int],
- heatmap_size: Tuple[int, int],
- sigma: float,
- unbiased: bool = False,
- blur_kernel_size: int = 11) -> None:
- super().__init__()
- self.input_size = input_size
- self.heatmap_size = heatmap_size
- self.sigma = sigma
- self.unbiased = unbiased
-
- # The Gaussian blur kernel size of the heatmap modulation
- # in DarkPose and the sigma value follows the expirical
- # formula :math:`sigma = 0.3*((ks-1)*0.5-1)+0.8`
- # which gives:
- # sigma~=3 if ks=17
- # sigma=2 if ks=11;
- # sigma~=1.5 if ks=7;
- # sigma~=1 if ks=3;
- self.blur_kernel_size = blur_kernel_size
- self.scale_factor = (np.array(input_size) /
- heatmap_size).astype(np.float32)
-
- def encode(self,
- keypoints: np.ndarray,
- keypoints_visible: Optional[np.ndarray] = None) -> dict:
- """Encode keypoints into heatmaps. Note that the original keypoint
- coordinates should be in the input image space.
-
- Args:
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
- keypoints_visible (np.ndarray): Keypoint visibilities in shape
- (N, K)
-
- Returns:
- dict:
- - heatmaps (np.ndarray): The generated heatmap in shape
- (K, H, W) where [W, H] is the `heatmap_size`
- - keypoint_weights (np.ndarray): The target weights in shape
- (N, K)
- """
-
- assert keypoints.shape[0] == 1, (
- f'{self.__class__.__name__} only support single-instance '
- 'keypoint encoding')
-
- if keypoints_visible is None:
- keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
-
- if self.unbiased:
- heatmaps, keypoint_weights = generate_unbiased_gaussian_heatmaps(
- heatmap_size=self.heatmap_size,
- keypoints=keypoints / self.scale_factor,
- keypoints_visible=keypoints_visible,
- sigma=self.sigma)
- else:
- heatmaps, keypoint_weights = generate_gaussian_heatmaps(
- heatmap_size=self.heatmap_size,
- keypoints=keypoints / self.scale_factor,
- keypoints_visible=keypoints_visible,
- sigma=self.sigma)
-
- encoded = dict(heatmaps=heatmaps, keypoint_weights=keypoint_weights)
-
- return encoded
-
- def decode(self, encoded: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
- """Decode keypoint coordinates from heatmaps. The decoded keypoint
- coordinates are in the input image space.
-
- Args:
- encoded (np.ndarray): Heatmaps in shape (K, H, W)
-
- Returns:
- tuple:
- - keypoints (np.ndarray): Decoded keypoint coordinates in shape
- (N, K, D)
- - scores (np.ndarray): The keypoint scores in shape (N, K). It
- usually represents the confidence of the keypoint prediction
- """
- heatmaps = encoded.copy()
- K, H, W = heatmaps.shape
-
- keypoints, scores = get_heatmap_maximum(heatmaps)
-
- # Unsqueeze the instance dimension for single-instance results
- keypoints, scores = keypoints[None], scores[None]
-
- if self.unbiased:
- # Alleviate biased coordinate
- keypoints = refine_keypoints_dark(
- keypoints, heatmaps, blur_kernel_size=self.blur_kernel_size)
-
- else:
- keypoints = refine_keypoints(keypoints, heatmaps)
-
- # Restore the keypoint scale
- keypoints = keypoints * self.scale_factor
-
- return keypoints, scores
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import numpy as np
+
+from mmpose.registry import KEYPOINT_CODECS
+from .base import BaseKeypointCodec
+from .utils.gaussian_heatmap import (generate_gaussian_heatmaps,
+ generate_unbiased_gaussian_heatmaps)
+from .utils.post_processing import get_heatmap_maximum
+from .utils.refinement import refine_keypoints, refine_keypoints_dark
+
+
+@KEYPOINT_CODECS.register_module()
+class MSRAHeatmap(BaseKeypointCodec):
+ """Represent keypoints as heatmaps via "MSRA" approach. See the paper:
+ `Simple Baselines for Human Pose Estimation and Tracking`_ by Xiao et al
+ (2018) for details.
+
+ Note:
+
+ - instance number: N
+ - keypoint number: K
+ - keypoint dimension: D
+ - image size: [w, h]
+ - heatmap size: [W, H]
+
+ Encoded:
+
+ - heatmaps (np.ndarray): The generated heatmap in shape (K, H, W)
+ where [W, H] is the `heatmap_size`
+ - keypoint_weights (np.ndarray): The target weights in shape (N, K)
+
+ Args:
+ input_size (tuple): Image size in [w, h]
+ heatmap_size (tuple): Heatmap size in [W, H]
+ sigma (float): The sigma value of the Gaussian heatmap
+ unbiased (bool): Whether use unbiased method (DarkPose) in ``'msra'``
+ encoding. See `Dark Pose`_ for details. Defaults to ``False``
+ blur_kernel_size (int): The Gaussian blur kernel size of the heatmap
+ modulation in DarkPose. The kernel size and sigma should follow
+ the expirical formula :math:`sigma = 0.3*((ks-1)*0.5-1)+0.8`.
+ Defaults to 11
+
+ .. _`Simple Baselines for Human Pose Estimation and Tracking`:
+ https://arxiv.org/abs/1804.06208
+ .. _`Dark Pose`: https://arxiv.org/abs/1910.06278
+ """
+
+ def __init__(self,
+ input_size: Tuple[int, int],
+ heatmap_size: Tuple[int, int],
+ sigma: float,
+ unbiased: bool = False,
+ blur_kernel_size: int = 11) -> None:
+ super().__init__()
+ self.input_size = input_size
+ self.heatmap_size = heatmap_size
+ self.sigma = sigma
+ self.unbiased = unbiased
+
+ # The Gaussian blur kernel size of the heatmap modulation
+ # in DarkPose and the sigma value follows the expirical
+ # formula :math:`sigma = 0.3*((ks-1)*0.5-1)+0.8`
+ # which gives:
+ # sigma~=3 if ks=17
+ # sigma=2 if ks=11;
+ # sigma~=1.5 if ks=7;
+ # sigma~=1 if ks=3;
+ self.blur_kernel_size = blur_kernel_size
+ self.scale_factor = (np.array(input_size) /
+ heatmap_size).astype(np.float32)
+
+ def encode(self,
+ keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray] = None) -> dict:
+ """Encode keypoints into heatmaps. Note that the original keypoint
+ coordinates should be in the input image space.
+
+ Args:
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ keypoints_visible (np.ndarray): Keypoint visibilities in shape
+ (N, K)
+
+ Returns:
+ dict:
+ - heatmaps (np.ndarray): The generated heatmap in shape
+ (K, H, W) where [W, H] is the `heatmap_size`
+ - keypoint_weights (np.ndarray): The target weights in shape
+ (N, K)
+ """
+
+ assert keypoints.shape[0] == 1, (
+ f'{self.__class__.__name__} only support single-instance '
+ 'keypoint encoding')
+
+ if keypoints_visible is None:
+ keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
+
+ if self.unbiased:
+ heatmaps, keypoint_weights = generate_unbiased_gaussian_heatmaps(
+ heatmap_size=self.heatmap_size,
+ keypoints=keypoints / self.scale_factor,
+ keypoints_visible=keypoints_visible,
+ sigma=self.sigma)
+ else:
+ heatmaps, keypoint_weights = generate_gaussian_heatmaps(
+ heatmap_size=self.heatmap_size,
+ keypoints=keypoints / self.scale_factor,
+ keypoints_visible=keypoints_visible,
+ sigma=self.sigma)
+
+ encoded = dict(heatmaps=heatmaps, keypoint_weights=keypoint_weights)
+
+ return encoded
+
+ def decode(self, encoded: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ """Decode keypoint coordinates from heatmaps. The decoded keypoint
+ coordinates are in the input image space.
+
+ Args:
+ encoded (np.ndarray): Heatmaps in shape (K, H, W)
+
+ Returns:
+ tuple:
+ - keypoints (np.ndarray): Decoded keypoint coordinates in shape
+ (N, K, D)
+ - scores (np.ndarray): The keypoint scores in shape (N, K). It
+ usually represents the confidence of the keypoint prediction
+ """
+ heatmaps = encoded.copy()
+ K, H, W = heatmaps.shape
+
+ keypoints, scores = get_heatmap_maximum(heatmaps)
+
+ # Unsqueeze the instance dimension for single-instance results
+ keypoints, scores = keypoints[None], scores[None]
+
+ if self.unbiased:
+ # Alleviate biased coordinate
+ keypoints = refine_keypoints_dark(
+ keypoints, heatmaps, blur_kernel_size=self.blur_kernel_size)
+
+ else:
+ keypoints = refine_keypoints(keypoints, heatmaps)
+
+ # Restore the keypoint scale
+ keypoints = keypoints * self.scale_factor
+
+ return keypoints, scores
diff --git a/mmpose/codecs/regression_label.py b/mmpose/codecs/regression_label.py
index f79195beb4..179c0113d7 100644
--- a/mmpose/codecs/regression_label.py
+++ b/mmpose/codecs/regression_label.py
@@ -1,103 +1,103 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-
-from typing import Optional, Tuple
-
-import numpy as np
-
-from mmpose.registry import KEYPOINT_CODECS
-from .base import BaseKeypointCodec
-
-
-@KEYPOINT_CODECS.register_module()
-class RegressionLabel(BaseKeypointCodec):
- r"""Generate keypoint coordinates.
-
- Note:
-
- - instance number: N
- - keypoint number: K
- - keypoint dimension: D
- - image size: [w, h]
-
- Encoded:
-
- - keypoint_labels (np.ndarray): The normalized regression labels in
- shape (N, K, D) where D is 2 for 2d coordinates
- - keypoint_weights (np.ndarray): The target weights in shape (N, K)
-
- Args:
- input_size (tuple): Input image size in [w, h]
-
- """
-
- def __init__(self, input_size: Tuple[int, int]) -> None:
- super().__init__()
-
- self.input_size = input_size
-
- def encode(self,
- keypoints: np.ndarray,
- keypoints_visible: Optional[np.ndarray] = None) -> dict:
- """Encoding keypoints from input image space to normalized space.
-
- Args:
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
- keypoints_visible (np.ndarray): Keypoint visibilities in shape
- (N, K)
-
- Returns:
- dict:
- - keypoint_labels (np.ndarray): The normalized regression labels in
- shape (N, K, D) where D is 2 for 2d coordinates
- - keypoint_weights (np.ndarray): The target weights in shape
- (N, K)
- """
- if keypoints_visible is None:
- keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
-
- w, h = self.input_size
- valid = ((keypoints >= 0) &
- (keypoints <= [w - 1, h - 1])).all(axis=-1) & (
- keypoints_visible > 0.5)
-
- keypoint_labels = (keypoints / np.array([w, h])).astype(np.float32)
- keypoint_weights = np.where(valid, 1., 0.).astype(np.float32)
-
- encoded = dict(
- keypoint_labels=keypoint_labels, keypoint_weights=keypoint_weights)
-
- return encoded
-
- def decode(self, encoded: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
- """Decode keypoint coordinates from normalized space to input image
- space.
-
- Args:
- encoded (np.ndarray): Coordinates in shape (N, K, D)
-
- Returns:
- tuple:
- - keypoints (np.ndarray): Decoded coordinates in shape (N, K, D)
- - scores (np.ndarray): The keypoint scores in shape (N, K).
- It usually represents the confidence of the keypoint prediction
- """
-
- if encoded.shape[-1] == 2:
- N, K, _ = encoded.shape
- normalized_coords = encoded.copy()
- scores = np.ones((N, K), dtype=np.float32)
- elif encoded.shape[-1] == 4:
- # split coords and sigma if outputs contain output_sigma
- normalized_coords = encoded[..., :2].copy()
- output_sigma = encoded[..., 2:4].copy()
-
- scores = (1 - output_sigma).mean(axis=-1)
- else:
- raise ValueError(
- 'Keypoint dimension should be 2 or 4 (with sigma), '
- f'but got {encoded.shape[-1]}')
-
- w, h = self.input_size
- keypoints = normalized_coords * np.array([w, h])
-
- return keypoints, scores
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from typing import Optional, Tuple
+
+import numpy as np
+
+from mmpose.registry import KEYPOINT_CODECS
+from .base import BaseKeypointCodec
+
+
+@KEYPOINT_CODECS.register_module()
+class RegressionLabel(BaseKeypointCodec):
+ r"""Generate keypoint coordinates.
+
+ Note:
+
+ - instance number: N
+ - keypoint number: K
+ - keypoint dimension: D
+ - image size: [w, h]
+
+ Encoded:
+
+ - keypoint_labels (np.ndarray): The normalized regression labels in
+ shape (N, K, D) where D is 2 for 2d coordinates
+ - keypoint_weights (np.ndarray): The target weights in shape (N, K)
+
+ Args:
+ input_size (tuple): Input image size in [w, h]
+
+ """
+
+ def __init__(self, input_size: Tuple[int, int]) -> None:
+ super().__init__()
+
+ self.input_size = input_size
+
+ def encode(self,
+ keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray] = None) -> dict:
+ """Encoding keypoints from input image space to normalized space.
+
+ Args:
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ keypoints_visible (np.ndarray): Keypoint visibilities in shape
+ (N, K)
+
+ Returns:
+ dict:
+ - keypoint_labels (np.ndarray): The normalized regression labels in
+ shape (N, K, D) where D is 2 for 2d coordinates
+ - keypoint_weights (np.ndarray): The target weights in shape
+ (N, K)
+ """
+ if keypoints_visible is None:
+ keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
+
+ w, h = self.input_size
+ valid = ((keypoints >= 0) &
+ (keypoints <= [w - 1, h - 1])).all(axis=-1) & (
+ keypoints_visible > 0.5)
+
+ keypoint_labels = (keypoints / np.array([w, h])).astype(np.float32)
+ keypoint_weights = np.where(valid, 1., 0.).astype(np.float32)
+
+ encoded = dict(
+ keypoint_labels=keypoint_labels, keypoint_weights=keypoint_weights)
+
+ return encoded
+
+ def decode(self, encoded: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ """Decode keypoint coordinates from normalized space to input image
+ space.
+
+ Args:
+ encoded (np.ndarray): Coordinates in shape (N, K, D)
+
+ Returns:
+ tuple:
+ - keypoints (np.ndarray): Decoded coordinates in shape (N, K, D)
+ - scores (np.ndarray): The keypoint scores in shape (N, K).
+ It usually represents the confidence of the keypoint prediction
+ """
+
+ if encoded.shape[-1] == 2:
+ N, K, _ = encoded.shape
+ normalized_coords = encoded.copy()
+ scores = np.ones((N, K), dtype=np.float32)
+ elif encoded.shape[-1] == 4:
+ # split coords and sigma if outputs contain output_sigma
+ normalized_coords = encoded[..., :2].copy()
+ output_sigma = encoded[..., 2:4].copy()
+
+ scores = (1 - output_sigma).mean(axis=-1)
+ else:
+ raise ValueError(
+ 'Keypoint dimension should be 2 or 4 (with sigma), '
+ f'but got {encoded.shape[-1]}')
+
+ w, h = self.input_size
+ keypoints = normalized_coords * np.array([w, h])
+
+ return keypoints, scores
diff --git a/mmpose/codecs/simcc_label.py b/mmpose/codecs/simcc_label.py
index a22498c352..ee2c31aa9b 100644
--- a/mmpose/codecs/simcc_label.py
+++ b/mmpose/codecs/simcc_label.py
@@ -1,286 +1,286 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from itertools import product
-from typing import Optional, Tuple, Union
-
-import numpy as np
-
-from mmpose.codecs.utils import get_simcc_maximum
-from mmpose.codecs.utils.refinement import refine_simcc_dark
-from mmpose.registry import KEYPOINT_CODECS
-from .base import BaseKeypointCodec
-
-
-@KEYPOINT_CODECS.register_module()
-class SimCCLabel(BaseKeypointCodec):
- r"""Generate keypoint representation via "SimCC" approach.
- See the paper: `SimCC: a Simple Coordinate Classification Perspective for
- Human Pose Estimation`_ by Li et al (2022) for more details.
- Old name: SimDR
-
- Note:
-
- - instance number: N
- - keypoint number: K
- - keypoint dimension: D
- - image size: [w, h]
-
- Encoded:
-
- - keypoint_x_labels (np.ndarray): The generated SimCC label for x-axis.
- The label shape is (N, K, Wx) if ``smoothing_type=='gaussian'``
- and (N, K) if `smoothing_type=='standard'``, where
- :math:`Wx=w*simcc_split_ratio`
- - keypoint_y_labels (np.ndarray): The generated SimCC label for y-axis.
- The label shape is (N, K, Wy) if ``smoothing_type=='gaussian'``
- and (N, K) if `smoothing_type=='standard'``, where
- :math:`Wy=h*simcc_split_ratio`
- - keypoint_weights (np.ndarray): The target weights in shape (N, K)
-
- Args:
- input_size (tuple): Input image size in [w, h]
- smoothing_type (str): The SimCC label smoothing strategy. Options are
- ``'gaussian'`` and ``'standard'``. Defaults to ``'gaussian'``
- sigma (float | int | tuple): The sigma value in the Gaussian SimCC
- label. Defaults to 6.0
- simcc_split_ratio (float): The ratio of the label size to the input
- size. For example, if the input width is ``w``, the x label size
- will be :math:`w*simcc_split_ratio`. Defaults to 2.0
- label_smooth_weight (float): Label Smoothing weight. Defaults to 0.0
- normalize (bool): Whether to normalize the heatmaps. Defaults to True.
-
- .. _`SimCC: a Simple Coordinate Classification Perspective for Human Pose
- Estimation`: https://arxiv.org/abs/2107.03332
- """
-
- def __init__(self,
- input_size: Tuple[int, int],
- smoothing_type: str = 'gaussian',
- sigma: Union[float, int, Tuple[float]] = 6.0,
- simcc_split_ratio: float = 2.0,
- label_smooth_weight: float = 0.0,
- normalize: bool = True,
- use_dark: bool = False) -> None:
- super().__init__()
-
- self.input_size = input_size
- self.smoothing_type = smoothing_type
- self.simcc_split_ratio = simcc_split_ratio
- self.label_smooth_weight = label_smooth_weight
- self.normalize = normalize
- self.use_dark = use_dark
-
- if isinstance(sigma, (float, int)):
- self.sigma = np.array([sigma, sigma])
- else:
- self.sigma = np.array(sigma)
-
- if self.smoothing_type not in {'gaussian', 'standard'}:
- raise ValueError(
- f'{self.__class__.__name__} got invalid `smoothing_type` value'
- f'{self.smoothing_type}. Should be one of '
- '{"gaussian", "standard"}')
-
- if self.smoothing_type == 'gaussian' and self.label_smooth_weight > 0:
- raise ValueError('Attribute `label_smooth_weight` is only '
- 'used for `standard` mode.')
-
- if self.label_smooth_weight < 0.0 or self.label_smooth_weight > 1.0:
- raise ValueError('`label_smooth_weight` should be in range [0, 1]')
-
- def encode(self,
- keypoints: np.ndarray,
- keypoints_visible: Optional[np.ndarray] = None) -> dict:
- """Encoding keypoints into SimCC labels. Note that the original
- keypoint coordinates should be in the input image space.
-
- Args:
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
- keypoints_visible (np.ndarray): Keypoint visibilities in shape
- (N, K)
-
- Returns:
- dict:
- - keypoint_x_labels (np.ndarray): The generated SimCC label for
- x-axis.
- The label shape is (N, K, Wx) if ``smoothing_type=='gaussian'``
- and (N, K) if `smoothing_type=='standard'``, where
- :math:`Wx=w*simcc_split_ratio`
- - keypoint_y_labels (np.ndarray): The generated SimCC label for
- y-axis.
- The label shape is (N, K, Wy) if ``smoothing_type=='gaussian'``
- and (N, K) if `smoothing_type=='standard'``, where
- :math:`Wy=h*simcc_split_ratio`
- - keypoint_weights (np.ndarray): The target weights in shape
- (N, K)
- """
- if keypoints_visible is None:
- keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
-
- if self.smoothing_type == 'gaussian':
- x_labels, y_labels, keypoint_weights = self._generate_gaussian(
- keypoints, keypoints_visible)
- elif self.smoothing_type == 'standard':
- x_labels, y_labels, keypoint_weights = self._generate_standard(
- keypoints, keypoints_visible)
- else:
- raise ValueError(
- f'{self.__class__.__name__} got invalid `smoothing_type` value'
- f'{self.smoothing_type}. Should be one of '
- '{"gaussian", "standard"}')
-
- encoded = dict(
- keypoint_x_labels=x_labels,
- keypoint_y_labels=y_labels,
- keypoint_weights=keypoint_weights)
-
- return encoded
-
- def decode(self, simcc_x: np.ndarray,
- simcc_y: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
- """Decode keypoint coordinates from SimCC representations. The decoded
- coordinates are in the input image space.
-
- Args:
- encoded (Tuple[np.ndarray, np.ndarray]): SimCC labels for x-axis
- and y-axis
- simcc_x (np.ndarray): SimCC label for x-axis
- simcc_y (np.ndarray): SimCC label for y-axis
-
- Returns:
- tuple:
- - keypoints (np.ndarray): Decoded coordinates in shape (N, K, D)
- - socres (np.ndarray): The keypoint scores in shape (N, K).
- It usually represents the confidence of the keypoint prediction
- """
-
- keypoints, scores = get_simcc_maximum(simcc_x, simcc_y)
-
- # Unsqueeze the instance dimension for single-instance results
- if keypoints.ndim == 2:
- keypoints = keypoints[None, :]
- scores = scores[None, :]
-
- if self.use_dark:
- x_blur = int((self.sigma[0] * 20 - 7) // 3)
- y_blur = int((self.sigma[1] * 20 - 7) // 3)
- x_blur -= int((x_blur % 2) == 0)
- y_blur -= int((y_blur % 2) == 0)
- keypoints[:, :, 0] = refine_simcc_dark(keypoints[:, :, 0], simcc_x,
- x_blur)
- keypoints[:, :, 1] = refine_simcc_dark(keypoints[:, :, 1], simcc_y,
- y_blur)
-
- keypoints /= self.simcc_split_ratio
-
- return keypoints, scores
-
- def _map_coordinates(
- self,
- keypoints: np.ndarray,
- keypoints_visible: Optional[np.ndarray] = None
- ) -> Tuple[np.ndarray, np.ndarray]:
- """Mapping keypoint coordinates into SimCC space."""
-
- keypoints_split = keypoints.copy()
- keypoints_split = np.around(keypoints_split * self.simcc_split_ratio)
- keypoints_split = keypoints_split.astype(np.int64)
- keypoint_weights = keypoints_visible.copy()
-
- return keypoints_split, keypoint_weights
-
- def _generate_standard(
- self,
- keypoints: np.ndarray,
- keypoints_visible: Optional[np.ndarray] = None
- ) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
- """Encoding keypoints into SimCC labels with Standard Label Smoothing
- strategy.
-
- Labels will be one-hot vectors if self.label_smooth_weight==0.0
- """
-
- N, K, _ = keypoints.shape
- w, h = self.input_size
- W = np.around(w * self.simcc_split_ratio).astype(int)
- H = np.around(h * self.simcc_split_ratio).astype(int)
-
- keypoints_split, keypoint_weights = self._map_coordinates(
- keypoints, keypoints_visible)
-
- target_x = np.zeros((N, K, W), dtype=np.float32)
- target_y = np.zeros((N, K, H), dtype=np.float32)
-
- for n, k in product(range(N), range(K)):
- # skip unlabled keypoints
- if keypoints_visible[n, k] < 0.5:
- continue
-
- # get center coordinates
- mu_x, mu_y = keypoints_split[n, k].astype(np.int64)
-
- # detect abnormal coords and assign the weight 0
- if mu_x >= W or mu_y >= H or mu_x < 0 or mu_y < 0:
- keypoint_weights[n, k] = 0
- continue
-
- if self.label_smooth_weight > 0:
- target_x[n, k] = self.label_smooth_weight / (W - 1)
- target_y[n, k] = self.label_smooth_weight / (H - 1)
-
- target_x[n, k, mu_x] = 1.0 - self.label_smooth_weight
- target_y[n, k, mu_y] = 1.0 - self.label_smooth_weight
-
- return target_x, target_y, keypoint_weights
-
- def _generate_gaussian(
- self,
- keypoints: np.ndarray,
- keypoints_visible: Optional[np.ndarray] = None
- ) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
- """Encoding keypoints into SimCC labels with Gaussian Label Smoothing
- strategy."""
-
- N, K, _ = keypoints.shape
- w, h = self.input_size
- W = np.around(w * self.simcc_split_ratio).astype(int)
- H = np.around(h * self.simcc_split_ratio).astype(int)
-
- keypoints_split, keypoint_weights = self._map_coordinates(
- keypoints, keypoints_visible)
-
- target_x = np.zeros((N, K, W), dtype=np.float32)
- target_y = np.zeros((N, K, H), dtype=np.float32)
-
- # 3-sigma rule
- radius = self.sigma * 3
-
- # xy grid
- x = np.arange(0, W, 1, dtype=np.float32)
- y = np.arange(0, H, 1, dtype=np.float32)
-
- for n, k in product(range(N), range(K)):
- # skip unlabled keypoints
- if keypoints_visible[n, k] < 0.5:
- continue
-
- mu = keypoints_split[n, k]
-
- # check that the gaussian has in-bounds part
- left, top = mu - radius
- right, bottom = mu + radius + 1
-
- if left >= W or top >= H or right < 0 or bottom < 0:
- keypoint_weights[n, k] = 0
- continue
-
- mu_x, mu_y = mu
-
- target_x[n, k] = np.exp(-((x - mu_x)**2) / (2 * self.sigma[0]**2))
- target_y[n, k] = np.exp(-((y - mu_y)**2) / (2 * self.sigma[1]**2))
-
- if self.normalize:
- norm_value = self.sigma * np.sqrt(np.pi * 2)
- target_x /= norm_value[0]
- target_y /= norm_value[1]
-
- return target_x, target_y, keypoint_weights
+# Copyright (c) OpenMMLab. All rights reserved.
+from itertools import product
+from typing import Optional, Tuple, Union
+
+import numpy as np
+
+from mmpose.codecs.utils import get_simcc_maximum
+from mmpose.codecs.utils.refinement import refine_simcc_dark
+from mmpose.registry import KEYPOINT_CODECS
+from .base import BaseKeypointCodec
+
+
+@KEYPOINT_CODECS.register_module()
+class SimCCLabel(BaseKeypointCodec):
+ r"""Generate keypoint representation via "SimCC" approach.
+ See the paper: `SimCC: a Simple Coordinate Classification Perspective for
+ Human Pose Estimation`_ by Li et al (2022) for more details.
+ Old name: SimDR
+
+ Note:
+
+ - instance number: N
+ - keypoint number: K
+ - keypoint dimension: D
+ - image size: [w, h]
+
+ Encoded:
+
+ - keypoint_x_labels (np.ndarray): The generated SimCC label for x-axis.
+ The label shape is (N, K, Wx) if ``smoothing_type=='gaussian'``
+ and (N, K) if `smoothing_type=='standard'``, where
+ :math:`Wx=w*simcc_split_ratio`
+ - keypoint_y_labels (np.ndarray): The generated SimCC label for y-axis.
+ The label shape is (N, K, Wy) if ``smoothing_type=='gaussian'``
+ and (N, K) if `smoothing_type=='standard'``, where
+ :math:`Wy=h*simcc_split_ratio`
+ - keypoint_weights (np.ndarray): The target weights in shape (N, K)
+
+ Args:
+ input_size (tuple): Input image size in [w, h]
+ smoothing_type (str): The SimCC label smoothing strategy. Options are
+ ``'gaussian'`` and ``'standard'``. Defaults to ``'gaussian'``
+ sigma (float | int | tuple): The sigma value in the Gaussian SimCC
+ label. Defaults to 6.0
+ simcc_split_ratio (float): The ratio of the label size to the input
+ size. For example, if the input width is ``w``, the x label size
+ will be :math:`w*simcc_split_ratio`. Defaults to 2.0
+ label_smooth_weight (float): Label Smoothing weight. Defaults to 0.0
+ normalize (bool): Whether to normalize the heatmaps. Defaults to True.
+
+ .. _`SimCC: a Simple Coordinate Classification Perspective for Human Pose
+ Estimation`: https://arxiv.org/abs/2107.03332
+ """
+
+ def __init__(self,
+ input_size: Tuple[int, int],
+ smoothing_type: str = 'gaussian',
+ sigma: Union[float, int, Tuple[float]] = 6.0,
+ simcc_split_ratio: float = 2.0,
+ label_smooth_weight: float = 0.0,
+ normalize: bool = True,
+ use_dark: bool = False) -> None:
+ super().__init__()
+
+ self.input_size = input_size
+ self.smoothing_type = smoothing_type
+ self.simcc_split_ratio = simcc_split_ratio
+ self.label_smooth_weight = label_smooth_weight
+ self.normalize = normalize
+ self.use_dark = use_dark
+
+ if isinstance(sigma, (float, int)):
+ self.sigma = np.array([sigma, sigma])
+ else:
+ self.sigma = np.array(sigma)
+
+ if self.smoothing_type not in {'gaussian', 'standard'}:
+ raise ValueError(
+ f'{self.__class__.__name__} got invalid `smoothing_type` value'
+ f'{self.smoothing_type}. Should be one of '
+ '{"gaussian", "standard"}')
+
+ if self.smoothing_type == 'gaussian' and self.label_smooth_weight > 0:
+ raise ValueError('Attribute `label_smooth_weight` is only '
+ 'used for `standard` mode.')
+
+ if self.label_smooth_weight < 0.0 or self.label_smooth_weight > 1.0:
+ raise ValueError('`label_smooth_weight` should be in range [0, 1]')
+
+ def encode(self,
+ keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray] = None) -> dict:
+ """Encoding keypoints into SimCC labels. Note that the original
+ keypoint coordinates should be in the input image space.
+
+ Args:
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ keypoints_visible (np.ndarray): Keypoint visibilities in shape
+ (N, K)
+
+ Returns:
+ dict:
+ - keypoint_x_labels (np.ndarray): The generated SimCC label for
+ x-axis.
+ The label shape is (N, K, Wx) if ``smoothing_type=='gaussian'``
+ and (N, K) if `smoothing_type=='standard'``, where
+ :math:`Wx=w*simcc_split_ratio`
+ - keypoint_y_labels (np.ndarray): The generated SimCC label for
+ y-axis.
+ The label shape is (N, K, Wy) if ``smoothing_type=='gaussian'``
+ and (N, K) if `smoothing_type=='standard'``, where
+ :math:`Wy=h*simcc_split_ratio`
+ - keypoint_weights (np.ndarray): The target weights in shape
+ (N, K)
+ """
+ if keypoints_visible is None:
+ keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
+
+ if self.smoothing_type == 'gaussian':
+ x_labels, y_labels, keypoint_weights = self._generate_gaussian(
+ keypoints, keypoints_visible)
+ elif self.smoothing_type == 'standard':
+ x_labels, y_labels, keypoint_weights = self._generate_standard(
+ keypoints, keypoints_visible)
+ else:
+ raise ValueError(
+ f'{self.__class__.__name__} got invalid `smoothing_type` value'
+ f'{self.smoothing_type}. Should be one of '
+ '{"gaussian", "standard"}')
+
+ encoded = dict(
+ keypoint_x_labels=x_labels,
+ keypoint_y_labels=y_labels,
+ keypoint_weights=keypoint_weights)
+
+ return encoded
+
+ def decode(self, simcc_x: np.ndarray,
+ simcc_y: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ """Decode keypoint coordinates from SimCC representations. The decoded
+ coordinates are in the input image space.
+
+ Args:
+ encoded (Tuple[np.ndarray, np.ndarray]): SimCC labels for x-axis
+ and y-axis
+ simcc_x (np.ndarray): SimCC label for x-axis
+ simcc_y (np.ndarray): SimCC label for y-axis
+
+ Returns:
+ tuple:
+ - keypoints (np.ndarray): Decoded coordinates in shape (N, K, D)
+ - socres (np.ndarray): The keypoint scores in shape (N, K).
+ It usually represents the confidence of the keypoint prediction
+ """
+
+ keypoints, scores = get_simcc_maximum(simcc_x, simcc_y)
+
+ # Unsqueeze the instance dimension for single-instance results
+ if keypoints.ndim == 2:
+ keypoints = keypoints[None, :]
+ scores = scores[None, :]
+
+ if self.use_dark:
+ x_blur = int((self.sigma[0] * 20 - 7) // 3)
+ y_blur = int((self.sigma[1] * 20 - 7) // 3)
+ x_blur -= int((x_blur % 2) == 0)
+ y_blur -= int((y_blur % 2) == 0)
+ keypoints[:, :, 0] = refine_simcc_dark(keypoints[:, :, 0], simcc_x,
+ x_blur)
+ keypoints[:, :, 1] = refine_simcc_dark(keypoints[:, :, 1], simcc_y,
+ y_blur)
+
+ keypoints /= self.simcc_split_ratio
+
+ return keypoints, scores
+
+ def _map_coordinates(
+ self,
+ keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray] = None
+ ) -> Tuple[np.ndarray, np.ndarray]:
+ """Mapping keypoint coordinates into SimCC space."""
+
+ keypoints_split = keypoints.copy()
+ keypoints_split = np.around(keypoints_split * self.simcc_split_ratio)
+ keypoints_split = keypoints_split.astype(np.int64)
+ keypoint_weights = keypoints_visible.copy()
+
+ return keypoints_split, keypoint_weights
+
+ def _generate_standard(
+ self,
+ keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray] = None
+ ) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
+ """Encoding keypoints into SimCC labels with Standard Label Smoothing
+ strategy.
+
+ Labels will be one-hot vectors if self.label_smooth_weight==0.0
+ """
+
+ N, K, _ = keypoints.shape
+ w, h = self.input_size
+ W = np.around(w * self.simcc_split_ratio).astype(int)
+ H = np.around(h * self.simcc_split_ratio).astype(int)
+
+ keypoints_split, keypoint_weights = self._map_coordinates(
+ keypoints, keypoints_visible)
+
+ target_x = np.zeros((N, K, W), dtype=np.float32)
+ target_y = np.zeros((N, K, H), dtype=np.float32)
+
+ for n, k in product(range(N), range(K)):
+ # skip unlabled keypoints
+ if keypoints_visible[n, k] < 0.5:
+ continue
+
+ # get center coordinates
+ mu_x, mu_y = keypoints_split[n, k].astype(np.int64)
+
+ # detect abnormal coords and assign the weight 0
+ if mu_x >= W or mu_y >= H or mu_x < 0 or mu_y < 0:
+ keypoint_weights[n, k] = 0
+ continue
+
+ if self.label_smooth_weight > 0:
+ target_x[n, k] = self.label_smooth_weight / (W - 1)
+ target_y[n, k] = self.label_smooth_weight / (H - 1)
+
+ target_x[n, k, mu_x] = 1.0 - self.label_smooth_weight
+ target_y[n, k, mu_y] = 1.0 - self.label_smooth_weight
+
+ return target_x, target_y, keypoint_weights
+
+ def _generate_gaussian(
+ self,
+ keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray] = None
+ ) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
+ """Encoding keypoints into SimCC labels with Gaussian Label Smoothing
+ strategy."""
+
+ N, K, _ = keypoints.shape
+ w, h = self.input_size
+ W = np.around(w * self.simcc_split_ratio).astype(int)
+ H = np.around(h * self.simcc_split_ratio).astype(int)
+
+ keypoints_split, keypoint_weights = self._map_coordinates(
+ keypoints, keypoints_visible)
+
+ target_x = np.zeros((N, K, W), dtype=np.float32)
+ target_y = np.zeros((N, K, H), dtype=np.float32)
+
+ # 3-sigma rule
+ radius = self.sigma * 3
+
+ # xy grid
+ x = np.arange(0, W, 1, dtype=np.float32)
+ y = np.arange(0, H, 1, dtype=np.float32)
+
+ for n, k in product(range(N), range(K)):
+ # skip unlabled keypoints
+ if keypoints_visible[n, k] < 0.5:
+ continue
+
+ mu = keypoints_split[n, k]
+
+ # check that the gaussian has in-bounds part
+ left, top = mu - radius
+ right, bottom = mu + radius + 1
+
+ if left >= W or top >= H or right < 0 or bottom < 0:
+ keypoint_weights[n, k] = 0
+ continue
+
+ mu_x, mu_y = mu
+
+ target_x[n, k] = np.exp(-((x - mu_x)**2) / (2 * self.sigma[0]**2))
+ target_y[n, k] = np.exp(-((y - mu_y)**2) / (2 * self.sigma[1]**2))
+
+ if self.normalize:
+ norm_value = self.sigma * np.sqrt(np.pi * 2)
+ target_x /= norm_value[0]
+ target_y /= norm_value[1]
+
+ return target_x, target_y, keypoint_weights
diff --git a/mmpose/codecs/spr.py b/mmpose/codecs/spr.py
index add6f5715b..6104e306b8 100644
--- a/mmpose/codecs/spr.py
+++ b/mmpose/codecs/spr.py
@@ -1,299 +1,299 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional, Tuple, Union
-
-import numpy as np
-import torch
-from torch import Tensor
-
-from mmpose.registry import KEYPOINT_CODECS
-from .base import BaseKeypointCodec
-from .utils import (batch_heatmap_nms, generate_displacement_heatmap,
- generate_gaussian_heatmaps, get_diagonal_lengths,
- get_instance_root)
-
-
-@KEYPOINT_CODECS.register_module()
-class SPR(BaseKeypointCodec):
- """Encode/decode keypoints with Structured Pose Representation (SPR).
-
- See the paper `Single-stage multi-person pose machines`_
- by Nie et al (2017) for details
-
- Note:
-
- - instance number: N
- - keypoint number: K
- - keypoint dimension: D
- - image size: [w, h]
- - heatmap size: [W, H]
-
- Encoded:
-
- - heatmaps (np.ndarray): The generated heatmap in shape (1, H, W)
- where [W, H] is the `heatmap_size`. If the keypoint heatmap is
- generated together, the output heatmap shape is (K+1, H, W)
- - heatmap_weights (np.ndarray): The target weights for heatmaps which
- has same shape with heatmaps.
- - displacements (np.ndarray): The dense keypoint displacement in
- shape (K*2, H, W).
- - displacement_weights (np.ndarray): The target weights for heatmaps
- which has same shape with displacements.
-
- Args:
- input_size (tuple): Image size in [w, h]
- heatmap_size (tuple): Heatmap size in [W, H]
- sigma (float or tuple, optional): The sigma values of the Gaussian
- heatmaps. If sigma is a tuple, it includes both sigmas for root
- and keypoint heatmaps. ``None`` means the sigmas are computed
- automatically from the heatmap size. Defaults to ``None``
- generate_keypoint_heatmaps (bool): Whether to generate Gaussian
- heatmaps for each keypoint. Defaults to ``False``
- root_type (str): The method to generate the instance root. Options
- are:
-
- - ``'kpt_center'``: Average coordinate of all visible keypoints.
- - ``'bbox_center'``: Center point of bounding boxes outlined by
- all visible keypoints.
-
- Defaults to ``'kpt_center'``
-
- minimal_diagonal_length (int or float): The threshold of diagonal
- length of instance bounding box. Small instances will not be
- used in training. Defaults to 32
- background_weight (float): Loss weight of background pixels.
- Defaults to 0.1
- decode_thr (float): The threshold of keypoint response value in
- heatmaps. Defaults to 0.01
- decode_nms_kernel (int): The kernel size of the NMS during decoding,
- which should be an odd integer. Defaults to 5
- decode_max_instances (int): The maximum number of instances
- to decode. Defaults to 30
-
- .. _`Single-stage multi-person pose machines`:
- https://arxiv.org/abs/1908.09220
- """
-
- def __init__(
- self,
- input_size: Tuple[int, int],
- heatmap_size: Tuple[int, int],
- sigma: Optional[Union[float, Tuple[float]]] = None,
- generate_keypoint_heatmaps: bool = False,
- root_type: str = 'kpt_center',
- minimal_diagonal_length: Union[int, float] = 5,
- background_weight: float = 0.1,
- decode_nms_kernel: int = 5,
- decode_max_instances: int = 30,
- decode_thr: float = 0.01,
- ):
- super().__init__()
-
- self.input_size = input_size
- self.heatmap_size = heatmap_size
- self.generate_keypoint_heatmaps = generate_keypoint_heatmaps
- self.root_type = root_type
- self.minimal_diagonal_length = minimal_diagonal_length
- self.background_weight = background_weight
- self.decode_nms_kernel = decode_nms_kernel
- self.decode_max_instances = decode_max_instances
- self.decode_thr = decode_thr
-
- self.scale_factor = (np.array(input_size) /
- heatmap_size).astype(np.float32)
-
- if sigma is None:
- sigma = (heatmap_size[0] * heatmap_size[1])**0.5 / 32
- if generate_keypoint_heatmaps:
- # sigma for root heatmap and keypoint heatmaps
- self.sigma = (sigma, sigma // 2)
- else:
- self.sigma = (sigma, )
- else:
- if not isinstance(sigma, (tuple, list)):
- sigma = (sigma, )
- if generate_keypoint_heatmaps:
- assert len(sigma) == 2, 'sigma for keypoints must be given ' \
- 'if `generate_keypoint_heatmaps` ' \
- 'is True. e.g. sigma=(4, 2)'
- self.sigma = sigma
-
- def _get_heatmap_weights(self,
- heatmaps,
- fg_weight: float = 1,
- bg_weight: float = 0):
- """Generate weight array for heatmaps.
-
- Args:
- heatmaps (np.ndarray): Root and keypoint (optional) heatmaps
- fg_weight (float): Weight for foreground pixels. Defaults to 1.0
- bg_weight (float): Weight for background pixels. Defaults to 0.0
-
- Returns:
- np.ndarray: Heatmap weight array in the same shape with heatmaps
- """
- heatmap_weights = np.ones(heatmaps.shape) * bg_weight
- heatmap_weights[heatmaps > 0] = fg_weight
- return heatmap_weights
-
- def encode(self,
- keypoints: np.ndarray,
- keypoints_visible: Optional[np.ndarray] = None) -> dict:
- """Encode keypoints into root heatmaps and keypoint displacement
- fields. Note that the original keypoint coordinates should be in the
- input image space.
-
- Args:
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
- keypoints_visible (np.ndarray): Keypoint visibilities in shape
- (N, K)
-
- Returns:
- dict:
- - heatmaps (np.ndarray): The generated heatmap in shape
- (1, H, W) where [W, H] is the `heatmap_size`. If keypoint
- heatmaps are generated together, the shape is (K+1, H, W)
- - heatmap_weights (np.ndarray): The pixel-wise weight for heatmaps
- which has same shape with `heatmaps`
- - displacements (np.ndarray): The generated displacement fields in
- shape (K*D, H, W). The vector on each pixels represents the
- displacement of keypoints belong to the associated instance
- from this pixel.
- - displacement_weights (np.ndarray): The pixel-wise weight for
- displacements which has same shape with `displacements`
- """
-
- if keypoints_visible is None:
- keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
-
- # keypoint coordinates in heatmap
- _keypoints = keypoints / self.scale_factor
-
- # compute the root and scale of each instance
- roots, roots_visible = get_instance_root(_keypoints, keypoints_visible,
- self.root_type)
- diagonal_lengths = get_diagonal_lengths(_keypoints, keypoints_visible)
-
- # discard the small instances
- roots_visible[diagonal_lengths < self.minimal_diagonal_length] = 0
-
- # generate heatmaps
- heatmaps, _ = generate_gaussian_heatmaps(
- heatmap_size=self.heatmap_size,
- keypoints=roots[:, None],
- keypoints_visible=roots_visible[:, None],
- sigma=self.sigma[0])
- heatmap_weights = self._get_heatmap_weights(
- heatmaps, bg_weight=self.background_weight)
-
- if self.generate_keypoint_heatmaps:
- keypoint_heatmaps, _ = generate_gaussian_heatmaps(
- heatmap_size=self.heatmap_size,
- keypoints=_keypoints,
- keypoints_visible=keypoints_visible,
- sigma=self.sigma[1])
-
- keypoint_heatmaps_weights = self._get_heatmap_weights(
- keypoint_heatmaps, bg_weight=self.background_weight)
-
- heatmaps = np.concatenate((keypoint_heatmaps, heatmaps), axis=0)
- heatmap_weights = np.concatenate(
- (keypoint_heatmaps_weights, heatmap_weights), axis=0)
-
- # generate displacements
- displacements, displacement_weights = \
- generate_displacement_heatmap(
- self.heatmap_size,
- _keypoints,
- keypoints_visible,
- roots,
- roots_visible,
- diagonal_lengths,
- self.sigma[0],
- )
-
- encoded = dict(
- heatmaps=heatmaps,
- heatmap_weights=heatmap_weights,
- displacements=displacements,
- displacement_weights=displacement_weights)
-
- return encoded
-
- def decode(self, heatmaps: Tensor,
- displacements: Tensor) -> Tuple[np.ndarray, np.ndarray]:
- """Decode the keypoint coordinates from heatmaps and displacements. The
- decoded keypoint coordinates are in the input image space.
-
- Args:
- heatmaps (Tensor): Encoded root and keypoints (optional) heatmaps
- in shape (1, H, W) or (K+1, H, W)
- displacements (Tensor): Encoded keypoints displacement fields
- in shape (K*D, H, W)
-
- Returns:
- tuple:
- - keypoints (Tensor): Decoded keypoint coordinates in shape
- (N, K, D)
- - scores (tuple):
- - root_scores (Tensor): The root scores in shape (N, )
- - keypoint_scores (Tensor): The keypoint scores in
- shape (N, K). If keypoint heatmaps are not generated,
- `keypoint_scores` will be `None`
- """
- # heatmaps, displacements = encoded
- _k, h, w = displacements.shape
- k = _k // 2
- displacements = displacements.view(k, 2, h, w)
-
- # convert displacements to a dense keypoint prediction
- y, x = torch.meshgrid(torch.arange(h), torch.arange(w))
- regular_grid = torch.stack([x, y], dim=0).to(displacements)
- posemaps = (regular_grid[None] + displacements).flatten(2)
-
- # find local maximum on root heatmap
- root_heatmap_peaks = batch_heatmap_nms(heatmaps[None, -1:],
- self.decode_nms_kernel)
- root_scores, pos_idx = root_heatmap_peaks.flatten().topk(
- self.decode_max_instances)
- mask = root_scores > self.decode_thr
- root_scores, pos_idx = root_scores[mask], pos_idx[mask]
-
- keypoints = posemaps[:, :, pos_idx].permute(2, 0, 1).contiguous()
-
- if self.generate_keypoint_heatmaps and heatmaps.shape[0] == 1 + k:
- # compute scores for each keypoint
- keypoint_scores = self.get_keypoint_scores(heatmaps[:k], keypoints)
- else:
- keypoint_scores = None
-
- keypoints = torch.cat([
- kpt * self.scale_factor[i]
- for i, kpt in enumerate(keypoints.split(1, -1))
- ],
- dim=-1)
- return keypoints, (root_scores, keypoint_scores)
-
- def get_keypoint_scores(self, heatmaps: Tensor, keypoints: Tensor):
- """Calculate the keypoint scores with keypoints heatmaps and
- coordinates.
-
- Args:
- heatmaps (Tensor): Keypoint heatmaps in shape (K, H, W)
- keypoints (Tensor): Keypoint coordinates in shape (N, K, D)
-
- Returns:
- Tensor: Keypoint scores in [N, K]
- """
- k, h, w = heatmaps.shape
- keypoints = torch.stack((
- keypoints[..., 0] / (w - 1) * 2 - 1,
- keypoints[..., 1] / (h - 1) * 2 - 1,
- ),
- dim=-1)
- keypoints = keypoints.transpose(0, 1).unsqueeze(1).contiguous()
-
- keypoint_scores = torch.nn.functional.grid_sample(
- heatmaps.unsqueeze(1), keypoints,
- padding_mode='border').view(k, -1).transpose(0, 1).contiguous()
-
- return keypoint_scores
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple, Union
+
+import numpy as np
+import torch
+from torch import Tensor
+
+from mmpose.registry import KEYPOINT_CODECS
+from .base import BaseKeypointCodec
+from .utils import (batch_heatmap_nms, generate_displacement_heatmap,
+ generate_gaussian_heatmaps, get_diagonal_lengths,
+ get_instance_root)
+
+
+@KEYPOINT_CODECS.register_module()
+class SPR(BaseKeypointCodec):
+ """Encode/decode keypoints with Structured Pose Representation (SPR).
+
+ See the paper `Single-stage multi-person pose machines`_
+ by Nie et al (2017) for details
+
+ Note:
+
+ - instance number: N
+ - keypoint number: K
+ - keypoint dimension: D
+ - image size: [w, h]
+ - heatmap size: [W, H]
+
+ Encoded:
+
+ - heatmaps (np.ndarray): The generated heatmap in shape (1, H, W)
+ where [W, H] is the `heatmap_size`. If the keypoint heatmap is
+ generated together, the output heatmap shape is (K+1, H, W)
+ - heatmap_weights (np.ndarray): The target weights for heatmaps which
+ has same shape with heatmaps.
+ - displacements (np.ndarray): The dense keypoint displacement in
+ shape (K*2, H, W).
+ - displacement_weights (np.ndarray): The target weights for heatmaps
+ which has same shape with displacements.
+
+ Args:
+ input_size (tuple): Image size in [w, h]
+ heatmap_size (tuple): Heatmap size in [W, H]
+ sigma (float or tuple, optional): The sigma values of the Gaussian
+ heatmaps. If sigma is a tuple, it includes both sigmas for root
+ and keypoint heatmaps. ``None`` means the sigmas are computed
+ automatically from the heatmap size. Defaults to ``None``
+ generate_keypoint_heatmaps (bool): Whether to generate Gaussian
+ heatmaps for each keypoint. Defaults to ``False``
+ root_type (str): The method to generate the instance root. Options
+ are:
+
+ - ``'kpt_center'``: Average coordinate of all visible keypoints.
+ - ``'bbox_center'``: Center point of bounding boxes outlined by
+ all visible keypoints.
+
+ Defaults to ``'kpt_center'``
+
+ minimal_diagonal_length (int or float): The threshold of diagonal
+ length of instance bounding box. Small instances will not be
+ used in training. Defaults to 32
+ background_weight (float): Loss weight of background pixels.
+ Defaults to 0.1
+ decode_thr (float): The threshold of keypoint response value in
+ heatmaps. Defaults to 0.01
+ decode_nms_kernel (int): The kernel size of the NMS during decoding,
+ which should be an odd integer. Defaults to 5
+ decode_max_instances (int): The maximum number of instances
+ to decode. Defaults to 30
+
+ .. _`Single-stage multi-person pose machines`:
+ https://arxiv.org/abs/1908.09220
+ """
+
+ def __init__(
+ self,
+ input_size: Tuple[int, int],
+ heatmap_size: Tuple[int, int],
+ sigma: Optional[Union[float, Tuple[float]]] = None,
+ generate_keypoint_heatmaps: bool = False,
+ root_type: str = 'kpt_center',
+ minimal_diagonal_length: Union[int, float] = 5,
+ background_weight: float = 0.1,
+ decode_nms_kernel: int = 5,
+ decode_max_instances: int = 30,
+ decode_thr: float = 0.01,
+ ):
+ super().__init__()
+
+ self.input_size = input_size
+ self.heatmap_size = heatmap_size
+ self.generate_keypoint_heatmaps = generate_keypoint_heatmaps
+ self.root_type = root_type
+ self.minimal_diagonal_length = minimal_diagonal_length
+ self.background_weight = background_weight
+ self.decode_nms_kernel = decode_nms_kernel
+ self.decode_max_instances = decode_max_instances
+ self.decode_thr = decode_thr
+
+ self.scale_factor = (np.array(input_size) /
+ heatmap_size).astype(np.float32)
+
+ if sigma is None:
+ sigma = (heatmap_size[0] * heatmap_size[1])**0.5 / 32
+ if generate_keypoint_heatmaps:
+ # sigma for root heatmap and keypoint heatmaps
+ self.sigma = (sigma, sigma // 2)
+ else:
+ self.sigma = (sigma, )
+ else:
+ if not isinstance(sigma, (tuple, list)):
+ sigma = (sigma, )
+ if generate_keypoint_heatmaps:
+ assert len(sigma) == 2, 'sigma for keypoints must be given ' \
+ 'if `generate_keypoint_heatmaps` ' \
+ 'is True. e.g. sigma=(4, 2)'
+ self.sigma = sigma
+
+ def _get_heatmap_weights(self,
+ heatmaps,
+ fg_weight: float = 1,
+ bg_weight: float = 0):
+ """Generate weight array for heatmaps.
+
+ Args:
+ heatmaps (np.ndarray): Root and keypoint (optional) heatmaps
+ fg_weight (float): Weight for foreground pixels. Defaults to 1.0
+ bg_weight (float): Weight for background pixels. Defaults to 0.0
+
+ Returns:
+ np.ndarray: Heatmap weight array in the same shape with heatmaps
+ """
+ heatmap_weights = np.ones(heatmaps.shape) * bg_weight
+ heatmap_weights[heatmaps > 0] = fg_weight
+ return heatmap_weights
+
+ def encode(self,
+ keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray] = None) -> dict:
+ """Encode keypoints into root heatmaps and keypoint displacement
+ fields. Note that the original keypoint coordinates should be in the
+ input image space.
+
+ Args:
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ keypoints_visible (np.ndarray): Keypoint visibilities in shape
+ (N, K)
+
+ Returns:
+ dict:
+ - heatmaps (np.ndarray): The generated heatmap in shape
+ (1, H, W) where [W, H] is the `heatmap_size`. If keypoint
+ heatmaps are generated together, the shape is (K+1, H, W)
+ - heatmap_weights (np.ndarray): The pixel-wise weight for heatmaps
+ which has same shape with `heatmaps`
+ - displacements (np.ndarray): The generated displacement fields in
+ shape (K*D, H, W). The vector on each pixels represents the
+ displacement of keypoints belong to the associated instance
+ from this pixel.
+ - displacement_weights (np.ndarray): The pixel-wise weight for
+ displacements which has same shape with `displacements`
+ """
+
+ if keypoints_visible is None:
+ keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
+
+ # keypoint coordinates in heatmap
+ _keypoints = keypoints / self.scale_factor
+
+ # compute the root and scale of each instance
+ roots, roots_visible = get_instance_root(_keypoints, keypoints_visible,
+ self.root_type)
+ diagonal_lengths = get_diagonal_lengths(_keypoints, keypoints_visible)
+
+ # discard the small instances
+ roots_visible[diagonal_lengths < self.minimal_diagonal_length] = 0
+
+ # generate heatmaps
+ heatmaps, _ = generate_gaussian_heatmaps(
+ heatmap_size=self.heatmap_size,
+ keypoints=roots[:, None],
+ keypoints_visible=roots_visible[:, None],
+ sigma=self.sigma[0])
+ heatmap_weights = self._get_heatmap_weights(
+ heatmaps, bg_weight=self.background_weight)
+
+ if self.generate_keypoint_heatmaps:
+ keypoint_heatmaps, _ = generate_gaussian_heatmaps(
+ heatmap_size=self.heatmap_size,
+ keypoints=_keypoints,
+ keypoints_visible=keypoints_visible,
+ sigma=self.sigma[1])
+
+ keypoint_heatmaps_weights = self._get_heatmap_weights(
+ keypoint_heatmaps, bg_weight=self.background_weight)
+
+ heatmaps = np.concatenate((keypoint_heatmaps, heatmaps), axis=0)
+ heatmap_weights = np.concatenate(
+ (keypoint_heatmaps_weights, heatmap_weights), axis=0)
+
+ # generate displacements
+ displacements, displacement_weights = \
+ generate_displacement_heatmap(
+ self.heatmap_size,
+ _keypoints,
+ keypoints_visible,
+ roots,
+ roots_visible,
+ diagonal_lengths,
+ self.sigma[0],
+ )
+
+ encoded = dict(
+ heatmaps=heatmaps,
+ heatmap_weights=heatmap_weights,
+ displacements=displacements,
+ displacement_weights=displacement_weights)
+
+ return encoded
+
+ def decode(self, heatmaps: Tensor,
+ displacements: Tensor) -> Tuple[np.ndarray, np.ndarray]:
+ """Decode the keypoint coordinates from heatmaps and displacements. The
+ decoded keypoint coordinates are in the input image space.
+
+ Args:
+ heatmaps (Tensor): Encoded root and keypoints (optional) heatmaps
+ in shape (1, H, W) or (K+1, H, W)
+ displacements (Tensor): Encoded keypoints displacement fields
+ in shape (K*D, H, W)
+
+ Returns:
+ tuple:
+ - keypoints (Tensor): Decoded keypoint coordinates in shape
+ (N, K, D)
+ - scores (tuple):
+ - root_scores (Tensor): The root scores in shape (N, )
+ - keypoint_scores (Tensor): The keypoint scores in
+ shape (N, K). If keypoint heatmaps are not generated,
+ `keypoint_scores` will be `None`
+ """
+ # heatmaps, displacements = encoded
+ _k, h, w = displacements.shape
+ k = _k // 2
+ displacements = displacements.view(k, 2, h, w)
+
+ # convert displacements to a dense keypoint prediction
+ y, x = torch.meshgrid(torch.arange(h), torch.arange(w))
+ regular_grid = torch.stack([x, y], dim=0).to(displacements)
+ posemaps = (regular_grid[None] + displacements).flatten(2)
+
+ # find local maximum on root heatmap
+ root_heatmap_peaks = batch_heatmap_nms(heatmaps[None, -1:],
+ self.decode_nms_kernel)
+ root_scores, pos_idx = root_heatmap_peaks.flatten().topk(
+ self.decode_max_instances)
+ mask = root_scores > self.decode_thr
+ root_scores, pos_idx = root_scores[mask], pos_idx[mask]
+
+ keypoints = posemaps[:, :, pos_idx].permute(2, 0, 1).contiguous()
+
+ if self.generate_keypoint_heatmaps and heatmaps.shape[0] == 1 + k:
+ # compute scores for each keypoint
+ keypoint_scores = self.get_keypoint_scores(heatmaps[:k], keypoints)
+ else:
+ keypoint_scores = None
+
+ keypoints = torch.cat([
+ kpt * self.scale_factor[i]
+ for i, kpt in enumerate(keypoints.split(1, -1))
+ ],
+ dim=-1)
+ return keypoints, (root_scores, keypoint_scores)
+
+ def get_keypoint_scores(self, heatmaps: Tensor, keypoints: Tensor):
+ """Calculate the keypoint scores with keypoints heatmaps and
+ coordinates.
+
+ Args:
+ heatmaps (Tensor): Keypoint heatmaps in shape (K, H, W)
+ keypoints (Tensor): Keypoint coordinates in shape (N, K, D)
+
+ Returns:
+ Tensor: Keypoint scores in [N, K]
+ """
+ k, h, w = heatmaps.shape
+ keypoints = torch.stack((
+ keypoints[..., 0] / (w - 1) * 2 - 1,
+ keypoints[..., 1] / (h - 1) * 2 - 1,
+ ),
+ dim=-1)
+ keypoints = keypoints.transpose(0, 1).unsqueeze(1).contiguous()
+
+ keypoint_scores = torch.nn.functional.grid_sample(
+ heatmaps.unsqueeze(1), keypoints,
+ padding_mode='border').view(k, -1).transpose(0, 1).contiguous()
+
+ return keypoint_scores
diff --git a/mmpose/codecs/udp_heatmap.py b/mmpose/codecs/udp_heatmap.py
index c38ea17be4..df95b50240 100644
--- a/mmpose/codecs/udp_heatmap.py
+++ b/mmpose/codecs/udp_heatmap.py
@@ -1,185 +1,185 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional, Tuple
-
-import cv2
-import numpy as np
-
-from mmpose.registry import KEYPOINT_CODECS
-from .base import BaseKeypointCodec
-from .utils import (generate_offset_heatmap, generate_udp_gaussian_heatmaps,
- get_heatmap_maximum, refine_keypoints_dark_udp)
-
-
-@KEYPOINT_CODECS.register_module()
-class UDPHeatmap(BaseKeypointCodec):
- r"""Generate keypoint heatmaps by Unbiased Data Processing (UDP).
- See the paper: `The Devil is in the Details: Delving into Unbiased Data
- Processing for Human Pose Estimation`_ by Huang et al (2020) for details.
-
- Note:
-
- - instance number: N
- - keypoint number: K
- - keypoint dimension: D
- - image size: [w, h]
- - heatmap size: [W, H]
-
- Encoded:
-
- - heatmap (np.ndarray): The generated heatmap in shape (C_out, H, W)
- where [W, H] is the `heatmap_size`, and the C_out is the output
- channel number which depends on the `heatmap_type`. If
- `heatmap_type=='gaussian'`, C_out equals to keypoint number K;
- if `heatmap_type=='combined'`, C_out equals to K*3
- (x_offset, y_offset and class label)
- - keypoint_weights (np.ndarray): The target weights in shape (K,)
-
- Args:
- input_size (tuple): Image size in [w, h]
- heatmap_size (tuple): Heatmap size in [W, H]
- heatmap_type (str): The heatmap type to encode the keypoitns. Options
- are:
-
- - ``'gaussian'``: Gaussian heatmap
- - ``'combined'``: Combination of a binary label map and offset
- maps for X and Y axes.
-
- sigma (float): The sigma value of the Gaussian heatmap when
- ``heatmap_type=='gaussian'``. Defaults to 2.0
- radius_factor (float): The radius factor of the binary label
- map when ``heatmap_type=='combined'``. The positive region is
- defined as the neighbor of the keypoit with the radius
- :math:`r=radius_factor*max(W, H)`. Defaults to 0.0546875
- blur_kernel_size (int): The Gaussian blur kernel size of the heatmap
- modulation in DarkPose. Defaults to 11
-
- .. _`The Devil is in the Details: Delving into Unbiased Data Processing for
- Human Pose Estimation`: https://arxiv.org/abs/1911.07524
- """
-
- def __init__(self,
- input_size: Tuple[int, int],
- heatmap_size: Tuple[int, int],
- heatmap_type: str = 'gaussian',
- sigma: float = 2.,
- radius_factor: float = 0.0546875,
- blur_kernel_size: int = 11) -> None:
- super().__init__()
- self.input_size = input_size
- self.heatmap_size = heatmap_size
- self.sigma = sigma
- self.radius_factor = radius_factor
- self.heatmap_type = heatmap_type
- self.blur_kernel_size = blur_kernel_size
- self.scale_factor = ((np.array(input_size) - 1) /
- (np.array(heatmap_size) - 1)).astype(np.float32)
-
- if self.heatmap_type not in {'gaussian', 'combined'}:
- raise ValueError(
- f'{self.__class__.__name__} got invalid `heatmap_type` value'
- f'{self.heatmap_type}. Should be one of '
- '{"gaussian", "combined"}')
-
- def encode(self,
- keypoints: np.ndarray,
- keypoints_visible: Optional[np.ndarray] = None) -> dict:
- """Encode keypoints into heatmaps. Note that the original keypoint
- coordinates should be in the input image space.
-
- Args:
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
- keypoints_visible (np.ndarray): Keypoint visibilities in shape
- (N, K)
-
- Returns:
- dict:
- - heatmap (np.ndarray): The generated heatmap in shape
- (C_out, H, W) where [W, H] is the `heatmap_size`, and the
- C_out is the output channel number which depends on the
- `heatmap_type`. If `heatmap_type=='gaussian'`, C_out equals to
- keypoint number K; if `heatmap_type=='combined'`, C_out
- equals to K*3 (x_offset, y_offset and class label)
- - keypoint_weights (np.ndarray): The target weights in shape
- (K,)
- """
- assert keypoints.shape[0] == 1, (
- f'{self.__class__.__name__} only support single-instance '
- 'keypoint encoding')
-
- if keypoints_visible is None:
- keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
-
- if self.heatmap_type == 'gaussian':
- heatmaps, keypoint_weights = generate_udp_gaussian_heatmaps(
- heatmap_size=self.heatmap_size,
- keypoints=keypoints / self.scale_factor,
- keypoints_visible=keypoints_visible,
- sigma=self.sigma)
- elif self.heatmap_type == 'combined':
- heatmaps, keypoint_weights = generate_offset_heatmap(
- heatmap_size=self.heatmap_size,
- keypoints=keypoints / self.scale_factor,
- keypoints_visible=keypoints_visible,
- radius_factor=self.radius_factor)
- else:
- raise ValueError(
- f'{self.__class__.__name__} got invalid `heatmap_type` value'
- f'{self.heatmap_type}. Should be one of '
- '{"gaussian", "combined"}')
-
- encoded = dict(heatmaps=heatmaps, keypoint_weights=keypoint_weights)
-
- return encoded
-
- def decode(self, encoded: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
- """Decode keypoint coordinates from heatmaps. The decoded keypoint
- coordinates are in the input image space.
-
- Args:
- encoded (np.ndarray): Heatmaps in shape (K, H, W)
-
- Returns:
- tuple:
- - keypoints (np.ndarray): Decoded keypoint coordinates in shape
- (N, K, D)
- - scores (np.ndarray): The keypoint scores in shape (N, K). It
- usually represents the confidence of the keypoint prediction
- """
- heatmaps = encoded.copy()
-
- if self.heatmap_type == 'gaussian':
- keypoints, scores = get_heatmap_maximum(heatmaps)
- # unsqueeze the instance dimension for single-instance results
- keypoints = keypoints[None]
- scores = scores[None]
-
- keypoints = refine_keypoints_dark_udp(
- keypoints, heatmaps, blur_kernel_size=self.blur_kernel_size)
-
- elif self.heatmap_type == 'combined':
- _K, H, W = heatmaps.shape
- K = _K // 3
-
- for cls_heatmap in heatmaps[::3]:
- # Apply Gaussian blur on classification maps
- ks = 2 * self.blur_kernel_size + 1
- cv2.GaussianBlur(cls_heatmap, (ks, ks), 0, cls_heatmap)
-
- # valid radius
- radius = self.radius_factor * max(W, H)
-
- x_offset = heatmaps[1::3].flatten() * radius
- y_offset = heatmaps[2::3].flatten() * radius
- keypoints, scores = get_heatmap_maximum(heatmaps=heatmaps[::3])
- index = (keypoints[..., 0] + keypoints[..., 1] * W).flatten()
- index += W * H * np.arange(0, K)
- index = index.astype(int)
- keypoints += np.stack((x_offset[index], y_offset[index]), axis=-1)
- # unsqueeze the instance dimension for single-instance results
- keypoints = keypoints[None].astype(np.float32)
- scores = scores[None]
-
- W, H = self.heatmap_size
- keypoints = keypoints / [W - 1, H - 1] * self.input_size
-
- return keypoints, scores
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import cv2
+import numpy as np
+
+from mmpose.registry import KEYPOINT_CODECS
+from .base import BaseKeypointCodec
+from .utils import (generate_offset_heatmap, generate_udp_gaussian_heatmaps,
+ get_heatmap_maximum, refine_keypoints_dark_udp)
+
+
+@KEYPOINT_CODECS.register_module()
+class UDPHeatmap(BaseKeypointCodec):
+ r"""Generate keypoint heatmaps by Unbiased Data Processing (UDP).
+ See the paper: `The Devil is in the Details: Delving into Unbiased Data
+ Processing for Human Pose Estimation`_ by Huang et al (2020) for details.
+
+ Note:
+
+ - instance number: N
+ - keypoint number: K
+ - keypoint dimension: D
+ - image size: [w, h]
+ - heatmap size: [W, H]
+
+ Encoded:
+
+ - heatmap (np.ndarray): The generated heatmap in shape (C_out, H, W)
+ where [W, H] is the `heatmap_size`, and the C_out is the output
+ channel number which depends on the `heatmap_type`. If
+ `heatmap_type=='gaussian'`, C_out equals to keypoint number K;
+ if `heatmap_type=='combined'`, C_out equals to K*3
+ (x_offset, y_offset and class label)
+ - keypoint_weights (np.ndarray): The target weights in shape (K,)
+
+ Args:
+ input_size (tuple): Image size in [w, h]
+ heatmap_size (tuple): Heatmap size in [W, H]
+ heatmap_type (str): The heatmap type to encode the keypoitns. Options
+ are:
+
+ - ``'gaussian'``: Gaussian heatmap
+ - ``'combined'``: Combination of a binary label map and offset
+ maps for X and Y axes.
+
+ sigma (float): The sigma value of the Gaussian heatmap when
+ ``heatmap_type=='gaussian'``. Defaults to 2.0
+ radius_factor (float): The radius factor of the binary label
+ map when ``heatmap_type=='combined'``. The positive region is
+ defined as the neighbor of the keypoit with the radius
+ :math:`r=radius_factor*max(W, H)`. Defaults to 0.0546875
+ blur_kernel_size (int): The Gaussian blur kernel size of the heatmap
+ modulation in DarkPose. Defaults to 11
+
+ .. _`The Devil is in the Details: Delving into Unbiased Data Processing for
+ Human Pose Estimation`: https://arxiv.org/abs/1911.07524
+ """
+
+ def __init__(self,
+ input_size: Tuple[int, int],
+ heatmap_size: Tuple[int, int],
+ heatmap_type: str = 'gaussian',
+ sigma: float = 2.,
+ radius_factor: float = 0.0546875,
+ blur_kernel_size: int = 11) -> None:
+ super().__init__()
+ self.input_size = input_size
+ self.heatmap_size = heatmap_size
+ self.sigma = sigma
+ self.radius_factor = radius_factor
+ self.heatmap_type = heatmap_type
+ self.blur_kernel_size = blur_kernel_size
+ self.scale_factor = ((np.array(input_size) - 1) /
+ (np.array(heatmap_size) - 1)).astype(np.float32)
+
+ if self.heatmap_type not in {'gaussian', 'combined'}:
+ raise ValueError(
+ f'{self.__class__.__name__} got invalid `heatmap_type` value'
+ f'{self.heatmap_type}. Should be one of '
+ '{"gaussian", "combined"}')
+
+ def encode(self,
+ keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray] = None) -> dict:
+ """Encode keypoints into heatmaps. Note that the original keypoint
+ coordinates should be in the input image space.
+
+ Args:
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ keypoints_visible (np.ndarray): Keypoint visibilities in shape
+ (N, K)
+
+ Returns:
+ dict:
+ - heatmap (np.ndarray): The generated heatmap in shape
+ (C_out, H, W) where [W, H] is the `heatmap_size`, and the
+ C_out is the output channel number which depends on the
+ `heatmap_type`. If `heatmap_type=='gaussian'`, C_out equals to
+ keypoint number K; if `heatmap_type=='combined'`, C_out
+ equals to K*3 (x_offset, y_offset and class label)
+ - keypoint_weights (np.ndarray): The target weights in shape
+ (K,)
+ """
+ assert keypoints.shape[0] == 1, (
+ f'{self.__class__.__name__} only support single-instance '
+ 'keypoint encoding')
+
+ if keypoints_visible is None:
+ keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
+
+ if self.heatmap_type == 'gaussian':
+ heatmaps, keypoint_weights = generate_udp_gaussian_heatmaps(
+ heatmap_size=self.heatmap_size,
+ keypoints=keypoints / self.scale_factor,
+ keypoints_visible=keypoints_visible,
+ sigma=self.sigma)
+ elif self.heatmap_type == 'combined':
+ heatmaps, keypoint_weights = generate_offset_heatmap(
+ heatmap_size=self.heatmap_size,
+ keypoints=keypoints / self.scale_factor,
+ keypoints_visible=keypoints_visible,
+ radius_factor=self.radius_factor)
+ else:
+ raise ValueError(
+ f'{self.__class__.__name__} got invalid `heatmap_type` value'
+ f'{self.heatmap_type}. Should be one of '
+ '{"gaussian", "combined"}')
+
+ encoded = dict(heatmaps=heatmaps, keypoint_weights=keypoint_weights)
+
+ return encoded
+
+ def decode(self, encoded: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ """Decode keypoint coordinates from heatmaps. The decoded keypoint
+ coordinates are in the input image space.
+
+ Args:
+ encoded (np.ndarray): Heatmaps in shape (K, H, W)
+
+ Returns:
+ tuple:
+ - keypoints (np.ndarray): Decoded keypoint coordinates in shape
+ (N, K, D)
+ - scores (np.ndarray): The keypoint scores in shape (N, K). It
+ usually represents the confidence of the keypoint prediction
+ """
+ heatmaps = encoded.copy()
+
+ if self.heatmap_type == 'gaussian':
+ keypoints, scores = get_heatmap_maximum(heatmaps)
+ # unsqueeze the instance dimension for single-instance results
+ keypoints = keypoints[None]
+ scores = scores[None]
+
+ keypoints = refine_keypoints_dark_udp(
+ keypoints, heatmaps, blur_kernel_size=self.blur_kernel_size)
+
+ elif self.heatmap_type == 'combined':
+ _K, H, W = heatmaps.shape
+ K = _K // 3
+
+ for cls_heatmap in heatmaps[::3]:
+ # Apply Gaussian blur on classification maps
+ ks = 2 * self.blur_kernel_size + 1
+ cv2.GaussianBlur(cls_heatmap, (ks, ks), 0, cls_heatmap)
+
+ # valid radius
+ radius = self.radius_factor * max(W, H)
+
+ x_offset = heatmaps[1::3].flatten() * radius
+ y_offset = heatmaps[2::3].flatten() * radius
+ keypoints, scores = get_heatmap_maximum(heatmaps=heatmaps[::3])
+ index = (keypoints[..., 0] + keypoints[..., 1] * W).flatten()
+ index += W * H * np.arange(0, K)
+ index = index.astype(int)
+ keypoints += np.stack((x_offset[index], y_offset[index]), axis=-1)
+ # unsqueeze the instance dimension for single-instance results
+ keypoints = keypoints[None].astype(np.float32)
+ scores = scores[None]
+
+ W, H = self.heatmap_size
+ keypoints = keypoints / [W - 1, H - 1] * self.input_size
+
+ return keypoints, scores
diff --git a/mmpose/codecs/utils/__init__.py b/mmpose/codecs/utils/__init__.py
index eaa093f12b..f1f87d21ab 100644
--- a/mmpose/codecs/utils/__init__.py
+++ b/mmpose/codecs/utils/__init__.py
@@ -1,23 +1,23 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .gaussian_heatmap import (generate_gaussian_heatmaps,
- generate_udp_gaussian_heatmaps,
- generate_unbiased_gaussian_heatmaps)
-from .instance_property import (get_diagonal_lengths, get_instance_bbox,
- get_instance_root)
-from .offset_heatmap import (generate_displacement_heatmap,
- generate_offset_heatmap)
-from .post_processing import (batch_heatmap_nms, gaussian_blur,
- gaussian_blur1d, get_heatmap_maximum,
- get_simcc_maximum, get_simcc_normalized)
-from .refinement import (refine_keypoints, refine_keypoints_dark,
- refine_keypoints_dark_udp, refine_simcc_dark)
-
-__all__ = [
- 'generate_gaussian_heatmaps', 'generate_udp_gaussian_heatmaps',
- 'generate_unbiased_gaussian_heatmaps', 'gaussian_blur',
- 'get_heatmap_maximum', 'get_simcc_maximum', 'generate_offset_heatmap',
- 'batch_heatmap_nms', 'refine_keypoints', 'refine_keypoints_dark',
- 'refine_keypoints_dark_udp', 'generate_displacement_heatmap',
- 'refine_simcc_dark', 'gaussian_blur1d', 'get_diagonal_lengths',
- 'get_instance_root', 'get_instance_bbox', 'get_simcc_normalized'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .gaussian_heatmap import (generate_gaussian_heatmaps,
+ generate_udp_gaussian_heatmaps,
+ generate_unbiased_gaussian_heatmaps)
+from .instance_property import (get_diagonal_lengths, get_instance_bbox,
+ get_instance_root)
+from .offset_heatmap import (generate_displacement_heatmap,
+ generate_offset_heatmap)
+from .post_processing import (batch_heatmap_nms, gaussian_blur,
+ gaussian_blur1d, get_heatmap_maximum,
+ get_simcc_maximum, get_simcc_normalized)
+from .refinement import (refine_keypoints, refine_keypoints_dark,
+ refine_keypoints_dark_udp, refine_simcc_dark)
+
+__all__ = [
+ 'generate_gaussian_heatmaps', 'generate_udp_gaussian_heatmaps',
+ 'generate_unbiased_gaussian_heatmaps', 'gaussian_blur',
+ 'get_heatmap_maximum', 'get_simcc_maximum', 'generate_offset_heatmap',
+ 'batch_heatmap_nms', 'refine_keypoints', 'refine_keypoints_dark',
+ 'refine_keypoints_dark_udp', 'generate_displacement_heatmap',
+ 'refine_simcc_dark', 'gaussian_blur1d', 'get_diagonal_lengths',
+ 'get_instance_root', 'get_instance_bbox', 'get_simcc_normalized'
+]
diff --git a/mmpose/codecs/utils/gaussian_heatmap.py b/mmpose/codecs/utils/gaussian_heatmap.py
index 91e08c2cdd..fe3cae3b4f 100644
--- a/mmpose/codecs/utils/gaussian_heatmap.py
+++ b/mmpose/codecs/utils/gaussian_heatmap.py
@@ -1,227 +1,227 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from itertools import product
-from typing import Tuple, Union
-
-import numpy as np
-
-
-def generate_gaussian_heatmaps(
- heatmap_size: Tuple[int, int],
- keypoints: np.ndarray,
- keypoints_visible: np.ndarray,
- sigma: Union[float, Tuple[float], np.ndarray],
-) -> Tuple[np.ndarray, np.ndarray]:
- """Generate gaussian heatmaps of keypoints.
-
- Args:
- heatmap_size (Tuple[int, int]): Heatmap size in [W, H]
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
- keypoints_visible (np.ndarray): Keypoint visibilities in shape
- (N, K)
- sigma (float or List[float]): A list of sigma values of the Gaussian
- heatmap for each instance. If sigma is given as a single float
- value, it will be expanded into a tuple
-
- Returns:
- tuple:
- - heatmaps (np.ndarray): The generated heatmap in shape
- (K, H, W) where [W, H] is the `heatmap_size`
- - keypoint_weights (np.ndarray): The target weights in shape
- (N, K)
- """
-
- N, K, _ = keypoints.shape
- W, H = heatmap_size
-
- heatmaps = np.zeros((K, H, W), dtype=np.float32)
- keypoint_weights = keypoints_visible.copy()
-
- if isinstance(sigma, (int, float)):
- sigma = (sigma, ) * N
-
- for n in range(N):
- # 3-sigma rule
- radius = sigma[n] * 3
-
- # xy grid
- gaussian_size = 2 * radius + 1
- x = np.arange(0, gaussian_size, 1, dtype=np.float32)
- y = x[:, None]
- x0 = y0 = gaussian_size // 2
-
- for k in range(K):
- # skip unlabled keypoints
- if keypoints_visible[n, k] < 0.5:
- continue
-
- # get gaussian center coordinates
- mu = (keypoints[n, k] + 0.5).astype(np.int64)
-
- # check that the gaussian has in-bounds part
- left, top = (mu - radius).astype(np.int64)
- right, bottom = (mu + radius + 1).astype(np.int64)
-
- if left >= W or top >= H or right < 0 or bottom < 0:
- keypoint_weights[n, k] = 0
- continue
-
- # The gaussian is not normalized,
- # we want the center value to equal 1
- gaussian = np.exp(-((x - x0)**2 + (y - y0)**2) / (2 * sigma[n]**2))
-
- # valid range in gaussian
- g_x1 = max(0, -left)
- g_x2 = min(W, right) - left
- g_y1 = max(0, -top)
- g_y2 = min(H, bottom) - top
-
- # valid range in heatmap
- h_x1 = max(0, left)
- h_x2 = min(W, right)
- h_y1 = max(0, top)
- h_y2 = min(H, bottom)
-
- heatmap_region = heatmaps[k, h_y1:h_y2, h_x1:h_x2]
- gaussian_regsion = gaussian[g_y1:g_y2, g_x1:g_x2]
-
- _ = np.maximum(
- heatmap_region, gaussian_regsion, out=heatmap_region)
-
- return heatmaps, keypoint_weights
-
-
-def generate_unbiased_gaussian_heatmaps(
- heatmap_size: Tuple[int, int],
- keypoints: np.ndarray,
- keypoints_visible: np.ndarray,
- sigma: float,
-) -> Tuple[np.ndarray, np.ndarray]:
- """Generate gaussian heatmaps of keypoints using `Dark Pose`_.
-
- Args:
- heatmap_size (Tuple[int, int]): Heatmap size in [W, H]
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
- keypoints_visible (np.ndarray): Keypoint visibilities in shape
- (N, K)
-
- Returns:
- tuple:
- - heatmaps (np.ndarray): The generated heatmap in shape
- (K, H, W) where [W, H] is the `heatmap_size`
- - keypoint_weights (np.ndarray): The target weights in shape
- (N, K)
-
- .. _`Dark Pose`: https://arxiv.org/abs/1910.06278
- """
-
- N, K, _ = keypoints.shape
- W, H = heatmap_size
-
- heatmaps = np.zeros((K, H, W), dtype=np.float32)
- keypoint_weights = keypoints_visible.copy()
-
- # 3-sigma rule
- radius = sigma * 3
-
- # xy grid
- x = np.arange(0, W, 1, dtype=np.float32)
- y = np.arange(0, H, 1, dtype=np.float32)[:, None]
-
- for n, k in product(range(N), range(K)):
- # skip unlabled keypoints
- if keypoints_visible[n, k] < 0.5:
- continue
-
- mu = keypoints[n, k]
- # check that the gaussian has in-bounds part
- left, top = mu - radius
- right, bottom = mu + radius + 1
-
- if left >= W or top >= H or right < 0 or bottom < 0:
- keypoint_weights[n, k] = 0
- continue
-
- gaussian = np.exp(-((x - mu[0])**2 + (y - mu[1])**2) / (2 * sigma**2))
-
- _ = np.maximum(gaussian, heatmaps[k], out=heatmaps[k])
-
- return heatmaps, keypoint_weights
-
-
-def generate_udp_gaussian_heatmaps(
- heatmap_size: Tuple[int, int],
- keypoints: np.ndarray,
- keypoints_visible: np.ndarray,
- sigma: float,
-) -> Tuple[np.ndarray, np.ndarray]:
- """Generate gaussian heatmaps of keypoints using `UDP`_.
-
- Args:
- heatmap_size (Tuple[int, int]): Heatmap size in [W, H]
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
- keypoints_visible (np.ndarray): Keypoint visibilities in shape
- (N, K)
- sigma (float): The sigma value of the Gaussian heatmap
-
- Returns:
- tuple:
- - heatmaps (np.ndarray): The generated heatmap in shape
- (K, H, W) where [W, H] is the `heatmap_size`
- - keypoint_weights (np.ndarray): The target weights in shape
- (N, K)
-
- .. _`UDP`: https://arxiv.org/abs/1911.07524
- """
-
- N, K, _ = keypoints.shape
- W, H = heatmap_size
-
- heatmaps = np.zeros((K, H, W), dtype=np.float32)
- keypoint_weights = keypoints_visible.copy()
-
- # 3-sigma rule
- radius = sigma * 3
-
- # xy grid
- gaussian_size = 2 * radius + 1
- x = np.arange(0, gaussian_size, 1, dtype=np.float32)
- y = x[:, None]
-
- for n, k in product(range(N), range(K)):
- # skip unlabled keypoints
- if keypoints_visible[n, k] < 0.5:
- continue
-
- mu = (keypoints[n, k] + 0.5).astype(np.int64)
- # check that the gaussian has in-bounds part
- left, top = (mu - radius).astype(np.int64)
- right, bottom = (mu + radius + 1).astype(np.int64)
-
- if left >= W or top >= H or right < 0 or bottom < 0:
- keypoint_weights[n, k] = 0
- continue
-
- mu_ac = keypoints[n, k]
- x0 = y0 = gaussian_size // 2
- x0 += mu_ac[0] - mu[0]
- y0 += mu_ac[1] - mu[1]
- gaussian = np.exp(-((x - x0)**2 + (y - y0)**2) / (2 * sigma**2))
-
- # valid range in gaussian
- g_x1 = max(0, -left)
- g_x2 = min(W, right) - left
- g_y1 = max(0, -top)
- g_y2 = min(H, bottom) - top
-
- # valid range in heatmap
- h_x1 = max(0, left)
- h_x2 = min(W, right)
- h_y1 = max(0, top)
- h_y2 = min(H, bottom)
-
- heatmap_region = heatmaps[k, h_y1:h_y2, h_x1:h_x2]
- gaussian_regsion = gaussian[g_y1:g_y2, g_x1:g_x2]
-
- _ = np.maximum(heatmap_region, gaussian_regsion, out=heatmap_region)
-
- return heatmaps, keypoint_weights
+# Copyright (c) OpenMMLab. All rights reserved.
+from itertools import product
+from typing import Tuple, Union
+
+import numpy as np
+
+
+def generate_gaussian_heatmaps(
+ heatmap_size: Tuple[int, int],
+ keypoints: np.ndarray,
+ keypoints_visible: np.ndarray,
+ sigma: Union[float, Tuple[float], np.ndarray],
+) -> Tuple[np.ndarray, np.ndarray]:
+ """Generate gaussian heatmaps of keypoints.
+
+ Args:
+ heatmap_size (Tuple[int, int]): Heatmap size in [W, H]
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ keypoints_visible (np.ndarray): Keypoint visibilities in shape
+ (N, K)
+ sigma (float or List[float]): A list of sigma values of the Gaussian
+ heatmap for each instance. If sigma is given as a single float
+ value, it will be expanded into a tuple
+
+ Returns:
+ tuple:
+ - heatmaps (np.ndarray): The generated heatmap in shape
+ (K, H, W) where [W, H] is the `heatmap_size`
+ - keypoint_weights (np.ndarray): The target weights in shape
+ (N, K)
+ """
+
+ N, K, _ = keypoints.shape
+ W, H = heatmap_size
+
+ heatmaps = np.zeros((K, H, W), dtype=np.float32)
+ keypoint_weights = keypoints_visible.copy()
+
+ if isinstance(sigma, (int, float)):
+ sigma = (sigma, ) * N
+
+ for n in range(N):
+ # 3-sigma rule
+ radius = sigma[n] * 3
+
+ # xy grid
+ gaussian_size = 2 * radius + 1
+ x = np.arange(0, gaussian_size, 1, dtype=np.float32)
+ y = x[:, None]
+ x0 = y0 = gaussian_size // 2
+
+ for k in range(K):
+ # skip unlabled keypoints
+ if keypoints_visible[n, k] < 0.5:
+ continue
+
+ # get gaussian center coordinates
+ mu = (keypoints[n, k] + 0.5).astype(np.int64)
+
+ # check that the gaussian has in-bounds part
+ left, top = (mu - radius).astype(np.int64)
+ right, bottom = (mu + radius + 1).astype(np.int64)
+
+ if left >= W or top >= H or right < 0 or bottom < 0:
+ keypoint_weights[n, k] = 0
+ continue
+
+ # The gaussian is not normalized,
+ # we want the center value to equal 1
+ gaussian = np.exp(-((x - x0)**2 + (y - y0)**2) / (2 * sigma[n]**2))
+
+ # valid range in gaussian
+ g_x1 = max(0, -left)
+ g_x2 = min(W, right) - left
+ g_y1 = max(0, -top)
+ g_y2 = min(H, bottom) - top
+
+ # valid range in heatmap
+ h_x1 = max(0, left)
+ h_x2 = min(W, right)
+ h_y1 = max(0, top)
+ h_y2 = min(H, bottom)
+
+ heatmap_region = heatmaps[k, h_y1:h_y2, h_x1:h_x2]
+ gaussian_regsion = gaussian[g_y1:g_y2, g_x1:g_x2]
+
+ _ = np.maximum(
+ heatmap_region, gaussian_regsion, out=heatmap_region)
+
+ return heatmaps, keypoint_weights
+
+
+def generate_unbiased_gaussian_heatmaps(
+ heatmap_size: Tuple[int, int],
+ keypoints: np.ndarray,
+ keypoints_visible: np.ndarray,
+ sigma: float,
+) -> Tuple[np.ndarray, np.ndarray]:
+ """Generate gaussian heatmaps of keypoints using `Dark Pose`_.
+
+ Args:
+ heatmap_size (Tuple[int, int]): Heatmap size in [W, H]
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ keypoints_visible (np.ndarray): Keypoint visibilities in shape
+ (N, K)
+
+ Returns:
+ tuple:
+ - heatmaps (np.ndarray): The generated heatmap in shape
+ (K, H, W) where [W, H] is the `heatmap_size`
+ - keypoint_weights (np.ndarray): The target weights in shape
+ (N, K)
+
+ .. _`Dark Pose`: https://arxiv.org/abs/1910.06278
+ """
+
+ N, K, _ = keypoints.shape
+ W, H = heatmap_size
+
+ heatmaps = np.zeros((K, H, W), dtype=np.float32)
+ keypoint_weights = keypoints_visible.copy()
+
+ # 3-sigma rule
+ radius = sigma * 3
+
+ # xy grid
+ x = np.arange(0, W, 1, dtype=np.float32)
+ y = np.arange(0, H, 1, dtype=np.float32)[:, None]
+
+ for n, k in product(range(N), range(K)):
+ # skip unlabled keypoints
+ if keypoints_visible[n, k] < 0.5:
+ continue
+
+ mu = keypoints[n, k]
+ # check that the gaussian has in-bounds part
+ left, top = mu - radius
+ right, bottom = mu + radius + 1
+
+ if left >= W or top >= H or right < 0 or bottom < 0:
+ keypoint_weights[n, k] = 0
+ continue
+
+ gaussian = np.exp(-((x - mu[0])**2 + (y - mu[1])**2) / (2 * sigma**2))
+
+ _ = np.maximum(gaussian, heatmaps[k], out=heatmaps[k])
+
+ return heatmaps, keypoint_weights
+
+
+def generate_udp_gaussian_heatmaps(
+ heatmap_size: Tuple[int, int],
+ keypoints: np.ndarray,
+ keypoints_visible: np.ndarray,
+ sigma: float,
+) -> Tuple[np.ndarray, np.ndarray]:
+ """Generate gaussian heatmaps of keypoints using `UDP`_.
+
+ Args:
+ heatmap_size (Tuple[int, int]): Heatmap size in [W, H]
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ keypoints_visible (np.ndarray): Keypoint visibilities in shape
+ (N, K)
+ sigma (float): The sigma value of the Gaussian heatmap
+
+ Returns:
+ tuple:
+ - heatmaps (np.ndarray): The generated heatmap in shape
+ (K, H, W) where [W, H] is the `heatmap_size`
+ - keypoint_weights (np.ndarray): The target weights in shape
+ (N, K)
+
+ .. _`UDP`: https://arxiv.org/abs/1911.07524
+ """
+
+ N, K, _ = keypoints.shape
+ W, H = heatmap_size
+
+ heatmaps = np.zeros((K, H, W), dtype=np.float32)
+ keypoint_weights = keypoints_visible.copy()
+
+ # 3-sigma rule
+ radius = sigma * 3
+
+ # xy grid
+ gaussian_size = 2 * radius + 1
+ x = np.arange(0, gaussian_size, 1, dtype=np.float32)
+ y = x[:, None]
+
+ for n, k in product(range(N), range(K)):
+ # skip unlabled keypoints
+ if keypoints_visible[n, k] < 0.5:
+ continue
+
+ mu = (keypoints[n, k] + 0.5).astype(np.int64)
+ # check that the gaussian has in-bounds part
+ left, top = (mu - radius).astype(np.int64)
+ right, bottom = (mu + radius + 1).astype(np.int64)
+
+ if left >= W or top >= H or right < 0 or bottom < 0:
+ keypoint_weights[n, k] = 0
+ continue
+
+ mu_ac = keypoints[n, k]
+ x0 = y0 = gaussian_size // 2
+ x0 += mu_ac[0] - mu[0]
+ y0 += mu_ac[1] - mu[1]
+ gaussian = np.exp(-((x - x0)**2 + (y - y0)**2) / (2 * sigma**2))
+
+ # valid range in gaussian
+ g_x1 = max(0, -left)
+ g_x2 = min(W, right) - left
+ g_y1 = max(0, -top)
+ g_y2 = min(H, bottom) - top
+
+ # valid range in heatmap
+ h_x1 = max(0, left)
+ h_x2 = min(W, right)
+ h_y1 = max(0, top)
+ h_y2 = min(H, bottom)
+
+ heatmap_region = heatmaps[k, h_y1:h_y2, h_x1:h_x2]
+ gaussian_regsion = gaussian[g_y1:g_y2, g_x1:g_x2]
+
+ _ = np.maximum(heatmap_region, gaussian_regsion, out=heatmap_region)
+
+ return heatmaps, keypoint_weights
diff --git a/mmpose/codecs/utils/instance_property.py b/mmpose/codecs/utils/instance_property.py
index 15ae30aef0..b592297fff 100644
--- a/mmpose/codecs/utils/instance_property.py
+++ b/mmpose/codecs/utils/instance_property.py
@@ -1,111 +1,111 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional
-
-import numpy as np
-
-
-def get_instance_root(keypoints: np.ndarray,
- keypoints_visible: Optional[np.ndarray] = None,
- root_type: str = 'kpt_center') -> np.ndarray:
- """Calculate the coordinates and visibility of instance roots.
-
- Args:
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
- keypoints_visible (np.ndarray): Keypoint visibilities in shape
- (N, K)
- root_type (str): Calculation of instance roots which should
- be one of the following options:
-
- - ``'kpt_center'``: The roots' coordinates are the mean
- coordinates of visible keypoints
- - ``'bbox_center'``: The roots' are the center of bounding
- boxes outlined by visible keypoints
-
- Defaults to ``'kpt_center'``
-
- Returns:
- tuple
- - roots_coordinate(np.ndarray): Coordinates of instance roots in
- shape [N, D]
- - roots_visible(np.ndarray): Visibility of instance roots in
- shape [N]
- """
-
- roots_coordinate = np.zeros((keypoints.shape[0], 2), dtype=np.float32)
- roots_visible = np.ones((keypoints.shape[0]), dtype=np.float32) * 2
-
- for i in range(keypoints.shape[0]):
-
- # collect visible keypoints
- if keypoints_visible is not None:
- visible_keypoints = keypoints[i][keypoints_visible[i] > 0]
- else:
- visible_keypoints = keypoints[i]
- if visible_keypoints.size == 0:
- roots_visible[i] = 0
- continue
-
- # compute the instance root with visible keypoints
- if root_type == 'kpt_center':
- roots_coordinate[i] = visible_keypoints.mean(axis=0)
- roots_visible[i] = 1
- elif root_type == 'bbox_center':
- roots_coordinate[i] = (visible_keypoints.max(axis=0) +
- visible_keypoints.min(axis=0)) / 2.0
- roots_visible[i] = 1
- else:
- raise ValueError(
- f'the value of `root_type` must be \'kpt_center\' or '
- f'\'bbox_center\', but got \'{root_type}\'')
-
- return roots_coordinate, roots_visible
-
-
-def get_instance_bbox(keypoints: np.ndarray,
- keypoints_visible: Optional[np.ndarray] = None
- ) -> np.ndarray:
- """Calculate the pseudo instance bounding box from visible keypoints. The
- bounding boxes are in the xyxy format.
-
- Args:
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
- keypoints_visible (np.ndarray): Keypoint visibilities in shape
- (N, K)
-
- Returns:
- np.ndarray: bounding boxes in [N, 4]
- """
- bbox = np.zeros((keypoints.shape[0], 4), dtype=np.float32)
- for i in range(keypoints.shape[0]):
- if keypoints_visible is not None:
- visible_keypoints = keypoints[i][keypoints_visible[i] > 0]
- else:
- visible_keypoints = keypoints[i]
- if visible_keypoints.size == 0:
- continue
-
- bbox[i, :2] = visible_keypoints.min(axis=0)
- bbox[i, 2:] = visible_keypoints.max(axis=0)
- return bbox
-
-
-def get_diagonal_lengths(keypoints: np.ndarray,
- keypoints_visible: Optional[np.ndarray] = None
- ) -> np.ndarray:
- """Calculate the diagonal length of instance bounding box from visible
- keypoints.
-
- Args:
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
- keypoints_visible (np.ndarray): Keypoint visibilities in shape
- (N, K)
-
- Returns:
- np.ndarray: bounding box diagonal length in [N]
- """
- pseudo_bbox = get_instance_bbox(keypoints, keypoints_visible)
- pseudo_bbox = pseudo_bbox.reshape(-1, 2, 2)
- h_w_diff = pseudo_bbox[:, 1] - pseudo_bbox[:, 0]
- diagonal_length = np.sqrt(np.power(h_w_diff, 2).sum(axis=1))
-
- return diagonal_length
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import numpy as np
+
+
+def get_instance_root(keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray] = None,
+ root_type: str = 'kpt_center') -> np.ndarray:
+ """Calculate the coordinates and visibility of instance roots.
+
+ Args:
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ keypoints_visible (np.ndarray): Keypoint visibilities in shape
+ (N, K)
+ root_type (str): Calculation of instance roots which should
+ be one of the following options:
+
+ - ``'kpt_center'``: The roots' coordinates are the mean
+ coordinates of visible keypoints
+ - ``'bbox_center'``: The roots' are the center of bounding
+ boxes outlined by visible keypoints
+
+ Defaults to ``'kpt_center'``
+
+ Returns:
+ tuple
+ - roots_coordinate(np.ndarray): Coordinates of instance roots in
+ shape [N, D]
+ - roots_visible(np.ndarray): Visibility of instance roots in
+ shape [N]
+ """
+
+ roots_coordinate = np.zeros((keypoints.shape[0], 2), dtype=np.float32)
+ roots_visible = np.ones((keypoints.shape[0]), dtype=np.float32) * 2
+
+ for i in range(keypoints.shape[0]):
+
+ # collect visible keypoints
+ if keypoints_visible is not None:
+ visible_keypoints = keypoints[i][keypoints_visible[i] > 0]
+ else:
+ visible_keypoints = keypoints[i]
+ if visible_keypoints.size == 0:
+ roots_visible[i] = 0
+ continue
+
+ # compute the instance root with visible keypoints
+ if root_type == 'kpt_center':
+ roots_coordinate[i] = visible_keypoints.mean(axis=0)
+ roots_visible[i] = 1
+ elif root_type == 'bbox_center':
+ roots_coordinate[i] = (visible_keypoints.max(axis=0) +
+ visible_keypoints.min(axis=0)) / 2.0
+ roots_visible[i] = 1
+ else:
+ raise ValueError(
+ f'the value of `root_type` must be \'kpt_center\' or '
+ f'\'bbox_center\', but got \'{root_type}\'')
+
+ return roots_coordinate, roots_visible
+
+
+def get_instance_bbox(keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray] = None
+ ) -> np.ndarray:
+ """Calculate the pseudo instance bounding box from visible keypoints. The
+ bounding boxes are in the xyxy format.
+
+ Args:
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ keypoints_visible (np.ndarray): Keypoint visibilities in shape
+ (N, K)
+
+ Returns:
+ np.ndarray: bounding boxes in [N, 4]
+ """
+ bbox = np.zeros((keypoints.shape[0], 4), dtype=np.float32)
+ for i in range(keypoints.shape[0]):
+ if keypoints_visible is not None:
+ visible_keypoints = keypoints[i][keypoints_visible[i] > 0]
+ else:
+ visible_keypoints = keypoints[i]
+ if visible_keypoints.size == 0:
+ continue
+
+ bbox[i, :2] = visible_keypoints.min(axis=0)
+ bbox[i, 2:] = visible_keypoints.max(axis=0)
+ return bbox
+
+
+def get_diagonal_lengths(keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray] = None
+ ) -> np.ndarray:
+ """Calculate the diagonal length of instance bounding box from visible
+ keypoints.
+
+ Args:
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ keypoints_visible (np.ndarray): Keypoint visibilities in shape
+ (N, K)
+
+ Returns:
+ np.ndarray: bounding box diagonal length in [N]
+ """
+ pseudo_bbox = get_instance_bbox(keypoints, keypoints_visible)
+ pseudo_bbox = pseudo_bbox.reshape(-1, 2, 2)
+ h_w_diff = pseudo_bbox[:, 1] - pseudo_bbox[:, 0]
+ diagonal_length = np.sqrt(np.power(h_w_diff, 2).sum(axis=1))
+
+ return diagonal_length
diff --git a/mmpose/codecs/utils/offset_heatmap.py b/mmpose/codecs/utils/offset_heatmap.py
index c3c1c32ed3..94a6cd511d 100644
--- a/mmpose/codecs/utils/offset_heatmap.py
+++ b/mmpose/codecs/utils/offset_heatmap.py
@@ -1,143 +1,143 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from itertools import product
-from typing import Tuple
-
-import numpy as np
-
-
-def generate_offset_heatmap(
- heatmap_size: Tuple[int, int],
- keypoints: np.ndarray,
- keypoints_visible: np.ndarray,
- radius_factor: float,
-) -> Tuple[np.ndarray, np.ndarray]:
- """Generate offset heatmaps of keypoints, where each keypoint is
- represented by 3 maps: one pixel-level class label map (1 for keypoint and
- 0 for non-keypoint) and 2 pixel-level offset maps for x and y directions
- respectively.
-
- Args:
- heatmap_size (Tuple[int, int]): Heatmap size in [W, H]
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
- keypoints_visible (np.ndarray): Keypoint visibilities in shape
- (N, K)
- radius_factor (float): The radius factor of the binary label
- map. The positive region is defined as the neighbor of the
- keypoint with the radius :math:`r=radius_factor*max(W, H)`
-
- Returns:
- tuple:
- - heatmap (np.ndarray): The generated heatmap in shape
- (K*3, H, W) where [W, H] is the `heatmap_size`
- - keypoint_weights (np.ndarray): The target weights in shape
- (K,)
- """
-
- N, K, _ = keypoints.shape
- W, H = heatmap_size
-
- heatmaps = np.zeros((K, 3, H, W), dtype=np.float32)
- keypoint_weights = keypoints_visible.copy()
-
- # xy grid
- x = np.arange(0, W, 1)
- y = np.arange(0, H, 1)[:, None]
-
- # positive area radius in the classification map
- radius = radius_factor * max(W, H)
-
- for n, k in product(range(N), range(K)):
- if keypoints_visible[n, k] < 0.5:
- continue
-
- mu = keypoints[n, k]
-
- x_offset = (mu[0] - x) / radius
- y_offset = (mu[1] - y) / radius
-
- heatmaps[k, 0] = np.where(x_offset**2 + y_offset**2 <= 1, 1., 0.)
- heatmaps[k, 1] = x_offset
- heatmaps[k, 2] = y_offset
-
- heatmaps = heatmaps.reshape(K * 3, H, W)
-
- return heatmaps, keypoint_weights
-
-
-def generate_displacement_heatmap(
- heatmap_size: Tuple[int, int],
- keypoints: np.ndarray,
- keypoints_visible: np.ndarray,
- roots: np.ndarray,
- roots_visible: np.ndarray,
- diagonal_lengths: np.ndarray,
- radius: float,
-):
- """Generate displacement heatmaps of keypoints, where each keypoint is
- represented by 3 maps: one pixel-level class label map (1 for keypoint and
- 0 for non-keypoint) and 2 pixel-level offset maps for x and y directions
- respectively.
-
- Args:
- heatmap_size (Tuple[int, int]): Heatmap size in [W, H]
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
- keypoints_visible (np.ndarray): Keypoint visibilities in shape
- (N, K)
- roots (np.ndarray): Coordinates of instance centers in shape (N, D).
- The displacement fields of each instance will locate around its
- center.
- roots_visible (np.ndarray): Roots visibilities in shape (N,)
- diagonal_lengths (np.ndarray): Diaginal length of the bounding boxes
- of each instance in shape (N,)
- radius (float): The radius factor of the binary label
- map. The positive region is defined as the neighbor of the
- keypoint with the radius :math:`r=radius_factor*max(W, H)`
-
- Returns:
- tuple:
- - displacements (np.ndarray): The generated displacement map in
- shape (K*2, H, W) where [W, H] is the `heatmap_size`
- - displacement_weights (np.ndarray): The target weights in shape
- (K*2, H, W)
- """
- N, K, _ = keypoints.shape
- W, H = heatmap_size
-
- displacements = np.zeros((K * 2, H, W), dtype=np.float32)
- displacement_weights = np.zeros((K * 2, H, W), dtype=np.float32)
- instance_size_map = np.zeros((H, W), dtype=np.float32)
-
- for n in range(N):
- if (roots_visible[n] < 1 or (roots[n, 0] < 0 or roots[n, 1] < 0)
- or (roots[n, 0] >= W or roots[n, 1] >= H)):
- continue
-
- diagonal_length = diagonal_lengths[n]
-
- for k in range(K):
- if keypoints_visible[n, k] < 1 or keypoints[n, k, 0] < 0 \
- or keypoints[n, k, 1] < 0 or keypoints[n, k, 0] >= W \
- or keypoints[n, k, 1] >= H:
- continue
-
- start_x = max(int(roots[n, 0] - radius), 0)
- start_y = max(int(roots[n, 1] - radius), 0)
- end_x = min(int(roots[n, 0] + radius), W)
- end_y = min(int(roots[n, 1] + radius), H)
-
- for x in range(start_x, end_x):
- for y in range(start_y, end_y):
- if displacements[2 * k, y,
- x] != 0 or displacements[2 * k + 1, y,
- x] != 0:
- if diagonal_length > instance_size_map[y, x]:
- # keep the gt displacement of smaller instance
- continue
-
- displacement_weights[2 * k:2 * k + 2, y,
- x] = 1 / diagonal_length
- displacements[2 * k:2 * k + 2, y,
- x] = keypoints[n, k] - [x, y]
- instance_size_map[y, x] = diagonal_length
-
- return displacements, displacement_weights
+# Copyright (c) OpenMMLab. All rights reserved.
+from itertools import product
+from typing import Tuple
+
+import numpy as np
+
+
+def generate_offset_heatmap(
+ heatmap_size: Tuple[int, int],
+ keypoints: np.ndarray,
+ keypoints_visible: np.ndarray,
+ radius_factor: float,
+) -> Tuple[np.ndarray, np.ndarray]:
+ """Generate offset heatmaps of keypoints, where each keypoint is
+ represented by 3 maps: one pixel-level class label map (1 for keypoint and
+ 0 for non-keypoint) and 2 pixel-level offset maps for x and y directions
+ respectively.
+
+ Args:
+ heatmap_size (Tuple[int, int]): Heatmap size in [W, H]
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ keypoints_visible (np.ndarray): Keypoint visibilities in shape
+ (N, K)
+ radius_factor (float): The radius factor of the binary label
+ map. The positive region is defined as the neighbor of the
+ keypoint with the radius :math:`r=radius_factor*max(W, H)`
+
+ Returns:
+ tuple:
+ - heatmap (np.ndarray): The generated heatmap in shape
+ (K*3, H, W) where [W, H] is the `heatmap_size`
+ - keypoint_weights (np.ndarray): The target weights in shape
+ (K,)
+ """
+
+ N, K, _ = keypoints.shape
+ W, H = heatmap_size
+
+ heatmaps = np.zeros((K, 3, H, W), dtype=np.float32)
+ keypoint_weights = keypoints_visible.copy()
+
+ # xy grid
+ x = np.arange(0, W, 1)
+ y = np.arange(0, H, 1)[:, None]
+
+ # positive area radius in the classification map
+ radius = radius_factor * max(W, H)
+
+ for n, k in product(range(N), range(K)):
+ if keypoints_visible[n, k] < 0.5:
+ continue
+
+ mu = keypoints[n, k]
+
+ x_offset = (mu[0] - x) / radius
+ y_offset = (mu[1] - y) / radius
+
+ heatmaps[k, 0] = np.where(x_offset**2 + y_offset**2 <= 1, 1., 0.)
+ heatmaps[k, 1] = x_offset
+ heatmaps[k, 2] = y_offset
+
+ heatmaps = heatmaps.reshape(K * 3, H, W)
+
+ return heatmaps, keypoint_weights
+
+
+def generate_displacement_heatmap(
+ heatmap_size: Tuple[int, int],
+ keypoints: np.ndarray,
+ keypoints_visible: np.ndarray,
+ roots: np.ndarray,
+ roots_visible: np.ndarray,
+ diagonal_lengths: np.ndarray,
+ radius: float,
+):
+ """Generate displacement heatmaps of keypoints, where each keypoint is
+ represented by 3 maps: one pixel-level class label map (1 for keypoint and
+ 0 for non-keypoint) and 2 pixel-level offset maps for x and y directions
+ respectively.
+
+ Args:
+ heatmap_size (Tuple[int, int]): Heatmap size in [W, H]
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ keypoints_visible (np.ndarray): Keypoint visibilities in shape
+ (N, K)
+ roots (np.ndarray): Coordinates of instance centers in shape (N, D).
+ The displacement fields of each instance will locate around its
+ center.
+ roots_visible (np.ndarray): Roots visibilities in shape (N,)
+ diagonal_lengths (np.ndarray): Diaginal length of the bounding boxes
+ of each instance in shape (N,)
+ radius (float): The radius factor of the binary label
+ map. The positive region is defined as the neighbor of the
+ keypoint with the radius :math:`r=radius_factor*max(W, H)`
+
+ Returns:
+ tuple:
+ - displacements (np.ndarray): The generated displacement map in
+ shape (K*2, H, W) where [W, H] is the `heatmap_size`
+ - displacement_weights (np.ndarray): The target weights in shape
+ (K*2, H, W)
+ """
+ N, K, _ = keypoints.shape
+ W, H = heatmap_size
+
+ displacements = np.zeros((K * 2, H, W), dtype=np.float32)
+ displacement_weights = np.zeros((K * 2, H, W), dtype=np.float32)
+ instance_size_map = np.zeros((H, W), dtype=np.float32)
+
+ for n in range(N):
+ if (roots_visible[n] < 1 or (roots[n, 0] < 0 or roots[n, 1] < 0)
+ or (roots[n, 0] >= W or roots[n, 1] >= H)):
+ continue
+
+ diagonal_length = diagonal_lengths[n]
+
+ for k in range(K):
+ if keypoints_visible[n, k] < 1 or keypoints[n, k, 0] < 0 \
+ or keypoints[n, k, 1] < 0 or keypoints[n, k, 0] >= W \
+ or keypoints[n, k, 1] >= H:
+ continue
+
+ start_x = max(int(roots[n, 0] - radius), 0)
+ start_y = max(int(roots[n, 1] - radius), 0)
+ end_x = min(int(roots[n, 0] + radius), W)
+ end_y = min(int(roots[n, 1] + radius), H)
+
+ for x in range(start_x, end_x):
+ for y in range(start_y, end_y):
+ if displacements[2 * k, y,
+ x] != 0 or displacements[2 * k + 1, y,
+ x] != 0:
+ if diagonal_length > instance_size_map[y, x]:
+ # keep the gt displacement of smaller instance
+ continue
+
+ displacement_weights[2 * k:2 * k + 2, y,
+ x] = 1 / diagonal_length
+ displacements[2 * k:2 * k + 2, y,
+ x] = keypoints[n, k] - [x, y]
+ instance_size_map[y, x] = diagonal_length
+
+ return displacements, displacement_weights
diff --git a/mmpose/codecs/utils/post_processing.py b/mmpose/codecs/utils/post_processing.py
index 75356388dc..36990d1241 100644
--- a/mmpose/codecs/utils/post_processing.py
+++ b/mmpose/codecs/utils/post_processing.py
@@ -1,227 +1,227 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from itertools import product
-from typing import Tuple
-
-import cv2
-import numpy as np
-import torch
-import torch.nn.functional as F
-from torch import Tensor
-
-
-def get_simcc_normalized(batch_pred_simcc, sigma=None):
- """Normalize the predicted SimCC.
-
- Args:
- batch_pred_simcc (torch.Tensor): The predicted SimCC.
- sigma (float): The sigma of the Gaussian distribution.
-
- Returns:
- torch.Tensor: The normalized SimCC.
- """
- B, K, _ = batch_pred_simcc.shape
-
- # Scale and clamp the tensor
- if sigma is not None:
- batch_pred_simcc = batch_pred_simcc / (sigma * np.sqrt(np.pi * 2))
- batch_pred_simcc = batch_pred_simcc.clamp(min=0)
-
- # Compute the binary mask
- mask = (batch_pred_simcc.amax(dim=-1) > 1).reshape(B, K, 1)
-
- # Normalize the tensor using the maximum value
- norm = (batch_pred_simcc / batch_pred_simcc.amax(dim=-1).reshape(B, K, 1))
-
- # Apply normalization
- batch_pred_simcc = torch.where(mask, norm, batch_pred_simcc)
-
- return batch_pred_simcc
-
-
-def get_simcc_maximum(simcc_x: np.ndarray,
- simcc_y: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
- """Get maximum response location and value from simcc representations.
-
- Note:
- instance number: N
- num_keypoints: K
- heatmap height: H
- heatmap width: W
-
- Args:
- simcc_x (np.ndarray): x-axis SimCC in shape (K, Wx) or (N, K, Wx)
- simcc_y (np.ndarray): y-axis SimCC in shape (K, Wy) or (N, K, Wy)
-
- Returns:
- tuple:
- - locs (np.ndarray): locations of maximum heatmap responses in shape
- (K, 2) or (N, K, 2)
- - vals (np.ndarray): values of maximum heatmap responses in shape
- (K,) or (N, K)
- """
-
- assert isinstance(simcc_x, np.ndarray), ('simcc_x should be numpy.ndarray')
- assert isinstance(simcc_y, np.ndarray), ('simcc_y should be numpy.ndarray')
- assert simcc_x.ndim == 2 or simcc_x.ndim == 3, (
- f'Invalid shape {simcc_x.shape}')
- assert simcc_y.ndim == 2 or simcc_y.ndim == 3, (
- f'Invalid shape {simcc_y.shape}')
- assert simcc_x.ndim == simcc_y.ndim, (
- f'{simcc_x.shape} != {simcc_y.shape}')
-
- if simcc_x.ndim == 3:
- N, K, Wx = simcc_x.shape
- simcc_x = simcc_x.reshape(N * K, -1)
- simcc_y = simcc_y.reshape(N * K, -1)
- else:
- N = None
-
- x_locs = np.argmax(simcc_x, axis=1)
- y_locs = np.argmax(simcc_y, axis=1)
- locs = np.stack((x_locs, y_locs), axis=-1).astype(np.float32)
- max_val_x = np.amax(simcc_x, axis=1)
- max_val_y = np.amax(simcc_y, axis=1)
-
- mask = max_val_x > max_val_y
- max_val_x[mask] = max_val_y[mask]
- vals = max_val_x
- locs[vals <= 0.] = -1
-
- if N:
- locs = locs.reshape(N, K, 2)
- vals = vals.reshape(N, K)
-
- return locs, vals
-
-
-def get_heatmap_maximum(heatmaps: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
- """Get maximum response location and value from heatmaps.
-
- Note:
- batch_size: B
- num_keypoints: K
- heatmap height: H
- heatmap width: W
-
- Args:
- heatmaps (np.ndarray): Heatmaps in shape (K, H, W) or (B, K, H, W)
-
- Returns:
- tuple:
- - locs (np.ndarray): locations of maximum heatmap responses in shape
- (K, 2) or (B, K, 2)
- - vals (np.ndarray): values of maximum heatmap responses in shape
- (K,) or (B, K)
- """
- assert isinstance(heatmaps,
- np.ndarray), ('heatmaps should be numpy.ndarray')
- assert heatmaps.ndim == 3 or heatmaps.ndim == 4, (
- f'Invalid shape {heatmaps.shape}')
-
- if heatmaps.ndim == 3:
- K, H, W = heatmaps.shape
- B = None
- heatmaps_flatten = heatmaps.reshape(K, -1)
- else:
- B, K, H, W = heatmaps.shape
- heatmaps_flatten = heatmaps.reshape(B * K, -1)
-
- y_locs, x_locs = np.unravel_index(
- np.argmax(heatmaps_flatten, axis=1), shape=(H, W))
- locs = np.stack((x_locs, y_locs), axis=-1).astype(np.float32)
- vals = np.amax(heatmaps_flatten, axis=1)
- locs[vals <= 0.] = -1
-
- if B:
- locs = locs.reshape(B, K, 2)
- vals = vals.reshape(B, K)
-
- return locs, vals
-
-
-def gaussian_blur(heatmaps: np.ndarray, kernel: int = 11) -> np.ndarray:
- """Modulate heatmap distribution with Gaussian.
-
- Note:
- - num_keypoints: K
- - heatmap height: H
- - heatmap width: W
-
- Args:
- heatmaps (np.ndarray[K, H, W]): model predicted heatmaps.
- kernel (int): Gaussian kernel size (K) for modulation, which should
- match the heatmap gaussian sigma when training.
- K=17 for sigma=3 and k=11 for sigma=2.
-
- Returns:
- np.ndarray ([K, H, W]): Modulated heatmap distribution.
- """
- assert kernel % 2 == 1
-
- border = (kernel - 1) // 2
- K, H, W = heatmaps.shape
-
- for k in range(K):
- origin_max = np.max(heatmaps[k])
- dr = np.zeros((H + 2 * border, W + 2 * border), dtype=np.float32)
- dr[border:-border, border:-border] = heatmaps[k].copy()
- dr = cv2.GaussianBlur(dr, (kernel, kernel), 0)
- heatmaps[k] = dr[border:-border, border:-border].copy()
- heatmaps[k] *= origin_max / np.max(heatmaps[k])
- return heatmaps
-
-
-def gaussian_blur1d(simcc: np.ndarray, kernel: int = 11) -> np.ndarray:
- """Modulate simcc distribution with Gaussian.
-
- Note:
- - num_keypoints: K
- - simcc length: Wx
-
- Args:
- simcc (np.ndarray[K, Wx]): model predicted simcc.
- kernel (int): Gaussian kernel size (K) for modulation, which should
- match the simcc gaussian sigma when training.
- K=17 for sigma=3 and k=11 for sigma=2.
-
- Returns:
- np.ndarray ([K, Wx]): Modulated simcc distribution.
- """
- assert kernel % 2 == 1
-
- border = (kernel - 1) // 2
- N, K, Wx = simcc.shape
-
- for n, k in product(range(N), range(K)):
- origin_max = np.max(simcc[n, k])
- dr = np.zeros((1, Wx + 2 * border), dtype=np.float32)
- dr[0, border:-border] = simcc[n, k].copy()
- dr = cv2.GaussianBlur(dr, (kernel, 1), 0)
- simcc[n, k] = dr[0, border:-border].copy()
- simcc[n, k] *= origin_max / np.max(simcc[n, k])
- return simcc
-
-
-def batch_heatmap_nms(batch_heatmaps: Tensor, kernel_size: int = 5):
- """Apply NMS on a batch of heatmaps.
-
- Args:
- batch_heatmaps (Tensor): batch heatmaps in shape (B, K, H, W)
- kernel_size (int): The kernel size of the NMS which should be
- a odd integer. Defaults to 5
-
- Returns:
- Tensor: The batch heatmaps after NMS.
- """
-
- assert isinstance(kernel_size, int) and kernel_size % 2 == 1, \
- f'The kernel_size should be an odd integer, got {kernel_size}'
-
- padding = (kernel_size - 1) // 2
-
- maximum = F.max_pool2d(
- batch_heatmaps, kernel_size, stride=1, padding=padding)
- maximum_indicator = torch.eq(batch_heatmaps, maximum)
- batch_heatmaps = batch_heatmaps * maximum_indicator.float()
-
- return batch_heatmaps
+# Copyright (c) OpenMMLab. All rights reserved.
+from itertools import product
+from typing import Tuple
+
+import cv2
+import numpy as np
+import torch
+import torch.nn.functional as F
+from torch import Tensor
+
+
+def get_simcc_normalized(batch_pred_simcc, sigma=None):
+ """Normalize the predicted SimCC.
+
+ Args:
+ batch_pred_simcc (torch.Tensor): The predicted SimCC.
+ sigma (float): The sigma of the Gaussian distribution.
+
+ Returns:
+ torch.Tensor: The normalized SimCC.
+ """
+ B, K, _ = batch_pred_simcc.shape
+
+ # Scale and clamp the tensor
+ if sigma is not None:
+ batch_pred_simcc = batch_pred_simcc / (sigma * np.sqrt(np.pi * 2))
+ batch_pred_simcc = batch_pred_simcc.clamp(min=0)
+
+ # Compute the binary mask
+ mask = (batch_pred_simcc.amax(dim=-1) > 1).reshape(B, K, 1)
+
+ # Normalize the tensor using the maximum value
+ norm = (batch_pred_simcc / batch_pred_simcc.amax(dim=-1).reshape(B, K, 1))
+
+ # Apply normalization
+ batch_pred_simcc = torch.where(mask, norm, batch_pred_simcc)
+
+ return batch_pred_simcc
+
+
+def get_simcc_maximum(simcc_x: np.ndarray,
+ simcc_y: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ """Get maximum response location and value from simcc representations.
+
+ Note:
+ instance number: N
+ num_keypoints: K
+ heatmap height: H
+ heatmap width: W
+
+ Args:
+ simcc_x (np.ndarray): x-axis SimCC in shape (K, Wx) or (N, K, Wx)
+ simcc_y (np.ndarray): y-axis SimCC in shape (K, Wy) or (N, K, Wy)
+
+ Returns:
+ tuple:
+ - locs (np.ndarray): locations of maximum heatmap responses in shape
+ (K, 2) or (N, K, 2)
+ - vals (np.ndarray): values of maximum heatmap responses in shape
+ (K,) or (N, K)
+ """
+
+ assert isinstance(simcc_x, np.ndarray), ('simcc_x should be numpy.ndarray')
+ assert isinstance(simcc_y, np.ndarray), ('simcc_y should be numpy.ndarray')
+ assert simcc_x.ndim == 2 or simcc_x.ndim == 3, (
+ f'Invalid shape {simcc_x.shape}')
+ assert simcc_y.ndim == 2 or simcc_y.ndim == 3, (
+ f'Invalid shape {simcc_y.shape}')
+ assert simcc_x.ndim == simcc_y.ndim, (
+ f'{simcc_x.shape} != {simcc_y.shape}')
+
+ if simcc_x.ndim == 3:
+ N, K, Wx = simcc_x.shape
+ simcc_x = simcc_x.reshape(N * K, -1)
+ simcc_y = simcc_y.reshape(N * K, -1)
+ else:
+ N = None
+
+ x_locs = np.argmax(simcc_x, axis=1)
+ y_locs = np.argmax(simcc_y, axis=1)
+ locs = np.stack((x_locs, y_locs), axis=-1).astype(np.float32)
+ max_val_x = np.amax(simcc_x, axis=1)
+ max_val_y = np.amax(simcc_y, axis=1)
+
+ mask = max_val_x > max_val_y
+ max_val_x[mask] = max_val_y[mask]
+ vals = max_val_x
+ locs[vals <= 0.] = -1
+
+ if N:
+ locs = locs.reshape(N, K, 2)
+ vals = vals.reshape(N, K)
+
+ return locs, vals
+
+
+def get_heatmap_maximum(heatmaps: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ """Get maximum response location and value from heatmaps.
+
+ Note:
+ batch_size: B
+ num_keypoints: K
+ heatmap height: H
+ heatmap width: W
+
+ Args:
+ heatmaps (np.ndarray): Heatmaps in shape (K, H, W) or (B, K, H, W)
+
+ Returns:
+ tuple:
+ - locs (np.ndarray): locations of maximum heatmap responses in shape
+ (K, 2) or (B, K, 2)
+ - vals (np.ndarray): values of maximum heatmap responses in shape
+ (K,) or (B, K)
+ """
+ assert isinstance(heatmaps,
+ np.ndarray), ('heatmaps should be numpy.ndarray')
+ assert heatmaps.ndim == 3 or heatmaps.ndim == 4, (
+ f'Invalid shape {heatmaps.shape}')
+
+ if heatmaps.ndim == 3:
+ K, H, W = heatmaps.shape
+ B = None
+ heatmaps_flatten = heatmaps.reshape(K, -1)
+ else:
+ B, K, H, W = heatmaps.shape
+ heatmaps_flatten = heatmaps.reshape(B * K, -1)
+
+ y_locs, x_locs = np.unravel_index(
+ np.argmax(heatmaps_flatten, axis=1), shape=(H, W))
+ locs = np.stack((x_locs, y_locs), axis=-1).astype(np.float32)
+ vals = np.amax(heatmaps_flatten, axis=1)
+ locs[vals <= 0.] = -1
+
+ if B:
+ locs = locs.reshape(B, K, 2)
+ vals = vals.reshape(B, K)
+
+ return locs, vals
+
+
+def gaussian_blur(heatmaps: np.ndarray, kernel: int = 11) -> np.ndarray:
+ """Modulate heatmap distribution with Gaussian.
+
+ Note:
+ - num_keypoints: K
+ - heatmap height: H
+ - heatmap width: W
+
+ Args:
+ heatmaps (np.ndarray[K, H, W]): model predicted heatmaps.
+ kernel (int): Gaussian kernel size (K) for modulation, which should
+ match the heatmap gaussian sigma when training.
+ K=17 for sigma=3 and k=11 for sigma=2.
+
+ Returns:
+ np.ndarray ([K, H, W]): Modulated heatmap distribution.
+ """
+ assert kernel % 2 == 1
+
+ border = (kernel - 1) // 2
+ K, H, W = heatmaps.shape
+
+ for k in range(K):
+ origin_max = np.max(heatmaps[k])
+ dr = np.zeros((H + 2 * border, W + 2 * border), dtype=np.float32)
+ dr[border:-border, border:-border] = heatmaps[k].copy()
+ dr = cv2.GaussianBlur(dr, (kernel, kernel), 0)
+ heatmaps[k] = dr[border:-border, border:-border].copy()
+ heatmaps[k] *= origin_max / np.max(heatmaps[k])
+ return heatmaps
+
+
+def gaussian_blur1d(simcc: np.ndarray, kernel: int = 11) -> np.ndarray:
+ """Modulate simcc distribution with Gaussian.
+
+ Note:
+ - num_keypoints: K
+ - simcc length: Wx
+
+ Args:
+ simcc (np.ndarray[K, Wx]): model predicted simcc.
+ kernel (int): Gaussian kernel size (K) for modulation, which should
+ match the simcc gaussian sigma when training.
+ K=17 for sigma=3 and k=11 for sigma=2.
+
+ Returns:
+ np.ndarray ([K, Wx]): Modulated simcc distribution.
+ """
+ assert kernel % 2 == 1
+
+ border = (kernel - 1) // 2
+ N, K, Wx = simcc.shape
+
+ for n, k in product(range(N), range(K)):
+ origin_max = np.max(simcc[n, k])
+ dr = np.zeros((1, Wx + 2 * border), dtype=np.float32)
+ dr[0, border:-border] = simcc[n, k].copy()
+ dr = cv2.GaussianBlur(dr, (kernel, 1), 0)
+ simcc[n, k] = dr[0, border:-border].copy()
+ simcc[n, k] *= origin_max / np.max(simcc[n, k])
+ return simcc
+
+
+def batch_heatmap_nms(batch_heatmaps: Tensor, kernel_size: int = 5):
+ """Apply NMS on a batch of heatmaps.
+
+ Args:
+ batch_heatmaps (Tensor): batch heatmaps in shape (B, K, H, W)
+ kernel_size (int): The kernel size of the NMS which should be
+ a odd integer. Defaults to 5
+
+ Returns:
+ Tensor: The batch heatmaps after NMS.
+ """
+
+ assert isinstance(kernel_size, int) and kernel_size % 2 == 1, \
+ f'The kernel_size should be an odd integer, got {kernel_size}'
+
+ padding = (kernel_size - 1) // 2
+
+ maximum = F.max_pool2d(
+ batch_heatmaps, kernel_size, stride=1, padding=padding)
+ maximum_indicator = torch.eq(batch_heatmaps, maximum)
+ batch_heatmaps = batch_heatmaps * maximum_indicator.float()
+
+ return batch_heatmaps
diff --git a/mmpose/codecs/utils/refinement.py b/mmpose/codecs/utils/refinement.py
index 3495f37d0a..2dd94feb71 100644
--- a/mmpose/codecs/utils/refinement.py
+++ b/mmpose/codecs/utils/refinement.py
@@ -1,215 +1,215 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from itertools import product
-
-import numpy as np
-
-from .post_processing import gaussian_blur, gaussian_blur1d
-
-
-def refine_keypoints(keypoints: np.ndarray,
- heatmaps: np.ndarray) -> np.ndarray:
- """Refine keypoint predictions by moving from the maximum towards the
- second maximum by 0.25 pixel. The operation is in-place.
-
- Note:
-
- - instance number: N
- - keypoint number: K
- - keypoint dimension: D
- - heatmap size: [W, H]
-
- Args:
- keypoints (np.ndarray): The keypoint coordinates in shape (N, K, D)
- heatmaps (np.ndarray): The heatmaps in shape (K, H, W)
-
- Returns:
- np.ndarray: Refine keypoint coordinates in shape (N, K, D)
- """
- N, K = keypoints.shape[:2]
- H, W = heatmaps.shape[1:]
-
- for n, k in product(range(N), range(K)):
- x, y = keypoints[n, k, :2].astype(int)
-
- if 1 < x < W - 1 and 0 < y < H:
- dx = heatmaps[k, y, x + 1] - heatmaps[k, y, x - 1]
- else:
- dx = 0.
-
- if 1 < y < H - 1 and 0 < x < W:
- dy = heatmaps[k, y + 1, x] - heatmaps[k, y - 1, x]
- else:
- dy = 0.
-
- keypoints[n, k] += np.sign([dx, dy], dtype=np.float32) * 0.25
-
- return keypoints
-
-
-def refine_keypoints_dark(keypoints: np.ndarray, heatmaps: np.ndarray,
- blur_kernel_size: int) -> np.ndarray:
- """Refine keypoint predictions using distribution aware coordinate
- decoding. See `Dark Pose`_ for details. The operation is in-place.
-
- Note:
-
- - instance number: N
- - keypoint number: K
- - keypoint dimension: D
- - heatmap size: [W, H]
-
- Args:
- keypoints (np.ndarray): The keypoint coordinates in shape (N, K, D)
- heatmaps (np.ndarray): The heatmaps in shape (K, H, W)
- blur_kernel_size (int): The Gaussian blur kernel size of the heatmap
- modulation
-
- Returns:
- np.ndarray: Refine keypoint coordinates in shape (N, K, D)
-
- .. _`Dark Pose`: https://arxiv.org/abs/1910.06278
- """
- N, K = keypoints.shape[:2]
- H, W = heatmaps.shape[1:]
-
- # modulate heatmaps
- heatmaps = gaussian_blur(heatmaps, blur_kernel_size)
- np.maximum(heatmaps, 1e-10, heatmaps)
- np.log(heatmaps, heatmaps)
-
- for n, k in product(range(N), range(K)):
- x, y = keypoints[n, k, :2].astype(int)
- if 1 < x < W - 2 and 1 < y < H - 2:
- dx = 0.5 * (heatmaps[k, y, x + 1] - heatmaps[k, y, x - 1])
- dy = 0.5 * (heatmaps[k, y + 1, x] - heatmaps[k, y - 1, x])
-
- dxx = 0.25 * (
- heatmaps[k, y, x + 2] - 2 * heatmaps[k, y, x] +
- heatmaps[k, y, x - 2])
- dxy = 0.25 * (
- heatmaps[k, y + 1, x + 1] - heatmaps[k, y - 1, x + 1] -
- heatmaps[k, y + 1, x - 1] + heatmaps[k, y - 1, x - 1])
- dyy = 0.25 * (
- heatmaps[k, y + 2, x] - 2 * heatmaps[k, y, x] +
- heatmaps[k, y - 2, x])
- derivative = np.array([[dx], [dy]])
- hessian = np.array([[dxx, dxy], [dxy, dyy]])
- if dxx * dyy - dxy**2 != 0:
- hessianinv = np.linalg.inv(hessian)
- offset = -hessianinv @ derivative
- offset = np.squeeze(np.array(offset.T), axis=0)
- keypoints[n, k, :2] += offset
- return keypoints
-
-
-def refine_keypoints_dark_udp(keypoints: np.ndarray, heatmaps: np.ndarray,
- blur_kernel_size: int) -> np.ndarray:
- """Refine keypoint predictions using distribution aware coordinate decoding
- for UDP. See `UDP`_ for details. The operation is in-place.
-
- Note:
-
- - instance number: N
- - keypoint number: K
- - keypoint dimension: D
- - heatmap size: [W, H]
-
- Args:
- keypoints (np.ndarray): The keypoint coordinates in shape (N, K, D)
- heatmaps (np.ndarray): The heatmaps in shape (K, H, W)
- blur_kernel_size (int): The Gaussian blur kernel size of the heatmap
- modulation
-
- Returns:
- np.ndarray: Refine keypoint coordinates in shape (N, K, D)
-
- .. _`UDP`: https://arxiv.org/abs/1911.07524
- """
- N, K = keypoints.shape[:2]
- H, W = heatmaps.shape[1:]
-
- # modulate heatmaps
- heatmaps = gaussian_blur(heatmaps, blur_kernel_size)
- np.clip(heatmaps, 1e-3, 50., heatmaps)
- np.log(heatmaps, heatmaps)
-
- heatmaps_pad = np.pad(
- heatmaps, ((0, 0), (1, 1), (1, 1)), mode='edge').flatten()
-
- for n in range(N):
- index = keypoints[n, :, 0] + 1 + (keypoints[n, :, 1] + 1) * (W + 2)
- index += (W + 2) * (H + 2) * np.arange(0, K)
- index = index.astype(int).reshape(-1, 1)
- i_ = heatmaps_pad[index]
- ix1 = heatmaps_pad[index + 1]
- iy1 = heatmaps_pad[index + W + 2]
- ix1y1 = heatmaps_pad[index + W + 3]
- ix1_y1_ = heatmaps_pad[index - W - 3]
- ix1_ = heatmaps_pad[index - 1]
- iy1_ = heatmaps_pad[index - 2 - W]
-
- dx = 0.5 * (ix1 - ix1_)
- dy = 0.5 * (iy1 - iy1_)
- derivative = np.concatenate([dx, dy], axis=1)
- derivative = derivative.reshape(K, 2, 1)
-
- dxx = ix1 - 2 * i_ + ix1_
- dyy = iy1 - 2 * i_ + iy1_
- dxy = 0.5 * (ix1y1 - ix1 - iy1 + i_ + i_ - ix1_ - iy1_ + ix1_y1_)
- hessian = np.concatenate([dxx, dxy, dxy, dyy], axis=1)
- hessian = hessian.reshape(K, 2, 2)
- hessian = np.linalg.inv(hessian + np.finfo(np.float32).eps * np.eye(2))
- keypoints[n] -= np.einsum('imn,ink->imk', hessian,
- derivative).squeeze()
-
- return keypoints
-
-
-def refine_simcc_dark(keypoints: np.ndarray, simcc: np.ndarray,
- blur_kernel_size: int) -> np.ndarray:
- """SimCC version. Refine keypoint predictions using distribution aware
- coordinate decoding for UDP. See `UDP`_ for details. The operation is in-
- place.
-
- Note:
-
- - instance number: N
- - keypoint number: K
- - keypoint dimension: D
-
- Args:
- keypoints (np.ndarray): The keypoint coordinates in shape (N, K, D)
- simcc (np.ndarray): The heatmaps in shape (N, K, Wx)
- blur_kernel_size (int): The Gaussian blur kernel size of the heatmap
- modulation
-
- Returns:
- np.ndarray: Refine keypoint coordinates in shape (N, K, D)
-
- .. _`UDP`: https://arxiv.org/abs/1911.07524
- """
- N = simcc.shape[0]
-
- # modulate simcc
- simcc = gaussian_blur1d(simcc, blur_kernel_size)
- np.clip(simcc, 1e-3, 50., simcc)
- np.log(simcc, simcc)
-
- simcc = np.pad(simcc, ((0, 0), (0, 0), (2, 2)), 'edge')
-
- for n in range(N):
- px = (keypoints[n] + 2.5).astype(np.int64).reshape(-1, 1) # K, 1
-
- dx0 = np.take_along_axis(simcc[n], px, axis=1) # K, 1
- dx1 = np.take_along_axis(simcc[n], px + 1, axis=1)
- dx_1 = np.take_along_axis(simcc[n], px - 1, axis=1)
- dx2 = np.take_along_axis(simcc[n], px + 2, axis=1)
- dx_2 = np.take_along_axis(simcc[n], px - 2, axis=1)
-
- dx = 0.5 * (dx1 - dx_1)
- dxx = 1e-9 + 0.25 * (dx2 - 2 * dx0 + dx_2)
-
- offset = dx / dxx
- keypoints[n] -= offset.reshape(-1)
-
- return keypoints
+# Copyright (c) OpenMMLab. All rights reserved.
+from itertools import product
+
+import numpy as np
+
+from .post_processing import gaussian_blur, gaussian_blur1d
+
+
+def refine_keypoints(keypoints: np.ndarray,
+ heatmaps: np.ndarray) -> np.ndarray:
+ """Refine keypoint predictions by moving from the maximum towards the
+ second maximum by 0.25 pixel. The operation is in-place.
+
+ Note:
+
+ - instance number: N
+ - keypoint number: K
+ - keypoint dimension: D
+ - heatmap size: [W, H]
+
+ Args:
+ keypoints (np.ndarray): The keypoint coordinates in shape (N, K, D)
+ heatmaps (np.ndarray): The heatmaps in shape (K, H, W)
+
+ Returns:
+ np.ndarray: Refine keypoint coordinates in shape (N, K, D)
+ """
+ N, K = keypoints.shape[:2]
+ H, W = heatmaps.shape[1:]
+
+ for n, k in product(range(N), range(K)):
+ x, y = keypoints[n, k, :2].astype(int)
+
+ if 1 < x < W - 1 and 0 < y < H:
+ dx = heatmaps[k, y, x + 1] - heatmaps[k, y, x - 1]
+ else:
+ dx = 0.
+
+ if 1 < y < H - 1 and 0 < x < W:
+ dy = heatmaps[k, y + 1, x] - heatmaps[k, y - 1, x]
+ else:
+ dy = 0.
+
+ keypoints[n, k] += np.sign([dx, dy], dtype=np.float32) * 0.25
+
+ return keypoints
+
+
+def refine_keypoints_dark(keypoints: np.ndarray, heatmaps: np.ndarray,
+ blur_kernel_size: int) -> np.ndarray:
+ """Refine keypoint predictions using distribution aware coordinate
+ decoding. See `Dark Pose`_ for details. The operation is in-place.
+
+ Note:
+
+ - instance number: N
+ - keypoint number: K
+ - keypoint dimension: D
+ - heatmap size: [W, H]
+
+ Args:
+ keypoints (np.ndarray): The keypoint coordinates in shape (N, K, D)
+ heatmaps (np.ndarray): The heatmaps in shape (K, H, W)
+ blur_kernel_size (int): The Gaussian blur kernel size of the heatmap
+ modulation
+
+ Returns:
+ np.ndarray: Refine keypoint coordinates in shape (N, K, D)
+
+ .. _`Dark Pose`: https://arxiv.org/abs/1910.06278
+ """
+ N, K = keypoints.shape[:2]
+ H, W = heatmaps.shape[1:]
+
+ # modulate heatmaps
+ heatmaps = gaussian_blur(heatmaps, blur_kernel_size)
+ np.maximum(heatmaps, 1e-10, heatmaps)
+ np.log(heatmaps, heatmaps)
+
+ for n, k in product(range(N), range(K)):
+ x, y = keypoints[n, k, :2].astype(int)
+ if 1 < x < W - 2 and 1 < y < H - 2:
+ dx = 0.5 * (heatmaps[k, y, x + 1] - heatmaps[k, y, x - 1])
+ dy = 0.5 * (heatmaps[k, y + 1, x] - heatmaps[k, y - 1, x])
+
+ dxx = 0.25 * (
+ heatmaps[k, y, x + 2] - 2 * heatmaps[k, y, x] +
+ heatmaps[k, y, x - 2])
+ dxy = 0.25 * (
+ heatmaps[k, y + 1, x + 1] - heatmaps[k, y - 1, x + 1] -
+ heatmaps[k, y + 1, x - 1] + heatmaps[k, y - 1, x - 1])
+ dyy = 0.25 * (
+ heatmaps[k, y + 2, x] - 2 * heatmaps[k, y, x] +
+ heatmaps[k, y - 2, x])
+ derivative = np.array([[dx], [dy]])
+ hessian = np.array([[dxx, dxy], [dxy, dyy]])
+ if dxx * dyy - dxy**2 != 0:
+ hessianinv = np.linalg.inv(hessian)
+ offset = -hessianinv @ derivative
+ offset = np.squeeze(np.array(offset.T), axis=0)
+ keypoints[n, k, :2] += offset
+ return keypoints
+
+
+def refine_keypoints_dark_udp(keypoints: np.ndarray, heatmaps: np.ndarray,
+ blur_kernel_size: int) -> np.ndarray:
+ """Refine keypoint predictions using distribution aware coordinate decoding
+ for UDP. See `UDP`_ for details. The operation is in-place.
+
+ Note:
+
+ - instance number: N
+ - keypoint number: K
+ - keypoint dimension: D
+ - heatmap size: [W, H]
+
+ Args:
+ keypoints (np.ndarray): The keypoint coordinates in shape (N, K, D)
+ heatmaps (np.ndarray): The heatmaps in shape (K, H, W)
+ blur_kernel_size (int): The Gaussian blur kernel size of the heatmap
+ modulation
+
+ Returns:
+ np.ndarray: Refine keypoint coordinates in shape (N, K, D)
+
+ .. _`UDP`: https://arxiv.org/abs/1911.07524
+ """
+ N, K = keypoints.shape[:2]
+ H, W = heatmaps.shape[1:]
+
+ # modulate heatmaps
+ heatmaps = gaussian_blur(heatmaps, blur_kernel_size)
+ np.clip(heatmaps, 1e-3, 50., heatmaps)
+ np.log(heatmaps, heatmaps)
+
+ heatmaps_pad = np.pad(
+ heatmaps, ((0, 0), (1, 1), (1, 1)), mode='edge').flatten()
+
+ for n in range(N):
+ index = keypoints[n, :, 0] + 1 + (keypoints[n, :, 1] + 1) * (W + 2)
+ index += (W + 2) * (H + 2) * np.arange(0, K)
+ index = index.astype(int).reshape(-1, 1)
+ i_ = heatmaps_pad[index]
+ ix1 = heatmaps_pad[index + 1]
+ iy1 = heatmaps_pad[index + W + 2]
+ ix1y1 = heatmaps_pad[index + W + 3]
+ ix1_y1_ = heatmaps_pad[index - W - 3]
+ ix1_ = heatmaps_pad[index - 1]
+ iy1_ = heatmaps_pad[index - 2 - W]
+
+ dx = 0.5 * (ix1 - ix1_)
+ dy = 0.5 * (iy1 - iy1_)
+ derivative = np.concatenate([dx, dy], axis=1)
+ derivative = derivative.reshape(K, 2, 1)
+
+ dxx = ix1 - 2 * i_ + ix1_
+ dyy = iy1 - 2 * i_ + iy1_
+ dxy = 0.5 * (ix1y1 - ix1 - iy1 + i_ + i_ - ix1_ - iy1_ + ix1_y1_)
+ hessian = np.concatenate([dxx, dxy, dxy, dyy], axis=1)
+ hessian = hessian.reshape(K, 2, 2)
+ hessian = np.linalg.inv(hessian + np.finfo(np.float32).eps * np.eye(2))
+ keypoints[n] -= np.einsum('imn,ink->imk', hessian,
+ derivative).squeeze()
+
+ return keypoints
+
+
+def refine_simcc_dark(keypoints: np.ndarray, simcc: np.ndarray,
+ blur_kernel_size: int) -> np.ndarray:
+ """SimCC version. Refine keypoint predictions using distribution aware
+ coordinate decoding for UDP. See `UDP`_ for details. The operation is in-
+ place.
+
+ Note:
+
+ - instance number: N
+ - keypoint number: K
+ - keypoint dimension: D
+
+ Args:
+ keypoints (np.ndarray): The keypoint coordinates in shape (N, K, D)
+ simcc (np.ndarray): The heatmaps in shape (N, K, Wx)
+ blur_kernel_size (int): The Gaussian blur kernel size of the heatmap
+ modulation
+
+ Returns:
+ np.ndarray: Refine keypoint coordinates in shape (N, K, D)
+
+ .. _`UDP`: https://arxiv.org/abs/1911.07524
+ """
+ N = simcc.shape[0]
+
+ # modulate simcc
+ simcc = gaussian_blur1d(simcc, blur_kernel_size)
+ np.clip(simcc, 1e-3, 50., simcc)
+ np.log(simcc, simcc)
+
+ simcc = np.pad(simcc, ((0, 0), (0, 0), (2, 2)), 'edge')
+
+ for n in range(N):
+ px = (keypoints[n] + 2.5).astype(np.int64).reshape(-1, 1) # K, 1
+
+ dx0 = np.take_along_axis(simcc[n], px, axis=1) # K, 1
+ dx1 = np.take_along_axis(simcc[n], px + 1, axis=1)
+ dx_1 = np.take_along_axis(simcc[n], px - 1, axis=1)
+ dx2 = np.take_along_axis(simcc[n], px + 2, axis=1)
+ dx_2 = np.take_along_axis(simcc[n], px - 2, axis=1)
+
+ dx = 0.5 * (dx1 - dx_1)
+ dxx = 1e-9 + 0.25 * (dx2 - 2 * dx0 + dx_2)
+
+ offset = dx / dxx
+ keypoints[n] -= offset.reshape(-1)
+
+ return keypoints
diff --git a/mmpose/codecs/video_pose_lifting.py b/mmpose/codecs/video_pose_lifting.py
index 56cf35fa2d..cdc17aa111 100644
--- a/mmpose/codecs/video_pose_lifting.py
+++ b/mmpose/codecs/video_pose_lifting.py
@@ -1,202 +1,202 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-
-from copy import deepcopy
-from typing import Optional, Tuple
-
-import numpy as np
-
-from mmpose.registry import KEYPOINT_CODECS
-from .base import BaseKeypointCodec
-
-
-@KEYPOINT_CODECS.register_module()
-class VideoPoseLifting(BaseKeypointCodec):
- r"""Generate keypoint coordinates for pose lifter.
-
- Note:
-
- - instance number: N
- - keypoint number: K
- - keypoint dimension: D
- - pose-lifitng target dimension: C
-
- Args:
- num_keypoints (int): The number of keypoints in the dataset.
- zero_center: Whether to zero-center the target around root. Default:
- ``True``.
- root_index (int): Root keypoint index in the pose. Default: 0.
- remove_root (bool): If true, remove the root keypoint from the pose.
- Default: ``False``.
- save_index (bool): If true, store the root position separated from the
- original pose, only takes effect if ``remove_root`` is ``True``.
- Default: ``False``.
- normalize_camera (bool): Whether to normalize camera intrinsics.
- Default: ``False``.
- """
-
- auxiliary_encode_keys = {
- 'lifting_target', 'lifting_target_visible', 'camera_param'
- }
-
- def __init__(self,
- num_keypoints: int,
- zero_center: bool = True,
- root_index: int = 0,
- remove_root: bool = False,
- save_index: bool = False,
- normalize_camera: bool = False):
- super().__init__()
-
- self.num_keypoints = num_keypoints
- self.zero_center = zero_center
- self.root_index = root_index
- self.remove_root = remove_root
- self.save_index = save_index
- self.normalize_camera = normalize_camera
-
- def encode(self,
- keypoints: np.ndarray,
- keypoints_visible: Optional[np.ndarray] = None,
- lifting_target: Optional[np.ndarray] = None,
- lifting_target_visible: Optional[np.ndarray] = None,
- camera_param: Optional[dict] = None) -> dict:
- """Encoding keypoints from input image space to normalized space.
-
- Args:
- keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D).
- keypoints_visible (np.ndarray, optional): Keypoint visibilities in
- shape (N, K).
- lifting_target (np.ndarray, optional): 3d target coordinate in
- shape (K, C).
- lifting_target_visible (np.ndarray, optional): Target coordinate in
- shape (K, ).
- camera_param (dict, optional): The camera parameter dictionary.
-
- Returns:
- encoded (dict): Contains the following items:
-
- - keypoint_labels (np.ndarray): The processed keypoints in
- shape (K * D, N) where D is 2 for 2d coordinates.
- - lifting_target_label: The processed target coordinate in
- shape (K, C) or (K-1, C).
- - lifting_target_weights (np.ndarray): The target weights in
- shape (K, ) or (K-1, ).
- - trajectory_weights (np.ndarray): The trajectory weights in
- shape (K, ).
-
- In addition, there are some optional items it may contain:
-
- - target_root (np.ndarray): The root coordinate of target in
- shape (C, ). Exists if ``self.zero_center`` is ``True``.
- - target_root_removed (bool): Indicate whether the root of
- pose-lifitng target is removed. Exists if
- ``self.remove_root`` is ``True``.
- - target_root_index (int): An integer indicating the index of
- root. Exists if ``self.remove_root`` and ``self.save_index``
- are ``True``.
- - camera_param (dict): The updated camera parameter dictionary.
- Exists if ``self.normalize_camera`` is ``True``.
- """
- if keypoints_visible is None:
- keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
-
- if lifting_target is None:
- lifting_target = keypoints[0]
-
- # set initial value for `lifting_target_weights`
- # and `trajectory_weights`
- if lifting_target_visible is None:
- lifting_target_visible = np.ones(
- lifting_target.shape[:-1], dtype=np.float32)
- lifting_target_weights = lifting_target_visible
- trajectory_weights = (1 / lifting_target[:, 2])
- else:
- valid = lifting_target_visible > 0.5
- lifting_target_weights = np.where(valid, 1., 0.).astype(np.float32)
- trajectory_weights = lifting_target_weights
-
- if camera_param is None:
- camera_param = dict()
-
- encoded = dict()
-
- lifting_target_label = lifting_target.copy()
- # Zero-center the target pose around a given root keypoint
- if self.zero_center:
- assert (lifting_target.ndim >= 2 and
- lifting_target.shape[-2] > self.root_index), \
- f'Got invalid joint shape {lifting_target.shape}'
-
- root = lifting_target[..., self.root_index, :]
- lifting_target_label = lifting_target_label - root
- encoded['target_root'] = root
-
- if self.remove_root:
- lifting_target_label = np.delete(
- lifting_target_label, self.root_index, axis=-2)
- assert lifting_target_weights.ndim in {1, 2}
- axis_to_remove = -2 if lifting_target_weights.ndim == 2 else -1
- lifting_target_weights = np.delete(
- lifting_target_weights,
- self.root_index,
- axis=axis_to_remove)
- # Add a flag to avoid latter transforms that rely on the root
- # joint or the original joint index
- encoded['target_root_removed'] = True
-
- # Save the root index for restoring the global pose
- if self.save_index:
- encoded['target_root_index'] = self.root_index
-
- # Normalize the 2D keypoint coordinate with image width and height
- _camera_param = deepcopy(camera_param)
- assert 'w' in _camera_param and 'h' in _camera_param
- center = np.array([0.5 * _camera_param['w'], 0.5 * _camera_param['h']],
- dtype=np.float32)
- scale = np.array(0.5 * _camera_param['w'], dtype=np.float32)
-
- keypoint_labels = (keypoints - center) / scale
-
- assert keypoint_labels.ndim in {2, 3}
- if keypoint_labels.ndim == 2:
- keypoint_labels = keypoint_labels[None, ...]
-
- if self.normalize_camera:
- assert 'f' in _camera_param and 'c' in _camera_param
- _camera_param['f'] = _camera_param['f'] / scale
- _camera_param['c'] = (_camera_param['c'] - center[:, None]) / scale
- encoded['camera_param'] = _camera_param
-
- encoded['keypoint_labels'] = keypoint_labels
- encoded['lifting_target_label'] = lifting_target_label
- encoded['lifting_target_weights'] = lifting_target_weights
- encoded['trajectory_weights'] = trajectory_weights
-
- return encoded
-
- def decode(self,
- encoded: np.ndarray,
- target_root: Optional[np.ndarray] = None
- ) -> Tuple[np.ndarray, np.ndarray]:
- """Decode keypoint coordinates from normalized space to input image
- space.
-
- Args:
- encoded (np.ndarray): Coordinates in shape (N, K, C).
- target_root (np.ndarray, optional): The pose-lifitng target root
- coordinate. Default: ``None``.
-
- Returns:
- keypoints (np.ndarray): Decoded coordinates in shape (N, K, C).
- scores (np.ndarray): The keypoint scores in shape (N, K).
- """
- keypoints = encoded.copy()
-
- if target_root.size > 0:
- keypoints = keypoints + np.expand_dims(target_root, axis=0)
- if self.remove_root:
- keypoints = np.insert(
- keypoints, self.root_index, target_root, axis=1)
- scores = np.ones(keypoints.shape[:-1], dtype=np.float32)
-
- return keypoints, scores
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from copy import deepcopy
+from typing import Optional, Tuple
+
+import numpy as np
+
+from mmpose.registry import KEYPOINT_CODECS
+from .base import BaseKeypointCodec
+
+
+@KEYPOINT_CODECS.register_module()
+class VideoPoseLifting(BaseKeypointCodec):
+ r"""Generate keypoint coordinates for pose lifter.
+
+ Note:
+
+ - instance number: N
+ - keypoint number: K
+ - keypoint dimension: D
+ - pose-lifitng target dimension: C
+
+ Args:
+ num_keypoints (int): The number of keypoints in the dataset.
+ zero_center: Whether to zero-center the target around root. Default:
+ ``True``.
+ root_index (int): Root keypoint index in the pose. Default: 0.
+ remove_root (bool): If true, remove the root keypoint from the pose.
+ Default: ``False``.
+ save_index (bool): If true, store the root position separated from the
+ original pose, only takes effect if ``remove_root`` is ``True``.
+ Default: ``False``.
+ normalize_camera (bool): Whether to normalize camera intrinsics.
+ Default: ``False``.
+ """
+
+ auxiliary_encode_keys = {
+ 'lifting_target', 'lifting_target_visible', 'camera_param'
+ }
+
+ def __init__(self,
+ num_keypoints: int,
+ zero_center: bool = True,
+ root_index: int = 0,
+ remove_root: bool = False,
+ save_index: bool = False,
+ normalize_camera: bool = False):
+ super().__init__()
+
+ self.num_keypoints = num_keypoints
+ self.zero_center = zero_center
+ self.root_index = root_index
+ self.remove_root = remove_root
+ self.save_index = save_index
+ self.normalize_camera = normalize_camera
+
+ def encode(self,
+ keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray] = None,
+ lifting_target: Optional[np.ndarray] = None,
+ lifting_target_visible: Optional[np.ndarray] = None,
+ camera_param: Optional[dict] = None) -> dict:
+ """Encoding keypoints from input image space to normalized space.
+
+ Args:
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D).
+ keypoints_visible (np.ndarray, optional): Keypoint visibilities in
+ shape (N, K).
+ lifting_target (np.ndarray, optional): 3d target coordinate in
+ shape (K, C).
+ lifting_target_visible (np.ndarray, optional): Target coordinate in
+ shape (K, ).
+ camera_param (dict, optional): The camera parameter dictionary.
+
+ Returns:
+ encoded (dict): Contains the following items:
+
+ - keypoint_labels (np.ndarray): The processed keypoints in
+ shape (K * D, N) where D is 2 for 2d coordinates.
+ - lifting_target_label: The processed target coordinate in
+ shape (K, C) or (K-1, C).
+ - lifting_target_weights (np.ndarray): The target weights in
+ shape (K, ) or (K-1, ).
+ - trajectory_weights (np.ndarray): The trajectory weights in
+ shape (K, ).
+
+ In addition, there are some optional items it may contain:
+
+ - target_root (np.ndarray): The root coordinate of target in
+ shape (C, ). Exists if ``self.zero_center`` is ``True``.
+ - target_root_removed (bool): Indicate whether the root of
+ pose-lifitng target is removed. Exists if
+ ``self.remove_root`` is ``True``.
+ - target_root_index (int): An integer indicating the index of
+ root. Exists if ``self.remove_root`` and ``self.save_index``
+ are ``True``.
+ - camera_param (dict): The updated camera parameter dictionary.
+ Exists if ``self.normalize_camera`` is ``True``.
+ """
+ if keypoints_visible is None:
+ keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
+
+ if lifting_target is None:
+ lifting_target = keypoints[0]
+
+ # set initial value for `lifting_target_weights`
+ # and `trajectory_weights`
+ if lifting_target_visible is None:
+ lifting_target_visible = np.ones(
+ lifting_target.shape[:-1], dtype=np.float32)
+ lifting_target_weights = lifting_target_visible
+ trajectory_weights = (1 / lifting_target[:, 2])
+ else:
+ valid = lifting_target_visible > 0.5
+ lifting_target_weights = np.where(valid, 1., 0.).astype(np.float32)
+ trajectory_weights = lifting_target_weights
+
+ if camera_param is None:
+ camera_param = dict()
+
+ encoded = dict()
+
+ lifting_target_label = lifting_target.copy()
+ # Zero-center the target pose around a given root keypoint
+ if self.zero_center:
+ assert (lifting_target.ndim >= 2 and
+ lifting_target.shape[-2] > self.root_index), \
+ f'Got invalid joint shape {lifting_target.shape}'
+
+ root = lifting_target[..., self.root_index, :]
+ lifting_target_label = lifting_target_label - root
+ encoded['target_root'] = root
+
+ if self.remove_root:
+ lifting_target_label = np.delete(
+ lifting_target_label, self.root_index, axis=-2)
+ assert lifting_target_weights.ndim in {1, 2}
+ axis_to_remove = -2 if lifting_target_weights.ndim == 2 else -1
+ lifting_target_weights = np.delete(
+ lifting_target_weights,
+ self.root_index,
+ axis=axis_to_remove)
+ # Add a flag to avoid latter transforms that rely on the root
+ # joint or the original joint index
+ encoded['target_root_removed'] = True
+
+ # Save the root index for restoring the global pose
+ if self.save_index:
+ encoded['target_root_index'] = self.root_index
+
+ # Normalize the 2D keypoint coordinate with image width and height
+ _camera_param = deepcopy(camera_param)
+ assert 'w' in _camera_param and 'h' in _camera_param
+ center = np.array([0.5 * _camera_param['w'], 0.5 * _camera_param['h']],
+ dtype=np.float32)
+ scale = np.array(0.5 * _camera_param['w'], dtype=np.float32)
+
+ keypoint_labels = (keypoints - center) / scale
+
+ assert keypoint_labels.ndim in {2, 3}
+ if keypoint_labels.ndim == 2:
+ keypoint_labels = keypoint_labels[None, ...]
+
+ if self.normalize_camera:
+ assert 'f' in _camera_param and 'c' in _camera_param
+ _camera_param['f'] = _camera_param['f'] / scale
+ _camera_param['c'] = (_camera_param['c'] - center[:, None]) / scale
+ encoded['camera_param'] = _camera_param
+
+ encoded['keypoint_labels'] = keypoint_labels
+ encoded['lifting_target_label'] = lifting_target_label
+ encoded['lifting_target_weights'] = lifting_target_weights
+ encoded['trajectory_weights'] = trajectory_weights
+
+ return encoded
+
+ def decode(self,
+ encoded: np.ndarray,
+ target_root: Optional[np.ndarray] = None
+ ) -> Tuple[np.ndarray, np.ndarray]:
+ """Decode keypoint coordinates from normalized space to input image
+ space.
+
+ Args:
+ encoded (np.ndarray): Coordinates in shape (N, K, C).
+ target_root (np.ndarray, optional): The pose-lifitng target root
+ coordinate. Default: ``None``.
+
+ Returns:
+ keypoints (np.ndarray): Decoded coordinates in shape (N, K, C).
+ scores (np.ndarray): The keypoint scores in shape (N, K).
+ """
+ keypoints = encoded.copy()
+
+ if target_root.size > 0:
+ keypoints = keypoints + np.expand_dims(target_root, axis=0)
+ if self.remove_root:
+ keypoints = np.insert(
+ keypoints, self.root_index, target_root, axis=1)
+ scores = np.ones(keypoints.shape[:-1], dtype=np.float32)
+
+ return keypoints, scores
diff --git a/mmpose/configs/_base_/default_runtime.py b/mmpose/configs/_base_/default_runtime.py
index 349ecf4b17..5df17b0db4 100644
--- a/mmpose/configs/_base_/default_runtime.py
+++ b/mmpose/configs/_base_/default_runtime.py
@@ -1,54 +1,54 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmengine.hooks import (CheckpointHook, DistSamplerSeedHook, IterTimerHook,
- LoggerHook, ParamSchedulerHook, SyncBuffersHook)
-from mmengine.runner import LogProcessor
-from mmengine.visualization import LocalVisBackend
-
-from mmpose.engine.hooks import PoseVisualizationHook
-from mmpose.visualization import PoseLocalVisualizer
-
-default_scope = None
-
-# hooks
-default_hooks = dict(
- timer=dict(type=IterTimerHook),
- logger=dict(type=LoggerHook, interval=50),
- param_scheduler=dict(type=ParamSchedulerHook),
- checkpoint=dict(type=CheckpointHook, interval=10),
- sampler_seed=dict(type=DistSamplerSeedHook),
- visualization=dict(type=PoseVisualizationHook, enable=False),
-)
-
-# custom hooks
-custom_hooks = [
- # Synchronize model buffers such as running_mean and running_var in BN
- # at the end of each epoch
- dict(type=SyncBuffersHook)
-]
-
-# multi-processing backend
-env_cfg = dict(
- cudnn_benchmark=False,
- mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
- dist_cfg=dict(backend='nccl'),
-)
-
-# visualizer
-vis_backends = [dict(type=LocalVisBackend)]
-visualizer = dict(
- type=PoseLocalVisualizer, vis_backends=vis_backends, name='visualizer')
-
-# logger
-log_processor = dict(
- type=LogProcessor, window_size=50, by_epoch=True, num_digits=6)
-log_level = 'INFO'
-load_from = None
-resume = False
-
-# file I/O backend
-backend_args = dict(backend='local')
-
-# training/validation/testing progress
-train_cfg = dict(by_epoch=True)
-val_cfg = dict()
-test_cfg = dict()
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.hooks import (CheckpointHook, DistSamplerSeedHook, IterTimerHook,
+ LoggerHook, ParamSchedulerHook, SyncBuffersHook)
+from mmengine.runner import LogProcessor
+from mmengine.visualization import LocalVisBackend
+
+from mmpose.engine.hooks import PoseVisualizationHook
+from mmpose.visualization import PoseLocalVisualizer
+
+default_scope = None
+
+# hooks
+default_hooks = dict(
+ timer=dict(type=IterTimerHook),
+ logger=dict(type=LoggerHook, interval=50),
+ param_scheduler=dict(type=ParamSchedulerHook),
+ checkpoint=dict(type=CheckpointHook, interval=10),
+ sampler_seed=dict(type=DistSamplerSeedHook),
+ visualization=dict(type=PoseVisualizationHook, enable=False),
+)
+
+# custom hooks
+custom_hooks = [
+ # Synchronize model buffers such as running_mean and running_var in BN
+ # at the end of each epoch
+ dict(type=SyncBuffersHook)
+]
+
+# multi-processing backend
+env_cfg = dict(
+ cudnn_benchmark=False,
+ mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
+ dist_cfg=dict(backend='nccl'),
+)
+
+# visualizer
+vis_backends = [dict(type=LocalVisBackend)]
+visualizer = dict(
+ type=PoseLocalVisualizer, vis_backends=vis_backends, name='visualizer')
+
+# logger
+log_processor = dict(
+ type=LogProcessor, window_size=50, by_epoch=True, num_digits=6)
+log_level = 'INFO'
+load_from = None
+resume = False
+
+# file I/O backend
+backend_args = dict(backend='local')
+
+# training/validation/testing progress
+train_cfg = dict(by_epoch=True)
+val_cfg = dict()
+test_cfg = dict()
diff --git a/mmpose/configs/body_2d_keypoint/rtmpose/coco/rtmpose_m_8xb256-420e_coco-256x192.py b/mmpose/configs/body_2d_keypoint/rtmpose/coco/rtmpose_m_8xb256-420e_coco-256x192.py
index af102ec20e..8fdd6929cc 100644
--- a/mmpose/configs/body_2d_keypoint/rtmpose/coco/rtmpose_m_8xb256-420e_coco-256x192.py
+++ b/mmpose/configs/body_2d_keypoint/rtmpose/coco/rtmpose_m_8xb256-420e_coco-256x192.py
@@ -1,253 +1,253 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmengine.config import read_base
-
-with read_base():
- from mmpose.configs._base_.default_runtime import *
-
-from albumentations.augmentations import Blur, CoarseDropout, MedianBlur
-from mmdet.datasets.transforms import YOLOXHSVRandomAug
-from mmdet.engine.hooks import PipelineSwitchHook
-from mmdet.models import CSPNeXt
-from mmengine.dataset import DefaultSampler
-from mmengine.hooks import EMAHook
-from mmengine.model import PretrainedInit
-from mmengine.optim import CosineAnnealingLR, LinearLR, OptimWrapper
-from torch.nn import SiLU, SyncBatchNorm
-from torch.optim import AdamW
-
-from mmpose.codecs import SimCCLabel
-from mmpose.datasets import (CocoDataset, GenerateTarget, GetBBoxCenterScale,
- LoadImage, PackPoseInputs, RandomFlip,
- RandomHalfBody, TopdownAffine)
-from mmpose.datasets.transforms.common_transforms import (Albumentation,
- RandomBBoxTransform)
-from mmpose.engine.hooks import ExpMomentumEMA
-from mmpose.evaluation import CocoMetric
-from mmpose.models import (KLDiscretLoss, PoseDataPreprocessor, RTMCCHead,
- TopdownPoseEstimator)
-
-# runtime
-max_epochs = 420
-stage2_num_epochs = 30
-base_lr = 4e-3
-
-train_cfg.update(max_epochs=max_epochs, val_interval=10)
-randomness = dict(seed=21)
-
-# optimizer
-optim_wrapper = dict(
- type=OptimWrapper,
- optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.05),
- paramwise_cfg=dict(
- norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
-
-# learning rate
-param_scheduler = [
- dict(
- type=LinearLR, start_factor=1.0e-5, by_epoch=False, begin=0, end=1000),
- dict(
- # use cosine lr from 210 to 420 epoch
- type=CosineAnnealingLR,
- eta_min=base_lr * 0.05,
- begin=max_epochs // 2,
- end=max_epochs,
- T_max=max_epochs // 2,
- by_epoch=True,
- convert_to_iter_based=True),
-]
-
-# automatically scaling LR based on the actual training batch size
-auto_scale_lr = dict(base_batch_size=1024)
-
-# codec settings
-codec = dict(
- type=SimCCLabel,
- input_size=(192, 256),
- sigma=(4.9, 5.66),
- simcc_split_ratio=2.0,
- normalize=False,
- use_dark=False)
-
-# model settings
-model = dict(
- type=TopdownPoseEstimator,
- data_preprocessor=dict(
- type=PoseDataPreprocessor,
- mean=[123.675, 116.28, 103.53],
- std=[58.395, 57.12, 57.375],
- bgr_to_rgb=True),
- backbone=dict(
- type=CSPNeXt,
- arch='P5',
- expand_ratio=0.5,
- deepen_factor=0.67,
- widen_factor=0.75,
- out_indices=(4, ),
- channel_attention=True,
- norm_cfg=dict(type=SyncBatchNorm),
- act_cfg=dict(type=SiLU),
- init_cfg=dict(
- type=PretrainedInit,
- prefix='backbone.',
- checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
- 'rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth' # noqa
- )),
- head=dict(
- type=RTMCCHead,
- in_channels=768,
- out_channels=17,
- input_size=codec['input_size'],
- in_featuremap_size=(6, 8),
- simcc_split_ratio=codec['simcc_split_ratio'],
- final_layer_kernel_size=7,
- gau_cfg=dict(
- hidden_dims=256,
- s=128,
- expansion_factor=2,
- dropout_rate=0.,
- drop_path=0.,
- act_fn='SiLU',
- use_rel_bias=False,
- pos_enc=False),
- loss=dict(
- type=KLDiscretLoss,
- use_target_weight=True,
- beta=10.,
- label_softmax=True),
- decoder=codec),
- test_cfg=dict(flip_test=True))
-
-# base dataset settings
-dataset_type = CocoDataset
-data_mode = 'topdown'
-data_root = 'data/coco/'
-
-backend_args = dict(backend='local')
-# backend_args = dict(
-# backend='petrel',
-# path_mapping=dict({
-# f'{data_root}': 's3://openmmlab/datasets/detection/coco/',
-# f'{data_root}': 's3://openmmlab/datasets/detection/coco/'
-# }))
-
-# pipelines
-train_pipeline = [
- dict(type=LoadImage, backend_args=backend_args),
- dict(type=GetBBoxCenterScale),
- dict(type=RandomFlip, direction='horizontal'),
- dict(type=RandomHalfBody),
- dict(type=RandomBBoxTransform, scale_factor=[0.6, 1.4], rotate_factor=80),
- dict(type=TopdownAffine, input_size=codec['input_size']),
- dict(type=YOLOXHSVRandomAug),
- dict(
- type=Albumentation,
- transforms=[
- dict(type=Blur, p=0.1),
- dict(type=MedianBlur, p=0.1),
- dict(
- type=CoarseDropout,
- max_holes=1,
- max_height=0.4,
- max_width=0.4,
- min_holes=1,
- min_height=0.2,
- min_width=0.2,
- p=1.),
- ]),
- dict(type=GenerateTarget, encoder=codec),
- dict(type=PackPoseInputs)
-]
-val_pipeline = [
- dict(type=LoadImage, backend_args=backend_args),
- dict(type=GetBBoxCenterScale),
- dict(type=TopdownAffine, input_size=codec['input_size']),
- dict(type=PackPoseInputs)
-]
-
-train_pipeline_stage2 = [
- dict(type=LoadImage, backend_args=backend_args),
- dict(type=GetBBoxCenterScale),
- dict(type=RandomFlip, direction='horizontal'),
- dict(type=RandomHalfBody),
- dict(
- type=RandomBBoxTransform,
- shift_factor=0.,
- scale_factor=[0.75, 1.25],
- rotate_factor=60),
- dict(type=TopdownAffine, input_size=codec['input_size']),
- dict(type=YOLOXHSVRandomAug),
- dict(
- type=Albumentation,
- transforms=[
- dict(type=Blur, p=0.1),
- dict(type=MedianBlur, p=0.1),
- dict(
- type=CoarseDropout,
- max_holes=1,
- max_height=0.4,
- max_width=0.4,
- min_holes=1,
- min_height=0.2,
- min_width=0.2,
- p=0.5),
- ]),
- dict(type=GenerateTarget, encoder=codec),
- dict(type=PackPoseInputs)
-]
-
-# data loaders
-train_dataloader = dict(
- batch_size=256,
- num_workers=10,
- persistent_workers=True,
- drop_last=True,
- sampler=dict(type=DefaultSampler, shuffle=True),
- dataset=dict(
- type=dataset_type,
- data_root=data_root,
- data_mode=data_mode,
- ann_file='annotations/person_keypoints_train2017.json',
- data_prefix=dict(img='train2017/'),
- pipeline=train_pipeline,
- ))
-val_dataloader = dict(
- batch_size=64,
- num_workers=10,
- persistent_workers=True,
- drop_last=False,
- sampler=dict(type=DefaultSampler, shuffle=False, round_up=False),
- dataset=dict(
- type=dataset_type,
- data_root=data_root,
- data_mode=data_mode,
- ann_file='annotations/person_keypoints_val2017.json',
- # bbox_file=f'{data_root}person_detection_results/'
- # 'COCO_val2017_detections_AP_H_56_person.json',
- data_prefix=dict(img='val2017/'),
- test_mode=True,
- pipeline=val_pipeline,
- ))
-test_dataloader = val_dataloader
-
-# hooks
-default_hooks.update(
- checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=1))
-
-custom_hooks = [
- dict(
- type=EMAHook,
- ema_type=ExpMomentumEMA,
- momentum=0.0002,
- update_buffers=True,
- priority=49),
- dict(
- type=PipelineSwitchHook,
- switch_epoch=max_epochs - stage2_num_epochs,
- switch_pipeline=train_pipeline_stage2)
-]
-
-# evaluators
-val_evaluator = dict(
- type=CocoMetric,
- ann_file=data_root + 'annotations/person_keypoints_val2017.json')
-test_evaluator = val_evaluator
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.config import read_base
+
+with read_base():
+ from mmpose.configs._base_.default_runtime import *
+
+from albumentations.augmentations import Blur, CoarseDropout, MedianBlur
+from mmdet.datasets.transforms import YOLOXHSVRandomAug
+from mmdet.engine.hooks import PipelineSwitchHook
+from mmdet.models import CSPNeXt
+from mmengine.dataset import DefaultSampler
+from mmengine.hooks import EMAHook
+from mmengine.model import PretrainedInit
+from mmengine.optim import CosineAnnealingLR, LinearLR, OptimWrapper
+from torch.nn import SiLU, SyncBatchNorm
+from torch.optim import AdamW
+
+from mmpose.codecs import SimCCLabel
+from mmpose.datasets import (CocoDataset, GenerateTarget, GetBBoxCenterScale,
+ LoadImage, PackPoseInputs, RandomFlip,
+ RandomHalfBody, TopdownAffine)
+from mmpose.datasets.transforms.common_transforms import (Albumentation,
+ RandomBBoxTransform)
+from mmpose.engine.hooks import ExpMomentumEMA
+from mmpose.evaluation import CocoMetric
+from mmpose.models import (KLDiscretLoss, PoseDataPreprocessor, RTMCCHead,
+ TopdownPoseEstimator)
+
+# runtime
+max_epochs = 420
+stage2_num_epochs = 30
+base_lr = 4e-3
+
+train_cfg.update(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type=OptimWrapper,
+ optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type=LinearLR, start_factor=1.0e-5, by_epoch=False, begin=0, end=1000),
+ dict(
+ # use cosine lr from 210 to 420 epoch
+ type=CosineAnnealingLR,
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=1024)
+
+# codec settings
+codec = dict(
+ type=SimCCLabel,
+ input_size=(192, 256),
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type=TopdownPoseEstimator,
+ data_preprocessor=dict(
+ type=PoseDataPreprocessor,
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type=CSPNeXt,
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=0.67,
+ widen_factor=0.75,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type=SyncBatchNorm),
+ act_cfg=dict(type=SiLU),
+ init_cfg=dict(
+ type=PretrainedInit,
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth' # noqa
+ )),
+ head=dict(
+ type=RTMCCHead,
+ in_channels=768,
+ out_channels=17,
+ input_size=codec['input_size'],
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type=KLDiscretLoss,
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True))
+
+# base dataset settings
+dataset_type = CocoDataset
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+backend_args = dict(backend='local')
+# backend_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/',
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/'
+# }))
+
+# pipelines
+train_pipeline = [
+ dict(type=LoadImage, backend_args=backend_args),
+ dict(type=GetBBoxCenterScale),
+ dict(type=RandomFlip, direction='horizontal'),
+ dict(type=RandomHalfBody),
+ dict(type=RandomBBoxTransform, scale_factor=[0.6, 1.4], rotate_factor=80),
+ dict(type=TopdownAffine, input_size=codec['input_size']),
+ dict(type=YOLOXHSVRandomAug),
+ dict(
+ type=Albumentation,
+ transforms=[
+ dict(type=Blur, p=0.1),
+ dict(type=MedianBlur, p=0.1),
+ dict(
+ type=CoarseDropout,
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.),
+ ]),
+ dict(type=GenerateTarget, encoder=codec),
+ dict(type=PackPoseInputs)
+]
+val_pipeline = [
+ dict(type=LoadImage, backend_args=backend_args),
+ dict(type=GetBBoxCenterScale),
+ dict(type=TopdownAffine, input_size=codec['input_size']),
+ dict(type=PackPoseInputs)
+]
+
+train_pipeline_stage2 = [
+ dict(type=LoadImage, backend_args=backend_args),
+ dict(type=GetBBoxCenterScale),
+ dict(type=RandomFlip, direction='horizontal'),
+ dict(type=RandomHalfBody),
+ dict(
+ type=RandomBBoxTransform,
+ shift_factor=0.,
+ scale_factor=[0.75, 1.25],
+ rotate_factor=60),
+ dict(type=TopdownAffine, input_size=codec['input_size']),
+ dict(type=YOLOXHSVRandomAug),
+ dict(
+ type=Albumentation,
+ transforms=[
+ dict(type=Blur, p=0.1),
+ dict(type=MedianBlur, p=0.1),
+ dict(
+ type=CoarseDropout,
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type=GenerateTarget, encoder=codec),
+ dict(type=PackPoseInputs)
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=256,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=True,
+ sampler=dict(type=DefaultSampler, shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=64,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type=DefaultSampler, shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_val2017.json',
+ # bbox_file=f'{data_root}person_detection_results/'
+ # 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks.update(
+ checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type=EMAHook,
+ ema_type=ExpMomentumEMA,
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type=PipelineSwitchHook,
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type=CocoMetric,
+ ann_file=data_root + 'annotations/person_keypoints_val2017.json')
+test_evaluator = val_evaluator
diff --git a/mmpose/configs/body_2d_keypoint/rtmpose/coco/rtmpose_s_8xb256_420e_aic_coco_256x192.py b/mmpose/configs/body_2d_keypoint/rtmpose/coco/rtmpose_s_8xb256_420e_aic_coco_256x192.py
index 6fc5ec0abe..563552ad0d 100644
--- a/mmpose/configs/body_2d_keypoint/rtmpose/coco/rtmpose_s_8xb256_420e_aic_coco_256x192.py
+++ b/mmpose/configs/body_2d_keypoint/rtmpose/coco/rtmpose_s_8xb256_420e_aic_coco_256x192.py
@@ -1,294 +1,294 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmengine.config import read_base
-
-with read_base():
- from mmpose.configs._base_.default_runtime import *
-
-from albumentations.augmentations import Blur, CoarseDropout, MedianBlur
-from mmdet.datasets.transforms import YOLOXHSVRandomAug
-from mmdet.engine.hooks import PipelineSwitchHook
-from mmdet.models import CSPNeXt
-from mmengine.dataset import DefaultSampler, RepeatDataset
-from mmengine.hooks import EMAHook
-from mmengine.model import PretrainedInit
-from mmengine.optim import CosineAnnealingLR, LinearLR, OptimWrapper
-from torch.nn import SiLU, SyncBatchNorm
-from torch.optim import AdamW
-
-from mmpose.codecs import SimCCLabel
-from mmpose.datasets import (AicDataset, CocoDataset, CombinedDataset,
- GenerateTarget, GetBBoxCenterScale,
- KeypointConverter, LoadImage, PackPoseInputs,
- RandomFlip, RandomHalfBody, TopdownAffine)
-from mmpose.datasets.transforms.common_transforms import (Albumentation,
- RandomBBoxTransform)
-from mmpose.engine.hooks import ExpMomentumEMA
-from mmpose.evaluation import CocoMetric
-from mmpose.models import (KLDiscretLoss, PoseDataPreprocessor, RTMCCHead,
- TopdownPoseEstimator)
-
-# runtime
-max_epochs = 420
-stage2_num_epochs = 30
-base_lr = 4e-3
-
-train_cfg.update(max_epochs=max_epochs, val_interval=10)
-randomness = dict(seed=21)
-
-# optimizer
-optim_wrapper = dict(
- type=OptimWrapper,
- optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.0),
- paramwise_cfg=dict(
- norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
-
-# learning rate
-param_scheduler = [
- dict(
- type=LinearLR, start_factor=1.0e-5, by_epoch=False, begin=0, end=1000),
- dict(
- # use cosine lr from 210 to 420 epoch
- type=CosineAnnealingLR,
- eta_min=base_lr * 0.05,
- begin=max_epochs // 2,
- end=max_epochs,
- T_max=max_epochs // 2,
- by_epoch=True,
- convert_to_iter_based=True),
-]
-
-# automatically scaling LR based on the actual training batch size
-auto_scale_lr = dict(base_batch_size=1024)
-
-# codec settings
-codec = dict(
- type=SimCCLabel,
- input_size=(192, 256),
- sigma=(4.9, 5.66),
- simcc_split_ratio=2.0,
- normalize=False,
- use_dark=False)
-
-# model settings
-model = dict(
- type=TopdownPoseEstimator,
- data_preprocessor=dict(
- type=PoseDataPreprocessor,
- mean=[123.675, 116.28, 103.53],
- std=[58.395, 57.12, 57.375],
- bgr_to_rgb=True),
- backbone=dict(
- _scope_='mmdet',
- type=CSPNeXt,
- arch='P5',
- expand_ratio=0.5,
- deepen_factor=0.33,
- widen_factor=0.5,
- out_indices=(4, ),
- channel_attention=True,
- norm_cfg=dict(type=SyncBatchNorm),
- act_cfg=dict(type=SiLU),
- init_cfg=dict(
- type=PretrainedInit,
- prefix='backbone.',
- checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
- 'rtmposev1/cspnext-s_udp-aic-coco_210e-256x192-92f5a029_20230130.pth' # noqa
- )),
- head=dict(
- type=RTMCCHead,
- in_channels=512,
- out_channels=17,
- input_size=codec['input_size'],
- in_featuremap_size=(6, 8),
- simcc_split_ratio=codec['simcc_split_ratio'],
- final_layer_kernel_size=7,
- gau_cfg=dict(
- hidden_dims=256,
- s=128,
- expansion_factor=2,
- dropout_rate=0.,
- drop_path=0.,
- act_fn='SiLU',
- use_rel_bias=False,
- pos_enc=False),
- loss=dict(
- type=KLDiscretLoss,
- use_target_weight=True,
- beta=10.,
- label_softmax=True),
- decoder=codec),
- test_cfg=dict(flip_test=True, ))
-
-# base dataset settings
-dataset_type = CocoDataset
-data_mode = 'topdown'
-data_root = 'data/'
-
-backend_args = dict(backend='local')
-# backend_args = dict(
-# backend='petrel',
-# path_mapping=dict({
-# f'{data_root}': 's3://openmmlab/datasets/',
-# f'{data_root}': 's3://openmmlab/datasets/'
-# }))
-
-# pipelines
-train_pipeline = [
- dict(type=LoadImage, backend_args=backend_args),
- dict(type=GetBBoxCenterScale),
- dict(type=RandomFlip, direction='horizontal'),
- dict(type=RandomHalfBody),
- dict(type=RandomBBoxTransform, scale_factor=[0.6, 1.4], rotate_factor=80),
- dict(type=TopdownAffine, input_size=codec['input_size']),
- dict(type=YOLOXHSVRandomAug),
- dict(
- type=Albumentation,
- transforms=[
- dict(type=Blur, p=0.1),
- dict(type=MedianBlur, p=0.1),
- dict(
- type=CoarseDropout,
- max_holes=1,
- max_height=0.4,
- max_width=0.4,
- min_holes=1,
- min_height=0.2,
- min_width=0.2,
- p=1.0),
- ]),
- dict(type=GenerateTarget, encoder=codec),
- dict(type=PackPoseInputs)
-]
-val_pipeline = [
- dict(type=LoadImage, backend_args=backend_args),
- dict(type=GetBBoxCenterScale),
- dict(type=TopdownAffine, input_size=codec['input_size']),
- dict(type=PackPoseInputs)
-]
-
-train_pipeline_stage2 = [
- dict(type=LoadImage, backend_args=backend_args),
- dict(type=GetBBoxCenterScale),
- dict(type=RandomFlip, direction='horizontal'),
- dict(type=RandomHalfBody),
- dict(
- type=RandomBBoxTransform,
- shift_factor=0.,
- scale_factor=[0.75, 1.25],
- rotate_factor=60),
- dict(type=TopdownAffine, input_size=codec['input_size']),
- dict(type=YOLOXHSVRandomAug),
- dict(
- type=Albumentation,
- transforms=[
- dict(type=Blur, p=0.1),
- dict(type=MedianBlur, p=0.1),
- dict(
- type=CoarseDropout,
- max_holes=1,
- max_height=0.4,
- max_width=0.4,
- min_holes=1,
- min_height=0.2,
- min_width=0.2,
- p=0.5),
- ]),
- dict(type=GenerateTarget, encoder=codec),
- dict(type=PackPoseInputs)
-]
-
-# train datasets
-dataset_coco = dict(
- type=RepeatDataset,
- dataset=dict(
- type=dataset_type,
- data_root=data_root,
- data_mode=data_mode,
- ann_file='coco/annotations/person_keypoints_train2017.json',
- data_prefix=dict(img='detection/coco/train2017/'),
- pipeline=[],
- ),
- times=3)
-
-dataset_aic = dict(
- type=AicDataset,
- data_root=data_root,
- data_mode=data_mode,
- ann_file='aic/annotations/aic_train.json',
- data_prefix=dict(img='pose/ai_challenge/ai_challenger_keypoint'
- '_train_20170902/keypoint_train_images_20170902/'),
- pipeline=[
- dict(
- type=KeypointConverter,
- num_keypoints=17,
- mapping=[
- (0, 6),
- (1, 8),
- (2, 10),
- (3, 5),
- (4, 7),
- (5, 9),
- (6, 12),
- (7, 14),
- (8, 16),
- (9, 11),
- (10, 13),
- (11, 15),
- ])
- ],
-)
-
-# data loaders
-train_dataloader = dict(
- batch_size=128 * 2,
- num_workers=10,
- persistent_workers=True,
- sampler=dict(type=DefaultSampler, shuffle=True),
- dataset=dict(
- type=CombinedDataset,
- metainfo=dict(from_file='configs/_base_/datasets/coco.py'),
- datasets=[dataset_coco, dataset_aic],
- pipeline=train_pipeline,
- test_mode=False,
- ))
-val_dataloader = dict(
- batch_size=64,
- num_workers=10,
- persistent_workers=True,
- drop_last=False,
- sampler=dict(type=DefaultSampler, shuffle=False, round_up=False),
- dataset=dict(
- type=dataset_type,
- data_root=data_root,
- data_mode=data_mode,
- ann_file='coco/annotations/person_keypoints_val2017.json',
- # bbox_file='data/coco/person_detection_results/'
- # 'COCO_val2017_detections_AP_H_56_person.json',
- data_prefix=dict(img='detection/coco/val2017/'),
- test_mode=True,
- pipeline=val_pipeline,
- ))
-test_dataloader = val_dataloader
-
-# hooks
-default_hooks.update(
- checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=1))
-
-custom_hooks = [
- dict(
- type=EMAHook,
- ema_type=ExpMomentumEMA,
- momentum=0.0002,
- update_buffers=True,
- priority=49),
- dict(
- type=PipelineSwitchHook,
- switch_epoch=max_epochs - stage2_num_epochs,
- switch_pipeline=train_pipeline_stage2)
-]
-
-# evaluators
-val_evaluator = dict(
- type=CocoMetric,
- ann_file=data_root + 'coco/annotations/person_keypoints_val2017.json')
-test_evaluator = val_evaluator
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.config import read_base
+
+with read_base():
+ from mmpose.configs._base_.default_runtime import *
+
+from albumentations.augmentations import Blur, CoarseDropout, MedianBlur
+from mmdet.datasets.transforms import YOLOXHSVRandomAug
+from mmdet.engine.hooks import PipelineSwitchHook
+from mmdet.models import CSPNeXt
+from mmengine.dataset import DefaultSampler, RepeatDataset
+from mmengine.hooks import EMAHook
+from mmengine.model import PretrainedInit
+from mmengine.optim import CosineAnnealingLR, LinearLR, OptimWrapper
+from torch.nn import SiLU, SyncBatchNorm
+from torch.optim import AdamW
+
+from mmpose.codecs import SimCCLabel
+from mmpose.datasets import (AicDataset, CocoDataset, CombinedDataset,
+ GenerateTarget, GetBBoxCenterScale,
+ KeypointConverter, LoadImage, PackPoseInputs,
+ RandomFlip, RandomHalfBody, TopdownAffine)
+from mmpose.datasets.transforms.common_transforms import (Albumentation,
+ RandomBBoxTransform)
+from mmpose.engine.hooks import ExpMomentumEMA
+from mmpose.evaluation import CocoMetric
+from mmpose.models import (KLDiscretLoss, PoseDataPreprocessor, RTMCCHead,
+ TopdownPoseEstimator)
+
+# runtime
+max_epochs = 420
+stage2_num_epochs = 30
+base_lr = 4e-3
+
+train_cfg.update(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type=OptimWrapper,
+ optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.0),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type=LinearLR, start_factor=1.0e-5, by_epoch=False, begin=0, end=1000),
+ dict(
+ # use cosine lr from 210 to 420 epoch
+ type=CosineAnnealingLR,
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=1024)
+
+# codec settings
+codec = dict(
+ type=SimCCLabel,
+ input_size=(192, 256),
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type=TopdownPoseEstimator,
+ data_preprocessor=dict(
+ type=PoseDataPreprocessor,
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type=CSPNeXt,
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=0.33,
+ widen_factor=0.5,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type=SyncBatchNorm),
+ act_cfg=dict(type=SiLU),
+ init_cfg=dict(
+ type=PretrainedInit,
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmposev1/cspnext-s_udp-aic-coco_210e-256x192-92f5a029_20230130.pth' # noqa
+ )),
+ head=dict(
+ type=RTMCCHead,
+ in_channels=512,
+ out_channels=17,
+ input_size=codec['input_size'],
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type=KLDiscretLoss,
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True, ))
+
+# base dataset settings
+dataset_type = CocoDataset
+data_mode = 'topdown'
+data_root = 'data/'
+
+backend_args = dict(backend='local')
+# backend_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# f'{data_root}': 's3://openmmlab/datasets/',
+# f'{data_root}': 's3://openmmlab/datasets/'
+# }))
+
+# pipelines
+train_pipeline = [
+ dict(type=LoadImage, backend_args=backend_args),
+ dict(type=GetBBoxCenterScale),
+ dict(type=RandomFlip, direction='horizontal'),
+ dict(type=RandomHalfBody),
+ dict(type=RandomBBoxTransform, scale_factor=[0.6, 1.4], rotate_factor=80),
+ dict(type=TopdownAffine, input_size=codec['input_size']),
+ dict(type=YOLOXHSVRandomAug),
+ dict(
+ type=Albumentation,
+ transforms=[
+ dict(type=Blur, p=0.1),
+ dict(type=MedianBlur, p=0.1),
+ dict(
+ type=CoarseDropout,
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.0),
+ ]),
+ dict(type=GenerateTarget, encoder=codec),
+ dict(type=PackPoseInputs)
+]
+val_pipeline = [
+ dict(type=LoadImage, backend_args=backend_args),
+ dict(type=GetBBoxCenterScale),
+ dict(type=TopdownAffine, input_size=codec['input_size']),
+ dict(type=PackPoseInputs)
+]
+
+train_pipeline_stage2 = [
+ dict(type=LoadImage, backend_args=backend_args),
+ dict(type=GetBBoxCenterScale),
+ dict(type=RandomFlip, direction='horizontal'),
+ dict(type=RandomHalfBody),
+ dict(
+ type=RandomBBoxTransform,
+ shift_factor=0.,
+ scale_factor=[0.75, 1.25],
+ rotate_factor=60),
+ dict(type=TopdownAffine, input_size=codec['input_size']),
+ dict(type=YOLOXHSVRandomAug),
+ dict(
+ type=Albumentation,
+ transforms=[
+ dict(type=Blur, p=0.1),
+ dict(type=MedianBlur, p=0.1),
+ dict(
+ type=CoarseDropout,
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type=GenerateTarget, encoder=codec),
+ dict(type=PackPoseInputs)
+]
+
+# train datasets
+dataset_coco = dict(
+ type=RepeatDataset,
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='coco/annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='detection/coco/train2017/'),
+ pipeline=[],
+ ),
+ times=3)
+
+dataset_aic = dict(
+ type=AicDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='aic/annotations/aic_train.json',
+ data_prefix=dict(img='pose/ai_challenge/ai_challenger_keypoint'
+ '_train_20170902/keypoint_train_images_20170902/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=17,
+ mapping=[
+ (0, 6),
+ (1, 8),
+ (2, 10),
+ (3, 5),
+ (4, 7),
+ (5, 9),
+ (6, 12),
+ (7, 14),
+ (8, 16),
+ (9, 11),
+ (10, 13),
+ (11, 15),
+ ])
+ ],
+)
+
+# data loaders
+train_dataloader = dict(
+ batch_size=128 * 2,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type=DefaultSampler, shuffle=True),
+ dataset=dict(
+ type=CombinedDataset,
+ metainfo=dict(from_file='configs/_base_/datasets/coco.py'),
+ datasets=[dataset_coco, dataset_aic],
+ pipeline=train_pipeline,
+ test_mode=False,
+ ))
+val_dataloader = dict(
+ batch_size=64,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type=DefaultSampler, shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='coco/annotations/person_keypoints_val2017.json',
+ # bbox_file='data/coco/person_detection_results/'
+ # 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='detection/coco/val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks.update(
+ checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type=EMAHook,
+ ema_type=ExpMomentumEMA,
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type=PipelineSwitchHook,
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type=CocoMetric,
+ ann_file=data_root + 'coco/annotations/person_keypoints_val2017.json')
+test_evaluator = val_evaluator
diff --git a/mmpose/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w48_udp-8xb32-210e_coco-256x192.py b/mmpose/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w48_udp-8xb32-210e_coco-256x192.py
index 1ecf3a704e..92ac486d0f 100644
--- a/mmpose/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w48_udp-8xb32-210e_coco-256x192.py
+++ b/mmpose/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w48_udp-8xb32-210e_coco-256x192.py
@@ -1,169 +1,169 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmengine.config import read_base
-
-with read_base():
- from mmpose.configs._base_.default_runtime import *
-
-from mmengine.dataset import DefaultSampler
-from mmengine.model import PretrainedInit
-from mmengine.optim import LinearLR, MultiStepLR
-from torch.optim import Adam
-
-from mmpose.codecs import UDPHeatmap
-from mmpose.datasets import (CocoDataset, GenerateTarget, GetBBoxCenterScale,
- LoadImage, PackPoseInputs, RandomFlip,
- RandomHalfBody, TopdownAffine)
-from mmpose.datasets.transforms.common_transforms import RandomBBoxTransform
-from mmpose.evaluation import CocoMetric
-from mmpose.models import (HeatmapHead, HRNet, KeypointMSELoss,
- PoseDataPreprocessor, TopdownPoseEstimator)
-
-# runtime
-train_cfg.update(max_epochs=210, val_interval=10)
-
-# optimizer
-optim_wrapper = dict(optimizer=dict(
- type=Adam,
- lr=5e-4,
-))
-
-# learning policy
-param_scheduler = [
- dict(type=LinearLR, begin=0, end=500, start_factor=0.001,
- by_epoch=False), # warm-up
- dict(
- type=MultiStepLR,
- begin=0,
- end=210,
- milestones=[170, 200],
- gamma=0.1,
- by_epoch=True)
-]
-
-# automatically scaling LR based on the actual training batch size
-auto_scale_lr = dict(base_batch_size=512)
-
-# hooks
-default_hooks.update(checkpoint=dict(save_best='coco/AP', rule='greater'))
-
-# codec settings
-codec = dict(
- type=UDPHeatmap, input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
-
-# model settings
-model = dict(
- type=TopdownPoseEstimator,
- data_preprocessor=dict(
- type=PoseDataPreprocessor,
- mean=[123.675, 116.28, 103.53],
- std=[58.395, 57.12, 57.375],
- bgr_to_rgb=True),
- backbone=dict(
- type=HRNet,
- in_channels=3,
- extra=dict(
- stage1=dict(
- num_modules=1,
- num_branches=1,
- block='BOTTLENECK',
- num_blocks=(4, ),
- num_channels=(64, )),
- stage2=dict(
- num_modules=1,
- num_branches=2,
- block='BASIC',
- num_blocks=(4, 4),
- num_channels=(48, 96)),
- stage3=dict(
- num_modules=4,
- num_branches=3,
- block='BASIC',
- num_blocks=(4, 4, 4),
- num_channels=(48, 96, 192)),
- stage4=dict(
- num_modules=3,
- num_branches=4,
- block='BASIC',
- num_blocks=(4, 4, 4, 4),
- num_channels=(48, 96, 192, 384))),
- init_cfg=dict(
- type=PretrainedInit,
- checkpoint='https://download.openmmlab.com/mmpose/'
- 'pretrain_models/hrnet_w48-8ef0771d.pth'),
- ),
- head=dict(
- type=HeatmapHead,
- in_channels=48,
- out_channels=17,
- deconv_out_channels=None,
- loss=dict(type=KeypointMSELoss, use_target_weight=True),
- decoder=codec),
- test_cfg=dict(
- flip_test=True,
- flip_mode='heatmap',
- shift_heatmap=False,
- ))
-
-# base dataset settings
-dataset_type = CocoDataset
-data_mode = 'topdown'
-data_root = 'data/coco/'
-
-backend_args = dict(backend='local')
-
-# pipelines
-train_pipeline = [
- dict(type=LoadImage, backend_args=backend_args),
- dict(type=GetBBoxCenterScale),
- dict(type=RandomFlip, direction='horizontal'),
- dict(type=RandomHalfBody),
- dict(type=RandomBBoxTransform),
- dict(type=TopdownAffine, input_size=codec['input_size'], use_udp=True),
- dict(type=GenerateTarget, encoder=codec),
- dict(type=PackPoseInputs)
-]
-val_pipeline = [
- dict(type=LoadImage, backend_args=backend_args),
- dict(type=GetBBoxCenterScale),
- dict(type=TopdownAffine, input_size=codec['input_size'], use_udp=True),
- dict(type=PackPoseInputs)
-]
-
-# data loaders
-train_dataloader = dict(
- batch_size=32,
- num_workers=2,
- persistent_workers=True,
- sampler=dict(type=DefaultSampler, shuffle=True),
- dataset=dict(
- type=dataset_type,
- data_root=data_root,
- data_mode=data_mode,
- ann_file='annotations/person_keypoints_train2017.json',
- data_prefix=dict(img='train2017/'),
- pipeline=train_pipeline,
- ))
-val_dataloader = dict(
- batch_size=32,
- num_workers=2,
- persistent_workers=True,
- drop_last=False,
- sampler=dict(type=DefaultSampler, shuffle=False, round_up=False),
- dataset=dict(
- type=dataset_type,
- data_root=data_root,
- data_mode=data_mode,
- ann_file='annotations/person_keypoints_val2017.json',
- bbox_file='data/coco/person_detection_results/'
- 'COCO_val2017_detections_AP_H_56_person.json',
- data_prefix=dict(img='val2017/'),
- test_mode=True,
- pipeline=val_pipeline,
- ))
-test_dataloader = val_dataloader
-
-# evaluators
-val_evaluator = dict(
- type=CocoMetric,
- ann_file=data_root + 'annotations/person_keypoints_val2017.json')
-test_evaluator = val_evaluator
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.config import read_base
+
+with read_base():
+ from mmpose.configs._base_.default_runtime import *
+
+from mmengine.dataset import DefaultSampler
+from mmengine.model import PretrainedInit
+from mmengine.optim import LinearLR, MultiStepLR
+from torch.optim import Adam
+
+from mmpose.codecs import UDPHeatmap
+from mmpose.datasets import (CocoDataset, GenerateTarget, GetBBoxCenterScale,
+ LoadImage, PackPoseInputs, RandomFlip,
+ RandomHalfBody, TopdownAffine)
+from mmpose.datasets.transforms.common_transforms import RandomBBoxTransform
+from mmpose.evaluation import CocoMetric
+from mmpose.models import (HeatmapHead, HRNet, KeypointMSELoss,
+ PoseDataPreprocessor, TopdownPoseEstimator)
+
+# runtime
+train_cfg.update(max_epochs=210, val_interval=10)
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(
+ type=Adam,
+ lr=5e-4,
+))
+
+# learning policy
+param_scheduler = [
+ dict(type=LinearLR, begin=0, end=500, start_factor=0.001,
+ by_epoch=False), # warm-up
+ dict(
+ type=MultiStepLR,
+ begin=0,
+ end=210,
+ milestones=[170, 200],
+ gamma=0.1,
+ by_epoch=True)
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# hooks
+default_hooks.update(checkpoint=dict(save_best='coco/AP', rule='greater'))
+
+# codec settings
+codec = dict(
+ type=UDPHeatmap, input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+# model settings
+model = dict(
+ type=TopdownPoseEstimator,
+ data_preprocessor=dict(
+ type=PoseDataPreprocessor,
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type=HRNet,
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ init_cfg=dict(
+ type=PretrainedInit,
+ checkpoint='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth'),
+ ),
+ head=dict(
+ type=HeatmapHead,
+ in_channels=48,
+ out_channels=17,
+ deconv_out_channels=None,
+ loss=dict(type=KeypointMSELoss, use_target_weight=True),
+ decoder=codec),
+ test_cfg=dict(
+ flip_test=True,
+ flip_mode='heatmap',
+ shift_heatmap=False,
+ ))
+
+# base dataset settings
+dataset_type = CocoDataset
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+backend_args = dict(backend='local')
+
+# pipelines
+train_pipeline = [
+ dict(type=LoadImage, backend_args=backend_args),
+ dict(type=GetBBoxCenterScale),
+ dict(type=RandomFlip, direction='horizontal'),
+ dict(type=RandomHalfBody),
+ dict(type=RandomBBoxTransform),
+ dict(type=TopdownAffine, input_size=codec['input_size'], use_udp=True),
+ dict(type=GenerateTarget, encoder=codec),
+ dict(type=PackPoseInputs)
+]
+val_pipeline = [
+ dict(type=LoadImage, backend_args=backend_args),
+ dict(type=GetBBoxCenterScale),
+ dict(type=TopdownAffine, input_size=codec['input_size'], use_udp=True),
+ dict(type=PackPoseInputs)
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type=DefaultSampler, shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type=DefaultSampler, shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_val2017.json',
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# evaluators
+val_evaluator = dict(
+ type=CocoMetric,
+ ann_file=data_root + 'annotations/person_keypoints_val2017.json')
+test_evaluator = val_evaluator
diff --git a/mmpose/datasets/__init__.py b/mmpose/datasets/__init__.py
index b90a12db49..0c8b91752e 100644
--- a/mmpose/datasets/__init__.py
+++ b/mmpose/datasets/__init__.py
@@ -1,8 +1,8 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .builder import build_dataset
-from .dataset_wrappers import CombinedDataset
-from .datasets import * # noqa
-from .samplers import MultiSourceSampler
-from .transforms import * # noqa
-
-__all__ = ['build_dataset', 'CombinedDataset', 'MultiSourceSampler']
+# Copyright (c) OpenMMLab. All rights reserved.
+from .builder import build_dataset
+from .dataset_wrappers import CombinedDataset
+from .datasets import * # noqa
+from .samplers import MultiSourceSampler
+from .transforms import * # noqa
+
+__all__ = ['build_dataset', 'CombinedDataset', 'MultiSourceSampler']
diff --git a/mmpose/datasets/builder.py b/mmpose/datasets/builder.py
index 2e5a236ff4..eaaf888c5c 100644
--- a/mmpose/datasets/builder.py
+++ b/mmpose/datasets/builder.py
@@ -1,90 +1,90 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-import platform
-import random
-
-import numpy as np
-import torch
-from mmengine import build_from_cfg, is_seq_of
-from mmengine.dataset import ConcatDataset, RepeatDataset
-
-from mmpose.registry import DATASETS
-
-if platform.system() != 'Windows':
- # https://github.com/pytorch/pytorch/issues/973
- import resource
- rlimit = resource.getrlimit(resource.RLIMIT_NOFILE)
- base_soft_limit = rlimit[0]
- hard_limit = rlimit[1]
- soft_limit = min(max(4096, base_soft_limit), hard_limit)
- resource.setrlimit(resource.RLIMIT_NOFILE, (soft_limit, hard_limit))
-
-
-def _concat_dataset(cfg, default_args=None):
- types = cfg['type']
- ann_files = cfg['ann_file']
- img_prefixes = cfg.get('img_prefix', None)
- dataset_infos = cfg.get('dataset_info', None)
-
- num_joints = cfg['data_cfg'].get('num_joints', None)
- dataset_channel = cfg['data_cfg'].get('dataset_channel', None)
-
- datasets = []
- num_dset = len(ann_files)
- for i in range(num_dset):
- cfg_copy = copy.deepcopy(cfg)
- cfg_copy['ann_file'] = ann_files[i]
-
- if isinstance(types, (list, tuple)):
- cfg_copy['type'] = types[i]
- if isinstance(img_prefixes, (list, tuple)):
- cfg_copy['img_prefix'] = img_prefixes[i]
- if isinstance(dataset_infos, (list, tuple)):
- cfg_copy['dataset_info'] = dataset_infos[i]
-
- if isinstance(num_joints, (list, tuple)):
- cfg_copy['data_cfg']['num_joints'] = num_joints[i]
-
- if is_seq_of(dataset_channel, list):
- cfg_copy['data_cfg']['dataset_channel'] = dataset_channel[i]
-
- datasets.append(build_dataset(cfg_copy, default_args))
-
- return ConcatDataset(datasets)
-
-
-def build_dataset(cfg, default_args=None):
- """Build a dataset from config dict.
-
- Args:
- cfg (dict): Config dict. It should at least contain the key "type".
- default_args (dict, optional): Default initialization arguments.
- Default: None.
-
- Returns:
- Dataset: The constructed dataset.
- """
-
- if isinstance(cfg, (list, tuple)):
- dataset = ConcatDataset([build_dataset(c, default_args) for c in cfg])
- elif cfg['type'] == 'ConcatDataset':
- dataset = ConcatDataset(
- [build_dataset(c, default_args) for c in cfg['datasets']])
- elif cfg['type'] == 'RepeatDataset':
- dataset = RepeatDataset(
- build_dataset(cfg['dataset'], default_args), cfg['times'])
- elif isinstance(cfg.get('ann_file'), (list, tuple)):
- dataset = _concat_dataset(cfg, default_args)
- else:
- dataset = build_from_cfg(cfg, DATASETS, default_args)
- return dataset
-
-
-def worker_init_fn(worker_id, num_workers, rank, seed):
- """Init the random seed for various workers."""
- # The seed of each worker equals to
- # num_worker * rank + worker_id + user_seed
- worker_seed = num_workers * rank + worker_id + seed
- np.random.seed(worker_seed)
- random.seed(worker_seed)
- torch.manual_seed(worker_seed)
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import platform
+import random
+
+import numpy as np
+import torch
+from mmengine import build_from_cfg, is_seq_of
+from mmengine.dataset import ConcatDataset, RepeatDataset
+
+from mmpose.registry import DATASETS
+
+if platform.system() != 'Windows':
+ # https://github.com/pytorch/pytorch/issues/973
+ import resource
+ rlimit = resource.getrlimit(resource.RLIMIT_NOFILE)
+ base_soft_limit = rlimit[0]
+ hard_limit = rlimit[1]
+ soft_limit = min(max(4096, base_soft_limit), hard_limit)
+ resource.setrlimit(resource.RLIMIT_NOFILE, (soft_limit, hard_limit))
+
+
+def _concat_dataset(cfg, default_args=None):
+ types = cfg['type']
+ ann_files = cfg['ann_file']
+ img_prefixes = cfg.get('img_prefix', None)
+ dataset_infos = cfg.get('dataset_info', None)
+
+ num_joints = cfg['data_cfg'].get('num_joints', None)
+ dataset_channel = cfg['data_cfg'].get('dataset_channel', None)
+
+ datasets = []
+ num_dset = len(ann_files)
+ for i in range(num_dset):
+ cfg_copy = copy.deepcopy(cfg)
+ cfg_copy['ann_file'] = ann_files[i]
+
+ if isinstance(types, (list, tuple)):
+ cfg_copy['type'] = types[i]
+ if isinstance(img_prefixes, (list, tuple)):
+ cfg_copy['img_prefix'] = img_prefixes[i]
+ if isinstance(dataset_infos, (list, tuple)):
+ cfg_copy['dataset_info'] = dataset_infos[i]
+
+ if isinstance(num_joints, (list, tuple)):
+ cfg_copy['data_cfg']['num_joints'] = num_joints[i]
+
+ if is_seq_of(dataset_channel, list):
+ cfg_copy['data_cfg']['dataset_channel'] = dataset_channel[i]
+
+ datasets.append(build_dataset(cfg_copy, default_args))
+
+ return ConcatDataset(datasets)
+
+
+def build_dataset(cfg, default_args=None):
+ """Build a dataset from config dict.
+
+ Args:
+ cfg (dict): Config dict. It should at least contain the key "type".
+ default_args (dict, optional): Default initialization arguments.
+ Default: None.
+
+ Returns:
+ Dataset: The constructed dataset.
+ """
+
+ if isinstance(cfg, (list, tuple)):
+ dataset = ConcatDataset([build_dataset(c, default_args) for c in cfg])
+ elif cfg['type'] == 'ConcatDataset':
+ dataset = ConcatDataset(
+ [build_dataset(c, default_args) for c in cfg['datasets']])
+ elif cfg['type'] == 'RepeatDataset':
+ dataset = RepeatDataset(
+ build_dataset(cfg['dataset'], default_args), cfg['times'])
+ elif isinstance(cfg.get('ann_file'), (list, tuple)):
+ dataset = _concat_dataset(cfg, default_args)
+ else:
+ dataset = build_from_cfg(cfg, DATASETS, default_args)
+ return dataset
+
+
+def worker_init_fn(worker_id, num_workers, rank, seed):
+ """Init the random seed for various workers."""
+ # The seed of each worker equals to
+ # num_worker * rank + worker_id + user_seed
+ worker_seed = num_workers * rank + worker_id + seed
+ np.random.seed(worker_seed)
+ random.seed(worker_seed)
+ torch.manual_seed(worker_seed)
diff --git a/mmpose/datasets/dataset_wrappers.py b/mmpose/datasets/dataset_wrappers.py
index 28eeac9945..7bf488d863 100644
--- a/mmpose/datasets/dataset_wrappers.py
+++ b/mmpose/datasets/dataset_wrappers.py
@@ -1,122 +1,122 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-
-from copy import deepcopy
-from typing import Any, Callable, List, Tuple, Union
-
-from mmengine.dataset import BaseDataset
-from mmengine.registry import build_from_cfg
-
-from mmpose.registry import DATASETS
-from .datasets.utils import parse_pose_metainfo
-
-
-@DATASETS.register_module()
-class CombinedDataset(BaseDataset):
- """A wrapper of combined dataset.
-
- Args:
- metainfo (dict): The meta information of combined dataset.
- datasets (list): The configs of datasets to be combined.
- pipeline (list, optional): Processing pipeline. Defaults to [].
- """
-
- def __init__(self,
- metainfo: dict,
- datasets: list,
- pipeline: List[Union[dict, Callable]] = [],
- **kwargs):
-
- self.datasets = []
-
- for cfg in datasets:
- dataset = build_from_cfg(cfg, DATASETS)
- self.datasets.append(dataset)
-
- self._lens = [len(dataset) for dataset in self.datasets]
- self._len = sum(self._lens)
-
- super(CombinedDataset, self).__init__(pipeline=pipeline, **kwargs)
- self._metainfo = parse_pose_metainfo(metainfo)
-
- @property
- def metainfo(self):
- return deepcopy(self._metainfo)
-
- def __len__(self):
- return self._len
-
- def _get_subset_index(self, index: int) -> Tuple[int, int]:
- """Given a data sample's global index, return the index of the sub-
- dataset the data sample belongs to, and the local index within that
- sub-dataset.
-
- Args:
- index (int): The global data sample index
-
- Returns:
- tuple[int, int]:
- - subset_index (int): The index of the sub-dataset
- - local_index (int): The index of the data sample within
- the sub-dataset
- """
- if index >= len(self) or index < -len(self):
- raise ValueError(
- f'index({index}) is out of bounds for dataset with '
- f'length({len(self)}).')
-
- if index < 0:
- index = index + len(self)
-
- subset_index = 0
- while index >= self._lens[subset_index]:
- index -= self._lens[subset_index]
- subset_index += 1
- return subset_index, index
-
- def prepare_data(self, idx: int) -> Any:
- """Get data processed by ``self.pipeline``.The source dataset is
- depending on the index.
-
- Args:
- idx (int): The index of ``data_info``.
-
- Returns:
- Any: Depends on ``self.pipeline``.
- """
-
- data_info = self.get_data_info(idx)
-
- return self.pipeline(data_info)
-
- def get_data_info(self, idx: int) -> dict:
- """Get annotation by index.
-
- Args:
- idx (int): Global index of ``CombinedDataset``.
- Returns:
- dict: The idx-th annotation of the datasets.
- """
- subset_idx, sample_idx = self._get_subset_index(idx)
- # Get data sample processed by ``subset.pipeline``
- data_info = self.datasets[subset_idx][sample_idx]
-
- # Add metainfo items that are required in the pipeline and the model
- metainfo_keys = [
- 'upper_body_ids', 'lower_body_ids', 'flip_pairs',
- 'dataset_keypoint_weights', 'flip_indices'
- ]
-
- for key in metainfo_keys:
- data_info[key] = deepcopy(self._metainfo[key])
-
- return data_info
-
- def full_init(self):
- """Fully initialize all sub datasets."""
-
- if self._fully_initialized:
- return
-
- for dataset in self.datasets:
- dataset.full_init()
- self._fully_initialized = True
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from copy import deepcopy
+from typing import Any, Callable, List, Tuple, Union
+
+from mmengine.dataset import BaseDataset
+from mmengine.registry import build_from_cfg
+
+from mmpose.registry import DATASETS
+from .datasets.utils import parse_pose_metainfo
+
+
+@DATASETS.register_module()
+class CombinedDataset(BaseDataset):
+ """A wrapper of combined dataset.
+
+ Args:
+ metainfo (dict): The meta information of combined dataset.
+ datasets (list): The configs of datasets to be combined.
+ pipeline (list, optional): Processing pipeline. Defaults to [].
+ """
+
+ def __init__(self,
+ metainfo: dict,
+ datasets: list,
+ pipeline: List[Union[dict, Callable]] = [],
+ **kwargs):
+
+ self.datasets = []
+
+ for cfg in datasets:
+ dataset = build_from_cfg(cfg, DATASETS)
+ self.datasets.append(dataset)
+
+ self._lens = [len(dataset) for dataset in self.datasets]
+ self._len = sum(self._lens)
+
+ super(CombinedDataset, self).__init__(pipeline=pipeline, **kwargs)
+ self._metainfo = parse_pose_metainfo(metainfo)
+
+ @property
+ def metainfo(self):
+ return deepcopy(self._metainfo)
+
+ def __len__(self):
+ return self._len
+
+ def _get_subset_index(self, index: int) -> Tuple[int, int]:
+ """Given a data sample's global index, return the index of the sub-
+ dataset the data sample belongs to, and the local index within that
+ sub-dataset.
+
+ Args:
+ index (int): The global data sample index
+
+ Returns:
+ tuple[int, int]:
+ - subset_index (int): The index of the sub-dataset
+ - local_index (int): The index of the data sample within
+ the sub-dataset
+ """
+ if index >= len(self) or index < -len(self):
+ raise ValueError(
+ f'index({index}) is out of bounds for dataset with '
+ f'length({len(self)}).')
+
+ if index < 0:
+ index = index + len(self)
+
+ subset_index = 0
+ while index >= self._lens[subset_index]:
+ index -= self._lens[subset_index]
+ subset_index += 1
+ return subset_index, index
+
+ def prepare_data(self, idx: int) -> Any:
+ """Get data processed by ``self.pipeline``.The source dataset is
+ depending on the index.
+
+ Args:
+ idx (int): The index of ``data_info``.
+
+ Returns:
+ Any: Depends on ``self.pipeline``.
+ """
+
+ data_info = self.get_data_info(idx)
+
+ return self.pipeline(data_info)
+
+ def get_data_info(self, idx: int) -> dict:
+ """Get annotation by index.
+
+ Args:
+ idx (int): Global index of ``CombinedDataset``.
+ Returns:
+ dict: The idx-th annotation of the datasets.
+ """
+ subset_idx, sample_idx = self._get_subset_index(idx)
+ # Get data sample processed by ``subset.pipeline``
+ data_info = self.datasets[subset_idx][sample_idx]
+
+ # Add metainfo items that are required in the pipeline and the model
+ metainfo_keys = [
+ 'upper_body_ids', 'lower_body_ids', 'flip_pairs',
+ 'dataset_keypoint_weights', 'flip_indices'
+ ]
+
+ for key in metainfo_keys:
+ data_info[key] = deepcopy(self._metainfo[key])
+
+ return data_info
+
+ def full_init(self):
+ """Fully initialize all sub datasets."""
+
+ if self._fully_initialized:
+ return
+
+ for dataset in self.datasets:
+ dataset.full_init()
+ self._fully_initialized = True
diff --git a/mmpose/datasets/datasets/__init__.py b/mmpose/datasets/datasets/__init__.py
index 0050716d73..2137b4ca0f 100644
--- a/mmpose/datasets/datasets/__init__.py
+++ b/mmpose/datasets/datasets/__init__.py
@@ -1,11 +1,11 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .animal import * # noqa: F401, F403
-from .base import * # noqa: F401, F403
-from .body import * # noqa: F401, F403
-from .body3d import * # noqa: F401, F403
-from .face import * # noqa: F401, F403
-from .fashion import * # noqa: F401, F403
-from .hand import * # noqa: F401, F403
-from .wholebody import * # noqa: F401, F403
-
-from .oct import *
+# Copyright (c) OpenMMLab. All rights reserved.
+from .animal import * # noqa: F401, F403
+from .base import * # noqa: F401, F403
+from .body import * # noqa: F401, F403
+from .body3d import * # noqa: F401, F403
+from .face import * # noqa: F401, F403
+from .fashion import * # noqa: F401, F403
+from .hand import * # noqa: F401, F403
+from .wholebody import * # noqa: F401, F403
+
+from .oct import *
diff --git a/mmpose/datasets/datasets/animal/__init__.py b/mmpose/datasets/datasets/animal/__init__.py
index 669f08cddd..eb7d510ea6 100644
--- a/mmpose/datasets/datasets/animal/__init__.py
+++ b/mmpose/datasets/datasets/animal/__init__.py
@@ -1,16 +1,16 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .animalkingdom_dataset import AnimalKingdomDataset
-from .animalpose_dataset import AnimalPoseDataset
-from .ap10k_dataset import AP10KDataset
-from .atrw_dataset import ATRWDataset
-from .fly_dataset import FlyDataset
-from .horse10_dataset import Horse10Dataset
-from .locust_dataset import LocustDataset
-from .macaque_dataset import MacaqueDataset
-from .zebra_dataset import ZebraDataset
-
-__all__ = [
- 'AnimalPoseDataset', 'AP10KDataset', 'Horse10Dataset', 'MacaqueDataset',
- 'FlyDataset', 'LocustDataset', 'ZebraDataset', 'ATRWDataset',
- 'AnimalKingdomDataset'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .animalkingdom_dataset import AnimalKingdomDataset
+from .animalpose_dataset import AnimalPoseDataset
+from .ap10k_dataset import AP10KDataset
+from .atrw_dataset import ATRWDataset
+from .fly_dataset import FlyDataset
+from .horse10_dataset import Horse10Dataset
+from .locust_dataset import LocustDataset
+from .macaque_dataset import MacaqueDataset
+from .zebra_dataset import ZebraDataset
+
+__all__ = [
+ 'AnimalPoseDataset', 'AP10KDataset', 'Horse10Dataset', 'MacaqueDataset',
+ 'FlyDataset', 'LocustDataset', 'ZebraDataset', 'ATRWDataset',
+ 'AnimalKingdomDataset'
+]
diff --git a/mmpose/datasets/datasets/animal/animalkingdom_dataset.py b/mmpose/datasets/datasets/animal/animalkingdom_dataset.py
index 35ccb8b67a..f38e90f040 100644
--- a/mmpose/datasets/datasets/animal/animalkingdom_dataset.py
+++ b/mmpose/datasets/datasets/animal/animalkingdom_dataset.py
@@ -1,86 +1,86 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class AnimalKingdomDataset(BaseCocoStyleDataset):
- """Animal Kingdom dataset for animal pose estimation.
-
- "[CVPR2022] Animal Kingdom:
- A Large and Diverse Dataset for Animal Behavior Understanding"
- More details can be found in the `paper
- `__ .
-
- Website:
-
- The dataset loads raw features and apply specified transforms
- to return a dict containing the image tensors and other information.
-
- Animal Kingdom keypoint indexes::
-
- 0: 'Head_Mid_Top',
- 1: 'Eye_Left',
- 2: 'Eye_Right',
- 3: 'Mouth_Front_Top',
- 4: 'Mouth_Back_Left',
- 5: 'Mouth_Back_Right',
- 6: 'Mouth_Front_Bottom',
- 7: 'Shoulder_Left',
- 8: 'Shoulder_Right',
- 9: 'Elbow_Left',
- 10: 'Elbow_Right',
- 11: 'Wrist_Left',
- 12: 'Wrist_Right',
- 13: 'Torso_Mid_Back',
- 14: 'Hip_Left',
- 15: 'Hip_Right',
- 16: 'Knee_Left',
- 17: 'Knee_Right',
- 18: 'Ankle_Left ',
- 19: 'Ankle_Right',
- 20: 'Tail_Top_Back',
- 21: 'Tail_Mid_Back',
- 22: 'Tail_End_Back
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/ak.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class AnimalKingdomDataset(BaseCocoStyleDataset):
+ """Animal Kingdom dataset for animal pose estimation.
+
+ "[CVPR2022] Animal Kingdom:
+ A Large and Diverse Dataset for Animal Behavior Understanding"
+ More details can be found in the `paper
+ `__ .
+
+ Website:
+
+ The dataset loads raw features and apply specified transforms
+ to return a dict containing the image tensors and other information.
+
+ Animal Kingdom keypoint indexes::
+
+ 0: 'Head_Mid_Top',
+ 1: 'Eye_Left',
+ 2: 'Eye_Right',
+ 3: 'Mouth_Front_Top',
+ 4: 'Mouth_Back_Left',
+ 5: 'Mouth_Back_Right',
+ 6: 'Mouth_Front_Bottom',
+ 7: 'Shoulder_Left',
+ 8: 'Shoulder_Right',
+ 9: 'Elbow_Left',
+ 10: 'Elbow_Right',
+ 11: 'Wrist_Left',
+ 12: 'Wrist_Right',
+ 13: 'Torso_Mid_Back',
+ 14: 'Hip_Left',
+ 15: 'Hip_Right',
+ 16: 'Knee_Left',
+ 17: 'Knee_Right',
+ 18: 'Ankle_Left ',
+ 19: 'Ankle_Right',
+ 20: 'Tail_Top_Back',
+ 21: 'Tail_Mid_Back',
+ 22: 'Tail_End_Back
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/ak.py')
diff --git a/mmpose/datasets/datasets/animal/animalpose_dataset.py b/mmpose/datasets/datasets/animal/animalpose_dataset.py
index 0279cf9de0..0293afe50c 100644
--- a/mmpose/datasets/datasets/animal/animalpose_dataset.py
+++ b/mmpose/datasets/datasets/animal/animalpose_dataset.py
@@ -1,75 +1,75 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class AnimalPoseDataset(BaseCocoStyleDataset):
- """Animal-Pose dataset for animal pose estimation.
-
- "Cross-domain Adaptation For Animal Pose Estimation" ICCV'2019
- More details can be found in the `paper
- `__ .
-
- Animal-Pose keypoints::
-
- 0: 'L_Eye',
- 1: 'R_Eye',
- 2: 'L_EarBase',
- 3: 'R_EarBase',
- 4: 'Nose',
- 5: 'Throat',
- 6: 'TailBase',
- 7: 'Withers',
- 8: 'L_F_Elbow',
- 9: 'R_F_Elbow',
- 10: 'L_B_Elbow',
- 11: 'R_B_Elbow',
- 12: 'L_F_Knee',
- 13: 'R_F_Knee',
- 14: 'L_B_Knee',
- 15: 'R_B_Knee',
- 16: 'L_F_Paw',
- 17: 'R_F_Paw',
- 18: 'L_B_Paw',
- 19: 'R_B_Paw'
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/animalpose.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class AnimalPoseDataset(BaseCocoStyleDataset):
+ """Animal-Pose dataset for animal pose estimation.
+
+ "Cross-domain Adaptation For Animal Pose Estimation" ICCV'2019
+ More details can be found in the `paper
+ `__ .
+
+ Animal-Pose keypoints::
+
+ 0: 'L_Eye',
+ 1: 'R_Eye',
+ 2: 'L_EarBase',
+ 3: 'R_EarBase',
+ 4: 'Nose',
+ 5: 'Throat',
+ 6: 'TailBase',
+ 7: 'Withers',
+ 8: 'L_F_Elbow',
+ 9: 'R_F_Elbow',
+ 10: 'L_B_Elbow',
+ 11: 'R_B_Elbow',
+ 12: 'L_F_Knee',
+ 13: 'R_F_Knee',
+ 14: 'L_B_Knee',
+ 15: 'R_B_Knee',
+ 16: 'L_F_Paw',
+ 17: 'R_F_Paw',
+ 18: 'L_B_Paw',
+ 19: 'R_B_Paw'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/animalpose.py')
diff --git a/mmpose/datasets/datasets/animal/ap10k_dataset.py b/mmpose/datasets/datasets/animal/ap10k_dataset.py
index de1efbc67f..f844379a0d 100644
--- a/mmpose/datasets/datasets/animal/ap10k_dataset.py
+++ b/mmpose/datasets/datasets/animal/ap10k_dataset.py
@@ -1,73 +1,73 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class AP10KDataset(BaseCocoStyleDataset):
- """AP-10K dataset for animal pose estimation.
-
- "AP-10K: A Benchmark for Animal Pose Estimation in the Wild"
- Neurips Dataset Track'2021.
- More details can be found in the `paper
- `__ .
-
- AP-10K keypoints::
-
- 0: 'L_Eye',
- 1: 'R_Eye',
- 2: 'Nose',
- 3: 'Neck',
- 4: 'root of tail',
- 5: 'L_Shoulder',
- 6: 'L_Elbow',
- 7: 'L_F_Paw',
- 8: 'R_Shoulder',
- 9: 'R_Elbow',
- 10: 'R_F_Paw,
- 11: 'L_Hip',
- 12: 'L_Knee',
- 13: 'L_B_Paw',
- 14: 'R_Hip',
- 15: 'R_Knee',
- 16: 'R_B_Paw'
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/ap10k.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class AP10KDataset(BaseCocoStyleDataset):
+ """AP-10K dataset for animal pose estimation.
+
+ "AP-10K: A Benchmark for Animal Pose Estimation in the Wild"
+ Neurips Dataset Track'2021.
+ More details can be found in the `paper
+ `__ .
+
+ AP-10K keypoints::
+
+ 0: 'L_Eye',
+ 1: 'R_Eye',
+ 2: 'Nose',
+ 3: 'Neck',
+ 4: 'root of tail',
+ 5: 'L_Shoulder',
+ 6: 'L_Elbow',
+ 7: 'L_F_Paw',
+ 8: 'R_Shoulder',
+ 9: 'R_Elbow',
+ 10: 'R_F_Paw,
+ 11: 'L_Hip',
+ 12: 'L_Knee',
+ 13: 'L_B_Paw',
+ 14: 'R_Hip',
+ 15: 'R_Knee',
+ 16: 'R_B_Paw'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/ap10k.py')
diff --git a/mmpose/datasets/datasets/animal/atrw_dataset.py b/mmpose/datasets/datasets/animal/atrw_dataset.py
index de5b1a09a0..2669c8dd03 100644
--- a/mmpose/datasets/datasets/animal/atrw_dataset.py
+++ b/mmpose/datasets/datasets/animal/atrw_dataset.py
@@ -1,71 +1,71 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class ATRWDataset(BaseCocoStyleDataset):
- """ATRW dataset for animal pose estimation.
-
- "ATRW: A Benchmark for Amur Tiger Re-identification in the Wild"
- ACM MM'2020.
- More details can be found in the `paper
- `__ .
-
- ATRW keypoints::
-
- 0: "left_ear",
- 1: "right_ear",
- 2: "nose",
- 3: "right_shoulder",
- 4: "right_front_paw",
- 5: "left_shoulder",
- 6: "left_front_paw",
- 7: "right_hip",
- 8: "right_knee",
- 9: "right_back_paw",
- 10: "left_hip",
- 11: "left_knee",
- 12: "left_back_paw",
- 13: "tail",
- 14: "center"
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/atrw.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class ATRWDataset(BaseCocoStyleDataset):
+ """ATRW dataset for animal pose estimation.
+
+ "ATRW: A Benchmark for Amur Tiger Re-identification in the Wild"
+ ACM MM'2020.
+ More details can be found in the `paper
+ `__ .
+
+ ATRW keypoints::
+
+ 0: "left_ear",
+ 1: "right_ear",
+ 2: "nose",
+ 3: "right_shoulder",
+ 4: "right_front_paw",
+ 5: "left_shoulder",
+ 6: "left_front_paw",
+ 7: "right_hip",
+ 8: "right_knee",
+ 9: "right_back_paw",
+ 10: "left_hip",
+ 11: "left_knee",
+ 12: "left_back_paw",
+ 13: "tail",
+ 14: "center"
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/atrw.py')
diff --git a/mmpose/datasets/datasets/animal/fly_dataset.py b/mmpose/datasets/datasets/animal/fly_dataset.py
index b614d9b9f7..a1605e61f8 100644
--- a/mmpose/datasets/datasets/animal/fly_dataset.py
+++ b/mmpose/datasets/datasets/animal/fly_dataset.py
@@ -1,88 +1,88 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class FlyDataset(BaseCocoStyleDataset):
- """FlyDataset for animal pose estimation.
-
- "Fast animal pose estimation using deep neural networks"
- Nature methods'2019. More details can be found in the `paper
- `__ .
-
- Vinegar Fly keypoints::
-
- 0: "head",
- 1: "eyeL",
- 2: "eyeR",
- 3: "neck",
- 4: "thorax",
- 5: "abdomen",
- 6: "forelegR1",
- 7: "forelegR2",
- 8: "forelegR3",
- 9: "forelegR4",
- 10: "midlegR1",
- 11: "midlegR2",
- 12: "midlegR3",
- 13: "midlegR4",
- 14: "hindlegR1",
- 15: "hindlegR2",
- 16: "hindlegR3",
- 17: "hindlegR4",
- 18: "forelegL1",
- 19: "forelegL2",
- 20: "forelegL3",
- 21: "forelegL4",
- 22: "midlegL1",
- 23: "midlegL2",
- 24: "midlegL3",
- 25: "midlegL4",
- 26: "hindlegL1",
- 27: "hindlegL2",
- 28: "hindlegL3",
- 29: "hindlegL4",
- 30: "wingL",
- 31: "wingR"
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/fly.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class FlyDataset(BaseCocoStyleDataset):
+ """FlyDataset for animal pose estimation.
+
+ "Fast animal pose estimation using deep neural networks"
+ Nature methods'2019. More details can be found in the `paper
+ `__ .
+
+ Vinegar Fly keypoints::
+
+ 0: "head",
+ 1: "eyeL",
+ 2: "eyeR",
+ 3: "neck",
+ 4: "thorax",
+ 5: "abdomen",
+ 6: "forelegR1",
+ 7: "forelegR2",
+ 8: "forelegR3",
+ 9: "forelegR4",
+ 10: "midlegR1",
+ 11: "midlegR2",
+ 12: "midlegR3",
+ 13: "midlegR4",
+ 14: "hindlegR1",
+ 15: "hindlegR2",
+ 16: "hindlegR3",
+ 17: "hindlegR4",
+ 18: "forelegL1",
+ 19: "forelegL2",
+ 20: "forelegL3",
+ 21: "forelegL4",
+ 22: "midlegL1",
+ 23: "midlegL2",
+ 24: "midlegL3",
+ 25: "midlegL4",
+ 26: "hindlegL1",
+ 27: "hindlegL2",
+ 28: "hindlegL3",
+ 29: "hindlegL4",
+ 30: "wingL",
+ 31: "wingR"
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/fly.py')
diff --git a/mmpose/datasets/datasets/animal/horse10_dataset.py b/mmpose/datasets/datasets/animal/horse10_dataset.py
index 0c25dba6a7..47f91624aa 100644
--- a/mmpose/datasets/datasets/animal/horse10_dataset.py
+++ b/mmpose/datasets/datasets/animal/horse10_dataset.py
@@ -1,77 +1,77 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class Horse10Dataset(BaseCocoStyleDataset):
- """Horse10Dataset for animal pose estimation.
-
- "Pretraining boosts out-of-domain robustness for pose estimation"
- WACV'2021. More details can be found in the `paper
- `__ .
-
- Horse-10 keypoints::
-
- 0: 'Nose',
- 1: 'Eye',
- 2: 'Nearknee',
- 3: 'Nearfrontfetlock',
- 4: 'Nearfrontfoot',
- 5: 'Offknee',
- 6: 'Offfrontfetlock',
- 7: 'Offfrontfoot',
- 8: 'Shoulder',
- 9: 'Midshoulder',
- 10: 'Elbow',
- 11: 'Girth',
- 12: 'Wither',
- 13: 'Nearhindhock',
- 14: 'Nearhindfetlock',
- 15: 'Nearhindfoot',
- 16: 'Hip',
- 17: 'Stifle',
- 18: 'Offhindhock',
- 19: 'Offhindfetlock',
- 20: 'Offhindfoot',
- 21: 'Ischium'
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/horse10.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class Horse10Dataset(BaseCocoStyleDataset):
+ """Horse10Dataset for animal pose estimation.
+
+ "Pretraining boosts out-of-domain robustness for pose estimation"
+ WACV'2021. More details can be found in the `paper
+ `__ .
+
+ Horse-10 keypoints::
+
+ 0: 'Nose',
+ 1: 'Eye',
+ 2: 'Nearknee',
+ 3: 'Nearfrontfetlock',
+ 4: 'Nearfrontfoot',
+ 5: 'Offknee',
+ 6: 'Offfrontfetlock',
+ 7: 'Offfrontfoot',
+ 8: 'Shoulder',
+ 9: 'Midshoulder',
+ 10: 'Elbow',
+ 11: 'Girth',
+ 12: 'Wither',
+ 13: 'Nearhindhock',
+ 14: 'Nearhindfetlock',
+ 15: 'Nearhindfoot',
+ 16: 'Hip',
+ 17: 'Stifle',
+ 18: 'Offhindhock',
+ 19: 'Offhindfetlock',
+ 20: 'Offhindfoot',
+ 21: 'Ischium'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/horse10.py')
diff --git a/mmpose/datasets/datasets/animal/locust_dataset.py b/mmpose/datasets/datasets/animal/locust_dataset.py
index 3ada76034d..2957b64019 100644
--- a/mmpose/datasets/datasets/animal/locust_dataset.py
+++ b/mmpose/datasets/datasets/animal/locust_dataset.py
@@ -1,140 +1,140 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os.path as osp
-from typing import Optional
-
-import numpy as np
-
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class LocustDataset(BaseCocoStyleDataset):
- """LocustDataset for animal pose estimation.
-
- "DeepPoseKit, a software toolkit for fast and robust animal
- pose estimation using deep learning" Elife'2019.
- More details can be found in the `paper
- `__ .
-
- Desert Locust keypoints::
-
- 0: "head",
- 1: "neck",
- 2: "thorax",
- 3: "abdomen1",
- 4: "abdomen2",
- 5: "anttipL",
- 6: "antbaseL",
- 7: "eyeL",
- 8: "forelegL1",
- 9: "forelegL2",
- 10: "forelegL3",
- 11: "forelegL4",
- 12: "midlegL1",
- 13: "midlegL2",
- 14: "midlegL3",
- 15: "midlegL4",
- 16: "hindlegL1",
- 17: "hindlegL2",
- 18: "hindlegL3",
- 19: "hindlegL4",
- 20: "anttipR",
- 21: "antbaseR",
- 22: "eyeR",
- 23: "forelegR1",
- 24: "forelegR2",
- 25: "forelegR3",
- 26: "forelegR4",
- 27: "midlegR1",
- 28: "midlegR2",
- 29: "midlegR3",
- 30: "midlegR4",
- 31: "hindlegR1",
- 32: "hindlegR2",
- 33: "hindlegR3",
- 34: "hindlegR4"
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/locust.py')
-
- def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
- """Parse raw Locust annotation of an instance.
-
- Args:
- raw_data_info (dict): Raw data information loaded from
- ``ann_file``. It should have following contents:
-
- - ``'raw_ann_info'``: Raw annotation of an instance
- - ``'raw_img_info'``: Raw information of the image that
- contains the instance
-
- Returns:
- dict: Parsed instance annotation
- """
-
- ann = raw_data_info['raw_ann_info']
- img = raw_data_info['raw_img_info']
-
- img_path = osp.join(self.data_prefix['img'], img['file_name'])
-
- # get bbox in shape [1, 4], formatted as xywh
- # use the entire image which is 160x160
- bbox = np.array([0, 0, 160, 160], dtype=np.float32).reshape(1, 4)
-
- # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
- _keypoints = np.array(
- ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
- keypoints = _keypoints[..., :2]
- keypoints_visible = np.minimum(1, _keypoints[..., 2])
-
- data_info = {
- 'img_id': ann['image_id'],
- 'img_path': img_path,
- 'bbox': bbox,
- 'bbox_score': np.ones(1, dtype=np.float32),
- 'num_keypoints': ann['num_keypoints'],
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- 'iscrowd': ann['iscrowd'],
- 'id': ann['id'],
- }
-
- return data_info
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import Optional
+
+import numpy as np
+
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class LocustDataset(BaseCocoStyleDataset):
+ """LocustDataset for animal pose estimation.
+
+ "DeepPoseKit, a software toolkit for fast and robust animal
+ pose estimation using deep learning" Elife'2019.
+ More details can be found in the `paper
+ `__ .
+
+ Desert Locust keypoints::
+
+ 0: "head",
+ 1: "neck",
+ 2: "thorax",
+ 3: "abdomen1",
+ 4: "abdomen2",
+ 5: "anttipL",
+ 6: "antbaseL",
+ 7: "eyeL",
+ 8: "forelegL1",
+ 9: "forelegL2",
+ 10: "forelegL3",
+ 11: "forelegL4",
+ 12: "midlegL1",
+ 13: "midlegL2",
+ 14: "midlegL3",
+ 15: "midlegL4",
+ 16: "hindlegL1",
+ 17: "hindlegL2",
+ 18: "hindlegL3",
+ 19: "hindlegL4",
+ 20: "anttipR",
+ 21: "antbaseR",
+ 22: "eyeR",
+ 23: "forelegR1",
+ 24: "forelegR2",
+ 25: "forelegR3",
+ 26: "forelegR4",
+ 27: "midlegR1",
+ 28: "midlegR2",
+ 29: "midlegR3",
+ 30: "midlegR4",
+ 31: "hindlegR1",
+ 32: "hindlegR2",
+ 33: "hindlegR3",
+ 34: "hindlegR4"
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/locust.py')
+
+ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
+ """Parse raw Locust annotation of an instance.
+
+ Args:
+ raw_data_info (dict): Raw data information loaded from
+ ``ann_file``. It should have following contents:
+
+ - ``'raw_ann_info'``: Raw annotation of an instance
+ - ``'raw_img_info'``: Raw information of the image that
+ contains the instance
+
+ Returns:
+ dict: Parsed instance annotation
+ """
+
+ ann = raw_data_info['raw_ann_info']
+ img = raw_data_info['raw_img_info']
+
+ img_path = osp.join(self.data_prefix['img'], img['file_name'])
+
+ # get bbox in shape [1, 4], formatted as xywh
+ # use the entire image which is 160x160
+ bbox = np.array([0, 0, 160, 160], dtype=np.float32).reshape(1, 4)
+
+ # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
+ _keypoints = np.array(
+ ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
+ keypoints = _keypoints[..., :2]
+ keypoints_visible = np.minimum(1, _keypoints[..., 2])
+
+ data_info = {
+ 'img_id': ann['image_id'],
+ 'img_path': img_path,
+ 'bbox': bbox,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'num_keypoints': ann['num_keypoints'],
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ 'iscrowd': ann['iscrowd'],
+ 'id': ann['id'],
+ }
+
+ return data_info
diff --git a/mmpose/datasets/datasets/animal/macaque_dataset.py b/mmpose/datasets/datasets/animal/macaque_dataset.py
index 08da981a1a..4947327c93 100644
--- a/mmpose/datasets/datasets/animal/macaque_dataset.py
+++ b/mmpose/datasets/datasets/animal/macaque_dataset.py
@@ -1,74 +1,74 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class MacaqueDataset(BaseCocoStyleDataset):
- """MacaquePose dataset for animal pose estimation.
-
- "MacaquePose: A novel 'in the wild' macaque monkey pose dataset
- for markerless motion capture" bioRxiv'2020.
- More details can be found in the `paper
- `__ .
-
- Macaque keypoints::
-
- 0: 'nose',
- 1: 'left_eye',
- 2: 'right_eye',
- 3: 'left_ear',
- 4: 'right_ear',
- 5: 'left_shoulder',
- 6: 'right_shoulder',
- 7: 'left_elbow',
- 8: 'right_elbow',
- 9: 'left_wrist',
- 10: 'right_wrist',
- 11: 'left_hip',
- 12: 'right_hip',
- 13: 'left_knee',
- 14: 'right_knee',
- 15: 'left_ankle',
- 16: 'right_ankle'
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/macaque.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class MacaqueDataset(BaseCocoStyleDataset):
+ """MacaquePose dataset for animal pose estimation.
+
+ "MacaquePose: A novel 'in the wild' macaque monkey pose dataset
+ for markerless motion capture" bioRxiv'2020.
+ More details can be found in the `paper
+ `__ .
+
+ Macaque keypoints::
+
+ 0: 'nose',
+ 1: 'left_eye',
+ 2: 'right_eye',
+ 3: 'left_ear',
+ 4: 'right_ear',
+ 5: 'left_shoulder',
+ 6: 'right_shoulder',
+ 7: 'left_elbow',
+ 8: 'right_elbow',
+ 9: 'left_wrist',
+ 10: 'right_wrist',
+ 11: 'left_hip',
+ 12: 'right_hip',
+ 13: 'left_knee',
+ 14: 'right_knee',
+ 15: 'left_ankle',
+ 16: 'right_ankle'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/macaque.py')
diff --git a/mmpose/datasets/datasets/animal/zebra_dataset.py b/mmpose/datasets/datasets/animal/zebra_dataset.py
index b399a8479b..194a78826e 100644
--- a/mmpose/datasets/datasets/animal/zebra_dataset.py
+++ b/mmpose/datasets/datasets/animal/zebra_dataset.py
@@ -1,116 +1,116 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os.path as osp
-from typing import Optional
-
-import numpy as np
-
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class ZebraDataset(BaseCocoStyleDataset):
- """ZebraDataset for animal pose estimation.
-
- "DeepPoseKit, a software toolkit for fast and robust animal
- pose estimation using deep learning" Elife'2019.
- More details can be found in the `paper
- `__ .
-
- Zebra keypoints::
-
- 0: "snout",
- 1: "head",
- 2: "neck",
- 3: "forelegL1",
- 4: "forelegR1",
- 5: "hindlegL1",
- 6: "hindlegR1",
- 7: "tailbase",
- 8: "tailtip"
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/zebra.py')
-
- def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
- """Parse raw Zebra annotation of an instance.
-
- Args:
- raw_data_info (dict): Raw data information loaded from
- ``ann_file``. It should have following contents:
-
- - ``'raw_ann_info'``: Raw annotation of an instance
- - ``'raw_img_info'``: Raw information of the image that
- contains the instance
-
- Returns:
- dict: Parsed instance annotation
- """
-
- ann = raw_data_info['raw_ann_info']
- img = raw_data_info['raw_img_info']
-
- img_path = osp.join(self.data_prefix['img'], img['file_name'])
-
- # get bbox in shape [1, 4], formatted as xywh
- # use the entire image which is 160x160
- bbox = np.array([0, 0, 160, 160], dtype=np.float32).reshape(1, 4)
-
- # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
- _keypoints = np.array(
- ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
- keypoints = _keypoints[..., :2]
- keypoints_visible = np.minimum(1, _keypoints[..., 2])
-
- num_keypoints = ann['num_keypoints']
-
- data_info = {
- 'img_id': ann['image_id'],
- 'img_path': img_path,
- 'bbox': bbox,
- 'bbox_score': np.ones(1, dtype=np.float32),
- 'num_keypoints': num_keypoints,
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- 'iscrowd': ann['iscrowd'],
- 'id': ann['id'],
- }
-
- return data_info
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import Optional
+
+import numpy as np
+
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class ZebraDataset(BaseCocoStyleDataset):
+ """ZebraDataset for animal pose estimation.
+
+ "DeepPoseKit, a software toolkit for fast and robust animal
+ pose estimation using deep learning" Elife'2019.
+ More details can be found in the `paper
+ `__ .
+
+ Zebra keypoints::
+
+ 0: "snout",
+ 1: "head",
+ 2: "neck",
+ 3: "forelegL1",
+ 4: "forelegR1",
+ 5: "hindlegL1",
+ 6: "hindlegR1",
+ 7: "tailbase",
+ 8: "tailtip"
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/zebra.py')
+
+ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
+ """Parse raw Zebra annotation of an instance.
+
+ Args:
+ raw_data_info (dict): Raw data information loaded from
+ ``ann_file``. It should have following contents:
+
+ - ``'raw_ann_info'``: Raw annotation of an instance
+ - ``'raw_img_info'``: Raw information of the image that
+ contains the instance
+
+ Returns:
+ dict: Parsed instance annotation
+ """
+
+ ann = raw_data_info['raw_ann_info']
+ img = raw_data_info['raw_img_info']
+
+ img_path = osp.join(self.data_prefix['img'], img['file_name'])
+
+ # get bbox in shape [1, 4], formatted as xywh
+ # use the entire image which is 160x160
+ bbox = np.array([0, 0, 160, 160], dtype=np.float32).reshape(1, 4)
+
+ # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
+ _keypoints = np.array(
+ ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
+ keypoints = _keypoints[..., :2]
+ keypoints_visible = np.minimum(1, _keypoints[..., 2])
+
+ num_keypoints = ann['num_keypoints']
+
+ data_info = {
+ 'img_id': ann['image_id'],
+ 'img_path': img_path,
+ 'bbox': bbox,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'num_keypoints': num_keypoints,
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ 'iscrowd': ann['iscrowd'],
+ 'id': ann['id'],
+ }
+
+ return data_info
diff --git a/mmpose/datasets/datasets/base/__init__.py b/mmpose/datasets/datasets/base/__init__.py
index 810440530e..aa682ddeb6 100644
--- a/mmpose/datasets/datasets/base/__init__.py
+++ b/mmpose/datasets/datasets/base/__init__.py
@@ -1,5 +1,5 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .base_coco_style_dataset import BaseCocoStyleDataset
-from .base_mocap_dataset import BaseMocapDataset
-
-__all__ = ['BaseCocoStyleDataset', 'BaseMocapDataset']
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base_coco_style_dataset import BaseCocoStyleDataset
+from .base_mocap_dataset import BaseMocapDataset
+
+__all__ = ['BaseCocoStyleDataset', 'BaseMocapDataset']
diff --git a/mmpose/datasets/datasets/base/base_coco_style_dataset.py b/mmpose/datasets/datasets/base/base_coco_style_dataset.py
index 3b592813d8..36b127028f 100644
--- a/mmpose/datasets/datasets/base/base_coco_style_dataset.py
+++ b/mmpose/datasets/datasets/base/base_coco_style_dataset.py
@@ -1,458 +1,458 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-import os.path as osp
-from copy import deepcopy
-from itertools import filterfalse, groupby
-from typing import Any, Callable, Dict, List, Optional, Sequence, Tuple, Union
-
-import numpy as np
-from mmengine.dataset import BaseDataset, force_full_init
-from mmengine.fileio import exists, get_local_path, load
-from mmengine.utils import is_list_of
-from xtcocotools.coco import COCO
-
-from mmpose.registry import DATASETS
-from mmpose.structures.bbox import bbox_xywh2xyxy
-from ..utils import parse_pose_metainfo
-
-
-@DATASETS.register_module()
-class BaseCocoStyleDataset(BaseDataset):
- """Base class for COCO-style datasets.
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data.
- Default: ``dict(img='')``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict()
-
- def __init__(self,
- ann_file: str = '',
- bbox_file: Optional[str] = None,
- data_mode: str = 'topdown',
- metainfo: Optional[dict] = None,
- data_root: Optional[str] = None,
- data_prefix: dict = dict(img=''),
- filter_cfg: Optional[dict] = None,
- indices: Optional[Union[int, Sequence[int]]] = None,
- serialize_data: bool = True,
- pipeline: List[Union[dict, Callable]] = [],
- test_mode: bool = False,
- lazy_init: bool = False,
- max_refetch: int = 1000):
-
- if data_mode not in {'topdown', 'bottomup'}:
- raise ValueError(
- f'{self.__class__.__name__} got invalid data_mode: '
- f'{data_mode}. Should be "topdown" or "bottomup".')
- self.data_mode = data_mode
-
- if bbox_file:
- if self.data_mode != 'topdown':
- raise ValueError(
- f'{self.__class__.__name__} is set to {self.data_mode}: '
- 'mode, while "bbox_file" is only '
- 'supported in topdown mode.')
-
- if not test_mode:
- raise ValueError(
- f'{self.__class__.__name__} has `test_mode==False` '
- 'while "bbox_file" is only '
- 'supported when `test_mode==True`.')
- self.bbox_file = bbox_file
-
- super().__init__(
- ann_file=ann_file,
- metainfo=metainfo,
- data_root=data_root,
- data_prefix=data_prefix,
- filter_cfg=filter_cfg,
- indices=indices,
- serialize_data=serialize_data,
- pipeline=pipeline,
- test_mode=test_mode,
- lazy_init=lazy_init,
- max_refetch=max_refetch)
-
- @classmethod
- def _load_metainfo(cls, metainfo: dict = None) -> dict:
- """Collect meta information from the dictionary of meta.
-
- Args:
- metainfo (dict): Raw data of pose meta information.
-
- Returns:
- dict: Parsed meta information.
- """
-
- if metainfo is None:
- metainfo = deepcopy(cls.METAINFO)
-
- if not isinstance(metainfo, dict):
- raise TypeError(
- f'metainfo should be a dict, but got {type(metainfo)}')
-
- # parse pose metainfo if it has been assigned
- if metainfo:
- metainfo = parse_pose_metainfo(metainfo)
- return metainfo
-
- @force_full_init
- def prepare_data(self, idx) -> Any:
- """Get data processed by ``self.pipeline``.
-
- :class:`BaseCocoStyleDataset` overrides this method from
- :class:`mmengine.dataset.BaseDataset` to add the metainfo into
- the ``data_info`` before it is passed to the pipeline.
-
- Args:
- idx (int): The index of ``data_info``.
-
- Returns:
- Any: Depends on ``self.pipeline``.
- """
- data_info = self.get_data_info(idx)
-
- return self.pipeline(data_info)
-
- def get_data_info(self, idx: int) -> dict:
- """Get data info by index.
-
- Args:
- idx (int): Index of data info.
-
- Returns:
- dict: Data info.
- """
- data_info = super().get_data_info(idx)
-
- # Add metainfo items that are required in the pipeline and the model
- metainfo_keys = [
- 'upper_body_ids', 'lower_body_ids', 'flip_pairs',
- 'dataset_keypoint_weights', 'flip_indices', 'skeleton_links'
- ]
-
- for key in metainfo_keys:
- assert key not in data_info, (
- f'"{key}" is a reserved key for `metainfo`, but already '
- 'exists in the `data_info`.')
-
- data_info[key] = deepcopy(self._metainfo[key])
-
- return data_info
-
- def load_data_list(self) -> List[dict]:
- """Load data list from COCO annotation file or person detection result
- file."""
-
- if self.bbox_file:
- data_list = self._load_detection_results()
- else:
- instance_list, image_list = self._load_annotations()
-
- if self.data_mode == 'topdown':
- data_list = self._get_topdown_data_infos(instance_list)
- else:
- data_list = self._get_bottomup_data_infos(
- instance_list, image_list)
-
- return data_list
-
- def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
- """Load data from annotations in COCO format."""
-
- assert exists(self.ann_file), 'Annotation file does not exist'
-
- with get_local_path(self.ann_file) as local_path:
- self.coco = COCO(local_path)
- # set the metainfo about categories, which is a list of dict
- # and each dict contains the 'id', 'name', etc. about this category
- self._metainfo['CLASSES'] = self.coco.loadCats(self.coco.getCatIds())
-
- instance_list = []
- image_list = []
-
- for img_id in self.coco.getImgIds():
- img = self.coco.loadImgs(img_id)[0]
- img.update({
- 'img_id':
- img_id,
- 'img_path':
- osp.join(self.data_prefix['img'], img['file_name']),
- })
- image_list.append(img)
-
- ann_ids = self.coco.getAnnIds(imgIds=img_id)
- for ann in self.coco.loadAnns(ann_ids):
-
- instance_info = self.parse_data_info(
- dict(raw_ann_info=ann, raw_img_info=img))
-
- # skip invalid instance annotation.
- if not instance_info:
- continue
-
- instance_list.append(instance_info)
- return instance_list, image_list
-
- def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
- """Parse raw COCO annotation of an instance.
-
- Args:
- raw_data_info (dict): Raw data information loaded from
- ``ann_file``. It should have following contents:
-
- - ``'raw_ann_info'``: Raw annotation of an instance
- - ``'raw_img_info'``: Raw information of the image that
- contains the instance
-
- Returns:
- dict | None: Parsed instance annotation
- """
-
- ann = raw_data_info['raw_ann_info']
- img = raw_data_info['raw_img_info']
-
- # filter invalid instance
- if 'bbox' not in ann or 'keypoints' not in ann:
- return None
-
- img_w, img_h = img['width'], img['height']
-
- # get bbox in shape [1, 4], formatted as xywh
- x, y, w, h = ann['bbox']
- x1 = np.clip(x, 0, img_w - 1)
- y1 = np.clip(y, 0, img_h - 1)
- x2 = np.clip(x + w, 0, img_w - 1)
- y2 = np.clip(y + h, 0, img_h - 1)
-
- bbox = np.array([x1, y1, x2, y2], dtype=np.float32).reshape(1, 4)
-
- # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
- _keypoints = np.array(
- ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
- keypoints = _keypoints[..., :2]
- keypoints_visible = np.minimum(1, _keypoints[..., 2])
-
- if 'num_keypoints' in ann:
- num_keypoints = ann['num_keypoints']
- else:
- num_keypoints = np.count_nonzero(keypoints.max(axis=2))
-
- data_info = {
- 'img_id': ann['image_id'],
- 'img_path': img['img_path'],
- 'bbox': bbox,
- 'bbox_score': np.ones(1, dtype=np.float32),
- 'num_keypoints': num_keypoints,
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- 'iscrowd': ann.get('iscrowd', 0),
- 'segmentation': ann.get('segmentation', None),
- 'id': ann['id'],
- 'category_id': ann['category_id'],
- # store the raw annotation of the instance
- # it is useful for evaluation without providing ann_file
- 'raw_ann_info': copy.deepcopy(ann),
- }
-
- if 'crowdIndex' in img:
- data_info['crowd_index'] = img['crowdIndex']
-
- return data_info
-
- @staticmethod
- def _is_valid_instance(data_info: Dict) -> bool:
- """Check a data info is an instance with valid bbox and keypoint
- annotations."""
- # crowd annotation
- if 'iscrowd' in data_info and data_info['iscrowd']:
- return False
- # invalid keypoints
- if 'num_keypoints' in data_info and data_info['num_keypoints'] == 0:
- return False
- # invalid bbox
- if 'bbox' in data_info:
- bbox = data_info['bbox'][0]
- w, h = bbox[2:4] - bbox[:2]
- if w <= 0 or h <= 0:
- return False
- # invalid keypoints
- if 'keypoints' in data_info:
- if np.max(data_info['keypoints']) <= 0:
- return False
- return True
-
- def _get_topdown_data_infos(self, instance_list: List[Dict]) -> List[Dict]:
- """Organize the data list in top-down mode."""
- # sanitize data samples
- data_list_tp = list(filter(self._is_valid_instance, instance_list))
-
- return data_list_tp
-
- def _get_bottomup_data_infos(self, instance_list: List[Dict],
- image_list: List[Dict]) -> List[Dict]:
- """Organize the data list in bottom-up mode."""
-
- # bottom-up data list
- data_list_bu = []
-
- used_img_ids = set()
-
- # group instances by img_id
- for img_id, data_infos in groupby(instance_list,
- lambda x: x['img_id']):
- used_img_ids.add(img_id)
- data_infos = list(data_infos)
-
- # image data
- img_path = data_infos[0]['img_path']
- data_info_bu = {
- 'img_id': img_id,
- 'img_path': img_path,
- }
-
- for key in data_infos[0].keys():
- if key not in data_info_bu:
- seq = [d[key] for d in data_infos]
- if isinstance(seq[0], np.ndarray):
- seq = np.concatenate(seq, axis=0)
- data_info_bu[key] = seq
-
- # The segmentation annotation of invalid objects will be used
- # to generate valid region mask in the pipeline.
- invalid_segs = []
- for data_info_invalid in filterfalse(self._is_valid_instance,
- data_infos):
- if 'segmentation' in data_info_invalid:
- invalid_segs.append(data_info_invalid['segmentation'])
- data_info_bu['invalid_segs'] = invalid_segs
-
- data_list_bu.append(data_info_bu)
-
- # add images without instance for evaluation
- if self.test_mode:
- for img_info in image_list:
- if img_info['img_id'] not in used_img_ids:
- data_info_bu = {
- 'img_id': img_info['img_id'],
- 'img_path': img_info['img_path'],
- 'id': list(),
- 'raw_ann_info': None,
- }
- data_list_bu.append(data_info_bu)
-
- return data_list_bu
-
- def _load_detection_results(self) -> List[dict]:
- """Load data from detection results with dummy keypoint annotations."""
-
- assert exists(self.ann_file), 'Annotation file does not exist'
- assert exists(self.bbox_file), 'Bbox file does not exist'
- # load detection results
- det_results = load(self.bbox_file)
- assert is_list_of(det_results, dict)
-
- # load coco annotations to build image id-to-name index
- with get_local_path(self.ann_file) as local_path:
- self.coco = COCO(local_path)
- # set the metainfo about categories, which is a list of dict
- # and each dict contains the 'id', 'name', etc. about this category
- self._metainfo['CLASSES'] = self.coco.loadCats(self.coco.getCatIds())
-
- num_keypoints = self.metainfo['num_keypoints']
- data_list = []
- id_ = 0
- for det in det_results:
- # remove non-human instances
- if det['category_id'] != 1:
- continue
-
- img = self.coco.loadImgs(det['image_id'])[0]
-
- img_path = osp.join(self.data_prefix['img'], img['file_name'])
- bbox_xywh = np.array(
- det['bbox'][:4], dtype=np.float32).reshape(1, 4)
- bbox = bbox_xywh2xyxy(bbox_xywh)
- bbox_score = np.array(det['score'], dtype=np.float32).reshape(1)
-
- # use dummy keypoint location and visibility
- keypoints = np.zeros((1, num_keypoints, 2), dtype=np.float32)
- keypoints_visible = np.ones((1, num_keypoints), dtype=np.float32)
-
- data_list.append({
- 'img_id': det['image_id'],
- 'img_path': img_path,
- 'img_shape': (img['height'], img['width']),
- 'bbox': bbox,
- 'bbox_score': bbox_score,
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- 'id': id_,
- })
-
- id_ += 1
-
- return data_list
-
- def filter_data(self) -> List[dict]:
- """Filter annotations according to filter_cfg. Defaults return full
- ``data_list``.
-
- If 'bbox_score_thr` in filter_cfg, the annotation with bbox_score below
- the threshold `bbox_score_thr` will be filtered out.
- """
-
- data_list = self.data_list
-
- if self.filter_cfg is None:
- return data_list
-
- # filter out annotations with a bbox_score below the threshold
- if 'bbox_score_thr' in self.filter_cfg:
-
- if self.data_mode != 'topdown':
- raise ValueError(
- f'{self.__class__.__name__} is set to {self.data_mode} '
- 'mode, while "bbox_score_thr" is only supported in '
- 'topdown mode.')
-
- thr = self.filter_cfg['bbox_score_thr']
- data_list = list(
- filterfalse(lambda ann: ann['bbox_score'] < thr, data_list))
-
- return data_list
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import os.path as osp
+from copy import deepcopy
+from itertools import filterfalse, groupby
+from typing import Any, Callable, Dict, List, Optional, Sequence, Tuple, Union
+
+import numpy as np
+from mmengine.dataset import BaseDataset, force_full_init
+from mmengine.fileio import exists, get_local_path, load
+from mmengine.utils import is_list_of
+from xtcocotools.coco import COCO
+
+from mmpose.registry import DATASETS
+from mmpose.structures.bbox import bbox_xywh2xyxy
+from ..utils import parse_pose_metainfo
+
+
+@DATASETS.register_module()
+class BaseCocoStyleDataset(BaseDataset):
+ """Base class for COCO-style datasets.
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data.
+ Default: ``dict(img='')``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict()
+
+ def __init__(self,
+ ann_file: str = '',
+ bbox_file: Optional[str] = None,
+ data_mode: str = 'topdown',
+ metainfo: Optional[dict] = None,
+ data_root: Optional[str] = None,
+ data_prefix: dict = dict(img=''),
+ filter_cfg: Optional[dict] = None,
+ indices: Optional[Union[int, Sequence[int]]] = None,
+ serialize_data: bool = True,
+ pipeline: List[Union[dict, Callable]] = [],
+ test_mode: bool = False,
+ lazy_init: bool = False,
+ max_refetch: int = 1000):
+
+ if data_mode not in {'topdown', 'bottomup'}:
+ raise ValueError(
+ f'{self.__class__.__name__} got invalid data_mode: '
+ f'{data_mode}. Should be "topdown" or "bottomup".')
+ self.data_mode = data_mode
+
+ if bbox_file:
+ if self.data_mode != 'topdown':
+ raise ValueError(
+ f'{self.__class__.__name__} is set to {self.data_mode}: '
+ 'mode, while "bbox_file" is only '
+ 'supported in topdown mode.')
+
+ if not test_mode:
+ raise ValueError(
+ f'{self.__class__.__name__} has `test_mode==False` '
+ 'while "bbox_file" is only '
+ 'supported when `test_mode==True`.')
+ self.bbox_file = bbox_file
+
+ super().__init__(
+ ann_file=ann_file,
+ metainfo=metainfo,
+ data_root=data_root,
+ data_prefix=data_prefix,
+ filter_cfg=filter_cfg,
+ indices=indices,
+ serialize_data=serialize_data,
+ pipeline=pipeline,
+ test_mode=test_mode,
+ lazy_init=lazy_init,
+ max_refetch=max_refetch)
+
+ @classmethod
+ def _load_metainfo(cls, metainfo: dict = None) -> dict:
+ """Collect meta information from the dictionary of meta.
+
+ Args:
+ metainfo (dict): Raw data of pose meta information.
+
+ Returns:
+ dict: Parsed meta information.
+ """
+
+ if metainfo is None:
+ metainfo = deepcopy(cls.METAINFO)
+
+ if not isinstance(metainfo, dict):
+ raise TypeError(
+ f'metainfo should be a dict, but got {type(metainfo)}')
+
+ # parse pose metainfo if it has been assigned
+ if metainfo:
+ metainfo = parse_pose_metainfo(metainfo)
+ return metainfo
+
+ @force_full_init
+ def prepare_data(self, idx) -> Any:
+ """Get data processed by ``self.pipeline``.
+
+ :class:`BaseCocoStyleDataset` overrides this method from
+ :class:`mmengine.dataset.BaseDataset` to add the metainfo into
+ the ``data_info`` before it is passed to the pipeline.
+
+ Args:
+ idx (int): The index of ``data_info``.
+
+ Returns:
+ Any: Depends on ``self.pipeline``.
+ """
+ data_info = self.get_data_info(idx)
+
+ return self.pipeline(data_info)
+
+ def get_data_info(self, idx: int) -> dict:
+ """Get data info by index.
+
+ Args:
+ idx (int): Index of data info.
+
+ Returns:
+ dict: Data info.
+ """
+ data_info = super().get_data_info(idx)
+
+ # Add metainfo items that are required in the pipeline and the model
+ metainfo_keys = [
+ 'upper_body_ids', 'lower_body_ids', 'flip_pairs',
+ 'dataset_keypoint_weights', 'flip_indices', 'skeleton_links'
+ ]
+
+ for key in metainfo_keys:
+ assert key not in data_info, (
+ f'"{key}" is a reserved key for `metainfo`, but already '
+ 'exists in the `data_info`.')
+
+ data_info[key] = deepcopy(self._metainfo[key])
+
+ return data_info
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list from COCO annotation file or person detection result
+ file."""
+
+ if self.bbox_file:
+ data_list = self._load_detection_results()
+ else:
+ instance_list, image_list = self._load_annotations()
+
+ if self.data_mode == 'topdown':
+ data_list = self._get_topdown_data_infos(instance_list)
+ else:
+ data_list = self._get_bottomup_data_infos(
+ instance_list, image_list)
+
+ return data_list
+
+ def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
+ """Load data from annotations in COCO format."""
+
+ assert exists(self.ann_file), 'Annotation file does not exist'
+
+ with get_local_path(self.ann_file) as local_path:
+ self.coco = COCO(local_path)
+ # set the metainfo about categories, which is a list of dict
+ # and each dict contains the 'id', 'name', etc. about this category
+ self._metainfo['CLASSES'] = self.coco.loadCats(self.coco.getCatIds())
+
+ instance_list = []
+ image_list = []
+
+ for img_id in self.coco.getImgIds():
+ img = self.coco.loadImgs(img_id)[0]
+ img.update({
+ 'img_id':
+ img_id,
+ 'img_path':
+ osp.join(self.data_prefix['img'], img['file_name']),
+ })
+ image_list.append(img)
+
+ ann_ids = self.coco.getAnnIds(imgIds=img_id)
+ for ann in self.coco.loadAnns(ann_ids):
+
+ instance_info = self.parse_data_info(
+ dict(raw_ann_info=ann, raw_img_info=img))
+
+ # skip invalid instance annotation.
+ if not instance_info:
+ continue
+
+ instance_list.append(instance_info)
+ return instance_list, image_list
+
+ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
+ """Parse raw COCO annotation of an instance.
+
+ Args:
+ raw_data_info (dict): Raw data information loaded from
+ ``ann_file``. It should have following contents:
+
+ - ``'raw_ann_info'``: Raw annotation of an instance
+ - ``'raw_img_info'``: Raw information of the image that
+ contains the instance
+
+ Returns:
+ dict | None: Parsed instance annotation
+ """
+
+ ann = raw_data_info['raw_ann_info']
+ img = raw_data_info['raw_img_info']
+
+ # filter invalid instance
+ if 'bbox' not in ann or 'keypoints' not in ann:
+ return None
+
+ img_w, img_h = img['width'], img['height']
+
+ # get bbox in shape [1, 4], formatted as xywh
+ x, y, w, h = ann['bbox']
+ x1 = np.clip(x, 0, img_w - 1)
+ y1 = np.clip(y, 0, img_h - 1)
+ x2 = np.clip(x + w, 0, img_w - 1)
+ y2 = np.clip(y + h, 0, img_h - 1)
+
+ bbox = np.array([x1, y1, x2, y2], dtype=np.float32).reshape(1, 4)
+
+ # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
+ _keypoints = np.array(
+ ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
+ keypoints = _keypoints[..., :2]
+ keypoints_visible = np.minimum(1, _keypoints[..., 2])
+
+ if 'num_keypoints' in ann:
+ num_keypoints = ann['num_keypoints']
+ else:
+ num_keypoints = np.count_nonzero(keypoints.max(axis=2))
+
+ data_info = {
+ 'img_id': ann['image_id'],
+ 'img_path': img['img_path'],
+ 'bbox': bbox,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'num_keypoints': num_keypoints,
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ 'iscrowd': ann.get('iscrowd', 0),
+ 'segmentation': ann.get('segmentation', None),
+ 'id': ann['id'],
+ 'category_id': ann['category_id'],
+ # store the raw annotation of the instance
+ # it is useful for evaluation without providing ann_file
+ 'raw_ann_info': copy.deepcopy(ann),
+ }
+
+ if 'crowdIndex' in img:
+ data_info['crowd_index'] = img['crowdIndex']
+
+ return data_info
+
+ @staticmethod
+ def _is_valid_instance(data_info: Dict) -> bool:
+ """Check a data info is an instance with valid bbox and keypoint
+ annotations."""
+ # crowd annotation
+ if 'iscrowd' in data_info and data_info['iscrowd']:
+ return False
+ # invalid keypoints
+ if 'num_keypoints' in data_info and data_info['num_keypoints'] == 0:
+ return False
+ # invalid bbox
+ if 'bbox' in data_info:
+ bbox = data_info['bbox'][0]
+ w, h = bbox[2:4] - bbox[:2]
+ if w <= 0 or h <= 0:
+ return False
+ # invalid keypoints
+ if 'keypoints' in data_info:
+ if np.max(data_info['keypoints']) <= 0:
+ return False
+ return True
+
+ def _get_topdown_data_infos(self, instance_list: List[Dict]) -> List[Dict]:
+ """Organize the data list in top-down mode."""
+ # sanitize data samples
+ data_list_tp = list(filter(self._is_valid_instance, instance_list))
+
+ return data_list_tp
+
+ def _get_bottomup_data_infos(self, instance_list: List[Dict],
+ image_list: List[Dict]) -> List[Dict]:
+ """Organize the data list in bottom-up mode."""
+
+ # bottom-up data list
+ data_list_bu = []
+
+ used_img_ids = set()
+
+ # group instances by img_id
+ for img_id, data_infos in groupby(instance_list,
+ lambda x: x['img_id']):
+ used_img_ids.add(img_id)
+ data_infos = list(data_infos)
+
+ # image data
+ img_path = data_infos[0]['img_path']
+ data_info_bu = {
+ 'img_id': img_id,
+ 'img_path': img_path,
+ }
+
+ for key in data_infos[0].keys():
+ if key not in data_info_bu:
+ seq = [d[key] for d in data_infos]
+ if isinstance(seq[0], np.ndarray):
+ seq = np.concatenate(seq, axis=0)
+ data_info_bu[key] = seq
+
+ # The segmentation annotation of invalid objects will be used
+ # to generate valid region mask in the pipeline.
+ invalid_segs = []
+ for data_info_invalid in filterfalse(self._is_valid_instance,
+ data_infos):
+ if 'segmentation' in data_info_invalid:
+ invalid_segs.append(data_info_invalid['segmentation'])
+ data_info_bu['invalid_segs'] = invalid_segs
+
+ data_list_bu.append(data_info_bu)
+
+ # add images without instance for evaluation
+ if self.test_mode:
+ for img_info in image_list:
+ if img_info['img_id'] not in used_img_ids:
+ data_info_bu = {
+ 'img_id': img_info['img_id'],
+ 'img_path': img_info['img_path'],
+ 'id': list(),
+ 'raw_ann_info': None,
+ }
+ data_list_bu.append(data_info_bu)
+
+ return data_list_bu
+
+ def _load_detection_results(self) -> List[dict]:
+ """Load data from detection results with dummy keypoint annotations."""
+
+ assert exists(self.ann_file), 'Annotation file does not exist'
+ assert exists(self.bbox_file), 'Bbox file does not exist'
+ # load detection results
+ det_results = load(self.bbox_file)
+ assert is_list_of(det_results, dict)
+
+ # load coco annotations to build image id-to-name index
+ with get_local_path(self.ann_file) as local_path:
+ self.coco = COCO(local_path)
+ # set the metainfo about categories, which is a list of dict
+ # and each dict contains the 'id', 'name', etc. about this category
+ self._metainfo['CLASSES'] = self.coco.loadCats(self.coco.getCatIds())
+
+ num_keypoints = self.metainfo['num_keypoints']
+ data_list = []
+ id_ = 0
+ for det in det_results:
+ # remove non-human instances
+ if det['category_id'] != 1:
+ continue
+
+ img = self.coco.loadImgs(det['image_id'])[0]
+
+ img_path = osp.join(self.data_prefix['img'], img['file_name'])
+ bbox_xywh = np.array(
+ det['bbox'][:4], dtype=np.float32).reshape(1, 4)
+ bbox = bbox_xywh2xyxy(bbox_xywh)
+ bbox_score = np.array(det['score'], dtype=np.float32).reshape(1)
+
+ # use dummy keypoint location and visibility
+ keypoints = np.zeros((1, num_keypoints, 2), dtype=np.float32)
+ keypoints_visible = np.ones((1, num_keypoints), dtype=np.float32)
+
+ data_list.append({
+ 'img_id': det['image_id'],
+ 'img_path': img_path,
+ 'img_shape': (img['height'], img['width']),
+ 'bbox': bbox,
+ 'bbox_score': bbox_score,
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ 'id': id_,
+ })
+
+ id_ += 1
+
+ return data_list
+
+ def filter_data(self) -> List[dict]:
+ """Filter annotations according to filter_cfg. Defaults return full
+ ``data_list``.
+
+ If 'bbox_score_thr` in filter_cfg, the annotation with bbox_score below
+ the threshold `bbox_score_thr` will be filtered out.
+ """
+
+ data_list = self.data_list
+
+ if self.filter_cfg is None:
+ return data_list
+
+ # filter out annotations with a bbox_score below the threshold
+ if 'bbox_score_thr' in self.filter_cfg:
+
+ if self.data_mode != 'topdown':
+ raise ValueError(
+ f'{self.__class__.__name__} is set to {self.data_mode} '
+ 'mode, while "bbox_score_thr" is only supported in '
+ 'topdown mode.')
+
+ thr = self.filter_cfg['bbox_score_thr']
+ data_list = list(
+ filterfalse(lambda ann: ann['bbox_score'] < thr, data_list))
+
+ return data_list
diff --git a/mmpose/datasets/datasets/base/base_mocap_dataset.py b/mmpose/datasets/datasets/base/base_mocap_dataset.py
index d671a6ae94..eafff4f2b7 100644
--- a/mmpose/datasets/datasets/base/base_mocap_dataset.py
+++ b/mmpose/datasets/datasets/base/base_mocap_dataset.py
@@ -1,403 +1,403 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os.path as osp
-from copy import deepcopy
-from itertools import filterfalse, groupby
-from typing import Any, Callable, Dict, List, Optional, Sequence, Tuple, Union
-
-import numpy as np
-from mmengine.dataset import BaseDataset, force_full_init
-from mmengine.fileio import exists, get_local_path, load
-from mmengine.utils import is_abs
-from PIL import Image
-
-from mmpose.registry import DATASETS
-from ..utils import parse_pose_metainfo
-
-
-@DATASETS.register_module()
-class BaseMocapDataset(BaseDataset):
- """Base class for 3d body datasets.
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- seq_len (int): Number of frames in a sequence. Default: 1.
- causal (bool): If set to ``True``, the rightmost input frame will be
- the target frame. Otherwise, the middle input frame will be the
- target frame. Default: ``True``.
- subset_frac (float): The fraction to reduce dataset size. If set to 1,
- the dataset size is not reduced. Default: 1.
- camera_param_file (str): Cameras' parameters file. Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data.
- Default: ``dict(img='')``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict()
-
- def __init__(self,
- ann_file: str = '',
- seq_len: int = 1,
- causal: bool = True,
- subset_frac: float = 1.0,
- camera_param_file: Optional[str] = None,
- data_mode: str = 'topdown',
- metainfo: Optional[dict] = None,
- data_root: Optional[str] = None,
- data_prefix: dict = dict(img=''),
- filter_cfg: Optional[dict] = None,
- indices: Optional[Union[int, Sequence[int]]] = None,
- serialize_data: bool = True,
- pipeline: List[Union[dict, Callable]] = [],
- test_mode: bool = False,
- lazy_init: bool = False,
- max_refetch: int = 1000):
-
- if data_mode not in {'topdown', 'bottomup'}:
- raise ValueError(
- f'{self.__class__.__name__} got invalid data_mode: '
- f'{data_mode}. Should be "topdown" or "bottomup".')
- self.data_mode = data_mode
-
- _ann_file = ann_file
- if not is_abs(_ann_file):
- _ann_file = osp.join(data_root, _ann_file)
- assert exists(_ann_file), 'Annotation file does not exist.'
- with get_local_path(_ann_file) as local_path:
- self.ann_data = np.load(local_path)
-
- self.camera_param_file = camera_param_file
- if self.camera_param_file:
- if not is_abs(self.camera_param_file):
- self.camera_param_file = osp.join(data_root,
- self.camera_param_file)
- assert exists(self.camera_param_file)
- self.camera_param = load(self.camera_param_file)
-
- self.seq_len = seq_len
- self.causal = causal
-
- assert 0 < subset_frac <= 1, (
- f'Unsupported `subset_frac` {subset_frac}. Supported range '
- 'is (0, 1].')
- self.subset_frac = subset_frac
-
- self.sequence_indices = self.get_sequence_indices()
-
- super().__init__(
- ann_file=ann_file,
- metainfo=metainfo,
- data_root=data_root,
- data_prefix=data_prefix,
- filter_cfg=filter_cfg,
- indices=indices,
- serialize_data=serialize_data,
- pipeline=pipeline,
- test_mode=test_mode,
- lazy_init=lazy_init,
- max_refetch=max_refetch)
-
- @classmethod
- def _load_metainfo(cls, metainfo: dict = None) -> dict:
- """Collect meta information from the dictionary of meta.
-
- Args:
- metainfo (dict): Raw data of pose meta information.
-
- Returns:
- dict: Parsed meta information.
- """
-
- if metainfo is None:
- metainfo = deepcopy(cls.METAINFO)
-
- if not isinstance(metainfo, dict):
- raise TypeError(
- f'metainfo should be a dict, but got {type(metainfo)}')
-
- # parse pose metainfo if it has been assigned
- if metainfo:
- metainfo = parse_pose_metainfo(metainfo)
- return metainfo
-
- @force_full_init
- def prepare_data(self, idx) -> Any:
- """Get data processed by ``self.pipeline``.
-
- :class:`BaseCocoStyleDataset` overrides this method from
- :class:`mmengine.dataset.BaseDataset` to add the metainfo into
- the ``data_info`` before it is passed to the pipeline.
-
- Args:
- idx (int): The index of ``data_info``.
-
- Returns:
- Any: Depends on ``self.pipeline``.
- """
- data_info = self.get_data_info(idx)
-
- return self.pipeline(data_info)
-
- def get_data_info(self, idx: int) -> dict:
- """Get data info by index.
-
- Args:
- idx (int): Index of data info.
-
- Returns:
- dict: Data info.
- """
- data_info = super().get_data_info(idx)
-
- # Add metainfo items that are required in the pipeline and the model
- metainfo_keys = [
- 'upper_body_ids', 'lower_body_ids', 'flip_pairs',
- 'dataset_keypoint_weights', 'flip_indices', 'skeleton_links'
- ]
-
- for key in metainfo_keys:
- assert key not in data_info, (
- f'"{key}" is a reserved key for `metainfo`, but already '
- 'exists in the `data_info`.')
-
- data_info[key] = deepcopy(self._metainfo[key])
-
- return data_info
-
- def load_data_list(self) -> List[dict]:
- """Load data list from COCO annotation file or person detection result
- file."""
-
- instance_list, image_list = self._load_annotations()
-
- if self.data_mode == 'topdown':
- data_list = self._get_topdown_data_infos(instance_list)
- else:
- data_list = self._get_bottomup_data_infos(instance_list,
- image_list)
-
- return data_list
-
- def get_img_info(self, img_idx, img_name):
- try:
- with get_local_path(osp.join(self.data_prefix['img'],
- img_name)) as local_path:
- im = Image.open(local_path)
- w, h = im.size
- im.close()
- except: # noqa: E722
- return None
-
- img = {
- 'file_name': img_name,
- 'height': h,
- 'width': w,
- 'id': img_idx,
- 'img_id': img_idx,
- 'img_path': osp.join(self.data_prefix['img'], img_name),
- }
- return img
-
- def get_sequence_indices(self) -> List[List[int]]:
- """Build sequence indices.
-
- The default method creates sample indices that each sample is a single
- frame (i.e. seq_len=1). Override this method in the subclass to define
- how frames are sampled to form data samples.
-
- Outputs:
- sample_indices: the frame indices of each sample.
- For a sample, all frames will be treated as an input sequence,
- and the ground-truth pose of the last frame will be the target.
- """
- sequence_indices = []
- if self.seq_len == 1:
- num_imgs = len(self.ann_data['imgname'])
- sequence_indices = [[idx] for idx in range(num_imgs)]
- else:
- raise NotImplementedError('Multi-frame data sample unsupported!')
- return sequence_indices
-
- def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
- """Load data from annotations in COCO format."""
- num_keypoints = self.metainfo['num_keypoints']
-
- img_names = self.ann_data['imgname']
- num_imgs = len(img_names)
-
- if 'S' in self.ann_data.keys():
- kpts_3d = self.ann_data['S']
- else:
- kpts_3d = np.zeros((num_imgs, num_keypoints, 4), dtype=np.float32)
-
- if 'part' in self.ann_data.keys():
- kpts_2d = self.ann_data['part']
- else:
- kpts_2d = np.zeros((num_imgs, num_keypoints, 3), dtype=np.float32)
-
- if 'center' in self.ann_data.keys():
- centers = self.ann_data['center']
- else:
- centers = np.zeros((num_imgs, 2), dtype=np.float32)
-
- if 'scale' in self.ann_data.keys():
- scales = self.ann_data['scale'].astype(np.float32)
- else:
- scales = np.zeros(num_imgs, dtype=np.float32)
-
- instance_list = []
- image_list = []
-
- for idx, frame_ids in enumerate(self.sequence_indices):
- assert len(frame_ids) == self.seq_len
-
- _img_names = img_names[frame_ids]
-
- _keypoints = kpts_2d[frame_ids].astype(np.float32)
- keypoints = _keypoints[..., :2]
- keypoints_visible = _keypoints[..., 2]
-
- _keypoints_3d = kpts_3d[frame_ids].astype(np.float32)
- keypoints_3d = _keypoints_3d[..., :3]
- keypoints_3d_visible = _keypoints_3d[..., 3]
-
- target_idx = -1 if self.causal else int(self.seq_len) // 2
-
- instance_info = {
- 'num_keypoints': num_keypoints,
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- 'keypoints_3d': keypoints_3d,
- 'keypoints_3d_visible': keypoints_3d_visible,
- 'scale': scales[idx],
- 'center': centers[idx].astype(np.float32).reshape(1, -1),
- 'id': idx,
- 'category_id': 1,
- 'iscrowd': 0,
- 'img_paths': list(_img_names),
- 'img_ids': frame_ids,
- 'lifting_target': keypoints_3d[target_idx],
- 'lifting_target_visible': keypoints_3d_visible[target_idx],
- 'target_img_path': _img_names[target_idx],
- }
-
- if self.camera_param_file:
- _cam_param = self.get_camera_param(_img_names[0])
- instance_info['camera_param'] = _cam_param
-
- instance_list.append(instance_info)
-
- for idx, imgname in enumerate(img_names):
- img_info = self.get_img_info(idx, imgname)
- image_list.append(img_info)
-
- return instance_list, image_list
-
- def get_camera_param(self, imgname):
- """Get camera parameters of a frame by its image name.
-
- Override this method to specify how to get camera parameters.
- """
- raise NotImplementedError
-
- @staticmethod
- def _is_valid_instance(data_info: Dict) -> bool:
- """Check a data info is an instance with valid bbox and keypoint
- annotations."""
- # crowd annotation
- if 'iscrowd' in data_info and data_info['iscrowd']:
- return False
- # invalid keypoints
- if 'num_keypoints' in data_info and data_info['num_keypoints'] == 0:
- return False
- # invalid keypoints
- if 'keypoints' in data_info:
- if np.max(data_info['keypoints']) <= 0:
- return False
- return True
-
- def _get_topdown_data_infos(self, instance_list: List[Dict]) -> List[Dict]:
- """Organize the data list in top-down mode."""
- # sanitize data samples
- data_list_tp = list(filter(self._is_valid_instance, instance_list))
-
- return data_list_tp
-
- def _get_bottomup_data_infos(self, instance_list: List[Dict],
- image_list: List[Dict]) -> List[Dict]:
- """Organize the data list in bottom-up mode."""
-
- # bottom-up data list
- data_list_bu = []
-
- used_img_ids = set()
-
- # group instances by img_id
- for img_ids, data_infos in groupby(instance_list,
- lambda x: x['img_ids']):
- for img_id in img_ids:
- used_img_ids.add(img_id)
- data_infos = list(data_infos)
-
- # image data
- img_paths = data_infos[0]['img_paths']
- data_info_bu = {
- 'img_ids': img_ids,
- 'img_paths': img_paths,
- }
-
- for key in data_infos[0].keys():
- if key not in data_info_bu:
- seq = [d[key] for d in data_infos]
- if isinstance(seq[0], np.ndarray):
- seq = np.concatenate(seq, axis=0)
- data_info_bu[key] = seq
-
- # The segmentation annotation of invalid objects will be used
- # to generate valid region mask in the pipeline.
- invalid_segs = []
- for data_info_invalid in filterfalse(self._is_valid_instance,
- data_infos):
- if 'segmentation' in data_info_invalid:
- invalid_segs.append(data_info_invalid['segmentation'])
- data_info_bu['invalid_segs'] = invalid_segs
-
- data_list_bu.append(data_info_bu)
-
- # add images without instance for evaluation
- if self.test_mode:
- for img_info in image_list:
- if img_info['img_id'] not in used_img_ids:
- data_info_bu = {
- 'img_ids': [img_info['img_id']],
- 'img_path': [img_info['img_path']],
- 'id': list(),
- }
- data_list_bu.append(data_info_bu)
-
- return data_list_bu
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from copy import deepcopy
+from itertools import filterfalse, groupby
+from typing import Any, Callable, Dict, List, Optional, Sequence, Tuple, Union
+
+import numpy as np
+from mmengine.dataset import BaseDataset, force_full_init
+from mmengine.fileio import exists, get_local_path, load
+from mmengine.utils import is_abs
+from PIL import Image
+
+from mmpose.registry import DATASETS
+from ..utils import parse_pose_metainfo
+
+
+@DATASETS.register_module()
+class BaseMocapDataset(BaseDataset):
+ """Base class for 3d body datasets.
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ seq_len (int): Number of frames in a sequence. Default: 1.
+ causal (bool): If set to ``True``, the rightmost input frame will be
+ the target frame. Otherwise, the middle input frame will be the
+ target frame. Default: ``True``.
+ subset_frac (float): The fraction to reduce dataset size. If set to 1,
+ the dataset size is not reduced. Default: 1.
+ camera_param_file (str): Cameras' parameters file. Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data.
+ Default: ``dict(img='')``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict()
+
+ def __init__(self,
+ ann_file: str = '',
+ seq_len: int = 1,
+ causal: bool = True,
+ subset_frac: float = 1.0,
+ camera_param_file: Optional[str] = None,
+ data_mode: str = 'topdown',
+ metainfo: Optional[dict] = None,
+ data_root: Optional[str] = None,
+ data_prefix: dict = dict(img=''),
+ filter_cfg: Optional[dict] = None,
+ indices: Optional[Union[int, Sequence[int]]] = None,
+ serialize_data: bool = True,
+ pipeline: List[Union[dict, Callable]] = [],
+ test_mode: bool = False,
+ lazy_init: bool = False,
+ max_refetch: int = 1000):
+
+ if data_mode not in {'topdown', 'bottomup'}:
+ raise ValueError(
+ f'{self.__class__.__name__} got invalid data_mode: '
+ f'{data_mode}. Should be "topdown" or "bottomup".')
+ self.data_mode = data_mode
+
+ _ann_file = ann_file
+ if not is_abs(_ann_file):
+ _ann_file = osp.join(data_root, _ann_file)
+ assert exists(_ann_file), 'Annotation file does not exist.'
+ with get_local_path(_ann_file) as local_path:
+ self.ann_data = np.load(local_path)
+
+ self.camera_param_file = camera_param_file
+ if self.camera_param_file:
+ if not is_abs(self.camera_param_file):
+ self.camera_param_file = osp.join(data_root,
+ self.camera_param_file)
+ assert exists(self.camera_param_file)
+ self.camera_param = load(self.camera_param_file)
+
+ self.seq_len = seq_len
+ self.causal = causal
+
+ assert 0 < subset_frac <= 1, (
+ f'Unsupported `subset_frac` {subset_frac}. Supported range '
+ 'is (0, 1].')
+ self.subset_frac = subset_frac
+
+ self.sequence_indices = self.get_sequence_indices()
+
+ super().__init__(
+ ann_file=ann_file,
+ metainfo=metainfo,
+ data_root=data_root,
+ data_prefix=data_prefix,
+ filter_cfg=filter_cfg,
+ indices=indices,
+ serialize_data=serialize_data,
+ pipeline=pipeline,
+ test_mode=test_mode,
+ lazy_init=lazy_init,
+ max_refetch=max_refetch)
+
+ @classmethod
+ def _load_metainfo(cls, metainfo: dict = None) -> dict:
+ """Collect meta information from the dictionary of meta.
+
+ Args:
+ metainfo (dict): Raw data of pose meta information.
+
+ Returns:
+ dict: Parsed meta information.
+ """
+
+ if metainfo is None:
+ metainfo = deepcopy(cls.METAINFO)
+
+ if not isinstance(metainfo, dict):
+ raise TypeError(
+ f'metainfo should be a dict, but got {type(metainfo)}')
+
+ # parse pose metainfo if it has been assigned
+ if metainfo:
+ metainfo = parse_pose_metainfo(metainfo)
+ return metainfo
+
+ @force_full_init
+ def prepare_data(self, idx) -> Any:
+ """Get data processed by ``self.pipeline``.
+
+ :class:`BaseCocoStyleDataset` overrides this method from
+ :class:`mmengine.dataset.BaseDataset` to add the metainfo into
+ the ``data_info`` before it is passed to the pipeline.
+
+ Args:
+ idx (int): The index of ``data_info``.
+
+ Returns:
+ Any: Depends on ``self.pipeline``.
+ """
+ data_info = self.get_data_info(idx)
+
+ return self.pipeline(data_info)
+
+ def get_data_info(self, idx: int) -> dict:
+ """Get data info by index.
+
+ Args:
+ idx (int): Index of data info.
+
+ Returns:
+ dict: Data info.
+ """
+ data_info = super().get_data_info(idx)
+
+ # Add metainfo items that are required in the pipeline and the model
+ metainfo_keys = [
+ 'upper_body_ids', 'lower_body_ids', 'flip_pairs',
+ 'dataset_keypoint_weights', 'flip_indices', 'skeleton_links'
+ ]
+
+ for key in metainfo_keys:
+ assert key not in data_info, (
+ f'"{key}" is a reserved key for `metainfo`, but already '
+ 'exists in the `data_info`.')
+
+ data_info[key] = deepcopy(self._metainfo[key])
+
+ return data_info
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list from COCO annotation file or person detection result
+ file."""
+
+ instance_list, image_list = self._load_annotations()
+
+ if self.data_mode == 'topdown':
+ data_list = self._get_topdown_data_infos(instance_list)
+ else:
+ data_list = self._get_bottomup_data_infos(instance_list,
+ image_list)
+
+ return data_list
+
+ def get_img_info(self, img_idx, img_name):
+ try:
+ with get_local_path(osp.join(self.data_prefix['img'],
+ img_name)) as local_path:
+ im = Image.open(local_path)
+ w, h = im.size
+ im.close()
+ except: # noqa: E722
+ return None
+
+ img = {
+ 'file_name': img_name,
+ 'height': h,
+ 'width': w,
+ 'id': img_idx,
+ 'img_id': img_idx,
+ 'img_path': osp.join(self.data_prefix['img'], img_name),
+ }
+ return img
+
+ def get_sequence_indices(self) -> List[List[int]]:
+ """Build sequence indices.
+
+ The default method creates sample indices that each sample is a single
+ frame (i.e. seq_len=1). Override this method in the subclass to define
+ how frames are sampled to form data samples.
+
+ Outputs:
+ sample_indices: the frame indices of each sample.
+ For a sample, all frames will be treated as an input sequence,
+ and the ground-truth pose of the last frame will be the target.
+ """
+ sequence_indices = []
+ if self.seq_len == 1:
+ num_imgs = len(self.ann_data['imgname'])
+ sequence_indices = [[idx] for idx in range(num_imgs)]
+ else:
+ raise NotImplementedError('Multi-frame data sample unsupported!')
+ return sequence_indices
+
+ def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
+ """Load data from annotations in COCO format."""
+ num_keypoints = self.metainfo['num_keypoints']
+
+ img_names = self.ann_data['imgname']
+ num_imgs = len(img_names)
+
+ if 'S' in self.ann_data.keys():
+ kpts_3d = self.ann_data['S']
+ else:
+ kpts_3d = np.zeros((num_imgs, num_keypoints, 4), dtype=np.float32)
+
+ if 'part' in self.ann_data.keys():
+ kpts_2d = self.ann_data['part']
+ else:
+ kpts_2d = np.zeros((num_imgs, num_keypoints, 3), dtype=np.float32)
+
+ if 'center' in self.ann_data.keys():
+ centers = self.ann_data['center']
+ else:
+ centers = np.zeros((num_imgs, 2), dtype=np.float32)
+
+ if 'scale' in self.ann_data.keys():
+ scales = self.ann_data['scale'].astype(np.float32)
+ else:
+ scales = np.zeros(num_imgs, dtype=np.float32)
+
+ instance_list = []
+ image_list = []
+
+ for idx, frame_ids in enumerate(self.sequence_indices):
+ assert len(frame_ids) == self.seq_len
+
+ _img_names = img_names[frame_ids]
+
+ _keypoints = kpts_2d[frame_ids].astype(np.float32)
+ keypoints = _keypoints[..., :2]
+ keypoints_visible = _keypoints[..., 2]
+
+ _keypoints_3d = kpts_3d[frame_ids].astype(np.float32)
+ keypoints_3d = _keypoints_3d[..., :3]
+ keypoints_3d_visible = _keypoints_3d[..., 3]
+
+ target_idx = -1 if self.causal else int(self.seq_len) // 2
+
+ instance_info = {
+ 'num_keypoints': num_keypoints,
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ 'keypoints_3d': keypoints_3d,
+ 'keypoints_3d_visible': keypoints_3d_visible,
+ 'scale': scales[idx],
+ 'center': centers[idx].astype(np.float32).reshape(1, -1),
+ 'id': idx,
+ 'category_id': 1,
+ 'iscrowd': 0,
+ 'img_paths': list(_img_names),
+ 'img_ids': frame_ids,
+ 'lifting_target': keypoints_3d[target_idx],
+ 'lifting_target_visible': keypoints_3d_visible[target_idx],
+ 'target_img_path': _img_names[target_idx],
+ }
+
+ if self.camera_param_file:
+ _cam_param = self.get_camera_param(_img_names[0])
+ instance_info['camera_param'] = _cam_param
+
+ instance_list.append(instance_info)
+
+ for idx, imgname in enumerate(img_names):
+ img_info = self.get_img_info(idx, imgname)
+ image_list.append(img_info)
+
+ return instance_list, image_list
+
+ def get_camera_param(self, imgname):
+ """Get camera parameters of a frame by its image name.
+
+ Override this method to specify how to get camera parameters.
+ """
+ raise NotImplementedError
+
+ @staticmethod
+ def _is_valid_instance(data_info: Dict) -> bool:
+ """Check a data info is an instance with valid bbox and keypoint
+ annotations."""
+ # crowd annotation
+ if 'iscrowd' in data_info and data_info['iscrowd']:
+ return False
+ # invalid keypoints
+ if 'num_keypoints' in data_info and data_info['num_keypoints'] == 0:
+ return False
+ # invalid keypoints
+ if 'keypoints' in data_info:
+ if np.max(data_info['keypoints']) <= 0:
+ return False
+ return True
+
+ def _get_topdown_data_infos(self, instance_list: List[Dict]) -> List[Dict]:
+ """Organize the data list in top-down mode."""
+ # sanitize data samples
+ data_list_tp = list(filter(self._is_valid_instance, instance_list))
+
+ return data_list_tp
+
+ def _get_bottomup_data_infos(self, instance_list: List[Dict],
+ image_list: List[Dict]) -> List[Dict]:
+ """Organize the data list in bottom-up mode."""
+
+ # bottom-up data list
+ data_list_bu = []
+
+ used_img_ids = set()
+
+ # group instances by img_id
+ for img_ids, data_infos in groupby(instance_list,
+ lambda x: x['img_ids']):
+ for img_id in img_ids:
+ used_img_ids.add(img_id)
+ data_infos = list(data_infos)
+
+ # image data
+ img_paths = data_infos[0]['img_paths']
+ data_info_bu = {
+ 'img_ids': img_ids,
+ 'img_paths': img_paths,
+ }
+
+ for key in data_infos[0].keys():
+ if key not in data_info_bu:
+ seq = [d[key] for d in data_infos]
+ if isinstance(seq[0], np.ndarray):
+ seq = np.concatenate(seq, axis=0)
+ data_info_bu[key] = seq
+
+ # The segmentation annotation of invalid objects will be used
+ # to generate valid region mask in the pipeline.
+ invalid_segs = []
+ for data_info_invalid in filterfalse(self._is_valid_instance,
+ data_infos):
+ if 'segmentation' in data_info_invalid:
+ invalid_segs.append(data_info_invalid['segmentation'])
+ data_info_bu['invalid_segs'] = invalid_segs
+
+ data_list_bu.append(data_info_bu)
+
+ # add images without instance for evaluation
+ if self.test_mode:
+ for img_info in image_list:
+ if img_info['img_id'] not in used_img_ids:
+ data_info_bu = {
+ 'img_ids': [img_info['img_id']],
+ 'img_path': [img_info['img_path']],
+ 'id': list(),
+ }
+ data_list_bu.append(data_info_bu)
+
+ return data_list_bu
diff --git a/mmpose/datasets/datasets/body/__init__.py b/mmpose/datasets/datasets/body/__init__.py
index 1405b0d675..93fdaa4e81 100644
--- a/mmpose/datasets/datasets/body/__init__.py
+++ b/mmpose/datasets/datasets/body/__init__.py
@@ -1,18 +1,18 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .aic_dataset import AicDataset
-from .coco_dataset import CocoDataset
-from .crowdpose_dataset import CrowdPoseDataset
-from .humanart_dataset import HumanArtDataset
-from .jhmdb_dataset import JhmdbDataset
-from .mhp_dataset import MhpDataset
-from .mpii_dataset import MpiiDataset
-from .mpii_trb_dataset import MpiiTrbDataset
-from .ochuman_dataset import OCHumanDataset
-from .posetrack18_dataset import PoseTrack18Dataset
-from .posetrack18_video_dataset import PoseTrack18VideoDataset
-
-__all__ = [
- 'CocoDataset', 'MpiiDataset', 'MpiiTrbDataset', 'AicDataset',
- 'CrowdPoseDataset', 'OCHumanDataset', 'MhpDataset', 'PoseTrack18Dataset',
- 'JhmdbDataset', 'PoseTrack18VideoDataset', 'HumanArtDataset'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .aic_dataset import AicDataset
+from .coco_dataset import CocoDataset
+from .crowdpose_dataset import CrowdPoseDataset
+from .humanart_dataset import HumanArtDataset
+from .jhmdb_dataset import JhmdbDataset
+from .mhp_dataset import MhpDataset
+from .mpii_dataset import MpiiDataset
+from .mpii_trb_dataset import MpiiTrbDataset
+from .ochuman_dataset import OCHumanDataset
+from .posetrack18_dataset import PoseTrack18Dataset
+from .posetrack18_video_dataset import PoseTrack18VideoDataset
+
+__all__ = [
+ 'CocoDataset', 'MpiiDataset', 'MpiiTrbDataset', 'AicDataset',
+ 'CrowdPoseDataset', 'OCHumanDataset', 'MhpDataset', 'PoseTrack18Dataset',
+ 'JhmdbDataset', 'PoseTrack18VideoDataset', 'HumanArtDataset'
+]
diff --git a/mmpose/datasets/datasets/body/aic_dataset.py b/mmpose/datasets/datasets/body/aic_dataset.py
index b9c7cccc76..5b3ab5353e 100644
--- a/mmpose/datasets/datasets/body/aic_dataset.py
+++ b/mmpose/datasets/datasets/body/aic_dataset.py
@@ -1,70 +1,70 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class AicDataset(BaseCocoStyleDataset):
- """AIC dataset for pose estimation.
-
- "AI Challenger : A Large-scale Dataset for Going Deeper
- in Image Understanding", arXiv'2017.
- More details can be found in the `paper
- `__
-
- AIC keypoints::
-
- 0: "right_shoulder",
- 1: "right_elbow",
- 2: "right_wrist",
- 3: "left_shoulder",
- 4: "left_elbow",
- 5: "left_wrist",
- 6: "right_hip",
- 7: "right_knee",
- 8: "right_ankle",
- 9: "left_hip",
- 10: "left_knee",
- 11: "left_ankle",
- 12: "head_top",
- 13: "neck"
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/aic.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class AicDataset(BaseCocoStyleDataset):
+ """AIC dataset for pose estimation.
+
+ "AI Challenger : A Large-scale Dataset for Going Deeper
+ in Image Understanding", arXiv'2017.
+ More details can be found in the `paper
+ `__
+
+ AIC keypoints::
+
+ 0: "right_shoulder",
+ 1: "right_elbow",
+ 2: "right_wrist",
+ 3: "left_shoulder",
+ 4: "left_elbow",
+ 5: "left_wrist",
+ 6: "right_hip",
+ 7: "right_knee",
+ 8: "right_ankle",
+ 9: "left_hip",
+ 10: "left_knee",
+ 11: "left_ankle",
+ 12: "head_top",
+ 13: "neck"
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/aic.py')
diff --git a/mmpose/datasets/datasets/body/coco_dataset.py b/mmpose/datasets/datasets/body/coco_dataset.py
index 7cc971f91f..789a1f0561 100644
--- a/mmpose/datasets/datasets/body/coco_dataset.py
+++ b/mmpose/datasets/datasets/body/coco_dataset.py
@@ -1,72 +1,72 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class CocoDataset(BaseCocoStyleDataset):
- """COCO dataset for pose estimation.
-
- "Microsoft COCO: Common Objects in Context", ECCV'2014.
- More details can be found in the `paper
- `__ .
-
- COCO keypoints::
-
- 0: 'nose',
- 1: 'left_eye',
- 2: 'right_eye',
- 3: 'left_ear',
- 4: 'right_ear',
- 5: 'left_shoulder',
- 6: 'right_shoulder',
- 7: 'left_elbow',
- 8: 'right_elbow',
- 9: 'left_wrist',
- 10: 'right_wrist',
- 11: 'left_hip',
- 12: 'right_hip',
- 13: 'left_knee',
- 14: 'right_knee',
- 15: 'left_ankle',
- 16: 'right_ankle'
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/coco.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class CocoDataset(BaseCocoStyleDataset):
+ """COCO dataset for pose estimation.
+
+ "Microsoft COCO: Common Objects in Context", ECCV'2014.
+ More details can be found in the `paper
+ `__ .
+
+ COCO keypoints::
+
+ 0: 'nose',
+ 1: 'left_eye',
+ 2: 'right_eye',
+ 3: 'left_ear',
+ 4: 'right_ear',
+ 5: 'left_shoulder',
+ 6: 'right_shoulder',
+ 7: 'left_elbow',
+ 8: 'right_elbow',
+ 9: 'left_wrist',
+ 10: 'right_wrist',
+ 11: 'left_hip',
+ 12: 'right_hip',
+ 13: 'left_knee',
+ 14: 'right_knee',
+ 15: 'left_ankle',
+ 16: 'right_ankle'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/coco.py')
diff --git a/mmpose/datasets/datasets/body/crowdpose_dataset.py b/mmpose/datasets/datasets/body/crowdpose_dataset.py
index 4218708ff2..56ca02cf63 100644
--- a/mmpose/datasets/datasets/body/crowdpose_dataset.py
+++ b/mmpose/datasets/datasets/body/crowdpose_dataset.py
@@ -1,70 +1,70 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class CrowdPoseDataset(BaseCocoStyleDataset):
- """CrowdPose dataset for pose estimation.
-
- "CrowdPose: Efficient Crowded Scenes Pose Estimation and
- A New Benchmark", CVPR'2019.
- More details can be found in the `paper
- `__.
-
- CrowdPose keypoints::
-
- 0: 'left_shoulder',
- 1: 'right_shoulder',
- 2: 'left_elbow',
- 3: 'right_elbow',
- 4: 'left_wrist',
- 5: 'right_wrist',
- 6: 'left_hip',
- 7: 'right_hip',
- 8: 'left_knee',
- 9: 'right_knee',
- 10: 'left_ankle',
- 11: 'right_ankle',
- 12: 'top_head',
- 13: 'neck'
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/crowdpose.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class CrowdPoseDataset(BaseCocoStyleDataset):
+ """CrowdPose dataset for pose estimation.
+
+ "CrowdPose: Efficient Crowded Scenes Pose Estimation and
+ A New Benchmark", CVPR'2019.
+ More details can be found in the `paper
+ `__.
+
+ CrowdPose keypoints::
+
+ 0: 'left_shoulder',
+ 1: 'right_shoulder',
+ 2: 'left_elbow',
+ 3: 'right_elbow',
+ 4: 'left_wrist',
+ 5: 'right_wrist',
+ 6: 'left_hip',
+ 7: 'right_hip',
+ 8: 'left_knee',
+ 9: 'right_knee',
+ 10: 'left_ankle',
+ 11: 'right_ankle',
+ 12: 'top_head',
+ 13: 'neck'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/crowdpose.py')
diff --git a/mmpose/datasets/datasets/body/humanart_dataset.py b/mmpose/datasets/datasets/body/humanart_dataset.py
index 719f35fc9e..9af5e4e5a2 100644
--- a/mmpose/datasets/datasets/body/humanart_dataset.py
+++ b/mmpose/datasets/datasets/body/humanart_dataset.py
@@ -1,73 +1,73 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class HumanArtDataset(BaseCocoStyleDataset):
- """Human-Art dataset for pose estimation.
-
- "Human-Art: A Versatile Human-Centric Dataset
- Bridging Natural and Artificial Scenes", CVPR'2023.
- More details can be found in the `paper
- `__ .
-
- Human-Art keypoints::
-
- 0: 'nose',
- 1: 'left_eye',
- 2: 'right_eye',
- 3: 'left_ear',
- 4: 'right_ear',
- 5: 'left_shoulder',
- 6: 'right_shoulder',
- 7: 'left_elbow',
- 8: 'right_elbow',
- 9: 'left_wrist',
- 10: 'right_wrist',
- 11: 'left_hip',
- 12: 'right_hip',
- 13: 'left_knee',
- 14: 'right_knee',
- 15: 'left_ankle',
- 16: 'right_ankle'
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/humanart.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class HumanArtDataset(BaseCocoStyleDataset):
+ """Human-Art dataset for pose estimation.
+
+ "Human-Art: A Versatile Human-Centric Dataset
+ Bridging Natural and Artificial Scenes", CVPR'2023.
+ More details can be found in the `paper
+ `__ .
+
+ Human-Art keypoints::
+
+ 0: 'nose',
+ 1: 'left_eye',
+ 2: 'right_eye',
+ 3: 'left_ear',
+ 4: 'right_ear',
+ 5: 'left_shoulder',
+ 6: 'right_shoulder',
+ 7: 'left_elbow',
+ 8: 'right_elbow',
+ 9: 'left_wrist',
+ 10: 'right_wrist',
+ 11: 'left_hip',
+ 12: 'right_hip',
+ 13: 'left_knee',
+ 14: 'right_knee',
+ 15: 'left_ankle',
+ 16: 'right_ankle'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/humanart.py')
diff --git a/mmpose/datasets/datasets/body/jhmdb_dataset.py b/mmpose/datasets/datasets/body/jhmdb_dataset.py
index 7d72a7ddc5..e76dec4de8 100644
--- a/mmpose/datasets/datasets/body/jhmdb_dataset.py
+++ b/mmpose/datasets/datasets/body/jhmdb_dataset.py
@@ -1,135 +1,135 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os.path as osp
-from typing import Optional
-
-import numpy as np
-
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class JhmdbDataset(BaseCocoStyleDataset):
- """JhmdbDataset dataset for pose estimation.
-
- "Towards understanding action recognition", ICCV'2013.
- More details can be found in the `paper
- `__
-
- sub-JHMDB keypoints::
-
- 0: "neck",
- 1: "belly",
- 2: "head",
- 3: "right_shoulder",
- 4: "left_shoulder",
- 5: "right_hip",
- 6: "left_hip",
- 7: "right_elbow",
- 8: "left_elbow",
- 9: "right_knee",
- 10: "left_knee",
- 11: "right_wrist",
- 12: "left_wrist",
- 13: "right_ankle",
- 14: "left_ankle"
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/jhmdb.py')
-
- def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
- """Parse raw COCO annotation of an instance.
-
- Args:
- raw_data_info (dict): Raw data information loaded from
- ``ann_file``. It should have following contents:
-
- - ``'raw_ann_info'``: Raw annotation of an instance
- - ``'raw_img_info'``: Raw information of the image that
- contains the instance
-
- Returns:
- dict: Parsed instance annotation
- """
-
- ann = raw_data_info['raw_ann_info']
- img = raw_data_info['raw_img_info']
-
- img_path = osp.join(self.data_prefix['img'], img['file_name'])
- img_w, img_h = img['width'], img['height']
-
- # get bbox in shape [1, 4], formatted as xywh
- x, y, w, h = ann['bbox']
- # JHMDB uses matlab format, index is 1-based,
- # we should first convert to 0-based index
- x -= 1
- y -= 1
- x1 = np.clip(x, 0, img_w - 1)
- y1 = np.clip(y, 0, img_h - 1)
- x2 = np.clip(x + w, 0, img_w - 1)
- y2 = np.clip(y + h, 0, img_h - 1)
-
- bbox = np.array([x1, y1, x2, y2], dtype=np.float32).reshape(1, 4)
-
- # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
- _keypoints = np.array(
- ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
- # JHMDB uses matlab format, index is 1-based,
- # we should first convert to 0-based index
- keypoints = _keypoints[..., :2] - 1
- keypoints_visible = np.minimum(1, _keypoints[..., 2])
-
- num_keypoints = np.count_nonzero(keypoints.max(axis=2))
-
- data_info = {
- 'img_id': ann['image_id'],
- 'img_path': img_path,
- 'bbox': bbox,
- 'bbox_score': np.ones(1, dtype=np.float32),
- 'num_keypoints': num_keypoints,
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- 'iscrowd': ann.get('iscrowd', 0),
- 'segmentation': ann.get('segmentation', None),
- 'id': ann['id'],
- }
-
- return data_info
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import Optional
+
+import numpy as np
+
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class JhmdbDataset(BaseCocoStyleDataset):
+ """JhmdbDataset dataset for pose estimation.
+
+ "Towards understanding action recognition", ICCV'2013.
+ More details can be found in the `paper
+ `__
+
+ sub-JHMDB keypoints::
+
+ 0: "neck",
+ 1: "belly",
+ 2: "head",
+ 3: "right_shoulder",
+ 4: "left_shoulder",
+ 5: "right_hip",
+ 6: "left_hip",
+ 7: "right_elbow",
+ 8: "left_elbow",
+ 9: "right_knee",
+ 10: "left_knee",
+ 11: "right_wrist",
+ 12: "left_wrist",
+ 13: "right_ankle",
+ 14: "left_ankle"
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/jhmdb.py')
+
+ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
+ """Parse raw COCO annotation of an instance.
+
+ Args:
+ raw_data_info (dict): Raw data information loaded from
+ ``ann_file``. It should have following contents:
+
+ - ``'raw_ann_info'``: Raw annotation of an instance
+ - ``'raw_img_info'``: Raw information of the image that
+ contains the instance
+
+ Returns:
+ dict: Parsed instance annotation
+ """
+
+ ann = raw_data_info['raw_ann_info']
+ img = raw_data_info['raw_img_info']
+
+ img_path = osp.join(self.data_prefix['img'], img['file_name'])
+ img_w, img_h = img['width'], img['height']
+
+ # get bbox in shape [1, 4], formatted as xywh
+ x, y, w, h = ann['bbox']
+ # JHMDB uses matlab format, index is 1-based,
+ # we should first convert to 0-based index
+ x -= 1
+ y -= 1
+ x1 = np.clip(x, 0, img_w - 1)
+ y1 = np.clip(y, 0, img_h - 1)
+ x2 = np.clip(x + w, 0, img_w - 1)
+ y2 = np.clip(y + h, 0, img_h - 1)
+
+ bbox = np.array([x1, y1, x2, y2], dtype=np.float32).reshape(1, 4)
+
+ # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
+ _keypoints = np.array(
+ ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
+ # JHMDB uses matlab format, index is 1-based,
+ # we should first convert to 0-based index
+ keypoints = _keypoints[..., :2] - 1
+ keypoints_visible = np.minimum(1, _keypoints[..., 2])
+
+ num_keypoints = np.count_nonzero(keypoints.max(axis=2))
+
+ data_info = {
+ 'img_id': ann['image_id'],
+ 'img_path': img_path,
+ 'bbox': bbox,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'num_keypoints': num_keypoints,
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ 'iscrowd': ann.get('iscrowd', 0),
+ 'segmentation': ann.get('segmentation', None),
+ 'id': ann['id'],
+ }
+
+ return data_info
diff --git a/mmpose/datasets/datasets/body/mhp_dataset.py b/mmpose/datasets/datasets/body/mhp_dataset.py
index 55d3360253..e8d5410f73 100644
--- a/mmpose/datasets/datasets/body/mhp_dataset.py
+++ b/mmpose/datasets/datasets/body/mhp_dataset.py
@@ -1,72 +1,72 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class MhpDataset(BaseCocoStyleDataset):
- """MHPv2.0 dataset for pose estimation.
-
- "Understanding Humans in Crowded Scenes: Deep Nested Adversarial
- Learning and A New Benchmark for Multi-Human Parsing", ACM MM'2018.
- More details can be found in the `paper
- `__
-
- MHP keypoints::
-
- 0: "right ankle",
- 1: "right knee",
- 2: "right hip",
- 3: "left hip",
- 4: "left knee",
- 5: "left ankle",
- 6: "pelvis",
- 7: "thorax",
- 8: "upper neck",
- 9: "head top",
- 10: "right wrist",
- 11: "right elbow",
- 12: "right shoulder",
- 13: "left shoulder",
- 14: "left elbow",
- 15: "left wrist",
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/mhp.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class MhpDataset(BaseCocoStyleDataset):
+ """MHPv2.0 dataset for pose estimation.
+
+ "Understanding Humans in Crowded Scenes: Deep Nested Adversarial
+ Learning and A New Benchmark for Multi-Human Parsing", ACM MM'2018.
+ More details can be found in the `paper
+ `__
+
+ MHP keypoints::
+
+ 0: "right ankle",
+ 1: "right knee",
+ 2: "right hip",
+ 3: "left hip",
+ 4: "left knee",
+ 5: "left ankle",
+ 6: "pelvis",
+ 7: "thorax",
+ 8: "upper neck",
+ 9: "head top",
+ 10: "right wrist",
+ 11: "right elbow",
+ 12: "right shoulder",
+ 13: "left shoulder",
+ 14: "left elbow",
+ 15: "left wrist",
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/mhp.py')
diff --git a/mmpose/datasets/datasets/body/mpii_dataset.py b/mmpose/datasets/datasets/body/mpii_dataset.py
index 237f1ab2b6..c90abd6003 100644
--- a/mmpose/datasets/datasets/body/mpii_dataset.py
+++ b/mmpose/datasets/datasets/body/mpii_dataset.py
@@ -1,212 +1,212 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import json
-import os.path as osp
-from typing import Callable, List, Optional, Sequence, Tuple, Union
-
-import numpy as np
-from mmengine.fileio import exists, get_local_path
-from scipy.io import loadmat
-
-from mmpose.registry import DATASETS
-from mmpose.structures.bbox import bbox_cs2xyxy
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class MpiiDataset(BaseCocoStyleDataset):
- """MPII Dataset for pose estimation.
-
- "2D Human Pose Estimation: New Benchmark and State of the Art Analysis"
- ,CVPR'2014. More details can be found in the `paper
- `__ .
-
- MPII keypoints::
-
- 0: 'right_ankle'
- 1: 'right_knee',
- 2: 'right_hip',
- 3: 'left_hip',
- 4: 'left_knee',
- 5: 'left_ankle',
- 6: 'pelvis',
- 7: 'thorax',
- 8: 'upper_neck',
- 9: 'head_top',
- 10: 'right_wrist',
- 11: 'right_elbow',
- 12: 'right_shoulder',
- 13: 'left_shoulder',
- 14: 'left_elbow',
- 15: 'left_wrist'
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- headbox_file (str, optional): The path of ``mpii_gt_val.mat`` which
- provides the headboxes information used for ``PCKh``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/mpii.py')
-
- def __init__(self,
- ann_file: str = '',
- bbox_file: Optional[str] = None,
- headbox_file: Optional[str] = None,
- data_mode: str = 'topdown',
- metainfo: Optional[dict] = None,
- data_root: Optional[str] = None,
- data_prefix: dict = dict(img=''),
- filter_cfg: Optional[dict] = None,
- indices: Optional[Union[int, Sequence[int]]] = None,
- serialize_data: bool = True,
- pipeline: List[Union[dict, Callable]] = [],
- test_mode: bool = False,
- lazy_init: bool = False,
- max_refetch: int = 1000):
-
- if headbox_file:
- if data_mode != 'topdown':
- raise ValueError(
- f'{self.__class__.__name__} is set to {data_mode}: '
- 'mode, while "headbox_file" is only '
- 'supported in topdown mode.')
-
- if not test_mode:
- raise ValueError(
- f'{self.__class__.__name__} has `test_mode==False` '
- 'while "headbox_file" is only '
- 'supported when `test_mode==True`.')
-
- headbox_file_type = headbox_file[-3:]
- allow_headbox_file_type = ['mat']
- if headbox_file_type not in allow_headbox_file_type:
- raise KeyError(
- f'The head boxes file type {headbox_file_type} is not '
- f'supported. Should be `mat` but got {headbox_file_type}.')
- self.headbox_file = headbox_file
-
- super().__init__(
- ann_file=ann_file,
- bbox_file=bbox_file,
- data_mode=data_mode,
- metainfo=metainfo,
- data_root=data_root,
- data_prefix=data_prefix,
- filter_cfg=filter_cfg,
- indices=indices,
- serialize_data=serialize_data,
- pipeline=pipeline,
- test_mode=test_mode,
- lazy_init=lazy_init,
- max_refetch=max_refetch)
-
- def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
- """Load data from annotations in MPII format."""
-
- assert exists(self.ann_file), 'Annotation file does not exist'
- with get_local_path(self.ann_file) as local_path:
- with open(local_path) as anno_file:
- self.anns = json.load(anno_file)
-
- if self.headbox_file:
- assert exists(self.headbox_file), 'Headbox file does not exist'
- with get_local_path(self.headbox_file) as local_path:
- self.headbox_dict = loadmat(local_path)
- headboxes_src = np.transpose(self.headbox_dict['headboxes_src'],
- [2, 0, 1])
- SC_BIAS = 0.6
-
- instance_list = []
- image_list = []
- used_img_ids = set()
- ann_id = 0
-
- # mpii bbox scales are normalized with factor 200.
- pixel_std = 200.
-
- for idx, ann in enumerate(self.anns):
- center = np.array(ann['center'], dtype=np.float32)
- scale = np.array([ann['scale'], ann['scale']],
- dtype=np.float32) * pixel_std
-
- # Adjust center/scale slightly to avoid cropping limbs
- if center[0] != -1:
- center[1] = center[1] + 15. / pixel_std * scale[1]
-
- # MPII uses matlab format, index is 1-based,
- # we should first convert to 0-based index
- center = center - 1
-
- # unify shape with coco datasets
- center = center.reshape(1, -1)
- scale = scale.reshape(1, -1)
- bbox = bbox_cs2xyxy(center, scale)
-
- # load keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
- keypoints = np.array(ann['joints']).reshape(1, -1, 2)
- keypoints_visible = np.array(ann['joints_vis']).reshape(1, -1)
-
- instance_info = {
- 'id': ann_id,
- 'img_id': int(ann['image'].split('.')[0]),
- 'img_path': osp.join(self.data_prefix['img'], ann['image']),
- 'bbox_center': center,
- 'bbox_scale': scale,
- 'bbox': bbox,
- 'bbox_score': np.ones(1, dtype=np.float32),
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- }
-
- if self.headbox_file:
- # calculate the diagonal length of head box as norm_factor
- headbox = headboxes_src[idx]
- head_size = np.linalg.norm(headbox[1] - headbox[0], axis=0)
- head_size *= SC_BIAS
- instance_info['head_size'] = head_size.reshape(1, -1)
-
- if instance_info['img_id'] not in used_img_ids:
- used_img_ids.add(instance_info['img_id'])
- image_list.append({
- 'img_id': instance_info['img_id'],
- 'img_path': instance_info['img_path'],
- })
-
- instance_list.append(instance_info)
- ann_id = ann_id + 1
-
- return instance_list, image_list
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import os.path as osp
+from typing import Callable, List, Optional, Sequence, Tuple, Union
+
+import numpy as np
+from mmengine.fileio import exists, get_local_path
+from scipy.io import loadmat
+
+from mmpose.registry import DATASETS
+from mmpose.structures.bbox import bbox_cs2xyxy
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class MpiiDataset(BaseCocoStyleDataset):
+ """MPII Dataset for pose estimation.
+
+ "2D Human Pose Estimation: New Benchmark and State of the Art Analysis"
+ ,CVPR'2014. More details can be found in the `paper
+ `__ .
+
+ MPII keypoints::
+
+ 0: 'right_ankle'
+ 1: 'right_knee',
+ 2: 'right_hip',
+ 3: 'left_hip',
+ 4: 'left_knee',
+ 5: 'left_ankle',
+ 6: 'pelvis',
+ 7: 'thorax',
+ 8: 'upper_neck',
+ 9: 'head_top',
+ 10: 'right_wrist',
+ 11: 'right_elbow',
+ 12: 'right_shoulder',
+ 13: 'left_shoulder',
+ 14: 'left_elbow',
+ 15: 'left_wrist'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ headbox_file (str, optional): The path of ``mpii_gt_val.mat`` which
+ provides the headboxes information used for ``PCKh``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/mpii.py')
+
+ def __init__(self,
+ ann_file: str = '',
+ bbox_file: Optional[str] = None,
+ headbox_file: Optional[str] = None,
+ data_mode: str = 'topdown',
+ metainfo: Optional[dict] = None,
+ data_root: Optional[str] = None,
+ data_prefix: dict = dict(img=''),
+ filter_cfg: Optional[dict] = None,
+ indices: Optional[Union[int, Sequence[int]]] = None,
+ serialize_data: bool = True,
+ pipeline: List[Union[dict, Callable]] = [],
+ test_mode: bool = False,
+ lazy_init: bool = False,
+ max_refetch: int = 1000):
+
+ if headbox_file:
+ if data_mode != 'topdown':
+ raise ValueError(
+ f'{self.__class__.__name__} is set to {data_mode}: '
+ 'mode, while "headbox_file" is only '
+ 'supported in topdown mode.')
+
+ if not test_mode:
+ raise ValueError(
+ f'{self.__class__.__name__} has `test_mode==False` '
+ 'while "headbox_file" is only '
+ 'supported when `test_mode==True`.')
+
+ headbox_file_type = headbox_file[-3:]
+ allow_headbox_file_type = ['mat']
+ if headbox_file_type not in allow_headbox_file_type:
+ raise KeyError(
+ f'The head boxes file type {headbox_file_type} is not '
+ f'supported. Should be `mat` but got {headbox_file_type}.')
+ self.headbox_file = headbox_file
+
+ super().__init__(
+ ann_file=ann_file,
+ bbox_file=bbox_file,
+ data_mode=data_mode,
+ metainfo=metainfo,
+ data_root=data_root,
+ data_prefix=data_prefix,
+ filter_cfg=filter_cfg,
+ indices=indices,
+ serialize_data=serialize_data,
+ pipeline=pipeline,
+ test_mode=test_mode,
+ lazy_init=lazy_init,
+ max_refetch=max_refetch)
+
+ def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
+ """Load data from annotations in MPII format."""
+
+ assert exists(self.ann_file), 'Annotation file does not exist'
+ with get_local_path(self.ann_file) as local_path:
+ with open(local_path) as anno_file:
+ self.anns = json.load(anno_file)
+
+ if self.headbox_file:
+ assert exists(self.headbox_file), 'Headbox file does not exist'
+ with get_local_path(self.headbox_file) as local_path:
+ self.headbox_dict = loadmat(local_path)
+ headboxes_src = np.transpose(self.headbox_dict['headboxes_src'],
+ [2, 0, 1])
+ SC_BIAS = 0.6
+
+ instance_list = []
+ image_list = []
+ used_img_ids = set()
+ ann_id = 0
+
+ # mpii bbox scales are normalized with factor 200.
+ pixel_std = 200.
+
+ for idx, ann in enumerate(self.anns):
+ center = np.array(ann['center'], dtype=np.float32)
+ scale = np.array([ann['scale'], ann['scale']],
+ dtype=np.float32) * pixel_std
+
+ # Adjust center/scale slightly to avoid cropping limbs
+ if center[0] != -1:
+ center[1] = center[1] + 15. / pixel_std * scale[1]
+
+ # MPII uses matlab format, index is 1-based,
+ # we should first convert to 0-based index
+ center = center - 1
+
+ # unify shape with coco datasets
+ center = center.reshape(1, -1)
+ scale = scale.reshape(1, -1)
+ bbox = bbox_cs2xyxy(center, scale)
+
+ # load keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
+ keypoints = np.array(ann['joints']).reshape(1, -1, 2)
+ keypoints_visible = np.array(ann['joints_vis']).reshape(1, -1)
+
+ instance_info = {
+ 'id': ann_id,
+ 'img_id': int(ann['image'].split('.')[0]),
+ 'img_path': osp.join(self.data_prefix['img'], ann['image']),
+ 'bbox_center': center,
+ 'bbox_scale': scale,
+ 'bbox': bbox,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ }
+
+ if self.headbox_file:
+ # calculate the diagonal length of head box as norm_factor
+ headbox = headboxes_src[idx]
+ head_size = np.linalg.norm(headbox[1] - headbox[0], axis=0)
+ head_size *= SC_BIAS
+ instance_info['head_size'] = head_size.reshape(1, -1)
+
+ if instance_info['img_id'] not in used_img_ids:
+ used_img_ids.add(instance_info['img_id'])
+ image_list.append({
+ 'img_id': instance_info['img_id'],
+ 'img_path': instance_info['img_path'],
+ })
+
+ instance_list.append(instance_info)
+ ann_id = ann_id + 1
+
+ return instance_list, image_list
diff --git a/mmpose/datasets/datasets/body/mpii_trb_dataset.py b/mmpose/datasets/datasets/body/mpii_trb_dataset.py
index bb96ad876f..3a46cf9e1b 100644
--- a/mmpose/datasets/datasets/body/mpii_trb_dataset.py
+++ b/mmpose/datasets/datasets/body/mpii_trb_dataset.py
@@ -1,169 +1,169 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import json
-import os.path as osp
-from typing import List, Tuple
-
-import numpy as np
-from mmengine.fileio import exists, get_local_path
-
-from mmpose.registry import DATASETS
-from mmpose.structures.bbox import bbox_cs2xyxy
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class MpiiTrbDataset(BaseCocoStyleDataset):
- """MPII-TRB Dataset dataset for pose estimation.
-
- "TRB: A Novel Triplet Representation for Understanding 2D Human Body",
- ICCV'2019. More details can be found in the `paper
- `__ .
-
- MPII-TRB keypoints::
-
- 0: 'left_shoulder'
- 1: 'right_shoulder'
- 2: 'left_elbow'
- 3: 'right_elbow'
- 4: 'left_wrist'
- 5: 'right_wrist'
- 6: 'left_hip'
- 7: 'right_hip'
- 8: 'left_knee'
- 9: 'right_knee'
- 10: 'left_ankle'
- 11: 'right_ankle'
- 12: 'head'
- 13: 'neck'
-
- 14: 'right_neck'
- 15: 'left_neck'
- 16: 'medial_right_shoulder'
- 17: 'lateral_right_shoulder'
- 18: 'medial_right_bow'
- 19: 'lateral_right_bow'
- 20: 'medial_right_wrist'
- 21: 'lateral_right_wrist'
- 22: 'medial_left_shoulder'
- 23: 'lateral_left_shoulder'
- 24: 'medial_left_bow'
- 25: 'lateral_left_bow'
- 26: 'medial_left_wrist'
- 27: 'lateral_left_wrist'
- 28: 'medial_right_hip'
- 29: 'lateral_right_hip'
- 30: 'medial_right_knee'
- 31: 'lateral_right_knee'
- 32: 'medial_right_ankle'
- 33: 'lateral_right_ankle'
- 34: 'medial_left_hip'
- 35: 'lateral_left_hip'
- 36: 'medial_left_knee'
- 37: 'lateral_left_knee'
- 38: 'medial_left_ankle'
- 39: 'lateral_left_ankle'
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/mpii_trb.py')
-
- def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
- """Load data from annotations in MPII-TRB format."""
-
- assert exists(self.ann_file), 'Annotation file does not exist'
- with get_local_path(self.ann_file) as local_path:
- with open(local_path) as anno_file:
- self.data = json.load(anno_file)
-
- imgid2info = {img['id']: img for img in self.data['images']}
-
- instance_list = []
- image_list = []
- used_img_ids = set()
-
- # mpii-trb bbox scales are normalized with factor 200.
- pixel_std = 200.
-
- for ann in self.data['annotations']:
- img_id = ann['image_id']
-
- # center, scale in shape [1, 2] and bbox in [1, 4]
- center = np.array([ann['center']], dtype=np.float32)
- scale = np.array([[ann['scale'], ann['scale']]],
- dtype=np.float32) * pixel_std
- bbox = bbox_cs2xyxy(center, scale)
-
- # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
- _keypoints = np.array(
- ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
- keypoints = _keypoints[..., :2]
- keypoints_visible = np.minimum(1, _keypoints[..., 2])
-
- img_path = osp.join(self.data_prefix['img'],
- imgid2info[img_id]['file_name'])
-
- instance_info = {
- 'id': ann['id'],
- 'img_id': img_id,
- 'img_path': img_path,
- 'bbox_center': center,
- 'bbox_scale': scale,
- 'bbox': bbox,
- 'bbox_score': np.ones(1, dtype=np.float32),
- 'num_keypoints': ann['num_joints'],
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- 'iscrowd': ann['iscrowd'],
- }
-
- # val set
- if 'headbox' in ann:
- instance_info['headbox'] = np.array(
- ann['headbox'], dtype=np.float32)
-
- instance_list.append(instance_info)
- if instance_info['img_id'] not in used_img_ids:
- used_img_ids.add(instance_info['img_id'])
- image_list.append({
- 'img_id': instance_info['img_id'],
- 'img_path': instance_info['img_path'],
- })
-
- instance_list = sorted(instance_list, key=lambda x: x['id'])
- return instance_list, image_list
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import os.path as osp
+from typing import List, Tuple
+
+import numpy as np
+from mmengine.fileio import exists, get_local_path
+
+from mmpose.registry import DATASETS
+from mmpose.structures.bbox import bbox_cs2xyxy
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class MpiiTrbDataset(BaseCocoStyleDataset):
+ """MPII-TRB Dataset dataset for pose estimation.
+
+ "TRB: A Novel Triplet Representation for Understanding 2D Human Body",
+ ICCV'2019. More details can be found in the `paper
+ `__ .
+
+ MPII-TRB keypoints::
+
+ 0: 'left_shoulder'
+ 1: 'right_shoulder'
+ 2: 'left_elbow'
+ 3: 'right_elbow'
+ 4: 'left_wrist'
+ 5: 'right_wrist'
+ 6: 'left_hip'
+ 7: 'right_hip'
+ 8: 'left_knee'
+ 9: 'right_knee'
+ 10: 'left_ankle'
+ 11: 'right_ankle'
+ 12: 'head'
+ 13: 'neck'
+
+ 14: 'right_neck'
+ 15: 'left_neck'
+ 16: 'medial_right_shoulder'
+ 17: 'lateral_right_shoulder'
+ 18: 'medial_right_bow'
+ 19: 'lateral_right_bow'
+ 20: 'medial_right_wrist'
+ 21: 'lateral_right_wrist'
+ 22: 'medial_left_shoulder'
+ 23: 'lateral_left_shoulder'
+ 24: 'medial_left_bow'
+ 25: 'lateral_left_bow'
+ 26: 'medial_left_wrist'
+ 27: 'lateral_left_wrist'
+ 28: 'medial_right_hip'
+ 29: 'lateral_right_hip'
+ 30: 'medial_right_knee'
+ 31: 'lateral_right_knee'
+ 32: 'medial_right_ankle'
+ 33: 'lateral_right_ankle'
+ 34: 'medial_left_hip'
+ 35: 'lateral_left_hip'
+ 36: 'medial_left_knee'
+ 37: 'lateral_left_knee'
+ 38: 'medial_left_ankle'
+ 39: 'lateral_left_ankle'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/mpii_trb.py')
+
+ def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
+ """Load data from annotations in MPII-TRB format."""
+
+ assert exists(self.ann_file), 'Annotation file does not exist'
+ with get_local_path(self.ann_file) as local_path:
+ with open(local_path) as anno_file:
+ self.data = json.load(anno_file)
+
+ imgid2info = {img['id']: img for img in self.data['images']}
+
+ instance_list = []
+ image_list = []
+ used_img_ids = set()
+
+ # mpii-trb bbox scales are normalized with factor 200.
+ pixel_std = 200.
+
+ for ann in self.data['annotations']:
+ img_id = ann['image_id']
+
+ # center, scale in shape [1, 2] and bbox in [1, 4]
+ center = np.array([ann['center']], dtype=np.float32)
+ scale = np.array([[ann['scale'], ann['scale']]],
+ dtype=np.float32) * pixel_std
+ bbox = bbox_cs2xyxy(center, scale)
+
+ # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
+ _keypoints = np.array(
+ ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
+ keypoints = _keypoints[..., :2]
+ keypoints_visible = np.minimum(1, _keypoints[..., 2])
+
+ img_path = osp.join(self.data_prefix['img'],
+ imgid2info[img_id]['file_name'])
+
+ instance_info = {
+ 'id': ann['id'],
+ 'img_id': img_id,
+ 'img_path': img_path,
+ 'bbox_center': center,
+ 'bbox_scale': scale,
+ 'bbox': bbox,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'num_keypoints': ann['num_joints'],
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ 'iscrowd': ann['iscrowd'],
+ }
+
+ # val set
+ if 'headbox' in ann:
+ instance_info['headbox'] = np.array(
+ ann['headbox'], dtype=np.float32)
+
+ instance_list.append(instance_info)
+ if instance_info['img_id'] not in used_img_ids:
+ used_img_ids.add(instance_info['img_id'])
+ image_list.append({
+ 'img_id': instance_info['img_id'],
+ 'img_path': instance_info['img_path'],
+ })
+
+ instance_list = sorted(instance_list, key=lambda x: x['id'])
+ return instance_list, image_list
diff --git a/mmpose/datasets/datasets/body/ochuman_dataset.py b/mmpose/datasets/datasets/body/ochuman_dataset.py
index 695d090ea9..df20d8f570 100644
--- a/mmpose/datasets/datasets/body/ochuman_dataset.py
+++ b/mmpose/datasets/datasets/body/ochuman_dataset.py
@@ -1,78 +1,78 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class OCHumanDataset(BaseCocoStyleDataset):
- """OChuman dataset for pose estimation.
-
- "Pose2Seg: Detection Free Human Instance Segmentation", CVPR'2019.
- More details can be found in the `paper
- `__ .
-
- "Occluded Human (OCHuman)" dataset contains 8110 heavily occluded
- human instances within 4731 images. OCHuman dataset is designed for
- validation and testing. To evaluate on OCHuman, the model should be
- trained on COCO training set, and then test the robustness of the
- model to occlusion using OCHuman.
-
- OCHuman keypoints (same as COCO)::
-
- 0: 'nose',
- 1: 'left_eye',
- 2: 'right_eye',
- 3: 'left_ear',
- 4: 'right_ear',
- 5: 'left_shoulder',
- 6: 'right_shoulder',
- 7: 'left_elbow',
- 8: 'right_elbow',
- 9: 'left_wrist',
- 10: 'right_wrist',
- 11: 'left_hip',
- 12: 'right_hip',
- 13: 'left_knee',
- 14: 'right_knee',
- 15: 'left_ankle',
- 16: 'right_ankle'
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/ochuman.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class OCHumanDataset(BaseCocoStyleDataset):
+ """OChuman dataset for pose estimation.
+
+ "Pose2Seg: Detection Free Human Instance Segmentation", CVPR'2019.
+ More details can be found in the `paper
+ `__ .
+
+ "Occluded Human (OCHuman)" dataset contains 8110 heavily occluded
+ human instances within 4731 images. OCHuman dataset is designed for
+ validation and testing. To evaluate on OCHuman, the model should be
+ trained on COCO training set, and then test the robustness of the
+ model to occlusion using OCHuman.
+
+ OCHuman keypoints (same as COCO)::
+
+ 0: 'nose',
+ 1: 'left_eye',
+ 2: 'right_eye',
+ 3: 'left_ear',
+ 4: 'right_ear',
+ 5: 'left_shoulder',
+ 6: 'right_shoulder',
+ 7: 'left_elbow',
+ 8: 'right_elbow',
+ 9: 'left_wrist',
+ 10: 'right_wrist',
+ 11: 'left_hip',
+ 12: 'right_hip',
+ 13: 'left_knee',
+ 14: 'right_knee',
+ 15: 'left_ankle',
+ 16: 'right_ankle'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/ochuman.py')
diff --git a/mmpose/datasets/datasets/body/posetrack18_dataset.py b/mmpose/datasets/datasets/body/posetrack18_dataset.py
index b8110c107f..45b0d38667 100644
--- a/mmpose/datasets/datasets/body/posetrack18_dataset.py
+++ b/mmpose/datasets/datasets/body/posetrack18_dataset.py
@@ -1,72 +1,72 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class PoseTrack18Dataset(BaseCocoStyleDataset):
- """PoseTrack18 dataset for pose estimation.
-
- "Posetrack: A benchmark for human pose estimation and tracking", CVPR'2018.
- More details can be found in the `paper
- `__ .
-
- PoseTrack2018 keypoints::
-
- 0: 'nose',
- 1: 'head_bottom',
- 2: 'head_top',
- 3: 'left_ear',
- 4: 'right_ear',
- 5: 'left_shoulder',
- 6: 'right_shoulder',
- 7: 'left_elbow',
- 8: 'right_elbow',
- 9: 'left_wrist',
- 10: 'right_wrist',
- 11: 'left_hip',
- 12: 'right_hip',
- 13: 'left_knee',
- 14: 'right_knee',
- 15: 'left_ankle',
- 16: 'right_ankle'
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/posetrack18.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class PoseTrack18Dataset(BaseCocoStyleDataset):
+ """PoseTrack18 dataset for pose estimation.
+
+ "Posetrack: A benchmark for human pose estimation and tracking", CVPR'2018.
+ More details can be found in the `paper
+ `__ .
+
+ PoseTrack2018 keypoints::
+
+ 0: 'nose',
+ 1: 'head_bottom',
+ 2: 'head_top',
+ 3: 'left_ear',
+ 4: 'right_ear',
+ 5: 'left_shoulder',
+ 6: 'right_shoulder',
+ 7: 'left_elbow',
+ 8: 'right_elbow',
+ 9: 'left_wrist',
+ 10: 'right_wrist',
+ 11: 'left_hip',
+ 12: 'right_hip',
+ 13: 'left_knee',
+ 14: 'right_knee',
+ 15: 'left_ankle',
+ 16: 'right_ankle'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/posetrack18.py')
diff --git a/mmpose/datasets/datasets/body/posetrack18_video_dataset.py b/mmpose/datasets/datasets/body/posetrack18_video_dataset.py
index cc5fe8646c..029484cf4d 100644
--- a/mmpose/datasets/datasets/body/posetrack18_video_dataset.py
+++ b/mmpose/datasets/datasets/body/posetrack18_video_dataset.py
@@ -1,389 +1,389 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os.path as osp
-from typing import Callable, List, Optional, Sequence, Union
-
-import numpy as np
-from mmengine.fileio import exists, get_local_path, load
-from mmengine.utils import is_list_of
-from xtcocotools.coco import COCO
-
-from mmpose.registry import DATASETS
-from mmpose.structures.bbox import bbox_xywh2xyxy
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class PoseTrack18VideoDataset(BaseCocoStyleDataset):
- """PoseTrack18 dataset for video pose estimation.
-
- "Posetrack: A benchmark for human pose estimation and tracking", CVPR'2018.
- More details can be found in the `paper
- `__ .
-
- PoseTrack2018 keypoints::
-
- 0: 'nose',
- 1: 'head_bottom',
- 2: 'head_top',
- 3: 'left_ear',
- 4: 'right_ear',
- 5: 'left_shoulder',
- 6: 'right_shoulder',
- 7: 'left_elbow',
- 8: 'right_elbow',
- 9: 'left_wrist',
- 10: 'right_wrist',
- 11: 'left_hip',
- 12: 'right_hip',
- 13: 'left_knee',
- 14: 'right_knee',
- 15: 'left_ankle',
- 16: 'right_ankle'
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- frame_weights (List[Union[int, float]] ): The weight of each frame
- for aggregation. The first weight is for the center frame, then on
- ascending order of frame indices. Note that the length of
- ``frame_weights`` should be consistent with the number of sampled
- frames. Default: [0.0, 1.0]
- frame_sampler_mode (str): Specifies the mode of frame sampler:
- ``'fixed'`` or ``'random'``. In ``'fixed'`` mode, each frame
- index relative to the center frame is fixed, specified by
- ``frame_indices``, while in ``'random'`` mode, each frame index
- relative to the center frame is sampled from ``frame_range``
- with certain randomness. Default: ``'random'``.
- frame_range (int | List[int], optional): The sampling range of
- supporting frames in the same video for center frame.
- Only valid when ``frame_sampler_mode`` is ``'random'``.
- Default: ``None``.
- num_sampled_frame(int, optional): The number of sampled frames, except
- the center frame. Only valid when ``frame_sampler_mode`` is
- ``'random'``. Default: 1.
- frame_indices (Sequence[int], optional): The sampled frame indices,
- including the center frame indicated by 0. Only valid when
- ``frame_sampler_mode`` is ``'fixed'``. Default: ``None``.
- ph_fill_len (int): The length of the placeholder to fill in the
- image filenames. Default: 6
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img='')``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/posetrack18.py')
-
- def __init__(self,
- ann_file: str = '',
- bbox_file: Optional[str] = None,
- data_mode: str = 'topdown',
- frame_weights: List[Union[int, float]] = [0.0, 1.0],
- frame_sampler_mode: str = 'random',
- frame_range: Optional[Union[int, List[int]]] = None,
- num_sampled_frame: Optional[int] = None,
- frame_indices: Optional[Sequence[int]] = None,
- ph_fill_len: int = 6,
- metainfo: Optional[dict] = None,
- data_root: Optional[str] = None,
- data_prefix: dict = dict(img=''),
- filter_cfg: Optional[dict] = None,
- indices: Optional[Union[int, Sequence[int]]] = None,
- serialize_data: bool = True,
- pipeline: List[Union[dict, Callable]] = [],
- test_mode: bool = False,
- lazy_init: bool = False,
- max_refetch: int = 1000):
- assert sum(frame_weights) == 1, 'Invalid `frame_weights`: should sum'\
- f' to 1.0, but got {frame_weights}.'
- for weight in frame_weights:
- assert weight >= 0, 'frame_weight can not be a negative value.'
- self.frame_weights = np.array(frame_weights)
-
- if frame_sampler_mode not in {'fixed', 'random'}:
- raise ValueError(
- f'{self.__class__.__name__} got invalid frame_sampler_mode: '
- f'{frame_sampler_mode}. Should be `"fixed"` or `"random"`.')
- self.frame_sampler_mode = frame_sampler_mode
-
- if frame_sampler_mode == 'random':
- assert frame_range is not None, \
- '`frame_sampler_mode` is set as `random`, ' \
- 'please specify the `frame_range`.'
-
- if isinstance(frame_range, int):
- assert frame_range >= 0, \
- 'frame_range can not be a negative value.'
- self.frame_range = [-frame_range, frame_range]
-
- elif isinstance(frame_range, Sequence):
- assert len(frame_range) == 2, 'The length must be 2.'
- assert frame_range[0] <= 0 and frame_range[
- 1] >= 0 and frame_range[1] > frame_range[
- 0], 'Invalid `frame_range`'
- for i in frame_range:
- assert isinstance(i, int), 'Each element must be int.'
- self.frame_range = frame_range
- else:
- raise TypeError(
- f'The type of `frame_range` must be int or Sequence, '
- f'but got {type(frame_range)}.')
-
- assert num_sampled_frame is not None, \
- '`frame_sampler_mode` is set as `random`, please specify ' \
- '`num_sampled_frame`, e.g. the number of sampled frames.'
-
- assert len(frame_weights) == num_sampled_frame + 1, \
- f'the length of frame_weights({len(frame_weights)}) '\
- f'does not match the number of sampled adjacent '\
- f'frames({num_sampled_frame})'
- self.frame_indices = None
- self.num_sampled_frame = num_sampled_frame
-
- if frame_sampler_mode == 'fixed':
- assert frame_indices is not None, \
- '`frame_sampler_mode` is set as `fixed`, ' \
- 'please specify the `frame_indices`.'
- assert len(frame_weights) == len(frame_indices), \
- f'the length of frame_weights({len(frame_weights)}) does not '\
- f'match the length of frame_indices({len(frame_indices)}).'
- frame_indices.sort()
- self.frame_indices = frame_indices
- self.frame_range = None
- self.num_sampled_frame = None
-
- self.ph_fill_len = ph_fill_len
-
- super().__init__(
- ann_file=ann_file,
- bbox_file=bbox_file,
- data_mode=data_mode,
- metainfo=metainfo,
- data_root=data_root,
- data_prefix=data_prefix,
- filter_cfg=filter_cfg,
- indices=indices,
- serialize_data=serialize_data,
- pipeline=pipeline,
- test_mode=test_mode,
- lazy_init=lazy_init,
- max_refetch=max_refetch)
-
- def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
- """Parse raw annotation of an instance.
-
- Args:
- raw_data_info (dict): Raw data information loaded from
- ``ann_file``. It should have following contents:
-
- - ``'raw_ann_info'``: Raw annotation of an instance
- - ``'raw_img_info'``: Raw information of the image that
- contains the instance
-
- Returns:
- dict: Parsed instance annotation
- """
-
- ann = raw_data_info['raw_ann_info']
- img = raw_data_info['raw_img_info']
-
- # filter invalid instance
- if 'bbox' not in ann or 'keypoints' not in ann or max(
- ann['keypoints']) == 0:
- return None
-
- img_w, img_h = img['width'], img['height']
- # get the bbox of the center frame
- # get bbox in shape [1, 4], formatted as xywh
- x, y, w, h = ann['bbox']
- x1 = np.clip(x, 0, img_w - 1)
- y1 = np.clip(y, 0, img_h - 1)
- x2 = np.clip(x + w, 0, img_w - 1)
- y2 = np.clip(y + h, 0, img_h - 1)
-
- bbox = np.array([x1, y1, x2, y2], dtype=np.float32).reshape(1, 4)
-
- # get the keypoints of the center frame
- # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
- _keypoints = np.array(
- ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
- keypoints = _keypoints[..., :2]
- keypoints_visible = np.minimum(1, _keypoints[..., 2])
-
- # deal with multiple image paths
- img_paths: list = []
- # get the image path of the center frame
- center_img_path = osp.join(self.data_prefix['img'], img['file_name'])
- # append the center image path first
- img_paths.append(center_img_path)
-
- # select the frame indices
- if self.frame_sampler_mode == 'fixed':
- indices = self.frame_indices
- else: # self.frame_sampler_mode == 'random':
- low, high = self.frame_range
- indices = np.random.randint(low, high + 1, self.num_sampled_frame)
-
- nframes = int(img['nframes'])
- file_name = img['file_name']
- ref_idx = int(osp.splitext(osp.basename(file_name))[0])
-
- for idx in indices:
- if self.test_mode and idx == 0:
- continue
- # the supporting frame index
- support_idx = ref_idx + idx
- # clip the frame index to make sure that it does not exceed
- # the boundings of frame indices
- support_idx = np.clip(support_idx, 0, nframes - 1)
- sup_img_path = osp.join(
- osp.dirname(center_img_path),
- str(support_idx).zfill(self.ph_fill_len) + '.jpg')
-
- img_paths.append(sup_img_path)
-
- data_info = {
- 'img_id': int(img['frame_id']),
- 'img_path': img_paths,
- 'bbox': bbox,
- 'bbox_score': np.ones(1, dtype=np.float32),
- 'num_keypoints': ann['num_keypoints'],
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- 'frame_weights': self.frame_weights,
- 'id': ann['id'],
- }
-
- return data_info
-
- def _load_detection_results(self) -> List[dict]:
- """Load data from detection results with dummy keypoint annotations."""
- assert exists(self.ann_file), 'Annotation file does not exist'
- assert exists(self.bbox_file), 'Bbox file does not exist'
-
- # load detection results
- det_results = load(self.bbox_file)
- assert is_list_of(det_results, dict)
-
- # load coco annotations to build image id-to-name index
- with get_local_path(self.ann_file) as local_path:
- self.coco = COCO(local_path)
-
- # mapping image name to id
- name2id = {}
- # mapping image id to name
- id2name = {}
- for img_id, image in self.coco.imgs.items():
- file_name = image['file_name']
- id2name[img_id] = file_name
- name2id[file_name] = img_id
-
- num_keypoints = self.metainfo['num_keypoints']
- data_list = []
- id_ = 0
- for det in det_results:
- # remove non-human instances
- if det['category_id'] != 1:
- continue
-
- # get the predicted bbox and bbox_score
- bbox_xywh = np.array(
- det['bbox'][:4], dtype=np.float32).reshape(1, 4)
- bbox = bbox_xywh2xyxy(bbox_xywh)
- bbox_score = np.array(det['score'], dtype=np.float32).reshape(1)
-
- # use dummy keypoint location and visibility
- keypoints = np.zeros((1, num_keypoints, 2), dtype=np.float32)
- keypoints_visible = np.ones((1, num_keypoints), dtype=np.float32)
-
- # deal with different bbox file formats
- if 'nframes' in det:
- nframes = int(det['nframes'])
- else:
- if 'image_name' in det:
- img_id = name2id[det['image_name']]
- else:
- img_id = det['image_id']
- img_ann = self.coco.loadImgs(img_id)[0]
- nframes = int(img_ann['nframes'])
-
- # deal with multiple image paths
- img_paths: list = []
- if 'image_name' in det:
- image_name = det['image_name']
- else:
- image_name = id2name[det['image_id']]
- # get the image path of the center frame
- center_img_path = osp.join(self.data_prefix['img'], image_name)
- # append the center image path first
- img_paths.append(center_img_path)
-
- # "images/val/012834_mpii_test/000000.jpg" -->> "000000.jpg"
- center_image_name = image_name.split('/')[-1]
- ref_idx = int(center_image_name.replace('.jpg', ''))
-
- # select the frame indices
- if self.frame_sampler_mode == 'fixed':
- indices = self.frame_indices
- else: # self.frame_sampler_mode == 'random':
- low, high = self.frame_range
- indices = np.random.randint(low, high + 1,
- self.num_sampled_frame)
-
- for idx in indices:
- if self.test_mode and idx == 0:
- continue
- # the supporting frame index
- support_idx = ref_idx + idx
- # clip the frame index to make sure that it does not exceed
- # the boundings of frame indices
- support_idx = np.clip(support_idx, 0, nframes - 1)
- sup_img_path = center_img_path.replace(
- center_image_name,
- str(support_idx).zfill(self.ph_fill_len) + '.jpg')
-
- img_paths.append(sup_img_path)
-
- data_list.append({
- 'img_id': det['image_id'],
- 'img_path': img_paths,
- 'frame_weights': self.frame_weights,
- 'bbox': bbox,
- 'bbox_score': bbox_score,
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- 'id': id_,
- })
-
- id_ += 1
-
- return data_list
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import Callable, List, Optional, Sequence, Union
+
+import numpy as np
+from mmengine.fileio import exists, get_local_path, load
+from mmengine.utils import is_list_of
+from xtcocotools.coco import COCO
+
+from mmpose.registry import DATASETS
+from mmpose.structures.bbox import bbox_xywh2xyxy
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class PoseTrack18VideoDataset(BaseCocoStyleDataset):
+ """PoseTrack18 dataset for video pose estimation.
+
+ "Posetrack: A benchmark for human pose estimation and tracking", CVPR'2018.
+ More details can be found in the `paper
+ `__ .
+
+ PoseTrack2018 keypoints::
+
+ 0: 'nose',
+ 1: 'head_bottom',
+ 2: 'head_top',
+ 3: 'left_ear',
+ 4: 'right_ear',
+ 5: 'left_shoulder',
+ 6: 'right_shoulder',
+ 7: 'left_elbow',
+ 8: 'right_elbow',
+ 9: 'left_wrist',
+ 10: 'right_wrist',
+ 11: 'left_hip',
+ 12: 'right_hip',
+ 13: 'left_knee',
+ 14: 'right_knee',
+ 15: 'left_ankle',
+ 16: 'right_ankle'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ frame_weights (List[Union[int, float]] ): The weight of each frame
+ for aggregation. The first weight is for the center frame, then on
+ ascending order of frame indices. Note that the length of
+ ``frame_weights`` should be consistent with the number of sampled
+ frames. Default: [0.0, 1.0]
+ frame_sampler_mode (str): Specifies the mode of frame sampler:
+ ``'fixed'`` or ``'random'``. In ``'fixed'`` mode, each frame
+ index relative to the center frame is fixed, specified by
+ ``frame_indices``, while in ``'random'`` mode, each frame index
+ relative to the center frame is sampled from ``frame_range``
+ with certain randomness. Default: ``'random'``.
+ frame_range (int | List[int], optional): The sampling range of
+ supporting frames in the same video for center frame.
+ Only valid when ``frame_sampler_mode`` is ``'random'``.
+ Default: ``None``.
+ num_sampled_frame(int, optional): The number of sampled frames, except
+ the center frame. Only valid when ``frame_sampler_mode`` is
+ ``'random'``. Default: 1.
+ frame_indices (Sequence[int], optional): The sampled frame indices,
+ including the center frame indicated by 0. Only valid when
+ ``frame_sampler_mode`` is ``'fixed'``. Default: ``None``.
+ ph_fill_len (int): The length of the placeholder to fill in the
+ image filenames. Default: 6
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img='')``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/posetrack18.py')
+
+ def __init__(self,
+ ann_file: str = '',
+ bbox_file: Optional[str] = None,
+ data_mode: str = 'topdown',
+ frame_weights: List[Union[int, float]] = [0.0, 1.0],
+ frame_sampler_mode: str = 'random',
+ frame_range: Optional[Union[int, List[int]]] = None,
+ num_sampled_frame: Optional[int] = None,
+ frame_indices: Optional[Sequence[int]] = None,
+ ph_fill_len: int = 6,
+ metainfo: Optional[dict] = None,
+ data_root: Optional[str] = None,
+ data_prefix: dict = dict(img=''),
+ filter_cfg: Optional[dict] = None,
+ indices: Optional[Union[int, Sequence[int]]] = None,
+ serialize_data: bool = True,
+ pipeline: List[Union[dict, Callable]] = [],
+ test_mode: bool = False,
+ lazy_init: bool = False,
+ max_refetch: int = 1000):
+ assert sum(frame_weights) == 1, 'Invalid `frame_weights`: should sum'\
+ f' to 1.0, but got {frame_weights}.'
+ for weight in frame_weights:
+ assert weight >= 0, 'frame_weight can not be a negative value.'
+ self.frame_weights = np.array(frame_weights)
+
+ if frame_sampler_mode not in {'fixed', 'random'}:
+ raise ValueError(
+ f'{self.__class__.__name__} got invalid frame_sampler_mode: '
+ f'{frame_sampler_mode}. Should be `"fixed"` or `"random"`.')
+ self.frame_sampler_mode = frame_sampler_mode
+
+ if frame_sampler_mode == 'random':
+ assert frame_range is not None, \
+ '`frame_sampler_mode` is set as `random`, ' \
+ 'please specify the `frame_range`.'
+
+ if isinstance(frame_range, int):
+ assert frame_range >= 0, \
+ 'frame_range can not be a negative value.'
+ self.frame_range = [-frame_range, frame_range]
+
+ elif isinstance(frame_range, Sequence):
+ assert len(frame_range) == 2, 'The length must be 2.'
+ assert frame_range[0] <= 0 and frame_range[
+ 1] >= 0 and frame_range[1] > frame_range[
+ 0], 'Invalid `frame_range`'
+ for i in frame_range:
+ assert isinstance(i, int), 'Each element must be int.'
+ self.frame_range = frame_range
+ else:
+ raise TypeError(
+ f'The type of `frame_range` must be int or Sequence, '
+ f'but got {type(frame_range)}.')
+
+ assert num_sampled_frame is not None, \
+ '`frame_sampler_mode` is set as `random`, please specify ' \
+ '`num_sampled_frame`, e.g. the number of sampled frames.'
+
+ assert len(frame_weights) == num_sampled_frame + 1, \
+ f'the length of frame_weights({len(frame_weights)}) '\
+ f'does not match the number of sampled adjacent '\
+ f'frames({num_sampled_frame})'
+ self.frame_indices = None
+ self.num_sampled_frame = num_sampled_frame
+
+ if frame_sampler_mode == 'fixed':
+ assert frame_indices is not None, \
+ '`frame_sampler_mode` is set as `fixed`, ' \
+ 'please specify the `frame_indices`.'
+ assert len(frame_weights) == len(frame_indices), \
+ f'the length of frame_weights({len(frame_weights)}) does not '\
+ f'match the length of frame_indices({len(frame_indices)}).'
+ frame_indices.sort()
+ self.frame_indices = frame_indices
+ self.frame_range = None
+ self.num_sampled_frame = None
+
+ self.ph_fill_len = ph_fill_len
+
+ super().__init__(
+ ann_file=ann_file,
+ bbox_file=bbox_file,
+ data_mode=data_mode,
+ metainfo=metainfo,
+ data_root=data_root,
+ data_prefix=data_prefix,
+ filter_cfg=filter_cfg,
+ indices=indices,
+ serialize_data=serialize_data,
+ pipeline=pipeline,
+ test_mode=test_mode,
+ lazy_init=lazy_init,
+ max_refetch=max_refetch)
+
+ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
+ """Parse raw annotation of an instance.
+
+ Args:
+ raw_data_info (dict): Raw data information loaded from
+ ``ann_file``. It should have following contents:
+
+ - ``'raw_ann_info'``: Raw annotation of an instance
+ - ``'raw_img_info'``: Raw information of the image that
+ contains the instance
+
+ Returns:
+ dict: Parsed instance annotation
+ """
+
+ ann = raw_data_info['raw_ann_info']
+ img = raw_data_info['raw_img_info']
+
+ # filter invalid instance
+ if 'bbox' not in ann or 'keypoints' not in ann or max(
+ ann['keypoints']) == 0:
+ return None
+
+ img_w, img_h = img['width'], img['height']
+ # get the bbox of the center frame
+ # get bbox in shape [1, 4], formatted as xywh
+ x, y, w, h = ann['bbox']
+ x1 = np.clip(x, 0, img_w - 1)
+ y1 = np.clip(y, 0, img_h - 1)
+ x2 = np.clip(x + w, 0, img_w - 1)
+ y2 = np.clip(y + h, 0, img_h - 1)
+
+ bbox = np.array([x1, y1, x2, y2], dtype=np.float32).reshape(1, 4)
+
+ # get the keypoints of the center frame
+ # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
+ _keypoints = np.array(
+ ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
+ keypoints = _keypoints[..., :2]
+ keypoints_visible = np.minimum(1, _keypoints[..., 2])
+
+ # deal with multiple image paths
+ img_paths: list = []
+ # get the image path of the center frame
+ center_img_path = osp.join(self.data_prefix['img'], img['file_name'])
+ # append the center image path first
+ img_paths.append(center_img_path)
+
+ # select the frame indices
+ if self.frame_sampler_mode == 'fixed':
+ indices = self.frame_indices
+ else: # self.frame_sampler_mode == 'random':
+ low, high = self.frame_range
+ indices = np.random.randint(low, high + 1, self.num_sampled_frame)
+
+ nframes = int(img['nframes'])
+ file_name = img['file_name']
+ ref_idx = int(osp.splitext(osp.basename(file_name))[0])
+
+ for idx in indices:
+ if self.test_mode and idx == 0:
+ continue
+ # the supporting frame index
+ support_idx = ref_idx + idx
+ # clip the frame index to make sure that it does not exceed
+ # the boundings of frame indices
+ support_idx = np.clip(support_idx, 0, nframes - 1)
+ sup_img_path = osp.join(
+ osp.dirname(center_img_path),
+ str(support_idx).zfill(self.ph_fill_len) + '.jpg')
+
+ img_paths.append(sup_img_path)
+
+ data_info = {
+ 'img_id': int(img['frame_id']),
+ 'img_path': img_paths,
+ 'bbox': bbox,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'num_keypoints': ann['num_keypoints'],
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ 'frame_weights': self.frame_weights,
+ 'id': ann['id'],
+ }
+
+ return data_info
+
+ def _load_detection_results(self) -> List[dict]:
+ """Load data from detection results with dummy keypoint annotations."""
+ assert exists(self.ann_file), 'Annotation file does not exist'
+ assert exists(self.bbox_file), 'Bbox file does not exist'
+
+ # load detection results
+ det_results = load(self.bbox_file)
+ assert is_list_of(det_results, dict)
+
+ # load coco annotations to build image id-to-name index
+ with get_local_path(self.ann_file) as local_path:
+ self.coco = COCO(local_path)
+
+ # mapping image name to id
+ name2id = {}
+ # mapping image id to name
+ id2name = {}
+ for img_id, image in self.coco.imgs.items():
+ file_name = image['file_name']
+ id2name[img_id] = file_name
+ name2id[file_name] = img_id
+
+ num_keypoints = self.metainfo['num_keypoints']
+ data_list = []
+ id_ = 0
+ for det in det_results:
+ # remove non-human instances
+ if det['category_id'] != 1:
+ continue
+
+ # get the predicted bbox and bbox_score
+ bbox_xywh = np.array(
+ det['bbox'][:4], dtype=np.float32).reshape(1, 4)
+ bbox = bbox_xywh2xyxy(bbox_xywh)
+ bbox_score = np.array(det['score'], dtype=np.float32).reshape(1)
+
+ # use dummy keypoint location and visibility
+ keypoints = np.zeros((1, num_keypoints, 2), dtype=np.float32)
+ keypoints_visible = np.ones((1, num_keypoints), dtype=np.float32)
+
+ # deal with different bbox file formats
+ if 'nframes' in det:
+ nframes = int(det['nframes'])
+ else:
+ if 'image_name' in det:
+ img_id = name2id[det['image_name']]
+ else:
+ img_id = det['image_id']
+ img_ann = self.coco.loadImgs(img_id)[0]
+ nframes = int(img_ann['nframes'])
+
+ # deal with multiple image paths
+ img_paths: list = []
+ if 'image_name' in det:
+ image_name = det['image_name']
+ else:
+ image_name = id2name[det['image_id']]
+ # get the image path of the center frame
+ center_img_path = osp.join(self.data_prefix['img'], image_name)
+ # append the center image path first
+ img_paths.append(center_img_path)
+
+ # "images/val/012834_mpii_test/000000.jpg" -->> "000000.jpg"
+ center_image_name = image_name.split('/')[-1]
+ ref_idx = int(center_image_name.replace('.jpg', ''))
+
+ # select the frame indices
+ if self.frame_sampler_mode == 'fixed':
+ indices = self.frame_indices
+ else: # self.frame_sampler_mode == 'random':
+ low, high = self.frame_range
+ indices = np.random.randint(low, high + 1,
+ self.num_sampled_frame)
+
+ for idx in indices:
+ if self.test_mode and idx == 0:
+ continue
+ # the supporting frame index
+ support_idx = ref_idx + idx
+ # clip the frame index to make sure that it does not exceed
+ # the boundings of frame indices
+ support_idx = np.clip(support_idx, 0, nframes - 1)
+ sup_img_path = center_img_path.replace(
+ center_image_name,
+ str(support_idx).zfill(self.ph_fill_len) + '.jpg')
+
+ img_paths.append(sup_img_path)
+
+ data_list.append({
+ 'img_id': det['image_id'],
+ 'img_path': img_paths,
+ 'frame_weights': self.frame_weights,
+ 'bbox': bbox,
+ 'bbox_score': bbox_score,
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ 'id': id_,
+ })
+
+ id_ += 1
+
+ return data_list
diff --git a/mmpose/datasets/datasets/body3d/__init__.py b/mmpose/datasets/datasets/body3d/__init__.py
index d5afeca578..e844bc46e0 100644
--- a/mmpose/datasets/datasets/body3d/__init__.py
+++ b/mmpose/datasets/datasets/body3d/__init__.py
@@ -1,4 +1,4 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .h36m_dataset import Human36mDataset
-
-__all__ = ['Human36mDataset']
+# Copyright (c) OpenMMLab. All rights reserved.
+from .h36m_dataset import Human36mDataset
+
+__all__ = ['Human36mDataset']
diff --git a/mmpose/datasets/datasets/body3d/h36m_dataset.py b/mmpose/datasets/datasets/body3d/h36m_dataset.py
index 60094aa254..d2cb9010be 100644
--- a/mmpose/datasets/datasets/body3d/h36m_dataset.py
+++ b/mmpose/datasets/datasets/body3d/h36m_dataset.py
@@ -1,259 +1,259 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os.path as osp
-from collections import defaultdict
-from typing import Callable, List, Optional, Sequence, Tuple, Union
-
-import numpy as np
-from mmengine.fileio import exists, get_local_path
-from mmengine.utils import is_abs
-
-from mmpose.datasets.datasets import BaseMocapDataset
-from mmpose.registry import DATASETS
-
-
-@DATASETS.register_module()
-class Human36mDataset(BaseMocapDataset):
- """Human3.6M dataset for 3D human pose estimation.
-
- "Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human
- Sensing in Natural Environments", TPAMI`2014.
- More details can be found in the `paper
- `__.
-
- Human3.6M keypoint indexes::
-
- 0: 'root (pelvis)',
- 1: 'right_hip',
- 2: 'right_knee',
- 3: 'right_foot',
- 4: 'left_hip',
- 5: 'left_knee',
- 6: 'left_foot',
- 7: 'spine',
- 8: 'thorax',
- 9: 'neck_base',
- 10: 'head',
- 11: 'left_shoulder',
- 12: 'left_elbow',
- 13: 'left_wrist',
- 14: 'right_shoulder',
- 15: 'right_elbow',
- 16: 'right_wrist'
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- seq_len (int): Number of frames in a sequence. Default: 1.
- seq_step (int): The interval for extracting frames from the video.
- Default: 1.
- pad_video_seq (bool): Whether to pad the video so that poses will be
- predicted for every frame in the video. Default: ``False``.
- causal (bool): If set to ``True``, the rightmost input frame will be
- the target frame. Otherwise, the middle input frame will be the
- target frame. Default: ``True``.
- subset_frac (float): The fraction to reduce dataset size. If set to 1,
- the dataset size is not reduced. Default: 1.
- keypoint_2d_src (str): Specifies 2D keypoint information options, which
- should be one of the following options:
-
- - ``'gt'``: load from the annotation file
- - ``'detection'``: load from a detection
- result file of 2D keypoint
- - 'pipeline': the information will be generated by the pipeline
-
- Default: ``'gt'``.
- keypoint_2d_det_file (str, optional): The 2D keypoint detection file.
- If set, 2d keypoint loaded from this file will be used instead of
- ground-truth keypoints. This setting is only when
- ``keypoint_2d_src`` is ``'detection'``. Default: ``None``.
- camera_param_file (str): Cameras' parameters file. Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data.
- Default: ``dict(img='')``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/h36m.py')
- SUPPORTED_keypoint_2d_src = {'gt', 'detection', 'pipeline'}
-
- def __init__(self,
- ann_file: str = '',
- seq_len: int = 1,
- seq_step: int = 1,
- pad_video_seq: bool = False,
- causal: bool = True,
- subset_frac: float = 1.0,
- keypoint_2d_src: str = 'gt',
- keypoint_2d_det_file: Optional[str] = None,
- camera_param_file: Optional[str] = None,
- data_mode: str = 'topdown',
- metainfo: Optional[dict] = None,
- data_root: Optional[str] = None,
- data_prefix: dict = dict(img=''),
- filter_cfg: Optional[dict] = None,
- indices: Optional[Union[int, Sequence[int]]] = None,
- serialize_data: bool = True,
- pipeline: List[Union[dict, Callable]] = [],
- test_mode: bool = False,
- lazy_init: bool = False,
- max_refetch: int = 1000):
- # check keypoint_2d_src
- self.keypoint_2d_src = keypoint_2d_src
- if self.keypoint_2d_src not in self.SUPPORTED_keypoint_2d_src:
- raise ValueError(
- f'Unsupported `keypoint_2d_src` "{self.keypoint_2d_src}". '
- f'Supported options are {self.SUPPORTED_keypoint_2d_src}')
-
- if keypoint_2d_det_file:
- if not is_abs(keypoint_2d_det_file):
- self.keypoint_2d_det_file = osp.join(data_root,
- keypoint_2d_det_file)
- else:
- self.keypoint_2d_det_file = keypoint_2d_det_file
-
- self.seq_step = seq_step
- self.pad_video_seq = pad_video_seq
-
- super().__init__(
- ann_file=ann_file,
- seq_len=seq_len,
- causal=causal,
- subset_frac=subset_frac,
- camera_param_file=camera_param_file,
- data_mode=data_mode,
- metainfo=metainfo,
- data_root=data_root,
- data_prefix=data_prefix,
- filter_cfg=filter_cfg,
- indices=indices,
- serialize_data=serialize_data,
- pipeline=pipeline,
- test_mode=test_mode,
- lazy_init=lazy_init,
- max_refetch=max_refetch)
-
- def get_sequence_indices(self) -> List[List[int]]:
- """Split original videos into sequences and build frame indices.
-
- This method overrides the default one in the base class.
- """
- imgnames = self.ann_data['imgname']
- video_frames = defaultdict(list)
- for idx, imgname in enumerate(imgnames):
- subj, action, camera = self._parse_h36m_imgname(imgname)
- video_frames[(subj, action, camera)].append(idx)
-
- # build sample indices
- sequence_indices = []
- _len = (self.seq_len - 1) * self.seq_step + 1
- _step = self.seq_step
- for _, _indices in sorted(video_frames.items()):
- n_frame = len(_indices)
-
- if self.pad_video_seq:
- # Pad the sequence so that every frame in the sequence will be
- # predicted.
- if self.causal:
- frames_left = self.seq_len - 1
- frames_right = 0
- else:
- frames_left = (self.seq_len - 1) // 2
- frames_right = frames_left
- for i in range(n_frame):
- pad_left = max(0, frames_left - i // _step)
- pad_right = max(0,
- frames_right - (n_frame - 1 - i) // _step)
- start = max(i % _step, i - frames_left * _step)
- end = min(n_frame - (n_frame - 1 - i) % _step,
- i + frames_right * _step + 1)
- sequence_indices.append([_indices[0]] * pad_left +
- _indices[start:end:_step] +
- [_indices[-1]] * pad_right)
- else:
- seqs_from_video = [
- _indices[i:(i + _len):_step]
- for i in range(0, n_frame - _len + 1)
- ]
- sequence_indices.extend(seqs_from_video)
-
- # reduce dataset size if needed
- subset_size = int(len(sequence_indices) * self.subset_frac)
- start = np.random.randint(0, len(sequence_indices) - subset_size + 1)
- end = start + subset_size
-
- return sequence_indices[start:end]
-
- def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
- instance_list, image_list = super()._load_annotations()
-
- h36m_data = self.ann_data
- kpts_3d = h36m_data['S']
-
- if self.keypoint_2d_src == 'detection':
- assert exists(self.keypoint_2d_det_file)
- kpts_2d = self._load_keypoint_2d_detection(
- self.keypoint_2d_det_file)
- assert kpts_2d.shape[0] == kpts_3d.shape[0]
- assert kpts_2d.shape[2] == 3
-
- for idx, frame_ids in enumerate(self.sequence_indices):
- kpt_2d = kpts_2d[frame_ids].astype(np.float32)
- keypoints = kpt_2d[..., :2]
- keypoints_visible = kpt_2d[..., 2]
- instance_list[idx].update({
- 'keypoints':
- keypoints,
- 'keypoints_visible':
- keypoints_visible
- })
-
- return instance_list, image_list
-
- @staticmethod
- def _parse_h36m_imgname(imgname) -> Tuple[str, str, str]:
- """Parse imgname to get information of subject, action and camera.
-
- A typical h36m image filename is like:
- S1_Directions_1.54138969_000001.jpg
- """
- subj, rest = osp.basename(imgname).split('_', 1)
- action, rest = rest.split('.', 1)
- camera, rest = rest.split('_', 1)
- return subj, action, camera
-
- def get_camera_param(self, imgname) -> dict:
- """Get camera parameters of a frame by its image name."""
- assert hasattr(self, 'camera_param')
- subj, _, camera = self._parse_h36m_imgname(imgname)
- return self.camera_param[(subj, camera)]
-
- def _load_keypoint_2d_detection(self, det_file):
- """"Load 2D joint detection results from file."""
- with get_local_path(det_file) as local_path:
- kpts_2d = np.load(local_path).astype(np.float32)
-
- return kpts_2d
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from collections import defaultdict
+from typing import Callable, List, Optional, Sequence, Tuple, Union
+
+import numpy as np
+from mmengine.fileio import exists, get_local_path
+from mmengine.utils import is_abs
+
+from mmpose.datasets.datasets import BaseMocapDataset
+from mmpose.registry import DATASETS
+
+
+@DATASETS.register_module()
+class Human36mDataset(BaseMocapDataset):
+ """Human3.6M dataset for 3D human pose estimation.
+
+ "Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human
+ Sensing in Natural Environments", TPAMI`2014.
+ More details can be found in the `paper
+ `__.
+
+ Human3.6M keypoint indexes::
+
+ 0: 'root (pelvis)',
+ 1: 'right_hip',
+ 2: 'right_knee',
+ 3: 'right_foot',
+ 4: 'left_hip',
+ 5: 'left_knee',
+ 6: 'left_foot',
+ 7: 'spine',
+ 8: 'thorax',
+ 9: 'neck_base',
+ 10: 'head',
+ 11: 'left_shoulder',
+ 12: 'left_elbow',
+ 13: 'left_wrist',
+ 14: 'right_shoulder',
+ 15: 'right_elbow',
+ 16: 'right_wrist'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ seq_len (int): Number of frames in a sequence. Default: 1.
+ seq_step (int): The interval for extracting frames from the video.
+ Default: 1.
+ pad_video_seq (bool): Whether to pad the video so that poses will be
+ predicted for every frame in the video. Default: ``False``.
+ causal (bool): If set to ``True``, the rightmost input frame will be
+ the target frame. Otherwise, the middle input frame will be the
+ target frame. Default: ``True``.
+ subset_frac (float): The fraction to reduce dataset size. If set to 1,
+ the dataset size is not reduced. Default: 1.
+ keypoint_2d_src (str): Specifies 2D keypoint information options, which
+ should be one of the following options:
+
+ - ``'gt'``: load from the annotation file
+ - ``'detection'``: load from a detection
+ result file of 2D keypoint
+ - 'pipeline': the information will be generated by the pipeline
+
+ Default: ``'gt'``.
+ keypoint_2d_det_file (str, optional): The 2D keypoint detection file.
+ If set, 2d keypoint loaded from this file will be used instead of
+ ground-truth keypoints. This setting is only when
+ ``keypoint_2d_src`` is ``'detection'``. Default: ``None``.
+ camera_param_file (str): Cameras' parameters file. Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data.
+ Default: ``dict(img='')``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/h36m.py')
+ SUPPORTED_keypoint_2d_src = {'gt', 'detection', 'pipeline'}
+
+ def __init__(self,
+ ann_file: str = '',
+ seq_len: int = 1,
+ seq_step: int = 1,
+ pad_video_seq: bool = False,
+ causal: bool = True,
+ subset_frac: float = 1.0,
+ keypoint_2d_src: str = 'gt',
+ keypoint_2d_det_file: Optional[str] = None,
+ camera_param_file: Optional[str] = None,
+ data_mode: str = 'topdown',
+ metainfo: Optional[dict] = None,
+ data_root: Optional[str] = None,
+ data_prefix: dict = dict(img=''),
+ filter_cfg: Optional[dict] = None,
+ indices: Optional[Union[int, Sequence[int]]] = None,
+ serialize_data: bool = True,
+ pipeline: List[Union[dict, Callable]] = [],
+ test_mode: bool = False,
+ lazy_init: bool = False,
+ max_refetch: int = 1000):
+ # check keypoint_2d_src
+ self.keypoint_2d_src = keypoint_2d_src
+ if self.keypoint_2d_src not in self.SUPPORTED_keypoint_2d_src:
+ raise ValueError(
+ f'Unsupported `keypoint_2d_src` "{self.keypoint_2d_src}". '
+ f'Supported options are {self.SUPPORTED_keypoint_2d_src}')
+
+ if keypoint_2d_det_file:
+ if not is_abs(keypoint_2d_det_file):
+ self.keypoint_2d_det_file = osp.join(data_root,
+ keypoint_2d_det_file)
+ else:
+ self.keypoint_2d_det_file = keypoint_2d_det_file
+
+ self.seq_step = seq_step
+ self.pad_video_seq = pad_video_seq
+
+ super().__init__(
+ ann_file=ann_file,
+ seq_len=seq_len,
+ causal=causal,
+ subset_frac=subset_frac,
+ camera_param_file=camera_param_file,
+ data_mode=data_mode,
+ metainfo=metainfo,
+ data_root=data_root,
+ data_prefix=data_prefix,
+ filter_cfg=filter_cfg,
+ indices=indices,
+ serialize_data=serialize_data,
+ pipeline=pipeline,
+ test_mode=test_mode,
+ lazy_init=lazy_init,
+ max_refetch=max_refetch)
+
+ def get_sequence_indices(self) -> List[List[int]]:
+ """Split original videos into sequences and build frame indices.
+
+ This method overrides the default one in the base class.
+ """
+ imgnames = self.ann_data['imgname']
+ video_frames = defaultdict(list)
+ for idx, imgname in enumerate(imgnames):
+ subj, action, camera = self._parse_h36m_imgname(imgname)
+ video_frames[(subj, action, camera)].append(idx)
+
+ # build sample indices
+ sequence_indices = []
+ _len = (self.seq_len - 1) * self.seq_step + 1
+ _step = self.seq_step
+ for _, _indices in sorted(video_frames.items()):
+ n_frame = len(_indices)
+
+ if self.pad_video_seq:
+ # Pad the sequence so that every frame in the sequence will be
+ # predicted.
+ if self.causal:
+ frames_left = self.seq_len - 1
+ frames_right = 0
+ else:
+ frames_left = (self.seq_len - 1) // 2
+ frames_right = frames_left
+ for i in range(n_frame):
+ pad_left = max(0, frames_left - i // _step)
+ pad_right = max(0,
+ frames_right - (n_frame - 1 - i) // _step)
+ start = max(i % _step, i - frames_left * _step)
+ end = min(n_frame - (n_frame - 1 - i) % _step,
+ i + frames_right * _step + 1)
+ sequence_indices.append([_indices[0]] * pad_left +
+ _indices[start:end:_step] +
+ [_indices[-1]] * pad_right)
+ else:
+ seqs_from_video = [
+ _indices[i:(i + _len):_step]
+ for i in range(0, n_frame - _len + 1)
+ ]
+ sequence_indices.extend(seqs_from_video)
+
+ # reduce dataset size if needed
+ subset_size = int(len(sequence_indices) * self.subset_frac)
+ start = np.random.randint(0, len(sequence_indices) - subset_size + 1)
+ end = start + subset_size
+
+ return sequence_indices[start:end]
+
+ def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
+ instance_list, image_list = super()._load_annotations()
+
+ h36m_data = self.ann_data
+ kpts_3d = h36m_data['S']
+
+ if self.keypoint_2d_src == 'detection':
+ assert exists(self.keypoint_2d_det_file)
+ kpts_2d = self._load_keypoint_2d_detection(
+ self.keypoint_2d_det_file)
+ assert kpts_2d.shape[0] == kpts_3d.shape[0]
+ assert kpts_2d.shape[2] == 3
+
+ for idx, frame_ids in enumerate(self.sequence_indices):
+ kpt_2d = kpts_2d[frame_ids].astype(np.float32)
+ keypoints = kpt_2d[..., :2]
+ keypoints_visible = kpt_2d[..., 2]
+ instance_list[idx].update({
+ 'keypoints':
+ keypoints,
+ 'keypoints_visible':
+ keypoints_visible
+ })
+
+ return instance_list, image_list
+
+ @staticmethod
+ def _parse_h36m_imgname(imgname) -> Tuple[str, str, str]:
+ """Parse imgname to get information of subject, action and camera.
+
+ A typical h36m image filename is like:
+ S1_Directions_1.54138969_000001.jpg
+ """
+ subj, rest = osp.basename(imgname).split('_', 1)
+ action, rest = rest.split('.', 1)
+ camera, rest = rest.split('_', 1)
+ return subj, action, camera
+
+ def get_camera_param(self, imgname) -> dict:
+ """Get camera parameters of a frame by its image name."""
+ assert hasattr(self, 'camera_param')
+ subj, _, camera = self._parse_h36m_imgname(imgname)
+ return self.camera_param[(subj, camera)]
+
+ def _load_keypoint_2d_detection(self, det_file):
+ """"Load 2D joint detection results from file."""
+ with get_local_path(det_file) as local_path:
+ kpts_2d = np.load(local_path).astype(np.float32)
+
+ return kpts_2d
diff --git a/mmpose/datasets/datasets/face/__init__.py b/mmpose/datasets/datasets/face/__init__.py
index 700cb605f7..1f8f86ec83 100644
--- a/mmpose/datasets/datasets/face/__init__.py
+++ b/mmpose/datasets/datasets/face/__init__.py
@@ -1,12 +1,12 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .aflw_dataset import AFLWDataset
-from .coco_wholebody_face_dataset import CocoWholeBodyFaceDataset
-from .cofw_dataset import COFWDataset
-from .face_300w_dataset import Face300WDataset
-from .lapa_dataset import LapaDataset
-from .wflw_dataset import WFLWDataset
-
-__all__ = [
- 'Face300WDataset', 'WFLWDataset', 'AFLWDataset', 'COFWDataset',
- 'CocoWholeBodyFaceDataset', 'LapaDataset'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .aflw_dataset import AFLWDataset
+from .coco_wholebody_face_dataset import CocoWholeBodyFaceDataset
+from .cofw_dataset import COFWDataset
+from .face_300w_dataset import Face300WDataset
+from .lapa_dataset import LapaDataset
+from .wflw_dataset import WFLWDataset
+
+__all__ = [
+ 'Face300WDataset', 'WFLWDataset', 'AFLWDataset', 'COFWDataset',
+ 'CocoWholeBodyFaceDataset', 'LapaDataset'
+]
diff --git a/mmpose/datasets/datasets/face/aflw_dataset.py b/mmpose/datasets/datasets/face/aflw_dataset.py
index deda0974bb..33927a3a7f 100644
--- a/mmpose/datasets/datasets/face/aflw_dataset.py
+++ b/mmpose/datasets/datasets/face/aflw_dataset.py
@@ -1,122 +1,122 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os.path as osp
-from typing import Optional
-
-import numpy as np
-
-from mmpose.registry import DATASETS
-from mmpose.structures.bbox import bbox_cs2xyxy
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class AFLWDataset(BaseCocoStyleDataset):
- """AFLW dataset for face keypoint localization.
-
- "Annotated Facial Landmarks in the Wild: A Large-scale,
- Real-world Database for Facial Landmark Localization".
- In Proc. First IEEE International Workshop on Benchmarking
- Facial Image Analysis Technologies, 2011.
-
- The landmark annotations follow the 19 points mark-up. The definition
- can be found in `https://www.tugraz.at/institute/icg/research`
- `/team-bischof/lrs/downloads/aflw/`
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/aflw.py')
-
- def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
- """Parse raw Face AFLW annotation of an instance.
-
- Args:
- raw_data_info (dict): Raw data information loaded from
- ``ann_file``. It should have following contents:
-
- - ``'raw_ann_info'``: Raw annotation of an instance
- - ``'raw_img_info'``: Raw information of the image that
- contains the instance
-
- Returns:
- dict: Parsed instance annotation
- """
-
- ann = raw_data_info['raw_ann_info']
- img = raw_data_info['raw_img_info']
-
- img_path = osp.join(self.data_prefix['img'], img['file_name'])
-
- # aflw bbox scales are normalized with factor 200.
- pixel_std = 200.
-
- # center, scale in shape [1, 2] and bbox in [1, 4]
- center = np.array([ann['center']], dtype=np.float32)
- scale = np.array([[ann['scale'], ann['scale']]],
- dtype=np.float32) * pixel_std
- bbox = bbox_cs2xyxy(center, scale)
-
- # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
- _keypoints = np.array(
- ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
- keypoints = _keypoints[..., :2]
- keypoints_visible = np.minimum(1, _keypoints[..., 2])
-
- num_keypoints = ann['num_keypoints']
-
- data_info = {
- 'img_id': ann['image_id'],
- 'img_path': img_path,
- 'bbox': bbox,
- 'bbox_center': center,
- 'bbox_scale': scale,
- 'bbox_score': np.ones(1, dtype=np.float32),
- 'num_keypoints': num_keypoints,
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- 'iscrowd': ann['iscrowd'],
- 'id': ann['id'],
- }
-
- if self.test_mode:
- # 'box_size' is used as normalization factor
- assert 'box_size' in ann, '"box_size" is missing in annotation, '\
- 'which is required for evaluation.'
- data_info['box_size'] = ann['box_size']
-
- return data_info
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import Optional
+
+import numpy as np
+
+from mmpose.registry import DATASETS
+from mmpose.structures.bbox import bbox_cs2xyxy
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class AFLWDataset(BaseCocoStyleDataset):
+ """AFLW dataset for face keypoint localization.
+
+ "Annotated Facial Landmarks in the Wild: A Large-scale,
+ Real-world Database for Facial Landmark Localization".
+ In Proc. First IEEE International Workshop on Benchmarking
+ Facial Image Analysis Technologies, 2011.
+
+ The landmark annotations follow the 19 points mark-up. The definition
+ can be found in `https://www.tugraz.at/institute/icg/research`
+ `/team-bischof/lrs/downloads/aflw/`
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/aflw.py')
+
+ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
+ """Parse raw Face AFLW annotation of an instance.
+
+ Args:
+ raw_data_info (dict): Raw data information loaded from
+ ``ann_file``. It should have following contents:
+
+ - ``'raw_ann_info'``: Raw annotation of an instance
+ - ``'raw_img_info'``: Raw information of the image that
+ contains the instance
+
+ Returns:
+ dict: Parsed instance annotation
+ """
+
+ ann = raw_data_info['raw_ann_info']
+ img = raw_data_info['raw_img_info']
+
+ img_path = osp.join(self.data_prefix['img'], img['file_name'])
+
+ # aflw bbox scales are normalized with factor 200.
+ pixel_std = 200.
+
+ # center, scale in shape [1, 2] and bbox in [1, 4]
+ center = np.array([ann['center']], dtype=np.float32)
+ scale = np.array([[ann['scale'], ann['scale']]],
+ dtype=np.float32) * pixel_std
+ bbox = bbox_cs2xyxy(center, scale)
+
+ # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
+ _keypoints = np.array(
+ ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
+ keypoints = _keypoints[..., :2]
+ keypoints_visible = np.minimum(1, _keypoints[..., 2])
+
+ num_keypoints = ann['num_keypoints']
+
+ data_info = {
+ 'img_id': ann['image_id'],
+ 'img_path': img_path,
+ 'bbox': bbox,
+ 'bbox_center': center,
+ 'bbox_scale': scale,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'num_keypoints': num_keypoints,
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ 'iscrowd': ann['iscrowd'],
+ 'id': ann['id'],
+ }
+
+ if self.test_mode:
+ # 'box_size' is used as normalization factor
+ assert 'box_size' in ann, '"box_size" is missing in annotation, '\
+ 'which is required for evaluation.'
+ data_info['box_size'] = ann['box_size']
+
+ return data_info
diff --git a/mmpose/datasets/datasets/face/coco_wholebody_face_dataset.py b/mmpose/datasets/datasets/face/coco_wholebody_face_dataset.py
index bc2c5be386..728da21ae1 100644
--- a/mmpose/datasets/datasets/face/coco_wholebody_face_dataset.py
+++ b/mmpose/datasets/datasets/face/coco_wholebody_face_dataset.py
@@ -1,115 +1,115 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os.path as osp
-from typing import Optional
-
-import numpy as np
-
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class CocoWholeBodyFaceDataset(BaseCocoStyleDataset):
- """CocoWholeBodyDataset for face keypoint localization.
-
- `Whole-Body Human Pose Estimation in the Wild', ECCV'2020.
- More details can be found in the `paper
- `__ .
-
- The face landmark annotations follow the 68 points mark-up.
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(
- from_file='configs/_base_/datasets/coco_wholebody_face.py')
-
- def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
- """Parse raw CocoWholeBody Face annotation of an instance.
-
- Args:
- raw_data_info (dict): Raw data information loaded from
- ``ann_file``. It should have following contents:
-
- - ``'raw_ann_info'``: Raw annotation of an instance
- - ``'raw_img_info'``: Raw information of the image that
- contains the instance
-
- Returns:
- dict: Parsed instance annotation
- """
-
- ann = raw_data_info['raw_ann_info']
- img = raw_data_info['raw_img_info']
-
- # filter invalid instance
- if not ann['face_valid'] or max(ann['face_kpts']) <= 0:
- return None
-
- img_path = osp.join(self.data_prefix['img'], img['file_name'])
- img_w, img_h = img['width'], img['height']
-
- # get bbox in shape [1, 4], formatted as xywh
- x, y, w, h = ann['face_box']
- x1 = np.clip(x, 0, img_w - 1)
- y1 = np.clip(y, 0, img_h - 1)
- x2 = np.clip(x + w, 0, img_w - 1)
- y2 = np.clip(y + h, 0, img_h - 1)
-
- bbox = np.array([x1, y1, x2, y2], dtype=np.float32).reshape(1, 4)
-
- # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
- _keypoints = np.array(
- ann['face_kpts'], dtype=np.float32).reshape(1, -1, 3)
- keypoints = _keypoints[..., :2]
- keypoints_visible = np.minimum(1, _keypoints[..., 2])
-
- num_keypoints = np.count_nonzero(keypoints.max(axis=2))
-
- data_info = {
- 'img_id': ann['image_id'],
- 'img_path': img_path,
- 'bbox': bbox,
- 'bbox_score': np.ones(1, dtype=np.float32),
- 'num_keypoints': num_keypoints,
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- 'iscrowd': ann['iscrowd'],
- 'id': ann['id'],
- }
- return data_info
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import Optional
+
+import numpy as np
+
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class CocoWholeBodyFaceDataset(BaseCocoStyleDataset):
+ """CocoWholeBodyDataset for face keypoint localization.
+
+ `Whole-Body Human Pose Estimation in the Wild', ECCV'2020.
+ More details can be found in the `paper
+ `__ .
+
+ The face landmark annotations follow the 68 points mark-up.
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(
+ from_file='configs/_base_/datasets/coco_wholebody_face.py')
+
+ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
+ """Parse raw CocoWholeBody Face annotation of an instance.
+
+ Args:
+ raw_data_info (dict): Raw data information loaded from
+ ``ann_file``. It should have following contents:
+
+ - ``'raw_ann_info'``: Raw annotation of an instance
+ - ``'raw_img_info'``: Raw information of the image that
+ contains the instance
+
+ Returns:
+ dict: Parsed instance annotation
+ """
+
+ ann = raw_data_info['raw_ann_info']
+ img = raw_data_info['raw_img_info']
+
+ # filter invalid instance
+ if not ann['face_valid'] or max(ann['face_kpts']) <= 0:
+ return None
+
+ img_path = osp.join(self.data_prefix['img'], img['file_name'])
+ img_w, img_h = img['width'], img['height']
+
+ # get bbox in shape [1, 4], formatted as xywh
+ x, y, w, h = ann['face_box']
+ x1 = np.clip(x, 0, img_w - 1)
+ y1 = np.clip(y, 0, img_h - 1)
+ x2 = np.clip(x + w, 0, img_w - 1)
+ y2 = np.clip(y + h, 0, img_h - 1)
+
+ bbox = np.array([x1, y1, x2, y2], dtype=np.float32).reshape(1, 4)
+
+ # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
+ _keypoints = np.array(
+ ann['face_kpts'], dtype=np.float32).reshape(1, -1, 3)
+ keypoints = _keypoints[..., :2]
+ keypoints_visible = np.minimum(1, _keypoints[..., 2])
+
+ num_keypoints = np.count_nonzero(keypoints.max(axis=2))
+
+ data_info = {
+ 'img_id': ann['image_id'],
+ 'img_path': img_path,
+ 'bbox': bbox,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'num_keypoints': num_keypoints,
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ 'iscrowd': ann['iscrowd'],
+ 'id': ann['id'],
+ }
+ return data_info
diff --git a/mmpose/datasets/datasets/face/cofw_dataset.py b/mmpose/datasets/datasets/face/cofw_dataset.py
index 5ec2a37efd..47fa634de9 100644
--- a/mmpose/datasets/datasets/face/cofw_dataset.py
+++ b/mmpose/datasets/datasets/face/cofw_dataset.py
@@ -1,53 +1,53 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class COFWDataset(BaseCocoStyleDataset):
- """COFW dataset for face keypoint localization.
-
- "Robust face landmark estimation under occlusion", ICCV'2013.
-
- The landmark annotations follow the 29 points mark-up. The definition
- can be found in `http://www.vision.caltech.edu/xpburgos/ICCV13/`__ .
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/cofw.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class COFWDataset(BaseCocoStyleDataset):
+ """COFW dataset for face keypoint localization.
+
+ "Robust face landmark estimation under occlusion", ICCV'2013.
+
+ The landmark annotations follow the 29 points mark-up. The definition
+ can be found in `http://www.vision.caltech.edu/xpburgos/ICCV13/`__ .
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/cofw.py')
diff --git a/mmpose/datasets/datasets/face/face_300w_dataset.py b/mmpose/datasets/datasets/face/face_300w_dataset.py
index c70e892b4f..0071c8799a 100644
--- a/mmpose/datasets/datasets/face/face_300w_dataset.py
+++ b/mmpose/datasets/datasets/face/face_300w_dataset.py
@@ -1,112 +1,112 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os.path as osp
-from typing import Optional
-
-import numpy as np
-
-from mmpose.registry import DATASETS
-from mmpose.structures.bbox import bbox_cs2xyxy
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class Face300WDataset(BaseCocoStyleDataset):
- """300W dataset for face keypoint localization.
-
- "300 faces In-the-wild challenge: Database and results",
- Image and Vision Computing (IMAVIS) 2019.
-
- The landmark annotations follow the 68 points mark-up. The definition
- can be found in `https://ibug.doc.ic.ac.uk/resources/300-W/`.
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/300w.py')
-
- def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
- """Parse raw Face300W annotation of an instance.
-
- Args:
- raw_data_info (dict): Raw data information loaded from
- ``ann_file``. It should have following contents:
-
- - ``'raw_ann_info'``: Raw annotation of an instance
- - ``'raw_img_info'``: Raw information of the image that
- contains the instance
-
- Returns:
- dict: Parsed instance annotation
- """
-
- ann = raw_data_info['raw_ann_info']
- img = raw_data_info['raw_img_info']
-
- img_path = osp.join(self.data_prefix['img'], img['file_name'])
-
- # 300w bbox scales are normalized with factor 200.
- pixel_std = 200.
-
- # center, scale in shape [1, 2] and bbox in [1, 4]
- center = np.array([ann['center']], dtype=np.float32)
- scale = np.array([[ann['scale'], ann['scale']]],
- dtype=np.float32) * pixel_std
- bbox = bbox_cs2xyxy(center, scale)
-
- # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
- _keypoints = np.array(
- ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
- keypoints = _keypoints[..., :2]
- keypoints_visible = np.minimum(1, _keypoints[..., 2])
-
- num_keypoints = ann['num_keypoints']
-
- data_info = {
- 'img_id': ann['image_id'],
- 'img_path': img_path,
- 'bbox': bbox,
- 'bbox_center': center,
- 'bbox_scale': scale,
- 'bbox_score': np.ones(1, dtype=np.float32),
- 'num_keypoints': num_keypoints,
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- 'iscrowd': ann['iscrowd'],
- 'id': ann['id'],
- }
- return data_info
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import Optional
+
+import numpy as np
+
+from mmpose.registry import DATASETS
+from mmpose.structures.bbox import bbox_cs2xyxy
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class Face300WDataset(BaseCocoStyleDataset):
+ """300W dataset for face keypoint localization.
+
+ "300 faces In-the-wild challenge: Database and results",
+ Image and Vision Computing (IMAVIS) 2019.
+
+ The landmark annotations follow the 68 points mark-up. The definition
+ can be found in `https://ibug.doc.ic.ac.uk/resources/300-W/`.
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/300w.py')
+
+ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
+ """Parse raw Face300W annotation of an instance.
+
+ Args:
+ raw_data_info (dict): Raw data information loaded from
+ ``ann_file``. It should have following contents:
+
+ - ``'raw_ann_info'``: Raw annotation of an instance
+ - ``'raw_img_info'``: Raw information of the image that
+ contains the instance
+
+ Returns:
+ dict: Parsed instance annotation
+ """
+
+ ann = raw_data_info['raw_ann_info']
+ img = raw_data_info['raw_img_info']
+
+ img_path = osp.join(self.data_prefix['img'], img['file_name'])
+
+ # 300w bbox scales are normalized with factor 200.
+ pixel_std = 200.
+
+ # center, scale in shape [1, 2] and bbox in [1, 4]
+ center = np.array([ann['center']], dtype=np.float32)
+ scale = np.array([[ann['scale'], ann['scale']]],
+ dtype=np.float32) * pixel_std
+ bbox = bbox_cs2xyxy(center, scale)
+
+ # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
+ _keypoints = np.array(
+ ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
+ keypoints = _keypoints[..., :2]
+ keypoints_visible = np.minimum(1, _keypoints[..., 2])
+
+ num_keypoints = ann['num_keypoints']
+
+ data_info = {
+ 'img_id': ann['image_id'],
+ 'img_path': img_path,
+ 'bbox': bbox,
+ 'bbox_center': center,
+ 'bbox_scale': scale,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'num_keypoints': num_keypoints,
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ 'iscrowd': ann['iscrowd'],
+ 'id': ann['id'],
+ }
+ return data_info
diff --git a/mmpose/datasets/datasets/face/lapa_dataset.py b/mmpose/datasets/datasets/face/lapa_dataset.py
index 1a5bdc4ec0..e7a7e0a767 100644
--- a/mmpose/datasets/datasets/face/lapa_dataset.py
+++ b/mmpose/datasets/datasets/face/lapa_dataset.py
@@ -1,54 +1,54 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class LapaDataset(BaseCocoStyleDataset):
- """LaPa dataset for face keypoint localization.
-
- "A New Dataset and Boundary-Attention Semantic Segmentation
- for Face Parsing", AAAI'2020.
-
- The landmark annotations follow the 106 points mark-up. The definition
- can be found in `https://github.com/JDAI-CV/lapa-dataset/`__ .
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/lapa.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class LapaDataset(BaseCocoStyleDataset):
+ """LaPa dataset for face keypoint localization.
+
+ "A New Dataset and Boundary-Attention Semantic Segmentation
+ for Face Parsing", AAAI'2020.
+
+ The landmark annotations follow the 106 points mark-up. The definition
+ can be found in `https://github.com/JDAI-CV/lapa-dataset/`__ .
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/lapa.py')
diff --git a/mmpose/datasets/datasets/face/wflw_dataset.py b/mmpose/datasets/datasets/face/wflw_dataset.py
index 9c1c23053c..7a4b21b27b 100644
--- a/mmpose/datasets/datasets/face/wflw_dataset.py
+++ b/mmpose/datasets/datasets/face/wflw_dataset.py
@@ -1,112 +1,112 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os.path as osp
-from typing import Optional
-
-import numpy as np
-
-from mmpose.registry import DATASETS
-from mmpose.structures.bbox import bbox_cs2xyxy
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class WFLWDataset(BaseCocoStyleDataset):
- """WFLW dataset for face keypoint localization.
-
- "Look at Boundary: A Boundary-Aware Face Alignment Algorithm",
- CVPR'2018.
-
- The landmark annotations follow the 98 points mark-up. The definition
- can be found in `https://wywu.github.io/projects/LAB/WFLW.html`__ .
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/wflw.py')
-
- def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
- """Parse raw Face WFLW annotation of an instance.
-
- Args:
- raw_data_info (dict): Raw data information loaded from
- ``ann_file``. It should have following contents:
-
- - ``'raw_ann_info'``: Raw annotation of an instance
- - ``'raw_img_info'``: Raw information of the image that
- contains the instance
-
- Returns:
- dict: Parsed instance annotation
- """
-
- ann = raw_data_info['raw_ann_info']
- img = raw_data_info['raw_img_info']
-
- img_path = osp.join(self.data_prefix['img'], img['file_name'])
-
- # wflw bbox scales are normalized with factor 200.
- pixel_std = 200.
-
- # center, scale in shape [1, 2] and bbox in [1, 4]
- center = np.array([ann['center']], dtype=np.float32)
- scale = np.array([[ann['scale'], ann['scale']]],
- dtype=np.float32) * pixel_std
- bbox = bbox_cs2xyxy(center, scale)
-
- # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
- _keypoints = np.array(
- ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
- keypoints = _keypoints[..., :2]
- keypoints_visible = np.minimum(1, _keypoints[..., 2])
-
- num_keypoints = ann['num_keypoints']
-
- data_info = {
- 'img_id': ann['image_id'],
- 'img_path': img_path,
- 'bbox': bbox,
- 'bbox_center': center,
- 'bbox_scale': scale,
- 'bbox_score': np.ones(1, dtype=np.float32),
- 'num_keypoints': num_keypoints,
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- 'iscrowd': ann['iscrowd'],
- 'id': ann['id'],
- }
- return data_info
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import Optional
+
+import numpy as np
+
+from mmpose.registry import DATASETS
+from mmpose.structures.bbox import bbox_cs2xyxy
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class WFLWDataset(BaseCocoStyleDataset):
+ """WFLW dataset for face keypoint localization.
+
+ "Look at Boundary: A Boundary-Aware Face Alignment Algorithm",
+ CVPR'2018.
+
+ The landmark annotations follow the 98 points mark-up. The definition
+ can be found in `https://wywu.github.io/projects/LAB/WFLW.html`__ .
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/wflw.py')
+
+ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
+ """Parse raw Face WFLW annotation of an instance.
+
+ Args:
+ raw_data_info (dict): Raw data information loaded from
+ ``ann_file``. It should have following contents:
+
+ - ``'raw_ann_info'``: Raw annotation of an instance
+ - ``'raw_img_info'``: Raw information of the image that
+ contains the instance
+
+ Returns:
+ dict: Parsed instance annotation
+ """
+
+ ann = raw_data_info['raw_ann_info']
+ img = raw_data_info['raw_img_info']
+
+ img_path = osp.join(self.data_prefix['img'], img['file_name'])
+
+ # wflw bbox scales are normalized with factor 200.
+ pixel_std = 200.
+
+ # center, scale in shape [1, 2] and bbox in [1, 4]
+ center = np.array([ann['center']], dtype=np.float32)
+ scale = np.array([[ann['scale'], ann['scale']]],
+ dtype=np.float32) * pixel_std
+ bbox = bbox_cs2xyxy(center, scale)
+
+ # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
+ _keypoints = np.array(
+ ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
+ keypoints = _keypoints[..., :2]
+ keypoints_visible = np.minimum(1, _keypoints[..., 2])
+
+ num_keypoints = ann['num_keypoints']
+
+ data_info = {
+ 'img_id': ann['image_id'],
+ 'img_path': img_path,
+ 'bbox': bbox,
+ 'bbox_center': center,
+ 'bbox_scale': scale,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'num_keypoints': num_keypoints,
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ 'iscrowd': ann['iscrowd'],
+ 'id': ann['id'],
+ }
+ return data_info
diff --git a/mmpose/datasets/datasets/fashion/__init__.py b/mmpose/datasets/datasets/fashion/__init__.py
index 8be25dede3..51a563a9d5 100644
--- a/mmpose/datasets/datasets/fashion/__init__.py
+++ b/mmpose/datasets/datasets/fashion/__init__.py
@@ -1,5 +1,5 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .deepfashion2_dataset import DeepFashion2Dataset
-from .deepfashion_dataset import DeepFashionDataset
-
-__all__ = ['DeepFashionDataset', 'DeepFashion2Dataset']
+# Copyright (c) OpenMMLab. All rights reserved.
+from .deepfashion2_dataset import DeepFashion2Dataset
+from .deepfashion_dataset import DeepFashionDataset
+
+__all__ = ['DeepFashionDataset', 'DeepFashion2Dataset']
diff --git a/mmpose/datasets/datasets/fashion/deepfashion2_dataset.py b/mmpose/datasets/datasets/fashion/deepfashion2_dataset.py
index c3cde9bf97..cbf7a98d99 100644
--- a/mmpose/datasets/datasets/fashion/deepfashion2_dataset.py
+++ b/mmpose/datasets/datasets/fashion/deepfashion2_dataset.py
@@ -1,10 +1,10 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module(name='DeepFashion2Dataset')
-class DeepFashion2Dataset(BaseCocoStyleDataset):
- """DeepFashion2 dataset for fashion landmark detection."""
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/deepfashion2.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module(name='DeepFashion2Dataset')
+class DeepFashion2Dataset(BaseCocoStyleDataset):
+ """DeepFashion2 dataset for fashion landmark detection."""
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/deepfashion2.py')
diff --git a/mmpose/datasets/datasets/fashion/deepfashion_dataset.py b/mmpose/datasets/datasets/fashion/deepfashion_dataset.py
index a0aa493732..edf24265ff 100644
--- a/mmpose/datasets/datasets/fashion/deepfashion_dataset.py
+++ b/mmpose/datasets/datasets/fashion/deepfashion_dataset.py
@@ -1,137 +1,137 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Callable, List, Optional, Sequence, Union
-
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class DeepFashionDataset(BaseCocoStyleDataset):
- """DeepFashion dataset (full-body clothes) for fashion landmark detection.
-
- "DeepFashion: Powering Robust Clothes Recognition
- and Retrieval with Rich Annotations", CVPR'2016.
- "Fashion Landmark Detection in the Wild", ECCV'2016.
-
- The dataset contains 3 categories for full-body, upper-body and lower-body.
-
- Fashion landmark indexes for upper-body clothes::
-
- 0: 'left collar',
- 1: 'right collar',
- 2: 'left sleeve',
- 3: 'right sleeve',
- 4: 'left hem',
- 5: 'right hem'
-
- Fashion landmark indexes for lower-body clothes::
-
- 0: 'left waistline',
- 1: 'right waistline',
- 2: 'left hem',
- 3: 'right hem'
-
- Fashion landmark indexes for full-body clothes::
-
- 0: 'left collar',
- 1: 'right collar',
- 2: 'left sleeve',
- 3: 'right sleeve',
- 4: 'left waistline',
- 5: 'right waistline',
- 6: 'left hem',
- 7: 'right hem'
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- subset (str): Specifies the subset of body: ``'full'``, ``'upper'`` or
- ``'lower'``. Default: '', which means ``'full'``.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img='')``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- def __init__(self,
- ann_file: str = '',
- subset: str = '',
- bbox_file: Optional[str] = None,
- data_mode: str = 'topdown',
- metainfo: Optional[dict] = None,
- data_root: Optional[str] = None,
- data_prefix: dict = dict(img=''),
- filter_cfg: Optional[dict] = None,
- indices: Optional[Union[int, Sequence[int]]] = None,
- serialize_data: bool = True,
- pipeline: List[Union[dict, Callable]] = [],
- test_mode: bool = False,
- lazy_init: bool = False,
- max_refetch: int = 1000):
- self._check_subset_and_metainfo(subset)
-
- super().__init__(
- ann_file=ann_file,
- bbox_file=bbox_file,
- data_mode=data_mode,
- metainfo=metainfo,
- data_root=data_root,
- data_prefix=data_prefix,
- filter_cfg=filter_cfg,
- indices=indices,
- serialize_data=serialize_data,
- pipeline=pipeline,
- test_mode=test_mode,
- lazy_init=lazy_init,
- max_refetch=max_refetch)
-
- @classmethod
- def _check_subset_and_metainfo(cls, subset: str = '') -> None:
- """Check the subset of body and set the corresponding metainfo.
-
- Args:
- subset(str): the subset of body: could be ``'full'``, ``'upper'``
- or ``'lower'``. Default: '', which means ``'full'``.
- """
- if subset == '' or subset == 'full':
- cls.METAINFO = dict(
- from_file='configs/_base_/datasets/deepfashion_full.py')
- elif subset == 'upper':
- cls.METAINFO = dict(
- from_file='configs/_base_/datasets/deepfashion_upper.py')
- elif subset == 'lower':
- cls.METAINFO = dict(
- from_file='configs/_base_/datasets/deepfashion_lower.py')
- else:
- raise ValueError(
- f'{cls.__class__.__name__} got invalid subset: '
- f'{subset}. Should be "full", "lower" or "upper".')
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Callable, List, Optional, Sequence, Union
+
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class DeepFashionDataset(BaseCocoStyleDataset):
+ """DeepFashion dataset (full-body clothes) for fashion landmark detection.
+
+ "DeepFashion: Powering Robust Clothes Recognition
+ and Retrieval with Rich Annotations", CVPR'2016.
+ "Fashion Landmark Detection in the Wild", ECCV'2016.
+
+ The dataset contains 3 categories for full-body, upper-body and lower-body.
+
+ Fashion landmark indexes for upper-body clothes::
+
+ 0: 'left collar',
+ 1: 'right collar',
+ 2: 'left sleeve',
+ 3: 'right sleeve',
+ 4: 'left hem',
+ 5: 'right hem'
+
+ Fashion landmark indexes for lower-body clothes::
+
+ 0: 'left waistline',
+ 1: 'right waistline',
+ 2: 'left hem',
+ 3: 'right hem'
+
+ Fashion landmark indexes for full-body clothes::
+
+ 0: 'left collar',
+ 1: 'right collar',
+ 2: 'left sleeve',
+ 3: 'right sleeve',
+ 4: 'left waistline',
+ 5: 'right waistline',
+ 6: 'left hem',
+ 7: 'right hem'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ subset (str): Specifies the subset of body: ``'full'``, ``'upper'`` or
+ ``'lower'``. Default: '', which means ``'full'``.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img='')``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ def __init__(self,
+ ann_file: str = '',
+ subset: str = '',
+ bbox_file: Optional[str] = None,
+ data_mode: str = 'topdown',
+ metainfo: Optional[dict] = None,
+ data_root: Optional[str] = None,
+ data_prefix: dict = dict(img=''),
+ filter_cfg: Optional[dict] = None,
+ indices: Optional[Union[int, Sequence[int]]] = None,
+ serialize_data: bool = True,
+ pipeline: List[Union[dict, Callable]] = [],
+ test_mode: bool = False,
+ lazy_init: bool = False,
+ max_refetch: int = 1000):
+ self._check_subset_and_metainfo(subset)
+
+ super().__init__(
+ ann_file=ann_file,
+ bbox_file=bbox_file,
+ data_mode=data_mode,
+ metainfo=metainfo,
+ data_root=data_root,
+ data_prefix=data_prefix,
+ filter_cfg=filter_cfg,
+ indices=indices,
+ serialize_data=serialize_data,
+ pipeline=pipeline,
+ test_mode=test_mode,
+ lazy_init=lazy_init,
+ max_refetch=max_refetch)
+
+ @classmethod
+ def _check_subset_and_metainfo(cls, subset: str = '') -> None:
+ """Check the subset of body and set the corresponding metainfo.
+
+ Args:
+ subset(str): the subset of body: could be ``'full'``, ``'upper'``
+ or ``'lower'``. Default: '', which means ``'full'``.
+ """
+ if subset == '' or subset == 'full':
+ cls.METAINFO = dict(
+ from_file='configs/_base_/datasets/deepfashion_full.py')
+ elif subset == 'upper':
+ cls.METAINFO = dict(
+ from_file='configs/_base_/datasets/deepfashion_upper.py')
+ elif subset == 'lower':
+ cls.METAINFO = dict(
+ from_file='configs/_base_/datasets/deepfashion_lower.py')
+ else:
+ raise ValueError(
+ f'{cls.__class__.__name__} got invalid subset: '
+ f'{subset}. Should be "full", "lower" or "upper".')
diff --git a/mmpose/datasets/datasets/hand/__init__.py b/mmpose/datasets/datasets/hand/__init__.py
index d5e2222be9..0a87fed008 100644
--- a/mmpose/datasets/datasets/hand/__init__.py
+++ b/mmpose/datasets/datasets/hand/__init__.py
@@ -1,11 +1,11 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .coco_wholebody_hand_dataset import CocoWholeBodyHandDataset
-from .freihand_dataset import FreiHandDataset
-from .onehand10k_dataset import OneHand10KDataset
-from .panoptic_hand2d_dataset import PanopticHand2DDataset
-from .rhd2d_dataset import Rhd2DDataset
-
-__all__ = [
- 'OneHand10KDataset', 'FreiHandDataset', 'PanopticHand2DDataset',
- 'Rhd2DDataset', 'CocoWholeBodyHandDataset'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .coco_wholebody_hand_dataset import CocoWholeBodyHandDataset
+from .freihand_dataset import FreiHandDataset
+from .onehand10k_dataset import OneHand10KDataset
+from .panoptic_hand2d_dataset import PanopticHand2DDataset
+from .rhd2d_dataset import Rhd2DDataset
+
+__all__ = [
+ 'OneHand10KDataset', 'FreiHandDataset', 'PanopticHand2DDataset',
+ 'Rhd2DDataset', 'CocoWholeBodyHandDataset'
+]
diff --git a/mmpose/datasets/datasets/hand/coco_wholebody_hand_dataset.py b/mmpose/datasets/datasets/hand/coco_wholebody_hand_dataset.py
index dba0132f58..7f508073dd 100644
--- a/mmpose/datasets/datasets/hand/coco_wholebody_hand_dataset.py
+++ b/mmpose/datasets/datasets/hand/coco_wholebody_hand_dataset.py
@@ -1,148 +1,148 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os.path as osp
-from typing import List, Tuple
-
-import numpy as np
-from mmengine.fileio import exists, get_local_path
-from xtcocotools.coco import COCO
-
-from mmpose.registry import DATASETS
-from mmpose.structures.bbox import bbox_xywh2xyxy
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class CocoWholeBodyHandDataset(BaseCocoStyleDataset):
- """CocoWholeBodyDataset for hand pose estimation.
-
- "Whole-Body Human Pose Estimation in the Wild", ECCV'2020.
- More details can be found in the `paper
- `__ .
-
- COCO-WholeBody Hand keypoints::
-
- 0: 'wrist',
- 1: 'thumb1',
- 2: 'thumb2',
- 3: 'thumb3',
- 4: 'thumb4',
- 5: 'forefinger1',
- 6: 'forefinger2',
- 7: 'forefinger3',
- 8: 'forefinger4',
- 9: 'middle_finger1',
- 10: 'middle_finger2',
- 11: 'middle_finger3',
- 12: 'middle_finger4',
- 13: 'ring_finger1',
- 14: 'ring_finger2',
- 15: 'ring_finger3',
- 16: 'ring_finger4',
- 17: 'pinky_finger1',
- 18: 'pinky_finger2',
- 19: 'pinky_finger3',
- 20: 'pinky_finger4'
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(
- from_file='configs/_base_/datasets/coco_wholebody_hand.py')
-
- def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
- """Load data from annotations in COCO format."""
-
- assert exists(self.ann_file), 'Annotation file does not exist'
-
- with get_local_path(self.ann_file) as local_path:
- self.coco = COCO(local_path)
- instance_list = []
- image_list = []
- id = 0
-
- for img_id in self.coco.getImgIds():
- img = self.coco.loadImgs(img_id)[0]
-
- img.update({
- 'img_id':
- img_id,
- 'img_path':
- osp.join(self.data_prefix['img'], img['file_name']),
- })
- image_list.append(img)
-
- ann_ids = self.coco.getAnnIds(imgIds=img_id, iscrowd=False)
- anns = self.coco.loadAnns(ann_ids)
- for ann in anns:
- for type in ['left', 'right']:
- # filter invalid hand annotations, there might be two
- # valid instances (left and right hand) in one image
- if ann[f'{type}hand_valid'] and max(
- ann[f'{type}hand_kpts']) > 0:
-
- bbox_xywh = np.array(
- ann[f'{type}hand_box'],
- dtype=np.float32).reshape(1, 4)
-
- bbox = bbox_xywh2xyxy(bbox_xywh)
-
- _keypoints = np.array(
- ann[f'{type}hand_kpts'],
- dtype=np.float32).reshape(1, -1, 3)
- keypoints = _keypoints[..., :2]
- keypoints_visible = np.minimum(1, _keypoints[..., 2])
-
- num_keypoints = np.count_nonzero(keypoints.max(axis=2))
-
- instance_info = {
- 'img_id': ann['image_id'],
- 'img_path': img['img_path'],
- 'bbox': bbox,
- 'bbox_score': np.ones(1, dtype=np.float32),
- 'num_keypoints': num_keypoints,
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- 'iscrowd': ann['iscrowd'],
- 'segmentation': ann['segmentation'],
- 'id': id,
- }
- instance_list.append(instance_info)
- id = id + 1
-
- instance_list = sorted(instance_list, key=lambda x: x['id'])
- return instance_list, image_list
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import List, Tuple
+
+import numpy as np
+from mmengine.fileio import exists, get_local_path
+from xtcocotools.coco import COCO
+
+from mmpose.registry import DATASETS
+from mmpose.structures.bbox import bbox_xywh2xyxy
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class CocoWholeBodyHandDataset(BaseCocoStyleDataset):
+ """CocoWholeBodyDataset for hand pose estimation.
+
+ "Whole-Body Human Pose Estimation in the Wild", ECCV'2020.
+ More details can be found in the `paper
+ `__ .
+
+ COCO-WholeBody Hand keypoints::
+
+ 0: 'wrist',
+ 1: 'thumb1',
+ 2: 'thumb2',
+ 3: 'thumb3',
+ 4: 'thumb4',
+ 5: 'forefinger1',
+ 6: 'forefinger2',
+ 7: 'forefinger3',
+ 8: 'forefinger4',
+ 9: 'middle_finger1',
+ 10: 'middle_finger2',
+ 11: 'middle_finger3',
+ 12: 'middle_finger4',
+ 13: 'ring_finger1',
+ 14: 'ring_finger2',
+ 15: 'ring_finger3',
+ 16: 'ring_finger4',
+ 17: 'pinky_finger1',
+ 18: 'pinky_finger2',
+ 19: 'pinky_finger3',
+ 20: 'pinky_finger4'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(
+ from_file='configs/_base_/datasets/coco_wholebody_hand.py')
+
+ def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
+ """Load data from annotations in COCO format."""
+
+ assert exists(self.ann_file), 'Annotation file does not exist'
+
+ with get_local_path(self.ann_file) as local_path:
+ self.coco = COCO(local_path)
+ instance_list = []
+ image_list = []
+ id = 0
+
+ for img_id in self.coco.getImgIds():
+ img = self.coco.loadImgs(img_id)[0]
+
+ img.update({
+ 'img_id':
+ img_id,
+ 'img_path':
+ osp.join(self.data_prefix['img'], img['file_name']),
+ })
+ image_list.append(img)
+
+ ann_ids = self.coco.getAnnIds(imgIds=img_id, iscrowd=False)
+ anns = self.coco.loadAnns(ann_ids)
+ for ann in anns:
+ for type in ['left', 'right']:
+ # filter invalid hand annotations, there might be two
+ # valid instances (left and right hand) in one image
+ if ann[f'{type}hand_valid'] and max(
+ ann[f'{type}hand_kpts']) > 0:
+
+ bbox_xywh = np.array(
+ ann[f'{type}hand_box'],
+ dtype=np.float32).reshape(1, 4)
+
+ bbox = bbox_xywh2xyxy(bbox_xywh)
+
+ _keypoints = np.array(
+ ann[f'{type}hand_kpts'],
+ dtype=np.float32).reshape(1, -1, 3)
+ keypoints = _keypoints[..., :2]
+ keypoints_visible = np.minimum(1, _keypoints[..., 2])
+
+ num_keypoints = np.count_nonzero(keypoints.max(axis=2))
+
+ instance_info = {
+ 'img_id': ann['image_id'],
+ 'img_path': img['img_path'],
+ 'bbox': bbox,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'num_keypoints': num_keypoints,
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ 'iscrowd': ann['iscrowd'],
+ 'segmentation': ann['segmentation'],
+ 'id': id,
+ }
+ instance_list.append(instance_info)
+ id = id + 1
+
+ instance_list = sorted(instance_list, key=lambda x: x['id'])
+ return instance_list, image_list
diff --git a/mmpose/datasets/datasets/hand/freihand_dataset.py b/mmpose/datasets/datasets/hand/freihand_dataset.py
index 8f0e23cdd5..b530779606 100644
--- a/mmpose/datasets/datasets/hand/freihand_dataset.py
+++ b/mmpose/datasets/datasets/hand/freihand_dataset.py
@@ -1,128 +1,128 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os.path as osp
-from typing import Optional
-
-import numpy as np
-
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class FreiHandDataset(BaseCocoStyleDataset):
- """FreiHand dataset for hand pose estimation.
-
- "FreiHAND: A Dataset for Markerless Capture of Hand Pose
- and Shape from Single RGB Images", ICCV'2019.
- More details can be found in the `paper
- `__ .
-
- FreiHand keypoints::
-
- 0: 'wrist',
- 1: 'thumb1',
- 2: 'thumb2',
- 3: 'thumb3',
- 4: 'thumb4',
- 5: 'forefinger1',
- 6: 'forefinger2',
- 7: 'forefinger3',
- 8: 'forefinger4',
- 9: 'middle_finger1',
- 10: 'middle_finger2',
- 11: 'middle_finger3',
- 12: 'middle_finger4',
- 13: 'ring_finger1',
- 14: 'ring_finger2',
- 15: 'ring_finger3',
- 16: 'ring_finger4',
- 17: 'pinky_finger1',
- 18: 'pinky_finger2',
- 19: 'pinky_finger3',
- 20: 'pinky_finger4'
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/freihand2d.py')
-
- def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
- """Parse raw COCO annotation of an instance.
-
- Args:
- raw_data_info (dict): Raw data information loaded from
- ``ann_file``. It should have following contents:
-
- - ``'raw_ann_info'``: Raw annotation of an instance
- - ``'raw_img_info'``: Raw information of the image that
- contains the instance
-
- Returns:
- dict: Parsed instance annotation
- """
-
- ann = raw_data_info['raw_ann_info']
- img = raw_data_info['raw_img_info']
-
- img_path = osp.join(self.data_prefix['img'], img['file_name'])
-
- # use the entire image which is 224x224
- bbox = np.array([0, 0, 224, 224], dtype=np.float32).reshape(1, 4)
-
- # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
- _keypoints = np.array(
- ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
- keypoints = _keypoints[..., :2]
- keypoints_visible = np.minimum(1, _keypoints[..., 2])
-
- num_keypoints = np.count_nonzero(keypoints.max(axis=2))
-
- data_info = {
- 'img_id': ann['image_id'],
- 'img_path': img_path,
- 'bbox': bbox,
- 'bbox_score': np.ones(1, dtype=np.float32),
- 'num_keypoints': num_keypoints,
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- 'iscrowd': ann['iscrowd'],
- 'segmentation': ann['segmentation'],
- 'id': ann['id'],
- }
-
- return data_info
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import Optional
+
+import numpy as np
+
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class FreiHandDataset(BaseCocoStyleDataset):
+ """FreiHand dataset for hand pose estimation.
+
+ "FreiHAND: A Dataset for Markerless Capture of Hand Pose
+ and Shape from Single RGB Images", ICCV'2019.
+ More details can be found in the `paper
+ `__ .
+
+ FreiHand keypoints::
+
+ 0: 'wrist',
+ 1: 'thumb1',
+ 2: 'thumb2',
+ 3: 'thumb3',
+ 4: 'thumb4',
+ 5: 'forefinger1',
+ 6: 'forefinger2',
+ 7: 'forefinger3',
+ 8: 'forefinger4',
+ 9: 'middle_finger1',
+ 10: 'middle_finger2',
+ 11: 'middle_finger3',
+ 12: 'middle_finger4',
+ 13: 'ring_finger1',
+ 14: 'ring_finger2',
+ 15: 'ring_finger3',
+ 16: 'ring_finger4',
+ 17: 'pinky_finger1',
+ 18: 'pinky_finger2',
+ 19: 'pinky_finger3',
+ 20: 'pinky_finger4'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/freihand2d.py')
+
+ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
+ """Parse raw COCO annotation of an instance.
+
+ Args:
+ raw_data_info (dict): Raw data information loaded from
+ ``ann_file``. It should have following contents:
+
+ - ``'raw_ann_info'``: Raw annotation of an instance
+ - ``'raw_img_info'``: Raw information of the image that
+ contains the instance
+
+ Returns:
+ dict: Parsed instance annotation
+ """
+
+ ann = raw_data_info['raw_ann_info']
+ img = raw_data_info['raw_img_info']
+
+ img_path = osp.join(self.data_prefix['img'], img['file_name'])
+
+ # use the entire image which is 224x224
+ bbox = np.array([0, 0, 224, 224], dtype=np.float32).reshape(1, 4)
+
+ # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
+ _keypoints = np.array(
+ ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
+ keypoints = _keypoints[..., :2]
+ keypoints_visible = np.minimum(1, _keypoints[..., 2])
+
+ num_keypoints = np.count_nonzero(keypoints.max(axis=2))
+
+ data_info = {
+ 'img_id': ann['image_id'],
+ 'img_path': img_path,
+ 'bbox': bbox,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'num_keypoints': num_keypoints,
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ 'iscrowd': ann['iscrowd'],
+ 'segmentation': ann['segmentation'],
+ 'id': ann['id'],
+ }
+
+ return data_info
diff --git a/mmpose/datasets/datasets/hand/onehand10k_dataset.py b/mmpose/datasets/datasets/hand/onehand10k_dataset.py
index 3519ace560..55cff8f5a5 100644
--- a/mmpose/datasets/datasets/hand/onehand10k_dataset.py
+++ b/mmpose/datasets/datasets/hand/onehand10k_dataset.py
@@ -1,77 +1,77 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class OneHand10KDataset(BaseCocoStyleDataset):
- """OneHand10K dataset for hand pose estimation.
-
- "Mask-pose Cascaded CNN for 2D Hand Pose Estimation from
- Single Color Images", TCSVT'2019.
- More details can be found in the `paper
- `__ .
-
- OneHand10K keypoints::
-
- 0: 'wrist',
- 1: 'thumb1',
- 2: 'thumb2',
- 3: 'thumb3',
- 4: 'thumb4',
- 5: 'forefinger1',
- 6: 'forefinger2',
- 7: 'forefinger3',
- 8: 'forefinger4',
- 9: 'middle_finger1',
- 10: 'middle_finger2',
- 11: 'middle_finger3',
- 12: 'middle_finger4',
- 13: 'ring_finger1',
- 14: 'ring_finger2',
- 15: 'ring_finger3',
- 16: 'ring_finger4',
- 17: 'pinky_finger1',
- 18: 'pinky_finger2',
- 19: 'pinky_finger3',
- 20: 'pinky_finger4'
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/onehand10k.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class OneHand10KDataset(BaseCocoStyleDataset):
+ """OneHand10K dataset for hand pose estimation.
+
+ "Mask-pose Cascaded CNN for 2D Hand Pose Estimation from
+ Single Color Images", TCSVT'2019.
+ More details can be found in the `paper
+ `__ .
+
+ OneHand10K keypoints::
+
+ 0: 'wrist',
+ 1: 'thumb1',
+ 2: 'thumb2',
+ 3: 'thumb3',
+ 4: 'thumb4',
+ 5: 'forefinger1',
+ 6: 'forefinger2',
+ 7: 'forefinger3',
+ 8: 'forefinger4',
+ 9: 'middle_finger1',
+ 10: 'middle_finger2',
+ 11: 'middle_finger3',
+ 12: 'middle_finger4',
+ 13: 'ring_finger1',
+ 14: 'ring_finger2',
+ 15: 'ring_finger3',
+ 16: 'ring_finger4',
+ 17: 'pinky_finger1',
+ 18: 'pinky_finger2',
+ 19: 'pinky_finger3',
+ 20: 'pinky_finger4'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/onehand10k.py')
diff --git a/mmpose/datasets/datasets/hand/panoptic_hand2d_dataset.py b/mmpose/datasets/datasets/hand/panoptic_hand2d_dataset.py
index 26d364840e..a3b03db9fe 100644
--- a/mmpose/datasets/datasets/hand/panoptic_hand2d_dataset.py
+++ b/mmpose/datasets/datasets/hand/panoptic_hand2d_dataset.py
@@ -1,137 +1,137 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os.path as osp
-from typing import Optional
-
-import numpy as np
-
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class PanopticHand2DDataset(BaseCocoStyleDataset):
- """Panoptic 2D dataset for hand pose estimation.
-
- "Hand Keypoint Detection in Single Images using Multiview
- Bootstrapping", CVPR'2017.
- More details can be found in the `paper
- `__ .
-
- Panoptic keypoints::
-
- 0: 'wrist',
- 1: 'thumb1',
- 2: 'thumb2',
- 3: 'thumb3',
- 4: 'thumb4',
- 5: 'forefinger1',
- 6: 'forefinger2',
- 7: 'forefinger3',
- 8: 'forefinger4',
- 9: 'middle_finger1',
- 10: 'middle_finger2',
- 11: 'middle_finger3',
- 12: 'middle_finger4',
- 13: 'ring_finger1',
- 14: 'ring_finger2',
- 15: 'ring_finger3',
- 16: 'ring_finger4',
- 17: 'pinky_finger1',
- 18: 'pinky_finger2',
- 19: 'pinky_finger3',
- 20: 'pinky_finger4'
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(
- from_file='configs/_base_/datasets/panoptic_hand2d.py')
-
- def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
- """Parse raw COCO annotation of an instance.
-
- Args:
- raw_data_info (dict): Raw data information loaded from
- ``ann_file``. It should have following contents:
-
- - ``'raw_ann_info'``: Raw annotation of an instance
- - ``'raw_img_info'``: Raw information of the image that
- contains the instance
-
- Returns:
- dict: Parsed instance annotation
- """
-
- ann = raw_data_info['raw_ann_info']
- img = raw_data_info['raw_img_info']
-
- img_path = osp.join(self.data_prefix['img'], img['file_name'])
- img_w, img_h = img['width'], img['height']
-
- # get bbox in shape [1, 4], formatted as xywh
- x, y, w, h = ann['bbox']
- x1 = np.clip(x, 0, img_w - 1)
- y1 = np.clip(y, 0, img_h - 1)
- x2 = np.clip(x + w, 0, img_w - 1)
- y2 = np.clip(y + h, 0, img_h - 1)
-
- bbox = np.array([x1, y1, x2, y2], dtype=np.float32).reshape(1, 4)
-
- # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
- _keypoints = np.array(
- ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
- keypoints = _keypoints[..., :2]
- keypoints_visible = np.minimum(1, _keypoints[..., 2])
-
- num_keypoints = np.count_nonzero(keypoints.max(axis=2))
-
- data_info = {
- 'img_id': ann['image_id'],
- 'img_path': img_path,
- 'bbox': bbox,
- 'bbox_score': np.ones(1, dtype=np.float32),
- 'num_keypoints': num_keypoints,
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- 'iscrowd': ann['iscrowd'],
- 'segmentation': ann['segmentation'],
- 'head_size': ann['head_size'],
- 'id': ann['id'],
- }
-
- return data_info
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import Optional
+
+import numpy as np
+
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class PanopticHand2DDataset(BaseCocoStyleDataset):
+ """Panoptic 2D dataset for hand pose estimation.
+
+ "Hand Keypoint Detection in Single Images using Multiview
+ Bootstrapping", CVPR'2017.
+ More details can be found in the `paper
+ `__ .
+
+ Panoptic keypoints::
+
+ 0: 'wrist',
+ 1: 'thumb1',
+ 2: 'thumb2',
+ 3: 'thumb3',
+ 4: 'thumb4',
+ 5: 'forefinger1',
+ 6: 'forefinger2',
+ 7: 'forefinger3',
+ 8: 'forefinger4',
+ 9: 'middle_finger1',
+ 10: 'middle_finger2',
+ 11: 'middle_finger3',
+ 12: 'middle_finger4',
+ 13: 'ring_finger1',
+ 14: 'ring_finger2',
+ 15: 'ring_finger3',
+ 16: 'ring_finger4',
+ 17: 'pinky_finger1',
+ 18: 'pinky_finger2',
+ 19: 'pinky_finger3',
+ 20: 'pinky_finger4'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(
+ from_file='configs/_base_/datasets/panoptic_hand2d.py')
+
+ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
+ """Parse raw COCO annotation of an instance.
+
+ Args:
+ raw_data_info (dict): Raw data information loaded from
+ ``ann_file``. It should have following contents:
+
+ - ``'raw_ann_info'``: Raw annotation of an instance
+ - ``'raw_img_info'``: Raw information of the image that
+ contains the instance
+
+ Returns:
+ dict: Parsed instance annotation
+ """
+
+ ann = raw_data_info['raw_ann_info']
+ img = raw_data_info['raw_img_info']
+
+ img_path = osp.join(self.data_prefix['img'], img['file_name'])
+ img_w, img_h = img['width'], img['height']
+
+ # get bbox in shape [1, 4], formatted as xywh
+ x, y, w, h = ann['bbox']
+ x1 = np.clip(x, 0, img_w - 1)
+ y1 = np.clip(y, 0, img_h - 1)
+ x2 = np.clip(x + w, 0, img_w - 1)
+ y2 = np.clip(y + h, 0, img_h - 1)
+
+ bbox = np.array([x1, y1, x2, y2], dtype=np.float32).reshape(1, 4)
+
+ # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
+ _keypoints = np.array(
+ ann['keypoints'], dtype=np.float32).reshape(1, -1, 3)
+ keypoints = _keypoints[..., :2]
+ keypoints_visible = np.minimum(1, _keypoints[..., 2])
+
+ num_keypoints = np.count_nonzero(keypoints.max(axis=2))
+
+ data_info = {
+ 'img_id': ann['image_id'],
+ 'img_path': img_path,
+ 'bbox': bbox,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'num_keypoints': num_keypoints,
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ 'iscrowd': ann['iscrowd'],
+ 'segmentation': ann['segmentation'],
+ 'head_size': ann['head_size'],
+ 'id': ann['id'],
+ }
+
+ return data_info
diff --git a/mmpose/datasets/datasets/hand/rhd2d_dataset.py b/mmpose/datasets/datasets/hand/rhd2d_dataset.py
index ebc4301590..fff6c87c93 100644
--- a/mmpose/datasets/datasets/hand/rhd2d_dataset.py
+++ b/mmpose/datasets/datasets/hand/rhd2d_dataset.py
@@ -1,77 +1,77 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class Rhd2DDataset(BaseCocoStyleDataset):
- """Rendered Handpose Dataset for hand pose estimation.
-
- "Learning to Estimate 3D Hand Pose from Single RGB Images",
- ICCV'2017.
- More details can be found in the `paper
- `__ .
-
- Rhd keypoints::
-
- 0: 'wrist',
- 1: 'thumb4',
- 2: 'thumb3',
- 3: 'thumb2',
- 4: 'thumb1',
- 5: 'forefinger4',
- 6: 'forefinger3',
- 7: 'forefinger2',
- 8: 'forefinger1',
- 9: 'middle_finger4',
- 10: 'middle_finger3',
- 11: 'middle_finger2',
- 12: 'middle_finger1',
- 13: 'ring_finger4',
- 14: 'ring_finger3',
- 15: 'ring_finger2',
- 16: 'ring_finger1',
- 17: 'pinky_finger4',
- 18: 'pinky_finger3',
- 19: 'pinky_finger2',
- 20: 'pinky_finger1'
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/rhd2d.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class Rhd2DDataset(BaseCocoStyleDataset):
+ """Rendered Handpose Dataset for hand pose estimation.
+
+ "Learning to Estimate 3D Hand Pose from Single RGB Images",
+ ICCV'2017.
+ More details can be found in the `paper
+ `__ .
+
+ Rhd keypoints::
+
+ 0: 'wrist',
+ 1: 'thumb4',
+ 2: 'thumb3',
+ 3: 'thumb2',
+ 4: 'thumb1',
+ 5: 'forefinger4',
+ 6: 'forefinger3',
+ 7: 'forefinger2',
+ 8: 'forefinger1',
+ 9: 'middle_finger4',
+ 10: 'middle_finger3',
+ 11: 'middle_finger2',
+ 12: 'middle_finger1',
+ 13: 'ring_finger4',
+ 14: 'ring_finger3',
+ 15: 'ring_finger2',
+ 16: 'ring_finger1',
+ 17: 'pinky_finger4',
+ 18: 'pinky_finger3',
+ 19: 'pinky_finger2',
+ 20: 'pinky_finger1'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/rhd2d.py')
diff --git a/mmpose/datasets/datasets/oct/__init__.py b/mmpose/datasets/datasets/oct/__init__.py
index 304c80e849..310c89b232 100644
--- a/mmpose/datasets/datasets/oct/__init__.py
+++ b/mmpose/datasets/datasets/oct/__init__.py
@@ -1,7 +1,7 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .octseg import OCTSegDataset
-
-
-__all__ = [
- 'OCTSegDataset'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .octseg import OCTSegDataset
+
+
+__all__ = [
+ 'OCTSegDataset'
+]
diff --git a/mmpose/datasets/datasets/oct/octseg.py b/mmpose/datasets/datasets/oct/octseg.py
index b63da450fe..5da19608bf 100644
--- a/mmpose/datasets/datasets/oct/octseg.py
+++ b/mmpose/datasets/datasets/oct/octseg.py
@@ -1,9 +1,9 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module(name='OCTSegDataset')
-class OCTSegDataset(BaseCocoStyleDataset):
-
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module(name='OCTSegDataset')
+class OCTSegDataset(BaseCocoStyleDataset):
+
METAINFO: dict = dict(from_file='configs/_base_/datasets/octseg.py')
\ No newline at end of file
diff --git a/mmpose/datasets/datasets/utils.py b/mmpose/datasets/datasets/utils.py
index 7433a168b9..da25fe6ae9 100644
--- a/mmpose/datasets/datasets/utils.py
+++ b/mmpose/datasets/datasets/utils.py
@@ -1,202 +1,202 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os.path as osp
-import warnings
-
-import numpy as np
-from mmengine import Config
-
-
-def parse_pose_metainfo(metainfo: dict):
- """Load meta information of pose dataset and check its integrity.
-
- Args:
- metainfo (dict): Raw data of pose meta information, which should
- contain following contents:
-
- - "dataset_name" (str): The name of the dataset
- - "keypoint_info" (dict): The keypoint-related meta information,
- e.g., name, upper/lower body, and symmetry
- - "skeleton_info" (dict): The skeleton-related meta information,
- e.g., start/end keypoint of limbs
- - "joint_weights" (list[float]): The loss weights of keypoints
- - "sigmas" (list[float]): The keypoint distribution parameters
- to calculate OKS score. See `COCO keypoint evaluation
- `__.
-
- An example of metainfo is shown as follows.
-
- .. code-block:: none
- {
- "dataset_name": "coco",
- "keypoint_info":
- {
- 0:
- {
- "name": "nose",
- "type": "upper",
- "swap": "",
- "color": [51, 153, 255],
- },
- 1:
- {
- "name": "right_eye",
- "type": "upper",
- "swap": "left_eye",
- "color": [51, 153, 255],
- },
- ...
- },
- "skeleton_info":
- {
- 0:
- {
- "link": ("left_ankle", "left_knee"),
- "color": [0, 255, 0],
- },
- ...
- },
- "joint_weights": [1., 1., ...],
- "sigmas": [0.026, 0.025, ...],
- }
-
-
- A special case is that `metainfo` can have the key "from_file",
- which should be the path of a config file. In this case, the
- actual metainfo will be loaded by:
-
- .. code-block:: python
- metainfo = mmengine.Config.fromfile(metainfo['from_file'])
-
- Returns:
- Dict: pose meta information that contains following contents:
-
- - "dataset_name" (str): Same as ``"dataset_name"`` in the input
- - "num_keypoints" (int): Number of keypoints
- - "keypoint_id2name" (dict): Mapping from keypoint id to name
- - "keypoint_name2id" (dict): Mapping from keypoint name to id
- - "upper_body_ids" (list): Ids of upper-body keypoint
- - "lower_body_ids" (list): Ids of lower-body keypoint
- - "flip_indices" (list): The Id of each keypoint's symmetric keypoint
- - "flip_pairs" (list): The Ids of symmetric keypoint pairs
- - "keypoint_colors" (numpy.ndarray): The keypoint color matrix of
- shape [K, 3], where each row is the color of one keypint in bgr
- - "num_skeleton_links" (int): The number of links
- - "skeleton_links" (list): The links represented by Id pairs of start
- and end points
- - "skeleton_link_colors" (numpy.ndarray): The link color matrix
- - "dataset_keypoint_weights" (numpy.ndarray): Same as the
- ``"joint_weights"`` in the input
- - "sigmas" (numpy.ndarray): Same as the ``"sigmas"`` in the input
- """
-
- if 'from_file' in metainfo:
- cfg_file = metainfo['from_file']
- if not osp.isfile(cfg_file):
- # Search configs in 'mmpose/.mim/configs/' in case that mmpose
- # is installed in non-editable mode.
- import mmpose
- mmpose_path = osp.dirname(mmpose.__file__)
- _cfg_file = osp.join(mmpose_path, '.mim', 'configs', '_base_',
- 'datasets', osp.basename(cfg_file))
- if osp.isfile(_cfg_file):
- warnings.warn(
- f'The metainfo config file "{cfg_file}" does not exist. '
- f'A matched config file "{_cfg_file}" will be used '
- 'instead.')
- cfg_file = _cfg_file
- else:
- raise FileNotFoundError(
- f'The metainfo config file "{cfg_file}" does not exist.')
-
- # TODO: remove the nested structure of dataset_info
- # metainfo = Config.fromfile(metainfo['from_file'])
- metainfo = Config.fromfile(cfg_file).dataset_info
-
- # check data integrity
- assert 'dataset_name' in metainfo
- assert 'keypoint_info' in metainfo
- assert 'skeleton_info' in metainfo
- assert 'joint_weights' in metainfo
- assert 'sigmas' in metainfo
-
- # parse metainfo
- parsed = dict(
- dataset_name=None,
- num_keypoints=None,
- keypoint_id2name={},
- keypoint_name2id={},
- upper_body_ids=[],
- lower_body_ids=[],
- flip_indices=[],
- flip_pairs=[],
- keypoint_colors=[],
- num_skeleton_links=None,
- skeleton_links=[],
- skeleton_link_colors=[],
- dataset_keypoint_weights=None,
- sigmas=None,
- )
-
- parsed['dataset_name'] = metainfo['dataset_name']
-
- # parse keypoint information
- parsed['num_keypoints'] = len(metainfo['keypoint_info'])
-
- for kpt_id, kpt in metainfo['keypoint_info'].items():
- kpt_name = kpt['name']
- parsed['keypoint_id2name'][kpt_id] = kpt_name
- parsed['keypoint_name2id'][kpt_name] = kpt_id
- parsed['keypoint_colors'].append(kpt.get('color', [255, 128, 0]))
-
- kpt_type = kpt.get('type', '')
- if kpt_type == 'upper':
- parsed['upper_body_ids'].append(kpt_id)
- elif kpt_type == 'lower':
- parsed['lower_body_ids'].append(kpt_id)
-
- swap_kpt = kpt.get('swap', '')
- if swap_kpt == kpt_name or swap_kpt == '':
- parsed['flip_indices'].append(kpt_name)
- else:
- parsed['flip_indices'].append(swap_kpt)
- pair = (swap_kpt, kpt_name)
- if pair not in parsed['flip_pairs']:
- parsed['flip_pairs'].append(pair)
-
- # parse skeleton information
- parsed['num_skeleton_links'] = len(metainfo['skeleton_info'])
- for _, sk in metainfo['skeleton_info'].items():
- parsed['skeleton_links'].append(sk['link'])
- parsed['skeleton_link_colors'].append(sk.get('color', [96, 96, 255]))
-
- # parse extra information
- parsed['dataset_keypoint_weights'] = np.array(
- metainfo['joint_weights'], dtype=np.float32)
- parsed['sigmas'] = np.array(metainfo['sigmas'], dtype=np.float32)
-
- if 'stats_info' in metainfo:
- parsed['stats_info'] = {}
- for name, val in metainfo['stats_info'].items():
- parsed['stats_info'][name] = np.array(val, dtype=np.float32)
-
- # formatting
- def _map(src, mapping: dict):
- if isinstance(src, (list, tuple)):
- cls = type(src)
- return cls(_map(s, mapping) for s in src)
- else:
- return mapping[src]
-
- parsed['flip_pairs'] = _map(
- parsed['flip_pairs'], mapping=parsed['keypoint_name2id'])
- parsed['flip_indices'] = _map(
- parsed['flip_indices'], mapping=parsed['keypoint_name2id'])
- parsed['skeleton_links'] = _map(
- parsed['skeleton_links'], mapping=parsed['keypoint_name2id'])
-
- parsed['keypoint_colors'] = np.array(
- parsed['keypoint_colors'], dtype=np.uint8)
- parsed['skeleton_link_colors'] = np.array(
- parsed['skeleton_link_colors'], dtype=np.uint8)
-
- return parsed
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import warnings
+
+import numpy as np
+from mmengine import Config
+
+
+def parse_pose_metainfo(metainfo: dict):
+ """Load meta information of pose dataset and check its integrity.
+
+ Args:
+ metainfo (dict): Raw data of pose meta information, which should
+ contain following contents:
+
+ - "dataset_name" (str): The name of the dataset
+ - "keypoint_info" (dict): The keypoint-related meta information,
+ e.g., name, upper/lower body, and symmetry
+ - "skeleton_info" (dict): The skeleton-related meta information,
+ e.g., start/end keypoint of limbs
+ - "joint_weights" (list[float]): The loss weights of keypoints
+ - "sigmas" (list[float]): The keypoint distribution parameters
+ to calculate OKS score. See `COCO keypoint evaluation
+ `__.
+
+ An example of metainfo is shown as follows.
+
+ .. code-block:: none
+ {
+ "dataset_name": "coco",
+ "keypoint_info":
+ {
+ 0:
+ {
+ "name": "nose",
+ "type": "upper",
+ "swap": "",
+ "color": [51, 153, 255],
+ },
+ 1:
+ {
+ "name": "right_eye",
+ "type": "upper",
+ "swap": "left_eye",
+ "color": [51, 153, 255],
+ },
+ ...
+ },
+ "skeleton_info":
+ {
+ 0:
+ {
+ "link": ("left_ankle", "left_knee"),
+ "color": [0, 255, 0],
+ },
+ ...
+ },
+ "joint_weights": [1., 1., ...],
+ "sigmas": [0.026, 0.025, ...],
+ }
+
+
+ A special case is that `metainfo` can have the key "from_file",
+ which should be the path of a config file. In this case, the
+ actual metainfo will be loaded by:
+
+ .. code-block:: python
+ metainfo = mmengine.Config.fromfile(metainfo['from_file'])
+
+ Returns:
+ Dict: pose meta information that contains following contents:
+
+ - "dataset_name" (str): Same as ``"dataset_name"`` in the input
+ - "num_keypoints" (int): Number of keypoints
+ - "keypoint_id2name" (dict): Mapping from keypoint id to name
+ - "keypoint_name2id" (dict): Mapping from keypoint name to id
+ - "upper_body_ids" (list): Ids of upper-body keypoint
+ - "lower_body_ids" (list): Ids of lower-body keypoint
+ - "flip_indices" (list): The Id of each keypoint's symmetric keypoint
+ - "flip_pairs" (list): The Ids of symmetric keypoint pairs
+ - "keypoint_colors" (numpy.ndarray): The keypoint color matrix of
+ shape [K, 3], where each row is the color of one keypint in bgr
+ - "num_skeleton_links" (int): The number of links
+ - "skeleton_links" (list): The links represented by Id pairs of start
+ and end points
+ - "skeleton_link_colors" (numpy.ndarray): The link color matrix
+ - "dataset_keypoint_weights" (numpy.ndarray): Same as the
+ ``"joint_weights"`` in the input
+ - "sigmas" (numpy.ndarray): Same as the ``"sigmas"`` in the input
+ """
+
+ if 'from_file' in metainfo:
+ cfg_file = metainfo['from_file']
+ if not osp.isfile(cfg_file):
+ # Search configs in 'mmpose/.mim/configs/' in case that mmpose
+ # is installed in non-editable mode.
+ import mmpose
+ mmpose_path = osp.dirname(mmpose.__file__)
+ _cfg_file = osp.join(mmpose_path, '.mim', 'configs', '_base_',
+ 'datasets', osp.basename(cfg_file))
+ if osp.isfile(_cfg_file):
+ warnings.warn(
+ f'The metainfo config file "{cfg_file}" does not exist. '
+ f'A matched config file "{_cfg_file}" will be used '
+ 'instead.')
+ cfg_file = _cfg_file
+ else:
+ raise FileNotFoundError(
+ f'The metainfo config file "{cfg_file}" does not exist.')
+
+ # TODO: remove the nested structure of dataset_info
+ # metainfo = Config.fromfile(metainfo['from_file'])
+ metainfo = Config.fromfile(cfg_file).dataset_info
+
+ # check data integrity
+ assert 'dataset_name' in metainfo
+ assert 'keypoint_info' in metainfo
+ assert 'skeleton_info' in metainfo
+ assert 'joint_weights' in metainfo
+ assert 'sigmas' in metainfo
+
+ # parse metainfo
+ parsed = dict(
+ dataset_name=None,
+ num_keypoints=None,
+ keypoint_id2name={},
+ keypoint_name2id={},
+ upper_body_ids=[],
+ lower_body_ids=[],
+ flip_indices=[],
+ flip_pairs=[],
+ keypoint_colors=[],
+ num_skeleton_links=None,
+ skeleton_links=[],
+ skeleton_link_colors=[],
+ dataset_keypoint_weights=None,
+ sigmas=None,
+ )
+
+ parsed['dataset_name'] = metainfo['dataset_name']
+
+ # parse keypoint information
+ parsed['num_keypoints'] = len(metainfo['keypoint_info'])
+
+ for kpt_id, kpt in metainfo['keypoint_info'].items():
+ kpt_name = kpt['name']
+ parsed['keypoint_id2name'][kpt_id] = kpt_name
+ parsed['keypoint_name2id'][kpt_name] = kpt_id
+ parsed['keypoint_colors'].append(kpt.get('color', [255, 128, 0]))
+
+ kpt_type = kpt.get('type', '')
+ if kpt_type == 'upper':
+ parsed['upper_body_ids'].append(kpt_id)
+ elif kpt_type == 'lower':
+ parsed['lower_body_ids'].append(kpt_id)
+
+ swap_kpt = kpt.get('swap', '')
+ if swap_kpt == kpt_name or swap_kpt == '':
+ parsed['flip_indices'].append(kpt_name)
+ else:
+ parsed['flip_indices'].append(swap_kpt)
+ pair = (swap_kpt, kpt_name)
+ if pair not in parsed['flip_pairs']:
+ parsed['flip_pairs'].append(pair)
+
+ # parse skeleton information
+ parsed['num_skeleton_links'] = len(metainfo['skeleton_info'])
+ for _, sk in metainfo['skeleton_info'].items():
+ parsed['skeleton_links'].append(sk['link'])
+ parsed['skeleton_link_colors'].append(sk.get('color', [96, 96, 255]))
+
+ # parse extra information
+ parsed['dataset_keypoint_weights'] = np.array(
+ metainfo['joint_weights'], dtype=np.float32)
+ parsed['sigmas'] = np.array(metainfo['sigmas'], dtype=np.float32)
+
+ if 'stats_info' in metainfo:
+ parsed['stats_info'] = {}
+ for name, val in metainfo['stats_info'].items():
+ parsed['stats_info'][name] = np.array(val, dtype=np.float32)
+
+ # formatting
+ def _map(src, mapping: dict):
+ if isinstance(src, (list, tuple)):
+ cls = type(src)
+ return cls(_map(s, mapping) for s in src)
+ else:
+ return mapping[src]
+
+ parsed['flip_pairs'] = _map(
+ parsed['flip_pairs'], mapping=parsed['keypoint_name2id'])
+ parsed['flip_indices'] = _map(
+ parsed['flip_indices'], mapping=parsed['keypoint_name2id'])
+ parsed['skeleton_links'] = _map(
+ parsed['skeleton_links'], mapping=parsed['keypoint_name2id'])
+
+ parsed['keypoint_colors'] = np.array(
+ parsed['keypoint_colors'], dtype=np.uint8)
+ parsed['skeleton_link_colors'] = np.array(
+ parsed['skeleton_link_colors'], dtype=np.uint8)
+
+ return parsed
diff --git a/mmpose/datasets/datasets/wholebody/__init__.py b/mmpose/datasets/datasets/wholebody/__init__.py
index 156094c2b0..dd28293d06 100644
--- a/mmpose/datasets/datasets/wholebody/__init__.py
+++ b/mmpose/datasets/datasets/wholebody/__init__.py
@@ -1,5 +1,5 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .coco_wholebody_dataset import CocoWholeBodyDataset
-from .halpe_dataset import HalpeDataset
-
-__all__ = ['CocoWholeBodyDataset', 'HalpeDataset']
+# Copyright (c) OpenMMLab. All rights reserved.
+from .coco_wholebody_dataset import CocoWholeBodyDataset
+from .halpe_dataset import HalpeDataset
+
+__all__ = ['CocoWholeBodyDataset', 'HalpeDataset']
diff --git a/mmpose/datasets/datasets/wholebody/coco_wholebody_dataset.py b/mmpose/datasets/datasets/wholebody/coco_wholebody_dataset.py
index 00a2ea418f..720e49a4ae 100644
--- a/mmpose/datasets/datasets/wholebody/coco_wholebody_dataset.py
+++ b/mmpose/datasets/datasets/wholebody/coco_wholebody_dataset.py
@@ -1,127 +1,127 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-import os.path as osp
-from typing import Optional
-
-import numpy as np
-
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class CocoWholeBodyDataset(BaseCocoStyleDataset):
- """CocoWholeBody dataset for pose estimation.
-
- "Whole-Body Human Pose Estimation in the Wild", ECCV'2020.
- More details can be found in the `paper
- `__ .
-
- COCO-WholeBody keypoints::
-
- 0-16: 17 body keypoints,
- 17-22: 6 foot keypoints,
- 23-90: 68 face keypoints,
- 91-132: 42 hand keypoints
-
- In total, we have 133 keypoints for wholebody pose estimation.
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(
- from_file='configs/_base_/datasets/coco_wholebody.py')
-
- def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
- """Parse raw COCO annotation of an instance.
-
- Args:
- raw_data_info (dict): Raw data information loaded from
- ``ann_file``. It should have following contents:
-
- - ``'raw_ann_info'``: Raw annotation of an instance
- - ``'raw_img_info'``: Raw information of the image that
- contains the instance
-
- Returns:
- dict: Parsed instance annotation
- """
-
- ann = raw_data_info['raw_ann_info']
- img = raw_data_info['raw_img_info']
-
- img_path = osp.join(self.data_prefix['img'], img['file_name'])
- img_w, img_h = img['width'], img['height']
-
- # get bbox in shape [1, 4], formatted as xywh
- x, y, w, h = ann['bbox']
- x1 = np.clip(x, 0, img_w - 1)
- y1 = np.clip(y, 0, img_h - 1)
- x2 = np.clip(x + w, 0, img_w - 1)
- y2 = np.clip(y + h, 0, img_h - 1)
-
- bbox = np.array([x1, y1, x2, y2], dtype=np.float32).reshape(1, 4)
-
- # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
- # COCO-Wholebody: consisting of body, foot, face and hand keypoints
- _keypoints = np.array(ann['keypoints'] + ann['foot_kpts'] +
- ann['face_kpts'] + ann['lefthand_kpts'] +
- ann['righthand_kpts']).reshape(1, -1, 3)
- keypoints = _keypoints[..., :2]
- keypoints_visible = np.minimum(1, _keypoints[..., 2] > 0)
-
- num_keypoints = ann['num_keypoints']
-
- data_info = {
- 'img_id': ann['image_id'],
- 'img_path': img_path,
- 'bbox': bbox,
- 'bbox_score': np.ones(1, dtype=np.float32),
- 'num_keypoints': num_keypoints,
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- 'iscrowd': ann['iscrowd'],
- 'segmentation': ann['segmentation'],
- 'id': ann['id'],
- 'category_id': ann['category_id'],
- # store the raw annotation of the instance
- # it is useful for evaluation without providing ann_file
- 'raw_ann_info': copy.deepcopy(ann),
- }
-
- return data_info
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import os.path as osp
+from typing import Optional
+
+import numpy as np
+
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class CocoWholeBodyDataset(BaseCocoStyleDataset):
+ """CocoWholeBody dataset for pose estimation.
+
+ "Whole-Body Human Pose Estimation in the Wild", ECCV'2020.
+ More details can be found in the `paper
+ `__ .
+
+ COCO-WholeBody keypoints::
+
+ 0-16: 17 body keypoints,
+ 17-22: 6 foot keypoints,
+ 23-90: 68 face keypoints,
+ 91-132: 42 hand keypoints
+
+ In total, we have 133 keypoints for wholebody pose estimation.
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(
+ from_file='configs/_base_/datasets/coco_wholebody.py')
+
+ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
+ """Parse raw COCO annotation of an instance.
+
+ Args:
+ raw_data_info (dict): Raw data information loaded from
+ ``ann_file``. It should have following contents:
+
+ - ``'raw_ann_info'``: Raw annotation of an instance
+ - ``'raw_img_info'``: Raw information of the image that
+ contains the instance
+
+ Returns:
+ dict: Parsed instance annotation
+ """
+
+ ann = raw_data_info['raw_ann_info']
+ img = raw_data_info['raw_img_info']
+
+ img_path = osp.join(self.data_prefix['img'], img['file_name'])
+ img_w, img_h = img['width'], img['height']
+
+ # get bbox in shape [1, 4], formatted as xywh
+ x, y, w, h = ann['bbox']
+ x1 = np.clip(x, 0, img_w - 1)
+ y1 = np.clip(y, 0, img_h - 1)
+ x2 = np.clip(x + w, 0, img_w - 1)
+ y2 = np.clip(y + h, 0, img_h - 1)
+
+ bbox = np.array([x1, y1, x2, y2], dtype=np.float32).reshape(1, 4)
+
+ # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
+ # COCO-Wholebody: consisting of body, foot, face and hand keypoints
+ _keypoints = np.array(ann['keypoints'] + ann['foot_kpts'] +
+ ann['face_kpts'] + ann['lefthand_kpts'] +
+ ann['righthand_kpts']).reshape(1, -1, 3)
+ keypoints = _keypoints[..., :2]
+ keypoints_visible = np.minimum(1, _keypoints[..., 2] > 0)
+
+ num_keypoints = ann['num_keypoints']
+
+ data_info = {
+ 'img_id': ann['image_id'],
+ 'img_path': img_path,
+ 'bbox': bbox,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'num_keypoints': num_keypoints,
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ 'iscrowd': ann['iscrowd'],
+ 'segmentation': ann['segmentation'],
+ 'id': ann['id'],
+ 'category_id': ann['category_id'],
+ # store the raw annotation of the instance
+ # it is useful for evaluation without providing ann_file
+ 'raw_ann_info': copy.deepcopy(ann),
+ }
+
+ return data_info
diff --git a/mmpose/datasets/datasets/wholebody/halpe_dataset.py b/mmpose/datasets/datasets/wholebody/halpe_dataset.py
index 0699f3b702..75819a2c56 100644
--- a/mmpose/datasets/datasets/wholebody/halpe_dataset.py
+++ b/mmpose/datasets/datasets/wholebody/halpe_dataset.py
@@ -1,59 +1,59 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.registry import DATASETS
-from ..base import BaseCocoStyleDataset
-
-
-@DATASETS.register_module()
-class HalpeDataset(BaseCocoStyleDataset):
- """Halpe dataset for pose estimation.
-
- 'https://github.com/Fang-Haoshu/Halpe-FullBody'
-
- Halpe keypoints::
-
- 0-19: 20 body keypoints,
- 20-25: 6 foot keypoints,
- 26-93: 68 face keypoints,
- 94-135: 42 hand keypoints
-
- In total, we have 136 keypoints for wholebody pose estimation.
-
- Args:
- ann_file (str): Annotation file path. Default: ''.
- bbox_file (str, optional): Detection result file path. If
- ``bbox_file`` is set, detected bboxes loaded from this file will
- be used instead of ground-truth bboxes. This setting is only for
- evaluation, i.e., ignored when ``test_mode`` is ``False``.
- Default: ``None``.
- data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
- ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
- one instance; while in ``'bottomup'`` mode, each data sample
- contains all instances in a image. Default: ``'topdown'``
- metainfo (dict, optional): Meta information for dataset, such as class
- information. Default: ``None``.
- data_root (str, optional): The root directory for ``data_prefix`` and
- ``ann_file``. Default: ``None``.
- data_prefix (dict, optional): Prefix for training data. Default:
- ``dict(img=None, ann=None)``.
- filter_cfg (dict, optional): Config for filter data. Default: `None`.
- indices (int or Sequence[int], optional): Support using first few
- data in annotation file to facilitate training/testing on a smaller
- dataset. Default: ``None`` which means using all ``data_infos``.
- serialize_data (bool, optional): Whether to hold memory using
- serialized objects, when enabled, data loader workers can use
- shared RAM from master process instead of making a copy.
- Default: ``True``.
- pipeline (list, optional): Processing pipeline. Default: [].
- test_mode (bool, optional): ``test_mode=True`` means in test phase.
- Default: ``False``.
- lazy_init (bool, optional): Whether to load annotation during
- instantiation. In some cases, such as visualization, only the meta
- information of the dataset is needed, which is not necessary to
- load annotation file. ``Basedataset`` can skip load annotations to
- save time by set ``lazy_init=False``. Default: ``False``.
- max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
- None img. The maximum extra number of cycles to get a valid
- image. Default: 1000.
- """
-
- METAINFO: dict = dict(from_file='configs/_base_/datasets/halpe.py')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class HalpeDataset(BaseCocoStyleDataset):
+ """Halpe dataset for pose estimation.
+
+ 'https://github.com/Fang-Haoshu/Halpe-FullBody'
+
+ Halpe keypoints::
+
+ 0-19: 20 body keypoints,
+ 20-25: 6 foot keypoints,
+ 26-93: 68 face keypoints,
+ 94-135: 42 hand keypoints
+
+ In total, we have 136 keypoints for wholebody pose estimation.
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/halpe.py')
diff --git a/mmpose/datasets/samplers.py b/mmpose/datasets/samplers.py
index d6bb34287a..f9def1ebda 100644
--- a/mmpose/datasets/samplers.py
+++ b/mmpose/datasets/samplers.py
@@ -1,114 +1,114 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import itertools
-import math
-from typing import Iterator, List, Optional, Sized, Union
-
-import torch
-from mmengine.dist import get_dist_info, sync_random_seed
-from torch.utils.data import Sampler
-
-from mmpose.datasets import CombinedDataset
-from mmpose.registry import DATA_SAMPLERS
-
-
-@DATA_SAMPLERS.register_module()
-class MultiSourceSampler(Sampler):
- """Multi-Source Sampler. According to the sampling ratio, sample data from
- different datasets to form batches.
-
- Args:
- dataset (Sized): The dataset
- batch_size (int): Size of mini-batch
- source_ratio (list[int | float]): The sampling ratio of different
- source datasets in a mini-batch
- shuffle (bool): Whether shuffle the dataset or not. Defaults to
- ``True``
- round_up (bool): Whether to add extra samples to make the number of
- samples evenly divisible by the world size. Defaults to True.
- seed (int, optional): Random seed. If ``None``, set a random seed.
- Defaults to ``None``
- """
-
- def __init__(self,
- dataset: Sized,
- batch_size: int,
- source_ratio: List[Union[int, float]],
- shuffle: bool = True,
- round_up: bool = True,
- seed: Optional[int] = None) -> None:
-
- assert isinstance(dataset, CombinedDataset),\
- f'The dataset must be CombinedDataset, but get {dataset}'
- assert isinstance(batch_size, int) and batch_size > 0, \
- 'batch_size must be a positive integer value, ' \
- f'but got batch_size={batch_size}'
- assert isinstance(source_ratio, list), \
- f'source_ratio must be a list, but got source_ratio={source_ratio}'
- assert len(source_ratio) == len(dataset._lens), \
- 'The length of source_ratio must be equal to ' \
- f'the number of datasets, but got source_ratio={source_ratio}'
-
- rank, world_size = get_dist_info()
- self.rank = rank
- self.world_size = world_size
-
- self.dataset = dataset
- self.cumulative_sizes = [0] + list(itertools.accumulate(dataset._lens))
- self.batch_size = batch_size
- self.source_ratio = source_ratio
- self.num_samples = int(math.ceil(len(self.dataset) * 1.0 / world_size))
- self.num_per_source = [
- int(batch_size * sr / sum(source_ratio)) for sr in source_ratio
- ]
- self.num_per_source[0] = batch_size - sum(self.num_per_source[1:])
-
- assert sum(self.num_per_source) == batch_size, \
- 'The sum of num_per_source must be equal to ' \
- f'batch_size, but get {self.num_per_source}'
-
- self.seed = sync_random_seed() if seed is None else seed
- self.shuffle = shuffle
- self.round_up = round_up
- self.source2inds = {
- source: self._indices_of_rank(len(ds))
- for source, ds in enumerate(dataset.datasets)
- }
-
- def _infinite_indices(self, sample_size: int) -> Iterator[int]:
- """Infinitely yield a sequence of indices."""
- g = torch.Generator()
- g.manual_seed(self.seed)
- while True:
- if self.shuffle:
- yield from torch.randperm(sample_size, generator=g).tolist()
- else:
- yield from torch.arange(sample_size).tolist()
-
- def _indices_of_rank(self, sample_size: int) -> Iterator[int]:
- """Slice the infinite indices by rank."""
- yield from itertools.islice(
- self._infinite_indices(sample_size), self.rank, None,
- self.world_size)
-
- def __iter__(self) -> Iterator[int]:
- batch_buffer = []
- num_iters = self.num_samples // self.batch_size
- if self.round_up and self.num_samples > num_iters * self.batch_size:
- num_iters += 1
- for i in range(num_iters):
- for source, num in enumerate(self.num_per_source):
- batch_buffer_per_source = []
- for idx in self.source2inds[source]:
- idx += self.cumulative_sizes[source]
- batch_buffer_per_source.append(idx)
- if len(batch_buffer_per_source) == num:
- batch_buffer += batch_buffer_per_source
- break
- return iter(batch_buffer)
-
- def __len__(self) -> int:
- return self.num_samples
-
- def set_epoch(self, epoch: int) -> None:
- """Compatible in `epoch-based runner."""
- pass
+# Copyright (c) OpenMMLab. All rights reserved.
+import itertools
+import math
+from typing import Iterator, List, Optional, Sized, Union
+
+import torch
+from mmengine.dist import get_dist_info, sync_random_seed
+from torch.utils.data import Sampler
+
+from mmpose.datasets import CombinedDataset
+from mmpose.registry import DATA_SAMPLERS
+
+
+@DATA_SAMPLERS.register_module()
+class MultiSourceSampler(Sampler):
+ """Multi-Source Sampler. According to the sampling ratio, sample data from
+ different datasets to form batches.
+
+ Args:
+ dataset (Sized): The dataset
+ batch_size (int): Size of mini-batch
+ source_ratio (list[int | float]): The sampling ratio of different
+ source datasets in a mini-batch
+ shuffle (bool): Whether shuffle the dataset or not. Defaults to
+ ``True``
+ round_up (bool): Whether to add extra samples to make the number of
+ samples evenly divisible by the world size. Defaults to True.
+ seed (int, optional): Random seed. If ``None``, set a random seed.
+ Defaults to ``None``
+ """
+
+ def __init__(self,
+ dataset: Sized,
+ batch_size: int,
+ source_ratio: List[Union[int, float]],
+ shuffle: bool = True,
+ round_up: bool = True,
+ seed: Optional[int] = None) -> None:
+
+ assert isinstance(dataset, CombinedDataset),\
+ f'The dataset must be CombinedDataset, but get {dataset}'
+ assert isinstance(batch_size, int) and batch_size > 0, \
+ 'batch_size must be a positive integer value, ' \
+ f'but got batch_size={batch_size}'
+ assert isinstance(source_ratio, list), \
+ f'source_ratio must be a list, but got source_ratio={source_ratio}'
+ assert len(source_ratio) == len(dataset._lens), \
+ 'The length of source_ratio must be equal to ' \
+ f'the number of datasets, but got source_ratio={source_ratio}'
+
+ rank, world_size = get_dist_info()
+ self.rank = rank
+ self.world_size = world_size
+
+ self.dataset = dataset
+ self.cumulative_sizes = [0] + list(itertools.accumulate(dataset._lens))
+ self.batch_size = batch_size
+ self.source_ratio = source_ratio
+ self.num_samples = int(math.ceil(len(self.dataset) * 1.0 / world_size))
+ self.num_per_source = [
+ int(batch_size * sr / sum(source_ratio)) for sr in source_ratio
+ ]
+ self.num_per_source[0] = batch_size - sum(self.num_per_source[1:])
+
+ assert sum(self.num_per_source) == batch_size, \
+ 'The sum of num_per_source must be equal to ' \
+ f'batch_size, but get {self.num_per_source}'
+
+ self.seed = sync_random_seed() if seed is None else seed
+ self.shuffle = shuffle
+ self.round_up = round_up
+ self.source2inds = {
+ source: self._indices_of_rank(len(ds))
+ for source, ds in enumerate(dataset.datasets)
+ }
+
+ def _infinite_indices(self, sample_size: int) -> Iterator[int]:
+ """Infinitely yield a sequence of indices."""
+ g = torch.Generator()
+ g.manual_seed(self.seed)
+ while True:
+ if self.shuffle:
+ yield from torch.randperm(sample_size, generator=g).tolist()
+ else:
+ yield from torch.arange(sample_size).tolist()
+
+ def _indices_of_rank(self, sample_size: int) -> Iterator[int]:
+ """Slice the infinite indices by rank."""
+ yield from itertools.islice(
+ self._infinite_indices(sample_size), self.rank, None,
+ self.world_size)
+
+ def __iter__(self) -> Iterator[int]:
+ batch_buffer = []
+ num_iters = self.num_samples // self.batch_size
+ if self.round_up and self.num_samples > num_iters * self.batch_size:
+ num_iters += 1
+ for i in range(num_iters):
+ for source, num in enumerate(self.num_per_source):
+ batch_buffer_per_source = []
+ for idx in self.source2inds[source]:
+ idx += self.cumulative_sizes[source]
+ batch_buffer_per_source.append(idx)
+ if len(batch_buffer_per_source) == num:
+ batch_buffer += batch_buffer_per_source
+ break
+ return iter(batch_buffer)
+
+ def __len__(self) -> int:
+ return self.num_samples
+
+ def set_epoch(self, epoch: int) -> None:
+ """Compatible in `epoch-based runner."""
+ pass
diff --git a/mmpose/datasets/transforms/__init__.py b/mmpose/datasets/transforms/__init__.py
index 7ccbf7dac2..6d9405837c 100644
--- a/mmpose/datasets/transforms/__init__.py
+++ b/mmpose/datasets/transforms/__init__.py
@@ -1,20 +1,22 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .bottomup_transforms import (BottomupGetHeatmapMask, BottomupRandomAffine,
- BottomupResize)
-from .common_transforms import (Albumentation, GenerateTarget,
- GetBBoxCenterScale, PhotometricDistortion,
- RandomBBoxTransform, RandomFlip,
- RandomHalfBody)
-from .converting import KeypointConverter
-from .formatting import PackPoseInputs
-from .loading import LoadImage
-from .pose3d_transforms import RandomFlipAroundRoot
-from .topdown_transforms import TopdownAffine
-
-__all__ = [
- 'GetBBoxCenterScale', 'RandomBBoxTransform', 'RandomFlip',
- 'RandomHalfBody', 'TopdownAffine', 'Albumentation',
- 'PhotometricDistortion', 'PackPoseInputs', 'LoadImage',
- 'BottomupGetHeatmapMask', 'BottomupRandomAffine', 'BottomupResize',
- 'GenerateTarget', 'KeypointConverter', 'RandomFlipAroundRoot'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .bottomup_transforms import (BottomupGetHeatmapMask, BottomupRandomAffine,
+ BottomupResize)
+from .common_transforms import (Albumentation, GenerateTarget,
+ GetBBoxCenterScale, PhotometricDistortion,
+ RandomBBoxTransform, RandomFlip,
+ RandomHalfBody)
+from .converting import KeypointConverter
+from .formatting import PackPoseInputs
+from .loading import LoadImage
+from .pose3d_transforms import RandomFlipAroundRoot
+from .topdown_transforms import TopdownAffine
+
+from .warping import Warping
+
+__all__ = [
+ 'GetBBoxCenterScale', 'RandomBBoxTransform', 'RandomFlip',
+ 'RandomHalfBody', 'TopdownAffine', 'Albumentation',
+ 'PhotometricDistortion', 'PackPoseInputs', 'LoadImage',
+ 'BottomupGetHeatmapMask', 'BottomupRandomAffine', 'BottomupResize',
+ 'GenerateTarget', 'KeypointConverter', 'RandomFlipAroundRoot'
+]
diff --git a/mmpose/datasets/transforms/bottomup_transforms.py b/mmpose/datasets/transforms/bottomup_transforms.py
index c31e0ae17d..a3e23a47f2 100644
--- a/mmpose/datasets/transforms/bottomup_transforms.py
+++ b/mmpose/datasets/transforms/bottomup_transforms.py
@@ -1,517 +1,517 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Dict, List, Optional, Tuple
-
-import cv2
-import numpy as np
-import xtcocotools.mask as cocomask
-from mmcv.image import imflip_, imresize
-from mmcv.transforms import BaseTransform
-from mmcv.transforms.utils import cache_randomness
-from scipy.stats import truncnorm
-
-from mmpose.registry import TRANSFORMS
-from mmpose.structures.bbox import get_udp_warp_matrix, get_warp_matrix
-
-
-@TRANSFORMS.register_module()
-class BottomupGetHeatmapMask(BaseTransform):
- """Generate the mask of valid regions from the segmentation annotation.
-
- Required Keys:
-
- - img_shape
- - invalid_segs (optional)
- - warp_mat (optional)
- - flip (optional)
- - flip_direction (optional)
- - heatmaps (optional)
-
- Added Keys:
-
- - heatmap_mask
- """
-
- def _segs_to_mask(self, segs: list, img_shape: Tuple[int,
- int]) -> np.ndarray:
- """Calculate mask from object segmentations.
-
- Args:
- segs (List): The object segmentation annotations in COCO format
- img_shape (Tuple): The image shape in (h, w)
-
- Returns:
- np.ndarray: The binary object mask in size (h, w), where the
- object pixels are 1 and background pixels are 0
- """
-
- # RLE is a simple yet efficient format for storing binary masks.
- # details can be found at `COCO tools `__
- rles = []
- for seg in segs:
- rle = cocomask.frPyObjects(seg, img_shape[0], img_shape[1])
- if isinstance(rle, list):
- # For non-crowded objects (e.g. human with no visible
- # keypoints), the results is a list of rles
- rles.extend(rle)
- else:
- # For crowded objects, the result is a single rle
- rles.append(rle)
-
- if rles:
- mask = cocomask.decode(cocomask.merge(rles))
- else:
- mask = np.zeros(img_shape, dtype=np.uint8)
-
- return mask
-
- def transform(self, results: Dict) -> Optional[dict]:
- """The transform function of :class:`BottomupGetHeatmapMask` to perform
- photometric distortion on images.
-
- See ``transform()`` method of :class:`BaseTransform` for details.
-
-
- Args:
- results (dict): Result dict from the data pipeline.
-
- Returns:
- dict: Result dict with images distorted.
- """
-
- invalid_segs = results.get('invalid_segs', [])
- img_shape = results['img_shape'] # (img_h, img_w)
- input_size = results['input_size']
-
- # Calculate the mask of the valid region by negating the segmentation
- # mask of invalid objects
- mask = 1 - self._segs_to_mask(invalid_segs, img_shape)
-
- # Apply an affine transform to the mask if the image has been
- # transformed
- if 'warp_mat' in results:
- warp_mat = results['warp_mat']
-
- mask = mask.astype(np.float32)
- mask = cv2.warpAffine(
- mask, warp_mat, input_size, flags=cv2.INTER_LINEAR)
-
- # Flip the mask if the image has been flipped
- if results.get('flip', False):
- flip_dir = results['flip_direction']
- if flip_dir is not None:
- mask = imflip_(mask, flip_dir)
-
- # Resize the mask to the same size of heatmaps
- if 'heatmaps' in results:
- heatmaps = results['heatmaps']
- if isinstance(heatmaps, list):
- # Multi-level heatmaps
- heatmap_mask = []
- for hm in results['heatmaps']:
- h, w = hm.shape[1:3]
- _mask = imresize(
- mask, size=(w, h), interpolation='bilinear')
- heatmap_mask.append(_mask)
- else:
- h, w = heatmaps.shape[1:3]
- heatmap_mask = imresize(
- mask, size=(w, h), interpolation='bilinear')
- else:
- heatmap_mask = mask
-
- # Binarize the mask(s)
- if isinstance(heatmap_mask, list):
- results['heatmap_mask'] = [hm > 0.5 for hm in heatmap_mask]
- else:
- results['heatmap_mask'] = heatmap_mask > 0.5
-
- return results
-
-
-@TRANSFORMS.register_module()
-class BottomupRandomAffine(BaseTransform):
- r"""Randomly shift, resize and rotate the image.
-
- Required Keys:
-
- - img
- - img_shape
- - keypoints (optional)
-
- Modified Keys:
-
- - img
- - keypoints (optional)
-
- Added Keys:
-
- - input_size
- - warp_mat
-
- Args:
- input_size (Tuple[int, int]): The input image size of the model in
- [w, h]
- shift_factor (float): Randomly shift the image in range
- :math:`[-dx, dx]` and :math:`[-dy, dy]` in X and Y directions,
- where :math:`dx(y) = img_w(h) \cdot shift_factor` in pixels.
- Defaults to 0.2
- shift_prob (float): Probability of applying random shift. Defaults to
- 1.0
- scale_factor (Tuple[float, float]): Randomly resize the image in range
- :math:`[scale_factor[0], scale_factor[1]]`. Defaults to
- (0.75, 1.5)
- scale_prob (float): Probability of applying random resizing. Defaults
- to 1.0
- scale_type (str): wrt ``long`` or ``short`` length of the image.
- Defaults to ``short``
- rotate_factor (float): Randomly rotate the bbox in
- :math:`[-rotate_factor, rotate_factor]` in degrees. Defaults
- to 40.0
- use_udp (bool): Whether use unbiased data processing. See
- `UDP (CVPR 2020)`_ for details. Defaults to ``False``
-
- .. _`UDP (CVPR 2020)`: https://arxiv.org/abs/1911.07524
- """
-
- def __init__(self,
- input_size: Tuple[int, int],
- shift_factor: float = 0.2,
- shift_prob: float = 1.,
- scale_factor: Tuple[float, float] = (0.75, 1.5),
- scale_prob: float = 1.,
- scale_type: str = 'short',
- rotate_factor: float = 30.,
- rotate_prob: float = 1,
- use_udp: bool = False) -> None:
- super().__init__()
-
- self.input_size = input_size
- self.shift_factor = shift_factor
- self.shift_prob = shift_prob
- self.scale_factor = scale_factor
- self.scale_prob = scale_prob
- self.scale_type = scale_type
- self.rotate_factor = rotate_factor
- self.rotate_prob = rotate_prob
- self.use_udp = use_udp
-
- @staticmethod
- def _truncnorm(low: float = -1.,
- high: float = 1.,
- size: tuple = ()) -> np.ndarray:
- """Sample from a truncated normal distribution."""
- return truncnorm.rvs(low, high, size=size).astype(np.float32)
-
- def _fix_aspect_ratio(self, scale: np.ndarray, aspect_ratio: float):
- """Extend the scale to match the given aspect ratio.
-
- Args:
- scale (np.ndarray): The image scale (w, h) in shape (2, )
- aspect_ratio (float): The ratio of ``w/h``
-
- Returns:
- np.ndarray: The reshaped image scale in (2, )
- """
- w, h = scale
- if w > h * aspect_ratio:
- if self.scale_type == 'long':
- _w, _h = w, w / aspect_ratio
- elif self.scale_type == 'short':
- _w, _h = h * aspect_ratio, h
- else:
- raise ValueError(f'Unknown scale type: {self.scale_type}')
- else:
- if self.scale_type == 'short':
- _w, _h = w, w / aspect_ratio
- elif self.scale_type == 'long':
- _w, _h = h * aspect_ratio, h
- else:
- raise ValueError(f'Unknown scale type: {self.scale_type}')
- return np.array([_w, _h], dtype=scale.dtype)
-
- @cache_randomness
- def _get_transform_params(self) -> Tuple:
- """Get random transform parameters.
-
- Returns:
- tuple:
- - offset (np.ndarray): Image offset rate in shape (2, )
- - scale (np.ndarray): Image scaling rate factor in shape (1, )
- - rotate (np.ndarray): Image rotation degree in shape (1, )
- """
- # get offset
- if np.random.rand() < self.shift_prob:
- offset = self._truncnorm(size=(2, )) * self.shift_factor
- else:
- offset = np.zeros((2, ), dtype=np.float32)
-
- # get scale
- if np.random.rand() < self.scale_prob:
- scale_min, scale_max = self.scale_factor
- scale = scale_min + (scale_max - scale_min) * (
- self._truncnorm(size=(1, )) + 1) / 2
- else:
- scale = np.ones(1, dtype=np.float32)
-
- # get rotation
- if np.random.rand() < self.rotate_prob:
- rotate = self._truncnorm() * self.rotate_factor
- else:
- rotate = 0
-
- return offset, scale, rotate
-
- def transform(self, results: Dict) -> Optional[dict]:
- """The transform function of :class:`BottomupRandomAffine` to perform
- photometric distortion on images.
-
- See ``transform()`` method of :class:`BaseTransform` for details.
-
-
- Args:
- results (dict): Result dict from the data pipeline.
-
- Returns:
- dict: Result dict with images distorted.
- """
-
- img_h, img_w = results['img_shape']
- w, h = self.input_size
-
- offset_rate, scale_rate, rotate = self._get_transform_params()
- offset = offset_rate * [img_w, img_h]
- scale = scale_rate * [img_w, img_h]
- # adjust the scale to match the target aspect ratio
- scale = self._fix_aspect_ratio(scale, aspect_ratio=w / h)
-
- if self.use_udp:
- center = np.array([(img_w - 1.0) / 2, (img_h - 1.0) / 2],
- dtype=np.float32)
- warp_mat = get_udp_warp_matrix(
- center=center + offset,
- scale=scale,
- rot=rotate,
- output_size=(w, h))
- else:
- center = np.array([img_w / 2, img_h / 2], dtype=np.float32)
- warp_mat = get_warp_matrix(
- center=center + offset,
- scale=scale,
- rot=rotate,
- output_size=(w, h))
-
- # warp image and keypoints
- results['img'] = cv2.warpAffine(
- results['img'], warp_mat, (int(w), int(h)), flags=cv2.INTER_LINEAR)
-
- if 'keypoints' in results:
- # Only transform (x, y) coordinates
- results['keypoints'][..., :2] = cv2.transform(
- results['keypoints'][..., :2], warp_mat)
-
- if 'bbox' in results:
- bbox = np.tile(results['bbox'], 2).reshape(-1, 4, 2)
- # corner order: left_top, left_bottom, right_top, right_bottom
- bbox[:, 1:3, 0] = bbox[:, 0:2, 0]
- results['bbox'] = cv2.transform(bbox, warp_mat).reshape(-1, 8)
-
- results['input_size'] = self.input_size
- results['warp_mat'] = warp_mat
-
- return results
-
-
-@TRANSFORMS.register_module()
-class BottomupResize(BaseTransform):
- """Resize the image to the input size of the model. Optionally, the image
- can be resized to multiple sizes to build a image pyramid for multi-scale
- inference.
-
- Required Keys:
-
- - img
- - ori_shape
-
- Modified Keys:
-
- - img
- - img_shape
-
- Added Keys:
-
- - input_size
- - warp_mat
- - aug_scale
-
- Args:
- input_size (Tuple[int, int]): The input size of the model in [w, h].
- Note that the actually size of the resized image will be affected
- by ``resize_mode`` and ``size_factor``, thus may not exactly equals
- to the ``input_size``
- aug_scales (List[float], optional): The extra input scales for
- multi-scale testing. If given, the input image will be resized
- to different scales to build a image pyramid. And heatmaps from
- all scales will be aggregated to make final prediction. Defaults
- to ``None``
- size_factor (int): The actual input size will be ceiled to
- a multiple of the `size_factor` value at both sides.
- Defaults to 16
- resize_mode (str): The method to resize the image to the input size.
- Options are:
-
- - ``'fit'``: The image will be resized according to the
- relatively longer side with the aspect ratio kept. The
- resized image will entirely fits into the range of the
- input size
- - ``'expand'``: The image will be resized according to the
- relatively shorter side with the aspect ratio kept. The
- resized image will exceed the given input size at the
- longer side
- use_udp (bool): Whether use unbiased data processing. See
- `UDP (CVPR 2020)`_ for details. Defaults to ``False``
-
- .. _`UDP (CVPR 2020)`: https://arxiv.org/abs/1911.07524
- """
-
- def __init__(self,
- input_size: Tuple[int, int],
- aug_scales: Optional[List[float]] = None,
- size_factor: int = 32,
- resize_mode: str = 'fit',
- use_udp: bool = False):
- super().__init__()
-
- self.input_size = input_size
- self.aug_scales = aug_scales
- self.resize_mode = resize_mode
- self.size_factor = size_factor
- self.use_udp = use_udp
-
- @staticmethod
- def _ceil_to_multiple(size: Tuple[int, int], base: int):
- """Ceil the given size (tuple of [w, h]) to a multiple of the base."""
- return tuple(int(np.ceil(s / base) * base) for s in size)
-
- def _get_input_size(self, img_size: Tuple[int, int],
- input_size: Tuple[int, int]) -> Tuple:
- """Calculate the actual input size (which the original image will be
- resized to) and the padded input size (which the resized image will be
- padded to, or which is the size of the model input).
-
- Args:
- img_size (Tuple[int, int]): The original image size in [w, h]
- input_size (Tuple[int, int]): The expected input size in [w, h]
-
- Returns:
- tuple:
- - actual_input_size (Tuple[int, int]): The target size to resize
- the image
- - padded_input_size (Tuple[int, int]): The target size to generate
- the model input which will contain the resized image
- """
- img_w, img_h = img_size
- ratio = img_w / img_h
-
- if self.resize_mode == 'fit':
- padded_input_size = self._ceil_to_multiple(input_size,
- self.size_factor)
- if padded_input_size != input_size:
- raise ValueError(
- 'When ``resize_mode==\'fit\', the input size (height and'
- ' width) should be mulitples of the size_factor('
- f'{self.size_factor}) at all scales. Got invalid input '
- f'size {input_size}.')
-
- pad_w, pad_h = padded_input_size
- rsz_w = min(pad_w, pad_h * ratio)
- rsz_h = min(pad_h, pad_w / ratio)
- actual_input_size = (rsz_w, rsz_h)
-
- elif self.resize_mode == 'expand':
- _padded_input_size = self._ceil_to_multiple(
- input_size, self.size_factor)
- pad_w, pad_h = _padded_input_size
- rsz_w = max(pad_w, pad_h * ratio)
- rsz_h = max(pad_h, pad_w / ratio)
-
- actual_input_size = (rsz_w, rsz_h)
- padded_input_size = self._ceil_to_multiple(actual_input_size,
- self.size_factor)
-
- else:
- raise ValueError(f'Invalid resize mode {self.resize_mode}')
-
- return actual_input_size, padded_input_size
-
- def transform(self, results: Dict) -> Optional[dict]:
- """The transform function of :class:`BottomupResize` to perform
- photometric distortion on images.
-
- See ``transform()`` method of :class:`BaseTransform` for details.
-
-
- Args:
- results (dict): Result dict from the data pipeline.
-
- Returns:
- dict: Result dict with images distorted.
- """
-
- img = results['img']
- img_h, img_w = results['ori_shape']
- w, h = self.input_size
-
- input_sizes = [(w, h)]
- if self.aug_scales:
- input_sizes += [(int(w * s), int(h * s)) for s in self.aug_scales]
-
- imgs = []
- for i, (_w, _h) in enumerate(input_sizes):
-
- actual_input_size, padded_input_size = self._get_input_size(
- img_size=(img_w, img_h), input_size=(_w, _h))
-
- if self.use_udp:
- center = np.array([(img_w - 1.0) / 2, (img_h - 1.0) / 2],
- dtype=np.float32)
- scale = np.array([img_w, img_h], dtype=np.float32)
- warp_mat = get_udp_warp_matrix(
- center=center,
- scale=scale,
- rot=0,
- output_size=actual_input_size)
- else:
- center = np.array([img_w / 2, img_h / 2], dtype=np.float32)
- scale = np.array([
- img_w * padded_input_size[0] / actual_input_size[0],
- img_h * padded_input_size[1] / actual_input_size[1]
- ],
- dtype=np.float32)
- warp_mat = get_warp_matrix(
- center=center,
- scale=scale,
- rot=0,
- output_size=padded_input_size)
-
- _img = cv2.warpAffine(
- img, warp_mat, padded_input_size, flags=cv2.INTER_LINEAR)
-
- imgs.append(_img)
-
- # Store the transform information w.r.t. the main input size
- if i == 0:
- results['img_shape'] = padded_input_size[::-1]
- results['input_center'] = center
- results['input_scale'] = scale
- results['input_size'] = padded_input_size
-
- if self.aug_scales:
- results['img'] = imgs
- results['aug_scales'] = self.aug_scales
- else:
- results['img'] = imgs[0]
- results['aug_scale'] = None
-
- return results
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Tuple
+
+import cv2
+import numpy as np
+import xtcocotools.mask as cocomask
+from mmcv.image import imflip_, imresize
+from mmcv.transforms import BaseTransform
+from mmcv.transforms.utils import cache_randomness
+from scipy.stats import truncnorm
+
+from mmpose.registry import TRANSFORMS
+from mmpose.structures.bbox import get_udp_warp_matrix, get_warp_matrix
+
+
+@TRANSFORMS.register_module()
+class BottomupGetHeatmapMask(BaseTransform):
+ """Generate the mask of valid regions from the segmentation annotation.
+
+ Required Keys:
+
+ - img_shape
+ - invalid_segs (optional)
+ - warp_mat (optional)
+ - flip (optional)
+ - flip_direction (optional)
+ - heatmaps (optional)
+
+ Added Keys:
+
+ - heatmap_mask
+ """
+
+ def _segs_to_mask(self, segs: list, img_shape: Tuple[int,
+ int]) -> np.ndarray:
+ """Calculate mask from object segmentations.
+
+ Args:
+ segs (List): The object segmentation annotations in COCO format
+ img_shape (Tuple): The image shape in (h, w)
+
+ Returns:
+ np.ndarray: The binary object mask in size (h, w), where the
+ object pixels are 1 and background pixels are 0
+ """
+
+ # RLE is a simple yet efficient format for storing binary masks.
+ # details can be found at `COCO tools `__
+ rles = []
+ for seg in segs:
+ rle = cocomask.frPyObjects(seg, img_shape[0], img_shape[1])
+ if isinstance(rle, list):
+ # For non-crowded objects (e.g. human with no visible
+ # keypoints), the results is a list of rles
+ rles.extend(rle)
+ else:
+ # For crowded objects, the result is a single rle
+ rles.append(rle)
+
+ if rles:
+ mask = cocomask.decode(cocomask.merge(rles))
+ else:
+ mask = np.zeros(img_shape, dtype=np.uint8)
+
+ return mask
+
+ def transform(self, results: Dict) -> Optional[dict]:
+ """The transform function of :class:`BottomupGetHeatmapMask` to perform
+ photometric distortion on images.
+
+ See ``transform()`` method of :class:`BaseTransform` for details.
+
+
+ Args:
+ results (dict): Result dict from the data pipeline.
+
+ Returns:
+ dict: Result dict with images distorted.
+ """
+
+ invalid_segs = results.get('invalid_segs', [])
+ img_shape = results['img_shape'] # (img_h, img_w)
+ input_size = results['input_size']
+
+ # Calculate the mask of the valid region by negating the segmentation
+ # mask of invalid objects
+ mask = 1 - self._segs_to_mask(invalid_segs, img_shape)
+
+ # Apply an affine transform to the mask if the image has been
+ # transformed
+ if 'warp_mat' in results:
+ warp_mat = results['warp_mat']
+
+ mask = mask.astype(np.float32)
+ mask = cv2.warpAffine(
+ mask, warp_mat, input_size, flags=cv2.INTER_LINEAR)
+
+ # Flip the mask if the image has been flipped
+ if results.get('flip', False):
+ flip_dir = results['flip_direction']
+ if flip_dir is not None:
+ mask = imflip_(mask, flip_dir)
+
+ # Resize the mask to the same size of heatmaps
+ if 'heatmaps' in results:
+ heatmaps = results['heatmaps']
+ if isinstance(heatmaps, list):
+ # Multi-level heatmaps
+ heatmap_mask = []
+ for hm in results['heatmaps']:
+ h, w = hm.shape[1:3]
+ _mask = imresize(
+ mask, size=(w, h), interpolation='bilinear')
+ heatmap_mask.append(_mask)
+ else:
+ h, w = heatmaps.shape[1:3]
+ heatmap_mask = imresize(
+ mask, size=(w, h), interpolation='bilinear')
+ else:
+ heatmap_mask = mask
+
+ # Binarize the mask(s)
+ if isinstance(heatmap_mask, list):
+ results['heatmap_mask'] = [hm > 0.5 for hm in heatmap_mask]
+ else:
+ results['heatmap_mask'] = heatmap_mask > 0.5
+
+ return results
+
+
+@TRANSFORMS.register_module()
+class BottomupRandomAffine(BaseTransform):
+ r"""Randomly shift, resize and rotate the image.
+
+ Required Keys:
+
+ - img
+ - img_shape
+ - keypoints (optional)
+
+ Modified Keys:
+
+ - img
+ - keypoints (optional)
+
+ Added Keys:
+
+ - input_size
+ - warp_mat
+
+ Args:
+ input_size (Tuple[int, int]): The input image size of the model in
+ [w, h]
+ shift_factor (float): Randomly shift the image in range
+ :math:`[-dx, dx]` and :math:`[-dy, dy]` in X and Y directions,
+ where :math:`dx(y) = img_w(h) \cdot shift_factor` in pixels.
+ Defaults to 0.2
+ shift_prob (float): Probability of applying random shift. Defaults to
+ 1.0
+ scale_factor (Tuple[float, float]): Randomly resize the image in range
+ :math:`[scale_factor[0], scale_factor[1]]`. Defaults to
+ (0.75, 1.5)
+ scale_prob (float): Probability of applying random resizing. Defaults
+ to 1.0
+ scale_type (str): wrt ``long`` or ``short`` length of the image.
+ Defaults to ``short``
+ rotate_factor (float): Randomly rotate the bbox in
+ :math:`[-rotate_factor, rotate_factor]` in degrees. Defaults
+ to 40.0
+ use_udp (bool): Whether use unbiased data processing. See
+ `UDP (CVPR 2020)`_ for details. Defaults to ``False``
+
+ .. _`UDP (CVPR 2020)`: https://arxiv.org/abs/1911.07524
+ """
+
+ def __init__(self,
+ input_size: Tuple[int, int],
+ shift_factor: float = 0.2,
+ shift_prob: float = 1.,
+ scale_factor: Tuple[float, float] = (0.75, 1.5),
+ scale_prob: float = 1.,
+ scale_type: str = 'short',
+ rotate_factor: float = 30.,
+ rotate_prob: float = 1,
+ use_udp: bool = False) -> None:
+ super().__init__()
+
+ self.input_size = input_size
+ self.shift_factor = shift_factor
+ self.shift_prob = shift_prob
+ self.scale_factor = scale_factor
+ self.scale_prob = scale_prob
+ self.scale_type = scale_type
+ self.rotate_factor = rotate_factor
+ self.rotate_prob = rotate_prob
+ self.use_udp = use_udp
+
+ @staticmethod
+ def _truncnorm(low: float = -1.,
+ high: float = 1.,
+ size: tuple = ()) -> np.ndarray:
+ """Sample from a truncated normal distribution."""
+ return truncnorm.rvs(low, high, size=size).astype(np.float32)
+
+ def _fix_aspect_ratio(self, scale: np.ndarray, aspect_ratio: float):
+ """Extend the scale to match the given aspect ratio.
+
+ Args:
+ scale (np.ndarray): The image scale (w, h) in shape (2, )
+ aspect_ratio (float): The ratio of ``w/h``
+
+ Returns:
+ np.ndarray: The reshaped image scale in (2, )
+ """
+ w, h = scale
+ if w > h * aspect_ratio:
+ if self.scale_type == 'long':
+ _w, _h = w, w / aspect_ratio
+ elif self.scale_type == 'short':
+ _w, _h = h * aspect_ratio, h
+ else:
+ raise ValueError(f'Unknown scale type: {self.scale_type}')
+ else:
+ if self.scale_type == 'short':
+ _w, _h = w, w / aspect_ratio
+ elif self.scale_type == 'long':
+ _w, _h = h * aspect_ratio, h
+ else:
+ raise ValueError(f'Unknown scale type: {self.scale_type}')
+ return np.array([_w, _h], dtype=scale.dtype)
+
+ @cache_randomness
+ def _get_transform_params(self) -> Tuple:
+ """Get random transform parameters.
+
+ Returns:
+ tuple:
+ - offset (np.ndarray): Image offset rate in shape (2, )
+ - scale (np.ndarray): Image scaling rate factor in shape (1, )
+ - rotate (np.ndarray): Image rotation degree in shape (1, )
+ """
+ # get offset
+ if np.random.rand() < self.shift_prob:
+ offset = self._truncnorm(size=(2, )) * self.shift_factor
+ else:
+ offset = np.zeros((2, ), dtype=np.float32)
+
+ # get scale
+ if np.random.rand() < self.scale_prob:
+ scale_min, scale_max = self.scale_factor
+ scale = scale_min + (scale_max - scale_min) * (
+ self._truncnorm(size=(1, )) + 1) / 2
+ else:
+ scale = np.ones(1, dtype=np.float32)
+
+ # get rotation
+ if np.random.rand() < self.rotate_prob:
+ rotate = self._truncnorm() * self.rotate_factor
+ else:
+ rotate = 0
+
+ return offset, scale, rotate
+
+ def transform(self, results: Dict) -> Optional[dict]:
+ """The transform function of :class:`BottomupRandomAffine` to perform
+ photometric distortion on images.
+
+ See ``transform()`` method of :class:`BaseTransform` for details.
+
+
+ Args:
+ results (dict): Result dict from the data pipeline.
+
+ Returns:
+ dict: Result dict with images distorted.
+ """
+
+ img_h, img_w = results['img_shape']
+ w, h = self.input_size
+
+ offset_rate, scale_rate, rotate = self._get_transform_params()
+ offset = offset_rate * [img_w, img_h]
+ scale = scale_rate * [img_w, img_h]
+ # adjust the scale to match the target aspect ratio
+ scale = self._fix_aspect_ratio(scale, aspect_ratio=w / h)
+
+ if self.use_udp:
+ center = np.array([(img_w - 1.0) / 2, (img_h - 1.0) / 2],
+ dtype=np.float32)
+ warp_mat = get_udp_warp_matrix(
+ center=center + offset,
+ scale=scale,
+ rot=rotate,
+ output_size=(w, h))
+ else:
+ center = np.array([img_w / 2, img_h / 2], dtype=np.float32)
+ warp_mat = get_warp_matrix(
+ center=center + offset,
+ scale=scale,
+ rot=rotate,
+ output_size=(w, h))
+
+ # warp image and keypoints
+ results['img'] = cv2.warpAffine(
+ results['img'], warp_mat, (int(w), int(h)), flags=cv2.INTER_LINEAR)
+
+ if 'keypoints' in results:
+ # Only transform (x, y) coordinates
+ results['keypoints'][..., :2] = cv2.transform(
+ results['keypoints'][..., :2], warp_mat)
+
+ if 'bbox' in results:
+ bbox = np.tile(results['bbox'], 2).reshape(-1, 4, 2)
+ # corner order: left_top, left_bottom, right_top, right_bottom
+ bbox[:, 1:3, 0] = bbox[:, 0:2, 0]
+ results['bbox'] = cv2.transform(bbox, warp_mat).reshape(-1, 8)
+
+ results['input_size'] = self.input_size
+ results['warp_mat'] = warp_mat
+
+ return results
+
+
+@TRANSFORMS.register_module()
+class BottomupResize(BaseTransform):
+ """Resize the image to the input size of the model. Optionally, the image
+ can be resized to multiple sizes to build a image pyramid for multi-scale
+ inference.
+
+ Required Keys:
+
+ - img
+ - ori_shape
+
+ Modified Keys:
+
+ - img
+ - img_shape
+
+ Added Keys:
+
+ - input_size
+ - warp_mat
+ - aug_scale
+
+ Args:
+ input_size (Tuple[int, int]): The input size of the model in [w, h].
+ Note that the actually size of the resized image will be affected
+ by ``resize_mode`` and ``size_factor``, thus may not exactly equals
+ to the ``input_size``
+ aug_scales (List[float], optional): The extra input scales for
+ multi-scale testing. If given, the input image will be resized
+ to different scales to build a image pyramid. And heatmaps from
+ all scales will be aggregated to make final prediction. Defaults
+ to ``None``
+ size_factor (int): The actual input size will be ceiled to
+ a multiple of the `size_factor` value at both sides.
+ Defaults to 16
+ resize_mode (str): The method to resize the image to the input size.
+ Options are:
+
+ - ``'fit'``: The image will be resized according to the
+ relatively longer side with the aspect ratio kept. The
+ resized image will entirely fits into the range of the
+ input size
+ - ``'expand'``: The image will be resized according to the
+ relatively shorter side with the aspect ratio kept. The
+ resized image will exceed the given input size at the
+ longer side
+ use_udp (bool): Whether use unbiased data processing. See
+ `UDP (CVPR 2020)`_ for details. Defaults to ``False``
+
+ .. _`UDP (CVPR 2020)`: https://arxiv.org/abs/1911.07524
+ """
+
+ def __init__(self,
+ input_size: Tuple[int, int],
+ aug_scales: Optional[List[float]] = None,
+ size_factor: int = 32,
+ resize_mode: str = 'fit',
+ use_udp: bool = False):
+ super().__init__()
+
+ self.input_size = input_size
+ self.aug_scales = aug_scales
+ self.resize_mode = resize_mode
+ self.size_factor = size_factor
+ self.use_udp = use_udp
+
+ @staticmethod
+ def _ceil_to_multiple(size: Tuple[int, int], base: int):
+ """Ceil the given size (tuple of [w, h]) to a multiple of the base."""
+ return tuple(int(np.ceil(s / base) * base) for s in size)
+
+ def _get_input_size(self, img_size: Tuple[int, int],
+ input_size: Tuple[int, int]) -> Tuple:
+ """Calculate the actual input size (which the original image will be
+ resized to) and the padded input size (which the resized image will be
+ padded to, or which is the size of the model input).
+
+ Args:
+ img_size (Tuple[int, int]): The original image size in [w, h]
+ input_size (Tuple[int, int]): The expected input size in [w, h]
+
+ Returns:
+ tuple:
+ - actual_input_size (Tuple[int, int]): The target size to resize
+ the image
+ - padded_input_size (Tuple[int, int]): The target size to generate
+ the model input which will contain the resized image
+ """
+ img_w, img_h = img_size
+ ratio = img_w / img_h
+
+ if self.resize_mode == 'fit':
+ padded_input_size = self._ceil_to_multiple(input_size,
+ self.size_factor)
+ if padded_input_size != input_size:
+ raise ValueError(
+ 'When ``resize_mode==\'fit\', the input size (height and'
+ ' width) should be mulitples of the size_factor('
+ f'{self.size_factor}) at all scales. Got invalid input '
+ f'size {input_size}.')
+
+ pad_w, pad_h = padded_input_size
+ rsz_w = min(pad_w, pad_h * ratio)
+ rsz_h = min(pad_h, pad_w / ratio)
+ actual_input_size = (rsz_w, rsz_h)
+
+ elif self.resize_mode == 'expand':
+ _padded_input_size = self._ceil_to_multiple(
+ input_size, self.size_factor)
+ pad_w, pad_h = _padded_input_size
+ rsz_w = max(pad_w, pad_h * ratio)
+ rsz_h = max(pad_h, pad_w / ratio)
+
+ actual_input_size = (rsz_w, rsz_h)
+ padded_input_size = self._ceil_to_multiple(actual_input_size,
+ self.size_factor)
+
+ else:
+ raise ValueError(f'Invalid resize mode {self.resize_mode}')
+
+ return actual_input_size, padded_input_size
+
+ def transform(self, results: Dict) -> Optional[dict]:
+ """The transform function of :class:`BottomupResize` to perform
+ photometric distortion on images.
+
+ See ``transform()`` method of :class:`BaseTransform` for details.
+
+
+ Args:
+ results (dict): Result dict from the data pipeline.
+
+ Returns:
+ dict: Result dict with images distorted.
+ """
+
+ img = results['img']
+ img_h, img_w = results['ori_shape']
+ w, h = self.input_size
+
+ input_sizes = [(w, h)]
+ if self.aug_scales:
+ input_sizes += [(int(w * s), int(h * s)) for s in self.aug_scales]
+
+ imgs = []
+ for i, (_w, _h) in enumerate(input_sizes):
+
+ actual_input_size, padded_input_size = self._get_input_size(
+ img_size=(img_w, img_h), input_size=(_w, _h))
+
+ if self.use_udp:
+ center = np.array([(img_w - 1.0) / 2, (img_h - 1.0) / 2],
+ dtype=np.float32)
+ scale = np.array([img_w, img_h], dtype=np.float32)
+ warp_mat = get_udp_warp_matrix(
+ center=center,
+ scale=scale,
+ rot=0,
+ output_size=actual_input_size)
+ else:
+ center = np.array([img_w / 2, img_h / 2], dtype=np.float32)
+ scale = np.array([
+ img_w * padded_input_size[0] / actual_input_size[0],
+ img_h * padded_input_size[1] / actual_input_size[1]
+ ],
+ dtype=np.float32)
+ warp_mat = get_warp_matrix(
+ center=center,
+ scale=scale,
+ rot=0,
+ output_size=padded_input_size)
+
+ _img = cv2.warpAffine(
+ img, warp_mat, padded_input_size, flags=cv2.INTER_LINEAR)
+
+ imgs.append(_img)
+
+ # Store the transform information w.r.t. the main input size
+ if i == 0:
+ results['img_shape'] = padded_input_size[::-1]
+ results['input_center'] = center
+ results['input_scale'] = scale
+ results['input_size'] = padded_input_size
+
+ if self.aug_scales:
+ results['img'] = imgs
+ results['aug_scales'] = self.aug_scales
+ else:
+ results['img'] = imgs[0]
+ results['aug_scale'] = None
+
+ return results
diff --git a/mmpose/datasets/transforms/common_transforms.py b/mmpose/datasets/transforms/common_transforms.py
index 87068246f8..92f9f5a115 100644
--- a/mmpose/datasets/transforms/common_transforms.py
+++ b/mmpose/datasets/transforms/common_transforms.py
@@ -1,1056 +1,1056 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import warnings
-from copy import deepcopy
-from typing import Dict, List, Optional, Sequence, Tuple, Union
-
-import mmcv
-import mmengine
-import numpy as np
-from mmcv.image import imflip
-from mmcv.transforms import BaseTransform
-from mmcv.transforms.utils import avoid_cache_randomness, cache_randomness
-from mmengine import is_list_of
-from mmengine.dist import get_dist_info
-from scipy.stats import truncnorm
-
-from mmpose.codecs import * # noqa: F401, F403
-from mmpose.registry import KEYPOINT_CODECS, TRANSFORMS
-from mmpose.structures.bbox import bbox_xyxy2cs, flip_bbox
-from mmpose.structures.keypoint import flip_keypoints
-from mmpose.utils.typing import MultiConfig
-
-try:
- import albumentations
-except ImportError:
- albumentations = None
-
-Number = Union[int, float]
-
-
-@TRANSFORMS.register_module()
-class GetBBoxCenterScale(BaseTransform):
- """Convert bboxes from [x, y, w, h] to center and scale.
-
- The center is the coordinates of the bbox center, and the scale is the
- bbox width and height normalized by a scale factor.
-
- Required Keys:
-
- - bbox
-
- Added Keys:
-
- - bbox_center
- - bbox_scale
-
- Args:
- padding (float): The bbox padding scale that will be multilied to
- `bbox_scale`. Defaults to 1.25
- """
-
- def __init__(self, padding: float = 1.25) -> None:
- super().__init__()
-
- self.padding = padding
-
- def transform(self, results: Dict) -> Optional[dict]:
- """The transform function of :class:`GetBBoxCenterScale`.
-
- See ``transform()`` method of :class:`BaseTransform` for details.
-
- Args:
- results (dict): The result dict
-
- Returns:
- dict: The result dict.
- """
- if 'bbox_center' in results and 'bbox_scale' in results:
- rank, _ = get_dist_info()
- if rank == 0:
- warnings.warn('Use the existing "bbox_center" and "bbox_scale"'
- '. The padding will still be applied.')
- results['bbox_scale'] *= self.padding
-
- else:
- bbox = results['bbox']
- center, scale = bbox_xyxy2cs(bbox, padding=self.padding)
-
- results['bbox_center'] = center
- results['bbox_scale'] = scale
-
- return results
-
- def __repr__(self) -> str:
- """print the basic information of the transform.
-
- Returns:
- str: Formatted string.
- """
- repr_str = self.__class__.__name__ + f'(padding={self.padding})'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class RandomFlip(BaseTransform):
- """Randomly flip the image, bbox and keypoints.
-
- Required Keys:
-
- - img
- - img_shape
- - flip_indices
- - input_size (optional)
- - bbox (optional)
- - bbox_center (optional)
- - keypoints (optional)
- - keypoints_visible (optional)
- - img_mask (optional)
-
- Modified Keys:
-
- - img
- - bbox (optional)
- - bbox_center (optional)
- - keypoints (optional)
- - keypoints_visible (optional)
- - img_mask (optional)
-
- Added Keys:
-
- - flip
- - flip_direction
-
- Args:
- prob (float | list[float]): The flipping probability. If a list is
- given, the argument `direction` should be a list with the same
- length. And each element in `prob` indicates the flipping
- probability of the corresponding one in ``direction``. Defaults
- to 0.5
- direction (str | list[str]): The flipping direction. Options are
- ``'horizontal'``, ``'vertical'`` and ``'diagonal'``. If a list is
- is given, each data sample's flipping direction will be sampled
- from a distribution determined by the argument ``prob``. Defaults
- to ``'horizontal'``.
- """
-
- def __init__(self,
- prob: Union[float, List[float]] = 0.5,
- direction: Union[str, List[str]] = 'horizontal') -> None:
- if isinstance(prob, list):
- assert is_list_of(prob, float)
- assert 0 <= sum(prob) <= 1
- elif isinstance(prob, float):
- assert 0 <= prob <= 1
- else:
- raise ValueError(f'probs must be float or list of float, but \
- got `{type(prob)}`.')
- self.prob = prob
-
- valid_directions = ['horizontal', 'vertical', 'diagonal']
- if isinstance(direction, str):
- assert direction in valid_directions
- elif isinstance(direction, list):
- assert is_list_of(direction, str)
- assert set(direction).issubset(set(valid_directions))
- else:
- raise ValueError(f'direction must be either str or list of str, \
- but got `{type(direction)}`.')
- self.direction = direction
-
- if isinstance(prob, list):
- assert len(prob) == len(self.direction)
-
- @cache_randomness
- def _choose_direction(self) -> str:
- """Choose the flip direction according to `prob` and `direction`"""
- if isinstance(self.direction,
- List) and not isinstance(self.direction, str):
- # None means non-flip
- direction_list: list = list(self.direction) + [None]
- elif isinstance(self.direction, str):
- # None means non-flip
- direction_list = [self.direction, None]
-
- if isinstance(self.prob, list):
- non_prob: float = 1 - sum(self.prob)
- prob_list = self.prob + [non_prob]
- elif isinstance(self.prob, float):
- non_prob = 1. - self.prob
- # exclude non-flip
- single_ratio = self.prob / (len(direction_list) - 1)
- prob_list = [single_ratio] * (len(direction_list) - 1) + [non_prob]
-
- cur_dir = np.random.choice(direction_list, p=prob_list)
-
- return cur_dir
-
- def transform(self, results: dict) -> dict:
- """The transform function of :class:`RandomFlip`.
-
- See ``transform()`` method of :class:`BaseTransform` for details.
-
- Args:
- results (dict): The result dict
-
- Returns:
- dict: The result dict.
- """
-
- flip_dir = self._choose_direction()
-
- if flip_dir is None:
- results['flip'] = False
- results['flip_direction'] = None
- else:
- results['flip'] = True
- results['flip_direction'] = flip_dir
-
- h, w = results.get('input_size', results['img_shape'])
- # flip image and mask
- if isinstance(results['img'], list):
- results['img'] = [
- imflip(img, direction=flip_dir) for img in results['img']
- ]
- else:
- results['img'] = imflip(results['img'], direction=flip_dir)
-
- if 'img_mask' in results:
- results['img_mask'] = imflip(
- results['img_mask'], direction=flip_dir)
-
- # flip bboxes
- if results.get('bbox', None) is not None:
- results['bbox'] = flip_bbox(
- results['bbox'],
- image_size=(w, h),
- bbox_format='xyxy',
- direction=flip_dir)
-
- if results.get('bbox_center', None) is not None:
- results['bbox_center'] = flip_bbox(
- results['bbox_center'],
- image_size=(w, h),
- bbox_format='center',
- direction=flip_dir)
-
- # flip keypoints
- if results.get('keypoints', None) is not None:
- keypoints, keypoints_visible = flip_keypoints(
- results['keypoints'],
- results.get('keypoints_visible', None),
- image_size=(w, h),
- flip_indices=results['flip_indices'],
- direction=flip_dir)
-
- results['keypoints'] = keypoints
- results['keypoints_visible'] = keypoints_visible
-
- return results
-
- def __repr__(self) -> str:
- """print the basic information of the transform.
-
- Returns:
- str: Formatted string.
- """
- repr_str = self.__class__.__name__
- repr_str += f'(prob={self.prob}, '
- repr_str += f'direction={self.direction})'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class RandomHalfBody(BaseTransform):
- """Data augmentation with half-body transform that keeps only the upper or
- lower body at random.
-
- Required Keys:
-
- - keypoints
- - keypoints_visible
- - upper_body_ids
- - lower_body_ids
-
- Modified Keys:
-
- - bbox
- - bbox_center
- - bbox_scale
-
- Args:
- min_total_keypoints (int): The minimum required number of total valid
- keypoints of a person to apply half-body transform. Defaults to 8
- min_half_keypoints (int): The minimum required number of valid
- half-body keypoints of a person to apply half-body transform.
- Defaults to 2
- padding (float): The bbox padding scale that will be multilied to
- `bbox_scale`. Defaults to 1.5
- prob (float): The probability to apply half-body transform when the
- keypoint number meets the requirement. Defaults to 0.3
- """
-
- def __init__(self,
- min_total_keypoints: int = 9,
- min_upper_keypoints: int = 2,
- min_lower_keypoints: int = 3,
- padding: float = 1.5,
- prob: float = 0.3,
- upper_prioritized_prob: float = 0.7) -> None:
- super().__init__()
- self.min_total_keypoints = min_total_keypoints
- self.min_upper_keypoints = min_upper_keypoints
- self.min_lower_keypoints = min_lower_keypoints
- self.padding = padding
- self.prob = prob
- self.upper_prioritized_prob = upper_prioritized_prob
-
- def _get_half_body_bbox(self, keypoints: np.ndarray,
- half_body_ids: List[int]
- ) -> Tuple[np.ndarray, np.ndarray]:
- """Get half-body bbox center and scale of a single instance.
-
- Args:
- keypoints (np.ndarray): Keypoints in shape (K, D)
- upper_body_ids (list): The list of half-body keypont indices
-
- Returns:
- tuple: A tuple containing half-body bbox center and scale
- - center: Center (x, y) of the bbox
- - scale: Scale (w, h) of the bbox
- """
-
- selected_keypoints = keypoints[half_body_ids]
- center = selected_keypoints.mean(axis=0)[:2]
-
- x1, y1 = selected_keypoints.min(axis=0)
- x2, y2 = selected_keypoints.max(axis=0)
- w = x2 - x1
- h = y2 - y1
- scale = np.array([w, h], dtype=center.dtype) * self.padding
-
- return center, scale
-
- @cache_randomness
- def _random_select_half_body(self, keypoints_visible: np.ndarray,
- upper_body_ids: List[int],
- lower_body_ids: List[int]
- ) -> List[Optional[List[int]]]:
- """Randomly determine whether applying half-body transform and get the
- half-body keyponit indices of each instances.
-
- Args:
- keypoints_visible (np.ndarray, optional): The visibility of
- keypoints in shape (N, K, 1).
- upper_body_ids (list): The list of upper body keypoint indices
- lower_body_ids (list): The list of lower body keypoint indices
-
- Returns:
- list[list[int] | None]: The selected half-body keypoint indices
- of each instance. ``None`` means not applying half-body transform.
- """
-
- half_body_ids = []
-
- for visible in keypoints_visible:
- if visible.sum() < self.min_total_keypoints:
- indices = None
- elif np.random.rand() > self.prob:
- indices = None
- else:
- upper_valid_ids = [i for i in upper_body_ids if visible[i] > 0]
- lower_valid_ids = [i for i in lower_body_ids if visible[i] > 0]
-
- num_upper = len(upper_valid_ids)
- num_lower = len(lower_valid_ids)
-
- prefer_upper = np.random.rand() < self.upper_prioritized_prob
- if (num_upper < self.min_upper_keypoints
- and num_lower < self.min_lower_keypoints):
- indices = None
- elif num_lower < self.min_lower_keypoints:
- indices = upper_valid_ids
- elif num_upper < self.min_upper_keypoints:
- indices = lower_valid_ids
- else:
- indices = (
- upper_valid_ids if prefer_upper else lower_valid_ids)
-
- half_body_ids.append(indices)
-
- return half_body_ids
-
- def transform(self, results: Dict) -> Optional[dict]:
- """The transform function of :class:`HalfBodyTransform`.
-
- See ``transform()`` method of :class:`BaseTransform` for details.
-
- Args:
- results (dict): The result dict
-
- Returns:
- dict: The result dict.
- """
-
- half_body_ids = self._random_select_half_body(
- keypoints_visible=results['keypoints_visible'],
- upper_body_ids=results['upper_body_ids'],
- lower_body_ids=results['lower_body_ids'])
-
- bbox_center = []
- bbox_scale = []
-
- for i, indices in enumerate(half_body_ids):
- if indices is None:
- bbox_center.append(results['bbox_center'][i])
- bbox_scale.append(results['bbox_scale'][i])
- else:
- _center, _scale = self._get_half_body_bbox(
- results['keypoints'][i], indices)
- bbox_center.append(_center)
- bbox_scale.append(_scale)
-
- results['bbox_center'] = np.stack(bbox_center)
- results['bbox_scale'] = np.stack(bbox_scale)
- return results
-
- def __repr__(self) -> str:
- """print the basic information of the transform.
-
- Returns:
- str: Formatted string.
- """
- repr_str = self.__class__.__name__
- repr_str += f'(min_total_keypoints={self.min_total_keypoints}, '
- repr_str += f'min_upper_keypoints={self.min_upper_keypoints}, '
- repr_str += f'min_lower_keypoints={self.min_lower_keypoints}, '
- repr_str += f'padding={self.padding}, '
- repr_str += f'prob={self.prob}, '
- repr_str += f'upper_prioritized_prob={self.upper_prioritized_prob})'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class RandomBBoxTransform(BaseTransform):
- r"""Rnadomly shift, resize and rotate the bounding boxes.
-
- Required Keys:
-
- - bbox_center
- - bbox_scale
-
- Modified Keys:
-
- - bbox_center
- - bbox_scale
-
- Added Keys:
- - bbox_rotation
-
- Args:
- shift_factor (float): Randomly shift the bbox in range
- :math:`[-dx, dx]` and :math:`[-dy, dy]` in X and Y directions,
- where :math:`dx(y) = x(y)_scale \cdot shift_factor` in pixels.
- Defaults to 0.16
- shift_prob (float): Probability of applying random shift. Defaults to
- 0.3
- scale_factor (Tuple[float, float]): Randomly resize the bbox in range
- :math:`[scale_factor[0], scale_factor[1]]`. Defaults to (0.5, 1.5)
- scale_prob (float): Probability of applying random resizing. Defaults
- to 1.0
- rotate_factor (float): Randomly rotate the bbox in
- :math:`[-rotate_factor, rotate_factor]` in degrees. Defaults
- to 80.0
- rotate_prob (float): Probability of applying random rotation. Defaults
- to 0.6
- """
-
- def __init__(self,
- shift_factor: float = 0.16,
- shift_prob: float = 0.3,
- scale_factor: Tuple[float, float] = (0.5, 1.5),
- scale_prob: float = 1.0,
- rotate_factor: float = 80.0,
- rotate_prob: float = 0.6) -> None:
- super().__init__()
-
- self.shift_factor = shift_factor
- self.shift_prob = shift_prob
- self.scale_factor = scale_factor
- self.scale_prob = scale_prob
- self.rotate_factor = rotate_factor
- self.rotate_prob = rotate_prob
-
- @staticmethod
- def _truncnorm(low: float = -1.,
- high: float = 1.,
- size: tuple = ()) -> np.ndarray:
- """Sample from a truncated normal distribution."""
- return truncnorm.rvs(low, high, size=size).astype(np.float32)
-
- @cache_randomness
- def _get_transform_params(self, num_bboxes: int) -> Tuple:
- """Get random transform parameters.
-
- Args:
- num_bboxes (int): The number of bboxes
-
- Returns:
- tuple:
- - offset (np.ndarray): Offset factor of each bbox in shape (n, 2)
- - scale (np.ndarray): Scaling factor of each bbox in shape (n, 1)
- - rotate (np.ndarray): Rotation degree of each bbox in shape (n,)
- """
- # Get shift parameters
- offset = self._truncnorm(size=(num_bboxes, 2)) * self.shift_factor
- offset = np.where(
- np.random.rand(num_bboxes, 1) < self.shift_prob, offset, 0.)
-
- # Get scaling parameters
- scale_min, scale_max = self.scale_factor
- mu = (scale_max + scale_min) * 0.5
- sigma = (scale_max - scale_min) * 0.5
- scale = self._truncnorm(size=(num_bboxes, 1)) * sigma + mu
- scale = np.where(
- np.random.rand(num_bboxes, 1) < self.scale_prob, scale, 1.)
-
- # Get rotation parameters
- rotate = self._truncnorm(size=(num_bboxes, )) * self.rotate_factor
- rotate = np.where(
- np.random.rand(num_bboxes) < self.rotate_prob, rotate, 0.)
-
- return offset, scale, rotate
-
- def transform(self, results: Dict) -> Optional[dict]:
- """The transform function of :class:`RandomBboxTransform`.
-
- See ``transform()`` method of :class:`BaseTransform` for details.
-
- Args:
- results (dict): The result dict
-
- Returns:
- dict: The result dict.
- """
- bbox_scale = results['bbox_scale']
- num_bboxes = bbox_scale.shape[0]
-
- offset, scale, rotate = self._get_transform_params(num_bboxes)
-
- results['bbox_center'] += offset * bbox_scale
- results['bbox_scale'] *= scale
- results['bbox_rotation'] = rotate
-
- return results
-
- def __repr__(self) -> str:
- """print the basic information of the transform.
-
- Returns:
- str: Formatted string.
- """
- repr_str = self.__class__.__name__
- repr_str += f'(shift_prob={self.shift_prob}, '
- repr_str += f'shift_factor={self.shift_factor}, '
- repr_str += f'scale_prob={self.scale_prob}, '
- repr_str += f'scale_factor={self.scale_factor}, '
- repr_str += f'rotate_prob={self.rotate_prob}, '
- repr_str += f'rotate_factor={self.rotate_factor})'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-@avoid_cache_randomness
-class Albumentation(BaseTransform):
- """Albumentation augmentation (pixel-level transforms only).
-
- Adds custom pixel-level transformations from Albumentations library.
- Please visit `https://albumentations.ai/docs/`
- to get more information.
-
- Note: we only support pixel-level transforms.
- Please visit `https://github.com/albumentations-team/`
- `albumentations#pixel-level-transforms`
- to get more information about pixel-level transforms.
-
- Required Keys:
-
- - img
-
- Modified Keys:
-
- - img
-
- Args:
- transforms (List[dict]): A list of Albumentation transforms.
- An example of ``transforms`` is as followed:
- .. code-block:: python
-
- [
- dict(
- type='RandomBrightnessContrast',
- brightness_limit=[0.1, 0.3],
- contrast_limit=[0.1, 0.3],
- p=0.2),
- dict(type='ChannelShuffle', p=0.1),
- dict(
- type='OneOf',
- transforms=[
- dict(type='Blur', blur_limit=3, p=1.0),
- dict(type='MedianBlur', blur_limit=3, p=1.0)
- ],
- p=0.1),
- ]
- keymap (dict | None): key mapping from ``input key`` to
- ``albumentation-style key``.
- Defaults to None, which will use {'img': 'image'}.
- """
-
- def __init__(self,
- transforms: List[dict],
- keymap: Optional[dict] = None) -> None:
- if albumentations is None:
- raise RuntimeError('albumentations is not installed')
-
- self.transforms = transforms
-
- self.aug = albumentations.Compose(
- [self.albu_builder(t) for t in self.transforms])
-
- if not keymap:
- self.keymap_to_albu = {
- 'img': 'image',
- }
- else:
- self.keymap_to_albu = keymap
-
- def albu_builder(self, cfg: dict) -> albumentations:
- """Import a module from albumentations.
-
- It resembles some of :func:`build_from_cfg` logic.
-
- Args:
- cfg (dict): Config dict. It should at least contain the key "type".
-
- Returns:
- albumentations.BasicTransform: The constructed transform object
- """
-
- assert isinstance(cfg, dict) and 'type' in cfg
- args = cfg.copy()
-
- obj_type = args.pop('type')
- if mmengine.is_str(obj_type):
- if albumentations is None:
- raise RuntimeError('albumentations is not installed')
- rank, _ = get_dist_info()
- if rank == 0 and not hasattr(
- albumentations.augmentations.transforms, obj_type):
- warnings.warn(
- f'{obj_type} is not pixel-level transformations. '
- 'Please use with caution.')
- obj_cls = getattr(albumentations, obj_type)
- elif isinstance(obj_type, type):
- obj_cls = obj_type
- else:
- raise TypeError(f'type must be a str, but got {type(obj_type)}')
-
- if 'transforms' in args:
- args['transforms'] = [
- self.albu_builder(transform)
- for transform in args['transforms']
- ]
-
- return obj_cls(**args)
-
- def transform(self, results: dict) -> dict:
- """The transform function of :class:`Albumentation` to apply
- albumentations transforms.
-
- See ``transform()`` method of :class:`BaseTransform` for details.
-
- Args:
- results (dict): Result dict from the data pipeline.
-
- Return:
- dict: updated result dict.
- """
- # map result dict to albumentations format
- results_albu = {}
- for k, v in self.keymap_to_albu.items():
- assert k in results, \
- f'The `{k}` is required to perform albumentations transforms'
- results_albu[v] = results[k]
-
- # Apply albumentations transforms
- results_albu = self.aug(**results_albu)
-
- # map the albu results back to the original format
- for k, v in self.keymap_to_albu.items():
- results[k] = results_albu[v]
-
- return results
-
- def __repr__(self) -> str:
- """print the basic information of the transform.
-
- Returns:
- str: Formatted string.
- """
- repr_str = self.__class__.__name__ + f'(transforms={self.transforms})'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class PhotometricDistortion(BaseTransform):
- """Apply photometric distortion to image sequentially, every transformation
- is applied with a probability of 0.5. The position of random contrast is in
- second or second to last.
-
- 1. random brightness
- 2. random contrast (mode 0)
- 3. convert color from BGR to HSV
- 4. random saturation
- 5. random hue
- 6. convert color from HSV to BGR
- 7. random contrast (mode 1)
- 8. randomly swap channels
-
- Required Keys:
-
- - img
-
- Modified Keys:
-
- - img
-
- Args:
- brightness_delta (int): delta of brightness.
- contrast_range (tuple): range of contrast.
- saturation_range (tuple): range of saturation.
- hue_delta (int): delta of hue.
- """
-
- def __init__(self,
- brightness_delta: int = 32,
- contrast_range: Sequence[Number] = (0.5, 1.5),
- saturation_range: Sequence[Number] = (0.5, 1.5),
- hue_delta: int = 18) -> None:
- self.brightness_delta = brightness_delta
- self.contrast_lower, self.contrast_upper = contrast_range
- self.saturation_lower, self.saturation_upper = saturation_range
- self.hue_delta = hue_delta
-
- @cache_randomness
- def _random_flags(self) -> Sequence[Number]:
- """Generate the random flags for subsequent transforms.
-
- Returns:
- Sequence[Number]: a sequence of numbers that indicate whether to
- do the corresponding transforms.
- """
- # contrast_mode == 0 --> do random contrast first
- # contrast_mode == 1 --> do random contrast last
- contrast_mode = np.random.randint(2)
- # whether to apply brightness distortion
- brightness_flag = np.random.randint(2)
- # whether to apply contrast distortion
- contrast_flag = np.random.randint(2)
- # the mode to convert color from BGR to HSV
- hsv_mode = np.random.randint(4)
- # whether to apply channel swap
- swap_flag = np.random.randint(2)
-
- # the beta in `self._convert` to be added to image array
- # in brightness distortion
- brightness_beta = np.random.uniform(-self.brightness_delta,
- self.brightness_delta)
- # the alpha in `self._convert` to be multiplied to image array
- # in contrast distortion
- contrast_alpha = np.random.uniform(self.contrast_lower,
- self.contrast_upper)
- # the alpha in `self._convert` to be multiplied to image array
- # in saturation distortion to hsv-formatted img
- saturation_alpha = np.random.uniform(self.saturation_lower,
- self.saturation_upper)
- # delta of hue to add to image array in hue distortion
- hue_delta = np.random.randint(-self.hue_delta, self.hue_delta)
- # the random permutation of channel order
- swap_channel_order = np.random.permutation(3)
-
- return (contrast_mode, brightness_flag, contrast_flag, hsv_mode,
- swap_flag, brightness_beta, contrast_alpha, saturation_alpha,
- hue_delta, swap_channel_order)
-
- def _convert(self,
- img: np.ndarray,
- alpha: float = 1,
- beta: float = 0) -> np.ndarray:
- """Multiple with alpha and add beta with clip.
-
- Args:
- img (np.ndarray): The image array.
- alpha (float): The random multiplier.
- beta (float): The random offset.
-
- Returns:
- np.ndarray: The updated image array.
- """
- img = img.astype(np.float32) * alpha + beta
- img = np.clip(img, 0, 255)
- return img.astype(np.uint8)
-
- def transform(self, results: dict) -> dict:
- """The transform function of :class:`PhotometricDistortion` to perform
- photometric distortion on images.
-
- See ``transform()`` method of :class:`BaseTransform` for details.
-
-
- Args:
- results (dict): Result dict from the data pipeline.
-
- Returns:
- dict: Result dict with images distorted.
- """
-
- assert 'img' in results, '`img` is not found in results'
- img = results['img']
-
- (contrast_mode, brightness_flag, contrast_flag, hsv_mode, swap_flag,
- brightness_beta, contrast_alpha, saturation_alpha, hue_delta,
- swap_channel_order) = self._random_flags()
-
- # random brightness distortion
- if brightness_flag:
- img = self._convert(img, beta=brightness_beta)
-
- # contrast_mode == 0 --> do random contrast first
- # contrast_mode == 1 --> do random contrast last
- if contrast_mode == 1:
- if contrast_flag:
- img = self._convert(img, alpha=contrast_alpha)
-
- if hsv_mode:
- # random saturation/hue distortion
- img = mmcv.bgr2hsv(img)
- if hsv_mode == 1 or hsv_mode == 3:
- # apply saturation distortion to hsv-formatted img
- img[:, :, 1] = self._convert(
- img[:, :, 1], alpha=saturation_alpha)
- if hsv_mode == 2 or hsv_mode == 3:
- # apply hue distortion to hsv-formatted img
- img[:, :, 0] = img[:, :, 0].astype(int) + hue_delta
- img = mmcv.hsv2bgr(img)
-
- if contrast_mode == 1:
- if contrast_flag:
- img = self._convert(img, alpha=contrast_alpha)
-
- # randomly swap channels
- if swap_flag:
- img = img[..., swap_channel_order]
-
- results['img'] = img
- return results
-
- def __repr__(self) -> str:
- """print the basic information of the transform.
-
- Returns:
- str: Formatted string.
- """
- repr_str = self.__class__.__name__
- repr_str += (f'(brightness_delta={self.brightness_delta}, '
- f'contrast_range=({self.contrast_lower}, '
- f'{self.contrast_upper}), '
- f'saturation_range=({self.saturation_lower}, '
- f'{self.saturation_upper}), '
- f'hue_delta={self.hue_delta})')
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class GenerateTarget(BaseTransform):
- """Encode keypoints into Target.
-
- The generated target is usually the supervision signal of the model
- learning, e.g. heatmaps or regression labels.
-
- Required Keys:
-
- - keypoints
- - keypoints_visible
- - dataset_keypoint_weights
-
- Added Keys:
-
- - The keys of the encoded items from the codec will be updated into
- the results, e.g. ``'heatmaps'`` or ``'keypoint_weights'``. See
- the specific codec for more details.
-
- Args:
- encoder (dict | list[dict]): The codec config for keypoint encoding.
- Both single encoder and multiple encoders (given as a list) are
- supported
- multilevel (bool): Determine the method to handle multiple encoders.
- If ``multilevel==True``, generate multilevel targets from a group
- of encoders of the same type (e.g. multiple :class:`MSRAHeatmap`
- encoders with different sigma values); If ``multilevel==False``,
- generate combined targets from a group of different encoders. This
- argument will have no effect in case of single encoder. Defaults
- to ``False``
- use_dataset_keypoint_weights (bool): Whether use the keypoint weights
- from the dataset meta information. Defaults to ``False``
- target_type (str, deprecated): This argument is deprecated and has no
- effect. Defaults to ``None``
- """
-
- def __init__(self,
- encoder: MultiConfig,
- target_type: Optional[str] = None,
- multilevel: bool = False,
- use_dataset_keypoint_weights: bool = False) -> None:
- super().__init__()
-
- if target_type is not None:
- rank, _ = get_dist_info()
- if rank == 0:
- warnings.warn(
- 'The argument `target_type` is deprecated in'
- ' GenerateTarget. The target type and encoded '
- 'keys will be determined by encoder(s).',
- DeprecationWarning)
-
- self.encoder_cfg = deepcopy(encoder)
- self.multilevel = multilevel
- self.use_dataset_keypoint_weights = use_dataset_keypoint_weights
-
- if isinstance(self.encoder_cfg, list):
- self.encoder = [
- KEYPOINT_CODECS.build(cfg) for cfg in self.encoder_cfg
- ]
- else:
- assert not self.multilevel, (
- 'Need multiple encoder configs if ``multilevel==True``')
- self.encoder = KEYPOINT_CODECS.build(self.encoder_cfg)
-
- def transform(self, results: Dict) -> Optional[dict]:
- """The transform function of :class:`GenerateTarget`.
-
- See ``transform()`` method of :class:`BaseTransform` for details.
- """
-
- if results.get('transformed_keypoints', None) is not None:
- # use keypoints transformed by TopdownAffine
- keypoints = results['transformed_keypoints']
- elif results.get('keypoints', None) is not None:
- # use original keypoints
- keypoints = results['keypoints']
- else:
- raise ValueError(
- 'GenerateTarget requires \'transformed_keypoints\' or'
- ' \'keypoints\' in the results.')
-
- keypoints_visible = results['keypoints_visible']
-
- # Encoded items from the encoder(s) will be updated into the results.
- # Please refer to the document of the specific codec for details about
- # encoded items.
- if not isinstance(self.encoder, list):
- # For single encoding, the encoded items will be directly added
- # into results.
- auxiliary_encode_kwargs = {
- key: results[key]
- for key in self.encoder.auxiliary_encode_keys
- }
- encoded = self.encoder.encode(
- keypoints=keypoints,
- keypoints_visible=keypoints_visible,
- **auxiliary_encode_kwargs)
-
- else:
- encoded_list = []
- for _encoder in self.encoder:
- auxiliary_encode_kwargs = {
- key: results[key]
- for key in _encoder.auxiliary_encode_keys
- }
- encoded_list.append(
- _encoder.encode(
- keypoints=keypoints,
- keypoints_visible=keypoints_visible,
- **auxiliary_encode_kwargs))
-
- if self.multilevel:
- # For multilevel encoding, the encoded items from each encoder
- # should have the same keys.
-
- keys = encoded_list[0].keys()
- if not all(_encoded.keys() == keys
- for _encoded in encoded_list):
- raise ValueError(
- 'Encoded items from all encoders must have the same '
- 'keys if ``multilevel==True``.')
-
- encoded = {
- k: [_encoded[k] for _encoded in encoded_list]
- for k in keys
- }
-
- else:
- # For combined encoding, the encoded items from different
- # encoders should have no overlapping items, except for
- # `keypoint_weights`. If multiple `keypoint_weights` are given,
- # they will be multiplied as the final `keypoint_weights`.
-
- encoded = dict()
- keypoint_weights = []
-
- for _encoded in encoded_list:
- for key, value in _encoded.items():
- if key == 'keypoint_weights':
- keypoint_weights.append(value)
- elif key not in encoded:
- encoded[key] = value
- else:
- raise ValueError(
- f'Overlapping item "{key}" from multiple '
- 'encoders, which is not supported when '
- '``multilevel==False``')
-
- if keypoint_weights:
- encoded['keypoint_weights'] = keypoint_weights
-
- if self.use_dataset_keypoint_weights and 'keypoint_weights' in encoded:
- if isinstance(encoded['keypoint_weights'], list):
- for w in encoded['keypoint_weights']:
- w *= results['dataset_keypoint_weights']
- else:
- encoded['keypoint_weights'] *= results[
- 'dataset_keypoint_weights']
-
- results.update(encoded)
-
- if results.get('keypoint_weights', None) is not None:
- results['transformed_keypoints_visible'] = results[
- 'keypoint_weights']
- elif results.get('keypoints', None) is not None:
- results['transformed_keypoints_visible'] = results[
- 'keypoints_visible']
- else:
- raise ValueError('GenerateTarget requires \'keypoint_weights\' or'
- ' \'keypoints_visible\' in the results.')
-
- return results
-
- def __repr__(self) -> str:
- """print the basic information of the transform.
-
- Returns:
- str: Formatted string.
- """
- repr_str = self.__class__.__name__
- repr_str += (f'(encoder={str(self.encoder_cfg)}, ')
- repr_str += ('use_dataset_keypoint_weights='
- f'{self.use_dataset_keypoint_weights})')
- return repr_str
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from copy import deepcopy
+from typing import Dict, List, Optional, Sequence, Tuple, Union
+
+import mmcv
+import mmengine
+import numpy as np
+from mmcv.image import imflip
+from mmcv.transforms import BaseTransform
+from mmcv.transforms.utils import avoid_cache_randomness, cache_randomness
+from mmengine import is_list_of
+from mmengine.dist import get_dist_info
+from scipy.stats import truncnorm
+
+from mmpose.codecs import * # noqa: F401, F403
+from mmpose.registry import KEYPOINT_CODECS, TRANSFORMS
+from mmpose.structures.bbox import bbox_xyxy2cs, flip_bbox
+from mmpose.structures.keypoint import flip_keypoints
+from mmpose.utils.typing import MultiConfig
+
+try:
+ import albumentations
+except ImportError:
+ albumentations = None
+
+Number = Union[int, float]
+
+
+@TRANSFORMS.register_module()
+class GetBBoxCenterScale(BaseTransform):
+ """Convert bboxes from [x, y, w, h] to center and scale.
+
+ The center is the coordinates of the bbox center, and the scale is the
+ bbox width and height normalized by a scale factor.
+
+ Required Keys:
+
+ - bbox
+
+ Added Keys:
+
+ - bbox_center
+ - bbox_scale
+
+ Args:
+ padding (float): The bbox padding scale that will be multilied to
+ `bbox_scale`. Defaults to 1.25
+ """
+
+ def __init__(self, padding: float = 1.25) -> None:
+ super().__init__()
+
+ self.padding = padding
+
+ def transform(self, results: Dict) -> Optional[dict]:
+ """The transform function of :class:`GetBBoxCenterScale`.
+
+ See ``transform()`` method of :class:`BaseTransform` for details.
+
+ Args:
+ results (dict): The result dict
+
+ Returns:
+ dict: The result dict.
+ """
+ if 'bbox_center' in results and 'bbox_scale' in results:
+ rank, _ = get_dist_info()
+ if rank == 0:
+ warnings.warn('Use the existing "bbox_center" and "bbox_scale"'
+ '. The padding will still be applied.')
+ results['bbox_scale'] *= self.padding
+
+ else:
+ bbox = results['bbox']
+ center, scale = bbox_xyxy2cs(bbox, padding=self.padding)
+
+ results['bbox_center'] = center
+ results['bbox_scale'] = scale
+
+ return results
+
+ def __repr__(self) -> str:
+ """print the basic information of the transform.
+
+ Returns:
+ str: Formatted string.
+ """
+ repr_str = self.__class__.__name__ + f'(padding={self.padding})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class RandomFlip(BaseTransform):
+ """Randomly flip the image, bbox and keypoints.
+
+ Required Keys:
+
+ - img
+ - img_shape
+ - flip_indices
+ - input_size (optional)
+ - bbox (optional)
+ - bbox_center (optional)
+ - keypoints (optional)
+ - keypoints_visible (optional)
+ - img_mask (optional)
+
+ Modified Keys:
+
+ - img
+ - bbox (optional)
+ - bbox_center (optional)
+ - keypoints (optional)
+ - keypoints_visible (optional)
+ - img_mask (optional)
+
+ Added Keys:
+
+ - flip
+ - flip_direction
+
+ Args:
+ prob (float | list[float]): The flipping probability. If a list is
+ given, the argument `direction` should be a list with the same
+ length. And each element in `prob` indicates the flipping
+ probability of the corresponding one in ``direction``. Defaults
+ to 0.5
+ direction (str | list[str]): The flipping direction. Options are
+ ``'horizontal'``, ``'vertical'`` and ``'diagonal'``. If a list is
+ is given, each data sample's flipping direction will be sampled
+ from a distribution determined by the argument ``prob``. Defaults
+ to ``'horizontal'``.
+ """
+
+ def __init__(self,
+ prob: Union[float, List[float]] = 0.5,
+ direction: Union[str, List[str]] = 'horizontal') -> None:
+ if isinstance(prob, list):
+ assert is_list_of(prob, float)
+ assert 0 <= sum(prob) <= 1
+ elif isinstance(prob, float):
+ assert 0 <= prob <= 1
+ else:
+ raise ValueError(f'probs must be float or list of float, but \
+ got `{type(prob)}`.')
+ self.prob = prob
+
+ valid_directions = ['horizontal', 'vertical', 'diagonal']
+ if isinstance(direction, str):
+ assert direction in valid_directions
+ elif isinstance(direction, list):
+ assert is_list_of(direction, str)
+ assert set(direction).issubset(set(valid_directions))
+ else:
+ raise ValueError(f'direction must be either str or list of str, \
+ but got `{type(direction)}`.')
+ self.direction = direction
+
+ if isinstance(prob, list):
+ assert len(prob) == len(self.direction)
+
+ @cache_randomness
+ def _choose_direction(self) -> str:
+ """Choose the flip direction according to `prob` and `direction`"""
+ if isinstance(self.direction,
+ List) and not isinstance(self.direction, str):
+ # None means non-flip
+ direction_list: list = list(self.direction) + [None]
+ elif isinstance(self.direction, str):
+ # None means non-flip
+ direction_list = [self.direction, None]
+
+ if isinstance(self.prob, list):
+ non_prob: float = 1 - sum(self.prob)
+ prob_list = self.prob + [non_prob]
+ elif isinstance(self.prob, float):
+ non_prob = 1. - self.prob
+ # exclude non-flip
+ single_ratio = self.prob / (len(direction_list) - 1)
+ prob_list = [single_ratio] * (len(direction_list) - 1) + [non_prob]
+
+ cur_dir = np.random.choice(direction_list, p=prob_list)
+
+ return cur_dir
+
+ def transform(self, results: dict) -> dict:
+ """The transform function of :class:`RandomFlip`.
+
+ See ``transform()`` method of :class:`BaseTransform` for details.
+
+ Args:
+ results (dict): The result dict
+
+ Returns:
+ dict: The result dict.
+ """
+
+ flip_dir = self._choose_direction()
+
+ if flip_dir is None:
+ results['flip'] = False
+ results['flip_direction'] = None
+ else:
+ results['flip'] = True
+ results['flip_direction'] = flip_dir
+
+ h, w = results.get('input_size', results['img_shape'])
+ # flip image and mask
+ if isinstance(results['img'], list):
+ results['img'] = [
+ imflip(img, direction=flip_dir) for img in results['img']
+ ]
+ else:
+ results['img'] = imflip(results['img'], direction=flip_dir)
+
+ if 'img_mask' in results:
+ results['img_mask'] = imflip(
+ results['img_mask'], direction=flip_dir)
+
+ # flip bboxes
+ if results.get('bbox', None) is not None:
+ results['bbox'] = flip_bbox(
+ results['bbox'],
+ image_size=(w, h),
+ bbox_format='xyxy',
+ direction=flip_dir)
+
+ if results.get('bbox_center', None) is not None:
+ results['bbox_center'] = flip_bbox(
+ results['bbox_center'],
+ image_size=(w, h),
+ bbox_format='center',
+ direction=flip_dir)
+
+ # flip keypoints
+ if results.get('keypoints', None) is not None:
+ keypoints, keypoints_visible = flip_keypoints(
+ results['keypoints'],
+ results.get('keypoints_visible', None),
+ image_size=(w, h),
+ flip_indices=results['flip_indices'],
+ direction=flip_dir)
+
+ results['keypoints'] = keypoints
+ results['keypoints_visible'] = keypoints_visible
+
+ return results
+
+ def __repr__(self) -> str:
+ """print the basic information of the transform.
+
+ Returns:
+ str: Formatted string.
+ """
+ repr_str = self.__class__.__name__
+ repr_str += f'(prob={self.prob}, '
+ repr_str += f'direction={self.direction})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class RandomHalfBody(BaseTransform):
+ """Data augmentation with half-body transform that keeps only the upper or
+ lower body at random.
+
+ Required Keys:
+
+ - keypoints
+ - keypoints_visible
+ - upper_body_ids
+ - lower_body_ids
+
+ Modified Keys:
+
+ - bbox
+ - bbox_center
+ - bbox_scale
+
+ Args:
+ min_total_keypoints (int): The minimum required number of total valid
+ keypoints of a person to apply half-body transform. Defaults to 8
+ min_half_keypoints (int): The minimum required number of valid
+ half-body keypoints of a person to apply half-body transform.
+ Defaults to 2
+ padding (float): The bbox padding scale that will be multilied to
+ `bbox_scale`. Defaults to 1.5
+ prob (float): The probability to apply half-body transform when the
+ keypoint number meets the requirement. Defaults to 0.3
+ """
+
+ def __init__(self,
+ min_total_keypoints: int = 9,
+ min_upper_keypoints: int = 2,
+ min_lower_keypoints: int = 3,
+ padding: float = 1.5,
+ prob: float = 0.3,
+ upper_prioritized_prob: float = 0.7) -> None:
+ super().__init__()
+ self.min_total_keypoints = min_total_keypoints
+ self.min_upper_keypoints = min_upper_keypoints
+ self.min_lower_keypoints = min_lower_keypoints
+ self.padding = padding
+ self.prob = prob
+ self.upper_prioritized_prob = upper_prioritized_prob
+
+ def _get_half_body_bbox(self, keypoints: np.ndarray,
+ half_body_ids: List[int]
+ ) -> Tuple[np.ndarray, np.ndarray]:
+ """Get half-body bbox center and scale of a single instance.
+
+ Args:
+ keypoints (np.ndarray): Keypoints in shape (K, D)
+ upper_body_ids (list): The list of half-body keypont indices
+
+ Returns:
+ tuple: A tuple containing half-body bbox center and scale
+ - center: Center (x, y) of the bbox
+ - scale: Scale (w, h) of the bbox
+ """
+
+ selected_keypoints = keypoints[half_body_ids]
+ center = selected_keypoints.mean(axis=0)[:2]
+
+ x1, y1 = selected_keypoints.min(axis=0)
+ x2, y2 = selected_keypoints.max(axis=0)
+ w = x2 - x1
+ h = y2 - y1
+ scale = np.array([w, h], dtype=center.dtype) * self.padding
+
+ return center, scale
+
+ @cache_randomness
+ def _random_select_half_body(self, keypoints_visible: np.ndarray,
+ upper_body_ids: List[int],
+ lower_body_ids: List[int]
+ ) -> List[Optional[List[int]]]:
+ """Randomly determine whether applying half-body transform and get the
+ half-body keyponit indices of each instances.
+
+ Args:
+ keypoints_visible (np.ndarray, optional): The visibility of
+ keypoints in shape (N, K, 1).
+ upper_body_ids (list): The list of upper body keypoint indices
+ lower_body_ids (list): The list of lower body keypoint indices
+
+ Returns:
+ list[list[int] | None]: The selected half-body keypoint indices
+ of each instance. ``None`` means not applying half-body transform.
+ """
+
+ half_body_ids = []
+
+ for visible in keypoints_visible:
+ if visible.sum() < self.min_total_keypoints:
+ indices = None
+ elif np.random.rand() > self.prob:
+ indices = None
+ else:
+ upper_valid_ids = [i for i in upper_body_ids if visible[i] > 0]
+ lower_valid_ids = [i for i in lower_body_ids if visible[i] > 0]
+
+ num_upper = len(upper_valid_ids)
+ num_lower = len(lower_valid_ids)
+
+ prefer_upper = np.random.rand() < self.upper_prioritized_prob
+ if (num_upper < self.min_upper_keypoints
+ and num_lower < self.min_lower_keypoints):
+ indices = None
+ elif num_lower < self.min_lower_keypoints:
+ indices = upper_valid_ids
+ elif num_upper < self.min_upper_keypoints:
+ indices = lower_valid_ids
+ else:
+ indices = (
+ upper_valid_ids if prefer_upper else lower_valid_ids)
+
+ half_body_ids.append(indices)
+
+ return half_body_ids
+
+ def transform(self, results: Dict) -> Optional[dict]:
+ """The transform function of :class:`HalfBodyTransform`.
+
+ See ``transform()`` method of :class:`BaseTransform` for details.
+
+ Args:
+ results (dict): The result dict
+
+ Returns:
+ dict: The result dict.
+ """
+
+ half_body_ids = self._random_select_half_body(
+ keypoints_visible=results['keypoints_visible'],
+ upper_body_ids=results['upper_body_ids'],
+ lower_body_ids=results['lower_body_ids'])
+
+ bbox_center = []
+ bbox_scale = []
+
+ for i, indices in enumerate(half_body_ids):
+ if indices is None:
+ bbox_center.append(results['bbox_center'][i])
+ bbox_scale.append(results['bbox_scale'][i])
+ else:
+ _center, _scale = self._get_half_body_bbox(
+ results['keypoints'][i], indices)
+ bbox_center.append(_center)
+ bbox_scale.append(_scale)
+
+ results['bbox_center'] = np.stack(bbox_center)
+ results['bbox_scale'] = np.stack(bbox_scale)
+ return results
+
+ def __repr__(self) -> str:
+ """print the basic information of the transform.
+
+ Returns:
+ str: Formatted string.
+ """
+ repr_str = self.__class__.__name__
+ repr_str += f'(min_total_keypoints={self.min_total_keypoints}, '
+ repr_str += f'min_upper_keypoints={self.min_upper_keypoints}, '
+ repr_str += f'min_lower_keypoints={self.min_lower_keypoints}, '
+ repr_str += f'padding={self.padding}, '
+ repr_str += f'prob={self.prob}, '
+ repr_str += f'upper_prioritized_prob={self.upper_prioritized_prob})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class RandomBBoxTransform(BaseTransform):
+ r"""Rnadomly shift, resize and rotate the bounding boxes.
+
+ Required Keys:
+
+ - bbox_center
+ - bbox_scale
+
+ Modified Keys:
+
+ - bbox_center
+ - bbox_scale
+
+ Added Keys:
+ - bbox_rotation
+
+ Args:
+ shift_factor (float): Randomly shift the bbox in range
+ :math:`[-dx, dx]` and :math:`[-dy, dy]` in X and Y directions,
+ where :math:`dx(y) = x(y)_scale \cdot shift_factor` in pixels.
+ Defaults to 0.16
+ shift_prob (float): Probability of applying random shift. Defaults to
+ 0.3
+ scale_factor (Tuple[float, float]): Randomly resize the bbox in range
+ :math:`[scale_factor[0], scale_factor[1]]`. Defaults to (0.5, 1.5)
+ scale_prob (float): Probability of applying random resizing. Defaults
+ to 1.0
+ rotate_factor (float): Randomly rotate the bbox in
+ :math:`[-rotate_factor, rotate_factor]` in degrees. Defaults
+ to 80.0
+ rotate_prob (float): Probability of applying random rotation. Defaults
+ to 0.6
+ """
+
+ def __init__(self,
+ shift_factor: float = 0.16,
+ shift_prob: float = 0.3,
+ scale_factor: Tuple[float, float] = (0.5, 1.5),
+ scale_prob: float = 1.0,
+ rotate_factor: float = 80.0,
+ rotate_prob: float = 0.6) -> None:
+ super().__init__()
+
+ self.shift_factor = shift_factor
+ self.shift_prob = shift_prob
+ self.scale_factor = scale_factor
+ self.scale_prob = scale_prob
+ self.rotate_factor = rotate_factor
+ self.rotate_prob = rotate_prob
+
+ @staticmethod
+ def _truncnorm(low: float = -1.,
+ high: float = 1.,
+ size: tuple = ()) -> np.ndarray:
+ """Sample from a truncated normal distribution."""
+ return truncnorm.rvs(low, high, size=size).astype(np.float32)
+
+ @cache_randomness
+ def _get_transform_params(self, num_bboxes: int) -> Tuple:
+ """Get random transform parameters.
+
+ Args:
+ num_bboxes (int): The number of bboxes
+
+ Returns:
+ tuple:
+ - offset (np.ndarray): Offset factor of each bbox in shape (n, 2)
+ - scale (np.ndarray): Scaling factor of each bbox in shape (n, 1)
+ - rotate (np.ndarray): Rotation degree of each bbox in shape (n,)
+ """
+ # Get shift parameters
+ offset = self._truncnorm(size=(num_bboxes, 2)) * self.shift_factor
+ offset = np.where(
+ np.random.rand(num_bboxes, 1) < self.shift_prob, offset, 0.)
+
+ # Get scaling parameters
+ scale_min, scale_max = self.scale_factor
+ mu = (scale_max + scale_min) * 0.5
+ sigma = (scale_max - scale_min) * 0.5
+ scale = self._truncnorm(size=(num_bboxes, 1)) * sigma + mu
+ scale = np.where(
+ np.random.rand(num_bboxes, 1) < self.scale_prob, scale, 1.)
+
+ # Get rotation parameters
+ rotate = self._truncnorm(size=(num_bboxes, )) * self.rotate_factor
+ rotate = np.where(
+ np.random.rand(num_bboxes) < self.rotate_prob, rotate, 0.)
+
+ return offset, scale, rotate
+
+ def transform(self, results: Dict) -> Optional[dict]:
+ """The transform function of :class:`RandomBboxTransform`.
+
+ See ``transform()`` method of :class:`BaseTransform` for details.
+
+ Args:
+ results (dict): The result dict
+
+ Returns:
+ dict: The result dict.
+ """
+ bbox_scale = results['bbox_scale']
+ num_bboxes = bbox_scale.shape[0]
+
+ offset, scale, rotate = self._get_transform_params(num_bboxes)
+
+ results['bbox_center'] += offset * bbox_scale
+ results['bbox_scale'] *= scale
+ results['bbox_rotation'] = rotate
+
+ return results
+
+ def __repr__(self) -> str:
+ """print the basic information of the transform.
+
+ Returns:
+ str: Formatted string.
+ """
+ repr_str = self.__class__.__name__
+ repr_str += f'(shift_prob={self.shift_prob}, '
+ repr_str += f'shift_factor={self.shift_factor}, '
+ repr_str += f'scale_prob={self.scale_prob}, '
+ repr_str += f'scale_factor={self.scale_factor}, '
+ repr_str += f'rotate_prob={self.rotate_prob}, '
+ repr_str += f'rotate_factor={self.rotate_factor})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+@avoid_cache_randomness
+class Albumentation(BaseTransform):
+ """Albumentation augmentation (pixel-level transforms only).
+
+ Adds custom pixel-level transformations from Albumentations library.
+ Please visit `https://albumentations.ai/docs/`
+ to get more information.
+
+ Note: we only support pixel-level transforms.
+ Please visit `https://github.com/albumentations-team/`
+ `albumentations#pixel-level-transforms`
+ to get more information about pixel-level transforms.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+
+ Args:
+ transforms (List[dict]): A list of Albumentation transforms.
+ An example of ``transforms`` is as followed:
+ .. code-block:: python
+
+ [
+ dict(
+ type='RandomBrightnessContrast',
+ brightness_limit=[0.1, 0.3],
+ contrast_limit=[0.1, 0.3],
+ p=0.2),
+ dict(type='ChannelShuffle', p=0.1),
+ dict(
+ type='OneOf',
+ transforms=[
+ dict(type='Blur', blur_limit=3, p=1.0),
+ dict(type='MedianBlur', blur_limit=3, p=1.0)
+ ],
+ p=0.1),
+ ]
+ keymap (dict | None): key mapping from ``input key`` to
+ ``albumentation-style key``.
+ Defaults to None, which will use {'img': 'image'}.
+ """
+
+ def __init__(self,
+ transforms: List[dict],
+ keymap: Optional[dict] = None) -> None:
+ if albumentations is None:
+ raise RuntimeError('albumentations is not installed')
+
+ self.transforms = transforms
+
+ self.aug = albumentations.Compose(
+ [self.albu_builder(t) for t in self.transforms])
+
+ if not keymap:
+ self.keymap_to_albu = {
+ 'img': 'image',
+ }
+ else:
+ self.keymap_to_albu = keymap
+
+ def albu_builder(self, cfg: dict) -> albumentations:
+ """Import a module from albumentations.
+
+ It resembles some of :func:`build_from_cfg` logic.
+
+ Args:
+ cfg (dict): Config dict. It should at least contain the key "type".
+
+ Returns:
+ albumentations.BasicTransform: The constructed transform object
+ """
+
+ assert isinstance(cfg, dict) and 'type' in cfg
+ args = cfg.copy()
+
+ obj_type = args.pop('type')
+ if mmengine.is_str(obj_type):
+ if albumentations is None:
+ raise RuntimeError('albumentations is not installed')
+ rank, _ = get_dist_info()
+ if rank == 0 and not hasattr(
+ albumentations.augmentations.transforms, obj_type):
+ warnings.warn(
+ f'{obj_type} is not pixel-level transformations. '
+ 'Please use with caution.')
+ obj_cls = getattr(albumentations, obj_type)
+ elif isinstance(obj_type, type):
+ obj_cls = obj_type
+ else:
+ raise TypeError(f'type must be a str, but got {type(obj_type)}')
+
+ if 'transforms' in args:
+ args['transforms'] = [
+ self.albu_builder(transform)
+ for transform in args['transforms']
+ ]
+
+ return obj_cls(**args)
+
+ def transform(self, results: dict) -> dict:
+ """The transform function of :class:`Albumentation` to apply
+ albumentations transforms.
+
+ See ``transform()`` method of :class:`BaseTransform` for details.
+
+ Args:
+ results (dict): Result dict from the data pipeline.
+
+ Return:
+ dict: updated result dict.
+ """
+ # map result dict to albumentations format
+ results_albu = {}
+ for k, v in self.keymap_to_albu.items():
+ assert k in results, \
+ f'The `{k}` is required to perform albumentations transforms'
+ results_albu[v] = results[k]
+
+ # Apply albumentations transforms
+ results_albu = self.aug(**results_albu)
+
+ # map the albu results back to the original format
+ for k, v in self.keymap_to_albu.items():
+ results[k] = results_albu[v]
+
+ return results
+
+ def __repr__(self) -> str:
+ """print the basic information of the transform.
+
+ Returns:
+ str: Formatted string.
+ """
+ repr_str = self.__class__.__name__ + f'(transforms={self.transforms})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class PhotometricDistortion(BaseTransform):
+ """Apply photometric distortion to image sequentially, every transformation
+ is applied with a probability of 0.5. The position of random contrast is in
+ second or second to last.
+
+ 1. random brightness
+ 2. random contrast (mode 0)
+ 3. convert color from BGR to HSV
+ 4. random saturation
+ 5. random hue
+ 6. convert color from HSV to BGR
+ 7. random contrast (mode 1)
+ 8. randomly swap channels
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+
+ Args:
+ brightness_delta (int): delta of brightness.
+ contrast_range (tuple): range of contrast.
+ saturation_range (tuple): range of saturation.
+ hue_delta (int): delta of hue.
+ """
+
+ def __init__(self,
+ brightness_delta: int = 32,
+ contrast_range: Sequence[Number] = (0.5, 1.5),
+ saturation_range: Sequence[Number] = (0.5, 1.5),
+ hue_delta: int = 18) -> None:
+ self.brightness_delta = brightness_delta
+ self.contrast_lower, self.contrast_upper = contrast_range
+ self.saturation_lower, self.saturation_upper = saturation_range
+ self.hue_delta = hue_delta
+
+ @cache_randomness
+ def _random_flags(self) -> Sequence[Number]:
+ """Generate the random flags for subsequent transforms.
+
+ Returns:
+ Sequence[Number]: a sequence of numbers that indicate whether to
+ do the corresponding transforms.
+ """
+ # contrast_mode == 0 --> do random contrast first
+ # contrast_mode == 1 --> do random contrast last
+ contrast_mode = np.random.randint(2)
+ # whether to apply brightness distortion
+ brightness_flag = np.random.randint(2)
+ # whether to apply contrast distortion
+ contrast_flag = np.random.randint(2)
+ # the mode to convert color from BGR to HSV
+ hsv_mode = np.random.randint(4)
+ # whether to apply channel swap
+ swap_flag = np.random.randint(2)
+
+ # the beta in `self._convert` to be added to image array
+ # in brightness distortion
+ brightness_beta = np.random.uniform(-self.brightness_delta,
+ self.brightness_delta)
+ # the alpha in `self._convert` to be multiplied to image array
+ # in contrast distortion
+ contrast_alpha = np.random.uniform(self.contrast_lower,
+ self.contrast_upper)
+ # the alpha in `self._convert` to be multiplied to image array
+ # in saturation distortion to hsv-formatted img
+ saturation_alpha = np.random.uniform(self.saturation_lower,
+ self.saturation_upper)
+ # delta of hue to add to image array in hue distortion
+ hue_delta = np.random.randint(-self.hue_delta, self.hue_delta)
+ # the random permutation of channel order
+ swap_channel_order = np.random.permutation(3)
+
+ return (contrast_mode, brightness_flag, contrast_flag, hsv_mode,
+ swap_flag, brightness_beta, contrast_alpha, saturation_alpha,
+ hue_delta, swap_channel_order)
+
+ def _convert(self,
+ img: np.ndarray,
+ alpha: float = 1,
+ beta: float = 0) -> np.ndarray:
+ """Multiple with alpha and add beta with clip.
+
+ Args:
+ img (np.ndarray): The image array.
+ alpha (float): The random multiplier.
+ beta (float): The random offset.
+
+ Returns:
+ np.ndarray: The updated image array.
+ """
+ img = img.astype(np.float32) * alpha + beta
+ img = np.clip(img, 0, 255)
+ return img.astype(np.uint8)
+
+ def transform(self, results: dict) -> dict:
+ """The transform function of :class:`PhotometricDistortion` to perform
+ photometric distortion on images.
+
+ See ``transform()`` method of :class:`BaseTransform` for details.
+
+
+ Args:
+ results (dict): Result dict from the data pipeline.
+
+ Returns:
+ dict: Result dict with images distorted.
+ """
+
+ assert 'img' in results, '`img` is not found in results'
+ img = results['img']
+
+ (contrast_mode, brightness_flag, contrast_flag, hsv_mode, swap_flag,
+ brightness_beta, contrast_alpha, saturation_alpha, hue_delta,
+ swap_channel_order) = self._random_flags()
+
+ # random brightness distortion
+ if brightness_flag:
+ img = self._convert(img, beta=brightness_beta)
+
+ # contrast_mode == 0 --> do random contrast first
+ # contrast_mode == 1 --> do random contrast last
+ if contrast_mode == 1:
+ if contrast_flag:
+ img = self._convert(img, alpha=contrast_alpha)
+
+ if hsv_mode:
+ # random saturation/hue distortion
+ img = mmcv.bgr2hsv(img)
+ if hsv_mode == 1 or hsv_mode == 3:
+ # apply saturation distortion to hsv-formatted img
+ img[:, :, 1] = self._convert(
+ img[:, :, 1], alpha=saturation_alpha)
+ if hsv_mode == 2 or hsv_mode == 3:
+ # apply hue distortion to hsv-formatted img
+ img[:, :, 0] = img[:, :, 0].astype(int) + hue_delta
+ img = mmcv.hsv2bgr(img)
+
+ if contrast_mode == 1:
+ if contrast_flag:
+ img = self._convert(img, alpha=contrast_alpha)
+
+ # randomly swap channels
+ if swap_flag:
+ img = img[..., swap_channel_order]
+
+ results['img'] = img
+ return results
+
+ def __repr__(self) -> str:
+ """print the basic information of the transform.
+
+ Returns:
+ str: Formatted string.
+ """
+ repr_str = self.__class__.__name__
+ repr_str += (f'(brightness_delta={self.brightness_delta}, '
+ f'contrast_range=({self.contrast_lower}, '
+ f'{self.contrast_upper}), '
+ f'saturation_range=({self.saturation_lower}, '
+ f'{self.saturation_upper}), '
+ f'hue_delta={self.hue_delta})')
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class GenerateTarget(BaseTransform):
+ """Encode keypoints into Target.
+
+ The generated target is usually the supervision signal of the model
+ learning, e.g. heatmaps or regression labels.
+
+ Required Keys:
+
+ - keypoints
+ - keypoints_visible
+ - dataset_keypoint_weights
+
+ Added Keys:
+
+ - The keys of the encoded items from the codec will be updated into
+ the results, e.g. ``'heatmaps'`` or ``'keypoint_weights'``. See
+ the specific codec for more details.
+
+ Args:
+ encoder (dict | list[dict]): The codec config for keypoint encoding.
+ Both single encoder and multiple encoders (given as a list) are
+ supported
+ multilevel (bool): Determine the method to handle multiple encoders.
+ If ``multilevel==True``, generate multilevel targets from a group
+ of encoders of the same type (e.g. multiple :class:`MSRAHeatmap`
+ encoders with different sigma values); If ``multilevel==False``,
+ generate combined targets from a group of different encoders. This
+ argument will have no effect in case of single encoder. Defaults
+ to ``False``
+ use_dataset_keypoint_weights (bool): Whether use the keypoint weights
+ from the dataset meta information. Defaults to ``False``
+ target_type (str, deprecated): This argument is deprecated and has no
+ effect. Defaults to ``None``
+ """
+
+ def __init__(self,
+ encoder: MultiConfig,
+ target_type: Optional[str] = None,
+ multilevel: bool = False,
+ use_dataset_keypoint_weights: bool = False) -> None:
+ super().__init__()
+
+ if target_type is not None:
+ rank, _ = get_dist_info()
+ if rank == 0:
+ warnings.warn(
+ 'The argument `target_type` is deprecated in'
+ ' GenerateTarget. The target type and encoded '
+ 'keys will be determined by encoder(s).',
+ DeprecationWarning)
+
+ self.encoder_cfg = deepcopy(encoder)
+ self.multilevel = multilevel
+ self.use_dataset_keypoint_weights = use_dataset_keypoint_weights
+
+ if isinstance(self.encoder_cfg, list):
+ self.encoder = [
+ KEYPOINT_CODECS.build(cfg) for cfg in self.encoder_cfg
+ ]
+ else:
+ assert not self.multilevel, (
+ 'Need multiple encoder configs if ``multilevel==True``')
+ self.encoder = KEYPOINT_CODECS.build(self.encoder_cfg)
+
+ def transform(self, results: Dict) -> Optional[dict]:
+ """The transform function of :class:`GenerateTarget`.
+
+ See ``transform()`` method of :class:`BaseTransform` for details.
+ """
+
+ if results.get('transformed_keypoints', None) is not None:
+ # use keypoints transformed by TopdownAffine
+ keypoints = results['transformed_keypoints']
+ elif results.get('keypoints', None) is not None:
+ # use original keypoints
+ keypoints = results['keypoints']
+ else:
+ raise ValueError(
+ 'GenerateTarget requires \'transformed_keypoints\' or'
+ ' \'keypoints\' in the results.')
+
+ keypoints_visible = results['keypoints_visible']
+
+ # Encoded items from the encoder(s) will be updated into the results.
+ # Please refer to the document of the specific codec for details about
+ # encoded items.
+ if not isinstance(self.encoder, list):
+ # For single encoding, the encoded items will be directly added
+ # into results.
+ auxiliary_encode_kwargs = {
+ key: results[key]
+ for key in self.encoder.auxiliary_encode_keys
+ }
+ encoded = self.encoder.encode(
+ keypoints=keypoints,
+ keypoints_visible=keypoints_visible,
+ **auxiliary_encode_kwargs)
+
+ else:
+ encoded_list = []
+ for _encoder in self.encoder:
+ auxiliary_encode_kwargs = {
+ key: results[key]
+ for key in _encoder.auxiliary_encode_keys
+ }
+ encoded_list.append(
+ _encoder.encode(
+ keypoints=keypoints,
+ keypoints_visible=keypoints_visible,
+ **auxiliary_encode_kwargs))
+
+ if self.multilevel:
+ # For multilevel encoding, the encoded items from each encoder
+ # should have the same keys.
+
+ keys = encoded_list[0].keys()
+ if not all(_encoded.keys() == keys
+ for _encoded in encoded_list):
+ raise ValueError(
+ 'Encoded items from all encoders must have the same '
+ 'keys if ``multilevel==True``.')
+
+ encoded = {
+ k: [_encoded[k] for _encoded in encoded_list]
+ for k in keys
+ }
+
+ else:
+ # For combined encoding, the encoded items from different
+ # encoders should have no overlapping items, except for
+ # `keypoint_weights`. If multiple `keypoint_weights` are given,
+ # they will be multiplied as the final `keypoint_weights`.
+
+ encoded = dict()
+ keypoint_weights = []
+
+ for _encoded in encoded_list:
+ for key, value in _encoded.items():
+ if key == 'keypoint_weights':
+ keypoint_weights.append(value)
+ elif key not in encoded:
+ encoded[key] = value
+ else:
+ raise ValueError(
+ f'Overlapping item "{key}" from multiple '
+ 'encoders, which is not supported when '
+ '``multilevel==False``')
+
+ if keypoint_weights:
+ encoded['keypoint_weights'] = keypoint_weights
+
+ if self.use_dataset_keypoint_weights and 'keypoint_weights' in encoded:
+ if isinstance(encoded['keypoint_weights'], list):
+ for w in encoded['keypoint_weights']:
+ w *= results['dataset_keypoint_weights']
+ else:
+ encoded['keypoint_weights'] *= results[
+ 'dataset_keypoint_weights']
+
+ results.update(encoded)
+
+ if results.get('keypoint_weights', None) is not None:
+ results['transformed_keypoints_visible'] = results[
+ 'keypoint_weights']
+ elif results.get('keypoints', None) is not None:
+ results['transformed_keypoints_visible'] = results[
+ 'keypoints_visible']
+ else:
+ raise ValueError('GenerateTarget requires \'keypoint_weights\' or'
+ ' \'keypoints_visible\' in the results.')
+
+ return results
+
+ def __repr__(self) -> str:
+ """print the basic information of the transform.
+
+ Returns:
+ str: Formatted string.
+ """
+ repr_str = self.__class__.__name__
+ repr_str += (f'(encoder={str(self.encoder_cfg)}, ')
+ repr_str += ('use_dataset_keypoint_weights='
+ f'{self.use_dataset_keypoint_weights})')
+ return repr_str
diff --git a/mmpose/datasets/transforms/converting.py b/mmpose/datasets/transforms/converting.py
index 38dcea0994..932cc424b3 100644
--- a/mmpose/datasets/transforms/converting.py
+++ b/mmpose/datasets/transforms/converting.py
@@ -1,125 +1,125 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import List, Tuple, Union
-
-import numpy as np
-from mmcv.transforms import BaseTransform
-
-from mmpose.registry import TRANSFORMS
-
-
-@TRANSFORMS.register_module()
-class KeypointConverter(BaseTransform):
- """Change the order of keypoints according to the given mapping.
-
- Required Keys:
-
- - keypoints
- - keypoints_visible
-
- Modified Keys:
-
- - keypoints
- - keypoints_visible
-
- Args:
- num_keypoints (int): The number of keypoints in target dataset.
- mapping (list): A list containing mapping indexes. Each element has
- format (source_index, target_index)
-
- Example:
- >>> import numpy as np
- >>> # case 1: 1-to-1 mapping
- >>> # (0, 0) means target[0] = source[0]
- >>> self = KeypointConverter(
- >>> num_keypoints=3,
- >>> mapping=[
- >>> (0, 0), (1, 1), (2, 2), (3, 3)
- >>> ])
- >>> results = dict(
- >>> keypoints=np.arange(34).reshape(2, 3, 2),
- >>> keypoints_visible=np.arange(34).reshape(2, 3, 2) % 2)
- >>> results = self(results)
- >>> assert np.equal(results['keypoints'],
- >>> np.arange(34).reshape(2, 3, 2)).all()
- >>> assert np.equal(results['keypoints_visible'],
- >>> np.arange(34).reshape(2, 3, 2) % 2).all()
- >>>
- >>> # case 2: 2-to-1 mapping
- >>> # ((1, 2), 0) means target[0] = (source[1] + source[2]) / 2
- >>> self = KeypointConverter(
- >>> num_keypoints=3,
- >>> mapping=[
- >>> ((1, 2), 0), (1, 1), (2, 2)
- >>> ])
- >>> results = dict(
- >>> keypoints=np.arange(34).reshape(2, 3, 2),
- >>> keypoints_visible=np.arange(34).reshape(2, 3, 2) % 2)
- >>> results = self(results)
- """
-
- def __init__(self, num_keypoints: int,
- mapping: Union[List[Tuple[int, int]], List[Tuple[Tuple,
- int]]]):
- self.num_keypoints = num_keypoints
- self.mapping = mapping
- source_index, target_index = zip(*mapping)
-
- src1, src2 = [], []
- interpolation = False
- for x in source_index:
- if isinstance(x, (list, tuple)):
- assert len(x) == 2, 'source_index should be a list/tuple of ' \
- 'length 2'
- src1.append(x[0])
- src2.append(x[1])
- interpolation = True
- else:
- src1.append(x)
- src2.append(x)
-
- # When paired source_indexes are input,
- # keep a self.source_index2 for interpolation
- if interpolation:
- self.source_index2 = src2
-
- self.source_index = src1
- self.target_index = target_index
- self.interpolation = interpolation
-
- def transform(self, results: dict) -> dict:
- num_instances = results['keypoints'].shape[0]
-
- keypoints = np.zeros((num_instances, self.num_keypoints, 2))
- keypoints_visible = np.zeros((num_instances, self.num_keypoints))
-
- # When paired source_indexes are input,
- # perform interpolation with self.source_index and self.source_index2
- if self.interpolation:
- keypoints[:, self.target_index] = 0.5 * (
- results['keypoints'][:, self.source_index] +
- results['keypoints'][:, self.source_index2])
-
- keypoints_visible[:, self.target_index] = results[
- 'keypoints_visible'][:, self.source_index] * \
- results['keypoints_visible'][:, self.source_index2]
- else:
- keypoints[:,
- self.target_index] = results['keypoints'][:, self.
- source_index]
- keypoints_visible[:, self.target_index] = results[
- 'keypoints_visible'][:, self.source_index]
-
- results['keypoints'] = keypoints
- results['keypoints_visible'] = keypoints_visible
- return results
-
- def __repr__(self) -> str:
- """print the basic information of the transform.
-
- Returns:
- str: Formatted string.
- """
- repr_str = self.__class__.__name__
- repr_str += f'(num_keypoints={self.num_keypoints}, '\
- f'mapping={self.mapping})'
- return repr_str
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple, Union
+
+import numpy as np
+from mmcv.transforms import BaseTransform
+
+from mmpose.registry import TRANSFORMS
+
+
+@TRANSFORMS.register_module()
+class KeypointConverter(BaseTransform):
+ """Change the order of keypoints according to the given mapping.
+
+ Required Keys:
+
+ - keypoints
+ - keypoints_visible
+
+ Modified Keys:
+
+ - keypoints
+ - keypoints_visible
+
+ Args:
+ num_keypoints (int): The number of keypoints in target dataset.
+ mapping (list): A list containing mapping indexes. Each element has
+ format (source_index, target_index)
+
+ Example:
+ >>> import numpy as np
+ >>> # case 1: 1-to-1 mapping
+ >>> # (0, 0) means target[0] = source[0]
+ >>> self = KeypointConverter(
+ >>> num_keypoints=3,
+ >>> mapping=[
+ >>> (0, 0), (1, 1), (2, 2), (3, 3)
+ >>> ])
+ >>> results = dict(
+ >>> keypoints=np.arange(34).reshape(2, 3, 2),
+ >>> keypoints_visible=np.arange(34).reshape(2, 3, 2) % 2)
+ >>> results = self(results)
+ >>> assert np.equal(results['keypoints'],
+ >>> np.arange(34).reshape(2, 3, 2)).all()
+ >>> assert np.equal(results['keypoints_visible'],
+ >>> np.arange(34).reshape(2, 3, 2) % 2).all()
+ >>>
+ >>> # case 2: 2-to-1 mapping
+ >>> # ((1, 2), 0) means target[0] = (source[1] + source[2]) / 2
+ >>> self = KeypointConverter(
+ >>> num_keypoints=3,
+ >>> mapping=[
+ >>> ((1, 2), 0), (1, 1), (2, 2)
+ >>> ])
+ >>> results = dict(
+ >>> keypoints=np.arange(34).reshape(2, 3, 2),
+ >>> keypoints_visible=np.arange(34).reshape(2, 3, 2) % 2)
+ >>> results = self(results)
+ """
+
+ def __init__(self, num_keypoints: int,
+ mapping: Union[List[Tuple[int, int]], List[Tuple[Tuple,
+ int]]]):
+ self.num_keypoints = num_keypoints
+ self.mapping = mapping
+ source_index, target_index = zip(*mapping)
+
+ src1, src2 = [], []
+ interpolation = False
+ for x in source_index:
+ if isinstance(x, (list, tuple)):
+ assert len(x) == 2, 'source_index should be a list/tuple of ' \
+ 'length 2'
+ src1.append(x[0])
+ src2.append(x[1])
+ interpolation = True
+ else:
+ src1.append(x)
+ src2.append(x)
+
+ # When paired source_indexes are input,
+ # keep a self.source_index2 for interpolation
+ if interpolation:
+ self.source_index2 = src2
+
+ self.source_index = src1
+ self.target_index = target_index
+ self.interpolation = interpolation
+
+ def transform(self, results: dict) -> dict:
+ num_instances = results['keypoints'].shape[0]
+
+ keypoints = np.zeros((num_instances, self.num_keypoints, 2))
+ keypoints_visible = np.zeros((num_instances, self.num_keypoints))
+
+ # When paired source_indexes are input,
+ # perform interpolation with self.source_index and self.source_index2
+ if self.interpolation:
+ keypoints[:, self.target_index] = 0.5 * (
+ results['keypoints'][:, self.source_index] +
+ results['keypoints'][:, self.source_index2])
+
+ keypoints_visible[:, self.target_index] = results[
+ 'keypoints_visible'][:, self.source_index] * \
+ results['keypoints_visible'][:, self.source_index2]
+ else:
+ keypoints[:,
+ self.target_index] = results['keypoints'][:, self.
+ source_index]
+ keypoints_visible[:, self.target_index] = results[
+ 'keypoints_visible'][:, self.source_index]
+
+ results['keypoints'] = keypoints
+ results['keypoints_visible'] = keypoints_visible
+ return results
+
+ def __repr__(self) -> str:
+ """print the basic information of the transform.
+
+ Returns:
+ str: Formatted string.
+ """
+ repr_str = self.__class__.__name__
+ repr_str += f'(num_keypoints={self.num_keypoints}, '\
+ f'mapping={self.mapping})'
+ return repr_str
diff --git a/mmpose/datasets/transforms/formatting.py b/mmpose/datasets/transforms/formatting.py
index 05aeef179f..749e4f8ca0 100644
--- a/mmpose/datasets/transforms/formatting.py
+++ b/mmpose/datasets/transforms/formatting.py
@@ -1,270 +1,270 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Sequence, Union
-
-import numpy as np
-import torch
-from mmcv.transforms import BaseTransform
-from mmengine.structures import InstanceData, PixelData
-from mmengine.utils import is_seq_of
-
-from mmpose.registry import TRANSFORMS
-from mmpose.structures import MultilevelPixelData, PoseDataSample
-
-
-def image_to_tensor(img: Union[np.ndarray,
- Sequence[np.ndarray]]) -> torch.torch.Tensor:
- """Translate image or sequence of images to tensor. Multiple image tensors
- will be stacked.
-
- Args:
- value (np.ndarray | Sequence[np.ndarray]): The original image or
- image sequence
-
- Returns:
- torch.Tensor: The output tensor.
- """
-
- if isinstance(img, np.ndarray):
- if len(img.shape) < 3:
- img = np.expand_dims(img, -1)
-
- img = np.ascontiguousarray(img)
- tensor = torch.from_numpy(img).permute(2, 0, 1).contiguous()
- else:
- assert is_seq_of(img, np.ndarray)
- tensor = torch.stack([image_to_tensor(_img) for _img in img])
-
- return tensor
-
-
-def keypoints_to_tensor(keypoints: Union[np.ndarray, Sequence[np.ndarray]]
- ) -> torch.torch.Tensor:
- """Translate keypoints or sequence of keypoints to tensor. Multiple
- keypoints tensors will be stacked.
-
- Args:
- keypoints (np.ndarray | Sequence[np.ndarray]): The keypoints or
- keypoints sequence.
-
- Returns:
- torch.Tensor: The output tensor.
- """
- if isinstance(keypoints, np.ndarray):
- keypoints = np.ascontiguousarray(keypoints)
- N = keypoints.shape[0]
- keypoints = keypoints.transpose(1, 2, 0).reshape(-1, N)
- tensor = torch.from_numpy(keypoints).contiguous()
- else:
- assert is_seq_of(keypoints, np.ndarray)
- tensor = torch.stack(
- [keypoints_to_tensor(_keypoints) for _keypoints in keypoints])
-
- return tensor
-
-
-@TRANSFORMS.register_module()
-class PackPoseInputs(BaseTransform):
- """Pack the inputs data for pose estimation.
-
- The ``img_meta`` item is always populated. The contents of the
- ``img_meta`` dictionary depends on ``meta_keys``. By default it includes:
-
- - ``id``: id of the data sample
-
- - ``img_id``: id of the image
-
- - ``'category_id'``: the id of the instance category
-
- - ``img_path``: path to the image file
-
- - ``crowd_index`` (optional): measure the crowding level of an image,
- defined in CrowdPose dataset
-
- - ``ori_shape``: original shape of the image as a tuple (h, w, c)
-
- - ``img_shape``: shape of the image input to the network as a tuple \
- (h, w). Note that images may be zero padded on the \
- bottom/right if the batch tensor is larger than this shape.
-
- - ``input_size``: the input size to the network
-
- - ``flip``: a boolean indicating if image flip transform was used
-
- - ``flip_direction``: the flipping direction
-
- - ``flip_indices``: the indices of each keypoint's symmetric keypoint
-
- - ``raw_ann_info`` (optional): raw annotation of the instance(s)
-
- Args:
- meta_keys (Sequence[str], optional): Meta keys which will be stored in
- :obj: `PoseDataSample` as meta info. Defaults to ``('id',
- 'img_id', 'img_path', 'category_id', 'crowd_index, 'ori_shape',
- 'img_shape',, 'input_size', 'input_center', 'input_scale', 'flip',
- 'flip_direction', 'flip_indices', 'raw_ann_info')``
- """
-
- # items in `instance_mapping_table` will be directly packed into
- # PoseDataSample.gt_instances without converting to Tensor
- instance_mapping_table = {
- 'bbox': 'bboxes',
- 'head_size': 'head_size',
- 'bbox_center': 'bbox_centers',
- 'bbox_scale': 'bbox_scales',
- 'bbox_score': 'bbox_scores',
- 'keypoints': 'keypoints',
- 'keypoints_visible': 'keypoints_visible',
- 'lifting_target': 'lifting_target',
- 'lifting_target_visible': 'lifting_target_visible',
- }
-
- # items in `label_mapping_table` will be packed into
- # PoseDataSample.gt_instance_labels and converted to Tensor. These items
- # will be used for computing losses
- label_mapping_table = {
- 'keypoint_labels': 'keypoint_labels',
- 'lifting_target_label': 'lifting_target_label',
- 'lifting_target_weights': 'lifting_target_weights',
- 'trajectory_weights': 'trajectory_weights',
- 'keypoint_x_labels': 'keypoint_x_labels',
- 'keypoint_y_labels': 'keypoint_y_labels',
- 'keypoint_weights': 'keypoint_weights',
- 'instance_coords': 'instance_coords',
- 'transformed_keypoints_visible': 'keypoints_visible',
- }
-
- # items in `field_mapping_table` will be packed into
- # PoseDataSample.gt_fields and converted to Tensor. These items will be
- # used for computing losses
- field_mapping_table = {
- 'heatmaps': 'heatmaps',
- 'instance_heatmaps': 'instance_heatmaps',
- 'heatmap_mask': 'heatmap_mask',
- 'heatmap_weights': 'heatmap_weights',
- 'displacements': 'displacements',
- 'displacement_weights': 'displacement_weights',
- }
-
- def __init__(self,
- meta_keys=('id', 'img_id', 'img_path', 'category_id',
- 'crowd_index', 'ori_shape', 'img_shape',
- 'input_size', 'input_center', 'input_scale',
- 'flip', 'flip_direction', 'flip_indices',
- 'raw_ann_info'),
- pack_transformed=False):
- self.meta_keys = meta_keys
- self.pack_transformed = pack_transformed
-
- def transform(self, results: dict) -> dict:
- """Method to pack the input data.
-
- Args:
- results (dict): Result dict from the data pipeline.
-
- Returns:
- dict:
-
- - 'inputs' (obj:`torch.Tensor`): The forward data of models.
- - 'data_samples' (obj:`PoseDataSample`): The annotation info of the
- sample.
- """
- # Pack image(s) for 2d pose estimation
- if 'img' in results:
- img = results['img']
- inputs_tensor = image_to_tensor(img)
- # Pack keypoints for 3d pose-lifting
- elif 'lifting_target' in results and 'keypoints' in results:
- if 'keypoint_labels' in results:
- keypoints = results['keypoint_labels']
- else:
- keypoints = results['keypoints']
- inputs_tensor = keypoints_to_tensor(keypoints)
-
- data_sample = PoseDataSample()
-
- # pack instance data
- gt_instances = InstanceData()
- for key, packed_key in self.instance_mapping_table.items():
- if key in results:
- if 'lifting_target' in results and key in {
- 'keypoints', 'keypoints_visible'
- }:
- continue
- gt_instances.set_field(results[key], packed_key)
-
- # pack `transformed_keypoints` for visualizing data transform
- # and augmentation results
- if self.pack_transformed and 'transformed_keypoints' in results:
- gt_instances.set_field(results['transformed_keypoints'],
- 'transformed_keypoints')
- if self.pack_transformed and \
- 'transformed_keypoints_visible' in results:
- gt_instances.set_field(results['transformed_keypoints_visible'],
- 'transformed_keypoints_visible')
-
- data_sample.gt_instances = gt_instances
-
- # pack instance labels
- gt_instance_labels = InstanceData()
- for key, packed_key in self.label_mapping_table.items():
- if key in results:
- # For pose-lifting, store only target-related fields
- if 'lifting_target_label' in results and key in {
- 'keypoint_labels', 'keypoint_weights',
- 'transformed_keypoints_visible'
- }:
- continue
- if isinstance(results[key], list):
- # A list of labels is usually generated by combined
- # multiple encoders (See ``GenerateTarget`` in
- # mmpose/datasets/transforms/common_transforms.py)
- # In this case, labels in list should have the same
- # shape and will be stacked.
- _labels = np.stack(results[key])
- gt_instance_labels.set_field(_labels, packed_key)
- else:
- gt_instance_labels.set_field(results[key], packed_key)
- data_sample.gt_instance_labels = gt_instance_labels.to_tensor()
-
- # pack fields
- gt_fields = None
- for key, packed_key in self.field_mapping_table.items():
- if key in results:
- if isinstance(results[key], list):
- if gt_fields is None:
- gt_fields = MultilevelPixelData()
- else:
- assert isinstance(
- gt_fields, MultilevelPixelData
- ), 'Got mixed single-level and multi-level pixel data.'
- else:
- if gt_fields is None:
- gt_fields = PixelData()
- else:
- assert isinstance(
- gt_fields, PixelData
- ), 'Got mixed single-level and multi-level pixel data.'
-
- gt_fields.set_field(results[key], packed_key)
-
- if gt_fields:
- data_sample.gt_fields = gt_fields.to_tensor()
-
- img_meta = {k: results[k] for k in self.meta_keys if k in results}
- data_sample.set_metainfo(img_meta)
-
- packed_results = dict()
- packed_results['inputs'] = inputs_tensor
- packed_results['data_samples'] = data_sample
-
- return packed_results
-
- def __repr__(self) -> str:
- """print the basic information of the transform.
-
- Returns:
- str: Formatted string.
- """
- repr_str = self.__class__.__name__
- repr_str += f'(meta_keys={self.meta_keys})'
- return repr_str
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Sequence, Union
+
+import numpy as np
+import torch
+from mmcv.transforms import BaseTransform
+from mmengine.structures import InstanceData, PixelData
+from mmengine.utils import is_seq_of
+
+from mmpose.registry import TRANSFORMS
+from mmpose.structures import MultilevelPixelData, PoseDataSample
+
+
+def image_to_tensor(img: Union[np.ndarray,
+ Sequence[np.ndarray]]) -> torch.torch.Tensor:
+ """Translate image or sequence of images to tensor. Multiple image tensors
+ will be stacked.
+
+ Args:
+ value (np.ndarray | Sequence[np.ndarray]): The original image or
+ image sequence
+
+ Returns:
+ torch.Tensor: The output tensor.
+ """
+
+ if isinstance(img, np.ndarray):
+ if len(img.shape) < 3:
+ img = np.expand_dims(img, -1)
+
+ img = np.ascontiguousarray(img)
+ tensor = torch.from_numpy(img).permute(2, 0, 1).contiguous()
+ else:
+ assert is_seq_of(img, np.ndarray)
+ tensor = torch.stack([image_to_tensor(_img) for _img in img])
+
+ return tensor
+
+
+def keypoints_to_tensor(keypoints: Union[np.ndarray, Sequence[np.ndarray]]
+ ) -> torch.torch.Tensor:
+ """Translate keypoints or sequence of keypoints to tensor. Multiple
+ keypoints tensors will be stacked.
+
+ Args:
+ keypoints (np.ndarray | Sequence[np.ndarray]): The keypoints or
+ keypoints sequence.
+
+ Returns:
+ torch.Tensor: The output tensor.
+ """
+ if isinstance(keypoints, np.ndarray):
+ keypoints = np.ascontiguousarray(keypoints)
+ N = keypoints.shape[0]
+ keypoints = keypoints.transpose(1, 2, 0).reshape(-1, N)
+ tensor = torch.from_numpy(keypoints).contiguous()
+ else:
+ assert is_seq_of(keypoints, np.ndarray)
+ tensor = torch.stack(
+ [keypoints_to_tensor(_keypoints) for _keypoints in keypoints])
+
+ return tensor
+
+
+@TRANSFORMS.register_module()
+class PackPoseInputs(BaseTransform):
+ """Pack the inputs data for pose estimation.
+
+ The ``img_meta`` item is always populated. The contents of the
+ ``img_meta`` dictionary depends on ``meta_keys``. By default it includes:
+
+ - ``id``: id of the data sample
+
+ - ``img_id``: id of the image
+
+ - ``'category_id'``: the id of the instance category
+
+ - ``img_path``: path to the image file
+
+ - ``crowd_index`` (optional): measure the crowding level of an image,
+ defined in CrowdPose dataset
+
+ - ``ori_shape``: original shape of the image as a tuple (h, w, c)
+
+ - ``img_shape``: shape of the image input to the network as a tuple \
+ (h, w). Note that images may be zero padded on the \
+ bottom/right if the batch tensor is larger than this shape.
+
+ - ``input_size``: the input size to the network
+
+ - ``flip``: a boolean indicating if image flip transform was used
+
+ - ``flip_direction``: the flipping direction
+
+ - ``flip_indices``: the indices of each keypoint's symmetric keypoint
+
+ - ``raw_ann_info`` (optional): raw annotation of the instance(s)
+
+ Args:
+ meta_keys (Sequence[str], optional): Meta keys which will be stored in
+ :obj: `PoseDataSample` as meta info. Defaults to ``('id',
+ 'img_id', 'img_path', 'category_id', 'crowd_index, 'ori_shape',
+ 'img_shape',, 'input_size', 'input_center', 'input_scale', 'flip',
+ 'flip_direction', 'flip_indices', 'raw_ann_info')``
+ """
+
+ # items in `instance_mapping_table` will be directly packed into
+ # PoseDataSample.gt_instances without converting to Tensor
+ instance_mapping_table = {
+ 'bbox': 'bboxes',
+ 'head_size': 'head_size',
+ 'bbox_center': 'bbox_centers',
+ 'bbox_scale': 'bbox_scales',
+ 'bbox_score': 'bbox_scores',
+ 'keypoints': 'keypoints',
+ 'keypoints_visible': 'keypoints_visible',
+ 'lifting_target': 'lifting_target',
+ 'lifting_target_visible': 'lifting_target_visible',
+ }
+
+ # items in `label_mapping_table` will be packed into
+ # PoseDataSample.gt_instance_labels and converted to Tensor. These items
+ # will be used for computing losses
+ label_mapping_table = {
+ 'keypoint_labels': 'keypoint_labels',
+ 'lifting_target_label': 'lifting_target_label',
+ 'lifting_target_weights': 'lifting_target_weights',
+ 'trajectory_weights': 'trajectory_weights',
+ 'keypoint_x_labels': 'keypoint_x_labels',
+ 'keypoint_y_labels': 'keypoint_y_labels',
+ 'keypoint_weights': 'keypoint_weights',
+ 'instance_coords': 'instance_coords',
+ 'transformed_keypoints_visible': 'keypoints_visible',
+ }
+
+ # items in `field_mapping_table` will be packed into
+ # PoseDataSample.gt_fields and converted to Tensor. These items will be
+ # used for computing losses
+ field_mapping_table = {
+ 'heatmaps': 'heatmaps',
+ 'instance_heatmaps': 'instance_heatmaps',
+ 'heatmap_mask': 'heatmap_mask',
+ 'heatmap_weights': 'heatmap_weights',
+ 'displacements': 'displacements',
+ 'displacement_weights': 'displacement_weights',
+ }
+
+ def __init__(self,
+ meta_keys=('id', 'img_id', 'img_path', 'category_id',
+ 'crowd_index', 'ori_shape', 'img_shape',
+ 'input_size', 'input_center', 'input_scale',
+ 'flip', 'flip_direction', 'flip_indices',
+ 'raw_ann_info'),
+ pack_transformed=False):
+ self.meta_keys = meta_keys
+ self.pack_transformed = pack_transformed
+
+ def transform(self, results: dict) -> dict:
+ """Method to pack the input data.
+
+ Args:
+ results (dict): Result dict from the data pipeline.
+
+ Returns:
+ dict:
+
+ - 'inputs' (obj:`torch.Tensor`): The forward data of models.
+ - 'data_samples' (obj:`PoseDataSample`): The annotation info of the
+ sample.
+ """
+ # Pack image(s) for 2d pose estimation
+ if 'img' in results:
+ img = results['img']
+ inputs_tensor = image_to_tensor(img)
+ # Pack keypoints for 3d pose-lifting
+ elif 'lifting_target' in results and 'keypoints' in results:
+ if 'keypoint_labels' in results:
+ keypoints = results['keypoint_labels']
+ else:
+ keypoints = results['keypoints']
+ inputs_tensor = keypoints_to_tensor(keypoints)
+
+ data_sample = PoseDataSample()
+
+ # pack instance data
+ gt_instances = InstanceData()
+ for key, packed_key in self.instance_mapping_table.items():
+ if key in results:
+ if 'lifting_target' in results and key in {
+ 'keypoints', 'keypoints_visible'
+ }:
+ continue
+ gt_instances.set_field(results[key], packed_key)
+
+ # pack `transformed_keypoints` for visualizing data transform
+ # and augmentation results
+ if self.pack_transformed and 'transformed_keypoints' in results:
+ gt_instances.set_field(results['transformed_keypoints'],
+ 'transformed_keypoints')
+ if self.pack_transformed and \
+ 'transformed_keypoints_visible' in results:
+ gt_instances.set_field(results['transformed_keypoints_visible'],
+ 'transformed_keypoints_visible')
+
+ data_sample.gt_instances = gt_instances
+
+ # pack instance labels
+ gt_instance_labels = InstanceData()
+ for key, packed_key in self.label_mapping_table.items():
+ if key in results:
+ # For pose-lifting, store only target-related fields
+ if 'lifting_target_label' in results and key in {
+ 'keypoint_labels', 'keypoint_weights',
+ 'transformed_keypoints_visible'
+ }:
+ continue
+ if isinstance(results[key], list):
+ # A list of labels is usually generated by combined
+ # multiple encoders (See ``GenerateTarget`` in
+ # mmpose/datasets/transforms/common_transforms.py)
+ # In this case, labels in list should have the same
+ # shape and will be stacked.
+ _labels = np.stack(results[key])
+ gt_instance_labels.set_field(_labels, packed_key)
+ else:
+ gt_instance_labels.set_field(results[key], packed_key)
+ data_sample.gt_instance_labels = gt_instance_labels.to_tensor()
+
+ # pack fields
+ gt_fields = None
+ for key, packed_key in self.field_mapping_table.items():
+ if key in results:
+ if isinstance(results[key], list):
+ if gt_fields is None:
+ gt_fields = MultilevelPixelData()
+ else:
+ assert isinstance(
+ gt_fields, MultilevelPixelData
+ ), 'Got mixed single-level and multi-level pixel data.'
+ else:
+ if gt_fields is None:
+ gt_fields = PixelData()
+ else:
+ assert isinstance(
+ gt_fields, PixelData
+ ), 'Got mixed single-level and multi-level pixel data.'
+
+ gt_fields.set_field(results[key], packed_key)
+
+ if gt_fields:
+ data_sample.gt_fields = gt_fields.to_tensor()
+
+ img_meta = {k: results[k] for k in self.meta_keys if k in results}
+ data_sample.set_metainfo(img_meta)
+
+ packed_results = dict()
+ packed_results['inputs'] = inputs_tensor
+ packed_results['data_samples'] = data_sample
+
+ return packed_results
+
+ def __repr__(self) -> str:
+ """print the basic information of the transform.
+
+ Returns:
+ str: Formatted string.
+ """
+ repr_str = self.__class__.__name__
+ repr_str += f'(meta_keys={self.meta_keys})'
+ return repr_str
diff --git a/mmpose/datasets/transforms/loading.py b/mmpose/datasets/transforms/loading.py
index 28edcb4806..2febbbdf2d 100644
--- a/mmpose/datasets/transforms/loading.py
+++ b/mmpose/datasets/transforms/loading.py
@@ -1,66 +1,66 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional
-
-import numpy as np
-from mmcv.transforms import LoadImageFromFile
-
-from mmpose.registry import TRANSFORMS
-
-
-@TRANSFORMS.register_module()
-class LoadImage(LoadImageFromFile):
- """Load an image from file or from the np.ndarray in ``results['img']``.
-
- Required Keys:
-
- - img_path
- - img (optional)
-
- Modified Keys:
-
- - img
- - img_shape
- - ori_shape
- - img_path (optional)
-
- Args:
- to_float32 (bool): Whether to convert the loaded image to a float32
- numpy array. If set to False, the loaded image is an uint8 array.
- Defaults to False.
- color_type (str): The flag argument for :func:``mmcv.imfrombytes``.
- Defaults to 'color'.
- imdecode_backend (str): The image decoding backend type. The backend
- argument for :func:``mmcv.imfrombytes``.
- See :func:``mmcv.imfrombytes`` for details.
- Defaults to 'cv2'.
- backend_args (dict, optional): Arguments to instantiate the preifx of
- uri corresponding backend. Defaults to None.
- ignore_empty (bool): Whether to allow loading empty image or file path
- not existent. Defaults to False.
- """
-
- def transform(self, results: dict) -> Optional[dict]:
- """The transform function of :class:`LoadImage`.
-
- Args:
- results (dict): The result dict
-
- Returns:
- dict: The result dict.
- """
-
- if 'img' not in results:
- # Load image from file by :meth:`LoadImageFromFile.transform`
- results = super().transform(results)
- else:
- img = results['img']
- assert isinstance(img, np.ndarray)
- if self.to_float32:
- img = img.astype(np.float32)
-
- if 'img_path' not in results:
- results['img_path'] = None
- results['img_shape'] = img.shape[:2]
- results['ori_shape'] = img.shape[:2]
-
- return results
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import numpy as np
+from mmcv.transforms import LoadImageFromFile
+
+from mmpose.registry import TRANSFORMS
+
+
+@TRANSFORMS.register_module()
+class LoadImage(LoadImageFromFile):
+ """Load an image from file or from the np.ndarray in ``results['img']``.
+
+ Required Keys:
+
+ - img_path
+ - img (optional)
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - ori_shape
+ - img_path (optional)
+
+ Args:
+ to_float32 (bool): Whether to convert the loaded image to a float32
+ numpy array. If set to False, the loaded image is an uint8 array.
+ Defaults to False.
+ color_type (str): The flag argument for :func:``mmcv.imfrombytes``.
+ Defaults to 'color'.
+ imdecode_backend (str): The image decoding backend type. The backend
+ argument for :func:``mmcv.imfrombytes``.
+ See :func:``mmcv.imfrombytes`` for details.
+ Defaults to 'cv2'.
+ backend_args (dict, optional): Arguments to instantiate the preifx of
+ uri corresponding backend. Defaults to None.
+ ignore_empty (bool): Whether to allow loading empty image or file path
+ not existent. Defaults to False.
+ """
+
+ def transform(self, results: dict) -> Optional[dict]:
+ """The transform function of :class:`LoadImage`.
+
+ Args:
+ results (dict): The result dict
+
+ Returns:
+ dict: The result dict.
+ """
+
+ if 'img' not in results:
+ # Load image from file by :meth:`LoadImageFromFile.transform`
+ results = super().transform(results)
+ else:
+ img = results['img']
+ assert isinstance(img, np.ndarray)
+ if self.to_float32:
+ img = img.astype(np.float32)
+
+ if 'img_path' not in results:
+ results['img_path'] = None
+ results['img_shape'] = img.shape[:2]
+ results['ori_shape'] = img.shape[:2]
+
+ return results
diff --git a/mmpose/datasets/transforms/pose3d_transforms.py b/mmpose/datasets/transforms/pose3d_transforms.py
index e6559fa398..096f892b32 100644
--- a/mmpose/datasets/transforms/pose3d_transforms.py
+++ b/mmpose/datasets/transforms/pose3d_transforms.py
@@ -1,105 +1,105 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from copy import deepcopy
-from typing import Dict
-
-import numpy as np
-from mmcv.transforms import BaseTransform
-
-from mmpose.registry import TRANSFORMS
-from mmpose.structures.keypoint import flip_keypoints_custom_center
-
-
-@TRANSFORMS.register_module()
-class RandomFlipAroundRoot(BaseTransform):
- """Data augmentation with random horizontal joint flip around a root joint.
-
- Args:
- keypoints_flip_cfg (dict): Configurations of the
- ``flip_keypoints_custom_center`` function for ``keypoints``. Please
- refer to the docstring of the ``flip_keypoints_custom_center``
- function for more details.
- target_flip_cfg (dict): Configurations of the
- ``flip_keypoints_custom_center`` function for ``lifting_target``.
- Please refer to the docstring of the
- ``flip_keypoints_custom_center`` function for more details.
- flip_prob (float): Probability of flip. Default: 0.5.
- flip_camera (bool): Whether to flip horizontal distortion coefficients.
- Default: ``False``.
-
- Required keys:
- keypoints
- lifting_target
-
- Modified keys:
- (keypoints, keypoints_visible, lifting_target, lifting_target_visible,
- camera_param)
- """
-
- def __init__(self,
- keypoints_flip_cfg,
- target_flip_cfg,
- flip_prob=0.5,
- flip_camera=False):
- self.keypoints_flip_cfg = keypoints_flip_cfg
- self.target_flip_cfg = target_flip_cfg
- self.flip_prob = flip_prob
- self.flip_camera = flip_camera
-
- def transform(self, results: Dict) -> dict:
- """The transform function of :class:`ZeroCenterPose`.
-
- See ``transform()`` method of :class:`BaseTransform` for details.
-
- Args:
- results (dict): The result dict
-
- Returns:
- dict: The result dict.
- """
-
- keypoints = results['keypoints']
- if 'keypoints_visible' in results:
- keypoints_visible = results['keypoints_visible']
- else:
- keypoints_visible = np.ones(keypoints.shape[:-1], dtype=np.float32)
- lifting_target = results['lifting_target']
- if 'lifting_target_visible' in results:
- lifting_target_visible = results['lifting_target_visible']
- else:
- lifting_target_visible = np.ones(
- lifting_target.shape[:-1], dtype=np.float32)
-
- if np.random.rand() <= self.flip_prob:
- if 'flip_indices' not in results:
- flip_indices = list(range(self.num_keypoints))
- else:
- flip_indices = results['flip_indices']
-
- # flip joint coordinates
- keypoints, keypoints_visible = flip_keypoints_custom_center(
- keypoints, keypoints_visible, flip_indices,
- **self.keypoints_flip_cfg)
- lifting_target, lifting_target_visible = flip_keypoints_custom_center( # noqa
- lifting_target, lifting_target_visible, flip_indices,
- **self.target_flip_cfg)
-
- results['keypoints'] = keypoints
- results['keypoints_visible'] = keypoints_visible
- results['lifting_target'] = lifting_target
- results['lifting_target_visible'] = lifting_target_visible
-
- # flip horizontal distortion coefficients
- if self.flip_camera:
- assert 'camera_param' in results, \
- 'Camera parameters are missing.'
- _camera_param = deepcopy(results['camera_param'])
-
- assert 'c' in _camera_param
- _camera_param['c'][0] *= -1
-
- if 'p' in _camera_param:
- _camera_param['p'][0] *= -1
-
- results['camera_param'].update(_camera_param)
-
- return results
+# Copyright (c) OpenMMLab. All rights reserved.
+from copy import deepcopy
+from typing import Dict
+
+import numpy as np
+from mmcv.transforms import BaseTransform
+
+from mmpose.registry import TRANSFORMS
+from mmpose.structures.keypoint import flip_keypoints_custom_center
+
+
+@TRANSFORMS.register_module()
+class RandomFlipAroundRoot(BaseTransform):
+ """Data augmentation with random horizontal joint flip around a root joint.
+
+ Args:
+ keypoints_flip_cfg (dict): Configurations of the
+ ``flip_keypoints_custom_center`` function for ``keypoints``. Please
+ refer to the docstring of the ``flip_keypoints_custom_center``
+ function for more details.
+ target_flip_cfg (dict): Configurations of the
+ ``flip_keypoints_custom_center`` function for ``lifting_target``.
+ Please refer to the docstring of the
+ ``flip_keypoints_custom_center`` function for more details.
+ flip_prob (float): Probability of flip. Default: 0.5.
+ flip_camera (bool): Whether to flip horizontal distortion coefficients.
+ Default: ``False``.
+
+ Required keys:
+ keypoints
+ lifting_target
+
+ Modified keys:
+ (keypoints, keypoints_visible, lifting_target, lifting_target_visible,
+ camera_param)
+ """
+
+ def __init__(self,
+ keypoints_flip_cfg,
+ target_flip_cfg,
+ flip_prob=0.5,
+ flip_camera=False):
+ self.keypoints_flip_cfg = keypoints_flip_cfg
+ self.target_flip_cfg = target_flip_cfg
+ self.flip_prob = flip_prob
+ self.flip_camera = flip_camera
+
+ def transform(self, results: Dict) -> dict:
+ """The transform function of :class:`ZeroCenterPose`.
+
+ See ``transform()`` method of :class:`BaseTransform` for details.
+
+ Args:
+ results (dict): The result dict
+
+ Returns:
+ dict: The result dict.
+ """
+
+ keypoints = results['keypoints']
+ if 'keypoints_visible' in results:
+ keypoints_visible = results['keypoints_visible']
+ else:
+ keypoints_visible = np.ones(keypoints.shape[:-1], dtype=np.float32)
+ lifting_target = results['lifting_target']
+ if 'lifting_target_visible' in results:
+ lifting_target_visible = results['lifting_target_visible']
+ else:
+ lifting_target_visible = np.ones(
+ lifting_target.shape[:-1], dtype=np.float32)
+
+ if np.random.rand() <= self.flip_prob:
+ if 'flip_indices' not in results:
+ flip_indices = list(range(self.num_keypoints))
+ else:
+ flip_indices = results['flip_indices']
+
+ # flip joint coordinates
+ keypoints, keypoints_visible = flip_keypoints_custom_center(
+ keypoints, keypoints_visible, flip_indices,
+ **self.keypoints_flip_cfg)
+ lifting_target, lifting_target_visible = flip_keypoints_custom_center( # noqa
+ lifting_target, lifting_target_visible, flip_indices,
+ **self.target_flip_cfg)
+
+ results['keypoints'] = keypoints
+ results['keypoints_visible'] = keypoints_visible
+ results['lifting_target'] = lifting_target
+ results['lifting_target_visible'] = lifting_target_visible
+
+ # flip horizontal distortion coefficients
+ if self.flip_camera:
+ assert 'camera_param' in results, \
+ 'Camera parameters are missing.'
+ _camera_param = deepcopy(results['camera_param'])
+
+ assert 'c' in _camera_param
+ _camera_param['c'][0] *= -1
+
+ if 'p' in _camera_param:
+ _camera_param['p'][0] *= -1
+
+ results['camera_param'].update(_camera_param)
+
+ return results
diff --git a/mmpose/datasets/transforms/topdown_transforms.py b/mmpose/datasets/transforms/topdown_transforms.py
index 29aa48eb06..d9992c7d8a 100644
--- a/mmpose/datasets/transforms/topdown_transforms.py
+++ b/mmpose/datasets/transforms/topdown_transforms.py
@@ -1,140 +1,140 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Dict, Optional, Tuple
-
-import cv2
-import numpy as np
-from mmcv.transforms import BaseTransform
-from mmengine import is_seq_of
-
-from mmpose.registry import TRANSFORMS
-from mmpose.structures.bbox import get_udp_warp_matrix, get_warp_matrix
-
-
-@TRANSFORMS.register_module()
-class TopdownAffine(BaseTransform):
- """Get the bbox image as the model input by affine transform.
-
- Required Keys:
-
- - img
- - bbox_center
- - bbox_scale
- - bbox_rotation (optional)
- - keypoints (optional)
-
- Modified Keys:
-
- - img
- - bbox_scale
-
- Added Keys:
-
- - input_size
- - transformed_keypoints
-
- Args:
- input_size (Tuple[int, int]): The input image size of the model in
- [w, h]. The bbox region will be cropped and resize to `input_size`
- use_udp (bool): Whether use unbiased data processing. See
- `UDP (CVPR 2020)`_ for details. Defaults to ``False``
-
- .. _`UDP (CVPR 2020)`: https://arxiv.org/abs/1911.07524
- """
-
- def __init__(self,
- input_size: Tuple[int, int],
- use_udp: bool = False) -> None:
- super().__init__()
-
- assert is_seq_of(input_size, int) and len(input_size) == 2, (
- f'Invalid input_size {input_size}')
-
- self.input_size = input_size
- self.use_udp = use_udp
-
- @staticmethod
- def _fix_aspect_ratio(bbox_scale: np.ndarray, aspect_ratio: float):
- """Reshape the bbox to a fixed aspect ratio.
-
- Args:
- bbox_scale (np.ndarray): The bbox scales (w, h) in shape (n, 2)
- aspect_ratio (float): The ratio of ``w/h``
-
- Returns:
- np.darray: The reshaped bbox scales in (n, 2)
- """
-
- w, h = np.hsplit(bbox_scale, [1])
- bbox_scale = np.where(w > h * aspect_ratio,
- np.hstack([w, w / aspect_ratio]),
- np.hstack([h * aspect_ratio, h]))
- return bbox_scale
-
- def transform(self, results: Dict) -> Optional[dict]:
- """The transform function of :class:`TopdownAffine`.
-
- See ``transform()`` method of :class:`BaseTransform` for details.
-
- Args:
- results (dict): The result dict
-
- Returns:
- dict: The result dict.
- """
-
- w, h = self.input_size
- warp_size = (int(w), int(h))
-
- # reshape bbox to fixed aspect ratio
- results['bbox_scale'] = self._fix_aspect_ratio(
- results['bbox_scale'], aspect_ratio=w / h)
-
- # TODO: support multi-instance
- assert results['bbox_center'].shape[0] == 1, (
- 'Top-down heatmap only supports single instance. Got invalid '
- f'shape of bbox_center {results["bbox_center"].shape}.')
-
- center = results['bbox_center'][0]
- scale = results['bbox_scale'][0]
- if 'bbox_rotation' in results:
- rot = results['bbox_rotation'][0]
- else:
- rot = 0.
-
- if self.use_udp:
- warp_mat = get_udp_warp_matrix(
- center, scale, rot, output_size=(w, h))
- else:
- warp_mat = get_warp_matrix(center, scale, rot, output_size=(w, h))
-
- if isinstance(results['img'], list):
- results['img'] = [
- cv2.warpAffine(
- img, warp_mat, warp_size, flags=cv2.INTER_LINEAR)
- for img in results['img']
- ]
- else:
- results['img'] = cv2.warpAffine(
- results['img'], warp_mat, warp_size, flags=cv2.INTER_LINEAR)
-
- if results.get('keypoints', None) is not None:
- transformed_keypoints = results['keypoints'].copy()
- # Only transform (x, y) coordinates
- transformed_keypoints[..., :2] = cv2.transform(
- results['keypoints'][..., :2], warp_mat)
- results['transformed_keypoints'] = transformed_keypoints
-
- results['input_size'] = (w, h)
-
- return results
-
- def __repr__(self) -> str:
- """print the basic information of the transform.
-
- Returns:
- str: Formatted string.
- """
- repr_str = self.__class__.__name__
- repr_str += f'(input_size={self.input_size}, '
- repr_str += f'use_udp={self.use_udp})'
- return repr_str
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, Optional, Tuple
+
+import cv2
+import numpy as np
+from mmcv.transforms import BaseTransform
+from mmengine import is_seq_of
+
+from mmpose.registry import TRANSFORMS
+from mmpose.structures.bbox import get_udp_warp_matrix, get_warp_matrix
+
+
+@TRANSFORMS.register_module()
+class TopdownAffine(BaseTransform):
+ """Get the bbox image as the model input by affine transform.
+
+ Required Keys:
+
+ - img
+ - bbox_center
+ - bbox_scale
+ - bbox_rotation (optional)
+ - keypoints (optional)
+
+ Modified Keys:
+
+ - img
+ - bbox_scale
+
+ Added Keys:
+
+ - input_size
+ - transformed_keypoints
+
+ Args:
+ input_size (Tuple[int, int]): The input image size of the model in
+ [w, h]. The bbox region will be cropped and resize to `input_size`
+ use_udp (bool): Whether use unbiased data processing. See
+ `UDP (CVPR 2020)`_ for details. Defaults to ``False``
+
+ .. _`UDP (CVPR 2020)`: https://arxiv.org/abs/1911.07524
+ """
+
+ def __init__(self,
+ input_size: Tuple[int, int],
+ use_udp: bool = False) -> None:
+ super().__init__()
+
+ assert is_seq_of(input_size, int) and len(input_size) == 2, (
+ f'Invalid input_size {input_size}')
+
+ self.input_size = input_size
+ self.use_udp = use_udp
+
+ @staticmethod
+ def _fix_aspect_ratio(bbox_scale: np.ndarray, aspect_ratio: float):
+ """Reshape the bbox to a fixed aspect ratio.
+
+ Args:
+ bbox_scale (np.ndarray): The bbox scales (w, h) in shape (n, 2)
+ aspect_ratio (float): The ratio of ``w/h``
+
+ Returns:
+ np.darray: The reshaped bbox scales in (n, 2)
+ """
+
+ w, h = np.hsplit(bbox_scale, [1])
+ bbox_scale = np.where(w > h * aspect_ratio,
+ np.hstack([w, w / aspect_ratio]),
+ np.hstack([h * aspect_ratio, h]))
+ return bbox_scale
+
+ def transform(self, results: Dict) -> Optional[dict]:
+ """The transform function of :class:`TopdownAffine`.
+
+ See ``transform()`` method of :class:`BaseTransform` for details.
+
+ Args:
+ results (dict): The result dict
+
+ Returns:
+ dict: The result dict.
+ """
+
+ w, h = self.input_size
+ warp_size = (int(w), int(h))
+
+ # reshape bbox to fixed aspect ratio
+ results['bbox_scale'] = self._fix_aspect_ratio(
+ results['bbox_scale'], aspect_ratio=w / h)
+
+ # TODO: support multi-instance
+ assert results['bbox_center'].shape[0] == 1, (
+ 'Top-down heatmap only supports single instance. Got invalid '
+ f'shape of bbox_center {results["bbox_center"].shape}.')
+
+ center = results['bbox_center'][0]
+ scale = results['bbox_scale'][0]
+ if 'bbox_rotation' in results:
+ rot = results['bbox_rotation'][0]
+ else:
+ rot = 0.
+
+ if self.use_udp:
+ warp_mat = get_udp_warp_matrix(
+ center, scale, rot, output_size=(w, h))
+ else:
+ warp_mat = get_warp_matrix(center, scale, rot, output_size=(w, h))
+
+ if isinstance(results['img'], list):
+ results['img'] = [
+ cv2.warpAffine(
+ img, warp_mat, warp_size, flags=cv2.INTER_LINEAR)
+ for img in results['img']
+ ]
+ else:
+ results['img'] = cv2.warpAffine(
+ results['img'], warp_mat, warp_size, flags=cv2.INTER_LINEAR)
+
+ if results.get('keypoints', None) is not None:
+ transformed_keypoints = results['keypoints'].copy()
+ # Only transform (x, y) coordinates
+ transformed_keypoints[..., :2] = cv2.transform(
+ results['keypoints'][..., :2], warp_mat)
+ results['transformed_keypoints'] = transformed_keypoints
+
+ results['input_size'] = (w, h)
+
+ return results
+
+ def __repr__(self) -> str:
+ """print the basic information of the transform.
+
+ Returns:
+ str: Formatted string.
+ """
+ repr_str = self.__class__.__name__
+ repr_str += f'(input_size={self.input_size}, '
+ repr_str += f'use_udp={self.use_udp})'
+ return repr_str
diff --git a/mmpose/datasets/transforms/warping.py b/mmpose/datasets/transforms/warping.py
new file mode 100644
index 0000000000..be0d827fcd
--- /dev/null
+++ b/mmpose/datasets/transforms/warping.py
@@ -0,0 +1,60 @@
+import cv2
+import numpy as np
+import mmcv
+from mmcv.transforms import BaseTransform, TRANSFORMS
+
+@TRANSFORMS.register_module()
+class Warping(BaseTransform):
+ def __init__(self, direction: str, n_beams: int, scale: float):
+ super().__init__()
+ self.direction = direction
+ self.n_beams = n_beams
+ self.scale = scale
+
+ def transform(self, results: dict) -> dict:
+ img = results['img']
+
+ if self.direction == 'cart2polar':
+ cart = img
+ ws = cart.shape[0]
+ cart = cv2.flip(cart, 0)
+
+ dsize = (ws, self.n_beams)
+ center = (ws // 2.0, ws // 2.0)
+ max_radius = ws // 2.0
+ flags = cv2.WARP_POLAR_LINEAR + cv2.WARP_FILL_OUTLIERS + cv2.INTER_CUBIC
+
+ polar = cv2.warpPolar(cart,
+ dsize=dsize,
+ center=center,
+ maxRadius=max_radius,
+ flags=flags
+ )
+
+ img = cv2.rotate(cart, cv2.ROTATE_90_CLOCKWISE)
+ else:
+ polar_dtype = polar.dtype
+ if polar_dtype == np.bool_:
+ polar = polar.astype(np.uint8) * 255
+
+ ws = int(2 * self.scale * polar.shape[1])
+ dsize = (ws, ws)
+ center = (ws // 2.0, ws // 2.0)
+ max_radius = ws // 2
+ flags = cv2.WARP_POLAR_LINEAR | cv2.WARP_INVERSE_MAP | cv2.WARP_FILL_OUTLIERS | cv2.INTER_CUBIC
+ polar = cv2.rotate(polar, cv2.ROTATE_90_COUNTERCLOCKWISE)
+ cart = cv2.warpPolar(polar,
+ dsize=dsize,
+ center=center,
+ maxRadius=max_radius,
+ flags=flags
+ )
+ cart = cv2.flip(cart, 0)
+
+ if polar_dtype == np.bool_:
+ cart = cart.astype(np.bool_)
+
+ img = cart
+
+ results['img'] = img
+ return results
\ No newline at end of file
diff --git a/mmpose/engine/__init__.py b/mmpose/engine/__init__.py
index ac85928986..53090550a7 100644
--- a/mmpose/engine/__init__.py
+++ b/mmpose/engine/__init__.py
@@ -1,3 +1,3 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .hooks import * # noqa: F401, F403
-from .optim_wrappers import * # noqa: F401, F403
+# Copyright (c) OpenMMLab. All rights reserved.
+from .hooks import * # noqa: F401, F403
+from .optim_wrappers import * # noqa: F401, F403
diff --git a/mmpose/engine/hooks/__init__.py b/mmpose/engine/hooks/__init__.py
index dadb9c5f91..4c98802fbb 100644
--- a/mmpose/engine/hooks/__init__.py
+++ b/mmpose/engine/hooks/__init__.py
@@ -1,5 +1,5 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .ema_hook import ExpMomentumEMA
-from .visualization_hook import PoseVisualizationHook
-
-__all__ = ['PoseVisualizationHook', 'ExpMomentumEMA']
+# Copyright (c) OpenMMLab. All rights reserved.
+from .ema_hook import ExpMomentumEMA
+from .visualization_hook import PoseVisualizationHook
+
+__all__ = ['PoseVisualizationHook', 'ExpMomentumEMA']
diff --git a/mmpose/engine/hooks/ema_hook.py b/mmpose/engine/hooks/ema_hook.py
index fd1a689f96..7d7da46d5c 100644
--- a/mmpose/engine/hooks/ema_hook.py
+++ b/mmpose/engine/hooks/ema_hook.py
@@ -1,69 +1,69 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import math
-from typing import Optional
-
-import torch
-import torch.nn as nn
-from mmengine.model import ExponentialMovingAverage
-from torch import Tensor
-
-from mmpose.registry import MODELS
-
-
-@MODELS.register_module()
-class ExpMomentumEMA(ExponentialMovingAverage):
- """Exponential moving average (EMA) with exponential momentum strategy,
- which is used in YOLOX.
-
- Ported from ` the implementation of MMDetection
- `_.
-
- Args:
- model (nn.Module): The model to be averaged.
- momentum (float): The momentum used for updating ema parameter.
- Ema's parameter are updated with the formula:
- `averaged_param = (1-momentum) * averaged_param + momentum *
- source_param`. Defaults to 0.0002.
- gamma (int): Use a larger momentum early in training and gradually
- annealing to a smaller value to update the ema model smoothly. The
- momentum is calculated as
- `(1 - momentum) * exp(-(1 + steps) / gamma) + momentum`.
- Defaults to 2000.
- interval (int): Interval between two updates. Defaults to 1.
- device (torch.device, optional): If provided, the averaged model will
- be stored on the :attr:`device`. Defaults to None.
- update_buffers (bool): if True, it will compute running averages for
- both the parameters and the buffers of the model. Defaults to
- False.
- """
-
- def __init__(self,
- model: nn.Module,
- momentum: float = 0.0002,
- gamma: int = 2000,
- interval=1,
- device: Optional[torch.device] = None,
- update_buffers: bool = False) -> None:
- super().__init__(
- model=model,
- momentum=momentum,
- interval=interval,
- device=device,
- update_buffers=update_buffers)
- assert gamma > 0, f'gamma must be greater than 0, but got {gamma}'
- self.gamma = gamma
-
- def avg_func(self, averaged_param: Tensor, source_param: Tensor,
- steps: int) -> None:
- """Compute the moving average of the parameters using the exponential
- momentum strategy.
-
- Args:
- averaged_param (Tensor): The averaged parameters.
- source_param (Tensor): The source parameters.
- steps (int): The number of times the parameters have been
- updated.
- """
- momentum = (1 - self.momentum) * math.exp(
- -float(1 + steps) / self.gamma) + self.momentum
- averaged_param.mul_(1 - momentum).add_(source_param, alpha=momentum)
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Optional
+
+import torch
+import torch.nn as nn
+from mmengine.model import ExponentialMovingAverage
+from torch import Tensor
+
+from mmpose.registry import MODELS
+
+
+@MODELS.register_module()
+class ExpMomentumEMA(ExponentialMovingAverage):
+ """Exponential moving average (EMA) with exponential momentum strategy,
+ which is used in YOLOX.
+
+ Ported from ` the implementation of MMDetection
+ `_.
+
+ Args:
+ model (nn.Module): The model to be averaged.
+ momentum (float): The momentum used for updating ema parameter.
+ Ema's parameter are updated with the formula:
+ `averaged_param = (1-momentum) * averaged_param + momentum *
+ source_param`. Defaults to 0.0002.
+ gamma (int): Use a larger momentum early in training and gradually
+ annealing to a smaller value to update the ema model smoothly. The
+ momentum is calculated as
+ `(1 - momentum) * exp(-(1 + steps) / gamma) + momentum`.
+ Defaults to 2000.
+ interval (int): Interval between two updates. Defaults to 1.
+ device (torch.device, optional): If provided, the averaged model will
+ be stored on the :attr:`device`. Defaults to None.
+ update_buffers (bool): if True, it will compute running averages for
+ both the parameters and the buffers of the model. Defaults to
+ False.
+ """
+
+ def __init__(self,
+ model: nn.Module,
+ momentum: float = 0.0002,
+ gamma: int = 2000,
+ interval=1,
+ device: Optional[torch.device] = None,
+ update_buffers: bool = False) -> None:
+ super().__init__(
+ model=model,
+ momentum=momentum,
+ interval=interval,
+ device=device,
+ update_buffers=update_buffers)
+ assert gamma > 0, f'gamma must be greater than 0, but got {gamma}'
+ self.gamma = gamma
+
+ def avg_func(self, averaged_param: Tensor, source_param: Tensor,
+ steps: int) -> None:
+ """Compute the moving average of the parameters using the exponential
+ momentum strategy.
+
+ Args:
+ averaged_param (Tensor): The averaged parameters.
+ source_param (Tensor): The source parameters.
+ steps (int): The number of times the parameters have been
+ updated.
+ """
+ momentum = (1 - self.momentum) * math.exp(
+ -float(1 + steps) / self.gamma) + self.momentum
+ averaged_param.mul_(1 - momentum).add_(source_param, alpha=momentum)
diff --git a/mmpose/engine/hooks/visualization_hook.py b/mmpose/engine/hooks/visualization_hook.py
index 24b845f282..6b5320a0b1 100644
--- a/mmpose/engine/hooks/visualization_hook.py
+++ b/mmpose/engine/hooks/visualization_hook.py
@@ -1,168 +1,168 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os
-import warnings
-from typing import Optional, Sequence
-
-import mmcv
-import mmengine
-import mmengine.fileio as fileio
-from mmengine.hooks import Hook
-from mmengine.runner import Runner
-from mmengine.visualization import Visualizer
-
-from mmpose.registry import HOOKS
-from mmpose.structures import PoseDataSample, merge_data_samples
-
-
-@HOOKS.register_module()
-class PoseVisualizationHook(Hook):
- """Pose Estimation Visualization Hook. Used to visualize validation and
- testing process prediction results.
-
- In the testing phase:
-
- 1. If ``show`` is True, it means that only the prediction results are
- visualized without storing data, so ``vis_backends`` needs to
- be excluded.
- 2. If ``out_dir`` is specified, it means that the prediction results
- need to be saved to ``out_dir``. In order to avoid vis_backends
- also storing data, so ``vis_backends`` needs to be excluded.
- 3. ``vis_backends`` takes effect if the user does not specify ``show``
- and `out_dir``. You can set ``vis_backends`` to WandbVisBackend or
- TensorboardVisBackend to store the prediction result in Wandb or
- Tensorboard.
-
- Args:
- enable (bool): whether to draw prediction results. If it is False,
- it means that no drawing will be done. Defaults to False.
- interval (int): The interval of visualization. Defaults to 50.
- score_thr (float): The threshold to visualize the bboxes
- and masks. Defaults to 0.3.
- show (bool): Whether to display the drawn image. Default to False.
- wait_time (float): The interval of show (s). Defaults to 0.
- out_dir (str, optional): directory where painted images
- will be saved in testing process.
- backend_args (dict, optional): Arguments to instantiate the preifx of
- uri corresponding backend. Defaults to None.
- """
-
- def __init__(
- self,
- enable: bool = False,
- interval: int = 50,
- kpt_thr: float = 0.3,
- show: bool = False,
- wait_time: float = 0.,
- out_dir: Optional[str] = None,
- backend_args: Optional[dict] = None,
- ):
- self._visualizer: Visualizer = Visualizer.get_current_instance()
- self.interval = interval
- self.kpt_thr = kpt_thr
- self.show = show
- if self.show:
- # No need to think about vis backends.
- self._visualizer._vis_backends = {}
- warnings.warn('The show is True, it means that only '
- 'the prediction results are visualized '
- 'without storing data, so vis_backends '
- 'needs to be excluded.')
-
- self.wait_time = wait_time
- self.enable = enable
- self.out_dir = out_dir
- self._test_index = 0
- self.backend_args = backend_args
-
- def after_val_iter(self, runner: Runner, batch_idx: int, data_batch: dict,
- outputs: Sequence[PoseDataSample]) -> None:
- """Run after every ``self.interval`` validation iterations.
-
- Args:
- runner (:obj:`Runner`): The runner of the validation process.
- batch_idx (int): The index of the current batch in the val loop.
- data_batch (dict): Data from dataloader.
- outputs (Sequence[:obj:`PoseDataSample`]): Outputs from model.
- """
- if self.enable is False:
- return
-
- self._visualizer.set_dataset_meta(runner.val_evaluator.dataset_meta)
-
- # There is no guarantee that the same batch of images
- # is visualized for each evaluation.
- total_curr_iter = runner.iter + batch_idx
-
- # Visualize only the first data
- img_path = data_batch['data_samples'][0].get('img_path')
- img_bytes = fileio.get(img_path, backend_args=self.backend_args)
- img = mmcv.imfrombytes(img_bytes, channel_order='rgb')
- data_sample = outputs[0]
-
- # revert the heatmap on the original image
- data_sample = merge_data_samples([data_sample])
-
- if total_curr_iter % self.interval == 0:
- self._visualizer.add_datasample(
- os.path.basename(img_path) if self.show else 'val_img',
- img,
- data_sample=data_sample,
- draw_gt=False,
- draw_bbox=True,
- draw_heatmap=True,
- show=self.show,
- wait_time=self.wait_time,
- kpt_thr=self.kpt_thr,
- step=total_curr_iter)
-
- def after_test_iter(self, runner: Runner, batch_idx: int, data_batch: dict,
- outputs: Sequence[PoseDataSample]) -> None:
- """Run after every testing iterations.
-
- Args:
- runner (:obj:`Runner`): The runner of the testing process.
- batch_idx (int): The index of the current batch in the test loop.
- data_batch (dict): Data from dataloader.
- outputs (Sequence[:obj:`PoseDataSample`]): Outputs from model.
- """
- if self.enable is False:
- return
-
- if self.out_dir is not None:
- self.out_dir = os.path.join(runner.work_dir, runner.timestamp,
- self.out_dir)
- mmengine.mkdir_or_exist(self.out_dir)
-
- self._visualizer.set_dataset_meta(runner.test_evaluator.dataset_meta)
-
- for data_sample in outputs:
- self._test_index += 1
-
- img_path = data_sample.get('img_path')
- img_bytes = fileio.get(img_path, backend_args=self.backend_args)
- img = mmcv.imfrombytes(img_bytes, channel_order='rgb')
- data_sample = merge_data_samples([data_sample])
-
- out_file = None
- if self.out_dir is not None:
- out_file_name, postfix = os.path.basename(img_path).rsplit(
- '.', 1)
- index = len([
- fname for fname in os.listdir(self.out_dir)
- if fname.startswith(out_file_name)
- ])
- out_file = f'{out_file_name}_{index}.{postfix}'
- out_file = os.path.join(self.out_dir, out_file)
-
- self._visualizer.add_datasample(
- os.path.basename(img_path) if self.show else 'test_img',
- img,
- data_sample=data_sample,
- show=self.show,
- draw_gt=False,
- draw_bbox=True,
- draw_heatmap=True,
- wait_time=self.wait_time,
- kpt_thr=self.kpt_thr,
- out_file=out_file,
- step=self._test_index)
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import warnings
+from typing import Optional, Sequence
+
+import mmcv
+import mmengine
+import mmengine.fileio as fileio
+from mmengine.hooks import Hook
+from mmengine.runner import Runner
+from mmengine.visualization import Visualizer
+
+from mmpose.registry import HOOKS
+from mmpose.structures import PoseDataSample, merge_data_samples
+
+
+@HOOKS.register_module()
+class PoseVisualizationHook(Hook):
+ """Pose Estimation Visualization Hook. Used to visualize validation and
+ testing process prediction results.
+
+ In the testing phase:
+
+ 1. If ``show`` is True, it means that only the prediction results are
+ visualized without storing data, so ``vis_backends`` needs to
+ be excluded.
+ 2. If ``out_dir`` is specified, it means that the prediction results
+ need to be saved to ``out_dir``. In order to avoid vis_backends
+ also storing data, so ``vis_backends`` needs to be excluded.
+ 3. ``vis_backends`` takes effect if the user does not specify ``show``
+ and `out_dir``. You can set ``vis_backends`` to WandbVisBackend or
+ TensorboardVisBackend to store the prediction result in Wandb or
+ Tensorboard.
+
+ Args:
+ enable (bool): whether to draw prediction results. If it is False,
+ it means that no drawing will be done. Defaults to False.
+ interval (int): The interval of visualization. Defaults to 50.
+ score_thr (float): The threshold to visualize the bboxes
+ and masks. Defaults to 0.3.
+ show (bool): Whether to display the drawn image. Default to False.
+ wait_time (float): The interval of show (s). Defaults to 0.
+ out_dir (str, optional): directory where painted images
+ will be saved in testing process.
+ backend_args (dict, optional): Arguments to instantiate the preifx of
+ uri corresponding backend. Defaults to None.
+ """
+
+ def __init__(
+ self,
+ enable: bool = False,
+ interval: int = 50,
+ kpt_thr: float = 0.3,
+ show: bool = False,
+ wait_time: float = 0.,
+ out_dir: Optional[str] = None,
+ backend_args: Optional[dict] = None,
+ ):
+ self._visualizer: Visualizer = Visualizer.get_current_instance()
+ self.interval = interval
+ self.kpt_thr = kpt_thr
+ self.show = show
+ if self.show:
+ # No need to think about vis backends.
+ self._visualizer._vis_backends = {}
+ warnings.warn('The show is True, it means that only '
+ 'the prediction results are visualized '
+ 'without storing data, so vis_backends '
+ 'needs to be excluded.')
+
+ self.wait_time = wait_time
+ self.enable = enable
+ self.out_dir = out_dir
+ self._test_index = 0
+ self.backend_args = backend_args
+
+ def after_val_iter(self, runner: Runner, batch_idx: int, data_batch: dict,
+ outputs: Sequence[PoseDataSample]) -> None:
+ """Run after every ``self.interval`` validation iterations.
+
+ Args:
+ runner (:obj:`Runner`): The runner of the validation process.
+ batch_idx (int): The index of the current batch in the val loop.
+ data_batch (dict): Data from dataloader.
+ outputs (Sequence[:obj:`PoseDataSample`]): Outputs from model.
+ """
+ if self.enable is False:
+ return
+
+ self._visualizer.set_dataset_meta(runner.val_evaluator.dataset_meta)
+
+ # There is no guarantee that the same batch of images
+ # is visualized for each evaluation.
+ total_curr_iter = runner.iter + batch_idx
+
+ # Visualize only the first data
+ img_path = data_batch['data_samples'][0].get('img_path')
+ img_bytes = fileio.get(img_path, backend_args=self.backend_args)
+ img = mmcv.imfrombytes(img_bytes, channel_order='rgb')
+ data_sample = outputs[0]
+
+ # revert the heatmap on the original image
+ data_sample = merge_data_samples([data_sample])
+
+ if total_curr_iter % self.interval == 0:
+ self._visualizer.add_datasample(
+ os.path.basename(img_path) if self.show else 'val_img',
+ img,
+ data_sample=data_sample,
+ draw_gt=False,
+ draw_bbox=True,
+ draw_heatmap=True,
+ show=self.show,
+ wait_time=self.wait_time,
+ kpt_thr=self.kpt_thr,
+ step=total_curr_iter)
+
+ def after_test_iter(self, runner: Runner, batch_idx: int, data_batch: dict,
+ outputs: Sequence[PoseDataSample]) -> None:
+ """Run after every testing iterations.
+
+ Args:
+ runner (:obj:`Runner`): The runner of the testing process.
+ batch_idx (int): The index of the current batch in the test loop.
+ data_batch (dict): Data from dataloader.
+ outputs (Sequence[:obj:`PoseDataSample`]): Outputs from model.
+ """
+ if self.enable is False:
+ return
+
+ if self.out_dir is not None:
+ self.out_dir = os.path.join(runner.work_dir, runner.timestamp,
+ self.out_dir)
+ mmengine.mkdir_or_exist(self.out_dir)
+
+ self._visualizer.set_dataset_meta(runner.test_evaluator.dataset_meta)
+
+ for data_sample in outputs:
+ self._test_index += 1
+
+ img_path = data_sample.get('img_path')
+ img_bytes = fileio.get(img_path, backend_args=self.backend_args)
+ img = mmcv.imfrombytes(img_bytes, channel_order='rgb')
+ data_sample = merge_data_samples([data_sample])
+
+ out_file = None
+ if self.out_dir is not None:
+ out_file_name, postfix = os.path.basename(img_path).rsplit(
+ '.', 1)
+ index = len([
+ fname for fname in os.listdir(self.out_dir)
+ if fname.startswith(out_file_name)
+ ])
+ out_file = f'{out_file_name}_{index}.{postfix}'
+ out_file = os.path.join(self.out_dir, out_file)
+
+ self._visualizer.add_datasample(
+ os.path.basename(img_path) if self.show else 'test_img',
+ img,
+ data_sample=data_sample,
+ show=self.show,
+ draw_gt=False,
+ draw_bbox=True,
+ draw_heatmap=True,
+ wait_time=self.wait_time,
+ kpt_thr=self.kpt_thr,
+ out_file=out_file,
+ step=self._test_index)
diff --git a/mmpose/engine/optim_wrappers/__init__.py b/mmpose/engine/optim_wrappers/__init__.py
index 7c0b1f533a..ca0b9fcc7a 100644
--- a/mmpose/engine/optim_wrappers/__init__.py
+++ b/mmpose/engine/optim_wrappers/__init__.py
@@ -1,4 +1,4 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .layer_decay_optim_wrapper import LayerDecayOptimWrapperConstructor
-
-__all__ = ['LayerDecayOptimWrapperConstructor']
+# Copyright (c) OpenMMLab. All rights reserved.
+from .layer_decay_optim_wrapper import LayerDecayOptimWrapperConstructor
+
+__all__ = ['LayerDecayOptimWrapperConstructor']
diff --git a/mmpose/engine/optim_wrappers/layer_decay_optim_wrapper.py b/mmpose/engine/optim_wrappers/layer_decay_optim_wrapper.py
index 6513e5593d..631a3cef23 100644
--- a/mmpose/engine/optim_wrappers/layer_decay_optim_wrapper.py
+++ b/mmpose/engine/optim_wrappers/layer_decay_optim_wrapper.py
@@ -1,73 +1,73 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmengine.dist.utils import get_dist_info
-from mmengine.optim import DefaultOptimWrapperConstructor
-from mmengine.registry import OPTIM_WRAPPER_CONSTRUCTORS
-
-
-def get_num_layer_for_vit(var_name, num_max_layer):
- if var_name in ('backbone.cls_token', 'backbone.mask_token',
- 'backbone.pos_embed'):
- return 0
- elif var_name.startswith('backbone.patch_embed'):
- return 0
- elif var_name.startswith('backbone.layers'):
- layer_id = int(var_name.split('.')[2])
- return layer_id + 1
- else:
- return num_max_layer - 1
-
-
-@OPTIM_WRAPPER_CONSTRUCTORS.register_module(force=True)
-class LayerDecayOptimWrapperConstructor(DefaultOptimWrapperConstructor):
-
- def __init__(self, optim_wrapper_cfg, paramwise_cfg=None):
- super().__init__(optim_wrapper_cfg, paramwise_cfg=None)
- self.layer_decay_rate = paramwise_cfg.get('layer_decay_rate', 0.5)
-
- super().__init__(optim_wrapper_cfg, paramwise_cfg)
-
- def add_params(self, params, module, prefix='', lr=None):
- parameter_groups = {}
- print(self.paramwise_cfg)
- num_layers = self.paramwise_cfg.get('num_layers') + 2
- layer_decay_rate = self.paramwise_cfg.get('layer_decay_rate')
- weight_decay = self.base_wd
-
- for name, param in module.named_parameters():
- if not param.requires_grad:
- continue # frozen weights
- if (len(param.shape) == 1 or name.endswith('.bias')
- or 'pos_embed' in name):
- group_name = 'no_decay'
- this_weight_decay = 0.
- else:
- group_name = 'decay'
- this_weight_decay = weight_decay
- layer_id = get_num_layer_for_vit(name, num_layers)
- group_name = 'layer_%d_%s' % (layer_id, group_name)
-
- if group_name not in parameter_groups:
- scale = layer_decay_rate**(num_layers - layer_id - 1)
-
- parameter_groups[group_name] = {
- 'weight_decay': this_weight_decay,
- 'params': [],
- 'param_names': [],
- 'lr_scale': scale,
- 'group_name': group_name,
- 'lr': scale * self.base_lr,
- }
-
- parameter_groups[group_name]['params'].append(param)
- parameter_groups[group_name]['param_names'].append(name)
- rank, _ = get_dist_info()
- if rank == 0:
- to_display = {}
- for key in parameter_groups:
- to_display[key] = {
- 'param_names': parameter_groups[key]['param_names'],
- 'lr_scale': parameter_groups[key]['lr_scale'],
- 'lr': parameter_groups[key]['lr'],
- 'weight_decay': parameter_groups[key]['weight_decay'],
- }
- params.extend(parameter_groups.values())
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.dist.utils import get_dist_info
+from mmengine.optim import DefaultOptimWrapperConstructor
+from mmengine.registry import OPTIM_WRAPPER_CONSTRUCTORS
+
+
+def get_num_layer_for_vit(var_name, num_max_layer):
+ if var_name in ('backbone.cls_token', 'backbone.mask_token',
+ 'backbone.pos_embed'):
+ return 0
+ elif var_name.startswith('backbone.patch_embed'):
+ return 0
+ elif var_name.startswith('backbone.layers'):
+ layer_id = int(var_name.split('.')[2])
+ return layer_id + 1
+ else:
+ return num_max_layer - 1
+
+
+@OPTIM_WRAPPER_CONSTRUCTORS.register_module(force=True)
+class LayerDecayOptimWrapperConstructor(DefaultOptimWrapperConstructor):
+
+ def __init__(self, optim_wrapper_cfg, paramwise_cfg=None):
+ super().__init__(optim_wrapper_cfg, paramwise_cfg=None)
+ self.layer_decay_rate = paramwise_cfg.get('layer_decay_rate', 0.5)
+
+ super().__init__(optim_wrapper_cfg, paramwise_cfg)
+
+ def add_params(self, params, module, prefix='', lr=None):
+ parameter_groups = {}
+ print(self.paramwise_cfg)
+ num_layers = self.paramwise_cfg.get('num_layers') + 2
+ layer_decay_rate = self.paramwise_cfg.get('layer_decay_rate')
+ weight_decay = self.base_wd
+
+ for name, param in module.named_parameters():
+ if not param.requires_grad:
+ continue # frozen weights
+ if (len(param.shape) == 1 or name.endswith('.bias')
+ or 'pos_embed' in name):
+ group_name = 'no_decay'
+ this_weight_decay = 0.
+ else:
+ group_name = 'decay'
+ this_weight_decay = weight_decay
+ layer_id = get_num_layer_for_vit(name, num_layers)
+ group_name = 'layer_%d_%s' % (layer_id, group_name)
+
+ if group_name not in parameter_groups:
+ scale = layer_decay_rate**(num_layers - layer_id - 1)
+
+ parameter_groups[group_name] = {
+ 'weight_decay': this_weight_decay,
+ 'params': [],
+ 'param_names': [],
+ 'lr_scale': scale,
+ 'group_name': group_name,
+ 'lr': scale * self.base_lr,
+ }
+
+ parameter_groups[group_name]['params'].append(param)
+ parameter_groups[group_name]['param_names'].append(name)
+ rank, _ = get_dist_info()
+ if rank == 0:
+ to_display = {}
+ for key in parameter_groups:
+ to_display[key] = {
+ 'param_names': parameter_groups[key]['param_names'],
+ 'lr_scale': parameter_groups[key]['lr_scale'],
+ 'lr': parameter_groups[key]['lr'],
+ 'weight_decay': parameter_groups[key]['weight_decay'],
+ }
+ params.extend(parameter_groups.values())
diff --git a/mmpose/evaluation/__init__.py b/mmpose/evaluation/__init__.py
index f70dc226d3..bf038e034f 100644
--- a/mmpose/evaluation/__init__.py
+++ b/mmpose/evaluation/__init__.py
@@ -1,3 +1,3 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .functional import * # noqa: F401,F403
-from .metrics import * # noqa: F401,F403
+# Copyright (c) OpenMMLab. All rights reserved.
+from .functional import * # noqa: F401,F403
+from .metrics import * # noqa: F401,F403
diff --git a/mmpose/evaluation/functional/__init__.py b/mmpose/evaluation/functional/__init__.py
index 49f243163c..f5cb4c80af 100644
--- a/mmpose/evaluation/functional/__init__.py
+++ b/mmpose/evaluation/functional/__init__.py
@@ -1,12 +1,12 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .keypoint_eval import (keypoint_auc, keypoint_epe, keypoint_mpjpe,
- keypoint_nme, keypoint_pck_accuracy,
- multilabel_classification_accuracy,
- pose_pck_accuracy, simcc_pck_accuracy)
-from .nms import nms, oks_nms, soft_oks_nms
-
-__all__ = [
- 'keypoint_pck_accuracy', 'keypoint_auc', 'keypoint_nme', 'keypoint_epe',
- 'pose_pck_accuracy', 'multilabel_classification_accuracy',
- 'simcc_pck_accuracy', 'nms', 'oks_nms', 'soft_oks_nms', 'keypoint_mpjpe'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .keypoint_eval import (keypoint_auc, keypoint_epe, keypoint_mpjpe,
+ keypoint_nme, keypoint_pck_accuracy,
+ multilabel_classification_accuracy,
+ pose_pck_accuracy, simcc_pck_accuracy)
+from .nms import nms, oks_nms, soft_oks_nms
+
+__all__ = [
+ 'keypoint_pck_accuracy', 'keypoint_auc', 'keypoint_nme', 'keypoint_epe',
+ 'pose_pck_accuracy', 'multilabel_classification_accuracy',
+ 'simcc_pck_accuracy', 'nms', 'oks_nms', 'soft_oks_nms', 'keypoint_mpjpe'
+]
diff --git a/mmpose/evaluation/functional/keypoint_eval.py b/mmpose/evaluation/functional/keypoint_eval.py
index 847faaf6d8..cab4fb8fda 100644
--- a/mmpose/evaluation/functional/keypoint_eval.py
+++ b/mmpose/evaluation/functional/keypoint_eval.py
@@ -1,375 +1,375 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional, Tuple
-
-import numpy as np
-
-from mmpose.codecs.utils import get_heatmap_maximum, get_simcc_maximum
-from .mesh_eval import compute_similarity_transform
-
-
-def _calc_distances(preds: np.ndarray, gts: np.ndarray, mask: np.ndarray,
- norm_factor: np.ndarray) -> np.ndarray:
- """Calculate the normalized distances between preds and target.
-
- Note:
- - instance number: N
- - keypoint number: K
- - keypoint dimension: D (normally, D=2 or D=3)
-
- Args:
- preds (np.ndarray[N, K, D]): Predicted keypoint location.
- gts (np.ndarray[N, K, D]): Groundtruth keypoint location.
- mask (np.ndarray[N, K]): Visibility of the target. False for invisible
- joints, and True for visible. Invisible joints will be ignored for
- accuracy calculation.
- norm_factor (np.ndarray[N, D]): Normalization factor.
- Typical value is heatmap_size.
-
- Returns:
- np.ndarray[K, N]: The normalized distances. \
- If target keypoints are missing, the distance is -1.
- """
- N, K, _ = preds.shape
- # set mask=0 when norm_factor==0
- _mask = mask.copy()
- _mask[np.where((norm_factor == 0).sum(1))[0], :] = False
-
- distances = np.full((N, K), -1, dtype=np.float32)
- # handle invalid values
- norm_factor[np.where(norm_factor <= 0)] = 1e6
- distances[_mask] = np.linalg.norm(
- ((preds - gts) / norm_factor[:, None, :])[_mask], axis=-1)
- return distances.T
-
-
-def _distance_acc(distances: np.ndarray, thr: float = 0.5) -> float:
- """Return the percentage below the distance threshold, while ignoring
- distances values with -1.
-
- Note:
- - instance number: N
-
- Args:
- distances (np.ndarray[N, ]): The normalized distances.
- thr (float): Threshold of the distances.
-
- Returns:
- float: Percentage of distances below the threshold. \
- If all target keypoints are missing, return -1.
- """
- distance_valid = distances != -1
- num_distance_valid = distance_valid.sum()
- if num_distance_valid > 0:
- return (distances[distance_valid] < thr).sum() / num_distance_valid
- return -1
-
-
-def keypoint_pck_accuracy(pred: np.ndarray, gt: np.ndarray, mask: np.ndarray,
- thr: np.ndarray, norm_factor: np.ndarray) -> tuple:
- """Calculate the pose accuracy of PCK for each individual keypoint and the
- averaged accuracy across all keypoints for coordinates.
-
- Note:
- PCK metric measures accuracy of the localization of the body joints.
- The distances between predicted positions and the ground-truth ones
- are typically normalized by the bounding box size.
- The threshold (thr) of the normalized distance is commonly set
- as 0.05, 0.1 or 0.2 etc.
-
- - instance number: N
- - keypoint number: K
-
- Args:
- pred (np.ndarray[N, K, 2]): Predicted keypoint location.
- gt (np.ndarray[N, K, 2]): Groundtruth keypoint location.
- mask (np.ndarray[N, K]): Visibility of the target. False for invisible
- joints, and True for visible. Invisible joints will be ignored for
- accuracy calculation.
- thr (float): Threshold of PCK calculation.
- norm_factor (np.ndarray[N, 2]): Normalization factor for H&W.
-
- Returns:
- tuple: A tuple containing keypoint accuracy.
-
- - acc (np.ndarray[K]): Accuracy of each keypoint.
- - avg_acc (float): Averaged accuracy across all keypoints.
- - cnt (int): Number of valid keypoints.
- """
- distances = _calc_distances(pred, gt, mask, norm_factor)
- acc = np.array([_distance_acc(d, thr) for d in distances])
- valid_acc = acc[acc >= 0]
- cnt = len(valid_acc)
- avg_acc = valid_acc.mean() if cnt > 0 else 0.0
- return acc, avg_acc, cnt
-
-
-def keypoint_auc(pred: np.ndarray,
- gt: np.ndarray,
- mask: np.ndarray,
- norm_factor: np.ndarray,
- num_thrs: int = 20) -> float:
- """Calculate the Area under curve (AUC) of keypoint PCK accuracy.
-
- Note:
- - instance number: N
- - keypoint number: K
-
- Args:
- pred (np.ndarray[N, K, 2]): Predicted keypoint location.
- gt (np.ndarray[N, K, 2]): Groundtruth keypoint location.
- mask (np.ndarray[N, K]): Visibility of the target. False for invisible
- joints, and True for visible. Invisible joints will be ignored for
- accuracy calculation.
- norm_factor (float): Normalization factor.
- num_thrs (int): number of thresholds to calculate auc.
-
- Returns:
- float: Area under curve (AUC) of keypoint PCK accuracy.
- """
- nor = np.tile(np.array([[norm_factor, norm_factor]]), (pred.shape[0], 1))
- thrs = [1.0 * i / num_thrs for i in range(num_thrs)]
- avg_accs = []
- for thr in thrs:
- _, avg_acc, _ = keypoint_pck_accuracy(pred, gt, mask, thr, nor)
- avg_accs.append(avg_acc)
-
- auc = 0
- for i in range(num_thrs):
- auc += 1.0 / num_thrs * avg_accs[i]
- return auc
-
-
-def keypoint_nme(pred: np.ndarray, gt: np.ndarray, mask: np.ndarray,
- normalize_factor: np.ndarray) -> float:
- """Calculate the normalized mean error (NME).
-
- Note:
- - instance number: N
- - keypoint number: K
-
- Args:
- pred (np.ndarray[N, K, 2]): Predicted keypoint location.
- gt (np.ndarray[N, K, 2]): Groundtruth keypoint location.
- mask (np.ndarray[N, K]): Visibility of the target. False for invisible
- joints, and True for visible. Invisible joints will be ignored for
- accuracy calculation.
- normalize_factor (np.ndarray[N, 2]): Normalization factor.
-
- Returns:
- float: normalized mean error
- """
- distances = _calc_distances(pred, gt, mask, normalize_factor)
- distance_valid = distances[distances != -1]
- return distance_valid.sum() / max(1, len(distance_valid))
-
-
-def keypoint_epe(pred: np.ndarray, gt: np.ndarray, mask: np.ndarray) -> float:
- """Calculate the end-point error.
-
- Note:
- - instance number: N
- - keypoint number: K
-
- Args:
- pred (np.ndarray[N, K, 2]): Predicted keypoint location.
- gt (np.ndarray[N, K, 2]): Groundtruth keypoint location.
- mask (np.ndarray[N, K]): Visibility of the target. False for invisible
- joints, and True for visible. Invisible joints will be ignored for
- accuracy calculation.
-
- Returns:
- float: Average end-point error.
- """
-
- distances = _calc_distances(
- pred, gt, mask,
- np.ones((pred.shape[0], pred.shape[2]), dtype=np.float32))
- distance_valid = distances[distances != -1]
- return distance_valid.sum() / max(1, len(distance_valid))
-
-
-def pose_pck_accuracy(output: np.ndarray,
- target: np.ndarray,
- mask: np.ndarray,
- thr: float = 0.05,
- normalize: Optional[np.ndarray] = None) -> tuple:
- """Calculate the pose accuracy of PCK for each individual keypoint and the
- averaged accuracy across all keypoints from heatmaps.
-
- Note:
- PCK metric measures accuracy of the localization of the body joints.
- The distances between predicted positions and the ground-truth ones
- are typically normalized by the bounding box size.
- The threshold (thr) of the normalized distance is commonly set
- as 0.05, 0.1 or 0.2 etc.
-
- - batch_size: N
- - num_keypoints: K
- - heatmap height: H
- - heatmap width: W
-
- Args:
- output (np.ndarray[N, K, H, W]): Model output heatmaps.
- target (np.ndarray[N, K, H, W]): Groundtruth heatmaps.
- mask (np.ndarray[N, K]): Visibility of the target. False for invisible
- joints, and True for visible. Invisible joints will be ignored for
- accuracy calculation.
- thr (float): Threshold of PCK calculation. Default 0.05.
- normalize (np.ndarray[N, 2]): Normalization factor for H&W.
-
- Returns:
- tuple: A tuple containing keypoint accuracy.
-
- - np.ndarray[K]: Accuracy of each keypoint.
- - float: Averaged accuracy across all keypoints.
- - int: Number of valid keypoints.
- """
- N, K, H, W = output.shape
- if K == 0:
- return None, 0, 0
- if normalize is None:
- normalize = np.tile(np.array([[H, W]]), (N, 1))
-
- pred, _ = get_heatmap_maximum(output)
- gt, _ = get_heatmap_maximum(target)
- return keypoint_pck_accuracy(pred, gt, mask, thr, normalize)
-
-
-def simcc_pck_accuracy(output: Tuple[np.ndarray, np.ndarray],
- target: Tuple[np.ndarray, np.ndarray],
- simcc_split_ratio: float,
- mask: np.ndarray,
- thr: float = 0.05,
- normalize: Optional[np.ndarray] = None) -> tuple:
- """Calculate the pose accuracy of PCK for each individual keypoint and the
- averaged accuracy across all keypoints from SimCC.
-
- Note:
- PCK metric measures accuracy of the localization of the body joints.
- The distances between predicted positions and the ground-truth ones
- are typically normalized by the bounding box size.
- The threshold (thr) of the normalized distance is commonly set
- as 0.05, 0.1 or 0.2 etc.
-
- - instance number: N
- - keypoint number: K
-
- Args:
- output (Tuple[np.ndarray, np.ndarray]): Model predicted SimCC.
- target (Tuple[np.ndarray, np.ndarray]): Groundtruth SimCC.
- mask (np.ndarray[N, K]): Visibility of the target. False for invisible
- joints, and True for visible. Invisible joints will be ignored for
- accuracy calculation.
- thr (float): Threshold of PCK calculation. Default 0.05.
- normalize (np.ndarray[N, 2]): Normalization factor for H&W.
-
- Returns:
- tuple: A tuple containing keypoint accuracy.
-
- - np.ndarray[K]: Accuracy of each keypoint.
- - float: Averaged accuracy across all keypoints.
- - int: Number of valid keypoints.
- """
- pred_x, pred_y = output
- gt_x, gt_y = target
-
- N, _, Wx = pred_x.shape
- _, _, Wy = pred_y.shape
- W, H = int(Wx / simcc_split_ratio), int(Wy / simcc_split_ratio)
-
- if normalize is None:
- normalize = np.tile(np.array([[H, W]]), (N, 1))
-
- pred_coords, _ = get_simcc_maximum(pred_x, pred_y)
- pred_coords /= simcc_split_ratio
- gt_coords, _ = get_simcc_maximum(gt_x, gt_y)
- gt_coords /= simcc_split_ratio
-
- return keypoint_pck_accuracy(pred_coords, gt_coords, mask, thr, normalize)
-
-
-def multilabel_classification_accuracy(pred: np.ndarray,
- gt: np.ndarray,
- mask: np.ndarray,
- thr: float = 0.5) -> float:
- """Get multi-label classification accuracy.
-
- Note:
- - batch size: N
- - label number: L
-
- Args:
- pred (np.ndarray[N, L, 2]): model predicted labels.
- gt (np.ndarray[N, L, 2]): ground-truth labels.
- mask (np.ndarray[N, 1] or np.ndarray[N, L] ): reliability of
- ground-truth labels.
- thr (float): Threshold for calculating accuracy.
-
- Returns:
- float: multi-label classification accuracy.
- """
- # we only compute accuracy on the samples with ground-truth of all labels.
- valid = (mask > 0).min(axis=1) if mask.ndim == 2 else (mask > 0)
- pred, gt = pred[valid], gt[valid]
-
- if pred.shape[0] == 0:
- acc = 0.0 # when no sample is with gt labels, set acc to 0.
- else:
- # The classification of a sample is regarded as correct
- # only if it's correct for all labels.
- acc = (((pred - thr) * (gt - thr)) > 0).all(axis=1).mean()
- return acc
-
-
-def keypoint_mpjpe(pred: np.ndarray,
- gt: np.ndarray,
- mask: np.ndarray,
- alignment: str = 'none'):
- """Calculate the mean per-joint position error (MPJPE) and the error after
- rigid alignment with the ground truth (P-MPJPE).
-
- Note:
- - batch_size: N
- - num_keypoints: K
- - keypoint_dims: C
-
- Args:
- pred (np.ndarray): Predicted keypoint location with shape [N, K, C].
- gt (np.ndarray): Groundtruth keypoint location with shape [N, K, C].
- mask (np.ndarray): Visibility of the target with shape [N, K].
- False for invisible joints, and True for visible.
- Invisible joints will be ignored for accuracy calculation.
- alignment (str, optional): method to align the prediction with the
- groundtruth. Supported options are:
-
- - ``'none'``: no alignment will be applied
- - ``'scale'``: align in the least-square sense in scale
- - ``'procrustes'``: align in the least-square sense in
- scale, rotation and translation.
-
- Returns:
- tuple: A tuple containing joint position errors
-
- - (float | np.ndarray): mean per-joint position error (mpjpe).
- - (float | np.ndarray): mpjpe after rigid alignment with the
- ground truth (p-mpjpe).
- """
- assert mask.any()
-
- if alignment == 'none':
- pass
- elif alignment == 'procrustes':
- pred = np.stack([
- compute_similarity_transform(pred_i, gt_i)
- for pred_i, gt_i in zip(pred, gt)
- ])
- elif alignment == 'scale':
- pred_dot_pred = np.einsum('nkc,nkc->n', pred, pred)
- pred_dot_gt = np.einsum('nkc,nkc->n', pred, gt)
- scale_factor = pred_dot_gt / pred_dot_pred
- pred = pred * scale_factor[:, None, None]
- else:
- raise ValueError(f'Invalid value for alignment: {alignment}')
- error = np.linalg.norm(pred - gt, ord=2, axis=-1)[mask].mean()
-
- return error
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import numpy as np
+
+from mmpose.codecs.utils import get_heatmap_maximum, get_simcc_maximum
+from .mesh_eval import compute_similarity_transform
+
+
+def _calc_distances(preds: np.ndarray, gts: np.ndarray, mask: np.ndarray,
+ norm_factor: np.ndarray) -> np.ndarray:
+ """Calculate the normalized distances between preds and target.
+
+ Note:
+ - instance number: N
+ - keypoint number: K
+ - keypoint dimension: D (normally, D=2 or D=3)
+
+ Args:
+ preds (np.ndarray[N, K, D]): Predicted keypoint location.
+ gts (np.ndarray[N, K, D]): Groundtruth keypoint location.
+ mask (np.ndarray[N, K]): Visibility of the target. False for invisible
+ joints, and True for visible. Invisible joints will be ignored for
+ accuracy calculation.
+ norm_factor (np.ndarray[N, D]): Normalization factor.
+ Typical value is heatmap_size.
+
+ Returns:
+ np.ndarray[K, N]: The normalized distances. \
+ If target keypoints are missing, the distance is -1.
+ """
+ N, K, _ = preds.shape
+ # set mask=0 when norm_factor==0
+ _mask = mask.copy()
+ _mask[np.where((norm_factor == 0).sum(1))[0], :] = False
+
+ distances = np.full((N, K), -1, dtype=np.float32)
+ # handle invalid values
+ norm_factor[np.where(norm_factor <= 0)] = 1e6
+ distances[_mask] = np.linalg.norm(
+ ((preds - gts) / norm_factor[:, None, :])[_mask], axis=-1)
+ return distances.T
+
+
+def _distance_acc(distances: np.ndarray, thr: float = 0.5) -> float:
+ """Return the percentage below the distance threshold, while ignoring
+ distances values with -1.
+
+ Note:
+ - instance number: N
+
+ Args:
+ distances (np.ndarray[N, ]): The normalized distances.
+ thr (float): Threshold of the distances.
+
+ Returns:
+ float: Percentage of distances below the threshold. \
+ If all target keypoints are missing, return -1.
+ """
+ distance_valid = distances != -1
+ num_distance_valid = distance_valid.sum()
+ if num_distance_valid > 0:
+ return (distances[distance_valid] < thr).sum() / num_distance_valid
+ return -1
+
+
+def keypoint_pck_accuracy(pred: np.ndarray, gt: np.ndarray, mask: np.ndarray,
+ thr: np.ndarray, norm_factor: np.ndarray) -> tuple:
+ """Calculate the pose accuracy of PCK for each individual keypoint and the
+ averaged accuracy across all keypoints for coordinates.
+
+ Note:
+ PCK metric measures accuracy of the localization of the body joints.
+ The distances between predicted positions and the ground-truth ones
+ are typically normalized by the bounding box size.
+ The threshold (thr) of the normalized distance is commonly set
+ as 0.05, 0.1 or 0.2 etc.
+
+ - instance number: N
+ - keypoint number: K
+
+ Args:
+ pred (np.ndarray[N, K, 2]): Predicted keypoint location.
+ gt (np.ndarray[N, K, 2]): Groundtruth keypoint location.
+ mask (np.ndarray[N, K]): Visibility of the target. False for invisible
+ joints, and True for visible. Invisible joints will be ignored for
+ accuracy calculation.
+ thr (float): Threshold of PCK calculation.
+ norm_factor (np.ndarray[N, 2]): Normalization factor for H&W.
+
+ Returns:
+ tuple: A tuple containing keypoint accuracy.
+
+ - acc (np.ndarray[K]): Accuracy of each keypoint.
+ - avg_acc (float): Averaged accuracy across all keypoints.
+ - cnt (int): Number of valid keypoints.
+ """
+ distances = _calc_distances(pred, gt, mask, norm_factor)
+ acc = np.array([_distance_acc(d, thr) for d in distances])
+ valid_acc = acc[acc >= 0]
+ cnt = len(valid_acc)
+ avg_acc = valid_acc.mean() if cnt > 0 else 0.0
+ return acc, avg_acc, cnt
+
+
+def keypoint_auc(pred: np.ndarray,
+ gt: np.ndarray,
+ mask: np.ndarray,
+ norm_factor: np.ndarray,
+ num_thrs: int = 20) -> float:
+ """Calculate the Area under curve (AUC) of keypoint PCK accuracy.
+
+ Note:
+ - instance number: N
+ - keypoint number: K
+
+ Args:
+ pred (np.ndarray[N, K, 2]): Predicted keypoint location.
+ gt (np.ndarray[N, K, 2]): Groundtruth keypoint location.
+ mask (np.ndarray[N, K]): Visibility of the target. False for invisible
+ joints, and True for visible. Invisible joints will be ignored for
+ accuracy calculation.
+ norm_factor (float): Normalization factor.
+ num_thrs (int): number of thresholds to calculate auc.
+
+ Returns:
+ float: Area under curve (AUC) of keypoint PCK accuracy.
+ """
+ nor = np.tile(np.array([[norm_factor, norm_factor]]), (pred.shape[0], 1))
+ thrs = [1.0 * i / num_thrs for i in range(num_thrs)]
+ avg_accs = []
+ for thr in thrs:
+ _, avg_acc, _ = keypoint_pck_accuracy(pred, gt, mask, thr, nor)
+ avg_accs.append(avg_acc)
+
+ auc = 0
+ for i in range(num_thrs):
+ auc += 1.0 / num_thrs * avg_accs[i]
+ return auc
+
+
+def keypoint_nme(pred: np.ndarray, gt: np.ndarray, mask: np.ndarray,
+ normalize_factor: np.ndarray) -> float:
+ """Calculate the normalized mean error (NME).
+
+ Note:
+ - instance number: N
+ - keypoint number: K
+
+ Args:
+ pred (np.ndarray[N, K, 2]): Predicted keypoint location.
+ gt (np.ndarray[N, K, 2]): Groundtruth keypoint location.
+ mask (np.ndarray[N, K]): Visibility of the target. False for invisible
+ joints, and True for visible. Invisible joints will be ignored for
+ accuracy calculation.
+ normalize_factor (np.ndarray[N, 2]): Normalization factor.
+
+ Returns:
+ float: normalized mean error
+ """
+ distances = _calc_distances(pred, gt, mask, normalize_factor)
+ distance_valid = distances[distances != -1]
+ return distance_valid.sum() / max(1, len(distance_valid))
+
+
+def keypoint_epe(pred: np.ndarray, gt: np.ndarray, mask: np.ndarray) -> float:
+ """Calculate the end-point error.
+
+ Note:
+ - instance number: N
+ - keypoint number: K
+
+ Args:
+ pred (np.ndarray[N, K, 2]): Predicted keypoint location.
+ gt (np.ndarray[N, K, 2]): Groundtruth keypoint location.
+ mask (np.ndarray[N, K]): Visibility of the target. False for invisible
+ joints, and True for visible. Invisible joints will be ignored for
+ accuracy calculation.
+
+ Returns:
+ float: Average end-point error.
+ """
+
+ distances = _calc_distances(
+ pred, gt, mask,
+ np.ones((pred.shape[0], pred.shape[2]), dtype=np.float32))
+ distance_valid = distances[distances != -1]
+ return distance_valid.sum() / max(1, len(distance_valid))
+
+
+def pose_pck_accuracy(output: np.ndarray,
+ target: np.ndarray,
+ mask: np.ndarray,
+ thr: float = 0.05,
+ normalize: Optional[np.ndarray] = None) -> tuple:
+ """Calculate the pose accuracy of PCK for each individual keypoint and the
+ averaged accuracy across all keypoints from heatmaps.
+
+ Note:
+ PCK metric measures accuracy of the localization of the body joints.
+ The distances between predicted positions and the ground-truth ones
+ are typically normalized by the bounding box size.
+ The threshold (thr) of the normalized distance is commonly set
+ as 0.05, 0.1 or 0.2 etc.
+
+ - batch_size: N
+ - num_keypoints: K
+ - heatmap height: H
+ - heatmap width: W
+
+ Args:
+ output (np.ndarray[N, K, H, W]): Model output heatmaps.
+ target (np.ndarray[N, K, H, W]): Groundtruth heatmaps.
+ mask (np.ndarray[N, K]): Visibility of the target. False for invisible
+ joints, and True for visible. Invisible joints will be ignored for
+ accuracy calculation.
+ thr (float): Threshold of PCK calculation. Default 0.05.
+ normalize (np.ndarray[N, 2]): Normalization factor for H&W.
+
+ Returns:
+ tuple: A tuple containing keypoint accuracy.
+
+ - np.ndarray[K]: Accuracy of each keypoint.
+ - float: Averaged accuracy across all keypoints.
+ - int: Number of valid keypoints.
+ """
+ N, K, H, W = output.shape
+ if K == 0:
+ return None, 0, 0
+ if normalize is None:
+ normalize = np.tile(np.array([[H, W]]), (N, 1))
+
+ pred, _ = get_heatmap_maximum(output)
+ gt, _ = get_heatmap_maximum(target)
+ return keypoint_pck_accuracy(pred, gt, mask, thr, normalize)
+
+
+def simcc_pck_accuracy(output: Tuple[np.ndarray, np.ndarray],
+ target: Tuple[np.ndarray, np.ndarray],
+ simcc_split_ratio: float,
+ mask: np.ndarray,
+ thr: float = 0.05,
+ normalize: Optional[np.ndarray] = None) -> tuple:
+ """Calculate the pose accuracy of PCK for each individual keypoint and the
+ averaged accuracy across all keypoints from SimCC.
+
+ Note:
+ PCK metric measures accuracy of the localization of the body joints.
+ The distances between predicted positions and the ground-truth ones
+ are typically normalized by the bounding box size.
+ The threshold (thr) of the normalized distance is commonly set
+ as 0.05, 0.1 or 0.2 etc.
+
+ - instance number: N
+ - keypoint number: K
+
+ Args:
+ output (Tuple[np.ndarray, np.ndarray]): Model predicted SimCC.
+ target (Tuple[np.ndarray, np.ndarray]): Groundtruth SimCC.
+ mask (np.ndarray[N, K]): Visibility of the target. False for invisible
+ joints, and True for visible. Invisible joints will be ignored for
+ accuracy calculation.
+ thr (float): Threshold of PCK calculation. Default 0.05.
+ normalize (np.ndarray[N, 2]): Normalization factor for H&W.
+
+ Returns:
+ tuple: A tuple containing keypoint accuracy.
+
+ - np.ndarray[K]: Accuracy of each keypoint.
+ - float: Averaged accuracy across all keypoints.
+ - int: Number of valid keypoints.
+ """
+ pred_x, pred_y = output
+ gt_x, gt_y = target
+
+ N, _, Wx = pred_x.shape
+ _, _, Wy = pred_y.shape
+ W, H = int(Wx / simcc_split_ratio), int(Wy / simcc_split_ratio)
+
+ if normalize is None:
+ normalize = np.tile(np.array([[H, W]]), (N, 1))
+
+ pred_coords, _ = get_simcc_maximum(pred_x, pred_y)
+ pred_coords /= simcc_split_ratio
+ gt_coords, _ = get_simcc_maximum(gt_x, gt_y)
+ gt_coords /= simcc_split_ratio
+
+ return keypoint_pck_accuracy(pred_coords, gt_coords, mask, thr, normalize)
+
+
+def multilabel_classification_accuracy(pred: np.ndarray,
+ gt: np.ndarray,
+ mask: np.ndarray,
+ thr: float = 0.5) -> float:
+ """Get multi-label classification accuracy.
+
+ Note:
+ - batch size: N
+ - label number: L
+
+ Args:
+ pred (np.ndarray[N, L, 2]): model predicted labels.
+ gt (np.ndarray[N, L, 2]): ground-truth labels.
+ mask (np.ndarray[N, 1] or np.ndarray[N, L] ): reliability of
+ ground-truth labels.
+ thr (float): Threshold for calculating accuracy.
+
+ Returns:
+ float: multi-label classification accuracy.
+ """
+ # we only compute accuracy on the samples with ground-truth of all labels.
+ valid = (mask > 0).min(axis=1) if mask.ndim == 2 else (mask > 0)
+ pred, gt = pred[valid], gt[valid]
+
+ if pred.shape[0] == 0:
+ acc = 0.0 # when no sample is with gt labels, set acc to 0.
+ else:
+ # The classification of a sample is regarded as correct
+ # only if it's correct for all labels.
+ acc = (((pred - thr) * (gt - thr)) > 0).all(axis=1).mean()
+ return acc
+
+
+def keypoint_mpjpe(pred: np.ndarray,
+ gt: np.ndarray,
+ mask: np.ndarray,
+ alignment: str = 'none'):
+ """Calculate the mean per-joint position error (MPJPE) and the error after
+ rigid alignment with the ground truth (P-MPJPE).
+
+ Note:
+ - batch_size: N
+ - num_keypoints: K
+ - keypoint_dims: C
+
+ Args:
+ pred (np.ndarray): Predicted keypoint location with shape [N, K, C].
+ gt (np.ndarray): Groundtruth keypoint location with shape [N, K, C].
+ mask (np.ndarray): Visibility of the target with shape [N, K].
+ False for invisible joints, and True for visible.
+ Invisible joints will be ignored for accuracy calculation.
+ alignment (str, optional): method to align the prediction with the
+ groundtruth. Supported options are:
+
+ - ``'none'``: no alignment will be applied
+ - ``'scale'``: align in the least-square sense in scale
+ - ``'procrustes'``: align in the least-square sense in
+ scale, rotation and translation.
+
+ Returns:
+ tuple: A tuple containing joint position errors
+
+ - (float | np.ndarray): mean per-joint position error (mpjpe).
+ - (float | np.ndarray): mpjpe after rigid alignment with the
+ ground truth (p-mpjpe).
+ """
+ assert mask.any()
+
+ if alignment == 'none':
+ pass
+ elif alignment == 'procrustes':
+ pred = np.stack([
+ compute_similarity_transform(pred_i, gt_i)
+ for pred_i, gt_i in zip(pred, gt)
+ ])
+ elif alignment == 'scale':
+ pred_dot_pred = np.einsum('nkc,nkc->n', pred, pred)
+ pred_dot_gt = np.einsum('nkc,nkc->n', pred, gt)
+ scale_factor = pred_dot_gt / pred_dot_pred
+ pred = pred * scale_factor[:, None, None]
+ else:
+ raise ValueError(f'Invalid value for alignment: {alignment}')
+ error = np.linalg.norm(pred - gt, ord=2, axis=-1)[mask].mean()
+
+ return error
diff --git a/mmpose/evaluation/functional/mesh_eval.py b/mmpose/evaluation/functional/mesh_eval.py
index 683b4539b2..18b5ae2c68 100644
--- a/mmpose/evaluation/functional/mesh_eval.py
+++ b/mmpose/evaluation/functional/mesh_eval.py
@@ -1,66 +1,66 @@
-# ------------------------------------------------------------------------------
-# Adapted from https://github.com/akanazawa/hmr
-# Original licence: Copyright (c) 2018 akanazawa, under the MIT License.
-# ------------------------------------------------------------------------------
-
-import numpy as np
-
-
-def compute_similarity_transform(source_points, target_points):
- """Computes a similarity transform (sR, t) that takes a set of 3D points
- source_points (N x 3) closest to a set of 3D points target_points, where R
- is an 3x3 rotation matrix, t 3x1 translation, s scale. And return the
- transformed 3D points source_points_hat (N x 3). i.e. solves the orthogonal
- Procrutes problem.
-
- Note:
- Points number: N
-
- Args:
- source_points (np.ndarray): Source point set with shape [N, 3].
- target_points (np.ndarray): Target point set with shape [N, 3].
-
- Returns:
- np.ndarray: Transformed source point set with shape [N, 3].
- """
-
- assert target_points.shape[0] == source_points.shape[0]
- assert target_points.shape[1] == 3 and source_points.shape[1] == 3
-
- source_points = source_points.T
- target_points = target_points.T
-
- # 1. Remove mean.
- mu1 = source_points.mean(axis=1, keepdims=True)
- mu2 = target_points.mean(axis=1, keepdims=True)
- X1 = source_points - mu1
- X2 = target_points - mu2
-
- # 2. Compute variance of X1 used for scale.
- var1 = np.sum(X1**2)
-
- # 3. The outer product of X1 and X2.
- K = X1.dot(X2.T)
-
- # 4. Solution that Maximizes trace(R'K) is R=U*V', where U, V are
- # singular vectors of K.
- U, _, Vh = np.linalg.svd(K)
- V = Vh.T
- # Construct Z that fixes the orientation of R to get det(R)=1.
- Z = np.eye(U.shape[0])
- Z[-1, -1] *= np.sign(np.linalg.det(U.dot(V.T)))
- # Construct R.
- R = V.dot(Z.dot(U.T))
-
- # 5. Recover scale.
- scale = np.trace(R.dot(K)) / var1
-
- # 6. Recover translation.
- t = mu2 - scale * (R.dot(mu1))
-
- # 7. Transform the source points:
- source_points_hat = scale * R.dot(source_points) + t
-
- source_points_hat = source_points_hat.T
-
- return source_points_hat
+# ------------------------------------------------------------------------------
+# Adapted from https://github.com/akanazawa/hmr
+# Original licence: Copyright (c) 2018 akanazawa, under the MIT License.
+# ------------------------------------------------------------------------------
+
+import numpy as np
+
+
+def compute_similarity_transform(source_points, target_points):
+ """Computes a similarity transform (sR, t) that takes a set of 3D points
+ source_points (N x 3) closest to a set of 3D points target_points, where R
+ is an 3x3 rotation matrix, t 3x1 translation, s scale. And return the
+ transformed 3D points source_points_hat (N x 3). i.e. solves the orthogonal
+ Procrutes problem.
+
+ Note:
+ Points number: N
+
+ Args:
+ source_points (np.ndarray): Source point set with shape [N, 3].
+ target_points (np.ndarray): Target point set with shape [N, 3].
+
+ Returns:
+ np.ndarray: Transformed source point set with shape [N, 3].
+ """
+
+ assert target_points.shape[0] == source_points.shape[0]
+ assert target_points.shape[1] == 3 and source_points.shape[1] == 3
+
+ source_points = source_points.T
+ target_points = target_points.T
+
+ # 1. Remove mean.
+ mu1 = source_points.mean(axis=1, keepdims=True)
+ mu2 = target_points.mean(axis=1, keepdims=True)
+ X1 = source_points - mu1
+ X2 = target_points - mu2
+
+ # 2. Compute variance of X1 used for scale.
+ var1 = np.sum(X1**2)
+
+ # 3. The outer product of X1 and X2.
+ K = X1.dot(X2.T)
+
+ # 4. Solution that Maximizes trace(R'K) is R=U*V', where U, V are
+ # singular vectors of K.
+ U, _, Vh = np.linalg.svd(K)
+ V = Vh.T
+ # Construct Z that fixes the orientation of R to get det(R)=1.
+ Z = np.eye(U.shape[0])
+ Z[-1, -1] *= np.sign(np.linalg.det(U.dot(V.T)))
+ # Construct R.
+ R = V.dot(Z.dot(U.T))
+
+ # 5. Recover scale.
+ scale = np.trace(R.dot(K)) / var1
+
+ # 6. Recover translation.
+ t = mu2 - scale * (R.dot(mu1))
+
+ # 7. Transform the source points:
+ source_points_hat = scale * R.dot(source_points) + t
+
+ source_points_hat = source_points_hat.T
+
+ return source_points_hat
diff --git a/mmpose/evaluation/functional/nms.py b/mmpose/evaluation/functional/nms.py
index eed4e5cf73..c3ac408045 100644
--- a/mmpose/evaluation/functional/nms.py
+++ b/mmpose/evaluation/functional/nms.py
@@ -1,327 +1,327 @@
-# ------------------------------------------------------------------------------
-# Adapted from https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
-# and https://github.com/HRNet/DEKR
-# Original licence: Copyright (c) Microsoft, under the MIT License.
-# ------------------------------------------------------------------------------
-
-from typing import List, Optional
-
-import numpy as np
-
-
-def nms(dets: np.ndarray, thr: float) -> List[int]:
- """Greedily select boxes with high confidence and overlap <= thr.
-
- Args:
- dets (np.ndarray): [[x1, y1, x2, y2, score]].
- thr (float): Retain overlap < thr.
-
- Returns:
- list: Indexes to keep.
- """
- if len(dets) == 0:
- return []
-
- x1 = dets[:, 0]
- y1 = dets[:, 1]
- x2 = dets[:, 2]
- y2 = dets[:, 3]
- scores = dets[:, 4]
-
- areas = (x2 - x1 + 1) * (y2 - y1 + 1)
- order = scores.argsort()[::-1]
-
- keep = []
- while len(order) > 0:
- i = order[0]
- keep.append(i)
- xx1 = np.maximum(x1[i], x1[order[1:]])
- yy1 = np.maximum(y1[i], y1[order[1:]])
- xx2 = np.minimum(x2[i], x2[order[1:]])
- yy2 = np.minimum(y2[i], y2[order[1:]])
-
- w = np.maximum(0.0, xx2 - xx1 + 1)
- h = np.maximum(0.0, yy2 - yy1 + 1)
- inter = w * h
- ovr = inter / (areas[i] + areas[order[1:]] - inter)
-
- inds = np.where(ovr <= thr)[0]
- order = order[inds + 1]
-
- return keep
-
-
-def oks_iou(g: np.ndarray,
- d: np.ndarray,
- a_g: float,
- a_d: np.ndarray,
- sigmas: Optional[np.ndarray] = None,
- vis_thr: Optional[float] = None) -> np.ndarray:
- """Calculate oks ious.
-
- Note:
-
- - number of keypoints: K
- - number of instances: N
-
- Args:
- g (np.ndarray): The instance to calculate OKS IOU with other
- instances. Containing the keypoints coordinates. Shape: (K*3, )
- d (np.ndarray): The rest instances. Containing the keypoints
- coordinates. Shape: (N, K*3)
- a_g (float): Area of the ground truth object.
- a_d (np.ndarray): Area of the detected object. Shape: (N, )
- sigmas (np.ndarray, optional): Keypoint labelling uncertainty.
- Please refer to `COCO keypoint evaluation
- `__ for more details.
- If not given, use the sigmas on COCO dataset.
- If specified, shape: (K, ). Defaults to ``None``
- vis_thr(float, optional): Threshold of the keypoint visibility.
- If specified, will calculate OKS based on those keypoints whose
- visibility higher than vis_thr. If not given, calculate the OKS
- based on all keypoints. Defaults to ``None``
-
- Returns:
- np.ndarray: The oks ious.
- """
- if sigmas is None:
- sigmas = np.array([
- .26, .25, .25, .35, .35, .79, .79, .72, .72, .62, .62, 1.07, 1.07,
- .87, .87, .89, .89
- ]) / 10.0
- vars = (sigmas * 2)**2
- xg = g[0::3]
- yg = g[1::3]
- vg = g[2::3]
- ious = np.zeros(len(d), dtype=np.float32)
- for n_d in range(0, len(d)):
- xd = d[n_d, 0::3]
- yd = d[n_d, 1::3]
- vd = d[n_d, 2::3]
- dx = xd - xg
- dy = yd - yg
- e = (dx**2 + dy**2) / vars / ((a_g + a_d[n_d]) / 2 + np.spacing(1)) / 2
- if vis_thr is not None:
- ind = list((vg > vis_thr) & (vd > vis_thr))
- e = e[ind]
- ious[n_d] = np.sum(np.exp(-e)) / len(e) if len(e) != 0 else 0.0
- return ious
-
-
-def oks_nms(kpts_db: List[dict],
- thr: float,
- sigmas: Optional[np.ndarray] = None,
- vis_thr: Optional[float] = None,
- score_per_joint: bool = False):
- """OKS NMS implementations.
-
- Args:
- kpts_db (List[dict]): The keypoints results of the same image.
- thr (float): The threshold of NMS. Will retain oks overlap < thr.
- sigmas (np.ndarray, optional): Keypoint labelling uncertainty.
- Please refer to `COCO keypoint evaluation
- `__ for more details.
- If not given, use the sigmas on COCO dataset. Defaults to ``None``
- vis_thr(float, optional): Threshold of the keypoint visibility.
- If specified, will calculate OKS based on those keypoints whose
- visibility higher than vis_thr. If not given, calculate the OKS
- based on all keypoints. Defaults to ``None``
- score_per_joint(bool): Whether the input scores (in kpts_db) are
- per-joint scores. Defaults to ``False``
-
- Returns:
- np.ndarray: indexes to keep.
- """
- if len(kpts_db) == 0:
- return []
-
- if score_per_joint:
- scores = np.array([k['score'].mean() for k in kpts_db])
- else:
- scores = np.array([k['score'] for k in kpts_db])
-
- kpts = np.array([k['keypoints'].flatten() for k in kpts_db])
- areas = np.array([k['area'] for k in kpts_db])
-
- order = scores.argsort()[::-1]
-
- keep = []
- while len(order) > 0:
- i = order[0]
- keep.append(i)
-
- oks_ovr = oks_iou(kpts[i], kpts[order[1:]], areas[i], areas[order[1:]],
- sigmas, vis_thr)
-
- inds = np.where(oks_ovr <= thr)[0]
- order = order[inds + 1]
-
- keep = np.array(keep)
-
- return keep
-
-
-def _rescore(overlap: np.ndarray,
- scores: np.ndarray,
- thr: float,
- type: str = 'gaussian'):
- """Rescoring mechanism gaussian or linear.
-
- Args:
- overlap (np.ndarray): The calculated oks ious.
- scores (np.ndarray): target scores.
- thr (float): retain oks overlap < thr.
- type (str): The rescoring type. Could be 'gaussian' or 'linear'.
- Defaults to ``'gaussian'``
-
- Returns:
- np.ndarray: indexes to keep
- """
- assert len(overlap) == len(scores)
- assert type in ['gaussian', 'linear']
-
- if type == 'linear':
- inds = np.where(overlap >= thr)[0]
- scores[inds] = scores[inds] * (1 - overlap[inds])
- else:
- scores = scores * np.exp(-overlap**2 / thr)
-
- return scores
-
-
-def soft_oks_nms(kpts_db: List[dict],
- thr: float,
- max_dets: int = 20,
- sigmas: Optional[np.ndarray] = None,
- vis_thr: Optional[float] = None,
- score_per_joint: bool = False):
- """Soft OKS NMS implementations.
-
- Args:
- kpts_db (List[dict]): The keypoints results of the same image.
- thr (float): The threshold of NMS. Will retain oks overlap < thr.
- max_dets (int): Maximum number of detections to keep. Defaults to 20
- sigmas (np.ndarray, optional): Keypoint labelling uncertainty.
- Please refer to `COCO keypoint evaluation
- `__ for more details.
- If not given, use the sigmas on COCO dataset. Defaults to ``None``
- vis_thr(float, optional): Threshold of the keypoint visibility.
- If specified, will calculate OKS based on those keypoints whose
- visibility higher than vis_thr. If not given, calculate the OKS
- based on all keypoints. Defaults to ``None``
- score_per_joint(bool): Whether the input scores (in kpts_db) are
- per-joint scores. Defaults to ``False``
-
- Returns:
- np.ndarray: indexes to keep.
- """
- if len(kpts_db) == 0:
- return []
-
- if score_per_joint:
- scores = np.array([k['score'].mean() for k in kpts_db])
- else:
- scores = np.array([k['score'] for k in kpts_db])
-
- kpts = np.array([k['keypoints'].flatten() for k in kpts_db])
- areas = np.array([k['area'] for k in kpts_db])
-
- order = scores.argsort()[::-1]
- scores = scores[order]
-
- keep = np.zeros(max_dets, dtype=np.intp)
- keep_cnt = 0
- while len(order) > 0 and keep_cnt < max_dets:
- i = order[0]
-
- oks_ovr = oks_iou(kpts[i], kpts[order[1:]], areas[i], areas[order[1:]],
- sigmas, vis_thr)
-
- order = order[1:]
- scores = _rescore(oks_ovr, scores[1:], thr)
-
- tmp = scores.argsort()[::-1]
- order = order[tmp]
- scores = scores[tmp]
-
- keep[keep_cnt] = i
- keep_cnt += 1
-
- keep = keep[:keep_cnt]
-
- return keep
-
-
-def nearby_joints_nms(
- kpts_db: List[dict],
- dist_thr: float,
- num_nearby_joints_thr: Optional[int] = None,
- score_per_joint: bool = False,
- max_dets: int = 30,
-):
- """Nearby joints NMS implementations. Instances with non-maximum scores
- will be suppressed if they have too much closed joints with other
- instances. This function is modified from project
- `DEKR`.
-
- Args:
- kpts_db (list[dict]): keypoints and scores.
- dist_thr (float): threshold for judging whether two joints are close.
- num_nearby_joints_thr (int): threshold for judging whether two
- instances are close.
- max_dets (int): max number of detections to keep.
- score_per_joint (bool): the input scores (in kpts_db) are per joint
- scores.
-
- Returns:
- np.ndarray: indexes to keep.
- """
-
- assert dist_thr > 0, '`dist_thr` must be greater than 0.'
- if len(kpts_db) == 0:
- return []
-
- if score_per_joint:
- scores = np.array([k['score'].mean() for k in kpts_db])
- else:
- scores = np.array([k['score'] for k in kpts_db])
-
- kpts = np.array([k['keypoints'] for k in kpts_db])
-
- num_people, num_joints, _ = kpts.shape
- if num_nearby_joints_thr is None:
- num_nearby_joints_thr = num_joints // 2
- assert num_nearby_joints_thr < num_joints, '`num_nearby_joints_thr` must '\
- 'be less than the number of joints.'
-
- # compute distance threshold
- pose_area = kpts.max(axis=1) - kpts.min(axis=1)
- pose_area = np.sqrt(np.power(pose_area, 2).sum(axis=1))
- pose_area = pose_area.reshape(num_people, 1, 1)
- pose_area = np.tile(pose_area, (num_people, num_joints))
- close_dist_thr = pose_area * dist_thr
-
- # count nearby joints between instances
- instance_dist = kpts[:, None] - kpts
- instance_dist = np.sqrt(np.power(instance_dist, 2).sum(axis=3))
- close_instance_num = (instance_dist < close_dist_thr).sum(2)
- close_instance = close_instance_num > num_nearby_joints_thr
-
- # apply nms
- ignored_pose_inds, keep_pose_inds = set(), list()
- indexes = np.argsort(scores)[::-1]
- for i in indexes:
- if i in ignored_pose_inds:
- continue
- keep_inds = close_instance[i].nonzero()[0]
- keep_ind = keep_inds[np.argmax(scores[keep_inds])]
- if keep_ind not in ignored_pose_inds:
- keep_pose_inds.append(keep_ind)
- ignored_pose_inds = ignored_pose_inds.union(set(keep_inds))
-
- # limit the number of output instances
- if max_dets > 0 and len(keep_pose_inds) > max_dets:
- sub_inds = np.argsort(scores[keep_pose_inds])[-1:-max_dets - 1:-1]
- keep_pose_inds = [keep_pose_inds[i] for i in sub_inds]
-
- return keep_pose_inds
+# ------------------------------------------------------------------------------
+# Adapted from https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
+# and https://github.com/HRNet/DEKR
+# Original licence: Copyright (c) Microsoft, under the MIT License.
+# ------------------------------------------------------------------------------
+
+from typing import List, Optional
+
+import numpy as np
+
+
+def nms(dets: np.ndarray, thr: float) -> List[int]:
+ """Greedily select boxes with high confidence and overlap <= thr.
+
+ Args:
+ dets (np.ndarray): [[x1, y1, x2, y2, score]].
+ thr (float): Retain overlap < thr.
+
+ Returns:
+ list: Indexes to keep.
+ """
+ if len(dets) == 0:
+ return []
+
+ x1 = dets[:, 0]
+ y1 = dets[:, 1]
+ x2 = dets[:, 2]
+ y2 = dets[:, 3]
+ scores = dets[:, 4]
+
+ areas = (x2 - x1 + 1) * (y2 - y1 + 1)
+ order = scores.argsort()[::-1]
+
+ keep = []
+ while len(order) > 0:
+ i = order[0]
+ keep.append(i)
+ xx1 = np.maximum(x1[i], x1[order[1:]])
+ yy1 = np.maximum(y1[i], y1[order[1:]])
+ xx2 = np.minimum(x2[i], x2[order[1:]])
+ yy2 = np.minimum(y2[i], y2[order[1:]])
+
+ w = np.maximum(0.0, xx2 - xx1 + 1)
+ h = np.maximum(0.0, yy2 - yy1 + 1)
+ inter = w * h
+ ovr = inter / (areas[i] + areas[order[1:]] - inter)
+
+ inds = np.where(ovr <= thr)[0]
+ order = order[inds + 1]
+
+ return keep
+
+
+def oks_iou(g: np.ndarray,
+ d: np.ndarray,
+ a_g: float,
+ a_d: np.ndarray,
+ sigmas: Optional[np.ndarray] = None,
+ vis_thr: Optional[float] = None) -> np.ndarray:
+ """Calculate oks ious.
+
+ Note:
+
+ - number of keypoints: K
+ - number of instances: N
+
+ Args:
+ g (np.ndarray): The instance to calculate OKS IOU with other
+ instances. Containing the keypoints coordinates. Shape: (K*3, )
+ d (np.ndarray): The rest instances. Containing the keypoints
+ coordinates. Shape: (N, K*3)
+ a_g (float): Area of the ground truth object.
+ a_d (np.ndarray): Area of the detected object. Shape: (N, )
+ sigmas (np.ndarray, optional): Keypoint labelling uncertainty.
+ Please refer to `COCO keypoint evaluation
+ `__ for more details.
+ If not given, use the sigmas on COCO dataset.
+ If specified, shape: (K, ). Defaults to ``None``
+ vis_thr(float, optional): Threshold of the keypoint visibility.
+ If specified, will calculate OKS based on those keypoints whose
+ visibility higher than vis_thr. If not given, calculate the OKS
+ based on all keypoints. Defaults to ``None``
+
+ Returns:
+ np.ndarray: The oks ious.
+ """
+ if sigmas is None:
+ sigmas = np.array([
+ .26, .25, .25, .35, .35, .79, .79, .72, .72, .62, .62, 1.07, 1.07,
+ .87, .87, .89, .89
+ ]) / 10.0
+ vars = (sigmas * 2)**2
+ xg = g[0::3]
+ yg = g[1::3]
+ vg = g[2::3]
+ ious = np.zeros(len(d), dtype=np.float32)
+ for n_d in range(0, len(d)):
+ xd = d[n_d, 0::3]
+ yd = d[n_d, 1::3]
+ vd = d[n_d, 2::3]
+ dx = xd - xg
+ dy = yd - yg
+ e = (dx**2 + dy**2) / vars / ((a_g + a_d[n_d]) / 2 + np.spacing(1)) / 2
+ if vis_thr is not None:
+ ind = list((vg > vis_thr) & (vd > vis_thr))
+ e = e[ind]
+ ious[n_d] = np.sum(np.exp(-e)) / len(e) if len(e) != 0 else 0.0
+ return ious
+
+
+def oks_nms(kpts_db: List[dict],
+ thr: float,
+ sigmas: Optional[np.ndarray] = None,
+ vis_thr: Optional[float] = None,
+ score_per_joint: bool = False):
+ """OKS NMS implementations.
+
+ Args:
+ kpts_db (List[dict]): The keypoints results of the same image.
+ thr (float): The threshold of NMS. Will retain oks overlap < thr.
+ sigmas (np.ndarray, optional): Keypoint labelling uncertainty.
+ Please refer to `COCO keypoint evaluation
+ `__ for more details.
+ If not given, use the sigmas on COCO dataset. Defaults to ``None``
+ vis_thr(float, optional): Threshold of the keypoint visibility.
+ If specified, will calculate OKS based on those keypoints whose
+ visibility higher than vis_thr. If not given, calculate the OKS
+ based on all keypoints. Defaults to ``None``
+ score_per_joint(bool): Whether the input scores (in kpts_db) are
+ per-joint scores. Defaults to ``False``
+
+ Returns:
+ np.ndarray: indexes to keep.
+ """
+ if len(kpts_db) == 0:
+ return []
+
+ if score_per_joint:
+ scores = np.array([k['score'].mean() for k in kpts_db])
+ else:
+ scores = np.array([k['score'] for k in kpts_db])
+
+ kpts = np.array([k['keypoints'].flatten() for k in kpts_db])
+ areas = np.array([k['area'] for k in kpts_db])
+
+ order = scores.argsort()[::-1]
+
+ keep = []
+ while len(order) > 0:
+ i = order[0]
+ keep.append(i)
+
+ oks_ovr = oks_iou(kpts[i], kpts[order[1:]], areas[i], areas[order[1:]],
+ sigmas, vis_thr)
+
+ inds = np.where(oks_ovr <= thr)[0]
+ order = order[inds + 1]
+
+ keep = np.array(keep)
+
+ return keep
+
+
+def _rescore(overlap: np.ndarray,
+ scores: np.ndarray,
+ thr: float,
+ type: str = 'gaussian'):
+ """Rescoring mechanism gaussian or linear.
+
+ Args:
+ overlap (np.ndarray): The calculated oks ious.
+ scores (np.ndarray): target scores.
+ thr (float): retain oks overlap < thr.
+ type (str): The rescoring type. Could be 'gaussian' or 'linear'.
+ Defaults to ``'gaussian'``
+
+ Returns:
+ np.ndarray: indexes to keep
+ """
+ assert len(overlap) == len(scores)
+ assert type in ['gaussian', 'linear']
+
+ if type == 'linear':
+ inds = np.where(overlap >= thr)[0]
+ scores[inds] = scores[inds] * (1 - overlap[inds])
+ else:
+ scores = scores * np.exp(-overlap**2 / thr)
+
+ return scores
+
+
+def soft_oks_nms(kpts_db: List[dict],
+ thr: float,
+ max_dets: int = 20,
+ sigmas: Optional[np.ndarray] = None,
+ vis_thr: Optional[float] = None,
+ score_per_joint: bool = False):
+ """Soft OKS NMS implementations.
+
+ Args:
+ kpts_db (List[dict]): The keypoints results of the same image.
+ thr (float): The threshold of NMS. Will retain oks overlap < thr.
+ max_dets (int): Maximum number of detections to keep. Defaults to 20
+ sigmas (np.ndarray, optional): Keypoint labelling uncertainty.
+ Please refer to `COCO keypoint evaluation
+ `__ for more details.
+ If not given, use the sigmas on COCO dataset. Defaults to ``None``
+ vis_thr(float, optional): Threshold of the keypoint visibility.
+ If specified, will calculate OKS based on those keypoints whose
+ visibility higher than vis_thr. If not given, calculate the OKS
+ based on all keypoints. Defaults to ``None``
+ score_per_joint(bool): Whether the input scores (in kpts_db) are
+ per-joint scores. Defaults to ``False``
+
+ Returns:
+ np.ndarray: indexes to keep.
+ """
+ if len(kpts_db) == 0:
+ return []
+
+ if score_per_joint:
+ scores = np.array([k['score'].mean() for k in kpts_db])
+ else:
+ scores = np.array([k['score'] for k in kpts_db])
+
+ kpts = np.array([k['keypoints'].flatten() for k in kpts_db])
+ areas = np.array([k['area'] for k in kpts_db])
+
+ order = scores.argsort()[::-1]
+ scores = scores[order]
+
+ keep = np.zeros(max_dets, dtype=np.intp)
+ keep_cnt = 0
+ while len(order) > 0 and keep_cnt < max_dets:
+ i = order[0]
+
+ oks_ovr = oks_iou(kpts[i], kpts[order[1:]], areas[i], areas[order[1:]],
+ sigmas, vis_thr)
+
+ order = order[1:]
+ scores = _rescore(oks_ovr, scores[1:], thr)
+
+ tmp = scores.argsort()[::-1]
+ order = order[tmp]
+ scores = scores[tmp]
+
+ keep[keep_cnt] = i
+ keep_cnt += 1
+
+ keep = keep[:keep_cnt]
+
+ return keep
+
+
+def nearby_joints_nms(
+ kpts_db: List[dict],
+ dist_thr: float,
+ num_nearby_joints_thr: Optional[int] = None,
+ score_per_joint: bool = False,
+ max_dets: int = 30,
+):
+ """Nearby joints NMS implementations. Instances with non-maximum scores
+ will be suppressed if they have too much closed joints with other
+ instances. This function is modified from project
+ `DEKR`.
+
+ Args:
+ kpts_db (list[dict]): keypoints and scores.
+ dist_thr (float): threshold for judging whether two joints are close.
+ num_nearby_joints_thr (int): threshold for judging whether two
+ instances are close.
+ max_dets (int): max number of detections to keep.
+ score_per_joint (bool): the input scores (in kpts_db) are per joint
+ scores.
+
+ Returns:
+ np.ndarray: indexes to keep.
+ """
+
+ assert dist_thr > 0, '`dist_thr` must be greater than 0.'
+ if len(kpts_db) == 0:
+ return []
+
+ if score_per_joint:
+ scores = np.array([k['score'].mean() for k in kpts_db])
+ else:
+ scores = np.array([k['score'] for k in kpts_db])
+
+ kpts = np.array([k['keypoints'] for k in kpts_db])
+
+ num_people, num_joints, _ = kpts.shape
+ if num_nearby_joints_thr is None:
+ num_nearby_joints_thr = num_joints // 2
+ assert num_nearby_joints_thr < num_joints, '`num_nearby_joints_thr` must '\
+ 'be less than the number of joints.'
+
+ # compute distance threshold
+ pose_area = kpts.max(axis=1) - kpts.min(axis=1)
+ pose_area = np.sqrt(np.power(pose_area, 2).sum(axis=1))
+ pose_area = pose_area.reshape(num_people, 1, 1)
+ pose_area = np.tile(pose_area, (num_people, num_joints))
+ close_dist_thr = pose_area * dist_thr
+
+ # count nearby joints between instances
+ instance_dist = kpts[:, None] - kpts
+ instance_dist = np.sqrt(np.power(instance_dist, 2).sum(axis=3))
+ close_instance_num = (instance_dist < close_dist_thr).sum(2)
+ close_instance = close_instance_num > num_nearby_joints_thr
+
+ # apply nms
+ ignored_pose_inds, keep_pose_inds = set(), list()
+ indexes = np.argsort(scores)[::-1]
+ for i in indexes:
+ if i in ignored_pose_inds:
+ continue
+ keep_inds = close_instance[i].nonzero()[0]
+ keep_ind = keep_inds[np.argmax(scores[keep_inds])]
+ if keep_ind not in ignored_pose_inds:
+ keep_pose_inds.append(keep_ind)
+ ignored_pose_inds = ignored_pose_inds.union(set(keep_inds))
+
+ # limit the number of output instances
+ if max_dets > 0 and len(keep_pose_inds) > max_dets:
+ sub_inds = np.argsort(scores[keep_pose_inds])[-1:-max_dets - 1:-1]
+ keep_pose_inds = [keep_pose_inds[i] for i in sub_inds]
+
+ return keep_pose_inds
diff --git a/mmpose/evaluation/metrics/__init__.py b/mmpose/evaluation/metrics/__init__.py
index ac7e21b5cc..3a81111bed 100644
--- a/mmpose/evaluation/metrics/__init__.py
+++ b/mmpose/evaluation/metrics/__init__.py
@@ -1,14 +1,14 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .coco_metric import CocoMetric
-from .coco_wholebody_metric import CocoWholeBodyMetric
-from .keypoint_2d_metrics import (AUC, EPE, NME, JhmdbPCKAccuracy,
- MpiiPCKAccuracy, PCKAccuracy)
-from .keypoint_3d_metrics import MPJPE
-from .keypoint_partition_metric import KeypointPartitionMetric
-from .posetrack18_metric import PoseTrack18Metric
-
-__all__ = [
- 'CocoMetric', 'PCKAccuracy', 'MpiiPCKAccuracy', 'JhmdbPCKAccuracy', 'AUC',
- 'EPE', 'NME', 'PoseTrack18Metric', 'CocoWholeBodyMetric',
- 'KeypointPartitionMetric', 'MPJPE'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .coco_metric import CocoMetric
+from .coco_wholebody_metric import CocoWholeBodyMetric
+from .keypoint_2d_metrics import (AUC, EPE, NME, JhmdbPCKAccuracy,
+ MpiiPCKAccuracy, PCKAccuracy)
+from .keypoint_3d_metrics import MPJPE
+from .keypoint_partition_metric import KeypointPartitionMetric
+from .posetrack18_metric import PoseTrack18Metric
+
+__all__ = [
+ 'CocoMetric', 'PCKAccuracy', 'MpiiPCKAccuracy', 'JhmdbPCKAccuracy', 'AUC',
+ 'EPE', 'NME', 'PoseTrack18Metric', 'CocoWholeBodyMetric',
+ 'KeypointPartitionMetric', 'MPJPE'
+]
diff --git a/mmpose/evaluation/metrics/coco_metric.py b/mmpose/evaluation/metrics/coco_metric.py
index 8327e2eca7..d09b329dfc 100644
--- a/mmpose/evaluation/metrics/coco_metric.py
+++ b/mmpose/evaluation/metrics/coco_metric.py
@@ -1,550 +1,550 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import datetime
-import os.path as osp
-import tempfile
-from collections import OrderedDict, defaultdict
-from typing import Dict, Optional, Sequence
-
-import numpy as np
-from mmengine.evaluator import BaseMetric
-from mmengine.fileio import dump, get_local_path, load
-from mmengine.logging import MMLogger
-from xtcocotools.coco import COCO
-from xtcocotools.cocoeval import COCOeval
-
-from mmpose.registry import METRICS
-from ..functional import oks_nms, soft_oks_nms
-
-
-@METRICS.register_module()
-class CocoMetric(BaseMetric):
- """COCO pose estimation task evaluation metric.
-
- Evaluate AR, AP, and mAP for keypoint detection tasks. Support COCO
- dataset and other datasets in COCO format. Please refer to
- `COCO keypoint evaluation `__
- for more details.
-
- Args:
- ann_file (str, optional): Path to the coco format annotation file.
- If not specified, ground truth annotations from the dataset will
- be converted to coco format. Defaults to None
- use_area (bool): Whether to use ``'area'`` message in the annotations.
- If the ground truth annotations (e.g. CrowdPose, AIC) do not have
- the field ``'area'``, please set ``use_area=False``.
- Defaults to ``True``
- iou_type (str): The same parameter as `iouType` in
- :class:`xtcocotools.COCOeval`, which can be ``'keypoints'``, or
- ``'keypoints_crowd'`` (used in CrowdPose dataset).
- Defaults to ``'keypoints'``
- score_mode (str): The mode to score the prediction results which
- should be one of the following options:
-
- - ``'bbox'``: Take the score of bbox as the score of the
- prediction results.
- - ``'bbox_keypoint'``: Use keypoint score to rescore the
- prediction results.
- - ``'bbox_rle'``: Use rle_score to rescore the
- prediction results.
-
- Defaults to ``'bbox_keypoint'`
- keypoint_score_thr (float): The threshold of keypoint score. The
- keypoints with score lower than it will not be included to
- rescore the prediction results. Valid only when ``score_mode`` is
- ``bbox_keypoint``. Defaults to ``0.2``
- nms_mode (str): The mode to perform Non-Maximum Suppression (NMS),
- which should be one of the following options:
-
- - ``'oks_nms'``: Use Object Keypoint Similarity (OKS) to
- perform NMS.
- - ``'soft_oks_nms'``: Use Object Keypoint Similarity (OKS)
- to perform soft NMS.
- - ``'none'``: Do not perform NMS. Typically for bottomup mode
- output.
-
- Defaults to ``'oks_nms'`
- nms_thr (float): The Object Keypoint Similarity (OKS) threshold
- used in NMS when ``nms_mode`` is ``'oks_nms'`` or
- ``'soft_oks_nms'``. Will retain the prediction results with OKS
- lower than ``nms_thr``. Defaults to ``0.9``
- format_only (bool): Whether only format the output results without
- doing quantitative evaluation. This is designed for the need of
- test submission when the ground truth annotations are absent. If
- set to ``True``, ``outfile_prefix`` should specify the path to
- store the output results. Defaults to ``False``
- outfile_prefix (str | None): The prefix of json files. It includes
- the file path and the prefix of filename, e.g., ``'a/b/prefix'``.
- If not specified, a temp file will be created. Defaults to ``None``
- collect_device (str): Device name used for collecting results from
- different ranks during distributed training. Must be ``'cpu'`` or
- ``'gpu'``. Defaults to ``'cpu'``
- prefix (str, optional): The prefix that will be added in the metric
- names to disambiguate homonymous metrics of different evaluators.
- If prefix is not provided in the argument, ``self.default_prefix``
- will be used instead. Defaults to ``None``
- """
- default_prefix: Optional[str] = 'coco'
-
- def __init__(self,
- ann_file: Optional[str] = None,
- use_area: bool = True,
- iou_type: str = 'keypoints',
- score_mode: str = 'bbox_keypoint',
- keypoint_score_thr: float = 0.2,
- nms_mode: str = 'oks_nms',
- nms_thr: float = 0.9,
- format_only: bool = False,
- outfile_prefix: Optional[str] = None,
- collect_device: str = 'cpu',
- prefix: Optional[str] = None) -> None:
- super().__init__(collect_device=collect_device, prefix=prefix)
- self.ann_file = ann_file
- # initialize coco helper with the annotation json file
- # if ann_file is not specified, initialize with the converted dataset
- if ann_file is not None:
- with get_local_path(ann_file) as local_path:
- self.coco = COCO(local_path)
- else:
- self.coco = None
-
- self.use_area = use_area
- self.iou_type = iou_type
-
- allowed_score_modes = ['bbox', 'bbox_keypoint', 'bbox_rle', 'keypoint']
- if score_mode not in allowed_score_modes:
- raise ValueError(
- "`score_mode` should be one of 'bbox', 'bbox_keypoint', "
- f"'bbox_rle', but got {score_mode}")
- self.score_mode = score_mode
- self.keypoint_score_thr = keypoint_score_thr
-
- allowed_nms_modes = ['oks_nms', 'soft_oks_nms', 'none']
- if nms_mode not in allowed_nms_modes:
- raise ValueError(
- "`nms_mode` should be one of 'oks_nms', 'soft_oks_nms', "
- f"'none', but got {nms_mode}")
- self.nms_mode = nms_mode
- self.nms_thr = nms_thr
-
- if format_only:
- assert outfile_prefix is not None, '`outfile_prefix` can not be '\
- 'None when `format_only` is True, otherwise the result file '\
- 'will be saved to a temp directory which will be cleaned up '\
- 'in the end.'
- elif ann_file is not None:
- # do evaluation only if the ground truth annotations exist
- assert 'annotations' in load(ann_file), \
- 'Ground truth annotations are required for evaluation '\
- 'when `format_only` is False.'
-
- self.format_only = format_only
- self.outfile_prefix = outfile_prefix
-
- def process(self, data_batch: Sequence[dict],
- data_samples: Sequence[dict]) -> None:
- """Process one batch of data samples and predictions. The processed
- results should be stored in ``self.results``, which will be used to
- compute the metrics when all batches have been processed.
-
- Args:
- data_batch (Sequence[dict]): A batch of data
- from the dataloader.
- data_samples (Sequence[dict]): A batch of outputs from
- the model, each of which has the following keys:
-
- - 'id': The id of the sample
- - 'img_id': The image_id of the sample
- - 'pred_instances': The prediction results of instance(s)
- """
- for data_sample in data_samples:
- if 'pred_instances' not in data_sample:
- raise ValueError(
- '`pred_instances` are required to process the '
- f'predictions results in {self.__class__.__name__}. ')
-
- # keypoints.shape: [N, K, 2],
- # N: number of instances, K: number of keypoints
- # for topdown-style output, N is usually 1, while for
- # bottomup-style output, N is the number of instances in the image
- keypoints = data_sample['pred_instances']['keypoints']
- # [N, K], the scores for all keypoints of all instances
- keypoint_scores = data_sample['pred_instances']['keypoint_scores']
- assert keypoint_scores.shape == keypoints.shape[:2]
-
- # parse prediction results
- pred = dict()
- pred['id'] = data_sample['id']
- pred['img_id'] = data_sample['img_id']
- pred['keypoints'] = keypoints
- pred['keypoint_scores'] = keypoint_scores
- pred['category_id'] = data_sample.get('category_id', 1)
-
- if 'bbox_scores' in data_sample['pred_instances']:
- # some one-stage models will predict bboxes and scores
- # together with keypoints
- bbox_scores = data_sample['pred_instances']['bbox_scores']
- elif ('bbox_scores' not in data_sample['gt_instances']
- or len(data_sample['gt_instances']['bbox_scores']) !=
- len(keypoints)):
- # bottom-up models might output different number of
- # instances from annotation
- bbox_scores = np.ones(len(keypoints))
- else:
- # top-down models use detected bboxes, the scores of which
- # are contained in the gt_instances
- bbox_scores = data_sample['gt_instances']['bbox_scores']
- pred['bbox_scores'] = bbox_scores
-
- # get area information
- if 'bbox_scales' in data_sample['gt_instances']:
- pred['areas'] = np.prod(
- data_sample['gt_instances']['bbox_scales'], axis=1)
-
- # parse gt
- gt = dict()
- if self.coco is None:
- gt['width'] = data_sample['ori_shape'][1]
- gt['height'] = data_sample['ori_shape'][0]
- gt['img_id'] = data_sample['img_id']
- if self.iou_type == 'keypoints_crowd':
- assert 'crowd_index' in data_sample, \
- '`crowd_index` is required when `self.iou_type` is ' \
- '`keypoints_crowd`'
- gt['crowd_index'] = data_sample['crowd_index']
- assert 'raw_ann_info' in data_sample, \
- 'The row ground truth annotations are required for ' \
- 'evaluation when `ann_file` is not provided'
- anns = data_sample['raw_ann_info']
- gt['raw_ann_info'] = anns if isinstance(anns, list) else [anns]
-
- # add converted result to the results list
- self.results.append((pred, gt))
-
- def gt_to_coco_json(self, gt_dicts: Sequence[dict],
- outfile_prefix: str) -> str:
- """Convert ground truth to coco format json file.
-
- Args:
- gt_dicts (Sequence[dict]): Ground truth of the dataset. Each dict
- contains the ground truth information about the data sample.
- Required keys of the each `gt_dict` in `gt_dicts`:
- - `img_id`: image id of the data sample
- - `width`: original image width
- - `height`: original image height
- - `raw_ann_info`: the raw annotation information
- Optional keys:
- - `crowd_index`: measure the crowding level of an image,
- defined in CrowdPose dataset
- It is worth mentioning that, in order to compute `CocoMetric`,
- there are some required keys in the `raw_ann_info`:
- - `id`: the id to distinguish different annotations
- - `image_id`: the image id of this annotation
- - `category_id`: the category of the instance.
- - `bbox`: the object bounding box
- - `keypoints`: the keypoints cooridinates along with their
- visibilities. Note that it need to be aligned
- with the official COCO format, e.g., a list with length
- N * 3, in which N is the number of keypoints. And each
- triplet represent the [x, y, visible] of the keypoint.
- - `iscrowd`: indicating whether the annotation is a crowd.
- It is useful when matching the detection results to
- the ground truth.
- There are some optional keys as well:
- - `area`: it is necessary when `self.use_area` is `True`
- - `num_keypoints`: it is necessary when `self.iou_type`
- is set as `keypoints_crowd`.
- outfile_prefix (str): The filename prefix of the json files. If the
- prefix is "somepath/xxx", the json file will be named
- "somepath/xxx.gt.json".
- Returns:
- str: The filename of the json file.
- """
- image_infos = []
- annotations = []
- img_ids = []
- ann_ids = []
-
- for gt_dict in gt_dicts:
- # filter duplicate image_info
- if gt_dict['img_id'] not in img_ids:
- image_info = dict(
- id=gt_dict['img_id'],
- width=gt_dict['width'],
- height=gt_dict['height'],
- )
- if self.iou_type == 'keypoints_crowd':
- image_info['crowdIndex'] = gt_dict['crowd_index']
-
- image_infos.append(image_info)
- img_ids.append(gt_dict['img_id'])
-
- # filter duplicate annotations
- for ann in gt_dict['raw_ann_info']:
- if ann is None:
- # during evaluation on bottom-up datasets, some images
- # do not have instance annotation
- continue
-
- annotation = dict(
- id=ann['id'],
- image_id=ann['image_id'],
- category_id=ann['category_id'],
- bbox=ann['bbox'],
- keypoints=ann['keypoints'],
- iscrowd=ann['iscrowd'],
- )
- if self.use_area:
- assert 'area' in ann, \
- '`area` is required when `self.use_area` is `True`'
- annotation['area'] = ann['area']
-
- if self.iou_type == 'keypoints_crowd':
- assert 'num_keypoints' in ann, \
- '`num_keypoints` is required when `self.iou_type` ' \
- 'is `keypoints_crowd`'
- annotation['num_keypoints'] = ann['num_keypoints']
-
- annotations.append(annotation)
- ann_ids.append(ann['id'])
-
- info = dict(
- date_created=str(datetime.datetime.now()),
- description='Coco json file converted by mmpose CocoMetric.')
- coco_json = dict(
- info=info,
- images=image_infos,
- categories=self.dataset_meta['CLASSES'],
- licenses=None,
- annotations=annotations,
- )
- converted_json_path = f'{outfile_prefix}.gt.json'
- dump(coco_json, converted_json_path, sort_keys=True, indent=4)
- return converted_json_path
-
- def compute_metrics(self, results: list) -> Dict[str, float]:
- """Compute the metrics from processed results.
-
- Args:
- results (list): The processed results of each batch.
-
- Returns:
- Dict[str, float]: The computed metrics. The keys are the names of
- the metrics, and the values are corresponding results.
- """
- logger: MMLogger = MMLogger.get_current_instance()
-
- # split prediction and gt list
- preds, gts = zip(*results)
-
- tmp_dir = None
- if self.outfile_prefix is None:
- tmp_dir = tempfile.TemporaryDirectory()
- outfile_prefix = osp.join(tmp_dir.name, 'results')
- else:
- outfile_prefix = self.outfile_prefix
-
- if self.coco is None:
- # use converted gt json file to initialize coco helper
- logger.info('Converting ground truth to coco format...')
- coco_json_path = self.gt_to_coco_json(
- gt_dicts=gts, outfile_prefix=outfile_prefix)
- self.coco = COCO(coco_json_path)
-
- kpts = defaultdict(list)
-
- # group the preds by img_id
- for pred in preds:
- img_id = pred['img_id']
- for idx in range(len(pred['keypoints'])):
- instance = {
- 'id': pred['id'],
- 'img_id': pred['img_id'],
- 'category_id': pred['category_id'],
- 'keypoints': pred['keypoints'][idx],
- 'keypoint_scores': pred['keypoint_scores'][idx],
- 'bbox_score': pred['bbox_scores'][idx],
- }
-
- if 'areas' in pred:
- instance['area'] = pred['areas'][idx]
- else:
- # use keypoint to calculate bbox and get area
- keypoints = pred['keypoints'][idx]
- area = (
- np.max(keypoints[:, 0]) - np.min(keypoints[:, 0])) * (
- np.max(keypoints[:, 1]) - np.min(keypoints[:, 1]))
- instance['area'] = area
-
- kpts[img_id].append(instance)
-
- # sort keypoint results according to id and remove duplicate ones
- kpts = self._sort_and_unique_bboxes(kpts, key='id')
-
- # score the prediction results according to `score_mode`
- # and perform NMS according to `nms_mode`
- valid_kpts = defaultdict(list)
- num_keypoints = self.dataset_meta['num_keypoints']
- for img_id, instances in kpts.items():
- for instance in instances:
- # concatenate the keypoint coordinates and scores
- instance['keypoints'] = np.concatenate([
- instance['keypoints'], instance['keypoint_scores'][:, None]
- ],
- axis=-1)
- if self.score_mode == 'bbox':
- instance['score'] = instance['bbox_score']
- elif self.score_mode == 'keypoint':
- instance['score'] = np.mean(instance['keypoint_scores'])
- else:
- bbox_score = instance['bbox_score']
- if self.score_mode == 'bbox_rle':
- keypoint_scores = instance['keypoint_scores']
- instance['score'] = float(bbox_score +
- np.mean(keypoint_scores) +
- np.max(keypoint_scores))
-
- else: # self.score_mode == 'bbox_keypoint':
- mean_kpt_score = 0
- valid_num = 0
- for kpt_idx in range(num_keypoints):
- kpt_score = instance['keypoint_scores'][kpt_idx]
- if kpt_score > self.keypoint_score_thr:
- mean_kpt_score += kpt_score
- valid_num += 1
- if valid_num != 0:
- mean_kpt_score /= valid_num
- instance['score'] = bbox_score * mean_kpt_score
- # perform nms
- if self.nms_mode == 'none':
- valid_kpts[img_id] = instances
- else:
- nms = oks_nms if self.nms_mode == 'oks_nms' else soft_oks_nms
- keep = nms(
- instances,
- self.nms_thr,
- sigmas=self.dataset_meta['sigmas'])
- valid_kpts[img_id] = [instances[_keep] for _keep in keep]
-
- # convert results to coco style and dump into a json file
- self.results2json(valid_kpts, outfile_prefix=outfile_prefix)
-
- # only format the results without doing quantitative evaluation
- if self.format_only:
- logger.info('results are saved in '
- f'{osp.dirname(outfile_prefix)}')
- return {}
-
- # evaluation results
- eval_results = OrderedDict()
- logger.info(f'Evaluating {self.__class__.__name__}...')
- info_str = self._do_python_keypoint_eval(outfile_prefix)
- name_value = OrderedDict(info_str)
- eval_results.update(name_value)
-
- if tmp_dir is not None:
- tmp_dir.cleanup()
- return eval_results
-
- def results2json(self, keypoints: Dict[int, list],
- outfile_prefix: str) -> str:
- """Dump the keypoint detection results to a COCO style json file.
-
- Args:
- keypoints (Dict[int, list]): Keypoint detection results
- of the dataset.
- outfile_prefix (str): The filename prefix of the json files. If the
- prefix is "somepath/xxx", the json files will be named
- "somepath/xxx.keypoints.json",
-
- Returns:
- str: The json file name of keypoint results.
- """
- # the results with category_id
- cat_results = []
-
- for _, img_kpts in keypoints.items():
- _keypoints = np.array(
- [img_kpt['keypoints'] for img_kpt in img_kpts])
- num_keypoints = self.dataset_meta['num_keypoints']
- # collect all the person keypoints in current image
- _keypoints = _keypoints.reshape(-1, num_keypoints * 3)
-
- result = [{
- 'image_id': img_kpt['img_id'],
- 'category_id': img_kpt['category_id'],
- 'keypoints': keypoint.tolist(),
- 'score': float(img_kpt['score']),
- } for img_kpt, keypoint in zip(img_kpts, _keypoints)]
-
- cat_results.extend(result)
-
- res_file = f'{outfile_prefix}.keypoints.json'
- dump(cat_results, res_file, sort_keys=True, indent=4)
-
- def _do_python_keypoint_eval(self, outfile_prefix: str) -> list:
- """Do keypoint evaluation using COCOAPI.
-
- Args:
- outfile_prefix (str): The filename prefix of the json files. If the
- prefix is "somepath/xxx", the json files will be named
- "somepath/xxx.keypoints.json",
-
- Returns:
- list: a list of tuples. Each tuple contains the evaluation stats
- name and corresponding stats value.
- """
- res_file = f'{outfile_prefix}.keypoints.json'
- coco_det = self.coco.loadRes(res_file)
- sigmas = self.dataset_meta['sigmas']
- coco_eval = COCOeval(self.coco, coco_det, self.iou_type, sigmas,
- self.use_area)
- coco_eval.params.useSegm = None
- coco_eval.evaluate()
- coco_eval.accumulate()
- coco_eval.summarize()
-
- if self.iou_type == 'keypoints_crowd':
- stats_names = [
- 'AP', 'AP .5', 'AP .75', 'AR', 'AR .5', 'AR .75', 'AP(E)',
- 'AP(M)', 'AP(H)'
- ]
- else:
- stats_names = [
- 'AP', 'AP .5', 'AP .75', 'AP (M)', 'AP (L)', 'AR', 'AR .5',
- 'AR .75', 'AR (M)', 'AR (L)'
- ]
-
- info_str = list(zip(stats_names, coco_eval.stats))
-
- return info_str
-
- def _sort_and_unique_bboxes(self,
- kpts: Dict[int, list],
- key: str = 'id') -> Dict[int, list]:
- """Sort keypoint detection results in each image and remove the
- duplicate ones. Usually performed in multi-batch testing.
-
- Args:
- kpts (Dict[int, list]): keypoint prediction results. The keys are
- '`img_id`' and the values are list that may contain
- keypoints of multiple persons. Each element in the list is a
- dict containing the ``'key'`` field.
- See the argument ``key`` for details.
- key (str): The key name in each person prediction results. The
- corresponding value will be used for sorting the results.
- Default: ``'id'``.
-
- Returns:
- Dict[int, list]: The sorted keypoint detection results.
- """
- for img_id, persons in kpts.items():
- # deal with bottomup-style output
- if isinstance(kpts[img_id][0][key], Sequence):
- return kpts
- num = len(persons)
- kpts[img_id] = sorted(kpts[img_id], key=lambda x: x[key])
- for i in range(num - 1, 0, -1):
- if kpts[img_id][i][key] == kpts[img_id][i - 1][key]:
- del kpts[img_id][i]
-
- return kpts
+# Copyright (c) OpenMMLab. All rights reserved.
+import datetime
+import os.path as osp
+import tempfile
+from collections import OrderedDict, defaultdict
+from typing import Dict, Optional, Sequence
+
+import numpy as np
+from mmengine.evaluator import BaseMetric
+from mmengine.fileio import dump, get_local_path, load
+from mmengine.logging import MMLogger
+from xtcocotools.coco import COCO
+from xtcocotools.cocoeval import COCOeval
+
+from mmpose.registry import METRICS
+from ..functional import oks_nms, soft_oks_nms
+
+
+@METRICS.register_module()
+class CocoMetric(BaseMetric):
+ """COCO pose estimation task evaluation metric.
+
+ Evaluate AR, AP, and mAP for keypoint detection tasks. Support COCO
+ dataset and other datasets in COCO format. Please refer to
+ `COCO keypoint evaluation `__
+ for more details.
+
+ Args:
+ ann_file (str, optional): Path to the coco format annotation file.
+ If not specified, ground truth annotations from the dataset will
+ be converted to coco format. Defaults to None
+ use_area (bool): Whether to use ``'area'`` message in the annotations.
+ If the ground truth annotations (e.g. CrowdPose, AIC) do not have
+ the field ``'area'``, please set ``use_area=False``.
+ Defaults to ``True``
+ iou_type (str): The same parameter as `iouType` in
+ :class:`xtcocotools.COCOeval`, which can be ``'keypoints'``, or
+ ``'keypoints_crowd'`` (used in CrowdPose dataset).
+ Defaults to ``'keypoints'``
+ score_mode (str): The mode to score the prediction results which
+ should be one of the following options:
+
+ - ``'bbox'``: Take the score of bbox as the score of the
+ prediction results.
+ - ``'bbox_keypoint'``: Use keypoint score to rescore the
+ prediction results.
+ - ``'bbox_rle'``: Use rle_score to rescore the
+ prediction results.
+
+ Defaults to ``'bbox_keypoint'`
+ keypoint_score_thr (float): The threshold of keypoint score. The
+ keypoints with score lower than it will not be included to
+ rescore the prediction results. Valid only when ``score_mode`` is
+ ``bbox_keypoint``. Defaults to ``0.2``
+ nms_mode (str): The mode to perform Non-Maximum Suppression (NMS),
+ which should be one of the following options:
+
+ - ``'oks_nms'``: Use Object Keypoint Similarity (OKS) to
+ perform NMS.
+ - ``'soft_oks_nms'``: Use Object Keypoint Similarity (OKS)
+ to perform soft NMS.
+ - ``'none'``: Do not perform NMS. Typically for bottomup mode
+ output.
+
+ Defaults to ``'oks_nms'`
+ nms_thr (float): The Object Keypoint Similarity (OKS) threshold
+ used in NMS when ``nms_mode`` is ``'oks_nms'`` or
+ ``'soft_oks_nms'``. Will retain the prediction results with OKS
+ lower than ``nms_thr``. Defaults to ``0.9``
+ format_only (bool): Whether only format the output results without
+ doing quantitative evaluation. This is designed for the need of
+ test submission when the ground truth annotations are absent. If
+ set to ``True``, ``outfile_prefix`` should specify the path to
+ store the output results. Defaults to ``False``
+ outfile_prefix (str | None): The prefix of json files. It includes
+ the file path and the prefix of filename, e.g., ``'a/b/prefix'``.
+ If not specified, a temp file will be created. Defaults to ``None``
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be ``'cpu'`` or
+ ``'gpu'``. Defaults to ``'cpu'``
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, ``self.default_prefix``
+ will be used instead. Defaults to ``None``
+ """
+ default_prefix: Optional[str] = 'coco'
+
+ def __init__(self,
+ ann_file: Optional[str] = None,
+ use_area: bool = True,
+ iou_type: str = 'keypoints',
+ score_mode: str = 'bbox_keypoint',
+ keypoint_score_thr: float = 0.2,
+ nms_mode: str = 'oks_nms',
+ nms_thr: float = 0.9,
+ format_only: bool = False,
+ outfile_prefix: Optional[str] = None,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ self.ann_file = ann_file
+ # initialize coco helper with the annotation json file
+ # if ann_file is not specified, initialize with the converted dataset
+ if ann_file is not None:
+ with get_local_path(ann_file) as local_path:
+ self.coco = COCO(local_path)
+ else:
+ self.coco = None
+
+ self.use_area = use_area
+ self.iou_type = iou_type
+
+ allowed_score_modes = ['bbox', 'bbox_keypoint', 'bbox_rle', 'keypoint']
+ if score_mode not in allowed_score_modes:
+ raise ValueError(
+ "`score_mode` should be one of 'bbox', 'bbox_keypoint', "
+ f"'bbox_rle', but got {score_mode}")
+ self.score_mode = score_mode
+ self.keypoint_score_thr = keypoint_score_thr
+
+ allowed_nms_modes = ['oks_nms', 'soft_oks_nms', 'none']
+ if nms_mode not in allowed_nms_modes:
+ raise ValueError(
+ "`nms_mode` should be one of 'oks_nms', 'soft_oks_nms', "
+ f"'none', but got {nms_mode}")
+ self.nms_mode = nms_mode
+ self.nms_thr = nms_thr
+
+ if format_only:
+ assert outfile_prefix is not None, '`outfile_prefix` can not be '\
+ 'None when `format_only` is True, otherwise the result file '\
+ 'will be saved to a temp directory which will be cleaned up '\
+ 'in the end.'
+ elif ann_file is not None:
+ # do evaluation only if the ground truth annotations exist
+ assert 'annotations' in load(ann_file), \
+ 'Ground truth annotations are required for evaluation '\
+ 'when `format_only` is False.'
+
+ self.format_only = format_only
+ self.outfile_prefix = outfile_prefix
+
+ def process(self, data_batch: Sequence[dict],
+ data_samples: Sequence[dict]) -> None:
+ """Process one batch of data samples and predictions. The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+
+ Args:
+ data_batch (Sequence[dict]): A batch of data
+ from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from
+ the model, each of which has the following keys:
+
+ - 'id': The id of the sample
+ - 'img_id': The image_id of the sample
+ - 'pred_instances': The prediction results of instance(s)
+ """
+ for data_sample in data_samples:
+ if 'pred_instances' not in data_sample:
+ raise ValueError(
+ '`pred_instances` are required to process the '
+ f'predictions results in {self.__class__.__name__}. ')
+
+ # keypoints.shape: [N, K, 2],
+ # N: number of instances, K: number of keypoints
+ # for topdown-style output, N is usually 1, while for
+ # bottomup-style output, N is the number of instances in the image
+ keypoints = data_sample['pred_instances']['keypoints']
+ # [N, K], the scores for all keypoints of all instances
+ keypoint_scores = data_sample['pred_instances']['keypoint_scores']
+ assert keypoint_scores.shape == keypoints.shape[:2]
+
+ # parse prediction results
+ pred = dict()
+ pred['id'] = data_sample['id']
+ pred['img_id'] = data_sample['img_id']
+ pred['keypoints'] = keypoints
+ pred['keypoint_scores'] = keypoint_scores
+ pred['category_id'] = data_sample.get('category_id', 1)
+
+ if 'bbox_scores' in data_sample['pred_instances']:
+ # some one-stage models will predict bboxes and scores
+ # together with keypoints
+ bbox_scores = data_sample['pred_instances']['bbox_scores']
+ elif ('bbox_scores' not in data_sample['gt_instances']
+ or len(data_sample['gt_instances']['bbox_scores']) !=
+ len(keypoints)):
+ # bottom-up models might output different number of
+ # instances from annotation
+ bbox_scores = np.ones(len(keypoints))
+ else:
+ # top-down models use detected bboxes, the scores of which
+ # are contained in the gt_instances
+ bbox_scores = data_sample['gt_instances']['bbox_scores']
+ pred['bbox_scores'] = bbox_scores
+
+ # get area information
+ if 'bbox_scales' in data_sample['gt_instances']:
+ pred['areas'] = np.prod(
+ data_sample['gt_instances']['bbox_scales'], axis=1)
+
+ # parse gt
+ gt = dict()
+ if self.coco is None:
+ gt['width'] = data_sample['ori_shape'][1]
+ gt['height'] = data_sample['ori_shape'][0]
+ gt['img_id'] = data_sample['img_id']
+ if self.iou_type == 'keypoints_crowd':
+ assert 'crowd_index' in data_sample, \
+ '`crowd_index` is required when `self.iou_type` is ' \
+ '`keypoints_crowd`'
+ gt['crowd_index'] = data_sample['crowd_index']
+ assert 'raw_ann_info' in data_sample, \
+ 'The row ground truth annotations are required for ' \
+ 'evaluation when `ann_file` is not provided'
+ anns = data_sample['raw_ann_info']
+ gt['raw_ann_info'] = anns if isinstance(anns, list) else [anns]
+
+ # add converted result to the results list
+ self.results.append((pred, gt))
+
+ def gt_to_coco_json(self, gt_dicts: Sequence[dict],
+ outfile_prefix: str) -> str:
+ """Convert ground truth to coco format json file.
+
+ Args:
+ gt_dicts (Sequence[dict]): Ground truth of the dataset. Each dict
+ contains the ground truth information about the data sample.
+ Required keys of the each `gt_dict` in `gt_dicts`:
+ - `img_id`: image id of the data sample
+ - `width`: original image width
+ - `height`: original image height
+ - `raw_ann_info`: the raw annotation information
+ Optional keys:
+ - `crowd_index`: measure the crowding level of an image,
+ defined in CrowdPose dataset
+ It is worth mentioning that, in order to compute `CocoMetric`,
+ there are some required keys in the `raw_ann_info`:
+ - `id`: the id to distinguish different annotations
+ - `image_id`: the image id of this annotation
+ - `category_id`: the category of the instance.
+ - `bbox`: the object bounding box
+ - `keypoints`: the keypoints cooridinates along with their
+ visibilities. Note that it need to be aligned
+ with the official COCO format, e.g., a list with length
+ N * 3, in which N is the number of keypoints. And each
+ triplet represent the [x, y, visible] of the keypoint.
+ - `iscrowd`: indicating whether the annotation is a crowd.
+ It is useful when matching the detection results to
+ the ground truth.
+ There are some optional keys as well:
+ - `area`: it is necessary when `self.use_area` is `True`
+ - `num_keypoints`: it is necessary when `self.iou_type`
+ is set as `keypoints_crowd`.
+ outfile_prefix (str): The filename prefix of the json files. If the
+ prefix is "somepath/xxx", the json file will be named
+ "somepath/xxx.gt.json".
+ Returns:
+ str: The filename of the json file.
+ """
+ image_infos = []
+ annotations = []
+ img_ids = []
+ ann_ids = []
+
+ for gt_dict in gt_dicts:
+ # filter duplicate image_info
+ if gt_dict['img_id'] not in img_ids:
+ image_info = dict(
+ id=gt_dict['img_id'],
+ width=gt_dict['width'],
+ height=gt_dict['height'],
+ )
+ if self.iou_type == 'keypoints_crowd':
+ image_info['crowdIndex'] = gt_dict['crowd_index']
+
+ image_infos.append(image_info)
+ img_ids.append(gt_dict['img_id'])
+
+ # filter duplicate annotations
+ for ann in gt_dict['raw_ann_info']:
+ if ann is None:
+ # during evaluation on bottom-up datasets, some images
+ # do not have instance annotation
+ continue
+
+ annotation = dict(
+ id=ann['id'],
+ image_id=ann['image_id'],
+ category_id=ann['category_id'],
+ bbox=ann['bbox'],
+ keypoints=ann['keypoints'],
+ iscrowd=ann['iscrowd'],
+ )
+ if self.use_area:
+ assert 'area' in ann, \
+ '`area` is required when `self.use_area` is `True`'
+ annotation['area'] = ann['area']
+
+ if self.iou_type == 'keypoints_crowd':
+ assert 'num_keypoints' in ann, \
+ '`num_keypoints` is required when `self.iou_type` ' \
+ 'is `keypoints_crowd`'
+ annotation['num_keypoints'] = ann['num_keypoints']
+
+ annotations.append(annotation)
+ ann_ids.append(ann['id'])
+
+ info = dict(
+ date_created=str(datetime.datetime.now()),
+ description='Coco json file converted by mmpose CocoMetric.')
+ coco_json = dict(
+ info=info,
+ images=image_infos,
+ categories=self.dataset_meta['CLASSES'],
+ licenses=None,
+ annotations=annotations,
+ )
+ converted_json_path = f'{outfile_prefix}.gt.json'
+ dump(coco_json, converted_json_path, sort_keys=True, indent=4)
+ return converted_json_path
+
+ def compute_metrics(self, results: list) -> Dict[str, float]:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ Dict[str, float]: The computed metrics. The keys are the names of
+ the metrics, and the values are corresponding results.
+ """
+ logger: MMLogger = MMLogger.get_current_instance()
+
+ # split prediction and gt list
+ preds, gts = zip(*results)
+
+ tmp_dir = None
+ if self.outfile_prefix is None:
+ tmp_dir = tempfile.TemporaryDirectory()
+ outfile_prefix = osp.join(tmp_dir.name, 'results')
+ else:
+ outfile_prefix = self.outfile_prefix
+
+ if self.coco is None:
+ # use converted gt json file to initialize coco helper
+ logger.info('Converting ground truth to coco format...')
+ coco_json_path = self.gt_to_coco_json(
+ gt_dicts=gts, outfile_prefix=outfile_prefix)
+ self.coco = COCO(coco_json_path)
+
+ kpts = defaultdict(list)
+
+ # group the preds by img_id
+ for pred in preds:
+ img_id = pred['img_id']
+ for idx in range(len(pred['keypoints'])):
+ instance = {
+ 'id': pred['id'],
+ 'img_id': pred['img_id'],
+ 'category_id': pred['category_id'],
+ 'keypoints': pred['keypoints'][idx],
+ 'keypoint_scores': pred['keypoint_scores'][idx],
+ 'bbox_score': pred['bbox_scores'][idx],
+ }
+
+ if 'areas' in pred:
+ instance['area'] = pred['areas'][idx]
+ else:
+ # use keypoint to calculate bbox and get area
+ keypoints = pred['keypoints'][idx]
+ area = (
+ np.max(keypoints[:, 0]) - np.min(keypoints[:, 0])) * (
+ np.max(keypoints[:, 1]) - np.min(keypoints[:, 1]))
+ instance['area'] = area
+
+ kpts[img_id].append(instance)
+
+ # sort keypoint results according to id and remove duplicate ones
+ kpts = self._sort_and_unique_bboxes(kpts, key='id')
+
+ # score the prediction results according to `score_mode`
+ # and perform NMS according to `nms_mode`
+ valid_kpts = defaultdict(list)
+ num_keypoints = self.dataset_meta['num_keypoints']
+ for img_id, instances in kpts.items():
+ for instance in instances:
+ # concatenate the keypoint coordinates and scores
+ instance['keypoints'] = np.concatenate([
+ instance['keypoints'], instance['keypoint_scores'][:, None]
+ ],
+ axis=-1)
+ if self.score_mode == 'bbox':
+ instance['score'] = instance['bbox_score']
+ elif self.score_mode == 'keypoint':
+ instance['score'] = np.mean(instance['keypoint_scores'])
+ else:
+ bbox_score = instance['bbox_score']
+ if self.score_mode == 'bbox_rle':
+ keypoint_scores = instance['keypoint_scores']
+ instance['score'] = float(bbox_score +
+ np.mean(keypoint_scores) +
+ np.max(keypoint_scores))
+
+ else: # self.score_mode == 'bbox_keypoint':
+ mean_kpt_score = 0
+ valid_num = 0
+ for kpt_idx in range(num_keypoints):
+ kpt_score = instance['keypoint_scores'][kpt_idx]
+ if kpt_score > self.keypoint_score_thr:
+ mean_kpt_score += kpt_score
+ valid_num += 1
+ if valid_num != 0:
+ mean_kpt_score /= valid_num
+ instance['score'] = bbox_score * mean_kpt_score
+ # perform nms
+ if self.nms_mode == 'none':
+ valid_kpts[img_id] = instances
+ else:
+ nms = oks_nms if self.nms_mode == 'oks_nms' else soft_oks_nms
+ keep = nms(
+ instances,
+ self.nms_thr,
+ sigmas=self.dataset_meta['sigmas'])
+ valid_kpts[img_id] = [instances[_keep] for _keep in keep]
+
+ # convert results to coco style and dump into a json file
+ self.results2json(valid_kpts, outfile_prefix=outfile_prefix)
+
+ # only format the results without doing quantitative evaluation
+ if self.format_only:
+ logger.info('results are saved in '
+ f'{osp.dirname(outfile_prefix)}')
+ return {}
+
+ # evaluation results
+ eval_results = OrderedDict()
+ logger.info(f'Evaluating {self.__class__.__name__}...')
+ info_str = self._do_python_keypoint_eval(outfile_prefix)
+ name_value = OrderedDict(info_str)
+ eval_results.update(name_value)
+
+ if tmp_dir is not None:
+ tmp_dir.cleanup()
+ return eval_results
+
+ def results2json(self, keypoints: Dict[int, list],
+ outfile_prefix: str) -> str:
+ """Dump the keypoint detection results to a COCO style json file.
+
+ Args:
+ keypoints (Dict[int, list]): Keypoint detection results
+ of the dataset.
+ outfile_prefix (str): The filename prefix of the json files. If the
+ prefix is "somepath/xxx", the json files will be named
+ "somepath/xxx.keypoints.json",
+
+ Returns:
+ str: The json file name of keypoint results.
+ """
+ # the results with category_id
+ cat_results = []
+
+ for _, img_kpts in keypoints.items():
+ _keypoints = np.array(
+ [img_kpt['keypoints'] for img_kpt in img_kpts])
+ num_keypoints = self.dataset_meta['num_keypoints']
+ # collect all the person keypoints in current image
+ _keypoints = _keypoints.reshape(-1, num_keypoints * 3)
+
+ result = [{
+ 'image_id': img_kpt['img_id'],
+ 'category_id': img_kpt['category_id'],
+ 'keypoints': keypoint.tolist(),
+ 'score': float(img_kpt['score']),
+ } for img_kpt, keypoint in zip(img_kpts, _keypoints)]
+
+ cat_results.extend(result)
+
+ res_file = f'{outfile_prefix}.keypoints.json'
+ dump(cat_results, res_file, sort_keys=True, indent=4)
+
+ def _do_python_keypoint_eval(self, outfile_prefix: str) -> list:
+ """Do keypoint evaluation using COCOAPI.
+
+ Args:
+ outfile_prefix (str): The filename prefix of the json files. If the
+ prefix is "somepath/xxx", the json files will be named
+ "somepath/xxx.keypoints.json",
+
+ Returns:
+ list: a list of tuples. Each tuple contains the evaluation stats
+ name and corresponding stats value.
+ """
+ res_file = f'{outfile_prefix}.keypoints.json'
+ coco_det = self.coco.loadRes(res_file)
+ sigmas = self.dataset_meta['sigmas']
+ coco_eval = COCOeval(self.coco, coco_det, self.iou_type, sigmas,
+ self.use_area)
+ coco_eval.params.useSegm = None
+ coco_eval.evaluate()
+ coco_eval.accumulate()
+ coco_eval.summarize()
+
+ if self.iou_type == 'keypoints_crowd':
+ stats_names = [
+ 'AP', 'AP .5', 'AP .75', 'AR', 'AR .5', 'AR .75', 'AP(E)',
+ 'AP(M)', 'AP(H)'
+ ]
+ else:
+ stats_names = [
+ 'AP', 'AP .5', 'AP .75', 'AP (M)', 'AP (L)', 'AR', 'AR .5',
+ 'AR .75', 'AR (M)', 'AR (L)'
+ ]
+
+ info_str = list(zip(stats_names, coco_eval.stats))
+
+ return info_str
+
+ def _sort_and_unique_bboxes(self,
+ kpts: Dict[int, list],
+ key: str = 'id') -> Dict[int, list]:
+ """Sort keypoint detection results in each image and remove the
+ duplicate ones. Usually performed in multi-batch testing.
+
+ Args:
+ kpts (Dict[int, list]): keypoint prediction results. The keys are
+ '`img_id`' and the values are list that may contain
+ keypoints of multiple persons. Each element in the list is a
+ dict containing the ``'key'`` field.
+ See the argument ``key`` for details.
+ key (str): The key name in each person prediction results. The
+ corresponding value will be used for sorting the results.
+ Default: ``'id'``.
+
+ Returns:
+ Dict[int, list]: The sorted keypoint detection results.
+ """
+ for img_id, persons in kpts.items():
+ # deal with bottomup-style output
+ if isinstance(kpts[img_id][0][key], Sequence):
+ return kpts
+ num = len(persons)
+ kpts[img_id] = sorted(kpts[img_id], key=lambda x: x[key])
+ for i in range(num - 1, 0, -1):
+ if kpts[img_id][i][key] == kpts[img_id][i - 1][key]:
+ del kpts[img_id][i]
+
+ return kpts
diff --git a/mmpose/evaluation/metrics/coco_wholebody_metric.py b/mmpose/evaluation/metrics/coco_wholebody_metric.py
index c5675f54c8..e42f686d46 100644
--- a/mmpose/evaluation/metrics/coco_wholebody_metric.py
+++ b/mmpose/evaluation/metrics/coco_wholebody_metric.py
@@ -1,312 +1,312 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import datetime
-from typing import Dict, Optional, Sequence
-
-import numpy as np
-from mmengine.fileio import dump
-from xtcocotools.cocoeval import COCOeval
-
-from mmpose.registry import METRICS
-from .coco_metric import CocoMetric
-
-
-@METRICS.register_module()
-class CocoWholeBodyMetric(CocoMetric):
- """COCO-WholeBody evaluation metric.
-
- Evaluate AR, AP, and mAP for COCO-WholeBody keypoint detection tasks.
- Support COCO-WholeBody dataset. Please refer to
- `COCO keypoint evaluation `__
- for more details.
-
- Args:
- ann_file (str, optional): Path to the coco format annotation file.
- If not specified, ground truth annotations from the dataset will
- be converted to coco format. Defaults to None
- use_area (bool): Whether to use ``'area'`` message in the annotations.
- If the ground truth annotations (e.g. CrowdPose, AIC) do not have
- the field ``'area'``, please set ``use_area=False``.
- Defaults to ``True``
- iou_type (str): The same parameter as `iouType` in
- :class:`xtcocotools.COCOeval`, which can be ``'keypoints'``, or
- ``'keypoints_crowd'`` (used in CrowdPose dataset).
- Defaults to ``'keypoints'``
- score_mode (str): The mode to score the prediction results which
- should be one of the following options:
-
- - ``'bbox'``: Take the score of bbox as the score of the
- prediction results.
- - ``'bbox_keypoint'``: Use keypoint score to rescore the
- prediction results.
- - ``'bbox_rle'``: Use rle_score to rescore the
- prediction results.
-
- Defaults to ``'bbox_keypoint'`
- keypoint_score_thr (float): The threshold of keypoint score. The
- keypoints with score lower than it will not be included to
- rescore the prediction results. Valid only when ``score_mode`` is
- ``bbox_keypoint``. Defaults to ``0.2``
- nms_mode (str): The mode to perform Non-Maximum Suppression (NMS),
- which should be one of the following options:
-
- - ``'oks_nms'``: Use Object Keypoint Similarity (OKS) to
- perform NMS.
- - ``'soft_oks_nms'``: Use Object Keypoint Similarity (OKS)
- to perform soft NMS.
- - ``'none'``: Do not perform NMS. Typically for bottomup mode
- output.
-
- Defaults to ``'oks_nms'`
- nms_thr (float): The Object Keypoint Similarity (OKS) threshold
- used in NMS when ``nms_mode`` is ``'oks_nms'`` or
- ``'soft_oks_nms'``. Will retain the prediction results with OKS
- lower than ``nms_thr``. Defaults to ``0.9``
- format_only (bool): Whether only format the output results without
- doing quantitative evaluation. This is designed for the need of
- test submission when the ground truth annotations are absent. If
- set to ``True``, ``outfile_prefix`` should specify the path to
- store the output results. Defaults to ``False``
- outfile_prefix (str | None): The prefix of json files. It includes
- the file path and the prefix of filename, e.g., ``'a/b/prefix'``.
- If not specified, a temp file will be created. Defaults to ``None``
- **kwargs: Keyword parameters passed to :class:`mmeval.BaseMetric`
- """
- default_prefix: Optional[str] = 'coco-wholebody'
- body_num = 17
- foot_num = 6
- face_num = 68
- left_hand_num = 21
- right_hand_num = 21
-
- def gt_to_coco_json(self, gt_dicts: Sequence[dict],
- outfile_prefix: str) -> str:
- """Convert ground truth to coco format json file.
-
- Args:
- gt_dicts (Sequence[dict]): Ground truth of the dataset. Each dict
- contains the ground truth information about the data sample.
- Required keys of the each `gt_dict` in `gt_dicts`:
- - `img_id`: image id of the data sample
- - `width`: original image width
- - `height`: original image height
- - `raw_ann_info`: the raw annotation information
- Optional keys:
- - `crowd_index`: measure the crowding level of an image,
- defined in CrowdPose dataset
- It is worth mentioning that, in order to compute `CocoMetric`,
- there are some required keys in the `raw_ann_info`:
- - `id`: the id to distinguish different annotations
- - `image_id`: the image id of this annotation
- - `category_id`: the category of the instance.
- - `bbox`: the object bounding box
- - `keypoints`: the keypoints cooridinates along with their
- visibilities. Note that it need to be aligned
- with the official COCO format, e.g., a list with length
- N * 3, in which N is the number of keypoints. And each
- triplet represent the [x, y, visible] of the keypoint.
- - 'keypoints'
- - `iscrowd`: indicating whether the annotation is a crowd.
- It is useful when matching the detection results to
- the ground truth.
- There are some optional keys as well:
- - `area`: it is necessary when `self.use_area` is `True`
- - `num_keypoints`: it is necessary when `self.iou_type`
- is set as `keypoints_crowd`.
- outfile_prefix (str): The filename prefix of the json files. If the
- prefix is "somepath/xxx", the json file will be named
- "somepath/xxx.gt.json".
- Returns:
- str: The filename of the json file.
- """
- image_infos = []
- annotations = []
- img_ids = []
- ann_ids = []
-
- for gt_dict in gt_dicts:
- # filter duplicate image_info
- if gt_dict['img_id'] not in img_ids:
- image_info = dict(
- id=gt_dict['img_id'],
- width=gt_dict['width'],
- height=gt_dict['height'],
- )
- if self.iou_type == 'keypoints_crowd':
- image_info['crowdIndex'] = gt_dict['crowd_index']
-
- image_infos.append(image_info)
- img_ids.append(gt_dict['img_id'])
-
- # filter duplicate annotations
- for ann in gt_dict['raw_ann_info']:
- annotation = dict(
- id=ann['id'],
- image_id=ann['image_id'],
- category_id=ann['category_id'],
- bbox=ann['bbox'],
- keypoints=ann['keypoints'],
- foot_kpts=ann['foot_kpts'],
- face_kpts=ann['face_kpts'],
- lefthand_kpts=ann['lefthand_kpts'],
- righthand_kpts=ann['righthand_kpts'],
- iscrowd=ann['iscrowd'],
- )
- if self.use_area:
- assert 'area' in ann, \
- '`area` is required when `self.use_area` is `True`'
- annotation['area'] = ann['area']
-
- annotations.append(annotation)
- ann_ids.append(ann['id'])
-
- info = dict(
- date_created=str(datetime.datetime.now()),
- description='Coco json file converted by mmpose CocoMetric.')
- coco_json: dict = dict(
- info=info,
- images=image_infos,
- categories=self.dataset_meta['CLASSES'],
- licenses=None,
- annotations=annotations,
- )
- converted_json_path = f'{outfile_prefix}.gt.json'
- dump(coco_json, converted_json_path, sort_keys=True, indent=4)
- return converted_json_path
-
- def results2json(self, keypoints: Dict[int, list],
- outfile_prefix: str) -> str:
- """Dump the keypoint detection results to a COCO style json file.
-
- Args:
- keypoints (Dict[int, list]): Keypoint detection results
- of the dataset.
- outfile_prefix (str): The filename prefix of the json files. If the
- prefix is "somepath/xxx", the json files will be named
- "somepath/xxx.keypoints.json",
-
- Returns:
- str: The json file name of keypoint results.
- """
- # the results with category_id
- cat_id = 1
- cat_results = []
-
- cuts = np.cumsum([
- 0, self.body_num, self.foot_num, self.face_num, self.left_hand_num,
- self.right_hand_num
- ]) * 3
-
- for _, img_kpts in keypoints.items():
- _keypoints = np.array(
- [img_kpt['keypoints'] for img_kpt in img_kpts])
- num_keypoints = self.dataset_meta['num_keypoints']
- # collect all the person keypoints in current image
- _keypoints = _keypoints.reshape(-1, num_keypoints * 3)
-
- result = [{
- 'image_id': img_kpt['img_id'],
- 'category_id': cat_id,
- 'keypoints': _keypoint[cuts[0]:cuts[1]].tolist(),
- 'foot_kpts': _keypoint[cuts[1]:cuts[2]].tolist(),
- 'face_kpts': _keypoint[cuts[2]:cuts[3]].tolist(),
- 'lefthand_kpts': _keypoint[cuts[3]:cuts[4]].tolist(),
- 'righthand_kpts': _keypoint[cuts[4]:cuts[5]].tolist(),
- 'score': float(img_kpt['score']),
- } for img_kpt, _keypoint in zip(img_kpts, _keypoints)]
-
- cat_results.extend(result)
-
- res_file = f'{outfile_prefix}.keypoints.json'
- dump(cat_results, res_file, sort_keys=True, indent=4)
-
- def _do_python_keypoint_eval(self, outfile_prefix: str) -> list:
- """Do keypoint evaluation using COCOAPI.
-
- Args:
- outfile_prefix (str): The filename prefix of the json files. If the
- prefix is "somepath/xxx", the json files will be named
- "somepath/xxx.keypoints.json",
-
- Returns:
- list: a list of tuples. Each tuple contains the evaluation stats
- name and corresponding stats value.
- """
- res_file = f'{outfile_prefix}.keypoints.json'
- coco_det = self.coco.loadRes(res_file)
- sigmas = self.dataset_meta['sigmas']
-
- cuts = np.cumsum([
- 0, self.body_num, self.foot_num, self.face_num, self.left_hand_num,
- self.right_hand_num
- ])
-
- coco_eval = COCOeval(
- self.coco,
- coco_det,
- 'keypoints_body',
- sigmas[cuts[0]:cuts[1]],
- use_area=True)
- coco_eval.params.useSegm = None
- coco_eval.evaluate()
- coco_eval.accumulate()
- coco_eval.summarize()
-
- coco_eval = COCOeval(
- self.coco,
- coco_det,
- 'keypoints_foot',
- sigmas[cuts[1]:cuts[2]],
- use_area=True)
- coco_eval.params.useSegm = None
- coco_eval.evaluate()
- coco_eval.accumulate()
- coco_eval.summarize()
-
- coco_eval = COCOeval(
- self.coco,
- coco_det,
- 'keypoints_face',
- sigmas[cuts[2]:cuts[3]],
- use_area=True)
- coco_eval.params.useSegm = None
- coco_eval.evaluate()
- coco_eval.accumulate()
- coco_eval.summarize()
-
- coco_eval = COCOeval(
- self.coco,
- coco_det,
- 'keypoints_lefthand',
- sigmas[cuts[3]:cuts[4]],
- use_area=True)
- coco_eval.params.useSegm = None
- coco_eval.evaluate()
- coco_eval.accumulate()
- coco_eval.summarize()
-
- coco_eval = COCOeval(
- self.coco,
- coco_det,
- 'keypoints_righthand',
- sigmas[cuts[4]:cuts[5]],
- use_area=True)
- coco_eval.params.useSegm = None
- coco_eval.evaluate()
- coco_eval.accumulate()
- coco_eval.summarize()
-
- coco_eval = COCOeval(
- self.coco, coco_det, 'keypoints_wholebody', sigmas, use_area=True)
- coco_eval.params.useSegm = None
- coco_eval.evaluate()
- coco_eval.accumulate()
- coco_eval.summarize()
-
- stats_names = [
- 'AP', 'AP .5', 'AP .75', 'AP (M)', 'AP (L)', 'AR', 'AR .5',
- 'AR .75', 'AR (M)', 'AR (L)'
- ]
-
- info_str = list(zip(stats_names, coco_eval.stats))
-
- return info_str
+# Copyright (c) OpenMMLab. All rights reserved.
+import datetime
+from typing import Dict, Optional, Sequence
+
+import numpy as np
+from mmengine.fileio import dump
+from xtcocotools.cocoeval import COCOeval
+
+from mmpose.registry import METRICS
+from .coco_metric import CocoMetric
+
+
+@METRICS.register_module()
+class CocoWholeBodyMetric(CocoMetric):
+ """COCO-WholeBody evaluation metric.
+
+ Evaluate AR, AP, and mAP for COCO-WholeBody keypoint detection tasks.
+ Support COCO-WholeBody dataset. Please refer to
+ `COCO keypoint evaluation `__
+ for more details.
+
+ Args:
+ ann_file (str, optional): Path to the coco format annotation file.
+ If not specified, ground truth annotations from the dataset will
+ be converted to coco format. Defaults to None
+ use_area (bool): Whether to use ``'area'`` message in the annotations.
+ If the ground truth annotations (e.g. CrowdPose, AIC) do not have
+ the field ``'area'``, please set ``use_area=False``.
+ Defaults to ``True``
+ iou_type (str): The same parameter as `iouType` in
+ :class:`xtcocotools.COCOeval`, which can be ``'keypoints'``, or
+ ``'keypoints_crowd'`` (used in CrowdPose dataset).
+ Defaults to ``'keypoints'``
+ score_mode (str): The mode to score the prediction results which
+ should be one of the following options:
+
+ - ``'bbox'``: Take the score of bbox as the score of the
+ prediction results.
+ - ``'bbox_keypoint'``: Use keypoint score to rescore the
+ prediction results.
+ - ``'bbox_rle'``: Use rle_score to rescore the
+ prediction results.
+
+ Defaults to ``'bbox_keypoint'`
+ keypoint_score_thr (float): The threshold of keypoint score. The
+ keypoints with score lower than it will not be included to
+ rescore the prediction results. Valid only when ``score_mode`` is
+ ``bbox_keypoint``. Defaults to ``0.2``
+ nms_mode (str): The mode to perform Non-Maximum Suppression (NMS),
+ which should be one of the following options:
+
+ - ``'oks_nms'``: Use Object Keypoint Similarity (OKS) to
+ perform NMS.
+ - ``'soft_oks_nms'``: Use Object Keypoint Similarity (OKS)
+ to perform soft NMS.
+ - ``'none'``: Do not perform NMS. Typically for bottomup mode
+ output.
+
+ Defaults to ``'oks_nms'`
+ nms_thr (float): The Object Keypoint Similarity (OKS) threshold
+ used in NMS when ``nms_mode`` is ``'oks_nms'`` or
+ ``'soft_oks_nms'``. Will retain the prediction results with OKS
+ lower than ``nms_thr``. Defaults to ``0.9``
+ format_only (bool): Whether only format the output results without
+ doing quantitative evaluation. This is designed for the need of
+ test submission when the ground truth annotations are absent. If
+ set to ``True``, ``outfile_prefix`` should specify the path to
+ store the output results. Defaults to ``False``
+ outfile_prefix (str | None): The prefix of json files. It includes
+ the file path and the prefix of filename, e.g., ``'a/b/prefix'``.
+ If not specified, a temp file will be created. Defaults to ``None``
+ **kwargs: Keyword parameters passed to :class:`mmeval.BaseMetric`
+ """
+ default_prefix: Optional[str] = 'coco-wholebody'
+ body_num = 17
+ foot_num = 6
+ face_num = 68
+ left_hand_num = 21
+ right_hand_num = 21
+
+ def gt_to_coco_json(self, gt_dicts: Sequence[dict],
+ outfile_prefix: str) -> str:
+ """Convert ground truth to coco format json file.
+
+ Args:
+ gt_dicts (Sequence[dict]): Ground truth of the dataset. Each dict
+ contains the ground truth information about the data sample.
+ Required keys of the each `gt_dict` in `gt_dicts`:
+ - `img_id`: image id of the data sample
+ - `width`: original image width
+ - `height`: original image height
+ - `raw_ann_info`: the raw annotation information
+ Optional keys:
+ - `crowd_index`: measure the crowding level of an image,
+ defined in CrowdPose dataset
+ It is worth mentioning that, in order to compute `CocoMetric`,
+ there are some required keys in the `raw_ann_info`:
+ - `id`: the id to distinguish different annotations
+ - `image_id`: the image id of this annotation
+ - `category_id`: the category of the instance.
+ - `bbox`: the object bounding box
+ - `keypoints`: the keypoints cooridinates along with their
+ visibilities. Note that it need to be aligned
+ with the official COCO format, e.g., a list with length
+ N * 3, in which N is the number of keypoints. And each
+ triplet represent the [x, y, visible] of the keypoint.
+ - 'keypoints'
+ - `iscrowd`: indicating whether the annotation is a crowd.
+ It is useful when matching the detection results to
+ the ground truth.
+ There are some optional keys as well:
+ - `area`: it is necessary when `self.use_area` is `True`
+ - `num_keypoints`: it is necessary when `self.iou_type`
+ is set as `keypoints_crowd`.
+ outfile_prefix (str): The filename prefix of the json files. If the
+ prefix is "somepath/xxx", the json file will be named
+ "somepath/xxx.gt.json".
+ Returns:
+ str: The filename of the json file.
+ """
+ image_infos = []
+ annotations = []
+ img_ids = []
+ ann_ids = []
+
+ for gt_dict in gt_dicts:
+ # filter duplicate image_info
+ if gt_dict['img_id'] not in img_ids:
+ image_info = dict(
+ id=gt_dict['img_id'],
+ width=gt_dict['width'],
+ height=gt_dict['height'],
+ )
+ if self.iou_type == 'keypoints_crowd':
+ image_info['crowdIndex'] = gt_dict['crowd_index']
+
+ image_infos.append(image_info)
+ img_ids.append(gt_dict['img_id'])
+
+ # filter duplicate annotations
+ for ann in gt_dict['raw_ann_info']:
+ annotation = dict(
+ id=ann['id'],
+ image_id=ann['image_id'],
+ category_id=ann['category_id'],
+ bbox=ann['bbox'],
+ keypoints=ann['keypoints'],
+ foot_kpts=ann['foot_kpts'],
+ face_kpts=ann['face_kpts'],
+ lefthand_kpts=ann['lefthand_kpts'],
+ righthand_kpts=ann['righthand_kpts'],
+ iscrowd=ann['iscrowd'],
+ )
+ if self.use_area:
+ assert 'area' in ann, \
+ '`area` is required when `self.use_area` is `True`'
+ annotation['area'] = ann['area']
+
+ annotations.append(annotation)
+ ann_ids.append(ann['id'])
+
+ info = dict(
+ date_created=str(datetime.datetime.now()),
+ description='Coco json file converted by mmpose CocoMetric.')
+ coco_json: dict = dict(
+ info=info,
+ images=image_infos,
+ categories=self.dataset_meta['CLASSES'],
+ licenses=None,
+ annotations=annotations,
+ )
+ converted_json_path = f'{outfile_prefix}.gt.json'
+ dump(coco_json, converted_json_path, sort_keys=True, indent=4)
+ return converted_json_path
+
+ def results2json(self, keypoints: Dict[int, list],
+ outfile_prefix: str) -> str:
+ """Dump the keypoint detection results to a COCO style json file.
+
+ Args:
+ keypoints (Dict[int, list]): Keypoint detection results
+ of the dataset.
+ outfile_prefix (str): The filename prefix of the json files. If the
+ prefix is "somepath/xxx", the json files will be named
+ "somepath/xxx.keypoints.json",
+
+ Returns:
+ str: The json file name of keypoint results.
+ """
+ # the results with category_id
+ cat_id = 1
+ cat_results = []
+
+ cuts = np.cumsum([
+ 0, self.body_num, self.foot_num, self.face_num, self.left_hand_num,
+ self.right_hand_num
+ ]) * 3
+
+ for _, img_kpts in keypoints.items():
+ _keypoints = np.array(
+ [img_kpt['keypoints'] for img_kpt in img_kpts])
+ num_keypoints = self.dataset_meta['num_keypoints']
+ # collect all the person keypoints in current image
+ _keypoints = _keypoints.reshape(-1, num_keypoints * 3)
+
+ result = [{
+ 'image_id': img_kpt['img_id'],
+ 'category_id': cat_id,
+ 'keypoints': _keypoint[cuts[0]:cuts[1]].tolist(),
+ 'foot_kpts': _keypoint[cuts[1]:cuts[2]].tolist(),
+ 'face_kpts': _keypoint[cuts[2]:cuts[3]].tolist(),
+ 'lefthand_kpts': _keypoint[cuts[3]:cuts[4]].tolist(),
+ 'righthand_kpts': _keypoint[cuts[4]:cuts[5]].tolist(),
+ 'score': float(img_kpt['score']),
+ } for img_kpt, _keypoint in zip(img_kpts, _keypoints)]
+
+ cat_results.extend(result)
+
+ res_file = f'{outfile_prefix}.keypoints.json'
+ dump(cat_results, res_file, sort_keys=True, indent=4)
+
+ def _do_python_keypoint_eval(self, outfile_prefix: str) -> list:
+ """Do keypoint evaluation using COCOAPI.
+
+ Args:
+ outfile_prefix (str): The filename prefix of the json files. If the
+ prefix is "somepath/xxx", the json files will be named
+ "somepath/xxx.keypoints.json",
+
+ Returns:
+ list: a list of tuples. Each tuple contains the evaluation stats
+ name and corresponding stats value.
+ """
+ res_file = f'{outfile_prefix}.keypoints.json'
+ coco_det = self.coco.loadRes(res_file)
+ sigmas = self.dataset_meta['sigmas']
+
+ cuts = np.cumsum([
+ 0, self.body_num, self.foot_num, self.face_num, self.left_hand_num,
+ self.right_hand_num
+ ])
+
+ coco_eval = COCOeval(
+ self.coco,
+ coco_det,
+ 'keypoints_body',
+ sigmas[cuts[0]:cuts[1]],
+ use_area=True)
+ coco_eval.params.useSegm = None
+ coco_eval.evaluate()
+ coco_eval.accumulate()
+ coco_eval.summarize()
+
+ coco_eval = COCOeval(
+ self.coco,
+ coco_det,
+ 'keypoints_foot',
+ sigmas[cuts[1]:cuts[2]],
+ use_area=True)
+ coco_eval.params.useSegm = None
+ coco_eval.evaluate()
+ coco_eval.accumulate()
+ coco_eval.summarize()
+
+ coco_eval = COCOeval(
+ self.coco,
+ coco_det,
+ 'keypoints_face',
+ sigmas[cuts[2]:cuts[3]],
+ use_area=True)
+ coco_eval.params.useSegm = None
+ coco_eval.evaluate()
+ coco_eval.accumulate()
+ coco_eval.summarize()
+
+ coco_eval = COCOeval(
+ self.coco,
+ coco_det,
+ 'keypoints_lefthand',
+ sigmas[cuts[3]:cuts[4]],
+ use_area=True)
+ coco_eval.params.useSegm = None
+ coco_eval.evaluate()
+ coco_eval.accumulate()
+ coco_eval.summarize()
+
+ coco_eval = COCOeval(
+ self.coco,
+ coco_det,
+ 'keypoints_righthand',
+ sigmas[cuts[4]:cuts[5]],
+ use_area=True)
+ coco_eval.params.useSegm = None
+ coco_eval.evaluate()
+ coco_eval.accumulate()
+ coco_eval.summarize()
+
+ coco_eval = COCOeval(
+ self.coco, coco_det, 'keypoints_wholebody', sigmas, use_area=True)
+ coco_eval.params.useSegm = None
+ coco_eval.evaluate()
+ coco_eval.accumulate()
+ coco_eval.summarize()
+
+ stats_names = [
+ 'AP', 'AP .5', 'AP .75', 'AP (M)', 'AP (L)', 'AR', 'AR .5',
+ 'AR .75', 'AR (M)', 'AR (L)'
+ ]
+
+ info_str = list(zip(stats_names, coco_eval.stats))
+
+ return info_str
diff --git a/mmpose/evaluation/metrics/keypoint_2d_metrics.py b/mmpose/evaluation/metrics/keypoint_2d_metrics.py
index 5c8d23ac08..67206575d6 100644
--- a/mmpose/evaluation/metrics/keypoint_2d_metrics.py
+++ b/mmpose/evaluation/metrics/keypoint_2d_metrics.py
@@ -1,912 +1,912 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import warnings
-from typing import Dict, Optional, Sequence, Union
-
-import numpy as np
-from mmengine.evaluator import BaseMetric
-from mmengine.logging import MMLogger
-
-from mmpose.registry import METRICS
-from ..functional import (keypoint_auc, keypoint_epe, keypoint_nme,
- keypoint_pck_accuracy)
-
-
-@METRICS.register_module()
-class PCKAccuracy(BaseMetric):
- """PCK accuracy evaluation metric.
- Calculate the pose accuracy of Percentage of Correct Keypoints (PCK) for
- each individual keypoint and the averaged accuracy across all keypoints.
- PCK metric measures accuracy of the localization of the body joints.
- The distances between predicted positions and the ground-truth ones
- are typically normalized by the person bounding box size.
- The threshold (thr) of the normalized distance is commonly set
- as 0.05, 0.1 or 0.2 etc.
- Note:
- - length of dataset: N
- - num_keypoints: K
- - number of keypoint dimensions: D (typically D = 2)
- Args:
- thr(float): Threshold of PCK calculation. Default: 0.05.
- norm_item (str | Sequence[str]): The item used for normalization.
- Valid items include 'bbox', 'head', 'torso', which correspond
- to 'PCK', 'PCKh' and 'tPCK' respectively. Default: ``'bbox'``.
- collect_device (str): Device name used for collecting results from
- different ranks during distributed training. Must be ``'cpu'`` or
- ``'gpu'``. Default: ``'cpu'``.
- prefix (str, optional): The prefix that will be added in the metric
- names to disambiguate homonymous metrics of different evaluators.
- If prefix is not provided in the argument, ``self.default_prefix``
- will be used instead. Default: ``None``.
-
- Examples:
-
- >>> from mmpose.evaluation.metrics import PCKAccuracy
- >>> import numpy as np
- >>> from mmengine.structures import InstanceData
- >>> num_keypoints = 15
- >>> keypoints = np.random.random((1, num_keypoints, 2)) * 10
- >>> gt_instances = InstanceData()
- >>> gt_instances.keypoints = keypoints
- >>> gt_instances.keypoints_visible = np.ones(
- ... (1, num_keypoints, 1)).astype(bool)
- >>> gt_instances.bboxes = np.random.random((1, 4)) * 20
- >>> pred_instances = InstanceData()
- >>> pred_instances.keypoints = keypoints
- >>> data_sample = {
- ... 'gt_instances': gt_instances.to_dict(),
- ... 'pred_instances': pred_instances.to_dict(),
- ... }
- >>> data_samples = [data_sample]
- >>> data_batch = [{'inputs': None}]
- >>> pck_metric = PCKAccuracy(thr=0.5, norm_item='bbox')
- ...: UserWarning: The prefix is not set in metric class PCKAccuracy.
- >>> pck_metric.process(data_batch, data_samples)
- >>> pck_metric.evaluate(1)
- 10/26 15:37:57 - mmengine - INFO - Evaluating PCKAccuracy (normalized by ``"bbox_size"``)... # noqa
- {'PCK': 1.0}
-
- """
-
- def __init__(self,
- thr: float = 0.05,
- norm_item: Union[str, Sequence[str]] = 'bbox',
- collect_device: str = 'cpu',
- prefix: Optional[str] = None) -> None:
- super().__init__(collect_device=collect_device, prefix=prefix)
- self.thr = thr
- self.norm_item = norm_item if isinstance(norm_item,
- (tuple,
- list)) else [norm_item]
- allow_normalized_items = ['bbox', 'head', 'torso']
- for item in self.norm_item:
- if item not in allow_normalized_items:
- raise KeyError(
- f'The normalized item {item} is not supported by '
- f"{self.__class__.__name__}. Should be one of 'bbox', "
- f"'head', 'torso', but got {item}.")
-
- def process(self, data_batch: Sequence[dict],
- data_samples: Sequence[dict]) -> None:
- """Process one batch of data samples and predictions.
-
- The processed
- results should be stored in ``self.results``, which will be used to
- compute the metrics when all batches have been processed.
- Args:
- data_batch (Sequence[dict]): A batch of data
- from the dataloader.
- data_samples (Sequence[dict]): A batch of outputs from
- the model.
- """
- for data_sample in data_samples:
- # predicted keypoints coordinates, [1, K, D]
- pred_coords = data_sample['pred_instances']['keypoints']
- # ground truth data_info
- gt = data_sample['gt_instances']
- # ground truth keypoints coordinates, [1, K, D]
- gt_coords = gt['keypoints']
- # ground truth keypoints_visible, [1, K, 1]
- mask = gt['keypoints_visible'].astype(bool).reshape(1, -1)
-
- result = {
- 'pred_coords': pred_coords,
- 'gt_coords': gt_coords,
- 'mask': mask,
- }
-
- if 'bbox' in self.norm_item:
- assert 'bboxes' in gt, 'The ground truth data info do not ' \
- 'have the expected normalized_item ``"bbox"``.'
- # ground truth bboxes, [1, 4]
- bbox_size_ = np.max(gt['bboxes'][0][2:] - gt['bboxes'][0][:2])
- bbox_size = np.array([bbox_size_, bbox_size_]).reshape(-1, 2)
- result['bbox_size'] = bbox_size
-
- if 'head' in self.norm_item:
- assert 'head_size' in gt, 'The ground truth data info do ' \
- 'not have the expected normalized_item ``"head_size"``.'
- # ground truth bboxes
- head_size_ = gt['head_size']
- head_size = np.array([head_size_, head_size_]).reshape(-1, 2)
- result['head_size'] = head_size
-
- if 'torso' in self.norm_item:
- # used in JhmdbDataset
- torso_size_ = np.linalg.norm(gt_coords[0][4] - gt_coords[0][5])
- if torso_size_ < 1:
- torso_size_ = np.linalg.norm(pred_coords[0][4] -
- pred_coords[0][5])
- warnings.warn('Ground truth torso size < 1. '
- 'Use torso size from predicted '
- 'keypoint results instead.')
- torso_size = np.array([torso_size_,
- torso_size_]).reshape(-1, 2)
- result['torso_size'] = torso_size
-
- self.results.append(result)
-
- def compute_metrics(self, results: list) -> Dict[str, float]:
- """Compute the metrics from processed results.
-
- Args:
- results (list): The processed results of each batch.
- Returns:
- Dict[str, float]: The computed metrics. The keys are the names of
- the metrics, and the values are corresponding results.
- The returned result dict may have the following keys:
- - 'PCK': The pck accuracy normalized by `bbox_size`.
- - 'PCKh': The pck accuracy normalized by `head_size`.
- - 'tPCK': The pck accuracy normalized by `torso_size`.
- """
- logger: MMLogger = MMLogger.get_current_instance()
-
- # pred_coords: [N, K, D]
- pred_coords = np.concatenate(
- [result['pred_coords'] for result in results])
- # gt_coords: [N, K, D]
- gt_coords = np.concatenate([result['gt_coords'] for result in results])
- # mask: [N, K]
- mask = np.concatenate([result['mask'] for result in results])
-
- metrics = dict()
- if 'bbox' in self.norm_item:
- norm_size_bbox = np.concatenate(
- [result['bbox_size'] for result in results])
-
- logger.info(f'Evaluating {self.__class__.__name__} '
- f'(normalized by ``"bbox_size"``)...')
-
- _, pck, _ = keypoint_pck_accuracy(pred_coords, gt_coords, mask,
- self.thr, norm_size_bbox)
- metrics['PCK'] = pck
-
- if 'head' in self.norm_item:
- norm_size_head = np.concatenate(
- [result['head_size'] for result in results])
-
- logger.info(f'Evaluating {self.__class__.__name__} '
- f'(normalized by ``"head_size"``)...')
-
- _, pckh, _ = keypoint_pck_accuracy(pred_coords, gt_coords, mask,
- self.thr, norm_size_head)
- metrics['PCKh'] = pckh
-
- if 'torso' in self.norm_item:
- norm_size_torso = np.concatenate(
- [result['torso_size'] for result in results])
-
- logger.info(f'Evaluating {self.__class__.__name__} '
- f'(normalized by ``"torso_size"``)...')
-
- _, tpck, _ = keypoint_pck_accuracy(pred_coords, gt_coords, mask,
- self.thr, norm_size_torso)
- metrics['tPCK'] = tpck
-
- return metrics
-
-
-@METRICS.register_module()
-class MpiiPCKAccuracy(PCKAccuracy):
- """PCKh accuracy evaluation metric for MPII dataset.
-
- Calculate the pose accuracy of Percentage of Correct Keypoints (PCK) for
- each individual keypoint and the averaged accuracy across all keypoints.
- PCK metric measures accuracy of the localization of the body joints.
- The distances between predicted positions and the ground-truth ones
- are typically normalized by the person bounding box size.
- The threshold (thr) of the normalized distance is commonly set
- as 0.05, 0.1 or 0.2 etc.
-
- Note:
- - length of dataset: N
- - num_keypoints: K
- - number of keypoint dimensions: D (typically D = 2)
-
- Args:
- thr(float): Threshold of PCK calculation. Default: 0.05.
- norm_item (str | Sequence[str]): The item used for normalization.
- Valid items include 'bbox', 'head', 'torso', which correspond
- to 'PCK', 'PCKh' and 'tPCK' respectively. Default: ``'head'``.
- collect_device (str): Device name used for collecting results from
- different ranks during distributed training. Must be ``'cpu'`` or
- ``'gpu'``. Default: ``'cpu'``.
- prefix (str, optional): The prefix that will be added in the metric
- names to disambiguate homonymous metrics of different evaluators.
- If prefix is not provided in the argument, ``self.default_prefix``
- will be used instead. Default: ``None``.
-
- Examples:
-
- >>> from mmpose.evaluation.metrics import MpiiPCKAccuracy
- >>> import numpy as np
- >>> from mmengine.structures import InstanceData
- >>> num_keypoints = 16
- >>> keypoints = np.random.random((1, num_keypoints, 2)) * 10
- >>> gt_instances = InstanceData()
- >>> gt_instances.keypoints = keypoints + 1.0
- >>> gt_instances.keypoints_visible = np.ones(
- ... (1, num_keypoints, 1)).astype(bool)
- >>> gt_instances.head_size = np.random.random((1, 1)) * 10
- >>> pred_instances = InstanceData()
- >>> pred_instances.keypoints = keypoints
- >>> data_sample = {
- ... 'gt_instances': gt_instances.to_dict(),
- ... 'pred_instances': pred_instances.to_dict(),
- ... }
- >>> data_samples = [data_sample]
- >>> data_batch = [{'inputs': None}]
- >>> mpii_pck_metric = MpiiPCKAccuracy(thr=0.3, norm_item='head')
- ... UserWarning: The prefix is not set in metric class MpiiPCKAccuracy.
- >>> mpii_pck_metric.process(data_batch, data_samples)
- >>> mpii_pck_metric.evaluate(1)
- 10/26 17:43:39 - mmengine - INFO - Evaluating MpiiPCKAccuracy (normalized by ``"head_size"``)... # noqa
- {'Head PCK': 100.0, 'Shoulder PCK': 100.0, 'Elbow PCK': 100.0,
- Wrist PCK': 100.0, 'Hip PCK': 100.0, 'Knee PCK': 100.0,
- 'Ankle PCK': 100.0, 'PCK': 100.0, 'PCK@0.1': 100.0}
- """
-
- def __init__(self,
- thr: float = 0.5,
- norm_item: Union[str, Sequence[str]] = 'head',
- collect_device: str = 'cpu',
- prefix: Optional[str] = None) -> None:
- super().__init__(
- thr=thr,
- norm_item=norm_item,
- collect_device=collect_device,
- prefix=prefix)
-
- def compute_metrics(self, results: list) -> Dict[str, float]:
- """Compute the metrics from processed results.
-
- Args:
- results (list): The processed results of each batch.
-
- Returns:
- Dict[str, float]: The computed metrics. The keys are the names of
- the metrics, and the values are corresponding results.
- If `'head'` in `self.norm_item`, the returned results are the pck
- accuracy normalized by `head_size`, which have the following keys:
- - 'Head PCK': The PCK of head
- - 'Shoulder PCK': The PCK of shoulder
- - 'Elbow PCK': The PCK of elbow
- - 'Wrist PCK': The PCK of wrist
- - 'Hip PCK': The PCK of hip
- - 'Knee PCK': The PCK of knee
- - 'Ankle PCK': The PCK of ankle
- - 'PCK': The mean PCK over all keypoints
- - 'PCK@0.1': The mean PCK at threshold 0.1
- """
- logger: MMLogger = MMLogger.get_current_instance()
-
- # pred_coords: [N, K, D]
- pred_coords = np.concatenate(
- [result['pred_coords'] for result in results])
- # gt_coords: [N, K, D]
- gt_coords = np.concatenate([result['gt_coords'] for result in results])
- # mask: [N, K]
- mask = np.concatenate([result['mask'] for result in results])
-
- # MPII uses matlab format, gt index is 1-based,
- # convert 0-based index to 1-based index
- pred_coords = pred_coords + 1.0
-
- metrics = {}
- if 'head' in self.norm_item:
- norm_size_head = np.concatenate(
- [result['head_size'] for result in results])
-
- logger.info(f'Evaluating {self.__class__.__name__} '
- f'(normalized by ``"head_size"``)...')
-
- pck_p, _, _ = keypoint_pck_accuracy(pred_coords, gt_coords, mask,
- self.thr, norm_size_head)
-
- jnt_count = np.sum(mask, axis=0)
- PCKh = 100. * pck_p
-
- rng = np.arange(0, 0.5 + 0.01, 0.01)
- pckAll = np.zeros((len(rng), 16), dtype=np.float32)
-
- for r, threshold in enumerate(rng):
- _pck, _, _ = keypoint_pck_accuracy(pred_coords, gt_coords,
- mask, threshold,
- norm_size_head)
- pckAll[r, :] = 100. * _pck
-
- PCKh = np.ma.array(PCKh, mask=False)
- PCKh.mask[6:8] = True
-
- jnt_count = np.ma.array(jnt_count, mask=False)
- jnt_count.mask[6:8] = True
- jnt_ratio = jnt_count / np.sum(jnt_count).astype(np.float64)
-
- # dataset_joints_idx:
- # head 9
- # lsho 13 rsho 12
- # lelb 14 relb 11
- # lwri 15 rwri 10
- # lhip 3 rhip 2
- # lkne 4 rkne 1
- # lank 5 rank 0
- stats = {
- 'Head PCK': PCKh[9],
- 'Shoulder PCK': 0.5 * (PCKh[13] + PCKh[12]),
- 'Elbow PCK': 0.5 * (PCKh[14] + PCKh[11]),
- 'Wrist PCK': 0.5 * (PCKh[15] + PCKh[10]),
- 'Hip PCK': 0.5 * (PCKh[3] + PCKh[2]),
- 'Knee PCK': 0.5 * (PCKh[4] + PCKh[1]),
- 'Ankle PCK': 0.5 * (PCKh[5] + PCKh[0]),
- 'PCK': np.sum(PCKh * jnt_ratio),
- 'PCK@0.1': np.sum(pckAll[10, :] * jnt_ratio)
- }
-
- for stats_name, stat in stats.items():
- metrics[stats_name] = stat
-
- return metrics
-
-
-@METRICS.register_module()
-class JhmdbPCKAccuracy(PCKAccuracy):
- """PCK accuracy evaluation metric for Jhmdb dataset.
-
- Calculate the pose accuracy of Percentage of Correct Keypoints (PCK) for
- each individual keypoint and the averaged accuracy across all keypoints.
- PCK metric measures accuracy of the localization of the body joints.
- The distances between predicted positions and the ground-truth ones
- are typically normalized by the person bounding box size.
- The threshold (thr) of the normalized distance is commonly set
- as 0.05, 0.1 or 0.2 etc.
-
- Note:
- - length of dataset: N
- - num_keypoints: K
- - number of keypoint dimensions: D (typically D = 2)
-
- Args:
- thr(float): Threshold of PCK calculation. Default: 0.05.
- norm_item (str | Sequence[str]): The item used for normalization.
- Valid items include 'bbox', 'head', 'torso', which correspond
- to 'PCK', 'PCKh' and 'tPCK' respectively. Default: ``'bbox'``.
- collect_device (str): Device name used for collecting results from
- different ranks during distributed training. Must be ``'cpu'`` or
- ``'gpu'``. Default: ``'cpu'``.
- prefix (str, optional): The prefix that will be added in the metric
- names to disambiguate homonymous metrics of different evaluators.
- If prefix is not provided in the argument, ``self.default_prefix``
- will be used instead. Default: ``None``.
-
- Examples:
-
- >>> from mmpose.evaluation.metrics import JhmdbPCKAccuracy
- >>> import numpy as np
- >>> from mmengine.structures import InstanceData
- >>> num_keypoints = 15
- >>> keypoints = np.random.random((1, num_keypoints, 2)) * 10
- >>> gt_instances = InstanceData()
- >>> gt_instances.keypoints = keypoints
- >>> gt_instances.keypoints_visible = np.ones(
- ... (1, num_keypoints, 1)).astype(bool)
- >>> gt_instances.bboxes = np.random.random((1, 4)) * 20
- >>> gt_instances.head_size = np.random.random((1, 1)) * 10
- >>> pred_instances = InstanceData()
- >>> pred_instances.keypoints = keypoints
- >>> data_sample = {
- ... 'gt_instances': gt_instances.to_dict(),
- ... 'pred_instances': pred_instances.to_dict(),
- ... }
- >>> data_samples = [data_sample]
- >>> data_batch = [{'inputs': None}]
- >>> jhmdb_pck_metric = JhmdbPCKAccuracy(thr=0.2, norm_item=['bbox', 'torso'])
- ... UserWarning: The prefix is not set in metric class JhmdbPCKAccuracy.
- >>> jhmdb_pck_metric.process(data_batch, data_samples)
- >>> jhmdb_pck_metric.evaluate(1)
- 10/26 17:48:09 - mmengine - INFO - Evaluating JhmdbPCKAccuracy (normalized by ``"bbox_size"``)... # noqa
- 10/26 17:48:09 - mmengine - INFO - Evaluating JhmdbPCKAccuracy (normalized by ``"torso_size"``)... # noqa
- {'Head PCK': 1.0, 'Sho PCK': 1.0, 'Elb PCK': 1.0, 'Wri PCK': 1.0,
- 'Hip PCK': 1.0, 'Knee PCK': 1.0, 'Ank PCK': 1.0, 'PCK': 1.0,
- 'Head tPCK': 1.0, 'Sho tPCK': 1.0, 'Elb tPCK': 1.0, 'Wri tPCK': 1.0,
- 'Hip tPCK': 1.0, 'Knee tPCK': 1.0, 'Ank tPCK': 1.0, 'tPCK': 1.0}
- """
-
- def __init__(self,
- thr: float = 0.05,
- norm_item: Union[str, Sequence[str]] = 'bbox',
- collect_device: str = 'cpu',
- prefix: Optional[str] = None) -> None:
- super().__init__(
- thr=thr,
- norm_item=norm_item,
- collect_device=collect_device,
- prefix=prefix)
-
- def compute_metrics(self, results: list) -> Dict[str, float]:
- """Compute the metrics from processed results.
-
- Args:
- results (list): The processed results of each batch.
-
- Returns:
- Dict[str, float]: The computed metrics. The keys are the names of
- the metrics, and the values are corresponding results.
- If `'bbox'` in `self.norm_item`, the returned results are the pck
- accuracy normalized by `bbox_size`, which have the following keys:
- - 'Head PCK': The PCK of head
- - 'Sho PCK': The PCK of shoulder
- - 'Elb PCK': The PCK of elbow
- - 'Wri PCK': The PCK of wrist
- - 'Hip PCK': The PCK of hip
- - 'Knee PCK': The PCK of knee
- - 'Ank PCK': The PCK of ankle
- - 'PCK': The mean PCK over all keypoints
- If `'torso'` in `self.norm_item`, the returned results are the pck
- accuracy normalized by `torso_size`, which have the following keys:
- - 'Head tPCK': The PCK of head
- - 'Sho tPCK': The PCK of shoulder
- - 'Elb tPCK': The PCK of elbow
- - 'Wri tPCK': The PCK of wrist
- - 'Hip tPCK': The PCK of hip
- - 'Knee tPCK': The PCK of knee
- - 'Ank tPCK': The PCK of ankle
- - 'tPCK': The mean PCK over all keypoints
- """
- logger: MMLogger = MMLogger.get_current_instance()
-
- # pred_coords: [N, K, D]
- pred_coords = np.concatenate(
- [result['pred_coords'] for result in results])
- # gt_coords: [N, K, D]
- gt_coords = np.concatenate([result['gt_coords'] for result in results])
- # mask: [N, K]
- mask = np.concatenate([result['mask'] for result in results])
-
- metrics = dict()
- if 'bbox' in self.norm_item:
- norm_size_bbox = np.concatenate(
- [result['bbox_size'] for result in results])
-
- logger.info(f'Evaluating {self.__class__.__name__} '
- f'(normalized by ``"bbox_size"``)...')
-
- pck_p, pck, _ = keypoint_pck_accuracy(pred_coords, gt_coords, mask,
- self.thr, norm_size_bbox)
- stats = {
- 'Head PCK': pck_p[2],
- 'Sho PCK': 0.5 * pck_p[3] + 0.5 * pck_p[4],
- 'Elb PCK': 0.5 * pck_p[7] + 0.5 * pck_p[8],
- 'Wri PCK': 0.5 * pck_p[11] + 0.5 * pck_p[12],
- 'Hip PCK': 0.5 * pck_p[5] + 0.5 * pck_p[6],
- 'Knee PCK': 0.5 * pck_p[9] + 0.5 * pck_p[10],
- 'Ank PCK': 0.5 * pck_p[13] + 0.5 * pck_p[14],
- 'PCK': pck
- }
-
- for stats_name, stat in stats.items():
- metrics[stats_name] = stat
-
- if 'torso' in self.norm_item:
- norm_size_torso = np.concatenate(
- [result['torso_size'] for result in results])
-
- logger.info(f'Evaluating {self.__class__.__name__} '
- f'(normalized by ``"torso_size"``)...')
-
- pck_p, pck, _ = keypoint_pck_accuracy(pred_coords, gt_coords, mask,
- self.thr, norm_size_torso)
-
- stats = {
- 'Head tPCK': pck_p[2],
- 'Sho tPCK': 0.5 * pck_p[3] + 0.5 * pck_p[4],
- 'Elb tPCK': 0.5 * pck_p[7] + 0.5 * pck_p[8],
- 'Wri tPCK': 0.5 * pck_p[11] + 0.5 * pck_p[12],
- 'Hip tPCK': 0.5 * pck_p[5] + 0.5 * pck_p[6],
- 'Knee tPCK': 0.5 * pck_p[9] + 0.5 * pck_p[10],
- 'Ank tPCK': 0.5 * pck_p[13] + 0.5 * pck_p[14],
- 'tPCK': pck
- }
-
- for stats_name, stat in stats.items():
- metrics[stats_name] = stat
-
- return metrics
-
-
-@METRICS.register_module()
-class AUC(BaseMetric):
- """AUC evaluation metric.
-
- Calculate the Area Under Curve (AUC) of keypoint PCK accuracy.
-
- By altering the threshold percentage in the calculation of PCK accuracy,
- AUC can be generated to further evaluate the pose estimation algorithms.
-
- Note:
- - length of dataset: N
- - num_keypoints: K
- - number of keypoint dimensions: D (typically D = 2)
-
- Args:
- norm_factor (float): AUC normalization factor, Default: 30 (pixels).
- num_thrs (int): number of thresholds to calculate auc. Default: 20.
- collect_device (str): Device name used for collecting results from
- different ranks during distributed training. Must be ``'cpu'`` or
- ``'gpu'``. Default: ``'cpu'``.
- prefix (str, optional): The prefix that will be added in the metric
- names to disambiguate homonymous metrics of different evaluators.
- If prefix is not provided in the argument, ``self.default_prefix``
- will be used instead. Default: ``None``.
- """
-
- def __init__(self,
- norm_factor: float = 30,
- num_thrs: int = 20,
- collect_device: str = 'cpu',
- prefix: Optional[str] = None) -> None:
- super().__init__(collect_device=collect_device, prefix=prefix)
- self.norm_factor = norm_factor
- self.num_thrs = num_thrs
-
- def process(self, data_batch: Sequence[dict],
- data_samples: Sequence[dict]) -> None:
- """Process one batch of data samples and predictions. The processed
- results should be stored in ``self.results``, which will be used to
- compute the metrics when all batches have been processed.
-
- Args:
- data_batch (Sequence[dict]): A batch of data
- from the dataloader.
- data_sample (Sequence[dict]): A batch of outputs from
- the model.
- """
- for data_sample in data_samples:
- # predicted keypoints coordinates, [1, K, D]
- pred_coords = data_sample['pred_instances']['keypoints']
- # ground truth data_info
- gt = data_sample['gt_instances']
- # ground truth keypoints coordinates, [1, K, D]
- gt_coords = gt['keypoints']
- # ground truth keypoints_visible, [1, K, 1]
- mask = gt['keypoints_visible'].astype(bool).reshape(1, -1)
-
- result = {
- 'pred_coords': pred_coords,
- 'gt_coords': gt_coords,
- 'mask': mask,
- }
-
- self.results.append(result)
-
- def compute_metrics(self, results: list) -> Dict[str, float]:
- """Compute the metrics from processed results.
-
- Args:
- results (list): The processed results of each batch.
-
- Returns:
- Dict[str, float]: The computed metrics. The keys are the names of
- the metrics, and the values are corresponding results.
- """
- logger: MMLogger = MMLogger.get_current_instance()
-
- # pred_coords: [N, K, D]
- pred_coords = np.concatenate(
- [result['pred_coords'] for result in results])
- # gt_coords: [N, K, D]
- gt_coords = np.concatenate([result['gt_coords'] for result in results])
- # mask: [N, K]
- mask = np.concatenate([result['mask'] for result in results])
-
- logger.info(f'Evaluating {self.__class__.__name__}...')
-
- auc = keypoint_auc(pred_coords, gt_coords, mask, self.norm_factor,
- self.num_thrs)
-
- metrics = dict()
- metrics['AUC'] = auc
-
- return metrics
-
-
-@METRICS.register_module()
-class EPE(BaseMetric):
- """EPE evaluation metric.
-
- Calculate the end-point error (EPE) of keypoints.
-
- Note:
- - length of dataset: N
- - num_keypoints: K
- - number of keypoint dimensions: D (typically D = 2)
-
- Args:
- collect_device (str): Device name used for collecting results from
- different ranks during distributed training. Must be ``'cpu'`` or
- ``'gpu'``. Default: ``'cpu'``.
- prefix (str, optional): The prefix that will be added in the metric
- names to disambiguate homonymous metrics of different evaluators.
- If prefix is not provided in the argument, ``self.default_prefix``
- will be used instead. Default: ``None``.
- """
-
- def process(self, data_batch: Sequence[dict],
- data_samples: Sequence[dict]) -> None:
- """Process one batch of data samples and predictions. The processed
- results should be stored in ``self.results``, which will be used to
- compute the metrics when all batches have been processed.
-
- Args:
- data_batch (Sequence[dict]): A batch of data
- from the dataloader.
- data_samples (Sequence[dict]): A batch of outputs from
- the model.
- """
- for data_sample in data_samples:
- # predicted keypoints coordinates, [1, K, D]
- pred_coords = data_sample['pred_instances']['keypoints']
- # ground truth data_info
- gt = data_sample['gt_instances']
- # ground truth keypoints coordinates, [1, K, D]
- gt_coords = gt['keypoints']
- # ground truth keypoints_visible, [1, K, 1]
- mask = gt['keypoints_visible'].astype(bool).reshape(1, -1)
-
- result = {
- 'pred_coords': pred_coords,
- 'gt_coords': gt_coords,
- 'mask': mask,
- }
-
- self.results.append(result)
-
- def compute_metrics(self, results: list) -> Dict[str, float]:
- """Compute the metrics from processed results.
-
- Args:
- results (list): The processed results of each batch.
-
- Returns:
- Dict[str, float]: The computed metrics. The keys are the names of
- the metrics, and the values are corresponding results.
- """
- logger: MMLogger = MMLogger.get_current_instance()
-
- # pred_coords: [N, K, D]
- pred_coords = np.concatenate(
- [result['pred_coords'] for result in results])
- # gt_coords: [N, K, D]
- gt_coords = np.concatenate([result['gt_coords'] for result in results])
- # mask: [N, K]
- mask = np.concatenate([result['mask'] for result in results])
-
- logger.info(f'Evaluating {self.__class__.__name__}...')
-
- epe = keypoint_epe(pred_coords, gt_coords, mask)
-
- metrics = dict()
- metrics['EPE'] = epe
-
- return metrics
-
-
-@METRICS.register_module()
-class NME(BaseMetric):
- """NME evaluation metric.
-
- Calculate the normalized mean error (NME) of keypoints.
-
- Note:
- - length of dataset: N
- - num_keypoints: K
- - number of keypoint dimensions: D (typically D = 2)
-
- Args:
- norm_mode (str): The normalization mode. There are two valid modes:
- `'use_norm_item'` and `'keypoint_distance'`.
- When set as `'use_norm_item'`, should specify the argument
- `norm_item`, which represents the item in the datainfo that
- will be used as the normalization factor.
- When set as `'keypoint_distance'`, should specify the argument
- `keypoint_indices` that are used to calculate the keypoint
- distance as the normalization factor.
- norm_item (str, optional): The item used as the normalization factor.
- For example, `'bbox_size'` in `'AFLWDataset'`. Only valid when
- ``norm_mode`` is ``use_norm_item``.
- Default: ``None``.
- keypoint_indices (Sequence[int], optional): The keypoint indices used
- to calculate the keypoint distance as the normalization factor.
- Only valid when ``norm_mode`` is ``keypoint_distance``.
- If set as None, will use the default ``keypoint_indices`` in
- `DEFAULT_KEYPOINT_INDICES` for specific datasets, else use the
- given ``keypoint_indices`` of the dataset. Default: ``None``.
- collect_device (str): Device name used for collecting results from
- different ranks during distributed training. Must be ``'cpu'`` or
- ``'gpu'``. Default: ``'cpu'``.
- prefix (str, optional): The prefix that will be added in the metric
- names to disambiguate homonymous metrics of different evaluators.
- If prefix is not provided in the argument, ``self.default_prefix``
- will be used instead. Default: ``None``.
- """
-
- DEFAULT_KEYPOINT_INDICES = {
- # horse10: corresponding to `nose` and `eye` keypoints
- 'horse10': [0, 1],
- # 300w: corresponding to `right-most` and `left-most` eye keypoints
- '300w': [36, 45],
- # coco_wholebody_face corresponding to `right-most` and `left-most`
- # eye keypoints
- 'coco_wholebody_face': [36, 45],
- # cofw: corresponding to `right-most` and `left-most` eye keypoints
- 'cofw': [8, 9],
- # wflw: corresponding to `right-most` and `left-most` eye keypoints
- 'wflw': [60, 72],
- # lapa: corresponding to `right-most` and `left-most` eye keypoints
- 'lapa': [66, 79],
- }
-
- def __init__(self,
- norm_mode: str,
- norm_item: Optional[str] = None,
- keypoint_indices: Optional[Sequence[int]] = None,
- collect_device: str = 'cpu',
- prefix: Optional[str] = None) -> None:
- super().__init__(collect_device=collect_device, prefix=prefix)
- allowed_norm_modes = ['use_norm_item', 'keypoint_distance']
- if norm_mode not in allowed_norm_modes:
- raise KeyError("`norm_mode` should be 'use_norm_item' or "
- f"'keypoint_distance', but got {norm_mode}.")
-
- self.norm_mode = norm_mode
- if self.norm_mode == 'use_norm_item':
- if not norm_item:
- raise KeyError('`norm_mode` is set to `"use_norm_item"`, '
- 'please specify the `norm_item` in the '
- 'datainfo used as the normalization factor.')
- self.norm_item = norm_item
- self.keypoint_indices = keypoint_indices
-
- def process(self, data_batch: Sequence[dict],
- data_samples: Sequence[dict]) -> None:
- """Process one batch of data samples and predictions. The processed
- results should be stored in ``self.results``, which will be used to
- compute the metrics when all batches have been processed.
-
- Args:
- data_batch (Sequence[dict]): A batch of data
- from the dataloader.
- data_samples (Sequence[dict]): A batch of outputs from
- the model.
- """
- for data_sample in data_samples:
- # predicted keypoints coordinates, [1, K, D]
- pred_coords = data_sample['pred_instances']['keypoints']
- # ground truth data_info
- gt = data_sample['gt_instances']
- # ground truth keypoints coordinates, [1, K, D]
- gt_coords = gt['keypoints']
- # ground truth keypoints_visible, [1, K, 1]
- mask = gt['keypoints_visible'].astype(bool).reshape(1, -1)
-
- result = {
- 'pred_coords': pred_coords,
- 'gt_coords': gt_coords,
- 'mask': mask,
- }
-
- if self.norm_item:
- if self.norm_item == 'bbox_size':
- assert 'bboxes' in gt, 'The ground truth data info do ' \
- 'not have the item ``bboxes`` for expected ' \
- 'normalized_item ``"bbox_size"``.'
- # ground truth bboxes, [1, 4]
- bbox_size = np.max(gt['bboxes'][0][2:] -
- gt['bboxes'][0][:2])
- result['bbox_size'] = np.array([bbox_size]).reshape(-1, 1)
- else:
- assert self.norm_item in gt, f'The ground truth data ' \
- f'info do not have the expected normalized factor ' \
- f'"{self.norm_item}"'
- # ground truth norm_item
- result[self.norm_item] = np.array(
- gt[self.norm_item]).reshape([-1, 1])
-
- self.results.append(result)
-
- def compute_metrics(self, results: list) -> Dict[str, float]:
- """Compute the metrics from processed results.
-
- Args:
- results (list): The processed results of each batch.
-
- Returns:
- Dict[str, float]: The computed metrics. The keys are the names of
- the metrics, and the values are corresponding results.
- """
- logger: MMLogger = MMLogger.get_current_instance()
-
- # pred_coords: [N, K, D]
- pred_coords = np.concatenate(
- [result['pred_coords'] for result in results])
- # gt_coords: [N, K, D]
- gt_coords = np.concatenate([result['gt_coords'] for result in results])
- # mask: [N, K]
- mask = np.concatenate([result['mask'] for result in results])
-
- logger.info(f'Evaluating {self.__class__.__name__}...')
- metrics = dict()
-
- if self.norm_mode == 'use_norm_item':
- normalize_factor_ = np.concatenate(
- [result[self.norm_item] for result in results])
- # normalize_factor: [N, 2]
- normalize_factor = np.tile(normalize_factor_, [1, 2])
- nme = keypoint_nme(pred_coords, gt_coords, mask, normalize_factor)
- metrics['NME'] = nme
-
- else:
- if self.keypoint_indices is None:
- # use default keypoint_indices in some datasets
- dataset_name = self.dataset_meta['dataset_name']
- if dataset_name not in self.DEFAULT_KEYPOINT_INDICES:
- raise KeyError(
- '`norm_mode` is set to `keypoint_distance`, and the '
- 'keypoint_indices is set to None, can not find the '
- 'keypoint_indices in `DEFAULT_KEYPOINT_INDICES`, '
- 'please specify `keypoint_indices` appropriately.')
- self.keypoint_indices = self.DEFAULT_KEYPOINT_INDICES[
- dataset_name]
- else:
- assert len(self.keypoint_indices) == 2, 'The keypoint '\
- 'indices used for normalization should be a pair.'
- keypoint_id2name = self.dataset_meta['keypoint_id2name']
- dataset_name = self.dataset_meta['dataset_name']
- for idx in self.keypoint_indices:
- assert idx in keypoint_id2name, f'The {dataset_name} '\
- f'dataset does not contain the required '\
- f'{idx}-th keypoint.'
- # normalize_factor: [N, 2]
- normalize_factor = self._get_normalize_factor(gt_coords=gt_coords)
- nme = keypoint_nme(pred_coords, gt_coords, mask, normalize_factor)
- metrics['NME'] = nme
-
- return metrics
-
- def _get_normalize_factor(self, gt_coords: np.ndarray) -> np.ndarray:
- """Get the normalize factor. generally inter-ocular distance measured
- as the Euclidean distance between the outer corners of the eyes is
- used.
-
- Args:
- gt_coords (np.ndarray[N, K, 2]): Groundtruth keypoint coordinates.
-
- Returns:
- np.ndarray[N, 2]: normalized factor
- """
- idx1, idx2 = self.keypoint_indices
-
- interocular = np.linalg.norm(
- gt_coords[:, idx1, :] - gt_coords[:, idx2, :],
- axis=1,
- keepdims=True)
-
- return np.tile(interocular, [1, 2])
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Dict, Optional, Sequence, Union
+
+import numpy as np
+from mmengine.evaluator import BaseMetric
+from mmengine.logging import MMLogger
+
+from mmpose.registry import METRICS
+from ..functional import (keypoint_auc, keypoint_epe, keypoint_nme,
+ keypoint_pck_accuracy)
+
+
+@METRICS.register_module()
+class PCKAccuracy(BaseMetric):
+ """PCK accuracy evaluation metric.
+ Calculate the pose accuracy of Percentage of Correct Keypoints (PCK) for
+ each individual keypoint and the averaged accuracy across all keypoints.
+ PCK metric measures accuracy of the localization of the body joints.
+ The distances between predicted positions and the ground-truth ones
+ are typically normalized by the person bounding box size.
+ The threshold (thr) of the normalized distance is commonly set
+ as 0.05, 0.1 or 0.2 etc.
+ Note:
+ - length of dataset: N
+ - num_keypoints: K
+ - number of keypoint dimensions: D (typically D = 2)
+ Args:
+ thr(float): Threshold of PCK calculation. Default: 0.05.
+ norm_item (str | Sequence[str]): The item used for normalization.
+ Valid items include 'bbox', 'head', 'torso', which correspond
+ to 'PCK', 'PCKh' and 'tPCK' respectively. Default: ``'bbox'``.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be ``'cpu'`` or
+ ``'gpu'``. Default: ``'cpu'``.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, ``self.default_prefix``
+ will be used instead. Default: ``None``.
+
+ Examples:
+
+ >>> from mmpose.evaluation.metrics import PCKAccuracy
+ >>> import numpy as np
+ >>> from mmengine.structures import InstanceData
+ >>> num_keypoints = 15
+ >>> keypoints = np.random.random((1, num_keypoints, 2)) * 10
+ >>> gt_instances = InstanceData()
+ >>> gt_instances.keypoints = keypoints
+ >>> gt_instances.keypoints_visible = np.ones(
+ ... (1, num_keypoints, 1)).astype(bool)
+ >>> gt_instances.bboxes = np.random.random((1, 4)) * 20
+ >>> pred_instances = InstanceData()
+ >>> pred_instances.keypoints = keypoints
+ >>> data_sample = {
+ ... 'gt_instances': gt_instances.to_dict(),
+ ... 'pred_instances': pred_instances.to_dict(),
+ ... }
+ >>> data_samples = [data_sample]
+ >>> data_batch = [{'inputs': None}]
+ >>> pck_metric = PCKAccuracy(thr=0.5, norm_item='bbox')
+ ...: UserWarning: The prefix is not set in metric class PCKAccuracy.
+ >>> pck_metric.process(data_batch, data_samples)
+ >>> pck_metric.evaluate(1)
+ 10/26 15:37:57 - mmengine - INFO - Evaluating PCKAccuracy (normalized by ``"bbox_size"``)... # noqa
+ {'PCK': 1.0}
+
+ """
+
+ def __init__(self,
+ thr: float = 0.05,
+ norm_item: Union[str, Sequence[str]] = 'bbox',
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ self.thr = thr
+ self.norm_item = norm_item if isinstance(norm_item,
+ (tuple,
+ list)) else [norm_item]
+ allow_normalized_items = ['bbox', 'head', 'torso']
+ for item in self.norm_item:
+ if item not in allow_normalized_items:
+ raise KeyError(
+ f'The normalized item {item} is not supported by '
+ f"{self.__class__.__name__}. Should be one of 'bbox', "
+ f"'head', 'torso', but got {item}.")
+
+ def process(self, data_batch: Sequence[dict],
+ data_samples: Sequence[dict]) -> None:
+ """Process one batch of data samples and predictions.
+
+ The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+ Args:
+ data_batch (Sequence[dict]): A batch of data
+ from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from
+ the model.
+ """
+ for data_sample in data_samples:
+ # predicted keypoints coordinates, [1, K, D]
+ pred_coords = data_sample['pred_instances']['keypoints']
+ # ground truth data_info
+ gt = data_sample['gt_instances']
+ # ground truth keypoints coordinates, [1, K, D]
+ gt_coords = gt['keypoints']
+ # ground truth keypoints_visible, [1, K, 1]
+ mask = gt['keypoints_visible'].astype(bool).reshape(1, -1)
+
+ result = {
+ 'pred_coords': pred_coords,
+ 'gt_coords': gt_coords,
+ 'mask': mask,
+ }
+
+ if 'bbox' in self.norm_item:
+ assert 'bboxes' in gt, 'The ground truth data info do not ' \
+ 'have the expected normalized_item ``"bbox"``.'
+ # ground truth bboxes, [1, 4]
+ bbox_size_ = np.max(gt['bboxes'][0][2:] - gt['bboxes'][0][:2])
+ bbox_size = np.array([bbox_size_, bbox_size_]).reshape(-1, 2)
+ result['bbox_size'] = bbox_size
+
+ if 'head' in self.norm_item:
+ assert 'head_size' in gt, 'The ground truth data info do ' \
+ 'not have the expected normalized_item ``"head_size"``.'
+ # ground truth bboxes
+ head_size_ = gt['head_size']
+ head_size = np.array([head_size_, head_size_]).reshape(-1, 2)
+ result['head_size'] = head_size
+
+ if 'torso' in self.norm_item:
+ # used in JhmdbDataset
+ torso_size_ = np.linalg.norm(gt_coords[0][4] - gt_coords[0][5])
+ if torso_size_ < 1:
+ torso_size_ = np.linalg.norm(pred_coords[0][4] -
+ pred_coords[0][5])
+ warnings.warn('Ground truth torso size < 1. '
+ 'Use torso size from predicted '
+ 'keypoint results instead.')
+ torso_size = np.array([torso_size_,
+ torso_size_]).reshape(-1, 2)
+ result['torso_size'] = torso_size
+
+ self.results.append(result)
+
+ def compute_metrics(self, results: list) -> Dict[str, float]:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+ Returns:
+ Dict[str, float]: The computed metrics. The keys are the names of
+ the metrics, and the values are corresponding results.
+ The returned result dict may have the following keys:
+ - 'PCK': The pck accuracy normalized by `bbox_size`.
+ - 'PCKh': The pck accuracy normalized by `head_size`.
+ - 'tPCK': The pck accuracy normalized by `torso_size`.
+ """
+ logger: MMLogger = MMLogger.get_current_instance()
+
+ # pred_coords: [N, K, D]
+ pred_coords = np.concatenate(
+ [result['pred_coords'] for result in results])
+ # gt_coords: [N, K, D]
+ gt_coords = np.concatenate([result['gt_coords'] for result in results])
+ # mask: [N, K]
+ mask = np.concatenate([result['mask'] for result in results])
+
+ metrics = dict()
+ if 'bbox' in self.norm_item:
+ norm_size_bbox = np.concatenate(
+ [result['bbox_size'] for result in results])
+
+ logger.info(f'Evaluating {self.__class__.__name__} '
+ f'(normalized by ``"bbox_size"``)...')
+
+ _, pck, _ = keypoint_pck_accuracy(pred_coords, gt_coords, mask,
+ self.thr, norm_size_bbox)
+ metrics['PCK'] = pck
+
+ if 'head' in self.norm_item:
+ norm_size_head = np.concatenate(
+ [result['head_size'] for result in results])
+
+ logger.info(f'Evaluating {self.__class__.__name__} '
+ f'(normalized by ``"head_size"``)...')
+
+ _, pckh, _ = keypoint_pck_accuracy(pred_coords, gt_coords, mask,
+ self.thr, norm_size_head)
+ metrics['PCKh'] = pckh
+
+ if 'torso' in self.norm_item:
+ norm_size_torso = np.concatenate(
+ [result['torso_size'] for result in results])
+
+ logger.info(f'Evaluating {self.__class__.__name__} '
+ f'(normalized by ``"torso_size"``)...')
+
+ _, tpck, _ = keypoint_pck_accuracy(pred_coords, gt_coords, mask,
+ self.thr, norm_size_torso)
+ metrics['tPCK'] = tpck
+
+ return metrics
+
+
+@METRICS.register_module()
+class MpiiPCKAccuracy(PCKAccuracy):
+ """PCKh accuracy evaluation metric for MPII dataset.
+
+ Calculate the pose accuracy of Percentage of Correct Keypoints (PCK) for
+ each individual keypoint and the averaged accuracy across all keypoints.
+ PCK metric measures accuracy of the localization of the body joints.
+ The distances between predicted positions and the ground-truth ones
+ are typically normalized by the person bounding box size.
+ The threshold (thr) of the normalized distance is commonly set
+ as 0.05, 0.1 or 0.2 etc.
+
+ Note:
+ - length of dataset: N
+ - num_keypoints: K
+ - number of keypoint dimensions: D (typically D = 2)
+
+ Args:
+ thr(float): Threshold of PCK calculation. Default: 0.05.
+ norm_item (str | Sequence[str]): The item used for normalization.
+ Valid items include 'bbox', 'head', 'torso', which correspond
+ to 'PCK', 'PCKh' and 'tPCK' respectively. Default: ``'head'``.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be ``'cpu'`` or
+ ``'gpu'``. Default: ``'cpu'``.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, ``self.default_prefix``
+ will be used instead. Default: ``None``.
+
+ Examples:
+
+ >>> from mmpose.evaluation.metrics import MpiiPCKAccuracy
+ >>> import numpy as np
+ >>> from mmengine.structures import InstanceData
+ >>> num_keypoints = 16
+ >>> keypoints = np.random.random((1, num_keypoints, 2)) * 10
+ >>> gt_instances = InstanceData()
+ >>> gt_instances.keypoints = keypoints + 1.0
+ >>> gt_instances.keypoints_visible = np.ones(
+ ... (1, num_keypoints, 1)).astype(bool)
+ >>> gt_instances.head_size = np.random.random((1, 1)) * 10
+ >>> pred_instances = InstanceData()
+ >>> pred_instances.keypoints = keypoints
+ >>> data_sample = {
+ ... 'gt_instances': gt_instances.to_dict(),
+ ... 'pred_instances': pred_instances.to_dict(),
+ ... }
+ >>> data_samples = [data_sample]
+ >>> data_batch = [{'inputs': None}]
+ >>> mpii_pck_metric = MpiiPCKAccuracy(thr=0.3, norm_item='head')
+ ... UserWarning: The prefix is not set in metric class MpiiPCKAccuracy.
+ >>> mpii_pck_metric.process(data_batch, data_samples)
+ >>> mpii_pck_metric.evaluate(1)
+ 10/26 17:43:39 - mmengine - INFO - Evaluating MpiiPCKAccuracy (normalized by ``"head_size"``)... # noqa
+ {'Head PCK': 100.0, 'Shoulder PCK': 100.0, 'Elbow PCK': 100.0,
+ Wrist PCK': 100.0, 'Hip PCK': 100.0, 'Knee PCK': 100.0,
+ 'Ankle PCK': 100.0, 'PCK': 100.0, 'PCK@0.1': 100.0}
+ """
+
+ def __init__(self,
+ thr: float = 0.5,
+ norm_item: Union[str, Sequence[str]] = 'head',
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ super().__init__(
+ thr=thr,
+ norm_item=norm_item,
+ collect_device=collect_device,
+ prefix=prefix)
+
+ def compute_metrics(self, results: list) -> Dict[str, float]:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ Dict[str, float]: The computed metrics. The keys are the names of
+ the metrics, and the values are corresponding results.
+ If `'head'` in `self.norm_item`, the returned results are the pck
+ accuracy normalized by `head_size`, which have the following keys:
+ - 'Head PCK': The PCK of head
+ - 'Shoulder PCK': The PCK of shoulder
+ - 'Elbow PCK': The PCK of elbow
+ - 'Wrist PCK': The PCK of wrist
+ - 'Hip PCK': The PCK of hip
+ - 'Knee PCK': The PCK of knee
+ - 'Ankle PCK': The PCK of ankle
+ - 'PCK': The mean PCK over all keypoints
+ - 'PCK@0.1': The mean PCK at threshold 0.1
+ """
+ logger: MMLogger = MMLogger.get_current_instance()
+
+ # pred_coords: [N, K, D]
+ pred_coords = np.concatenate(
+ [result['pred_coords'] for result in results])
+ # gt_coords: [N, K, D]
+ gt_coords = np.concatenate([result['gt_coords'] for result in results])
+ # mask: [N, K]
+ mask = np.concatenate([result['mask'] for result in results])
+
+ # MPII uses matlab format, gt index is 1-based,
+ # convert 0-based index to 1-based index
+ pred_coords = pred_coords + 1.0
+
+ metrics = {}
+ if 'head' in self.norm_item:
+ norm_size_head = np.concatenate(
+ [result['head_size'] for result in results])
+
+ logger.info(f'Evaluating {self.__class__.__name__} '
+ f'(normalized by ``"head_size"``)...')
+
+ pck_p, _, _ = keypoint_pck_accuracy(pred_coords, gt_coords, mask,
+ self.thr, norm_size_head)
+
+ jnt_count = np.sum(mask, axis=0)
+ PCKh = 100. * pck_p
+
+ rng = np.arange(0, 0.5 + 0.01, 0.01)
+ pckAll = np.zeros((len(rng), 16), dtype=np.float32)
+
+ for r, threshold in enumerate(rng):
+ _pck, _, _ = keypoint_pck_accuracy(pred_coords, gt_coords,
+ mask, threshold,
+ norm_size_head)
+ pckAll[r, :] = 100. * _pck
+
+ PCKh = np.ma.array(PCKh, mask=False)
+ PCKh.mask[6:8] = True
+
+ jnt_count = np.ma.array(jnt_count, mask=False)
+ jnt_count.mask[6:8] = True
+ jnt_ratio = jnt_count / np.sum(jnt_count).astype(np.float64)
+
+ # dataset_joints_idx:
+ # head 9
+ # lsho 13 rsho 12
+ # lelb 14 relb 11
+ # lwri 15 rwri 10
+ # lhip 3 rhip 2
+ # lkne 4 rkne 1
+ # lank 5 rank 0
+ stats = {
+ 'Head PCK': PCKh[9],
+ 'Shoulder PCK': 0.5 * (PCKh[13] + PCKh[12]),
+ 'Elbow PCK': 0.5 * (PCKh[14] + PCKh[11]),
+ 'Wrist PCK': 0.5 * (PCKh[15] + PCKh[10]),
+ 'Hip PCK': 0.5 * (PCKh[3] + PCKh[2]),
+ 'Knee PCK': 0.5 * (PCKh[4] + PCKh[1]),
+ 'Ankle PCK': 0.5 * (PCKh[5] + PCKh[0]),
+ 'PCK': np.sum(PCKh * jnt_ratio),
+ 'PCK@0.1': np.sum(pckAll[10, :] * jnt_ratio)
+ }
+
+ for stats_name, stat in stats.items():
+ metrics[stats_name] = stat
+
+ return metrics
+
+
+@METRICS.register_module()
+class JhmdbPCKAccuracy(PCKAccuracy):
+ """PCK accuracy evaluation metric for Jhmdb dataset.
+
+ Calculate the pose accuracy of Percentage of Correct Keypoints (PCK) for
+ each individual keypoint and the averaged accuracy across all keypoints.
+ PCK metric measures accuracy of the localization of the body joints.
+ The distances between predicted positions and the ground-truth ones
+ are typically normalized by the person bounding box size.
+ The threshold (thr) of the normalized distance is commonly set
+ as 0.05, 0.1 or 0.2 etc.
+
+ Note:
+ - length of dataset: N
+ - num_keypoints: K
+ - number of keypoint dimensions: D (typically D = 2)
+
+ Args:
+ thr(float): Threshold of PCK calculation. Default: 0.05.
+ norm_item (str | Sequence[str]): The item used for normalization.
+ Valid items include 'bbox', 'head', 'torso', which correspond
+ to 'PCK', 'PCKh' and 'tPCK' respectively. Default: ``'bbox'``.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be ``'cpu'`` or
+ ``'gpu'``. Default: ``'cpu'``.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, ``self.default_prefix``
+ will be used instead. Default: ``None``.
+
+ Examples:
+
+ >>> from mmpose.evaluation.metrics import JhmdbPCKAccuracy
+ >>> import numpy as np
+ >>> from mmengine.structures import InstanceData
+ >>> num_keypoints = 15
+ >>> keypoints = np.random.random((1, num_keypoints, 2)) * 10
+ >>> gt_instances = InstanceData()
+ >>> gt_instances.keypoints = keypoints
+ >>> gt_instances.keypoints_visible = np.ones(
+ ... (1, num_keypoints, 1)).astype(bool)
+ >>> gt_instances.bboxes = np.random.random((1, 4)) * 20
+ >>> gt_instances.head_size = np.random.random((1, 1)) * 10
+ >>> pred_instances = InstanceData()
+ >>> pred_instances.keypoints = keypoints
+ >>> data_sample = {
+ ... 'gt_instances': gt_instances.to_dict(),
+ ... 'pred_instances': pred_instances.to_dict(),
+ ... }
+ >>> data_samples = [data_sample]
+ >>> data_batch = [{'inputs': None}]
+ >>> jhmdb_pck_metric = JhmdbPCKAccuracy(thr=0.2, norm_item=['bbox', 'torso'])
+ ... UserWarning: The prefix is not set in metric class JhmdbPCKAccuracy.
+ >>> jhmdb_pck_metric.process(data_batch, data_samples)
+ >>> jhmdb_pck_metric.evaluate(1)
+ 10/26 17:48:09 - mmengine - INFO - Evaluating JhmdbPCKAccuracy (normalized by ``"bbox_size"``)... # noqa
+ 10/26 17:48:09 - mmengine - INFO - Evaluating JhmdbPCKAccuracy (normalized by ``"torso_size"``)... # noqa
+ {'Head PCK': 1.0, 'Sho PCK': 1.0, 'Elb PCK': 1.0, 'Wri PCK': 1.0,
+ 'Hip PCK': 1.0, 'Knee PCK': 1.0, 'Ank PCK': 1.0, 'PCK': 1.0,
+ 'Head tPCK': 1.0, 'Sho tPCK': 1.0, 'Elb tPCK': 1.0, 'Wri tPCK': 1.0,
+ 'Hip tPCK': 1.0, 'Knee tPCK': 1.0, 'Ank tPCK': 1.0, 'tPCK': 1.0}
+ """
+
+ def __init__(self,
+ thr: float = 0.05,
+ norm_item: Union[str, Sequence[str]] = 'bbox',
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ super().__init__(
+ thr=thr,
+ norm_item=norm_item,
+ collect_device=collect_device,
+ prefix=prefix)
+
+ def compute_metrics(self, results: list) -> Dict[str, float]:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ Dict[str, float]: The computed metrics. The keys are the names of
+ the metrics, and the values are corresponding results.
+ If `'bbox'` in `self.norm_item`, the returned results are the pck
+ accuracy normalized by `bbox_size`, which have the following keys:
+ - 'Head PCK': The PCK of head
+ - 'Sho PCK': The PCK of shoulder
+ - 'Elb PCK': The PCK of elbow
+ - 'Wri PCK': The PCK of wrist
+ - 'Hip PCK': The PCK of hip
+ - 'Knee PCK': The PCK of knee
+ - 'Ank PCK': The PCK of ankle
+ - 'PCK': The mean PCK over all keypoints
+ If `'torso'` in `self.norm_item`, the returned results are the pck
+ accuracy normalized by `torso_size`, which have the following keys:
+ - 'Head tPCK': The PCK of head
+ - 'Sho tPCK': The PCK of shoulder
+ - 'Elb tPCK': The PCK of elbow
+ - 'Wri tPCK': The PCK of wrist
+ - 'Hip tPCK': The PCK of hip
+ - 'Knee tPCK': The PCK of knee
+ - 'Ank tPCK': The PCK of ankle
+ - 'tPCK': The mean PCK over all keypoints
+ """
+ logger: MMLogger = MMLogger.get_current_instance()
+
+ # pred_coords: [N, K, D]
+ pred_coords = np.concatenate(
+ [result['pred_coords'] for result in results])
+ # gt_coords: [N, K, D]
+ gt_coords = np.concatenate([result['gt_coords'] for result in results])
+ # mask: [N, K]
+ mask = np.concatenate([result['mask'] for result in results])
+
+ metrics = dict()
+ if 'bbox' in self.norm_item:
+ norm_size_bbox = np.concatenate(
+ [result['bbox_size'] for result in results])
+
+ logger.info(f'Evaluating {self.__class__.__name__} '
+ f'(normalized by ``"bbox_size"``)...')
+
+ pck_p, pck, _ = keypoint_pck_accuracy(pred_coords, gt_coords, mask,
+ self.thr, norm_size_bbox)
+ stats = {
+ 'Head PCK': pck_p[2],
+ 'Sho PCK': 0.5 * pck_p[3] + 0.5 * pck_p[4],
+ 'Elb PCK': 0.5 * pck_p[7] + 0.5 * pck_p[8],
+ 'Wri PCK': 0.5 * pck_p[11] + 0.5 * pck_p[12],
+ 'Hip PCK': 0.5 * pck_p[5] + 0.5 * pck_p[6],
+ 'Knee PCK': 0.5 * pck_p[9] + 0.5 * pck_p[10],
+ 'Ank PCK': 0.5 * pck_p[13] + 0.5 * pck_p[14],
+ 'PCK': pck
+ }
+
+ for stats_name, stat in stats.items():
+ metrics[stats_name] = stat
+
+ if 'torso' in self.norm_item:
+ norm_size_torso = np.concatenate(
+ [result['torso_size'] for result in results])
+
+ logger.info(f'Evaluating {self.__class__.__name__} '
+ f'(normalized by ``"torso_size"``)...')
+
+ pck_p, pck, _ = keypoint_pck_accuracy(pred_coords, gt_coords, mask,
+ self.thr, norm_size_torso)
+
+ stats = {
+ 'Head tPCK': pck_p[2],
+ 'Sho tPCK': 0.5 * pck_p[3] + 0.5 * pck_p[4],
+ 'Elb tPCK': 0.5 * pck_p[7] + 0.5 * pck_p[8],
+ 'Wri tPCK': 0.5 * pck_p[11] + 0.5 * pck_p[12],
+ 'Hip tPCK': 0.5 * pck_p[5] + 0.5 * pck_p[6],
+ 'Knee tPCK': 0.5 * pck_p[9] + 0.5 * pck_p[10],
+ 'Ank tPCK': 0.5 * pck_p[13] + 0.5 * pck_p[14],
+ 'tPCK': pck
+ }
+
+ for stats_name, stat in stats.items():
+ metrics[stats_name] = stat
+
+ return metrics
+
+
+@METRICS.register_module()
+class AUC(BaseMetric):
+ """AUC evaluation metric.
+
+ Calculate the Area Under Curve (AUC) of keypoint PCK accuracy.
+
+ By altering the threshold percentage in the calculation of PCK accuracy,
+ AUC can be generated to further evaluate the pose estimation algorithms.
+
+ Note:
+ - length of dataset: N
+ - num_keypoints: K
+ - number of keypoint dimensions: D (typically D = 2)
+
+ Args:
+ norm_factor (float): AUC normalization factor, Default: 30 (pixels).
+ num_thrs (int): number of thresholds to calculate auc. Default: 20.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be ``'cpu'`` or
+ ``'gpu'``. Default: ``'cpu'``.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, ``self.default_prefix``
+ will be used instead. Default: ``None``.
+ """
+
+ def __init__(self,
+ norm_factor: float = 30,
+ num_thrs: int = 20,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ self.norm_factor = norm_factor
+ self.num_thrs = num_thrs
+
+ def process(self, data_batch: Sequence[dict],
+ data_samples: Sequence[dict]) -> None:
+ """Process one batch of data samples and predictions. The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+
+ Args:
+ data_batch (Sequence[dict]): A batch of data
+ from the dataloader.
+ data_sample (Sequence[dict]): A batch of outputs from
+ the model.
+ """
+ for data_sample in data_samples:
+ # predicted keypoints coordinates, [1, K, D]
+ pred_coords = data_sample['pred_instances']['keypoints']
+ # ground truth data_info
+ gt = data_sample['gt_instances']
+ # ground truth keypoints coordinates, [1, K, D]
+ gt_coords = gt['keypoints']
+ # ground truth keypoints_visible, [1, K, 1]
+ mask = gt['keypoints_visible'].astype(bool).reshape(1, -1)
+
+ result = {
+ 'pred_coords': pred_coords,
+ 'gt_coords': gt_coords,
+ 'mask': mask,
+ }
+
+ self.results.append(result)
+
+ def compute_metrics(self, results: list) -> Dict[str, float]:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ Dict[str, float]: The computed metrics. The keys are the names of
+ the metrics, and the values are corresponding results.
+ """
+ logger: MMLogger = MMLogger.get_current_instance()
+
+ # pred_coords: [N, K, D]
+ pred_coords = np.concatenate(
+ [result['pred_coords'] for result in results])
+ # gt_coords: [N, K, D]
+ gt_coords = np.concatenate([result['gt_coords'] for result in results])
+ # mask: [N, K]
+ mask = np.concatenate([result['mask'] for result in results])
+
+ logger.info(f'Evaluating {self.__class__.__name__}...')
+
+ auc = keypoint_auc(pred_coords, gt_coords, mask, self.norm_factor,
+ self.num_thrs)
+
+ metrics = dict()
+ metrics['AUC'] = auc
+
+ return metrics
+
+
+@METRICS.register_module()
+class EPE(BaseMetric):
+ """EPE evaluation metric.
+
+ Calculate the end-point error (EPE) of keypoints.
+
+ Note:
+ - length of dataset: N
+ - num_keypoints: K
+ - number of keypoint dimensions: D (typically D = 2)
+
+ Args:
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be ``'cpu'`` or
+ ``'gpu'``. Default: ``'cpu'``.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, ``self.default_prefix``
+ will be used instead. Default: ``None``.
+ """
+
+ def process(self, data_batch: Sequence[dict],
+ data_samples: Sequence[dict]) -> None:
+ """Process one batch of data samples and predictions. The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+
+ Args:
+ data_batch (Sequence[dict]): A batch of data
+ from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from
+ the model.
+ """
+ for data_sample in data_samples:
+ # predicted keypoints coordinates, [1, K, D]
+ pred_coords = data_sample['pred_instances']['keypoints']
+ # ground truth data_info
+ gt = data_sample['gt_instances']
+ # ground truth keypoints coordinates, [1, K, D]
+ gt_coords = gt['keypoints']
+ # ground truth keypoints_visible, [1, K, 1]
+ mask = gt['keypoints_visible'].astype(bool).reshape(1, -1)
+
+ result = {
+ 'pred_coords': pred_coords,
+ 'gt_coords': gt_coords,
+ 'mask': mask,
+ }
+
+ self.results.append(result)
+
+ def compute_metrics(self, results: list) -> Dict[str, float]:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ Dict[str, float]: The computed metrics. The keys are the names of
+ the metrics, and the values are corresponding results.
+ """
+ logger: MMLogger = MMLogger.get_current_instance()
+
+ # pred_coords: [N, K, D]
+ pred_coords = np.concatenate(
+ [result['pred_coords'] for result in results])
+ # gt_coords: [N, K, D]
+ gt_coords = np.concatenate([result['gt_coords'] for result in results])
+ # mask: [N, K]
+ mask = np.concatenate([result['mask'] for result in results])
+
+ logger.info(f'Evaluating {self.__class__.__name__}...')
+
+ epe = keypoint_epe(pred_coords, gt_coords, mask)
+
+ metrics = dict()
+ metrics['EPE'] = epe
+
+ return metrics
+
+
+@METRICS.register_module()
+class NME(BaseMetric):
+ """NME evaluation metric.
+
+ Calculate the normalized mean error (NME) of keypoints.
+
+ Note:
+ - length of dataset: N
+ - num_keypoints: K
+ - number of keypoint dimensions: D (typically D = 2)
+
+ Args:
+ norm_mode (str): The normalization mode. There are two valid modes:
+ `'use_norm_item'` and `'keypoint_distance'`.
+ When set as `'use_norm_item'`, should specify the argument
+ `norm_item`, which represents the item in the datainfo that
+ will be used as the normalization factor.
+ When set as `'keypoint_distance'`, should specify the argument
+ `keypoint_indices` that are used to calculate the keypoint
+ distance as the normalization factor.
+ norm_item (str, optional): The item used as the normalization factor.
+ For example, `'bbox_size'` in `'AFLWDataset'`. Only valid when
+ ``norm_mode`` is ``use_norm_item``.
+ Default: ``None``.
+ keypoint_indices (Sequence[int], optional): The keypoint indices used
+ to calculate the keypoint distance as the normalization factor.
+ Only valid when ``norm_mode`` is ``keypoint_distance``.
+ If set as None, will use the default ``keypoint_indices`` in
+ `DEFAULT_KEYPOINT_INDICES` for specific datasets, else use the
+ given ``keypoint_indices`` of the dataset. Default: ``None``.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be ``'cpu'`` or
+ ``'gpu'``. Default: ``'cpu'``.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, ``self.default_prefix``
+ will be used instead. Default: ``None``.
+ """
+
+ DEFAULT_KEYPOINT_INDICES = {
+ # horse10: corresponding to `nose` and `eye` keypoints
+ 'horse10': [0, 1],
+ # 300w: corresponding to `right-most` and `left-most` eye keypoints
+ '300w': [36, 45],
+ # coco_wholebody_face corresponding to `right-most` and `left-most`
+ # eye keypoints
+ 'coco_wholebody_face': [36, 45],
+ # cofw: corresponding to `right-most` and `left-most` eye keypoints
+ 'cofw': [8, 9],
+ # wflw: corresponding to `right-most` and `left-most` eye keypoints
+ 'wflw': [60, 72],
+ # lapa: corresponding to `right-most` and `left-most` eye keypoints
+ 'lapa': [66, 79],
+ }
+
+ def __init__(self,
+ norm_mode: str,
+ norm_item: Optional[str] = None,
+ keypoint_indices: Optional[Sequence[int]] = None,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ allowed_norm_modes = ['use_norm_item', 'keypoint_distance']
+ if norm_mode not in allowed_norm_modes:
+ raise KeyError("`norm_mode` should be 'use_norm_item' or "
+ f"'keypoint_distance', but got {norm_mode}.")
+
+ self.norm_mode = norm_mode
+ if self.norm_mode == 'use_norm_item':
+ if not norm_item:
+ raise KeyError('`norm_mode` is set to `"use_norm_item"`, '
+ 'please specify the `norm_item` in the '
+ 'datainfo used as the normalization factor.')
+ self.norm_item = norm_item
+ self.keypoint_indices = keypoint_indices
+
+ def process(self, data_batch: Sequence[dict],
+ data_samples: Sequence[dict]) -> None:
+ """Process one batch of data samples and predictions. The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+
+ Args:
+ data_batch (Sequence[dict]): A batch of data
+ from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from
+ the model.
+ """
+ for data_sample in data_samples:
+ # predicted keypoints coordinates, [1, K, D]
+ pred_coords = data_sample['pred_instances']['keypoints']
+ # ground truth data_info
+ gt = data_sample['gt_instances']
+ # ground truth keypoints coordinates, [1, K, D]
+ gt_coords = gt['keypoints']
+ # ground truth keypoints_visible, [1, K, 1]
+ mask = gt['keypoints_visible'].astype(bool).reshape(1, -1)
+
+ result = {
+ 'pred_coords': pred_coords,
+ 'gt_coords': gt_coords,
+ 'mask': mask,
+ }
+
+ if self.norm_item:
+ if self.norm_item == 'bbox_size':
+ assert 'bboxes' in gt, 'The ground truth data info do ' \
+ 'not have the item ``bboxes`` for expected ' \
+ 'normalized_item ``"bbox_size"``.'
+ # ground truth bboxes, [1, 4]
+ bbox_size = np.max(gt['bboxes'][0][2:] -
+ gt['bboxes'][0][:2])
+ result['bbox_size'] = np.array([bbox_size]).reshape(-1, 1)
+ else:
+ assert self.norm_item in gt, f'The ground truth data ' \
+ f'info do not have the expected normalized factor ' \
+ f'"{self.norm_item}"'
+ # ground truth norm_item
+ result[self.norm_item] = np.array(
+ gt[self.norm_item]).reshape([-1, 1])
+
+ self.results.append(result)
+
+ def compute_metrics(self, results: list) -> Dict[str, float]:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ Dict[str, float]: The computed metrics. The keys are the names of
+ the metrics, and the values are corresponding results.
+ """
+ logger: MMLogger = MMLogger.get_current_instance()
+
+ # pred_coords: [N, K, D]
+ pred_coords = np.concatenate(
+ [result['pred_coords'] for result in results])
+ # gt_coords: [N, K, D]
+ gt_coords = np.concatenate([result['gt_coords'] for result in results])
+ # mask: [N, K]
+ mask = np.concatenate([result['mask'] for result in results])
+
+ logger.info(f'Evaluating {self.__class__.__name__}...')
+ metrics = dict()
+
+ if self.norm_mode == 'use_norm_item':
+ normalize_factor_ = np.concatenate(
+ [result[self.norm_item] for result in results])
+ # normalize_factor: [N, 2]
+ normalize_factor = np.tile(normalize_factor_, [1, 2])
+ nme = keypoint_nme(pred_coords, gt_coords, mask, normalize_factor)
+ metrics['NME'] = nme
+
+ else:
+ if self.keypoint_indices is None:
+ # use default keypoint_indices in some datasets
+ dataset_name = self.dataset_meta['dataset_name']
+ if dataset_name not in self.DEFAULT_KEYPOINT_INDICES:
+ raise KeyError(
+ '`norm_mode` is set to `keypoint_distance`, and the '
+ 'keypoint_indices is set to None, can not find the '
+ 'keypoint_indices in `DEFAULT_KEYPOINT_INDICES`, '
+ 'please specify `keypoint_indices` appropriately.')
+ self.keypoint_indices = self.DEFAULT_KEYPOINT_INDICES[
+ dataset_name]
+ else:
+ assert len(self.keypoint_indices) == 2, 'The keypoint '\
+ 'indices used for normalization should be a pair.'
+ keypoint_id2name = self.dataset_meta['keypoint_id2name']
+ dataset_name = self.dataset_meta['dataset_name']
+ for idx in self.keypoint_indices:
+ assert idx in keypoint_id2name, f'The {dataset_name} '\
+ f'dataset does not contain the required '\
+ f'{idx}-th keypoint.'
+ # normalize_factor: [N, 2]
+ normalize_factor = self._get_normalize_factor(gt_coords=gt_coords)
+ nme = keypoint_nme(pred_coords, gt_coords, mask, normalize_factor)
+ metrics['NME'] = nme
+
+ return metrics
+
+ def _get_normalize_factor(self, gt_coords: np.ndarray) -> np.ndarray:
+ """Get the normalize factor. generally inter-ocular distance measured
+ as the Euclidean distance between the outer corners of the eyes is
+ used.
+
+ Args:
+ gt_coords (np.ndarray[N, K, 2]): Groundtruth keypoint coordinates.
+
+ Returns:
+ np.ndarray[N, 2]: normalized factor
+ """
+ idx1, idx2 = self.keypoint_indices
+
+ interocular = np.linalg.norm(
+ gt_coords[:, idx1, :] - gt_coords[:, idx2, :],
+ axis=1,
+ keepdims=True)
+
+ return np.tile(interocular, [1, 2])
diff --git a/mmpose/evaluation/metrics/keypoint_3d_metrics.py b/mmpose/evaluation/metrics/keypoint_3d_metrics.py
index e945650c30..0697020320 100644
--- a/mmpose/evaluation/metrics/keypoint_3d_metrics.py
+++ b/mmpose/evaluation/metrics/keypoint_3d_metrics.py
@@ -1,131 +1,131 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from collections import defaultdict
-from os import path as osp
-from typing import Dict, Optional, Sequence
-
-import numpy as np
-from mmengine.evaluator import BaseMetric
-from mmengine.logging import MMLogger
-
-from mmpose.registry import METRICS
-from ..functional import keypoint_mpjpe
-
-
-@METRICS.register_module()
-class MPJPE(BaseMetric):
- """MPJPE evaluation metric.
-
- Calculate the mean per-joint position error (MPJPE) of keypoints.
-
- Note:
- - length of dataset: N
- - num_keypoints: K
- - number of keypoint dimensions: D (typically D = 2)
-
- Args:
- mode (str): Method to align the prediction with the
- ground truth. Supported options are:
-
- - ``'mpjpe'``: no alignment will be applied
- - ``'p-mpjpe'``: align in the least-square sense in scale
- - ``'n-mpjpe'``: align in the least-square sense in
- scale, rotation, and translation.
-
- collect_device (str): Device name used for collecting results from
- different ranks during distributed training. Must be ``'cpu'`` or
- ``'gpu'``. Default: ``'cpu'``.
- prefix (str, optional): The prefix that will be added in the metric
- names to disambiguate homonymous metrics of different evaluators.
- If prefix is not provided in the argument, ``self.default_prefix``
- will be used instead. Default: ``None``.
- """
-
- ALIGNMENT = {'mpjpe': 'none', 'p-mpjpe': 'procrustes', 'n-mpjpe': 'scale'}
-
- def __init__(self,
- mode: str = 'mpjpe',
- collect_device: str = 'cpu',
- prefix: Optional[str] = None) -> None:
- super().__init__(collect_device=collect_device, prefix=prefix)
- allowed_modes = self.ALIGNMENT.keys()
- if mode not in allowed_modes:
- raise KeyError("`mode` should be 'mpjpe', 'p-mpjpe', or "
- f"'n-mpjpe', but got '{mode}'.")
-
- self.mode = mode
-
- def process(self, data_batch: Sequence[dict],
- data_samples: Sequence[dict]) -> None:
- """Process one batch of data samples and predictions. The processed
- results should be stored in ``self.results``, which will be used to
- compute the metrics when all batches have been processed.
-
- Args:
- data_batch (Sequence[dict]): A batch of data
- from the dataloader.
- data_samples (Sequence[dict]): A batch of outputs from
- the model.
- """
- for data_sample in data_samples:
- # predicted keypoints coordinates, [1, K, D]
- pred_coords = data_sample['pred_instances']['keypoints']
- # ground truth data_info
- gt = data_sample['gt_instances']
- # ground truth keypoints coordinates, [1, K, D]
- gt_coords = gt['lifting_target']
- # ground truth keypoints_visible, [1, K, 1]
- mask = gt['lifting_target_visible'].astype(bool).reshape(1, -1)
- # instance action
- img_path = data_sample['target_img_path']
- _, rest = osp.basename(img_path).split('_', 1)
- action, _ = rest.split('.', 1)
-
- result = {
- 'pred_coords': pred_coords,
- 'gt_coords': gt_coords,
- 'mask': mask,
- 'action': action
- }
-
- self.results.append(result)
-
- def compute_metrics(self, results: list) -> Dict[str, float]:
- """Compute the metrics from processed results.
-
- Args:
- results (list): The processed results of each batch.
-
- Returns:
- Dict[str, float]: The computed metrics. The keys are the names of
- the metrics, and the values are the corresponding results.
- """
- logger: MMLogger = MMLogger.get_current_instance()
-
- # pred_coords: [N, K, D]
- pred_coords = np.concatenate(
- [result['pred_coords'] for result in results])
- if pred_coords.ndim == 4 and pred_coords.shape[1] == 1:
- pred_coords = np.squeeze(pred_coords, axis=1)
- # gt_coords: [N, K, D]
- gt_coords = np.stack([result['gt_coords'] for result in results])
- # mask: [N, K]
- mask = np.concatenate([result['mask'] for result in results])
- # action_category_indices: Dict[List[int]]
- action_category_indices = defaultdict(list)
- for idx, result in enumerate(results):
- action_category = result['action'].split('_')[0]
- action_category_indices[action_category].append(idx)
-
- error_name = self.mode.upper()
-
- logger.info(f'Evaluating {self.mode.upper()}...')
- metrics = dict()
-
- metrics[error_name] = keypoint_mpjpe(pred_coords, gt_coords, mask,
- self.ALIGNMENT[self.mode])
-
- for action_category, indices in action_category_indices.items():
- metrics[f'{error_name}_{action_category}'] = keypoint_mpjpe(
- pred_coords[indices], gt_coords[indices], mask[indices])
-
- return metrics
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections import defaultdict
+from os import path as osp
+from typing import Dict, Optional, Sequence
+
+import numpy as np
+from mmengine.evaluator import BaseMetric
+from mmengine.logging import MMLogger
+
+from mmpose.registry import METRICS
+from ..functional import keypoint_mpjpe
+
+
+@METRICS.register_module()
+class MPJPE(BaseMetric):
+ """MPJPE evaluation metric.
+
+ Calculate the mean per-joint position error (MPJPE) of keypoints.
+
+ Note:
+ - length of dataset: N
+ - num_keypoints: K
+ - number of keypoint dimensions: D (typically D = 2)
+
+ Args:
+ mode (str): Method to align the prediction with the
+ ground truth. Supported options are:
+
+ - ``'mpjpe'``: no alignment will be applied
+ - ``'p-mpjpe'``: align in the least-square sense in scale
+ - ``'n-mpjpe'``: align in the least-square sense in
+ scale, rotation, and translation.
+
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be ``'cpu'`` or
+ ``'gpu'``. Default: ``'cpu'``.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, ``self.default_prefix``
+ will be used instead. Default: ``None``.
+ """
+
+ ALIGNMENT = {'mpjpe': 'none', 'p-mpjpe': 'procrustes', 'n-mpjpe': 'scale'}
+
+ def __init__(self,
+ mode: str = 'mpjpe',
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ allowed_modes = self.ALIGNMENT.keys()
+ if mode not in allowed_modes:
+ raise KeyError("`mode` should be 'mpjpe', 'p-mpjpe', or "
+ f"'n-mpjpe', but got '{mode}'.")
+
+ self.mode = mode
+
+ def process(self, data_batch: Sequence[dict],
+ data_samples: Sequence[dict]) -> None:
+ """Process one batch of data samples and predictions. The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+
+ Args:
+ data_batch (Sequence[dict]): A batch of data
+ from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from
+ the model.
+ """
+ for data_sample in data_samples:
+ # predicted keypoints coordinates, [1, K, D]
+ pred_coords = data_sample['pred_instances']['keypoints']
+ # ground truth data_info
+ gt = data_sample['gt_instances']
+ # ground truth keypoints coordinates, [1, K, D]
+ gt_coords = gt['lifting_target']
+ # ground truth keypoints_visible, [1, K, 1]
+ mask = gt['lifting_target_visible'].astype(bool).reshape(1, -1)
+ # instance action
+ img_path = data_sample['target_img_path']
+ _, rest = osp.basename(img_path).split('_', 1)
+ action, _ = rest.split('.', 1)
+
+ result = {
+ 'pred_coords': pred_coords,
+ 'gt_coords': gt_coords,
+ 'mask': mask,
+ 'action': action
+ }
+
+ self.results.append(result)
+
+ def compute_metrics(self, results: list) -> Dict[str, float]:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ Dict[str, float]: The computed metrics. The keys are the names of
+ the metrics, and the values are the corresponding results.
+ """
+ logger: MMLogger = MMLogger.get_current_instance()
+
+ # pred_coords: [N, K, D]
+ pred_coords = np.concatenate(
+ [result['pred_coords'] for result in results])
+ if pred_coords.ndim == 4 and pred_coords.shape[1] == 1:
+ pred_coords = np.squeeze(pred_coords, axis=1)
+ # gt_coords: [N, K, D]
+ gt_coords = np.stack([result['gt_coords'] for result in results])
+ # mask: [N, K]
+ mask = np.concatenate([result['mask'] for result in results])
+ # action_category_indices: Dict[List[int]]
+ action_category_indices = defaultdict(list)
+ for idx, result in enumerate(results):
+ action_category = result['action'].split('_')[0]
+ action_category_indices[action_category].append(idx)
+
+ error_name = self.mode.upper()
+
+ logger.info(f'Evaluating {self.mode.upper()}...')
+ metrics = dict()
+
+ metrics[error_name] = keypoint_mpjpe(pred_coords, gt_coords, mask,
+ self.ALIGNMENT[self.mode])
+
+ for action_category, indices in action_category_indices.items():
+ metrics[f'{error_name}_{action_category}'] = keypoint_mpjpe(
+ pred_coords[indices], gt_coords[indices], mask[indices])
+
+ return metrics
diff --git a/mmpose/evaluation/metrics/keypoint_partition_metric.py b/mmpose/evaluation/metrics/keypoint_partition_metric.py
index fb30eca0d5..eb0c581ed8 100644
--- a/mmpose/evaluation/metrics/keypoint_partition_metric.py
+++ b/mmpose/evaluation/metrics/keypoint_partition_metric.py
@@ -1,203 +1,203 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import warnings
-from collections import OrderedDict
-from copy import deepcopy
-from typing import Sequence
-
-import numpy as np
-from mmengine.evaluator import BaseMetric
-
-from mmpose.registry import METRICS
-
-
-@METRICS.register_module()
-class KeypointPartitionMetric(BaseMetric):
- """Wrapper metric for evaluating pose metric on user-defined body parts.
-
- Sometimes one may be interested in the performance of a pose model on
- certain body parts rather than on all the keypoints. For example,
- ``CocoWholeBodyMetric`` evaluates coco metric on body, foot, face,
- lefthand and righthand. However, ``CocoWholeBodyMetric`` cannot be
- applied to arbitrary custom datasets. This wrapper metric solves this
- problem.
-
- Supported metrics:
- ``CocoMetric`` Note 1: all keypoint ground truth should be stored in
- `keypoints` not other data fields. Note 2: `ann_file` is not
- supported, it will be ignored. Note 3: `score_mode` other than
- 'bbox' may produce results different from the
- ``CocoWholebodyMetric``. Note 4: `nms_mode` other than 'none' may
- produce results different from the ``CocoWholebodyMetric``.
- ``PCKAccuracy`` Note 1: data fields required by ``PCKAccuracy`` should
- be provided, such as bbox, head_size, etc. Note 2: In terms of
- 'torso', since it is specifically designed for ``JhmdbDataset``, it is
- not recommended to use it for other datasets.
- ``AUC`` supported without limitations.
- ``EPE`` supported without limitations.
- ``NME`` only `norm_mode` = 'use_norm_item' is supported,
- 'keypoint_distance' is incompatible with ``KeypointPartitionMetric``.
-
- Incompatible metrics:
- The following metrics are dataset specific metrics:
- ``CocoWholeBodyMetric``
- ``MpiiPCKAccuracy``
- ``JhmdbPCKAccuracy``
- ``PoseTrack18Metric``
- Keypoint partitioning is included in these metrics.
-
- Args:
- metric (dict): arguments to instantiate a metric, please refer to the
- arguments required by the metric of your choice.
- partitions (dict): definition of body partitions. For example, if we
- have 10 keypoints in total, the first 7 keypoints belong to body
- and the last 3 keypoints belong to foot, this field can be like
- this:
- dict(
- body=[0, 1, 2, 3, 4, 5, 6],
- foot=[7, 8, 9],
- all=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
- )
- where the numbers are the indices of keypoints and they can be
- discontinuous.
- """
-
- def __init__(
- self,
- metric: dict,
- partitions: dict,
- ) -> None:
- super().__init__()
- # check metric type
- supported_metric_types = [
- 'CocoMetric', 'PCKAccuracy', 'AUC', 'EPE', 'NME'
- ]
- if metric['type'] not in supported_metric_types:
- raise ValueError(
- 'Metrics supported by KeypointPartitionMetric are CocoMetric, '
- 'PCKAccuracy, AUC, EPE and NME, '
- f"but got {metric['type']}")
-
- # check CocoMetric arguments
- if metric['type'] == 'CocoMetric':
- if 'ann_file' in metric:
- warnings.warn(
- 'KeypointPartitionMetric does not support the ann_file '
- 'argument of CocoMetric, this argument will be ignored.')
- metric['ann_file'] = None
- score_mode = metric.get('score_mode', 'bbox_keypoint')
- if score_mode != 'bbox':
- warnings.warn(
- 'When using KeypointPartitionMetric with CocoMetric, '
- "if score_mode is not 'bbox', pose scores will be "
- "calculated part by part rather than by 'wholebody'. "
- 'Therefore, this may produce results different from the '
- 'CocoWholebodyMetric.')
- nms_mode = metric.get('nms_mode', 'oks_nms')
- if nms_mode != 'none':
- warnings.warn(
- 'When using KeypointPartitionMetric with CocoMetric, '
- 'oks_nms and soft_oks_nms will be calculated part by part '
- "rather than by 'wholebody'. Therefore, this may produce "
- 'results different from the CocoWholebodyMetric.')
-
- # check PCKAccuracy arguments
- if metric['type'] == 'PCKAccuracy':
- norm_item = metric.get('norm_item', 'bbox')
- if norm_item == 'torso' or 'torso' in norm_item:
- warnings.warn(
- 'norm_item torso is used in JhmdbDataset, it may not be '
- 'compatible with other datasets, use at your own risk.')
-
- # check NME arguments
- if metric['type'] == 'NME':
- assert 'norm_mode' in metric, \
- 'Missing norm_mode required by the NME metric.'
- if metric['norm_mode'] != 'use_norm_item':
- raise ValueError(
- "NME norm_mode 'keypoint_distance' is incompatible with "
- 'KeypointPartitionMetric.')
-
- # check partitions
- assert len(partitions) > 0, 'There should be at least one partition.'
- for partition_name, partition in partitions.items():
- assert isinstance(partition, Sequence), \
- 'Each partition should be a sequence.'
- assert len(partition) > 0, \
- 'Each partition should have at least one element.'
- self.partitions = partitions
-
- # instantiate metrics for each partition
- self.metrics = {}
- for partition_name in partitions.keys():
- _metric = deepcopy(metric)
- if 'outfile_prefix' in _metric:
- _metric['outfile_prefix'] = _metric[
- 'outfile_prefix'] + '.' + partition_name
- self.metrics[partition_name] = METRICS.build(_metric)
-
- @BaseMetric.dataset_meta.setter
- def dataset_meta(self, dataset_meta: dict) -> None:
- """Set the dataset meta info to the metric."""
- self._dataset_meta = dataset_meta
- # sigmas required by coco metric have to be split as well
- for partition_name, keypoint_ids in self.partitions.items():
- _dataset_meta = deepcopy(dataset_meta)
- _dataset_meta['num_keypoints'] = len(keypoint_ids)
- _dataset_meta['sigmas'] = _dataset_meta['sigmas'][keypoint_ids]
- self.metrics[partition_name].dataset_meta = _dataset_meta
-
- def process(self, data_batch: Sequence[dict],
- data_samples: Sequence[dict]) -> None:
- """Split data samples by partitions, then call metric.process part by
- part."""
- parted_data_samples = {
- partition_name: []
- for partition_name in self.partitions.keys()
- }
- for data_sample in data_samples:
- for partition_name, keypoint_ids in self.partitions.items():
- _data_sample = deepcopy(data_sample)
- if 'keypoint_scores' in _data_sample['pred_instances']:
- _data_sample['pred_instances'][
- 'keypoint_scores'] = _data_sample['pred_instances'][
- 'keypoint_scores'][:, keypoint_ids]
- _data_sample['pred_instances']['keypoints'] = _data_sample[
- 'pred_instances']['keypoints'][:, keypoint_ids]
- _data_sample['gt_instances']['keypoints'] = _data_sample[
- 'gt_instances']['keypoints'][:, keypoint_ids]
- _data_sample['gt_instances'][
- 'keypoints_visible'] = _data_sample['gt_instances'][
- 'keypoints_visible'][:, keypoint_ids]
-
- # for coco metric
- if 'raw_ann_info' in _data_sample:
- raw_ann_info = _data_sample['raw_ann_info']
- anns = raw_ann_info if isinstance(
- raw_ann_info, list) else [raw_ann_info]
- for ann in anns:
- if 'keypoints' in ann:
- keypoints = np.array(ann['keypoints']).reshape(
- -1, 3)
- keypoints = keypoints[keypoint_ids]
- num_keypoints = np.sum(keypoints[:, 2] > 0)
- ann['keypoints'] = keypoints.flatten().tolist()
- ann['num_keypoints'] = num_keypoints
-
- parted_data_samples[partition_name].append(_data_sample)
-
- for partition_name, metric in self.metrics.items():
- metric.process(data_batch, parted_data_samples[partition_name])
-
- def compute_metrics(self, results: list) -> dict:
- pass
-
- def evaluate(self, size: int) -> dict:
- """Run evaluation for each partition."""
- eval_results = OrderedDict()
- for partition_name, metric in self.metrics.items():
- _eval_results = metric.evaluate(size)
- for key in list(_eval_results.keys()):
- new_key = partition_name + '/' + key
- _eval_results[new_key] = _eval_results.pop(key)
- eval_results.update(_eval_results)
- return eval_results
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from collections import OrderedDict
+from copy import deepcopy
+from typing import Sequence
+
+import numpy as np
+from mmengine.evaluator import BaseMetric
+
+from mmpose.registry import METRICS
+
+
+@METRICS.register_module()
+class KeypointPartitionMetric(BaseMetric):
+ """Wrapper metric for evaluating pose metric on user-defined body parts.
+
+ Sometimes one may be interested in the performance of a pose model on
+ certain body parts rather than on all the keypoints. For example,
+ ``CocoWholeBodyMetric`` evaluates coco metric on body, foot, face,
+ lefthand and righthand. However, ``CocoWholeBodyMetric`` cannot be
+ applied to arbitrary custom datasets. This wrapper metric solves this
+ problem.
+
+ Supported metrics:
+ ``CocoMetric`` Note 1: all keypoint ground truth should be stored in
+ `keypoints` not other data fields. Note 2: `ann_file` is not
+ supported, it will be ignored. Note 3: `score_mode` other than
+ 'bbox' may produce results different from the
+ ``CocoWholebodyMetric``. Note 4: `nms_mode` other than 'none' may
+ produce results different from the ``CocoWholebodyMetric``.
+ ``PCKAccuracy`` Note 1: data fields required by ``PCKAccuracy`` should
+ be provided, such as bbox, head_size, etc. Note 2: In terms of
+ 'torso', since it is specifically designed for ``JhmdbDataset``, it is
+ not recommended to use it for other datasets.
+ ``AUC`` supported without limitations.
+ ``EPE`` supported without limitations.
+ ``NME`` only `norm_mode` = 'use_norm_item' is supported,
+ 'keypoint_distance' is incompatible with ``KeypointPartitionMetric``.
+
+ Incompatible metrics:
+ The following metrics are dataset specific metrics:
+ ``CocoWholeBodyMetric``
+ ``MpiiPCKAccuracy``
+ ``JhmdbPCKAccuracy``
+ ``PoseTrack18Metric``
+ Keypoint partitioning is included in these metrics.
+
+ Args:
+ metric (dict): arguments to instantiate a metric, please refer to the
+ arguments required by the metric of your choice.
+ partitions (dict): definition of body partitions. For example, if we
+ have 10 keypoints in total, the first 7 keypoints belong to body
+ and the last 3 keypoints belong to foot, this field can be like
+ this:
+ dict(
+ body=[0, 1, 2, 3, 4, 5, 6],
+ foot=[7, 8, 9],
+ all=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
+ )
+ where the numbers are the indices of keypoints and they can be
+ discontinuous.
+ """
+
+ def __init__(
+ self,
+ metric: dict,
+ partitions: dict,
+ ) -> None:
+ super().__init__()
+ # check metric type
+ supported_metric_types = [
+ 'CocoMetric', 'PCKAccuracy', 'AUC', 'EPE', 'NME'
+ ]
+ if metric['type'] not in supported_metric_types:
+ raise ValueError(
+ 'Metrics supported by KeypointPartitionMetric are CocoMetric, '
+ 'PCKAccuracy, AUC, EPE and NME, '
+ f"but got {metric['type']}")
+
+ # check CocoMetric arguments
+ if metric['type'] == 'CocoMetric':
+ if 'ann_file' in metric:
+ warnings.warn(
+ 'KeypointPartitionMetric does not support the ann_file '
+ 'argument of CocoMetric, this argument will be ignored.')
+ metric['ann_file'] = None
+ score_mode = metric.get('score_mode', 'bbox_keypoint')
+ if score_mode != 'bbox':
+ warnings.warn(
+ 'When using KeypointPartitionMetric with CocoMetric, '
+ "if score_mode is not 'bbox', pose scores will be "
+ "calculated part by part rather than by 'wholebody'. "
+ 'Therefore, this may produce results different from the '
+ 'CocoWholebodyMetric.')
+ nms_mode = metric.get('nms_mode', 'oks_nms')
+ if nms_mode != 'none':
+ warnings.warn(
+ 'When using KeypointPartitionMetric with CocoMetric, '
+ 'oks_nms and soft_oks_nms will be calculated part by part '
+ "rather than by 'wholebody'. Therefore, this may produce "
+ 'results different from the CocoWholebodyMetric.')
+
+ # check PCKAccuracy arguments
+ if metric['type'] == 'PCKAccuracy':
+ norm_item = metric.get('norm_item', 'bbox')
+ if norm_item == 'torso' or 'torso' in norm_item:
+ warnings.warn(
+ 'norm_item torso is used in JhmdbDataset, it may not be '
+ 'compatible with other datasets, use at your own risk.')
+
+ # check NME arguments
+ if metric['type'] == 'NME':
+ assert 'norm_mode' in metric, \
+ 'Missing norm_mode required by the NME metric.'
+ if metric['norm_mode'] != 'use_norm_item':
+ raise ValueError(
+ "NME norm_mode 'keypoint_distance' is incompatible with "
+ 'KeypointPartitionMetric.')
+
+ # check partitions
+ assert len(partitions) > 0, 'There should be at least one partition.'
+ for partition_name, partition in partitions.items():
+ assert isinstance(partition, Sequence), \
+ 'Each partition should be a sequence.'
+ assert len(partition) > 0, \
+ 'Each partition should have at least one element.'
+ self.partitions = partitions
+
+ # instantiate metrics for each partition
+ self.metrics = {}
+ for partition_name in partitions.keys():
+ _metric = deepcopy(metric)
+ if 'outfile_prefix' in _metric:
+ _metric['outfile_prefix'] = _metric[
+ 'outfile_prefix'] + '.' + partition_name
+ self.metrics[partition_name] = METRICS.build(_metric)
+
+ @BaseMetric.dataset_meta.setter
+ def dataset_meta(self, dataset_meta: dict) -> None:
+ """Set the dataset meta info to the metric."""
+ self._dataset_meta = dataset_meta
+ # sigmas required by coco metric have to be split as well
+ for partition_name, keypoint_ids in self.partitions.items():
+ _dataset_meta = deepcopy(dataset_meta)
+ _dataset_meta['num_keypoints'] = len(keypoint_ids)
+ _dataset_meta['sigmas'] = _dataset_meta['sigmas'][keypoint_ids]
+ self.metrics[partition_name].dataset_meta = _dataset_meta
+
+ def process(self, data_batch: Sequence[dict],
+ data_samples: Sequence[dict]) -> None:
+ """Split data samples by partitions, then call metric.process part by
+ part."""
+ parted_data_samples = {
+ partition_name: []
+ for partition_name in self.partitions.keys()
+ }
+ for data_sample in data_samples:
+ for partition_name, keypoint_ids in self.partitions.items():
+ _data_sample = deepcopy(data_sample)
+ if 'keypoint_scores' in _data_sample['pred_instances']:
+ _data_sample['pred_instances'][
+ 'keypoint_scores'] = _data_sample['pred_instances'][
+ 'keypoint_scores'][:, keypoint_ids]
+ _data_sample['pred_instances']['keypoints'] = _data_sample[
+ 'pred_instances']['keypoints'][:, keypoint_ids]
+ _data_sample['gt_instances']['keypoints'] = _data_sample[
+ 'gt_instances']['keypoints'][:, keypoint_ids]
+ _data_sample['gt_instances'][
+ 'keypoints_visible'] = _data_sample['gt_instances'][
+ 'keypoints_visible'][:, keypoint_ids]
+
+ # for coco metric
+ if 'raw_ann_info' in _data_sample:
+ raw_ann_info = _data_sample['raw_ann_info']
+ anns = raw_ann_info if isinstance(
+ raw_ann_info, list) else [raw_ann_info]
+ for ann in anns:
+ if 'keypoints' in ann:
+ keypoints = np.array(ann['keypoints']).reshape(
+ -1, 3)
+ keypoints = keypoints[keypoint_ids]
+ num_keypoints = np.sum(keypoints[:, 2] > 0)
+ ann['keypoints'] = keypoints.flatten().tolist()
+ ann['num_keypoints'] = num_keypoints
+
+ parted_data_samples[partition_name].append(_data_sample)
+
+ for partition_name, metric in self.metrics.items():
+ metric.process(data_batch, parted_data_samples[partition_name])
+
+ def compute_metrics(self, results: list) -> dict:
+ pass
+
+ def evaluate(self, size: int) -> dict:
+ """Run evaluation for each partition."""
+ eval_results = OrderedDict()
+ for partition_name, metric in self.metrics.items():
+ _eval_results = metric.evaluate(size)
+ for key in list(_eval_results.keys()):
+ new_key = partition_name + '/' + key
+ _eval_results[new_key] = _eval_results.pop(key)
+ eval_results.update(_eval_results)
+ return eval_results
diff --git a/mmpose/evaluation/metrics/posetrack18_metric.py b/mmpose/evaluation/metrics/posetrack18_metric.py
index 86f801455a..0abf5c4c12 100644
--- a/mmpose/evaluation/metrics/posetrack18_metric.py
+++ b/mmpose/evaluation/metrics/posetrack18_metric.py
@@ -1,220 +1,220 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os
-import os.path as osp
-from typing import Dict, List, Optional
-
-import numpy as np
-from mmengine.fileio import dump, load
-from mmengine.logging import MMLogger
-
-from mmpose.registry import METRICS
-from .coco_metric import CocoMetric
-
-try:
- from poseval import eval_helpers
- from poseval.evaluateAP import evaluateAP
- has_poseval = True
-except (ImportError, ModuleNotFoundError):
- has_poseval = False
-
-
-@METRICS.register_module()
-class PoseTrack18Metric(CocoMetric):
- """PoseTrack18 evaluation metric.
-
- Evaluate AP, and mAP for keypoint detection tasks.
- Support PoseTrack18 (video) dataset. Please refer to
- ``__
- for more details.
-
- Args:
- ann_file (str, optional): Path to the coco format annotation file.
- If not specified, ground truth annotations from the dataset will
- be converted to coco format. Defaults to None
- score_mode (str): The mode to score the prediction results which
- should be one of the following options:
-
- - ``'bbox'``: Take the score of bbox as the score of the
- prediction results.
- - ``'bbox_keypoint'``: Use keypoint score to rescore the
- prediction results.
-
- Defaults to ``'bbox_keypoint'`
- keypoint_score_thr (float): The threshold of keypoint score. The
- keypoints with score lower than it will not be included to
- rescore the prediction results. Valid only when ``score_mode`` is
- ``bbox_keypoint``. Defaults to ``0.2``
- nms_mode (str): The mode to perform Non-Maximum Suppression (NMS),
- which should be one of the following options:
-
- - ``'oks_nms'``: Use Object Keypoint Similarity (OKS) to
- perform NMS.
- - ``'soft_oks_nms'``: Use Object Keypoint Similarity (OKS)
- to perform soft NMS.
- - ``'none'``: Do not perform NMS. Typically for bottomup mode
- output.
-
- Defaults to ``'oks_nms'`
- nms_thr (float): The Object Keypoint Similarity (OKS) threshold
- used in NMS when ``nms_mode`` is ``'oks_nms'`` or
- ``'soft_oks_nms'``. Will retain the prediction results with OKS
- lower than ``nms_thr``. Defaults to ``0.9``
- format_only (bool): Whether only format the output results without
- doing quantitative evaluation. This is designed for the need of
- test submission when the ground truth annotations are absent. If
- set to ``True``, ``outfile_prefix`` should specify the path to
- store the output results. Defaults to ``False``
- outfile_prefix (str | None): The prefix of json files. It includes
- the file path and the prefix of filename, e.g., ``'a/b/prefix'``.
- If not specified, a temp file will be created. Defaults to ``None``
- **kwargs: Keyword parameters passed to :class:`mmeval.BaseMetric`
- """
- default_prefix: Optional[str] = 'posetrack18'
-
- def __init__(self,
- ann_file: Optional[str] = None,
- score_mode: str = 'bbox_keypoint',
- keypoint_score_thr: float = 0.2,
- nms_mode: str = 'oks_nms',
- nms_thr: float = 0.9,
- format_only: bool = False,
- outfile_prefix: Optional[str] = None,
- collect_device: str = 'cpu',
- prefix: Optional[str] = None) -> None:
- # raise an error to avoid long time running without getting results
- if not has_poseval:
- raise ImportError('Please install ``poseval`` package for '
- 'evaluation on PoseTrack dataset '
- '(see `requirements/optional.txt`)')
- super().__init__(
- ann_file=ann_file,
- score_mode=score_mode,
- keypoint_score_thr=keypoint_score_thr,
- nms_mode=nms_mode,
- nms_thr=nms_thr,
- format_only=format_only,
- outfile_prefix=outfile_prefix,
- collect_device=collect_device,
- prefix=prefix)
-
- def results2json(self, keypoints: Dict[int, list],
- outfile_prefix: str) -> str:
- """Dump the keypoint detection results into a json file.
-
- Args:
- keypoints (Dict[int, list]): Keypoint detection results
- of the dataset.
- outfile_prefix (str): The filename prefix of the json files.
- If the prefix is "somepath/xxx", the json files will be named
- "somepath/xxx.keypoints.json".
-
- Returns:
- str: The json file name of keypoint results.
- """
- categories = []
-
- cat = {}
- cat['supercategory'] = 'person'
- cat['id'] = 1
- cat['name'] = 'person'
- cat['keypoints'] = [
- 'nose', 'head_bottom', 'head_top', 'left_ear', 'right_ear',
- 'left_shoulder', 'right_shoulder', 'left_elbow', 'right_elbow',
- 'left_wrist', 'right_wrist', 'left_hip', 'right_hip', 'left_knee',
- 'right_knee', 'left_ankle', 'right_ankle'
- ]
- cat['skeleton'] = [[16, 14], [14, 12], [17, 15], [15, 13], [12, 13],
- [6, 12], [7, 13], [6, 7], [6, 8], [7, 9], [8, 10],
- [9, 11], [2, 3], [1, 2], [1, 3], [2, 4], [3, 5],
- [4, 6], [5, 7]]
- categories.append(cat)
-
- # path of directory for official gt files
- gt_folder = osp.join(
- osp.dirname(self.ann_file),
- osp.splitext(self.ann_file.split('_')[-1])[0])
- # the json file for each video sequence
- json_files = [
- pos for pos in os.listdir(gt_folder) if pos.endswith('.json')
- ]
-
- for json_file in json_files:
- gt = load(osp.join(gt_folder, json_file))
- annotations = []
- images = []
-
- for image in gt['images']:
- img = {}
- img['id'] = image['id']
- img['file_name'] = image['file_name']
- images.append(img)
-
- img_kpts = keypoints[img['id']]
-
- for track_id, img_kpt in enumerate(img_kpts):
- ann = {}
- ann['image_id'] = img_kpt['img_id']
- ann['keypoints'] = np.array(
- img_kpt['keypoints']).reshape(-1).tolist()
- ann['scores'] = np.array(ann['keypoints']).reshape(
- [-1, 3])[:, 2].tolist()
- ann['score'] = float(img_kpt['score'])
- ann['track_id'] = track_id
- annotations.append(ann)
-
- pred_file = osp.join(osp.dirname(outfile_prefix), json_file)
- info = {}
- info['images'] = images
- info['categories'] = categories
- info['annotations'] = annotations
-
- dump(info, pred_file, sort_keys=True, indent=4)
-
- def _do_python_keypoint_eval(self, outfile_prefix: str) -> List[tuple]:
- """Do keypoint evaluation using `poseval` package.
-
- Args:
- outfile_prefix (str): The filename prefix of the json files.
- If the prefix is "somepath/xxx", the json files will be named
- "somepath/xxx.keypoints.json".
-
- Returns:
- list: a list of tuples. Each tuple contains the evaluation stats
- name and corresponding stats value.
- """
- logger: MMLogger = MMLogger.get_current_instance()
-
- # path of directory for official gt files
- # 'xxx/posetrack18_train.json' -> 'xxx/train/'
- gt_folder = osp.join(
- osp.dirname(self.ann_file),
- osp.splitext(self.ann_file.split('_')[-1])[0])
- pred_folder = osp.dirname(outfile_prefix)
-
- argv = ['', gt_folder + '/', pred_folder + '/']
-
- logger.info('Loading data')
- gtFramesAll, prFramesAll = eval_helpers.load_data_dir(argv)
-
- logger.info(f'# gt frames : {len(gtFramesAll)}')
- logger.info(f'# pred frames: {len(prFramesAll)}')
-
- # evaluate per-frame multi-person pose estimation (AP)
- # compute AP
- logger.info('Evaluation of per-frame multi-person pose estimation')
- apAll, _, _ = evaluateAP(gtFramesAll, prFramesAll, None, False, False)
-
- # print AP
- logger.info('Average Precision (AP) metric:')
- eval_helpers.printTable(apAll)
-
- stats = eval_helpers.getCum(apAll)
-
- stats_names = [
- 'Head AP', 'Shou AP', 'Elb AP', 'Wri AP', 'Hip AP', 'Knee AP',
- 'Ankl AP', 'AP'
- ]
-
- info_str = list(zip(stats_names, stats))
-
- return info_str
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import os.path as osp
+from typing import Dict, List, Optional
+
+import numpy as np
+from mmengine.fileio import dump, load
+from mmengine.logging import MMLogger
+
+from mmpose.registry import METRICS
+from .coco_metric import CocoMetric
+
+try:
+ from poseval import eval_helpers
+ from poseval.evaluateAP import evaluateAP
+ has_poseval = True
+except (ImportError, ModuleNotFoundError):
+ has_poseval = False
+
+
+@METRICS.register_module()
+class PoseTrack18Metric(CocoMetric):
+ """PoseTrack18 evaluation metric.
+
+ Evaluate AP, and mAP for keypoint detection tasks.
+ Support PoseTrack18 (video) dataset. Please refer to
+ ``__
+ for more details.
+
+ Args:
+ ann_file (str, optional): Path to the coco format annotation file.
+ If not specified, ground truth annotations from the dataset will
+ be converted to coco format. Defaults to None
+ score_mode (str): The mode to score the prediction results which
+ should be one of the following options:
+
+ - ``'bbox'``: Take the score of bbox as the score of the
+ prediction results.
+ - ``'bbox_keypoint'``: Use keypoint score to rescore the
+ prediction results.
+
+ Defaults to ``'bbox_keypoint'`
+ keypoint_score_thr (float): The threshold of keypoint score. The
+ keypoints with score lower than it will not be included to
+ rescore the prediction results. Valid only when ``score_mode`` is
+ ``bbox_keypoint``. Defaults to ``0.2``
+ nms_mode (str): The mode to perform Non-Maximum Suppression (NMS),
+ which should be one of the following options:
+
+ - ``'oks_nms'``: Use Object Keypoint Similarity (OKS) to
+ perform NMS.
+ - ``'soft_oks_nms'``: Use Object Keypoint Similarity (OKS)
+ to perform soft NMS.
+ - ``'none'``: Do not perform NMS. Typically for bottomup mode
+ output.
+
+ Defaults to ``'oks_nms'`
+ nms_thr (float): The Object Keypoint Similarity (OKS) threshold
+ used in NMS when ``nms_mode`` is ``'oks_nms'`` or
+ ``'soft_oks_nms'``. Will retain the prediction results with OKS
+ lower than ``nms_thr``. Defaults to ``0.9``
+ format_only (bool): Whether only format the output results without
+ doing quantitative evaluation. This is designed for the need of
+ test submission when the ground truth annotations are absent. If
+ set to ``True``, ``outfile_prefix`` should specify the path to
+ store the output results. Defaults to ``False``
+ outfile_prefix (str | None): The prefix of json files. It includes
+ the file path and the prefix of filename, e.g., ``'a/b/prefix'``.
+ If not specified, a temp file will be created. Defaults to ``None``
+ **kwargs: Keyword parameters passed to :class:`mmeval.BaseMetric`
+ """
+ default_prefix: Optional[str] = 'posetrack18'
+
+ def __init__(self,
+ ann_file: Optional[str] = None,
+ score_mode: str = 'bbox_keypoint',
+ keypoint_score_thr: float = 0.2,
+ nms_mode: str = 'oks_nms',
+ nms_thr: float = 0.9,
+ format_only: bool = False,
+ outfile_prefix: Optional[str] = None,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ # raise an error to avoid long time running without getting results
+ if not has_poseval:
+ raise ImportError('Please install ``poseval`` package for '
+ 'evaluation on PoseTrack dataset '
+ '(see `requirements/optional.txt`)')
+ super().__init__(
+ ann_file=ann_file,
+ score_mode=score_mode,
+ keypoint_score_thr=keypoint_score_thr,
+ nms_mode=nms_mode,
+ nms_thr=nms_thr,
+ format_only=format_only,
+ outfile_prefix=outfile_prefix,
+ collect_device=collect_device,
+ prefix=prefix)
+
+ def results2json(self, keypoints: Dict[int, list],
+ outfile_prefix: str) -> str:
+ """Dump the keypoint detection results into a json file.
+
+ Args:
+ keypoints (Dict[int, list]): Keypoint detection results
+ of the dataset.
+ outfile_prefix (str): The filename prefix of the json files.
+ If the prefix is "somepath/xxx", the json files will be named
+ "somepath/xxx.keypoints.json".
+
+ Returns:
+ str: The json file name of keypoint results.
+ """
+ categories = []
+
+ cat = {}
+ cat['supercategory'] = 'person'
+ cat['id'] = 1
+ cat['name'] = 'person'
+ cat['keypoints'] = [
+ 'nose', 'head_bottom', 'head_top', 'left_ear', 'right_ear',
+ 'left_shoulder', 'right_shoulder', 'left_elbow', 'right_elbow',
+ 'left_wrist', 'right_wrist', 'left_hip', 'right_hip', 'left_knee',
+ 'right_knee', 'left_ankle', 'right_ankle'
+ ]
+ cat['skeleton'] = [[16, 14], [14, 12], [17, 15], [15, 13], [12, 13],
+ [6, 12], [7, 13], [6, 7], [6, 8], [7, 9], [8, 10],
+ [9, 11], [2, 3], [1, 2], [1, 3], [2, 4], [3, 5],
+ [4, 6], [5, 7]]
+ categories.append(cat)
+
+ # path of directory for official gt files
+ gt_folder = osp.join(
+ osp.dirname(self.ann_file),
+ osp.splitext(self.ann_file.split('_')[-1])[0])
+ # the json file for each video sequence
+ json_files = [
+ pos for pos in os.listdir(gt_folder) if pos.endswith('.json')
+ ]
+
+ for json_file in json_files:
+ gt = load(osp.join(gt_folder, json_file))
+ annotations = []
+ images = []
+
+ for image in gt['images']:
+ img = {}
+ img['id'] = image['id']
+ img['file_name'] = image['file_name']
+ images.append(img)
+
+ img_kpts = keypoints[img['id']]
+
+ for track_id, img_kpt in enumerate(img_kpts):
+ ann = {}
+ ann['image_id'] = img_kpt['img_id']
+ ann['keypoints'] = np.array(
+ img_kpt['keypoints']).reshape(-1).tolist()
+ ann['scores'] = np.array(ann['keypoints']).reshape(
+ [-1, 3])[:, 2].tolist()
+ ann['score'] = float(img_kpt['score'])
+ ann['track_id'] = track_id
+ annotations.append(ann)
+
+ pred_file = osp.join(osp.dirname(outfile_prefix), json_file)
+ info = {}
+ info['images'] = images
+ info['categories'] = categories
+ info['annotations'] = annotations
+
+ dump(info, pred_file, sort_keys=True, indent=4)
+
+ def _do_python_keypoint_eval(self, outfile_prefix: str) -> List[tuple]:
+ """Do keypoint evaluation using `poseval` package.
+
+ Args:
+ outfile_prefix (str): The filename prefix of the json files.
+ If the prefix is "somepath/xxx", the json files will be named
+ "somepath/xxx.keypoints.json".
+
+ Returns:
+ list: a list of tuples. Each tuple contains the evaluation stats
+ name and corresponding stats value.
+ """
+ logger: MMLogger = MMLogger.get_current_instance()
+
+ # path of directory for official gt files
+ # 'xxx/posetrack18_train.json' -> 'xxx/train/'
+ gt_folder = osp.join(
+ osp.dirname(self.ann_file),
+ osp.splitext(self.ann_file.split('_')[-1])[0])
+ pred_folder = osp.dirname(outfile_prefix)
+
+ argv = ['', gt_folder + '/', pred_folder + '/']
+
+ logger.info('Loading data')
+ gtFramesAll, prFramesAll = eval_helpers.load_data_dir(argv)
+
+ logger.info(f'# gt frames : {len(gtFramesAll)}')
+ logger.info(f'# pred frames: {len(prFramesAll)}')
+
+ # evaluate per-frame multi-person pose estimation (AP)
+ # compute AP
+ logger.info('Evaluation of per-frame multi-person pose estimation')
+ apAll, _, _ = evaluateAP(gtFramesAll, prFramesAll, None, False, False)
+
+ # print AP
+ logger.info('Average Precision (AP) metric:')
+ eval_helpers.printTable(apAll)
+
+ stats = eval_helpers.getCum(apAll)
+
+ stats_names = [
+ 'Head AP', 'Shou AP', 'Elb AP', 'Wri AP', 'Hip AP', 'Knee AP',
+ 'Ankl AP', 'AP'
+ ]
+
+ info_str = list(zip(stats_names, stats))
+
+ return info_str
diff --git a/mmpose/models/__init__.py b/mmpose/models/__init__.py
index 4e236f9928..1590e10fdb 100644
--- a/mmpose/models/__init__.py
+++ b/mmpose/models/__init__.py
@@ -1,15 +1,15 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .backbones import * # noqa
-from .builder import (BACKBONES, HEADS, LOSSES, NECKS, build_backbone,
- build_head, build_loss, build_neck, build_pose_estimator,
- build_posenet)
-from .data_preprocessors import * # noqa
-from .heads import * # noqa
-from .losses import * # noqa
-from .necks import * # noqa
-from .pose_estimators import * # noqa
-
-__all__ = [
- 'BACKBONES', 'HEADS', 'NECKS', 'LOSSES', 'build_backbone', 'build_head',
- 'build_loss', 'build_posenet', 'build_neck', 'build_pose_estimator'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .backbones import * # noqa
+from .builder import (BACKBONES, HEADS, LOSSES, NECKS, build_backbone,
+ build_head, build_loss, build_neck, build_pose_estimator,
+ build_posenet)
+from .data_preprocessors import * # noqa
+from .heads import * # noqa
+from .losses import * # noqa
+from .necks import * # noqa
+from .pose_estimators import * # noqa
+
+__all__ = [
+ 'BACKBONES', 'HEADS', 'NECKS', 'LOSSES', 'build_backbone', 'build_head',
+ 'build_loss', 'build_posenet', 'build_neck', 'build_pose_estimator'
+]
diff --git a/mmpose/models/backbones/__init__.py b/mmpose/models/backbones/__init__.py
index cb2498560a..e7937f6b75 100644
--- a/mmpose/models/backbones/__init__.py
+++ b/mmpose/models/backbones/__init__.py
@@ -1,37 +1,41 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .alexnet import AlexNet
-from .cpm import CPM
-from .hourglass import HourglassNet
-from .hourglass_ae import HourglassAENet
-from .hrformer import HRFormer
-from .hrnet import HRNet
-from .litehrnet import LiteHRNet
-from .mobilenet_v2 import MobileNetV2
-from .mobilenet_v3 import MobileNetV3
-from .mspn import MSPN
-from .pvt import PyramidVisionTransformer, PyramidVisionTransformerV2
-from .regnet import RegNet
-from .resnest import ResNeSt
-from .resnet import ResNet, ResNetV1d
-from .resnext import ResNeXt
-from .rsn import RSN
-from .scnet import SCNet
-from .seresnet import SEResNet
-from .seresnext import SEResNeXt
-from .shufflenet_v1 import ShuffleNetV1
-from .shufflenet_v2 import ShuffleNetV2
-from .swin import SwinTransformer
-from .tcn import TCN
-from .v2v_net import V2VNet
-from .vgg import VGG
-from .vipnas_mbv3 import ViPNAS_MobileNetV3
-from .vipnas_resnet import ViPNAS_ResNet
-
-__all__ = [
- 'AlexNet', 'HourglassNet', 'HourglassAENet', 'HRNet', 'MobileNetV2',
- 'MobileNetV3', 'RegNet', 'ResNet', 'ResNetV1d', 'ResNeXt', 'SCNet',
- 'SEResNet', 'SEResNeXt', 'ShuffleNetV1', 'ShuffleNetV2', 'CPM', 'RSN',
- 'MSPN', 'ResNeSt', 'VGG', 'TCN', 'ViPNAS_ResNet', 'ViPNAS_MobileNetV3',
- 'LiteHRNet', 'V2VNet', 'HRFormer', 'PyramidVisionTransformer',
- 'PyramidVisionTransformerV2', 'SwinTransformer'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .alexnet import AlexNet
+from .cpm import CPM
+from .hourglass import HourglassNet
+from .hourglass_ae import HourglassAENet
+from .hrformer import HRFormer
+from .hrnet import HRNet
+from .litehrnet import LiteHRNet
+from .mobilenet_v2 import MobileNetV2
+from .mobilenet_v3 import MobileNetV3
+from .mspn import MSPN
+from .pvt import PyramidVisionTransformer, PyramidVisionTransformerV2
+from .regnet import RegNet
+from .resnest import ResNeSt
+from .resnet import ResNet, ResNetV1d
+from .resnext import ResNeXt
+from .rsn import RSN
+from .scnet import SCNet
+from .seresnet import SEResNet
+from .seresnext import SEResNeXt
+from .shufflenet_v1 import ShuffleNetV1
+from .shufflenet_v2 import ShuffleNetV2
+from .swin import SwinTransformer
+from .tcn import TCN
+from .v2v_net import V2VNet
+from .vgg import VGG
+from .vipnas_mbv3 import ViPNAS_MobileNetV3
+from .vipnas_resnet import ViPNAS_ResNet
+
+from .octsb1 import OCTSB1
+from .octsb2 import OCTSB2
+
+__all__ = [
+ 'AlexNet', 'HourglassNet', 'HourglassAENet', 'HRNet', 'MobileNetV2',
+ 'MobileNetV3', 'RegNet', 'ResNet', 'ResNetV1d', 'ResNeXt', 'SCNet',
+ 'SEResNet', 'SEResNeXt', 'ShuffleNetV1', 'ShuffleNetV2', 'CPM', 'RSN',
+ 'MSPN', 'ResNeSt', 'VGG', 'TCN', 'ViPNAS_ResNet', 'ViPNAS_MobileNetV3',
+ 'LiteHRNet', 'V2VNet', 'HRFormer', 'PyramidVisionTransformer',
+ 'PyramidVisionTransformerV2', 'SwinTransformer',
+ 'OCTSB1', 'OCTSB2'
+]
diff --git a/mmpose/models/backbones/alexnet.py b/mmpose/models/backbones/alexnet.py
index 2262658f47..f570ee508a 100644
--- a/mmpose/models/backbones/alexnet.py
+++ b/mmpose/models/backbones/alexnet.py
@@ -1,58 +1,58 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import torch.nn as nn
-
-from mmpose.registry import MODELS
-from .base_backbone import BaseBackbone
-
-
-@MODELS.register_module()
-class AlexNet(BaseBackbone):
- """`AlexNet `__ backbone.
-
- The input for AlexNet is a 224x224 RGB image.
-
- Args:
- num_classes (int): number of classes for classification.
- The default value is -1, which uses the backbone as
- a feature extractor without the top classifier.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self, num_classes=-1, init_cfg=None):
- super().__init__(init_cfg=init_cfg)
- self.num_classes = num_classes
- self.features = nn.Sequential(
- nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
- nn.ReLU(inplace=True),
- nn.MaxPool2d(kernel_size=3, stride=2),
- nn.Conv2d(64, 192, kernel_size=5, padding=2),
- nn.ReLU(inplace=True),
- nn.MaxPool2d(kernel_size=3, stride=2),
- nn.Conv2d(192, 384, kernel_size=3, padding=1),
- nn.ReLU(inplace=True),
- nn.Conv2d(384, 256, kernel_size=3, padding=1),
- nn.ReLU(inplace=True),
- nn.Conv2d(256, 256, kernel_size=3, padding=1),
- nn.ReLU(inplace=True),
- nn.MaxPool2d(kernel_size=3, stride=2),
- )
- if self.num_classes > 0:
- self.classifier = nn.Sequential(
- nn.Dropout(),
- nn.Linear(256 * 6 * 6, 4096),
- nn.ReLU(inplace=True),
- nn.Dropout(),
- nn.Linear(4096, 4096),
- nn.ReLU(inplace=True),
- nn.Linear(4096, num_classes),
- )
-
- def forward(self, x):
-
- x = self.features(x)
- if self.num_classes > 0:
- x = x.view(x.size(0), 256 * 6 * 6)
- x = self.classifier(x)
-
- return (x, )
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+
+
+@MODELS.register_module()
+class AlexNet(BaseBackbone):
+ """`AlexNet `__ backbone.
+
+ The input for AlexNet is a 224x224 RGB image.
+
+ Args:
+ num_classes (int): number of classes for classification.
+ The default value is -1, which uses the backbone as
+ a feature extractor without the top classifier.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self, num_classes=-1, init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ self.num_classes = num_classes
+ self.features = nn.Sequential(
+ nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
+ nn.ReLU(inplace=True),
+ nn.MaxPool2d(kernel_size=3, stride=2),
+ nn.Conv2d(64, 192, kernel_size=5, padding=2),
+ nn.ReLU(inplace=True),
+ nn.MaxPool2d(kernel_size=3, stride=2),
+ nn.Conv2d(192, 384, kernel_size=3, padding=1),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(384, 256, kernel_size=3, padding=1),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(256, 256, kernel_size=3, padding=1),
+ nn.ReLU(inplace=True),
+ nn.MaxPool2d(kernel_size=3, stride=2),
+ )
+ if self.num_classes > 0:
+ self.classifier = nn.Sequential(
+ nn.Dropout(),
+ nn.Linear(256 * 6 * 6, 4096),
+ nn.ReLU(inplace=True),
+ nn.Dropout(),
+ nn.Linear(4096, 4096),
+ nn.ReLU(inplace=True),
+ nn.Linear(4096, num_classes),
+ )
+
+ def forward(self, x):
+
+ x = self.features(x)
+ if self.num_classes > 0:
+ x = x.view(x.size(0), 256 * 6 * 6)
+ x = self.classifier(x)
+
+ return (x, )
diff --git a/mmpose/models/backbones/base_backbone.py b/mmpose/models/backbones/base_backbone.py
index 6094b4e831..2b0d90c1f8 100644
--- a/mmpose/models/backbones/base_backbone.py
+++ b/mmpose/models/backbones/base_backbone.py
@@ -1,29 +1,29 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from abc import ABCMeta, abstractmethod
-
-from mmengine.model import BaseModule
-
-
-class BaseBackbone(BaseModule, metaclass=ABCMeta):
- """Base backbone.
-
- This class defines the basic functions of a backbone. Any backbone that
- inherits this class should at least define its own `forward` function.
- """
-
- @abstractmethod
- def forward(self, x):
- """Forward function.
-
- Args:
- x (Tensor | tuple[Tensor]): x could be a torch.Tensor or a tuple of
- torch.Tensor, containing input data for forward computation.
- """
-
- def train(self, mode=True):
- """Set module status before forward computation.
-
- Args:
- mode (bool): Whether it is train_mode or test_mode
- """
- super(BaseBackbone, self).train(mode)
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+
+from mmengine.model import BaseModule
+
+
+class BaseBackbone(BaseModule, metaclass=ABCMeta):
+ """Base backbone.
+
+ This class defines the basic functions of a backbone. Any backbone that
+ inherits this class should at least define its own `forward` function.
+ """
+
+ @abstractmethod
+ def forward(self, x):
+ """Forward function.
+
+ Args:
+ x (Tensor | tuple[Tensor]): x could be a torch.Tensor or a tuple of
+ torch.Tensor, containing input data for forward computation.
+ """
+
+ def train(self, mode=True):
+ """Set module status before forward computation.
+
+ Args:
+ mode (bool): Whether it is train_mode or test_mode
+ """
+ super(BaseBackbone, self).train(mode)
diff --git a/mmpose/models/backbones/cpm.py b/mmpose/models/backbones/cpm.py
index 256769c43a..1ad19a9006 100644
--- a/mmpose/models/backbones/cpm.py
+++ b/mmpose/models/backbones/cpm.py
@@ -1,183 +1,183 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-
-import torch
-import torch.nn as nn
-from mmcv.cnn import ConvModule
-from mmengine.model import BaseModule
-
-from mmpose.registry import MODELS
-from .base_backbone import BaseBackbone
-
-
-class CpmBlock(BaseModule):
- """CpmBlock for Convolutional Pose Machine.
-
- Args:
- in_channels (int): Input channels of this block.
- channels (list): Output channels of each conv module.
- kernels (list): Kernel sizes of each conv module.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- in_channels,
- channels=(128, 128, 128),
- kernels=(11, 11, 11),
- norm_cfg=None,
- init_cfg=None):
- super().__init__(init_cfg=init_cfg)
-
- assert len(channels) == len(kernels)
- layers = []
- for i in range(len(channels)):
- if i == 0:
- input_channels = in_channels
- else:
- input_channels = channels[i - 1]
- layers.append(
- ConvModule(
- input_channels,
- channels[i],
- kernels[i],
- padding=(kernels[i] - 1) // 2,
- norm_cfg=norm_cfg))
- self.model = nn.Sequential(*layers)
-
- def forward(self, x):
- """Model forward function."""
- out = self.model(x)
- return out
-
-
-@MODELS.register_module()
-class CPM(BaseBackbone):
- """CPM backbone.
-
- Convolutional Pose Machines.
- More details can be found in the `paper
- `__ .
-
- Args:
- in_channels (int): The input channels of the CPM.
- out_channels (int): The output channels of the CPM.
- feat_channels (int): Feature channel of each CPM stage.
- middle_channels (int): Feature channel of conv after the middle stage.
- num_stages (int): Number of stages.
- norm_cfg (dict): Dictionary to construct and config norm layer.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Normal', std=0.001, layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]``
-
- Example:
- >>> from mmpose.models import CPM
- >>> import torch
- >>> self = CPM(3, 17)
- >>> self.eval()
- >>> inputs = torch.rand(1, 3, 368, 368)
- >>> level_outputs = self.forward(inputs)
- >>> for level_output in level_outputs:
- ... print(tuple(level_output.shape))
- (1, 17, 46, 46)
- (1, 17, 46, 46)
- (1, 17, 46, 46)
- (1, 17, 46, 46)
- (1, 17, 46, 46)
- (1, 17, 46, 46)
- """
-
- def __init__(
- self,
- in_channels,
- out_channels,
- feat_channels=128,
- middle_channels=32,
- num_stages=6,
- norm_cfg=dict(type='BN', requires_grad=True),
- init_cfg=[
- dict(type='Normal', std=0.001, layer=['Conv2d']),
- dict(type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])
- ],
- ):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
-
- assert in_channels == 3
-
- self.num_stages = num_stages
- assert self.num_stages >= 1
-
- self.stem = nn.Sequential(
- ConvModule(in_channels, 128, 9, padding=4, norm_cfg=norm_cfg),
- nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
- ConvModule(128, 128, 9, padding=4, norm_cfg=norm_cfg),
- nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
- ConvModule(128, 128, 9, padding=4, norm_cfg=norm_cfg),
- nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
- ConvModule(128, 32, 5, padding=2, norm_cfg=norm_cfg),
- ConvModule(32, 512, 9, padding=4, norm_cfg=norm_cfg),
- ConvModule(512, 512, 1, padding=0, norm_cfg=norm_cfg),
- ConvModule(512, out_channels, 1, padding=0, act_cfg=None))
-
- self.middle = nn.Sequential(
- ConvModule(in_channels, 128, 9, padding=4, norm_cfg=norm_cfg),
- nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
- ConvModule(128, 128, 9, padding=4, norm_cfg=norm_cfg),
- nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
- ConvModule(128, 128, 9, padding=4, norm_cfg=norm_cfg),
- nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
-
- self.cpm_stages = nn.ModuleList([
- CpmBlock(
- middle_channels + out_channels,
- channels=[feat_channels, feat_channels, feat_channels],
- kernels=[11, 11, 11],
- norm_cfg=norm_cfg) for _ in range(num_stages - 1)
- ])
-
- self.middle_conv = nn.ModuleList([
- nn.Sequential(
- ConvModule(
- 128, middle_channels, 5, padding=2, norm_cfg=norm_cfg))
- for _ in range(num_stages - 1)
- ])
-
- self.out_convs = nn.ModuleList([
- nn.Sequential(
- ConvModule(
- feat_channels,
- feat_channels,
- 1,
- padding=0,
- norm_cfg=norm_cfg),
- ConvModule(feat_channels, out_channels, 1, act_cfg=None))
- for _ in range(num_stages - 1)
- ])
-
- def forward(self, x):
- """Model forward function."""
- stage1_out = self.stem(x)
- middle_out = self.middle(x)
- out_feats = []
-
- out_feats.append(stage1_out)
-
- for ind in range(self.num_stages - 1):
- single_stage = self.cpm_stages[ind]
- out_conv = self.out_convs[ind]
-
- inp_feat = torch.cat(
- [out_feats[-1], self.middle_conv[ind](middle_out)], 1)
- cpm_feat = single_stage(inp_feat)
- out_feat = out_conv(cpm_feat)
- out_feats.append(out_feat)
-
- return out_feats
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+
+
+class CpmBlock(BaseModule):
+ """CpmBlock for Convolutional Pose Machine.
+
+ Args:
+ in_channels (int): Input channels of this block.
+ channels (list): Output channels of each conv module.
+ kernels (list): Kernel sizes of each conv module.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ channels=(128, 128, 128),
+ kernels=(11, 11, 11),
+ norm_cfg=None,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ assert len(channels) == len(kernels)
+ layers = []
+ for i in range(len(channels)):
+ if i == 0:
+ input_channels = in_channels
+ else:
+ input_channels = channels[i - 1]
+ layers.append(
+ ConvModule(
+ input_channels,
+ channels[i],
+ kernels[i],
+ padding=(kernels[i] - 1) // 2,
+ norm_cfg=norm_cfg))
+ self.model = nn.Sequential(*layers)
+
+ def forward(self, x):
+ """Model forward function."""
+ out = self.model(x)
+ return out
+
+
+@MODELS.register_module()
+class CPM(BaseBackbone):
+ """CPM backbone.
+
+ Convolutional Pose Machines.
+ More details can be found in the `paper
+ `__ .
+
+ Args:
+ in_channels (int): The input channels of the CPM.
+ out_channels (int): The output channels of the CPM.
+ feat_channels (int): Feature channel of each CPM stage.
+ middle_channels (int): Feature channel of conv after the middle stage.
+ num_stages (int): Number of stages.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+
+ Example:
+ >>> from mmpose.models import CPM
+ >>> import torch
+ >>> self = CPM(3, 17)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 368, 368)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_output in level_outputs:
+ ... print(tuple(level_output.shape))
+ (1, 17, 46, 46)
+ (1, 17, 46, 46)
+ (1, 17, 46, 46)
+ (1, 17, 46, 46)
+ (1, 17, 46, 46)
+ (1, 17, 46, 46)
+ """
+
+ def __init__(
+ self,
+ in_channels,
+ out_channels,
+ feat_channels=128,
+ middle_channels=32,
+ num_stages=6,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ init_cfg=[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])
+ ],
+ ):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+
+ assert in_channels == 3
+
+ self.num_stages = num_stages
+ assert self.num_stages >= 1
+
+ self.stem = nn.Sequential(
+ ConvModule(in_channels, 128, 9, padding=4, norm_cfg=norm_cfg),
+ nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
+ ConvModule(128, 128, 9, padding=4, norm_cfg=norm_cfg),
+ nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
+ ConvModule(128, 128, 9, padding=4, norm_cfg=norm_cfg),
+ nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
+ ConvModule(128, 32, 5, padding=2, norm_cfg=norm_cfg),
+ ConvModule(32, 512, 9, padding=4, norm_cfg=norm_cfg),
+ ConvModule(512, 512, 1, padding=0, norm_cfg=norm_cfg),
+ ConvModule(512, out_channels, 1, padding=0, act_cfg=None))
+
+ self.middle = nn.Sequential(
+ ConvModule(in_channels, 128, 9, padding=4, norm_cfg=norm_cfg),
+ nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
+ ConvModule(128, 128, 9, padding=4, norm_cfg=norm_cfg),
+ nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
+ ConvModule(128, 128, 9, padding=4, norm_cfg=norm_cfg),
+ nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
+
+ self.cpm_stages = nn.ModuleList([
+ CpmBlock(
+ middle_channels + out_channels,
+ channels=[feat_channels, feat_channels, feat_channels],
+ kernels=[11, 11, 11],
+ norm_cfg=norm_cfg) for _ in range(num_stages - 1)
+ ])
+
+ self.middle_conv = nn.ModuleList([
+ nn.Sequential(
+ ConvModule(
+ 128, middle_channels, 5, padding=2, norm_cfg=norm_cfg))
+ for _ in range(num_stages - 1)
+ ])
+
+ self.out_convs = nn.ModuleList([
+ nn.Sequential(
+ ConvModule(
+ feat_channels,
+ feat_channels,
+ 1,
+ padding=0,
+ norm_cfg=norm_cfg),
+ ConvModule(feat_channels, out_channels, 1, act_cfg=None))
+ for _ in range(num_stages - 1)
+ ])
+
+ def forward(self, x):
+ """Model forward function."""
+ stage1_out = self.stem(x)
+ middle_out = self.middle(x)
+ out_feats = []
+
+ out_feats.append(stage1_out)
+
+ for ind in range(self.num_stages - 1):
+ single_stage = self.cpm_stages[ind]
+ out_conv = self.out_convs[ind]
+
+ inp_feat = torch.cat(
+ [out_feats[-1], self.middle_conv[ind](middle_out)], 1)
+ cpm_feat = single_stage(inp_feat)
+ out_feat = out_conv(cpm_feat)
+ out_feats.append(out_feat)
+
+ return out_feats
diff --git a/mmpose/models/backbones/hourglass.py b/mmpose/models/backbones/hourglass.py
index cfc8d6d328..6429487b36 100644
--- a/mmpose/models/backbones/hourglass.py
+++ b/mmpose/models/backbones/hourglass.py
@@ -1,209 +1,209 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-
-import torch.nn as nn
-from mmcv.cnn import ConvModule
-from mmengine.model import BaseModule
-
-from mmpose.registry import MODELS
-from .base_backbone import BaseBackbone
-from .resnet import BasicBlock, ResLayer
-
-
-class HourglassModule(BaseModule):
- """Hourglass Module for HourglassNet backbone.
-
- Generate module recursively and use BasicBlock as the base unit.
-
- Args:
- depth (int): Depth of current HourglassModule.
- stage_channels (list[int]): Feature channels of sub-modules in current
- and follow-up HourglassModule.
- stage_blocks (list[int]): Number of sub-modules stacked in current and
- follow-up HourglassModule.
- norm_cfg (dict): Dictionary to construct and config norm layer.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- depth,
- stage_channels,
- stage_blocks,
- norm_cfg=dict(type='BN', requires_grad=True),
- init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
-
- self.depth = depth
-
- cur_block = stage_blocks[0]
- next_block = stage_blocks[1]
-
- cur_channel = stage_channels[0]
- next_channel = stage_channels[1]
-
- self.up1 = ResLayer(
- BasicBlock, cur_block, cur_channel, cur_channel, norm_cfg=norm_cfg)
-
- self.low1 = ResLayer(
- BasicBlock,
- cur_block,
- cur_channel,
- next_channel,
- stride=2,
- norm_cfg=norm_cfg)
-
- if self.depth > 1:
- self.low2 = HourglassModule(depth - 1, stage_channels[1:],
- stage_blocks[1:])
- else:
- self.low2 = ResLayer(
- BasicBlock,
- next_block,
- next_channel,
- next_channel,
- norm_cfg=norm_cfg)
-
- self.low3 = ResLayer(
- BasicBlock,
- cur_block,
- next_channel,
- cur_channel,
- norm_cfg=norm_cfg,
- downsample_first=False)
-
- self.up2 = nn.Upsample(scale_factor=2)
-
- def forward(self, x):
- """Model forward function."""
- up1 = self.up1(x)
- low1 = self.low1(x)
- low2 = self.low2(low1)
- low3 = self.low3(low2)
- up2 = self.up2(low3)
- return up1 + up2
-
-
-@MODELS.register_module()
-class HourglassNet(BaseBackbone):
- """HourglassNet backbone.
-
- Stacked Hourglass Networks for Human Pose Estimation.
- More details can be found in the `paper
- `__ .
-
- Args:
- downsample_times (int): Downsample times in a HourglassModule.
- num_stacks (int): Number of HourglassModule modules stacked,
- 1 for Hourglass-52, 2 for Hourglass-104.
- stage_channels (list[int]): Feature channel of each sub-module in a
- HourglassModule.
- stage_blocks (list[int]): Number of sub-modules stacked in a
- HourglassModule.
- feat_channel (int): Feature channel of conv after a HourglassModule.
- norm_cfg (dict): Dictionary to construct and config norm layer.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Normal', std=0.001, layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]``
-
- Example:
- >>> from mmpose.models import HourglassNet
- >>> import torch
- >>> self = HourglassNet()
- >>> self.eval()
- >>> inputs = torch.rand(1, 3, 511, 511)
- >>> level_outputs = self.forward(inputs)
- >>> for level_output in level_outputs:
- ... print(tuple(level_output.shape))
- (1, 256, 128, 128)
- (1, 256, 128, 128)
- """
-
- def __init__(
- self,
- downsample_times=5,
- num_stacks=2,
- stage_channels=(256, 256, 384, 384, 384, 512),
- stage_blocks=(2, 2, 2, 2, 2, 4),
- feat_channel=256,
- norm_cfg=dict(type='BN', requires_grad=True),
- init_cfg=[
- dict(type='Normal', std=0.001, layer=['Conv2d']),
- dict(type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])
- ],
- ):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
-
- self.num_stacks = num_stacks
- assert self.num_stacks >= 1
- assert len(stage_channels) == len(stage_blocks)
- assert len(stage_channels) > downsample_times
-
- cur_channel = stage_channels[0]
-
- self.stem = nn.Sequential(
- ConvModule(3, 128, 7, padding=3, stride=2, norm_cfg=norm_cfg),
- ResLayer(BasicBlock, 1, 128, 256, stride=2, norm_cfg=norm_cfg))
-
- self.hourglass_modules = nn.ModuleList([
- HourglassModule(downsample_times, stage_channels, stage_blocks)
- for _ in range(num_stacks)
- ])
-
- self.inters = ResLayer(
- BasicBlock,
- num_stacks - 1,
- cur_channel,
- cur_channel,
- norm_cfg=norm_cfg)
-
- self.conv1x1s = nn.ModuleList([
- ConvModule(
- cur_channel, cur_channel, 1, norm_cfg=norm_cfg, act_cfg=None)
- for _ in range(num_stacks - 1)
- ])
-
- self.out_convs = nn.ModuleList([
- ConvModule(
- cur_channel, feat_channel, 3, padding=1, norm_cfg=norm_cfg)
- for _ in range(num_stacks)
- ])
-
- self.remap_convs = nn.ModuleList([
- ConvModule(
- feat_channel, cur_channel, 1, norm_cfg=norm_cfg, act_cfg=None)
- for _ in range(num_stacks - 1)
- ])
-
- self.relu = nn.ReLU(inplace=True)
-
- def forward(self, x):
- """Model forward function."""
- inter_feat = self.stem(x)
- out_feats = []
-
- for ind in range(self.num_stacks):
- single_hourglass = self.hourglass_modules[ind]
- out_conv = self.out_convs[ind]
-
- hourglass_feat = single_hourglass(inter_feat)
- out_feat = out_conv(hourglass_feat)
- out_feats.append(out_feat)
-
- if ind < self.num_stacks - 1:
- inter_feat = self.conv1x1s[ind](
- inter_feat) + self.remap_convs[ind](
- out_feat)
- inter_feat = self.inters[ind](self.relu(inter_feat))
-
- return out_feats
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+from .resnet import BasicBlock, ResLayer
+
+
+class HourglassModule(BaseModule):
+ """Hourglass Module for HourglassNet backbone.
+
+ Generate module recursively and use BasicBlock as the base unit.
+
+ Args:
+ depth (int): Depth of current HourglassModule.
+ stage_channels (list[int]): Feature channels of sub-modules in current
+ and follow-up HourglassModule.
+ stage_blocks (list[int]): Number of sub-modules stacked in current and
+ follow-up HourglassModule.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ depth,
+ stage_channels,
+ stage_blocks,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+
+ self.depth = depth
+
+ cur_block = stage_blocks[0]
+ next_block = stage_blocks[1]
+
+ cur_channel = stage_channels[0]
+ next_channel = stage_channels[1]
+
+ self.up1 = ResLayer(
+ BasicBlock, cur_block, cur_channel, cur_channel, norm_cfg=norm_cfg)
+
+ self.low1 = ResLayer(
+ BasicBlock,
+ cur_block,
+ cur_channel,
+ next_channel,
+ stride=2,
+ norm_cfg=norm_cfg)
+
+ if self.depth > 1:
+ self.low2 = HourglassModule(depth - 1, stage_channels[1:],
+ stage_blocks[1:])
+ else:
+ self.low2 = ResLayer(
+ BasicBlock,
+ next_block,
+ next_channel,
+ next_channel,
+ norm_cfg=norm_cfg)
+
+ self.low3 = ResLayer(
+ BasicBlock,
+ cur_block,
+ next_channel,
+ cur_channel,
+ norm_cfg=norm_cfg,
+ downsample_first=False)
+
+ self.up2 = nn.Upsample(scale_factor=2)
+
+ def forward(self, x):
+ """Model forward function."""
+ up1 = self.up1(x)
+ low1 = self.low1(x)
+ low2 = self.low2(low1)
+ low3 = self.low3(low2)
+ up2 = self.up2(low3)
+ return up1 + up2
+
+
+@MODELS.register_module()
+class HourglassNet(BaseBackbone):
+ """HourglassNet backbone.
+
+ Stacked Hourglass Networks for Human Pose Estimation.
+ More details can be found in the `paper
+ `__ .
+
+ Args:
+ downsample_times (int): Downsample times in a HourglassModule.
+ num_stacks (int): Number of HourglassModule modules stacked,
+ 1 for Hourglass-52, 2 for Hourglass-104.
+ stage_channels (list[int]): Feature channel of each sub-module in a
+ HourglassModule.
+ stage_blocks (list[int]): Number of sub-modules stacked in a
+ HourglassModule.
+ feat_channel (int): Feature channel of conv after a HourglassModule.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+
+ Example:
+ >>> from mmpose.models import HourglassNet
+ >>> import torch
+ >>> self = HourglassNet()
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 511, 511)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_output in level_outputs:
+ ... print(tuple(level_output.shape))
+ (1, 256, 128, 128)
+ (1, 256, 128, 128)
+ """
+
+ def __init__(
+ self,
+ downsample_times=5,
+ num_stacks=2,
+ stage_channels=(256, 256, 384, 384, 384, 512),
+ stage_blocks=(2, 2, 2, 2, 2, 4),
+ feat_channel=256,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ init_cfg=[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])
+ ],
+ ):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+
+ self.num_stacks = num_stacks
+ assert self.num_stacks >= 1
+ assert len(stage_channels) == len(stage_blocks)
+ assert len(stage_channels) > downsample_times
+
+ cur_channel = stage_channels[0]
+
+ self.stem = nn.Sequential(
+ ConvModule(3, 128, 7, padding=3, stride=2, norm_cfg=norm_cfg),
+ ResLayer(BasicBlock, 1, 128, 256, stride=2, norm_cfg=norm_cfg))
+
+ self.hourglass_modules = nn.ModuleList([
+ HourglassModule(downsample_times, stage_channels, stage_blocks)
+ for _ in range(num_stacks)
+ ])
+
+ self.inters = ResLayer(
+ BasicBlock,
+ num_stacks - 1,
+ cur_channel,
+ cur_channel,
+ norm_cfg=norm_cfg)
+
+ self.conv1x1s = nn.ModuleList([
+ ConvModule(
+ cur_channel, cur_channel, 1, norm_cfg=norm_cfg, act_cfg=None)
+ for _ in range(num_stacks - 1)
+ ])
+
+ self.out_convs = nn.ModuleList([
+ ConvModule(
+ cur_channel, feat_channel, 3, padding=1, norm_cfg=norm_cfg)
+ for _ in range(num_stacks)
+ ])
+
+ self.remap_convs = nn.ModuleList([
+ ConvModule(
+ feat_channel, cur_channel, 1, norm_cfg=norm_cfg, act_cfg=None)
+ for _ in range(num_stacks - 1)
+ ])
+
+ self.relu = nn.ReLU(inplace=True)
+
+ def forward(self, x):
+ """Model forward function."""
+ inter_feat = self.stem(x)
+ out_feats = []
+
+ for ind in range(self.num_stacks):
+ single_hourglass = self.hourglass_modules[ind]
+ out_conv = self.out_convs[ind]
+
+ hourglass_feat = single_hourglass(inter_feat)
+ out_feat = out_conv(hourglass_feat)
+ out_feats.append(out_feat)
+
+ if ind < self.num_stacks - 1:
+ inter_feat = self.conv1x1s[ind](
+ inter_feat) + self.remap_convs[ind](
+ out_feat)
+ inter_feat = self.inters[ind](self.relu(inter_feat))
+
+ return out_feats
diff --git a/mmpose/models/backbones/hourglass_ae.py b/mmpose/models/backbones/hourglass_ae.py
index 93e62dd406..25388ada64 100644
--- a/mmpose/models/backbones/hourglass_ae.py
+++ b/mmpose/models/backbones/hourglass_ae.py
@@ -1,209 +1,209 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-
-import torch.nn as nn
-from mmcv.cnn import ConvModule, MaxPool2d
-from mmengine.model import BaseModule
-
-from mmpose.registry import MODELS
-from .base_backbone import BaseBackbone
-
-
-class HourglassAEModule(BaseModule):
- """Modified Hourglass Module for HourglassNet_AE backbone.
-
- Generate module recursively and use BasicBlock as the base unit.
-
- Args:
- depth (int): Depth of current HourglassModule.
- stage_channels (list[int]): Feature channels of sub-modules in current
- and follow-up HourglassModule.
- norm_cfg (dict): Dictionary to construct and config norm layer.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- depth,
- stage_channels,
- norm_cfg=dict(type='BN', requires_grad=True),
- init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
-
- self.depth = depth
-
- cur_channel = stage_channels[0]
- next_channel = stage_channels[1]
-
- self.up1 = ConvModule(
- cur_channel, cur_channel, 3, padding=1, norm_cfg=norm_cfg)
-
- self.pool1 = MaxPool2d(2, 2)
-
- self.low1 = ConvModule(
- cur_channel, next_channel, 3, padding=1, norm_cfg=norm_cfg)
-
- if self.depth > 1:
- self.low2 = HourglassAEModule(depth - 1, stage_channels[1:])
- else:
- self.low2 = ConvModule(
- next_channel, next_channel, 3, padding=1, norm_cfg=norm_cfg)
-
- self.low3 = ConvModule(
- next_channel, cur_channel, 3, padding=1, norm_cfg=norm_cfg)
-
- self.up2 = nn.UpsamplingNearest2d(scale_factor=2)
-
- def forward(self, x):
- """Model forward function."""
- up1 = self.up1(x)
- pool1 = self.pool1(x)
- low1 = self.low1(pool1)
- low2 = self.low2(low1)
- low3 = self.low3(low2)
- up2 = self.up2(low3)
- return up1 + up2
-
-
-@MODELS.register_module()
-class HourglassAENet(BaseBackbone):
- """Hourglass-AE Network proposed by Newell et al.
-
- Associative Embedding: End-to-End Learning for Joint
- Detection and Grouping.
-
- More details can be found in the `paper
- `__ .
-
- Args:
- downsample_times (int): Downsample times in a HourglassModule.
- num_stacks (int): Number of HourglassModule modules stacked,
- 1 for Hourglass-52, 2 for Hourglass-104.
- stage_channels (list[int]): Feature channel of each sub-module in a
- HourglassModule.
- stage_blocks (list[int]): Number of sub-modules stacked in a
- HourglassModule.
- feat_channels (int): Feature channel of conv after a HourglassModule.
- norm_cfg (dict): Dictionary to construct and config norm layer.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Normal', std=0.001, layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]``
-
- Example:
- >>> from mmpose.models import HourglassAENet
- >>> import torch
- >>> self = HourglassAENet()
- >>> self.eval()
- >>> inputs = torch.rand(1, 3, 512, 512)
- >>> level_outputs = self.forward(inputs)
- >>> for level_output in level_outputs:
- ... print(tuple(level_output.shape))
- (1, 34, 128, 128)
- """
-
- def __init__(
- self,
- downsample_times=4,
- num_stacks=1,
- out_channels=34,
- stage_channels=(256, 384, 512, 640, 768),
- feat_channels=256,
- norm_cfg=dict(type='BN', requires_grad=True),
- init_cfg=[
- dict(type='Normal', std=0.001, layer=['Conv2d']),
- dict(type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])
- ],
- ):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
-
- self.num_stacks = num_stacks
- assert self.num_stacks >= 1
- assert len(stage_channels) > downsample_times
-
- cur_channels = stage_channels[0]
-
- self.stem = nn.Sequential(
- ConvModule(3, 64, 7, padding=3, stride=2, norm_cfg=norm_cfg),
- ConvModule(64, 128, 3, padding=1, norm_cfg=norm_cfg),
- MaxPool2d(2, 2),
- ConvModule(128, 128, 3, padding=1, norm_cfg=norm_cfg),
- ConvModule(128, feat_channels, 3, padding=1, norm_cfg=norm_cfg),
- )
-
- self.hourglass_modules = nn.ModuleList([
- nn.Sequential(
- HourglassAEModule(
- downsample_times, stage_channels, norm_cfg=norm_cfg),
- ConvModule(
- feat_channels,
- feat_channels,
- 3,
- padding=1,
- norm_cfg=norm_cfg),
- ConvModule(
- feat_channels,
- feat_channels,
- 3,
- padding=1,
- norm_cfg=norm_cfg)) for _ in range(num_stacks)
- ])
-
- self.out_convs = nn.ModuleList([
- ConvModule(
- cur_channels,
- out_channels,
- 1,
- padding=0,
- norm_cfg=None,
- act_cfg=None) for _ in range(num_stacks)
- ])
-
- self.remap_out_convs = nn.ModuleList([
- ConvModule(
- out_channels,
- feat_channels,
- 1,
- norm_cfg=norm_cfg,
- act_cfg=None) for _ in range(num_stacks - 1)
- ])
-
- self.remap_feature_convs = nn.ModuleList([
- ConvModule(
- feat_channels,
- feat_channels,
- 1,
- norm_cfg=norm_cfg,
- act_cfg=None) for _ in range(num_stacks - 1)
- ])
-
- self.relu = nn.ReLU(inplace=True)
-
- def forward(self, x):
- """Model forward function."""
- inter_feat = self.stem(x)
- out_feats = []
-
- for ind in range(self.num_stacks):
- single_hourglass = self.hourglass_modules[ind]
- out_conv = self.out_convs[ind]
-
- hourglass_feat = single_hourglass(inter_feat)
- out_feat = out_conv(hourglass_feat)
- out_feats.append(out_feat)
-
- if ind < self.num_stacks - 1:
- inter_feat = inter_feat + self.remap_out_convs[ind](
- out_feat) + self.remap_feature_convs[ind](
- hourglass_feat)
-
- return out_feats
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule, MaxPool2d
+from mmengine.model import BaseModule
+
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+
+
+class HourglassAEModule(BaseModule):
+ """Modified Hourglass Module for HourglassNet_AE backbone.
+
+ Generate module recursively and use BasicBlock as the base unit.
+
+ Args:
+ depth (int): Depth of current HourglassModule.
+ stage_channels (list[int]): Feature channels of sub-modules in current
+ and follow-up HourglassModule.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ depth,
+ stage_channels,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+
+ self.depth = depth
+
+ cur_channel = stage_channels[0]
+ next_channel = stage_channels[1]
+
+ self.up1 = ConvModule(
+ cur_channel, cur_channel, 3, padding=1, norm_cfg=norm_cfg)
+
+ self.pool1 = MaxPool2d(2, 2)
+
+ self.low1 = ConvModule(
+ cur_channel, next_channel, 3, padding=1, norm_cfg=norm_cfg)
+
+ if self.depth > 1:
+ self.low2 = HourglassAEModule(depth - 1, stage_channels[1:])
+ else:
+ self.low2 = ConvModule(
+ next_channel, next_channel, 3, padding=1, norm_cfg=norm_cfg)
+
+ self.low3 = ConvModule(
+ next_channel, cur_channel, 3, padding=1, norm_cfg=norm_cfg)
+
+ self.up2 = nn.UpsamplingNearest2d(scale_factor=2)
+
+ def forward(self, x):
+ """Model forward function."""
+ up1 = self.up1(x)
+ pool1 = self.pool1(x)
+ low1 = self.low1(pool1)
+ low2 = self.low2(low1)
+ low3 = self.low3(low2)
+ up2 = self.up2(low3)
+ return up1 + up2
+
+
+@MODELS.register_module()
+class HourglassAENet(BaseBackbone):
+ """Hourglass-AE Network proposed by Newell et al.
+
+ Associative Embedding: End-to-End Learning for Joint
+ Detection and Grouping.
+
+ More details can be found in the `paper
+ `__ .
+
+ Args:
+ downsample_times (int): Downsample times in a HourglassModule.
+ num_stacks (int): Number of HourglassModule modules stacked,
+ 1 for Hourglass-52, 2 for Hourglass-104.
+ stage_channels (list[int]): Feature channel of each sub-module in a
+ HourglassModule.
+ stage_blocks (list[int]): Number of sub-modules stacked in a
+ HourglassModule.
+ feat_channels (int): Feature channel of conv after a HourglassModule.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+
+ Example:
+ >>> from mmpose.models import HourglassAENet
+ >>> import torch
+ >>> self = HourglassAENet()
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 512, 512)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_output in level_outputs:
+ ... print(tuple(level_output.shape))
+ (1, 34, 128, 128)
+ """
+
+ def __init__(
+ self,
+ downsample_times=4,
+ num_stacks=1,
+ out_channels=34,
+ stage_channels=(256, 384, 512, 640, 768),
+ feat_channels=256,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ init_cfg=[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])
+ ],
+ ):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+
+ self.num_stacks = num_stacks
+ assert self.num_stacks >= 1
+ assert len(stage_channels) > downsample_times
+
+ cur_channels = stage_channels[0]
+
+ self.stem = nn.Sequential(
+ ConvModule(3, 64, 7, padding=3, stride=2, norm_cfg=norm_cfg),
+ ConvModule(64, 128, 3, padding=1, norm_cfg=norm_cfg),
+ MaxPool2d(2, 2),
+ ConvModule(128, 128, 3, padding=1, norm_cfg=norm_cfg),
+ ConvModule(128, feat_channels, 3, padding=1, norm_cfg=norm_cfg),
+ )
+
+ self.hourglass_modules = nn.ModuleList([
+ nn.Sequential(
+ HourglassAEModule(
+ downsample_times, stage_channels, norm_cfg=norm_cfg),
+ ConvModule(
+ feat_channels,
+ feat_channels,
+ 3,
+ padding=1,
+ norm_cfg=norm_cfg),
+ ConvModule(
+ feat_channels,
+ feat_channels,
+ 3,
+ padding=1,
+ norm_cfg=norm_cfg)) for _ in range(num_stacks)
+ ])
+
+ self.out_convs = nn.ModuleList([
+ ConvModule(
+ cur_channels,
+ out_channels,
+ 1,
+ padding=0,
+ norm_cfg=None,
+ act_cfg=None) for _ in range(num_stacks)
+ ])
+
+ self.remap_out_convs = nn.ModuleList([
+ ConvModule(
+ out_channels,
+ feat_channels,
+ 1,
+ norm_cfg=norm_cfg,
+ act_cfg=None) for _ in range(num_stacks - 1)
+ ])
+
+ self.remap_feature_convs = nn.ModuleList([
+ ConvModule(
+ feat_channels,
+ feat_channels,
+ 1,
+ norm_cfg=norm_cfg,
+ act_cfg=None) for _ in range(num_stacks - 1)
+ ])
+
+ self.relu = nn.ReLU(inplace=True)
+
+ def forward(self, x):
+ """Model forward function."""
+ inter_feat = self.stem(x)
+ out_feats = []
+
+ for ind in range(self.num_stacks):
+ single_hourglass = self.hourglass_modules[ind]
+ out_conv = self.out_convs[ind]
+
+ hourglass_feat = single_hourglass(inter_feat)
+ out_feat = out_conv(hourglass_feat)
+ out_feats.append(out_feat)
+
+ if ind < self.num_stacks - 1:
+ inter_feat = inter_feat + self.remap_out_convs[ind](
+ out_feat) + self.remap_feature_convs[ind](
+ hourglass_feat)
+
+ return out_feats
diff --git a/mmpose/models/backbones/hrformer.py b/mmpose/models/backbones/hrformer.py
index 0b86617f14..e50641a45e 100644
--- a/mmpose/models/backbones/hrformer.py
+++ b/mmpose/models/backbones/hrformer.py
@@ -1,758 +1,758 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-
-import math
-
-import torch
-import torch.nn as nn
-from mmcv.cnn import build_activation_layer, build_conv_layer, build_norm_layer
-from mmcv.cnn.bricks.transformer import build_dropout
-from mmengine.model import BaseModule, trunc_normal_init
-from torch.nn.functional import pad
-
-from mmpose.registry import MODELS
-from .hrnet import Bottleneck, HRModule, HRNet
-
-
-def nlc_to_nchw(x, hw_shape):
- """Convert [N, L, C] shape tensor to [N, C, H, W] shape tensor.
-
- Args:
- x (Tensor): The input tensor of shape [N, L, C] before conversion.
- hw_shape (Sequence[int]): The height and width of output feature map.
-
- Returns:
- Tensor: The output tensor of shape [N, C, H, W] after conversion.
- """
- H, W = hw_shape
- assert len(x.shape) == 3
- B, L, C = x.shape
- assert L == H * W, 'The seq_len doesn\'t match H, W'
- return x.transpose(1, 2).reshape(B, C, H, W)
-
-
-def nchw_to_nlc(x):
- """Flatten [N, C, H, W] shape tensor to [N, L, C] shape tensor.
-
- Args:
- x (Tensor): The input tensor of shape [N, C, H, W] before conversion.
-
- Returns:
- Tensor: The output tensor of shape [N, L, C] after conversion.
- """
- assert len(x.shape) == 4
- return x.flatten(2).transpose(1, 2).contiguous()
-
-
-def build_drop_path(drop_path_rate):
- """Build drop path layer."""
- return build_dropout(dict(type='DropPath', drop_prob=drop_path_rate))
-
-
-class WindowMSA(BaseModule):
- """Window based multi-head self-attention (W-MSA) module with relative
- position bias.
-
- Args:
- embed_dims (int): Number of input channels.
- num_heads (int): Number of attention heads.
- window_size (tuple[int]): The height and width of the window.
- qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
- Default: True.
- qk_scale (float | None, optional): Override default qk scale of
- head_dim ** -0.5 if set. Default: None.
- attn_drop_rate (float, optional): Dropout ratio of attention weight.
- Default: 0.0
- proj_drop_rate (float, optional): Dropout ratio of output. Default: 0.
- with_rpe (bool, optional): If True, use relative position bias.
- Default: True.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None.
- """
-
- def __init__(self,
- embed_dims,
- num_heads,
- window_size,
- qkv_bias=True,
- qk_scale=None,
- attn_drop_rate=0.,
- proj_drop_rate=0.,
- with_rpe=True,
- init_cfg=None):
-
- super().__init__(init_cfg=init_cfg)
- self.embed_dims = embed_dims
- self.window_size = window_size # Wh, Ww
- self.num_heads = num_heads
- head_embed_dims = embed_dims // num_heads
- self.scale = qk_scale or head_embed_dims**-0.5
-
- self.with_rpe = with_rpe
- if self.with_rpe:
- # define a parameter table of relative position bias
- self.relative_position_bias_table = nn.Parameter(
- torch.zeros(
- (2 * window_size[0] - 1) * (2 * window_size[1] - 1),
- num_heads)) # 2*Wh-1 * 2*Ww-1, nH
-
- Wh, Ww = self.window_size
- rel_index_coords = self.double_step_seq(2 * Ww - 1, Wh, 1, Ww)
- rel_position_index = rel_index_coords + rel_index_coords.T
- rel_position_index = rel_position_index.flip(1).contiguous()
- self.register_buffer('relative_position_index', rel_position_index)
-
- self.qkv = nn.Linear(embed_dims, embed_dims * 3, bias=qkv_bias)
- self.attn_drop = nn.Dropout(attn_drop_rate)
- self.proj = nn.Linear(embed_dims, embed_dims)
- self.proj_drop = nn.Dropout(proj_drop_rate)
-
- self.softmax = nn.Softmax(dim=-1)
-
- def init_weights(self):
- trunc_normal_init(self.relative_position_bias_table, std=0.02)
-
- def forward(self, x, mask=None):
- """
- Args:
-
- x (tensor): input features with shape of (B*num_windows, N, C)
- mask (tensor | None, Optional): mask with shape of (num_windows,
- Wh*Ww, Wh*Ww), value should be between (-inf, 0].
- """
- B, N, C = x.shape
- qkv = self.qkv(x).reshape(B, N, 3, self.num_heads,
- C // self.num_heads).permute(2, 0, 3, 1, 4)
- q, k, v = qkv[0], qkv[1], qkv[2]
-
- q = q * self.scale
- attn = (q @ k.transpose(-2, -1))
-
- if self.with_rpe:
- relative_position_bias = self.relative_position_bias_table[
- self.relative_position_index.view(-1)].view(
- self.window_size[0] * self.window_size[1],
- self.window_size[0] * self.window_size[1],
- -1) # Wh*Ww,Wh*Ww,nH
- relative_position_bias = relative_position_bias.permute(
- 2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
- attn = attn + relative_position_bias.unsqueeze(0)
-
- if mask is not None:
- nW = mask.shape[0]
- attn = attn.view(B // nW, nW, self.num_heads, N,
- N) + mask.unsqueeze(1).unsqueeze(0)
- attn = attn.view(-1, self.num_heads, N, N)
- attn = self.softmax(attn)
-
- attn = self.attn_drop(attn)
-
- x = (attn @ v).transpose(1, 2).reshape(B, N, C)
- x = self.proj(x)
- x = self.proj_drop(x)
- return x
-
- @staticmethod
- def double_step_seq(step1, len1, step2, len2):
- seq1 = torch.arange(0, step1 * len1, step1)
- seq2 = torch.arange(0, step2 * len2, step2)
- return (seq1[:, None] + seq2[None, :]).reshape(1, -1)
-
-
-class LocalWindowSelfAttention(BaseModule):
- r""" Local-window Self Attention (LSA) module with relative position bias.
-
- This module is the short-range self-attention module in the
- Interlaced Sparse Self-Attention `_.
-
- Args:
- embed_dims (int): Number of input channels.
- num_heads (int): Number of attention heads.
- window_size (tuple[int] | int): The height and width of the window.
- qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
- Default: True.
- qk_scale (float | None, optional): Override default qk scale of
- head_dim ** -0.5 if set. Default: None.
- attn_drop_rate (float, optional): Dropout ratio of attention weight.
- Default: 0.0
- proj_drop_rate (float, optional): Dropout ratio of output. Default: 0.
- with_rpe (bool, optional): If True, use relative position bias.
- Default: True.
- with_pad_mask (bool, optional): If True, mask out the padded tokens in
- the attention process. Default: False.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None.
- """
-
- def __init__(self,
- embed_dims,
- num_heads,
- window_size,
- qkv_bias=True,
- qk_scale=None,
- attn_drop_rate=0.,
- proj_drop_rate=0.,
- with_rpe=True,
- with_pad_mask=False,
- init_cfg=None):
- super().__init__(init_cfg=init_cfg)
- if isinstance(window_size, int):
- window_size = (window_size, window_size)
- self.window_size = window_size
- self.with_pad_mask = with_pad_mask
- self.attn = WindowMSA(
- embed_dims=embed_dims,
- num_heads=num_heads,
- window_size=window_size,
- qkv_bias=qkv_bias,
- qk_scale=qk_scale,
- attn_drop_rate=attn_drop_rate,
- proj_drop_rate=proj_drop_rate,
- with_rpe=with_rpe,
- init_cfg=init_cfg)
-
- def forward(self, x, H, W, **kwargs):
- """Forward function."""
- B, N, C = x.shape
- x = x.view(B, H, W, C)
- Wh, Ww = self.window_size
-
- # center-pad the feature on H and W axes
- pad_h = math.ceil(H / Wh) * Wh - H
- pad_w = math.ceil(W / Ww) * Ww - W
- x = pad(x, (0, 0, pad_w // 2, pad_w - pad_w // 2, pad_h // 2,
- pad_h - pad_h // 2))
-
- # permute
- x = x.view(B, math.ceil(H / Wh), Wh, math.ceil(W / Ww), Ww, C)
- x = x.permute(0, 1, 3, 2, 4, 5)
- x = x.reshape(-1, Wh * Ww, C) # (B*num_window, Wh*Ww, C)
-
- # attention
- if self.with_pad_mask and pad_h > 0 and pad_w > 0:
- pad_mask = x.new_zeros(1, H, W, 1)
- pad_mask = pad(
- pad_mask, [
- 0, 0, pad_w // 2, pad_w - pad_w // 2, pad_h // 2,
- pad_h - pad_h // 2
- ],
- value=-float('inf'))
- pad_mask = pad_mask.view(1, math.ceil(H / Wh), Wh,
- math.ceil(W / Ww), Ww, 1)
- pad_mask = pad_mask.permute(1, 3, 0, 2, 4, 5)
- pad_mask = pad_mask.reshape(-1, Wh * Ww)
- pad_mask = pad_mask[:, None, :].expand([-1, Wh * Ww, -1])
- out = self.attn(x, pad_mask, **kwargs)
- else:
- out = self.attn(x, **kwargs)
-
- # reverse permutation
- out = out.reshape(B, math.ceil(H / Wh), math.ceil(W / Ww), Wh, Ww, C)
- out = out.permute(0, 1, 3, 2, 4, 5)
- out = out.reshape(B, H + pad_h, W + pad_w, C)
-
- # de-pad
- out = out[:, pad_h // 2:H + pad_h // 2, pad_w // 2:W + pad_w // 2]
- return out.reshape(B, N, C)
-
-
-class CrossFFN(BaseModule):
- r"""FFN with Depthwise Conv of HRFormer.
-
- Args:
- in_features (int): The feature dimension.
- hidden_features (int, optional): The hidden dimension of FFNs.
- Defaults: The same as in_features.
- act_cfg (dict, optional): Config of activation layer.
- Default: dict(type='GELU').
- dw_act_cfg (dict, optional): Config of activation layer appended
- right after DW Conv. Default: dict(type='GELU').
- norm_cfg (dict, optional): Config of norm layer.
- Default: dict(type='SyncBN').
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None.
- """
-
- def __init__(self,
- in_features,
- hidden_features=None,
- out_features=None,
- act_cfg=dict(type='GELU'),
- dw_act_cfg=dict(type='GELU'),
- norm_cfg=dict(type='SyncBN'),
- init_cfg=None):
- super().__init__(init_cfg=init_cfg)
- out_features = out_features or in_features
- hidden_features = hidden_features or in_features
- self.fc1 = nn.Conv2d(in_features, hidden_features, kernel_size=1)
- self.act1 = build_activation_layer(act_cfg)
- self.norm1 = build_norm_layer(norm_cfg, hidden_features)[1]
- self.dw3x3 = nn.Conv2d(
- hidden_features,
- hidden_features,
- kernel_size=3,
- stride=1,
- groups=hidden_features,
- padding=1)
- self.act2 = build_activation_layer(dw_act_cfg)
- self.norm2 = build_norm_layer(norm_cfg, hidden_features)[1]
- self.fc2 = nn.Conv2d(hidden_features, out_features, kernel_size=1)
- self.act3 = build_activation_layer(act_cfg)
- self.norm3 = build_norm_layer(norm_cfg, out_features)[1]
-
- def forward(self, x, H, W):
- """Forward function."""
- x = nlc_to_nchw(x, (H, W))
- x = self.act1(self.norm1(self.fc1(x)))
- x = self.act2(self.norm2(self.dw3x3(x)))
- x = self.act3(self.norm3(self.fc2(x)))
- x = nchw_to_nlc(x)
- return x
-
-
-class HRFormerBlock(BaseModule):
- """High-Resolution Block for HRFormer.
-
- Args:
- in_features (int): The input dimension.
- out_features (int): The output dimension.
- num_heads (int): The number of head within each LSA.
- window_size (int, optional): The window size for the LSA.
- Default: 7
- mlp_ratio (int, optional): The expansion ration of FFN.
- Default: 4
- act_cfg (dict, optional): Config of activation layer.
- Default: dict(type='GELU').
- norm_cfg (dict, optional): Config of norm layer.
- Default: dict(type='SyncBN').
- transformer_norm_cfg (dict, optional): Config of transformer norm
- layer. Default: dict(type='LN', eps=1e-6).
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None.
- """
-
- expansion = 1
-
- def __init__(self,
- in_features,
- out_features,
- num_heads,
- window_size=7,
- mlp_ratio=4.0,
- drop_path=0.0,
- act_cfg=dict(type='GELU'),
- norm_cfg=dict(type='SyncBN'),
- transformer_norm_cfg=dict(type='LN', eps=1e-6),
- init_cfg=None,
- **kwargs):
- super(HRFormerBlock, self).__init__(init_cfg=init_cfg)
- self.num_heads = num_heads
- self.window_size = window_size
- self.mlp_ratio = mlp_ratio
-
- self.norm1 = build_norm_layer(transformer_norm_cfg, in_features)[1]
- self.attn = LocalWindowSelfAttention(
- in_features,
- num_heads=num_heads,
- window_size=window_size,
- init_cfg=None,
- **kwargs)
-
- self.norm2 = build_norm_layer(transformer_norm_cfg, out_features)[1]
- self.ffn = CrossFFN(
- in_features=in_features,
- hidden_features=int(in_features * mlp_ratio),
- out_features=out_features,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg,
- dw_act_cfg=act_cfg,
- init_cfg=None)
-
- self.drop_path = build_drop_path(
- drop_path) if drop_path > 0.0 else nn.Identity()
-
- def forward(self, x):
- """Forward function."""
- B, C, H, W = x.size()
- # Attention
- x = x.view(B, C, -1).permute(0, 2, 1)
- x = x + self.drop_path(self.attn(self.norm1(x), H, W))
- # FFN
- x = x + self.drop_path(self.ffn(self.norm2(x), H, W))
- x = x.permute(0, 2, 1).view(B, C, H, W)
- return x
-
- def extra_repr(self):
- """(Optional) Set the extra information about this module."""
- return 'num_heads={}, window_size={}, mlp_ratio={}'.format(
- self.num_heads, self.window_size, self.mlp_ratio)
-
-
-class HRFomerModule(HRModule):
- """High-Resolution Module for HRFormer.
-
- Args:
- num_branches (int): The number of branches in the HRFormerModule.
- block (nn.Module): The building block of HRFormer.
- The block should be the HRFormerBlock.
- num_blocks (tuple): The number of blocks in each branch.
- The length must be equal to num_branches.
- num_inchannels (tuple): The number of input channels in each branch.
- The length must be equal to num_branches.
- num_channels (tuple): The number of channels in each branch.
- The length must be equal to num_branches.
- num_heads (tuple): The number of heads within the LSAs.
- num_window_sizes (tuple): The window size for the LSAs.
- num_mlp_ratios (tuple): The expansion ratio for the FFNs.
- drop_path (int, optional): The drop path rate of HRFomer.
- Default: 0.0
- multiscale_output (bool, optional): Whether to output multi-level
- features produced by multiple branches. If False, only the first
- level feature will be output. Default: True.
- conv_cfg (dict, optional): Config of the conv layers.
- Default: None.
- norm_cfg (dict, optional): Config of the norm layers appended
- right after conv. Default: dict(type='SyncBN', requires_grad=True)
- transformer_norm_cfg (dict, optional): Config of the norm layers.
- Default: dict(type='LN', eps=1e-6)
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed. Default: False
- upsample_cfg(dict, optional): The config of upsample layers in fuse
- layers. Default: dict(mode='bilinear', align_corners=False)
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None.
- """
-
- def __init__(self,
- num_branches,
- block,
- num_blocks,
- num_inchannels,
- num_channels,
- num_heads,
- num_window_sizes,
- num_mlp_ratios,
- multiscale_output=True,
- drop_paths=0.0,
- with_rpe=True,
- with_pad_mask=False,
- conv_cfg=None,
- norm_cfg=dict(type='SyncBN', requires_grad=True),
- transformer_norm_cfg=dict(type='LN', eps=1e-6),
- with_cp=False,
- upsample_cfg=dict(mode='bilinear', align_corners=False),
- **kwargs):
-
- self.transformer_norm_cfg = transformer_norm_cfg
- self.drop_paths = drop_paths
- self.num_heads = num_heads
- self.num_window_sizes = num_window_sizes
- self.num_mlp_ratios = num_mlp_ratios
- self.with_rpe = with_rpe
- self.with_pad_mask = with_pad_mask
-
- super().__init__(num_branches, block, num_blocks, num_inchannels,
- num_channels, multiscale_output, with_cp, conv_cfg,
- norm_cfg, upsample_cfg, **kwargs)
-
- def _make_one_branch(self,
- branch_index,
- block,
- num_blocks,
- num_channels,
- stride=1):
- """Build one branch."""
- # HRFormerBlock does not support down sample layer yet.
- assert stride == 1 and self.in_channels[branch_index] == num_channels[
- branch_index]
- layers = []
- layers.append(
- block(
- self.in_channels[branch_index],
- num_channels[branch_index],
- num_heads=self.num_heads[branch_index],
- window_size=self.num_window_sizes[branch_index],
- mlp_ratio=self.num_mlp_ratios[branch_index],
- drop_path=self.drop_paths[0],
- norm_cfg=self.norm_cfg,
- transformer_norm_cfg=self.transformer_norm_cfg,
- init_cfg=None,
- with_rpe=self.with_rpe,
- with_pad_mask=self.with_pad_mask))
-
- self.in_channels[
- branch_index] = self.in_channels[branch_index] * block.expansion
- for i in range(1, num_blocks[branch_index]):
- layers.append(
- block(
- self.in_channels[branch_index],
- num_channels[branch_index],
- num_heads=self.num_heads[branch_index],
- window_size=self.num_window_sizes[branch_index],
- mlp_ratio=self.num_mlp_ratios[branch_index],
- drop_path=self.drop_paths[i],
- norm_cfg=self.norm_cfg,
- transformer_norm_cfg=self.transformer_norm_cfg,
- init_cfg=None,
- with_rpe=self.with_rpe,
- with_pad_mask=self.with_pad_mask))
- return nn.Sequential(*layers)
-
- def _make_fuse_layers(self):
- """Build fuse layers."""
- if self.num_branches == 1:
- return None
- num_branches = self.num_branches
- num_inchannels = self.in_channels
- fuse_layers = []
- for i in range(num_branches if self.multiscale_output else 1):
- fuse_layer = []
- for j in range(num_branches):
- if j > i:
- fuse_layer.append(
- nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- num_inchannels[j],
- num_inchannels[i],
- kernel_size=1,
- stride=1,
- bias=False),
- build_norm_layer(self.norm_cfg,
- num_inchannels[i])[1],
- nn.Upsample(
- scale_factor=2**(j - i),
- mode=self.upsample_cfg['mode'],
- align_corners=self.
- upsample_cfg['align_corners'])))
- elif j == i:
- fuse_layer.append(None)
- else:
- conv3x3s = []
- for k in range(i - j):
- if k == i - j - 1:
- num_outchannels_conv3x3 = num_inchannels[i]
- with_out_act = False
- else:
- num_outchannels_conv3x3 = num_inchannels[j]
- with_out_act = True
- sub_modules = [
- build_conv_layer(
- self.conv_cfg,
- num_inchannels[j],
- num_inchannels[j],
- kernel_size=3,
- stride=2,
- padding=1,
- groups=num_inchannels[j],
- bias=False,
- ),
- build_norm_layer(self.norm_cfg,
- num_inchannels[j])[1],
- build_conv_layer(
- self.conv_cfg,
- num_inchannels[j],
- num_outchannels_conv3x3,
- kernel_size=1,
- stride=1,
- bias=False,
- ),
- build_norm_layer(self.norm_cfg,
- num_outchannels_conv3x3)[1]
- ]
- if with_out_act:
- sub_modules.append(nn.ReLU(False))
- conv3x3s.append(nn.Sequential(*sub_modules))
- fuse_layer.append(nn.Sequential(*conv3x3s))
- fuse_layers.append(nn.ModuleList(fuse_layer))
-
- return nn.ModuleList(fuse_layers)
-
- def get_num_inchannels(self):
- """Return the number of input channels."""
- return self.in_channels
-
-
-@MODELS.register_module()
-class HRFormer(HRNet):
- """HRFormer backbone.
-
- This backbone is the implementation of `HRFormer: High-Resolution
- Transformer for Dense Prediction `_.
-
- Args:
- extra (dict): Detailed configuration for each stage of HRNet.
- There must be 4 stages, the configuration for each stage must have
- 5 keys:
-
- - num_modules (int): The number of HRModule in this stage.
- - num_branches (int): The number of branches in the HRModule.
- - block (str): The type of block.
- - num_blocks (tuple): The number of blocks in each branch.
- The length must be equal to num_branches.
- - num_channels (tuple): The number of channels in each branch.
- The length must be equal to num_branches.
- in_channels (int): Number of input image channels. Normally 3.
- conv_cfg (dict): Dictionary to construct and config conv layer.
- Default: None.
- norm_cfg (dict): Config of norm layer.
- Use `SyncBN` by default.
- transformer_norm_cfg (dict): Config of transformer norm layer.
- Use `LN` by default.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only. Default: False.
- zero_init_residual (bool): Whether to use zero init for last norm layer
- in resblocks to let them behave as identity. Default: False.
- frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
- -1 means not freezing any parameters. Default: -1.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Normal', std=0.001, layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]``
-
- Example:
- >>> from mmpose.models import HRFormer
- >>> import torch
- >>> extra = dict(
- >>> stage1=dict(
- >>> num_modules=1,
- >>> num_branches=1,
- >>> block='BOTTLENECK',
- >>> num_blocks=(2, ),
- >>> num_channels=(64, )),
- >>> stage2=dict(
- >>> num_modules=1,
- >>> num_branches=2,
- >>> block='HRFORMER',
- >>> window_sizes=(7, 7),
- >>> num_heads=(1, 2),
- >>> mlp_ratios=(4, 4),
- >>> num_blocks=(2, 2),
- >>> num_channels=(32, 64)),
- >>> stage3=dict(
- >>> num_modules=4,
- >>> num_branches=3,
- >>> block='HRFORMER',
- >>> window_sizes=(7, 7, 7),
- >>> num_heads=(1, 2, 4),
- >>> mlp_ratios=(4, 4, 4),
- >>> num_blocks=(2, 2, 2),
- >>> num_channels=(32, 64, 128)),
- >>> stage4=dict(
- >>> num_modules=2,
- >>> num_branches=4,
- >>> block='HRFORMER',
- >>> window_sizes=(7, 7, 7, 7),
- >>> num_heads=(1, 2, 4, 8),
- >>> mlp_ratios=(4, 4, 4, 4),
- >>> num_blocks=(2, 2, 2, 2),
- >>> num_channels=(32, 64, 128, 256)))
- >>> self = HRFormer(extra, in_channels=1)
- >>> self.eval()
- >>> inputs = torch.rand(1, 1, 32, 32)
- >>> level_outputs = self.forward(inputs)
- >>> for level_out in level_outputs:
- ... print(tuple(level_out.shape))
- (1, 32, 8, 8)
- (1, 64, 4, 4)
- (1, 128, 2, 2)
- (1, 256, 1, 1)
- """
-
- blocks_dict = {'BOTTLENECK': Bottleneck, 'HRFORMERBLOCK': HRFormerBlock}
-
- def __init__(
- self,
- extra,
- in_channels=3,
- conv_cfg=None,
- norm_cfg=dict(type='BN', requires_grad=True),
- transformer_norm_cfg=dict(type='LN', eps=1e-6),
- norm_eval=False,
- with_cp=False,
- zero_init_residual=False,
- frozen_stages=-1,
- init_cfg=[
- dict(type='Normal', std=0.001, layer=['Conv2d']),
- dict(type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])
- ],
- ):
-
- # stochastic depth
- depths = [
- extra[stage]['num_blocks'][0] * extra[stage]['num_modules']
- for stage in ['stage2', 'stage3', 'stage4']
- ]
- depth_s2, depth_s3, _ = depths
- drop_path_rate = extra['drop_path_rate']
- dpr = [
- x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))
- ]
- extra['stage2']['drop_path_rates'] = dpr[0:depth_s2]
- extra['stage3']['drop_path_rates'] = dpr[depth_s2:depth_s2 + depth_s3]
- extra['stage4']['drop_path_rates'] = dpr[depth_s2 + depth_s3:]
-
- # HRFormer use bilinear upsample as default
- upsample_cfg = extra.get('upsample', {
- 'mode': 'bilinear',
- 'align_corners': False
- })
- extra['upsample'] = upsample_cfg
- self.transformer_norm_cfg = transformer_norm_cfg
- self.with_rpe = extra.get('with_rpe', True)
- self.with_pad_mask = extra.get('with_pad_mask', False)
-
- super().__init__(extra, in_channels, conv_cfg, norm_cfg, norm_eval,
- with_cp, zero_init_residual, frozen_stages, init_cfg)
-
- def _make_stage(self,
- layer_config,
- num_inchannels,
- multiscale_output=True):
- """Make each stage."""
- num_modules = layer_config['num_modules']
- num_branches = layer_config['num_branches']
- num_blocks = layer_config['num_blocks']
- num_channels = layer_config['num_channels']
- block = self.blocks_dict[layer_config['block']]
- num_heads = layer_config['num_heads']
- num_window_sizes = layer_config['window_sizes']
- num_mlp_ratios = layer_config['mlp_ratios']
- drop_path_rates = layer_config['drop_path_rates']
-
- modules = []
- for i in range(num_modules):
- # multiscale_output is only used at the last module
- if not multiscale_output and i == num_modules - 1:
- reset_multiscale_output = False
- else:
- reset_multiscale_output = True
-
- modules.append(
- HRFomerModule(
- num_branches,
- block,
- num_blocks,
- num_inchannels,
- num_channels,
- num_heads,
- num_window_sizes,
- num_mlp_ratios,
- reset_multiscale_output,
- drop_paths=drop_path_rates[num_blocks[0] *
- i:num_blocks[0] * (i + 1)],
- with_rpe=self.with_rpe,
- with_pad_mask=self.with_pad_mask,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- transformer_norm_cfg=self.transformer_norm_cfg,
- with_cp=self.with_cp,
- upsample_cfg=self.upsample_cfg))
- num_inchannels = modules[-1].get_num_inchannels()
-
- return nn.Sequential(*modules), num_inchannels
+# Copyright (c) OpenMMLab. All rights reserved.
+
+import math
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import build_activation_layer, build_conv_layer, build_norm_layer
+from mmcv.cnn.bricks.transformer import build_dropout
+from mmengine.model import BaseModule, trunc_normal_init
+from torch.nn.functional import pad
+
+from mmpose.registry import MODELS
+from .hrnet import Bottleneck, HRModule, HRNet
+
+
+def nlc_to_nchw(x, hw_shape):
+ """Convert [N, L, C] shape tensor to [N, C, H, W] shape tensor.
+
+ Args:
+ x (Tensor): The input tensor of shape [N, L, C] before conversion.
+ hw_shape (Sequence[int]): The height and width of output feature map.
+
+ Returns:
+ Tensor: The output tensor of shape [N, C, H, W] after conversion.
+ """
+ H, W = hw_shape
+ assert len(x.shape) == 3
+ B, L, C = x.shape
+ assert L == H * W, 'The seq_len doesn\'t match H, W'
+ return x.transpose(1, 2).reshape(B, C, H, W)
+
+
+def nchw_to_nlc(x):
+ """Flatten [N, C, H, W] shape tensor to [N, L, C] shape tensor.
+
+ Args:
+ x (Tensor): The input tensor of shape [N, C, H, W] before conversion.
+
+ Returns:
+ Tensor: The output tensor of shape [N, L, C] after conversion.
+ """
+ assert len(x.shape) == 4
+ return x.flatten(2).transpose(1, 2).contiguous()
+
+
+def build_drop_path(drop_path_rate):
+ """Build drop path layer."""
+ return build_dropout(dict(type='DropPath', drop_prob=drop_path_rate))
+
+
+class WindowMSA(BaseModule):
+ """Window based multi-head self-attention (W-MSA) module with relative
+ position bias.
+
+ Args:
+ embed_dims (int): Number of input channels.
+ num_heads (int): Number of attention heads.
+ window_size (tuple[int]): The height and width of the window.
+ qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
+ Default: True.
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ attn_drop_rate (float, optional): Dropout ratio of attention weight.
+ Default: 0.0
+ proj_drop_rate (float, optional): Dropout ratio of output. Default: 0.
+ with_rpe (bool, optional): If True, use relative position bias.
+ Default: True.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ window_size,
+ qkv_bias=True,
+ qk_scale=None,
+ attn_drop_rate=0.,
+ proj_drop_rate=0.,
+ with_rpe=True,
+ init_cfg=None):
+
+ super().__init__(init_cfg=init_cfg)
+ self.embed_dims = embed_dims
+ self.window_size = window_size # Wh, Ww
+ self.num_heads = num_heads
+ head_embed_dims = embed_dims // num_heads
+ self.scale = qk_scale or head_embed_dims**-0.5
+
+ self.with_rpe = with_rpe
+ if self.with_rpe:
+ # define a parameter table of relative position bias
+ self.relative_position_bias_table = nn.Parameter(
+ torch.zeros(
+ (2 * window_size[0] - 1) * (2 * window_size[1] - 1),
+ num_heads)) # 2*Wh-1 * 2*Ww-1, nH
+
+ Wh, Ww = self.window_size
+ rel_index_coords = self.double_step_seq(2 * Ww - 1, Wh, 1, Ww)
+ rel_position_index = rel_index_coords + rel_index_coords.T
+ rel_position_index = rel_position_index.flip(1).contiguous()
+ self.register_buffer('relative_position_index', rel_position_index)
+
+ self.qkv = nn.Linear(embed_dims, embed_dims * 3, bias=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop_rate)
+ self.proj = nn.Linear(embed_dims, embed_dims)
+ self.proj_drop = nn.Dropout(proj_drop_rate)
+
+ self.softmax = nn.Softmax(dim=-1)
+
+ def init_weights(self):
+ trunc_normal_init(self.relative_position_bias_table, std=0.02)
+
+ def forward(self, x, mask=None):
+ """
+ Args:
+
+ x (tensor): input features with shape of (B*num_windows, N, C)
+ mask (tensor | None, Optional): mask with shape of (num_windows,
+ Wh*Ww, Wh*Ww), value should be between (-inf, 0].
+ """
+ B, N, C = x.shape
+ qkv = self.qkv(x).reshape(B, N, 3, self.num_heads,
+ C // self.num_heads).permute(2, 0, 3, 1, 4)
+ q, k, v = qkv[0], qkv[1], qkv[2]
+
+ q = q * self.scale
+ attn = (q @ k.transpose(-2, -1))
+
+ if self.with_rpe:
+ relative_position_bias = self.relative_position_bias_table[
+ self.relative_position_index.view(-1)].view(
+ self.window_size[0] * self.window_size[1],
+ self.window_size[0] * self.window_size[1],
+ -1) # Wh*Ww,Wh*Ww,nH
+ relative_position_bias = relative_position_bias.permute(
+ 2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
+ attn = attn + relative_position_bias.unsqueeze(0)
+
+ if mask is not None:
+ nW = mask.shape[0]
+ attn = attn.view(B // nW, nW, self.num_heads, N,
+ N) + mask.unsqueeze(1).unsqueeze(0)
+ attn = attn.view(-1, self.num_heads, N, N)
+ attn = self.softmax(attn)
+
+ attn = self.attn_drop(attn)
+
+ x = (attn @ v).transpose(1, 2).reshape(B, N, C)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+ @staticmethod
+ def double_step_seq(step1, len1, step2, len2):
+ seq1 = torch.arange(0, step1 * len1, step1)
+ seq2 = torch.arange(0, step2 * len2, step2)
+ return (seq1[:, None] + seq2[None, :]).reshape(1, -1)
+
+
+class LocalWindowSelfAttention(BaseModule):
+ r""" Local-window Self Attention (LSA) module with relative position bias.
+
+ This module is the short-range self-attention module in the
+ Interlaced Sparse Self-Attention `_.
+
+ Args:
+ embed_dims (int): Number of input channels.
+ num_heads (int): Number of attention heads.
+ window_size (tuple[int] | int): The height and width of the window.
+ qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
+ Default: True.
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ attn_drop_rate (float, optional): Dropout ratio of attention weight.
+ Default: 0.0
+ proj_drop_rate (float, optional): Dropout ratio of output. Default: 0.
+ with_rpe (bool, optional): If True, use relative position bias.
+ Default: True.
+ with_pad_mask (bool, optional): If True, mask out the padded tokens in
+ the attention process. Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ window_size,
+ qkv_bias=True,
+ qk_scale=None,
+ attn_drop_rate=0.,
+ proj_drop_rate=0.,
+ with_rpe=True,
+ with_pad_mask=False,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ if isinstance(window_size, int):
+ window_size = (window_size, window_size)
+ self.window_size = window_size
+ self.with_pad_mask = with_pad_mask
+ self.attn = WindowMSA(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ window_size=window_size,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ attn_drop_rate=attn_drop_rate,
+ proj_drop_rate=proj_drop_rate,
+ with_rpe=with_rpe,
+ init_cfg=init_cfg)
+
+ def forward(self, x, H, W, **kwargs):
+ """Forward function."""
+ B, N, C = x.shape
+ x = x.view(B, H, W, C)
+ Wh, Ww = self.window_size
+
+ # center-pad the feature on H and W axes
+ pad_h = math.ceil(H / Wh) * Wh - H
+ pad_w = math.ceil(W / Ww) * Ww - W
+ x = pad(x, (0, 0, pad_w // 2, pad_w - pad_w // 2, pad_h // 2,
+ pad_h - pad_h // 2))
+
+ # permute
+ x = x.view(B, math.ceil(H / Wh), Wh, math.ceil(W / Ww), Ww, C)
+ x = x.permute(0, 1, 3, 2, 4, 5)
+ x = x.reshape(-1, Wh * Ww, C) # (B*num_window, Wh*Ww, C)
+
+ # attention
+ if self.with_pad_mask and pad_h > 0 and pad_w > 0:
+ pad_mask = x.new_zeros(1, H, W, 1)
+ pad_mask = pad(
+ pad_mask, [
+ 0, 0, pad_w // 2, pad_w - pad_w // 2, pad_h // 2,
+ pad_h - pad_h // 2
+ ],
+ value=-float('inf'))
+ pad_mask = pad_mask.view(1, math.ceil(H / Wh), Wh,
+ math.ceil(W / Ww), Ww, 1)
+ pad_mask = pad_mask.permute(1, 3, 0, 2, 4, 5)
+ pad_mask = pad_mask.reshape(-1, Wh * Ww)
+ pad_mask = pad_mask[:, None, :].expand([-1, Wh * Ww, -1])
+ out = self.attn(x, pad_mask, **kwargs)
+ else:
+ out = self.attn(x, **kwargs)
+
+ # reverse permutation
+ out = out.reshape(B, math.ceil(H / Wh), math.ceil(W / Ww), Wh, Ww, C)
+ out = out.permute(0, 1, 3, 2, 4, 5)
+ out = out.reshape(B, H + pad_h, W + pad_w, C)
+
+ # de-pad
+ out = out[:, pad_h // 2:H + pad_h // 2, pad_w // 2:W + pad_w // 2]
+ return out.reshape(B, N, C)
+
+
+class CrossFFN(BaseModule):
+ r"""FFN with Depthwise Conv of HRFormer.
+
+ Args:
+ in_features (int): The feature dimension.
+ hidden_features (int, optional): The hidden dimension of FFNs.
+ Defaults: The same as in_features.
+ act_cfg (dict, optional): Config of activation layer.
+ Default: dict(type='GELU').
+ dw_act_cfg (dict, optional): Config of activation layer appended
+ right after DW Conv. Default: dict(type='GELU').
+ norm_cfg (dict, optional): Config of norm layer.
+ Default: dict(type='SyncBN').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_features,
+ hidden_features=None,
+ out_features=None,
+ act_cfg=dict(type='GELU'),
+ dw_act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='SyncBN'),
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ out_features = out_features or in_features
+ hidden_features = hidden_features or in_features
+ self.fc1 = nn.Conv2d(in_features, hidden_features, kernel_size=1)
+ self.act1 = build_activation_layer(act_cfg)
+ self.norm1 = build_norm_layer(norm_cfg, hidden_features)[1]
+ self.dw3x3 = nn.Conv2d(
+ hidden_features,
+ hidden_features,
+ kernel_size=3,
+ stride=1,
+ groups=hidden_features,
+ padding=1)
+ self.act2 = build_activation_layer(dw_act_cfg)
+ self.norm2 = build_norm_layer(norm_cfg, hidden_features)[1]
+ self.fc2 = nn.Conv2d(hidden_features, out_features, kernel_size=1)
+ self.act3 = build_activation_layer(act_cfg)
+ self.norm3 = build_norm_layer(norm_cfg, out_features)[1]
+
+ def forward(self, x, H, W):
+ """Forward function."""
+ x = nlc_to_nchw(x, (H, W))
+ x = self.act1(self.norm1(self.fc1(x)))
+ x = self.act2(self.norm2(self.dw3x3(x)))
+ x = self.act3(self.norm3(self.fc2(x)))
+ x = nchw_to_nlc(x)
+ return x
+
+
+class HRFormerBlock(BaseModule):
+ """High-Resolution Block for HRFormer.
+
+ Args:
+ in_features (int): The input dimension.
+ out_features (int): The output dimension.
+ num_heads (int): The number of head within each LSA.
+ window_size (int, optional): The window size for the LSA.
+ Default: 7
+ mlp_ratio (int, optional): The expansion ration of FFN.
+ Default: 4
+ act_cfg (dict, optional): Config of activation layer.
+ Default: dict(type='GELU').
+ norm_cfg (dict, optional): Config of norm layer.
+ Default: dict(type='SyncBN').
+ transformer_norm_cfg (dict, optional): Config of transformer norm
+ layer. Default: dict(type='LN', eps=1e-6).
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ expansion = 1
+
+ def __init__(self,
+ in_features,
+ out_features,
+ num_heads,
+ window_size=7,
+ mlp_ratio=4.0,
+ drop_path=0.0,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='SyncBN'),
+ transformer_norm_cfg=dict(type='LN', eps=1e-6),
+ init_cfg=None,
+ **kwargs):
+ super(HRFormerBlock, self).__init__(init_cfg=init_cfg)
+ self.num_heads = num_heads
+ self.window_size = window_size
+ self.mlp_ratio = mlp_ratio
+
+ self.norm1 = build_norm_layer(transformer_norm_cfg, in_features)[1]
+ self.attn = LocalWindowSelfAttention(
+ in_features,
+ num_heads=num_heads,
+ window_size=window_size,
+ init_cfg=None,
+ **kwargs)
+
+ self.norm2 = build_norm_layer(transformer_norm_cfg, out_features)[1]
+ self.ffn = CrossFFN(
+ in_features=in_features,
+ hidden_features=int(in_features * mlp_ratio),
+ out_features=out_features,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ dw_act_cfg=act_cfg,
+ init_cfg=None)
+
+ self.drop_path = build_drop_path(
+ drop_path) if drop_path > 0.0 else nn.Identity()
+
+ def forward(self, x):
+ """Forward function."""
+ B, C, H, W = x.size()
+ # Attention
+ x = x.view(B, C, -1).permute(0, 2, 1)
+ x = x + self.drop_path(self.attn(self.norm1(x), H, W))
+ # FFN
+ x = x + self.drop_path(self.ffn(self.norm2(x), H, W))
+ x = x.permute(0, 2, 1).view(B, C, H, W)
+ return x
+
+ def extra_repr(self):
+ """(Optional) Set the extra information about this module."""
+ return 'num_heads={}, window_size={}, mlp_ratio={}'.format(
+ self.num_heads, self.window_size, self.mlp_ratio)
+
+
+class HRFomerModule(HRModule):
+ """High-Resolution Module for HRFormer.
+
+ Args:
+ num_branches (int): The number of branches in the HRFormerModule.
+ block (nn.Module): The building block of HRFormer.
+ The block should be the HRFormerBlock.
+ num_blocks (tuple): The number of blocks in each branch.
+ The length must be equal to num_branches.
+ num_inchannels (tuple): The number of input channels in each branch.
+ The length must be equal to num_branches.
+ num_channels (tuple): The number of channels in each branch.
+ The length must be equal to num_branches.
+ num_heads (tuple): The number of heads within the LSAs.
+ num_window_sizes (tuple): The window size for the LSAs.
+ num_mlp_ratios (tuple): The expansion ratio for the FFNs.
+ drop_path (int, optional): The drop path rate of HRFomer.
+ Default: 0.0
+ multiscale_output (bool, optional): Whether to output multi-level
+ features produced by multiple branches. If False, only the first
+ level feature will be output. Default: True.
+ conv_cfg (dict, optional): Config of the conv layers.
+ Default: None.
+ norm_cfg (dict, optional): Config of the norm layers appended
+ right after conv. Default: dict(type='SyncBN', requires_grad=True)
+ transformer_norm_cfg (dict, optional): Config of the norm layers.
+ Default: dict(type='LN', eps=1e-6)
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False
+ upsample_cfg(dict, optional): The config of upsample layers in fuse
+ layers. Default: dict(mode='bilinear', align_corners=False)
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ num_branches,
+ block,
+ num_blocks,
+ num_inchannels,
+ num_channels,
+ num_heads,
+ num_window_sizes,
+ num_mlp_ratios,
+ multiscale_output=True,
+ drop_paths=0.0,
+ with_rpe=True,
+ with_pad_mask=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='SyncBN', requires_grad=True),
+ transformer_norm_cfg=dict(type='LN', eps=1e-6),
+ with_cp=False,
+ upsample_cfg=dict(mode='bilinear', align_corners=False),
+ **kwargs):
+
+ self.transformer_norm_cfg = transformer_norm_cfg
+ self.drop_paths = drop_paths
+ self.num_heads = num_heads
+ self.num_window_sizes = num_window_sizes
+ self.num_mlp_ratios = num_mlp_ratios
+ self.with_rpe = with_rpe
+ self.with_pad_mask = with_pad_mask
+
+ super().__init__(num_branches, block, num_blocks, num_inchannels,
+ num_channels, multiscale_output, with_cp, conv_cfg,
+ norm_cfg, upsample_cfg, **kwargs)
+
+ def _make_one_branch(self,
+ branch_index,
+ block,
+ num_blocks,
+ num_channels,
+ stride=1):
+ """Build one branch."""
+ # HRFormerBlock does not support down sample layer yet.
+ assert stride == 1 and self.in_channels[branch_index] == num_channels[
+ branch_index]
+ layers = []
+ layers.append(
+ block(
+ self.in_channels[branch_index],
+ num_channels[branch_index],
+ num_heads=self.num_heads[branch_index],
+ window_size=self.num_window_sizes[branch_index],
+ mlp_ratio=self.num_mlp_ratios[branch_index],
+ drop_path=self.drop_paths[0],
+ norm_cfg=self.norm_cfg,
+ transformer_norm_cfg=self.transformer_norm_cfg,
+ init_cfg=None,
+ with_rpe=self.with_rpe,
+ with_pad_mask=self.with_pad_mask))
+
+ self.in_channels[
+ branch_index] = self.in_channels[branch_index] * block.expansion
+ for i in range(1, num_blocks[branch_index]):
+ layers.append(
+ block(
+ self.in_channels[branch_index],
+ num_channels[branch_index],
+ num_heads=self.num_heads[branch_index],
+ window_size=self.num_window_sizes[branch_index],
+ mlp_ratio=self.num_mlp_ratios[branch_index],
+ drop_path=self.drop_paths[i],
+ norm_cfg=self.norm_cfg,
+ transformer_norm_cfg=self.transformer_norm_cfg,
+ init_cfg=None,
+ with_rpe=self.with_rpe,
+ with_pad_mask=self.with_pad_mask))
+ return nn.Sequential(*layers)
+
+ def _make_fuse_layers(self):
+ """Build fuse layers."""
+ if self.num_branches == 1:
+ return None
+ num_branches = self.num_branches
+ num_inchannels = self.in_channels
+ fuse_layers = []
+ for i in range(num_branches if self.multiscale_output else 1):
+ fuse_layer = []
+ for j in range(num_branches):
+ if j > i:
+ fuse_layer.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ num_inchannels[j],
+ num_inchannels[i],
+ kernel_size=1,
+ stride=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ num_inchannels[i])[1],
+ nn.Upsample(
+ scale_factor=2**(j - i),
+ mode=self.upsample_cfg['mode'],
+ align_corners=self.
+ upsample_cfg['align_corners'])))
+ elif j == i:
+ fuse_layer.append(None)
+ else:
+ conv3x3s = []
+ for k in range(i - j):
+ if k == i - j - 1:
+ num_outchannels_conv3x3 = num_inchannels[i]
+ with_out_act = False
+ else:
+ num_outchannels_conv3x3 = num_inchannels[j]
+ with_out_act = True
+ sub_modules = [
+ build_conv_layer(
+ self.conv_cfg,
+ num_inchannels[j],
+ num_inchannels[j],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ groups=num_inchannels[j],
+ bias=False,
+ ),
+ build_norm_layer(self.norm_cfg,
+ num_inchannels[j])[1],
+ build_conv_layer(
+ self.conv_cfg,
+ num_inchannels[j],
+ num_outchannels_conv3x3,
+ kernel_size=1,
+ stride=1,
+ bias=False,
+ ),
+ build_norm_layer(self.norm_cfg,
+ num_outchannels_conv3x3)[1]
+ ]
+ if with_out_act:
+ sub_modules.append(nn.ReLU(False))
+ conv3x3s.append(nn.Sequential(*sub_modules))
+ fuse_layer.append(nn.Sequential(*conv3x3s))
+ fuse_layers.append(nn.ModuleList(fuse_layer))
+
+ return nn.ModuleList(fuse_layers)
+
+ def get_num_inchannels(self):
+ """Return the number of input channels."""
+ return self.in_channels
+
+
+@MODELS.register_module()
+class HRFormer(HRNet):
+ """HRFormer backbone.
+
+ This backbone is the implementation of `HRFormer: High-Resolution
+ Transformer for Dense Prediction `_.
+
+ Args:
+ extra (dict): Detailed configuration for each stage of HRNet.
+ There must be 4 stages, the configuration for each stage must have
+ 5 keys:
+
+ - num_modules (int): The number of HRModule in this stage.
+ - num_branches (int): The number of branches in the HRModule.
+ - block (str): The type of block.
+ - num_blocks (tuple): The number of blocks in each branch.
+ The length must be equal to num_branches.
+ - num_channels (tuple): The number of channels in each branch.
+ The length must be equal to num_branches.
+ in_channels (int): Number of input image channels. Normally 3.
+ conv_cfg (dict): Dictionary to construct and config conv layer.
+ Default: None.
+ norm_cfg (dict): Config of norm layer.
+ Use `SyncBN` by default.
+ transformer_norm_cfg (dict): Config of transformer norm layer.
+ Use `LN` by default.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ zero_init_residual (bool): Whether to use zero init for last norm layer
+ in resblocks to let them behave as identity. Default: False.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters. Default: -1.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+
+ Example:
+ >>> from mmpose.models import HRFormer
+ >>> import torch
+ >>> extra = dict(
+ >>> stage1=dict(
+ >>> num_modules=1,
+ >>> num_branches=1,
+ >>> block='BOTTLENECK',
+ >>> num_blocks=(2, ),
+ >>> num_channels=(64, )),
+ >>> stage2=dict(
+ >>> num_modules=1,
+ >>> num_branches=2,
+ >>> block='HRFORMER',
+ >>> window_sizes=(7, 7),
+ >>> num_heads=(1, 2),
+ >>> mlp_ratios=(4, 4),
+ >>> num_blocks=(2, 2),
+ >>> num_channels=(32, 64)),
+ >>> stage3=dict(
+ >>> num_modules=4,
+ >>> num_branches=3,
+ >>> block='HRFORMER',
+ >>> window_sizes=(7, 7, 7),
+ >>> num_heads=(1, 2, 4),
+ >>> mlp_ratios=(4, 4, 4),
+ >>> num_blocks=(2, 2, 2),
+ >>> num_channels=(32, 64, 128)),
+ >>> stage4=dict(
+ >>> num_modules=2,
+ >>> num_branches=4,
+ >>> block='HRFORMER',
+ >>> window_sizes=(7, 7, 7, 7),
+ >>> num_heads=(1, 2, 4, 8),
+ >>> mlp_ratios=(4, 4, 4, 4),
+ >>> num_blocks=(2, 2, 2, 2),
+ >>> num_channels=(32, 64, 128, 256)))
+ >>> self = HRFormer(extra, in_channels=1)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 1, 32, 32)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 32, 8, 8)
+ (1, 64, 4, 4)
+ (1, 128, 2, 2)
+ (1, 256, 1, 1)
+ """
+
+ blocks_dict = {'BOTTLENECK': Bottleneck, 'HRFORMERBLOCK': HRFormerBlock}
+
+ def __init__(
+ self,
+ extra,
+ in_channels=3,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ transformer_norm_cfg=dict(type='LN', eps=1e-6),
+ norm_eval=False,
+ with_cp=False,
+ zero_init_residual=False,
+ frozen_stages=-1,
+ init_cfg=[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])
+ ],
+ ):
+
+ # stochastic depth
+ depths = [
+ extra[stage]['num_blocks'][0] * extra[stage]['num_modules']
+ for stage in ['stage2', 'stage3', 'stage4']
+ ]
+ depth_s2, depth_s3, _ = depths
+ drop_path_rate = extra['drop_path_rate']
+ dpr = [
+ x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))
+ ]
+ extra['stage2']['drop_path_rates'] = dpr[0:depth_s2]
+ extra['stage3']['drop_path_rates'] = dpr[depth_s2:depth_s2 + depth_s3]
+ extra['stage4']['drop_path_rates'] = dpr[depth_s2 + depth_s3:]
+
+ # HRFormer use bilinear upsample as default
+ upsample_cfg = extra.get('upsample', {
+ 'mode': 'bilinear',
+ 'align_corners': False
+ })
+ extra['upsample'] = upsample_cfg
+ self.transformer_norm_cfg = transformer_norm_cfg
+ self.with_rpe = extra.get('with_rpe', True)
+ self.with_pad_mask = extra.get('with_pad_mask', False)
+
+ super().__init__(extra, in_channels, conv_cfg, norm_cfg, norm_eval,
+ with_cp, zero_init_residual, frozen_stages, init_cfg)
+
+ def _make_stage(self,
+ layer_config,
+ num_inchannels,
+ multiscale_output=True):
+ """Make each stage."""
+ num_modules = layer_config['num_modules']
+ num_branches = layer_config['num_branches']
+ num_blocks = layer_config['num_blocks']
+ num_channels = layer_config['num_channels']
+ block = self.blocks_dict[layer_config['block']]
+ num_heads = layer_config['num_heads']
+ num_window_sizes = layer_config['window_sizes']
+ num_mlp_ratios = layer_config['mlp_ratios']
+ drop_path_rates = layer_config['drop_path_rates']
+
+ modules = []
+ for i in range(num_modules):
+ # multiscale_output is only used at the last module
+ if not multiscale_output and i == num_modules - 1:
+ reset_multiscale_output = False
+ else:
+ reset_multiscale_output = True
+
+ modules.append(
+ HRFomerModule(
+ num_branches,
+ block,
+ num_blocks,
+ num_inchannels,
+ num_channels,
+ num_heads,
+ num_window_sizes,
+ num_mlp_ratios,
+ reset_multiscale_output,
+ drop_paths=drop_path_rates[num_blocks[0] *
+ i:num_blocks[0] * (i + 1)],
+ with_rpe=self.with_rpe,
+ with_pad_mask=self.with_pad_mask,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ transformer_norm_cfg=self.transformer_norm_cfg,
+ with_cp=self.with_cp,
+ upsample_cfg=self.upsample_cfg))
+ num_inchannels = modules[-1].get_num_inchannels()
+
+ return nn.Sequential(*modules), num_inchannels
diff --git a/mmpose/models/backbones/hrnet.py b/mmpose/models/backbones/hrnet.py
index 381b22d60e..4b291b48fe 100644
--- a/mmpose/models/backbones/hrnet.py
+++ b/mmpose/models/backbones/hrnet.py
@@ -1,610 +1,610 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-
-import torch.nn as nn
-from mmcv.cnn import build_conv_layer, build_norm_layer
-from mmengine.model import BaseModule, constant_init
-from torch.nn.modules.batchnorm import _BatchNorm
-
-from mmpose.registry import MODELS
-from .base_backbone import BaseBackbone
-from .resnet import BasicBlock, Bottleneck, get_expansion
-
-
-class HRModule(BaseModule):
- """High-Resolution Module for HRNet.
-
- In this module, every branch has 4 BasicBlocks/Bottlenecks. Fusion/Exchange
- is in this module.
- """
-
- def __init__(self,
- num_branches,
- blocks,
- num_blocks,
- in_channels,
- num_channels,
- multiscale_output=False,
- with_cp=False,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- upsample_cfg=dict(mode='nearest', align_corners=None),
- init_cfg=None):
-
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
- self._check_branches(num_branches, num_blocks, in_channels,
- num_channels)
-
- self.in_channels = in_channels
- self.num_branches = num_branches
-
- self.multiscale_output = multiscale_output
- self.norm_cfg = norm_cfg
- self.conv_cfg = conv_cfg
- self.upsample_cfg = upsample_cfg
- self.with_cp = with_cp
- self.branches = self._make_branches(num_branches, blocks, num_blocks,
- num_channels)
- self.fuse_layers = self._make_fuse_layers()
- self.relu = nn.ReLU(inplace=True)
-
- @staticmethod
- def _check_branches(num_branches, num_blocks, in_channels, num_channels):
- """Check input to avoid ValueError."""
- if num_branches != len(num_blocks):
- error_msg = f'NUM_BRANCHES({num_branches}) ' \
- f'!= NUM_BLOCKS({len(num_blocks)})'
- raise ValueError(error_msg)
-
- if num_branches != len(num_channels):
- error_msg = f'NUM_BRANCHES({num_branches}) ' \
- f'!= NUM_CHANNELS({len(num_channels)})'
- raise ValueError(error_msg)
-
- if num_branches != len(in_channels):
- error_msg = f'NUM_BRANCHES({num_branches}) ' \
- f'!= NUM_INCHANNELS({len(in_channels)})'
- raise ValueError(error_msg)
-
- def _make_one_branch(self,
- branch_index,
- block,
- num_blocks,
- num_channels,
- stride=1):
- """Make one branch."""
- downsample = None
- if stride != 1 or \
- self.in_channels[branch_index] != \
- num_channels[branch_index] * get_expansion(block):
- downsample = nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- self.in_channels[branch_index],
- num_channels[branch_index] * get_expansion(block),
- kernel_size=1,
- stride=stride,
- bias=False),
- build_norm_layer(
- self.norm_cfg,
- num_channels[branch_index] * get_expansion(block))[1])
-
- layers = []
- layers.append(
- block(
- self.in_channels[branch_index],
- num_channels[branch_index] * get_expansion(block),
- stride=stride,
- downsample=downsample,
- with_cp=self.with_cp,
- norm_cfg=self.norm_cfg,
- conv_cfg=self.conv_cfg))
- self.in_channels[branch_index] = \
- num_channels[branch_index] * get_expansion(block)
- for _ in range(1, num_blocks[branch_index]):
- layers.append(
- block(
- self.in_channels[branch_index],
- num_channels[branch_index] * get_expansion(block),
- with_cp=self.with_cp,
- norm_cfg=self.norm_cfg,
- conv_cfg=self.conv_cfg))
-
- return nn.Sequential(*layers)
-
- def _make_branches(self, num_branches, block, num_blocks, num_channels):
- """Make branches."""
- branches = []
-
- for i in range(num_branches):
- branches.append(
- self._make_one_branch(i, block, num_blocks, num_channels))
-
- return nn.ModuleList(branches)
-
- def _make_fuse_layers(self):
- """Make fuse layer."""
- if self.num_branches == 1:
- return None
-
- num_branches = self.num_branches
- in_channels = self.in_channels
- fuse_layers = []
- num_out_branches = num_branches if self.multiscale_output else 1
-
- for i in range(num_out_branches):
- fuse_layer = []
- for j in range(num_branches):
- if j > i:
- fuse_layer.append(
- nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- in_channels[j],
- in_channels[i],
- kernel_size=1,
- stride=1,
- padding=0,
- bias=False),
- build_norm_layer(self.norm_cfg, in_channels[i])[1],
- nn.Upsample(
- scale_factor=2**(j - i),
- mode=self.upsample_cfg['mode'],
- align_corners=self.
- upsample_cfg['align_corners'])))
- elif j == i:
- fuse_layer.append(None)
- else:
- conv_downsamples = []
- for k in range(i - j):
- if k == i - j - 1:
- conv_downsamples.append(
- nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- in_channels[j],
- in_channels[i],
- kernel_size=3,
- stride=2,
- padding=1,
- bias=False),
- build_norm_layer(self.norm_cfg,
- in_channels[i])[1]))
- else:
- conv_downsamples.append(
- nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- in_channels[j],
- in_channels[j],
- kernel_size=3,
- stride=2,
- padding=1,
- bias=False),
- build_norm_layer(self.norm_cfg,
- in_channels[j])[1],
- nn.ReLU(inplace=True)))
- fuse_layer.append(nn.Sequential(*conv_downsamples))
- fuse_layers.append(nn.ModuleList(fuse_layer))
-
- return nn.ModuleList(fuse_layers)
-
- def forward(self, x):
- """Forward function."""
- if self.num_branches == 1:
- return [self.branches[0](x[0])]
-
- for i in range(self.num_branches):
- x[i] = self.branches[i](x[i])
-
- x_fuse = []
- for i in range(len(self.fuse_layers)):
- y = 0
- for j in range(self.num_branches):
- if i == j:
- y += x[j]
- else:
- y += self.fuse_layers[i][j](x[j])
- x_fuse.append(self.relu(y))
- return x_fuse
-
-
-@MODELS.register_module()
-class HRNet(BaseBackbone):
- """HRNet backbone.
-
- `High-Resolution Representations for Labeling Pixels and Regions
- `__
-
- Args:
- extra (dict): detailed configuration for each stage of HRNet.
- in_channels (int): Number of input image channels. Default: 3.
- conv_cfg (dict): dictionary to construct and config conv layer.
- norm_cfg (dict): dictionary to construct and config norm layer.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only. Default: False
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed.
- zero_init_residual (bool): whether to use zero init for last norm layer
- in resblocks to let them behave as identity.
- frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
- -1 means not freezing any parameters. Default: -1.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Normal', std=0.001, layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]``
-
- Example:
- >>> from mmpose.models import HRNet
- >>> import torch
- >>> extra = dict(
- >>> stage1=dict(
- >>> num_modules=1,
- >>> num_branches=1,
- >>> block='BOTTLENECK',
- >>> num_blocks=(4, ),
- >>> num_channels=(64, )),
- >>> stage2=dict(
- >>> num_modules=1,
- >>> num_branches=2,
- >>> block='BASIC',
- >>> num_blocks=(4, 4),
- >>> num_channels=(32, 64)),
- >>> stage3=dict(
- >>> num_modules=4,
- >>> num_branches=3,
- >>> block='BASIC',
- >>> num_blocks=(4, 4, 4),
- >>> num_channels=(32, 64, 128)),
- >>> stage4=dict(
- >>> num_modules=3,
- >>> num_branches=4,
- >>> block='BASIC',
- >>> num_blocks=(4, 4, 4, 4),
- >>> num_channels=(32, 64, 128, 256)))
- >>> self = HRNet(extra, in_channels=1)
- >>> self.eval()
- >>> inputs = torch.rand(1, 1, 32, 32)
- >>> level_outputs = self.forward(inputs)
- >>> for level_out in level_outputs:
- ... print(tuple(level_out.shape))
- (1, 32, 8, 8)
- """
-
- blocks_dict = {'BASIC': BasicBlock, 'BOTTLENECK': Bottleneck}
-
- def __init__(
- self,
- extra,
- in_channels=3,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- norm_eval=False,
- with_cp=False,
- zero_init_residual=False,
- frozen_stages=-1,
- init_cfg=[
- dict(type='Normal', std=0.001, layer=['Conv2d']),
- dict(type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])
- ],
- ):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
- self.extra = extra
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- self.init_cfg = init_cfg
- self.norm_eval = norm_eval
- self.with_cp = with_cp
- self.zero_init_residual = zero_init_residual
- self.frozen_stages = frozen_stages
-
- # stem net
- self.norm1_name, norm1 = build_norm_layer(self.norm_cfg, 64, postfix=1)
- self.norm2_name, norm2 = build_norm_layer(self.norm_cfg, 64, postfix=2)
-
- self.conv1 = build_conv_layer(
- self.conv_cfg,
- in_channels,
- 64,
- kernel_size=3,
- stride=2,
- padding=1,
- bias=False)
-
- self.add_module(self.norm1_name, norm1)
- self.conv2 = build_conv_layer(
- self.conv_cfg,
- 64,
- 64,
- kernel_size=3,
- stride=2,
- padding=1,
- bias=False)
-
- self.add_module(self.norm2_name, norm2)
- self.relu = nn.ReLU(inplace=True)
-
- self.upsample_cfg = self.extra.get('upsample', {
- 'mode': 'nearest',
- 'align_corners': None
- })
-
- # stage 1
- self.stage1_cfg = self.extra['stage1']
- num_channels = self.stage1_cfg['num_channels'][0]
- block_type = self.stage1_cfg['block']
- num_blocks = self.stage1_cfg['num_blocks'][0]
-
- block = self.blocks_dict[block_type]
- stage1_out_channels = num_channels * get_expansion(block)
- self.layer1 = self._make_layer(block, 64, stage1_out_channels,
- num_blocks)
-
- # stage 2
- self.stage2_cfg = self.extra['stage2']
- num_channels = self.stage2_cfg['num_channels']
- block_type = self.stage2_cfg['block']
-
- block = self.blocks_dict[block_type]
- num_channels = [
- channel * get_expansion(block) for channel in num_channels
- ]
- self.transition1 = self._make_transition_layer([stage1_out_channels],
- num_channels)
- self.stage2, pre_stage_channels = self._make_stage(
- self.stage2_cfg, num_channels)
-
- # stage 3
- self.stage3_cfg = self.extra['stage3']
- num_channels = self.stage3_cfg['num_channels']
- block_type = self.stage3_cfg['block']
-
- block = self.blocks_dict[block_type]
- num_channels = [
- channel * get_expansion(block) for channel in num_channels
- ]
- self.transition2 = self._make_transition_layer(pre_stage_channels,
- num_channels)
- self.stage3, pre_stage_channels = self._make_stage(
- self.stage3_cfg, num_channels)
-
- # stage 4
- self.stage4_cfg = self.extra['stage4']
- num_channels = self.stage4_cfg['num_channels']
- block_type = self.stage4_cfg['block']
-
- block = self.blocks_dict[block_type]
- num_channels = [
- channel * get_expansion(block) for channel in num_channels
- ]
- self.transition3 = self._make_transition_layer(pre_stage_channels,
- num_channels)
-
- self.stage4, pre_stage_channels = self._make_stage(
- self.stage4_cfg,
- num_channels,
- multiscale_output=self.stage4_cfg.get('multiscale_output', False))
-
- self._freeze_stages()
-
- @property
- def norm1(self):
- """nn.Module: the normalization layer named "norm1" """
- return getattr(self, self.norm1_name)
-
- @property
- def norm2(self):
- """nn.Module: the normalization layer named "norm2" """
- return getattr(self, self.norm2_name)
-
- def _make_transition_layer(self, num_channels_pre_layer,
- num_channels_cur_layer):
- """Make transition layer."""
- num_branches_cur = len(num_channels_cur_layer)
- num_branches_pre = len(num_channels_pre_layer)
-
- transition_layers = []
- for i in range(num_branches_cur):
- if i < num_branches_pre:
- if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
- transition_layers.append(
- nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- num_channels_pre_layer[i],
- num_channels_cur_layer[i],
- kernel_size=3,
- stride=1,
- padding=1,
- bias=False),
- build_norm_layer(self.norm_cfg,
- num_channels_cur_layer[i])[1],
- nn.ReLU(inplace=True)))
- else:
- transition_layers.append(None)
- else:
- conv_downsamples = []
- for j in range(i + 1 - num_branches_pre):
- in_channels = num_channels_pre_layer[-1]
- out_channels = num_channels_cur_layer[i] \
- if j == i - num_branches_pre else in_channels
- conv_downsamples.append(
- nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- in_channels,
- out_channels,
- kernel_size=3,
- stride=2,
- padding=1,
- bias=False),
- build_norm_layer(self.norm_cfg, out_channels)[1],
- nn.ReLU(inplace=True)))
- transition_layers.append(nn.Sequential(*conv_downsamples))
-
- return nn.ModuleList(transition_layers)
-
- def _make_layer(self, block, in_channels, out_channels, blocks, stride=1):
- """Make layer."""
- downsample = None
- if stride != 1 or in_channels != out_channels:
- downsample = nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- in_channels,
- out_channels,
- kernel_size=1,
- stride=stride,
- bias=False),
- build_norm_layer(self.norm_cfg, out_channels)[1])
-
- layers = []
- layers.append(
- block(
- in_channels,
- out_channels,
- stride=stride,
- downsample=downsample,
- with_cp=self.with_cp,
- norm_cfg=self.norm_cfg,
- conv_cfg=self.conv_cfg))
- for _ in range(1, blocks):
- layers.append(
- block(
- out_channels,
- out_channels,
- with_cp=self.with_cp,
- norm_cfg=self.norm_cfg,
- conv_cfg=self.conv_cfg))
-
- return nn.Sequential(*layers)
-
- def _make_stage(self, layer_config, in_channels, multiscale_output=True):
- """Make stage."""
- num_modules = layer_config['num_modules']
- num_branches = layer_config['num_branches']
- num_blocks = layer_config['num_blocks']
- num_channels = layer_config['num_channels']
- block = self.blocks_dict[layer_config['block']]
-
- hr_modules = []
- for i in range(num_modules):
- # multi_scale_output is only used for the last module
- if not multiscale_output and i == num_modules - 1:
- reset_multiscale_output = False
- else:
- reset_multiscale_output = True
-
- hr_modules.append(
- HRModule(
- num_branches,
- block,
- num_blocks,
- in_channels,
- num_channels,
- reset_multiscale_output,
- with_cp=self.with_cp,
- norm_cfg=self.norm_cfg,
- conv_cfg=self.conv_cfg,
- upsample_cfg=self.upsample_cfg))
-
- in_channels = hr_modules[-1].in_channels
-
- return nn.Sequential(*hr_modules), in_channels
-
- def _freeze_stages(self):
- """Freeze parameters."""
- if self.frozen_stages >= 0:
- self.norm1.eval()
- self.norm2.eval()
-
- for m in [self.conv1, self.norm1, self.conv2, self.norm2]:
- for param in m.parameters():
- param.requires_grad = False
-
- for i in range(1, self.frozen_stages + 1):
- if i == 1:
- m = getattr(self, 'layer1')
- else:
- m = getattr(self, f'stage{i}')
-
- m.eval()
- for param in m.parameters():
- param.requires_grad = False
-
- if i < 4:
- m = getattr(self, f'transition{i}')
- m.eval()
- for param in m.parameters():
- param.requires_grad = False
-
- def init_weights(self):
- """Initialize the weights in backbone."""
- super(HRNet, self).init_weights()
-
- if (isinstance(self.init_cfg, dict)
- and self.init_cfg['type'] == 'Pretrained'):
- # Suppress zero_init_residual if use pretrained model.
- return
-
- if self.zero_init_residual:
- for m in self.modules():
- if isinstance(m, Bottleneck):
- constant_init(m.norm3, 0)
- elif isinstance(m, BasicBlock):
- constant_init(m.norm2, 0)
-
- def forward(self, x):
- """Forward function."""
- x = self.conv1(x)
- x = self.norm1(x)
- x = self.relu(x)
- x = self.conv2(x)
- x = self.norm2(x)
- x = self.relu(x)
- x = self.layer1(x)
-
- x_list = []
- for i in range(self.stage2_cfg['num_branches']):
- if self.transition1[i] is not None:
- x_list.append(self.transition1[i](x))
- else:
- x_list.append(x)
- y_list = self.stage2(x_list)
-
- x_list = []
- for i in range(self.stage3_cfg['num_branches']):
- if self.transition2[i] is not None:
- x_list.append(self.transition2[i](y_list[-1]))
- else:
- x_list.append(y_list[i])
- y_list = self.stage3(x_list)
-
- x_list = []
- for i in range(self.stage4_cfg['num_branches']):
- if self.transition3[i] is not None:
- x_list.append(self.transition3[i](y_list[-1]))
- else:
- x_list.append(y_list[i])
- y_list = self.stage4(x_list)
-
- return tuple(y_list)
-
- def train(self, mode=True):
- """Convert the model into training mode."""
- super().train(mode)
- self._freeze_stages()
- if mode and self.norm_eval:
- for m in self.modules():
- if isinstance(m, _BatchNorm):
- m.eval()
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import torch.nn as nn
+from mmcv.cnn import build_conv_layer, build_norm_layer
+from mmengine.model import BaseModule, constant_init
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+from .resnet import BasicBlock, Bottleneck, get_expansion
+
+
+class HRModule(BaseModule):
+ """High-Resolution Module for HRNet.
+
+ In this module, every branch has 4 BasicBlocks/Bottlenecks. Fusion/Exchange
+ is in this module.
+ """
+
+ def __init__(self,
+ num_branches,
+ blocks,
+ num_blocks,
+ in_channels,
+ num_channels,
+ multiscale_output=False,
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ upsample_cfg=dict(mode='nearest', align_corners=None),
+ init_cfg=None):
+
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self._check_branches(num_branches, num_blocks, in_channels,
+ num_channels)
+
+ self.in_channels = in_channels
+ self.num_branches = num_branches
+
+ self.multiscale_output = multiscale_output
+ self.norm_cfg = norm_cfg
+ self.conv_cfg = conv_cfg
+ self.upsample_cfg = upsample_cfg
+ self.with_cp = with_cp
+ self.branches = self._make_branches(num_branches, blocks, num_blocks,
+ num_channels)
+ self.fuse_layers = self._make_fuse_layers()
+ self.relu = nn.ReLU(inplace=True)
+
+ @staticmethod
+ def _check_branches(num_branches, num_blocks, in_channels, num_channels):
+ """Check input to avoid ValueError."""
+ if num_branches != len(num_blocks):
+ error_msg = f'NUM_BRANCHES({num_branches}) ' \
+ f'!= NUM_BLOCKS({len(num_blocks)})'
+ raise ValueError(error_msg)
+
+ if num_branches != len(num_channels):
+ error_msg = f'NUM_BRANCHES({num_branches}) ' \
+ f'!= NUM_CHANNELS({len(num_channels)})'
+ raise ValueError(error_msg)
+
+ if num_branches != len(in_channels):
+ error_msg = f'NUM_BRANCHES({num_branches}) ' \
+ f'!= NUM_INCHANNELS({len(in_channels)})'
+ raise ValueError(error_msg)
+
+ def _make_one_branch(self,
+ branch_index,
+ block,
+ num_blocks,
+ num_channels,
+ stride=1):
+ """Make one branch."""
+ downsample = None
+ if stride != 1 or \
+ self.in_channels[branch_index] != \
+ num_channels[branch_index] * get_expansion(block):
+ downsample = nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ self.in_channels[branch_index],
+ num_channels[branch_index] * get_expansion(block),
+ kernel_size=1,
+ stride=stride,
+ bias=False),
+ build_norm_layer(
+ self.norm_cfg,
+ num_channels[branch_index] * get_expansion(block))[1])
+
+ layers = []
+ layers.append(
+ block(
+ self.in_channels[branch_index],
+ num_channels[branch_index] * get_expansion(block),
+ stride=stride,
+ downsample=downsample,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg))
+ self.in_channels[branch_index] = \
+ num_channels[branch_index] * get_expansion(block)
+ for _ in range(1, num_blocks[branch_index]):
+ layers.append(
+ block(
+ self.in_channels[branch_index],
+ num_channels[branch_index] * get_expansion(block),
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg))
+
+ return nn.Sequential(*layers)
+
+ def _make_branches(self, num_branches, block, num_blocks, num_channels):
+ """Make branches."""
+ branches = []
+
+ for i in range(num_branches):
+ branches.append(
+ self._make_one_branch(i, block, num_blocks, num_channels))
+
+ return nn.ModuleList(branches)
+
+ def _make_fuse_layers(self):
+ """Make fuse layer."""
+ if self.num_branches == 1:
+ return None
+
+ num_branches = self.num_branches
+ in_channels = self.in_channels
+ fuse_layers = []
+ num_out_branches = num_branches if self.multiscale_output else 1
+
+ for i in range(num_out_branches):
+ fuse_layer = []
+ for j in range(num_branches):
+ if j > i:
+ fuse_layer.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[i],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False),
+ build_norm_layer(self.norm_cfg, in_channels[i])[1],
+ nn.Upsample(
+ scale_factor=2**(j - i),
+ mode=self.upsample_cfg['mode'],
+ align_corners=self.
+ upsample_cfg['align_corners'])))
+ elif j == i:
+ fuse_layer.append(None)
+ else:
+ conv_downsamples = []
+ for k in range(i - j):
+ if k == i - j - 1:
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[i],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[i])[1]))
+ else:
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[j],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[j])[1],
+ nn.ReLU(inplace=True)))
+ fuse_layer.append(nn.Sequential(*conv_downsamples))
+ fuse_layers.append(nn.ModuleList(fuse_layer))
+
+ return nn.ModuleList(fuse_layers)
+
+ def forward(self, x):
+ """Forward function."""
+ if self.num_branches == 1:
+ return [self.branches[0](x[0])]
+
+ for i in range(self.num_branches):
+ x[i] = self.branches[i](x[i])
+
+ x_fuse = []
+ for i in range(len(self.fuse_layers)):
+ y = 0
+ for j in range(self.num_branches):
+ if i == j:
+ y += x[j]
+ else:
+ y += self.fuse_layers[i][j](x[j])
+ x_fuse.append(self.relu(y))
+ return x_fuse
+
+
+@MODELS.register_module()
+class HRNet(BaseBackbone):
+ """HRNet backbone.
+
+ `High-Resolution Representations for Labeling Pixels and Regions
+ `__
+
+ Args:
+ extra (dict): detailed configuration for each stage of HRNet.
+ in_channels (int): Number of input image channels. Default: 3.
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ zero_init_residual (bool): whether to use zero init for last norm layer
+ in resblocks to let them behave as identity.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters. Default: -1.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+
+ Example:
+ >>> from mmpose.models import HRNet
+ >>> import torch
+ >>> extra = dict(
+ >>> stage1=dict(
+ >>> num_modules=1,
+ >>> num_branches=1,
+ >>> block='BOTTLENECK',
+ >>> num_blocks=(4, ),
+ >>> num_channels=(64, )),
+ >>> stage2=dict(
+ >>> num_modules=1,
+ >>> num_branches=2,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4),
+ >>> num_channels=(32, 64)),
+ >>> stage3=dict(
+ >>> num_modules=4,
+ >>> num_branches=3,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4, 4),
+ >>> num_channels=(32, 64, 128)),
+ >>> stage4=dict(
+ >>> num_modules=3,
+ >>> num_branches=4,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4, 4, 4),
+ >>> num_channels=(32, 64, 128, 256)))
+ >>> self = HRNet(extra, in_channels=1)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 1, 32, 32)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 32, 8, 8)
+ """
+
+ blocks_dict = {'BASIC': BasicBlock, 'BOTTLENECK': Bottleneck}
+
+ def __init__(
+ self,
+ extra,
+ in_channels=3,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ norm_eval=False,
+ with_cp=False,
+ zero_init_residual=False,
+ frozen_stages=-1,
+ init_cfg=[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])
+ ],
+ ):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self.extra = extra
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.init_cfg = init_cfg
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+ self.zero_init_residual = zero_init_residual
+ self.frozen_stages = frozen_stages
+
+ # stem net
+ self.norm1_name, norm1 = build_norm_layer(self.norm_cfg, 64, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(self.norm_cfg, 64, postfix=2)
+
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ 64,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False)
+
+ self.add_module(self.norm1_name, norm1)
+ self.conv2 = build_conv_layer(
+ self.conv_cfg,
+ 64,
+ 64,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False)
+
+ self.add_module(self.norm2_name, norm2)
+ self.relu = nn.ReLU(inplace=True)
+
+ self.upsample_cfg = self.extra.get('upsample', {
+ 'mode': 'nearest',
+ 'align_corners': None
+ })
+
+ # stage 1
+ self.stage1_cfg = self.extra['stage1']
+ num_channels = self.stage1_cfg['num_channels'][0]
+ block_type = self.stage1_cfg['block']
+ num_blocks = self.stage1_cfg['num_blocks'][0]
+
+ block = self.blocks_dict[block_type]
+ stage1_out_channels = num_channels * get_expansion(block)
+ self.layer1 = self._make_layer(block, 64, stage1_out_channels,
+ num_blocks)
+
+ # stage 2
+ self.stage2_cfg = self.extra['stage2']
+ num_channels = self.stage2_cfg['num_channels']
+ block_type = self.stage2_cfg['block']
+
+ block = self.blocks_dict[block_type]
+ num_channels = [
+ channel * get_expansion(block) for channel in num_channels
+ ]
+ self.transition1 = self._make_transition_layer([stage1_out_channels],
+ num_channels)
+ self.stage2, pre_stage_channels = self._make_stage(
+ self.stage2_cfg, num_channels)
+
+ # stage 3
+ self.stage3_cfg = self.extra['stage3']
+ num_channels = self.stage3_cfg['num_channels']
+ block_type = self.stage3_cfg['block']
+
+ block = self.blocks_dict[block_type]
+ num_channels = [
+ channel * get_expansion(block) for channel in num_channels
+ ]
+ self.transition2 = self._make_transition_layer(pre_stage_channels,
+ num_channels)
+ self.stage3, pre_stage_channels = self._make_stage(
+ self.stage3_cfg, num_channels)
+
+ # stage 4
+ self.stage4_cfg = self.extra['stage4']
+ num_channels = self.stage4_cfg['num_channels']
+ block_type = self.stage4_cfg['block']
+
+ block = self.blocks_dict[block_type]
+ num_channels = [
+ channel * get_expansion(block) for channel in num_channels
+ ]
+ self.transition3 = self._make_transition_layer(pre_stage_channels,
+ num_channels)
+
+ self.stage4, pre_stage_channels = self._make_stage(
+ self.stage4_cfg,
+ num_channels,
+ multiscale_output=self.stage4_cfg.get('multiscale_output', False))
+
+ self._freeze_stages()
+
+ @property
+ def norm1(self):
+ """nn.Module: the normalization layer named "norm1" """
+ return getattr(self, self.norm1_name)
+
+ @property
+ def norm2(self):
+ """nn.Module: the normalization layer named "norm2" """
+ return getattr(self, self.norm2_name)
+
+ def _make_transition_layer(self, num_channels_pre_layer,
+ num_channels_cur_layer):
+ """Make transition layer."""
+ num_branches_cur = len(num_channels_cur_layer)
+ num_branches_pre = len(num_channels_pre_layer)
+
+ transition_layers = []
+ for i in range(num_branches_cur):
+ if i < num_branches_pre:
+ if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
+ transition_layers.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ num_channels_pre_layer[i],
+ num_channels_cur_layer[i],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ num_channels_cur_layer[i])[1],
+ nn.ReLU(inplace=True)))
+ else:
+ transition_layers.append(None)
+ else:
+ conv_downsamples = []
+ for j in range(i + 1 - num_branches_pre):
+ in_channels = num_channels_pre_layer[-1]
+ out_channels = num_channels_cur_layer[i] \
+ if j == i - num_branches_pre else in_channels
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg, out_channels)[1],
+ nn.ReLU(inplace=True)))
+ transition_layers.append(nn.Sequential(*conv_downsamples))
+
+ return nn.ModuleList(transition_layers)
+
+ def _make_layer(self, block, in_channels, out_channels, blocks, stride=1):
+ """Make layer."""
+ downsample = None
+ if stride != 1 or in_channels != out_channels:
+ downsample = nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ out_channels,
+ kernel_size=1,
+ stride=stride,
+ bias=False),
+ build_norm_layer(self.norm_cfg, out_channels)[1])
+
+ layers = []
+ layers.append(
+ block(
+ in_channels,
+ out_channels,
+ stride=stride,
+ downsample=downsample,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg))
+ for _ in range(1, blocks):
+ layers.append(
+ block(
+ out_channels,
+ out_channels,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg))
+
+ return nn.Sequential(*layers)
+
+ def _make_stage(self, layer_config, in_channels, multiscale_output=True):
+ """Make stage."""
+ num_modules = layer_config['num_modules']
+ num_branches = layer_config['num_branches']
+ num_blocks = layer_config['num_blocks']
+ num_channels = layer_config['num_channels']
+ block = self.blocks_dict[layer_config['block']]
+
+ hr_modules = []
+ for i in range(num_modules):
+ # multi_scale_output is only used for the last module
+ if not multiscale_output and i == num_modules - 1:
+ reset_multiscale_output = False
+ else:
+ reset_multiscale_output = True
+
+ hr_modules.append(
+ HRModule(
+ num_branches,
+ block,
+ num_blocks,
+ in_channels,
+ num_channels,
+ reset_multiscale_output,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg,
+ upsample_cfg=self.upsample_cfg))
+
+ in_channels = hr_modules[-1].in_channels
+
+ return nn.Sequential(*hr_modules), in_channels
+
+ def _freeze_stages(self):
+ """Freeze parameters."""
+ if self.frozen_stages >= 0:
+ self.norm1.eval()
+ self.norm2.eval()
+
+ for m in [self.conv1, self.norm1, self.conv2, self.norm2]:
+ for param in m.parameters():
+ param.requires_grad = False
+
+ for i in range(1, self.frozen_stages + 1):
+ if i == 1:
+ m = getattr(self, 'layer1')
+ else:
+ m = getattr(self, f'stage{i}')
+
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ if i < 4:
+ m = getattr(self, f'transition{i}')
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ def init_weights(self):
+ """Initialize the weights in backbone."""
+ super(HRNet, self).init_weights()
+
+ if (isinstance(self.init_cfg, dict)
+ and self.init_cfg['type'] == 'Pretrained'):
+ # Suppress zero_init_residual if use pretrained model.
+ return
+
+ if self.zero_init_residual:
+ for m in self.modules():
+ if isinstance(m, Bottleneck):
+ constant_init(m.norm3, 0)
+ elif isinstance(m, BasicBlock):
+ constant_init(m.norm2, 0)
+
+ def forward(self, x):
+ """Forward function."""
+ x = self.conv1(x)
+ x = self.norm1(x)
+ x = self.relu(x)
+ x = self.conv2(x)
+ x = self.norm2(x)
+ x = self.relu(x)
+ x = self.layer1(x)
+
+ x_list = []
+ for i in range(self.stage2_cfg['num_branches']):
+ if self.transition1[i] is not None:
+ x_list.append(self.transition1[i](x))
+ else:
+ x_list.append(x)
+ y_list = self.stage2(x_list)
+
+ x_list = []
+ for i in range(self.stage3_cfg['num_branches']):
+ if self.transition2[i] is not None:
+ x_list.append(self.transition2[i](y_list[-1]))
+ else:
+ x_list.append(y_list[i])
+ y_list = self.stage3(x_list)
+
+ x_list = []
+ for i in range(self.stage4_cfg['num_branches']):
+ if self.transition3[i] is not None:
+ x_list.append(self.transition3[i](y_list[-1]))
+ else:
+ x_list.append(y_list[i])
+ y_list = self.stage4(x_list)
+
+ return tuple(y_list)
+
+ def train(self, mode=True):
+ """Convert the model into training mode."""
+ super().train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, _BatchNorm):
+ m.eval()
diff --git a/mmpose/models/backbones/litehrnet.py b/mmpose/models/backbones/litehrnet.py
index 1ad5f63014..753523e068 100644
--- a/mmpose/models/backbones/litehrnet.py
+++ b/mmpose/models/backbones/litehrnet.py
@@ -1,999 +1,999 @@
-# ------------------------------------------------------------------------------
-# Adapted from https://github.com/HRNet/Lite-HRNet
-# Original licence: Apache License 2.0.
-# ------------------------------------------------------------------------------
-
-import mmengine
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-import torch.utils.checkpoint as cp
-from mmcv.cnn import (ConvModule, DepthwiseSeparableConvModule,
- build_conv_layer, build_norm_layer)
-from mmengine.model import BaseModule
-from torch.nn.modules.batchnorm import _BatchNorm
-
-from mmpose.registry import MODELS
-from .base_backbone import BaseBackbone
-from .utils import channel_shuffle
-
-
-class SpatialWeighting(BaseModule):
- """Spatial weighting module.
-
- Args:
- channels (int): The channels of the module.
- ratio (int): channel reduction ratio.
- conv_cfg (dict): Config dict for convolution layer.
- Default: None, which means using conv2d.
- norm_cfg (dict): Config dict for normalization layer.
- Default: None.
- act_cfg (dict): Config dict for activation layer.
- Default: (dict(type='ReLU'), dict(type='Sigmoid')).
- The last ConvModule uses Sigmoid by default.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- channels,
- ratio=16,
- conv_cfg=None,
- norm_cfg=None,
- act_cfg=(dict(type='ReLU'), dict(type='Sigmoid')),
- init_cfg=None):
- super().__init__(init_cfg=init_cfg)
- if isinstance(act_cfg, dict):
- act_cfg = (act_cfg, act_cfg)
- assert len(act_cfg) == 2
- assert mmengine.is_tuple_of(act_cfg, dict)
- self.global_avgpool = nn.AdaptiveAvgPool2d(1)
- self.conv1 = ConvModule(
- in_channels=channels,
- out_channels=int(channels / ratio),
- kernel_size=1,
- stride=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg[0])
- self.conv2 = ConvModule(
- in_channels=int(channels / ratio),
- out_channels=channels,
- kernel_size=1,
- stride=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg[1])
-
- def forward(self, x):
- out = self.global_avgpool(x)
- out = self.conv1(out)
- out = self.conv2(out)
- return x * out
-
-
-class CrossResolutionWeighting(BaseModule):
- """Cross-resolution channel weighting module.
-
- Args:
- channels (int): The channels of the module.
- ratio (int): channel reduction ratio.
- conv_cfg (dict): Config dict for convolution layer.
- Default: None, which means using conv2d.
- norm_cfg (dict): Config dict for normalization layer.
- Default: None.
- act_cfg (dict): Config dict for activation layer.
- Default: (dict(type='ReLU'), dict(type='Sigmoid')).
- The last ConvModule uses Sigmoid by default.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- channels,
- ratio=16,
- conv_cfg=None,
- norm_cfg=None,
- act_cfg=(dict(type='ReLU'), dict(type='Sigmoid')),
- init_cfg=None):
- super().__init__(init_cfg=init_cfg)
- if isinstance(act_cfg, dict):
- act_cfg = (act_cfg, act_cfg)
- assert len(act_cfg) == 2
- assert mmengine.is_tuple_of(act_cfg, dict)
- self.channels = channels
- total_channel = sum(channels)
- self.conv1 = ConvModule(
- in_channels=total_channel,
- out_channels=int(total_channel / ratio),
- kernel_size=1,
- stride=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg[0])
- self.conv2 = ConvModule(
- in_channels=int(total_channel / ratio),
- out_channels=total_channel,
- kernel_size=1,
- stride=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg[1])
-
- def forward(self, x):
- mini_size = x[-1].size()[-2:]
- out = [F.adaptive_avg_pool2d(s, mini_size) for s in x[:-1]] + [x[-1]]
- out = torch.cat(out, dim=1)
- out = self.conv1(out)
- out = self.conv2(out)
- out = torch.split(out, self.channels, dim=1)
- out = [
- s * F.interpolate(a, size=s.size()[-2:], mode='nearest')
- for s, a in zip(x, out)
- ]
- return out
-
-
-class ConditionalChannelWeighting(BaseModule):
- """Conditional channel weighting block.
-
- Args:
- in_channels (int): The input channels of the block.
- stride (int): Stride of the 3x3 convolution layer.
- reduce_ratio (int): channel reduction ratio.
- conv_cfg (dict): Config dict for convolution layer.
- Default: None, which means using conv2d.
- norm_cfg (dict): Config dict for normalization layer.
- Default: dict(type='BN').
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed. Default: False.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- in_channels,
- stride,
- reduce_ratio,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- with_cp=False,
- init_cfg=None):
- super().__init__(init_cfg=init_cfg)
- self.with_cp = with_cp
- self.stride = stride
- assert stride in [1, 2]
-
- branch_channels = [channel // 2 for channel in in_channels]
-
- self.cross_resolution_weighting = CrossResolutionWeighting(
- branch_channels,
- ratio=reduce_ratio,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg)
-
- self.depthwise_convs = nn.ModuleList([
- ConvModule(
- channel,
- channel,
- kernel_size=3,
- stride=self.stride,
- padding=1,
- groups=channel,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=None) for channel in branch_channels
- ])
-
- self.spatial_weighting = nn.ModuleList([
- SpatialWeighting(channels=channel, ratio=4)
- for channel in branch_channels
- ])
-
- def forward(self, x):
-
- def _inner_forward(x):
- x = [s.chunk(2, dim=1) for s in x]
- x1 = [s[0] for s in x]
- x2 = [s[1] for s in x]
-
- x2 = self.cross_resolution_weighting(x2)
- x2 = [dw(s) for s, dw in zip(x2, self.depthwise_convs)]
- x2 = [sw(s) for s, sw in zip(x2, self.spatial_weighting)]
-
- out = [torch.cat([s1, s2], dim=1) for s1, s2 in zip(x1, x2)]
- out = [channel_shuffle(s, 2) for s in out]
-
- return out
-
- if self.with_cp and x.requires_grad:
- out = cp.checkpoint(_inner_forward, x)
- else:
- out = _inner_forward(x)
-
- return out
-
-
-class Stem(BaseModule):
- """Stem network block.
-
- Args:
- in_channels (int): The input channels of the block.
- stem_channels (int): Output channels of the stem layer.
- out_channels (int): The output channels of the block.
- expand_ratio (int): adjusts number of channels of the hidden layer
- in InvertedResidual by this amount.
- conv_cfg (dict): Config dict for convolution layer.
- Default: None, which means using conv2d.
- norm_cfg (dict): Config dict for normalization layer.
- Default: dict(type='BN').
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed. Default: False.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- in_channels,
- stem_channels,
- out_channels,
- expand_ratio,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- with_cp=False,
- init_cfg=None):
- super().__init__(init_cfg=init_cfg)
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- self.with_cp = with_cp
-
- self.conv1 = ConvModule(
- in_channels=in_channels,
- out_channels=stem_channels,
- kernel_size=3,
- stride=2,
- padding=1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=dict(type='ReLU'))
-
- mid_channels = int(round(stem_channels * expand_ratio))
- branch_channels = stem_channels // 2
- if stem_channels == self.out_channels:
- inc_channels = self.out_channels - branch_channels
- else:
- inc_channels = self.out_channels - stem_channels
-
- self.branch1 = nn.Sequential(
- ConvModule(
- branch_channels,
- branch_channels,
- kernel_size=3,
- stride=2,
- padding=1,
- groups=branch_channels,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=None),
- ConvModule(
- branch_channels,
- inc_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=dict(type='ReLU')),
- )
-
- self.expand_conv = ConvModule(
- branch_channels,
- mid_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=dict(type='ReLU'))
- self.depthwise_conv = ConvModule(
- mid_channels,
- mid_channels,
- kernel_size=3,
- stride=2,
- padding=1,
- groups=mid_channels,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=None)
- self.linear_conv = ConvModule(
- mid_channels,
- branch_channels
- if stem_channels == self.out_channels else stem_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=dict(type='ReLU'))
-
- def forward(self, x):
-
- def _inner_forward(x):
- x = self.conv1(x)
- x1, x2 = x.chunk(2, dim=1)
-
- x2 = self.expand_conv(x2)
- x2 = self.depthwise_conv(x2)
- x2 = self.linear_conv(x2)
-
- out = torch.cat((self.branch1(x1), x2), dim=1)
-
- out = channel_shuffle(out, 2)
-
- return out
-
- if self.with_cp and x.requires_grad:
- out = cp.checkpoint(_inner_forward, x)
- else:
- out = _inner_forward(x)
-
- return out
-
-
-class IterativeHead(BaseModule):
- """Extra iterative head for feature learning.
-
- Args:
- in_channels (int): The input channels of the block.
- norm_cfg (dict): Config dict for normalization layer.
- Default: dict(type='BN').
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self, in_channels, norm_cfg=dict(type='BN'), init_cfg=None):
- super().__init__(init_cfg=init_cfg)
- projects = []
- num_branchs = len(in_channels)
- self.in_channels = in_channels[::-1]
-
- for i in range(num_branchs):
- if i != num_branchs - 1:
- projects.append(
- DepthwiseSeparableConvModule(
- in_channels=self.in_channels[i],
- out_channels=self.in_channels[i + 1],
- kernel_size=3,
- stride=1,
- padding=1,
- norm_cfg=norm_cfg,
- act_cfg=dict(type='ReLU'),
- dw_act_cfg=None,
- pw_act_cfg=dict(type='ReLU')))
- else:
- projects.append(
- DepthwiseSeparableConvModule(
- in_channels=self.in_channels[i],
- out_channels=self.in_channels[i],
- kernel_size=3,
- stride=1,
- padding=1,
- norm_cfg=norm_cfg,
- act_cfg=dict(type='ReLU'),
- dw_act_cfg=None,
- pw_act_cfg=dict(type='ReLU')))
- self.projects = nn.ModuleList(projects)
-
- def forward(self, x):
- x = x[::-1]
-
- y = []
- last_x = None
- for i, s in enumerate(x):
- if last_x is not None:
- last_x = F.interpolate(
- last_x,
- size=s.size()[-2:],
- mode='bilinear',
- align_corners=True)
- s = s + last_x
- s = self.projects[i](s)
- y.append(s)
- last_x = s
-
- return y[::-1]
-
-
-class ShuffleUnit(BaseModule):
- """InvertedResidual block for ShuffleNetV2 backbone.
-
- Args:
- in_channels (int): The input channels of the block.
- out_channels (int): The output channels of the block.
- stride (int): Stride of the 3x3 convolution layer. Default: 1
- conv_cfg (dict): Config dict for convolution layer.
- Default: None, which means using conv2d.
- norm_cfg (dict): Config dict for normalization layer.
- Default: dict(type='BN').
- act_cfg (dict): Config dict for activation layer.
- Default: dict(type='ReLU').
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed. Default: False.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- stride=1,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- act_cfg=dict(type='ReLU'),
- with_cp=False,
- init_cfg=None):
- super().__init__(init_cfg=init_cfg)
- self.stride = stride
- self.with_cp = with_cp
-
- branch_features = out_channels // 2
- if self.stride == 1:
- assert in_channels == branch_features * 2, (
- f'in_channels ({in_channels}) should equal to '
- f'branch_features * 2 ({branch_features * 2}) '
- 'when stride is 1')
-
- if in_channels != branch_features * 2:
- assert self.stride != 1, (
- f'stride ({self.stride}) should not equal 1 when '
- f'in_channels != branch_features * 2')
-
- if self.stride > 1:
- self.branch1 = nn.Sequential(
- ConvModule(
- in_channels,
- in_channels,
- kernel_size=3,
- stride=self.stride,
- padding=1,
- groups=in_channels,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=None),
- ConvModule(
- in_channels,
- branch_features,
- kernel_size=1,
- stride=1,
- padding=0,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg),
- )
-
- self.branch2 = nn.Sequential(
- ConvModule(
- in_channels if (self.stride > 1) else branch_features,
- branch_features,
- kernel_size=1,
- stride=1,
- padding=0,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg),
- ConvModule(
- branch_features,
- branch_features,
- kernel_size=3,
- stride=self.stride,
- padding=1,
- groups=branch_features,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=None),
- ConvModule(
- branch_features,
- branch_features,
- kernel_size=1,
- stride=1,
- padding=0,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg))
-
- def forward(self, x):
-
- def _inner_forward(x):
- if self.stride > 1:
- out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
- else:
- x1, x2 = x.chunk(2, dim=1)
- out = torch.cat((x1, self.branch2(x2)), dim=1)
-
- out = channel_shuffle(out, 2)
-
- return out
-
- if self.with_cp and x.requires_grad:
- out = cp.checkpoint(_inner_forward, x)
- else:
- out = _inner_forward(x)
-
- return out
-
-
-class LiteHRModule(BaseModule):
- """High-Resolution Module for LiteHRNet.
-
- It contains conditional channel weighting blocks and
- shuffle blocks.
-
-
- Args:
- num_branches (int): Number of branches in the module.
- num_blocks (int): Number of blocks in the module.
- in_channels (list(int)): Number of input image channels.
- reduce_ratio (int): Channel reduction ratio.
- module_type (str): 'LITE' or 'NAIVE'
- multiscale_output (bool): Whether to output multi-scale features.
- with_fuse (bool): Whether to use fuse layers.
- conv_cfg (dict): dictionary to construct and config conv layer.
- norm_cfg (dict): dictionary to construct and config norm layer.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- num_branches,
- num_blocks,
- in_channels,
- reduce_ratio,
- module_type,
- multiscale_output=False,
- with_fuse=True,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- with_cp=False,
- init_cfg=None):
- super().__init__(init_cfg=init_cfg)
- self._check_branches(num_branches, in_channels)
-
- self.in_channels = in_channels
- self.num_branches = num_branches
-
- self.module_type = module_type
- self.multiscale_output = multiscale_output
- self.with_fuse = with_fuse
- self.norm_cfg = norm_cfg
- self.conv_cfg = conv_cfg
- self.with_cp = with_cp
-
- if self.module_type.upper() == 'LITE':
- self.layers = self._make_weighting_blocks(num_blocks, reduce_ratio)
- elif self.module_type.upper() == 'NAIVE':
- self.layers = self._make_naive_branches(num_branches, num_blocks)
- else:
- raise ValueError("module_type should be either 'LITE' or 'NAIVE'.")
- if self.with_fuse:
- self.fuse_layers = self._make_fuse_layers()
- self.relu = nn.ReLU()
-
- def _check_branches(self, num_branches, in_channels):
- """Check input to avoid ValueError."""
- if num_branches != len(in_channels):
- error_msg = f'NUM_BRANCHES({num_branches}) ' \
- f'!= NUM_INCHANNELS({len(in_channels)})'
- raise ValueError(error_msg)
-
- def _make_weighting_blocks(self, num_blocks, reduce_ratio, stride=1):
- """Make channel weighting blocks."""
- layers = []
- for i in range(num_blocks):
- layers.append(
- ConditionalChannelWeighting(
- self.in_channels,
- stride=stride,
- reduce_ratio=reduce_ratio,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- with_cp=self.with_cp))
-
- return nn.Sequential(*layers)
-
- def _make_one_branch(self, branch_index, num_blocks, stride=1):
- """Make one branch."""
- layers = []
- layers.append(
- ShuffleUnit(
- self.in_channels[branch_index],
- self.in_channels[branch_index],
- stride=stride,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=dict(type='ReLU'),
- with_cp=self.with_cp))
- for i in range(1, num_blocks):
- layers.append(
- ShuffleUnit(
- self.in_channels[branch_index],
- self.in_channels[branch_index],
- stride=1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=dict(type='ReLU'),
- with_cp=self.with_cp))
-
- return nn.Sequential(*layers)
-
- def _make_naive_branches(self, num_branches, num_blocks):
- """Make branches."""
- branches = []
-
- for i in range(num_branches):
- branches.append(self._make_one_branch(i, num_blocks))
-
- return nn.ModuleList(branches)
-
- def _make_fuse_layers(self):
- """Make fuse layer."""
- if self.num_branches == 1:
- return None
-
- num_branches = self.num_branches
- in_channels = self.in_channels
- fuse_layers = []
- num_out_branches = num_branches if self.multiscale_output else 1
- for i in range(num_out_branches):
- fuse_layer = []
- for j in range(num_branches):
- if j > i:
- fuse_layer.append(
- nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- in_channels[j],
- in_channels[i],
- kernel_size=1,
- stride=1,
- padding=0,
- bias=False),
- build_norm_layer(self.norm_cfg, in_channels[i])[1],
- nn.Upsample(
- scale_factor=2**(j - i), mode='nearest')))
- elif j == i:
- fuse_layer.append(None)
- else:
- conv_downsamples = []
- for k in range(i - j):
- if k == i - j - 1:
- conv_downsamples.append(
- nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- in_channels[j],
- in_channels[j],
- kernel_size=3,
- stride=2,
- padding=1,
- groups=in_channels[j],
- bias=False),
- build_norm_layer(self.norm_cfg,
- in_channels[j])[1],
- build_conv_layer(
- self.conv_cfg,
- in_channels[j],
- in_channels[i],
- kernel_size=1,
- stride=1,
- padding=0,
- bias=False),
- build_norm_layer(self.norm_cfg,
- in_channels[i])[1]))
- else:
- conv_downsamples.append(
- nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- in_channels[j],
- in_channels[j],
- kernel_size=3,
- stride=2,
- padding=1,
- groups=in_channels[j],
- bias=False),
- build_norm_layer(self.norm_cfg,
- in_channels[j])[1],
- build_conv_layer(
- self.conv_cfg,
- in_channels[j],
- in_channels[j],
- kernel_size=1,
- stride=1,
- padding=0,
- bias=False),
- build_norm_layer(self.norm_cfg,
- in_channels[j])[1],
- nn.ReLU(inplace=True)))
- fuse_layer.append(nn.Sequential(*conv_downsamples))
- fuse_layers.append(nn.ModuleList(fuse_layer))
-
- return nn.ModuleList(fuse_layers)
-
- def forward(self, x):
- """Forward function."""
- if self.num_branches == 1:
- return [self.layers[0](x[0])]
-
- if self.module_type.upper() == 'LITE':
- out = self.layers(x)
- elif self.module_type.upper() == 'NAIVE':
- for i in range(self.num_branches):
- x[i] = self.layers[i](x[i])
- out = x
-
- if self.with_fuse:
- out_fuse = []
- for i in range(len(self.fuse_layers)):
- # `y = 0` will lead to decreased accuracy (0.5~1 mAP)
- y = out[0] if i == 0 else self.fuse_layers[i][0](out[0])
- for j in range(self.num_branches):
- if i == j:
- y += out[j]
- else:
- y += self.fuse_layers[i][j](out[j])
- out_fuse.append(self.relu(y))
- out = out_fuse
- if not self.multiscale_output:
- out = [out[0]]
- return out
-
-
-@MODELS.register_module()
-class LiteHRNet(BaseBackbone):
- """Lite-HRNet backbone.
-
- `Lite-HRNet: A Lightweight High-Resolution Network
- `_.
-
- Code adapted from 'https://github.com/HRNet/Lite-HRNet'.
-
- Args:
- extra (dict): detailed configuration for each stage of HRNet.
- in_channels (int): Number of input image channels. Default: 3.
- conv_cfg (dict): dictionary to construct and config conv layer.
- norm_cfg (dict): dictionary to construct and config norm layer.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only. Default: False
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Normal', std=0.001, layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]``
-
- Example:
- >>> from mmpose.models import LiteHRNet
- >>> import torch
- >>> extra=dict(
- >>> stem=dict(stem_channels=32, out_channels=32, expand_ratio=1),
- >>> num_stages=3,
- >>> stages_spec=dict(
- >>> num_modules=(2, 4, 2),
- >>> num_branches=(2, 3, 4),
- >>> num_blocks=(2, 2, 2),
- >>> module_type=('LITE', 'LITE', 'LITE'),
- >>> with_fuse=(True, True, True),
- >>> reduce_ratios=(8, 8, 8),
- >>> num_channels=(
- >>> (40, 80),
- >>> (40, 80, 160),
- >>> (40, 80, 160, 320),
- >>> )),
- >>> with_head=False)
- >>> self = LiteHRNet(extra, in_channels=1)
- >>> self.eval()
- >>> inputs = torch.rand(1, 1, 32, 32)
- >>> level_outputs = self.forward(inputs)
- >>> for level_out in level_outputs:
- ... print(tuple(level_out.shape))
- (1, 40, 8, 8)
- """
-
- def __init__(self,
- extra,
- in_channels=3,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- norm_eval=False,
- with_cp=False,
- init_cfg=[
- dict(type='Normal', std=0.001, layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]):
- super().__init__(init_cfg=init_cfg)
- self.extra = extra
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- self.norm_eval = norm_eval
- self.with_cp = with_cp
-
- self.stem = Stem(
- in_channels,
- stem_channels=self.extra['stem']['stem_channels'],
- out_channels=self.extra['stem']['out_channels'],
- expand_ratio=self.extra['stem']['expand_ratio'],
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg)
-
- self.num_stages = self.extra['num_stages']
- self.stages_spec = self.extra['stages_spec']
-
- num_channels_last = [
- self.stem.out_channels,
- ]
- for i in range(self.num_stages):
- num_channels = self.stages_spec['num_channels'][i]
- num_channels = [num_channels[i] for i in range(len(num_channels))]
- setattr(
- self, f'transition{i}',
- self._make_transition_layer(num_channels_last, num_channels))
-
- stage, num_channels_last = self._make_stage(
- self.stages_spec, i, num_channels, multiscale_output=True)
- setattr(self, f'stage{i}', stage)
-
- self.with_head = self.extra['with_head']
- if self.with_head:
- self.head_layer = IterativeHead(
- in_channels=num_channels_last,
- norm_cfg=self.norm_cfg,
- )
-
- def _make_transition_layer(self, num_channels_pre_layer,
- num_channels_cur_layer):
- """Make transition layer."""
- num_branches_cur = len(num_channels_cur_layer)
- num_branches_pre = len(num_channels_pre_layer)
-
- transition_layers = []
- for i in range(num_branches_cur):
- if i < num_branches_pre:
- if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
- transition_layers.append(
- nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- num_channels_pre_layer[i],
- num_channels_pre_layer[i],
- kernel_size=3,
- stride=1,
- padding=1,
- groups=num_channels_pre_layer[i],
- bias=False),
- build_norm_layer(self.norm_cfg,
- num_channels_pre_layer[i])[1],
- build_conv_layer(
- self.conv_cfg,
- num_channels_pre_layer[i],
- num_channels_cur_layer[i],
- kernel_size=1,
- stride=1,
- padding=0,
- bias=False),
- build_norm_layer(self.norm_cfg,
- num_channels_cur_layer[i])[1],
- nn.ReLU()))
- else:
- transition_layers.append(None)
- else:
- conv_downsamples = []
- for j in range(i + 1 - num_branches_pre):
- in_channels = num_channels_pre_layer[-1]
- out_channels = num_channels_cur_layer[i] \
- if j == i - num_branches_pre else in_channels
- conv_downsamples.append(
- nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- in_channels,
- in_channels,
- kernel_size=3,
- stride=2,
- padding=1,
- groups=in_channels,
- bias=False),
- build_norm_layer(self.norm_cfg, in_channels)[1],
- build_conv_layer(
- self.conv_cfg,
- in_channels,
- out_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- bias=False),
- build_norm_layer(self.norm_cfg, out_channels)[1],
- nn.ReLU()))
- transition_layers.append(nn.Sequential(*conv_downsamples))
-
- return nn.ModuleList(transition_layers)
-
- def _make_stage(self,
- stages_spec,
- stage_index,
- in_channels,
- multiscale_output=True):
- num_modules = stages_spec['num_modules'][stage_index]
- num_branches = stages_spec['num_branches'][stage_index]
- num_blocks = stages_spec['num_blocks'][stage_index]
- reduce_ratio = stages_spec['reduce_ratios'][stage_index]
- with_fuse = stages_spec['with_fuse'][stage_index]
- module_type = stages_spec['module_type'][stage_index]
-
- modules = []
- for i in range(num_modules):
- # multi_scale_output is only used last module
- if not multiscale_output and i == num_modules - 1:
- reset_multiscale_output = False
- else:
- reset_multiscale_output = True
-
- modules.append(
- LiteHRModule(
- num_branches,
- num_blocks,
- in_channels,
- reduce_ratio,
- module_type,
- multiscale_output=reset_multiscale_output,
- with_fuse=with_fuse,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- with_cp=self.with_cp))
- in_channels = modules[-1].in_channels
-
- return nn.Sequential(*modules), in_channels
-
- def forward(self, x):
- """Forward function."""
- x = self.stem(x)
-
- y_list = [x]
- for i in range(self.num_stages):
- x_list = []
- transition = getattr(self, f'transition{i}')
- for j in range(self.stages_spec['num_branches'][i]):
- if transition[j]:
- if j >= len(y_list):
- x_list.append(transition[j](y_list[-1]))
- else:
- x_list.append(transition[j](y_list[j]))
- else:
- x_list.append(y_list[j])
- y_list = getattr(self, f'stage{i}')(x_list)
-
- x = y_list
- if self.with_head:
- x = self.head_layer(x)
-
- return (x[0], )
-
- def train(self, mode=True):
- """Convert the model into training mode."""
- super().train(mode)
- if mode and self.norm_eval:
- for m in self.modules():
- if isinstance(m, _BatchNorm):
- m.eval()
+# ------------------------------------------------------------------------------
+# Adapted from https://github.com/HRNet/Lite-HRNet
+# Original licence: Apache License 2.0.
+# ------------------------------------------------------------------------------
+
+import mmengine
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint as cp
+from mmcv.cnn import (ConvModule, DepthwiseSeparableConvModule,
+ build_conv_layer, build_norm_layer)
+from mmengine.model import BaseModule
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+from .utils import channel_shuffle
+
+
+class SpatialWeighting(BaseModule):
+ """Spatial weighting module.
+
+ Args:
+ channels (int): The channels of the module.
+ ratio (int): channel reduction ratio.
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: None.
+ act_cfg (dict): Config dict for activation layer.
+ Default: (dict(type='ReLU'), dict(type='Sigmoid')).
+ The last ConvModule uses Sigmoid by default.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ channels,
+ ratio=16,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=(dict(type='ReLU'), dict(type='Sigmoid')),
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ if isinstance(act_cfg, dict):
+ act_cfg = (act_cfg, act_cfg)
+ assert len(act_cfg) == 2
+ assert mmengine.is_tuple_of(act_cfg, dict)
+ self.global_avgpool = nn.AdaptiveAvgPool2d(1)
+ self.conv1 = ConvModule(
+ in_channels=channels,
+ out_channels=int(channels / ratio),
+ kernel_size=1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg[0])
+ self.conv2 = ConvModule(
+ in_channels=int(channels / ratio),
+ out_channels=channels,
+ kernel_size=1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg[1])
+
+ def forward(self, x):
+ out = self.global_avgpool(x)
+ out = self.conv1(out)
+ out = self.conv2(out)
+ return x * out
+
+
+class CrossResolutionWeighting(BaseModule):
+ """Cross-resolution channel weighting module.
+
+ Args:
+ channels (int): The channels of the module.
+ ratio (int): channel reduction ratio.
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: None.
+ act_cfg (dict): Config dict for activation layer.
+ Default: (dict(type='ReLU'), dict(type='Sigmoid')).
+ The last ConvModule uses Sigmoid by default.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ channels,
+ ratio=16,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=(dict(type='ReLU'), dict(type='Sigmoid')),
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ if isinstance(act_cfg, dict):
+ act_cfg = (act_cfg, act_cfg)
+ assert len(act_cfg) == 2
+ assert mmengine.is_tuple_of(act_cfg, dict)
+ self.channels = channels
+ total_channel = sum(channels)
+ self.conv1 = ConvModule(
+ in_channels=total_channel,
+ out_channels=int(total_channel / ratio),
+ kernel_size=1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg[0])
+ self.conv2 = ConvModule(
+ in_channels=int(total_channel / ratio),
+ out_channels=total_channel,
+ kernel_size=1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg[1])
+
+ def forward(self, x):
+ mini_size = x[-1].size()[-2:]
+ out = [F.adaptive_avg_pool2d(s, mini_size) for s in x[:-1]] + [x[-1]]
+ out = torch.cat(out, dim=1)
+ out = self.conv1(out)
+ out = self.conv2(out)
+ out = torch.split(out, self.channels, dim=1)
+ out = [
+ s * F.interpolate(a, size=s.size()[-2:], mode='nearest')
+ for s, a in zip(x, out)
+ ]
+ return out
+
+
+class ConditionalChannelWeighting(BaseModule):
+ """Conditional channel weighting block.
+
+ Args:
+ in_channels (int): The input channels of the block.
+ stride (int): Stride of the 3x3 convolution layer.
+ reduce_ratio (int): channel reduction ratio.
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ stride,
+ reduce_ratio,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ with_cp=False,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ self.with_cp = with_cp
+ self.stride = stride
+ assert stride in [1, 2]
+
+ branch_channels = [channel // 2 for channel in in_channels]
+
+ self.cross_resolution_weighting = CrossResolutionWeighting(
+ branch_channels,
+ ratio=reduce_ratio,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg)
+
+ self.depthwise_convs = nn.ModuleList([
+ ConvModule(
+ channel,
+ channel,
+ kernel_size=3,
+ stride=self.stride,
+ padding=1,
+ groups=channel,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None) for channel in branch_channels
+ ])
+
+ self.spatial_weighting = nn.ModuleList([
+ SpatialWeighting(channels=channel, ratio=4)
+ for channel in branch_channels
+ ])
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ x = [s.chunk(2, dim=1) for s in x]
+ x1 = [s[0] for s in x]
+ x2 = [s[1] for s in x]
+
+ x2 = self.cross_resolution_weighting(x2)
+ x2 = [dw(s) for s, dw in zip(x2, self.depthwise_convs)]
+ x2 = [sw(s) for s, sw in zip(x2, self.spatial_weighting)]
+
+ out = [torch.cat([s1, s2], dim=1) for s1, s2 in zip(x1, x2)]
+ out = [channel_shuffle(s, 2) for s in out]
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
+
+
+class Stem(BaseModule):
+ """Stem network block.
+
+ Args:
+ in_channels (int): The input channels of the block.
+ stem_channels (int): Output channels of the stem layer.
+ out_channels (int): The output channels of the block.
+ expand_ratio (int): adjusts number of channels of the hidden layer
+ in InvertedResidual by this amount.
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ stem_channels,
+ out_channels,
+ expand_ratio,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ with_cp=False,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.with_cp = with_cp
+
+ self.conv1 = ConvModule(
+ in_channels=in_channels,
+ out_channels=stem_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=dict(type='ReLU'))
+
+ mid_channels = int(round(stem_channels * expand_ratio))
+ branch_channels = stem_channels // 2
+ if stem_channels == self.out_channels:
+ inc_channels = self.out_channels - branch_channels
+ else:
+ inc_channels = self.out_channels - stem_channels
+
+ self.branch1 = nn.Sequential(
+ ConvModule(
+ branch_channels,
+ branch_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ groups=branch_channels,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None),
+ ConvModule(
+ branch_channels,
+ inc_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU')),
+ )
+
+ self.expand_conv = ConvModule(
+ branch_channels,
+ mid_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU'))
+ self.depthwise_conv = ConvModule(
+ mid_channels,
+ mid_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ groups=mid_channels,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+ self.linear_conv = ConvModule(
+ mid_channels,
+ branch_channels
+ if stem_channels == self.out_channels else stem_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU'))
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ x = self.conv1(x)
+ x1, x2 = x.chunk(2, dim=1)
+
+ x2 = self.expand_conv(x2)
+ x2 = self.depthwise_conv(x2)
+ x2 = self.linear_conv(x2)
+
+ out = torch.cat((self.branch1(x1), x2), dim=1)
+
+ out = channel_shuffle(out, 2)
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
+
+
+class IterativeHead(BaseModule):
+ """Extra iterative head for feature learning.
+
+ Args:
+ in_channels (int): The input channels of the block.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self, in_channels, norm_cfg=dict(type='BN'), init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ projects = []
+ num_branchs = len(in_channels)
+ self.in_channels = in_channels[::-1]
+
+ for i in range(num_branchs):
+ if i != num_branchs - 1:
+ projects.append(
+ DepthwiseSeparableConvModule(
+ in_channels=self.in_channels[i],
+ out_channels=self.in_channels[i + 1],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU'),
+ dw_act_cfg=None,
+ pw_act_cfg=dict(type='ReLU')))
+ else:
+ projects.append(
+ DepthwiseSeparableConvModule(
+ in_channels=self.in_channels[i],
+ out_channels=self.in_channels[i],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU'),
+ dw_act_cfg=None,
+ pw_act_cfg=dict(type='ReLU')))
+ self.projects = nn.ModuleList(projects)
+
+ def forward(self, x):
+ x = x[::-1]
+
+ y = []
+ last_x = None
+ for i, s in enumerate(x):
+ if last_x is not None:
+ last_x = F.interpolate(
+ last_x,
+ size=s.size()[-2:],
+ mode='bilinear',
+ align_corners=True)
+ s = s + last_x
+ s = self.projects[i](s)
+ y.append(s)
+ last_x = s
+
+ return y[::-1]
+
+
+class ShuffleUnit(BaseModule):
+ """InvertedResidual block for ShuffleNetV2 backbone.
+
+ Args:
+ in_channels (int): The input channels of the block.
+ out_channels (int): The output channels of the block.
+ stride (int): Stride of the 3x3 convolution layer. Default: 1
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='ReLU').
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ stride=1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ with_cp=False,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ self.stride = stride
+ self.with_cp = with_cp
+
+ branch_features = out_channels // 2
+ if self.stride == 1:
+ assert in_channels == branch_features * 2, (
+ f'in_channels ({in_channels}) should equal to '
+ f'branch_features * 2 ({branch_features * 2}) '
+ 'when stride is 1')
+
+ if in_channels != branch_features * 2:
+ assert self.stride != 1, (
+ f'stride ({self.stride}) should not equal 1 when '
+ f'in_channels != branch_features * 2')
+
+ if self.stride > 1:
+ self.branch1 = nn.Sequential(
+ ConvModule(
+ in_channels,
+ in_channels,
+ kernel_size=3,
+ stride=self.stride,
+ padding=1,
+ groups=in_channels,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None),
+ ConvModule(
+ in_channels,
+ branch_features,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ )
+
+ self.branch2 = nn.Sequential(
+ ConvModule(
+ in_channels if (self.stride > 1) else branch_features,
+ branch_features,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ branch_features,
+ branch_features,
+ kernel_size=3,
+ stride=self.stride,
+ padding=1,
+ groups=branch_features,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None),
+ ConvModule(
+ branch_features,
+ branch_features,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ if self.stride > 1:
+ out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
+ else:
+ x1, x2 = x.chunk(2, dim=1)
+ out = torch.cat((x1, self.branch2(x2)), dim=1)
+
+ out = channel_shuffle(out, 2)
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
+
+
+class LiteHRModule(BaseModule):
+ """High-Resolution Module for LiteHRNet.
+
+ It contains conditional channel weighting blocks and
+ shuffle blocks.
+
+
+ Args:
+ num_branches (int): Number of branches in the module.
+ num_blocks (int): Number of blocks in the module.
+ in_channels (list(int)): Number of input image channels.
+ reduce_ratio (int): Channel reduction ratio.
+ module_type (str): 'LITE' or 'NAIVE'
+ multiscale_output (bool): Whether to output multi-scale features.
+ with_fuse (bool): Whether to use fuse layers.
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ num_branches,
+ num_blocks,
+ in_channels,
+ reduce_ratio,
+ module_type,
+ multiscale_output=False,
+ with_fuse=True,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ with_cp=False,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ self._check_branches(num_branches, in_channels)
+
+ self.in_channels = in_channels
+ self.num_branches = num_branches
+
+ self.module_type = module_type
+ self.multiscale_output = multiscale_output
+ self.with_fuse = with_fuse
+ self.norm_cfg = norm_cfg
+ self.conv_cfg = conv_cfg
+ self.with_cp = with_cp
+
+ if self.module_type.upper() == 'LITE':
+ self.layers = self._make_weighting_blocks(num_blocks, reduce_ratio)
+ elif self.module_type.upper() == 'NAIVE':
+ self.layers = self._make_naive_branches(num_branches, num_blocks)
+ else:
+ raise ValueError("module_type should be either 'LITE' or 'NAIVE'.")
+ if self.with_fuse:
+ self.fuse_layers = self._make_fuse_layers()
+ self.relu = nn.ReLU()
+
+ def _check_branches(self, num_branches, in_channels):
+ """Check input to avoid ValueError."""
+ if num_branches != len(in_channels):
+ error_msg = f'NUM_BRANCHES({num_branches}) ' \
+ f'!= NUM_INCHANNELS({len(in_channels)})'
+ raise ValueError(error_msg)
+
+ def _make_weighting_blocks(self, num_blocks, reduce_ratio, stride=1):
+ """Make channel weighting blocks."""
+ layers = []
+ for i in range(num_blocks):
+ layers.append(
+ ConditionalChannelWeighting(
+ self.in_channels,
+ stride=stride,
+ reduce_ratio=reduce_ratio,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ with_cp=self.with_cp))
+
+ return nn.Sequential(*layers)
+
+ def _make_one_branch(self, branch_index, num_blocks, stride=1):
+ """Make one branch."""
+ layers = []
+ layers.append(
+ ShuffleUnit(
+ self.in_channels[branch_index],
+ self.in_channels[branch_index],
+ stride=stride,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=dict(type='ReLU'),
+ with_cp=self.with_cp))
+ for i in range(1, num_blocks):
+ layers.append(
+ ShuffleUnit(
+ self.in_channels[branch_index],
+ self.in_channels[branch_index],
+ stride=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=dict(type='ReLU'),
+ with_cp=self.with_cp))
+
+ return nn.Sequential(*layers)
+
+ def _make_naive_branches(self, num_branches, num_blocks):
+ """Make branches."""
+ branches = []
+
+ for i in range(num_branches):
+ branches.append(self._make_one_branch(i, num_blocks))
+
+ return nn.ModuleList(branches)
+
+ def _make_fuse_layers(self):
+ """Make fuse layer."""
+ if self.num_branches == 1:
+ return None
+
+ num_branches = self.num_branches
+ in_channels = self.in_channels
+ fuse_layers = []
+ num_out_branches = num_branches if self.multiscale_output else 1
+ for i in range(num_out_branches):
+ fuse_layer = []
+ for j in range(num_branches):
+ if j > i:
+ fuse_layer.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[i],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False),
+ build_norm_layer(self.norm_cfg, in_channels[i])[1],
+ nn.Upsample(
+ scale_factor=2**(j - i), mode='nearest')))
+ elif j == i:
+ fuse_layer.append(None)
+ else:
+ conv_downsamples = []
+ for k in range(i - j):
+ if k == i - j - 1:
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[j],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ groups=in_channels[j],
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[j])[1],
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[i],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[i])[1]))
+ else:
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[j],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ groups=in_channels[j],
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[j])[1],
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[j],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[j])[1],
+ nn.ReLU(inplace=True)))
+ fuse_layer.append(nn.Sequential(*conv_downsamples))
+ fuse_layers.append(nn.ModuleList(fuse_layer))
+
+ return nn.ModuleList(fuse_layers)
+
+ def forward(self, x):
+ """Forward function."""
+ if self.num_branches == 1:
+ return [self.layers[0](x[0])]
+
+ if self.module_type.upper() == 'LITE':
+ out = self.layers(x)
+ elif self.module_type.upper() == 'NAIVE':
+ for i in range(self.num_branches):
+ x[i] = self.layers[i](x[i])
+ out = x
+
+ if self.with_fuse:
+ out_fuse = []
+ for i in range(len(self.fuse_layers)):
+ # `y = 0` will lead to decreased accuracy (0.5~1 mAP)
+ y = out[0] if i == 0 else self.fuse_layers[i][0](out[0])
+ for j in range(self.num_branches):
+ if i == j:
+ y += out[j]
+ else:
+ y += self.fuse_layers[i][j](out[j])
+ out_fuse.append(self.relu(y))
+ out = out_fuse
+ if not self.multiscale_output:
+ out = [out[0]]
+ return out
+
+
+@MODELS.register_module()
+class LiteHRNet(BaseBackbone):
+ """Lite-HRNet backbone.
+
+ `Lite-HRNet: A Lightweight High-Resolution Network
+ `_.
+
+ Code adapted from 'https://github.com/HRNet/Lite-HRNet'.
+
+ Args:
+ extra (dict): detailed configuration for each stage of HRNet.
+ in_channels (int): Number of input image channels. Default: 3.
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+
+ Example:
+ >>> from mmpose.models import LiteHRNet
+ >>> import torch
+ >>> extra=dict(
+ >>> stem=dict(stem_channels=32, out_channels=32, expand_ratio=1),
+ >>> num_stages=3,
+ >>> stages_spec=dict(
+ >>> num_modules=(2, 4, 2),
+ >>> num_branches=(2, 3, 4),
+ >>> num_blocks=(2, 2, 2),
+ >>> module_type=('LITE', 'LITE', 'LITE'),
+ >>> with_fuse=(True, True, True),
+ >>> reduce_ratios=(8, 8, 8),
+ >>> num_channels=(
+ >>> (40, 80),
+ >>> (40, 80, 160),
+ >>> (40, 80, 160, 320),
+ >>> )),
+ >>> with_head=False)
+ >>> self = LiteHRNet(extra, in_channels=1)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 1, 32, 32)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 40, 8, 8)
+ """
+
+ def __init__(self,
+ extra,
+ in_channels=3,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ norm_eval=False,
+ with_cp=False,
+ init_cfg=[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]):
+ super().__init__(init_cfg=init_cfg)
+ self.extra = extra
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+
+ self.stem = Stem(
+ in_channels,
+ stem_channels=self.extra['stem']['stem_channels'],
+ out_channels=self.extra['stem']['out_channels'],
+ expand_ratio=self.extra['stem']['expand_ratio'],
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg)
+
+ self.num_stages = self.extra['num_stages']
+ self.stages_spec = self.extra['stages_spec']
+
+ num_channels_last = [
+ self.stem.out_channels,
+ ]
+ for i in range(self.num_stages):
+ num_channels = self.stages_spec['num_channels'][i]
+ num_channels = [num_channels[i] for i in range(len(num_channels))]
+ setattr(
+ self, f'transition{i}',
+ self._make_transition_layer(num_channels_last, num_channels))
+
+ stage, num_channels_last = self._make_stage(
+ self.stages_spec, i, num_channels, multiscale_output=True)
+ setattr(self, f'stage{i}', stage)
+
+ self.with_head = self.extra['with_head']
+ if self.with_head:
+ self.head_layer = IterativeHead(
+ in_channels=num_channels_last,
+ norm_cfg=self.norm_cfg,
+ )
+
+ def _make_transition_layer(self, num_channels_pre_layer,
+ num_channels_cur_layer):
+ """Make transition layer."""
+ num_branches_cur = len(num_channels_cur_layer)
+ num_branches_pre = len(num_channels_pre_layer)
+
+ transition_layers = []
+ for i in range(num_branches_cur):
+ if i < num_branches_pre:
+ if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
+ transition_layers.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ num_channels_pre_layer[i],
+ num_channels_pre_layer[i],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ groups=num_channels_pre_layer[i],
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ num_channels_pre_layer[i])[1],
+ build_conv_layer(
+ self.conv_cfg,
+ num_channels_pre_layer[i],
+ num_channels_cur_layer[i],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ num_channels_cur_layer[i])[1],
+ nn.ReLU()))
+ else:
+ transition_layers.append(None)
+ else:
+ conv_downsamples = []
+ for j in range(i + 1 - num_branches_pre):
+ in_channels = num_channels_pre_layer[-1]
+ out_channels = num_channels_cur_layer[i] \
+ if j == i - num_branches_pre else in_channels
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ groups=in_channels,
+ bias=False),
+ build_norm_layer(self.norm_cfg, in_channels)[1],
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False),
+ build_norm_layer(self.norm_cfg, out_channels)[1],
+ nn.ReLU()))
+ transition_layers.append(nn.Sequential(*conv_downsamples))
+
+ return nn.ModuleList(transition_layers)
+
+ def _make_stage(self,
+ stages_spec,
+ stage_index,
+ in_channels,
+ multiscale_output=True):
+ num_modules = stages_spec['num_modules'][stage_index]
+ num_branches = stages_spec['num_branches'][stage_index]
+ num_blocks = stages_spec['num_blocks'][stage_index]
+ reduce_ratio = stages_spec['reduce_ratios'][stage_index]
+ with_fuse = stages_spec['with_fuse'][stage_index]
+ module_type = stages_spec['module_type'][stage_index]
+
+ modules = []
+ for i in range(num_modules):
+ # multi_scale_output is only used last module
+ if not multiscale_output and i == num_modules - 1:
+ reset_multiscale_output = False
+ else:
+ reset_multiscale_output = True
+
+ modules.append(
+ LiteHRModule(
+ num_branches,
+ num_blocks,
+ in_channels,
+ reduce_ratio,
+ module_type,
+ multiscale_output=reset_multiscale_output,
+ with_fuse=with_fuse,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ with_cp=self.with_cp))
+ in_channels = modules[-1].in_channels
+
+ return nn.Sequential(*modules), in_channels
+
+ def forward(self, x):
+ """Forward function."""
+ x = self.stem(x)
+
+ y_list = [x]
+ for i in range(self.num_stages):
+ x_list = []
+ transition = getattr(self, f'transition{i}')
+ for j in range(self.stages_spec['num_branches'][i]):
+ if transition[j]:
+ if j >= len(y_list):
+ x_list.append(transition[j](y_list[-1]))
+ else:
+ x_list.append(transition[j](y_list[j]))
+ else:
+ x_list.append(y_list[j])
+ y_list = getattr(self, f'stage{i}')(x_list)
+
+ x = y_list
+ if self.with_head:
+ x = self.head_layer(x)
+
+ return (x[0], )
+
+ def train(self, mode=True):
+ """Convert the model into training mode."""
+ super().train(mode)
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, _BatchNorm):
+ m.eval()
diff --git a/mmpose/models/backbones/mobilenet_v2.py b/mmpose/models/backbones/mobilenet_v2.py
index b64c0d73d4..3c62394076 100644
--- a/mmpose/models/backbones/mobilenet_v2.py
+++ b/mmpose/models/backbones/mobilenet_v2.py
@@ -1,279 +1,279 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-
-import torch.nn as nn
-import torch.utils.checkpoint as cp
-from mmcv.cnn import ConvModule
-from mmengine.model import BaseModule
-from torch.nn.modules.batchnorm import _BatchNorm
-
-from mmpose.registry import MODELS
-from .base_backbone import BaseBackbone
-from .utils import make_divisible
-
-
-class InvertedResidual(BaseModule):
- """InvertedResidual block for MobileNetV2.
-
- Args:
- in_channels (int): The input channels of the InvertedResidual block.
- out_channels (int): The output channels of the InvertedResidual block.
- stride (int): Stride of the middle (first) 3x3 convolution.
- expand_ratio (int): adjusts number of channels of the hidden layer
- in InvertedResidual by this amount.
- conv_cfg (dict): Config dict for convolution layer.
- Default: None, which means using conv2d.
- norm_cfg (dict): Config dict for normalization layer.
- Default: dict(type='BN').
- act_cfg (dict): Config dict for activation layer.
- Default: dict(type='ReLU6').
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed. Default: False.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- stride,
- expand_ratio,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- act_cfg=dict(type='ReLU6'),
- with_cp=False,
- init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- act_cfg = copy.deepcopy(act_cfg)
- super().__init__(init_cfg=init_cfg)
- self.stride = stride
- assert stride in [1, 2], f'stride must in [1, 2]. ' \
- f'But received {stride}.'
- self.with_cp = with_cp
- self.use_res_connect = self.stride == 1 and in_channels == out_channels
- hidden_dim = int(round(in_channels * expand_ratio))
-
- layers = []
- if expand_ratio != 1:
- layers.append(
- ConvModule(
- in_channels=in_channels,
- out_channels=hidden_dim,
- kernel_size=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg))
- layers.extend([
- ConvModule(
- in_channels=hidden_dim,
- out_channels=hidden_dim,
- kernel_size=3,
- stride=stride,
- padding=1,
- groups=hidden_dim,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg),
- ConvModule(
- in_channels=hidden_dim,
- out_channels=out_channels,
- kernel_size=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=None)
- ])
- self.conv = nn.Sequential(*layers)
-
- def forward(self, x):
-
- def _inner_forward(x):
- if self.use_res_connect:
- return x + self.conv(x)
- return self.conv(x)
-
- if self.with_cp and x.requires_grad:
- out = cp.checkpoint(_inner_forward, x)
- else:
- out = _inner_forward(x)
-
- return out
-
-
-@MODELS.register_module()
-class MobileNetV2(BaseBackbone):
- """MobileNetV2 backbone.
-
- Args:
- widen_factor (float): Width multiplier, multiply number of
- channels in each layer by this amount. Default: 1.0.
- out_indices (None or Sequence[int]): Output from which stages.
- Default: (7, ).
- frozen_stages (int): Stages to be frozen (all param fixed).
- Default: -1, which means not freezing any parameters.
- conv_cfg (dict): Config dict for convolution layer.
- Default: None, which means using conv2d.
- norm_cfg (dict): Config dict for normalization layer.
- Default: dict(type='BN').
- act_cfg (dict): Config dict for activation layer.
- Default: dict(type='ReLU6').
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only. Default: False.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed. Default: False.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Kaiming', layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]``
- """
-
- # Parameters to build layers. 4 parameters are needed to construct a
- # layer, from left to right: expand_ratio, channel, num_blocks, stride.
- arch_settings = [[1, 16, 1, 1], [6, 24, 2, 2], [6, 32, 3, 2],
- [6, 64, 4, 2], [6, 96, 3, 1], [6, 160, 3, 2],
- [6, 320, 1, 1]]
-
- def __init__(self,
- widen_factor=1.,
- out_indices=(7, ),
- frozen_stages=-1,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- act_cfg=dict(type='ReLU6'),
- norm_eval=False,
- with_cp=False,
- init_cfg=[
- dict(type='Kaiming', layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- act_cfg = copy.deepcopy(act_cfg)
- super().__init__(init_cfg=init_cfg)
- self.widen_factor = widen_factor
- self.out_indices = out_indices
- for index in out_indices:
- if index not in range(0, 8):
- raise ValueError('the item in out_indices must in '
- f'range(0, 8). But received {index}')
-
- if frozen_stages not in range(-1, 8):
- raise ValueError('frozen_stages must be in range(-1, 8). '
- f'But received {frozen_stages}')
- self.out_indices = out_indices
- self.frozen_stages = frozen_stages
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- self.act_cfg = act_cfg
- self.norm_eval = norm_eval
- self.with_cp = with_cp
-
- self.in_channels = make_divisible(32 * widen_factor, 8)
-
- self.conv1 = ConvModule(
- in_channels=3,
- out_channels=self.in_channels,
- kernel_size=3,
- stride=2,
- padding=1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg)
-
- self.layers = []
-
- for i, layer_cfg in enumerate(self.arch_settings):
- expand_ratio, channel, num_blocks, stride = layer_cfg
- out_channels = make_divisible(channel * widen_factor, 8)
- inverted_res_layer = self.make_layer(
- out_channels=out_channels,
- num_blocks=num_blocks,
- stride=stride,
- expand_ratio=expand_ratio)
- layer_name = f'layer{i + 1}'
- self.add_module(layer_name, inverted_res_layer)
- self.layers.append(layer_name)
-
- if widen_factor > 1.0:
- self.out_channel = int(1280 * widen_factor)
- else:
- self.out_channel = 1280
-
- layer = ConvModule(
- in_channels=self.in_channels,
- out_channels=self.out_channel,
- kernel_size=1,
- stride=1,
- padding=0,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg)
- self.add_module('conv2', layer)
- self.layers.append('conv2')
-
- def make_layer(self, out_channels, num_blocks, stride, expand_ratio):
- """Stack InvertedResidual blocks to build a layer for MobileNetV2.
-
- Args:
- out_channels (int): out_channels of block.
- num_blocks (int): number of blocks.
- stride (int): stride of the first block. Default: 1
- expand_ratio (int): Expand the number of channels of the
- hidden layer in InvertedResidual by this ratio. Default: 6.
- """
- layers = []
- for i in range(num_blocks):
- if i >= 1:
- stride = 1
- layers.append(
- InvertedResidual(
- self.in_channels,
- out_channels,
- stride,
- expand_ratio=expand_ratio,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg,
- with_cp=self.with_cp))
- self.in_channels = out_channels
-
- return nn.Sequential(*layers)
-
- def forward(self, x):
- x = self.conv1(x)
-
- outs = []
- for i, layer_name in enumerate(self.layers):
- layer = getattr(self, layer_name)
- x = layer(x)
- if i in self.out_indices:
- outs.append(x)
-
- return tuple(outs)
-
- def _freeze_stages(self):
- if self.frozen_stages >= 0:
- for param in self.conv1.parameters():
- param.requires_grad = False
- for i in range(1, self.frozen_stages + 1):
- layer = getattr(self, f'layer{i}')
- layer.eval()
- for param in layer.parameters():
- param.requires_grad = False
-
- def train(self, mode=True):
- super().train(mode)
- self._freeze_stages()
- if mode and self.norm_eval:
- for m in self.modules():
- if isinstance(m, _BatchNorm):
- m.eval()
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import torch.nn as nn
+import torch.utils.checkpoint as cp
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+from .utils import make_divisible
+
+
+class InvertedResidual(BaseModule):
+ """InvertedResidual block for MobileNetV2.
+
+ Args:
+ in_channels (int): The input channels of the InvertedResidual block.
+ out_channels (int): The output channels of the InvertedResidual block.
+ stride (int): Stride of the middle (first) 3x3 convolution.
+ expand_ratio (int): adjusts number of channels of the hidden layer
+ in InvertedResidual by this amount.
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='ReLU6').
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ stride,
+ expand_ratio,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU6'),
+ with_cp=False,
+ init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ act_cfg = copy.deepcopy(act_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self.stride = stride
+ assert stride in [1, 2], f'stride must in [1, 2]. ' \
+ f'But received {stride}.'
+ self.with_cp = with_cp
+ self.use_res_connect = self.stride == 1 and in_channels == out_channels
+ hidden_dim = int(round(in_channels * expand_ratio))
+
+ layers = []
+ if expand_ratio != 1:
+ layers.append(
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=hidden_dim,
+ kernel_size=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ layers.extend([
+ ConvModule(
+ in_channels=hidden_dim,
+ out_channels=hidden_dim,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ groups=hidden_dim,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ in_channels=hidden_dim,
+ out_channels=out_channels,
+ kernel_size=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+ ])
+ self.conv = nn.Sequential(*layers)
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ if self.use_res_connect:
+ return x + self.conv(x)
+ return self.conv(x)
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
+
+
+@MODELS.register_module()
+class MobileNetV2(BaseBackbone):
+ """MobileNetV2 backbone.
+
+ Args:
+ widen_factor (float): Width multiplier, multiply number of
+ channels in each layer by this amount. Default: 1.0.
+ out_indices (None or Sequence[int]): Output from which stages.
+ Default: (7, ).
+ frozen_stages (int): Stages to be frozen (all param fixed).
+ Default: -1, which means not freezing any parameters.
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='ReLU6').
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Kaiming', layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+ """
+
+ # Parameters to build layers. 4 parameters are needed to construct a
+ # layer, from left to right: expand_ratio, channel, num_blocks, stride.
+ arch_settings = [[1, 16, 1, 1], [6, 24, 2, 2], [6, 32, 3, 2],
+ [6, 64, 4, 2], [6, 96, 3, 1], [6, 160, 3, 2],
+ [6, 320, 1, 1]]
+
+ def __init__(self,
+ widen_factor=1.,
+ out_indices=(7, ),
+ frozen_stages=-1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU6'),
+ norm_eval=False,
+ with_cp=False,
+ init_cfg=[
+ dict(type='Kaiming', layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ act_cfg = copy.deepcopy(act_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self.widen_factor = widen_factor
+ self.out_indices = out_indices
+ for index in out_indices:
+ if index not in range(0, 8):
+ raise ValueError('the item in out_indices must in '
+ f'range(0, 8). But received {index}')
+
+ if frozen_stages not in range(-1, 8):
+ raise ValueError('frozen_stages must be in range(-1, 8). '
+ f'But received {frozen_stages}')
+ self.out_indices = out_indices
+ self.frozen_stages = frozen_stages
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+
+ self.in_channels = make_divisible(32 * widen_factor, 8)
+
+ self.conv1 = ConvModule(
+ in_channels=3,
+ out_channels=self.in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ self.layers = []
+
+ for i, layer_cfg in enumerate(self.arch_settings):
+ expand_ratio, channel, num_blocks, stride = layer_cfg
+ out_channels = make_divisible(channel * widen_factor, 8)
+ inverted_res_layer = self.make_layer(
+ out_channels=out_channels,
+ num_blocks=num_blocks,
+ stride=stride,
+ expand_ratio=expand_ratio)
+ layer_name = f'layer{i + 1}'
+ self.add_module(layer_name, inverted_res_layer)
+ self.layers.append(layer_name)
+
+ if widen_factor > 1.0:
+ self.out_channel = int(1280 * widen_factor)
+ else:
+ self.out_channel = 1280
+
+ layer = ConvModule(
+ in_channels=self.in_channels,
+ out_channels=self.out_channel,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.add_module('conv2', layer)
+ self.layers.append('conv2')
+
+ def make_layer(self, out_channels, num_blocks, stride, expand_ratio):
+ """Stack InvertedResidual blocks to build a layer for MobileNetV2.
+
+ Args:
+ out_channels (int): out_channels of block.
+ num_blocks (int): number of blocks.
+ stride (int): stride of the first block. Default: 1
+ expand_ratio (int): Expand the number of channels of the
+ hidden layer in InvertedResidual by this ratio. Default: 6.
+ """
+ layers = []
+ for i in range(num_blocks):
+ if i >= 1:
+ stride = 1
+ layers.append(
+ InvertedResidual(
+ self.in_channels,
+ out_channels,
+ stride,
+ expand_ratio=expand_ratio,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ with_cp=self.with_cp))
+ self.in_channels = out_channels
+
+ return nn.Sequential(*layers)
+
+ def forward(self, x):
+ x = self.conv1(x)
+
+ outs = []
+ for i, layer_name in enumerate(self.layers):
+ layer = getattr(self, layer_name)
+ x = layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+
+ return tuple(outs)
+
+ def _freeze_stages(self):
+ if self.frozen_stages >= 0:
+ for param in self.conv1.parameters():
+ param.requires_grad = False
+ for i in range(1, self.frozen_stages + 1):
+ layer = getattr(self, f'layer{i}')
+ layer.eval()
+ for param in layer.parameters():
+ param.requires_grad = False
+
+ def train(self, mode=True):
+ super().train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, _BatchNorm):
+ m.eval()
diff --git a/mmpose/models/backbones/mobilenet_v3.py b/mmpose/models/backbones/mobilenet_v3.py
index 03ecf90dd2..89edbb68ee 100644
--- a/mmpose/models/backbones/mobilenet_v3.py
+++ b/mmpose/models/backbones/mobilenet_v3.py
@@ -1,185 +1,185 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-
-from mmcv.cnn import ConvModule
-from torch.nn.modules.batchnorm import _BatchNorm
-
-from mmpose.registry import MODELS
-from .base_backbone import BaseBackbone
-from .utils import InvertedResidual
-
-
-@MODELS.register_module()
-class MobileNetV3(BaseBackbone):
- """MobileNetV3 backbone.
-
- Args:
- arch (str): Architecture of mobilnetv3, from {small, big}.
- Default: small.
- conv_cfg (dict): Config dict for convolution layer.
- Default: None, which means using conv2d.
- norm_cfg (dict): Config dict for normalization layer.
- Default: dict(type='BN').
- out_indices (None or Sequence[int]): Output from which stages.
- Default: (-1, ), which means output tensors from final stage.
- frozen_stages (int): Stages to be frozen (all param fixed).
- Default: -1, which means not freezing any parameters.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only. Default: False.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save
- some memory while slowing down the training speed.
- Default: False.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Kaiming', layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm'])
- ]``
- """
- # Parameters to build each block:
- # [kernel size, mid channels, out channels, with_se, act type, stride]
- arch_settings = {
- 'small': [[3, 16, 16, True, 'ReLU', 2],
- [3, 72, 24, False, 'ReLU', 2],
- [3, 88, 24, False, 'ReLU', 1],
- [5, 96, 40, True, 'HSwish', 2],
- [5, 240, 40, True, 'HSwish', 1],
- [5, 240, 40, True, 'HSwish', 1],
- [5, 120, 48, True, 'HSwish', 1],
- [5, 144, 48, True, 'HSwish', 1],
- [5, 288, 96, True, 'HSwish', 2],
- [5, 576, 96, True, 'HSwish', 1],
- [5, 576, 96, True, 'HSwish', 1]],
- 'big': [[3, 16, 16, False, 'ReLU', 1],
- [3, 64, 24, False, 'ReLU', 2],
- [3, 72, 24, False, 'ReLU', 1],
- [5, 72, 40, True, 'ReLU', 2],
- [5, 120, 40, True, 'ReLU', 1],
- [5, 120, 40, True, 'ReLU', 1],
- [3, 240, 80, False, 'HSwish', 2],
- [3, 200, 80, False, 'HSwish', 1],
- [3, 184, 80, False, 'HSwish', 1],
- [3, 184, 80, False, 'HSwish', 1],
- [3, 480, 112, True, 'HSwish', 1],
- [3, 672, 112, True, 'HSwish', 1],
- [5, 672, 160, True, 'HSwish', 1],
- [5, 672, 160, True, 'HSwish', 2],
- [5, 960, 160, True, 'HSwish', 1]]
- } # yapf: disable
-
- def __init__(self,
- arch='small',
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- out_indices=(-1, ),
- frozen_stages=-1,
- norm_eval=False,
- with_cp=False,
- init_cfg=[
- dict(type='Kaiming', layer=['Conv2d']),
- dict(type='Constant', val=1, layer=['_BatchNorm'])
- ]):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
- assert arch in self.arch_settings
- for index in out_indices:
- if index not in range(-len(self.arch_settings[arch]),
- len(self.arch_settings[arch])):
- raise ValueError('the item in out_indices must in '
- f'range(0, {len(self.arch_settings[arch])}). '
- f'But received {index}')
-
- if frozen_stages not in range(-1, len(self.arch_settings[arch])):
- raise ValueError('frozen_stages must be in range(-1, '
- f'{len(self.arch_settings[arch])}). '
- f'But received {frozen_stages}')
- self.arch = arch
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- self.out_indices = out_indices
- self.frozen_stages = frozen_stages
- self.norm_eval = norm_eval
- self.with_cp = with_cp
-
- self.in_channels = 16
- self.conv1 = ConvModule(
- in_channels=3,
- out_channels=self.in_channels,
- kernel_size=3,
- stride=2,
- padding=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=dict(type='HSwish'))
-
- self.layers = self._make_layer()
- self.feat_dim = self.arch_settings[arch][-1][2]
-
- def _make_layer(self):
- layers = []
- layer_setting = self.arch_settings[self.arch]
- for i, params in enumerate(layer_setting):
- (kernel_size, mid_channels, out_channels, with_se, act,
- stride) = params
- if with_se:
- se_cfg = dict(
- channels=mid_channels,
- ratio=4,
- act_cfg=(dict(type='ReLU'),
- dict(type='HSigmoid', bias=1.0, divisor=2.0)))
- else:
- se_cfg = None
-
- layer = InvertedResidual(
- in_channels=self.in_channels,
- out_channels=out_channels,
- mid_channels=mid_channels,
- kernel_size=kernel_size,
- stride=stride,
- se_cfg=se_cfg,
- with_expand_conv=True,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=dict(type=act),
- with_cp=self.with_cp)
- self.in_channels = out_channels
- layer_name = f'layer{i + 1}'
- self.add_module(layer_name, layer)
- layers.append(layer_name)
- return layers
-
- def forward(self, x):
- x = self.conv1(x)
-
- outs = []
- for i, layer_name in enumerate(self.layers):
- layer = getattr(self, layer_name)
- x = layer(x)
- if i in self.out_indices or \
- i - len(self.layers) in self.out_indices:
- outs.append(x)
-
- return tuple(outs)
-
- def _freeze_stages(self):
- if self.frozen_stages >= 0:
- for param in self.conv1.parameters():
- param.requires_grad = False
- for i in range(1, self.frozen_stages + 1):
- layer = getattr(self, f'layer{i}')
- layer.eval()
- for param in layer.parameters():
- param.requires_grad = False
-
- def train(self, mode=True):
- super().train(mode)
- self._freeze_stages()
- if mode and self.norm_eval:
- for m in self.modules():
- if isinstance(m, _BatchNorm):
- m.eval()
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+from mmcv.cnn import ConvModule
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+from .utils import InvertedResidual
+
+
+@MODELS.register_module()
+class MobileNetV3(BaseBackbone):
+ """MobileNetV3 backbone.
+
+ Args:
+ arch (str): Architecture of mobilnetv3, from {small, big}.
+ Default: small.
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ out_indices (None or Sequence[int]): Output from which stages.
+ Default: (-1, ), which means output tensors from final stage.
+ frozen_stages (int): Stages to be frozen (all param fixed).
+ Default: -1, which means not freezing any parameters.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save
+ some memory while slowing down the training speed.
+ Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Kaiming', layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm'])
+ ]``
+ """
+ # Parameters to build each block:
+ # [kernel size, mid channels, out channels, with_se, act type, stride]
+ arch_settings = {
+ 'small': [[3, 16, 16, True, 'ReLU', 2],
+ [3, 72, 24, False, 'ReLU', 2],
+ [3, 88, 24, False, 'ReLU', 1],
+ [5, 96, 40, True, 'HSwish', 2],
+ [5, 240, 40, True, 'HSwish', 1],
+ [5, 240, 40, True, 'HSwish', 1],
+ [5, 120, 48, True, 'HSwish', 1],
+ [5, 144, 48, True, 'HSwish', 1],
+ [5, 288, 96, True, 'HSwish', 2],
+ [5, 576, 96, True, 'HSwish', 1],
+ [5, 576, 96, True, 'HSwish', 1]],
+ 'big': [[3, 16, 16, False, 'ReLU', 1],
+ [3, 64, 24, False, 'ReLU', 2],
+ [3, 72, 24, False, 'ReLU', 1],
+ [5, 72, 40, True, 'ReLU', 2],
+ [5, 120, 40, True, 'ReLU', 1],
+ [5, 120, 40, True, 'ReLU', 1],
+ [3, 240, 80, False, 'HSwish', 2],
+ [3, 200, 80, False, 'HSwish', 1],
+ [3, 184, 80, False, 'HSwish', 1],
+ [3, 184, 80, False, 'HSwish', 1],
+ [3, 480, 112, True, 'HSwish', 1],
+ [3, 672, 112, True, 'HSwish', 1],
+ [5, 672, 160, True, 'HSwish', 1],
+ [5, 672, 160, True, 'HSwish', 2],
+ [5, 960, 160, True, 'HSwish', 1]]
+ } # yapf: disable
+
+ def __init__(self,
+ arch='small',
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ out_indices=(-1, ),
+ frozen_stages=-1,
+ norm_eval=False,
+ with_cp=False,
+ init_cfg=[
+ dict(type='Kaiming', layer=['Conv2d']),
+ dict(type='Constant', val=1, layer=['_BatchNorm'])
+ ]):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ assert arch in self.arch_settings
+ for index in out_indices:
+ if index not in range(-len(self.arch_settings[arch]),
+ len(self.arch_settings[arch])):
+ raise ValueError('the item in out_indices must in '
+ f'range(0, {len(self.arch_settings[arch])}). '
+ f'But received {index}')
+
+ if frozen_stages not in range(-1, len(self.arch_settings[arch])):
+ raise ValueError('frozen_stages must be in range(-1, '
+ f'{len(self.arch_settings[arch])}). '
+ f'But received {frozen_stages}')
+ self.arch = arch
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.out_indices = out_indices
+ self.frozen_stages = frozen_stages
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+
+ self.in_channels = 16
+ self.conv1 = ConvModule(
+ in_channels=3,
+ out_channels=self.in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='HSwish'))
+
+ self.layers = self._make_layer()
+ self.feat_dim = self.arch_settings[arch][-1][2]
+
+ def _make_layer(self):
+ layers = []
+ layer_setting = self.arch_settings[self.arch]
+ for i, params in enumerate(layer_setting):
+ (kernel_size, mid_channels, out_channels, with_se, act,
+ stride) = params
+ if with_se:
+ se_cfg = dict(
+ channels=mid_channels,
+ ratio=4,
+ act_cfg=(dict(type='ReLU'),
+ dict(type='HSigmoid', bias=1.0, divisor=2.0)))
+ else:
+ se_cfg = None
+
+ layer = InvertedResidual(
+ in_channels=self.in_channels,
+ out_channels=out_channels,
+ mid_channels=mid_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ se_cfg=se_cfg,
+ with_expand_conv=True,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=dict(type=act),
+ with_cp=self.with_cp)
+ self.in_channels = out_channels
+ layer_name = f'layer{i + 1}'
+ self.add_module(layer_name, layer)
+ layers.append(layer_name)
+ return layers
+
+ def forward(self, x):
+ x = self.conv1(x)
+
+ outs = []
+ for i, layer_name in enumerate(self.layers):
+ layer = getattr(self, layer_name)
+ x = layer(x)
+ if i in self.out_indices or \
+ i - len(self.layers) in self.out_indices:
+ outs.append(x)
+
+ return tuple(outs)
+
+ def _freeze_stages(self):
+ if self.frozen_stages >= 0:
+ for param in self.conv1.parameters():
+ param.requires_grad = False
+ for i in range(1, self.frozen_stages + 1):
+ layer = getattr(self, f'layer{i}')
+ layer.eval()
+ for param in layer.parameters():
+ param.requires_grad = False
+
+ def train(self, mode=True):
+ super().train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, _BatchNorm):
+ m.eval()
diff --git a/mmpose/models/backbones/mspn.py b/mmpose/models/backbones/mspn.py
index bcb636b1a3..4753f927d7 100644
--- a/mmpose/models/backbones/mspn.py
+++ b/mmpose/models/backbones/mspn.py
@@ -1,541 +1,541 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy as cp
-from collections import OrderedDict
-
-import torch.nn as nn
-import torch.nn.functional as F
-from mmcv.cnn import ConvModule, MaxPool2d
-from mmengine.model import BaseModule
-from mmengine.runner import load_state_dict
-
-from mmpose.registry import MODELS
-from mmpose.utils import get_root_logger
-from .base_backbone import BaseBackbone
-from .resnet import Bottleneck as _Bottleneck
-from .utils import get_state_dict
-
-
-class Bottleneck(_Bottleneck):
- expansion = 4
- """Bottleneck block for MSPN.
-
- Args:
- in_channels (int): Input channels of this block.
- out_channels (int): Output channels of this block.
- stride (int): stride of the block. Default: 1
- downsample (nn.Module): downsample operation on identity branch.
- Default: None
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self, in_channels, out_channels, **kwargs):
- super().__init__(in_channels, out_channels * 4, **kwargs)
-
-
-class DownsampleModule(BaseModule):
- """Downsample module for MSPN.
-
- Args:
- block (nn.Module): Downsample block.
- num_blocks (list): Number of blocks in each downsample unit.
- num_units (int): Numbers of downsample units. Default: 4
- has_skip (bool): Have skip connections from prior upsample
- module or not. Default:False
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- in_channels (int): Number of channels of the input feature to
- downsample module. Default: 64
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- block,
- num_blocks,
- num_units=4,
- has_skip=False,
- norm_cfg=dict(type='BN'),
- in_channels=64,
- init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = cp.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
- self.has_skip = has_skip
- self.in_channels = in_channels
- assert len(num_blocks) == num_units
- self.num_blocks = num_blocks
- self.num_units = num_units
- self.norm_cfg = norm_cfg
- self.layer1 = self._make_layer(block, in_channels, num_blocks[0])
- for i in range(1, num_units):
- module_name = f'layer{i + 1}'
- self.add_module(
- module_name,
- self._make_layer(
- block, in_channels * pow(2, i), num_blocks[i], stride=2))
-
- def _make_layer(self, block, out_channels, blocks, stride=1):
- downsample = None
- if stride != 1 or self.in_channels != out_channels * block.expansion:
- downsample = ConvModule(
- self.in_channels,
- out_channels * block.expansion,
- kernel_size=1,
- stride=stride,
- padding=0,
- norm_cfg=self.norm_cfg,
- act_cfg=None,
- inplace=True)
-
- units = list()
- units.append(
- block(
- self.in_channels,
- out_channels,
- stride=stride,
- downsample=downsample,
- norm_cfg=self.norm_cfg))
- self.in_channels = out_channels * block.expansion
- for _ in range(1, blocks):
- units.append(block(self.in_channels, out_channels))
-
- return nn.Sequential(*units)
-
- def forward(self, x, skip1, skip2):
- out = list()
- for i in range(self.num_units):
- module_name = f'layer{i + 1}'
- module_i = getattr(self, module_name)
- x = module_i(x)
- if self.has_skip:
- x = x + skip1[i] + skip2[i]
- out.append(x)
- out.reverse()
-
- return tuple(out)
-
-
-class UpsampleUnit(BaseModule):
- """Upsample unit for upsample module.
-
- Args:
- ind (int): Indicates whether to interpolate (>0) and whether to
- generate feature map for the next hourglass-like module.
- num_units (int): Number of units that form a upsample module. Along
- with ind and gen_cross_conv, nm_units is used to decide whether
- to generate feature map for the next hourglass-like module.
- in_channels (int): Channel number of the skip-in feature maps from
- the corresponding downsample unit.
- unit_channels (int): Channel number in this unit. Default:256.
- gen_skip: (bool): Whether or not to generate skips for the posterior
- downsample module. Default:False
- gen_cross_conv (bool): Whether to generate feature map for the next
- hourglass-like module. Default:False
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- out_channels (int): Number of channels of feature output by upsample
- module. Must equal to in_channels of downsample module. Default:64
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- ind,
- num_units,
- in_channels,
- unit_channels=256,
- gen_skip=False,
- gen_cross_conv=False,
- norm_cfg=dict(type='BN'),
- out_channels=64,
- init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = cp.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
- self.num_units = num_units
- self.norm_cfg = norm_cfg
- self.in_skip = ConvModule(
- in_channels,
- unit_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- norm_cfg=self.norm_cfg,
- act_cfg=None,
- inplace=True)
- self.relu = nn.ReLU(inplace=True)
-
- self.ind = ind
- if self.ind > 0:
- self.up_conv = ConvModule(
- unit_channels,
- unit_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- norm_cfg=self.norm_cfg,
- act_cfg=None,
- inplace=True)
-
- self.gen_skip = gen_skip
- if self.gen_skip:
- self.out_skip1 = ConvModule(
- in_channels,
- in_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- norm_cfg=self.norm_cfg,
- inplace=True)
-
- self.out_skip2 = ConvModule(
- unit_channels,
- in_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- norm_cfg=self.norm_cfg,
- inplace=True)
-
- self.gen_cross_conv = gen_cross_conv
- if self.ind == num_units - 1 and self.gen_cross_conv:
- self.cross_conv = ConvModule(
- unit_channels,
- out_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- norm_cfg=self.norm_cfg,
- inplace=True)
-
- def forward(self, x, up_x):
- out = self.in_skip(x)
-
- if self.ind > 0:
- up_x = F.interpolate(
- up_x,
- size=(x.size(2), x.size(3)),
- mode='bilinear',
- align_corners=True)
- up_x = self.up_conv(up_x)
- out = out + up_x
- out = self.relu(out)
-
- skip1 = None
- skip2 = None
- if self.gen_skip:
- skip1 = self.out_skip1(x)
- skip2 = self.out_skip2(out)
-
- cross_conv = None
- if self.ind == self.num_units - 1 and self.gen_cross_conv:
- cross_conv = self.cross_conv(out)
-
- return out, skip1, skip2, cross_conv
-
-
-class UpsampleModule(BaseModule):
- """Upsample module for MSPN.
-
- Args:
- unit_channels (int): Channel number in the upsample units.
- Default:256.
- num_units (int): Numbers of upsample units. Default: 4
- gen_skip (bool): Whether to generate skip for posterior downsample
- module or not. Default:False
- gen_cross_conv (bool): Whether to generate feature map for the next
- hourglass-like module. Default:False
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- out_channels (int): Number of channels of feature output by upsample
- module. Must equal to in_channels of downsample module. Default:64
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- unit_channels=256,
- num_units=4,
- gen_skip=False,
- gen_cross_conv=False,
- norm_cfg=dict(type='BN'),
- out_channels=64,
- init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = cp.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
- self.in_channels = list()
- for i in range(num_units):
- self.in_channels.append(Bottleneck.expansion * out_channels *
- pow(2, i))
- self.in_channels.reverse()
- self.num_units = num_units
- self.gen_skip = gen_skip
- self.gen_cross_conv = gen_cross_conv
- self.norm_cfg = norm_cfg
- for i in range(num_units):
- module_name = f'up{i + 1}'
- self.add_module(
- module_name,
- UpsampleUnit(
- i,
- self.num_units,
- self.in_channels[i],
- unit_channels,
- self.gen_skip,
- self.gen_cross_conv,
- norm_cfg=self.norm_cfg,
- out_channels=64))
-
- def forward(self, x):
- out = list()
- skip1 = list()
- skip2 = list()
- cross_conv = None
- for i in range(self.num_units):
- module_i = getattr(self, f'up{i + 1}')
- if i == 0:
- outi, skip1_i, skip2_i, _ = module_i(x[i], None)
- elif i == self.num_units - 1:
- outi, skip1_i, skip2_i, cross_conv = module_i(x[i], out[i - 1])
- else:
- outi, skip1_i, skip2_i, _ = module_i(x[i], out[i - 1])
- out.append(outi)
- skip1.append(skip1_i)
- skip2.append(skip2_i)
- skip1.reverse()
- skip2.reverse()
-
- return out, skip1, skip2, cross_conv
-
-
-class SingleStageNetwork(BaseModule):
- """Single_stage Network.
-
- Args:
- unit_channels (int): Channel number in the upsample units. Default:256.
- num_units (int): Numbers of downsample/upsample units. Default: 4
- gen_skip (bool): Whether to generate skip for posterior downsample
- module or not. Default:False
- gen_cross_conv (bool): Whether to generate feature map for the next
- hourglass-like module. Default:False
- has_skip (bool): Have skip connections from prior upsample
- module or not. Default:False
- num_blocks (list): Number of blocks in each downsample unit.
- Default: [2, 2, 2, 2] Note: Make sure num_units==len(num_blocks)
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- in_channels (int): Number of channels of the feature from ResNetTop.
- Default: 64.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- has_skip=False,
- gen_skip=False,
- gen_cross_conv=False,
- unit_channels=256,
- num_units=4,
- num_blocks=[2, 2, 2, 2],
- norm_cfg=dict(type='BN'),
- in_channels=64,
- init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = cp.deepcopy(norm_cfg)
- num_blocks = cp.deepcopy(num_blocks)
- super().__init__(init_cfg=init_cfg)
- assert len(num_blocks) == num_units
- self.has_skip = has_skip
- self.gen_skip = gen_skip
- self.gen_cross_conv = gen_cross_conv
- self.num_units = num_units
- self.unit_channels = unit_channels
- self.num_blocks = num_blocks
- self.norm_cfg = norm_cfg
-
- self.downsample = DownsampleModule(Bottleneck, num_blocks, num_units,
- has_skip, norm_cfg, in_channels)
- self.upsample = UpsampleModule(unit_channels, num_units, gen_skip,
- gen_cross_conv, norm_cfg, in_channels)
-
- def forward(self, x, skip1, skip2):
- mid = self.downsample(x, skip1, skip2)
- out, skip1, skip2, cross_conv = self.upsample(mid)
-
- return out, skip1, skip2, cross_conv
-
-
-class ResNetTop(BaseModule):
- """ResNet top for MSPN.
-
- Args:
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- channels (int): Number of channels of the feature output by ResNetTop.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self, norm_cfg=dict(type='BN'), channels=64, init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = cp.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
- self.top = nn.Sequential(
- ConvModule(
- 3,
- channels,
- kernel_size=7,
- stride=2,
- padding=3,
- norm_cfg=norm_cfg,
- inplace=True), MaxPool2d(kernel_size=3, stride=2, padding=1))
-
- def forward(self, img):
- return self.top(img)
-
-
-@MODELS.register_module()
-class MSPN(BaseBackbone):
- """MSPN backbone. Paper ref: Li et al. "Rethinking on Multi-Stage Networks
- for Human Pose Estimation" (CVPR 2020).
-
- Args:
- unit_channels (int): Number of Channels in an upsample unit.
- Default: 256
- num_stages (int): Number of stages in a multi-stage MSPN. Default: 4
- num_units (int): Number of downsample/upsample units in a single-stage
- network. Default: 4
- Note: Make sure num_units == len(self.num_blocks)
- num_blocks (list): Number of bottlenecks in each
- downsample unit. Default: [2, 2, 2, 2]
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- res_top_channels (int): Number of channels of feature from ResNetTop.
- Default: 64.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Kaiming', layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm']),
- dict(
- type='Normal',
- std=0.01,
- layer=['Linear']),
- ]``
-
- Example:
- >>> from mmpose.models import MSPN
- >>> import torch
- >>> self = MSPN(num_stages=2,num_units=2,num_blocks=[2,2])
- >>> self.eval()
- >>> inputs = torch.rand(1, 3, 511, 511)
- >>> level_outputs = self.forward(inputs)
- >>> for level_output in level_outputs:
- ... for feature in level_output:
- ... print(tuple(feature.shape))
- ...
- (1, 256, 64, 64)
- (1, 256, 128, 128)
- (1, 256, 64, 64)
- (1, 256, 128, 128)
- """
-
- def __init__(self,
- unit_channels=256,
- num_stages=4,
- num_units=4,
- num_blocks=[2, 2, 2, 2],
- norm_cfg=dict(type='BN'),
- res_top_channels=64,
- init_cfg=[
- dict(type='Kaiming', layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm']),
- dict(type='Normal', std=0.01, layer=['Linear']),
- ]):
- # Protect mutable default arguments
- norm_cfg = cp.deepcopy(norm_cfg)
- num_blocks = cp.deepcopy(num_blocks)
- super().__init__(init_cfg=init_cfg)
- self.unit_channels = unit_channels
- self.num_stages = num_stages
- self.num_units = num_units
- self.num_blocks = num_blocks
- self.norm_cfg = norm_cfg
-
- assert self.num_stages > 0
- assert self.num_units > 1
- assert self.num_units == len(self.num_blocks)
- self.top = ResNetTop(norm_cfg=norm_cfg)
- self.multi_stage_mspn = nn.ModuleList([])
- for i in range(self.num_stages):
- if i == 0:
- has_skip = False
- else:
- has_skip = True
- if i != self.num_stages - 1:
- gen_skip = True
- gen_cross_conv = True
- else:
- gen_skip = False
- gen_cross_conv = False
- self.multi_stage_mspn.append(
- SingleStageNetwork(has_skip, gen_skip, gen_cross_conv,
- unit_channels, num_units, num_blocks,
- norm_cfg, res_top_channels))
-
- def forward(self, x):
- """Model forward function."""
- out_feats = []
- skip1 = None
- skip2 = None
- x = self.top(x)
- for i in range(self.num_stages):
- out, skip1, skip2, x = self.multi_stage_mspn[i](x, skip1, skip2)
- out_feats.append(out)
-
- return out_feats
-
- def init_weights(self):
- """Initialize model weights."""
- if (isinstance(self.init_cfg, dict)
- and self.init_cfg['type'] == 'Pretrained'):
- logger = get_root_logger()
- state_dict_tmp = get_state_dict(self.init_cfg['checkpoint'])
- state_dict = OrderedDict()
- state_dict['top'] = OrderedDict()
- state_dict['bottlenecks'] = OrderedDict()
- for k, v in state_dict_tmp.items():
- if k.startswith('layer'):
- if 'downsample.0' in k:
- state_dict['bottlenecks'][k.replace(
- 'downsample.0', 'downsample.conv')] = v
- elif 'downsample.1' in k:
- state_dict['bottlenecks'][k.replace(
- 'downsample.1', 'downsample.bn')] = v
- else:
- state_dict['bottlenecks'][k] = v
- elif k.startswith('conv1'):
- state_dict['top'][k.replace('conv1', 'top.0.conv')] = v
- elif k.startswith('bn1'):
- state_dict['top'][k.replace('bn1', 'top.0.bn')] = v
-
- load_state_dict(
- self.top, state_dict['top'], strict=False, logger=logger)
- for i in range(self.num_stages):
- load_state_dict(
- self.multi_stage_mspn[i].downsample,
- state_dict['bottlenecks'],
- strict=False,
- logger=logger)
- else:
- super(MSPN, self).init_weights()
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy as cp
+from collections import OrderedDict
+
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule, MaxPool2d
+from mmengine.model import BaseModule
+from mmengine.runner import load_state_dict
+
+from mmpose.registry import MODELS
+from mmpose.utils import get_root_logger
+from .base_backbone import BaseBackbone
+from .resnet import Bottleneck as _Bottleneck
+from .utils import get_state_dict
+
+
+class Bottleneck(_Bottleneck):
+ expansion = 4
+ """Bottleneck block for MSPN.
+
+ Args:
+ in_channels (int): Input channels of this block.
+ out_channels (int): Output channels of this block.
+ stride (int): stride of the block. Default: 1
+ downsample (nn.Module): downsample operation on identity branch.
+ Default: None
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self, in_channels, out_channels, **kwargs):
+ super().__init__(in_channels, out_channels * 4, **kwargs)
+
+
+class DownsampleModule(BaseModule):
+ """Downsample module for MSPN.
+
+ Args:
+ block (nn.Module): Downsample block.
+ num_blocks (list): Number of blocks in each downsample unit.
+ num_units (int): Numbers of downsample units. Default: 4
+ has_skip (bool): Have skip connections from prior upsample
+ module or not. Default:False
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ in_channels (int): Number of channels of the input feature to
+ downsample module. Default: 64
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ block,
+ num_blocks,
+ num_units=4,
+ has_skip=False,
+ norm_cfg=dict(type='BN'),
+ in_channels=64,
+ init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = cp.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self.has_skip = has_skip
+ self.in_channels = in_channels
+ assert len(num_blocks) == num_units
+ self.num_blocks = num_blocks
+ self.num_units = num_units
+ self.norm_cfg = norm_cfg
+ self.layer1 = self._make_layer(block, in_channels, num_blocks[0])
+ for i in range(1, num_units):
+ module_name = f'layer{i + 1}'
+ self.add_module(
+ module_name,
+ self._make_layer(
+ block, in_channels * pow(2, i), num_blocks[i], stride=2))
+
+ def _make_layer(self, block, out_channels, blocks, stride=1):
+ downsample = None
+ if stride != 1 or self.in_channels != out_channels * block.expansion:
+ downsample = ConvModule(
+ self.in_channels,
+ out_channels * block.expansion,
+ kernel_size=1,
+ stride=stride,
+ padding=0,
+ norm_cfg=self.norm_cfg,
+ act_cfg=None,
+ inplace=True)
+
+ units = list()
+ units.append(
+ block(
+ self.in_channels,
+ out_channels,
+ stride=stride,
+ downsample=downsample,
+ norm_cfg=self.norm_cfg))
+ self.in_channels = out_channels * block.expansion
+ for _ in range(1, blocks):
+ units.append(block(self.in_channels, out_channels))
+
+ return nn.Sequential(*units)
+
+ def forward(self, x, skip1, skip2):
+ out = list()
+ for i in range(self.num_units):
+ module_name = f'layer{i + 1}'
+ module_i = getattr(self, module_name)
+ x = module_i(x)
+ if self.has_skip:
+ x = x + skip1[i] + skip2[i]
+ out.append(x)
+ out.reverse()
+
+ return tuple(out)
+
+
+class UpsampleUnit(BaseModule):
+ """Upsample unit for upsample module.
+
+ Args:
+ ind (int): Indicates whether to interpolate (>0) and whether to
+ generate feature map for the next hourglass-like module.
+ num_units (int): Number of units that form a upsample module. Along
+ with ind and gen_cross_conv, nm_units is used to decide whether
+ to generate feature map for the next hourglass-like module.
+ in_channels (int): Channel number of the skip-in feature maps from
+ the corresponding downsample unit.
+ unit_channels (int): Channel number in this unit. Default:256.
+ gen_skip: (bool): Whether or not to generate skips for the posterior
+ downsample module. Default:False
+ gen_cross_conv (bool): Whether to generate feature map for the next
+ hourglass-like module. Default:False
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ out_channels (int): Number of channels of feature output by upsample
+ module. Must equal to in_channels of downsample module. Default:64
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ ind,
+ num_units,
+ in_channels,
+ unit_channels=256,
+ gen_skip=False,
+ gen_cross_conv=False,
+ norm_cfg=dict(type='BN'),
+ out_channels=64,
+ init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = cp.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self.num_units = num_units
+ self.norm_cfg = norm_cfg
+ self.in_skip = ConvModule(
+ in_channels,
+ unit_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ norm_cfg=self.norm_cfg,
+ act_cfg=None,
+ inplace=True)
+ self.relu = nn.ReLU(inplace=True)
+
+ self.ind = ind
+ if self.ind > 0:
+ self.up_conv = ConvModule(
+ unit_channels,
+ unit_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ norm_cfg=self.norm_cfg,
+ act_cfg=None,
+ inplace=True)
+
+ self.gen_skip = gen_skip
+ if self.gen_skip:
+ self.out_skip1 = ConvModule(
+ in_channels,
+ in_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ norm_cfg=self.norm_cfg,
+ inplace=True)
+
+ self.out_skip2 = ConvModule(
+ unit_channels,
+ in_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ norm_cfg=self.norm_cfg,
+ inplace=True)
+
+ self.gen_cross_conv = gen_cross_conv
+ if self.ind == num_units - 1 and self.gen_cross_conv:
+ self.cross_conv = ConvModule(
+ unit_channels,
+ out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ norm_cfg=self.norm_cfg,
+ inplace=True)
+
+ def forward(self, x, up_x):
+ out = self.in_skip(x)
+
+ if self.ind > 0:
+ up_x = F.interpolate(
+ up_x,
+ size=(x.size(2), x.size(3)),
+ mode='bilinear',
+ align_corners=True)
+ up_x = self.up_conv(up_x)
+ out = out + up_x
+ out = self.relu(out)
+
+ skip1 = None
+ skip2 = None
+ if self.gen_skip:
+ skip1 = self.out_skip1(x)
+ skip2 = self.out_skip2(out)
+
+ cross_conv = None
+ if self.ind == self.num_units - 1 and self.gen_cross_conv:
+ cross_conv = self.cross_conv(out)
+
+ return out, skip1, skip2, cross_conv
+
+
+class UpsampleModule(BaseModule):
+ """Upsample module for MSPN.
+
+ Args:
+ unit_channels (int): Channel number in the upsample units.
+ Default:256.
+ num_units (int): Numbers of upsample units. Default: 4
+ gen_skip (bool): Whether to generate skip for posterior downsample
+ module or not. Default:False
+ gen_cross_conv (bool): Whether to generate feature map for the next
+ hourglass-like module. Default:False
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ out_channels (int): Number of channels of feature output by upsample
+ module. Must equal to in_channels of downsample module. Default:64
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ unit_channels=256,
+ num_units=4,
+ gen_skip=False,
+ gen_cross_conv=False,
+ norm_cfg=dict(type='BN'),
+ out_channels=64,
+ init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = cp.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self.in_channels = list()
+ for i in range(num_units):
+ self.in_channels.append(Bottleneck.expansion * out_channels *
+ pow(2, i))
+ self.in_channels.reverse()
+ self.num_units = num_units
+ self.gen_skip = gen_skip
+ self.gen_cross_conv = gen_cross_conv
+ self.norm_cfg = norm_cfg
+ for i in range(num_units):
+ module_name = f'up{i + 1}'
+ self.add_module(
+ module_name,
+ UpsampleUnit(
+ i,
+ self.num_units,
+ self.in_channels[i],
+ unit_channels,
+ self.gen_skip,
+ self.gen_cross_conv,
+ norm_cfg=self.norm_cfg,
+ out_channels=64))
+
+ def forward(self, x):
+ out = list()
+ skip1 = list()
+ skip2 = list()
+ cross_conv = None
+ for i in range(self.num_units):
+ module_i = getattr(self, f'up{i + 1}')
+ if i == 0:
+ outi, skip1_i, skip2_i, _ = module_i(x[i], None)
+ elif i == self.num_units - 1:
+ outi, skip1_i, skip2_i, cross_conv = module_i(x[i], out[i - 1])
+ else:
+ outi, skip1_i, skip2_i, _ = module_i(x[i], out[i - 1])
+ out.append(outi)
+ skip1.append(skip1_i)
+ skip2.append(skip2_i)
+ skip1.reverse()
+ skip2.reverse()
+
+ return out, skip1, skip2, cross_conv
+
+
+class SingleStageNetwork(BaseModule):
+ """Single_stage Network.
+
+ Args:
+ unit_channels (int): Channel number in the upsample units. Default:256.
+ num_units (int): Numbers of downsample/upsample units. Default: 4
+ gen_skip (bool): Whether to generate skip for posterior downsample
+ module or not. Default:False
+ gen_cross_conv (bool): Whether to generate feature map for the next
+ hourglass-like module. Default:False
+ has_skip (bool): Have skip connections from prior upsample
+ module or not. Default:False
+ num_blocks (list): Number of blocks in each downsample unit.
+ Default: [2, 2, 2, 2] Note: Make sure num_units==len(num_blocks)
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ in_channels (int): Number of channels of the feature from ResNetTop.
+ Default: 64.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ has_skip=False,
+ gen_skip=False,
+ gen_cross_conv=False,
+ unit_channels=256,
+ num_units=4,
+ num_blocks=[2, 2, 2, 2],
+ norm_cfg=dict(type='BN'),
+ in_channels=64,
+ init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = cp.deepcopy(norm_cfg)
+ num_blocks = cp.deepcopy(num_blocks)
+ super().__init__(init_cfg=init_cfg)
+ assert len(num_blocks) == num_units
+ self.has_skip = has_skip
+ self.gen_skip = gen_skip
+ self.gen_cross_conv = gen_cross_conv
+ self.num_units = num_units
+ self.unit_channels = unit_channels
+ self.num_blocks = num_blocks
+ self.norm_cfg = norm_cfg
+
+ self.downsample = DownsampleModule(Bottleneck, num_blocks, num_units,
+ has_skip, norm_cfg, in_channels)
+ self.upsample = UpsampleModule(unit_channels, num_units, gen_skip,
+ gen_cross_conv, norm_cfg, in_channels)
+
+ def forward(self, x, skip1, skip2):
+ mid = self.downsample(x, skip1, skip2)
+ out, skip1, skip2, cross_conv = self.upsample(mid)
+
+ return out, skip1, skip2, cross_conv
+
+
+class ResNetTop(BaseModule):
+ """ResNet top for MSPN.
+
+ Args:
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ channels (int): Number of channels of the feature output by ResNetTop.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self, norm_cfg=dict(type='BN'), channels=64, init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = cp.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self.top = nn.Sequential(
+ ConvModule(
+ 3,
+ channels,
+ kernel_size=7,
+ stride=2,
+ padding=3,
+ norm_cfg=norm_cfg,
+ inplace=True), MaxPool2d(kernel_size=3, stride=2, padding=1))
+
+ def forward(self, img):
+ return self.top(img)
+
+
+@MODELS.register_module()
+class MSPN(BaseBackbone):
+ """MSPN backbone. Paper ref: Li et al. "Rethinking on Multi-Stage Networks
+ for Human Pose Estimation" (CVPR 2020).
+
+ Args:
+ unit_channels (int): Number of Channels in an upsample unit.
+ Default: 256
+ num_stages (int): Number of stages in a multi-stage MSPN. Default: 4
+ num_units (int): Number of downsample/upsample units in a single-stage
+ network. Default: 4
+ Note: Make sure num_units == len(self.num_blocks)
+ num_blocks (list): Number of bottlenecks in each
+ downsample unit. Default: [2, 2, 2, 2]
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ res_top_channels (int): Number of channels of feature from ResNetTop.
+ Default: 64.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Kaiming', layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm']),
+ dict(
+ type='Normal',
+ std=0.01,
+ layer=['Linear']),
+ ]``
+
+ Example:
+ >>> from mmpose.models import MSPN
+ >>> import torch
+ >>> self = MSPN(num_stages=2,num_units=2,num_blocks=[2,2])
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 511, 511)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_output in level_outputs:
+ ... for feature in level_output:
+ ... print(tuple(feature.shape))
+ ...
+ (1, 256, 64, 64)
+ (1, 256, 128, 128)
+ (1, 256, 64, 64)
+ (1, 256, 128, 128)
+ """
+
+ def __init__(self,
+ unit_channels=256,
+ num_stages=4,
+ num_units=4,
+ num_blocks=[2, 2, 2, 2],
+ norm_cfg=dict(type='BN'),
+ res_top_channels=64,
+ init_cfg=[
+ dict(type='Kaiming', layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm']),
+ dict(type='Normal', std=0.01, layer=['Linear']),
+ ]):
+ # Protect mutable default arguments
+ norm_cfg = cp.deepcopy(norm_cfg)
+ num_blocks = cp.deepcopy(num_blocks)
+ super().__init__(init_cfg=init_cfg)
+ self.unit_channels = unit_channels
+ self.num_stages = num_stages
+ self.num_units = num_units
+ self.num_blocks = num_blocks
+ self.norm_cfg = norm_cfg
+
+ assert self.num_stages > 0
+ assert self.num_units > 1
+ assert self.num_units == len(self.num_blocks)
+ self.top = ResNetTop(norm_cfg=norm_cfg)
+ self.multi_stage_mspn = nn.ModuleList([])
+ for i in range(self.num_stages):
+ if i == 0:
+ has_skip = False
+ else:
+ has_skip = True
+ if i != self.num_stages - 1:
+ gen_skip = True
+ gen_cross_conv = True
+ else:
+ gen_skip = False
+ gen_cross_conv = False
+ self.multi_stage_mspn.append(
+ SingleStageNetwork(has_skip, gen_skip, gen_cross_conv,
+ unit_channels, num_units, num_blocks,
+ norm_cfg, res_top_channels))
+
+ def forward(self, x):
+ """Model forward function."""
+ out_feats = []
+ skip1 = None
+ skip2 = None
+ x = self.top(x)
+ for i in range(self.num_stages):
+ out, skip1, skip2, x = self.multi_stage_mspn[i](x, skip1, skip2)
+ out_feats.append(out)
+
+ return out_feats
+
+ def init_weights(self):
+ """Initialize model weights."""
+ if (isinstance(self.init_cfg, dict)
+ and self.init_cfg['type'] == 'Pretrained'):
+ logger = get_root_logger()
+ state_dict_tmp = get_state_dict(self.init_cfg['checkpoint'])
+ state_dict = OrderedDict()
+ state_dict['top'] = OrderedDict()
+ state_dict['bottlenecks'] = OrderedDict()
+ for k, v in state_dict_tmp.items():
+ if k.startswith('layer'):
+ if 'downsample.0' in k:
+ state_dict['bottlenecks'][k.replace(
+ 'downsample.0', 'downsample.conv')] = v
+ elif 'downsample.1' in k:
+ state_dict['bottlenecks'][k.replace(
+ 'downsample.1', 'downsample.bn')] = v
+ else:
+ state_dict['bottlenecks'][k] = v
+ elif k.startswith('conv1'):
+ state_dict['top'][k.replace('conv1', 'top.0.conv')] = v
+ elif k.startswith('bn1'):
+ state_dict['top'][k.replace('bn1', 'top.0.bn')] = v
+
+ load_state_dict(
+ self.top, state_dict['top'], strict=False, logger=logger)
+ for i in range(self.num_stages):
+ load_state_dict(
+ self.multi_stage_mspn[i].downsample,
+ state_dict['bottlenecks'],
+ strict=False,
+ logger=logger)
+ else:
+ super(MSPN, self).init_weights()
diff --git a/mmpose/models/backbones/octsb1.py b/mmpose/models/backbones/octsb1.py
new file mode 100644
index 0000000000..d9bf00d6b4
--- /dev/null
+++ b/mmpose/models/backbones/octsb1.py
@@ -0,0 +1,653 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import torch.nn as nn
+from mmcv.cnn import build_conv_layer, build_norm_layer
+from mmengine.model import BaseModule, constant_init
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+from .resnet import BasicBlock, Bottleneck, get_expansion
+
+import os.path as osp
+
+import torch
+import torch.nn.functional as F
+
+# HRNet + Lumen segmentation
+
+class HRModule(BaseModule):
+ """High-Resolution Module for HRNet.
+
+ In this module, every branch has 4 BasicBlocks/Bottlenecks. Fusion/Exchange
+ is in this module.
+ """
+
+ def __init__(self,
+ num_branches,
+ blocks,
+ num_blocks,
+ in_channels,
+ num_channels,
+ multiscale_output=False,
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ upsample_cfg=dict(mode='nearest', align_corners=None),
+ init_cfg=None):
+
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self._check_branches(num_branches, num_blocks, in_channels,
+ num_channels)
+
+ self.in_channels = in_channels
+ self.num_branches = num_branches
+
+ self.multiscale_output = multiscale_output
+ self.norm_cfg = norm_cfg
+ self.conv_cfg = conv_cfg
+ self.upsample_cfg = upsample_cfg
+ self.with_cp = with_cp
+ self.branches = self._make_branches(num_branches, blocks, num_blocks,
+ num_channels)
+ self.fuse_layers = self._make_fuse_layers()
+ self.relu = nn.ReLU(inplace=True)
+
+ @staticmethod
+ def _check_branches(num_branches, num_blocks, in_channels, num_channels):
+ """Check input to avoid ValueError."""
+ if num_branches != len(num_blocks):
+ error_msg = f'NUM_BRANCHES({num_branches}) ' \
+ f'!= NUM_BLOCKS({len(num_blocks)})'
+ raise ValueError(error_msg)
+
+ if num_branches != len(num_channels):
+ error_msg = f'NUM_BRANCHES({num_branches}) ' \
+ f'!= NUM_CHANNELS({len(num_channels)})'
+ raise ValueError(error_msg)
+
+ if num_branches != len(in_channels):
+ error_msg = f'NUM_BRANCHES({num_branches}) ' \
+ f'!= NUM_INCHANNELS({len(in_channels)})'
+ raise ValueError(error_msg)
+
+ def _make_one_branch(self,
+ branch_index,
+ block,
+ num_blocks,
+ num_channels,
+ stride=1):
+ """Make one branch."""
+ downsample = None
+ if stride != 1 or \
+ self.in_channels[branch_index] != \
+ num_channels[branch_index] * get_expansion(block):
+ downsample = nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ self.in_channels[branch_index],
+ num_channels[branch_index] * get_expansion(block),
+ kernel_size=1,
+ stride=stride,
+ bias=False),
+ build_norm_layer(
+ self.norm_cfg,
+ num_channels[branch_index] * get_expansion(block))[1])
+
+ layers = []
+ layers.append(
+ block(
+ self.in_channels[branch_index],
+ num_channels[branch_index] * get_expansion(block),
+ stride=stride,
+ downsample=downsample,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg))
+ self.in_channels[branch_index] = \
+ num_channels[branch_index] * get_expansion(block)
+ for _ in range(1, num_blocks[branch_index]):
+ layers.append(
+ block(
+ self.in_channels[branch_index],
+ num_channels[branch_index] * get_expansion(block),
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg))
+
+ return nn.Sequential(*layers)
+
+ def _make_branches(self, num_branches, block, num_blocks, num_channels):
+ """Make branches."""
+ branches = []
+
+ for i in range(num_branches):
+ branches.append(
+ self._make_one_branch(i, block, num_blocks, num_channels))
+
+ return nn.ModuleList(branches)
+
+ def _make_fuse_layers(self):
+ """Make fuse layer."""
+ if self.num_branches == 1:
+ return None
+
+ num_branches = self.num_branches
+ in_channels = self.in_channels
+ fuse_layers = []
+ num_out_branches = num_branches if self.multiscale_output else 1
+
+ for i in range(num_out_branches):
+ fuse_layer = []
+ for j in range(num_branches):
+ if j > i:
+ fuse_layer.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[i],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False),
+ build_norm_layer(self.norm_cfg, in_channels[i])[1],
+ nn.Upsample(
+ scale_factor=2**(j - i),
+ mode=self.upsample_cfg['mode'],
+ align_corners=self.
+ upsample_cfg['align_corners'])))
+ elif j == i:
+ fuse_layer.append(None)
+ else:
+ conv_downsamples = []
+ for k in range(i - j):
+ if k == i - j - 1:
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[i],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[i])[1]))
+ else:
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[j],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[j])[1],
+ nn.ReLU(inplace=True)))
+ fuse_layer.append(nn.Sequential(*conv_downsamples))
+ fuse_layers.append(nn.ModuleList(fuse_layer))
+
+ return nn.ModuleList(fuse_layers)
+
+ def forward(self, x):
+ """Forward function."""
+ if self.num_branches == 1:
+ return [self.branches[0](x[0])]
+
+ for i in range(self.num_branches):
+ x[i] = self.branches[i](x[i])
+
+ x_fuse = []
+ for i in range(len(self.fuse_layers)):
+ y = 0
+ for j in range(self.num_branches):
+ if i == j:
+ y += x[j]
+ else:
+ y += self.fuse_layers[i][j](x[j])
+ x_fuse.append(self.relu(y))
+ return x_fuse
+
+
+@MODELS.register_module()
+class OCTSB1(BaseBackbone):
+ """HRNet backbone.
+
+ `High-Resolution Representations for Labeling Pixels and Regions
+ `__
+
+ Args:
+ extra (dict): detailed configuration for each stage of HRNet.
+ in_channels (int): Number of input image channels. Default: 3.
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ zero_init_residual (bool): whether to use zero init for last norm layer
+ in resblocks to let them behave as identity.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters. Default: -1.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+
+ Example:
+ >>> from mmpose.models import HRNet
+ >>> import torch
+ >>> extra = dict(
+ >>> stage1=dict(
+ >>> num_modules=1,
+ >>> num_branches=1,
+ >>> block='BOTTLENECK',
+ >>> num_blocks=(4, ),
+ >>> num_channels=(64, )),
+ >>> stage2=dict(
+ >>> num_modules=1,
+ >>> num_branches=2,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4),
+ >>> num_channels=(32, 64)),
+ >>> stage3=dict(
+ >>> num_modules=4,
+ >>> num_branches=3,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4, 4),
+ >>> num_channels=(32, 64, 128)),
+ >>> stage4=dict(
+ >>> num_modules=3,
+ >>> num_branches=4,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4, 4, 4),
+ >>> num_channels=(32, 64, 128, 256)))
+ >>> self = HRNet(extra, in_channels=1)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 1, 32, 32)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 32, 8, 8)
+ """
+
+ blocks_dict = {'BASIC': BasicBlock, 'BOTTLENECK': Bottleneck}
+
+ def __init__(
+ self,
+ extra,
+ lumen_cfg,
+ in_channels=3,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ norm_eval=False,
+ with_cp=False,
+ zero_init_residual=False,
+ frozen_stages=-1,
+ init_cfg=[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ ):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+
+
+ # Load pretrained lumen segmentation model
+ # lumen_config_path = lumen_cfg['config_path']
+ # lumen_config_path = lumen_cfg['config_path']
+ lumen_checkpoint_path = lumen_cfg['checkpoint_path']
+ # print('lumen config_path:', osp.abspath(lumen_config_path))
+ print('lumen checkpoint_path:', osp.abspath(lumen_checkpoint_path))
+ print('Initializing lumen segmentation model')
+
+ # self.lumen_net = init_seg_model(lumen_config_path, lumen_checkpoint_path)
+ self.lumen_net = torch.jit.load(lumen_checkpoint_path, map_location=torch.device('cuda'))
+ self.lumen_net.eval()
+ if torch.cuda.is_available(): self.lumen_net = self.lumen_net.to('cuda')
+ # print('lumen_net:.device:', self.lumen_net.device)
+
+
+ self.extra = extra
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.init_cfg = init_cfg
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+ self.zero_init_residual = zero_init_residual
+ self.frozen_stages = frozen_stages
+
+ # stem net
+ self.norm1_name, norm1 = build_norm_layer(self.norm_cfg, 64, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(self.norm_cfg, 64, postfix=2)
+
+ in_channels = in_channels * 2 # image channel + lumen segmentation mask channel
+
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ 64,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False)
+
+ self.add_module(self.norm1_name, norm1)
+ self.conv2 = build_conv_layer(
+ self.conv_cfg,
+ 64,
+ 64,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False)
+
+ self.add_module(self.norm2_name, norm2)
+ self.relu = nn.ReLU(inplace=True)
+
+ self.upsample_cfg = self.extra.get('upsample', {
+ 'mode': 'nearest',
+ 'align_corners': None
+ })
+
+ # stage 1
+ self.stage1_cfg = self.extra['stage1']
+ num_channels = self.stage1_cfg['num_channels'][0]
+ block_type = self.stage1_cfg['block']
+ num_blocks = self.stage1_cfg['num_blocks'][0]
+
+ block = self.blocks_dict[block_type]
+ stage1_out_channels = num_channels * get_expansion(block)
+ self.layer1 = self._make_layer(block, 64, stage1_out_channels,
+ num_blocks)
+
+ # stage 2
+ self.stage2_cfg = self.extra['stage2']
+ num_channels = self.stage2_cfg['num_channels']
+ block_type = self.stage2_cfg['block']
+
+ block = self.blocks_dict[block_type]
+ num_channels = [
+ channel * get_expansion(block) for channel in num_channels
+ ]
+ self.transition1 = self._make_transition_layer([stage1_out_channels],
+ num_channels)
+ self.stage2, pre_stage_channels = self._make_stage(
+ self.stage2_cfg, num_channels)
+
+ # stage 3
+ self.stage3_cfg = self.extra['stage3']
+ num_channels = self.stage3_cfg['num_channels']
+ block_type = self.stage3_cfg['block']
+
+ block = self.blocks_dict[block_type]
+ num_channels = [
+ channel * get_expansion(block) for channel in num_channels
+ ]
+ self.transition2 = self._make_transition_layer(pre_stage_channels,
+ num_channels)
+ self.stage3, pre_stage_channels = self._make_stage(
+ self.stage3_cfg, num_channels)
+
+ # stage 4
+ self.stage4_cfg = self.extra['stage4']
+ num_channels = self.stage4_cfg['num_channels']
+ block_type = self.stage4_cfg['block']
+
+ block = self.blocks_dict[block_type]
+ num_channels = [
+ channel * get_expansion(block) for channel in num_channels
+ ]
+ self.transition3 = self._make_transition_layer(pre_stage_channels,
+ num_channels)
+
+ self.stage4, pre_stage_channels = self._make_stage(
+ self.stage4_cfg,
+ num_channels,
+ multiscale_output=self.stage4_cfg.get('multiscale_output', False))
+
+ self._freeze_stages()
+
+ @property
+ def norm1(self):
+ """nn.Module: the normalization layer named "norm1" """
+ return getattr(self, self.norm1_name)
+
+ @property
+ def norm2(self):
+ """nn.Module: the normalization layer named "norm2" """
+ return getattr(self, self.norm2_name)
+
+ def _make_transition_layer(self, num_channels_pre_layer,
+ num_channels_cur_layer):
+ """Make transition layer."""
+ num_branches_cur = len(num_channels_cur_layer)
+ num_branches_pre = len(num_channels_pre_layer)
+
+ transition_layers = []
+ for i in range(num_branches_cur):
+ if i < num_branches_pre:
+ if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
+ transition_layers.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ num_channels_pre_layer[i],
+ num_channels_cur_layer[i],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ num_channels_cur_layer[i])[1],
+ nn.ReLU(inplace=True)))
+ else:
+ transition_layers.append(None)
+ else:
+ conv_downsamples = []
+ for j in range(i + 1 - num_branches_pre):
+ in_channels = num_channels_pre_layer[-1]
+ out_channels = num_channels_cur_layer[i] \
+ if j == i - num_branches_pre else in_channels
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg, out_channels)[1],
+ nn.ReLU(inplace=True)))
+ transition_layers.append(nn.Sequential(*conv_downsamples))
+
+ return nn.ModuleList(transition_layers)
+
+ def _make_layer(self, block, in_channels, out_channels, blocks, stride=1):
+ """Make layer."""
+ downsample = None
+ if stride != 1 or in_channels != out_channels:
+ downsample = nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ out_channels,
+ kernel_size=1,
+ stride=stride,
+ bias=False),
+ build_norm_layer(self.norm_cfg, out_channels)[1])
+
+ layers = []
+ layers.append(
+ block(
+ in_channels,
+ out_channels,
+ stride=stride,
+ downsample=downsample,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg))
+ for _ in range(1, blocks):
+ layers.append(
+ block(
+ out_channels,
+ out_channels,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg))
+
+ return nn.Sequential(*layers)
+
+ def _make_stage(self, layer_config, in_channels, multiscale_output=True):
+ """Make stage."""
+ num_modules = layer_config['num_modules']
+ num_branches = layer_config['num_branches']
+ num_blocks = layer_config['num_blocks']
+ num_channels = layer_config['num_channels']
+ block = self.blocks_dict[layer_config['block']]
+
+ hr_modules = []
+ for i in range(num_modules):
+ # multi_scale_output is only used for the last module
+ if not multiscale_output and i == num_modules - 1:
+ reset_multiscale_output = False
+ else:
+ reset_multiscale_output = True
+
+ hr_modules.append(
+ HRModule(
+ num_branches,
+ block,
+ num_blocks,
+ in_channels,
+ num_channels,
+ reset_multiscale_output,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg,
+ upsample_cfg=self.upsample_cfg))
+
+ in_channels = hr_modules[-1].in_channels
+
+ return nn.Sequential(*hr_modules), in_channels
+
+ def _freeze_stages(self):
+ """Freeze parameters."""
+ if self.frozen_stages >= 0:
+ self.norm1.eval()
+ self.norm2.eval()
+
+ for m in [self.conv1, self.norm1, self.conv2, self.norm2]:
+ for param in m.parameters():
+ param.requires_grad = False
+
+ for i in range(1, self.frozen_stages + 1):
+ if i == 1:
+ m = getattr(self, 'layer1')
+ else:
+ m = getattr(self, f'stage{i}')
+
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ if i < 4:
+ m = getattr(self, f'transition{i}')
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ def init_weights(self):
+ """Initialize the weights in backbone."""
+ super(OCTSB1, self).init_weights()
+
+ if (isinstance(self.init_cfg, dict)
+ and self.init_cfg['type'] == 'Pretrained'):
+ # Suppress zero_init_residual if use pretrained model.
+ return
+
+ if self.zero_init_residual:
+ for m in self.modules():
+ if isinstance(m, Bottleneck):
+ constant_init(m.norm3, 0)
+ elif isinstance(m, BasicBlock):
+ constant_init(m.norm2, 0)
+
+ def forward(self, x):
+ """Forward function."""
+ # print('x:', x)
+ # print('hrnet input x.shape:', x.shape)
+ # print('hrnet input x.device:', x.device)
+ with torch.no_grad():
+ m = self.lumen_net(x) #.to(x.device)
+ # print('m:', m)
+ # print('Segmentation m.shape:', m.shape)
+ # print('Segmentation m.device:', m.device)
+ x = torch.cat([x, m], dim=1).detach()
+ # print('x+m:', x)
+ # print('x+m.shape:', x.shape)
+ x = self.conv1(x)
+ x = self.norm1(x)
+ x = self.relu(x)
+ x = self.conv2(x)
+ x = self.norm2(x)
+ x = self.relu(x)
+ x = self.layer1(x)
+
+ x_list = []
+ for i in range(self.stage2_cfg['num_branches']):
+ if self.transition1[i] is not None:
+ x_list.append(self.transition1[i](x))
+ else:
+ x_list.append(x)
+ y_list = self.stage2(x_list)
+
+ x_list = []
+ for i in range(self.stage3_cfg['num_branches']):
+ if self.transition2[i] is not None:
+ x_list.append(self.transition2[i](y_list[-1]))
+ else:
+ x_list.append(y_list[i])
+ y_list = self.stage3(x_list)
+
+ x_list = []
+ for i in range(self.stage4_cfg['num_branches']):
+ if self.transition3[i] is not None:
+ x_list.append(self.transition3[i](y_list[-1]))
+ else:
+ x_list.append(y_list[i])
+ y_list = self.stage4(x_list)
+
+ return tuple(y_list)
+
+ def train(self, mode=True):
+ """Convert the model into training mode."""
+ super().train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, _BatchNorm):
+ m.eval()
+
+ # def forward_lumen(self, x):
+ # p = self.lumen_net(x)
+ # p = F.softmax(p, dim=1)
+ # m = p >= 0.5
+ # return m
\ No newline at end of file
diff --git a/mmpose/models/backbones/octsb2.py b/mmpose/models/backbones/octsb2.py
new file mode 100644
index 0000000000..bf86f66526
--- /dev/null
+++ b/mmpose/models/backbones/octsb2.py
@@ -0,0 +1,656 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import torch.nn as nn
+from mmcv.cnn import build_conv_layer, build_norm_layer
+from mmengine.model import BaseModule, constant_init
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+from .resnet import BasicBlock, Bottleneck, get_expansion
+
+import os.path as osp
+
+import torch
+import torch.nn.functional as F
+
+# HRNet + Guidewire segmentation with x-axis along masked
+
+class HRModule(BaseModule):
+ """High-Resolution Module for HRNet.
+
+ In this module, every branch has 4 BasicBlocks/Bottlenecks. Fusion/Exchange
+ is in this module.
+ """
+
+ def __init__(self,
+ num_branches,
+ blocks,
+ num_blocks,
+ in_channels,
+ num_channels,
+ multiscale_output=False,
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ upsample_cfg=dict(mode='nearest', align_corners=None),
+ init_cfg=None):
+
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self._check_branches(num_branches, num_blocks, in_channels,
+ num_channels)
+
+ self.in_channels = in_channels
+ self.num_branches = num_branches
+
+ self.multiscale_output = multiscale_output
+ self.norm_cfg = norm_cfg
+ self.conv_cfg = conv_cfg
+ self.upsample_cfg = upsample_cfg
+ self.with_cp = with_cp
+ self.branches = self._make_branches(num_branches, blocks, num_blocks,
+ num_channels)
+ self.fuse_layers = self._make_fuse_layers()
+ self.relu = nn.ReLU(inplace=True)
+
+ @staticmethod
+ def _check_branches(num_branches, num_blocks, in_channels, num_channels):
+ """Check input to avoid ValueError."""
+ if num_branches != len(num_blocks):
+ error_msg = f'NUM_BRANCHES({num_branches}) ' \
+ f'!= NUM_BLOCKS({len(num_blocks)})'
+ raise ValueError(error_msg)
+
+ if num_branches != len(num_channels):
+ error_msg = f'NUM_BRANCHES({num_branches}) ' \
+ f'!= NUM_CHANNELS({len(num_channels)})'
+ raise ValueError(error_msg)
+
+ if num_branches != len(in_channels):
+ error_msg = f'NUM_BRANCHES({num_branches}) ' \
+ f'!= NUM_INCHANNELS({len(in_channels)})'
+ raise ValueError(error_msg)
+
+ def _make_one_branch(self,
+ branch_index,
+ block,
+ num_blocks,
+ num_channels,
+ stride=1):
+ """Make one branch."""
+ downsample = None
+ if stride != 1 or \
+ self.in_channels[branch_index] != \
+ num_channels[branch_index] * get_expansion(block):
+ downsample = nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ self.in_channels[branch_index],
+ num_channels[branch_index] * get_expansion(block),
+ kernel_size=1,
+ stride=stride,
+ bias=False),
+ build_norm_layer(
+ self.norm_cfg,
+ num_channels[branch_index] * get_expansion(block))[1])
+
+ layers = []
+ layers.append(
+ block(
+ self.in_channels[branch_index],
+ num_channels[branch_index] * get_expansion(block),
+ stride=stride,
+ downsample=downsample,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg))
+ self.in_channels[branch_index] = \
+ num_channels[branch_index] * get_expansion(block)
+ for _ in range(1, num_blocks[branch_index]):
+ layers.append(
+ block(
+ self.in_channels[branch_index],
+ num_channels[branch_index] * get_expansion(block),
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg))
+
+ return nn.Sequential(*layers)
+
+ def _make_branches(self, num_branches, block, num_blocks, num_channels):
+ """Make branches."""
+ branches = []
+
+ for i in range(num_branches):
+ branches.append(
+ self._make_one_branch(i, block, num_blocks, num_channels))
+
+ return nn.ModuleList(branches)
+
+ def _make_fuse_layers(self):
+ """Make fuse layer."""
+ if self.num_branches == 1:
+ return None
+
+ num_branches = self.num_branches
+ in_channels = self.in_channels
+ fuse_layers = []
+ num_out_branches = num_branches if self.multiscale_output else 1
+
+ for i in range(num_out_branches):
+ fuse_layer = []
+ for j in range(num_branches):
+ if j > i:
+ fuse_layer.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[i],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False),
+ build_norm_layer(self.norm_cfg, in_channels[i])[1],
+ nn.Upsample(
+ scale_factor=2**(j - i),
+ mode=self.upsample_cfg['mode'],
+ align_corners=self.
+ upsample_cfg['align_corners'])))
+ elif j == i:
+ fuse_layer.append(None)
+ else:
+ conv_downsamples = []
+ for k in range(i - j):
+ if k == i - j - 1:
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[i],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[i])[1]))
+ else:
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[j],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[j])[1],
+ nn.ReLU(inplace=True)))
+ fuse_layer.append(nn.Sequential(*conv_downsamples))
+ fuse_layers.append(nn.ModuleList(fuse_layer))
+
+ return nn.ModuleList(fuse_layers)
+
+ def forward(self, x):
+ """Forward function."""
+ if self.num_branches == 1:
+ return [self.branches[0](x[0])]
+
+ for i in range(self.num_branches):
+ x[i] = self.branches[i](x[i])
+
+ x_fuse = []
+ for i in range(len(self.fuse_layers)):
+ y = 0
+ for j in range(self.num_branches):
+ if i == j:
+ y += x[j]
+ else:
+ y += self.fuse_layers[i][j](x[j])
+ x_fuse.append(self.relu(y))
+ return x_fuse
+
+
+@MODELS.register_module()
+class OCTSB2(BaseBackbone):
+ """HRNet backbone.
+
+ `High-Resolution Representations for Labeling Pixels and Regions
+ `__
+
+ Args:
+ extra (dict): detailed configuration for each stage of HRNet.
+ in_channels (int): Number of input image channels. Default: 3.
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ zero_init_residual (bool): whether to use zero init for last norm layer
+ in resblocks to let them behave as identity.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters. Default: -1.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+
+ Example:
+ >>> from mmpose.models import HRNet
+ >>> import torch
+ >>> extra = dict(
+ >>> stage1=dict(
+ >>> num_modules=1,
+ >>> num_branches=1,
+ >>> block='BOTTLENECK',
+ >>> num_blocks=(4, ),
+ >>> num_channels=(64, )),
+ >>> stage2=dict(
+ >>> num_modules=1,
+ >>> num_branches=2,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4),
+ >>> num_channels=(32, 64)),
+ >>> stage3=dict(
+ >>> num_modules=4,
+ >>> num_branches=3,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4, 4),
+ >>> num_channels=(32, 64, 128)),
+ >>> stage4=dict(
+ >>> num_modules=3,
+ >>> num_branches=4,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4, 4, 4),
+ >>> num_channels=(32, 64, 128, 256)))
+ >>> self = HRNet(extra, in_channels=1)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 1, 32, 32)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 32, 8, 8)
+ """
+
+ blocks_dict = {'BASIC': BasicBlock, 'BOTTLENECK': Bottleneck}
+
+ def __init__(
+ self,
+ extra,
+ lumen_cfg,
+ in_channels=3,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ norm_eval=False,
+ with_cp=False,
+ zero_init_residual=False,
+ frozen_stages=-1,
+ init_cfg=[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ ):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+
+
+ # Load pretrained lumen segmentation model
+ # lumen_config_path = lumen_cfg['config_path']
+ # lumen_config_path = lumen_cfg['config_path']
+ lumen_checkpoint_path = lumen_cfg['checkpoint_path']
+ # print('lumen config_path:', osp.abspath(lumen_config_path))
+ print('lumen checkpoint_path:', osp.abspath(lumen_checkpoint_path))
+ print('Initializing lumen segmentation model')
+
+ self.guidewire_net = torch.jit.load(lumen_checkpoint_path, map_location=torch.device('cuda'))
+ self.guidewire_net.eval()
+ if torch.cuda.is_available(): self.guidewire_net = self.guidewire_net.to('cuda')
+ # print('guidewire_net:.device:', self.guidewire_net.device)
+
+
+ self.extra = extra
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.init_cfg = init_cfg
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+ self.zero_init_residual = zero_init_residual
+ self.frozen_stages = frozen_stages
+
+ # stem net
+ self.norm1_name, norm1 = build_norm_layer(self.norm_cfg, 64, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(self.norm_cfg, 64, postfix=2)
+
+ in_channels = in_channels * 2 # image channel + lumen segmentation mask channel
+
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ 64,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False)
+
+ self.add_module(self.norm1_name, norm1)
+ self.conv2 = build_conv_layer(
+ self.conv_cfg,
+ 64,
+ 64,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False)
+
+ self.add_module(self.norm2_name, norm2)
+ self.relu = nn.ReLU(inplace=True)
+
+ self.upsample_cfg = self.extra.get('upsample', {
+ 'mode': 'nearest',
+ 'align_corners': None
+ })
+
+ # stage 1
+ self.stage1_cfg = self.extra['stage1']
+ num_channels = self.stage1_cfg['num_channels'][0]
+ block_type = self.stage1_cfg['block']
+ num_blocks = self.stage1_cfg['num_blocks'][0]
+
+ block = self.blocks_dict[block_type]
+ stage1_out_channels = num_channels * get_expansion(block)
+ self.layer1 = self._make_layer(block, 64, stage1_out_channels,
+ num_blocks)
+
+ # stage 2
+ self.stage2_cfg = self.extra['stage2']
+ num_channels = self.stage2_cfg['num_channels']
+ block_type = self.stage2_cfg['block']
+
+ block = self.blocks_dict[block_type]
+ num_channels = [
+ channel * get_expansion(block) for channel in num_channels
+ ]
+ self.transition1 = self._make_transition_layer([stage1_out_channels],
+ num_channels)
+ self.stage2, pre_stage_channels = self._make_stage(
+ self.stage2_cfg, num_channels)
+
+ # stage 3
+ self.stage3_cfg = self.extra['stage3']
+ num_channels = self.stage3_cfg['num_channels']
+ block_type = self.stage3_cfg['block']
+
+ block = self.blocks_dict[block_type]
+ num_channels = [
+ channel * get_expansion(block) for channel in num_channels
+ ]
+ self.transition2 = self._make_transition_layer(pre_stage_channels,
+ num_channels)
+ self.stage3, pre_stage_channels = self._make_stage(
+ self.stage3_cfg, num_channels)
+
+ # stage 4
+ self.stage4_cfg = self.extra['stage4']
+ num_channels = self.stage4_cfg['num_channels']
+ block_type = self.stage4_cfg['block']
+
+ block = self.blocks_dict[block_type]
+ num_channels = [
+ channel * get_expansion(block) for channel in num_channels
+ ]
+ self.transition3 = self._make_transition_layer(pre_stage_channels,
+ num_channels)
+
+ self.stage4, pre_stage_channels = self._make_stage(
+ self.stage4_cfg,
+ num_channels,
+ multiscale_output=self.stage4_cfg.get('multiscale_output', False))
+
+ self._freeze_stages()
+
+ @property
+ def norm1(self):
+ """nn.Module: the normalization layer named "norm1" """
+ return getattr(self, self.norm1_name)
+
+ @property
+ def norm2(self):
+ """nn.Module: the normalization layer named "norm2" """
+ return getattr(self, self.norm2_name)
+
+ def _make_transition_layer(self, num_channels_pre_layer,
+ num_channels_cur_layer):
+ """Make transition layer."""
+ num_branches_cur = len(num_channels_cur_layer)
+ num_branches_pre = len(num_channels_pre_layer)
+
+ transition_layers = []
+ for i in range(num_branches_cur):
+ if i < num_branches_pre:
+ if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
+ transition_layers.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ num_channels_pre_layer[i],
+ num_channels_cur_layer[i],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ num_channels_cur_layer[i])[1],
+ nn.ReLU(inplace=True)))
+ else:
+ transition_layers.append(None)
+ else:
+ conv_downsamples = []
+ for j in range(i + 1 - num_branches_pre):
+ in_channels = num_channels_pre_layer[-1]
+ out_channels = num_channels_cur_layer[i] \
+ if j == i - num_branches_pre else in_channels
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg, out_channels)[1],
+ nn.ReLU(inplace=True)))
+ transition_layers.append(nn.Sequential(*conv_downsamples))
+
+ return nn.ModuleList(transition_layers)
+
+ def _make_layer(self, block, in_channels, out_channels, blocks, stride=1):
+ """Make layer."""
+ downsample = None
+ if stride != 1 or in_channels != out_channels:
+ downsample = nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ out_channels,
+ kernel_size=1,
+ stride=stride,
+ bias=False),
+ build_norm_layer(self.norm_cfg, out_channels)[1])
+
+ layers = []
+ layers.append(
+ block(
+ in_channels,
+ out_channels,
+ stride=stride,
+ downsample=downsample,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg))
+ for _ in range(1, blocks):
+ layers.append(
+ block(
+ out_channels,
+ out_channels,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg))
+
+ return nn.Sequential(*layers)
+
+ def _make_stage(self, layer_config, in_channels, multiscale_output=True):
+ """Make stage."""
+ num_modules = layer_config['num_modules']
+ num_branches = layer_config['num_branches']
+ num_blocks = layer_config['num_blocks']
+ num_channels = layer_config['num_channels']
+ block = self.blocks_dict[layer_config['block']]
+
+ hr_modules = []
+ for i in range(num_modules):
+ # multi_scale_output is only used for the last module
+ if not multiscale_output and i == num_modules - 1:
+ reset_multiscale_output = False
+ else:
+ reset_multiscale_output = True
+
+ hr_modules.append(
+ HRModule(
+ num_branches,
+ block,
+ num_blocks,
+ in_channels,
+ num_channels,
+ reset_multiscale_output,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg,
+ upsample_cfg=self.upsample_cfg))
+
+ in_channels = hr_modules[-1].in_channels
+
+ return nn.Sequential(*hr_modules), in_channels
+
+ def _freeze_stages(self):
+ """Freeze parameters."""
+ if self.frozen_stages >= 0:
+ self.norm1.eval()
+ self.norm2.eval()
+
+ for m in [self.conv1, self.norm1, self.conv2, self.norm2]:
+ for param in m.parameters():
+ param.requires_grad = False
+
+ for i in range(1, self.frozen_stages + 1):
+ if i == 1:
+ m = getattr(self, 'layer1')
+ else:
+ m = getattr(self, f'stage{i}')
+
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ if i < 4:
+ m = getattr(self, f'transition{i}')
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ def init_weights(self):
+ """Initialize the weights in backbone."""
+ super(OCTSB2, self).init_weights()
+
+ if (isinstance(self.init_cfg, dict)
+ and self.init_cfg['type'] == 'Pretrained'):
+ # Suppress zero_init_residual if use pretrained model.
+ return
+
+ if self.zero_init_residual:
+ for m in self.modules():
+ if isinstance(m, Bottleneck):
+ constant_init(m.norm3, 0)
+ elif isinstance(m, BasicBlock):
+ constant_init(m.norm2, 0)
+
+ def forward(self, x):
+ """Forward function."""
+ # print('x:', x)
+ # print('hrnet input x.shape:', x.shape)
+ # print('hrnet input x.device:', x.device)
+ with torch.no_grad():
+ m = self.guidewire_net(x) #.to(x.device)
+ # print('m:', m)
+ # print('Segmentation m.shape:', m.shape)
+ # print('Segmentation m.device:', m.device)
+ x = torch.cat([x, m], dim=1).detach()
+ # print('x+m:', x)
+ # print('x+m.shape:', x.shape)
+ x = self.conv1(x)
+ x = self.norm1(x)
+ x = self.relu(x)
+ x = self.conv2(x)
+ x = self.norm2(x)
+ x = self.relu(x)
+ x = self.layer1(x)
+
+ x_list = []
+ for i in range(self.stage2_cfg['num_branches']):
+ if self.transition1[i] is not None:
+ x_list.append(self.transition1[i](x))
+ else:
+ x_list.append(x)
+ y_list = self.stage2(x_list)
+
+ x_list = []
+ for i in range(self.stage3_cfg['num_branches']):
+ if self.transition2[i] is not None:
+ x_list.append(self.transition2[i](y_list[-1]))
+ else:
+ x_list.append(y_list[i])
+ y_list = self.stage3(x_list)
+
+ x_list = []
+ for i in range(self.stage4_cfg['num_branches']):
+ if self.transition3[i] is not None:
+ x_list.append(self.transition3[i](y_list[-1]))
+ else:
+ x_list.append(y_list[i])
+ y_list = self.stage4(x_list)
+
+ return tuple(y_list)
+
+ def train(self, mode=True):
+ """Convert the model into training mode."""
+ super().train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, _BatchNorm):
+ m.eval()
+
+ def forward_guidewire(self, x):
+ p = self.guidewire_net(x)
+ p = p.sigmoid()
+ m = p >= 0.3
+ nz = m.nonzero()
+ x_ = nz[:, 3].unique()
+ m[:, :, :, x_] = 1
+ m = m.float()
+ return m
\ No newline at end of file
diff --git a/mmpose/models/backbones/pvt.py b/mmpose/models/backbones/pvt.py
index 3f2b649548..c953ee354f 100644
--- a/mmpose/models/backbones/pvt.py
+++ b/mmpose/models/backbones/pvt.py
@@ -1,569 +1,569 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import warnings
-
-import numpy as np
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from mmcv.cnn import Conv2d, build_activation_layer, build_norm_layer
-from mmcv.cnn.bricks.drop import build_dropout
-from mmcv.cnn.bricks.transformer import MultiheadAttention
-from mmengine.model import BaseModule, ModuleList, Sequential
-from mmengine.model.weight_init import trunc_normal_
-from mmengine.runner import load_state_dict
-from mmengine.utils import to_2tuple
-
-from mmpose.registry import MODELS
-from ...utils import get_root_logger
-from ..utils import PatchEmbed, nchw_to_nlc, nlc_to_nchw, pvt_convert
-from .utils import get_state_dict
-
-
-class MixFFN(BaseModule):
- """An implementation of MixFFN of PVT.
-
- The differences between MixFFN & FFN:
- 1. Use 1X1 Conv to replace Linear layer.
- 2. Introduce 3X3 Depth-wise Conv to encode positional information.
-
- Args:
- embed_dims (int): The feature dimension. Same as
- `MultiheadAttention`.
- feedforward_channels (int): The hidden dimension of FFNs.
- act_cfg (dict, optional): The activation config for FFNs.
- Default: dict(type='GELU').
- ffn_drop (float, optional): Probability of an element to be
- zeroed in FFN. Default 0.0.
- dropout_layer (obj:`ConfigDict`): The dropout_layer used
- when adding the shortcut.
- Default: None.
- use_conv (bool): If True, add 3x3 DWConv between two Linear layers.
- Defaults: False.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- embed_dims,
- feedforward_channels,
- act_cfg=dict(type='GELU'),
- ffn_drop=0.,
- dropout_layer=None,
- use_conv=False,
- init_cfg=None):
- super(MixFFN, self).__init__(init_cfg=init_cfg)
-
- self.embed_dims = embed_dims
- self.feedforward_channels = feedforward_channels
- self.act_cfg = act_cfg
- activate = build_activation_layer(act_cfg)
-
- in_channels = embed_dims
- fc1 = Conv2d(
- in_channels=in_channels,
- out_channels=feedforward_channels,
- kernel_size=1,
- stride=1,
- bias=True)
- if use_conv:
- # 3x3 depth wise conv to provide positional encode information
- dw_conv = Conv2d(
- in_channels=feedforward_channels,
- out_channels=feedforward_channels,
- kernel_size=3,
- stride=1,
- padding=(3 - 1) // 2,
- bias=True,
- groups=feedforward_channels)
- fc2 = Conv2d(
- in_channels=feedforward_channels,
- out_channels=in_channels,
- kernel_size=1,
- stride=1,
- bias=True)
- drop = nn.Dropout(ffn_drop)
- layers = [fc1, activate, drop, fc2, drop]
- if use_conv:
- layers.insert(1, dw_conv)
- self.layers = Sequential(*layers)
- self.dropout_layer = build_dropout(
- dropout_layer) if dropout_layer else torch.nn.Identity()
-
- def forward(self, x, hw_shape, identity=None):
- out = nlc_to_nchw(x, hw_shape)
- out = self.layers(out)
- out = nchw_to_nlc(out)
- if identity is None:
- identity = x
- return identity + self.dropout_layer(out)
-
-
-class SpatialReductionAttention(MultiheadAttention):
- """An implementation of Spatial Reduction Attention of PVT.
-
- This module is modified from MultiheadAttention which is a module from
- mmcv.cnn.bricks.transformer.
-
- Args:
- embed_dims (int): The embedding dimension.
- num_heads (int): Parallel attention heads.
- attn_drop (float): A Dropout layer on attn_output_weights.
- Default: 0.0.
- proj_drop (float): A Dropout layer after `nn.MultiheadAttention`.
- Default: 0.0.
- dropout_layer (obj:`ConfigDict`): The dropout_layer used
- when adding the shortcut. Default: None.
- batch_first (bool): Key, Query and Value are shape of
- (batch, n, embed_dim)
- or (n, batch, embed_dim). Default: False.
- qkv_bias (bool): enable bias for qkv if True. Default: True.
- norm_cfg (dict): Config dict for normalization layer.
- Default: dict(type='LN').
- sr_ratio (int): The ratio of spatial reduction of Spatial Reduction
- Attention of PVT. Default: 1.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- embed_dims,
- num_heads,
- attn_drop=0.,
- proj_drop=0.,
- dropout_layer=None,
- batch_first=True,
- qkv_bias=True,
- norm_cfg=dict(type='LN'),
- sr_ratio=1,
- init_cfg=None):
- super().__init__(
- embed_dims,
- num_heads,
- attn_drop,
- proj_drop,
- batch_first=batch_first,
- dropout_layer=dropout_layer,
- bias=qkv_bias,
- init_cfg=init_cfg)
-
- self.sr_ratio = sr_ratio
- if sr_ratio > 1:
- self.sr = Conv2d(
- in_channels=embed_dims,
- out_channels=embed_dims,
- kernel_size=sr_ratio,
- stride=sr_ratio)
- # The ret[0] of build_norm_layer is norm name.
- self.norm = build_norm_layer(norm_cfg, embed_dims)[1]
-
- # handle the BC-breaking from https://github.com/open-mmlab/mmcv/pull/1418 # noqa
- from mmpose import digit_version, mmcv_version
- if mmcv_version < digit_version('1.3.17'):
- warnings.warn('The legacy version of forward function in'
- 'SpatialReductionAttention is deprecated in'
- 'mmcv>=1.3.17 and will no longer support in the'
- 'future. Please upgrade your mmcv.')
- self.forward = self.legacy_forward
-
- def forward(self, x, hw_shape, identity=None):
-
- x_q = x
- if self.sr_ratio > 1:
- x_kv = nlc_to_nchw(x, hw_shape)
- x_kv = self.sr(x_kv)
- x_kv = nchw_to_nlc(x_kv)
- x_kv = self.norm(x_kv)
- else:
- x_kv = x
-
- if identity is None:
- identity = x_q
-
- # Because the dataflow('key', 'query', 'value') of
- # ``torch.nn.MultiheadAttention`` is (num_query, batch,
- # embed_dims), We should adjust the shape of dataflow from
- # batch_first (batch, num_query, embed_dims) to num_query_first
- # (num_query ,batch, embed_dims), and recover ``attn_output``
- # from num_query_first to batch_first.
- if self.batch_first:
- x_q = x_q.transpose(0, 1)
- x_kv = x_kv.transpose(0, 1)
-
- out = self.attn(query=x_q, key=x_kv, value=x_kv)[0]
-
- if self.batch_first:
- out = out.transpose(0, 1)
-
- return identity + self.dropout_layer(self.proj_drop(out))
-
- def legacy_forward(self, x, hw_shape, identity=None):
- """multi head attention forward in mmcv version < 1.3.17."""
- x_q = x
- if self.sr_ratio > 1:
- x_kv = nlc_to_nchw(x, hw_shape)
- x_kv = self.sr(x_kv)
- x_kv = nchw_to_nlc(x_kv)
- x_kv = self.norm(x_kv)
- else:
- x_kv = x
-
- if identity is None:
- identity = x_q
-
- out = self.attn(query=x_q, key=x_kv, value=x_kv)[0]
-
- return identity + self.dropout_layer(self.proj_drop(out))
-
-
-class PVTEncoderLayer(BaseModule):
- """Implements one encoder layer in PVT.
-
- Args:
- embed_dims (int): The feature dimension.
- num_heads (int): Parallel attention heads.
- feedforward_channels (int): The hidden dimension for FFNs.
- drop_rate (float): Probability of an element to be zeroed.
- after the feed forward layer. Default: 0.0.
- attn_drop_rate (float): The drop out rate for attention layer.
- Default: 0.0.
- drop_path_rate (float): stochastic depth rate. Default: 0.0.
- qkv_bias (bool): enable bias for qkv if True.
- Default: True.
- act_cfg (dict): The activation config for FFNs.
- Default: dict(type='GELU').
- norm_cfg (dict): Config dict for normalization layer.
- Default: dict(type='LN').
- sr_ratio (int): The ratio of spatial reduction of Spatial Reduction
- Attention of PVT. Default: 1.
- use_conv_ffn (bool): If True, use Convolutional FFN to replace FFN.
- Default: False.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- embed_dims,
- num_heads,
- feedforward_channels,
- drop_rate=0.,
- attn_drop_rate=0.,
- drop_path_rate=0.,
- qkv_bias=True,
- act_cfg=dict(type='GELU'),
- norm_cfg=dict(type='LN'),
- sr_ratio=1,
- use_conv_ffn=False,
- init_cfg=None):
- super(PVTEncoderLayer, self).__init__(init_cfg=init_cfg)
-
- # The ret[0] of build_norm_layer is norm name.
- self.norm1 = build_norm_layer(norm_cfg, embed_dims)[1]
-
- self.attn = SpatialReductionAttention(
- embed_dims=embed_dims,
- num_heads=num_heads,
- attn_drop=attn_drop_rate,
- proj_drop=drop_rate,
- dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
- qkv_bias=qkv_bias,
- norm_cfg=norm_cfg,
- sr_ratio=sr_ratio)
-
- # The ret[0] of build_norm_layer is norm name.
- self.norm2 = build_norm_layer(norm_cfg, embed_dims)[1]
-
- self.ffn = MixFFN(
- embed_dims=embed_dims,
- feedforward_channels=feedforward_channels,
- ffn_drop=drop_rate,
- dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
- use_conv=use_conv_ffn,
- act_cfg=act_cfg)
-
- def forward(self, x, hw_shape):
- x = self.attn(self.norm1(x), hw_shape, identity=x)
- x = self.ffn(self.norm2(x), hw_shape, identity=x)
-
- return x
-
-
-class AbsolutePositionEmbedding(BaseModule):
- """An implementation of the absolute position embedding in PVT.
-
- Args:
- pos_shape (int): The shape of the absolute position embedding.
- pos_dim (int): The dimension of the absolute position embedding.
- drop_rate (float): Probability of an element to be zeroed.
- Default: 0.0.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None.
- """
-
- def __init__(self, pos_shape, pos_dim, drop_rate=0., init_cfg=None):
- super().__init__(init_cfg=init_cfg)
-
- if isinstance(pos_shape, int):
- pos_shape = to_2tuple(pos_shape)
- elif isinstance(pos_shape, tuple):
- if len(pos_shape) == 1:
- pos_shape = to_2tuple(pos_shape[0])
- assert len(pos_shape) == 2, \
- f'The size of image should have length 1 or 2, ' \
- f'but got {len(pos_shape)}'
- self.pos_shape = pos_shape
- self.pos_dim = pos_dim
-
- self.pos_embed = nn.Parameter(
- torch.zeros(1, pos_shape[0] * pos_shape[1], pos_dim))
- self.drop = nn.Dropout(p=drop_rate)
-
- def init_weights(self):
- trunc_normal_(self.pos_embed, std=0.02)
-
- def resize_pos_embed(self, pos_embed, input_shape, mode='bilinear'):
- """Resize pos_embed weights.
-
- Resize pos_embed using bilinear interpolate method.
-
- Args:
- pos_embed (torch.Tensor): Position embedding weights.
- input_shape (tuple): Tuple for (downsampled input image height,
- downsampled input image width).
- mode (str): Algorithm used for upsampling:
- ``'nearest'`` | ``'linear'`` | ``'bilinear'`` | ``'bicubic'`` |
- ``'trilinear'``. Default: ``'bilinear'``.
-
- Return:
- torch.Tensor: The resized pos_embed of shape [B, L_new, C].
- """
- assert pos_embed.ndim == 3, 'shape of pos_embed must be [B, L, C]'
- pos_h, pos_w = self.pos_shape
- pos_embed_weight = pos_embed[:, (-1 * pos_h * pos_w):]
- pos_embed_weight = pos_embed_weight.reshape(
- 1, pos_h, pos_w, self.pos_dim).permute(0, 3, 1, 2).contiguous()
- pos_embed_weight = F.interpolate(
- pos_embed_weight, size=input_shape, mode=mode)
- pos_embed_weight = torch.flatten(pos_embed_weight,
- 2).transpose(1, 2).contiguous()
- pos_embed = pos_embed_weight
-
- return pos_embed
-
- def forward(self, x, hw_shape, mode='bilinear'):
- pos_embed = self.resize_pos_embed(self.pos_embed, hw_shape, mode)
- return self.drop(x + pos_embed)
-
-
-@MODELS.register_module()
-class PyramidVisionTransformer(BaseModule):
- """Pyramid Vision Transformer (PVT)
-
- Implementation of `Pyramid Vision Transformer: A Versatile Backbone for
- Dense Prediction without Convolutions
- `_.
-
- Args:
- pretrain_img_size (int | tuple[int]): The size of input image when
- pretrain. Defaults: 224.
- in_channels (int): Number of input channels. Default: 3.
- embed_dims (int): Embedding dimension. Default: 64.
- num_stags (int): The num of stages. Default: 4.
- num_layers (Sequence[int]): The layer number of each transformer encode
- layer. Default: [3, 4, 6, 3].
- num_heads (Sequence[int]): The attention heads of each transformer
- encode layer. Default: [1, 2, 5, 8].
- patch_sizes (Sequence[int]): The patch_size of each patch embedding.
- Default: [4, 2, 2, 2].
- strides (Sequence[int]): The stride of each patch embedding.
- Default: [4, 2, 2, 2].
- paddings (Sequence[int]): The padding of each patch embedding.
- Default: [0, 0, 0, 0].
- sr_ratios (Sequence[int]): The spatial reduction rate of each
- transformer encode layer. Default: [8, 4, 2, 1].
- out_indices (Sequence[int] | int): Output from which stages.
- Default: (0, 1, 2, 3).
- mlp_ratios (Sequence[int]): The ratio of the mlp hidden dim to the
- embedding dim of each transformer encode layer.
- Default: [8, 8, 4, 4].
- qkv_bias (bool): Enable bias for qkv if True. Default: True.
- drop_rate (float): Probability of an element to be zeroed.
- Default 0.0.
- attn_drop_rate (float): The drop out rate for attention layer.
- Default 0.0.
- drop_path_rate (float): stochastic depth rate. Default 0.1.
- use_abs_pos_embed (bool): If True, add absolute position embedding to
- the patch embedding. Defaults: True.
- use_conv_ffn (bool): If True, use Convolutional FFN to replace FFN.
- Default: False.
- act_cfg (dict): The activation config for FFNs.
- Default: dict(type='GELU').
- norm_cfg (dict): Config dict for normalization layer.
- Default: dict(type='LN').
- pretrained (str, optional): model pretrained path. Default: None.
- convert_weights (bool): The flag indicates whether the
- pre-trained model is from the original repo. We may need
- to convert some keys to make it compatible.
- Default: True.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='TruncNormal', std=.02, layer=['Linear']),
- dict(type='Constant', val=1, layer=['LayerNorm']),
- dict(type='Normal', std=0.01, layer=['Conv2d'])
- ]``
- """
-
- def __init__(self,
- pretrain_img_size=224,
- in_channels=3,
- embed_dims=64,
- num_stages=4,
- num_layers=[3, 4, 6, 3],
- num_heads=[1, 2, 5, 8],
- patch_sizes=[4, 2, 2, 2],
- strides=[4, 2, 2, 2],
- paddings=[0, 0, 0, 0],
- sr_ratios=[8, 4, 2, 1],
- out_indices=(0, 1, 2, 3),
- mlp_ratios=[8, 8, 4, 4],
- qkv_bias=True,
- drop_rate=0.,
- attn_drop_rate=0.,
- drop_path_rate=0.1,
- use_abs_pos_embed=True,
- norm_after_stage=False,
- use_conv_ffn=False,
- act_cfg=dict(type='GELU'),
- norm_cfg=dict(type='LN', eps=1e-6),
- convert_weights=True,
- init_cfg=[
- dict(type='TruncNormal', std=.02, layer=['Linear']),
- dict(type='Constant', val=1, layer=['LayerNorm']),
- dict(type='Kaiming', layer=['Conv2d'])
- ]):
- super().__init__(init_cfg=init_cfg)
-
- self.convert_weights = convert_weights
- if isinstance(pretrain_img_size, int):
- pretrain_img_size = to_2tuple(pretrain_img_size)
- elif isinstance(pretrain_img_size, tuple):
- if len(pretrain_img_size) == 1:
- pretrain_img_size = to_2tuple(pretrain_img_size[0])
- assert len(pretrain_img_size) == 2, \
- f'The size of image should have length 1 or 2, ' \
- f'but got {len(pretrain_img_size)}'
-
- self.embed_dims = embed_dims
-
- self.num_stages = num_stages
- self.num_layers = num_layers
- self.num_heads = num_heads
- self.patch_sizes = patch_sizes
- self.strides = strides
- self.sr_ratios = sr_ratios
- assert num_stages == len(num_layers) == len(num_heads) \
- == len(patch_sizes) == len(strides) == len(sr_ratios)
-
- self.out_indices = out_indices
- assert max(out_indices) < self.num_stages
-
- # transformer encoder
- dpr = [
- x.item()
- for x in torch.linspace(0, drop_path_rate, sum(num_layers))
- ] # stochastic num_layer decay rule
-
- cur = 0
- self.layers = ModuleList()
- for i, num_layer in enumerate(num_layers):
- embed_dims_i = embed_dims * num_heads[i]
- patch_embed = PatchEmbed(
- in_channels=in_channels,
- embed_dims=embed_dims_i,
- kernel_size=patch_sizes[i],
- stride=strides[i],
- padding=paddings[i],
- bias=True,
- norm_cfg=norm_cfg)
-
- layers = ModuleList()
- if use_abs_pos_embed:
- pos_shape = pretrain_img_size // np.prod(patch_sizes[:i + 1])
- pos_embed = AbsolutePositionEmbedding(
- pos_shape=pos_shape,
- pos_dim=embed_dims_i,
- drop_rate=drop_rate)
- layers.append(pos_embed)
- layers.extend([
- PVTEncoderLayer(
- embed_dims=embed_dims_i,
- num_heads=num_heads[i],
- feedforward_channels=mlp_ratios[i] * embed_dims_i,
- drop_rate=drop_rate,
- attn_drop_rate=attn_drop_rate,
- drop_path_rate=dpr[cur + idx],
- qkv_bias=qkv_bias,
- act_cfg=act_cfg,
- norm_cfg=norm_cfg,
- sr_ratio=sr_ratios[i],
- use_conv_ffn=use_conv_ffn) for idx in range(num_layer)
- ])
- in_channels = embed_dims_i
- # The ret[0] of build_norm_layer is norm name.
- if norm_after_stage:
- norm = build_norm_layer(norm_cfg, embed_dims_i)[1]
- else:
- norm = nn.Identity()
- self.layers.append(ModuleList([patch_embed, layers, norm]))
- cur += num_layer
-
- def init_weights(self):
- """Initialize the weights in backbone."""
-
- if (isinstance(self.init_cfg, dict)
- and self.init_cfg['type'] == 'Pretrained'):
- logger = get_root_logger()
- state_dict = get_state_dict(
- self.init_cfg['checkpoint'], map_location='cpu')
- logger.warn(f'Load pre-trained model for '
- f'{self.__class__.__name__} from original repo')
-
- if self.convert_weights:
- # Because pvt backbones are not supported by mmcls,
- # so we need to convert pre-trained weights to match this
- # implementation.
- state_dict = pvt_convert(state_dict)
- load_state_dict(self, state_dict, strict=False, logger=logger)
-
- else:
- super(PyramidVisionTransformer, self).init_weights()
-
- def forward(self, x):
- outs = []
-
- for i, layer in enumerate(self.layers):
- x, hw_shape = layer[0](x)
-
- for block in layer[1]:
- x = block(x, hw_shape)
- x = layer[2](x)
- x = nlc_to_nchw(x, hw_shape)
- if i in self.out_indices:
- outs.append(x)
-
- return outs
-
-
-@MODELS.register_module()
-class PyramidVisionTransformerV2(PyramidVisionTransformer):
- """Implementation of `PVTv2: Improved Baselines with Pyramid Vision
- Transformer `_."""
-
- def __init__(self, **kwargs):
- super(PyramidVisionTransformerV2, self).__init__(
- patch_sizes=[7, 3, 3, 3],
- paddings=[3, 1, 1, 1],
- use_abs_pos_embed=False,
- norm_after_stage=True,
- use_conv_ffn=True,
- **kwargs)
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import Conv2d, build_activation_layer, build_norm_layer
+from mmcv.cnn.bricks.drop import build_dropout
+from mmcv.cnn.bricks.transformer import MultiheadAttention
+from mmengine.model import BaseModule, ModuleList, Sequential
+from mmengine.model.weight_init import trunc_normal_
+from mmengine.runner import load_state_dict
+from mmengine.utils import to_2tuple
+
+from mmpose.registry import MODELS
+from ...utils import get_root_logger
+from ..utils import PatchEmbed, nchw_to_nlc, nlc_to_nchw, pvt_convert
+from .utils import get_state_dict
+
+
+class MixFFN(BaseModule):
+ """An implementation of MixFFN of PVT.
+
+ The differences between MixFFN & FFN:
+ 1. Use 1X1 Conv to replace Linear layer.
+ 2. Introduce 3X3 Depth-wise Conv to encode positional information.
+
+ Args:
+ embed_dims (int): The feature dimension. Same as
+ `MultiheadAttention`.
+ feedforward_channels (int): The hidden dimension of FFNs.
+ act_cfg (dict, optional): The activation config for FFNs.
+ Default: dict(type='GELU').
+ ffn_drop (float, optional): Probability of an element to be
+ zeroed in FFN. Default 0.0.
+ dropout_layer (obj:`ConfigDict`): The dropout_layer used
+ when adding the shortcut.
+ Default: None.
+ use_conv (bool): If True, add 3x3 DWConv between two Linear layers.
+ Defaults: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ embed_dims,
+ feedforward_channels,
+ act_cfg=dict(type='GELU'),
+ ffn_drop=0.,
+ dropout_layer=None,
+ use_conv=False,
+ init_cfg=None):
+ super(MixFFN, self).__init__(init_cfg=init_cfg)
+
+ self.embed_dims = embed_dims
+ self.feedforward_channels = feedforward_channels
+ self.act_cfg = act_cfg
+ activate = build_activation_layer(act_cfg)
+
+ in_channels = embed_dims
+ fc1 = Conv2d(
+ in_channels=in_channels,
+ out_channels=feedforward_channels,
+ kernel_size=1,
+ stride=1,
+ bias=True)
+ if use_conv:
+ # 3x3 depth wise conv to provide positional encode information
+ dw_conv = Conv2d(
+ in_channels=feedforward_channels,
+ out_channels=feedforward_channels,
+ kernel_size=3,
+ stride=1,
+ padding=(3 - 1) // 2,
+ bias=True,
+ groups=feedforward_channels)
+ fc2 = Conv2d(
+ in_channels=feedforward_channels,
+ out_channels=in_channels,
+ kernel_size=1,
+ stride=1,
+ bias=True)
+ drop = nn.Dropout(ffn_drop)
+ layers = [fc1, activate, drop, fc2, drop]
+ if use_conv:
+ layers.insert(1, dw_conv)
+ self.layers = Sequential(*layers)
+ self.dropout_layer = build_dropout(
+ dropout_layer) if dropout_layer else torch.nn.Identity()
+
+ def forward(self, x, hw_shape, identity=None):
+ out = nlc_to_nchw(x, hw_shape)
+ out = self.layers(out)
+ out = nchw_to_nlc(out)
+ if identity is None:
+ identity = x
+ return identity + self.dropout_layer(out)
+
+
+class SpatialReductionAttention(MultiheadAttention):
+ """An implementation of Spatial Reduction Attention of PVT.
+
+ This module is modified from MultiheadAttention which is a module from
+ mmcv.cnn.bricks.transformer.
+
+ Args:
+ embed_dims (int): The embedding dimension.
+ num_heads (int): Parallel attention heads.
+ attn_drop (float): A Dropout layer on attn_output_weights.
+ Default: 0.0.
+ proj_drop (float): A Dropout layer after `nn.MultiheadAttention`.
+ Default: 0.0.
+ dropout_layer (obj:`ConfigDict`): The dropout_layer used
+ when adding the shortcut. Default: None.
+ batch_first (bool): Key, Query and Value are shape of
+ (batch, n, embed_dim)
+ or (n, batch, embed_dim). Default: False.
+ qkv_bias (bool): enable bias for qkv if True. Default: True.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ sr_ratio (int): The ratio of spatial reduction of Spatial Reduction
+ Attention of PVT. Default: 1.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ attn_drop=0.,
+ proj_drop=0.,
+ dropout_layer=None,
+ batch_first=True,
+ qkv_bias=True,
+ norm_cfg=dict(type='LN'),
+ sr_ratio=1,
+ init_cfg=None):
+ super().__init__(
+ embed_dims,
+ num_heads,
+ attn_drop,
+ proj_drop,
+ batch_first=batch_first,
+ dropout_layer=dropout_layer,
+ bias=qkv_bias,
+ init_cfg=init_cfg)
+
+ self.sr_ratio = sr_ratio
+ if sr_ratio > 1:
+ self.sr = Conv2d(
+ in_channels=embed_dims,
+ out_channels=embed_dims,
+ kernel_size=sr_ratio,
+ stride=sr_ratio)
+ # The ret[0] of build_norm_layer is norm name.
+ self.norm = build_norm_layer(norm_cfg, embed_dims)[1]
+
+ # handle the BC-breaking from https://github.com/open-mmlab/mmcv/pull/1418 # noqa
+ from mmpose import digit_version, mmcv_version
+ if mmcv_version < digit_version('1.3.17'):
+ warnings.warn('The legacy version of forward function in'
+ 'SpatialReductionAttention is deprecated in'
+ 'mmcv>=1.3.17 and will no longer support in the'
+ 'future. Please upgrade your mmcv.')
+ self.forward = self.legacy_forward
+
+ def forward(self, x, hw_shape, identity=None):
+
+ x_q = x
+ if self.sr_ratio > 1:
+ x_kv = nlc_to_nchw(x, hw_shape)
+ x_kv = self.sr(x_kv)
+ x_kv = nchw_to_nlc(x_kv)
+ x_kv = self.norm(x_kv)
+ else:
+ x_kv = x
+
+ if identity is None:
+ identity = x_q
+
+ # Because the dataflow('key', 'query', 'value') of
+ # ``torch.nn.MultiheadAttention`` is (num_query, batch,
+ # embed_dims), We should adjust the shape of dataflow from
+ # batch_first (batch, num_query, embed_dims) to num_query_first
+ # (num_query ,batch, embed_dims), and recover ``attn_output``
+ # from num_query_first to batch_first.
+ if self.batch_first:
+ x_q = x_q.transpose(0, 1)
+ x_kv = x_kv.transpose(0, 1)
+
+ out = self.attn(query=x_q, key=x_kv, value=x_kv)[0]
+
+ if self.batch_first:
+ out = out.transpose(0, 1)
+
+ return identity + self.dropout_layer(self.proj_drop(out))
+
+ def legacy_forward(self, x, hw_shape, identity=None):
+ """multi head attention forward in mmcv version < 1.3.17."""
+ x_q = x
+ if self.sr_ratio > 1:
+ x_kv = nlc_to_nchw(x, hw_shape)
+ x_kv = self.sr(x_kv)
+ x_kv = nchw_to_nlc(x_kv)
+ x_kv = self.norm(x_kv)
+ else:
+ x_kv = x
+
+ if identity is None:
+ identity = x_q
+
+ out = self.attn(query=x_q, key=x_kv, value=x_kv)[0]
+
+ return identity + self.dropout_layer(self.proj_drop(out))
+
+
+class PVTEncoderLayer(BaseModule):
+ """Implements one encoder layer in PVT.
+
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ drop_rate (float): Probability of an element to be zeroed.
+ after the feed forward layer. Default: 0.0.
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default: 0.0.
+ drop_path_rate (float): stochastic depth rate. Default: 0.0.
+ qkv_bias (bool): enable bias for qkv if True.
+ Default: True.
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ sr_ratio (int): The ratio of spatial reduction of Spatial Reduction
+ Attention of PVT. Default: 1.
+ use_conv_ffn (bool): If True, use Convolutional FFN to replace FFN.
+ Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ qkv_bias=True,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ sr_ratio=1,
+ use_conv_ffn=False,
+ init_cfg=None):
+ super(PVTEncoderLayer, self).__init__(init_cfg=init_cfg)
+
+ # The ret[0] of build_norm_layer is norm name.
+ self.norm1 = build_norm_layer(norm_cfg, embed_dims)[1]
+
+ self.attn = SpatialReductionAttention(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ attn_drop=attn_drop_rate,
+ proj_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ qkv_bias=qkv_bias,
+ norm_cfg=norm_cfg,
+ sr_ratio=sr_ratio)
+
+ # The ret[0] of build_norm_layer is norm name.
+ self.norm2 = build_norm_layer(norm_cfg, embed_dims)[1]
+
+ self.ffn = MixFFN(
+ embed_dims=embed_dims,
+ feedforward_channels=feedforward_channels,
+ ffn_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ use_conv=use_conv_ffn,
+ act_cfg=act_cfg)
+
+ def forward(self, x, hw_shape):
+ x = self.attn(self.norm1(x), hw_shape, identity=x)
+ x = self.ffn(self.norm2(x), hw_shape, identity=x)
+
+ return x
+
+
+class AbsolutePositionEmbedding(BaseModule):
+ """An implementation of the absolute position embedding in PVT.
+
+ Args:
+ pos_shape (int): The shape of the absolute position embedding.
+ pos_dim (int): The dimension of the absolute position embedding.
+ drop_rate (float): Probability of an element to be zeroed.
+ Default: 0.0.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self, pos_shape, pos_dim, drop_rate=0., init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ if isinstance(pos_shape, int):
+ pos_shape = to_2tuple(pos_shape)
+ elif isinstance(pos_shape, tuple):
+ if len(pos_shape) == 1:
+ pos_shape = to_2tuple(pos_shape[0])
+ assert len(pos_shape) == 2, \
+ f'The size of image should have length 1 or 2, ' \
+ f'but got {len(pos_shape)}'
+ self.pos_shape = pos_shape
+ self.pos_dim = pos_dim
+
+ self.pos_embed = nn.Parameter(
+ torch.zeros(1, pos_shape[0] * pos_shape[1], pos_dim))
+ self.drop = nn.Dropout(p=drop_rate)
+
+ def init_weights(self):
+ trunc_normal_(self.pos_embed, std=0.02)
+
+ def resize_pos_embed(self, pos_embed, input_shape, mode='bilinear'):
+ """Resize pos_embed weights.
+
+ Resize pos_embed using bilinear interpolate method.
+
+ Args:
+ pos_embed (torch.Tensor): Position embedding weights.
+ input_shape (tuple): Tuple for (downsampled input image height,
+ downsampled input image width).
+ mode (str): Algorithm used for upsampling:
+ ``'nearest'`` | ``'linear'`` | ``'bilinear'`` | ``'bicubic'`` |
+ ``'trilinear'``. Default: ``'bilinear'``.
+
+ Return:
+ torch.Tensor: The resized pos_embed of shape [B, L_new, C].
+ """
+ assert pos_embed.ndim == 3, 'shape of pos_embed must be [B, L, C]'
+ pos_h, pos_w = self.pos_shape
+ pos_embed_weight = pos_embed[:, (-1 * pos_h * pos_w):]
+ pos_embed_weight = pos_embed_weight.reshape(
+ 1, pos_h, pos_w, self.pos_dim).permute(0, 3, 1, 2).contiguous()
+ pos_embed_weight = F.interpolate(
+ pos_embed_weight, size=input_shape, mode=mode)
+ pos_embed_weight = torch.flatten(pos_embed_weight,
+ 2).transpose(1, 2).contiguous()
+ pos_embed = pos_embed_weight
+
+ return pos_embed
+
+ def forward(self, x, hw_shape, mode='bilinear'):
+ pos_embed = self.resize_pos_embed(self.pos_embed, hw_shape, mode)
+ return self.drop(x + pos_embed)
+
+
+@MODELS.register_module()
+class PyramidVisionTransformer(BaseModule):
+ """Pyramid Vision Transformer (PVT)
+
+ Implementation of `Pyramid Vision Transformer: A Versatile Backbone for
+ Dense Prediction without Convolutions
+ `_.
+
+ Args:
+ pretrain_img_size (int | tuple[int]): The size of input image when
+ pretrain. Defaults: 224.
+ in_channels (int): Number of input channels. Default: 3.
+ embed_dims (int): Embedding dimension. Default: 64.
+ num_stags (int): The num of stages. Default: 4.
+ num_layers (Sequence[int]): The layer number of each transformer encode
+ layer. Default: [3, 4, 6, 3].
+ num_heads (Sequence[int]): The attention heads of each transformer
+ encode layer. Default: [1, 2, 5, 8].
+ patch_sizes (Sequence[int]): The patch_size of each patch embedding.
+ Default: [4, 2, 2, 2].
+ strides (Sequence[int]): The stride of each patch embedding.
+ Default: [4, 2, 2, 2].
+ paddings (Sequence[int]): The padding of each patch embedding.
+ Default: [0, 0, 0, 0].
+ sr_ratios (Sequence[int]): The spatial reduction rate of each
+ transformer encode layer. Default: [8, 4, 2, 1].
+ out_indices (Sequence[int] | int): Output from which stages.
+ Default: (0, 1, 2, 3).
+ mlp_ratios (Sequence[int]): The ratio of the mlp hidden dim to the
+ embedding dim of each transformer encode layer.
+ Default: [8, 8, 4, 4].
+ qkv_bias (bool): Enable bias for qkv if True. Default: True.
+ drop_rate (float): Probability of an element to be zeroed.
+ Default 0.0.
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default 0.0.
+ drop_path_rate (float): stochastic depth rate. Default 0.1.
+ use_abs_pos_embed (bool): If True, add absolute position embedding to
+ the patch embedding. Defaults: True.
+ use_conv_ffn (bool): If True, use Convolutional FFN to replace FFN.
+ Default: False.
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ pretrained (str, optional): model pretrained path. Default: None.
+ convert_weights (bool): The flag indicates whether the
+ pre-trained model is from the original repo. We may need
+ to convert some keys to make it compatible.
+ Default: True.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='TruncNormal', std=.02, layer=['Linear']),
+ dict(type='Constant', val=1, layer=['LayerNorm']),
+ dict(type='Normal', std=0.01, layer=['Conv2d'])
+ ]``
+ """
+
+ def __init__(self,
+ pretrain_img_size=224,
+ in_channels=3,
+ embed_dims=64,
+ num_stages=4,
+ num_layers=[3, 4, 6, 3],
+ num_heads=[1, 2, 5, 8],
+ patch_sizes=[4, 2, 2, 2],
+ strides=[4, 2, 2, 2],
+ paddings=[0, 0, 0, 0],
+ sr_ratios=[8, 4, 2, 1],
+ out_indices=(0, 1, 2, 3),
+ mlp_ratios=[8, 8, 4, 4],
+ qkv_bias=True,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.1,
+ use_abs_pos_embed=True,
+ norm_after_stage=False,
+ use_conv_ffn=False,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN', eps=1e-6),
+ convert_weights=True,
+ init_cfg=[
+ dict(type='TruncNormal', std=.02, layer=['Linear']),
+ dict(type='Constant', val=1, layer=['LayerNorm']),
+ dict(type='Kaiming', layer=['Conv2d'])
+ ]):
+ super().__init__(init_cfg=init_cfg)
+
+ self.convert_weights = convert_weights
+ if isinstance(pretrain_img_size, int):
+ pretrain_img_size = to_2tuple(pretrain_img_size)
+ elif isinstance(pretrain_img_size, tuple):
+ if len(pretrain_img_size) == 1:
+ pretrain_img_size = to_2tuple(pretrain_img_size[0])
+ assert len(pretrain_img_size) == 2, \
+ f'The size of image should have length 1 or 2, ' \
+ f'but got {len(pretrain_img_size)}'
+
+ self.embed_dims = embed_dims
+
+ self.num_stages = num_stages
+ self.num_layers = num_layers
+ self.num_heads = num_heads
+ self.patch_sizes = patch_sizes
+ self.strides = strides
+ self.sr_ratios = sr_ratios
+ assert num_stages == len(num_layers) == len(num_heads) \
+ == len(patch_sizes) == len(strides) == len(sr_ratios)
+
+ self.out_indices = out_indices
+ assert max(out_indices) < self.num_stages
+
+ # transformer encoder
+ dpr = [
+ x.item()
+ for x in torch.linspace(0, drop_path_rate, sum(num_layers))
+ ] # stochastic num_layer decay rule
+
+ cur = 0
+ self.layers = ModuleList()
+ for i, num_layer in enumerate(num_layers):
+ embed_dims_i = embed_dims * num_heads[i]
+ patch_embed = PatchEmbed(
+ in_channels=in_channels,
+ embed_dims=embed_dims_i,
+ kernel_size=patch_sizes[i],
+ stride=strides[i],
+ padding=paddings[i],
+ bias=True,
+ norm_cfg=norm_cfg)
+
+ layers = ModuleList()
+ if use_abs_pos_embed:
+ pos_shape = pretrain_img_size // np.prod(patch_sizes[:i + 1])
+ pos_embed = AbsolutePositionEmbedding(
+ pos_shape=pos_shape,
+ pos_dim=embed_dims_i,
+ drop_rate=drop_rate)
+ layers.append(pos_embed)
+ layers.extend([
+ PVTEncoderLayer(
+ embed_dims=embed_dims_i,
+ num_heads=num_heads[i],
+ feedforward_channels=mlp_ratios[i] * embed_dims_i,
+ drop_rate=drop_rate,
+ attn_drop_rate=attn_drop_rate,
+ drop_path_rate=dpr[cur + idx],
+ qkv_bias=qkv_bias,
+ act_cfg=act_cfg,
+ norm_cfg=norm_cfg,
+ sr_ratio=sr_ratios[i],
+ use_conv_ffn=use_conv_ffn) for idx in range(num_layer)
+ ])
+ in_channels = embed_dims_i
+ # The ret[0] of build_norm_layer is norm name.
+ if norm_after_stage:
+ norm = build_norm_layer(norm_cfg, embed_dims_i)[1]
+ else:
+ norm = nn.Identity()
+ self.layers.append(ModuleList([patch_embed, layers, norm]))
+ cur += num_layer
+
+ def init_weights(self):
+ """Initialize the weights in backbone."""
+
+ if (isinstance(self.init_cfg, dict)
+ and self.init_cfg['type'] == 'Pretrained'):
+ logger = get_root_logger()
+ state_dict = get_state_dict(
+ self.init_cfg['checkpoint'], map_location='cpu')
+ logger.warn(f'Load pre-trained model for '
+ f'{self.__class__.__name__} from original repo')
+
+ if self.convert_weights:
+ # Because pvt backbones are not supported by mmcls,
+ # so we need to convert pre-trained weights to match this
+ # implementation.
+ state_dict = pvt_convert(state_dict)
+ load_state_dict(self, state_dict, strict=False, logger=logger)
+
+ else:
+ super(PyramidVisionTransformer, self).init_weights()
+
+ def forward(self, x):
+ outs = []
+
+ for i, layer in enumerate(self.layers):
+ x, hw_shape = layer[0](x)
+
+ for block in layer[1]:
+ x = block(x, hw_shape)
+ x = layer[2](x)
+ x = nlc_to_nchw(x, hw_shape)
+ if i in self.out_indices:
+ outs.append(x)
+
+ return outs
+
+
+@MODELS.register_module()
+class PyramidVisionTransformerV2(PyramidVisionTransformer):
+ """Implementation of `PVTv2: Improved Baselines with Pyramid Vision
+ Transformer `_."""
+
+ def __init__(self, **kwargs):
+ super(PyramidVisionTransformerV2, self).__init__(
+ patch_sizes=[7, 3, 3, 3],
+ paddings=[3, 1, 1, 1],
+ use_abs_pos_embed=False,
+ norm_after_stage=True,
+ use_conv_ffn=True,
+ **kwargs)
diff --git a/mmpose/models/backbones/regnet.py b/mmpose/models/backbones/regnet.py
index 120523e658..de3ee9957f 100644
--- a/mmpose/models/backbones/regnet.py
+++ b/mmpose/models/backbones/regnet.py
@@ -1,331 +1,331 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-
-import numpy as np
-import torch.nn as nn
-from mmcv.cnn import build_conv_layer, build_norm_layer
-
-from mmpose.registry import MODELS
-from .resnet import ResNet
-from .resnext import Bottleneck
-
-
-@MODELS.register_module()
-class RegNet(ResNet):
- """RegNet backbone.
-
- More details can be found in `paper `__ .
-
- Args:
- arch (dict): The parameter of RegNets.
- - w0 (int): initial width
- - wa (float): slope of width
- - wm (float): quantization parameter to quantize the width
- - depth (int): depth of the backbone
- - group_w (int): width of group
- - bot_mul (float): bottleneck ratio, i.e. expansion of bottleneck.
- strides (Sequence[int]): Strides of the first block of each stage.
- base_channels (int): Base channels after stem layer.
- in_channels (int): Number of input image channels. Default: 3.
- dilations (Sequence[int]): Dilation of each stage.
- out_indices (Sequence[int]): Output from which stages.
- style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
- layer is the 3x3 conv layer, otherwise the stride-two layer is
- the first 1x1 conv layer. Default: "pytorch".
- frozen_stages (int): Stages to be frozen (all param fixed). -1 means
- not freezing any parameters. Default: -1.
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN', requires_grad=True).
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only. Default: False.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed. Default: False.
- zero_init_residual (bool): whether to use zero init for last norm layer
- in resblocks to let them behave as identity. Default: True.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Kaiming', layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]``
-
- Example:
- >>> from mmpose.models import RegNet
- >>> import torch
- >>> self = RegNet(
- arch=dict(
- w0=88,
- wa=26.31,
- wm=2.25,
- group_w=48,
- depth=25,
- bot_mul=1.0),
- out_indices=(0, 1, 2, 3))
- >>> self.eval()
- >>> inputs = torch.rand(1, 3, 32, 32)
- >>> level_outputs = self.forward(inputs)
- >>> for level_out in level_outputs:
- ... print(tuple(level_out.shape))
- (1, 96, 8, 8)
- (1, 192, 4, 4)
- (1, 432, 2, 2)
- (1, 1008, 1, 1)
- """
- arch_settings = {
- 'regnetx_400mf':
- dict(w0=24, wa=24.48, wm=2.54, group_w=16, depth=22, bot_mul=1.0),
- 'regnetx_800mf':
- dict(w0=56, wa=35.73, wm=2.28, group_w=16, depth=16, bot_mul=1.0),
- 'regnetx_1.6gf':
- dict(w0=80, wa=34.01, wm=2.25, group_w=24, depth=18, bot_mul=1.0),
- 'regnetx_3.2gf':
- dict(w0=88, wa=26.31, wm=2.25, group_w=48, depth=25, bot_mul=1.0),
- 'regnetx_4.0gf':
- dict(w0=96, wa=38.65, wm=2.43, group_w=40, depth=23, bot_mul=1.0),
- 'regnetx_6.4gf':
- dict(w0=184, wa=60.83, wm=2.07, group_w=56, depth=17, bot_mul=1.0),
- 'regnetx_8.0gf':
- dict(w0=80, wa=49.56, wm=2.88, group_w=120, depth=23, bot_mul=1.0),
- 'regnetx_12gf':
- dict(w0=168, wa=73.36, wm=2.37, group_w=112, depth=19, bot_mul=1.0),
- }
-
- def __init__(self,
- arch,
- in_channels=3,
- stem_channels=32,
- base_channels=32,
- strides=(2, 2, 2, 2),
- dilations=(1, 1, 1, 1),
- out_indices=(3, ),
- style='pytorch',
- deep_stem=False,
- avg_down=False,
- frozen_stages=-1,
- conv_cfg=None,
- norm_cfg=dict(type='BN', requires_grad=True),
- norm_eval=False,
- with_cp=False,
- zero_init_residual=True,
- init_cfg=[
- dict(type='Kaiming', layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- super(ResNet, self).__init__(init_cfg=init_cfg)
-
- # Generate RegNet parameters first
- if isinstance(arch, str):
- assert arch in self.arch_settings, \
- f'"arch": "{arch}" is not one of the' \
- ' arch_settings'
- arch = self.arch_settings[arch]
- elif not isinstance(arch, dict):
- raise TypeError('Expect "arch" to be either a string '
- f'or a dict, got {type(arch)}')
-
- widths, num_stages = self.generate_regnet(
- arch['w0'],
- arch['wa'],
- arch['wm'],
- arch['depth'],
- )
- # Convert to per stage format
- stage_widths, stage_blocks = self.get_stages_from_blocks(widths)
- # Generate group widths and bot muls
- group_widths = [arch['group_w'] for _ in range(num_stages)]
- self.bottleneck_ratio = [arch['bot_mul'] for _ in range(num_stages)]
- # Adjust the compatibility of stage_widths and group_widths
- stage_widths, group_widths = self.adjust_width_group(
- stage_widths, self.bottleneck_ratio, group_widths)
-
- # Group params by stage
- self.stage_widths = stage_widths
- self.group_widths = group_widths
- self.depth = sum(stage_blocks)
- self.stem_channels = stem_channels
- self.base_channels = base_channels
- self.num_stages = num_stages
- assert 1 <= num_stages <= 4
- self.strides = strides
- self.dilations = dilations
- assert len(strides) == len(dilations) == num_stages
- self.out_indices = out_indices
- assert max(out_indices) < num_stages
- self.style = style
- self.deep_stem = deep_stem
- if self.deep_stem:
- raise NotImplementedError(
- 'deep_stem has not been implemented for RegNet')
- self.avg_down = avg_down
- self.frozen_stages = frozen_stages
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- self.with_cp = with_cp
- self.norm_eval = norm_eval
- self.zero_init_residual = zero_init_residual
- self.stage_blocks = stage_blocks[:num_stages]
-
- self._make_stem_layer(in_channels, stem_channels)
-
- _in_channels = stem_channels
- self.res_layers = []
- for i, num_blocks in enumerate(self.stage_blocks):
- stride = self.strides[i]
- dilation = self.dilations[i]
- group_width = self.group_widths[i]
- width = int(round(self.stage_widths[i] * self.bottleneck_ratio[i]))
- stage_groups = width // group_width
-
- res_layer = self.make_res_layer(
- block=Bottleneck,
- num_blocks=num_blocks,
- in_channels=_in_channels,
- out_channels=self.stage_widths[i],
- expansion=1,
- stride=stride,
- dilation=dilation,
- style=self.style,
- avg_down=self.avg_down,
- with_cp=self.with_cp,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- base_channels=self.stage_widths[i],
- groups=stage_groups,
- width_per_group=group_width)
- _in_channels = self.stage_widths[i]
- layer_name = f'layer{i + 1}'
- self.add_module(layer_name, res_layer)
- self.res_layers.append(layer_name)
-
- self._freeze_stages()
-
- self.feat_dim = stage_widths[-1]
-
- def _make_stem_layer(self, in_channels, base_channels):
- self.conv1 = build_conv_layer(
- self.conv_cfg,
- in_channels,
- base_channels,
- kernel_size=3,
- stride=2,
- padding=1,
- bias=False)
- self.norm1_name, norm1 = build_norm_layer(
- self.norm_cfg, base_channels, postfix=1)
- self.add_module(self.norm1_name, norm1)
- self.relu = nn.ReLU(inplace=True)
-
- @staticmethod
- def generate_regnet(initial_width,
- width_slope,
- width_parameter,
- depth,
- divisor=8):
- """Generates per block width from RegNet parameters.
-
- Args:
- initial_width ([int]): Initial width of the backbone
- width_slope ([float]): Slope of the quantized linear function
- width_parameter ([int]): Parameter used to quantize the width.
- depth ([int]): Depth of the backbone.
- divisor (int, optional): The divisor of channels. Defaults to 8.
-
- Returns:
- list, int: return a list of widths of each stage and the number of
- stages
- """
- assert width_slope >= 0
- assert initial_width > 0
- assert width_parameter > 1
- assert initial_width % divisor == 0
- widths_cont = np.arange(depth) * width_slope + initial_width
- ks = np.round(
- np.log(widths_cont / initial_width) / np.log(width_parameter))
- widths = initial_width * np.power(width_parameter, ks)
- widths = np.round(np.divide(widths, divisor)) * divisor
- num_stages = len(np.unique(widths))
- widths, widths_cont = widths.astype(int).tolist(), widths_cont.tolist()
- return widths, num_stages
-
- @staticmethod
- def quantize_float(number, divisor):
- """Converts a float to closest non-zero int divisible by divior.
-
- Args:
- number (int): Original number to be quantized.
- divisor (int): Divisor used to quantize the number.
-
- Returns:
- int: quantized number that is divisible by devisor.
- """
- return int(round(number / divisor) * divisor)
-
- def adjust_width_group(self, widths, bottleneck_ratio, groups):
- """Adjusts the compatibility of widths and groups.
-
- Args:
- widths (list[int]): Width of each stage.
- bottleneck_ratio (float): Bottleneck ratio.
- groups (int): number of groups in each stage
-
- Returns:
- tuple(list): The adjusted widths and groups of each stage.
- """
- bottleneck_width = [
- int(w * b) for w, b in zip(widths, bottleneck_ratio)
- ]
- groups = [min(g, w_bot) for g, w_bot in zip(groups, bottleneck_width)]
- bottleneck_width = [
- self.quantize_float(w_bot, g)
- for w_bot, g in zip(bottleneck_width, groups)
- ]
- widths = [
- int(w_bot / b)
- for w_bot, b in zip(bottleneck_width, bottleneck_ratio)
- ]
- return widths, groups
-
- def get_stages_from_blocks(self, widths):
- """Gets widths/stage_blocks of network at each stage.
-
- Args:
- widths (list[int]): Width in each stage.
-
- Returns:
- tuple(list): width and depth of each stage
- """
- width_diff = [
- width != width_prev
- for width, width_prev in zip(widths + [0], [0] + widths)
- ]
- stage_widths = [
- width for width, diff in zip(widths, width_diff[:-1]) if diff
- ]
- stage_blocks = np.diff([
- depth for depth, diff in zip(range(len(width_diff)), width_diff)
- if diff
- ]).tolist()
- return stage_widths, stage_blocks
-
- def forward(self, x):
- x = self.conv1(x)
- x = self.norm1(x)
- x = self.relu(x)
-
- outs = []
- for i, layer_name in enumerate(self.res_layers):
- res_layer = getattr(self, layer_name)
- x = res_layer(x)
- if i in self.out_indices:
- outs.append(x)
-
- return tuple(outs)
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import numpy as np
+import torch.nn as nn
+from mmcv.cnn import build_conv_layer, build_norm_layer
+
+from mmpose.registry import MODELS
+from .resnet import ResNet
+from .resnext import Bottleneck
+
+
+@MODELS.register_module()
+class RegNet(ResNet):
+ """RegNet backbone.
+
+ More details can be found in `paper `__ .
+
+ Args:
+ arch (dict): The parameter of RegNets.
+ - w0 (int): initial width
+ - wa (float): slope of width
+ - wm (float): quantization parameter to quantize the width
+ - depth (int): depth of the backbone
+ - group_w (int): width of group
+ - bot_mul (float): bottleneck ratio, i.e. expansion of bottleneck.
+ strides (Sequence[int]): Strides of the first block of each stage.
+ base_channels (int): Base channels after stem layer.
+ in_channels (int): Number of input image channels. Default: 3.
+ dilations (Sequence[int]): Dilation of each stage.
+ out_indices (Sequence[int]): Output from which stages.
+ style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
+ layer is the 3x3 conv layer, otherwise the stride-two layer is
+ the first 1x1 conv layer. Default: "pytorch".
+ frozen_stages (int): Stages to be frozen (all param fixed). -1 means
+ not freezing any parameters. Default: -1.
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN', requires_grad=True).
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ zero_init_residual (bool): whether to use zero init for last norm layer
+ in resblocks to let them behave as identity. Default: True.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Kaiming', layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+
+ Example:
+ >>> from mmpose.models import RegNet
+ >>> import torch
+ >>> self = RegNet(
+ arch=dict(
+ w0=88,
+ wa=26.31,
+ wm=2.25,
+ group_w=48,
+ depth=25,
+ bot_mul=1.0),
+ out_indices=(0, 1, 2, 3))
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 32, 32)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 96, 8, 8)
+ (1, 192, 4, 4)
+ (1, 432, 2, 2)
+ (1, 1008, 1, 1)
+ """
+ arch_settings = {
+ 'regnetx_400mf':
+ dict(w0=24, wa=24.48, wm=2.54, group_w=16, depth=22, bot_mul=1.0),
+ 'regnetx_800mf':
+ dict(w0=56, wa=35.73, wm=2.28, group_w=16, depth=16, bot_mul=1.0),
+ 'regnetx_1.6gf':
+ dict(w0=80, wa=34.01, wm=2.25, group_w=24, depth=18, bot_mul=1.0),
+ 'regnetx_3.2gf':
+ dict(w0=88, wa=26.31, wm=2.25, group_w=48, depth=25, bot_mul=1.0),
+ 'regnetx_4.0gf':
+ dict(w0=96, wa=38.65, wm=2.43, group_w=40, depth=23, bot_mul=1.0),
+ 'regnetx_6.4gf':
+ dict(w0=184, wa=60.83, wm=2.07, group_w=56, depth=17, bot_mul=1.0),
+ 'regnetx_8.0gf':
+ dict(w0=80, wa=49.56, wm=2.88, group_w=120, depth=23, bot_mul=1.0),
+ 'regnetx_12gf':
+ dict(w0=168, wa=73.36, wm=2.37, group_w=112, depth=19, bot_mul=1.0),
+ }
+
+ def __init__(self,
+ arch,
+ in_channels=3,
+ stem_channels=32,
+ base_channels=32,
+ strides=(2, 2, 2, 2),
+ dilations=(1, 1, 1, 1),
+ out_indices=(3, ),
+ style='pytorch',
+ deep_stem=False,
+ avg_down=False,
+ frozen_stages=-1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=False,
+ with_cp=False,
+ zero_init_residual=True,
+ init_cfg=[
+ dict(type='Kaiming', layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super(ResNet, self).__init__(init_cfg=init_cfg)
+
+ # Generate RegNet parameters first
+ if isinstance(arch, str):
+ assert arch in self.arch_settings, \
+ f'"arch": "{arch}" is not one of the' \
+ ' arch_settings'
+ arch = self.arch_settings[arch]
+ elif not isinstance(arch, dict):
+ raise TypeError('Expect "arch" to be either a string '
+ f'or a dict, got {type(arch)}')
+
+ widths, num_stages = self.generate_regnet(
+ arch['w0'],
+ arch['wa'],
+ arch['wm'],
+ arch['depth'],
+ )
+ # Convert to per stage format
+ stage_widths, stage_blocks = self.get_stages_from_blocks(widths)
+ # Generate group widths and bot muls
+ group_widths = [arch['group_w'] for _ in range(num_stages)]
+ self.bottleneck_ratio = [arch['bot_mul'] for _ in range(num_stages)]
+ # Adjust the compatibility of stage_widths and group_widths
+ stage_widths, group_widths = self.adjust_width_group(
+ stage_widths, self.bottleneck_ratio, group_widths)
+
+ # Group params by stage
+ self.stage_widths = stage_widths
+ self.group_widths = group_widths
+ self.depth = sum(stage_blocks)
+ self.stem_channels = stem_channels
+ self.base_channels = base_channels
+ self.num_stages = num_stages
+ assert 1 <= num_stages <= 4
+ self.strides = strides
+ self.dilations = dilations
+ assert len(strides) == len(dilations) == num_stages
+ self.out_indices = out_indices
+ assert max(out_indices) < num_stages
+ self.style = style
+ self.deep_stem = deep_stem
+ if self.deep_stem:
+ raise NotImplementedError(
+ 'deep_stem has not been implemented for RegNet')
+ self.avg_down = avg_down
+ self.frozen_stages = frozen_stages
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.with_cp = with_cp
+ self.norm_eval = norm_eval
+ self.zero_init_residual = zero_init_residual
+ self.stage_blocks = stage_blocks[:num_stages]
+
+ self._make_stem_layer(in_channels, stem_channels)
+
+ _in_channels = stem_channels
+ self.res_layers = []
+ for i, num_blocks in enumerate(self.stage_blocks):
+ stride = self.strides[i]
+ dilation = self.dilations[i]
+ group_width = self.group_widths[i]
+ width = int(round(self.stage_widths[i] * self.bottleneck_ratio[i]))
+ stage_groups = width // group_width
+
+ res_layer = self.make_res_layer(
+ block=Bottleneck,
+ num_blocks=num_blocks,
+ in_channels=_in_channels,
+ out_channels=self.stage_widths[i],
+ expansion=1,
+ stride=stride,
+ dilation=dilation,
+ style=self.style,
+ avg_down=self.avg_down,
+ with_cp=self.with_cp,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ base_channels=self.stage_widths[i],
+ groups=stage_groups,
+ width_per_group=group_width)
+ _in_channels = self.stage_widths[i]
+ layer_name = f'layer{i + 1}'
+ self.add_module(layer_name, res_layer)
+ self.res_layers.append(layer_name)
+
+ self._freeze_stages()
+
+ self.feat_dim = stage_widths[-1]
+
+ def _make_stem_layer(self, in_channels, base_channels):
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ base_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False)
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, base_channels, postfix=1)
+ self.add_module(self.norm1_name, norm1)
+ self.relu = nn.ReLU(inplace=True)
+
+ @staticmethod
+ def generate_regnet(initial_width,
+ width_slope,
+ width_parameter,
+ depth,
+ divisor=8):
+ """Generates per block width from RegNet parameters.
+
+ Args:
+ initial_width ([int]): Initial width of the backbone
+ width_slope ([float]): Slope of the quantized linear function
+ width_parameter ([int]): Parameter used to quantize the width.
+ depth ([int]): Depth of the backbone.
+ divisor (int, optional): The divisor of channels. Defaults to 8.
+
+ Returns:
+ list, int: return a list of widths of each stage and the number of
+ stages
+ """
+ assert width_slope >= 0
+ assert initial_width > 0
+ assert width_parameter > 1
+ assert initial_width % divisor == 0
+ widths_cont = np.arange(depth) * width_slope + initial_width
+ ks = np.round(
+ np.log(widths_cont / initial_width) / np.log(width_parameter))
+ widths = initial_width * np.power(width_parameter, ks)
+ widths = np.round(np.divide(widths, divisor)) * divisor
+ num_stages = len(np.unique(widths))
+ widths, widths_cont = widths.astype(int).tolist(), widths_cont.tolist()
+ return widths, num_stages
+
+ @staticmethod
+ def quantize_float(number, divisor):
+ """Converts a float to closest non-zero int divisible by divior.
+
+ Args:
+ number (int): Original number to be quantized.
+ divisor (int): Divisor used to quantize the number.
+
+ Returns:
+ int: quantized number that is divisible by devisor.
+ """
+ return int(round(number / divisor) * divisor)
+
+ def adjust_width_group(self, widths, bottleneck_ratio, groups):
+ """Adjusts the compatibility of widths and groups.
+
+ Args:
+ widths (list[int]): Width of each stage.
+ bottleneck_ratio (float): Bottleneck ratio.
+ groups (int): number of groups in each stage
+
+ Returns:
+ tuple(list): The adjusted widths and groups of each stage.
+ """
+ bottleneck_width = [
+ int(w * b) for w, b in zip(widths, bottleneck_ratio)
+ ]
+ groups = [min(g, w_bot) for g, w_bot in zip(groups, bottleneck_width)]
+ bottleneck_width = [
+ self.quantize_float(w_bot, g)
+ for w_bot, g in zip(bottleneck_width, groups)
+ ]
+ widths = [
+ int(w_bot / b)
+ for w_bot, b in zip(bottleneck_width, bottleneck_ratio)
+ ]
+ return widths, groups
+
+ def get_stages_from_blocks(self, widths):
+ """Gets widths/stage_blocks of network at each stage.
+
+ Args:
+ widths (list[int]): Width in each stage.
+
+ Returns:
+ tuple(list): width and depth of each stage
+ """
+ width_diff = [
+ width != width_prev
+ for width, width_prev in zip(widths + [0], [0] + widths)
+ ]
+ stage_widths = [
+ width for width, diff in zip(widths, width_diff[:-1]) if diff
+ ]
+ stage_blocks = np.diff([
+ depth for depth, diff in zip(range(len(width_diff)), width_diff)
+ if diff
+ ]).tolist()
+ return stage_widths, stage_blocks
+
+ def forward(self, x):
+ x = self.conv1(x)
+ x = self.norm1(x)
+ x = self.relu(x)
+
+ outs = []
+ for i, layer_name in enumerate(self.res_layers):
+ res_layer = getattr(self, layer_name)
+ x = res_layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+
+ return tuple(outs)
diff --git a/mmpose/models/backbones/resnest.py b/mmpose/models/backbones/resnest.py
index b5eea8ad7e..5bcc3d6c19 100644
--- a/mmpose/models/backbones/resnest.py
+++ b/mmpose/models/backbones/resnest.py
@@ -1,353 +1,353 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-import torch.utils.checkpoint as cp
-from mmcv.cnn import build_conv_layer, build_norm_layer
-from mmengine.model import BaseModule
-
-from mmpose.registry import MODELS
-from .resnet import Bottleneck as _Bottleneck
-from .resnet import ResLayer, ResNetV1d
-
-
-class RSoftmax(nn.Module):
- """Radix Softmax module in ``SplitAttentionConv2d``.
-
- Args:
- radix (int): Radix of input.
- groups (int): Groups of input.
- """
-
- def __init__(self, radix, groups):
- super().__init__()
- self.radix = radix
- self.groups = groups
-
- def forward(self, x):
- batch = x.size(0)
- if self.radix > 1:
- x = x.view(batch, self.groups, self.radix, -1).transpose(1, 2)
- x = F.softmax(x, dim=1)
- x = x.reshape(batch, -1)
- else:
- x = torch.sigmoid(x)
- return x
-
-
-class SplitAttentionConv2d(BaseModule):
- """Split-Attention Conv2d.
-
- Args:
- in_channels (int): Same as nn.Conv2d.
- out_channels (int): Same as nn.Conv2d.
- kernel_size (int | tuple[int]): Same as nn.Conv2d.
- stride (int | tuple[int]): Same as nn.Conv2d.
- padding (int | tuple[int]): Same as nn.Conv2d.
- dilation (int | tuple[int]): Same as nn.Conv2d.
- groups (int): Same as nn.Conv2d.
- radix (int): Radix of SpltAtConv2d. Default: 2
- reduction_factor (int): Reduction factor of SplitAttentionConv2d.
- Default: 4.
- conv_cfg (dict): Config dict for convolution layer. Default: None,
- which means using conv2d.
- norm_cfg (dict): Config dict for normalization layer. Default: None.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- in_channels,
- channels,
- kernel_size,
- stride=1,
- padding=0,
- dilation=1,
- groups=1,
- radix=2,
- reduction_factor=4,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- init_cfg=None):
- super().__init__(init_cfg=init_cfg)
- inter_channels = max(in_channels * radix // reduction_factor, 32)
- self.radix = radix
- self.groups = groups
- self.channels = channels
- self.conv = build_conv_layer(
- conv_cfg,
- in_channels,
- channels * radix,
- kernel_size,
- stride=stride,
- padding=padding,
- dilation=dilation,
- groups=groups * radix,
- bias=False)
- self.norm0_name, norm0 = build_norm_layer(
- norm_cfg, channels * radix, postfix=0)
- self.add_module(self.norm0_name, norm0)
- self.relu = nn.ReLU(inplace=True)
- self.fc1 = build_conv_layer(
- None, channels, inter_channels, 1, groups=self.groups)
- self.norm1_name, norm1 = build_norm_layer(
- norm_cfg, inter_channels, postfix=1)
- self.add_module(self.norm1_name, norm1)
- self.fc2 = build_conv_layer(
- None, inter_channels, channels * radix, 1, groups=self.groups)
- self.rsoftmax = RSoftmax(radix, groups)
-
- @property
- def norm0(self):
- return getattr(self, self.norm0_name)
-
- @property
- def norm1(self):
- return getattr(self, self.norm1_name)
-
- def forward(self, x):
- x = self.conv(x)
- x = self.norm0(x)
- x = self.relu(x)
-
- batch, rchannel = x.shape[:2]
- if self.radix > 1:
- splits = x.view(batch, self.radix, -1, *x.shape[2:])
- gap = splits.sum(dim=1)
- else:
- gap = x
- gap = F.adaptive_avg_pool2d(gap, 1)
- gap = self.fc1(gap)
-
- gap = self.norm1(gap)
- gap = self.relu(gap)
-
- atten = self.fc2(gap)
- atten = self.rsoftmax(atten).view(batch, -1, 1, 1)
-
- if self.radix > 1:
- attens = atten.view(batch, self.radix, -1, *atten.shape[2:])
- out = torch.sum(attens * splits, dim=1)
- else:
- out = atten * x
- return out.contiguous()
-
-
-class Bottleneck(_Bottleneck):
- """Bottleneck block for ResNeSt.
-
- Args:
- in_channels (int): Input channels of this block.
- out_channels (int): Output channels of this block.
- groups (int): Groups of conv2.
- width_per_group (int): Width per group of conv2. 64x4d indicates
- ``groups=64, width_per_group=4`` and 32x8d indicates
- ``groups=32, width_per_group=8``.
- radix (int): Radix of SpltAtConv2d. Default: 2
- reduction_factor (int): Reduction factor of SplitAttentionConv2d.
- Default: 4.
- avg_down_stride (bool): Whether to use average pool for stride in
- Bottleneck. Default: True.
- stride (int): stride of the block. Default: 1
- dilation (int): dilation of convolution. Default: 1
- downsample (nn.Module): downsample operation on identity branch.
- Default: None
- style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
- layer is the 3x3 conv layer, otherwise the stride-two layer is
- the first 1x1 conv layer.
- conv_cfg (dict): dictionary to construct and config conv layer.
- Default: None
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- groups=1,
- width_per_group=4,
- base_channels=64,
- radix=2,
- reduction_factor=4,
- avg_down_stride=True,
- **kwargs):
- super().__init__(in_channels, out_channels, **kwargs)
-
- self.groups = groups
- self.width_per_group = width_per_group
-
- # For ResNet bottleneck, middle channels are determined by expansion
- # and out_channels, but for ResNeXt bottleneck, it is determined by
- # groups and width_per_group and the stage it is located in.
- if groups != 1:
- assert self.mid_channels % base_channels == 0
- self.mid_channels = (
- groups * width_per_group * self.mid_channels // base_channels)
-
- self.avg_down_stride = avg_down_stride and self.conv2_stride > 1
-
- self.norm1_name, norm1 = build_norm_layer(
- self.norm_cfg, self.mid_channels, postfix=1)
- self.norm3_name, norm3 = build_norm_layer(
- self.norm_cfg, self.out_channels, postfix=3)
-
- self.conv1 = build_conv_layer(
- self.conv_cfg,
- self.in_channels,
- self.mid_channels,
- kernel_size=1,
- stride=self.conv1_stride,
- bias=False)
- self.add_module(self.norm1_name, norm1)
- self.conv2 = SplitAttentionConv2d(
- self.mid_channels,
- self.mid_channels,
- kernel_size=3,
- stride=1 if self.avg_down_stride else self.conv2_stride,
- padding=self.dilation,
- dilation=self.dilation,
- groups=groups,
- radix=radix,
- reduction_factor=reduction_factor,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg)
- delattr(self, self.norm2_name)
-
- if self.avg_down_stride:
- self.avd_layer = nn.AvgPool2d(3, self.conv2_stride, padding=1)
-
- self.conv3 = build_conv_layer(
- self.conv_cfg,
- self.mid_channels,
- self.out_channels,
- kernel_size=1,
- bias=False)
- self.add_module(self.norm3_name, norm3)
-
- def forward(self, x):
-
- def _inner_forward(x):
- identity = x
-
- out = self.conv1(x)
- out = self.norm1(out)
- out = self.relu(out)
-
- out = self.conv2(out)
-
- if self.avg_down_stride:
- out = self.avd_layer(out)
-
- out = self.conv3(out)
- out = self.norm3(out)
-
- if self.downsample is not None:
- identity = self.downsample(x)
-
- out += identity
-
- return out
-
- if self.with_cp and x.requires_grad:
- out = cp.checkpoint(_inner_forward, x)
- else:
- out = _inner_forward(x)
-
- out = self.relu(out)
-
- return out
-
-
-@MODELS.register_module()
-class ResNeSt(ResNetV1d):
- """ResNeSt backbone.
-
- Please refer to the `paper `__
- for details.
-
- Args:
- depth (int): Network depth, from {50, 101, 152, 200}.
- groups (int): Groups of conv2 in Bottleneck. Default: 32.
- width_per_group (int): Width per group of conv2 in Bottleneck.
- Default: 4.
- radix (int): Radix of SpltAtConv2d. Default: 2
- reduction_factor (int): Reduction factor of SplitAttentionConv2d.
- Default: 4.
- avg_down_stride (bool): Whether to use average pool for stride in
- Bottleneck. Default: True.
- in_channels (int): Number of input image channels. Default: 3.
- stem_channels (int): Output channels of the stem layer. Default: 64.
- num_stages (int): Stages of the network. Default: 4.
- strides (Sequence[int]): Strides of the first block of each stage.
- Default: ``(1, 2, 2, 2)``.
- dilations (Sequence[int]): Dilation of each stage.
- Default: ``(1, 1, 1, 1)``.
- out_indices (Sequence[int]): Output from which stages. If only one
- stage is specified, a single tensor (feature map) is returned,
- otherwise multiple stages are specified, a tuple of tensors will
- be returned. Default: ``(3, )``.
- style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
- layer is the 3x3 conv layer, otherwise the stride-two layer is
- the first 1x1 conv layer.
- deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv.
- Default: False.
- avg_down (bool): Use AvgPool instead of stride conv when
- downsampling in the bottleneck. Default: False.
- frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
- -1 means not freezing any parameters. Default: -1.
- conv_cfg (dict | None): The config dict for conv layers. Default: None.
- norm_cfg (dict): The config dict for norm layers.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only. Default: False.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed. Default: False.
- zero_init_residual (bool): Whether to use zero init for last norm layer
- in resblocks to let them behave as identity. Default: True.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Kaiming', layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]``
- """
-
- arch_settings = {
- 50: (Bottleneck, (3, 4, 6, 3)),
- 101: (Bottleneck, (3, 4, 23, 3)),
- 152: (Bottleneck, (3, 8, 36, 3)),
- 200: (Bottleneck, (3, 24, 36, 3)),
- 269: (Bottleneck, (3, 30, 48, 8))
- }
-
- def __init__(self,
- depth,
- groups=1,
- width_per_group=4,
- radix=2,
- reduction_factor=4,
- avg_down_stride=True,
- **kwargs):
- self.groups = groups
- self.width_per_group = width_per_group
- self.radix = radix
- self.reduction_factor = reduction_factor
- self.avg_down_stride = avg_down_stride
- super().__init__(depth=depth, **kwargs)
-
- def make_res_layer(self, **kwargs):
- return ResLayer(
- groups=self.groups,
- width_per_group=self.width_per_group,
- base_channels=self.base_channels,
- radix=self.radix,
- reduction_factor=self.reduction_factor,
- avg_down_stride=self.avg_down_stride,
- **kwargs)
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint as cp
+from mmcv.cnn import build_conv_layer, build_norm_layer
+from mmengine.model import BaseModule
+
+from mmpose.registry import MODELS
+from .resnet import Bottleneck as _Bottleneck
+from .resnet import ResLayer, ResNetV1d
+
+
+class RSoftmax(nn.Module):
+ """Radix Softmax module in ``SplitAttentionConv2d``.
+
+ Args:
+ radix (int): Radix of input.
+ groups (int): Groups of input.
+ """
+
+ def __init__(self, radix, groups):
+ super().__init__()
+ self.radix = radix
+ self.groups = groups
+
+ def forward(self, x):
+ batch = x.size(0)
+ if self.radix > 1:
+ x = x.view(batch, self.groups, self.radix, -1).transpose(1, 2)
+ x = F.softmax(x, dim=1)
+ x = x.reshape(batch, -1)
+ else:
+ x = torch.sigmoid(x)
+ return x
+
+
+class SplitAttentionConv2d(BaseModule):
+ """Split-Attention Conv2d.
+
+ Args:
+ in_channels (int): Same as nn.Conv2d.
+ out_channels (int): Same as nn.Conv2d.
+ kernel_size (int | tuple[int]): Same as nn.Conv2d.
+ stride (int | tuple[int]): Same as nn.Conv2d.
+ padding (int | tuple[int]): Same as nn.Conv2d.
+ dilation (int | tuple[int]): Same as nn.Conv2d.
+ groups (int): Same as nn.Conv2d.
+ radix (int): Radix of SpltAtConv2d. Default: 2
+ reduction_factor (int): Reduction factor of SplitAttentionConv2d.
+ Default: 4.
+ conv_cfg (dict): Config dict for convolution layer. Default: None,
+ which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ channels,
+ kernel_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ radix=2,
+ reduction_factor=4,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ inter_channels = max(in_channels * radix // reduction_factor, 32)
+ self.radix = radix
+ self.groups = groups
+ self.channels = channels
+ self.conv = build_conv_layer(
+ conv_cfg,
+ in_channels,
+ channels * radix,
+ kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ groups=groups * radix,
+ bias=False)
+ self.norm0_name, norm0 = build_norm_layer(
+ norm_cfg, channels * radix, postfix=0)
+ self.add_module(self.norm0_name, norm0)
+ self.relu = nn.ReLU(inplace=True)
+ self.fc1 = build_conv_layer(
+ None, channels, inter_channels, 1, groups=self.groups)
+ self.norm1_name, norm1 = build_norm_layer(
+ norm_cfg, inter_channels, postfix=1)
+ self.add_module(self.norm1_name, norm1)
+ self.fc2 = build_conv_layer(
+ None, inter_channels, channels * radix, 1, groups=self.groups)
+ self.rsoftmax = RSoftmax(radix, groups)
+
+ @property
+ def norm0(self):
+ return getattr(self, self.norm0_name)
+
+ @property
+ def norm1(self):
+ return getattr(self, self.norm1_name)
+
+ def forward(self, x):
+ x = self.conv(x)
+ x = self.norm0(x)
+ x = self.relu(x)
+
+ batch, rchannel = x.shape[:2]
+ if self.radix > 1:
+ splits = x.view(batch, self.radix, -1, *x.shape[2:])
+ gap = splits.sum(dim=1)
+ else:
+ gap = x
+ gap = F.adaptive_avg_pool2d(gap, 1)
+ gap = self.fc1(gap)
+
+ gap = self.norm1(gap)
+ gap = self.relu(gap)
+
+ atten = self.fc2(gap)
+ atten = self.rsoftmax(atten).view(batch, -1, 1, 1)
+
+ if self.radix > 1:
+ attens = atten.view(batch, self.radix, -1, *atten.shape[2:])
+ out = torch.sum(attens * splits, dim=1)
+ else:
+ out = atten * x
+ return out.contiguous()
+
+
+class Bottleneck(_Bottleneck):
+ """Bottleneck block for ResNeSt.
+
+ Args:
+ in_channels (int): Input channels of this block.
+ out_channels (int): Output channels of this block.
+ groups (int): Groups of conv2.
+ width_per_group (int): Width per group of conv2. 64x4d indicates
+ ``groups=64, width_per_group=4`` and 32x8d indicates
+ ``groups=32, width_per_group=8``.
+ radix (int): Radix of SpltAtConv2d. Default: 2
+ reduction_factor (int): Reduction factor of SplitAttentionConv2d.
+ Default: 4.
+ avg_down_stride (bool): Whether to use average pool for stride in
+ Bottleneck. Default: True.
+ stride (int): stride of the block. Default: 1
+ dilation (int): dilation of convolution. Default: 1
+ downsample (nn.Module): downsample operation on identity branch.
+ Default: None
+ style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
+ layer is the 3x3 conv layer, otherwise the stride-two layer is
+ the first 1x1 conv layer.
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ Default: None
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ groups=1,
+ width_per_group=4,
+ base_channels=64,
+ radix=2,
+ reduction_factor=4,
+ avg_down_stride=True,
+ **kwargs):
+ super().__init__(in_channels, out_channels, **kwargs)
+
+ self.groups = groups
+ self.width_per_group = width_per_group
+
+ # For ResNet bottleneck, middle channels are determined by expansion
+ # and out_channels, but for ResNeXt bottleneck, it is determined by
+ # groups and width_per_group and the stage it is located in.
+ if groups != 1:
+ assert self.mid_channels % base_channels == 0
+ self.mid_channels = (
+ groups * width_per_group * self.mid_channels // base_channels)
+
+ self.avg_down_stride = avg_down_stride and self.conv2_stride > 1
+
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, self.mid_channels, postfix=1)
+ self.norm3_name, norm3 = build_norm_layer(
+ self.norm_cfg, self.out_channels, postfix=3)
+
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ self.in_channels,
+ self.mid_channels,
+ kernel_size=1,
+ stride=self.conv1_stride,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+ self.conv2 = SplitAttentionConv2d(
+ self.mid_channels,
+ self.mid_channels,
+ kernel_size=3,
+ stride=1 if self.avg_down_stride else self.conv2_stride,
+ padding=self.dilation,
+ dilation=self.dilation,
+ groups=groups,
+ radix=radix,
+ reduction_factor=reduction_factor,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg)
+ delattr(self, self.norm2_name)
+
+ if self.avg_down_stride:
+ self.avd_layer = nn.AvgPool2d(3, self.conv2_stride, padding=1)
+
+ self.conv3 = build_conv_layer(
+ self.conv_cfg,
+ self.mid_channels,
+ self.out_channels,
+ kernel_size=1,
+ bias=False)
+ self.add_module(self.norm3_name, norm3)
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ identity = x
+
+ out = self.conv1(x)
+ out = self.norm1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+
+ if self.avg_down_stride:
+ out = self.avd_layer(out)
+
+ out = self.conv3(out)
+ out = self.norm3(out)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ out = self.relu(out)
+
+ return out
+
+
+@MODELS.register_module()
+class ResNeSt(ResNetV1d):
+ """ResNeSt backbone.
+
+ Please refer to the `paper `__
+ for details.
+
+ Args:
+ depth (int): Network depth, from {50, 101, 152, 200}.
+ groups (int): Groups of conv2 in Bottleneck. Default: 32.
+ width_per_group (int): Width per group of conv2 in Bottleneck.
+ Default: 4.
+ radix (int): Radix of SpltAtConv2d. Default: 2
+ reduction_factor (int): Reduction factor of SplitAttentionConv2d.
+ Default: 4.
+ avg_down_stride (bool): Whether to use average pool for stride in
+ Bottleneck. Default: True.
+ in_channels (int): Number of input image channels. Default: 3.
+ stem_channels (int): Output channels of the stem layer. Default: 64.
+ num_stages (int): Stages of the network. Default: 4.
+ strides (Sequence[int]): Strides of the first block of each stage.
+ Default: ``(1, 2, 2, 2)``.
+ dilations (Sequence[int]): Dilation of each stage.
+ Default: ``(1, 1, 1, 1)``.
+ out_indices (Sequence[int]): Output from which stages. If only one
+ stage is specified, a single tensor (feature map) is returned,
+ otherwise multiple stages are specified, a tuple of tensors will
+ be returned. Default: ``(3, )``.
+ style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
+ layer is the 3x3 conv layer, otherwise the stride-two layer is
+ the first 1x1 conv layer.
+ deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv.
+ Default: False.
+ avg_down (bool): Use AvgPool instead of stride conv when
+ downsampling in the bottleneck. Default: False.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters. Default: -1.
+ conv_cfg (dict | None): The config dict for conv layers. Default: None.
+ norm_cfg (dict): The config dict for norm layers.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ zero_init_residual (bool): Whether to use zero init for last norm layer
+ in resblocks to let them behave as identity. Default: True.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Kaiming', layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+ """
+
+ arch_settings = {
+ 50: (Bottleneck, (3, 4, 6, 3)),
+ 101: (Bottleneck, (3, 4, 23, 3)),
+ 152: (Bottleneck, (3, 8, 36, 3)),
+ 200: (Bottleneck, (3, 24, 36, 3)),
+ 269: (Bottleneck, (3, 30, 48, 8))
+ }
+
+ def __init__(self,
+ depth,
+ groups=1,
+ width_per_group=4,
+ radix=2,
+ reduction_factor=4,
+ avg_down_stride=True,
+ **kwargs):
+ self.groups = groups
+ self.width_per_group = width_per_group
+ self.radix = radix
+ self.reduction_factor = reduction_factor
+ self.avg_down_stride = avg_down_stride
+ super().__init__(depth=depth, **kwargs)
+
+ def make_res_layer(self, **kwargs):
+ return ResLayer(
+ groups=self.groups,
+ width_per_group=self.width_per_group,
+ base_channels=self.base_channels,
+ radix=self.radix,
+ reduction_factor=self.reduction_factor,
+ avg_down_stride=self.avg_down_stride,
+ **kwargs)
diff --git a/mmpose/models/backbones/resnet.py b/mmpose/models/backbones/resnet.py
index a04853f60d..1a2b3622b4 100644
--- a/mmpose/models/backbones/resnet.py
+++ b/mmpose/models/backbones/resnet.py
@@ -1,715 +1,715 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-
-import torch.nn as nn
-import torch.utils.checkpoint as cp
-from mmcv.cnn import ConvModule, build_conv_layer, build_norm_layer
-from mmengine.model import BaseModule, constant_init
-from mmengine.utils.dl_utils.parrots_wrapper import _BatchNorm
-
-from mmpose.registry import MODELS
-from .base_backbone import BaseBackbone
-
-
-class BasicBlock(BaseModule):
- """BasicBlock for ResNet.
-
- Args:
- in_channels (int): Input channels of this block.
- out_channels (int): Output channels of this block.
- expansion (int): The ratio of ``out_channels/mid_channels`` where
- ``mid_channels`` is the output channels of conv1. This is a
- reserved argument in BasicBlock and should always be 1. Default: 1.
- stride (int): stride of the block. Default: 1
- dilation (int): dilation of convolution. Default: 1
- downsample (nn.Module): downsample operation on identity branch.
- Default: None.
- style (str): `pytorch` or `caffe`. It is unused and reserved for
- unified API with Bottleneck.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed.
- conv_cfg (dict): dictionary to construct and config conv layer.
- Default: None
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- expansion=1,
- stride=1,
- dilation=1,
- downsample=None,
- style='pytorch',
- with_cp=False,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.expansion = expansion
- assert self.expansion == 1
- assert out_channels % expansion == 0
- self.mid_channels = out_channels // expansion
- self.stride = stride
- self.dilation = dilation
- self.style = style
- self.with_cp = with_cp
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
-
- self.norm1_name, norm1 = build_norm_layer(
- norm_cfg, self.mid_channels, postfix=1)
- self.norm2_name, norm2 = build_norm_layer(
- norm_cfg, out_channels, postfix=2)
-
- self.conv1 = build_conv_layer(
- conv_cfg,
- in_channels,
- self.mid_channels,
- 3,
- stride=stride,
- padding=dilation,
- dilation=dilation,
- bias=False)
- self.add_module(self.norm1_name, norm1)
- self.conv2 = build_conv_layer(
- conv_cfg,
- self.mid_channels,
- out_channels,
- 3,
- padding=1,
- bias=False)
- self.add_module(self.norm2_name, norm2)
-
- self.relu = nn.ReLU(inplace=True)
- self.downsample = downsample
-
- @property
- def norm1(self):
- """nn.Module: the normalization layer named "norm1" """
- return getattr(self, self.norm1_name)
-
- @property
- def norm2(self):
- """nn.Module: the normalization layer named "norm2" """
- return getattr(self, self.norm2_name)
-
- def forward(self, x):
- """Forward function."""
-
- def _inner_forward(x):
- identity = x
-
- out = self.conv1(x)
- out = self.norm1(out)
- out = self.relu(out)
-
- out = self.conv2(out)
- out = self.norm2(out)
-
- if self.downsample is not None:
- identity = self.downsample(x)
-
- out += identity
-
- return out
-
- if self.with_cp and x.requires_grad:
- out = cp.checkpoint(_inner_forward, x)
- else:
- out = _inner_forward(x)
-
- out = self.relu(out)
-
- return out
-
-
-class Bottleneck(BaseModule):
- """Bottleneck block for ResNet.
-
- Args:
- in_channels (int): Input channels of this block.
- out_channels (int): Output channels of this block.
- expansion (int): The ratio of ``out_channels/mid_channels`` where
- ``mid_channels`` is the input/output channels of conv2. Default: 4.
- stride (int): stride of the block. Default: 1
- dilation (int): dilation of convolution. Default: 1
- downsample (nn.Module): downsample operation on identity branch.
- Default: None.
- style (str): ``"pytorch"`` or ``"caffe"``. If set to "pytorch", the
- stride-two layer is the 3x3 conv layer, otherwise the stride-two
- layer is the first 1x1 conv layer. Default: "pytorch".
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed.
- conv_cfg (dict): dictionary to construct and config conv layer.
- Default: None
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- expansion=4,
- stride=1,
- dilation=1,
- downsample=None,
- style='pytorch',
- with_cp=False,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
- assert style in ['pytorch', 'caffe']
-
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.expansion = expansion
- assert out_channels % expansion == 0
- self.mid_channels = out_channels // expansion
- self.stride = stride
- self.dilation = dilation
- self.style = style
- self.with_cp = with_cp
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
-
- if self.style == 'pytorch':
- self.conv1_stride = 1
- self.conv2_stride = stride
- else:
- self.conv1_stride = stride
- self.conv2_stride = 1
-
- self.norm1_name, norm1 = build_norm_layer(
- norm_cfg, self.mid_channels, postfix=1)
- self.norm2_name, norm2 = build_norm_layer(
- norm_cfg, self.mid_channels, postfix=2)
- self.norm3_name, norm3 = build_norm_layer(
- norm_cfg, out_channels, postfix=3)
-
- self.conv1 = build_conv_layer(
- conv_cfg,
- in_channels,
- self.mid_channels,
- kernel_size=1,
- stride=self.conv1_stride,
- bias=False)
- self.add_module(self.norm1_name, norm1)
- self.conv2 = build_conv_layer(
- conv_cfg,
- self.mid_channels,
- self.mid_channels,
- kernel_size=3,
- stride=self.conv2_stride,
- padding=dilation,
- dilation=dilation,
- bias=False)
-
- self.add_module(self.norm2_name, norm2)
- self.conv3 = build_conv_layer(
- conv_cfg,
- self.mid_channels,
- out_channels,
- kernel_size=1,
- bias=False)
- self.add_module(self.norm3_name, norm3)
-
- self.relu = nn.ReLU(inplace=True)
- self.downsample = downsample
-
- @property
- def norm1(self):
- """nn.Module: the normalization layer named "norm1" """
- return getattr(self, self.norm1_name)
-
- @property
- def norm2(self):
- """nn.Module: the normalization layer named "norm2" """
- return getattr(self, self.norm2_name)
-
- @property
- def norm3(self):
- """nn.Module: the normalization layer named "norm3" """
- return getattr(self, self.norm3_name)
-
- def forward(self, x):
- """Forward function."""
-
- def _inner_forward(x):
- identity = x
-
- out = self.conv1(x)
- out = self.norm1(out)
- out = self.relu(out)
-
- out = self.conv2(out)
- out = self.norm2(out)
- out = self.relu(out)
-
- out = self.conv3(out)
- out = self.norm3(out)
-
- if self.downsample is not None:
- identity = self.downsample(x)
-
- out += identity
-
- return out
-
- if self.with_cp and x.requires_grad:
- out = cp.checkpoint(_inner_forward, x)
- else:
- out = _inner_forward(x)
-
- out = self.relu(out)
-
- return out
-
-
-def get_expansion(block, expansion=None):
- """Get the expansion of a residual block.
-
- The block expansion will be obtained by the following order:
-
- 1. If ``expansion`` is given, just return it.
- 2. If ``block`` has the attribute ``expansion``, then return
- ``block.expansion``.
- 3. Return the default value according the the block type:
- 1 for ``BasicBlock`` and 4 for ``Bottleneck``.
-
- Args:
- block (class): The block class.
- expansion (int | None): The given expansion ratio.
-
- Returns:
- int: The expansion of the block.
- """
- if isinstance(expansion, int):
- assert expansion > 0
- elif expansion is None:
- if hasattr(block, 'expansion'):
- expansion = block.expansion
- elif issubclass(block, BasicBlock):
- expansion = 1
- elif issubclass(block, Bottleneck):
- expansion = 4
- else:
- raise TypeError(f'expansion is not specified for {block.__name__}')
- else:
- raise TypeError('expansion must be an integer or None')
-
- return expansion
-
-
-class ResLayer(nn.Sequential):
- """ResLayer to build ResNet style backbone.
-
- Args:
- block (nn.Module): Residual block used to build ResLayer.
- num_blocks (int): Number of blocks.
- in_channels (int): Input channels of this block.
- out_channels (int): Output channels of this block.
- expansion (int, optional): The expansion for BasicBlock/Bottleneck.
- If not specified, it will firstly be obtained via
- ``block.expansion``. If the block has no attribute "expansion",
- the following default values will be used: 1 for BasicBlock and
- 4 for Bottleneck. Default: None.
- stride (int): stride of the first block. Default: 1.
- avg_down (bool): Use AvgPool instead of stride conv when
- downsampling in the bottleneck. Default: False
- conv_cfg (dict): dictionary to construct and config conv layer.
- Default: None
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- downsample_first (bool): Downsample at the first block or last block.
- False for Hourglass, True for ResNet. Default: True
- """
-
- def __init__(self,
- block,
- num_blocks,
- in_channels,
- out_channels,
- expansion=None,
- stride=1,
- avg_down=False,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- downsample_first=True,
- **kwargs):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- self.block = block
- self.expansion = get_expansion(block, expansion)
-
- downsample = None
- if stride != 1 or in_channels != out_channels:
- downsample = []
- conv_stride = stride
- if avg_down and stride != 1:
- conv_stride = 1
- downsample.append(
- nn.AvgPool2d(
- kernel_size=stride,
- stride=stride,
- ceil_mode=True,
- count_include_pad=False))
- downsample.extend([
- build_conv_layer(
- conv_cfg,
- in_channels,
- out_channels,
- kernel_size=1,
- stride=conv_stride,
- bias=False),
- build_norm_layer(norm_cfg, out_channels)[1]
- ])
- downsample = nn.Sequential(*downsample)
-
- layers = []
- if downsample_first:
- layers.append(
- block(
- in_channels=in_channels,
- out_channels=out_channels,
- expansion=self.expansion,
- stride=stride,
- downsample=downsample,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- **kwargs))
- in_channels = out_channels
- for _ in range(1, num_blocks):
- layers.append(
- block(
- in_channels=in_channels,
- out_channels=out_channels,
- expansion=self.expansion,
- stride=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- **kwargs))
- else: # downsample_first=False is for HourglassModule
- for i in range(0, num_blocks - 1):
- layers.append(
- block(
- in_channels=in_channels,
- out_channels=in_channels,
- expansion=self.expansion,
- stride=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- **kwargs))
- layers.append(
- block(
- in_channels=in_channels,
- out_channels=out_channels,
- expansion=self.expansion,
- stride=stride,
- downsample=downsample,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- **kwargs))
-
- super().__init__(*layers)
-
-
-@MODELS.register_module()
-class ResNet(BaseBackbone):
- """ResNet backbone.
-
- Please refer to the `paper `__ for
- details.
-
- Args:
- depth (int): Network depth, from {18, 34, 50, 101, 152}.
- in_channels (int): Number of input image channels. Default: 3.
- stem_channels (int): Output channels of the stem layer. Default: 64.
- base_channels (int): Middle channels of the first stage. Default: 64.
- num_stages (int): Stages of the network. Default: 4.
- strides (Sequence[int]): Strides of the first block of each stage.
- Default: ``(1, 2, 2, 2)``.
- dilations (Sequence[int]): Dilation of each stage.
- Default: ``(1, 1, 1, 1)``.
- out_indices (Sequence[int]): Output from which stages. If only one
- stage is specified, a single tensor (feature map) is returned,
- otherwise multiple stages are specified, a tuple of tensors will
- be returned. Default: ``(3, )``.
- style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
- layer is the 3x3 conv layer, otherwise the stride-two layer is
- the first 1x1 conv layer.
- deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv.
- Default: False.
- avg_down (bool): Use AvgPool instead of stride conv when
- downsampling in the bottleneck. Default: False.
- frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
- -1 means not freezing any parameters. Default: -1.
- conv_cfg (dict | None): The config dict for conv layers. Default: None.
- norm_cfg (dict): The config dict for norm layers.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only. Default: False.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed. Default: False.
- zero_init_residual (bool): Whether to use zero init for last norm layer
- in resblocks to let them behave as identity. Default: True.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Kaiming', layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]``
-
- Example:
- >>> from mmpose.models import ResNet
- >>> import torch
- >>> self = ResNet(depth=18, out_indices=(0, 1, 2, 3))
- >>> self.eval()
- >>> inputs = torch.rand(1, 3, 32, 32)
- >>> level_outputs = self.forward(inputs)
- >>> for level_out in level_outputs:
- ... print(tuple(level_out.shape))
- (1, 64, 8, 8)
- (1, 128, 4, 4)
- (1, 256, 2, 2)
- (1, 512, 1, 1)
- """
-
- arch_settings = {
- 18: (BasicBlock, (2, 2, 2, 2)),
- 34: (BasicBlock, (3, 4, 6, 3)),
- 50: (Bottleneck, (3, 4, 6, 3)),
- 101: (Bottleneck, (3, 4, 23, 3)),
- 152: (Bottleneck, (3, 8, 36, 3))
- }
-
- def __init__(self,
- depth,
- in_channels=3,
- stem_channels=64,
- base_channels=64,
- expansion=None,
- num_stages=4,
- strides=(1, 2, 2, 2),
- dilations=(1, 1, 1, 1),
- out_indices=(3, ),
- style='pytorch',
- deep_stem=False,
- avg_down=False,
- frozen_stages=-1,
- conv_cfg=None,
- norm_cfg=dict(type='BN', requires_grad=True),
- norm_eval=False,
- with_cp=False,
- zero_init_residual=True,
- init_cfg=[
- dict(type='Kaiming', layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- super(ResNet, self).__init__(init_cfg)
- if depth not in self.arch_settings:
- raise KeyError(f'invalid depth {depth} for resnet')
- self.depth = depth
- self.stem_channels = stem_channels
- self.base_channels = base_channels
- self.num_stages = num_stages
- assert 1 <= num_stages <= 4
- self.strides = strides
- self.dilations = dilations
- assert len(strides) == len(dilations) == num_stages
- self.out_indices = out_indices
- assert max(out_indices) < num_stages
- self.style = style
- self.deep_stem = deep_stem
- self.avg_down = avg_down
- self.frozen_stages = frozen_stages
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- self.with_cp = with_cp
- self.norm_eval = norm_eval
- self.zero_init_residual = zero_init_residual
- self.block, stage_blocks = self.arch_settings[depth]
- self.stage_blocks = stage_blocks[:num_stages]
- self.expansion = get_expansion(self.block, expansion)
-
- self._make_stem_layer(in_channels, stem_channels)
-
- self.res_layers = []
- _in_channels = stem_channels
- _out_channels = base_channels * self.expansion
- for i, num_blocks in enumerate(self.stage_blocks):
- stride = strides[i]
- dilation = dilations[i]
- res_layer = self.make_res_layer(
- block=self.block,
- num_blocks=num_blocks,
- in_channels=_in_channels,
- out_channels=_out_channels,
- expansion=self.expansion,
- stride=stride,
- dilation=dilation,
- style=self.style,
- avg_down=self.avg_down,
- with_cp=with_cp,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg)
- _in_channels = _out_channels
- _out_channels *= 2
- layer_name = f'layer{i + 1}'
- self.add_module(layer_name, res_layer)
- self.res_layers.append(layer_name)
-
- self._freeze_stages()
-
- self.feat_dim = res_layer[-1].out_channels
-
- def make_res_layer(self, **kwargs):
- """Make a ResLayer."""
- return ResLayer(**kwargs)
-
- @property
- def norm1(self):
- """nn.Module: the normalization layer named "norm1" """
- return getattr(self, self.norm1_name)
-
- def _make_stem_layer(self, in_channels, stem_channels):
- """Make stem layer."""
- if self.deep_stem:
- self.stem = nn.Sequential(
- ConvModule(
- in_channels,
- stem_channels // 2,
- kernel_size=3,
- stride=2,
- padding=1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- inplace=True),
- ConvModule(
- stem_channels // 2,
- stem_channels // 2,
- kernel_size=3,
- stride=1,
- padding=1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- inplace=True),
- ConvModule(
- stem_channels // 2,
- stem_channels,
- kernel_size=3,
- stride=1,
- padding=1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- inplace=True))
- else:
- self.conv1 = build_conv_layer(
- self.conv_cfg,
- in_channels,
- stem_channels,
- kernel_size=7,
- stride=2,
- padding=3,
- bias=False)
- self.norm1_name, norm1 = build_norm_layer(
- self.norm_cfg, stem_channels, postfix=1)
- self.add_module(self.norm1_name, norm1)
- self.relu = nn.ReLU(inplace=True)
- self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
-
- def _freeze_stages(self):
- """Freeze parameters."""
- if self.frozen_stages >= 0:
- if self.deep_stem:
- self.stem.eval()
- for param in self.stem.parameters():
- param.requires_grad = False
- else:
- self.norm1.eval()
- for m in [self.conv1, self.norm1]:
- for param in m.parameters():
- param.requires_grad = False
-
- for i in range(1, self.frozen_stages + 1):
- m = getattr(self, f'layer{i}')
- m.eval()
- for param in m.parameters():
- param.requires_grad = False
-
- def init_weights(self):
- """Initialize the weights in backbone."""
- super(ResNet, self).init_weights()
-
- if (isinstance(self.init_cfg, dict)
- and self.init_cfg['type'] == 'Pretrained'):
- # Suppress zero_init_residual if use pretrained model.
- return
-
- if self.zero_init_residual:
- for m in self.modules():
- if isinstance(m, Bottleneck):
- constant_init(m.norm3, 0)
- elif isinstance(m, BasicBlock):
- constant_init(m.norm2, 0)
-
- def forward(self, x):
- """Forward function."""
- if self.deep_stem:
- x = self.stem(x)
- else:
- x = self.conv1(x)
- x = self.norm1(x)
- x = self.relu(x)
- x = self.maxpool(x)
- outs = []
- for i, layer_name in enumerate(self.res_layers):
- res_layer = getattr(self, layer_name)
- x = res_layer(x)
- if i in self.out_indices:
- outs.append(x)
- return tuple(outs)
-
- def train(self, mode=True):
- """Convert the model into training mode."""
- super().train(mode)
- self._freeze_stages()
- if mode and self.norm_eval:
- for m in self.modules():
- # trick: eval have effect on BatchNorm only
- if isinstance(m, _BatchNorm):
- m.eval()
-
-
-@MODELS.register_module()
-class ResNetV1d(ResNet):
- r"""ResNetV1d variant described in `Bag of Tricks
- `__.
-
- Compared with default ResNet(ResNetV1b), ResNetV1d replaces the 7x7 conv in
- the input stem with three 3x3 convs. And in the downsampling block, a 2x2
- avg_pool with stride 2 is added before conv, whose stride is changed to 1.
- """
-
- def __init__(self, **kwargs):
- super().__init__(deep_stem=True, avg_down=True, **kwargs)
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import torch.nn as nn
+import torch.utils.checkpoint as cp
+from mmcv.cnn import ConvModule, build_conv_layer, build_norm_layer
+from mmengine.model import BaseModule, constant_init
+from mmengine.utils.dl_utils.parrots_wrapper import _BatchNorm
+
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+
+
+class BasicBlock(BaseModule):
+ """BasicBlock for ResNet.
+
+ Args:
+ in_channels (int): Input channels of this block.
+ out_channels (int): Output channels of this block.
+ expansion (int): The ratio of ``out_channels/mid_channels`` where
+ ``mid_channels`` is the output channels of conv1. This is a
+ reserved argument in BasicBlock and should always be 1. Default: 1.
+ stride (int): stride of the block. Default: 1
+ dilation (int): dilation of convolution. Default: 1
+ downsample (nn.Module): downsample operation on identity branch.
+ Default: None.
+ style (str): `pytorch` or `caffe`. It is unused and reserved for
+ unified API with Bottleneck.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ Default: None
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ expansion=1,
+ stride=1,
+ dilation=1,
+ downsample=None,
+ style='pytorch',
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.expansion = expansion
+ assert self.expansion == 1
+ assert out_channels % expansion == 0
+ self.mid_channels = out_channels // expansion
+ self.stride = stride
+ self.dilation = dilation
+ self.style = style
+ self.with_cp = with_cp
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+
+ self.norm1_name, norm1 = build_norm_layer(
+ norm_cfg, self.mid_channels, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(
+ norm_cfg, out_channels, postfix=2)
+
+ self.conv1 = build_conv_layer(
+ conv_cfg,
+ in_channels,
+ self.mid_channels,
+ 3,
+ stride=stride,
+ padding=dilation,
+ dilation=dilation,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+ self.conv2 = build_conv_layer(
+ conv_cfg,
+ self.mid_channels,
+ out_channels,
+ 3,
+ padding=1,
+ bias=False)
+ self.add_module(self.norm2_name, norm2)
+
+ self.relu = nn.ReLU(inplace=True)
+ self.downsample = downsample
+
+ @property
+ def norm1(self):
+ """nn.Module: the normalization layer named "norm1" """
+ return getattr(self, self.norm1_name)
+
+ @property
+ def norm2(self):
+ """nn.Module: the normalization layer named "norm2" """
+ return getattr(self, self.norm2_name)
+
+ def forward(self, x):
+ """Forward function."""
+
+ def _inner_forward(x):
+ identity = x
+
+ out = self.conv1(x)
+ out = self.norm1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+ out = self.norm2(out)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ out = self.relu(out)
+
+ return out
+
+
+class Bottleneck(BaseModule):
+ """Bottleneck block for ResNet.
+
+ Args:
+ in_channels (int): Input channels of this block.
+ out_channels (int): Output channels of this block.
+ expansion (int): The ratio of ``out_channels/mid_channels`` where
+ ``mid_channels`` is the input/output channels of conv2. Default: 4.
+ stride (int): stride of the block. Default: 1
+ dilation (int): dilation of convolution. Default: 1
+ downsample (nn.Module): downsample operation on identity branch.
+ Default: None.
+ style (str): ``"pytorch"`` or ``"caffe"``. If set to "pytorch", the
+ stride-two layer is the 3x3 conv layer, otherwise the stride-two
+ layer is the first 1x1 conv layer. Default: "pytorch".
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ Default: None
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ expansion=4,
+ stride=1,
+ dilation=1,
+ downsample=None,
+ style='pytorch',
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ assert style in ['pytorch', 'caffe']
+
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.expansion = expansion
+ assert out_channels % expansion == 0
+ self.mid_channels = out_channels // expansion
+ self.stride = stride
+ self.dilation = dilation
+ self.style = style
+ self.with_cp = with_cp
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+
+ if self.style == 'pytorch':
+ self.conv1_stride = 1
+ self.conv2_stride = stride
+ else:
+ self.conv1_stride = stride
+ self.conv2_stride = 1
+
+ self.norm1_name, norm1 = build_norm_layer(
+ norm_cfg, self.mid_channels, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(
+ norm_cfg, self.mid_channels, postfix=2)
+ self.norm3_name, norm3 = build_norm_layer(
+ norm_cfg, out_channels, postfix=3)
+
+ self.conv1 = build_conv_layer(
+ conv_cfg,
+ in_channels,
+ self.mid_channels,
+ kernel_size=1,
+ stride=self.conv1_stride,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+ self.conv2 = build_conv_layer(
+ conv_cfg,
+ self.mid_channels,
+ self.mid_channels,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=dilation,
+ dilation=dilation,
+ bias=False)
+
+ self.add_module(self.norm2_name, norm2)
+ self.conv3 = build_conv_layer(
+ conv_cfg,
+ self.mid_channels,
+ out_channels,
+ kernel_size=1,
+ bias=False)
+ self.add_module(self.norm3_name, norm3)
+
+ self.relu = nn.ReLU(inplace=True)
+ self.downsample = downsample
+
+ @property
+ def norm1(self):
+ """nn.Module: the normalization layer named "norm1" """
+ return getattr(self, self.norm1_name)
+
+ @property
+ def norm2(self):
+ """nn.Module: the normalization layer named "norm2" """
+ return getattr(self, self.norm2_name)
+
+ @property
+ def norm3(self):
+ """nn.Module: the normalization layer named "norm3" """
+ return getattr(self, self.norm3_name)
+
+ def forward(self, x):
+ """Forward function."""
+
+ def _inner_forward(x):
+ identity = x
+
+ out = self.conv1(x)
+ out = self.norm1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+ out = self.norm2(out)
+ out = self.relu(out)
+
+ out = self.conv3(out)
+ out = self.norm3(out)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ out = self.relu(out)
+
+ return out
+
+
+def get_expansion(block, expansion=None):
+ """Get the expansion of a residual block.
+
+ The block expansion will be obtained by the following order:
+
+ 1. If ``expansion`` is given, just return it.
+ 2. If ``block`` has the attribute ``expansion``, then return
+ ``block.expansion``.
+ 3. Return the default value according the the block type:
+ 1 for ``BasicBlock`` and 4 for ``Bottleneck``.
+
+ Args:
+ block (class): The block class.
+ expansion (int | None): The given expansion ratio.
+
+ Returns:
+ int: The expansion of the block.
+ """
+ if isinstance(expansion, int):
+ assert expansion > 0
+ elif expansion is None:
+ if hasattr(block, 'expansion'):
+ expansion = block.expansion
+ elif issubclass(block, BasicBlock):
+ expansion = 1
+ elif issubclass(block, Bottleneck):
+ expansion = 4
+ else:
+ raise TypeError(f'expansion is not specified for {block.__name__}')
+ else:
+ raise TypeError('expansion must be an integer or None')
+
+ return expansion
+
+
+class ResLayer(nn.Sequential):
+ """ResLayer to build ResNet style backbone.
+
+ Args:
+ block (nn.Module): Residual block used to build ResLayer.
+ num_blocks (int): Number of blocks.
+ in_channels (int): Input channels of this block.
+ out_channels (int): Output channels of this block.
+ expansion (int, optional): The expansion for BasicBlock/Bottleneck.
+ If not specified, it will firstly be obtained via
+ ``block.expansion``. If the block has no attribute "expansion",
+ the following default values will be used: 1 for BasicBlock and
+ 4 for Bottleneck. Default: None.
+ stride (int): stride of the first block. Default: 1.
+ avg_down (bool): Use AvgPool instead of stride conv when
+ downsampling in the bottleneck. Default: False
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ Default: None
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ downsample_first (bool): Downsample at the first block or last block.
+ False for Hourglass, True for ResNet. Default: True
+ """
+
+ def __init__(self,
+ block,
+ num_blocks,
+ in_channels,
+ out_channels,
+ expansion=None,
+ stride=1,
+ avg_down=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ downsample_first=True,
+ **kwargs):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ self.block = block
+ self.expansion = get_expansion(block, expansion)
+
+ downsample = None
+ if stride != 1 or in_channels != out_channels:
+ downsample = []
+ conv_stride = stride
+ if avg_down and stride != 1:
+ conv_stride = 1
+ downsample.append(
+ nn.AvgPool2d(
+ kernel_size=stride,
+ stride=stride,
+ ceil_mode=True,
+ count_include_pad=False))
+ downsample.extend([
+ build_conv_layer(
+ conv_cfg,
+ in_channels,
+ out_channels,
+ kernel_size=1,
+ stride=conv_stride,
+ bias=False),
+ build_norm_layer(norm_cfg, out_channels)[1]
+ ])
+ downsample = nn.Sequential(*downsample)
+
+ layers = []
+ if downsample_first:
+ layers.append(
+ block(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ expansion=self.expansion,
+ stride=stride,
+ downsample=downsample,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ **kwargs))
+ in_channels = out_channels
+ for _ in range(1, num_blocks):
+ layers.append(
+ block(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ expansion=self.expansion,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ **kwargs))
+ else: # downsample_first=False is for HourglassModule
+ for i in range(0, num_blocks - 1):
+ layers.append(
+ block(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ expansion=self.expansion,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ **kwargs))
+ layers.append(
+ block(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ expansion=self.expansion,
+ stride=stride,
+ downsample=downsample,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ **kwargs))
+
+ super().__init__(*layers)
+
+
+@MODELS.register_module()
+class ResNet(BaseBackbone):
+ """ResNet backbone.
+
+ Please refer to the `paper `__ for
+ details.
+
+ Args:
+ depth (int): Network depth, from {18, 34, 50, 101, 152}.
+ in_channels (int): Number of input image channels. Default: 3.
+ stem_channels (int): Output channels of the stem layer. Default: 64.
+ base_channels (int): Middle channels of the first stage. Default: 64.
+ num_stages (int): Stages of the network. Default: 4.
+ strides (Sequence[int]): Strides of the first block of each stage.
+ Default: ``(1, 2, 2, 2)``.
+ dilations (Sequence[int]): Dilation of each stage.
+ Default: ``(1, 1, 1, 1)``.
+ out_indices (Sequence[int]): Output from which stages. If only one
+ stage is specified, a single tensor (feature map) is returned,
+ otherwise multiple stages are specified, a tuple of tensors will
+ be returned. Default: ``(3, )``.
+ style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
+ layer is the 3x3 conv layer, otherwise the stride-two layer is
+ the first 1x1 conv layer.
+ deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv.
+ Default: False.
+ avg_down (bool): Use AvgPool instead of stride conv when
+ downsampling in the bottleneck. Default: False.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters. Default: -1.
+ conv_cfg (dict | None): The config dict for conv layers. Default: None.
+ norm_cfg (dict): The config dict for norm layers.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ zero_init_residual (bool): Whether to use zero init for last norm layer
+ in resblocks to let them behave as identity. Default: True.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Kaiming', layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+
+ Example:
+ >>> from mmpose.models import ResNet
+ >>> import torch
+ >>> self = ResNet(depth=18, out_indices=(0, 1, 2, 3))
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 32, 32)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 64, 8, 8)
+ (1, 128, 4, 4)
+ (1, 256, 2, 2)
+ (1, 512, 1, 1)
+ """
+
+ arch_settings = {
+ 18: (BasicBlock, (2, 2, 2, 2)),
+ 34: (BasicBlock, (3, 4, 6, 3)),
+ 50: (Bottleneck, (3, 4, 6, 3)),
+ 101: (Bottleneck, (3, 4, 23, 3)),
+ 152: (Bottleneck, (3, 8, 36, 3))
+ }
+
+ def __init__(self,
+ depth,
+ in_channels=3,
+ stem_channels=64,
+ base_channels=64,
+ expansion=None,
+ num_stages=4,
+ strides=(1, 2, 2, 2),
+ dilations=(1, 1, 1, 1),
+ out_indices=(3, ),
+ style='pytorch',
+ deep_stem=False,
+ avg_down=False,
+ frozen_stages=-1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=False,
+ with_cp=False,
+ zero_init_residual=True,
+ init_cfg=[
+ dict(type='Kaiming', layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super(ResNet, self).__init__(init_cfg)
+ if depth not in self.arch_settings:
+ raise KeyError(f'invalid depth {depth} for resnet')
+ self.depth = depth
+ self.stem_channels = stem_channels
+ self.base_channels = base_channels
+ self.num_stages = num_stages
+ assert 1 <= num_stages <= 4
+ self.strides = strides
+ self.dilations = dilations
+ assert len(strides) == len(dilations) == num_stages
+ self.out_indices = out_indices
+ assert max(out_indices) < num_stages
+ self.style = style
+ self.deep_stem = deep_stem
+ self.avg_down = avg_down
+ self.frozen_stages = frozen_stages
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.with_cp = with_cp
+ self.norm_eval = norm_eval
+ self.zero_init_residual = zero_init_residual
+ self.block, stage_blocks = self.arch_settings[depth]
+ self.stage_blocks = stage_blocks[:num_stages]
+ self.expansion = get_expansion(self.block, expansion)
+
+ self._make_stem_layer(in_channels, stem_channels)
+
+ self.res_layers = []
+ _in_channels = stem_channels
+ _out_channels = base_channels * self.expansion
+ for i, num_blocks in enumerate(self.stage_blocks):
+ stride = strides[i]
+ dilation = dilations[i]
+ res_layer = self.make_res_layer(
+ block=self.block,
+ num_blocks=num_blocks,
+ in_channels=_in_channels,
+ out_channels=_out_channels,
+ expansion=self.expansion,
+ stride=stride,
+ dilation=dilation,
+ style=self.style,
+ avg_down=self.avg_down,
+ with_cp=with_cp,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg)
+ _in_channels = _out_channels
+ _out_channels *= 2
+ layer_name = f'layer{i + 1}'
+ self.add_module(layer_name, res_layer)
+ self.res_layers.append(layer_name)
+
+ self._freeze_stages()
+
+ self.feat_dim = res_layer[-1].out_channels
+
+ def make_res_layer(self, **kwargs):
+ """Make a ResLayer."""
+ return ResLayer(**kwargs)
+
+ @property
+ def norm1(self):
+ """nn.Module: the normalization layer named "norm1" """
+ return getattr(self, self.norm1_name)
+
+ def _make_stem_layer(self, in_channels, stem_channels):
+ """Make stem layer."""
+ if self.deep_stem:
+ self.stem = nn.Sequential(
+ ConvModule(
+ in_channels,
+ stem_channels // 2,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ inplace=True),
+ ConvModule(
+ stem_channels // 2,
+ stem_channels // 2,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ inplace=True),
+ ConvModule(
+ stem_channels // 2,
+ stem_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ inplace=True))
+ else:
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ stem_channels,
+ kernel_size=7,
+ stride=2,
+ padding=3,
+ bias=False)
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, stem_channels, postfix=1)
+ self.add_module(self.norm1_name, norm1)
+ self.relu = nn.ReLU(inplace=True)
+ self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
+
+ def _freeze_stages(self):
+ """Freeze parameters."""
+ if self.frozen_stages >= 0:
+ if self.deep_stem:
+ self.stem.eval()
+ for param in self.stem.parameters():
+ param.requires_grad = False
+ else:
+ self.norm1.eval()
+ for m in [self.conv1, self.norm1]:
+ for param in m.parameters():
+ param.requires_grad = False
+
+ for i in range(1, self.frozen_stages + 1):
+ m = getattr(self, f'layer{i}')
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ def init_weights(self):
+ """Initialize the weights in backbone."""
+ super(ResNet, self).init_weights()
+
+ if (isinstance(self.init_cfg, dict)
+ and self.init_cfg['type'] == 'Pretrained'):
+ # Suppress zero_init_residual if use pretrained model.
+ return
+
+ if self.zero_init_residual:
+ for m in self.modules():
+ if isinstance(m, Bottleneck):
+ constant_init(m.norm3, 0)
+ elif isinstance(m, BasicBlock):
+ constant_init(m.norm2, 0)
+
+ def forward(self, x):
+ """Forward function."""
+ if self.deep_stem:
+ x = self.stem(x)
+ else:
+ x = self.conv1(x)
+ x = self.norm1(x)
+ x = self.relu(x)
+ x = self.maxpool(x)
+ outs = []
+ for i, layer_name in enumerate(self.res_layers):
+ res_layer = getattr(self, layer_name)
+ x = res_layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+ return tuple(outs)
+
+ def train(self, mode=True):
+ """Convert the model into training mode."""
+ super().train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ # trick: eval have effect on BatchNorm only
+ if isinstance(m, _BatchNorm):
+ m.eval()
+
+
+@MODELS.register_module()
+class ResNetV1d(ResNet):
+ r"""ResNetV1d variant described in `Bag of Tricks
+ `__.
+
+ Compared with default ResNet(ResNetV1b), ResNetV1d replaces the 7x7 conv in
+ the input stem with three 3x3 convs. And in the downsampling block, a 2x2
+ avg_pool with stride 2 is added before conv, whose stride is changed to 1.
+ """
+
+ def __init__(self, **kwargs):
+ super().__init__(deep_stem=True, avg_down=True, **kwargs)
diff --git a/mmpose/models/backbones/resnext.py b/mmpose/models/backbones/resnext.py
index 241f83a114..cc4d907e3a 100644
--- a/mmpose/models/backbones/resnext.py
+++ b/mmpose/models/backbones/resnext.py
@@ -1,171 +1,171 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmcv.cnn import build_conv_layer, build_norm_layer
-
-from mmpose.registry import MODELS
-from .resnet import Bottleneck as _Bottleneck
-from .resnet import ResLayer, ResNet
-
-
-class Bottleneck(_Bottleneck):
- """Bottleneck block for ResNeXt.
-
- Args:
- in_channels (int): Input channels of this block.
- out_channels (int): Output channels of this block.
- groups (int): Groups of conv2.
- width_per_group (int): Width per group of conv2. 64x4d indicates
- ``groups=64, width_per_group=4`` and 32x8d indicates
- ``groups=32, width_per_group=8``.
- stride (int): stride of the block. Default: 1
- dilation (int): dilation of convolution. Default: 1
- downsample (nn.Module): downsample operation on identity branch.
- Default: None
- style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
- layer is the 3x3 conv layer, otherwise the stride-two layer is
- the first 1x1 conv layer.
- conv_cfg (dict): dictionary to construct and config conv layer.
- Default: None
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed.
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- base_channels=64,
- groups=32,
- width_per_group=4,
- **kwargs):
- super().__init__(in_channels, out_channels, **kwargs)
- self.groups = groups
- self.width_per_group = width_per_group
-
- # For ResNet bottleneck, middle channels are determined by expansion
- # and out_channels, but for ResNeXt bottleneck, it is determined by
- # groups and width_per_group and the stage it is located in.
- if groups != 1:
- assert self.mid_channels % base_channels == 0
- self.mid_channels = (
- groups * width_per_group * self.mid_channels // base_channels)
-
- self.norm1_name, norm1 = build_norm_layer(
- self.norm_cfg, self.mid_channels, postfix=1)
- self.norm2_name, norm2 = build_norm_layer(
- self.norm_cfg, self.mid_channels, postfix=2)
- self.norm3_name, norm3 = build_norm_layer(
- self.norm_cfg, self.out_channels, postfix=3)
-
- self.conv1 = build_conv_layer(
- self.conv_cfg,
- self.in_channels,
- self.mid_channels,
- kernel_size=1,
- stride=self.conv1_stride,
- bias=False)
- self.add_module(self.norm1_name, norm1)
- self.conv2 = build_conv_layer(
- self.conv_cfg,
- self.mid_channels,
- self.mid_channels,
- kernel_size=3,
- stride=self.conv2_stride,
- padding=self.dilation,
- dilation=self.dilation,
- groups=groups,
- bias=False)
-
- self.add_module(self.norm2_name, norm2)
- self.conv3 = build_conv_layer(
- self.conv_cfg,
- self.mid_channels,
- self.out_channels,
- kernel_size=1,
- bias=False)
- self.add_module(self.norm3_name, norm3)
-
-
-@MODELS.register_module()
-class ResNeXt(ResNet):
- """ResNeXt backbone.
-
- Please refer to the `paper `__ for
- details.
-
- Args:
- depth (int): Network depth, from {50, 101, 152}.
- groups (int): Groups of conv2 in Bottleneck. Default: 32.
- width_per_group (int): Width per group of conv2 in Bottleneck.
- Default: 4.
- in_channels (int): Number of input image channels. Default: 3.
- stem_channels (int): Output channels of the stem layer. Default: 64.
- num_stages (int): Stages of the network. Default: 4.
- strides (Sequence[int]): Strides of the first block of each stage.
- Default: ``(1, 2, 2, 2)``.
- dilations (Sequence[int]): Dilation of each stage.
- Default: ``(1, 1, 1, 1)``.
- out_indices (Sequence[int]): Output from which stages. If only one
- stage is specified, a single tensor (feature map) is returned,
- otherwise multiple stages are specified, a tuple of tensors will
- be returned. Default: ``(3, )``.
- style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
- layer is the 3x3 conv layer, otherwise the stride-two layer is
- the first 1x1 conv layer.
- deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv.
- Default: False.
- avg_down (bool): Use AvgPool instead of stride conv when
- downsampling in the bottleneck. Default: False.
- frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
- -1 means not freezing any parameters. Default: -1.
- conv_cfg (dict | None): The config dict for conv layers. Default: None.
- norm_cfg (dict): The config dict for norm layers.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only. Default: False.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed. Default: False.
- zero_init_residual (bool): Whether to use zero init for last norm layer
- in resblocks to let them behave as identity. Default: True.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Kaiming', layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]``
-
- Example:
- >>> from mmpose.models import ResNeXt
- >>> import torch
- >>> self = ResNeXt(depth=50, out_indices=(0, 1, 2, 3))
- >>> self.eval()
- >>> inputs = torch.rand(1, 3, 32, 32)
- >>> level_outputs = self.forward(inputs)
- >>> for level_out in level_outputs:
- ... print(tuple(level_out.shape))
- (1, 256, 8, 8)
- (1, 512, 4, 4)
- (1, 1024, 2, 2)
- (1, 2048, 1, 1)
- """
-
- arch_settings = {
- 50: (Bottleneck, (3, 4, 6, 3)),
- 101: (Bottleneck, (3, 4, 23, 3)),
- 152: (Bottleneck, (3, 8, 36, 3))
- }
-
- def __init__(self, depth, groups=32, width_per_group=4, **kwargs):
- self.groups = groups
- self.width_per_group = width_per_group
- super().__init__(depth, **kwargs)
-
- def make_res_layer(self, **kwargs):
- return ResLayer(
- groups=self.groups,
- width_per_group=self.width_per_group,
- base_channels=self.base_channels,
- **kwargs)
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.cnn import build_conv_layer, build_norm_layer
+
+from mmpose.registry import MODELS
+from .resnet import Bottleneck as _Bottleneck
+from .resnet import ResLayer, ResNet
+
+
+class Bottleneck(_Bottleneck):
+ """Bottleneck block for ResNeXt.
+
+ Args:
+ in_channels (int): Input channels of this block.
+ out_channels (int): Output channels of this block.
+ groups (int): Groups of conv2.
+ width_per_group (int): Width per group of conv2. 64x4d indicates
+ ``groups=64, width_per_group=4`` and 32x8d indicates
+ ``groups=32, width_per_group=8``.
+ stride (int): stride of the block. Default: 1
+ dilation (int): dilation of convolution. Default: 1
+ downsample (nn.Module): downsample operation on identity branch.
+ Default: None
+ style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
+ layer is the 3x3 conv layer, otherwise the stride-two layer is
+ the first 1x1 conv layer.
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ Default: None
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ base_channels=64,
+ groups=32,
+ width_per_group=4,
+ **kwargs):
+ super().__init__(in_channels, out_channels, **kwargs)
+ self.groups = groups
+ self.width_per_group = width_per_group
+
+ # For ResNet bottleneck, middle channels are determined by expansion
+ # and out_channels, but for ResNeXt bottleneck, it is determined by
+ # groups and width_per_group and the stage it is located in.
+ if groups != 1:
+ assert self.mid_channels % base_channels == 0
+ self.mid_channels = (
+ groups * width_per_group * self.mid_channels // base_channels)
+
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, self.mid_channels, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(
+ self.norm_cfg, self.mid_channels, postfix=2)
+ self.norm3_name, norm3 = build_norm_layer(
+ self.norm_cfg, self.out_channels, postfix=3)
+
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ self.in_channels,
+ self.mid_channels,
+ kernel_size=1,
+ stride=self.conv1_stride,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+ self.conv2 = build_conv_layer(
+ self.conv_cfg,
+ self.mid_channels,
+ self.mid_channels,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=self.dilation,
+ dilation=self.dilation,
+ groups=groups,
+ bias=False)
+
+ self.add_module(self.norm2_name, norm2)
+ self.conv3 = build_conv_layer(
+ self.conv_cfg,
+ self.mid_channels,
+ self.out_channels,
+ kernel_size=1,
+ bias=False)
+ self.add_module(self.norm3_name, norm3)
+
+
+@MODELS.register_module()
+class ResNeXt(ResNet):
+ """ResNeXt backbone.
+
+ Please refer to the `paper `__ for
+ details.
+
+ Args:
+ depth (int): Network depth, from {50, 101, 152}.
+ groups (int): Groups of conv2 in Bottleneck. Default: 32.
+ width_per_group (int): Width per group of conv2 in Bottleneck.
+ Default: 4.
+ in_channels (int): Number of input image channels. Default: 3.
+ stem_channels (int): Output channels of the stem layer. Default: 64.
+ num_stages (int): Stages of the network. Default: 4.
+ strides (Sequence[int]): Strides of the first block of each stage.
+ Default: ``(1, 2, 2, 2)``.
+ dilations (Sequence[int]): Dilation of each stage.
+ Default: ``(1, 1, 1, 1)``.
+ out_indices (Sequence[int]): Output from which stages. If only one
+ stage is specified, a single tensor (feature map) is returned,
+ otherwise multiple stages are specified, a tuple of tensors will
+ be returned. Default: ``(3, )``.
+ style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
+ layer is the 3x3 conv layer, otherwise the stride-two layer is
+ the first 1x1 conv layer.
+ deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv.
+ Default: False.
+ avg_down (bool): Use AvgPool instead of stride conv when
+ downsampling in the bottleneck. Default: False.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters. Default: -1.
+ conv_cfg (dict | None): The config dict for conv layers. Default: None.
+ norm_cfg (dict): The config dict for norm layers.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ zero_init_residual (bool): Whether to use zero init for last norm layer
+ in resblocks to let them behave as identity. Default: True.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Kaiming', layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+
+ Example:
+ >>> from mmpose.models import ResNeXt
+ >>> import torch
+ >>> self = ResNeXt(depth=50, out_indices=(0, 1, 2, 3))
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 32, 32)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 256, 8, 8)
+ (1, 512, 4, 4)
+ (1, 1024, 2, 2)
+ (1, 2048, 1, 1)
+ """
+
+ arch_settings = {
+ 50: (Bottleneck, (3, 4, 6, 3)),
+ 101: (Bottleneck, (3, 4, 23, 3)),
+ 152: (Bottleneck, (3, 8, 36, 3))
+ }
+
+ def __init__(self, depth, groups=32, width_per_group=4, **kwargs):
+ self.groups = groups
+ self.width_per_group = width_per_group
+ super().__init__(depth, **kwargs)
+
+ def make_res_layer(self, **kwargs):
+ return ResLayer(
+ groups=self.groups,
+ width_per_group=self.width_per_group,
+ base_channels=self.base_channels,
+ **kwargs)
diff --git a/mmpose/models/backbones/rsn.py b/mmpose/models/backbones/rsn.py
index 8267d23d95..74c689f7a7 100644
--- a/mmpose/models/backbones/rsn.py
+++ b/mmpose/models/backbones/rsn.py
@@ -1,640 +1,640 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy as cp
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from mmcv.cnn import ConvModule, MaxPool2d
-from mmengine.model import BaseModule
-
-from mmpose.registry import MODELS
-from .base_backbone import BaseBackbone
-
-
-class RSB(BaseModule):
- """Residual Steps block for RSN. Paper ref: Cai et al. "Learning Delicate
- Local Representations for Multi-Person Pose Estimation" (ECCV 2020).
-
- Args:
- in_channels (int): Input channels of this block.
- out_channels (int): Output channels of this block.
- num_steps (int): Numbers of steps in RSB
- stride (int): stride of the block. Default: 1
- downsample (nn.Module): downsample operation on identity branch.
- Default: None.
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- expand_times (int): Times by which the in_channels are expanded.
- Default:26.
- res_top_channels (int): Number of channels of feature output by
- ResNet_top. Default:64.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- expansion = 1
-
- def __init__(self,
- in_channels,
- out_channels,
- num_steps=4,
- stride=1,
- downsample=None,
- with_cp=False,
- norm_cfg=dict(type='BN'),
- expand_times=26,
- res_top_channels=64,
- init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = cp.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
- assert num_steps > 1
- self.in_channels = in_channels
- self.branch_channels = self.in_channels * expand_times
- self.branch_channels //= res_top_channels
- self.out_channels = out_channels
- self.stride = stride
- self.downsample = downsample
- self.with_cp = with_cp
- self.norm_cfg = norm_cfg
- self.num_steps = num_steps
- self.conv_bn_relu1 = ConvModule(
- self.in_channels,
- self.num_steps * self.branch_channels,
- kernel_size=1,
- stride=self.stride,
- padding=0,
- norm_cfg=self.norm_cfg,
- inplace=False)
- for i in range(self.num_steps):
- for j in range(i + 1):
- module_name = f'conv_bn_relu2_{i + 1}_{j + 1}'
- self.add_module(
- module_name,
- ConvModule(
- self.branch_channels,
- self.branch_channels,
- kernel_size=3,
- stride=1,
- padding=1,
- norm_cfg=self.norm_cfg,
- inplace=False))
- self.conv_bn3 = ConvModule(
- self.num_steps * self.branch_channels,
- self.out_channels * self.expansion,
- kernel_size=1,
- stride=1,
- padding=0,
- act_cfg=None,
- norm_cfg=self.norm_cfg,
- inplace=False)
- self.relu = nn.ReLU(inplace=False)
-
- def forward(self, x):
- """Forward function."""
-
- identity = x
- x = self.conv_bn_relu1(x)
- spx = torch.split(x, self.branch_channels, 1)
- outputs = list()
- outs = list()
- for i in range(self.num_steps):
- outputs_i = list()
- outputs.append(outputs_i)
- for j in range(i + 1):
- if j == 0:
- inputs = spx[i]
- else:
- inputs = outputs[i][j - 1]
- if i > j:
- inputs = inputs + outputs[i - 1][j]
- module_name = f'conv_bn_relu2_{i + 1}_{j + 1}'
- module_i_j = getattr(self, module_name)
- outputs[i].append(module_i_j(inputs))
-
- outs.append(outputs[i][i])
- out = torch.cat(tuple(outs), 1)
- out = self.conv_bn3(out)
-
- if self.downsample is not None:
- identity = self.downsample(identity)
- out = out + identity
-
- out = self.relu(out)
-
- return out
-
-
-class Downsample_module(BaseModule):
- """Downsample module for RSN.
-
- Args:
- block (nn.Module): Downsample block.
- num_blocks (list): Number of blocks in each downsample unit.
- num_units (int): Numbers of downsample units. Default: 4
- has_skip (bool): Have skip connections from prior upsample
- module or not. Default:False
- num_steps (int): Number of steps in a block. Default:4
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- in_channels (int): Number of channels of the input feature to
- downsample module. Default: 64
- expand_times (int): Times by which the in_channels are expanded.
- Default:26.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- block,
- num_blocks,
- num_steps=4,
- num_units=4,
- has_skip=False,
- norm_cfg=dict(type='BN'),
- in_channels=64,
- expand_times=26,
- init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = cp.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
- self.has_skip = has_skip
- self.in_channels = in_channels
- assert len(num_blocks) == num_units
- self.num_blocks = num_blocks
- self.num_units = num_units
- self.num_steps = num_steps
- self.norm_cfg = norm_cfg
- self.layer1 = self._make_layer(
- block,
- in_channels,
- num_blocks[0],
- expand_times=expand_times,
- res_top_channels=in_channels)
- for i in range(1, num_units):
- module_name = f'layer{i + 1}'
- self.add_module(
- module_name,
- self._make_layer(
- block,
- in_channels * pow(2, i),
- num_blocks[i],
- stride=2,
- expand_times=expand_times,
- res_top_channels=in_channels))
-
- def _make_layer(self,
- block,
- out_channels,
- blocks,
- stride=1,
- expand_times=26,
- res_top_channels=64):
- downsample = None
- if stride != 1 or self.in_channels != out_channels * block.expansion:
- downsample = ConvModule(
- self.in_channels,
- out_channels * block.expansion,
- kernel_size=1,
- stride=stride,
- padding=0,
- norm_cfg=self.norm_cfg,
- act_cfg=None,
- inplace=True)
-
- units = list()
- units.append(
- block(
- self.in_channels,
- out_channels,
- num_steps=self.num_steps,
- stride=stride,
- downsample=downsample,
- norm_cfg=self.norm_cfg,
- expand_times=expand_times,
- res_top_channels=res_top_channels))
- self.in_channels = out_channels * block.expansion
- for _ in range(1, blocks):
- units.append(
- block(
- self.in_channels,
- out_channels,
- num_steps=self.num_steps,
- expand_times=expand_times,
- res_top_channels=res_top_channels))
-
- return nn.Sequential(*units)
-
- def forward(self, x, skip1, skip2):
- out = list()
- for i in range(self.num_units):
- module_name = f'layer{i + 1}'
- module_i = getattr(self, module_name)
- x = module_i(x)
- if self.has_skip:
- x = x + skip1[i] + skip2[i]
- out.append(x)
- out.reverse()
-
- return tuple(out)
-
-
-class Upsample_unit(BaseModule):
- """Upsample unit for upsample module.
-
- Args:
- ind (int): Indicates whether to interpolate (>0) and whether to
- generate feature map for the next hourglass-like module.
- num_units (int): Number of units that form a upsample module. Along
- with ind and gen_cross_conv, nm_units is used to decide whether
- to generate feature map for the next hourglass-like module.
- in_channels (int): Channel number of the skip-in feature maps from
- the corresponding downsample unit.
- unit_channels (int): Channel number in this unit. Default:256.
- gen_skip: (bool): Whether or not to generate skips for the posterior
- downsample module. Default:False
- gen_cross_conv (bool): Whether to generate feature map for the next
- hourglass-like module. Default:False
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- out_channels (in): Number of channels of feature output by upsample
- module. Must equal to in_channels of downsample module. Default:64
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- ind,
- num_units,
- in_channels,
- unit_channels=256,
- gen_skip=False,
- gen_cross_conv=False,
- norm_cfg=dict(type='BN'),
- out_channels=64,
- init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = cp.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
- self.num_units = num_units
- self.norm_cfg = norm_cfg
- self.in_skip = ConvModule(
- in_channels,
- unit_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- norm_cfg=self.norm_cfg,
- act_cfg=None,
- inplace=True)
- self.relu = nn.ReLU(inplace=True)
-
- self.ind = ind
- if self.ind > 0:
- self.up_conv = ConvModule(
- unit_channels,
- unit_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- norm_cfg=self.norm_cfg,
- act_cfg=None,
- inplace=True)
-
- self.gen_skip = gen_skip
- if self.gen_skip:
- self.out_skip1 = ConvModule(
- in_channels,
- in_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- norm_cfg=self.norm_cfg,
- inplace=True)
-
- self.out_skip2 = ConvModule(
- unit_channels,
- in_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- norm_cfg=self.norm_cfg,
- inplace=True)
-
- self.gen_cross_conv = gen_cross_conv
- if self.ind == num_units - 1 and self.gen_cross_conv:
- self.cross_conv = ConvModule(
- unit_channels,
- out_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- norm_cfg=self.norm_cfg,
- inplace=True)
-
- def forward(self, x, up_x):
- out = self.in_skip(x)
-
- if self.ind > 0:
- up_x = F.interpolate(
- up_x,
- size=(x.size(2), x.size(3)),
- mode='bilinear',
- align_corners=True)
- up_x = self.up_conv(up_x)
- out = out + up_x
- out = self.relu(out)
-
- skip1 = None
- skip2 = None
- if self.gen_skip:
- skip1 = self.out_skip1(x)
- skip2 = self.out_skip2(out)
-
- cross_conv = None
- if self.ind == self.num_units - 1 and self.gen_cross_conv:
- cross_conv = self.cross_conv(out)
-
- return out, skip1, skip2, cross_conv
-
-
-class Upsample_module(BaseModule):
- """Upsample module for RSN.
-
- Args:
- unit_channels (int): Channel number in the upsample units.
- Default:256.
- num_units (int): Numbers of upsample units. Default: 4
- gen_skip (bool): Whether to generate skip for posterior downsample
- module or not. Default:False
- gen_cross_conv (bool): Whether to generate feature map for the next
- hourglass-like module. Default:False
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- out_channels (int): Number of channels of feature output by upsample
- module. Must equal to in_channels of downsample module. Default:64
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- unit_channels=256,
- num_units=4,
- gen_skip=False,
- gen_cross_conv=False,
- norm_cfg=dict(type='BN'),
- out_channels=64,
- init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = cp.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
- self.in_channels = list()
- for i in range(num_units):
- self.in_channels.append(RSB.expansion * out_channels * pow(2, i))
- self.in_channels.reverse()
- self.num_units = num_units
- self.gen_skip = gen_skip
- self.gen_cross_conv = gen_cross_conv
- self.norm_cfg = norm_cfg
- for i in range(num_units):
- module_name = f'up{i + 1}'
- self.add_module(
- module_name,
- Upsample_unit(
- i,
- self.num_units,
- self.in_channels[i],
- unit_channels,
- self.gen_skip,
- self.gen_cross_conv,
- norm_cfg=self.norm_cfg,
- out_channels=64))
-
- def forward(self, x):
- out = list()
- skip1 = list()
- skip2 = list()
- cross_conv = None
- for i in range(self.num_units):
- module_i = getattr(self, f'up{i + 1}')
- if i == 0:
- outi, skip1_i, skip2_i, _ = module_i(x[i], None)
- elif i == self.num_units - 1:
- outi, skip1_i, skip2_i, cross_conv = module_i(x[i], out[i - 1])
- else:
- outi, skip1_i, skip2_i, _ = module_i(x[i], out[i - 1])
- out.append(outi)
- skip1.append(skip1_i)
- skip2.append(skip2_i)
- skip1.reverse()
- skip2.reverse()
-
- return out, skip1, skip2, cross_conv
-
-
-class Single_stage_RSN(BaseModule):
- """Single_stage Residual Steps Network.
-
- Args:
- unit_channels (int): Channel number in the upsample units. Default:256.
- num_units (int): Numbers of downsample/upsample units. Default: 4
- gen_skip (bool): Whether to generate skip for posterior downsample
- module or not. Default:False
- gen_cross_conv (bool): Whether to generate feature map for the next
- hourglass-like module. Default:False
- has_skip (bool): Have skip connections from prior upsample
- module or not. Default:False
- num_steps (int): Number of steps in RSB. Default: 4
- num_blocks (list): Number of blocks in each downsample unit.
- Default: [2, 2, 2, 2] Note: Make sure num_units==len(num_blocks)
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- in_channels (int): Number of channels of the feature from ResNet_Top.
- Default: 64.
- expand_times (int): Times by which the in_channels are expanded in RSB.
- Default:26.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- has_skip=False,
- gen_skip=False,
- gen_cross_conv=False,
- unit_channels=256,
- num_units=4,
- num_steps=4,
- num_blocks=[2, 2, 2, 2],
- norm_cfg=dict(type='BN'),
- in_channels=64,
- expand_times=26,
- init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = cp.deepcopy(norm_cfg)
- num_blocks = cp.deepcopy(num_blocks)
- super().__init__(init_cfg=init_cfg)
- assert len(num_blocks) == num_units
- self.has_skip = has_skip
- self.gen_skip = gen_skip
- self.gen_cross_conv = gen_cross_conv
- self.num_units = num_units
- self.num_steps = num_steps
- self.unit_channels = unit_channels
- self.num_blocks = num_blocks
- self.norm_cfg = norm_cfg
-
- self.downsample = Downsample_module(RSB, num_blocks, num_steps,
- num_units, has_skip, norm_cfg,
- in_channels, expand_times)
- self.upsample = Upsample_module(unit_channels, num_units, gen_skip,
- gen_cross_conv, norm_cfg, in_channels)
-
- def forward(self, x, skip1, skip2):
- mid = self.downsample(x, skip1, skip2)
- out, skip1, skip2, cross_conv = self.upsample(mid)
-
- return out, skip1, skip2, cross_conv
-
-
-class ResNet_top(BaseModule):
- """ResNet top for RSN.
-
- Args:
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- channels (int): Number of channels of the feature output by ResNet_top.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self, norm_cfg=dict(type='BN'), channels=64, init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = cp.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
- self.top = nn.Sequential(
- ConvModule(
- 3,
- channels,
- kernel_size=7,
- stride=2,
- padding=3,
- norm_cfg=norm_cfg,
- inplace=True), MaxPool2d(kernel_size=3, stride=2, padding=1))
-
- def forward(self, img):
- return self.top(img)
-
-
-@MODELS.register_module()
-class RSN(BaseBackbone):
- """Residual Steps Network backbone. Paper ref: Cai et al. "Learning
- Delicate Local Representations for Multi-Person Pose Estimation" (ECCV
- 2020).
-
- Args:
- unit_channels (int): Number of Channels in an upsample unit.
- Default: 256
- num_stages (int): Number of stages in a multi-stage RSN. Default: 4
- num_units (int): NUmber of downsample/upsample units in a single-stage
- RSN. Default: 4 Note: Make sure num_units == len(self.num_blocks)
- num_blocks (list): Number of RSBs (Residual Steps Block) in each
- downsample unit. Default: [2, 2, 2, 2]
- num_steps (int): Number of steps in a RSB. Default:4
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- res_top_channels (int): Number of channels of feature from ResNet_top.
- Default: 64.
- expand_times (int): Times by which the in_channels are expanded in RSB.
- Default:26.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Kaiming', layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm']),
- dict(
- type='Normal',
- std=0.01,
- layer=['Linear']),
- ]``
- Example:
- >>> from mmpose.models import RSN
- >>> import torch
- >>> self = RSN(num_stages=2,num_units=2,num_blocks=[2,2])
- >>> self.eval()
- >>> inputs = torch.rand(1, 3, 511, 511)
- >>> level_outputs = self.forward(inputs)
- >>> for level_output in level_outputs:
- ... for feature in level_output:
- ... print(tuple(feature.shape))
- ...
- (1, 256, 64, 64)
- (1, 256, 128, 128)
- (1, 256, 64, 64)
- (1, 256, 128, 128)
- """
-
- def __init__(self,
- unit_channels=256,
- num_stages=4,
- num_units=4,
- num_blocks=[2, 2, 2, 2],
- num_steps=4,
- norm_cfg=dict(type='BN'),
- res_top_channels=64,
- expand_times=26,
- init_cfg=[
- dict(type='Kaiming', layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm']),
- dict(type='Normal', std=0.01, layer=['Linear']),
- ]):
- # Protect mutable default arguments
- norm_cfg = cp.deepcopy(norm_cfg)
- num_blocks = cp.deepcopy(num_blocks)
- super().__init__(init_cfg=init_cfg)
- self.unit_channels = unit_channels
- self.num_stages = num_stages
- self.num_units = num_units
- self.num_blocks = num_blocks
- self.num_steps = num_steps
- self.norm_cfg = norm_cfg
-
- assert self.num_stages > 0
- assert self.num_steps > 1
- assert self.num_units > 1
- assert self.num_units == len(self.num_blocks)
- self.top = ResNet_top(norm_cfg=norm_cfg)
- self.multi_stage_rsn = nn.ModuleList([])
- for i in range(self.num_stages):
- if i == 0:
- has_skip = False
- else:
- has_skip = True
- if i != self.num_stages - 1:
- gen_skip = True
- gen_cross_conv = True
- else:
- gen_skip = False
- gen_cross_conv = False
- self.multi_stage_rsn.append(
- Single_stage_RSN(has_skip, gen_skip, gen_cross_conv,
- unit_channels, num_units, num_steps,
- num_blocks, norm_cfg, res_top_channels,
- expand_times))
-
- def forward(self, x):
- """Model forward function."""
- out_feats = []
- skip1 = None
- skip2 = None
- x = self.top(x)
- for i in range(self.num_stages):
- out, skip1, skip2, x = self.multi_stage_rsn[i](x, skip1, skip2)
- out_feats.append(out)
-
- return out_feats
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy as cp
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule, MaxPool2d
+from mmengine.model import BaseModule
+
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+
+
+class RSB(BaseModule):
+ """Residual Steps block for RSN. Paper ref: Cai et al. "Learning Delicate
+ Local Representations for Multi-Person Pose Estimation" (ECCV 2020).
+
+ Args:
+ in_channels (int): Input channels of this block.
+ out_channels (int): Output channels of this block.
+ num_steps (int): Numbers of steps in RSB
+ stride (int): stride of the block. Default: 1
+ downsample (nn.Module): downsample operation on identity branch.
+ Default: None.
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ expand_times (int): Times by which the in_channels are expanded.
+ Default:26.
+ res_top_channels (int): Number of channels of feature output by
+ ResNet_top. Default:64.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ expansion = 1
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_steps=4,
+ stride=1,
+ downsample=None,
+ with_cp=False,
+ norm_cfg=dict(type='BN'),
+ expand_times=26,
+ res_top_channels=64,
+ init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = cp.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ assert num_steps > 1
+ self.in_channels = in_channels
+ self.branch_channels = self.in_channels * expand_times
+ self.branch_channels //= res_top_channels
+ self.out_channels = out_channels
+ self.stride = stride
+ self.downsample = downsample
+ self.with_cp = with_cp
+ self.norm_cfg = norm_cfg
+ self.num_steps = num_steps
+ self.conv_bn_relu1 = ConvModule(
+ self.in_channels,
+ self.num_steps * self.branch_channels,
+ kernel_size=1,
+ stride=self.stride,
+ padding=0,
+ norm_cfg=self.norm_cfg,
+ inplace=False)
+ for i in range(self.num_steps):
+ for j in range(i + 1):
+ module_name = f'conv_bn_relu2_{i + 1}_{j + 1}'
+ self.add_module(
+ module_name,
+ ConvModule(
+ self.branch_channels,
+ self.branch_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ inplace=False))
+ self.conv_bn3 = ConvModule(
+ self.num_steps * self.branch_channels,
+ self.out_channels * self.expansion,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ act_cfg=None,
+ norm_cfg=self.norm_cfg,
+ inplace=False)
+ self.relu = nn.ReLU(inplace=False)
+
+ def forward(self, x):
+ """Forward function."""
+
+ identity = x
+ x = self.conv_bn_relu1(x)
+ spx = torch.split(x, self.branch_channels, 1)
+ outputs = list()
+ outs = list()
+ for i in range(self.num_steps):
+ outputs_i = list()
+ outputs.append(outputs_i)
+ for j in range(i + 1):
+ if j == 0:
+ inputs = spx[i]
+ else:
+ inputs = outputs[i][j - 1]
+ if i > j:
+ inputs = inputs + outputs[i - 1][j]
+ module_name = f'conv_bn_relu2_{i + 1}_{j + 1}'
+ module_i_j = getattr(self, module_name)
+ outputs[i].append(module_i_j(inputs))
+
+ outs.append(outputs[i][i])
+ out = torch.cat(tuple(outs), 1)
+ out = self.conv_bn3(out)
+
+ if self.downsample is not None:
+ identity = self.downsample(identity)
+ out = out + identity
+
+ out = self.relu(out)
+
+ return out
+
+
+class Downsample_module(BaseModule):
+ """Downsample module for RSN.
+
+ Args:
+ block (nn.Module): Downsample block.
+ num_blocks (list): Number of blocks in each downsample unit.
+ num_units (int): Numbers of downsample units. Default: 4
+ has_skip (bool): Have skip connections from prior upsample
+ module or not. Default:False
+ num_steps (int): Number of steps in a block. Default:4
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ in_channels (int): Number of channels of the input feature to
+ downsample module. Default: 64
+ expand_times (int): Times by which the in_channels are expanded.
+ Default:26.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ block,
+ num_blocks,
+ num_steps=4,
+ num_units=4,
+ has_skip=False,
+ norm_cfg=dict(type='BN'),
+ in_channels=64,
+ expand_times=26,
+ init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = cp.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self.has_skip = has_skip
+ self.in_channels = in_channels
+ assert len(num_blocks) == num_units
+ self.num_blocks = num_blocks
+ self.num_units = num_units
+ self.num_steps = num_steps
+ self.norm_cfg = norm_cfg
+ self.layer1 = self._make_layer(
+ block,
+ in_channels,
+ num_blocks[0],
+ expand_times=expand_times,
+ res_top_channels=in_channels)
+ for i in range(1, num_units):
+ module_name = f'layer{i + 1}'
+ self.add_module(
+ module_name,
+ self._make_layer(
+ block,
+ in_channels * pow(2, i),
+ num_blocks[i],
+ stride=2,
+ expand_times=expand_times,
+ res_top_channels=in_channels))
+
+ def _make_layer(self,
+ block,
+ out_channels,
+ blocks,
+ stride=1,
+ expand_times=26,
+ res_top_channels=64):
+ downsample = None
+ if stride != 1 or self.in_channels != out_channels * block.expansion:
+ downsample = ConvModule(
+ self.in_channels,
+ out_channels * block.expansion,
+ kernel_size=1,
+ stride=stride,
+ padding=0,
+ norm_cfg=self.norm_cfg,
+ act_cfg=None,
+ inplace=True)
+
+ units = list()
+ units.append(
+ block(
+ self.in_channels,
+ out_channels,
+ num_steps=self.num_steps,
+ stride=stride,
+ downsample=downsample,
+ norm_cfg=self.norm_cfg,
+ expand_times=expand_times,
+ res_top_channels=res_top_channels))
+ self.in_channels = out_channels * block.expansion
+ for _ in range(1, blocks):
+ units.append(
+ block(
+ self.in_channels,
+ out_channels,
+ num_steps=self.num_steps,
+ expand_times=expand_times,
+ res_top_channels=res_top_channels))
+
+ return nn.Sequential(*units)
+
+ def forward(self, x, skip1, skip2):
+ out = list()
+ for i in range(self.num_units):
+ module_name = f'layer{i + 1}'
+ module_i = getattr(self, module_name)
+ x = module_i(x)
+ if self.has_skip:
+ x = x + skip1[i] + skip2[i]
+ out.append(x)
+ out.reverse()
+
+ return tuple(out)
+
+
+class Upsample_unit(BaseModule):
+ """Upsample unit for upsample module.
+
+ Args:
+ ind (int): Indicates whether to interpolate (>0) and whether to
+ generate feature map for the next hourglass-like module.
+ num_units (int): Number of units that form a upsample module. Along
+ with ind and gen_cross_conv, nm_units is used to decide whether
+ to generate feature map for the next hourglass-like module.
+ in_channels (int): Channel number of the skip-in feature maps from
+ the corresponding downsample unit.
+ unit_channels (int): Channel number in this unit. Default:256.
+ gen_skip: (bool): Whether or not to generate skips for the posterior
+ downsample module. Default:False
+ gen_cross_conv (bool): Whether to generate feature map for the next
+ hourglass-like module. Default:False
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ out_channels (in): Number of channels of feature output by upsample
+ module. Must equal to in_channels of downsample module. Default:64
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ ind,
+ num_units,
+ in_channels,
+ unit_channels=256,
+ gen_skip=False,
+ gen_cross_conv=False,
+ norm_cfg=dict(type='BN'),
+ out_channels=64,
+ init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = cp.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self.num_units = num_units
+ self.norm_cfg = norm_cfg
+ self.in_skip = ConvModule(
+ in_channels,
+ unit_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ norm_cfg=self.norm_cfg,
+ act_cfg=None,
+ inplace=True)
+ self.relu = nn.ReLU(inplace=True)
+
+ self.ind = ind
+ if self.ind > 0:
+ self.up_conv = ConvModule(
+ unit_channels,
+ unit_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ norm_cfg=self.norm_cfg,
+ act_cfg=None,
+ inplace=True)
+
+ self.gen_skip = gen_skip
+ if self.gen_skip:
+ self.out_skip1 = ConvModule(
+ in_channels,
+ in_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ norm_cfg=self.norm_cfg,
+ inplace=True)
+
+ self.out_skip2 = ConvModule(
+ unit_channels,
+ in_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ norm_cfg=self.norm_cfg,
+ inplace=True)
+
+ self.gen_cross_conv = gen_cross_conv
+ if self.ind == num_units - 1 and self.gen_cross_conv:
+ self.cross_conv = ConvModule(
+ unit_channels,
+ out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ norm_cfg=self.norm_cfg,
+ inplace=True)
+
+ def forward(self, x, up_x):
+ out = self.in_skip(x)
+
+ if self.ind > 0:
+ up_x = F.interpolate(
+ up_x,
+ size=(x.size(2), x.size(3)),
+ mode='bilinear',
+ align_corners=True)
+ up_x = self.up_conv(up_x)
+ out = out + up_x
+ out = self.relu(out)
+
+ skip1 = None
+ skip2 = None
+ if self.gen_skip:
+ skip1 = self.out_skip1(x)
+ skip2 = self.out_skip2(out)
+
+ cross_conv = None
+ if self.ind == self.num_units - 1 and self.gen_cross_conv:
+ cross_conv = self.cross_conv(out)
+
+ return out, skip1, skip2, cross_conv
+
+
+class Upsample_module(BaseModule):
+ """Upsample module for RSN.
+
+ Args:
+ unit_channels (int): Channel number in the upsample units.
+ Default:256.
+ num_units (int): Numbers of upsample units. Default: 4
+ gen_skip (bool): Whether to generate skip for posterior downsample
+ module or not. Default:False
+ gen_cross_conv (bool): Whether to generate feature map for the next
+ hourglass-like module. Default:False
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ out_channels (int): Number of channels of feature output by upsample
+ module. Must equal to in_channels of downsample module. Default:64
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ unit_channels=256,
+ num_units=4,
+ gen_skip=False,
+ gen_cross_conv=False,
+ norm_cfg=dict(type='BN'),
+ out_channels=64,
+ init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = cp.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self.in_channels = list()
+ for i in range(num_units):
+ self.in_channels.append(RSB.expansion * out_channels * pow(2, i))
+ self.in_channels.reverse()
+ self.num_units = num_units
+ self.gen_skip = gen_skip
+ self.gen_cross_conv = gen_cross_conv
+ self.norm_cfg = norm_cfg
+ for i in range(num_units):
+ module_name = f'up{i + 1}'
+ self.add_module(
+ module_name,
+ Upsample_unit(
+ i,
+ self.num_units,
+ self.in_channels[i],
+ unit_channels,
+ self.gen_skip,
+ self.gen_cross_conv,
+ norm_cfg=self.norm_cfg,
+ out_channels=64))
+
+ def forward(self, x):
+ out = list()
+ skip1 = list()
+ skip2 = list()
+ cross_conv = None
+ for i in range(self.num_units):
+ module_i = getattr(self, f'up{i + 1}')
+ if i == 0:
+ outi, skip1_i, skip2_i, _ = module_i(x[i], None)
+ elif i == self.num_units - 1:
+ outi, skip1_i, skip2_i, cross_conv = module_i(x[i], out[i - 1])
+ else:
+ outi, skip1_i, skip2_i, _ = module_i(x[i], out[i - 1])
+ out.append(outi)
+ skip1.append(skip1_i)
+ skip2.append(skip2_i)
+ skip1.reverse()
+ skip2.reverse()
+
+ return out, skip1, skip2, cross_conv
+
+
+class Single_stage_RSN(BaseModule):
+ """Single_stage Residual Steps Network.
+
+ Args:
+ unit_channels (int): Channel number in the upsample units. Default:256.
+ num_units (int): Numbers of downsample/upsample units. Default: 4
+ gen_skip (bool): Whether to generate skip for posterior downsample
+ module or not. Default:False
+ gen_cross_conv (bool): Whether to generate feature map for the next
+ hourglass-like module. Default:False
+ has_skip (bool): Have skip connections from prior upsample
+ module or not. Default:False
+ num_steps (int): Number of steps in RSB. Default: 4
+ num_blocks (list): Number of blocks in each downsample unit.
+ Default: [2, 2, 2, 2] Note: Make sure num_units==len(num_blocks)
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ in_channels (int): Number of channels of the feature from ResNet_Top.
+ Default: 64.
+ expand_times (int): Times by which the in_channels are expanded in RSB.
+ Default:26.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ has_skip=False,
+ gen_skip=False,
+ gen_cross_conv=False,
+ unit_channels=256,
+ num_units=4,
+ num_steps=4,
+ num_blocks=[2, 2, 2, 2],
+ norm_cfg=dict(type='BN'),
+ in_channels=64,
+ expand_times=26,
+ init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = cp.deepcopy(norm_cfg)
+ num_blocks = cp.deepcopy(num_blocks)
+ super().__init__(init_cfg=init_cfg)
+ assert len(num_blocks) == num_units
+ self.has_skip = has_skip
+ self.gen_skip = gen_skip
+ self.gen_cross_conv = gen_cross_conv
+ self.num_units = num_units
+ self.num_steps = num_steps
+ self.unit_channels = unit_channels
+ self.num_blocks = num_blocks
+ self.norm_cfg = norm_cfg
+
+ self.downsample = Downsample_module(RSB, num_blocks, num_steps,
+ num_units, has_skip, norm_cfg,
+ in_channels, expand_times)
+ self.upsample = Upsample_module(unit_channels, num_units, gen_skip,
+ gen_cross_conv, norm_cfg, in_channels)
+
+ def forward(self, x, skip1, skip2):
+ mid = self.downsample(x, skip1, skip2)
+ out, skip1, skip2, cross_conv = self.upsample(mid)
+
+ return out, skip1, skip2, cross_conv
+
+
+class ResNet_top(BaseModule):
+ """ResNet top for RSN.
+
+ Args:
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ channels (int): Number of channels of the feature output by ResNet_top.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self, norm_cfg=dict(type='BN'), channels=64, init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = cp.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self.top = nn.Sequential(
+ ConvModule(
+ 3,
+ channels,
+ kernel_size=7,
+ stride=2,
+ padding=3,
+ norm_cfg=norm_cfg,
+ inplace=True), MaxPool2d(kernel_size=3, stride=2, padding=1))
+
+ def forward(self, img):
+ return self.top(img)
+
+
+@MODELS.register_module()
+class RSN(BaseBackbone):
+ """Residual Steps Network backbone. Paper ref: Cai et al. "Learning
+ Delicate Local Representations for Multi-Person Pose Estimation" (ECCV
+ 2020).
+
+ Args:
+ unit_channels (int): Number of Channels in an upsample unit.
+ Default: 256
+ num_stages (int): Number of stages in a multi-stage RSN. Default: 4
+ num_units (int): NUmber of downsample/upsample units in a single-stage
+ RSN. Default: 4 Note: Make sure num_units == len(self.num_blocks)
+ num_blocks (list): Number of RSBs (Residual Steps Block) in each
+ downsample unit. Default: [2, 2, 2, 2]
+ num_steps (int): Number of steps in a RSB. Default:4
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ res_top_channels (int): Number of channels of feature from ResNet_top.
+ Default: 64.
+ expand_times (int): Times by which the in_channels are expanded in RSB.
+ Default:26.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Kaiming', layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm']),
+ dict(
+ type='Normal',
+ std=0.01,
+ layer=['Linear']),
+ ]``
+ Example:
+ >>> from mmpose.models import RSN
+ >>> import torch
+ >>> self = RSN(num_stages=2,num_units=2,num_blocks=[2,2])
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 511, 511)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_output in level_outputs:
+ ... for feature in level_output:
+ ... print(tuple(feature.shape))
+ ...
+ (1, 256, 64, 64)
+ (1, 256, 128, 128)
+ (1, 256, 64, 64)
+ (1, 256, 128, 128)
+ """
+
+ def __init__(self,
+ unit_channels=256,
+ num_stages=4,
+ num_units=4,
+ num_blocks=[2, 2, 2, 2],
+ num_steps=4,
+ norm_cfg=dict(type='BN'),
+ res_top_channels=64,
+ expand_times=26,
+ init_cfg=[
+ dict(type='Kaiming', layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm']),
+ dict(type='Normal', std=0.01, layer=['Linear']),
+ ]):
+ # Protect mutable default arguments
+ norm_cfg = cp.deepcopy(norm_cfg)
+ num_blocks = cp.deepcopy(num_blocks)
+ super().__init__(init_cfg=init_cfg)
+ self.unit_channels = unit_channels
+ self.num_stages = num_stages
+ self.num_units = num_units
+ self.num_blocks = num_blocks
+ self.num_steps = num_steps
+ self.norm_cfg = norm_cfg
+
+ assert self.num_stages > 0
+ assert self.num_steps > 1
+ assert self.num_units > 1
+ assert self.num_units == len(self.num_blocks)
+ self.top = ResNet_top(norm_cfg=norm_cfg)
+ self.multi_stage_rsn = nn.ModuleList([])
+ for i in range(self.num_stages):
+ if i == 0:
+ has_skip = False
+ else:
+ has_skip = True
+ if i != self.num_stages - 1:
+ gen_skip = True
+ gen_cross_conv = True
+ else:
+ gen_skip = False
+ gen_cross_conv = False
+ self.multi_stage_rsn.append(
+ Single_stage_RSN(has_skip, gen_skip, gen_cross_conv,
+ unit_channels, num_units, num_steps,
+ num_blocks, norm_cfg, res_top_channels,
+ expand_times))
+
+ def forward(self, x):
+ """Model forward function."""
+ out_feats = []
+ skip1 = None
+ skip2 = None
+ x = self.top(x)
+ for i in range(self.num_stages):
+ out, skip1, skip2, x = self.multi_stage_rsn[i](x, skip1, skip2)
+ out_feats.append(out)
+
+ return out_feats
diff --git a/mmpose/models/backbones/scnet.py b/mmpose/models/backbones/scnet.py
index 5c802d256e..a99afe2c38 100644
--- a/mmpose/models/backbones/scnet.py
+++ b/mmpose/models/backbones/scnet.py
@@ -1,252 +1,252 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-import torch.utils.checkpoint as cp
-from mmcv.cnn import build_conv_layer, build_norm_layer
-from mmengine.model import BaseModule
-
-from mmpose.registry import MODELS
-from .resnet import Bottleneck, ResNet
-
-
-class SCConv(BaseModule):
- """SCConv (Self-calibrated Convolution)
-
- Args:
- in_channels (int): The input channels of the SCConv.
- out_channels (int): The output channel of the SCConv.
- stride (int): stride of SCConv.
- pooling_r (int): size of pooling for scconv.
- conv_cfg (dict): dictionary to construct and config conv layer.
- Default: None
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- stride,
- pooling_r,
- conv_cfg=None,
- norm_cfg=dict(type='BN', momentum=0.1),
- init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
-
- assert in_channels == out_channels
-
- self.k2 = nn.Sequential(
- nn.AvgPool2d(kernel_size=pooling_r, stride=pooling_r),
- build_conv_layer(
- conv_cfg,
- in_channels,
- in_channels,
- kernel_size=3,
- stride=1,
- padding=1,
- bias=False),
- build_norm_layer(norm_cfg, in_channels)[1],
- )
- self.k3 = nn.Sequential(
- build_conv_layer(
- conv_cfg,
- in_channels,
- in_channels,
- kernel_size=3,
- stride=1,
- padding=1,
- bias=False),
- build_norm_layer(norm_cfg, in_channels)[1],
- )
- self.k4 = nn.Sequential(
- build_conv_layer(
- conv_cfg,
- in_channels,
- in_channels,
- kernel_size=3,
- stride=stride,
- padding=1,
- bias=False),
- build_norm_layer(norm_cfg, out_channels)[1],
- nn.ReLU(inplace=True),
- )
-
- def forward(self, x):
- """Forward function."""
- identity = x
-
- out = torch.sigmoid(
- torch.add(identity, F.interpolate(self.k2(x),
- identity.size()[2:])))
- out = torch.mul(self.k3(x), out)
- out = self.k4(out)
-
- return out
-
-
-class SCBottleneck(Bottleneck):
- """SC(Self-calibrated) Bottleneck.
-
- Args:
- in_channels (int): The input channels of the SCBottleneck block.
- out_channels (int): The output channel of the SCBottleneck block.
- """
-
- pooling_r = 4
-
- def __init__(self, in_channels, out_channels, **kwargs):
- super().__init__(in_channels, out_channels, **kwargs)
- self.mid_channels = out_channels // self.expansion // 2
-
- self.norm1_name, norm1 = build_norm_layer(
- self.norm_cfg, self.mid_channels, postfix=1)
- self.norm2_name, norm2 = build_norm_layer(
- self.norm_cfg, self.mid_channels, postfix=2)
- self.norm3_name, norm3 = build_norm_layer(
- self.norm_cfg, out_channels, postfix=3)
-
- self.conv1 = build_conv_layer(
- self.conv_cfg,
- in_channels,
- self.mid_channels,
- kernel_size=1,
- stride=1,
- bias=False)
- self.add_module(self.norm1_name, norm1)
-
- self.k1 = nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- self.mid_channels,
- self.mid_channels,
- kernel_size=3,
- stride=self.stride,
- padding=1,
- bias=False),
- build_norm_layer(self.norm_cfg, self.mid_channels)[1],
- nn.ReLU(inplace=True))
-
- self.conv2 = build_conv_layer(
- self.conv_cfg,
- in_channels,
- self.mid_channels,
- kernel_size=1,
- stride=1,
- bias=False)
- self.add_module(self.norm2_name, norm2)
-
- self.scconv = SCConv(self.mid_channels, self.mid_channels, self.stride,
- self.pooling_r, self.conv_cfg, self.norm_cfg)
-
- self.conv3 = build_conv_layer(
- self.conv_cfg,
- self.mid_channels * 2,
- out_channels,
- kernel_size=1,
- stride=1,
- bias=False)
- self.add_module(self.norm3_name, norm3)
-
- def forward(self, x):
- """Forward function."""
-
- def _inner_forward(x):
- identity = x
-
- out_a = self.conv1(x)
- out_a = self.norm1(out_a)
- out_a = self.relu(out_a)
-
- out_a = self.k1(out_a)
-
- out_b = self.conv2(x)
- out_b = self.norm2(out_b)
- out_b = self.relu(out_b)
-
- out_b = self.scconv(out_b)
-
- out = self.conv3(torch.cat([out_a, out_b], dim=1))
- out = self.norm3(out)
-
- if self.downsample is not None:
- identity = self.downsample(x)
-
- out += identity
-
- return out
-
- if self.with_cp and x.requires_grad:
- out = cp.checkpoint(_inner_forward, x)
- else:
- out = _inner_forward(x)
-
- out = self.relu(out)
-
- return out
-
-
-@MODELS.register_module()
-class SCNet(ResNet):
- """SCNet backbone.
-
- Improving Convolutional Networks with Self-Calibrated Convolutions,
- Jiang-Jiang Liu, Qibin Hou, Ming-Ming Cheng, Changhu Wang, Jiashi Feng,
- IEEE CVPR, 2020.
- http://mftp.mmcheng.net/Papers/20cvprSCNet.pdf
-
- Args:
- depth (int): Depth of scnet, from {50, 101}.
- in_channels (int): Number of input image channels. Normally 3.
- base_channels (int): Number of base channels of hidden layer.
- num_stages (int): SCNet stages, normally 4.
- strides (Sequence[int]): Strides of the first block of each stage.
- dilations (Sequence[int]): Dilation of each stage.
- out_indices (Sequence[int]): Output from which stages.
- style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
- layer is the 3x3 conv layer, otherwise the stride-two layer is
- the first 1x1 conv layer.
- deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv
- avg_down (bool): Use AvgPool instead of stride conv when
- downsampling in the bottleneck.
- frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
- -1 means not freezing any parameters.
- norm_cfg (dict): Dictionary to construct and config norm layer.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed.
- zero_init_residual (bool): Whether to use zero init for last norm layer
- in resblocks to let them behave as identity.
-
- Example:
- >>> from mmpose.models import SCNet
- >>> import torch
- >>> self = SCNet(depth=50, out_indices=(0, 1, 2, 3))
- >>> self.eval()
- >>> inputs = torch.rand(1, 3, 224, 224)
- >>> level_outputs = self.forward(inputs)
- >>> for level_out in level_outputs:
- ... print(tuple(level_out.shape))
- (1, 256, 56, 56)
- (1, 512, 28, 28)
- (1, 1024, 14, 14)
- (1, 2048, 7, 7)
- """
-
- arch_settings = {
- 50: (SCBottleneck, [3, 4, 6, 3]),
- 101: (SCBottleneck, [3, 4, 23, 3])
- }
-
- def __init__(self, depth, **kwargs):
- if depth not in self.arch_settings:
- raise KeyError(f'invalid depth {depth} for SCNet')
- super().__init__(depth, **kwargs)
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint as cp
+from mmcv.cnn import build_conv_layer, build_norm_layer
+from mmengine.model import BaseModule
+
+from mmpose.registry import MODELS
+from .resnet import Bottleneck, ResNet
+
+
+class SCConv(BaseModule):
+ """SCConv (Self-calibrated Convolution)
+
+ Args:
+ in_channels (int): The input channels of the SCConv.
+ out_channels (int): The output channel of the SCConv.
+ stride (int): stride of SCConv.
+ pooling_r (int): size of pooling for scconv.
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ Default: None
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ stride,
+ pooling_r,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', momentum=0.1),
+ init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+
+ assert in_channels == out_channels
+
+ self.k2 = nn.Sequential(
+ nn.AvgPool2d(kernel_size=pooling_r, stride=pooling_r),
+ build_conv_layer(
+ conv_cfg,
+ in_channels,
+ in_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False),
+ build_norm_layer(norm_cfg, in_channels)[1],
+ )
+ self.k3 = nn.Sequential(
+ build_conv_layer(
+ conv_cfg,
+ in_channels,
+ in_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False),
+ build_norm_layer(norm_cfg, in_channels)[1],
+ )
+ self.k4 = nn.Sequential(
+ build_conv_layer(
+ conv_cfg,
+ in_channels,
+ in_channels,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ bias=False),
+ build_norm_layer(norm_cfg, out_channels)[1],
+ nn.ReLU(inplace=True),
+ )
+
+ def forward(self, x):
+ """Forward function."""
+ identity = x
+
+ out = torch.sigmoid(
+ torch.add(identity, F.interpolate(self.k2(x),
+ identity.size()[2:])))
+ out = torch.mul(self.k3(x), out)
+ out = self.k4(out)
+
+ return out
+
+
+class SCBottleneck(Bottleneck):
+ """SC(Self-calibrated) Bottleneck.
+
+ Args:
+ in_channels (int): The input channels of the SCBottleneck block.
+ out_channels (int): The output channel of the SCBottleneck block.
+ """
+
+ pooling_r = 4
+
+ def __init__(self, in_channels, out_channels, **kwargs):
+ super().__init__(in_channels, out_channels, **kwargs)
+ self.mid_channels = out_channels // self.expansion // 2
+
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, self.mid_channels, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(
+ self.norm_cfg, self.mid_channels, postfix=2)
+ self.norm3_name, norm3 = build_norm_layer(
+ self.norm_cfg, out_channels, postfix=3)
+
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ self.mid_channels,
+ kernel_size=1,
+ stride=1,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+
+ self.k1 = nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ self.mid_channels,
+ self.mid_channels,
+ kernel_size=3,
+ stride=self.stride,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg, self.mid_channels)[1],
+ nn.ReLU(inplace=True))
+
+ self.conv2 = build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ self.mid_channels,
+ kernel_size=1,
+ stride=1,
+ bias=False)
+ self.add_module(self.norm2_name, norm2)
+
+ self.scconv = SCConv(self.mid_channels, self.mid_channels, self.stride,
+ self.pooling_r, self.conv_cfg, self.norm_cfg)
+
+ self.conv3 = build_conv_layer(
+ self.conv_cfg,
+ self.mid_channels * 2,
+ out_channels,
+ kernel_size=1,
+ stride=1,
+ bias=False)
+ self.add_module(self.norm3_name, norm3)
+
+ def forward(self, x):
+ """Forward function."""
+
+ def _inner_forward(x):
+ identity = x
+
+ out_a = self.conv1(x)
+ out_a = self.norm1(out_a)
+ out_a = self.relu(out_a)
+
+ out_a = self.k1(out_a)
+
+ out_b = self.conv2(x)
+ out_b = self.norm2(out_b)
+ out_b = self.relu(out_b)
+
+ out_b = self.scconv(out_b)
+
+ out = self.conv3(torch.cat([out_a, out_b], dim=1))
+ out = self.norm3(out)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ out = self.relu(out)
+
+ return out
+
+
+@MODELS.register_module()
+class SCNet(ResNet):
+ """SCNet backbone.
+
+ Improving Convolutional Networks with Self-Calibrated Convolutions,
+ Jiang-Jiang Liu, Qibin Hou, Ming-Ming Cheng, Changhu Wang, Jiashi Feng,
+ IEEE CVPR, 2020.
+ http://mftp.mmcheng.net/Papers/20cvprSCNet.pdf
+
+ Args:
+ depth (int): Depth of scnet, from {50, 101}.
+ in_channels (int): Number of input image channels. Normally 3.
+ base_channels (int): Number of base channels of hidden layer.
+ num_stages (int): SCNet stages, normally 4.
+ strides (Sequence[int]): Strides of the first block of each stage.
+ dilations (Sequence[int]): Dilation of each stage.
+ out_indices (Sequence[int]): Output from which stages.
+ style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
+ layer is the 3x3 conv layer, otherwise the stride-two layer is
+ the first 1x1 conv layer.
+ deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv
+ avg_down (bool): Use AvgPool instead of stride conv when
+ downsampling in the bottleneck.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ zero_init_residual (bool): Whether to use zero init for last norm layer
+ in resblocks to let them behave as identity.
+
+ Example:
+ >>> from mmpose.models import SCNet
+ >>> import torch
+ >>> self = SCNet(depth=50, out_indices=(0, 1, 2, 3))
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 224, 224)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 256, 56, 56)
+ (1, 512, 28, 28)
+ (1, 1024, 14, 14)
+ (1, 2048, 7, 7)
+ """
+
+ arch_settings = {
+ 50: (SCBottleneck, [3, 4, 6, 3]),
+ 101: (SCBottleneck, [3, 4, 23, 3])
+ }
+
+ def __init__(self, depth, **kwargs):
+ if depth not in self.arch_settings:
+ raise KeyError(f'invalid depth {depth} for SCNet')
+ super().__init__(depth, **kwargs)
diff --git a/mmpose/models/backbones/seresnet.py b/mmpose/models/backbones/seresnet.py
index 617a1b72be..042d3cc961 100644
--- a/mmpose/models/backbones/seresnet.py
+++ b/mmpose/models/backbones/seresnet.py
@@ -1,134 +1,134 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import torch.utils.checkpoint as cp
-
-from mmpose.registry import MODELS
-from .resnet import Bottleneck, ResLayer, ResNet
-from .utils.se_layer import SELayer
-
-
-class SEBottleneck(Bottleneck):
- """SEBottleneck block for SEResNet.
-
- Args:
- in_channels (int): The input channels of the SEBottleneck block.
- out_channels (int): The output channel of the SEBottleneck block.
- se_ratio (int): Squeeze ratio in SELayer. Default: 16
- """
-
- def __init__(self, in_channels, out_channels, se_ratio=16, **kwargs):
- super().__init__(in_channels, out_channels, **kwargs)
- self.se_layer = SELayer(out_channels, ratio=se_ratio)
-
- def forward(self, x):
-
- def _inner_forward(x):
- identity = x
-
- out = self.conv1(x)
- out = self.norm1(out)
- out = self.relu(out)
-
- out = self.conv2(out)
- out = self.norm2(out)
- out = self.relu(out)
-
- out = self.conv3(out)
- out = self.norm3(out)
-
- out = self.se_layer(out)
-
- if self.downsample is not None:
- identity = self.downsample(x)
-
- out += identity
-
- return out
-
- if self.with_cp and x.requires_grad:
- out = cp.checkpoint(_inner_forward, x)
- else:
- out = _inner_forward(x)
-
- out = self.relu(out)
-
- return out
-
-
-@MODELS.register_module()
-class SEResNet(ResNet):
- """SEResNet backbone.
-
- Please refer to the `paper `__ for
- details.
-
- Args:
- depth (int): Network depth, from {50, 101, 152}.
- se_ratio (int): Squeeze ratio in SELayer. Default: 16.
- in_channels (int): Number of input image channels. Default: 3.
- stem_channels (int): Output channels of the stem layer. Default: 64.
- num_stages (int): Stages of the network. Default: 4.
- strides (Sequence[int]): Strides of the first block of each stage.
- Default: ``(1, 2, 2, 2)``.
- dilations (Sequence[int]): Dilation of each stage.
- Default: ``(1, 1, 1, 1)``.
- out_indices (Sequence[int]): Output from which stages. If only one
- stage is specified, a single tensor (feature map) is returned,
- otherwise multiple stages are specified, a tuple of tensors will
- be returned. Default: ``(3, )``.
- style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
- layer is the 3x3 conv layer, otherwise the stride-two layer is
- the first 1x1 conv layer.
- deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv.
- Default: False.
- avg_down (bool): Use AvgPool instead of stride conv when
- downsampling in the bottleneck. Default: False.
- frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
- -1 means not freezing any parameters. Default: -1.
- conv_cfg (dict | None): The config dict for conv layers. Default: None.
- norm_cfg (dict): The config dict for norm layers.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only. Default: False.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed. Default: False.
- zero_init_residual (bool): Whether to use zero init for last norm layer
- in resblocks to let them behave as identity. Default: True.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Kaiming', layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]``
-
- Example:
- >>> from mmpose.models import SEResNet
- >>> import torch
- >>> self = SEResNet(depth=50, out_indices=(0, 1, 2, 3))
- >>> self.eval()
- >>> inputs = torch.rand(1, 3, 224, 224)
- >>> level_outputs = self.forward(inputs)
- >>> for level_out in level_outputs:
- ... print(tuple(level_out.shape))
- (1, 256, 56, 56)
- (1, 512, 28, 28)
- (1, 1024, 14, 14)
- (1, 2048, 7, 7)
- """
-
- arch_settings = {
- 50: (SEBottleneck, (3, 4, 6, 3)),
- 101: (SEBottleneck, (3, 4, 23, 3)),
- 152: (SEBottleneck, (3, 8, 36, 3))
- }
-
- def __init__(self, depth, se_ratio=16, **kwargs):
- if depth not in self.arch_settings:
- raise KeyError(f'invalid depth {depth} for SEResNet')
- self.se_ratio = se_ratio
- super().__init__(depth, **kwargs)
-
- def make_res_layer(self, **kwargs):
- return ResLayer(se_ratio=self.se_ratio, **kwargs)
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.utils.checkpoint as cp
+
+from mmpose.registry import MODELS
+from .resnet import Bottleneck, ResLayer, ResNet
+from .utils.se_layer import SELayer
+
+
+class SEBottleneck(Bottleneck):
+ """SEBottleneck block for SEResNet.
+
+ Args:
+ in_channels (int): The input channels of the SEBottleneck block.
+ out_channels (int): The output channel of the SEBottleneck block.
+ se_ratio (int): Squeeze ratio in SELayer. Default: 16
+ """
+
+ def __init__(self, in_channels, out_channels, se_ratio=16, **kwargs):
+ super().__init__(in_channels, out_channels, **kwargs)
+ self.se_layer = SELayer(out_channels, ratio=se_ratio)
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ identity = x
+
+ out = self.conv1(x)
+ out = self.norm1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+ out = self.norm2(out)
+ out = self.relu(out)
+
+ out = self.conv3(out)
+ out = self.norm3(out)
+
+ out = self.se_layer(out)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ out = self.relu(out)
+
+ return out
+
+
+@MODELS.register_module()
+class SEResNet(ResNet):
+ """SEResNet backbone.
+
+ Please refer to the `paper `__ for
+ details.
+
+ Args:
+ depth (int): Network depth, from {50, 101, 152}.
+ se_ratio (int): Squeeze ratio in SELayer. Default: 16.
+ in_channels (int): Number of input image channels. Default: 3.
+ stem_channels (int): Output channels of the stem layer. Default: 64.
+ num_stages (int): Stages of the network. Default: 4.
+ strides (Sequence[int]): Strides of the first block of each stage.
+ Default: ``(1, 2, 2, 2)``.
+ dilations (Sequence[int]): Dilation of each stage.
+ Default: ``(1, 1, 1, 1)``.
+ out_indices (Sequence[int]): Output from which stages. If only one
+ stage is specified, a single tensor (feature map) is returned,
+ otherwise multiple stages are specified, a tuple of tensors will
+ be returned. Default: ``(3, )``.
+ style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
+ layer is the 3x3 conv layer, otherwise the stride-two layer is
+ the first 1x1 conv layer.
+ deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv.
+ Default: False.
+ avg_down (bool): Use AvgPool instead of stride conv when
+ downsampling in the bottleneck. Default: False.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters. Default: -1.
+ conv_cfg (dict | None): The config dict for conv layers. Default: None.
+ norm_cfg (dict): The config dict for norm layers.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ zero_init_residual (bool): Whether to use zero init for last norm layer
+ in resblocks to let them behave as identity. Default: True.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Kaiming', layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+
+ Example:
+ >>> from mmpose.models import SEResNet
+ >>> import torch
+ >>> self = SEResNet(depth=50, out_indices=(0, 1, 2, 3))
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 224, 224)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 256, 56, 56)
+ (1, 512, 28, 28)
+ (1, 1024, 14, 14)
+ (1, 2048, 7, 7)
+ """
+
+ arch_settings = {
+ 50: (SEBottleneck, (3, 4, 6, 3)),
+ 101: (SEBottleneck, (3, 4, 23, 3)),
+ 152: (SEBottleneck, (3, 8, 36, 3))
+ }
+
+ def __init__(self, depth, se_ratio=16, **kwargs):
+ if depth not in self.arch_settings:
+ raise KeyError(f'invalid depth {depth} for SEResNet')
+ self.se_ratio = se_ratio
+ super().__init__(depth, **kwargs)
+
+ def make_res_layer(self, **kwargs):
+ return ResLayer(se_ratio=self.se_ratio, **kwargs)
diff --git a/mmpose/models/backbones/seresnext.py b/mmpose/models/backbones/seresnext.py
index c1f5a6c8f3..7469dfddab 100644
--- a/mmpose/models/backbones/seresnext.py
+++ b/mmpose/models/backbones/seresnext.py
@@ -1,179 +1,179 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmcv.cnn import build_conv_layer, build_norm_layer
-
-from mmpose.registry import MODELS
-from .resnet import ResLayer
-from .seresnet import SEBottleneck as _SEBottleneck
-from .seresnet import SEResNet
-
-
-class SEBottleneck(_SEBottleneck):
- """SEBottleneck block for SEResNeXt.
-
- Args:
- in_channels (int): Input channels of this block.
- out_channels (int): Output channels of this block.
- base_channels (int): Middle channels of the first stage. Default: 64.
- groups (int): Groups of conv2.
- width_per_group (int): Width per group of conv2. 64x4d indicates
- ``groups=64, width_per_group=4`` and 32x8d indicates
- ``groups=32, width_per_group=8``.
- stride (int): stride of the block. Default: 1
- dilation (int): dilation of convolution. Default: 1
- downsample (nn.Module): downsample operation on identity branch.
- Default: None
- se_ratio (int): Squeeze ratio in SELayer. Default: 16
- style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
- layer is the 3x3 conv layer, otherwise the stride-two layer is
- the first 1x1 conv layer.
- conv_cfg (dict): dictionary to construct and config conv layer.
- Default: None
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- base_channels=64,
- groups=32,
- width_per_group=4,
- se_ratio=16,
- **kwargs):
- super().__init__(in_channels, out_channels, se_ratio, **kwargs)
- self.groups = groups
- self.width_per_group = width_per_group
-
- # We follow the same rational of ResNext to compute mid_channels.
- # For SEResNet bottleneck, middle channels are determined by expansion
- # and out_channels, but for SEResNeXt bottleneck, it is determined by
- # groups and width_per_group and the stage it is located in.
- if groups != 1:
- assert self.mid_channels % base_channels == 0
- self.mid_channels = (
- groups * width_per_group * self.mid_channels // base_channels)
-
- self.norm1_name, norm1 = build_norm_layer(
- self.norm_cfg, self.mid_channels, postfix=1)
- self.norm2_name, norm2 = build_norm_layer(
- self.norm_cfg, self.mid_channels, postfix=2)
- self.norm3_name, norm3 = build_norm_layer(
- self.norm_cfg, self.out_channels, postfix=3)
-
- self.conv1 = build_conv_layer(
- self.conv_cfg,
- self.in_channels,
- self.mid_channels,
- kernel_size=1,
- stride=self.conv1_stride,
- bias=False)
- self.add_module(self.norm1_name, norm1)
- self.conv2 = build_conv_layer(
- self.conv_cfg,
- self.mid_channels,
- self.mid_channels,
- kernel_size=3,
- stride=self.conv2_stride,
- padding=self.dilation,
- dilation=self.dilation,
- groups=groups,
- bias=False)
-
- self.add_module(self.norm2_name, norm2)
- self.conv3 = build_conv_layer(
- self.conv_cfg,
- self.mid_channels,
- self.out_channels,
- kernel_size=1,
- bias=False)
- self.add_module(self.norm3_name, norm3)
-
-
-@MODELS.register_module()
-class SEResNeXt(SEResNet):
- """SEResNeXt backbone.
-
- Please refer to the `paper `__ for
- details.
-
- Args:
- depth (int): Network depth, from {50, 101, 152}.
- groups (int): Groups of conv2 in Bottleneck. Default: 32.
- width_per_group (int): Width per group of conv2 in Bottleneck.
- Default: 4.
- se_ratio (int): Squeeze ratio in SELayer. Default: 16.
- in_channels (int): Number of input image channels. Default: 3.
- stem_channels (int): Output channels of the stem layer. Default: 64.
- num_stages (int): Stages of the network. Default: 4.
- strides (Sequence[int]): Strides of the first block of each stage.
- Default: ``(1, 2, 2, 2)``.
- dilations (Sequence[int]): Dilation of each stage.
- Default: ``(1, 1, 1, 1)``.
- out_indices (Sequence[int]): Output from which stages. If only one
- stage is specified, a single tensor (feature map) is returned,
- otherwise multiple stages are specified, a tuple of tensors will
- be returned. Default: ``(3, )``.
- style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
- layer is the 3x3 conv layer, otherwise the stride-two layer is
- the first 1x1 conv layer.
- deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv.
- Default: False.
- avg_down (bool): Use AvgPool instead of stride conv when
- downsampling in the bottleneck. Default: False.
- frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
- -1 means not freezing any parameters. Default: -1.
- conv_cfg (dict | None): The config dict for conv layers. Default: None.
- norm_cfg (dict): The config dict for norm layers.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only. Default: False.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed. Default: False.
- zero_init_residual (bool): Whether to use zero init for last norm layer
- in resblocks to let them behave as identity. Default: True.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Kaiming', layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]``
-
- Example:
- >>> from mmpose.models import SEResNeXt
- >>> import torch
- >>> self = SEResNet(depth=50, out_indices=(0, 1, 2, 3))
- >>> self.eval()
- >>> inputs = torch.rand(1, 3, 224, 224)
- >>> level_outputs = self.forward(inputs)
- >>> for level_out in level_outputs:
- ... print(tuple(level_out.shape))
- (1, 256, 56, 56)
- (1, 512, 28, 28)
- (1, 1024, 14, 14)
- (1, 2048, 7, 7)
- """
-
- arch_settings = {
- 50: (SEBottleneck, (3, 4, 6, 3)),
- 101: (SEBottleneck, (3, 4, 23, 3)),
- 152: (SEBottleneck, (3, 8, 36, 3))
- }
-
- def __init__(self, depth, groups=32, width_per_group=4, **kwargs):
- self.groups = groups
- self.width_per_group = width_per_group
- super().__init__(depth, **kwargs)
-
- def make_res_layer(self, **kwargs):
- return ResLayer(
- groups=self.groups,
- width_per_group=self.width_per_group,
- base_channels=self.base_channels,
- **kwargs)
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.cnn import build_conv_layer, build_norm_layer
+
+from mmpose.registry import MODELS
+from .resnet import ResLayer
+from .seresnet import SEBottleneck as _SEBottleneck
+from .seresnet import SEResNet
+
+
+class SEBottleneck(_SEBottleneck):
+ """SEBottleneck block for SEResNeXt.
+
+ Args:
+ in_channels (int): Input channels of this block.
+ out_channels (int): Output channels of this block.
+ base_channels (int): Middle channels of the first stage. Default: 64.
+ groups (int): Groups of conv2.
+ width_per_group (int): Width per group of conv2. 64x4d indicates
+ ``groups=64, width_per_group=4`` and 32x8d indicates
+ ``groups=32, width_per_group=8``.
+ stride (int): stride of the block. Default: 1
+ dilation (int): dilation of convolution. Default: 1
+ downsample (nn.Module): downsample operation on identity branch.
+ Default: None
+ se_ratio (int): Squeeze ratio in SELayer. Default: 16
+ style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
+ layer is the 3x3 conv layer, otherwise the stride-two layer is
+ the first 1x1 conv layer.
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ Default: None
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ base_channels=64,
+ groups=32,
+ width_per_group=4,
+ se_ratio=16,
+ **kwargs):
+ super().__init__(in_channels, out_channels, se_ratio, **kwargs)
+ self.groups = groups
+ self.width_per_group = width_per_group
+
+ # We follow the same rational of ResNext to compute mid_channels.
+ # For SEResNet bottleneck, middle channels are determined by expansion
+ # and out_channels, but for SEResNeXt bottleneck, it is determined by
+ # groups and width_per_group and the stage it is located in.
+ if groups != 1:
+ assert self.mid_channels % base_channels == 0
+ self.mid_channels = (
+ groups * width_per_group * self.mid_channels // base_channels)
+
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, self.mid_channels, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(
+ self.norm_cfg, self.mid_channels, postfix=2)
+ self.norm3_name, norm3 = build_norm_layer(
+ self.norm_cfg, self.out_channels, postfix=3)
+
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ self.in_channels,
+ self.mid_channels,
+ kernel_size=1,
+ stride=self.conv1_stride,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+ self.conv2 = build_conv_layer(
+ self.conv_cfg,
+ self.mid_channels,
+ self.mid_channels,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=self.dilation,
+ dilation=self.dilation,
+ groups=groups,
+ bias=False)
+
+ self.add_module(self.norm2_name, norm2)
+ self.conv3 = build_conv_layer(
+ self.conv_cfg,
+ self.mid_channels,
+ self.out_channels,
+ kernel_size=1,
+ bias=False)
+ self.add_module(self.norm3_name, norm3)
+
+
+@MODELS.register_module()
+class SEResNeXt(SEResNet):
+ """SEResNeXt backbone.
+
+ Please refer to the `paper `__ for
+ details.
+
+ Args:
+ depth (int): Network depth, from {50, 101, 152}.
+ groups (int): Groups of conv2 in Bottleneck. Default: 32.
+ width_per_group (int): Width per group of conv2 in Bottleneck.
+ Default: 4.
+ se_ratio (int): Squeeze ratio in SELayer. Default: 16.
+ in_channels (int): Number of input image channels. Default: 3.
+ stem_channels (int): Output channels of the stem layer. Default: 64.
+ num_stages (int): Stages of the network. Default: 4.
+ strides (Sequence[int]): Strides of the first block of each stage.
+ Default: ``(1, 2, 2, 2)``.
+ dilations (Sequence[int]): Dilation of each stage.
+ Default: ``(1, 1, 1, 1)``.
+ out_indices (Sequence[int]): Output from which stages. If only one
+ stage is specified, a single tensor (feature map) is returned,
+ otherwise multiple stages are specified, a tuple of tensors will
+ be returned. Default: ``(3, )``.
+ style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
+ layer is the 3x3 conv layer, otherwise the stride-two layer is
+ the first 1x1 conv layer.
+ deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv.
+ Default: False.
+ avg_down (bool): Use AvgPool instead of stride conv when
+ downsampling in the bottleneck. Default: False.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters. Default: -1.
+ conv_cfg (dict | None): The config dict for conv layers. Default: None.
+ norm_cfg (dict): The config dict for norm layers.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ zero_init_residual (bool): Whether to use zero init for last norm layer
+ in resblocks to let them behave as identity. Default: True.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Kaiming', layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+
+ Example:
+ >>> from mmpose.models import SEResNeXt
+ >>> import torch
+ >>> self = SEResNet(depth=50, out_indices=(0, 1, 2, 3))
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 224, 224)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 256, 56, 56)
+ (1, 512, 28, 28)
+ (1, 1024, 14, 14)
+ (1, 2048, 7, 7)
+ """
+
+ arch_settings = {
+ 50: (SEBottleneck, (3, 4, 6, 3)),
+ 101: (SEBottleneck, (3, 4, 23, 3)),
+ 152: (SEBottleneck, (3, 8, 36, 3))
+ }
+
+ def __init__(self, depth, groups=32, width_per_group=4, **kwargs):
+ self.groups = groups
+ self.width_per_group = width_per_group
+ super().__init__(depth, **kwargs)
+
+ def make_res_layer(self, **kwargs):
+ return ResLayer(
+ groups=self.groups,
+ width_per_group=self.width_per_group,
+ base_channels=self.base_channels,
+ **kwargs)
diff --git a/mmpose/models/backbones/shufflenet_v1.py b/mmpose/models/backbones/shufflenet_v1.py
index 17491910e9..462c204065 100644
--- a/mmpose/models/backbones/shufflenet_v1.py
+++ b/mmpose/models/backbones/shufflenet_v1.py
@@ -1,338 +1,338 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-
-import torch
-import torch.nn as nn
-import torch.utils.checkpoint as cp
-from mmcv.cnn import ConvModule, build_activation_layer
-from mmengine.model import BaseModule
-from torch.nn.modules.batchnorm import _BatchNorm
-
-from mmpose.registry import MODELS
-from .base_backbone import BaseBackbone
-from .utils import channel_shuffle, make_divisible
-
-
-class ShuffleUnit(BaseModule):
- """ShuffleUnit block.
-
- ShuffleNet unit with pointwise group convolution (GConv) and channel
- shuffle.
-
- Args:
- in_channels (int): The input channels of the ShuffleUnit.
- out_channels (int): The output channels of the ShuffleUnit.
- groups (int, optional): The number of groups to be used in grouped 1x1
- convolutions in each ShuffleUnit. Default: 3
- first_block (bool, optional): Whether it is the first ShuffleUnit of a
- sequential ShuffleUnits. Default: True, which means not using the
- grouped 1x1 convolution.
- combine (str, optional): The ways to combine the input and output
- branches. Default: 'add'.
- conv_cfg (dict): Config dict for convolution layer. Default: None,
- which means using conv2d.
- norm_cfg (dict): Config dict for normalization layer.
- Default: dict(type='BN').
- act_cfg (dict): Config dict for activation layer.
- Default: dict(type='ReLU').
- with_cp (bool, optional): Use checkpoint or not. Using checkpoint
- will save some memory while slowing down the training speed.
- Default: False.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
-
- Returns:
- Tensor: The output tensor.
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- groups=3,
- first_block=True,
- combine='add',
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- act_cfg=dict(type='ReLU'),
- with_cp=False,
- init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- act_cfg = copy.deepcopy(act_cfg)
- super().__init__(init_cfg=init_cfg)
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.first_block = first_block
- self.combine = combine
- self.groups = groups
- self.bottleneck_channels = self.out_channels // 4
- self.with_cp = with_cp
-
- if self.combine == 'add':
- self.depthwise_stride = 1
- self._combine_func = self._add
- assert in_channels == out_channels, (
- 'in_channels must be equal to out_channels when combine '
- 'is add')
- elif self.combine == 'concat':
- self.depthwise_stride = 2
- self._combine_func = self._concat
- self.out_channels -= self.in_channels
- self.avgpool = nn.AvgPool2d(kernel_size=3, stride=2, padding=1)
- else:
- raise ValueError(f'Cannot combine tensors with {self.combine}. '
- 'Only "add" and "concat" are supported')
-
- self.first_1x1_groups = 1 if first_block else self.groups
- self.g_conv_1x1_compress = ConvModule(
- in_channels=self.in_channels,
- out_channels=self.bottleneck_channels,
- kernel_size=1,
- groups=self.first_1x1_groups,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg)
-
- self.depthwise_conv3x3_bn = ConvModule(
- in_channels=self.bottleneck_channels,
- out_channels=self.bottleneck_channels,
- kernel_size=3,
- stride=self.depthwise_stride,
- padding=1,
- groups=self.bottleneck_channels,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=None)
-
- self.g_conv_1x1_expand = ConvModule(
- in_channels=self.bottleneck_channels,
- out_channels=self.out_channels,
- kernel_size=1,
- groups=self.groups,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=None)
-
- self.act = build_activation_layer(act_cfg)
-
- @staticmethod
- def _add(x, out):
- # residual connection
- return x + out
-
- @staticmethod
- def _concat(x, out):
- # concatenate along channel axis
- return torch.cat((x, out), 1)
-
- def forward(self, x):
-
- def _inner_forward(x):
- residual = x
-
- out = self.g_conv_1x1_compress(x)
- out = self.depthwise_conv3x3_bn(out)
-
- if self.groups > 1:
- out = channel_shuffle(out, self.groups)
-
- out = self.g_conv_1x1_expand(out)
-
- if self.combine == 'concat':
- residual = self.avgpool(residual)
- out = self.act(out)
- out = self._combine_func(residual, out)
- else:
- out = self._combine_func(residual, out)
- out = self.act(out)
- return out
-
- if self.with_cp and x.requires_grad:
- out = cp.checkpoint(_inner_forward, x)
- else:
- out = _inner_forward(x)
-
- return out
-
-
-@MODELS.register_module()
-class ShuffleNetV1(BaseBackbone):
- """ShuffleNetV1 backbone.
-
- Args:
- groups (int, optional): The number of groups to be used in grouped 1x1
- convolutions in each ShuffleUnit. Default: 3.
- widen_factor (float, optional): Width multiplier - adjusts the number
- of channels in each layer by this amount. Default: 1.0.
- out_indices (Sequence[int]): Output from which stages.
- Default: (2, )
- frozen_stages (int): Stages to be frozen (all param fixed).
- Default: -1, which means not freezing any parameters.
- conv_cfg (dict): Config dict for convolution layer. Default: None,
- which means using conv2d.
- norm_cfg (dict): Config dict for normalization layer.
- Default: dict(type='BN').
- act_cfg (dict): Config dict for activation layer.
- Default: dict(type='ReLU').
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only. Default: False.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed. Default: False.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Normal', std=0.01, layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- bias=0.0001
- layer=['_BatchNorm', 'GroupNorm'])
- ]``
- """
-
- def __init__(self,
- groups=3,
- widen_factor=1.0,
- out_indices=(2, ),
- frozen_stages=-1,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- act_cfg=dict(type='ReLU'),
- norm_eval=False,
- with_cp=False,
- init_cfg=[
- dict(type='Normal', std=0.01, layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- bias=0.0001,
- layer=['_BatchNorm', 'GroupNorm'])
- ]):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- act_cfg = copy.deepcopy(act_cfg)
- super().__init__(init_cfg=init_cfg)
- self.stage_blocks = [4, 8, 4]
- self.groups = groups
-
- for index in out_indices:
- if index not in range(0, 3):
- raise ValueError('the item in out_indices must in '
- f'range(0, 3). But received {index}')
-
- if frozen_stages not in range(-1, 3):
- raise ValueError('frozen_stages must be in range(-1, 3). '
- f'But received {frozen_stages}')
- self.out_indices = out_indices
- self.frozen_stages = frozen_stages
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- self.act_cfg = act_cfg
- self.norm_eval = norm_eval
- self.with_cp = with_cp
-
- if groups == 1:
- channels = (144, 288, 576)
- elif groups == 2:
- channels = (200, 400, 800)
- elif groups == 3:
- channels = (240, 480, 960)
- elif groups == 4:
- channels = (272, 544, 1088)
- elif groups == 8:
- channels = (384, 768, 1536)
- else:
- raise ValueError(f'{groups} groups is not supported for 1x1 '
- 'Grouped Convolutions')
-
- channels = [make_divisible(ch * widen_factor, 8) for ch in channels]
-
- self.in_channels = int(24 * widen_factor)
-
- self.conv1 = ConvModule(
- in_channels=3,
- out_channels=self.in_channels,
- kernel_size=3,
- stride=2,
- padding=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg)
- self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
-
- self.layers = nn.ModuleList()
- for i, num_blocks in enumerate(self.stage_blocks):
- first_block = (i == 0)
- layer = self.make_layer(channels[i], num_blocks, first_block)
- self.layers.append(layer)
-
- def _freeze_stages(self):
- if self.frozen_stages >= 0:
- for param in self.conv1.parameters():
- param.requires_grad = False
- for i in range(self.frozen_stages):
- layer = self.layers[i]
- layer.eval()
- for param in layer.parameters():
- param.requires_grad = False
-
- def init_weights(self, pretrained=None):
- super(ShuffleNetV1, self).init_weights()
-
- if (isinstance(self.init_cfg, dict)
- and self.init_cfg['type'] == 'Pretrained'):
- return
-
- for name, m in self.named_modules():
- if isinstance(m, nn.Conv2d) and 'conv1' not in name:
- nn.init.normal_(m.weight, mean=0, std=1.0 / m.weight.shape[1])
-
- def make_layer(self, out_channels, num_blocks, first_block=False):
- """Stack ShuffleUnit blocks to make a layer.
-
- Args:
- out_channels (int): out_channels of the block.
- num_blocks (int): Number of blocks.
- first_block (bool, optional): Whether is the first ShuffleUnit of a
- sequential ShuffleUnits. Default: False, which means using
- the grouped 1x1 convolution.
- """
- layers = []
- for i in range(num_blocks):
- first_block = first_block if i == 0 else False
- combine_mode = 'concat' if i == 0 else 'add'
- layers.append(
- ShuffleUnit(
- self.in_channels,
- out_channels,
- groups=self.groups,
- first_block=first_block,
- combine=combine_mode,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg,
- with_cp=self.with_cp))
- self.in_channels = out_channels
-
- return nn.Sequential(*layers)
-
- def forward(self, x):
- x = self.conv1(x)
- x = self.maxpool(x)
-
- outs = []
- for i, layer in enumerate(self.layers):
- x = layer(x)
- if i in self.out_indices:
- outs.append(x)
-
- return tuple(outs)
-
- def train(self, mode=True):
- super().train(mode)
- self._freeze_stages()
- if mode and self.norm_eval:
- for m in self.modules():
- if isinstance(m, _BatchNorm):
- m.eval()
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint as cp
+from mmcv.cnn import ConvModule, build_activation_layer
+from mmengine.model import BaseModule
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+from .utils import channel_shuffle, make_divisible
+
+
+class ShuffleUnit(BaseModule):
+ """ShuffleUnit block.
+
+ ShuffleNet unit with pointwise group convolution (GConv) and channel
+ shuffle.
+
+ Args:
+ in_channels (int): The input channels of the ShuffleUnit.
+ out_channels (int): The output channels of the ShuffleUnit.
+ groups (int, optional): The number of groups to be used in grouped 1x1
+ convolutions in each ShuffleUnit. Default: 3
+ first_block (bool, optional): Whether it is the first ShuffleUnit of a
+ sequential ShuffleUnits. Default: True, which means not using the
+ grouped 1x1 convolution.
+ combine (str, optional): The ways to combine the input and output
+ branches. Default: 'add'.
+ conv_cfg (dict): Config dict for convolution layer. Default: None,
+ which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='ReLU').
+ with_cp (bool, optional): Use checkpoint or not. Using checkpoint
+ will save some memory while slowing down the training speed.
+ Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+
+ Returns:
+ Tensor: The output tensor.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ groups=3,
+ first_block=True,
+ combine='add',
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ with_cp=False,
+ init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ act_cfg = copy.deepcopy(act_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.first_block = first_block
+ self.combine = combine
+ self.groups = groups
+ self.bottleneck_channels = self.out_channels // 4
+ self.with_cp = with_cp
+
+ if self.combine == 'add':
+ self.depthwise_stride = 1
+ self._combine_func = self._add
+ assert in_channels == out_channels, (
+ 'in_channels must be equal to out_channels when combine '
+ 'is add')
+ elif self.combine == 'concat':
+ self.depthwise_stride = 2
+ self._combine_func = self._concat
+ self.out_channels -= self.in_channels
+ self.avgpool = nn.AvgPool2d(kernel_size=3, stride=2, padding=1)
+ else:
+ raise ValueError(f'Cannot combine tensors with {self.combine}. '
+ 'Only "add" and "concat" are supported')
+
+ self.first_1x1_groups = 1 if first_block else self.groups
+ self.g_conv_1x1_compress = ConvModule(
+ in_channels=self.in_channels,
+ out_channels=self.bottleneck_channels,
+ kernel_size=1,
+ groups=self.first_1x1_groups,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ self.depthwise_conv3x3_bn = ConvModule(
+ in_channels=self.bottleneck_channels,
+ out_channels=self.bottleneck_channels,
+ kernel_size=3,
+ stride=self.depthwise_stride,
+ padding=1,
+ groups=self.bottleneck_channels,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+
+ self.g_conv_1x1_expand = ConvModule(
+ in_channels=self.bottleneck_channels,
+ out_channels=self.out_channels,
+ kernel_size=1,
+ groups=self.groups,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+
+ self.act = build_activation_layer(act_cfg)
+
+ @staticmethod
+ def _add(x, out):
+ # residual connection
+ return x + out
+
+ @staticmethod
+ def _concat(x, out):
+ # concatenate along channel axis
+ return torch.cat((x, out), 1)
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ residual = x
+
+ out = self.g_conv_1x1_compress(x)
+ out = self.depthwise_conv3x3_bn(out)
+
+ if self.groups > 1:
+ out = channel_shuffle(out, self.groups)
+
+ out = self.g_conv_1x1_expand(out)
+
+ if self.combine == 'concat':
+ residual = self.avgpool(residual)
+ out = self.act(out)
+ out = self._combine_func(residual, out)
+ else:
+ out = self._combine_func(residual, out)
+ out = self.act(out)
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
+
+
+@MODELS.register_module()
+class ShuffleNetV1(BaseBackbone):
+ """ShuffleNetV1 backbone.
+
+ Args:
+ groups (int, optional): The number of groups to be used in grouped 1x1
+ convolutions in each ShuffleUnit. Default: 3.
+ widen_factor (float, optional): Width multiplier - adjusts the number
+ of channels in each layer by this amount. Default: 1.0.
+ out_indices (Sequence[int]): Output from which stages.
+ Default: (2, )
+ frozen_stages (int): Stages to be frozen (all param fixed).
+ Default: -1, which means not freezing any parameters.
+ conv_cfg (dict): Config dict for convolution layer. Default: None,
+ which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='ReLU').
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Normal', std=0.01, layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ bias=0.0001
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+ """
+
+ def __init__(self,
+ groups=3,
+ widen_factor=1.0,
+ out_indices=(2, ),
+ frozen_stages=-1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ norm_eval=False,
+ with_cp=False,
+ init_cfg=[
+ dict(type='Normal', std=0.01, layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ bias=0.0001,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ act_cfg = copy.deepcopy(act_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self.stage_blocks = [4, 8, 4]
+ self.groups = groups
+
+ for index in out_indices:
+ if index not in range(0, 3):
+ raise ValueError('the item in out_indices must in '
+ f'range(0, 3). But received {index}')
+
+ if frozen_stages not in range(-1, 3):
+ raise ValueError('frozen_stages must be in range(-1, 3). '
+ f'But received {frozen_stages}')
+ self.out_indices = out_indices
+ self.frozen_stages = frozen_stages
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+
+ if groups == 1:
+ channels = (144, 288, 576)
+ elif groups == 2:
+ channels = (200, 400, 800)
+ elif groups == 3:
+ channels = (240, 480, 960)
+ elif groups == 4:
+ channels = (272, 544, 1088)
+ elif groups == 8:
+ channels = (384, 768, 1536)
+ else:
+ raise ValueError(f'{groups} groups is not supported for 1x1 '
+ 'Grouped Convolutions')
+
+ channels = [make_divisible(ch * widen_factor, 8) for ch in channels]
+
+ self.in_channels = int(24 * widen_factor)
+
+ self.conv1 = ConvModule(
+ in_channels=3,
+ out_channels=self.in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
+
+ self.layers = nn.ModuleList()
+ for i, num_blocks in enumerate(self.stage_blocks):
+ first_block = (i == 0)
+ layer = self.make_layer(channels[i], num_blocks, first_block)
+ self.layers.append(layer)
+
+ def _freeze_stages(self):
+ if self.frozen_stages >= 0:
+ for param in self.conv1.parameters():
+ param.requires_grad = False
+ for i in range(self.frozen_stages):
+ layer = self.layers[i]
+ layer.eval()
+ for param in layer.parameters():
+ param.requires_grad = False
+
+ def init_weights(self, pretrained=None):
+ super(ShuffleNetV1, self).init_weights()
+
+ if (isinstance(self.init_cfg, dict)
+ and self.init_cfg['type'] == 'Pretrained'):
+ return
+
+ for name, m in self.named_modules():
+ if isinstance(m, nn.Conv2d) and 'conv1' not in name:
+ nn.init.normal_(m.weight, mean=0, std=1.0 / m.weight.shape[1])
+
+ def make_layer(self, out_channels, num_blocks, first_block=False):
+ """Stack ShuffleUnit blocks to make a layer.
+
+ Args:
+ out_channels (int): out_channels of the block.
+ num_blocks (int): Number of blocks.
+ first_block (bool, optional): Whether is the first ShuffleUnit of a
+ sequential ShuffleUnits. Default: False, which means using
+ the grouped 1x1 convolution.
+ """
+ layers = []
+ for i in range(num_blocks):
+ first_block = first_block if i == 0 else False
+ combine_mode = 'concat' if i == 0 else 'add'
+ layers.append(
+ ShuffleUnit(
+ self.in_channels,
+ out_channels,
+ groups=self.groups,
+ first_block=first_block,
+ combine=combine_mode,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ with_cp=self.with_cp))
+ self.in_channels = out_channels
+
+ return nn.Sequential(*layers)
+
+ def forward(self, x):
+ x = self.conv1(x)
+ x = self.maxpool(x)
+
+ outs = []
+ for i, layer in enumerate(self.layers):
+ x = layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+
+ return tuple(outs)
+
+ def train(self, mode=True):
+ super().train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, _BatchNorm):
+ m.eval()
diff --git a/mmpose/models/backbones/shufflenet_v2.py b/mmpose/models/backbones/shufflenet_v2.py
index 9757841e73..dabf383e58 100644
--- a/mmpose/models/backbones/shufflenet_v2.py
+++ b/mmpose/models/backbones/shufflenet_v2.py
@@ -1,311 +1,311 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-
-import torch
-import torch.nn as nn
-import torch.utils.checkpoint as cp
-from mmcv.cnn import ConvModule
-from mmengine.model import BaseModule
-
-from mmpose.registry import MODELS
-from .base_backbone import BaseBackbone
-from .utils import channel_shuffle
-
-
-class InvertedResidual(BaseModule):
- """InvertedResidual block for ShuffleNetV2 backbone.
-
- Args:
- in_channels (int): The input channels of the block.
- out_channels (int): The output channels of the block.
- stride (int): Stride of the 3x3 convolution layer. Default: 1
- conv_cfg (dict): Config dict for convolution layer.
- Default: None, which means using conv2d.
- norm_cfg (dict): Config dict for normalization layer.
- Default: dict(type='BN').
- act_cfg (dict): Config dict for activation layer.
- Default: dict(type='ReLU').
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed. Default: False.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- stride=1,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- act_cfg=dict(type='ReLU'),
- with_cp=False,
- init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- act_cfg = copy.deepcopy(act_cfg)
- super().__init__(init_cfg=init_cfg)
- self.stride = stride
- self.with_cp = with_cp
-
- branch_features = out_channels // 2
- if self.stride == 1:
- assert in_channels == branch_features * 2, (
- f'in_channels ({in_channels}) should equal to '
- f'branch_features * 2 ({branch_features * 2}) '
- 'when stride is 1')
-
- if in_channels != branch_features * 2:
- assert self.stride != 1, (
- f'stride ({self.stride}) should not equal 1 when '
- f'in_channels != branch_features * 2')
-
- if self.stride > 1:
- self.branch1 = nn.Sequential(
- ConvModule(
- in_channels,
- in_channels,
- kernel_size=3,
- stride=self.stride,
- padding=1,
- groups=in_channels,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=None),
- ConvModule(
- in_channels,
- branch_features,
- kernel_size=1,
- stride=1,
- padding=0,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg),
- )
-
- self.branch2 = nn.Sequential(
- ConvModule(
- in_channels if (self.stride > 1) else branch_features,
- branch_features,
- kernel_size=1,
- stride=1,
- padding=0,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg),
- ConvModule(
- branch_features,
- branch_features,
- kernel_size=3,
- stride=self.stride,
- padding=1,
- groups=branch_features,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=None),
- ConvModule(
- branch_features,
- branch_features,
- kernel_size=1,
- stride=1,
- padding=0,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg))
-
- def forward(self, x):
-
- def _inner_forward(x):
- if self.stride > 1:
- out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
- else:
- x1, x2 = x.chunk(2, dim=1)
- out = torch.cat((x1, self.branch2(x2)), dim=1)
-
- out = channel_shuffle(out, 2)
-
- return out
-
- if self.with_cp and x.requires_grad:
- out = cp.checkpoint(_inner_forward, x)
- else:
- out = _inner_forward(x)
-
- return out
-
-
-@MODELS.register_module()
-class ShuffleNetV2(BaseBackbone):
- """ShuffleNetV2 backbone.
-
- Args:
- widen_factor (float): Width multiplier - adjusts the number of
- channels in each layer by this amount. Default: 1.0.
- out_indices (Sequence[int]): Output from which stages.
- Default: (0, 1, 2, 3).
- frozen_stages (int): Stages to be frozen (all param fixed).
- Default: -1, which means not freezing any parameters.
- conv_cfg (dict): Config dict for convolution layer.
- Default: None, which means using conv2d.
- norm_cfg (dict): Config dict for normalization layer.
- Default: dict(type='BN').
- act_cfg (dict): Config dict for activation layer.
- Default: dict(type='ReLU').
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only. Default: False.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed. Default: False.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Normal', std=0.01, layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- bias=0.0001
- layer=['_BatchNorm', 'GroupNorm'])
- ]``
- """
-
- def __init__(self,
- widen_factor=1.0,
- out_indices=(3, ),
- frozen_stages=-1,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- act_cfg=dict(type='ReLU'),
- norm_eval=False,
- with_cp=False,
- init_cfg=[
- dict(type='Normal', std=0.01, layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- bias=0.0001,
- layer=['_BatchNorm', 'GroupNorm'])
- ]):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- act_cfg = copy.deepcopy(act_cfg)
- super().__init__(init_cfg=init_cfg)
- self.stage_blocks = [4, 8, 4]
- for index in out_indices:
- if index not in range(0, 4):
- raise ValueError('the item in out_indices must in '
- f'range(0, 4). But received {index}')
-
- if frozen_stages not in range(-1, 4):
- raise ValueError('frozen_stages must be in range(-1, 4). '
- f'But received {frozen_stages}')
- self.out_indices = out_indices
- self.frozen_stages = frozen_stages
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- self.act_cfg = act_cfg
- self.norm_eval = norm_eval
- self.with_cp = with_cp
-
- if widen_factor == 0.5:
- channels = [48, 96, 192, 1024]
- elif widen_factor == 1.0:
- channels = [116, 232, 464, 1024]
- elif widen_factor == 1.5:
- channels = [176, 352, 704, 1024]
- elif widen_factor == 2.0:
- channels = [244, 488, 976, 2048]
- else:
- raise ValueError('widen_factor must be in [0.5, 1.0, 1.5, 2.0]. '
- f'But received {widen_factor}')
-
- self.in_channels = 24
- self.conv1 = ConvModule(
- in_channels=3,
- out_channels=self.in_channels,
- kernel_size=3,
- stride=2,
- padding=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg)
-
- self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
-
- self.layers = nn.ModuleList()
- for i, num_blocks in enumerate(self.stage_blocks):
- layer = self._make_layer(channels[i], num_blocks)
- self.layers.append(layer)
-
- output_channels = channels[-1]
- self.layers.append(
- ConvModule(
- in_channels=self.in_channels,
- out_channels=output_channels,
- kernel_size=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg))
-
- def _make_layer(self, out_channels, num_blocks):
- """Stack blocks to make a layer.
-
- Args:
- out_channels (int): out_channels of the block.
- num_blocks (int): number of blocks.
- """
- layers = []
- for i in range(num_blocks):
- stride = 2 if i == 0 else 1
- layers.append(
- InvertedResidual(
- in_channels=self.in_channels,
- out_channels=out_channels,
- stride=stride,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg,
- with_cp=self.with_cp))
- self.in_channels = out_channels
-
- return nn.Sequential(*layers)
-
- def _freeze_stages(self):
- if self.frozen_stages >= 0:
- for param in self.conv1.parameters():
- param.requires_grad = False
-
- for i in range(self.frozen_stages):
- m = self.layers[i]
- m.eval()
- for param in m.parameters():
- param.requires_grad = False
-
- def init_weights(self):
- super(ShuffleNetV2, self).init_weights()
-
- if (isinstance(self.init_cfg, dict)
- and self.init_cfg['type'] == 'Pretrained'):
- return
-
- for name, m in self.named_modules():
- if isinstance(m, nn.Conv2d) and 'conv1' not in name:
- nn.init.normal_(m.weight, mean=0, std=1.0 / m.weight.shape[1])
-
- def forward(self, x):
- x = self.conv1(x)
- x = self.maxpool(x)
-
- outs = []
- for i, layer in enumerate(self.layers):
- x = layer(x)
- if i in self.out_indices:
- outs.append(x)
-
- return tuple(outs)
-
- def train(self, mode=True):
- super().train(mode)
- self._freeze_stages()
- if mode and self.norm_eval:
- for m in self.modules():
- if isinstance(m, nn.BatchNorm2d):
- m.eval()
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint as cp
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+from .utils import channel_shuffle
+
+
+class InvertedResidual(BaseModule):
+ """InvertedResidual block for ShuffleNetV2 backbone.
+
+ Args:
+ in_channels (int): The input channels of the block.
+ out_channels (int): The output channels of the block.
+ stride (int): Stride of the 3x3 convolution layer. Default: 1
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='ReLU').
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ stride=1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ with_cp=False,
+ init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ act_cfg = copy.deepcopy(act_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self.stride = stride
+ self.with_cp = with_cp
+
+ branch_features = out_channels // 2
+ if self.stride == 1:
+ assert in_channels == branch_features * 2, (
+ f'in_channels ({in_channels}) should equal to '
+ f'branch_features * 2 ({branch_features * 2}) '
+ 'when stride is 1')
+
+ if in_channels != branch_features * 2:
+ assert self.stride != 1, (
+ f'stride ({self.stride}) should not equal 1 when '
+ f'in_channels != branch_features * 2')
+
+ if self.stride > 1:
+ self.branch1 = nn.Sequential(
+ ConvModule(
+ in_channels,
+ in_channels,
+ kernel_size=3,
+ stride=self.stride,
+ padding=1,
+ groups=in_channels,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None),
+ ConvModule(
+ in_channels,
+ branch_features,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ )
+
+ self.branch2 = nn.Sequential(
+ ConvModule(
+ in_channels if (self.stride > 1) else branch_features,
+ branch_features,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ branch_features,
+ branch_features,
+ kernel_size=3,
+ stride=self.stride,
+ padding=1,
+ groups=branch_features,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None),
+ ConvModule(
+ branch_features,
+ branch_features,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ if self.stride > 1:
+ out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
+ else:
+ x1, x2 = x.chunk(2, dim=1)
+ out = torch.cat((x1, self.branch2(x2)), dim=1)
+
+ out = channel_shuffle(out, 2)
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
+
+
+@MODELS.register_module()
+class ShuffleNetV2(BaseBackbone):
+ """ShuffleNetV2 backbone.
+
+ Args:
+ widen_factor (float): Width multiplier - adjusts the number of
+ channels in each layer by this amount. Default: 1.0.
+ out_indices (Sequence[int]): Output from which stages.
+ Default: (0, 1, 2, 3).
+ frozen_stages (int): Stages to be frozen (all param fixed).
+ Default: -1, which means not freezing any parameters.
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='ReLU').
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Normal', std=0.01, layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ bias=0.0001
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+ """
+
+ def __init__(self,
+ widen_factor=1.0,
+ out_indices=(3, ),
+ frozen_stages=-1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ norm_eval=False,
+ with_cp=False,
+ init_cfg=[
+ dict(type='Normal', std=0.01, layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ bias=0.0001,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ act_cfg = copy.deepcopy(act_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self.stage_blocks = [4, 8, 4]
+ for index in out_indices:
+ if index not in range(0, 4):
+ raise ValueError('the item in out_indices must in '
+ f'range(0, 4). But received {index}')
+
+ if frozen_stages not in range(-1, 4):
+ raise ValueError('frozen_stages must be in range(-1, 4). '
+ f'But received {frozen_stages}')
+ self.out_indices = out_indices
+ self.frozen_stages = frozen_stages
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+
+ if widen_factor == 0.5:
+ channels = [48, 96, 192, 1024]
+ elif widen_factor == 1.0:
+ channels = [116, 232, 464, 1024]
+ elif widen_factor == 1.5:
+ channels = [176, 352, 704, 1024]
+ elif widen_factor == 2.0:
+ channels = [244, 488, 976, 2048]
+ else:
+ raise ValueError('widen_factor must be in [0.5, 1.0, 1.5, 2.0]. '
+ f'But received {widen_factor}')
+
+ self.in_channels = 24
+ self.conv1 = ConvModule(
+ in_channels=3,
+ out_channels=self.in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
+
+ self.layers = nn.ModuleList()
+ for i, num_blocks in enumerate(self.stage_blocks):
+ layer = self._make_layer(channels[i], num_blocks)
+ self.layers.append(layer)
+
+ output_channels = channels[-1]
+ self.layers.append(
+ ConvModule(
+ in_channels=self.in_channels,
+ out_channels=output_channels,
+ kernel_size=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def _make_layer(self, out_channels, num_blocks):
+ """Stack blocks to make a layer.
+
+ Args:
+ out_channels (int): out_channels of the block.
+ num_blocks (int): number of blocks.
+ """
+ layers = []
+ for i in range(num_blocks):
+ stride = 2 if i == 0 else 1
+ layers.append(
+ InvertedResidual(
+ in_channels=self.in_channels,
+ out_channels=out_channels,
+ stride=stride,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ with_cp=self.with_cp))
+ self.in_channels = out_channels
+
+ return nn.Sequential(*layers)
+
+ def _freeze_stages(self):
+ if self.frozen_stages >= 0:
+ for param in self.conv1.parameters():
+ param.requires_grad = False
+
+ for i in range(self.frozen_stages):
+ m = self.layers[i]
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ def init_weights(self):
+ super(ShuffleNetV2, self).init_weights()
+
+ if (isinstance(self.init_cfg, dict)
+ and self.init_cfg['type'] == 'Pretrained'):
+ return
+
+ for name, m in self.named_modules():
+ if isinstance(m, nn.Conv2d) and 'conv1' not in name:
+ nn.init.normal_(m.weight, mean=0, std=1.0 / m.weight.shape[1])
+
+ def forward(self, x):
+ x = self.conv1(x)
+ x = self.maxpool(x)
+
+ outs = []
+ for i, layer in enumerate(self.layers):
+ x = layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+
+ return tuple(outs)
+
+ def train(self, mode=True):
+ super().train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, nn.BatchNorm2d):
+ m.eval()
diff --git a/mmpose/models/backbones/swin.py b/mmpose/models/backbones/swin.py
index a8f7c97278..a2251fd74c 100644
--- a/mmpose/models/backbones/swin.py
+++ b/mmpose/models/backbones/swin.py
@@ -1,739 +1,739 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from copy import deepcopy
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-import torch.utils.checkpoint as cp
-from mmcv.cnn import build_norm_layer
-from mmcv.cnn.bricks.transformer import FFN, build_dropout
-from mmengine.model import BaseModule
-from mmengine.model.weight_init import trunc_normal_
-from mmengine.runner import load_state_dict
-from mmengine.utils import to_2tuple
-
-from mmpose.registry import MODELS
-from mmpose.utils import get_root_logger
-from ..utils.transformer import PatchEmbed, PatchMerging
-from .base_backbone import BaseBackbone
-from .utils import get_state_dict
-from .utils.ckpt_convert import swin_converter
-
-
-class WindowMSA(BaseModule):
- """Window based multi-head self-attention (W-MSA) module with relative
- position bias.
-
- Args:
- embed_dims (int): Number of input channels.
- num_heads (int): Number of attention heads.
- window_size (tuple[int]): The height and width of the window.
- qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
- Default: True.
- qk_scale (float | None, optional): Override default qk scale of
- head_dim ** -0.5 if set. Default: None.
- attn_drop_rate (float, optional): Dropout ratio of attention weight.
- Default: 0.0
- proj_drop_rate (float, optional): Dropout ratio of output. Default: 0.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None.
- """
-
- def __init__(self,
- embed_dims,
- num_heads,
- window_size,
- qkv_bias=True,
- qk_scale=None,
- attn_drop_rate=0.,
- proj_drop_rate=0.,
- init_cfg=None):
-
- super().__init__(init_cfg=init_cfg)
- self.embed_dims = embed_dims
- self.window_size = window_size # Wh, Ww
- self.num_heads = num_heads
- head_embed_dims = embed_dims // num_heads
- self.scale = qk_scale or head_embed_dims**-0.5
-
- # define a parameter table of relative position bias
- self.relative_position_bias_table = nn.Parameter(
- torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1),
- num_heads)) # 2*Wh-1 * 2*Ww-1, nH
-
- # About 2x faster than original impl
- Wh, Ww = self.window_size
- rel_index_coords = self.double_step_seq(2 * Ww - 1, Wh, 1, Ww)
- rel_position_index = rel_index_coords + rel_index_coords.T
- rel_position_index = rel_position_index.flip(1).contiguous()
- self.register_buffer('relative_position_index', rel_position_index)
-
- self.qkv = nn.Linear(embed_dims, embed_dims * 3, bias=qkv_bias)
- self.attn_drop = nn.Dropout(attn_drop_rate)
- self.proj = nn.Linear(embed_dims, embed_dims)
- self.proj_drop = nn.Dropout(proj_drop_rate)
-
- self.softmax = nn.Softmax(dim=-1)
-
- def init_weights(self):
- trunc_normal_(self.relative_position_bias_table, std=0.02)
-
- def forward(self, x, mask=None):
- """
- Args:
-
- x (tensor): input features with shape of (num_windows*B, N, C)
- mask (tensor | None, Optional): mask with shape of (num_windows,
- Wh*Ww, Wh*Ww), value should be between (-inf, 0].
- """
- B, N, C = x.shape
- qkv = self.qkv(x).reshape(B, N, 3, self.num_heads,
- C // self.num_heads).permute(2, 0, 3, 1, 4)
- # make torchscript happy (cannot use tensor as tuple)
- q, k, v = qkv[0], qkv[1], qkv[2]
-
- q = q * self.scale
- attn = (q @ k.transpose(-2, -1))
-
- relative_position_bias = self.relative_position_bias_table[
- self.relative_position_index.view(-1)].view(
- self.window_size[0] * self.window_size[1],
- self.window_size[0] * self.window_size[1],
- -1) # Wh*Ww,Wh*Ww,nH
- relative_position_bias = relative_position_bias.permute(
- 2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
- attn = attn + relative_position_bias.unsqueeze(0)
-
- if mask is not None:
- nW = mask.shape[0]
- attn = attn.view(B // nW, nW, self.num_heads, N,
- N) + mask.unsqueeze(1).unsqueeze(0)
- attn = attn.view(-1, self.num_heads, N, N)
- attn = self.softmax(attn)
-
- attn = self.attn_drop(attn)
-
- x = (attn @ v).transpose(1, 2).reshape(B, N, C)
- x = self.proj(x)
- x = self.proj_drop(x)
- return x
-
- @staticmethod
- def double_step_seq(step1, len1, step2, len2):
- seq1 = torch.arange(0, step1 * len1, step1)
- seq2 = torch.arange(0, step2 * len2, step2)
- return (seq1[:, None] + seq2[None, :]).reshape(1, -1)
-
-
-class ShiftWindowMSA(BaseModule):
- """Shifted Window Multihead Self-Attention Module.
-
- Args:
- embed_dims (int): Number of input channels.
- num_heads (int): Number of attention heads.
- window_size (int): The height and width of the window.
- shift_size (int, optional): The shift step of each window towards
- right-bottom. If zero, act as regular window-msa. Defaults to 0.
- qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
- Default: True
- qk_scale (float | None, optional): Override default qk scale of
- head_dim ** -0.5 if set. Defaults: None.
- attn_drop_rate (float, optional): Dropout ratio of attention weight.
- Defaults: 0.
- proj_drop_rate (float, optional): Dropout ratio of output.
- Defaults: 0.
- dropout_layer (dict, optional): The dropout_layer used before output.
- Defaults: dict(type='DropPath', drop_prob=0.).
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- embed_dims,
- num_heads,
- window_size,
- shift_size=0,
- qkv_bias=True,
- qk_scale=None,
- attn_drop_rate=0,
- proj_drop_rate=0,
- dropout_layer=dict(type='DropPath', drop_prob=0.),
- init_cfg=None):
- super().__init__(init_cfg=init_cfg)
-
- self.window_size = window_size
- self.shift_size = shift_size
- assert 0 <= self.shift_size < self.window_size
-
- self.w_msa = WindowMSA(
- embed_dims=embed_dims,
- num_heads=num_heads,
- window_size=to_2tuple(window_size),
- qkv_bias=qkv_bias,
- qk_scale=qk_scale,
- attn_drop_rate=attn_drop_rate,
- proj_drop_rate=proj_drop_rate)
-
- self.drop = build_dropout(dropout_layer)
-
- def forward(self, query, hw_shape):
- B, L, C = query.shape
- H, W = hw_shape
- assert L == H * W, 'input feature has wrong size'
- query = query.view(B, H, W, C)
-
- # pad feature maps to multiples of window size
- pad_r = (self.window_size - W % self.window_size) % self.window_size
- pad_b = (self.window_size - H % self.window_size) % self.window_size
- query = F.pad(query, (0, 0, 0, pad_r, 0, pad_b))
- H_pad, W_pad = query.shape[1], query.shape[2]
-
- # cyclic shift
- if self.shift_size > 0:
- shifted_query = torch.roll(
- query,
- shifts=(-self.shift_size, -self.shift_size),
- dims=(1, 2))
-
- # calculate attention mask for SW-MSA
- img_mask = torch.zeros((1, H_pad, W_pad, 1), device=query.device)
- h_slices = (slice(0, -self.window_size),
- slice(-self.window_size,
- -self.shift_size), slice(-self.shift_size, None))
- w_slices = (slice(0, -self.window_size),
- slice(-self.window_size,
- -self.shift_size), slice(-self.shift_size, None))
- cnt = 0
- for h in h_slices:
- for w in w_slices:
- img_mask[:, h, w, :] = cnt
- cnt += 1
-
- # nW, window_size, window_size, 1
- mask_windows = self.window_partition(img_mask)
- mask_windows = mask_windows.view(
- -1, self.window_size * self.window_size)
- attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
- attn_mask = attn_mask.masked_fill(attn_mask != 0,
- float(-100.0)).masked_fill(
- attn_mask == 0, float(0.0))
- else:
- shifted_query = query
- attn_mask = None
-
- # nW*B, window_size, window_size, C
- query_windows = self.window_partition(shifted_query)
- # nW*B, window_size*window_size, C
- query_windows = query_windows.view(-1, self.window_size**2, C)
-
- # W-MSA/SW-MSA (nW*B, window_size*window_size, C)
- attn_windows = self.w_msa(query_windows, mask=attn_mask)
-
- # merge windows
- attn_windows = attn_windows.view(-1, self.window_size,
- self.window_size, C)
-
- # B H' W' C
- shifted_x = self.window_reverse(attn_windows, H_pad, W_pad)
- # reverse cyclic shift
- if self.shift_size > 0:
- x = torch.roll(
- shifted_x,
- shifts=(self.shift_size, self.shift_size),
- dims=(1, 2))
- else:
- x = shifted_x
-
- if pad_r > 0 or pad_b:
- x = x[:, :H, :W, :].contiguous()
-
- x = x.view(B, H * W, C)
-
- x = self.drop(x)
- return x
-
- def window_reverse(self, windows, H, W):
- """
- Args:
- windows: (num_windows*B, window_size, window_size, C)
- H (int): Height of image
- W (int): Width of image
- Returns:
- x: (B, H, W, C)
- """
- window_size = self.window_size
- B = int(windows.shape[0] / (H * W / window_size / window_size))
- x = windows.view(B, H // window_size, W // window_size, window_size,
- window_size, -1)
- x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
- return x
-
- def window_partition(self, x):
- """
- Args:
- x: (B, H, W, C)
- Returns:
- windows: (num_windows*B, window_size, window_size, C)
- """
- B, H, W, C = x.shape
- window_size = self.window_size
- x = x.view(B, H // window_size, window_size, W // window_size,
- window_size, C)
- windows = x.permute(0, 1, 3, 2, 4, 5).contiguous()
- windows = windows.view(-1, window_size, window_size, C)
- return windows
-
-
-class SwinBlock(BaseModule):
- """"
- Args:
- embed_dims (int): The feature dimension.
- num_heads (int): Parallel attention heads.
- feedforward_channels (int): The hidden dimension for FFNs.
- window_size (int, optional): The local window scale. Default: 7.
- shift (bool, optional): whether to shift window or not. Default False.
- qkv_bias (bool, optional): enable bias for qkv if True. Default: True.
- qk_scale (float | None, optional): Override default qk scale of
- head_dim ** -0.5 if set. Default: None.
- drop_rate (float, optional): Dropout rate. Default: 0.
- attn_drop_rate (float, optional): Attention dropout rate. Default: 0.
- drop_path_rate (float, optional): Stochastic depth rate. Default: 0.
- act_cfg (dict, optional): The config dict of activation function.
- Default: dict(type='GELU').
- norm_cfg (dict, optional): The config dict of normalization.
- Default: dict(type='LN').
- with_cp (bool, optional): Use checkpoint or not. Using checkpoint
- will save some memory while slowing down the training speed.
- Default: False.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- embed_dims,
- num_heads,
- feedforward_channels,
- window_size=7,
- shift=False,
- qkv_bias=True,
- qk_scale=None,
- drop_rate=0.,
- attn_drop_rate=0.,
- drop_path_rate=0.,
- act_cfg=dict(type='GELU'),
- norm_cfg=dict(type='LN'),
- with_cp=False,
- init_cfg=None):
-
- super(SwinBlock, self).__init__(init_cfg=init_cfg)
-
- self.with_cp = with_cp
-
- self.norm1 = build_norm_layer(norm_cfg, embed_dims)[1]
- self.attn = ShiftWindowMSA(
- embed_dims=embed_dims,
- num_heads=num_heads,
- window_size=window_size,
- shift_size=window_size // 2 if shift else 0,
- qkv_bias=qkv_bias,
- qk_scale=qk_scale,
- attn_drop_rate=attn_drop_rate,
- proj_drop_rate=drop_rate,
- dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate))
-
- self.norm2 = build_norm_layer(norm_cfg, embed_dims)[1]
- self.ffn = FFN(
- embed_dims=embed_dims,
- feedforward_channels=feedforward_channels,
- num_fcs=2,
- ffn_drop=drop_rate,
- dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
- act_cfg=act_cfg,
- add_identity=True,
- init_cfg=None)
-
- def forward(self, x, hw_shape):
-
- def _inner_forward(x):
- identity = x
- x = self.norm1(x)
- x = self.attn(x, hw_shape)
-
- x = x + identity
-
- identity = x
- x = self.norm2(x)
- x = self.ffn(x, identity=identity)
-
- return x
-
- if self.with_cp and x.requires_grad:
- x = cp.checkpoint(_inner_forward, x)
- else:
- x = _inner_forward(x)
-
- return x
-
-
-class SwinBlockSequence(BaseModule):
- """Implements one stage in Swin Transformer.
-
- Args:
- embed_dims (int): The feature dimension.
- num_heads (int): Parallel attention heads.
- feedforward_channels (int): The hidden dimension for FFNs.
- depth (int): The number of blocks in this stage.
- window_size (int, optional): The local window scale. Default: 7.
- qkv_bias (bool, optional): enable bias for qkv if True. Default: True.
- qk_scale (float | None, optional): Override default qk scale of
- head_dim ** -0.5 if set. Default: None.
- drop_rate (float, optional): Dropout rate. Default: 0.
- attn_drop_rate (float, optional): Attention dropout rate. Default: 0.
- drop_path_rate (float | list[float], optional): Stochastic depth
- rate. Default: 0.
- downsample (nn.Module | None, optional): The downsample operation
- module. Default: None.
- act_cfg (dict, optional): The config dict of activation function.
- Default: dict(type='GELU').
- norm_cfg (dict, optional): The config dict of normalization.
- Default: dict(type='LN').
- with_cp (bool, optional): Use checkpoint or not. Using checkpoint
- will save some memory while slowing down the training speed.
- Default: False.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- embed_dims,
- num_heads,
- feedforward_channels,
- depth,
- window_size=7,
- qkv_bias=True,
- qk_scale=None,
- drop_rate=0.,
- attn_drop_rate=0.,
- drop_path_rate=0.,
- downsample=None,
- act_cfg=dict(type='GELU'),
- norm_cfg=dict(type='LN'),
- with_cp=False,
- init_cfg=None):
- super().__init__(init_cfg=init_cfg)
-
- if isinstance(drop_path_rate, list):
- drop_path_rates = drop_path_rate
- assert len(drop_path_rates) == depth
- else:
- drop_path_rates = [deepcopy(drop_path_rate) for _ in range(depth)]
-
- self.blocks = nn.ModuleList()
- for i in range(depth):
- block = SwinBlock(
- embed_dims=embed_dims,
- num_heads=num_heads,
- feedforward_channels=feedforward_channels,
- window_size=window_size,
- shift=False if i % 2 == 0 else True,
- qkv_bias=qkv_bias,
- qk_scale=qk_scale,
- drop_rate=drop_rate,
- attn_drop_rate=attn_drop_rate,
- drop_path_rate=drop_path_rates[i],
- act_cfg=act_cfg,
- norm_cfg=norm_cfg,
- with_cp=with_cp)
- self.blocks.append(block)
-
- self.downsample = downsample
-
- def forward(self, x, hw_shape):
- for block in self.blocks:
- x = block(x, hw_shape)
-
- if self.downsample:
- x_down, down_hw_shape = self.downsample(x, hw_shape)
- return x_down, down_hw_shape, x, hw_shape
- else:
- return x, hw_shape, x, hw_shape
-
-
-@MODELS.register_module()
-class SwinTransformer(BaseBackbone):
- """ Swin Transformer
- A PyTorch implement of : `Swin Transformer:
- Hierarchical Vision Transformer using Shifted Windows` -
- https://arxiv.org/abs/2103.14030
-
- Inspiration from
- https://github.com/microsoft/Swin-Transformer
-
- Args:
- pretrain_img_size (int | tuple[int]): The size of input image when
- pretrain. Defaults: 224.
- in_channels (int): The num of input channels.
- Defaults: 3.
- embed_dims (int): The feature dimension. Default: 96.
- patch_size (int | tuple[int]): Patch size. Default: 4.
- window_size (int): Window size. Default: 7.
- mlp_ratio (int): Ratio of mlp hidden dim to embedding dim.
- Default: 4.
- depths (tuple[int]): Depths of each Swin Transformer stage.
- Default: (2, 2, 6, 2).
- num_heads (tuple[int]): Parallel attention heads of each Swin
- Transformer stage. Default: (3, 6, 12, 24).
- strides (tuple[int]): The patch merging or patch embedding stride of
- each Swin Transformer stage. (In swin, we set kernel size equal to
- stride.) Default: (4, 2, 2, 2).
- out_indices (tuple[int]): Output from which stages.
- Default: (0, 1, 2, 3).
- qkv_bias (bool, optional): If True, add a learnable bias to query, key,
- value. Default: True
- qk_scale (float | None, optional): Override default qk scale of
- head_dim ** -0.5 if set. Default: None.
- patch_norm (bool): If add a norm layer for patch embed and patch
- merging. Default: True.
- drop_rate (float): Dropout rate. Defaults: 0.
- attn_drop_rate (float): Attention dropout rate. Default: 0.
- drop_path_rate (float): Stochastic depth rate. Defaults: 0.1.
- use_abs_pos_embed (bool): If True, add absolute position embedding to
- the patch embedding. Defaults: False.
- act_cfg (dict): Config dict for activation layer.
- Default: dict(type='LN').
- norm_cfg (dict): Config dict for normalization layer at
- output of backone. Defaults: dict(type='LN').
- with_cp (bool, optional): Use checkpoint or not. Using checkpoint
- will save some memory while slowing down the training speed.
- Default: False.
- pretrained (str, optional): model pretrained path. Default: None.
- convert_weights (bool): The flag indicates whether the
- pre-trained model is from the original repo. We may need
- to convert some keys to make it compatible.
- Default: False.
- frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
- Default: -1 (-1 means not freezing any parameters).
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: ``[
- dict(type='TruncNormal', std=.02, layer=['Linear']),
- dict(type='Constant', val=1, layer=['LayerNorm']),
- ]``
- """
-
- def __init__(self,
- pretrain_img_size=224,
- in_channels=3,
- embed_dims=96,
- patch_size=4,
- window_size=7,
- mlp_ratio=4,
- depths=(2, 2, 6, 2),
- num_heads=(3, 6, 12, 24),
- strides=(4, 2, 2, 2),
- out_indices=(0, 1, 2, 3),
- qkv_bias=True,
- qk_scale=None,
- patch_norm=True,
- drop_rate=0.,
- attn_drop_rate=0.,
- drop_path_rate=0.1,
- use_abs_pos_embed=False,
- act_cfg=dict(type='GELU'),
- norm_cfg=dict(type='LN'),
- with_cp=False,
- convert_weights=False,
- frozen_stages=-1,
- init_cfg=[
- dict(type='TruncNormal', std=.02, layer=['Linear']),
- dict(type='Constant', val=1, layer=['LayerNorm']),
- ]):
- self.convert_weights = convert_weights
- self.frozen_stages = frozen_stages
- if isinstance(pretrain_img_size, int):
- pretrain_img_size = to_2tuple(pretrain_img_size)
- elif isinstance(pretrain_img_size, tuple):
- if len(pretrain_img_size) == 1:
- pretrain_img_size = to_2tuple(pretrain_img_size[0])
- assert len(pretrain_img_size) == 2, \
- f'The size of image should have length 1 or 2, ' \
- f'but got {len(pretrain_img_size)}'
-
- super(SwinTransformer, self).__init__(init_cfg=init_cfg)
-
- num_layers = len(depths)
- self.out_indices = out_indices
- self.use_abs_pos_embed = use_abs_pos_embed
-
- assert strides[0] == patch_size, 'Use non-overlapping patch embed.'
-
- self.patch_embed = PatchEmbed(
- in_channels=in_channels,
- embed_dims=embed_dims,
- conv_type='Conv2d',
- kernel_size=patch_size,
- stride=strides[0],
- norm_cfg=norm_cfg if patch_norm else None,
- init_cfg=None)
-
- if self.use_abs_pos_embed:
- patch_row = pretrain_img_size[0] // patch_size
- patch_col = pretrain_img_size[1] // patch_size
- num_patches = patch_row * patch_col
- self.absolute_pos_embed = nn.Parameter(
- torch.zeros((1, num_patches, embed_dims)))
-
- self.drop_after_pos = nn.Dropout(p=drop_rate)
-
- # set stochastic depth decay rule
- total_depth = sum(depths)
- dpr = [
- x.item() for x in torch.linspace(0, drop_path_rate, total_depth)
- ]
-
- self.stages = nn.ModuleList()
- in_channels = embed_dims
- for i in range(num_layers):
- if i < num_layers - 1:
- downsample = PatchMerging(
- in_channels=in_channels,
- out_channels=2 * in_channels,
- stride=strides[i + 1],
- norm_cfg=norm_cfg if patch_norm else None,
- init_cfg=None)
- else:
- downsample = None
-
- stage = SwinBlockSequence(
- embed_dims=in_channels,
- num_heads=num_heads[i],
- feedforward_channels=mlp_ratio * in_channels,
- depth=depths[i],
- window_size=window_size,
- qkv_bias=qkv_bias,
- qk_scale=qk_scale,
- drop_rate=drop_rate,
- attn_drop_rate=attn_drop_rate,
- drop_path_rate=dpr[sum(depths[:i]):sum(depths[:i + 1])],
- downsample=downsample,
- act_cfg=act_cfg,
- norm_cfg=norm_cfg,
- with_cp=with_cp)
- self.stages.append(stage)
- if downsample:
- in_channels = downsample.out_channels
-
- self.num_features = [int(embed_dims * 2**i) for i in range(num_layers)]
- # Add a norm layer for each output
- for i in out_indices:
- layer = build_norm_layer(norm_cfg, self.num_features[i])[1]
- layer_name = f'norm{i}'
- self.add_module(layer_name, layer)
-
- def train(self, mode=True):
- """Convert the model into training mode while keep layers freezed."""
- super(SwinTransformer, self).train(mode)
- self._freeze_stages()
-
- def _freeze_stages(self):
- if self.frozen_stages >= 0:
- self.patch_embed.eval()
- for param in self.patch_embed.parameters():
- param.requires_grad = False
- if self.use_abs_pos_embed:
- self.absolute_pos_embed.requires_grad = False
- self.drop_after_pos.eval()
-
- for i in range(1, self.frozen_stages + 1):
-
- if (i - 1) in self.out_indices:
- norm_layer = getattr(self, f'norm{i-1}')
- norm_layer.eval()
- for param in norm_layer.parameters():
- param.requires_grad = False
-
- m = self.stages[i - 1]
- m.eval()
- for param in m.parameters():
- param.requires_grad = False
-
- def init_weights(self, pretrained=None):
- """Initialize the weights in backbone.
-
- Args:
- pretrained (str, optional): Path to pre-trained weights.
- Defaults to None.
- """
- if (isinstance(self.init_cfg, dict)
- and self.init_cfg['type'] == 'Pretrained'):
- # Suppress zero_init_residual if use pretrained model.
- logger = get_root_logger()
- state_dict = get_state_dict(
- self.init_cfg['checkpoint'], map_location='cpu')
- if self.convert_weights:
- # supported loading weight from original repo
- state_dict = swin_converter(state_dict)
-
- # strip prefix of state_dict
- if list(state_dict.keys())[0].startswith('module.'):
- state_dict = {k[7:]: v for k, v in state_dict.items()}
-
- # reshape absolute position embedding
- if state_dict.get('absolute_pos_embed') is not None:
- absolute_pos_embed = state_dict['absolute_pos_embed']
- N1, L, C1 = absolute_pos_embed.size()
- N2, C2, H, W = self.absolute_pos_embed.size()
- if N1 != N2 or C1 != C2 or L != H * W:
- logger.warning('Error in loading absolute_pos_embed, pass')
- else:
- state_dict['absolute_pos_embed'] = absolute_pos_embed.view(
- N2, H, W, C2).permute(0, 3, 1, 2).contiguous()
-
- # interpolate position bias table if needed
- relative_position_bias_table_keys = [
- k for k in state_dict.keys()
- if 'relative_position_bias_table' in k
- ]
- for table_key in relative_position_bias_table_keys:
- table_pretrained = state_dict[table_key]
- table_current = self.state_dict()[table_key]
- L1, nH1 = table_pretrained.size()
- L2, nH2 = table_current.size()
- if nH1 != nH2:
- logger.warning(f'Error in loading {table_key}, pass')
- elif L1 != L2:
- S1 = int(L1**0.5)
- S2 = int(L2**0.5)
- table_pretrained_resized = F.interpolate(
- table_pretrained.permute(1, 0).reshape(1, nH1, S1, S1),
- size=(S2, S2),
- mode='bicubic')
- state_dict[table_key] = table_pretrained_resized.view(
- nH2, L2).permute(1, 0).contiguous()
-
- # load state_dict
- load_state_dict(self, state_dict, strict=False, logger=logger)
-
- else:
- super(SwinTransformer, self).init_weights()
- if self.use_abs_pos_embed:
- trunc_normal_(self.absolute_pos_embed, std=0.02)
-
- def forward(self, x):
- x, hw_shape = self.patch_embed(x)
-
- if self.use_abs_pos_embed:
- x = x + self.absolute_pos_embed
- x = self.drop_after_pos(x)
-
- outs = []
- for i, stage in enumerate(self.stages):
- x, hw_shape, out, out_hw_shape = stage(x, hw_shape)
- if i in self.out_indices:
- norm_layer = getattr(self, f'norm{i}')
- out = norm_layer(out)
- out = out.view(-1, *out_hw_shape,
- self.num_features[i]).permute(0, 3, 1,
- 2).contiguous()
- outs.append(out)
-
- return tuple(outs)
+# Copyright (c) OpenMMLab. All rights reserved.
+from copy import deepcopy
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint as cp
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.bricks.transformer import FFN, build_dropout
+from mmengine.model import BaseModule
+from mmengine.model.weight_init import trunc_normal_
+from mmengine.runner import load_state_dict
+from mmengine.utils import to_2tuple
+
+from mmpose.registry import MODELS
+from mmpose.utils import get_root_logger
+from ..utils.transformer import PatchEmbed, PatchMerging
+from .base_backbone import BaseBackbone
+from .utils import get_state_dict
+from .utils.ckpt_convert import swin_converter
+
+
+class WindowMSA(BaseModule):
+ """Window based multi-head self-attention (W-MSA) module with relative
+ position bias.
+
+ Args:
+ embed_dims (int): Number of input channels.
+ num_heads (int): Number of attention heads.
+ window_size (tuple[int]): The height and width of the window.
+ qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
+ Default: True.
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ attn_drop_rate (float, optional): Dropout ratio of attention weight.
+ Default: 0.0
+ proj_drop_rate (float, optional): Dropout ratio of output. Default: 0.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ window_size,
+ qkv_bias=True,
+ qk_scale=None,
+ attn_drop_rate=0.,
+ proj_drop_rate=0.,
+ init_cfg=None):
+
+ super().__init__(init_cfg=init_cfg)
+ self.embed_dims = embed_dims
+ self.window_size = window_size # Wh, Ww
+ self.num_heads = num_heads
+ head_embed_dims = embed_dims // num_heads
+ self.scale = qk_scale or head_embed_dims**-0.5
+
+ # define a parameter table of relative position bias
+ self.relative_position_bias_table = nn.Parameter(
+ torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1),
+ num_heads)) # 2*Wh-1 * 2*Ww-1, nH
+
+ # About 2x faster than original impl
+ Wh, Ww = self.window_size
+ rel_index_coords = self.double_step_seq(2 * Ww - 1, Wh, 1, Ww)
+ rel_position_index = rel_index_coords + rel_index_coords.T
+ rel_position_index = rel_position_index.flip(1).contiguous()
+ self.register_buffer('relative_position_index', rel_position_index)
+
+ self.qkv = nn.Linear(embed_dims, embed_dims * 3, bias=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop_rate)
+ self.proj = nn.Linear(embed_dims, embed_dims)
+ self.proj_drop = nn.Dropout(proj_drop_rate)
+
+ self.softmax = nn.Softmax(dim=-1)
+
+ def init_weights(self):
+ trunc_normal_(self.relative_position_bias_table, std=0.02)
+
+ def forward(self, x, mask=None):
+ """
+ Args:
+
+ x (tensor): input features with shape of (num_windows*B, N, C)
+ mask (tensor | None, Optional): mask with shape of (num_windows,
+ Wh*Ww, Wh*Ww), value should be between (-inf, 0].
+ """
+ B, N, C = x.shape
+ qkv = self.qkv(x).reshape(B, N, 3, self.num_heads,
+ C // self.num_heads).permute(2, 0, 3, 1, 4)
+ # make torchscript happy (cannot use tensor as tuple)
+ q, k, v = qkv[0], qkv[1], qkv[2]
+
+ q = q * self.scale
+ attn = (q @ k.transpose(-2, -1))
+
+ relative_position_bias = self.relative_position_bias_table[
+ self.relative_position_index.view(-1)].view(
+ self.window_size[0] * self.window_size[1],
+ self.window_size[0] * self.window_size[1],
+ -1) # Wh*Ww,Wh*Ww,nH
+ relative_position_bias = relative_position_bias.permute(
+ 2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
+ attn = attn + relative_position_bias.unsqueeze(0)
+
+ if mask is not None:
+ nW = mask.shape[0]
+ attn = attn.view(B // nW, nW, self.num_heads, N,
+ N) + mask.unsqueeze(1).unsqueeze(0)
+ attn = attn.view(-1, self.num_heads, N, N)
+ attn = self.softmax(attn)
+
+ attn = self.attn_drop(attn)
+
+ x = (attn @ v).transpose(1, 2).reshape(B, N, C)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+ @staticmethod
+ def double_step_seq(step1, len1, step2, len2):
+ seq1 = torch.arange(0, step1 * len1, step1)
+ seq2 = torch.arange(0, step2 * len2, step2)
+ return (seq1[:, None] + seq2[None, :]).reshape(1, -1)
+
+
+class ShiftWindowMSA(BaseModule):
+ """Shifted Window Multihead Self-Attention Module.
+
+ Args:
+ embed_dims (int): Number of input channels.
+ num_heads (int): Number of attention heads.
+ window_size (int): The height and width of the window.
+ shift_size (int, optional): The shift step of each window towards
+ right-bottom. If zero, act as regular window-msa. Defaults to 0.
+ qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
+ Default: True
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Defaults: None.
+ attn_drop_rate (float, optional): Dropout ratio of attention weight.
+ Defaults: 0.
+ proj_drop_rate (float, optional): Dropout ratio of output.
+ Defaults: 0.
+ dropout_layer (dict, optional): The dropout_layer used before output.
+ Defaults: dict(type='DropPath', drop_prob=0.).
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ window_size,
+ shift_size=0,
+ qkv_bias=True,
+ qk_scale=None,
+ attn_drop_rate=0,
+ proj_drop_rate=0,
+ dropout_layer=dict(type='DropPath', drop_prob=0.),
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ self.window_size = window_size
+ self.shift_size = shift_size
+ assert 0 <= self.shift_size < self.window_size
+
+ self.w_msa = WindowMSA(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ window_size=to_2tuple(window_size),
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ attn_drop_rate=attn_drop_rate,
+ proj_drop_rate=proj_drop_rate)
+
+ self.drop = build_dropout(dropout_layer)
+
+ def forward(self, query, hw_shape):
+ B, L, C = query.shape
+ H, W = hw_shape
+ assert L == H * W, 'input feature has wrong size'
+ query = query.view(B, H, W, C)
+
+ # pad feature maps to multiples of window size
+ pad_r = (self.window_size - W % self.window_size) % self.window_size
+ pad_b = (self.window_size - H % self.window_size) % self.window_size
+ query = F.pad(query, (0, 0, 0, pad_r, 0, pad_b))
+ H_pad, W_pad = query.shape[1], query.shape[2]
+
+ # cyclic shift
+ if self.shift_size > 0:
+ shifted_query = torch.roll(
+ query,
+ shifts=(-self.shift_size, -self.shift_size),
+ dims=(1, 2))
+
+ # calculate attention mask for SW-MSA
+ img_mask = torch.zeros((1, H_pad, W_pad, 1), device=query.device)
+ h_slices = (slice(0, -self.window_size),
+ slice(-self.window_size,
+ -self.shift_size), slice(-self.shift_size, None))
+ w_slices = (slice(0, -self.window_size),
+ slice(-self.window_size,
+ -self.shift_size), slice(-self.shift_size, None))
+ cnt = 0
+ for h in h_slices:
+ for w in w_slices:
+ img_mask[:, h, w, :] = cnt
+ cnt += 1
+
+ # nW, window_size, window_size, 1
+ mask_windows = self.window_partition(img_mask)
+ mask_windows = mask_windows.view(
+ -1, self.window_size * self.window_size)
+ attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
+ attn_mask = attn_mask.masked_fill(attn_mask != 0,
+ float(-100.0)).masked_fill(
+ attn_mask == 0, float(0.0))
+ else:
+ shifted_query = query
+ attn_mask = None
+
+ # nW*B, window_size, window_size, C
+ query_windows = self.window_partition(shifted_query)
+ # nW*B, window_size*window_size, C
+ query_windows = query_windows.view(-1, self.window_size**2, C)
+
+ # W-MSA/SW-MSA (nW*B, window_size*window_size, C)
+ attn_windows = self.w_msa(query_windows, mask=attn_mask)
+
+ # merge windows
+ attn_windows = attn_windows.view(-1, self.window_size,
+ self.window_size, C)
+
+ # B H' W' C
+ shifted_x = self.window_reverse(attn_windows, H_pad, W_pad)
+ # reverse cyclic shift
+ if self.shift_size > 0:
+ x = torch.roll(
+ shifted_x,
+ shifts=(self.shift_size, self.shift_size),
+ dims=(1, 2))
+ else:
+ x = shifted_x
+
+ if pad_r > 0 or pad_b:
+ x = x[:, :H, :W, :].contiguous()
+
+ x = x.view(B, H * W, C)
+
+ x = self.drop(x)
+ return x
+
+ def window_reverse(self, windows, H, W):
+ """
+ Args:
+ windows: (num_windows*B, window_size, window_size, C)
+ H (int): Height of image
+ W (int): Width of image
+ Returns:
+ x: (B, H, W, C)
+ """
+ window_size = self.window_size
+ B = int(windows.shape[0] / (H * W / window_size / window_size))
+ x = windows.view(B, H // window_size, W // window_size, window_size,
+ window_size, -1)
+ x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
+ return x
+
+ def window_partition(self, x):
+ """
+ Args:
+ x: (B, H, W, C)
+ Returns:
+ windows: (num_windows*B, window_size, window_size, C)
+ """
+ B, H, W, C = x.shape
+ window_size = self.window_size
+ x = x.view(B, H // window_size, window_size, W // window_size,
+ window_size, C)
+ windows = x.permute(0, 1, 3, 2, 4, 5).contiguous()
+ windows = windows.view(-1, window_size, window_size, C)
+ return windows
+
+
+class SwinBlock(BaseModule):
+ """"
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ window_size (int, optional): The local window scale. Default: 7.
+ shift (bool, optional): whether to shift window or not. Default False.
+ qkv_bias (bool, optional): enable bias for qkv if True. Default: True.
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ drop_rate (float, optional): Dropout rate. Default: 0.
+ attn_drop_rate (float, optional): Attention dropout rate. Default: 0.
+ drop_path_rate (float, optional): Stochastic depth rate. Default: 0.
+ act_cfg (dict, optional): The config dict of activation function.
+ Default: dict(type='GELU').
+ norm_cfg (dict, optional): The config dict of normalization.
+ Default: dict(type='LN').
+ with_cp (bool, optional): Use checkpoint or not. Using checkpoint
+ will save some memory while slowing down the training speed.
+ Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ window_size=7,
+ shift=False,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ with_cp=False,
+ init_cfg=None):
+
+ super(SwinBlock, self).__init__(init_cfg=init_cfg)
+
+ self.with_cp = with_cp
+
+ self.norm1 = build_norm_layer(norm_cfg, embed_dims)[1]
+ self.attn = ShiftWindowMSA(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ window_size=window_size,
+ shift_size=window_size // 2 if shift else 0,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ attn_drop_rate=attn_drop_rate,
+ proj_drop_rate=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate))
+
+ self.norm2 = build_norm_layer(norm_cfg, embed_dims)[1]
+ self.ffn = FFN(
+ embed_dims=embed_dims,
+ feedforward_channels=feedforward_channels,
+ num_fcs=2,
+ ffn_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ act_cfg=act_cfg,
+ add_identity=True,
+ init_cfg=None)
+
+ def forward(self, x, hw_shape):
+
+ def _inner_forward(x):
+ identity = x
+ x = self.norm1(x)
+ x = self.attn(x, hw_shape)
+
+ x = x + identity
+
+ identity = x
+ x = self.norm2(x)
+ x = self.ffn(x, identity=identity)
+
+ return x
+
+ if self.with_cp and x.requires_grad:
+ x = cp.checkpoint(_inner_forward, x)
+ else:
+ x = _inner_forward(x)
+
+ return x
+
+
+class SwinBlockSequence(BaseModule):
+ """Implements one stage in Swin Transformer.
+
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ depth (int): The number of blocks in this stage.
+ window_size (int, optional): The local window scale. Default: 7.
+ qkv_bias (bool, optional): enable bias for qkv if True. Default: True.
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ drop_rate (float, optional): Dropout rate. Default: 0.
+ attn_drop_rate (float, optional): Attention dropout rate. Default: 0.
+ drop_path_rate (float | list[float], optional): Stochastic depth
+ rate. Default: 0.
+ downsample (nn.Module | None, optional): The downsample operation
+ module. Default: None.
+ act_cfg (dict, optional): The config dict of activation function.
+ Default: dict(type='GELU').
+ norm_cfg (dict, optional): The config dict of normalization.
+ Default: dict(type='LN').
+ with_cp (bool, optional): Use checkpoint or not. Using checkpoint
+ will save some memory while slowing down the training speed.
+ Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ depth,
+ window_size=7,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ downsample=None,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ with_cp=False,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ if isinstance(drop_path_rate, list):
+ drop_path_rates = drop_path_rate
+ assert len(drop_path_rates) == depth
+ else:
+ drop_path_rates = [deepcopy(drop_path_rate) for _ in range(depth)]
+
+ self.blocks = nn.ModuleList()
+ for i in range(depth):
+ block = SwinBlock(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ feedforward_channels=feedforward_channels,
+ window_size=window_size,
+ shift=False if i % 2 == 0 else True,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop_rate=drop_rate,
+ attn_drop_rate=attn_drop_rate,
+ drop_path_rate=drop_path_rates[i],
+ act_cfg=act_cfg,
+ norm_cfg=norm_cfg,
+ with_cp=with_cp)
+ self.blocks.append(block)
+
+ self.downsample = downsample
+
+ def forward(self, x, hw_shape):
+ for block in self.blocks:
+ x = block(x, hw_shape)
+
+ if self.downsample:
+ x_down, down_hw_shape = self.downsample(x, hw_shape)
+ return x_down, down_hw_shape, x, hw_shape
+ else:
+ return x, hw_shape, x, hw_shape
+
+
+@MODELS.register_module()
+class SwinTransformer(BaseBackbone):
+ """ Swin Transformer
+ A PyTorch implement of : `Swin Transformer:
+ Hierarchical Vision Transformer using Shifted Windows` -
+ https://arxiv.org/abs/2103.14030
+
+ Inspiration from
+ https://github.com/microsoft/Swin-Transformer
+
+ Args:
+ pretrain_img_size (int | tuple[int]): The size of input image when
+ pretrain. Defaults: 224.
+ in_channels (int): The num of input channels.
+ Defaults: 3.
+ embed_dims (int): The feature dimension. Default: 96.
+ patch_size (int | tuple[int]): Patch size. Default: 4.
+ window_size (int): Window size. Default: 7.
+ mlp_ratio (int): Ratio of mlp hidden dim to embedding dim.
+ Default: 4.
+ depths (tuple[int]): Depths of each Swin Transformer stage.
+ Default: (2, 2, 6, 2).
+ num_heads (tuple[int]): Parallel attention heads of each Swin
+ Transformer stage. Default: (3, 6, 12, 24).
+ strides (tuple[int]): The patch merging or patch embedding stride of
+ each Swin Transformer stage. (In swin, we set kernel size equal to
+ stride.) Default: (4, 2, 2, 2).
+ out_indices (tuple[int]): Output from which stages.
+ Default: (0, 1, 2, 3).
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key,
+ value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ patch_norm (bool): If add a norm layer for patch embed and patch
+ merging. Default: True.
+ drop_rate (float): Dropout rate. Defaults: 0.
+ attn_drop_rate (float): Attention dropout rate. Default: 0.
+ drop_path_rate (float): Stochastic depth rate. Defaults: 0.1.
+ use_abs_pos_embed (bool): If True, add absolute position embedding to
+ the patch embedding. Defaults: False.
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='LN').
+ norm_cfg (dict): Config dict for normalization layer at
+ output of backone. Defaults: dict(type='LN').
+ with_cp (bool, optional): Use checkpoint or not. Using checkpoint
+ will save some memory while slowing down the training speed.
+ Default: False.
+ pretrained (str, optional): model pretrained path. Default: None.
+ convert_weights (bool): The flag indicates whether the
+ pre-trained model is from the original repo. We may need
+ to convert some keys to make it compatible.
+ Default: False.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ Default: -1 (-1 means not freezing any parameters).
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: ``[
+ dict(type='TruncNormal', std=.02, layer=['Linear']),
+ dict(type='Constant', val=1, layer=['LayerNorm']),
+ ]``
+ """
+
+ def __init__(self,
+ pretrain_img_size=224,
+ in_channels=3,
+ embed_dims=96,
+ patch_size=4,
+ window_size=7,
+ mlp_ratio=4,
+ depths=(2, 2, 6, 2),
+ num_heads=(3, 6, 12, 24),
+ strides=(4, 2, 2, 2),
+ out_indices=(0, 1, 2, 3),
+ qkv_bias=True,
+ qk_scale=None,
+ patch_norm=True,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.1,
+ use_abs_pos_embed=False,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ with_cp=False,
+ convert_weights=False,
+ frozen_stages=-1,
+ init_cfg=[
+ dict(type='TruncNormal', std=.02, layer=['Linear']),
+ dict(type='Constant', val=1, layer=['LayerNorm']),
+ ]):
+ self.convert_weights = convert_weights
+ self.frozen_stages = frozen_stages
+ if isinstance(pretrain_img_size, int):
+ pretrain_img_size = to_2tuple(pretrain_img_size)
+ elif isinstance(pretrain_img_size, tuple):
+ if len(pretrain_img_size) == 1:
+ pretrain_img_size = to_2tuple(pretrain_img_size[0])
+ assert len(pretrain_img_size) == 2, \
+ f'The size of image should have length 1 or 2, ' \
+ f'but got {len(pretrain_img_size)}'
+
+ super(SwinTransformer, self).__init__(init_cfg=init_cfg)
+
+ num_layers = len(depths)
+ self.out_indices = out_indices
+ self.use_abs_pos_embed = use_abs_pos_embed
+
+ assert strides[0] == patch_size, 'Use non-overlapping patch embed.'
+
+ self.patch_embed = PatchEmbed(
+ in_channels=in_channels,
+ embed_dims=embed_dims,
+ conv_type='Conv2d',
+ kernel_size=patch_size,
+ stride=strides[0],
+ norm_cfg=norm_cfg if patch_norm else None,
+ init_cfg=None)
+
+ if self.use_abs_pos_embed:
+ patch_row = pretrain_img_size[0] // patch_size
+ patch_col = pretrain_img_size[1] // patch_size
+ num_patches = patch_row * patch_col
+ self.absolute_pos_embed = nn.Parameter(
+ torch.zeros((1, num_patches, embed_dims)))
+
+ self.drop_after_pos = nn.Dropout(p=drop_rate)
+
+ # set stochastic depth decay rule
+ total_depth = sum(depths)
+ dpr = [
+ x.item() for x in torch.linspace(0, drop_path_rate, total_depth)
+ ]
+
+ self.stages = nn.ModuleList()
+ in_channels = embed_dims
+ for i in range(num_layers):
+ if i < num_layers - 1:
+ downsample = PatchMerging(
+ in_channels=in_channels,
+ out_channels=2 * in_channels,
+ stride=strides[i + 1],
+ norm_cfg=norm_cfg if patch_norm else None,
+ init_cfg=None)
+ else:
+ downsample = None
+
+ stage = SwinBlockSequence(
+ embed_dims=in_channels,
+ num_heads=num_heads[i],
+ feedforward_channels=mlp_ratio * in_channels,
+ depth=depths[i],
+ window_size=window_size,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop_rate=drop_rate,
+ attn_drop_rate=attn_drop_rate,
+ drop_path_rate=dpr[sum(depths[:i]):sum(depths[:i + 1])],
+ downsample=downsample,
+ act_cfg=act_cfg,
+ norm_cfg=norm_cfg,
+ with_cp=with_cp)
+ self.stages.append(stage)
+ if downsample:
+ in_channels = downsample.out_channels
+
+ self.num_features = [int(embed_dims * 2**i) for i in range(num_layers)]
+ # Add a norm layer for each output
+ for i in out_indices:
+ layer = build_norm_layer(norm_cfg, self.num_features[i])[1]
+ layer_name = f'norm{i}'
+ self.add_module(layer_name, layer)
+
+ def train(self, mode=True):
+ """Convert the model into training mode while keep layers freezed."""
+ super(SwinTransformer, self).train(mode)
+ self._freeze_stages()
+
+ def _freeze_stages(self):
+ if self.frozen_stages >= 0:
+ self.patch_embed.eval()
+ for param in self.patch_embed.parameters():
+ param.requires_grad = False
+ if self.use_abs_pos_embed:
+ self.absolute_pos_embed.requires_grad = False
+ self.drop_after_pos.eval()
+
+ for i in range(1, self.frozen_stages + 1):
+
+ if (i - 1) in self.out_indices:
+ norm_layer = getattr(self, f'norm{i-1}')
+ norm_layer.eval()
+ for param in norm_layer.parameters():
+ param.requires_grad = False
+
+ m = self.stages[i - 1]
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ def init_weights(self, pretrained=None):
+ """Initialize the weights in backbone.
+
+ Args:
+ pretrained (str, optional): Path to pre-trained weights.
+ Defaults to None.
+ """
+ if (isinstance(self.init_cfg, dict)
+ and self.init_cfg['type'] == 'Pretrained'):
+ # Suppress zero_init_residual if use pretrained model.
+ logger = get_root_logger()
+ state_dict = get_state_dict(
+ self.init_cfg['checkpoint'], map_location='cpu')
+ if self.convert_weights:
+ # supported loading weight from original repo
+ state_dict = swin_converter(state_dict)
+
+ # strip prefix of state_dict
+ if list(state_dict.keys())[0].startswith('module.'):
+ state_dict = {k[7:]: v for k, v in state_dict.items()}
+
+ # reshape absolute position embedding
+ if state_dict.get('absolute_pos_embed') is not None:
+ absolute_pos_embed = state_dict['absolute_pos_embed']
+ N1, L, C1 = absolute_pos_embed.size()
+ N2, C2, H, W = self.absolute_pos_embed.size()
+ if N1 != N2 or C1 != C2 or L != H * W:
+ logger.warning('Error in loading absolute_pos_embed, pass')
+ else:
+ state_dict['absolute_pos_embed'] = absolute_pos_embed.view(
+ N2, H, W, C2).permute(0, 3, 1, 2).contiguous()
+
+ # interpolate position bias table if needed
+ relative_position_bias_table_keys = [
+ k for k in state_dict.keys()
+ if 'relative_position_bias_table' in k
+ ]
+ for table_key in relative_position_bias_table_keys:
+ table_pretrained = state_dict[table_key]
+ table_current = self.state_dict()[table_key]
+ L1, nH1 = table_pretrained.size()
+ L2, nH2 = table_current.size()
+ if nH1 != nH2:
+ logger.warning(f'Error in loading {table_key}, pass')
+ elif L1 != L2:
+ S1 = int(L1**0.5)
+ S2 = int(L2**0.5)
+ table_pretrained_resized = F.interpolate(
+ table_pretrained.permute(1, 0).reshape(1, nH1, S1, S1),
+ size=(S2, S2),
+ mode='bicubic')
+ state_dict[table_key] = table_pretrained_resized.view(
+ nH2, L2).permute(1, 0).contiguous()
+
+ # load state_dict
+ load_state_dict(self, state_dict, strict=False, logger=logger)
+
+ else:
+ super(SwinTransformer, self).init_weights()
+ if self.use_abs_pos_embed:
+ trunc_normal_(self.absolute_pos_embed, std=0.02)
+
+ def forward(self, x):
+ x, hw_shape = self.patch_embed(x)
+
+ if self.use_abs_pos_embed:
+ x = x + self.absolute_pos_embed
+ x = self.drop_after_pos(x)
+
+ outs = []
+ for i, stage in enumerate(self.stages):
+ x, hw_shape, out, out_hw_shape = stage(x, hw_shape)
+ if i in self.out_indices:
+ norm_layer = getattr(self, f'norm{i}')
+ out = norm_layer(out)
+ out = out.view(-1, *out_hw_shape,
+ self.num_features[i]).permute(0, 3, 1,
+ 2).contiguous()
+ outs.append(out)
+
+ return tuple(outs)
diff --git a/mmpose/models/backbones/tcn.py b/mmpose/models/backbones/tcn.py
index ef49a1ff07..476769c297 100644
--- a/mmpose/models/backbones/tcn.py
+++ b/mmpose/models/backbones/tcn.py
@@ -1,284 +1,284 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-
-import torch.nn as nn
-from mmcv.cnn import ConvModule, build_conv_layer
-from mmengine.model import BaseModule
-
-from mmpose.registry import MODELS
-from ..utils.regularizations import WeightNormClipHook
-from .base_backbone import BaseBackbone
-
-
-class BasicTemporalBlock(BaseModule):
- """Basic block for VideoPose3D.
-
- Args:
- in_channels (int): Input channels of this block.
- out_channels (int): Output channels of this block.
- mid_channels (int): The output channels of conv1. Default: 1024.
- kernel_size (int): Size of the convolving kernel. Default: 3.
- dilation (int): Spacing between kernel elements. Default: 3.
- dropout (float): Dropout rate. Default: 0.25.
- causal (bool): Use causal convolutions instead of symmetric
- convolutions (for real-time applications). Default: False.
- residual (bool): Use residual connection. Default: True.
- use_stride_conv (bool): Use optimized TCN that designed
- specifically for single-frame batching, i.e. where batches have
- input length = receptive field, and output length = 1. This
- implementation replaces dilated convolutions with strided
- convolutions to avoid generating unused intermediate results.
- Default: False.
- conv_cfg (dict): dictionary to construct and config conv layer.
- Default: dict(type='Conv1d').
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN1d').
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- mid_channels=1024,
- kernel_size=3,
- dilation=3,
- dropout=0.25,
- causal=False,
- residual=True,
- use_stride_conv=False,
- conv_cfg=dict(type='Conv1d'),
- norm_cfg=dict(type='BN1d'),
- init_cfg=None):
- # Protect mutable default arguments
- conv_cfg = copy.deepcopy(conv_cfg)
- norm_cfg = copy.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.mid_channels = mid_channels
- self.kernel_size = kernel_size
- self.dilation = dilation
- self.dropout = dropout
- self.causal = causal
- self.residual = residual
- self.use_stride_conv = use_stride_conv
-
- self.pad = (kernel_size - 1) * dilation // 2
- if use_stride_conv:
- self.stride = kernel_size
- self.causal_shift = kernel_size // 2 if causal else 0
- self.dilation = 1
- else:
- self.stride = 1
- self.causal_shift = kernel_size // 2 * dilation if causal else 0
-
- self.conv1 = nn.Sequential(
- ConvModule(
- in_channels,
- mid_channels,
- kernel_size=kernel_size,
- stride=self.stride,
- dilation=self.dilation,
- bias='auto',
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg))
- self.conv2 = nn.Sequential(
- ConvModule(
- mid_channels,
- out_channels,
- kernel_size=1,
- bias='auto',
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg))
-
- if residual and in_channels != out_channels:
- self.short_cut = build_conv_layer(conv_cfg, in_channels,
- out_channels, 1)
- else:
- self.short_cut = None
-
- self.dropout = nn.Dropout(dropout) if dropout > 0 else None
-
- def forward(self, x):
- """Forward function."""
- if self.use_stride_conv:
- assert self.causal_shift + self.kernel_size // 2 < x.shape[2]
- else:
- assert 0 <= self.pad + self.causal_shift < x.shape[2] - \
- self.pad + self.causal_shift <= x.shape[2]
-
- out = self.conv1(x)
- if self.dropout is not None:
- out = self.dropout(out)
-
- out = self.conv2(out)
- if self.dropout is not None:
- out = self.dropout(out)
-
- if self.residual:
- if self.use_stride_conv:
- res = x[:, :, self.causal_shift +
- self.kernel_size // 2::self.kernel_size]
- else:
- res = x[:, :,
- (self.pad + self.causal_shift):(x.shape[2] - self.pad +
- self.causal_shift)]
-
- if self.short_cut is not None:
- res = self.short_cut(res)
- out = out + res
-
- return out
-
-
-@MODELS.register_module()
-class TCN(BaseBackbone):
- """TCN backbone.
-
- Temporal Convolutional Networks.
- More details can be found in the
- `paper `__ .
-
- Args:
- in_channels (int): Number of input channels, which equals to
- num_keypoints * num_features.
- stem_channels (int): Number of feature channels. Default: 1024.
- num_blocks (int): NUmber of basic temporal convolutional blocks.
- Default: 2.
- kernel_sizes (Sequence[int]): Sizes of the convolving kernel of
- each basic block. Default: ``(3, 3, 3)``.
- dropout (float): Dropout rate. Default: 0.25.
- causal (bool): Use causal convolutions instead of symmetric
- convolutions (for real-time applications).
- Default: False.
- residual (bool): Use residual connection. Default: True.
- use_stride_conv (bool): Use TCN backbone optimized for
- single-frame batching, i.e. where batches have input length =
- receptive field, and output length = 1. This implementation
- replaces dilated convolutions with strided convolutions to avoid
- generating unused intermediate results. The weights are
- interchangeable with the reference implementation. Default: False
- conv_cfg (dict): dictionary to construct and config conv layer.
- Default: dict(type='Conv1d').
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN1d').
- max_norm (float|None): if not None, the weight of convolution layers
- will be clipped to have a maximum norm of max_norm.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(
- type='Kaiming',
- mode='fan_in',
- nonlinearity='relu',
- layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]``
-
- Example:
- >>> from mmpose.models import TCN
- >>> import torch
- >>> self = TCN(in_channels=34)
- >>> self.eval()
- >>> inputs = torch.rand(1, 34, 243)
- >>> level_outputs = self.forward(inputs)
- >>> for level_out in level_outputs:
- ... print(tuple(level_out.shape))
- (1, 1024, 235)
- (1, 1024, 217)
- """
-
- def __init__(self,
- in_channels,
- stem_channels=1024,
- num_blocks=2,
- kernel_sizes=(3, 3, 3),
- dropout=0.25,
- causal=False,
- residual=True,
- use_stride_conv=False,
- conv_cfg=dict(type='Conv1d'),
- norm_cfg=dict(type='BN1d'),
- max_norm=None,
- init_cfg=[
- dict(
- type='Kaiming',
- mode='fan_in',
- nonlinearity='relu',
- layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]):
- # Protect mutable default arguments
- conv_cfg = copy.deepcopy(conv_cfg)
- norm_cfg = copy.deepcopy(norm_cfg)
- super().__init__()
- self.in_channels = in_channels
- self.stem_channels = stem_channels
- self.num_blocks = num_blocks
- self.kernel_sizes = kernel_sizes
- self.dropout = dropout
- self.causal = causal
- self.residual = residual
- self.use_stride_conv = use_stride_conv
- self.max_norm = max_norm
-
- assert num_blocks == len(kernel_sizes) - 1
- for ks in kernel_sizes:
- assert ks % 2 == 1, 'Only odd filter widths are supported.'
-
- self.expand_conv = ConvModule(
- in_channels,
- stem_channels,
- kernel_size=kernel_sizes[0],
- stride=kernel_sizes[0] if use_stride_conv else 1,
- bias='auto',
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg)
-
- dilation = kernel_sizes[0]
- self.tcn_blocks = nn.ModuleList()
- for i in range(1, num_blocks + 1):
- self.tcn_blocks.append(
- BasicTemporalBlock(
- in_channels=stem_channels,
- out_channels=stem_channels,
- mid_channels=stem_channels,
- kernel_size=kernel_sizes[i],
- dilation=dilation,
- dropout=dropout,
- causal=causal,
- residual=residual,
- use_stride_conv=use_stride_conv,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg))
- dilation *= kernel_sizes[i]
-
- if self.max_norm is not None:
- # Apply weight norm clip to conv layers
- weight_clip = WeightNormClipHook(self.max_norm)
- for module in self.modules():
- if isinstance(module, nn.modules.conv._ConvNd):
- weight_clip.register(module)
-
- self.dropout = nn.Dropout(dropout) if dropout > 0 else None
-
- def forward(self, x):
- """Forward function."""
- x = self.expand_conv(x)
-
- if self.dropout is not None:
- x = self.dropout(x)
-
- outs = []
- for i in range(self.num_blocks):
- x = self.tcn_blocks[i](x)
- outs.append(x)
-
- return tuple(outs)
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule, build_conv_layer
+from mmengine.model import BaseModule
+
+from mmpose.registry import MODELS
+from ..utils.regularizations import WeightNormClipHook
+from .base_backbone import BaseBackbone
+
+
+class BasicTemporalBlock(BaseModule):
+ """Basic block for VideoPose3D.
+
+ Args:
+ in_channels (int): Input channels of this block.
+ out_channels (int): Output channels of this block.
+ mid_channels (int): The output channels of conv1. Default: 1024.
+ kernel_size (int): Size of the convolving kernel. Default: 3.
+ dilation (int): Spacing between kernel elements. Default: 3.
+ dropout (float): Dropout rate. Default: 0.25.
+ causal (bool): Use causal convolutions instead of symmetric
+ convolutions (for real-time applications). Default: False.
+ residual (bool): Use residual connection. Default: True.
+ use_stride_conv (bool): Use optimized TCN that designed
+ specifically for single-frame batching, i.e. where batches have
+ input length = receptive field, and output length = 1. This
+ implementation replaces dilated convolutions with strided
+ convolutions to avoid generating unused intermediate results.
+ Default: False.
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ Default: dict(type='Conv1d').
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN1d').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ mid_channels=1024,
+ kernel_size=3,
+ dilation=3,
+ dropout=0.25,
+ causal=False,
+ residual=True,
+ use_stride_conv=False,
+ conv_cfg=dict(type='Conv1d'),
+ norm_cfg=dict(type='BN1d'),
+ init_cfg=None):
+ # Protect mutable default arguments
+ conv_cfg = copy.deepcopy(conv_cfg)
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.mid_channels = mid_channels
+ self.kernel_size = kernel_size
+ self.dilation = dilation
+ self.dropout = dropout
+ self.causal = causal
+ self.residual = residual
+ self.use_stride_conv = use_stride_conv
+
+ self.pad = (kernel_size - 1) * dilation // 2
+ if use_stride_conv:
+ self.stride = kernel_size
+ self.causal_shift = kernel_size // 2 if causal else 0
+ self.dilation = 1
+ else:
+ self.stride = 1
+ self.causal_shift = kernel_size // 2 * dilation if causal else 0
+
+ self.conv1 = nn.Sequential(
+ ConvModule(
+ in_channels,
+ mid_channels,
+ kernel_size=kernel_size,
+ stride=self.stride,
+ dilation=self.dilation,
+ bias='auto',
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg))
+ self.conv2 = nn.Sequential(
+ ConvModule(
+ mid_channels,
+ out_channels,
+ kernel_size=1,
+ bias='auto',
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg))
+
+ if residual and in_channels != out_channels:
+ self.short_cut = build_conv_layer(conv_cfg, in_channels,
+ out_channels, 1)
+ else:
+ self.short_cut = None
+
+ self.dropout = nn.Dropout(dropout) if dropout > 0 else None
+
+ def forward(self, x):
+ """Forward function."""
+ if self.use_stride_conv:
+ assert self.causal_shift + self.kernel_size // 2 < x.shape[2]
+ else:
+ assert 0 <= self.pad + self.causal_shift < x.shape[2] - \
+ self.pad + self.causal_shift <= x.shape[2]
+
+ out = self.conv1(x)
+ if self.dropout is not None:
+ out = self.dropout(out)
+
+ out = self.conv2(out)
+ if self.dropout is not None:
+ out = self.dropout(out)
+
+ if self.residual:
+ if self.use_stride_conv:
+ res = x[:, :, self.causal_shift +
+ self.kernel_size // 2::self.kernel_size]
+ else:
+ res = x[:, :,
+ (self.pad + self.causal_shift):(x.shape[2] - self.pad +
+ self.causal_shift)]
+
+ if self.short_cut is not None:
+ res = self.short_cut(res)
+ out = out + res
+
+ return out
+
+
+@MODELS.register_module()
+class TCN(BaseBackbone):
+ """TCN backbone.
+
+ Temporal Convolutional Networks.
+ More details can be found in the
+ `paper `__ .
+
+ Args:
+ in_channels (int): Number of input channels, which equals to
+ num_keypoints * num_features.
+ stem_channels (int): Number of feature channels. Default: 1024.
+ num_blocks (int): NUmber of basic temporal convolutional blocks.
+ Default: 2.
+ kernel_sizes (Sequence[int]): Sizes of the convolving kernel of
+ each basic block. Default: ``(3, 3, 3)``.
+ dropout (float): Dropout rate. Default: 0.25.
+ causal (bool): Use causal convolutions instead of symmetric
+ convolutions (for real-time applications).
+ Default: False.
+ residual (bool): Use residual connection. Default: True.
+ use_stride_conv (bool): Use TCN backbone optimized for
+ single-frame batching, i.e. where batches have input length =
+ receptive field, and output length = 1. This implementation
+ replaces dilated convolutions with strided convolutions to avoid
+ generating unused intermediate results. The weights are
+ interchangeable with the reference implementation. Default: False
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ Default: dict(type='Conv1d').
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN1d').
+ max_norm (float|None): if not None, the weight of convolution layers
+ will be clipped to have a maximum norm of max_norm.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(
+ type='Kaiming',
+ mode='fan_in',
+ nonlinearity='relu',
+ layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+
+ Example:
+ >>> from mmpose.models import TCN
+ >>> import torch
+ >>> self = TCN(in_channels=34)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 34, 243)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 1024, 235)
+ (1, 1024, 217)
+ """
+
+ def __init__(self,
+ in_channels,
+ stem_channels=1024,
+ num_blocks=2,
+ kernel_sizes=(3, 3, 3),
+ dropout=0.25,
+ causal=False,
+ residual=True,
+ use_stride_conv=False,
+ conv_cfg=dict(type='Conv1d'),
+ norm_cfg=dict(type='BN1d'),
+ max_norm=None,
+ init_cfg=[
+ dict(
+ type='Kaiming',
+ mode='fan_in',
+ nonlinearity='relu',
+ layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]):
+ # Protect mutable default arguments
+ conv_cfg = copy.deepcopy(conv_cfg)
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__()
+ self.in_channels = in_channels
+ self.stem_channels = stem_channels
+ self.num_blocks = num_blocks
+ self.kernel_sizes = kernel_sizes
+ self.dropout = dropout
+ self.causal = causal
+ self.residual = residual
+ self.use_stride_conv = use_stride_conv
+ self.max_norm = max_norm
+
+ assert num_blocks == len(kernel_sizes) - 1
+ for ks in kernel_sizes:
+ assert ks % 2 == 1, 'Only odd filter widths are supported.'
+
+ self.expand_conv = ConvModule(
+ in_channels,
+ stem_channels,
+ kernel_size=kernel_sizes[0],
+ stride=kernel_sizes[0] if use_stride_conv else 1,
+ bias='auto',
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg)
+
+ dilation = kernel_sizes[0]
+ self.tcn_blocks = nn.ModuleList()
+ for i in range(1, num_blocks + 1):
+ self.tcn_blocks.append(
+ BasicTemporalBlock(
+ in_channels=stem_channels,
+ out_channels=stem_channels,
+ mid_channels=stem_channels,
+ kernel_size=kernel_sizes[i],
+ dilation=dilation,
+ dropout=dropout,
+ causal=causal,
+ residual=residual,
+ use_stride_conv=use_stride_conv,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg))
+ dilation *= kernel_sizes[i]
+
+ if self.max_norm is not None:
+ # Apply weight norm clip to conv layers
+ weight_clip = WeightNormClipHook(self.max_norm)
+ for module in self.modules():
+ if isinstance(module, nn.modules.conv._ConvNd):
+ weight_clip.register(module)
+
+ self.dropout = nn.Dropout(dropout) if dropout > 0 else None
+
+ def forward(self, x):
+ """Forward function."""
+ x = self.expand_conv(x)
+
+ if self.dropout is not None:
+ x = self.dropout(x)
+
+ outs = []
+ for i in range(self.num_blocks):
+ x = self.tcn_blocks[i](x)
+ outs.append(x)
+
+ return tuple(outs)
diff --git a/mmpose/models/backbones/utils/__init__.py b/mmpose/models/backbones/utils/__init__.py
index 07e42f8912..a3febdd053 100644
--- a/mmpose/models/backbones/utils/__init__.py
+++ b/mmpose/models/backbones/utils/__init__.py
@@ -1,11 +1,11 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .channel_shuffle import channel_shuffle
-from .inverted_residual import InvertedResidual
-from .make_divisible import make_divisible
-from .se_layer import SELayer
-from .utils import get_state_dict, load_checkpoint
-
-__all__ = [
- 'channel_shuffle', 'make_divisible', 'InvertedResidual', 'SELayer',
- 'load_checkpoint', 'get_state_dict'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .channel_shuffle import channel_shuffle
+from .inverted_residual import InvertedResidual
+from .make_divisible import make_divisible
+from .se_layer import SELayer
+from .utils import get_state_dict, load_checkpoint
+
+__all__ = [
+ 'channel_shuffle', 'make_divisible', 'InvertedResidual', 'SELayer',
+ 'load_checkpoint', 'get_state_dict'
+]
diff --git a/mmpose/models/backbones/utils/channel_shuffle.py b/mmpose/models/backbones/utils/channel_shuffle.py
index aedd826bee..3805e5eb9e 100644
--- a/mmpose/models/backbones/utils/channel_shuffle.py
+++ b/mmpose/models/backbones/utils/channel_shuffle.py
@@ -1,29 +1,29 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import torch
-
-
-def channel_shuffle(x, groups):
- """Channel Shuffle operation.
-
- This function enables cross-group information flow for multiple groups
- convolution layers.
-
- Args:
- x (Tensor): The input tensor.
- groups (int): The number of groups to divide the input tensor
- in the channel dimension.
-
- Returns:
- Tensor: The output tensor after channel shuffle operation.
- """
-
- batch_size, num_channels, height, width = x.size()
- assert (num_channels % groups == 0), ('num_channels should be '
- 'divisible by groups')
- channels_per_group = num_channels // groups
-
- x = x.view(batch_size, groups, channels_per_group, height, width)
- x = torch.transpose(x, 1, 2).contiguous()
- x = x.view(batch_size, groups * channels_per_group, height, width)
-
- return x
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+
+def channel_shuffle(x, groups):
+ """Channel Shuffle operation.
+
+ This function enables cross-group information flow for multiple groups
+ convolution layers.
+
+ Args:
+ x (Tensor): The input tensor.
+ groups (int): The number of groups to divide the input tensor
+ in the channel dimension.
+
+ Returns:
+ Tensor: The output tensor after channel shuffle operation.
+ """
+
+ batch_size, num_channels, height, width = x.size()
+ assert (num_channels % groups == 0), ('num_channels should be '
+ 'divisible by groups')
+ channels_per_group = num_channels // groups
+
+ x = x.view(batch_size, groups, channels_per_group, height, width)
+ x = torch.transpose(x, 1, 2).contiguous()
+ x = x.view(batch_size, groups * channels_per_group, height, width)
+
+ return x
diff --git a/mmpose/models/backbones/utils/ckpt_convert.py b/mmpose/models/backbones/utils/ckpt_convert.py
index 14a43892c6..903f2d0975 100644
--- a/mmpose/models/backbones/utils/ckpt_convert.py
+++ b/mmpose/models/backbones/utils/ckpt_convert.py
@@ -1,62 +1,62 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-
-# This script consists of several convert functions which
-# can modify the weights of model in original repo to be
-# pre-trained weights.
-
-from collections import OrderedDict
-
-
-def swin_converter(ckpt):
-
- new_ckpt = OrderedDict()
-
- def correct_unfold_reduction_order(x):
- out_channel, in_channel = x.shape
- x = x.reshape(out_channel, 4, in_channel // 4)
- x = x[:, [0, 2, 1, 3], :].transpose(1,
- 2).reshape(out_channel, in_channel)
- return x
-
- def correct_unfold_norm_order(x):
- in_channel = x.shape[0]
- x = x.reshape(4, in_channel // 4)
- x = x[[0, 2, 1, 3], :].transpose(0, 1).reshape(in_channel)
- return x
-
- for k, v in ckpt.items():
- if k.startswith('head'):
- continue
- elif k.startswith('layers'):
- new_v = v
- if 'attn.' in k:
- new_k = k.replace('attn.', 'attn.w_msa.')
- elif 'mlp.' in k:
- if 'mlp.fc1.' in k:
- new_k = k.replace('mlp.fc1.', 'ffn.layers.0.0.')
- elif 'mlp.fc2.' in k:
- new_k = k.replace('mlp.fc2.', 'ffn.layers.1.')
- else:
- new_k = k.replace('mlp.', 'ffn.')
- elif 'downsample' in k:
- new_k = k
- if 'reduction.' in k:
- new_v = correct_unfold_reduction_order(v)
- elif 'norm.' in k:
- new_v = correct_unfold_norm_order(v)
- else:
- new_k = k
- new_k = new_k.replace('layers', 'stages', 1)
- elif k.startswith('patch_embed'):
- new_v = v
- if 'proj' in k:
- new_k = k.replace('proj', 'projection')
- else:
- new_k = k
- else:
- new_v = v
- new_k = k
-
- new_ckpt['backbone.' + new_k] = new_v
-
- return new_ckpt
+# Copyright (c) OpenMMLab. All rights reserved.
+
+# This script consists of several convert functions which
+# can modify the weights of model in original repo to be
+# pre-trained weights.
+
+from collections import OrderedDict
+
+
+def swin_converter(ckpt):
+
+ new_ckpt = OrderedDict()
+
+ def correct_unfold_reduction_order(x):
+ out_channel, in_channel = x.shape
+ x = x.reshape(out_channel, 4, in_channel // 4)
+ x = x[:, [0, 2, 1, 3], :].transpose(1,
+ 2).reshape(out_channel, in_channel)
+ return x
+
+ def correct_unfold_norm_order(x):
+ in_channel = x.shape[0]
+ x = x.reshape(4, in_channel // 4)
+ x = x[[0, 2, 1, 3], :].transpose(0, 1).reshape(in_channel)
+ return x
+
+ for k, v in ckpt.items():
+ if k.startswith('head'):
+ continue
+ elif k.startswith('layers'):
+ new_v = v
+ if 'attn.' in k:
+ new_k = k.replace('attn.', 'attn.w_msa.')
+ elif 'mlp.' in k:
+ if 'mlp.fc1.' in k:
+ new_k = k.replace('mlp.fc1.', 'ffn.layers.0.0.')
+ elif 'mlp.fc2.' in k:
+ new_k = k.replace('mlp.fc2.', 'ffn.layers.1.')
+ else:
+ new_k = k.replace('mlp.', 'ffn.')
+ elif 'downsample' in k:
+ new_k = k
+ if 'reduction.' in k:
+ new_v = correct_unfold_reduction_order(v)
+ elif 'norm.' in k:
+ new_v = correct_unfold_norm_order(v)
+ else:
+ new_k = k
+ new_k = new_k.replace('layers', 'stages', 1)
+ elif k.startswith('patch_embed'):
+ new_v = v
+ if 'proj' in k:
+ new_k = k.replace('proj', 'projection')
+ else:
+ new_k = k
+ else:
+ new_v = v
+ new_k = k
+
+ new_ckpt['backbone.' + new_k] = new_v
+
+ return new_ckpt
diff --git a/mmpose/models/backbones/utils/inverted_residual.py b/mmpose/models/backbones/utils/inverted_residual.py
index dff762c570..528e1f8281 100644
--- a/mmpose/models/backbones/utils/inverted_residual.py
+++ b/mmpose/models/backbones/utils/inverted_residual.py
@@ -1,128 +1,128 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-
-import torch.nn as nn
-import torch.utils.checkpoint as cp
-from mmcv.cnn import ConvModule
-
-from .se_layer import SELayer
-
-
-class InvertedResidual(nn.Module):
- """Inverted Residual Block.
-
- Args:
- in_channels (int): The input channels of this Module.
- out_channels (int): The output channels of this Module.
- mid_channels (int): The input channels of the depthwise convolution.
- kernel_size (int): The kernel size of the depthwise convolution.
- Default: 3.
- groups (None or int): The group number of the depthwise convolution.
- Default: None, which means group number = mid_channels.
- stride (int): The stride of the depthwise convolution. Default: 1.
- se_cfg (dict): Config dict for se layer. Default: None, which means no
- se layer.
- with_expand_conv (bool): Use expand conv or not. If set False,
- mid_channels must be the same with in_channels.
- Default: True.
- conv_cfg (dict): Config dict for convolution layer. Default: None,
- which means using conv2d.
- norm_cfg (dict): Config dict for normalization layer.
- Default: dict(type='BN').
- act_cfg (dict): Config dict for activation layer.
- Default: dict(type='ReLU').
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed. Default: False.
-
- Returns:
- Tensor: The output tensor.
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- mid_channels,
- kernel_size=3,
- groups=None,
- stride=1,
- se_cfg=None,
- with_expand_conv=True,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- act_cfg=dict(type='ReLU'),
- with_cp=False):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- act_cfg = copy.deepcopy(act_cfg)
- super().__init__()
- self.with_res_shortcut = (stride == 1 and in_channels == out_channels)
- assert stride in [1, 2]
- self.with_cp = with_cp
- self.with_se = se_cfg is not None
- self.with_expand_conv = with_expand_conv
-
- if groups is None:
- groups = mid_channels
-
- if self.with_se:
- assert isinstance(se_cfg, dict)
- if not self.with_expand_conv:
- assert mid_channels == in_channels
-
- if self.with_expand_conv:
- self.expand_conv = ConvModule(
- in_channels=in_channels,
- out_channels=mid_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg)
- self.depthwise_conv = ConvModule(
- in_channels=mid_channels,
- out_channels=mid_channels,
- kernel_size=kernel_size,
- stride=stride,
- padding=kernel_size // 2,
- groups=groups,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg)
- if self.with_se:
- self.se = SELayer(**se_cfg)
- self.linear_conv = ConvModule(
- in_channels=mid_channels,
- out_channels=out_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=None)
-
- def forward(self, x):
-
- def _inner_forward(x):
- out = x
-
- if self.with_expand_conv:
- out = self.expand_conv(out)
-
- out = self.depthwise_conv(out)
-
- if self.with_se:
- out = self.se(out)
-
- out = self.linear_conv(out)
-
- if self.with_res_shortcut:
- return x + out
- return out
-
- if self.with_cp and x.requires_grad:
- out = cp.checkpoint(_inner_forward, x)
- else:
- out = _inner_forward(x)
-
- return out
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import torch.nn as nn
+import torch.utils.checkpoint as cp
+from mmcv.cnn import ConvModule
+
+from .se_layer import SELayer
+
+
+class InvertedResidual(nn.Module):
+ """Inverted Residual Block.
+
+ Args:
+ in_channels (int): The input channels of this Module.
+ out_channels (int): The output channels of this Module.
+ mid_channels (int): The input channels of the depthwise convolution.
+ kernel_size (int): The kernel size of the depthwise convolution.
+ Default: 3.
+ groups (None or int): The group number of the depthwise convolution.
+ Default: None, which means group number = mid_channels.
+ stride (int): The stride of the depthwise convolution. Default: 1.
+ se_cfg (dict): Config dict for se layer. Default: None, which means no
+ se layer.
+ with_expand_conv (bool): Use expand conv or not. If set False,
+ mid_channels must be the same with in_channels.
+ Default: True.
+ conv_cfg (dict): Config dict for convolution layer. Default: None,
+ which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='ReLU').
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+
+ Returns:
+ Tensor: The output tensor.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ mid_channels,
+ kernel_size=3,
+ groups=None,
+ stride=1,
+ se_cfg=None,
+ with_expand_conv=True,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ with_cp=False):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ act_cfg = copy.deepcopy(act_cfg)
+ super().__init__()
+ self.with_res_shortcut = (stride == 1 and in_channels == out_channels)
+ assert stride in [1, 2]
+ self.with_cp = with_cp
+ self.with_se = se_cfg is not None
+ self.with_expand_conv = with_expand_conv
+
+ if groups is None:
+ groups = mid_channels
+
+ if self.with_se:
+ assert isinstance(se_cfg, dict)
+ if not self.with_expand_conv:
+ assert mid_channels == in_channels
+
+ if self.with_expand_conv:
+ self.expand_conv = ConvModule(
+ in_channels=in_channels,
+ out_channels=mid_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.depthwise_conv = ConvModule(
+ in_channels=mid_channels,
+ out_channels=mid_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=kernel_size // 2,
+ groups=groups,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ if self.with_se:
+ self.se = SELayer(**se_cfg)
+ self.linear_conv = ConvModule(
+ in_channels=mid_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ out = x
+
+ if self.with_expand_conv:
+ out = self.expand_conv(out)
+
+ out = self.depthwise_conv(out)
+
+ if self.with_se:
+ out = self.se(out)
+
+ out = self.linear_conv(out)
+
+ if self.with_res_shortcut:
+ return x + out
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
diff --git a/mmpose/models/backbones/utils/make_divisible.py b/mmpose/models/backbones/utils/make_divisible.py
index b7666be659..5347ed112d 100644
--- a/mmpose/models/backbones/utils/make_divisible.py
+++ b/mmpose/models/backbones/utils/make_divisible.py
@@ -1,25 +1,25 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-def make_divisible(value, divisor, min_value=None, min_ratio=0.9):
- """Make divisible function.
-
- This function rounds the channel number down to the nearest value that can
- be divisible by the divisor.
-
- Args:
- value (int): The original channel number.
- divisor (int): The divisor to fully divide the channel number.
- min_value (int, optional): The minimum value of the output channel.
- Default: None, means that the minimum value equal to the divisor.
- min_ratio (float, optional): The minimum ratio of the rounded channel
- number to the original channel number. Default: 0.9.
- Returns:
- int: The modified output channel number
- """
-
- if min_value is None:
- min_value = divisor
- new_value = max(min_value, int(value + divisor / 2) // divisor * divisor)
- # Make sure that round down does not go down by more than (1-min_ratio).
- if new_value < min_ratio * value:
- new_value += divisor
- return new_value
+# Copyright (c) OpenMMLab. All rights reserved.
+def make_divisible(value, divisor, min_value=None, min_ratio=0.9):
+ """Make divisible function.
+
+ This function rounds the channel number down to the nearest value that can
+ be divisible by the divisor.
+
+ Args:
+ value (int): The original channel number.
+ divisor (int): The divisor to fully divide the channel number.
+ min_value (int, optional): The minimum value of the output channel.
+ Default: None, means that the minimum value equal to the divisor.
+ min_ratio (float, optional): The minimum ratio of the rounded channel
+ number to the original channel number. Default: 0.9.
+ Returns:
+ int: The modified output channel number
+ """
+
+ if min_value is None:
+ min_value = divisor
+ new_value = max(min_value, int(value + divisor / 2) // divisor * divisor)
+ # Make sure that round down does not go down by more than (1-min_ratio).
+ if new_value < min_ratio * value:
+ new_value += divisor
+ return new_value
diff --git a/mmpose/models/backbones/utils/se_layer.py b/mmpose/models/backbones/utils/se_layer.py
index ec6d7aeaa9..8bcde2bff6 100644
--- a/mmpose/models/backbones/utils/se_layer.py
+++ b/mmpose/models/backbones/utils/se_layer.py
@@ -1,54 +1,54 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import mmengine
-import torch.nn as nn
-from mmcv.cnn import ConvModule
-
-
-class SELayer(nn.Module):
- """Squeeze-and-Excitation Module.
-
- Args:
- channels (int): The input (and output) channels of the SE layer.
- ratio (int): Squeeze ratio in SELayer, the intermediate channel will be
- ``int(channels/ratio)``. Default: 16.
- conv_cfg (None or dict): Config dict for convolution layer.
- Default: None, which means using conv2d.
- act_cfg (dict or Sequence[dict]): Config dict for activation layer.
- If act_cfg is a dict, two activation layers will be configurated
- by this dict. If act_cfg is a sequence of dicts, the first
- activation layer will be configurated by the first dict and the
- second activation layer will be configurated by the second dict.
- Default: (dict(type='ReLU'), dict(type='Sigmoid'))
- """
-
- def __init__(self,
- channels,
- ratio=16,
- conv_cfg=None,
- act_cfg=(dict(type='ReLU'), dict(type='Sigmoid'))):
- super().__init__()
- if isinstance(act_cfg, dict):
- act_cfg = (act_cfg, act_cfg)
- assert len(act_cfg) == 2
- assert mmengine.is_tuple_of(act_cfg, dict)
- self.global_avgpool = nn.AdaptiveAvgPool2d(1)
- self.conv1 = ConvModule(
- in_channels=channels,
- out_channels=int(channels / ratio),
- kernel_size=1,
- stride=1,
- conv_cfg=conv_cfg,
- act_cfg=act_cfg[0])
- self.conv2 = ConvModule(
- in_channels=int(channels / ratio),
- out_channels=channels,
- kernel_size=1,
- stride=1,
- conv_cfg=conv_cfg,
- act_cfg=act_cfg[1])
-
- def forward(self, x):
- out = self.global_avgpool(x)
- out = self.conv1(out)
- out = self.conv2(out)
- return x * out
+# Copyright (c) OpenMMLab. All rights reserved.
+import mmengine
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+
+class SELayer(nn.Module):
+ """Squeeze-and-Excitation Module.
+
+ Args:
+ channels (int): The input (and output) channels of the SE layer.
+ ratio (int): Squeeze ratio in SELayer, the intermediate channel will be
+ ``int(channels/ratio)``. Default: 16.
+ conv_cfg (None or dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ act_cfg (dict or Sequence[dict]): Config dict for activation layer.
+ If act_cfg is a dict, two activation layers will be configurated
+ by this dict. If act_cfg is a sequence of dicts, the first
+ activation layer will be configurated by the first dict and the
+ second activation layer will be configurated by the second dict.
+ Default: (dict(type='ReLU'), dict(type='Sigmoid'))
+ """
+
+ def __init__(self,
+ channels,
+ ratio=16,
+ conv_cfg=None,
+ act_cfg=(dict(type='ReLU'), dict(type='Sigmoid'))):
+ super().__init__()
+ if isinstance(act_cfg, dict):
+ act_cfg = (act_cfg, act_cfg)
+ assert len(act_cfg) == 2
+ assert mmengine.is_tuple_of(act_cfg, dict)
+ self.global_avgpool = nn.AdaptiveAvgPool2d(1)
+ self.conv1 = ConvModule(
+ in_channels=channels,
+ out_channels=int(channels / ratio),
+ kernel_size=1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ act_cfg=act_cfg[0])
+ self.conv2 = ConvModule(
+ in_channels=int(channels / ratio),
+ out_channels=channels,
+ kernel_size=1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ act_cfg=act_cfg[1])
+
+ def forward(self, x):
+ out = self.global_avgpool(x)
+ out = self.conv1(out)
+ out = self.conv2(out)
+ return x * out
diff --git a/mmpose/models/backbones/utils/utils.py b/mmpose/models/backbones/utils/utils.py
index ebc4fe40cd..bd8c7d89fd 100644
--- a/mmpose/models/backbones/utils/utils.py
+++ b/mmpose/models/backbones/utils/utils.py
@@ -1,89 +1,89 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from collections import OrderedDict
-
-from mmengine.runner import CheckpointLoader, load_state_dict
-
-
-def load_checkpoint(model,
- filename,
- map_location='cpu',
- strict=False,
- logger=None):
- """Load checkpoint from a file or URI.
-
- Args:
- model (Module): Module to load checkpoint.
- filename (str): Accept local filepath, URL, ``torchvision://xxx``,
- ``open-mmlab://xxx``.
- map_location (str): Same as :func:`torch.load`.
- strict (bool): Whether to allow different params for the model and
- checkpoint.
- logger (:mod:`logging.Logger` or None): The logger for error message.
-
- Returns:
- dict or OrderedDict: The loaded checkpoint.
- """
- checkpoint = CheckpointLoader.load_checkpoint(filename, map_location)
- # OrderedDict is a subclass of dict
- if not isinstance(checkpoint, dict):
- raise RuntimeError(
- f'No state_dict found in checkpoint file {filename}')
- # get state_dict from checkpoint
- if 'state_dict' in checkpoint:
- state_dict_tmp = checkpoint['state_dict']
- elif 'model' in checkpoint:
- state_dict_tmp = checkpoint['model']
- else:
- state_dict_tmp = checkpoint
-
- state_dict = OrderedDict()
- # strip prefix of state_dict
- for k, v in state_dict_tmp.items():
- if k.startswith('module.backbone.'):
- state_dict[k[16:]] = v
- elif k.startswith('module.'):
- state_dict[k[7:]] = v
- elif k.startswith('backbone.'):
- state_dict[k[9:]] = v
- else:
- state_dict[k] = v
- # load state_dict
- load_state_dict(model, state_dict, strict, logger)
- return checkpoint
-
-
-def get_state_dict(filename, map_location='cpu'):
- """Get state_dict from a file or URI.
-
- Args:
- filename (str): Accept local filepath, URL, ``torchvision://xxx``,
- ``open-mmlab://xxx``.
- map_location (str): Same as :func:`torch.load`.
-
- Returns:
- OrderedDict: The state_dict.
- """
- checkpoint = CheckpointLoader.load_checkpoint(filename, map_location)
- # OrderedDict is a subclass of dict
- if not isinstance(checkpoint, dict):
- raise RuntimeError(
- f'No state_dict found in checkpoint file {filename}')
- # get state_dict from checkpoint
- if 'state_dict' in checkpoint:
- state_dict_tmp = checkpoint['state_dict']
- else:
- state_dict_tmp = checkpoint
-
- state_dict = OrderedDict()
- # strip prefix of state_dict
- for k, v in state_dict_tmp.items():
- if k.startswith('module.backbone.'):
- state_dict[k[16:]] = v
- elif k.startswith('module.'):
- state_dict[k[7:]] = v
- elif k.startswith('backbone.'):
- state_dict[k[9:]] = v
- else:
- state_dict[k] = v
-
- return state_dict
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections import OrderedDict
+
+from mmengine.runner import CheckpointLoader, load_state_dict
+
+
+def load_checkpoint(model,
+ filename,
+ map_location='cpu',
+ strict=False,
+ logger=None):
+ """Load checkpoint from a file or URI.
+
+ Args:
+ model (Module): Module to load checkpoint.
+ filename (str): Accept local filepath, URL, ``torchvision://xxx``,
+ ``open-mmlab://xxx``.
+ map_location (str): Same as :func:`torch.load`.
+ strict (bool): Whether to allow different params for the model and
+ checkpoint.
+ logger (:mod:`logging.Logger` or None): The logger for error message.
+
+ Returns:
+ dict or OrderedDict: The loaded checkpoint.
+ """
+ checkpoint = CheckpointLoader.load_checkpoint(filename, map_location)
+ # OrderedDict is a subclass of dict
+ if not isinstance(checkpoint, dict):
+ raise RuntimeError(
+ f'No state_dict found in checkpoint file {filename}')
+ # get state_dict from checkpoint
+ if 'state_dict' in checkpoint:
+ state_dict_tmp = checkpoint['state_dict']
+ elif 'model' in checkpoint:
+ state_dict_tmp = checkpoint['model']
+ else:
+ state_dict_tmp = checkpoint
+
+ state_dict = OrderedDict()
+ # strip prefix of state_dict
+ for k, v in state_dict_tmp.items():
+ if k.startswith('module.backbone.'):
+ state_dict[k[16:]] = v
+ elif k.startswith('module.'):
+ state_dict[k[7:]] = v
+ elif k.startswith('backbone.'):
+ state_dict[k[9:]] = v
+ else:
+ state_dict[k] = v
+ # load state_dict
+ load_state_dict(model, state_dict, strict, logger)
+ return checkpoint
+
+
+def get_state_dict(filename, map_location='cpu'):
+ """Get state_dict from a file or URI.
+
+ Args:
+ filename (str): Accept local filepath, URL, ``torchvision://xxx``,
+ ``open-mmlab://xxx``.
+ map_location (str): Same as :func:`torch.load`.
+
+ Returns:
+ OrderedDict: The state_dict.
+ """
+ checkpoint = CheckpointLoader.load_checkpoint(filename, map_location)
+ # OrderedDict is a subclass of dict
+ if not isinstance(checkpoint, dict):
+ raise RuntimeError(
+ f'No state_dict found in checkpoint file {filename}')
+ # get state_dict from checkpoint
+ if 'state_dict' in checkpoint:
+ state_dict_tmp = checkpoint['state_dict']
+ else:
+ state_dict_tmp = checkpoint
+
+ state_dict = OrderedDict()
+ # strip prefix of state_dict
+ for k, v in state_dict_tmp.items():
+ if k.startswith('module.backbone.'):
+ state_dict[k[16:]] = v
+ elif k.startswith('module.'):
+ state_dict[k[7:]] = v
+ elif k.startswith('backbone.'):
+ state_dict[k[9:]] = v
+ else:
+ state_dict[k] = v
+
+ return state_dict
diff --git a/mmpose/models/backbones/v2v_net.py b/mmpose/models/backbones/v2v_net.py
index 2cd1ab93b1..85b567b2a7 100644
--- a/mmpose/models/backbones/v2v_net.py
+++ b/mmpose/models/backbones/v2v_net.py
@@ -1,275 +1,275 @@
-# ------------------------------------------------------------------------------
-# Copyright and License Information
-# Adapted from
-# https://github.com/microsoft/voxelpose-pytorch/blob/main/lib/models/v2v_net.py
-# Original Licence: MIT License
-# ------------------------------------------------------------------------------
-
-import torch.nn as nn
-import torch.nn.functional as F
-from mmcv.cnn import ConvModule
-from mmengine.model import BaseModule
-
-from mmpose.registry import MODELS
-from .base_backbone import BaseBackbone
-
-
-class Basic3DBlock(BaseModule):
- """A basic 3D convolutional block.
-
- Args:
- in_channels (int): Input channels of this block.
- out_channels (int): Output channels of this block.
- kernel_size (int): Kernel size of the convolution operation
- conv_cfg (dict): Dictionary to construct and config conv layer.
- Default: dict(type='Conv3d')
- norm_cfg (dict): Dictionary to construct and config norm layer.
- Default: dict(type='BN3d')
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- kernel_size,
- conv_cfg=dict(type='Conv3d'),
- norm_cfg=dict(type='BN3d'),
- init_cfg=None):
- super(Basic3DBlock, self).__init__(init_cfg=init_cfg)
- self.block = ConvModule(
- in_channels,
- out_channels,
- kernel_size,
- stride=1,
- padding=((kernel_size - 1) // 2),
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- bias=True)
-
- def forward(self, x):
- """Forward function."""
- return self.block(x)
-
-
-class Res3DBlock(BaseModule):
- """A residual 3D convolutional block.
-
- Args:
- in_channels (int): Input channels of this block.
- out_channels (int): Output channels of this block.
- kernel_size (int): Kernel size of the convolution operation
- Default: 3
- conv_cfg (dict): Dictionary to construct and config conv layer.
- Default: dict(type='Conv3d')
- norm_cfg (dict): Dictionary to construct and config norm layer.
- Default: dict(type='BN3d')
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- kernel_size=3,
- conv_cfg=dict(type='Conv3d'),
- norm_cfg=dict(type='BN3d'),
- init_cfg=None):
- super(Res3DBlock, self).__init__(init_cfg=init_cfg)
- self.res_branch = nn.Sequential(
- ConvModule(
- in_channels,
- out_channels,
- kernel_size,
- stride=1,
- padding=((kernel_size - 1) // 2),
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- bias=True),
- ConvModule(
- out_channels,
- out_channels,
- kernel_size,
- stride=1,
- padding=((kernel_size - 1) // 2),
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=None,
- bias=True))
-
- if in_channels == out_channels:
- self.skip_con = nn.Sequential()
- else:
- self.skip_con = ConvModule(
- in_channels,
- out_channels,
- 1,
- stride=1,
- padding=0,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=None,
- bias=True)
-
- def forward(self, x):
- """Forward function."""
- res = self.res_branch(x)
- skip = self.skip_con(x)
- return F.relu(res + skip, True)
-
-
-class Pool3DBlock(BaseModule):
- """A 3D max-pool block.
-
- Args:
- pool_size (int): Pool size of the 3D max-pool layer
- """
-
- def __init__(self, pool_size):
- super(Pool3DBlock, self).__init__()
- self.pool_size = pool_size
-
- def forward(self, x):
- """Forward function."""
- return F.max_pool3d(
- x, kernel_size=self.pool_size, stride=self.pool_size)
-
-
-class Upsample3DBlock(BaseModule):
- """A 3D upsample block.
-
- Args:
- in_channels (int): Input channels of this block.
- out_channels (int): Output channels of this block.
- kernel_size (int): Kernel size of the transposed convolution operation.
- Default: 2
- stride (int): Kernel size of the transposed convolution operation.
- Default: 2
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- kernel_size=2,
- stride=2,
- init_cfg=None):
- super(Upsample3DBlock, self).__init__(init_cfg=init_cfg)
- assert kernel_size == 2
- assert stride == 2
- self.block = nn.Sequential(
- nn.ConvTranspose3d(
- in_channels,
- out_channels,
- kernel_size=kernel_size,
- stride=stride,
- padding=0,
- output_padding=0), nn.BatchNorm3d(out_channels), nn.ReLU(True))
-
- def forward(self, x):
- """Forward function."""
- return self.block(x)
-
-
-class EncoderDecorder(BaseModule):
- """An encoder-decoder block.
-
- Args:
- in_channels (int): Input channels of this block
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self, in_channels=32, init_cfg=None):
- super(EncoderDecorder, self).__init__(init_cfg=init_cfg)
-
- self.encoder_pool1 = Pool3DBlock(2)
- self.encoder_res1 = Res3DBlock(in_channels, in_channels * 2)
- self.encoder_pool2 = Pool3DBlock(2)
- self.encoder_res2 = Res3DBlock(in_channels * 2, in_channels * 4)
-
- self.mid_res = Res3DBlock(in_channels * 4, in_channels * 4)
-
- self.decoder_res2 = Res3DBlock(in_channels * 4, in_channels * 4)
- self.decoder_upsample2 = Upsample3DBlock(in_channels * 4,
- in_channels * 2, 2, 2)
- self.decoder_res1 = Res3DBlock(in_channels * 2, in_channels * 2)
- self.decoder_upsample1 = Upsample3DBlock(in_channels * 2, in_channels,
- 2, 2)
-
- self.skip_res1 = Res3DBlock(in_channels, in_channels)
- self.skip_res2 = Res3DBlock(in_channels * 2, in_channels * 2)
-
- def forward(self, x):
- """Forward function."""
- skip_x1 = self.skip_res1(x)
- x = self.encoder_pool1(x)
- x = self.encoder_res1(x)
-
- skip_x2 = self.skip_res2(x)
- x = self.encoder_pool2(x)
- x = self.encoder_res2(x)
-
- x = self.mid_res(x)
-
- x = self.decoder_res2(x)
- x = self.decoder_upsample2(x)
- x = x + skip_x2
-
- x = self.decoder_res1(x)
- x = self.decoder_upsample1(x)
- x = x + skip_x1
-
- return x
-
-
-@MODELS.register_module()
-class V2VNet(BaseBackbone):
- """V2VNet.
-
- Please refer to the `paper `
- for details.
-
- Args:
- input_channels (int):
- Number of channels of the input feature volume.
- output_channels (int):
- Number of channels of the output volume.
- mid_channels (int):
- Input and output channels of the encoder-decoder block.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: ``dict(
- type='Normal',
- std=0.001,
- layer=['Conv3d', 'ConvTranspose3d']
- )``
- """
-
- def __init__(self,
- input_channels,
- output_channels,
- mid_channels=32,
- init_cfg=dict(
- type='Normal',
- std=0.001,
- layer=['Conv3d', 'ConvTranspose3d'])):
- super(V2VNet, self).__init__(init_cfg=init_cfg)
-
- self.front_layers = nn.Sequential(
- Basic3DBlock(input_channels, mid_channels // 2, 7),
- Res3DBlock(mid_channels // 2, mid_channels),
- )
-
- self.encoder_decoder = EncoderDecorder(in_channels=mid_channels)
-
- self.output_layer = nn.Conv3d(
- mid_channels, output_channels, kernel_size=1, stride=1, padding=0)
-
- def forward(self, x):
- """Forward function."""
- x = self.front_layers(x)
- x = self.encoder_decoder(x)
- x = self.output_layer(x)
-
- return (x, )
+# ------------------------------------------------------------------------------
+# Copyright and License Information
+# Adapted from
+# https://github.com/microsoft/voxelpose-pytorch/blob/main/lib/models/v2v_net.py
+# Original Licence: MIT License
+# ------------------------------------------------------------------------------
+
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+
+
+class Basic3DBlock(BaseModule):
+ """A basic 3D convolutional block.
+
+ Args:
+ in_channels (int): Input channels of this block.
+ out_channels (int): Output channels of this block.
+ kernel_size (int): Kernel size of the convolution operation
+ conv_cfg (dict): Dictionary to construct and config conv layer.
+ Default: dict(type='Conv3d')
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Default: dict(type='BN3d')
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ conv_cfg=dict(type='Conv3d'),
+ norm_cfg=dict(type='BN3d'),
+ init_cfg=None):
+ super(Basic3DBlock, self).__init__(init_cfg=init_cfg)
+ self.block = ConvModule(
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ padding=((kernel_size - 1) // 2),
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ bias=True)
+
+ def forward(self, x):
+ """Forward function."""
+ return self.block(x)
+
+
+class Res3DBlock(BaseModule):
+ """A residual 3D convolutional block.
+
+ Args:
+ in_channels (int): Input channels of this block.
+ out_channels (int): Output channels of this block.
+ kernel_size (int): Kernel size of the convolution operation
+ Default: 3
+ conv_cfg (dict): Dictionary to construct and config conv layer.
+ Default: dict(type='Conv3d')
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Default: dict(type='BN3d')
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ conv_cfg=dict(type='Conv3d'),
+ norm_cfg=dict(type='BN3d'),
+ init_cfg=None):
+ super(Res3DBlock, self).__init__(init_cfg=init_cfg)
+ self.res_branch = nn.Sequential(
+ ConvModule(
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ padding=((kernel_size - 1) // 2),
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ bias=True),
+ ConvModule(
+ out_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ padding=((kernel_size - 1) // 2),
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None,
+ bias=True))
+
+ if in_channels == out_channels:
+ self.skip_con = nn.Sequential()
+ else:
+ self.skip_con = ConvModule(
+ in_channels,
+ out_channels,
+ 1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None,
+ bias=True)
+
+ def forward(self, x):
+ """Forward function."""
+ res = self.res_branch(x)
+ skip = self.skip_con(x)
+ return F.relu(res + skip, True)
+
+
+class Pool3DBlock(BaseModule):
+ """A 3D max-pool block.
+
+ Args:
+ pool_size (int): Pool size of the 3D max-pool layer
+ """
+
+ def __init__(self, pool_size):
+ super(Pool3DBlock, self).__init__()
+ self.pool_size = pool_size
+
+ def forward(self, x):
+ """Forward function."""
+ return F.max_pool3d(
+ x, kernel_size=self.pool_size, stride=self.pool_size)
+
+
+class Upsample3DBlock(BaseModule):
+ """A 3D upsample block.
+
+ Args:
+ in_channels (int): Input channels of this block.
+ out_channels (int): Output channels of this block.
+ kernel_size (int): Kernel size of the transposed convolution operation.
+ Default: 2
+ stride (int): Kernel size of the transposed convolution operation.
+ Default: 2
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size=2,
+ stride=2,
+ init_cfg=None):
+ super(Upsample3DBlock, self).__init__(init_cfg=init_cfg)
+ assert kernel_size == 2
+ assert stride == 2
+ self.block = nn.Sequential(
+ nn.ConvTranspose3d(
+ in_channels,
+ out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=0,
+ output_padding=0), nn.BatchNorm3d(out_channels), nn.ReLU(True))
+
+ def forward(self, x):
+ """Forward function."""
+ return self.block(x)
+
+
+class EncoderDecorder(BaseModule):
+ """An encoder-decoder block.
+
+ Args:
+ in_channels (int): Input channels of this block
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self, in_channels=32, init_cfg=None):
+ super(EncoderDecorder, self).__init__(init_cfg=init_cfg)
+
+ self.encoder_pool1 = Pool3DBlock(2)
+ self.encoder_res1 = Res3DBlock(in_channels, in_channels * 2)
+ self.encoder_pool2 = Pool3DBlock(2)
+ self.encoder_res2 = Res3DBlock(in_channels * 2, in_channels * 4)
+
+ self.mid_res = Res3DBlock(in_channels * 4, in_channels * 4)
+
+ self.decoder_res2 = Res3DBlock(in_channels * 4, in_channels * 4)
+ self.decoder_upsample2 = Upsample3DBlock(in_channels * 4,
+ in_channels * 2, 2, 2)
+ self.decoder_res1 = Res3DBlock(in_channels * 2, in_channels * 2)
+ self.decoder_upsample1 = Upsample3DBlock(in_channels * 2, in_channels,
+ 2, 2)
+
+ self.skip_res1 = Res3DBlock(in_channels, in_channels)
+ self.skip_res2 = Res3DBlock(in_channels * 2, in_channels * 2)
+
+ def forward(self, x):
+ """Forward function."""
+ skip_x1 = self.skip_res1(x)
+ x = self.encoder_pool1(x)
+ x = self.encoder_res1(x)
+
+ skip_x2 = self.skip_res2(x)
+ x = self.encoder_pool2(x)
+ x = self.encoder_res2(x)
+
+ x = self.mid_res(x)
+
+ x = self.decoder_res2(x)
+ x = self.decoder_upsample2(x)
+ x = x + skip_x2
+
+ x = self.decoder_res1(x)
+ x = self.decoder_upsample1(x)
+ x = x + skip_x1
+
+ return x
+
+
+@MODELS.register_module()
+class V2VNet(BaseBackbone):
+ """V2VNet.
+
+ Please refer to the `paper `
+ for details.
+
+ Args:
+ input_channels (int):
+ Number of channels of the input feature volume.
+ output_channels (int):
+ Number of channels of the output volume.
+ mid_channels (int):
+ Input and output channels of the encoder-decoder block.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: ``dict(
+ type='Normal',
+ std=0.001,
+ layer=['Conv3d', 'ConvTranspose3d']
+ )``
+ """
+
+ def __init__(self,
+ input_channels,
+ output_channels,
+ mid_channels=32,
+ init_cfg=dict(
+ type='Normal',
+ std=0.001,
+ layer=['Conv3d', 'ConvTranspose3d'])):
+ super(V2VNet, self).__init__(init_cfg=init_cfg)
+
+ self.front_layers = nn.Sequential(
+ Basic3DBlock(input_channels, mid_channels // 2, 7),
+ Res3DBlock(mid_channels // 2, mid_channels),
+ )
+
+ self.encoder_decoder = EncoderDecorder(in_channels=mid_channels)
+
+ self.output_layer = nn.Conv3d(
+ mid_channels, output_channels, kernel_size=1, stride=1, padding=0)
+
+ def forward(self, x):
+ """Forward function."""
+ x = self.front_layers(x)
+ x = self.encoder_decoder(x)
+ x = self.output_layer(x)
+
+ return (x, )
diff --git a/mmpose/models/backbones/vgg.py b/mmpose/models/backbones/vgg.py
index 8fa09d8dc7..52fd2a1913 100644
--- a/mmpose/models/backbones/vgg.py
+++ b/mmpose/models/backbones/vgg.py
@@ -1,201 +1,201 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import torch.nn as nn
-from mmcv.cnn import ConvModule
-from mmengine.utils.dl_utils.parrots_wrapper import _BatchNorm
-
-from mmpose.registry import MODELS
-from .base_backbone import BaseBackbone
-
-
-def make_vgg_layer(in_channels,
- out_channels,
- num_blocks,
- conv_cfg=None,
- norm_cfg=None,
- act_cfg=dict(type='ReLU'),
- dilation=1,
- with_norm=False,
- ceil_mode=False):
- layers = []
- for _ in range(num_blocks):
- layer = ConvModule(
- in_channels=in_channels,
- out_channels=out_channels,
- kernel_size=3,
- dilation=dilation,
- padding=dilation,
- bias=True,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg)
- layers.append(layer)
- in_channels = out_channels
- layers.append(nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=ceil_mode))
-
- return layers
-
-
-@MODELS.register_module()
-class VGG(BaseBackbone):
- """VGG backbone.
-
- Args:
- depth (int): Depth of vgg, from {11, 13, 16, 19}.
- with_norm (bool): Use BatchNorm or not.
- num_classes (int): number of classes for classification.
- num_stages (int): VGG stages, normally 5.
- dilations (Sequence[int]): Dilation of each stage.
- out_indices (Sequence[int]): Output from which stages. If only one
- stage is specified, a single tensor (feature map) is returned,
- otherwise multiple stages are specified, a tuple of tensors will
- be returned. When it is None, the default behavior depends on
- whether num_classes is specified. If num_classes <= 0, the default
- value is (4, ), outputting the last feature map before classifier.
- If num_classes > 0, the default value is (5, ), outputting the
- classification score. Default: None.
- frozen_stages (int): Stages to be frozen (all param fixed). -1 means
- not freezing any parameters.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only. Default: False.
- ceil_mode (bool): Whether to use ceil_mode of MaxPool. Default: False.
- with_last_pool (bool): Whether to keep the last pooling before
- classifier. Default: True.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Kaiming', layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm']),
- dict(
- type='Normal',
- std=0.01,
- layer=['Linear']),
- ]``
- """
-
- # Parameters to build layers. Each element specifies the number of conv in
- # each stage. For example, VGG11 contains 11 layers with learnable
- # parameters. 11 is computed as 11 = (1 + 1 + 2 + 2 + 2) + 3,
- # where 3 indicates the last three fully-connected layers.
- arch_settings = {
- 11: (1, 1, 2, 2, 2),
- 13: (2, 2, 2, 2, 2),
- 16: (2, 2, 3, 3, 3),
- 19: (2, 2, 4, 4, 4)
- }
-
- def __init__(self,
- depth,
- num_classes=-1,
- num_stages=5,
- dilations=(1, 1, 1, 1, 1),
- out_indices=None,
- frozen_stages=-1,
- conv_cfg=None,
- norm_cfg=None,
- act_cfg=dict(type='ReLU'),
- norm_eval=False,
- ceil_mode=False,
- with_last_pool=True,
- init_cfg=[
- dict(type='Kaiming', layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm']),
- dict(type='Normal', std=0.01, layer=['Linear']),
- ]):
- super().__init__(init_cfg=init_cfg)
- if depth not in self.arch_settings:
- raise KeyError(f'invalid depth {depth} for vgg')
- assert num_stages >= 1 and num_stages <= 5
- stage_blocks = self.arch_settings[depth]
- self.stage_blocks = stage_blocks[:num_stages]
- assert len(dilations) == num_stages
-
- self.num_classes = num_classes
- self.frozen_stages = frozen_stages
- self.norm_eval = norm_eval
- with_norm = norm_cfg is not None
-
- if out_indices is None:
- out_indices = (5, ) if num_classes > 0 else (4, )
- assert max(out_indices) <= num_stages
- self.out_indices = out_indices
-
- self.in_channels = 3
- start_idx = 0
- vgg_layers = []
- self.range_sub_modules = []
- for i, num_blocks in enumerate(self.stage_blocks):
- num_modules = num_blocks + 1
- end_idx = start_idx + num_modules
- dilation = dilations[i]
- out_channels = 64 * 2**i if i < 4 else 512
- vgg_layer = make_vgg_layer(
- self.in_channels,
- out_channels,
- num_blocks,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg,
- dilation=dilation,
- with_norm=with_norm,
- ceil_mode=ceil_mode)
- vgg_layers.extend(vgg_layer)
- self.in_channels = out_channels
- self.range_sub_modules.append([start_idx, end_idx])
- start_idx = end_idx
- if not with_last_pool:
- vgg_layers.pop(-1)
- self.range_sub_modules[-1][1] -= 1
- self.module_name = 'features'
- self.add_module(self.module_name, nn.Sequential(*vgg_layers))
-
- if self.num_classes > 0:
- self.classifier = nn.Sequential(
- nn.Linear(512 * 7 * 7, 4096),
- nn.ReLU(True),
- nn.Dropout(),
- nn.Linear(4096, 4096),
- nn.ReLU(True),
- nn.Dropout(),
- nn.Linear(4096, num_classes),
- )
-
- def forward(self, x):
- outs = []
- vgg_layers = getattr(self, self.module_name)
- for i in range(len(self.stage_blocks)):
- for j in range(*self.range_sub_modules[i]):
- vgg_layer = vgg_layers[j]
- x = vgg_layer(x)
- if i in self.out_indices:
- outs.append(x)
- if self.num_classes > 0:
- x = x.view(x.size(0), -1)
- x = self.classifier(x)
- outs.append(x)
-
- return tuple(outs)
-
- def _freeze_stages(self):
- vgg_layers = getattr(self, self.module_name)
- for i in range(self.frozen_stages):
- for j in range(*self.range_sub_modules[i]):
- m = vgg_layers[j]
- m.eval()
- for param in m.parameters():
- param.requires_grad = False
-
- def train(self, mode=True):
- super().train(mode)
- self._freeze_stages()
- if mode and self.norm_eval:
- for m in self.modules():
- # trick: eval have effect on BatchNorm only
- if isinstance(m, _BatchNorm):
- m.eval()
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmengine.utils.dl_utils.parrots_wrapper import _BatchNorm
+
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+
+
+def make_vgg_layer(in_channels,
+ out_channels,
+ num_blocks,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=dict(type='ReLU'),
+ dilation=1,
+ with_norm=False,
+ ceil_mode=False):
+ layers = []
+ for _ in range(num_blocks):
+ layer = ConvModule(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=3,
+ dilation=dilation,
+ padding=dilation,
+ bias=True,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ layers.append(layer)
+ in_channels = out_channels
+ layers.append(nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=ceil_mode))
+
+ return layers
+
+
+@MODELS.register_module()
+class VGG(BaseBackbone):
+ """VGG backbone.
+
+ Args:
+ depth (int): Depth of vgg, from {11, 13, 16, 19}.
+ with_norm (bool): Use BatchNorm or not.
+ num_classes (int): number of classes for classification.
+ num_stages (int): VGG stages, normally 5.
+ dilations (Sequence[int]): Dilation of each stage.
+ out_indices (Sequence[int]): Output from which stages. If only one
+ stage is specified, a single tensor (feature map) is returned,
+ otherwise multiple stages are specified, a tuple of tensors will
+ be returned. When it is None, the default behavior depends on
+ whether num_classes is specified. If num_classes <= 0, the default
+ value is (4, ), outputting the last feature map before classifier.
+ If num_classes > 0, the default value is (5, ), outputting the
+ classification score. Default: None.
+ frozen_stages (int): Stages to be frozen (all param fixed). -1 means
+ not freezing any parameters.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ ceil_mode (bool): Whether to use ceil_mode of MaxPool. Default: False.
+ with_last_pool (bool): Whether to keep the last pooling before
+ classifier. Default: True.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Kaiming', layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm']),
+ dict(
+ type='Normal',
+ std=0.01,
+ layer=['Linear']),
+ ]``
+ """
+
+ # Parameters to build layers. Each element specifies the number of conv in
+ # each stage. For example, VGG11 contains 11 layers with learnable
+ # parameters. 11 is computed as 11 = (1 + 1 + 2 + 2 + 2) + 3,
+ # where 3 indicates the last three fully-connected layers.
+ arch_settings = {
+ 11: (1, 1, 2, 2, 2),
+ 13: (2, 2, 2, 2, 2),
+ 16: (2, 2, 3, 3, 3),
+ 19: (2, 2, 4, 4, 4)
+ }
+
+ def __init__(self,
+ depth,
+ num_classes=-1,
+ num_stages=5,
+ dilations=(1, 1, 1, 1, 1),
+ out_indices=None,
+ frozen_stages=-1,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=dict(type='ReLU'),
+ norm_eval=False,
+ ceil_mode=False,
+ with_last_pool=True,
+ init_cfg=[
+ dict(type='Kaiming', layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm']),
+ dict(type='Normal', std=0.01, layer=['Linear']),
+ ]):
+ super().__init__(init_cfg=init_cfg)
+ if depth not in self.arch_settings:
+ raise KeyError(f'invalid depth {depth} for vgg')
+ assert num_stages >= 1 and num_stages <= 5
+ stage_blocks = self.arch_settings[depth]
+ self.stage_blocks = stage_blocks[:num_stages]
+ assert len(dilations) == num_stages
+
+ self.num_classes = num_classes
+ self.frozen_stages = frozen_stages
+ self.norm_eval = norm_eval
+ with_norm = norm_cfg is not None
+
+ if out_indices is None:
+ out_indices = (5, ) if num_classes > 0 else (4, )
+ assert max(out_indices) <= num_stages
+ self.out_indices = out_indices
+
+ self.in_channels = 3
+ start_idx = 0
+ vgg_layers = []
+ self.range_sub_modules = []
+ for i, num_blocks in enumerate(self.stage_blocks):
+ num_modules = num_blocks + 1
+ end_idx = start_idx + num_modules
+ dilation = dilations[i]
+ out_channels = 64 * 2**i if i < 4 else 512
+ vgg_layer = make_vgg_layer(
+ self.in_channels,
+ out_channels,
+ num_blocks,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ dilation=dilation,
+ with_norm=with_norm,
+ ceil_mode=ceil_mode)
+ vgg_layers.extend(vgg_layer)
+ self.in_channels = out_channels
+ self.range_sub_modules.append([start_idx, end_idx])
+ start_idx = end_idx
+ if not with_last_pool:
+ vgg_layers.pop(-1)
+ self.range_sub_modules[-1][1] -= 1
+ self.module_name = 'features'
+ self.add_module(self.module_name, nn.Sequential(*vgg_layers))
+
+ if self.num_classes > 0:
+ self.classifier = nn.Sequential(
+ nn.Linear(512 * 7 * 7, 4096),
+ nn.ReLU(True),
+ nn.Dropout(),
+ nn.Linear(4096, 4096),
+ nn.ReLU(True),
+ nn.Dropout(),
+ nn.Linear(4096, num_classes),
+ )
+
+ def forward(self, x):
+ outs = []
+ vgg_layers = getattr(self, self.module_name)
+ for i in range(len(self.stage_blocks)):
+ for j in range(*self.range_sub_modules[i]):
+ vgg_layer = vgg_layers[j]
+ x = vgg_layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+ if self.num_classes > 0:
+ x = x.view(x.size(0), -1)
+ x = self.classifier(x)
+ outs.append(x)
+
+ return tuple(outs)
+
+ def _freeze_stages(self):
+ vgg_layers = getattr(self, self.module_name)
+ for i in range(self.frozen_stages):
+ for j in range(*self.range_sub_modules[i]):
+ m = vgg_layers[j]
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ def train(self, mode=True):
+ super().train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ # trick: eval have effect on BatchNorm only
+ if isinstance(m, _BatchNorm):
+ m.eval()
diff --git a/mmpose/models/backbones/vipnas_mbv3.py b/mmpose/models/backbones/vipnas_mbv3.py
index 9156cafa56..3e56439b01 100644
--- a/mmpose/models/backbones/vipnas_mbv3.py
+++ b/mmpose/models/backbones/vipnas_mbv3.py
@@ -1,173 +1,173 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-
-from mmcv.cnn import ConvModule
-from torch.nn.modules.batchnorm import _BatchNorm
-
-from mmpose.registry import MODELS
-from .base_backbone import BaseBackbone
-from .utils import InvertedResidual
-
-
-@MODELS.register_module()
-class ViPNAS_MobileNetV3(BaseBackbone):
- """ViPNAS_MobileNetV3 backbone.
-
- "ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search"
- More details can be found in the `paper
- `__ .
-
- Args:
- wid (list(int)): Searched width config for each stage.
- expan (list(int)): Searched expansion ratio config for each stage.
- dep (list(int)): Searched depth config for each stage.
- ks (list(int)): Searched kernel size config for each stage.
- group (list(int)): Searched group number config for each stage.
- att (list(bool)): Searched attention config for each stage.
- stride (list(int)): Stride config for each stage.
- act (list(dict)): Activation config for each stage.
- conv_cfg (dict): Config dict for convolution layer.
- Default: None, which means using conv2d.
- norm_cfg (dict): Config dict for normalization layer.
- Default: dict(type='BN').
- frozen_stages (int): Stages to be frozen (all param fixed).
- Default: -1, which means not freezing any parameters.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only. Default: False.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save
- some memory while slowing down the training speed.
- Default: False.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Normal', std=0.001, layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]``
- """
-
- def __init__(
- self,
- wid=[16, 16, 24, 40, 80, 112, 160],
- expan=[None, 1, 5, 4, 5, 5, 6],
- dep=[None, 1, 4, 4, 4, 4, 4],
- ks=[3, 3, 7, 7, 5, 7, 5],
- group=[None, 8, 120, 20, 100, 280, 240],
- att=[None, True, True, False, True, True, True],
- stride=[2, 1, 2, 2, 2, 1, 2],
- act=['HSwish', 'ReLU', 'ReLU', 'ReLU', 'HSwish', 'HSwish', 'HSwish'],
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- frozen_stages=-1,
- norm_eval=False,
- with_cp=False,
- init_cfg=[
- dict(type='Normal', std=0.001, layer=['Conv2d']),
- dict(type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])
- ],
- ):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
- self.wid = wid
- self.expan = expan
- self.dep = dep
- self.ks = ks
- self.group = group
- self.att = att
- self.stride = stride
- self.act = act
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- self.frozen_stages = frozen_stages
- self.norm_eval = norm_eval
- self.with_cp = with_cp
-
- self.conv1 = ConvModule(
- in_channels=3,
- out_channels=self.wid[0],
- kernel_size=self.ks[0],
- stride=self.stride[0],
- padding=self.ks[0] // 2,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=dict(type=self.act[0]))
-
- self.layers = self._make_layer()
-
- def _make_layer(self):
- layers = []
- layer_index = 0
- for i, dep in enumerate(self.dep[1:]):
- mid_channels = self.wid[i + 1] * self.expan[i + 1]
-
- if self.att[i + 1]:
- se_cfg = dict(
- channels=mid_channels,
- ratio=4,
- act_cfg=(dict(type='ReLU'),
- dict(type='HSigmoid', bias=1.0, divisor=2.0)))
- else:
- se_cfg = None
-
- if self.expan[i + 1] == 1:
- with_expand_conv = False
- else:
- with_expand_conv = True
-
- for j in range(dep):
- if j == 0:
- stride = self.stride[i + 1]
- in_channels = self.wid[i]
- else:
- stride = 1
- in_channels = self.wid[i + 1]
-
- layer = InvertedResidual(
- in_channels=in_channels,
- out_channels=self.wid[i + 1],
- mid_channels=mid_channels,
- kernel_size=self.ks[i + 1],
- groups=self.group[i + 1],
- stride=stride,
- se_cfg=se_cfg,
- with_expand_conv=with_expand_conv,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=dict(type=self.act[i + 1]),
- with_cp=self.with_cp)
- layer_index += 1
- layer_name = f'layer{layer_index}'
- self.add_module(layer_name, layer)
- layers.append(layer_name)
- return layers
-
- def forward(self, x):
- x = self.conv1(x)
-
- for i, layer_name in enumerate(self.layers):
- layer = getattr(self, layer_name)
- x = layer(x)
-
- return (x, )
-
- def _freeze_stages(self):
- if self.frozen_stages >= 0:
- for param in self.conv1.parameters():
- param.requires_grad = False
- for i in range(1, self.frozen_stages + 1):
- layer = getattr(self, f'layer{i}')
- layer.eval()
- for param in layer.parameters():
- param.requires_grad = False
-
- def train(self, mode=True):
- super().train(mode)
- self._freeze_stages()
- if mode and self.norm_eval:
- for m in self.modules():
- if isinstance(m, _BatchNorm):
- m.eval()
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+from mmcv.cnn import ConvModule
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+from .utils import InvertedResidual
+
+
+@MODELS.register_module()
+class ViPNAS_MobileNetV3(BaseBackbone):
+ """ViPNAS_MobileNetV3 backbone.
+
+ "ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search"
+ More details can be found in the `paper
+ `__ .
+
+ Args:
+ wid (list(int)): Searched width config for each stage.
+ expan (list(int)): Searched expansion ratio config for each stage.
+ dep (list(int)): Searched depth config for each stage.
+ ks (list(int)): Searched kernel size config for each stage.
+ group (list(int)): Searched group number config for each stage.
+ att (list(bool)): Searched attention config for each stage.
+ stride (list(int)): Stride config for each stage.
+ act (list(dict)): Activation config for each stage.
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ frozen_stages (int): Stages to be frozen (all param fixed).
+ Default: -1, which means not freezing any parameters.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save
+ some memory while slowing down the training speed.
+ Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+ """
+
+ def __init__(
+ self,
+ wid=[16, 16, 24, 40, 80, 112, 160],
+ expan=[None, 1, 5, 4, 5, 5, 6],
+ dep=[None, 1, 4, 4, 4, 4, 4],
+ ks=[3, 3, 7, 7, 5, 7, 5],
+ group=[None, 8, 120, 20, 100, 280, 240],
+ att=[None, True, True, False, True, True, True],
+ stride=[2, 1, 2, 2, 2, 1, 2],
+ act=['HSwish', 'ReLU', 'ReLU', 'ReLU', 'HSwish', 'HSwish', 'HSwish'],
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ frozen_stages=-1,
+ norm_eval=False,
+ with_cp=False,
+ init_cfg=[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])
+ ],
+ ):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ self.wid = wid
+ self.expan = expan
+ self.dep = dep
+ self.ks = ks
+ self.group = group
+ self.att = att
+ self.stride = stride
+ self.act = act
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.frozen_stages = frozen_stages
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+
+ self.conv1 = ConvModule(
+ in_channels=3,
+ out_channels=self.wid[0],
+ kernel_size=self.ks[0],
+ stride=self.stride[0],
+ padding=self.ks[0] // 2,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type=self.act[0]))
+
+ self.layers = self._make_layer()
+
+ def _make_layer(self):
+ layers = []
+ layer_index = 0
+ for i, dep in enumerate(self.dep[1:]):
+ mid_channels = self.wid[i + 1] * self.expan[i + 1]
+
+ if self.att[i + 1]:
+ se_cfg = dict(
+ channels=mid_channels,
+ ratio=4,
+ act_cfg=(dict(type='ReLU'),
+ dict(type='HSigmoid', bias=1.0, divisor=2.0)))
+ else:
+ se_cfg = None
+
+ if self.expan[i + 1] == 1:
+ with_expand_conv = False
+ else:
+ with_expand_conv = True
+
+ for j in range(dep):
+ if j == 0:
+ stride = self.stride[i + 1]
+ in_channels = self.wid[i]
+ else:
+ stride = 1
+ in_channels = self.wid[i + 1]
+
+ layer = InvertedResidual(
+ in_channels=in_channels,
+ out_channels=self.wid[i + 1],
+ mid_channels=mid_channels,
+ kernel_size=self.ks[i + 1],
+ groups=self.group[i + 1],
+ stride=stride,
+ se_cfg=se_cfg,
+ with_expand_conv=with_expand_conv,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=dict(type=self.act[i + 1]),
+ with_cp=self.with_cp)
+ layer_index += 1
+ layer_name = f'layer{layer_index}'
+ self.add_module(layer_name, layer)
+ layers.append(layer_name)
+ return layers
+
+ def forward(self, x):
+ x = self.conv1(x)
+
+ for i, layer_name in enumerate(self.layers):
+ layer = getattr(self, layer_name)
+ x = layer(x)
+
+ return (x, )
+
+ def _freeze_stages(self):
+ if self.frozen_stages >= 0:
+ for param in self.conv1.parameters():
+ param.requires_grad = False
+ for i in range(1, self.frozen_stages + 1):
+ layer = getattr(self, f'layer{i}')
+ layer.eval()
+ for param in layer.parameters():
+ param.requires_grad = False
+
+ def train(self, mode=True):
+ super().train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, _BatchNorm):
+ m.eval()
diff --git a/mmpose/models/backbones/vipnas_resnet.py b/mmpose/models/backbones/vipnas_resnet.py
index 7be810b449..6e55a70998 100644
--- a/mmpose/models/backbones/vipnas_resnet.py
+++ b/mmpose/models/backbones/vipnas_resnet.py
@@ -1,596 +1,596 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-
-import torch.nn as nn
-import torch.utils.checkpoint as cp
-from mmcv.cnn import ConvModule, build_conv_layer, build_norm_layer
-from mmcv.cnn.bricks import ContextBlock
-from mmengine.model import BaseModule, Sequential
-from mmengine.utils.dl_utils.parrots_wrapper import _BatchNorm
-
-from mmpose.registry import MODELS
-from .base_backbone import BaseBackbone
-
-
-class ViPNAS_Bottleneck(BaseModule):
- """Bottleneck block for ViPNAS_ResNet.
-
- Args:
- in_channels (int): Input channels of this block.
- out_channels (int): Output channels of this block.
- expansion (int): The ratio of ``out_channels/mid_channels`` where
- ``mid_channels`` is the input/output channels of conv2. Default: 4.
- stride (int): stride of the block. Default: 1
- dilation (int): dilation of convolution. Default: 1
- downsample (nn.Module): downsample operation on identity branch.
- Default: None.
- style (str): ``"pytorch"`` or ``"caffe"``. If set to "pytorch", the
- stride-two layer is the 3x3 conv layer, otherwise the stride-two
- layer is the first 1x1 conv layer. Default: "pytorch".
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed.
- conv_cfg (dict): dictionary to construct and config conv layer.
- Default: None
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- kernel_size (int): kernel size of conv2 searched in ViPANS.
- groups (int): group number of conv2 searched in ViPNAS.
- attention (bool): whether to use attention module in the end of
- the block.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- expansion=4,
- stride=1,
- dilation=1,
- downsample=None,
- style='pytorch',
- with_cp=False,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- kernel_size=3,
- groups=1,
- attention=False,
- init_cfg=None):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
- assert style in ['pytorch', 'caffe']
-
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.expansion = expansion
- assert out_channels % expansion == 0
- self.mid_channels = out_channels // expansion
- self.stride = stride
- self.dilation = dilation
- self.style = style
- self.with_cp = with_cp
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
-
- if self.style == 'pytorch':
- self.conv1_stride = 1
- self.conv2_stride = stride
- else:
- self.conv1_stride = stride
- self.conv2_stride = 1
-
- self.norm1_name, norm1 = build_norm_layer(
- norm_cfg, self.mid_channels, postfix=1)
- self.norm2_name, norm2 = build_norm_layer(
- norm_cfg, self.mid_channels, postfix=2)
- self.norm3_name, norm3 = build_norm_layer(
- norm_cfg, out_channels, postfix=3)
-
- self.conv1 = build_conv_layer(
- conv_cfg,
- in_channels,
- self.mid_channels,
- kernel_size=1,
- stride=self.conv1_stride,
- bias=False)
- self.add_module(self.norm1_name, norm1)
- self.conv2 = build_conv_layer(
- conv_cfg,
- self.mid_channels,
- self.mid_channels,
- kernel_size=kernel_size,
- stride=self.conv2_stride,
- padding=kernel_size // 2,
- groups=groups,
- dilation=dilation,
- bias=False)
-
- self.add_module(self.norm2_name, norm2)
- self.conv3 = build_conv_layer(
- conv_cfg,
- self.mid_channels,
- out_channels,
- kernel_size=1,
- bias=False)
- self.add_module(self.norm3_name, norm3)
-
- if attention:
- self.attention = ContextBlock(out_channels,
- max(1.0 / 16, 16.0 / out_channels))
- else:
- self.attention = None
-
- self.relu = nn.ReLU(inplace=True)
- self.downsample = downsample
-
- @property
- def norm1(self):
- """nn.Module: the normalization layer named "norm1" """
- return getattr(self, self.norm1_name)
-
- @property
- def norm2(self):
- """nn.Module: the normalization layer named "norm2" """
- return getattr(self, self.norm2_name)
-
- @property
- def norm3(self):
- """nn.Module: the normalization layer named "norm3" """
- return getattr(self, self.norm3_name)
-
- def forward(self, x):
- """Forward function."""
-
- def _inner_forward(x):
- identity = x
-
- out = self.conv1(x)
- out = self.norm1(out)
- out = self.relu(out)
-
- out = self.conv2(out)
- out = self.norm2(out)
- out = self.relu(out)
-
- out = self.conv3(out)
- out = self.norm3(out)
-
- if self.attention is not None:
- out = self.attention(out)
-
- if self.downsample is not None:
- identity = self.downsample(x)
-
- out += identity
-
- return out
-
- if self.with_cp and x.requires_grad:
- out = cp.checkpoint(_inner_forward, x)
- else:
- out = _inner_forward(x)
-
- out = self.relu(out)
-
- return out
-
-
-def get_expansion(block, expansion=None):
- """Get the expansion of a residual block.
-
- The block expansion will be obtained by the following order:
-
- 1. If ``expansion`` is given, just return it.
- 2. If ``block`` has the attribute ``expansion``, then return
- ``block.expansion``.
- 3. Return the default value according the the block type:
- 4 for ``ViPNAS_Bottleneck``.
-
- Args:
- block (class): The block class.
- expansion (int | None): The given expansion ratio.
-
- Returns:
- int: The expansion of the block.
- """
- if isinstance(expansion, int):
- assert expansion > 0
- elif expansion is None:
- if hasattr(block, 'expansion'):
- expansion = block.expansion
- elif issubclass(block, ViPNAS_Bottleneck):
- expansion = 1
- else:
- raise TypeError(f'expansion is not specified for {block.__name__}')
- else:
- raise TypeError('expansion must be an integer or None')
-
- return expansion
-
-
-class ViPNAS_ResLayer(Sequential):
- """ViPNAS_ResLayer to build ResNet style backbone.
-
- Args:
- block (nn.Module): Residual block used to build ViPNAS ResLayer.
- num_blocks (int): Number of blocks.
- in_channels (int): Input channels of this block.
- out_channels (int): Output channels of this block.
- expansion (int, optional): The expansion for BasicBlock/Bottleneck.
- If not specified, it will firstly be obtained via
- ``block.expansion``. If the block has no attribute "expansion",
- the following default values will be used: 1 for BasicBlock and
- 4 for Bottleneck. Default: None.
- stride (int): stride of the first block. Default: 1.
- avg_down (bool): Use AvgPool instead of stride conv when
- downsampling in the bottleneck. Default: False
- conv_cfg (dict): dictionary to construct and config conv layer.
- Default: None
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- downsample_first (bool): Downsample at the first block or last block.
- False for Hourglass, True for ResNet. Default: True
- kernel_size (int): Kernel Size of the corresponding convolution layer
- searched in the block.
- groups (int): Group number of the corresponding convolution layer
- searched in the block.
- attention (bool): Whether to use attention module in the end of the
- block.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
- """
-
- def __init__(self,
- block,
- num_blocks,
- in_channels,
- out_channels,
- expansion=None,
- stride=1,
- avg_down=False,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- downsample_first=True,
- kernel_size=3,
- groups=1,
- attention=False,
- init_cfg=None,
- **kwargs):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- self.block = block
- self.expansion = get_expansion(block, expansion)
-
- downsample = None
- if stride != 1 or in_channels != out_channels:
- downsample = []
- conv_stride = stride
- if avg_down and stride != 1:
- conv_stride = 1
- downsample.append(
- nn.AvgPool2d(
- kernel_size=stride,
- stride=stride,
- ceil_mode=True,
- count_include_pad=False))
- downsample.extend([
- build_conv_layer(
- conv_cfg,
- in_channels,
- out_channels,
- kernel_size=1,
- stride=conv_stride,
- bias=False),
- build_norm_layer(norm_cfg, out_channels)[1]
- ])
- downsample = nn.Sequential(*downsample)
-
- layers = []
- if downsample_first:
- layers.append(
- block(
- in_channels=in_channels,
- out_channels=out_channels,
- expansion=self.expansion,
- stride=stride,
- downsample=downsample,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- kernel_size=kernel_size,
- groups=groups,
- attention=attention,
- **kwargs))
- in_channels = out_channels
- for _ in range(1, num_blocks):
- layers.append(
- block(
- in_channels=in_channels,
- out_channels=out_channels,
- expansion=self.expansion,
- stride=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- kernel_size=kernel_size,
- groups=groups,
- attention=attention,
- **kwargs))
- else: # downsample_first=False is for HourglassModule
- for i in range(0, num_blocks - 1):
- layers.append(
- block(
- in_channels=in_channels,
- out_channels=in_channels,
- expansion=self.expansion,
- stride=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- kernel_size=kernel_size,
- groups=groups,
- attention=attention,
- **kwargs))
- layers.append(
- block(
- in_channels=in_channels,
- out_channels=out_channels,
- expansion=self.expansion,
- stride=stride,
- downsample=downsample,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- kernel_size=kernel_size,
- groups=groups,
- attention=attention,
- **kwargs))
-
- super().__init__(*layers, init_cfg=init_cfg)
-
-
-@MODELS.register_module()
-class ViPNAS_ResNet(BaseBackbone):
- """ViPNAS_ResNet backbone.
-
- "ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search"
- More details can be found in the `paper
- `__ .
-
- Args:
- depth (int): Network depth, from {18, 34, 50, 101, 152}.
- in_channels (int): Number of input image channels. Default: 3.
- num_stages (int): Stages of the network. Default: 4.
- strides (Sequence[int]): Strides of the first block of each stage.
- Default: ``(1, 2, 2, 2)``.
- dilations (Sequence[int]): Dilation of each stage.
- Default: ``(1, 1, 1, 1)``.
- out_indices (Sequence[int]): Output from which stages. If only one
- stage is specified, a single tensor (feature map) is returned,
- otherwise multiple stages are specified, a tuple of tensors will
- be returned. Default: ``(3, )``.
- style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
- layer is the 3x3 conv layer, otherwise the stride-two layer is
- the first 1x1 conv layer.
- deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv.
- Default: False.
- avg_down (bool): Use AvgPool instead of stride conv when
- downsampling in the bottleneck. Default: False.
- frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
- -1 means not freezing any parameters. Default: -1.
- conv_cfg (dict | None): The config dict for conv layers. Default: None.
- norm_cfg (dict): The config dict for norm layers.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only. Default: False.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed. Default: False.
- zero_init_residual (bool): Whether to use zero init for last norm layer
- in resblocks to let them behave as identity. Default: True.
- wid (list(int)): Searched width config for each stage.
- expan (list(int)): Searched expansion ratio config for each stage.
- dep (list(int)): Searched depth config for each stage.
- ks (list(int)): Searched kernel size config for each stage.
- group (list(int)): Searched group number config for each stage.
- att (list(bool)): Searched attention config for each stage.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default:
- ``[
- dict(type='Normal', std=0.001, layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]``
- """
-
- arch_settings = {
- 50: ViPNAS_Bottleneck,
- }
-
- def __init__(self,
- depth,
- in_channels=3,
- num_stages=4,
- strides=(1, 2, 2, 2),
- dilations=(1, 1, 1, 1),
- out_indices=(3, ),
- style='pytorch',
- deep_stem=False,
- avg_down=False,
- frozen_stages=-1,
- conv_cfg=None,
- norm_cfg=dict(type='BN', requires_grad=True),
- norm_eval=False,
- with_cp=False,
- zero_init_residual=True,
- wid=[48, 80, 160, 304, 608],
- expan=[None, 1, 1, 1, 1],
- dep=[None, 4, 6, 7, 3],
- ks=[7, 3, 5, 5, 5],
- group=[None, 16, 16, 16, 16],
- att=[None, True, False, True, True],
- init_cfg=[
- dict(type='Normal', std=0.001, layer=['Conv2d']),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]):
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- super().__init__(init_cfg=init_cfg)
- if depth not in self.arch_settings:
- raise KeyError(f'invalid depth {depth} for resnet')
- self.depth = depth
- self.stem_channels = dep[0]
- self.num_stages = num_stages
- assert 1 <= num_stages <= 4
- self.strides = strides
- self.dilations = dilations
- assert len(strides) == len(dilations) == num_stages
- self.out_indices = out_indices
- assert max(out_indices) < num_stages
- self.style = style
- self.deep_stem = deep_stem
- self.avg_down = avg_down
- self.frozen_stages = frozen_stages
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- self.with_cp = with_cp
- self.norm_eval = norm_eval
- self.zero_init_residual = zero_init_residual
- self.block = self.arch_settings[depth]
- self.stage_blocks = dep[1:1 + num_stages]
-
- self._make_stem_layer(in_channels, wid[0], ks[0])
-
- self.res_layers = []
- _in_channels = wid[0]
- for i, num_blocks in enumerate(self.stage_blocks):
- expansion = get_expansion(self.block, expan[i + 1])
- _out_channels = wid[i + 1] * expansion
- stride = strides[i]
- dilation = dilations[i]
- res_layer = self.make_res_layer(
- block=self.block,
- num_blocks=num_blocks,
- in_channels=_in_channels,
- out_channels=_out_channels,
- expansion=expansion,
- stride=stride,
- dilation=dilation,
- style=self.style,
- avg_down=self.avg_down,
- with_cp=with_cp,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- kernel_size=ks[i + 1],
- groups=group[i + 1],
- attention=att[i + 1])
- _in_channels = _out_channels
- layer_name = f'layer{i + 1}'
- self.add_module(layer_name, res_layer)
- self.res_layers.append(layer_name)
-
- self._freeze_stages()
-
- self.feat_dim = res_layer[-1].out_channels
-
- def make_res_layer(self, **kwargs):
- """Make a ViPNAS ResLayer."""
- return ViPNAS_ResLayer(**kwargs)
-
- @property
- def norm1(self):
- """nn.Module: the normalization layer named "norm1" """
- return getattr(self, self.norm1_name)
-
- def _make_stem_layer(self, in_channels, stem_channels, kernel_size):
- """Make stem layer."""
- if self.deep_stem:
- self.stem = nn.Sequential(
- ConvModule(
- in_channels,
- stem_channels // 2,
- kernel_size=3,
- stride=2,
- padding=1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- inplace=True),
- ConvModule(
- stem_channels // 2,
- stem_channels // 2,
- kernel_size=3,
- stride=1,
- padding=1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- inplace=True),
- ConvModule(
- stem_channels // 2,
- stem_channels,
- kernel_size=3,
- stride=1,
- padding=1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- inplace=True))
- else:
- self.conv1 = build_conv_layer(
- self.conv_cfg,
- in_channels,
- stem_channels,
- kernel_size=kernel_size,
- stride=2,
- padding=kernel_size // 2,
- bias=False)
- self.norm1_name, norm1 = build_norm_layer(
- self.norm_cfg, stem_channels, postfix=1)
- self.add_module(self.norm1_name, norm1)
- self.relu = nn.ReLU(inplace=True)
- self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
-
- def _freeze_stages(self):
- """Freeze parameters."""
- if self.frozen_stages >= 0:
- if self.deep_stem:
- self.stem.eval()
- for param in self.stem.parameters():
- param.requires_grad = False
- else:
- self.norm1.eval()
- for m in [self.conv1, self.norm1]:
- for param in m.parameters():
- param.requires_grad = False
-
- for i in range(1, self.frozen_stages + 1):
- m = getattr(self, f'layer{i}')
- m.eval()
- for param in m.parameters():
- param.requires_grad = False
-
- def forward(self, x):
- """Forward function."""
- if self.deep_stem:
- x = self.stem(x)
- else:
- x = self.conv1(x)
- x = self.norm1(x)
- x = self.relu(x)
- x = self.maxpool(x)
- outs = []
- for i, layer_name in enumerate(self.res_layers):
- res_layer = getattr(self, layer_name)
- x = res_layer(x)
- if i in self.out_indices:
- outs.append(x)
- return tuple(outs)
-
- def train(self, mode=True):
- """Convert the model into training mode."""
- super().train(mode)
- self._freeze_stages()
- if mode and self.norm_eval:
- for m in self.modules():
- # trick: eval have effect on BatchNorm only
- if isinstance(m, _BatchNorm):
- m.eval()
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import torch.nn as nn
+import torch.utils.checkpoint as cp
+from mmcv.cnn import ConvModule, build_conv_layer, build_norm_layer
+from mmcv.cnn.bricks import ContextBlock
+from mmengine.model import BaseModule, Sequential
+from mmengine.utils.dl_utils.parrots_wrapper import _BatchNorm
+
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+
+
+class ViPNAS_Bottleneck(BaseModule):
+ """Bottleneck block for ViPNAS_ResNet.
+
+ Args:
+ in_channels (int): Input channels of this block.
+ out_channels (int): Output channels of this block.
+ expansion (int): The ratio of ``out_channels/mid_channels`` where
+ ``mid_channels`` is the input/output channels of conv2. Default: 4.
+ stride (int): stride of the block. Default: 1
+ dilation (int): dilation of convolution. Default: 1
+ downsample (nn.Module): downsample operation on identity branch.
+ Default: None.
+ style (str): ``"pytorch"`` or ``"caffe"``. If set to "pytorch", the
+ stride-two layer is the 3x3 conv layer, otherwise the stride-two
+ layer is the first 1x1 conv layer. Default: "pytorch".
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ Default: None
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ kernel_size (int): kernel size of conv2 searched in ViPANS.
+ groups (int): group number of conv2 searched in ViPNAS.
+ attention (bool): whether to use attention module in the end of
+ the block.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ expansion=4,
+ stride=1,
+ dilation=1,
+ downsample=None,
+ style='pytorch',
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ kernel_size=3,
+ groups=1,
+ attention=False,
+ init_cfg=None):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ assert style in ['pytorch', 'caffe']
+
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.expansion = expansion
+ assert out_channels % expansion == 0
+ self.mid_channels = out_channels // expansion
+ self.stride = stride
+ self.dilation = dilation
+ self.style = style
+ self.with_cp = with_cp
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+
+ if self.style == 'pytorch':
+ self.conv1_stride = 1
+ self.conv2_stride = stride
+ else:
+ self.conv1_stride = stride
+ self.conv2_stride = 1
+
+ self.norm1_name, norm1 = build_norm_layer(
+ norm_cfg, self.mid_channels, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(
+ norm_cfg, self.mid_channels, postfix=2)
+ self.norm3_name, norm3 = build_norm_layer(
+ norm_cfg, out_channels, postfix=3)
+
+ self.conv1 = build_conv_layer(
+ conv_cfg,
+ in_channels,
+ self.mid_channels,
+ kernel_size=1,
+ stride=self.conv1_stride,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+ self.conv2 = build_conv_layer(
+ conv_cfg,
+ self.mid_channels,
+ self.mid_channels,
+ kernel_size=kernel_size,
+ stride=self.conv2_stride,
+ padding=kernel_size // 2,
+ groups=groups,
+ dilation=dilation,
+ bias=False)
+
+ self.add_module(self.norm2_name, norm2)
+ self.conv3 = build_conv_layer(
+ conv_cfg,
+ self.mid_channels,
+ out_channels,
+ kernel_size=1,
+ bias=False)
+ self.add_module(self.norm3_name, norm3)
+
+ if attention:
+ self.attention = ContextBlock(out_channels,
+ max(1.0 / 16, 16.0 / out_channels))
+ else:
+ self.attention = None
+
+ self.relu = nn.ReLU(inplace=True)
+ self.downsample = downsample
+
+ @property
+ def norm1(self):
+ """nn.Module: the normalization layer named "norm1" """
+ return getattr(self, self.norm1_name)
+
+ @property
+ def norm2(self):
+ """nn.Module: the normalization layer named "norm2" """
+ return getattr(self, self.norm2_name)
+
+ @property
+ def norm3(self):
+ """nn.Module: the normalization layer named "norm3" """
+ return getattr(self, self.norm3_name)
+
+ def forward(self, x):
+ """Forward function."""
+
+ def _inner_forward(x):
+ identity = x
+
+ out = self.conv1(x)
+ out = self.norm1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+ out = self.norm2(out)
+ out = self.relu(out)
+
+ out = self.conv3(out)
+ out = self.norm3(out)
+
+ if self.attention is not None:
+ out = self.attention(out)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ out = self.relu(out)
+
+ return out
+
+
+def get_expansion(block, expansion=None):
+ """Get the expansion of a residual block.
+
+ The block expansion will be obtained by the following order:
+
+ 1. If ``expansion`` is given, just return it.
+ 2. If ``block`` has the attribute ``expansion``, then return
+ ``block.expansion``.
+ 3. Return the default value according the the block type:
+ 4 for ``ViPNAS_Bottleneck``.
+
+ Args:
+ block (class): The block class.
+ expansion (int | None): The given expansion ratio.
+
+ Returns:
+ int: The expansion of the block.
+ """
+ if isinstance(expansion, int):
+ assert expansion > 0
+ elif expansion is None:
+ if hasattr(block, 'expansion'):
+ expansion = block.expansion
+ elif issubclass(block, ViPNAS_Bottleneck):
+ expansion = 1
+ else:
+ raise TypeError(f'expansion is not specified for {block.__name__}')
+ else:
+ raise TypeError('expansion must be an integer or None')
+
+ return expansion
+
+
+class ViPNAS_ResLayer(Sequential):
+ """ViPNAS_ResLayer to build ResNet style backbone.
+
+ Args:
+ block (nn.Module): Residual block used to build ViPNAS ResLayer.
+ num_blocks (int): Number of blocks.
+ in_channels (int): Input channels of this block.
+ out_channels (int): Output channels of this block.
+ expansion (int, optional): The expansion for BasicBlock/Bottleneck.
+ If not specified, it will firstly be obtained via
+ ``block.expansion``. If the block has no attribute "expansion",
+ the following default values will be used: 1 for BasicBlock and
+ 4 for Bottleneck. Default: None.
+ stride (int): stride of the first block. Default: 1.
+ avg_down (bool): Use AvgPool instead of stride conv when
+ downsampling in the bottleneck. Default: False
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ Default: None
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ downsample_first (bool): Downsample at the first block or last block.
+ False for Hourglass, True for ResNet. Default: True
+ kernel_size (int): Kernel Size of the corresponding convolution layer
+ searched in the block.
+ groups (int): Group number of the corresponding convolution layer
+ searched in the block.
+ attention (bool): Whether to use attention module in the end of the
+ block.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ block,
+ num_blocks,
+ in_channels,
+ out_channels,
+ expansion=None,
+ stride=1,
+ avg_down=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ downsample_first=True,
+ kernel_size=3,
+ groups=1,
+ attention=False,
+ init_cfg=None,
+ **kwargs):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ self.block = block
+ self.expansion = get_expansion(block, expansion)
+
+ downsample = None
+ if stride != 1 or in_channels != out_channels:
+ downsample = []
+ conv_stride = stride
+ if avg_down and stride != 1:
+ conv_stride = 1
+ downsample.append(
+ nn.AvgPool2d(
+ kernel_size=stride,
+ stride=stride,
+ ceil_mode=True,
+ count_include_pad=False))
+ downsample.extend([
+ build_conv_layer(
+ conv_cfg,
+ in_channels,
+ out_channels,
+ kernel_size=1,
+ stride=conv_stride,
+ bias=False),
+ build_norm_layer(norm_cfg, out_channels)[1]
+ ])
+ downsample = nn.Sequential(*downsample)
+
+ layers = []
+ if downsample_first:
+ layers.append(
+ block(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ expansion=self.expansion,
+ stride=stride,
+ downsample=downsample,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ kernel_size=kernel_size,
+ groups=groups,
+ attention=attention,
+ **kwargs))
+ in_channels = out_channels
+ for _ in range(1, num_blocks):
+ layers.append(
+ block(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ expansion=self.expansion,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ kernel_size=kernel_size,
+ groups=groups,
+ attention=attention,
+ **kwargs))
+ else: # downsample_first=False is for HourglassModule
+ for i in range(0, num_blocks - 1):
+ layers.append(
+ block(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ expansion=self.expansion,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ kernel_size=kernel_size,
+ groups=groups,
+ attention=attention,
+ **kwargs))
+ layers.append(
+ block(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ expansion=self.expansion,
+ stride=stride,
+ downsample=downsample,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ kernel_size=kernel_size,
+ groups=groups,
+ attention=attention,
+ **kwargs))
+
+ super().__init__(*layers, init_cfg=init_cfg)
+
+
+@MODELS.register_module()
+class ViPNAS_ResNet(BaseBackbone):
+ """ViPNAS_ResNet backbone.
+
+ "ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search"
+ More details can be found in the `paper
+ `__ .
+
+ Args:
+ depth (int): Network depth, from {18, 34, 50, 101, 152}.
+ in_channels (int): Number of input image channels. Default: 3.
+ num_stages (int): Stages of the network. Default: 4.
+ strides (Sequence[int]): Strides of the first block of each stage.
+ Default: ``(1, 2, 2, 2)``.
+ dilations (Sequence[int]): Dilation of each stage.
+ Default: ``(1, 1, 1, 1)``.
+ out_indices (Sequence[int]): Output from which stages. If only one
+ stage is specified, a single tensor (feature map) is returned,
+ otherwise multiple stages are specified, a tuple of tensors will
+ be returned. Default: ``(3, )``.
+ style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
+ layer is the 3x3 conv layer, otherwise the stride-two layer is
+ the first 1x1 conv layer.
+ deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv.
+ Default: False.
+ avg_down (bool): Use AvgPool instead of stride conv when
+ downsampling in the bottleneck. Default: False.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters. Default: -1.
+ conv_cfg (dict | None): The config dict for conv layers. Default: None.
+ norm_cfg (dict): The config dict for norm layers.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ zero_init_residual (bool): Whether to use zero init for last norm layer
+ in resblocks to let them behave as identity. Default: True.
+ wid (list(int)): Searched width config for each stage.
+ expan (list(int)): Searched expansion ratio config for each stage.
+ dep (list(int)): Searched depth config for each stage.
+ ks (list(int)): Searched kernel size config for each stage.
+ group (list(int)): Searched group number config for each stage.
+ att (list(bool)): Searched attention config for each stage.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default:
+ ``[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]``
+ """
+
+ arch_settings = {
+ 50: ViPNAS_Bottleneck,
+ }
+
+ def __init__(self,
+ depth,
+ in_channels=3,
+ num_stages=4,
+ strides=(1, 2, 2, 2),
+ dilations=(1, 1, 1, 1),
+ out_indices=(3, ),
+ style='pytorch',
+ deep_stem=False,
+ avg_down=False,
+ frozen_stages=-1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=False,
+ with_cp=False,
+ zero_init_residual=True,
+ wid=[48, 80, 160, 304, 608],
+ expan=[None, 1, 1, 1, 1],
+ dep=[None, 4, 6, 7, 3],
+ ks=[7, 3, 5, 5, 5],
+ group=[None, 16, 16, 16, 16],
+ att=[None, True, False, True, True],
+ init_cfg=[
+ dict(type='Normal', std=0.001, layer=['Conv2d']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]):
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ super().__init__(init_cfg=init_cfg)
+ if depth not in self.arch_settings:
+ raise KeyError(f'invalid depth {depth} for resnet')
+ self.depth = depth
+ self.stem_channels = dep[0]
+ self.num_stages = num_stages
+ assert 1 <= num_stages <= 4
+ self.strides = strides
+ self.dilations = dilations
+ assert len(strides) == len(dilations) == num_stages
+ self.out_indices = out_indices
+ assert max(out_indices) < num_stages
+ self.style = style
+ self.deep_stem = deep_stem
+ self.avg_down = avg_down
+ self.frozen_stages = frozen_stages
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.with_cp = with_cp
+ self.norm_eval = norm_eval
+ self.zero_init_residual = zero_init_residual
+ self.block = self.arch_settings[depth]
+ self.stage_blocks = dep[1:1 + num_stages]
+
+ self._make_stem_layer(in_channels, wid[0], ks[0])
+
+ self.res_layers = []
+ _in_channels = wid[0]
+ for i, num_blocks in enumerate(self.stage_blocks):
+ expansion = get_expansion(self.block, expan[i + 1])
+ _out_channels = wid[i + 1] * expansion
+ stride = strides[i]
+ dilation = dilations[i]
+ res_layer = self.make_res_layer(
+ block=self.block,
+ num_blocks=num_blocks,
+ in_channels=_in_channels,
+ out_channels=_out_channels,
+ expansion=expansion,
+ stride=stride,
+ dilation=dilation,
+ style=self.style,
+ avg_down=self.avg_down,
+ with_cp=with_cp,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ kernel_size=ks[i + 1],
+ groups=group[i + 1],
+ attention=att[i + 1])
+ _in_channels = _out_channels
+ layer_name = f'layer{i + 1}'
+ self.add_module(layer_name, res_layer)
+ self.res_layers.append(layer_name)
+
+ self._freeze_stages()
+
+ self.feat_dim = res_layer[-1].out_channels
+
+ def make_res_layer(self, **kwargs):
+ """Make a ViPNAS ResLayer."""
+ return ViPNAS_ResLayer(**kwargs)
+
+ @property
+ def norm1(self):
+ """nn.Module: the normalization layer named "norm1" """
+ return getattr(self, self.norm1_name)
+
+ def _make_stem_layer(self, in_channels, stem_channels, kernel_size):
+ """Make stem layer."""
+ if self.deep_stem:
+ self.stem = nn.Sequential(
+ ConvModule(
+ in_channels,
+ stem_channels // 2,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ inplace=True),
+ ConvModule(
+ stem_channels // 2,
+ stem_channels // 2,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ inplace=True),
+ ConvModule(
+ stem_channels // 2,
+ stem_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ inplace=True))
+ else:
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ stem_channels,
+ kernel_size=kernel_size,
+ stride=2,
+ padding=kernel_size // 2,
+ bias=False)
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, stem_channels, postfix=1)
+ self.add_module(self.norm1_name, norm1)
+ self.relu = nn.ReLU(inplace=True)
+ self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
+
+ def _freeze_stages(self):
+ """Freeze parameters."""
+ if self.frozen_stages >= 0:
+ if self.deep_stem:
+ self.stem.eval()
+ for param in self.stem.parameters():
+ param.requires_grad = False
+ else:
+ self.norm1.eval()
+ for m in [self.conv1, self.norm1]:
+ for param in m.parameters():
+ param.requires_grad = False
+
+ for i in range(1, self.frozen_stages + 1):
+ m = getattr(self, f'layer{i}')
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ def forward(self, x):
+ """Forward function."""
+ if self.deep_stem:
+ x = self.stem(x)
+ else:
+ x = self.conv1(x)
+ x = self.norm1(x)
+ x = self.relu(x)
+ x = self.maxpool(x)
+ outs = []
+ for i, layer_name in enumerate(self.res_layers):
+ res_layer = getattr(self, layer_name)
+ x = res_layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+ return tuple(outs)
+
+ def train(self, mode=True):
+ """Convert the model into training mode."""
+ super().train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ # trick: eval have effect on BatchNorm only
+ if isinstance(m, _BatchNorm):
+ m.eval()
diff --git a/mmpose/models/builder.py b/mmpose/models/builder.py
index cefaedc291..1bcfc060ad 100644
--- a/mmpose/models/builder.py
+++ b/mmpose/models/builder.py
@@ -1,43 +1,43 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import warnings
-
-from mmpose.registry import MODELS
-
-BACKBONES = MODELS
-NECKS = MODELS
-HEADS = MODELS
-LOSSES = MODELS
-POSE_ESTIMATORS = MODELS
-
-
-def build_backbone(cfg):
- """Build backbone."""
- return BACKBONES.build(cfg)
-
-
-def build_neck(cfg):
- """Build neck."""
- return NECKS.build(cfg)
-
-
-def build_head(cfg):
- """Build head."""
- return HEADS.build(cfg)
-
-
-def build_loss(cfg):
- """Build loss."""
- return LOSSES.build(cfg)
-
-
-def build_pose_estimator(cfg):
- """Build pose estimator."""
- return POSE_ESTIMATORS.build(cfg)
-
-
-def build_posenet(cfg):
- """Build posenet."""
- warnings.warn(
- '``build_posenet`` will be deprecated soon, '
- 'please use ``build_pose_estimator`` instead.', DeprecationWarning)
- return build_pose_estimator(cfg)
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+from mmpose.registry import MODELS
+
+BACKBONES = MODELS
+NECKS = MODELS
+HEADS = MODELS
+LOSSES = MODELS
+POSE_ESTIMATORS = MODELS
+
+
+def build_backbone(cfg):
+ """Build backbone."""
+ return BACKBONES.build(cfg)
+
+
+def build_neck(cfg):
+ """Build neck."""
+ return NECKS.build(cfg)
+
+
+def build_head(cfg):
+ """Build head."""
+ return HEADS.build(cfg)
+
+
+def build_loss(cfg):
+ """Build loss."""
+ return LOSSES.build(cfg)
+
+
+def build_pose_estimator(cfg):
+ """Build pose estimator."""
+ return POSE_ESTIMATORS.build(cfg)
+
+
+def build_posenet(cfg):
+ """Build posenet."""
+ warnings.warn(
+ '``build_posenet`` will be deprecated soon, '
+ 'please use ``build_pose_estimator`` instead.', DeprecationWarning)
+ return build_pose_estimator(cfg)
diff --git a/mmpose/models/data_preprocessors/__init__.py b/mmpose/models/data_preprocessors/__init__.py
index 7c9bd22e2b..77fc080fc9 100644
--- a/mmpose/models/data_preprocessors/__init__.py
+++ b/mmpose/models/data_preprocessors/__init__.py
@@ -1,4 +1,4 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .data_preprocessor import PoseDataPreprocessor
-
-__all__ = ['PoseDataPreprocessor']
+# Copyright (c) OpenMMLab. All rights reserved.
+from .data_preprocessor import PoseDataPreprocessor
+
+__all__ = ['PoseDataPreprocessor']
diff --git a/mmpose/models/data_preprocessors/data_preprocessor.py b/mmpose/models/data_preprocessors/data_preprocessor.py
index bcfe54ab59..572151a81c 100644
--- a/mmpose/models/data_preprocessors/data_preprocessor.py
+++ b/mmpose/models/data_preprocessors/data_preprocessor.py
@@ -1,9 +1,9 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmengine.model import ImgDataPreprocessor
-
-from mmpose.registry import MODELS
-
-
-@MODELS.register_module()
-class PoseDataPreprocessor(ImgDataPreprocessor):
- """Image pre-processor for pose estimation tasks."""
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.model import ImgDataPreprocessor
+
+from mmpose.registry import MODELS
+
+
+@MODELS.register_module()
+class PoseDataPreprocessor(ImgDataPreprocessor):
+ """Image pre-processor for pose estimation tasks."""
diff --git a/mmpose/models/heads/__init__.py b/mmpose/models/heads/__init__.py
index e01f2269e3..8631b0def8 100644
--- a/mmpose/models/heads/__init__.py
+++ b/mmpose/models/heads/__init__.py
@@ -1,17 +1,17 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .base_head import BaseHead
-from .coord_cls_heads import RTMCCHead, SimCCHead
-from .heatmap_heads import (AssociativeEmbeddingHead, CIDHead, CPMHead,
- HeatmapHead, MSPNHead, ViPNASHead)
-from .hybrid_heads import DEKRHead, VisPredictHead
-from .regression_heads import (DSNTHead, IntegralRegressionHead,
- RegressionHead, RLEHead, TemporalRegressionHead,
- TrajectoryRegressionHead)
-
-__all__ = [
- 'BaseHead', 'HeatmapHead', 'CPMHead', 'MSPNHead', 'ViPNASHead',
- 'RegressionHead', 'IntegralRegressionHead', 'SimCCHead', 'RLEHead',
- 'DSNTHead', 'AssociativeEmbeddingHead', 'DEKRHead', 'VisPredictHead',
- 'CIDHead', 'RTMCCHead', 'TemporalRegressionHead',
- 'TrajectoryRegressionHead'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base_head import BaseHead
+from .coord_cls_heads import RTMCCHead, SimCCHead
+from .heatmap_heads import (AssociativeEmbeddingHead, CIDHead, CPMHead,
+ HeatmapHead, MSPNHead, ViPNASHead)
+from .hybrid_heads import DEKRHead, VisPredictHead
+from .regression_heads import (DSNTHead, IntegralRegressionHead,
+ RegressionHead, RLEHead, TemporalRegressionHead,
+ TrajectoryRegressionHead)
+
+__all__ = [
+ 'BaseHead', 'HeatmapHead', 'CPMHead', 'MSPNHead', 'ViPNASHead',
+ 'RegressionHead', 'IntegralRegressionHead', 'SimCCHead', 'RLEHead',
+ 'DSNTHead', 'AssociativeEmbeddingHead', 'DEKRHead', 'VisPredictHead',
+ 'CIDHead', 'RTMCCHead', 'TemporalRegressionHead',
+ 'TrajectoryRegressionHead'
+]
diff --git a/mmpose/models/heads/base_head.py b/mmpose/models/heads/base_head.py
index 14882db243..da9c765740 100644
--- a/mmpose/models/heads/base_head.py
+++ b/mmpose/models/heads/base_head.py
@@ -1,83 +1,83 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from abc import ABCMeta, abstractmethod
-from typing import Tuple, Union
-
-from mmengine.model import BaseModule
-from mmengine.structures import InstanceData
-from torch import Tensor
-
-from mmpose.utils.tensor_utils import to_numpy
-from mmpose.utils.typing import (Features, InstanceList, OptConfigType,
- OptSampleList, Predictions)
-
-
-class BaseHead(BaseModule, metaclass=ABCMeta):
- """Base head. A subclass should override :meth:`predict` and :meth:`loss`.
-
- Args:
- init_cfg (dict, optional): The extra init config of layers.
- Defaults to None.
- """
-
- @abstractmethod
- def forward(self, feats: Tuple[Tensor]):
- """Forward the network."""
-
- @abstractmethod
- def predict(self,
- feats: Features,
- batch_data_samples: OptSampleList,
- test_cfg: OptConfigType = {}) -> Predictions:
- """Predict results from features."""
-
- @abstractmethod
- def loss(self,
- feats: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- train_cfg: OptConfigType = {}) -> dict:
- """Calculate losses from a batch of inputs and data samples."""
-
- def decode(self, batch_outputs: Union[Tensor,
- Tuple[Tensor]]) -> InstanceList:
- """Decode keypoints from outputs.
-
- Args:
- batch_outputs (Tensor | Tuple[Tensor]): The network outputs of
- a data batch
-
- Returns:
- List[InstanceData]: A list of InstanceData, each contains the
- decoded pose information of the instances of one data sample.
- """
-
- def _pack_and_call(args, func):
- if not isinstance(args, tuple):
- args = (args, )
- return func(*args)
-
- if self.decoder is None:
- raise RuntimeError(
- f'The decoder has not been set in {self.__class__.__name__}. '
- 'Please set the decoder configs in the init parameters to '
- 'enable head methods `head.predict()` and `head.decode()`')
-
- if self.decoder.support_batch_decoding:
- batch_keypoints, batch_scores = _pack_and_call(
- batch_outputs, self.decoder.batch_decode)
-
- else:
- batch_output_np = to_numpy(batch_outputs, unzip=True)
- batch_keypoints = []
- batch_scores = []
- for outputs in batch_output_np:
- keypoints, scores = _pack_and_call(outputs,
- self.decoder.decode)
- batch_keypoints.append(keypoints)
- batch_scores.append(scores)
-
- preds = [
- InstanceData(keypoints=keypoints, keypoint_scores=scores)
- for keypoints, scores in zip(batch_keypoints, batch_scores)
- ]
-
- return preds
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+from typing import Tuple, Union
+
+from mmengine.model import BaseModule
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import (Features, InstanceList, OptConfigType,
+ OptSampleList, Predictions)
+
+
+class BaseHead(BaseModule, metaclass=ABCMeta):
+ """Base head. A subclass should override :meth:`predict` and :meth:`loss`.
+
+ Args:
+ init_cfg (dict, optional): The extra init config of layers.
+ Defaults to None.
+ """
+
+ @abstractmethod
+ def forward(self, feats: Tuple[Tensor]):
+ """Forward the network."""
+
+ @abstractmethod
+ def predict(self,
+ feats: Features,
+ batch_data_samples: OptSampleList,
+ test_cfg: OptConfigType = {}) -> Predictions:
+ """Predict results from features."""
+
+ @abstractmethod
+ def loss(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: OptConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples."""
+
+ def decode(self, batch_outputs: Union[Tensor,
+ Tuple[Tensor]]) -> InstanceList:
+ """Decode keypoints from outputs.
+
+ Args:
+ batch_outputs (Tensor | Tuple[Tensor]): The network outputs of
+ a data batch
+
+ Returns:
+ List[InstanceData]: A list of InstanceData, each contains the
+ decoded pose information of the instances of one data sample.
+ """
+
+ def _pack_and_call(args, func):
+ if not isinstance(args, tuple):
+ args = (args, )
+ return func(*args)
+
+ if self.decoder is None:
+ raise RuntimeError(
+ f'The decoder has not been set in {self.__class__.__name__}. '
+ 'Please set the decoder configs in the init parameters to '
+ 'enable head methods `head.predict()` and `head.decode()`')
+
+ if self.decoder.support_batch_decoding:
+ batch_keypoints, batch_scores = _pack_and_call(
+ batch_outputs, self.decoder.batch_decode)
+
+ else:
+ batch_output_np = to_numpy(batch_outputs, unzip=True)
+ batch_keypoints = []
+ batch_scores = []
+ for outputs in batch_output_np:
+ keypoints, scores = _pack_and_call(outputs,
+ self.decoder.decode)
+ batch_keypoints.append(keypoints)
+ batch_scores.append(scores)
+
+ preds = [
+ InstanceData(keypoints=keypoints, keypoint_scores=scores)
+ for keypoints, scores in zip(batch_keypoints, batch_scores)
+ ]
+
+ return preds
diff --git a/mmpose/models/heads/coord_cls_heads/__init__.py b/mmpose/models/heads/coord_cls_heads/__init__.py
index 104ff91308..108b4795f3 100644
--- a/mmpose/models/heads/coord_cls_heads/__init__.py
+++ b/mmpose/models/heads/coord_cls_heads/__init__.py
@@ -1,5 +1,5 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .rtmcc_head import RTMCCHead
-from .simcc_head import SimCCHead
-
-__all__ = ['SimCCHead', 'RTMCCHead']
+# Copyright (c) OpenMMLab. All rights reserved.
+from .rtmcc_head import RTMCCHead
+from .simcc_head import SimCCHead
+
+__all__ = ['SimCCHead', 'RTMCCHead']
diff --git a/mmpose/models/heads/coord_cls_heads/rtmcc_head.py b/mmpose/models/heads/coord_cls_heads/rtmcc_head.py
index 5df0733c48..f4ef8513aa 100644
--- a/mmpose/models/heads/coord_cls_heads/rtmcc_head.py
+++ b/mmpose/models/heads/coord_cls_heads/rtmcc_head.py
@@ -1,303 +1,303 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import warnings
-from typing import Optional, Sequence, Tuple, Union
-
-import torch
-from mmengine.dist import get_dist_info
-from mmengine.structures import PixelData
-from torch import Tensor, nn
-
-from mmpose.codecs.utils import get_simcc_normalized
-from mmpose.evaluation.functional import simcc_pck_accuracy
-from mmpose.models.utils.rtmcc_block import RTMCCBlock, ScaleNorm
-from mmpose.models.utils.tta import flip_vectors
-from mmpose.registry import KEYPOINT_CODECS, MODELS
-from mmpose.utils.tensor_utils import to_numpy
-from mmpose.utils.typing import (ConfigType, InstanceList, OptConfigType,
- OptSampleList)
-from ..base_head import BaseHead
-
-OptIntSeq = Optional[Sequence[int]]
-
-
-@MODELS.register_module()
-class RTMCCHead(BaseHead):
- """Top-down head introduced in RTMPose (2023). The head is composed of a
- large-kernel convolutional layer, a fully-connected layer and a Gated
- Attention Unit to generate 1d representation from low-resolution feature
- maps.
-
- Args:
- in_channels (int | sequence[int]): Number of channels in the input
- feature map.
- out_channels (int): Number of channels in the output heatmap.
- input_size (tuple): Size of input image in shape [w, h].
- in_featuremap_size (int | sequence[int]): Size of input feature map.
- simcc_split_ratio (float): Split ratio of pixels.
- Default: 2.0.
- final_layer_kernel_size (int): Kernel size of the convolutional layer.
- Default: 1.
- gau_cfg (Config): Config dict for the Gated Attention Unit.
- Default: dict(
- hidden_dims=256,
- s=128,
- expansion_factor=2,
- dropout_rate=0.,
- drop_path=0.,
- act_fn='ReLU',
- use_rel_bias=False,
- pos_enc=False).
- loss (Config): Config of the keypoint loss. Defaults to use
- :class:`KLDiscretLoss`
- decoder (Config, optional): The decoder config that controls decoding
- keypoint coordinates from the network output. Defaults to ``None``
- init_cfg (Config, optional): Config to control the initialization. See
- :attr:`default_init_cfg` for default settings
- """
-
- def __init__(
- self,
- in_channels: Union[int, Sequence[int]],
- out_channels: int,
- input_size: Tuple[int, int],
- in_featuremap_size: Tuple[int, int],
- simcc_split_ratio: float = 2.0,
- final_layer_kernel_size: int = 1,
- gau_cfg: ConfigType = dict(
- hidden_dims=256,
- s=128,
- expansion_factor=2,
- dropout_rate=0.,
- drop_path=0.,
- act_fn='ReLU',
- use_rel_bias=False,
- pos_enc=False),
- loss: ConfigType = dict(type='KLDiscretLoss', use_target_weight=True),
- decoder: OptConfigType = None,
- init_cfg: OptConfigType = None,
- ):
-
- if init_cfg is None:
- init_cfg = self.default_init_cfg
-
- super().__init__(init_cfg)
-
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.input_size = input_size
- self.in_featuremap_size = in_featuremap_size
- self.simcc_split_ratio = simcc_split_ratio
-
- self.loss_module = MODELS.build(loss)
- if decoder is not None:
- self.decoder = KEYPOINT_CODECS.build(decoder)
- else:
- self.decoder = None
-
- if isinstance(in_channels, (tuple, list)):
- raise ValueError(
- f'{self.__class__.__name__} does not support selecting '
- 'multiple input features.')
-
- # Define SimCC layers
- flatten_dims = self.in_featuremap_size[0] * self.in_featuremap_size[1]
-
- self.final_layer = nn.Conv2d(
- in_channels,
- out_channels,
- kernel_size=final_layer_kernel_size,
- stride=1,
- padding=final_layer_kernel_size // 2)
- self.mlp = nn.Sequential(
- ScaleNorm(flatten_dims),
- nn.Linear(flatten_dims, gau_cfg['hidden_dims'], bias=False))
-
- W = int(self.input_size[0] * self.simcc_split_ratio)
- H = int(self.input_size[1] * self.simcc_split_ratio)
-
- self.gau = RTMCCBlock(
- self.out_channels,
- gau_cfg['hidden_dims'],
- gau_cfg['hidden_dims'],
- s=gau_cfg['s'],
- expansion_factor=gau_cfg['expansion_factor'],
- dropout_rate=gau_cfg['dropout_rate'],
- drop_path=gau_cfg['drop_path'],
- attn_type='self-attn',
- act_fn=gau_cfg['act_fn'],
- use_rel_bias=gau_cfg['use_rel_bias'],
- pos_enc=gau_cfg['pos_enc'])
-
- self.cls_x = nn.Linear(gau_cfg['hidden_dims'], W, bias=False)
- self.cls_y = nn.Linear(gau_cfg['hidden_dims'], H, bias=False)
-
- def forward(self, feats: Tuple[Tensor]) -> Tuple[Tensor, Tensor]:
- """Forward the network.
-
- The input is the featuremap extracted by backbone and the
- output is the simcc representation.
-
- Args:
- feats (Tuple[Tensor]): Multi scale feature maps.
-
- Returns:
- pred_x (Tensor): 1d representation of x.
- pred_y (Tensor): 1d representation of y.
- """
- feats = feats[-1]
-
- feats = self.final_layer(feats) # -> B, K, H, W
-
- # flatten the output heatmap
- feats = torch.flatten(feats, 2)
-
- feats = self.mlp(feats) # -> B, K, hidden
-
- feats = self.gau(feats)
-
- pred_x = self.cls_x(feats)
- pred_y = self.cls_y(feats)
-
- return pred_x, pred_y
-
- def predict(
- self,
- feats: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- test_cfg: OptConfigType = {},
- ) -> InstanceList:
- """Predict results from features.
-
- Args:
- feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
- features (or multiple multi-stage features in TTA)
- batch_data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples
- test_cfg (dict): The runtime config for testing process. Defaults
- to {}
-
- Returns:
- List[InstanceData]: The pose predictions, each contains
- the following fields:
- - keypoints (np.ndarray): predicted keypoint coordinates in
- shape (num_instances, K, D) where K is the keypoint number
- and D is the keypoint dimension
- - keypoint_scores (np.ndarray): predicted keypoint scores in
- shape (num_instances, K)
- - keypoint_x_labels (np.ndarray, optional): The predicted 1-D
- intensity distribution in the x direction
- - keypoint_y_labels (np.ndarray, optional): The predicted 1-D
- intensity distribution in the y direction
- """
-
- if test_cfg.get('flip_test', False):
- # TTA: flip test -> feats = [orig, flipped]
- assert isinstance(feats, list) and len(feats) == 2
- flip_indices = batch_data_samples[0].metainfo['flip_indices']
- _feats, _feats_flip = feats
-
- _batch_pred_x, _batch_pred_y = self.forward(_feats)
-
- _batch_pred_x_flip, _batch_pred_y_flip = self.forward(_feats_flip)
- _batch_pred_x_flip, _batch_pred_y_flip = flip_vectors(
- _batch_pred_x_flip,
- _batch_pred_y_flip,
- flip_indices=flip_indices)
-
- batch_pred_x = (_batch_pred_x + _batch_pred_x_flip) * 0.5
- batch_pred_y = (_batch_pred_y + _batch_pred_y_flip) * 0.5
- else:
- batch_pred_x, batch_pred_y = self.forward(feats)
-
- preds = self.decode((batch_pred_x, batch_pred_y))
-
- if test_cfg.get('output_heatmaps', False):
- rank, _ = get_dist_info()
- if rank == 0:
- warnings.warn('The predicted simcc values are normalized for '
- 'visualization. This may cause discrepancy '
- 'between the keypoint scores and the 1D heatmaps'
- '.')
-
- # normalize the predicted 1d distribution
- batch_pred_x = get_simcc_normalized(batch_pred_x)
- batch_pred_y = get_simcc_normalized(batch_pred_y)
-
- B, K, _ = batch_pred_x.shape
- # B, K, Wx -> B, K, Wx, 1
- x = batch_pred_x.reshape(B, K, 1, -1)
- # B, K, Wy -> B, K, 1, Wy
- y = batch_pred_y.reshape(B, K, -1, 1)
- # B, K, Wx, Wy
- batch_heatmaps = torch.matmul(y, x)
- pred_fields = [
- PixelData(heatmaps=hm) for hm in batch_heatmaps.detach()
- ]
-
- for pred_instances, pred_x, pred_y in zip(preds,
- to_numpy(batch_pred_x),
- to_numpy(batch_pred_y)):
-
- pred_instances.keypoint_x_labels = pred_x[None]
- pred_instances.keypoint_y_labels = pred_y[None]
-
- return preds, pred_fields
- else:
- return preds
-
- def loss(
- self,
- feats: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- train_cfg: OptConfigType = {},
- ) -> dict:
- """Calculate losses from a batch of inputs and data samples."""
-
- pred_x, pred_y = self.forward(feats)
-
- gt_x = torch.cat([
- d.gt_instance_labels.keypoint_x_labels for d in batch_data_samples
- ],
- dim=0)
- gt_y = torch.cat([
- d.gt_instance_labels.keypoint_y_labels for d in batch_data_samples
- ],
- dim=0)
- keypoint_weights = torch.cat(
- [
- d.gt_instance_labels.keypoint_weights
- for d in batch_data_samples
- ],
- dim=0,
- )
-
- pred_simcc = (pred_x, pred_y)
- gt_simcc = (gt_x, gt_y)
-
- # calculate losses
- losses = dict()
- loss = self.loss_module(pred_simcc, gt_simcc, keypoint_weights)
-
- losses.update(loss_kpt=loss)
-
- # calculate accuracy
- _, avg_acc, _ = simcc_pck_accuracy(
- output=to_numpy(pred_simcc),
- target=to_numpy(gt_simcc),
- simcc_split_ratio=self.simcc_split_ratio,
- mask=to_numpy(keypoint_weights) > 0,
- )
-
- acc_pose = torch.tensor(avg_acc, device=gt_x.device)
- losses.update(acc_pose=acc_pose)
-
- return losses
-
- @property
- def default_init_cfg(self):
- init_cfg = [
- dict(type='Normal', layer=['Conv2d'], std=0.001),
- dict(type='Constant', layer='BatchNorm2d', val=1),
- dict(type='Normal', layer=['Linear'], std=0.01, bias=0),
- ]
- return init_cfg
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Optional, Sequence, Tuple, Union
+
+import torch
+from mmengine.dist import get_dist_info
+from mmengine.structures import PixelData
+from torch import Tensor, nn
+
+from mmpose.codecs.utils import get_simcc_normalized
+from mmpose.evaluation.functional import simcc_pck_accuracy
+from mmpose.models.utils.rtmcc_block import RTMCCBlock, ScaleNorm
+from mmpose.models.utils.tta import flip_vectors
+from mmpose.registry import KEYPOINT_CODECS, MODELS
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import (ConfigType, InstanceList, OptConfigType,
+ OptSampleList)
+from ..base_head import BaseHead
+
+OptIntSeq = Optional[Sequence[int]]
+
+
+@MODELS.register_module()
+class RTMCCHead(BaseHead):
+ """Top-down head introduced in RTMPose (2023). The head is composed of a
+ large-kernel convolutional layer, a fully-connected layer and a Gated
+ Attention Unit to generate 1d representation from low-resolution feature
+ maps.
+
+ Args:
+ in_channels (int | sequence[int]): Number of channels in the input
+ feature map.
+ out_channels (int): Number of channels in the output heatmap.
+ input_size (tuple): Size of input image in shape [w, h].
+ in_featuremap_size (int | sequence[int]): Size of input feature map.
+ simcc_split_ratio (float): Split ratio of pixels.
+ Default: 2.0.
+ final_layer_kernel_size (int): Kernel size of the convolutional layer.
+ Default: 1.
+ gau_cfg (Config): Config dict for the Gated Attention Unit.
+ Default: dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='ReLU',
+ use_rel_bias=False,
+ pos_enc=False).
+ loss (Config): Config of the keypoint loss. Defaults to use
+ :class:`KLDiscretLoss`
+ decoder (Config, optional): The decoder config that controls decoding
+ keypoint coordinates from the network output. Defaults to ``None``
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+ """
+
+ def __init__(
+ self,
+ in_channels: Union[int, Sequence[int]],
+ out_channels: int,
+ input_size: Tuple[int, int],
+ in_featuremap_size: Tuple[int, int],
+ simcc_split_ratio: float = 2.0,
+ final_layer_kernel_size: int = 1,
+ gau_cfg: ConfigType = dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='ReLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss: ConfigType = dict(type='KLDiscretLoss', use_target_weight=True),
+ decoder: OptConfigType = None,
+ init_cfg: OptConfigType = None,
+ ):
+
+ if init_cfg is None:
+ init_cfg = self.default_init_cfg
+
+ super().__init__(init_cfg)
+
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.input_size = input_size
+ self.in_featuremap_size = in_featuremap_size
+ self.simcc_split_ratio = simcc_split_ratio
+
+ self.loss_module = MODELS.build(loss)
+ if decoder is not None:
+ self.decoder = KEYPOINT_CODECS.build(decoder)
+ else:
+ self.decoder = None
+
+ if isinstance(in_channels, (tuple, list)):
+ raise ValueError(
+ f'{self.__class__.__name__} does not support selecting '
+ 'multiple input features.')
+
+ # Define SimCC layers
+ flatten_dims = self.in_featuremap_size[0] * self.in_featuremap_size[1]
+
+ self.final_layer = nn.Conv2d(
+ in_channels,
+ out_channels,
+ kernel_size=final_layer_kernel_size,
+ stride=1,
+ padding=final_layer_kernel_size // 2)
+ self.mlp = nn.Sequential(
+ ScaleNorm(flatten_dims),
+ nn.Linear(flatten_dims, gau_cfg['hidden_dims'], bias=False))
+
+ W = int(self.input_size[0] * self.simcc_split_ratio)
+ H = int(self.input_size[1] * self.simcc_split_ratio)
+
+ self.gau = RTMCCBlock(
+ self.out_channels,
+ gau_cfg['hidden_dims'],
+ gau_cfg['hidden_dims'],
+ s=gau_cfg['s'],
+ expansion_factor=gau_cfg['expansion_factor'],
+ dropout_rate=gau_cfg['dropout_rate'],
+ drop_path=gau_cfg['drop_path'],
+ attn_type='self-attn',
+ act_fn=gau_cfg['act_fn'],
+ use_rel_bias=gau_cfg['use_rel_bias'],
+ pos_enc=gau_cfg['pos_enc'])
+
+ self.cls_x = nn.Linear(gau_cfg['hidden_dims'], W, bias=False)
+ self.cls_y = nn.Linear(gau_cfg['hidden_dims'], H, bias=False)
+
+ def forward(self, feats: Tuple[Tensor]) -> Tuple[Tensor, Tensor]:
+ """Forward the network.
+
+ The input is the featuremap extracted by backbone and the
+ output is the simcc representation.
+
+ Args:
+ feats (Tuple[Tensor]): Multi scale feature maps.
+
+ Returns:
+ pred_x (Tensor): 1d representation of x.
+ pred_y (Tensor): 1d representation of y.
+ """
+ feats = feats[-1]
+
+ feats = self.final_layer(feats) # -> B, K, H, W
+
+ # flatten the output heatmap
+ feats = torch.flatten(feats, 2)
+
+ feats = self.mlp(feats) # -> B, K, hidden
+
+ feats = self.gau(feats)
+
+ pred_x = self.cls_x(feats)
+ pred_y = self.cls_y(feats)
+
+ return pred_x, pred_y
+
+ def predict(
+ self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ test_cfg: OptConfigType = {},
+ ) -> InstanceList:
+ """Predict results from features.
+
+ Args:
+ feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
+ features (or multiple multi-stage features in TTA)
+ batch_data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+ test_cfg (dict): The runtime config for testing process. Defaults
+ to {}
+
+ Returns:
+ List[InstanceData]: The pose predictions, each contains
+ the following fields:
+ - keypoints (np.ndarray): predicted keypoint coordinates in
+ shape (num_instances, K, D) where K is the keypoint number
+ and D is the keypoint dimension
+ - keypoint_scores (np.ndarray): predicted keypoint scores in
+ shape (num_instances, K)
+ - keypoint_x_labels (np.ndarray, optional): The predicted 1-D
+ intensity distribution in the x direction
+ - keypoint_y_labels (np.ndarray, optional): The predicted 1-D
+ intensity distribution in the y direction
+ """
+
+ if test_cfg.get('flip_test', False):
+ # TTA: flip test -> feats = [orig, flipped]
+ assert isinstance(feats, list) and len(feats) == 2
+ flip_indices = batch_data_samples[0].metainfo['flip_indices']
+ _feats, _feats_flip = feats
+
+ _batch_pred_x, _batch_pred_y = self.forward(_feats)
+
+ _batch_pred_x_flip, _batch_pred_y_flip = self.forward(_feats_flip)
+ _batch_pred_x_flip, _batch_pred_y_flip = flip_vectors(
+ _batch_pred_x_flip,
+ _batch_pred_y_flip,
+ flip_indices=flip_indices)
+
+ batch_pred_x = (_batch_pred_x + _batch_pred_x_flip) * 0.5
+ batch_pred_y = (_batch_pred_y + _batch_pred_y_flip) * 0.5
+ else:
+ batch_pred_x, batch_pred_y = self.forward(feats)
+
+ preds = self.decode((batch_pred_x, batch_pred_y))
+
+ if test_cfg.get('output_heatmaps', False):
+ rank, _ = get_dist_info()
+ if rank == 0:
+ warnings.warn('The predicted simcc values are normalized for '
+ 'visualization. This may cause discrepancy '
+ 'between the keypoint scores and the 1D heatmaps'
+ '.')
+
+ # normalize the predicted 1d distribution
+ batch_pred_x = get_simcc_normalized(batch_pred_x)
+ batch_pred_y = get_simcc_normalized(batch_pred_y)
+
+ B, K, _ = batch_pred_x.shape
+ # B, K, Wx -> B, K, Wx, 1
+ x = batch_pred_x.reshape(B, K, 1, -1)
+ # B, K, Wy -> B, K, 1, Wy
+ y = batch_pred_y.reshape(B, K, -1, 1)
+ # B, K, Wx, Wy
+ batch_heatmaps = torch.matmul(y, x)
+ pred_fields = [
+ PixelData(heatmaps=hm) for hm in batch_heatmaps.detach()
+ ]
+
+ for pred_instances, pred_x, pred_y in zip(preds,
+ to_numpy(batch_pred_x),
+ to_numpy(batch_pred_y)):
+
+ pred_instances.keypoint_x_labels = pred_x[None]
+ pred_instances.keypoint_y_labels = pred_y[None]
+
+ return preds, pred_fields
+ else:
+ return preds
+
+ def loss(
+ self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: OptConfigType = {},
+ ) -> dict:
+ """Calculate losses from a batch of inputs and data samples."""
+
+ pred_x, pred_y = self.forward(feats)
+
+ gt_x = torch.cat([
+ d.gt_instance_labels.keypoint_x_labels for d in batch_data_samples
+ ],
+ dim=0)
+ gt_y = torch.cat([
+ d.gt_instance_labels.keypoint_y_labels for d in batch_data_samples
+ ],
+ dim=0)
+ keypoint_weights = torch.cat(
+ [
+ d.gt_instance_labels.keypoint_weights
+ for d in batch_data_samples
+ ],
+ dim=0,
+ )
+
+ pred_simcc = (pred_x, pred_y)
+ gt_simcc = (gt_x, gt_y)
+
+ # calculate losses
+ losses = dict()
+ loss = self.loss_module(pred_simcc, gt_simcc, keypoint_weights)
+
+ losses.update(loss_kpt=loss)
+
+ # calculate accuracy
+ _, avg_acc, _ = simcc_pck_accuracy(
+ output=to_numpy(pred_simcc),
+ target=to_numpy(gt_simcc),
+ simcc_split_ratio=self.simcc_split_ratio,
+ mask=to_numpy(keypoint_weights) > 0,
+ )
+
+ acc_pose = torch.tensor(avg_acc, device=gt_x.device)
+ losses.update(acc_pose=acc_pose)
+
+ return losses
+
+ @property
+ def default_init_cfg(self):
+ init_cfg = [
+ dict(type='Normal', layer=['Conv2d'], std=0.001),
+ dict(type='Constant', layer='BatchNorm2d', val=1),
+ dict(type='Normal', layer=['Linear'], std=0.01, bias=0),
+ ]
+ return init_cfg
diff --git a/mmpose/models/heads/coord_cls_heads/simcc_head.py b/mmpose/models/heads/coord_cls_heads/simcc_head.py
index d9e7001cbc..7d9ca62ddc 100644
--- a/mmpose/models/heads/coord_cls_heads/simcc_head.py
+++ b/mmpose/models/heads/coord_cls_heads/simcc_head.py
@@ -1,371 +1,371 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import warnings
-from typing import Optional, Sequence, Tuple, Union
-
-import torch
-from mmcv.cnn import build_conv_layer
-from mmengine.dist import get_dist_info
-from mmengine.structures import PixelData
-from torch import Tensor, nn
-
-from mmpose.codecs.utils import get_simcc_normalized
-from mmpose.evaluation.functional import simcc_pck_accuracy
-from mmpose.models.utils.tta import flip_vectors
-from mmpose.registry import KEYPOINT_CODECS, MODELS
-from mmpose.utils.tensor_utils import to_numpy
-from mmpose.utils.typing import (ConfigType, InstanceList, OptConfigType,
- OptSampleList)
-from ..base_head import BaseHead
-
-OptIntSeq = Optional[Sequence[int]]
-
-
-@MODELS.register_module()
-class SimCCHead(BaseHead):
- """Top-down heatmap head introduced in `SimCC`_ by Li et al (2022). The
- head is composed of a few deconvolutional layers followed by a fully-
- connected layer to generate 1d representation from low-resolution feature
- maps.
-
- Args:
- in_channels (int | sequence[int]): Number of channels in the input
- feature map
- out_channels (int): Number of channels in the output heatmap
- input_size (tuple): Input image size in shape [w, h]
- in_featuremap_size (int | sequence[int]): Size of input feature map
- simcc_split_ratio (float): Split ratio of pixels
- deconv_type (str, optional): The type of deconv head which should
- be one of the following options:
-
- - ``'heatmap'``: make deconv layers in `HeatmapHead`
- - ``'vipnas'``: make deconv layers in `ViPNASHead`
-
- Defaults to ``'Heatmap'``
- deconv_out_channels (sequence[int]): The output channel number of each
- deconv layer. Defaults to ``(256, 256, 256)``
- deconv_kernel_sizes (sequence[int | tuple], optional): The kernel size
- of each deconv layer. Each element should be either an integer for
- both height and width dimensions, or a tuple of two integers for
- the height and the width dimension respectively.Defaults to
- ``(4, 4, 4)``
- deconv_num_groups (Sequence[int], optional): The group number of each
- deconv layer. Defaults to ``(16, 16, 16)``
- conv_out_channels (sequence[int], optional): The output channel number
- of each intermediate conv layer. ``None`` means no intermediate
- conv layer between deconv layers and the final conv layer.
- Defaults to ``None``
- conv_kernel_sizes (sequence[int | tuple], optional): The kernel size
- of each intermediate conv layer. Defaults to ``None``
- final_layer (dict): Arguments of the final Conv2d layer.
- Defaults to ``dict(kernel_size=1)``
- loss (Config): Config of the keypoint loss. Defaults to use
- :class:`KLDiscretLoss`
- decoder (Config, optional): The decoder config that controls decoding
- keypoint coordinates from the network output. Defaults to ``None``
- init_cfg (Config, optional): Config to control the initialization. See
- :attr:`default_init_cfg` for default settings
-
- .. _`SimCC`: https://arxiv.org/abs/2107.03332
- """
-
- _version = 2
-
- def __init__(
- self,
- in_channels: Union[int, Sequence[int]],
- out_channels: int,
- input_size: Tuple[int, int],
- in_featuremap_size: Tuple[int, int],
- simcc_split_ratio: float = 2.0,
- deconv_type: str = 'heatmap',
- deconv_out_channels: OptIntSeq = (256, 256, 256),
- deconv_kernel_sizes: OptIntSeq = (4, 4, 4),
- deconv_num_groups: OptIntSeq = (16, 16, 16),
- conv_out_channels: OptIntSeq = None,
- conv_kernel_sizes: OptIntSeq = None,
- final_layer: dict = dict(kernel_size=1),
- loss: ConfigType = dict(type='KLDiscretLoss', use_target_weight=True),
- decoder: OptConfigType = None,
- init_cfg: OptConfigType = None,
- ):
-
- if init_cfg is None:
- init_cfg = self.default_init_cfg
-
- super().__init__(init_cfg)
-
- if deconv_type not in {'heatmap', 'vipnas'}:
- raise ValueError(
- f'{self.__class__.__name__} got invalid `deconv_type` value'
- f'{deconv_type}. Should be one of '
- '{"heatmap", "vipnas"}')
-
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.input_size = input_size
- self.in_featuremap_size = in_featuremap_size
- self.simcc_split_ratio = simcc_split_ratio
- self.loss_module = MODELS.build(loss)
- if decoder is not None:
- self.decoder = KEYPOINT_CODECS.build(decoder)
- else:
- self.decoder = None
-
- num_deconv = len(deconv_out_channels) if deconv_out_channels else 0
- if num_deconv != 0:
- self.heatmap_size = tuple(
- [s * (2**num_deconv) for s in in_featuremap_size])
-
- # deconv layers + 1x1 conv
- self.deconv_head = self._make_deconv_head(
- in_channels=in_channels,
- out_channels=out_channels,
- deconv_type=deconv_type,
- deconv_out_channels=deconv_out_channels,
- deconv_kernel_sizes=deconv_kernel_sizes,
- deconv_num_groups=deconv_num_groups,
- conv_out_channels=conv_out_channels,
- conv_kernel_sizes=conv_kernel_sizes,
- final_layer=final_layer)
-
- if final_layer is not None:
- in_channels = out_channels
- else:
- in_channels = deconv_out_channels[-1]
-
- else:
- self.deconv_head = None
-
- if final_layer is not None:
- cfg = dict(
- type='Conv2d',
- in_channels=in_channels,
- out_channels=out_channels,
- kernel_size=1)
- cfg.update(final_layer)
- self.final_layer = build_conv_layer(cfg)
- else:
- self.final_layer = None
-
- self.heatmap_size = in_featuremap_size
-
- # Define SimCC layers
- flatten_dims = self.heatmap_size[0] * self.heatmap_size[1]
-
- W = int(self.input_size[0] * self.simcc_split_ratio)
- H = int(self.input_size[1] * self.simcc_split_ratio)
-
- self.mlp_head_x = nn.Linear(flatten_dims, W)
- self.mlp_head_y = nn.Linear(flatten_dims, H)
-
- def _make_deconv_head(
- self,
- in_channels: Union[int, Sequence[int]],
- out_channels: int,
- deconv_type: str = 'heatmap',
- deconv_out_channels: OptIntSeq = (256, 256, 256),
- deconv_kernel_sizes: OptIntSeq = (4, 4, 4),
- deconv_num_groups: OptIntSeq = (16, 16, 16),
- conv_out_channels: OptIntSeq = None,
- conv_kernel_sizes: OptIntSeq = None,
- final_layer: dict = dict(kernel_size=1)
- ) -> nn.Module:
- """Create deconvolutional layers by given parameters."""
-
- if deconv_type == 'heatmap':
- deconv_head = MODELS.build(
- dict(
- type='HeatmapHead',
- in_channels=self.in_channels,
- out_channels=out_channels,
- deconv_out_channels=deconv_out_channels,
- deconv_kernel_sizes=deconv_kernel_sizes,
- conv_out_channels=conv_out_channels,
- conv_kernel_sizes=conv_kernel_sizes,
- final_layer=final_layer))
- else:
- deconv_head = MODELS.build(
- dict(
- type='ViPNASHead',
- in_channels=in_channels,
- out_channels=out_channels,
- deconv_out_channels=deconv_out_channels,
- deconv_num_groups=deconv_num_groups,
- conv_out_channels=conv_out_channels,
- conv_kernel_sizes=conv_kernel_sizes,
- final_layer=final_layer))
-
- return deconv_head
-
- def forward(self, feats: Tuple[Tensor]) -> Tuple[Tensor, Tensor]:
- """Forward the network.
-
- The input is the featuremap extracted by backbone and the
- output is the simcc representation.
-
- Args:
- feats (Tuple[Tensor]): Multi scale feature maps.
-
- Returns:
- pred_x (Tensor): 1d representation of x.
- pred_y (Tensor): 1d representation of y.
- """
- if self.deconv_head is None:
- feats = feats[-1]
- if self.final_layer is not None:
- feats = self.final_layer(feats)
- else:
- feats = self.deconv_head(feats)
-
- # flatten the output heatmap
- x = torch.flatten(feats, 2)
-
- pred_x = self.mlp_head_x(x)
- pred_y = self.mlp_head_y(x)
-
- return pred_x, pred_y
-
- def predict(
- self,
- feats: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- test_cfg: OptConfigType = {},
- ) -> InstanceList:
- """Predict results from features.
-
- Args:
- feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
- features (or multiple multi-stage features in TTA)
- batch_data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples
- test_cfg (dict): The runtime config for testing process. Defaults
- to {}
-
- Returns:
- List[InstanceData]: The pose predictions, each contains
- the following fields:
-
- - keypoints (np.ndarray): predicted keypoint coordinates in
- shape (num_instances, K, D) where K is the keypoint number
- and D is the keypoint dimension
- - keypoint_scores (np.ndarray): predicted keypoint scores in
- shape (num_instances, K)
- - keypoint_x_labels (np.ndarray, optional): The predicted 1-D
- intensity distribution in the x direction
- - keypoint_y_labels (np.ndarray, optional): The predicted 1-D
- intensity distribution in the y direction
- """
-
- if test_cfg.get('flip_test', False):
- # TTA: flip test -> feats = [orig, flipped]
- assert isinstance(feats, list) and len(feats) == 2
- flip_indices = batch_data_samples[0].metainfo['flip_indices']
- _feats, _feats_flip = feats
-
- _batch_pred_x, _batch_pred_y = self.forward(_feats)
-
- _batch_pred_x_flip, _batch_pred_y_flip = self.forward(_feats_flip)
- _batch_pred_x_flip, _batch_pred_y_flip = flip_vectors(
- _batch_pred_x_flip,
- _batch_pred_y_flip,
- flip_indices=flip_indices)
-
- batch_pred_x = (_batch_pred_x + _batch_pred_x_flip) * 0.5
- batch_pred_y = (_batch_pred_y + _batch_pred_y_flip) * 0.5
- else:
- batch_pred_x, batch_pred_y = self.forward(feats)
-
- preds = self.decode((batch_pred_x, batch_pred_y))
-
- if test_cfg.get('output_heatmaps', False):
- rank, _ = get_dist_info()
- if rank == 0:
- warnings.warn('The predicted simcc values are normalized for '
- 'visualization. This may cause discrepancy '
- 'between the keypoint scores and the 1D heatmaps'
- '.')
-
- # normalize the predicted 1d distribution
- sigma = self.decoder.sigma
- batch_pred_x = get_simcc_normalized(batch_pred_x, sigma[0])
- batch_pred_y = get_simcc_normalized(batch_pred_y, sigma[1])
-
- B, K, _ = batch_pred_x.shape
- # B, K, Wx -> B, K, Wx, 1
- x = batch_pred_x.reshape(B, K, 1, -1)
- # B, K, Wy -> B, K, 1, Wy
- y = batch_pred_y.reshape(B, K, -1, 1)
- # B, K, Wx, Wy
- batch_heatmaps = torch.matmul(y, x)
- pred_fields = [
- PixelData(heatmaps=hm) for hm in batch_heatmaps.detach()
- ]
-
- for pred_instances, pred_x, pred_y in zip(preds,
- to_numpy(batch_pred_x),
- to_numpy(batch_pred_y)):
-
- pred_instances.keypoint_x_labels = pred_x[None]
- pred_instances.keypoint_y_labels = pred_y[None]
-
- return preds, pred_fields
- else:
- return preds
-
- def loss(
- self,
- feats: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- train_cfg: OptConfigType = {},
- ) -> dict:
- """Calculate losses from a batch of inputs and data samples."""
-
- pred_x, pred_y = self.forward(feats)
-
- gt_x = torch.cat([
- d.gt_instance_labels.keypoint_x_labels for d in batch_data_samples
- ],
- dim=0)
- gt_y = torch.cat([
- d.gt_instance_labels.keypoint_y_labels for d in batch_data_samples
- ],
- dim=0)
- keypoint_weights = torch.cat(
- [
- d.gt_instance_labels.keypoint_weights
- for d in batch_data_samples
- ],
- dim=0,
- )
-
- pred_simcc = (pred_x, pred_y)
- gt_simcc = (gt_x, gt_y)
-
- # calculate losses
- losses = dict()
- loss = self.loss_module(pred_simcc, gt_simcc, keypoint_weights)
-
- losses.update(loss_kpt=loss)
-
- # calculate accuracy
- _, avg_acc, _ = simcc_pck_accuracy(
- output=to_numpy(pred_simcc),
- target=to_numpy(gt_simcc),
- simcc_split_ratio=self.simcc_split_ratio,
- mask=to_numpy(keypoint_weights) > 0,
- )
-
- acc_pose = torch.tensor(avg_acc, device=gt_x.device)
- losses.update(acc_pose=acc_pose)
-
- return losses
-
- @property
- def default_init_cfg(self):
- init_cfg = [
- dict(
- type='Normal', layer=['Conv2d', 'ConvTranspose2d'], std=0.001),
- dict(type='Constant', layer='BatchNorm2d', val=1),
- dict(type='Normal', layer=['Linear'], std=0.01, bias=0),
- ]
- return init_cfg
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Optional, Sequence, Tuple, Union
+
+import torch
+from mmcv.cnn import build_conv_layer
+from mmengine.dist import get_dist_info
+from mmengine.structures import PixelData
+from torch import Tensor, nn
+
+from mmpose.codecs.utils import get_simcc_normalized
+from mmpose.evaluation.functional import simcc_pck_accuracy
+from mmpose.models.utils.tta import flip_vectors
+from mmpose.registry import KEYPOINT_CODECS, MODELS
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import (ConfigType, InstanceList, OptConfigType,
+ OptSampleList)
+from ..base_head import BaseHead
+
+OptIntSeq = Optional[Sequence[int]]
+
+
+@MODELS.register_module()
+class SimCCHead(BaseHead):
+ """Top-down heatmap head introduced in `SimCC`_ by Li et al (2022). The
+ head is composed of a few deconvolutional layers followed by a fully-
+ connected layer to generate 1d representation from low-resolution feature
+ maps.
+
+ Args:
+ in_channels (int | sequence[int]): Number of channels in the input
+ feature map
+ out_channels (int): Number of channels in the output heatmap
+ input_size (tuple): Input image size in shape [w, h]
+ in_featuremap_size (int | sequence[int]): Size of input feature map
+ simcc_split_ratio (float): Split ratio of pixels
+ deconv_type (str, optional): The type of deconv head which should
+ be one of the following options:
+
+ - ``'heatmap'``: make deconv layers in `HeatmapHead`
+ - ``'vipnas'``: make deconv layers in `ViPNASHead`
+
+ Defaults to ``'Heatmap'``
+ deconv_out_channels (sequence[int]): The output channel number of each
+ deconv layer. Defaults to ``(256, 256, 256)``
+ deconv_kernel_sizes (sequence[int | tuple], optional): The kernel size
+ of each deconv layer. Each element should be either an integer for
+ both height and width dimensions, or a tuple of two integers for
+ the height and the width dimension respectively.Defaults to
+ ``(4, 4, 4)``
+ deconv_num_groups (Sequence[int], optional): The group number of each
+ deconv layer. Defaults to ``(16, 16, 16)``
+ conv_out_channels (sequence[int], optional): The output channel number
+ of each intermediate conv layer. ``None`` means no intermediate
+ conv layer between deconv layers and the final conv layer.
+ Defaults to ``None``
+ conv_kernel_sizes (sequence[int | tuple], optional): The kernel size
+ of each intermediate conv layer. Defaults to ``None``
+ final_layer (dict): Arguments of the final Conv2d layer.
+ Defaults to ``dict(kernel_size=1)``
+ loss (Config): Config of the keypoint loss. Defaults to use
+ :class:`KLDiscretLoss`
+ decoder (Config, optional): The decoder config that controls decoding
+ keypoint coordinates from the network output. Defaults to ``None``
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+
+ .. _`SimCC`: https://arxiv.org/abs/2107.03332
+ """
+
+ _version = 2
+
+ def __init__(
+ self,
+ in_channels: Union[int, Sequence[int]],
+ out_channels: int,
+ input_size: Tuple[int, int],
+ in_featuremap_size: Tuple[int, int],
+ simcc_split_ratio: float = 2.0,
+ deconv_type: str = 'heatmap',
+ deconv_out_channels: OptIntSeq = (256, 256, 256),
+ deconv_kernel_sizes: OptIntSeq = (4, 4, 4),
+ deconv_num_groups: OptIntSeq = (16, 16, 16),
+ conv_out_channels: OptIntSeq = None,
+ conv_kernel_sizes: OptIntSeq = None,
+ final_layer: dict = dict(kernel_size=1),
+ loss: ConfigType = dict(type='KLDiscretLoss', use_target_weight=True),
+ decoder: OptConfigType = None,
+ init_cfg: OptConfigType = None,
+ ):
+
+ if init_cfg is None:
+ init_cfg = self.default_init_cfg
+
+ super().__init__(init_cfg)
+
+ if deconv_type not in {'heatmap', 'vipnas'}:
+ raise ValueError(
+ f'{self.__class__.__name__} got invalid `deconv_type` value'
+ f'{deconv_type}. Should be one of '
+ '{"heatmap", "vipnas"}')
+
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.input_size = input_size
+ self.in_featuremap_size = in_featuremap_size
+ self.simcc_split_ratio = simcc_split_ratio
+ self.loss_module = MODELS.build(loss)
+ if decoder is not None:
+ self.decoder = KEYPOINT_CODECS.build(decoder)
+ else:
+ self.decoder = None
+
+ num_deconv = len(deconv_out_channels) if deconv_out_channels else 0
+ if num_deconv != 0:
+ self.heatmap_size = tuple(
+ [s * (2**num_deconv) for s in in_featuremap_size])
+
+ # deconv layers + 1x1 conv
+ self.deconv_head = self._make_deconv_head(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ deconv_type=deconv_type,
+ deconv_out_channels=deconv_out_channels,
+ deconv_kernel_sizes=deconv_kernel_sizes,
+ deconv_num_groups=deconv_num_groups,
+ conv_out_channels=conv_out_channels,
+ conv_kernel_sizes=conv_kernel_sizes,
+ final_layer=final_layer)
+
+ if final_layer is not None:
+ in_channels = out_channels
+ else:
+ in_channels = deconv_out_channels[-1]
+
+ else:
+ self.deconv_head = None
+
+ if final_layer is not None:
+ cfg = dict(
+ type='Conv2d',
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1)
+ cfg.update(final_layer)
+ self.final_layer = build_conv_layer(cfg)
+ else:
+ self.final_layer = None
+
+ self.heatmap_size = in_featuremap_size
+
+ # Define SimCC layers
+ flatten_dims = self.heatmap_size[0] * self.heatmap_size[1]
+
+ W = int(self.input_size[0] * self.simcc_split_ratio)
+ H = int(self.input_size[1] * self.simcc_split_ratio)
+
+ self.mlp_head_x = nn.Linear(flatten_dims, W)
+ self.mlp_head_y = nn.Linear(flatten_dims, H)
+
+ def _make_deconv_head(
+ self,
+ in_channels: Union[int, Sequence[int]],
+ out_channels: int,
+ deconv_type: str = 'heatmap',
+ deconv_out_channels: OptIntSeq = (256, 256, 256),
+ deconv_kernel_sizes: OptIntSeq = (4, 4, 4),
+ deconv_num_groups: OptIntSeq = (16, 16, 16),
+ conv_out_channels: OptIntSeq = None,
+ conv_kernel_sizes: OptIntSeq = None,
+ final_layer: dict = dict(kernel_size=1)
+ ) -> nn.Module:
+ """Create deconvolutional layers by given parameters."""
+
+ if deconv_type == 'heatmap':
+ deconv_head = MODELS.build(
+ dict(
+ type='HeatmapHead',
+ in_channels=self.in_channels,
+ out_channels=out_channels,
+ deconv_out_channels=deconv_out_channels,
+ deconv_kernel_sizes=deconv_kernel_sizes,
+ conv_out_channels=conv_out_channels,
+ conv_kernel_sizes=conv_kernel_sizes,
+ final_layer=final_layer))
+ else:
+ deconv_head = MODELS.build(
+ dict(
+ type='ViPNASHead',
+ in_channels=in_channels,
+ out_channels=out_channels,
+ deconv_out_channels=deconv_out_channels,
+ deconv_num_groups=deconv_num_groups,
+ conv_out_channels=conv_out_channels,
+ conv_kernel_sizes=conv_kernel_sizes,
+ final_layer=final_layer))
+
+ return deconv_head
+
+ def forward(self, feats: Tuple[Tensor]) -> Tuple[Tensor, Tensor]:
+ """Forward the network.
+
+ The input is the featuremap extracted by backbone and the
+ output is the simcc representation.
+
+ Args:
+ feats (Tuple[Tensor]): Multi scale feature maps.
+
+ Returns:
+ pred_x (Tensor): 1d representation of x.
+ pred_y (Tensor): 1d representation of y.
+ """
+ if self.deconv_head is None:
+ feats = feats[-1]
+ if self.final_layer is not None:
+ feats = self.final_layer(feats)
+ else:
+ feats = self.deconv_head(feats)
+
+ # flatten the output heatmap
+ x = torch.flatten(feats, 2)
+
+ pred_x = self.mlp_head_x(x)
+ pred_y = self.mlp_head_y(x)
+
+ return pred_x, pred_y
+
+ def predict(
+ self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ test_cfg: OptConfigType = {},
+ ) -> InstanceList:
+ """Predict results from features.
+
+ Args:
+ feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
+ features (or multiple multi-stage features in TTA)
+ batch_data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+ test_cfg (dict): The runtime config for testing process. Defaults
+ to {}
+
+ Returns:
+ List[InstanceData]: The pose predictions, each contains
+ the following fields:
+
+ - keypoints (np.ndarray): predicted keypoint coordinates in
+ shape (num_instances, K, D) where K is the keypoint number
+ and D is the keypoint dimension
+ - keypoint_scores (np.ndarray): predicted keypoint scores in
+ shape (num_instances, K)
+ - keypoint_x_labels (np.ndarray, optional): The predicted 1-D
+ intensity distribution in the x direction
+ - keypoint_y_labels (np.ndarray, optional): The predicted 1-D
+ intensity distribution in the y direction
+ """
+
+ if test_cfg.get('flip_test', False):
+ # TTA: flip test -> feats = [orig, flipped]
+ assert isinstance(feats, list) and len(feats) == 2
+ flip_indices = batch_data_samples[0].metainfo['flip_indices']
+ _feats, _feats_flip = feats
+
+ _batch_pred_x, _batch_pred_y = self.forward(_feats)
+
+ _batch_pred_x_flip, _batch_pred_y_flip = self.forward(_feats_flip)
+ _batch_pred_x_flip, _batch_pred_y_flip = flip_vectors(
+ _batch_pred_x_flip,
+ _batch_pred_y_flip,
+ flip_indices=flip_indices)
+
+ batch_pred_x = (_batch_pred_x + _batch_pred_x_flip) * 0.5
+ batch_pred_y = (_batch_pred_y + _batch_pred_y_flip) * 0.5
+ else:
+ batch_pred_x, batch_pred_y = self.forward(feats)
+
+ preds = self.decode((batch_pred_x, batch_pred_y))
+
+ if test_cfg.get('output_heatmaps', False):
+ rank, _ = get_dist_info()
+ if rank == 0:
+ warnings.warn('The predicted simcc values are normalized for '
+ 'visualization. This may cause discrepancy '
+ 'between the keypoint scores and the 1D heatmaps'
+ '.')
+
+ # normalize the predicted 1d distribution
+ sigma = self.decoder.sigma
+ batch_pred_x = get_simcc_normalized(batch_pred_x, sigma[0])
+ batch_pred_y = get_simcc_normalized(batch_pred_y, sigma[1])
+
+ B, K, _ = batch_pred_x.shape
+ # B, K, Wx -> B, K, Wx, 1
+ x = batch_pred_x.reshape(B, K, 1, -1)
+ # B, K, Wy -> B, K, 1, Wy
+ y = batch_pred_y.reshape(B, K, -1, 1)
+ # B, K, Wx, Wy
+ batch_heatmaps = torch.matmul(y, x)
+ pred_fields = [
+ PixelData(heatmaps=hm) for hm in batch_heatmaps.detach()
+ ]
+
+ for pred_instances, pred_x, pred_y in zip(preds,
+ to_numpy(batch_pred_x),
+ to_numpy(batch_pred_y)):
+
+ pred_instances.keypoint_x_labels = pred_x[None]
+ pred_instances.keypoint_y_labels = pred_y[None]
+
+ return preds, pred_fields
+ else:
+ return preds
+
+ def loss(
+ self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: OptConfigType = {},
+ ) -> dict:
+ """Calculate losses from a batch of inputs and data samples."""
+
+ pred_x, pred_y = self.forward(feats)
+
+ gt_x = torch.cat([
+ d.gt_instance_labels.keypoint_x_labels for d in batch_data_samples
+ ],
+ dim=0)
+ gt_y = torch.cat([
+ d.gt_instance_labels.keypoint_y_labels for d in batch_data_samples
+ ],
+ dim=0)
+ keypoint_weights = torch.cat(
+ [
+ d.gt_instance_labels.keypoint_weights
+ for d in batch_data_samples
+ ],
+ dim=0,
+ )
+
+ pred_simcc = (pred_x, pred_y)
+ gt_simcc = (gt_x, gt_y)
+
+ # calculate losses
+ losses = dict()
+ loss = self.loss_module(pred_simcc, gt_simcc, keypoint_weights)
+
+ losses.update(loss_kpt=loss)
+
+ # calculate accuracy
+ _, avg_acc, _ = simcc_pck_accuracy(
+ output=to_numpy(pred_simcc),
+ target=to_numpy(gt_simcc),
+ simcc_split_ratio=self.simcc_split_ratio,
+ mask=to_numpy(keypoint_weights) > 0,
+ )
+
+ acc_pose = torch.tensor(avg_acc, device=gt_x.device)
+ losses.update(acc_pose=acc_pose)
+
+ return losses
+
+ @property
+ def default_init_cfg(self):
+ init_cfg = [
+ dict(
+ type='Normal', layer=['Conv2d', 'ConvTranspose2d'], std=0.001),
+ dict(type='Constant', layer='BatchNorm2d', val=1),
+ dict(type='Normal', layer=['Linear'], std=0.01, bias=0),
+ ]
+ return init_cfg
diff --git a/mmpose/models/heads/heatmap_heads/__init__.py b/mmpose/models/heads/heatmap_heads/__init__.py
index b482216b36..3e0945c16e 100644
--- a/mmpose/models/heads/heatmap_heads/__init__.py
+++ b/mmpose/models/heads/heatmap_heads/__init__.py
@@ -1,12 +1,12 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .ae_head import AssociativeEmbeddingHead
-from .cid_head import CIDHead
-from .cpm_head import CPMHead
-from .heatmap_head import HeatmapHead
-from .mspn_head import MSPNHead
-from .vipnas_head import ViPNASHead
-
-__all__ = [
- 'HeatmapHead', 'CPMHead', 'MSPNHead', 'ViPNASHead',
- 'AssociativeEmbeddingHead', 'CIDHead'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .ae_head import AssociativeEmbeddingHead
+from .cid_head import CIDHead
+from .cpm_head import CPMHead
+from .heatmap_head import HeatmapHead
+from .mspn_head import MSPNHead
+from .vipnas_head import ViPNASHead
+
+__all__ = [
+ 'HeatmapHead', 'CPMHead', 'MSPNHead', 'ViPNASHead',
+ 'AssociativeEmbeddingHead', 'CIDHead'
+]
diff --git a/mmpose/models/heads/heatmap_heads/ae_head.py b/mmpose/models/heads/heatmap_heads/ae_head.py
index bd12d57a33..69b29fc7fe 100644
--- a/mmpose/models/heads/heatmap_heads/ae_head.py
+++ b/mmpose/models/heads/heatmap_heads/ae_head.py
@@ -1,291 +1,291 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import List, Optional, Sequence, Tuple, Union
-
-import torch
-from mmengine.structures import PixelData
-from mmengine.utils import is_list_of
-from torch import Tensor
-
-from mmpose.models.utils.tta import aggregate_heatmaps, flip_heatmaps
-from mmpose.registry import MODELS
-from mmpose.utils.typing import (ConfigType, Features, OptConfigType,
- OptSampleList, Predictions)
-from .heatmap_head import HeatmapHead
-
-OptIntSeq = Optional[Sequence[int]]
-
-
-@MODELS.register_module()
-class AssociativeEmbeddingHead(HeatmapHead):
-
- def __init__(self,
- in_channels: Union[int, Sequence[int]],
- num_keypoints: int,
- tag_dim: int = 1,
- tag_per_keypoint: bool = True,
- deconv_out_channels: OptIntSeq = (256, 256, 256),
- deconv_kernel_sizes: OptIntSeq = (4, 4, 4),
- conv_out_channels: OptIntSeq = None,
- conv_kernel_sizes: OptIntSeq = None,
- final_layer: dict = dict(kernel_size=1),
- keypoint_loss: ConfigType = dict(type='KeypointMSELoss'),
- tag_loss: ConfigType = dict(type='AssociativeEmbeddingLoss'),
- decoder: OptConfigType = None,
- init_cfg: OptConfigType = None):
-
- if tag_per_keypoint:
- out_channels = num_keypoints * (1 + tag_dim)
- else:
- out_channels = num_keypoints + tag_dim
-
- loss = dict(
- type='CombinedLoss',
- losses=dict(keypoint_loss=keypoint_loss, tag_loss=tag_loss))
-
- super().__init__(
- in_channels=in_channels,
- out_channels=out_channels,
- deconv_out_channels=deconv_out_channels,
- deconv_kernel_sizes=deconv_kernel_sizes,
- conv_out_channels=conv_out_channels,
- conv_kernel_sizes=conv_kernel_sizes,
- final_layer=final_layer,
- loss=loss,
- decoder=decoder,
- init_cfg=init_cfg)
-
- self.num_keypoints = num_keypoints
- self.tag_dim = tag_dim
- self.tag_per_keypoint = tag_per_keypoint
-
- def predict(self,
- feats: Features,
- batch_data_samples: OptSampleList,
- test_cfg: ConfigType = {}) -> Predictions:
- """Predict results from features.
-
- Args:
- feats (Features): The features which could be in following forms:
-
- - Tuple[Tensor]: multi-stage features from the backbone
- - List[Tuple[Tensor]]: multiple features for TTA where either
- `flip_test` or `multiscale_test` is applied
- - List[List[Tuple[Tensor]]]: multiple features for TTA where
- both `flip_test` and `multiscale_test` are applied
-
- batch_data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples
- test_cfg (dict): The runtime config for testing process. Defaults
- to {}
-
- Returns:
- Union[InstanceList | Tuple[InstanceList | PixelDataList]]: If
- ``test_cfg['output_heatmap']==True``, return both pose and heatmap
- prediction; otherwise only return the pose prediction.
-
- The pose prediction is a list of ``InstanceData``, each contains
- the following fields:
-
- - keypoints (np.ndarray): predicted keypoint coordinates in
- shape (num_instances, K, D) where K is the keypoint number
- and D is the keypoint dimension
- - keypoint_scores (np.ndarray): predicted keypoint scores in
- shape (num_instances, K)
-
- The heatmap prediction is a list of ``PixelData``, each contains
- the following fields:
-
- - heatmaps (Tensor): The predicted heatmaps in shape (K, h, w)
- """
- # test configs
- multiscale_test = test_cfg.get('multiscale_test', False)
- flip_test = test_cfg.get('flip_test', False)
- shift_heatmap = test_cfg.get('shift_heatmap', False)
- align_corners = test_cfg.get('align_corners', False)
- restore_heatmap_size = test_cfg.get('restore_heatmap_size', False)
- output_heatmaps = test_cfg.get('output_heatmaps', False)
-
- # enable multi-scale test
- if multiscale_test:
- # TTA: multi-scale test
- assert is_list_of(feats, list if flip_test else tuple)
- else:
- assert is_list_of(feats, tuple if flip_test else Tensor)
- feats = [feats]
-
- # resize heatmaps to align with with input size
- if restore_heatmap_size:
- img_shape = batch_data_samples[0].metainfo['img_shape']
- assert all(d.metainfo['img_shape'] == img_shape
- for d in batch_data_samples)
- img_h, img_w = img_shape
- heatmap_size = (img_w, img_h)
- else:
- heatmap_size = None
-
- multiscale_heatmaps = []
- multiscale_tags = []
-
- for scale_idx, _feats in enumerate(feats):
- if not flip_test:
- _heatmaps, _tags = self.forward(_feats)
-
- else:
- # TTA: flip test
- assert isinstance(_feats, list) and len(_feats) == 2
- flip_indices = batch_data_samples[0].metainfo['flip_indices']
- # original
- _feats_orig, _feats_flip = _feats
- _heatmaps_orig, _tags_orig = self.forward(_feats_orig)
-
- # flipped
- _heatmaps_flip, _tags_flip = self.forward(_feats_flip)
- _heatmaps_flip = flip_heatmaps(
- _heatmaps_flip,
- flip_mode='heatmap',
- flip_indices=flip_indices,
- shift_heatmap=shift_heatmap)
- _tags_flip = self._flip_tags(
- _tags_flip,
- flip_indices=flip_indices,
- shift_heatmap=shift_heatmap)
-
- # aggregated heatmaps
- _heatmaps = aggregate_heatmaps(
- [_heatmaps_orig, _heatmaps_flip],
- size=heatmap_size,
- align_corners=align_corners,
- mode='average')
-
- # aggregated tags (only at original scale)
- if scale_idx == 0:
- _tags = aggregate_heatmaps([_tags_orig, _tags_flip],
- size=heatmap_size,
- align_corners=align_corners,
- mode='concat')
- else:
- _tags = None
-
- multiscale_heatmaps.append(_heatmaps)
- multiscale_tags.append(_tags)
-
- # aggregate multi-scale heatmaps
- if len(feats) > 1:
- batch_heatmaps = aggregate_heatmaps(
- multiscale_heatmaps,
- align_corners=align_corners,
- mode='average')
- else:
- batch_heatmaps = multiscale_heatmaps[0]
- # only keep tags at original scale
- batch_tags = multiscale_tags[0]
-
- batch_outputs = tuple([batch_heatmaps, batch_tags])
- preds = self.decode(batch_outputs)
-
- if output_heatmaps:
- pred_fields = []
- for _heatmaps, _tags in zip(batch_heatmaps.detach(),
- batch_tags.detach()):
- pred_fields.append(PixelData(heatmaps=_heatmaps, tags=_tags))
-
- return preds, pred_fields
- else:
- return preds
-
- def _flip_tags(self,
- tags: Tensor,
- flip_indices: List[int],
- shift_heatmap: bool = True):
- """Flip the tagging heatmaps horizontally for test-time augmentation.
-
- Args:
- tags (Tensor): batched tagging heatmaps to flip
- flip_indices (List[int]): The indices of each keypoint's symmetric
- keypoint
- shift_heatmap (bool): Shift the flipped heatmaps to align with the
- original heatmaps and improve accuracy. Defaults to ``True``
-
- Returns:
- Tensor: flipped tagging heatmaps
- """
- B, C, H, W = tags.shape
- K = self.num_keypoints
- L = self.tag_dim
-
- tags = tags.flip(-1)
-
- if self.tag_per_keypoint:
- assert C == K * L
- tags = tags.view(B, L, K, H, W)
- tags = tags[:, :, flip_indices]
- tags = tags.view(B, C, H, W)
-
- if shift_heatmap:
- tags[..., 1:] = tags[..., :-1].clone()
-
- return tags
-
- def forward(self, feats: Tuple[Tensor]) -> Tuple[Tensor, Tensor]:
- """Forward the network. The input is multi scale feature maps and the
- output is the heatmaps and tags.
-
- Args:
- feats (Tuple[Tensor]): Multi scale feature maps.
-
- Returns:
- tuple:
- - heatmaps (Tensor): output heatmaps
- - tags (Tensor): output tags
- """
-
- output = super().forward(feats)
- heatmaps = output[:, :self.num_keypoints]
- tags = output[:, self.num_keypoints:]
- return heatmaps, tags
-
- def loss(self,
- feats: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- train_cfg: ConfigType = {}) -> dict:
- """Calculate losses from a batch of inputs and data samples.
-
- Args:
- feats (Tuple[Tensor]): The multi-stage features
- batch_data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples
- train_cfg (dict): The runtime config for training process.
- Defaults to {}
-
- Returns:
- dict: A dictionary of losses.
- """
- pred_heatmaps, pred_tags = self.forward(feats)
-
- if not self.tag_per_keypoint:
- pred_tags = pred_tags.repeat((1, self.num_keypoints, 1, 1))
-
- gt_heatmaps = torch.stack(
- [d.gt_fields.heatmaps for d in batch_data_samples])
- gt_masks = torch.stack(
- [d.gt_fields.heatmap_mask for d in batch_data_samples])
- keypoint_weights = torch.cat([
- d.gt_instance_labels.keypoint_weights for d in batch_data_samples
- ])
- keypoint_indices = [
- d.gt_instance_labels.keypoint_indices for d in batch_data_samples
- ]
-
- loss_kpt = self.loss_module.keypoint_loss(pred_heatmaps, gt_heatmaps,
- keypoint_weights, gt_masks)
-
- loss_pull, loss_push = self.loss_module.tag_loss(
- pred_tags, keypoint_indices)
-
- losses = {
- 'loss_kpt': loss_kpt,
- 'loss_pull': loss_pull,
- 'loss_push': loss_push
- }
-
- return losses
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Sequence, Tuple, Union
+
+import torch
+from mmengine.structures import PixelData
+from mmengine.utils import is_list_of
+from torch import Tensor
+
+from mmpose.models.utils.tta import aggregate_heatmaps, flip_heatmaps
+from mmpose.registry import MODELS
+from mmpose.utils.typing import (ConfigType, Features, OptConfigType,
+ OptSampleList, Predictions)
+from .heatmap_head import HeatmapHead
+
+OptIntSeq = Optional[Sequence[int]]
+
+
+@MODELS.register_module()
+class AssociativeEmbeddingHead(HeatmapHead):
+
+ def __init__(self,
+ in_channels: Union[int, Sequence[int]],
+ num_keypoints: int,
+ tag_dim: int = 1,
+ tag_per_keypoint: bool = True,
+ deconv_out_channels: OptIntSeq = (256, 256, 256),
+ deconv_kernel_sizes: OptIntSeq = (4, 4, 4),
+ conv_out_channels: OptIntSeq = None,
+ conv_kernel_sizes: OptIntSeq = None,
+ final_layer: dict = dict(kernel_size=1),
+ keypoint_loss: ConfigType = dict(type='KeypointMSELoss'),
+ tag_loss: ConfigType = dict(type='AssociativeEmbeddingLoss'),
+ decoder: OptConfigType = None,
+ init_cfg: OptConfigType = None):
+
+ if tag_per_keypoint:
+ out_channels = num_keypoints * (1 + tag_dim)
+ else:
+ out_channels = num_keypoints + tag_dim
+
+ loss = dict(
+ type='CombinedLoss',
+ losses=dict(keypoint_loss=keypoint_loss, tag_loss=tag_loss))
+
+ super().__init__(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ deconv_out_channels=deconv_out_channels,
+ deconv_kernel_sizes=deconv_kernel_sizes,
+ conv_out_channels=conv_out_channels,
+ conv_kernel_sizes=conv_kernel_sizes,
+ final_layer=final_layer,
+ loss=loss,
+ decoder=decoder,
+ init_cfg=init_cfg)
+
+ self.num_keypoints = num_keypoints
+ self.tag_dim = tag_dim
+ self.tag_per_keypoint = tag_per_keypoint
+
+ def predict(self,
+ feats: Features,
+ batch_data_samples: OptSampleList,
+ test_cfg: ConfigType = {}) -> Predictions:
+ """Predict results from features.
+
+ Args:
+ feats (Features): The features which could be in following forms:
+
+ - Tuple[Tensor]: multi-stage features from the backbone
+ - List[Tuple[Tensor]]: multiple features for TTA where either
+ `flip_test` or `multiscale_test` is applied
+ - List[List[Tuple[Tensor]]]: multiple features for TTA where
+ both `flip_test` and `multiscale_test` are applied
+
+ batch_data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+ test_cfg (dict): The runtime config for testing process. Defaults
+ to {}
+
+ Returns:
+ Union[InstanceList | Tuple[InstanceList | PixelDataList]]: If
+ ``test_cfg['output_heatmap']==True``, return both pose and heatmap
+ prediction; otherwise only return the pose prediction.
+
+ The pose prediction is a list of ``InstanceData``, each contains
+ the following fields:
+
+ - keypoints (np.ndarray): predicted keypoint coordinates in
+ shape (num_instances, K, D) where K is the keypoint number
+ and D is the keypoint dimension
+ - keypoint_scores (np.ndarray): predicted keypoint scores in
+ shape (num_instances, K)
+
+ The heatmap prediction is a list of ``PixelData``, each contains
+ the following fields:
+
+ - heatmaps (Tensor): The predicted heatmaps in shape (K, h, w)
+ """
+ # test configs
+ multiscale_test = test_cfg.get('multiscale_test', False)
+ flip_test = test_cfg.get('flip_test', False)
+ shift_heatmap = test_cfg.get('shift_heatmap', False)
+ align_corners = test_cfg.get('align_corners', False)
+ restore_heatmap_size = test_cfg.get('restore_heatmap_size', False)
+ output_heatmaps = test_cfg.get('output_heatmaps', False)
+
+ # enable multi-scale test
+ if multiscale_test:
+ # TTA: multi-scale test
+ assert is_list_of(feats, list if flip_test else tuple)
+ else:
+ assert is_list_of(feats, tuple if flip_test else Tensor)
+ feats = [feats]
+
+ # resize heatmaps to align with with input size
+ if restore_heatmap_size:
+ img_shape = batch_data_samples[0].metainfo['img_shape']
+ assert all(d.metainfo['img_shape'] == img_shape
+ for d in batch_data_samples)
+ img_h, img_w = img_shape
+ heatmap_size = (img_w, img_h)
+ else:
+ heatmap_size = None
+
+ multiscale_heatmaps = []
+ multiscale_tags = []
+
+ for scale_idx, _feats in enumerate(feats):
+ if not flip_test:
+ _heatmaps, _tags = self.forward(_feats)
+
+ else:
+ # TTA: flip test
+ assert isinstance(_feats, list) and len(_feats) == 2
+ flip_indices = batch_data_samples[0].metainfo['flip_indices']
+ # original
+ _feats_orig, _feats_flip = _feats
+ _heatmaps_orig, _tags_orig = self.forward(_feats_orig)
+
+ # flipped
+ _heatmaps_flip, _tags_flip = self.forward(_feats_flip)
+ _heatmaps_flip = flip_heatmaps(
+ _heatmaps_flip,
+ flip_mode='heatmap',
+ flip_indices=flip_indices,
+ shift_heatmap=shift_heatmap)
+ _tags_flip = self._flip_tags(
+ _tags_flip,
+ flip_indices=flip_indices,
+ shift_heatmap=shift_heatmap)
+
+ # aggregated heatmaps
+ _heatmaps = aggregate_heatmaps(
+ [_heatmaps_orig, _heatmaps_flip],
+ size=heatmap_size,
+ align_corners=align_corners,
+ mode='average')
+
+ # aggregated tags (only at original scale)
+ if scale_idx == 0:
+ _tags = aggregate_heatmaps([_tags_orig, _tags_flip],
+ size=heatmap_size,
+ align_corners=align_corners,
+ mode='concat')
+ else:
+ _tags = None
+
+ multiscale_heatmaps.append(_heatmaps)
+ multiscale_tags.append(_tags)
+
+ # aggregate multi-scale heatmaps
+ if len(feats) > 1:
+ batch_heatmaps = aggregate_heatmaps(
+ multiscale_heatmaps,
+ align_corners=align_corners,
+ mode='average')
+ else:
+ batch_heatmaps = multiscale_heatmaps[0]
+ # only keep tags at original scale
+ batch_tags = multiscale_tags[0]
+
+ batch_outputs = tuple([batch_heatmaps, batch_tags])
+ preds = self.decode(batch_outputs)
+
+ if output_heatmaps:
+ pred_fields = []
+ for _heatmaps, _tags in zip(batch_heatmaps.detach(),
+ batch_tags.detach()):
+ pred_fields.append(PixelData(heatmaps=_heatmaps, tags=_tags))
+
+ return preds, pred_fields
+ else:
+ return preds
+
+ def _flip_tags(self,
+ tags: Tensor,
+ flip_indices: List[int],
+ shift_heatmap: bool = True):
+ """Flip the tagging heatmaps horizontally for test-time augmentation.
+
+ Args:
+ tags (Tensor): batched tagging heatmaps to flip
+ flip_indices (List[int]): The indices of each keypoint's symmetric
+ keypoint
+ shift_heatmap (bool): Shift the flipped heatmaps to align with the
+ original heatmaps and improve accuracy. Defaults to ``True``
+
+ Returns:
+ Tensor: flipped tagging heatmaps
+ """
+ B, C, H, W = tags.shape
+ K = self.num_keypoints
+ L = self.tag_dim
+
+ tags = tags.flip(-1)
+
+ if self.tag_per_keypoint:
+ assert C == K * L
+ tags = tags.view(B, L, K, H, W)
+ tags = tags[:, :, flip_indices]
+ tags = tags.view(B, C, H, W)
+
+ if shift_heatmap:
+ tags[..., 1:] = tags[..., :-1].clone()
+
+ return tags
+
+ def forward(self, feats: Tuple[Tensor]) -> Tuple[Tensor, Tensor]:
+ """Forward the network. The input is multi scale feature maps and the
+ output is the heatmaps and tags.
+
+ Args:
+ feats (Tuple[Tensor]): Multi scale feature maps.
+
+ Returns:
+ tuple:
+ - heatmaps (Tensor): output heatmaps
+ - tags (Tensor): output tags
+ """
+
+ output = super().forward(feats)
+ heatmaps = output[:, :self.num_keypoints]
+ tags = output[:, self.num_keypoints:]
+ return heatmaps, tags
+
+ def loss(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: ConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ feats (Tuple[Tensor]): The multi-stage features
+ batch_data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+ train_cfg (dict): The runtime config for training process.
+ Defaults to {}
+
+ Returns:
+ dict: A dictionary of losses.
+ """
+ pred_heatmaps, pred_tags = self.forward(feats)
+
+ if not self.tag_per_keypoint:
+ pred_tags = pred_tags.repeat((1, self.num_keypoints, 1, 1))
+
+ gt_heatmaps = torch.stack(
+ [d.gt_fields.heatmaps for d in batch_data_samples])
+ gt_masks = torch.stack(
+ [d.gt_fields.heatmap_mask for d in batch_data_samples])
+ keypoint_weights = torch.cat([
+ d.gt_instance_labels.keypoint_weights for d in batch_data_samples
+ ])
+ keypoint_indices = [
+ d.gt_instance_labels.keypoint_indices for d in batch_data_samples
+ ]
+
+ loss_kpt = self.loss_module.keypoint_loss(pred_heatmaps, gt_heatmaps,
+ keypoint_weights, gt_masks)
+
+ loss_pull, loss_push = self.loss_module.tag_loss(
+ pred_tags, keypoint_indices)
+
+ losses = {
+ 'loss_kpt': loss_kpt,
+ 'loss_pull': loss_pull,
+ 'loss_push': loss_push
+ }
+
+ return losses
diff --git a/mmpose/models/heads/heatmap_heads/cid_head.py b/mmpose/models/heads/heatmap_heads/cid_head.py
index 39e0211a3e..42f6c50dcc 100644
--- a/mmpose/models/heads/heatmap_heads/cid_head.py
+++ b/mmpose/models/heads/heatmap_heads/cid_head.py
@@ -1,743 +1,743 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import math
-from typing import Dict, Optional, Sequence, Tuple, Union
-
-import numpy as np
-import torch
-import torch.nn as nn
-from mmcv.cnn import build_conv_layer
-from mmengine.model import BaseModule, ModuleDict
-from mmengine.structures import InstanceData, PixelData
-from torch import Tensor
-
-from mmpose.models.utils.tta import flip_heatmaps
-from mmpose.registry import KEYPOINT_CODECS, MODELS
-from mmpose.utils.typing import (ConfigType, Features, OptConfigType,
- OptSampleList, Predictions)
-from ..base_head import BaseHead
-
-
-def smooth_heatmaps(heatmaps: Tensor, blur_kernel_size: int) -> Tensor:
- """Smooth the heatmaps by blurring and averaging.
-
- Args:
- heatmaps (Tensor): The heatmaps to smooth.
- blur_kernel_size (int): The kernel size for blurring the heatmaps.
-
- Returns:
- Tensor: The smoothed heatmaps.
- """
- smoothed_heatmaps = torch.nn.functional.avg_pool2d(
- heatmaps, blur_kernel_size, 1, (blur_kernel_size - 1) // 2)
- smoothed_heatmaps = (heatmaps + smoothed_heatmaps) / 2.0
- return smoothed_heatmaps
-
-
-class TruncSigmoid(nn.Sigmoid):
- """A sigmoid activation function that truncates the output to the given
- range.
-
- Args:
- min (float, optional): The minimum value to clamp the output to.
- Defaults to 0.0
- max (float, optional): The maximum value to clamp the output to.
- Defaults to 1.0
- """
-
- def __init__(self, min: float = 0.0, max: float = 1.0):
- super(TruncSigmoid, self).__init__()
- self.min = min
- self.max = max
-
- def forward(self, input: Tensor) -> Tensor:
- """Computes the truncated sigmoid activation of the input tensor."""
- output = torch.sigmoid(input)
- output = output.clamp(min=self.min, max=self.max)
- return output
-
-
-class IIAModule(BaseModule):
- """Instance Information Abstraction module introduced in `CID`. This module
- extracts the feature representation vectors for each instance.
-
- Args:
- in_channels (int): Number of channels in the input feature tensor
- out_channels (int): Number of channels of the output heatmaps
- clamp_delta (float, optional): A small value that prevents the sigmoid
- activation from becoming saturated. Defaults to 1e-4.
- init_cfg (Config, optional): Config to control the initialization. See
- :attr:`default_init_cfg` for default settings
- """
-
- def __init__(
- self,
- in_channels: int,
- out_channels: int,
- clamp_delta: float = 1e-4,
- init_cfg: OptConfigType = None,
- ):
- super().__init__(init_cfg=init_cfg)
-
- self.keypoint_root_conv = build_conv_layer(
- dict(
- type='Conv2d',
- in_channels=in_channels,
- out_channels=out_channels,
- kernel_size=1))
- self.sigmoid = TruncSigmoid(min=clamp_delta, max=1 - clamp_delta)
-
- def forward(self, feats: Tensor):
- heatmaps = self.keypoint_root_conv(feats)
- heatmaps = self.sigmoid(heatmaps)
- return heatmaps
-
- def _sample_feats(self, feats: Tensor, indices: Tensor) -> Tensor:
- """Extract feature vectors at the specified indices from the input
- feature map.
-
- Args:
- feats (Tensor): Input feature map.
- indices (Tensor): Indices of the feature vectors to extract.
-
- Returns:
- Tensor: Extracted feature vectors.
- """
- assert indices.dtype == torch.long
- if indices.shape[1] == 3:
- b, w, h = [ind.squeeze(-1) for ind in indices.split(1, -1)]
- instance_feats = feats[b, :, h, w]
- elif indices.shape[1] == 2:
- w, h = [ind.squeeze(-1) for ind in indices.split(1, -1)]
- instance_feats = feats[:, :, h, w]
- instance_feats = instance_feats.permute(0, 2, 1)
- instance_feats = instance_feats.reshape(-1,
- instance_feats.shape[-1])
-
- else:
- raise ValueError(f'`indices` should have 2 or 3 channels, '
- f'but got f{indices.shape[1]}')
- return instance_feats
-
- def _hierarchical_pool(self, heatmaps: Tensor) -> Tensor:
- """Conduct max pooling on the input heatmaps with different kernel size
- according to the input size.
-
- Args:
- heatmaps (Tensor): Input heatmaps.
-
- Returns:
- Tensor: Result of hierarchical pooling.
- """
- map_size = (heatmaps.shape[-1] + heatmaps.shape[-2]) / 2.0
- if map_size > 300:
- maxm = torch.nn.functional.max_pool2d(heatmaps, 7, 1, 3)
- elif map_size > 200:
- maxm = torch.nn.functional.max_pool2d(heatmaps, 5, 1, 2)
- else:
- maxm = torch.nn.functional.max_pool2d(heatmaps, 3, 1, 1)
- return maxm
-
- def forward_train(self, feats: Tensor, instance_coords: Tensor,
- instance_imgids: Tensor) -> Tuple[Tensor, Tensor]:
- """Forward pass during training.
-
- Args:
- feats (Tensor): Input feature tensor.
- instance_coords (Tensor): Coordinates of the instance roots.
- instance_imgids (Tensor): Sample indices of each instances
- in the batch.
-
- Returns:
- Tuple[Tensor, Tensor]: Extracted feature vectors and heatmaps
- for the instances.
- """
- heatmaps = self.forward(feats)
- indices = torch.cat((instance_imgids[:, None], instance_coords), dim=1)
- instance_feats = self._sample_feats(feats, indices)
-
- return instance_feats, heatmaps
-
- def forward_test(
- self, feats: Tensor, test_cfg: Dict
- ) -> Tuple[Optional[Tensor], Optional[Tensor], Optional[Tensor]]:
- """Forward pass during testing.
-
- Args:
- feats (Tensor): Input feature tensor.
- test_cfg (Dict): Testing configuration, including:
- - blur_kernel_size (int, optional): Kernel size for blurring
- the heatmaps. Defaults to 3.
- - max_instances (int, optional): Maximum number of instances
- to extract. Defaults to 30.
- - score_threshold (float, optional): Minimum score for
- extracting an instance. Defaults to 0.01.
- - flip_test (bool, optional): Whether to compute the average
- of the heatmaps across the batch dimension.
- Defaults to False.
-
- Returns:
- A tuple of Tensor including extracted feature vectors,
- coordinates, and scores of the instances. Any of these can be
- empty Tensor if no instances are extracted.
- """
- blur_kernel_size = test_cfg.get('blur_kernel_size', 3)
- max_instances = test_cfg.get('max_instances', 30)
- score_threshold = test_cfg.get('score_threshold', 0.01)
- H, W = feats.shape[-2:]
-
- # compute heatmaps
- heatmaps = self.forward(feats).narrow(1, -1, 1)
- if test_cfg.get('flip_test', False):
- heatmaps = heatmaps.mean(dim=0, keepdims=True)
- smoothed_heatmaps = smooth_heatmaps(heatmaps, blur_kernel_size)
-
- # decode heatmaps
- maximums = self._hierarchical_pool(smoothed_heatmaps)
- maximums = torch.eq(maximums, smoothed_heatmaps).float()
- maximums = (smoothed_heatmaps * maximums).reshape(-1)
- scores, pos_ind = maximums.topk(max_instances, dim=0)
- select_ind = (scores > (score_threshold)).nonzero().squeeze(1)
- scores, pos_ind = scores[select_ind], pos_ind[select_ind]
-
- # sample feature vectors from feature map
- instance_coords = torch.stack((pos_ind % W, pos_ind // W), dim=1)
- instance_feats = self._sample_feats(feats, instance_coords)
-
- return instance_feats, instance_coords, scores
-
-
-class ChannelAttention(nn.Module):
- """Channel-wise attention module introduced in `CID`.
-
- Args:
- in_channels (int): The number of channels of the input instance
- vectors.
- out_channels (int): The number of channels of the transformed instance
- vectors.
- """
-
- def __init__(self, in_channels: int, out_channels: int):
- super(ChannelAttention, self).__init__()
- self.atn = nn.Linear(in_channels, out_channels)
-
- def forward(self, global_feats: Tensor, instance_feats: Tensor) -> Tensor:
- """Applies attention to the channel dimension of the input tensor."""
-
- instance_feats = self.atn(instance_feats).unsqueeze(2).unsqueeze(3)
- return global_feats * instance_feats
-
-
-class SpatialAttention(nn.Module):
- """Spatial-wise attention module introduced in `CID`.
-
- Args:
- in_channels (int): The number of channels of the input instance
- vectors.
- out_channels (int): The number of channels of the transformed instance
- vectors.
- """
-
- def __init__(self, in_channels, out_channels):
- super(SpatialAttention, self).__init__()
- self.atn = nn.Linear(in_channels, out_channels)
- self.feat_stride = 4
- self.conv = nn.Conv2d(3, 1, 5, 1, 2)
-
- def _get_pixel_coords(self, heatmap_size: Tuple, device: str = 'cpu'):
- """Get pixel coordinates for each element in the heatmap.
-
- Args:
- heatmap_size (tuple): Size of the heatmap in (W, H) format.
- device (str): Device to put the resulting tensor on.
-
- Returns:
- Tensor of shape (batch_size, num_pixels, 2) containing the pixel
- coordinates for each element in the heatmap.
- """
- w, h = heatmap_size
- y, x = torch.meshgrid(torch.arange(h), torch.arange(w))
- pixel_coords = torch.stack((x, y), dim=-1).reshape(-1, 2)
- pixel_coords = pixel_coords.float().to(device) + 0.5
- return pixel_coords
-
- def forward(self, global_feats: Tensor, instance_feats: Tensor,
- instance_coords: Tensor) -> Tensor:
- """Perform spatial attention.
-
- Args:
- global_feats (Tensor): Tensor containing the global features.
- instance_feats (Tensor): Tensor containing the instance feature
- vectors.
- instance_coords (Tensor): Tensor containing the root coordinates
- of the instances.
-
- Returns:
- Tensor containing the modulated global features.
- """
- B, C, H, W = global_feats.size()
-
- instance_feats = self.atn(instance_feats).reshape(B, C, 1, 1)
- feats = global_feats * instance_feats.expand_as(global_feats)
- fsum = torch.sum(feats, dim=1, keepdim=True)
-
- pixel_coords = self._get_pixel_coords((W, H), feats.device)
- relative_coords = instance_coords.reshape(
- -1, 1, 2) - pixel_coords.reshape(1, -1, 2)
- relative_coords = relative_coords.permute(0, 2, 1) / 32.0
- relative_coords = relative_coords.reshape(B, 2, H, W)
-
- input_feats = torch.cat((fsum, relative_coords), dim=1)
- mask = self.conv(input_feats).sigmoid()
- return global_feats * mask
-
-
-class GFDModule(BaseModule):
- """Global Feature Decoupling module introduced in `CID`. This module
- extracts the decoupled heatmaps for each instance.
-
- Args:
- in_channels (int): Number of channels in the input feature map
- out_channels (int): Number of channels of the output heatmaps
- for each instance
- gfd_channels (int): Number of channels in the transformed feature map
- clamp_delta (float, optional): A small value that prevents the sigmoid
- activation from becoming saturated. Defaults to 1e-4.
- init_cfg (Config, optional): Config to control the initialization. See
- :attr:`default_init_cfg` for default settings
- """
-
- def __init__(
- self,
- in_channels: int,
- out_channels: int,
- gfd_channels: int,
- clamp_delta: float = 1e-4,
- init_cfg: OptConfigType = None,
- ):
- super().__init__(init_cfg=init_cfg)
-
- self.conv_down = build_conv_layer(
- dict(
- type='Conv2d',
- in_channels=in_channels,
- out_channels=gfd_channels,
- kernel_size=1))
-
- self.channel_attention = ChannelAttention(in_channels, gfd_channels)
- self.spatial_attention = SpatialAttention(in_channels, gfd_channels)
- self.fuse_attention = build_conv_layer(
- dict(
- type='Conv2d',
- in_channels=gfd_channels * 2,
- out_channels=gfd_channels,
- kernel_size=1))
- self.heatmap_conv = build_conv_layer(
- dict(
- type='Conv2d',
- in_channels=gfd_channels,
- out_channels=out_channels,
- kernel_size=1))
- self.sigmoid = TruncSigmoid(min=clamp_delta, max=1 - clamp_delta)
-
- def forward(
- self,
- feats: Tensor,
- instance_feats: Tensor,
- instance_coords: Tensor,
- instance_imgids: Tensor,
- ) -> Tensor:
- """Extract decoupled heatmaps for each instance.
-
- Args:
- feats (Tensor): Input feature maps.
- instance_feats (Tensor): Tensor containing the instance feature
- vectors.
- instance_coords (Tensor): Tensor containing the root coordinates
- of the instances.
- instance_imgids (Tensor): Sample indices of each instances
- in the batch.
-
- Returns:
- A tensor containing decoupled heatmaps.
- """
-
- global_feats = self.conv_down(feats)
- global_feats = global_feats[instance_imgids]
- cond_instance_feats = torch.cat(
- (self.channel_attention(global_feats, instance_feats),
- self.spatial_attention(global_feats, instance_feats,
- instance_coords)),
- dim=1)
-
- cond_instance_feats = self.fuse_attention(cond_instance_feats)
- cond_instance_feats = torch.nn.functional.relu(cond_instance_feats)
- cond_instance_feats = self.heatmap_conv(cond_instance_feats)
- heatmaps = self.sigmoid(cond_instance_feats)
-
- return heatmaps
-
-
-@MODELS.register_module()
-class CIDHead(BaseHead):
- """Contextual Instance Decoupling head introduced in `Contextual Instance
- Decoupling for Robust Multi-Person Pose Estimation (CID)`_ by Wang et al
- (2022). The head is composed of an Instance Information Abstraction (IIA)
- module and a Global Feature Decoupling (GFD) module.
-
- Args:
- in_channels (int | Sequence[int]): Number of channels in the input
- feature map
- num_keypoints (int): Number of keypoints
- gfd_channels (int): Number of filters in GFD module
- max_train_instances (int): Maximum number of instances in a batch
- during training. Defaults to 200
- heatmap_loss (Config): Config of the heatmap loss. Defaults to use
- :class:`KeypointMSELoss`
- coupled_heatmap_loss (Config): Config of the loss for coupled heatmaps.
- Defaults to use :class:`SoftWeightSmoothL1Loss`
- decoupled_heatmap_loss (Config): Config of the loss for decoupled
- heatmaps. Defaults to use :class:`SoftWeightSmoothL1Loss`
- contrastive_loss (Config): Config of the contrastive loss for
- representation vectors of instances. Defaults to use
- :class:`InfoNCELoss`
- decoder (Config, optional): The decoder config that controls decoding
- keypoint coordinates from the network output. Defaults to ``None``
- init_cfg (Config, optional): Config to control the initialization. See
- :attr:`default_init_cfg` for default settings
-
- .. _`CID`: https://openaccess.thecvf.com/content/CVPR2022/html/Wang_
- Contextual_Instance_Decoupling_for_Robust_Multi-Person_Pose_Estimation_
- CVPR_2022_paper.html
- """
- _version = 2
-
- def __init__(self,
- in_channels: Union[int, Sequence[int]],
- gfd_channels: int,
- num_keypoints: int,
- prior_prob: float = 0.01,
- coupled_heatmap_loss: OptConfigType = dict(
- type='FocalHeatmapLoss'),
- decoupled_heatmap_loss: OptConfigType = dict(
- type='FocalHeatmapLoss'),
- contrastive_loss: OptConfigType = dict(type='InfoNCELoss'),
- decoder: OptConfigType = None,
- init_cfg: OptConfigType = None):
-
- if init_cfg is None:
- init_cfg = self.default_init_cfg
-
- super().__init__(init_cfg)
-
- self.in_channels = in_channels
- self.num_keypoints = num_keypoints
- if decoder is not None:
- self.decoder = KEYPOINT_CODECS.build(decoder)
- else:
- self.decoder = None
-
- # build sub-modules
- bias_value = -math.log((1 - prior_prob) / prior_prob)
- self.iia_module = IIAModule(
- in_channels,
- num_keypoints + 1,
- init_cfg=init_cfg + [
- dict(
- type='Normal',
- layer=['Conv2d', 'Linear'],
- std=0.001,
- override=dict(
- name='keypoint_root_conv',
- type='Normal',
- std=0.001,
- bias=bias_value))
- ])
- self.gfd_module = GFDModule(
- in_channels,
- num_keypoints,
- gfd_channels,
- init_cfg=init_cfg + [
- dict(
- type='Normal',
- layer=['Conv2d', 'Linear'],
- std=0.001,
- override=dict(
- name='heatmap_conv',
- type='Normal',
- std=0.001,
- bias=bias_value))
- ])
-
- # build losses
- self.loss_module = ModuleDict(
- dict(
- heatmap_coupled=MODELS.build(coupled_heatmap_loss),
- heatmap_decoupled=MODELS.build(decoupled_heatmap_loss),
- contrastive=MODELS.build(contrastive_loss),
- ))
-
- # Register the hook to automatically convert old version state dicts
- self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
-
- @property
- def default_init_cfg(self):
- init_cfg = [
- dict(type='Normal', layer=['Conv2d', 'Linear'], std=0.001),
- dict(type='Constant', layer='BatchNorm2d', val=1)
- ]
- return init_cfg
-
- def forward(self, feats: Tuple[Tensor]) -> Tensor:
- """Forward the network. The input is multi scale feature maps and the
- output is the heatmap.
-
- Args:
- feats (Tuple[Tensor]): Multi scale feature maps.
-
- Returns:
- Tensor: output heatmap.
- """
- feats = feats[-1]
- instance_info = self.iia_module.forward_test(feats, {})
- instance_feats, instance_coords, instance_scores = instance_info
- instance_imgids = torch.zeros(
- instance_coords.size(0), dtype=torch.long, device=feats.device)
- instance_heatmaps = self.gfd_module(feats, instance_feats,
- instance_coords, instance_imgids)
-
- return instance_heatmaps
-
- def predict(self,
- feats: Features,
- batch_data_samples: OptSampleList,
- test_cfg: ConfigType = {}) -> Predictions:
- """Predict results from features.
-
- Args:
- feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
- features (or multiple multi-stage features in TTA)
- batch_data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples
- test_cfg (dict): The runtime config for testing process. Defaults
- to {}
-
- Returns:
- Union[InstanceList | Tuple[InstanceList | PixelDataList]]: If
- ``test_cfg['output_heatmap']==True``, return both pose and heatmap
- prediction; otherwise only return the pose prediction.
-
- The pose prediction is a list of ``InstanceData``, each contains
- the following fields:
-
- - keypoints (np.ndarray): predicted keypoint coordinates in
- shape (num_instances, K, D) where K is the keypoint number
- and D is the keypoint dimension
- - keypoint_scores (np.ndarray): predicted keypoint scores in
- shape (num_instances, K)
-
- The heatmap prediction is a list of ``PixelData``, each contains
- the following fields:
-
- - heatmaps (Tensor): The predicted heatmaps in shape (K, h, w)
- """
- metainfo = batch_data_samples[0].metainfo
-
- if test_cfg.get('flip_test', False):
- assert isinstance(feats, list) and len(feats) == 2
-
- feats_flipped = flip_heatmaps(feats[1][-1], shift_heatmap=False)
- feats = torch.cat((feats[0][-1], feats_flipped))
- else:
- feats = feats[-1]
-
- instance_info = self.iia_module.forward_test(feats, test_cfg)
- instance_feats, instance_coords, instance_scores = instance_info
- if len(instance_coords) > 0:
- instance_imgids = torch.zeros(
- instance_coords.size(0), dtype=torch.long, device=feats.device)
- if test_cfg.get('flip_test', False):
- instance_coords = torch.cat((instance_coords, instance_coords))
- instance_imgids = torch.cat(
- (instance_imgids, instance_imgids + 1))
- instance_heatmaps = self.gfd_module(feats, instance_feats,
- instance_coords,
- instance_imgids)
- if test_cfg.get('flip_test', False):
- flip_indices = batch_data_samples[0].metainfo['flip_indices']
- instance_heatmaps, instance_heatmaps_flip = torch.chunk(
- instance_heatmaps, 2, dim=0)
- instance_heatmaps_flip = \
- instance_heatmaps_flip[:, flip_indices, :, :]
- instance_heatmaps = (instance_heatmaps +
- instance_heatmaps_flip) / 2.0
- instance_heatmaps = smooth_heatmaps(
- instance_heatmaps, test_cfg.get('blur_kernel_size', 3))
-
- preds = self.decode((instance_heatmaps, instance_scores[:, None]))
- preds = InstanceData.cat(preds)
- preds.keypoints[..., 0] += metainfo['input_size'][
- 0] / instance_heatmaps.shape[-1] / 2.0
- preds.keypoints[..., 1] += metainfo['input_size'][
- 1] / instance_heatmaps.shape[-2] / 2.0
- preds = [preds]
-
- else:
- preds = [
- InstanceData(
- keypoints=np.empty((0, self.num_keypoints, 2)),
- keypoint_scores=np.empty((0, self.num_keypoints)))
- ]
- instance_heatmaps = torch.empty(0, self.num_keypoints,
- *feats.shape[-2:])
-
- if test_cfg.get('output_heatmaps', False):
- pred_fields = [
- PixelData(
- heatmaps=instance_heatmaps.reshape(
- -1, *instance_heatmaps.shape[-2:]))
- ]
- return preds, pred_fields
- else:
- return preds
-
- def loss(self,
- feats: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- train_cfg: ConfigType = {}) -> dict:
- """Calculate losses from a batch of inputs and data samples.
-
- Args:
- feats (Tuple[Tensor]): The multi-stage features
- batch_data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples
- train_cfg (dict): The runtime config for training process.
- Defaults to {}
-
- Returns:
- dict: A dictionary of losses.
- """
-
- # load targets
- gt_heatmaps, gt_instance_coords, keypoint_weights = [], [], []
- heatmap_mask = []
- instance_imgids, gt_instance_heatmaps = [], []
- for i, d in enumerate(batch_data_samples):
- gt_heatmaps.append(d.gt_fields.heatmaps)
- gt_instance_coords.append(d.gt_instance_labels.instance_coords)
- keypoint_weights.append(d.gt_instance_labels.keypoint_weights)
- instance_imgids.append(
- torch.ones(
- len(d.gt_instance_labels.instance_coords),
- dtype=torch.long) * i)
-
- instance_heatmaps = d.gt_fields.instance_heatmaps.reshape(
- -1, self.num_keypoints,
- *d.gt_fields.instance_heatmaps.shape[1:])
- gt_instance_heatmaps.append(instance_heatmaps)
-
- if 'heatmap_mask' in d.gt_fields:
- heatmap_mask.append(d.gt_fields.heatmap_mask)
-
- gt_heatmaps = torch.stack(gt_heatmaps)
- heatmap_mask = torch.stack(heatmap_mask) if heatmap_mask else None
-
- gt_instance_coords = torch.cat(gt_instance_coords, dim=0)
- gt_instance_heatmaps = torch.cat(gt_instance_heatmaps, dim=0)
- keypoint_weights = torch.cat(keypoint_weights, dim=0)
- instance_imgids = torch.cat(instance_imgids).to(gt_heatmaps.device)
-
- # feed-forward
- feats = feats[-1]
- pred_instance_feats, pred_heatmaps = self.iia_module.forward_train(
- feats, gt_instance_coords, instance_imgids)
-
- # conpute contrastive loss
- contrastive_loss = 0
- for i in range(len(batch_data_samples)):
- pred_instance_feat = pred_instance_feats[instance_imgids == i]
- contrastive_loss += self.loss_module['contrastive'](
- pred_instance_feat)
- contrastive_loss = contrastive_loss / max(1, len(instance_imgids))
-
- # limit the number of instances
- max_train_instances = train_cfg.get('max_train_instances', -1)
- if (max_train_instances > 0
- and len(instance_imgids) > max_train_instances):
- selected_indices = torch.randperm(
- len(instance_imgids),
- device=gt_heatmaps.device,
- dtype=torch.long)[:max_train_instances]
- gt_instance_coords = gt_instance_coords[selected_indices]
- keypoint_weights = keypoint_weights[selected_indices]
- gt_instance_heatmaps = gt_instance_heatmaps[selected_indices]
- instance_imgids = instance_imgids[selected_indices]
- pred_instance_feats = pred_instance_feats[selected_indices]
-
- # calculate the decoupled heatmaps for each instance
- pred_instance_heatmaps = self.gfd_module(feats, pred_instance_feats,
- gt_instance_coords,
- instance_imgids)
-
- # calculate losses
- losses = {
- 'loss/heatmap_coupled':
- self.loss_module['heatmap_coupled'](pred_heatmaps, gt_heatmaps,
- None, heatmap_mask)
- }
- if len(instance_imgids) > 0:
- losses.update({
- 'loss/heatmap_decoupled':
- self.loss_module['heatmap_decoupled'](pred_instance_heatmaps,
- gt_instance_heatmaps,
- keypoint_weights),
- 'loss/contrastive':
- contrastive_loss
- })
-
- return losses
-
- def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
- **kwargs):
- """A hook function to convert old-version state dict of
- :class:`CIDHead` (before MMPose v1.0.0) to a compatible format
- of :class:`CIDHead`.
-
- The hook will be automatically registered during initialization.
- """
- version = local_meta.get('version', None)
- if version and version >= self._version:
- return
-
- # convert old-version state dict
- keys = list(state_dict.keys())
- for k in keys:
- if 'keypoint_center_conv' in k:
- v = state_dict.pop(k)
- k = k.replace('keypoint_center_conv',
- 'iia_module.keypoint_root_conv')
- state_dict[k] = v
-
- if 'conv_down' in k:
- v = state_dict.pop(k)
- k = k.replace('conv_down', 'gfd_module.conv_down')
- state_dict[k] = v
-
- if 'c_attn' in k:
- v = state_dict.pop(k)
- k = k.replace('c_attn', 'gfd_module.channel_attention')
- state_dict[k] = v
-
- if 's_attn' in k:
- v = state_dict.pop(k)
- k = k.replace('s_attn', 'gfd_module.spatial_attention')
- state_dict[k] = v
-
- if 'fuse_attn' in k:
- v = state_dict.pop(k)
- k = k.replace('fuse_attn', 'gfd_module.fuse_attention')
- state_dict[k] = v
-
- if 'heatmap_conv' in k:
- v = state_dict.pop(k)
- k = k.replace('heatmap_conv', 'gfd_module.heatmap_conv')
- state_dict[k] = v
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Dict, Optional, Sequence, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn as nn
+from mmcv.cnn import build_conv_layer
+from mmengine.model import BaseModule, ModuleDict
+from mmengine.structures import InstanceData, PixelData
+from torch import Tensor
+
+from mmpose.models.utils.tta import flip_heatmaps
+from mmpose.registry import KEYPOINT_CODECS, MODELS
+from mmpose.utils.typing import (ConfigType, Features, OptConfigType,
+ OptSampleList, Predictions)
+from ..base_head import BaseHead
+
+
+def smooth_heatmaps(heatmaps: Tensor, blur_kernel_size: int) -> Tensor:
+ """Smooth the heatmaps by blurring and averaging.
+
+ Args:
+ heatmaps (Tensor): The heatmaps to smooth.
+ blur_kernel_size (int): The kernel size for blurring the heatmaps.
+
+ Returns:
+ Tensor: The smoothed heatmaps.
+ """
+ smoothed_heatmaps = torch.nn.functional.avg_pool2d(
+ heatmaps, blur_kernel_size, 1, (blur_kernel_size - 1) // 2)
+ smoothed_heatmaps = (heatmaps + smoothed_heatmaps) / 2.0
+ return smoothed_heatmaps
+
+
+class TruncSigmoid(nn.Sigmoid):
+ """A sigmoid activation function that truncates the output to the given
+ range.
+
+ Args:
+ min (float, optional): The minimum value to clamp the output to.
+ Defaults to 0.0
+ max (float, optional): The maximum value to clamp the output to.
+ Defaults to 1.0
+ """
+
+ def __init__(self, min: float = 0.0, max: float = 1.0):
+ super(TruncSigmoid, self).__init__()
+ self.min = min
+ self.max = max
+
+ def forward(self, input: Tensor) -> Tensor:
+ """Computes the truncated sigmoid activation of the input tensor."""
+ output = torch.sigmoid(input)
+ output = output.clamp(min=self.min, max=self.max)
+ return output
+
+
+class IIAModule(BaseModule):
+ """Instance Information Abstraction module introduced in `CID`. This module
+ extracts the feature representation vectors for each instance.
+
+ Args:
+ in_channels (int): Number of channels in the input feature tensor
+ out_channels (int): Number of channels of the output heatmaps
+ clamp_delta (float, optional): A small value that prevents the sigmoid
+ activation from becoming saturated. Defaults to 1e-4.
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+ """
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ clamp_delta: float = 1e-4,
+ init_cfg: OptConfigType = None,
+ ):
+ super().__init__(init_cfg=init_cfg)
+
+ self.keypoint_root_conv = build_conv_layer(
+ dict(
+ type='Conv2d',
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1))
+ self.sigmoid = TruncSigmoid(min=clamp_delta, max=1 - clamp_delta)
+
+ def forward(self, feats: Tensor):
+ heatmaps = self.keypoint_root_conv(feats)
+ heatmaps = self.sigmoid(heatmaps)
+ return heatmaps
+
+ def _sample_feats(self, feats: Tensor, indices: Tensor) -> Tensor:
+ """Extract feature vectors at the specified indices from the input
+ feature map.
+
+ Args:
+ feats (Tensor): Input feature map.
+ indices (Tensor): Indices of the feature vectors to extract.
+
+ Returns:
+ Tensor: Extracted feature vectors.
+ """
+ assert indices.dtype == torch.long
+ if indices.shape[1] == 3:
+ b, w, h = [ind.squeeze(-1) for ind in indices.split(1, -1)]
+ instance_feats = feats[b, :, h, w]
+ elif indices.shape[1] == 2:
+ w, h = [ind.squeeze(-1) for ind in indices.split(1, -1)]
+ instance_feats = feats[:, :, h, w]
+ instance_feats = instance_feats.permute(0, 2, 1)
+ instance_feats = instance_feats.reshape(-1,
+ instance_feats.shape[-1])
+
+ else:
+ raise ValueError(f'`indices` should have 2 or 3 channels, '
+ f'but got f{indices.shape[1]}')
+ return instance_feats
+
+ def _hierarchical_pool(self, heatmaps: Tensor) -> Tensor:
+ """Conduct max pooling on the input heatmaps with different kernel size
+ according to the input size.
+
+ Args:
+ heatmaps (Tensor): Input heatmaps.
+
+ Returns:
+ Tensor: Result of hierarchical pooling.
+ """
+ map_size = (heatmaps.shape[-1] + heatmaps.shape[-2]) / 2.0
+ if map_size > 300:
+ maxm = torch.nn.functional.max_pool2d(heatmaps, 7, 1, 3)
+ elif map_size > 200:
+ maxm = torch.nn.functional.max_pool2d(heatmaps, 5, 1, 2)
+ else:
+ maxm = torch.nn.functional.max_pool2d(heatmaps, 3, 1, 1)
+ return maxm
+
+ def forward_train(self, feats: Tensor, instance_coords: Tensor,
+ instance_imgids: Tensor) -> Tuple[Tensor, Tensor]:
+ """Forward pass during training.
+
+ Args:
+ feats (Tensor): Input feature tensor.
+ instance_coords (Tensor): Coordinates of the instance roots.
+ instance_imgids (Tensor): Sample indices of each instances
+ in the batch.
+
+ Returns:
+ Tuple[Tensor, Tensor]: Extracted feature vectors and heatmaps
+ for the instances.
+ """
+ heatmaps = self.forward(feats)
+ indices = torch.cat((instance_imgids[:, None], instance_coords), dim=1)
+ instance_feats = self._sample_feats(feats, indices)
+
+ return instance_feats, heatmaps
+
+ def forward_test(
+ self, feats: Tensor, test_cfg: Dict
+ ) -> Tuple[Optional[Tensor], Optional[Tensor], Optional[Tensor]]:
+ """Forward pass during testing.
+
+ Args:
+ feats (Tensor): Input feature tensor.
+ test_cfg (Dict): Testing configuration, including:
+ - blur_kernel_size (int, optional): Kernel size for blurring
+ the heatmaps. Defaults to 3.
+ - max_instances (int, optional): Maximum number of instances
+ to extract. Defaults to 30.
+ - score_threshold (float, optional): Minimum score for
+ extracting an instance. Defaults to 0.01.
+ - flip_test (bool, optional): Whether to compute the average
+ of the heatmaps across the batch dimension.
+ Defaults to False.
+
+ Returns:
+ A tuple of Tensor including extracted feature vectors,
+ coordinates, and scores of the instances. Any of these can be
+ empty Tensor if no instances are extracted.
+ """
+ blur_kernel_size = test_cfg.get('blur_kernel_size', 3)
+ max_instances = test_cfg.get('max_instances', 30)
+ score_threshold = test_cfg.get('score_threshold', 0.01)
+ H, W = feats.shape[-2:]
+
+ # compute heatmaps
+ heatmaps = self.forward(feats).narrow(1, -1, 1)
+ if test_cfg.get('flip_test', False):
+ heatmaps = heatmaps.mean(dim=0, keepdims=True)
+ smoothed_heatmaps = smooth_heatmaps(heatmaps, blur_kernel_size)
+
+ # decode heatmaps
+ maximums = self._hierarchical_pool(smoothed_heatmaps)
+ maximums = torch.eq(maximums, smoothed_heatmaps).float()
+ maximums = (smoothed_heatmaps * maximums).reshape(-1)
+ scores, pos_ind = maximums.topk(max_instances, dim=0)
+ select_ind = (scores > (score_threshold)).nonzero().squeeze(1)
+ scores, pos_ind = scores[select_ind], pos_ind[select_ind]
+
+ # sample feature vectors from feature map
+ instance_coords = torch.stack((pos_ind % W, pos_ind // W), dim=1)
+ instance_feats = self._sample_feats(feats, instance_coords)
+
+ return instance_feats, instance_coords, scores
+
+
+class ChannelAttention(nn.Module):
+ """Channel-wise attention module introduced in `CID`.
+
+ Args:
+ in_channels (int): The number of channels of the input instance
+ vectors.
+ out_channels (int): The number of channels of the transformed instance
+ vectors.
+ """
+
+ def __init__(self, in_channels: int, out_channels: int):
+ super(ChannelAttention, self).__init__()
+ self.atn = nn.Linear(in_channels, out_channels)
+
+ def forward(self, global_feats: Tensor, instance_feats: Tensor) -> Tensor:
+ """Applies attention to the channel dimension of the input tensor."""
+
+ instance_feats = self.atn(instance_feats).unsqueeze(2).unsqueeze(3)
+ return global_feats * instance_feats
+
+
+class SpatialAttention(nn.Module):
+ """Spatial-wise attention module introduced in `CID`.
+
+ Args:
+ in_channels (int): The number of channels of the input instance
+ vectors.
+ out_channels (int): The number of channels of the transformed instance
+ vectors.
+ """
+
+ def __init__(self, in_channels, out_channels):
+ super(SpatialAttention, self).__init__()
+ self.atn = nn.Linear(in_channels, out_channels)
+ self.feat_stride = 4
+ self.conv = nn.Conv2d(3, 1, 5, 1, 2)
+
+ def _get_pixel_coords(self, heatmap_size: Tuple, device: str = 'cpu'):
+ """Get pixel coordinates for each element in the heatmap.
+
+ Args:
+ heatmap_size (tuple): Size of the heatmap in (W, H) format.
+ device (str): Device to put the resulting tensor on.
+
+ Returns:
+ Tensor of shape (batch_size, num_pixels, 2) containing the pixel
+ coordinates for each element in the heatmap.
+ """
+ w, h = heatmap_size
+ y, x = torch.meshgrid(torch.arange(h), torch.arange(w))
+ pixel_coords = torch.stack((x, y), dim=-1).reshape(-1, 2)
+ pixel_coords = pixel_coords.float().to(device) + 0.5
+ return pixel_coords
+
+ def forward(self, global_feats: Tensor, instance_feats: Tensor,
+ instance_coords: Tensor) -> Tensor:
+ """Perform spatial attention.
+
+ Args:
+ global_feats (Tensor): Tensor containing the global features.
+ instance_feats (Tensor): Tensor containing the instance feature
+ vectors.
+ instance_coords (Tensor): Tensor containing the root coordinates
+ of the instances.
+
+ Returns:
+ Tensor containing the modulated global features.
+ """
+ B, C, H, W = global_feats.size()
+
+ instance_feats = self.atn(instance_feats).reshape(B, C, 1, 1)
+ feats = global_feats * instance_feats.expand_as(global_feats)
+ fsum = torch.sum(feats, dim=1, keepdim=True)
+
+ pixel_coords = self._get_pixel_coords((W, H), feats.device)
+ relative_coords = instance_coords.reshape(
+ -1, 1, 2) - pixel_coords.reshape(1, -1, 2)
+ relative_coords = relative_coords.permute(0, 2, 1) / 32.0
+ relative_coords = relative_coords.reshape(B, 2, H, W)
+
+ input_feats = torch.cat((fsum, relative_coords), dim=1)
+ mask = self.conv(input_feats).sigmoid()
+ return global_feats * mask
+
+
+class GFDModule(BaseModule):
+ """Global Feature Decoupling module introduced in `CID`. This module
+ extracts the decoupled heatmaps for each instance.
+
+ Args:
+ in_channels (int): Number of channels in the input feature map
+ out_channels (int): Number of channels of the output heatmaps
+ for each instance
+ gfd_channels (int): Number of channels in the transformed feature map
+ clamp_delta (float, optional): A small value that prevents the sigmoid
+ activation from becoming saturated. Defaults to 1e-4.
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+ """
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ gfd_channels: int,
+ clamp_delta: float = 1e-4,
+ init_cfg: OptConfigType = None,
+ ):
+ super().__init__(init_cfg=init_cfg)
+
+ self.conv_down = build_conv_layer(
+ dict(
+ type='Conv2d',
+ in_channels=in_channels,
+ out_channels=gfd_channels,
+ kernel_size=1))
+
+ self.channel_attention = ChannelAttention(in_channels, gfd_channels)
+ self.spatial_attention = SpatialAttention(in_channels, gfd_channels)
+ self.fuse_attention = build_conv_layer(
+ dict(
+ type='Conv2d',
+ in_channels=gfd_channels * 2,
+ out_channels=gfd_channels,
+ kernel_size=1))
+ self.heatmap_conv = build_conv_layer(
+ dict(
+ type='Conv2d',
+ in_channels=gfd_channels,
+ out_channels=out_channels,
+ kernel_size=1))
+ self.sigmoid = TruncSigmoid(min=clamp_delta, max=1 - clamp_delta)
+
+ def forward(
+ self,
+ feats: Tensor,
+ instance_feats: Tensor,
+ instance_coords: Tensor,
+ instance_imgids: Tensor,
+ ) -> Tensor:
+ """Extract decoupled heatmaps for each instance.
+
+ Args:
+ feats (Tensor): Input feature maps.
+ instance_feats (Tensor): Tensor containing the instance feature
+ vectors.
+ instance_coords (Tensor): Tensor containing the root coordinates
+ of the instances.
+ instance_imgids (Tensor): Sample indices of each instances
+ in the batch.
+
+ Returns:
+ A tensor containing decoupled heatmaps.
+ """
+
+ global_feats = self.conv_down(feats)
+ global_feats = global_feats[instance_imgids]
+ cond_instance_feats = torch.cat(
+ (self.channel_attention(global_feats, instance_feats),
+ self.spatial_attention(global_feats, instance_feats,
+ instance_coords)),
+ dim=1)
+
+ cond_instance_feats = self.fuse_attention(cond_instance_feats)
+ cond_instance_feats = torch.nn.functional.relu(cond_instance_feats)
+ cond_instance_feats = self.heatmap_conv(cond_instance_feats)
+ heatmaps = self.sigmoid(cond_instance_feats)
+
+ return heatmaps
+
+
+@MODELS.register_module()
+class CIDHead(BaseHead):
+ """Contextual Instance Decoupling head introduced in `Contextual Instance
+ Decoupling for Robust Multi-Person Pose Estimation (CID)`_ by Wang et al
+ (2022). The head is composed of an Instance Information Abstraction (IIA)
+ module and a Global Feature Decoupling (GFD) module.
+
+ Args:
+ in_channels (int | Sequence[int]): Number of channels in the input
+ feature map
+ num_keypoints (int): Number of keypoints
+ gfd_channels (int): Number of filters in GFD module
+ max_train_instances (int): Maximum number of instances in a batch
+ during training. Defaults to 200
+ heatmap_loss (Config): Config of the heatmap loss. Defaults to use
+ :class:`KeypointMSELoss`
+ coupled_heatmap_loss (Config): Config of the loss for coupled heatmaps.
+ Defaults to use :class:`SoftWeightSmoothL1Loss`
+ decoupled_heatmap_loss (Config): Config of the loss for decoupled
+ heatmaps. Defaults to use :class:`SoftWeightSmoothL1Loss`
+ contrastive_loss (Config): Config of the contrastive loss for
+ representation vectors of instances. Defaults to use
+ :class:`InfoNCELoss`
+ decoder (Config, optional): The decoder config that controls decoding
+ keypoint coordinates from the network output. Defaults to ``None``
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+
+ .. _`CID`: https://openaccess.thecvf.com/content/CVPR2022/html/Wang_
+ Contextual_Instance_Decoupling_for_Robust_Multi-Person_Pose_Estimation_
+ CVPR_2022_paper.html
+ """
+ _version = 2
+
+ def __init__(self,
+ in_channels: Union[int, Sequence[int]],
+ gfd_channels: int,
+ num_keypoints: int,
+ prior_prob: float = 0.01,
+ coupled_heatmap_loss: OptConfigType = dict(
+ type='FocalHeatmapLoss'),
+ decoupled_heatmap_loss: OptConfigType = dict(
+ type='FocalHeatmapLoss'),
+ contrastive_loss: OptConfigType = dict(type='InfoNCELoss'),
+ decoder: OptConfigType = None,
+ init_cfg: OptConfigType = None):
+
+ if init_cfg is None:
+ init_cfg = self.default_init_cfg
+
+ super().__init__(init_cfg)
+
+ self.in_channels = in_channels
+ self.num_keypoints = num_keypoints
+ if decoder is not None:
+ self.decoder = KEYPOINT_CODECS.build(decoder)
+ else:
+ self.decoder = None
+
+ # build sub-modules
+ bias_value = -math.log((1 - prior_prob) / prior_prob)
+ self.iia_module = IIAModule(
+ in_channels,
+ num_keypoints + 1,
+ init_cfg=init_cfg + [
+ dict(
+ type='Normal',
+ layer=['Conv2d', 'Linear'],
+ std=0.001,
+ override=dict(
+ name='keypoint_root_conv',
+ type='Normal',
+ std=0.001,
+ bias=bias_value))
+ ])
+ self.gfd_module = GFDModule(
+ in_channels,
+ num_keypoints,
+ gfd_channels,
+ init_cfg=init_cfg + [
+ dict(
+ type='Normal',
+ layer=['Conv2d', 'Linear'],
+ std=0.001,
+ override=dict(
+ name='heatmap_conv',
+ type='Normal',
+ std=0.001,
+ bias=bias_value))
+ ])
+
+ # build losses
+ self.loss_module = ModuleDict(
+ dict(
+ heatmap_coupled=MODELS.build(coupled_heatmap_loss),
+ heatmap_decoupled=MODELS.build(decoupled_heatmap_loss),
+ contrastive=MODELS.build(contrastive_loss),
+ ))
+
+ # Register the hook to automatically convert old version state dicts
+ self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
+
+ @property
+ def default_init_cfg(self):
+ init_cfg = [
+ dict(type='Normal', layer=['Conv2d', 'Linear'], std=0.001),
+ dict(type='Constant', layer='BatchNorm2d', val=1)
+ ]
+ return init_cfg
+
+ def forward(self, feats: Tuple[Tensor]) -> Tensor:
+ """Forward the network. The input is multi scale feature maps and the
+ output is the heatmap.
+
+ Args:
+ feats (Tuple[Tensor]): Multi scale feature maps.
+
+ Returns:
+ Tensor: output heatmap.
+ """
+ feats = feats[-1]
+ instance_info = self.iia_module.forward_test(feats, {})
+ instance_feats, instance_coords, instance_scores = instance_info
+ instance_imgids = torch.zeros(
+ instance_coords.size(0), dtype=torch.long, device=feats.device)
+ instance_heatmaps = self.gfd_module(feats, instance_feats,
+ instance_coords, instance_imgids)
+
+ return instance_heatmaps
+
+ def predict(self,
+ feats: Features,
+ batch_data_samples: OptSampleList,
+ test_cfg: ConfigType = {}) -> Predictions:
+ """Predict results from features.
+
+ Args:
+ feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
+ features (or multiple multi-stage features in TTA)
+ batch_data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+ test_cfg (dict): The runtime config for testing process. Defaults
+ to {}
+
+ Returns:
+ Union[InstanceList | Tuple[InstanceList | PixelDataList]]: If
+ ``test_cfg['output_heatmap']==True``, return both pose and heatmap
+ prediction; otherwise only return the pose prediction.
+
+ The pose prediction is a list of ``InstanceData``, each contains
+ the following fields:
+
+ - keypoints (np.ndarray): predicted keypoint coordinates in
+ shape (num_instances, K, D) where K is the keypoint number
+ and D is the keypoint dimension
+ - keypoint_scores (np.ndarray): predicted keypoint scores in
+ shape (num_instances, K)
+
+ The heatmap prediction is a list of ``PixelData``, each contains
+ the following fields:
+
+ - heatmaps (Tensor): The predicted heatmaps in shape (K, h, w)
+ """
+ metainfo = batch_data_samples[0].metainfo
+
+ if test_cfg.get('flip_test', False):
+ assert isinstance(feats, list) and len(feats) == 2
+
+ feats_flipped = flip_heatmaps(feats[1][-1], shift_heatmap=False)
+ feats = torch.cat((feats[0][-1], feats_flipped))
+ else:
+ feats = feats[-1]
+
+ instance_info = self.iia_module.forward_test(feats, test_cfg)
+ instance_feats, instance_coords, instance_scores = instance_info
+ if len(instance_coords) > 0:
+ instance_imgids = torch.zeros(
+ instance_coords.size(0), dtype=torch.long, device=feats.device)
+ if test_cfg.get('flip_test', False):
+ instance_coords = torch.cat((instance_coords, instance_coords))
+ instance_imgids = torch.cat(
+ (instance_imgids, instance_imgids + 1))
+ instance_heatmaps = self.gfd_module(feats, instance_feats,
+ instance_coords,
+ instance_imgids)
+ if test_cfg.get('flip_test', False):
+ flip_indices = batch_data_samples[0].metainfo['flip_indices']
+ instance_heatmaps, instance_heatmaps_flip = torch.chunk(
+ instance_heatmaps, 2, dim=0)
+ instance_heatmaps_flip = \
+ instance_heatmaps_flip[:, flip_indices, :, :]
+ instance_heatmaps = (instance_heatmaps +
+ instance_heatmaps_flip) / 2.0
+ instance_heatmaps = smooth_heatmaps(
+ instance_heatmaps, test_cfg.get('blur_kernel_size', 3))
+
+ preds = self.decode((instance_heatmaps, instance_scores[:, None]))
+ preds = InstanceData.cat(preds)
+ preds.keypoints[..., 0] += metainfo['input_size'][
+ 0] / instance_heatmaps.shape[-1] / 2.0
+ preds.keypoints[..., 1] += metainfo['input_size'][
+ 1] / instance_heatmaps.shape[-2] / 2.0
+ preds = [preds]
+
+ else:
+ preds = [
+ InstanceData(
+ keypoints=np.empty((0, self.num_keypoints, 2)),
+ keypoint_scores=np.empty((0, self.num_keypoints)))
+ ]
+ instance_heatmaps = torch.empty(0, self.num_keypoints,
+ *feats.shape[-2:])
+
+ if test_cfg.get('output_heatmaps', False):
+ pred_fields = [
+ PixelData(
+ heatmaps=instance_heatmaps.reshape(
+ -1, *instance_heatmaps.shape[-2:]))
+ ]
+ return preds, pred_fields
+ else:
+ return preds
+
+ def loss(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: ConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ feats (Tuple[Tensor]): The multi-stage features
+ batch_data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+ train_cfg (dict): The runtime config for training process.
+ Defaults to {}
+
+ Returns:
+ dict: A dictionary of losses.
+ """
+
+ # load targets
+ gt_heatmaps, gt_instance_coords, keypoint_weights = [], [], []
+ heatmap_mask = []
+ instance_imgids, gt_instance_heatmaps = [], []
+ for i, d in enumerate(batch_data_samples):
+ gt_heatmaps.append(d.gt_fields.heatmaps)
+ gt_instance_coords.append(d.gt_instance_labels.instance_coords)
+ keypoint_weights.append(d.gt_instance_labels.keypoint_weights)
+ instance_imgids.append(
+ torch.ones(
+ len(d.gt_instance_labels.instance_coords),
+ dtype=torch.long) * i)
+
+ instance_heatmaps = d.gt_fields.instance_heatmaps.reshape(
+ -1, self.num_keypoints,
+ *d.gt_fields.instance_heatmaps.shape[1:])
+ gt_instance_heatmaps.append(instance_heatmaps)
+
+ if 'heatmap_mask' in d.gt_fields:
+ heatmap_mask.append(d.gt_fields.heatmap_mask)
+
+ gt_heatmaps = torch.stack(gt_heatmaps)
+ heatmap_mask = torch.stack(heatmap_mask) if heatmap_mask else None
+
+ gt_instance_coords = torch.cat(gt_instance_coords, dim=0)
+ gt_instance_heatmaps = torch.cat(gt_instance_heatmaps, dim=0)
+ keypoint_weights = torch.cat(keypoint_weights, dim=0)
+ instance_imgids = torch.cat(instance_imgids).to(gt_heatmaps.device)
+
+ # feed-forward
+ feats = feats[-1]
+ pred_instance_feats, pred_heatmaps = self.iia_module.forward_train(
+ feats, gt_instance_coords, instance_imgids)
+
+ # conpute contrastive loss
+ contrastive_loss = 0
+ for i in range(len(batch_data_samples)):
+ pred_instance_feat = pred_instance_feats[instance_imgids == i]
+ contrastive_loss += self.loss_module['contrastive'](
+ pred_instance_feat)
+ contrastive_loss = contrastive_loss / max(1, len(instance_imgids))
+
+ # limit the number of instances
+ max_train_instances = train_cfg.get('max_train_instances', -1)
+ if (max_train_instances > 0
+ and len(instance_imgids) > max_train_instances):
+ selected_indices = torch.randperm(
+ len(instance_imgids),
+ device=gt_heatmaps.device,
+ dtype=torch.long)[:max_train_instances]
+ gt_instance_coords = gt_instance_coords[selected_indices]
+ keypoint_weights = keypoint_weights[selected_indices]
+ gt_instance_heatmaps = gt_instance_heatmaps[selected_indices]
+ instance_imgids = instance_imgids[selected_indices]
+ pred_instance_feats = pred_instance_feats[selected_indices]
+
+ # calculate the decoupled heatmaps for each instance
+ pred_instance_heatmaps = self.gfd_module(feats, pred_instance_feats,
+ gt_instance_coords,
+ instance_imgids)
+
+ # calculate losses
+ losses = {
+ 'loss/heatmap_coupled':
+ self.loss_module['heatmap_coupled'](pred_heatmaps, gt_heatmaps,
+ None, heatmap_mask)
+ }
+ if len(instance_imgids) > 0:
+ losses.update({
+ 'loss/heatmap_decoupled':
+ self.loss_module['heatmap_decoupled'](pred_instance_heatmaps,
+ gt_instance_heatmaps,
+ keypoint_weights),
+ 'loss/contrastive':
+ contrastive_loss
+ })
+
+ return losses
+
+ def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
+ **kwargs):
+ """A hook function to convert old-version state dict of
+ :class:`CIDHead` (before MMPose v1.0.0) to a compatible format
+ of :class:`CIDHead`.
+
+ The hook will be automatically registered during initialization.
+ """
+ version = local_meta.get('version', None)
+ if version and version >= self._version:
+ return
+
+ # convert old-version state dict
+ keys = list(state_dict.keys())
+ for k in keys:
+ if 'keypoint_center_conv' in k:
+ v = state_dict.pop(k)
+ k = k.replace('keypoint_center_conv',
+ 'iia_module.keypoint_root_conv')
+ state_dict[k] = v
+
+ if 'conv_down' in k:
+ v = state_dict.pop(k)
+ k = k.replace('conv_down', 'gfd_module.conv_down')
+ state_dict[k] = v
+
+ if 'c_attn' in k:
+ v = state_dict.pop(k)
+ k = k.replace('c_attn', 'gfd_module.channel_attention')
+ state_dict[k] = v
+
+ if 's_attn' in k:
+ v = state_dict.pop(k)
+ k = k.replace('s_attn', 'gfd_module.spatial_attention')
+ state_dict[k] = v
+
+ if 'fuse_attn' in k:
+ v = state_dict.pop(k)
+ k = k.replace('fuse_attn', 'gfd_module.fuse_attention')
+ state_dict[k] = v
+
+ if 'heatmap_conv' in k:
+ v = state_dict.pop(k)
+ k = k.replace('heatmap_conv', 'gfd_module.heatmap_conv')
+ state_dict[k] = v
diff --git a/mmpose/models/heads/heatmap_heads/cpm_head.py b/mmpose/models/heads/heatmap_heads/cpm_head.py
index 1ba46357ec..287d591106 100644
--- a/mmpose/models/heads/heatmap_heads/cpm_head.py
+++ b/mmpose/models/heads/heatmap_heads/cpm_head.py
@@ -1,307 +1,307 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import List, Optional, Sequence, Union
-
-import torch
-from mmcv.cnn import build_conv_layer, build_upsample_layer
-from mmengine.structures import PixelData
-from torch import Tensor, nn
-
-from mmpose.evaluation.functional import pose_pck_accuracy
-from mmpose.models.utils.tta import flip_heatmaps
-from mmpose.registry import KEYPOINT_CODECS, MODELS
-from mmpose.utils.tensor_utils import to_numpy
-from mmpose.utils.typing import (Features, MultiConfig, OptConfigType,
- OptSampleList, Predictions)
-from ..base_head import BaseHead
-
-OptIntSeq = Optional[Sequence[int]]
-
-
-@MODELS.register_module()
-class CPMHead(BaseHead):
- """Multi-stage heatmap head introduced in `Convolutional Pose Machines`_ by
- Wei et al (2016) and used by `Stacked Hourglass Networks`_ by Newell et al
- (2016). The head consists of multiple branches, each of which has some
- deconv layers and a simple conv2d layer.
-
- Args:
- in_channels (int | Sequence[int]): Number of channels in the input
- feature maps.
- out_channels (int): Number of channels in the output heatmaps.
- num_stages (int): Number of stages.
- deconv_out_channels (Sequence[int], optional): The output channel
- number of each deconv layer. Defaults to ``(256, 256, 256)``
- deconv_kernel_sizes (Sequence[int | tuple], optional): The kernel size
- of each deconv layer. Each element should be either an integer for
- both height and width dimensions, or a tuple of two integers for
- the height and the width dimension respectively.
- Defaults to ``(4, 4, 4)``
- final_layer (dict): Arguments of the final Conv2d layer.
- Defaults to ``dict(kernel_size=1)``
- loss (Config | List[Config]): Config of the keypoint loss of different
- stages. Defaults to use :class:`KeypointMSELoss`.
- decoder (Config, optional): The decoder config that controls decoding
- keypoint coordinates from the network output. Defaults to ``None``
- init_cfg (Config, optional): Config to control the initialization. See
- :attr:`default_init_cfg` for default settings
-
- .. _`Convolutional Pose Machines`: https://arxiv.org/abs/1602.00134
- .. _`Stacked Hourglass Networks`: https://arxiv.org/abs/1603.06937
- """
-
- _version = 2
-
- def __init__(self,
- in_channels: Union[int, Sequence[int]],
- out_channels: int,
- num_stages: int,
- deconv_out_channels: OptIntSeq = None,
- deconv_kernel_sizes: OptIntSeq = None,
- final_layer: dict = dict(kernel_size=1),
- loss: MultiConfig = dict(
- type='KeypointMSELoss', use_target_weight=True),
- decoder: OptConfigType = None,
- init_cfg: OptConfigType = None):
-
- if init_cfg is None:
- init_cfg = self.default_init_cfg
- super().__init__(init_cfg)
-
- self.num_stages = num_stages
- self.in_channels = in_channels
- self.out_channels = out_channels
-
- if isinstance(loss, list):
- if len(loss) != num_stages:
- raise ValueError(
- f'The length of loss_module({len(loss)}) did not match '
- f'`num_stages`({num_stages})')
- self.loss_module = nn.ModuleList(
- MODELS.build(_loss) for _loss in loss)
- else:
- self.loss_module = MODELS.build(loss)
-
- if decoder is not None:
- self.decoder = KEYPOINT_CODECS.build(decoder)
- else:
- self.decoder = None
-
- # build multi-stage deconv layers
- self.multi_deconv_layers = nn.ModuleList([])
- if deconv_out_channels:
- if deconv_kernel_sizes is None or len(deconv_out_channels) != len(
- deconv_kernel_sizes):
- raise ValueError(
- '"deconv_out_channels" and "deconv_kernel_sizes" should '
- 'be integer sequences with the same length. Got '
- f'mismatched lengths {deconv_out_channels} and '
- f'{deconv_kernel_sizes}')
-
- for _ in range(self.num_stages):
- deconv_layers = self._make_deconv_layers(
- in_channels=in_channels,
- layer_out_channels=deconv_out_channels,
- layer_kernel_sizes=deconv_kernel_sizes,
- )
- self.multi_deconv_layers.append(deconv_layers)
- in_channels = deconv_out_channels[-1]
- else:
- for _ in range(self.num_stages):
- self.multi_deconv_layers.append(nn.Identity())
-
- # build multi-stage final layers
- self.multi_final_layers = nn.ModuleList([])
- if final_layer is not None:
- cfg = dict(
- type='Conv2d',
- in_channels=in_channels,
- out_channels=out_channels,
- kernel_size=1)
- cfg.update(final_layer)
- for _ in range(self.num_stages):
- self.multi_final_layers.append(build_conv_layer(cfg))
- else:
- for _ in range(self.num_stages):
- self.multi_final_layers.append(nn.Identity())
-
- @property
- def default_init_cfg(self):
- init_cfg = [
- dict(
- type='Normal', layer=['Conv2d', 'ConvTranspose2d'], std=0.001),
- dict(type='Constant', layer='BatchNorm2d', val=1)
- ]
- return init_cfg
-
- def _make_deconv_layers(self, in_channels: int,
- layer_out_channels: Sequence[int],
- layer_kernel_sizes: Sequence[int]) -> nn.Module:
- """Create deconvolutional layers by given parameters."""
-
- layers = []
- for out_channels, kernel_size in zip(layer_out_channels,
- layer_kernel_sizes):
- if kernel_size == 4:
- padding = 1
- output_padding = 0
- elif kernel_size == 3:
- padding = 1
- output_padding = 1
- elif kernel_size == 2:
- padding = 0
- output_padding = 0
- else:
- raise ValueError(f'Unsupported kernel size {kernel_size} for'
- 'deconvlutional layers in '
- f'{self.__class__.__name__}')
- cfg = dict(
- type='deconv',
- in_channels=in_channels,
- out_channels=out_channels,
- kernel_size=kernel_size,
- stride=2,
- padding=padding,
- output_padding=output_padding,
- bias=False)
- layers.append(build_upsample_layer(cfg))
- layers.append(nn.BatchNorm2d(num_features=out_channels))
- layers.append(nn.ReLU(inplace=True))
- in_channels = out_channels
-
- return nn.Sequential(*layers)
-
- def forward(self, feats: Sequence[Tensor]) -> List[Tensor]:
- """Forward the network. The input is multi-stage feature maps and the
- output is a list of heatmaps from multiple stages.
-
- Args:
- feats (Sequence[Tensor]): Multi-stage feature maps.
-
- Returns:
- List[Tensor]: A list of output heatmaps from multiple stages.
- """
- out = []
- assert len(feats) == self.num_stages, (
- f'The length of feature maps did not match the '
- f'`num_stages` in {self.__class__.__name__}')
- for i in range(self.num_stages):
- y = self.multi_deconv_layers[i](feats[i])
- y = self.multi_final_layers[i](y)
- out.append(y)
-
- return out
-
- def predict(self,
- feats: Features,
- batch_data_samples: OptSampleList,
- test_cfg: OptConfigType = {}) -> Predictions:
- """Predict results from multi-stage feature maps.
-
- Args:
- feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
- features (or multiple multi-stage features in TTA)
- batch_data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples
- test_cfg (dict): The runtime config for testing process. Defaults
- to {}
-
- Returns:
- Union[InstanceList | Tuple[InstanceList | PixelDataList]]: If
- ``test_cfg['output_heatmap']==True``, return both pose and heatmap
- prediction; otherwise only return the pose prediction.
-
- The pose prediction is a list of ``InstanceData``, each contains
- the following fields:
-
- - keypoints (np.ndarray): predicted keypoint coordinates in
- shape (num_instances, K, D) where K is the keypoint number
- and D is the keypoint dimension
- - keypoint_scores (np.ndarray): predicted keypoint scores in
- shape (num_instances, K)
-
- The heatmap prediction is a list of ``PixelData``, each contains
- the following fields:
-
- - heatmaps (Tensor): The predicted heatmaps in shape (K, h, w)
- """
-
- if test_cfg.get('flip_test', False):
- # TTA: flip test
- assert isinstance(feats, list) and len(feats) == 2
- flip_indices = batch_data_samples[0].metainfo['flip_indices']
- _feats, _feats_flip = feats
- _batch_heatmaps = self.forward(_feats)[-1]
- _batch_heatmaps_flip = flip_heatmaps(
- self.forward(_feats_flip)[-1],
- flip_mode=test_cfg.get('flip_mode', 'heatmap'),
- flip_indices=flip_indices,
- shift_heatmap=test_cfg.get('shift_heatmap', False))
- batch_heatmaps = (_batch_heatmaps + _batch_heatmaps_flip) * 0.5
- else:
- multi_stage_heatmaps = self.forward(feats)
- batch_heatmaps = multi_stage_heatmaps[-1]
-
- preds = self.decode(batch_heatmaps)
-
- if test_cfg.get('output_heatmaps', False):
- pred_fields = [
- PixelData(heatmaps=hm) for hm in batch_heatmaps.detach()
- ]
- return preds, pred_fields
- else:
- return preds
-
- def loss(self,
- feats: Sequence[Tensor],
- batch_data_samples: OptSampleList,
- train_cfg: OptConfigType = {}) -> dict:
- """Calculate losses from a batch of inputs and data samples.
-
- Args:
- feats (Sequence[Tensor]): Multi-stage feature maps.
- batch_data_samples (List[:obj:`PoseDataSample`]): The Data
- Samples. It usually includes information such as
- `gt_instances`.
- train_cfg (Config, optional): The training config.
-
- Returns:
- dict: A dictionary of loss components.
- """
- multi_stage_pred_heatmaps = self.forward(feats)
-
- gt_heatmaps = torch.stack(
- [d.gt_fields.heatmaps for d in batch_data_samples])
- keypoint_weights = torch.cat([
- d.gt_instance_labels.keypoint_weights for d in batch_data_samples
- ])
-
- # calculate losses over multiple stages
- losses = dict()
- for i in range(self.num_stages):
- if isinstance(self.loss_module, nn.ModuleList):
- # use different loss_module over different stages
- loss_func = self.loss_module[i]
- else:
- # use the same loss_module over different stages
- loss_func = self.loss_module
-
- # the `gt_heatmaps` and `keypoint_weights` used to calculate loss
- # for different stages are the same
- loss_i = loss_func(multi_stage_pred_heatmaps[i], gt_heatmaps,
- keypoint_weights)
-
- if 'loss_kpt' not in losses:
- losses['loss_kpt'] = loss_i
- else:
- losses['loss_kpt'] += loss_i
-
- # calculate accuracy
- _, avg_acc, _ = pose_pck_accuracy(
- output=to_numpy(multi_stage_pred_heatmaps[-1]),
- target=to_numpy(gt_heatmaps),
- mask=to_numpy(keypoint_weights) > 0)
-
- acc_pose = torch.tensor(avg_acc, device=gt_heatmaps.device)
- losses.update(acc_pose=acc_pose)
-
- return losses
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Sequence, Union
+
+import torch
+from mmcv.cnn import build_conv_layer, build_upsample_layer
+from mmengine.structures import PixelData
+from torch import Tensor, nn
+
+from mmpose.evaluation.functional import pose_pck_accuracy
+from mmpose.models.utils.tta import flip_heatmaps
+from mmpose.registry import KEYPOINT_CODECS, MODELS
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import (Features, MultiConfig, OptConfigType,
+ OptSampleList, Predictions)
+from ..base_head import BaseHead
+
+OptIntSeq = Optional[Sequence[int]]
+
+
+@MODELS.register_module()
+class CPMHead(BaseHead):
+ """Multi-stage heatmap head introduced in `Convolutional Pose Machines`_ by
+ Wei et al (2016) and used by `Stacked Hourglass Networks`_ by Newell et al
+ (2016). The head consists of multiple branches, each of which has some
+ deconv layers and a simple conv2d layer.
+
+ Args:
+ in_channels (int | Sequence[int]): Number of channels in the input
+ feature maps.
+ out_channels (int): Number of channels in the output heatmaps.
+ num_stages (int): Number of stages.
+ deconv_out_channels (Sequence[int], optional): The output channel
+ number of each deconv layer. Defaults to ``(256, 256, 256)``
+ deconv_kernel_sizes (Sequence[int | tuple], optional): The kernel size
+ of each deconv layer. Each element should be either an integer for
+ both height and width dimensions, or a tuple of two integers for
+ the height and the width dimension respectively.
+ Defaults to ``(4, 4, 4)``
+ final_layer (dict): Arguments of the final Conv2d layer.
+ Defaults to ``dict(kernel_size=1)``
+ loss (Config | List[Config]): Config of the keypoint loss of different
+ stages. Defaults to use :class:`KeypointMSELoss`.
+ decoder (Config, optional): The decoder config that controls decoding
+ keypoint coordinates from the network output. Defaults to ``None``
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+
+ .. _`Convolutional Pose Machines`: https://arxiv.org/abs/1602.00134
+ .. _`Stacked Hourglass Networks`: https://arxiv.org/abs/1603.06937
+ """
+
+ _version = 2
+
+ def __init__(self,
+ in_channels: Union[int, Sequence[int]],
+ out_channels: int,
+ num_stages: int,
+ deconv_out_channels: OptIntSeq = None,
+ deconv_kernel_sizes: OptIntSeq = None,
+ final_layer: dict = dict(kernel_size=1),
+ loss: MultiConfig = dict(
+ type='KeypointMSELoss', use_target_weight=True),
+ decoder: OptConfigType = None,
+ init_cfg: OptConfigType = None):
+
+ if init_cfg is None:
+ init_cfg = self.default_init_cfg
+ super().__init__(init_cfg)
+
+ self.num_stages = num_stages
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+
+ if isinstance(loss, list):
+ if len(loss) != num_stages:
+ raise ValueError(
+ f'The length of loss_module({len(loss)}) did not match '
+ f'`num_stages`({num_stages})')
+ self.loss_module = nn.ModuleList(
+ MODELS.build(_loss) for _loss in loss)
+ else:
+ self.loss_module = MODELS.build(loss)
+
+ if decoder is not None:
+ self.decoder = KEYPOINT_CODECS.build(decoder)
+ else:
+ self.decoder = None
+
+ # build multi-stage deconv layers
+ self.multi_deconv_layers = nn.ModuleList([])
+ if deconv_out_channels:
+ if deconv_kernel_sizes is None or len(deconv_out_channels) != len(
+ deconv_kernel_sizes):
+ raise ValueError(
+ '"deconv_out_channels" and "deconv_kernel_sizes" should '
+ 'be integer sequences with the same length. Got '
+ f'mismatched lengths {deconv_out_channels} and '
+ f'{deconv_kernel_sizes}')
+
+ for _ in range(self.num_stages):
+ deconv_layers = self._make_deconv_layers(
+ in_channels=in_channels,
+ layer_out_channels=deconv_out_channels,
+ layer_kernel_sizes=deconv_kernel_sizes,
+ )
+ self.multi_deconv_layers.append(deconv_layers)
+ in_channels = deconv_out_channels[-1]
+ else:
+ for _ in range(self.num_stages):
+ self.multi_deconv_layers.append(nn.Identity())
+
+ # build multi-stage final layers
+ self.multi_final_layers = nn.ModuleList([])
+ if final_layer is not None:
+ cfg = dict(
+ type='Conv2d',
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1)
+ cfg.update(final_layer)
+ for _ in range(self.num_stages):
+ self.multi_final_layers.append(build_conv_layer(cfg))
+ else:
+ for _ in range(self.num_stages):
+ self.multi_final_layers.append(nn.Identity())
+
+ @property
+ def default_init_cfg(self):
+ init_cfg = [
+ dict(
+ type='Normal', layer=['Conv2d', 'ConvTranspose2d'], std=0.001),
+ dict(type='Constant', layer='BatchNorm2d', val=1)
+ ]
+ return init_cfg
+
+ def _make_deconv_layers(self, in_channels: int,
+ layer_out_channels: Sequence[int],
+ layer_kernel_sizes: Sequence[int]) -> nn.Module:
+ """Create deconvolutional layers by given parameters."""
+
+ layers = []
+ for out_channels, kernel_size in zip(layer_out_channels,
+ layer_kernel_sizes):
+ if kernel_size == 4:
+ padding = 1
+ output_padding = 0
+ elif kernel_size == 3:
+ padding = 1
+ output_padding = 1
+ elif kernel_size == 2:
+ padding = 0
+ output_padding = 0
+ else:
+ raise ValueError(f'Unsupported kernel size {kernel_size} for'
+ 'deconvlutional layers in '
+ f'{self.__class__.__name__}')
+ cfg = dict(
+ type='deconv',
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=2,
+ padding=padding,
+ output_padding=output_padding,
+ bias=False)
+ layers.append(build_upsample_layer(cfg))
+ layers.append(nn.BatchNorm2d(num_features=out_channels))
+ layers.append(nn.ReLU(inplace=True))
+ in_channels = out_channels
+
+ return nn.Sequential(*layers)
+
+ def forward(self, feats: Sequence[Tensor]) -> List[Tensor]:
+ """Forward the network. The input is multi-stage feature maps and the
+ output is a list of heatmaps from multiple stages.
+
+ Args:
+ feats (Sequence[Tensor]): Multi-stage feature maps.
+
+ Returns:
+ List[Tensor]: A list of output heatmaps from multiple stages.
+ """
+ out = []
+ assert len(feats) == self.num_stages, (
+ f'The length of feature maps did not match the '
+ f'`num_stages` in {self.__class__.__name__}')
+ for i in range(self.num_stages):
+ y = self.multi_deconv_layers[i](feats[i])
+ y = self.multi_final_layers[i](y)
+ out.append(y)
+
+ return out
+
+ def predict(self,
+ feats: Features,
+ batch_data_samples: OptSampleList,
+ test_cfg: OptConfigType = {}) -> Predictions:
+ """Predict results from multi-stage feature maps.
+
+ Args:
+ feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
+ features (or multiple multi-stage features in TTA)
+ batch_data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+ test_cfg (dict): The runtime config for testing process. Defaults
+ to {}
+
+ Returns:
+ Union[InstanceList | Tuple[InstanceList | PixelDataList]]: If
+ ``test_cfg['output_heatmap']==True``, return both pose and heatmap
+ prediction; otherwise only return the pose prediction.
+
+ The pose prediction is a list of ``InstanceData``, each contains
+ the following fields:
+
+ - keypoints (np.ndarray): predicted keypoint coordinates in
+ shape (num_instances, K, D) where K is the keypoint number
+ and D is the keypoint dimension
+ - keypoint_scores (np.ndarray): predicted keypoint scores in
+ shape (num_instances, K)
+
+ The heatmap prediction is a list of ``PixelData``, each contains
+ the following fields:
+
+ - heatmaps (Tensor): The predicted heatmaps in shape (K, h, w)
+ """
+
+ if test_cfg.get('flip_test', False):
+ # TTA: flip test
+ assert isinstance(feats, list) and len(feats) == 2
+ flip_indices = batch_data_samples[0].metainfo['flip_indices']
+ _feats, _feats_flip = feats
+ _batch_heatmaps = self.forward(_feats)[-1]
+ _batch_heatmaps_flip = flip_heatmaps(
+ self.forward(_feats_flip)[-1],
+ flip_mode=test_cfg.get('flip_mode', 'heatmap'),
+ flip_indices=flip_indices,
+ shift_heatmap=test_cfg.get('shift_heatmap', False))
+ batch_heatmaps = (_batch_heatmaps + _batch_heatmaps_flip) * 0.5
+ else:
+ multi_stage_heatmaps = self.forward(feats)
+ batch_heatmaps = multi_stage_heatmaps[-1]
+
+ preds = self.decode(batch_heatmaps)
+
+ if test_cfg.get('output_heatmaps', False):
+ pred_fields = [
+ PixelData(heatmaps=hm) for hm in batch_heatmaps.detach()
+ ]
+ return preds, pred_fields
+ else:
+ return preds
+
+ def loss(self,
+ feats: Sequence[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: OptConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ feats (Sequence[Tensor]): Multi-stage feature maps.
+ batch_data_samples (List[:obj:`PoseDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instances`.
+ train_cfg (Config, optional): The training config.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ multi_stage_pred_heatmaps = self.forward(feats)
+
+ gt_heatmaps = torch.stack(
+ [d.gt_fields.heatmaps for d in batch_data_samples])
+ keypoint_weights = torch.cat([
+ d.gt_instance_labels.keypoint_weights for d in batch_data_samples
+ ])
+
+ # calculate losses over multiple stages
+ losses = dict()
+ for i in range(self.num_stages):
+ if isinstance(self.loss_module, nn.ModuleList):
+ # use different loss_module over different stages
+ loss_func = self.loss_module[i]
+ else:
+ # use the same loss_module over different stages
+ loss_func = self.loss_module
+
+ # the `gt_heatmaps` and `keypoint_weights` used to calculate loss
+ # for different stages are the same
+ loss_i = loss_func(multi_stage_pred_heatmaps[i], gt_heatmaps,
+ keypoint_weights)
+
+ if 'loss_kpt' not in losses:
+ losses['loss_kpt'] = loss_i
+ else:
+ losses['loss_kpt'] += loss_i
+
+ # calculate accuracy
+ _, avg_acc, _ = pose_pck_accuracy(
+ output=to_numpy(multi_stage_pred_heatmaps[-1]),
+ target=to_numpy(gt_heatmaps),
+ mask=to_numpy(keypoint_weights) > 0)
+
+ acc_pose = torch.tensor(avg_acc, device=gt_heatmaps.device)
+ losses.update(acc_pose=acc_pose)
+
+ return losses
diff --git a/mmpose/models/heads/heatmap_heads/heatmap_head.py b/mmpose/models/heads/heatmap_heads/heatmap_head.py
index 0b0fa3f475..784670514f 100644
--- a/mmpose/models/heads/heatmap_heads/heatmap_head.py
+++ b/mmpose/models/heads/heatmap_heads/heatmap_head.py
@@ -1,369 +1,369 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional, Sequence, Tuple, Union
-
-import torch
-from mmcv.cnn import build_conv_layer, build_upsample_layer
-from mmengine.structures import PixelData
-from torch import Tensor, nn
-
-from mmpose.evaluation.functional import pose_pck_accuracy
-from mmpose.models.utils.tta import flip_heatmaps
-from mmpose.registry import KEYPOINT_CODECS, MODELS
-from mmpose.utils.tensor_utils import to_numpy
-from mmpose.utils.typing import (ConfigType, Features, OptConfigType,
- OptSampleList, Predictions)
-from ..base_head import BaseHead
-
-OptIntSeq = Optional[Sequence[int]]
-
-
-@MODELS.register_module()
-class HeatmapHead(BaseHead):
- """Top-down heatmap head introduced in `Simple Baselines`_ by Xiao et al
- (2018). The head is composed of a few deconvolutional layers followed by a
- convolutional layer to generate heatmaps from low-resolution feature maps.
-
- Args:
- in_channels (int | Sequence[int]): Number of channels in the input
- feature map
- out_channels (int): Number of channels in the output heatmap
- deconv_out_channels (Sequence[int], optional): The output channel
- number of each deconv layer. Defaults to ``(256, 256, 256)``
- deconv_kernel_sizes (Sequence[int | tuple], optional): The kernel size
- of each deconv layer. Each element should be either an integer for
- both height and width dimensions, or a tuple of two integers for
- the height and the width dimension respectively.Defaults to
- ``(4, 4, 4)``
- conv_out_channels (Sequence[int], optional): The output channel number
- of each intermediate conv layer. ``None`` means no intermediate
- conv layer between deconv layers and the final conv layer.
- Defaults to ``None``
- conv_kernel_sizes (Sequence[int | tuple], optional): The kernel size
- of each intermediate conv layer. Defaults to ``None``
- final_layer (dict): Arguments of the final Conv2d layer.
- Defaults to ``dict(kernel_size=1)``
- loss (Config): Config of the keypoint loss. Defaults to use
- :class:`KeypointMSELoss`
- decoder (Config, optional): The decoder config that controls decoding
- keypoint coordinates from the network output. Defaults to ``None``
- init_cfg (Config, optional): Config to control the initialization. See
- :attr:`default_init_cfg` for default settings
- extra (dict, optional): Extra configurations.
- Defaults to ``None``
-
- .. _`Simple Baselines`: https://arxiv.org/abs/1804.06208
- """
-
- _version = 2
-
- def __init__(self,
- in_channels: Union[int, Sequence[int]],
- out_channels: int,
- deconv_out_channels: OptIntSeq = (256, 256, 256),
- deconv_kernel_sizes: OptIntSeq = (4, 4, 4),
- conv_out_channels: OptIntSeq = None,
- conv_kernel_sizes: OptIntSeq = None,
- final_layer: dict = dict(kernel_size=1),
- loss: ConfigType = dict(
- type='KeypointMSELoss', use_target_weight=True),
- decoder: OptConfigType = None,
- init_cfg: OptConfigType = None):
-
- if init_cfg is None:
- init_cfg = self.default_init_cfg
-
- super().__init__(init_cfg)
-
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.loss_module = MODELS.build(loss)
- if decoder is not None:
- self.decoder = KEYPOINT_CODECS.build(decoder)
- else:
- self.decoder = None
-
- if deconv_out_channels:
- if deconv_kernel_sizes is None or len(deconv_out_channels) != len(
- deconv_kernel_sizes):
- raise ValueError(
- '"deconv_out_channels" and "deconv_kernel_sizes" should '
- 'be integer sequences with the same length. Got '
- f'mismatched lengths {deconv_out_channels} and '
- f'{deconv_kernel_sizes}')
-
- self.deconv_layers = self._make_deconv_layers(
- in_channels=in_channels,
- layer_out_channels=deconv_out_channels,
- layer_kernel_sizes=deconv_kernel_sizes,
- )
- in_channels = deconv_out_channels[-1]
- else:
- self.deconv_layers = nn.Identity()
-
- if conv_out_channels:
- if conv_kernel_sizes is None or len(conv_out_channels) != len(
- conv_kernel_sizes):
- raise ValueError(
- '"conv_out_channels" and "conv_kernel_sizes" should '
- 'be integer sequences with the same length. Got '
- f'mismatched lengths {conv_out_channels} and '
- f'{conv_kernel_sizes}')
-
- self.conv_layers = self._make_conv_layers(
- in_channels=in_channels,
- layer_out_channels=conv_out_channels,
- layer_kernel_sizes=conv_kernel_sizes)
- in_channels = conv_out_channels[-1]
- else:
- self.conv_layers = nn.Identity()
-
- if final_layer is not None:
- cfg = dict(
- type='Conv2d',
- in_channels=in_channels,
- out_channels=out_channels,
- kernel_size=1)
- cfg.update(final_layer)
- self.final_layer = build_conv_layer(cfg)
- else:
- self.final_layer = nn.Identity()
-
- # Register the hook to automatically convert old version state dicts
- self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
-
- def _make_conv_layers(self, in_channels: int,
- layer_out_channels: Sequence[int],
- layer_kernel_sizes: Sequence[int]) -> nn.Module:
- """Create convolutional layers by given parameters."""
-
- layers = []
- for out_channels, kernel_size in zip(layer_out_channels,
- layer_kernel_sizes):
- padding = (kernel_size - 1) // 2
- cfg = dict(
- type='Conv2d',
- in_channels=in_channels,
- out_channels=out_channels,
- kernel_size=kernel_size,
- stride=1,
- padding=padding)
- layers.append(build_conv_layer(cfg))
- layers.append(nn.BatchNorm2d(num_features=out_channels))
- layers.append(nn.ReLU(inplace=True))
- in_channels = out_channels
-
- return nn.Sequential(*layers)
-
- def _make_deconv_layers(self, in_channels: int,
- layer_out_channels: Sequence[int],
- layer_kernel_sizes: Sequence[int]) -> nn.Module:
- """Create deconvolutional layers by given parameters."""
-
- layers = []
- for out_channels, kernel_size in zip(layer_out_channels,
- layer_kernel_sizes):
- if kernel_size == 4:
- padding = 1
- output_padding = 0
- elif kernel_size == 3:
- padding = 1
- output_padding = 1
- elif kernel_size == 2:
- padding = 0
- output_padding = 0
- else:
- raise ValueError(f'Unsupported kernel size {kernel_size} for'
- 'deconvlutional layers in '
- f'{self.__class__.__name__}')
- cfg = dict(
- type='deconv',
- in_channels=in_channels,
- out_channels=out_channels,
- kernel_size=kernel_size,
- stride=2,
- padding=padding,
- output_padding=output_padding,
- bias=False)
- layers.append(build_upsample_layer(cfg))
- layers.append(nn.BatchNorm2d(num_features=out_channels))
- layers.append(nn.ReLU(inplace=True))
- in_channels = out_channels
-
- return nn.Sequential(*layers)
-
- @property
- def default_init_cfg(self):
- init_cfg = [
- dict(
- type='Normal', layer=['Conv2d', 'ConvTranspose2d'], std=0.001),
- dict(type='Constant', layer='BatchNorm2d', val=1)
- ]
- return init_cfg
-
- def forward(self, feats: Tuple[Tensor]) -> Tensor:
- """Forward the network. The input is multi scale feature maps and the
- output is the heatmap.
-
- Args:
- feats (Tuple[Tensor]): Multi scale feature maps.
-
- Returns:
- Tensor: output heatmap.
- """
- x = feats[-1]
-
- x = self.deconv_layers(x)
- x = self.conv_layers(x)
- x = self.final_layer(x)
-
- return x
-
- def predict(self,
- feats: Features,
- batch_data_samples: OptSampleList,
- test_cfg: ConfigType = {}) -> Predictions:
- """Predict results from features.
-
- Args:
- feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
- features (or multiple multi-stage features in TTA)
- batch_data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples
- test_cfg (dict): The runtime config for testing process. Defaults
- to {}
-
- Returns:
- Union[InstanceList | Tuple[InstanceList | PixelDataList]]: If
- ``test_cfg['output_heatmap']==True``, return both pose and heatmap
- prediction; otherwise only return the pose prediction.
-
- The pose prediction is a list of ``InstanceData``, each contains
- the following fields:
-
- - keypoints (np.ndarray): predicted keypoint coordinates in
- shape (num_instances, K, D) where K is the keypoint number
- and D is the keypoint dimension
- - keypoint_scores (np.ndarray): predicted keypoint scores in
- shape (num_instances, K)
-
- The heatmap prediction is a list of ``PixelData``, each contains
- the following fields:
-
- - heatmaps (Tensor): The predicted heatmaps in shape (K, h, w)
- """
-
- if test_cfg.get('flip_test', False):
- # TTA: flip test -> feats = [orig, flipped]
- assert isinstance(feats, list) and len(feats) == 2
- flip_indices = batch_data_samples[0].metainfo['flip_indices']
- _feats, _feats_flip = feats
- _batch_heatmaps = self.forward(_feats)
- _batch_heatmaps_flip = flip_heatmaps(
- self.forward(_feats_flip),
- flip_mode=test_cfg.get('flip_mode', 'heatmap'),
- flip_indices=flip_indices,
- shift_heatmap=test_cfg.get('shift_heatmap', False))
- batch_heatmaps = (_batch_heatmaps + _batch_heatmaps_flip) * 0.5
- else:
- batch_heatmaps = self.forward(feats)
-
- preds = self.decode(batch_heatmaps)
-
- if test_cfg.get('output_heatmaps', False):
- pred_fields = [
- PixelData(heatmaps=hm) for hm in batch_heatmaps.detach()
- ]
- return preds, pred_fields
- else:
- return preds
-
- def loss(self,
- feats: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- train_cfg: ConfigType = {}) -> dict:
- """Calculate losses from a batch of inputs and data samples.
-
- Args:
- feats (Tuple[Tensor]): The multi-stage features
- batch_data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples
- train_cfg (dict): The runtime config for training process.
- Defaults to {}
-
- Returns:
- dict: A dictionary of losses.
- """
- pred_fields = self.forward(feats)
- gt_heatmaps = torch.stack(
- [d.gt_fields.heatmaps for d in batch_data_samples])
- keypoint_weights = torch.cat([
- d.gt_instance_labels.keypoint_weights for d in batch_data_samples
- ])
-
- # calculate losses
- losses = dict()
- loss = self.loss_module(pred_fields, gt_heatmaps, keypoint_weights)
-
- losses.update(loss_kpt=loss)
-
- # calculate accuracy
- if train_cfg.get('compute_acc', True):
- _, avg_acc, _ = pose_pck_accuracy(
- output=to_numpy(pred_fields),
- target=to_numpy(gt_heatmaps),
- mask=to_numpy(keypoint_weights) > 0)
-
- acc_pose = torch.tensor(avg_acc, device=gt_heatmaps.device)
- losses.update(acc_pose=acc_pose)
-
- return losses
-
- def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
- **kwargs):
- """A hook function to convert old-version state dict of
- :class:`DeepposeRegressionHead` (before MMPose v1.0.0) to a
- compatible format of :class:`RegressionHead`.
-
- The hook will be automatically registered during initialization.
- """
- version = local_meta.get('version', None)
- if version and version >= self._version:
- return
-
- # convert old-version state dict
- keys = list(state_dict.keys())
- for _k in keys:
- if not _k.startswith(prefix):
- continue
- v = state_dict.pop(_k)
- k = _k[len(prefix):]
- # In old version, "final_layer" includes both intermediate
- # conv layers (new "conv_layers") and final conv layers (new
- # "final_layer").
- #
- # If there is no intermediate conv layer, old "final_layer" will
- # have keys like "final_layer.xxx", which should be still
- # named "final_layer.xxx";
- #
- # If there are intermediate conv layers, old "final_layer" will
- # have keys like "final_layer.n.xxx", where the weights of the last
- # one should be renamed "final_layer.xxx", and others should be
- # renamed "conv_layers.n.xxx"
- k_parts = k.split('.')
- if k_parts[0] == 'final_layer':
- if len(k_parts) == 3:
- assert isinstance(self.conv_layers, nn.Sequential)
- idx = int(k_parts[1])
- if idx < len(self.conv_layers):
- # final_layer.n.xxx -> conv_layers.n.xxx
- k_new = 'conv_layers.' + '.'.join(k_parts[1:])
- else:
- # final_layer.n.xxx -> final_layer.xxx
- k_new = 'final_layer.' + k_parts[2]
- else:
- # final_layer.xxx remains final_layer.xxx
- k_new = k
- else:
- k_new = k
-
- state_dict[prefix + k_new] = v
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Sequence, Tuple, Union
+
+import torch
+from mmcv.cnn import build_conv_layer, build_upsample_layer
+from mmengine.structures import PixelData
+from torch import Tensor, nn
+
+from mmpose.evaluation.functional import pose_pck_accuracy
+from mmpose.models.utils.tta import flip_heatmaps
+from mmpose.registry import KEYPOINT_CODECS, MODELS
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import (ConfigType, Features, OptConfigType,
+ OptSampleList, Predictions)
+from ..base_head import BaseHead
+
+OptIntSeq = Optional[Sequence[int]]
+
+
+@MODELS.register_module()
+class HeatmapHead(BaseHead):
+ """Top-down heatmap head introduced in `Simple Baselines`_ by Xiao et al
+ (2018). The head is composed of a few deconvolutional layers followed by a
+ convolutional layer to generate heatmaps from low-resolution feature maps.
+
+ Args:
+ in_channels (int | Sequence[int]): Number of channels in the input
+ feature map
+ out_channels (int): Number of channels in the output heatmap
+ deconv_out_channels (Sequence[int], optional): The output channel
+ number of each deconv layer. Defaults to ``(256, 256, 256)``
+ deconv_kernel_sizes (Sequence[int | tuple], optional): The kernel size
+ of each deconv layer. Each element should be either an integer for
+ both height and width dimensions, or a tuple of two integers for
+ the height and the width dimension respectively.Defaults to
+ ``(4, 4, 4)``
+ conv_out_channels (Sequence[int], optional): The output channel number
+ of each intermediate conv layer. ``None`` means no intermediate
+ conv layer between deconv layers and the final conv layer.
+ Defaults to ``None``
+ conv_kernel_sizes (Sequence[int | tuple], optional): The kernel size
+ of each intermediate conv layer. Defaults to ``None``
+ final_layer (dict): Arguments of the final Conv2d layer.
+ Defaults to ``dict(kernel_size=1)``
+ loss (Config): Config of the keypoint loss. Defaults to use
+ :class:`KeypointMSELoss`
+ decoder (Config, optional): The decoder config that controls decoding
+ keypoint coordinates from the network output. Defaults to ``None``
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+ extra (dict, optional): Extra configurations.
+ Defaults to ``None``
+
+ .. _`Simple Baselines`: https://arxiv.org/abs/1804.06208
+ """
+
+ _version = 2
+
+ def __init__(self,
+ in_channels: Union[int, Sequence[int]],
+ out_channels: int,
+ deconv_out_channels: OptIntSeq = (256, 256, 256),
+ deconv_kernel_sizes: OptIntSeq = (4, 4, 4),
+ conv_out_channels: OptIntSeq = None,
+ conv_kernel_sizes: OptIntSeq = None,
+ final_layer: dict = dict(kernel_size=1),
+ loss: ConfigType = dict(
+ type='KeypointMSELoss', use_target_weight=True),
+ decoder: OptConfigType = None,
+ init_cfg: OptConfigType = None):
+
+ if init_cfg is None:
+ init_cfg = self.default_init_cfg
+
+ super().__init__(init_cfg)
+
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.loss_module = MODELS.build(loss)
+ if decoder is not None:
+ self.decoder = KEYPOINT_CODECS.build(decoder)
+ else:
+ self.decoder = None
+
+ if deconv_out_channels:
+ if deconv_kernel_sizes is None or len(deconv_out_channels) != len(
+ deconv_kernel_sizes):
+ raise ValueError(
+ '"deconv_out_channels" and "deconv_kernel_sizes" should '
+ 'be integer sequences with the same length. Got '
+ f'mismatched lengths {deconv_out_channels} and '
+ f'{deconv_kernel_sizes}')
+
+ self.deconv_layers = self._make_deconv_layers(
+ in_channels=in_channels,
+ layer_out_channels=deconv_out_channels,
+ layer_kernel_sizes=deconv_kernel_sizes,
+ )
+ in_channels = deconv_out_channels[-1]
+ else:
+ self.deconv_layers = nn.Identity()
+
+ if conv_out_channels:
+ if conv_kernel_sizes is None or len(conv_out_channels) != len(
+ conv_kernel_sizes):
+ raise ValueError(
+ '"conv_out_channels" and "conv_kernel_sizes" should '
+ 'be integer sequences with the same length. Got '
+ f'mismatched lengths {conv_out_channels} and '
+ f'{conv_kernel_sizes}')
+
+ self.conv_layers = self._make_conv_layers(
+ in_channels=in_channels,
+ layer_out_channels=conv_out_channels,
+ layer_kernel_sizes=conv_kernel_sizes)
+ in_channels = conv_out_channels[-1]
+ else:
+ self.conv_layers = nn.Identity()
+
+ if final_layer is not None:
+ cfg = dict(
+ type='Conv2d',
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1)
+ cfg.update(final_layer)
+ self.final_layer = build_conv_layer(cfg)
+ else:
+ self.final_layer = nn.Identity()
+
+ # Register the hook to automatically convert old version state dicts
+ self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
+
+ def _make_conv_layers(self, in_channels: int,
+ layer_out_channels: Sequence[int],
+ layer_kernel_sizes: Sequence[int]) -> nn.Module:
+ """Create convolutional layers by given parameters."""
+
+ layers = []
+ for out_channels, kernel_size in zip(layer_out_channels,
+ layer_kernel_sizes):
+ padding = (kernel_size - 1) // 2
+ cfg = dict(
+ type='Conv2d',
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=1,
+ padding=padding)
+ layers.append(build_conv_layer(cfg))
+ layers.append(nn.BatchNorm2d(num_features=out_channels))
+ layers.append(nn.ReLU(inplace=True))
+ in_channels = out_channels
+
+ return nn.Sequential(*layers)
+
+ def _make_deconv_layers(self, in_channels: int,
+ layer_out_channels: Sequence[int],
+ layer_kernel_sizes: Sequence[int]) -> nn.Module:
+ """Create deconvolutional layers by given parameters."""
+
+ layers = []
+ for out_channels, kernel_size in zip(layer_out_channels,
+ layer_kernel_sizes):
+ if kernel_size == 4:
+ padding = 1
+ output_padding = 0
+ elif kernel_size == 3:
+ padding = 1
+ output_padding = 1
+ elif kernel_size == 2:
+ padding = 0
+ output_padding = 0
+ else:
+ raise ValueError(f'Unsupported kernel size {kernel_size} for'
+ 'deconvlutional layers in '
+ f'{self.__class__.__name__}')
+ cfg = dict(
+ type='deconv',
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=2,
+ padding=padding,
+ output_padding=output_padding,
+ bias=False)
+ layers.append(build_upsample_layer(cfg))
+ layers.append(nn.BatchNorm2d(num_features=out_channels))
+ layers.append(nn.ReLU(inplace=True))
+ in_channels = out_channels
+
+ return nn.Sequential(*layers)
+
+ @property
+ def default_init_cfg(self):
+ init_cfg = [
+ dict(
+ type='Normal', layer=['Conv2d', 'ConvTranspose2d'], std=0.001),
+ dict(type='Constant', layer='BatchNorm2d', val=1)
+ ]
+ return init_cfg
+
+ def forward(self, feats: Tuple[Tensor]) -> Tensor:
+ """Forward the network. The input is multi scale feature maps and the
+ output is the heatmap.
+
+ Args:
+ feats (Tuple[Tensor]): Multi scale feature maps.
+
+ Returns:
+ Tensor: output heatmap.
+ """
+ x = feats[-1]
+
+ x = self.deconv_layers(x)
+ x = self.conv_layers(x)
+ x = self.final_layer(x)
+
+ return x
+
+ def predict(self,
+ feats: Features,
+ batch_data_samples: OptSampleList,
+ test_cfg: ConfigType = {}) -> Predictions:
+ """Predict results from features.
+
+ Args:
+ feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
+ features (or multiple multi-stage features in TTA)
+ batch_data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+ test_cfg (dict): The runtime config for testing process. Defaults
+ to {}
+
+ Returns:
+ Union[InstanceList | Tuple[InstanceList | PixelDataList]]: If
+ ``test_cfg['output_heatmap']==True``, return both pose and heatmap
+ prediction; otherwise only return the pose prediction.
+
+ The pose prediction is a list of ``InstanceData``, each contains
+ the following fields:
+
+ - keypoints (np.ndarray): predicted keypoint coordinates in
+ shape (num_instances, K, D) where K is the keypoint number
+ and D is the keypoint dimension
+ - keypoint_scores (np.ndarray): predicted keypoint scores in
+ shape (num_instances, K)
+
+ The heatmap prediction is a list of ``PixelData``, each contains
+ the following fields:
+
+ - heatmaps (Tensor): The predicted heatmaps in shape (K, h, w)
+ """
+
+ if test_cfg.get('flip_test', False):
+ # TTA: flip test -> feats = [orig, flipped]
+ assert isinstance(feats, list) and len(feats) == 2
+ flip_indices = batch_data_samples[0].metainfo['flip_indices']
+ _feats, _feats_flip = feats
+ _batch_heatmaps = self.forward(_feats)
+ _batch_heatmaps_flip = flip_heatmaps(
+ self.forward(_feats_flip),
+ flip_mode=test_cfg.get('flip_mode', 'heatmap'),
+ flip_indices=flip_indices,
+ shift_heatmap=test_cfg.get('shift_heatmap', False))
+ batch_heatmaps = (_batch_heatmaps + _batch_heatmaps_flip) * 0.5
+ else:
+ batch_heatmaps = self.forward(feats)
+
+ preds = self.decode(batch_heatmaps)
+
+ if test_cfg.get('output_heatmaps', False):
+ pred_fields = [
+ PixelData(heatmaps=hm) for hm in batch_heatmaps.detach()
+ ]
+ return preds, pred_fields
+ else:
+ return preds
+
+ def loss(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: ConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ feats (Tuple[Tensor]): The multi-stage features
+ batch_data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+ train_cfg (dict): The runtime config for training process.
+ Defaults to {}
+
+ Returns:
+ dict: A dictionary of losses.
+ """
+ pred_fields = self.forward(feats)
+ gt_heatmaps = torch.stack(
+ [d.gt_fields.heatmaps for d in batch_data_samples])
+ keypoint_weights = torch.cat([
+ d.gt_instance_labels.keypoint_weights for d in batch_data_samples
+ ])
+
+ # calculate losses
+ losses = dict()
+ loss = self.loss_module(pred_fields, gt_heatmaps, keypoint_weights)
+
+ losses.update(loss_kpt=loss)
+
+ # calculate accuracy
+ if train_cfg.get('compute_acc', True):
+ _, avg_acc, _ = pose_pck_accuracy(
+ output=to_numpy(pred_fields),
+ target=to_numpy(gt_heatmaps),
+ mask=to_numpy(keypoint_weights) > 0)
+
+ acc_pose = torch.tensor(avg_acc, device=gt_heatmaps.device)
+ losses.update(acc_pose=acc_pose)
+
+ return losses
+
+ def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
+ **kwargs):
+ """A hook function to convert old-version state dict of
+ :class:`DeepposeRegressionHead` (before MMPose v1.0.0) to a
+ compatible format of :class:`RegressionHead`.
+
+ The hook will be automatically registered during initialization.
+ """
+ version = local_meta.get('version', None)
+ if version and version >= self._version:
+ return
+
+ # convert old-version state dict
+ keys = list(state_dict.keys())
+ for _k in keys:
+ if not _k.startswith(prefix):
+ continue
+ v = state_dict.pop(_k)
+ k = _k[len(prefix):]
+ # In old version, "final_layer" includes both intermediate
+ # conv layers (new "conv_layers") and final conv layers (new
+ # "final_layer").
+ #
+ # If there is no intermediate conv layer, old "final_layer" will
+ # have keys like "final_layer.xxx", which should be still
+ # named "final_layer.xxx";
+ #
+ # If there are intermediate conv layers, old "final_layer" will
+ # have keys like "final_layer.n.xxx", where the weights of the last
+ # one should be renamed "final_layer.xxx", and others should be
+ # renamed "conv_layers.n.xxx"
+ k_parts = k.split('.')
+ if k_parts[0] == 'final_layer':
+ if len(k_parts) == 3:
+ assert isinstance(self.conv_layers, nn.Sequential)
+ idx = int(k_parts[1])
+ if idx < len(self.conv_layers):
+ # final_layer.n.xxx -> conv_layers.n.xxx
+ k_new = 'conv_layers.' + '.'.join(k_parts[1:])
+ else:
+ # final_layer.n.xxx -> final_layer.xxx
+ k_new = 'final_layer.' + k_parts[2]
+ else:
+ # final_layer.xxx remains final_layer.xxx
+ k_new = k
+ else:
+ k_new = k
+
+ state_dict[prefix + k_new] = v
diff --git a/mmpose/models/heads/heatmap_heads/mspn_head.py b/mmpose/models/heads/heatmap_heads/mspn_head.py
index 8b7cddf798..ebd5b66fdd 100644
--- a/mmpose/models/heads/heatmap_heads/mspn_head.py
+++ b/mmpose/models/heads/heatmap_heads/mspn_head.py
@@ -1,432 +1,432 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-from typing import List, Optional, Sequence, Union
-
-import torch
-from mmcv.cnn import (ConvModule, DepthwiseSeparableConvModule, Linear,
- build_activation_layer, build_norm_layer)
-from mmengine.structures import PixelData
-from torch import Tensor, nn
-
-from mmpose.evaluation.functional import pose_pck_accuracy
-from mmpose.models.utils.tta import flip_heatmaps
-from mmpose.registry import KEYPOINT_CODECS, MODELS
-from mmpose.utils.tensor_utils import to_numpy
-from mmpose.utils.typing import (ConfigType, MultiConfig, OptConfigType,
- OptSampleList, Predictions)
-from ..base_head import BaseHead
-
-OptIntSeq = Optional[Sequence[int]]
-MSMUFeatures = Sequence[Sequence[Tensor]] # Multi-stage multi-unit features
-
-
-class PRM(nn.Module):
- """Pose Refine Machine.
-
- Please refer to "Learning Delicate Local Representations
- for Multi-Person Pose Estimation" (ECCV 2020).
-
- Args:
- out_channels (int): Number of the output channels, equals to
- the number of keypoints.
- norm_cfg (Config): Config to construct the norm layer.
- Defaults to ``dict(type='BN')``
- """
-
- def __init__(self,
- out_channels: int,
- norm_cfg: ConfigType = dict(type='BN')):
- super().__init__()
-
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- self.out_channels = out_channels
- self.global_pooling = nn.AdaptiveAvgPool2d((1, 1))
- self.middle_path = nn.Sequential(
- Linear(self.out_channels, self.out_channels),
- build_norm_layer(dict(type='BN1d'), out_channels)[1],
- build_activation_layer(dict(type='ReLU')),
- Linear(self.out_channels, self.out_channels),
- build_norm_layer(dict(type='BN1d'), out_channels)[1],
- build_activation_layer(dict(type='ReLU')),
- build_activation_layer(dict(type='Sigmoid')))
-
- self.bottom_path = nn.Sequential(
- ConvModule(
- self.out_channels,
- self.out_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- norm_cfg=norm_cfg,
- inplace=False),
- DepthwiseSeparableConvModule(
- self.out_channels,
- 1,
- kernel_size=9,
- stride=1,
- padding=4,
- norm_cfg=norm_cfg,
- inplace=False), build_activation_layer(dict(type='Sigmoid')))
- self.conv_bn_relu_prm_1 = ConvModule(
- self.out_channels,
- self.out_channels,
- kernel_size=3,
- stride=1,
- padding=1,
- norm_cfg=norm_cfg,
- inplace=False)
-
- def forward(self, x: Tensor) -> Tensor:
- """Forward the network. The input heatmaps will be refined.
-
- Args:
- x (Tensor): The input heatmaps.
-
- Returns:
- Tensor: output heatmaps.
- """
- out = self.conv_bn_relu_prm_1(x)
- out_1 = out
-
- out_2 = self.global_pooling(out_1)
- out_2 = out_2.view(out_2.size(0), -1)
- out_2 = self.middle_path(out_2)
- out_2 = out_2.unsqueeze(2)
- out_2 = out_2.unsqueeze(3)
-
- out_3 = self.bottom_path(out_1)
- out = out_1 * (1 + out_2 * out_3)
-
- return out
-
-
-class PredictHeatmap(nn.Module):
- """Predict the heatmap for an input feature.
-
- Args:
- unit_channels (int): Number of input channels.
- out_channels (int): Number of output channels.
- out_shape (tuple): Shape of the output heatmaps.
- use_prm (bool): Whether to use pose refine machine. Default: False.
- norm_cfg (Config): Config to construct the norm layer.
- Defaults to ``dict(type='BN')``
- """
-
- def __init__(self,
- unit_channels: int,
- out_channels: int,
- out_shape: tuple,
- use_prm: bool = False,
- norm_cfg: ConfigType = dict(type='BN')):
-
- super().__init__()
-
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
- self.unit_channels = unit_channels
- self.out_channels = out_channels
- self.out_shape = out_shape
- self.use_prm = use_prm
- if use_prm:
- self.prm = PRM(out_channels, norm_cfg=norm_cfg)
- self.conv_layers = nn.Sequential(
- ConvModule(
- unit_channels,
- unit_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- norm_cfg=norm_cfg,
- inplace=False),
- ConvModule(
- unit_channels,
- out_channels,
- kernel_size=3,
- stride=1,
- padding=1,
- norm_cfg=norm_cfg,
- act_cfg=None,
- inplace=False))
-
- def forward(self, feature: Tensor) -> Tensor:
- """Forward the network.
-
- Args:
- feature (Tensor): The input feature maps.
-
- Returns:
- Tensor: output heatmaps.
- """
- feature = self.conv_layers(feature)
- output = nn.functional.interpolate(
- feature, size=self.out_shape, mode='bilinear', align_corners=True)
- if self.use_prm:
- output = self.prm(output)
- return output
-
-
-@MODELS.register_module()
-class MSPNHead(BaseHead):
- """Multi-stage multi-unit heatmap head introduced in `Multi-Stage Pose
- estimation Network (MSPN)`_ by Li et al (2019), and used by `Residual Steps
- Networks (RSN)`_ by Cai et al (2020). The head consists of multiple stages
- and each stage consists of multiple units. Each unit of each stage has some
- conv layers.
-
- Args:
- num_stages (int): Number of stages.
- num_units (int): Number of units in each stage.
- out_shape (tuple): The output shape of the output heatmaps.
- unit_channels (int): Number of input channels.
- out_channels (int): Number of output channels.
- out_shape (tuple): Shape of the output heatmaps.
- use_prm (bool): Whether to use pose refine machine (PRM).
- Defaults to ``False``.
- norm_cfg (Config): Config to construct the norm layer.
- Defaults to ``dict(type='BN')``
- loss (Config | List[Config]): Config of the keypoint loss for
- different stages and different units.
- Defaults to use :class:`KeypointMSELoss`.
- level_indices (Sequence[int]): The indices that specified the level
- of target heatmaps.
- decoder (Config, optional): The decoder config that controls decoding
- keypoint coordinates from the network output. Defaults to ``None``
- init_cfg (Config, optional): Config to control the initialization. See
- :attr:`default_init_cfg` for default settings
-
- .. _`MSPN`: https://arxiv.org/abs/1901.00148
- .. _`RSN`: https://arxiv.org/abs/2003.04030
- """
- _version = 2
-
- def __init__(self,
- num_stages: int = 4,
- num_units: int = 4,
- out_shape: tuple = (64, 48),
- unit_channels: int = 256,
- out_channels: int = 17,
- use_prm: bool = False,
- norm_cfg: ConfigType = dict(type='BN'),
- level_indices: Sequence[int] = [],
- loss: MultiConfig = dict(
- type='KeypointMSELoss', use_target_weight=True),
- decoder: OptConfigType = None,
- init_cfg: OptConfigType = None):
- if init_cfg is None:
- init_cfg = self.default_init_cfg
- super().__init__(init_cfg)
-
- self.num_stages = num_stages
- self.num_units = num_units
- self.out_shape = out_shape
- self.unit_channels = unit_channels
- self.out_channels = out_channels
- if len(level_indices) != num_stages * num_units:
- raise ValueError(
- f'The length of level_indices({len(level_indices)}) did not '
- f'match `num_stages`({num_stages}) * `num_units`({num_units})')
-
- self.level_indices = level_indices
-
- if isinstance(loss, list) and len(loss) != num_stages * num_units:
- raise ValueError(
- f'The length of loss_module({len(loss)}) did not match '
- f'`num_stages`({num_stages}) * `num_units`({num_units})')
-
- if isinstance(loss, list):
- if len(loss) != num_stages * num_units:
- raise ValueError(
- f'The length of loss_module({len(loss)}) did not match '
- f'`num_stages`({num_stages}) * `num_units`({num_units})')
- self.loss_module = nn.ModuleList(
- MODELS.build(_loss) for _loss in loss)
- else:
- self.loss_module = MODELS.build(loss)
-
- if decoder is not None:
- self.decoder = KEYPOINT_CODECS.build(decoder)
- else:
- self.decoder = None
-
- # Protect mutable default arguments
- norm_cfg = copy.deepcopy(norm_cfg)
-
- self.predict_layers = nn.ModuleList([])
- for i in range(self.num_stages):
- for j in range(self.num_units):
- self.predict_layers.append(
- PredictHeatmap(
- unit_channels,
- out_channels,
- out_shape,
- use_prm,
- norm_cfg=norm_cfg))
-
- @property
- def default_init_cfg(self):
- """Default config for weight initialization."""
- init_cfg = [
- dict(type='Kaiming', layer='Conv2d'),
- dict(type='Normal', layer='Linear', std=0.01),
- dict(type='Constant', layer='BatchNorm2d', val=1),
- ]
- return init_cfg
-
- def forward(self, feats: Sequence[Sequence[Tensor]]) -> List[Tensor]:
- """Forward the network. The input is multi-stage multi-unit feature
- maps and the output is a list of heatmaps from multiple stages.
-
- Args:
- feats (Sequence[Sequence[Tensor]]): Feature maps from multiple
- stages and units.
-
- Returns:
- List[Tensor]: A list of output heatmaps from multiple stages
- and units.
- """
- out = []
- assert len(feats) == self.num_stages, (
- f'The length of feature maps did not match the '
- f'`num_stages` in {self.__class__.__name__}')
- for feat in feats:
- assert len(feat) == self.num_units, (
- f'The length of feature maps did not match the '
- f'`num_units` in {self.__class__.__name__}')
- for f in feat:
- assert f.shape[1] == self.unit_channels, (
- f'The number of feature map channels did not match the '
- f'`unit_channels` in {self.__class__.__name__}')
-
- for i in range(self.num_stages):
- for j in range(self.num_units):
- y = self.predict_layers[i * self.num_units + j](feats[i][j])
- out.append(y)
- return out
-
- def predict(self,
- feats: Union[MSMUFeatures, List[MSMUFeatures]],
- batch_data_samples: OptSampleList,
- test_cfg: OptConfigType = {}) -> Predictions:
- """Predict results from multi-stage feature maps.
-
- Args:
- feats (Sequence[Sequence[Tensor]]): Multi-stage multi-unit
- features (or multiple MSMU features for TTA)
- batch_data_samples (List[:obj:`PoseDataSample`]): The Data
- Samples. It usually includes information such as
- `gt_instance_labels`.
- test_cfg (Config, optional): The testing/inference config
-
- Returns:
- Union[InstanceList | Tuple[InstanceList | PixelDataList]]: If
- ``test_cfg['output_heatmap']==True``, return both pose and heatmap
- prediction; otherwise only return the pose prediction.
-
- The pose prediction is a list of ``InstanceData``, each contains
- the following fields:
-
- - keypoints (np.ndarray): predicted keypoint coordinates in
- shape (num_instances, K, D) where K is the keypoint number
- and D is the keypoint dimension
- - keypoint_scores (np.ndarray): predicted keypoint scores in
- shape (num_instances, K)
-
- The heatmap prediction is a list of ``PixelData``, each contains
- the following fields:
-
- - heatmaps (Tensor): The predicted heatmaps in shape (K, h, w)
- """
- # multi-stage multi-unit batch heatmaps
- if test_cfg.get('flip_test', False):
- # TTA: flip test
- assert isinstance(feats, list) and len(feats) == 2
- flip_indices = batch_data_samples[0].metainfo['flip_indices']
- _feats, _feats_flip = feats
- _batch_heatmaps = self.forward(_feats)[-1]
- _batch_heatmaps_flip = flip_heatmaps(
- self.forward(_feats_flip)[-1],
- flip_mode=test_cfg.get('flip_mode', 'heatmap'),
- flip_indices=flip_indices,
- shift_heatmap=test_cfg.get('shift_heatmap', False))
- batch_heatmaps = (_batch_heatmaps + _batch_heatmaps_flip) * 0.5
- else:
- msmu_batch_heatmaps = self.forward(feats)
- batch_heatmaps = msmu_batch_heatmaps[-1]
-
- preds = self.decode(batch_heatmaps)
-
- if test_cfg.get('output_heatmaps', False):
- pred_fields = [
- PixelData(heatmaps=hm) for hm in batch_heatmaps.detach()
- ]
- return preds, pred_fields
- else:
- return preds
-
- def loss(self,
- feats: MSMUFeatures,
- batch_data_samples: OptSampleList,
- train_cfg: OptConfigType = {}) -> dict:
- """Calculate losses from a batch of inputs and data samples.
-
- Note:
- - batch_size: B
- - num_output_heatmap_levels: L
- - num_keypoints: K
- - heatmaps height: H
- - heatmaps weight: W
- - num_instances: N (usually 1 in topdown heatmap heads)
-
- Args:
- feats (Sequence[Sequence[Tensor]]): Feature maps from multiple
- stages and units
- batch_data_samples (List[:obj:`PoseDataSample`]): The Data
- Samples. It usually includes information such as
- `gt_instance_labels` and `gt_fields`.
- train_cfg (Config, optional): The training config
-
- Returns:
- dict: A dictionary of loss components.
- """
- # multi-stage multi-unit predict heatmaps
- msmu_pred_heatmaps = self.forward(feats)
-
- keypoint_weights = torch.cat([
- d.gt_instance_labels.keypoint_weights for d in batch_data_samples
- ]) # shape: [B*N, L, K]
-
- # calculate losses over multiple stages and multiple units
- losses = dict()
- for i in range(self.num_stages * self.num_units):
- if isinstance(self.loss_module, nn.ModuleList):
- # use different loss_module over different stages and units
- loss_func = self.loss_module[i]
- else:
- # use the same loss_module over different stages and units
- loss_func = self.loss_module
-
- # select `gt_heatmaps` and `keypoint_weights` for different level
- # according to `self.level_indices` to calculate loss
- gt_heatmaps = torch.stack([
- d.gt_fields[self.level_indices[i]].heatmaps
- for d in batch_data_samples
- ])
- loss_i = loss_func(msmu_pred_heatmaps[i], gt_heatmaps,
- keypoint_weights[:, self.level_indices[i]])
-
- if 'loss_kpt' not in losses:
- losses['loss_kpt'] = loss_i
- else:
- losses['loss_kpt'] += loss_i
-
- # calculate accuracy
- _, avg_acc, _ = pose_pck_accuracy(
- output=to_numpy(msmu_pred_heatmaps[-1]),
- target=to_numpy(gt_heatmaps),
- mask=to_numpy(keypoint_weights[:, -1]) > 0)
-
- acc_pose = torch.tensor(avg_acc, device=gt_heatmaps.device)
- losses.update(acc_pose=acc_pose)
-
- return losses
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import List, Optional, Sequence, Union
+
+import torch
+from mmcv.cnn import (ConvModule, DepthwiseSeparableConvModule, Linear,
+ build_activation_layer, build_norm_layer)
+from mmengine.structures import PixelData
+from torch import Tensor, nn
+
+from mmpose.evaluation.functional import pose_pck_accuracy
+from mmpose.models.utils.tta import flip_heatmaps
+from mmpose.registry import KEYPOINT_CODECS, MODELS
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import (ConfigType, MultiConfig, OptConfigType,
+ OptSampleList, Predictions)
+from ..base_head import BaseHead
+
+OptIntSeq = Optional[Sequence[int]]
+MSMUFeatures = Sequence[Sequence[Tensor]] # Multi-stage multi-unit features
+
+
+class PRM(nn.Module):
+ """Pose Refine Machine.
+
+ Please refer to "Learning Delicate Local Representations
+ for Multi-Person Pose Estimation" (ECCV 2020).
+
+ Args:
+ out_channels (int): Number of the output channels, equals to
+ the number of keypoints.
+ norm_cfg (Config): Config to construct the norm layer.
+ Defaults to ``dict(type='BN')``
+ """
+
+ def __init__(self,
+ out_channels: int,
+ norm_cfg: ConfigType = dict(type='BN')):
+ super().__init__()
+
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ self.out_channels = out_channels
+ self.global_pooling = nn.AdaptiveAvgPool2d((1, 1))
+ self.middle_path = nn.Sequential(
+ Linear(self.out_channels, self.out_channels),
+ build_norm_layer(dict(type='BN1d'), out_channels)[1],
+ build_activation_layer(dict(type='ReLU')),
+ Linear(self.out_channels, self.out_channels),
+ build_norm_layer(dict(type='BN1d'), out_channels)[1],
+ build_activation_layer(dict(type='ReLU')),
+ build_activation_layer(dict(type='Sigmoid')))
+
+ self.bottom_path = nn.Sequential(
+ ConvModule(
+ self.out_channels,
+ self.out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ norm_cfg=norm_cfg,
+ inplace=False),
+ DepthwiseSeparableConvModule(
+ self.out_channels,
+ 1,
+ kernel_size=9,
+ stride=1,
+ padding=4,
+ norm_cfg=norm_cfg,
+ inplace=False), build_activation_layer(dict(type='Sigmoid')))
+ self.conv_bn_relu_prm_1 = ConvModule(
+ self.out_channels,
+ self.out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ norm_cfg=norm_cfg,
+ inplace=False)
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward the network. The input heatmaps will be refined.
+
+ Args:
+ x (Tensor): The input heatmaps.
+
+ Returns:
+ Tensor: output heatmaps.
+ """
+ out = self.conv_bn_relu_prm_1(x)
+ out_1 = out
+
+ out_2 = self.global_pooling(out_1)
+ out_2 = out_2.view(out_2.size(0), -1)
+ out_2 = self.middle_path(out_2)
+ out_2 = out_2.unsqueeze(2)
+ out_2 = out_2.unsqueeze(3)
+
+ out_3 = self.bottom_path(out_1)
+ out = out_1 * (1 + out_2 * out_3)
+
+ return out
+
+
+class PredictHeatmap(nn.Module):
+ """Predict the heatmap for an input feature.
+
+ Args:
+ unit_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ out_shape (tuple): Shape of the output heatmaps.
+ use_prm (bool): Whether to use pose refine machine. Default: False.
+ norm_cfg (Config): Config to construct the norm layer.
+ Defaults to ``dict(type='BN')``
+ """
+
+ def __init__(self,
+ unit_channels: int,
+ out_channels: int,
+ out_shape: tuple,
+ use_prm: bool = False,
+ norm_cfg: ConfigType = dict(type='BN')):
+
+ super().__init__()
+
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+ self.unit_channels = unit_channels
+ self.out_channels = out_channels
+ self.out_shape = out_shape
+ self.use_prm = use_prm
+ if use_prm:
+ self.prm = PRM(out_channels, norm_cfg=norm_cfg)
+ self.conv_layers = nn.Sequential(
+ ConvModule(
+ unit_channels,
+ unit_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ norm_cfg=norm_cfg,
+ inplace=False),
+ ConvModule(
+ unit_channels,
+ out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=None,
+ inplace=False))
+
+ def forward(self, feature: Tensor) -> Tensor:
+ """Forward the network.
+
+ Args:
+ feature (Tensor): The input feature maps.
+
+ Returns:
+ Tensor: output heatmaps.
+ """
+ feature = self.conv_layers(feature)
+ output = nn.functional.interpolate(
+ feature, size=self.out_shape, mode='bilinear', align_corners=True)
+ if self.use_prm:
+ output = self.prm(output)
+ return output
+
+
+@MODELS.register_module()
+class MSPNHead(BaseHead):
+ """Multi-stage multi-unit heatmap head introduced in `Multi-Stage Pose
+ estimation Network (MSPN)`_ by Li et al (2019), and used by `Residual Steps
+ Networks (RSN)`_ by Cai et al (2020). The head consists of multiple stages
+ and each stage consists of multiple units. Each unit of each stage has some
+ conv layers.
+
+ Args:
+ num_stages (int): Number of stages.
+ num_units (int): Number of units in each stage.
+ out_shape (tuple): The output shape of the output heatmaps.
+ unit_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ out_shape (tuple): Shape of the output heatmaps.
+ use_prm (bool): Whether to use pose refine machine (PRM).
+ Defaults to ``False``.
+ norm_cfg (Config): Config to construct the norm layer.
+ Defaults to ``dict(type='BN')``
+ loss (Config | List[Config]): Config of the keypoint loss for
+ different stages and different units.
+ Defaults to use :class:`KeypointMSELoss`.
+ level_indices (Sequence[int]): The indices that specified the level
+ of target heatmaps.
+ decoder (Config, optional): The decoder config that controls decoding
+ keypoint coordinates from the network output. Defaults to ``None``
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+
+ .. _`MSPN`: https://arxiv.org/abs/1901.00148
+ .. _`RSN`: https://arxiv.org/abs/2003.04030
+ """
+ _version = 2
+
+ def __init__(self,
+ num_stages: int = 4,
+ num_units: int = 4,
+ out_shape: tuple = (64, 48),
+ unit_channels: int = 256,
+ out_channels: int = 17,
+ use_prm: bool = False,
+ norm_cfg: ConfigType = dict(type='BN'),
+ level_indices: Sequence[int] = [],
+ loss: MultiConfig = dict(
+ type='KeypointMSELoss', use_target_weight=True),
+ decoder: OptConfigType = None,
+ init_cfg: OptConfigType = None):
+ if init_cfg is None:
+ init_cfg = self.default_init_cfg
+ super().__init__(init_cfg)
+
+ self.num_stages = num_stages
+ self.num_units = num_units
+ self.out_shape = out_shape
+ self.unit_channels = unit_channels
+ self.out_channels = out_channels
+ if len(level_indices) != num_stages * num_units:
+ raise ValueError(
+ f'The length of level_indices({len(level_indices)}) did not '
+ f'match `num_stages`({num_stages}) * `num_units`({num_units})')
+
+ self.level_indices = level_indices
+
+ if isinstance(loss, list) and len(loss) != num_stages * num_units:
+ raise ValueError(
+ f'The length of loss_module({len(loss)}) did not match '
+ f'`num_stages`({num_stages}) * `num_units`({num_units})')
+
+ if isinstance(loss, list):
+ if len(loss) != num_stages * num_units:
+ raise ValueError(
+ f'The length of loss_module({len(loss)}) did not match '
+ f'`num_stages`({num_stages}) * `num_units`({num_units})')
+ self.loss_module = nn.ModuleList(
+ MODELS.build(_loss) for _loss in loss)
+ else:
+ self.loss_module = MODELS.build(loss)
+
+ if decoder is not None:
+ self.decoder = KEYPOINT_CODECS.build(decoder)
+ else:
+ self.decoder = None
+
+ # Protect mutable default arguments
+ norm_cfg = copy.deepcopy(norm_cfg)
+
+ self.predict_layers = nn.ModuleList([])
+ for i in range(self.num_stages):
+ for j in range(self.num_units):
+ self.predict_layers.append(
+ PredictHeatmap(
+ unit_channels,
+ out_channels,
+ out_shape,
+ use_prm,
+ norm_cfg=norm_cfg))
+
+ @property
+ def default_init_cfg(self):
+ """Default config for weight initialization."""
+ init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(type='Normal', layer='Linear', std=0.01),
+ dict(type='Constant', layer='BatchNorm2d', val=1),
+ ]
+ return init_cfg
+
+ def forward(self, feats: Sequence[Sequence[Tensor]]) -> List[Tensor]:
+ """Forward the network. The input is multi-stage multi-unit feature
+ maps and the output is a list of heatmaps from multiple stages.
+
+ Args:
+ feats (Sequence[Sequence[Tensor]]): Feature maps from multiple
+ stages and units.
+
+ Returns:
+ List[Tensor]: A list of output heatmaps from multiple stages
+ and units.
+ """
+ out = []
+ assert len(feats) == self.num_stages, (
+ f'The length of feature maps did not match the '
+ f'`num_stages` in {self.__class__.__name__}')
+ for feat in feats:
+ assert len(feat) == self.num_units, (
+ f'The length of feature maps did not match the '
+ f'`num_units` in {self.__class__.__name__}')
+ for f in feat:
+ assert f.shape[1] == self.unit_channels, (
+ f'The number of feature map channels did not match the '
+ f'`unit_channels` in {self.__class__.__name__}')
+
+ for i in range(self.num_stages):
+ for j in range(self.num_units):
+ y = self.predict_layers[i * self.num_units + j](feats[i][j])
+ out.append(y)
+ return out
+
+ def predict(self,
+ feats: Union[MSMUFeatures, List[MSMUFeatures]],
+ batch_data_samples: OptSampleList,
+ test_cfg: OptConfigType = {}) -> Predictions:
+ """Predict results from multi-stage feature maps.
+
+ Args:
+ feats (Sequence[Sequence[Tensor]]): Multi-stage multi-unit
+ features (or multiple MSMU features for TTA)
+ batch_data_samples (List[:obj:`PoseDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance_labels`.
+ test_cfg (Config, optional): The testing/inference config
+
+ Returns:
+ Union[InstanceList | Tuple[InstanceList | PixelDataList]]: If
+ ``test_cfg['output_heatmap']==True``, return both pose and heatmap
+ prediction; otherwise only return the pose prediction.
+
+ The pose prediction is a list of ``InstanceData``, each contains
+ the following fields:
+
+ - keypoints (np.ndarray): predicted keypoint coordinates in
+ shape (num_instances, K, D) where K is the keypoint number
+ and D is the keypoint dimension
+ - keypoint_scores (np.ndarray): predicted keypoint scores in
+ shape (num_instances, K)
+
+ The heatmap prediction is a list of ``PixelData``, each contains
+ the following fields:
+
+ - heatmaps (Tensor): The predicted heatmaps in shape (K, h, w)
+ """
+ # multi-stage multi-unit batch heatmaps
+ if test_cfg.get('flip_test', False):
+ # TTA: flip test
+ assert isinstance(feats, list) and len(feats) == 2
+ flip_indices = batch_data_samples[0].metainfo['flip_indices']
+ _feats, _feats_flip = feats
+ _batch_heatmaps = self.forward(_feats)[-1]
+ _batch_heatmaps_flip = flip_heatmaps(
+ self.forward(_feats_flip)[-1],
+ flip_mode=test_cfg.get('flip_mode', 'heatmap'),
+ flip_indices=flip_indices,
+ shift_heatmap=test_cfg.get('shift_heatmap', False))
+ batch_heatmaps = (_batch_heatmaps + _batch_heatmaps_flip) * 0.5
+ else:
+ msmu_batch_heatmaps = self.forward(feats)
+ batch_heatmaps = msmu_batch_heatmaps[-1]
+
+ preds = self.decode(batch_heatmaps)
+
+ if test_cfg.get('output_heatmaps', False):
+ pred_fields = [
+ PixelData(heatmaps=hm) for hm in batch_heatmaps.detach()
+ ]
+ return preds, pred_fields
+ else:
+ return preds
+
+ def loss(self,
+ feats: MSMUFeatures,
+ batch_data_samples: OptSampleList,
+ train_cfg: OptConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Note:
+ - batch_size: B
+ - num_output_heatmap_levels: L
+ - num_keypoints: K
+ - heatmaps height: H
+ - heatmaps weight: W
+ - num_instances: N (usually 1 in topdown heatmap heads)
+
+ Args:
+ feats (Sequence[Sequence[Tensor]]): Feature maps from multiple
+ stages and units
+ batch_data_samples (List[:obj:`PoseDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance_labels` and `gt_fields`.
+ train_cfg (Config, optional): The training config
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ # multi-stage multi-unit predict heatmaps
+ msmu_pred_heatmaps = self.forward(feats)
+
+ keypoint_weights = torch.cat([
+ d.gt_instance_labels.keypoint_weights for d in batch_data_samples
+ ]) # shape: [B*N, L, K]
+
+ # calculate losses over multiple stages and multiple units
+ losses = dict()
+ for i in range(self.num_stages * self.num_units):
+ if isinstance(self.loss_module, nn.ModuleList):
+ # use different loss_module over different stages and units
+ loss_func = self.loss_module[i]
+ else:
+ # use the same loss_module over different stages and units
+ loss_func = self.loss_module
+
+ # select `gt_heatmaps` and `keypoint_weights` for different level
+ # according to `self.level_indices` to calculate loss
+ gt_heatmaps = torch.stack([
+ d.gt_fields[self.level_indices[i]].heatmaps
+ for d in batch_data_samples
+ ])
+ loss_i = loss_func(msmu_pred_heatmaps[i], gt_heatmaps,
+ keypoint_weights[:, self.level_indices[i]])
+
+ if 'loss_kpt' not in losses:
+ losses['loss_kpt'] = loss_i
+ else:
+ losses['loss_kpt'] += loss_i
+
+ # calculate accuracy
+ _, avg_acc, _ = pose_pck_accuracy(
+ output=to_numpy(msmu_pred_heatmaps[-1]),
+ target=to_numpy(gt_heatmaps),
+ mask=to_numpy(keypoint_weights[:, -1]) > 0)
+
+ acc_pose = torch.tensor(avg_acc, device=gt_heatmaps.device)
+ losses.update(acc_pose=acc_pose)
+
+ return losses
diff --git a/mmpose/models/heads/heatmap_heads/vipnas_head.py b/mmpose/models/heads/heatmap_heads/vipnas_head.py
index 949ee95b09..7a77dd2a08 100644
--- a/mmpose/models/heads/heatmap_heads/vipnas_head.py
+++ b/mmpose/models/heads/heatmap_heads/vipnas_head.py
@@ -1,179 +1,179 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional, Sequence, Union
-
-from mmcv.cnn import build_conv_layer, build_upsample_layer
-from torch import nn
-
-from mmpose.registry import KEYPOINT_CODECS, MODELS
-from mmpose.utils.typing import ConfigType, OptConfigType
-from .heatmap_head import HeatmapHead
-
-OptIntSeq = Optional[Sequence[int]]
-
-
-@MODELS.register_module()
-class ViPNASHead(HeatmapHead):
- """ViPNAS heatmap head introduced in `ViPNAS`_ by Xu et al (2021). The head
- is composed of a few deconvolutional layers followed by a convolutional
- layer to generate heatmaps from low-resolution feature maps. Specifically,
- different from the :class: `HeatmapHead` introduced by `Simple Baselines`_,
- the group numbers in the deconvolutional layers are elastic and thus can be
- optimized by neural architecture search (NAS).
-
- Args:
- in_channels (int | Sequence[int]): Number of channels in the input
- feature map
- out_channels (int): Number of channels in the output heatmap
- deconv_out_channels (Sequence[int], optional): The output channel
- number of each deconv layer. Defaults to ``(144, 144, 144)``
- deconv_kernel_sizes (Sequence[int | tuple], optional): The kernel size
- of each deconv layer. Each element should be either an integer for
- both height and width dimensions, or a tuple of two integers for
- the height and the width dimension respectively.Defaults to
- ``(4, 4, 4)``
- deconv_num_groups (Sequence[int], optional): The group number of each
- deconv layer. Defaults to ``(16, 16, 16)``
- conv_out_channels (Sequence[int], optional): The output channel number
- of each intermediate conv layer. ``None`` means no intermediate
- conv layer between deconv layers and the final conv layer.
- Defaults to ``None``
- conv_kernel_sizes (Sequence[int | tuple], optional): The kernel size
- of each intermediate conv layer. Defaults to ``None``
- final_layer (dict): Arguments of the final Conv2d layer.
- Defaults to ``dict(kernel_size=1)``
- loss (Config): Config of the keypoint loss. Defaults to use
- :class:`KeypointMSELoss`
- decoder (Config, optional): The decoder config that controls decoding
- keypoint coordinates from the network output. Defaults to ``None``
- init_cfg (Config, optional): Config to control the initialization. See
- :attr:`default_init_cfg` for default settings
-
- .. _`ViPNAS`: https://arxiv.org/abs/2105.10154
- .. _`Simple Baselines`: https://arxiv.org/abs/1804.06208
- """
-
- _version = 2
-
- def __init__(self,
- in_channels: Union[int, Sequence[int]],
- out_channels: int,
- deconv_out_channels: OptIntSeq = (144, 144, 144),
- deconv_kernel_sizes: OptIntSeq = (4, 4, 4),
- deconv_num_groups: OptIntSeq = (16, 16, 16),
- conv_out_channels: OptIntSeq = None,
- conv_kernel_sizes: OptIntSeq = None,
- final_layer: dict = dict(kernel_size=1),
- loss: ConfigType = dict(
- type='KeypointMSELoss', use_target_weight=True),
- decoder: OptConfigType = None,
- init_cfg: OptConfigType = None):
-
- if init_cfg is None:
- init_cfg = self.default_init_cfg
-
- super(HeatmapHead, self).__init__(init_cfg)
-
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.loss_module = MODELS.build(loss)
- if decoder is not None:
- self.decoder = KEYPOINT_CODECS.build(decoder)
- else:
- self.decoder = None
-
- if deconv_out_channels:
- if deconv_kernel_sizes is None or len(deconv_out_channels) != len(
- deconv_kernel_sizes):
- raise ValueError(
- '"deconv_out_channels" and "deconv_kernel_sizes" should '
- 'be integer sequences with the same length. Got '
- f'mismatched lengths {deconv_out_channels} and '
- f'{deconv_kernel_sizes}')
- if deconv_num_groups is None or len(deconv_out_channels) != len(
- deconv_num_groups):
- raise ValueError(
- '"deconv_out_channels" and "deconv_num_groups" should '
- 'be integer sequences with the same length. Got '
- f'mismatched lengths {deconv_out_channels} and '
- f'{deconv_num_groups}')
-
- self.deconv_layers = self._make_deconv_layers(
- in_channels=in_channels,
- layer_out_channels=deconv_out_channels,
- layer_kernel_sizes=deconv_kernel_sizes,
- layer_groups=deconv_num_groups,
- )
- in_channels = deconv_out_channels[-1]
- else:
- self.deconv_layers = nn.Identity()
-
- if conv_out_channels:
- if conv_kernel_sizes is None or len(conv_out_channels) != len(
- conv_kernel_sizes):
- raise ValueError(
- '"conv_out_channels" and "conv_kernel_sizes" should '
- 'be integer sequences with the same length. Got '
- f'mismatched lengths {conv_out_channels} and '
- f'{conv_kernel_sizes}')
-
- self.conv_layers = self._make_conv_layers(
- in_channels=in_channels,
- layer_out_channels=conv_out_channels,
- layer_kernel_sizes=conv_kernel_sizes)
- in_channels = conv_out_channels[-1]
- else:
- self.conv_layers = nn.Identity()
-
- if final_layer is not None:
- cfg = dict(
- type='Conv2d',
- in_channels=in_channels,
- out_channels=out_channels,
- kernel_size=1)
- cfg.update(final_layer)
- self.final_layer = build_conv_layer(cfg)
- else:
- self.final_layer = nn.Identity()
-
- # Register the hook to automatically convert old version state dicts
- self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
-
- def _make_deconv_layers(self, in_channels: int,
- layer_out_channels: Sequence[int],
- layer_kernel_sizes: Sequence[int],
- layer_groups: Sequence[int]) -> nn.Module:
- """Create deconvolutional layers by given parameters."""
-
- layers = []
- for out_channels, kernel_size, groups in zip(layer_out_channels,
- layer_kernel_sizes,
- layer_groups):
- if kernel_size == 4:
- padding = 1
- output_padding = 0
- elif kernel_size == 3:
- padding = 1
- output_padding = 1
- elif kernel_size == 2:
- padding = 0
- output_padding = 0
- else:
- raise ValueError(f'Unsupported kernel size {kernel_size} for'
- 'deconvlutional layers in '
- f'{self.__class__.__name__}')
- cfg = dict(
- type='deconv',
- in_channels=in_channels,
- out_channels=out_channels,
- kernel_size=kernel_size,
- groups=groups,
- stride=2,
- padding=padding,
- output_padding=output_padding,
- bias=False)
- layers.append(build_upsample_layer(cfg))
- layers.append(nn.BatchNorm2d(num_features=out_channels))
- layers.append(nn.ReLU(inplace=True))
- in_channels = out_channels
-
- return nn.Sequential(*layers)
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Sequence, Union
+
+from mmcv.cnn import build_conv_layer, build_upsample_layer
+from torch import nn
+
+from mmpose.registry import KEYPOINT_CODECS, MODELS
+from mmpose.utils.typing import ConfigType, OptConfigType
+from .heatmap_head import HeatmapHead
+
+OptIntSeq = Optional[Sequence[int]]
+
+
+@MODELS.register_module()
+class ViPNASHead(HeatmapHead):
+ """ViPNAS heatmap head introduced in `ViPNAS`_ by Xu et al (2021). The head
+ is composed of a few deconvolutional layers followed by a convolutional
+ layer to generate heatmaps from low-resolution feature maps. Specifically,
+ different from the :class: `HeatmapHead` introduced by `Simple Baselines`_,
+ the group numbers in the deconvolutional layers are elastic and thus can be
+ optimized by neural architecture search (NAS).
+
+ Args:
+ in_channels (int | Sequence[int]): Number of channels in the input
+ feature map
+ out_channels (int): Number of channels in the output heatmap
+ deconv_out_channels (Sequence[int], optional): The output channel
+ number of each deconv layer. Defaults to ``(144, 144, 144)``
+ deconv_kernel_sizes (Sequence[int | tuple], optional): The kernel size
+ of each deconv layer. Each element should be either an integer for
+ both height and width dimensions, or a tuple of two integers for
+ the height and the width dimension respectively.Defaults to
+ ``(4, 4, 4)``
+ deconv_num_groups (Sequence[int], optional): The group number of each
+ deconv layer. Defaults to ``(16, 16, 16)``
+ conv_out_channels (Sequence[int], optional): The output channel number
+ of each intermediate conv layer. ``None`` means no intermediate
+ conv layer between deconv layers and the final conv layer.
+ Defaults to ``None``
+ conv_kernel_sizes (Sequence[int | tuple], optional): The kernel size
+ of each intermediate conv layer. Defaults to ``None``
+ final_layer (dict): Arguments of the final Conv2d layer.
+ Defaults to ``dict(kernel_size=1)``
+ loss (Config): Config of the keypoint loss. Defaults to use
+ :class:`KeypointMSELoss`
+ decoder (Config, optional): The decoder config that controls decoding
+ keypoint coordinates from the network output. Defaults to ``None``
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+
+ .. _`ViPNAS`: https://arxiv.org/abs/2105.10154
+ .. _`Simple Baselines`: https://arxiv.org/abs/1804.06208
+ """
+
+ _version = 2
+
+ def __init__(self,
+ in_channels: Union[int, Sequence[int]],
+ out_channels: int,
+ deconv_out_channels: OptIntSeq = (144, 144, 144),
+ deconv_kernel_sizes: OptIntSeq = (4, 4, 4),
+ deconv_num_groups: OptIntSeq = (16, 16, 16),
+ conv_out_channels: OptIntSeq = None,
+ conv_kernel_sizes: OptIntSeq = None,
+ final_layer: dict = dict(kernel_size=1),
+ loss: ConfigType = dict(
+ type='KeypointMSELoss', use_target_weight=True),
+ decoder: OptConfigType = None,
+ init_cfg: OptConfigType = None):
+
+ if init_cfg is None:
+ init_cfg = self.default_init_cfg
+
+ super(HeatmapHead, self).__init__(init_cfg)
+
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.loss_module = MODELS.build(loss)
+ if decoder is not None:
+ self.decoder = KEYPOINT_CODECS.build(decoder)
+ else:
+ self.decoder = None
+
+ if deconv_out_channels:
+ if deconv_kernel_sizes is None or len(deconv_out_channels) != len(
+ deconv_kernel_sizes):
+ raise ValueError(
+ '"deconv_out_channels" and "deconv_kernel_sizes" should '
+ 'be integer sequences with the same length. Got '
+ f'mismatched lengths {deconv_out_channels} and '
+ f'{deconv_kernel_sizes}')
+ if deconv_num_groups is None or len(deconv_out_channels) != len(
+ deconv_num_groups):
+ raise ValueError(
+ '"deconv_out_channels" and "deconv_num_groups" should '
+ 'be integer sequences with the same length. Got '
+ f'mismatched lengths {deconv_out_channels} and '
+ f'{deconv_num_groups}')
+
+ self.deconv_layers = self._make_deconv_layers(
+ in_channels=in_channels,
+ layer_out_channels=deconv_out_channels,
+ layer_kernel_sizes=deconv_kernel_sizes,
+ layer_groups=deconv_num_groups,
+ )
+ in_channels = deconv_out_channels[-1]
+ else:
+ self.deconv_layers = nn.Identity()
+
+ if conv_out_channels:
+ if conv_kernel_sizes is None or len(conv_out_channels) != len(
+ conv_kernel_sizes):
+ raise ValueError(
+ '"conv_out_channels" and "conv_kernel_sizes" should '
+ 'be integer sequences with the same length. Got '
+ f'mismatched lengths {conv_out_channels} and '
+ f'{conv_kernel_sizes}')
+
+ self.conv_layers = self._make_conv_layers(
+ in_channels=in_channels,
+ layer_out_channels=conv_out_channels,
+ layer_kernel_sizes=conv_kernel_sizes)
+ in_channels = conv_out_channels[-1]
+ else:
+ self.conv_layers = nn.Identity()
+
+ if final_layer is not None:
+ cfg = dict(
+ type='Conv2d',
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1)
+ cfg.update(final_layer)
+ self.final_layer = build_conv_layer(cfg)
+ else:
+ self.final_layer = nn.Identity()
+
+ # Register the hook to automatically convert old version state dicts
+ self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
+
+ def _make_deconv_layers(self, in_channels: int,
+ layer_out_channels: Sequence[int],
+ layer_kernel_sizes: Sequence[int],
+ layer_groups: Sequence[int]) -> nn.Module:
+ """Create deconvolutional layers by given parameters."""
+
+ layers = []
+ for out_channels, kernel_size, groups in zip(layer_out_channels,
+ layer_kernel_sizes,
+ layer_groups):
+ if kernel_size == 4:
+ padding = 1
+ output_padding = 0
+ elif kernel_size == 3:
+ padding = 1
+ output_padding = 1
+ elif kernel_size == 2:
+ padding = 0
+ output_padding = 0
+ else:
+ raise ValueError(f'Unsupported kernel size {kernel_size} for'
+ 'deconvlutional layers in '
+ f'{self.__class__.__name__}')
+ cfg = dict(
+ type='deconv',
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ groups=groups,
+ stride=2,
+ padding=padding,
+ output_padding=output_padding,
+ bias=False)
+ layers.append(build_upsample_layer(cfg))
+ layers.append(nn.BatchNorm2d(num_features=out_channels))
+ layers.append(nn.ReLU(inplace=True))
+ in_channels = out_channels
+
+ return nn.Sequential(*layers)
diff --git a/mmpose/models/heads/hybrid_heads/__init__.py b/mmpose/models/heads/hybrid_heads/__init__.py
index 6431b6a2c2..af3c5a4b05 100644
--- a/mmpose/models/heads/hybrid_heads/__init__.py
+++ b/mmpose/models/heads/hybrid_heads/__init__.py
@@ -1,5 +1,5 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .dekr_head import DEKRHead
-from .vis_head import VisPredictHead
-
-__all__ = ['DEKRHead', 'VisPredictHead']
+# Copyright (c) OpenMMLab. All rights reserved.
+from .dekr_head import DEKRHead
+from .vis_head import VisPredictHead
+
+__all__ = ['DEKRHead', 'VisPredictHead']
diff --git a/mmpose/models/heads/hybrid_heads/dekr_head.py b/mmpose/models/heads/hybrid_heads/dekr_head.py
index 41f7cfc4ce..3a6bf69414 100644
--- a/mmpose/models/heads/hybrid_heads/dekr_head.py
+++ b/mmpose/models/heads/hybrid_heads/dekr_head.py
@@ -1,581 +1,581 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Sequence, Tuple, Union
-
-import torch
-from mmcv.cnn import (ConvModule, build_activation_layer, build_conv_layer,
- build_norm_layer)
-from mmengine.model import BaseModule, ModuleDict, Sequential
-from mmengine.structures import InstanceData, PixelData
-from torch import Tensor
-
-from mmpose.evaluation.functional.nms import nearby_joints_nms
-from mmpose.models.utils.tta import flip_heatmaps
-from mmpose.registry import KEYPOINT_CODECS, MODELS
-from mmpose.utils.tensor_utils import to_numpy
-from mmpose.utils.typing import (ConfigType, Features, InstanceList,
- OptConfigType, OptSampleList, Predictions)
-from ...backbones.resnet import BasicBlock
-from ..base_head import BaseHead
-
-try:
- from mmcv.ops import DeformConv2d
- has_mmcv_full = True
-except (ImportError, ModuleNotFoundError):
- has_mmcv_full = False
-
-
-class AdaptiveActivationBlock(BaseModule):
- """Adaptive activation convolution block. "Bottom-up human pose estimation
- via disentangled keypoint regression", CVPR'2021.
-
- Args:
- in_channels (int): Number of input channels
- out_channels (int): Number of output channels
- groups (int): Number of groups. Generally equal to the
- number of joints.
- norm_cfg (dict): Config for normalization layers.
- act_cfg (dict): Config for activation layers.
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- groups=1,
- norm_cfg=dict(type='BN'),
- act_cfg=dict(type='ReLU'),
- init_cfg=None):
- super(AdaptiveActivationBlock, self).__init__(init_cfg=init_cfg)
-
- assert in_channels % groups == 0 and out_channels % groups == 0
- self.groups = groups
-
- regular_matrix = torch.tensor([[-1, -1, -1, 0, 0, 0, 1, 1, 1],
- [-1, 0, 1, -1, 0, 1, -1, 0, 1],
- [1, 1, 1, 1, 1, 1, 1, 1, 1]])
- self.register_buffer('regular_matrix', regular_matrix.float())
-
- self.transform_matrix_conv = build_conv_layer(
- dict(type='Conv2d'),
- in_channels=in_channels,
- out_channels=6 * groups,
- kernel_size=3,
- padding=1,
- groups=groups,
- bias=True)
-
- if has_mmcv_full:
- self.adapt_conv = DeformConv2d(
- in_channels,
- out_channels,
- kernel_size=3,
- padding=1,
- bias=False,
- groups=groups,
- deform_groups=groups)
- else:
- raise ImportError('Please install the full version of mmcv '
- 'to use `DeformConv2d`.')
-
- self.norm = build_norm_layer(norm_cfg, out_channels)[1]
- self.act = build_activation_layer(act_cfg)
-
- def forward(self, x):
- B, _, H, W = x.size()
- residual = x
-
- affine_matrix = self.transform_matrix_conv(x)
- affine_matrix = affine_matrix.permute(0, 2, 3, 1).contiguous()
- affine_matrix = affine_matrix.view(B, H, W, self.groups, 2, 3)
- offset = torch.matmul(affine_matrix, self.regular_matrix)
- offset = offset.transpose(4, 5).reshape(B, H, W, self.groups * 18)
- offset = offset.permute(0, 3, 1, 2).contiguous()
-
- x = self.adapt_conv(x, offset)
- x = self.norm(x)
- x = self.act(x + residual)
-
- return x
-
-
-class RescoreNet(BaseModule):
- """Rescore net used to predict the OKS score of predicted pose. We use the
- off-the-shelf rescore net pretrained by authors of DEKR.
-
- Args:
- in_channels (int): Input channels
- norm_indexes (Tuple(int)): Indices of torso in skeleton
- init_cfg (dict, optional): Initialization config dict
- """
-
- def __init__(
- self,
- in_channels,
- norm_indexes,
- init_cfg=None,
- ):
- super(RescoreNet, self).__init__(init_cfg=init_cfg)
-
- self.norm_indexes = norm_indexes
-
- hidden = 256
-
- self.l1 = torch.nn.Linear(in_channels, hidden, bias=True)
- self.l2 = torch.nn.Linear(hidden, hidden, bias=True)
- self.l3 = torch.nn.Linear(hidden, 1, bias=True)
- self.relu = torch.nn.ReLU()
-
- def make_feature(self, keypoints, keypoint_scores, skeleton):
- """Combine original scores, joint distance and relative distance to
- make feature.
-
- Args:
- keypoints (torch.Tensor): predicetd keypoints
- keypoint_scores (torch.Tensor): predicetd keypoint scores
- skeleton (list(list(int))): joint links
-
- Returns:
- torch.Tensor: feature for each instance
- """
- joint_1, joint_2 = zip(*skeleton)
- num_link = len(skeleton)
-
- joint_relate = (keypoints[:, joint_1] -
- keypoints[:, joint_2])[:, :, :2]
- joint_length = joint_relate.norm(dim=2)
-
- # To use the torso distance to normalize
- normalize = (joint_length[:, self.norm_indexes[0]] +
- joint_length[:, self.norm_indexes[1]]) / 2
- normalize = normalize.unsqueeze(1).expand(normalize.size(0), num_link)
- normalize = normalize.clamp(min=1).contiguous()
-
- joint_length = joint_length / normalize[:, :]
- joint_relate = joint_relate / normalize.unsqueeze(-1)
- joint_relate = joint_relate.flatten(1)
-
- feature = torch.cat((joint_relate, joint_length, keypoint_scores),
- dim=1).float()
- return feature
-
- def forward(self, keypoints, keypoint_scores, skeleton):
- feature = self.make_feature(keypoints, keypoint_scores, skeleton)
- x = self.relu(self.l1(feature))
- x = self.relu(self.l2(x))
- x = self.l3(x)
- return x.squeeze(1)
-
-
-@MODELS.register_module()
-class DEKRHead(BaseHead):
- """DisEntangled Keypoint Regression head introduced in `Bottom-up human
- pose estimation via disentangled keypoint regression`_ by Geng et al
- (2021). The head is composed of a heatmap branch and a displacement branch.
-
- Args:
- in_channels (int | Sequence[int]): Number of channels in the input
- feature map
- num_joints (int): Number of joints
- num_heatmap_filters (int): Number of filters for heatmap branch.
- Defaults to 32
- num_offset_filters_per_joint (int): Number of filters for each joint
- in displacement branch. Defaults to 15
- heatmap_loss (Config): Config of the heatmap loss. Defaults to use
- :class:`KeypointMSELoss`
- displacement_loss (Config): Config of the displacement regression loss.
- Defaults to use :class:`SoftWeightSmoothL1Loss`
- decoder (Config, optional): The decoder config that controls decoding
- keypoint coordinates from the network output. Defaults to ``None``
- rescore_cfg (Config, optional): The config for rescore net which
- estimates OKS via predicted keypoints and keypoint scores.
- Defaults to ``None``
- init_cfg (Config, optional): Config to control the initialization. See
- :attr:`default_init_cfg` for default settings
-
- .. _`Bottom-up human pose estimation via disentangled keypoint regression`:
- https://arxiv.org/abs/2104.02300
- """
-
- _version = 2
-
- def __init__(self,
- in_channels: Union[int, Sequence[int]],
- num_keypoints: int,
- num_heatmap_filters: int = 32,
- num_displacement_filters_per_keypoint: int = 15,
- heatmap_loss: ConfigType = dict(
- type='KeypointMSELoss', use_target_weight=True),
- displacement_loss: ConfigType = dict(
- type='SoftWeightSmoothL1Loss',
- use_target_weight=True,
- supervise_empty=False),
- decoder: OptConfigType = None,
- rescore_cfg: OptConfigType = None,
- init_cfg: OptConfigType = None):
-
- if init_cfg is None:
- init_cfg = self.default_init_cfg
-
- super().__init__(init_cfg)
-
- self.in_channels = in_channels
- self.num_keypoints = num_keypoints
-
- # build heatmap branch
- self.heatmap_conv_layers = self._make_heatmap_conv_layers(
- in_channels=in_channels,
- out_channels=1 + num_keypoints,
- num_filters=num_heatmap_filters,
- )
-
- # build displacement branch
- self.displacement_conv_layers = self._make_displacement_conv_layers(
- in_channels=in_channels,
- out_channels=2 * num_keypoints,
- num_filters=num_keypoints * num_displacement_filters_per_keypoint,
- groups=num_keypoints)
-
- # build losses
- self.loss_module = ModuleDict(
- dict(
- heatmap=MODELS.build(heatmap_loss),
- displacement=MODELS.build(displacement_loss),
- ))
-
- # build decoder
- if decoder is not None:
- self.decoder = KEYPOINT_CODECS.build(decoder)
- else:
- self.decoder = None
-
- # build rescore net
- if rescore_cfg is not None:
- self.rescore_net = RescoreNet(**rescore_cfg)
- else:
- self.rescore_net = None
-
- # Register the hook to automatically convert old version state dicts
- self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
-
- @property
- def default_init_cfg(self):
- init_cfg = [
- dict(
- type='Normal', layer=['Conv2d', 'ConvTranspose2d'], std=0.001),
- dict(type='Constant', layer='BatchNorm2d', val=1)
- ]
- return init_cfg
-
- def _make_heatmap_conv_layers(self, in_channels: int, out_channels: int,
- num_filters: int):
- """Create convolutional layers of heatmap branch by given
- parameters."""
- layers = [
- ConvModule(
- in_channels=in_channels,
- out_channels=num_filters,
- kernel_size=1,
- norm_cfg=dict(type='BN')),
- BasicBlock(num_filters, num_filters),
- build_conv_layer(
- dict(type='Conv2d'),
- in_channels=num_filters,
- out_channels=out_channels,
- kernel_size=1),
- ]
-
- return Sequential(*layers)
-
- def _make_displacement_conv_layers(self, in_channels: int,
- out_channels: int, num_filters: int,
- groups: int):
- """Create convolutional layers of displacement branch by given
- parameters."""
- layers = [
- ConvModule(
- in_channels=in_channels,
- out_channels=num_filters,
- kernel_size=1,
- norm_cfg=dict(type='BN')),
- AdaptiveActivationBlock(num_filters, num_filters, groups=groups),
- AdaptiveActivationBlock(num_filters, num_filters, groups=groups),
- build_conv_layer(
- dict(type='Conv2d'),
- in_channels=num_filters,
- out_channels=out_channels,
- kernel_size=1,
- groups=groups)
- ]
-
- return Sequential(*layers)
-
- def forward(self, feats: Tuple[Tensor]) -> Tensor:
- """Forward the network. The input is multi scale feature maps and the
- output is a tuple of heatmap and displacement.
-
- Args:
- feats (Tuple[Tensor]): Multi scale feature maps.
-
- Returns:
- Tuple[Tensor]: output heatmap and displacement.
- """
- x = feats[-1]
-
- heatmaps = self.heatmap_conv_layers(x)
- displacements = self.displacement_conv_layers(x)
-
- return heatmaps, displacements
-
- def loss(self,
- feats: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- train_cfg: ConfigType = {}) -> dict:
- """Calculate losses from a batch of inputs and data samples.
-
- Args:
- feats (Tuple[Tensor]): The multi-stage features
- batch_data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples
- train_cfg (dict): The runtime config for training process.
- Defaults to {}
-
- Returns:
- dict: A dictionary of losses.
- """
- pred_heatmaps, pred_displacements = self.forward(feats)
- gt_heatmaps = torch.stack(
- [d.gt_fields.heatmaps for d in batch_data_samples])
- heatmap_weights = torch.stack(
- [d.gt_fields.heatmap_weights for d in batch_data_samples])
- gt_displacements = torch.stack(
- [d.gt_fields.displacements for d in batch_data_samples])
- displacement_weights = torch.stack(
- [d.gt_fields.displacement_weights for d in batch_data_samples])
-
- if 'heatmap_mask' in batch_data_samples[0].gt_fields.keys():
- heatmap_mask = torch.stack(
- [d.gt_fields.heatmap_mask for d in batch_data_samples])
- else:
- heatmap_mask = None
-
- # calculate losses
- losses = dict()
- heatmap_loss = self.loss_module['heatmap'](pred_heatmaps, gt_heatmaps,
- heatmap_weights,
- heatmap_mask)
- displacement_loss = self.loss_module['displacement'](
- pred_displacements, gt_displacements, displacement_weights)
-
- losses.update({
- 'loss/heatmap': heatmap_loss,
- 'loss/displacement': displacement_loss,
- })
-
- return losses
-
- def predict(self,
- feats: Features,
- batch_data_samples: OptSampleList,
- test_cfg: ConfigType = {}) -> Predictions:
- """Predict results from features.
-
- Args:
- feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
- features (or multiple multi-scale features in TTA)
- batch_data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples
- test_cfg (dict): The runtime config for testing process. Defaults
- to {}
-
- Returns:
- Union[InstanceList | Tuple[InstanceList | PixelDataList]]: If
- ``test_cfg['output_heatmap']==True``, return both pose and heatmap
- prediction; otherwise only return the pose prediction.
-
- The pose prediction is a list of ``InstanceData``, each contains
- the following fields:
-
- - keypoints (np.ndarray): predicted keypoint coordinates in
- shape (num_instances, K, D) where K is the keypoint number
- and D is the keypoint dimension
- - keypoint_scores (np.ndarray): predicted keypoint scores in
- shape (num_instances, K)
-
- The heatmap prediction is a list of ``PixelData``, each contains
- the following fields:
-
- - heatmaps (Tensor): The predicted heatmaps in shape (1, h, w)
- or (K+1, h, w) if keypoint heatmaps are predicted
- - displacements (Tensor): The predicted displacement fields
- in shape (K*2, h, w)
- """
-
- assert len(batch_data_samples) == 1, f'DEKRHead only supports ' \
- f'prediction with batch_size 1, but got {len(batch_data_samples)}'
-
- multiscale_test = test_cfg.get('multiscale_test', False)
- flip_test = test_cfg.get('flip_test', False)
- metainfo = batch_data_samples[0].metainfo
- aug_scales = [1]
-
- if not multiscale_test:
- feats = [feats]
- else:
- aug_scales = aug_scales + metainfo['aug_scales']
-
- heatmaps, displacements = [], []
- for feat, s in zip(feats, aug_scales):
- if flip_test:
- assert isinstance(feat, list) and len(feat) == 2
- flip_indices = metainfo['flip_indices']
- _feat, _feat_flip = feat
- _heatmaps, _displacements = self.forward(_feat)
- _heatmaps_flip, _displacements_flip = self.forward(_feat_flip)
-
- _heatmaps_flip = flip_heatmaps(
- _heatmaps_flip,
- flip_mode='heatmap',
- flip_indices=flip_indices + [len(flip_indices)],
- shift_heatmap=test_cfg.get('shift_heatmap', False))
- _heatmaps = (_heatmaps + _heatmaps_flip) / 2.0
-
- _displacements_flip = flip_heatmaps(
- _displacements_flip,
- flip_mode='offset',
- flip_indices=flip_indices,
- shift_heatmap=False)
-
- # this is a coordinate amendment.
- x_scale_factor = s * (
- metainfo['input_size'][0] / _heatmaps.shape[-1])
- _displacements_flip[:, ::2] += (x_scale_factor - 1) / (
- x_scale_factor)
- _displacements = (_displacements + _displacements_flip) / 2.0
-
- else:
- _heatmaps, _displacements = self.forward(feat)
-
- heatmaps.append(_heatmaps)
- displacements.append(_displacements)
-
- preds = self.decode(heatmaps, displacements, test_cfg, metainfo)
-
- if test_cfg.get('output_heatmaps', False):
- heatmaps = [hm.detach() for hm in heatmaps]
- displacements = [dm.detach() for dm in displacements]
- B = heatmaps[0].shape[0]
- pred_fields = []
- for i in range(B):
- pred_fields.append(
- PixelData(
- heatmaps=heatmaps[0][i],
- displacements=displacements[0][i]))
- return preds, pred_fields
- else:
- return preds
-
- def decode(self,
- heatmaps: Tuple[Tensor],
- displacements: Tuple[Tensor],
- test_cfg: ConfigType = {},
- metainfo: dict = {}) -> InstanceList:
- """Decode keypoints from outputs.
-
- Args:
- heatmaps (Tuple[Tensor]): The output heatmaps inferred from one
- image or multi-scale images.
- displacements (Tuple[Tensor]): The output displacement fields
- inferred from one image or multi-scale images.
- test_cfg (dict): The runtime config for testing process. Defaults
- to {}
- metainfo (dict): The metainfo of test dataset. Defaults to {}
-
- Returns:
- List[InstanceData]: A list of InstanceData, each contains the
- decoded pose information of the instances of one data sample.
- """
-
- if self.decoder is None:
- raise RuntimeError(
- f'The decoder has not been set in {self.__class__.__name__}. '
- 'Please set the decoder configs in the init parameters to '
- 'enable head methods `head.predict()` and `head.decode()`')
-
- multiscale_test = test_cfg.get('multiscale_test', False)
- skeleton = metainfo.get('skeleton_links', None)
-
- preds = []
- batch_size = heatmaps[0].shape[0]
-
- for b in range(batch_size):
- if multiscale_test:
- raise NotImplementedError
- else:
- keypoints, (root_scores,
- keypoint_scores) = self.decoder.decode(
- heatmaps[0][b], displacements[0][b])
-
- # rescore each instance
- if self.rescore_net is not None and skeleton and len(
- keypoints) > 0:
- instance_scores = self.rescore_net(keypoints, keypoint_scores,
- skeleton)
- instance_scores[torch.isnan(instance_scores)] = 0
- root_scores = root_scores * instance_scores
-
- # nms
- keypoints, keypoint_scores = to_numpy((keypoints, keypoint_scores))
- scores = to_numpy(root_scores)[..., None] * keypoint_scores
- if len(keypoints) > 0 and test_cfg.get('nms_dist_thr', 0) > 0:
- kpts_db = []
- for i in range(len(keypoints)):
- kpts_db.append(
- dict(keypoints=keypoints[i], score=keypoint_scores[i]))
- keep_instance_inds = nearby_joints_nms(
- kpts_db,
- test_cfg['nms_dist_thr'],
- test_cfg.get('nms_joints_thr', None),
- score_per_joint=True,
- max_dets=test_cfg.get('max_num_people', 30))
- keypoints = keypoints[keep_instance_inds]
- scores = scores[keep_instance_inds]
-
- # pack outputs
- preds.append(
- InstanceData(keypoints=keypoints, keypoint_scores=scores))
-
- return preds
-
- def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
- **kwargs):
- """A hook function to convert old-version state dict of
- :class:`DEKRHead` (before MMPose v1.0.0) to a compatible format
- of :class:`DEKRHead`.
-
- The hook will be automatically registered during initialization.
- """
- version = local_meta.get('version', None)
- if version and version >= self._version:
- return
-
- # convert old-version state dict
- keys = list(state_dict.keys())
- for k in keys:
- if 'offset_conv_layer' in k:
- v = state_dict.pop(k)
- k = k.replace('offset_conv_layers', 'displacement_conv_layers')
- if 'displacement_conv_layers.3.' in k:
- # the source and target of displacement vectors are
- # opposite between two versions.
- v = -v
- state_dict[k] = v
-
- if 'heatmap_conv_layers.2' in k:
- # root heatmap is at the first/last channel of the
- # heatmap tensor in MMPose v0.x/1.x, respectively.
- v = state_dict.pop(k)
- state_dict[k] = torch.cat((v[1:], v[:1]))
-
- if 'rescore_net' in k:
- v = state_dict.pop(k)
- k = k.replace('rescore_net', 'head.rescore_net')
- state_dict[k] = v
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Sequence, Tuple, Union
+
+import torch
+from mmcv.cnn import (ConvModule, build_activation_layer, build_conv_layer,
+ build_norm_layer)
+from mmengine.model import BaseModule, ModuleDict, Sequential
+from mmengine.structures import InstanceData, PixelData
+from torch import Tensor
+
+from mmpose.evaluation.functional.nms import nearby_joints_nms
+from mmpose.models.utils.tta import flip_heatmaps
+from mmpose.registry import KEYPOINT_CODECS, MODELS
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import (ConfigType, Features, InstanceList,
+ OptConfigType, OptSampleList, Predictions)
+from ...backbones.resnet import BasicBlock
+from ..base_head import BaseHead
+
+try:
+ from mmcv.ops import DeformConv2d
+ has_mmcv_full = True
+except (ImportError, ModuleNotFoundError):
+ has_mmcv_full = False
+
+
+class AdaptiveActivationBlock(BaseModule):
+ """Adaptive activation convolution block. "Bottom-up human pose estimation
+ via disentangled keypoint regression", CVPR'2021.
+
+ Args:
+ in_channels (int): Number of input channels
+ out_channels (int): Number of output channels
+ groups (int): Number of groups. Generally equal to the
+ number of joints.
+ norm_cfg (dict): Config for normalization layers.
+ act_cfg (dict): Config for activation layers.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ groups=1,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(AdaptiveActivationBlock, self).__init__(init_cfg=init_cfg)
+
+ assert in_channels % groups == 0 and out_channels % groups == 0
+ self.groups = groups
+
+ regular_matrix = torch.tensor([[-1, -1, -1, 0, 0, 0, 1, 1, 1],
+ [-1, 0, 1, -1, 0, 1, -1, 0, 1],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1]])
+ self.register_buffer('regular_matrix', regular_matrix.float())
+
+ self.transform_matrix_conv = build_conv_layer(
+ dict(type='Conv2d'),
+ in_channels=in_channels,
+ out_channels=6 * groups,
+ kernel_size=3,
+ padding=1,
+ groups=groups,
+ bias=True)
+
+ if has_mmcv_full:
+ self.adapt_conv = DeformConv2d(
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ padding=1,
+ bias=False,
+ groups=groups,
+ deform_groups=groups)
+ else:
+ raise ImportError('Please install the full version of mmcv '
+ 'to use `DeformConv2d`.')
+
+ self.norm = build_norm_layer(norm_cfg, out_channels)[1]
+ self.act = build_activation_layer(act_cfg)
+
+ def forward(self, x):
+ B, _, H, W = x.size()
+ residual = x
+
+ affine_matrix = self.transform_matrix_conv(x)
+ affine_matrix = affine_matrix.permute(0, 2, 3, 1).contiguous()
+ affine_matrix = affine_matrix.view(B, H, W, self.groups, 2, 3)
+ offset = torch.matmul(affine_matrix, self.regular_matrix)
+ offset = offset.transpose(4, 5).reshape(B, H, W, self.groups * 18)
+ offset = offset.permute(0, 3, 1, 2).contiguous()
+
+ x = self.adapt_conv(x, offset)
+ x = self.norm(x)
+ x = self.act(x + residual)
+
+ return x
+
+
+class RescoreNet(BaseModule):
+ """Rescore net used to predict the OKS score of predicted pose. We use the
+ off-the-shelf rescore net pretrained by authors of DEKR.
+
+ Args:
+ in_channels (int): Input channels
+ norm_indexes (Tuple(int)): Indices of torso in skeleton
+ init_cfg (dict, optional): Initialization config dict
+ """
+
+ def __init__(
+ self,
+ in_channels,
+ norm_indexes,
+ init_cfg=None,
+ ):
+ super(RescoreNet, self).__init__(init_cfg=init_cfg)
+
+ self.norm_indexes = norm_indexes
+
+ hidden = 256
+
+ self.l1 = torch.nn.Linear(in_channels, hidden, bias=True)
+ self.l2 = torch.nn.Linear(hidden, hidden, bias=True)
+ self.l3 = torch.nn.Linear(hidden, 1, bias=True)
+ self.relu = torch.nn.ReLU()
+
+ def make_feature(self, keypoints, keypoint_scores, skeleton):
+ """Combine original scores, joint distance and relative distance to
+ make feature.
+
+ Args:
+ keypoints (torch.Tensor): predicetd keypoints
+ keypoint_scores (torch.Tensor): predicetd keypoint scores
+ skeleton (list(list(int))): joint links
+
+ Returns:
+ torch.Tensor: feature for each instance
+ """
+ joint_1, joint_2 = zip(*skeleton)
+ num_link = len(skeleton)
+
+ joint_relate = (keypoints[:, joint_1] -
+ keypoints[:, joint_2])[:, :, :2]
+ joint_length = joint_relate.norm(dim=2)
+
+ # To use the torso distance to normalize
+ normalize = (joint_length[:, self.norm_indexes[0]] +
+ joint_length[:, self.norm_indexes[1]]) / 2
+ normalize = normalize.unsqueeze(1).expand(normalize.size(0), num_link)
+ normalize = normalize.clamp(min=1).contiguous()
+
+ joint_length = joint_length / normalize[:, :]
+ joint_relate = joint_relate / normalize.unsqueeze(-1)
+ joint_relate = joint_relate.flatten(1)
+
+ feature = torch.cat((joint_relate, joint_length, keypoint_scores),
+ dim=1).float()
+ return feature
+
+ def forward(self, keypoints, keypoint_scores, skeleton):
+ feature = self.make_feature(keypoints, keypoint_scores, skeleton)
+ x = self.relu(self.l1(feature))
+ x = self.relu(self.l2(x))
+ x = self.l3(x)
+ return x.squeeze(1)
+
+
+@MODELS.register_module()
+class DEKRHead(BaseHead):
+ """DisEntangled Keypoint Regression head introduced in `Bottom-up human
+ pose estimation via disentangled keypoint regression`_ by Geng et al
+ (2021). The head is composed of a heatmap branch and a displacement branch.
+
+ Args:
+ in_channels (int | Sequence[int]): Number of channels in the input
+ feature map
+ num_joints (int): Number of joints
+ num_heatmap_filters (int): Number of filters for heatmap branch.
+ Defaults to 32
+ num_offset_filters_per_joint (int): Number of filters for each joint
+ in displacement branch. Defaults to 15
+ heatmap_loss (Config): Config of the heatmap loss. Defaults to use
+ :class:`KeypointMSELoss`
+ displacement_loss (Config): Config of the displacement regression loss.
+ Defaults to use :class:`SoftWeightSmoothL1Loss`
+ decoder (Config, optional): The decoder config that controls decoding
+ keypoint coordinates from the network output. Defaults to ``None``
+ rescore_cfg (Config, optional): The config for rescore net which
+ estimates OKS via predicted keypoints and keypoint scores.
+ Defaults to ``None``
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+
+ .. _`Bottom-up human pose estimation via disentangled keypoint regression`:
+ https://arxiv.org/abs/2104.02300
+ """
+
+ _version = 2
+
+ def __init__(self,
+ in_channels: Union[int, Sequence[int]],
+ num_keypoints: int,
+ num_heatmap_filters: int = 32,
+ num_displacement_filters_per_keypoint: int = 15,
+ heatmap_loss: ConfigType = dict(
+ type='KeypointMSELoss', use_target_weight=True),
+ displacement_loss: ConfigType = dict(
+ type='SoftWeightSmoothL1Loss',
+ use_target_weight=True,
+ supervise_empty=False),
+ decoder: OptConfigType = None,
+ rescore_cfg: OptConfigType = None,
+ init_cfg: OptConfigType = None):
+
+ if init_cfg is None:
+ init_cfg = self.default_init_cfg
+
+ super().__init__(init_cfg)
+
+ self.in_channels = in_channels
+ self.num_keypoints = num_keypoints
+
+ # build heatmap branch
+ self.heatmap_conv_layers = self._make_heatmap_conv_layers(
+ in_channels=in_channels,
+ out_channels=1 + num_keypoints,
+ num_filters=num_heatmap_filters,
+ )
+
+ # build displacement branch
+ self.displacement_conv_layers = self._make_displacement_conv_layers(
+ in_channels=in_channels,
+ out_channels=2 * num_keypoints,
+ num_filters=num_keypoints * num_displacement_filters_per_keypoint,
+ groups=num_keypoints)
+
+ # build losses
+ self.loss_module = ModuleDict(
+ dict(
+ heatmap=MODELS.build(heatmap_loss),
+ displacement=MODELS.build(displacement_loss),
+ ))
+
+ # build decoder
+ if decoder is not None:
+ self.decoder = KEYPOINT_CODECS.build(decoder)
+ else:
+ self.decoder = None
+
+ # build rescore net
+ if rescore_cfg is not None:
+ self.rescore_net = RescoreNet(**rescore_cfg)
+ else:
+ self.rescore_net = None
+
+ # Register the hook to automatically convert old version state dicts
+ self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
+
+ @property
+ def default_init_cfg(self):
+ init_cfg = [
+ dict(
+ type='Normal', layer=['Conv2d', 'ConvTranspose2d'], std=0.001),
+ dict(type='Constant', layer='BatchNorm2d', val=1)
+ ]
+ return init_cfg
+
+ def _make_heatmap_conv_layers(self, in_channels: int, out_channels: int,
+ num_filters: int):
+ """Create convolutional layers of heatmap branch by given
+ parameters."""
+ layers = [
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=num_filters,
+ kernel_size=1,
+ norm_cfg=dict(type='BN')),
+ BasicBlock(num_filters, num_filters),
+ build_conv_layer(
+ dict(type='Conv2d'),
+ in_channels=num_filters,
+ out_channels=out_channels,
+ kernel_size=1),
+ ]
+
+ return Sequential(*layers)
+
+ def _make_displacement_conv_layers(self, in_channels: int,
+ out_channels: int, num_filters: int,
+ groups: int):
+ """Create convolutional layers of displacement branch by given
+ parameters."""
+ layers = [
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=num_filters,
+ kernel_size=1,
+ norm_cfg=dict(type='BN')),
+ AdaptiveActivationBlock(num_filters, num_filters, groups=groups),
+ AdaptiveActivationBlock(num_filters, num_filters, groups=groups),
+ build_conv_layer(
+ dict(type='Conv2d'),
+ in_channels=num_filters,
+ out_channels=out_channels,
+ kernel_size=1,
+ groups=groups)
+ ]
+
+ return Sequential(*layers)
+
+ def forward(self, feats: Tuple[Tensor]) -> Tensor:
+ """Forward the network. The input is multi scale feature maps and the
+ output is a tuple of heatmap and displacement.
+
+ Args:
+ feats (Tuple[Tensor]): Multi scale feature maps.
+
+ Returns:
+ Tuple[Tensor]: output heatmap and displacement.
+ """
+ x = feats[-1]
+
+ heatmaps = self.heatmap_conv_layers(x)
+ displacements = self.displacement_conv_layers(x)
+
+ return heatmaps, displacements
+
+ def loss(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: ConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ feats (Tuple[Tensor]): The multi-stage features
+ batch_data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+ train_cfg (dict): The runtime config for training process.
+ Defaults to {}
+
+ Returns:
+ dict: A dictionary of losses.
+ """
+ pred_heatmaps, pred_displacements = self.forward(feats)
+ gt_heatmaps = torch.stack(
+ [d.gt_fields.heatmaps for d in batch_data_samples])
+ heatmap_weights = torch.stack(
+ [d.gt_fields.heatmap_weights for d in batch_data_samples])
+ gt_displacements = torch.stack(
+ [d.gt_fields.displacements for d in batch_data_samples])
+ displacement_weights = torch.stack(
+ [d.gt_fields.displacement_weights for d in batch_data_samples])
+
+ if 'heatmap_mask' in batch_data_samples[0].gt_fields.keys():
+ heatmap_mask = torch.stack(
+ [d.gt_fields.heatmap_mask for d in batch_data_samples])
+ else:
+ heatmap_mask = None
+
+ # calculate losses
+ losses = dict()
+ heatmap_loss = self.loss_module['heatmap'](pred_heatmaps, gt_heatmaps,
+ heatmap_weights,
+ heatmap_mask)
+ displacement_loss = self.loss_module['displacement'](
+ pred_displacements, gt_displacements, displacement_weights)
+
+ losses.update({
+ 'loss/heatmap': heatmap_loss,
+ 'loss/displacement': displacement_loss,
+ })
+
+ return losses
+
+ def predict(self,
+ feats: Features,
+ batch_data_samples: OptSampleList,
+ test_cfg: ConfigType = {}) -> Predictions:
+ """Predict results from features.
+
+ Args:
+ feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
+ features (or multiple multi-scale features in TTA)
+ batch_data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+ test_cfg (dict): The runtime config for testing process. Defaults
+ to {}
+
+ Returns:
+ Union[InstanceList | Tuple[InstanceList | PixelDataList]]: If
+ ``test_cfg['output_heatmap']==True``, return both pose and heatmap
+ prediction; otherwise only return the pose prediction.
+
+ The pose prediction is a list of ``InstanceData``, each contains
+ the following fields:
+
+ - keypoints (np.ndarray): predicted keypoint coordinates in
+ shape (num_instances, K, D) where K is the keypoint number
+ and D is the keypoint dimension
+ - keypoint_scores (np.ndarray): predicted keypoint scores in
+ shape (num_instances, K)
+
+ The heatmap prediction is a list of ``PixelData``, each contains
+ the following fields:
+
+ - heatmaps (Tensor): The predicted heatmaps in shape (1, h, w)
+ or (K+1, h, w) if keypoint heatmaps are predicted
+ - displacements (Tensor): The predicted displacement fields
+ in shape (K*2, h, w)
+ """
+
+ assert len(batch_data_samples) == 1, f'DEKRHead only supports ' \
+ f'prediction with batch_size 1, but got {len(batch_data_samples)}'
+
+ multiscale_test = test_cfg.get('multiscale_test', False)
+ flip_test = test_cfg.get('flip_test', False)
+ metainfo = batch_data_samples[0].metainfo
+ aug_scales = [1]
+
+ if not multiscale_test:
+ feats = [feats]
+ else:
+ aug_scales = aug_scales + metainfo['aug_scales']
+
+ heatmaps, displacements = [], []
+ for feat, s in zip(feats, aug_scales):
+ if flip_test:
+ assert isinstance(feat, list) and len(feat) == 2
+ flip_indices = metainfo['flip_indices']
+ _feat, _feat_flip = feat
+ _heatmaps, _displacements = self.forward(_feat)
+ _heatmaps_flip, _displacements_flip = self.forward(_feat_flip)
+
+ _heatmaps_flip = flip_heatmaps(
+ _heatmaps_flip,
+ flip_mode='heatmap',
+ flip_indices=flip_indices + [len(flip_indices)],
+ shift_heatmap=test_cfg.get('shift_heatmap', False))
+ _heatmaps = (_heatmaps + _heatmaps_flip) / 2.0
+
+ _displacements_flip = flip_heatmaps(
+ _displacements_flip,
+ flip_mode='offset',
+ flip_indices=flip_indices,
+ shift_heatmap=False)
+
+ # this is a coordinate amendment.
+ x_scale_factor = s * (
+ metainfo['input_size'][0] / _heatmaps.shape[-1])
+ _displacements_flip[:, ::2] += (x_scale_factor - 1) / (
+ x_scale_factor)
+ _displacements = (_displacements + _displacements_flip) / 2.0
+
+ else:
+ _heatmaps, _displacements = self.forward(feat)
+
+ heatmaps.append(_heatmaps)
+ displacements.append(_displacements)
+
+ preds = self.decode(heatmaps, displacements, test_cfg, metainfo)
+
+ if test_cfg.get('output_heatmaps', False):
+ heatmaps = [hm.detach() for hm in heatmaps]
+ displacements = [dm.detach() for dm in displacements]
+ B = heatmaps[0].shape[0]
+ pred_fields = []
+ for i in range(B):
+ pred_fields.append(
+ PixelData(
+ heatmaps=heatmaps[0][i],
+ displacements=displacements[0][i]))
+ return preds, pred_fields
+ else:
+ return preds
+
+ def decode(self,
+ heatmaps: Tuple[Tensor],
+ displacements: Tuple[Tensor],
+ test_cfg: ConfigType = {},
+ metainfo: dict = {}) -> InstanceList:
+ """Decode keypoints from outputs.
+
+ Args:
+ heatmaps (Tuple[Tensor]): The output heatmaps inferred from one
+ image or multi-scale images.
+ displacements (Tuple[Tensor]): The output displacement fields
+ inferred from one image or multi-scale images.
+ test_cfg (dict): The runtime config for testing process. Defaults
+ to {}
+ metainfo (dict): The metainfo of test dataset. Defaults to {}
+
+ Returns:
+ List[InstanceData]: A list of InstanceData, each contains the
+ decoded pose information of the instances of one data sample.
+ """
+
+ if self.decoder is None:
+ raise RuntimeError(
+ f'The decoder has not been set in {self.__class__.__name__}. '
+ 'Please set the decoder configs in the init parameters to '
+ 'enable head methods `head.predict()` and `head.decode()`')
+
+ multiscale_test = test_cfg.get('multiscale_test', False)
+ skeleton = metainfo.get('skeleton_links', None)
+
+ preds = []
+ batch_size = heatmaps[0].shape[0]
+
+ for b in range(batch_size):
+ if multiscale_test:
+ raise NotImplementedError
+ else:
+ keypoints, (root_scores,
+ keypoint_scores) = self.decoder.decode(
+ heatmaps[0][b], displacements[0][b])
+
+ # rescore each instance
+ if self.rescore_net is not None and skeleton and len(
+ keypoints) > 0:
+ instance_scores = self.rescore_net(keypoints, keypoint_scores,
+ skeleton)
+ instance_scores[torch.isnan(instance_scores)] = 0
+ root_scores = root_scores * instance_scores
+
+ # nms
+ keypoints, keypoint_scores = to_numpy((keypoints, keypoint_scores))
+ scores = to_numpy(root_scores)[..., None] * keypoint_scores
+ if len(keypoints) > 0 and test_cfg.get('nms_dist_thr', 0) > 0:
+ kpts_db = []
+ for i in range(len(keypoints)):
+ kpts_db.append(
+ dict(keypoints=keypoints[i], score=keypoint_scores[i]))
+ keep_instance_inds = nearby_joints_nms(
+ kpts_db,
+ test_cfg['nms_dist_thr'],
+ test_cfg.get('nms_joints_thr', None),
+ score_per_joint=True,
+ max_dets=test_cfg.get('max_num_people', 30))
+ keypoints = keypoints[keep_instance_inds]
+ scores = scores[keep_instance_inds]
+
+ # pack outputs
+ preds.append(
+ InstanceData(keypoints=keypoints, keypoint_scores=scores))
+
+ return preds
+
+ def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
+ **kwargs):
+ """A hook function to convert old-version state dict of
+ :class:`DEKRHead` (before MMPose v1.0.0) to a compatible format
+ of :class:`DEKRHead`.
+
+ The hook will be automatically registered during initialization.
+ """
+ version = local_meta.get('version', None)
+ if version and version >= self._version:
+ return
+
+ # convert old-version state dict
+ keys = list(state_dict.keys())
+ for k in keys:
+ if 'offset_conv_layer' in k:
+ v = state_dict.pop(k)
+ k = k.replace('offset_conv_layers', 'displacement_conv_layers')
+ if 'displacement_conv_layers.3.' in k:
+ # the source and target of displacement vectors are
+ # opposite between two versions.
+ v = -v
+ state_dict[k] = v
+
+ if 'heatmap_conv_layers.2' in k:
+ # root heatmap is at the first/last channel of the
+ # heatmap tensor in MMPose v0.x/1.x, respectively.
+ v = state_dict.pop(k)
+ state_dict[k] = torch.cat((v[1:], v[:1]))
+
+ if 'rescore_net' in k:
+ v = state_dict.pop(k)
+ k = k.replace('rescore_net', 'head.rescore_net')
+ state_dict[k] = v
diff --git a/mmpose/models/heads/hybrid_heads/vis_head.py b/mmpose/models/heads/hybrid_heads/vis_head.py
index e9ea271ac5..781fd32c8a 100644
--- a/mmpose/models/heads/hybrid_heads/vis_head.py
+++ b/mmpose/models/heads/hybrid_heads/vis_head.py
@@ -1,229 +1,229 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Tuple, Union
-
-import torch
-from torch import Tensor, nn
-
-from mmpose.models.utils.tta import flip_visibility
-from mmpose.registry import MODELS
-from mmpose.utils.tensor_utils import to_numpy
-from mmpose.utils.typing import (ConfigType, InstanceList, OptConfigType,
- OptSampleList, Predictions)
-from ..base_head import BaseHead
-
-
-@MODELS.register_module()
-class VisPredictHead(BaseHead):
- """VisPredictHead must be used together with other heads. It can predict
- keypoints coordinates of and their visibility simultaneously. In the
- current version, it only supports top-down approaches.
-
- Args:
- pose_cfg (Config): Config to construct keypoints prediction head
- loss (Config): Config for visibility loss. Defaults to use
- :class:`BCELoss`
- use_sigmoid (bool): Whether to use sigmoid activation function
- init_cfg (Config, optional): Config to control the initialization. See
- :attr:`default_init_cfg` for default settings
- """
-
- def __init__(self,
- pose_cfg: ConfigType,
- loss: ConfigType = dict(
- type='BCELoss', use_target_weight=False,
- with_logits=True),
- use_sigmoid: bool = False,
- init_cfg: OptConfigType = None):
-
- if init_cfg is None:
- init_cfg = self.default_init_cfg
-
- super().__init__(init_cfg)
-
- self.in_channels = pose_cfg['in_channels']
- if pose_cfg.get('num_joints', None) is not None:
- self.out_channels = pose_cfg['num_joints']
- elif pose_cfg.get('out_channels', None) is not None:
- self.out_channels = pose_cfg['out_channels']
- else:
- raise ValueError('VisPredictHead requires \'num_joints\' or'
- ' \'out_channels\' in the pose_cfg.')
-
- self.loss_module = MODELS.build(loss)
-
- self.pose_head = MODELS.build(pose_cfg)
- self.pose_cfg = pose_cfg
-
- self.use_sigmoid = use_sigmoid
-
- modules = [
- nn.AdaptiveAvgPool2d(1),
- nn.Flatten(),
- nn.Linear(self.in_channels, self.out_channels)
- ]
- if use_sigmoid:
- modules.append(nn.Sigmoid())
-
- self.vis_head = nn.Sequential(*modules)
-
- def vis_forward(self, feats: Tuple[Tensor]):
- """Forward the vis_head. The input is multi scale feature maps and the
- output is coordinates visibility.
-
- Args:
- feats (Tuple[Tensor]): Multi scale feature maps.
-
- Returns:
- Tensor: output coordinates visibility.
- """
- x = feats[-1]
- while len(x.shape) < 4:
- x.unsqueeze_(-1)
- x = self.vis_head(x)
- return x.reshape(-1, self.out_channels)
-
- def forward(self, feats: Tuple[Tensor]):
- """Forward the network. The input is multi scale feature maps and the
- output is coordinates and coordinates visibility.
-
- Args:
- feats (Tuple[Tensor]): Multi scale feature maps.
-
- Returns:
- Tuple[Tensor]: output coordinates and coordinates visibility.
- """
- x_pose = self.pose_head.forward(feats)
- x_vis = self.vis_forward(feats)
-
- return x_pose, x_vis
-
- def integrate(self, batch_vis: Tensor,
- pose_preds: Union[Tuple, Predictions]) -> InstanceList:
- """Add keypoints visibility prediction to pose prediction.
-
- Overwrite the original keypoint_scores.
- """
- if isinstance(pose_preds, tuple):
- pose_pred_instances, pose_pred_fields = pose_preds
- else:
- pose_pred_instances = pose_preds
- pose_pred_fields = None
-
- batch_vis_np = to_numpy(batch_vis, unzip=True)
-
- assert len(pose_pred_instances) == len(batch_vis_np)
- for index, _ in enumerate(pose_pred_instances):
- pose_pred_instances[index].keypoint_scores = batch_vis_np[index]
-
- return pose_pred_instances, pose_pred_fields
-
- def predict(self,
- feats: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- test_cfg: ConfigType = {}) -> Predictions:
- """Predict results from features.
-
- Args:
- feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
- features (or multiple multi-stage features in TTA)
- batch_data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples
- test_cfg (dict): The runtime config for testing process. Defaults
- to {}
-
- Returns:
- Union[InstanceList | Tuple[InstanceList | PixelDataList]]: If
- posehead's ``test_cfg['output_heatmap']==True``, return both
- pose and heatmap prediction; otherwise only return the pose
- prediction.
-
- The pose prediction is a list of ``InstanceData``, each contains
- the following fields:
-
- - keypoints (np.ndarray): predicted keypoint coordinates in
- shape (num_instances, K, D) where K is the keypoint number
- and D is the keypoint dimension
- - keypoint_scores (np.ndarray): predicted keypoint scores in
- shape (num_instances, K)
- - keypoint_visibility (np.ndarray): predicted keypoints
- visibility in shape (num_instances, K)
-
- The heatmap prediction is a list of ``PixelData``, each contains
- the following fields:
-
- - heatmaps (Tensor): The predicted heatmaps in shape (K, h, w)
- """
- if test_cfg.get('flip_test', False):
- # TTA: flip test -> feats = [orig, flipped]
- assert isinstance(feats, list) and len(feats) == 2
- flip_indices = batch_data_samples[0].metainfo['flip_indices']
- _feats, _feats_flip = feats
-
- _batch_vis = self.vis_forward(_feats)
- _batch_vis_flip = flip_visibility(
- self.vis_forward(_feats_flip), flip_indices=flip_indices)
- batch_vis = (_batch_vis + _batch_vis_flip) * 0.5
- else:
- batch_vis = self.vis_forward(feats) # (B, K, D)
-
- batch_vis.unsqueeze_(dim=1) # (B, N, K, D)
-
- if not self.use_sigmoid:
- batch_vis = torch.sigmoid(batch_vis)
-
- batch_pose = self.pose_head.predict(feats, batch_data_samples,
- test_cfg)
-
- return self.integrate(batch_vis, batch_pose)
-
- def vis_accuracy(self, vis_pred_outputs, vis_labels):
- """Calculate visibility prediction accuracy."""
- probabilities = torch.sigmoid(torch.flatten(vis_pred_outputs))
- threshold = 0.5
- predictions = (probabilities >= threshold).int()
- labels = torch.flatten(vis_labels)
- correct = torch.sum(predictions == labels).item()
- accuracy = correct / len(labels)
- return torch.tensor(accuracy)
-
- def loss(self,
- feats: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- train_cfg: OptConfigType = {}) -> dict:
- """Calculate losses from a batch of inputs and data samples.
-
- Args:
- feats (Tuple[Tensor]): The multi-stage features
- batch_data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples
- train_cfg (dict): The runtime config for training process.
- Defaults to {}
-
- Returns:
- dict: A dictionary of losses.
- """
- vis_pred_outputs = self.vis_forward(feats)
- vis_labels = torch.cat([
- d.gt_instance_labels.keypoint_weights for d in batch_data_samples
- ])
-
- # calculate vis losses
- losses = dict()
- loss_vis = self.loss_module(vis_pred_outputs, vis_labels)
-
- losses.update(loss_vis=loss_vis)
-
- # calculate vis accuracy
- acc_vis = self.vis_accuracy(vis_pred_outputs, vis_labels)
- losses.update(acc_vis=acc_vis)
-
- # calculate keypoints losses
- loss_kpt = self.pose_head.loss(feats, batch_data_samples)
- losses.update(loss_kpt)
-
- return losses
-
- @property
- def default_init_cfg(self):
- init_cfg = [dict(type='Normal', layer=['Linear'], std=0.01, bias=0)]
- return init_cfg
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Tuple, Union
+
+import torch
+from torch import Tensor, nn
+
+from mmpose.models.utils.tta import flip_visibility
+from mmpose.registry import MODELS
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import (ConfigType, InstanceList, OptConfigType,
+ OptSampleList, Predictions)
+from ..base_head import BaseHead
+
+
+@MODELS.register_module()
+class VisPredictHead(BaseHead):
+ """VisPredictHead must be used together with other heads. It can predict
+ keypoints coordinates of and their visibility simultaneously. In the
+ current version, it only supports top-down approaches.
+
+ Args:
+ pose_cfg (Config): Config to construct keypoints prediction head
+ loss (Config): Config for visibility loss. Defaults to use
+ :class:`BCELoss`
+ use_sigmoid (bool): Whether to use sigmoid activation function
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+ """
+
+ def __init__(self,
+ pose_cfg: ConfigType,
+ loss: ConfigType = dict(
+ type='BCELoss', use_target_weight=False,
+ with_logits=True),
+ use_sigmoid: bool = False,
+ init_cfg: OptConfigType = None):
+
+ if init_cfg is None:
+ init_cfg = self.default_init_cfg
+
+ super().__init__(init_cfg)
+
+ self.in_channels = pose_cfg['in_channels']
+ if pose_cfg.get('num_joints', None) is not None:
+ self.out_channels = pose_cfg['num_joints']
+ elif pose_cfg.get('out_channels', None) is not None:
+ self.out_channels = pose_cfg['out_channels']
+ else:
+ raise ValueError('VisPredictHead requires \'num_joints\' or'
+ ' \'out_channels\' in the pose_cfg.')
+
+ self.loss_module = MODELS.build(loss)
+
+ self.pose_head = MODELS.build(pose_cfg)
+ self.pose_cfg = pose_cfg
+
+ self.use_sigmoid = use_sigmoid
+
+ modules = [
+ nn.AdaptiveAvgPool2d(1),
+ nn.Flatten(),
+ nn.Linear(self.in_channels, self.out_channels)
+ ]
+ if use_sigmoid:
+ modules.append(nn.Sigmoid())
+
+ self.vis_head = nn.Sequential(*modules)
+
+ def vis_forward(self, feats: Tuple[Tensor]):
+ """Forward the vis_head. The input is multi scale feature maps and the
+ output is coordinates visibility.
+
+ Args:
+ feats (Tuple[Tensor]): Multi scale feature maps.
+
+ Returns:
+ Tensor: output coordinates visibility.
+ """
+ x = feats[-1]
+ while len(x.shape) < 4:
+ x.unsqueeze_(-1)
+ x = self.vis_head(x)
+ return x.reshape(-1, self.out_channels)
+
+ def forward(self, feats: Tuple[Tensor]):
+ """Forward the network. The input is multi scale feature maps and the
+ output is coordinates and coordinates visibility.
+
+ Args:
+ feats (Tuple[Tensor]): Multi scale feature maps.
+
+ Returns:
+ Tuple[Tensor]: output coordinates and coordinates visibility.
+ """
+ x_pose = self.pose_head.forward(feats)
+ x_vis = self.vis_forward(feats)
+
+ return x_pose, x_vis
+
+ def integrate(self, batch_vis: Tensor,
+ pose_preds: Union[Tuple, Predictions]) -> InstanceList:
+ """Add keypoints visibility prediction to pose prediction.
+
+ Overwrite the original keypoint_scores.
+ """
+ if isinstance(pose_preds, tuple):
+ pose_pred_instances, pose_pred_fields = pose_preds
+ else:
+ pose_pred_instances = pose_preds
+ pose_pred_fields = None
+
+ batch_vis_np = to_numpy(batch_vis, unzip=True)
+
+ assert len(pose_pred_instances) == len(batch_vis_np)
+ for index, _ in enumerate(pose_pred_instances):
+ pose_pred_instances[index].keypoint_scores = batch_vis_np[index]
+
+ return pose_pred_instances, pose_pred_fields
+
+ def predict(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ test_cfg: ConfigType = {}) -> Predictions:
+ """Predict results from features.
+
+ Args:
+ feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
+ features (or multiple multi-stage features in TTA)
+ batch_data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+ test_cfg (dict): The runtime config for testing process. Defaults
+ to {}
+
+ Returns:
+ Union[InstanceList | Tuple[InstanceList | PixelDataList]]: If
+ posehead's ``test_cfg['output_heatmap']==True``, return both
+ pose and heatmap prediction; otherwise only return the pose
+ prediction.
+
+ The pose prediction is a list of ``InstanceData``, each contains
+ the following fields:
+
+ - keypoints (np.ndarray): predicted keypoint coordinates in
+ shape (num_instances, K, D) where K is the keypoint number
+ and D is the keypoint dimension
+ - keypoint_scores (np.ndarray): predicted keypoint scores in
+ shape (num_instances, K)
+ - keypoint_visibility (np.ndarray): predicted keypoints
+ visibility in shape (num_instances, K)
+
+ The heatmap prediction is a list of ``PixelData``, each contains
+ the following fields:
+
+ - heatmaps (Tensor): The predicted heatmaps in shape (K, h, w)
+ """
+ if test_cfg.get('flip_test', False):
+ # TTA: flip test -> feats = [orig, flipped]
+ assert isinstance(feats, list) and len(feats) == 2
+ flip_indices = batch_data_samples[0].metainfo['flip_indices']
+ _feats, _feats_flip = feats
+
+ _batch_vis = self.vis_forward(_feats)
+ _batch_vis_flip = flip_visibility(
+ self.vis_forward(_feats_flip), flip_indices=flip_indices)
+ batch_vis = (_batch_vis + _batch_vis_flip) * 0.5
+ else:
+ batch_vis = self.vis_forward(feats) # (B, K, D)
+
+ batch_vis.unsqueeze_(dim=1) # (B, N, K, D)
+
+ if not self.use_sigmoid:
+ batch_vis = torch.sigmoid(batch_vis)
+
+ batch_pose = self.pose_head.predict(feats, batch_data_samples,
+ test_cfg)
+
+ return self.integrate(batch_vis, batch_pose)
+
+ def vis_accuracy(self, vis_pred_outputs, vis_labels):
+ """Calculate visibility prediction accuracy."""
+ probabilities = torch.sigmoid(torch.flatten(vis_pred_outputs))
+ threshold = 0.5
+ predictions = (probabilities >= threshold).int()
+ labels = torch.flatten(vis_labels)
+ correct = torch.sum(predictions == labels).item()
+ accuracy = correct / len(labels)
+ return torch.tensor(accuracy)
+
+ def loss(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: OptConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ feats (Tuple[Tensor]): The multi-stage features
+ batch_data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+ train_cfg (dict): The runtime config for training process.
+ Defaults to {}
+
+ Returns:
+ dict: A dictionary of losses.
+ """
+ vis_pred_outputs = self.vis_forward(feats)
+ vis_labels = torch.cat([
+ d.gt_instance_labels.keypoint_weights for d in batch_data_samples
+ ])
+
+ # calculate vis losses
+ losses = dict()
+ loss_vis = self.loss_module(vis_pred_outputs, vis_labels)
+
+ losses.update(loss_vis=loss_vis)
+
+ # calculate vis accuracy
+ acc_vis = self.vis_accuracy(vis_pred_outputs, vis_labels)
+ losses.update(acc_vis=acc_vis)
+
+ # calculate keypoints losses
+ loss_kpt = self.pose_head.loss(feats, batch_data_samples)
+ losses.update(loss_kpt)
+
+ return losses
+
+ @property
+ def default_init_cfg(self):
+ init_cfg = [dict(type='Normal', layer=['Linear'], std=0.01, bias=0)]
+ return init_cfg
diff --git a/mmpose/models/heads/regression_heads/__init__.py b/mmpose/models/heads/regression_heads/__init__.py
index ce9cd5e1b0..1911c39a8c 100644
--- a/mmpose/models/heads/regression_heads/__init__.py
+++ b/mmpose/models/heads/regression_heads/__init__.py
@@ -1,16 +1,16 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .dsnt_head import DSNTHead
-from .integral_regression_head import IntegralRegressionHead
-from .regression_head import RegressionHead
-from .rle_head import RLEHead
-from .temporal_regression_head import TemporalRegressionHead
-from .trajectory_regression_head import TrajectoryRegressionHead
-
-__all__ = [
- 'RegressionHead',
- 'IntegralRegressionHead',
- 'DSNTHead',
- 'RLEHead',
- 'TemporalRegressionHead',
- 'TrajectoryRegressionHead',
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .dsnt_head import DSNTHead
+from .integral_regression_head import IntegralRegressionHead
+from .regression_head import RegressionHead
+from .rle_head import RLEHead
+from .temporal_regression_head import TemporalRegressionHead
+from .trajectory_regression_head import TrajectoryRegressionHead
+
+__all__ = [
+ 'RegressionHead',
+ 'IntegralRegressionHead',
+ 'DSNTHead',
+ 'RLEHead',
+ 'TemporalRegressionHead',
+ 'TrajectoryRegressionHead',
+]
diff --git a/mmpose/models/heads/regression_heads/dsnt_head.py b/mmpose/models/heads/regression_heads/dsnt_head.py
index 3bd49e385d..43f20a6257 100644
--- a/mmpose/models/heads/regression_heads/dsnt_head.py
+++ b/mmpose/models/heads/regression_heads/dsnt_head.py
@@ -1,146 +1,146 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional, Sequence, Tuple, Union
-
-import numpy as np
-import torch
-from mmengine.logging import MessageHub
-from torch import Tensor
-
-from mmpose.evaluation.functional import keypoint_pck_accuracy
-from mmpose.registry import MODELS
-from mmpose.utils.tensor_utils import to_numpy
-from mmpose.utils.typing import ConfigType, OptConfigType, OptSampleList
-from .integral_regression_head import IntegralRegressionHead
-
-OptIntSeq = Optional[Sequence[int]]
-
-
-@MODELS.register_module()
-class DSNTHead(IntegralRegressionHead):
- """Top-down integral regression head introduced in `DSNT`_ by Nibali et
- al(2018). The head contains a differentiable spatial to numerical transform
- (DSNT) layer that do soft-argmax operation on the predicted heatmaps to
- regress the coordinates.
-
- This head is used for algorithms that require supervision of heatmaps
- in `DSNT` approach.
-
- Args:
- in_channels (int | sequence[int]): Number of input channels
- in_featuremap_size (int | sequence[int]): Size of input feature map
- num_joints (int): Number of joints
- lambda_t (int): Discard heatmap-based loss when current
- epoch > lambda_t. Defaults to -1.
- debias (bool): Whether to remove the bias of Integral Pose Regression.
- see `Removing the Bias of Integral Pose Regression`_ by Gu et al
- (2021). Defaults to ``False``.
- beta (float): A smoothing parameter in softmax. Defaults to ``1.0``.
- deconv_out_channels (sequence[int]): The output channel number of each
- deconv layer. Defaults to ``(256, 256, 256)``
- deconv_kernel_sizes (sequence[int | tuple], optional): The kernel size
- of each deconv layer. Each element should be either an integer for
- both height and width dimensions, or a tuple of two integers for
- the height and the width dimension respectively.Defaults to
- ``(4, 4, 4)``
- conv_out_channels (sequence[int], optional): The output channel number
- of each intermediate conv layer. ``None`` means no intermediate
- conv layer between deconv layers and the final conv layer.
- Defaults to ``None``
- conv_kernel_sizes (sequence[int | tuple], optional): The kernel size
- of each intermediate conv layer. Defaults to ``None``
- final_layer (dict): Arguments of the final Conv2d layer.
- Defaults to ``dict(kernel_size=1)``
- loss (Config): Config for keypoint loss. Defaults to use
- :class:`DSNTLoss`
- decoder (Config, optional): The decoder config that controls decoding
- keypoint coordinates from the network output. Defaults to ``None``
- init_cfg (Config, optional): Config to control the initialization. See
- :attr:`default_init_cfg` for default settings
-
- .. _`DSNT`: https://arxiv.org/abs/1801.07372
- """
-
- _version = 2
-
- def __init__(self,
- in_channels: Union[int, Sequence[int]],
- in_featuremap_size: Tuple[int, int],
- num_joints: int,
- lambda_t: int = -1,
- debias: bool = False,
- beta: float = 1.0,
- deconv_out_channels: OptIntSeq = (256, 256, 256),
- deconv_kernel_sizes: OptIntSeq = (4, 4, 4),
- conv_out_channels: OptIntSeq = None,
- conv_kernel_sizes: OptIntSeq = None,
- final_layer: dict = dict(kernel_size=1),
- loss: ConfigType = dict(
- type='MultipleLossWrapper',
- losses=[
- dict(type='SmoothL1Loss', use_target_weight=True),
- dict(type='JSDiscretLoss', use_target_weight=True)
- ]),
- decoder: OptConfigType = None,
- init_cfg: OptConfigType = None):
-
- super().__init__(
- in_channels=in_channels,
- in_featuremap_size=in_featuremap_size,
- num_joints=num_joints,
- debias=debias,
- beta=beta,
- deconv_out_channels=deconv_out_channels,
- deconv_kernel_sizes=deconv_kernel_sizes,
- conv_out_channels=conv_out_channels,
- conv_kernel_sizes=conv_kernel_sizes,
- final_layer=final_layer,
- loss=loss,
- decoder=decoder,
- init_cfg=init_cfg)
-
- self.lambda_t = lambda_t
-
- def loss(self,
- inputs: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- train_cfg: ConfigType = {}) -> dict:
- """Calculate losses from a batch of inputs and data samples."""
-
- pred_coords, pred_heatmaps = self.forward(inputs)
- keypoint_labels = torch.cat(
- [d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
- keypoint_weights = torch.cat([
- d.gt_instance_labels.keypoint_weights for d in batch_data_samples
- ])
- gt_heatmaps = torch.stack(
- [d.gt_fields.heatmaps for d in batch_data_samples])
-
- input_list = [pred_coords, pred_heatmaps]
- target_list = [keypoint_labels, gt_heatmaps]
- # calculate losses
- losses = dict()
-
- loss_list = self.loss_module(input_list, target_list, keypoint_weights)
-
- loss = loss_list[0] + loss_list[1]
-
- if self.lambda_t > 0:
- mh = MessageHub.get_current_instance()
- cur_epoch = mh.get_info('epoch')
- if cur_epoch >= self.lambda_t:
- loss = loss_list[0]
-
- losses.update(loss_kpt=loss)
-
- # calculate accuracy
- _, avg_acc, _ = keypoint_pck_accuracy(
- pred=to_numpy(pred_coords),
- gt=to_numpy(keypoint_labels),
- mask=to_numpy(keypoint_weights) > 0,
- thr=0.05,
- norm_factor=np.ones((pred_coords.size(0), 2), dtype=np.float32))
-
- acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
- losses.update(acc_pose=acc_pose)
-
- return losses
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Sequence, Tuple, Union
+
+import numpy as np
+import torch
+from mmengine.logging import MessageHub
+from torch import Tensor
+
+from mmpose.evaluation.functional import keypoint_pck_accuracy
+from mmpose.registry import MODELS
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import ConfigType, OptConfigType, OptSampleList
+from .integral_regression_head import IntegralRegressionHead
+
+OptIntSeq = Optional[Sequence[int]]
+
+
+@MODELS.register_module()
+class DSNTHead(IntegralRegressionHead):
+ """Top-down integral regression head introduced in `DSNT`_ by Nibali et
+ al(2018). The head contains a differentiable spatial to numerical transform
+ (DSNT) layer that do soft-argmax operation on the predicted heatmaps to
+ regress the coordinates.
+
+ This head is used for algorithms that require supervision of heatmaps
+ in `DSNT` approach.
+
+ Args:
+ in_channels (int | sequence[int]): Number of input channels
+ in_featuremap_size (int | sequence[int]): Size of input feature map
+ num_joints (int): Number of joints
+ lambda_t (int): Discard heatmap-based loss when current
+ epoch > lambda_t. Defaults to -1.
+ debias (bool): Whether to remove the bias of Integral Pose Regression.
+ see `Removing the Bias of Integral Pose Regression`_ by Gu et al
+ (2021). Defaults to ``False``.
+ beta (float): A smoothing parameter in softmax. Defaults to ``1.0``.
+ deconv_out_channels (sequence[int]): The output channel number of each
+ deconv layer. Defaults to ``(256, 256, 256)``
+ deconv_kernel_sizes (sequence[int | tuple], optional): The kernel size
+ of each deconv layer. Each element should be either an integer for
+ both height and width dimensions, or a tuple of two integers for
+ the height and the width dimension respectively.Defaults to
+ ``(4, 4, 4)``
+ conv_out_channels (sequence[int], optional): The output channel number
+ of each intermediate conv layer. ``None`` means no intermediate
+ conv layer between deconv layers and the final conv layer.
+ Defaults to ``None``
+ conv_kernel_sizes (sequence[int | tuple], optional): The kernel size
+ of each intermediate conv layer. Defaults to ``None``
+ final_layer (dict): Arguments of the final Conv2d layer.
+ Defaults to ``dict(kernel_size=1)``
+ loss (Config): Config for keypoint loss. Defaults to use
+ :class:`DSNTLoss`
+ decoder (Config, optional): The decoder config that controls decoding
+ keypoint coordinates from the network output. Defaults to ``None``
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+
+ .. _`DSNT`: https://arxiv.org/abs/1801.07372
+ """
+
+ _version = 2
+
+ def __init__(self,
+ in_channels: Union[int, Sequence[int]],
+ in_featuremap_size: Tuple[int, int],
+ num_joints: int,
+ lambda_t: int = -1,
+ debias: bool = False,
+ beta: float = 1.0,
+ deconv_out_channels: OptIntSeq = (256, 256, 256),
+ deconv_kernel_sizes: OptIntSeq = (4, 4, 4),
+ conv_out_channels: OptIntSeq = None,
+ conv_kernel_sizes: OptIntSeq = None,
+ final_layer: dict = dict(kernel_size=1),
+ loss: ConfigType = dict(
+ type='MultipleLossWrapper',
+ losses=[
+ dict(type='SmoothL1Loss', use_target_weight=True),
+ dict(type='JSDiscretLoss', use_target_weight=True)
+ ]),
+ decoder: OptConfigType = None,
+ init_cfg: OptConfigType = None):
+
+ super().__init__(
+ in_channels=in_channels,
+ in_featuremap_size=in_featuremap_size,
+ num_joints=num_joints,
+ debias=debias,
+ beta=beta,
+ deconv_out_channels=deconv_out_channels,
+ deconv_kernel_sizes=deconv_kernel_sizes,
+ conv_out_channels=conv_out_channels,
+ conv_kernel_sizes=conv_kernel_sizes,
+ final_layer=final_layer,
+ loss=loss,
+ decoder=decoder,
+ init_cfg=init_cfg)
+
+ self.lambda_t = lambda_t
+
+ def loss(self,
+ inputs: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: ConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples."""
+
+ pred_coords, pred_heatmaps = self.forward(inputs)
+ keypoint_labels = torch.cat(
+ [d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
+ keypoint_weights = torch.cat([
+ d.gt_instance_labels.keypoint_weights for d in batch_data_samples
+ ])
+ gt_heatmaps = torch.stack(
+ [d.gt_fields.heatmaps for d in batch_data_samples])
+
+ input_list = [pred_coords, pred_heatmaps]
+ target_list = [keypoint_labels, gt_heatmaps]
+ # calculate losses
+ losses = dict()
+
+ loss_list = self.loss_module(input_list, target_list, keypoint_weights)
+
+ loss = loss_list[0] + loss_list[1]
+
+ if self.lambda_t > 0:
+ mh = MessageHub.get_current_instance()
+ cur_epoch = mh.get_info('epoch')
+ if cur_epoch >= self.lambda_t:
+ loss = loss_list[0]
+
+ losses.update(loss_kpt=loss)
+
+ # calculate accuracy
+ _, avg_acc, _ = keypoint_pck_accuracy(
+ pred=to_numpy(pred_coords),
+ gt=to_numpy(keypoint_labels),
+ mask=to_numpy(keypoint_weights) > 0,
+ thr=0.05,
+ norm_factor=np.ones((pred_coords.size(0), 2), dtype=np.float32))
+
+ acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
+ losses.update(acc_pose=acc_pose)
+
+ return losses
diff --git a/mmpose/models/heads/regression_heads/integral_regression_head.py b/mmpose/models/heads/regression_heads/integral_regression_head.py
index 9046d94ad4..add813b429 100644
--- a/mmpose/models/heads/regression_heads/integral_regression_head.py
+++ b/mmpose/models/heads/regression_heads/integral_regression_head.py
@@ -1,339 +1,339 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-
-from typing import Optional, Sequence, Tuple, Union
-
-import numpy as np
-import torch
-import torch.nn.functional as F
-from mmcv.cnn import build_conv_layer
-from mmengine.structures import PixelData
-from torch import Tensor, nn
-
-from mmpose.evaluation.functional import keypoint_pck_accuracy
-from mmpose.models.utils.tta import flip_coordinates, flip_heatmaps
-from mmpose.registry import KEYPOINT_CODECS, MODELS
-from mmpose.utils.tensor_utils import to_numpy
-from mmpose.utils.typing import (ConfigType, OptConfigType, OptSampleList,
- Predictions)
-from .. import HeatmapHead
-from ..base_head import BaseHead
-
-OptIntSeq = Optional[Sequence[int]]
-
-
-@MODELS.register_module()
-class IntegralRegressionHead(BaseHead):
- """Top-down integral regression head introduced in `IPR`_ by Xiao et
- al(2018). The head contains a differentiable spatial to numerical transform
- (DSNT) layer that do soft-argmax operation on the predicted heatmaps to
- regress the coordinates.
-
- This head is used for algorithms that only supervise the coordinates.
-
- Args:
- in_channels (int | sequence[int]): Number of input channels
- in_featuremap_size (int | sequence[int]): Size of input feature map
- num_joints (int): Number of joints
- debias (bool): Whether to remove the bias of Integral Pose Regression.
- see `Removing the Bias of Integral Pose Regression`_ by Gu et al
- (2021). Defaults to ``False``.
- beta (float): A smoothing parameter in softmax. Defaults to ``1.0``.
- deconv_out_channels (sequence[int]): The output channel number of each
- deconv layer. Defaults to ``(256, 256, 256)``
- deconv_kernel_sizes (sequence[int | tuple], optional): The kernel size
- of each deconv layer. Each element should be either an integer for
- both height and width dimensions, or a tuple of two integers for
- the height and the width dimension respectively.Defaults to
- ``(4, 4, 4)``
- conv_out_channels (sequence[int], optional): The output channel number
- of each intermediate conv layer. ``None`` means no intermediate
- conv layer between deconv layers and the final conv layer.
- Defaults to ``None``
- conv_kernel_sizes (sequence[int | tuple], optional): The kernel size
- of each intermediate conv layer. Defaults to ``None``
- final_layer (dict): Arguments of the final Conv2d layer.
- Defaults to ``dict(kernel_size=1)``
- loss (Config): Config for keypoint loss. Defaults to use
- :class:`SmoothL1Loss`
- decoder (Config, optional): The decoder config that controls decoding
- keypoint coordinates from the network output. Defaults to ``None``
- init_cfg (Config, optional): Config to control the initialization. See
- :attr:`default_init_cfg` for default settings
-
- .. _`IPR`: https://arxiv.org/abs/1711.08229
- .. _`Debias`:
- """
-
- _version = 2
-
- def __init__(self,
- in_channels: Union[int, Sequence[int]],
- in_featuremap_size: Tuple[int, int],
- num_joints: int,
- debias: bool = False,
- beta: float = 1.0,
- deconv_out_channels: OptIntSeq = (256, 256, 256),
- deconv_kernel_sizes: OptIntSeq = (4, 4, 4),
- conv_out_channels: OptIntSeq = None,
- conv_kernel_sizes: OptIntSeq = None,
- final_layer: dict = dict(kernel_size=1),
- loss: ConfigType = dict(
- type='SmoothL1Loss', use_target_weight=True),
- decoder: OptConfigType = None,
- init_cfg: OptConfigType = None):
-
- if init_cfg is None:
- init_cfg = self.default_init_cfg
-
- super().__init__(init_cfg)
-
- self.in_channels = in_channels
- self.num_joints = num_joints
- self.debias = debias
- self.beta = beta
- self.loss_module = MODELS.build(loss)
- if decoder is not None:
- self.decoder = KEYPOINT_CODECS.build(decoder)
- else:
- self.decoder = None
-
- num_deconv = len(deconv_out_channels) if deconv_out_channels else 0
- if num_deconv != 0:
-
- self.heatmap_size = tuple(
- [s * (2**num_deconv) for s in in_featuremap_size])
-
- # deconv layers + 1x1 conv
- self.simplebaseline_head = HeatmapHead(
- in_channels=in_channels,
- out_channels=num_joints,
- deconv_out_channels=deconv_out_channels,
- deconv_kernel_sizes=deconv_kernel_sizes,
- conv_out_channels=conv_out_channels,
- conv_kernel_sizes=conv_kernel_sizes,
- final_layer=final_layer)
-
- if final_layer is not None:
- in_channels = num_joints
- else:
- in_channels = deconv_out_channels[-1]
-
- else:
- self.simplebaseline_head = None
-
- if final_layer is not None:
- cfg = dict(
- type='Conv2d',
- in_channels=in_channels,
- out_channels=num_joints,
- kernel_size=1)
- cfg.update(final_layer)
- self.final_layer = build_conv_layer(cfg)
- else:
- self.final_layer = None
-
- self.heatmap_size = in_featuremap_size
-
- if isinstance(in_channels, list):
- raise ValueError(
- f'{self.__class__.__name__} does not support selecting '
- 'multiple input features.')
-
- W, H = self.heatmap_size
- self.linspace_x = torch.arange(0.0, 1.0 * W, 1).reshape(1, 1, 1, W) / W
- self.linspace_y = torch.arange(0.0, 1.0 * H, 1).reshape(1, 1, H, 1) / H
-
- self.linspace_x = nn.Parameter(self.linspace_x, requires_grad=False)
- self.linspace_y = nn.Parameter(self.linspace_y, requires_grad=False)
-
- self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
-
- def _linear_expectation(self, heatmaps: Tensor,
- linspace: Tensor) -> Tensor:
- """Calculate linear expectation."""
-
- B, N, _, _ = heatmaps.shape
- heatmaps = heatmaps.mul(linspace).reshape(B, N, -1)
- expectation = torch.sum(heatmaps, dim=2, keepdim=True)
-
- return expectation
-
- def _flat_softmax(self, featmaps: Tensor) -> Tensor:
- """Use Softmax to normalize the featmaps in depthwise."""
-
- _, N, H, W = featmaps.shape
-
- featmaps = featmaps.reshape(-1, N, H * W)
- heatmaps = F.softmax(featmaps, dim=2)
-
- return heatmaps.reshape(-1, N, H, W)
-
- def forward(self, feats: Tuple[Tensor]) -> Union[Tensor, Tuple[Tensor]]:
- """Forward the network. The input is multi scale feature maps and the
- output is the coordinates.
-
- Args:
- feats (Tuple[Tensor]): Multi scale feature maps.
-
- Returns:
- Tensor: output coordinates(and sigmas[optional]).
- """
- if self.simplebaseline_head is None:
- feats = feats[-1]
- if self.final_layer is not None:
- feats = self.final_layer(feats)
- else:
- feats = self.simplebaseline_head(feats)
-
- heatmaps = self._flat_softmax(feats * self.beta)
-
- pred_x = self._linear_expectation(heatmaps, self.linspace_x)
- pred_y = self._linear_expectation(heatmaps, self.linspace_y)
-
- if self.debias:
- B, N, H, W = feats.shape
- C = feats.reshape(B, N, H * W).exp().sum(dim=2).reshape(B, N, 1)
- pred_x = C / (C - 1) * (pred_x - 1 / (2 * C))
- pred_y = C / (C - 1) * (pred_y - 1 / (2 * C))
-
- coords = torch.cat([pred_x, pred_y], dim=-1)
- return coords, heatmaps
-
- def predict(self,
- feats: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- test_cfg: ConfigType = {}) -> Predictions:
- """Predict results from features.
-
- Args:
- feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
- features (or multiple multi-stage features in TTA)
- batch_data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples
- test_cfg (dict): The runtime config for testing process. Defaults
- to {}
-
- Returns:
- Union[InstanceList | Tuple[InstanceList | PixelDataList]]: If
- ``test_cfg['output_heatmap']==True``, return both pose and heatmap
- prediction; otherwise only return the pose prediction.
-
- The pose prediction is a list of ``InstanceData``, each contains
- the following fields:
-
- - keypoints (np.ndarray): predicted keypoint coordinates in
- shape (num_instances, K, D) where K is the keypoint number
- and D is the keypoint dimension
- - keypoint_scores (np.ndarray): predicted keypoint scores in
- shape (num_instances, K)
-
- The heatmap prediction is a list of ``PixelData``, each contains
- the following fields:
-
- - heatmaps (Tensor): The predicted heatmaps in shape (K, h, w)
- """
-
- if test_cfg.get('flip_test', False):
- # TTA: flip test -> feats = [orig, flipped]
- assert isinstance(feats, list) and len(feats) == 2
- flip_indices = batch_data_samples[0].metainfo['flip_indices']
- input_size = batch_data_samples[0].metainfo['input_size']
- _feats, _feats_flip = feats
-
- _batch_coords, _batch_heatmaps = self.forward(_feats)
-
- _batch_coords_flip, _batch_heatmaps_flip = self.forward(
- _feats_flip)
- _batch_coords_flip = flip_coordinates(
- _batch_coords_flip,
- flip_indices=flip_indices,
- shift_coords=test_cfg.get('shift_coords', True),
- input_size=input_size)
- _batch_heatmaps_flip = flip_heatmaps(
- _batch_heatmaps_flip,
- flip_mode='heatmap',
- flip_indices=flip_indices,
- shift_heatmap=test_cfg.get('shift_heatmap', False))
-
- batch_coords = (_batch_coords + _batch_coords_flip) * 0.5
- batch_heatmaps = (_batch_heatmaps + _batch_heatmaps_flip) * 0.5
- else:
- batch_coords, batch_heatmaps = self.forward(feats) # (B, K, D)
-
- batch_coords.unsqueeze_(dim=1) # (B, N, K, D)
- preds = self.decode(batch_coords)
-
- if test_cfg.get('output_heatmaps', False):
- pred_fields = [
- PixelData(heatmaps=hm) for hm in batch_heatmaps.detach()
- ]
- return preds, pred_fields
- else:
- return preds
-
- def loss(self,
- inputs: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- train_cfg: ConfigType = {}) -> dict:
- """Calculate losses from a batch of inputs and data samples."""
-
- pred_coords, _ = self.forward(inputs)
- keypoint_labels = torch.cat(
- [d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
- keypoint_weights = torch.cat([
- d.gt_instance_labels.keypoint_weights for d in batch_data_samples
- ])
-
- # calculate losses
- losses = dict()
-
- # TODO: multi-loss calculation
- loss = self.loss_module(pred_coords, keypoint_labels, keypoint_weights)
-
- losses.update(loss_kpt=loss)
-
- # calculate accuracy
- _, avg_acc, _ = keypoint_pck_accuracy(
- pred=to_numpy(pred_coords),
- gt=to_numpy(keypoint_labels),
- mask=to_numpy(keypoint_weights) > 0,
- thr=0.05,
- norm_factor=np.ones((pred_coords.size(0), 2), dtype=np.float32))
-
- acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
- losses.update(acc_pose=acc_pose)
-
- return losses
-
- @property
- def default_init_cfg(self):
- init_cfg = [dict(type='Normal', layer=['Linear'], std=0.01, bias=0)]
- return init_cfg
-
- def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
- **kwargs):
- """A hook function to load weights of deconv layers from
- :class:`HeatmapHead` into `simplebaseline_head`.
-
- The hook will be automatically registered during initialization.
- """
-
- # convert old-version state dict
- keys = list(state_dict.keys())
- for _k in keys:
- if not _k.startswith(prefix):
- continue
- v = state_dict.pop(_k)
- k = _k.lstrip(prefix)
-
- k_new = _k
- k_parts = k.split('.')
- if self.simplebaseline_head is not None:
- if k_parts[0] == 'conv_layers':
- k_new = (
- prefix + 'simplebaseline_head.deconv_layers.' +
- '.'.join(k_parts[1:]))
- elif k_parts[0] == 'final_layer':
- k_new = prefix + 'simplebaseline_head.' + k
-
- state_dict[k_new] = v
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from typing import Optional, Sequence, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+from mmcv.cnn import build_conv_layer
+from mmengine.structures import PixelData
+from torch import Tensor, nn
+
+from mmpose.evaluation.functional import keypoint_pck_accuracy
+from mmpose.models.utils.tta import flip_coordinates, flip_heatmaps
+from mmpose.registry import KEYPOINT_CODECS, MODELS
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import (ConfigType, OptConfigType, OptSampleList,
+ Predictions)
+from .. import HeatmapHead
+from ..base_head import BaseHead
+
+OptIntSeq = Optional[Sequence[int]]
+
+
+@MODELS.register_module()
+class IntegralRegressionHead(BaseHead):
+ """Top-down integral regression head introduced in `IPR`_ by Xiao et
+ al(2018). The head contains a differentiable spatial to numerical transform
+ (DSNT) layer that do soft-argmax operation on the predicted heatmaps to
+ regress the coordinates.
+
+ This head is used for algorithms that only supervise the coordinates.
+
+ Args:
+ in_channels (int | sequence[int]): Number of input channels
+ in_featuremap_size (int | sequence[int]): Size of input feature map
+ num_joints (int): Number of joints
+ debias (bool): Whether to remove the bias of Integral Pose Regression.
+ see `Removing the Bias of Integral Pose Regression`_ by Gu et al
+ (2021). Defaults to ``False``.
+ beta (float): A smoothing parameter in softmax. Defaults to ``1.0``.
+ deconv_out_channels (sequence[int]): The output channel number of each
+ deconv layer. Defaults to ``(256, 256, 256)``
+ deconv_kernel_sizes (sequence[int | tuple], optional): The kernel size
+ of each deconv layer. Each element should be either an integer for
+ both height and width dimensions, or a tuple of two integers for
+ the height and the width dimension respectively.Defaults to
+ ``(4, 4, 4)``
+ conv_out_channels (sequence[int], optional): The output channel number
+ of each intermediate conv layer. ``None`` means no intermediate
+ conv layer between deconv layers and the final conv layer.
+ Defaults to ``None``
+ conv_kernel_sizes (sequence[int | tuple], optional): The kernel size
+ of each intermediate conv layer. Defaults to ``None``
+ final_layer (dict): Arguments of the final Conv2d layer.
+ Defaults to ``dict(kernel_size=1)``
+ loss (Config): Config for keypoint loss. Defaults to use
+ :class:`SmoothL1Loss`
+ decoder (Config, optional): The decoder config that controls decoding
+ keypoint coordinates from the network output. Defaults to ``None``
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+
+ .. _`IPR`: https://arxiv.org/abs/1711.08229
+ .. _`Debias`:
+ """
+
+ _version = 2
+
+ def __init__(self,
+ in_channels: Union[int, Sequence[int]],
+ in_featuremap_size: Tuple[int, int],
+ num_joints: int,
+ debias: bool = False,
+ beta: float = 1.0,
+ deconv_out_channels: OptIntSeq = (256, 256, 256),
+ deconv_kernel_sizes: OptIntSeq = (4, 4, 4),
+ conv_out_channels: OptIntSeq = None,
+ conv_kernel_sizes: OptIntSeq = None,
+ final_layer: dict = dict(kernel_size=1),
+ loss: ConfigType = dict(
+ type='SmoothL1Loss', use_target_weight=True),
+ decoder: OptConfigType = None,
+ init_cfg: OptConfigType = None):
+
+ if init_cfg is None:
+ init_cfg = self.default_init_cfg
+
+ super().__init__(init_cfg)
+
+ self.in_channels = in_channels
+ self.num_joints = num_joints
+ self.debias = debias
+ self.beta = beta
+ self.loss_module = MODELS.build(loss)
+ if decoder is not None:
+ self.decoder = KEYPOINT_CODECS.build(decoder)
+ else:
+ self.decoder = None
+
+ num_deconv = len(deconv_out_channels) if deconv_out_channels else 0
+ if num_deconv != 0:
+
+ self.heatmap_size = tuple(
+ [s * (2**num_deconv) for s in in_featuremap_size])
+
+ # deconv layers + 1x1 conv
+ self.simplebaseline_head = HeatmapHead(
+ in_channels=in_channels,
+ out_channels=num_joints,
+ deconv_out_channels=deconv_out_channels,
+ deconv_kernel_sizes=deconv_kernel_sizes,
+ conv_out_channels=conv_out_channels,
+ conv_kernel_sizes=conv_kernel_sizes,
+ final_layer=final_layer)
+
+ if final_layer is not None:
+ in_channels = num_joints
+ else:
+ in_channels = deconv_out_channels[-1]
+
+ else:
+ self.simplebaseline_head = None
+
+ if final_layer is not None:
+ cfg = dict(
+ type='Conv2d',
+ in_channels=in_channels,
+ out_channels=num_joints,
+ kernel_size=1)
+ cfg.update(final_layer)
+ self.final_layer = build_conv_layer(cfg)
+ else:
+ self.final_layer = None
+
+ self.heatmap_size = in_featuremap_size
+
+ if isinstance(in_channels, list):
+ raise ValueError(
+ f'{self.__class__.__name__} does not support selecting '
+ 'multiple input features.')
+
+ W, H = self.heatmap_size
+ self.linspace_x = torch.arange(0.0, 1.0 * W, 1).reshape(1, 1, 1, W) / W
+ self.linspace_y = torch.arange(0.0, 1.0 * H, 1).reshape(1, 1, H, 1) / H
+
+ self.linspace_x = nn.Parameter(self.linspace_x, requires_grad=False)
+ self.linspace_y = nn.Parameter(self.linspace_y, requires_grad=False)
+
+ self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
+
+ def _linear_expectation(self, heatmaps: Tensor,
+ linspace: Tensor) -> Tensor:
+ """Calculate linear expectation."""
+
+ B, N, _, _ = heatmaps.shape
+ heatmaps = heatmaps.mul(linspace).reshape(B, N, -1)
+ expectation = torch.sum(heatmaps, dim=2, keepdim=True)
+
+ return expectation
+
+ def _flat_softmax(self, featmaps: Tensor) -> Tensor:
+ """Use Softmax to normalize the featmaps in depthwise."""
+
+ _, N, H, W = featmaps.shape
+
+ featmaps = featmaps.reshape(-1, N, H * W)
+ heatmaps = F.softmax(featmaps, dim=2)
+
+ return heatmaps.reshape(-1, N, H, W)
+
+ def forward(self, feats: Tuple[Tensor]) -> Union[Tensor, Tuple[Tensor]]:
+ """Forward the network. The input is multi scale feature maps and the
+ output is the coordinates.
+
+ Args:
+ feats (Tuple[Tensor]): Multi scale feature maps.
+
+ Returns:
+ Tensor: output coordinates(and sigmas[optional]).
+ """
+ if self.simplebaseline_head is None:
+ feats = feats[-1]
+ if self.final_layer is not None:
+ feats = self.final_layer(feats)
+ else:
+ feats = self.simplebaseline_head(feats)
+
+ heatmaps = self._flat_softmax(feats * self.beta)
+
+ pred_x = self._linear_expectation(heatmaps, self.linspace_x)
+ pred_y = self._linear_expectation(heatmaps, self.linspace_y)
+
+ if self.debias:
+ B, N, H, W = feats.shape
+ C = feats.reshape(B, N, H * W).exp().sum(dim=2).reshape(B, N, 1)
+ pred_x = C / (C - 1) * (pred_x - 1 / (2 * C))
+ pred_y = C / (C - 1) * (pred_y - 1 / (2 * C))
+
+ coords = torch.cat([pred_x, pred_y], dim=-1)
+ return coords, heatmaps
+
+ def predict(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ test_cfg: ConfigType = {}) -> Predictions:
+ """Predict results from features.
+
+ Args:
+ feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
+ features (or multiple multi-stage features in TTA)
+ batch_data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+ test_cfg (dict): The runtime config for testing process. Defaults
+ to {}
+
+ Returns:
+ Union[InstanceList | Tuple[InstanceList | PixelDataList]]: If
+ ``test_cfg['output_heatmap']==True``, return both pose and heatmap
+ prediction; otherwise only return the pose prediction.
+
+ The pose prediction is a list of ``InstanceData``, each contains
+ the following fields:
+
+ - keypoints (np.ndarray): predicted keypoint coordinates in
+ shape (num_instances, K, D) where K is the keypoint number
+ and D is the keypoint dimension
+ - keypoint_scores (np.ndarray): predicted keypoint scores in
+ shape (num_instances, K)
+
+ The heatmap prediction is a list of ``PixelData``, each contains
+ the following fields:
+
+ - heatmaps (Tensor): The predicted heatmaps in shape (K, h, w)
+ """
+
+ if test_cfg.get('flip_test', False):
+ # TTA: flip test -> feats = [orig, flipped]
+ assert isinstance(feats, list) and len(feats) == 2
+ flip_indices = batch_data_samples[0].metainfo['flip_indices']
+ input_size = batch_data_samples[0].metainfo['input_size']
+ _feats, _feats_flip = feats
+
+ _batch_coords, _batch_heatmaps = self.forward(_feats)
+
+ _batch_coords_flip, _batch_heatmaps_flip = self.forward(
+ _feats_flip)
+ _batch_coords_flip = flip_coordinates(
+ _batch_coords_flip,
+ flip_indices=flip_indices,
+ shift_coords=test_cfg.get('shift_coords', True),
+ input_size=input_size)
+ _batch_heatmaps_flip = flip_heatmaps(
+ _batch_heatmaps_flip,
+ flip_mode='heatmap',
+ flip_indices=flip_indices,
+ shift_heatmap=test_cfg.get('shift_heatmap', False))
+
+ batch_coords = (_batch_coords + _batch_coords_flip) * 0.5
+ batch_heatmaps = (_batch_heatmaps + _batch_heatmaps_flip) * 0.5
+ else:
+ batch_coords, batch_heatmaps = self.forward(feats) # (B, K, D)
+
+ batch_coords.unsqueeze_(dim=1) # (B, N, K, D)
+ preds = self.decode(batch_coords)
+
+ if test_cfg.get('output_heatmaps', False):
+ pred_fields = [
+ PixelData(heatmaps=hm) for hm in batch_heatmaps.detach()
+ ]
+ return preds, pred_fields
+ else:
+ return preds
+
+ def loss(self,
+ inputs: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: ConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples."""
+
+ pred_coords, _ = self.forward(inputs)
+ keypoint_labels = torch.cat(
+ [d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
+ keypoint_weights = torch.cat([
+ d.gt_instance_labels.keypoint_weights for d in batch_data_samples
+ ])
+
+ # calculate losses
+ losses = dict()
+
+ # TODO: multi-loss calculation
+ loss = self.loss_module(pred_coords, keypoint_labels, keypoint_weights)
+
+ losses.update(loss_kpt=loss)
+
+ # calculate accuracy
+ _, avg_acc, _ = keypoint_pck_accuracy(
+ pred=to_numpy(pred_coords),
+ gt=to_numpy(keypoint_labels),
+ mask=to_numpy(keypoint_weights) > 0,
+ thr=0.05,
+ norm_factor=np.ones((pred_coords.size(0), 2), dtype=np.float32))
+
+ acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
+ losses.update(acc_pose=acc_pose)
+
+ return losses
+
+ @property
+ def default_init_cfg(self):
+ init_cfg = [dict(type='Normal', layer=['Linear'], std=0.01, bias=0)]
+ return init_cfg
+
+ def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
+ **kwargs):
+ """A hook function to load weights of deconv layers from
+ :class:`HeatmapHead` into `simplebaseline_head`.
+
+ The hook will be automatically registered during initialization.
+ """
+
+ # convert old-version state dict
+ keys = list(state_dict.keys())
+ for _k in keys:
+ if not _k.startswith(prefix):
+ continue
+ v = state_dict.pop(_k)
+ k = _k.lstrip(prefix)
+
+ k_new = _k
+ k_parts = k.split('.')
+ if self.simplebaseline_head is not None:
+ if k_parts[0] == 'conv_layers':
+ k_new = (
+ prefix + 'simplebaseline_head.deconv_layers.' +
+ '.'.join(k_parts[1:]))
+ elif k_parts[0] == 'final_layer':
+ k_new = prefix + 'simplebaseline_head.' + k
+
+ state_dict[k_new] = v
diff --git a/mmpose/models/heads/regression_heads/regression_head.py b/mmpose/models/heads/regression_heads/regression_head.py
index 8ff73aa6ef..514bbf56db 100644
--- a/mmpose/models/heads/regression_heads/regression_head.py
+++ b/mmpose/models/heads/regression_heads/regression_head.py
@@ -1,146 +1,146 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional, Sequence, Tuple, Union
-
-import numpy as np
-import torch
-from torch import Tensor, nn
-
-from mmpose.evaluation.functional import keypoint_pck_accuracy
-from mmpose.models.utils.tta import flip_coordinates
-from mmpose.registry import KEYPOINT_CODECS, MODELS
-from mmpose.utils.tensor_utils import to_numpy
-from mmpose.utils.typing import (ConfigType, OptConfigType, OptSampleList,
- Predictions)
-from ..base_head import BaseHead
-
-OptIntSeq = Optional[Sequence[int]]
-
-
-@MODELS.register_module()
-class RegressionHead(BaseHead):
- """Top-down regression head introduced in `Deeppose`_ by Toshev et al
- (2014). The head is composed of fully-connected layers to predict the
- coordinates directly.
-
- Args:
- in_channels (int | sequence[int]): Number of input channels
- num_joints (int): Number of joints
- loss (Config): Config for keypoint loss. Defaults to use
- :class:`SmoothL1Loss`
- decoder (Config, optional): The decoder config that controls decoding
- keypoint coordinates from the network output. Defaults to ``None``
- init_cfg (Config, optional): Config to control the initialization. See
- :attr:`default_init_cfg` for default settings
-
- .. _`Deeppose`: https://arxiv.org/abs/1312.4659
- """
-
- _version = 2
-
- def __init__(self,
- in_channels: Union[int, Sequence[int]],
- num_joints: int,
- loss: ConfigType = dict(
- type='SmoothL1Loss', use_target_weight=True),
- decoder: OptConfigType = None,
- init_cfg: OptConfigType = None):
-
- if init_cfg is None:
- init_cfg = self.default_init_cfg
-
- super().__init__(init_cfg)
-
- self.in_channels = in_channels
- self.num_joints = num_joints
- self.loss_module = MODELS.build(loss)
- if decoder is not None:
- self.decoder = KEYPOINT_CODECS.build(decoder)
- else:
- self.decoder = None
-
- # Define fully-connected layers
- self.fc = nn.Linear(in_channels, self.num_joints * 2)
-
- def forward(self, feats: Tuple[Tensor]) -> Tensor:
- """Forward the network. The input is multi scale feature maps and the
- output is the coordinates.
-
- Args:
- feats (Tuple[Tensor]): Multi scale feature maps.
-
- Returns:
- Tensor: output coordinates(and sigmas[optional]).
- """
- x = feats[-1]
-
- x = torch.flatten(x, 1)
- x = self.fc(x)
-
- return x.reshape(-1, self.num_joints, 2)
-
- def predict(self,
- feats: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- test_cfg: ConfigType = {}) -> Predictions:
- """Predict results from outputs."""
-
- if test_cfg.get('flip_test', False):
- # TTA: flip test -> feats = [orig, flipped]
- assert isinstance(feats, list) and len(feats) == 2
- flip_indices = batch_data_samples[0].metainfo['flip_indices']
- input_size = batch_data_samples[0].metainfo['input_size']
- _feats, _feats_flip = feats
-
- _batch_coords = self.forward(_feats)
- _batch_coords_flip = flip_coordinates(
- self.forward(_feats_flip),
- flip_indices=flip_indices,
- shift_coords=test_cfg.get('shift_coords', True),
- input_size=input_size)
- batch_coords = (_batch_coords + _batch_coords_flip) * 0.5
- else:
- batch_coords = self.forward(feats) # (B, K, D)
-
- batch_coords.unsqueeze_(dim=1) # (B, N, K, D)
- preds = self.decode(batch_coords)
-
- return preds
-
- def loss(self,
- inputs: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- train_cfg: ConfigType = {}) -> dict:
- """Calculate losses from a batch of inputs and data samples."""
-
- pred_outputs = self.forward(inputs)
-
- keypoint_labels = torch.cat(
- [d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
- keypoint_weights = torch.cat([
- d.gt_instance_labels.keypoint_weights for d in batch_data_samples
- ])
-
- # calculate losses
- losses = dict()
- loss = self.loss_module(pred_outputs, keypoint_labels,
- keypoint_weights.unsqueeze(-1))
-
- losses.update(loss_kpt=loss)
-
- # calculate accuracy
- _, avg_acc, _ = keypoint_pck_accuracy(
- pred=to_numpy(pred_outputs),
- gt=to_numpy(keypoint_labels),
- mask=to_numpy(keypoint_weights) > 0,
- thr=0.05,
- norm_factor=np.ones((pred_outputs.size(0), 2), dtype=np.float32))
-
- acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
- losses.update(acc_pose=acc_pose)
-
- return losses
-
- @property
- def default_init_cfg(self):
- init_cfg = [dict(type='Normal', layer=['Linear'], std=0.01, bias=0)]
- return init_cfg
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Sequence, Tuple, Union
+
+import numpy as np
+import torch
+from torch import Tensor, nn
+
+from mmpose.evaluation.functional import keypoint_pck_accuracy
+from mmpose.models.utils.tta import flip_coordinates
+from mmpose.registry import KEYPOINT_CODECS, MODELS
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import (ConfigType, OptConfigType, OptSampleList,
+ Predictions)
+from ..base_head import BaseHead
+
+OptIntSeq = Optional[Sequence[int]]
+
+
+@MODELS.register_module()
+class RegressionHead(BaseHead):
+ """Top-down regression head introduced in `Deeppose`_ by Toshev et al
+ (2014). The head is composed of fully-connected layers to predict the
+ coordinates directly.
+
+ Args:
+ in_channels (int | sequence[int]): Number of input channels
+ num_joints (int): Number of joints
+ loss (Config): Config for keypoint loss. Defaults to use
+ :class:`SmoothL1Loss`
+ decoder (Config, optional): The decoder config that controls decoding
+ keypoint coordinates from the network output. Defaults to ``None``
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+
+ .. _`Deeppose`: https://arxiv.org/abs/1312.4659
+ """
+
+ _version = 2
+
+ def __init__(self,
+ in_channels: Union[int, Sequence[int]],
+ num_joints: int,
+ loss: ConfigType = dict(
+ type='SmoothL1Loss', use_target_weight=True),
+ decoder: OptConfigType = None,
+ init_cfg: OptConfigType = None):
+
+ if init_cfg is None:
+ init_cfg = self.default_init_cfg
+
+ super().__init__(init_cfg)
+
+ self.in_channels = in_channels
+ self.num_joints = num_joints
+ self.loss_module = MODELS.build(loss)
+ if decoder is not None:
+ self.decoder = KEYPOINT_CODECS.build(decoder)
+ else:
+ self.decoder = None
+
+ # Define fully-connected layers
+ self.fc = nn.Linear(in_channels, self.num_joints * 2)
+
+ def forward(self, feats: Tuple[Tensor]) -> Tensor:
+ """Forward the network. The input is multi scale feature maps and the
+ output is the coordinates.
+
+ Args:
+ feats (Tuple[Tensor]): Multi scale feature maps.
+
+ Returns:
+ Tensor: output coordinates(and sigmas[optional]).
+ """
+ x = feats[-1]
+
+ x = torch.flatten(x, 1)
+ x = self.fc(x)
+
+ return x.reshape(-1, self.num_joints, 2)
+
+ def predict(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ test_cfg: ConfigType = {}) -> Predictions:
+ """Predict results from outputs."""
+
+ if test_cfg.get('flip_test', False):
+ # TTA: flip test -> feats = [orig, flipped]
+ assert isinstance(feats, list) and len(feats) == 2
+ flip_indices = batch_data_samples[0].metainfo['flip_indices']
+ input_size = batch_data_samples[0].metainfo['input_size']
+ _feats, _feats_flip = feats
+
+ _batch_coords = self.forward(_feats)
+ _batch_coords_flip = flip_coordinates(
+ self.forward(_feats_flip),
+ flip_indices=flip_indices,
+ shift_coords=test_cfg.get('shift_coords', True),
+ input_size=input_size)
+ batch_coords = (_batch_coords + _batch_coords_flip) * 0.5
+ else:
+ batch_coords = self.forward(feats) # (B, K, D)
+
+ batch_coords.unsqueeze_(dim=1) # (B, N, K, D)
+ preds = self.decode(batch_coords)
+
+ return preds
+
+ def loss(self,
+ inputs: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: ConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples."""
+
+ pred_outputs = self.forward(inputs)
+
+ keypoint_labels = torch.cat(
+ [d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
+ keypoint_weights = torch.cat([
+ d.gt_instance_labels.keypoint_weights for d in batch_data_samples
+ ])
+
+ # calculate losses
+ losses = dict()
+ loss = self.loss_module(pred_outputs, keypoint_labels,
+ keypoint_weights.unsqueeze(-1))
+
+ losses.update(loss_kpt=loss)
+
+ # calculate accuracy
+ _, avg_acc, _ = keypoint_pck_accuracy(
+ pred=to_numpy(pred_outputs),
+ gt=to_numpy(keypoint_labels),
+ mask=to_numpy(keypoint_weights) > 0,
+ thr=0.05,
+ norm_factor=np.ones((pred_outputs.size(0), 2), dtype=np.float32))
+
+ acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
+ losses.update(acc_pose=acc_pose)
+
+ return losses
+
+ @property
+ def default_init_cfg(self):
+ init_cfg = [dict(type='Normal', layer=['Linear'], std=0.01, bias=0)]
+ return init_cfg
diff --git a/mmpose/models/heads/regression_heads/rle_head.py b/mmpose/models/heads/regression_heads/rle_head.py
index ef62d7d9ac..ff7c4f022d 100644
--- a/mmpose/models/heads/regression_heads/rle_head.py
+++ b/mmpose/models/heads/regression_heads/rle_head.py
@@ -1,187 +1,187 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional, Sequence, Tuple, Union
-
-import numpy as np
-import torch
-from torch import Tensor, nn
-
-from mmpose.evaluation.functional import keypoint_pck_accuracy
-from mmpose.models.utils.tta import flip_coordinates
-from mmpose.registry import KEYPOINT_CODECS, MODELS
-from mmpose.utils.tensor_utils import to_numpy
-from mmpose.utils.typing import (ConfigType, OptConfigType, OptSampleList,
- Predictions)
-from ..base_head import BaseHead
-
-OptIntSeq = Optional[Sequence[int]]
-
-
-@MODELS.register_module()
-class RLEHead(BaseHead):
- """Top-down regression head introduced in `RLE`_ by Li et al(2021). The
- head is composed of fully-connected layers to predict the coordinates and
- sigma(the variance of the coordinates) together.
-
- Args:
- in_channels (int | sequence[int]): Number of input channels
- num_joints (int): Number of joints
- loss (Config): Config for keypoint loss. Defaults to use
- :class:`RLELoss`
- decoder (Config, optional): The decoder config that controls decoding
- keypoint coordinates from the network output. Defaults to ``None``
- init_cfg (Config, optional): Config to control the initialization. See
- :attr:`default_init_cfg` for default settings
-
- .. _`RLE`: https://arxiv.org/abs/2107.11291
- """
-
- _version = 2
-
- def __init__(self,
- in_channels: Union[int, Sequence[int]],
- num_joints: int,
- loss: ConfigType = dict(
- type='RLELoss', use_target_weight=True),
- decoder: OptConfigType = None,
- init_cfg: OptConfigType = None):
-
- if init_cfg is None:
- init_cfg = self.default_init_cfg
-
- super().__init__(init_cfg)
-
- self.in_channels = in_channels
- self.num_joints = num_joints
- self.loss_module = MODELS.build(loss)
- if decoder is not None:
- self.decoder = KEYPOINT_CODECS.build(decoder)
- else:
- self.decoder = None
-
- # Define fully-connected layers
- self.fc = nn.Linear(in_channels, self.num_joints * 4)
-
- # Register the hook to automatically convert old version state dicts
- self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
-
- def forward(self, feats: Tuple[Tensor]) -> Tensor:
- """Forward the network. The input is multi scale feature maps and the
- output is the coordinates.
-
- Args:
- feats (Tuple[Tensor]): Multi scale feature maps.
-
- Returns:
- Tensor: output coordinates(and sigmas[optional]).
- """
- x = feats[-1]
-
- x = torch.flatten(x, 1)
- x = self.fc(x)
-
- return x.reshape(-1, self.num_joints, 4)
-
- def predict(self,
- feats: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- test_cfg: ConfigType = {}) -> Predictions:
- """Predict results from outputs."""
-
- if test_cfg.get('flip_test', False):
- # TTA: flip test -> feats = [orig, flipped]
- assert isinstance(feats, list) and len(feats) == 2
- flip_indices = batch_data_samples[0].metainfo['flip_indices']
- input_size = batch_data_samples[0].metainfo['input_size']
-
- _feats, _feats_flip = feats
-
- _batch_coords = self.forward(_feats)
- _batch_coords[..., 2:] = _batch_coords[..., 2:].sigmoid()
-
- _batch_coords_flip = flip_coordinates(
- self.forward(_feats_flip),
- flip_indices=flip_indices,
- shift_coords=test_cfg.get('shift_coords', True),
- input_size=input_size)
- _batch_coords_flip[..., 2:] = _batch_coords_flip[..., 2:].sigmoid()
-
- batch_coords = (_batch_coords + _batch_coords_flip) * 0.5
- else:
- batch_coords = self.forward(feats) # (B, K, D)
- batch_coords[..., 2:] = batch_coords[..., 2:].sigmoid()
-
- batch_coords.unsqueeze_(dim=1) # (B, N, K, D)
- preds = self.decode(batch_coords)
-
- return preds
-
- def loss(self,
- inputs: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- train_cfg: ConfigType = {}) -> dict:
- """Calculate losses from a batch of inputs and data samples."""
-
- pred_outputs = self.forward(inputs)
-
- keypoint_labels = torch.cat(
- [d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
- keypoint_weights = torch.cat([
- d.gt_instance_labels.keypoint_weights for d in batch_data_samples
- ])
-
- pred_coords = pred_outputs[:, :, :2]
- pred_sigma = pred_outputs[:, :, 2:4]
-
- # calculate losses
- losses = dict()
- loss = self.loss_module(pred_coords, pred_sigma, keypoint_labels,
- keypoint_weights.unsqueeze(-1))
-
- losses.update(loss_kpt=loss)
-
- # calculate accuracy
- _, avg_acc, _ = keypoint_pck_accuracy(
- pred=to_numpy(pred_coords),
- gt=to_numpy(keypoint_labels),
- mask=to_numpy(keypoint_weights) > 0,
- thr=0.05,
- norm_factor=np.ones((pred_coords.size(0), 2), dtype=np.float32))
-
- acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
- losses.update(acc_pose=acc_pose)
-
- return losses
-
- def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
- **kwargs):
- """A hook function to convert old-version state dict of
- :class:`TopdownHeatmapSimpleHead` (before MMPose v1.0.0) to a
- compatible format of :class:`HeatmapHead`.
-
- The hook will be automatically registered during initialization.
- """
-
- version = local_meta.get('version', None)
- if version and version >= self._version:
- return
-
- # convert old-version state dict
- keys = list(state_dict.keys())
- for _k in keys:
- v = state_dict.pop(_k)
- k = _k.lstrip(prefix)
- # In old version, "loss" includes the instances of loss,
- # now it should be renamed "loss_module"
- k_parts = k.split('.')
- if k_parts[0] == 'loss':
- # loss.xxx -> loss_module.xxx
- k_new = prefix + 'loss_module.' + '.'.join(k_parts[1:])
- else:
- k_new = _k
-
- state_dict[k_new] = v
-
- @property
- def default_init_cfg(self):
- init_cfg = [dict(type='Normal', layer=['Linear'], std=0.01, bias=0)]
- return init_cfg
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Sequence, Tuple, Union
+
+import numpy as np
+import torch
+from torch import Tensor, nn
+
+from mmpose.evaluation.functional import keypoint_pck_accuracy
+from mmpose.models.utils.tta import flip_coordinates
+from mmpose.registry import KEYPOINT_CODECS, MODELS
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import (ConfigType, OptConfigType, OptSampleList,
+ Predictions)
+from ..base_head import BaseHead
+
+OptIntSeq = Optional[Sequence[int]]
+
+
+@MODELS.register_module()
+class RLEHead(BaseHead):
+ """Top-down regression head introduced in `RLE`_ by Li et al(2021). The
+ head is composed of fully-connected layers to predict the coordinates and
+ sigma(the variance of the coordinates) together.
+
+ Args:
+ in_channels (int | sequence[int]): Number of input channels
+ num_joints (int): Number of joints
+ loss (Config): Config for keypoint loss. Defaults to use
+ :class:`RLELoss`
+ decoder (Config, optional): The decoder config that controls decoding
+ keypoint coordinates from the network output. Defaults to ``None``
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+
+ .. _`RLE`: https://arxiv.org/abs/2107.11291
+ """
+
+ _version = 2
+
+ def __init__(self,
+ in_channels: Union[int, Sequence[int]],
+ num_joints: int,
+ loss: ConfigType = dict(
+ type='RLELoss', use_target_weight=True),
+ decoder: OptConfigType = None,
+ init_cfg: OptConfigType = None):
+
+ if init_cfg is None:
+ init_cfg = self.default_init_cfg
+
+ super().__init__(init_cfg)
+
+ self.in_channels = in_channels
+ self.num_joints = num_joints
+ self.loss_module = MODELS.build(loss)
+ if decoder is not None:
+ self.decoder = KEYPOINT_CODECS.build(decoder)
+ else:
+ self.decoder = None
+
+ # Define fully-connected layers
+ self.fc = nn.Linear(in_channels, self.num_joints * 4)
+
+ # Register the hook to automatically convert old version state dicts
+ self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
+
+ def forward(self, feats: Tuple[Tensor]) -> Tensor:
+ """Forward the network. The input is multi scale feature maps and the
+ output is the coordinates.
+
+ Args:
+ feats (Tuple[Tensor]): Multi scale feature maps.
+
+ Returns:
+ Tensor: output coordinates(and sigmas[optional]).
+ """
+ x = feats[-1]
+
+ x = torch.flatten(x, 1)
+ x = self.fc(x)
+
+ return x.reshape(-1, self.num_joints, 4)
+
+ def predict(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ test_cfg: ConfigType = {}) -> Predictions:
+ """Predict results from outputs."""
+
+ if test_cfg.get('flip_test', False):
+ # TTA: flip test -> feats = [orig, flipped]
+ assert isinstance(feats, list) and len(feats) == 2
+ flip_indices = batch_data_samples[0].metainfo['flip_indices']
+ input_size = batch_data_samples[0].metainfo['input_size']
+
+ _feats, _feats_flip = feats
+
+ _batch_coords = self.forward(_feats)
+ _batch_coords[..., 2:] = _batch_coords[..., 2:].sigmoid()
+
+ _batch_coords_flip = flip_coordinates(
+ self.forward(_feats_flip),
+ flip_indices=flip_indices,
+ shift_coords=test_cfg.get('shift_coords', True),
+ input_size=input_size)
+ _batch_coords_flip[..., 2:] = _batch_coords_flip[..., 2:].sigmoid()
+
+ batch_coords = (_batch_coords + _batch_coords_flip) * 0.5
+ else:
+ batch_coords = self.forward(feats) # (B, K, D)
+ batch_coords[..., 2:] = batch_coords[..., 2:].sigmoid()
+
+ batch_coords.unsqueeze_(dim=1) # (B, N, K, D)
+ preds = self.decode(batch_coords)
+
+ return preds
+
+ def loss(self,
+ inputs: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: ConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples."""
+
+ pred_outputs = self.forward(inputs)
+
+ keypoint_labels = torch.cat(
+ [d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
+ keypoint_weights = torch.cat([
+ d.gt_instance_labels.keypoint_weights for d in batch_data_samples
+ ])
+
+ pred_coords = pred_outputs[:, :, :2]
+ pred_sigma = pred_outputs[:, :, 2:4]
+
+ # calculate losses
+ losses = dict()
+ loss = self.loss_module(pred_coords, pred_sigma, keypoint_labels,
+ keypoint_weights.unsqueeze(-1))
+
+ losses.update(loss_kpt=loss)
+
+ # calculate accuracy
+ _, avg_acc, _ = keypoint_pck_accuracy(
+ pred=to_numpy(pred_coords),
+ gt=to_numpy(keypoint_labels),
+ mask=to_numpy(keypoint_weights) > 0,
+ thr=0.05,
+ norm_factor=np.ones((pred_coords.size(0), 2), dtype=np.float32))
+
+ acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
+ losses.update(acc_pose=acc_pose)
+
+ return losses
+
+ def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
+ **kwargs):
+ """A hook function to convert old-version state dict of
+ :class:`TopdownHeatmapSimpleHead` (before MMPose v1.0.0) to a
+ compatible format of :class:`HeatmapHead`.
+
+ The hook will be automatically registered during initialization.
+ """
+
+ version = local_meta.get('version', None)
+ if version and version >= self._version:
+ return
+
+ # convert old-version state dict
+ keys = list(state_dict.keys())
+ for _k in keys:
+ v = state_dict.pop(_k)
+ k = _k.lstrip(prefix)
+ # In old version, "loss" includes the instances of loss,
+ # now it should be renamed "loss_module"
+ k_parts = k.split('.')
+ if k_parts[0] == 'loss':
+ # loss.xxx -> loss_module.xxx
+ k_new = prefix + 'loss_module.' + '.'.join(k_parts[1:])
+ else:
+ k_new = _k
+
+ state_dict[k_new] = v
+
+ @property
+ def default_init_cfg(self):
+ init_cfg = [dict(type='Normal', layer=['Linear'], std=0.01, bias=0)]
+ return init_cfg
diff --git a/mmpose/models/heads/regression_heads/temporal_regression_head.py b/mmpose/models/heads/regression_heads/temporal_regression_head.py
index ac76316842..2af58156f7 100644
--- a/mmpose/models/heads/regression_heads/temporal_regression_head.py
+++ b/mmpose/models/heads/regression_heads/temporal_regression_head.py
@@ -1,151 +1,151 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional, Sequence, Tuple, Union
-
-import numpy as np
-import torch
-from torch import Tensor, nn
-
-from mmpose.evaluation.functional import keypoint_pck_accuracy
-from mmpose.registry import KEYPOINT_CODECS, MODELS
-from mmpose.utils.tensor_utils import to_numpy
-from mmpose.utils.typing import (ConfigType, OptConfigType, OptSampleList,
- Predictions)
-from ..base_head import BaseHead
-
-OptIntSeq = Optional[Sequence[int]]
-
-
-@MODELS.register_module()
-class TemporalRegressionHead(BaseHead):
- """Temporal Regression head of `VideoPose3D`_ by Dario et al (CVPR'2019).
-
- Args:
- in_channels (int | sequence[int]): Number of input channels
- num_joints (int): Number of joints
- loss (Config): Config for keypoint loss. Defaults to use
- :class:`SmoothL1Loss`
- decoder (Config, optional): The decoder config that controls decoding
- keypoint coordinates from the network output. Defaults to ``None``
- init_cfg (Config, optional): Config to control the initialization. See
- :attr:`default_init_cfg` for default settings
-
- .. _`VideoPose3D`: https://arxiv.org/abs/1811.11742
- """
-
- _version = 2
-
- def __init__(self,
- in_channels: Union[int, Sequence[int]],
- num_joints: int,
- loss: ConfigType = dict(
- type='MSELoss', use_target_weight=True),
- decoder: OptConfigType = None,
- init_cfg: OptConfigType = None):
-
- if init_cfg is None:
- init_cfg = self.default_init_cfg
-
- super().__init__(init_cfg)
-
- self.in_channels = in_channels
- self.num_joints = num_joints
- self.loss_module = MODELS.build(loss)
- if decoder is not None:
- self.decoder = KEYPOINT_CODECS.build(decoder)
- else:
- self.decoder = None
-
- # Define fully-connected layers
- self.conv = nn.Conv1d(in_channels, self.num_joints * 3, 1)
-
- def forward(self, feats: Tuple[Tensor]) -> Tensor:
- """Forward the network. The input is multi scale feature maps and the
- output is the coordinates.
-
- Args:
- feats (Tuple[Tensor]): Multi scale feature maps.
-
- Returns:
- Tensor: Output coordinates (and sigmas[optional]).
- """
- x = feats[-1]
-
- x = self.conv(x)
-
- return x.reshape(-1, self.num_joints, 3)
-
- def predict(self,
- feats: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- test_cfg: ConfigType = {}) -> Predictions:
- """Predict results from outputs.
-
- Returns:
- preds (sequence[InstanceData]): Prediction results.
- Each contains the following fields:
-
- - keypoints: Predicted keypoints of shape (B, N, K, D).
- - keypoint_scores: Scores of predicted keypoints of shape
- (B, N, K).
- """
-
- batch_coords = self.forward(feats) # (B, K, D)
-
- # Restore global position with target_root
- target_root = batch_data_samples[0].metainfo.get('target_root', None)
- if target_root is not None:
- target_root = torch.stack([
- torch.from_numpy(b.metainfo['target_root'])
- for b in batch_data_samples
- ])
- else:
- target_root = torch.stack([
- torch.empty((0), dtype=torch.float32)
- for _ in batch_data_samples[0].metainfo
- ])
-
- preds = self.decode((batch_coords, target_root))
-
- return preds
-
- def loss(self,
- inputs: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- train_cfg: ConfigType = {}) -> dict:
- """Calculate losses from a batch of inputs and data samples."""
-
- pred_outputs = self.forward(inputs)
-
- lifting_target_label = torch.cat([
- d.gt_instance_labels.lifting_target_label
- for d in batch_data_samples
- ])
- lifting_target_weights = torch.cat([
- d.gt_instance_labels.lifting_target_weights
- for d in batch_data_samples
- ])
-
- # calculate losses
- losses = dict()
- loss = self.loss_module(pred_outputs, lifting_target_label,
- lifting_target_weights.unsqueeze(-1))
-
- losses.update(loss_pose3d=loss)
-
- # calculate accuracy
- _, avg_acc, _ = keypoint_pck_accuracy(
- pred=to_numpy(pred_outputs),
- gt=to_numpy(lifting_target_label),
- mask=to_numpy(lifting_target_weights) > 0,
- thr=0.05,
- norm_factor=np.ones((pred_outputs.size(0), 3), dtype=np.float32))
-
- mpjpe_pose = torch.tensor(avg_acc, device=lifting_target_label.device)
- losses.update(mpjpe=mpjpe_pose)
-
- return losses
-
- @property
- def default_init_cfg(self):
- init_cfg = [dict(type='Normal', layer=['Linear'], std=0.01, bias=0)]
- return init_cfg
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Sequence, Tuple, Union
+
+import numpy as np
+import torch
+from torch import Tensor, nn
+
+from mmpose.evaluation.functional import keypoint_pck_accuracy
+from mmpose.registry import KEYPOINT_CODECS, MODELS
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import (ConfigType, OptConfigType, OptSampleList,
+ Predictions)
+from ..base_head import BaseHead
+
+OptIntSeq = Optional[Sequence[int]]
+
+
+@MODELS.register_module()
+class TemporalRegressionHead(BaseHead):
+ """Temporal Regression head of `VideoPose3D`_ by Dario et al (CVPR'2019).
+
+ Args:
+ in_channels (int | sequence[int]): Number of input channels
+ num_joints (int): Number of joints
+ loss (Config): Config for keypoint loss. Defaults to use
+ :class:`SmoothL1Loss`
+ decoder (Config, optional): The decoder config that controls decoding
+ keypoint coordinates from the network output. Defaults to ``None``
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+
+ .. _`VideoPose3D`: https://arxiv.org/abs/1811.11742
+ """
+
+ _version = 2
+
+ def __init__(self,
+ in_channels: Union[int, Sequence[int]],
+ num_joints: int,
+ loss: ConfigType = dict(
+ type='MSELoss', use_target_weight=True),
+ decoder: OptConfigType = None,
+ init_cfg: OptConfigType = None):
+
+ if init_cfg is None:
+ init_cfg = self.default_init_cfg
+
+ super().__init__(init_cfg)
+
+ self.in_channels = in_channels
+ self.num_joints = num_joints
+ self.loss_module = MODELS.build(loss)
+ if decoder is not None:
+ self.decoder = KEYPOINT_CODECS.build(decoder)
+ else:
+ self.decoder = None
+
+ # Define fully-connected layers
+ self.conv = nn.Conv1d(in_channels, self.num_joints * 3, 1)
+
+ def forward(self, feats: Tuple[Tensor]) -> Tensor:
+ """Forward the network. The input is multi scale feature maps and the
+ output is the coordinates.
+
+ Args:
+ feats (Tuple[Tensor]): Multi scale feature maps.
+
+ Returns:
+ Tensor: Output coordinates (and sigmas[optional]).
+ """
+ x = feats[-1]
+
+ x = self.conv(x)
+
+ return x.reshape(-1, self.num_joints, 3)
+
+ def predict(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ test_cfg: ConfigType = {}) -> Predictions:
+ """Predict results from outputs.
+
+ Returns:
+ preds (sequence[InstanceData]): Prediction results.
+ Each contains the following fields:
+
+ - keypoints: Predicted keypoints of shape (B, N, K, D).
+ - keypoint_scores: Scores of predicted keypoints of shape
+ (B, N, K).
+ """
+
+ batch_coords = self.forward(feats) # (B, K, D)
+
+ # Restore global position with target_root
+ target_root = batch_data_samples[0].metainfo.get('target_root', None)
+ if target_root is not None:
+ target_root = torch.stack([
+ torch.from_numpy(b.metainfo['target_root'])
+ for b in batch_data_samples
+ ])
+ else:
+ target_root = torch.stack([
+ torch.empty((0), dtype=torch.float32)
+ for _ in batch_data_samples[0].metainfo
+ ])
+
+ preds = self.decode((batch_coords, target_root))
+
+ return preds
+
+ def loss(self,
+ inputs: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: ConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples."""
+
+ pred_outputs = self.forward(inputs)
+
+ lifting_target_label = torch.cat([
+ d.gt_instance_labels.lifting_target_label
+ for d in batch_data_samples
+ ])
+ lifting_target_weights = torch.cat([
+ d.gt_instance_labels.lifting_target_weights
+ for d in batch_data_samples
+ ])
+
+ # calculate losses
+ losses = dict()
+ loss = self.loss_module(pred_outputs, lifting_target_label,
+ lifting_target_weights.unsqueeze(-1))
+
+ losses.update(loss_pose3d=loss)
+
+ # calculate accuracy
+ _, avg_acc, _ = keypoint_pck_accuracy(
+ pred=to_numpy(pred_outputs),
+ gt=to_numpy(lifting_target_label),
+ mask=to_numpy(lifting_target_weights) > 0,
+ thr=0.05,
+ norm_factor=np.ones((pred_outputs.size(0), 3), dtype=np.float32))
+
+ mpjpe_pose = torch.tensor(avg_acc, device=lifting_target_label.device)
+ losses.update(mpjpe=mpjpe_pose)
+
+ return losses
+
+ @property
+ def default_init_cfg(self):
+ init_cfg = [dict(type='Normal', layer=['Linear'], std=0.01, bias=0)]
+ return init_cfg
diff --git a/mmpose/models/heads/regression_heads/trajectory_regression_head.py b/mmpose/models/heads/regression_heads/trajectory_regression_head.py
index adfd7353d3..ca2958bc01 100644
--- a/mmpose/models/heads/regression_heads/trajectory_regression_head.py
+++ b/mmpose/models/heads/regression_heads/trajectory_regression_head.py
@@ -1,150 +1,150 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional, Sequence, Tuple, Union
-
-import numpy as np
-import torch
-from torch import Tensor, nn
-
-from mmpose.evaluation.functional import keypoint_pck_accuracy
-from mmpose.registry import KEYPOINT_CODECS, MODELS
-from mmpose.utils.tensor_utils import to_numpy
-from mmpose.utils.typing import (ConfigType, OptConfigType, OptSampleList,
- Predictions)
-from ..base_head import BaseHead
-
-OptIntSeq = Optional[Sequence[int]]
-
-
-@MODELS.register_module()
-class TrajectoryRegressionHead(BaseHead):
- """Trajectory Regression head of `VideoPose3D`_ by Dario et al (CVPR'2019).
-
- Args:
- in_channels (int | sequence[int]): Number of input channels
- num_joints (int): Number of joints
- loss (Config): Config for trajectory loss. Defaults to use
- :class:`MPJPELoss`
- decoder (Config, optional): The decoder config that controls decoding
- keypoint coordinates from the network output. Defaults to ``None``
- init_cfg (Config, optional): Config to control the initialization. See
- :attr:`default_init_cfg` for default settings
-
- .. _`VideoPose3D`: https://arxiv.org/abs/1811.11742
- """
-
- _version = 2
-
- def __init__(self,
- in_channels: Union[int, Sequence[int]],
- num_joints: int,
- loss: ConfigType = dict(
- type='MPJPELoss', use_target_weight=True),
- decoder: OptConfigType = None,
- init_cfg: OptConfigType = None):
-
- if init_cfg is None:
- init_cfg = self.default_init_cfg
-
- super().__init__(init_cfg)
-
- self.in_channels = in_channels
- self.num_joints = num_joints
- self.loss_module = MODELS.build(loss)
- if decoder is not None:
- self.decoder = KEYPOINT_CODECS.build(decoder)
- else:
- self.decoder = None
-
- # Define fully-connected layers
- self.conv = nn.Conv1d(in_channels, self.num_joints * 3, 1)
-
- def forward(self, feats: Tuple[Tensor]) -> Tensor:
- """Forward the network. The input is multi scale feature maps and the
- output is the coordinates.
-
- Args:
- feats (Tuple[Tensor]): Multi scale feature maps.
-
- Returns:
- Tensor: output coordinates(and sigmas[optional]).
- """
- x = feats[-1]
-
- x = self.conv(x)
-
- return x.reshape(-1, self.num_joints, 3)
-
- def predict(self,
- feats: Tuple[Tensor],
- batch_data_samples: OptSampleList,
- test_cfg: ConfigType = {}) -> Predictions:
- """Predict results from outputs.
-
- Returns:
- preds (sequence[InstanceData]): Prediction results.
- Each contains the following fields:
-
- - keypoints: Predicted keypoints of shape (B, N, K, D).
- - keypoint_scores: Scores of predicted keypoints of shape
- (B, N, K).
- """
-
- batch_coords = self.forward(feats) # (B, K, D)
-
- # Restore global position with target_root
- target_root = batch_data_samples[0].metainfo.get('target_root', None)
- if target_root is not None:
- target_root = torch.stack([
- torch.from_numpy(b.metainfo['target_root'])
- for b in batch_data_samples
- ])
- else:
- target_root = torch.stack([
- torch.empty((0), dtype=torch.float32)
- for _ in batch_data_samples[0].metainfo
- ])
-
- preds = self.decode((batch_coords, target_root))
-
- return preds
-
- def loss(self,
- inputs: Union[Tensor, Tuple[Tensor]],
- batch_data_samples: OptSampleList,
- train_cfg: ConfigType = {}) -> dict:
- """Calculate losses from a batch of inputs and data samples."""
-
- pred_outputs = self.forward(inputs)
-
- lifting_target_label = torch.cat([
- d.gt_instance_labels.lifting_target_label
- for d in batch_data_samples
- ])
- trajectory_weights = torch.cat([
- d.gt_instance_labels.trajectory_weights for d in batch_data_samples
- ])
-
- # calculate losses
- losses = dict()
- loss = self.loss_module(pred_outputs, lifting_target_label,
- trajectory_weights.unsqueeze(-1))
-
- losses.update(loss_traj=loss)
-
- # calculate accuracy
- _, avg_acc, _ = keypoint_pck_accuracy(
- pred=to_numpy(pred_outputs),
- gt=to_numpy(lifting_target_label),
- mask=to_numpy(trajectory_weights) > 0,
- thr=0.05,
- norm_factor=np.ones((pred_outputs.size(0), 3), dtype=np.float32))
-
- mpjpe_traj = torch.tensor(avg_acc, device=lifting_target_label.device)
- losses.update(mpjpe_traj=mpjpe_traj)
-
- return losses
-
- @property
- def default_init_cfg(self):
- init_cfg = [dict(type='Normal', layer=['Linear'], std=0.01, bias=0)]
- return init_cfg
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Sequence, Tuple, Union
+
+import numpy as np
+import torch
+from torch import Tensor, nn
+
+from mmpose.evaluation.functional import keypoint_pck_accuracy
+from mmpose.registry import KEYPOINT_CODECS, MODELS
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import (ConfigType, OptConfigType, OptSampleList,
+ Predictions)
+from ..base_head import BaseHead
+
+OptIntSeq = Optional[Sequence[int]]
+
+
+@MODELS.register_module()
+class TrajectoryRegressionHead(BaseHead):
+ """Trajectory Regression head of `VideoPose3D`_ by Dario et al (CVPR'2019).
+
+ Args:
+ in_channels (int | sequence[int]): Number of input channels
+ num_joints (int): Number of joints
+ loss (Config): Config for trajectory loss. Defaults to use
+ :class:`MPJPELoss`
+ decoder (Config, optional): The decoder config that controls decoding
+ keypoint coordinates from the network output. Defaults to ``None``
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+
+ .. _`VideoPose3D`: https://arxiv.org/abs/1811.11742
+ """
+
+ _version = 2
+
+ def __init__(self,
+ in_channels: Union[int, Sequence[int]],
+ num_joints: int,
+ loss: ConfigType = dict(
+ type='MPJPELoss', use_target_weight=True),
+ decoder: OptConfigType = None,
+ init_cfg: OptConfigType = None):
+
+ if init_cfg is None:
+ init_cfg = self.default_init_cfg
+
+ super().__init__(init_cfg)
+
+ self.in_channels = in_channels
+ self.num_joints = num_joints
+ self.loss_module = MODELS.build(loss)
+ if decoder is not None:
+ self.decoder = KEYPOINT_CODECS.build(decoder)
+ else:
+ self.decoder = None
+
+ # Define fully-connected layers
+ self.conv = nn.Conv1d(in_channels, self.num_joints * 3, 1)
+
+ def forward(self, feats: Tuple[Tensor]) -> Tensor:
+ """Forward the network. The input is multi scale feature maps and the
+ output is the coordinates.
+
+ Args:
+ feats (Tuple[Tensor]): Multi scale feature maps.
+
+ Returns:
+ Tensor: output coordinates(and sigmas[optional]).
+ """
+ x = feats[-1]
+
+ x = self.conv(x)
+
+ return x.reshape(-1, self.num_joints, 3)
+
+ def predict(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ test_cfg: ConfigType = {}) -> Predictions:
+ """Predict results from outputs.
+
+ Returns:
+ preds (sequence[InstanceData]): Prediction results.
+ Each contains the following fields:
+
+ - keypoints: Predicted keypoints of shape (B, N, K, D).
+ - keypoint_scores: Scores of predicted keypoints of shape
+ (B, N, K).
+ """
+
+ batch_coords = self.forward(feats) # (B, K, D)
+
+ # Restore global position with target_root
+ target_root = batch_data_samples[0].metainfo.get('target_root', None)
+ if target_root is not None:
+ target_root = torch.stack([
+ torch.from_numpy(b.metainfo['target_root'])
+ for b in batch_data_samples
+ ])
+ else:
+ target_root = torch.stack([
+ torch.empty((0), dtype=torch.float32)
+ for _ in batch_data_samples[0].metainfo
+ ])
+
+ preds = self.decode((batch_coords, target_root))
+
+ return preds
+
+ def loss(self,
+ inputs: Union[Tensor, Tuple[Tensor]],
+ batch_data_samples: OptSampleList,
+ train_cfg: ConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples."""
+
+ pred_outputs = self.forward(inputs)
+
+ lifting_target_label = torch.cat([
+ d.gt_instance_labels.lifting_target_label
+ for d in batch_data_samples
+ ])
+ trajectory_weights = torch.cat([
+ d.gt_instance_labels.trajectory_weights for d in batch_data_samples
+ ])
+
+ # calculate losses
+ losses = dict()
+ loss = self.loss_module(pred_outputs, lifting_target_label,
+ trajectory_weights.unsqueeze(-1))
+
+ losses.update(loss_traj=loss)
+
+ # calculate accuracy
+ _, avg_acc, _ = keypoint_pck_accuracy(
+ pred=to_numpy(pred_outputs),
+ gt=to_numpy(lifting_target_label),
+ mask=to_numpy(trajectory_weights) > 0,
+ thr=0.05,
+ norm_factor=np.ones((pred_outputs.size(0), 3), dtype=np.float32))
+
+ mpjpe_traj = torch.tensor(avg_acc, device=lifting_target_label.device)
+ losses.update(mpjpe_traj=mpjpe_traj)
+
+ return losses
+
+ @property
+ def default_init_cfg(self):
+ init_cfg = [dict(type='Normal', layer=['Linear'], std=0.01, bias=0)]
+ return init_cfg
diff --git a/mmpose/models/losses/__init__.py b/mmpose/models/losses/__init__.py
index f21071e156..db989e969e 100644
--- a/mmpose/models/losses/__init__.py
+++ b/mmpose/models/losses/__init__.py
@@ -1,17 +1,17 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .ae_loss import AssociativeEmbeddingLoss
-from .classification_loss import BCELoss, JSDiscretLoss, KLDiscretLoss
-from .heatmap_loss import (AdaptiveWingLoss, KeypointMSELoss,
- KeypointOHKMMSELoss)
-from .loss_wrappers import CombinedLoss, MultipleLossWrapper
-from .regression_loss import (BoneLoss, L1Loss, MPJPELoss, MSELoss, RLELoss,
- SemiSupervisionLoss, SmoothL1Loss,
- SoftWeightSmoothL1Loss, SoftWingLoss, WingLoss)
-
-__all__ = [
- 'KeypointMSELoss', 'KeypointOHKMMSELoss', 'SmoothL1Loss', 'WingLoss',
- 'MPJPELoss', 'MSELoss', 'L1Loss', 'BCELoss', 'BoneLoss',
- 'SemiSupervisionLoss', 'SoftWingLoss', 'AdaptiveWingLoss', 'RLELoss',
- 'KLDiscretLoss', 'MultipleLossWrapper', 'JSDiscretLoss', 'CombinedLoss',
- 'AssociativeEmbeddingLoss', 'SoftWeightSmoothL1Loss'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .ae_loss import AssociativeEmbeddingLoss
+from .classification_loss import BCELoss, JSDiscretLoss, KLDiscretLoss
+from .heatmap_loss import (AdaptiveWingLoss, KeypointMSELoss,
+ KeypointOHKMMSELoss)
+from .loss_wrappers import CombinedLoss, MultipleLossWrapper
+from .regression_loss import (BoneLoss, L1Loss, MPJPELoss, MSELoss, RLELoss,
+ SemiSupervisionLoss, SmoothL1Loss,
+ SoftWeightSmoothL1Loss, SoftWingLoss, WingLoss)
+
+__all__ = [
+ 'KeypointMSELoss', 'KeypointOHKMMSELoss', 'SmoothL1Loss', 'WingLoss',
+ 'MPJPELoss', 'MSELoss', 'L1Loss', 'BCELoss', 'BoneLoss',
+ 'SemiSupervisionLoss', 'SoftWingLoss', 'AdaptiveWingLoss', 'RLELoss',
+ 'KLDiscretLoss', 'MultipleLossWrapper', 'JSDiscretLoss', 'CombinedLoss',
+ 'AssociativeEmbeddingLoss', 'SoftWeightSmoothL1Loss'
+]
diff --git a/mmpose/models/losses/ae_loss.py b/mmpose/models/losses/ae_loss.py
index 1f1e08181b..49ff745f58 100644
--- a/mmpose/models/losses/ae_loss.py
+++ b/mmpose/models/losses/ae_loss.py
@@ -1,123 +1,123 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-
-from typing import List, Union
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from torch import Tensor
-
-from mmpose.registry import MODELS
-
-
-@MODELS.register_module()
-class AssociativeEmbeddingLoss(nn.Module):
- """Associative Embedding loss.
-
- Details can be found in
- `Associative Embedding `_
-
- Note:
-
- - batch size: B
- - instance number: N
- - keypoint number: K
- - keypoint dimension: D
- - embedding tag dimension: L
- - heatmap size: [W, H]
-
- Args:
- loss_weight (float): Weight of the loss. Defaults to 1.0
- push_loss_factor (float): A factor that controls the weight between
- the push loss and the pull loss. Defaults to 0.5
- """
-
- def __init__(self,
- loss_weight: float = 1.0,
- push_loss_factor: float = 0.5) -> None:
- super().__init__()
- self.loss_weight = loss_weight
- self.push_loss_factor = push_loss_factor
-
- def _ae_loss_per_image(self, tags: Tensor, keypoint_indices: Tensor):
- """Compute associative embedding loss for one image.
-
- Args:
- tags (Tensor): Tagging heatmaps in shape (K*L, H, W)
- keypoint_indices (Tensor): Ground-truth keypint position indices
- in shape (N, K, 2)
- """
- K = keypoint_indices.shape[1]
- C, H, W = tags.shape
- L = C // K
-
- tags = tags.view(L, K, H * W)
- instance_tags = []
- instance_kpt_tags = []
-
- for keypoint_indices_n in keypoint_indices:
- _kpt_tags = []
- for k in range(K):
- if keypoint_indices_n[k, 1]:
- _kpt_tags.append(tags[:, k, keypoint_indices_n[k, 0]])
-
- if _kpt_tags:
- kpt_tags = torch.stack(_kpt_tags)
- instance_kpt_tags.append(kpt_tags)
- instance_tags.append(kpt_tags.mean(dim=0))
-
- N = len(instance_kpt_tags) # number of instances with valid keypoints
-
- if N == 0:
- pull_loss = tags.new_zeros(size=(), requires_grad=True)
- push_loss = tags.new_zeros(size=(), requires_grad=True)
- else:
- pull_loss = sum(
- F.mse_loss(_kpt_tags, _tag.expand_as(_kpt_tags))
- for (_kpt_tags, _tag) in zip(instance_kpt_tags, instance_tags))
-
- if N == 1:
- push_loss = tags.new_zeros(size=(), requires_grad=True)
- else:
- tag_mat = torch.stack(instance_tags) # (N, L)
- diff = tag_mat[None] - tag_mat[:, None] # (N, N, L)
- push_loss = torch.sum(torch.exp(-diff.pow(2)))
-
- # normalization
- eps = 1e-6
- pull_loss = pull_loss / (N + eps)
- push_loss = push_loss / ((N - 1) * N + eps)
-
- return pull_loss, push_loss
-
- def forward(self, tags: Tensor, keypoint_indices: Union[List[Tensor],
- Tensor]):
- """Compute associative embedding loss on a batch of data.
-
- Args:
- tags (Tensor): Tagging heatmaps in shape (B, L*K, H, W)
- keypoint_indices (Tensor|List[Tensor]): Ground-truth keypint
- position indices represented by a Tensor in shape
- (B, N, K, 2), or a list of B Tensors in shape (N_i, K, 2)
- Each keypoint's index is represented as [i, v], where i is the
- position index in the heatmap (:math:`i=y*w+x`) and v is the
- visibility
-
- Returns:
- tuple:
- - pull_loss (Tensor)
- - push_loss (Tensor)
- """
-
- assert tags.shape[0] == len(keypoint_indices)
-
- pull_loss = 0.
- push_loss = 0.
-
- for i in range(tags.shape[0]):
- _pull, _push = self._ae_loss_per_image(tags[i],
- keypoint_indices[i])
- pull_loss += _pull * self.loss_weight
- push_loss += _push * self.loss_weight * self.push_loss_factor
-
- return pull_loss, push_loss
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from typing import List, Union
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch import Tensor
+
+from mmpose.registry import MODELS
+
+
+@MODELS.register_module()
+class AssociativeEmbeddingLoss(nn.Module):
+ """Associative Embedding loss.
+
+ Details can be found in
+ `Associative Embedding `_
+
+ Note:
+
+ - batch size: B
+ - instance number: N
+ - keypoint number: K
+ - keypoint dimension: D
+ - embedding tag dimension: L
+ - heatmap size: [W, H]
+
+ Args:
+ loss_weight (float): Weight of the loss. Defaults to 1.0
+ push_loss_factor (float): A factor that controls the weight between
+ the push loss and the pull loss. Defaults to 0.5
+ """
+
+ def __init__(self,
+ loss_weight: float = 1.0,
+ push_loss_factor: float = 0.5) -> None:
+ super().__init__()
+ self.loss_weight = loss_weight
+ self.push_loss_factor = push_loss_factor
+
+ def _ae_loss_per_image(self, tags: Tensor, keypoint_indices: Tensor):
+ """Compute associative embedding loss for one image.
+
+ Args:
+ tags (Tensor): Tagging heatmaps in shape (K*L, H, W)
+ keypoint_indices (Tensor): Ground-truth keypint position indices
+ in shape (N, K, 2)
+ """
+ K = keypoint_indices.shape[1]
+ C, H, W = tags.shape
+ L = C // K
+
+ tags = tags.view(L, K, H * W)
+ instance_tags = []
+ instance_kpt_tags = []
+
+ for keypoint_indices_n in keypoint_indices:
+ _kpt_tags = []
+ for k in range(K):
+ if keypoint_indices_n[k, 1]:
+ _kpt_tags.append(tags[:, k, keypoint_indices_n[k, 0]])
+
+ if _kpt_tags:
+ kpt_tags = torch.stack(_kpt_tags)
+ instance_kpt_tags.append(kpt_tags)
+ instance_tags.append(kpt_tags.mean(dim=0))
+
+ N = len(instance_kpt_tags) # number of instances with valid keypoints
+
+ if N == 0:
+ pull_loss = tags.new_zeros(size=(), requires_grad=True)
+ push_loss = tags.new_zeros(size=(), requires_grad=True)
+ else:
+ pull_loss = sum(
+ F.mse_loss(_kpt_tags, _tag.expand_as(_kpt_tags))
+ for (_kpt_tags, _tag) in zip(instance_kpt_tags, instance_tags))
+
+ if N == 1:
+ push_loss = tags.new_zeros(size=(), requires_grad=True)
+ else:
+ tag_mat = torch.stack(instance_tags) # (N, L)
+ diff = tag_mat[None] - tag_mat[:, None] # (N, N, L)
+ push_loss = torch.sum(torch.exp(-diff.pow(2)))
+
+ # normalization
+ eps = 1e-6
+ pull_loss = pull_loss / (N + eps)
+ push_loss = push_loss / ((N - 1) * N + eps)
+
+ return pull_loss, push_loss
+
+ def forward(self, tags: Tensor, keypoint_indices: Union[List[Tensor],
+ Tensor]):
+ """Compute associative embedding loss on a batch of data.
+
+ Args:
+ tags (Tensor): Tagging heatmaps in shape (B, L*K, H, W)
+ keypoint_indices (Tensor|List[Tensor]): Ground-truth keypint
+ position indices represented by a Tensor in shape
+ (B, N, K, 2), or a list of B Tensors in shape (N_i, K, 2)
+ Each keypoint's index is represented as [i, v], where i is the
+ position index in the heatmap (:math:`i=y*w+x`) and v is the
+ visibility
+
+ Returns:
+ tuple:
+ - pull_loss (Tensor)
+ - push_loss (Tensor)
+ """
+
+ assert tags.shape[0] == len(keypoint_indices)
+
+ pull_loss = 0.
+ push_loss = 0.
+
+ for i in range(tags.shape[0]):
+ _pull, _push = self._ae_loss_per_image(tags[i],
+ keypoint_indices[i])
+ pull_loss += _pull * self.loss_weight
+ push_loss += _push * self.loss_weight * self.push_loss_factor
+
+ return pull_loss, push_loss
diff --git a/mmpose/models/losses/classification_loss.py b/mmpose/models/losses/classification_loss.py
index 4605acabd3..656ebf7379 100644
--- a/mmpose/models/losses/classification_loss.py
+++ b/mmpose/models/losses/classification_loss.py
@@ -1,218 +1,218 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-
-from mmpose.registry import MODELS
-
-
-@MODELS.register_module()
-class BCELoss(nn.Module):
- """Binary Cross Entropy loss.
-
- Args:
- use_target_weight (bool): Option to use weighted loss.
- Different joint types may have different target weights.
- loss_weight (float): Weight of the loss. Default: 1.0.
- with_logits (bool): Whether to use BCEWithLogitsLoss. Default: False.
- """
-
- def __init__(self,
- use_target_weight=False,
- loss_weight=1.,
- with_logits=False):
- super().__init__()
- self.criterion = F.binary_cross_entropy if not with_logits\
- else F.binary_cross_entropy_with_logits
- self.use_target_weight = use_target_weight
- self.loss_weight = loss_weight
-
- def forward(self, output, target, target_weight=None):
- """Forward function.
-
- Note:
- - batch_size: N
- - num_labels: K
-
- Args:
- output (torch.Tensor[N, K]): Output classification.
- target (torch.Tensor[N, K]): Target classification.
- target_weight (torch.Tensor[N, K] or torch.Tensor[N]):
- Weights across different labels.
- """
-
- if self.use_target_weight:
- assert target_weight is not None
- loss = self.criterion(output, target, reduction='none')
- if target_weight.dim() == 1:
- target_weight = target_weight[:, None]
- loss = (loss * target_weight).mean()
- else:
- loss = self.criterion(output, target)
-
- return loss * self.loss_weight
-
-
-@MODELS.register_module()
-class JSDiscretLoss(nn.Module):
- """Discrete JS Divergence loss for DSNT with Gaussian Heatmap.
-
- Modified from `the official implementation
- `_.
-
- Args:
- use_target_weight (bool): Option to use weighted loss.
- Different joint types may have different target weights.
- size_average (bool): Option to average the loss by the batch_size.
- """
-
- def __init__(
- self,
- use_target_weight=True,
- size_average: bool = True,
- ):
- super(JSDiscretLoss, self).__init__()
- self.use_target_weight = use_target_weight
- self.size_average = size_average
- self.kl_loss = nn.KLDivLoss(reduction='none')
-
- def kl(self, p, q):
- """Kullback-Leibler Divergence."""
-
- eps = 1e-24
- kl_values = self.kl_loss((q + eps).log(), p)
- return kl_values
-
- def js(self, pred_hm, gt_hm):
- """Jensen-Shannon Divergence."""
-
- m = 0.5 * (pred_hm + gt_hm)
- js_values = 0.5 * (self.kl(pred_hm, m) + self.kl(gt_hm, m))
- return js_values
-
- def forward(self, pred_hm, gt_hm, target_weight=None):
- """Forward function.
-
- Args:
- pred_hm (torch.Tensor[N, K, H, W]): Predicted heatmaps.
- gt_hm (torch.Tensor[N, K, H, W]): Target heatmaps.
- target_weight (torch.Tensor[N, K] or torch.Tensor[N]):
- Weights across different labels.
-
- Returns:
- torch.Tensor: Loss value.
- """
-
- if self.use_target_weight:
- assert target_weight is not None
- assert pred_hm.ndim >= target_weight.ndim
-
- for i in range(pred_hm.ndim - target_weight.ndim):
- target_weight = target_weight.unsqueeze(-1)
-
- loss = self.js(pred_hm * target_weight, gt_hm * target_weight)
- else:
- loss = self.js(pred_hm, gt_hm)
-
- if self.size_average:
- loss /= len(gt_hm)
-
- return loss.sum()
-
-
-@MODELS.register_module()
-class KLDiscretLoss(nn.Module):
- """Discrete KL Divergence loss for SimCC with Gaussian Label Smoothing.
- Modified from `the official implementation.
-
- `_.
- Args:
- beta (float): Temperature factor of Softmax.
- label_softmax (bool): Whether to use Softmax on labels.
- use_target_weight (bool): Option to use weighted loss.
- Different joint types may have different target weights.
- """
-
- def __init__(self, beta=1.0, label_softmax=False, use_target_weight=True):
- super(KLDiscretLoss, self).__init__()
- self.beta = beta
- self.label_softmax = label_softmax
- self.use_target_weight = use_target_weight
-
- self.log_softmax = nn.LogSoftmax(dim=1)
- self.kl_loss = nn.KLDivLoss(reduction='none')
-
- def criterion(self, dec_outs, labels):
- """Criterion function."""
- log_pt = self.log_softmax(dec_outs * self.beta)
- if self.label_softmax:
- labels = F.softmax(labels * self.beta, dim=1)
- loss = torch.mean(self.kl_loss(log_pt, labels), dim=1)
- return loss
-
- def forward(self, pred_simcc, gt_simcc, target_weight):
- """Forward function.
-
- Args:
- pred_simcc (Tuple[Tensor, Tensor]): Predicted SimCC vectors of
- x-axis and y-axis.
- gt_simcc (Tuple[Tensor, Tensor]): Target representations.
- target_weight (torch.Tensor[N, K] or torch.Tensor[N]):
- Weights across different labels.
- """
- num_joints = pred_simcc[0].size(1)
- loss = 0
-
- if self.use_target_weight:
- weight = target_weight.reshape(-1)
- else:
- weight = 1.
-
- for pred, target in zip(pred_simcc, gt_simcc):
- pred = pred.reshape(-1, pred.size(-1))
- target = target.reshape(-1, target.size(-1))
-
- loss += self.criterion(pred, target).mul(weight).sum()
-
- return loss / num_joints
-
-
-@MODELS.register_module()
-class InfoNCELoss(nn.Module):
- """InfoNCE loss for training a discriminative representation space with a
- contrastive manner.
-
- `Representation Learning with Contrastive Predictive Coding
- arXiv: `_.
-
- Args:
- temperature (float, optional): The temperature to use in the softmax
- function. Higher temperatures lead to softer probability
- distributions. Defaults to 1.0.
- loss_weight (float, optional): The weight to apply to the loss.
- Defaults to 1.0.
- """
-
- def __init__(self, temperature: float = 1.0, loss_weight=1.0) -> None:
- super(InfoNCELoss, self).__init__()
- assert temperature > 0, f'the argument `temperature` must be ' \
- f'positive, but got {temperature}'
- self.temp = temperature
- self.loss_weight = loss_weight
-
- def forward(self, features: torch.Tensor) -> torch.Tensor:
- """Computes the InfoNCE loss.
-
- Args:
- features (Tensor): A tensor containing the feature
- representations of different samples.
-
- Returns:
- Tensor: A tensor of shape (1,) containing the InfoNCE loss.
- """
- n = features.size(0)
- features_norm = F.normalize(features, dim=1)
- logits = features_norm.mm(features_norm.t()) / self.temp
- targets = torch.arange(n, dtype=torch.long, device=features.device)
- loss = F.cross_entropy(logits, targets, reduction='sum')
- return loss * self.loss_weight
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmpose.registry import MODELS
+
+
+@MODELS.register_module()
+class BCELoss(nn.Module):
+ """Binary Cross Entropy loss.
+
+ Args:
+ use_target_weight (bool): Option to use weighted loss.
+ Different joint types may have different target weights.
+ loss_weight (float): Weight of the loss. Default: 1.0.
+ with_logits (bool): Whether to use BCEWithLogitsLoss. Default: False.
+ """
+
+ def __init__(self,
+ use_target_weight=False,
+ loss_weight=1.,
+ with_logits=False):
+ super().__init__()
+ self.criterion = F.binary_cross_entropy if not with_logits\
+ else F.binary_cross_entropy_with_logits
+ self.use_target_weight = use_target_weight
+ self.loss_weight = loss_weight
+
+ def forward(self, output, target, target_weight=None):
+ """Forward function.
+
+ Note:
+ - batch_size: N
+ - num_labels: K
+
+ Args:
+ output (torch.Tensor[N, K]): Output classification.
+ target (torch.Tensor[N, K]): Target classification.
+ target_weight (torch.Tensor[N, K] or torch.Tensor[N]):
+ Weights across different labels.
+ """
+
+ if self.use_target_weight:
+ assert target_weight is not None
+ loss = self.criterion(output, target, reduction='none')
+ if target_weight.dim() == 1:
+ target_weight = target_weight[:, None]
+ loss = (loss * target_weight).mean()
+ else:
+ loss = self.criterion(output, target)
+
+ return loss * self.loss_weight
+
+
+@MODELS.register_module()
+class JSDiscretLoss(nn.Module):
+ """Discrete JS Divergence loss for DSNT with Gaussian Heatmap.
+
+ Modified from `the official implementation
+ `_.
+
+ Args:
+ use_target_weight (bool): Option to use weighted loss.
+ Different joint types may have different target weights.
+ size_average (bool): Option to average the loss by the batch_size.
+ """
+
+ def __init__(
+ self,
+ use_target_weight=True,
+ size_average: bool = True,
+ ):
+ super(JSDiscretLoss, self).__init__()
+ self.use_target_weight = use_target_weight
+ self.size_average = size_average
+ self.kl_loss = nn.KLDivLoss(reduction='none')
+
+ def kl(self, p, q):
+ """Kullback-Leibler Divergence."""
+
+ eps = 1e-24
+ kl_values = self.kl_loss((q + eps).log(), p)
+ return kl_values
+
+ def js(self, pred_hm, gt_hm):
+ """Jensen-Shannon Divergence."""
+
+ m = 0.5 * (pred_hm + gt_hm)
+ js_values = 0.5 * (self.kl(pred_hm, m) + self.kl(gt_hm, m))
+ return js_values
+
+ def forward(self, pred_hm, gt_hm, target_weight=None):
+ """Forward function.
+
+ Args:
+ pred_hm (torch.Tensor[N, K, H, W]): Predicted heatmaps.
+ gt_hm (torch.Tensor[N, K, H, W]): Target heatmaps.
+ target_weight (torch.Tensor[N, K] or torch.Tensor[N]):
+ Weights across different labels.
+
+ Returns:
+ torch.Tensor: Loss value.
+ """
+
+ if self.use_target_weight:
+ assert target_weight is not None
+ assert pred_hm.ndim >= target_weight.ndim
+
+ for i in range(pred_hm.ndim - target_weight.ndim):
+ target_weight = target_weight.unsqueeze(-1)
+
+ loss = self.js(pred_hm * target_weight, gt_hm * target_weight)
+ else:
+ loss = self.js(pred_hm, gt_hm)
+
+ if self.size_average:
+ loss /= len(gt_hm)
+
+ return loss.sum()
+
+
+@MODELS.register_module()
+class KLDiscretLoss(nn.Module):
+ """Discrete KL Divergence loss for SimCC with Gaussian Label Smoothing.
+ Modified from `the official implementation.
+
+ `_.
+ Args:
+ beta (float): Temperature factor of Softmax.
+ label_softmax (bool): Whether to use Softmax on labels.
+ use_target_weight (bool): Option to use weighted loss.
+ Different joint types may have different target weights.
+ """
+
+ def __init__(self, beta=1.0, label_softmax=False, use_target_weight=True):
+ super(KLDiscretLoss, self).__init__()
+ self.beta = beta
+ self.label_softmax = label_softmax
+ self.use_target_weight = use_target_weight
+
+ self.log_softmax = nn.LogSoftmax(dim=1)
+ self.kl_loss = nn.KLDivLoss(reduction='none')
+
+ def criterion(self, dec_outs, labels):
+ """Criterion function."""
+ log_pt = self.log_softmax(dec_outs * self.beta)
+ if self.label_softmax:
+ labels = F.softmax(labels * self.beta, dim=1)
+ loss = torch.mean(self.kl_loss(log_pt, labels), dim=1)
+ return loss
+
+ def forward(self, pred_simcc, gt_simcc, target_weight):
+ """Forward function.
+
+ Args:
+ pred_simcc (Tuple[Tensor, Tensor]): Predicted SimCC vectors of
+ x-axis and y-axis.
+ gt_simcc (Tuple[Tensor, Tensor]): Target representations.
+ target_weight (torch.Tensor[N, K] or torch.Tensor[N]):
+ Weights across different labels.
+ """
+ num_joints = pred_simcc[0].size(1)
+ loss = 0
+
+ if self.use_target_weight:
+ weight = target_weight.reshape(-1)
+ else:
+ weight = 1.
+
+ for pred, target in zip(pred_simcc, gt_simcc):
+ pred = pred.reshape(-1, pred.size(-1))
+ target = target.reshape(-1, target.size(-1))
+
+ loss += self.criterion(pred, target).mul(weight).sum()
+
+ return loss / num_joints
+
+
+@MODELS.register_module()
+class InfoNCELoss(nn.Module):
+ """InfoNCE loss for training a discriminative representation space with a
+ contrastive manner.
+
+ `Representation Learning with Contrastive Predictive Coding
+ arXiv: `_.
+
+ Args:
+ temperature (float, optional): The temperature to use in the softmax
+ function. Higher temperatures lead to softer probability
+ distributions. Defaults to 1.0.
+ loss_weight (float, optional): The weight to apply to the loss.
+ Defaults to 1.0.
+ """
+
+ def __init__(self, temperature: float = 1.0, loss_weight=1.0) -> None:
+ super(InfoNCELoss, self).__init__()
+ assert temperature > 0, f'the argument `temperature` must be ' \
+ f'positive, but got {temperature}'
+ self.temp = temperature
+ self.loss_weight = loss_weight
+
+ def forward(self, features: torch.Tensor) -> torch.Tensor:
+ """Computes the InfoNCE loss.
+
+ Args:
+ features (Tensor): A tensor containing the feature
+ representations of different samples.
+
+ Returns:
+ Tensor: A tensor of shape (1,) containing the InfoNCE loss.
+ """
+ n = features.size(0)
+ features_norm = F.normalize(features, dim=1)
+ logits = features_norm.mm(features_norm.t()) / self.temp
+ targets = torch.arange(n, dtype=torch.long, device=features.device)
+ loss = F.cross_entropy(logits, targets, reduction='sum')
+ return loss * self.loss_weight
diff --git a/mmpose/models/losses/heatmap_loss.py b/mmpose/models/losses/heatmap_loss.py
index ffe5cd1e80..8a73579007 100644
--- a/mmpose/models/losses/heatmap_loss.py
+++ b/mmpose/models/losses/heatmap_loss.py
@@ -1,455 +1,455 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from torch import Tensor
-
-from mmpose.registry import MODELS
-
-
-@MODELS.register_module()
-class KeypointMSELoss(nn.Module):
- """MSE loss for heatmaps.
-
- Args:
- use_target_weight (bool): Option to use weighted MSE loss.
- Different joint types may have different target weights.
- Defaults to ``False``
- skip_empty_channel (bool): If ``True``, heatmap channels with no
- non-zero value (which means no visible ground-truth keypoint
- in the image) will not be used to calculate the loss. Defaults to
- ``False``
- loss_weight (float): Weight of the loss. Defaults to 1.0
- """
-
- def __init__(self,
- use_target_weight: bool = False,
- skip_empty_channel: bool = False,
- loss_weight: float = 1.):
- super().__init__()
- self.use_target_weight = use_target_weight
- self.skip_empty_channel = skip_empty_channel
- self.loss_weight = loss_weight
-
- def forward(self,
- output: Tensor,
- target: Tensor,
- target_weights: Optional[Tensor] = None,
- mask: Optional[Tensor] = None) -> Tensor:
- """Forward function of loss.
-
- Note:
- - batch_size: B
- - num_keypoints: K
- - heatmaps height: H
- - heatmaps weight: W
-
- Args:
- output (Tensor): The output heatmaps with shape [B, K, H, W]
- target (Tensor): The target heatmaps with shape [B, K, H, W]
- target_weights (Tensor, optional): The target weights of differet
- keypoints, with shape [B, K] (keypoint-wise) or
- [B, K, H, W] (pixel-wise).
- mask (Tensor, optional): The masks of valid heatmap pixels in
- shape [B, K, H, W] or [B, 1, H, W]. If ``None``, no mask will
- be applied. Defaults to ``None``
-
- Returns:
- Tensor: The calculated loss.
- """
-
- _mask = self._get_mask(target, target_weights, mask)
- if _mask is None:
- loss = F.mse_loss(output, target)
- else:
- _loss = F.mse_loss(output, target, reduction='none')
- loss = (_loss * _mask).mean()
-
- return loss * self.loss_weight
-
- def _get_mask(self, target: Tensor, target_weights: Optional[Tensor],
- mask: Optional[Tensor]) -> Optional[Tensor]:
- """Generate the heatmap mask w.r.t. the given mask, target weight and
- `skip_empty_channel` setting.
-
- Returns:
- Tensor: The mask in shape (B, K, *) or ``None`` if no mask is
- needed.
- """
- # Given spatial mask
- if mask is not None:
- # check mask has matching type with target
- assert (mask.ndim == target.ndim and all(
- d_m == d_t or d_m == 1
- for d_m, d_t in zip(mask.shape, target.shape))), (
- f'mask and target have mismatched shapes {mask.shape} v.s.'
- f'{target.shape}')
-
- # Mask by target weights (keypoint-wise mask)
- if target_weights is not None:
- # check target weight has matching shape with target
- assert (target_weights.ndim in (2, 4) and target_weights.shape
- == target.shape[:target_weights.ndim]), (
- 'target_weights and target have mismatched shapes '
- f'{target_weights.shape} v.s. {target.shape}')
-
- ndim_pad = target.ndim - target_weights.ndim
- _mask = target_weights.view(target_weights.shape +
- (1, ) * ndim_pad)
-
- if mask is None:
- mask = _mask
- else:
- mask = mask * _mask
-
- # Mask by ``skip_empty_channel``
- if self.skip_empty_channel:
- _mask = (target != 0).flatten(2).any(dim=2)
- ndim_pad = target.ndim - _mask.ndim
- _mask = _mask.view(_mask.shape + (1, ) * ndim_pad)
-
- if mask is None:
- mask = _mask
- else:
- mask = mask * _mask
-
- return mask
-
-
-@MODELS.register_module()
-class CombinedTargetMSELoss(nn.Module):
- """MSE loss for combined target.
-
- CombinedTarget: The combination of classification target
- (response map) and regression target (offset map).
- Paper ref: Huang et al. The Devil is in the Details: Delving into
- Unbiased Data Processing for Human Pose Estimation (CVPR 2020).
-
- Args:
- use_target_weight (bool): Option to use weighted MSE loss.
- Different joint types may have different target weights.
- Defaults to ``False``
- loss_weight (float): Weight of the loss. Defaults to 1.0
- """
-
- def __init__(self,
- use_target_weight: bool = False,
- loss_weight: float = 1.):
- super().__init__()
- self.criterion = nn.MSELoss(reduction='mean')
- self.use_target_weight = use_target_weight
- self.loss_weight = loss_weight
-
- def forward(self, output: Tensor, target: Tensor,
- target_weights: Tensor) -> Tensor:
- """Forward function of loss.
-
- Note:
- - batch_size: B
- - num_channels: C
- - heatmaps height: H
- - heatmaps weight: W
- - num_keypoints: K
- Here, C = 3 * K
-
- Args:
- output (Tensor): The output feature maps with shape [B, C, H, W].
- target (Tensor): The target feature maps with shape [B, C, H, W].
- target_weights (Tensor): The target weights of differet keypoints,
- with shape [B, K].
-
- Returns:
- Tensor: The calculated loss.
- """
- batch_size = output.size(0)
- num_channels = output.size(1)
- heatmaps_pred = output.reshape(
- (batch_size, num_channels, -1)).split(1, 1)
- heatmaps_gt = target.reshape(
- (batch_size, num_channels, -1)).split(1, 1)
- loss = 0.
- num_joints = num_channels // 3
- for idx in range(num_joints):
- heatmap_pred = heatmaps_pred[idx * 3].squeeze()
- heatmap_gt = heatmaps_gt[idx * 3].squeeze()
- offset_x_pred = heatmaps_pred[idx * 3 + 1].squeeze()
- offset_x_gt = heatmaps_gt[idx * 3 + 1].squeeze()
- offset_y_pred = heatmaps_pred[idx * 3 + 2].squeeze()
- offset_y_gt = heatmaps_gt[idx * 3 + 2].squeeze()
- if self.use_target_weight:
- target_weight = target_weights[:, idx, None]
- heatmap_pred = heatmap_pred * target_weight
- heatmap_gt = heatmap_gt * target_weight
- # classification loss
- loss += 0.5 * self.criterion(heatmap_pred, heatmap_gt)
- # regression loss
- loss += 0.5 * self.criterion(heatmap_gt * offset_x_pred,
- heatmap_gt * offset_x_gt)
- loss += 0.5 * self.criterion(heatmap_gt * offset_y_pred,
- heatmap_gt * offset_y_gt)
- return loss / num_joints * self.loss_weight
-
-
-@MODELS.register_module()
-class KeypointOHKMMSELoss(nn.Module):
- """MSE loss with online hard keypoint mining.
-
- Args:
- use_target_weight (bool): Option to use weighted MSE loss.
- Different joint types may have different target weights.
- Defaults to ``False``
- topk (int): Only top k joint losses are kept. Defaults to 8
- loss_weight (float): Weight of the loss. Defaults to 1.0
- """
-
- def __init__(self,
- use_target_weight: bool = False,
- topk: int = 8,
- loss_weight: float = 1.):
- super().__init__()
- assert topk > 0
- self.criterion = nn.MSELoss(reduction='none')
- self.use_target_weight = use_target_weight
- self.topk = topk
- self.loss_weight = loss_weight
-
- def _ohkm(self, losses: Tensor) -> Tensor:
- """Online hard keypoint mining.
-
- Note:
- - batch_size: B
- - num_keypoints: K
-
- Args:
- loss (Tensor): The losses with shape [B, K]
-
- Returns:
- Tensor: The calculated loss.
- """
- ohkm_loss = 0.
- B = losses.shape[0]
- for i in range(B):
- sub_loss = losses[i]
- _, topk_idx = torch.topk(
- sub_loss, k=self.topk, dim=0, sorted=False)
- tmp_loss = torch.gather(sub_loss, 0, topk_idx)
- ohkm_loss += torch.sum(tmp_loss) / self.topk
- ohkm_loss /= B
- return ohkm_loss
-
- def forward(self, output: Tensor, target: Tensor,
- target_weights: Tensor) -> Tensor:
- """Forward function of loss.
-
- Note:
- - batch_size: B
- - num_keypoints: K
- - heatmaps height: H
- - heatmaps weight: W
-
- Args:
- output (Tensor): The output heatmaps with shape [B, K, H, W].
- target (Tensor): The target heatmaps with shape [B, K, H, W].
- target_weights (Tensor): The target weights of differet keypoints,
- with shape [B, K].
-
- Returns:
- Tensor: The calculated loss.
- """
- num_keypoints = output.size(1)
- if num_keypoints < self.topk:
- raise ValueError(f'topk ({self.topk}) should not be '
- f'larger than num_keypoints ({num_keypoints}).')
-
- losses = []
- for idx in range(num_keypoints):
- if self.use_target_weight:
- target_weight = target_weights[:, idx, None, None]
- losses.append(
- self.criterion(output[:, idx] * target_weight,
- target[:, idx] * target_weight))
- else:
- losses.append(self.criterion(output[:, idx], target[:, idx]))
-
- losses = [loss.mean(dim=(1, 2)).unsqueeze(dim=1) for loss in losses]
- losses = torch.cat(losses, dim=1)
-
- return self._ohkm(losses) * self.loss_weight
-
-
-@MODELS.register_module()
-class AdaptiveWingLoss(nn.Module):
- """Adaptive wing loss. paper ref: 'Adaptive Wing Loss for Robust Face
- Alignment via Heatmap Regression' Wang et al. ICCV'2019.
-
- Args:
- alpha (float), omega (float), epsilon (float), theta (float)
- are hyper-parameters.
- use_target_weight (bool): Option to use weighted MSE loss.
- Different joint types may have different target weights.
- loss_weight (float): Weight of the loss. Default: 1.0.
- """
-
- def __init__(self,
- alpha=2.1,
- omega=14,
- epsilon=1,
- theta=0.5,
- use_target_weight=False,
- loss_weight=1.):
- super().__init__()
- self.alpha = float(alpha)
- self.omega = float(omega)
- self.epsilon = float(epsilon)
- self.theta = float(theta)
- self.use_target_weight = use_target_weight
- self.loss_weight = loss_weight
-
- def criterion(self, pred, target):
- """Criterion of wingloss.
-
- Note:
- batch_size: N
- num_keypoints: K
-
- Args:
- pred (torch.Tensor[NxKxHxW]): Predicted heatmaps.
- target (torch.Tensor[NxKxHxW]): Target heatmaps.
- """
- H, W = pred.shape[2:4]
- delta = (target - pred).abs()
-
- A = self.omega * (
- 1 / (1 + torch.pow(self.theta / self.epsilon, self.alpha - target))
- ) * (self.alpha - target) * (torch.pow(
- self.theta / self.epsilon,
- self.alpha - target - 1)) * (1 / self.epsilon)
- C = self.theta * A - self.omega * torch.log(
- 1 + torch.pow(self.theta / self.epsilon, self.alpha - target))
-
- losses = torch.where(
- delta < self.theta,
- self.omega *
- torch.log(1 +
- torch.pow(delta / self.epsilon, self.alpha - target)),
- A * delta - C)
-
- return torch.mean(losses)
-
- def forward(self,
- output: Tensor,
- target: Tensor,
- target_weights: Optional[Tensor] = None):
- """Forward function.
-
- Note:
- batch_size: N
- num_keypoints: K
-
- Args:
- output (torch.Tensor[N, K, H, W]): Output heatmaps.
- target (torch.Tensor[N, K, H, W]): Target heatmaps.
- target_weight (torch.Tensor[N, K]):
- Weights across different joint types.
- """
- if self.use_target_weight:
- assert (target_weights.ndim in (2, 4) and target_weights.shape
- == target.shape[:target_weights.ndim]), (
- 'target_weights and target have mismatched shapes '
- f'{target_weights.shape} v.s. {target.shape}')
-
- ndim_pad = target.ndim - target_weights.ndim
- target_weights = target_weights.view(target_weights.shape +
- (1, ) * ndim_pad)
- loss = self.criterion(output * target_weights,
- target * target_weights)
- else:
- loss = self.criterion(output, target)
-
- return loss * self.loss_weight
-
-
-@MODELS.register_module()
-class FocalHeatmapLoss(KeypointMSELoss):
- """A class for calculating the modified focal loss for heatmap prediction.
-
- This loss function is exactly the same as the one used in CornerNet. It
- runs faster and costs a little bit more memory.
-
- `CornerNet: Detecting Objects as Paired Keypoints
- arXiv: `_.
-
- Arguments:
- alpha (int): The alpha parameter in the focal loss equation.
- beta (int): The beta parameter in the focal loss equation.
- use_target_weight (bool): Option to use weighted MSE loss.
- Different joint types may have different target weights.
- Defaults to ``False``
- skip_empty_channel (bool): If ``True``, heatmap channels with no
- non-zero value (which means no visible ground-truth keypoint
- in the image) will not be used to calculate the loss. Defaults to
- ``False``
- loss_weight (float): Weight of the loss. Defaults to 1.0
- """
-
- def __init__(self,
- alpha: int = 2,
- beta: int = 4,
- use_target_weight: bool = False,
- skip_empty_channel: bool = False,
- loss_weight: float = 1.0):
- super(FocalHeatmapLoss, self).__init__(use_target_weight,
- skip_empty_channel, loss_weight)
- self.alpha = alpha
- self.beta = beta
-
- def forward(self,
- output: Tensor,
- target: Tensor,
- target_weights: Optional[Tensor] = None,
- mask: Optional[Tensor] = None) -> Tensor:
- """Calculate the modified focal loss for heatmap prediction.
-
- Note:
- - batch_size: B
- - num_keypoints: K
- - heatmaps height: H
- - heatmaps weight: W
-
- Args:
- output (Tensor): The output heatmaps with shape [B, K, H, W]
- target (Tensor): The target heatmaps with shape [B, K, H, W]
- target_weights (Tensor, optional): The target weights of differet
- keypoints, with shape [B, K] (keypoint-wise) or
- [B, K, H, W] (pixel-wise).
- mask (Tensor, optional): The masks of valid heatmap pixels in
- shape [B, K, H, W] or [B, 1, H, W]. If ``None``, no mask will
- be applied. Defaults to ``None``
-
- Returns:
- Tensor: The calculated loss.
- """
- _mask = self._get_mask(target, target_weights, mask)
-
- pos_inds = target.eq(1).float()
- neg_inds = target.lt(1).float()
-
- if _mask is not None:
- pos_inds = pos_inds * _mask
- neg_inds = neg_inds * _mask
-
- neg_weights = torch.pow(1 - target, self.beta)
-
- pos_loss = torch.log(output) * torch.pow(1 - output,
- self.alpha) * pos_inds
- neg_loss = torch.log(1 - output) * torch.pow(
- output, self.alpha) * neg_weights * neg_inds
-
- num_pos = pos_inds.float().sum()
- if num_pos == 0:
- loss = -neg_loss.sum()
- else:
- loss = -(pos_loss.sum() + neg_loss.sum()) / num_pos
- return loss * self.loss_weight
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch import Tensor
+
+from mmpose.registry import MODELS
+
+
+@MODELS.register_module()
+class KeypointMSELoss(nn.Module):
+ """MSE loss for heatmaps.
+
+ Args:
+ use_target_weight (bool): Option to use weighted MSE loss.
+ Different joint types may have different target weights.
+ Defaults to ``False``
+ skip_empty_channel (bool): If ``True``, heatmap channels with no
+ non-zero value (which means no visible ground-truth keypoint
+ in the image) will not be used to calculate the loss. Defaults to
+ ``False``
+ loss_weight (float): Weight of the loss. Defaults to 1.0
+ """
+
+ def __init__(self,
+ use_target_weight: bool = False,
+ skip_empty_channel: bool = False,
+ loss_weight: float = 1.):
+ super().__init__()
+ self.use_target_weight = use_target_weight
+ self.skip_empty_channel = skip_empty_channel
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ output: Tensor,
+ target: Tensor,
+ target_weights: Optional[Tensor] = None,
+ mask: Optional[Tensor] = None) -> Tensor:
+ """Forward function of loss.
+
+ Note:
+ - batch_size: B
+ - num_keypoints: K
+ - heatmaps height: H
+ - heatmaps weight: W
+
+ Args:
+ output (Tensor): The output heatmaps with shape [B, K, H, W]
+ target (Tensor): The target heatmaps with shape [B, K, H, W]
+ target_weights (Tensor, optional): The target weights of differet
+ keypoints, with shape [B, K] (keypoint-wise) or
+ [B, K, H, W] (pixel-wise).
+ mask (Tensor, optional): The masks of valid heatmap pixels in
+ shape [B, K, H, W] or [B, 1, H, W]. If ``None``, no mask will
+ be applied. Defaults to ``None``
+
+ Returns:
+ Tensor: The calculated loss.
+ """
+
+ _mask = self._get_mask(target, target_weights, mask)
+ if _mask is None:
+ loss = F.mse_loss(output, target)
+ else:
+ _loss = F.mse_loss(output, target, reduction='none')
+ loss = (_loss * _mask).mean()
+
+ return loss * self.loss_weight
+
+ def _get_mask(self, target: Tensor, target_weights: Optional[Tensor],
+ mask: Optional[Tensor]) -> Optional[Tensor]:
+ """Generate the heatmap mask w.r.t. the given mask, target weight and
+ `skip_empty_channel` setting.
+
+ Returns:
+ Tensor: The mask in shape (B, K, *) or ``None`` if no mask is
+ needed.
+ """
+ # Given spatial mask
+ if mask is not None:
+ # check mask has matching type with target
+ assert (mask.ndim == target.ndim and all(
+ d_m == d_t or d_m == 1
+ for d_m, d_t in zip(mask.shape, target.shape))), (
+ f'mask and target have mismatched shapes {mask.shape} v.s.'
+ f'{target.shape}')
+
+ # Mask by target weights (keypoint-wise mask)
+ if target_weights is not None:
+ # check target weight has matching shape with target
+ assert (target_weights.ndim in (2, 4) and target_weights.shape
+ == target.shape[:target_weights.ndim]), (
+ 'target_weights and target have mismatched shapes '
+ f'{target_weights.shape} v.s. {target.shape}')
+
+ ndim_pad = target.ndim - target_weights.ndim
+ _mask = target_weights.view(target_weights.shape +
+ (1, ) * ndim_pad)
+
+ if mask is None:
+ mask = _mask
+ else:
+ mask = mask * _mask
+
+ # Mask by ``skip_empty_channel``
+ if self.skip_empty_channel:
+ _mask = (target != 0).flatten(2).any(dim=2)
+ ndim_pad = target.ndim - _mask.ndim
+ _mask = _mask.view(_mask.shape + (1, ) * ndim_pad)
+
+ if mask is None:
+ mask = _mask
+ else:
+ mask = mask * _mask
+
+ return mask
+
+
+@MODELS.register_module()
+class CombinedTargetMSELoss(nn.Module):
+ """MSE loss for combined target.
+
+ CombinedTarget: The combination of classification target
+ (response map) and regression target (offset map).
+ Paper ref: Huang et al. The Devil is in the Details: Delving into
+ Unbiased Data Processing for Human Pose Estimation (CVPR 2020).
+
+ Args:
+ use_target_weight (bool): Option to use weighted MSE loss.
+ Different joint types may have different target weights.
+ Defaults to ``False``
+ loss_weight (float): Weight of the loss. Defaults to 1.0
+ """
+
+ def __init__(self,
+ use_target_weight: bool = False,
+ loss_weight: float = 1.):
+ super().__init__()
+ self.criterion = nn.MSELoss(reduction='mean')
+ self.use_target_weight = use_target_weight
+ self.loss_weight = loss_weight
+
+ def forward(self, output: Tensor, target: Tensor,
+ target_weights: Tensor) -> Tensor:
+ """Forward function of loss.
+
+ Note:
+ - batch_size: B
+ - num_channels: C
+ - heatmaps height: H
+ - heatmaps weight: W
+ - num_keypoints: K
+ Here, C = 3 * K
+
+ Args:
+ output (Tensor): The output feature maps with shape [B, C, H, W].
+ target (Tensor): The target feature maps with shape [B, C, H, W].
+ target_weights (Tensor): The target weights of differet keypoints,
+ with shape [B, K].
+
+ Returns:
+ Tensor: The calculated loss.
+ """
+ batch_size = output.size(0)
+ num_channels = output.size(1)
+ heatmaps_pred = output.reshape(
+ (batch_size, num_channels, -1)).split(1, 1)
+ heatmaps_gt = target.reshape(
+ (batch_size, num_channels, -1)).split(1, 1)
+ loss = 0.
+ num_joints = num_channels // 3
+ for idx in range(num_joints):
+ heatmap_pred = heatmaps_pred[idx * 3].squeeze()
+ heatmap_gt = heatmaps_gt[idx * 3].squeeze()
+ offset_x_pred = heatmaps_pred[idx * 3 + 1].squeeze()
+ offset_x_gt = heatmaps_gt[idx * 3 + 1].squeeze()
+ offset_y_pred = heatmaps_pred[idx * 3 + 2].squeeze()
+ offset_y_gt = heatmaps_gt[idx * 3 + 2].squeeze()
+ if self.use_target_weight:
+ target_weight = target_weights[:, idx, None]
+ heatmap_pred = heatmap_pred * target_weight
+ heatmap_gt = heatmap_gt * target_weight
+ # classification loss
+ loss += 0.5 * self.criterion(heatmap_pred, heatmap_gt)
+ # regression loss
+ loss += 0.5 * self.criterion(heatmap_gt * offset_x_pred,
+ heatmap_gt * offset_x_gt)
+ loss += 0.5 * self.criterion(heatmap_gt * offset_y_pred,
+ heatmap_gt * offset_y_gt)
+ return loss / num_joints * self.loss_weight
+
+
+@MODELS.register_module()
+class KeypointOHKMMSELoss(nn.Module):
+ """MSE loss with online hard keypoint mining.
+
+ Args:
+ use_target_weight (bool): Option to use weighted MSE loss.
+ Different joint types may have different target weights.
+ Defaults to ``False``
+ topk (int): Only top k joint losses are kept. Defaults to 8
+ loss_weight (float): Weight of the loss. Defaults to 1.0
+ """
+
+ def __init__(self,
+ use_target_weight: bool = False,
+ topk: int = 8,
+ loss_weight: float = 1.):
+ super().__init__()
+ assert topk > 0
+ self.criterion = nn.MSELoss(reduction='none')
+ self.use_target_weight = use_target_weight
+ self.topk = topk
+ self.loss_weight = loss_weight
+
+ def _ohkm(self, losses: Tensor) -> Tensor:
+ """Online hard keypoint mining.
+
+ Note:
+ - batch_size: B
+ - num_keypoints: K
+
+ Args:
+ loss (Tensor): The losses with shape [B, K]
+
+ Returns:
+ Tensor: The calculated loss.
+ """
+ ohkm_loss = 0.
+ B = losses.shape[0]
+ for i in range(B):
+ sub_loss = losses[i]
+ _, topk_idx = torch.topk(
+ sub_loss, k=self.topk, dim=0, sorted=False)
+ tmp_loss = torch.gather(sub_loss, 0, topk_idx)
+ ohkm_loss += torch.sum(tmp_loss) / self.topk
+ ohkm_loss /= B
+ return ohkm_loss
+
+ def forward(self, output: Tensor, target: Tensor,
+ target_weights: Tensor) -> Tensor:
+ """Forward function of loss.
+
+ Note:
+ - batch_size: B
+ - num_keypoints: K
+ - heatmaps height: H
+ - heatmaps weight: W
+
+ Args:
+ output (Tensor): The output heatmaps with shape [B, K, H, W].
+ target (Tensor): The target heatmaps with shape [B, K, H, W].
+ target_weights (Tensor): The target weights of differet keypoints,
+ with shape [B, K].
+
+ Returns:
+ Tensor: The calculated loss.
+ """
+ num_keypoints = output.size(1)
+ if num_keypoints < self.topk:
+ raise ValueError(f'topk ({self.topk}) should not be '
+ f'larger than num_keypoints ({num_keypoints}).')
+
+ losses = []
+ for idx in range(num_keypoints):
+ if self.use_target_weight:
+ target_weight = target_weights[:, idx, None, None]
+ losses.append(
+ self.criterion(output[:, idx] * target_weight,
+ target[:, idx] * target_weight))
+ else:
+ losses.append(self.criterion(output[:, idx], target[:, idx]))
+
+ losses = [loss.mean(dim=(1, 2)).unsqueeze(dim=1) for loss in losses]
+ losses = torch.cat(losses, dim=1)
+
+ return self._ohkm(losses) * self.loss_weight
+
+
+@MODELS.register_module()
+class AdaptiveWingLoss(nn.Module):
+ """Adaptive wing loss. paper ref: 'Adaptive Wing Loss for Robust Face
+ Alignment via Heatmap Regression' Wang et al. ICCV'2019.
+
+ Args:
+ alpha (float), omega (float), epsilon (float), theta (float)
+ are hyper-parameters.
+ use_target_weight (bool): Option to use weighted MSE loss.
+ Different joint types may have different target weights.
+ loss_weight (float): Weight of the loss. Default: 1.0.
+ """
+
+ def __init__(self,
+ alpha=2.1,
+ omega=14,
+ epsilon=1,
+ theta=0.5,
+ use_target_weight=False,
+ loss_weight=1.):
+ super().__init__()
+ self.alpha = float(alpha)
+ self.omega = float(omega)
+ self.epsilon = float(epsilon)
+ self.theta = float(theta)
+ self.use_target_weight = use_target_weight
+ self.loss_weight = loss_weight
+
+ def criterion(self, pred, target):
+ """Criterion of wingloss.
+
+ Note:
+ batch_size: N
+ num_keypoints: K
+
+ Args:
+ pred (torch.Tensor[NxKxHxW]): Predicted heatmaps.
+ target (torch.Tensor[NxKxHxW]): Target heatmaps.
+ """
+ H, W = pred.shape[2:4]
+ delta = (target - pred).abs()
+
+ A = self.omega * (
+ 1 / (1 + torch.pow(self.theta / self.epsilon, self.alpha - target))
+ ) * (self.alpha - target) * (torch.pow(
+ self.theta / self.epsilon,
+ self.alpha - target - 1)) * (1 / self.epsilon)
+ C = self.theta * A - self.omega * torch.log(
+ 1 + torch.pow(self.theta / self.epsilon, self.alpha - target))
+
+ losses = torch.where(
+ delta < self.theta,
+ self.omega *
+ torch.log(1 +
+ torch.pow(delta / self.epsilon, self.alpha - target)),
+ A * delta - C)
+
+ return torch.mean(losses)
+
+ def forward(self,
+ output: Tensor,
+ target: Tensor,
+ target_weights: Optional[Tensor] = None):
+ """Forward function.
+
+ Note:
+ batch_size: N
+ num_keypoints: K
+
+ Args:
+ output (torch.Tensor[N, K, H, W]): Output heatmaps.
+ target (torch.Tensor[N, K, H, W]): Target heatmaps.
+ target_weight (torch.Tensor[N, K]):
+ Weights across different joint types.
+ """
+ if self.use_target_weight:
+ assert (target_weights.ndim in (2, 4) and target_weights.shape
+ == target.shape[:target_weights.ndim]), (
+ 'target_weights and target have mismatched shapes '
+ f'{target_weights.shape} v.s. {target.shape}')
+
+ ndim_pad = target.ndim - target_weights.ndim
+ target_weights = target_weights.view(target_weights.shape +
+ (1, ) * ndim_pad)
+ loss = self.criterion(output * target_weights,
+ target * target_weights)
+ else:
+ loss = self.criterion(output, target)
+
+ return loss * self.loss_weight
+
+
+@MODELS.register_module()
+class FocalHeatmapLoss(KeypointMSELoss):
+ """A class for calculating the modified focal loss for heatmap prediction.
+
+ This loss function is exactly the same as the one used in CornerNet. It
+ runs faster and costs a little bit more memory.
+
+ `CornerNet: Detecting Objects as Paired Keypoints
+ arXiv: `_.
+
+ Arguments:
+ alpha (int): The alpha parameter in the focal loss equation.
+ beta (int): The beta parameter in the focal loss equation.
+ use_target_weight (bool): Option to use weighted MSE loss.
+ Different joint types may have different target weights.
+ Defaults to ``False``
+ skip_empty_channel (bool): If ``True``, heatmap channels with no
+ non-zero value (which means no visible ground-truth keypoint
+ in the image) will not be used to calculate the loss. Defaults to
+ ``False``
+ loss_weight (float): Weight of the loss. Defaults to 1.0
+ """
+
+ def __init__(self,
+ alpha: int = 2,
+ beta: int = 4,
+ use_target_weight: bool = False,
+ skip_empty_channel: bool = False,
+ loss_weight: float = 1.0):
+ super(FocalHeatmapLoss, self).__init__(use_target_weight,
+ skip_empty_channel, loss_weight)
+ self.alpha = alpha
+ self.beta = beta
+
+ def forward(self,
+ output: Tensor,
+ target: Tensor,
+ target_weights: Optional[Tensor] = None,
+ mask: Optional[Tensor] = None) -> Tensor:
+ """Calculate the modified focal loss for heatmap prediction.
+
+ Note:
+ - batch_size: B
+ - num_keypoints: K
+ - heatmaps height: H
+ - heatmaps weight: W
+
+ Args:
+ output (Tensor): The output heatmaps with shape [B, K, H, W]
+ target (Tensor): The target heatmaps with shape [B, K, H, W]
+ target_weights (Tensor, optional): The target weights of differet
+ keypoints, with shape [B, K] (keypoint-wise) or
+ [B, K, H, W] (pixel-wise).
+ mask (Tensor, optional): The masks of valid heatmap pixels in
+ shape [B, K, H, W] or [B, 1, H, W]. If ``None``, no mask will
+ be applied. Defaults to ``None``
+
+ Returns:
+ Tensor: The calculated loss.
+ """
+ _mask = self._get_mask(target, target_weights, mask)
+
+ pos_inds = target.eq(1).float()
+ neg_inds = target.lt(1).float()
+
+ if _mask is not None:
+ pos_inds = pos_inds * _mask
+ neg_inds = neg_inds * _mask
+
+ neg_weights = torch.pow(1 - target, self.beta)
+
+ pos_loss = torch.log(output) * torch.pow(1 - output,
+ self.alpha) * pos_inds
+ neg_loss = torch.log(1 - output) * torch.pow(
+ output, self.alpha) * neg_weights * neg_inds
+
+ num_pos = pos_inds.float().sum()
+ if num_pos == 0:
+ loss = -neg_loss.sum()
+ else:
+ loss = -(pos_loss.sum() + neg_loss.sum()) / num_pos
+ return loss * self.loss_weight
diff --git a/mmpose/models/losses/loss_wrappers.py b/mmpose/models/losses/loss_wrappers.py
index d821661b48..431e15df9a 100644
--- a/mmpose/models/losses/loss_wrappers.py
+++ b/mmpose/models/losses/loss_wrappers.py
@@ -1,82 +1,82 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Dict
-
-import torch.nn as nn
-
-from mmpose.registry import MODELS
-from mmpose.utils.typing import ConfigType
-
-
-@MODELS.register_module()
-class MultipleLossWrapper(nn.Module):
- """A wrapper to collect multiple loss functions together and return a list
- of losses in the same order.
-
- Args:
- losses (list): List of Loss Config
- """
-
- def __init__(self, losses: list):
- super().__init__()
- self.num_losses = len(losses)
-
- loss_modules = []
- for loss_cfg in losses:
- t_loss = MODELS.build(loss_cfg)
- loss_modules.append(t_loss)
- self.loss_modules = nn.ModuleList(loss_modules)
-
- def forward(self, input_list, target_list, keypoint_weights=None):
- """Forward function.
-
- Note:
- - batch_size: N
- - num_keypoints: K
- - dimension of keypoints: D (D=2 or D=3)
-
- Args:
- input_list (List[Tensor]): List of inputs.
- target_list (List[Tensor]): List of targets.
- keypoint_weights (Tensor[N, K, D]):
- Weights across different joint types.
- """
- assert isinstance(input_list, list), ''
- assert isinstance(target_list, list), ''
- assert len(input_list) == len(target_list), ''
-
- losses = []
- for i in range(self.num_losses):
- input_i = input_list[i]
- target_i = target_list[i]
-
- loss_i = self.loss_modules[i](input_i, target_i, keypoint_weights)
- losses.append(loss_i)
-
- return losses
-
-
-@MODELS.register_module()
-class CombinedLoss(nn.ModuleDict):
- """A wrapper to combine multiple loss functions. These loss functions can
- have different input type (e.g. heatmaps or regression values), and can
- only be involed individually and explixitly.
-
- Args:
- losses (Dict[str, ConfigType]): The names and configs of loss
- functions to be wrapped
-
- Example::
- >>> heatmap_loss_cfg = dict(type='KeypointMSELoss')
- >>> ae_loss_cfg = dict(type='AssociativeEmbeddingLoss')
- >>> loss_module = CombinedLoss(
- ... losses=dict(
- ... heatmap_loss=heatmap_loss_cfg,
- ... ae_loss=ae_loss_cfg))
- >>> loss_hm = loss_module.heatmap_loss(pred_heatmap, gt_heatmap)
- >>> loss_ae = loss_module.ae_loss(pred_tags, keypoint_indices)
- """
-
- def __init__(self, losses: Dict[str, ConfigType]):
- super().__init__()
- for loss_name, loss_cfg in losses.items():
- self.add_module(loss_name, MODELS.build(loss_cfg))
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict
+
+import torch.nn as nn
+
+from mmpose.registry import MODELS
+from mmpose.utils.typing import ConfigType
+
+
+@MODELS.register_module()
+class MultipleLossWrapper(nn.Module):
+ """A wrapper to collect multiple loss functions together and return a list
+ of losses in the same order.
+
+ Args:
+ losses (list): List of Loss Config
+ """
+
+ def __init__(self, losses: list):
+ super().__init__()
+ self.num_losses = len(losses)
+
+ loss_modules = []
+ for loss_cfg in losses:
+ t_loss = MODELS.build(loss_cfg)
+ loss_modules.append(t_loss)
+ self.loss_modules = nn.ModuleList(loss_modules)
+
+ def forward(self, input_list, target_list, keypoint_weights=None):
+ """Forward function.
+
+ Note:
+ - batch_size: N
+ - num_keypoints: K
+ - dimension of keypoints: D (D=2 or D=3)
+
+ Args:
+ input_list (List[Tensor]): List of inputs.
+ target_list (List[Tensor]): List of targets.
+ keypoint_weights (Tensor[N, K, D]):
+ Weights across different joint types.
+ """
+ assert isinstance(input_list, list), ''
+ assert isinstance(target_list, list), ''
+ assert len(input_list) == len(target_list), ''
+
+ losses = []
+ for i in range(self.num_losses):
+ input_i = input_list[i]
+ target_i = target_list[i]
+
+ loss_i = self.loss_modules[i](input_i, target_i, keypoint_weights)
+ losses.append(loss_i)
+
+ return losses
+
+
+@MODELS.register_module()
+class CombinedLoss(nn.ModuleDict):
+ """A wrapper to combine multiple loss functions. These loss functions can
+ have different input type (e.g. heatmaps or regression values), and can
+ only be involed individually and explixitly.
+
+ Args:
+ losses (Dict[str, ConfigType]): The names and configs of loss
+ functions to be wrapped
+
+ Example::
+ >>> heatmap_loss_cfg = dict(type='KeypointMSELoss')
+ >>> ae_loss_cfg = dict(type='AssociativeEmbeddingLoss')
+ >>> loss_module = CombinedLoss(
+ ... losses=dict(
+ ... heatmap_loss=heatmap_loss_cfg,
+ ... ae_loss=ae_loss_cfg))
+ >>> loss_hm = loss_module.heatmap_loss(pred_heatmap, gt_heatmap)
+ >>> loss_ae = loss_module.ae_loss(pred_tags, keypoint_indices)
+ """
+
+ def __init__(self, losses: Dict[str, ConfigType]):
+ super().__init__()
+ for loss_name, loss_cfg in losses.items():
+ self.add_module(loss_name, MODELS.build(loss_cfg))
diff --git a/mmpose/models/losses/regression_loss.py b/mmpose/models/losses/regression_loss.py
index 9a64a4adfe..ba0a070893 100644
--- a/mmpose/models/losses/regression_loss.py
+++ b/mmpose/models/losses/regression_loss.py
@@ -1,618 +1,618 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import math
-from functools import partial
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-
-from mmpose.registry import MODELS
-from ..utils.realnvp import RealNVP
-
-
-@MODELS.register_module()
-class RLELoss(nn.Module):
- """RLE Loss.
-
- `Human Pose Regression With Residual Log-Likelihood Estimation
- arXiv: `_.
-
- Code is modified from `the official implementation
- `_.
-
- Args:
- use_target_weight (bool): Option to use weighted loss.
- Different joint types may have different target weights.
- size_average (bool): Option to average the loss by the batch_size.
- residual (bool): Option to add L1 loss and let the flow
- learn the residual error distribution.
- q_dis (string): Option for the identity Q(error) distribution,
- Options: "laplace" or "gaussian"
- """
-
- def __init__(self,
- use_target_weight=False,
- size_average=True,
- residual=True,
- q_distribution='laplace'):
- super(RLELoss, self).__init__()
- self.size_average = size_average
- self.use_target_weight = use_target_weight
- self.residual = residual
- self.q_distribution = q_distribution
-
- self.flow_model = RealNVP()
-
- def forward(self, pred, sigma, target, target_weight=None):
- """Forward function.
-
- Note:
- - batch_size: N
- - num_keypoints: K
- - dimension of keypoints: D (D=2 or D=3)
-
- Args:
- pred (Tensor[N, K, D]): Output regression.
- sigma (Tensor[N, K, D]): Output sigma.
- target (Tensor[N, K, D]): Target regression.
- target_weight (Tensor[N, K, D]):
- Weights across different joint types.
- """
- sigma = sigma.sigmoid()
-
- error = (pred - target) / (sigma + 1e-9)
- # (B, K, 2)
- log_phi = self.flow_model.log_prob(error.reshape(-1, 2))
- log_phi = log_phi.reshape(target.shape[0], target.shape[1], 1)
- log_sigma = torch.log(sigma).reshape(target.shape[0], target.shape[1],
- 2)
- nf_loss = log_sigma - log_phi
-
- if self.residual:
- assert self.q_distribution in ['laplace', 'gaussian']
- if self.q_distribution == 'laplace':
- loss_q = torch.log(sigma * 2) + torch.abs(error)
- else:
- loss_q = torch.log(
- sigma * math.sqrt(2 * math.pi)) + 0.5 * error**2
-
- loss = nf_loss + loss_q
- else:
- loss = nf_loss
-
- if self.use_target_weight:
- assert target_weight is not None
- loss *= target_weight
-
- if self.size_average:
- loss /= len(loss)
-
- return loss.sum()
-
-
-@MODELS.register_module()
-class SmoothL1Loss(nn.Module):
- """SmoothL1Loss loss.
-
- Args:
- use_target_weight (bool): Option to use weighted MSE loss.
- Different joint types may have different target weights.
- loss_weight (float): Weight of the loss. Default: 1.0.
- """
-
- def __init__(self, use_target_weight=False, loss_weight=1.):
- super().__init__()
- self.criterion = F.smooth_l1_loss
- self.use_target_weight = use_target_weight
- self.loss_weight = loss_weight
-
- def forward(self, output, target, target_weight=None):
- """Forward function.
-
- Note:
- - batch_size: N
- - num_keypoints: K
- - dimension of keypoints: D (D=2 or D=3)
-
- Args:
- output (torch.Tensor[N, K, D]): Output regression.
- target (torch.Tensor[N, K, D]): Target regression.
- target_weight (torch.Tensor[N, K, D]):
- Weights across different joint types.
- """
-
- if self.use_target_weight:
- assert target_weight is not None
- assert output.ndim >= target_weight.ndim
-
- for i in range(output.ndim - target_weight.ndim):
- target_weight = target_weight.unsqueeze(-1)
-
- loss = self.criterion(output * target_weight,
- target * target_weight)
- else:
- loss = self.criterion(output, target)
-
- return loss * self.loss_weight
-
-
-@MODELS.register_module()
-class SoftWeightSmoothL1Loss(nn.Module):
- """Smooth L1 loss with soft weight for regression.
-
- Args:
- use_target_weight (bool): Option to use weighted MSE loss.
- Different joint types may have different target weights.
- supervise_empty (bool): Whether to supervise the output with zero
- weight.
- beta (float): Specifies the threshold at which to change between
- L1 and L2 loss.
- loss_weight (float): Weight of the loss. Default: 1.0.
- """
-
- def __init__(self,
- use_target_weight=False,
- supervise_empty=True,
- beta=1.0,
- loss_weight=1.):
- super().__init__()
-
- reduction = 'none' if use_target_weight else 'mean'
- self.criterion = partial(
- self.smooth_l1_loss, reduction=reduction, beta=beta)
-
- self.supervise_empty = supervise_empty
- self.use_target_weight = use_target_weight
- self.loss_weight = loss_weight
-
- @staticmethod
- def smooth_l1_loss(input, target, reduction='none', beta=1.0):
- """Re-implement torch.nn.functional.smooth_l1_loss with beta to support
- pytorch <= 1.6."""
- delta = input - target
- mask = delta.abs() < beta
- delta[mask] = (delta[mask]).pow(2) / (2 * beta)
- delta[~mask] = delta[~mask].abs() - beta / 2
-
- if reduction == 'mean':
- return delta.mean()
- elif reduction == 'sum':
- return delta.sum()
- elif reduction == 'none':
- return delta
- else:
- raise ValueError(f'reduction must be \'mean\', \'sum\' or '
- f'\'none\', but got \'{reduction}\'')
-
- def forward(self, output, target, target_weight=None):
- """Forward function.
-
- Note:
- - batch_size: N
- - num_keypoints: K
- - dimension of keypoints: D (D=2 or D=3)
-
- Args:
- output (torch.Tensor[N, K, D]): Output regression.
- target (torch.Tensor[N, K, D]): Target regression.
- target_weight (torch.Tensor[N, K, D]):
- Weights across different joint types.
- """
- if self.use_target_weight:
- assert target_weight is not None
- assert output.ndim >= target_weight.ndim
-
- for i in range(output.ndim - target_weight.ndim):
- target_weight = target_weight.unsqueeze(-1)
-
- loss = self.criterion(output, target) * target_weight
- if self.supervise_empty:
- loss = loss.mean()
- else:
- num_elements = torch.nonzero(target_weight > 0).size()[0]
- loss = loss.sum() / max(num_elements, 1.0)
- else:
- loss = self.criterion(output, target)
-
- return loss * self.loss_weight
-
-
-@MODELS.register_module()
-class WingLoss(nn.Module):
- """Wing Loss. paper ref: 'Wing Loss for Robust Facial Landmark Localisation
- with Convolutional Neural Networks' Feng et al. CVPR'2018.
-
- Args:
- omega (float): Also referred to as width.
- epsilon (float): Also referred to as curvature.
- use_target_weight (bool): Option to use weighted MSE loss.
- Different joint types may have different target weights.
- loss_weight (float): Weight of the loss. Default: 1.0.
- """
-
- def __init__(self,
- omega=10.0,
- epsilon=2.0,
- use_target_weight=False,
- loss_weight=1.):
- super().__init__()
- self.omega = omega
- self.epsilon = epsilon
- self.use_target_weight = use_target_weight
- self.loss_weight = loss_weight
-
- # constant that smoothly links the piecewise-defined linear
- # and nonlinear parts
- self.C = self.omega * (1.0 - math.log(1.0 + self.omega / self.epsilon))
-
- def criterion(self, pred, target):
- """Criterion of wingloss.
-
- Note:
- - batch_size: N
- - num_keypoints: K
- - dimension of keypoints: D (D=2 or D=3)
-
- Args:
- pred (torch.Tensor[N, K, D]): Output regression.
- target (torch.Tensor[N, K, D]): Target regression.
- """
- delta = (target - pred).abs()
- losses = torch.where(
- delta < self.omega,
- self.omega * torch.log(1.0 + delta / self.epsilon), delta - self.C)
- return torch.mean(torch.sum(losses, dim=[1, 2]), dim=0)
-
- def forward(self, output, target, target_weight=None):
- """Forward function.
-
- Note:
- - batch_size: N
- - num_keypoints: K
- - dimension of keypoints: D (D=2 or D=3)
-
- Args:
- output (torch.Tensor[N, K, D]): Output regression.
- target (torch.Tensor[N, K, D]): Target regression.
- target_weight (torch.Tensor[N,K,D]):
- Weights across different joint types.
- """
- if self.use_target_weight:
- assert target_weight is not None
- loss = self.criterion(output * target_weight,
- target * target_weight)
- else:
- loss = self.criterion(output, target)
-
- return loss * self.loss_weight
-
-
-@MODELS.register_module()
-class SoftWingLoss(nn.Module):
- """Soft Wing Loss 'Structure-Coherent Deep Feature Learning for Robust Face
- Alignment' Lin et al. TIP'2021.
-
- loss =
- 1. |x| , if |x| < omega1
- 2. omega2*ln(1+|x|/epsilon) + B, if |x| >= omega1
-
- Args:
- omega1 (float): The first threshold.
- omega2 (float): The second threshold.
- epsilon (float): Also referred to as curvature.
- use_target_weight (bool): Option to use weighted MSE loss.
- Different joint types may have different target weights.
- loss_weight (float): Weight of the loss. Default: 1.0.
- """
-
- def __init__(self,
- omega1=2.0,
- omega2=20.0,
- epsilon=0.5,
- use_target_weight=False,
- loss_weight=1.):
- super().__init__()
- self.omega1 = omega1
- self.omega2 = omega2
- self.epsilon = epsilon
- self.use_target_weight = use_target_weight
- self.loss_weight = loss_weight
-
- # constant that smoothly links the piecewise-defined linear
- # and nonlinear parts
- self.B = self.omega1 - self.omega2 * math.log(1.0 + self.omega1 /
- self.epsilon)
-
- def criterion(self, pred, target):
- """Criterion of wingloss.
-
- Note:
- batch_size: N
- num_keypoints: K
- dimension of keypoints: D (D=2 or D=3)
-
- Args:
- pred (torch.Tensor[N, K, D]): Output regression.
- target (torch.Tensor[N, K, D]): Target regression.
- """
- delta = (target - pred).abs()
- losses = torch.where(
- delta < self.omega1, delta,
- self.omega2 * torch.log(1.0 + delta / self.epsilon) + self.B)
- return torch.mean(torch.sum(losses, dim=[1, 2]), dim=0)
-
- def forward(self, output, target, target_weight=None):
- """Forward function.
-
- Note:
- batch_size: N
- num_keypoints: K
- dimension of keypoints: D (D=2 or D=3)
-
- Args:
- output (torch.Tensor[N, K, D]): Output regression.
- target (torch.Tensor[N, K, D]): Target regression.
- target_weight (torch.Tensor[N, K, D]):
- Weights across different joint types.
- """
- if self.use_target_weight:
- assert target_weight is not None
- loss = self.criterion(output * target_weight,
- target * target_weight)
- else:
- loss = self.criterion(output, target)
-
- return loss * self.loss_weight
-
-
-@MODELS.register_module()
-class MPJPELoss(nn.Module):
- """MPJPE (Mean Per Joint Position Error) loss.
-
- Args:
- use_target_weight (bool): Option to use weighted MSE loss.
- Different joint types may have different target weights.
- loss_weight (float): Weight of the loss. Default: 1.0.
- """
-
- def __init__(self, use_target_weight=False, loss_weight=1.):
- super().__init__()
- self.use_target_weight = use_target_weight
- self.loss_weight = loss_weight
-
- def forward(self, output, target, target_weight=None):
- """Forward function.
-
- Note:
- - batch_size: N
- - num_keypoints: K
- - dimension of keypoints: D (D=2 or D=3)
-
- Args:
- output (torch.Tensor[N, K, D]): Output regression.
- target (torch.Tensor[N, K, D]): Target regression.
- target_weight (torch.Tensor[N,K,D]):
- Weights across different joint types.
- """
-
- if self.use_target_weight:
- assert target_weight is not None
- loss = torch.mean(
- torch.norm((output - target) * target_weight, dim=-1))
- else:
- loss = torch.mean(torch.norm(output - target, dim=-1))
-
- return loss * self.loss_weight
-
-
-@MODELS.register_module()
-class L1Loss(nn.Module):
- """L1Loss loss ."""
-
- def __init__(self, use_target_weight=False, loss_weight=1.):
- super().__init__()
- self.criterion = F.l1_loss
- self.use_target_weight = use_target_weight
- self.loss_weight = loss_weight
-
- def forward(self, output, target, target_weight=None):
- """Forward function.
-
- Note:
- - batch_size: N
- - num_keypoints: K
-
- Args:
- output (torch.Tensor[N, K, 2]): Output regression.
- target (torch.Tensor[N, K, 2]): Target regression.
- target_weight (torch.Tensor[N, K, 2]):
- Weights across different joint types.
- """
- if self.use_target_weight:
- assert target_weight is not None
- loss = self.criterion(output * target_weight,
- target * target_weight)
- else:
- loss = self.criterion(output, target)
-
- return loss * self.loss_weight
-
-
-@MODELS.register_module()
-class MSELoss(nn.Module):
- """MSE loss for coordinate regression."""
-
- def __init__(self, use_target_weight=False, loss_weight=1.):
- super().__init__()
- self.criterion = F.mse_loss
- self.use_target_weight = use_target_weight
- self.loss_weight = loss_weight
-
- def forward(self, output, target, target_weight=None):
- """Forward function.
-
- Note:
- - batch_size: N
- - num_keypoints: K
-
- Args:
- output (torch.Tensor[N, K, 2]): Output regression.
- target (torch.Tensor[N, K, 2]): Target regression.
- target_weight (torch.Tensor[N, K, 2]):
- Weights across different joint types.
- """
-
- if self.use_target_weight:
- assert target_weight is not None
- loss = self.criterion(output * target_weight,
- target * target_weight)
- else:
- loss = self.criterion(output, target)
-
- return loss * self.loss_weight
-
-
-@MODELS.register_module()
-class BoneLoss(nn.Module):
- """Bone length loss.
-
- Args:
- joint_parents (list): Indices of each joint's parent joint.
- use_target_weight (bool): Option to use weighted bone loss.
- Different bone types may have different target weights.
- loss_weight (float): Weight of the loss. Default: 1.0.
- """
-
- def __init__(self, joint_parents, use_target_weight=False, loss_weight=1.):
- super().__init__()
- self.joint_parents = joint_parents
- self.use_target_weight = use_target_weight
- self.loss_weight = loss_weight
-
- self.non_root_indices = []
- for i in range(len(self.joint_parents)):
- if i != self.joint_parents[i]:
- self.non_root_indices.append(i)
-
- def forward(self, output, target, target_weight=None):
- """Forward function.
-
- Note:
- - batch_size: N
- - num_keypoints: K
- - dimension of keypoints: D (D=2 or D=3)
-
- Args:
- output (torch.Tensor[N, K, D]): Output regression.
- target (torch.Tensor[N, K, D]): Target regression.
- target_weight (torch.Tensor[N, K-1]):
- Weights across different bone types.
- """
- output_bone = torch.norm(
- output - output[:, self.joint_parents, :],
- dim=-1)[:, self.non_root_indices]
- target_bone = torch.norm(
- target - target[:, self.joint_parents, :],
- dim=-1)[:, self.non_root_indices]
- if self.use_target_weight:
- assert target_weight is not None
- loss = torch.mean(
- torch.abs((output_bone * target_weight).mean(dim=0) -
- (target_bone * target_weight).mean(dim=0)))
- else:
- loss = torch.mean(
- torch.abs(output_bone.mean(dim=0) - target_bone.mean(dim=0)))
-
- return loss * self.loss_weight
-
-
-@MODELS.register_module()
-class SemiSupervisionLoss(nn.Module):
- """Semi-supervision loss for unlabeled data. It is composed of projection
- loss and bone loss.
-
- Paper ref: `3D human pose estimation in video with temporal convolutions
- and semi-supervised training` Dario Pavllo et al. CVPR'2019.
-
- Args:
- joint_parents (list): Indices of each joint's parent joint.
- projection_loss_weight (float): Weight for projection loss.
- bone_loss_weight (float): Weight for bone loss.
- warmup_iterations (int): Number of warmup iterations. In the first
- `warmup_iterations` iterations, the model is trained only on
- labeled data, and semi-supervision loss will be 0.
- This is a workaround since currently we cannot access
- epoch number in loss functions. Note that the iteration number in
- an epoch can be changed due to different GPU numbers in multi-GPU
- settings. So please set this parameter carefully.
- warmup_iterations = dataset_size // samples_per_gpu // gpu_num
- * warmup_epochs
- """
-
- def __init__(self,
- joint_parents,
- projection_loss_weight=1.,
- bone_loss_weight=1.,
- warmup_iterations=0):
- super().__init__()
- self.criterion_projection = MPJPELoss(
- loss_weight=projection_loss_weight)
- self.criterion_bone = BoneLoss(
- joint_parents, loss_weight=bone_loss_weight)
- self.warmup_iterations = warmup_iterations
- self.num_iterations = 0
-
- @staticmethod
- def project_joints(x, intrinsics):
- """Project 3D joint coordinates to 2D image plane using camera
- intrinsic parameters.
-
- Args:
- x (torch.Tensor[N, K, 3]): 3D joint coordinates.
- intrinsics (torch.Tensor[N, 4] | torch.Tensor[N, 9]): Camera
- intrinsics: f (2), c (2), k (3), p (2).
- """
- while intrinsics.dim() < x.dim():
- intrinsics.unsqueeze_(1)
- f = intrinsics[..., :2]
- c = intrinsics[..., 2:4]
- _x = torch.clamp(x[:, :, :2] / x[:, :, 2:], -1, 1)
- if intrinsics.shape[-1] == 9:
- k = intrinsics[..., 4:7]
- p = intrinsics[..., 7:9]
-
- r2 = torch.sum(_x[:, :, :2]**2, dim=-1, keepdim=True)
- radial = 1 + torch.sum(
- k * torch.cat((r2, r2**2, r2**3), dim=-1),
- dim=-1,
- keepdim=True)
- tan = torch.sum(p * _x, dim=-1, keepdim=True)
- _x = _x * (radial + tan) + p * r2
- _x = f * _x + c
- return _x
-
- def forward(self, output, target):
- losses = dict()
-
- self.num_iterations += 1
- if self.num_iterations <= self.warmup_iterations:
- return losses
-
- labeled_pose = output['labeled_pose']
- unlabeled_pose = output['unlabeled_pose']
- unlabeled_traj = output['unlabeled_traj']
- unlabeled_target_2d = target['unlabeled_target_2d']
- intrinsics = target['intrinsics']
-
- # projection loss
- unlabeled_output = unlabeled_pose + unlabeled_traj
- unlabeled_output_2d = self.project_joints(unlabeled_output, intrinsics)
- loss_proj = self.criterion_projection(unlabeled_output_2d,
- unlabeled_target_2d, None)
- losses['proj_loss'] = loss_proj
-
- # bone loss
- loss_bone = self.criterion_bone(unlabeled_pose, labeled_pose, None)
- losses['bone_loss'] = loss_bone
-
- return losses
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from functools import partial
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmpose.registry import MODELS
+from ..utils.realnvp import RealNVP
+
+
+@MODELS.register_module()
+class RLELoss(nn.Module):
+ """RLE Loss.
+
+ `Human Pose Regression With Residual Log-Likelihood Estimation
+ arXiv: `_.
+
+ Code is modified from `the official implementation
+ `_.
+
+ Args:
+ use_target_weight (bool): Option to use weighted loss.
+ Different joint types may have different target weights.
+ size_average (bool): Option to average the loss by the batch_size.
+ residual (bool): Option to add L1 loss and let the flow
+ learn the residual error distribution.
+ q_dis (string): Option for the identity Q(error) distribution,
+ Options: "laplace" or "gaussian"
+ """
+
+ def __init__(self,
+ use_target_weight=False,
+ size_average=True,
+ residual=True,
+ q_distribution='laplace'):
+ super(RLELoss, self).__init__()
+ self.size_average = size_average
+ self.use_target_weight = use_target_weight
+ self.residual = residual
+ self.q_distribution = q_distribution
+
+ self.flow_model = RealNVP()
+
+ def forward(self, pred, sigma, target, target_weight=None):
+ """Forward function.
+
+ Note:
+ - batch_size: N
+ - num_keypoints: K
+ - dimension of keypoints: D (D=2 or D=3)
+
+ Args:
+ pred (Tensor[N, K, D]): Output regression.
+ sigma (Tensor[N, K, D]): Output sigma.
+ target (Tensor[N, K, D]): Target regression.
+ target_weight (Tensor[N, K, D]):
+ Weights across different joint types.
+ """
+ sigma = sigma.sigmoid()
+
+ error = (pred - target) / (sigma + 1e-9)
+ # (B, K, 2)
+ log_phi = self.flow_model.log_prob(error.reshape(-1, 2))
+ log_phi = log_phi.reshape(target.shape[0], target.shape[1], 1)
+ log_sigma = torch.log(sigma).reshape(target.shape[0], target.shape[1],
+ 2)
+ nf_loss = log_sigma - log_phi
+
+ if self.residual:
+ assert self.q_distribution in ['laplace', 'gaussian']
+ if self.q_distribution == 'laplace':
+ loss_q = torch.log(sigma * 2) + torch.abs(error)
+ else:
+ loss_q = torch.log(
+ sigma * math.sqrt(2 * math.pi)) + 0.5 * error**2
+
+ loss = nf_loss + loss_q
+ else:
+ loss = nf_loss
+
+ if self.use_target_weight:
+ assert target_weight is not None
+ loss *= target_weight
+
+ if self.size_average:
+ loss /= len(loss)
+
+ return loss.sum()
+
+
+@MODELS.register_module()
+class SmoothL1Loss(nn.Module):
+ """SmoothL1Loss loss.
+
+ Args:
+ use_target_weight (bool): Option to use weighted MSE loss.
+ Different joint types may have different target weights.
+ loss_weight (float): Weight of the loss. Default: 1.0.
+ """
+
+ def __init__(self, use_target_weight=False, loss_weight=1.):
+ super().__init__()
+ self.criterion = F.smooth_l1_loss
+ self.use_target_weight = use_target_weight
+ self.loss_weight = loss_weight
+
+ def forward(self, output, target, target_weight=None):
+ """Forward function.
+
+ Note:
+ - batch_size: N
+ - num_keypoints: K
+ - dimension of keypoints: D (D=2 or D=3)
+
+ Args:
+ output (torch.Tensor[N, K, D]): Output regression.
+ target (torch.Tensor[N, K, D]): Target regression.
+ target_weight (torch.Tensor[N, K, D]):
+ Weights across different joint types.
+ """
+
+ if self.use_target_weight:
+ assert target_weight is not None
+ assert output.ndim >= target_weight.ndim
+
+ for i in range(output.ndim - target_weight.ndim):
+ target_weight = target_weight.unsqueeze(-1)
+
+ loss = self.criterion(output * target_weight,
+ target * target_weight)
+ else:
+ loss = self.criterion(output, target)
+
+ return loss * self.loss_weight
+
+
+@MODELS.register_module()
+class SoftWeightSmoothL1Loss(nn.Module):
+ """Smooth L1 loss with soft weight for regression.
+
+ Args:
+ use_target_weight (bool): Option to use weighted MSE loss.
+ Different joint types may have different target weights.
+ supervise_empty (bool): Whether to supervise the output with zero
+ weight.
+ beta (float): Specifies the threshold at which to change between
+ L1 and L2 loss.
+ loss_weight (float): Weight of the loss. Default: 1.0.
+ """
+
+ def __init__(self,
+ use_target_weight=False,
+ supervise_empty=True,
+ beta=1.0,
+ loss_weight=1.):
+ super().__init__()
+
+ reduction = 'none' if use_target_weight else 'mean'
+ self.criterion = partial(
+ self.smooth_l1_loss, reduction=reduction, beta=beta)
+
+ self.supervise_empty = supervise_empty
+ self.use_target_weight = use_target_weight
+ self.loss_weight = loss_weight
+
+ @staticmethod
+ def smooth_l1_loss(input, target, reduction='none', beta=1.0):
+ """Re-implement torch.nn.functional.smooth_l1_loss with beta to support
+ pytorch <= 1.6."""
+ delta = input - target
+ mask = delta.abs() < beta
+ delta[mask] = (delta[mask]).pow(2) / (2 * beta)
+ delta[~mask] = delta[~mask].abs() - beta / 2
+
+ if reduction == 'mean':
+ return delta.mean()
+ elif reduction == 'sum':
+ return delta.sum()
+ elif reduction == 'none':
+ return delta
+ else:
+ raise ValueError(f'reduction must be \'mean\', \'sum\' or '
+ f'\'none\', but got \'{reduction}\'')
+
+ def forward(self, output, target, target_weight=None):
+ """Forward function.
+
+ Note:
+ - batch_size: N
+ - num_keypoints: K
+ - dimension of keypoints: D (D=2 or D=3)
+
+ Args:
+ output (torch.Tensor[N, K, D]): Output regression.
+ target (torch.Tensor[N, K, D]): Target regression.
+ target_weight (torch.Tensor[N, K, D]):
+ Weights across different joint types.
+ """
+ if self.use_target_weight:
+ assert target_weight is not None
+ assert output.ndim >= target_weight.ndim
+
+ for i in range(output.ndim - target_weight.ndim):
+ target_weight = target_weight.unsqueeze(-1)
+
+ loss = self.criterion(output, target) * target_weight
+ if self.supervise_empty:
+ loss = loss.mean()
+ else:
+ num_elements = torch.nonzero(target_weight > 0).size()[0]
+ loss = loss.sum() / max(num_elements, 1.0)
+ else:
+ loss = self.criterion(output, target)
+
+ return loss * self.loss_weight
+
+
+@MODELS.register_module()
+class WingLoss(nn.Module):
+ """Wing Loss. paper ref: 'Wing Loss for Robust Facial Landmark Localisation
+ with Convolutional Neural Networks' Feng et al. CVPR'2018.
+
+ Args:
+ omega (float): Also referred to as width.
+ epsilon (float): Also referred to as curvature.
+ use_target_weight (bool): Option to use weighted MSE loss.
+ Different joint types may have different target weights.
+ loss_weight (float): Weight of the loss. Default: 1.0.
+ """
+
+ def __init__(self,
+ omega=10.0,
+ epsilon=2.0,
+ use_target_weight=False,
+ loss_weight=1.):
+ super().__init__()
+ self.omega = omega
+ self.epsilon = epsilon
+ self.use_target_weight = use_target_weight
+ self.loss_weight = loss_weight
+
+ # constant that smoothly links the piecewise-defined linear
+ # and nonlinear parts
+ self.C = self.omega * (1.0 - math.log(1.0 + self.omega / self.epsilon))
+
+ def criterion(self, pred, target):
+ """Criterion of wingloss.
+
+ Note:
+ - batch_size: N
+ - num_keypoints: K
+ - dimension of keypoints: D (D=2 or D=3)
+
+ Args:
+ pred (torch.Tensor[N, K, D]): Output regression.
+ target (torch.Tensor[N, K, D]): Target regression.
+ """
+ delta = (target - pred).abs()
+ losses = torch.where(
+ delta < self.omega,
+ self.omega * torch.log(1.0 + delta / self.epsilon), delta - self.C)
+ return torch.mean(torch.sum(losses, dim=[1, 2]), dim=0)
+
+ def forward(self, output, target, target_weight=None):
+ """Forward function.
+
+ Note:
+ - batch_size: N
+ - num_keypoints: K
+ - dimension of keypoints: D (D=2 or D=3)
+
+ Args:
+ output (torch.Tensor[N, K, D]): Output regression.
+ target (torch.Tensor[N, K, D]): Target regression.
+ target_weight (torch.Tensor[N,K,D]):
+ Weights across different joint types.
+ """
+ if self.use_target_weight:
+ assert target_weight is not None
+ loss = self.criterion(output * target_weight,
+ target * target_weight)
+ else:
+ loss = self.criterion(output, target)
+
+ return loss * self.loss_weight
+
+
+@MODELS.register_module()
+class SoftWingLoss(nn.Module):
+ """Soft Wing Loss 'Structure-Coherent Deep Feature Learning for Robust Face
+ Alignment' Lin et al. TIP'2021.
+
+ loss =
+ 1. |x| , if |x| < omega1
+ 2. omega2*ln(1+|x|/epsilon) + B, if |x| >= omega1
+
+ Args:
+ omega1 (float): The first threshold.
+ omega2 (float): The second threshold.
+ epsilon (float): Also referred to as curvature.
+ use_target_weight (bool): Option to use weighted MSE loss.
+ Different joint types may have different target weights.
+ loss_weight (float): Weight of the loss. Default: 1.0.
+ """
+
+ def __init__(self,
+ omega1=2.0,
+ omega2=20.0,
+ epsilon=0.5,
+ use_target_weight=False,
+ loss_weight=1.):
+ super().__init__()
+ self.omega1 = omega1
+ self.omega2 = omega2
+ self.epsilon = epsilon
+ self.use_target_weight = use_target_weight
+ self.loss_weight = loss_weight
+
+ # constant that smoothly links the piecewise-defined linear
+ # and nonlinear parts
+ self.B = self.omega1 - self.omega2 * math.log(1.0 + self.omega1 /
+ self.epsilon)
+
+ def criterion(self, pred, target):
+ """Criterion of wingloss.
+
+ Note:
+ batch_size: N
+ num_keypoints: K
+ dimension of keypoints: D (D=2 or D=3)
+
+ Args:
+ pred (torch.Tensor[N, K, D]): Output regression.
+ target (torch.Tensor[N, K, D]): Target regression.
+ """
+ delta = (target - pred).abs()
+ losses = torch.where(
+ delta < self.omega1, delta,
+ self.omega2 * torch.log(1.0 + delta / self.epsilon) + self.B)
+ return torch.mean(torch.sum(losses, dim=[1, 2]), dim=0)
+
+ def forward(self, output, target, target_weight=None):
+ """Forward function.
+
+ Note:
+ batch_size: N
+ num_keypoints: K
+ dimension of keypoints: D (D=2 or D=3)
+
+ Args:
+ output (torch.Tensor[N, K, D]): Output regression.
+ target (torch.Tensor[N, K, D]): Target regression.
+ target_weight (torch.Tensor[N, K, D]):
+ Weights across different joint types.
+ """
+ if self.use_target_weight:
+ assert target_weight is not None
+ loss = self.criterion(output * target_weight,
+ target * target_weight)
+ else:
+ loss = self.criterion(output, target)
+
+ return loss * self.loss_weight
+
+
+@MODELS.register_module()
+class MPJPELoss(nn.Module):
+ """MPJPE (Mean Per Joint Position Error) loss.
+
+ Args:
+ use_target_weight (bool): Option to use weighted MSE loss.
+ Different joint types may have different target weights.
+ loss_weight (float): Weight of the loss. Default: 1.0.
+ """
+
+ def __init__(self, use_target_weight=False, loss_weight=1.):
+ super().__init__()
+ self.use_target_weight = use_target_weight
+ self.loss_weight = loss_weight
+
+ def forward(self, output, target, target_weight=None):
+ """Forward function.
+
+ Note:
+ - batch_size: N
+ - num_keypoints: K
+ - dimension of keypoints: D (D=2 or D=3)
+
+ Args:
+ output (torch.Tensor[N, K, D]): Output regression.
+ target (torch.Tensor[N, K, D]): Target regression.
+ target_weight (torch.Tensor[N,K,D]):
+ Weights across different joint types.
+ """
+
+ if self.use_target_weight:
+ assert target_weight is not None
+ loss = torch.mean(
+ torch.norm((output - target) * target_weight, dim=-1))
+ else:
+ loss = torch.mean(torch.norm(output - target, dim=-1))
+
+ return loss * self.loss_weight
+
+
+@MODELS.register_module()
+class L1Loss(nn.Module):
+ """L1Loss loss ."""
+
+ def __init__(self, use_target_weight=False, loss_weight=1.):
+ super().__init__()
+ self.criterion = F.l1_loss
+ self.use_target_weight = use_target_weight
+ self.loss_weight = loss_weight
+
+ def forward(self, output, target, target_weight=None):
+ """Forward function.
+
+ Note:
+ - batch_size: N
+ - num_keypoints: K
+
+ Args:
+ output (torch.Tensor[N, K, 2]): Output regression.
+ target (torch.Tensor[N, K, 2]): Target regression.
+ target_weight (torch.Tensor[N, K, 2]):
+ Weights across different joint types.
+ """
+ if self.use_target_weight:
+ assert target_weight is not None
+ loss = self.criterion(output * target_weight,
+ target * target_weight)
+ else:
+ loss = self.criterion(output, target)
+
+ return loss * self.loss_weight
+
+
+@MODELS.register_module()
+class MSELoss(nn.Module):
+ """MSE loss for coordinate regression."""
+
+ def __init__(self, use_target_weight=False, loss_weight=1.):
+ super().__init__()
+ self.criterion = F.mse_loss
+ self.use_target_weight = use_target_weight
+ self.loss_weight = loss_weight
+
+ def forward(self, output, target, target_weight=None):
+ """Forward function.
+
+ Note:
+ - batch_size: N
+ - num_keypoints: K
+
+ Args:
+ output (torch.Tensor[N, K, 2]): Output regression.
+ target (torch.Tensor[N, K, 2]): Target regression.
+ target_weight (torch.Tensor[N, K, 2]):
+ Weights across different joint types.
+ """
+
+ if self.use_target_weight:
+ assert target_weight is not None
+ loss = self.criterion(output * target_weight,
+ target * target_weight)
+ else:
+ loss = self.criterion(output, target)
+
+ return loss * self.loss_weight
+
+
+@MODELS.register_module()
+class BoneLoss(nn.Module):
+ """Bone length loss.
+
+ Args:
+ joint_parents (list): Indices of each joint's parent joint.
+ use_target_weight (bool): Option to use weighted bone loss.
+ Different bone types may have different target weights.
+ loss_weight (float): Weight of the loss. Default: 1.0.
+ """
+
+ def __init__(self, joint_parents, use_target_weight=False, loss_weight=1.):
+ super().__init__()
+ self.joint_parents = joint_parents
+ self.use_target_weight = use_target_weight
+ self.loss_weight = loss_weight
+
+ self.non_root_indices = []
+ for i in range(len(self.joint_parents)):
+ if i != self.joint_parents[i]:
+ self.non_root_indices.append(i)
+
+ def forward(self, output, target, target_weight=None):
+ """Forward function.
+
+ Note:
+ - batch_size: N
+ - num_keypoints: K
+ - dimension of keypoints: D (D=2 or D=3)
+
+ Args:
+ output (torch.Tensor[N, K, D]): Output regression.
+ target (torch.Tensor[N, K, D]): Target regression.
+ target_weight (torch.Tensor[N, K-1]):
+ Weights across different bone types.
+ """
+ output_bone = torch.norm(
+ output - output[:, self.joint_parents, :],
+ dim=-1)[:, self.non_root_indices]
+ target_bone = torch.norm(
+ target - target[:, self.joint_parents, :],
+ dim=-1)[:, self.non_root_indices]
+ if self.use_target_weight:
+ assert target_weight is not None
+ loss = torch.mean(
+ torch.abs((output_bone * target_weight).mean(dim=0) -
+ (target_bone * target_weight).mean(dim=0)))
+ else:
+ loss = torch.mean(
+ torch.abs(output_bone.mean(dim=0) - target_bone.mean(dim=0)))
+
+ return loss * self.loss_weight
+
+
+@MODELS.register_module()
+class SemiSupervisionLoss(nn.Module):
+ """Semi-supervision loss for unlabeled data. It is composed of projection
+ loss and bone loss.
+
+ Paper ref: `3D human pose estimation in video with temporal convolutions
+ and semi-supervised training` Dario Pavllo et al. CVPR'2019.
+
+ Args:
+ joint_parents (list): Indices of each joint's parent joint.
+ projection_loss_weight (float): Weight for projection loss.
+ bone_loss_weight (float): Weight for bone loss.
+ warmup_iterations (int): Number of warmup iterations. In the first
+ `warmup_iterations` iterations, the model is trained only on
+ labeled data, and semi-supervision loss will be 0.
+ This is a workaround since currently we cannot access
+ epoch number in loss functions. Note that the iteration number in
+ an epoch can be changed due to different GPU numbers in multi-GPU
+ settings. So please set this parameter carefully.
+ warmup_iterations = dataset_size // samples_per_gpu // gpu_num
+ * warmup_epochs
+ """
+
+ def __init__(self,
+ joint_parents,
+ projection_loss_weight=1.,
+ bone_loss_weight=1.,
+ warmup_iterations=0):
+ super().__init__()
+ self.criterion_projection = MPJPELoss(
+ loss_weight=projection_loss_weight)
+ self.criterion_bone = BoneLoss(
+ joint_parents, loss_weight=bone_loss_weight)
+ self.warmup_iterations = warmup_iterations
+ self.num_iterations = 0
+
+ @staticmethod
+ def project_joints(x, intrinsics):
+ """Project 3D joint coordinates to 2D image plane using camera
+ intrinsic parameters.
+
+ Args:
+ x (torch.Tensor[N, K, 3]): 3D joint coordinates.
+ intrinsics (torch.Tensor[N, 4] | torch.Tensor[N, 9]): Camera
+ intrinsics: f (2), c (2), k (3), p (2).
+ """
+ while intrinsics.dim() < x.dim():
+ intrinsics.unsqueeze_(1)
+ f = intrinsics[..., :2]
+ c = intrinsics[..., 2:4]
+ _x = torch.clamp(x[:, :, :2] / x[:, :, 2:], -1, 1)
+ if intrinsics.shape[-1] == 9:
+ k = intrinsics[..., 4:7]
+ p = intrinsics[..., 7:9]
+
+ r2 = torch.sum(_x[:, :, :2]**2, dim=-1, keepdim=True)
+ radial = 1 + torch.sum(
+ k * torch.cat((r2, r2**2, r2**3), dim=-1),
+ dim=-1,
+ keepdim=True)
+ tan = torch.sum(p * _x, dim=-1, keepdim=True)
+ _x = _x * (radial + tan) + p * r2
+ _x = f * _x + c
+ return _x
+
+ def forward(self, output, target):
+ losses = dict()
+
+ self.num_iterations += 1
+ if self.num_iterations <= self.warmup_iterations:
+ return losses
+
+ labeled_pose = output['labeled_pose']
+ unlabeled_pose = output['unlabeled_pose']
+ unlabeled_traj = output['unlabeled_traj']
+ unlabeled_target_2d = target['unlabeled_target_2d']
+ intrinsics = target['intrinsics']
+
+ # projection loss
+ unlabeled_output = unlabeled_pose + unlabeled_traj
+ unlabeled_output_2d = self.project_joints(unlabeled_output, intrinsics)
+ loss_proj = self.criterion_projection(unlabeled_output_2d,
+ unlabeled_target_2d, None)
+ losses['proj_loss'] = loss_proj
+
+ # bone loss
+ loss_bone = self.criterion_bone(unlabeled_pose, labeled_pose, None)
+ losses['bone_loss'] = loss_bone
+
+ return losses
diff --git a/mmpose/models/necks/__init__.py b/mmpose/models/necks/__init__.py
index b4f9105cb3..a983d6ecb7 100644
--- a/mmpose/models/necks/__init__.py
+++ b/mmpose/models/necks/__init__.py
@@ -1,9 +1,9 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .fmap_proc_neck import FeatureMapProcessor
-from .fpn import FPN
-from .gap_neck import GlobalAveragePooling
-from .posewarper_neck import PoseWarperNeck
-
-__all__ = [
- 'GlobalAveragePooling', 'PoseWarperNeck', 'FPN', 'FeatureMapProcessor'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .fmap_proc_neck import FeatureMapProcessor
+from .fpn import FPN
+from .gap_neck import GlobalAveragePooling
+from .posewarper_neck import PoseWarperNeck
+
+__all__ = [
+ 'GlobalAveragePooling', 'PoseWarperNeck', 'FPN', 'FeatureMapProcessor'
+]
diff --git a/mmpose/models/necks/fmap_proc_neck.py b/mmpose/models/necks/fmap_proc_neck.py
index 2c3a4d7bf4..76e9d398de 100644
--- a/mmpose/models/necks/fmap_proc_neck.py
+++ b/mmpose/models/necks/fmap_proc_neck.py
@@ -1,101 +1,101 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import List, Optional, Sequence, Tuple, Union
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from torch import Tensor
-
-from mmpose.models.utils.ops import resize
-from mmpose.registry import MODELS
-
-
-@MODELS.register_module()
-class FeatureMapProcessor(nn.Module):
- """A PyTorch module for selecting, concatenating, and rescaling feature
- maps.
-
- Args:
- select_index (Optional[Union[int, Tuple[int]]], optional): Index or
- indices of feature maps to select. Defaults to None, which means
- all feature maps are used.
- concat (bool, optional): Whether to concatenate the selected feature
- maps. Defaults to False.
- scale_factor (float, optional): The scaling factor to apply to the
- feature maps. Defaults to 1.0.
- apply_relu (bool, optional): Whether to apply ReLU on input feature
- maps. Defaults to False.
- align_corners (bool, optional): Whether to align corners when resizing
- the feature maps. Defaults to False.
- """
-
- def __init__(
- self,
- select_index: Optional[Union[int, Tuple[int]]] = None,
- concat: bool = False,
- scale_factor: float = 1.0,
- apply_relu: bool = False,
- align_corners: bool = False,
- ):
- super().__init__()
-
- if isinstance(select_index, int):
- select_index = (select_index, )
- self.select_index = select_index
- self.concat = concat
-
- assert (
- scale_factor > 0
- ), f'the argument `scale_factor` must be positive, ' \
- f'but got {scale_factor}'
- self.scale_factor = scale_factor
- self.apply_relu = apply_relu
- self.align_corners = align_corners
-
- def forward(self, inputs: Union[Tensor, Sequence[Tensor]]
- ) -> Union[Tensor, List[Tensor]]:
-
- if not isinstance(inputs, (tuple, list)):
- sequential_input = False
- inputs = [inputs]
- else:
- sequential_input = True
-
- if self.select_index is not None:
- inputs = [inputs[i] for i in self.select_index]
-
- if self.concat:
- inputs = self._concat(inputs)
-
- if self.apply_relu:
- inputs = [F.relu(x) for x in inputs]
-
- if self.scale_factor != 1.0:
- inputs = self._rescale(inputs)
-
- if not sequential_input:
- inputs = inputs[0]
-
- return inputs
-
- def _concat(self, inputs: Sequence[Tensor]) -> List[Tensor]:
- size = inputs[0].shape[-2:]
- resized_inputs = [
- resize(
- x,
- size=size,
- mode='bilinear',
- align_corners=self.align_corners) for x in inputs
- ]
- return [torch.cat(resized_inputs, dim=1)]
-
- def _rescale(self, inputs: Sequence[Tensor]) -> List[Tensor]:
- rescaled_inputs = [
- resize(
- x,
- scale_factor=self.scale_factor,
- mode='bilinear',
- align_corners=self.align_corners,
- ) for x in inputs
- ]
- return rescaled_inputs
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Sequence, Tuple, Union
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch import Tensor
+
+from mmpose.models.utils.ops import resize
+from mmpose.registry import MODELS
+
+
+@MODELS.register_module()
+class FeatureMapProcessor(nn.Module):
+ """A PyTorch module for selecting, concatenating, and rescaling feature
+ maps.
+
+ Args:
+ select_index (Optional[Union[int, Tuple[int]]], optional): Index or
+ indices of feature maps to select. Defaults to None, which means
+ all feature maps are used.
+ concat (bool, optional): Whether to concatenate the selected feature
+ maps. Defaults to False.
+ scale_factor (float, optional): The scaling factor to apply to the
+ feature maps. Defaults to 1.0.
+ apply_relu (bool, optional): Whether to apply ReLU on input feature
+ maps. Defaults to False.
+ align_corners (bool, optional): Whether to align corners when resizing
+ the feature maps. Defaults to False.
+ """
+
+ def __init__(
+ self,
+ select_index: Optional[Union[int, Tuple[int]]] = None,
+ concat: bool = False,
+ scale_factor: float = 1.0,
+ apply_relu: bool = False,
+ align_corners: bool = False,
+ ):
+ super().__init__()
+
+ if isinstance(select_index, int):
+ select_index = (select_index, )
+ self.select_index = select_index
+ self.concat = concat
+
+ assert (
+ scale_factor > 0
+ ), f'the argument `scale_factor` must be positive, ' \
+ f'but got {scale_factor}'
+ self.scale_factor = scale_factor
+ self.apply_relu = apply_relu
+ self.align_corners = align_corners
+
+ def forward(self, inputs: Union[Tensor, Sequence[Tensor]]
+ ) -> Union[Tensor, List[Tensor]]:
+
+ if not isinstance(inputs, (tuple, list)):
+ sequential_input = False
+ inputs = [inputs]
+ else:
+ sequential_input = True
+
+ if self.select_index is not None:
+ inputs = [inputs[i] for i in self.select_index]
+
+ if self.concat:
+ inputs = self._concat(inputs)
+
+ if self.apply_relu:
+ inputs = [F.relu(x) for x in inputs]
+
+ if self.scale_factor != 1.0:
+ inputs = self._rescale(inputs)
+
+ if not sequential_input:
+ inputs = inputs[0]
+
+ return inputs
+
+ def _concat(self, inputs: Sequence[Tensor]) -> List[Tensor]:
+ size = inputs[0].shape[-2:]
+ resized_inputs = [
+ resize(
+ x,
+ size=size,
+ mode='bilinear',
+ align_corners=self.align_corners) for x in inputs
+ ]
+ return [torch.cat(resized_inputs, dim=1)]
+
+ def _rescale(self, inputs: Sequence[Tensor]) -> List[Tensor]:
+ rescaled_inputs = [
+ resize(
+ x,
+ scale_factor=self.scale_factor,
+ mode='bilinear',
+ align_corners=self.align_corners,
+ ) for x in inputs
+ ]
+ return rescaled_inputs
diff --git a/mmpose/models/necks/fpn.py b/mmpose/models/necks/fpn.py
index d4d3311bda..7696f0cc71 100644
--- a/mmpose/models/necks/fpn.py
+++ b/mmpose/models/necks/fpn.py
@@ -1,206 +1,206 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import torch.nn as nn
-import torch.nn.functional as F
-from mmcv.cnn import ConvModule
-from mmengine.model import xavier_init
-
-from mmpose.registry import MODELS
-
-
-@MODELS.register_module()
-class FPN(nn.Module):
- r"""Feature Pyramid Network.
-
- This is an implementation of paper `Feature Pyramid Networks for Object
- Detection `_.
-
- Args:
- in_channels (list[int]): Number of input channels per scale.
- out_channels (int): Number of output channels (used at each scale).
- num_outs (int): Number of output scales.
- start_level (int): Index of the start input backbone level used to
- build the feature pyramid. Default: 0.
- end_level (int): Index of the end input backbone level (exclusive) to
- build the feature pyramid. Default: -1, which means the last level.
- add_extra_convs (bool | str): If bool, it decides whether to add conv
- layers on top of the original feature maps. Default to False.
- If True, it is equivalent to `add_extra_convs='on_input'`.
- If str, it specifies the source feature map of the extra convs.
- Only the following options are allowed
-
- - 'on_input': Last feat map of neck inputs (i.e. backbone feature).
- - 'on_lateral': Last feature map after lateral convs.
- - 'on_output': The last output feature map after fpn convs.
- relu_before_extra_convs (bool): Whether to apply relu before the extra
- conv. Default: False.
- no_norm_on_lateral (bool): Whether to apply norm on lateral.
- Default: False.
- conv_cfg (dict): Config dict for convolution layer. Default: None.
- norm_cfg (dict): Config dict for normalization layer. Default: None.
- act_cfg (dict): Config dict for activation layer in ConvModule.
- Default: None.
- upsample_cfg (dict): Config dict for interpolate layer.
- Default: dict(mode='nearest').
-
- Example:
- >>> import torch
- >>> in_channels = [2, 3, 5, 7]
- >>> scales = [340, 170, 84, 43]
- >>> inputs = [torch.rand(1, c, s, s)
- ... for c, s in zip(in_channels, scales)]
- >>> self = FPN(in_channels, 11, len(in_channels)).eval()
- >>> outputs = self.forward(inputs)
- >>> for i in range(len(outputs)):
- ... print(f'outputs[{i}].shape = {outputs[i].shape}')
- outputs[0].shape = torch.Size([1, 11, 340, 340])
- outputs[1].shape = torch.Size([1, 11, 170, 170])
- outputs[2].shape = torch.Size([1, 11, 84, 84])
- outputs[3].shape = torch.Size([1, 11, 43, 43])
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- num_outs,
- start_level=0,
- end_level=-1,
- add_extra_convs=False,
- relu_before_extra_convs=False,
- no_norm_on_lateral=False,
- conv_cfg=None,
- norm_cfg=None,
- act_cfg=None,
- upsample_cfg=dict(mode='nearest')):
- super().__init__()
- assert isinstance(in_channels, list)
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.num_ins = len(in_channels)
- self.num_outs = num_outs
- self.relu_before_extra_convs = relu_before_extra_convs
- self.no_norm_on_lateral = no_norm_on_lateral
- self.fp16_enabled = False
- self.upsample_cfg = upsample_cfg.copy()
-
- if end_level == -1 or end_level == self.num_ins - 1:
- self.backbone_end_level = self.num_ins
- assert num_outs >= self.num_ins - start_level
- else:
- # if end_level is not the last level, no extra level is allowed
- self.backbone_end_level = end_level + 1
- assert end_level < self.num_ins
- assert num_outs == end_level - start_level + 1
- self.start_level = start_level
- self.end_level = end_level
- self.add_extra_convs = add_extra_convs
- assert isinstance(add_extra_convs, (str, bool))
- if isinstance(add_extra_convs, str):
- # Extra_convs_source choices: 'on_input', 'on_lateral', 'on_output'
- assert add_extra_convs in ('on_input', 'on_lateral', 'on_output')
- elif add_extra_convs: # True
- self.add_extra_convs = 'on_input'
-
- self.lateral_convs = nn.ModuleList()
- self.fpn_convs = nn.ModuleList()
-
- for i in range(self.start_level, self.backbone_end_level):
- l_conv = ConvModule(
- in_channels[i],
- out_channels,
- 1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg if not self.no_norm_on_lateral else None,
- act_cfg=act_cfg,
- inplace=False)
- fpn_conv = ConvModule(
- out_channels,
- out_channels,
- 3,
- padding=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg,
- inplace=False)
-
- self.lateral_convs.append(l_conv)
- self.fpn_convs.append(fpn_conv)
-
- # add extra conv layers (e.g., RetinaNet)
- extra_levels = num_outs - self.backbone_end_level + self.start_level
- if self.add_extra_convs and extra_levels >= 1:
- for i in range(extra_levels):
- if i == 0 and self.add_extra_convs == 'on_input':
- in_channels = self.in_channels[self.backbone_end_level - 1]
- else:
- in_channels = out_channels
- extra_fpn_conv = ConvModule(
- in_channels,
- out_channels,
- 3,
- stride=2,
- padding=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg,
- inplace=False)
- self.fpn_convs.append(extra_fpn_conv)
-
- def init_weights(self):
- """Initialize model weights."""
- for m in self.modules():
- if isinstance(m, nn.Conv2d):
- xavier_init(m, distribution='uniform')
-
- def forward(self, inputs):
- """Forward function."""
- assert len(inputs) == len(self.in_channels)
-
- # build laterals
- laterals = [
- lateral_conv(inputs[i + self.start_level])
- for i, lateral_conv in enumerate(self.lateral_convs)
- ]
-
- # build top-down path
- used_backbone_levels = len(laterals)
- for i in range(used_backbone_levels - 1, 0, -1):
- # In some cases, fixing `scale factor` (e.g. 2) is preferred, but
- # it cannot co-exist with `size` in `F.interpolate`.
- if 'scale_factor' in self.upsample_cfg:
- # fix runtime error of "+=" inplace operation in PyTorch 1.10
- laterals[i - 1] = laterals[i - 1] + F.interpolate(
- laterals[i], **self.upsample_cfg)
- else:
- prev_shape = laterals[i - 1].shape[2:]
- laterals[i - 1] = laterals[i - 1] + F.interpolate(
- laterals[i], size=prev_shape, **self.upsample_cfg)
-
- # build outputs
- # part 1: from original levels
- outs = [
- self.fpn_convs[i](laterals[i]) for i in range(used_backbone_levels)
- ]
- # part 2: add extra levels
- if self.num_outs > len(outs):
- # use max pool to get more levels on top of outputs
- # (e.g., Faster R-CNN, Mask R-CNN)
- if not self.add_extra_convs:
- for i in range(self.num_outs - used_backbone_levels):
- outs.append(F.max_pool2d(outs[-1], 1, stride=2))
- # add conv layers on top of original feature maps (RetinaNet)
- else:
- if self.add_extra_convs == 'on_input':
- extra_source = inputs[self.backbone_end_level - 1]
- elif self.add_extra_convs == 'on_lateral':
- extra_source = laterals[-1]
- elif self.add_extra_convs == 'on_output':
- extra_source = outs[-1]
- else:
- raise NotImplementedError
- outs.append(self.fpn_convs[used_backbone_levels](extra_source))
- for i in range(used_backbone_levels + 1, self.num_outs):
- if self.relu_before_extra_convs:
- outs.append(self.fpn_convs[i](F.relu(outs[-1])))
- else:
- outs.append(self.fpn_convs[i](outs[-1]))
- return outs
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmengine.model import xavier_init
+
+from mmpose.registry import MODELS
+
+
+@MODELS.register_module()
+class FPN(nn.Module):
+ r"""Feature Pyramid Network.
+
+ This is an implementation of paper `Feature Pyramid Networks for Object
+ Detection `_.
+
+ Args:
+ in_channels (list[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale).
+ num_outs (int): Number of output scales.
+ start_level (int): Index of the start input backbone level used to
+ build the feature pyramid. Default: 0.
+ end_level (int): Index of the end input backbone level (exclusive) to
+ build the feature pyramid. Default: -1, which means the last level.
+ add_extra_convs (bool | str): If bool, it decides whether to add conv
+ layers on top of the original feature maps. Default to False.
+ If True, it is equivalent to `add_extra_convs='on_input'`.
+ If str, it specifies the source feature map of the extra convs.
+ Only the following options are allowed
+
+ - 'on_input': Last feat map of neck inputs (i.e. backbone feature).
+ - 'on_lateral': Last feature map after lateral convs.
+ - 'on_output': The last output feature map after fpn convs.
+ relu_before_extra_convs (bool): Whether to apply relu before the extra
+ conv. Default: False.
+ no_norm_on_lateral (bool): Whether to apply norm on lateral.
+ Default: False.
+ conv_cfg (dict): Config dict for convolution layer. Default: None.
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ act_cfg (dict): Config dict for activation layer in ConvModule.
+ Default: None.
+ upsample_cfg (dict): Config dict for interpolate layer.
+ Default: dict(mode='nearest').
+
+ Example:
+ >>> import torch
+ >>> in_channels = [2, 3, 5, 7]
+ >>> scales = [340, 170, 84, 43]
+ >>> inputs = [torch.rand(1, c, s, s)
+ ... for c, s in zip(in_channels, scales)]
+ >>> self = FPN(in_channels, 11, len(in_channels)).eval()
+ >>> outputs = self.forward(inputs)
+ >>> for i in range(len(outputs)):
+ ... print(f'outputs[{i}].shape = {outputs[i].shape}')
+ outputs[0].shape = torch.Size([1, 11, 340, 340])
+ outputs[1].shape = torch.Size([1, 11, 170, 170])
+ outputs[2].shape = torch.Size([1, 11, 84, 84])
+ outputs[3].shape = torch.Size([1, 11, 43, 43])
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_outs,
+ start_level=0,
+ end_level=-1,
+ add_extra_convs=False,
+ relu_before_extra_convs=False,
+ no_norm_on_lateral=False,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=None,
+ upsample_cfg=dict(mode='nearest')):
+ super().__init__()
+ assert isinstance(in_channels, list)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.num_ins = len(in_channels)
+ self.num_outs = num_outs
+ self.relu_before_extra_convs = relu_before_extra_convs
+ self.no_norm_on_lateral = no_norm_on_lateral
+ self.fp16_enabled = False
+ self.upsample_cfg = upsample_cfg.copy()
+
+ if end_level == -1 or end_level == self.num_ins - 1:
+ self.backbone_end_level = self.num_ins
+ assert num_outs >= self.num_ins - start_level
+ else:
+ # if end_level is not the last level, no extra level is allowed
+ self.backbone_end_level = end_level + 1
+ assert end_level < self.num_ins
+ assert num_outs == end_level - start_level + 1
+ self.start_level = start_level
+ self.end_level = end_level
+ self.add_extra_convs = add_extra_convs
+ assert isinstance(add_extra_convs, (str, bool))
+ if isinstance(add_extra_convs, str):
+ # Extra_convs_source choices: 'on_input', 'on_lateral', 'on_output'
+ assert add_extra_convs in ('on_input', 'on_lateral', 'on_output')
+ elif add_extra_convs: # True
+ self.add_extra_convs = 'on_input'
+
+ self.lateral_convs = nn.ModuleList()
+ self.fpn_convs = nn.ModuleList()
+
+ for i in range(self.start_level, self.backbone_end_level):
+ l_conv = ConvModule(
+ in_channels[i],
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg if not self.no_norm_on_lateral else None,
+ act_cfg=act_cfg,
+ inplace=False)
+ fpn_conv = ConvModule(
+ out_channels,
+ out_channels,
+ 3,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+
+ self.lateral_convs.append(l_conv)
+ self.fpn_convs.append(fpn_conv)
+
+ # add extra conv layers (e.g., RetinaNet)
+ extra_levels = num_outs - self.backbone_end_level + self.start_level
+ if self.add_extra_convs and extra_levels >= 1:
+ for i in range(extra_levels):
+ if i == 0 and self.add_extra_convs == 'on_input':
+ in_channels = self.in_channels[self.backbone_end_level - 1]
+ else:
+ in_channels = out_channels
+ extra_fpn_conv = ConvModule(
+ in_channels,
+ out_channels,
+ 3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+ self.fpn_convs.append(extra_fpn_conv)
+
+ def init_weights(self):
+ """Initialize model weights."""
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ xavier_init(m, distribution='uniform')
+
+ def forward(self, inputs):
+ """Forward function."""
+ assert len(inputs) == len(self.in_channels)
+
+ # build laterals
+ laterals = [
+ lateral_conv(inputs[i + self.start_level])
+ for i, lateral_conv in enumerate(self.lateral_convs)
+ ]
+
+ # build top-down path
+ used_backbone_levels = len(laterals)
+ for i in range(used_backbone_levels - 1, 0, -1):
+ # In some cases, fixing `scale factor` (e.g. 2) is preferred, but
+ # it cannot co-exist with `size` in `F.interpolate`.
+ if 'scale_factor' in self.upsample_cfg:
+ # fix runtime error of "+=" inplace operation in PyTorch 1.10
+ laterals[i - 1] = laterals[i - 1] + F.interpolate(
+ laterals[i], **self.upsample_cfg)
+ else:
+ prev_shape = laterals[i - 1].shape[2:]
+ laterals[i - 1] = laterals[i - 1] + F.interpolate(
+ laterals[i], size=prev_shape, **self.upsample_cfg)
+
+ # build outputs
+ # part 1: from original levels
+ outs = [
+ self.fpn_convs[i](laterals[i]) for i in range(used_backbone_levels)
+ ]
+ # part 2: add extra levels
+ if self.num_outs > len(outs):
+ # use max pool to get more levels on top of outputs
+ # (e.g., Faster R-CNN, Mask R-CNN)
+ if not self.add_extra_convs:
+ for i in range(self.num_outs - used_backbone_levels):
+ outs.append(F.max_pool2d(outs[-1], 1, stride=2))
+ # add conv layers on top of original feature maps (RetinaNet)
+ else:
+ if self.add_extra_convs == 'on_input':
+ extra_source = inputs[self.backbone_end_level - 1]
+ elif self.add_extra_convs == 'on_lateral':
+ extra_source = laterals[-1]
+ elif self.add_extra_convs == 'on_output':
+ extra_source = outs[-1]
+ else:
+ raise NotImplementedError
+ outs.append(self.fpn_convs[used_backbone_levels](extra_source))
+ for i in range(used_backbone_levels + 1, self.num_outs):
+ if self.relu_before_extra_convs:
+ outs.append(self.fpn_convs[i](F.relu(outs[-1])))
+ else:
+ outs.append(self.fpn_convs[i](outs[-1]))
+ return outs
diff --git a/mmpose/models/necks/gap_neck.py b/mmpose/models/necks/gap_neck.py
index 58ce5d939f..c096d790ae 100644
--- a/mmpose/models/necks/gap_neck.py
+++ b/mmpose/models/necks/gap_neck.py
@@ -1,39 +1,39 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import torch
-import torch.nn as nn
-
-from mmpose.registry import MODELS
-
-
-@MODELS.register_module()
-class GlobalAveragePooling(nn.Module):
- """Global Average Pooling neck.
-
- Note that we use `view` to remove extra channel after pooling. We do not
- use `squeeze` as it will also remove the batch dimension when the tensor
- has a batch dimension of size 1, which can lead to unexpected errors.
- """
-
- def __init__(self):
- super().__init__()
- self.gap = nn.AdaptiveAvgPool2d((1, 1))
-
- def init_weights(self):
- pass
-
- def forward(self, inputs):
- """Forward function."""
-
- if isinstance(inputs, tuple):
- outs = tuple([self.gap(x) for x in inputs])
- outs = tuple(
- [out.view(x.size(0), -1) for out, x in zip(outs, inputs)])
- elif isinstance(inputs, list):
- outs = [self.gap(x) for x in inputs]
- outs = [out.view(x.size(0), -1) for out, x in zip(outs, inputs)]
- elif isinstance(inputs, torch.Tensor):
- outs = self.gap(inputs)
- outs = outs.view(inputs.size(0), -1)
- else:
- raise TypeError('neck inputs should be tuple or torch.tensor')
- return outs
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+
+from mmpose.registry import MODELS
+
+
+@MODELS.register_module()
+class GlobalAveragePooling(nn.Module):
+ """Global Average Pooling neck.
+
+ Note that we use `view` to remove extra channel after pooling. We do not
+ use `squeeze` as it will also remove the batch dimension when the tensor
+ has a batch dimension of size 1, which can lead to unexpected errors.
+ """
+
+ def __init__(self):
+ super().__init__()
+ self.gap = nn.AdaptiveAvgPool2d((1, 1))
+
+ def init_weights(self):
+ pass
+
+ def forward(self, inputs):
+ """Forward function."""
+
+ if isinstance(inputs, tuple):
+ outs = tuple([self.gap(x) for x in inputs])
+ outs = tuple(
+ [out.view(x.size(0), -1) for out, x in zip(outs, inputs)])
+ elif isinstance(inputs, list):
+ outs = [self.gap(x) for x in inputs]
+ outs = [out.view(x.size(0), -1) for out, x in zip(outs, inputs)]
+ elif isinstance(inputs, torch.Tensor):
+ outs = self.gap(inputs)
+ outs = outs.view(inputs.size(0), -1)
+ else:
+ raise TypeError('neck inputs should be tuple or torch.tensor')
+ return outs
diff --git a/mmpose/models/necks/posewarper_neck.py b/mmpose/models/necks/posewarper_neck.py
index 517fabd2e8..5bf675ab8f 100644
--- a/mmpose/models/necks/posewarper_neck.py
+++ b/mmpose/models/necks/posewarper_neck.py
@@ -1,329 +1,329 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import mmcv
-import torch
-import torch.nn as nn
-from mmcv.cnn import build_conv_layer, build_norm_layer
-from mmengine.model import constant_init, normal_init
-from mmengine.utils import digit_version
-from torch.nn.modules.batchnorm import _BatchNorm
-
-from mmpose.models.utils.ops import resize
-from mmpose.registry import MODELS
-from ..backbones.resnet import BasicBlock, Bottleneck
-
-try:
- from mmcv.ops import DeformConv2d
- has_mmcv_full = True
-except (ImportError, ModuleNotFoundError):
- has_mmcv_full = False
-
-
-@MODELS.register_module()
-class PoseWarperNeck(nn.Module):
- """PoseWarper neck.
-
- `"Learning temporal pose estimation from sparsely-labeled videos"
- `_.
-
- Args:
- in_channels (int): Number of input channels from backbone
- out_channels (int): Number of output channels
- inner_channels (int): Number of intermediate channels of the res block
- deform_groups (int): Number of groups in the deformable conv
- dilations (list|tuple): different dilations of the offset conv layers
- trans_conv_kernel (int): the kernel of the trans conv layer, which is
- used to get heatmap from the output of backbone. Default: 1
- res_blocks_cfg (dict|None): config of residual blocks. If None,
- use the default values. If not None, it should contain the
- following keys:
-
- - block (str): the type of residual block, Default: 'BASIC'.
- - num_blocks (int): the number of blocks, Default: 20.
-
- offsets_kernel (int): the kernel of offset conv layer.
- deform_conv_kernel (int): the kernel of defomrable conv layer.
- in_index (int|Sequence[int]): Input feature index. Default: 0
- input_transform (str|None): Transformation type of input features.
- Options: 'resize_concat', 'multiple_select', None.
- Default: None.
-
- - 'resize_concat': Multiple feature maps will be resize to \
- the same size as first one and than concat together. \
- Usually used in FCN head of HRNet.
- - 'multiple_select': Multiple feature maps will be bundle into \
- a list and passed into decode head.
- - None: Only one select feature map is allowed.
-
- freeze_trans_layer (bool): Whether to freeze the transition layer
- (stop grad and set eval mode). Default: True.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only. Default: False.
- im2col_step (int): the argument `im2col_step` in deformable conv,
- Default: 80.
- """
- blocks_dict = {'BASIC': BasicBlock, 'BOTTLENECK': Bottleneck}
- minimum_mmcv_version = '1.3.17'
-
- def __init__(self,
- in_channels,
- out_channels,
- inner_channels,
- deform_groups=17,
- dilations=(3, 6, 12, 18, 24),
- trans_conv_kernel=1,
- res_blocks_cfg=None,
- offsets_kernel=3,
- deform_conv_kernel=3,
- in_index=0,
- input_transform=None,
- freeze_trans_layer=True,
- norm_eval=False,
- im2col_step=80):
- super().__init__()
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.inner_channels = inner_channels
- self.deform_groups = deform_groups
- self.dilations = dilations
- self.trans_conv_kernel = trans_conv_kernel
- self.res_blocks_cfg = res_blocks_cfg
- self.offsets_kernel = offsets_kernel
- self.deform_conv_kernel = deform_conv_kernel
- self.in_index = in_index
- self.input_transform = input_transform
- self.freeze_trans_layer = freeze_trans_layer
- self.norm_eval = norm_eval
- self.im2col_step = im2col_step
-
- identity_trans_layer = False
-
- assert trans_conv_kernel in [0, 1, 3]
- kernel_size = trans_conv_kernel
- if kernel_size == 3:
- padding = 1
- elif kernel_size == 1:
- padding = 0
- else:
- # 0 for Identity mapping.
- identity_trans_layer = True
-
- if identity_trans_layer:
- self.trans_layer = nn.Identity()
- else:
- self.trans_layer = build_conv_layer(
- cfg=dict(type='Conv2d'),
- in_channels=in_channels,
- out_channels=out_channels,
- kernel_size=kernel_size,
- stride=1,
- padding=padding)
-
- # build chain of residual blocks
- if res_blocks_cfg is not None and not isinstance(res_blocks_cfg, dict):
- raise TypeError('res_blocks_cfg should be dict or None.')
-
- if res_blocks_cfg is None:
- block_type = 'BASIC'
- num_blocks = 20
- else:
- block_type = res_blocks_cfg.get('block', 'BASIC')
- num_blocks = res_blocks_cfg.get('num_blocks', 20)
-
- block = self.blocks_dict[block_type]
-
- res_layers = []
- downsample = nn.Sequential(
- build_conv_layer(
- cfg=dict(type='Conv2d'),
- in_channels=out_channels,
- out_channels=inner_channels,
- kernel_size=1,
- stride=1,
- bias=False),
- build_norm_layer(dict(type='BN'), inner_channels)[1])
- res_layers.append(
- block(
- in_channels=out_channels,
- out_channels=inner_channels,
- downsample=downsample))
-
- for _ in range(1, num_blocks):
- res_layers.append(block(inner_channels, inner_channels))
- self.offset_feats = nn.Sequential(*res_layers)
-
- # build offset layers
- self.num_offset_layers = len(dilations)
- assert self.num_offset_layers > 0, 'Number of offset layers ' \
- 'should be larger than 0.'
-
- target_offset_channels = 2 * offsets_kernel**2 * deform_groups
-
- offset_layers = [
- build_conv_layer(
- cfg=dict(type='Conv2d'),
- in_channels=inner_channels,
- out_channels=target_offset_channels,
- kernel_size=offsets_kernel,
- stride=1,
- dilation=dilations[i],
- padding=dilations[i],
- bias=False,
- ) for i in range(self.num_offset_layers)
- ]
- self.offset_layers = nn.ModuleList(offset_layers)
-
- # build deformable conv layers
- assert digit_version(mmcv.__version__) >= \
- digit_version(self.minimum_mmcv_version), \
- f'Current MMCV version: {mmcv.__version__}, ' \
- f'but MMCV >= {self.minimum_mmcv_version} is required, see ' \
- f'https://github.com/open-mmlab/mmcv/issues/1440, ' \
- f'Please install the latest MMCV.'
-
- if has_mmcv_full:
- deform_conv_layers = [
- DeformConv2d(
- in_channels=out_channels,
- out_channels=out_channels,
- kernel_size=deform_conv_kernel,
- stride=1,
- padding=int(deform_conv_kernel / 2) * dilations[i],
- dilation=dilations[i],
- deform_groups=deform_groups,
- im2col_step=self.im2col_step,
- ) for i in range(self.num_offset_layers)
- ]
- else:
- raise ImportError('Please install the full version of mmcv '
- 'to use `DeformConv2d`.')
-
- self.deform_conv_layers = nn.ModuleList(deform_conv_layers)
-
- self.freeze_layers()
-
- def freeze_layers(self):
- if self.freeze_trans_layer:
- self.trans_layer.eval()
-
- for param in self.trans_layer.parameters():
- param.requires_grad = False
-
- def init_weights(self):
- for m in self.modules():
- if isinstance(m, nn.Conv2d):
- normal_init(m, std=0.001)
- elif isinstance(m, (_BatchNorm, nn.GroupNorm)):
- constant_init(m, 1)
- elif isinstance(m, DeformConv2d):
- filler = torch.zeros([
- m.weight.size(0),
- m.weight.size(1),
- m.weight.size(2),
- m.weight.size(3)
- ],
- dtype=torch.float32,
- device=m.weight.device)
- for k in range(m.weight.size(0)):
- filler[k, k,
- int(m.weight.size(2) / 2),
- int(m.weight.size(3) / 2)] = 1.0
- m.weight = torch.nn.Parameter(filler)
- m.weight.requires_grad = True
-
- # posewarper offset layer weight initialization
- for m in self.offset_layers.modules():
- constant_init(m, 0)
-
- def _transform_inputs(self, inputs):
- """Transform inputs for decoder.
-
- Args:
- inputs (list[Tensor] | Tensor): multi-level img features.
-
- Returns:
- Tensor: The transformed inputs
- """
- if not isinstance(inputs, list):
- return inputs
-
- if self.input_transform == 'resize_concat':
- inputs = [inputs[i] for i in self.in_index]
- upsampled_inputs = [
- resize(
- input=x,
- size=inputs[0].shape[2:],
- mode='bilinear',
- align_corners=self.align_corners) for x in inputs
- ]
- inputs = torch.cat(upsampled_inputs, dim=1)
- elif self.input_transform == 'multiple_select':
- inputs = [inputs[i] for i in self.in_index]
- else:
- inputs = inputs[self.in_index]
-
- return inputs
-
- def forward(self, inputs, frame_weight):
- assert isinstance(inputs, (list, tuple)), 'PoseWarperNeck inputs ' \
- 'should be list or tuple, even though the length is 1, ' \
- 'for unified processing.'
-
- output_heatmap = 0
- if len(inputs) > 1:
- inputs = [self._transform_inputs(input) for input in inputs]
- inputs = [self.trans_layer(input) for input in inputs]
-
- # calculate difference features
- diff_features = [
- self.offset_feats(inputs[0] - input) for input in inputs
- ]
-
- for i in range(len(inputs)):
- if frame_weight[i] == 0:
- continue
- warped_heatmap = 0
- for j in range(self.num_offset_layers):
- offset = (self.offset_layers[j](diff_features[i]))
- warped_heatmap_tmp = self.deform_conv_layers[j](inputs[i],
- offset)
- warped_heatmap += warped_heatmap_tmp / \
- self.num_offset_layers
-
- output_heatmap += warped_heatmap * frame_weight[i]
-
- else:
- inputs = inputs[0]
- inputs = self._transform_inputs(inputs)
- inputs = self.trans_layer(inputs)
-
- num_frames = len(frame_weight)
- batch_size = inputs.size(0) // num_frames
- ref_x = inputs[:batch_size]
- ref_x_tiled = ref_x.repeat(num_frames, 1, 1, 1)
-
- offset_features = self.offset_feats(ref_x_tiled - inputs)
-
- warped_heatmap = 0
- for j in range(self.num_offset_layers):
- offset = self.offset_layers[j](offset_features)
-
- warped_heatmap_tmp = self.deform_conv_layers[j](inputs, offset)
- warped_heatmap += warped_heatmap_tmp / self.num_offset_layers
-
- for i in range(num_frames):
- if frame_weight[i] == 0:
- continue
- output_heatmap += warped_heatmap[i * batch_size:(i + 1) *
- batch_size] * frame_weight[i]
-
- return output_heatmap
-
- def train(self, mode=True):
- """Convert the model into training mode."""
- super().train(mode)
- self.freeze_layers()
- if mode and self.norm_eval:
- for m in self.modules():
- if isinstance(m, _BatchNorm):
- m.eval()
+# Copyright (c) OpenMMLab. All rights reserved.
+import mmcv
+import torch
+import torch.nn as nn
+from mmcv.cnn import build_conv_layer, build_norm_layer
+from mmengine.model import constant_init, normal_init
+from mmengine.utils import digit_version
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmpose.models.utils.ops import resize
+from mmpose.registry import MODELS
+from ..backbones.resnet import BasicBlock, Bottleneck
+
+try:
+ from mmcv.ops import DeformConv2d
+ has_mmcv_full = True
+except (ImportError, ModuleNotFoundError):
+ has_mmcv_full = False
+
+
+@MODELS.register_module()
+class PoseWarperNeck(nn.Module):
+ """PoseWarper neck.
+
+ `"Learning temporal pose estimation from sparsely-labeled videos"
+ `_.
+
+ Args:
+ in_channels (int): Number of input channels from backbone
+ out_channels (int): Number of output channels
+ inner_channels (int): Number of intermediate channels of the res block
+ deform_groups (int): Number of groups in the deformable conv
+ dilations (list|tuple): different dilations of the offset conv layers
+ trans_conv_kernel (int): the kernel of the trans conv layer, which is
+ used to get heatmap from the output of backbone. Default: 1
+ res_blocks_cfg (dict|None): config of residual blocks. If None,
+ use the default values. If not None, it should contain the
+ following keys:
+
+ - block (str): the type of residual block, Default: 'BASIC'.
+ - num_blocks (int): the number of blocks, Default: 20.
+
+ offsets_kernel (int): the kernel of offset conv layer.
+ deform_conv_kernel (int): the kernel of defomrable conv layer.
+ in_index (int|Sequence[int]): Input feature index. Default: 0
+ input_transform (str|None): Transformation type of input features.
+ Options: 'resize_concat', 'multiple_select', None.
+ Default: None.
+
+ - 'resize_concat': Multiple feature maps will be resize to \
+ the same size as first one and than concat together. \
+ Usually used in FCN head of HRNet.
+ - 'multiple_select': Multiple feature maps will be bundle into \
+ a list and passed into decode head.
+ - None: Only one select feature map is allowed.
+
+ freeze_trans_layer (bool): Whether to freeze the transition layer
+ (stop grad and set eval mode). Default: True.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ im2col_step (int): the argument `im2col_step` in deformable conv,
+ Default: 80.
+ """
+ blocks_dict = {'BASIC': BasicBlock, 'BOTTLENECK': Bottleneck}
+ minimum_mmcv_version = '1.3.17'
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ inner_channels,
+ deform_groups=17,
+ dilations=(3, 6, 12, 18, 24),
+ trans_conv_kernel=1,
+ res_blocks_cfg=None,
+ offsets_kernel=3,
+ deform_conv_kernel=3,
+ in_index=0,
+ input_transform=None,
+ freeze_trans_layer=True,
+ norm_eval=False,
+ im2col_step=80):
+ super().__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.inner_channels = inner_channels
+ self.deform_groups = deform_groups
+ self.dilations = dilations
+ self.trans_conv_kernel = trans_conv_kernel
+ self.res_blocks_cfg = res_blocks_cfg
+ self.offsets_kernel = offsets_kernel
+ self.deform_conv_kernel = deform_conv_kernel
+ self.in_index = in_index
+ self.input_transform = input_transform
+ self.freeze_trans_layer = freeze_trans_layer
+ self.norm_eval = norm_eval
+ self.im2col_step = im2col_step
+
+ identity_trans_layer = False
+
+ assert trans_conv_kernel in [0, 1, 3]
+ kernel_size = trans_conv_kernel
+ if kernel_size == 3:
+ padding = 1
+ elif kernel_size == 1:
+ padding = 0
+ else:
+ # 0 for Identity mapping.
+ identity_trans_layer = True
+
+ if identity_trans_layer:
+ self.trans_layer = nn.Identity()
+ else:
+ self.trans_layer = build_conv_layer(
+ cfg=dict(type='Conv2d'),
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=1,
+ padding=padding)
+
+ # build chain of residual blocks
+ if res_blocks_cfg is not None and not isinstance(res_blocks_cfg, dict):
+ raise TypeError('res_blocks_cfg should be dict or None.')
+
+ if res_blocks_cfg is None:
+ block_type = 'BASIC'
+ num_blocks = 20
+ else:
+ block_type = res_blocks_cfg.get('block', 'BASIC')
+ num_blocks = res_blocks_cfg.get('num_blocks', 20)
+
+ block = self.blocks_dict[block_type]
+
+ res_layers = []
+ downsample = nn.Sequential(
+ build_conv_layer(
+ cfg=dict(type='Conv2d'),
+ in_channels=out_channels,
+ out_channels=inner_channels,
+ kernel_size=1,
+ stride=1,
+ bias=False),
+ build_norm_layer(dict(type='BN'), inner_channels)[1])
+ res_layers.append(
+ block(
+ in_channels=out_channels,
+ out_channels=inner_channels,
+ downsample=downsample))
+
+ for _ in range(1, num_blocks):
+ res_layers.append(block(inner_channels, inner_channels))
+ self.offset_feats = nn.Sequential(*res_layers)
+
+ # build offset layers
+ self.num_offset_layers = len(dilations)
+ assert self.num_offset_layers > 0, 'Number of offset layers ' \
+ 'should be larger than 0.'
+
+ target_offset_channels = 2 * offsets_kernel**2 * deform_groups
+
+ offset_layers = [
+ build_conv_layer(
+ cfg=dict(type='Conv2d'),
+ in_channels=inner_channels,
+ out_channels=target_offset_channels,
+ kernel_size=offsets_kernel,
+ stride=1,
+ dilation=dilations[i],
+ padding=dilations[i],
+ bias=False,
+ ) for i in range(self.num_offset_layers)
+ ]
+ self.offset_layers = nn.ModuleList(offset_layers)
+
+ # build deformable conv layers
+ assert digit_version(mmcv.__version__) >= \
+ digit_version(self.minimum_mmcv_version), \
+ f'Current MMCV version: {mmcv.__version__}, ' \
+ f'but MMCV >= {self.minimum_mmcv_version} is required, see ' \
+ f'https://github.com/open-mmlab/mmcv/issues/1440, ' \
+ f'Please install the latest MMCV.'
+
+ if has_mmcv_full:
+ deform_conv_layers = [
+ DeformConv2d(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ kernel_size=deform_conv_kernel,
+ stride=1,
+ padding=int(deform_conv_kernel / 2) * dilations[i],
+ dilation=dilations[i],
+ deform_groups=deform_groups,
+ im2col_step=self.im2col_step,
+ ) for i in range(self.num_offset_layers)
+ ]
+ else:
+ raise ImportError('Please install the full version of mmcv '
+ 'to use `DeformConv2d`.')
+
+ self.deform_conv_layers = nn.ModuleList(deform_conv_layers)
+
+ self.freeze_layers()
+
+ def freeze_layers(self):
+ if self.freeze_trans_layer:
+ self.trans_layer.eval()
+
+ for param in self.trans_layer.parameters():
+ param.requires_grad = False
+
+ def init_weights(self):
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ normal_init(m, std=0.001)
+ elif isinstance(m, (_BatchNorm, nn.GroupNorm)):
+ constant_init(m, 1)
+ elif isinstance(m, DeformConv2d):
+ filler = torch.zeros([
+ m.weight.size(0),
+ m.weight.size(1),
+ m.weight.size(2),
+ m.weight.size(3)
+ ],
+ dtype=torch.float32,
+ device=m.weight.device)
+ for k in range(m.weight.size(0)):
+ filler[k, k,
+ int(m.weight.size(2) / 2),
+ int(m.weight.size(3) / 2)] = 1.0
+ m.weight = torch.nn.Parameter(filler)
+ m.weight.requires_grad = True
+
+ # posewarper offset layer weight initialization
+ for m in self.offset_layers.modules():
+ constant_init(m, 0)
+
+ def _transform_inputs(self, inputs):
+ """Transform inputs for decoder.
+
+ Args:
+ inputs (list[Tensor] | Tensor): multi-level img features.
+
+ Returns:
+ Tensor: The transformed inputs
+ """
+ if not isinstance(inputs, list):
+ return inputs
+
+ if self.input_transform == 'resize_concat':
+ inputs = [inputs[i] for i in self.in_index]
+ upsampled_inputs = [
+ resize(
+ input=x,
+ size=inputs[0].shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners) for x in inputs
+ ]
+ inputs = torch.cat(upsampled_inputs, dim=1)
+ elif self.input_transform == 'multiple_select':
+ inputs = [inputs[i] for i in self.in_index]
+ else:
+ inputs = inputs[self.in_index]
+
+ return inputs
+
+ def forward(self, inputs, frame_weight):
+ assert isinstance(inputs, (list, tuple)), 'PoseWarperNeck inputs ' \
+ 'should be list or tuple, even though the length is 1, ' \
+ 'for unified processing.'
+
+ output_heatmap = 0
+ if len(inputs) > 1:
+ inputs = [self._transform_inputs(input) for input in inputs]
+ inputs = [self.trans_layer(input) for input in inputs]
+
+ # calculate difference features
+ diff_features = [
+ self.offset_feats(inputs[0] - input) for input in inputs
+ ]
+
+ for i in range(len(inputs)):
+ if frame_weight[i] == 0:
+ continue
+ warped_heatmap = 0
+ for j in range(self.num_offset_layers):
+ offset = (self.offset_layers[j](diff_features[i]))
+ warped_heatmap_tmp = self.deform_conv_layers[j](inputs[i],
+ offset)
+ warped_heatmap += warped_heatmap_tmp / \
+ self.num_offset_layers
+
+ output_heatmap += warped_heatmap * frame_weight[i]
+
+ else:
+ inputs = inputs[0]
+ inputs = self._transform_inputs(inputs)
+ inputs = self.trans_layer(inputs)
+
+ num_frames = len(frame_weight)
+ batch_size = inputs.size(0) // num_frames
+ ref_x = inputs[:batch_size]
+ ref_x_tiled = ref_x.repeat(num_frames, 1, 1, 1)
+
+ offset_features = self.offset_feats(ref_x_tiled - inputs)
+
+ warped_heatmap = 0
+ for j in range(self.num_offset_layers):
+ offset = self.offset_layers[j](offset_features)
+
+ warped_heatmap_tmp = self.deform_conv_layers[j](inputs, offset)
+ warped_heatmap += warped_heatmap_tmp / self.num_offset_layers
+
+ for i in range(num_frames):
+ if frame_weight[i] == 0:
+ continue
+ output_heatmap += warped_heatmap[i * batch_size:(i + 1) *
+ batch_size] * frame_weight[i]
+
+ return output_heatmap
+
+ def train(self, mode=True):
+ """Convert the model into training mode."""
+ super().train(mode)
+ self.freeze_layers()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, _BatchNorm):
+ m.eval()
diff --git a/mmpose/models/pose_estimators/__init__.py b/mmpose/models/pose_estimators/__init__.py
index c5287e0c2c..a5af255256 100644
--- a/mmpose/models/pose_estimators/__init__.py
+++ b/mmpose/models/pose_estimators/__init__.py
@@ -1,6 +1,6 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .bottomup import BottomupPoseEstimator
-from .pose_lifter import PoseLifter
-from .topdown import TopdownPoseEstimator
-
-__all__ = ['TopdownPoseEstimator', 'BottomupPoseEstimator', 'PoseLifter']
+# Copyright (c) OpenMMLab. All rights reserved.
+from .bottomup import BottomupPoseEstimator
+from .pose_lifter import PoseLifter
+from .topdown import TopdownPoseEstimator
+
+__all__ = ['TopdownPoseEstimator', 'BottomupPoseEstimator', 'PoseLifter']
diff --git a/mmpose/models/pose_estimators/base.py b/mmpose/models/pose_estimators/base.py
index 0ae921d0ec..7bb0711d80 100644
--- a/mmpose/models/pose_estimators/base.py
+++ b/mmpose/models/pose_estimators/base.py
@@ -1,212 +1,212 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from abc import ABCMeta, abstractmethod
-from typing import Tuple, Union
-
-import torch
-from mmengine.model import BaseModel
-from torch import Tensor
-
-from mmpose.datasets.datasets.utils import parse_pose_metainfo
-from mmpose.models.utils import check_and_update_config
-from mmpose.registry import MODELS
-from mmpose.utils.typing import (ConfigType, ForwardResults, OptConfigType,
- Optional, OptMultiConfig, OptSampleList,
- SampleList)
-
-
-class BasePoseEstimator(BaseModel, metaclass=ABCMeta):
- """Base class for pose estimators.
-
- Args:
- data_preprocessor (dict | ConfigDict, optional): The pre-processing
- config of :class:`BaseDataPreprocessor`. Defaults to ``None``
- init_cfg (dict | ConfigDict): The model initialization config.
- Defaults to ``None``
- metainfo (dict): Meta information for dataset, such as keypoints
- definition and properties. If set, the metainfo of the input data
- batch will be overridden. For more details, please refer to
- https://mmpose.readthedocs.io/en/latest/user_guides/
- prepare_datasets.html#create-a-custom-dataset-info-
- config-file-for-the-dataset. Defaults to ``None``
- """
- _version = 2
-
- def __init__(self,
- backbone: ConfigType,
- neck: OptConfigType = None,
- head: OptConfigType = None,
- train_cfg: OptConfigType = None,
- test_cfg: OptConfigType = None,
- data_preprocessor: OptConfigType = None,
- init_cfg: OptMultiConfig = None,
- metainfo: Optional[dict] = None):
- super().__init__(
- data_preprocessor=data_preprocessor, init_cfg=init_cfg)
- self.metainfo = self._load_metainfo(metainfo)
-
- self.backbone = MODELS.build(backbone)
-
- # the PR #2108 and #2126 modified the interface of neck and head.
- # The following function automatically detects outdated
- # configurations and updates them accordingly, while also providing
- # clear and concise information on the changes made.
- neck, head = check_and_update_config(neck, head)
-
- if neck is not None:
- self.neck = MODELS.build(neck)
-
- if head is not None:
- self.head = MODELS.build(head)
-
- self.train_cfg = train_cfg if train_cfg else {}
- self.test_cfg = test_cfg if test_cfg else {}
-
- # Register the hook to automatically convert old version state dicts
- self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
-
- @property
- def with_neck(self) -> bool:
- """bool: whether the pose estimator has a neck."""
- return hasattr(self, 'neck') and self.neck is not None
-
- @property
- def with_head(self) -> bool:
- """bool: whether the pose estimator has a head."""
- return hasattr(self, 'head') and self.head is not None
-
- @staticmethod
- def _load_metainfo(metainfo: dict = None) -> dict:
- """Collect meta information from the dictionary of meta.
-
- Args:
- metainfo (dict): Raw data of pose meta information.
-
- Returns:
- dict: Parsed meta information.
- """
-
- if metainfo is None:
- return None
-
- if not isinstance(metainfo, dict):
- raise TypeError(
- f'metainfo should be a dict, but got {type(metainfo)}')
-
- metainfo = parse_pose_metainfo(metainfo)
- return metainfo
-
- def forward(self,
- inputs: torch.Tensor,
- data_samples: OptSampleList,
- mode: str = 'tensor') -> ForwardResults:
- """The unified entry for a forward process in both training and test.
-
- The method should accept three modes: 'tensor', 'predict' and 'loss':
-
- - 'tensor': Forward the whole network and return tensor or tuple of
- tensor without any post-processing, same as a common nn.Module.
- - 'predict': Forward and return the predictions, which are fully
- processed to a list of :obj:`PoseDataSample`.
- - 'loss': Forward and return a dict of losses according to the given
- inputs and data samples.
-
- Note that this method doesn't handle neither back propagation nor
- optimizer updating, which are done in the :meth:`train_step`.
-
- Args:
- inputs (torch.Tensor): The input tensor with shape
- (N, C, ...) in general
- data_samples (list[:obj:`PoseDataSample`], optional): The
- annotation of every sample. Defaults to ``None``
- mode (str): Set the forward mode and return value type. Defaults
- to ``'tensor'``
-
- Returns:
- The return type depends on ``mode``.
-
- - If ``mode='tensor'``, return a tensor or a tuple of tensors
- - If ``mode='predict'``, return a list of :obj:``PoseDataSample``
- that contains the pose predictions
- - If ``mode='loss'``, return a dict of tensor(s) which is the loss
- function value
- """
- if isinstance(inputs, list):
- inputs = torch.stack(inputs)
- if mode == 'loss':
- return self.loss(inputs, data_samples)
- elif mode == 'predict':
- # use customed metainfo to override the default metainfo
- if self.metainfo is not None:
- for data_sample in data_samples:
- data_sample.set_metainfo(self.metainfo)
- return self.predict(inputs, data_samples)
- elif mode == 'tensor':
- return self._forward(inputs)
- else:
- raise RuntimeError(f'Invalid mode "{mode}". '
- 'Only supports loss, predict and tensor mode.')
-
- @abstractmethod
- def loss(self, inputs: Tensor, data_samples: SampleList) -> dict:
- """Calculate losses from a batch of inputs and data samples."""
-
- @abstractmethod
- def predict(self, inputs: Tensor, data_samples: SampleList) -> SampleList:
- """Predict results from a batch of inputs and data samples with post-
- processing."""
-
- def _forward(self,
- inputs: Tensor,
- data_samples: OptSampleList = None
- ) -> Union[Tensor, Tuple[Tensor]]:
- """Network forward process. Usually includes backbone, neck and head
- forward without any post-processing.
-
- Args:
- inputs (Tensor): Inputs with shape (N, C, H, W).
-
- Returns:
- Union[Tensor | Tuple[Tensor]]: forward output of the network.
- """
-
- x = self.extract_feat(inputs)
- if self.with_head:
- x = self.head.forward(x)
-
- return x
-
- def extract_feat(self, inputs: Tensor) -> Tuple[Tensor]:
- """Extract features.
-
- Args:
- inputs (Tensor): Image tensor with shape (N, C, H ,W).
-
- Returns:
- tuple[Tensor]: Multi-level features that may have various
- resolutions.
- """
- x = self.backbone(inputs)
- if self.with_neck:
- x = self.neck(x)
-
- return x
-
- def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
- **kwargs):
- """A hook function to convert old-version state dict of
- :class:`TopdownHeatmapSimpleHead` (before MMPose v1.0.0) to a
- compatible format of :class:`HeatmapHead`.
-
- The hook will be automatically registered during initialization.
- """
- version = local_meta.get('version', None)
- if version and version >= self._version:
- return
-
- # convert old-version state dict
- keys = list(state_dict.keys())
- for k in keys:
- if 'keypoint_head' in k:
- v = state_dict.pop(k)
- k = k.replace('keypoint_head', 'head')
- state_dict[k] = v
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+from typing import Tuple, Union
+
+import torch
+from mmengine.model import BaseModel
+from torch import Tensor
+
+from mmpose.datasets.datasets.utils import parse_pose_metainfo
+from mmpose.models.utils import check_and_update_config
+from mmpose.registry import MODELS
+from mmpose.utils.typing import (ConfigType, ForwardResults, OptConfigType,
+ Optional, OptMultiConfig, OptSampleList,
+ SampleList)
+
+
+class BasePoseEstimator(BaseModel, metaclass=ABCMeta):
+ """Base class for pose estimators.
+
+ Args:
+ data_preprocessor (dict | ConfigDict, optional): The pre-processing
+ config of :class:`BaseDataPreprocessor`. Defaults to ``None``
+ init_cfg (dict | ConfigDict): The model initialization config.
+ Defaults to ``None``
+ metainfo (dict): Meta information for dataset, such as keypoints
+ definition and properties. If set, the metainfo of the input data
+ batch will be overridden. For more details, please refer to
+ https://mmpose.readthedocs.io/en/latest/user_guides/
+ prepare_datasets.html#create-a-custom-dataset-info-
+ config-file-for-the-dataset. Defaults to ``None``
+ """
+ _version = 2
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: OptConfigType = None,
+ head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None,
+ metainfo: Optional[dict] = None):
+ super().__init__(
+ data_preprocessor=data_preprocessor, init_cfg=init_cfg)
+ self.metainfo = self._load_metainfo(metainfo)
+
+ self.backbone = MODELS.build(backbone)
+
+ # the PR #2108 and #2126 modified the interface of neck and head.
+ # The following function automatically detects outdated
+ # configurations and updates them accordingly, while also providing
+ # clear and concise information on the changes made.
+ neck, head = check_and_update_config(neck, head)
+
+ if neck is not None:
+ self.neck = MODELS.build(neck)
+
+ if head is not None:
+ self.head = MODELS.build(head)
+
+ self.train_cfg = train_cfg if train_cfg else {}
+ self.test_cfg = test_cfg if test_cfg else {}
+
+ # Register the hook to automatically convert old version state dicts
+ self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
+
+ @property
+ def with_neck(self) -> bool:
+ """bool: whether the pose estimator has a neck."""
+ return hasattr(self, 'neck') and self.neck is not None
+
+ @property
+ def with_head(self) -> bool:
+ """bool: whether the pose estimator has a head."""
+ return hasattr(self, 'head') and self.head is not None
+
+ @staticmethod
+ def _load_metainfo(metainfo: dict = None) -> dict:
+ """Collect meta information from the dictionary of meta.
+
+ Args:
+ metainfo (dict): Raw data of pose meta information.
+
+ Returns:
+ dict: Parsed meta information.
+ """
+
+ if metainfo is None:
+ return None
+
+ if not isinstance(metainfo, dict):
+ raise TypeError(
+ f'metainfo should be a dict, but got {type(metainfo)}')
+
+ metainfo = parse_pose_metainfo(metainfo)
+ return metainfo
+
+ def forward(self,
+ inputs: torch.Tensor,
+ data_samples: OptSampleList,
+ mode: str = 'tensor') -> ForwardResults:
+ """The unified entry for a forward process in both training and test.
+
+ The method should accept three modes: 'tensor', 'predict' and 'loss':
+
+ - 'tensor': Forward the whole network and return tensor or tuple of
+ tensor without any post-processing, same as a common nn.Module.
+ - 'predict': Forward and return the predictions, which are fully
+ processed to a list of :obj:`PoseDataSample`.
+ - 'loss': Forward and return a dict of losses according to the given
+ inputs and data samples.
+
+ Note that this method doesn't handle neither back propagation nor
+ optimizer updating, which are done in the :meth:`train_step`.
+
+ Args:
+ inputs (torch.Tensor): The input tensor with shape
+ (N, C, ...) in general
+ data_samples (list[:obj:`PoseDataSample`], optional): The
+ annotation of every sample. Defaults to ``None``
+ mode (str): Set the forward mode and return value type. Defaults
+ to ``'tensor'``
+
+ Returns:
+ The return type depends on ``mode``.
+
+ - If ``mode='tensor'``, return a tensor or a tuple of tensors
+ - If ``mode='predict'``, return a list of :obj:``PoseDataSample``
+ that contains the pose predictions
+ - If ``mode='loss'``, return a dict of tensor(s) which is the loss
+ function value
+ """
+ if isinstance(inputs, list):
+ inputs = torch.stack(inputs)
+ if mode == 'loss':
+ return self.loss(inputs, data_samples)
+ elif mode == 'predict':
+ # use customed metainfo to override the default metainfo
+ if self.metainfo is not None:
+ for data_sample in data_samples:
+ data_sample.set_metainfo(self.metainfo)
+ return self.predict(inputs, data_samples)
+ elif mode == 'tensor':
+ return self._forward(inputs)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}". '
+ 'Only supports loss, predict and tensor mode.')
+
+ @abstractmethod
+ def loss(self, inputs: Tensor, data_samples: SampleList) -> dict:
+ """Calculate losses from a batch of inputs and data samples."""
+
+ @abstractmethod
+ def predict(self, inputs: Tensor, data_samples: SampleList) -> SampleList:
+ """Predict results from a batch of inputs and data samples with post-
+ processing."""
+
+ def _forward(self,
+ inputs: Tensor,
+ data_samples: OptSampleList = None
+ ) -> Union[Tensor, Tuple[Tensor]]:
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ inputs (Tensor): Inputs with shape (N, C, H, W).
+
+ Returns:
+ Union[Tensor | Tuple[Tensor]]: forward output of the network.
+ """
+
+ x = self.extract_feat(inputs)
+ if self.with_head:
+ x = self.head.forward(x)
+
+ return x
+
+ def extract_feat(self, inputs: Tensor) -> Tuple[Tensor]:
+ """Extract features.
+
+ Args:
+ inputs (Tensor): Image tensor with shape (N, C, H ,W).
+
+ Returns:
+ tuple[Tensor]: Multi-level features that may have various
+ resolutions.
+ """
+ x = self.backbone(inputs)
+ if self.with_neck:
+ x = self.neck(x)
+
+ return x
+
+ def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
+ **kwargs):
+ """A hook function to convert old-version state dict of
+ :class:`TopdownHeatmapSimpleHead` (before MMPose v1.0.0) to a
+ compatible format of :class:`HeatmapHead`.
+
+ The hook will be automatically registered during initialization.
+ """
+ version = local_meta.get('version', None)
+ if version and version >= self._version:
+ return
+
+ # convert old-version state dict
+ keys = list(state_dict.keys())
+ for k in keys:
+ if 'keypoint_head' in k:
+ v = state_dict.pop(k)
+ k = k.replace('keypoint_head', 'head')
+ state_dict[k] = v
diff --git a/mmpose/models/pose_estimators/bottomup.py b/mmpose/models/pose_estimators/bottomup.py
index 5400f2478e..8b7a6d8ec2 100644
--- a/mmpose/models/pose_estimators/bottomup.py
+++ b/mmpose/models/pose_estimators/bottomup.py
@@ -1,178 +1,178 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from itertools import zip_longest
-from typing import List, Optional, Union
-
-from mmengine.utils import is_list_of
-from torch import Tensor
-
-from mmpose.registry import MODELS
-from mmpose.utils.typing import (ConfigType, InstanceList, OptConfigType,
- OptMultiConfig, PixelDataList, SampleList)
-from .base import BasePoseEstimator
-
-
-@MODELS.register_module()
-class BottomupPoseEstimator(BasePoseEstimator):
- """Base class for bottom-up pose estimators.
-
- Args:
- backbone (dict): The backbone config
- neck (dict, optional): The neck config. Defaults to ``None``
- head (dict, optional): The head config. Defaults to ``None``
- train_cfg (dict, optional): The runtime config for training process.
- Defaults to ``None``
- test_cfg (dict, optional): The runtime config for testing process.
- Defaults to ``None``
- data_preprocessor (dict, optional): The data preprocessing config to
- build the instance of :class:`BaseDataPreprocessor`. Defaults to
- ``None``.
- init_cfg (dict, optional): The config to control the initialization.
- Defaults to ``None``
- """
-
- def __init__(self,
- backbone: ConfigType,
- neck: OptConfigType = None,
- head: OptConfigType = None,
- train_cfg: OptConfigType = None,
- test_cfg: OptConfigType = None,
- data_preprocessor: OptConfigType = None,
- init_cfg: OptMultiConfig = None):
- super().__init__(
- backbone=backbone,
- neck=neck,
- head=head,
- train_cfg=train_cfg,
- test_cfg=test_cfg,
- data_preprocessor=data_preprocessor,
- init_cfg=init_cfg)
-
- def loss(self, inputs: Tensor, data_samples: SampleList) -> dict:
- """Calculate losses from a batch of inputs and data samples.
-
- Args:
- inputs (Tensor): Inputs with shape (N, C, H, W).
- data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples.
-
- Returns:
- dict: A dictionary of losses.
- """
- feats = self.extract_feat(inputs)
-
- losses = dict()
-
- if self.with_head:
- losses.update(
- self.head.loss(feats, data_samples, train_cfg=self.train_cfg))
-
- return losses
-
- def predict(self, inputs: Union[Tensor, List[Tensor]],
- data_samples: SampleList) -> SampleList:
- """Predict results from a batch of inputs and data samples with post-
- processing.
-
- Args:
- inputs (Tensor | List[Tensor]): Input image in tensor or image
- pyramid as a list of tensors. Each tensor is in shape
- [B, C, H, W]
- data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples
-
- Returns:
- list[:obj:`PoseDataSample`]: The pose estimation results of the
- input images. The return value is `PoseDataSample` instances with
- ``pred_instances`` and ``pred_fields``(optional) field , and
- ``pred_instances`` usually contains the following keys:
-
- - keypoints (Tensor): predicted keypoint coordinates in shape
- (num_instances, K, D) where K is the keypoint number and D
- is the keypoint dimension
- - keypoint_scores (Tensor): predicted keypoint scores in shape
- (num_instances, K)
- """
- assert self.with_head, (
- 'The model must have head to perform prediction.')
-
- multiscale_test = self.test_cfg.get('multiscale_test', False)
- flip_test = self.test_cfg.get('flip_test', False)
-
- # enable multi-scale test
- aug_scales = data_samples[0].metainfo.get('aug_scales', None)
- if multiscale_test:
- assert isinstance(aug_scales, list)
- assert is_list_of(inputs, Tensor)
- # `inputs` includes images in original and augmented scales
- assert len(inputs) == len(aug_scales) + 1
- else:
- assert isinstance(inputs, Tensor)
- # single-scale test
- inputs = [inputs]
-
- feats = []
- for _inputs in inputs:
- if flip_test:
- _feats_orig = self.extract_feat(_inputs)
- _feats_flip = self.extract_feat(_inputs.flip(-1))
- _feats = [_feats_orig, _feats_flip]
- else:
- _feats = self.extract_feat(_inputs)
-
- feats.append(_feats)
-
- if not multiscale_test:
- feats = feats[0]
-
- preds = self.head.predict(feats, data_samples, test_cfg=self.test_cfg)
-
- if isinstance(preds, tuple):
- batch_pred_instances, batch_pred_fields = preds
- else:
- batch_pred_instances = preds
- batch_pred_fields = None
-
- results = self.add_pred_to_datasample(batch_pred_instances,
- batch_pred_fields, data_samples)
-
- return results
-
- def add_pred_to_datasample(self, batch_pred_instances: InstanceList,
- batch_pred_fields: Optional[PixelDataList],
- batch_data_samples: SampleList) -> SampleList:
- """Add predictions into data samples.
-
- Args:
- batch_pred_instances (List[InstanceData]): The predicted instances
- of the input data batch
- batch_pred_fields (List[PixelData], optional): The predicted
- fields (e.g. heatmaps) of the input batch
- batch_data_samples (List[PoseDataSample]): The input data batch
-
- Returns:
- List[PoseDataSample]: A list of data samples where the predictions
- are stored in the ``pred_instances`` field of each data sample.
- The length of the list is the batch size when ``merge==False``, or
- 1 when ``merge==True``.
- """
- assert len(batch_pred_instances) == len(batch_data_samples)
- if batch_pred_fields is None:
- batch_pred_fields = []
-
- for pred_instances, pred_fields, data_sample in zip_longest(
- batch_pred_instances, batch_pred_fields, batch_data_samples):
-
- # convert keypoint coordinates from input space to image space
- input_size = data_sample.metainfo['input_size']
- input_center = data_sample.metainfo['input_center']
- input_scale = data_sample.metainfo['input_scale']
-
- pred_instances.keypoints = pred_instances.keypoints / input_size \
- * input_scale + input_center - 0.5 * input_scale
-
- data_sample.pred_instances = pred_instances
-
- if pred_fields is not None:
- data_sample.pred_fields = pred_fields
-
- return batch_data_samples
+# Copyright (c) OpenMMLab. All rights reserved.
+from itertools import zip_longest
+from typing import List, Optional, Union
+
+from mmengine.utils import is_list_of
+from torch import Tensor
+
+from mmpose.registry import MODELS
+from mmpose.utils.typing import (ConfigType, InstanceList, OptConfigType,
+ OptMultiConfig, PixelDataList, SampleList)
+from .base import BasePoseEstimator
+
+
+@MODELS.register_module()
+class BottomupPoseEstimator(BasePoseEstimator):
+ """Base class for bottom-up pose estimators.
+
+ Args:
+ backbone (dict): The backbone config
+ neck (dict, optional): The neck config. Defaults to ``None``
+ head (dict, optional): The head config. Defaults to ``None``
+ train_cfg (dict, optional): The runtime config for training process.
+ Defaults to ``None``
+ test_cfg (dict, optional): The runtime config for testing process.
+ Defaults to ``None``
+ data_preprocessor (dict, optional): The data preprocessing config to
+ build the instance of :class:`BaseDataPreprocessor`. Defaults to
+ ``None``.
+ init_cfg (dict, optional): The config to control the initialization.
+ Defaults to ``None``
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: OptConfigType = None,
+ head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None):
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ head=head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
+
+ def loss(self, inputs: Tensor, data_samples: SampleList) -> dict:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ inputs (Tensor): Inputs with shape (N, C, H, W).
+ data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples.
+
+ Returns:
+ dict: A dictionary of losses.
+ """
+ feats = self.extract_feat(inputs)
+
+ losses = dict()
+
+ if self.with_head:
+ losses.update(
+ self.head.loss(feats, data_samples, train_cfg=self.train_cfg))
+
+ return losses
+
+ def predict(self, inputs: Union[Tensor, List[Tensor]],
+ data_samples: SampleList) -> SampleList:
+ """Predict results from a batch of inputs and data samples with post-
+ processing.
+
+ Args:
+ inputs (Tensor | List[Tensor]): Input image in tensor or image
+ pyramid as a list of tensors. Each tensor is in shape
+ [B, C, H, W]
+ data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+
+ Returns:
+ list[:obj:`PoseDataSample`]: The pose estimation results of the
+ input images. The return value is `PoseDataSample` instances with
+ ``pred_instances`` and ``pred_fields``(optional) field , and
+ ``pred_instances`` usually contains the following keys:
+
+ - keypoints (Tensor): predicted keypoint coordinates in shape
+ (num_instances, K, D) where K is the keypoint number and D
+ is the keypoint dimension
+ - keypoint_scores (Tensor): predicted keypoint scores in shape
+ (num_instances, K)
+ """
+ assert self.with_head, (
+ 'The model must have head to perform prediction.')
+
+ multiscale_test = self.test_cfg.get('multiscale_test', False)
+ flip_test = self.test_cfg.get('flip_test', False)
+
+ # enable multi-scale test
+ aug_scales = data_samples[0].metainfo.get('aug_scales', None)
+ if multiscale_test:
+ assert isinstance(aug_scales, list)
+ assert is_list_of(inputs, Tensor)
+ # `inputs` includes images in original and augmented scales
+ assert len(inputs) == len(aug_scales) + 1
+ else:
+ assert isinstance(inputs, Tensor)
+ # single-scale test
+ inputs = [inputs]
+
+ feats = []
+ for _inputs in inputs:
+ if flip_test:
+ _feats_orig = self.extract_feat(_inputs)
+ _feats_flip = self.extract_feat(_inputs.flip(-1))
+ _feats = [_feats_orig, _feats_flip]
+ else:
+ _feats = self.extract_feat(_inputs)
+
+ feats.append(_feats)
+
+ if not multiscale_test:
+ feats = feats[0]
+
+ preds = self.head.predict(feats, data_samples, test_cfg=self.test_cfg)
+
+ if isinstance(preds, tuple):
+ batch_pred_instances, batch_pred_fields = preds
+ else:
+ batch_pred_instances = preds
+ batch_pred_fields = None
+
+ results = self.add_pred_to_datasample(batch_pred_instances,
+ batch_pred_fields, data_samples)
+
+ return results
+
+ def add_pred_to_datasample(self, batch_pred_instances: InstanceList,
+ batch_pred_fields: Optional[PixelDataList],
+ batch_data_samples: SampleList) -> SampleList:
+ """Add predictions into data samples.
+
+ Args:
+ batch_pred_instances (List[InstanceData]): The predicted instances
+ of the input data batch
+ batch_pred_fields (List[PixelData], optional): The predicted
+ fields (e.g. heatmaps) of the input batch
+ batch_data_samples (List[PoseDataSample]): The input data batch
+
+ Returns:
+ List[PoseDataSample]: A list of data samples where the predictions
+ are stored in the ``pred_instances`` field of each data sample.
+ The length of the list is the batch size when ``merge==False``, or
+ 1 when ``merge==True``.
+ """
+ assert len(batch_pred_instances) == len(batch_data_samples)
+ if batch_pred_fields is None:
+ batch_pred_fields = []
+
+ for pred_instances, pred_fields, data_sample in zip_longest(
+ batch_pred_instances, batch_pred_fields, batch_data_samples):
+
+ # convert keypoint coordinates from input space to image space
+ input_size = data_sample.metainfo['input_size']
+ input_center = data_sample.metainfo['input_center']
+ input_scale = data_sample.metainfo['input_scale']
+
+ pred_instances.keypoints = pred_instances.keypoints / input_size \
+ * input_scale + input_center - 0.5 * input_scale
+
+ data_sample.pred_instances = pred_instances
+
+ if pred_fields is not None:
+ data_sample.pred_fields = pred_fields
+
+ return batch_data_samples
diff --git a/mmpose/models/pose_estimators/pose_lifter.py b/mmpose/models/pose_estimators/pose_lifter.py
index 5bad3dde3c..5069b8736a 100644
--- a/mmpose/models/pose_estimators/pose_lifter.py
+++ b/mmpose/models/pose_estimators/pose_lifter.py
@@ -1,340 +1,340 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from itertools import zip_longest
-from typing import Tuple, Union
-
-from torch import Tensor
-
-from mmpose.models.utils import check_and_update_config
-from mmpose.registry import MODELS
-from mmpose.utils.typing import (ConfigType, InstanceList, OptConfigType,
- Optional, OptMultiConfig, OptSampleList,
- PixelDataList, SampleList)
-from .base import BasePoseEstimator
-
-
-@MODELS.register_module()
-class PoseLifter(BasePoseEstimator):
- """Base class for pose lifter.
-
- Args:
- backbone (dict): The backbone config
- neck (dict, optional): The neck config. Defaults to ``None``
- head (dict, optional): The head config. Defaults to ``None``
- traj_backbone (dict, optional): The backbone config for trajectory
- model. Defaults to ``None``
- traj_neck (dict, optional): The neck config for trajectory model.
- Defaults to ``None``
- traj_head (dict, optional): The head config for trajectory model.
- Defaults to ``None``
- semi_loss (dict, optional): The semi-supervised loss config.
- Defaults to ``None``
- train_cfg (dict, optional): The runtime config for training process.
- Defaults to ``None``
- test_cfg (dict, optional): The runtime config for testing process.
- Defaults to ``None``
- data_preprocessor (dict, optional): The data preprocessing config to
- build the instance of :class:`BaseDataPreprocessor`. Defaults to
- ``None``
- init_cfg (dict, optional): The config to control the initialization.
- Defaults to ``None``
- metainfo (dict): Meta information for dataset, such as keypoints
- definition and properties. If set, the metainfo of the input data
- batch will be overridden. For more details, please refer to
- https://mmpose.readthedocs.io/en/latest/user_guides/
- prepare_datasets.html#create-a-custom-dataset-info-
- config-file-for-the-dataset. Defaults to ``None``
- """
-
- def __init__(self,
- backbone: ConfigType,
- neck: OptConfigType = None,
- head: OptConfigType = None,
- traj_backbone: OptConfigType = None,
- traj_neck: OptConfigType = None,
- traj_head: OptConfigType = None,
- semi_loss: OptConfigType = None,
- train_cfg: OptConfigType = None,
- test_cfg: OptConfigType = None,
- data_preprocessor: OptConfigType = None,
- init_cfg: OptMultiConfig = None,
- metainfo: Optional[dict] = None):
- super().__init__(
- backbone=backbone,
- neck=neck,
- head=head,
- train_cfg=train_cfg,
- test_cfg=test_cfg,
- data_preprocessor=data_preprocessor,
- init_cfg=init_cfg,
- metainfo=metainfo)
-
- # trajectory model
- self.share_backbone = False
- if traj_head is not None:
- if traj_backbone is not None:
- self.traj_backbone = MODELS.build(traj_backbone)
- else:
- self.share_backbone = True
-
- # the PR #2108 and #2126 modified the interface of neck and head.
- # The following function automatically detects outdated
- # configurations and updates them accordingly, while also providing
- # clear and concise information on the changes made.
- traj_neck, traj_head = check_and_update_config(
- traj_neck, traj_head)
-
- if traj_neck is not None:
- self.traj_neck = MODELS.build(traj_neck)
-
- self.traj_head = MODELS.build(traj_head)
-
- # semi-supervised loss
- self.semi_supervised = semi_loss is not None
- if self.semi_supervised:
- assert any([head, traj_head])
- self.semi_loss = MODELS.build(semi_loss)
-
- @property
- def with_traj_backbone(self):
- """bool: Whether the pose lifter has trajectory backbone."""
- return hasattr(self, 'traj_backbone') and \
- self.traj_backbone is not None
-
- @property
- def with_traj_neck(self):
- """bool: Whether the pose lifter has trajectory neck."""
- return hasattr(self, 'traj_neck') and self.traj_neck is not None
-
- @property
- def with_traj(self):
- """bool: Whether the pose lifter has trajectory head."""
- return hasattr(self, 'traj_head')
-
- @property
- def causal(self):
- """bool: Whether the pose lifter is causal."""
- if hasattr(self.backbone, 'causal'):
- return self.backbone.causal
- else:
- raise AttributeError('A PoseLifter\'s backbone should have '
- 'the bool attribute "causal" to indicate if'
- 'it performs causal inference.')
-
- def extract_feat(self, inputs: Tensor) -> Tuple[Tensor]:
- """Extract features.
-
- Args:
- inputs (Tensor): Image tensor with shape (N, K, C, T).
-
- Returns:
- tuple[Tensor]: Multi-level features that may have various
- resolutions.
- """
- # supervised learning
- # pose model
- feats = self.backbone(inputs)
- if self.with_neck:
- feats = self.neck(feats)
-
- # trajectory model
- if self.with_traj:
- if self.share_backbone:
- traj_x = feats
- else:
- traj_x = self.traj_backbone(inputs)
-
- if self.with_traj_neck:
- traj_x = self.traj_neck(traj_x)
- return feats, traj_x
- else:
- return feats
-
- def _forward(self,
- inputs: Tensor,
- data_samples: OptSampleList = None
- ) -> Union[Tensor, Tuple[Tensor]]:
- """Network forward process. Usually includes backbone, neck and head
- forward without any post-processing.
-
- Args:
- inputs (Tensor): Inputs with shape (N, K, C, T).
-
- Returns:
- Union[Tensor | Tuple[Tensor]]: forward output of the network.
- """
- feats = self.extract_feat(inputs)
-
- if self.with_traj:
- # forward with trajectory model
- x, traj_x = feats
- if self.with_head:
- x = self.head.forward(x)
-
- traj_x = self.traj_head.forward(traj_x)
- return x, traj_x
- else:
- # forward without trajectory model
- x = feats
- if self.with_head:
- x = self.head.forward(x)
- return x
-
- def loss(self, inputs: Tensor, data_samples: SampleList) -> dict:
- """Calculate losses from a batch of inputs and data samples.
-
- Args:
- inputs (Tensor): Inputs with shape (N, K, C, T).
- data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples.
-
- Returns:
- dict: A dictionary of losses.
- """
- feats = self.extract_feat(inputs)
-
- losses = {}
-
- if self.with_traj:
- x, traj_x = feats
- # loss of trajectory model
- losses.update(
- self.traj_head.loss(
- traj_x, data_samples, train_cfg=self.train_cfg))
- else:
- x = feats
-
- if self.with_head:
- # loss of pose model
- losses.update(
- self.head.loss(x, data_samples, train_cfg=self.train_cfg))
-
- # TODO: support semi-supervised learning
- if self.semi_supervised:
- losses.update(semi_loss=self.semi_loss(inputs, data_samples))
-
- return losses
-
- def predict(self, inputs: Tensor, data_samples: SampleList) -> SampleList:
- """Predict results from a batch of inputs and data samples with post-
- processing.
-
- Note:
- - batch_size: B
- - num_input_keypoints: K
- - input_keypoint_dim: C
- - input_sequence_len: T
-
- Args:
- inputs (Tensor): Inputs with shape like (B, K, C, T).
- data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples
-
- Returns:
- list[:obj:`PoseDataSample`]: The pose estimation results of the
- input images. The return value is `PoseDataSample` instances with
- ``pred_instances`` and ``pred_fields``(optional) field , and
- ``pred_instances`` usually contains the following keys:
-
- - keypoints (Tensor): predicted keypoint coordinates in shape
- (num_instances, K, D) where K is the keypoint number and D
- is the keypoint dimension
- - keypoint_scores (Tensor): predicted keypoint scores in shape
- (num_instances, K)
- """
- assert self.with_head, (
- 'The model must have head to perform prediction.')
-
- feats = self.extract_feat(inputs)
-
- pose_preds, batch_pred_instances, batch_pred_fields = None, None, None
- traj_preds, batch_traj_instances, batch_traj_fields = None, None, None
- if self.with_traj:
- x, traj_x = feats
- traj_preds = self.traj_head.predict(
- traj_x, data_samples, test_cfg=self.test_cfg)
- else:
- x = feats
-
- if self.with_head:
- pose_preds = self.head.predict(
- x, data_samples, test_cfg=self.test_cfg)
-
- if isinstance(pose_preds, tuple):
- batch_pred_instances, batch_pred_fields = pose_preds
- else:
- batch_pred_instances = pose_preds
-
- if isinstance(traj_preds, tuple):
- batch_traj_instances, batch_traj_fields = traj_preds
- else:
- batch_traj_instances = traj_preds
-
- results = self.add_pred_to_datasample(batch_pred_instances,
- batch_pred_fields,
- batch_traj_instances,
- batch_traj_fields, data_samples)
-
- return results
-
- def add_pred_to_datasample(
- self,
- batch_pred_instances: InstanceList,
- batch_pred_fields: Optional[PixelDataList],
- batch_traj_instances: InstanceList,
- batch_traj_fields: Optional[PixelDataList],
- batch_data_samples: SampleList,
- ) -> SampleList:
- """Add predictions into data samples.
-
- Args:
- batch_pred_instances (List[InstanceData]): The predicted instances
- of the input data batch
- batch_pred_fields (List[PixelData], optional): The predicted
- fields (e.g. heatmaps) of the input batch
- batch_traj_instances (List[InstanceData]): The predicted instances
- of the input data batch
- batch_traj_fields (List[PixelData], optional): The predicted
- fields (e.g. heatmaps) of the input batch
- batch_data_samples (List[PoseDataSample]): The input data batch
-
- Returns:
- List[PoseDataSample]: A list of data samples where the predictions
- are stored in the ``pred_instances`` field of each data sample.
- """
- assert len(batch_pred_instances) == len(batch_data_samples)
- if batch_pred_fields is None:
- batch_pred_fields, batch_traj_fields = [], []
- if batch_traj_instances is None:
- batch_traj_instances = []
- output_keypoint_indices = self.test_cfg.get('output_keypoint_indices',
- None)
-
- for (pred_instances, pred_fields, traj_instances, traj_fields,
- data_sample) in zip_longest(batch_pred_instances,
- batch_pred_fields,
- batch_traj_instances,
- batch_traj_fields,
- batch_data_samples):
-
- if output_keypoint_indices is not None:
- # select output keypoints with given indices
- num_keypoints = pred_instances.keypoints.shape[1]
- for key, value in pred_instances.all_items():
- if key.startswith('keypoint'):
- pred_instances.set_field(
- value[:, output_keypoint_indices], key)
-
- data_sample.pred_instances = pred_instances
-
- if pred_fields is not None:
- if output_keypoint_indices is not None:
- # select output heatmap channels with keypoint indices
- # when the number of heatmap channel matches num_keypoints
- for key, value in pred_fields.all_items():
- if value.shape[0] != num_keypoints:
- continue
- pred_fields.set_field(value[output_keypoint_indices],
- key)
- data_sample.pred_fields = pred_fields
-
- return batch_data_samples
+# Copyright (c) OpenMMLab. All rights reserved.
+from itertools import zip_longest
+from typing import Tuple, Union
+
+from torch import Tensor
+
+from mmpose.models.utils import check_and_update_config
+from mmpose.registry import MODELS
+from mmpose.utils.typing import (ConfigType, InstanceList, OptConfigType,
+ Optional, OptMultiConfig, OptSampleList,
+ PixelDataList, SampleList)
+from .base import BasePoseEstimator
+
+
+@MODELS.register_module()
+class PoseLifter(BasePoseEstimator):
+ """Base class for pose lifter.
+
+ Args:
+ backbone (dict): The backbone config
+ neck (dict, optional): The neck config. Defaults to ``None``
+ head (dict, optional): The head config. Defaults to ``None``
+ traj_backbone (dict, optional): The backbone config for trajectory
+ model. Defaults to ``None``
+ traj_neck (dict, optional): The neck config for trajectory model.
+ Defaults to ``None``
+ traj_head (dict, optional): The head config for trajectory model.
+ Defaults to ``None``
+ semi_loss (dict, optional): The semi-supervised loss config.
+ Defaults to ``None``
+ train_cfg (dict, optional): The runtime config for training process.
+ Defaults to ``None``
+ test_cfg (dict, optional): The runtime config for testing process.
+ Defaults to ``None``
+ data_preprocessor (dict, optional): The data preprocessing config to
+ build the instance of :class:`BaseDataPreprocessor`. Defaults to
+ ``None``
+ init_cfg (dict, optional): The config to control the initialization.
+ Defaults to ``None``
+ metainfo (dict): Meta information for dataset, such as keypoints
+ definition and properties. If set, the metainfo of the input data
+ batch will be overridden. For more details, please refer to
+ https://mmpose.readthedocs.io/en/latest/user_guides/
+ prepare_datasets.html#create-a-custom-dataset-info-
+ config-file-for-the-dataset. Defaults to ``None``
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: OptConfigType = None,
+ head: OptConfigType = None,
+ traj_backbone: OptConfigType = None,
+ traj_neck: OptConfigType = None,
+ traj_head: OptConfigType = None,
+ semi_loss: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None,
+ metainfo: Optional[dict] = None):
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ head=head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg,
+ metainfo=metainfo)
+
+ # trajectory model
+ self.share_backbone = False
+ if traj_head is not None:
+ if traj_backbone is not None:
+ self.traj_backbone = MODELS.build(traj_backbone)
+ else:
+ self.share_backbone = True
+
+ # the PR #2108 and #2126 modified the interface of neck and head.
+ # The following function automatically detects outdated
+ # configurations and updates them accordingly, while also providing
+ # clear and concise information on the changes made.
+ traj_neck, traj_head = check_and_update_config(
+ traj_neck, traj_head)
+
+ if traj_neck is not None:
+ self.traj_neck = MODELS.build(traj_neck)
+
+ self.traj_head = MODELS.build(traj_head)
+
+ # semi-supervised loss
+ self.semi_supervised = semi_loss is not None
+ if self.semi_supervised:
+ assert any([head, traj_head])
+ self.semi_loss = MODELS.build(semi_loss)
+
+ @property
+ def with_traj_backbone(self):
+ """bool: Whether the pose lifter has trajectory backbone."""
+ return hasattr(self, 'traj_backbone') and \
+ self.traj_backbone is not None
+
+ @property
+ def with_traj_neck(self):
+ """bool: Whether the pose lifter has trajectory neck."""
+ return hasattr(self, 'traj_neck') and self.traj_neck is not None
+
+ @property
+ def with_traj(self):
+ """bool: Whether the pose lifter has trajectory head."""
+ return hasattr(self, 'traj_head')
+
+ @property
+ def causal(self):
+ """bool: Whether the pose lifter is causal."""
+ if hasattr(self.backbone, 'causal'):
+ return self.backbone.causal
+ else:
+ raise AttributeError('A PoseLifter\'s backbone should have '
+ 'the bool attribute "causal" to indicate if'
+ 'it performs causal inference.')
+
+ def extract_feat(self, inputs: Tensor) -> Tuple[Tensor]:
+ """Extract features.
+
+ Args:
+ inputs (Tensor): Image tensor with shape (N, K, C, T).
+
+ Returns:
+ tuple[Tensor]: Multi-level features that may have various
+ resolutions.
+ """
+ # supervised learning
+ # pose model
+ feats = self.backbone(inputs)
+ if self.with_neck:
+ feats = self.neck(feats)
+
+ # trajectory model
+ if self.with_traj:
+ if self.share_backbone:
+ traj_x = feats
+ else:
+ traj_x = self.traj_backbone(inputs)
+
+ if self.with_traj_neck:
+ traj_x = self.traj_neck(traj_x)
+ return feats, traj_x
+ else:
+ return feats
+
+ def _forward(self,
+ inputs: Tensor,
+ data_samples: OptSampleList = None
+ ) -> Union[Tensor, Tuple[Tensor]]:
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ inputs (Tensor): Inputs with shape (N, K, C, T).
+
+ Returns:
+ Union[Tensor | Tuple[Tensor]]: forward output of the network.
+ """
+ feats = self.extract_feat(inputs)
+
+ if self.with_traj:
+ # forward with trajectory model
+ x, traj_x = feats
+ if self.with_head:
+ x = self.head.forward(x)
+
+ traj_x = self.traj_head.forward(traj_x)
+ return x, traj_x
+ else:
+ # forward without trajectory model
+ x = feats
+ if self.with_head:
+ x = self.head.forward(x)
+ return x
+
+ def loss(self, inputs: Tensor, data_samples: SampleList) -> dict:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ inputs (Tensor): Inputs with shape (N, K, C, T).
+ data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples.
+
+ Returns:
+ dict: A dictionary of losses.
+ """
+ feats = self.extract_feat(inputs)
+
+ losses = {}
+
+ if self.with_traj:
+ x, traj_x = feats
+ # loss of trajectory model
+ losses.update(
+ self.traj_head.loss(
+ traj_x, data_samples, train_cfg=self.train_cfg))
+ else:
+ x = feats
+
+ if self.with_head:
+ # loss of pose model
+ losses.update(
+ self.head.loss(x, data_samples, train_cfg=self.train_cfg))
+
+ # TODO: support semi-supervised learning
+ if self.semi_supervised:
+ losses.update(semi_loss=self.semi_loss(inputs, data_samples))
+
+ return losses
+
+ def predict(self, inputs: Tensor, data_samples: SampleList) -> SampleList:
+ """Predict results from a batch of inputs and data samples with post-
+ processing.
+
+ Note:
+ - batch_size: B
+ - num_input_keypoints: K
+ - input_keypoint_dim: C
+ - input_sequence_len: T
+
+ Args:
+ inputs (Tensor): Inputs with shape like (B, K, C, T).
+ data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+
+ Returns:
+ list[:obj:`PoseDataSample`]: The pose estimation results of the
+ input images. The return value is `PoseDataSample` instances with
+ ``pred_instances`` and ``pred_fields``(optional) field , and
+ ``pred_instances`` usually contains the following keys:
+
+ - keypoints (Tensor): predicted keypoint coordinates in shape
+ (num_instances, K, D) where K is the keypoint number and D
+ is the keypoint dimension
+ - keypoint_scores (Tensor): predicted keypoint scores in shape
+ (num_instances, K)
+ """
+ assert self.with_head, (
+ 'The model must have head to perform prediction.')
+
+ feats = self.extract_feat(inputs)
+
+ pose_preds, batch_pred_instances, batch_pred_fields = None, None, None
+ traj_preds, batch_traj_instances, batch_traj_fields = None, None, None
+ if self.with_traj:
+ x, traj_x = feats
+ traj_preds = self.traj_head.predict(
+ traj_x, data_samples, test_cfg=self.test_cfg)
+ else:
+ x = feats
+
+ if self.with_head:
+ pose_preds = self.head.predict(
+ x, data_samples, test_cfg=self.test_cfg)
+
+ if isinstance(pose_preds, tuple):
+ batch_pred_instances, batch_pred_fields = pose_preds
+ else:
+ batch_pred_instances = pose_preds
+
+ if isinstance(traj_preds, tuple):
+ batch_traj_instances, batch_traj_fields = traj_preds
+ else:
+ batch_traj_instances = traj_preds
+
+ results = self.add_pred_to_datasample(batch_pred_instances,
+ batch_pred_fields,
+ batch_traj_instances,
+ batch_traj_fields, data_samples)
+
+ return results
+
+ def add_pred_to_datasample(
+ self,
+ batch_pred_instances: InstanceList,
+ batch_pred_fields: Optional[PixelDataList],
+ batch_traj_instances: InstanceList,
+ batch_traj_fields: Optional[PixelDataList],
+ batch_data_samples: SampleList,
+ ) -> SampleList:
+ """Add predictions into data samples.
+
+ Args:
+ batch_pred_instances (List[InstanceData]): The predicted instances
+ of the input data batch
+ batch_pred_fields (List[PixelData], optional): The predicted
+ fields (e.g. heatmaps) of the input batch
+ batch_traj_instances (List[InstanceData]): The predicted instances
+ of the input data batch
+ batch_traj_fields (List[PixelData], optional): The predicted
+ fields (e.g. heatmaps) of the input batch
+ batch_data_samples (List[PoseDataSample]): The input data batch
+
+ Returns:
+ List[PoseDataSample]: A list of data samples where the predictions
+ are stored in the ``pred_instances`` field of each data sample.
+ """
+ assert len(batch_pred_instances) == len(batch_data_samples)
+ if batch_pred_fields is None:
+ batch_pred_fields, batch_traj_fields = [], []
+ if batch_traj_instances is None:
+ batch_traj_instances = []
+ output_keypoint_indices = self.test_cfg.get('output_keypoint_indices',
+ None)
+
+ for (pred_instances, pred_fields, traj_instances, traj_fields,
+ data_sample) in zip_longest(batch_pred_instances,
+ batch_pred_fields,
+ batch_traj_instances,
+ batch_traj_fields,
+ batch_data_samples):
+
+ if output_keypoint_indices is not None:
+ # select output keypoints with given indices
+ num_keypoints = pred_instances.keypoints.shape[1]
+ for key, value in pred_instances.all_items():
+ if key.startswith('keypoint'):
+ pred_instances.set_field(
+ value[:, output_keypoint_indices], key)
+
+ data_sample.pred_instances = pred_instances
+
+ if pred_fields is not None:
+ if output_keypoint_indices is not None:
+ # select output heatmap channels with keypoint indices
+ # when the number of heatmap channel matches num_keypoints
+ for key, value in pred_fields.all_items():
+ if value.shape[0] != num_keypoints:
+ continue
+ pred_fields.set_field(value[output_keypoint_indices],
+ key)
+ data_sample.pred_fields = pred_fields
+
+ return batch_data_samples
diff --git a/mmpose/models/pose_estimators/topdown.py b/mmpose/models/pose_estimators/topdown.py
index 89b332893f..2ceb79fcb8 100644
--- a/mmpose/models/pose_estimators/topdown.py
+++ b/mmpose/models/pose_estimators/topdown.py
@@ -1,182 +1,182 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from itertools import zip_longest
-from typing import Optional
-
-from torch import Tensor
-
-from mmpose.registry import MODELS
-from mmpose.utils.typing import (ConfigType, InstanceList, OptConfigType,
- OptMultiConfig, PixelDataList, SampleList)
-from .base import BasePoseEstimator
-
-
-@MODELS.register_module()
-class TopdownPoseEstimator(BasePoseEstimator):
- """Base class for top-down pose estimators.
-
- Args:
- backbone (dict): The backbone config
- neck (dict, optional): The neck config. Defaults to ``None``
- head (dict, optional): The head config. Defaults to ``None``
- train_cfg (dict, optional): The runtime config for training process.
- Defaults to ``None``
- test_cfg (dict, optional): The runtime config for testing process.
- Defaults to ``None``
- data_preprocessor (dict, optional): The data preprocessing config to
- build the instance of :class:`BaseDataPreprocessor`. Defaults to
- ``None``
- init_cfg (dict, optional): The config to control the initialization.
- Defaults to ``None``
- metainfo (dict): Meta information for dataset, such as keypoints
- definition and properties. If set, the metainfo of the input data
- batch will be overridden. For more details, please refer to
- https://mmpose.readthedocs.io/en/latest/user_guides/
- prepare_datasets.html#create-a-custom-dataset-info-
- config-file-for-the-dataset. Defaults to ``None``
- """
-
- def __init__(self,
- backbone: ConfigType,
- neck: OptConfigType = None,
- head: OptConfigType = None,
- train_cfg: OptConfigType = None,
- test_cfg: OptConfigType = None,
- data_preprocessor: OptConfigType = None,
- init_cfg: OptMultiConfig = None,
- metainfo: Optional[dict] = None):
- super().__init__(
- backbone=backbone,
- neck=neck,
- head=head,
- train_cfg=train_cfg,
- test_cfg=test_cfg,
- data_preprocessor=data_preprocessor,
- init_cfg=init_cfg,
- metainfo=metainfo)
-
- def loss(self, inputs: Tensor, data_samples: SampleList) -> dict:
- """Calculate losses from a batch of inputs and data samples.
-
- Args:
- inputs (Tensor): Inputs with shape (N, C, H, W).
- data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples.
-
- Returns:
- dict: A dictionary of losses.
- """
- feats = self.extract_feat(inputs)
-
- losses = dict()
-
- if self.with_head:
- losses.update(
- self.head.loss(feats, data_samples, train_cfg=self.train_cfg))
-
- return losses
-
- def predict(self, inputs: Tensor, data_samples: SampleList) -> SampleList:
- """Predict results from a batch of inputs and data samples with post-
- processing.
-
- Args:
- inputs (Tensor): Inputs with shape (N, C, H, W)
- data_samples (List[:obj:`PoseDataSample`]): The batch
- data samples
-
- Returns:
- list[:obj:`PoseDataSample`]: The pose estimation results of the
- input images. The return value is `PoseDataSample` instances with
- ``pred_instances`` and ``pred_fields``(optional) field , and
- ``pred_instances`` usually contains the following keys:
-
- - keypoints (Tensor): predicted keypoint coordinates in shape
- (num_instances, K, D) where K is the keypoint number and D
- is the keypoint dimension
- - keypoint_scores (Tensor): predicted keypoint scores in shape
- (num_instances, K)
- """
- assert self.with_head, (
- 'The model must have head to perform prediction.')
-
- if self.test_cfg.get('flip_test', False):
- _feats = self.extract_feat(inputs)
- _feats_flip = self.extract_feat(inputs.flip(-1))
- feats = [_feats, _feats_flip]
- else:
- feats = self.extract_feat(inputs)
-
- preds = self.head.predict(feats, data_samples, test_cfg=self.test_cfg)
-
- if isinstance(preds, tuple):
- batch_pred_instances, batch_pred_fields = preds
- else:
- batch_pred_instances = preds
- batch_pred_fields = None
-
- results = self.add_pred_to_datasample(batch_pred_instances,
- batch_pred_fields, data_samples)
-
- return results
-
- def add_pred_to_datasample(self, batch_pred_instances: InstanceList,
- batch_pred_fields: Optional[PixelDataList],
- batch_data_samples: SampleList) -> SampleList:
- """Add predictions into data samples.
-
- Args:
- batch_pred_instances (List[InstanceData]): The predicted instances
- of the input data batch
- batch_pred_fields (List[PixelData], optional): The predicted
- fields (e.g. heatmaps) of the input batch
- batch_data_samples (List[PoseDataSample]): The input data batch
-
- Returns:
- List[PoseDataSample]: A list of data samples where the predictions
- are stored in the ``pred_instances`` field of each data sample.
- """
- assert len(batch_pred_instances) == len(batch_data_samples)
- if batch_pred_fields is None:
- batch_pred_fields = []
- output_keypoint_indices = self.test_cfg.get('output_keypoint_indices',
- None)
-
- for pred_instances, pred_fields, data_sample in zip_longest(
- batch_pred_instances, batch_pred_fields, batch_data_samples):
-
- gt_instances = data_sample.gt_instances
-
- # convert keypoint coordinates from input space to image space
- bbox_centers = gt_instances.bbox_centers
- bbox_scales = gt_instances.bbox_scales
- input_size = data_sample.metainfo['input_size']
-
- pred_instances.keypoints = pred_instances.keypoints / input_size \
- * bbox_scales + bbox_centers - 0.5 * bbox_scales
-
- if output_keypoint_indices is not None:
- # select output keypoints with given indices
- num_keypoints = pred_instances.keypoints.shape[1]
- for key, value in pred_instances.all_items():
- if key.startswith('keypoint'):
- pred_instances.set_field(
- value[:, output_keypoint_indices], key)
-
- # add bbox information into pred_instances
- pred_instances.bboxes = gt_instances.bboxes
- pred_instances.bbox_scores = gt_instances.bbox_scores
-
- data_sample.pred_instances = pred_instances
-
- if pred_fields is not None:
- if output_keypoint_indices is not None:
- # select output heatmap channels with keypoint indices
- # when the number of heatmap channel matches num_keypoints
- for key, value in pred_fields.all_items():
- if value.shape[0] != num_keypoints:
- continue
- pred_fields.set_field(value[output_keypoint_indices],
- key)
- data_sample.pred_fields = pred_fields
-
- return batch_data_samples
+# Copyright (c) OpenMMLab. All rights reserved.
+from itertools import zip_longest
+from typing import Optional
+
+from torch import Tensor
+
+from mmpose.registry import MODELS
+from mmpose.utils.typing import (ConfigType, InstanceList, OptConfigType,
+ OptMultiConfig, PixelDataList, SampleList)
+from .base import BasePoseEstimator
+
+
+@MODELS.register_module()
+class TopdownPoseEstimator(BasePoseEstimator):
+ """Base class for top-down pose estimators.
+
+ Args:
+ backbone (dict): The backbone config
+ neck (dict, optional): The neck config. Defaults to ``None``
+ head (dict, optional): The head config. Defaults to ``None``
+ train_cfg (dict, optional): The runtime config for training process.
+ Defaults to ``None``
+ test_cfg (dict, optional): The runtime config for testing process.
+ Defaults to ``None``
+ data_preprocessor (dict, optional): The data preprocessing config to
+ build the instance of :class:`BaseDataPreprocessor`. Defaults to
+ ``None``
+ init_cfg (dict, optional): The config to control the initialization.
+ Defaults to ``None``
+ metainfo (dict): Meta information for dataset, such as keypoints
+ definition and properties. If set, the metainfo of the input data
+ batch will be overridden. For more details, please refer to
+ https://mmpose.readthedocs.io/en/latest/user_guides/
+ prepare_datasets.html#create-a-custom-dataset-info-
+ config-file-for-the-dataset. Defaults to ``None``
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: OptConfigType = None,
+ head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None,
+ metainfo: Optional[dict] = None):
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ head=head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg,
+ metainfo=metainfo)
+
+ def loss(self, inputs: Tensor, data_samples: SampleList) -> dict:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ inputs (Tensor): Inputs with shape (N, C, H, W).
+ data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples.
+
+ Returns:
+ dict: A dictionary of losses.
+ """
+ feats = self.extract_feat(inputs)
+
+ losses = dict()
+
+ if self.with_head:
+ losses.update(
+ self.head.loss(feats, data_samples, train_cfg=self.train_cfg))
+
+ return losses
+
+ def predict(self, inputs: Tensor, data_samples: SampleList) -> SampleList:
+ """Predict results from a batch of inputs and data samples with post-
+ processing.
+
+ Args:
+ inputs (Tensor): Inputs with shape (N, C, H, W)
+ data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+
+ Returns:
+ list[:obj:`PoseDataSample`]: The pose estimation results of the
+ input images. The return value is `PoseDataSample` instances with
+ ``pred_instances`` and ``pred_fields``(optional) field , and
+ ``pred_instances`` usually contains the following keys:
+
+ - keypoints (Tensor): predicted keypoint coordinates in shape
+ (num_instances, K, D) where K is the keypoint number and D
+ is the keypoint dimension
+ - keypoint_scores (Tensor): predicted keypoint scores in shape
+ (num_instances, K)
+ """
+ assert self.with_head, (
+ 'The model must have head to perform prediction.')
+
+ if self.test_cfg.get('flip_test', False):
+ _feats = self.extract_feat(inputs)
+ _feats_flip = self.extract_feat(inputs.flip(-1))
+ feats = [_feats, _feats_flip]
+ else:
+ feats = self.extract_feat(inputs)
+
+ preds = self.head.predict(feats, data_samples, test_cfg=self.test_cfg)
+
+ if isinstance(preds, tuple):
+ batch_pred_instances, batch_pred_fields = preds
+ else:
+ batch_pred_instances = preds
+ batch_pred_fields = None
+
+ results = self.add_pred_to_datasample(batch_pred_instances,
+ batch_pred_fields, data_samples)
+
+ return results
+
+ def add_pred_to_datasample(self, batch_pred_instances: InstanceList,
+ batch_pred_fields: Optional[PixelDataList],
+ batch_data_samples: SampleList) -> SampleList:
+ """Add predictions into data samples.
+
+ Args:
+ batch_pred_instances (List[InstanceData]): The predicted instances
+ of the input data batch
+ batch_pred_fields (List[PixelData], optional): The predicted
+ fields (e.g. heatmaps) of the input batch
+ batch_data_samples (List[PoseDataSample]): The input data batch
+
+ Returns:
+ List[PoseDataSample]: A list of data samples where the predictions
+ are stored in the ``pred_instances`` field of each data sample.
+ """
+ assert len(batch_pred_instances) == len(batch_data_samples)
+ if batch_pred_fields is None:
+ batch_pred_fields = []
+ output_keypoint_indices = self.test_cfg.get('output_keypoint_indices',
+ None)
+
+ for pred_instances, pred_fields, data_sample in zip_longest(
+ batch_pred_instances, batch_pred_fields, batch_data_samples):
+
+ gt_instances = data_sample.gt_instances
+
+ # convert keypoint coordinates from input space to image space
+ bbox_centers = gt_instances.bbox_centers
+ bbox_scales = gt_instances.bbox_scales
+ input_size = data_sample.metainfo['input_size']
+
+ pred_instances.keypoints = pred_instances.keypoints / input_size \
+ * bbox_scales + bbox_centers - 0.5 * bbox_scales
+
+ if output_keypoint_indices is not None:
+ # select output keypoints with given indices
+ num_keypoints = pred_instances.keypoints.shape[1]
+ for key, value in pred_instances.all_items():
+ if key.startswith('keypoint'):
+ pred_instances.set_field(
+ value[:, output_keypoint_indices], key)
+
+ # add bbox information into pred_instances
+ pred_instances.bboxes = gt_instances.bboxes
+ pred_instances.bbox_scores = gt_instances.bbox_scores
+
+ data_sample.pred_instances = pred_instances
+
+ if pred_fields is not None:
+ if output_keypoint_indices is not None:
+ # select output heatmap channels with keypoint indices
+ # when the number of heatmap channel matches num_keypoints
+ for key, value in pred_fields.all_items():
+ if value.shape[0] != num_keypoints:
+ continue
+ pred_fields.set_field(value[output_keypoint_indices],
+ key)
+ data_sample.pred_fields = pred_fields
+
+ return batch_data_samples
diff --git a/mmpose/models/utils/__init__.py b/mmpose/models/utils/__init__.py
index 22d8a89b41..5d03bafa4c 100644
--- a/mmpose/models/utils/__init__.py
+++ b/mmpose/models/utils/__init__.py
@@ -1,10 +1,10 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .check_and_update_config import check_and_update_config
-from .ckpt_convert import pvt_convert
-from .rtmcc_block import RTMCCBlock, rope
-from .transformer import PatchEmbed, nchw_to_nlc, nlc_to_nchw
-
-__all__ = [
- 'PatchEmbed', 'nchw_to_nlc', 'nlc_to_nchw', 'pvt_convert', 'RTMCCBlock',
- 'rope', 'check_and_update_config'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .check_and_update_config import check_and_update_config
+from .ckpt_convert import pvt_convert
+from .rtmcc_block import RTMCCBlock, rope
+from .transformer import PatchEmbed, nchw_to_nlc, nlc_to_nchw
+
+__all__ = [
+ 'PatchEmbed', 'nchw_to_nlc', 'nlc_to_nchw', 'pvt_convert', 'RTMCCBlock',
+ 'rope', 'check_and_update_config'
+]
diff --git a/mmpose/models/utils/check_and_update_config.py b/mmpose/models/utils/check_and_update_config.py
index 4cd1efa39b..3156151948 100644
--- a/mmpose/models/utils/check_and_update_config.py
+++ b/mmpose/models/utils/check_and_update_config.py
@@ -1,230 +1,230 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Dict, Optional, Tuple, Union
-
-from mmengine.config import Config, ConfigDict
-from mmengine.dist import master_only
-from mmengine.logging import MMLogger
-
-ConfigType = Union[Config, ConfigDict]
-
-
-def process_input_transform(input_transform: str, head: Dict, head_new: Dict,
- head_deleted_dict: Dict, head_append_dict: Dict,
- neck_new: Dict, input_index: Tuple[int],
- align_corners: bool) -> None:
- """Process the input_transform field and update head and neck
- dictionaries."""
- if input_transform == 'resize_concat':
- in_channels = head_new.pop('in_channels')
- head_deleted_dict['in_channels'] = str(in_channels)
- in_channels = sum([in_channels[i] for i in input_index])
- head_new['in_channels'] = in_channels
- head_append_dict['in_channels'] = str(in_channels)
-
- neck_new.update(
- dict(
- type='FeatureMapProcessor',
- concat=True,
- select_index=input_index,
- ))
- if align_corners:
- neck_new['align_corners'] = align_corners
-
- elif input_transform == 'select':
- if input_index != (-1, ):
- neck_new.update(
- dict(type='FeatureMapProcessor', select_index=input_index))
- if isinstance(head['in_channels'], tuple):
- in_channels = head_new.pop('in_channels')
- head_deleted_dict['in_channels'] = str(in_channels)
- if isinstance(input_index, int):
- in_channels = in_channels[input_index]
- else:
- in_channels = tuple([in_channels[i] for i in input_index])
- head_new['in_channels'] = in_channels
- head_append_dict['in_channels'] = str(in_channels)
- if align_corners:
- neck_new['align_corners'] = align_corners
-
- else:
- raise ValueError(f'model.head get invalid value for argument '
- f'input_transform: {input_transform}')
-
-
-def process_extra_field(extra: Dict, head_new: Dict, head_deleted_dict: Dict,
- head_append_dict: Dict, neck_new: Dict) -> None:
- """Process the extra field and update head and neck dictionaries."""
- head_deleted_dict['extra'] = 'dict('
- for key, value in extra.items():
- head_deleted_dict['extra'] += f'{key}={value},'
- head_deleted_dict['extra'] = head_deleted_dict['extra'][:-1] + ')'
- if 'final_conv_kernel' in extra:
- kernel_size = extra['final_conv_kernel']
- if kernel_size > 1:
- padding = kernel_size // 2
- head_new['final_layer'] = dict(
- kernel_size=kernel_size, padding=padding)
- head_append_dict[
- 'final_layer'] = f'dict(kernel_size={kernel_size}, ' \
- f'padding={padding})'
- else:
- head_new['final_layer'] = dict(kernel_size=kernel_size)
- head_append_dict[
- 'final_layer'] = f'dict(kernel_size={kernel_size})'
- if 'upsample' in extra:
- neck_new.update(
- dict(
- type='FeatureMapProcessor',
- scale_factor=float(extra['upsample']),
- apply_relu=True,
- ))
-
-
-def process_has_final_layer(has_final_layer: bool, head_new: Dict,
- head_deleted_dict: Dict,
- head_append_dict: Dict) -> None:
- """Process the has_final_layer field and update the head dictionary."""
- head_deleted_dict['has_final_layer'] = str(has_final_layer)
- if not has_final_layer:
- if 'final_layer' not in head_new:
- head_new['final_layer'] = None
- head_append_dict['final_layer'] = 'None'
-
-
-def check_and_update_config(neck: Optional[ConfigType],
- head: ConfigType) -> Tuple[Optional[Dict], Dict]:
- """Check and update the configuration of the head and neck components.
- Args:
- neck (Optional[ConfigType]): Configuration for the neck component.
- head (ConfigType): Configuration for the head component.
-
- Returns:
- Tuple[Optional[Dict], Dict]: Updated configurations for the neck
- and head components.
- """
- head_new, neck_new = head.copy(), neck.copy() if isinstance(neck,
- dict) else {}
- head_deleted_dict, head_append_dict = {}, {}
-
- if 'input_transform' in head:
- input_transform = head_new.pop('input_transform')
- head_deleted_dict['input_transform'] = f'\'{input_transform}\''
- else:
- input_transform = 'select'
-
- if 'input_index' in head:
- input_index = head_new.pop('input_index')
- head_deleted_dict['input_index'] = str(input_index)
- else:
- input_index = (-1, )
-
- if 'align_corners' in head:
- align_corners = head_new.pop('align_corners')
- head_deleted_dict['align_corners'] = str(align_corners)
- else:
- align_corners = False
-
- process_input_transform(input_transform, head, head_new, head_deleted_dict,
- head_append_dict, neck_new, input_index,
- align_corners)
-
- if 'extra' in head:
- extra = head_new.pop('extra')
- process_extra_field(extra, head_new, head_deleted_dict,
- head_append_dict, neck_new)
-
- if 'has_final_layer' in head:
- has_final_layer = head_new.pop('has_final_layer')
- process_has_final_layer(has_final_layer, head_new, head_deleted_dict,
- head_append_dict)
-
- display_modifications(head_deleted_dict, head_append_dict, neck_new)
-
- neck_new = neck_new if len(neck_new) else None
- return neck_new, head_new
-
-
-@master_only
-def display_modifications(head_deleted_dict: Dict, head_append_dict: Dict,
- neck: Dict) -> None:
- """Display the modifications made to the head and neck configurations.
-
- Args:
- head_deleted_dict (Dict): Dictionary of deleted fields in the head.
- head_append_dict (Dict): Dictionary of appended fields in the head.
- neck (Dict): Updated neck configuration.
- """
- if len(head_deleted_dict) + len(head_append_dict) == 0:
- return
-
- old_model_info, new_model_info = build_model_info(head_deleted_dict,
- head_append_dict, neck)
-
- total_info = '\nThe config you are using is outdated. '\
- 'The following section of the config:\n```\n'
- total_info += old_model_info
- total_info += '```\nshould be updated to\n```\n'
- total_info += new_model_info
- total_info += '```\nFor more information, please refer to '\
- 'https://mmpose.readthedocs.io/en/latest/' \
- 'guide_to_framework.html#step3-model'
-
- logger: MMLogger = MMLogger.get_current_instance()
- logger.warning(total_info)
-
-
-def build_model_info(head_deleted_dict: Dict, head_append_dict: Dict,
- neck: Dict) -> Tuple[str, str]:
- """Build the old and new model information strings.
- Args:
- head_deleted_dict (Dict): Dictionary of deleted fields in the head.
- head_append_dict (Dict): Dictionary of appended fields in the head.
- neck (Dict): Updated neck configuration.
-
- Returns:
- Tuple[str, str]: Old and new model information strings.
- """
- old_head_info = build_head_info(head_deleted_dict)
- new_head_info = build_head_info(head_append_dict)
- neck_info = build_neck_info(neck)
-
- old_model_info = 'model=dict(\n' + ' ' * 4 + '...,\n' + old_head_info
- new_model_info = 'model=dict(\n' + ' ' * 4 + '...,\n' \
- + neck_info + new_head_info
-
- return old_model_info, new_model_info
-
-
-def build_head_info(head_dict: Dict) -> str:
- """Build the head information string.
-
- Args:
- head_dict (Dict): Dictionary of fields in the head configuration.
- Returns:
- str: Head information string.
- """
- head_info = ' ' * 4 + 'head=dict(\n'
- for key, value in head_dict.items():
- head_info += ' ' * 8 + f'{key}={value},\n'
- head_info += ' ' * 8 + '...),\n'
- return head_info
-
-
-def build_neck_info(neck: Dict) -> str:
- """Build the neck information string.
- Args:
- neck (Dict): Updated neck configuration.
-
- Returns:
- str: Neck information string.
- """
- if len(neck) > 0:
- neck = neck.copy()
- neck_info = ' ' * 4 + 'neck=dict(\n' + ' ' * 8 + \
- f'type=\'{neck.pop("type")}\',\n'
- for key, value in neck.items():
- neck_info += ' ' * 8 + f'{key}={str(value)},\n'
- neck_info += ' ' * 4 + '),\n'
- else:
- neck_info = ''
- return neck_info
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, Optional, Tuple, Union
+
+from mmengine.config import Config, ConfigDict
+from mmengine.dist import master_only
+from mmengine.logging import MMLogger
+
+ConfigType = Union[Config, ConfigDict]
+
+
+def process_input_transform(input_transform: str, head: Dict, head_new: Dict,
+ head_deleted_dict: Dict, head_append_dict: Dict,
+ neck_new: Dict, input_index: Tuple[int],
+ align_corners: bool) -> None:
+ """Process the input_transform field and update head and neck
+ dictionaries."""
+ if input_transform == 'resize_concat':
+ in_channels = head_new.pop('in_channels')
+ head_deleted_dict['in_channels'] = str(in_channels)
+ in_channels = sum([in_channels[i] for i in input_index])
+ head_new['in_channels'] = in_channels
+ head_append_dict['in_channels'] = str(in_channels)
+
+ neck_new.update(
+ dict(
+ type='FeatureMapProcessor',
+ concat=True,
+ select_index=input_index,
+ ))
+ if align_corners:
+ neck_new['align_corners'] = align_corners
+
+ elif input_transform == 'select':
+ if input_index != (-1, ):
+ neck_new.update(
+ dict(type='FeatureMapProcessor', select_index=input_index))
+ if isinstance(head['in_channels'], tuple):
+ in_channels = head_new.pop('in_channels')
+ head_deleted_dict['in_channels'] = str(in_channels)
+ if isinstance(input_index, int):
+ in_channels = in_channels[input_index]
+ else:
+ in_channels = tuple([in_channels[i] for i in input_index])
+ head_new['in_channels'] = in_channels
+ head_append_dict['in_channels'] = str(in_channels)
+ if align_corners:
+ neck_new['align_corners'] = align_corners
+
+ else:
+ raise ValueError(f'model.head get invalid value for argument '
+ f'input_transform: {input_transform}')
+
+
+def process_extra_field(extra: Dict, head_new: Dict, head_deleted_dict: Dict,
+ head_append_dict: Dict, neck_new: Dict) -> None:
+ """Process the extra field and update head and neck dictionaries."""
+ head_deleted_dict['extra'] = 'dict('
+ for key, value in extra.items():
+ head_deleted_dict['extra'] += f'{key}={value},'
+ head_deleted_dict['extra'] = head_deleted_dict['extra'][:-1] + ')'
+ if 'final_conv_kernel' in extra:
+ kernel_size = extra['final_conv_kernel']
+ if kernel_size > 1:
+ padding = kernel_size // 2
+ head_new['final_layer'] = dict(
+ kernel_size=kernel_size, padding=padding)
+ head_append_dict[
+ 'final_layer'] = f'dict(kernel_size={kernel_size}, ' \
+ f'padding={padding})'
+ else:
+ head_new['final_layer'] = dict(kernel_size=kernel_size)
+ head_append_dict[
+ 'final_layer'] = f'dict(kernel_size={kernel_size})'
+ if 'upsample' in extra:
+ neck_new.update(
+ dict(
+ type='FeatureMapProcessor',
+ scale_factor=float(extra['upsample']),
+ apply_relu=True,
+ ))
+
+
+def process_has_final_layer(has_final_layer: bool, head_new: Dict,
+ head_deleted_dict: Dict,
+ head_append_dict: Dict) -> None:
+ """Process the has_final_layer field and update the head dictionary."""
+ head_deleted_dict['has_final_layer'] = str(has_final_layer)
+ if not has_final_layer:
+ if 'final_layer' not in head_new:
+ head_new['final_layer'] = None
+ head_append_dict['final_layer'] = 'None'
+
+
+def check_and_update_config(neck: Optional[ConfigType],
+ head: ConfigType) -> Tuple[Optional[Dict], Dict]:
+ """Check and update the configuration of the head and neck components.
+ Args:
+ neck (Optional[ConfigType]): Configuration for the neck component.
+ head (ConfigType): Configuration for the head component.
+
+ Returns:
+ Tuple[Optional[Dict], Dict]: Updated configurations for the neck
+ and head components.
+ """
+ head_new, neck_new = head.copy(), neck.copy() if isinstance(neck,
+ dict) else {}
+ head_deleted_dict, head_append_dict = {}, {}
+
+ if 'input_transform' in head:
+ input_transform = head_new.pop('input_transform')
+ head_deleted_dict['input_transform'] = f'\'{input_transform}\''
+ else:
+ input_transform = 'select'
+
+ if 'input_index' in head:
+ input_index = head_new.pop('input_index')
+ head_deleted_dict['input_index'] = str(input_index)
+ else:
+ input_index = (-1, )
+
+ if 'align_corners' in head:
+ align_corners = head_new.pop('align_corners')
+ head_deleted_dict['align_corners'] = str(align_corners)
+ else:
+ align_corners = False
+
+ process_input_transform(input_transform, head, head_new, head_deleted_dict,
+ head_append_dict, neck_new, input_index,
+ align_corners)
+
+ if 'extra' in head:
+ extra = head_new.pop('extra')
+ process_extra_field(extra, head_new, head_deleted_dict,
+ head_append_dict, neck_new)
+
+ if 'has_final_layer' in head:
+ has_final_layer = head_new.pop('has_final_layer')
+ process_has_final_layer(has_final_layer, head_new, head_deleted_dict,
+ head_append_dict)
+
+ display_modifications(head_deleted_dict, head_append_dict, neck_new)
+
+ neck_new = neck_new if len(neck_new) else None
+ return neck_new, head_new
+
+
+@master_only
+def display_modifications(head_deleted_dict: Dict, head_append_dict: Dict,
+ neck: Dict) -> None:
+ """Display the modifications made to the head and neck configurations.
+
+ Args:
+ head_deleted_dict (Dict): Dictionary of deleted fields in the head.
+ head_append_dict (Dict): Dictionary of appended fields in the head.
+ neck (Dict): Updated neck configuration.
+ """
+ if len(head_deleted_dict) + len(head_append_dict) == 0:
+ return
+
+ old_model_info, new_model_info = build_model_info(head_deleted_dict,
+ head_append_dict, neck)
+
+ total_info = '\nThe config you are using is outdated. '\
+ 'The following section of the config:\n```\n'
+ total_info += old_model_info
+ total_info += '```\nshould be updated to\n```\n'
+ total_info += new_model_info
+ total_info += '```\nFor more information, please refer to '\
+ 'https://mmpose.readthedocs.io/en/latest/' \
+ 'guide_to_framework.html#step3-model'
+
+ logger: MMLogger = MMLogger.get_current_instance()
+ logger.warning(total_info)
+
+
+def build_model_info(head_deleted_dict: Dict, head_append_dict: Dict,
+ neck: Dict) -> Tuple[str, str]:
+ """Build the old and new model information strings.
+ Args:
+ head_deleted_dict (Dict): Dictionary of deleted fields in the head.
+ head_append_dict (Dict): Dictionary of appended fields in the head.
+ neck (Dict): Updated neck configuration.
+
+ Returns:
+ Tuple[str, str]: Old and new model information strings.
+ """
+ old_head_info = build_head_info(head_deleted_dict)
+ new_head_info = build_head_info(head_append_dict)
+ neck_info = build_neck_info(neck)
+
+ old_model_info = 'model=dict(\n' + ' ' * 4 + '...,\n' + old_head_info
+ new_model_info = 'model=dict(\n' + ' ' * 4 + '...,\n' \
+ + neck_info + new_head_info
+
+ return old_model_info, new_model_info
+
+
+def build_head_info(head_dict: Dict) -> str:
+ """Build the head information string.
+
+ Args:
+ head_dict (Dict): Dictionary of fields in the head configuration.
+ Returns:
+ str: Head information string.
+ """
+ head_info = ' ' * 4 + 'head=dict(\n'
+ for key, value in head_dict.items():
+ head_info += ' ' * 8 + f'{key}={value},\n'
+ head_info += ' ' * 8 + '...),\n'
+ return head_info
+
+
+def build_neck_info(neck: Dict) -> str:
+ """Build the neck information string.
+ Args:
+ neck (Dict): Updated neck configuration.
+
+ Returns:
+ str: Neck information string.
+ """
+ if len(neck) > 0:
+ neck = neck.copy()
+ neck_info = ' ' * 4 + 'neck=dict(\n' + ' ' * 8 + \
+ f'type=\'{neck.pop("type")}\',\n'
+ for key, value in neck.items():
+ neck_info += ' ' * 8 + f'{key}={str(value)},\n'
+ neck_info += ' ' * 4 + '),\n'
+ else:
+ neck_info = ''
+ return neck_info
diff --git a/mmpose/models/utils/ckpt_convert.py b/mmpose/models/utils/ckpt_convert.py
index 05f5cdb4a3..b883547085 100644
--- a/mmpose/models/utils/ckpt_convert.py
+++ b/mmpose/models/utils/ckpt_convert.py
@@ -1,82 +1,82 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-
-# This script consists of several convert functions which
-# can modify the weights of model in original repo to be
-# pre-trained weights.
-
-from collections import OrderedDict
-
-import torch
-
-
-def pvt_convert(ckpt):
- new_ckpt = OrderedDict()
- # Process the concat between q linear weights and kv linear weights
- use_abs_pos_embed = False
- use_conv_ffn = False
- for k in ckpt.keys():
- if k.startswith('pos_embed'):
- use_abs_pos_embed = True
- if k.find('dwconv') >= 0:
- use_conv_ffn = True
- for k, v in ckpt.items():
- if k.startswith('head'):
- continue
- if k.startswith('norm.'):
- continue
- if k.startswith('cls_token'):
- continue
- if k.startswith('pos_embed'):
- stage_i = int(k.replace('pos_embed', ''))
- new_k = k.replace(f'pos_embed{stage_i}',
- f'layers.{stage_i - 1}.1.0.pos_embed')
- if stage_i == 4 and v.size(1) == 50: # 1 (cls token) + 7 * 7
- new_v = v[:, 1:, :] # remove cls token
- else:
- new_v = v
- elif k.startswith('patch_embed'):
- stage_i = int(k.split('.')[0].replace('patch_embed', ''))
- new_k = k.replace(f'patch_embed{stage_i}',
- f'layers.{stage_i - 1}.0')
- new_v = v
- if 'proj.' in new_k:
- new_k = new_k.replace('proj.', 'projection.')
- elif k.startswith('block'):
- stage_i = int(k.split('.')[0].replace('block', ''))
- layer_i = int(k.split('.')[1])
- new_layer_i = layer_i + use_abs_pos_embed
- new_k = k.replace(f'block{stage_i}.{layer_i}',
- f'layers.{stage_i - 1}.1.{new_layer_i}')
- new_v = v
- if 'attn.q.' in new_k:
- sub_item_k = k.replace('q.', 'kv.')
- new_k = new_k.replace('q.', 'attn.in_proj_')
- new_v = torch.cat([v, ckpt[sub_item_k]], dim=0)
- elif 'attn.kv.' in new_k:
- continue
- elif 'attn.proj.' in new_k:
- new_k = new_k.replace('proj.', 'attn.out_proj.')
- elif 'attn.sr.' in new_k:
- new_k = new_k.replace('sr.', 'sr.')
- elif 'mlp.' in new_k:
- string = f'{new_k}-'
- new_k = new_k.replace('mlp.', 'ffn.layers.')
- if 'fc1.weight' in new_k or 'fc2.weight' in new_k:
- new_v = v.reshape((*v.shape, 1, 1))
- new_k = new_k.replace('fc1.', '0.')
- new_k = new_k.replace('dwconv.dwconv.', '1.')
- if use_conv_ffn:
- new_k = new_k.replace('fc2.', '4.')
- else:
- new_k = new_k.replace('fc2.', '3.')
- string += f'{new_k} {v.shape}-{new_v.shape}'
- elif k.startswith('norm'):
- stage_i = int(k[4])
- new_k = k.replace(f'norm{stage_i}', f'layers.{stage_i - 1}.2')
- new_v = v
- else:
- new_k = k
- new_v = v
- new_ckpt[new_k] = new_v
-
- return new_ckpt
+# Copyright (c) OpenMMLab. All rights reserved.
+
+# This script consists of several convert functions which
+# can modify the weights of model in original repo to be
+# pre-trained weights.
+
+from collections import OrderedDict
+
+import torch
+
+
+def pvt_convert(ckpt):
+ new_ckpt = OrderedDict()
+ # Process the concat between q linear weights and kv linear weights
+ use_abs_pos_embed = False
+ use_conv_ffn = False
+ for k in ckpt.keys():
+ if k.startswith('pos_embed'):
+ use_abs_pos_embed = True
+ if k.find('dwconv') >= 0:
+ use_conv_ffn = True
+ for k, v in ckpt.items():
+ if k.startswith('head'):
+ continue
+ if k.startswith('norm.'):
+ continue
+ if k.startswith('cls_token'):
+ continue
+ if k.startswith('pos_embed'):
+ stage_i = int(k.replace('pos_embed', ''))
+ new_k = k.replace(f'pos_embed{stage_i}',
+ f'layers.{stage_i - 1}.1.0.pos_embed')
+ if stage_i == 4 and v.size(1) == 50: # 1 (cls token) + 7 * 7
+ new_v = v[:, 1:, :] # remove cls token
+ else:
+ new_v = v
+ elif k.startswith('patch_embed'):
+ stage_i = int(k.split('.')[0].replace('patch_embed', ''))
+ new_k = k.replace(f'patch_embed{stage_i}',
+ f'layers.{stage_i - 1}.0')
+ new_v = v
+ if 'proj.' in new_k:
+ new_k = new_k.replace('proj.', 'projection.')
+ elif k.startswith('block'):
+ stage_i = int(k.split('.')[0].replace('block', ''))
+ layer_i = int(k.split('.')[1])
+ new_layer_i = layer_i + use_abs_pos_embed
+ new_k = k.replace(f'block{stage_i}.{layer_i}',
+ f'layers.{stage_i - 1}.1.{new_layer_i}')
+ new_v = v
+ if 'attn.q.' in new_k:
+ sub_item_k = k.replace('q.', 'kv.')
+ new_k = new_k.replace('q.', 'attn.in_proj_')
+ new_v = torch.cat([v, ckpt[sub_item_k]], dim=0)
+ elif 'attn.kv.' in new_k:
+ continue
+ elif 'attn.proj.' in new_k:
+ new_k = new_k.replace('proj.', 'attn.out_proj.')
+ elif 'attn.sr.' in new_k:
+ new_k = new_k.replace('sr.', 'sr.')
+ elif 'mlp.' in new_k:
+ string = f'{new_k}-'
+ new_k = new_k.replace('mlp.', 'ffn.layers.')
+ if 'fc1.weight' in new_k or 'fc2.weight' in new_k:
+ new_v = v.reshape((*v.shape, 1, 1))
+ new_k = new_k.replace('fc1.', '0.')
+ new_k = new_k.replace('dwconv.dwconv.', '1.')
+ if use_conv_ffn:
+ new_k = new_k.replace('fc2.', '4.')
+ else:
+ new_k = new_k.replace('fc2.', '3.')
+ string += f'{new_k} {v.shape}-{new_v.shape}'
+ elif k.startswith('norm'):
+ stage_i = int(k[4])
+ new_k = k.replace(f'norm{stage_i}', f'layers.{stage_i - 1}.2')
+ new_v = v
+ else:
+ new_k = k
+ new_v = v
+ new_ckpt[new_k] = new_v
+
+ return new_ckpt
diff --git a/mmpose/models/utils/geometry.py b/mmpose/models/utils/geometry.py
index 0ceadaec30..4821364496 100644
--- a/mmpose/models/utils/geometry.py
+++ b/mmpose/models/utils/geometry.py
@@ -1,68 +1,68 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import torch
-from torch.nn import functional as F
-
-
-def rot6d_to_rotmat(x):
- """Convert 6D rotation representation to 3x3 rotation matrix.
-
- Based on Zhou et al., "On the Continuity of Rotation
- Representations in Neural Networks", CVPR 2019
- Input:
- (B,6) Batch of 6-D rotation representations
- Output:
- (B,3,3) Batch of corresponding rotation matrices
- """
- x = x.view(-1, 3, 2)
- a1 = x[:, :, 0]
- a2 = x[:, :, 1]
- b1 = F.normalize(a1)
- b2 = F.normalize(a2 - torch.einsum('bi,bi->b', b1, a2).unsqueeze(-1) * b1)
- b3 = torch.cross(b1, b2)
- return torch.stack((b1, b2, b3), dim=-1)
-
-
-def batch_rodrigues(theta):
- """Convert axis-angle representation to rotation matrix.
- Args:
- theta: size = [B, 3]
- Returns:
- Rotation matrix corresponding to the quaternion
- -- size = [B, 3, 3]
- """
- l2norm = torch.norm(theta + 1e-8, p=2, dim=1)
- angle = torch.unsqueeze(l2norm, -1)
- normalized = torch.div(theta, angle)
- angle = angle * 0.5
- v_cos = torch.cos(angle)
- v_sin = torch.sin(angle)
- quat = torch.cat([v_cos, v_sin * normalized], dim=1)
- return quat_to_rotmat(quat)
-
-
-def quat_to_rotmat(quat):
- """Convert quaternion coefficients to rotation matrix.
- Args:
- quat: size = [B, 4] 4 <===>(w, x, y, z)
- Returns:
- Rotation matrix corresponding to the quaternion
- -- size = [B, 3, 3]
- """
- norm_quat = quat
- norm_quat = norm_quat / norm_quat.norm(p=2, dim=1, keepdim=True)
- w, x, y, z = norm_quat[:, 0], norm_quat[:, 1],\
- norm_quat[:, 2], norm_quat[:, 3]
-
- B = quat.size(0)
-
- w2, x2, y2, z2 = w.pow(2), x.pow(2), y.pow(2), z.pow(2)
- wx, wy, wz = w * x, w * y, w * z
- xy, xz, yz = x * y, x * z, y * z
-
- rotMat = torch.stack([
- w2 + x2 - y2 - z2, 2 * xy - 2 * wz, 2 * wy + 2 * xz, 2 * wz + 2 * xy,
- w2 - x2 + y2 - z2, 2 * yz - 2 * wx, 2 * xz - 2 * wy, 2 * wx + 2 * yz,
- w2 - x2 - y2 + z2
- ],
- dim=1).view(B, 3, 3)
- return rotMat
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from torch.nn import functional as F
+
+
+def rot6d_to_rotmat(x):
+ """Convert 6D rotation representation to 3x3 rotation matrix.
+
+ Based on Zhou et al., "On the Continuity of Rotation
+ Representations in Neural Networks", CVPR 2019
+ Input:
+ (B,6) Batch of 6-D rotation representations
+ Output:
+ (B,3,3) Batch of corresponding rotation matrices
+ """
+ x = x.view(-1, 3, 2)
+ a1 = x[:, :, 0]
+ a2 = x[:, :, 1]
+ b1 = F.normalize(a1)
+ b2 = F.normalize(a2 - torch.einsum('bi,bi->b', b1, a2).unsqueeze(-1) * b1)
+ b3 = torch.cross(b1, b2)
+ return torch.stack((b1, b2, b3), dim=-1)
+
+
+def batch_rodrigues(theta):
+ """Convert axis-angle representation to rotation matrix.
+ Args:
+ theta: size = [B, 3]
+ Returns:
+ Rotation matrix corresponding to the quaternion
+ -- size = [B, 3, 3]
+ """
+ l2norm = torch.norm(theta + 1e-8, p=2, dim=1)
+ angle = torch.unsqueeze(l2norm, -1)
+ normalized = torch.div(theta, angle)
+ angle = angle * 0.5
+ v_cos = torch.cos(angle)
+ v_sin = torch.sin(angle)
+ quat = torch.cat([v_cos, v_sin * normalized], dim=1)
+ return quat_to_rotmat(quat)
+
+
+def quat_to_rotmat(quat):
+ """Convert quaternion coefficients to rotation matrix.
+ Args:
+ quat: size = [B, 4] 4 <===>(w, x, y, z)
+ Returns:
+ Rotation matrix corresponding to the quaternion
+ -- size = [B, 3, 3]
+ """
+ norm_quat = quat
+ norm_quat = norm_quat / norm_quat.norm(p=2, dim=1, keepdim=True)
+ w, x, y, z = norm_quat[:, 0], norm_quat[:, 1],\
+ norm_quat[:, 2], norm_quat[:, 3]
+
+ B = quat.size(0)
+
+ w2, x2, y2, z2 = w.pow(2), x.pow(2), y.pow(2), z.pow(2)
+ wx, wy, wz = w * x, w * y, w * z
+ xy, xz, yz = x * y, x * z, y * z
+
+ rotMat = torch.stack([
+ w2 + x2 - y2 - z2, 2 * xy - 2 * wz, 2 * wy + 2 * xz, 2 * wz + 2 * xy,
+ w2 - x2 + y2 - z2, 2 * yz - 2 * wx, 2 * xz - 2 * wy, 2 * wx + 2 * yz,
+ w2 - x2 - y2 + z2
+ ],
+ dim=1).view(B, 3, 3)
+ return rotMat
diff --git a/mmpose/models/utils/ops.py b/mmpose/models/utils/ops.py
index 0c94352647..0acbfe41e1 100644
--- a/mmpose/models/utils/ops.py
+++ b/mmpose/models/utils/ops.py
@@ -1,52 +1,52 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import warnings
-from typing import Optional, Tuple, Union
-
-import torch
-from torch.nn import functional as F
-
-
-def resize(input: torch.Tensor,
- size: Optional[Union[Tuple[int, int], torch.Size]] = None,
- scale_factor: Optional[float] = None,
- mode: str = 'nearest',
- align_corners: Optional[bool] = None,
- warning: bool = True) -> torch.Tensor:
- """Resize a given input tensor using specified size or scale_factor.
-
- Args:
- input (torch.Tensor): The input tensor to be resized.
- size (Optional[Union[Tuple[int, int], torch.Size]]): The desired
- output size. Defaults to None.
- scale_factor (Optional[float]): The scaling factor for resizing.
- Defaults to None.
- mode (str): The interpolation mode. Defaults to 'nearest'.
- align_corners (Optional[bool]): Determines whether to align the
- corners when using certain interpolation modes. Defaults to None.
- warning (bool): Whether to display a warning when the input and
- output sizes are not ideal for alignment. Defaults to True.
-
- Returns:
- torch.Tensor: The resized tensor.
- """
- # Check if a warning should be displayed regarding input and output sizes
- if warning:
- if size is not None and align_corners:
- input_h, input_w = tuple(int(x) for x in input.shape[2:])
- output_h, output_w = tuple(int(x) for x in size)
- if output_h > input_h or output_w > output_h:
- if ((output_h > 1 and output_w > 1 and input_h > 1
- and input_w > 1) and (output_h - 1) % (input_h - 1)
- and (output_w - 1) % (input_w - 1)):
- warnings.warn(
- f'When align_corners={align_corners}, '
- 'the output would be more aligned if '
- f'input size {(input_h, input_w)} is `x+1` and '
- f'out size {(output_h, output_w)} is `nx+1`')
-
- # Convert torch.Size to tuple if necessary
- if isinstance(size, torch.Size):
- size = tuple(int(x) for x in size)
-
- # Perform the resizing operation
- return F.interpolate(input, size, scale_factor, mode, align_corners)
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Optional, Tuple, Union
+
+import torch
+from torch.nn import functional as F
+
+
+def resize(input: torch.Tensor,
+ size: Optional[Union[Tuple[int, int], torch.Size]] = None,
+ scale_factor: Optional[float] = None,
+ mode: str = 'nearest',
+ align_corners: Optional[bool] = None,
+ warning: bool = True) -> torch.Tensor:
+ """Resize a given input tensor using specified size or scale_factor.
+
+ Args:
+ input (torch.Tensor): The input tensor to be resized.
+ size (Optional[Union[Tuple[int, int], torch.Size]]): The desired
+ output size. Defaults to None.
+ scale_factor (Optional[float]): The scaling factor for resizing.
+ Defaults to None.
+ mode (str): The interpolation mode. Defaults to 'nearest'.
+ align_corners (Optional[bool]): Determines whether to align the
+ corners when using certain interpolation modes. Defaults to None.
+ warning (bool): Whether to display a warning when the input and
+ output sizes are not ideal for alignment. Defaults to True.
+
+ Returns:
+ torch.Tensor: The resized tensor.
+ """
+ # Check if a warning should be displayed regarding input and output sizes
+ if warning:
+ if size is not None and align_corners:
+ input_h, input_w = tuple(int(x) for x in input.shape[2:])
+ output_h, output_w = tuple(int(x) for x in size)
+ if output_h > input_h or output_w > output_h:
+ if ((output_h > 1 and output_w > 1 and input_h > 1
+ and input_w > 1) and (output_h - 1) % (input_h - 1)
+ and (output_w - 1) % (input_w - 1)):
+ warnings.warn(
+ f'When align_corners={align_corners}, '
+ 'the output would be more aligned if '
+ f'input size {(input_h, input_w)} is `x+1` and '
+ f'out size {(output_h, output_w)} is `nx+1`')
+
+ # Convert torch.Size to tuple if necessary
+ if isinstance(size, torch.Size):
+ size = tuple(int(x) for x in size)
+
+ # Perform the resizing operation
+ return F.interpolate(input, size, scale_factor, mode, align_corners)
diff --git a/mmpose/models/utils/realnvp.py b/mmpose/models/utils/realnvp.py
index 911953e8f9..befd569e03 100644
--- a/mmpose/models/utils/realnvp.py
+++ b/mmpose/models/utils/realnvp.py
@@ -1,76 +1,76 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import torch
-import torch.nn as nn
-from torch import distributions
-
-
-class RealNVP(nn.Module):
- """RealNVP: a flow-based generative model
-
- `Density estimation using Real NVP
- arXiv: `_.
-
- Code is modified from `the official implementation of RLE
- `_.
-
- See also `real-nvp-pytorch
- `_.
- """
-
- @staticmethod
- def get_scale_net():
- """Get the scale model in a single invertable mapping."""
- return nn.Sequential(
- nn.Linear(2, 64), nn.LeakyReLU(), nn.Linear(64, 64),
- nn.LeakyReLU(), nn.Linear(64, 2), nn.Tanh())
-
- @staticmethod
- def get_trans_net():
- """Get the translation model in a single invertable mapping."""
- return nn.Sequential(
- nn.Linear(2, 64), nn.LeakyReLU(), nn.Linear(64, 64),
- nn.LeakyReLU(), nn.Linear(64, 2))
-
- @property
- def prior(self):
- """The prior distribution."""
- return distributions.MultivariateNormal(self.loc, self.cov)
-
- def __init__(self):
- super(RealNVP, self).__init__()
-
- self.register_buffer('loc', torch.zeros(2))
- self.register_buffer('cov', torch.eye(2))
- self.register_buffer(
- 'mask', torch.tensor([[0, 1], [1, 0]] * 3, dtype=torch.float32))
-
- self.s = torch.nn.ModuleList(
- [self.get_scale_net() for _ in range(len(self.mask))])
- self.t = torch.nn.ModuleList(
- [self.get_trans_net() for _ in range(len(self.mask))])
- self.init_weights()
-
- def init_weights(self):
- """Initialization model weights."""
- for m in self.modules():
- if isinstance(m, nn.Linear):
- nn.init.xavier_uniform_(m.weight, gain=0.01)
-
- def backward_p(self, x):
- """Apply mapping form the data space to the latent space and calculate
- the log determinant of the Jacobian matrix."""
-
- log_det_jacob, z = x.new_zeros(x.shape[0]), x
- for i in reversed(range(len(self.t))):
- z_ = self.mask[i] * z
- s = self.s[i](z_) * (1 - self.mask[i]) # torch.exp(s): betas
- t = self.t[i](z_) * (1 - self.mask[i]) # gammas
- z = (1 - self.mask[i]) * (z - t) * torch.exp(-s) + z_
- log_det_jacob -= s.sum(dim=1)
- return z, log_det_jacob
-
- def log_prob(self, x):
- """Calculate the log probability of given sample in data space."""
-
- z, log_det = self.backward_p(x)
- return self.prior.log_prob(z) + log_det
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from torch import distributions
+
+
+class RealNVP(nn.Module):
+ """RealNVP: a flow-based generative model
+
+ `Density estimation using Real NVP
+ arXiv: `_.
+
+ Code is modified from `the official implementation of RLE
+ `_.
+
+ See also `real-nvp-pytorch
+ `_.
+ """
+
+ @staticmethod
+ def get_scale_net():
+ """Get the scale model in a single invertable mapping."""
+ return nn.Sequential(
+ nn.Linear(2, 64), nn.LeakyReLU(), nn.Linear(64, 64),
+ nn.LeakyReLU(), nn.Linear(64, 2), nn.Tanh())
+
+ @staticmethod
+ def get_trans_net():
+ """Get the translation model in a single invertable mapping."""
+ return nn.Sequential(
+ nn.Linear(2, 64), nn.LeakyReLU(), nn.Linear(64, 64),
+ nn.LeakyReLU(), nn.Linear(64, 2))
+
+ @property
+ def prior(self):
+ """The prior distribution."""
+ return distributions.MultivariateNormal(self.loc, self.cov)
+
+ def __init__(self):
+ super(RealNVP, self).__init__()
+
+ self.register_buffer('loc', torch.zeros(2))
+ self.register_buffer('cov', torch.eye(2))
+ self.register_buffer(
+ 'mask', torch.tensor([[0, 1], [1, 0]] * 3, dtype=torch.float32))
+
+ self.s = torch.nn.ModuleList(
+ [self.get_scale_net() for _ in range(len(self.mask))])
+ self.t = torch.nn.ModuleList(
+ [self.get_trans_net() for _ in range(len(self.mask))])
+ self.init_weights()
+
+ def init_weights(self):
+ """Initialization model weights."""
+ for m in self.modules():
+ if isinstance(m, nn.Linear):
+ nn.init.xavier_uniform_(m.weight, gain=0.01)
+
+ def backward_p(self, x):
+ """Apply mapping form the data space to the latent space and calculate
+ the log determinant of the Jacobian matrix."""
+
+ log_det_jacob, z = x.new_zeros(x.shape[0]), x
+ for i in reversed(range(len(self.t))):
+ z_ = self.mask[i] * z
+ s = self.s[i](z_) * (1 - self.mask[i]) # torch.exp(s): betas
+ t = self.t[i](z_) * (1 - self.mask[i]) # gammas
+ z = (1 - self.mask[i]) * (z - t) * torch.exp(-s) + z_
+ log_det_jacob -= s.sum(dim=1)
+ return z, log_det_jacob
+
+ def log_prob(self, x):
+ """Calculate the log probability of given sample in data space."""
+
+ z, log_det = self.backward_p(x)
+ return self.prior.log_prob(z) + log_det
diff --git a/mmpose/models/utils/regularizations.py b/mmpose/models/utils/regularizations.py
index d8c7449038..1911ad6090 100644
--- a/mmpose/models/utils/regularizations.py
+++ b/mmpose/models/utils/regularizations.py
@@ -1,86 +1,86 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from abc import ABCMeta, abstractmethod, abstractproperty
-
-import torch
-
-
-class PytorchModuleHook(metaclass=ABCMeta):
- """Base class for PyTorch module hook registers.
-
- An instance of a subclass of PytorchModuleHook can be used to
- register hook to a pytorch module using the `register` method like:
- hook_register.register(module)
-
- Subclasses should add/overwrite the following methods:
- - __init__
- - hook
- - hook_type
- """
-
- @abstractmethod
- def hook(self, *args, **kwargs):
- """Hook function."""
-
- @abstractproperty
- def hook_type(self) -> str:
- """Hook type Subclasses should overwrite this function to return a
- string value in.
-
- {`forward`, `forward_pre`, `backward`}
- """
-
- def register(self, module):
- """Register the hook function to the module.
-
- Args:
- module (pytorch module): the module to register the hook.
-
- Returns:
- handle (torch.utils.hooks.RemovableHandle): a handle to remove
- the hook by calling handle.remove()
- """
- assert isinstance(module, torch.nn.Module)
-
- if self.hook_type == 'forward':
- h = module.register_forward_hook(self.hook)
- elif self.hook_type == 'forward_pre':
- h = module.register_forward_pre_hook(self.hook)
- elif self.hook_type == 'backward':
- h = module.register_backward_hook(self.hook)
- else:
- raise ValueError(f'Invalid hook type {self.hook}')
-
- return h
-
-
-class WeightNormClipHook(PytorchModuleHook):
- """Apply weight norm clip regularization.
-
- The module's parameter will be clip to a given maximum norm before each
- forward pass.
-
- Args:
- max_norm (float): The maximum norm of the parameter.
- module_param_names (str|list): The parameter name (or name list) to
- apply weight norm clip.
- """
-
- def __init__(self, max_norm=1.0, module_param_names='weight'):
- self.module_param_names = module_param_names if isinstance(
- module_param_names, list) else [module_param_names]
- self.max_norm = max_norm
-
- @property
- def hook_type(self):
- return 'forward_pre'
-
- def hook(self, module, _input):
- for name in self.module_param_names:
- assert name in module._parameters, f'{name} is not a parameter' \
- f' of the module {type(module)}'
- param = module._parameters[name]
-
- with torch.no_grad():
- m = param.norm().item()
- if m > self.max_norm:
- param.mul_(self.max_norm / (m + 1e-6))
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod, abstractproperty
+
+import torch
+
+
+class PytorchModuleHook(metaclass=ABCMeta):
+ """Base class for PyTorch module hook registers.
+
+ An instance of a subclass of PytorchModuleHook can be used to
+ register hook to a pytorch module using the `register` method like:
+ hook_register.register(module)
+
+ Subclasses should add/overwrite the following methods:
+ - __init__
+ - hook
+ - hook_type
+ """
+
+ @abstractmethod
+ def hook(self, *args, **kwargs):
+ """Hook function."""
+
+ @abstractproperty
+ def hook_type(self) -> str:
+ """Hook type Subclasses should overwrite this function to return a
+ string value in.
+
+ {`forward`, `forward_pre`, `backward`}
+ """
+
+ def register(self, module):
+ """Register the hook function to the module.
+
+ Args:
+ module (pytorch module): the module to register the hook.
+
+ Returns:
+ handle (torch.utils.hooks.RemovableHandle): a handle to remove
+ the hook by calling handle.remove()
+ """
+ assert isinstance(module, torch.nn.Module)
+
+ if self.hook_type == 'forward':
+ h = module.register_forward_hook(self.hook)
+ elif self.hook_type == 'forward_pre':
+ h = module.register_forward_pre_hook(self.hook)
+ elif self.hook_type == 'backward':
+ h = module.register_backward_hook(self.hook)
+ else:
+ raise ValueError(f'Invalid hook type {self.hook}')
+
+ return h
+
+
+class WeightNormClipHook(PytorchModuleHook):
+ """Apply weight norm clip regularization.
+
+ The module's parameter will be clip to a given maximum norm before each
+ forward pass.
+
+ Args:
+ max_norm (float): The maximum norm of the parameter.
+ module_param_names (str|list): The parameter name (or name list) to
+ apply weight norm clip.
+ """
+
+ def __init__(self, max_norm=1.0, module_param_names='weight'):
+ self.module_param_names = module_param_names if isinstance(
+ module_param_names, list) else [module_param_names]
+ self.max_norm = max_norm
+
+ @property
+ def hook_type(self):
+ return 'forward_pre'
+
+ def hook(self, module, _input):
+ for name in self.module_param_names:
+ assert name in module._parameters, f'{name} is not a parameter' \
+ f' of the module {type(module)}'
+ param = module._parameters[name]
+
+ with torch.no_grad():
+ m = param.norm().item()
+ if m > self.max_norm:
+ param.mul_(self.max_norm / (m + 1e-6))
diff --git a/mmpose/models/utils/rtmcc_block.py b/mmpose/models/utils/rtmcc_block.py
index bd4929454c..82fbaf7106 100644
--- a/mmpose/models/utils/rtmcc_block.py
+++ b/mmpose/models/utils/rtmcc_block.py
@@ -1,305 +1,305 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import math
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from mmcv.cnn.bricks import DropPath
-from mmengine.utils import digit_version
-from mmengine.utils.dl_utils import TORCH_VERSION
-
-
-def rope(x, dim):
- """Applies Rotary Position Embedding to input tensor.
-
- Args:
- x (torch.Tensor): Input tensor.
- dim (int | list[int]): The spatial dimension(s) to apply
- rotary position embedding.
-
- Returns:
- torch.Tensor: The tensor after applying rotary position
- embedding.
-
- Reference:
- `RoFormer: Enhanced Transformer with Rotary
- Position Embedding `_
- """
- shape = x.shape
- if isinstance(dim, int):
- dim = [dim]
-
- spatial_shape = [shape[i] for i in dim]
- total_len = 1
- for i in spatial_shape:
- total_len *= i
-
- position = torch.reshape(
- torch.arange(total_len, dtype=torch.int, device=x.device),
- spatial_shape)
-
- for i in range(dim[-1] + 1, len(shape) - 1, 1):
- position = torch.unsqueeze(position, dim=-1)
-
- half_size = shape[-1] // 2
- freq_seq = -torch.arange(
- half_size, dtype=torch.int, device=x.device) / float(half_size)
- inv_freq = 10000**-freq_seq
-
- sinusoid = position[..., None] * inv_freq[None, None, :]
-
- sin = torch.sin(sinusoid)
- cos = torch.cos(sinusoid)
- x1, x2 = torch.chunk(x, 2, dim=-1)
-
- return torch.cat([x1 * cos - x2 * sin, x2 * cos + x1 * sin], dim=-1)
-
-
-class Scale(nn.Module):
- """Scale vector by element multiplications.
-
- Args:
- dim (int): The dimension of the scale vector.
- init_value (float, optional): The initial value of the scale vector.
- Defaults to 1.0.
- trainable (bool, optional): Whether the scale vector is trainable.
- Defaults to True.
- """
-
- def __init__(self, dim, init_value=1., trainable=True):
- super().__init__()
- self.scale = nn.Parameter(
- init_value * torch.ones(dim), requires_grad=trainable)
-
- def forward(self, x):
- """Forward function."""
-
- return x * self.scale
-
-
-class ScaleNorm(nn.Module):
- """Scale Norm.
-
- Args:
- dim (int): The dimension of the scale vector.
- eps (float, optional): The minimum value in clamp. Defaults to 1e-5.
-
- Reference:
- `Transformers without Tears: Improving the Normalization
- of Self-Attention `_
- """
-
- def __init__(self, dim, eps=1e-5):
- super().__init__()
- self.scale = dim**-0.5
- self.eps = eps
- self.g = nn.Parameter(torch.ones(1))
-
- def forward(self, x):
- """Forward function.
-
- Args:
- x (torch.Tensor): Input tensor.
-
- Returns:
- torch.Tensor: The tensor after applying scale norm.
- """
-
- norm = torch.norm(x, dim=2, keepdim=True) * self.scale
- return x / norm.clamp(min=self.eps) * self.g
-
-
-class RTMCCBlock(nn.Module):
- """Gated Attention Unit (GAU) in RTMBlock.
-
- Args:
- num_token (int): The number of tokens.
- in_token_dims (int): The input token dimension.
- out_token_dims (int): The output token dimension.
- expansion_factor (int, optional): The expansion factor of the
- intermediate token dimension. Defaults to 2.
- s (int, optional): The self-attention feature dimension.
- Defaults to 128.
- eps (float, optional): The minimum value in clamp. Defaults to 1e-5.
- dropout_rate (float, optional): The dropout rate. Defaults to 0.0.
- drop_path (float, optional): The drop path rate. Defaults to 0.0.
- attn_type (str, optional): Type of attention which should be one of
- the following options:
-
- - 'self-attn': Self-attention.
- - 'cross-attn': Cross-attention.
-
- Defaults to 'self-attn'.
- act_fn (str, optional): The activation function which should be one
- of the following options:
-
- - 'ReLU': ReLU activation.
- - 'SiLU': SiLU activation.
-
- Defaults to 'SiLU'.
- bias (bool, optional): Whether to use bias in linear layers.
- Defaults to False.
- use_rel_bias (bool, optional): Whether to use relative bias.
- Defaults to True.
- pos_enc (bool, optional): Whether to use rotary position
- embedding. Defaults to False.
-
- Reference:
- `Transformer Quality in Linear Time
- `_
- """
-
- def __init__(self,
- num_token,
- in_token_dims,
- out_token_dims,
- expansion_factor=2,
- s=128,
- eps=1e-5,
- dropout_rate=0.,
- drop_path=0.,
- attn_type='self-attn',
- act_fn='SiLU',
- bias=False,
- use_rel_bias=True,
- pos_enc=False):
-
- super(RTMCCBlock, self).__init__()
- self.s = s
- self.num_token = num_token
- self.use_rel_bias = use_rel_bias
- self.attn_type = attn_type
- self.pos_enc = pos_enc
- self.drop_path = DropPath(drop_path) \
- if drop_path > 0. else nn.Identity()
-
- self.e = int(in_token_dims * expansion_factor)
- if use_rel_bias:
- if attn_type == 'self-attn':
- self.w = nn.Parameter(
- torch.rand([2 * num_token - 1], dtype=torch.float))
- else:
- self.a = nn.Parameter(torch.rand([1, s], dtype=torch.float))
- self.b = nn.Parameter(torch.rand([1, s], dtype=torch.float))
- self.o = nn.Linear(self.e, out_token_dims, bias=bias)
-
- if attn_type == 'self-attn':
- self.uv = nn.Linear(in_token_dims, 2 * self.e + self.s, bias=bias)
- self.gamma = nn.Parameter(torch.rand((2, self.s)))
- self.beta = nn.Parameter(torch.rand((2, self.s)))
- else:
- self.uv = nn.Linear(in_token_dims, self.e + self.s, bias=bias)
- self.k_fc = nn.Linear(in_token_dims, self.s, bias=bias)
- self.v_fc = nn.Linear(in_token_dims, self.e, bias=bias)
- nn.init.xavier_uniform_(self.k_fc.weight)
- nn.init.xavier_uniform_(self.v_fc.weight)
-
- self.ln = ScaleNorm(in_token_dims, eps=eps)
-
- nn.init.xavier_uniform_(self.uv.weight)
-
- if act_fn == 'SiLU':
- assert digit_version(TORCH_VERSION) >= digit_version('1.7.0'), \
- 'SiLU activation requires PyTorch version >= 1.7'
-
- self.act_fn = nn.SiLU(True)
- else:
- self.act_fn = nn.ReLU(True)
-
- if in_token_dims == out_token_dims:
- self.shortcut = True
- self.res_scale = Scale(in_token_dims)
- else:
- self.shortcut = False
-
- self.sqrt_s = math.sqrt(s)
-
- self.dropout_rate = dropout_rate
-
- if dropout_rate > 0.:
- self.dropout = nn.Dropout(dropout_rate)
-
- def rel_pos_bias(self, seq_len, k_len=None):
- """Add relative position bias."""
-
- if self.attn_type == 'self-attn':
- t = F.pad(self.w[:2 * seq_len - 1], [0, seq_len]).repeat(seq_len)
- t = t[..., :-seq_len].reshape(-1, seq_len, 3 * seq_len - 2)
- r = (2 * seq_len - 1) // 2
- t = t[..., r:-r]
- else:
- a = rope(self.a.repeat(seq_len, 1), dim=0)
- b = rope(self.b.repeat(k_len, 1), dim=0)
- t = torch.bmm(a, b.permute(0, 2, 1))
- return t
-
- def _forward(self, inputs):
- """GAU Forward function."""
-
- if self.attn_type == 'self-attn':
- x = inputs
- else:
- x, k, v = inputs
-
- x = self.ln(x)
-
- # [B, K, in_token_dims] -> [B, K, e + e + s]
- uv = self.uv(x)
- uv = self.act_fn(uv)
-
- if self.attn_type == 'self-attn':
- # [B, K, e + e + s] -> [B, K, e], [B, K, e], [B, K, s]
- u, v, base = torch.split(uv, [self.e, self.e, self.s], dim=2)
- # [B, K, 1, s] * [1, 1, 2, s] + [2, s] -> [B, K, 2, s]
- base = base.unsqueeze(2) * self.gamma[None, None, :] + self.beta
-
- if self.pos_enc:
- base = rope(base, dim=1)
- # [B, K, 2, s] -> [B, K, s], [B, K, s]
- q, k = torch.unbind(base, dim=2)
-
- else:
- # [B, K, e + s] -> [B, K, e], [B, K, s]
- u, q = torch.split(uv, [self.e, self.s], dim=2)
-
- k = self.k_fc(k) # -> [B, K, s]
- v = self.v_fc(v) # -> [B, K, e]
-
- if self.pos_enc:
- q = rope(q, 1)
- k = rope(k, 1)
-
- # [B, K, s].permute() -> [B, s, K]
- # [B, K, s] x [B, s, K] -> [B, K, K]
- qk = torch.bmm(q, k.permute(0, 2, 1))
-
- if self.use_rel_bias:
- if self.attn_type == 'self-attn':
- bias = self.rel_pos_bias(q.size(1))
- else:
- bias = self.rel_pos_bias(q.size(1), k.size(1))
- qk += bias[:, :q.size(1), :k.size(1)]
- # [B, K, K]
- kernel = torch.square(F.relu(qk / self.sqrt_s))
-
- if self.dropout_rate > 0.:
- kernel = self.dropout(kernel)
- # [B, K, K] x [B, K, e] -> [B, K, e]
- x = u * torch.bmm(kernel, v)
- # [B, K, e] -> [B, K, out_token_dims]
- x = self.o(x)
-
- return x
-
- def forward(self, x):
- """Forward function."""
-
- if self.shortcut:
- if self.attn_type == 'cross-attn':
- res_shortcut = x[0]
- else:
- res_shortcut = x
- main_branch = self.drop_path(self._forward(x))
- return self.res_scale(res_shortcut) + main_branch
- else:
- return self.drop_path(self._forward(x))
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn.bricks import DropPath
+from mmengine.utils import digit_version
+from mmengine.utils.dl_utils import TORCH_VERSION
+
+
+def rope(x, dim):
+ """Applies Rotary Position Embedding to input tensor.
+
+ Args:
+ x (torch.Tensor): Input tensor.
+ dim (int | list[int]): The spatial dimension(s) to apply
+ rotary position embedding.
+
+ Returns:
+ torch.Tensor: The tensor after applying rotary position
+ embedding.
+
+ Reference:
+ `RoFormer: Enhanced Transformer with Rotary
+ Position Embedding `_
+ """
+ shape = x.shape
+ if isinstance(dim, int):
+ dim = [dim]
+
+ spatial_shape = [shape[i] for i in dim]
+ total_len = 1
+ for i in spatial_shape:
+ total_len *= i
+
+ position = torch.reshape(
+ torch.arange(total_len, dtype=torch.int, device=x.device),
+ spatial_shape)
+
+ for i in range(dim[-1] + 1, len(shape) - 1, 1):
+ position = torch.unsqueeze(position, dim=-1)
+
+ half_size = shape[-1] // 2
+ freq_seq = -torch.arange(
+ half_size, dtype=torch.int, device=x.device) / float(half_size)
+ inv_freq = 10000**-freq_seq
+
+ sinusoid = position[..., None] * inv_freq[None, None, :]
+
+ sin = torch.sin(sinusoid)
+ cos = torch.cos(sinusoid)
+ x1, x2 = torch.chunk(x, 2, dim=-1)
+
+ return torch.cat([x1 * cos - x2 * sin, x2 * cos + x1 * sin], dim=-1)
+
+
+class Scale(nn.Module):
+ """Scale vector by element multiplications.
+
+ Args:
+ dim (int): The dimension of the scale vector.
+ init_value (float, optional): The initial value of the scale vector.
+ Defaults to 1.0.
+ trainable (bool, optional): Whether the scale vector is trainable.
+ Defaults to True.
+ """
+
+ def __init__(self, dim, init_value=1., trainable=True):
+ super().__init__()
+ self.scale = nn.Parameter(
+ init_value * torch.ones(dim), requires_grad=trainable)
+
+ def forward(self, x):
+ """Forward function."""
+
+ return x * self.scale
+
+
+class ScaleNorm(nn.Module):
+ """Scale Norm.
+
+ Args:
+ dim (int): The dimension of the scale vector.
+ eps (float, optional): The minimum value in clamp. Defaults to 1e-5.
+
+ Reference:
+ `Transformers without Tears: Improving the Normalization
+ of Self-Attention `_
+ """
+
+ def __init__(self, dim, eps=1e-5):
+ super().__init__()
+ self.scale = dim**-0.5
+ self.eps = eps
+ self.g = nn.Parameter(torch.ones(1))
+
+ def forward(self, x):
+ """Forward function.
+
+ Args:
+ x (torch.Tensor): Input tensor.
+
+ Returns:
+ torch.Tensor: The tensor after applying scale norm.
+ """
+
+ norm = torch.norm(x, dim=2, keepdim=True) * self.scale
+ return x / norm.clamp(min=self.eps) * self.g
+
+
+class RTMCCBlock(nn.Module):
+ """Gated Attention Unit (GAU) in RTMBlock.
+
+ Args:
+ num_token (int): The number of tokens.
+ in_token_dims (int): The input token dimension.
+ out_token_dims (int): The output token dimension.
+ expansion_factor (int, optional): The expansion factor of the
+ intermediate token dimension. Defaults to 2.
+ s (int, optional): The self-attention feature dimension.
+ Defaults to 128.
+ eps (float, optional): The minimum value in clamp. Defaults to 1e-5.
+ dropout_rate (float, optional): The dropout rate. Defaults to 0.0.
+ drop_path (float, optional): The drop path rate. Defaults to 0.0.
+ attn_type (str, optional): Type of attention which should be one of
+ the following options:
+
+ - 'self-attn': Self-attention.
+ - 'cross-attn': Cross-attention.
+
+ Defaults to 'self-attn'.
+ act_fn (str, optional): The activation function which should be one
+ of the following options:
+
+ - 'ReLU': ReLU activation.
+ - 'SiLU': SiLU activation.
+
+ Defaults to 'SiLU'.
+ bias (bool, optional): Whether to use bias in linear layers.
+ Defaults to False.
+ use_rel_bias (bool, optional): Whether to use relative bias.
+ Defaults to True.
+ pos_enc (bool, optional): Whether to use rotary position
+ embedding. Defaults to False.
+
+ Reference:
+ `Transformer Quality in Linear Time
+ `_
+ """
+
+ def __init__(self,
+ num_token,
+ in_token_dims,
+ out_token_dims,
+ expansion_factor=2,
+ s=128,
+ eps=1e-5,
+ dropout_rate=0.,
+ drop_path=0.,
+ attn_type='self-attn',
+ act_fn='SiLU',
+ bias=False,
+ use_rel_bias=True,
+ pos_enc=False):
+
+ super(RTMCCBlock, self).__init__()
+ self.s = s
+ self.num_token = num_token
+ self.use_rel_bias = use_rel_bias
+ self.attn_type = attn_type
+ self.pos_enc = pos_enc
+ self.drop_path = DropPath(drop_path) \
+ if drop_path > 0. else nn.Identity()
+
+ self.e = int(in_token_dims * expansion_factor)
+ if use_rel_bias:
+ if attn_type == 'self-attn':
+ self.w = nn.Parameter(
+ torch.rand([2 * num_token - 1], dtype=torch.float))
+ else:
+ self.a = nn.Parameter(torch.rand([1, s], dtype=torch.float))
+ self.b = nn.Parameter(torch.rand([1, s], dtype=torch.float))
+ self.o = nn.Linear(self.e, out_token_dims, bias=bias)
+
+ if attn_type == 'self-attn':
+ self.uv = nn.Linear(in_token_dims, 2 * self.e + self.s, bias=bias)
+ self.gamma = nn.Parameter(torch.rand((2, self.s)))
+ self.beta = nn.Parameter(torch.rand((2, self.s)))
+ else:
+ self.uv = nn.Linear(in_token_dims, self.e + self.s, bias=bias)
+ self.k_fc = nn.Linear(in_token_dims, self.s, bias=bias)
+ self.v_fc = nn.Linear(in_token_dims, self.e, bias=bias)
+ nn.init.xavier_uniform_(self.k_fc.weight)
+ nn.init.xavier_uniform_(self.v_fc.weight)
+
+ self.ln = ScaleNorm(in_token_dims, eps=eps)
+
+ nn.init.xavier_uniform_(self.uv.weight)
+
+ if act_fn == 'SiLU':
+ assert digit_version(TORCH_VERSION) >= digit_version('1.7.0'), \
+ 'SiLU activation requires PyTorch version >= 1.7'
+
+ self.act_fn = nn.SiLU(True)
+ else:
+ self.act_fn = nn.ReLU(True)
+
+ if in_token_dims == out_token_dims:
+ self.shortcut = True
+ self.res_scale = Scale(in_token_dims)
+ else:
+ self.shortcut = False
+
+ self.sqrt_s = math.sqrt(s)
+
+ self.dropout_rate = dropout_rate
+
+ if dropout_rate > 0.:
+ self.dropout = nn.Dropout(dropout_rate)
+
+ def rel_pos_bias(self, seq_len, k_len=None):
+ """Add relative position bias."""
+
+ if self.attn_type == 'self-attn':
+ t = F.pad(self.w[:2 * seq_len - 1], [0, seq_len]).repeat(seq_len)
+ t = t[..., :-seq_len].reshape(-1, seq_len, 3 * seq_len - 2)
+ r = (2 * seq_len - 1) // 2
+ t = t[..., r:-r]
+ else:
+ a = rope(self.a.repeat(seq_len, 1), dim=0)
+ b = rope(self.b.repeat(k_len, 1), dim=0)
+ t = torch.bmm(a, b.permute(0, 2, 1))
+ return t
+
+ def _forward(self, inputs):
+ """GAU Forward function."""
+
+ if self.attn_type == 'self-attn':
+ x = inputs
+ else:
+ x, k, v = inputs
+
+ x = self.ln(x)
+
+ # [B, K, in_token_dims] -> [B, K, e + e + s]
+ uv = self.uv(x)
+ uv = self.act_fn(uv)
+
+ if self.attn_type == 'self-attn':
+ # [B, K, e + e + s] -> [B, K, e], [B, K, e], [B, K, s]
+ u, v, base = torch.split(uv, [self.e, self.e, self.s], dim=2)
+ # [B, K, 1, s] * [1, 1, 2, s] + [2, s] -> [B, K, 2, s]
+ base = base.unsqueeze(2) * self.gamma[None, None, :] + self.beta
+
+ if self.pos_enc:
+ base = rope(base, dim=1)
+ # [B, K, 2, s] -> [B, K, s], [B, K, s]
+ q, k = torch.unbind(base, dim=2)
+
+ else:
+ # [B, K, e + s] -> [B, K, e], [B, K, s]
+ u, q = torch.split(uv, [self.e, self.s], dim=2)
+
+ k = self.k_fc(k) # -> [B, K, s]
+ v = self.v_fc(v) # -> [B, K, e]
+
+ if self.pos_enc:
+ q = rope(q, 1)
+ k = rope(k, 1)
+
+ # [B, K, s].permute() -> [B, s, K]
+ # [B, K, s] x [B, s, K] -> [B, K, K]
+ qk = torch.bmm(q, k.permute(0, 2, 1))
+
+ if self.use_rel_bias:
+ if self.attn_type == 'self-attn':
+ bias = self.rel_pos_bias(q.size(1))
+ else:
+ bias = self.rel_pos_bias(q.size(1), k.size(1))
+ qk += bias[:, :q.size(1), :k.size(1)]
+ # [B, K, K]
+ kernel = torch.square(F.relu(qk / self.sqrt_s))
+
+ if self.dropout_rate > 0.:
+ kernel = self.dropout(kernel)
+ # [B, K, K] x [B, K, e] -> [B, K, e]
+ x = u * torch.bmm(kernel, v)
+ # [B, K, e] -> [B, K, out_token_dims]
+ x = self.o(x)
+
+ return x
+
+ def forward(self, x):
+ """Forward function."""
+
+ if self.shortcut:
+ if self.attn_type == 'cross-attn':
+ res_shortcut = x[0]
+ else:
+ res_shortcut = x
+ main_branch = self.drop_path(self._forward(x))
+ return self.res_scale(res_shortcut) + main_branch
+ else:
+ return self.drop_path(self._forward(x))
diff --git a/mmpose/models/utils/transformer.py b/mmpose/models/utils/transformer.py
index 103b9e9970..a2d5ec2022 100644
--- a/mmpose/models/utils/transformer.py
+++ b/mmpose/models/utils/transformer.py
@@ -1,369 +1,369 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import math
-from typing import Sequence
-
-import torch.nn as nn
-import torch.nn.functional as F
-from mmcv.cnn import build_conv_layer, build_norm_layer
-from mmengine.model import BaseModule
-from mmengine.utils import to_2tuple
-
-
-def nlc_to_nchw(x, hw_shape):
- """Convert [N, L, C] shape tensor to [N, C, H, W] shape tensor.
-
- Args:
- x (Tensor): The input tensor of shape [N, L, C] before conversion.
- hw_shape (Sequence[int]): The height and width of output feature map.
-
- Returns:
- Tensor: The output tensor of shape [N, C, H, W] after conversion.
- """
- H, W = hw_shape
- assert len(x.shape) == 3
- B, L, C = x.shape
- assert L == H * W, 'The seq_len does not match H, W'
- return x.transpose(1, 2).reshape(B, C, H, W).contiguous()
-
-
-def nchw_to_nlc(x):
- """Flatten [N, C, H, W] shape tensor to [N, L, C] shape tensor.
-
- Args:
- x (Tensor): The input tensor of shape [N, C, H, W] before conversion.
-
- Returns:
- Tensor: The output tensor of shape [N, L, C] after conversion.
- """
- assert len(x.shape) == 4
- return x.flatten(2).transpose(1, 2).contiguous()
-
-
-class AdaptivePadding(nn.Module):
- """Applies padding to input (if needed) so that input can get fully covered
- by filter you specified. It support two modes "same" and "corner". The
- "same" mode is same with "SAME" padding mode in TensorFlow, pad zero around
- input. The "corner" mode would pad zero to bottom right.
-
- Args:
- kernel_size (int | tuple): Size of the kernel:
- stride (int | tuple): Stride of the filter. Default: 1:
- dilation (int | tuple): Spacing between kernel elements.
- Default: 1
- padding (str): Support "same" and "corner", "corner" mode
- would pad zero to bottom right, and "same" mode would
- pad zero around input. Default: "corner".
- Example:
- >>> kernel_size = 16
- >>> stride = 16
- >>> dilation = 1
- >>> input = torch.rand(1, 1, 15, 17)
- >>> adap_pad = AdaptivePadding(
- >>> kernel_size=kernel_size,
- >>> stride=stride,
- >>> dilation=dilation,
- >>> padding="corner")
- >>> out = adap_pad(input)
- >>> assert (out.shape[2], out.shape[3]) == (16, 32)
- >>> input = torch.rand(1, 1, 16, 17)
- >>> out = adap_pad(input)
- >>> assert (out.shape[2], out.shape[3]) == (16, 32)
- """
-
- def __init__(self, kernel_size=1, stride=1, dilation=1, padding='corner'):
-
- super(AdaptivePadding, self).__init__()
-
- assert padding in ('same', 'corner')
-
- kernel_size = to_2tuple(kernel_size)
- stride = to_2tuple(stride)
- padding = to_2tuple(padding)
- dilation = to_2tuple(dilation)
-
- self.padding = padding
- self.kernel_size = kernel_size
- self.stride = stride
- self.dilation = dilation
-
- def get_pad_shape(self, input_shape):
- """Get horizontal and vertical padding shapes."""
-
- input_h, input_w = input_shape
- kernel_h, kernel_w = self.kernel_size
- stride_h, stride_w = self.stride
- output_h = math.ceil(input_h / stride_h)
- output_w = math.ceil(input_w / stride_w)
- pad_h = max((output_h - 1) * stride_h +
- (kernel_h - 1) * self.dilation[0] + 1 - input_h, 0)
- pad_w = max((output_w - 1) * stride_w +
- (kernel_w - 1) * self.dilation[1] + 1 - input_w, 0)
- return pad_h, pad_w
-
- def forward(self, x):
- """Forward function."""
-
- pad_h, pad_w = self.get_pad_shape(x.size()[-2:])
- if pad_h > 0 or pad_w > 0:
- if self.padding == 'corner':
- x = F.pad(x, [0, pad_w, 0, pad_h])
- elif self.padding == 'same':
- x = F.pad(x, [
- pad_w // 2, pad_w - pad_w // 2, pad_h // 2,
- pad_h - pad_h // 2
- ])
- return x
-
-
-class PatchEmbed(BaseModule):
- """Image to Patch Embedding.
-
- We use a conv layer to implement PatchEmbed.
-
- Args:
- in_channels (int): The num of input channels. Default: 3
- embed_dims (int): The dimensions of embedding. Default: 768
- conv_type (str): The config dict for embedding
- conv layer type selection. Default: "Conv2d.
- kernel_size (int): The kernel_size of embedding conv. Default: 16.
- stride (int): The slide stride of embedding conv.
- Default: None (Would be set as `kernel_size`).
- padding (int | tuple | string ): The padding length of
- embedding conv. When it is a string, it means the mode
- of adaptive padding, support "same" and "corner" now.
- Default: "corner".
- dilation (int): The dilation rate of embedding conv. Default: 1.
- bias (bool): Bias of embed conv. Default: True.
- norm_cfg (dict, optional): Config dict for normalization layer.
- Default: None.
- input_size (int | tuple | None): The size of input, which will be
- used to calculate the out size. Only work when `dynamic_size`
- is False. Default: None.
- init_cfg (`mmcv.ConfigDict`, optional): The Config for initialization.
- Default: None.
- """
-
- def __init__(
- self,
- in_channels=3,
- embed_dims=768,
- conv_type='Conv2d',
- kernel_size=16,
- stride=16,
- padding='corner',
- dilation=1,
- bias=True,
- norm_cfg=None,
- input_size=None,
- init_cfg=None,
- ):
- super(PatchEmbed, self).__init__(init_cfg=init_cfg)
-
- self.embed_dims = embed_dims
- if stride is None:
- stride = kernel_size
-
- kernel_size = to_2tuple(kernel_size)
- stride = to_2tuple(stride)
- dilation = to_2tuple(dilation)
-
- if isinstance(padding, str):
- self.adap_padding = AdaptivePadding(
- kernel_size=kernel_size,
- stride=stride,
- dilation=dilation,
- padding=padding)
- # disable the padding of conv
- padding = 0
- else:
- self.adap_padding = None
- padding = to_2tuple(padding)
-
- self.projection = build_conv_layer(
- dict(type=conv_type),
- in_channels=in_channels,
- out_channels=embed_dims,
- kernel_size=kernel_size,
- stride=stride,
- padding=padding,
- dilation=dilation,
- bias=bias)
-
- if norm_cfg is not None:
- self.norm = build_norm_layer(norm_cfg, embed_dims)[1]
- else:
- self.norm = None
-
- if input_size:
- input_size = to_2tuple(input_size)
- # `init_out_size` would be used outside to
- # calculate the num_patches
- # when `use_abs_pos_embed` outside
- self.init_input_size = input_size
- if self.adap_padding:
- pad_h, pad_w = self.adap_padding.get_pad_shape(input_size)
- input_h, input_w = input_size
- input_h = input_h + pad_h
- input_w = input_w + pad_w
- input_size = (input_h, input_w)
-
- # https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html
- h_out = (input_size[0] + 2 * padding[0] - dilation[0] *
- (kernel_size[0] - 1) - 1) // stride[0] + 1
- w_out = (input_size[1] + 2 * padding[1] - dilation[1] *
- (kernel_size[1] - 1) - 1) // stride[1] + 1
- self.init_out_size = (h_out, w_out)
- else:
- self.init_input_size = None
- self.init_out_size = None
-
- def forward(self, x):
- """
- Args:
- x (Tensor): Has shape (B, C, H, W). In most case, C is 3.
-
- Returns:
- tuple: Contains merged results and its spatial shape.
-
- - x (Tensor): Has shape (B, out_h * out_w, embed_dims)
- - out_size (tuple[int]): Spatial shape of x, arrange as
- (out_h, out_w).
- """
-
- if self.adap_padding:
- x = self.adap_padding(x)
-
- x = self.projection(x)
- out_size = (x.shape[2], x.shape[3])
- x = x.flatten(2).transpose(1, 2)
- if self.norm is not None:
- x = self.norm(x)
- return x, out_size
-
-
-class PatchMerging(BaseModule):
- """Merge patch feature map.
-
- This layer groups feature map by kernel_size, and applies norm and linear
- layers to the grouped feature map. Our implementation uses `nn.Unfold` to
- merge patch, which is about 25% faster than original implementation.
- Instead, we need to modify pretrained models for compatibility.
-
- Args:
- in_channels (int): The num of input channels.
- to gets fully covered by filter and stride you specified..
- Default: True.
- out_channels (int): The num of output channels.
- kernel_size (int | tuple, optional): the kernel size in the unfold
- layer. Defaults to 2.
- stride (int | tuple, optional): the stride of the sliding blocks in the
- unfold layer. Default: None. (Would be set as `kernel_size`)
- padding (int | tuple | string ): The padding length of
- embedding conv. When it is a string, it means the mode
- of adaptive padding, support "same" and "corner" now.
- Default: "corner".
- dilation (int | tuple, optional): dilation parameter in the unfold
- layer. Default: 1.
- bias (bool, optional): Whether to add bias in linear layer or not.
- Defaults: False.
- norm_cfg (dict, optional): Config dict for normalization layer.
- Default: dict(type='LN').
- init_cfg (dict, optional): The extra config for initialization.
- Default: None.
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- kernel_size=2,
- stride=None,
- padding='corner',
- dilation=1,
- bias=False,
- norm_cfg=dict(type='LN'),
- init_cfg=None):
- super().__init__(init_cfg=init_cfg)
- self.in_channels = in_channels
- self.out_channels = out_channels
- if stride:
- stride = stride
- else:
- stride = kernel_size
-
- kernel_size = to_2tuple(kernel_size)
- stride = to_2tuple(stride)
- dilation = to_2tuple(dilation)
-
- if isinstance(padding, str):
- self.adap_padding = AdaptivePadding(
- kernel_size=kernel_size,
- stride=stride,
- dilation=dilation,
- padding=padding)
- # disable the padding of unfold
- padding = 0
- else:
- self.adap_padding = None
-
- padding = to_2tuple(padding)
- self.sampler = nn.Unfold(
- kernel_size=kernel_size,
- dilation=dilation,
- padding=padding,
- stride=stride)
-
- sample_dim = kernel_size[0] * kernel_size[1] * in_channels
-
- if norm_cfg is not None:
- self.norm = build_norm_layer(norm_cfg, sample_dim)[1]
- else:
- self.norm = None
-
- self.reduction = nn.Linear(sample_dim, out_channels, bias=bias)
-
- def forward(self, x, input_size):
- """
- Args:
- x (Tensor): Has shape (B, H*W, C_in).
- input_size (tuple[int]): The spatial shape of x, arrange as (H, W).
- Default: None.
-
- Returns:
- tuple: Contains merged results and its spatial shape.
-
- - x (Tensor): Has shape (B, Merged_H * Merged_W, C_out)
- - out_size (tuple[int]): Spatial shape of x, arrange as
- (Merged_H, Merged_W).
- """
- B, L, C = x.shape
- assert isinstance(input_size, Sequence), f'Expect ' \
- f'input_size is ' \
- f'`Sequence` ' \
- f'but get {input_size}'
-
- H, W = input_size
- assert L == H * W, 'input feature has wrong size'
-
- x = x.view(B, H, W, C).permute([0, 3, 1, 2]) # B, C, H, W
- # Use nn.Unfold to merge patch. About 25% faster than original method,
- # but need to modify pretrained model for compatibility
-
- if self.adap_padding:
- x = self.adap_padding(x)
- H, W = x.shape[-2:]
-
- x = self.sampler(x)
- # if kernel_size=2 and stride=2, x should has shape (B, 4*C, H/2*W/2)
-
- out_h = (H + 2 * self.sampler.padding[0] - self.sampler.dilation[0] *
- (self.sampler.kernel_size[0] - 1) -
- 1) // self.sampler.stride[0] + 1
- out_w = (W + 2 * self.sampler.padding[1] - self.sampler.dilation[1] *
- (self.sampler.kernel_size[1] - 1) -
- 1) // self.sampler.stride[1] + 1
-
- output_size = (out_h, out_w)
- x = x.transpose(1, 2) # B, H/2*W/2, 4*C
- x = self.norm(x) if self.norm else x
- x = self.reduction(x)
- return x, output_size
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Sequence
+
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import build_conv_layer, build_norm_layer
+from mmengine.model import BaseModule
+from mmengine.utils import to_2tuple
+
+
+def nlc_to_nchw(x, hw_shape):
+ """Convert [N, L, C] shape tensor to [N, C, H, W] shape tensor.
+
+ Args:
+ x (Tensor): The input tensor of shape [N, L, C] before conversion.
+ hw_shape (Sequence[int]): The height and width of output feature map.
+
+ Returns:
+ Tensor: The output tensor of shape [N, C, H, W] after conversion.
+ """
+ H, W = hw_shape
+ assert len(x.shape) == 3
+ B, L, C = x.shape
+ assert L == H * W, 'The seq_len does not match H, W'
+ return x.transpose(1, 2).reshape(B, C, H, W).contiguous()
+
+
+def nchw_to_nlc(x):
+ """Flatten [N, C, H, W] shape tensor to [N, L, C] shape tensor.
+
+ Args:
+ x (Tensor): The input tensor of shape [N, C, H, W] before conversion.
+
+ Returns:
+ Tensor: The output tensor of shape [N, L, C] after conversion.
+ """
+ assert len(x.shape) == 4
+ return x.flatten(2).transpose(1, 2).contiguous()
+
+
+class AdaptivePadding(nn.Module):
+ """Applies padding to input (if needed) so that input can get fully covered
+ by filter you specified. It support two modes "same" and "corner". The
+ "same" mode is same with "SAME" padding mode in TensorFlow, pad zero around
+ input. The "corner" mode would pad zero to bottom right.
+
+ Args:
+ kernel_size (int | tuple): Size of the kernel:
+ stride (int | tuple): Stride of the filter. Default: 1:
+ dilation (int | tuple): Spacing between kernel elements.
+ Default: 1
+ padding (str): Support "same" and "corner", "corner" mode
+ would pad zero to bottom right, and "same" mode would
+ pad zero around input. Default: "corner".
+ Example:
+ >>> kernel_size = 16
+ >>> stride = 16
+ >>> dilation = 1
+ >>> input = torch.rand(1, 1, 15, 17)
+ >>> adap_pad = AdaptivePadding(
+ >>> kernel_size=kernel_size,
+ >>> stride=stride,
+ >>> dilation=dilation,
+ >>> padding="corner")
+ >>> out = adap_pad(input)
+ >>> assert (out.shape[2], out.shape[3]) == (16, 32)
+ >>> input = torch.rand(1, 1, 16, 17)
+ >>> out = adap_pad(input)
+ >>> assert (out.shape[2], out.shape[3]) == (16, 32)
+ """
+
+ def __init__(self, kernel_size=1, stride=1, dilation=1, padding='corner'):
+
+ super(AdaptivePadding, self).__init__()
+
+ assert padding in ('same', 'corner')
+
+ kernel_size = to_2tuple(kernel_size)
+ stride = to_2tuple(stride)
+ padding = to_2tuple(padding)
+ dilation = to_2tuple(dilation)
+
+ self.padding = padding
+ self.kernel_size = kernel_size
+ self.stride = stride
+ self.dilation = dilation
+
+ def get_pad_shape(self, input_shape):
+ """Get horizontal and vertical padding shapes."""
+
+ input_h, input_w = input_shape
+ kernel_h, kernel_w = self.kernel_size
+ stride_h, stride_w = self.stride
+ output_h = math.ceil(input_h / stride_h)
+ output_w = math.ceil(input_w / stride_w)
+ pad_h = max((output_h - 1) * stride_h +
+ (kernel_h - 1) * self.dilation[0] + 1 - input_h, 0)
+ pad_w = max((output_w - 1) * stride_w +
+ (kernel_w - 1) * self.dilation[1] + 1 - input_w, 0)
+ return pad_h, pad_w
+
+ def forward(self, x):
+ """Forward function."""
+
+ pad_h, pad_w = self.get_pad_shape(x.size()[-2:])
+ if pad_h > 0 or pad_w > 0:
+ if self.padding == 'corner':
+ x = F.pad(x, [0, pad_w, 0, pad_h])
+ elif self.padding == 'same':
+ x = F.pad(x, [
+ pad_w // 2, pad_w - pad_w // 2, pad_h // 2,
+ pad_h - pad_h // 2
+ ])
+ return x
+
+
+class PatchEmbed(BaseModule):
+ """Image to Patch Embedding.
+
+ We use a conv layer to implement PatchEmbed.
+
+ Args:
+ in_channels (int): The num of input channels. Default: 3
+ embed_dims (int): The dimensions of embedding. Default: 768
+ conv_type (str): The config dict for embedding
+ conv layer type selection. Default: "Conv2d.
+ kernel_size (int): The kernel_size of embedding conv. Default: 16.
+ stride (int): The slide stride of embedding conv.
+ Default: None (Would be set as `kernel_size`).
+ padding (int | tuple | string ): The padding length of
+ embedding conv. When it is a string, it means the mode
+ of adaptive padding, support "same" and "corner" now.
+ Default: "corner".
+ dilation (int): The dilation rate of embedding conv. Default: 1.
+ bias (bool): Bias of embed conv. Default: True.
+ norm_cfg (dict, optional): Config dict for normalization layer.
+ Default: None.
+ input_size (int | tuple | None): The size of input, which will be
+ used to calculate the out size. Only work when `dynamic_size`
+ is False. Default: None.
+ init_cfg (`mmcv.ConfigDict`, optional): The Config for initialization.
+ Default: None.
+ """
+
+ def __init__(
+ self,
+ in_channels=3,
+ embed_dims=768,
+ conv_type='Conv2d',
+ kernel_size=16,
+ stride=16,
+ padding='corner',
+ dilation=1,
+ bias=True,
+ norm_cfg=None,
+ input_size=None,
+ init_cfg=None,
+ ):
+ super(PatchEmbed, self).__init__(init_cfg=init_cfg)
+
+ self.embed_dims = embed_dims
+ if stride is None:
+ stride = kernel_size
+
+ kernel_size = to_2tuple(kernel_size)
+ stride = to_2tuple(stride)
+ dilation = to_2tuple(dilation)
+
+ if isinstance(padding, str):
+ self.adap_padding = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ # disable the padding of conv
+ padding = 0
+ else:
+ self.adap_padding = None
+ padding = to_2tuple(padding)
+
+ self.projection = build_conv_layer(
+ dict(type=conv_type),
+ in_channels=in_channels,
+ out_channels=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ if norm_cfg is not None:
+ self.norm = build_norm_layer(norm_cfg, embed_dims)[1]
+ else:
+ self.norm = None
+
+ if input_size:
+ input_size = to_2tuple(input_size)
+ # `init_out_size` would be used outside to
+ # calculate the num_patches
+ # when `use_abs_pos_embed` outside
+ self.init_input_size = input_size
+ if self.adap_padding:
+ pad_h, pad_w = self.adap_padding.get_pad_shape(input_size)
+ input_h, input_w = input_size
+ input_h = input_h + pad_h
+ input_w = input_w + pad_w
+ input_size = (input_h, input_w)
+
+ # https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html
+ h_out = (input_size[0] + 2 * padding[0] - dilation[0] *
+ (kernel_size[0] - 1) - 1) // stride[0] + 1
+ w_out = (input_size[1] + 2 * padding[1] - dilation[1] *
+ (kernel_size[1] - 1) - 1) // stride[1] + 1
+ self.init_out_size = (h_out, w_out)
+ else:
+ self.init_input_size = None
+ self.init_out_size = None
+
+ def forward(self, x):
+ """
+ Args:
+ x (Tensor): Has shape (B, C, H, W). In most case, C is 3.
+
+ Returns:
+ tuple: Contains merged results and its spatial shape.
+
+ - x (Tensor): Has shape (B, out_h * out_w, embed_dims)
+ - out_size (tuple[int]): Spatial shape of x, arrange as
+ (out_h, out_w).
+ """
+
+ if self.adap_padding:
+ x = self.adap_padding(x)
+
+ x = self.projection(x)
+ out_size = (x.shape[2], x.shape[3])
+ x = x.flatten(2).transpose(1, 2)
+ if self.norm is not None:
+ x = self.norm(x)
+ return x, out_size
+
+
+class PatchMerging(BaseModule):
+ """Merge patch feature map.
+
+ This layer groups feature map by kernel_size, and applies norm and linear
+ layers to the grouped feature map. Our implementation uses `nn.Unfold` to
+ merge patch, which is about 25% faster than original implementation.
+ Instead, we need to modify pretrained models for compatibility.
+
+ Args:
+ in_channels (int): The num of input channels.
+ to gets fully covered by filter and stride you specified..
+ Default: True.
+ out_channels (int): The num of output channels.
+ kernel_size (int | tuple, optional): the kernel size in the unfold
+ layer. Defaults to 2.
+ stride (int | tuple, optional): the stride of the sliding blocks in the
+ unfold layer. Default: None. (Would be set as `kernel_size`)
+ padding (int | tuple | string ): The padding length of
+ embedding conv. When it is a string, it means the mode
+ of adaptive padding, support "same" and "corner" now.
+ Default: "corner".
+ dilation (int | tuple, optional): dilation parameter in the unfold
+ layer. Default: 1.
+ bias (bool, optional): Whether to add bias in linear layer or not.
+ Defaults: False.
+ norm_cfg (dict, optional): Config dict for normalization layer.
+ Default: dict(type='LN').
+ init_cfg (dict, optional): The extra config for initialization.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size=2,
+ stride=None,
+ padding='corner',
+ dilation=1,
+ bias=False,
+ norm_cfg=dict(type='LN'),
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ if stride:
+ stride = stride
+ else:
+ stride = kernel_size
+
+ kernel_size = to_2tuple(kernel_size)
+ stride = to_2tuple(stride)
+ dilation = to_2tuple(dilation)
+
+ if isinstance(padding, str):
+ self.adap_padding = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ # disable the padding of unfold
+ padding = 0
+ else:
+ self.adap_padding = None
+
+ padding = to_2tuple(padding)
+ self.sampler = nn.Unfold(
+ kernel_size=kernel_size,
+ dilation=dilation,
+ padding=padding,
+ stride=stride)
+
+ sample_dim = kernel_size[0] * kernel_size[1] * in_channels
+
+ if norm_cfg is not None:
+ self.norm = build_norm_layer(norm_cfg, sample_dim)[1]
+ else:
+ self.norm = None
+
+ self.reduction = nn.Linear(sample_dim, out_channels, bias=bias)
+
+ def forward(self, x, input_size):
+ """
+ Args:
+ x (Tensor): Has shape (B, H*W, C_in).
+ input_size (tuple[int]): The spatial shape of x, arrange as (H, W).
+ Default: None.
+
+ Returns:
+ tuple: Contains merged results and its spatial shape.
+
+ - x (Tensor): Has shape (B, Merged_H * Merged_W, C_out)
+ - out_size (tuple[int]): Spatial shape of x, arrange as
+ (Merged_H, Merged_W).
+ """
+ B, L, C = x.shape
+ assert isinstance(input_size, Sequence), f'Expect ' \
+ f'input_size is ' \
+ f'`Sequence` ' \
+ f'but get {input_size}'
+
+ H, W = input_size
+ assert L == H * W, 'input feature has wrong size'
+
+ x = x.view(B, H, W, C).permute([0, 3, 1, 2]) # B, C, H, W
+ # Use nn.Unfold to merge patch. About 25% faster than original method,
+ # but need to modify pretrained model for compatibility
+
+ if self.adap_padding:
+ x = self.adap_padding(x)
+ H, W = x.shape[-2:]
+
+ x = self.sampler(x)
+ # if kernel_size=2 and stride=2, x should has shape (B, 4*C, H/2*W/2)
+
+ out_h = (H + 2 * self.sampler.padding[0] - self.sampler.dilation[0] *
+ (self.sampler.kernel_size[0] - 1) -
+ 1) // self.sampler.stride[0] + 1
+ out_w = (W + 2 * self.sampler.padding[1] - self.sampler.dilation[1] *
+ (self.sampler.kernel_size[1] - 1) -
+ 1) // self.sampler.stride[1] + 1
+
+ output_size = (out_h, out_w)
+ x = x.transpose(1, 2) # B, H/2*W/2, 4*C
+ x = self.norm(x) if self.norm else x
+ x = self.reduction(x)
+ return x, output_size
diff --git a/mmpose/models/utils/tta.py b/mmpose/models/utils/tta.py
index 41d2f2fd47..77dbdd2dae 100644
--- a/mmpose/models/utils/tta.py
+++ b/mmpose/models/utils/tta.py
@@ -1,183 +1,183 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import List, Optional, Tuple
-
-import torch
-import torch.nn.functional as F
-from torch import Tensor
-
-
-def flip_heatmaps(heatmaps: Tensor,
- flip_indices: Optional[List[int]] = None,
- flip_mode: str = 'heatmap',
- shift_heatmap: bool = True):
- """Flip heatmaps for test-time augmentation.
-
- Args:
- heatmaps (Tensor): The heatmaps to flip. Should be a tensor in shape
- [B, C, H, W]
- flip_indices (List[int]): The indices of each keypoint's symmetric
- keypoint. Defaults to ``None``
- flip_mode (str): Specify the flipping mode. Options are:
-
- - ``'heatmap'``: horizontally flip the heatmaps and swap heatmaps
- of symmetric keypoints according to ``flip_indices``
- - ``'udp_combined'``: similar to ``'heatmap'`` mode but further
- flip the x_offset values
- - ``'offset'``: horizontally flip the offset fields and swap
- heatmaps of symmetric keypoints according to
- ``flip_indices``. x_offset values are also reversed
- shift_heatmap (bool): Shift the flipped heatmaps to align with the
- original heatmaps and improve accuracy. Defaults to ``True``
-
- Returns:
- Tensor: flipped heatmaps in shape [B, C, H, W]
- """
-
- if flip_mode == 'heatmap':
- heatmaps = heatmaps.flip(-1)
- if flip_indices is not None:
- assert len(flip_indices) == heatmaps.shape[1]
- heatmaps = heatmaps[:, flip_indices]
- elif flip_mode == 'udp_combined':
- B, C, H, W = heatmaps.shape
- heatmaps = heatmaps.view(B, C // 3, 3, H, W)
- heatmaps = heatmaps.flip(-1)
- if flip_indices is not None:
- assert len(flip_indices) == C // 3
- heatmaps = heatmaps[:, flip_indices]
- heatmaps[:, :, 1] = -heatmaps[:, :, 1]
- heatmaps = heatmaps.view(B, C, H, W)
-
- elif flip_mode == 'offset':
- B, C, H, W = heatmaps.shape
- heatmaps = heatmaps.view(B, C // 2, -1, H, W)
- heatmaps = heatmaps.flip(-1)
- if flip_indices is not None:
- assert len(flip_indices) == C // 2
- heatmaps = heatmaps[:, flip_indices]
- heatmaps[:, :, 0] = -heatmaps[:, :, 0]
- heatmaps = heatmaps.view(B, C, H, W)
-
- else:
- raise ValueError(f'Invalid flip_mode value "{flip_mode}"')
-
- if shift_heatmap:
- # clone data to avoid unexpected in-place operation when using CPU
- heatmaps[..., 1:] = heatmaps[..., :-1].clone()
-
- return heatmaps
-
-
-def flip_vectors(x_labels: Tensor, y_labels: Tensor, flip_indices: List[int]):
- """Flip instance-level labels in specific axis for test-time augmentation.
-
- Args:
- x_labels (Tensor): The vector labels in x-axis to flip. Should be
- a tensor in shape [B, C, Wx]
- y_labels (Tensor): The vector labels in y-axis to flip. Should be
- a tensor in shape [B, C, Wy]
- flip_indices (List[int]): The indices of each keypoint's symmetric
- keypoint
- """
- assert x_labels.ndim == 3 and y_labels.ndim == 3
- assert len(flip_indices) == x_labels.shape[1] and len(
- flip_indices) == y_labels.shape[1]
- x_labels = x_labels[:, flip_indices].flip(-1)
- y_labels = y_labels[:, flip_indices]
-
- return x_labels, y_labels
-
-
-def flip_coordinates(coords: Tensor, flip_indices: List[int],
- shift_coords: bool, input_size: Tuple[int, int]):
- """Flip normalized coordinates for test-time augmentation.
-
- Args:
- coords (Tensor): The coordinates to flip. Should be a tensor in shape
- [B, K, D]
- flip_indices (List[int]): The indices of each keypoint's symmetric
- keypoint
- shift_coords (bool): Shift the flipped coordinates to align with the
- original coordinates and improve accuracy. Defaults to ``True``
- input_size (Tuple[int, int]): The size of input image in [w, h]
- """
- assert coords.ndim == 3
- assert len(flip_indices) == coords.shape[1]
-
- coords[:, :, 0] = 1.0 - coords[:, :, 0]
-
- if shift_coords:
- img_width = input_size[0]
- coords[:, :, 0] -= 1.0 / img_width
-
- coords = coords[:, flip_indices]
- return coords
-
-
-def flip_visibility(vis: Tensor, flip_indices: List[int]):
- """Flip keypoints visibility for test-time augmentation.
-
- Args:
- vis (Tensor): The keypoints visibility to flip. Should be a tensor
- in shape [B, K]
- flip_indices (List[int]): The indices of each keypoint's symmetric
- keypoint
- """
- assert vis.ndim == 2
-
- vis = vis[:, flip_indices]
- return vis
-
-
-def aggregate_heatmaps(heatmaps: List[Tensor],
- size: Optional[Tuple[int, int]],
- align_corners: bool = False,
- mode: str = 'average'):
- """Aggregate multiple heatmaps.
-
- Args:
- heatmaps (List[Tensor]): Multiple heatmaps to aggregate. Each should
- be in shape (B, C, H, W)
- size (Tuple[int, int], optional): The target size in (w, h). All
- heatmaps will be resized to the target size. If not given, the
- first heatmap tensor's width and height will be used as the target
- size. Defaults to ``None``
- align_corners (bool): Whether align corners when resizing heatmaps.
- Defaults to ``False``
- mode (str): Aggregation mode in one of the following:
-
- - ``'average'``: Get average of heatmaps. All heatmaps mush have
- the same channel number
- - ``'concat'``: Concate the heatmaps at the channel dim
- """
-
- if mode not in {'average', 'concat'}:
- raise ValueError(f'Invalid aggregation mode `{mode}`')
-
- if size is None:
- h, w = heatmaps[0].shape[2:4]
- else:
- w, h = size
-
- for i, _heatmaps in enumerate(heatmaps):
- assert _heatmaps.ndim == 4
- if mode == 'average':
- assert _heatmaps.shape[:2] == heatmaps[0].shape[:2]
- else:
- assert _heatmaps.shape[0] == heatmaps[0].shape[0]
-
- if _heatmaps.shape[2:4] != (h, w):
- heatmaps[i] = F.interpolate(
- _heatmaps,
- size=(h, w),
- mode='bilinear',
- align_corners=align_corners)
-
- if mode == 'average':
- output = sum(heatmaps).div(len(heatmaps))
- elif mode == 'concat':
- output = torch.cat(heatmaps, dim=1)
- else:
- raise ValueError()
-
- return output
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple
+
+import torch
+import torch.nn.functional as F
+from torch import Tensor
+
+
+def flip_heatmaps(heatmaps: Tensor,
+ flip_indices: Optional[List[int]] = None,
+ flip_mode: str = 'heatmap',
+ shift_heatmap: bool = True):
+ """Flip heatmaps for test-time augmentation.
+
+ Args:
+ heatmaps (Tensor): The heatmaps to flip. Should be a tensor in shape
+ [B, C, H, W]
+ flip_indices (List[int]): The indices of each keypoint's symmetric
+ keypoint. Defaults to ``None``
+ flip_mode (str): Specify the flipping mode. Options are:
+
+ - ``'heatmap'``: horizontally flip the heatmaps and swap heatmaps
+ of symmetric keypoints according to ``flip_indices``
+ - ``'udp_combined'``: similar to ``'heatmap'`` mode but further
+ flip the x_offset values
+ - ``'offset'``: horizontally flip the offset fields and swap
+ heatmaps of symmetric keypoints according to
+ ``flip_indices``. x_offset values are also reversed
+ shift_heatmap (bool): Shift the flipped heatmaps to align with the
+ original heatmaps and improve accuracy. Defaults to ``True``
+
+ Returns:
+ Tensor: flipped heatmaps in shape [B, C, H, W]
+ """
+
+ if flip_mode == 'heatmap':
+ heatmaps = heatmaps.flip(-1)
+ if flip_indices is not None:
+ assert len(flip_indices) == heatmaps.shape[1]
+ heatmaps = heatmaps[:, flip_indices]
+ elif flip_mode == 'udp_combined':
+ B, C, H, W = heatmaps.shape
+ heatmaps = heatmaps.view(B, C // 3, 3, H, W)
+ heatmaps = heatmaps.flip(-1)
+ if flip_indices is not None:
+ assert len(flip_indices) == C // 3
+ heatmaps = heatmaps[:, flip_indices]
+ heatmaps[:, :, 1] = -heatmaps[:, :, 1]
+ heatmaps = heatmaps.view(B, C, H, W)
+
+ elif flip_mode == 'offset':
+ B, C, H, W = heatmaps.shape
+ heatmaps = heatmaps.view(B, C // 2, -1, H, W)
+ heatmaps = heatmaps.flip(-1)
+ if flip_indices is not None:
+ assert len(flip_indices) == C // 2
+ heatmaps = heatmaps[:, flip_indices]
+ heatmaps[:, :, 0] = -heatmaps[:, :, 0]
+ heatmaps = heatmaps.view(B, C, H, W)
+
+ else:
+ raise ValueError(f'Invalid flip_mode value "{flip_mode}"')
+
+ if shift_heatmap:
+ # clone data to avoid unexpected in-place operation when using CPU
+ heatmaps[..., 1:] = heatmaps[..., :-1].clone()
+
+ return heatmaps
+
+
+def flip_vectors(x_labels: Tensor, y_labels: Tensor, flip_indices: List[int]):
+ """Flip instance-level labels in specific axis for test-time augmentation.
+
+ Args:
+ x_labels (Tensor): The vector labels in x-axis to flip. Should be
+ a tensor in shape [B, C, Wx]
+ y_labels (Tensor): The vector labels in y-axis to flip. Should be
+ a tensor in shape [B, C, Wy]
+ flip_indices (List[int]): The indices of each keypoint's symmetric
+ keypoint
+ """
+ assert x_labels.ndim == 3 and y_labels.ndim == 3
+ assert len(flip_indices) == x_labels.shape[1] and len(
+ flip_indices) == y_labels.shape[1]
+ x_labels = x_labels[:, flip_indices].flip(-1)
+ y_labels = y_labels[:, flip_indices]
+
+ return x_labels, y_labels
+
+
+def flip_coordinates(coords: Tensor, flip_indices: List[int],
+ shift_coords: bool, input_size: Tuple[int, int]):
+ """Flip normalized coordinates for test-time augmentation.
+
+ Args:
+ coords (Tensor): The coordinates to flip. Should be a tensor in shape
+ [B, K, D]
+ flip_indices (List[int]): The indices of each keypoint's symmetric
+ keypoint
+ shift_coords (bool): Shift the flipped coordinates to align with the
+ original coordinates and improve accuracy. Defaults to ``True``
+ input_size (Tuple[int, int]): The size of input image in [w, h]
+ """
+ assert coords.ndim == 3
+ assert len(flip_indices) == coords.shape[1]
+
+ coords[:, :, 0] = 1.0 - coords[:, :, 0]
+
+ if shift_coords:
+ img_width = input_size[0]
+ coords[:, :, 0] -= 1.0 / img_width
+
+ coords = coords[:, flip_indices]
+ return coords
+
+
+def flip_visibility(vis: Tensor, flip_indices: List[int]):
+ """Flip keypoints visibility for test-time augmentation.
+
+ Args:
+ vis (Tensor): The keypoints visibility to flip. Should be a tensor
+ in shape [B, K]
+ flip_indices (List[int]): The indices of each keypoint's symmetric
+ keypoint
+ """
+ assert vis.ndim == 2
+
+ vis = vis[:, flip_indices]
+ return vis
+
+
+def aggregate_heatmaps(heatmaps: List[Tensor],
+ size: Optional[Tuple[int, int]],
+ align_corners: bool = False,
+ mode: str = 'average'):
+ """Aggregate multiple heatmaps.
+
+ Args:
+ heatmaps (List[Tensor]): Multiple heatmaps to aggregate. Each should
+ be in shape (B, C, H, W)
+ size (Tuple[int, int], optional): The target size in (w, h). All
+ heatmaps will be resized to the target size. If not given, the
+ first heatmap tensor's width and height will be used as the target
+ size. Defaults to ``None``
+ align_corners (bool): Whether align corners when resizing heatmaps.
+ Defaults to ``False``
+ mode (str): Aggregation mode in one of the following:
+
+ - ``'average'``: Get average of heatmaps. All heatmaps mush have
+ the same channel number
+ - ``'concat'``: Concate the heatmaps at the channel dim
+ """
+
+ if mode not in {'average', 'concat'}:
+ raise ValueError(f'Invalid aggregation mode `{mode}`')
+
+ if size is None:
+ h, w = heatmaps[0].shape[2:4]
+ else:
+ w, h = size
+
+ for i, _heatmaps in enumerate(heatmaps):
+ assert _heatmaps.ndim == 4
+ if mode == 'average':
+ assert _heatmaps.shape[:2] == heatmaps[0].shape[:2]
+ else:
+ assert _heatmaps.shape[0] == heatmaps[0].shape[0]
+
+ if _heatmaps.shape[2:4] != (h, w):
+ heatmaps[i] = F.interpolate(
+ _heatmaps,
+ size=(h, w),
+ mode='bilinear',
+ align_corners=align_corners)
+
+ if mode == 'average':
+ output = sum(heatmaps).div(len(heatmaps))
+ elif mode == 'concat':
+ output = torch.cat(heatmaps, dim=1)
+ else:
+ raise ValueError()
+
+ return output
diff --git a/mmpose/registry.py b/mmpose/registry.py
index e3b8d17c4c..cd53e25346 100644
--- a/mmpose/registry.py
+++ b/mmpose/registry.py
@@ -1,132 +1,132 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-"""MMPose provides following registry nodes to support using modules across
-projects.
-
-Each node is a child of the root registry in MMEngine.
-More details can be found at
-https://mmengine.readthedocs.io/en/latest/tutorials/registry.html.
-"""
-
-from mmengine.registry import DATA_SAMPLERS as MMENGINE_DATA_SAMPLERS
-from mmengine.registry import DATASETS as MMENGINE_DATASETS
-from mmengine.registry import EVALUATOR as MMENGINE_EVALUATOR
-from mmengine.registry import HOOKS as MMENGINE_HOOKS
-from mmengine.registry import INFERENCERS as MMENGINE_INFERENCERS
-from mmengine.registry import LOG_PROCESSORS as MMENGINE_LOG_PROCESSORS
-from mmengine.registry import LOOPS as MMENGINE_LOOPS
-from mmengine.registry import METRICS as MMENGINE_METRICS
-from mmengine.registry import MODEL_WRAPPERS as MMENGINE_MODEL_WRAPPERS
-from mmengine.registry import MODELS as MMENGINE_MODELS
-from mmengine.registry import \
- OPTIM_WRAPPER_CONSTRUCTORS as MMENGINE_OPTIM_WRAPPER_CONSTRUCTORS
-from mmengine.registry import OPTIM_WRAPPERS as MMENGINE_OPTIM_WRAPPERS
-from mmengine.registry import OPTIMIZERS as MMENGINE_OPTIMIZERS
-from mmengine.registry import PARAM_SCHEDULERS as MMENGINE_PARAM_SCHEDULERS
-from mmengine.registry import \
- RUNNER_CONSTRUCTORS as MMENGINE_RUNNER_CONSTRUCTORS
-from mmengine.registry import RUNNERS as MMENGINE_RUNNERS
-from mmengine.registry import TASK_UTILS as MMENGINE_TASK_UTILS
-from mmengine.registry import TRANSFORMS as MMENGINE_TRANSFORMS
-from mmengine.registry import VISBACKENDS as MMENGINE_VISBACKENDS
-from mmengine.registry import VISUALIZERS as MMENGINE_VISUALIZERS
-from mmengine.registry import \
- WEIGHT_INITIALIZERS as MMENGINE_WEIGHT_INITIALIZERS
-from mmengine.registry import Registry
-
-# Registries For Runner and the related
-# manage all kinds of runners like `EpochBasedRunner` and `IterBasedRunner`
-RUNNERS = Registry('runner', parent=MMENGINE_RUNNERS)
-# manage runner constructors that define how to initialize runners
-RUNNER_CONSTRUCTORS = Registry(
- 'runner constructor', parent=MMENGINE_RUNNER_CONSTRUCTORS)
-# manage all kinds of loops like `EpochBasedTrainLoop`
-LOOPS = Registry('loop', parent=MMENGINE_LOOPS)
-# manage all kinds of hooks like `CheckpointHook`
-HOOKS = Registry(
- 'hook', parent=MMENGINE_HOOKS, locations=['mmpose.engine.hooks'])
-
-# Registries For Data and the related
-# manage data-related modules
-DATASETS = Registry(
- 'dataset', parent=MMENGINE_DATASETS, locations=['mmpose.datasets'])
-DATA_SAMPLERS = Registry(
- 'data sampler',
- parent=MMENGINE_DATA_SAMPLERS,
- locations=['mmpose.datasets.samplers'])
-TRANSFORMS = Registry(
- 'transform',
- parent=MMENGINE_TRANSFORMS,
- locations=['mmpose.datasets.transforms'])
-
-# manage all kinds of modules inheriting `nn.Module`
-MODELS = Registry('model', parent=MMENGINE_MODELS, locations=['mmpose.models'])
-# manage all kinds of model wrappers like 'MMDistributedDataParallel'
-MODEL_WRAPPERS = Registry(
- 'model_wrapper',
- parent=MMENGINE_MODEL_WRAPPERS,
- locations=['mmpose.models'])
-# manage all kinds of weight initialization modules like `Uniform`
-WEIGHT_INITIALIZERS = Registry(
- 'weight initializer',
- parent=MMENGINE_WEIGHT_INITIALIZERS,
- locations=['mmpose.models'])
-# manage all kinds of batch augmentations like Mixup and CutMix.
-BATCH_AUGMENTS = Registry('batch augment', locations=['mmpose.models'])
-
-# Registries For Optimizer and the related
-# manage all kinds of optimizers like `SGD` and `Adam`
-OPTIMIZERS = Registry(
- 'optimizer', parent=MMENGINE_OPTIMIZERS, locations=['mmpose.engine'])
-# manage optimizer wrapper
-OPTIM_WRAPPERS = Registry(
- 'optimizer_wrapper',
- parent=MMENGINE_OPTIM_WRAPPERS,
- locations=['mmpose.engine'])
-# manage constructors that customize the optimization hyperparameters.
-OPTIM_WRAPPER_CONSTRUCTORS = Registry(
- 'optimizer wrapper constructor',
- parent=MMENGINE_OPTIM_WRAPPER_CONSTRUCTORS,
- locations=['mmpose.engine.optim_wrappers'])
-# manage all kinds of parameter schedulers like `MultiStepLR`
-PARAM_SCHEDULERS = Registry(
- 'parameter scheduler',
- parent=MMENGINE_PARAM_SCHEDULERS,
- locations=['mmpose.engine'])
-
-# manage all kinds of metrics
-METRICS = Registry(
- 'metric', parent=MMENGINE_METRICS, locations=['mmpose.evaluation.metrics'])
-# manage all kinds of evaluators
-EVALUATORS = Registry(
- 'evaluator', parent=MMENGINE_EVALUATOR, locations=['mmpose.evaluation'])
-
-# manage task-specific modules like anchor generators and box coders
-TASK_UTILS = Registry(
- 'task util', parent=MMENGINE_TASK_UTILS, locations=['mmpose.models'])
-
-# Registries For Visualizer and the related
-# manage visualizer
-VISUALIZERS = Registry(
- 'visualizer',
- parent=MMENGINE_VISUALIZERS,
- locations=['mmpose.visualization'])
-# manage visualizer backend
-VISBACKENDS = Registry(
- 'vis_backend',
- parent=MMENGINE_VISBACKENDS,
- locations=['mmpose.visualization'])
-
-# manage all kinds log processors
-LOG_PROCESSORS = Registry(
- 'log processor',
- parent=MMENGINE_LOG_PROCESSORS,
- locations=['mmpose.visualization'])
-
-# manager keypoint encoder/decoder
-KEYPOINT_CODECS = Registry('KEYPOINT_CODECS', locations=['mmpose.codecs'])
-
-# manage inferencer
-INFERENCERS = Registry(
- 'inferencer',
- parent=MMENGINE_INFERENCERS,
- locations=['mmpose.apis.inferencers'])
+# Copyright (c) OpenMMLab. All rights reserved.
+"""MMPose provides following registry nodes to support using modules across
+projects.
+
+Each node is a child of the root registry in MMEngine.
+More details can be found at
+https://mmengine.readthedocs.io/en/latest/tutorials/registry.html.
+"""
+
+from mmengine.registry import DATA_SAMPLERS as MMENGINE_DATA_SAMPLERS
+from mmengine.registry import DATASETS as MMENGINE_DATASETS
+from mmengine.registry import EVALUATOR as MMENGINE_EVALUATOR
+from mmengine.registry import HOOKS as MMENGINE_HOOKS
+from mmengine.registry import INFERENCERS as MMENGINE_INFERENCERS
+from mmengine.registry import LOG_PROCESSORS as MMENGINE_LOG_PROCESSORS
+from mmengine.registry import LOOPS as MMENGINE_LOOPS
+from mmengine.registry import METRICS as MMENGINE_METRICS
+from mmengine.registry import MODEL_WRAPPERS as MMENGINE_MODEL_WRAPPERS
+from mmengine.registry import MODELS as MMENGINE_MODELS
+from mmengine.registry import \
+ OPTIM_WRAPPER_CONSTRUCTORS as MMENGINE_OPTIM_WRAPPER_CONSTRUCTORS
+from mmengine.registry import OPTIM_WRAPPERS as MMENGINE_OPTIM_WRAPPERS
+from mmengine.registry import OPTIMIZERS as MMENGINE_OPTIMIZERS
+from mmengine.registry import PARAM_SCHEDULERS as MMENGINE_PARAM_SCHEDULERS
+from mmengine.registry import \
+ RUNNER_CONSTRUCTORS as MMENGINE_RUNNER_CONSTRUCTORS
+from mmengine.registry import RUNNERS as MMENGINE_RUNNERS
+from mmengine.registry import TASK_UTILS as MMENGINE_TASK_UTILS
+from mmengine.registry import TRANSFORMS as MMENGINE_TRANSFORMS
+from mmengine.registry import VISBACKENDS as MMENGINE_VISBACKENDS
+from mmengine.registry import VISUALIZERS as MMENGINE_VISUALIZERS
+from mmengine.registry import \
+ WEIGHT_INITIALIZERS as MMENGINE_WEIGHT_INITIALIZERS
+from mmengine.registry import Registry
+
+# Registries For Runner and the related
+# manage all kinds of runners like `EpochBasedRunner` and `IterBasedRunner`
+RUNNERS = Registry('runner', parent=MMENGINE_RUNNERS)
+# manage runner constructors that define how to initialize runners
+RUNNER_CONSTRUCTORS = Registry(
+ 'runner constructor', parent=MMENGINE_RUNNER_CONSTRUCTORS)
+# manage all kinds of loops like `EpochBasedTrainLoop`
+LOOPS = Registry('loop', parent=MMENGINE_LOOPS)
+# manage all kinds of hooks like `CheckpointHook`
+HOOKS = Registry(
+ 'hook', parent=MMENGINE_HOOKS, locations=['mmpose.engine.hooks'])
+
+# Registries For Data and the related
+# manage data-related modules
+DATASETS = Registry(
+ 'dataset', parent=MMENGINE_DATASETS, locations=['mmpose.datasets'])
+DATA_SAMPLERS = Registry(
+ 'data sampler',
+ parent=MMENGINE_DATA_SAMPLERS,
+ locations=['mmpose.datasets.samplers'])
+TRANSFORMS = Registry(
+ 'transform',
+ parent=MMENGINE_TRANSFORMS,
+ locations=['mmpose.datasets.transforms'])
+
+# manage all kinds of modules inheriting `nn.Module`
+MODELS = Registry('model', parent=MMENGINE_MODELS, locations=['mmpose.models'])
+# manage all kinds of model wrappers like 'MMDistributedDataParallel'
+MODEL_WRAPPERS = Registry(
+ 'model_wrapper',
+ parent=MMENGINE_MODEL_WRAPPERS,
+ locations=['mmpose.models'])
+# manage all kinds of weight initialization modules like `Uniform`
+WEIGHT_INITIALIZERS = Registry(
+ 'weight initializer',
+ parent=MMENGINE_WEIGHT_INITIALIZERS,
+ locations=['mmpose.models'])
+# manage all kinds of batch augmentations like Mixup and CutMix.
+BATCH_AUGMENTS = Registry('batch augment', locations=['mmpose.models'])
+
+# Registries For Optimizer and the related
+# manage all kinds of optimizers like `SGD` and `Adam`
+OPTIMIZERS = Registry(
+ 'optimizer', parent=MMENGINE_OPTIMIZERS, locations=['mmpose.engine'])
+# manage optimizer wrapper
+OPTIM_WRAPPERS = Registry(
+ 'optimizer_wrapper',
+ parent=MMENGINE_OPTIM_WRAPPERS,
+ locations=['mmpose.engine'])
+# manage constructors that customize the optimization hyperparameters.
+OPTIM_WRAPPER_CONSTRUCTORS = Registry(
+ 'optimizer wrapper constructor',
+ parent=MMENGINE_OPTIM_WRAPPER_CONSTRUCTORS,
+ locations=['mmpose.engine.optim_wrappers'])
+# manage all kinds of parameter schedulers like `MultiStepLR`
+PARAM_SCHEDULERS = Registry(
+ 'parameter scheduler',
+ parent=MMENGINE_PARAM_SCHEDULERS,
+ locations=['mmpose.engine'])
+
+# manage all kinds of metrics
+METRICS = Registry(
+ 'metric', parent=MMENGINE_METRICS, locations=['mmpose.evaluation.metrics'])
+# manage all kinds of evaluators
+EVALUATORS = Registry(
+ 'evaluator', parent=MMENGINE_EVALUATOR, locations=['mmpose.evaluation'])
+
+# manage task-specific modules like anchor generators and box coders
+TASK_UTILS = Registry(
+ 'task util', parent=MMENGINE_TASK_UTILS, locations=['mmpose.models'])
+
+# Registries For Visualizer and the related
+# manage visualizer
+VISUALIZERS = Registry(
+ 'visualizer',
+ parent=MMENGINE_VISUALIZERS,
+ locations=['mmpose.visualization'])
+# manage visualizer backend
+VISBACKENDS = Registry(
+ 'vis_backend',
+ parent=MMENGINE_VISBACKENDS,
+ locations=['mmpose.visualization'])
+
+# manage all kinds log processors
+LOG_PROCESSORS = Registry(
+ 'log processor',
+ parent=MMENGINE_LOG_PROCESSORS,
+ locations=['mmpose.visualization'])
+
+# manager keypoint encoder/decoder
+KEYPOINT_CODECS = Registry('KEYPOINT_CODECS', locations=['mmpose.codecs'])
+
+# manage inferencer
+INFERENCERS = Registry(
+ 'inferencer',
+ parent=MMENGINE_INFERENCERS,
+ locations=['mmpose.apis.inferencers'])
diff --git a/mmpose/structures/__init__.py b/mmpose/structures/__init__.py
index e4384af1cd..8b326f985f 100644
--- a/mmpose/structures/__init__.py
+++ b/mmpose/structures/__init__.py
@@ -1,15 +1,15 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .bbox import (bbox_cs2xywh, bbox_cs2xyxy, bbox_xywh2cs, bbox_xywh2xyxy,
- bbox_xyxy2cs, bbox_xyxy2xywh, flip_bbox,
- get_udp_warp_matrix, get_warp_matrix)
-from .keypoint import flip_keypoints
-from .multilevel_pixel_data import MultilevelPixelData
-from .pose_data_sample import PoseDataSample
-from .utils import merge_data_samples, revert_heatmap, split_instances
-
-__all__ = [
- 'PoseDataSample', 'MultilevelPixelData', 'bbox_cs2xywh', 'bbox_cs2xyxy',
- 'bbox_xywh2cs', 'bbox_xywh2xyxy', 'bbox_xyxy2cs', 'bbox_xyxy2xywh',
- 'flip_bbox', 'get_udp_warp_matrix', 'get_warp_matrix', 'flip_keypoints',
- 'merge_data_samples', 'revert_heatmap', 'split_instances'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .bbox import (bbox_cs2xywh, bbox_cs2xyxy, bbox_xywh2cs, bbox_xywh2xyxy,
+ bbox_xyxy2cs, bbox_xyxy2xywh, flip_bbox,
+ get_udp_warp_matrix, get_warp_matrix)
+from .keypoint import flip_keypoints
+from .multilevel_pixel_data import MultilevelPixelData
+from .pose_data_sample import PoseDataSample
+from .utils import merge_data_samples, revert_heatmap, split_instances
+
+__all__ = [
+ 'PoseDataSample', 'MultilevelPixelData', 'bbox_cs2xywh', 'bbox_cs2xyxy',
+ 'bbox_xywh2cs', 'bbox_xywh2xyxy', 'bbox_xyxy2cs', 'bbox_xyxy2xywh',
+ 'flip_bbox', 'get_udp_warp_matrix', 'get_warp_matrix', 'flip_keypoints',
+ 'merge_data_samples', 'revert_heatmap', 'split_instances'
+]
diff --git a/mmpose/structures/bbox/__init__.py b/mmpose/structures/bbox/__init__.py
index a3e723918c..a91af7e9be 100644
--- a/mmpose/structures/bbox/__init__.py
+++ b/mmpose/structures/bbox/__init__.py
@@ -1,10 +1,10 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .transforms import (bbox_cs2xywh, bbox_cs2xyxy, bbox_xywh2cs,
- bbox_xywh2xyxy, bbox_xyxy2cs, bbox_xyxy2xywh,
- flip_bbox, get_udp_warp_matrix, get_warp_matrix)
-
-__all__ = [
- 'bbox_cs2xywh', 'bbox_cs2xyxy', 'bbox_xywh2cs', 'bbox_xywh2xyxy',
- 'bbox_xyxy2cs', 'bbox_xyxy2xywh', 'flip_bbox', 'get_udp_warp_matrix',
- 'get_warp_matrix'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .transforms import (bbox_cs2xywh, bbox_cs2xyxy, bbox_xywh2cs,
+ bbox_xywh2xyxy, bbox_xyxy2cs, bbox_xyxy2xywh,
+ flip_bbox, get_udp_warp_matrix, get_warp_matrix)
+
+__all__ = [
+ 'bbox_cs2xywh', 'bbox_cs2xyxy', 'bbox_xywh2cs', 'bbox_xywh2xyxy',
+ 'bbox_xyxy2cs', 'bbox_xyxy2xywh', 'flip_bbox', 'get_udp_warp_matrix',
+ 'get_warp_matrix'
+]
diff --git a/mmpose/structures/bbox/transforms.py b/mmpose/structures/bbox/transforms.py
index c0c8e73395..3b89bb9664 100644
--- a/mmpose/structures/bbox/transforms.py
+++ b/mmpose/structures/bbox/transforms.py
@@ -1,361 +1,361 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import math
-from typing import Tuple
-
-import cv2
-import numpy as np
-
-
-def bbox_xyxy2xywh(bbox_xyxy: np.ndarray) -> np.ndarray:
- """Transform the bbox format from x1y1x2y2 to xywh.
-
- Args:
- bbox_xyxy (np.ndarray): Bounding boxes (with scores), shaped (n, 4) or
- (n, 5). (left, top, right, bottom, [score])
-
- Returns:
- np.ndarray: Bounding boxes (with scores),
- shaped (n, 4) or (n, 5). (left, top, width, height, [score])
- """
- bbox_xywh = bbox_xyxy.copy()
- bbox_xywh[:, 2] = bbox_xywh[:, 2] - bbox_xywh[:, 0]
- bbox_xywh[:, 3] = bbox_xywh[:, 3] - bbox_xywh[:, 1]
-
- return bbox_xywh
-
-
-def bbox_xywh2xyxy(bbox_xywh: np.ndarray) -> np.ndarray:
- """Transform the bbox format from xywh to x1y1x2y2.
-
- Args:
- bbox_xywh (ndarray): Bounding boxes (with scores),
- shaped (n, 4) or (n, 5). (left, top, width, height, [score])
- Returns:
- np.ndarray: Bounding boxes (with scores), shaped (n, 4) or
- (n, 5). (left, top, right, bottom, [score])
- """
- bbox_xyxy = bbox_xywh.copy()
- bbox_xyxy[:, 2] = bbox_xyxy[:, 2] + bbox_xyxy[:, 0]
- bbox_xyxy[:, 3] = bbox_xyxy[:, 3] + bbox_xyxy[:, 1]
-
- return bbox_xyxy
-
-
-def bbox_xyxy2cs(bbox: np.ndarray,
- padding: float = 1.) -> Tuple[np.ndarray, np.ndarray]:
- """Transform the bbox format from (x,y,w,h) into (center, scale)
-
- Args:
- bbox (ndarray): Bounding box(es) in shape (4,) or (n, 4), formatted
- as (left, top, right, bottom)
- padding (float): BBox padding factor that will be multilied to scale.
- Default: 1.0
-
- Returns:
- tuple: A tuple containing center and scale.
- - np.ndarray[float32]: Center (x, y) of the bbox in shape (2,) or
- (n, 2)
- - np.ndarray[float32]: Scale (w, h) of the bbox in shape (2,) or
- (n, 2)
- """
- # convert single bbox from (4, ) to (1, 4)
- dim = bbox.ndim
- if dim == 1:
- bbox = bbox[None, :]
-
- x1, y1, x2, y2 = np.hsplit(bbox, [1, 2, 3])
- center = np.hstack([x1 + x2, y1 + y2]) * 0.5
- scale = np.hstack([x2 - x1, y2 - y1]) * padding
-
- if dim == 1:
- center = center[0]
- scale = scale[0]
-
- return center, scale
-
-
-def bbox_xywh2cs(bbox: np.ndarray,
- padding: float = 1.) -> Tuple[np.ndarray, np.ndarray]:
- """Transform the bbox format from (x,y,w,h) into (center, scale)
-
- Args:
- bbox (ndarray): Bounding box(es) in shape (4,) or (n, 4), formatted
- as (x, y, h, w)
- padding (float): BBox padding factor that will be multilied to scale.
- Default: 1.0
-
- Returns:
- tuple: A tuple containing center and scale.
- - np.ndarray[float32]: Center (x, y) of the bbox in shape (2,) or
- (n, 2)
- - np.ndarray[float32]: Scale (w, h) of the bbox in shape (2,) or
- (n, 2)
- """
-
- # convert single bbox from (4, ) to (1, 4)
- dim = bbox.ndim
- if dim == 1:
- bbox = bbox[None, :]
-
- x, y, w, h = np.hsplit(bbox, [1, 2, 3])
- center = np.hstack([x + w * 0.5, y + h * 0.5])
- scale = np.hstack([w, h]) * padding
-
- if dim == 1:
- center = center[0]
- scale = scale[0]
-
- return center, scale
-
-
-def bbox_cs2xyxy(center: np.ndarray,
- scale: np.ndarray,
- padding: float = 1.) -> np.ndarray:
- """Transform the bbox format from (center, scale) to (x1,y1,x2,y2).
-
- Args:
- center (ndarray): BBox center (x, y) in shape (2,) or (n, 2)
- scale (ndarray): BBox scale (w, h) in shape (2,) or (n, 2)
- padding (float): BBox padding factor that will be multilied to scale.
- Default: 1.0
-
- Returns:
- ndarray[float32]: BBox (x1, y1, x2, y2) in shape (4, ) or (n, 4)
- """
-
- dim = center.ndim
- assert scale.ndim == dim
-
- if dim == 1:
- center = center[None, :]
- scale = scale[None, :]
-
- wh = scale / padding
- xy = center - 0.5 * wh
- bbox = np.hstack((xy, xy + wh))
-
- if dim == 1:
- bbox = bbox[0]
-
- return bbox
-
-
-def bbox_cs2xywh(center: np.ndarray,
- scale: np.ndarray,
- padding: float = 1.) -> np.ndarray:
- """Transform the bbox format from (center, scale) to (x,y,w,h).
-
- Args:
- center (ndarray): BBox center (x, y) in shape (2,) or (n, 2)
- scale (ndarray): BBox scale (w, h) in shape (2,) or (n, 2)
- padding (float): BBox padding factor that will be multilied to scale.
- Default: 1.0
-
- Returns:
- ndarray[float32]: BBox (x, y, w, h) in shape (4, ) or (n, 4)
- """
-
- dim = center.ndim
- assert scale.ndim == dim
-
- if dim == 1:
- center = center[None, :]
- scale = scale[None, :]
-
- wh = scale / padding
- xy = center - 0.5 * wh
- bbox = np.hstack((xy, wh))
-
- if dim == 1:
- bbox = bbox[0]
-
- return bbox
-
-
-def flip_bbox(bbox: np.ndarray,
- image_size: Tuple[int, int],
- bbox_format: str = 'xywh',
- direction: str = 'horizontal') -> np.ndarray:
- """Flip the bbox in the given direction.
-
- Args:
- bbox (np.ndarray): The bounding boxes. The shape should be (..., 4)
- if ``bbox_format`` is ``'xyxy'`` or ``'xywh'``, and (..., 2) if
- ``bbox_format`` is ``'center'``
- image_size (tuple): The image shape in [w, h]
- bbox_format (str): The bbox format. Options are ``'xywh'``, ``'xyxy'``
- and ``'center'``.
- direction (str): The flip direction. Options are ``'horizontal'``,
- ``'vertical'`` and ``'diagonal'``. Defaults to ``'horizontal'``
-
- Returns:
- np.ndarray: The flipped bounding boxes.
- """
- direction_options = {'horizontal', 'vertical', 'diagonal'}
- assert direction in direction_options, (
- f'Invalid flipping direction "{direction}". '
- f'Options are {direction_options}')
-
- format_options = {'xywh', 'xyxy', 'center'}
- assert bbox_format in format_options, (
- f'Invalid bbox format "{bbox_format}". '
- f'Options are {format_options}')
-
- bbox_flipped = bbox.copy()
- w, h = image_size
-
- # TODO: consider using "integer corner" coordinate system
- if direction == 'horizontal':
- if bbox_format == 'xywh' or bbox_format == 'center':
- bbox_flipped[..., 0] = w - bbox[..., 0] - 1
- elif bbox_format == 'xyxy':
- bbox_flipped[..., ::2] = w - bbox[..., ::2] - 1
- elif direction == 'vertical':
- if bbox_format == 'xywh' or bbox_format == 'center':
- bbox_flipped[..., 1] = h - bbox[..., 1] - 1
- elif bbox_format == 'xyxy':
- bbox_flipped[..., 1::2] = h - bbox[..., 1::2] - 1
- elif direction == 'diagonal':
- if bbox_format == 'xywh' or bbox_format == 'center':
- bbox_flipped[..., :2] = [w, h] - bbox[..., :2] - 1
- elif bbox_format == 'xyxy':
- bbox_flipped[...] = [w, h, w, h] - bbox - 1
-
- return bbox_flipped
-
-
-def get_udp_warp_matrix(
- center: np.ndarray,
- scale: np.ndarray,
- rot: float,
- output_size: Tuple[int, int],
-) -> np.ndarray:
- """Calculate the affine transformation matrix under the unbiased
- constraint. See `UDP (CVPR 2020)`_ for details.
-
- Note:
-
- - The bbox number: N
-
- Args:
- center (np.ndarray[2, ]): Center of the bounding box (x, y).
- scale (np.ndarray[2, ]): Scale of the bounding box
- wrt [width, height].
- rot (float): Rotation angle (degree).
- output_size (tuple): Size ([w, h]) of the output image
-
- Returns:
- np.ndarray: A 2x3 transformation matrix
-
- .. _`UDP (CVPR 2020)`: https://arxiv.org/abs/1911.07524
- """
- assert len(center) == 2
- assert len(scale) == 2
- assert len(output_size) == 2
-
- input_size = center * 2
- rot_rad = np.deg2rad(rot)
- warp_mat = np.zeros((2, 3), dtype=np.float32)
- scale_x = (output_size[0] - 1) / scale[0]
- scale_y = (output_size[1] - 1) / scale[1]
- warp_mat[0, 0] = math.cos(rot_rad) * scale_x
- warp_mat[0, 1] = -math.sin(rot_rad) * scale_x
- warp_mat[0, 2] = scale_x * (-0.5 * input_size[0] * math.cos(rot_rad) +
- 0.5 * input_size[1] * math.sin(rot_rad) +
- 0.5 * scale[0])
- warp_mat[1, 0] = math.sin(rot_rad) * scale_y
- warp_mat[1, 1] = math.cos(rot_rad) * scale_y
- warp_mat[1, 2] = scale_y * (-0.5 * input_size[0] * math.sin(rot_rad) -
- 0.5 * input_size[1] * math.cos(rot_rad) +
- 0.5 * scale[1])
- return warp_mat
-
-
-def get_warp_matrix(center: np.ndarray,
- scale: np.ndarray,
- rot: float,
- output_size: Tuple[int, int],
- shift: Tuple[float, float] = (0., 0.),
- inv: bool = False) -> np.ndarray:
- """Calculate the affine transformation matrix that can warp the bbox area
- in the input image to the output size.
-
- Args:
- center (np.ndarray[2, ]): Center of the bounding box (x, y).
- scale (np.ndarray[2, ]): Scale of the bounding box
- wrt [width, height].
- rot (float): Rotation angle (degree).
- output_size (np.ndarray[2, ] | list(2,)): Size of the
- destination heatmaps.
- shift (0-100%): Shift translation ratio wrt the width/height.
- Default (0., 0.).
- inv (bool): Option to inverse the affine transform direction.
- (inv=False: src->dst or inv=True: dst->src)
-
- Returns:
- np.ndarray: A 2x3 transformation matrix
- """
- assert len(center) == 2
- assert len(scale) == 2
- assert len(output_size) == 2
- assert len(shift) == 2
-
- shift = np.array(shift)
- src_w = scale[0]
- dst_w = output_size[0]
- dst_h = output_size[1]
-
- rot_rad = np.deg2rad(rot)
- src_dir = _rotate_point(np.array([0., src_w * -0.5]), rot_rad)
- dst_dir = np.array([0., dst_w * -0.5])
-
- src = np.zeros((3, 2), dtype=np.float32)
- src[0, :] = center + scale * shift
- src[1, :] = center + src_dir + scale * shift
- src[2, :] = _get_3rd_point(src[0, :], src[1, :])
-
- dst = np.zeros((3, 2), dtype=np.float32)
- dst[0, :] = [dst_w * 0.5, dst_h * 0.5]
- dst[1, :] = np.array([dst_w * 0.5, dst_h * 0.5]) + dst_dir
- dst[2, :] = _get_3rd_point(dst[0, :], dst[1, :])
-
- if inv:
- warp_mat = cv2.getAffineTransform(np.float32(dst), np.float32(src))
- else:
- warp_mat = cv2.getAffineTransform(np.float32(src), np.float32(dst))
- return warp_mat
-
-
-def _rotate_point(pt: np.ndarray, angle_rad: float) -> np.ndarray:
- """Rotate a point by an angle.
-
- Args:
- pt (np.ndarray): 2D point coordinates (x, y) in shape (2, )
- angle_rad (float): rotation angle in radian
-
- Returns:
- np.ndarray: Rotated point in shape (2, )
- """
-
- sn, cs = np.sin(angle_rad), np.cos(angle_rad)
- rot_mat = np.array([[cs, -sn], [sn, cs]])
- return rot_mat @ pt
-
-
-def _get_3rd_point(a: np.ndarray, b: np.ndarray):
- """To calculate the affine matrix, three pairs of points are required. This
- function is used to get the 3rd point, given 2D points a & b.
-
- The 3rd point is defined by rotating vector `a - b` by 90 degrees
- anticlockwise, using b as the rotation center.
-
- Args:
- a (np.ndarray): The 1st point (x,y) in shape (2, )
- b (np.ndarray): The 2nd point (x,y) in shape (2, )
-
- Returns:
- np.ndarray: The 3rd point.
- """
- direction = a - b
- c = b + np.r_[-direction[1], direction[0]]
- return c
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Tuple
+
+import cv2
+import numpy as np
+
+
+def bbox_xyxy2xywh(bbox_xyxy: np.ndarray) -> np.ndarray:
+ """Transform the bbox format from x1y1x2y2 to xywh.
+
+ Args:
+ bbox_xyxy (np.ndarray): Bounding boxes (with scores), shaped (n, 4) or
+ (n, 5). (left, top, right, bottom, [score])
+
+ Returns:
+ np.ndarray: Bounding boxes (with scores),
+ shaped (n, 4) or (n, 5). (left, top, width, height, [score])
+ """
+ bbox_xywh = bbox_xyxy.copy()
+ bbox_xywh[:, 2] = bbox_xywh[:, 2] - bbox_xywh[:, 0]
+ bbox_xywh[:, 3] = bbox_xywh[:, 3] - bbox_xywh[:, 1]
+
+ return bbox_xywh
+
+
+def bbox_xywh2xyxy(bbox_xywh: np.ndarray) -> np.ndarray:
+ """Transform the bbox format from xywh to x1y1x2y2.
+
+ Args:
+ bbox_xywh (ndarray): Bounding boxes (with scores),
+ shaped (n, 4) or (n, 5). (left, top, width, height, [score])
+ Returns:
+ np.ndarray: Bounding boxes (with scores), shaped (n, 4) or
+ (n, 5). (left, top, right, bottom, [score])
+ """
+ bbox_xyxy = bbox_xywh.copy()
+ bbox_xyxy[:, 2] = bbox_xyxy[:, 2] + bbox_xyxy[:, 0]
+ bbox_xyxy[:, 3] = bbox_xyxy[:, 3] + bbox_xyxy[:, 1]
+
+ return bbox_xyxy
+
+
+def bbox_xyxy2cs(bbox: np.ndarray,
+ padding: float = 1.) -> Tuple[np.ndarray, np.ndarray]:
+ """Transform the bbox format from (x,y,w,h) into (center, scale)
+
+ Args:
+ bbox (ndarray): Bounding box(es) in shape (4,) or (n, 4), formatted
+ as (left, top, right, bottom)
+ padding (float): BBox padding factor that will be multilied to scale.
+ Default: 1.0
+
+ Returns:
+ tuple: A tuple containing center and scale.
+ - np.ndarray[float32]: Center (x, y) of the bbox in shape (2,) or
+ (n, 2)
+ - np.ndarray[float32]: Scale (w, h) of the bbox in shape (2,) or
+ (n, 2)
+ """
+ # convert single bbox from (4, ) to (1, 4)
+ dim = bbox.ndim
+ if dim == 1:
+ bbox = bbox[None, :]
+
+ x1, y1, x2, y2 = np.hsplit(bbox, [1, 2, 3])
+ center = np.hstack([x1 + x2, y1 + y2]) * 0.5
+ scale = np.hstack([x2 - x1, y2 - y1]) * padding
+
+ if dim == 1:
+ center = center[0]
+ scale = scale[0]
+
+ return center, scale
+
+
+def bbox_xywh2cs(bbox: np.ndarray,
+ padding: float = 1.) -> Tuple[np.ndarray, np.ndarray]:
+ """Transform the bbox format from (x,y,w,h) into (center, scale)
+
+ Args:
+ bbox (ndarray): Bounding box(es) in shape (4,) or (n, 4), formatted
+ as (x, y, h, w)
+ padding (float): BBox padding factor that will be multilied to scale.
+ Default: 1.0
+
+ Returns:
+ tuple: A tuple containing center and scale.
+ - np.ndarray[float32]: Center (x, y) of the bbox in shape (2,) or
+ (n, 2)
+ - np.ndarray[float32]: Scale (w, h) of the bbox in shape (2,) or
+ (n, 2)
+ """
+
+ # convert single bbox from (4, ) to (1, 4)
+ dim = bbox.ndim
+ if dim == 1:
+ bbox = bbox[None, :]
+
+ x, y, w, h = np.hsplit(bbox, [1, 2, 3])
+ center = np.hstack([x + w * 0.5, y + h * 0.5])
+ scale = np.hstack([w, h]) * padding
+
+ if dim == 1:
+ center = center[0]
+ scale = scale[0]
+
+ return center, scale
+
+
+def bbox_cs2xyxy(center: np.ndarray,
+ scale: np.ndarray,
+ padding: float = 1.) -> np.ndarray:
+ """Transform the bbox format from (center, scale) to (x1,y1,x2,y2).
+
+ Args:
+ center (ndarray): BBox center (x, y) in shape (2,) or (n, 2)
+ scale (ndarray): BBox scale (w, h) in shape (2,) or (n, 2)
+ padding (float): BBox padding factor that will be multilied to scale.
+ Default: 1.0
+
+ Returns:
+ ndarray[float32]: BBox (x1, y1, x2, y2) in shape (4, ) or (n, 4)
+ """
+
+ dim = center.ndim
+ assert scale.ndim == dim
+
+ if dim == 1:
+ center = center[None, :]
+ scale = scale[None, :]
+
+ wh = scale / padding
+ xy = center - 0.5 * wh
+ bbox = np.hstack((xy, xy + wh))
+
+ if dim == 1:
+ bbox = bbox[0]
+
+ return bbox
+
+
+def bbox_cs2xywh(center: np.ndarray,
+ scale: np.ndarray,
+ padding: float = 1.) -> np.ndarray:
+ """Transform the bbox format from (center, scale) to (x,y,w,h).
+
+ Args:
+ center (ndarray): BBox center (x, y) in shape (2,) or (n, 2)
+ scale (ndarray): BBox scale (w, h) in shape (2,) or (n, 2)
+ padding (float): BBox padding factor that will be multilied to scale.
+ Default: 1.0
+
+ Returns:
+ ndarray[float32]: BBox (x, y, w, h) in shape (4, ) or (n, 4)
+ """
+
+ dim = center.ndim
+ assert scale.ndim == dim
+
+ if dim == 1:
+ center = center[None, :]
+ scale = scale[None, :]
+
+ wh = scale / padding
+ xy = center - 0.5 * wh
+ bbox = np.hstack((xy, wh))
+
+ if dim == 1:
+ bbox = bbox[0]
+
+ return bbox
+
+
+def flip_bbox(bbox: np.ndarray,
+ image_size: Tuple[int, int],
+ bbox_format: str = 'xywh',
+ direction: str = 'horizontal') -> np.ndarray:
+ """Flip the bbox in the given direction.
+
+ Args:
+ bbox (np.ndarray): The bounding boxes. The shape should be (..., 4)
+ if ``bbox_format`` is ``'xyxy'`` or ``'xywh'``, and (..., 2) if
+ ``bbox_format`` is ``'center'``
+ image_size (tuple): The image shape in [w, h]
+ bbox_format (str): The bbox format. Options are ``'xywh'``, ``'xyxy'``
+ and ``'center'``.
+ direction (str): The flip direction. Options are ``'horizontal'``,
+ ``'vertical'`` and ``'diagonal'``. Defaults to ``'horizontal'``
+
+ Returns:
+ np.ndarray: The flipped bounding boxes.
+ """
+ direction_options = {'horizontal', 'vertical', 'diagonal'}
+ assert direction in direction_options, (
+ f'Invalid flipping direction "{direction}". '
+ f'Options are {direction_options}')
+
+ format_options = {'xywh', 'xyxy', 'center'}
+ assert bbox_format in format_options, (
+ f'Invalid bbox format "{bbox_format}". '
+ f'Options are {format_options}')
+
+ bbox_flipped = bbox.copy()
+ w, h = image_size
+
+ # TODO: consider using "integer corner" coordinate system
+ if direction == 'horizontal':
+ if bbox_format == 'xywh' or bbox_format == 'center':
+ bbox_flipped[..., 0] = w - bbox[..., 0] - 1
+ elif bbox_format == 'xyxy':
+ bbox_flipped[..., ::2] = w - bbox[..., ::2] - 1
+ elif direction == 'vertical':
+ if bbox_format == 'xywh' or bbox_format == 'center':
+ bbox_flipped[..., 1] = h - bbox[..., 1] - 1
+ elif bbox_format == 'xyxy':
+ bbox_flipped[..., 1::2] = h - bbox[..., 1::2] - 1
+ elif direction == 'diagonal':
+ if bbox_format == 'xywh' or bbox_format == 'center':
+ bbox_flipped[..., :2] = [w, h] - bbox[..., :2] - 1
+ elif bbox_format == 'xyxy':
+ bbox_flipped[...] = [w, h, w, h] - bbox - 1
+
+ return bbox_flipped
+
+
+def get_udp_warp_matrix(
+ center: np.ndarray,
+ scale: np.ndarray,
+ rot: float,
+ output_size: Tuple[int, int],
+) -> np.ndarray:
+ """Calculate the affine transformation matrix under the unbiased
+ constraint. See `UDP (CVPR 2020)`_ for details.
+
+ Note:
+
+ - The bbox number: N
+
+ Args:
+ center (np.ndarray[2, ]): Center of the bounding box (x, y).
+ scale (np.ndarray[2, ]): Scale of the bounding box
+ wrt [width, height].
+ rot (float): Rotation angle (degree).
+ output_size (tuple): Size ([w, h]) of the output image
+
+ Returns:
+ np.ndarray: A 2x3 transformation matrix
+
+ .. _`UDP (CVPR 2020)`: https://arxiv.org/abs/1911.07524
+ """
+ assert len(center) == 2
+ assert len(scale) == 2
+ assert len(output_size) == 2
+
+ input_size = center * 2
+ rot_rad = np.deg2rad(rot)
+ warp_mat = np.zeros((2, 3), dtype=np.float32)
+ scale_x = (output_size[0] - 1) / scale[0]
+ scale_y = (output_size[1] - 1) / scale[1]
+ warp_mat[0, 0] = math.cos(rot_rad) * scale_x
+ warp_mat[0, 1] = -math.sin(rot_rad) * scale_x
+ warp_mat[0, 2] = scale_x * (-0.5 * input_size[0] * math.cos(rot_rad) +
+ 0.5 * input_size[1] * math.sin(rot_rad) +
+ 0.5 * scale[0])
+ warp_mat[1, 0] = math.sin(rot_rad) * scale_y
+ warp_mat[1, 1] = math.cos(rot_rad) * scale_y
+ warp_mat[1, 2] = scale_y * (-0.5 * input_size[0] * math.sin(rot_rad) -
+ 0.5 * input_size[1] * math.cos(rot_rad) +
+ 0.5 * scale[1])
+ return warp_mat
+
+
+def get_warp_matrix(center: np.ndarray,
+ scale: np.ndarray,
+ rot: float,
+ output_size: Tuple[int, int],
+ shift: Tuple[float, float] = (0., 0.),
+ inv: bool = False) -> np.ndarray:
+ """Calculate the affine transformation matrix that can warp the bbox area
+ in the input image to the output size.
+
+ Args:
+ center (np.ndarray[2, ]): Center of the bounding box (x, y).
+ scale (np.ndarray[2, ]): Scale of the bounding box
+ wrt [width, height].
+ rot (float): Rotation angle (degree).
+ output_size (np.ndarray[2, ] | list(2,)): Size of the
+ destination heatmaps.
+ shift (0-100%): Shift translation ratio wrt the width/height.
+ Default (0., 0.).
+ inv (bool): Option to inverse the affine transform direction.
+ (inv=False: src->dst or inv=True: dst->src)
+
+ Returns:
+ np.ndarray: A 2x3 transformation matrix
+ """
+ assert len(center) == 2
+ assert len(scale) == 2
+ assert len(output_size) == 2
+ assert len(shift) == 2
+
+ shift = np.array(shift)
+ src_w = scale[0]
+ dst_w = output_size[0]
+ dst_h = output_size[1]
+
+ rot_rad = np.deg2rad(rot)
+ src_dir = _rotate_point(np.array([0., src_w * -0.5]), rot_rad)
+ dst_dir = np.array([0., dst_w * -0.5])
+
+ src = np.zeros((3, 2), dtype=np.float32)
+ src[0, :] = center + scale * shift
+ src[1, :] = center + src_dir + scale * shift
+ src[2, :] = _get_3rd_point(src[0, :], src[1, :])
+
+ dst = np.zeros((3, 2), dtype=np.float32)
+ dst[0, :] = [dst_w * 0.5, dst_h * 0.5]
+ dst[1, :] = np.array([dst_w * 0.5, dst_h * 0.5]) + dst_dir
+ dst[2, :] = _get_3rd_point(dst[0, :], dst[1, :])
+
+ if inv:
+ warp_mat = cv2.getAffineTransform(np.float32(dst), np.float32(src))
+ else:
+ warp_mat = cv2.getAffineTransform(np.float32(src), np.float32(dst))
+ return warp_mat
+
+
+def _rotate_point(pt: np.ndarray, angle_rad: float) -> np.ndarray:
+ """Rotate a point by an angle.
+
+ Args:
+ pt (np.ndarray): 2D point coordinates (x, y) in shape (2, )
+ angle_rad (float): rotation angle in radian
+
+ Returns:
+ np.ndarray: Rotated point in shape (2, )
+ """
+
+ sn, cs = np.sin(angle_rad), np.cos(angle_rad)
+ rot_mat = np.array([[cs, -sn], [sn, cs]])
+ return rot_mat @ pt
+
+
+def _get_3rd_point(a: np.ndarray, b: np.ndarray):
+ """To calculate the affine matrix, three pairs of points are required. This
+ function is used to get the 3rd point, given 2D points a & b.
+
+ The 3rd point is defined by rotating vector `a - b` by 90 degrees
+ anticlockwise, using b as the rotation center.
+
+ Args:
+ a (np.ndarray): The 1st point (x,y) in shape (2, )
+ b (np.ndarray): The 2nd point (x,y) in shape (2, )
+
+ Returns:
+ np.ndarray: The 3rd point.
+ """
+ direction = a - b
+ c = b + np.r_[-direction[1], direction[0]]
+ return c
diff --git a/mmpose/structures/keypoint/__init__.py b/mmpose/structures/keypoint/__init__.py
index 12ee96cf7c..468d77ddfb 100644
--- a/mmpose/structures/keypoint/__init__.py
+++ b/mmpose/structures/keypoint/__init__.py
@@ -1,5 +1,5 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-
-from .transforms import flip_keypoints, flip_keypoints_custom_center
-
-__all__ = ['flip_keypoints', 'flip_keypoints_custom_center']
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from .transforms import flip_keypoints, flip_keypoints_custom_center
+
+__all__ = ['flip_keypoints', 'flip_keypoints_custom_center']
diff --git a/mmpose/structures/keypoint/transforms.py b/mmpose/structures/keypoint/transforms.py
index b50da4f8fe..fa94a8055c 100644
--- a/mmpose/structures/keypoint/transforms.py
+++ b/mmpose/structures/keypoint/transforms.py
@@ -1,121 +1,121 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import List, Optional, Tuple
-
-import numpy as np
-
-
-def flip_keypoints(keypoints: np.ndarray,
- keypoints_visible: Optional[np.ndarray],
- image_size: Tuple[int, int],
- flip_indices: List[int],
- direction: str = 'horizontal'
- ) -> Tuple[np.ndarray, Optional[np.ndarray]]:
- """Flip keypoints in the given direction.
-
- Note:
-
- - keypoint number: K
- - keypoint dimension: D
-
- Args:
- keypoints (np.ndarray): Keypoints in shape (..., K, D)
- keypoints_visible (np.ndarray, optional): The visibility of keypoints
- in shape (..., K, 1). Set ``None`` if the keypoint visibility is
- unavailable
- image_size (tuple): The image shape in [w, h]
- flip_indices (List[int]): The indices of each keypoint's symmetric
- keypoint
- direction (str): The flip direction. Options are ``'horizontal'``,
- ``'vertical'`` and ``'diagonal'``. Defaults to ``'horizontal'``
-
- Returns:
- tuple:
- - keypoints_flipped (np.ndarray): Flipped keypoints in shape
- (..., K, D)
- - keypoints_visible_flipped (np.ndarray, optional): Flipped keypoints'
- visibility in shape (..., K, 1). Return ``None`` if the input
- ``keypoints_visible`` is ``None``
- """
-
- assert keypoints.shape[:-1] == keypoints_visible.shape, (
- f'Mismatched shapes of keypoints {keypoints.shape} and '
- f'keypoints_visible {keypoints_visible.shape}')
-
- direction_options = {'horizontal', 'vertical', 'diagonal'}
- assert direction in direction_options, (
- f'Invalid flipping direction "{direction}". '
- f'Options are {direction_options}')
-
- # swap the symmetric keypoint pairs
- if direction == 'horizontal' or direction == 'vertical':
- keypoints = keypoints[..., flip_indices, :]
- if keypoints_visible is not None:
- keypoints_visible = keypoints_visible[..., flip_indices]
-
- # flip the keypoints
- w, h = image_size
- if direction == 'horizontal':
- keypoints[..., 0] = w - 1 - keypoints[..., 0]
- elif direction == 'vertical':
- keypoints[..., 1] = h - 1 - keypoints[..., 1]
- else:
- keypoints = [w, h] - keypoints - 1
-
- return keypoints, keypoints_visible
-
-
-def flip_keypoints_custom_center(keypoints: np.ndarray,
- keypoints_visible: np.ndarray,
- flip_indices: List[int],
- center_mode: str = 'static',
- center_x: float = 0.5,
- center_index: int = 0):
- """Flip human joints horizontally.
-
- Note:
- - num_keypoint: K
- - dimension: D
-
- Args:
- keypoints (np.ndarray([..., K, D])): Coordinates of keypoints.
- keypoints_visible (np.ndarray([..., K])): Visibility item of keypoints.
- flip_indices (list[int]): The indices to flip the keypoints.
- center_mode (str): The mode to set the center location on the x-axis
- to flip around. Options are:
-
- - static: use a static x value (see center_x also)
- - root: use a root joint (see center_index also)
-
- Defaults: ``'static'``.
- center_x (float): Set the x-axis location of the flip center. Only used
- when ``center_mode`` is ``'static'``. Defaults: 0.5.
- center_index (int): Set the index of the root joint, whose x location
- will be used as the flip center. Only used when ``center_mode`` is
- ``'root'``. Defaults: 0.
-
- Returns:
- np.ndarray([..., K, C]): Flipped joints.
- """
-
- assert keypoints.ndim >= 2, f'Invalid pose shape {keypoints.shape}'
-
- allowed_center_mode = {'static', 'root'}
- assert center_mode in allowed_center_mode, 'Get invalid center_mode ' \
- f'{center_mode}, allowed choices are {allowed_center_mode}'
-
- if center_mode == 'static':
- x_c = center_x
- elif center_mode == 'root':
- assert keypoints.shape[-2] > center_index
- x_c = keypoints[..., center_index, 0]
-
- keypoints_flipped = keypoints.copy()
- keypoints_visible_flipped = keypoints_visible.copy()
- # Swap left-right parts
- for left, right in enumerate(flip_indices):
- keypoints_flipped[..., left, :] = keypoints[..., right, :]
- keypoints_visible_flipped[..., left] = keypoints_visible[..., right]
-
- # Flip horizontally
- keypoints_flipped[..., 0] = x_c * 2 - keypoints_flipped[..., 0]
- return keypoints_flipped, keypoints_visible_flipped
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple
+
+import numpy as np
+
+
+def flip_keypoints(keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray],
+ image_size: Tuple[int, int],
+ flip_indices: List[int],
+ direction: str = 'horizontal'
+ ) -> Tuple[np.ndarray, Optional[np.ndarray]]:
+ """Flip keypoints in the given direction.
+
+ Note:
+
+ - keypoint number: K
+ - keypoint dimension: D
+
+ Args:
+ keypoints (np.ndarray): Keypoints in shape (..., K, D)
+ keypoints_visible (np.ndarray, optional): The visibility of keypoints
+ in shape (..., K, 1). Set ``None`` if the keypoint visibility is
+ unavailable
+ image_size (tuple): The image shape in [w, h]
+ flip_indices (List[int]): The indices of each keypoint's symmetric
+ keypoint
+ direction (str): The flip direction. Options are ``'horizontal'``,
+ ``'vertical'`` and ``'diagonal'``. Defaults to ``'horizontal'``
+
+ Returns:
+ tuple:
+ - keypoints_flipped (np.ndarray): Flipped keypoints in shape
+ (..., K, D)
+ - keypoints_visible_flipped (np.ndarray, optional): Flipped keypoints'
+ visibility in shape (..., K, 1). Return ``None`` if the input
+ ``keypoints_visible`` is ``None``
+ """
+
+ assert keypoints.shape[:-1] == keypoints_visible.shape, (
+ f'Mismatched shapes of keypoints {keypoints.shape} and '
+ f'keypoints_visible {keypoints_visible.shape}')
+
+ direction_options = {'horizontal', 'vertical', 'diagonal'}
+ assert direction in direction_options, (
+ f'Invalid flipping direction "{direction}". '
+ f'Options are {direction_options}')
+
+ # swap the symmetric keypoint pairs
+ if direction == 'horizontal' or direction == 'vertical':
+ keypoints = keypoints[..., flip_indices, :]
+ if keypoints_visible is not None:
+ keypoints_visible = keypoints_visible[..., flip_indices]
+
+ # flip the keypoints
+ w, h = image_size
+ if direction == 'horizontal':
+ keypoints[..., 0] = w - 1 - keypoints[..., 0]
+ elif direction == 'vertical':
+ keypoints[..., 1] = h - 1 - keypoints[..., 1]
+ else:
+ keypoints = [w, h] - keypoints - 1
+
+ return keypoints, keypoints_visible
+
+
+def flip_keypoints_custom_center(keypoints: np.ndarray,
+ keypoints_visible: np.ndarray,
+ flip_indices: List[int],
+ center_mode: str = 'static',
+ center_x: float = 0.5,
+ center_index: int = 0):
+ """Flip human joints horizontally.
+
+ Note:
+ - num_keypoint: K
+ - dimension: D
+
+ Args:
+ keypoints (np.ndarray([..., K, D])): Coordinates of keypoints.
+ keypoints_visible (np.ndarray([..., K])): Visibility item of keypoints.
+ flip_indices (list[int]): The indices to flip the keypoints.
+ center_mode (str): The mode to set the center location on the x-axis
+ to flip around. Options are:
+
+ - static: use a static x value (see center_x also)
+ - root: use a root joint (see center_index also)
+
+ Defaults: ``'static'``.
+ center_x (float): Set the x-axis location of the flip center. Only used
+ when ``center_mode`` is ``'static'``. Defaults: 0.5.
+ center_index (int): Set the index of the root joint, whose x location
+ will be used as the flip center. Only used when ``center_mode`` is
+ ``'root'``. Defaults: 0.
+
+ Returns:
+ np.ndarray([..., K, C]): Flipped joints.
+ """
+
+ assert keypoints.ndim >= 2, f'Invalid pose shape {keypoints.shape}'
+
+ allowed_center_mode = {'static', 'root'}
+ assert center_mode in allowed_center_mode, 'Get invalid center_mode ' \
+ f'{center_mode}, allowed choices are {allowed_center_mode}'
+
+ if center_mode == 'static':
+ x_c = center_x
+ elif center_mode == 'root':
+ assert keypoints.shape[-2] > center_index
+ x_c = keypoints[..., center_index, 0]
+
+ keypoints_flipped = keypoints.copy()
+ keypoints_visible_flipped = keypoints_visible.copy()
+ # Swap left-right parts
+ for left, right in enumerate(flip_indices):
+ keypoints_flipped[..., left, :] = keypoints[..., right, :]
+ keypoints_visible_flipped[..., left] = keypoints_visible[..., right]
+
+ # Flip horizontally
+ keypoints_flipped[..., 0] = x_c * 2 - keypoints_flipped[..., 0]
+ return keypoints_flipped, keypoints_visible_flipped
diff --git a/mmpose/structures/multilevel_pixel_data.py b/mmpose/structures/multilevel_pixel_data.py
index bea191e729..2a961e8947 100644
--- a/mmpose/structures/multilevel_pixel_data.py
+++ b/mmpose/structures/multilevel_pixel_data.py
@@ -1,273 +1,273 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from collections import abc
-from typing import Any, Callable, List, Optional, Sequence, Tuple, Type, Union
-
-import numpy as np
-import torch
-from mmengine.structures import BaseDataElement, PixelData
-from mmengine.utils import is_list_of
-
-IndexType = Union[str, slice, int, list, torch.LongTensor,
- torch.cuda.LongTensor, torch.BoolTensor,
- torch.cuda.BoolTensor, np.ndarray]
-
-
-class MultilevelPixelData(BaseDataElement):
- """Data structure for multi-level pixel-wise annotations or predictions.
-
- All data items in ``data_fields`` of ``MultilevelPixelData`` are lists
- of np.ndarray or torch.Tensor, and should meet the following requirements:
-
- - Have the same length, which is the number of levels
- - At each level, the data should have 3 dimensions in order of channel,
- height and weight
- - At each level, the data should have the same height and weight
-
- Examples:
- >>> metainfo = dict(num_keypoints=17)
- >>> sizes = [(64, 48), (128, 96), (256, 192)]
- >>> heatmaps = [np.random.rand(17, h, w) for h, w in sizes]
- >>> masks = [torch.rand(1, h, w) for h, w in sizes]
- >>> data = MultilevelPixelData(metainfo=metainfo,
- ... heatmaps=heatmaps,
- ... masks=masks)
-
- >>> # get data item
- >>> heatmaps = data.heatmaps # A list of 3 numpy.ndarrays
- >>> masks = data.masks # A list of 3 torch.Tensors
-
- >>> # get level
- >>> data_l0 = data[0] # PixelData with fields 'heatmaps' and 'masks'
- >>> data.nlevel
- 3
-
- >>> # get shape
- >>> data.shape
- ((64, 48), (128, 96), (256, 192))
-
- >>> # set
- >>> offset_maps = [torch.rand(2, h, w) for h, w in sizes]
- >>> data.offset_maps = offset_maps
- """
-
- def __init__(self, *, metainfo: Optional[dict] = None, **kwargs) -> None:
- object.__setattr__(self, '_nlevel', None)
- super().__init__(metainfo=metainfo, **kwargs)
-
- @property
- def nlevel(self):
- """Return the level number.
-
- Returns:
- Optional[int]: The level number, or ``None`` if the data has not
- been assigned.
- """
- return self._nlevel
-
- def __getitem__(self, item: Union[int, str, list,
- slice]) -> Union[PixelData, Sequence]:
- if isinstance(item, int):
- if self.nlevel is None or item >= self.nlevel:
- raise IndexError(
- f'Lcale index {item} out of range ({self.nlevel})')
- return self.get(f'_level_{item}')
-
- if isinstance(item, str):
- if item not in self:
- raise KeyError(item)
- return getattr(self, item)
-
- # TODO: support indexing by list and slice over levels
- raise NotImplementedError(
- f'{self.__class__.__name__} does not support index type '
- f'{type(item)}')
-
- def levels(self) -> List[PixelData]:
- if self.nlevel:
- return list(self[i] for i in range(self.nlevel))
- return []
-
- @property
- def shape(self) -> Optional[Tuple[Tuple]]:
- """Get the shape of multi-level pixel data.
-
- Returns:
- Optional[tuple]: A tuple of data shape at each level, or ``None``
- if the data has not been assigned.
- """
- if self.nlevel is None:
- return None
-
- return tuple(level.shape for level in self.levels())
-
- def set_data(self, data: dict) -> None:
- """Set or change key-value pairs in ``data_field`` by parameter
- ``data``.
-
- Args:
- data (dict): A dict contains annotations of image or
- model predictions.
- """
- assert isinstance(data,
- dict), f'meta should be a `dict` but got {data}'
- for k, v in data.items():
- self.set_field(v, k, field_type='data')
-
- def set_field(self,
- value: Any,
- name: str,
- dtype: Optional[Union[Type, Tuple[Type, ...]]] = None,
- field_type: str = 'data') -> None:
- """Special method for set union field, used as property.setter
- functions."""
- assert field_type in ['metainfo', 'data']
- if dtype is not None:
- assert isinstance(
- value,
- dtype), f'{value} should be a {dtype} but got {type(value)}'
-
- if name.startswith('_level_'):
- raise AttributeError(
- f'Cannot set {name} to be a field because the pattern '
- '<_level_{n}> is reserved for inner data field')
-
- if field_type == 'metainfo':
- if name in self._data_fields:
- raise AttributeError(
- f'Cannot set {name} to be a field of metainfo '
- f'because {name} is already a data field')
- self._metainfo_fields.add(name)
-
- else:
- if name in self._metainfo_fields:
- raise AttributeError(
- f'Cannot set {name} to be a field of data '
- f'because {name} is already a metainfo field')
-
- if not isinstance(value, abc.Sequence):
- raise TypeError(
- 'The value should be a sequence (of numpy.ndarray or'
- f'torch.Tesnor), but got a {type(value)}')
-
- if len(value) == 0:
- raise ValueError('Setting empty value is not allowed')
-
- if not isinstance(value[0], (torch.Tensor, np.ndarray)):
- raise TypeError(
- 'The value should be a sequence of numpy.ndarray or'
- f'torch.Tesnor, but got a sequence of {type(value[0])}')
-
- if self.nlevel is not None:
- assert len(value) == self.nlevel, (
- f'The length of the value ({len(value)}) should match the'
- f'number of the levels ({self.nlevel})')
- else:
- object.__setattr__(self, '_nlevel', len(value))
- for i in range(self.nlevel):
- object.__setattr__(self, f'_level_{i}', PixelData())
-
- for i, v in enumerate(value):
- self[i].set_field(v, name, field_type='data')
-
- self._data_fields.add(name)
-
- object.__setattr__(self, name, value)
-
- def __delattr__(self, item: str):
- """delete the item in dataelement.
-
- Args:
- item (str): The key to delete.
- """
- if item in ('_metainfo_fields', '_data_fields'):
- raise AttributeError(f'{item} has been used as a '
- 'private attribute, which is immutable. ')
-
- if item in self._metainfo_fields:
- super().__delattr__(item)
- else:
- for level in self.levels():
- level.__delattr__(item)
- self._data_fields.remove(item)
-
- def __getattr__(self, name):
- if name in {'_data_fields', '_metainfo_fields'
- } or name not in self._data_fields:
- raise AttributeError(
- f'\'{self.__class__.__name__}\' object has no attribute '
- f'\'{name}\'')
-
- return [getattr(level, name) for level in self.levels()]
-
- def pop(self, *args) -> Any:
- """pop property in data and metainfo as the same as python."""
- assert len(args) < 3, '``pop`` get more than 2 arguments'
- name = args[0]
- if name in self._metainfo_fields:
- self._metainfo_fields.remove(name)
- return self.__dict__.pop(*args)
-
- elif name in self._data_fields:
- self._data_fields.remove(name)
- return [level.pop(*args) for level in self.levels()]
-
- # with default value
- elif len(args) == 2:
- return args[1]
- else:
- # don't just use 'self.__dict__.pop(*args)' for only popping key in
- # metainfo or data
- raise KeyError(f'{args[0]} is not contained in metainfo or data')
-
- def _convert(self, apply_to: Type,
- func: Callable[[Any], Any]) -> 'MultilevelPixelData':
- """Convert data items with the given function.
-
- Args:
- apply_to (Type): The type of data items to apply the conversion
- func (Callable): The conversion function that takes a data item
- as the input and return the converted result
-
- Returns:
- MultilevelPixelData: the converted data element.
- """
- new_data = self.new()
- for k, v in self.items():
- if is_list_of(v, apply_to):
- v = [func(_v) for _v in v]
- data = {k: v}
- new_data.set_data(data)
- return new_data
-
- def cpu(self) -> 'MultilevelPixelData':
- """Convert all tensors to CPU in data."""
- return self._convert(apply_to=torch.Tensor, func=lambda x: x.cpu())
-
- def cuda(self) -> 'MultilevelPixelData':
- """Convert all tensors to GPU in data."""
- return self._convert(apply_to=torch.Tensor, func=lambda x: x.cuda())
-
- def detach(self) -> 'MultilevelPixelData':
- """Detach all tensors in data."""
- return self._convert(apply_to=torch.Tensor, func=lambda x: x.detach())
-
- def numpy(self) -> 'MultilevelPixelData':
- """Convert all tensor to np.narray in data."""
- return self._convert(
- apply_to=torch.Tensor, func=lambda x: x.detach().cpu().numpy())
-
- def to_tensor(self) -> 'MultilevelPixelData':
- """Convert all tensor to np.narray in data."""
- return self._convert(
- apply_to=np.ndarray, func=lambda x: torch.from_numpy(x))
-
- # Tensor-like methods
- def to(self, *args, **kwargs) -> 'MultilevelPixelData':
- """Apply same name function to all tensors in data_fields."""
- new_data = self.new()
- for k, v in self.items():
- if hasattr(v[0], 'to'):
- v = [v_.to(*args, **kwargs) for v_ in v]
- data = {k: v}
- new_data.set_data(data)
- return new_data
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections import abc
+from typing import Any, Callable, List, Optional, Sequence, Tuple, Type, Union
+
+import numpy as np
+import torch
+from mmengine.structures import BaseDataElement, PixelData
+from mmengine.utils import is_list_of
+
+IndexType = Union[str, slice, int, list, torch.LongTensor,
+ torch.cuda.LongTensor, torch.BoolTensor,
+ torch.cuda.BoolTensor, np.ndarray]
+
+
+class MultilevelPixelData(BaseDataElement):
+ """Data structure for multi-level pixel-wise annotations or predictions.
+
+ All data items in ``data_fields`` of ``MultilevelPixelData`` are lists
+ of np.ndarray or torch.Tensor, and should meet the following requirements:
+
+ - Have the same length, which is the number of levels
+ - At each level, the data should have 3 dimensions in order of channel,
+ height and weight
+ - At each level, the data should have the same height and weight
+
+ Examples:
+ >>> metainfo = dict(num_keypoints=17)
+ >>> sizes = [(64, 48), (128, 96), (256, 192)]
+ >>> heatmaps = [np.random.rand(17, h, w) for h, w in sizes]
+ >>> masks = [torch.rand(1, h, w) for h, w in sizes]
+ >>> data = MultilevelPixelData(metainfo=metainfo,
+ ... heatmaps=heatmaps,
+ ... masks=masks)
+
+ >>> # get data item
+ >>> heatmaps = data.heatmaps # A list of 3 numpy.ndarrays
+ >>> masks = data.masks # A list of 3 torch.Tensors
+
+ >>> # get level
+ >>> data_l0 = data[0] # PixelData with fields 'heatmaps' and 'masks'
+ >>> data.nlevel
+ 3
+
+ >>> # get shape
+ >>> data.shape
+ ((64, 48), (128, 96), (256, 192))
+
+ >>> # set
+ >>> offset_maps = [torch.rand(2, h, w) for h, w in sizes]
+ >>> data.offset_maps = offset_maps
+ """
+
+ def __init__(self, *, metainfo: Optional[dict] = None, **kwargs) -> None:
+ object.__setattr__(self, '_nlevel', None)
+ super().__init__(metainfo=metainfo, **kwargs)
+
+ @property
+ def nlevel(self):
+ """Return the level number.
+
+ Returns:
+ Optional[int]: The level number, or ``None`` if the data has not
+ been assigned.
+ """
+ return self._nlevel
+
+ def __getitem__(self, item: Union[int, str, list,
+ slice]) -> Union[PixelData, Sequence]:
+ if isinstance(item, int):
+ if self.nlevel is None or item >= self.nlevel:
+ raise IndexError(
+ f'Lcale index {item} out of range ({self.nlevel})')
+ return self.get(f'_level_{item}')
+
+ if isinstance(item, str):
+ if item not in self:
+ raise KeyError(item)
+ return getattr(self, item)
+
+ # TODO: support indexing by list and slice over levels
+ raise NotImplementedError(
+ f'{self.__class__.__name__} does not support index type '
+ f'{type(item)}')
+
+ def levels(self) -> List[PixelData]:
+ if self.nlevel:
+ return list(self[i] for i in range(self.nlevel))
+ return []
+
+ @property
+ def shape(self) -> Optional[Tuple[Tuple]]:
+ """Get the shape of multi-level pixel data.
+
+ Returns:
+ Optional[tuple]: A tuple of data shape at each level, or ``None``
+ if the data has not been assigned.
+ """
+ if self.nlevel is None:
+ return None
+
+ return tuple(level.shape for level in self.levels())
+
+ def set_data(self, data: dict) -> None:
+ """Set or change key-value pairs in ``data_field`` by parameter
+ ``data``.
+
+ Args:
+ data (dict): A dict contains annotations of image or
+ model predictions.
+ """
+ assert isinstance(data,
+ dict), f'meta should be a `dict` but got {data}'
+ for k, v in data.items():
+ self.set_field(v, k, field_type='data')
+
+ def set_field(self,
+ value: Any,
+ name: str,
+ dtype: Optional[Union[Type, Tuple[Type, ...]]] = None,
+ field_type: str = 'data') -> None:
+ """Special method for set union field, used as property.setter
+ functions."""
+ assert field_type in ['metainfo', 'data']
+ if dtype is not None:
+ assert isinstance(
+ value,
+ dtype), f'{value} should be a {dtype} but got {type(value)}'
+
+ if name.startswith('_level_'):
+ raise AttributeError(
+ f'Cannot set {name} to be a field because the pattern '
+ '<_level_{n}> is reserved for inner data field')
+
+ if field_type == 'metainfo':
+ if name in self._data_fields:
+ raise AttributeError(
+ f'Cannot set {name} to be a field of metainfo '
+ f'because {name} is already a data field')
+ self._metainfo_fields.add(name)
+
+ else:
+ if name in self._metainfo_fields:
+ raise AttributeError(
+ f'Cannot set {name} to be a field of data '
+ f'because {name} is already a metainfo field')
+
+ if not isinstance(value, abc.Sequence):
+ raise TypeError(
+ 'The value should be a sequence (of numpy.ndarray or'
+ f'torch.Tesnor), but got a {type(value)}')
+
+ if len(value) == 0:
+ raise ValueError('Setting empty value is not allowed')
+
+ if not isinstance(value[0], (torch.Tensor, np.ndarray)):
+ raise TypeError(
+ 'The value should be a sequence of numpy.ndarray or'
+ f'torch.Tesnor, but got a sequence of {type(value[0])}')
+
+ if self.nlevel is not None:
+ assert len(value) == self.nlevel, (
+ f'The length of the value ({len(value)}) should match the'
+ f'number of the levels ({self.nlevel})')
+ else:
+ object.__setattr__(self, '_nlevel', len(value))
+ for i in range(self.nlevel):
+ object.__setattr__(self, f'_level_{i}', PixelData())
+
+ for i, v in enumerate(value):
+ self[i].set_field(v, name, field_type='data')
+
+ self._data_fields.add(name)
+
+ object.__setattr__(self, name, value)
+
+ def __delattr__(self, item: str):
+ """delete the item in dataelement.
+
+ Args:
+ item (str): The key to delete.
+ """
+ if item in ('_metainfo_fields', '_data_fields'):
+ raise AttributeError(f'{item} has been used as a '
+ 'private attribute, which is immutable. ')
+
+ if item in self._metainfo_fields:
+ super().__delattr__(item)
+ else:
+ for level in self.levels():
+ level.__delattr__(item)
+ self._data_fields.remove(item)
+
+ def __getattr__(self, name):
+ if name in {'_data_fields', '_metainfo_fields'
+ } or name not in self._data_fields:
+ raise AttributeError(
+ f'\'{self.__class__.__name__}\' object has no attribute '
+ f'\'{name}\'')
+
+ return [getattr(level, name) for level in self.levels()]
+
+ def pop(self, *args) -> Any:
+ """pop property in data and metainfo as the same as python."""
+ assert len(args) < 3, '``pop`` get more than 2 arguments'
+ name = args[0]
+ if name in self._metainfo_fields:
+ self._metainfo_fields.remove(name)
+ return self.__dict__.pop(*args)
+
+ elif name in self._data_fields:
+ self._data_fields.remove(name)
+ return [level.pop(*args) for level in self.levels()]
+
+ # with default value
+ elif len(args) == 2:
+ return args[1]
+ else:
+ # don't just use 'self.__dict__.pop(*args)' for only popping key in
+ # metainfo or data
+ raise KeyError(f'{args[0]} is not contained in metainfo or data')
+
+ def _convert(self, apply_to: Type,
+ func: Callable[[Any], Any]) -> 'MultilevelPixelData':
+ """Convert data items with the given function.
+
+ Args:
+ apply_to (Type): The type of data items to apply the conversion
+ func (Callable): The conversion function that takes a data item
+ as the input and return the converted result
+
+ Returns:
+ MultilevelPixelData: the converted data element.
+ """
+ new_data = self.new()
+ for k, v in self.items():
+ if is_list_of(v, apply_to):
+ v = [func(_v) for _v in v]
+ data = {k: v}
+ new_data.set_data(data)
+ return new_data
+
+ def cpu(self) -> 'MultilevelPixelData':
+ """Convert all tensors to CPU in data."""
+ return self._convert(apply_to=torch.Tensor, func=lambda x: x.cpu())
+
+ def cuda(self) -> 'MultilevelPixelData':
+ """Convert all tensors to GPU in data."""
+ return self._convert(apply_to=torch.Tensor, func=lambda x: x.cuda())
+
+ def detach(self) -> 'MultilevelPixelData':
+ """Detach all tensors in data."""
+ return self._convert(apply_to=torch.Tensor, func=lambda x: x.detach())
+
+ def numpy(self) -> 'MultilevelPixelData':
+ """Convert all tensor to np.narray in data."""
+ return self._convert(
+ apply_to=torch.Tensor, func=lambda x: x.detach().cpu().numpy())
+
+ def to_tensor(self) -> 'MultilevelPixelData':
+ """Convert all tensor to np.narray in data."""
+ return self._convert(
+ apply_to=np.ndarray, func=lambda x: torch.from_numpy(x))
+
+ # Tensor-like methods
+ def to(self, *args, **kwargs) -> 'MultilevelPixelData':
+ """Apply same name function to all tensors in data_fields."""
+ new_data = self.new()
+ for k, v in self.items():
+ if hasattr(v[0], 'to'):
+ v = [v_.to(*args, **kwargs) for v_ in v]
+ data = {k: v}
+ new_data.set_data(data)
+ return new_data
diff --git a/mmpose/structures/pose_data_sample.py b/mmpose/structures/pose_data_sample.py
index 2c1d69034e..56d1b4cf1e 100644
--- a/mmpose/structures/pose_data_sample.py
+++ b/mmpose/structures/pose_data_sample.py
@@ -1,104 +1,104 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Union
-
-from mmengine.structures import BaseDataElement, InstanceData, PixelData
-
-from mmpose.structures import MultilevelPixelData
-
-
-class PoseDataSample(BaseDataElement):
- """The base data structure of MMPose that is used as the interface between
- modules.
-
- The attributes of ``PoseDataSample`` includes:
-
- - ``gt_instances``(InstanceData): Ground truth of instances with
- keypoint annotations
- - ``pred_instances``(InstanceData): Instances with keypoint
- predictions
- - ``gt_fields``(PixelData): Ground truth of spatial distribution
- annotations like keypoint heatmaps and part affine fields (PAF)
- - ``pred_fields``(PixelData): Predictions of spatial distributions
-
- Examples:
- >>> import torch
- >>> from mmengine.structures import InstanceData, PixelData
- >>> from mmpose.structures import PoseDataSample
-
- >>> pose_meta = dict(img_shape=(800, 1216),
- ... crop_size=(256, 192),
- ... heatmap_size=(64, 48))
- >>> gt_instances = InstanceData()
- >>> gt_instances.bboxes = torch.rand((1, 4))
- >>> gt_instances.keypoints = torch.rand((1, 17, 2))
- >>> gt_instances.keypoints_visible = torch.rand((1, 17, 1))
- >>> gt_fields = PixelData()
- >>> gt_fields.heatmaps = torch.rand((17, 64, 48))
-
- >>> data_sample = PoseDataSample(gt_instances=gt_instances,
- ... gt_fields=gt_fields,
- ... metainfo=pose_meta)
- >>> assert 'img_shape' in data_sample
- >>> len(data_sample.gt_intances)
- 1
- """
-
- @property
- def gt_instances(self) -> InstanceData:
- return self._gt_instances
-
- @gt_instances.setter
- def gt_instances(self, value: InstanceData):
- self.set_field(value, '_gt_instances', dtype=InstanceData)
-
- @gt_instances.deleter
- def gt_instances(self):
- del self._gt_instances
-
- @property
- def gt_instance_labels(self) -> InstanceData:
- return self._gt_instance_labels
-
- @gt_instance_labels.setter
- def gt_instance_labels(self, value: InstanceData):
- self.set_field(value, '_gt_instance_labels', dtype=InstanceData)
-
- @gt_instance_labels.deleter
- def gt_instance_labels(self):
- del self._gt_instance_labels
-
- @property
- def pred_instances(self) -> InstanceData:
- return self._pred_instances
-
- @pred_instances.setter
- def pred_instances(self, value: InstanceData):
- self.set_field(value, '_pred_instances', dtype=InstanceData)
-
- @pred_instances.deleter
- def pred_instances(self):
- del self._pred_instances
-
- @property
- def gt_fields(self) -> Union[PixelData, MultilevelPixelData]:
- return self._gt_fields
-
- @gt_fields.setter
- def gt_fields(self, value: Union[PixelData, MultilevelPixelData]):
- self.set_field(value, '_gt_fields', dtype=type(value))
-
- @gt_fields.deleter
- def gt_fields(self):
- del self._gt_fields
-
- @property
- def pred_fields(self) -> PixelData:
- return self._pred_heatmaps
-
- @pred_fields.setter
- def pred_fields(self, value: PixelData):
- self.set_field(value, '_pred_heatmaps', dtype=PixelData)
-
- @pred_fields.deleter
- def pred_fields(self):
- del self._pred_heatmaps
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Union
+
+from mmengine.structures import BaseDataElement, InstanceData, PixelData
+
+from mmpose.structures import MultilevelPixelData
+
+
+class PoseDataSample(BaseDataElement):
+ """The base data structure of MMPose that is used as the interface between
+ modules.
+
+ The attributes of ``PoseDataSample`` includes:
+
+ - ``gt_instances``(InstanceData): Ground truth of instances with
+ keypoint annotations
+ - ``pred_instances``(InstanceData): Instances with keypoint
+ predictions
+ - ``gt_fields``(PixelData): Ground truth of spatial distribution
+ annotations like keypoint heatmaps and part affine fields (PAF)
+ - ``pred_fields``(PixelData): Predictions of spatial distributions
+
+ Examples:
+ >>> import torch
+ >>> from mmengine.structures import InstanceData, PixelData
+ >>> from mmpose.structures import PoseDataSample
+
+ >>> pose_meta = dict(img_shape=(800, 1216),
+ ... crop_size=(256, 192),
+ ... heatmap_size=(64, 48))
+ >>> gt_instances = InstanceData()
+ >>> gt_instances.bboxes = torch.rand((1, 4))
+ >>> gt_instances.keypoints = torch.rand((1, 17, 2))
+ >>> gt_instances.keypoints_visible = torch.rand((1, 17, 1))
+ >>> gt_fields = PixelData()
+ >>> gt_fields.heatmaps = torch.rand((17, 64, 48))
+
+ >>> data_sample = PoseDataSample(gt_instances=gt_instances,
+ ... gt_fields=gt_fields,
+ ... metainfo=pose_meta)
+ >>> assert 'img_shape' in data_sample
+ >>> len(data_sample.gt_intances)
+ 1
+ """
+
+ @property
+ def gt_instances(self) -> InstanceData:
+ return self._gt_instances
+
+ @gt_instances.setter
+ def gt_instances(self, value: InstanceData):
+ self.set_field(value, '_gt_instances', dtype=InstanceData)
+
+ @gt_instances.deleter
+ def gt_instances(self):
+ del self._gt_instances
+
+ @property
+ def gt_instance_labels(self) -> InstanceData:
+ return self._gt_instance_labels
+
+ @gt_instance_labels.setter
+ def gt_instance_labels(self, value: InstanceData):
+ self.set_field(value, '_gt_instance_labels', dtype=InstanceData)
+
+ @gt_instance_labels.deleter
+ def gt_instance_labels(self):
+ del self._gt_instance_labels
+
+ @property
+ def pred_instances(self) -> InstanceData:
+ return self._pred_instances
+
+ @pred_instances.setter
+ def pred_instances(self, value: InstanceData):
+ self.set_field(value, '_pred_instances', dtype=InstanceData)
+
+ @pred_instances.deleter
+ def pred_instances(self):
+ del self._pred_instances
+
+ @property
+ def gt_fields(self) -> Union[PixelData, MultilevelPixelData]:
+ return self._gt_fields
+
+ @gt_fields.setter
+ def gt_fields(self, value: Union[PixelData, MultilevelPixelData]):
+ self.set_field(value, '_gt_fields', dtype=type(value))
+
+ @gt_fields.deleter
+ def gt_fields(self):
+ del self._gt_fields
+
+ @property
+ def pred_fields(self) -> PixelData:
+ return self._pred_heatmaps
+
+ @pred_fields.setter
+ def pred_fields(self, value: PixelData):
+ self.set_field(value, '_pred_heatmaps', dtype=PixelData)
+
+ @pred_fields.deleter
+ def pred_fields(self):
+ del self._pred_heatmaps
diff --git a/mmpose/structures/utils.py b/mmpose/structures/utils.py
index 882cda8603..132b8f6397 100644
--- a/mmpose/structures/utils.py
+++ b/mmpose/structures/utils.py
@@ -1,138 +1,138 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import warnings
-from typing import List
-
-import cv2
-import numpy as np
-import torch
-from mmengine.structures import InstanceData, PixelData
-from mmengine.utils import is_list_of
-
-from .bbox.transforms import get_warp_matrix
-from .pose_data_sample import PoseDataSample
-
-
-def merge_data_samples(data_samples: List[PoseDataSample]) -> PoseDataSample:
- """Merge the given data samples into a single data sample.
-
- This function can be used to merge the top-down predictions with
- bboxes from the same image. The merged data sample will contain all
- instances from the input data samples, and the identical metainfo with
- the first input data sample.
-
- Args:
- data_samples (List[:obj:`PoseDataSample`]): The data samples to
- merge
-
- Returns:
- PoseDataSample: The merged data sample.
- """
-
- if not is_list_of(data_samples, PoseDataSample):
- raise ValueError('Invalid input type, should be a list of '
- ':obj:`PoseDataSample`')
-
- if len(data_samples) == 0:
- warnings.warn('Try to merge an empty list of data samples.')
- return PoseDataSample()
-
- merged = PoseDataSample(metainfo=data_samples[0].metainfo)
-
- if 'gt_instances' in data_samples[0]:
- merged.gt_instances = InstanceData.cat(
- [d.gt_instances for d in data_samples])
-
- if 'pred_instances' in data_samples[0]:
- merged.pred_instances = InstanceData.cat(
- [d.pred_instances for d in data_samples])
-
- if 'pred_fields' in data_samples[0] and 'heatmaps' in data_samples[
- 0].pred_fields:
- reverted_heatmaps = [
- revert_heatmap(data_sample.pred_fields.heatmaps,
- data_sample.gt_instances.bbox_centers,
- data_sample.gt_instances.bbox_scales,
- data_sample.ori_shape)
- for data_sample in data_samples
- ]
-
- merged_heatmaps = np.max(reverted_heatmaps, axis=0)
- pred_fields = PixelData()
- pred_fields.set_data(dict(heatmaps=merged_heatmaps))
- merged.pred_fields = pred_fields
-
- if 'gt_fields' in data_samples[0] and 'heatmaps' in data_samples[
- 0].gt_fields:
- reverted_heatmaps = [
- revert_heatmap(data_sample.gt_fields.heatmaps,
- data_sample.gt_instances.bbox_centers,
- data_sample.gt_instances.bbox_scales,
- data_sample.ori_shape)
- for data_sample in data_samples
- ]
-
- merged_heatmaps = np.max(reverted_heatmaps, axis=0)
- gt_fields = PixelData()
- gt_fields.set_data(dict(heatmaps=merged_heatmaps))
- merged.gt_fields = gt_fields
-
- return merged
-
-
-def revert_heatmap(heatmap, bbox_center, bbox_scale, img_shape):
- """Revert predicted heatmap on the original image.
-
- Args:
- heatmap (np.ndarray or torch.tensor): predicted heatmap.
- bbox_center (np.ndarray): bounding box center coordinate.
- bbox_scale (np.ndarray): bounding box scale.
- img_shape (tuple or list): size of original image.
- """
- if torch.is_tensor(heatmap):
- heatmap = heatmap.cpu().detach().numpy()
-
- ndim = heatmap.ndim
- # [K, H, W] -> [H, W, K]
- if ndim == 3:
- heatmap = heatmap.transpose(1, 2, 0)
-
- hm_h, hm_w = heatmap.shape[:2]
- img_h, img_w = img_shape
- warp_mat = get_warp_matrix(
- bbox_center.reshape((2, )),
- bbox_scale.reshape((2, )),
- rot=0,
- output_size=(hm_w, hm_h),
- inv=True)
-
- heatmap = cv2.warpAffine(
- heatmap, warp_mat, (img_w, img_h), flags=cv2.INTER_LINEAR)
-
- # [H, W, K] -> [K, H, W]
- if ndim == 3:
- heatmap = heatmap.transpose(2, 0, 1)
-
- return heatmap
-
-
-def split_instances(instances: InstanceData) -> List[InstanceData]:
- """Convert instances into a list where each element is a dict that contains
- information about one instance."""
- results = []
-
- # return an empty list if there is no instance detected by the model
- if instances is None:
- return results
-
- for i in range(len(instances.keypoints)):
- result = dict(
- keypoints=instances.keypoints[i].tolist(),
- keypoint_scores=instances.keypoint_scores[i].tolist(),
- )
- if 'bboxes' in instances:
- result['bbox'] = instances.bboxes[i].tolist(),
- if 'bbox_scores' in instances:
- result['bbox_score'] = instances.bbox_scores[i]
- results.append(result)
-
- return results
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import List
+
+import cv2
+import numpy as np
+import torch
+from mmengine.structures import InstanceData, PixelData
+from mmengine.utils import is_list_of
+
+from .bbox.transforms import get_warp_matrix
+from .pose_data_sample import PoseDataSample
+
+
+def merge_data_samples(data_samples: List[PoseDataSample]) -> PoseDataSample:
+ """Merge the given data samples into a single data sample.
+
+ This function can be used to merge the top-down predictions with
+ bboxes from the same image. The merged data sample will contain all
+ instances from the input data samples, and the identical metainfo with
+ the first input data sample.
+
+ Args:
+ data_samples (List[:obj:`PoseDataSample`]): The data samples to
+ merge
+
+ Returns:
+ PoseDataSample: The merged data sample.
+ """
+
+ if not is_list_of(data_samples, PoseDataSample):
+ raise ValueError('Invalid input type, should be a list of '
+ ':obj:`PoseDataSample`')
+
+ if len(data_samples) == 0:
+ warnings.warn('Try to merge an empty list of data samples.')
+ return PoseDataSample()
+
+ merged = PoseDataSample(metainfo=data_samples[0].metainfo)
+
+ if 'gt_instances' in data_samples[0]:
+ merged.gt_instances = InstanceData.cat(
+ [d.gt_instances for d in data_samples])
+
+ if 'pred_instances' in data_samples[0]:
+ merged.pred_instances = InstanceData.cat(
+ [d.pred_instances for d in data_samples])
+
+ if 'pred_fields' in data_samples[0] and 'heatmaps' in data_samples[
+ 0].pred_fields:
+ reverted_heatmaps = [
+ revert_heatmap(data_sample.pred_fields.heatmaps,
+ data_sample.gt_instances.bbox_centers,
+ data_sample.gt_instances.bbox_scales,
+ data_sample.ori_shape)
+ for data_sample in data_samples
+ ]
+
+ merged_heatmaps = np.max(reverted_heatmaps, axis=0)
+ pred_fields = PixelData()
+ pred_fields.set_data(dict(heatmaps=merged_heatmaps))
+ merged.pred_fields = pred_fields
+
+ if 'gt_fields' in data_samples[0] and 'heatmaps' in data_samples[
+ 0].gt_fields:
+ reverted_heatmaps = [
+ revert_heatmap(data_sample.gt_fields.heatmaps,
+ data_sample.gt_instances.bbox_centers,
+ data_sample.gt_instances.bbox_scales,
+ data_sample.ori_shape)
+ for data_sample in data_samples
+ ]
+
+ merged_heatmaps = np.max(reverted_heatmaps, axis=0)
+ gt_fields = PixelData()
+ gt_fields.set_data(dict(heatmaps=merged_heatmaps))
+ merged.gt_fields = gt_fields
+
+ return merged
+
+
+def revert_heatmap(heatmap, bbox_center, bbox_scale, img_shape):
+ """Revert predicted heatmap on the original image.
+
+ Args:
+ heatmap (np.ndarray or torch.tensor): predicted heatmap.
+ bbox_center (np.ndarray): bounding box center coordinate.
+ bbox_scale (np.ndarray): bounding box scale.
+ img_shape (tuple or list): size of original image.
+ """
+ if torch.is_tensor(heatmap):
+ heatmap = heatmap.cpu().detach().numpy()
+
+ ndim = heatmap.ndim
+ # [K, H, W] -> [H, W, K]
+ if ndim == 3:
+ heatmap = heatmap.transpose(1, 2, 0)
+
+ hm_h, hm_w = heatmap.shape[:2]
+ img_h, img_w = img_shape
+ warp_mat = get_warp_matrix(
+ bbox_center.reshape((2, )),
+ bbox_scale.reshape((2, )),
+ rot=0,
+ output_size=(hm_w, hm_h),
+ inv=True)
+
+ heatmap = cv2.warpAffine(
+ heatmap, warp_mat, (img_w, img_h), flags=cv2.INTER_LINEAR)
+
+ # [H, W, K] -> [K, H, W]
+ if ndim == 3:
+ heatmap = heatmap.transpose(2, 0, 1)
+
+ return heatmap
+
+
+def split_instances(instances: InstanceData) -> List[InstanceData]:
+ """Convert instances into a list where each element is a dict that contains
+ information about one instance."""
+ results = []
+
+ # return an empty list if there is no instance detected by the model
+ if instances is None:
+ return results
+
+ for i in range(len(instances.keypoints)):
+ result = dict(
+ keypoints=instances.keypoints[i].tolist(),
+ keypoint_scores=instances.keypoint_scores[i].tolist(),
+ )
+ if 'bboxes' in instances:
+ result['bbox'] = instances.bboxes[i].tolist(),
+ if 'bbox_scores' in instances:
+ result['bbox_score'] = instances.bbox_scores[i]
+ results.append(result)
+
+ return results
diff --git a/mmpose/testing/__init__.py b/mmpose/testing/__init__.py
index 5612dac6c6..de4f28e6fc 100644
--- a/mmpose/testing/__init__.py
+++ b/mmpose/testing/__init__.py
@@ -1,8 +1,8 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from ._utils import (get_coco_sample, get_config_file, get_packed_inputs,
- get_pose_estimator_cfg, get_repo_dir)
-
-__all__ = [
- 'get_packed_inputs', 'get_coco_sample', 'get_config_file',
- 'get_pose_estimator_cfg', 'get_repo_dir'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from ._utils import (get_coco_sample, get_config_file, get_packed_inputs,
+ get_pose_estimator_cfg, get_repo_dir)
+
+__all__ = [
+ 'get_packed_inputs', 'get_coco_sample', 'get_config_file',
+ 'get_pose_estimator_cfg', 'get_repo_dir'
+]
diff --git a/mmpose/testing/_utils.py b/mmpose/testing/_utils.py
index 1908129be8..5b0a5c5a31 100644
--- a/mmpose/testing/_utils.py
+++ b/mmpose/testing/_utils.py
@@ -1,248 +1,248 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os.path as osp
-from copy import deepcopy
-from typing import Optional
-
-import numpy as np
-import torch
-from mmengine.config import Config
-from mmengine.dataset import pseudo_collate
-from mmengine.structures import InstanceData, PixelData
-
-from mmpose.structures import MultilevelPixelData, PoseDataSample
-from mmpose.structures.bbox import bbox_xyxy2cs
-
-
-def get_coco_sample(
- img_shape=(240, 320),
- img_fill: Optional[int] = None,
- num_instances=1,
- with_bbox_cs=True,
- with_img_mask=False,
- random_keypoints_visible=False,
- non_occlusion=False):
- """Create a dummy data sample in COCO style."""
- rng = np.random.RandomState(0)
- h, w = img_shape
- if img_fill is None:
- img = np.random.randint(0, 256, (h, w, 3), dtype=np.uint8)
- else:
- img = np.full((h, w, 3), img_fill, dtype=np.uint8)
-
- if non_occlusion:
- bbox = _rand_bboxes(rng, num_instances, w / num_instances, h)
- for i in range(num_instances):
- bbox[i, 0::2] += w / num_instances * i
- else:
- bbox = _rand_bboxes(rng, num_instances, w, h)
-
- keypoints = _rand_keypoints(rng, bbox, 17)
- if random_keypoints_visible:
- keypoints_visible = np.random.randint(0, 2, (num_instances,
- 17)).astype(np.float32)
- else:
- keypoints_visible = np.full((num_instances, 17), 1, dtype=np.float32)
-
- upper_body_ids = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
- lower_body_ids = [11, 12, 13, 14, 15, 16]
- flip_pairs = [[2, 1], [1, 2], [4, 3], [3, 4], [6, 5], [5, 6], [8, 7],
- [7, 8], [10, 9], [9, 10], [12, 11], [11, 12], [14, 13],
- [13, 14], [16, 15], [15, 16]]
- flip_indices = [0, 2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15]
- dataset_keypoint_weights = np.array([
- 1., 1., 1., 1., 1., 1., 1., 1.2, 1.2, 1.5, 1.5, 1., 1., 1.2, 1.2, 1.5,
- 1.5
- ]).astype(np.float32)
-
- data = {
- 'img': img,
- 'img_shape': img_shape,
- 'ori_shape': img_shape,
- 'bbox': bbox,
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- 'upper_body_ids': upper_body_ids,
- 'lower_body_ids': lower_body_ids,
- 'flip_pairs': flip_pairs,
- 'flip_indices': flip_indices,
- 'dataset_keypoint_weights': dataset_keypoint_weights,
- 'invalid_segs': [],
- }
-
- if with_bbox_cs:
- data['bbox_center'], data['bbox_scale'] = bbox_xyxy2cs(data['bbox'])
-
- if with_img_mask:
- data['img_mask'] = np.random.randint(0, 2, (h, w), dtype=np.uint8)
-
- return data
-
-
-def get_packed_inputs(batch_size=2,
- num_instances=1,
- num_keypoints=17,
- num_levels=1,
- img_shape=(256, 192),
- input_size=(192, 256),
- heatmap_size=(48, 64),
- simcc_split_ratio=2.0,
- with_heatmap=True,
- with_reg_label=True,
- with_simcc_label=True):
- """Create a dummy batch of model inputs and data samples."""
- rng = np.random.RandomState(0)
-
- inputs_list = []
- for idx in range(batch_size):
- inputs = dict()
-
- # input
- h, w = img_shape
- image = rng.randint(0, 255, size=(3, h, w), dtype=np.uint8)
- inputs['inputs'] = torch.from_numpy(image)
-
- # meta
- img_meta = {
- 'id': idx,
- 'img_id': idx,
- 'img_path': '.png',
- 'img_shape': img_shape,
- 'input_size': input_size,
- 'flip': False,
- 'flip_direction': None,
- 'flip_indices': list(range(num_keypoints))
- }
-
- np.random.shuffle(img_meta['flip_indices'])
- data_sample = PoseDataSample(metainfo=img_meta)
-
- # gt_instance
- gt_instances = InstanceData()
- gt_instance_labels = InstanceData()
- bboxes = _rand_bboxes(rng, num_instances, w, h)
- bbox_centers, bbox_scales = bbox_xyxy2cs(bboxes)
-
- keypoints = _rand_keypoints(rng, bboxes, num_keypoints)
- keypoints_visible = np.ones((num_instances, num_keypoints),
- dtype=np.float32)
-
- # [N, K] -> [N, num_levels, K]
- # keep the first dimension as the num_instances
- if num_levels > 1:
- keypoint_weights = np.tile(keypoints_visible[:, None],
- (1, num_levels, 1))
- else:
- keypoint_weights = keypoints_visible.copy()
-
- gt_instances.bboxes = bboxes
- gt_instances.bbox_centers = bbox_centers
- gt_instances.bbox_scales = bbox_scales
- gt_instances.bbox_scores = np.ones((num_instances, ), dtype=np.float32)
- gt_instances.keypoints = keypoints
- gt_instances.keypoints_visible = keypoints_visible
-
- gt_instance_labels.keypoint_weights = torch.FloatTensor(
- keypoint_weights)
-
- if with_reg_label:
- gt_instance_labels.keypoint_labels = torch.FloatTensor(keypoints /
- input_size)
-
- if with_simcc_label:
- len_x = np.around(input_size[0] * simcc_split_ratio)
- len_y = np.around(input_size[1] * simcc_split_ratio)
- gt_instance_labels.keypoint_x_labels = torch.FloatTensor(
- _rand_simcc_label(rng, num_instances, num_keypoints, len_x))
- gt_instance_labels.keypoint_y_labels = torch.FloatTensor(
- _rand_simcc_label(rng, num_instances, num_keypoints, len_y))
-
- # gt_fields
- if with_heatmap:
- if num_levels == 1:
- gt_fields = PixelData()
- # generate single-level heatmaps
- W, H = heatmap_size
- heatmaps = rng.rand(num_keypoints, H, W)
- gt_fields.heatmaps = torch.FloatTensor(heatmaps)
- else:
- # generate multilevel heatmaps
- heatmaps = []
- for _ in range(num_levels):
- W, H = heatmap_size
- heatmaps_ = rng.rand(num_keypoints, H, W)
- heatmaps.append(torch.FloatTensor(heatmaps_))
- # [num_levels*K, H, W]
- gt_fields = MultilevelPixelData()
- gt_fields.heatmaps = heatmaps
- data_sample.gt_fields = gt_fields
-
- data_sample.gt_instances = gt_instances
- data_sample.gt_instance_labels = gt_instance_labels
-
- inputs['data_samples'] = data_sample
- inputs_list.append(inputs)
-
- packed_inputs = pseudo_collate(inputs_list)
- return packed_inputs
-
-
-def _rand_keypoints(rng, bboxes, num_keypoints):
- n = bboxes.shape[0]
- relative_pos = rng.rand(n, num_keypoints, 2)
- keypoints = relative_pos * bboxes[:, None, :2] + (
- 1 - relative_pos) * bboxes[:, None, 2:4]
-
- return keypoints
-
-
-def _rand_simcc_label(rng, num_instances, num_keypoints, len_feats):
- simcc_label = rng.rand(num_instances, num_keypoints, int(len_feats))
- return simcc_label
-
-
-def _rand_bboxes(rng, num_instances, img_w, img_h):
- cx, cy = rng.rand(num_instances, 2).T
- bw, bh = 0.2 + 0.8 * rng.rand(num_instances, 2).T
-
- tl_x = ((cx * img_w) - (img_w * bw / 2)).clip(0, img_w)
- tl_y = ((cy * img_h) - (img_h * bh / 2)).clip(0, img_h)
- br_x = ((cx * img_w) + (img_w * bw / 2)).clip(0, img_w)
- br_y = ((cy * img_h) + (img_h * bh / 2)).clip(0, img_h)
-
- bboxes = np.vstack([tl_x, tl_y, br_x, br_y]).T
- return bboxes
-
-
-def get_repo_dir():
- """Return the path of the MMPose repo directory."""
- try:
- # Assume the function in invoked is the source mmpose repo
- repo_dir = osp.dirname(osp.dirname(osp.dirname(__file__)))
- except NameError:
- # For IPython development when __file__ is not defined
- import mmpose
- repo_dir = osp.dirname(osp.dirname(mmpose.__file__))
-
- return repo_dir
-
-
-def get_config_file(fn: str):
- """Return full path of a config file from the given relative path."""
- repo_dir = get_repo_dir()
- if fn.startswith('configs'):
- fn_config = osp.join(repo_dir, fn)
- else:
- fn_config = osp.join(repo_dir, 'configs', fn)
-
- if not osp.isfile(fn_config):
- raise FileNotFoundError(f'Cannot find config file {fn_config}')
-
- return fn_config
-
-
-def get_pose_estimator_cfg(fn: str):
- """Load model config from a config file."""
-
- fn_config = get_config_file(fn)
- config = Config.fromfile(fn_config)
- return deepcopy(config.model)
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from copy import deepcopy
+from typing import Optional
+
+import numpy as np
+import torch
+from mmengine.config import Config
+from mmengine.dataset import pseudo_collate
+from mmengine.structures import InstanceData, PixelData
+
+from mmpose.structures import MultilevelPixelData, PoseDataSample
+from mmpose.structures.bbox import bbox_xyxy2cs
+
+
+def get_coco_sample(
+ img_shape=(240, 320),
+ img_fill: Optional[int] = None,
+ num_instances=1,
+ with_bbox_cs=True,
+ with_img_mask=False,
+ random_keypoints_visible=False,
+ non_occlusion=False):
+ """Create a dummy data sample in COCO style."""
+ rng = np.random.RandomState(0)
+ h, w = img_shape
+ if img_fill is None:
+ img = np.random.randint(0, 256, (h, w, 3), dtype=np.uint8)
+ else:
+ img = np.full((h, w, 3), img_fill, dtype=np.uint8)
+
+ if non_occlusion:
+ bbox = _rand_bboxes(rng, num_instances, w / num_instances, h)
+ for i in range(num_instances):
+ bbox[i, 0::2] += w / num_instances * i
+ else:
+ bbox = _rand_bboxes(rng, num_instances, w, h)
+
+ keypoints = _rand_keypoints(rng, bbox, 17)
+ if random_keypoints_visible:
+ keypoints_visible = np.random.randint(0, 2, (num_instances,
+ 17)).astype(np.float32)
+ else:
+ keypoints_visible = np.full((num_instances, 17), 1, dtype=np.float32)
+
+ upper_body_ids = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
+ lower_body_ids = [11, 12, 13, 14, 15, 16]
+ flip_pairs = [[2, 1], [1, 2], [4, 3], [3, 4], [6, 5], [5, 6], [8, 7],
+ [7, 8], [10, 9], [9, 10], [12, 11], [11, 12], [14, 13],
+ [13, 14], [16, 15], [15, 16]]
+ flip_indices = [0, 2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15]
+ dataset_keypoint_weights = np.array([
+ 1., 1., 1., 1., 1., 1., 1., 1.2, 1.2, 1.5, 1.5, 1., 1., 1.2, 1.2, 1.5,
+ 1.5
+ ]).astype(np.float32)
+
+ data = {
+ 'img': img,
+ 'img_shape': img_shape,
+ 'ori_shape': img_shape,
+ 'bbox': bbox,
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ 'upper_body_ids': upper_body_ids,
+ 'lower_body_ids': lower_body_ids,
+ 'flip_pairs': flip_pairs,
+ 'flip_indices': flip_indices,
+ 'dataset_keypoint_weights': dataset_keypoint_weights,
+ 'invalid_segs': [],
+ }
+
+ if with_bbox_cs:
+ data['bbox_center'], data['bbox_scale'] = bbox_xyxy2cs(data['bbox'])
+
+ if with_img_mask:
+ data['img_mask'] = np.random.randint(0, 2, (h, w), dtype=np.uint8)
+
+ return data
+
+
+def get_packed_inputs(batch_size=2,
+ num_instances=1,
+ num_keypoints=17,
+ num_levels=1,
+ img_shape=(256, 192),
+ input_size=(192, 256),
+ heatmap_size=(48, 64),
+ simcc_split_ratio=2.0,
+ with_heatmap=True,
+ with_reg_label=True,
+ with_simcc_label=True):
+ """Create a dummy batch of model inputs and data samples."""
+ rng = np.random.RandomState(0)
+
+ inputs_list = []
+ for idx in range(batch_size):
+ inputs = dict()
+
+ # input
+ h, w = img_shape
+ image = rng.randint(0, 255, size=(3, h, w), dtype=np.uint8)
+ inputs['inputs'] = torch.from_numpy(image)
+
+ # meta
+ img_meta = {
+ 'id': idx,
+ 'img_id': idx,
+ 'img_path': '.png',
+ 'img_shape': img_shape,
+ 'input_size': input_size,
+ 'flip': False,
+ 'flip_direction': None,
+ 'flip_indices': list(range(num_keypoints))
+ }
+
+ np.random.shuffle(img_meta['flip_indices'])
+ data_sample = PoseDataSample(metainfo=img_meta)
+
+ # gt_instance
+ gt_instances = InstanceData()
+ gt_instance_labels = InstanceData()
+ bboxes = _rand_bboxes(rng, num_instances, w, h)
+ bbox_centers, bbox_scales = bbox_xyxy2cs(bboxes)
+
+ keypoints = _rand_keypoints(rng, bboxes, num_keypoints)
+ keypoints_visible = np.ones((num_instances, num_keypoints),
+ dtype=np.float32)
+
+ # [N, K] -> [N, num_levels, K]
+ # keep the first dimension as the num_instances
+ if num_levels > 1:
+ keypoint_weights = np.tile(keypoints_visible[:, None],
+ (1, num_levels, 1))
+ else:
+ keypoint_weights = keypoints_visible.copy()
+
+ gt_instances.bboxes = bboxes
+ gt_instances.bbox_centers = bbox_centers
+ gt_instances.bbox_scales = bbox_scales
+ gt_instances.bbox_scores = np.ones((num_instances, ), dtype=np.float32)
+ gt_instances.keypoints = keypoints
+ gt_instances.keypoints_visible = keypoints_visible
+
+ gt_instance_labels.keypoint_weights = torch.FloatTensor(
+ keypoint_weights)
+
+ if with_reg_label:
+ gt_instance_labels.keypoint_labels = torch.FloatTensor(keypoints /
+ input_size)
+
+ if with_simcc_label:
+ len_x = np.around(input_size[0] * simcc_split_ratio)
+ len_y = np.around(input_size[1] * simcc_split_ratio)
+ gt_instance_labels.keypoint_x_labels = torch.FloatTensor(
+ _rand_simcc_label(rng, num_instances, num_keypoints, len_x))
+ gt_instance_labels.keypoint_y_labels = torch.FloatTensor(
+ _rand_simcc_label(rng, num_instances, num_keypoints, len_y))
+
+ # gt_fields
+ if with_heatmap:
+ if num_levels == 1:
+ gt_fields = PixelData()
+ # generate single-level heatmaps
+ W, H = heatmap_size
+ heatmaps = rng.rand(num_keypoints, H, W)
+ gt_fields.heatmaps = torch.FloatTensor(heatmaps)
+ else:
+ # generate multilevel heatmaps
+ heatmaps = []
+ for _ in range(num_levels):
+ W, H = heatmap_size
+ heatmaps_ = rng.rand(num_keypoints, H, W)
+ heatmaps.append(torch.FloatTensor(heatmaps_))
+ # [num_levels*K, H, W]
+ gt_fields = MultilevelPixelData()
+ gt_fields.heatmaps = heatmaps
+ data_sample.gt_fields = gt_fields
+
+ data_sample.gt_instances = gt_instances
+ data_sample.gt_instance_labels = gt_instance_labels
+
+ inputs['data_samples'] = data_sample
+ inputs_list.append(inputs)
+
+ packed_inputs = pseudo_collate(inputs_list)
+ return packed_inputs
+
+
+def _rand_keypoints(rng, bboxes, num_keypoints):
+ n = bboxes.shape[0]
+ relative_pos = rng.rand(n, num_keypoints, 2)
+ keypoints = relative_pos * bboxes[:, None, :2] + (
+ 1 - relative_pos) * bboxes[:, None, 2:4]
+
+ return keypoints
+
+
+def _rand_simcc_label(rng, num_instances, num_keypoints, len_feats):
+ simcc_label = rng.rand(num_instances, num_keypoints, int(len_feats))
+ return simcc_label
+
+
+def _rand_bboxes(rng, num_instances, img_w, img_h):
+ cx, cy = rng.rand(num_instances, 2).T
+ bw, bh = 0.2 + 0.8 * rng.rand(num_instances, 2).T
+
+ tl_x = ((cx * img_w) - (img_w * bw / 2)).clip(0, img_w)
+ tl_y = ((cy * img_h) - (img_h * bh / 2)).clip(0, img_h)
+ br_x = ((cx * img_w) + (img_w * bw / 2)).clip(0, img_w)
+ br_y = ((cy * img_h) + (img_h * bh / 2)).clip(0, img_h)
+
+ bboxes = np.vstack([tl_x, tl_y, br_x, br_y]).T
+ return bboxes
+
+
+def get_repo_dir():
+ """Return the path of the MMPose repo directory."""
+ try:
+ # Assume the function in invoked is the source mmpose repo
+ repo_dir = osp.dirname(osp.dirname(osp.dirname(__file__)))
+ except NameError:
+ # For IPython development when __file__ is not defined
+ import mmpose
+ repo_dir = osp.dirname(osp.dirname(mmpose.__file__))
+
+ return repo_dir
+
+
+def get_config_file(fn: str):
+ """Return full path of a config file from the given relative path."""
+ repo_dir = get_repo_dir()
+ if fn.startswith('configs'):
+ fn_config = osp.join(repo_dir, fn)
+ else:
+ fn_config = osp.join(repo_dir, 'configs', fn)
+
+ if not osp.isfile(fn_config):
+ raise FileNotFoundError(f'Cannot find config file {fn_config}')
+
+ return fn_config
+
+
+def get_pose_estimator_cfg(fn: str):
+ """Load model config from a config file."""
+
+ fn_config = get_config_file(fn)
+ config = Config.fromfile(fn_config)
+ return deepcopy(config.model)
diff --git a/mmpose/utils/__init__.py b/mmpose/utils/__init__.py
index c48ca01cea..09966bd606 100644
--- a/mmpose/utils/__init__.py
+++ b/mmpose/utils/__init__.py
@@ -1,13 +1,13 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .camera import SimpleCamera, SimpleCameraTorch
-from .collect_env import collect_env
-from .config_utils import adapt_mmdet_pipeline
-from .logger import get_root_logger
-from .setup_env import register_all_modules, setup_multi_processes
-from .timer import StopWatch
-
-__all__ = [
- 'get_root_logger', 'collect_env', 'StopWatch', 'setup_multi_processes',
- 'register_all_modules', 'SimpleCamera', 'SimpleCameraTorch',
- 'adapt_mmdet_pipeline'
-]
+# Copyright (c) OpenMMLab. All rights reserved.
+from .camera import SimpleCamera, SimpleCameraTorch
+from .collect_env import collect_env
+from .config_utils import adapt_mmdet_pipeline
+from .logger import get_root_logger
+from .setup_env import register_all_modules, setup_multi_processes
+from .timer import StopWatch
+
+__all__ = [
+ 'get_root_logger', 'collect_env', 'StopWatch', 'setup_multi_processes',
+ 'register_all_modules', 'SimpleCamera', 'SimpleCameraTorch',
+ 'adapt_mmdet_pipeline'
+]
diff --git a/mmpose/utils/camera.py b/mmpose/utils/camera.py
index a7759d308f..795789261b 100644
--- a/mmpose/utils/camera.py
+++ b/mmpose/utils/camera.py
@@ -1,280 +1,280 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from abc import ABCMeta, abstractmethod
-
-import numpy as np
-import torch
-from mmengine.registry import Registry
-
-CAMERAS = Registry('camera')
-
-
-class SingleCameraBase(metaclass=ABCMeta):
- """Base class for single camera model.
-
- Args:
- param (dict): Camera parameters
-
- Methods:
- world_to_camera: Project points from world coordinates to camera
- coordinates
- camera_to_world: Project points from camera coordinates to world
- coordinates
- camera_to_pixel: Project points from camera coordinates to pixel
- coordinates
- world_to_pixel: Project points from world coordinates to pixel
- coordinates
- """
-
- @abstractmethod
- def __init__(self, param):
- """Load camera parameters and check validity."""
-
- def world_to_camera(self, X):
- """Project points from world coordinates to camera coordinates."""
- raise NotImplementedError
-
- def camera_to_world(self, X):
- """Project points from camera coordinates to world coordinates."""
- raise NotImplementedError
-
- def camera_to_pixel(self, X):
- """Project points from camera coordinates to pixel coordinates."""
- raise NotImplementedError
-
- def world_to_pixel(self, X):
- """Project points from world coordinates to pixel coordinates."""
- _X = self.world_to_camera(X)
- return self.camera_to_pixel(_X)
-
-
-@CAMERAS.register_module()
-class SimpleCamera(SingleCameraBase):
- """Camera model to calculate coordinate transformation with given
- intrinsic/extrinsic camera parameters.
-
- Note:
- The keypoint coordinate should be an np.ndarray with a shape of
- [...,J, C] where J is the keypoint number of an instance, and C is
- the coordinate dimension. For example:
-
- [J, C]: shape of joint coordinates of a person with J joints.
- [N, J, C]: shape of a batch of person joint coordinates.
- [N, T, J, C]: shape of a batch of pose sequences.
-
- Args:
- param (dict): camera parameters including:
- - R: 3x3, camera rotation matrix (camera-to-world)
- - T: 3x1, camera translation (camera-to-world)
- - K: (optional) 2x3, camera intrinsic matrix
- - k: (optional) nx1, camera radial distortion coefficients
- - p: (optional) mx1, camera tangential distortion coefficients
- - f: (optional) 2x1, camera focal length
- - c: (optional) 2x1, camera center
- if K is not provided, it will be calculated from f and c.
-
- Methods:
- world_to_camera: Project points from world coordinates to camera
- coordinates
- camera_to_pixel: Project points from camera coordinates to pixel
- coordinates
- world_to_pixel: Project points from world coordinates to pixel
- coordinates
- """
-
- def __init__(self, param):
-
- self.param = {}
- # extrinsic param
- R = np.array(param['R'], dtype=np.float32)
- T = np.array(param['T'], dtype=np.float32)
- assert R.shape == (3, 3)
- assert T.shape == (3, 1)
- # The camera matrices are transposed in advance because the joint
- # coordinates are stored as row vectors.
- self.param['R_c2w'] = R.T
- self.param['T_c2w'] = T.T
- self.param['R_w2c'] = R
- self.param['T_w2c'] = -self.param['T_c2w'] @ self.param['R_w2c']
-
- # intrinsic param
- if 'K' in param:
- K = np.array(param['K'], dtype=np.float32)
- assert K.shape == (2, 3)
- self.param['K'] = K.T
- self.param['f'] = np.array([K[0, 0], K[1, 1]])[:, np.newaxis]
- self.param['c'] = np.array([K[0, 2], K[1, 2]])[:, np.newaxis]
- elif 'f' in param and 'c' in param:
- f = np.array(param['f'], dtype=np.float32)
- c = np.array(param['c'], dtype=np.float32)
- assert f.shape == (2, 1)
- assert c.shape == (2, 1)
- self.param['K'] = np.concatenate((np.diagflat(f), c), axis=-1).T
- self.param['f'] = f
- self.param['c'] = c
- else:
- raise ValueError('Camera intrinsic parameters are missing. '
- 'Either "K" or "f"&"c" should be provided.')
-
- # distortion param
- if 'k' in param and 'p' in param:
- self.undistortion = True
- self.param['k'] = np.array(param['k'], dtype=np.float32).flatten()
- self.param['p'] = np.array(param['p'], dtype=np.float32).flatten()
- assert self.param['k'].size in {3, 6}
- assert self.param['p'].size == 2
- else:
- self.undistortion = False
-
- def world_to_camera(self, X):
- assert isinstance(X, np.ndarray)
- assert X.ndim >= 2 and X.shape[-1] == 3
- return X @ self.param['R_w2c'] + self.param['T_w2c']
-
- def camera_to_world(self, X):
- assert isinstance(X, np.ndarray)
- assert X.ndim >= 2 and X.shape[-1] == 3
- return X @ self.param['R_c2w'] + self.param['T_c2w']
-
- def camera_to_pixel(self, X):
- assert isinstance(X, np.ndarray)
- assert X.ndim >= 2 and X.shape[-1] == 3
-
- _X = X / X[..., 2:]
-
- if self.undistortion:
- k = self.param['k']
- p = self.param['p']
- _X_2d = _X[..., :2]
- r2 = (_X_2d**2).sum(-1)
- radial = 1 + sum(ki * r2**(i + 1) for i, ki in enumerate(k[:3]))
- if k.size == 6:
- radial /= 1 + sum(
- (ki * r2**(i + 1) for i, ki in enumerate(k[3:])))
-
- tangential = 2 * (p[1] * _X[..., 0] + p[0] * _X[..., 1])
-
- _X[..., :2] = _X_2d * (radial + tangential)[..., None] + np.outer(
- r2, p[::-1]).reshape(_X_2d.shape)
- return _X @ self.param['K']
-
- def pixel_to_camera(self, X):
- assert isinstance(X, np.ndarray)
- assert X.ndim >= 2 and X.shape[-1] == 3
- _X = X.copy()
- _X[:, :2] = (X[:, :2] - self.param['c'].T) / self.param['f'].T * X[:,
- [2]]
- return _X
-
-
-@CAMERAS.register_module()
-class SimpleCameraTorch(SingleCameraBase):
- """Camera model to calculate coordinate transformation with given
- intrinsic/extrinsic camera parameters.
-
- Notes:
- The keypoint coordinate should be an np.ndarray with a shape of
- [...,J, C] where J is the keypoint number of an instance, and C is
- the coordinate dimension. For example:
-
- [J, C]: shape of joint coordinates of a person with J joints.
- [N, J, C]: shape of a batch of person joint coordinates.
- [N, T, J, C]: shape of a batch of pose sequences.
-
- Args:
- param (dict): camera parameters including:
- - R: 3x3, camera rotation matrix (camera-to-world)
- - T: 3x1, camera translation (camera-to-world)
- - K: (optional) 2x3, camera intrinsic matrix
- - k: (optional) nx1, camera radial distortion coefficients
- - p: (optional) mx1, camera tangential distortion coefficients
- - f: (optional) 2x1, camera focal length
- - c: (optional) 2x1, camera center
- if K is not provided, it will be calculated from f and c.
-
- Methods:
- world_to_camera: Project points from world coordinates to camera
- coordinates
- camera_to_pixel: Project points from camera coordinates to pixel
- coordinates
- world_to_pixel: Project points from world coordinates to pixel
- coordinates
- """
-
- def __init__(self, param, device):
-
- self.param = {}
- # extrinsic param
- R = torch.tensor(param['R'], device=device)
- T = torch.tensor(param['T'], device=device)
-
- assert R.shape == (3, 3)
- assert T.shape == (3, 1)
- # The camera matrices are transposed in advance because the joint
- # coordinates are stored as row vectors.
- self.param['R_c2w'] = R.T
- self.param['T_c2w'] = T.T
- self.param['R_w2c'] = R
- self.param['T_w2c'] = -self.param['T_c2w'] @ self.param['R_w2c']
-
- # intrinsic param
- if 'K' in param:
- K = torch.tensor(param['K'], device=device)
- assert K.shape == (2, 3)
- self.param['K'] = K.T
- self.param['f'] = torch.tensor([[K[0, 0]], [K[1, 1]]],
- device=device)
- self.param['c'] = torch.tensor([[K[0, 2]], [K[1, 2]]],
- device=device)
- elif 'f' in param and 'c' in param:
- f = torch.tensor(param['f'], device=device)
- c = torch.tensor(param['c'], device=device)
- assert f.shape == (2, 1)
- assert c.shape == (2, 1)
- self.param['K'] = torch.cat([torch.diagflat(f), c], dim=-1).T
- self.param['f'] = f
- self.param['c'] = c
- else:
- raise ValueError('Camera intrinsic parameters are missing. '
- 'Either "K" or "f"&"c" should be provided.')
-
- # distortion param
- if 'k' in param and 'p' in param:
- self.undistortion = True
- self.param['k'] = torch.tensor(param['k'], device=device).view(-1)
- self.param['p'] = torch.tensor(param['p'], device=device).view(-1)
- assert len(self.param['k']) in {3, 6}
- assert len(self.param['p']) == 2
- else:
- self.undistortion = False
-
- def world_to_camera(self, X):
- assert isinstance(X, torch.Tensor)
- assert X.ndim >= 2 and X.shape[-1] == 3
- return X @ self.param['R_w2c'] + self.param['T_w2c']
-
- def camera_to_world(self, X):
- assert isinstance(X, torch.Tensor)
- assert X.ndim >= 2 and X.shape[-1] == 3
- return X @ self.param['R_c2w'] + self.param['T_c2w']
-
- def camera_to_pixel(self, X):
- assert isinstance(X, torch.Tensor)
- assert X.ndim >= 2 and X.shape[-1] == 3
-
- _X = X / X[..., 2:]
-
- if self.undistortion:
- k = self.param['k']
- p = self.param['p']
- _X_2d = _X[..., :2]
- r2 = (_X_2d**2).sum(-1)
- radial = 1 + sum(ki * r2**(i + 1) for i, ki in enumerate(k[:3]))
- if k.size == 6:
- radial /= 1 + sum(
- (ki * r2**(i + 1) for i, ki in enumerate(k[3:])))
-
- tangential = 2 * (p[1] * _X[..., 0] + p[0] * _X[..., 1])
-
- _X[..., :2] = _X_2d * (radial + tangential)[..., None] + torch.ger(
- r2, p.flip([0])).reshape(_X_2d.shape)
- return _X @ self.param['K']
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+
+import numpy as np
+import torch
+from mmengine.registry import Registry
+
+CAMERAS = Registry('camera')
+
+
+class SingleCameraBase(metaclass=ABCMeta):
+ """Base class for single camera model.
+
+ Args:
+ param (dict): Camera parameters
+
+ Methods:
+ world_to_camera: Project points from world coordinates to camera
+ coordinates
+ camera_to_world: Project points from camera coordinates to world
+ coordinates
+ camera_to_pixel: Project points from camera coordinates to pixel
+ coordinates
+ world_to_pixel: Project points from world coordinates to pixel
+ coordinates
+ """
+
+ @abstractmethod
+ def __init__(self, param):
+ """Load camera parameters and check validity."""
+
+ def world_to_camera(self, X):
+ """Project points from world coordinates to camera coordinates."""
+ raise NotImplementedError
+
+ def camera_to_world(self, X):
+ """Project points from camera coordinates to world coordinates."""
+ raise NotImplementedError
+
+ def camera_to_pixel(self, X):
+ """Project points from camera coordinates to pixel coordinates."""
+ raise NotImplementedError
+
+ def world_to_pixel(self, X):
+ """Project points from world coordinates to pixel coordinates."""
+ _X = self.world_to_camera(X)
+ return self.camera_to_pixel(_X)
+
+
+@CAMERAS.register_module()
+class SimpleCamera(SingleCameraBase):
+ """Camera model to calculate coordinate transformation with given
+ intrinsic/extrinsic camera parameters.
+
+ Note:
+ The keypoint coordinate should be an np.ndarray with a shape of
+ [...,J, C] where J is the keypoint number of an instance, and C is
+ the coordinate dimension. For example:
+
+ [J, C]: shape of joint coordinates of a person with J joints.
+ [N, J, C]: shape of a batch of person joint coordinates.
+ [N, T, J, C]: shape of a batch of pose sequences.
+
+ Args:
+ param (dict): camera parameters including:
+ - R: 3x3, camera rotation matrix (camera-to-world)
+ - T: 3x1, camera translation (camera-to-world)
+ - K: (optional) 2x3, camera intrinsic matrix
+ - k: (optional) nx1, camera radial distortion coefficients
+ - p: (optional) mx1, camera tangential distortion coefficients
+ - f: (optional) 2x1, camera focal length
+ - c: (optional) 2x1, camera center
+ if K is not provided, it will be calculated from f and c.
+
+ Methods:
+ world_to_camera: Project points from world coordinates to camera
+ coordinates
+ camera_to_pixel: Project points from camera coordinates to pixel
+ coordinates
+ world_to_pixel: Project points from world coordinates to pixel
+ coordinates
+ """
+
+ def __init__(self, param):
+
+ self.param = {}
+ # extrinsic param
+ R = np.array(param['R'], dtype=np.float32)
+ T = np.array(param['T'], dtype=np.float32)
+ assert R.shape == (3, 3)
+ assert T.shape == (3, 1)
+ # The camera matrices are transposed in advance because the joint
+ # coordinates are stored as row vectors.
+ self.param['R_c2w'] = R.T
+ self.param['T_c2w'] = T.T
+ self.param['R_w2c'] = R
+ self.param['T_w2c'] = -self.param['T_c2w'] @ self.param['R_w2c']
+
+ # intrinsic param
+ if 'K' in param:
+ K = np.array(param['K'], dtype=np.float32)
+ assert K.shape == (2, 3)
+ self.param['K'] = K.T
+ self.param['f'] = np.array([K[0, 0], K[1, 1]])[:, np.newaxis]
+ self.param['c'] = np.array([K[0, 2], K[1, 2]])[:, np.newaxis]
+ elif 'f' in param and 'c' in param:
+ f = np.array(param['f'], dtype=np.float32)
+ c = np.array(param['c'], dtype=np.float32)
+ assert f.shape == (2, 1)
+ assert c.shape == (2, 1)
+ self.param['K'] = np.concatenate((np.diagflat(f), c), axis=-1).T
+ self.param['f'] = f
+ self.param['c'] = c
+ else:
+ raise ValueError('Camera intrinsic parameters are missing. '
+ 'Either "K" or "f"&"c" should be provided.')
+
+ # distortion param
+ if 'k' in param and 'p' in param:
+ self.undistortion = True
+ self.param['k'] = np.array(param['k'], dtype=np.float32).flatten()
+ self.param['p'] = np.array(param['p'], dtype=np.float32).flatten()
+ assert self.param['k'].size in {3, 6}
+ assert self.param['p'].size == 2
+ else:
+ self.undistortion = False
+
+ def world_to_camera(self, X):
+ assert isinstance(X, np.ndarray)
+ assert X.ndim >= 2 and X.shape[-1] == 3
+ return X @ self.param['R_w2c'] + self.param['T_w2c']
+
+ def camera_to_world(self, X):
+ assert isinstance(X, np.ndarray)
+ assert X.ndim >= 2 and X.shape[-1] == 3
+ return X @ self.param['R_c2w'] + self.param['T_c2w']
+
+ def camera_to_pixel(self, X):
+ assert isinstance(X, np.ndarray)
+ assert X.ndim >= 2 and X.shape[-1] == 3
+
+ _X = X / X[..., 2:]
+
+ if self.undistortion:
+ k = self.param['k']
+ p = self.param['p']
+ _X_2d = _X[..., :2]
+ r2 = (_X_2d**2).sum(-1)
+ radial = 1 + sum(ki * r2**(i + 1) for i, ki in enumerate(k[:3]))
+ if k.size == 6:
+ radial /= 1 + sum(
+ (ki * r2**(i + 1) for i, ki in enumerate(k[3:])))
+
+ tangential = 2 * (p[1] * _X[..., 0] + p[0] * _X[..., 1])
+
+ _X[..., :2] = _X_2d * (radial + tangential)[..., None] + np.outer(
+ r2, p[::-1]).reshape(_X_2d.shape)
+ return _X @ self.param['K']
+
+ def pixel_to_camera(self, X):
+ assert isinstance(X, np.ndarray)
+ assert X.ndim >= 2 and X.shape[-1] == 3
+ _X = X.copy()
+ _X[:, :2] = (X[:, :2] - self.param['c'].T) / self.param['f'].T * X[:,
+ [2]]
+ return _X
+
+
+@CAMERAS.register_module()
+class SimpleCameraTorch(SingleCameraBase):
+ """Camera model to calculate coordinate transformation with given
+ intrinsic/extrinsic camera parameters.
+
+ Notes:
+ The keypoint coordinate should be an np.ndarray with a shape of
+ [...,J, C] where J is the keypoint number of an instance, and C is
+ the coordinate dimension. For example:
+
+ [J, C]: shape of joint coordinates of a person with J joints.
+ [N, J, C]: shape of a batch of person joint coordinates.
+ [N, T, J, C]: shape of a batch of pose sequences.
+
+ Args:
+ param (dict): camera parameters including:
+ - R: 3x3, camera rotation matrix (camera-to-world)
+ - T: 3x1, camera translation (camera-to-world)
+ - K: (optional) 2x3, camera intrinsic matrix
+ - k: (optional) nx1, camera radial distortion coefficients
+ - p: (optional) mx1, camera tangential distortion coefficients
+ - f: (optional) 2x1, camera focal length
+ - c: (optional) 2x1, camera center
+ if K is not provided, it will be calculated from f and c.
+
+ Methods:
+ world_to_camera: Project points from world coordinates to camera
+ coordinates
+ camera_to_pixel: Project points from camera coordinates to pixel
+ coordinates
+ world_to_pixel: Project points from world coordinates to pixel
+ coordinates
+ """
+
+ def __init__(self, param, device):
+
+ self.param = {}
+ # extrinsic param
+ R = torch.tensor(param['R'], device=device)
+ T = torch.tensor(param['T'], device=device)
+
+ assert R.shape == (3, 3)
+ assert T.shape == (3, 1)
+ # The camera matrices are transposed in advance because the joint
+ # coordinates are stored as row vectors.
+ self.param['R_c2w'] = R.T
+ self.param['T_c2w'] = T.T
+ self.param['R_w2c'] = R
+ self.param['T_w2c'] = -self.param['T_c2w'] @ self.param['R_w2c']
+
+ # intrinsic param
+ if 'K' in param:
+ K = torch.tensor(param['K'], device=device)
+ assert K.shape == (2, 3)
+ self.param['K'] = K.T
+ self.param['f'] = torch.tensor([[K[0, 0]], [K[1, 1]]],
+ device=device)
+ self.param['c'] = torch.tensor([[K[0, 2]], [K[1, 2]]],
+ device=device)
+ elif 'f' in param and 'c' in param:
+ f = torch.tensor(param['f'], device=device)
+ c = torch.tensor(param['c'], device=device)
+ assert f.shape == (2, 1)
+ assert c.shape == (2, 1)
+ self.param['K'] = torch.cat([torch.diagflat(f), c], dim=-1).T
+ self.param['f'] = f
+ self.param['c'] = c
+ else:
+ raise ValueError('Camera intrinsic parameters are missing. '
+ 'Either "K" or "f"&"c" should be provided.')
+
+ # distortion param
+ if 'k' in param and 'p' in param:
+ self.undistortion = True
+ self.param['k'] = torch.tensor(param['k'], device=device).view(-1)
+ self.param['p'] = torch.tensor(param['p'], device=device).view(-1)
+ assert len(self.param['k']) in {3, 6}
+ assert len(self.param['p']) == 2
+ else:
+ self.undistortion = False
+
+ def world_to_camera(self, X):
+ assert isinstance(X, torch.Tensor)
+ assert X.ndim >= 2 and X.shape[-1] == 3
+ return X @ self.param['R_w2c'] + self.param['T_w2c']
+
+ def camera_to_world(self, X):
+ assert isinstance(X, torch.Tensor)
+ assert X.ndim >= 2 and X.shape[-1] == 3
+ return X @ self.param['R_c2w'] + self.param['T_c2w']
+
+ def camera_to_pixel(self, X):
+ assert isinstance(X, torch.Tensor)
+ assert X.ndim >= 2 and X.shape[-1] == 3
+
+ _X = X / X[..., 2:]
+
+ if self.undistortion:
+ k = self.param['k']
+ p = self.param['p']
+ _X_2d = _X[..., :2]
+ r2 = (_X_2d**2).sum(-1)
+ radial = 1 + sum(ki * r2**(i + 1) for i, ki in enumerate(k[:3]))
+ if k.size == 6:
+ radial /= 1 + sum(
+ (ki * r2**(i + 1) for i, ki in enumerate(k[3:])))
+
+ tangential = 2 * (p[1] * _X[..., 0] + p[0] * _X[..., 1])
+
+ _X[..., :2] = _X_2d * (radial + tangential)[..., None] + torch.ger(
+ r2, p.flip([0])).reshape(_X_2d.shape)
+ return _X @ self.param['K']
diff --git a/mmpose/utils/collect_env.py b/mmpose/utils/collect_env.py
index e8fb5f35e1..e60c686172 100644
--- a/mmpose/utils/collect_env.py
+++ b/mmpose/utils/collect_env.py
@@ -1,16 +1,16 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmengine.utils import get_git_hash
-from mmengine.utils.dl_utils import collect_env as collect_base_env
-
-import mmpose
-
-
-def collect_env():
- env_info = collect_base_env()
- env_info['MMPose'] = (mmpose.__version__ + '+' + get_git_hash(digits=7))
- return env_info
-
-
-if __name__ == '__main__':
- for name, val in collect_env().items():
- print(f'{name}: {val}')
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.utils import get_git_hash
+from mmengine.utils.dl_utils import collect_env as collect_base_env
+
+import mmpose
+
+
+def collect_env():
+ env_info = collect_base_env()
+ env_info['MMPose'] = (mmpose.__version__ + '+' + get_git_hash(digits=7))
+ return env_info
+
+
+if __name__ == '__main__':
+ for name, val in collect_env().items():
+ print(f'{name}: {val}')
diff --git a/mmpose/utils/config_utils.py b/mmpose/utils/config_utils.py
index 2f54d2ef24..62f618e4ff 100644
--- a/mmpose/utils/config_utils.py
+++ b/mmpose/utils/config_utils.py
@@ -1,26 +1,26 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from mmpose.utils.typing import ConfigDict
-
-
-def adapt_mmdet_pipeline(cfg: ConfigDict) -> ConfigDict:
- """Converts pipeline types in MMDetection's test dataloader to use the
- 'mmdet' namespace.
-
- Args:
- cfg (ConfigDict): Configuration dictionary for MMDetection.
-
- Returns:
- ConfigDict: Configuration dictionary with updated pipeline types.
- """
- # use lazy import to avoid hard dependence on mmdet
- from mmdet.datasets import transforms
-
- if 'test_dataloader' not in cfg:
- return cfg
-
- pipeline = cfg.test_dataloader.dataset.pipeline
- for trans in pipeline:
- if trans['type'] in dir(transforms):
- trans['type'] = 'mmdet.' + trans['type']
-
- return cfg
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.utils.typing import ConfigDict
+
+
+def adapt_mmdet_pipeline(cfg: ConfigDict) -> ConfigDict:
+ """Converts pipeline types in MMDetection's test dataloader to use the
+ 'mmdet' namespace.
+
+ Args:
+ cfg (ConfigDict): Configuration dictionary for MMDetection.
+
+ Returns:
+ ConfigDict: Configuration dictionary with updated pipeline types.
+ """
+ # use lazy import to avoid hard dependence on mmdet
+ from mmdet.datasets import transforms
+
+ if 'test_dataloader' not in cfg:
+ return cfg
+
+ pipeline = cfg.test_dataloader.dataset.pipeline
+ for trans in pipeline:
+ if trans['type'] in dir(transforms):
+ trans['type'] = 'mmdet.' + trans['type']
+
+ return cfg
diff --git a/mmpose/utils/hooks.py b/mmpose/utils/hooks.py
index b68940f2b7..a5cfb4f0f8 100644
--- a/mmpose/utils/hooks.py
+++ b/mmpose/utils/hooks.py
@@ -1,60 +1,60 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import functools
-
-
-class OutputHook:
-
- def __init__(self, module, outputs=None, as_tensor=False):
- self.outputs = outputs
- self.as_tensor = as_tensor
- self.layer_outputs = {}
- self.register(module)
-
- def register(self, module):
-
- def hook_wrapper(name):
-
- def hook(model, input, output):
- if self.as_tensor:
- self.layer_outputs[name] = output
- else:
- if isinstance(output, list):
- self.layer_outputs[name] = [
- out.detach().cpu().numpy() for out in output
- ]
- else:
- self.layer_outputs[name] = output.detach().cpu().numpy(
- )
-
- return hook
-
- self.handles = []
- if isinstance(self.outputs, (list, tuple)):
- for name in self.outputs:
- try:
- layer = rgetattr(module, name)
- h = layer.register_forward_hook(hook_wrapper(name))
- except ModuleNotFoundError as module_not_found:
- raise ModuleNotFoundError(
- f'Module {name} not found') from module_not_found
- self.handles.append(h)
-
- def remove(self):
- for h in self.handles:
- h.remove()
-
- def __enter__(self):
- return self
-
- def __exit__(self, exc_type, exc_val, exc_tb):
- self.remove()
-
-
-# using wonder's beautiful simplification:
-# https://stackoverflow.com/questions/31174295/getattr-and-setattr-on-nested-objects
-def rgetattr(obj, attr, *args):
-
- def _getattr(obj, attr):
- return getattr(obj, attr, *args)
-
- return functools.reduce(_getattr, [obj] + attr.split('.'))
+# Copyright (c) OpenMMLab. All rights reserved.
+import functools
+
+
+class OutputHook:
+
+ def __init__(self, module, outputs=None, as_tensor=False):
+ self.outputs = outputs
+ self.as_tensor = as_tensor
+ self.layer_outputs = {}
+ self.register(module)
+
+ def register(self, module):
+
+ def hook_wrapper(name):
+
+ def hook(model, input, output):
+ if self.as_tensor:
+ self.layer_outputs[name] = output
+ else:
+ if isinstance(output, list):
+ self.layer_outputs[name] = [
+ out.detach().cpu().numpy() for out in output
+ ]
+ else:
+ self.layer_outputs[name] = output.detach().cpu().numpy(
+ )
+
+ return hook
+
+ self.handles = []
+ if isinstance(self.outputs, (list, tuple)):
+ for name in self.outputs:
+ try:
+ layer = rgetattr(module, name)
+ h = layer.register_forward_hook(hook_wrapper(name))
+ except ModuleNotFoundError as module_not_found:
+ raise ModuleNotFoundError(
+ f'Module {name} not found') from module_not_found
+ self.handles.append(h)
+
+ def remove(self):
+ for h in self.handles:
+ h.remove()
+
+ def __enter__(self):
+ return self
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ self.remove()
+
+
+# using wonder's beautiful simplification:
+# https://stackoverflow.com/questions/31174295/getattr-and-setattr-on-nested-objects
+def rgetattr(obj, attr, *args):
+
+ def _getattr(obj, attr):
+ return getattr(obj, attr, *args)
+
+ return functools.reduce(_getattr, [obj] + attr.split('.'))
diff --git a/mmpose/utils/logger.py b/mmpose/utils/logger.py
index f67e56efeb..6edd46cbc0 100644
--- a/mmpose/utils/logger.py
+++ b/mmpose/utils/logger.py
@@ -1,25 +1,25 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import logging
-
-from mmengine.logging import MMLogger
-
-
-def get_root_logger(log_file=None, log_level=logging.INFO):
- """Use `MMLogger` class in mmengine to get the root logger.
-
- The logger will be initialized if it has not been initialized. By default a
- StreamHandler will be added. If `log_file` is specified, a FileHandler will
- also be added. The name of the root logger is the top-level package name,
- e.g., "mmpose".
-
- Args:
- log_file (str | None): The log filename. If specified, a FileHandler
- will be added to the root logger.
- log_level (int): The root logger level. Note that only the process of
- rank 0 is affected, while other processes will set the level to
- "Error" and be silent most of the time.
-
- Returns:
- logging.Logger: The root logger.
- """
- return MMLogger('MMLogger', __name__.split('.')[0], log_file, log_level)
+# Copyright (c) OpenMMLab. All rights reserved.
+import logging
+
+from mmengine.logging import MMLogger
+
+
+def get_root_logger(log_file=None, log_level=logging.INFO):
+ """Use `MMLogger` class in mmengine to get the root logger.
+
+ The logger will be initialized if it has not been initialized. By default a
+ StreamHandler will be added. If `log_file` is specified, a FileHandler will
+ also be added. The name of the root logger is the top-level package name,
+ e.g., "mmpose".
+
+ Args:
+ log_file (str | None): The log filename. If specified, a FileHandler
+ will be added to the root logger.
+ log_level (int): The root logger level. Note that only the process of
+ rank 0 is affected, while other processes will set the level to
+ "Error" and be silent most of the time.
+
+ Returns:
+ logging.Logger: The root logger.
+ """
+ return MMLogger('MMLogger', __name__.split('.')[0], log_file, log_level)
diff --git a/mmpose/utils/setup_env.py b/mmpose/utils/setup_env.py
index ff299539ef..e0aad4fd04 100644
--- a/mmpose/utils/setup_env.py
+++ b/mmpose/utils/setup_env.py
@@ -1,86 +1,86 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import datetime
-import os
-import platform
-import warnings
-
-import cv2
-import torch.multiprocessing as mp
-from mmengine import DefaultScope
-
-
-def setup_multi_processes(cfg):
- """Setup multi-processing environment variables."""
- # set multi-process start method as `fork` to speed up the training
- if platform.system() != 'Windows':
- mp_start_method = cfg.get('mp_start_method', 'fork')
- current_method = mp.get_start_method(allow_none=True)
- if current_method is not None and current_method != mp_start_method:
- warnings.warn(
- f'Multi-processing start method `{mp_start_method}` is '
- f'different from the previous setting `{current_method}`.'
- f'It will be force set to `{mp_start_method}`. You can change '
- f'this behavior by changing `mp_start_method` in your config.')
- mp.set_start_method(mp_start_method, force=True)
-
- # disable opencv multithreading to avoid system being overloaded
- opencv_num_threads = cfg.get('opencv_num_threads', 0)
- cv2.setNumThreads(opencv_num_threads)
-
- # setup OMP threads
- # This code is referred from https://github.com/pytorch/pytorch/blob/master/torch/distributed/run.py # noqa
- if 'OMP_NUM_THREADS' not in os.environ and cfg.data.workers_per_gpu > 1:
- omp_num_threads = 1
- warnings.warn(
- f'Setting OMP_NUM_THREADS environment variable for each process '
- f'to be {omp_num_threads} in default, to avoid your system being '
- f'overloaded, please further tune the variable for optimal '
- f'performance in your application as needed.')
- os.environ['OMP_NUM_THREADS'] = str(omp_num_threads)
-
- # setup MKL threads
- if 'MKL_NUM_THREADS' not in os.environ and cfg.data.workers_per_gpu > 1:
- mkl_num_threads = 1
- warnings.warn(
- f'Setting MKL_NUM_THREADS environment variable for each process '
- f'to be {mkl_num_threads} in default, to avoid your system being '
- f'overloaded, please further tune the variable for optimal '
- f'performance in your application as needed.')
- os.environ['MKL_NUM_THREADS'] = str(mkl_num_threads)
-
-
-def register_all_modules(init_default_scope: bool = True) -> None:
- """Register all modules in mmpose into the registries.
-
- Args:
- init_default_scope (bool): Whether initialize the mmpose default scope.
- When `init_default_scope=True`, the global default scope will be
- set to `mmpose`, and all registries will build modules from mmpose's
- registry node. To understand more about the registry, please refer
- to https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/registry.md
- Defaults to True.
- """ # noqa
-
- import mmpose.codecs # noqa: F401, F403
- import mmpose.datasets # noqa: F401,F403
- import mmpose.engine # noqa: F401,F403
- import mmpose.evaluation # noqa: F401,F403
- import mmpose.models # noqa: F401,F403
- import mmpose.visualization # noqa: F401,F403
-
- if init_default_scope:
- never_created = DefaultScope.get_current_instance() is None \
- or not DefaultScope.check_instance_created('mmpose')
- if never_created:
- DefaultScope.get_instance('mmpose', scope_name='mmpose')
- return
- current_scope = DefaultScope.get_current_instance()
- if current_scope.scope_name != 'mmpose':
- warnings.warn('The current default scope '
- f'"{current_scope.scope_name}" is not "mmpose", '
- '`register_all_modules` will force the current'
- 'default scope to be "mmpose". If this is not '
- 'expected, please set `init_default_scope=False`.')
- # avoid name conflict
- new_instance_name = f'mmpose-{datetime.datetime.now()}'
- DefaultScope.get_instance(new_instance_name, scope_name='mmpose')
+# Copyright (c) OpenMMLab. All rights reserved.
+import datetime
+import os
+import platform
+import warnings
+
+import cv2
+import torch.multiprocessing as mp
+from mmengine import DefaultScope
+
+
+def setup_multi_processes(cfg):
+ """Setup multi-processing environment variables."""
+ # set multi-process start method as `fork` to speed up the training
+ if platform.system() != 'Windows':
+ mp_start_method = cfg.get('mp_start_method', 'fork')
+ current_method = mp.get_start_method(allow_none=True)
+ if current_method is not None and current_method != mp_start_method:
+ warnings.warn(
+ f'Multi-processing start method `{mp_start_method}` is '
+ f'different from the previous setting `{current_method}`.'
+ f'It will be force set to `{mp_start_method}`. You can change '
+ f'this behavior by changing `mp_start_method` in your config.')
+ mp.set_start_method(mp_start_method, force=True)
+
+ # disable opencv multithreading to avoid system being overloaded
+ opencv_num_threads = cfg.get('opencv_num_threads', 0)
+ cv2.setNumThreads(opencv_num_threads)
+
+ # setup OMP threads
+ # This code is referred from https://github.com/pytorch/pytorch/blob/master/torch/distributed/run.py # noqa
+ if 'OMP_NUM_THREADS' not in os.environ and cfg.data.workers_per_gpu > 1:
+ omp_num_threads = 1
+ warnings.warn(
+ f'Setting OMP_NUM_THREADS environment variable for each process '
+ f'to be {omp_num_threads} in default, to avoid your system being '
+ f'overloaded, please further tune the variable for optimal '
+ f'performance in your application as needed.')
+ os.environ['OMP_NUM_THREADS'] = str(omp_num_threads)
+
+ # setup MKL threads
+ if 'MKL_NUM_THREADS' not in os.environ and cfg.data.workers_per_gpu > 1:
+ mkl_num_threads = 1
+ warnings.warn(
+ f'Setting MKL_NUM_THREADS environment variable for each process '
+ f'to be {mkl_num_threads} in default, to avoid your system being '
+ f'overloaded, please further tune the variable for optimal '
+ f'performance in your application as needed.')
+ os.environ['MKL_NUM_THREADS'] = str(mkl_num_threads)
+
+
+def register_all_modules(init_default_scope: bool = True) -> None:
+ """Register all modules in mmpose into the registries.
+
+ Args:
+ init_default_scope (bool): Whether initialize the mmpose default scope.
+ When `init_default_scope=True`, the global default scope will be
+ set to `mmpose`, and all registries will build modules from mmpose's
+ registry node. To understand more about the registry, please refer
+ to https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/registry.md
+ Defaults to True.
+ """ # noqa
+
+ import mmpose.codecs # noqa: F401, F403
+ import mmpose.datasets # noqa: F401,F403
+ import mmpose.engine # noqa: F401,F403
+ import mmpose.evaluation # noqa: F401,F403
+ import mmpose.models # noqa: F401,F403
+ import mmpose.visualization # noqa: F401,F403
+
+ if init_default_scope:
+ never_created = DefaultScope.get_current_instance() is None \
+ or not DefaultScope.check_instance_created('mmpose')
+ if never_created:
+ DefaultScope.get_instance('mmpose', scope_name='mmpose')
+ return
+ current_scope = DefaultScope.get_current_instance()
+ if current_scope.scope_name != 'mmpose':
+ warnings.warn('The current default scope '
+ f'"{current_scope.scope_name}" is not "mmpose", '
+ '`register_all_modules` will force the current'
+ 'default scope to be "mmpose". If this is not '
+ 'expected, please set `init_default_scope=False`.')
+ # avoid name conflict
+ new_instance_name = f'mmpose-{datetime.datetime.now()}'
+ DefaultScope.get_instance(new_instance_name, scope_name='mmpose')
diff --git a/mmpose/utils/tensor_utils.py b/mmpose/utils/tensor_utils.py
index 1be73f8991..95793b0d63 100644
--- a/mmpose/utils/tensor_utils.py
+++ b/mmpose/utils/tensor_utils.py
@@ -1,71 +1,71 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-
-from typing import Any, Optional, Sequence, Union
-
-import numpy as np
-import torch
-from mmengine.utils import is_seq_of
-from torch import Tensor
-
-
-def to_numpy(x: Union[Tensor, Sequence[Tensor]],
- return_device: bool = False,
- unzip: bool = False) -> Union[np.ndarray, tuple]:
- """Convert torch tensor to numpy.ndarray.
-
- Args:
- x (Tensor | Sequence[Tensor]): A single tensor or a sequence of
- tensors
- return_device (bool): Whether return the tensor device. Defaults to
- ``False``
- unzip (bool): Whether unzip the input sequence. Defaults to ``False``
-
- Returns:
- np.ndarray | tuple: If ``return_device`` is ``True``, return a tuple
- of converted numpy array(s) and the device indicator; otherwise only
- return the numpy array(s)
- """
-
- if isinstance(x, Tensor):
- arrays = x.detach().cpu().numpy()
- device = x.device
- elif is_seq_of(x, Tensor):
- if unzip:
- # convert (A, B) -> [(A[0], B[0]), (A[1], B[1]), ...]
- arrays = [
- tuple(to_numpy(_x[None, :]) for _x in _each)
- for _each in zip(*x)
- ]
- else:
- arrays = [to_numpy(_x) for _x in x]
-
- device = x[0].device
-
- else:
- raise ValueError(f'Invalid input type {type(x)}')
-
- if return_device:
- return arrays, device
- else:
- return arrays
-
-
-def to_tensor(x: Union[np.ndarray, Sequence[np.ndarray]],
- device: Optional[Any] = None) -> Union[Tensor, Sequence[Tensor]]:
- """Convert numpy.ndarray to torch tensor.
-
- Args:
- x (np.ndarray | Sequence[np.ndarray]): A single np.ndarray or a
- sequence of tensors
- tensor (Any, optional): The device indicator. Defaults to ``None``
-
- Returns:
- tuple:
- - Tensor | Sequence[Tensor]: The converted Tensor or Tensor sequence
- """
- if isinstance(x, np.ndarray):
- return torch.tensor(x, device=device)
- elif is_seq_of(x, np.ndarray):
- return [to_tensor(_x, device=device) for _x in x]
- else:
- raise ValueError(f'Invalid input type {type(x)}')
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from typing import Any, Optional, Sequence, Union
+
+import numpy as np
+import torch
+from mmengine.utils import is_seq_of
+from torch import Tensor
+
+
+def to_numpy(x: Union[Tensor, Sequence[Tensor]],
+ return_device: bool = False,
+ unzip: bool = False) -> Union[np.ndarray, tuple]:
+ """Convert torch tensor to numpy.ndarray.
+
+ Args:
+ x (Tensor | Sequence[Tensor]): A single tensor or a sequence of
+ tensors
+ return_device (bool): Whether return the tensor device. Defaults to
+ ``False``
+ unzip (bool): Whether unzip the input sequence. Defaults to ``False``
+
+ Returns:
+ np.ndarray | tuple: If ``return_device`` is ``True``, return a tuple
+ of converted numpy array(s) and the device indicator; otherwise only
+ return the numpy array(s)
+ """
+
+ if isinstance(x, Tensor):
+ arrays = x.detach().cpu().numpy()
+ device = x.device
+ elif is_seq_of(x, Tensor):
+ if unzip:
+ # convert (A, B) -> [(A[0], B[0]), (A[1], B[1]), ...]
+ arrays = [
+ tuple(to_numpy(_x[None, :]) for _x in _each)
+ for _each in zip(*x)
+ ]
+ else:
+ arrays = [to_numpy(_x) for _x in x]
+
+ device = x[0].device
+
+ else:
+ raise ValueError(f'Invalid input type {type(x)}')
+
+ if return_device:
+ return arrays, device
+ else:
+ return arrays
+
+
+def to_tensor(x: Union[np.ndarray, Sequence[np.ndarray]],
+ device: Optional[Any] = None) -> Union[Tensor, Sequence[Tensor]]:
+ """Convert numpy.ndarray to torch tensor.
+
+ Args:
+ x (np.ndarray | Sequence[np.ndarray]): A single np.ndarray or a
+ sequence of tensors
+ tensor (Any, optional): The device indicator. Defaults to ``None``
+
+ Returns:
+ tuple:
+ - Tensor | Sequence[Tensor]: The converted Tensor or Tensor sequence
+ """
+ if isinstance(x, np.ndarray):
+ return torch.tensor(x, device=device)
+ elif is_seq_of(x, np.ndarray):
+ return [to_tensor(_x, device=device) for _x in x]
+ else:
+ raise ValueError(f'Invalid input type {type(x)}')
diff --git a/mmpose/utils/timer.py b/mmpose/utils/timer.py
index c219c04069..66dab46a4d 100644
--- a/mmpose/utils/timer.py
+++ b/mmpose/utils/timer.py
@@ -1,117 +1,117 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from collections import defaultdict
-from contextlib import contextmanager
-from functools import partial
-
-import numpy as np
-from mmengine import Timer
-
-
-class RunningAverage():
- r"""A helper class to calculate running average in a sliding window.
-
- Args:
- window (int): The size of the sliding window.
- """
-
- def __init__(self, window: int = 1):
- self.window = window
- self._data = []
-
- def update(self, value):
- """Update a new data sample."""
- self._data.append(value)
- self._data = self._data[-self.window:]
-
- def average(self):
- """Get the average value of current window."""
- return np.mean(self._data)
-
-
-class StopWatch:
- r"""A helper class to measure FPS and detailed time consuming of each phase
- in a video processing loop or similar scenarios.
-
- Args:
- window (int): The sliding window size to calculate the running average
- of the time consuming.
-
- Example:
- >>> from mmpose.utils import StopWatch
- >>> import time
- >>> stop_watch = StopWatch(window=10)
- >>> with stop_watch.timeit('total'):
- >>> time.sleep(0.1)
- >>> # 'timeit' support nested use
- >>> with stop_watch.timeit('phase1'):
- >>> time.sleep(0.1)
- >>> with stop_watch.timeit('phase2'):
- >>> time.sleep(0.2)
- >>> time.sleep(0.2)
- >>> report = stop_watch.report()
- """
-
- def __init__(self, window=1):
- self.window = window
- self._record = defaultdict(partial(RunningAverage, window=self.window))
- self._timer_stack = []
-
- @contextmanager
- def timeit(self, timer_name='_FPS_'):
- """Timing a code snippet with an assigned name.
-
- Args:
- timer_name (str): The unique name of the interested code snippet to
- handle multiple timers and generate reports. Note that '_FPS_'
- is a special key that the measurement will be in `fps` instead
- of `millisecond`. Also see `report` and `report_strings`.
- Default: '_FPS_'.
- Note:
- This function should always be used in a `with` statement, as shown
- in the example.
- """
- self._timer_stack.append((timer_name, Timer()))
- try:
- yield
- finally:
- timer_name, timer = self._timer_stack.pop()
- self._record[timer_name].update(timer.since_start())
-
- def report(self, key=None):
- """Report timing information.
-
- Returns:
- dict: The key is the timer name and the value is the \
- corresponding average time consuming.
- """
- result = {
- name: r.average() * 1000.
- for name, r in self._record.items()
- }
-
- if '_FPS_' in result:
- result['_FPS_'] = 1000. / result.pop('_FPS_')
-
- if key is None:
- return result
- return result[key]
-
- def report_strings(self):
- """Report timing information in texture strings.
-
- Returns:
- list(str): Each element is the information string of a timed \
- event, in format of '{timer_name}: {time_in_ms}'. \
- Specially, if timer_name is '_FPS_', the result will \
- be converted to fps.
- """
- result = self.report()
- strings = []
- if '_FPS_' in result:
- strings.append(f'FPS: {result["_FPS_"]:>5.1f}')
- strings += [f'{name}: {val:>3.0f}' for name, val in result.items()]
- return strings
-
- def reset(self):
- self._record = defaultdict(list)
- self._active_timer_stack = []
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections import defaultdict
+from contextlib import contextmanager
+from functools import partial
+
+import numpy as np
+from mmengine import Timer
+
+
+class RunningAverage():
+ r"""A helper class to calculate running average in a sliding window.
+
+ Args:
+ window (int): The size of the sliding window.
+ """
+
+ def __init__(self, window: int = 1):
+ self.window = window
+ self._data = []
+
+ def update(self, value):
+ """Update a new data sample."""
+ self._data.append(value)
+ self._data = self._data[-self.window:]
+
+ def average(self):
+ """Get the average value of current window."""
+ return np.mean(self._data)
+
+
+class StopWatch:
+ r"""A helper class to measure FPS and detailed time consuming of each phase
+ in a video processing loop or similar scenarios.
+
+ Args:
+ window (int): The sliding window size to calculate the running average
+ of the time consuming.
+
+ Example:
+ >>> from mmpose.utils import StopWatch
+ >>> import time
+ >>> stop_watch = StopWatch(window=10)
+ >>> with stop_watch.timeit('total'):
+ >>> time.sleep(0.1)
+ >>> # 'timeit' support nested use
+ >>> with stop_watch.timeit('phase1'):
+ >>> time.sleep(0.1)
+ >>> with stop_watch.timeit('phase2'):
+ >>> time.sleep(0.2)
+ >>> time.sleep(0.2)
+ >>> report = stop_watch.report()
+ """
+
+ def __init__(self, window=1):
+ self.window = window
+ self._record = defaultdict(partial(RunningAverage, window=self.window))
+ self._timer_stack = []
+
+ @contextmanager
+ def timeit(self, timer_name='_FPS_'):
+ """Timing a code snippet with an assigned name.
+
+ Args:
+ timer_name (str): The unique name of the interested code snippet to
+ handle multiple timers and generate reports. Note that '_FPS_'
+ is a special key that the measurement will be in `fps` instead
+ of `millisecond`. Also see `report` and `report_strings`.
+ Default: '_FPS_'.
+ Note:
+ This function should always be used in a `with` statement, as shown
+ in the example.
+ """
+ self._timer_stack.append((timer_name, Timer()))
+ try:
+ yield
+ finally:
+ timer_name, timer = self._timer_stack.pop()
+ self._record[timer_name].update(timer.since_start())
+
+ def report(self, key=None):
+ """Report timing information.
+
+ Returns:
+ dict: The key is the timer name and the value is the \
+ corresponding average time consuming.
+ """
+ result = {
+ name: r.average() * 1000.
+ for name, r in self._record.items()
+ }
+
+ if '_FPS_' in result:
+ result['_FPS_'] = 1000. / result.pop('_FPS_')
+
+ if key is None:
+ return result
+ return result[key]
+
+ def report_strings(self):
+ """Report timing information in texture strings.
+
+ Returns:
+ list(str): Each element is the information string of a timed \
+ event, in format of '{timer_name}: {time_in_ms}'. \
+ Specially, if timer_name is '_FPS_', the result will \
+ be converted to fps.
+ """
+ result = self.report()
+ strings = []
+ if '_FPS_' in result:
+ strings.append(f'FPS: {result["_FPS_"]:>5.1f}')
+ strings += [f'{name}: {val:>3.0f}' for name, val in result.items()]
+ return strings
+
+ def reset(self):
+ self._record = defaultdict(list)
+ self._active_timer_stack = []
diff --git a/mmpose/utils/typing.py b/mmpose/utils/typing.py
index 557891b3b9..3549b13a87 100644
--- a/mmpose/utils/typing.py
+++ b/mmpose/utils/typing.py
@@ -1,29 +1,29 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Dict, List, Optional, Tuple, Union
-
-from mmengine.config import ConfigDict
-from mmengine.structures import InstanceData, PixelData
-from torch import Tensor
-
-from mmpose.structures import PoseDataSample
-
-# Type hint of config data
-ConfigType = Union[ConfigDict, dict]
-OptConfigType = Optional[ConfigType]
-# Type hint of one or more config data
-MultiConfig = Union[ConfigType, List[ConfigType]]
-OptMultiConfig = Optional[MultiConfig]
-# Type hint of data samples
-SampleList = List[PoseDataSample]
-OptSampleList = Optional[SampleList]
-InstanceList = List[InstanceData]
-PixelDataList = List[PixelData]
-Predictions = Union[InstanceList, Tuple[InstanceList, PixelDataList]]
-# Type hint of model outputs
-ForwardResults = Union[Dict[str, Tensor], List[PoseDataSample], Tuple[Tensor],
- Tensor]
-# Type hint of features
-# - Tuple[Tensor]: multi-level features extracted by the network
-# - List[Tuple[Tensor]]: multiple feature pyramids for TTA
-# - List[List[Tuple[Tensor]]]: multi-scale feature pyramids
-Features = Union[Tuple[Tensor], List[Tuple[Tensor]], List[List[Tuple[Tensor]]]]
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Tuple, Union
+
+from mmengine.config import ConfigDict
+from mmengine.structures import InstanceData, PixelData
+from torch import Tensor
+
+from mmpose.structures import PoseDataSample
+
+# Type hint of config data
+ConfigType = Union[ConfigDict, dict]
+OptConfigType = Optional[ConfigType]
+# Type hint of one or more config data
+MultiConfig = Union[ConfigType, List[ConfigType]]
+OptMultiConfig = Optional[MultiConfig]
+# Type hint of data samples
+SampleList = List[PoseDataSample]
+OptSampleList = Optional[SampleList]
+InstanceList = List[InstanceData]
+PixelDataList = List[PixelData]
+Predictions = Union[InstanceList, Tuple[InstanceList, PixelDataList]]
+# Type hint of model outputs
+ForwardResults = Union[Dict[str, Tensor], List[PoseDataSample], Tuple[Tensor],
+ Tensor]
+# Type hint of features
+# - Tuple[Tensor]: multi-level features extracted by the network
+# - List[Tuple[Tensor]]: multiple feature pyramids for TTA
+# - List[List[Tuple[Tensor]]]: multi-scale feature pyramids
+Features = Union[Tuple[Tensor], List[Tuple[Tensor]], List[List[Tuple[Tensor]]]]
diff --git a/mmpose/version.py b/mmpose/version.py
index bf58664b39..924449a908 100644
--- a/mmpose/version.py
+++ b/mmpose/version.py
@@ -1,31 +1,31 @@
-# Copyright (c) Open-MMLab. All rights reserved.
-
-__version__ = '1.1.0'
-short_version = __version__
-
-
-def parse_version_info(version_str):
- """Parse a version string into a tuple.
-
- Args:
- version_str (str): The version string.
- Returns:
- tuple[int | str]: The version info, e.g., "1.3.0" is parsed into
- (1, 3, 0), and "2.0.0rc1" is parsed into (2, 0, 0, 'rc1').
- """
- version_info = []
- for x in version_str.split('.'):
- if x.isdigit():
- version_info.append(int(x))
- elif x.find('rc') != -1:
- patch_version = x.split('rc')
- version_info.append(int(patch_version[0]))
- version_info.append(f'rc{patch_version[1]}')
- elif x.find('b') != -1:
- patch_version = x.split('b')
- version_info.append(int(patch_version[0]))
- version_info.append(f'b{patch_version[1]}')
- return tuple(version_info)
-
-
-version_info = parse_version_info(__version__)
+# Copyright (c) Open-MMLab. All rights reserved.
+
+__version__ = '1.1.0'
+short_version = __version__
+
+
+def parse_version_info(version_str):
+ """Parse a version string into a tuple.
+
+ Args:
+ version_str (str): The version string.
+ Returns:
+ tuple[int | str]: The version info, e.g., "1.3.0" is parsed into
+ (1, 3, 0), and "2.0.0rc1" is parsed into (2, 0, 0, 'rc1').
+ """
+ version_info = []
+ for x in version_str.split('.'):
+ if x.isdigit():
+ version_info.append(int(x))
+ elif x.find('rc') != -1:
+ patch_version = x.split('rc')
+ version_info.append(int(patch_version[0]))
+ version_info.append(f'rc{patch_version[1]}')
+ elif x.find('b') != -1:
+ patch_version = x.split('b')
+ version_info.append(int(patch_version[0]))
+ version_info.append(f'b{patch_version[1]}')
+ return tuple(version_info)
+
+
+version_info = parse_version_info(__version__)
diff --git a/mmpose/visualization/__init__.py b/mmpose/visualization/__init__.py
index 4a18e8bc5b..a144d8762f 100644
--- a/mmpose/visualization/__init__.py
+++ b/mmpose/visualization/__init__.py
@@ -1,6 +1,6 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .fast_visualizer import FastVisualizer
-from .local_visualizer import PoseLocalVisualizer
-from .local_visualizer_3d import Pose3dLocalVisualizer
-
-__all__ = ['PoseLocalVisualizer', 'FastVisualizer', 'Pose3dLocalVisualizer']
+# Copyright (c) OpenMMLab. All rights reserved.
+from .fast_visualizer import FastVisualizer
+from .local_visualizer import PoseLocalVisualizer
+from .local_visualizer_3d import Pose3dLocalVisualizer
+
+__all__ = ['PoseLocalVisualizer', 'FastVisualizer', 'Pose3dLocalVisualizer']
diff --git a/mmpose/visualization/fast_visualizer.py b/mmpose/visualization/fast_visualizer.py
index fa0cb38527..f6ddb3ffda 100644
--- a/mmpose/visualization/fast_visualizer.py
+++ b/mmpose/visualization/fast_visualizer.py
@@ -1,78 +1,78 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import cv2
-
-
-class FastVisualizer:
- """MMPose Fast Visualizer.
-
- A simple yet fast visualizer for video/webcam inference.
-
- Args:
- metainfo (dict): pose meta information
- radius (int, optional)): Keypoint radius for visualization.
- Defaults to 6.
- line_width (int, optional): Link width for visualization.
- Defaults to 3.
- kpt_thr (float, optional): Threshold for keypoints' confidence score,
- keypoints with score below this value will not be drawn.
- Defaults to 0.3.
- """
-
- def __init__(self, metainfo, radius=6, line_width=3, kpt_thr=0.3):
- self.radius = radius
- self.line_width = line_width
- self.kpt_thr = kpt_thr
-
- self.keypoint_id2name = metainfo['keypoint_id2name']
- self.keypoint_name2id = metainfo['keypoint_name2id']
- self.keypoint_colors = metainfo['keypoint_colors']
- self.skeleton_links = metainfo['skeleton_links']
- self.skeleton_link_colors = metainfo['skeleton_link_colors']
-
- def draw_pose(self, img, instances):
- """Draw pose estimations on the given image.
-
- This method draws keypoints and skeleton links on the input image
- using the provided instances.
-
- Args:
- img (numpy.ndarray): The input image on which to
- draw the pose estimations.
- instances (object): An object containing detected instances'
- information, including keypoints and keypoint_scores.
-
- Returns:
- None: The input image will be modified in place.
- """
-
- if instances is None:
- print('no instance detected')
- return
-
- keypoints = instances.keypoints
- scores = instances.keypoint_scores
-
- for kpts, score in zip(keypoints, scores):
- for sk_id, sk in enumerate(self.skeleton_links):
- if score[sk[0]] < self.kpt_thr or score[sk[1]] < self.kpt_thr:
- # skip the link that should not be drawn
- continue
-
- pos1 = (int(kpts[sk[0], 0]), int(kpts[sk[0], 1]))
- pos2 = (int(kpts[sk[1], 0]), int(kpts[sk[1], 1]))
-
- color = self.skeleton_link_colors[sk_id].tolist()
- cv2.line(img, pos1, pos2, color, thickness=self.line_width)
-
- for kid, kpt in enumerate(kpts):
- if score[kid] < self.kpt_thr:
- # skip the point that should not be drawn
- continue
-
- x_coord, y_coord = int(kpt[0]), int(kpt[1])
-
- color = self.keypoint_colors[kid].tolist()
- cv2.circle(img, (int(x_coord), int(y_coord)), self.radius,
- color, -1)
- cv2.circle(img, (int(x_coord), int(y_coord)), self.radius,
- (255, 255, 255))
+# Copyright (c) OpenMMLab. All rights reserved.
+import cv2
+
+
+class FastVisualizer:
+ """MMPose Fast Visualizer.
+
+ A simple yet fast visualizer for video/webcam inference.
+
+ Args:
+ metainfo (dict): pose meta information
+ radius (int, optional)): Keypoint radius for visualization.
+ Defaults to 6.
+ line_width (int, optional): Link width for visualization.
+ Defaults to 3.
+ kpt_thr (float, optional): Threshold for keypoints' confidence score,
+ keypoints with score below this value will not be drawn.
+ Defaults to 0.3.
+ """
+
+ def __init__(self, metainfo, radius=6, line_width=3, kpt_thr=0.3):
+ self.radius = radius
+ self.line_width = line_width
+ self.kpt_thr = kpt_thr
+
+ self.keypoint_id2name = metainfo['keypoint_id2name']
+ self.keypoint_name2id = metainfo['keypoint_name2id']
+ self.keypoint_colors = metainfo['keypoint_colors']
+ self.skeleton_links = metainfo['skeleton_links']
+ self.skeleton_link_colors = metainfo['skeleton_link_colors']
+
+ def draw_pose(self, img, instances):
+ """Draw pose estimations on the given image.
+
+ This method draws keypoints and skeleton links on the input image
+ using the provided instances.
+
+ Args:
+ img (numpy.ndarray): The input image on which to
+ draw the pose estimations.
+ instances (object): An object containing detected instances'
+ information, including keypoints and keypoint_scores.
+
+ Returns:
+ None: The input image will be modified in place.
+ """
+
+ if instances is None:
+ print('no instance detected')
+ return
+
+ keypoints = instances.keypoints
+ scores = instances.keypoint_scores
+
+ for kpts, score in zip(keypoints, scores):
+ for sk_id, sk in enumerate(self.skeleton_links):
+ if score[sk[0]] < self.kpt_thr or score[sk[1]] < self.kpt_thr:
+ # skip the link that should not be drawn
+ continue
+
+ pos1 = (int(kpts[sk[0], 0]), int(kpts[sk[0], 1]))
+ pos2 = (int(kpts[sk[1], 0]), int(kpts[sk[1], 1]))
+
+ color = self.skeleton_link_colors[sk_id].tolist()
+ cv2.line(img, pos1, pos2, color, thickness=self.line_width)
+
+ for kid, kpt in enumerate(kpts):
+ if score[kid] < self.kpt_thr:
+ # skip the point that should not be drawn
+ continue
+
+ x_coord, y_coord = int(kpt[0]), int(kpt[1])
+
+ color = self.keypoint_colors[kid].tolist()
+ cv2.circle(img, (int(x_coord), int(y_coord)), self.radius,
+ color, -1)
+ cv2.circle(img, (int(x_coord), int(y_coord)), self.radius,
+ (255, 255, 255))
diff --git a/mmpose/visualization/local_visualizer.py b/mmpose/visualization/local_visualizer.py
index 080e628e33..4696852600 100644
--- a/mmpose/visualization/local_visualizer.py
+++ b/mmpose/visualization/local_visualizer.py
@@ -1,583 +1,583 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import math
-from typing import Dict, List, Optional, Tuple, Union
-
-import cv2
-import mmcv
-import numpy as np
-import torch
-from mmengine.dist import master_only
-from mmengine.structures import InstanceData, PixelData
-
-from mmpose.datasets.datasets.utils import parse_pose_metainfo
-from mmpose.registry import VISUALIZERS
-from mmpose.structures import PoseDataSample
-from .opencv_backend_visualizer import OpencvBackendVisualizer
-from .simcc_vis import SimCCVisualizer
-
-
-def _get_adaptive_scales(areas: np.ndarray,
- min_area: int = 800,
- max_area: int = 30000) -> np.ndarray:
- """Get adaptive scales according to areas.
-
- The scale range is [0.5, 1.0]. When the area is less than
- ``min_area``, the scale is 0.5 while the area is larger than
- ``max_area``, the scale is 1.0.
-
- Args:
- areas (ndarray): The areas of bboxes or masks with the
- shape of (n, ).
- min_area (int): Lower bound areas for adaptive scales.
- Defaults to 800.
- max_area (int): Upper bound areas for adaptive scales.
- Defaults to 30000.
-
- Returns:
- ndarray: The adaotive scales with the shape of (n, ).
- """
- scales = 0.5 + (areas - min_area) / (max_area - min_area)
- scales = np.clip(scales, 0.5, 1.0)
- return scales
-
-
-@VISUALIZERS.register_module()
-class PoseLocalVisualizer(OpencvBackendVisualizer):
- """MMPose Local Visualizer.
-
- Args:
- name (str): Name of the instance. Defaults to 'visualizer'.
- image (np.ndarray, optional): the origin image to draw. The format
- should be RGB. Defaults to ``None``
- vis_backends (list, optional): Visual backend config list. Defaults to
- ``None``
- save_dir (str, optional): Save file dir for all storage backends.
- If it is ``None``, the backend storage will not save any data.
- Defaults to ``None``
- bbox_color (str, tuple(int), optional): Color of bbox lines.
- The tuple of color should be in BGR order. Defaults to ``'green'``
- kpt_color (str, tuple(tuple(int)), optional): Color of keypoints.
- The tuple of color should be in BGR order. Defaults to ``'red'``
- link_color (str, tuple(tuple(int)), optional): Color of skeleton.
- The tuple of color should be in BGR order. Defaults to ``None``
- line_width (int, float): The width of lines. Defaults to 1
- radius (int, float): The radius of keypoints. Defaults to 4
- show_keypoint_weight (bool): Whether to adjust the transparency
- of keypoints according to their score. Defaults to ``False``
- alpha (int, float): The transparency of bboxes. Defaults to ``1.0``
-
- Examples:
- >>> import numpy as np
- >>> from mmengine.structures import InstanceData
- >>> from mmpose.structures import PoseDataSample
- >>> from mmpose.visualization import PoseLocalVisualizer
-
- >>> pose_local_visualizer = PoseLocalVisualizer(radius=1)
- >>> image = np.random.randint(0, 256,
- ... size=(10, 12, 3)).astype('uint8')
- >>> gt_instances = InstanceData()
- >>> gt_instances.keypoints = np.array([[[1, 1], [2, 2], [4, 4],
- ... [8, 8]]])
- >>> gt_pose_data_sample = PoseDataSample()
- >>> gt_pose_data_sample.gt_instances = gt_instances
- >>> dataset_meta = {'skeleton_links': [[0, 1], [1, 2], [2, 3]]}
- >>> pose_local_visualizer.set_dataset_meta(dataset_meta)
- >>> pose_local_visualizer.add_datasample('image', image,
- ... gt_pose_data_sample)
- >>> pose_local_visualizer.add_datasample(
- ... 'image', image, gt_pose_data_sample,
- ... out_file='out_file.jpg')
- >>> pose_local_visualizer.add_datasample(
- ... 'image', image, gt_pose_data_sample,
- ... show=True)
- >>> pred_instances = InstanceData()
- >>> pred_instances.keypoints = np.array([[[1, 1], [2, 2], [4, 4],
- ... [8, 8]]])
- >>> pred_instances.score = np.array([0.8, 1, 0.9, 1])
- >>> pred_pose_data_sample = PoseDataSample()
- >>> pred_pose_data_sample.pred_instances = pred_instances
- >>> pose_local_visualizer.add_datasample('image', image,
- ... gt_pose_data_sample,
- ... pred_pose_data_sample)
- """
-
- def __init__(self,
- name: str = 'visualizer',
- image: Optional[np.ndarray] = None,
- vis_backends: Optional[Dict] = None,
- save_dir: Optional[str] = None,
- bbox_color: Optional[Union[str, Tuple[int]]] = 'green',
- kpt_color: Optional[Union[str, Tuple[Tuple[int]]]] = 'red',
- link_color: Optional[Union[str, Tuple[Tuple[int]]]] = None,
- text_color: Optional[Union[str,
- Tuple[int]]] = (255, 255, 255),
- skeleton: Optional[Union[List, Tuple]] = None,
- line_width: Union[int, float] = 1,
- radius: Union[int, float] = 3,
- show_keypoint_weight: bool = False,
- backend: str = 'opencv',
- alpha: float = 1.0):
- super().__init__(
- name=name,
- image=image,
- vis_backends=vis_backends,
- save_dir=save_dir,
- backend=backend)
-
- self.bbox_color = bbox_color
- self.kpt_color = kpt_color
- self.link_color = link_color
- self.line_width = line_width
- self.text_color = text_color
- self.skeleton = skeleton
- self.radius = radius
- self.alpha = alpha
- self.show_keypoint_weight = show_keypoint_weight
- # Set default value. When calling
- # `PoseLocalVisualizer().set_dataset_meta(xxx)`,
- # it will override the default value.
- self.dataset_meta = {}
-
- def set_dataset_meta(self,
- dataset_meta: Dict,
- skeleton_style: str = 'mmpose'):
- """Assign dataset_meta to the visualizer. The default visualization
- settings will be overridden.
-
- Args:
- dataset_meta (dict): meta information of dataset.
- """
- if dataset_meta.get(
- 'dataset_name') == 'coco' and skeleton_style == 'openpose':
- dataset_meta = parse_pose_metainfo(
- dict(from_file='configs/_base_/datasets/coco_openpose.py'))
-
- if isinstance(dataset_meta, dict):
- self.dataset_meta = dataset_meta.copy()
- self.bbox_color = dataset_meta.get('bbox_color', self.bbox_color)
- self.kpt_color = dataset_meta.get('keypoint_colors',
- self.kpt_color)
- self.link_color = dataset_meta.get('skeleton_link_colors',
- self.link_color)
- self.skeleton = dataset_meta.get('skeleton_links', self.skeleton)
- # sometimes self.dataset_meta is manually set, which might be None.
- # it should be converted to a dict at these times
- if self.dataset_meta is None:
- self.dataset_meta = {}
-
- def _draw_instances_bbox(self, image: np.ndarray,
- instances: InstanceData) -> np.ndarray:
- """Draw bounding boxes and corresponding labels of GT or prediction.
-
- Args:
- image (np.ndarray): The image to draw.
- instances (:obj:`InstanceData`): Data structure for
- instance-level annotations or predictions.
-
- Returns:
- np.ndarray: the drawn image which channel is RGB.
- """
- self.set_image(image)
-
- if 'bboxes' in instances:
- bboxes = instances.bboxes
- self.draw_bboxes(
- bboxes,
- edge_colors=self.bbox_color,
- alpha=self.alpha,
- line_widths=self.line_width)
- else:
- return self.get_image()
-
- if 'labels' in instances and self.text_color is not None:
- classes = self.dataset_meta.get('classes', None)
- labels = instances.labels
-
- positions = bboxes[:, :2]
- areas = (bboxes[:, 3] - bboxes[:, 1]) * (
- bboxes[:, 2] - bboxes[:, 0])
- scales = _get_adaptive_scales(areas)
-
- for i, (pos, label) in enumerate(zip(positions, labels)):
- label_text = classes[
- label] if classes is not None else f'class {label}'
-
- if isinstance(self.bbox_color,
- tuple) and max(self.bbox_color) > 1:
- facecolor = [c / 255.0 for c in self.bbox_color]
- else:
- facecolor = self.bbox_color
-
- self.draw_texts(
- label_text,
- pos,
- colors=self.text_color,
- font_sizes=int(13 * scales[i]),
- vertical_alignments='bottom',
- bboxes=[{
- 'facecolor': facecolor,
- 'alpha': 0.8,
- 'pad': 0.7,
- 'edgecolor': 'none'
- }])
-
- return self.get_image()
-
- def _draw_instances_kpts(self,
- image: np.ndarray,
- instances: InstanceData,
- kpt_thr: float = 0.3,
- show_kpt_idx: bool = False,
- skeleton_style: str = 'mmpose'):
- """Draw keypoints and skeletons (optional) of GT or prediction.
-
- Args:
- image (np.ndarray): The image to draw.
- instances (:obj:`InstanceData`): Data structure for
- instance-level annotations or predictions.
- kpt_thr (float, optional): Minimum threshold of keypoints
- to be shown. Default: 0.3.
- show_kpt_idx (bool): Whether to show the index of keypoints.
- Defaults to ``False``
- skeleton_style (str): Skeleton style selection. Defaults to
- ``'mmpose'``
-
- Returns:
- np.ndarray: the drawn image which channel is RGB.
- """
-
- self.set_image(image)
- img_h, img_w, _ = image.shape
-
- if 'keypoints' in instances:
- keypoints = instances.get('transformed_keypoints',
- instances.keypoints)
-
- if 'keypoint_scores' in instances:
- scores = instances.keypoint_scores
- else:
- scores = np.ones(keypoints.shape[:-1])
-
- if 'keypoints_visible' in instances:
- keypoints_visible = instances.keypoints_visible
- else:
- keypoints_visible = np.ones(keypoints.shape[:-1])
-
- if skeleton_style == 'openpose':
- keypoints_info = np.concatenate(
- (keypoints, scores[..., None], keypoints_visible[...,
- None]),
- axis=-1)
- # compute neck joint
- neck = np.mean(keypoints_info[:, [5, 6]], axis=1)
- # neck score when visualizing pred
- neck[:, 2:4] = np.logical_and(
- keypoints_info[:, 5, 2:4] > kpt_thr,
- keypoints_info[:, 6, 2:4] > kpt_thr).astype(int)
- new_keypoints_info = np.insert(
- keypoints_info, 17, neck, axis=1)
-
- mmpose_idx = [
- 17, 6, 8, 10, 7, 9, 12, 14, 16, 13, 15, 2, 1, 4, 3
- ]
- openpose_idx = [
- 1, 2, 3, 4, 6, 7, 8, 9, 10, 12, 13, 14, 15, 16, 17
- ]
- new_keypoints_info[:, openpose_idx] = \
- new_keypoints_info[:, mmpose_idx]
- keypoints_info = new_keypoints_info
-
- keypoints, scores, keypoints_visible = keypoints_info[
- ..., :2], keypoints_info[..., 2], keypoints_info[..., 3]
-
- for kpts, score, visible in zip(keypoints, scores,
- keypoints_visible):
- kpts = np.array(kpts, copy=False)
-
- if self.kpt_color is None or isinstance(self.kpt_color, str):
- kpt_color = [self.kpt_color] * len(kpts)
- elif len(self.kpt_color) == len(kpts):
- kpt_color = self.kpt_color
- else:
- raise ValueError(
- f'the length of kpt_color '
- f'({len(self.kpt_color)}) does not matches '
- f'that of keypoints ({len(kpts)})')
-
- # draw links
- if self.skeleton is not None and self.link_color is not None:
- if self.link_color is None or isinstance(
- self.link_color, str):
- link_color = [self.link_color] * len(self.skeleton)
- elif len(self.link_color) == len(self.skeleton):
- link_color = self.link_color
- else:
- raise ValueError(
- f'the length of link_color '
- f'({len(self.link_color)}) does not matches '
- f'that of skeleton ({len(self.skeleton)})')
-
- for sk_id, sk in enumerate(self.skeleton):
- pos1 = (int(kpts[sk[0], 0]), int(kpts[sk[0], 1]))
- pos2 = (int(kpts[sk[1], 0]), int(kpts[sk[1], 1]))
- if not (visible[sk[0]] and visible[sk[1]]):
- continue
-
- if (pos1[0] <= 0 or pos1[0] >= img_w or pos1[1] <= 0
- or pos1[1] >= img_h or pos2[0] <= 0
- or pos2[0] >= img_w or pos2[1] <= 0
- or pos2[1] >= img_h or score[sk[0]] < kpt_thr
- or score[sk[1]] < kpt_thr
- or link_color[sk_id] is None):
- # skip the link that should not be drawn
- continue
- X = np.array((pos1[0], pos2[0]))
- Y = np.array((pos1[1], pos2[1]))
- color = link_color[sk_id]
- if not isinstance(color, str):
- color = tuple(int(c) for c in color)
- transparency = self.alpha
- if self.show_keypoint_weight:
- transparency *= max(
- 0, min(1, 0.5 * (score[sk[0]] + score[sk[1]])))
-
- if skeleton_style == 'openpose':
- mX = np.mean(X)
- mY = np.mean(Y)
- length = ((Y[0] - Y[1])**2 + (X[0] - X[1])**2)**0.5
- transparency = 0.6
- angle = math.degrees(
- math.atan2(Y[0] - Y[1], X[0] - X[1]))
- polygons = cv2.ellipse2Poly(
- (int(mX), int(mY)),
- (int(length / 2), int(self.line_width)),
- int(angle), 0, 360, 1)
-
- self.draw_polygons(
- polygons,
- edge_colors=color,
- face_colors=color,
- alpha=transparency)
-
- else:
- self.draw_lines(
- X, Y, color, line_widths=self.line_width)
-
- # draw each point on image
- for kid, kpt in enumerate(kpts):
- if score[kid] < kpt_thr or not visible[
- kid] or kpt_color[kid] is None:
- # skip the point that should not be drawn
- continue
-
- color = kpt_color[kid]
- if not isinstance(color, str):
- color = tuple(int(c) for c in color)
- transparency = self.alpha
- if self.show_keypoint_weight:
- transparency *= max(0, min(1, score[kid]))
- self.draw_circles(
- kpt,
- radius=np.array([self.radius]),
- face_colors=color,
- edge_colors=color,
- alpha=transparency,
- line_widths=self.radius)
- if show_kpt_idx:
- kpt[0] += self.radius
- kpt[1] -= self.radius
- self.draw_texts(
- str(kid),
- kpt,
- colors=color,
- font_sizes=self.radius * 3,
- vertical_alignments='bottom',
- horizontal_alignments='center')
-
- return self.get_image()
-
- def _draw_instance_heatmap(
- self,
- fields: PixelData,
- overlaid_image: Optional[np.ndarray] = None,
- ):
- """Draw heatmaps of GT or prediction.
-
- Args:
- fields (:obj:`PixelData`): Data structure for
- pixel-level annotations or predictions.
- overlaid_image (np.ndarray): The image to draw.
-
- Returns:
- np.ndarray: the drawn image which channel is RGB.
- """
- if 'heatmaps' not in fields:
- return None
- heatmaps = fields.heatmaps
- if isinstance(heatmaps, np.ndarray):
- heatmaps = torch.from_numpy(heatmaps)
- if heatmaps.dim() == 3:
- heatmaps, _ = heatmaps.max(dim=0)
- heatmaps = heatmaps.unsqueeze(0)
- out_image = self.draw_featmap(heatmaps, overlaid_image)
- return out_image
-
- def _draw_instance_xy_heatmap(
- self,
- fields: PixelData,
- overlaid_image: Optional[np.ndarray] = None,
- n: int = 20,
- ):
- """Draw heatmaps of GT or prediction.
-
- Args:
- fields (:obj:`PixelData`): Data structure for
- pixel-level annotations or predictions.
- overlaid_image (np.ndarray): The image to draw.
- n (int): Number of keypoint, up to 20.
-
- Returns:
- np.ndarray: the drawn image which channel is RGB.
- """
- if 'heatmaps' not in fields:
- return None
- heatmaps = fields.heatmaps
- _, h, w = heatmaps.shape
- if isinstance(heatmaps, np.ndarray):
- heatmaps = torch.from_numpy(heatmaps)
- out_image = SimCCVisualizer().draw_instance_xy_heatmap(
- heatmaps, overlaid_image, n)
- out_image = cv2.resize(out_image[:, :, ::-1], (w, h))
- return out_image
-
- @master_only
- def add_datasample(self,
- name: str,
- image: np.ndarray,
- data_sample: PoseDataSample,
- draw_gt: bool = True,
- draw_pred: bool = True,
- draw_heatmap: bool = False,
- draw_bbox: bool = False,
- show_kpt_idx: bool = False,
- skeleton_style: str = 'mmpose',
- show: bool = False,
- wait_time: float = 0,
- out_file: Optional[str] = None,
- kpt_thr: float = 0.3,
- step: int = 0) -> None:
- """Draw datasample and save to all backends.
-
- - If GT and prediction are plotted at the same time, they are
- displayed in a stitched image where the left image is the
- ground truth and the right image is the prediction.
- - If ``show`` is True, all storage backends are ignored, and
- the images will be displayed in a local window.
- - If ``out_file`` is specified, the drawn image will be
- saved to ``out_file``. t is usually used when the display
- is not available.
-
- Args:
- name (str): The image identifier
- image (np.ndarray): The image to draw
- data_sample (:obj:`PoseDataSample`, optional): The data sample
- to visualize
- draw_gt (bool): Whether to draw GT PoseDataSample. Default to
- ``True``
- draw_pred (bool): Whether to draw Prediction PoseDataSample.
- Defaults to ``True``
- draw_bbox (bool): Whether to draw bounding boxes. Default to
- ``False``
- draw_heatmap (bool): Whether to draw heatmaps. Defaults to
- ``False``
- show_kpt_idx (bool): Whether to show the index of keypoints.
- Defaults to ``False``
- skeleton_style (str): Skeleton style selection. Defaults to
- ``'mmpose'``
- show (bool): Whether to display the drawn image. Default to
- ``False``
- wait_time (float): The interval of show (s). Defaults to 0
- out_file (str): Path to output file. Defaults to ``None``
- kpt_thr (float, optional): Minimum threshold of keypoints
- to be shown. Default: 0.3.
- step (int): Global step value to record. Defaults to 0
- """
-
- gt_img_data = None
- pred_img_data = None
-
- if draw_gt:
- gt_img_data = image.copy()
- gt_img_heatmap = None
-
- # draw bboxes & keypoints
- if 'gt_instances' in data_sample:
- gt_img_data = self._draw_instances_kpts(
- gt_img_data, data_sample.gt_instances, kpt_thr,
- show_kpt_idx, skeleton_style)
- if draw_bbox:
- gt_img_data = self._draw_instances_bbox(
- gt_img_data, data_sample.gt_instances)
-
- # draw heatmaps
- if 'gt_fields' in data_sample and draw_heatmap:
- gt_img_heatmap = self._draw_instance_heatmap(
- data_sample.gt_fields, image)
- if gt_img_heatmap is not None:
- gt_img_data = np.concatenate((gt_img_data, gt_img_heatmap),
- axis=0)
-
- if draw_pred:
- pred_img_data = image.copy()
- pred_img_heatmap = None
-
- # draw bboxes & keypoints
- if 'pred_instances' in data_sample:
- pred_img_data = self._draw_instances_kpts(
- pred_img_data, data_sample.pred_instances, kpt_thr,
- show_kpt_idx, skeleton_style)
- if draw_bbox:
- pred_img_data = self._draw_instances_bbox(
- pred_img_data, data_sample.pred_instances)
-
- # draw heatmaps
- if 'pred_fields' in data_sample and draw_heatmap:
- if 'keypoint_x_labels' in data_sample.pred_instances:
- pred_img_heatmap = self._draw_instance_xy_heatmap(
- data_sample.pred_fields, image)
- else:
- pred_img_heatmap = self._draw_instance_heatmap(
- data_sample.pred_fields, image)
- if pred_img_heatmap is not None:
- pred_img_data = np.concatenate(
- (pred_img_data, pred_img_heatmap), axis=0)
-
- # merge visualization results
- if gt_img_data is not None and pred_img_data is not None:
- if gt_img_heatmap is None and pred_img_heatmap is not None:
- gt_img_data = np.concatenate((gt_img_data, image), axis=0)
- elif gt_img_heatmap is not None and pred_img_heatmap is None:
- pred_img_data = np.concatenate((pred_img_data, image), axis=0)
-
- drawn_img = np.concatenate((gt_img_data, pred_img_data), axis=1)
-
- elif gt_img_data is not None:
- drawn_img = gt_img_data
- else:
- drawn_img = pred_img_data
-
- # It is convenient for users to obtain the drawn image.
- # For example, the user wants to obtain the drawn image and
- # save it as a video during video inference.
- self.set_image(drawn_img)
-
- if show:
- self.show(drawn_img, win_name=name, wait_time=wait_time)
-
- if out_file is not None:
- mmcv.imwrite(drawn_img[..., ::-1], out_file)
- else:
- # save drawn_img to backends
- self.add_image(name, drawn_img, step)
-
- return self.get_image()
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Dict, List, Optional, Tuple, Union
+
+import cv2
+import mmcv
+import numpy as np
+import torch
+from mmengine.dist import master_only
+from mmengine.structures import InstanceData, PixelData
+
+from mmpose.datasets.datasets.utils import parse_pose_metainfo
+from mmpose.registry import VISUALIZERS
+from mmpose.structures import PoseDataSample
+from .opencv_backend_visualizer import OpencvBackendVisualizer
+from .simcc_vis import SimCCVisualizer
+
+
+def _get_adaptive_scales(areas: np.ndarray,
+ min_area: int = 800,
+ max_area: int = 30000) -> np.ndarray:
+ """Get adaptive scales according to areas.
+
+ The scale range is [0.5, 1.0]. When the area is less than
+ ``min_area``, the scale is 0.5 while the area is larger than
+ ``max_area``, the scale is 1.0.
+
+ Args:
+ areas (ndarray): The areas of bboxes or masks with the
+ shape of (n, ).
+ min_area (int): Lower bound areas for adaptive scales.
+ Defaults to 800.
+ max_area (int): Upper bound areas for adaptive scales.
+ Defaults to 30000.
+
+ Returns:
+ ndarray: The adaotive scales with the shape of (n, ).
+ """
+ scales = 0.5 + (areas - min_area) / (max_area - min_area)
+ scales = np.clip(scales, 0.5, 1.0)
+ return scales
+
+
+@VISUALIZERS.register_module()
+class PoseLocalVisualizer(OpencvBackendVisualizer):
+ """MMPose Local Visualizer.
+
+ Args:
+ name (str): Name of the instance. Defaults to 'visualizer'.
+ image (np.ndarray, optional): the origin image to draw. The format
+ should be RGB. Defaults to ``None``
+ vis_backends (list, optional): Visual backend config list. Defaults to
+ ``None``
+ save_dir (str, optional): Save file dir for all storage backends.
+ If it is ``None``, the backend storage will not save any data.
+ Defaults to ``None``
+ bbox_color (str, tuple(int), optional): Color of bbox lines.
+ The tuple of color should be in BGR order. Defaults to ``'green'``
+ kpt_color (str, tuple(tuple(int)), optional): Color of keypoints.
+ The tuple of color should be in BGR order. Defaults to ``'red'``
+ link_color (str, tuple(tuple(int)), optional): Color of skeleton.
+ The tuple of color should be in BGR order. Defaults to ``None``
+ line_width (int, float): The width of lines. Defaults to 1
+ radius (int, float): The radius of keypoints. Defaults to 4
+ show_keypoint_weight (bool): Whether to adjust the transparency
+ of keypoints according to their score. Defaults to ``False``
+ alpha (int, float): The transparency of bboxes. Defaults to ``1.0``
+
+ Examples:
+ >>> import numpy as np
+ >>> from mmengine.structures import InstanceData
+ >>> from mmpose.structures import PoseDataSample
+ >>> from mmpose.visualization import PoseLocalVisualizer
+
+ >>> pose_local_visualizer = PoseLocalVisualizer(radius=1)
+ >>> image = np.random.randint(0, 256,
+ ... size=(10, 12, 3)).astype('uint8')
+ >>> gt_instances = InstanceData()
+ >>> gt_instances.keypoints = np.array([[[1, 1], [2, 2], [4, 4],
+ ... [8, 8]]])
+ >>> gt_pose_data_sample = PoseDataSample()
+ >>> gt_pose_data_sample.gt_instances = gt_instances
+ >>> dataset_meta = {'skeleton_links': [[0, 1], [1, 2], [2, 3]]}
+ >>> pose_local_visualizer.set_dataset_meta(dataset_meta)
+ >>> pose_local_visualizer.add_datasample('image', image,
+ ... gt_pose_data_sample)
+ >>> pose_local_visualizer.add_datasample(
+ ... 'image', image, gt_pose_data_sample,
+ ... out_file='out_file.jpg')
+ >>> pose_local_visualizer.add_datasample(
+ ... 'image', image, gt_pose_data_sample,
+ ... show=True)
+ >>> pred_instances = InstanceData()
+ >>> pred_instances.keypoints = np.array([[[1, 1], [2, 2], [4, 4],
+ ... [8, 8]]])
+ >>> pred_instances.score = np.array([0.8, 1, 0.9, 1])
+ >>> pred_pose_data_sample = PoseDataSample()
+ >>> pred_pose_data_sample.pred_instances = pred_instances
+ >>> pose_local_visualizer.add_datasample('image', image,
+ ... gt_pose_data_sample,
+ ... pred_pose_data_sample)
+ """
+
+ def __init__(self,
+ name: str = 'visualizer',
+ image: Optional[np.ndarray] = None,
+ vis_backends: Optional[Dict] = None,
+ save_dir: Optional[str] = None,
+ bbox_color: Optional[Union[str, Tuple[int]]] = 'green',
+ kpt_color: Optional[Union[str, Tuple[Tuple[int]]]] = 'red',
+ link_color: Optional[Union[str, Tuple[Tuple[int]]]] = None,
+ text_color: Optional[Union[str,
+ Tuple[int]]] = (255, 255, 255),
+ skeleton: Optional[Union[List, Tuple]] = None,
+ line_width: Union[int, float] = 1,
+ radius: Union[int, float] = 3,
+ show_keypoint_weight: bool = False,
+ backend: str = 'opencv',
+ alpha: float = 1.0):
+ super().__init__(
+ name=name,
+ image=image,
+ vis_backends=vis_backends,
+ save_dir=save_dir,
+ backend=backend)
+
+ self.bbox_color = bbox_color
+ self.kpt_color = kpt_color
+ self.link_color = link_color
+ self.line_width = line_width
+ self.text_color = text_color
+ self.skeleton = skeleton
+ self.radius = radius
+ self.alpha = alpha
+ self.show_keypoint_weight = show_keypoint_weight
+ # Set default value. When calling
+ # `PoseLocalVisualizer().set_dataset_meta(xxx)`,
+ # it will override the default value.
+ self.dataset_meta = {}
+
+ def set_dataset_meta(self,
+ dataset_meta: Dict,
+ skeleton_style: str = 'mmpose'):
+ """Assign dataset_meta to the visualizer. The default visualization
+ settings will be overridden.
+
+ Args:
+ dataset_meta (dict): meta information of dataset.
+ """
+ if dataset_meta.get(
+ 'dataset_name') == 'coco' and skeleton_style == 'openpose':
+ dataset_meta = parse_pose_metainfo(
+ dict(from_file='configs/_base_/datasets/coco_openpose.py'))
+
+ if isinstance(dataset_meta, dict):
+ self.dataset_meta = dataset_meta.copy()
+ self.bbox_color = dataset_meta.get('bbox_color', self.bbox_color)
+ self.kpt_color = dataset_meta.get('keypoint_colors',
+ self.kpt_color)
+ self.link_color = dataset_meta.get('skeleton_link_colors',
+ self.link_color)
+ self.skeleton = dataset_meta.get('skeleton_links', self.skeleton)
+ # sometimes self.dataset_meta is manually set, which might be None.
+ # it should be converted to a dict at these times
+ if self.dataset_meta is None:
+ self.dataset_meta = {}
+
+ def _draw_instances_bbox(self, image: np.ndarray,
+ instances: InstanceData) -> np.ndarray:
+ """Draw bounding boxes and corresponding labels of GT or prediction.
+
+ Args:
+ image (np.ndarray): The image to draw.
+ instances (:obj:`InstanceData`): Data structure for
+ instance-level annotations or predictions.
+
+ Returns:
+ np.ndarray: the drawn image which channel is RGB.
+ """
+ self.set_image(image)
+
+ if 'bboxes' in instances:
+ bboxes = instances.bboxes
+ self.draw_bboxes(
+ bboxes,
+ edge_colors=self.bbox_color,
+ alpha=self.alpha,
+ line_widths=self.line_width)
+ else:
+ return self.get_image()
+
+ if 'labels' in instances and self.text_color is not None:
+ classes = self.dataset_meta.get('classes', None)
+ labels = instances.labels
+
+ positions = bboxes[:, :2]
+ areas = (bboxes[:, 3] - bboxes[:, 1]) * (
+ bboxes[:, 2] - bboxes[:, 0])
+ scales = _get_adaptive_scales(areas)
+
+ for i, (pos, label) in enumerate(zip(positions, labels)):
+ label_text = classes[
+ label] if classes is not None else f'class {label}'
+
+ if isinstance(self.bbox_color,
+ tuple) and max(self.bbox_color) > 1:
+ facecolor = [c / 255.0 for c in self.bbox_color]
+ else:
+ facecolor = self.bbox_color
+
+ self.draw_texts(
+ label_text,
+ pos,
+ colors=self.text_color,
+ font_sizes=int(13 * scales[i]),
+ vertical_alignments='bottom',
+ bboxes=[{
+ 'facecolor': facecolor,
+ 'alpha': 0.8,
+ 'pad': 0.7,
+ 'edgecolor': 'none'
+ }])
+
+ return self.get_image()
+
+ def _draw_instances_kpts(self,
+ image: np.ndarray,
+ instances: InstanceData,
+ kpt_thr: float = 0.3,
+ show_kpt_idx: bool = False,
+ skeleton_style: str = 'mmpose'):
+ """Draw keypoints and skeletons (optional) of GT or prediction.
+
+ Args:
+ image (np.ndarray): The image to draw.
+ instances (:obj:`InstanceData`): Data structure for
+ instance-level annotations or predictions.
+ kpt_thr (float, optional): Minimum threshold of keypoints
+ to be shown. Default: 0.3.
+ show_kpt_idx (bool): Whether to show the index of keypoints.
+ Defaults to ``False``
+ skeleton_style (str): Skeleton style selection. Defaults to
+ ``'mmpose'``
+
+ Returns:
+ np.ndarray: the drawn image which channel is RGB.
+ """
+
+ self.set_image(image)
+ img_h, img_w, _ = image.shape
+
+ if 'keypoints' in instances:
+ keypoints = instances.get('transformed_keypoints',
+ instances.keypoints)
+
+ if 'keypoint_scores' in instances:
+ scores = instances.keypoint_scores
+ else:
+ scores = np.ones(keypoints.shape[:-1])
+
+ if 'keypoints_visible' in instances:
+ keypoints_visible = instances.keypoints_visible
+ else:
+ keypoints_visible = np.ones(keypoints.shape[:-1])
+
+ if skeleton_style == 'openpose':
+ keypoints_info = np.concatenate(
+ (keypoints, scores[..., None], keypoints_visible[...,
+ None]),
+ axis=-1)
+ # compute neck joint
+ neck = np.mean(keypoints_info[:, [5, 6]], axis=1)
+ # neck score when visualizing pred
+ neck[:, 2:4] = np.logical_and(
+ keypoints_info[:, 5, 2:4] > kpt_thr,
+ keypoints_info[:, 6, 2:4] > kpt_thr).astype(int)
+ new_keypoints_info = np.insert(
+ keypoints_info, 17, neck, axis=1)
+
+ mmpose_idx = [
+ 17, 6, 8, 10, 7, 9, 12, 14, 16, 13, 15, 2, 1, 4, 3
+ ]
+ openpose_idx = [
+ 1, 2, 3, 4, 6, 7, 8, 9, 10, 12, 13, 14, 15, 16, 17
+ ]
+ new_keypoints_info[:, openpose_idx] = \
+ new_keypoints_info[:, mmpose_idx]
+ keypoints_info = new_keypoints_info
+
+ keypoints, scores, keypoints_visible = keypoints_info[
+ ..., :2], keypoints_info[..., 2], keypoints_info[..., 3]
+
+ for kpts, score, visible in zip(keypoints, scores,
+ keypoints_visible):
+ kpts = np.array(kpts, copy=False)
+
+ if self.kpt_color is None or isinstance(self.kpt_color, str):
+ kpt_color = [self.kpt_color] * len(kpts)
+ elif len(self.kpt_color) == len(kpts):
+ kpt_color = self.kpt_color
+ else:
+ raise ValueError(
+ f'the length of kpt_color '
+ f'({len(self.kpt_color)}) does not matches '
+ f'that of keypoints ({len(kpts)})')
+
+ # draw links
+ if self.skeleton is not None and self.link_color is not None:
+ if self.link_color is None or isinstance(
+ self.link_color, str):
+ link_color = [self.link_color] * len(self.skeleton)
+ elif len(self.link_color) == len(self.skeleton):
+ link_color = self.link_color
+ else:
+ raise ValueError(
+ f'the length of link_color '
+ f'({len(self.link_color)}) does not matches '
+ f'that of skeleton ({len(self.skeleton)})')
+
+ for sk_id, sk in enumerate(self.skeleton):
+ pos1 = (int(kpts[sk[0], 0]), int(kpts[sk[0], 1]))
+ pos2 = (int(kpts[sk[1], 0]), int(kpts[sk[1], 1]))
+ if not (visible[sk[0]] and visible[sk[1]]):
+ continue
+
+ if (pos1[0] <= 0 or pos1[0] >= img_w or pos1[1] <= 0
+ or pos1[1] >= img_h or pos2[0] <= 0
+ or pos2[0] >= img_w or pos2[1] <= 0
+ or pos2[1] >= img_h or score[sk[0]] < kpt_thr
+ or score[sk[1]] < kpt_thr
+ or link_color[sk_id] is None):
+ # skip the link that should not be drawn
+ continue
+ X = np.array((pos1[0], pos2[0]))
+ Y = np.array((pos1[1], pos2[1]))
+ color = link_color[sk_id]
+ if not isinstance(color, str):
+ color = tuple(int(c) for c in color)
+ transparency = self.alpha
+ if self.show_keypoint_weight:
+ transparency *= max(
+ 0, min(1, 0.5 * (score[sk[0]] + score[sk[1]])))
+
+ if skeleton_style == 'openpose':
+ mX = np.mean(X)
+ mY = np.mean(Y)
+ length = ((Y[0] - Y[1])**2 + (X[0] - X[1])**2)**0.5
+ transparency = 0.6
+ angle = math.degrees(
+ math.atan2(Y[0] - Y[1], X[0] - X[1]))
+ polygons = cv2.ellipse2Poly(
+ (int(mX), int(mY)),
+ (int(length / 2), int(self.line_width)),
+ int(angle), 0, 360, 1)
+
+ self.draw_polygons(
+ polygons,
+ edge_colors=color,
+ face_colors=color,
+ alpha=transparency)
+
+ else:
+ self.draw_lines(
+ X, Y, color, line_widths=self.line_width)
+
+ # draw each point on image
+ for kid, kpt in enumerate(kpts):
+ if score[kid] < kpt_thr or not visible[
+ kid] or kpt_color[kid] is None:
+ # skip the point that should not be drawn
+ continue
+
+ color = kpt_color[kid]
+ if not isinstance(color, str):
+ color = tuple(int(c) for c in color)
+ transparency = self.alpha
+ if self.show_keypoint_weight:
+ transparency *= max(0, min(1, score[kid]))
+ self.draw_circles(
+ kpt,
+ radius=np.array([self.radius]),
+ face_colors=color,
+ edge_colors=color,
+ alpha=transparency,
+ line_widths=self.radius)
+ if show_kpt_idx:
+ kpt[0] += self.radius
+ kpt[1] -= self.radius
+ self.draw_texts(
+ str(kid),
+ kpt,
+ colors=color,
+ font_sizes=self.radius * 3,
+ vertical_alignments='bottom',
+ horizontal_alignments='center')
+
+ return self.get_image()
+
+ def _draw_instance_heatmap(
+ self,
+ fields: PixelData,
+ overlaid_image: Optional[np.ndarray] = None,
+ ):
+ """Draw heatmaps of GT or prediction.
+
+ Args:
+ fields (:obj:`PixelData`): Data structure for
+ pixel-level annotations or predictions.
+ overlaid_image (np.ndarray): The image to draw.
+
+ Returns:
+ np.ndarray: the drawn image which channel is RGB.
+ """
+ if 'heatmaps' not in fields:
+ return None
+ heatmaps = fields.heatmaps
+ if isinstance(heatmaps, np.ndarray):
+ heatmaps = torch.from_numpy(heatmaps)
+ if heatmaps.dim() == 3:
+ heatmaps, _ = heatmaps.max(dim=0)
+ heatmaps = heatmaps.unsqueeze(0)
+ out_image = self.draw_featmap(heatmaps, overlaid_image)
+ return out_image
+
+ def _draw_instance_xy_heatmap(
+ self,
+ fields: PixelData,
+ overlaid_image: Optional[np.ndarray] = None,
+ n: int = 20,
+ ):
+ """Draw heatmaps of GT or prediction.
+
+ Args:
+ fields (:obj:`PixelData`): Data structure for
+ pixel-level annotations or predictions.
+ overlaid_image (np.ndarray): The image to draw.
+ n (int): Number of keypoint, up to 20.
+
+ Returns:
+ np.ndarray: the drawn image which channel is RGB.
+ """
+ if 'heatmaps' not in fields:
+ return None
+ heatmaps = fields.heatmaps
+ _, h, w = heatmaps.shape
+ if isinstance(heatmaps, np.ndarray):
+ heatmaps = torch.from_numpy(heatmaps)
+ out_image = SimCCVisualizer().draw_instance_xy_heatmap(
+ heatmaps, overlaid_image, n)
+ out_image = cv2.resize(out_image[:, :, ::-1], (w, h))
+ return out_image
+
+ @master_only
+ def add_datasample(self,
+ name: str,
+ image: np.ndarray,
+ data_sample: PoseDataSample,
+ draw_gt: bool = True,
+ draw_pred: bool = True,
+ draw_heatmap: bool = False,
+ draw_bbox: bool = False,
+ show_kpt_idx: bool = False,
+ skeleton_style: str = 'mmpose',
+ show: bool = False,
+ wait_time: float = 0,
+ out_file: Optional[str] = None,
+ kpt_thr: float = 0.3,
+ step: int = 0) -> None:
+ """Draw datasample and save to all backends.
+
+ - If GT and prediction are plotted at the same time, they are
+ displayed in a stitched image where the left image is the
+ ground truth and the right image is the prediction.
+ - If ``show`` is True, all storage backends are ignored, and
+ the images will be displayed in a local window.
+ - If ``out_file`` is specified, the drawn image will be
+ saved to ``out_file``. t is usually used when the display
+ is not available.
+
+ Args:
+ name (str): The image identifier
+ image (np.ndarray): The image to draw
+ data_sample (:obj:`PoseDataSample`, optional): The data sample
+ to visualize
+ draw_gt (bool): Whether to draw GT PoseDataSample. Default to
+ ``True``
+ draw_pred (bool): Whether to draw Prediction PoseDataSample.
+ Defaults to ``True``
+ draw_bbox (bool): Whether to draw bounding boxes. Default to
+ ``False``
+ draw_heatmap (bool): Whether to draw heatmaps. Defaults to
+ ``False``
+ show_kpt_idx (bool): Whether to show the index of keypoints.
+ Defaults to ``False``
+ skeleton_style (str): Skeleton style selection. Defaults to
+ ``'mmpose'``
+ show (bool): Whether to display the drawn image. Default to
+ ``False``
+ wait_time (float): The interval of show (s). Defaults to 0
+ out_file (str): Path to output file. Defaults to ``None``
+ kpt_thr (float, optional): Minimum threshold of keypoints
+ to be shown. Default: 0.3.
+ step (int): Global step value to record. Defaults to 0
+ """
+
+ gt_img_data = None
+ pred_img_data = None
+
+ if draw_gt:
+ gt_img_data = image.copy()
+ gt_img_heatmap = None
+
+ # draw bboxes & keypoints
+ if 'gt_instances' in data_sample:
+ gt_img_data = self._draw_instances_kpts(
+ gt_img_data, data_sample.gt_instances, kpt_thr,
+ show_kpt_idx, skeleton_style)
+ if draw_bbox:
+ gt_img_data = self._draw_instances_bbox(
+ gt_img_data, data_sample.gt_instances)
+
+ # draw heatmaps
+ if 'gt_fields' in data_sample and draw_heatmap:
+ gt_img_heatmap = self._draw_instance_heatmap(
+ data_sample.gt_fields, image)
+ if gt_img_heatmap is not None:
+ gt_img_data = np.concatenate((gt_img_data, gt_img_heatmap),
+ axis=0)
+
+ if draw_pred:
+ pred_img_data = image.copy()
+ pred_img_heatmap = None
+
+ # draw bboxes & keypoints
+ if 'pred_instances' in data_sample:
+ pred_img_data = self._draw_instances_kpts(
+ pred_img_data, data_sample.pred_instances, kpt_thr,
+ show_kpt_idx, skeleton_style)
+ if draw_bbox:
+ pred_img_data = self._draw_instances_bbox(
+ pred_img_data, data_sample.pred_instances)
+
+ # draw heatmaps
+ if 'pred_fields' in data_sample and draw_heatmap:
+ if 'keypoint_x_labels' in data_sample.pred_instances:
+ pred_img_heatmap = self._draw_instance_xy_heatmap(
+ data_sample.pred_fields, image)
+ else:
+ pred_img_heatmap = self._draw_instance_heatmap(
+ data_sample.pred_fields, image)
+ if pred_img_heatmap is not None:
+ pred_img_data = np.concatenate(
+ (pred_img_data, pred_img_heatmap), axis=0)
+
+ # merge visualization results
+ if gt_img_data is not None and pred_img_data is not None:
+ if gt_img_heatmap is None and pred_img_heatmap is not None:
+ gt_img_data = np.concatenate((gt_img_data, image), axis=0)
+ elif gt_img_heatmap is not None and pred_img_heatmap is None:
+ pred_img_data = np.concatenate((pred_img_data, image), axis=0)
+
+ drawn_img = np.concatenate((gt_img_data, pred_img_data), axis=1)
+
+ elif gt_img_data is not None:
+ drawn_img = gt_img_data
+ else:
+ drawn_img = pred_img_data
+
+ # It is convenient for users to obtain the drawn image.
+ # For example, the user wants to obtain the drawn image and
+ # save it as a video during video inference.
+ self.set_image(drawn_img)
+
+ if show:
+ self.show(drawn_img, win_name=name, wait_time=wait_time)
+
+ if out_file is not None:
+ mmcv.imwrite(drawn_img[..., ::-1], out_file)
+ else:
+ # save drawn_img to backends
+ self.add_image(name, drawn_img, step)
+
+ return self.get_image()
diff --git a/mmpose/visualization/local_visualizer_3d.py b/mmpose/visualization/local_visualizer_3d.py
index 7e3462ce79..6aee7ba2c1 100644
--- a/mmpose/visualization/local_visualizer_3d.py
+++ b/mmpose/visualization/local_visualizer_3d.py
@@ -1,564 +1,564 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import math
-from typing import Dict, List, Optional, Tuple, Union
-
-import cv2
-import mmcv
-import numpy as np
-from matplotlib import pyplot as plt
-from mmengine.dist import master_only
-from mmengine.structures import InstanceData
-
-from mmpose.registry import VISUALIZERS
-from mmpose.structures import PoseDataSample
-from . import PoseLocalVisualizer
-
-
-@VISUALIZERS.register_module()
-class Pose3dLocalVisualizer(PoseLocalVisualizer):
- """MMPose 3d Local Visualizer.
-
- Args:
- name (str): Name of the instance. Defaults to 'visualizer'.
- image (np.ndarray, optional): the origin image to draw. The format
- should be RGB. Defaults to ``None``
- vis_backends (list, optional): Visual backend config list. Defaults to
- ``None``
- save_dir (str, optional): Save file dir for all storage backends.
- If it is ``None``, the backend storage will not save any data.
- Defaults to ``None``
- bbox_color (str, tuple(int), optional): Color of bbox lines.
- The tuple of color should be in BGR order. Defaults to ``'green'``
- kpt_color (str, tuple(tuple(int)), optional): Color of keypoints.
- The tuple of color should be in BGR order. Defaults to ``'red'``
- link_color (str, tuple(tuple(int)), optional): Color of skeleton.
- The tuple of color should be in BGR order. Defaults to ``None``
- line_width (int, float): The width of lines. Defaults to 1
- radius (int, float): The radius of keypoints. Defaults to 4
- show_keypoint_weight (bool): Whether to adjust the transparency
- of keypoints according to their score. Defaults to ``False``
- alpha (int, float): The transparency of bboxes. Defaults to ``0.8``
- det_kpt_color (str, tuple(tuple(int)), optional): Keypoints color
- info for detection. Defaults to ``None``
- det_dataset_skeleton (list): Skeleton info for detection. Defaults to
- ``None``
- det_dataset_link_color (list): Link color for detection. Defaults to
- ``None``
- """
-
- def __init__(
- self,
- name: str = 'visualizer',
- image: Optional[np.ndarray] = None,
- vis_backends: Optional[Dict] = None,
- save_dir: Optional[str] = None,
- bbox_color: Optional[Union[str, Tuple[int]]] = 'green',
- kpt_color: Optional[Union[str, Tuple[Tuple[int]]]] = 'red',
- link_color: Optional[Union[str, Tuple[Tuple[int]]]] = None,
- text_color: Optional[Union[str, Tuple[int]]] = (255, 255, 255),
- skeleton: Optional[Union[List, Tuple]] = None,
- line_width: Union[int, float] = 1,
- radius: Union[int, float] = 3,
- show_keypoint_weight: bool = False,
- backend: str = 'opencv',
- alpha: float = 0.8,
- det_kpt_color: Optional[Union[str, Tuple[Tuple[int]]]] = None,
- det_dataset_skeleton: Optional[Union[str,
- Tuple[Tuple[int]]]] = None,
- det_dataset_link_color: Optional[np.ndarray] = None):
- super().__init__(name, image, vis_backends, save_dir, bbox_color,
- kpt_color, link_color, text_color, skeleton,
- line_width, radius, show_keypoint_weight, backend,
- alpha)
- self.det_kpt_color = det_kpt_color
- self.det_dataset_skeleton = det_dataset_skeleton
- self.det_dataset_link_color = det_dataset_link_color
-
- def _draw_3d_data_samples(
- self,
- image: np.ndarray,
- pose_samples: PoseDataSample,
- draw_gt: bool = True,
- kpt_thr: float = 0.3,
- num_instances=-1,
- axis_azimuth: float = 70,
- axis_limit: float = 1.7,
- axis_dist: float = 10.0,
- axis_elev: float = 15.0,
- ):
- """Draw keypoints and skeletons (optional) of GT or prediction.
-
- Args:
- image (np.ndarray): The image to draw.
- instances (:obj:`InstanceData`): Data structure for
- instance-level annotations or predictions.
- draw_gt (bool): Whether to draw GT PoseDataSample. Default to
- ``True``
- kpt_thr (float, optional): Minimum threshold of keypoints
- to be shown. Default: 0.3.
- num_instances (int): Number of instances to be shown in 3D. If
- smaller than 0, all the instances in the pose_result will be
- shown. Otherwise, pad or truncate the pose_result to a length
- of num_instances.
- axis_azimuth (float): axis azimuth angle for 3D visualizations.
- axis_dist (float): axis distance for 3D visualizations.
- axis_elev (float): axis elevation view angle for 3D visualizations.
- axis_limit (float): The axis limit to visualize 3d pose. The xyz
- range will be set as:
- - x: [x_c - axis_limit/2, x_c + axis_limit/2]
- - y: [y_c - axis_limit/2, y_c + axis_limit/2]
- - z: [0, axis_limit]
- Where x_c, y_c is the mean value of x and y coordinates
-
- Returns:
- Tuple(np.ndarray): the drawn image which channel is RGB.
- """
- vis_height, vis_width, _ = image.shape
-
- if 'pred_instances' in pose_samples:
- pred_instances = pose_samples.pred_instances
- else:
- pred_instances = InstanceData()
- if num_instances < 0:
- if 'keypoints' in pred_instances:
- num_instances = len(pred_instances)
- else:
- num_instances = 0
- else:
- if len(pred_instances) > num_instances:
- pred_instances_ = InstanceData()
- for k in pred_instances.keys():
- new_val = pred_instances[k][:num_instances]
- pred_instances_.set_field(new_val, k)
- pred_instances = pred_instances_
- elif num_instances < len(pred_instances):
- num_instances = len(pred_instances)
-
- num_fig = num_instances
- if draw_gt:
- vis_width *= 2
- num_fig *= 2
-
- plt.ioff()
- fig = plt.figure(
- figsize=(vis_width * num_instances * 0.01, vis_height * 0.01))
-
- def _draw_3d_instances_kpts(keypoints,
- scores,
- keypoints_visible,
- fig_idx,
- title=None):
-
- for idx, (kpts, score, visible) in enumerate(
- zip(keypoints, scores, keypoints_visible)):
-
- valid = np.logical_and(score >= kpt_thr,
- np.any(~np.isnan(kpts), axis=-1))
-
- ax = fig.add_subplot(
- 1, num_fig, fig_idx * (idx + 1), projection='3d')
- ax.view_init(elev=axis_elev, azim=axis_azimuth)
- ax.set_zlim3d([0, axis_limit])
- ax.set_aspect('auto')
- ax.set_xticks([])
- ax.set_yticks([])
- ax.set_zticks([])
- ax.set_xticklabels([])
- ax.set_yticklabels([])
- ax.set_zticklabels([])
- ax.scatter([0], [0], [0], marker='o', color='red')
- if title:
- ax.set_title(f'{title} ({idx})')
- ax.dist = axis_dist
-
- x_c = np.mean(kpts[valid, 0]) if valid.any() else 0
- y_c = np.mean(kpts[valid, 1]) if valid.any() else 0
-
- ax.set_xlim3d([x_c - axis_limit / 2, x_c + axis_limit / 2])
- ax.set_ylim3d([y_c - axis_limit / 2, y_c + axis_limit / 2])
-
- kpts = np.array(kpts, copy=False)
-
- if self.kpt_color is None or isinstance(self.kpt_color, str):
- kpt_color = [self.kpt_color] * len(kpts)
- elif len(self.kpt_color) == len(kpts):
- kpt_color = self.kpt_color
- else:
- raise ValueError(
- f'the length of kpt_color '
- f'({len(self.kpt_color)}) does not matches '
- f'that of keypoints ({len(kpts)})')
-
- kpts = kpts[valid]
- x_3d, y_3d, z_3d = np.split(kpts[:, :3], [1, 2], axis=1)
-
- kpt_color = kpt_color[valid][..., ::-1] / 255.
-
- ax.scatter(x_3d, y_3d, z_3d, marker='o', color=kpt_color)
-
- for kpt_idx in range(len(x_3d)):
- ax.text(x_3d[kpt_idx][0], y_3d[kpt_idx][0],
- z_3d[kpt_idx][0], str(kpt_idx))
-
- if self.skeleton is not None and self.link_color is not None:
- if self.link_color is None or isinstance(
- self.link_color, str):
- link_color = [self.link_color] * len(self.skeleton)
- elif len(self.link_color) == len(self.skeleton):
- link_color = self.link_color
- else:
- raise ValueError(
- f'the length of link_color '
- f'({len(self.link_color)}) does not matches '
- f'that of skeleton ({len(self.skeleton)})')
-
- for sk_id, sk in enumerate(self.skeleton):
- sk_indices = [_i for _i in sk]
- xs_3d = kpts[sk_indices, 0]
- ys_3d = kpts[sk_indices, 1]
- zs_3d = kpts[sk_indices, 2]
- kpt_score = score[sk_indices]
- if kpt_score.min() > kpt_thr:
- # matplotlib uses RGB color in [0, 1] value range
- _color = link_color[sk_id][::-1] / 255.
- ax.plot(
- xs_3d, ys_3d, zs_3d, color=_color, zdir='z')
-
- if 'keypoints' in pred_instances:
- keypoints = pred_instances.get('keypoints',
- pred_instances.keypoints)
-
- if 'keypoint_scores' in pred_instances:
- scores = pred_instances.keypoint_scores
- else:
- scores = np.ones(keypoints.shape[:-1])
-
- if 'keypoints_visible' in pred_instances:
- keypoints_visible = pred_instances.keypoints_visible
- else:
- keypoints_visible = np.ones(keypoints.shape[:-1])
-
- _draw_3d_instances_kpts(keypoints, scores, keypoints_visible, 1,
- 'Prediction')
-
- if draw_gt and 'gt_instances' in pose_samples:
- gt_instances = pose_samples.gt_instances
- if 'lifting_target' in gt_instances:
- keypoints = gt_instances.get('lifting_target',
- gt_instances.lifting_target)
- scores = np.ones(keypoints.shape[:-1])
-
- if 'lifting_target_visible' in gt_instances:
- keypoints_visible = gt_instances.lifting_target_visible
- else:
- keypoints_visible = np.ones(keypoints.shape[:-1])
-
- _draw_3d_instances_kpts(keypoints, scores, keypoints_visible,
- 2, 'Ground Truth')
-
- # convert figure to numpy array
- fig.tight_layout()
- fig.canvas.draw()
-
- pred_img_data = fig.canvas.tostring_rgb()
- pred_img_data = np.frombuffer(
- fig.canvas.tostring_rgb(), dtype=np.uint8)
-
- if not pred_img_data.any():
- pred_img_data = np.full((vis_height, vis_width, 3), 255)
- else:
- pred_img_data = pred_img_data.reshape(vis_height,
- vis_width * num_instances,
- -1)
-
- plt.close(fig)
-
- return pred_img_data
-
- def _draw_instances_kpts(self,
- image: np.ndarray,
- instances: InstanceData,
- kpt_thr: float = 0.3,
- show_kpt_idx: bool = False,
- skeleton_style: str = 'mmpose'):
- """Draw keypoints and skeletons (optional) of GT or prediction.
-
- Args:
- image (np.ndarray): The image to draw.
- instances (:obj:`InstanceData`): Data structure for
- instance-level annotations or predictions.
- kpt_thr (float, optional): Minimum threshold of keypoints
- to be shown. Default: 0.3.
- show_kpt_idx (bool): Whether to show the index of keypoints.
- Defaults to ``False``
- skeleton_style (str): Skeleton style selection. Defaults to
- ``'mmpose'``
-
- Returns:
- np.ndarray: the drawn image which channel is RGB.
- """
-
- self.set_image(image)
- img_h, img_w, _ = image.shape
-
- if 'keypoints' in instances:
- keypoints = instances.get('transformed_keypoints',
- instances.keypoints)
-
- if 'keypoint_scores' in instances:
- scores = instances.keypoint_scores
- else:
- scores = np.ones(keypoints.shape[:-1])
-
- if 'keypoints_visible' in instances:
- keypoints_visible = instances.keypoints_visible
- else:
- keypoints_visible = np.ones(keypoints.shape[:-1])
-
- if skeleton_style == 'openpose':
- keypoints_info = np.concatenate(
- (keypoints, scores[..., None], keypoints_visible[...,
- None]),
- axis=-1)
- # compute neck joint
- neck = np.mean(keypoints_info[:, [5, 6]], axis=1)
- # neck score when visualizing pred
- neck[:, 2:4] = np.logical_and(
- keypoints_info[:, 5, 2:4] > kpt_thr,
- keypoints_info[:, 6, 2:4] > kpt_thr).astype(int)
- new_keypoints_info = np.insert(
- keypoints_info, 17, neck, axis=1)
-
- mmpose_idx = [
- 17, 6, 8, 10, 7, 9, 12, 14, 16, 13, 15, 2, 1, 4, 3
- ]
- openpose_idx = [
- 1, 2, 3, 4, 6, 7, 8, 9, 10, 12, 13, 14, 15, 16, 17
- ]
- new_keypoints_info[:, openpose_idx] = \
- new_keypoints_info[:, mmpose_idx]
- keypoints_info = new_keypoints_info
-
- keypoints, scores, keypoints_visible = keypoints_info[
- ..., :2], keypoints_info[..., 2], keypoints_info[..., 3]
-
- kpt_color = self.kpt_color
- if self.det_kpt_color is not None:
- kpt_color = self.det_kpt_color
-
- for kpts, score, visible in zip(keypoints, scores,
- keypoints_visible):
- kpts = np.array(kpts, copy=False)
-
- if kpt_color is None or isinstance(kpt_color, str):
- kpt_color = [kpt_color] * len(kpts)
- elif len(kpt_color) == len(kpts):
- kpt_color = kpt_color
- else:
- raise ValueError(f'the length of kpt_color '
- f'({len(kpt_color)}) does not matches '
- f'that of keypoints ({len(kpts)})')
-
- # draw each point on image
- for kid, kpt in enumerate(kpts):
- if score[kid] < kpt_thr or not visible[
- kid] or kpt_color[kid] is None:
- # skip the point that should not be drawn
- continue
-
- color = kpt_color[kid]
- if not isinstance(color, str):
- color = tuple(int(c) for c in color)
- transparency = self.alpha
- if self.show_keypoint_weight:
- transparency *= max(0, min(1, score[kid]))
- self.draw_circles(
- kpt,
- radius=np.array([self.radius]),
- face_colors=color,
- edge_colors=color,
- alpha=transparency,
- line_widths=self.radius)
- if show_kpt_idx:
- self.draw_texts(
- str(kid),
- kpt,
- colors=color,
- font_sizes=self.radius * 3,
- vertical_alignments='bottom',
- horizontal_alignments='center')
-
- # draw links
- skeleton = self.skeleton
- if self.det_dataset_skeleton is not None:
- skeleton = self.det_dataset_skeleton
- link_color = self.link_color
- if self.det_dataset_link_color is not None:
- link_color = self.det_dataset_link_color
- if skeleton is not None and link_color is not None:
- if link_color is None or isinstance(link_color, str):
- link_color = [link_color] * len(skeleton)
- elif len(link_color) == len(skeleton):
- link_color = link_color
- else:
- raise ValueError(
- f'the length of link_color '
- f'({len(link_color)}) does not matches '
- f'that of skeleton ({len(skeleton)})')
-
- for sk_id, sk in enumerate(skeleton):
- pos1 = (int(kpts[sk[0], 0]), int(kpts[sk[0], 1]))
- pos2 = (int(kpts[sk[1], 0]), int(kpts[sk[1], 1]))
- if not (visible[sk[0]] and visible[sk[1]]):
- continue
-
- if (pos1[0] <= 0 or pos1[0] >= img_w or pos1[1] <= 0
- or pos1[1] >= img_h or pos2[0] <= 0
- or pos2[0] >= img_w or pos2[1] <= 0
- or pos2[1] >= img_h or score[sk[0]] < kpt_thr
- or score[sk[1]] < kpt_thr
- or link_color[sk_id] is None):
- # skip the link that should not be drawn
- continue
- X = np.array((pos1[0], pos2[0]))
- Y = np.array((pos1[1], pos2[1]))
- color = link_color[sk_id]
- if not isinstance(color, str):
- color = tuple(int(c) for c in color)
- transparency = self.alpha
- if self.show_keypoint_weight:
- transparency *= max(
- 0, min(1, 0.5 * (score[sk[0]] + score[sk[1]])))
-
- if skeleton_style == 'openpose':
- mX = np.mean(X)
- mY = np.mean(Y)
- length = ((Y[0] - Y[1])**2 + (X[0] - X[1])**2)**0.5
- angle = math.degrees(
- math.atan2(Y[0] - Y[1], X[0] - X[1]))
- stickwidth = 2
- polygons = cv2.ellipse2Poly(
- (int(mX), int(mY)),
- (int(length / 2), int(stickwidth)), int(angle),
- 0, 360, 1)
-
- self.draw_polygons(
- polygons,
- edge_colors=color,
- face_colors=color,
- alpha=transparency)
-
- else:
- self.draw_lines(
- X, Y, color, line_widths=self.line_width)
-
- return self.get_image()
-
- @master_only
- def add_datasample(self,
- name: str,
- image: np.ndarray,
- data_sample: PoseDataSample,
- det_data_sample: Optional[PoseDataSample] = None,
- draw_gt: bool = True,
- draw_pred: bool = True,
- draw_2d: bool = True,
- draw_bbox: bool = False,
- show_kpt_idx: bool = False,
- skeleton_style: str = 'mmpose',
- num_instances: int = -1,
- show: bool = False,
- wait_time: float = 0,
- out_file: Optional[str] = None,
- kpt_thr: float = 0.3,
- step: int = 0) -> None:
- """Draw datasample and save to all backends.
-
- - If GT and prediction are plotted at the same time, they are
- displayed in a stitched image where the left image is the
- ground truth and the right image is the prediction.
- - If ``show`` is True, all storage backends are ignored, and
- the images will be displayed in a local window.
- - If ``out_file`` is specified, the drawn image will be
- saved to ``out_file``. t is usually used when the display
- is not available.
-
- Args:
- name (str): The image identifier
- image (np.ndarray): The image to draw
- data_sample (:obj:`PoseDataSample`): The 3d data sample
- to visualize
- det_data_sample (:obj:`PoseDataSample`, optional): The 2d detection
- data sample to visualize
- draw_gt (bool): Whether to draw GT PoseDataSample. Default to
- ``True``
- draw_pred (bool): Whether to draw Prediction PoseDataSample.
- Defaults to ``True``
- draw_2d (bool): Whether to draw 2d detection results. Defaults to
- ``True``
- draw_bbox (bool): Whether to draw bounding boxes. Default to
- ``False``
- show_kpt_idx (bool): Whether to show the index of keypoints.
- Defaults to ``False``
- skeleton_style (str): Skeleton style selection. Defaults to
- ``'mmpose'``
- num_instances (int): Number of instances to be shown in 3D. If
- smaller than 0, all the instances in the pose_result will be
- shown. Otherwise, pad or truncate the pose_result to a length
- of num_instances. Defaults to -1
- show (bool): Whether to display the drawn image. Default to
- ``False``
- wait_time (float): The interval of show (s). Defaults to 0
- out_file (str): Path to output file. Defaults to ``None``
- kpt_thr (float, optional): Minimum threshold of keypoints
- to be shown. Default: 0.3.
- step (int): Global step value to record. Defaults to 0
- """
-
- det_img_data = None
- gt_img_data = None
-
- if draw_2d:
- det_img_data = image.copy()
-
- # draw bboxes & keypoints
- if 'pred_instances' in det_data_sample:
- det_img_data = self._draw_instances_kpts(
- det_img_data, det_data_sample.pred_instances, kpt_thr,
- show_kpt_idx, skeleton_style)
- if draw_bbox:
- det_img_data = self._draw_instances_bbox(
- det_img_data, det_data_sample.pred_instances)
-
- pred_img_data = self._draw_3d_data_samples(
- image.copy(),
- data_sample,
- draw_gt=draw_gt,
- num_instances=num_instances)
-
- # merge visualization results
- if det_img_data is not None and gt_img_data is not None:
- drawn_img = np.concatenate(
- (det_img_data, pred_img_data, gt_img_data), axis=1)
- elif det_img_data is not None:
- drawn_img = np.concatenate((det_img_data, pred_img_data), axis=1)
- elif gt_img_data is not None:
- drawn_img = np.concatenate((det_img_data, gt_img_data), axis=1)
- else:
- drawn_img = pred_img_data
-
- # It is convenient for users to obtain the drawn image.
- # For example, the user wants to obtain the drawn image and
- # save it as a video during video inference.
- self.set_image(drawn_img)
-
- if show:
- self.show(drawn_img, win_name=name, wait_time=wait_time)
-
- if out_file is not None:
- mmcv.imwrite(drawn_img[..., ::-1], out_file)
- else:
- # save drawn_img to backends
- self.add_image(name, drawn_img, step)
-
- return self.get_image()
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Dict, List, Optional, Tuple, Union
+
+import cv2
+import mmcv
+import numpy as np
+from matplotlib import pyplot as plt
+from mmengine.dist import master_only
+from mmengine.structures import InstanceData
+
+from mmpose.registry import VISUALIZERS
+from mmpose.structures import PoseDataSample
+from . import PoseLocalVisualizer
+
+
+@VISUALIZERS.register_module()
+class Pose3dLocalVisualizer(PoseLocalVisualizer):
+ """MMPose 3d Local Visualizer.
+
+ Args:
+ name (str): Name of the instance. Defaults to 'visualizer'.
+ image (np.ndarray, optional): the origin image to draw. The format
+ should be RGB. Defaults to ``None``
+ vis_backends (list, optional): Visual backend config list. Defaults to
+ ``None``
+ save_dir (str, optional): Save file dir for all storage backends.
+ If it is ``None``, the backend storage will not save any data.
+ Defaults to ``None``
+ bbox_color (str, tuple(int), optional): Color of bbox lines.
+ The tuple of color should be in BGR order. Defaults to ``'green'``
+ kpt_color (str, tuple(tuple(int)), optional): Color of keypoints.
+ The tuple of color should be in BGR order. Defaults to ``'red'``
+ link_color (str, tuple(tuple(int)), optional): Color of skeleton.
+ The tuple of color should be in BGR order. Defaults to ``None``
+ line_width (int, float): The width of lines. Defaults to 1
+ radius (int, float): The radius of keypoints. Defaults to 4
+ show_keypoint_weight (bool): Whether to adjust the transparency
+ of keypoints according to their score. Defaults to ``False``
+ alpha (int, float): The transparency of bboxes. Defaults to ``0.8``
+ det_kpt_color (str, tuple(tuple(int)), optional): Keypoints color
+ info for detection. Defaults to ``None``
+ det_dataset_skeleton (list): Skeleton info for detection. Defaults to
+ ``None``
+ det_dataset_link_color (list): Link color for detection. Defaults to
+ ``None``
+ """
+
+ def __init__(
+ self,
+ name: str = 'visualizer',
+ image: Optional[np.ndarray] = None,
+ vis_backends: Optional[Dict] = None,
+ save_dir: Optional[str] = None,
+ bbox_color: Optional[Union[str, Tuple[int]]] = 'green',
+ kpt_color: Optional[Union[str, Tuple[Tuple[int]]]] = 'red',
+ link_color: Optional[Union[str, Tuple[Tuple[int]]]] = None,
+ text_color: Optional[Union[str, Tuple[int]]] = (255, 255, 255),
+ skeleton: Optional[Union[List, Tuple]] = None,
+ line_width: Union[int, float] = 1,
+ radius: Union[int, float] = 3,
+ show_keypoint_weight: bool = False,
+ backend: str = 'opencv',
+ alpha: float = 0.8,
+ det_kpt_color: Optional[Union[str, Tuple[Tuple[int]]]] = None,
+ det_dataset_skeleton: Optional[Union[str,
+ Tuple[Tuple[int]]]] = None,
+ det_dataset_link_color: Optional[np.ndarray] = None):
+ super().__init__(name, image, vis_backends, save_dir, bbox_color,
+ kpt_color, link_color, text_color, skeleton,
+ line_width, radius, show_keypoint_weight, backend,
+ alpha)
+ self.det_kpt_color = det_kpt_color
+ self.det_dataset_skeleton = det_dataset_skeleton
+ self.det_dataset_link_color = det_dataset_link_color
+
+ def _draw_3d_data_samples(
+ self,
+ image: np.ndarray,
+ pose_samples: PoseDataSample,
+ draw_gt: bool = True,
+ kpt_thr: float = 0.3,
+ num_instances=-1,
+ axis_azimuth: float = 70,
+ axis_limit: float = 1.7,
+ axis_dist: float = 10.0,
+ axis_elev: float = 15.0,
+ ):
+ """Draw keypoints and skeletons (optional) of GT or prediction.
+
+ Args:
+ image (np.ndarray): The image to draw.
+ instances (:obj:`InstanceData`): Data structure for
+ instance-level annotations or predictions.
+ draw_gt (bool): Whether to draw GT PoseDataSample. Default to
+ ``True``
+ kpt_thr (float, optional): Minimum threshold of keypoints
+ to be shown. Default: 0.3.
+ num_instances (int): Number of instances to be shown in 3D. If
+ smaller than 0, all the instances in the pose_result will be
+ shown. Otherwise, pad or truncate the pose_result to a length
+ of num_instances.
+ axis_azimuth (float): axis azimuth angle for 3D visualizations.
+ axis_dist (float): axis distance for 3D visualizations.
+ axis_elev (float): axis elevation view angle for 3D visualizations.
+ axis_limit (float): The axis limit to visualize 3d pose. The xyz
+ range will be set as:
+ - x: [x_c - axis_limit/2, x_c + axis_limit/2]
+ - y: [y_c - axis_limit/2, y_c + axis_limit/2]
+ - z: [0, axis_limit]
+ Where x_c, y_c is the mean value of x and y coordinates
+
+ Returns:
+ Tuple(np.ndarray): the drawn image which channel is RGB.
+ """
+ vis_height, vis_width, _ = image.shape
+
+ if 'pred_instances' in pose_samples:
+ pred_instances = pose_samples.pred_instances
+ else:
+ pred_instances = InstanceData()
+ if num_instances < 0:
+ if 'keypoints' in pred_instances:
+ num_instances = len(pred_instances)
+ else:
+ num_instances = 0
+ else:
+ if len(pred_instances) > num_instances:
+ pred_instances_ = InstanceData()
+ for k in pred_instances.keys():
+ new_val = pred_instances[k][:num_instances]
+ pred_instances_.set_field(new_val, k)
+ pred_instances = pred_instances_
+ elif num_instances < len(pred_instances):
+ num_instances = len(pred_instances)
+
+ num_fig = num_instances
+ if draw_gt:
+ vis_width *= 2
+ num_fig *= 2
+
+ plt.ioff()
+ fig = plt.figure(
+ figsize=(vis_width * num_instances * 0.01, vis_height * 0.01))
+
+ def _draw_3d_instances_kpts(keypoints,
+ scores,
+ keypoints_visible,
+ fig_idx,
+ title=None):
+
+ for idx, (kpts, score, visible) in enumerate(
+ zip(keypoints, scores, keypoints_visible)):
+
+ valid = np.logical_and(score >= kpt_thr,
+ np.any(~np.isnan(kpts), axis=-1))
+
+ ax = fig.add_subplot(
+ 1, num_fig, fig_idx * (idx + 1), projection='3d')
+ ax.view_init(elev=axis_elev, azim=axis_azimuth)
+ ax.set_zlim3d([0, axis_limit])
+ ax.set_aspect('auto')
+ ax.set_xticks([])
+ ax.set_yticks([])
+ ax.set_zticks([])
+ ax.set_xticklabels([])
+ ax.set_yticklabels([])
+ ax.set_zticklabels([])
+ ax.scatter([0], [0], [0], marker='o', color='red')
+ if title:
+ ax.set_title(f'{title} ({idx})')
+ ax.dist = axis_dist
+
+ x_c = np.mean(kpts[valid, 0]) if valid.any() else 0
+ y_c = np.mean(kpts[valid, 1]) if valid.any() else 0
+
+ ax.set_xlim3d([x_c - axis_limit / 2, x_c + axis_limit / 2])
+ ax.set_ylim3d([y_c - axis_limit / 2, y_c + axis_limit / 2])
+
+ kpts = np.array(kpts, copy=False)
+
+ if self.kpt_color is None or isinstance(self.kpt_color, str):
+ kpt_color = [self.kpt_color] * len(kpts)
+ elif len(self.kpt_color) == len(kpts):
+ kpt_color = self.kpt_color
+ else:
+ raise ValueError(
+ f'the length of kpt_color '
+ f'({len(self.kpt_color)}) does not matches '
+ f'that of keypoints ({len(kpts)})')
+
+ kpts = kpts[valid]
+ x_3d, y_3d, z_3d = np.split(kpts[:, :3], [1, 2], axis=1)
+
+ kpt_color = kpt_color[valid][..., ::-1] / 255.
+
+ ax.scatter(x_3d, y_3d, z_3d, marker='o', color=kpt_color)
+
+ for kpt_idx in range(len(x_3d)):
+ ax.text(x_3d[kpt_idx][0], y_3d[kpt_idx][0],
+ z_3d[kpt_idx][0], str(kpt_idx))
+
+ if self.skeleton is not None and self.link_color is not None:
+ if self.link_color is None or isinstance(
+ self.link_color, str):
+ link_color = [self.link_color] * len(self.skeleton)
+ elif len(self.link_color) == len(self.skeleton):
+ link_color = self.link_color
+ else:
+ raise ValueError(
+ f'the length of link_color '
+ f'({len(self.link_color)}) does not matches '
+ f'that of skeleton ({len(self.skeleton)})')
+
+ for sk_id, sk in enumerate(self.skeleton):
+ sk_indices = [_i for _i in sk]
+ xs_3d = kpts[sk_indices, 0]
+ ys_3d = kpts[sk_indices, 1]
+ zs_3d = kpts[sk_indices, 2]
+ kpt_score = score[sk_indices]
+ if kpt_score.min() > kpt_thr:
+ # matplotlib uses RGB color in [0, 1] value range
+ _color = link_color[sk_id][::-1] / 255.
+ ax.plot(
+ xs_3d, ys_3d, zs_3d, color=_color, zdir='z')
+
+ if 'keypoints' in pred_instances:
+ keypoints = pred_instances.get('keypoints',
+ pred_instances.keypoints)
+
+ if 'keypoint_scores' in pred_instances:
+ scores = pred_instances.keypoint_scores
+ else:
+ scores = np.ones(keypoints.shape[:-1])
+
+ if 'keypoints_visible' in pred_instances:
+ keypoints_visible = pred_instances.keypoints_visible
+ else:
+ keypoints_visible = np.ones(keypoints.shape[:-1])
+
+ _draw_3d_instances_kpts(keypoints, scores, keypoints_visible, 1,
+ 'Prediction')
+
+ if draw_gt and 'gt_instances' in pose_samples:
+ gt_instances = pose_samples.gt_instances
+ if 'lifting_target' in gt_instances:
+ keypoints = gt_instances.get('lifting_target',
+ gt_instances.lifting_target)
+ scores = np.ones(keypoints.shape[:-1])
+
+ if 'lifting_target_visible' in gt_instances:
+ keypoints_visible = gt_instances.lifting_target_visible
+ else:
+ keypoints_visible = np.ones(keypoints.shape[:-1])
+
+ _draw_3d_instances_kpts(keypoints, scores, keypoints_visible,
+ 2, 'Ground Truth')
+
+ # convert figure to numpy array
+ fig.tight_layout()
+ fig.canvas.draw()
+
+ pred_img_data = fig.canvas.tostring_rgb()
+ pred_img_data = np.frombuffer(
+ fig.canvas.tostring_rgb(), dtype=np.uint8)
+
+ if not pred_img_data.any():
+ pred_img_data = np.full((vis_height, vis_width, 3), 255)
+ else:
+ pred_img_data = pred_img_data.reshape(vis_height,
+ vis_width * num_instances,
+ -1)
+
+ plt.close(fig)
+
+ return pred_img_data
+
+ def _draw_instances_kpts(self,
+ image: np.ndarray,
+ instances: InstanceData,
+ kpt_thr: float = 0.3,
+ show_kpt_idx: bool = False,
+ skeleton_style: str = 'mmpose'):
+ """Draw keypoints and skeletons (optional) of GT or prediction.
+
+ Args:
+ image (np.ndarray): The image to draw.
+ instances (:obj:`InstanceData`): Data structure for
+ instance-level annotations or predictions.
+ kpt_thr (float, optional): Minimum threshold of keypoints
+ to be shown. Default: 0.3.
+ show_kpt_idx (bool): Whether to show the index of keypoints.
+ Defaults to ``False``
+ skeleton_style (str): Skeleton style selection. Defaults to
+ ``'mmpose'``
+
+ Returns:
+ np.ndarray: the drawn image which channel is RGB.
+ """
+
+ self.set_image(image)
+ img_h, img_w, _ = image.shape
+
+ if 'keypoints' in instances:
+ keypoints = instances.get('transformed_keypoints',
+ instances.keypoints)
+
+ if 'keypoint_scores' in instances:
+ scores = instances.keypoint_scores
+ else:
+ scores = np.ones(keypoints.shape[:-1])
+
+ if 'keypoints_visible' in instances:
+ keypoints_visible = instances.keypoints_visible
+ else:
+ keypoints_visible = np.ones(keypoints.shape[:-1])
+
+ if skeleton_style == 'openpose':
+ keypoints_info = np.concatenate(
+ (keypoints, scores[..., None], keypoints_visible[...,
+ None]),
+ axis=-1)
+ # compute neck joint
+ neck = np.mean(keypoints_info[:, [5, 6]], axis=1)
+ # neck score when visualizing pred
+ neck[:, 2:4] = np.logical_and(
+ keypoints_info[:, 5, 2:4] > kpt_thr,
+ keypoints_info[:, 6, 2:4] > kpt_thr).astype(int)
+ new_keypoints_info = np.insert(
+ keypoints_info, 17, neck, axis=1)
+
+ mmpose_idx = [
+ 17, 6, 8, 10, 7, 9, 12, 14, 16, 13, 15, 2, 1, 4, 3
+ ]
+ openpose_idx = [
+ 1, 2, 3, 4, 6, 7, 8, 9, 10, 12, 13, 14, 15, 16, 17
+ ]
+ new_keypoints_info[:, openpose_idx] = \
+ new_keypoints_info[:, mmpose_idx]
+ keypoints_info = new_keypoints_info
+
+ keypoints, scores, keypoints_visible = keypoints_info[
+ ..., :2], keypoints_info[..., 2], keypoints_info[..., 3]
+
+ kpt_color = self.kpt_color
+ if self.det_kpt_color is not None:
+ kpt_color = self.det_kpt_color
+
+ for kpts, score, visible in zip(keypoints, scores,
+ keypoints_visible):
+ kpts = np.array(kpts, copy=False)
+
+ if kpt_color is None or isinstance(kpt_color, str):
+ kpt_color = [kpt_color] * len(kpts)
+ elif len(kpt_color) == len(kpts):
+ kpt_color = kpt_color
+ else:
+ raise ValueError(f'the length of kpt_color '
+ f'({len(kpt_color)}) does not matches '
+ f'that of keypoints ({len(kpts)})')
+
+ # draw each point on image
+ for kid, kpt in enumerate(kpts):
+ if score[kid] < kpt_thr or not visible[
+ kid] or kpt_color[kid] is None:
+ # skip the point that should not be drawn
+ continue
+
+ color = kpt_color[kid]
+ if not isinstance(color, str):
+ color = tuple(int(c) for c in color)
+ transparency = self.alpha
+ if self.show_keypoint_weight:
+ transparency *= max(0, min(1, score[kid]))
+ self.draw_circles(
+ kpt,
+ radius=np.array([self.radius]),
+ face_colors=color,
+ edge_colors=color,
+ alpha=transparency,
+ line_widths=self.radius)
+ if show_kpt_idx:
+ self.draw_texts(
+ str(kid),
+ kpt,
+ colors=color,
+ font_sizes=self.radius * 3,
+ vertical_alignments='bottom',
+ horizontal_alignments='center')
+
+ # draw links
+ skeleton = self.skeleton
+ if self.det_dataset_skeleton is not None:
+ skeleton = self.det_dataset_skeleton
+ link_color = self.link_color
+ if self.det_dataset_link_color is not None:
+ link_color = self.det_dataset_link_color
+ if skeleton is not None and link_color is not None:
+ if link_color is None or isinstance(link_color, str):
+ link_color = [link_color] * len(skeleton)
+ elif len(link_color) == len(skeleton):
+ link_color = link_color
+ else:
+ raise ValueError(
+ f'the length of link_color '
+ f'({len(link_color)}) does not matches '
+ f'that of skeleton ({len(skeleton)})')
+
+ for sk_id, sk in enumerate(skeleton):
+ pos1 = (int(kpts[sk[0], 0]), int(kpts[sk[0], 1]))
+ pos2 = (int(kpts[sk[1], 0]), int(kpts[sk[1], 1]))
+ if not (visible[sk[0]] and visible[sk[1]]):
+ continue
+
+ if (pos1[0] <= 0 or pos1[0] >= img_w or pos1[1] <= 0
+ or pos1[1] >= img_h or pos2[0] <= 0
+ or pos2[0] >= img_w or pos2[1] <= 0
+ or pos2[1] >= img_h or score[sk[0]] < kpt_thr
+ or score[sk[1]] < kpt_thr
+ or link_color[sk_id] is None):
+ # skip the link that should not be drawn
+ continue
+ X = np.array((pos1[0], pos2[0]))
+ Y = np.array((pos1[1], pos2[1]))
+ color = link_color[sk_id]
+ if not isinstance(color, str):
+ color = tuple(int(c) for c in color)
+ transparency = self.alpha
+ if self.show_keypoint_weight:
+ transparency *= max(
+ 0, min(1, 0.5 * (score[sk[0]] + score[sk[1]])))
+
+ if skeleton_style == 'openpose':
+ mX = np.mean(X)
+ mY = np.mean(Y)
+ length = ((Y[0] - Y[1])**2 + (X[0] - X[1])**2)**0.5
+ angle = math.degrees(
+ math.atan2(Y[0] - Y[1], X[0] - X[1]))
+ stickwidth = 2
+ polygons = cv2.ellipse2Poly(
+ (int(mX), int(mY)),
+ (int(length / 2), int(stickwidth)), int(angle),
+ 0, 360, 1)
+
+ self.draw_polygons(
+ polygons,
+ edge_colors=color,
+ face_colors=color,
+ alpha=transparency)
+
+ else:
+ self.draw_lines(
+ X, Y, color, line_widths=self.line_width)
+
+ return self.get_image()
+
+ @master_only
+ def add_datasample(self,
+ name: str,
+ image: np.ndarray,
+ data_sample: PoseDataSample,
+ det_data_sample: Optional[PoseDataSample] = None,
+ draw_gt: bool = True,
+ draw_pred: bool = True,
+ draw_2d: bool = True,
+ draw_bbox: bool = False,
+ show_kpt_idx: bool = False,
+ skeleton_style: str = 'mmpose',
+ num_instances: int = -1,
+ show: bool = False,
+ wait_time: float = 0,
+ out_file: Optional[str] = None,
+ kpt_thr: float = 0.3,
+ step: int = 0) -> None:
+ """Draw datasample and save to all backends.
+
+ - If GT and prediction are plotted at the same time, they are
+ displayed in a stitched image where the left image is the
+ ground truth and the right image is the prediction.
+ - If ``show`` is True, all storage backends are ignored, and
+ the images will be displayed in a local window.
+ - If ``out_file`` is specified, the drawn image will be
+ saved to ``out_file``. t is usually used when the display
+ is not available.
+
+ Args:
+ name (str): The image identifier
+ image (np.ndarray): The image to draw
+ data_sample (:obj:`PoseDataSample`): The 3d data sample
+ to visualize
+ det_data_sample (:obj:`PoseDataSample`, optional): The 2d detection
+ data sample to visualize
+ draw_gt (bool): Whether to draw GT PoseDataSample. Default to
+ ``True``
+ draw_pred (bool): Whether to draw Prediction PoseDataSample.
+ Defaults to ``True``
+ draw_2d (bool): Whether to draw 2d detection results. Defaults to
+ ``True``
+ draw_bbox (bool): Whether to draw bounding boxes. Default to
+ ``False``
+ show_kpt_idx (bool): Whether to show the index of keypoints.
+ Defaults to ``False``
+ skeleton_style (str): Skeleton style selection. Defaults to
+ ``'mmpose'``
+ num_instances (int): Number of instances to be shown in 3D. If
+ smaller than 0, all the instances in the pose_result will be
+ shown. Otherwise, pad or truncate the pose_result to a length
+ of num_instances. Defaults to -1
+ show (bool): Whether to display the drawn image. Default to
+ ``False``
+ wait_time (float): The interval of show (s). Defaults to 0
+ out_file (str): Path to output file. Defaults to ``None``
+ kpt_thr (float, optional): Minimum threshold of keypoints
+ to be shown. Default: 0.3.
+ step (int): Global step value to record. Defaults to 0
+ """
+
+ det_img_data = None
+ gt_img_data = None
+
+ if draw_2d:
+ det_img_data = image.copy()
+
+ # draw bboxes & keypoints
+ if 'pred_instances' in det_data_sample:
+ det_img_data = self._draw_instances_kpts(
+ det_img_data, det_data_sample.pred_instances, kpt_thr,
+ show_kpt_idx, skeleton_style)
+ if draw_bbox:
+ det_img_data = self._draw_instances_bbox(
+ det_img_data, det_data_sample.pred_instances)
+
+ pred_img_data = self._draw_3d_data_samples(
+ image.copy(),
+ data_sample,
+ draw_gt=draw_gt,
+ num_instances=num_instances)
+
+ # merge visualization results
+ if det_img_data is not None and gt_img_data is not None:
+ drawn_img = np.concatenate(
+ (det_img_data, pred_img_data, gt_img_data), axis=1)
+ elif det_img_data is not None:
+ drawn_img = np.concatenate((det_img_data, pred_img_data), axis=1)
+ elif gt_img_data is not None:
+ drawn_img = np.concatenate((det_img_data, gt_img_data), axis=1)
+ else:
+ drawn_img = pred_img_data
+
+ # It is convenient for users to obtain the drawn image.
+ # For example, the user wants to obtain the drawn image and
+ # save it as a video during video inference.
+ self.set_image(drawn_img)
+
+ if show:
+ self.show(drawn_img, win_name=name, wait_time=wait_time)
+
+ if out_file is not None:
+ mmcv.imwrite(drawn_img[..., ::-1], out_file)
+ else:
+ # save drawn_img to backends
+ self.add_image(name, drawn_img, step)
+
+ return self.get_image()
diff --git a/mmpose/visualization/opencv_backend_visualizer.py b/mmpose/visualization/opencv_backend_visualizer.py
index 1c17506640..3d4753f733 100644
--- a/mmpose/visualization/opencv_backend_visualizer.py
+++ b/mmpose/visualization/opencv_backend_visualizer.py
@@ -1,464 +1,464 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import List, Optional, Union
-
-import cv2
-import mmcv
-import numpy as np
-import torch
-from mmengine.dist import master_only
-from mmengine.visualization import Visualizer
-
-
-class OpencvBackendVisualizer(Visualizer):
- """Base visualizer with opencv backend support.
-
- Args:
- name (str): Name of the instance. Defaults to 'visualizer'.
- image (np.ndarray, optional): the origin image to draw. The format
- should be RGB. Defaults to None.
- vis_backends (list, optional): Visual backend config list.
- Defaults to None.
- save_dir (str, optional): Save file dir for all storage backends.
- If it is None, the backend storage will not save any data.
- fig_save_cfg (dict): Keyword parameters of figure for saving.
- Defaults to empty dict.
- fig_show_cfg (dict): Keyword parameters of figure for showing.
- Defaults to empty dict.
- backend (str): Backend used to draw elements on the image and display
- the image. Defaults to 'matplotlib'.
- alpha (int, float): The transparency of bboxes. Defaults to ``1.0``
- """
-
- def __init__(self,
- name='visualizer',
- backend: str = 'matplotlib',
- *args,
- **kwargs):
- super().__init__(name, *args, **kwargs)
- assert backend in ('opencv', 'matplotlib'), f'the argument ' \
- f'\'backend\' must be either \'opencv\' or \'matplotlib\', ' \
- f'but got \'{backend}\'.'
- self.backend = backend
-
- @master_only
- def set_image(self, image: np.ndarray) -> None:
- """Set the image to draw.
-
- Args:
- image (np.ndarray): The image to draw.
- backend (str): The backend to save the image.
- """
- assert image is not None
- image = image.astype('uint8')
- self._image = image
- self.width, self.height = image.shape[1], image.shape[0]
- self._default_font_size = max(
- np.sqrt(self.height * self.width) // 90, 10)
-
- if self.backend == 'matplotlib':
- # add a small 1e-2 to avoid precision lost due to matplotlib's
- # truncation (https://github.com/matplotlib/matplotlib/issues/15363) # noqa
- self.fig_save.set_size_inches( # type: ignore
- (self.width + 1e-2) / self.dpi,
- (self.height + 1e-2) / self.dpi)
- # self.canvas = mpl.backends.backend_cairo.FigureCanvasCairo(fig)
- self.ax_save.cla()
- self.ax_save.axis(False)
- self.ax_save.imshow(
- image,
- extent=(0, self.width, self.height, 0),
- interpolation='none')
-
- @master_only
- def get_image(self) -> np.ndarray:
- """Get the drawn image. The format is RGB.
-
- Returns:
- np.ndarray: the drawn image which channel is RGB.
- """
- assert self._image is not None, 'Please set image using `set_image`'
- if self.backend == 'matplotlib':
- return super().get_image()
- else:
- return self._image
-
- @master_only
- def draw_circles(self,
- center: Union[np.ndarray, torch.Tensor],
- radius: Union[np.ndarray, torch.Tensor],
- face_colors: Union[str, tuple, List[str],
- List[tuple]] = 'none',
- alpha: float = 1.0,
- **kwargs) -> 'Visualizer':
- """Draw single or multiple circles.
-
- Args:
- center (Union[np.ndarray, torch.Tensor]): The x coordinate of
- each line' start and end points.
- radius (Union[np.ndarray, torch.Tensor]): The y coordinate of
- each line' start and end points.
- edge_colors (Union[str, tuple, List[str], List[tuple]]): The
- colors of circles. ``colors`` can have the same length with
- lines or just single value. If ``colors`` is single value,
- all the lines will have the same colors. Reference to
- https://matplotlib.org/stable/gallery/color/named_colors.html
- for more details. Defaults to 'g.
- line_styles (Union[str, List[str]]): The linestyle
- of lines. ``line_styles`` can have the same length with
- texts or just single value. If ``line_styles`` is single
- value, all the lines will have the same linestyle.
- Reference to
- https://matplotlib.org/stable/api/collections_api.html?highlight=collection#matplotlib.collections.AsteriskPolygonCollection.set_linestyle
- for more details. Defaults to '-'.
- line_widths (Union[Union[int, float], List[Union[int, float]]]):
- The linewidth of lines. ``line_widths`` can have
- the same length with lines or just single value.
- If ``line_widths`` is single value, all the lines will
- have the same linewidth. Defaults to 2.
- face_colors (Union[str, tuple, List[str], List[tuple]]):
- The face colors. Defaults to None.
- alpha (Union[int, float]): The transparency of circles.
- Defaults to 0.8.
- """
- if self.backend == 'matplotlib':
- super().draw_circles(
- center=center,
- radius=radius,
- face_colors=face_colors,
- alpha=alpha,
- **kwargs)
- elif self.backend == 'opencv':
- if isinstance(face_colors, str):
- face_colors = mmcv.color_val(face_colors)
-
- if alpha == 1.0:
- self._image = cv2.circle(self._image,
- (int(center[0]), int(center[1])),
- int(radius), face_colors, -1)
- else:
- img = cv2.circle(self._image.copy(),
- (int(center[0]), int(center[1])), int(radius),
- face_colors, -1)
- self._image = cv2.addWeighted(self._image, 1 - alpha, img,
- alpha, 0)
- else:
- raise ValueError(f'got unsupported backend {self.backend}')
-
- @master_only
- def draw_texts(
- self,
- texts: Union[str, List[str]],
- positions: Union[np.ndarray, torch.Tensor],
- font_sizes: Optional[Union[int, List[int]]] = None,
- colors: Union[str, tuple, List[str], List[tuple]] = 'g',
- vertical_alignments: Union[str, List[str]] = 'top',
- horizontal_alignments: Union[str, List[str]] = 'left',
- bboxes: Optional[Union[dict, List[dict]]] = None,
- **kwargs,
- ) -> 'Visualizer':
- """Draw single or multiple text boxes.
-
- Args:
- texts (Union[str, List[str]]): Texts to draw.
- positions (Union[np.ndarray, torch.Tensor]): The position to draw
- the texts, which should have the same length with texts and
- each dim contain x and y.
- font_sizes (Union[int, List[int]], optional): The font size of
- texts. ``font_sizes`` can have the same length with texts or
- just single value. If ``font_sizes`` is single value, all the
- texts will have the same font size. Defaults to None.
- colors (Union[str, tuple, List[str], List[tuple]]): The colors
- of texts. ``colors`` can have the same length with texts or
- just single value. If ``colors`` is single value, all the
- texts will have the same colors. Reference to
- https://matplotlib.org/stable/gallery/color/named_colors.html
- for more details. Defaults to 'g.
- vertical_alignments (Union[str, List[str]]): The verticalalignment
- of texts. verticalalignment controls whether the y positional
- argument for the text indicates the bottom, center or top side
- of the text bounding box.
- ``vertical_alignments`` can have the same length with
- texts or just single value. If ``vertical_alignments`` is
- single value, all the texts will have the same
- verticalalignment. verticalalignment can be 'center' or
- 'top', 'bottom' or 'baseline'. Defaults to 'top'.
- horizontal_alignments (Union[str, List[str]]): The
- horizontalalignment of texts. Horizontalalignment controls
- whether the x positional argument for the text indicates the
- left, center or right side of the text bounding box.
- ``horizontal_alignments`` can have
- the same length with texts or just single value.
- If ``horizontal_alignments`` is single value, all the texts
- will have the same horizontalalignment. Horizontalalignment
- can be 'center','right' or 'left'. Defaults to 'left'.
- font_families (Union[str, List[str]]): The font family of
- texts. ``font_families`` can have the same length with texts or
- just single value. If ``font_families`` is single value, all
- the texts will have the same font family.
- font_familiy can be 'serif', 'sans-serif', 'cursive', 'fantasy'
- or 'monospace'. Defaults to 'sans-serif'.
- bboxes (Union[dict, List[dict]], optional): The bounding box of the
- texts. If bboxes is None, there are no bounding box around
- texts. ``bboxes`` can have the same length with texts or
- just single value. If ``bboxes`` is single value, all
- the texts will have the same bbox. Reference to
- https://matplotlib.org/stable/api/_as_gen/matplotlib.patches.FancyBboxPatch.html#matplotlib.patches.FancyBboxPatch
- for more details. Defaults to None.
- font_properties (Union[FontProperties, List[FontProperties]], optional):
- The font properties of texts. FontProperties is
- a ``font_manager.FontProperties()`` object.
- If you want to draw Chinese texts, you need to prepare
- a font file that can show Chinese characters properly.
- For example: `simhei.ttf`, `simsun.ttc`, `simkai.ttf` and so on.
- Then set ``font_properties=matplotlib.font_manager.FontProperties(fname='path/to/font_file')``
- ``font_properties`` can have the same length with texts or
- just single value. If ``font_properties`` is single value,
- all the texts will have the same font properties.
- Defaults to None.
- `New in version 0.6.0.`
- """ # noqa: E501
-
- if self.backend == 'matplotlib':
- super().draw_texts(
- texts=texts,
- positions=positions,
- font_sizes=font_sizes,
- colors=colors,
- vertical_alignments=vertical_alignments,
- horizontal_alignments=horizontal_alignments,
- bboxes=bboxes,
- **kwargs)
-
- elif self.backend == 'opencv':
- font_scale = max(0.1, font_sizes / 30)
- thickness = max(1, font_sizes // 15)
-
- text_size, text_baseline = cv2.getTextSize(texts,
- cv2.FONT_HERSHEY_DUPLEX,
- font_scale, thickness)
-
- x = int(positions[0])
- if horizontal_alignments == 'right':
- x = max(0, x - text_size[0])
- y = int(positions[1])
- if vertical_alignments == 'top':
- y = min(self.height, y + text_size[1])
-
- if bboxes is not None:
- bbox_color = bboxes[0]['facecolor']
- if isinstance(bbox_color, str):
- bbox_color = mmcv.color_val(bbox_color)
-
- y = y - text_baseline // 2
- self._image = cv2.rectangle(
- self._image, (x, y - text_size[1] - text_baseline // 2),
- (x + text_size[0], y + text_baseline // 2), bbox_color,
- cv2.FILLED)
-
- self._image = cv2.putText(self._image, texts, (x, y),
- cv2.FONT_HERSHEY_SIMPLEX, font_scale,
- colors, thickness - 1)
- else:
- raise ValueError(f'got unsupported backend {self.backend}')
-
- @master_only
- def draw_bboxes(self,
- bboxes: Union[np.ndarray, torch.Tensor],
- edge_colors: Union[str, tuple, List[str],
- List[tuple]] = 'g',
- line_widths: Union[Union[int, float],
- List[Union[int, float]]] = 2,
- **kwargs) -> 'Visualizer':
- """Draw single or multiple bboxes.
-
- Args:
- bboxes (Union[np.ndarray, torch.Tensor]): The bboxes to draw with
- the format of(x1,y1,x2,y2).
- edge_colors (Union[str, tuple, List[str], List[tuple]]): The
- colors of bboxes. ``colors`` can have the same length with
- lines or just single value. If ``colors`` is single value, all
- the lines will have the same colors. Refer to `matplotlib.
- colors` for full list of formats that are accepted.
- Defaults to 'g'.
- line_styles (Union[str, List[str]]): The linestyle
- of lines. ``line_styles`` can have the same length with
- texts or just single value. If ``line_styles`` is single
- value, all the lines will have the same linestyle.
- Reference to
- https://matplotlib.org/stable/api/collections_api.html?highlight=collection#matplotlib.collections.AsteriskPolygonCollection.set_linestyle
- for more details. Defaults to '-'.
- line_widths (Union[Union[int, float], List[Union[int, float]]]):
- The linewidth of lines. ``line_widths`` can have
- the same length with lines or just single value.
- If ``line_widths`` is single value, all the lines will
- have the same linewidth. Defaults to 2.
- face_colors (Union[str, tuple, List[str], List[tuple]]):
- The face colors. Defaults to None.
- alpha (Union[int, float]): The transparency of bboxes.
- Defaults to 0.8.
- """
- if self.backend == 'matplotlib':
- super().draw_bboxes(
- bboxes=bboxes,
- edge_colors=edge_colors,
- line_widths=line_widths,
- **kwargs)
-
- elif self.backend == 'opencv':
- self._image = mmcv.imshow_bboxes(
- self._image,
- bboxes,
- edge_colors,
- top_k=-1,
- thickness=line_widths,
- show=False)
- else:
- raise ValueError(f'got unsupported backend {self.backend}')
-
- @master_only
- def draw_lines(self,
- x_datas: Union[np.ndarray, torch.Tensor],
- y_datas: Union[np.ndarray, torch.Tensor],
- colors: Union[str, tuple, List[str], List[tuple]] = 'g',
- line_widths: Union[Union[int, float],
- List[Union[int, float]]] = 2,
- **kwargs) -> 'Visualizer':
- """Draw single or multiple line segments.
-
- Args:
- x_datas (Union[np.ndarray, torch.Tensor]): The x coordinate of
- each line' start and end points.
- y_datas (Union[np.ndarray, torch.Tensor]): The y coordinate of
- each line' start and end points.
- colors (Union[str, tuple, List[str], List[tuple]]): The colors of
- lines. ``colors`` can have the same length with lines or just
- single value. If ``colors`` is single value, all the lines
- will have the same colors. Reference to
- https://matplotlib.org/stable/gallery/color/named_colors.html
- for more details. Defaults to 'g'.
- line_styles (Union[str, List[str]]): The linestyle
- of lines. ``line_styles`` can have the same length with
- texts or just single value. If ``line_styles`` is single
- value, all the lines will have the same linestyle.
- Reference to
- https://matplotlib.org/stable/api/collections_api.html?highlight=collection#matplotlib.collections.AsteriskPolygonCollection.set_linestyle
- for more details. Defaults to '-'.
- line_widths (Union[Union[int, float], List[Union[int, float]]]):
- The linewidth of lines. ``line_widths`` can have
- the same length with lines or just single value.
- If ``line_widths`` is single value, all the lines will
- have the same linewidth. Defaults to 2.
- """
- if self.backend == 'matplotlib':
- super().draw_lines(
- x_datas=x_datas,
- y_datas=y_datas,
- colors=colors,
- line_widths=line_widths,
- **kwargs)
-
- elif self.backend == 'opencv':
-
- self._image = cv2.line(
- self._image, (x_datas[0], y_datas[0]),
- (x_datas[1], y_datas[1]),
- colors,
- thickness=line_widths)
- else:
- raise ValueError(f'got unsupported backend {self.backend}')
-
- @master_only
- def draw_polygons(self,
- polygons: Union[Union[np.ndarray, torch.Tensor],
- List[Union[np.ndarray, torch.Tensor]]],
- edge_colors: Union[str, tuple, List[str],
- List[tuple]] = 'g',
- alpha: float = 1.0,
- **kwargs) -> 'Visualizer':
- """Draw single or multiple bboxes.
-
- Args:
- polygons (Union[Union[np.ndarray, torch.Tensor],\
- List[Union[np.ndarray, torch.Tensor]]]): The polygons to draw
- with the format of (x1,y1,x2,y2,...,xn,yn).
- edge_colors (Union[str, tuple, List[str], List[tuple]]): The
- colors of polygons. ``colors`` can have the same length with
- lines or just single value. If ``colors`` is single value,
- all the lines will have the same colors. Refer to
- `matplotlib.colors` for full list of formats that are accepted.
- Defaults to 'g.
- line_styles (Union[str, List[str]]): The linestyle
- of lines. ``line_styles`` can have the same length with
- texts or just single value. If ``line_styles`` is single
- value, all the lines will have the same linestyle.
- Reference to
- https://matplotlib.org/stable/api/collections_api.html?highlight=collection#matplotlib.collections.AsteriskPolygonCollection.set_linestyle
- for more details. Defaults to '-'.
- line_widths (Union[Union[int, float], List[Union[int, float]]]):
- The linewidth of lines. ``line_widths`` can have
- the same length with lines or just single value.
- If ``line_widths`` is single value, all the lines will
- have the same linewidth. Defaults to 2.
- face_colors (Union[str, tuple, List[str], List[tuple]]):
- The face colors. Defaults to None.
- alpha (Union[int, float]): The transparency of polygons.
- Defaults to 0.8.
- """
- if self.backend == 'matplotlib':
- super().draw_polygons(
- polygons=polygons,
- edge_colors=edge_colors,
- alpha=alpha,
- **kwargs)
-
- elif self.backend == 'opencv':
- if alpha == 1.0:
- self._image = cv2.fillConvexPoly(self._image, polygons,
- edge_colors)
- else:
- img = cv2.fillConvexPoly(self._image.copy(), polygons,
- edge_colors)
- self._image = cv2.addWeighted(self._image, 1 - alpha, img,
- alpha, 0)
- else:
- raise ValueError(f'got unsupported backend {self.backend}')
-
- @master_only
- def show(self,
- drawn_img: Optional[np.ndarray] = None,
- win_name: str = 'image',
- wait_time: float = 0.,
- continue_key=' ') -> None:
- """Show the drawn image.
-
- Args:
- drawn_img (np.ndarray, optional): The image to show. If drawn_img
- is None, it will show the image got by Visualizer. Defaults
- to None.
- win_name (str): The image title. Defaults to 'image'.
- wait_time (float): Delay in seconds. 0 is the special
- value that means "forever". Defaults to 0.
- continue_key (str): The key for users to continue. Defaults to
- the space key.
- """
- if self.backend == 'matplotlib':
- super().show(
- drawn_img=drawn_img,
- win_name=win_name,
- wait_time=wait_time,
- continue_key=continue_key)
-
- elif self.backend == 'opencv':
- # Keep images are shown in the same window, and the title of window
- # will be updated with `win_name`.
- if not hasattr(self, win_name):
- self._cv_win_name = win_name
- cv2.namedWindow(winname=f'{id(self)}')
- cv2.setWindowTitle(f'{id(self)}', win_name)
- else:
- cv2.setWindowTitle(f'{id(self)}', win_name)
- shown_img = self.get_image() if drawn_img is None else drawn_img
- cv2.imshow(str(id(self)), mmcv.bgr2rgb(shown_img))
- cv2.waitKey(int(np.ceil(wait_time * 1000)))
- else:
- raise ValueError(f'got unsupported backend {self.backend}')
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Union
+
+import cv2
+import mmcv
+import numpy as np
+import torch
+from mmengine.dist import master_only
+from mmengine.visualization import Visualizer
+
+
+class OpencvBackendVisualizer(Visualizer):
+ """Base visualizer with opencv backend support.
+
+ Args:
+ name (str): Name of the instance. Defaults to 'visualizer'.
+ image (np.ndarray, optional): the origin image to draw. The format
+ should be RGB. Defaults to None.
+ vis_backends (list, optional): Visual backend config list.
+ Defaults to None.
+ save_dir (str, optional): Save file dir for all storage backends.
+ If it is None, the backend storage will not save any data.
+ fig_save_cfg (dict): Keyword parameters of figure for saving.
+ Defaults to empty dict.
+ fig_show_cfg (dict): Keyword parameters of figure for showing.
+ Defaults to empty dict.
+ backend (str): Backend used to draw elements on the image and display
+ the image. Defaults to 'matplotlib'.
+ alpha (int, float): The transparency of bboxes. Defaults to ``1.0``
+ """
+
+ def __init__(self,
+ name='visualizer',
+ backend: str = 'matplotlib',
+ *args,
+ **kwargs):
+ super().__init__(name, *args, **kwargs)
+ assert backend in ('opencv', 'matplotlib'), f'the argument ' \
+ f'\'backend\' must be either \'opencv\' or \'matplotlib\', ' \
+ f'but got \'{backend}\'.'
+ self.backend = backend
+
+ @master_only
+ def set_image(self, image: np.ndarray) -> None:
+ """Set the image to draw.
+
+ Args:
+ image (np.ndarray): The image to draw.
+ backend (str): The backend to save the image.
+ """
+ assert image is not None
+ image = image.astype('uint8')
+ self._image = image
+ self.width, self.height = image.shape[1], image.shape[0]
+ self._default_font_size = max(
+ np.sqrt(self.height * self.width) // 90, 10)
+
+ if self.backend == 'matplotlib':
+ # add a small 1e-2 to avoid precision lost due to matplotlib's
+ # truncation (https://github.com/matplotlib/matplotlib/issues/15363) # noqa
+ self.fig_save.set_size_inches( # type: ignore
+ (self.width + 1e-2) / self.dpi,
+ (self.height + 1e-2) / self.dpi)
+ # self.canvas = mpl.backends.backend_cairo.FigureCanvasCairo(fig)
+ self.ax_save.cla()
+ self.ax_save.axis(False)
+ self.ax_save.imshow(
+ image,
+ extent=(0, self.width, self.height, 0),
+ interpolation='none')
+
+ @master_only
+ def get_image(self) -> np.ndarray:
+ """Get the drawn image. The format is RGB.
+
+ Returns:
+ np.ndarray: the drawn image which channel is RGB.
+ """
+ assert self._image is not None, 'Please set image using `set_image`'
+ if self.backend == 'matplotlib':
+ return super().get_image()
+ else:
+ return self._image
+
+ @master_only
+ def draw_circles(self,
+ center: Union[np.ndarray, torch.Tensor],
+ radius: Union[np.ndarray, torch.Tensor],
+ face_colors: Union[str, tuple, List[str],
+ List[tuple]] = 'none',
+ alpha: float = 1.0,
+ **kwargs) -> 'Visualizer':
+ """Draw single or multiple circles.
+
+ Args:
+ center (Union[np.ndarray, torch.Tensor]): The x coordinate of
+ each line' start and end points.
+ radius (Union[np.ndarray, torch.Tensor]): The y coordinate of
+ each line' start and end points.
+ edge_colors (Union[str, tuple, List[str], List[tuple]]): The
+ colors of circles. ``colors`` can have the same length with
+ lines or just single value. If ``colors`` is single value,
+ all the lines will have the same colors. Reference to
+ https://matplotlib.org/stable/gallery/color/named_colors.html
+ for more details. Defaults to 'g.
+ line_styles (Union[str, List[str]]): The linestyle
+ of lines. ``line_styles`` can have the same length with
+ texts or just single value. If ``line_styles`` is single
+ value, all the lines will have the same linestyle.
+ Reference to
+ https://matplotlib.org/stable/api/collections_api.html?highlight=collection#matplotlib.collections.AsteriskPolygonCollection.set_linestyle
+ for more details. Defaults to '-'.
+ line_widths (Union[Union[int, float], List[Union[int, float]]]):
+ The linewidth of lines. ``line_widths`` can have
+ the same length with lines or just single value.
+ If ``line_widths`` is single value, all the lines will
+ have the same linewidth. Defaults to 2.
+ face_colors (Union[str, tuple, List[str], List[tuple]]):
+ The face colors. Defaults to None.
+ alpha (Union[int, float]): The transparency of circles.
+ Defaults to 0.8.
+ """
+ if self.backend == 'matplotlib':
+ super().draw_circles(
+ center=center,
+ radius=radius,
+ face_colors=face_colors,
+ alpha=alpha,
+ **kwargs)
+ elif self.backend == 'opencv':
+ if isinstance(face_colors, str):
+ face_colors = mmcv.color_val(face_colors)
+
+ if alpha == 1.0:
+ self._image = cv2.circle(self._image,
+ (int(center[0]), int(center[1])),
+ int(radius), face_colors, -1)
+ else:
+ img = cv2.circle(self._image.copy(),
+ (int(center[0]), int(center[1])), int(radius),
+ face_colors, -1)
+ self._image = cv2.addWeighted(self._image, 1 - alpha, img,
+ alpha, 0)
+ else:
+ raise ValueError(f'got unsupported backend {self.backend}')
+
+ @master_only
+ def draw_texts(
+ self,
+ texts: Union[str, List[str]],
+ positions: Union[np.ndarray, torch.Tensor],
+ font_sizes: Optional[Union[int, List[int]]] = None,
+ colors: Union[str, tuple, List[str], List[tuple]] = 'g',
+ vertical_alignments: Union[str, List[str]] = 'top',
+ horizontal_alignments: Union[str, List[str]] = 'left',
+ bboxes: Optional[Union[dict, List[dict]]] = None,
+ **kwargs,
+ ) -> 'Visualizer':
+ """Draw single or multiple text boxes.
+
+ Args:
+ texts (Union[str, List[str]]): Texts to draw.
+ positions (Union[np.ndarray, torch.Tensor]): The position to draw
+ the texts, which should have the same length with texts and
+ each dim contain x and y.
+ font_sizes (Union[int, List[int]], optional): The font size of
+ texts. ``font_sizes`` can have the same length with texts or
+ just single value. If ``font_sizes`` is single value, all the
+ texts will have the same font size. Defaults to None.
+ colors (Union[str, tuple, List[str], List[tuple]]): The colors
+ of texts. ``colors`` can have the same length with texts or
+ just single value. If ``colors`` is single value, all the
+ texts will have the same colors. Reference to
+ https://matplotlib.org/stable/gallery/color/named_colors.html
+ for more details. Defaults to 'g.
+ vertical_alignments (Union[str, List[str]]): The verticalalignment
+ of texts. verticalalignment controls whether the y positional
+ argument for the text indicates the bottom, center or top side
+ of the text bounding box.
+ ``vertical_alignments`` can have the same length with
+ texts or just single value. If ``vertical_alignments`` is
+ single value, all the texts will have the same
+ verticalalignment. verticalalignment can be 'center' or
+ 'top', 'bottom' or 'baseline'. Defaults to 'top'.
+ horizontal_alignments (Union[str, List[str]]): The
+ horizontalalignment of texts. Horizontalalignment controls
+ whether the x positional argument for the text indicates the
+ left, center or right side of the text bounding box.
+ ``horizontal_alignments`` can have
+ the same length with texts or just single value.
+ If ``horizontal_alignments`` is single value, all the texts
+ will have the same horizontalalignment. Horizontalalignment
+ can be 'center','right' or 'left'. Defaults to 'left'.
+ font_families (Union[str, List[str]]): The font family of
+ texts. ``font_families`` can have the same length with texts or
+ just single value. If ``font_families`` is single value, all
+ the texts will have the same font family.
+ font_familiy can be 'serif', 'sans-serif', 'cursive', 'fantasy'
+ or 'monospace'. Defaults to 'sans-serif'.
+ bboxes (Union[dict, List[dict]], optional): The bounding box of the
+ texts. If bboxes is None, there are no bounding box around
+ texts. ``bboxes`` can have the same length with texts or
+ just single value. If ``bboxes`` is single value, all
+ the texts will have the same bbox. Reference to
+ https://matplotlib.org/stable/api/_as_gen/matplotlib.patches.FancyBboxPatch.html#matplotlib.patches.FancyBboxPatch
+ for more details. Defaults to None.
+ font_properties (Union[FontProperties, List[FontProperties]], optional):
+ The font properties of texts. FontProperties is
+ a ``font_manager.FontProperties()`` object.
+ If you want to draw Chinese texts, you need to prepare
+ a font file that can show Chinese characters properly.
+ For example: `simhei.ttf`, `simsun.ttc`, `simkai.ttf` and so on.
+ Then set ``font_properties=matplotlib.font_manager.FontProperties(fname='path/to/font_file')``
+ ``font_properties`` can have the same length with texts or
+ just single value. If ``font_properties`` is single value,
+ all the texts will have the same font properties.
+ Defaults to None.
+ `New in version 0.6.0.`
+ """ # noqa: E501
+
+ if self.backend == 'matplotlib':
+ super().draw_texts(
+ texts=texts,
+ positions=positions,
+ font_sizes=font_sizes,
+ colors=colors,
+ vertical_alignments=vertical_alignments,
+ horizontal_alignments=horizontal_alignments,
+ bboxes=bboxes,
+ **kwargs)
+
+ elif self.backend == 'opencv':
+ font_scale = max(0.1, font_sizes / 30)
+ thickness = max(1, font_sizes // 15)
+
+ text_size, text_baseline = cv2.getTextSize(texts,
+ cv2.FONT_HERSHEY_DUPLEX,
+ font_scale, thickness)
+
+ x = int(positions[0])
+ if horizontal_alignments == 'right':
+ x = max(0, x - text_size[0])
+ y = int(positions[1])
+ if vertical_alignments == 'top':
+ y = min(self.height, y + text_size[1])
+
+ if bboxes is not None:
+ bbox_color = bboxes[0]['facecolor']
+ if isinstance(bbox_color, str):
+ bbox_color = mmcv.color_val(bbox_color)
+
+ y = y - text_baseline // 2
+ self._image = cv2.rectangle(
+ self._image, (x, y - text_size[1] - text_baseline // 2),
+ (x + text_size[0], y + text_baseline // 2), bbox_color,
+ cv2.FILLED)
+
+ self._image = cv2.putText(self._image, texts, (x, y),
+ cv2.FONT_HERSHEY_SIMPLEX, font_scale,
+ colors, thickness - 1)
+ else:
+ raise ValueError(f'got unsupported backend {self.backend}')
+
+ @master_only
+ def draw_bboxes(self,
+ bboxes: Union[np.ndarray, torch.Tensor],
+ edge_colors: Union[str, tuple, List[str],
+ List[tuple]] = 'g',
+ line_widths: Union[Union[int, float],
+ List[Union[int, float]]] = 2,
+ **kwargs) -> 'Visualizer':
+ """Draw single or multiple bboxes.
+
+ Args:
+ bboxes (Union[np.ndarray, torch.Tensor]): The bboxes to draw with
+ the format of(x1,y1,x2,y2).
+ edge_colors (Union[str, tuple, List[str], List[tuple]]): The
+ colors of bboxes. ``colors`` can have the same length with
+ lines or just single value. If ``colors`` is single value, all
+ the lines will have the same colors. Refer to `matplotlib.
+ colors` for full list of formats that are accepted.
+ Defaults to 'g'.
+ line_styles (Union[str, List[str]]): The linestyle
+ of lines. ``line_styles`` can have the same length with
+ texts or just single value. If ``line_styles`` is single
+ value, all the lines will have the same linestyle.
+ Reference to
+ https://matplotlib.org/stable/api/collections_api.html?highlight=collection#matplotlib.collections.AsteriskPolygonCollection.set_linestyle
+ for more details. Defaults to '-'.
+ line_widths (Union[Union[int, float], List[Union[int, float]]]):
+ The linewidth of lines. ``line_widths`` can have
+ the same length with lines or just single value.
+ If ``line_widths`` is single value, all the lines will
+ have the same linewidth. Defaults to 2.
+ face_colors (Union[str, tuple, List[str], List[tuple]]):
+ The face colors. Defaults to None.
+ alpha (Union[int, float]): The transparency of bboxes.
+ Defaults to 0.8.
+ """
+ if self.backend == 'matplotlib':
+ super().draw_bboxes(
+ bboxes=bboxes,
+ edge_colors=edge_colors,
+ line_widths=line_widths,
+ **kwargs)
+
+ elif self.backend == 'opencv':
+ self._image = mmcv.imshow_bboxes(
+ self._image,
+ bboxes,
+ edge_colors,
+ top_k=-1,
+ thickness=line_widths,
+ show=False)
+ else:
+ raise ValueError(f'got unsupported backend {self.backend}')
+
+ @master_only
+ def draw_lines(self,
+ x_datas: Union[np.ndarray, torch.Tensor],
+ y_datas: Union[np.ndarray, torch.Tensor],
+ colors: Union[str, tuple, List[str], List[tuple]] = 'g',
+ line_widths: Union[Union[int, float],
+ List[Union[int, float]]] = 2,
+ **kwargs) -> 'Visualizer':
+ """Draw single or multiple line segments.
+
+ Args:
+ x_datas (Union[np.ndarray, torch.Tensor]): The x coordinate of
+ each line' start and end points.
+ y_datas (Union[np.ndarray, torch.Tensor]): The y coordinate of
+ each line' start and end points.
+ colors (Union[str, tuple, List[str], List[tuple]]): The colors of
+ lines. ``colors`` can have the same length with lines or just
+ single value. If ``colors`` is single value, all the lines
+ will have the same colors. Reference to
+ https://matplotlib.org/stable/gallery/color/named_colors.html
+ for more details. Defaults to 'g'.
+ line_styles (Union[str, List[str]]): The linestyle
+ of lines. ``line_styles`` can have the same length with
+ texts or just single value. If ``line_styles`` is single
+ value, all the lines will have the same linestyle.
+ Reference to
+ https://matplotlib.org/stable/api/collections_api.html?highlight=collection#matplotlib.collections.AsteriskPolygonCollection.set_linestyle
+ for more details. Defaults to '-'.
+ line_widths (Union[Union[int, float], List[Union[int, float]]]):
+ The linewidth of lines. ``line_widths`` can have
+ the same length with lines or just single value.
+ If ``line_widths`` is single value, all the lines will
+ have the same linewidth. Defaults to 2.
+ """
+ if self.backend == 'matplotlib':
+ super().draw_lines(
+ x_datas=x_datas,
+ y_datas=y_datas,
+ colors=colors,
+ line_widths=line_widths,
+ **kwargs)
+
+ elif self.backend == 'opencv':
+
+ self._image = cv2.line(
+ self._image, (x_datas[0], y_datas[0]),
+ (x_datas[1], y_datas[1]),
+ colors,
+ thickness=line_widths)
+ else:
+ raise ValueError(f'got unsupported backend {self.backend}')
+
+ @master_only
+ def draw_polygons(self,
+ polygons: Union[Union[np.ndarray, torch.Tensor],
+ List[Union[np.ndarray, torch.Tensor]]],
+ edge_colors: Union[str, tuple, List[str],
+ List[tuple]] = 'g',
+ alpha: float = 1.0,
+ **kwargs) -> 'Visualizer':
+ """Draw single or multiple bboxes.
+
+ Args:
+ polygons (Union[Union[np.ndarray, torch.Tensor],\
+ List[Union[np.ndarray, torch.Tensor]]]): The polygons to draw
+ with the format of (x1,y1,x2,y2,...,xn,yn).
+ edge_colors (Union[str, tuple, List[str], List[tuple]]): The
+ colors of polygons. ``colors`` can have the same length with
+ lines or just single value. If ``colors`` is single value,
+ all the lines will have the same colors. Refer to
+ `matplotlib.colors` for full list of formats that are accepted.
+ Defaults to 'g.
+ line_styles (Union[str, List[str]]): The linestyle
+ of lines. ``line_styles`` can have the same length with
+ texts or just single value. If ``line_styles`` is single
+ value, all the lines will have the same linestyle.
+ Reference to
+ https://matplotlib.org/stable/api/collections_api.html?highlight=collection#matplotlib.collections.AsteriskPolygonCollection.set_linestyle
+ for more details. Defaults to '-'.
+ line_widths (Union[Union[int, float], List[Union[int, float]]]):
+ The linewidth of lines. ``line_widths`` can have
+ the same length with lines or just single value.
+ If ``line_widths`` is single value, all the lines will
+ have the same linewidth. Defaults to 2.
+ face_colors (Union[str, tuple, List[str], List[tuple]]):
+ The face colors. Defaults to None.
+ alpha (Union[int, float]): The transparency of polygons.
+ Defaults to 0.8.
+ """
+ if self.backend == 'matplotlib':
+ super().draw_polygons(
+ polygons=polygons,
+ edge_colors=edge_colors,
+ alpha=alpha,
+ **kwargs)
+
+ elif self.backend == 'opencv':
+ if alpha == 1.0:
+ self._image = cv2.fillConvexPoly(self._image, polygons,
+ edge_colors)
+ else:
+ img = cv2.fillConvexPoly(self._image.copy(), polygons,
+ edge_colors)
+ self._image = cv2.addWeighted(self._image, 1 - alpha, img,
+ alpha, 0)
+ else:
+ raise ValueError(f'got unsupported backend {self.backend}')
+
+ @master_only
+ def show(self,
+ drawn_img: Optional[np.ndarray] = None,
+ win_name: str = 'image',
+ wait_time: float = 0.,
+ continue_key=' ') -> None:
+ """Show the drawn image.
+
+ Args:
+ drawn_img (np.ndarray, optional): The image to show. If drawn_img
+ is None, it will show the image got by Visualizer. Defaults
+ to None.
+ win_name (str): The image title. Defaults to 'image'.
+ wait_time (float): Delay in seconds. 0 is the special
+ value that means "forever". Defaults to 0.
+ continue_key (str): The key for users to continue. Defaults to
+ the space key.
+ """
+ if self.backend == 'matplotlib':
+ super().show(
+ drawn_img=drawn_img,
+ win_name=win_name,
+ wait_time=wait_time,
+ continue_key=continue_key)
+
+ elif self.backend == 'opencv':
+ # Keep images are shown in the same window, and the title of window
+ # will be updated with `win_name`.
+ if not hasattr(self, win_name):
+ self._cv_win_name = win_name
+ cv2.namedWindow(winname=f'{id(self)}')
+ cv2.setWindowTitle(f'{id(self)}', win_name)
+ else:
+ cv2.setWindowTitle(f'{id(self)}', win_name)
+ shown_img = self.get_image() if drawn_img is None else drawn_img
+ cv2.imshow(str(id(self)), mmcv.bgr2rgb(shown_img))
+ cv2.waitKey(int(np.ceil(wait_time * 1000)))
+ else:
+ raise ValueError(f'got unsupported backend {self.backend}')
diff --git a/mmpose/visualization/simcc_vis.py b/mmpose/visualization/simcc_vis.py
index 3a5b602fb5..fe1a6d965a 100644
--- a/mmpose/visualization/simcc_vis.py
+++ b/mmpose/visualization/simcc_vis.py
@@ -1,136 +1,136 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional, Union
-
-import cv2 as cv
-import numpy as np
-import torch
-from torchvision.transforms import ToPILImage
-
-
-class SimCCVisualizer:
-
- def draw_instance_xy_heatmap(self,
- heatmap: torch.Tensor,
- overlaid_image: Optional[np.ndarray],
- n: int = 20,
- mix: bool = True,
- weight: float = 0.5):
- """Draw heatmaps of GT or prediction.
-
- Args:
- heatmap (torch.Tensor): Tensor of heatmap.
- overlaid_image (np.ndarray): The image to draw.
- n (int): Number of keypoint, up to 20.
- mix (bool):Whether to merge heatmap and original image.
- weight (float): Weight of original image during fusion.
-
- Returns:
- np.ndarray: the drawn image which channel is RGB.
- """
- heatmap2d = heatmap.data.max(0, keepdim=True)[0]
- xy_heatmap, K = self.split_simcc_xy(heatmap)
- K = K if K <= n else n
- blank_size = tuple(heatmap.size()[1:])
- maps = {'x': [], 'y': []}
- for i in xy_heatmap:
- x, y = self.draw_1d_heatmaps(i['x']), self.draw_1d_heatmaps(i['y'])
- maps['x'].append(x)
- maps['y'].append(y)
- white = self.creat_blank(blank_size, K)
- map2d = self.draw_2d_heatmaps(heatmap2d)
- if mix:
- map2d = cv.addWeighted(overlaid_image, 1 - weight, map2d, weight,
- 0)
- self.image_cover(white, map2d, int(blank_size[1] * 0.1),
- int(blank_size[0] * 0.1))
- white = self.add_1d_heatmaps(maps, white, blank_size, K)
- return white
-
- def split_simcc_xy(self, heatmap: Union[np.ndarray, torch.Tensor]):
- """Extract one-dimensional heatmap from two-dimensional heatmap and
- calculate the number of keypoint."""
- size = heatmap.size()
- k = size[0] if size[0] <= 20 else 20
- maps = []
- for _ in range(k):
- xy_dict = {}
- single_heatmap = heatmap[_]
- xy_dict['x'], xy_dict['y'] = self.merge_maps(single_heatmap)
- maps.append(xy_dict)
- return maps, k
-
- def merge_maps(self, map_2d):
- """Synthesis of one-dimensional heatmap."""
- x = map_2d.data.max(0, keepdim=True)[0]
- y = map_2d.data.max(1, keepdim=True)[0]
- return x, y
-
- def draw_1d_heatmaps(self, heatmap_1d):
- """Draw one-dimensional heatmap."""
- size = heatmap_1d.size()
- length = max(size)
- np_heatmap = ToPILImage()(heatmap_1d).convert('RGB')
- cv_img = cv.cvtColor(np.asarray(np_heatmap), cv.COLOR_RGB2BGR)
- if size[0] < size[1]:
- cv_img = cv.resize(cv_img, (length, 15))
- else:
- cv_img = cv.resize(cv_img, (15, length))
- single_map = cv.applyColorMap(cv_img, cv.COLORMAP_JET)
- return single_map
-
- def creat_blank(self,
- size: Union[list, tuple],
- K: int = 20,
- interval: int = 10):
- """Create the background."""
- blank_height = int(
- max(size[0] * 2, size[0] * 1.1 + (K + 1) * (15 + interval)))
- blank_width = int(
- max(size[1] * 2, size[1] * 1.1 + (K + 1) * (15 + interval)))
- blank = np.zeros((blank_height, blank_width, 3), np.uint8)
- blank.fill(255)
- return blank
-
- def draw_2d_heatmaps(self, heatmap_2d):
- """Draw a two-dimensional heatmap fused with the original image."""
- np_heatmap = ToPILImage()(heatmap_2d).convert('RGB')
- cv_img = cv.cvtColor(np.asarray(np_heatmap), cv.COLOR_RGB2BGR)
- map_2d = cv.applyColorMap(cv_img, cv.COLORMAP_JET)
- return map_2d
-
- def image_cover(self, background: np.ndarray, foreground: np.ndarray,
- x: int, y: int):
- """Paste the foreground on the background."""
- fore_size = foreground.shape
- background[y:y + fore_size[0], x:x + fore_size[1]] = foreground
- return background
-
- def add_1d_heatmaps(self,
- maps: dict,
- background: np.ndarray,
- map2d_size: Union[tuple, list],
- K: int,
- interval: int = 10):
- """Paste one-dimensional heatmaps onto the background in turn."""
- y_startpoint, x_startpoint = [int(1.1*map2d_size[1]),
- int(0.1*map2d_size[0])],\
- [int(0.1*map2d_size[1]),
- int(1.1*map2d_size[0])]
- x_startpoint[1] += interval * 2
- y_startpoint[0] += interval * 2
- add = interval + 10
- for i in range(K):
- self.image_cover(background, maps['x'][i], x_startpoint[0],
- x_startpoint[1])
- cv.putText(background, str(i),
- (x_startpoint[0] - 30, x_startpoint[1] + 10),
- cv.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 2)
- self.image_cover(background, maps['y'][i], y_startpoint[0],
- y_startpoint[1])
- cv.putText(background, str(i),
- (y_startpoint[0], y_startpoint[1] - 5),
- cv.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 2)
- x_startpoint[1] += add
- y_startpoint[0] += add
- return background[:x_startpoint[1] + y_startpoint[1] +
- 1, :y_startpoint[0] + x_startpoint[0] + 1]
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Union
+
+import cv2 as cv
+import numpy as np
+import torch
+from torchvision.transforms import ToPILImage
+
+
+class SimCCVisualizer:
+
+ def draw_instance_xy_heatmap(self,
+ heatmap: torch.Tensor,
+ overlaid_image: Optional[np.ndarray],
+ n: int = 20,
+ mix: bool = True,
+ weight: float = 0.5):
+ """Draw heatmaps of GT or prediction.
+
+ Args:
+ heatmap (torch.Tensor): Tensor of heatmap.
+ overlaid_image (np.ndarray): The image to draw.
+ n (int): Number of keypoint, up to 20.
+ mix (bool):Whether to merge heatmap and original image.
+ weight (float): Weight of original image during fusion.
+
+ Returns:
+ np.ndarray: the drawn image which channel is RGB.
+ """
+ heatmap2d = heatmap.data.max(0, keepdim=True)[0]
+ xy_heatmap, K = self.split_simcc_xy(heatmap)
+ K = K if K <= n else n
+ blank_size = tuple(heatmap.size()[1:])
+ maps = {'x': [], 'y': []}
+ for i in xy_heatmap:
+ x, y = self.draw_1d_heatmaps(i['x']), self.draw_1d_heatmaps(i['y'])
+ maps['x'].append(x)
+ maps['y'].append(y)
+ white = self.creat_blank(blank_size, K)
+ map2d = self.draw_2d_heatmaps(heatmap2d)
+ if mix:
+ map2d = cv.addWeighted(overlaid_image, 1 - weight, map2d, weight,
+ 0)
+ self.image_cover(white, map2d, int(blank_size[1] * 0.1),
+ int(blank_size[0] * 0.1))
+ white = self.add_1d_heatmaps(maps, white, blank_size, K)
+ return white
+
+ def split_simcc_xy(self, heatmap: Union[np.ndarray, torch.Tensor]):
+ """Extract one-dimensional heatmap from two-dimensional heatmap and
+ calculate the number of keypoint."""
+ size = heatmap.size()
+ k = size[0] if size[0] <= 20 else 20
+ maps = []
+ for _ in range(k):
+ xy_dict = {}
+ single_heatmap = heatmap[_]
+ xy_dict['x'], xy_dict['y'] = self.merge_maps(single_heatmap)
+ maps.append(xy_dict)
+ return maps, k
+
+ def merge_maps(self, map_2d):
+ """Synthesis of one-dimensional heatmap."""
+ x = map_2d.data.max(0, keepdim=True)[0]
+ y = map_2d.data.max(1, keepdim=True)[0]
+ return x, y
+
+ def draw_1d_heatmaps(self, heatmap_1d):
+ """Draw one-dimensional heatmap."""
+ size = heatmap_1d.size()
+ length = max(size)
+ np_heatmap = ToPILImage()(heatmap_1d).convert('RGB')
+ cv_img = cv.cvtColor(np.asarray(np_heatmap), cv.COLOR_RGB2BGR)
+ if size[0] < size[1]:
+ cv_img = cv.resize(cv_img, (length, 15))
+ else:
+ cv_img = cv.resize(cv_img, (15, length))
+ single_map = cv.applyColorMap(cv_img, cv.COLORMAP_JET)
+ return single_map
+
+ def creat_blank(self,
+ size: Union[list, tuple],
+ K: int = 20,
+ interval: int = 10):
+ """Create the background."""
+ blank_height = int(
+ max(size[0] * 2, size[0] * 1.1 + (K + 1) * (15 + interval)))
+ blank_width = int(
+ max(size[1] * 2, size[1] * 1.1 + (K + 1) * (15 + interval)))
+ blank = np.zeros((blank_height, blank_width, 3), np.uint8)
+ blank.fill(255)
+ return blank
+
+ def draw_2d_heatmaps(self, heatmap_2d):
+ """Draw a two-dimensional heatmap fused with the original image."""
+ np_heatmap = ToPILImage()(heatmap_2d).convert('RGB')
+ cv_img = cv.cvtColor(np.asarray(np_heatmap), cv.COLOR_RGB2BGR)
+ map_2d = cv.applyColorMap(cv_img, cv.COLORMAP_JET)
+ return map_2d
+
+ def image_cover(self, background: np.ndarray, foreground: np.ndarray,
+ x: int, y: int):
+ """Paste the foreground on the background."""
+ fore_size = foreground.shape
+ background[y:y + fore_size[0], x:x + fore_size[1]] = foreground
+ return background
+
+ def add_1d_heatmaps(self,
+ maps: dict,
+ background: np.ndarray,
+ map2d_size: Union[tuple, list],
+ K: int,
+ interval: int = 10):
+ """Paste one-dimensional heatmaps onto the background in turn."""
+ y_startpoint, x_startpoint = [int(1.1*map2d_size[1]),
+ int(0.1*map2d_size[0])],\
+ [int(0.1*map2d_size[1]),
+ int(1.1*map2d_size[0])]
+ x_startpoint[1] += interval * 2
+ y_startpoint[0] += interval * 2
+ add = interval + 10
+ for i in range(K):
+ self.image_cover(background, maps['x'][i], x_startpoint[0],
+ x_startpoint[1])
+ cv.putText(background, str(i),
+ (x_startpoint[0] - 30, x_startpoint[1] + 10),
+ cv.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 2)
+ self.image_cover(background, maps['y'][i], y_startpoint[0],
+ y_startpoint[1])
+ cv.putText(background, str(i),
+ (y_startpoint[0], y_startpoint[1] - 5),
+ cv.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 2)
+ x_startpoint[1] += add
+ y_startpoint[0] += add
+ return background[:x_startpoint[1] + y_startpoint[1] +
+ 1, :y_startpoint[0] + x_startpoint[0] + 1]
diff --git a/model-index.yml b/model-index.yml
index 498e5bc743..446e15cad4 100644
--- a/model-index.yml
+++ b/model-index.yml
@@ -1,121 +1,121 @@
-Import:
-- configs/animal_2d_keypoint/rtmpose/ap10k/rtmpose_ap10k.yml
-- configs/animal_2d_keypoint/topdown_heatmap/animalpose/hrnet_animalpose.yml
-- configs/animal_2d_keypoint/topdown_heatmap/animalpose/resnet_animalpose.yml
-- configs/animal_2d_keypoint/topdown_heatmap/ap10k/resnet_ap10k.yml
-- configs/animal_2d_keypoint/topdown_heatmap/ap10k/hrnet_ap10k.yml
-- configs/animal_2d_keypoint/topdown_heatmap/ap10k/cspnext_udp_ap10k.yml
-- configs/animal_2d_keypoint/topdown_heatmap/locust/resnet_locust.yml
-- configs/animal_2d_keypoint/topdown_heatmap/zebra/resnet_zebra.yml
-- configs/body_2d_keypoint/cid/coco/hrnet_coco.yml
-- configs/body_2d_keypoint/dekr/coco/hrnet_coco.yml
-- configs/body_2d_keypoint/dekr/crowdpose/hrnet_crowdpose.yml
-- configs/body_2d_keypoint/integral_regression/coco/resnet_ipr_coco.yml
-- configs/body_2d_keypoint/integral_regression/coco/resnet_dsnt_coco.yml
-- configs/body_2d_keypoint/integral_regression/coco/resnet_debias_coco.yml
-- configs/body_2d_keypoint/rtmpose/coco/rtmpose_coco.yml
-- configs/body_2d_keypoint/rtmpose/crowdpose/rtmpose_crowdpose.yml
-- configs/body_2d_keypoint/rtmpose/mpii/rtmpose_mpii.yml
-- configs/body_2d_keypoint/simcc/coco/mobilenetv2_coco.yml
-- configs/body_2d_keypoint/simcc/coco/resnet_coco.yml
-- configs/body_2d_keypoint/simcc/coco/vipnas_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/aic/hrnet_aic.yml
-- configs/body_2d_keypoint/topdown_heatmap/aic/resnet_aic.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/hourglass_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/hrnet_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/litehrnet_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/mspn_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/vitpose_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/alexnet_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/resnet_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/cpm_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/hrformer_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/hrnet_augmentation_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/hrnet_dark_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/hrnet_udp_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/mobilenetv2_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/pvt_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/resnest_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/resnet_dark_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/cspnext_udp_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/resnetv1d_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/resnext_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/rsn_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/scnet_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/seresnet_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/shufflenetv1_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/shufflenetv2_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/swin_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/vgg_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/coco/vipnas_coco.yml
-- configs/body_2d_keypoint/topdown_heatmap/crowdpose/hrnet_crowdpose.yml
-- configs/body_2d_keypoint/topdown_heatmap/crowdpose/resnet_crowdpose.yml
-- configs/body_2d_keypoint/topdown_heatmap/crowdpose/cspnext_udp_crowdpose.yml
-- configs/body_2d_keypoint/topdown_heatmap/jhmdb/cpm_jhmdb.yml
-- configs/body_2d_keypoint/topdown_heatmap/jhmdb/resnet_jhmdb.yml
-- configs/body_2d_keypoint/topdown_heatmap/mpii/cpm_mpii.yml
-- configs/body_2d_keypoint/topdown_heatmap/mpii/hourglass_mpii.yml
-- configs/body_2d_keypoint/topdown_heatmap/mpii/cspnext_udp_mpii.yml
-- configs/body_2d_keypoint/topdown_heatmap/mpii/hrnet_dark_mpii.yml
-- configs/body_2d_keypoint/topdown_heatmap/mpii/hrnet_mpii.yml
-- configs/body_2d_keypoint/topdown_heatmap/mpii/litehrnet_mpii.yml
-- configs/body_2d_keypoint/topdown_heatmap/mpii/mobilenetv2_mpii.yml
-- configs/body_2d_keypoint/topdown_heatmap/mpii/resnet_mpii.yml
-- configs/body_2d_keypoint/topdown_heatmap/mpii/resnetv1d_mpii.yml
-- configs/body_2d_keypoint/topdown_heatmap/mpii/resnext_mpii.yml
-- configs/body_2d_keypoint/topdown_heatmap/mpii/scnet_mpii.yml
-- configs/body_2d_keypoint/topdown_heatmap/mpii/seresnet_mpii.yml
-- configs/body_2d_keypoint/topdown_heatmap/mpii/shufflenetv1_mpii.yml
-- configs/body_2d_keypoint/topdown_heatmap/mpii/shufflenetv2_mpii.yml
-- configs/body_2d_keypoint/topdown_heatmap/posetrack18/hrnet_posetrack18.yml
-- configs/body_2d_keypoint/topdown_heatmap/posetrack18/resnet_posetrack18.yml
-- configs/body_2d_keypoint/topdown_regression/coco/resnet_coco.yml
-- configs/body_2d_keypoint/topdown_regression/coco/resnet_rle_coco.yml
-- configs/body_2d_keypoint/topdown_regression/coco/mobilenetv2_rle_coco.yml
-- configs/body_2d_keypoint/topdown_regression/mpii/resnet_mpii.yml
-- configs/body_2d_keypoint/topdown_regression/mpii/resnet_rle_mpii.yml
-- configs/body_3d_keypoint/pose_lift/h36m/videopose3d_h36m.yml
-- configs/face_2d_keypoint/rtmpose/coco_wholebody_face/rtmpose_coco_wholebody_face.yml
-- configs/face_2d_keypoint/rtmpose/wflw/rtmpose_wflw.yml
-- configs/face_2d_keypoint/topdown_heatmap/300w/hrnetv2_300w.yml
-- configs/face_2d_keypoint/topdown_heatmap/aflw/hrnetv2_aflw.yml
-- configs/face_2d_keypoint/topdown_heatmap/aflw/hrnetv2_dark_aflw.yml
-- configs/face_2d_keypoint/topdown_heatmap/coco_wholebody_face/hourglass_coco_wholebody_face.yml
-- configs/face_2d_keypoint/topdown_heatmap/coco_wholebody_face/hrnetv2_coco_wholebody_face.yml
-- configs/face_2d_keypoint/topdown_heatmap/coco_wholebody_face/hrnetv2_dark_coco_wholebody_face.yml
-- configs/face_2d_keypoint/topdown_heatmap/coco_wholebody_face/mobilenetv2_coco_wholebody_face.yml
-- configs/face_2d_keypoint/topdown_heatmap/coco_wholebody_face/resnet_coco_wholebody_face.yml
-- configs/face_2d_keypoint/topdown_heatmap/coco_wholebody_face/scnet_coco_wholebody_face.yml
-- configs/face_2d_keypoint/topdown_heatmap/cofw/hrnetv2_cofw.yml
-- configs/face_2d_keypoint/topdown_heatmap/wflw/hrnetv2_wflw.yml
-- configs/face_2d_keypoint/topdown_heatmap/wflw/hrnetv2_dark_wflw.yml
-- configs/face_2d_keypoint/topdown_heatmap/wflw/hrnetv2_awing_wflw.yml
-- configs/hand_2d_keypoint/rtmpose/coco_wholebody_hand/rtmpose_coco_wholebody_hand.yml
-- configs/hand_2d_keypoint/topdown_heatmap/coco_wholebody_hand/hourglass_coco_wholebody_hand.yml
-- configs/hand_2d_keypoint/topdown_heatmap/coco_wholebody_hand/hrnetv2_coco_wholebody_hand.yml
-- configs/hand_2d_keypoint/topdown_heatmap/coco_wholebody_hand/hrnetv2_dark_coco_wholebody_hand.yml
-- configs/hand_2d_keypoint/topdown_heatmap/coco_wholebody_hand/litehrnet_coco_wholebody_hand.yml
-- configs/hand_2d_keypoint/topdown_heatmap/coco_wholebody_hand/mobilenetv2_coco_wholebody_hand.yml
-- configs/hand_2d_keypoint/topdown_heatmap/coco_wholebody_hand/resnet_coco_wholebody_hand.yml
-- configs/hand_2d_keypoint/topdown_heatmap/coco_wholebody_hand/scnet_coco_wholebody_hand.yml
-- configs/hand_2d_keypoint/topdown_heatmap/freihand2d/resnet_freihand2d.yml
-- configs/hand_2d_keypoint/topdown_heatmap/onehand10k/resnet_onehand10k.yml
-- configs/hand_2d_keypoint/topdown_heatmap/onehand10k/hrnetv2_dark_onehand10k.yml
-- configs/hand_2d_keypoint/topdown_heatmap/onehand10k/hrnetv2_onehand10k.yml
-- configs/hand_2d_keypoint/topdown_heatmap/onehand10k/hrnetv2_udp_onehand10k.yml
-- configs/hand_2d_keypoint/topdown_heatmap/onehand10k/mobilenetv2_onehand10k.yml
-- configs/hand_2d_keypoint/topdown_heatmap/rhd2d/hrnetv2_dark_rhd2d.yml
-- configs/hand_2d_keypoint/topdown_heatmap/rhd2d/hrnetv2_rhd2d.yml
-- configs/hand_2d_keypoint/topdown_heatmap/rhd2d/hrnetv2_udp_rhd2d.yml
-- configs/hand_2d_keypoint/topdown_heatmap/rhd2d/mobilenetv2_rhd2d.yml
-- configs/hand_2d_keypoint/topdown_heatmap/rhd2d/resnet_rhd2d.yml
-- configs/hand_2d_keypoint/topdown_regression/onehand10k/resnet_onehand10k.yml
-- configs/hand_2d_keypoint/topdown_regression/rhd2d/resnet_rhd2d.yml
-- configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/rtmpose_coco-wholebody.yml
-- configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/hrnet_coco-wholebody.yml
-- configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/hrnet_dark_coco-wholebody.yml
-- configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/resnet_coco-wholebody.yml
-- configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/vipnas_coco-wholebody.yml
-- configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/vipnas_dark_coco-wholebody.yml
-- configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/cspnext_udp_coco-wholebody.yml
-- configs/fashion_2d_keypoint/topdown_heatmap/deepfashion2/res50_deepfasion2.yml
+Import:
+- configs/animal_2d_keypoint/rtmpose/ap10k/rtmpose_ap10k.yml
+- configs/animal_2d_keypoint/topdown_heatmap/animalpose/hrnet_animalpose.yml
+- configs/animal_2d_keypoint/topdown_heatmap/animalpose/resnet_animalpose.yml
+- configs/animal_2d_keypoint/topdown_heatmap/ap10k/resnet_ap10k.yml
+- configs/animal_2d_keypoint/topdown_heatmap/ap10k/hrnet_ap10k.yml
+- configs/animal_2d_keypoint/topdown_heatmap/ap10k/cspnext_udp_ap10k.yml
+- configs/animal_2d_keypoint/topdown_heatmap/locust/resnet_locust.yml
+- configs/animal_2d_keypoint/topdown_heatmap/zebra/resnet_zebra.yml
+- configs/body_2d_keypoint/cid/coco/hrnet_coco.yml
+- configs/body_2d_keypoint/dekr/coco/hrnet_coco.yml
+- configs/body_2d_keypoint/dekr/crowdpose/hrnet_crowdpose.yml
+- configs/body_2d_keypoint/integral_regression/coco/resnet_ipr_coco.yml
+- configs/body_2d_keypoint/integral_regression/coco/resnet_dsnt_coco.yml
+- configs/body_2d_keypoint/integral_regression/coco/resnet_debias_coco.yml
+- configs/body_2d_keypoint/rtmpose/coco/rtmpose_coco.yml
+- configs/body_2d_keypoint/rtmpose/crowdpose/rtmpose_crowdpose.yml
+- configs/body_2d_keypoint/rtmpose/mpii/rtmpose_mpii.yml
+- configs/body_2d_keypoint/simcc/coco/mobilenetv2_coco.yml
+- configs/body_2d_keypoint/simcc/coco/resnet_coco.yml
+- configs/body_2d_keypoint/simcc/coco/vipnas_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/aic/hrnet_aic.yml
+- configs/body_2d_keypoint/topdown_heatmap/aic/resnet_aic.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/hourglass_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/hrnet_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/litehrnet_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/mspn_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/vitpose_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/alexnet_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/resnet_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/cpm_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/hrformer_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/hrnet_augmentation_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/hrnet_dark_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/hrnet_udp_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/mobilenetv2_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/pvt_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/resnest_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/resnet_dark_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/cspnext_udp_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/resnetv1d_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/resnext_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/rsn_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/scnet_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/seresnet_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/shufflenetv1_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/shufflenetv2_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/swin_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/vgg_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/coco/vipnas_coco.yml
+- configs/body_2d_keypoint/topdown_heatmap/crowdpose/hrnet_crowdpose.yml
+- configs/body_2d_keypoint/topdown_heatmap/crowdpose/resnet_crowdpose.yml
+- configs/body_2d_keypoint/topdown_heatmap/crowdpose/cspnext_udp_crowdpose.yml
+- configs/body_2d_keypoint/topdown_heatmap/jhmdb/cpm_jhmdb.yml
+- configs/body_2d_keypoint/topdown_heatmap/jhmdb/resnet_jhmdb.yml
+- configs/body_2d_keypoint/topdown_heatmap/mpii/cpm_mpii.yml
+- configs/body_2d_keypoint/topdown_heatmap/mpii/hourglass_mpii.yml
+- configs/body_2d_keypoint/topdown_heatmap/mpii/cspnext_udp_mpii.yml
+- configs/body_2d_keypoint/topdown_heatmap/mpii/hrnet_dark_mpii.yml
+- configs/body_2d_keypoint/topdown_heatmap/mpii/hrnet_mpii.yml
+- configs/body_2d_keypoint/topdown_heatmap/mpii/litehrnet_mpii.yml
+- configs/body_2d_keypoint/topdown_heatmap/mpii/mobilenetv2_mpii.yml
+- configs/body_2d_keypoint/topdown_heatmap/mpii/resnet_mpii.yml
+- configs/body_2d_keypoint/topdown_heatmap/mpii/resnetv1d_mpii.yml
+- configs/body_2d_keypoint/topdown_heatmap/mpii/resnext_mpii.yml
+- configs/body_2d_keypoint/topdown_heatmap/mpii/scnet_mpii.yml
+- configs/body_2d_keypoint/topdown_heatmap/mpii/seresnet_mpii.yml
+- configs/body_2d_keypoint/topdown_heatmap/mpii/shufflenetv1_mpii.yml
+- configs/body_2d_keypoint/topdown_heatmap/mpii/shufflenetv2_mpii.yml
+- configs/body_2d_keypoint/topdown_heatmap/posetrack18/hrnet_posetrack18.yml
+- configs/body_2d_keypoint/topdown_heatmap/posetrack18/resnet_posetrack18.yml
+- configs/body_2d_keypoint/topdown_regression/coco/resnet_coco.yml
+- configs/body_2d_keypoint/topdown_regression/coco/resnet_rle_coco.yml
+- configs/body_2d_keypoint/topdown_regression/coco/mobilenetv2_rle_coco.yml
+- configs/body_2d_keypoint/topdown_regression/mpii/resnet_mpii.yml
+- configs/body_2d_keypoint/topdown_regression/mpii/resnet_rle_mpii.yml
+- configs/body_3d_keypoint/pose_lift/h36m/videopose3d_h36m.yml
+- configs/face_2d_keypoint/rtmpose/coco_wholebody_face/rtmpose_coco_wholebody_face.yml
+- configs/face_2d_keypoint/rtmpose/wflw/rtmpose_wflw.yml
+- configs/face_2d_keypoint/topdown_heatmap/300w/hrnetv2_300w.yml
+- configs/face_2d_keypoint/topdown_heatmap/aflw/hrnetv2_aflw.yml
+- configs/face_2d_keypoint/topdown_heatmap/aflw/hrnetv2_dark_aflw.yml
+- configs/face_2d_keypoint/topdown_heatmap/coco_wholebody_face/hourglass_coco_wholebody_face.yml
+- configs/face_2d_keypoint/topdown_heatmap/coco_wholebody_face/hrnetv2_coco_wholebody_face.yml
+- configs/face_2d_keypoint/topdown_heatmap/coco_wholebody_face/hrnetv2_dark_coco_wholebody_face.yml
+- configs/face_2d_keypoint/topdown_heatmap/coco_wholebody_face/mobilenetv2_coco_wholebody_face.yml
+- configs/face_2d_keypoint/topdown_heatmap/coco_wholebody_face/resnet_coco_wholebody_face.yml
+- configs/face_2d_keypoint/topdown_heatmap/coco_wholebody_face/scnet_coco_wholebody_face.yml
+- configs/face_2d_keypoint/topdown_heatmap/cofw/hrnetv2_cofw.yml
+- configs/face_2d_keypoint/topdown_heatmap/wflw/hrnetv2_wflw.yml
+- configs/face_2d_keypoint/topdown_heatmap/wflw/hrnetv2_dark_wflw.yml
+- configs/face_2d_keypoint/topdown_heatmap/wflw/hrnetv2_awing_wflw.yml
+- configs/hand_2d_keypoint/rtmpose/coco_wholebody_hand/rtmpose_coco_wholebody_hand.yml
+- configs/hand_2d_keypoint/topdown_heatmap/coco_wholebody_hand/hourglass_coco_wholebody_hand.yml
+- configs/hand_2d_keypoint/topdown_heatmap/coco_wholebody_hand/hrnetv2_coco_wholebody_hand.yml
+- configs/hand_2d_keypoint/topdown_heatmap/coco_wholebody_hand/hrnetv2_dark_coco_wholebody_hand.yml
+- configs/hand_2d_keypoint/topdown_heatmap/coco_wholebody_hand/litehrnet_coco_wholebody_hand.yml
+- configs/hand_2d_keypoint/topdown_heatmap/coco_wholebody_hand/mobilenetv2_coco_wholebody_hand.yml
+- configs/hand_2d_keypoint/topdown_heatmap/coco_wholebody_hand/resnet_coco_wholebody_hand.yml
+- configs/hand_2d_keypoint/topdown_heatmap/coco_wholebody_hand/scnet_coco_wholebody_hand.yml
+- configs/hand_2d_keypoint/topdown_heatmap/freihand2d/resnet_freihand2d.yml
+- configs/hand_2d_keypoint/topdown_heatmap/onehand10k/resnet_onehand10k.yml
+- configs/hand_2d_keypoint/topdown_heatmap/onehand10k/hrnetv2_dark_onehand10k.yml
+- configs/hand_2d_keypoint/topdown_heatmap/onehand10k/hrnetv2_onehand10k.yml
+- configs/hand_2d_keypoint/topdown_heatmap/onehand10k/hrnetv2_udp_onehand10k.yml
+- configs/hand_2d_keypoint/topdown_heatmap/onehand10k/mobilenetv2_onehand10k.yml
+- configs/hand_2d_keypoint/topdown_heatmap/rhd2d/hrnetv2_dark_rhd2d.yml
+- configs/hand_2d_keypoint/topdown_heatmap/rhd2d/hrnetv2_rhd2d.yml
+- configs/hand_2d_keypoint/topdown_heatmap/rhd2d/hrnetv2_udp_rhd2d.yml
+- configs/hand_2d_keypoint/topdown_heatmap/rhd2d/mobilenetv2_rhd2d.yml
+- configs/hand_2d_keypoint/topdown_heatmap/rhd2d/resnet_rhd2d.yml
+- configs/hand_2d_keypoint/topdown_regression/onehand10k/resnet_onehand10k.yml
+- configs/hand_2d_keypoint/topdown_regression/rhd2d/resnet_rhd2d.yml
+- configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/rtmpose_coco-wholebody.yml
+- configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/hrnet_coco-wholebody.yml
+- configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/hrnet_dark_coco-wholebody.yml
+- configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/resnet_coco-wholebody.yml
+- configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/vipnas_coco-wholebody.yml
+- configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/vipnas_dark_coco-wholebody.yml
+- configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/cspnext_udp_coco-wholebody.yml
+- configs/fashion_2d_keypoint/topdown_heatmap/deepfashion2/res50_deepfasion2.yml
diff --git a/myconfigs/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py b/myconfigs/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py
index 7a1bee42b4..32286ade4d 100644
--- a/myconfigs/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py
+++ b/myconfigs/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py
@@ -1,150 +1,150 @@
-_base_ = ['../default_runtime.py']
-
-# runtime
-train_cfg = dict(max_epochs=210, val_interval=10)
-
-# optimizer
-optim_wrapper = dict(optimizer=dict(
- type='Adam',
- lr=5e-4,
-))
-
-# learning policy
-param_scheduler = [
- dict(
- type='LinearLR', begin=0, end=500, start_factor=0.001,
- by_epoch=False), # warm-up
- dict(
- type='MultiStepLR',
- begin=0,
- end=210,
- milestones=[170, 200],
- gamma=0.1,
- by_epoch=True)
-]
-
-# automatically scaling LR based on the actual training batch size
-auto_scale_lr = dict(base_batch_size=512)
-
-# hooks
-default_hooks = dict(checkpoint=dict(save_best='coco/AP', rule='greater'))
-
-# codec settings
-codec = dict(
- type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
-
-# model settings
-model = dict(
- type='TopdownPoseEstimator',
- data_preprocessor=dict(
- type='PoseDataPreprocessor',
- mean=[123.675, 116.28, 103.53],
- std=[58.395, 57.12, 57.375],
- bgr_to_rgb=True),
- backbone=dict(
- type='HRNet',
- in_channels=3,
- extra=dict(
- stage1=dict(
- num_modules=1,
- num_branches=1,
- block='BOTTLENECK',
- num_blocks=(4, ),
- num_channels=(64, )),
- stage2=dict(
- num_modules=1,
- num_branches=2,
- block='BASIC',
- num_blocks=(4, 4),
- num_channels=(32, 64)),
- stage3=dict(
- num_modules=4,
- num_branches=3,
- block='BASIC',
- num_blocks=(4, 4, 4),
- num_channels=(32, 64, 128)),
- stage4=dict(
- num_modules=3,
- num_branches=4,
- block='BASIC',
- num_blocks=(4, 4, 4, 4),
- num_channels=(32, 64, 128, 256))),
- init_cfg=dict(
- type='Pretrained',
- checkpoint='https://download.openmmlab.com/mmpose/'
- 'pretrain_models/hrnet_w32-36af842e.pth'),
- ),
- head=dict(
- type='HeatmapHead',
- in_channels=32,
- out_channels=17,
- deconv_out_channels=None,
- loss=dict(type='KeypointMSELoss', use_target_weight=True),
- decoder=codec),
- test_cfg=dict(
- flip_test=True,
- flip_mode='heatmap',
- shift_heatmap=True,
- ))
-
-# base dataset settings
-dataset_type = 'CocoDataset'
-data_mode = 'topdown'
-data_root = '../../data/datasets/coco/'
-
-# pipelines
-train_pipeline = [
- dict(type='LoadImage'),
- dict(type='GetBBoxCenterScale'),
- dict(type='RandomFlip', direction='horizontal'),
- dict(type='RandomHalfBody'),
- dict(type='RandomBBoxTransform'),
- dict(type='TopdownAffine', input_size=codec['input_size']),
- dict(type='GenerateTarget', encoder=codec),
- dict(type='PackPoseInputs')
-]
-val_pipeline = [
- dict(type='LoadImage'),
- dict(type='GetBBoxCenterScale'),
- dict(type='TopdownAffine', input_size=codec['input_size']),
- dict(type='PackPoseInputs')
-]
-
-# data loaders
-train_dataloader = dict(
- batch_size=64,
- num_workers=2,
- persistent_workers=True,
- sampler=dict(type='DefaultSampler', shuffle=True),
- dataset=dict(
- type=dataset_type,
- data_root=data_root,
- data_mode=data_mode,
- ann_file='annotations/person_keypoints_train2017.json',
- data_prefix=dict(img='images/train2017/'),
- pipeline=train_pipeline,
- ))
-val_dataloader = dict(
- batch_size=32,
- num_workers=2,
- persistent_workers=True,
- drop_last=False,
- sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
- dataset=dict(
- type=dataset_type,
- data_root=data_root,
- data_mode=data_mode,
- ann_file='annotations/person_keypoints_val2017.json',
- bbox_file='../../data/datasets/coco/person_detection_results/'
- 'COCO_val2017_detections_AP_H_56_person.json',
- data_prefix=dict(img='images/val2017/'),
- test_mode=True,
- pipeline=val_pipeline,
- ))
-test_dataloader = val_dataloader
-
-# evaluators
-val_evaluator = dict(
- type='CocoMetric',
- ann_file=data_root + 'annotations/person_keypoints_val2017.json')
-test_evaluator = val_evaluator
+_base_ = ['../default_runtime.py']
+
+# runtime
+train_cfg = dict(max_epochs=210, val_interval=10)
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(
+ type='Adam',
+ lr=5e-4,
+))
+
+# learning policy
+param_scheduler = [
+ dict(
+ type='LinearLR', begin=0, end=500, start_factor=0.001,
+ by_epoch=False), # warm-up
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=210,
+ milestones=[170, 200],
+ gamma=0.1,
+ by_epoch=True)
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# hooks
+default_hooks = dict(checkpoint=dict(save_best='coco/AP', rule='greater'))
+
+# codec settings
+codec = dict(
+ type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth'),
+ ),
+ head=dict(
+ type='HeatmapHead',
+ in_channels=32,
+ out_channels=17,
+ deconv_out_channels=None,
+ loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ decoder=codec),
+ test_cfg=dict(
+ flip_test=True,
+ flip_mode='heatmap',
+ shift_heatmap=True,
+ ))
+
+# base dataset settings
+dataset_type = 'CocoDataset'
+data_mode = 'topdown'
+data_root = '../../data/datasets/coco/'
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=64,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='images/train2017/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_val2017.json',
+ bbox_file='../../data/datasets/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='images/val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# evaluators
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/person_keypoints_val2017.json')
+test_evaluator = val_evaluator
diff --git a/myconfigs/default_runtime.py b/myconfigs/default_runtime.py
index 561d574fa7..1235dfafb6 100644
--- a/myconfigs/default_runtime.py
+++ b/myconfigs/default_runtime.py
@@ -1,49 +1,49 @@
-default_scope = 'mmpose'
-
-# hooks
-default_hooks = dict(
- timer=dict(type='IterTimerHook'),
- logger=dict(type='LoggerHook', interval=50),
- param_scheduler=dict(type='ParamSchedulerHook'),
- checkpoint=dict(type='CheckpointHook', interval=10),
- sampler_seed=dict(type='DistSamplerSeedHook'),
- visualization=dict(type='PoseVisualizationHook', enable=False),
-)
-
-# custom hooks
-custom_hooks = [
- # Synchronize model buffers such as running_mean and running_var in BN
- # at the end of each epoch
- dict(type='SyncBuffersHook')
-]
-
-# multi-processing backend
-env_cfg = dict(
- cudnn_benchmark=False,
- mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
- dist_cfg=dict(backend='nccl'),
-)
-
-# visualizer
-vis_backends = [
- dict(type='LocalVisBackend'),
- # dict(type='TensorboardVisBackend'),
- # dict(type='WandbVisBackend'),
-]
-visualizer = dict(
- type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
-
-# logger
-log_processor = dict(
- type='LogProcessor', window_size=50, by_epoch=True, num_digits=6)
-log_level = 'INFO'
-load_from = None
-resume = False
-
-# file I/O backend
-backend_args = dict(backend='local')
-
-# training/validation/testing progress
-train_cfg = dict(by_epoch=True)
-val_cfg = dict()
-test_cfg = dict()
+default_scope = 'mmpose'
+
+# hooks
+default_hooks = dict(
+ timer=dict(type='IterTimerHook'),
+ logger=dict(type='LoggerHook', interval=50),
+ param_scheduler=dict(type='ParamSchedulerHook'),
+ checkpoint=dict(type='CheckpointHook', interval=10),
+ sampler_seed=dict(type='DistSamplerSeedHook'),
+ visualization=dict(type='PoseVisualizationHook', enable=False),
+)
+
+# custom hooks
+custom_hooks = [
+ # Synchronize model buffers such as running_mean and running_var in BN
+ # at the end of each epoch
+ dict(type='SyncBuffersHook')
+]
+
+# multi-processing backend
+env_cfg = dict(
+ cudnn_benchmark=False,
+ mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
+ dist_cfg=dict(backend='nccl'),
+)
+
+# visualizer
+vis_backends = [
+ dict(type='LocalVisBackend'),
+ # dict(type='TensorboardVisBackend'),
+ # dict(type='WandbVisBackend'),
+]
+visualizer = dict(
+ type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
+
+# logger
+log_processor = dict(
+ type='LogProcessor', window_size=50, by_epoch=True, num_digits=6)
+log_level = 'INFO'
+load_from = None
+resume = False
+
+# file I/O backend
+backend_args = dict(backend='local')
+
+# training/validation/testing progress
+train_cfg = dict(by_epoch=True)
+val_cfg = dict()
+test_cfg = dict()
diff --git a/myconfigs/octseg/dekr_hrnet-w32_8xb10-140e_octseg-512x512.py b/myconfigs/octseg/dekr_hrnet-w32_8xb10-140e_octseg-512x512.py
index 0f91e07209..4cb7dc1536 100644
--- a/myconfigs/octseg/dekr_hrnet-w32_8xb10-140e_octseg-512x512.py
+++ b/myconfigs/octseg/dekr_hrnet-w32_8xb10-140e_octseg-512x512.py
@@ -1,206 +1,206 @@
-_base_ = ['../default_runtime.py']
-
-# runtime
-train_cfg = dict(max_epochs=1260, val_interval=60)
-
-# optimizer
-optim_wrapper = dict(optimizer=dict(
- type='Adam',
- lr=1e-3,
-))
-
-# learning policy
-param_scheduler = [
- dict(
- type='LinearLR', begin=0, end=500, start_factor=0.001,
- by_epoch=False), # warm-up
- dict(
- type='MultiStepLR',
- begin=0,
- end=140,
- milestones=[90, 120],
- gamma=0.1,
- by_epoch=True)
-]
-
-# automatically scaling LR based on the actual training batch size
-auto_scale_lr = dict(base_batch_size=80)
-
-# hooks
-default_hooks = dict(checkpoint=dict(save_best='coco/AP', rule='greater'))
-
-# codec settings
-codec = dict(
- type='SPR',
- input_size=(512, 512),
- heatmap_size=(128, 128),
- sigma=(4, 2),
- minimal_diagonal_length=32**0.5,
- generate_keypoint_heatmaps=True,
- decode_max_instances=30)
-
-# model settings
-model = dict(
- type='BottomupPoseEstimator',
- data_preprocessor=dict(
- type='PoseDataPreprocessor',
- # mean=[123.675, 116.28, 103.53],
- # std=[58.395, 57.12, 57.375],
- mean=[21.002],
- std=[25.754]
- # bgr_to_rgb=True
- ),
- backbone=dict(
- type='HRNet',
- # in_channels=3,
- in_channels=1,
- extra=dict(
- stage1=dict(
- num_modules=1,
- num_branches=1,
- block='BOTTLENECK',
- num_blocks=(4, ),
- num_channels=(64, )),
- stage2=dict(
- num_modules=1,
- num_branches=2,
- block='BASIC',
- num_blocks=(4, 4),
- num_channels=(32, 64)),
- stage3=dict(
- num_modules=4,
- num_branches=3,
- block='BASIC',
- num_blocks=(4, 4, 4),
- num_channels=(32, 64, 128)),
- stage4=dict(
- num_modules=3,
- num_branches=4,
- block='BASIC',
- num_blocks=(4, 4, 4, 4),
- num_channels=(32, 64, 128, 256),
- multiscale_output=True)),
- init_cfg=dict(
- type='Pretrained',
- checkpoint='https://download.openmmlab.com/mmpose/'
- 'pretrain_models/hrnet_w32-36af842e.pth'),
- ),
- neck=dict(
- type='FeatureMapProcessor',
- concat=True,
- ),
- head=dict(
- type='DEKRHead',
- in_channels=480,
- # num_keypoints=17,
- num_keypoints=2,
- heatmap_loss=dict(type='KeypointMSELoss', use_target_weight=True),
- displacement_loss=dict(
- type='SoftWeightSmoothL1Loss',
- use_target_weight=True,
- supervise_empty=False,
- beta=1 / 9,
- loss_weight=0.002,
- ),
- decoder=codec
- # rescore_cfg=dict(
- # in_channels=74,
- # norm_indexes=(5, 6),
- # init_cfg=dict(
- # type='Pretrained',
- # checkpoint='https://download.openmmlab.com/mmpose/'
- # 'pretrain_models/kpt_rescore_coco-33d58c5c.pth')),
- ),
- test_cfg=dict(
- multiscale_test=False,
- flip_test=True,
- nms_dist_thr=0.05,
- shift_heatmap=True,
- align_corners=False))
-
-# enable DDP training when rescore net is used
-find_unused_parameters = True
-
-# base dataset settings
-dataset_type = 'OCTSegDataset'
-data_mode = 'bottomup'
-data_root = '../../data/datasets/octseg/'
-
-# pipelines
-train_pipeline = [
- # dict(type='LoadImage'),
- dict(type='LoadImage', color_type='unchanged'),
- dict(type='BottomupRandomAffine', input_size=codec['input_size']),
- dict(type='RandomFlip', direction='horizontal'), # check flip!!
- dict(type='GenerateTarget', encoder=codec),
- # dict(type='BottomupGetHeatmapMask'),
- dict(type='PackPoseInputs'),
-]
-val_pipeline = [
- dict(type='LoadImage', color_type='unchanged'),
- dict(
- type='BottomupResize',
- input_size=codec['input_size'],
- size_factor=32,
- resize_mode='expand'),
- dict(
- type='PackPoseInputs',
- meta_keys=('id', 'img_id', 'img_path', 'crowd_index', 'ori_shape',
- 'img_shape', 'input_size', 'input_center', 'input_scale',
- 'flip', 'flip_direction', 'flip_indices', 'raw_ann_info',
- 'skeleton_links'))
-]
-
-# data loaders
-train_dataloader = dict(
- batch_size=20,
- num_workers=2,
- persistent_workers=True,
- sampler=dict(type='DefaultSampler', shuffle=True),
- dataset=dict(
- type=dataset_type,
- data_root=data_root,
- data_mode=data_mode,
- ann_file='sidebranch_round_train.json',
- data_prefix=dict(img='train/round/'),
- pipeline=train_pipeline,
- ))
-val_dataloader = dict(
- batch_size=10,
- num_workers=1,
- persistent_workers=True,
- drop_last=False,
- sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
- dataset=dict(
- type=dataset_type,
- data_root=data_root,
- data_mode=data_mode,
- ann_file='sidebranch_round_test.json',
- data_prefix=dict(img='test/round/'),
- test_mode=True,
- pipeline=val_pipeline,
- ))
-test_dataloader = dict(
- batch_size=1,
- num_workers=1,
- persistent_workers=True,
- drop_last=False,
- sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
- dataset=dict(
- type=dataset_type,
- data_root=data_root,
- data_mode=data_mode,
- ann_file='sidebranch_round_test.json',
- data_prefix=dict(img='test/round/'),
- test_mode=True,
- pipeline=val_pipeline,
- ))
-
-# evaluators
-val_evaluator = dict(
- type='CocoMetric',
- ann_file=data_root + 'sidebranch_round_test.json',
- nms_mode='none',
- score_mode='keypoint',
-)
-test_evaluator = val_evaluator
+_base_ = ['../default_runtime.py']
+
+# runtime
+train_cfg = dict(max_epochs=1260, val_interval=60)
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(
+ type='Adam',
+ lr=1e-3,
+))
+
+# learning policy
+param_scheduler = [
+ dict(
+ type='LinearLR', begin=0, end=500, start_factor=0.001,
+ by_epoch=False), # warm-up
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=140,
+ milestones=[90, 120],
+ gamma=0.1,
+ by_epoch=True)
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=80)
+
+# hooks
+default_hooks = dict(checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=2))
+
+# codec settings
+codec = dict(
+ type='SPR',
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ sigma=(4, 2),
+ minimal_diagonal_length=32**0.5,
+ generate_keypoint_heatmaps=True,
+ decode_max_instances=30)
+
+# model settings
+model = dict(
+ type='BottomupPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ # mean=[123.675, 116.28, 103.53],
+ # std=[58.395, 57.12, 57.375],
+ mean=[21.002],
+ std=[25.754]
+ # bgr_to_rgb=True
+ ),
+ backbone=dict(
+ type='HRNet',
+ # in_channels=3,
+ in_channels=1,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256),
+ multiscale_output=True)),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth'),
+ ),
+ neck=dict(
+ type='FeatureMapProcessor',
+ concat=True,
+ ),
+ head=dict(
+ type='DEKRHead',
+ in_channels=480,
+ # num_keypoints=17,
+ num_keypoints=2,
+ heatmap_loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ displacement_loss=dict(
+ type='SoftWeightSmoothL1Loss',
+ use_target_weight=True,
+ supervise_empty=False,
+ beta=1 / 9,
+ loss_weight=0.002,
+ ),
+ decoder=codec
+ # rescore_cfg=dict(
+ # in_channels=74,
+ # norm_indexes=(5, 6),
+ # init_cfg=dict(
+ # type='Pretrained',
+ # checkpoint='https://download.openmmlab.com/mmpose/'
+ # 'pretrain_models/kpt_rescore_coco-33d58c5c.pth')),
+ ),
+ test_cfg=dict(
+ multiscale_test=False,
+ flip_test=True,
+ nms_dist_thr=0.05,
+ shift_heatmap=True,
+ align_corners=False))
+
+# enable DDP training when rescore net is used
+find_unused_parameters = True
+
+# base dataset settings
+dataset_type = 'OCTSegDataset'
+data_mode = 'bottomup'
+data_root = '../../data/datasets/octseg/'
+
+# pipelines
+train_pipeline = [
+ # dict(type='LoadImage'),
+ dict(type='LoadImage', color_type='unchanged'),
+ dict(type='BottomupRandomAffine', input_size=codec['input_size']),
+ dict(type='RandomFlip', direction='horizontal'), # check flip!!
+ dict(type='GenerateTarget', encoder=codec),
+ # dict(type='BottomupGetHeatmapMask'),
+ dict(type='PackPoseInputs'),
+]
+val_pipeline = [
+ dict(type='LoadImage', color_type='unchanged'),
+ dict(
+ type='BottomupResize',
+ input_size=codec['input_size'],
+ size_factor=32,
+ resize_mode='expand'),
+ dict(
+ type='PackPoseInputs',
+ meta_keys=('id', 'img_id', 'img_path', 'crowd_index', 'ori_shape',
+ 'img_shape', 'input_size', 'input_center', 'input_scale',
+ 'flip', 'flip_direction', 'flip_indices', 'raw_ann_info',
+ 'skeleton_links'))
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=20,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='sidebranch_round_train.json',
+ data_prefix=dict(img='train/round/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=1,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='sidebranch_round_test.json',
+ data_prefix=dict(img='test/round/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = dict(
+ batch_size=1,
+ num_workers=1,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='sidebranch_round_test.json',
+ data_prefix=dict(img='test/round/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+
+# evaluators
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'sidebranch_round_test.json',
+ nms_mode='none',
+ score_mode='keypoint',
+)
+test_evaluator = val_evaluator
diff --git a/myconfigs/octseg/dekr_octsb1-w32_8xb10-140e_octseg-round-512x512.py b/myconfigs/octseg/dekr_octsb1-w32_8xb10-140e_octseg-round-512x512.py
new file mode 100644
index 0000000000..b41832d823
--- /dev/null
+++ b/myconfigs/octseg/dekr_octsb1-w32_8xb10-140e_octseg-round-512x512.py
@@ -0,0 +1,209 @@
+_base_ = ['../default_runtime.py']
+
+# runtime
+train_cfg = dict(max_epochs=1260, val_interval=60)
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(
+ type='Adam',
+ lr=1e-3,
+))
+
+# learning policy
+param_scheduler = [
+ dict(
+ type='LinearLR', begin=0, end=500, start_factor=0.001,
+ by_epoch=False), # warm-up
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=140,
+ milestones=[90, 120],
+ gamma=0.1,
+ by_epoch=True)
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=80)
+
+# hooks
+default_hooks = dict(checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=2))
+
+# codec settings
+codec = dict(
+ type='SPR',
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ sigma=(4, 2),
+ minimal_diagonal_length=32**0.5,
+ generate_keypoint_heatmaps=True,
+ decode_max_instances=30)
+
+# model settings
+model = dict(
+ type='BottomupPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ # mean=[123.675, 116.28, 103.53],
+ # std=[58.395, 57.12, 57.375],
+ mean=[0],
+ std=[255]
+ # bgr_to_rgb=True
+ ),
+ backbone=dict(
+ type='OCTSB1',
+ # in_channels=3,
+ in_channels=1,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256),
+ multiscale_output=True)),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth'),
+ lumen_cfg=dict(
+ checkpoint_path='../../data/mmsegmentation/z-torchscript_models/unet-s5-d16_fcn-bce_4xb4-1280k_octlumen-round-random_resize512x512-crop256x256-no_wrapped-torchinput512x512.jit.pth'
+ )
+ ),
+ neck=dict(
+ type='FeatureMapProcessor',
+ concat=True,
+ ),
+ head=dict(
+ type='DEKRHead',
+ in_channels=480,
+ # num_keypoints=17,
+ num_keypoints=2,
+ heatmap_loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ displacement_loss=dict(
+ type='SoftWeightSmoothL1Loss',
+ use_target_weight=True,
+ supervise_empty=False,
+ beta=1 / 9,
+ loss_weight=0.002,
+ ),
+ decoder=codec
+ # rescore_cfg=dict(
+ # in_channels=74,
+ # norm_indexes=(5, 6),
+ # init_cfg=dict(
+ # type='Pretrained',
+ # checkpoint='https://download.openmmlab.com/mmpose/'
+ # 'pretrain_models/kpt_rescore_coco-33d58c5c.pth')),
+ ),
+ test_cfg=dict(
+ multiscale_test=False,
+ flip_test=True,
+ nms_dist_thr=0.05,
+ shift_heatmap=True,
+ align_corners=False))
+
+# enable DDP training when rescore net is used
+find_unused_parameters = True
+
+# base dataset settings
+dataset_type = 'OCTSegDataset'
+data_mode = 'bottomup'
+data_root = '../../data/datasets/octseg/'
+
+# pipelines
+train_pipeline = [
+ # dict(type='LoadImage'),
+ dict(type='LoadImage', color_type='unchanged'),
+ dict(type='BottomupRandomAffine', input_size=codec['input_size']),
+ dict(type='RandomFlip', direction='horizontal'), # check flip!!
+ dict(type='GenerateTarget', encoder=codec),
+ # dict(type='BottomupGetHeatmapMask'),
+ dict(type='PackPoseInputs'),
+]
+val_pipeline = [
+ dict(type='LoadImage', color_type='unchanged'),
+ dict(
+ type='BottomupResize',
+ input_size=codec['input_size'],
+ size_factor=32,
+ resize_mode='expand'),
+ dict(
+ type='PackPoseInputs',
+ meta_keys=('id', 'img_id', 'img_path', 'crowd_index', 'ori_shape',
+ 'img_shape', 'input_size', 'input_center', 'input_scale',
+ 'flip', 'flip_direction', 'flip_indices', 'raw_ann_info',
+ 'skeleton_links'))
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=16,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='sidebranch_round_train.json',
+ data_prefix=dict(img='train/round/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=1,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='sidebranch_round_test.json',
+ data_prefix=dict(img='test/round/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = dict(
+ batch_size=1,
+ num_workers=1,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='sidebranch_round_test.json',
+ data_prefix=dict(img='test/round/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+
+# evaluators
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'sidebranch_round_test.json',
+ nms_mode='none',
+ score_mode='keypoint',
+)
+test_evaluator = val_evaluator
diff --git a/myconfigs/octseg/dekr_octsb1-w32_8xb10-140e_octsegflat-512x512.py b/myconfigs/octseg/dekr_octsb1-w32_8xb10-140e_octsegflat-512x512.py
new file mode 100644
index 0000000000..b359f3ee35
--- /dev/null
+++ b/myconfigs/octseg/dekr_octsb1-w32_8xb10-140e_octsegflat-512x512.py
@@ -0,0 +1,211 @@
+_base_ = ['../default_runtime.py']
+
+# runtime
+train_cfg = dict(max_epochs=1260, val_interval=60)
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(
+ type='Adam',
+ lr=1e-3,
+))
+
+# learning policy
+param_scheduler = [
+ dict(
+ type='LinearLR', begin=0, end=500, start_factor=0.001,
+ by_epoch=False), # warm-up
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=140,
+ milestones=[90, 120],
+ gamma=0.1,
+ by_epoch=True)
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=80)
+
+# hooks
+default_hooks = dict(checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=2))
+
+# codec settings
+codec = dict(
+ type='SPR',
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ sigma=(4, 2),
+ minimal_diagonal_length=32**0.5,
+ generate_keypoint_heatmaps=True,
+ decode_max_instances=30)
+
+# model settings
+model = dict(
+ type='BottomupPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ # mean=[123.675, 116.28, 103.53],
+ # std=[58.395, 57.12, 57.375],
+ mean=[0],
+ std=[255]
+ # bgr_to_rgb=True
+ ),
+ backbone=dict(
+ type='OCTSB1',
+ # in_channels=3,
+ in_channels=1,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256),
+ multiscale_output=True)),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth'),
+ lumen_cfg=dict(
+ # config_path='../../data/mmsegmentation/work_dirs/unet-s5-d16_fcn-bce_4xb4-1280k_octlumen-random_resize512x512-crop256x256/unet-s5-d16_fcn-bce_4xb4-1280k_octlumen-random_resize512x512-crop256x256.py',
+ # checkpoint_path='../../data/mmsegmentation/work_dirs/unet-s5-d16_fcn-bce_4xb4-1280k_octlumen-random_resize512x512-crop256x256/best_mIoU_iter_768000.pth',
+ checkpoint_path='../../data/mmsegmentation/z-torchscript_models/unet-s5-d16_fcn-bce_4xb4-1280k_octlumen-random_resize512x512-crop256x256-no_wrapped-torchinput512x512.jit.pth'
+ )
+ ),
+ neck=dict(
+ type='FeatureMapProcessor',
+ concat=True,
+ ),
+ head=dict(
+ type='DEKRHead',
+ in_channels=480,
+ # num_keypoints=17,
+ num_keypoints=2,
+ heatmap_loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ displacement_loss=dict(
+ type='SoftWeightSmoothL1Loss',
+ use_target_weight=True,
+ supervise_empty=False,
+ beta=1 / 9,
+ loss_weight=0.002,
+ ),
+ decoder=codec
+ # rescore_cfg=dict(
+ # in_channels=74,
+ # norm_indexes=(5, 6),
+ # init_cfg=dict(
+ # type='Pretrained',
+ # checkpoint='https://download.openmmlab.com/mmpose/'
+ # 'pretrain_models/kpt_rescore_coco-33d58c5c.pth')),
+ ),
+ test_cfg=dict(
+ multiscale_test=False,
+ flip_test=True,
+ nms_dist_thr=0.05,
+ shift_heatmap=True,
+ align_corners=False))
+
+# enable DDP training when rescore net is used
+find_unused_parameters = True
+
+# base dataset settings
+dataset_type = 'OCTSegDataset'
+data_mode = 'bottomup'
+data_root = '../../data/datasets/octseg/'
+
+# pipelines
+train_pipeline = [
+ # dict(type='LoadImage'),
+ dict(type='LoadImage', color_type='unchanged'),
+ dict(type='BottomupRandomAffine', input_size=codec['input_size']),
+ dict(type='RandomFlip', direction='horizontal'), # check flip!!
+ dict(type='GenerateTarget', encoder=codec),
+ # dict(type='BottomupGetHeatmapMask'),
+ dict(type='PackPoseInputs'),
+]
+val_pipeline = [
+ dict(type='LoadImage', color_type='unchanged'),
+ dict(
+ type='BottomupResize',
+ input_size=codec['input_size'],
+ size_factor=32,
+ resize_mode='expand'),
+ dict(
+ type='PackPoseInputs',
+ meta_keys=('id', 'img_id', 'img_path', 'crowd_index', 'ori_shape',
+ 'img_shape', 'input_size', 'input_center', 'input_scale',
+ 'flip', 'flip_direction', 'flip_indices', 'raw_ann_info',
+ 'skeleton_links'))
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=16,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='sidebranch_flat_train.json',
+ data_prefix=dict(img='train/flat/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=1,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='sidebranch_flat_test.json',
+ data_prefix=dict(img='test/flat/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = dict(
+ batch_size=1,
+ num_workers=1,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='sidebranch_flat_test.json',
+ data_prefix=dict(img='test/flat/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+
+# evaluators
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'sidebranch_flat_test.json',
+ nms_mode='none',
+ score_mode='keypoint',
+)
+test_evaluator = val_evaluator
diff --git a/myconfigs/octseg/dekr_octsb2-w32_8xb10-140e_octsegflat-512x512.py b/myconfigs/octseg/dekr_octsb2-w32_8xb10-140e_octsegflat-512x512.py
new file mode 100644
index 0000000000..4f5175d8f4
--- /dev/null
+++ b/myconfigs/octseg/dekr_octsb2-w32_8xb10-140e_octsegflat-512x512.py
@@ -0,0 +1,209 @@
+_base_ = ['../default_runtime.py']
+
+# runtime
+train_cfg = dict(max_epochs=1260, val_interval=60)
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(
+ type='Adam',
+ lr=1e-3,
+))
+
+# learning policy
+param_scheduler = [
+ dict(
+ type='LinearLR', begin=0, end=500, start_factor=0.001,
+ by_epoch=False), # warm-up
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=140,
+ milestones=[90, 120],
+ gamma=0.1,
+ by_epoch=True)
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=80)
+
+# hooks
+default_hooks = dict(checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=2))
+
+# codec settings
+codec = dict(
+ type='SPR',
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ sigma=(4, 2),
+ minimal_diagonal_length=32**0.5,
+ generate_keypoint_heatmaps=True,
+ decode_max_instances=30)
+
+# model settings
+model = dict(
+ type='BottomupPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ # mean=[123.675, 116.28, 103.53],
+ # std=[58.395, 57.12, 57.375],
+ mean=[0],
+ std=[255]
+ # bgr_to_rgb=True
+ ),
+ backbone=dict(
+ type='OCTSB2',
+ # in_channels=3,
+ in_channels=1,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256),
+ multiscale_output=True)),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth'),
+ lumen_cfg=dict(
+ checkpoint_path='../../data/mmsegmentation/z-torchscript_models/unet-s5-d16_fcn-bce_4xb4-1280k_octflatguidewires-random_resize512x512-crop256x256-no_wrapped-torchinput512x512.jit.pth'
+ )
+ ),
+ neck=dict(
+ type='FeatureMapProcessor',
+ concat=True,
+ ),
+ head=dict(
+ type='DEKRHead',
+ in_channels=480,
+ # num_keypoints=17,
+ num_keypoints=2,
+ heatmap_loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ displacement_loss=dict(
+ type='SoftWeightSmoothL1Loss',
+ use_target_weight=True,
+ supervise_empty=False,
+ beta=1 / 9,
+ loss_weight=0.002,
+ ),
+ decoder=codec
+ # rescore_cfg=dict(
+ # in_channels=74,
+ # norm_indexes=(5, 6),
+ # init_cfg=dict(
+ # type='Pretrained',
+ # checkpoint='https://download.openmmlab.com/mmpose/'
+ # 'pretrain_models/kpt_rescore_coco-33d58c5c.pth')),
+ ),
+ test_cfg=dict(
+ multiscale_test=False,
+ flip_test=True,
+ nms_dist_thr=0.05,
+ shift_heatmap=True,
+ align_corners=False))
+
+# enable DDP training when rescore net is used
+find_unused_parameters = True
+
+# base dataset settings
+dataset_type = 'OCTSegDataset'
+data_mode = 'bottomup'
+data_root = '../../data/datasets/octseg/'
+
+# pipelines
+train_pipeline = [
+ # dict(type='LoadImage'),
+ dict(type='LoadImage', color_type='unchanged'),
+ dict(type='BottomupRandomAffine', input_size=codec['input_size']),
+ dict(type='RandomFlip', direction='horizontal'), # check flip!!
+ dict(type='GenerateTarget', encoder=codec),
+ # dict(type='BottomupGetHeatmapMask'),
+ dict(type='PackPoseInputs'),
+]
+val_pipeline = [
+ dict(type='LoadImage', color_type='unchanged'),
+ dict(
+ type='BottomupResize',
+ input_size=codec['input_size'],
+ size_factor=32,
+ resize_mode='expand'),
+ dict(
+ type='PackPoseInputs',
+ meta_keys=('id', 'img_id', 'img_path', 'crowd_index', 'ori_shape',
+ 'img_shape', 'input_size', 'input_center', 'input_scale',
+ 'flip', 'flip_direction', 'flip_indices', 'raw_ann_info',
+ 'skeleton_links'))
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=16,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='sidebranch_flat_train.json',
+ data_prefix=dict(img='train/flat/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=1,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='sidebranch_flat_test.json',
+ data_prefix=dict(img='test/flat/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = dict(
+ batch_size=1,
+ num_workers=1,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='sidebranch_flat_test.json',
+ data_prefix=dict(img='test/flat/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+
+# evaluators
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'sidebranch_flat_test.json',
+ nms_mode='none',
+ score_mode='keypoint',
+)
+test_evaluator = val_evaluator
diff --git a/myconfigs/octseg/dekr_octsb3-warping-w32_8xb10-140e_octsegflat-512x512.py b/myconfigs/octseg/dekr_octsb3-warping-w32_8xb10-140e_octsegflat-512x512.py
new file mode 100644
index 0000000000..526c299e63
--- /dev/null
+++ b/myconfigs/octseg/dekr_octsb3-warping-w32_8xb10-140e_octsegflat-512x512.py
@@ -0,0 +1,211 @@
+_base_ = ['../default_runtime.py']
+
+# runtime
+train_cfg = dict(max_epochs=1260, val_interval=60)
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(
+ type='Adam',
+ lr=1e-3,
+))
+
+# learning policy
+param_scheduler = [
+ dict(
+ type='LinearLR', begin=0, end=500, start_factor=0.001,
+ by_epoch=False), # warm-up
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=140,
+ milestones=[90, 120],
+ gamma=0.1,
+ by_epoch=True)
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=80)
+
+# hooks
+default_hooks = dict(checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=2))
+
+# codec settings
+codec = dict(
+ type='SPR',
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ sigma=(4, 2),
+ minimal_diagonal_length=32**0.5,
+ generate_keypoint_heatmaps=True,
+ decode_max_instances=30)
+
+# model settings
+model = dict(
+ type='BottomupPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ # mean=[123.675, 116.28, 103.53],
+ # std=[58.395, 57.12, 57.375],
+ mean=[0],
+ std=[255]
+ # bgr_to_rgb=True
+ ),
+ backbone=dict(
+ type='OCTSB2',
+ # in_channels=3,
+ in_channels=1,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256),
+ multiscale_output=True)),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth'),
+ lumen_cfg=dict(
+ checkpoint_path='../../data/mmsegmentation/z-torchscript_models/unet-s5-d16_fcn-bce_4xb4-1280k_octroundguidewires-random_resize512x512-crop256x256-no_wrapped-torchinput512x512.jit.pth'
+ )
+ ),
+ neck=dict(
+ type='FeatureMapProcessor',
+ concat=True,
+ ),
+ head=dict(
+ type='DEKRHead',
+ in_channels=480,
+ # num_keypoints=17,
+ num_keypoints=2,
+ heatmap_loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ displacement_loss=dict(
+ type='SoftWeightSmoothL1Loss',
+ use_target_weight=True,
+ supervise_empty=False,
+ beta=1 / 9,
+ loss_weight=0.002,
+ ),
+ decoder=codec
+ # rescore_cfg=dict(
+ # in_channels=74,
+ # norm_indexes=(5, 6),
+ # init_cfg=dict(
+ # type='Pretrained',
+ # checkpoint='https://download.openmmlab.com/mmpose/'
+ # 'pretrain_models/kpt_rescore_coco-33d58c5c.pth')),
+ ),
+ test_cfg=dict(
+ multiscale_test=False,
+ flip_test=True,
+ nms_dist_thr=0.05,
+ shift_heatmap=True,
+ align_corners=False))
+
+# enable DDP training when rescore net is used
+find_unused_parameters = True
+
+# base dataset settings
+dataset_type = 'OCTSegDataset'
+data_mode = 'bottomup'
+data_root = '../../data/datasets/octseg/'
+
+# pipelines
+train_pipeline = [
+ # dict(type='LoadImage'),
+ dict(type='LoadImage', color_type='unchanged'),
+ # dict(type='Warping', direction='cart2polar', n_beams=512, scale=1),
+ dict(type='BottomupRandomAffine', input_size=codec['input_size']),
+ dict(type='RandomFlip', direction=['horizontal', 'vertical']), # check flip!!
+ dict(type='GenerateTarget', encoder=codec),
+ # dict(type='BottomupGetHeatmapMask'),
+ dict(type='PackPoseInputs'),
+]
+val_pipeline = [
+ dict(type='LoadImage', color_type='unchanged'),
+ # dict(type='Warping', direction='cart2polar', n_beams=512, scale=1),
+ dict(
+ type='BottomupResize',
+ input_size=codec['input_size'],
+ size_factor=32,
+ resize_mode='expand'),
+ dict(
+ type='PackPoseInputs',
+ meta_keys=('id', 'img_id', 'img_path', 'crowd_index', 'ori_shape',
+ 'img_shape', 'input_size', 'input_center', 'input_scale',
+ 'flip', 'flip_direction', 'flip_indices', 'raw_ann_info',
+ 'skeleton_links'))
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=16,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='sidebranch_round_train.json',
+ data_prefix=dict(img='train/round/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=1,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='sidebranch_round_test.json',
+ data_prefix=dict(img='test/round/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = dict(
+ batch_size=1,
+ num_workers=1,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='sidebranch_round_test.json',
+ data_prefix=dict(img='test/round/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+
+# evaluators
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'sidebranch_round_test.json',
+ nms_mode='none',
+ score_mode='keypoint',
+)
+test_evaluator = val_evaluator
diff --git a/myconfigs/octseg/td-hm_hrnet-w32_8xb64-210e_octseg-256x192.py b/myconfigs/octseg/td-hm_hrnet-w32_8xb64-210e_octseg-256x192.py
index 0472d22479..a575238b00 100644
--- a/myconfigs/octseg/td-hm_hrnet-w32_8xb64-210e_octseg-256x192.py
+++ b/myconfigs/octseg/td-hm_hrnet-w32_8xb64-210e_octseg-256x192.py
@@ -1,88 +1,88 @@
-_base_ = ['../default_runtime.py']
-
-# runtime
-train_cfg = dict(max_epochs=210, val_interval=10)
-
-# optimizer
-optim_wrapper = dict(optimizer=dict(
- type='Adam',
- lr=5e-4,
-))
-
-# learning policy
-param_scheduler = [
- dict(
- type='LinearLR', begin=0, end=500, start_factor=0.001,
- by_epoch=False), # warm-up
- dict(
- type='MultiStepLR',
- begin=0,
- end=210,
- milestones=[170, 200],
- gamma=0.1,
- by_epoch=True)
-]
-
-# automatically scaling LR based on the actual training batch size
-auto_scale_lr = dict(base_batch_size=512)
-
-# hooks
-default_hooks = dict(checkpoint=dict(save_best='coco/AP', rule='greater'))
-
-# codec settings
-codec = dict(
- type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
-
-# model settings
-model = dict(
- type='TopdownPoseEstimator',
- data_preprocessor=dict(
- type='PoseDataPreprocessor',
- mean=[123.675, 116.28, 103.53],
- std=[58.395, 57.12, 57.375],
- bgr_to_rgb=True),
- backbone=dict(
- type='HRNet',
- in_channels=3,
- extra=dict(
- stage1=dict(
- num_modules=1,
- num_branches=1,
- block='BOTTLENECK',
- num_blocks=(4, ),
- num_channels=(64, )),
- stage2=dict(
- num_modules=1,
- num_branches=2,
- block='BASIC',
- num_blocks=(4, 4),
- num_channels=(32, 64)),
- stage3=dict(
- num_modules=4,
- num_branches=3,
- block='BASIC',
- num_blocks=(4, 4, 4),
- num_channels=(32, 64, 128)),
- stage4=dict(
- num_modules=3,
- num_branches=4,
- block='BASIC',
- num_blocks=(4, 4, 4, 4),
- num_channels=(32, 64, 128, 256))),
- init_cfg=dict(
- type='Pretrained',
- checkpoint='https://download.openmmlab.com/mmpose/'
- 'pretrain_models/hrnet_w32-36af842e.pth'),
- ),
- head=dict(
- type='HeatmapHead',
- in_channels=32,
- out_channels=17,
- deconv_out_channels=None,
- loss=dict(type='KeypointMSELoss', use_target_weight=True),
- decoder=codec),
- test_cfg=dict(
- flip_test=True,
- flip_mode='heatmap',
- shift_heatmap=True,
- ))
+_base_ = ['../default_runtime.py']
+
+# runtime
+train_cfg = dict(max_epochs=210, val_interval=10)
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(
+ type='Adam',
+ lr=5e-4,
+))
+
+# learning policy
+param_scheduler = [
+ dict(
+ type='LinearLR', begin=0, end=500, start_factor=0.001,
+ by_epoch=False), # warm-up
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=210,
+ milestones=[170, 200],
+ gamma=0.1,
+ by_epoch=True)
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# hooks
+default_hooks = dict(checkpoint=dict(save_best='coco/AP', rule='greater'))
+
+# codec settings
+codec = dict(
+ type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth'),
+ ),
+ head=dict(
+ type='HeatmapHead',
+ in_channels=32,
+ out_channels=17,
+ deconv_out_channels=None,
+ loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ decoder=codec),
+ test_cfg=dict(
+ flip_test=True,
+ flip_mode='heatmap',
+ shift_heatmap=True,
+ ))
diff --git a/myconfigs/octseg/td-hm_hrnet-w48_8xb32-210e_octseg-256x192.py b/myconfigs/octseg/td-hm_hrnet-w48_8xb32-210e_octseg-256x192.py
index 650630368d..514353eee3 100644
--- a/myconfigs/octseg/td-hm_hrnet-w48_8xb32-210e_octseg-256x192.py
+++ b/myconfigs/octseg/td-hm_hrnet-w48_8xb32-210e_octseg-256x192.py
@@ -1,198 +1,198 @@
-default_scope = 'mmpose'
-default_hooks = dict(
- timer=dict(type='IterTimerHook'),
- logger=dict(type='LoggerHook', interval=50),
- param_scheduler=dict(type='ParamSchedulerHook'),
- checkpoint=dict(
- type='CheckpointHook',
- interval=10,
- save_best='coco/AP',
- rule='greater'),
- sampler_seed=dict(type='DistSamplerSeedHook'),
- visualization=dict(type='PoseVisualizationHook', enable=False))
-custom_hooks = [dict(type='SyncBuffersHook')]
-env_cfg = dict(
- cudnn_benchmark=False,
- mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
- dist_cfg=dict(backend='nccl'))
-vis_backends = [dict(type='LocalVisBackend')]
-visualizer = dict(
- type='PoseLocalVisualizer',
- vis_backends=[dict(type='LocalVisBackend')],
- name='visualizer')
-log_processor = dict(
- type='LogProcessor', window_size=50, by_epoch=True, num_digits=6)
-log_level = 'INFO'
-load_from = None
-resume = False
-backend_args = dict(backend='local')
-train_cfg = dict(by_epoch=True, max_epochs=210, val_interval=10)
-val_cfg = dict()
-test_cfg = dict()
-optim_wrapper = dict(optimizer=dict(type='Adam', lr=0.0005))
-param_scheduler = [
- dict(
- type='LinearLR', begin=0, end=500, start_factor=0.001, by_epoch=False),
- dict(
- type='MultiStepLR',
- begin=0,
- end=210,
- milestones=[170, 200],
- gamma=0.1,
- by_epoch=True)
-]
-auto_scale_lr = dict(base_batch_size=512)
-codec = dict(
- type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
-model = dict(
- type='TopdownPoseEstimator',
- data_preprocessor=dict(
- type='PoseDataPreprocessor',
- mean=[123.675, 116.28, 103.53],
- std=[58.395, 57.12, 57.375],
- bgr_to_rgb=True),
- backbone=dict(
- type='HRNet',
- in_channels=3,
- extra=dict(
- stage1=dict(
- num_modules=1,
- num_branches=1,
- block='BOTTLENECK',
- num_blocks=(4, ),
- num_channels=(64, )),
- stage2=dict(
- num_modules=1,
- num_branches=2,
- block='BASIC',
- num_blocks=(4, 4),
- num_channels=(48, 96)),
- stage3=dict(
- num_modules=4,
- num_branches=3,
- block='BASIC',
- num_blocks=(4, 4, 4),
- num_channels=(48, 96, 192)),
- stage4=dict(
- num_modules=3,
- num_branches=4,
- block='BASIC',
- num_blocks=(4, 4, 4, 4),
- num_channels=(48, 96, 192, 384))),
- init_cfg=dict(
- type='Pretrained',
- checkpoint=
- 'https://download.openmmlab.com/mmpose/pretrain_models/hrnet_w48-8ef0771d.pth'
- )),
- head=dict(
- type='HeatmapHead',
- in_channels=48,
- out_channels=17,
- deconv_out_channels=None,
- loss=dict(type='KeypointMSELoss', use_target_weight=True),
- decoder=dict(
- type='MSRAHeatmap',
- input_size=(192, 256),
- heatmap_size=(48, 64),
- sigma=2)),
- test_cfg=dict(flip_test=True, flip_mode='heatmap', shift_heatmap=True))
-dataset_type = 'CocoDataset'
-data_mode = 'topdown'
-data_root = 'data/coco/'
-train_pipeline = [
- dict(type='LoadImage'),
- dict(type='GetBBoxCenterScale'),
- dict(type='RandomFlip', direction='horizontal'),
- dict(type='RandomHalfBody'),
- dict(type='RandomBBoxTransform'),
- dict(type='TopdownAffine', input_size=(192, 256)),
- dict(
- type='GenerateTarget',
- encoder=dict(
- type='MSRAHeatmap',
- input_size=(192, 256),
- heatmap_size=(48, 64),
- sigma=2)),
- dict(type='PackPoseInputs')
-]
-val_pipeline = [
- dict(type='LoadImage'),
- dict(type='GetBBoxCenterScale'),
- dict(type='TopdownAffine', input_size=(192, 256)),
- dict(type='PackPoseInputs')
-]
-train_dataloader = dict(
- batch_size=32,
- num_workers=2,
- persistent_workers=True,
- sampler=dict(type='DefaultSampler', shuffle=True),
- dataset=dict(
- type='CocoDataset',
- data_root='data/coco/',
- data_mode='topdown',
- ann_file='annotations/person_keypoints_train2017.json',
- data_prefix=dict(img='train2017/'),
- pipeline=[
- dict(type='LoadImage'),
- dict(type='GetBBoxCenterScale'),
- dict(type='RandomFlip', direction='horizontal'),
- dict(type='RandomHalfBody'),
- dict(type='RandomBBoxTransform'),
- dict(type='TopdownAffine', input_size=(192, 256)),
- dict(
- type='GenerateTarget',
- encoder=dict(
- type='MSRAHeatmap',
- input_size=(192, 256),
- heatmap_size=(48, 64),
- sigma=2)),
- dict(type='PackPoseInputs')
- ]))
-val_dataloader = dict(
- batch_size=32,
- num_workers=2,
- persistent_workers=True,
- drop_last=False,
- sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
- dataset=dict(
- type='CocoDataset',
- data_root='data/coco/',
- data_mode='topdown',
- ann_file='annotations/person_keypoints_val2017.json',
- bbox_file=
- 'data/coco/person_detection_results/COCO_val2017_detections_AP_H_56_person.json',
- data_prefix=dict(img='val2017/'),
- test_mode=True,
- pipeline=[
- dict(type='LoadImage'),
- dict(type='GetBBoxCenterScale'),
- dict(type='TopdownAffine', input_size=(192, 256)),
- dict(type='PackPoseInputs')
- ]))
-test_dataloader = dict(
- batch_size=32,
- num_workers=2,
- persistent_workers=True,
- drop_last=False,
- sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
- dataset=dict(
- type='CocoDataset',
- data_root='data/coco/',
- data_mode='topdown',
- ann_file='annotations/person_keypoints_val2017.json',
- bbox_file=
- 'data/coco/person_detection_results/COCO_val2017_detections_AP_H_56_person.json',
- data_prefix=dict(img='val2017/'),
- test_mode=True,
- pipeline=[
- dict(type='LoadImage'),
- dict(type='GetBBoxCenterScale'),
- dict(type='TopdownAffine', input_size=(192, 256)),
- dict(type='PackPoseInputs')
- ]))
-val_evaluator = dict(
- type='CocoMetric',
- ann_file='data/coco/annotations/person_keypoints_val2017.json')
-test_evaluator = dict(
- type='CocoMetric',
- ann_file='data/coco/annotations/person_keypoints_val2017.json')
+default_scope = 'mmpose'
+default_hooks = dict(
+ timer=dict(type='IterTimerHook'),
+ logger=dict(type='LoggerHook', interval=50),
+ param_scheduler=dict(type='ParamSchedulerHook'),
+ checkpoint=dict(
+ type='CheckpointHook',
+ interval=10,
+ save_best='coco/AP',
+ rule='greater'),
+ sampler_seed=dict(type='DistSamplerSeedHook'),
+ visualization=dict(type='PoseVisualizationHook', enable=False))
+custom_hooks = [dict(type='SyncBuffersHook')]
+env_cfg = dict(
+ cudnn_benchmark=False,
+ mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
+ dist_cfg=dict(backend='nccl'))
+vis_backends = [dict(type='LocalVisBackend')]
+visualizer = dict(
+ type='PoseLocalVisualizer',
+ vis_backends=[dict(type='LocalVisBackend')],
+ name='visualizer')
+log_processor = dict(
+ type='LogProcessor', window_size=50, by_epoch=True, num_digits=6)
+log_level = 'INFO'
+load_from = None
+resume = False
+backend_args = dict(backend='local')
+train_cfg = dict(by_epoch=True, max_epochs=210, val_interval=10)
+val_cfg = dict()
+test_cfg = dict()
+optim_wrapper = dict(optimizer=dict(type='Adam', lr=0.0005))
+param_scheduler = [
+ dict(
+ type='LinearLR', begin=0, end=500, start_factor=0.001, by_epoch=False),
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=210,
+ milestones=[170, 200],
+ gamma=0.1,
+ by_epoch=True)
+]
+auto_scale_lr = dict(base_batch_size=512)
+codec = dict(
+ type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint=
+ 'https://download.openmmlab.com/mmpose/pretrain_models/hrnet_w48-8ef0771d.pth'
+ )),
+ head=dict(
+ type='HeatmapHead',
+ in_channels=48,
+ out_channels=17,
+ deconv_out_channels=None,
+ loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ decoder=dict(
+ type='MSRAHeatmap',
+ input_size=(192, 256),
+ heatmap_size=(48, 64),
+ sigma=2)),
+ test_cfg=dict(flip_test=True, flip_mode='heatmap', shift_heatmap=True))
+dataset_type = 'CocoDataset'
+data_mode = 'topdown'
+data_root = 'data/coco/'
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=(192, 256)),
+ dict(
+ type='GenerateTarget',
+ encoder=dict(
+ type='MSRAHeatmap',
+ input_size=(192, 256),
+ heatmap_size=(48, 64),
+ sigma=2)),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=(192, 256)),
+ dict(type='PackPoseInputs')
+]
+train_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type='CocoDataset',
+ data_root='data/coco/',
+ data_mode='topdown',
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=[
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=(192, 256)),
+ dict(
+ type='GenerateTarget',
+ encoder=dict(
+ type='MSRAHeatmap',
+ input_size=(192, 256),
+ heatmap_size=(48, 64),
+ sigma=2)),
+ dict(type='PackPoseInputs')
+ ]))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type='CocoDataset',
+ data_root='data/coco/',
+ data_mode='topdown',
+ ann_file='annotations/person_keypoints_val2017.json',
+ bbox_file=
+ 'data/coco/person_detection_results/COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=[
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=(192, 256)),
+ dict(type='PackPoseInputs')
+ ]))
+test_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type='CocoDataset',
+ data_root='data/coco/',
+ data_mode='topdown',
+ ann_file='annotations/person_keypoints_val2017.json',
+ bbox_file=
+ 'data/coco/person_detection_results/COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=[
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=(192, 256)),
+ dict(type='PackPoseInputs')
+ ]))
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file='data/coco/annotations/person_keypoints_val2017.json')
+test_evaluator = dict(
+ type='CocoMetric',
+ ann_file='data/coco/annotations/person_keypoints_val2017.json')
diff --git a/mytests/common.py b/mytests/common.py
new file mode 100644
index 0000000000..ab0ea970e5
--- /dev/null
+++ b/mytests/common.py
@@ -0,0 +1,30 @@
+import os
+import os.path as osp
+import cv2
+import numpy as np
+
+def draw_img_with_mask(img, mask, color=(255,255,255), alpha=0.8):
+ if img.ndim == 2:
+ img = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB)
+
+ img = img.astype(np.float32)
+ img_draw = img.copy()
+ img_draw[mask] = color
+ out = img * (1 - alpha) + img_draw * alpha
+
+ return out.astype(np.uint8)
+
+def select_checkpoint(work_dir):
+ print("work_dir:", osp.abspath(work_dir))
+ dirs = sorted(os.listdir(work_dir))
+
+ for i, d in enumerate(dirs, 0):
+ print("({}) {}".format(i, d))
+ d_idx = input("Select checkpoint that you want to load: ")
+
+ path_opt = dirs[int(d_idx)]
+ chosen_checkpoint = osp.abspath(os.path.join(work_dir, path_opt))
+
+ print(f'loaded {chosen_checkpoint}')
+
+ return chosen_checkpoint
\ No newline at end of file
diff --git a/mytests/test_warping.py b/mytests/test_warping.py
new file mode 100644
index 0000000000..9ee3bef905
--- /dev/null
+++ b/mytests/test_warping.py
@@ -0,0 +1,173 @@
+import os
+import os.path as osp
+import argparse
+import glob
+import cv2
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmengine.config import Config
+from mmseg.apis import init_model
+
+import numpy as np
+from math import pi as PI
+
+from common import draw_img_with_mask
+
+def select_work_dir(work_dir, checkpoint):
+ print("work_dir:", osp.abspath(work_dir))
+ dirs = sorted(os.listdir(work_dir))
+
+ for i, d in enumerate(dirs, 0):
+ print("({}) {}".format(i, d))
+ d_idx = input("Select directory that you want to load: ")
+
+ path_opt = dirs[int(d_idx)]
+ config_dir = osp.abspath(os.path.join(work_dir, path_opt))
+ config_path = glob.glob(osp.join(config_dir, '*.py'))[0]
+
+ if checkpoint == 'last':
+ with open(osp.join(config_dir, 'last_checkpoint')) as cf:
+ pth_path = cf.readline()
+ else:
+ best_pths =glob.glob(osp.join(config_dir, 'best*.pth'))
+ pth_path = best_pths[len(best_pths) - 1]
+
+ pth = osp.basename(pth_path)
+ pth_path = osp.join(config_dir, pth)
+
+ # print('config_path:', config_path)
+ # print('pth_path:', pth_path)
+
+ return config_path, pth_path
+
+class Warping(nn.Module):
+ def __init__(self, direction: str='cart2polar', n_beams: int=512, scale: float=0.5):
+ super.__init__()
+
+ self.direction = direction
+ self.n_beams = n_beams
+ self.scale = scale
+
+ def forward(self, x):
+ if self.direction == 'cart2polar':
+ cart = x
+ rho = torch.norm(cart, p=2, dim=-1).view(-1, 1)
+ theta = torch.atan2(cart[..., 1], cart[..., 0]).view(-1, 1)
+ theta = theta + (theta < 0).type_as(theta) * (2 * PI)
+ polar = torch.cat([rho, theta], dim=-1)
+ out = polar
+
+ out = out
+ return out
+
+ def backward(self):
+ self.loss.backward()
+
+
+
+if __name__ == '__main__':
+ work_dir = '../../../data/mmsegmentation/work_dirs'
+ parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser.add_argument('--work_dir', type=str, default=work_dir,
+ help='specify working directory of trainined model')
+ parser.add_argument('--checkpoint', type=str, default='best', choices=['last', 'best'],
+ help='select which chekpoint will be chosen [last|best]')
+ parser.add_argument('--input_size', type=int, default=512,
+ help='the size of input image')
+ parser.add_argument('--verbose', action='store_true',
+ help='show summary of the model')
+
+ args = parser.parse_args()
+
+ config_path, pth_path = select_work_dir(args.work_dir, args.checkpoint)
+ configname, _ = osp.splitext(osp.basename(config_path))
+ cfg = Config.fromfile(config_path)
+
+ # init model and load checkpoint
+ device = 'cuda:0'
+ print(f'Initializing model with {config_path} and {pth_path}')
+ net = init_model(config_path, pth_path)
+
+ # print('net:', net)
+ net = net.to(device)
+
+ warping = Warping()
+ warping = warping.to(device)
+
+
+ test_dir = osp.join('..', cfg.test_dataloader.dataset.data_root, cfg.test_dataloader.dataset.data_prefix.img_path)
+ annot_dir = osp.join('..', cfg.test_dataloader.dataset.data_root, cfg.test_dataloader.dataset.data_prefix.seg_map_path)
+
+ case_list = os.listdir(test_dir)
+
+ if '.png' in case_list[0]:
+ case_list = ['.']
+
+ for case in case_list:
+ case_dir = osp.join(test_dir, case)
+ file_list = os.listdir(case_dir)
+ annot_case_dir = osp.join(annot_dir, case)
+
+
+ # save_case_dir = osp.join(save_dir, case)
+ # os.makedirs(save_case_dir, exist_ok=True)
+ for fp in file_list:
+ # fp = file_list[4]
+ img_path = osp.join(case_dir, fp)
+ annot_path = osp.join(annot_case_dir, fp)
+ # result_path= osp.join(save_case_dir, fp)
+ # result_path= osp.join(save_dir, fp)
+ print(f'Inference on {img_path}')
+
+ flat_np =cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
+ annot_np = cv2.imread(annot_path, cv2.IMREAD_GRAYSCALE)
+ annot_np = annot_np == np.max(annot_np) # Make int data type to boolean
+
+ flat_t = torch.from_numpy(flat_np).float().to(device)
+ flat_t = flat_t.reshape((1, 1, flat_t.shape[0], flat_t.shape[1]))
+ flat_t = flat_t / 255.0
+
+ round_t = warping(flat_t)
+ round_np = round_t.squeeze().to('cpu').detach().numpy()
+
+ cv2.imshow('results', round_np)
+ cv2.waitKey()
+
+
+ # # out_t = net(flat_t, mode='predict')
+ # # mask_t = out_t[0].pred_sem_seg.data
+
+
+ # out_t = net(flat_t, mode='tensor')
+ # if '-ce' in pth_path:
+ # print('multi class')
+ # mask_t = torch.argmax(out_t, dim=1)
+ # else:
+ # print('binary class')
+ # # print('out_t:', out_t)
+ # # out_t = F.sigmoid(out_t)
+
+ # out_t = out_t.sigmoid()
+ # # print('sigmoid out_t', out_t)
+ # mask_t = out_t >= 0.3
+ # print('mask_t.shape:', mask_t.shape)
+
+ # nz = mask_t.nonzero()
+ # print('nz_.shape:', nz.shape)
+ # print('nz:', nz)
+ # x_ = nz[:, 3]
+ # print('x_.shape:', x_.shape)
+ # print('x_:', x_)
+ # x_ = x_.unique()
+ # print('unique x_', x_)
+ # mask_t[:, :, :, x_] = 1
+
+ # pred_np = mask_t.squeeze().to('cpu').detach().numpy().astype(np.bool_)
+ # pred_masked = draw_img_with_mask(flat_np, pred_np, color=(0, 255, 0), alpha=0.2)
+ # gt_masked = draw_img_with_mask(flat_np, annot_np, color=(0, 0, 255), alpha=0.2)
+
+ # results = np.concatenate([pred_masked, gt_masked], axis=1)
+
+ cv2.imshow('results', results)
+ cv2.waitKey()
diff --git a/projects/README.md b/projects/README.md
index a10ccad65a..a81a94f947 100644
--- a/projects/README.md
+++ b/projects/README.md
@@ -1,57 +1,57 @@
-# Welcome to Projects of MMPose
-
-Hey there! This is the place for you to contribute your awesome keypoint detection techniques to MMPose!
-
-We know the unit tests in core package can be a bit intimidating, so we've made it easier and more efficient for you to implement your algorithms here.
-
-And the **best part**?
-
-- Projects in this folder are designed to be **easier to merge**!
-
-- Projects in this folder are **NOT** strictly required for **writing unit tests**!
-
-- We want to make it **as painless as possible** for you to contribute and make MMPose even greater.
-
-If you're not sure where to start, check out our [example project](./example_project) to see how to add your algorithms easily. And if you have any questions, take a look at our [FAQ](./faq.md).
-
-We also provide some documentation listed below to help you get started:
-
-- [New Model Guide](https://mmpose.readthedocs.io/en/latest/guide_to_framework.html#step3-model)
-
- A guide to help you add new models to MMPose.
-
-- [Contribution Guide](https://mmpose.readthedocs.io/en/latest/contribution_guide.html)
-
- A guide for new contributors on how to add their projects to MMPose.
-
-- [Discussions](https://github.com/open-mmlab/mmpose/discussions)
-
- We encourage you to start a discussion and share your ideas!
-
-## Project List
-
-- **[:zap:RTMPose](./rtmpose)**: Real-Time Multi-Person Pose Estimation toolkit based on MMPose
-
-
-
-
-
-- **[:art:MMPose4AIGC](./mmpose4aigc)**: Guide AI image generation with MMPose
-
-
-
-
-
-- **[:bulb:YOLOX-Pose](./yolox-pose)**: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss
-
-
-
-
-
-- **[📖Awesome MMPose](./awesome-mmpose/)**: A list of Tutorials, Papers, Datasets related to MMPose
-
-
-
-
-
-- **What's next? Join the rank of *MMPose contributors* by creating a new project**!
+# Welcome to Projects of MMPose
+
+Hey there! This is the place for you to contribute your awesome keypoint detection techniques to MMPose!
+
+We know the unit tests in core package can be a bit intimidating, so we've made it easier and more efficient for you to implement your algorithms here.
+
+And the **best part**?
+
+- Projects in this folder are designed to be **easier to merge**!
+
+- Projects in this folder are **NOT** strictly required for **writing unit tests**!
+
+- We want to make it **as painless as possible** for you to contribute and make MMPose even greater.
+
+If you're not sure where to start, check out our [example project](./example_project) to see how to add your algorithms easily. And if you have any questions, take a look at our [FAQ](./faq.md).
+
+We also provide some documentation listed below to help you get started:
+
+- [New Model Guide](https://mmpose.readthedocs.io/en/latest/guide_to_framework.html#step3-model)
+
+ A guide to help you add new models to MMPose.
+
+- [Contribution Guide](https://mmpose.readthedocs.io/en/latest/contribution_guide.html)
+
+ A guide for new contributors on how to add their projects to MMPose.
+
+- [Discussions](https://github.com/open-mmlab/mmpose/discussions)
+
+ We encourage you to start a discussion and share your ideas!
+
+## Project List
+
+- **[:zap:RTMPose](./rtmpose)**: Real-Time Multi-Person Pose Estimation toolkit based on MMPose
+
+
+
+
+
+- **[:art:MMPose4AIGC](./mmpose4aigc)**: Guide AI image generation with MMPose
+
+
+
+
+
+- **[:bulb:YOLOX-Pose](./yolox-pose)**: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss
+
+
+
+
+
+- **[📖Awesome MMPose](./awesome-mmpose/)**: A list of Tutorials, Papers, Datasets related to MMPose
+
+
+
+
+
+- **What's next? Join the rank of *MMPose contributors* by creating a new project**!
diff --git a/projects/awesome-mmpose/README.md b/projects/awesome-mmpose/README.md
index 99a6472269..cdd2a3cf4e 100644
--- a/projects/awesome-mmpose/README.md
+++ b/projects/awesome-mmpose/README.md
@@ -1,80 +1,80 @@
-# Awesome MMPose
-
-A list of resources related to MMPose. Feel free to contribute!
-
-
-
-- [OpenMMLab Course](https://github.com/open-mmlab/OpenMMLabCourse)
-
- This repository hosts articles, lectures and tutorials on computer vision and OpenMMLab, helping learners to understand algorithms and master our toolboxes in a systematical way.
-
-## Papers
-
-- [\[paper\]](https://arxiv.org/abs/2207.10387) [\[code\]](https://github.com/luminxu/Pose-for-Everything)
-
- ECCV 2022, Pose for Everything: Towards Category-Agnostic Pose Estimation
-
-- [\[paper\]](https://arxiv.org/abs/2201.04676) [\[code\]](https://github.com/Sense-X/UniFormer)
-
- ICLR 2022, UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning
-
-- [\[paper\]](https://arxiv.org/abs/2201.07412) [\[code\]](https://github.com/aim-uofa/Poseur)
-
- ECCV 2022, Poseur:Direct Human Pose Regression with Transformers
-
-- [\[paper\]](https://arxiv.org/abs/2106.03348) [\[code\]](https://github.com/ViTAE-Transformer/ViTAE-Transformer)
-
- NeurIPS 2022, ViTAEv2: Vision Transformer Advanced by Exploring Inductive Bias for Image Recognition and Beyond
-
-- [\[paper\]](https://arxiv.org/abs/2204.10762) [\[code\]](https://github.com/ZiyiZhang27/Dite-HRNet)
-
- IJCAI-ECAI 2021, Dite-HRNet:Dynamic Lightweight High-Resolution Network for Human Pose Estimation
-
-- [\[paper\]](https://arxiv.org/abs/2302.08453) [\[code\]](https://github.com/TencentARC/T2I-Adapter)
-
- T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
-
-- [\[paper\]](https://arxiv.org/pdf/2303.11638.pdf) [\[code\]](https://github.com/Gengzigang/PCT)
-
- CVPR 2023, Human Pose as Compositional Tokens
-
-## Datasets
-
-- [\[github\]](https://github.com/luminxu/Pose-for-Everything) **MP-100**
-
- Multi-category Pose (MP-100) dataset, which is a 2D pose dataset of 100 object categories containing over 20K instances and is well-designed for developing CAPE algorithms.
-
-
-
-
-
-- [\[github\]](https://github.com/facebookresearch/Ego4d/) **Ego4D**
-
- EGO4D is the world's largest egocentric (first person) video ML dataset and benchmark suite, with 3,600 hrs (and counting) of densely narrated video and a wide range of annotations across five new benchmark tasks. It covers hundreds of scenarios (household, outdoor, workplace, leisure, etc.) of daily life activity captured in-the-wild by 926 unique camera wearers from 74 worldwide locations and 9 different countries.
-
-
-
-
-
-## Projects
-
-Waiting for your contribution!
+# Awesome MMPose
+
+A list of resources related to MMPose. Feel free to contribute!
+
+
+
+- [OpenMMLab Course](https://github.com/open-mmlab/OpenMMLabCourse)
+
+ This repository hosts articles, lectures and tutorials on computer vision and OpenMMLab, helping learners to understand algorithms and master our toolboxes in a systematical way.
+
+## Papers
+
+- [\[paper\]](https://arxiv.org/abs/2207.10387) [\[code\]](https://github.com/luminxu/Pose-for-Everything)
+
+ ECCV 2022, Pose for Everything: Towards Category-Agnostic Pose Estimation
+
+- [\[paper\]](https://arxiv.org/abs/2201.04676) [\[code\]](https://github.com/Sense-X/UniFormer)
+
+ ICLR 2022, UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning
+
+- [\[paper\]](https://arxiv.org/abs/2201.07412) [\[code\]](https://github.com/aim-uofa/Poseur)
+
+ ECCV 2022, Poseur:Direct Human Pose Regression with Transformers
+
+- [\[paper\]](https://arxiv.org/abs/2106.03348) [\[code\]](https://github.com/ViTAE-Transformer/ViTAE-Transformer)
+
+ NeurIPS 2022, ViTAEv2: Vision Transformer Advanced by Exploring Inductive Bias for Image Recognition and Beyond
+
+- [\[paper\]](https://arxiv.org/abs/2204.10762) [\[code\]](https://github.com/ZiyiZhang27/Dite-HRNet)
+
+ IJCAI-ECAI 2021, Dite-HRNet:Dynamic Lightweight High-Resolution Network for Human Pose Estimation
+
+- [\[paper\]](https://arxiv.org/abs/2302.08453) [\[code\]](https://github.com/TencentARC/T2I-Adapter)
+
+ T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
+
+- [\[paper\]](https://arxiv.org/pdf/2303.11638.pdf) [\[code\]](https://github.com/Gengzigang/PCT)
+
+ CVPR 2023, Human Pose as Compositional Tokens
+
+## Datasets
+
+- [\[github\]](https://github.com/luminxu/Pose-for-Everything) **MP-100**
+
+ Multi-category Pose (MP-100) dataset, which is a 2D pose dataset of 100 object categories containing over 20K instances and is well-designed for developing CAPE algorithms.
+
+
+
+
+
+- [\[github\]](https://github.com/facebookresearch/Ego4d/) **Ego4D**
+
+ EGO4D is the world's largest egocentric (first person) video ML dataset and benchmark suite, with 3,600 hrs (and counting) of densely narrated video and a wide range of annotations across five new benchmark tasks. It covers hundreds of scenarios (household, outdoor, workplace, leisure, etc.) of daily life activity captured in-the-wild by 926 unique camera wearers from 74 worldwide locations and 9 different countries.
+
+
+
+
+
+## Projects
+
+Waiting for your contribution!
diff --git a/projects/example_project/README.md b/projects/example_project/README.md
index d355741aa4..dfafc6c980 100644
--- a/projects/example_project/README.md
+++ b/projects/example_project/README.md
@@ -1,166 +1,166 @@
-# Example Project
-
-> A README.md template for releasing a project.
->
-> All the fields in this README are **mandatory** for others to understand what you have achieved in this implementation.
-> Please read our [Projects FAQ](../faq.md) if you still feel unclear about the requirements, or raise an [issue](https://github.com/open-mmlab/mmpose/issues) to us!
-
-## Description
-
-> Share any information you would like others to know. For example:
->
-> Author: @xxx.
->
-> This is an implementation of \[XXX\].
-
-Author: @xxx.
-
-This project implements a top-down pose estimator with custom head and loss functions that have been seamlessly inherited from existing modules within MMPose.
-
-## Usage
-
-> For a typical model, this section should contain the commands for training and testing.
-> You are also suggested to dump your environment specification to env.yml by `conda env export > env.yml`.
-
-### Prerequisites
-
-- Python 3.7
-- PyTorch 1.6 or higher
-- [MIM](https://github.com/open-mmlab/mim) v0.33 or higher
-- [MMPose](https://github.com/open-mmlab/mmpose) v1.0.0rc0 or higher
-
-All the commands below rely on the correct configuration of `PYTHONPATH`, which should point to the project's directory so that Python can locate the module files. In `example_project/` root directory, run the following line to add the current directory to `PYTHONPATH`:
-
-```shell
-export PYTHONPATH=`pwd`:$PYTHONPATH
-```
-
-### Data Preparation
-
-Prepare the COCO dataset according to the [instruction](https://mmpose.readthedocs.io/en/dev-1.x/dataset_zoo/2d_body_keypoint.html#coco).
-
-### Training commands
-
-**To train with single GPU:**
-
-```shell
-mim train mmpose configs/example-head-loss_hrnet-w32_8xb64-210e_coco-256x192.py
-```
-
-**To train with multiple GPUs:**
-
-```shell
-mim train mmpose configs/example-head-loss_hrnet-w32_8xb64-210e_coco-256x192.py --launcher pytorch --gpus 8
-```
-
-**To train with multiple GPUs by slurm:**
-
-```shell
-mim train mmpose configs/example-head-loss_hrnet-w32_8xb64-210e_coco-256x192.py --launcher slurm \
- --gpus 16 --gpus-per-node 8 --partition $PARTITION
-```
-
-### Testing commands
-
-**To test with single GPU:**
-
-```shell
-mim test mmpose configs/example-head-loss_hrnet-w32_8xb64-210e_coco-256x192.py $CHECKPOINT
-```
-
-**To test with multiple GPUs:**
-
-```shell
-mim test mmpose configs/example-head-loss_hrnet-w32_8xb64-210e_coco-256x192.py $CHECKPOINT --launcher pytorch --gpus 8
-```
-
-**To test with multiple GPUs by slurm:**
-
-```shell
-mim test mmpose configs/example-head-loss_hrnet-w32_8xb64-210e_coco-256x192.py $CHECKPOINT --launcher slurm \
- --gpus 16 --gpus-per-node 8 --partition $PARTITION
-```
-
-## Results
-
-> List the results as usually done in other model's README. Here is an [Example](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/hrnet_coco.md).
-
-> You should claim whether this is based on the pre-trained weights, which are converted from the official release; or it's a reproduced result obtained from retraining the model in this project
-
-| Model | Backbone | Input Size | AP | AP50 | AP75 | AR | AR50 | Download |
-| :-----------------------------------------------------------: | :-------: | :--------: | :---: | :-------------: | :-------------: | :---: | :-------------: | :---------------------------------------------------------------: |
-| [ExampleHead + ExampleLoss](./configs/example-head-loss_hrnet-w32_8xb64-210e_coco-256x192.py) | HRNet-w32 | 256x912 | 0.749 | 0.906 | 0.821 | 0.804 | 0.945 | [model](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192-81c58e40_20220909.pth) \| [log](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192_20220909.log) |
-
-## Citation
-
-> You may remove this section if not applicable.
-
-```bibtex
-@misc{mmpose2020,
- title={OpenMMLab Pose Estimation Toolbox and Benchmark},
- author={MMPose Contributors},
- howpublished = {\url{https://github.com/open-mmlab/mmpose}},
- year={2020}
-}
-```
-
-## Checklist
-
-Here is a checklist of this project's progress. And you can ignore this part if you don't plan to contribute
-to MMPose projects.
-
-> The PIC (person in charge) or contributors of this project should check all the items that they believe have been finished, which will further be verified by codebase maintainers via a PR.
-
-> OpenMMLab's maintainer will review the code to ensure the project's quality. Reaching the first milestone means that this project suffices the minimum requirement of being merged into 'projects/'. But this project is only eligible to become a part of the core package upon attaining the last milestone.
-
-> Note that keeping this section up-to-date is crucial not only for this project's developers but the entire community, since there might be some other contributors joining this project and deciding their starting point from this list. It also helps maintainers accurately estimate time and effort on further code polishing, if needed.
-
-> A project does not necessarily have to be finished in a single PR, but it's essential for the project to at least reach the first milestone in its very first PR.
-
-- [ ] Milestone 1: PR-ready, and acceptable to be one of the `projects/`.
-
- - [ ] Finish the code
-
- > The code's design shall follow existing interfaces and convention. For example, each model component should be registered into `mmpose.registry.MODELS` and configurable via a config file.
-
- - [ ] Basic docstrings & proper citation
-
- > Each major class should contains a docstring, describing its functionality and arguments. If your code is copied or modified from other open-source projects, don't forget to cite the source project in docstring and make sure your behavior is not against its license. Typically, we do not accept any code snippet under GPL license. [A Short Guide to Open Source Licenses](https://medium.com/nationwide-technology/a-short-guide-to-open-source-licenses-cf5b1c329edd)
-
- - [ ] Test-time correctness
-
- > If you are reproducing the result from a paper, make sure your model's inference-time performance matches that in the original paper. The weights usually could be obtained by simply renaming the keys in the official pre-trained weights. This test could be skipped though, if you are able to prove the training-time correctness and check the second milestone.
-
- - [ ] A full README
-
- > As this template does.
-
-- [ ] Milestone 2: Indicates a successful model implementation.
-
- - [ ] Training-time correctness
-
- > If you are reproducing the result from a paper, checking this item means that you should have trained your model from scratch based on the original paper's specification and verified that the final result matches the report within a minor error range.
-
-- [ ] Milestone 3: Good to be a part of our core package!
-
- - [ ] Type hints and docstrings
-
- > Ideally *all* the methods should have [type hints](https://www.pythontutorial.net/python-basics/python-type-hints/) and [docstrings](https://google.github.io/styleguide/pyguide.html#381-docstrings). [Example](https://github.com/open-mmlab/mmpose/blob/0fb7f22000197181dc0629f767dd99d881d23d76/mmpose/utils/tensor_utils.py#L53)
-
- - [ ] Unit tests
-
- > Unit tests for the major module are required. [Example](https://github.com/open-mmlab/mmpose/blob/dev-1.x/tests/test_models/test_heads/test_heatmap_heads/test_heatmap_head.py)
-
- - [ ] Code polishing
-
- > Refactor your code according to reviewer's comment.
-
- - [ ] Metafile.yml
-
- > It will be parsed by MIM and Inferencer. [Example](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/hrnet_coco.yml)
-
- - [ ] Move your modules into the core package following the codebase's file hierarchy structure.
-
- > In particular, you may have to refactor this README into a standard one. [Example](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/README.md)
-
- - [ ] Refactor your modules into the core package following the codebase's file hierarchy structure.
+# Example Project
+
+> A README.md template for releasing a project.
+>
+> All the fields in this README are **mandatory** for others to understand what you have achieved in this implementation.
+> Please read our [Projects FAQ](../faq.md) if you still feel unclear about the requirements, or raise an [issue](https://github.com/open-mmlab/mmpose/issues) to us!
+
+## Description
+
+> Share any information you would like others to know. For example:
+>
+> Author: @xxx.
+>
+> This is an implementation of \[XXX\].
+
+Author: @xxx.
+
+This project implements a top-down pose estimator with custom head and loss functions that have been seamlessly inherited from existing modules within MMPose.
+
+## Usage
+
+> For a typical model, this section should contain the commands for training and testing.
+> You are also suggested to dump your environment specification to env.yml by `conda env export > env.yml`.
+
+### Prerequisites
+
+- Python 3.7
+- PyTorch 1.6 or higher
+- [MIM](https://github.com/open-mmlab/mim) v0.33 or higher
+- [MMPose](https://github.com/open-mmlab/mmpose) v1.0.0rc0 or higher
+
+All the commands below rely on the correct configuration of `PYTHONPATH`, which should point to the project's directory so that Python can locate the module files. In `example_project/` root directory, run the following line to add the current directory to `PYTHONPATH`:
+
+```shell
+export PYTHONPATH=`pwd`:$PYTHONPATH
+```
+
+### Data Preparation
+
+Prepare the COCO dataset according to the [instruction](https://mmpose.readthedocs.io/en/dev-1.x/dataset_zoo/2d_body_keypoint.html#coco).
+
+### Training commands
+
+**To train with single GPU:**
+
+```shell
+mim train mmpose configs/example-head-loss_hrnet-w32_8xb64-210e_coco-256x192.py
+```
+
+**To train with multiple GPUs:**
+
+```shell
+mim train mmpose configs/example-head-loss_hrnet-w32_8xb64-210e_coco-256x192.py --launcher pytorch --gpus 8
+```
+
+**To train with multiple GPUs by slurm:**
+
+```shell
+mim train mmpose configs/example-head-loss_hrnet-w32_8xb64-210e_coco-256x192.py --launcher slurm \
+ --gpus 16 --gpus-per-node 8 --partition $PARTITION
+```
+
+### Testing commands
+
+**To test with single GPU:**
+
+```shell
+mim test mmpose configs/example-head-loss_hrnet-w32_8xb64-210e_coco-256x192.py $CHECKPOINT
+```
+
+**To test with multiple GPUs:**
+
+```shell
+mim test mmpose configs/example-head-loss_hrnet-w32_8xb64-210e_coco-256x192.py $CHECKPOINT --launcher pytorch --gpus 8
+```
+
+**To test with multiple GPUs by slurm:**
+
+```shell
+mim test mmpose configs/example-head-loss_hrnet-w32_8xb64-210e_coco-256x192.py $CHECKPOINT --launcher slurm \
+ --gpus 16 --gpus-per-node 8 --partition $PARTITION
+```
+
+## Results
+
+> List the results as usually done in other model's README. Here is an [Example](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/hrnet_coco.md).
+
+> You should claim whether this is based on the pre-trained weights, which are converted from the official release; or it's a reproduced result obtained from retraining the model in this project
+
+| Model | Backbone | Input Size | AP | AP50 | AP75 | AR | AR50 | Download |
+| :-----------------------------------------------------------: | :-------: | :--------: | :---: | :-------------: | :-------------: | :---: | :-------------: | :---------------------------------------------------------------: |
+| [ExampleHead + ExampleLoss](./configs/example-head-loss_hrnet-w32_8xb64-210e_coco-256x192.py) | HRNet-w32 | 256x912 | 0.749 | 0.906 | 0.821 | 0.804 | 0.945 | [model](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192-81c58e40_20220909.pth) \| [log](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192_20220909.log) |
+
+## Citation
+
+> You may remove this section if not applicable.
+
+```bibtex
+@misc{mmpose2020,
+ title={OpenMMLab Pose Estimation Toolbox and Benchmark},
+ author={MMPose Contributors},
+ howpublished = {\url{https://github.com/open-mmlab/mmpose}},
+ year={2020}
+}
+```
+
+## Checklist
+
+Here is a checklist of this project's progress. And you can ignore this part if you don't plan to contribute
+to MMPose projects.
+
+> The PIC (person in charge) or contributors of this project should check all the items that they believe have been finished, which will further be verified by codebase maintainers via a PR.
+
+> OpenMMLab's maintainer will review the code to ensure the project's quality. Reaching the first milestone means that this project suffices the minimum requirement of being merged into 'projects/'. But this project is only eligible to become a part of the core package upon attaining the last milestone.
+
+> Note that keeping this section up-to-date is crucial not only for this project's developers but the entire community, since there might be some other contributors joining this project and deciding their starting point from this list. It also helps maintainers accurately estimate time and effort on further code polishing, if needed.
+
+> A project does not necessarily have to be finished in a single PR, but it's essential for the project to at least reach the first milestone in its very first PR.
+
+- [ ] Milestone 1: PR-ready, and acceptable to be one of the `projects/`.
+
+ - [ ] Finish the code
+
+ > The code's design shall follow existing interfaces and convention. For example, each model component should be registered into `mmpose.registry.MODELS` and configurable via a config file.
+
+ - [ ] Basic docstrings & proper citation
+
+ > Each major class should contains a docstring, describing its functionality and arguments. If your code is copied or modified from other open-source projects, don't forget to cite the source project in docstring and make sure your behavior is not against its license. Typically, we do not accept any code snippet under GPL license. [A Short Guide to Open Source Licenses](https://medium.com/nationwide-technology/a-short-guide-to-open-source-licenses-cf5b1c329edd)
+
+ - [ ] Test-time correctness
+
+ > If you are reproducing the result from a paper, make sure your model's inference-time performance matches that in the original paper. The weights usually could be obtained by simply renaming the keys in the official pre-trained weights. This test could be skipped though, if you are able to prove the training-time correctness and check the second milestone.
+
+ - [ ] A full README
+
+ > As this template does.
+
+- [ ] Milestone 2: Indicates a successful model implementation.
+
+ - [ ] Training-time correctness
+
+ > If you are reproducing the result from a paper, checking this item means that you should have trained your model from scratch based on the original paper's specification and verified that the final result matches the report within a minor error range.
+
+- [ ] Milestone 3: Good to be a part of our core package!
+
+ - [ ] Type hints and docstrings
+
+ > Ideally *all* the methods should have [type hints](https://www.pythontutorial.net/python-basics/python-type-hints/) and [docstrings](https://google.github.io/styleguide/pyguide.html#381-docstrings). [Example](https://github.com/open-mmlab/mmpose/blob/0fb7f22000197181dc0629f767dd99d881d23d76/mmpose/utils/tensor_utils.py#L53)
+
+ - [ ] Unit tests
+
+ > Unit tests for the major module are required. [Example](https://github.com/open-mmlab/mmpose/blob/dev-1.x/tests/test_models/test_heads/test_heatmap_heads/test_heatmap_head.py)
+
+ - [ ] Code polishing
+
+ > Refactor your code according to reviewer's comment.
+
+ - [ ] Metafile.yml
+
+ > It will be parsed by MIM and Inferencer. [Example](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/hrnet_coco.yml)
+
+ - [ ] Move your modules into the core package following the codebase's file hierarchy structure.
+
+ > In particular, you may have to refactor this README into a standard one. [Example](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/README.md)
+
+ - [ ] Refactor your modules into the core package following the codebase's file hierarchy structure.
diff --git a/projects/example_project/configs/example-head-loss_hrnet-w32_8xb64-210e_coco-256x192.py b/projects/example_project/configs/example-head-loss_hrnet-w32_8xb64-210e_coco-256x192.py
index 99b19d478c..8cd169254e 100644
--- a/projects/example_project/configs/example-head-loss_hrnet-w32_8xb64-210e_coco-256x192.py
+++ b/projects/example_project/configs/example-head-loss_hrnet-w32_8xb64-210e_coco-256x192.py
@@ -1,15 +1,15 @@
-# Directly inherit the entire recipe you want to use.
-_base_ = 'mmpose::body_2d_keypoint/topdown_heatmap/coco/' \
- 'td-hm_hrnet-w32_8xb64-210e_coco-256x192.py'
-
-# This line is to import your own modules.
-custom_imports = dict(imports='models')
-
-# Modify the model to use your own head and loss.
-_base_['model']['head'] = dict(
- type='ExampleHead',
- in_channels=32,
- out_channels=17,
- deconv_out_channels=None,
- loss=dict(type='ExampleLoss', use_target_weight=True),
- decoder=_base_['codec'])
+# Directly inherit the entire recipe you want to use.
+_base_ = 'mmpose::body_2d_keypoint/topdown_heatmap/coco/' \
+ 'td-hm_hrnet-w32_8xb64-210e_coco-256x192.py'
+
+# This line is to import your own modules.
+custom_imports = dict(imports='models')
+
+# Modify the model to use your own head and loss.
+_base_['model']['head'] = dict(
+ type='ExampleHead',
+ in_channels=32,
+ out_channels=17,
+ deconv_out_channels=None,
+ loss=dict(type='ExampleLoss', use_target_weight=True),
+ decoder=_base_['codec'])
diff --git a/projects/example_project/models/__init__.py b/projects/example_project/models/__init__.py
index 61dc5dac0e..dd4a1337c6 100644
--- a/projects/example_project/models/__init__.py
+++ b/projects/example_project/models/__init__.py
@@ -1,4 +1,4 @@
-from .example_head import ExampleHead
-from .example_loss import ExampleLoss
-
-__all__ = ['ExampleHead', 'ExampleLoss']
+from .example_head import ExampleHead
+from .example_loss import ExampleLoss
+
+__all__ = ['ExampleHead', 'ExampleLoss']
diff --git a/projects/example_project/models/example_head.py b/projects/example_project/models/example_head.py
index c5da95d481..d59a68dab6 100644
--- a/projects/example_project/models/example_head.py
+++ b/projects/example_project/models/example_head.py
@@ -1,77 +1,77 @@
-from mmpose.models import HeatmapHead
-from mmpose.registry import MODELS
-
-
-# Register your head to the `MODELS`.
-@MODELS.register_module()
-class ExampleHead(HeatmapHead):
- """Implements an example head.
-
- Implement the model head just like a normal pytorch module.
- """
-
- def __init__(self, **kwargs) -> None:
- print('Initializing ExampleHead...')
- super().__init__(**kwargs)
-
- def forward(self, feats):
- """Forward the network. The input is multi scale feature maps and the
- output is the coordinates.
-
- Args:
- feats (Tuple[Tensor]): Multi scale feature maps.
-
- Returns:
- Tensor: output coordinates or heatmaps.
- """
- return super().forward(feats)
-
- def predict(self, feats, batch_data_samples, test_cfg={}):
- """Predict results from outputs. The behaviour of head during testing
- should be defined in this function.
-
- Args:
- feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
- features (or multiple multi-stage features in TTA)
- batch_data_samples (List[:obj:`PoseDataSample`]): A list of
- data samples for instances in a batch
- test_cfg (dict): The runtime config for testing process. Defaults
- to {}
-
- Returns:
- Union[InstanceList | Tuple[InstanceList | PixelDataList]]: If
- ``test_cfg['output_heatmap']==True``, return both pose and heatmap
- prediction; otherwise only return the pose prediction.
-
- The pose prediction is a list of ``InstanceData``, each contains
- the following fields:
-
- - keypoints (np.ndarray): predicted keypoint coordinates in
- shape (num_instances, K, D) where K is the keypoint number
- and D is the keypoint dimension
- - keypoint_scores (np.ndarray): predicted keypoint scores in
- shape (num_instances, K)
-
- The heatmap prediction is a list of ``PixelData``, each contains
- the following fields:
-
- - heatmaps (Tensor): The predicted heatmaps in shape (K, h, w)
- """
- return super().predict(feats, batch_data_samples, test_cfg)
-
- def loss(self, feats, batch_data_samples, train_cfg={}) -> dict:
- """Calculate losses from a batch of inputs and data samples. The
- behaviour of head during training should be defined in this function.
-
- Args:
- feats (Tuple[Tensor]): The multi-stage features
- batch_data_samples (List[:obj:`PoseDataSample`]): A list of
- data samples for instances in a batch
- train_cfg (dict): The runtime config for training process.
- Defaults to {}
-
- Returns:
- dict: A dictionary of losses.
- """
-
- return super().loss(feats, batch_data_samples, train_cfg)
+from mmpose.models import HeatmapHead
+from mmpose.registry import MODELS
+
+
+# Register your head to the `MODELS`.
+@MODELS.register_module()
+class ExampleHead(HeatmapHead):
+ """Implements an example head.
+
+ Implement the model head just like a normal pytorch module.
+ """
+
+ def __init__(self, **kwargs) -> None:
+ print('Initializing ExampleHead...')
+ super().__init__(**kwargs)
+
+ def forward(self, feats):
+ """Forward the network. The input is multi scale feature maps and the
+ output is the coordinates.
+
+ Args:
+ feats (Tuple[Tensor]): Multi scale feature maps.
+
+ Returns:
+ Tensor: output coordinates or heatmaps.
+ """
+ return super().forward(feats)
+
+ def predict(self, feats, batch_data_samples, test_cfg={}):
+ """Predict results from outputs. The behaviour of head during testing
+ should be defined in this function.
+
+ Args:
+ feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
+ features (or multiple multi-stage features in TTA)
+ batch_data_samples (List[:obj:`PoseDataSample`]): A list of
+ data samples for instances in a batch
+ test_cfg (dict): The runtime config for testing process. Defaults
+ to {}
+
+ Returns:
+ Union[InstanceList | Tuple[InstanceList | PixelDataList]]: If
+ ``test_cfg['output_heatmap']==True``, return both pose and heatmap
+ prediction; otherwise only return the pose prediction.
+
+ The pose prediction is a list of ``InstanceData``, each contains
+ the following fields:
+
+ - keypoints (np.ndarray): predicted keypoint coordinates in
+ shape (num_instances, K, D) where K is the keypoint number
+ and D is the keypoint dimension
+ - keypoint_scores (np.ndarray): predicted keypoint scores in
+ shape (num_instances, K)
+
+ The heatmap prediction is a list of ``PixelData``, each contains
+ the following fields:
+
+ - heatmaps (Tensor): The predicted heatmaps in shape (K, h, w)
+ """
+ return super().predict(feats, batch_data_samples, test_cfg)
+
+ def loss(self, feats, batch_data_samples, train_cfg={}) -> dict:
+ """Calculate losses from a batch of inputs and data samples. The
+ behaviour of head during training should be defined in this function.
+
+ Args:
+ feats (Tuple[Tensor]): The multi-stage features
+ batch_data_samples (List[:obj:`PoseDataSample`]): A list of
+ data samples for instances in a batch
+ train_cfg (dict): The runtime config for training process.
+ Defaults to {}
+
+ Returns:
+ dict: A dictionary of losses.
+ """
+
+ return super().loss(feats, batch_data_samples, train_cfg)
diff --git a/projects/example_project/models/example_loss.py b/projects/example_project/models/example_loss.py
index e55d03537e..c9186b3ce2 100644
--- a/projects/example_project/models/example_loss.py
+++ b/projects/example_project/models/example_loss.py
@@ -1,40 +1,40 @@
-from mmpose.models import KeypointMSELoss
-from mmpose.registry import MODELS
-
-
-# Register your loss to the `MODELS`.
-@MODELS.register_module()
-class ExampleLoss(KeypointMSELoss):
- """Implements an example loss.
-
- Implement the loss just like a normal pytorch module.
- """
-
- def __init__(self, **kwargs) -> None:
- print('Initializing ExampleLoss...')
- super().__init__(**kwargs)
-
- def forward(self, output, target, target_weights=None, mask=None):
- """Forward function of loss. The input arguments should match those
- given in `head.loss` function.
-
- Note:
- - batch_size: B
- - num_keypoints: K
- - heatmaps height: H
- - heatmaps weight: W
-
- Args:
- output (Tensor): The output heatmaps with shape [B, K, H, W]
- target (Tensor): The target heatmaps with shape [B, K, H, W]
- target_weights (Tensor, optional): The target weights of differet
- keypoints, with shape [B, K] (keypoint-wise) or
- [B, K, H, W] (pixel-wise).
- mask (Tensor, optional): The masks of valid heatmap pixels in
- shape [B, K, H, W] or [B, 1, H, W]. If ``None``, no mask will
- be applied. Defaults to ``None``
-
- Returns:
- Tensor: The calculated loss.
- """
- return super().forward(output, target, target_weights, mask)
+from mmpose.models import KeypointMSELoss
+from mmpose.registry import MODELS
+
+
+# Register your loss to the `MODELS`.
+@MODELS.register_module()
+class ExampleLoss(KeypointMSELoss):
+ """Implements an example loss.
+
+ Implement the loss just like a normal pytorch module.
+ """
+
+ def __init__(self, **kwargs) -> None:
+ print('Initializing ExampleLoss...')
+ super().__init__(**kwargs)
+
+ def forward(self, output, target, target_weights=None, mask=None):
+ """Forward function of loss. The input arguments should match those
+ given in `head.loss` function.
+
+ Note:
+ - batch_size: B
+ - num_keypoints: K
+ - heatmaps height: H
+ - heatmaps weight: W
+
+ Args:
+ output (Tensor): The output heatmaps with shape [B, K, H, W]
+ target (Tensor): The target heatmaps with shape [B, K, H, W]
+ target_weights (Tensor, optional): The target weights of differet
+ keypoints, with shape [B, K] (keypoint-wise) or
+ [B, K, H, W] (pixel-wise).
+ mask (Tensor, optional): The masks of valid heatmap pixels in
+ shape [B, K, H, W] or [B, 1, H, W]. If ``None``, no mask will
+ be applied. Defaults to ``None``
+
+ Returns:
+ Tensor: The calculated loss.
+ """
+ return super().forward(output, target, target_weights, mask)
diff --git a/projects/faq.md b/projects/faq.md
index 3f62e14ec5..8f88599fa7 100644
--- a/projects/faq.md
+++ b/projects/faq.md
@@ -1,23 +1,23 @@
-# FAQ
-
-To help users better understand the `projects/` folder and how to use it effectively, we've created this FAQ page. Here, users can find answers to common questions and learn more about various aspects of the `projects/` folder, such as its usage and contribution guidance.
-
-## Q1: Why set up `projects/` folder?
-
-Implementing new models and features into OpenMMLab's algorithm libraries could be troublesome due to the rigorous requirements on code quality, which could hinder the fast iteration of SOTA models and might discourage our members from sharing their latest outcomes here. And that's why we have this `projects/` folder now, where some experimental features, frameworks and models are placed, only needed to satisfy the minimum requirement on the code quality, and can be used as standalone libraries. Users are welcome to use them if they [use MMPose from source](https://mmpose.readthedocs.io/en/dev-1.x/installation.html#best-practices).
-
-## Q2: Why should there be a checklist for a project?
-
-This checkelist is crucial not only for this project's developers but the entire community, since there might be some other contributors joining this project and deciding their starting point from this list. It also helps maintainers accurately estimate time and effort on further code polishing, if needed.
-
-## Q3: What kind of PR will be merged?
-
-Reaching the first milestone means that this project suffices the minimum requirement of being merged into 'projects/'. That is, the very first PR of a project must have all the terms in the first milestone checked. We do not have any extra requirements on the project's following PRs, so they can be a minor bug fix or update, and do not have to achieve one milestone at once. But keep in mind that this project is only eligible to become a part of the core package upon attaining the last milestone.
-
-## Q4: Compared to other models in the core packages, why do the model implementations in projects have different training/testing commands?
-
-Projects are organized independently from the core package, and therefore their modules cannot be directly imported by `train.py` and `test.py`. Each model implementation in projects should either use `mim` for training/testing as suggested in the example project or provide a custom `train.py`/`test.py`.
-
-## Q5: How to debug a project with a debugger?
-
-Debugger makes our lives easier, but using it becomes a bit tricky if we have to train/test a model via `mim`. The way to circumvent that is that we can take advantage of relative path to import these modules. Assuming that we are developing a project X and the core modules are placed under `projects/X/modules`, then simply adding `custom_imports = dict(imports='projects.X.modules')` to the config allows us to debug from usual entrypoints (e.g. `tools/train.py`) from the root directory of the algorithm library. Just don't forget to remove 'projects.X' before project publishment.
+# FAQ
+
+To help users better understand the `projects/` folder and how to use it effectively, we've created this FAQ page. Here, users can find answers to common questions and learn more about various aspects of the `projects/` folder, such as its usage and contribution guidance.
+
+## Q1: Why set up `projects/` folder?
+
+Implementing new models and features into OpenMMLab's algorithm libraries could be troublesome due to the rigorous requirements on code quality, which could hinder the fast iteration of SOTA models and might discourage our members from sharing their latest outcomes here. And that's why we have this `projects/` folder now, where some experimental features, frameworks and models are placed, only needed to satisfy the minimum requirement on the code quality, and can be used as standalone libraries. Users are welcome to use them if they [use MMPose from source](https://mmpose.readthedocs.io/en/dev-1.x/installation.html#best-practices).
+
+## Q2: Why should there be a checklist for a project?
+
+This checkelist is crucial not only for this project's developers but the entire community, since there might be some other contributors joining this project and deciding their starting point from this list. It also helps maintainers accurately estimate time and effort on further code polishing, if needed.
+
+## Q3: What kind of PR will be merged?
+
+Reaching the first milestone means that this project suffices the minimum requirement of being merged into 'projects/'. That is, the very first PR of a project must have all the terms in the first milestone checked. We do not have any extra requirements on the project's following PRs, so they can be a minor bug fix or update, and do not have to achieve one milestone at once. But keep in mind that this project is only eligible to become a part of the core package upon attaining the last milestone.
+
+## Q4: Compared to other models in the core packages, why do the model implementations in projects have different training/testing commands?
+
+Projects are organized independently from the core package, and therefore their modules cannot be directly imported by `train.py` and `test.py`. Each model implementation in projects should either use `mim` for training/testing as suggested in the example project or provide a custom `train.py`/`test.py`.
+
+## Q5: How to debug a project with a debugger?
+
+Debugger makes our lives easier, but using it becomes a bit tricky if we have to train/test a model via `mim`. The way to circumvent that is that we can take advantage of relative path to import these modules. Assuming that we are developing a project X and the core modules are placed under `projects/X/modules`, then simply adding `custom_imports = dict(imports='projects.X.modules')` to the config allows us to debug from usual entrypoints (e.g. `tools/train.py`) from the root directory of the algorithm library. Just don't forget to remove 'projects.X' before project publishment.
diff --git a/projects/mmpose4aigc/README.md b/projects/mmpose4aigc/README.md
index c3759d846c..b46f2267cb 100644
--- a/projects/mmpose4aigc/README.md
+++ b/projects/mmpose4aigc/README.md
@@ -1,111 +1,111 @@
-# MMPose for AIGC (AI Generated Content)
-
-
-
-
-
-English | [简体中文](./README_CN.md)
-
-This project will demonstrate how to use MMPose to generate skeleton images for pose guided AI image generation.
-
-Currently, we support:
-
-- [T2I Adapter](https://huggingface.co/spaces/Adapter/T2I-Adapter)
-
-Please feel free to share interesting pose-guided AIGC projects to us!
-
-## Get Started
-
-### Generate OpenPose-style Skeleton
-
-#### Step 1: Preparation
-
-Run the following commands to prepare the project:
-
-```shell
-# install mmpose mmdet
-pip install openmim
-git clone https://github.com/open-mmlab/mmpose.git
-cd mmpose
-mim install -e .
-mim install "mmdet>=3.0.0rc6"
-
-# download models
-bash download_models.sh
-```
-
-#### Step 2: Generate a Skeleton Image
-
-Run the following command to generate a skeleton image:
-
-```shell
-# generate a skeleton image
-bash mmpose_openpose.sh ../../tests/data/coco/000000000785.jpg
-```
-
-The input image and its skeleton are as follows:
-
-
-
-
-
-### Generate MMPose-style Skeleton
-
-#### Step 1: Preparation
-
-**Env Requirements:**
-
-- GCC >= 7.5
-- cmake >= 3.14
-
-Run the following commands to install the project:
-
-```shell
-bash install_posetracker_linux.sh
-```
-
-After installation, files are organized as follows:
-
-```shell
-|----mmdeploy-1.0.0-linux-x86_64-cxx11abi
-| |----README.md
-| |----rtmpose-ort
-| | |----rtmdet-nano
-| | |----rtmpose-m
-| | |----000000147979.jpg
-| | |----t2i-adapter_skeleton.txt
-```
-
-#### Step 2: Generate a Skeleton Image
-
-Run the following command to generate a skeleton image:
-
-```shell
-# generate a skeleton image
-bash mmpose_style_skeleton.sh \
- mmdeploy-1.0.0-linux-x86_64-cxx11abi/rtmpose-ort/000000147979.jpg
-```
-
-For more details, you can refer to [RTMPose](../rtmpose/README.md).
-
-The input image and its skeleton are as follows:
-
-
-
-
-
-### Upload to T2I-Adapter
-
-The demo page of T2I- Adapter is [Here](https://huggingface.co/spaces/Adapter/T2I-Adapter).
-
-[](https://huggingface.co/spaces/ChongMou/T2I-Adapter)
-
-
-
-
-
-## Gallery
-
-
-
-
+# MMPose for AIGC (AI Generated Content)
+
+
+
+
+
+English | [简体中文](./README_CN.md)
+
+This project will demonstrate how to use MMPose to generate skeleton images for pose guided AI image generation.
+
+Currently, we support:
+
+- [T2I Adapter](https://huggingface.co/spaces/Adapter/T2I-Adapter)
+
+Please feel free to share interesting pose-guided AIGC projects to us!
+
+## Get Started
+
+### Generate OpenPose-style Skeleton
+
+#### Step 1: Preparation
+
+Run the following commands to prepare the project:
+
+```shell
+# install mmpose mmdet
+pip install openmim
+git clone https://github.com/open-mmlab/mmpose.git
+cd mmpose
+mim install -e .
+mim install "mmdet>=3.0.0rc6"
+
+# download models
+bash download_models.sh
+```
+
+#### Step 2: Generate a Skeleton Image
+
+Run the following command to generate a skeleton image:
+
+```shell
+# generate a skeleton image
+bash mmpose_openpose.sh ../../tests/data/coco/000000000785.jpg
+```
+
+The input image and its skeleton are as follows:
+
+
+
+
+
+### Generate MMPose-style Skeleton
+
+#### Step 1: Preparation
+
+**Env Requirements:**
+
+- GCC >= 7.5
+- cmake >= 3.14
+
+Run the following commands to install the project:
+
+```shell
+bash install_posetracker_linux.sh
+```
+
+After installation, files are organized as follows:
+
+```shell
+|----mmdeploy-1.0.0-linux-x86_64-cxx11abi
+| |----README.md
+| |----rtmpose-ort
+| | |----rtmdet-nano
+| | |----rtmpose-m
+| | |----000000147979.jpg
+| | |----t2i-adapter_skeleton.txt
+```
+
+#### Step 2: Generate a Skeleton Image
+
+Run the following command to generate a skeleton image:
+
+```shell
+# generate a skeleton image
+bash mmpose_style_skeleton.sh \
+ mmdeploy-1.0.0-linux-x86_64-cxx11abi/rtmpose-ort/000000147979.jpg
+```
+
+For more details, you can refer to [RTMPose](../rtmpose/README.md).
+
+The input image and its skeleton are as follows:
+
+
+
+
+
+### Upload to T2I-Adapter
+
+The demo page of T2I- Adapter is [Here](https://huggingface.co/spaces/Adapter/T2I-Adapter).
+
+[](https://huggingface.co/spaces/ChongMou/T2I-Adapter)
+
+
-
-# RTMPose: Real-Time Multi-Person Pose Estimation toolkit based on MMPose
-
-> [RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose](https://arxiv.org/abs/2303.07399)
-
-
-
-English | [简体中文](README_CN.md)
-
-
-
-______________________________________________________________________
-
-## Abstract
-
-Recent studies on 2D pose estimation have achieved excellent performance on public benchmarks, yet its application in the industrial community still suffers from heavy model parameters and high latency.
-In order to bridge this gap, we empirically study five aspects that affect the performance of multi-person pose estimation algorithms: paradigm, backbone network, localization algorithm, training strategy, and deployment inference, and present a high-performance real-time multi-person pose estimation framework, **RTMPose**, based on MMPose.
-Our RTMPose-m achieves **75.8% AP** on COCO with **90+ FPS** on an Intel i7-11700 CPU and **430+ FPS** on an NVIDIA GTX 1660 Ti GPU.
-To further evaluate RTMPose's capability in critical real-time applications, we also report the performance after deploying on the mobile device. Our RTMPose-s achieves **72.2% AP** on COCO with **70+ FPS** on a Snapdragon 865 chip, outperforming existing open-source libraries.
-With the help of MMDeploy, our project supports various platforms like CPU, GPU, NVIDIA Jetson, and mobile devices and multiple inference backends such as ONNXRuntime, TensorRT, ncnn, etc.
-
-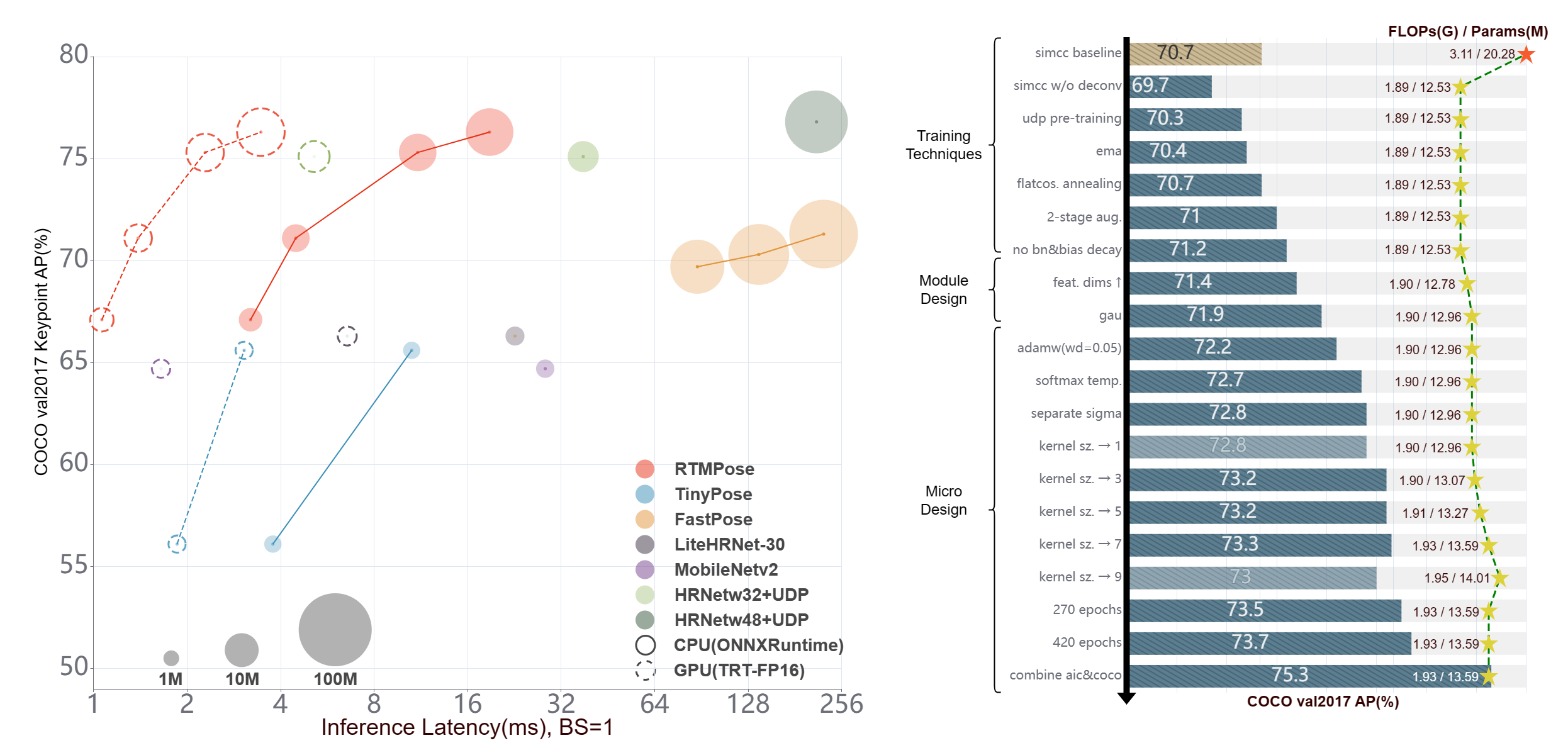
-
-______________________________________________________________________
-
-## 📄 Table of Contents
-
-- [🥳 🚀 What's New](#--whats-new-)
-- [📖 Introduction](#-introduction-)
-- [🙌 Community](#-community-)
-- [⚡ Pipeline Performance](#-pipeline-performance-)
-- [📊 Model Zoo](#-model-zoo-)
-- [👀 Visualization](#-visualization-)
-- [😎 Get Started](#-get-started-)
-- [👨🏫 How to Train](#-how-to-train-)
-- [🏗️ How to Deploy](#️-how-to-deploy-)
-- [📚 Common Usage](#️-common-usage-)
- - [🚀 Inference Speed Test](#-inference-speed-test-)
- - [📊 Model Test](#-model-test-)
-- [📜 Citation](#-citation-)
-
-## 🥳 🚀 What's New [🔝](#-table-of-contents)
-
-- Jun. 2023:
- - Release 26-keypoint Body models trained on combined datasets.
-- May. 2023:
- - Add [code examples](./examples/) of RTMPose.
- - Release Hand, Face, Body models trained on combined datasets.
-- Mar. 2023: RTMPose is released. RTMPose-m runs at 430+ FPS and achieves 75.8 mAP on COCO val set.
-
-## 📖 Introduction [🔝](#-table-of-contents)
-
-
-
-
-
-
-
-
-
-
-
-
-### ✨ Major Features
-
-- 🚀 **High efficiency and high accuracy**
-
- | Model | AP(COCO) | CPU-FPS | GPU-FPS |
- | :---: | :------: | :-----: | :-----: |
- | t | 68.5 | 300+ | 940+ |
- | s | 72.2 | 200+ | 710+ |
- | m | 75.8 | 90+ | 430+ |
- | l | 76.5 | 50+ | 280+ |
-
-- 🛠️ **Easy to deploy**
-
- - Step-by-step deployment tutorials.
- - Support various backends including
- - ONNX
- - TensorRT
- - ncnn
- - OpenVINO
- - etc.
- - Support various platforms including
- - Linux
- - Windows
- - NVIDIA Jetson
- - ARM
- - etc.
-
-- 🏗️ **Design for practical applications**
-
- - Pipeline inference API and SDK for
- - Python
- - C++
- - C#
- - JAVA
- - etc.
-
-## 🙌 Community [🔝](#-table-of-contents)
-
-RTMPose is a long-term project dedicated to the training, optimization and deployment of high-performance real-time pose estimation algorithms in practical scenarios, so we are looking forward to the power from the community. Welcome to share the training configurations and tricks based on RTMPose in different business applications to help more community users!
-
-✨ ✨ ✨
-
-- **If you are a new user of RTMPose, we eagerly hope you can fill out this [Google Questionnaire](https://docs.google.com/forms/d/e/1FAIpQLSfzwWr3eNlDzhU98qzk2Eph44Zio6hi5r0iSwfO9wSARkHdWg/viewform?usp=sf_link)/[Chinese version](https://uua478.fanqier.cn/f/xxmynrki), it's very important for our work!**
-
-✨ ✨ ✨
-
-Feel free to join our community group for more help:
-
-- WeChat Group:
-
-


 -
-



 -
-
 -
- -
- -
-



 +# Gesture Recognition
+
+Gesture recognition aims to recognize the hand gestures in the video, such as thumbs up.
+
+## Data preparation
+
+Please follow [DATA Preparation](/docs/en/dataset_zoo/2d_hand_gesture.md) to prepare data.
+
+## Demo
+
+Please follow [Demo](/demo/docs/en/gesture_recognition_demo.md) to run the demo.
+
+
+# Gesture Recognition
+
+Gesture recognition aims to recognize the hand gestures in the video, such as thumbs up.
+
+## Data preparation
+
+Please follow [DATA Preparation](/docs/en/dataset_zoo/2d_hand_gesture.md) to prepare data.
+
+## Demo
+
+Please follow [Demo](/demo/docs/en/gesture_recognition_demo.md) to run the demo.
+
+


 -
-In addition, the Inferencer supports saving predicted poses. For more information, please refer to the [inferencer document](https://mmpose.readthedocs.io/en/dev-1.x/user_guides/inference.html#inferencer-a-unified-inference-interface).
-
-### Speed Up Inference
-
-Some tips to speed up MMPose inference:
-
-1. set `model.test_cfg.flip_test=False` in [animalpose_hrnet-w32](../../configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py#85).
-2. use faster human bounding box detector, see [MMDetection](https://mmdetection.readthedocs.io/en/3.x/model_zoo.html).
+## 2D Animal Pose Demo
+
+We provide a demo script to test a single image or video with top-down pose estimators and animal detectors. Assume that you have already installed [mmdet](https://github.com/open-mmlab/mmdetection) with version >= 3.0.
+
+### 2D Animal Pose Image Demo
+
+```shell
+python demo/topdown_demo_with_mmdet.py \
+ ${MMDET_CONFIG_FILE} ${MMDET_CHECKPOINT_FILE} \
+ ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \
+ --input ${INPUT_PATH} --det-cat-id ${DET_CAT_ID} \
+ [--show] [--output-root ${OUTPUT_DIR}] [--save-predictions] \
+ [--draw-heatmap ${DRAW_HEATMAP}] [--radius ${KPT_RADIUS}] \
+ [--kpt-thr ${KPT_SCORE_THR}] [--bbox-thr ${BBOX_SCORE_THR}] \
+ [--device ${GPU_ID or CPU}]
+```
+
+The pre-trained animal pose estimation model can be found from [model zoo](https://mmpose.readthedocs.io/en/latest/model_zoo/animal_2d_keypoint.html).
+Take [animalpose model](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth) as an example:
+
+```shell
+python demo/topdown_demo_with_mmdet.py \
+ demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
+ https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py \
+ https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth \
+ --input tests/data/animalpose/ca110.jpeg \
+ --show --draw-heatmap --det-cat-id=15
+```
+
+Visualization result:
+
+
-
-In addition, the Inferencer supports saving predicted poses. For more information, please refer to the [inferencer document](https://mmpose.readthedocs.io/en/dev-1.x/user_guides/inference.html#inferencer-a-unified-inference-interface).
-
-### Speed Up Inference
-
-Some tips to speed up MMPose inference:
-
-1. set `model.test_cfg.flip_test=False` in [animalpose_hrnet-w32](../../configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py#85).
-2. use faster human bounding box detector, see [MMDetection](https://mmdetection.readthedocs.io/en/3.x/model_zoo.html).
+## 2D Animal Pose Demo
+
+We provide a demo script to test a single image or video with top-down pose estimators and animal detectors. Assume that you have already installed [mmdet](https://github.com/open-mmlab/mmdetection) with version >= 3.0.
+
+### 2D Animal Pose Image Demo
+
+```shell
+python demo/topdown_demo_with_mmdet.py \
+ ${MMDET_CONFIG_FILE} ${MMDET_CHECKPOINT_FILE} \
+ ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \
+ --input ${INPUT_PATH} --det-cat-id ${DET_CAT_ID} \
+ [--show] [--output-root ${OUTPUT_DIR}] [--save-predictions] \
+ [--draw-heatmap ${DRAW_HEATMAP}] [--radius ${KPT_RADIUS}] \
+ [--kpt-thr ${KPT_SCORE_THR}] [--bbox-thr ${BBOX_SCORE_THR}] \
+ [--device ${GPU_ID or CPU}]
+```
+
+The pre-trained animal pose estimation model can be found from [model zoo](https://mmpose.readthedocs.io/en/latest/model_zoo/animal_2d_keypoint.html).
+Take [animalpose model](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth) as an example:
+
+```shell
+python demo/topdown_demo_with_mmdet.py \
+ demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
+ https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py \
+ https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth \
+ --input tests/data/animalpose/ca110.jpeg \
+ --show --draw-heatmap --det-cat-id=15
+```
+
+Visualization result:
+
+

 -
-
-
- -
-In addition, the Inferencer supports saving predicted poses. For more information, please refer to the [inferencer document](https://mmpose.readthedocs.io/en/dev-1.x/user_guides/inference.html#inferencer-a-unified-inference-interface).
-
-### Speed Up Inference
-
-For 2D face keypoint estimation models, try to edit the config file. For example, set `model.test_cfg.flip_test=False` in line 90 of [aflw_hrnetv2](../../../configs/face_2d_keypoint/topdown_heatmap/aflw/td-hm_hrnetv2-w18_8xb64-60e_aflw-256x256.py).
+## 2D Face Keypoint Demo
+
+We provide a demo script to test a single image or video with face detectors and top-down pose estimators. Assume that you have already installed [mmdet](https://github.com/open-mmlab/mmdetection) with version >= 3.0.
+
+**Face Bounding Box Model Preparation:** The pre-trained face box estimation model can be found in [mmdet model zoo](/demo/docs/en/mmdet_modelzoo.md#face-bounding-box-detection-models).
+
+### 2D Face Image Demo
+
+```shell
+python demo/topdown_demo_with_mmdet.py \
+ ${MMDET_CONFIG_FILE} ${MMDET_CHECKPOINT_FILE} \
+ ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \
+ --input ${INPUT_PATH} [--output-root ${OUTPUT_DIR}] \
+ [--show] [--device ${GPU_ID or CPU}] [--save-predictions] \
+ [--draw-heatmap ${DRAW_HEATMAP}] [--radius ${KPT_RADIUS}] \
+ [--kpt-thr ${KPT_SCORE_THR}] [--bbox-thr ${BBOX_SCORE_THR}]
+```
+
+The pre-trained face keypoint estimation models can be found from [model zoo](https://mmpose.readthedocs.io/en/latest/model_zoo/face_2d_keypoint.html).
+Take [aflw model](https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth) as an example:
+
+```shell
+python demo/topdown_demo_with_mmdet.py \
+ demo/mmdetection_cfg/yolox-s_8xb8-300e_coco-face.py \
+ https://download.openmmlab.com/mmpose/mmdet_pretrained/yolo-x_8xb8-300e_coco-face_13274d7c.pth \
+ configs/face_2d_keypoint/topdown_heatmap/aflw/td-hm_hrnetv2-w18_8xb64-60e_aflw-256x256.py \
+ https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth \
+ --input tests/data/cofw/001766.jpg \
+ --show --draw-heatmap
+```
+
+Visualization result:
+
+
-
-In addition, the Inferencer supports saving predicted poses. For more information, please refer to the [inferencer document](https://mmpose.readthedocs.io/en/dev-1.x/user_guides/inference.html#inferencer-a-unified-inference-interface).
-
-### Speed Up Inference
-
-For 2D face keypoint estimation models, try to edit the config file. For example, set `model.test_cfg.flip_test=False` in line 90 of [aflw_hrnetv2](../../../configs/face_2d_keypoint/topdown_heatmap/aflw/td-hm_hrnetv2-w18_8xb64-60e_aflw-256x256.py).
+## 2D Face Keypoint Demo
+
+We provide a demo script to test a single image or video with face detectors and top-down pose estimators. Assume that you have already installed [mmdet](https://github.com/open-mmlab/mmdetection) with version >= 3.0.
+
+**Face Bounding Box Model Preparation:** The pre-trained face box estimation model can be found in [mmdet model zoo](/demo/docs/en/mmdet_modelzoo.md#face-bounding-box-detection-models).
+
+### 2D Face Image Demo
+
+```shell
+python demo/topdown_demo_with_mmdet.py \
+ ${MMDET_CONFIG_FILE} ${MMDET_CHECKPOINT_FILE} \
+ ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \
+ --input ${INPUT_PATH} [--output-root ${OUTPUT_DIR}] \
+ [--show] [--device ${GPU_ID or CPU}] [--save-predictions] \
+ [--draw-heatmap ${DRAW_HEATMAP}] [--radius ${KPT_RADIUS}] \
+ [--kpt-thr ${KPT_SCORE_THR}] [--bbox-thr ${BBOX_SCORE_THR}]
+```
+
+The pre-trained face keypoint estimation models can be found from [model zoo](https://mmpose.readthedocs.io/en/latest/model_zoo/face_2d_keypoint.html).
+Take [aflw model](https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth) as an example:
+
+```shell
+python demo/topdown_demo_with_mmdet.py \
+ demo/mmdetection_cfg/yolox-s_8xb8-300e_coco-face.py \
+ https://download.openmmlab.com/mmpose/mmdet_pretrained/yolo-x_8xb8-300e_coco-face_13274d7c.pth \
+ configs/face_2d_keypoint/topdown_heatmap/aflw/td-hm_hrnetv2-w18_8xb64-60e_aflw-256x256.py \
+ https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth \
+ --input tests/data/cofw/001766.jpg \
+ --show --draw-heatmap
+```
+
+Visualization result:
+
+



 -
-In addition, the Inferencer supports saving predicted poses. For more information, please refer to the [inferencer document](https://mmpose.readthedocs.io/en/dev-1.x/user_guides/inference.html#inferencer-a-unified-inference-interface).
-
-### Speed Up Inference
-
-For 2D hand keypoint estimation models, try to edit the config file. For example, set `model.test_cfg.flip_test=False` in [onehand10k_hrnetv2](../../configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py#90).
+## 2D Hand Keypoint Demo
+
+We provide a demo script to test a single image or video with hand detectors and top-down pose estimators. Assume that you have already installed [mmdet](https://github.com/open-mmlab/mmdetection) with version >= 3.0.
+
+**Hand Box Model Preparation:** The pre-trained hand box estimation model can be found in [mmdet model zoo](/demo/docs/en/mmdet_modelzoo.md#hand-bounding-box-detection-models).
+
+### 2D Hand Image Demo
+
+```shell
+python demo/topdown_demo_with_mmdet.py \
+ ${MMDET_CONFIG_FILE} ${MMDET_CHECKPOINT_FILE} \
+ ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \
+ --input ${INPUT_PATH} [--output-root ${OUTPUT_DIR}] \
+ [--show] [--device ${GPU_ID or CPU}] [--save-predictions] \
+ [--draw-heatmap ${DRAW_HEATMAP}] [--radius ${KPT_RADIUS}] \
+ [--kpt-thr ${KPT_SCORE_THR}] [--bbox-thr ${BBOX_SCORE_THR}]
+```
+
+The pre-trained hand pose estimation model can be downloaded from [model zoo](https://mmpose.readthedocs.io/en/latest/model_zoo/hand_2d_keypoint.html).
+Take [onehand10k model](https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth) as an example:
+
+```shell
+python demo/topdown_demo_with_mmdet.py \
+ demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \
+ https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \
+ configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py \
+ https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth \
+ --input tests/data/onehand10k/9.jpg \
+ --show --draw-heatmap
+```
+
+Visualization result:
+
+
-
-In addition, the Inferencer supports saving predicted poses. For more information, please refer to the [inferencer document](https://mmpose.readthedocs.io/en/dev-1.x/user_guides/inference.html#inferencer-a-unified-inference-interface).
-
-### Speed Up Inference
-
-For 2D hand keypoint estimation models, try to edit the config file. For example, set `model.test_cfg.flip_test=False` in [onehand10k_hrnetv2](../../configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py#90).
+## 2D Hand Keypoint Demo
+
+We provide a demo script to test a single image or video with hand detectors and top-down pose estimators. Assume that you have already installed [mmdet](https://github.com/open-mmlab/mmdetection) with version >= 3.0.
+
+**Hand Box Model Preparation:** The pre-trained hand box estimation model can be found in [mmdet model zoo](/demo/docs/en/mmdet_modelzoo.md#hand-bounding-box-detection-models).
+
+### 2D Hand Image Demo
+
+```shell
+python demo/topdown_demo_with_mmdet.py \
+ ${MMDET_CONFIG_FILE} ${MMDET_CHECKPOINT_FILE} \
+ ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \
+ --input ${INPUT_PATH} [--output-root ${OUTPUT_DIR}] \
+ [--show] [--device ${GPU_ID or CPU}] [--save-predictions] \
+ [--draw-heatmap ${DRAW_HEATMAP}] [--radius ${KPT_RADIUS}] \
+ [--kpt-thr ${KPT_SCORE_THR}] [--bbox-thr ${BBOX_SCORE_THR}]
+```
+
+The pre-trained hand pose estimation model can be downloaded from [model zoo](https://mmpose.readthedocs.io/en/latest/model_zoo/hand_2d_keypoint.html).
+Take [onehand10k model](https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth) as an example:
+
+```shell
+python demo/topdown_demo_with_mmdet.py \
+ demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \
+ https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \
+ configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py \
+ https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth \
+ --input tests/data/onehand10k/9.jpg \
+ --show --draw-heatmap
+```
+
+Visualization result:
+
+

 -
-In addition, the Inferencer supports saving predicted poses. For more information, please refer to the [inferencer document](https://mmpose.readthedocs.io/en/dev-1.x/user_guides/inference.html#inferencer-a-unified-inference-interface).
-
-### Speed Up Inference
-
-Some tips to speed up MMPose inference:
-
-For top-down models, try to edit the config file. For example,
-
-1. set `model.test_cfg.flip_test=False` in [topdown-res50](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py#L56).
-2. use faster human bounding box detector, see [MMDetection](https://mmdetection.readthedocs.io/en/3.x/model_zoo.html).
+## 2D Human Pose Demo
+
+We provide demo scripts to perform human pose estimation on images or videos.
+
+### 2D Human Pose Top-Down Image Demo
+
+#### Use full image as input
+
+We provide a demo script to test a single image, using the full image as input bounding box.
+
+```shell
+python demo/image_demo.py \
+ ${IMG_FILE} ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \
+ --out-file ${OUTPUT_FILE} \
+ [--device ${GPU_ID or CPU}] \
+ [--draw_heatmap]
+```
+
+If you use a heatmap-based model and set argument `--draw-heatmap`, the predicted heatmap will be visualized together with the keypoints.
+
+The pre-trained human pose estimation models can be downloaded from [model zoo](https://mmpose.readthedocs.io/en/latest/model_zoo/body_2d_keypoint.html).
+Take [coco model](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth) as an example:
+
+```shell
+python demo/image_demo.py \
+ tests/data/coco/000000000785.jpg \
+ configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w48_8xb32-210e_coco-256x192.py \
+ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \
+ --out-file vis_results.jpg \
+ --draw-heatmap
+```
+
+To run this demo on CPU:
+
+```shell
+python demo/image_demo.py \
+ tests/data/coco/000000000785.jpg \
+ configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w48_8xb32-210e_coco-256x192.py \
+ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \
+ --out-file vis_results.jpg \
+ --draw-heatmap \
+ --device=cpu
+```
+
+Visualization result:
+
+
-
-In addition, the Inferencer supports saving predicted poses. For more information, please refer to the [inferencer document](https://mmpose.readthedocs.io/en/dev-1.x/user_guides/inference.html#inferencer-a-unified-inference-interface).
-
-### Speed Up Inference
-
-Some tips to speed up MMPose inference:
-
-For top-down models, try to edit the config file. For example,
-
-1. set `model.test_cfg.flip_test=False` in [topdown-res50](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py#L56).
-2. use faster human bounding box detector, see [MMDetection](https://mmdetection.readthedocs.io/en/3.x/model_zoo.html).
+## 2D Human Pose Demo
+
+We provide demo scripts to perform human pose estimation on images or videos.
+
+### 2D Human Pose Top-Down Image Demo
+
+#### Use full image as input
+
+We provide a demo script to test a single image, using the full image as input bounding box.
+
+```shell
+python demo/image_demo.py \
+ ${IMG_FILE} ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \
+ --out-file ${OUTPUT_FILE} \
+ [--device ${GPU_ID or CPU}] \
+ [--draw_heatmap]
+```
+
+If you use a heatmap-based model and set argument `--draw-heatmap`, the predicted heatmap will be visualized together with the keypoints.
+
+The pre-trained human pose estimation models can be downloaded from [model zoo](https://mmpose.readthedocs.io/en/latest/model_zoo/body_2d_keypoint.html).
+Take [coco model](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth) as an example:
+
+```shell
+python demo/image_demo.py \
+ tests/data/coco/000000000785.jpg \
+ configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w48_8xb32-210e_coco-256x192.py \
+ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \
+ --out-file vis_results.jpg \
+ --draw-heatmap
+```
+
+To run this demo on CPU:
+
+```shell
+python demo/image_demo.py \
+ tests/data/coco/000000000785.jpg \
+ configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w48_8xb32-210e_coco-256x192.py \
+ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \
+ --out-file vis_results.jpg \
+ --draw-heatmap \
+ --device=cpu
+```
+
+Visualization result:
+
+

 -
-In addition, the Inferencer supports saving predicted poses. For more information, please refer to the [inferencer document](https://mmpose.readthedocs.io/en/dev-1.x/user_guides/inference.html#inferencer-a-unified-inference-interface).
-
-### Speed Up Inference
-
-Some tips to speed up MMPose inference:
-
-For top-down models, try to edit the config file. For example,
-
-1. set `model.test_cfg.flip_test=False` in [pose_hrnet_w48_dark+](/configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/td-hm_hrnet-w48_dark-8xb32-210e_coco-wholebody-384x288.py#L90).
-2. use faster human bounding box detector, see [MMDetection](https://mmdetection.readthedocs.io/en/3.x/model_zoo.html).
+## 2D Human Whole-Body Pose Demo
+
+### 2D Human Whole-Body Pose Top-Down Image Demo
+
+#### Use full image as input
+
+We provide a demo script to test a single image, using the full image as input bounding box.
+
+```shell
+python demo/image_demo.py \
+ ${IMG_FILE} ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \
+ --out-file ${OUTPUT_FILE} \
+ [--device ${GPU_ID or CPU}] \
+ [--draw_heatmap]
+```
+
+The pre-trained hand pose estimation models can be downloaded from [model zoo](https://mmpose.readthedocs.io/en/latest/model_zoo/2d_wholebody_keypoint.html).
+Take [coco-wholebody_vipnas_res50_dark](https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_res50_wholebody_256x192_dark-67c0ce35_20211112.pth) model as an example:
+
+```shell
+python demo/image_demo.py \
+ tests/data/coco/000000000785.jpg \
+ configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/td-hm_vipnas-res50_dark-8xb64-210e_coco-wholebody-256x192.py \
+ https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_res50_wholebody_256x192_dark-67c0ce35_20211112.pth \
+ --out-file vis_results.jpg
+```
+
+To run demos on CPU:
+
+```shell
+python demo/image_demo.py \
+ tests/data/coco/000000000785.jpg \
+ configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/td-hm_vipnas-res50_dark-8xb64-210e_coco-wholebody-256x192.py \
+ https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_res50_wholebody_256x192_dark-67c0ce35_20211112.pth \
+ --out-file vis_results.jpg \
+ --device=cpu
+```
+
+#### Use mmdet for human bounding box detection
+
+We provide a demo script to run mmdet for human detection, and mmpose for pose estimation.
+
+Assume that you have already installed [mmdet](https://github.com/open-mmlab/mmdetection) with version >= 3.0.
+
+```shell
+python demo/topdown_demo_with_mmdet.py \
+ ${MMDET_CONFIG_FILE} ${MMDET_CHECKPOINT_FILE} \
+ ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \
+ --input ${INPUT_PATH} \
+ [--output-root ${OUTPUT_DIR}] [--save-predictions] \
+ [--show] [--draw-heatmap] [--device ${GPU_ID or CPU}] \
+ [--bbox-thr ${BBOX_SCORE_THR}] [--kpt-thr ${KPT_SCORE_THR}]
+```
+
+Examples:
+
+```shell
+python demo/topdown_demo_with_mmdet.py \
+ demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
+ https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/td-hm_hrnet-w48_dark-8xb32-210e_coco-wholebody-384x288.py \
+ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \
+ --input tests/data/coco/000000196141.jpg \
+ --output-root vis_results/ --show
+```
+
+To save the predicted results on disk, please specify `--save-predictions`.
+
+### 2D Human Whole-Body Pose Top-Down Video Demo
+
+The above demo script can also take video as input, and run mmdet for human detection, and mmpose for pose estimation.
+
+Assume that you have already installed [mmdet](https://github.com/open-mmlab/mmdetection).
+
+Examples:
+
+```shell
+python demo/topdown_demo_with_mmdet.py \
+ demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
+ https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/td-hm_hrnet-w48_dark-8xb32-210e_coco-wholebody-384x288.py \
+ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \
+ --input https://user-images.githubusercontent.com/87690686/137440639-fb08603d-9a35-474e-b65f-46b5c06b68d6.mp4 \
+ --output-root vis_results/ --show
+```
+
+Visualization result:
+
+
-
-In addition, the Inferencer supports saving predicted poses. For more information, please refer to the [inferencer document](https://mmpose.readthedocs.io/en/dev-1.x/user_guides/inference.html#inferencer-a-unified-inference-interface).
-
-### Speed Up Inference
-
-Some tips to speed up MMPose inference:
-
-For top-down models, try to edit the config file. For example,
-
-1. set `model.test_cfg.flip_test=False` in [pose_hrnet_w48_dark+](/configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/td-hm_hrnet-w48_dark-8xb32-210e_coco-wholebody-384x288.py#L90).
-2. use faster human bounding box detector, see [MMDetection](https://mmdetection.readthedocs.io/en/3.x/model_zoo.html).
+## 2D Human Whole-Body Pose Demo
+
+### 2D Human Whole-Body Pose Top-Down Image Demo
+
+#### Use full image as input
+
+We provide a demo script to test a single image, using the full image as input bounding box.
+
+```shell
+python demo/image_demo.py \
+ ${IMG_FILE} ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \
+ --out-file ${OUTPUT_FILE} \
+ [--device ${GPU_ID or CPU}] \
+ [--draw_heatmap]
+```
+
+The pre-trained hand pose estimation models can be downloaded from [model zoo](https://mmpose.readthedocs.io/en/latest/model_zoo/2d_wholebody_keypoint.html).
+Take [coco-wholebody_vipnas_res50_dark](https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_res50_wholebody_256x192_dark-67c0ce35_20211112.pth) model as an example:
+
+```shell
+python demo/image_demo.py \
+ tests/data/coco/000000000785.jpg \
+ configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/td-hm_vipnas-res50_dark-8xb64-210e_coco-wholebody-256x192.py \
+ https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_res50_wholebody_256x192_dark-67c0ce35_20211112.pth \
+ --out-file vis_results.jpg
+```
+
+To run demos on CPU:
+
+```shell
+python demo/image_demo.py \
+ tests/data/coco/000000000785.jpg \
+ configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/td-hm_vipnas-res50_dark-8xb64-210e_coco-wholebody-256x192.py \
+ https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_res50_wholebody_256x192_dark-67c0ce35_20211112.pth \
+ --out-file vis_results.jpg \
+ --device=cpu
+```
+
+#### Use mmdet for human bounding box detection
+
+We provide a demo script to run mmdet for human detection, and mmpose for pose estimation.
+
+Assume that you have already installed [mmdet](https://github.com/open-mmlab/mmdetection) with version >= 3.0.
+
+```shell
+python demo/topdown_demo_with_mmdet.py \
+ ${MMDET_CONFIG_FILE} ${MMDET_CHECKPOINT_FILE} \
+ ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \
+ --input ${INPUT_PATH} \
+ [--output-root ${OUTPUT_DIR}] [--save-predictions] \
+ [--show] [--draw-heatmap] [--device ${GPU_ID or CPU}] \
+ [--bbox-thr ${BBOX_SCORE_THR}] [--kpt-thr ${KPT_SCORE_THR}]
+```
+
+Examples:
+
+```shell
+python demo/topdown_demo_with_mmdet.py \
+ demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
+ https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/td-hm_hrnet-w48_dark-8xb32-210e_coco-wholebody-384x288.py \
+ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \
+ --input tests/data/coco/000000196141.jpg \
+ --output-root vis_results/ --show
+```
+
+To save the predicted results on disk, please specify `--save-predictions`.
+
+### 2D Human Whole-Body Pose Top-Down Video Demo
+
+The above demo script can also take video as input, and run mmdet for human detection, and mmpose for pose estimation.
+
+Assume that you have already installed [mmdet](https://github.com/open-mmlab/mmdetection).
+
+Examples:
+
+```shell
+python demo/topdown_demo_with_mmdet.py \
+ demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
+ https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/td-hm_hrnet-w48_dark-8xb32-210e_coco-wholebody-384x288.py \
+ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \
+ --input https://user-images.githubusercontent.com/87690686/137440639-fb08603d-9a35-474e-b65f-46b5c06b68d6.mp4 \
+ --output-root vis_results/ --show
+```
+
+Visualization result:
+
+ -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
-






 -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
-  -
-  -
-  -
-  -
-  -
- 
 -
-
 -
- -
- -
-
 -
- -
- -
- -
-
 -
- 



