diff --git a/.circleci/config.yml b/.circleci/config.yml
index 4e6718005ab7..1b3a57c76f75 100644
--- a/.circleci/config.yml
+++ b/.circleci/config.yml
@@ -157,11 +157,10 @@ jobs:
command: pip freeze | tee installed.txt
- store_artifacts:
path: ~/transformers/installed.txt
- - run: black --check examples tests src utils
- - run: ruff examples tests src utils
+ - run: ruff check examples tests src utils
+ - run: ruff format tests src utils --check
- run: python utils/custom_init_isort.py --check_only
- run: python utils/sort_auto_mappings.py --check_only
- - run: doc-builder style src/transformers docs/source --max_len 119 --check_only --path_to_docs docs/source
- run: python utils/check_doc_toc.py
check_repository_consistency:
diff --git a/.circleci/create_circleci_config.py b/.circleci/create_circleci_config.py
index 6dda676126c1..41e83d87438e 100644
--- a/.circleci/create_circleci_config.py
+++ b/.circleci/create_circleci_config.py
@@ -15,7 +15,6 @@
import argparse
import copy
-import glob
import os
import random
from dataclasses import dataclass
@@ -239,7 +238,7 @@ def to_dict(self):
py_command = f'import os; fp = open("reports/{self.job_name}/summary_short.txt"); failed = os.linesep.join([x for x in fp.read().split(os.linesep) if x.startswith("ERROR ")]); fp.close(); fp = open("summary_short.txt", "w"); fp.write(failed); fp.close()'
check_test_command += f"$(python3 -c '{py_command}'); "
- check_test_command += f'cat summary_short.txt; echo ""; exit -1; '
+ check_test_command += 'cat summary_short.txt; echo ""; exit -1; '
# Deeal with failed tests
check_test_command += f'elif [ -s reports/{self.job_name}/failures_short.txt ]; '
@@ -249,7 +248,7 @@ def to_dict(self):
py_command = f'import os; fp = open("reports/{self.job_name}/summary_short.txt"); failed = os.linesep.join([x for x in fp.read().split(os.linesep) if x.startswith("FAILED ")]); fp.close(); fp = open("summary_short.txt", "w"); fp.write(failed); fp.close()'
check_test_command += f"$(python3 -c '{py_command}'); "
- check_test_command += f'cat summary_short.txt; echo ""; exit -1; '
+ check_test_command += 'cat summary_short.txt; echo ""; exit -1; '
check_test_command += f'elif [ -s reports/{self.job_name}/stats.txt ]; then echo "All tests pass!"; '
@@ -283,7 +282,7 @@ def job_name(self):
"pip install --upgrade --upgrade-strategy eager pip",
"pip install -U --upgrade-strategy eager .[sklearn,tf-cpu,torch,testing,sentencepiece,torch-speech,vision]",
"pip install -U --upgrade-strategy eager tensorflow_probability",
- "pip install -U --upgrade-strategy eager git+https://github.com/huggingface/accelerate",
+ "pip install -U --upgrade-strategy eager -e git+https://github.com/huggingface/accelerate@main#egg=accelerate",
],
marker="is_pt_tf_cross_test",
pytest_options={"rA": None, "durations": 0},
@@ -297,7 +296,7 @@ def job_name(self):
"sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng",
"pip install -U --upgrade-strategy eager --upgrade pip",
"pip install -U --upgrade-strategy eager .[sklearn,flax,torch,testing,sentencepiece,torch-speech,vision]",
- "pip install -U --upgrade-strategy eager git+https://github.com/huggingface/accelerate",
+ "pip install -U --upgrade-strategy eager -e git+https://github.com/huggingface/accelerate@main#egg=accelerate",
],
marker="is_pt_flax_cross_test",
pytest_options={"rA": None, "durations": 0},
@@ -310,7 +309,7 @@ def job_name(self):
"sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng time",
"pip install --upgrade --upgrade-strategy eager pip",
"pip install -U --upgrade-strategy eager .[sklearn,torch,testing,sentencepiece,torch-speech,vision,timm]",
- "pip install -U --upgrade-strategy eager git+https://github.com/huggingface/accelerate",
+ "pip install -U --upgrade-strategy eager -e git+https://github.com/huggingface/accelerate@main#egg=accelerate",
],
parallelism=1,
pytest_num_workers=6,
@@ -397,13 +396,16 @@ def job_name(self):
examples_torch_job = CircleCIJob(
"examples_torch",
+ additional_env={"OMP_NUM_THREADS": 8},
cache_name="torch_examples",
install_steps=[
"sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng",
"pip install --upgrade --upgrade-strategy eager pip",
"pip install -U --upgrade-strategy eager .[sklearn,torch,sentencepiece,testing,torch-speech]",
"pip install -U --upgrade-strategy eager -r examples/pytorch/_tests_requirements.txt",
+ "pip install -U --upgrade-strategy eager -e git+https://github.com/huggingface/accelerate@main#egg=accelerate",
],
+ pytest_num_workers=1,
)
@@ -510,7 +512,7 @@ def job_name(self):
"sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng time ffmpeg",
"pip install --upgrade --upgrade-strategy eager pip",
"pip install -U --upgrade-strategy eager -e .[dev]",
- "pip install -U --upgrade-strategy eager git+https://github.com/huggingface/accelerate",
+ "pip install -U --upgrade-strategy eager -e git+https://github.com/huggingface/accelerate@main#egg=accelerate",
"pip install --upgrade --upgrade-strategy eager pytest pytest-sugar",
"pip install -U --upgrade-strategy eager natten",
"find -name __pycache__ -delete",
diff --git a/.github/conda/meta.yaml b/.github/conda/meta.yaml
index 6bf33f842fbf..89dc353b1277 100644
--- a/.github/conda/meta.yaml
+++ b/.github/conda/meta.yaml
@@ -26,6 +26,8 @@ requirements:
- protobuf
- tokenizers >=0.11.1,!=0.11.3,<0.13
- pyyaml >=5.1
+ - safetensors
+ - fsspec
run:
- python
- numpy >=1.17
@@ -40,6 +42,8 @@ requirements:
- protobuf
- tokenizers >=0.11.1,!=0.11.3,<0.13
- pyyaml >=5.1
+ - safetensors
+ - fsspec
test:
imports:
diff --git a/.github/workflows/add-model-like.yml b/.github/workflows/add-model-like.yml
index 68133a7e2243..8bdd66e4466d 100644
--- a/.github/workflows/add-model-like.yml
+++ b/.github/workflows/add-model-like.yml
@@ -14,7 +14,7 @@ on:
jobs:
run_tests_templates_like:
name: "Add new model like template tests"
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
steps:
- uses: actions/checkout@v3
diff --git a/.github/workflows/build-docker-images.yml b/.github/workflows/build-docker-images.yml
index 710ad7afe77a..b267ad7882d8 100644
--- a/.github/workflows/build-docker-images.yml
+++ b/.github/workflows/build-docker-images.yml
@@ -20,7 +20,7 @@ concurrency:
jobs:
latest-docker:
name: "Latest PyTorch + TensorFlow [dev]"
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
steps:
- name: Cleanup disk
run: |
@@ -69,7 +69,7 @@ jobs:
latest-torch-deepspeed-docker:
name: "Latest PyTorch + DeepSpeed"
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
steps:
- name: Cleanup disk
run: |
@@ -106,7 +106,7 @@ jobs:
# Can't build 2 images in a single job `latest-torch-deepspeed-docker` (for `nvcr.io/nvidia`)
latest-torch-deepspeed-docker-for-push-ci-daily-build:
name: "Latest PyTorch + DeepSpeed (Push CI - Daily Build)"
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
steps:
- name: Cleanup disk
run: |
@@ -148,7 +148,7 @@ jobs:
name: "Doc builder"
# Push CI doesn't need this image
if: inputs.image_postfix != '-push-ci'
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
steps:
-
name: Set up Docker Buildx
@@ -174,7 +174,7 @@ jobs:
name: "Latest PyTorch [dev]"
# Push CI doesn't need this image
if: inputs.image_postfix != '-push-ci'
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
steps:
- name: Cleanup disk
run: |
@@ -208,46 +208,47 @@ jobs:
push: true
tags: huggingface/transformers-pytorch-gpu
- latest-pytorch-amd:
- name: "Latest PyTorch (AMD) [dev]"
- runs-on: [self-hosted, docker-gpu, amd-gpu, single-gpu, mi210]
- steps:
- - name: Set up Docker Buildx
- uses: docker/setup-buildx-action@v3
- - name: Check out code
- uses: actions/checkout@v3
- - name: Login to DockerHub
- uses: docker/login-action@v3
- with:
- username: ${{ secrets.DOCKERHUB_USERNAME }}
- password: ${{ secrets.DOCKERHUB_PASSWORD }}
- - name: Build and push
- uses: docker/build-push-action@v5
- with:
- context: ./docker/transformers-pytorch-amd-gpu
- build-args: |
- REF=main
- push: true
- tags: huggingface/transformers-pytorch-amd-gpu${{ inputs.image_postfix }}
- # Push CI images still need to be re-built daily
- -
- name: Build and push (for Push CI) in a daily basis
- # This condition allows `schedule` events, or `push` events that trigger this workflow NOT via `workflow_call`.
- # The later case is useful for manual image building for debugging purpose. Use another tag in this case!
- if: inputs.image_postfix != '-push-ci'
- uses: docker/build-push-action@v5
- with:
- context: ./docker/transformers-pytorch-amd-gpu
- build-args: |
- REF=main
- push: true
- tags: huggingface/transformers-pytorch-amd-gpu-push-ci
+# Need to be fixed with the help from Guillaume.
+# latest-pytorch-amd:
+# name: "Latest PyTorch (AMD) [dev]"
+# runs-on: [self-hosted, docker-gpu, amd-gpu, single-gpu, mi210]
+# steps:
+# - name: Set up Docker Buildx
+# uses: docker/setup-buildx-action@v3
+# - name: Check out code
+# uses: actions/checkout@v3
+# - name: Login to DockerHub
+# uses: docker/login-action@v3
+# with:
+# username: ${{ secrets.DOCKERHUB_USERNAME }}
+# password: ${{ secrets.DOCKERHUB_PASSWORD }}
+# - name: Build and push
+# uses: docker/build-push-action@v5
+# with:
+# context: ./docker/transformers-pytorch-amd-gpu
+# build-args: |
+# REF=main
+# push: true
+# tags: huggingface/transformers-pytorch-amd-gpu${{ inputs.image_postfix }}
+# # Push CI images still need to be re-built daily
+# -
+# name: Build and push (for Push CI) in a daily basis
+# # This condition allows `schedule` events, or `push` events that trigger this workflow NOT via `workflow_call`.
+# # The later case is useful for manual image building for debugging purpose. Use another tag in this case!
+# if: inputs.image_postfix != '-push-ci'
+# uses: docker/build-push-action@v5
+# with:
+# context: ./docker/transformers-pytorch-amd-gpu
+# build-args: |
+# REF=main
+# push: true
+# tags: huggingface/transformers-pytorch-amd-gpu-push-ci
latest-tensorflow:
name: "Latest TensorFlow [dev]"
# Push CI doesn't need this image
if: inputs.image_postfix != '-push-ci'
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
steps:
-
name: Set up Docker Buildx
diff --git a/.github/workflows/build-nightly-ci-docker-images.yml b/.github/workflows/build-nightly-ci-docker-images.yml
index 1b8cab864d92..63bc7daa7434 100644
--- a/.github/workflows/build-nightly-ci-docker-images.yml
+++ b/.github/workflows/build-nightly-ci-docker-images.yml
@@ -13,7 +13,7 @@ concurrency:
jobs:
latest-with-torch-nightly-docker:
name: "Nightly PyTorch + Stable TensorFlow"
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
steps:
- name: Cleanup disk
run: |
@@ -50,7 +50,7 @@ jobs:
nightly-torch-deepspeed-docker:
name: "Nightly PyTorch + DeepSpeed"
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
steps:
- name: Cleanup disk
run: |
diff --git a/.github/workflows/build-past-ci-docker-images.yml b/.github/workflows/build-past-ci-docker-images.yml
index aa47dfd08c2d..21028568c963 100644
--- a/.github/workflows/build-past-ci-docker-images.yml
+++ b/.github/workflows/build-past-ci-docker-images.yml
@@ -16,7 +16,7 @@ jobs:
fail-fast: false
matrix:
version: ["1.13", "1.12", "1.11", "1.10"]
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
steps:
-
name: Set up Docker Buildx
@@ -60,7 +60,7 @@ jobs:
fail-fast: false
matrix:
version: ["2.11", "2.10", "2.9", "2.8", "2.7", "2.6", "2.5"]
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
steps:
-
name: Set up Docker Buildx
diff --git a/.github/workflows/build_documentation.yml b/.github/workflows/build_documentation.yml
index 0dfa16f19332..99f0f15230a0 100644
--- a/.github/workflows/build_documentation.yml
+++ b/.github/workflows/build_documentation.yml
@@ -15,7 +15,7 @@ jobs:
commit_sha: ${{ github.sha }}
package: transformers
notebook_folder: transformers_doc
- languages: de en es fr hi it ko pt zh ja te
+ languages: de en es fr hi it ko pt tr zh ja te
secrets:
token: ${{ secrets.HUGGINGFACE_PUSH }}
hf_token: ${{ secrets.HF_DOC_BUILD_PUSH }}
diff --git a/.github/workflows/build_pr_documentation.yml b/.github/workflows/build_pr_documentation.yml
index 2fddc9531013..f6fa4c8d537c 100644
--- a/.github/workflows/build_pr_documentation.yml
+++ b/.github/workflows/build_pr_documentation.yml
@@ -14,4 +14,4 @@ jobs:
commit_sha: ${{ github.event.pull_request.head.sha }}
pr_number: ${{ github.event.number }}
package: transformers
- languages: de en es fr hi it ko pt zh ja te
+ languages: de en es fr hi it ko pt tr zh ja te
diff --git a/.github/workflows/check_runner_status.yml b/.github/workflows/check_runner_status.yml
index 7d0e3853b5df..328d284223a8 100644
--- a/.github/workflows/check_runner_status.yml
+++ b/.github/workflows/check_runner_status.yml
@@ -18,7 +18,7 @@ env:
jobs:
check_runner_status:
name: Check Runner Status
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
outputs:
offline_runners: ${{ steps.set-offline_runners.outputs.offline_runners }}
steps:
@@ -39,7 +39,7 @@ jobs:
send_results:
name: Send results to webhook
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
needs: check_runner_status
if: ${{ failure() }}
steps:
diff --git a/.github/workflows/check_tiny_models.yml b/.github/workflows/check_tiny_models.yml
index 5a4cb9622f06..898e441a4234 100644
--- a/.github/workflows/check_tiny_models.yml
+++ b/.github/workflows/check_tiny_models.yml
@@ -14,7 +14,7 @@ env:
jobs:
check_tiny_models:
name: Check tiny models
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
steps:
- name: Checkout transformers
uses: actions/checkout@v3
diff --git a/.github/workflows/doctests.yml b/.github/workflows/doctests.yml
index 236ccbcd253a..0384144ceac7 100644
--- a/.github/workflows/doctests.yml
+++ b/.github/workflows/doctests.yml
@@ -20,7 +20,7 @@ env:
jobs:
run_doctests:
- runs-on: [single-gpu, nvidia-gpu, t4, doctest-ci]
+ runs-on: [single-gpu, nvidia-gpu, t4, ci]
container:
image: huggingface/transformers-all-latest-gpu
options: --gpus 0 --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
@@ -66,7 +66,7 @@ jobs:
send_results:
name: Send results to webhook
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
if: always()
needs: [run_doctests]
steps:
diff --git a/.github/workflows/model-templates.yml b/.github/workflows/model-templates.yml
index 3830c23fe048..eb77d9dcbe1e 100644
--- a/.github/workflows/model-templates.yml
+++ b/.github/workflows/model-templates.yml
@@ -7,7 +7,7 @@ on:
jobs:
run_tests_templates:
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
steps:
- name: Checkout repository
uses: actions/checkout@v3
diff --git a/.github/workflows/release-conda.yml b/.github/workflows/release-conda.yml
index 4cc0b662fcc8..7a1990eec6b3 100644
--- a/.github/workflows/release-conda.yml
+++ b/.github/workflows/release-conda.yml
@@ -12,7 +12,7 @@ env:
jobs:
build_and_package:
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
defaults:
run:
shell: bash -l {0}
diff --git a/.github/workflows/self-nightly-scheduled.yml b/.github/workflows/self-nightly-scheduled.yml
index 713e004d8e58..e4b4f7f77cf0 100644
--- a/.github/workflows/self-nightly-scheduled.yml
+++ b/.github/workflows/self-nightly-scheduled.yml
@@ -19,38 +19,11 @@ env:
SIGOPT_API_TOKEN: ${{ secrets.SIGOPT_API_TOKEN }}
TF_FORCE_GPU_ALLOW_GROWTH: true
RUN_PT_TF_CROSS_TESTS: 1
+ CUDA_VISIBLE_DEVICES: 0,1
jobs:
- check_runner_status:
- name: Check Runner Status
- runs-on: ubuntu-latest
- steps:
- - name: Checkout transformers
- uses: actions/checkout@v3
- with:
- fetch-depth: 2
-
- - name: Check Runner Status
- run: python utils/check_self_hosted_runner.py --target_runners single-gpu-past-ci-runner-docker,multi-gpu-past-ci-runner-docker --token ${{ secrets.ACCESS_REPO_INFO_TOKEN }}
-
- check_runners:
- name: Check Runners
- needs: check_runner_status
- strategy:
- matrix:
- machine_type: [single-gpu, multi-gpu]
- runs-on: ['${{ matrix.machine_type }}', nvidia-gpu, t4, past-ci]
- container:
- image: huggingface/transformers-all-latest-torch-nightly-gpu
- options: --gpus 0 --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
- steps:
- - name: NVIDIA-SMI
- run: |
- nvidia-smi
-
setup:
name: Setup
- needs: check_runners
strategy:
matrix:
machine_type: [single-gpu, multi-gpu]
@@ -273,11 +246,9 @@ jobs:
send_results:
name: Send results to webhook
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
if: always()
needs: [
- check_runner_status,
- check_runners,
setup,
run_tests_single_gpu,
run_tests_multi_gpu,
@@ -288,8 +259,6 @@ jobs:
shell: bash
# For the meaning of these environment variables, see the job `Setup`
run: |
- echo "Runner availability: ${{ needs.check_runner_status.result }}"
- echo "Runner status: ${{ needs.check_runners.result }}"
echo "Setup status: ${{ needs.setup.result }}"
- uses: actions/checkout@v3
@@ -303,8 +272,6 @@ jobs:
CI_SLACK_REPORT_CHANNEL_ID: ${{ secrets.CI_SLACK_CHANNEL_ID_PAST_FUTURE }}
ACCESS_REPO_INFO_TOKEN: ${{ secrets.ACCESS_REPO_INFO_TOKEN }}
CI_EVENT: Nightly CI
- RUNNER_STATUS: ${{ needs.check_runner_status.result }}
- RUNNER_ENV_STATUS: ${{ needs.check_runners.result }}
SETUP_STATUS: ${{ needs.setup.result }}
# We pass `needs.setup.outputs.matrix` as the argument. A processing in `notification_service.py` to change
# `models/bert` to `models_bert` is required, as the artifact names use `_` instead of `/`.
diff --git a/.github/workflows/self-past.yml b/.github/workflows/self-past.yml
index 71f904c831e9..2ece4388d27c 100644
--- a/.github/workflows/self-past.yml
+++ b/.github/workflows/self-past.yml
@@ -30,38 +30,11 @@ env:
SIGOPT_API_TOKEN: ${{ secrets.SIGOPT_API_TOKEN }}
TF_FORCE_GPU_ALLOW_GROWTH: true
RUN_PT_TF_CROSS_TESTS: 1
+ CUDA_VISIBLE_DEVICES: 0,1
jobs:
- check_runner_status:
- name: Check Runner Status
- runs-on: ubuntu-latest
- steps:
- - name: Checkout transformers
- uses: actions/checkout@v3
- with:
- fetch-depth: 2
-
- - name: Check Runner Status
- run: python utils/check_self_hosted_runner.py --target_runners single-gpu-past-ci-runner-docker,multi-gpu-past-ci-runner-docker --token ${{ secrets.ACCESS_REPO_INFO_TOKEN }}
-
- check_runners:
- name: Check Runners
- needs: check_runner_status
- strategy:
- matrix:
- machine_type: [single-gpu, multi-gpu]
- runs-on: ['${{ matrix.machine_type }}', nvidia-gpu, t4, past-ci]
- container:
- image: huggingface/transformers-${{ inputs.framework }}-past-${{ inputs.version }}-gpu
- options: --gpus 0 --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
- steps:
- - name: NVIDIA-SMI
- run: |
- nvidia-smi
-
setup:
name: Setup
- needs: check_runners
strategy:
matrix:
machine_type: [single-gpu, multi-gpu]
@@ -115,6 +88,10 @@ jobs:
working-directory: /transformers
run: python3 -m pip uninstall -y transformers && python3 -m pip install -e .
+ - name: Update some packages
+ working-directory: /transformers
+ run: python3 -m pip install -U datasets
+
- name: Echo folder ${{ matrix.folders }}
shell: bash
# For folders like `models/bert`, set an env. var. (`matrix_folders`) to `models_bert`, which will be used to
@@ -191,6 +168,10 @@ jobs:
working-directory: /transformers
run: python3 -m pip uninstall -y transformers && python3 -m pip install -e .
+ - name: Update some packages
+ working-directory: /transformers
+ run: python3 -m pip install -U datasets
+
- name: Echo folder ${{ matrix.folders }}
shell: bash
# For folders like `models/bert`, set an env. var. (`matrix_folders`) to `models_bert`, which will be used to
@@ -267,6 +248,10 @@ jobs:
working-directory: /transformers
run: python3 -m pip uninstall -y transformers && python3 -m pip install -e .
+ - name: Update some packages
+ working-directory: /transformers
+ run: python3 -m pip install -U datasets
+
- name: Install
working-directory: /transformers
run: |
@@ -316,11 +301,9 @@ jobs:
send_results:
name: Send results to webhook
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
if: always()
needs: [
- check_runner_status,
- check_runners,
setup,
run_tests_single_gpu,
run_tests_multi_gpu,
@@ -331,8 +314,6 @@ jobs:
shell: bash
# For the meaning of these environment variables, see the job `Setup`
run: |
- echo "Runner availability: ${{ needs.check_runner_status.result }}"
- echo "Runner status: ${{ needs.check_runners.result }}"
echo "Setup status: ${{ needs.setup.result }}"
- uses: actions/checkout@v3
@@ -351,8 +332,6 @@ jobs:
CI_SLACK_REPORT_CHANNEL_ID: ${{ secrets.CI_SLACK_CHANNEL_ID_PAST_FUTURE }}
ACCESS_REPO_INFO_TOKEN: ${{ secrets.ACCESS_REPO_INFO_TOKEN }}
CI_EVENT: Past CI - ${{ inputs.framework }}-${{ inputs.version }}
- RUNNER_STATUS: ${{ needs.check_runner_status.result }}
- RUNNER_ENV_STATUS: ${{ needs.check_runners.result }}
SETUP_STATUS: ${{ needs.setup.result }}
# We pass `needs.setup.outputs.matrix` as the argument. A processing in `notification_service.py` to change
# `models/bert` to `models_bert` is required, as the artifact names use `_` instead of `/`.
diff --git a/.github/workflows/self-push-amd-mi210-caller.yml b/.github/workflows/self-push-amd-mi210-caller.yml
index 5dd010ef66d8..918cdbcdbceb 100644
--- a/.github/workflows/self-push-amd-mi210-caller.yml
+++ b/.github/workflows/self-push-amd-mi210-caller.yml
@@ -18,7 +18,7 @@ on:
jobs:
run_amd_ci:
name: AMD mi210
- if: (cancelled() != true) && ((github.event_name != 'schedule') || ((github.event_name == 'push') && startsWith(github.ref_name, 'run_amd_push_ci_caller')))
+ if: (cancelled() != true) && ((github.event_name == 'schedule') || ((github.event_name == 'push') && startsWith(github.ref_name, 'run_amd_push_ci_caller')))
uses: ./.github/workflows/self-push-amd.yml
with:
gpu_flavor: mi210
diff --git a/.github/workflows/self-push-amd-mi250-caller.yml b/.github/workflows/self-push-amd-mi250-caller.yml
index a55378c4caa5..fb139b28a03c 100644
--- a/.github/workflows/self-push-amd-mi250-caller.yml
+++ b/.github/workflows/self-push-amd-mi250-caller.yml
@@ -18,7 +18,7 @@ on:
jobs:
run_amd_ci:
name: AMD mi250
- if: (cancelled() != true) && ((github.event_name != 'schedule') || ((github.event_name == 'push') && startsWith(github.ref_name, 'run_amd_push_ci_caller')))
+ if: (cancelled() != true) && ((github.event_name == 'schedule') || ((github.event_name == 'push') && startsWith(github.ref_name, 'run_amd_push_ci_caller')))
uses: ./.github/workflows/self-push-amd.yml
with:
gpu_flavor: mi250
diff --git a/.github/workflows/self-push-amd.yml b/.github/workflows/self-push-amd.yml
index 875169827768..19857981b12d 100644
--- a/.github/workflows/self-push-amd.yml
+++ b/.github/workflows/self-push-amd.yml
@@ -19,7 +19,7 @@ env:
jobs:
check_runner_status:
name: Check Runner Status
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
steps:
- name: Checkout transformers
uses: actions/checkout@v3
@@ -38,14 +38,16 @@ jobs:
runs-on: [self-hosted, docker-gpu, amd-gpu, '${{ matrix.machine_type }}', '${{ inputs.gpu_flavor }}']
container:
image: huggingface/transformers-pytorch-amd-gpu-push-ci # <--- We test only for PyTorch for now
- options: --device /dev/kfd --device /dev/dri --env HIP_VISIBLE_DEVICES --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ options: --device /dev/kfd --device /dev/dri --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
steps:
- name: ROCM-SMI
+ run: |
+ rocm-smi
+ - name: ROCM-INFO
run: |
rocminfo | grep "Agent" -A 14
- - name: Show HIP environment
+ - name: Show ROCR environment
run: |
- echo "HIP: $HIP_VISIBLE_DEVICES"
echo "ROCR: $ROCR_VISIBLE_DEVICES"
setup_gpu:
@@ -57,7 +59,7 @@ jobs:
runs-on: [self-hosted, docker-gpu, amd-gpu, '${{ matrix.machine_type }}', '${{ inputs.gpu_flavor }}']
container:
image: huggingface/transformers-pytorch-amd-gpu-push-ci # <--- We test only for PyTorch for now
- options: --device /dev/kfd --device /dev/dri --env HIP_VISIBLE_DEVICES --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ options: --device /dev/kfd --device /dev/dri --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
outputs:
matrix: ${{ steps.set-matrix.outputs.matrix }}
test_map: ${{ steps.set-matrix.outputs.test_map }}
@@ -155,7 +157,7 @@ jobs:
runs-on: [self-hosted, docker-gpu, amd-gpu, '${{ matrix.machine_type }}', '${{ inputs.gpu_flavor }}']
container:
image: huggingface/transformers-pytorch-amd-gpu-push-ci # <--- We test only for PyTorch for now
- options: --device /dev/kfd --device /dev/dri --env HIP_VISIBLE_DEVICES --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ options: --device /dev/kfd --device /dev/dri --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
steps:
# Necessary to get the correct branch name and commit SHA for `workflow_run` event
# We also take into account the `push` event (we might want to test some changes in a branch)
@@ -206,11 +208,13 @@ jobs:
echo "matrix_folders=$matrix_folders" >> $GITHUB_ENV
- name: ROCM-SMI
+ run: |
+ rocm-smi
+ - name: ROCM-INFO
run: |
rocminfo | grep "Agent" -A 14
- - name: Show HIP environment
+ - name: Show ROCR environment
run: |
- echo "HIP: $HIP_VISIBLE_DEVICES"
echo "ROCR: $ROCR_VISIBLE_DEVICES"
- name: Environment
@@ -241,7 +245,7 @@ jobs:
send_results:
name: Send results to webhook
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
if: always()
needs: [
check_runner_status,
diff --git a/.github/workflows/self-push-caller.yml b/.github/workflows/self-push-caller.yml
index 994567c5cdbd..9247848b89ec 100644
--- a/.github/workflows/self-push-caller.yml
+++ b/.github/workflows/self-push-caller.yml
@@ -14,7 +14,7 @@ on:
jobs:
check-for-setup:
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
name: Check if setup was changed
outputs:
changed: ${{ steps.was_changed.outputs.changed }}
@@ -46,7 +46,7 @@ jobs:
run_push_ci:
name: Trigger Push CI
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
if: ${{ always() }}
needs: build-docker-containers
steps:
diff --git a/.github/workflows/self-push.yml b/.github/workflows/self-push.yml
index e4b1b3b4b235..a6ea5b1e04b9 100644
--- a/.github/workflows/self-push.yml
+++ b/.github/workflows/self-push.yml
@@ -25,38 +25,11 @@ env:
PYTEST_TIMEOUT: 60
TF_FORCE_GPU_ALLOW_GROWTH: true
RUN_PT_TF_CROSS_TESTS: 1
+ CUDA_VISIBLE_DEVICES: 0,1
jobs:
- check_runner_status:
- name: Check Runner Status
- runs-on: ubuntu-latest
- steps:
- - name: Checkout transformers
- uses: actions/checkout@v3
- with:
- fetch-depth: 2
-
- - name: Check Runner Status
- run: python utils/check_self_hosted_runner.py --target_runners single-gpu-ci-runner-docker,multi-gpu-ci-runner-docker --token ${{ secrets.ACCESS_REPO_INFO_TOKEN }}
-
- check_runners:
- name: Check Runners
- needs: check_runner_status
- strategy:
- matrix:
- machine_type: [single-gpu, multi-gpu]
- runs-on: ['${{ matrix.machine_type }}', nvidia-gpu, t4, push-ci]
- container:
- image: huggingface/transformers-all-latest-gpu-push-ci
- options: --gpus 0 --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
- steps:
- - name: NVIDIA-SMI
- run: |
- nvidia-smi
-
setup:
name: Setup
- needs: check_runners
strategy:
matrix:
machine_type: [single-gpu, multi-gpu]
@@ -518,11 +491,9 @@ jobs:
send_results:
name: Send results to webhook
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
if: always()
needs: [
- check_runner_status,
- check_runners,
setup,
run_tests_single_gpu,
run_tests_multi_gpu,
@@ -534,9 +505,7 @@ jobs:
shell: bash
# For the meaning of these environment variables, see the job `Setup`
run: |
- echo "Runner availability: ${{ needs.check_runner_status.result }}"
echo "Setup status: ${{ needs.setup.result }}"
- echo "Runner status: ${{ needs.check_runners.result }}"
# Necessary to get the correct branch name and commit SHA for `workflow_run` event
# We also take into account the `push` event (we might want to test some changes in a branch)
@@ -589,8 +558,6 @@ jobs:
CI_TITLE_PUSH: ${{ github.event.head_commit.message }}
CI_TITLE_WORKFLOW_RUN: ${{ github.event.workflow_run.head_commit.message }}
CI_SHA: ${{ env.CI_SHA }}
- RUNNER_STATUS: ${{ needs.check_runner_status.result }}
- RUNNER_ENV_STATUS: ${{ needs.check_runners.result }}
SETUP_STATUS: ${{ needs.setup.result }}
# We pass `needs.setup.outputs.matrix` as the argument. A processing in `notification_service.py` to change
diff --git a/.github/workflows/self-scheduled-amd-caller.yml b/.github/workflows/self-scheduled-amd-caller.yml
new file mode 100644
index 000000000000..4755bd868249
--- /dev/null
+++ b/.github/workflows/self-scheduled-amd-caller.yml
@@ -0,0 +1,25 @@
+name: Self-hosted runner (AMD scheduled CI caller)
+
+on:
+ schedule:
+ - cron: "17 2 * * *"
+ push:
+ branches:
+ - run_amd_scheduled_ci_caller*
+
+jobs:
+ run_amd_ci_mi210:
+ name: AMD mi210
+ if: (cancelled() != true) && ((github.event_name == 'schedule') || ((github.event_name == 'push') && startsWith(github.ref_name, 'run_amd_scheduled_ci_caller')))
+ uses: ./.github/workflows/self-scheduled-amd.yml
+ with:
+ gpu_flavor: mi210
+ secrets: inherit
+
+ run_amd_ci_mi250:
+ name: AMD mi250
+ if: (cancelled() != true) && ((github.event_name == 'schedule') || ((github.event_name == 'push') && startsWith(github.ref_name, 'run_amd_scheduled_ci_caller')))
+ uses: ./.github/workflows/self-scheduled-amd.yml
+ with:
+ gpu_flavor: mi250
+ secrets: inherit
diff --git a/.github/workflows/self-scheduled-amd.yml b/.github/workflows/self-scheduled-amd.yml
new file mode 100644
index 000000000000..17e907e40a57
--- /dev/null
+++ b/.github/workflows/self-scheduled-amd.yml
@@ -0,0 +1,461 @@
+name: Self-hosted runner (scheduled-amd)
+
+# Note: For the AMD CI, we rely on a caller workflow and on the workflow_call event to trigger the
+# CI in order to run it on both MI210 and MI250, without having to use matrix here which pushes
+# us towards the limit of allowed jobs on GitHub Actions.
+on:
+ workflow_call:
+ inputs:
+ gpu_flavor:
+ required: true
+ type: string
+
+env:
+ HF_HOME: /mnt/cache
+ TRANSFORMERS_IS_CI: yes
+ OMP_NUM_THREADS: 8
+ MKL_NUM_THREADS: 8
+ RUN_SLOW: yes
+ SIGOPT_API_TOKEN: ${{ secrets.SIGOPT_API_TOKEN }}
+
+
+# Important note: each job (run_tests_single_gpu, run_tests_multi_gpu, run_examples_gpu, run_pipelines_torch_gpu) requires all the previous jobs before running.
+# This is done so that we avoid parallelizing the scheduled tests, to leave available
+# runners for the push CI that is running on the same machine.
+jobs:
+ check_runner_status:
+ name: Check Runner Status
+ runs-on: ubuntu-22.04
+ steps:
+ - name: Checkout transformers
+ uses: actions/checkout@v3
+ with:
+ fetch-depth: 2
+
+ - name: Check Runner Status
+ run: python utils/check_self_hosted_runner.py --target_runners hf-amd-mi210-ci-1gpu-1,hf-amd-mi250-ci-1gpu-1 --token ${{ secrets.ACCESS_REPO_INFO_TOKEN }}
+
+ check_runners:
+ name: Check Runners
+ needs: check_runner_status
+ strategy:
+ matrix:
+ machine_type: [single-gpu, multi-gpu]
+ runs-on: [self-hosted, docker-gpu, amd-gpu, '${{ matrix.machine_type }}', '${{ inputs.gpu_flavor }}']
+ container:
+ image: huggingface/transformers-pytorch-amd-gpu
+ options: --device /dev/kfd --device /dev/dri --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ steps:
+ - name: ROCM-SMI
+ run: |
+ rocm-smi
+ - name: ROCM-INFO
+ run: |
+ rocminfo | grep "Agent" -A 14
+ - name: Show ROCR environment
+ run: |
+ echo "ROCR: $ROCR_VISIBLE_DEVICES"
+
+ setup:
+ name: Setup
+ needs: check_runners
+ strategy:
+ matrix:
+ machine_type: [single-gpu, multi-gpu]
+ runs-on: [self-hosted, docker-gpu, amd-gpu, '${{ matrix.machine_type }}', '${{ inputs.gpu_flavor }}']
+ container:
+ image: huggingface/transformers-pytorch-amd-gpu
+ options: --device /dev/kfd --device /dev/dri --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ outputs:
+ matrix: ${{ steps.set-matrix.outputs.matrix }}
+ steps:
+ - name: Update clone
+ working-directory: /transformers
+ run: |
+ git fetch && git checkout ${{ github.sha }}
+
+ - name: Cleanup
+ working-directory: /transformers
+ run: |
+ rm -rf tests/__pycache__
+ rm -rf tests/models/__pycache__
+ rm -rf reports
+
+ - name: Show installed libraries and their versions
+ working-directory: /transformers
+ run: pip freeze
+
+ - id: set-matrix
+ name: Identify models to test
+ working-directory: /transformers/tests
+ run: |
+ echo "matrix=$(python3 -c 'import os; tests = os.getcwd(); model_tests = os.listdir(os.path.join(tests, "models")); d1 = sorted(list(filter(os.path.isdir, os.listdir(tests)))); d2 = sorted(list(filter(os.path.isdir, [f"models/{x}" for x in model_tests]))); d1.remove("models"); d = d2 + d1; print(d)')" >> $GITHUB_OUTPUT
+
+ - name: ROCM-SMI
+ run: |
+ rocm-smi
+
+ - name: ROCM-INFO
+ run: |
+ rocminfo | grep "Agent" -A 14
+ - name: Show ROCR environment
+ run: |
+ echo "ROCR: $ROCR_VISIBLE_DEVICES"
+
+ - name: Environment
+ working-directory: /transformers
+ run: |
+ python3 utils/print_env.py
+
+ run_tests_single_gpu:
+ name: Single GPU tests
+ strategy:
+ max-parallel: 1 # For now, not to parallelize. Can change later if it works well.
+ fail-fast: false
+ matrix:
+ folders: ${{ fromJson(needs.setup.outputs.matrix) }}
+ machine_type: [single-gpu]
+ runs-on: [self-hosted, docker-gpu, amd-gpu, '${{ matrix.machine_type }}', '${{ inputs.gpu_flavor }}']
+ container:
+ image: huggingface/transformers-pytorch-amd-gpu
+ options: --device /dev/kfd --device /dev/dri --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ needs: setup
+ steps:
+ - name: Echo folder ${{ matrix.folders }}
+ shell: bash
+ # For folders like `models/bert`, set an env. var. (`matrix_folders`) to `models_bert`, which will be used to
+ # set the artifact folder names (because the character `/` is not allowed).
+ run: |
+ echo "${{ matrix.folders }}"
+ matrix_folders=${{ matrix.folders }}
+ matrix_folders=${matrix_folders/'models/'/'models_'}
+ echo "$matrix_folders"
+ echo "matrix_folders=$matrix_folders" >> $GITHUB_ENV
+
+ - name: Update clone
+ working-directory: /transformers
+ run: git fetch && git checkout ${{ github.sha }}
+
+ - name: Reinstall transformers in edit mode (remove the one installed during docker image build)
+ working-directory: /transformers
+ run: python3 -m pip uninstall -y transformers && python3 -m pip install -e .
+
+ - name: ROCM-SMI
+ run: |
+ rocm-smi
+ - name: ROCM-INFO
+ run: |
+ rocminfo | grep "Agent" -A 14
+ - name: Show ROCR environment
+ run: |
+ echo "ROCR: $ROCR_VISIBLE_DEVICES"
+
+ - name: Environment
+ working-directory: /transformers
+ run: |
+ python3 utils/print_env.py
+
+ - name: Show installed libraries and their versions
+ working-directory: /transformers
+ run: pip freeze
+
+ - name: Run all tests on GPU
+ working-directory: /transformers
+ run: python3 -m pytest -v --make-reports=${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }} tests/${{ matrix.folders }}
+
+ - name: Failure short reports
+ if: ${{ failure() }}
+ continue-on-error: true
+ run: cat /transformers/reports/${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }}/failures_short.txt
+
+ - name: Test suite reports artifacts
+ if: ${{ always() }}
+ uses: actions/upload-artifact@v3
+ with:
+ name: ${{ matrix.machine_type }}_run_all_tests_gpu_${{ env.matrix_folders }}_test_reports
+ path: /transformers/reports/${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }}
+
+ run_tests_multi_gpu:
+ name: Multi GPU tests
+ strategy:
+ max-parallel: 1
+ fail-fast: false
+ matrix:
+ folders: ${{ fromJson(needs.setup.outputs.matrix) }}
+ machine_type: [multi-gpu]
+ runs-on: [self-hosted, docker-gpu, amd-gpu, '${{ matrix.machine_type }}', '${{ inputs.gpu_flavor }}']
+ container:
+ image: huggingface/transformers-pytorch-amd-gpu
+ options: --device /dev/kfd --device /dev/dri --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ needs: setup
+ steps:
+ - name: Echo folder ${{ matrix.folders }}
+ shell: bash
+ # For folders like `models/bert`, set an env. var. (`matrix_folders`) to `models_bert`, which will be used to
+ # set the artifact folder names (because the character `/` is not allowed).
+ run: |
+ echo "${{ matrix.folders }}"
+ matrix_folders=${{ matrix.folders }}
+ matrix_folders=${matrix_folders/'models/'/'models_'}
+ echo "$matrix_folders"
+ echo "matrix_folders=$matrix_folders" >> $GITHUB_ENV
+
+ - name: Update clone
+ working-directory: /transformers
+ run: git fetch && git checkout ${{ github.sha }}
+
+ - name: Reinstall transformers in edit mode (remove the one installed during docker image build)
+ working-directory: /transformers
+ run: python3 -m pip uninstall -y transformers && python3 -m pip install -e .
+
+ - name: ROCM-SMI
+ run: |
+ rocm-smi
+ - name: ROCM-INFO
+ run: |
+ rocminfo | grep "Agent" -A 14
+ - name: Show ROCR environment
+ run: |
+ echo "ROCR: $ROCR_VISIBLE_DEVICES"
+
+ - name: Environment
+ working-directory: /transformers
+ run: |
+ python3 utils/print_env.py
+
+ - name: Show installed libraries and their versions
+ working-directory: /transformers
+ run: pip freeze
+
+ - name: Run all tests on GPU
+ working-directory: /transformers
+ run: python3 -m pytest -v --make-reports=${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }} tests/${{ matrix.folders }}
+
+ - name: Failure short reports
+ if: ${{ failure() }}
+ continue-on-error: true
+ run: cat /transformers/reports/${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }}/failures_short.txt
+
+ - name: Test suite reports artifacts
+ if: ${{ always() }}
+ uses: actions/upload-artifact@v3
+ with:
+ name: ${{ matrix.machine_type }}_run_all_tests_gpu_${{ env.matrix_folders }}_test_reports
+ path: /transformers/reports/${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }}
+
+ run_examples_gpu:
+ name: Examples tests
+ strategy:
+ fail-fast: false
+ matrix:
+ machine_type: [single-gpu]
+ runs-on: [self-hosted, docker-gpu, amd-gpu, '${{ matrix.machine_type }}', '${{ inputs.gpu_flavor }}']
+ container:
+ image: huggingface/transformers-pytorch-amd-gpu
+ options: --device /dev/kfd --device /dev/dri --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ needs: setup
+ steps:
+ - name: Update clone
+ working-directory: /transformers
+ run: git fetch && git checkout ${{ github.sha }}
+
+ - name: Reinstall transformers in edit mode (remove the one installed during docker image build)
+ working-directory: /transformers
+ run: python3 -m pip uninstall -y transformers && python3 -m pip install -e .
+
+ - name: ROCM-SMI
+ run: |
+ rocm-smi
+ - name: ROCM-INFO
+ run: |
+ rocminfo | grep "Agent" -A 14
+ - name: Show ROCR environment
+ run: |
+ echo "ROCR: $ROCR_VISIBLE_DEVICES"
+
+ - name: Environment
+ working-directory: /transformers
+ run: |
+ python3 utils/print_env.py
+
+ - name: Show installed libraries and their versions
+ working-directory: /transformers
+ run: pip freeze
+
+ - name: Run examples tests on GPU
+ working-directory: /transformers
+ run: |
+ pip install -r examples/pytorch/_tests_requirements.txt
+ python3 -m pytest -v --make-reports=${{ matrix.machine_type }}_examples_gpu examples/pytorch
+
+ - name: Failure short reports
+ if: ${{ failure() }}
+ continue-on-error: true
+ run: cat /transformers/reports/${{ matrix.machine_type }}_examples_gpu/failures_short.txt
+
+ - name: Test suite reports artifacts
+ if: ${{ always() }}
+ uses: actions/upload-artifact@v3
+ with:
+ name: ${{ matrix.machine_type }}_run_examples_gpu
+ path: /transformers/reports/${{ matrix.machine_type }}_examples_gpu
+
+ run_pipelines_torch_gpu:
+ name: PyTorch pipelines tests
+ strategy:
+ fail-fast: false
+ matrix:
+ machine_type: [single-gpu, multi-gpu]
+ runs-on: [self-hosted, docker-gpu, amd-gpu, '${{ matrix.machine_type }}', '${{ inputs.gpu_flavor }}']
+ container:
+ image: huggingface/transformers-pytorch-amd-gpu
+ options: --device /dev/kfd --device /dev/dri --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ needs: setup
+ steps:
+ - name: Update clone
+ working-directory: /transformers
+ run: git fetch && git checkout ${{ github.sha }}
+
+ - name: Reinstall transformers in edit mode (remove the one installed during docker image build)
+ working-directory: /transformers
+ run: python3 -m pip uninstall -y transformers && python3 -m pip install -e .
+
+ - name: ROCM-SMI
+ run: |
+ rocm-smi
+ - name: ROCM-INFO
+ run: |
+ rocminfo | grep "Agent" -A 14
+ - name: Show ROCR environment
+ run: |
+ echo "ROCR: $ROCR_VISIBLE_DEVICES"
+
+ - name: Environment
+ working-directory: /transformers
+ run: |
+ python3 utils/print_env.py
+
+ - name: Show installed libraries and their versions
+ working-directory: /transformers
+ run: pip freeze
+
+ - name: Run all pipeline tests on GPU
+ working-directory: /transformers
+ run: |
+ python3 -m pytest -n 1 -v --dist=loadfile --make-reports=${{ matrix.machine_type }}_tests_torch_pipeline_gpu tests/pipelines
+
+ - name: Failure short reports
+ if: ${{ failure() }}
+ continue-on-error: true
+ run: cat /transformers/reports/${{ matrix.machine_type }}_tests_torch_pipeline_gpu/failures_short.txt
+
+ - name: Test suite reports artifacts
+ if: ${{ always() }}
+ uses: actions/upload-artifact@v3
+ with:
+ name: ${{ matrix.machine_type }}_run_tests_torch_pipeline_gpu
+ path: /transformers/reports/${{ matrix.machine_type }}_tests_torch_pipeline_gpu
+
+ run_extract_warnings:
+ name: Extract warnings in CI artifacts
+ runs-on: ubuntu-22.04
+ if: always()
+ needs: [
+ check_runner_status,
+ check_runners,
+ setup,
+ run_tests_single_gpu,
+ run_tests_multi_gpu,
+ run_examples_gpu,
+ run_pipelines_torch_gpu,
+ # run_all_tests_torch_cuda_extensions_gpu
+ ]
+ steps:
+ - name: Checkout transformers
+ uses: actions/checkout@v3
+ with:
+ fetch-depth: 2
+
+ - name: Install transformers
+ run: pip install transformers
+
+ - name: Show installed libraries and their versions
+ run: pip freeze
+
+ - name: Create output directory
+ run: mkdir warnings_in_ci
+
+ - uses: actions/download-artifact@v3
+ with:
+ path: warnings_in_ci
+
+ - name: Show artifacts
+ run: echo "$(python3 -c 'import os; d = os.listdir(); print(d)')"
+ working-directory: warnings_in_ci
+
+ - name: Extract warnings in CI artifacts
+ run: |
+ python3 utils/extract_warnings.py --workflow_run_id ${{ github.run_id }} --output_dir warnings_in_ci --token ${{ secrets.ACCESS_REPO_INFO_TOKEN }} --from_gh
+ echo "$(python3 -c 'import os; import json; fp = open("warnings_in_ci/selected_warnings.json"); d = json.load(fp); d = "\n".join(d) ;print(d)')"
+
+ - name: Upload artifact
+ if: ${{ always() }}
+ uses: actions/upload-artifact@v3
+ with:
+ name: warnings_in_ci
+ path: warnings_in_ci/selected_warnings.json
+
+ send_results:
+ name: Send results to webhook
+ runs-on: ubuntu-22.04
+ if: always()
+ needs: [
+ check_runner_status,
+ check_runners,
+ setup,
+ run_tests_single_gpu,
+ run_tests_multi_gpu,
+ run_examples_gpu,
+ run_pipelines_torch_gpu,
+ # run_all_tests_torch_cuda_extensions_gpu,
+ run_extract_warnings
+ ]
+ steps:
+ - name: Preliminary job status
+ shell: bash
+ # For the meaning of these environment variables, see the job `Setup`
+ run: |
+ echo "Runner availability: ${{ needs.check_runner_status.result }}"
+ echo "Runner status: ${{ needs.check_runners.result }}"
+ echo "Setup status: ${{ needs.setup.result }}"
+
+ - uses: actions/checkout@v3
+ - uses: actions/download-artifact@v3
+ - name: Send message to Slack
+ env:
+ CI_SLACK_BOT_TOKEN: ${{ secrets.CI_SLACK_BOT_TOKEN }}
+ CI_SLACK_CHANNEL_ID_DAILY_AMD: ${{ secrets.CI_SLACK_CHANNEL_ID_DAILY_AMD }}
+ CI_SLACK_CHANNEL_DUMMY_TESTS: ${{ secrets.CI_SLACK_CHANNEL_DUMMY_TESTS }}
+ CI_SLACK_REPORT_CHANNEL_ID: ${{ secrets.CI_SLACK_CHANNEL_ID_DAILY_AMD }}
+ ACCESS_REPO_INFO_TOKEN: ${{ secrets.ACCESS_REPO_INFO_TOKEN }}
+ CI_EVENT: Scheduled CI (AMD)
+ CI_SHA: ${{ github.sha }}
+ CI_WORKFLOW_REF: ${{ github.workflow_ref }}
+ RUNNER_STATUS: ${{ needs.check_runner_status.result }}
+ RUNNER_ENV_STATUS: ${{ needs.check_runners.result }}
+ SETUP_STATUS: ${{ needs.setup.result }}
+ # We pass `needs.setup.outputs.matrix` as the argument. A processing in `notification_service.py` to change
+ # `models/bert` to `models_bert` is required, as the artifact names use `_` instead of `/`.
+ run: |
+ sudo apt-get install -y curl
+ pip install slack_sdk
+ pip show slack_sdk
+ python utils/notification_service.py "${{ needs.setup.outputs.matrix }}"
+
+ # Upload complete failure tables, as they might be big and only truncated versions could be sent to Slack.
+ - name: Failure table artifacts
+ if: ${{ always() }}
+ uses: actions/upload-artifact@v3
+ with:
+ name: test_failure_tables
+ path: test_failure_tables
diff --git a/.github/workflows/self-scheduled.yml b/.github/workflows/self-scheduled.yml
index 2bd6bbade1cb..4a04cb14ac7b 100644
--- a/.github/workflows/self-scheduled.yml
+++ b/.github/workflows/self-scheduled.yml
@@ -23,38 +23,11 @@ env:
SIGOPT_API_TOKEN: ${{ secrets.SIGOPT_API_TOKEN }}
TF_FORCE_GPU_ALLOW_GROWTH: true
RUN_PT_TF_CROSS_TESTS: 1
+ CUDA_VISIBLE_DEVICES: 0,1
jobs:
- check_runner_status:
- name: Check Runner Status
- runs-on: ubuntu-latest
- steps:
- - name: Checkout transformers
- uses: actions/checkout@v3
- with:
- fetch-depth: 2
-
- - name: Check Runner Status
- run: python utils/check_self_hosted_runner.py --target_runners single-gpu-scheduled-ci-runner-docker,multi-gpu-scheduled-ci-runner-docker --token ${{ secrets.ACCESS_REPO_INFO_TOKEN }}
-
- check_runners:
- name: Check Runners
- needs: check_runner_status
- strategy:
- matrix:
- machine_type: [single-gpu, multi-gpu]
- runs-on: ['${{ matrix.machine_type }}', nvidia-gpu, t4, daily-ci]
- container:
- image: huggingface/transformers-all-latest-gpu
- options: --gpus 0 --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
- steps:
- - name: NVIDIA-SMI
- run: |
- nvidia-smi
-
setup:
name: Setup
- needs: check_runners
strategy:
matrix:
machine_type: [single-gpu, multi-gpu]
@@ -427,11 +400,9 @@ jobs:
run_extract_warnings:
name: Extract warnings in CI artifacts
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
if: always()
needs: [
- check_runner_status,
- check_runners,
setup,
run_tests_single_gpu,
run_tests_multi_gpu,
@@ -477,11 +448,9 @@ jobs:
send_results:
name: Send results to webhook
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
if: always()
needs: [
- check_runner_status,
- check_runners,
setup,
run_tests_single_gpu,
run_tests_multi_gpu,
@@ -496,8 +465,6 @@ jobs:
shell: bash
# For the meaning of these environment variables, see the job `Setup`
run: |
- echo "Runner availability: ${{ needs.check_runner_status.result }}"
- echo "Runner status: ${{ needs.check_runners.result }}"
echo "Setup status: ${{ needs.setup.result }}"
- uses: actions/checkout@v3
@@ -513,8 +480,6 @@ jobs:
CI_EVENT: scheduled
CI_SHA: ${{ github.sha }}
CI_WORKFLOW_REF: ${{ github.workflow_ref }}
- RUNNER_STATUS: ${{ needs.check_runner_status.result }}
- RUNNER_ENV_STATUS: ${{ needs.check_runners.result }}
SETUP_STATUS: ${{ needs.setup.result }}
# We pass `needs.setup.outputs.matrix` as the argument. A processing in `notification_service.py` to change
# `models/bert` to `models_bert` is required, as the artifact names use `_` instead of `/`.
diff --git a/.github/workflows/stale.yml b/.github/workflows/stale.yml
index 1211d71a32e2..4a7e94bac429 100644
--- a/.github/workflows/stale.yml
+++ b/.github/workflows/stale.yml
@@ -8,7 +8,7 @@ jobs:
close_stale_issues:
name: Close Stale Issues
if: github.repository == 'huggingface/transformers'
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
steps:
diff --git a/.github/workflows/update_metdata.yml b/.github/workflows/update_metdata.yml
index de25fe0a08a2..a2269e32e4d3 100644
--- a/.github/workflows/update_metdata.yml
+++ b/.github/workflows/update_metdata.yml
@@ -8,7 +8,7 @@ on:
jobs:
build_and_package:
- runs-on: ubuntu-latest
+ runs-on: ubuntu-22.04
defaults:
run:
shell: bash -l {0}
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 6cfa3e47398c..9ccfc46c2c14 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -40,8 +40,8 @@ There are several ways you can contribute to 🤗 Transformers:
If you don't know where to start, there is a special [Good First
Issue](https://github.com/huggingface/transformers/contribute) listing. It will give you a list of
-open issues that are beginner-friendly and help you start contributing to open-source. Just comment in the issue that you'd like to work
-on it.
+open issues that are beginner-friendly and help you start contributing to open-source. Just comment on the issue that you'd like to work
+on.
For something slightly more challenging, you can also take a look at the [Good Second Issue](https://github.com/huggingface/transformers/labels/Good%20Second%20Issue) list. In general though, if you feel like you know what you're doing, go for it and we'll help you get there! 🚀
@@ -62,7 +62,7 @@ feedback.
The 🤗 Transformers library is robust and reliable thanks to users who report the problems they encounter.
Before you report an issue, we would really appreciate it if you could **make sure the bug was not
-already reported** (use the search bar on GitHub under Issues). Your issue should also be related to bugs in the library itself, and not your code. If you're unsure whether the bug is in your code or the library, please ask on the [forum](https://discuss.huggingface.co/) first. This helps us respond quicker to fixing issues related to the library versus general questions.
+already reported** (use the search bar on GitHub under Issues). Your issue should also be related to bugs in the library itself, and not your code. If you're unsure whether the bug is in your code or the library, please ask in the [forum](https://discuss.huggingface.co/) first. This helps us respond quicker to fixing issues related to the library versus general questions.
Once you've confirmed the bug hasn't already been reported, please include the following information in your issue so we can quickly resolve it:
@@ -105,7 +105,7 @@ We have added [templates](https://github.com/huggingface/transformers/tree/main/
New models are constantly released and if you want to implement a new model, please provide the following information
-* A short description of the model and link to the paper.
+* A short description of the model and a link to the paper.
* Link to the implementation if it is open-sourced.
* Link to the model weights if they are available.
@@ -172,7 +172,7 @@ You'll need **[Python 3.8]((https://github.com/huggingface/transformers/blob/mai
which should be enough for most use cases.
-5. Develop the features on your branch.
+5. Develop the features in your branch.
As you work on your code, you should make sure the test suite
passes. Run the tests impacted by your changes like this:
@@ -208,7 +208,7 @@ You'll need **[Python 3.8]((https://github.com/huggingface/transformers/blob/mai
make quality
```
- Finally, we have a lot of scripts to make sure we didn't forget to update
+ Finally, we have a lot of scripts to make sure we don't forget to update
some files when adding a new model. You can run these scripts with:
```bash
@@ -218,7 +218,7 @@ You'll need **[Python 3.8]((https://github.com/huggingface/transformers/blob/mai
To learn more about those checks and how to fix any issues with them, check out the
[Checks on a Pull Request](https://huggingface.co/docs/transformers/pr_checks) guide.
- If you're modifying documents under `docs/source` directory, make sure the documentation can still be built. This check will also run in the CI when you open a pull request. To run a local check
+ If you're modifying documents under the `docs/source` directory, make sure the documentation can still be built. This check will also run in the CI when you open a pull request. To run a local check
make sure you install the documentation builder:
```bash
@@ -234,7 +234,7 @@ You'll need **[Python 3.8]((https://github.com/huggingface/transformers/blob/mai
This will build the documentation in the `~/tmp/test-build` folder where you can inspect the generated
Markdown files with your favorite editor. You can also preview the docs on GitHub when you open a pull request.
- Once you're happy with your changes, add changed files with `git add` and
+ Once you're happy with your changes, add the changed files with `git add` and
record your changes locally with `git commit`:
```bash
@@ -261,7 +261,7 @@ You'll need **[Python 3.8]((https://github.com/huggingface/transformers/blob/mai
If you've already opened a pull request, you'll need to force push with the `--force` flag. Otherwise, if the pull request hasn't been opened yet, you can just push your changes normally.
-6. Now you can go to your fork of the repository on GitHub and click on **Pull request** to open a pull request. Make sure you tick off all the boxes in our [checklist](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md/#pull-request-checklist) below. When you're ready, you can send your changes to the project maintainers for review.
+6. Now you can go to your fork of the repository on GitHub and click on **Pull Request** to open a pull request. Make sure you tick off all the boxes on our [checklist](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md/#pull-request-checklist) below. When you're ready, you can send your changes to the project maintainers for review.
7. It's ok if maintainers request changes, it happens to our core contributors
too! So everyone can see the changes in the pull request, work in your local
diff --git a/ISSUES.md b/ISSUES.md
index 95f2334b26c8..a5969a3027f8 100644
--- a/ISSUES.md
+++ b/ISSUES.md
@@ -152,7 +152,7 @@ You are not required to read the following guidelines before opening an issue. H
```bash
cd examples/seq2seq
- python -m torch.distributed.launch --nproc_per_node=2 ./finetune_trainer.py \
+ torchrun --nproc_per_node=2 ./finetune_trainer.py \
--model_name_or_path sshleifer/distill-mbart-en-ro-12-4 --data_dir wmt_en_ro \
--output_dir output_dir --overwrite_output_dir \
--do_train --n_train 500 --num_train_epochs 1 \
diff --git a/Makefile b/Makefile
index 0c51598594c0..befdce08a26c 100644
--- a/Makefile
+++ b/Makefile
@@ -9,8 +9,8 @@ modified_only_fixup:
$(eval modified_py_files := $(shell python utils/get_modified_files.py $(check_dirs)))
@if test -n "$(modified_py_files)"; then \
echo "Checking/fixing $(modified_py_files)"; \
- black $(modified_py_files); \
- ruff $(modified_py_files) --fix; \
+ ruff check $(modified_py_files) --fix; \
+ ruff format $(modified_py_files);\
else \
echo "No library .py files were modified"; \
fi
@@ -48,11 +48,10 @@ repo-consistency:
# this target runs checks on all files
quality:
- black --check $(check_dirs) setup.py conftest.py
+ ruff check $(check_dirs) setup.py conftest.py
+ ruff format --check $(check_dirs) setup.py conftest.py
python utils/custom_init_isort.py --check_only
python utils/sort_auto_mappings.py --check_only
- ruff $(check_dirs) setup.py conftest.py
- doc-builder style src/transformers docs/source --max_len 119 --check_only --path_to_docs docs/source
python utils/check_doc_toc.py
# Format source code automatically and check is there are any problems left that need manual fixing
@@ -60,14 +59,13 @@ quality:
extra_style_checks:
python utils/custom_init_isort.py
python utils/sort_auto_mappings.py
- doc-builder style src/transformers docs/source --max_len 119 --path_to_docs docs/source
python utils/check_doc_toc.py --fix_and_overwrite
# this target runs checks on all files and potentially modifies some of them
style:
- black $(check_dirs) setup.py conftest.py
- ruff $(check_dirs) setup.py conftest.py --fix
+ ruff check $(check_dirs) setup.py conftest.py --fix
+ ruff format $(check_dirs) setup.py conftest.py
${MAKE} autogenerate_code
${MAKE} extra_style_checks
diff --git a/README.md b/README.md
index 6d390e364ad7..e65d512defc4 100644
--- a/README.md
+++ b/README.md
@@ -244,7 +244,7 @@ The model itself is a regular [Pytorch `nn.Module`](https://pytorch.org/docs/sta
- This library is not a modular toolbox of building blocks for neural nets. The code in the model files is not refactored with additional abstractions on purpose, so that researchers can quickly iterate on each of the models without diving into additional abstractions/files.
- The training API is not intended to work on any model but is optimized to work with the models provided by the library. For generic machine learning loops, you should use another library (possibly, [Accelerate](https://huggingface.co/docs/accelerate)).
-- While we strive to present as many use cases as possible, the scripts in our [examples folder](https://github.com/huggingface/transformers/tree/main/examples) are just that: examples. It is expected that they won't work out-of-the box on your specific problem and that you will be required to change a few lines of code to adapt them to your needs.
+- While we strive to present as many use cases as possible, the scripts in our [examples folder](https://github.com/huggingface/transformers/tree/main/examples) are just that: examples. It is expected that they won't work out-of-the-box on your specific problem and that you will be required to change a few lines of code to adapt them to your needs.
## Installation
@@ -283,7 +283,7 @@ Follow the installation pages of Flax, PyTorch or TensorFlow to see how to insta
## Model architectures
-**[All the model checkpoints](https://huggingface.co/models)** provided by 🤗 Transformers are seamlessly integrated from the huggingface.co [model hub](https://huggingface.co/models) where they are uploaded directly by [users](https://huggingface.co/users) and [organizations](https://huggingface.co/organizations).
+**[All the model checkpoints](https://huggingface.co/models)** provided by 🤗 Transformers are seamlessly integrated from the huggingface.co [model hub](https://huggingface.co/models), where they are uploaded directly by [users](https://huggingface.co/users) and [organizations](https://huggingface.co/organizations).
Current number of checkpoints: 
@@ -321,6 +321,7 @@ Current number of checkpoints: ** (from LAION-AI) released with the paper [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687) by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
+1. **[CLVP](https://huggingface.co/docs/transformers/main/model_doc/clvp)** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (from MetaAI) released with the paper [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
@@ -386,6 +387,7 @@ Current number of checkpoints: ** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
+1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
@@ -433,14 +435,15 @@ Current number of checkpoints: ** (from Meta AI) released with the paper [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) by Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic.
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
-1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
+1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
-1. **[OWLv2](https://huggingface.co/docs/transformers/main/model_doc/owlv2)** (from Google AI) released with the paper [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
+1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (from Google AI) released with the paper [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[Persimmon](https://huggingface.co/docs/transformers/model_doc/persimmon)** (from ADEPT) released in a [blog post](https://www.adept.ai/blog/persimmon-8b) by Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani.
+1. **[Phi](https://huggingface.co/docs/transformers/main/model_doc/phi)** (from Microsoft) released with the papers - [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li, [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (from Google) released with the paper [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
@@ -460,7 +463,7 @@ Current number of checkpoints: ** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (from Bo Peng), released on [this repo](https://github.com/BlinkDL/RWKV-LM) by Bo Peng.
-1. **[SeamlessM4T](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
+1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
@@ -486,10 +489,12 @@ Current number of checkpoints: ** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
+1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[UnivNet](https://huggingface.co/docs/transformers/main/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
diff --git a/README_es.md b/README_es.md
index 4f0bb9e8e594..d42750237fc2 100644
--- a/README_es.md
+++ b/README_es.md
@@ -296,6 +296,7 @@ Número actual de puntos de control: ** (from LAION-AI) released with the paper [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687) by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
+1. **[CLVP](https://huggingface.co/docs/transformers/main/model_doc/clvp)** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (from MetaAI) released with the paper [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
@@ -361,6 +362,7 @@ Número actual de puntos de control: ** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
+1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
@@ -408,14 +410,15 @@ Número actual de puntos de control: ** (from Meta AI) released with the paper [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) by Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic.
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
-1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
+1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
-1. **[OWLv2](https://huggingface.co/docs/transformers/main/model_doc/owlv2)** (from Google AI) released with the paper [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
+1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (from Google AI) released with the paper [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[Persimmon](https://huggingface.co/docs/transformers/model_doc/persimmon)** (from ADEPT) released with the paper [blog post](https://www.adept.ai/blog/persimmon-8b) by Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani.
+1. **[Phi](https://huggingface.co/docs/transformers/main/model_doc/phi)** (from Microsoft) released with the papers - [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li, [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (from Google) released with the paper [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
@@ -435,7 +438,7 @@ Número actual de puntos de control: ** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (from Bo Peng) released with the paper [this repo](https://github.com/BlinkDL/RWKV-LM) by Bo Peng.
-1. **[SeamlessM4T](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
+1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
@@ -461,10 +464,12 @@ Número actual de puntos de control: ** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
+1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[UnivNet](https://huggingface.co/docs/transformers/main/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
diff --git a/README_hd.md b/README_hd.md
index 2a0a30b2237e..e4dd69943f4c 100644
--- a/README_hd.md
+++ b/README_hd.md
@@ -270,6 +270,7 @@ conda install -c huggingface transformers
1. **[CLAP](https://huggingface.co/docs/transformers/model_doc/clap)** (LAION-AI से) Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov. द्वाराअनुसंधान पत्र [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687) के साथ जारी किया गया
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (OpenAI से) साथ वाला पेपर [लर्निंग ट्रांसफरेबल विजुअल मॉडल फ्रॉम नेचुरल लैंग्वेज सुपरविजन](https://arxiv.org /abs/2103.00020) एलेक रैडफोर्ड, जोंग वूक किम, क्रिस हैलासी, आदित्य रमेश, गेब्रियल गोह, संध्या अग्रवाल, गिरीश शास्त्री, अमांडा एस्केल, पामेला मिश्किन, जैक क्लार्क, ग्रेचेन क्रुएगर, इल्या सुत्स्केवर द्वारा।
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
+1. **[CLVP](https://huggingface.co/docs/transformers/main/model_doc/clvp)** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (सेल्सफोर्स से) साथ में पेपर [प्रोग्राम सिंथेसिस के लिए एक संवादात्मक प्रतिमान](https://arxiv.org/abs/2203.13474) एरिक निजकैंप, बो पैंग, हिरोआकी हयाशी, लिफू तू, हुआन वांग, यिंगबो झोउ, सिल्वियो सावरेस, कैमिंग जिओंग रिलीज।
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (MetaAI से) Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve. द्वाराअनुसंधान पत्र [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) के साथ जारी किया गया
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (माइक्रोसॉफ्ट रिसर्च एशिया से) कागज के साथ [फास्ट ट्रेनिंग कन्वर्जेंस के लिए सशर्त डीईटीआर](https://arxiv. org/abs/2108.06152) डेपू मेंग, ज़ियाओकांग चेन, ज़ेजिया फैन, गैंग ज़ेंग, होउकियांग ली, युहुई युआन, लेई सन, जिंगडोंग वांग द्वारा।
@@ -335,6 +336,7 @@ conda install -c huggingface transformers
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (Salesforce से) Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi. द्वाराअनुसंधान पत्र [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) के साथ जारी किया गया
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
+1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (माइक्रोसॉफ्ट रिसर्च एशिया से) साथ देने वाला पेपर [लेआउटएलएमवी3: यूनिफाइड टेक्स्ट और इमेज मास्किंग के साथ दस्तावेज़ एआई के लिए पूर्व-प्रशिक्षण](https://arxiv.org/abs/2204.08387) युपन हुआंग, टेंगचाओ लव, लेई कुई, युटोंग लू, फुरु वेई द्वारा पोस्ट किया गया।
@@ -382,14 +384,15 @@ conda install -c huggingface transformers
1. **[Nougat](https://huggingface.co/docs/transformers/model_doc/nougat)** (Meta AI से) Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic. द्वाराअनुसंधान पत्र [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) के साथ जारी किया गया
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (विस्कॉन्सिन विश्वविद्यालय - मैडिसन से) साथ में कागज [Nyströmformer: A Nyström- आधारित एल्गोरिथम आत्म-ध्यान का अनुमान लगाने के लिए ](https://arxiv.org/abs/2102.03902) युनयांग ज़िओंग, झानपेंग ज़ेंग, रुद्रसिस चक्रवर्ती, मिंगक्सिंग टैन, ग्लेन फंग, यिन ली, विकास सिंह द्वारा पोस्ट किया गया।
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (SHI Labs से) पेपर [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) जितेश जैन, जिआचेन ली, मांगटिक चिउ, अली हसनी, निकिता ओरलोव, हम्फ्री शि के द्वारा जारी किया गया है।
-1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
+1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (Google AI से) साथ में कागज [विज़न ट्रांसफॉर्मर्स के साथ सिंपल ओपन-वोकैबुलरी ऑब्जेक्ट डिटेक्शन](https:/ /arxiv.org/abs/2205.06230) मैथियास मिंडरर, एलेक्सी ग्रिट्सेंको, ऑस्टिन स्टोन, मैक्सिम न्यूमैन, डिर्क वीसेनबोर्न, एलेक्सी डोसोवित्स्की, अरविंद महेंद्रन, अनुराग अर्नब, मुस्तफा देहघानी, ज़ुओरन शेन, जिओ वांग, ज़ियाओहुआ झाई, थॉमस किफ़, और नील हॉल्सबी द्वारा पोस्ट किया गया।
-1. **[OWLv2](https://huggingface.co/docs/transformers/main/model_doc/owlv2)** (Google AI से) Matthias Minderer, Alexey Gritsenko, Neil Houlsby. द्वाराअनुसंधान पत्र [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) के साथ जारी किया गया
+1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (Google AI से) Matthias Minderer, Alexey Gritsenko, Neil Houlsby. द्वाराअनुसंधान पत्र [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) के साथ जारी किया गया
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (Google की ओर से) साथ में दिया गया पेपर [लंबे इनपुट सारांश के लिए ट्रांसफ़ॉर्मरों को बेहतर तरीके से एक्सटेंड करना](https://arxiv .org/abs/2208.04347) जेसन फांग, याओ झाओ, पीटर जे लियू द्वारा।
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (दीपमाइंड से) साथ में पेपर [पर्सीवर आईओ: संरचित इनपुट और आउटपुट के लिए एक सामान्य वास्तुकला] (https://arxiv.org/abs/2107.14795) एंड्रयू जेगल, सेबेस्टियन बोरग्यूड, जीन-बैप्टिस्ट अलायराक, कार्ल डोर्श, कैटलिन इओनेस्कु, डेविड द्वारा डिंग, स्कंद कोप्पुला, डैनियल ज़ोरान, एंड्रयू ब्रॉक, इवान शेलहैमर, ओलिवियर हेनाफ, मैथ्यू एम। बोट्विनिक, एंड्रयू ज़िसरमैन, ओरिओल विनियल्स, जोआओ कैरेरा द्वारा पोस्ट किया गया।
1. **[Persimmon](https://huggingface.co/docs/transformers/model_doc/persimmon)** (ADEPT से) Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani. द्वाराअनुसंधान पत्र [blog post](https://www.adept.ai/blog/persimmon-8b) के साथ जारी किया गया
+1. **[Phi](https://huggingface.co/docs/transformers/main/model_doc/phi)** (from Microsoft) released with the papers - [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li, [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (VinAI Research से) कागज के साथ [PhoBERT: वियतनामी के लिए पूर्व-प्रशिक्षित भाषा मॉडल](https://www .aclweb.org/anthology/2020.findings-emnlp.92/) डैट क्वोक गुयेन और अन्ह तुआन गुयेन द्वारा पोस्ट किया गया।
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (Google से) Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova. द्वाराअनुसंधान पत्र [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) के साथ जारी किया गया
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (UCLA NLP से) साथ वाला पेपर [प्रोग्राम अंडरस्टैंडिंग एंड जेनरेशन के लिए यूनिफाइड प्री-ट्रेनिंग](https://arxiv .org/abs/2103.06333) वसी उद्दीन अहमद, सैकत चक्रवर्ती, बैशाखी रे, काई-वेई चांग द्वारा।
@@ -409,7 +412,7 @@ conda install -c huggingface transformers
1. **[RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (झुईई टेक्नोलॉजी से), साथ में पेपर [रोफॉर्मर: रोटरी पोजिशन एंबेडिंग के साथ एन्हांस्ड ट्रांसफॉर्मर] (https://arxiv.org/pdf/2104.09864v1.pdf) जियानलिन सु और यू लू और शेंगफेंग पैन और बो वेन और युनफेंग लियू द्वारा प्रकाशित।
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (Bo Peng से) Bo Peng. द्वाराअनुसंधान पत्र [this repo](https://github.com/BlinkDL/RWKV-LM) के साथ जारी किया गया
-1. **[SeamlessM4T](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
+1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (Meta AI से) Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick. द्वाराअनुसंधान पत्र [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) के साथ जारी किया गया
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP से) साथ देने वाला पेपर [भाषण पहचान के लिए अनसुपरवाइज्ड प्री-ट्रेनिंग में परफॉर्मेंस-एफिशिएंसी ट्रेड-ऑफ्स](https ://arxiv.org/abs/2109.06870) फेलिक्स वू, क्वांगयुन किम, जिंग पैन, क्यू हान, किलियन क्यू. वेनबर्गर, योव आर्टज़ी द्वारा।
@@ -435,10 +438,12 @@ conda install -c huggingface transformers
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (Google/CMU की ओर से) कागज के साथ [संस्करण-एक्स: एक ब्लॉग मॉडल चौकस चौक मॉडल मॉडल] (https://arxivorg/abs/1901.02860) क्वोकोक वी. ले, रुस्लैन सलाखुतदी
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft) released with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
+1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (Google Research से) Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant. द्वाराअनुसंधान पत्र [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) के साथ जारी किया गया
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (माइक्रोसॉफ्ट रिसर्च से) साथ में दिया गया पेपर [UniSpeech: यूनिफाइड स्पीच रिप्रेजेंटेशन लर्निंग विद लेबलेड एंड अनलेबल्ड डेटा](https:/ /arxiv.org/abs/2101.07597) चेंगई वांग, यू वू, याओ कियान, केनिची कुमातानी, शुजी लियू, फुरु वेई, माइकल ज़ेंग, ज़ुएदोंग हुआंग द्वारा।
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (माइक्रोसॉफ्ट रिसर्च से) कागज के साथ [UNISPEECH-SAT: यूनिवर्सल स्पीच रिप्रेजेंटेशन लर्निंग विद स्पीकर अवेयर प्री-ट्रेनिंग ](https://arxiv.org/abs/2110.05752) सानयुआन चेन, यू वू, चेंग्यी वांग, झेंगयांग चेन, झूओ चेन, शुजी लियू, जियान वू, याओ कियान, फुरु वेई, जिन्यु ली, जियांगज़ान यू द्वारा पोस्ट किया गया।
+1. **[UnivNet](https://huggingface.co/docs/transformers/main/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (सिंघुआ यूनिवर्सिटी और ननकाई यूनिवर्सिटी से) साथ में पेपर [विजुअल अटेंशन नेटवर्क](https://arxiv.org/ pdf/2202.09741.pdf) मेंग-हाओ गुओ, चेंग-ज़े लू, झेंग-निंग लियू, मिंग-मिंग चेंग, शि-मिन हू द्वारा।
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (मल्टीमीडिया कम्प्यूटिंग ग्रुप, नानजिंग यूनिवर्सिटी से) साथ में पेपर [वीडियोएमएई: मास्क्ड ऑटोएन्कोडर स्व-पर्यवेक्षित वीडियो प्री-ट्रेनिंग के लिए डेटा-कुशल सीखने वाले हैं] (https://arxiv.org/abs/2203.12602) ज़ान टोंग, यिबिंग सॉन्ग, जुए द्वारा वांग, लिमिन वांग द्वारा पोस्ट किया गया।
diff --git a/README_ja.md b/README_ja.md
index 0e13c7292e30..ea8de35ff3de 100644
--- a/README_ja.md
+++ b/README_ja.md
@@ -330,6 +330,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[CLAP](https://huggingface.co/docs/transformers/model_doc/clap)** (LAION-AI から) Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov. から公開された研究論文 [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687)
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (OpenAI から) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever から公開された研究論文: [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020)
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (University of Göttingen から) Timo Lüddecke and Alexander Ecker から公開された研究論文: [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003)
+1. **[CLVP](https://huggingface.co/docs/transformers/main/model_doc/clvp)** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (Salesforce から) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong から公開された研究論文: [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474)
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (MetaAI から) Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve. から公開された研究論文 [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/)
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (Microsoft Research Asia から) Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang から公開された研究論文: [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152)
@@ -395,6 +396,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (Salesforce から) Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi. から公開された研究論文 [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500)
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (OpenAI から) Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever から公開された研究論文: [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf)
+1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (Microsoft Research Asia から) Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou から公開された研究論文: [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318)
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (Microsoft Research Asia から) Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou から公開された研究論文: [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740)
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (Microsoft Research Asia から) Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei から公開された研究論文: [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387)
@@ -442,14 +444,15 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[Nougat](https://huggingface.co/docs/transformers/model_doc/nougat)** (Meta AI から) Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic. から公開された研究論文 [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418)
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (the University of Wisconsin - Madison から) Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh から公開された研究論文: [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902)
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (SHI Labs から) Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi から公開された研究論文: [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220)
-1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
+1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (Meta AI から) Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al から公開された研究論文: [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068)
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (Google AI から) Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby から公開された研究論文: [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230)
-1. **[OWLv2](https://huggingface.co/docs/transformers/main/model_doc/owlv2)** (Google AI から) Matthias Minderer, Alexey Gritsenko, Neil Houlsby. から公開された研究論文 [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683)
+1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (Google AI から) Matthias Minderer, Alexey Gritsenko, Neil Houlsby. から公開された研究論文 [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683)
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (Google から) Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu から公開された研究論文: [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777)
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (Google から) Jason Phang, Yao Zhao, and Peter J. Liu から公開された研究論文: [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347)
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (Deepmind から) Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira から公開された研究論文: [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795)
1. **[Persimmon](https://huggingface.co/docs/transformers/model_doc/persimmon)** (ADEPT から) Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani. から公開された研究論文 [blog post](https://www.adept.ai/blog/persimmon-8b)
+1. **[Phi](https://huggingface.co/docs/transformers/main/model_doc/phi)** (from Microsoft) released with the papers - [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li, [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (VinAI Research から) Dat Quoc Nguyen and Anh Tuan Nguyen から公開された研究論文: [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/)
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (Google から) Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova. から公開された研究論文 [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347)
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (UCLA NLP から) Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang から公開された研究論文: [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333)
@@ -469,7 +472,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert)** (WeChatAI から) HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou から公開された研究論文: [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf)
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (ZhuiyiTechnology から), Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu から公開された研究論文: [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864)
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (Bo Peng から) Bo Peng. から公開された研究論文 [this repo](https://github.com/BlinkDL/RWKV-LM)
-1. **[SeamlessM4T](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
+1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (NVIDIA から) Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo から公開された研究論文: [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203)
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (Meta AI から) Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick. から公開された研究論文 [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf)
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP から) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi から公開された研究論文: [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870)
@@ -495,10 +498,12 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (Google/CMU から) Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov から公開された研究論文: [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860)
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (Microsoft から), Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei から公開された研究論文: [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282)
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill から), Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal から公開された研究論文: [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156)
+1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (Intel から), Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding から公開された研究論文: [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995)
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (Google Research から) Yi Tay, Mostafa Dehghani, Vinh Q から公開された研究論文: [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (Google Research から) Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant. から公開された研究論文 [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi)
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (Microsoft Research から) Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang から公開された研究論文: [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597)
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (Microsoft Research から) Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu から公開された研究論文: [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752)
+1. **[UnivNet](https://huggingface.co/docs/transformers/main/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (Peking University から) Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun. から公開された研究論文 [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221)
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (Tsinghua University and Nankai University から) Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu から公開された研究論文: [Visual Attention Network](https://arxiv.org/abs/2202.09741)
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (Multimedia Computing Group, Nanjing University から) Zhan Tong, Yibing Song, Jue Wang, Limin Wang から公開された研究論文: [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602)
diff --git a/README_ko.md b/README_ko.md
index 1ca116e7d081..c88d62a9ad9f 100644
--- a/README_ko.md
+++ b/README_ko.md
@@ -245,6 +245,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[CLAP](https://huggingface.co/docs/transformers/model_doc/clap)** (LAION-AI 에서 제공)은 Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.의 [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687)논문과 함께 발표했습니다.
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (OpenAI 에서) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever 의 [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) 논문과 함께 발표했습니다.
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (University of Göttingen 에서) Timo Lüddecke and Alexander Ecker 의 [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) 논문과 함께 발표했습니다.
+1. **[CLVP](https://huggingface.co/docs/transformers/main/model_doc/clvp)** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (Salesforce 에서) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong 의 [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) 논문과 함께 발표했습니다.
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (MetaAI 에서 제공)은 Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.의 [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/)논문과 함께 발표했습니다.
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (Microsoft Research Asia 에서) Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang 의 [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) 논문과 함께 발표했습니다.
@@ -310,6 +311,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (Salesforce 에서 제공)은 Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.의 [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500)논문과 함께 발표했습니다.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (OpenAI 에서) Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever 의 [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) 논문과 함께 발표했습니다.
+1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (Microsoft Research Asia 에서) Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou 의 [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) 논문과 함께 발표했습니다.
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (Microsoft Research Asia 에서) Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou 의 [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) 논문과 함께 발표했습니다.
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (Microsoft Research Asia 에서) Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei 의 [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) 논문과 함께 발표했습니다.
@@ -357,14 +359,15 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[Nougat](https://huggingface.co/docs/transformers/model_doc/nougat)** (Meta AI 에서 제공)은 Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic.의 [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418)논문과 함께 발표했습니다.
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (the University of Wisconsin - Madison 에서) Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh 의 [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) 논문과 함께 발표했습니다.
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (SHI Labs 에서) Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi 의 [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) 논문과 함께 발표했습니다.
-1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
+1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (Meta AI 에서) Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al 의 [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) 논문과 함께 발표했습니다.
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (Google AI 에서) Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby 의 [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) 논문과 함께 발표했습니다.
-1. **[OWLv2](https://huggingface.co/docs/transformers/main/model_doc/owlv2)** (Google AI 에서 제공)은 Matthias Minderer, Alexey Gritsenko, Neil Houlsby.의 [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683)논문과 함께 발표했습니다.
+1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (Google AI 에서 제공)은 Matthias Minderer, Alexey Gritsenko, Neil Houlsby.의 [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683)논문과 함께 발표했습니다.
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (Google 에서) Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu 의 [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) 논문과 함께 발표했습니다.
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (Google 에서) Jason Phang, Yao Zhao, Peter J. Liu 의 [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) 논문과 함께 발표했습니다.
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (Deepmind 에서) Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira 의 [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) 논문과 함께 발표했습니다.
1. **[Persimmon](https://huggingface.co/docs/transformers/model_doc/persimmon)** (ADEPT 에서 제공)은 Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani.의 [blog post](https://www.adept.ai/blog/persimmon-8b)논문과 함께 발표했습니다.
+1. **[Phi](https://huggingface.co/docs/transformers/main/model_doc/phi)** (from Microsoft) released with the papers - [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li, [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (VinAI Research 에서) Dat Quoc Nguyen and Anh Tuan Nguyen 의 [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) 논문과 함께 발표했습니다.
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (Google 에서 제공)은 Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.의 [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347)논문과 함께 발표했습니다.
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (UCLA NLP 에서) Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang 의 [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) 논문과 함께 발표했습니다.
@@ -384,7 +387,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert)** (WeChatAI 에서) HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou 의 [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) 논문과 함께 발표했습니다.
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (ZhuiyiTechnology 에서) Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu 의 a [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/pdf/2104.09864v1.pdf) 논문과 함께 발표했습니다.
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (Bo Peng 에서 제공)은 Bo Peng.의 [this repo](https://github.com/BlinkDL/RWKV-LM)논문과 함께 발표했습니다.
-1. **[SeamlessM4T](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
+1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (NVIDIA 에서) Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo 의 [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) 논문과 함께 발표했습니다.
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (Meta AI 에서 제공)은 Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.의 [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf)논문과 함께 발표했습니다.
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP 에서) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi 의 [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) 논문과 함께 발표했습니다.
@@ -410,10 +413,12 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (Google/CMU 에서) Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov 의 [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) 논문과 함께 발표했습니다.
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (Microsoft 에서) Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei 의 [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) 논문과 함께 발표했습니다.
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill 에서) Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal 의 [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) 논문과 함께 발표했습니다.
+1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (Intel 에서) Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding 의 [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) 논문과 함께 발표했습니다.
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (Google Research 에서) Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzle 의 [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) 논문과 함께 발표했습니다.
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (Google Research 에서 제공)은 Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.의 [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi)논문과 함께 발표했습니다.
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (Microsoft Research 에서) Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang 의 [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) 논문과 함께 발표했습니다.
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (Microsoft Research 에서) Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu 의 [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) 논문과 함께 발표했습니다.
+1. **[UnivNet](https://huggingface.co/docs/transformers/main/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (Peking University 에서 제공)은 Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.의 [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221)논문과 함께 발표했습니다.
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (Tsinghua University and Nankai University 에서) Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu 의 [Visual Attention Network](https://arxiv.org/pdf/2202.09741.pdf) 논문과 함께 발표했습니다.
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (Multimedia Computing Group, Nanjing University 에서) Zhan Tong, Yibing Song, Jue Wang, Limin Wang 의 [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) 논문과 함께 발표했습니다.
diff --git a/README_pt-br.md b/README_pt-br.md
index c15cd4867bd9..0e5f638bc5f6 100644
--- a/README_pt-br.md
+++ b/README_pt-br.md
@@ -441,7 +441,7 @@ Número atual de pontos de verificação: ** (from Meta AI) released with the paper [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) by Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic.
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
-1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
+1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
@@ -563,14 +563,3 @@ Agora temos um [artigo](https://www.aclweb.org/anthology/2020.emnlp-demos.6/) qu
pages = "38--45"
}
```
-
-
-
-
-
-
-
-
-
-
-
diff --git a/README_ru.md b/README_ru.md
index 4cb1bf924ee8..cf63f7c67ef9 100644
--- a/README_ru.md
+++ b/README_ru.md
@@ -429,13 +429,14 @@ conda install -c huggingface transformers
1. **[NLLB-MOE](https://huggingface.co/docs/transformers/model_doc/nllb-moe)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
-1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
+1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[Persimmon](https://huggingface.co/docs/transformers/main/model_doc/persimmon)** (from ADEPT) released in a [blog post](https://www.adept.ai/blog/persimmon-8b) by Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani.
+1. **[Phi](https://huggingface.co/docs/main/transformers/model_doc/phi)** (from Microsoft Research) released with the papers - [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li, [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (from Google) released with the paper [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
diff --git a/README_te.md b/README_te.md
index 8bf4f5082740..1b6a1812fa04 100644
--- a/README_te.md
+++ b/README_te.md
@@ -434,7 +434,7 @@ Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టా
1. **[Nougat](https://huggingface.co/docs/transformers/model_doc/nougat)** (from Meta AI) released with the paper [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) by Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic.
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
-1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
+1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
1. **[OWLv2](https://huggingface.co/docs/transformers/main/model_doc/owlv2)** (from Google AI) released with the paper [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
diff --git a/README_zh-hans.md b/README_zh-hans.md
index 7ea09edc91c9..e6e6ab59cd06 100644
--- a/README_zh-hans.md
+++ b/README_zh-hans.md
@@ -269,6 +269,7 @@ conda install -c huggingface transformers
1. **[CLAP](https://huggingface.co/docs/transformers/model_doc/clap)** (来自 LAION-AI) 伴随论文 [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687) 由 Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov 发布。
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (来自 OpenAI) 伴随论文 [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) 由 Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever 发布。
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (来自 University of Göttingen) 伴随论文 [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) 由 Timo Lüddecke and Alexander Ecker 发布。
+1. **[CLVP](https://huggingface.co/docs/transformers/main/model_doc/clvp)** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (来自 Salesforce) 伴随论文 [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) 由 Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong 发布。
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (来自 MetaAI) 伴随论文 [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) 由 Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve 发布。
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (来自 Microsoft Research Asia) 伴随论文 [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) 由 Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang 发布。
@@ -334,6 +335,7 @@ conda install -c huggingface transformers
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (来自 Salesforce) 伴随论文 [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) 由 Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi 发布。
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
+1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (来自 Microsoft Research Asia) 伴随论文 [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) 由 Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou 发布。
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (来自 Microsoft Research Asia) 伴随论文 [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) 由 Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou 发布。
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (来自 Microsoft Research Asia) 伴随论文 [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) 由 Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei 发布。
@@ -381,14 +383,15 @@ conda install -c huggingface transformers
1. **[Nougat](https://huggingface.co/docs/transformers/model_doc/nougat)** (来自 Meta AI) 伴随论文 [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) 由 Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic 发布。
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (来自 the University of Wisconsin - Madison) 伴随论文 [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) 由 Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh 发布。
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (来自 SHI Labs) 伴随论文 [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) 由 Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi 发布。
-1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (来自 [s-JoL](https://huggingface.co/s-JoL)) 由 [Open-Llama](https://github.com/s-JoL/Open-Llama) 发布.
+1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (来自 [s-JoL](https://huggingface.co/s-JoL)) 由 GitHub (现已删除).
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (来自 Meta AI) 伴随论文 [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) 由 Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al 发布。
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (来自 Google AI) 伴随论文 [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) 由 Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby 发布。
-1. **[OWLv2](https://huggingface.co/docs/transformers/main/model_doc/owlv2)** (来自 Google AI) 伴随论文 [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) 由 Matthias Minderer, Alexey Gritsenko, Neil Houlsby 发布。
+1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (来自 Google AI) 伴随论文 [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) 由 Matthias Minderer, Alexey Gritsenko, Neil Houlsby 发布。
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (来自 Google) 伴随论文 [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) 由 Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu 发布。
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (来自 Google) 伴随论文 [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) 由 Jason Phang, Yao Zhao, Peter J. Liu 发布。
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (来自 Deepmind) 伴随论文 [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) 由 Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira 发布。
1. **[Persimmon](https://huggingface.co/docs/transformers/model_doc/persimmon)** (来自 ADEPT) 伴随论文 [blog post](https://www.adept.ai/blog/persimmon-8b) 由 Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani 发布。
+1. **[Phi](https://huggingface.co/docs/transformers/main/model_doc/phi)** (from Microsoft) released with the papers - [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li, [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (来自 VinAI Research) 伴随论文 [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) 由 Dat Quoc Nguyen and Anh Tuan Nguyen 发布。
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (来自 Google) 伴随论文 [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) 由 Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova 发布。
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (来自 UCLA NLP) 伴随论文 [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) 由 Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang 发布。
@@ -408,7 +411,7 @@ conda install -c huggingface transformers
1. **[RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert)** (来自 WeChatAI), 伴随论文 [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) 由 HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou 发布。
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (来自 ZhuiyiTechnology), 伴随论文 [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/pdf/2104.09864v1.pdf) 由 Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu 发布。
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (来自 Bo Peng) 伴随论文 [this repo](https://github.com/BlinkDL/RWKV-LM) 由 Bo Peng 发布。
-1. **[SeamlessM4T](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
+1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (来自 NVIDIA) 伴随论文 [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) 由 Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo 发布。
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (来自 Meta AI) 伴随论文 [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) 由 Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick 发布。
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (来自 ASAPP) 伴随论文 [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) 由 Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi 发布。
@@ -434,10 +437,12 @@ conda install -c huggingface transformers
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (来自 Google/CMU) 伴随论文 [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) 由 Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov 发布。
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (来自 Microsoft) 伴随论文 [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) 由 Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei 发布。
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (来自 UNC Chapel Hill) 伴随论文 [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) 由 Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal 发布。
+1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (来自 Intel) 伴随论文 [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) 由 Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding 发布.
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (来自 Google Research) 伴随论文 [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) 由 Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant 发布。
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (来自 Microsoft Research) 伴随论文 [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) 由 Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang 发布。
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (来自 Microsoft Research) 伴随论文 [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) 由 Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu 发布。
+1. **[UnivNet](https://huggingface.co/docs/transformers/main/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (来自 Peking University) 伴随论文 [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) 由 Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun 发布。
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (来自 Tsinghua University and Nankai University) 伴随论文 [Visual Attention Network](https://arxiv.org/pdf/2202.09741.pdf) 由 Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu 发布。
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (来自 Multimedia Computing Group, Nanjing University) 伴随论文 [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) 由 Zhan Tong, Yibing Song, Jue Wang, Limin Wang 发布。
diff --git a/README_zh-hant.md b/README_zh-hant.md
index aced5a5b22ae..21cbe14be804 100644
--- a/README_zh-hant.md
+++ b/README_zh-hant.md
@@ -281,6 +281,7 @@ conda install -c huggingface transformers
1. **[CLAP](https://huggingface.co/docs/transformers/model_doc/clap)** (from LAION-AI) released with the paper [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687) by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
+1. **[CLVP](https://huggingface.co/docs/transformers/main/model_doc/clvp)** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (from MetaAI) released with the paper [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
@@ -346,6 +347,7 @@ conda install -c huggingface transformers
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
+1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
@@ -393,14 +395,15 @@ conda install -c huggingface transformers
1. **[Nougat](https://huggingface.co/docs/transformers/model_doc/nougat)** (from Meta AI) released with the paper [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) by Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic.
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
-1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
+1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
-1. **[OWLv2](https://huggingface.co/docs/transformers/main/model_doc/owlv2)** (from Google AI) released with the paper [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
+1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (from Google AI) released with the paper [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, Peter J. Liu.
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[Persimmon](https://huggingface.co/docs/transformers/model_doc/persimmon)** (from ADEPT) released with the paper [blog post](https://www.adept.ai/blog/persimmon-8b) by Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani.
+1. **[Phi](https://huggingface.co/docs/transformers/main/model_doc/phi)** (from Microsoft) released with the papers - [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li, [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (from Google) released with the paper [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
@@ -420,7 +423,7 @@ conda install -c huggingface transformers
1. **[RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper a [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/pdf/2104.09864v1.pdf) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (from Bo Peng) released with the paper [this repo](https://github.com/BlinkDL/RWKV-LM) by Bo Peng.
-1. **[SeamlessM4T](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
+1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
@@ -446,10 +449,12 @@ conda install -c huggingface transformers
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft) released with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
+1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[UnivNet](https://huggingface.co/docs/transformers/main/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/pdf/2202.09741.pdf) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
diff --git a/docker/transformers-all-latest-gpu/Dockerfile b/docker/transformers-all-latest-gpu/Dockerfile
index d531e130c02e..d108ba5ace58 100644
--- a/docker/transformers-all-latest-gpu/Dockerfile
+++ b/docker/transformers-all-latest-gpu/Dockerfile
@@ -11,7 +11,7 @@ SHELL ["sh", "-lc"]
ARG PYTORCH='2.1.0'
# (not always a valid torch version)
-ARG INTEL_TORCH_EXT='1.11.0'
+ARG INTEL_TORCH_EXT='2.1.0'
# Example: `cu102`, `cu113`, etc.
ARG CUDA='cu118'
@@ -37,7 +37,7 @@ RUN python3 -m pip install --no-cache-dir -e ./transformers[dev,onnxruntime]
RUN python3 -m pip uninstall -y flax jax
-RUN python3 -m pip install --no-cache-dir intel_extension_for_pytorch==$INTEL_TORCH_EXT+cpu -f https://developer.intel.com/ipex-whl-stable-cpu
+RUN python3 -m pip install --no-cache-dir intel_extension_for_pytorch==$INTEL_TORCH_EXT -f https://developer.intel.com/ipex-whl-stable-cpu
RUN python3 -m pip install --no-cache-dir git+https://github.com/facebookresearch/detectron2.git pytesseract
RUN python3 -m pip install -U "itsdangerous<2.1.0"
@@ -55,6 +55,9 @@ RUN python3 -m pip install --no-cache-dir auto-gptq --extra-index-url https://hu
# Add einops for additional model testing
RUN python3 -m pip install --no-cache-dir einops
+# Add autoawq for quantization testing
+RUN python3 -m pip install --no-cache-dir https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.6/autoawq-0.1.6+cu118-cp38-cp38-linux_x86_64.whl
+
# For bettertransformer + gptq
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/optimum@main#egg=optimum
@@ -64,6 +67,9 @@ RUN python3 -m pip install --no-cache-dir decord av==9.2.0
# For `dinat` model
RUN python3 -m pip install --no-cache-dir natten -f https://shi-labs.com/natten/wheels/$CUDA/
+# For `nougat` tokenizer
+RUN python3 -m pip install --no-cache-dir python-Levenshtein
+
# When installing in editable mode, `transformers` is not recognized as a package.
# this line must be added in order for python to be aware of transformers.
RUN cd transformers && python3 setup.py develop
diff --git a/docker/transformers-pytorch-amd-gpu/Dockerfile b/docker/transformers-pytorch-amd-gpu/Dockerfile
index f19cd4edb0e4..216ff4c43855 100644
--- a/docker/transformers-pytorch-amd-gpu/Dockerfile
+++ b/docker/transformers-pytorch-amd-gpu/Dockerfile
@@ -1,23 +1,24 @@
-FROM rocm/pytorch:rocm5.6_ubuntu20.04_py3.8_pytorch_2.0.1
+FROM rocm/dev-ubuntu-20.04:5.6
+# rocm/pytorch has no version with 2.1.0
LABEL maintainer="Hugging Face"
ARG DEBIAN_FRONTEND=noninteractive
+ARG PYTORCH='2.1.0'
+ARG TORCH_VISION='0.16.0'
+ARG TORCH_AUDIO='2.1.0'
+ARG ROCM='5.6'
+
RUN apt update && \
- apt install -y --no-install-recommends git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-pip ffmpeg && \
+ apt install -y --no-install-recommends git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-dev python3-pip ffmpeg && \
apt clean && \
rm -rf /var/lib/apt/lists/*
-RUN python3 -m pip install --no-cache-dir --upgrade pip setuptools ninja git+https://github.com/facebookresearch/detectron2.git pytesseract "itsdangerous<2.1.0"
+RUN python3 -m pip install --no-cache-dir --upgrade pip
-# If set to nothing, will install the latest version
-ARG PYTORCH='2.0.1'
-ARG TORCH_VISION='0.15.2'
-ARG TORCH_AUDIO='2.0.2'
-ARG ROCM='5.6'
+RUN python3 -m pip install torch==$PYTORCH torchvision==$TORCH_VISION torchaudio==$TORCH_AUDIO --index-url https://download.pytorch.org/whl/rocm$ROCM
-RUN git clone --depth 1 --branch v$TORCH_AUDIO https://github.com/pytorch/audio.git
-RUN cd audio && USE_ROCM=1 USE_CUDA=0 python setup.py install
+RUN python3 -m pip install --no-cache-dir --upgrade pip setuptools ninja git+https://github.com/facebookresearch/detectron2.git pytesseract "itsdangerous<2.1.0"
ARG REF=main
WORKDIR /
diff --git a/docs/source/_config.py b/docs/source/_config.py
index 4a7a86cc23d8..d26d908aa29e 100644
--- a/docs/source/_config.py
+++ b/docs/source/_config.py
@@ -10,5 +10,5 @@
black_avoid_patterns = {
"{processor_class}": "FakeProcessorClass",
"{model_class}": "FakeModelClass",
- "{object_class}": "FakeObjectClass",
+ "{object_class}": "FakeObjectClass",
}
diff --git a/docs/source/de/preprocessing.md b/docs/source/de/preprocessing.md
index 1e8f6ff4062a..9c977e10a538 100644
--- a/docs/source/de/preprocessing.md
+++ b/docs/source/de/preprocessing.md
@@ -209,7 +209,7 @@ Audioeingaben werden anders vorverarbeitet als Texteingaben, aber das Endziel bl
pip install datasets
```
-Laden Sie den [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) Datensatz (weitere Informationen zum Laden eines Datensatzes finden Sie im 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub.html)):
+Laden Sie den [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) Datensatz (weitere Informationen zum Laden eines Datensatzes finden Sie im 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub)):
```py
>>> from datasets import load_dataset, Audio
@@ -344,7 +344,7 @@ Laden wir den [food101](https://huggingface.co/datasets/food101) Datensatz für
>>> dataset = load_dataset("food101", split="train[:100]")
```
-Als Nächstes sehen Sie sich das Bild mit dem Merkmal 🤗 Datensätze [Bild] (https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=image#datasets.Image) an:
+Als Nächstes sehen Sie sich das Bild mit dem Merkmal 🤗 Datensätze [Bild] (https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=image#datasets.Image) an:
```py
>>> dataset[0]["image"]
@@ -385,7 +385,7 @@ Bei Bildverarbeitungsaufgaben ist es üblich, den Bildern als Teil der Vorverarb
... return examples
```
-3. Dann verwenden Sie 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process.html#format-transform), um die Transformationen im laufenden Betrieb anzuwenden:
+3. Dann verwenden Sie 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process#format-transform), um die Transformationen im laufenden Betrieb anzuwenden:
```py
>>> dataset.set_transform(transforms)
diff --git a/docs/source/de/quicktour.md b/docs/source/de/quicktour.md
index 139869e5d1ee..2b66d2d6a917 100644
--- a/docs/source/de/quicktour.md
+++ b/docs/source/de/quicktour.md
@@ -121,7 +121,7 @@ Erstellen wir eine [`pipeline`] mit der Aufgabe die wir lösen und dem Modell we
>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
```
-Als nächstes laden wir den Datensatz (siehe 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart.html) für mehr Details) welches wir nutzen möchten. Zum Beispiel laden wir den [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) Datensatz:
+Als nächstes laden wir den Datensatz (siehe 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart) für mehr Details) welches wir nutzen möchten. Zum Beispiel laden wir den [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) Datensatz:
```py
>>> from datasets import load_dataset, Audio
diff --git a/docs/source/de/run_scripts.md b/docs/source/de/run_scripts.md
index 2902d4c08414..4afe72dae6d6 100644
--- a/docs/source/de/run_scripts.md
+++ b/docs/source/de/run_scripts.md
@@ -130,7 +130,7 @@ Der [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) unt
- Legen Sie die Anzahl der zu verwendenden GPUs mit dem Argument `nproc_per_node` fest.
```bash
-python -m torch.distributed.launch \
+torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
diff --git a/docs/source/de/training.md b/docs/source/de/training.md
index 493de3052bbf..b1b7c14f261a 100644
--- a/docs/source/de/training.md
+++ b/docs/source/de/training.md
@@ -43,7 +43,7 @@ Laden Sie zunächst den Datensatz [Yelp Reviews](https://huggingface.co/datasets
'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
```
-Wie Sie nun wissen, benötigen Sie einen Tokenizer, um den Text zu verarbeiten und eine Auffüll- und Abschneidungsstrategie einzubauen, um mit variablen Sequenzlängen umzugehen. Um Ihren Datensatz in einem Schritt zu verarbeiten, verwenden Sie die 🤗 Methode Datasets [`map`](https://huggingface.co/docs/datasets/process.html#map), um eine Vorverarbeitungsfunktion auf den gesamten Datensatz anzuwenden:
+Wie Sie nun wissen, benötigen Sie einen Tokenizer, um den Text zu verarbeiten und eine Auffüll- und Abschneidungsstrategie einzubauen, um mit variablen Sequenzlängen umzugehen. Um Ihren Datensatz in einem Schritt zu verarbeiten, verwenden Sie die 🤗 Methode Datasets [`map`](https://huggingface.co/docs/datasets/process#map), um eine Vorverarbeitungsfunktion auf den gesamten Datensatz anzuwenden:
```py
>>> from transformers import AutoTokenizer
diff --git a/docs/source/en/_config.py b/docs/source/en/_config.py
index cd76263e9a5c..a6d75853f572 100644
--- a/docs/source/en/_config.py
+++ b/docs/source/en/_config.py
@@ -10,5 +10,5 @@
black_avoid_patterns = {
"{processor_class}": "FakeProcessorClass",
"{model_class}": "FakeModelClass",
- "{object_class}": "FakeObjectClass",
+ "{object_class}": "FakeObjectClass",
}
diff --git a/docs/source/en/_redirects.yml b/docs/source/en/_redirects.yml
new file mode 100644
index 000000000000..b6575a6b02f2
--- /dev/null
+++ b/docs/source/en/_redirects.yml
@@ -0,0 +1,3 @@
+# Optimizing inference
+
+perf_infer_gpu_many: perf_infer_gpu_one
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 84e306a786f9..af29898966ba 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -60,7 +60,7 @@
- local: tasks/image_classification
title: Image classification
- local: tasks/semantic_segmentation
- title: Semantic segmentation
+ title: Image segmentation
- local: tasks/video_classification
title: Video classification
- local: tasks/object_detection
@@ -155,13 +155,9 @@
title: Efficient training techniques
- sections:
- local: perf_infer_cpu
- title: Inference on CPU
+ title: CPU inference
- local: perf_infer_gpu_one
- title: Inference on one GPU
- - local: perf_infer_gpu_many
- title: Inference on many GPUs
- - local: perf_infer_special
- title: Inference on Specialized Hardware
+ title: GPU inference
title: Optimizing inference
- local: big_models
title: Instantiating a big model
@@ -428,6 +424,8 @@
title: PEGASUS-X
- local: model_doc/persimmon
title: Persimmon
+ - local: model_doc/phi
+ title: Phi
- local: model_doc/phobert
title: PhoBERT
- local: model_doc/plbart
@@ -630,6 +628,8 @@
title: UniSpeech
- local: model_doc/unispeech-sat
title: UniSpeech-SAT
+ - local: model_doc/univnet
+ title: UnivNet
- local: model_doc/vits
title: VITS
- local: model_doc/wav2vec2
@@ -667,6 +667,8 @@
title: CLIP
- local: model_doc/clipseg
title: CLIPSeg
+ - local: model_doc/clvp
+ title: CLVP
- local: model_doc/data2vec
title: Data2Vec
- local: model_doc/deplot
@@ -683,6 +685,8 @@
title: IDEFICS
- local: model_doc/instructblip
title: InstructBLIP
+ - local: model_doc/kosmos-2
+ title: KOSMOS-2
- local: model_doc/layoutlm
title: LayoutLM
- local: model_doc/layoutlmv2
@@ -721,6 +725,8 @@
title: TrOCR
- local: model_doc/tvlt
title: TVLT
+ - local: model_doc/tvp
+ title: TVP
- local: model_doc/vilt
title: ViLT
- local: model_doc/vision-encoder-decoder
diff --git a/docs/source/en/chat_templating.md b/docs/source/en/chat_templating.md
index 115c9f51677d..82bdf591ae5f 100644
--- a/docs/source/en/chat_templating.md
+++ b/docs/source/en/chat_templating.md
@@ -20,25 +20,11 @@ rendered properly in your Markdown viewer.
An increasingly common use case for LLMs is **chat**. In a chat context, rather than continuing a single string
of text (as is the case with a standard language model), the model instead continues a conversation that consists
-of one or more **messages**, each of which includes a **role** as well as message text.
+of one or more **messages**, each of which includes a **role**, like "user" or "assistant", as well as message text.
-Most commonly, these roles are "user" for messages sent by the user, and "assistant" for messages sent by the model.
-Some models also support a "system" role. System messages are usually sent at the beginning of the conversation
-and include directives about how the model should behave in the subsequent chat.
-
-All language models, including models fine-tuned for chat, operate on linear sequences of tokens and do not intrinsically
-have special handling for roles. This means that role information is usually injected by adding control tokens
-between messages, to indicate both the message boundary and the relevant roles.
-
-Unfortunately, there isn't (yet!) a standard for which tokens to use, and so different models have been trained
-with wildly different formatting and control tokens for chat. This can be a real problem for users - if you use the
-wrong format, then the model will be confused by your input, and your performance will be a lot worse than it should be.
-This is the problem that **chat templates** aim to resolve.
-
-Chat conversations are typically represented as a list of dictionaries, where each dictionary contains `role`
-and `content` keys, and represents a single chat message. Chat templates are strings containing a Jinja template that
-specifies how to format a conversation for a given model into a single tokenizable sequence. By storing this information
-with the tokenizer, we can ensure that models get input data in the format they expect.
+Much like tokenization, different models expect very different input formats for chat. This is the reason we added
+**chat templates** as a feature. Chat templates are part of the tokenizer. They specify how to convert conversations,
+represented as lists of messages, into a single tokenizable string in the format that the model expects.
Let's make this concrete with a quick example using the `BlenderBot` model. BlenderBot has an extremely simple default
template, which mostly just adds whitespace between rounds of dialogue:
@@ -48,9 +34,9 @@ template, which mostly just adds whitespace between rounds of dialogue:
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
>>> chat = [
-... {"role": "user", "content": "Hello, how are you?"},
-... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
-... {"role": "user", "content": "I'd like to show off how chat templating works!"},
+... {"role": "user", "content": "Hello, how are you?"},
+... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
+... {"role": "user", "content": "I'd like to show off how chat templating works!"},
... ]
>>> tokenizer.apply_chat_template(chat, tokenize=False)
@@ -59,28 +45,196 @@ template, which mostly just adds whitespace between rounds of dialogue:
Notice how the entire chat is condensed into a single string. If we use `tokenize=True`, which is the default setting,
that string will also be tokenized for us. To see a more complex template in action, though, let's use the
-`meta-llama/Llama-2-7b-chat-hf` model. Note that this model has gated access, so you will have to
-[request access on the repo](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) if you want to run this code yourself:
+`mistralai/Mistral-7B-Instruct-v0.1` model.
```python
->> from transformers import AutoTokenizer
->> tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
+>>> from transformers import AutoTokenizer
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
->> chat = [
+>>> chat = [
... {"role": "user", "content": "Hello, how are you?"},
... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
... {"role": "user", "content": "I'd like to show off how chat templating works!"},
... ]
->> tokenizer.use_default_system_prompt = False
->> tokenizer.apply_chat_template(chat, tokenize=False)
-"[INST] Hello, how are you? [/INST] I'm doing great. How can I help you today? [INST] I'd like to show off how chat templating works! [/INST]"
+>>> tokenizer.apply_chat_template(chat, tokenize=False)
+"[INST] Hello, how are you? [/INST]I'm doing great. How can I help you today? [INST] I'd like to show off how chat templating works! [/INST]"
```
Note that this time, the tokenizer has added the control tokens [INST] and [/INST] to indicate the start and end of
-user messages (but not assistant messages!)
+user messages (but not assistant messages!). Mistral-instruct was trained with these tokens, but BlenderBot was not.
+
+## How do I use chat templates?
+
+As you can see in the example above, chat templates are easy to use. Simply build a list of messages, with `role`
+and `content` keys, and then pass it to the [`~PreTrainedTokenizer.apply_chat_template`] method. Once you do that,
+you'll get output that's ready to go! When using chat templates as input for model generation, it's also a good idea
+to use `add_generation_prompt=True` to add a [generation prompt](#what-are-generation-prompts).
+
+Here's an example of preparing input for `model.generate()`, using the `Zephyr` assistant model:
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+checkpoint = "HuggingFaceH4/zephyr-7b-beta"
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+model = AutoModelForCausalLM.from_pretrained(checkpoint) # You may want to use bfloat16 and/or move to GPU here
+
+messages = [
+ {
+ "role": "system",
+ "content": "You are a friendly chatbot who always responds in the style of a pirate",
+ },
+ {"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
+ ]
+tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
+print(tokenizer.decode(tokenized_chat[0]))
+```
+This will yield a string in the input format that Zephyr expects.
+```text
+<|system|>
+You are a friendly chatbot who always responds in the style of a pirate
+<|user|>
+How many helicopters can a human eat in one sitting?
+<|assistant|>
+```
+
+Now that our input is formatted correctly for Zephyr, we can use the model to generate a response to the user's question:
+
+```python
+outputs = model.generate(tokenized_chat, max_new_tokens=128)
+print(tokenizer.decode(outputs[0]))
+```
+
+This will yield:
+
+```text
+<|system|>
+You are a friendly chatbot who always responds in the style of a pirate
+<|user|>
+How many helicopters can a human eat in one sitting?
+<|assistant|>
+Matey, I'm afraid I must inform ye that humans cannot eat helicopters. Helicopters are not food, they are flying machines. Food is meant to be eaten, like a hearty plate o' grog, a savory bowl o' stew, or a delicious loaf o' bread. But helicopters, they be for transportin' and movin' around, not for eatin'. So, I'd say none, me hearties. None at all.
+```
+
+Arr, 'twas easy after all!
+
+## Is there an automated pipeline for chat?
+
+Yes, there is: [`ConversationalPipeline`]. This pipeline is designed to make it easy to use chat models. Let's try
+the `Zephyr` example again, but this time using the pipeline:
+
+```python
+from transformers import pipeline
+
+pipe = pipeline("conversational", "HuggingFaceH4/zephyr-7b-beta")
+messages = [
+ {
+ "role": "system",
+ "content": "You are a friendly chatbot who always responds in the style of a pirate",
+ },
+ {"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
+]
+print(pipe(messages))
+```
+
+```text
+Conversation id: 76d886a0-74bd-454e-9804-0467041a63dc
+system: You are a friendly chatbot who always responds in the style of a pirate
+user: How many helicopters can a human eat in one sitting?
+assistant: Matey, I'm afraid I must inform ye that humans cannot eat helicopters. Helicopters are not food, they are flying machines. Food is meant to be eaten, like a hearty plate o' grog, a savory bowl o' stew, or a delicious loaf o' bread. But helicopters, they be for transportin' and movin' around, not for eatin'. So, I'd say none, me hearties. None at all.
+```
+
+[`ConversationalPipeline`] will take care of all the details of tokenization and calling `apply_chat_template` for you -
+once the model has a chat template, all you need to do is initialize the pipeline and pass it the list of messages!
+
+## What are "generation prompts"?
+
+You may have noticed that the `apply_chat_template` method has an `add_generation_prompt` argument. This argument tells
+the template to add tokens that indicate the start of a bot response. For example, consider the following chat:
+
+```python
+messages = [
+ {"role": "user", "content": "Hi there!"},
+ {"role": "assistant", "content": "Nice to meet you!"},
+ {"role": "user", "content": "Can I ask a question?"}
+]
+```
+
+Here's what this will look like without a generation prompt, using the ChatML template we saw in the Zephyr example:
+
+```python
+tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)
+"""<|im_start|>user
+Hi there!<|im_end|>
+<|im_start|>assistant
+Nice to meet you!<|im_end|>
+<|im_start|>user
+Can I ask a question?<|im_end|>
+"""
+```
+
+And here's what it looks like **with** a generation prompt:
+
+```python
+tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
+"""<|im_start|>user
+Hi there!<|im_end|>
+<|im_start|>assistant
+Nice to meet you!<|im_end|>
+<|im_start|>user
+Can I ask a question?<|im_end|>
+<|im_start|>assistant
+"""
+```
+
+Note that this time, we've added the tokens that indicate the start of a bot response. This ensures that when the model
+generates text it will write a bot response instead of doing something unexpected, like continuing the user's
+message. Remember, chat models are still just language models - they're trained to continue text, and chat is just a
+special kind of text to them! You need to guide them with the appropriate control tokens so they know what they're
+supposed to be doing.
+
+Not all models require generation prompts. Some models, like BlenderBot and LLaMA, don't have any
+special tokens before bot responses. In these cases, the `add_generation_prompt` argument will have no effect. The exact
+effect that `add_generation_prompt` has will depend on the template being used.
+
+## Can I use chat templates in training?
+
+Yes! We recommend that you apply the chat template as a preprocessing step for your dataset. After this, you
+can simply continue like any other language model training task. When training, you should usually set
+`add_generation_prompt=False`, because the added tokens to prompt an assistant response will not be helpful during
+training. Let's see an example:
+
+```python
+from transformers import AutoTokenizer
+from datasets import Dataset
+
+tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-beta")
+
+chat1 = [
+ {"role": "user", "content": "Which is bigger, the moon or the sun?"},
+ {"role": "assistant", "content": "The sun."}
+]
+chat2 = [
+ {"role": "user", "content": "Which is bigger, a virus or a bacterium?"},
+ {"role": "assistant", "content": "A bacterium."}
+]
+
+dataset = Dataset.from_dict({"chat": [chat1, chat2]})
+dataset = dataset.map(lambda x: {"formatted_chat": tokenizer.apply_chat_template(x["chat"], tokenize=False, add_generation_prompt=False)})
+print(dataset['formatted_chat'][0])
+```
+And we get:
+```text
+<|user|>
+Which is bigger, the moon or the sun?
+<|assistant|>
+The sun.
+```
-## How do chat templates work?
+From here, just continue training like you would with a standard language modelling task, using the `formatted_chat` column.
+
+## Advanced: How do chat templates work?
The chat template for a model is stored on the `tokenizer.chat_template` attribute. If no chat template is set, the
default template for that model class is used instead. Let's take a look at the template for `BlenderBot`:
@@ -154,7 +308,9 @@ Hopefully if you stare at this for a little bit you can see what this template i
on the "role" of each message, which represents who sent it. User, assistant and system messages are clearly
distinguishable to the model because of the tokens they're wrapped in.
-## How do I create a chat template?
+## Advanced: Adding and editing chat templates
+
+### How do I create a chat template?
Simple, just write a jinja template and set `tokenizer.chat_template`. You may find it easier to start with an
existing template from another model and simply edit it for your needs! For example, we could take the LLaMA template
@@ -187,7 +343,7 @@ tokenizer.push_to_hub("model_name") # Upload your new template to the Hub!
The method [`~PreTrainedTokenizer.apply_chat_template`] which uses your chat template is called by the [`ConversationalPipeline`] class, so
once you set the correct chat template, your model will automatically become compatible with [`ConversationalPipeline`].
-## What are "default" templates?
+### What are "default" templates?
Before the introduction of chat templates, chat handling was hardcoded at the model class level. For backwards
compatibility, we have retained this class-specific handling as default templates, also set at the class level. If a
@@ -200,7 +356,7 @@ the class template is appropriate for your model, we strongly recommend overridi
setting the `chat_template` attribute explicitly to make it clear to users that your model has been correctly configured
for chat, and to future-proof in case the default templates are ever altered or deprecated.
-## What template should I use?
+### What template should I use?
When setting the template for a model that's already been trained for chat, you should ensure that the template
exactly matches the message formatting that the model saw during training, or else you will probably experience
@@ -229,7 +385,7 @@ tokenizer.chat_template = "{% if not add_generation_prompt is defined %}{% set a
This template wraps each message in `<|im_start|>` and `<|im_end|>` tokens, and simply writes the role as a string, which
allows for flexibility in the roles you train with. The output looks like this:
-```
+```text
<|im_start|>system
You are a helpful chatbot that will do its best not to say anything so stupid that people tweet about it.<|im_end|>
<|im_start|>user
@@ -242,62 +398,12 @@ The "user", "system" and "assistant" roles are the standard for chat, and we rec
particularly if you want your model to operate well with [`ConversationalPipeline`]. However, you are not limited
to these roles - templating is extremely flexible, and any string can be a role.
-## What are "generation prompts"?
-
-You may notice that the `apply_chat_template` method has an `add_generation_prompt` argument. This argument tells
-the template to add tokens that indicate the start of a bot response. For example, consider the following chat:
-
-```python
-messages = [
- {"role": "user", "content": "Hi there!"},
- {"role": "assistant", "content": "Nice to meet you!"},
- {"role": "user", "content": "Can I ask a question?"}
-]
-```
-
-Here's what this will look like without a generation prompt, using the ChatML template we described above:
-
-```python
->> tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)
-"""<|im_start|>user
-Hi there!<|im_end|>
-<|im_start|>assistant
-Nice to meet you!<|im_end|>
-<|im_start|>user
-Can I ask a question?<|im_end|>
-"""
-```
-
-And here's what it looks like **with** a generation prompt:
-
-```python
->> tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
-"""<|im_start|>user
-Hi there!<|im_end|>
-<|im_start|>assistant
-Nice to meet you!<|im_end|>
-<|im_start|>user
-Can I ask a question?<|im_end|>
-<|im_start|>assistant
-"""
-```
-
-Note that this time, we've added the tokens that indicate the start of a bot response. This ensures that when the model
-generates text it will write a bot response instead of doing something unexpected, like continuing the user's
-message. Remember, chat models are still just language models - they're trained to continue text, and chat is just a
-special kind of text to them! You need to guide them with the appropriate control tokens so they know what they're
-supposed to be doing.
-
-Not all models require generation prompts. Some models, like BlenderBot and LLaMA, don't have any
-special tokens before bot responses. In these cases, the `add_generation_prompt` argument will have no effect. The exact
-effect that `add_generation_prompt` has will depend on the template being used.
-
-## I want to use chat templates! How should I get started?
+### I want to add some chat templates! How should I get started?
If you have any chat models, you should set their `tokenizer.chat_template` attribute and test it using
-[`~PreTrainedTokenizer.apply_chat_template`]. This applies even if you're not the model owner - if you're using a model
-with an empty chat template, or one that's still using the default class template, please open a [pull request](https://huggingface.co/docs/hub/repositories-pull-requests-discussions) to
-the model repository so that this attribute can be set properly!
+[`~PreTrainedTokenizer.apply_chat_template`], then push the updated tokenizer to the Hub. This applies even if you're
+not the model owner - if you're using a model with an empty chat template, or one that's still using the default class
+template, please open a [pull request](https://huggingface.co/docs/hub/repositories-pull-requests-discussions) to the model repository so that this attribute can be set properly!
Once the attribute is set, that's it, you're done! `tokenizer.apply_chat_template` will now work correctly for that
model, which means it is also automatically supported in places like `ConversationalPipeline`!
@@ -306,7 +412,7 @@ By ensuring that models have this attribute, we can make sure that the whole com
open-source models. Formatting mismatches have been haunting the field and silently harming performance for too long -
it's time to put an end to them!
-## Template writing tips
+## Advanced: Template writing tips
If you're unfamiliar with Jinja, we generally find that the easiest way to write a chat template is to first
write a short Python script that formats messages the way you want, and then convert that script into a template.
diff --git a/docs/source/en/create_a_model.md b/docs/source/en/create_a_model.md
index ba384d437b80..a70a734c2e3f 100644
--- a/docs/source/en/create_a_model.md
+++ b/docs/source/en/create_a_model.md
@@ -110,7 +110,7 @@ You can also save your configuration file as a dictionary or even just the diffe
## Model
-The next step is to create a [model](main_classes/models). The model - also loosely referred to as the architecture - defines what each layer is doing and what operations are happening. Attributes like `num_hidden_layers` from the configuration are used to define the architecture. Every model shares the base class [`PreTrainedModel`] and a few common methods like resizing input embeddings and pruning self-attention heads. In addition, all models are also either a [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) or [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/flax.linen.html#module) subclass. This means models are compatible with each of their respective framework's usage.
+The next step is to create a [model](main_classes/models). The model - also loosely referred to as the architecture - defines what each layer is doing and what operations are happening. Attributes like `num_hidden_layers` from the configuration are used to define the architecture. Every model shares the base class [`PreTrainedModel`] and a few common methods like resizing input embeddings and pruning self-attention heads. In addition, all models are also either a [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) or [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html) subclass. This means models are compatible with each of their respective framework's usage.
diff --git a/docs/source/en/custom_models.md b/docs/source/en/custom_models.md
index d709772eed06..22ba58b9d9dd 100644
--- a/docs/source/en/custom_models.md
+++ b/docs/source/en/custom_models.md
@@ -14,7 +14,7 @@ rendered properly in your Markdown viewer.
-->
-# Sharing custom models
+# Building custom models
The 🤗 Transformers library is designed to be easily extensible. Every model is fully coded in a given subfolder
of the repository with no abstraction, so you can easily copy a modeling file and tweak it to your needs.
@@ -22,7 +22,8 @@ of the repository with no abstraction, so you can easily copy a modeling file an
If you are writing a brand new model, it might be easier to start from scratch. In this tutorial, we will show you
how to write a custom model and its configuration so it can be used inside Transformers, and how you can share it
with the community (with the code it relies on) so that anyone can use it, even if it's not present in the 🤗
-Transformers library.
+Transformers library. We'll see how to build upon transformers and extend the framework with your hooks and
+custom code.
We will illustrate all of this on a ResNet model, by wrapping the ResNet class of the
[timm library](https://github.com/rwightman/pytorch-image-models) into a [`PreTrainedModel`].
@@ -218,6 +219,27 @@ resnet50d.model.load_state_dict(pretrained_model.state_dict())
Now let's see how to make sure that when we do [`~PreTrainedModel.save_pretrained`] or [`~PreTrainedModel.push_to_hub`], the
code of the model is saved.
+## Registering a model with custom code to the auto classes
+
+If you are writing a library that extends 🤗 Transformers, you may want to extend the auto classes to include your own
+model. This is different from pushing the code to the Hub in the sense that users will need to import your library to
+get the custom models (contrarily to automatically downloading the model code from the Hub).
+
+As long as your config has a `model_type` attribute that is different from existing model types, and that your model
+classes have the right `config_class` attributes, you can just add them to the auto classes like this:
+
+```py
+from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
+
+AutoConfig.register("resnet", ResnetConfig)
+AutoModel.register(ResnetConfig, ResnetModel)
+AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
+```
+
+Note that the first argument used when registering your custom config to [`AutoConfig`] needs to match the `model_type`
+of your custom config, and the first argument used when registering your custom models to any auto model class needs
+to match the `config_class` of those models.
+
## Sending the code to the Hub
@@ -272,6 +294,22 @@ Note that there is no need to specify an auto class for the configuration (there
[`AutoConfig`]) but it's different for models. Your custom model could be suitable for many different tasks, so you
have to specify which one of the auto classes is the correct one for your model.
+
+
+Use `register_for_auto_class()` if you want the code files to be copied. If you instead prefer to use code on the Hub from another repo,
+you don't need to call it. In cases where there's more than one auto class, you can modify the `config.json` directly using the
+following structure:
+
+```
+"auto_map": {
+ "AutoConfig": "--",
+ "AutoModel": "--",
+ "AutoModelFor": "--",
+},
+```
+
+
+
Next, let's create the config and models as we did before:
```py
@@ -334,23 +372,3 @@ model = AutoModelForImageClassification.from_pretrained(
Note that when browsing the commit history of the model repo on the Hub, there is a button to easily copy the commit
hash of any commit.
-## Registering a model with custom code to the auto classes
-
-If you are writing a library that extends 🤗 Transformers, you may want to extend the auto classes to include your own
-model. This is different from pushing the code to the Hub in the sense that users will need to import your library to
-get the custom models (contrarily to automatically downloading the model code from the Hub).
-
-As long as your config has a `model_type` attribute that is different from existing model types, and that your model
-classes have the right `config_class` attributes, you can just add them to the auto classes like this:
-
-```py
-from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
-
-AutoConfig.register("resnet", ResnetConfig)
-AutoModel.register(ResnetConfig, ResnetModel)
-AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
-```
-
-Note that the first argument used when registering your custom config to [`AutoConfig`] needs to match the `model_type`
-of your custom config, and the first argument used when registering your custom models to any auto model class needs
-to match the `config_class` of those models.
diff --git a/docs/source/en/hpo_train.md b/docs/source/en/hpo_train.md
index 882193d9e837..c516c501f882 100644
--- a/docs/source/en/hpo_train.md
+++ b/docs/source/en/hpo_train.md
@@ -99,7 +99,7 @@ Define a `model_init` function and pass it to the [`Trainer`], as an example:
... config=config,
... cache_dir=model_args.cache_dir,
... revision=model_args.model_revision,
-... use_auth_token=True if model_args.use_auth_token else None,
+... token=True if model_args.use_auth_token else None,
... )
```
diff --git a/docs/source/en/index.md b/docs/source/en/index.md
index 9a9692f35d9b..b631db63529c 100644
--- a/docs/source/en/index.md
+++ b/docs/source/en/index.md
@@ -92,12 +92,13 @@ Flax), PyTorch, and/or TensorFlow.
| [CLAP](model_doc/clap) | ✅ | ❌ | ❌ |
| [CLIP](model_doc/clip) | ✅ | ✅ | ✅ |
| [CLIPSeg](model_doc/clipseg) | ✅ | ❌ | ❌ |
+| [CLVP](model_doc/clvp) | ✅ | ❌ | ❌ |
| [CodeGen](model_doc/codegen) | ✅ | ❌ | ❌ |
| [CodeLlama](model_doc/code_llama) | ✅ | ❌ | ❌ |
| [Conditional DETR](model_doc/conditional_detr) | ✅ | ❌ | ❌ |
| [ConvBERT](model_doc/convbert) | ✅ | ✅ | ❌ |
| [ConvNeXT](model_doc/convnext) | ✅ | ✅ | ❌ |
-| [ConvNeXTV2](model_doc/convnextv2) | ✅ | ❌ | ❌ |
+| [ConvNeXTV2](model_doc/convnextv2) | ✅ | ✅ | ❌ |
| [CPM](model_doc/cpm) | ✅ | ✅ | ✅ |
| [CPM-Ant](model_doc/cpmant) | ✅ | ❌ | ❌ |
| [CTRL](model_doc/ctrl) | ✅ | ✅ | ❌ |
@@ -158,6 +159,7 @@ Flax), PyTorch, and/or TensorFlow.
| [Informer](model_doc/informer) | ✅ | ❌ | ❌ |
| [InstructBLIP](model_doc/instructblip) | ✅ | ❌ | ❌ |
| [Jukebox](model_doc/jukebox) | ✅ | ❌ | ❌ |
+| [KOSMOS-2](model_doc/kosmos-2) | ✅ | ❌ | ❌ |
| [LayoutLM](model_doc/layoutlm) | ✅ | ✅ | ❌ |
| [LayoutLMv2](model_doc/layoutlmv2) | ✅ | ❌ | ❌ |
| [LayoutLMv3](model_doc/layoutlmv3) | ✅ | ✅ | ❌ |
@@ -215,6 +217,7 @@ Flax), PyTorch, and/or TensorFlow.
| [PEGASUS-X](model_doc/pegasus_x) | ✅ | ❌ | ❌ |
| [Perceiver](model_doc/perceiver) | ✅ | ❌ | ❌ |
| [Persimmon](model_doc/persimmon) | ✅ | ❌ | ❌ |
+| [Phi](model_doc/phi) | ✅ | ❌ | ❌ |
| [PhoBERT](model_doc/phobert) | ✅ | ✅ | ✅ |
| [Pix2Struct](model_doc/pix2struct) | ✅ | ❌ | ❌ |
| [PLBart](model_doc/plbart) | ✅ | ❌ | ❌ |
@@ -261,10 +264,12 @@ Flax), PyTorch, and/or TensorFlow.
| [Transformer-XL](model_doc/transfo-xl) | ✅ | ✅ | ❌ |
| [TrOCR](model_doc/trocr) | ✅ | ❌ | ❌ |
| [TVLT](model_doc/tvlt) | ✅ | ❌ | ❌ |
+| [TVP](model_doc/tvp) | ✅ | ❌ | ❌ |
| [UL2](model_doc/ul2) | ✅ | ✅ | ✅ |
| [UMT5](model_doc/umt5) | ✅ | ❌ | ❌ |
| [UniSpeech](model_doc/unispeech) | ✅ | ❌ | ❌ |
| [UniSpeechSat](model_doc/unispeech-sat) | ✅ | ❌ | ❌ |
+| [UnivNet](model_doc/univnet) | ✅ | ❌ | ❌ |
| [UPerNet](model_doc/upernet) | ✅ | ❌ | ❌ |
| [VAN](model_doc/van) | ✅ | ❌ | ❌ |
| [VideoMAE](model_doc/videomae) | ✅ | ❌ | ❌ |
diff --git a/docs/source/en/llm_tutorial_optimization.md b/docs/source/en/llm_tutorial_optimization.md
index 497e624820d4..a90fc045aff4 100644
--- a/docs/source/en/llm_tutorial_optimization.md
+++ b/docs/source/en/llm_tutorial_optimization.md
@@ -22,7 +22,7 @@ The crux of these challenges lies in augmenting the computational and memory cap
In this guide, we will go over the effective techniques for efficient LLM deployment:
-1. **Lower Precision**: Research has shown that operating at reduced numerical precision, namely [8-bit and 4-bit](./main_classes/quantization.md) can achieve computational advantages without a considerable decline in model performance.
+1. **Lower Precision:** Research has shown that operating at reduced numerical precision, namely [8-bit and 4-bit](./main_classes/quantization.md) can achieve computational advantages without a considerable decline in model performance.
2. **Flash Attention:** Flash Attention is a variation of the attention algorithm that not only provides a more memory-efficient approach but also realizes increased efficiency due to optimized GPU memory utilization.
@@ -58,7 +58,7 @@ As of writing this document, the largest GPU chip on the market is the A100 & H1
🤗 Transformers does not support tensor parallelism out of the box as it requires the model architecture to be written in a specific way. If you're interested in writing models in a tensor-parallelism-friendly way, feel free to have a look at [the text-generation-inference library](https://github.com/huggingface/text-generation-inference/tree/main/server/text_generation_server/models/custom_modeling).
Naive pipeline parallelism is supported out of the box. For this, simply load the model with `device="auto"` which will automatically place the different layers on the available GPUs as explained [here](https://huggingface.co/docs/accelerate/v0.22.0/en/concept_guides/big_model_inference).
-Note, however that while very effective, this naive pipeline parallelism does not tackle the issues of GPU idling. For this more advanced pipeline parallelism is required as explained [here](https://huggingface.co/docs/transformers/v4.34.0/en/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism).
+Note, however that while very effective, this naive pipeline parallelism does not tackle the issues of GPU idling. For this more advanced pipeline parallelism is required as explained [here](https://huggingface.co/docs/transformers/en/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism).
If you have access to an 8 x 80GB A100 node, you could load BLOOM as follows
@@ -286,7 +286,7 @@ If GPU memory is not a constraint for your use case, there is often no need to l
For more in-detail usage information, we strongly recommend taking a look at the [Transformers Quantization Docs](https://huggingface.co/docs/transformers/main_classes/quantization#general-usage).
Next, let's look into how we can improve computational and memory efficiency by using better algorithms and an improved model architecture.
-# 2. Flash Attention
+## 2. Flash Attention
Today's top-performing LLMs share more or less the same fundamental architecture that consists of feed-forward layers, activation layers, layer normalization layers, and most crucially, self-attention layers.
@@ -484,7 +484,9 @@ We can observe that we only use roughly 100MB more GPU memory when passing a ver
```py
flush()
```
-For more information on how to use Flash Attention, please have a look at [this doc page](https://huggingface.co/docs/transformers/v4.34.0/en/perf_infer_gpu_one#flash-attention-2).
+
+For more information on how to use Flash Attention, please have a look at [this doc page](https://huggingface.co/docs/transformers/en/perf_infer_gpu_one#flashattention-2).
+
## 3. Architectural Innovations
So far we have looked into improving computational and memory efficiency by:
@@ -662,7 +664,15 @@ Using the key-value cache has two advantages:
> One should *always* make use of the key-value cache as it leads to identical results and a significant speed-up for longer input sequences. Transformers has the key-value cache enabled by default when making use of the text pipeline or the [`generate` method](https://huggingface.co/docs/transformers/main_classes/text_generation).
-Note that the key-value cache is especially useful for applications such as chat where multiple passes of auto-regressive decoding are required. Let's look at an example.
+
+
+Note that, despite our advice to use key-value caches, your LLM output may be slightly different when you use them. This is a property of the matrix multiplication kernels themselves -- you can read more about it [here](https://github.com/huggingface/transformers/issues/25420#issuecomment-1775317535).
+
+
+
+#### 3.2.1 Multi-round conversation
+
+The key-value cache is especially useful for applications such as chat where multiple passes of auto-regressive decoding are required. Let's look at an example.
```
User: How many people live in France?
@@ -672,14 +682,45 @@ Assistant: Germany has ca. 81 million inhabitants
```
In this chat, the LLM runs auto-regressive decoding twice:
-- 1. The first time, the key-value cache is empty and the input prompt is `"User: How many people live in France?"` and the model auto-regressively generates the text `"Roughly 75 million people live in France"` while increasing the key-value cache at every decoding step.
-- 2. The second time the input prompt is `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many in Germany?"`. Thanks to the cache, all key-value vectors for the first two sentences are already computed. Therefore the input prompt only consists of `"User: And how many in Germany?"`. While processing the shortened input prompt, it's computed key-value vectors are concatenated to the key-value cache of the first decoding. The second Assistant's answer `"Germany has ca. 81 million inhabitants"` is then auto-regressively generated with the key-value cache consisting of encoded key-value vectors of `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many are in Germany?"`.
+ 1. The first time, the key-value cache is empty and the input prompt is `"User: How many people live in France?"` and the model auto-regressively generates the text `"Roughly 75 million people live in France"` while increasing the key-value cache at every decoding step.
+ 2. The second time the input prompt is `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many in Germany?"`. Thanks to the cache, all key-value vectors for the first two sentences are already computed. Therefore the input prompt only consists of `"User: And how many in Germany?"`. While processing the shortened input prompt, it's computed key-value vectors are concatenated to the key-value cache of the first decoding. The second Assistant's answer `"Germany has ca. 81 million inhabitants"` is then auto-regressively generated with the key-value cache consisting of encoded key-value vectors of `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many are in Germany?"`.
Two things should be noted here:
1. Keeping all the context is crucial for LLMs deployed in chat so that the LLM understands all the previous context of the conversation. E.g. for the example above the LLM needs to understand that the user refers to the population when asking `"And how many are in Germany"`.
2. The key-value cache is extremely useful for chat as it allows us to continuously grow the encoded chat history instead of having to re-encode the chat history again from scratch (as e.g. would be the case when using an encoder-decoder architecture).
-There is however one catch. While the required peak memory for the \\( \mathbf{QK}^T \\) matrix is significantly reduced, holding the key-value cache in memory can become very memory expensive for long input sequences or multi-turn chat. Remember that the key-value cache needs to store the key-value vectors for all previous input vectors \\( \mathbf{x}_i \text{, for } i \in \{1, \ldots, c - 1\} \\) for all self-attention layers and for all attention heads.
+In `transformers`, a `generate` call will return `past_key_values` when `return_dict_in_generate=True` is passed, in addition to the default `use_cache=True`. Note that it is not yet available through the `pipeline` interface.
+
+```python
+# Generation as usual
+prompt = system_prompt + "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"
+model_inputs = tokenizer(prompt, return_tensors='pt')
+generation_output = model.generate(**model_inputs, max_new_tokens=60, return_dict_in_generate=True)
+decoded_output = tokenizer.batch_decode(generation_output.sequences)[0]
+
+# Piping the returned `past_key_values` to speed up the next conversation round
+prompt = decoded_output + "\nQuestion: How can I modify the function above to return Mega bytes instead?\n\nAnswer: Here"
+model_inputs = tokenizer(prompt, return_tensors='pt')
+generation_output = model.generate(
+ **model_inputs,
+ past_key_values=generation_output.past_key_values,
+ max_new_tokens=60,
+ return_dict_in_generate=True
+)
+tokenizer.batch_decode(generation_output.sequences)[0][len(prompt):]
+```
+
+**Output**:
+```
+ is a modified version of the function that returns Mega bytes instead.
+
+def bytes_to_megabytes(bytes):
+ return bytes / 1024 / 1024
+
+Answer: The function takes a number of bytes as input and returns the number of
+```
+
+Great, no additional time is spent recomputing the same key and values for the attention layer! There is however one catch. While the required peak memory for the \\( \mathbf{QK}^T \\) matrix is significantly reduced, holding the key-value cache in memory can become very memory expensive for long input sequences or multi-turn chat. Remember that the key-value cache needs to store the key-value vectors for all previous input vectors \\( \mathbf{x}_i \text{, for } i \in \{1, \ldots, c - 1\} \\) for all self-attention layers and for all attention heads.
Let's compute the number of float values that need to be stored in the key-value cache for the LLM `bigcode/octocoder` that we used before.
The number of float values amounts to two times the sequence length times the number of attention heads times the attention head dimension and times the number of layers.
@@ -696,11 +737,11 @@ config = model.config
```
Roughly 8 billion float values! Storing 8 billion float values in `float16` precision requires around 15 GB of RAM which is circa half as much as the model weights themselves!
-Researchers have proposed two methods that allow to significantly reduce the memory cost of storing the key-value cache:
+Researchers have proposed two methods that allow to significantly reduce the memory cost of storing the key-value cache, which are explored in the next subsections.
- 1. [Multi-Query-Attention (MQA)](https://arxiv.org/abs/1911.02150)
+#### 3.2.2 Multi-Query-Attention (MQA)
-Multi-Query-Attention was proposed in Noam Shazeer's *Fast Transformer Decoding: One Write-Head is All You Need* paper. As the title says, Noam found out that instead of using `n_head` key-value projections weights, one can use a single head-value projection weight pair that is shared across all attention heads without that the model's performance significantly degrades.
+[Multi-Query-Attention](https://arxiv.org/abs/1911.02150) was proposed in Noam Shazeer's *Fast Transformer Decoding: One Write-Head is All You Need* paper. As the title says, Noam found out that instead of using `n_head` key-value projections weights, one can use a single head-value projection weight pair that is shared across all attention heads without that the model's performance significantly degrades.
> By using a single head-value projection weight pair, the key value vectors \\( \mathbf{k}_i, \mathbf{v}_i \\) have to be identical across all attention heads which in turn means that we only need to store 1 key-value projection pair in the cache instead of `n_head` ones.
@@ -720,9 +761,9 @@ MQA has seen wide adoption by the community and is now used by many of the most
Also, the checkpoint used in this notebook - `bigcode/octocoder` - makes use of MQA.
- 2. [Grouped-Query-Attention (GQA)](https://arxiv.org/abs/2305.13245)
+#### 3.2.3 Grouped-Query-Attention (GQA)
-Grouped-Query-Attention, as proposed by Ainslie et al. from Google, found that using MQA can often lead to quality degradation compared to using vanilla multi-key-value head projections. The paper argues that more model performance can be kept by less drastically reducing the number of query head projection weights. Instead of using just a single key-value projection weight, `n < n_head` key-value projection weights should be used. By choosing `n` to a significantly smaller value than `n_head`, such as 2,4 or 8 almost all of the memory and speed gains from MQA can be kept while sacrificing less model capacity and thus arguably less performance.
+[Grouped-Query-Attention](https://arxiv.org/abs/2305.13245), as proposed by Ainslie et al. from Google, found that using MQA can often lead to quality degradation compared to using vanilla multi-key-value head projections. The paper argues that more model performance can be kept by less drastically reducing the number of query head projection weights. Instead of using just a single key-value projection weight, `n < n_head` key-value projection weights should be used. By choosing `n` to a significantly smaller value than `n_head`, such as 2,4 or 8 almost all of the memory and speed gains from MQA can be kept while sacrificing less model capacity and thus arguably less performance.
Moreover, the authors of GQA found out that existing model checkpoints can be *uptrained* to have a GQA architecture with as little as 5% of the original pre-training compute. While 5% of the original pre-training compute can still be a massive amount, GQA *uptraining* allows existing checkpoints to be useful for longer input sequences.
@@ -731,6 +772,7 @@ The most notable application of GQA is [Llama-v2](https://huggingface.co/meta-ll
> As a conclusion, it is strongly recommended to make use of either GQA or MQA if the LLM is deployed with auto-regressive decoding and is required to handle large input sequences as is the case for example for chat.
+
## Conclusion
The research community is constantly coming up with new, nifty ways to speed up inference time for ever-larger LLMs. As an example, one such promising research direction is [speculative decoding](https://arxiv.org/abs/2211.17192) where "easy tokens" are generated by smaller, faster language models and only "hard tokens" are generated by the LLM itself. Going into more detail is out of the scope of this notebook, but can be read upon in this [nice blog post](https://huggingface.co/blog/assisted-generation).
diff --git a/docs/source/en/main_classes/callback.md b/docs/source/en/main_classes/callback.md
index 87bf0d63af1f..bc7323f5911e 100644
--- a/docs/source/en/main_classes/callback.md
+++ b/docs/source/en/main_classes/callback.md
@@ -44,6 +44,7 @@ By default, `TrainingArguments.report_to` is set to `"all"`, so a [`Trainer`] wi
- [`~integrations.ClearMLCallback`] if [clearml](https://github.com/allegroai/clearml) is installed.
- [`~integrations.DagsHubCallback`] if [dagshub](https://dagshub.com/) is installed.
- [`~integrations.FlyteCallback`] if [flyte](https://flyte.org/) is installed.
+- [`~integrations.DVCLiveCallback`] if [dvclive](https://dvc.org/doc/dvclive) is installed.
If a package is installed but you don't wish to use the accompanying integration, you can change `TrainingArguments.report_to` to a list of just those integrations you want to use (e.g. `["azure_ml", "wandb"]`).
@@ -88,6 +89,9 @@ Here is the list of the available [`TrainerCallback`] in the library:
[[autodoc]] integrations.FlyteCallback
+[[autodoc]] integrations.DVCLiveCallback
+ - setup
+
## TrainerCallback
[[autodoc]] TrainerCallback
diff --git a/docs/source/en/main_classes/deepspeed.md b/docs/source/en/main_classes/deepspeed.md
index 277610ce9cda..8133f6c097c9 100644
--- a/docs/source/en/main_classes/deepspeed.md
+++ b/docs/source/en/main_classes/deepspeed.md
@@ -287,7 +287,7 @@ The information in this section isn't not specific to the DeepSpeed integration
For the duration of this section let's assume that you have 2 nodes with 8 gpus each. And you can reach the first node with `ssh hostname1` and second node with `ssh hostname2`, and both must be able to reach each other via ssh locally without a password. Of course, you will need to rename these host (node) names to the actual host names you are working with.
-#### The torch.distributed.run launcher
+#### The torch.distributed.run(torchrun) launcher
For example, to use `torch.distributed.run`, you could do:
diff --git a/docs/source/en/main_classes/output.md b/docs/source/en/main_classes/output.md
index 578b9e6542d1..64101fd82445 100644
--- a/docs/source/en/main_classes/output.md
+++ b/docs/source/en/main_classes/output.md
@@ -44,6 +44,7 @@ an optional `attentions` attribute. Here we have the `loss` since we passed alon
When passing `output_hidden_states=True` you may expect the `outputs.hidden_states[-1]` to match `outputs.last_hidden_states` exactly.
However, this is not always the case. Some models apply normalization or subsequent process to the last hidden state when it's returned.
+
diff --git a/docs/source/en/main_classes/pipelines.md b/docs/source/en/main_classes/pipelines.md
index b105cb544ffc..3bb3f0d45242 100644
--- a/docs/source/en/main_classes/pipelines.md
+++ b/docs/source/en/main_classes/pipelines.md
@@ -225,7 +225,7 @@ For users, a rule of thumb is:
- **Measure performance on your load, with your hardware. Measure, measure, and keep measuring. Real numbers are the
only way to go.**
-- If you are latency constrained (live product doing inference), don't batch
+- If you are latency constrained (live product doing inference), don't batch.
- If you are using CPU, don't batch.
- If you are using throughput (you want to run your model on a bunch of static data), on GPU, then:
diff --git a/docs/source/en/main_classes/processors.md b/docs/source/en/main_classes/processors.md
index 9763122ef4f9..5e943fc9fdd5 100644
--- a/docs/source/en/main_classes/processors.md
+++ b/docs/source/en/main_classes/processors.md
@@ -86,7 +86,7 @@ This library hosts the processor to load the XNLI data:
Please note that since the gold labels are available on the test set, evaluation is performed on the test set.
-An example using these processors is given in the [run_xnli.py](https://github.com/huggingface/transformers/tree/main/examples/legacy/text-classification/run_xnli.py) script.
+An example using these processors is given in the [run_xnli.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_xnli.py) script.
## SQuAD
diff --git a/docs/source/en/main_classes/quantization.md b/docs/source/en/main_classes/quantization.md
index 36ef2eefa896..7200039e3f50 100644
--- a/docs/source/en/main_classes/quantization.md
+++ b/docs/source/en/main_classes/quantization.md
@@ -16,6 +16,97 @@ rendered properly in your Markdown viewer.
# Quantize 🤗 Transformers models
+## AWQ integration
+
+AWQ method has been introduced in the [*AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration* paper](https://arxiv.org/abs/2306.00978). With AWQ you can run models in 4-bit precision, while preserving its original quality (i.e. no performance degradation) with a superior throughput that other quantization methods presented below - reaching similar throughput as pure `float16` inference.
+
+We now support inference with any AWQ model, meaning anyone can load and use AWQ weights that are pushed on the Hub or saved locally. Note that using AWQ requires to have access to a NVIDIA GPU. CPU inference is not supported yet.
+
+### Quantizing a model
+
+We advise users to look at different existing tools in the ecosystem to quantize their models with AWQ algorithm, such as:
+
+- [`llm-awq`](https://github.com/mit-han-lab/llm-awq) from MIT Han Lab
+- [`autoawq`](https://github.com/casper-hansen/AutoAWQ) from [`casper-hansen`](https://github.com/casper-hansen)
+- Intel neural compressor from Intel - through [`optimum-intel`](https://huggingface.co/docs/optimum/main/en/intel/optimization_inc)
+
+Many other tools might exist in the ecosystem, please feel free to open a PR to add them to the list.
+Currently the integration with 🤗 Transformers is only available for models that have been quantized using `autoawq` library and `llm-awq`. Most of the models quantized with `auto-awq` can be found under [`TheBloke`](https://huggingface.co/TheBloke) namespace of 🤗 Hub, and to quantize models with `llm-awq` please refer to the [`convert_to_hf.py`](https://github.com/mit-han-lab/llm-awq/blob/main/examples/convert_to_hf.py) script in the examples folder of [`llm-awq`](https://github.com/mit-han-lab/llm-awq/).
+
+### Load a quantized model
+
+You can load a quantized model from the Hub using the `from_pretrained` method. Make sure that the pushed weights are quantized, by checking that the attribute `quantization_config` is present in the model's configuration file (`configuration.json`). You can confirm that the model is quantized in the AWQ format by checking the field `quantization_config.quant_method` which should be set to `"awq"`. Note that loading the model will set other weights in `float16` by default for performance reasons. If you want to change that behavior, you can pass `torch_dtype` argument to `torch.float32` or `torch.bfloat16`. You can find in the sections below some example snippets and notebook.
+
+## Example usage
+
+First, you need to install [`autoawq`](https://github.com/casper-hansen/AutoAWQ) library
+
+```bash
+pip install autoawq
+```
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model_id = "TheBloke/zephyr-7B-alpha-AWQ"
+model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda:0")
+```
+
+In case you first load your model on CPU, make sure to move it to your GPU device before using
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model_id = "TheBloke/zephyr-7B-alpha-AWQ"
+model = AutoModelForCausalLM.from_pretrained(model_id).to("cuda:0")
+```
+
+### Combining AWQ and Flash Attention
+
+You can combine AWQ quantization with Flash Attention to get a model that is both quantized and faster. Simply load the model using `from_pretrained` and pass `use_flash_attention_2=True` argument.
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model = AutoModelForCausalLM.from_pretrained("TheBloke/zephyr-7B-alpha-AWQ", use_flash_attention_2=True, device_map="cuda:0")
+```
+
+### Benchmarks
+
+We performed some speed, throughput and latency benchmarks using [`optimum-benchmark`](https://github.com/huggingface/optimum-benchmark) library.
+
+Note at that time of writing this documentation section, the available quantization methods were: `awq`, `gptq` and `bitsandbytes`.
+
+The benchmark was run on a NVIDIA-A100 instance and the model used was [`TheBloke/Mistral-7B-v0.1-AWQ`](https://huggingface.co/TheBloke/Mistral-7B-v0.1-AWQ) for the AWQ model, [`TheBloke/Mistral-7B-v0.1-GPTQ`](https://huggingface.co/TheBloke/Mistral-7B-v0.1-GPTQ) for the GPTQ model. We also benchmarked it against `bitsandbytes` quantization methods and native `float16` model. Some results are shown below:
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+You can find the full results together with packages versions in [this link](https://github.com/huggingface/optimum-benchmark/tree/main/examples/running-mistrals).
+
+From the results it appears that AWQ quantization method is the fastest quantization method for inference, text generation and among the lowest peak memory for text generation. However, AWQ seems to have the largest forward latency per batch size.
+
+### Google colab demo
+
+Check out how to use this integration throughout this [Google Colab demo](https://colab.research.google.com/drive/1HzZH89yAXJaZgwJDhQj9LqSBux932BvY)!
+
+### AwqConfig
+
+[[autodoc]] AwqConfig
+
## `AutoGPTQ` Integration
🤗 Transformers has integrated `optimum` API to perform GPTQ quantization on language models. You can load and quantize your model in 8, 4, 3 or even 2 bits without a big drop of performance and faster inference speed! This is supported by most GPU hardwares.
@@ -48,6 +139,7 @@ Note that GPTQ integration supports for now only text models and you may encount
GPTQ is a quantization method that requires weights calibration before using the quantized models. If you want to quantize transformers model from scratch, it might take some time before producing the quantized model (~5 min on a Google colab for `facebook/opt-350m` model).
Hence, there are two different scenarios where you want to use GPTQ-quantized models. The first use case would be to load models that has been already quantized by other users that are available on the Hub, the second use case would be to quantize your model from scratch and save it or push it on the Hub so that other users can also use it.
+
#### GPTQ Configuration
In order to load and quantize a model, you need to create a [`GPTQConfig`]. You need to pass the number of `bits`, a `dataset` in order to calibrate the quantization and the `tokenizer` of the model in order prepare the dataset.
@@ -59,6 +151,7 @@ gptq_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)
```
Note that you can pass your own dataset as a list of string. However, it is highly recommended to use the dataset from the GPTQ paper.
+
```python
dataset = ["auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm."]
quantization = GPTQConfig(bits=4, dataset = dataset, tokenizer=tokenizer)
@@ -71,14 +164,17 @@ You can quantize a model by using `from_pretrained` and setting the `quantizatio
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=gptq_config)
+
```
Note that you will need a GPU to quantize a model. We will put the model in the cpu and move the modules back and forth to the gpu in order to quantize them.
If you want to maximize your gpus usage while using cpu offload, you can set `device_map = "auto"`.
+
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=gptq_config)
```
+
Note that disk offload is not supported. Furthermore, if you are out of memory because of the dataset, you may have to pass `max_memory` in `from_pretained`. Checkout this [guide](https://huggingface.co/docs/accelerate/usage_guides/big_modeling#designing-a-device-map) to learn more about `device_map` and `max_memory`.
@@ -95,12 +191,14 @@ tokenizer.push_to_hub("opt-125m-gptq")
```
If you want to save your quantized model on your local machine, you can also do it with `save_pretrained`:
+
```python
quantized_model.save_pretrained("opt-125m-gptq")
tokenizer.save_pretrained("opt-125m-gptq")
```
-Note that if you have quantized your model with a `device_map`, make sure to move the entire model to one of your gpus or the `cpu` before saving it.
+Note that if you have quantized your model with a `device_map`, make sure to move the entire model to one of your gpus or the `cpu` before saving it.
+
```python
quantized_model.to("cpu")
quantized_model.save_pretrained("opt-125m-gptq")
@@ -117,6 +215,7 @@ model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq")
```
If you want to load a model faster and without allocating more memory than needed, the `device_map` argument also works with quantized model. Make sure that you have `accelerate` library installed.
+
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto")
@@ -124,16 +223,25 @@ model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", de
### Exllama kernels for faster inference
-For 4-bit model, you can use the exllama kernels in order to a faster inference speed. It is activated by default. You can change that behavior by passing `disable_exllama` in [`GPTQConfig`]. This will overwrite the quantization config stored in the config. Note that you will only be able to overwrite the attributes related to the kernels. Furthermore, you need to have the entire model on gpus if you want to use exllama kernels.
+For 4-bit model, you can use the exllama kernels in order to a faster inference speed. It is activated by default. You can change that behavior by passing `use_exllama` in [`GPTQConfig`]. This will overwrite the quantization config stored in the config. Note that you will only be able to overwrite the attributes related to the kernels. Furthermore, you need to have the entire model on gpus if you want to use exllama kernels. Also, you can perform CPU inference using Auto-GPTQ for Auto-GPTQ version > 0.4.2 by passing `device_map` = "cpu". For CPU inference, you have to pass `use_exllama = False` in the `GPTQConfig.`
```py
import torch
-gptq_config = GPTQConfig(bits=4, disable_exllama=False)
+gptq_config = GPTQConfig(bits=4)
+model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto", quantization_config=gptq_config)
+```
+
+With the release of the exllamav2 kernels, you can get faster inference speed compared to the exllama kernels. You just need to pass `exllama_config={"version": 2}` in [`GPTQConfig`]:
+
+```py
+import torch
+gptq_config = GPTQConfig(bits=4, exllama_config={"version":2})
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto", quantization_config = gptq_config)
```
Note that only 4-bit models are supported for now. Furthermore, it is recommended to deactivate the exllama kernels if you are finetuning a quantized model with peft.
+You can find the benchmark of these kernels [here](https://github.com/huggingface/optimum/tree/main/tests/benchmark#gptq-benchmark)
#### Fine-tune a quantized model
With the official support of adapters in the Hugging Face ecosystem, you can fine-tune models that have been quantized with GPTQ.
@@ -336,6 +444,7 @@ from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("{your_username}/bloom-560m-8bit", device_map="auto")
```
+
Note that in this case, you don't need to specify the arguments `load_in_8bit=True`, but you need to make sure that `bitsandbytes` and `accelerate` are installed.
Note also that `device_map` is optional but setting `device_map = 'auto'` is prefered for inference as it will dispatch efficiently the model on the available ressources.
@@ -356,6 +465,7 @@ quantization_config = BitsAndBytesConfig(llm_int8_enable_fp32_cpu_offload=True)
```
Let's say you want to load `bigscience/bloom-1b7` model, and you have just enough GPU RAM to fit the entire model except the `lm_head`. Therefore write a custom device_map as follows:
+
```python
device_map = {
"transformer.word_embeddings": 0,
diff --git a/docs/source/en/main_classes/tokenizer.md b/docs/source/en/main_classes/tokenizer.md
index bf43014ee51d..2ad7e450404e 100644
--- a/docs/source/en/main_classes/tokenizer.md
+++ b/docs/source/en/main_classes/tokenizer.md
@@ -55,6 +55,8 @@ to a given token).
[[autodoc]] PreTrainedTokenizer
- __call__
+ - add_tokens
+ - add_special_tokens
- apply_chat_template
- batch_decode
- decode
@@ -69,6 +71,8 @@ loaded very simply into 🤗 transformers. Take a look at the [Using tokenizers
[[autodoc]] PreTrainedTokenizerFast
- __call__
+ - add_tokens
+ - add_special_tokens
- apply_chat_template
- batch_decode
- decode
diff --git a/docs/source/en/main_classes/trainer.md b/docs/source/en/main_classes/trainer.md
index 46341804ce75..cf1dd672d3d4 100644
--- a/docs/source/en/main_classes/trainer.md
+++ b/docs/source/en/main_classes/trainer.md
@@ -26,7 +26,7 @@ If you're looking to fine-tune a language model like Llama-2 or Mistral on a tex
Before instantiating your [`Trainer`], create a [`TrainingArguments`] to access all the points of customization during training.
-The API supports distributed training on multiple GPUs/TPUs, mixed precision through [NVIDIA Apex](https://github.com/NVIDIA/apex) and Native AMP for PyTorch.
+The API supports distributed training on multiple GPUs/TPUs, mixed precision through [NVIDIA Apex] for NVIDIA GPUs, [ROCm APEX](https://github.com/ROCmSoftwarePlatform/apex) for AMD GPUs, and Native AMP for PyTorch.
The [`Trainer`] contains the basic training loop which supports the above features. To inject custom behavior you can subclass them and override the following methods:
@@ -206,10 +206,11 @@ Let's discuss how you can tell your program which GPUs are to be used and in wha
When using [`DistributedDataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html) to use only a subset of your GPUs, you simply specify the number of GPUs to use. For example, if you have 4 GPUs, but you wish to use the first 2 you can do:
```bash
-python -m torch.distributed.launch --nproc_per_node=2 trainer-program.py ...
+torchrun --nproc_per_node=2 trainer-program.py ...
```
if you have either [`accelerate`](https://github.com/huggingface/accelerate) or [`deepspeed`](https://github.com/microsoft/DeepSpeed) installed you can also accomplish the same by using one of:
+
```bash
accelerate launch --num_processes 2 trainer-program.py ...
```
@@ -218,7 +219,7 @@ accelerate launch --num_processes 2 trainer-program.py ...
deepspeed --num_gpus 2 trainer-program.py ...
```
-You don't need to use the Accelerate or [the Deepspeed integration](Deepspeed) features to use these launchers.
+You don't need to use the Accelerate or [the Deepspeed integration](deepspeed) features to use these launchers.
Until now you were able to tell the program how many GPUs to use. Now let's discuss how to select specific GPUs and control their order.
@@ -232,7 +233,7 @@ If you have multiple GPUs and you'd like to use only 1 or a few of those GPUs, s
For example, let's say you have 4 GPUs: 0, 1, 2 and 3. To run only on the physical GPUs 0 and 2, you can do:
```bash
-CUDA_VISIBLE_DEVICES=0,2 python -m torch.distributed.launch trainer-program.py ...
+CUDA_VISIBLE_DEVICES=0,2 torchrun trainer-program.py ...
```
So now pytorch will see only 2 GPUs, where your physical GPUs 0 and 2 are mapped to `cuda:0` and `cuda:1` correspondingly.
@@ -240,12 +241,13 @@ So now pytorch will see only 2 GPUs, where your physical GPUs 0 and 2 are mapped
You can even change their order:
```bash
-CUDA_VISIBLE_DEVICES=2,0 python -m torch.distributed.launch trainer-program.py ...
+CUDA_VISIBLE_DEVICES=2,0 torchrun trainer-program.py ...
```
Here your physical GPUs 0 and 2 are mapped to `cuda:1` and `cuda:0` correspondingly.
The above examples were all for `DistributedDataParallel` use pattern, but the same method works for [`DataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html) as well:
+
```bash
CUDA_VISIBLE_DEVICES=2,0 python trainer-program.py ...
```
@@ -261,7 +263,7 @@ As with any environment variable you can, of course, export those instead of add
```bash
export CUDA_VISIBLE_DEVICES=0,2
-python -m torch.distributed.launch trainer-program.py ...
+torchrun trainer-program.py ...
```
but this approach can be confusing since you may forget you set up the environment variable earlier and not understand why the wrong GPUs are used. Therefore, it's a common practice to set the environment variable just for a specific run on the same command line as it's shown in most examples of this section.
@@ -270,7 +272,7 @@ but this approach can be confusing since you may forget you set up the environme
There is an additional environment variable `CUDA_DEVICE_ORDER` that controls how the physical devices are ordered. The two choices are:
-1. ordered by PCIe bus IDs (matches `nvidia-smi`'s order) - this is the default.
+1. ordered by PCIe bus IDs (matches `nvidia-smi` and `rocm-smi`'s order) - this is the default.
```bash
export CUDA_DEVICE_ORDER=PCI_BUS_ID
@@ -282,7 +284,7 @@ export CUDA_DEVICE_ORDER=PCI_BUS_ID
export CUDA_DEVICE_ORDER=FASTEST_FIRST
```
-Most of the time you don't need to care about this environment variable, but it's very helpful if you have a lopsided setup where you have an old and a new GPUs physically inserted in such a way so that the slow older card appears to be first. One way to fix that is to swap the cards. But if you can't swap the cards (e.g., if the cooling of the devices gets impacted) then setting `CUDA_DEVICE_ORDER=FASTEST_FIRST` will always put the newer faster card first. It'll be somewhat confusing though since `nvidia-smi` will still report them in the PCIe order.
+Most of the time you don't need to care about this environment variable, but it's very helpful if you have a lopsided setup where you have an old and a new GPUs physically inserted in such a way so that the slow older card appears to be first. One way to fix that is to swap the cards. But if you can't swap the cards (e.g., if the cooling of the devices gets impacted) then setting `CUDA_DEVICE_ORDER=FASTEST_FIRST` will always put the newer faster card first. It'll be somewhat confusing though since `nvidia-smi` (or `rocm-smi`) will still report them in the PCIe order.
The other solution to swapping the order is to use:
@@ -424,8 +426,7 @@ To read more about it and the benefits, check out the [Fully Sharded Data Parall
We have integrated the latest PyTorch's Fully Sharded Data Parallel (FSDP) training feature.
All you need to do is enable it through the config.
-**Required PyTorch version for FSDP support**: PyTorch Nightly (or 1.12.0 if you read this after it has been released)
-as the model saving with FSDP activated is only available with recent fixes.
+**Required PyTorch version for FSDP support**: PyTorch >=2.1.0
**Usage**:
@@ -438,6 +439,8 @@ as the model saving with FSDP activated is only available with recent fixes.
- SHARD_GRAD_OP : Shards optimizer states + gradients across data parallel workers/GPUs.
For this, add `--fsdp shard_grad_op` to the command line arguments.
- NO_SHARD : No sharding. For this, add `--fsdp no_shard` to the command line arguments.
+ - HYBRID_SHARD : No sharding. For this, add `--fsdp hybrid_shard` to the command line arguments.
+ - HYBRID_SHARD_ZERO2 : No sharding. For this, add `--fsdp hybrid_shard_zero2` to the command line arguments.
- To offload the parameters and gradients to the CPU,
add `--fsdp "full_shard offload"` or `--fsdp "shard_grad_op offload"` to the command line arguments.
- To automatically recursively wrap layers with FSDP using `default_auto_wrap_policy`,
@@ -447,18 +450,18 @@ as the model saving with FSDP activated is only available with recent fixes.
- Remaining FSDP config is passed via `--fsdp_config `. It is either a location of
FSDP json config file (e.g., `fsdp_config.json`) or an already loaded json file as `dict`.
- If auto wrapping is enabled, you can either use transformer based auto wrap policy or size based auto wrap policy.
- - For transformer based auto wrap policy, it is recommended to specify `fsdp_transformer_layer_cls_to_wrap` in the config file. If not specified, the default value is `model._no_split_modules` when available.
+ - For transformer based auto wrap policy, it is recommended to specify `transformer_layer_cls_to_wrap` in the config file. If not specified, the default value is `model._no_split_modules` when available.
This specifies the list of transformer layer class name (case-sensitive) to wrap ,e.g, [`BertLayer`], [`GPTJBlock`], [`T5Block`] ....
This is important because submodules that share weights (e.g., embedding layer) should not end up in different FSDP wrapped units.
Using this policy, wrapping happens for each block containing Multi-Head Attention followed by couple of MLP layers.
Remaining layers including the shared embeddings are conveniently wrapped in same outermost FSDP unit.
Therefore, use this for transformer based models.
- - For size based auto wrap policy, please add `fsdp_min_num_params` in the config file.
+ - For size based auto wrap policy, please add `min_num_params` in the config file.
It specifies FSDP's minimum number of parameters for auto wrapping.
- - `fsdp_backward_prefetch` can be specified in the config file. It controls when to prefetch next set of parameters.
+ - `backward_prefetch` can be specified in the config file. It controls when to prefetch next set of parameters.
`backward_pre` and `backward_pos` are available options.
For more information refer `torch.distributed.fsdp.fully_sharded_data_parallel.BackwardPrefetch`
- - `fsdp_forward_prefetch` can be specified in the config file. It controls when to prefetch next set of parameters.
+ - `forward_prefetch` can be specified in the config file. It controls when to prefetch next set of parameters.
If `"True"`, FSDP explicitly prefetches the next upcoming all-gather while executing in the forward pass.
- `limit_all_gathers` can be specified in the config file.
If `"True"`, FSDP explicitly synchronizes the CPU thread to prevent too many in-flight all-gathers.
@@ -466,6 +469,20 @@ as the model saving with FSDP activated is only available with recent fixes.
If `"True"`, FSDP activation checkpointing is a technique to reduce memory usage by clearing activations of
certain layers and recomputing them during a backward pass. Effectively, this trades extra computation time
for reduced memory usage.
+ - `use_orig_params` can be specified in the config file.
+ If True, allows non-uniform `requires_grad` during init, which means support for interspersed frozen and trainable paramteres. Useful in cases such as parameter-efficient fine-tuning. This also enables to have different optimizer param groups. This should be `True` when creating optimizer object before preparing/wrapping the model with FSDP.
+ Please refer this [blog](https://dev-discuss.pytorch.org/t/rethinking-pytorch-fully-sharded-data-parallel-fsdp-from-first-principles/1019).
+
+**Saving and loading**
+Saving entire intermediate checkpoints using `FULL_STATE_DICT` state_dict_type with CPU offloading on rank 0 takes a lot of time and often results in NCCL Timeout errors due to indefinite hanging during broadcasting. However, at the end of training, we want the whole model state dict instead of the sharded state dict which is only compatible with FSDP. Use `SHARDED_STATE_DICT` (default) state_dict_type to save the intermediate checkpoints and optimizer states in this format recommended by the PyTorch team.
+
+Saving the final checkpoint in transformers format using default `safetensors` format requires below changes.
+```python
+if trainer.is_fsdp_enabled:
+ trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
+
+trainer.save_model(script_args.output_dir)
+```
**Few caveats to be aware of**
- it is incompatible with `generate`, thus is incompatible with `--predict_with_generate`
@@ -490,15 +507,15 @@ Pass `--fsdp "full shard"` along with following changes to be made in `--fsdp_co
https://github.com/pytorch/xla/blob/master/torch_xla/distributed/fsdp/xla_fully_sharded_data_parallel.py).
- `xla_fsdp_grad_ckpt`. When `True`, uses gradient checkpointing over each nested XLA FSDP wrapped layer.
This setting can only be used when the xla flag is set to true, and an auto wrapping policy is specified through
- `fsdp_min_num_params` or `fsdp_transformer_layer_cls_to_wrap`.
+ `min_num_params` or `transformer_layer_cls_to_wrap`.
- You can either use transformer based auto wrap policy or size based auto wrap policy.
- - For transformer based auto wrap policy, it is recommended to specify `fsdp_transformer_layer_cls_to_wrap` in the config file. If not specified, the default value is `model._no_split_modules` when available.
+ - For transformer based auto wrap policy, it is recommended to specify `transformer_layer_cls_to_wrap` in the config file. If not specified, the default value is `model._no_split_modules` when available.
This specifies the list of transformer layer class name (case-sensitive) to wrap ,e.g, [`BertLayer`], [`GPTJBlock`], [`T5Block`] ....
This is important because submodules that share weights (e.g., embedding layer) should not end up in different FSDP wrapped units.
Using this policy, wrapping happens for each block containing Multi-Head Attention followed by couple of MLP layers.
Remaining layers including the shared embeddings are conveniently wrapped in same outermost FSDP unit.
Therefore, use this for transformer based models.
- - For size based auto wrap policy, please add `fsdp_min_num_params` in the config file.
+ - For size based auto wrap policy, please add `min_num_params` in the config file.
It specifies FSDP's minimum number of parameters for auto wrapping.
@@ -738,3 +755,27 @@ Sections that were moved:
| Gradient Clipping
| Getting The Model Weights Out
]
+
+## Boost your fine-tuning performances using NEFTune
+
+
+NEFTune is a technique to boost the performance of chat models and was introduced by the paper “NEFTune: Noisy Embeddings Improve Instruction Finetuning” from Jain et al. it consists of adding noise to the embedding vectors during training. According to the abstract of the paper:
+
+> Standard finetuning of LLaMA-2-7B using Alpaca achieves 29.79% on AlpacaEval, which rises to 64.69% using noisy embeddings. NEFTune also improves over strong baselines on modern instruction datasets. Models trained with Evol-Instruct see a 10% improvement, with ShareGPT an 8% improvement, and with OpenPlatypus an 8% improvement. Even powerful models further refined with RLHF such as LLaMA-2-Chat benefit from additional training with NEFTune.
+
+
+
+
+
+To use it in `Trainer` simply pass `neftune_noise_alpha` when creating your `TrainingArguments` instance. Note that to avoid any surprising behaviour, NEFTune is disabled after training to retrieve back the original behaviour of the embedding layer.
+
+```python
+from transformers import Trainer, TrainingArguments
+
+args = TrainingArguments(..., neftune_noise_alpha=0.1)
+trainer = Trainer(..., args=args)
+
+...
+
+trainer.train()
+```
diff --git a/docs/source/en/model_doc/albert.md b/docs/source/en/model_doc/albert.md
index 9e821f2f4d02..a75e67578048 100644
--- a/docs/source/en/model_doc/albert.md
+++ b/docs/source/en/model_doc/albert.md
@@ -45,7 +45,10 @@ self-supervised loss that focuses on modeling inter-sentence coherence, and show
with multi-sentence inputs. As a result, our best model establishes new state-of-the-art results on the GLUE, RACE, and
SQuAD benchmarks while having fewer parameters compared to BERT-large.*
-Tips:
+This model was contributed by [lysandre](https://huggingface.co/lysandre). This model jax version was contributed by
+[kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/google-research/ALBERT).
+
+## Usage tips
- ALBERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather
than the left.
@@ -57,16 +60,66 @@ Tips:
Next sentence prediction is replaced by a sentence ordering prediction: in the inputs, we have two sentences A and B (that are consecutive) and we either feed A followed by B or B followed by A. The model must predict if they have been swapped or not.
+
This model was contributed by [lysandre](https://huggingface.co/lysandre). This model jax version was contributed by
[kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/google-research/ALBERT).
-## Documentation resources
-- [Text classification task guide](../tasks/sequence_classification)
-- [Token classification task guide](../tasks/token_classification)
-- [Question answering task guide](../tasks/question_answering)
-- [Masked language modeling task guide](../tasks/masked_language_modeling)
-- [Multiple choice task guide](../tasks/multiple_choice)
+## Resources
+
+
+The resources provided in the following sections consist of a list of official Hugging Face and community (indicated by 🌎) resources to help you get started with AlBERT. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+
+
+- [`AlbertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification).
+
+
+- [`TFAlbertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification).
+
+- [`FlaxAlbertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_flax.ipynb).
+- Check the [Text classification task guide](../tasks/sequence_classification) on how to use the model.
+
+
+
+
+
+- [`AlbertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification).
+
+
+- [`TFAlbertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
+
+
+
+- [`FlaxAlbertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/token-classification).
+- [Token classification](https://huggingface.co/course/chapter7/2?fw=pt) chapter of the 🤗 Hugging Face Course.
+- Check the [Token classification task guide](../tasks/token_classification) on how to use the model.
+
+
+
+- [`AlbertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
+- [`TFAlbertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
+- [`FlaxAlbertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb).
+- [Masked language modeling](https://huggingface.co/course/chapter7/3?fw=pt) chapter of the 🤗 Hugging Face Course.
+- Check the [Masked language modeling task guide](../tasks/masked_language_modeling) on how to use the model.
+
+
+
+- [`AlbertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb).
+- [`TFAlbertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb).
+- [`FlaxAlbertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/question-answering).
+- [Question answering](https://huggingface.co/course/chapter7/7?fw=pt) chapter of the 🤗 Hugging Face Course.
+- Check the [Question answering task guide](../tasks/question_answering) on how to use the model.
+
+**Multiple choice**
+
+- [`AlbertForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb).
+- [`TFAlbertForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb).
+
+- Check the [Multiple choice task guide](../tasks/multiple_choice) on how to use the model.
+
## AlbertConfig
@@ -90,6 +143,9 @@ This model was contributed by [lysandre](https://huggingface.co/lysandre). This
[[autodoc]] models.albert.modeling_tf_albert.TFAlbertForPreTrainingOutput
+
+
+
## AlbertModel
[[autodoc]] AlbertModel
@@ -124,6 +180,10 @@ This model was contributed by [lysandre](https://huggingface.co/lysandre). This
[[autodoc]] AlbertForQuestionAnswering
- forward
+
+
+
+
## TFAlbertModel
[[autodoc]] TFAlbertModel
@@ -159,6 +219,9 @@ This model was contributed by [lysandre](https://huggingface.co/lysandre). This
[[autodoc]] TFAlbertForQuestionAnswering
- call
+
+
+
## FlaxAlbertModel
[[autodoc]] FlaxAlbertModel
@@ -193,3 +256,8 @@ This model was contributed by [lysandre](https://huggingface.co/lysandre). This
[[autodoc]] FlaxAlbertForQuestionAnswering
- __call__
+
+
+
+
+
diff --git a/docs/source/en/model_doc/align.md b/docs/source/en/model_doc/align.md
index faf76853f609..5e41dac6024a 100644
--- a/docs/source/en/model_doc/align.md
+++ b/docs/source/en/model_doc/align.md
@@ -24,7 +24,10 @@ The abstract from the paper is the following:
*Pre-trained representations are becoming crucial for many NLP and perception tasks. While representation learning in NLP has transitioned to training on raw text without human annotations, visual and vision-language representations still rely heavily on curated training datasets that are expensive or require expert knowledge. For vision applications, representations are mostly learned using datasets with explicit class labels such as ImageNet or OpenImages. For vision-language, popular datasets like Conceptual Captions, MSCOCO, or CLIP all involve a non-trivial data collection (and cleaning) process. This costly curation process limits the size of datasets and hence hinders the scaling of trained models. In this paper, we leverage a noisy dataset of over one billion image alt-text pairs, obtained without expensive filtering or post-processing steps in the Conceptual Captions dataset. A simple dual-encoder architecture learns to align visual and language representations of the image and text pairs using a contrastive loss. We show that the scale of our corpus can make up for its noise and leads to state-of-the-art representations even with such a simple learning scheme. Our visual representation achieves strong performance when transferred to classification tasks such as ImageNet and VTAB. The aligned visual and language representations enables zero-shot image classification and also set new state-of-the-art results on Flickr30K and MSCOCO image-text retrieval benchmarks, even when compared with more sophisticated cross-attention models. The representations also enable cross-modality search with complex text and text + image queries.*
-## Usage
+This model was contributed by [Alara Dirik](https://huggingface.co/adirik).
+The original code is not released, this implementation is based on the Kakao Brain implementation based on the original paper.
+
+## Usage example
ALIGN uses EfficientNet to get visual features and BERT to get the text features. Both the text and visual features are then projected to a latent space with identical dimension. The dot product between the projected image and text features is then used as a similarity score.
@@ -56,9 +59,6 @@ probs = logits_per_image.softmax(dim=1)
print(probs)
```
-This model was contributed by [Alara Dirik](https://huggingface.co/adirik).
-The original code is not released, this implementation is based on the Kakao Brain implementation based on the original paper.
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ALIGN.
@@ -69,7 +69,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it. The resource should ideally demonstrate something new instead of duplicating an existing resource.
-
## AlignConfig
[[autodoc]] AlignConfig
diff --git a/docs/source/en/model_doc/altclip.md b/docs/source/en/model_doc/altclip.md
index 23cdcb63fbd2..b1fc9b382694 100644
--- a/docs/source/en/model_doc/altclip.md
+++ b/docs/source/en/model_doc/altclip.md
@@ -31,7 +31,9 @@ teacher learning and contrastive learning. We validate our method through evalua
performances on a bunch of tasks including ImageNet-CN, Flicker30k- CN, and COCO-CN. Further, we obtain very close performances with
CLIP on almost all tasks, suggesting that one can simply alter the text encoder in CLIP for extended capabilities such as multilingual understanding.*
-## Usage
+This model was contributed by [jongjyh](https://huggingface.co/jongjyh).
+
+## Usage tips and example
The usage of AltCLIP is very similar to the CLIP. the difference between CLIP is the text encoder. Note that we use bidirectional attention instead of casual attention
and we take the [CLS] token in XLM-R to represent text embedding.
@@ -50,7 +52,6 @@ The [`AltCLIPProcessor`] wraps a [`CLIPImageProcessor`] and a [`XLMRobertaTokeni
encode the text and prepare the images. The following example shows how to get the image-text similarity scores using
[`AltCLIPProcessor`] and [`AltCLIPModel`].
-
```python
>>> from PIL import Image
>>> import requests
@@ -70,11 +71,11 @@ encode the text and prepare the images. The following example shows how to get t
>>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
```
-Tips:
+
-This model is build on `CLIPModel`, so use it like a original CLIP.
+This model is based on `CLIPModel`, use it like you would use the original [CLIP](clip).
-This model was contributed by [jongjyh](https://huggingface.co/jongjyh).
+
## AltCLIPConfig
diff --git a/docs/source/en/model_doc/audio-spectrogram-transformer.md b/docs/source/en/model_doc/audio-spectrogram-transformer.md
index df9fe78c2d4c..3eac3781667e 100644
--- a/docs/source/en/model_doc/audio-spectrogram-transformer.md
+++ b/docs/source/en/model_doc/audio-spectrogram-transformer.md
@@ -26,7 +26,15 @@ The abstract from the paper is the following:
*In the past decade, convolutional neural networks (CNNs) have been widely adopted as the main building block for end-to-end audio classification models, which aim to learn a direct mapping from audio spectrograms to corresponding labels. To better capture long-range global context, a recent trend is to add a self-attention mechanism on top of the CNN, forming a CNN-attention hybrid model. However, it is unclear whether the reliance on a CNN is necessary, and if neural networks purely based on attention are sufficient to obtain good performance in audio classification. In this paper, we answer the question by introducing the Audio Spectrogram Transformer (AST), the first convolution-free, purely attention-based model for audio classification. We evaluate AST on various audio classification benchmarks, where it achieves new state-of-the-art results of 0.485 mAP on AudioSet, 95.6% accuracy on ESC-50, and 98.1% accuracy on Speech Commands V2.*
-Tips:
+
+
+ Audio Spectrogram Transformer architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/YuanGongND/ast).
+
+## Usage tips
- When fine-tuning the Audio Spectrogram Transformer (AST) on your own dataset, it's recommended to take care of the input normalization (to make
sure the input has mean of 0 and std of 0.5). [`ASTFeatureExtractor`] takes care of this. Note that it uses the AudioSet
@@ -35,14 +43,6 @@ the authors compute the stats for a downstream dataset.
- Note that the AST needs a low learning rate (the authors use a 10 times smaller learning rate compared to their CNN model proposed in the
[PSLA paper](https://arxiv.org/abs/2102.01243)) and converges quickly, so please search for a suitable learning rate and learning rate scheduler for your task.
-
-
- Audio pectrogram Transformer architecture. Taken from the original paper.
-
-This model was contributed by [nielsr](https://huggingface.co/nielsr).
-The original code can be found [here](https://github.com/YuanGongND/ast).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with the Audio Spectrogram Transformer.
@@ -72,4 +72,4 @@ If you're interested in submitting a resource to be included here, please feel f
## ASTForAudioClassification
[[autodoc]] ASTForAudioClassification
- - forward
\ No newline at end of file
+ - forward
diff --git a/docs/source/en/model_doc/autoformer.md b/docs/source/en/model_doc/autoformer.md
index 20977c71cae9..bb423e941c78 100644
--- a/docs/source/en/model_doc/autoformer.md
+++ b/docs/source/en/model_doc/autoformer.md
@@ -39,13 +39,11 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] AutoformerConfig
-
## AutoformerModel
[[autodoc]] AutoformerModel
- forward
-
## AutoformerForPrediction
[[autodoc]] AutoformerForPrediction
diff --git a/docs/source/en/model_doc/bark.md b/docs/source/en/model_doc/bark.md
index e287df13fe04..2160159bd783 100644
--- a/docs/source/en/model_doc/bark.md
+++ b/docs/source/en/model_doc/bark.md
@@ -14,8 +14,7 @@ specific language governing permissions and limitations under the License.
## Overview
-Bark is a transformer-based text-to-speech model proposed by Suno AI in [suno-ai/bark](https://github.com/suno-ai/bark).
-
+Bark is a transformer-based text-to-speech model proposed by Suno AI in [suno-ai/bark](https://github.com/suno-ai/bark).
Bark is made of 4 main models:
@@ -26,6 +25,9 @@ Bark is made of 4 main models:
It should be noted that each of the first three modules can support conditional speaker embeddings to condition the output sound according to specific predefined voice.
+This model was contributed by [Yoach Lacombe (ylacombe)](https://huggingface.co/ylacombe) and [Sanchit Gandhi (sanchit-gandhi)](https://github.com/sanchit-gandhi).
+The original code can be found [here](https://github.com/suno-ai/bark).
+
### Optimizing Bark
Bark can be optimized with just a few extra lines of code, which **significantly reduces its memory footprint** and **accelerates inference**.
@@ -42,7 +44,19 @@ device = "cuda" if torch.cuda.is_available() else "cpu"
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
```
-#### Using 🤗 Better Transformer
+#### Using CPU offload
+
+As mentioned above, Bark is made up of 4 sub-models, which are called up sequentially during audio generation. In other words, while one sub-model is in use, the other sub-models are idle.
+
+If you're using a CUDA device, a simple solution to benefit from an 80% reduction in memory footprint is to offload the submodels from GPU to CPU when they're idle. This operation is called *CPU offloading*. You can use it with one line of code as follows:
+
+```python
+model.enable_cpu_offload()
+```
+
+Note that 🤗 Accelerate must be installed before using this feature. [Here's how to install it.](https://huggingface.co/docs/accelerate/basic_tutorials/install)
+
+#### Using Better Transformer
Better Transformer is an 🤗 Optimum feature that performs kernel fusion under the hood. You can gain 20% to 30% in speed with zero performance degradation. It only requires one line of code to export the model to 🤗 Better Transformer:
@@ -52,21 +66,46 @@ model = model.to_bettertransformer()
Note that 🤗 Optimum must be installed before using this feature. [Here's how to install it.](https://huggingface.co/docs/optimum/installation)
-#### Using CPU offload
+#### Using Flash Attention 2
-As mentioned above, Bark is made up of 4 sub-models, which are called up sequentially during audio generation. In other words, while one sub-model is in use, the other sub-models are idle.
+Flash Attention 2 is an even faster, optimized version of the previous optimization.
+
+##### Installation
-If you're using a CUDA device, a simple solution to benefit from an 80% reduction in memory footprint is to offload the GPU's submodels when they're idle. This operation is called CPU offloading. You can use it with one line of code.
+First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the [official documentation](https://github.com/Dao-AILab/flash-attention#installation-and-features). If your hardware is not compatible with Flash Attention 2, you can still benefit from attention kernel optimisations through Better Transformer support covered [above](https://huggingface.co/docs/transformers/main/en/model_doc/bark#using-better-transformer).
+
+Next, [install](https://github.com/Dao-AILab/flash-attention#installation-and-features) the latest version of Flash Attention 2:
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+
+##### Usage
+
+To load a model using Flash Attention 2, we can pass the `use_flash_attention_2` flag to [`.from_pretrained`](https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.PreTrainedModel.from_pretrained). We'll also load the model in half-precision (e.g. `torch.float16`), since it results in almost no degradation to audio quality but significantly lower memory usage and faster inference:
```python
-model.enable_cpu_offload()
+model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16, use_flash_attention_2=True).to(device)
```
-Note that 🤗 Accelerate must be installed before using this feature. [Here's how to install it.](https://huggingface.co/docs/accelerate/basic_tutorials/install)
+##### Performance comparison
+
+
+The following diagram shows the latency for the native attention implementation (no optimisation) against Better Transformer and Flash Attention 2. In all cases, we generate 400 semantic tokens on a 40GB A100 GPU with PyTorch 2.1. Flash Attention 2 is also consistently faster than Better Transformer, and its performance improves even more as batch sizes increase:
+
+
+
+
+
+To put this into perspective, on an NVIDIA A100 and when generating 400 semantic tokens with a batch size of 16, you can get 17 times the [throughput](https://huggingface.co/blog/optimizing-bark#throughput) and still be 2 seconds faster than generating sentences one by one with the native model implementation. In other words, all the samples will be generated 17 times faster.
+
+At batch size 8, on an NVIDIA A100, Flash Attention 2 is also 10% faster than Better Transformer, and at batch size 16, 25%.
+
#### Combining optimization techniques
-You can combine optimization techniques, and use CPU offload, half-precision and 🤗 Better Transformer all at once.
+You can combine optimization techniques, and use CPU offload, half-precision and Flash Attention 2 (or 🤗 Better Transformer) all at once.
```python
from transformers import BarkModel
@@ -74,11 +113,8 @@ import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
-# load in fp16
-model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
-
-# convert to bettertransformer
-model = BetterTransformer.transform(model, keep_original_model=False)
+# load in fp16 and use Flash Attention 2
+model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16, use_flash_attention_2=True).to(device)
# enable CPU offload
model.enable_cpu_offload()
@@ -86,7 +122,7 @@ model.enable_cpu_offload()
Find out more on inference optimization techniques [here](https://huggingface.co/docs/transformers/perf_infer_gpu_one).
-### Tips
+### Usage tips
Suno offers a library of voice presets in a number of languages [here](https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c).
These presets are also uploaded in the hub [here](https://huggingface.co/suno/bark-small/tree/main/speaker_embeddings) or [here](https://huggingface.co/suno/bark/tree/main/speaker_embeddings).
@@ -142,11 +178,6 @@ To save the audio, simply take the sample rate from the model config and some sc
>>> write_wav("bark_generation.wav", sample_rate, audio_array)
```
-
-This model was contributed by [Yoach Lacombe (ylacombe)](https://huggingface.co/ylacombe) and [Sanchit Gandhi (sanchit-gandhi)](https://github.com/sanchit-gandhi).
-The original code can be found [here](https://github.com/suno-ai/bark).
-
-
## BarkConfig
[[autodoc]] BarkConfig
diff --git a/docs/source/en/model_doc/bart.md b/docs/source/en/model_doc/bart.md
index dcf149fd85e1..7986228915cf 100644
--- a/docs/source/en/model_doc/bart.md
+++ b/docs/source/en/model_doc/bart.md
@@ -25,9 +25,6 @@ rendered properly in your Markdown viewer.
-**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
-@patrickvonplaten
-
## Overview
The Bart model was proposed in [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation,
@@ -45,7 +42,9 @@ According to the abstract,
state-of-the-art results on a range of abstractive dialogue, question answering, and summarization tasks, with gains
of up to 6 ROUGE.
-Tips:
+This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The authors' code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/bart).
+
+## Usage tips:
- BART is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
@@ -57,18 +56,6 @@ Tips:
* permute sentences
* rotate the document to make it start at a specific token
-This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The Authors' code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/bart).
-
-
-### Examples
-
-- Examples and scripts for fine-tuning BART and other models for sequence to sequence tasks can be found in
- [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
-- An example of how to train [`BartForConditionalGeneration`] with a Hugging Face `datasets`
- object can be found in this [forum discussion](https://discuss.huggingface.co/t/train-bart-for-conditional-generation-e-g-summarization/1904).
-- [Distilled checkpoints](https://huggingface.co/models?search=distilbart) are described in this [paper](https://arxiv.org/abs/2010.13002).
-
-
## Implementation Notes
- Bart doesn't use `token_type_ids` for sequence classification. Use [`BartTokenizer`] or
@@ -112,6 +99,7 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
- [`BartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb).
- [`TFBartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb).
- [`FlaxBartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/summarization).
+- An example of how to train [`BartForConditionalGeneration`] with a Hugging Face `datasets` object can be found in this [forum discussion](https://discuss.huggingface.co/t/train-bart-for-conditional-generation-e-g-summarization/1904)
- [Summarization](https://huggingface.co/course/chapter7/5?fw=pt#summarization) chapter of the 🤗 Hugging Face course.
- [Summarization task guide](../tasks/summarization)
@@ -134,6 +122,7 @@ See also:
- [Text classification task guide](../tasks/sequence_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
+- [Distilled checkpoints](https://huggingface.co/models?search=distilbart) are described in this [paper](https://arxiv.org/abs/2010.13002).
## BartConfig
@@ -150,6 +139,10 @@ See also:
[[autodoc]] BartTokenizerFast
- all
+
+
+
+
## BartModel
[[autodoc]] BartModel
@@ -175,6 +168,9 @@ See also:
[[autodoc]] BartForCausalLM
- forward
+
+
+
## TFBartModel
[[autodoc]] TFBartModel
@@ -190,6 +186,9 @@ See also:
[[autodoc]] TFBartForSequenceClassification
- call
+
+
+
## FlaxBartModel
[[autodoc]] FlaxBartModel
@@ -222,3 +221,8 @@ See also:
[[autodoc]] FlaxBartForCausalLM
- __call__
+
+
+
+
+
diff --git a/docs/source/en/model_doc/barthez.md b/docs/source/en/model_doc/barthez.md
index fdeb8e2fed23..1b571e242f47 100644
--- a/docs/source/en/model_doc/barthez.md
+++ b/docs/source/en/model_doc/barthez.md
@@ -38,8 +38,14 @@ provides a significant boost over vanilla BARThez, and is on par with or outperf
This model was contributed by [moussakam](https://huggingface.co/moussakam). The Authors' code can be found [here](https://github.com/moussaKam/BARThez).
+
-### Examples
+BARThez implementation is the same as BART, except for tokenization. Refer to [BART documentation](bart) for information on
+configuration classes and their parameters. BARThez-specific tokenizers are documented below.
+
+
+
+## Resources
- BARThez can be fine-tuned on sequence-to-sequence tasks in a similar way as BART, check:
[examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
diff --git a/docs/source/en/model_doc/bartpho.md b/docs/source/en/model_doc/bartpho.md
index 3529c11a7ed2..8f0a5f8bfe24 100644
--- a/docs/source/en/model_doc/bartpho.md
+++ b/docs/source/en/model_doc/bartpho.md
@@ -29,7 +29,9 @@ on a downstream task of Vietnamese text summarization show that in both automati
outperforms the strong baseline mBART and improves the state-of-the-art. We release BARTpho to facilitate future
research and applications of generative Vietnamese NLP tasks.*
-Example of use:
+This model was contributed by [dqnguyen](https://huggingface.co/dqnguyen). The original code can be found [here](https://github.com/VinAIResearch/BARTpho).
+
+## Usage example
```python
>>> import torch
@@ -54,7 +56,7 @@ Example of use:
>>> features = bartpho(**input_ids)
```
-Tips:
+## Usage tips
- Following mBART, BARTpho uses the "large" architecture of BART with an additional layer-normalization layer on top of
both the encoder and decoder. Thus, usage examples in the [documentation of BART](bart), when adapting to use
@@ -79,8 +81,6 @@ Tips:
Other languages, if employing this pre-trained multilingual SentencePiece model "vocab_file" for subword
segmentation, can reuse BartphoTokenizer with their own language-specialized "monolingual_vocab_file".
-This model was contributed by [dqnguyen](https://huggingface.co/dqnguyen). The original code can be found [here](https://github.com/VinAIResearch/BARTpho).
-
## BartphoTokenizer
[[autodoc]] BartphoTokenizer
diff --git a/docs/source/en/model_doc/beit.md b/docs/source/en/model_doc/beit.md
index 69586724713d..f7605ebcdf90 100644
--- a/docs/source/en/model_doc/beit.md
+++ b/docs/source/en/model_doc/beit.md
@@ -39,7 +39,10 @@ with previous pre-training methods. For example, base-size BEiT achieves 83.2% t
significantly outperforming from-scratch DeiT training (81.8%) with the same setup. Moreover, large-size BEiT obtains
86.3% only using ImageNet-1K, even outperforming ViT-L with supervised pre-training on ImageNet-22K (85.2%).*
-Tips:
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The JAX/FLAX version of this model was
+contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/beit).
+
+## Usage tips
- BEiT models are regular Vision Transformers, but pre-trained in a self-supervised way rather than supervised. They
outperform both the [original model (ViT)](vit) as well as [Data-efficient Image Transformers (DeiT)](deit) when fine-tuned on ImageNet-1K and CIFAR-100. You can check out demo notebooks regarding inference as well as
@@ -68,9 +71,6 @@ alt="drawing" width="600"/>
BEiT pre-training. Taken from the original paper.
-This model was contributed by [nielsr](https://huggingface.co/nielsr). The JAX/FLAX version of this model was
-contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/beit).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BEiT.
@@ -107,6 +107,9 @@ If you're interested in submitting a resource to be included here, please feel f
- preprocess
- post_process_semantic_segmentation
+
+
+
## BeitModel
[[autodoc]] BeitModel
@@ -127,6 +130,9 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] BeitForSemanticSegmentation
- forward
+
+
+
## FlaxBeitModel
[[autodoc]] FlaxBeitModel
@@ -141,3 +147,6 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] FlaxBeitForImageClassification
- __call__
+
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/bert-generation.md b/docs/source/en/model_doc/bert-generation.md
index 9cc7bac6c7e4..7edbf38694ed 100644
--- a/docs/source/en/model_doc/bert-generation.md
+++ b/docs/source/en/model_doc/bert-generation.md
@@ -33,10 +33,13 @@ GPT-2 and RoBERTa checkpoints and conducted an extensive empirical study on the
encoder and decoder, with these checkpoints. Our models result in new state-of-the-art results on Machine Translation,
Text Summarization, Sentence Splitting, and Sentence Fusion.*
-Usage:
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
+found [here](https://tfhub.dev/s?module-type=text-generation&subtype=module,placeholder).
-- The model can be used in combination with the [`EncoderDecoderModel`] to leverage two pretrained
- BERT checkpoints for subsequent fine-tuning.
+## Usage examples and tips
+
+The model can be used in combination with the [`EncoderDecoderModel`] to leverage two pretrained BERT checkpoints for
+subsequent fine-tuning:
```python
>>> # leverage checkpoints for Bert2Bert model...
@@ -61,8 +64,7 @@ Usage:
>>> loss.backward()
```
-- Pretrained [`EncoderDecoderModel`] are also directly available in the model hub, e.g.,
-
+Pretrained [`EncoderDecoderModel`] are also directly available in the model hub, e.g.:
```python
>>> # instantiate sentence fusion model
@@ -85,9 +87,6 @@ Tips:
- For summarization, sentence splitting, sentence fusion and translation, no special tokens are required for the input.
Therefore, no EOS token should be added to the end of the input.
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
-found [here](https://tfhub.dev/s?module-type=text-generation&subtype=module,placeholder).
-
## BertGenerationConfig
[[autodoc]] BertGenerationConfig
diff --git a/docs/source/en/model_doc/bert-japanese.md b/docs/source/en/model_doc/bert-japanese.md
index 208b775307a6..d68bb221d577 100644
--- a/docs/source/en/model_doc/bert-japanese.md
+++ b/docs/source/en/model_doc/bert-japanese.md
@@ -67,11 +67,15 @@ Example of using a model with Character tokenization:
>>> outputs = bertjapanese(**inputs)
```
-Tips:
+This model was contributed by [cl-tohoku](https://huggingface.co/cl-tohoku).
-- This implementation is the same as BERT, except for tokenization method. Refer to the [documentation of BERT](bert) for more usage examples.
+
+
+This implementation is the same as BERT, except for tokenization method. Refer to [BERT documentation](bert) for
+API reference information.
+
+
-This model was contributed by [cl-tohoku](https://huggingface.co/cl-tohoku).
## BertJapaneseTokenizer
diff --git a/docs/source/en/model_doc/bert.md b/docs/source/en/model_doc/bert.md
index 19d15cfc05a4..bdf4566b43ad 100644
--- a/docs/source/en/model_doc/bert.md
+++ b/docs/source/en/model_doc/bert.md
@@ -45,7 +45,9 @@ language processing tasks, including pushing the GLUE score to 80.5% (7.7% point
accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute
improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement).*
-Tips:
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/google-research/bert).
+
+## Usage tips
- BERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
@@ -59,10 +61,6 @@ Tips:
- The model must predict the original sentence, but has a second objective: inputs are two sentences A and B (with a separation token in between). With probability 50%, the sentences are consecutive in the corpus, in the remaining 50% they are not related. The model has to predict if the sentences are consecutive or not.
-
-
-This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/google-research/bert).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BERT. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
@@ -137,14 +135,23 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
- create_token_type_ids_from_sequences
- save_vocabulary
+
+
+
## BertTokenizerFast
[[autodoc]] BertTokenizerFast
+
+
+
## TFBertTokenizer
[[autodoc]] TFBertTokenizer
+
+
+
## Bert specific outputs
[[autodoc]] models.bert.modeling_bert.BertForPreTrainingOutput
@@ -153,6 +160,10 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] models.bert.modeling_flax_bert.FlaxBertForPreTrainingOutput
+
+
+
+
## BertModel
[[autodoc]] BertModel
@@ -198,6 +209,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] BertForQuestionAnswering
- forward
+
+
+
## TFBertModel
[[autodoc]] TFBertModel
@@ -243,6 +257,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] TFBertForQuestionAnswering
- call
+
+
+
## FlaxBertModel
[[autodoc]] FlaxBertModel
@@ -287,3 +304,8 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] FlaxBertForQuestionAnswering
- __call__
+
+
+
+
+
diff --git a/docs/source/en/model_doc/bertweet.md b/docs/source/en/model_doc/bertweet.md
index 50629445aee8..c4c883b21ad7 100644
--- a/docs/source/en/model_doc/bertweet.md
+++ b/docs/source/en/model_doc/bertweet.md
@@ -28,7 +28,9 @@ al., 2019). Experiments show that BERTweet outperforms strong baselines RoBERTa-
2020), producing better performance results than the previous state-of-the-art models on three Tweet NLP tasks:
Part-of-speech tagging, Named-entity recognition and text classification.*
-Example of use:
+This model was contributed by [dqnguyen](https://huggingface.co/dqnguyen). The original code can be found [here](https://github.com/VinAIResearch/BERTweet).
+
+## Usage example
```python
>>> import torch
@@ -55,7 +57,12 @@ Example of use:
>>> # bertweet = TFAutoModel.from_pretrained("vinai/bertweet-base")
```
-This model was contributed by [dqnguyen](https://huggingface.co/dqnguyen). The original code can be found [here](https://github.com/VinAIResearch/BERTweet).
+
+
+This implementation is the same as BERT, except for tokenization method. Refer to [BERT documentation](bert) for
+API reference information.
+
+
## BertweetTokenizer
diff --git a/docs/source/en/model_doc/big_bird.md b/docs/source/en/model_doc/big_bird.md
index b8bbb388d6e9..3d1ef91d5606 100644
--- a/docs/source/en/model_doc/big_bird.md
+++ b/docs/source/en/model_doc/big_bird.md
@@ -41,7 +41,10 @@ sequence as part of the sparse attention mechanism. The proposed sparse attentio
BigBird drastically improves performance on various NLP tasks such as question answering and summarization. We also
propose novel applications to genomics data.*
-Tips:
+This model was contributed by [vasudevgupta](https://huggingface.co/vasudevgupta). The original code can be found
+[here](https://github.com/google-research/bigbird).
+
+## Usage tips
- For an in-detail explanation on how BigBird's attention works, see [this blog post](https://huggingface.co/blog/big-bird).
- BigBird comes with 2 implementations: **original_full** & **block_sparse**. For the sequence length < 1024, using
@@ -53,10 +56,8 @@ Tips:
- BigBird is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
-This model was contributed by [vasudevgupta](https://huggingface.co/vasudevgupta). The original code can be found
-[here](https://github.com/google-research/bigbird).
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -85,6 +86,9 @@ This model was contributed by [vasudevgupta](https://huggingface.co/vasudevgupta
[[autodoc]] models.big_bird.modeling_big_bird.BigBirdForPreTrainingOutput
+
+
+
## BigBirdModel
[[autodoc]] BigBirdModel
@@ -125,6 +129,9 @@ This model was contributed by [vasudevgupta](https://huggingface.co/vasudevgupta
[[autodoc]] BigBirdForQuestionAnswering
- forward
+
+
+
## FlaxBigBirdModel
[[autodoc]] FlaxBigBirdModel
@@ -164,3 +171,8 @@ This model was contributed by [vasudevgupta](https://huggingface.co/vasudevgupta
[[autodoc]] FlaxBigBirdForQuestionAnswering
- __call__
+
+
+
+
+
diff --git a/docs/source/en/model_doc/bigbird_pegasus.md b/docs/source/en/model_doc/bigbird_pegasus.md
index d767f548a768..003e5643719b 100644
--- a/docs/source/en/model_doc/bigbird_pegasus.md
+++ b/docs/source/en/model_doc/bigbird_pegasus.md
@@ -41,7 +41,9 @@ sequence as part of the sparse attention mechanism. The proposed sparse attentio
BigBird drastically improves performance on various NLP tasks such as question answering and summarization. We also
propose novel applications to genomics data.*
-Tips:
+The original code can be found [here](https://github.com/google-research/bigbird).
+
+## Usage tips
- For an in-detail explanation on how BigBird's attention works, see [this blog post](https://huggingface.co/blog/big-bird).
- BigBird comes with 2 implementations: **original_full** & **block_sparse**. For the sequence length < 1024, using
@@ -54,9 +56,7 @@ Tips:
- BigBird is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
-The original code can be found [here](https://github.com/google-research/bigbird).
-
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Question answering task guide](../tasks/question_answering)
diff --git a/docs/source/en/model_doc/biogpt.md b/docs/source/en/model_doc/biogpt.md
index 29327df21a02..1cac6d10990d 100644
--- a/docs/source/en/model_doc/biogpt.md
+++ b/docs/source/en/model_doc/biogpt.md
@@ -25,15 +25,15 @@ The abstract from the paper is the following:
*Pre-trained language models have attracted increasing attention in the biomedical domain, inspired by their great success in the general natural language domain. Among the two main branches of pre-trained language models in the general language domain, i.e. BERT (and its variants) and GPT (and its variants), the first one has been extensively studied in the biomedical domain, such as BioBERT and PubMedBERT. While they have achieved great success on a variety of discriminative downstream biomedical tasks, the lack of generation ability constrains their application scope. In this paper, we propose BioGPT, a domain-specific generative Transformer language model pre-trained on large-scale biomedical literature. We evaluate BioGPT on six biomedical natural language processing tasks and demonstrate that our model outperforms previous models on most tasks. Especially, we get 44.98%, 38.42% and 40.76% F1 score on BC5CDR, KD-DTI and DDI end-to-end relation extraction tasks, respectively, and 78.2% accuracy on PubMedQA, creating a new record. Our case study on text generation further demonstrates the advantage of BioGPT on biomedical literature to generate fluent descriptions for biomedical terms.*
-Tips:
+This model was contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/microsoft/BioGPT).
+
+## Usage tips
-- BioGPT is a model with absolute position embeddings so it’s usually advised to pad the inputs on the right rather than the left.
+- BioGPT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than the left.
- BioGPT was trained with a causal language modeling (CLM) objective and is therefore powerful at predicting the next token in a sequence. Leveraging this feature allows BioGPT to generate syntactically coherent text as it can be observed in the run_generation.py example script.
- The model can take the `past_key_values` (for PyTorch) as input, which is the previously computed key/value attention pairs. Using this (past_key_values or past) value prevents the model from re-computing pre-computed values in the context of text generation. For PyTorch, see past_key_values argument of the BioGptForCausalLM.forward() method for more information on its usage.
-This model was contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/microsoft/BioGPT).
-
-## Documentation resources
+## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
diff --git a/docs/source/en/model_doc/bit.md b/docs/source/en/model_doc/bit.md
index 80b9fdd2caff..7f8a8ea67c45 100644
--- a/docs/source/en/model_doc/bit.md
+++ b/docs/source/en/model_doc/bit.md
@@ -25,15 +25,15 @@ The abstract from the paper is the following:
*Transfer of pre-trained representations improves sample efficiency and simplifies hyperparameter tuning when training deep neural networks for vision. We revisit the paradigm of pre-training on large supervised datasets and fine-tuning the model on a target task. We scale up pre-training, and propose a simple recipe that we call Big Transfer (BiT). By combining a few carefully selected components, and transferring using a simple heuristic, we achieve strong performance on over 20 datasets. BiT performs well across a surprisingly wide range of data regimes -- from 1 example per class to 1M total examples. BiT achieves 87.5% top-1 accuracy on ILSVRC-2012, 99.4% on CIFAR-10, and 76.3% on the 19 task Visual Task Adaptation Benchmark (VTAB). On small datasets, BiT attains 76.8% on ILSVRC-2012 with 10 examples per class, and 97.0% on CIFAR-10 with 10 examples per class. We conduct detailed analysis of the main components that lead to high transfer performance.*
-Tips:
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/google-research/big_transfer).
+
+## Usage tips
- BiT models are equivalent to ResNetv2 in terms of architecture, except that: 1) all batch normalization layers are replaced by [group normalization](https://arxiv.org/abs/1803.08494),
2) [weight standardization](https://arxiv.org/abs/1903.10520) is used for convolutional layers. The authors show that the combination of both is useful for training with large batch sizes, and has a significant
impact on transfer learning.
-This model was contributed by [nielsr](https://huggingface.co/nielsr).
-The original code can be found [here](https://github.com/google-research/big_transfer).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BiT.
@@ -62,5 +62,4 @@ If you're interested in submitting a resource to be included here, please feel f
## BitForImageClassification
[[autodoc]] BitForImageClassification
- - forward
-
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/blenderbot-small.md b/docs/source/en/model_doc/blenderbot-small.md
index c126bc9b1451..d5f4a7d849b7 100644
--- a/docs/source/en/model_doc/blenderbot-small.md
+++ b/docs/source/en/model_doc/blenderbot-small.md
@@ -40,15 +40,16 @@ and code publicly available. Human evaluations show our best models are superior
dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing
failure cases of our models.*
-Tips:
-
-- Blenderbot Small is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
- the left.
-
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The authors' code can be
found [here](https://github.com/facebookresearch/ParlAI).
-## Documentation resources
+## Usage tips
+
+Blenderbot Small is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
+the left.
+
+
+## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
@@ -70,6 +71,9 @@ found [here](https://github.com/facebookresearch/ParlAI).
[[autodoc]] BlenderbotSmallTokenizerFast
+
+
+
## BlenderbotSmallModel
[[autodoc]] BlenderbotSmallModel
@@ -85,6 +89,9 @@ found [here](https://github.com/facebookresearch/ParlAI).
[[autodoc]] BlenderbotSmallForCausalLM
- forward
+
+
+
## TFBlenderbotSmallModel
[[autodoc]] TFBlenderbotSmallModel
@@ -95,6 +102,9 @@ found [here](https://github.com/facebookresearch/ParlAI).
[[autodoc]] TFBlenderbotSmallForConditionalGeneration
- call
+
+
+
## FlaxBlenderbotSmallModel
[[autodoc]] FlaxBlenderbotSmallModel
@@ -108,3 +118,6 @@ found [here](https://github.com/facebookresearch/ParlAI).
- __call__
- encode
- decode
+
+
+
diff --git a/docs/source/en/model_doc/blenderbot.md b/docs/source/en/model_doc/blenderbot.md
index 5a10af77b698..42e1710cb2d5 100644
--- a/docs/source/en/model_doc/blenderbot.md
+++ b/docs/source/en/model_doc/blenderbot.md
@@ -16,8 +16,6 @@ rendered properly in your Markdown viewer.
# Blenderbot
-**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) .
-
## Overview
The Blender chatbot model was proposed in [Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu,
@@ -36,26 +34,14 @@ and code publicly available. Human evaluations show our best models are superior
dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing
failure cases of our models.*
-Tips:
-
-- Blenderbot is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
- the left.
-
This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The authors' code can be found [here](https://github.com/facebookresearch/ParlAI) .
+## Usage tips and example
-## Implementation Notes
-
-- Blenderbot uses a standard [seq2seq model transformer](https://arxiv.org/pdf/1706.03762.pdf) based architecture.
-- Available checkpoints can be found in the [model hub](https://huggingface.co/models?search=blenderbot).
-- This is the *default* Blenderbot model class. However, some smaller checkpoints, such as
- `facebook/blenderbot_small_90M`, have a different architecture and consequently should be used with
- [BlenderbotSmall](blenderbot-small).
-
-
-## Usage
+Blenderbot is a model with absolute position embeddings so it's usually advised to pad the inputs on the right
+rather than the left.
-Here is an example of model usage:
+An example:
```python
>>> from transformers import BlenderbotTokenizer, BlenderbotForConditionalGeneration
@@ -70,7 +56,16 @@ Here is an example of model usage:
[" That's unfortunate. Are they trying to lose weight or are they just trying to be healthier?"]
```
-## Documentation resources
+## Implementation Notes
+
+- Blenderbot uses a standard [seq2seq model transformer](https://arxiv.org/pdf/1706.03762.pdf) based architecture.
+- Available checkpoints can be found in the [model hub](https://huggingface.co/models?search=blenderbot).
+- This is the *default* Blenderbot model class. However, some smaller checkpoints, such as
+ `facebook/blenderbot_small_90M`, have a different architecture and consequently should be used with
+ [BlenderbotSmall](blenderbot-small).
+
+
+## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
@@ -90,9 +85,13 @@ Here is an example of model usage:
[[autodoc]] BlenderbotTokenizerFast
- build_inputs_with_special_tokens
+
+
+
+
## BlenderbotModel
-See `transformers.BartModel` for arguments to *forward* and *generate*
+See [`~transformers.BartModel`] for arguments to *forward* and *generate*
[[autodoc]] BlenderbotModel
- forward
@@ -109,6 +108,9 @@ See [`~transformers.BartForConditionalGeneration`] for arguments to *forward* an
[[autodoc]] BlenderbotForCausalLM
- forward
+
+
+
## TFBlenderbotModel
[[autodoc]] TFBlenderbotModel
@@ -119,6 +121,9 @@ See [`~transformers.BartForConditionalGeneration`] for arguments to *forward* an
[[autodoc]] TFBlenderbotForConditionalGeneration
- call
+
+
+
## FlaxBlenderbotModel
[[autodoc]] FlaxBlenderbotModel
@@ -132,3 +137,8 @@ See [`~transformers.BartForConditionalGeneration`] for arguments to *forward* an
- __call__
- encode
- decode
+
+
+
+
+
diff --git a/docs/source/en/model_doc/blip-2.md b/docs/source/en/model_doc/blip-2.md
index 0890e612561a..d2a47e7af8f1 100644
--- a/docs/source/en/model_doc/blip-2.md
+++ b/docs/source/en/model_doc/blip-2.md
@@ -27,11 +27,6 @@ The abstract from the paper is the following:
*The cost of vision-and-language pre-training has become increasingly prohibitive due to end-to-end training of large-scale models. This paper proposes BLIP-2, a generic and efficient pre-training strategy that bootstraps vision-language pre-training from off-the-shelf frozen pre-trained image encoders and frozen large language models. BLIP-2 bridges the modality gap with a lightweight Querying Transformer, which is pre-trained in two stages. The first stage bootstraps vision-language representation learning from a frozen image encoder. The second stage bootstraps vision-to-language generative learning from a frozen language model. BLIP-2 achieves state-of-the-art performance on various vision-language tasks, despite having significantly fewer trainable parameters than existing methods. For example, our model outperforms Flamingo80B by 8.7% on zero-shot VQAv2 with 54x fewer trainable parameters. We also demonstrate the model's emerging capabilities of zero-shot image-to-text generation that can follow natural language instructions.*
-Tips:
-
-- BLIP-2 can be used for conditional text generation given an image and an optional text prompt. At inference time, it's recommended to use the [`generate`] method.
-- One can use [`Blip2Processor`] to prepare images for the model, and decode the predicted tokens ID's back to text.
-
@@ -40,6 +35,11 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207).
+## Usage tips
+
+- BLIP-2 can be used for conditional text generation given an image and an optional text prompt. At inference time, it's recommended to use the [`generate`] method.
+- One can use [`Blip2Processor`] to prepare images for the model, and decode the predicted tokens ID's back to text.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BLIP-2.
diff --git a/docs/source/en/model_doc/blip.md b/docs/source/en/model_doc/blip.md
index 8afed63311f8..bc122c942a67 100644
--- a/docs/source/en/model_doc/blip.md
+++ b/docs/source/en/model_doc/blip.md
@@ -20,7 +20,7 @@ rendered properly in your Markdown viewer.
The BLIP model was proposed in [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
-BLIP is a model that is able to perform various multi-modal tasks including
+BLIP is a model that is able to perform various multi-modal tasks including:
- Visual Question Answering
- Image-Text retrieval (Image-text matching)
- Image Captioning
@@ -39,7 +39,6 @@ The original code can be found [here](https://github.com/salesforce/BLIP).
- [Jupyter notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) on how to fine-tune BLIP for image captioning on a custom dataset
-
## BlipConfig
[[autodoc]] BlipConfig
@@ -57,12 +56,14 @@ The original code can be found [here](https://github.com/salesforce/BLIP).
[[autodoc]] BlipProcessor
-
## BlipImageProcessor
[[autodoc]] BlipImageProcessor
- preprocess
+
+
+
## BlipModel
[[autodoc]] BlipModel
@@ -75,30 +76,29 @@ The original code can be found [here](https://github.com/salesforce/BLIP).
[[autodoc]] BlipTextModel
- forward
-
## BlipVisionModel
[[autodoc]] BlipVisionModel
- forward
-
## BlipForConditionalGeneration
[[autodoc]] BlipForConditionalGeneration
- forward
-
## BlipForImageTextRetrieval
[[autodoc]] BlipForImageTextRetrieval
- forward
-
## BlipForQuestionAnswering
[[autodoc]] BlipForQuestionAnswering
- forward
+
+
+
## TFBlipModel
[[autodoc]] TFBlipModel
@@ -111,26 +111,24 @@ The original code can be found [here](https://github.com/salesforce/BLIP).
[[autodoc]] TFBlipTextModel
- call
-
## TFBlipVisionModel
[[autodoc]] TFBlipVisionModel
- call
-
## TFBlipForConditionalGeneration
[[autodoc]] TFBlipForConditionalGeneration
- call
-
## TFBlipForImageTextRetrieval
[[autodoc]] TFBlipForImageTextRetrieval
- call
-
## TFBlipForQuestionAnswering
[[autodoc]] TFBlipForQuestionAnswering
- - call
\ No newline at end of file
+ - call
+
+
diff --git a/docs/source/en/model_doc/bloom.md b/docs/source/en/model_doc/bloom.md
index 3c155fa58782..a1d39d13ad00 100644
--- a/docs/source/en/model_doc/bloom.md
+++ b/docs/source/en/model_doc/bloom.md
@@ -56,16 +56,20 @@ See also:
[[autodoc]] BloomConfig
- all
-## BloomModel
-
-[[autodoc]] BloomModel
- - forward
-
## BloomTokenizerFast
[[autodoc]] BloomTokenizerFast
- all
+
+
+
+
+## BloomModel
+
+[[autodoc]] BloomModel
+ - forward
+
## BloomForCausalLM
[[autodoc]] BloomForCausalLM
@@ -86,6 +90,9 @@ See also:
[[autodoc]] BloomForQuestionAnswering
- forward
+
+
+
## FlaxBloomModel
[[autodoc]] FlaxBloomModel
@@ -95,3 +102,8 @@ See also:
[[autodoc]] FlaxBloomForCausalLM
- __call__
+
+
+
+
+
diff --git a/docs/source/en/model_doc/bort.md b/docs/source/en/model_doc/bort.md
index dccf2b560b68..1542d464d9fd 100644
--- a/docs/source/en/model_doc/bort.md
+++ b/docs/source/en/model_doc/bort.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
-This model is in maintenance mode only, so we won't accept any new PRs changing its code.
+This model is in maintenance mode only, we do not accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
You can do so by running the following command: `pip install -U transformers==4.30.0`.
@@ -43,13 +43,15 @@ hardware. It is also 7.9x faster on a CPU, as well as being better performing th
architecture, and some of the non-compressed variants: it obtains performance improvements of between 0.3% and 31%,
absolute, with respect to BERT-large, on multiple public natural language understanding (NLU) benchmarks.*
-Tips:
+This model was contributed by [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/alexa/bort/).
+
+## Usage tips
-- BORT's model architecture is based on BERT, so one can refer to [BERT's documentation page](bert) for the
- model's API as well as usage examples.
-- BORT uses the RoBERTa tokenizer instead of the BERT tokenizer, so one can refer to [RoBERTa's documentation page](roberta) for the tokenizer's API as well as usage examples.
+- BORT's model architecture is based on BERT, refer to [BERT's documentation page](bert) for the
+ model's API reference as well as usage examples.
+- BORT uses the RoBERTa tokenizer instead of the BERT tokenizer, refer to [RoBERTa's documentation page](roberta) for the tokenizer's API reference as well as usage examples.
- BORT requires a specific fine-tuning algorithm, called [Agora](https://adewynter.github.io/notes/bort_algorithms_and_applications.html#fine-tuning-with-algebraic-topology) ,
that is sadly not open-sourced yet. It would be very useful for the community, if someone tries to implement the
algorithm to make BORT fine-tuning work.
-This model was contributed by [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/alexa/bort/).
+
diff --git a/docs/source/en/model_doc/bridgetower.md b/docs/source/en/model_doc/bridgetower.md
index ba98cea91d21..013fea06c277 100644
--- a/docs/source/en/model_doc/bridgetower.md
+++ b/docs/source/en/model_doc/bridgetower.md
@@ -37,7 +37,9 @@ alt="drawing" width="600"/>
BridgeTower architecture. Taken from the original paper.
-## Usage
+This model was contributed by [Anahita Bhiwandiwalla](https://huggingface.co/anahita-b), [Tiep Le](https://huggingface.co/Tile) and [Shaoyen Tseng](https://huggingface.co/shaoyent). The original code can be found [here](https://github.com/microsoft/BridgeTower).
+
+## Usage tips and examples
BridgeTower consists of a visual encoder, a textual encoder and cross-modal encoder with multiple lightweight bridge layers.
The goal of this approach was to build a bridge between each uni-modal encoder and the cross-modal encoder to enable comprehensive and detailed interaction at each layer of the cross-modal encoder.
@@ -116,9 +118,6 @@ The following example shows how to run masked language modeling using [`BridgeTo
.a cat looking out of the window.
```
-This model was contributed by [Anahita Bhiwandiwalla](https://huggingface.co/anahita-b), [Tiep Le](https://huggingface.co/Tile) and [Shaoyen Tseng](https://huggingface.co/shaoyent). The original code can be found [here](https://github.com/microsoft/BridgeTower).
-
-
Tips:
- This implementation of BridgeTower uses [`RobertaTokenizer`] to generate text embeddings and OpenAI's CLIP/ViT model to compute visual embeddings.
diff --git a/docs/source/en/model_doc/bros.md b/docs/source/en/model_doc/bros.md
index 1c8e3f50605c..419e725e75e8 100644
--- a/docs/source/en/model_doc/bros.md
+++ b/docs/source/en/model_doc/bros.md
@@ -31,12 +31,13 @@ AMLM is a 2D version of TMLM. It randomly masks text tokens and predicts with th
BROS achieves comparable or better result on Key Information Extraction (KIE) benchmarks such as FUNSD, SROIE, CORD and SciTSR, without relying on explicit visual features.
-
The abstract from the paper is the following:
*Key information extraction (KIE) from document images requires understanding the contextual and spatial semantics of texts in two-dimensional (2D) space. Many recent studies try to solve the task by developing pre-trained language models focusing on combining visual features from document images with texts and their layout. On the other hand, this paper tackles the problem by going back to the basic: effective combination of text and layout. Specifically, we propose a pre-trained language model, named BROS (BERT Relying On Spatiality), that encodes relative positions of texts in 2D space and learns from unlabeled documents with area-masking strategy. With this optimized training scheme for understanding texts in 2D space, BROS shows comparable or better performance compared to previous methods on four KIE benchmarks (FUNSD, SROIE*, CORD, and SciTSR) without relying on visual features. This paper also reveals two real-world challenges in KIE tasks-(1) minimizing the error from incorrect text ordering and (2) efficient learning from fewer downstream examples-and demonstrates the superiority of BROS over previous methods.*
-Tips:
+This model was contributed by [jinho8345](https://huggingface.co/jinho8345). The original code can be found [here](https://github.com/clovaai/bros).
+
+## Usage tips and examples
- [`~transformers.BrosModel.forward`] requires `input_ids` and `bbox` (bounding box). Each bounding box should be in (x0, y0, x1, y1) format (top-left corner, bottom-right corner). Obtaining of Bounding boxes depends on external OCR system. The `x` coordinate should be normalized by document image width, and the `y` coordinate should be normalized by document image height.
@@ -78,9 +79,9 @@ def make_box_first_token_mask(bboxes, words, tokenizer, max_seq_length=512):
```
-- Demo scripts can be found [here](https://github.com/clovaai/bros).
+## Resources
-This model was contributed by [jinho8345](https://huggingface.co/jinho8345). The original code can be found [here](https://github.com/clovaai/bros).
+- Demo scripts can be found [here](https://github.com/clovaai/bros).
## BrosConfig
@@ -102,13 +103,11 @@ This model was contributed by [jinho8345](https://huggingface.co/jinho8345). The
[[autodoc]] BrosForTokenClassification
- forward
-
## BrosSpadeEEForTokenClassification
[[autodoc]] BrosSpadeEEForTokenClassification
- forward
-
## BrosSpadeELForTokenClassification
[[autodoc]] BrosSpadeELForTokenClassification
diff --git a/docs/source/en/model_doc/byt5.md b/docs/source/en/model_doc/byt5.md
index 2df7c4ddaa24..dc2942e33bbe 100644
--- a/docs/source/en/model_doc/byt5.md
+++ b/docs/source/en/model_doc/byt5.md
@@ -40,14 +40,18 @@ experiments.*
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
found [here](https://github.com/google-research/byt5).
-ByT5's architecture is based on the T5v1.1 model, so one can refer to [T5v1.1's documentation page](t5v1.1). They
+
+
+ByT5's architecture is based on the T5v1.1 model, refer to [T5v1.1's documentation page](t5v1.1) for the API reference. They
only differ in how inputs should be prepared for the model, see the code examples below.
+
+
Since ByT5 was pre-trained unsupervisedly, there's no real advantage to using a task prefix during single-task
fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
-### Example
+## Usage example
ByT5 works on raw UTF-8 bytes, so it can be used without a tokenizer:
diff --git a/docs/source/en/model_doc/camembert.md b/docs/source/en/model_doc/camembert.md
index 3ec4cd5dd0b1..dc217fe619bf 100644
--- a/docs/source/en/model_doc/camembert.md
+++ b/docs/source/en/model_doc/camembert.md
@@ -34,14 +34,16 @@ dependency parsing, named-entity recognition, and natural language inference. Ca
for most of the tasks considered. We release the pretrained model for CamemBERT hoping to foster research and
downstream applications for French NLP.*
-Tips:
+This model was contributed by [camembert](https://huggingface.co/camembert). The original code can be found [here](https://camembert-model.fr/).
-- This implementation is the same as RoBERTa. Refer to the [documentation of RoBERTa](roberta) for usage examples
- as well as the information relative to the inputs and outputs.
+
-This model was contributed by [camembert](https://huggingface.co/camembert). The original code can be found [here](https://camembert-model.fr/).
+This implementation is the same as RoBERTa. Refer to the [documentation of RoBERTa](roberta) for usage examples as well
+as the information relative to the inputs and outputs.
-## Documentation resources
+
+
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -66,6 +68,9 @@ This model was contributed by [camembert](https://huggingface.co/camembert). The
[[autodoc]] CamembertTokenizerFast
+
+
+
## CamembertModel
[[autodoc]] CamembertModel
@@ -94,6 +99,9 @@ This model was contributed by [camembert](https://huggingface.co/camembert). The
[[autodoc]] CamembertForQuestionAnswering
+
+
+
## TFCamembertModel
[[autodoc]] TFCamembertModel
@@ -121,3 +129,7 @@ This model was contributed by [camembert](https://huggingface.co/camembert). The
## TFCamembertForQuestionAnswering
[[autodoc]] TFCamembertForQuestionAnswering
+
+
+
+
diff --git a/docs/source/en/model_doc/canine.md b/docs/source/en/model_doc/canine.md
index 748ec63eccce..7729d8aa91d7 100644
--- a/docs/source/en/model_doc/canine.md
+++ b/docs/source/en/model_doc/canine.md
@@ -37,7 +37,9 @@ To use its finer-grained input effectively and efficiently, CANINE combines down
sequence length, with a deep transformer stack, which encodes context. CANINE outperforms a comparable mBERT model by
2.8 F1 on TyDi QA, a challenging multilingual benchmark, despite having 28% fewer model parameters.*
-Tips:
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/google-research/language/tree/master/language/canine).
+
+## Usage tips
- CANINE uses no less than 3 Transformer encoders internally: 2 "shallow" encoders (which only consist of a single
layer) and 1 "deep" encoder (which is a regular BERT encoder). First, a "shallow" encoder is used to contextualize
@@ -50,19 +52,18 @@ Tips:
(which has a predefined Unicode code point). For token classification tasks however, the downsampled sequence of
tokens needs to be upsampled again to match the length of the original character sequence (which is 2048). The
details for this can be found in the paper.
-- Models:
+
+Model checkpoints:
- [google/canine-c](https://huggingface.co/google/canine-c): Pre-trained with autoregressive character loss,
12-layer, 768-hidden, 12-heads, 121M parameters (size ~500 MB).
- [google/canine-s](https://huggingface.co/google/canine-s): Pre-trained with subword loss, 12-layer,
768-hidden, 12-heads, 121M parameters (size ~500 MB).
-This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/google-research/language/tree/master/language/canine).
+## Usage example
-### Example
-
-CANINE works on raw characters, so it can be used without a tokenizer:
+CANINE works on raw characters, so it can be used **without a tokenizer**:
```python
>>> from transformers import CanineModel
@@ -96,17 +97,13 @@ sequences to the same length):
>>> sequence_output = outputs.last_hidden_state
```
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Multiple choice task guide](../tasks/multiple_choice)
-## CANINE specific outputs
-
-[[autodoc]] models.canine.modeling_canine.CanineModelOutputWithPooling
-
## CanineConfig
[[autodoc]] CanineConfig
@@ -118,6 +115,10 @@ sequences to the same length):
- get_special_tokens_mask
- create_token_type_ids_from_sequences
+## CANINE specific outputs
+
+[[autodoc]] models.canine.modeling_canine.CanineModelOutputWithPooling
+
## CanineModel
[[autodoc]] CanineModel
diff --git a/docs/source/en/model_doc/chinese_clip.md b/docs/source/en/model_doc/chinese_clip.md
index 430a734014c5..b2d27a844e9e 100644
--- a/docs/source/en/model_doc/chinese_clip.md
+++ b/docs/source/en/model_doc/chinese_clip.md
@@ -25,7 +25,9 @@ The abstract from the paper is the following:
*The tremendous success of CLIP (Radford et al., 2021) has promoted the research and application of contrastive learning for vision-language pretraining. In this work, we construct a large-scale dataset of image-text pairs in Chinese, where most data are retrieved from publicly available datasets, and we pretrain Chinese CLIP models on the new dataset. We develop 5 Chinese CLIP models of multiple sizes, spanning from 77 to 958 million parameters. Furthermore, we propose a two-stage pretraining method, where the model is first trained with the image encoder frozen and then trained with all parameters being optimized, to achieve enhanced model performance. Our comprehensive experiments demonstrate that Chinese CLIP can achieve the state-of-the-art performance on MUGE, Flickr30K-CN, and COCO-CN in the setups of zero-shot learning and finetuning, and it is able to achieve competitive performance in zero-shot image classification based on the evaluation on the ELEVATER benchmark (Li et al., 2022). Our codes, pretrained models, and demos have been released.*
-## Usage
+The Chinese-CLIP model was contributed by [OFA-Sys](https://huggingface.co/OFA-Sys).
+
+## Usage example
The code snippet below shows how to compute image & text features and similarities:
@@ -59,15 +61,13 @@ The code snippet below shows how to compute image & text features and similariti
>>> probs = logits_per_image.softmax(dim=1) # probs: [[1.2686e-03, 5.4499e-02, 6.7968e-04, 9.4355e-01]]
```
-Currently, we release the following scales of pretrained Chinese-CLIP models at HF Model Hub:
+Currently, following scales of pretrained Chinese-CLIP models are available on 🤗 Hub:
- [OFA-Sys/chinese-clip-vit-base-patch16](https://huggingface.co/OFA-Sys/chinese-clip-vit-base-patch16)
- [OFA-Sys/chinese-clip-vit-large-patch14](https://huggingface.co/OFA-Sys/chinese-clip-vit-large-patch14)
- [OFA-Sys/chinese-clip-vit-large-patch14-336px](https://huggingface.co/OFA-Sys/chinese-clip-vit-large-patch14-336px)
- [OFA-Sys/chinese-clip-vit-huge-patch14](https://huggingface.co/OFA-Sys/chinese-clip-vit-huge-patch14)
-The Chinese-CLIP model was contributed by [OFA-Sys](https://huggingface.co/OFA-Sys).
-
## ChineseCLIPConfig
[[autodoc]] ChineseCLIPConfig
diff --git a/docs/source/en/model_doc/clap.md b/docs/source/en/model_doc/clap.md
index 54082ec8aada..2bd2814e1b06 100644
--- a/docs/source/en/model_doc/clap.md
+++ b/docs/source/en/model_doc/clap.md
@@ -27,10 +27,9 @@ The abstract from the paper is the following:
*Contrastive learning has shown remarkable success in the field of multimodal representation learning. In this paper, we propose a pipeline of contrastive language-audio pretraining to develop an audio representation by combining audio data with natural language descriptions. To accomplish this target, we first release LAION-Audio-630K, a large collection of 633,526 audio-text pairs from different data sources. Second, we construct a contrastive language-audio pretraining model by considering different audio encoders and text encoders. We incorporate the feature fusion mechanism and keyword-to-caption augmentation into the model design to further enable the model to process audio inputs of variable lengths and enhance the performance. Third, we perform comprehensive experiments to evaluate our model across three tasks: text-to-audio retrieval, zero-shot audio classification, and supervised audio classification. The results demonstrate that our model achieves superior performance in text-to-audio retrieval task. In audio classification tasks, the model achieves state-of-the-art performance in the zeroshot setting and is able to obtain performance comparable to models' results in the non-zero-shot setting. LAION-Audio-6*
-This model was contributed by [Younes Belkada](https://huggingface.co/ybelkada) and [Arthur Zucker](https://huggingface.co/ArtZucker) .
+This model was contributed by [Younes Belkada](https://huggingface.co/ybelkada) and [Arthur Zucker](https://huggingface.co/ArthurZ) .
The original code can be found [here](https://github.com/LAION-AI/Clap).
-
## ClapConfig
[[autodoc]] ClapConfig
@@ -78,4 +77,3 @@ The original code can be found [here](https://github.com/LAION-AI/Clap).
[[autodoc]] ClapAudioModelWithProjection
- forward
-
diff --git a/docs/source/en/model_doc/clip.md b/docs/source/en/model_doc/clip.md
index 29b074f1cbbc..ed4fd8df7899 100644
--- a/docs/source/en/model_doc/clip.md
+++ b/docs/source/en/model_doc/clip.md
@@ -40,7 +40,9 @@ for any dataset specific training. For instance, we match the accuracy of the or
without needing to use any of the 1.28 million training examples it was trained on. We release our code and pre-trained
model weights at this https URL.*
-## Usage
+This model was contributed by [valhalla](https://huggingface.co/valhalla). The original code can be found [here](https://github.com/openai/CLIP).
+
+## Usage tips and example
CLIP is a multi-modal vision and language model. It can be used for image-text similarity and for zero-shot image
classification. CLIP uses a ViT like transformer to get visual features and a causal language model to get the text
@@ -77,8 +79,6 @@ encode the text and prepare the images. The following example shows how to get t
>>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
```
-This model was contributed by [valhalla](https://huggingface.co/valhalla). The original code can be found [here](https://github.com/openai/CLIP).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CLIP.
@@ -142,6 +142,9 @@ The resource should ideally demonstrate something new instead of duplicating an
[[autodoc]] CLIPProcessor
+
+
+
## CLIPModel
[[autodoc]] CLIPModel
@@ -164,12 +167,14 @@ The resource should ideally demonstrate something new instead of duplicating an
[[autodoc]] CLIPVisionModelWithProjection
- forward
-
## CLIPVisionModel
[[autodoc]] CLIPVisionModel
- forward
+
+
+
## TFCLIPModel
[[autodoc]] TFCLIPModel
@@ -187,6 +192,9 @@ The resource should ideally demonstrate something new instead of duplicating an
[[autodoc]] TFCLIPVisionModel
- call
+
+
+
## FlaxCLIPModel
[[autodoc]] FlaxCLIPModel
@@ -208,3 +216,6 @@ The resource should ideally demonstrate something new instead of duplicating an
[[autodoc]] FlaxCLIPVisionModel
- __call__
+
+
+
diff --git a/docs/source/en/model_doc/clipseg.md b/docs/source/en/model_doc/clipseg.md
index c4c60a48d055..320095bc1905 100644
--- a/docs/source/en/model_doc/clipseg.md
+++ b/docs/source/en/model_doc/clipseg.md
@@ -41,13 +41,6 @@ to any binary segmentation task where a text or image query
can be formulated. Finally, we find our system to adapt well
to generalized queries involving affordances or properties*
-Tips:
-
-- [`CLIPSegForImageSegmentation`] adds a decoder on top of [`CLIPSegModel`]. The latter is identical to [`CLIPModel`].
-- [`CLIPSegForImageSegmentation`] can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text
-(provided to the model as `input_ids`) or an image (provided to the model as `conditional_pixel_values`). One can also provide custom
-conditional embeddings (provided to the model as `conditional_embeddings`).
-
@@ -56,6 +49,13 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/timojl/clipseg).
+## Usage tips
+
+- [`CLIPSegForImageSegmentation`] adds a decoder on top of [`CLIPSegModel`]. The latter is identical to [`CLIPModel`].
+- [`CLIPSegForImageSegmentation`] can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text
+(provided to the model as `input_ids`) or an image (provided to the model as `conditional_pixel_values`). One can also provide custom
+conditional embeddings (provided to the model as `conditional_embeddings`).
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CLIPSeg. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
diff --git a/docs/source/en/model_doc/clvp.md b/docs/source/en/model_doc/clvp.md
new file mode 100644
index 000000000000..a30269faf9ca
--- /dev/null
+++ b/docs/source/en/model_doc/clvp.md
@@ -0,0 +1,126 @@
+
+
+# CLVP
+
+## Overview
+
+The CLVP (Contrastive Language-Voice Pretrained Transformer) model was proposed in [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
+
+The abstract from the paper is the following:
+
+*In recent years, the field of image generation has been revolutionized by the application of autoregressive transformers and DDPMs. These approaches model the process of image generation as a step-wise probabilistic processes and leverage large amounts of compute and data to learn the image distribution. This methodology of improving performance need not be confined to images. This paper describes a way to apply advances in the image generative domain to speech synthesis. The result is TorToise - an expressive, multi-voice text-to-speech system.*
+
+
+This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
+The original code can be found [here](https://github.com/neonbjb/tortoise-tts).
+
+
+## Usage tips
+
+1. CLVP is an integral part of the Tortoise TTS model.
+2. CLVP can be used to compare different generated speech candidates with the provided text, and the best speech tokens are forwarded to the diffusion model.
+3. The use of the [`ClvpModelForConditionalGeneration.generate()`] method is strongly recommended for tortoise usage.
+4. Note that the CLVP model expects the audio to be sampled at 22.05 kHz contrary to other audio models which expects 16 kHz.
+
+
+## Brief Explanation:
+
+- The [`ClvpTokenizer`] tokenizes the text input, and the [`ClvpFeatureExtractor`] extracts the log mel-spectrogram from the desired audio.
+- [`ClvpConditioningEncoder`] takes those text tokens and audio representations and converts them into embeddings conditioned on the text and audio.
+- The [`ClvpForCausalLM`] uses those embeddings to generate multiple speech candidates.
+- Each speech candidate is passed through the speech encoder ([`ClvpEncoder`]) which converts them into a vector representation, and the text encoder ([`ClvpEncoder`]) converts the text tokens into the same latent space.
+- At the end, we compare each speech vector with the text vector to see which speech vector is most similar to the text vector.
+- [`ClvpModelForConditionalGeneration.generate()`] compresses all of the logic described above into a single method.
+
+
+Example :
+
+```python
+>>> import datasets
+>>> from transformers import ClvpProcessor, ClvpModelForConditionalGeneration
+
+>>> # Define the Text and Load the Audio (We are taking an audio example from HuggingFace Hub using `datasets` library).
+>>> text = "This is an example text."
+
+>>> ds = datasets.load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> ds = ds.cast_column("audio", datasets.Audio(sampling_rate=22050))
+>>> sample = ds[0]["audio"]
+
+>>> # Define processor and model.
+>>> processor = ClvpProcessor.from_pretrained("susnato/clvp_dev")
+>>> model = ClvpModelForConditionalGeneration.from_pretrained("susnato/clvp_dev")
+
+>>> # Generate processor output and model output.
+>>> processor_output = processor(raw_speech=sample["array"], sampling_rate=sample["sampling_rate"], text=text, return_tensors="pt")
+>>> generated_output = model.generate(**processor_output)
+```
+
+
+## ClvpConfig
+
+[[autodoc]] ClvpConfig
+ - from_sub_model_configs
+
+## ClvpEncoderConfig
+
+[[autodoc]] ClvpEncoderConfig
+
+## ClvpDecoderConfig
+
+[[autodoc]] ClvpDecoderConfig
+
+## ClvpTokenizer
+
+[[autodoc]] ClvpTokenizer
+ - save_vocabulary
+
+## ClvpFeatureExtractor
+
+[[autodoc]] ClvpFeatureExtractor
+ - __call__
+
+## ClvpProcessor
+
+[[autodoc]] ClvpProcessor
+ - __call__
+ - decode
+ - batch_decode
+
+## ClvpModelForConditionalGeneration
+
+[[autodoc]] ClvpModelForConditionalGeneration
+ - forward
+ - generate
+ - get_text_features
+ - get_speech_features
+
+## ClvpForCausalLM
+
+[[autodoc]] ClvpForCausalLM
+
+## ClvpModel
+
+[[autodoc]] ClvpModel
+
+## ClvpEncoder
+
+[[autodoc]] ClvpEncoder
+
+## ClvpDecoder
+
+[[autodoc]] ClvpDecoder
+
diff --git a/docs/source/en/model_doc/code_llama.md b/docs/source/en/model_doc/code_llama.md
index a60cf1641533..38d50c87334d 100644
--- a/docs/source/en/model_doc/code_llama.md
+++ b/docs/source/en/model_doc/code_llama.md
@@ -24,7 +24,11 @@ The abstract from the paper is the following:
*We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. We provide multiple flavors to cover a wide range of applications: foundation models (Code Llama), Python specializations (Code Llama - Python), and instruction-following models (Code Llama - Instruct) with 7B, 13B and 34B parameters each. All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens. 7B and 13B Code Llama and Code Llama - Instruct variants support infilling based on surrounding content. Code Llama reaches state-of-the-art performance among open models on several code benchmarks, with scores of up to 53% and 55% on HumanEval and MBPP, respectively. Notably, Code Llama - Python 7B outperforms Llama 2 70B on HumanEval and MBPP, and all our models outperform every other publicly available model on MultiPL-E. We release Code Llama under a permissive license that allows for both research and commercial use.*
-Check out all Code Llama models [here](https://huggingface.co/models?search=code_llama) and the officially released ones in the [codellama org](https://huggingface.co/codellama).
+Check out all Code Llama model checkpoints [here](https://huggingface.co/models?search=code_llama) and the officially released ones in the [codellama org](https://huggingface.co/codellama).
+
+This model was contributed by [ArthurZucker](https://huggingface.co/ArthurZ). The original code of the authors can be found [here](https://github.com/facebookresearch/llama).
+
+## Usage tips and examples
@@ -38,21 +42,22 @@ As mentioned above, the `dtype` of the storage weights is mostly irrelevant unle
-Tips:
-- These models have the same architecture as the `Llama2` models
+Tips:
- The infilling task is supported out of the box. You should be using the `tokenizer.fill_token` where you want your input to be filled.
- The model conversion script is the same as for the `Llama2` family:
-Here is a sample usage
+Here is a sample usage:
+
```bash
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
```
+
Note that executing the script requires enough CPU RAM to host the whole model in float16 precision (even if the biggest versions
come in several checkpoints they each contain a part of each weight of the model, so we need to load them all in RAM).
-- After conversion, the model and tokenizer can be loaded via:
+After conversion, the model and tokenizer can be loaded via:
```python
>>> from transformers import LlamaForCausalLM, CodeLlamaTokenizer
@@ -95,9 +100,13 @@ If you only want the infilled part:
Under the hood, the tokenizer [automatically splits by ``](https://huggingface.co/docs/transformers/main/model_doc/code_llama#transformers.CodeLlamaTokenizer.fill_token) to create a formatted input string that follows [the original training pattern](https://github.com/facebookresearch/codellama/blob/cb51c14ec761370ba2e2bc351374a79265d0465e/llama/generation.py#L402). This is more robust than preparing the pattern yourself: it avoids pitfalls, such as token glueing, that are very hard to debug. To see how much CPU and GPU memory you need for this model or others, try [this calculator](https://huggingface.co/spaces/hf-accelerate/model-memory-usage) which can help determine that value.
-- The LLaMA tokenizer is a BPE model based on [sentencepiece](https://github.com/google/sentencepiece). One quirk of sentencepiece is that when decoding a sequence, if the first token is the start of the word (e.g. "Banana"), the tokenizer does not prepend the prefix space to the string.
+The LLaMA tokenizer is a BPE model based on [sentencepiece](https://github.com/google/sentencepiece). One quirk of sentencepiece is that when decoding a sequence, if the first token is the start of the word (e.g. "Banana"), the tokenizer does not prepend the prefix space to the string.
-This model was contributed by [ArthurZucker](https://huggingface.co/ArthurZ). The original code of the authors can be found [here](https://github.com/facebookresearch/llama).
+
+
+Code Llama has the same architecture as the `Llama2` models, refer to [Llama2's documentation page](llama2) for the API reference.
+Find Code Llama tokenizer reference below.
+
## CodeLlamaTokenizer
diff --git a/docs/source/en/model_doc/codegen.md b/docs/source/en/model_doc/codegen.md
index 695f45f9ae17..78be813db1a6 100644
--- a/docs/source/en/model_doc/codegen.md
+++ b/docs/source/en/model_doc/codegen.md
@@ -40,7 +40,7 @@ The original code can be found [here](https://github.com/salesforce/codegen).
* `mono`: Initialized with `multi`, then further pre-trained on Python data
* For example, `Salesforce/codegen-350M-mono` offers a 350 million-parameter checkpoint pre-trained sequentially on the Pile, multiple programming languages, and Python.
-## How to use
+## Usage example
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
@@ -60,7 +60,7 @@ def hello_world():
hello_world()
```
-## Documentation resources
+## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
diff --git a/docs/source/en/model_doc/conditional_detr.md b/docs/source/en/model_doc/conditional_detr.md
index 8993fb384316..516e1c436855 100644
--- a/docs/source/en/model_doc/conditional_detr.md
+++ b/docs/source/en/model_doc/conditional_detr.md
@@ -31,7 +31,7 @@ alt="drawing" width="600"/>
This model was contributed by [DepuMeng](https://huggingface.co/DepuMeng). The original code can be found [here](https://github.com/Atten4Vis/ConditionalDETR).
-## Documentation resources
+## Resources
- [Object detection task guide](../tasks/object_detection)
diff --git a/docs/source/en/model_doc/convbert.md b/docs/source/en/model_doc/convbert.md
index 8a0aa7a946cc..17b5d7920c6c 100644
--- a/docs/source/en/model_doc/convbert.md
+++ b/docs/source/en/model_doc/convbert.md
@@ -44,12 +44,14 @@ ConvBERT significantly outperforms BERT and its variants in various downstream t
fewer model parameters. Remarkably, ConvBERTbase model achieves 86.4 GLUE score, 0.7 higher than ELECTRAbase, while
using less than 1/4 training cost. Code and pre-trained models will be released.*
-ConvBERT training tips are similar to those of BERT.
-
This model was contributed by [abhishek](https://huggingface.co/abhishek). The original implementation can be found
here: https://github.com/yitu-opensource/ConvBert
-## Documentation resources
+## Usage tips
+
+ConvBERT training tips are similar to those of BERT. For usage tips refer to [BERT documentation](bert).
+
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -73,6 +75,9 @@ here: https://github.com/yitu-opensource/ConvBert
[[autodoc]] ConvBertTokenizerFast
+
+
+
## ConvBertModel
[[autodoc]] ConvBertModel
@@ -103,6 +108,9 @@ here: https://github.com/yitu-opensource/ConvBert
[[autodoc]] ConvBertForQuestionAnswering
- forward
+
+
+
## TFConvBertModel
[[autodoc]] TFConvBertModel
@@ -132,3 +140,6 @@ here: https://github.com/yitu-opensource/ConvBert
[[autodoc]] TFConvBertForQuestionAnswering
- call
+
+
+
diff --git a/docs/source/en/model_doc/convnext.md b/docs/source/en/model_doc/convnext.md
index acbb0265b2e6..5222834b1f69 100644
--- a/docs/source/en/model_doc/convnext.md
+++ b/docs/source/en/model_doc/convnext.md
@@ -32,10 +32,6 @@ of a vision Transformer, and discover several key components that contribute to
dubbed ConvNeXt. Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy
and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.*
-Tips:
-
-- See the code examples below each model regarding usage.
-
@@ -68,6 +64,9 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] ConvNextImageProcessor
- preprocess
+
+
+
## ConvNextModel
[[autodoc]] ConvNextModel
@@ -78,14 +77,18 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] ConvNextForImageClassification
- forward
+
+
## TFConvNextModel
[[autodoc]] TFConvNextModel
- call
-
## TFConvNextForImageClassification
[[autodoc]] TFConvNextForImageClassification
- call
+
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/convnextv2.md b/docs/source/en/model_doc/convnextv2.md
index 9479cdd56fa1..8cd142c2765f 100644
--- a/docs/source/en/model_doc/convnextv2.md
+++ b/docs/source/en/model_doc/convnextv2.md
@@ -25,10 +25,6 @@ The abstract from the paper is the following:
*Driven by improved architectures and better representation learning frameworks, the field of visual recognition has enjoyed rapid modernization and performance boost in the early 2020s. For example, modern ConvNets, represented by ConvNeXt, have demonstrated strong performance in various scenarios. While these models were originally designed for supervised learning with ImageNet labels, they can also potentially benefit from self-supervised learning techniques such as masked autoencoders (MAE). However, we found that simply combining these two approaches leads to subpar performance. In this paper, we propose a fully convolutional masked autoencoder framework and a new Global Response Normalization (GRN) layer that can be added to the ConvNeXt architecture to enhance inter-channel feature competition. This co-design of self-supervised learning techniques and architectural improvement results in a new model family called ConvNeXt V2, which significantly improves the performance of pure ConvNets on various recognition benchmarks, including ImageNet classification, COCO detection, and ADE20K segmentation. We also provide pre-trained ConvNeXt V2 models of various sizes, ranging from an efficient 3.7M-parameter Atto model with 76.7% top-1 accuracy on ImageNet, to a 650M Huge model that achieves a state-of-the-art 88.9% accuracy using only public training data.*
-Tips:
-
-- See the code examples below each model regarding usage.
-
@@ -58,4 +54,15 @@ If you're interested in submitting a resource to be included here, please feel f
## ConvNextV2ForImageClassification
[[autodoc]] ConvNextV2ForImageClassification
- - forward
\ No newline at end of file
+ - forward
+
+## TFConvNextV2Model
+
+[[autodoc]] TFConvNextV2Model
+ - call
+
+
+## TFConvNextV2ForImageClassification
+
+[[autodoc]] TFConvNextV2ForImageClassification
+ - call
diff --git a/docs/source/en/model_doc/cpm.md b/docs/source/en/model_doc/cpm.md
index a2ecf1a1e092..129c4ed3a377 100644
--- a/docs/source/en/model_doc/cpm.md
+++ b/docs/source/en/model_doc/cpm.md
@@ -37,7 +37,14 @@ NLP tasks in the settings of few-shot (even zero-shot) learning.*
This model was contributed by [canwenxu](https://huggingface.co/canwenxu). The original implementation can be found
here: https://github.com/TsinghuaAI/CPM-Generate
-Note: We only have a tokenizer here, since the model architecture is the same as GPT-2.
+
+
+
+CPM's architecture is the same as GPT-2, except for tokenization method. Refer to [GPT-2 documentation](gpt2) for
+API reference information.
+
+
+
## CpmTokenizer
diff --git a/docs/source/en/model_doc/cpmant.md b/docs/source/en/model_doc/cpmant.md
index 2c4ad92a629e..4bcf774507fb 100644
--- a/docs/source/en/model_doc/cpmant.md
+++ b/docs/source/en/model_doc/cpmant.md
@@ -20,11 +20,10 @@ rendered properly in your Markdown viewer.
CPM-Ant is an open-source Chinese pre-trained language model (PLM) with 10B parameters. It is also the first milestone of the live training process of CPM-Live. The training process is cost-effective and environment-friendly. CPM-Ant also achieves promising results with delta tuning on the CUGE benchmark. Besides the full model, we also provide various compressed versions to meet the requirements of different hardware configurations. [See more](https://github.com/OpenBMB/CPM-Live/tree/cpm-ant/cpm-live)
-Tips:
-
This model was contributed by [OpenBMB](https://huggingface.co/openbmb). The original code can be found [here](https://github.com/OpenBMB/CPM-Live/tree/cpm-ant/cpm-live).
-⚙️ Training & Inference
+## Resources
+
- A tutorial on [CPM-Live](https://github.com/OpenBMB/CPM-Live/tree/cpm-ant/cpm-live).
## CpmAntConfig
diff --git a/docs/source/en/model_doc/ctrl.md b/docs/source/en/model_doc/ctrl.md
index 9c2413d27769..be9fa85c7073 100644
--- a/docs/source/en/model_doc/ctrl.md
+++ b/docs/source/en/model_doc/ctrl.md
@@ -41,7 +41,10 @@ providing more explicit control over text generation. These codes also allow CTR
training data are most likely given a sequence. This provides a potential method for analyzing large amounts of data
via model-based source attribution.*
-Tips:
+This model was contributed by [keskarnitishr](https://huggingface.co/keskarnitishr). The original code can be found
+[here](https://github.com/salesforce/ctrl).
+
+## Usage tips
- CTRL makes use of control codes to generate text: it requires generations to be started by certain words, sentences
or links to generate coherent text. Refer to the [original implementation](https://github.com/salesforce/ctrl) for
@@ -56,10 +59,8 @@ Tips:
pre-computed values in the context of text generation. See the [`forward`](model_doc/ctrl#transformers.CTRLModel.forward)
method for more information on the usage of this argument.
-This model was contributed by [keskarnitishr](https://huggingface.co/keskarnitishr). The original code can be found
-[here](https://github.com/salesforce/ctrl).
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
@@ -73,6 +74,9 @@ This model was contributed by [keskarnitishr](https://huggingface.co/keskarnitis
[[autodoc]] CTRLTokenizer
- save_vocabulary
+
+
+
## CTRLModel
[[autodoc]] CTRLModel
@@ -88,6 +92,9 @@ This model was contributed by [keskarnitishr](https://huggingface.co/keskarnitis
[[autodoc]] CTRLForSequenceClassification
- forward
+
+
+
## TFCTRLModel
[[autodoc]] TFCTRLModel
@@ -102,3 +109,6 @@ This model was contributed by [keskarnitishr](https://huggingface.co/keskarnitis
[[autodoc]] TFCTRLForSequenceClassification
- call
+
+
+
diff --git a/docs/source/en/model_doc/cvt.md b/docs/source/en/model_doc/cvt.md
index 6c9aea5ec863..503f97795c0e 100644
--- a/docs/source/en/model_doc/cvt.md
+++ b/docs/source/en/model_doc/cvt.md
@@ -33,15 +33,15 @@ performance gains are maintained when pretrained on larger datasets (\eg ImageNe
ImageNet-22k, our CvT-W24 obtains a top-1 accuracy of 87.7\% on the ImageNet-1k val set. Finally, our results show that the positional encoding,
a crucial component in existing Vision Transformers, can be safely removed in our model, simplifying the design for higher resolution vision tasks.*
-Tips:
+This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/microsoft/CvT).
+
+## Usage tips
- CvT models are regular Vision Transformers, but trained with convolutions. They outperform the [original model (ViT)](vit) when fine-tuned on ImageNet-1K and CIFAR-100.
- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer) (you can just replace [`ViTFeatureExtractor`] by [`AutoImageProcessor`] and [`ViTForImageClassification`] by [`CvtForImageClassification`]).
- The available checkpoints are either (1) pre-trained on [ImageNet-22k](http://www.image-net.org/) (a collection of 14 million images and 22k classes) only, (2) also fine-tuned on ImageNet-22k or (3) also fine-tuned on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/) (also referred to as ILSVRC 2012, a collection of 1.3 million
images and 1,000 classes).
-This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/microsoft/CvT).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CvT.
@@ -57,6 +57,9 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] CvtConfig
+
+
+
## CvtModel
[[autodoc]] CvtModel
@@ -67,6 +70,9 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] CvtForImageClassification
- forward
+
+
+
## TFCvtModel
[[autodoc]] TFCvtModel
@@ -77,3 +83,5 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] TFCvtForImageClassification
- call
+
+
diff --git a/docs/source/en/model_doc/data2vec.md b/docs/source/en/model_doc/data2vec.md
index dc05c44be90c..517a51ce46a3 100644
--- a/docs/source/en/model_doc/data2vec.md
+++ b/docs/source/en/model_doc/data2vec.md
@@ -35,19 +35,18 @@ the entire input. Experiments on the major benchmarks of speech recognition, ima
natural language understanding demonstrate a new state of the art or competitive performance to predominant approaches.
Models and code are available at www.github.com/pytorch/fairseq/tree/master/examples/data2vec.*
-Tips:
-
-- Data2VecAudio, Data2VecText, and Data2VecVision have all been trained using the same self-supervised learning method.
-- For Data2VecAudio, preprocessing is identical to [`Wav2Vec2Model`], including feature extraction
-- For Data2VecText, preprocessing is identical to [`RobertaModel`], including tokenization.
-- For Data2VecVision, preprocessing is identical to [`BeitModel`], including feature extraction.
-
This model was contributed by [edugp](https://huggingface.co/edugp) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
[sayakpaul](https://github.com/sayakpaul) and [Rocketknight1](https://github.com/Rocketknight1) contributed Data2Vec for vision in TensorFlow.
The original code (for NLP and Speech) can be found [here](https://github.com/pytorch/fairseq/tree/main/examples/data2vec).
The original code for vision can be found [here](https://github.com/facebookresearch/data2vec_vision/tree/main/beit).
+## Usage tips
+
+- Data2VecAudio, Data2VecText, and Data2VecVision have all been trained using the same self-supervised learning method.
+- For Data2VecAudio, preprocessing is identical to [`Wav2Vec2Model`], including feature extraction
+- For Data2VecText, preprocessing is identical to [`RobertaModel`], including tokenization.
+- For Data2VecVision, preprocessing is identical to [`BeitModel`], including feature extraction.
## Resources
@@ -88,6 +87,8 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] Data2VecVisionConfig
+
+
## Data2VecAudioModel
@@ -164,6 +165,9 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] Data2VecVisionForSemanticSegmentation
- forward
+
+
+
## TFData2VecVisionModel
[[autodoc]] TFData2VecVisionModel
@@ -178,3 +182,6 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] TFData2VecVisionForSemanticSegmentation
- call
+
+
+
diff --git a/docs/source/en/model_doc/deberta-v2.md b/docs/source/en/model_doc/deberta-v2.md
index 8dec57a17173..e3bd91e8e4fa 100644
--- a/docs/source/en/model_doc/deberta-v2.md
+++ b/docs/source/en/model_doc/deberta-v2.md
@@ -62,7 +62,7 @@ New in v2:
This model was contributed by [DeBERTa](https://huggingface.co/DeBERTa). This model TF 2.0 implementation was
contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/microsoft/DeBERTa).
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -88,6 +88,9 @@ contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code
- build_inputs_with_special_tokens
- create_token_type_ids_from_sequences
+
+
+
## DebertaV2Model
[[autodoc]] DebertaV2Model
@@ -123,6 +126,9 @@ contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code
[[autodoc]] DebertaV2ForMultipleChoice
- forward
+
+
+
## TFDebertaV2Model
[[autodoc]] TFDebertaV2Model
@@ -157,3 +163,6 @@ contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code
[[autodoc]] TFDebertaV2ForMultipleChoice
- call
+
+
+
diff --git a/docs/source/en/model_doc/deberta.md b/docs/source/en/model_doc/deberta.md
index ed66364a4b5a..342a3bc47960 100644
--- a/docs/source/en/model_doc/deberta.md
+++ b/docs/source/en/model_doc/deberta.md
@@ -94,6 +94,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
- build_inputs_with_special_tokens
- create_token_type_ids_from_sequences
+
+
+
## DebertaModel
[[autodoc]] DebertaModel
@@ -123,6 +126,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] DebertaForQuestionAnswering
- forward
+
+
+
## TFDebertaModel
[[autodoc]] TFDebertaModel
@@ -152,3 +158,7 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] TFDebertaForQuestionAnswering
- call
+
+
+
+
diff --git a/docs/source/en/model_doc/decision_transformer.md b/docs/source/en/model_doc/decision_transformer.md
index a46673d87ac8..07ef2ecbdc8e 100644
--- a/docs/source/en/model_doc/decision_transformer.md
+++ b/docs/source/en/model_doc/decision_transformer.md
@@ -33,9 +33,7 @@ This allows us to draw upon the simplicity and scalability of the Transformer ar
Decision Transformer matches or exceeds the performance of state-of-the-art model-free offline RL baselines on
Atari, OpenAI Gym, and Key-to-Door tasks.*
-Tips:
-
-This version of the model is for tasks where the state is a vector, image-based states will come soon.
+This version of the model is for tasks where the state is a vector.
This model was contributed by [edbeeching](https://huggingface.co/edbeeching). The original code can be found [here](https://github.com/kzl/decision-transformer).
diff --git a/docs/source/en/model_doc/deformable_detr.md b/docs/source/en/model_doc/deformable_detr.md
index 0bceb0bdf39b..726fa0d0ca9a 100644
--- a/docs/source/en/model_doc/deformable_detr.md
+++ b/docs/source/en/model_doc/deformable_detr.md
@@ -25,11 +25,6 @@ The abstract from the paper is the following:
*DETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. However, it suffers from slow convergence and limited feature spatial resolution, due to the limitation of Transformer attention modules in processing image feature maps. To mitigate these issues, we proposed Deformable DETR, whose attention modules only attend to a small set of key sampling points around a reference. Deformable DETR can achieve better performance than DETR (especially on small objects) with 10 times less training epochs. Extensive experiments on the COCO benchmark demonstrate the effectiveness of our approach.*
-Tips:
-
-- One can use [`DeformableDetrImageProcessor`] to prepare images (and optional targets) for the model.
-- Training Deformable DETR is equivalent to training the original [DETR](detr) model. See the [resources](#resources) section below for demo notebooks.
-
@@ -37,6 +32,10 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/fundamentalvision/Deformable-DETR).
+## Usage tips
+
+- Training Deformable DETR is equivalent to training the original [DETR](detr) model. See the [resources](#resources) section below for demo notebooks.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Deformable DETR.
diff --git a/docs/source/en/model_doc/deit.md b/docs/source/en/model_doc/deit.md
index ef32e05ebd92..7d9918a45eee 100644
--- a/docs/source/en/model_doc/deit.md
+++ b/docs/source/en/model_doc/deit.md
@@ -16,13 +16,6 @@ rendered properly in your Markdown viewer.
# DeiT
-
-
-This is a recently introduced model so the API hasn't been tested extensively. There may be some bugs or slight
-breaking changes to fix it in the future. If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
-
-
-
## Overview
The DeiT model was proposed in [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre
@@ -45,7 +38,9 @@ distillation, especially when using a convnet as a teacher. This leads us to rep
for both Imagenet (where we obtain up to 85.2% accuracy) and when transferring to other tasks. We share our code and
models.*
-Tips:
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version of this model was added by [amyeroberts](https://huggingface.co/amyeroberts).
+
+## Usage tips
- Compared to ViT, DeiT models use a so-called distillation token to effectively learn from a teacher (which, in the
DeiT paper, is a ResNet like-model). The distillation token is learned through backpropagation, by interacting with
@@ -73,8 +68,6 @@ Tips:
*facebook/deit-base-patch16-384*. Note that one should use [`DeiTImageProcessor`] in order to
prepare images for the model.
-This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version of this model was added by [amyeroberts](https://huggingface.co/amyeroberts).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DeiT.
@@ -104,6 +97,9 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] DeiTImageProcessor
- preprocess
+
+
+
## DeiTModel
[[autodoc]] DeiTModel
@@ -124,6 +120,9 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] DeiTForImageClassificationWithTeacher
- forward
+
+
+
## TFDeiTModel
[[autodoc]] TFDeiTModel
@@ -143,3 +142,6 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] TFDeiTForImageClassificationWithTeacher
- call
+
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/deplot.md b/docs/source/en/model_doc/deplot.md
index f425a8268fdf..a77bee39de76 100644
--- a/docs/source/en/model_doc/deplot.md
+++ b/docs/source/en/model_doc/deplot.md
@@ -24,12 +24,10 @@ The abstract of the paper states the following:
*Visual language such as charts and plots is ubiquitous in the human world. Comprehending plots and charts requires strong reasoning skills. Prior state-of-the-art (SOTA) models require at least tens of thousands of training examples and their reasoning capabilities are still much limited, especially on complex human-written queries. This paper presents the first one-shot solution to visual language reasoning. We decompose the challenge of visual language reasoning into two steps: (1) plot-to-text translation, and (2) reasoning over the translated text. The key in this method is a modality conversion module, named as DePlot, which translates the image of a plot or chart to a linearized table. The output of DePlot can then be directly used to prompt a pretrained large language model (LLM), exploiting the few-shot reasoning capabilities of LLMs. To obtain DePlot, we standardize the plot-to-table task by establishing unified task formats and metrics, and train DePlot end-to-end on this task. DePlot can then be used off-the-shelf together with LLMs in a plug-and-play fashion. Compared with a SOTA model finetuned on more than >28k data points, DePlot+LLM with just one-shot prompting achieves a 24.0% improvement over finetuned SOTA on human-written queries from the task of chart QA.*
-## Model description
-
DePlot is a model that is trained using `Pix2Struct` architecture. You can find more information about `Pix2Struct` in the [Pix2Struct documentation](https://huggingface.co/docs/transformers/main/en/model_doc/pix2struct).
DePlot is a Visual Question Answering subset of `Pix2Struct` architecture. It renders the input question on the image and predicts the answer.
-## Usage
+## Usage example
Currently one checkpoint is available for DePlot:
@@ -59,4 +57,10 @@ from transformers.optimization import Adafactor, get_cosine_schedule_with_warmup
optimizer = Adafactor(self.parameters(), scale_parameter=False, relative_step=False, lr=0.01, weight_decay=1e-05)
scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=1000, num_training_steps=40000)
-```
\ No newline at end of file
+```
+
+
+
+DePlot is a model trained using `Pix2Struct` architecture. For API reference, see [`Pix2Struct` documentation](pix2struct).
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/deta.md b/docs/source/en/model_doc/deta.md
index d384f5564e5e..1eed98832ac7 100644
--- a/docs/source/en/model_doc/deta.md
+++ b/docs/source/en/model_doc/deta.md
@@ -26,10 +26,6 @@ The abstract from the paper is the following:
*Detection Transformer (DETR) directly transforms queries to unique objects by using one-to-one bipartite matching during training and enables end-to-end object detection. Recently, these models have surpassed traditional detectors on COCO with undeniable elegance. However, they differ from traditional detectors in multiple designs, including model architecture and training schedules, and thus the effectiveness of one-to-one matching is not fully understood. In this work, we conduct a strict comparison between the one-to-one Hungarian matching in DETRs and the one-to-many label assignments in traditional detectors with non-maximum supervision (NMS). Surprisingly, we observe one-to-many assignments with NMS consistently outperform standard one-to-one matching under the same setting, with a significant gain of up to 2.5 mAP. Our detector that trains Deformable-DETR with traditional IoU-based label assignment achieved 50.2 COCO mAP within 12 epochs (1x schedule) with ResNet50 backbone, outperforming all existing traditional or transformer-based detectors in this setting. On multiple datasets, schedules, and architectures, we consistently show bipartite matching is unnecessary for performant detection transformers. Furthermore, we attribute the success of detection transformers to their expressive transformer architecture.*
-Tips:
-
-- One can use [`DetaImageProcessor`] to prepare images and optional targets for the model.
-
@@ -51,20 +47,17 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] DetaConfig
-
## DetaImageProcessor
[[autodoc]] DetaImageProcessor
- preprocess
- post_process_object_detection
-
## DetaModel
[[autodoc]] DetaModel
- forward
-
## DetaForObjectDetection
[[autodoc]] DetaForObjectDetection
diff --git a/docs/source/en/model_doc/detr.md b/docs/source/en/model_doc/detr.md
index 2c03a0f8b851..c36bd4380edf 100644
--- a/docs/source/en/model_doc/detr.md
+++ b/docs/source/en/model_doc/detr.md
@@ -41,6 +41,8 @@ baselines.*
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/facebookresearch/detr).
+## How DETR works
+
Here's a TLDR explaining how [`~transformers.DetrForObjectDetection`] works:
First, an image is sent through a pre-trained convolutional backbone (in the paper, the authors use
@@ -79,7 +81,7 @@ where one first trains a [`~transformers.DetrForObjectDetection`] model to detec
the mask head for 25 epochs. Experimentally, these two approaches give similar results. Note that predicting boxes is
required for the training to be possible, since the Hungarian matching is computed using distances between boxes.
-Tips:
+## Usage tips
- DETR uses so-called **object queries** to detect objects in an image. The number of queries determines the maximum
number of objects that can be detected in a single image, and is set to 100 by default (see parameter
@@ -165,14 +167,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
-## DETR specific outputs
-
-[[autodoc]] models.detr.modeling_detr.DetrModelOutput
-
-[[autodoc]] models.detr.modeling_detr.DetrObjectDetectionOutput
-
-[[autodoc]] models.detr.modeling_detr.DetrSegmentationOutput
-
## DetrConfig
[[autodoc]] DetrConfig
@@ -195,6 +189,14 @@ If you're interested in submitting a resource to be included here, please feel f
- post_process_instance_segmentation
- post_process_panoptic_segmentation
+## DETR specific outputs
+
+[[autodoc]] models.detr.modeling_detr.DetrModelOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrObjectDetectionOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrSegmentationOutput
+
## DetrModel
[[autodoc]] DetrModel
diff --git a/docs/source/en/model_doc/dialogpt.md b/docs/source/en/model_doc/dialogpt.md
index 70929409b294..558b91d76d25 100644
--- a/docs/source/en/model_doc/dialogpt.md
+++ b/docs/source/en/model_doc/dialogpt.md
@@ -32,7 +32,9 @@ that leverage DialoGPT generate more relevant, contentful and context-consistent
systems. The pre-trained model and training pipeline are publicly released to facilitate research into neural response
generation and the development of more intelligent open-domain dialogue systems.*
-Tips:
+The original code can be found [here](https://github.com/microsoft/DialoGPT).
+
+## Usage tips
- DialoGPT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather
than the left.
@@ -47,7 +49,8 @@ follow the OpenAI GPT-2 to model a multiturn dialogue session as a long text and
modeling. We first concatenate all dialog turns within a dialogue session into a long text x_1,..., x_N (N is the
sequence length), ended by the end-of-text token.* For more information please confer to the original paper.
+
-DialoGPT's architecture is based on the GPT2 model, so one can refer to [GPT2's documentation page](gpt2).
+DialoGPT's architecture is based on the GPT2 model, refer to [GPT2's documentation page](gpt2) for API reference and examples.
-The original code can be found [here](https://github.com/microsoft/DialoGPT).
+
diff --git a/docs/source/en/model_doc/dinat.md b/docs/source/en/model_doc/dinat.md
index 2317b13b7f9c..23dfa3b74fb0 100644
--- a/docs/source/en/model_doc/dinat.md
+++ b/docs/source/en/model_doc/dinat.md
@@ -44,17 +44,6 @@ and ADE20K (48.5 PQ), and instance segmentation model on Cityscapes (44.5 AP) an
It also matches the state of the art specialized semantic segmentation models on ADE20K (58.2 mIoU),
and ranks second on Cityscapes (84.5 mIoU) (no extra data). *
-Tips:
-- One can use the [`AutoImageProcessor`] API to prepare images for the model.
-- DiNAT can be used as a *backbone*. When `output_hidden_states = True`,
-it will output both `hidden_states` and `reshaped_hidden_states`. The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than `(batch_size, height, width, num_channels)`.
-
-Notes:
-- DiNAT depends on [NATTEN](https://github.com/SHI-Labs/NATTEN/)'s implementation of Neighborhood Attention and Dilated Neighborhood Attention.
-You can install it with pre-built wheels for Linux by referring to [shi-labs.com/natten](https://shi-labs.com/natten), or build on your system by running `pip install natten`.
-Note that the latter will likely take time to compile. NATTEN does not support Windows devices yet.
-- Patch size of 4 is only supported at the moment.
-
@@ -65,6 +54,17 @@ Taken from the original paper.
+
+- [`Dinov2ForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## Dinov2Config
diff --git a/docs/source/en/model_doc/distilbert.md b/docs/source/en/model_doc/distilbert.md
index 2e68119a20b2..233a182a553f 100644
--- a/docs/source/en/model_doc/distilbert.md
+++ b/docs/source/en/model_doc/distilbert.md
@@ -32,7 +32,7 @@ rendered properly in your Markdown viewer.
The DistilBERT model was proposed in the blog post [Smaller, faster, cheaper, lighter: Introducing DistilBERT, a
distilled version of BERT](https://medium.com/huggingface/distilbert-8cf3380435b5), and the paper [DistilBERT, a
-distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/papers/1910.01108). DistilBERT is a
+distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108). DistilBERT is a
small, fast, cheap and light Transformer model trained by distilling BERT base. It has 40% less parameters than
*bert-base-uncased*, runs 60% faster while preserving over 95% of BERT's performances as measured on the GLUE language
understanding benchmark.
@@ -51,7 +51,10 @@ distillation and cosine-distance losses. Our smaller, faster and lighter model i
demonstrate its capabilities for on-device computations in a proof-of-concept experiment and a comparative on-device
study.*
-Tips:
+This model was contributed by [victorsanh](https://huggingface.co/victorsanh). This model jax version was
+contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation).
+
+## Usage tips
- DistilBERT doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. Just
separate your segments with the separation token `tokenizer.sep_token` (or `[SEP]`).
@@ -63,8 +66,6 @@ Tips:
* predicting the masked tokens correctly (but no next-sentence objective)
* a cosine similarity between the hidden states of the student and the teacher model
-This model was contributed by [victorsanh](https://huggingface.co/victorsanh). This model jax version was
-contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation).
## Resources
@@ -132,6 +133,37 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
- A blog post on how to [deploy DistilBERT with Amazon SageMaker](https://huggingface.co/blog/deploy-hugging-face-models-easily-with-amazon-sagemaker).
- A blog post on how to [Deploy BERT with Hugging Face Transformers, Amazon SageMaker and Terraform module](https://www.philschmid.de/terraform-huggingface-amazon-sagemaker).
+
+## Combining DistilBERT and Flash Attention 2
+
+First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16`)
+
+To load and run a model using Flash Attention 2, refer to the snippet below:
+
+```python
+>>> import torch
+>>> from transformers import AutoTokenizer, AutoModel
+
+>>> device = "cuda" # the device to load the model onto
+
+>>> tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
+>>> model = AutoModel.from_pretrained("distilbert-base-uncased", torch_dtype=torch.float16, use_flash_attention_2=True)
+
+>>> text = "Replace me by any text you'd like."
+
+>>> encoded_input = tokenizer(text, return_tensors='pt').to(device)
+>>> model.to(device)
+
+>>> output = model(**encoded_input)
+```
+
+
## DistilBertConfig
[[autodoc]] DistilBertConfig
@@ -144,6 +176,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] DistilBertTokenizerFast
+
+
+
## DistilBertModel
[[autodoc]] DistilBertModel
@@ -174,6 +209,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] DistilBertForQuestionAnswering
- forward
+
+
+
## TFDistilBertModel
[[autodoc]] TFDistilBertModel
@@ -204,6 +242,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] TFDistilBertForQuestionAnswering
- call
+
+
+
## FlaxDistilBertModel
[[autodoc]] FlaxDistilBertModel
@@ -233,3 +274,10 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] FlaxDistilBertForQuestionAnswering
- __call__
+
+
+
+
+
+
+
diff --git a/docs/source/en/model_doc/dit.md b/docs/source/en/model_doc/dit.md
index 7d5f873e78bb..7f6691a15bc4 100644
--- a/docs/source/en/model_doc/dit.md
+++ b/docs/source/en/model_doc/dit.md
@@ -37,6 +37,10 @@ alt="drawing" width="600"/>
Summary of the approach. Taken from the [original paper](https://arxiv.org/abs/2203.02378).
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/dit).
+
+## Usage tips
+
One can directly use the weights of DiT with the AutoModel API:
```python
@@ -66,10 +70,6 @@ model = AutoModelForImageClassification.from_pretrained("microsoft/dit-base-fine
This particular checkpoint was fine-tuned on [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/), an important benchmark for document image classification.
A notebook that illustrates inference for document image classification can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DiT/Inference_with_DiT_(Document_Image_Transformer)_for_document_image_classification.ipynb).
-As DiT's architecture is equivalent to that of BEiT, one can refer to [BEiT's documentation page](beit) for all tips, code examples and notebooks.
-
-This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/dit).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DiT.
@@ -78,4 +78,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
- [`BeitForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
-If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
\ No newline at end of file
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+ As DiT's architecture is equivalent to that of BEiT, one can refer to [BEiT's documentation page](beit) for all tips, code examples and notebooks.
+
diff --git a/docs/source/en/model_doc/donut.md b/docs/source/en/model_doc/donut.md
index cfbf79972d57..6e5cfe648d09 100644
--- a/docs/source/en/model_doc/donut.md
+++ b/docs/source/en/model_doc/donut.md
@@ -34,14 +34,14 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
[here](https://github.com/clovaai/donut).
-Tips:
+## Usage tips
- The quickest way to get started with Donut is by checking the [tutorial
notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Donut), which show how to use the model
at inference time as well as fine-tuning on custom data.
- Donut is always used within the [VisionEncoderDecoder](vision-encoder-decoder) framework.
-## Inference
+## Inference examples
Donut's [`VisionEncoderDecoder`] model accepts images as input and makes use of
[`~generation.GenerationMixin.generate`] to autoregressively generate text given the input image.
diff --git a/docs/source/en/model_doc/dpr.md b/docs/source/en/model_doc/dpr.md
index 10bc76b72dd6..8b9f352b637b 100644
--- a/docs/source/en/model_doc/dpr.md
+++ b/docs/source/en/model_doc/dpr.md
@@ -43,7 +43,8 @@ benchmarks.*
This model was contributed by [lhoestq](https://huggingface.co/lhoestq). The original code can be found [here](https://github.com/facebookresearch/DPR).
-Tips:
+## Usage tips
+
- DPR consists in three models:
* Question encoder: encode questions as vectors
@@ -86,6 +87,9 @@ Tips:
[[autodoc]] models.dpr.modeling_dpr.DPRReaderOutput
+
+
+
## DPRContextEncoder
[[autodoc]] DPRContextEncoder
@@ -101,6 +105,9 @@ Tips:
[[autodoc]] DPRReader
- forward
+
+
+
## TFDPRContextEncoder
[[autodoc]] TFDPRContextEncoder
@@ -115,3 +122,7 @@ Tips:
[[autodoc]] TFDPRReader
- call
+
+
+
+
diff --git a/docs/source/en/model_doc/dpt.md b/docs/source/en/model_doc/dpt.md
index 5e3e25343cdd..a02313a31235 100644
--- a/docs/source/en/model_doc/dpt.md
+++ b/docs/source/en/model_doc/dpt.md
@@ -32,6 +32,21 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/isl-org/DPT).
+## Usage tips
+
+DPT is compatible with the [`AutoBackbone`] class. This allows to use the DPT framework with various computer vision backbones available in the library, such as [`VitDetBackbone`] or [`Dinov2Backbone`]. One can create it as follows:
+
+```python
+from transformers import Dinov2Config, DPTConfig, DPTForDepthEstimation
+
+# initialize with a Transformer-based backbone such as DINOv2
+# in that case, we also specify `reshape_hidden_states=False` to get feature maps of shape (batch_size, num_channels, height, width)
+backbone_config = Dinov2Config.from_pretrained("facebook/dinov2-base", out_features=["stage1", "stage2", "stage3", "stage4"], reshape_hidden_states=False)
+
+config = DPTConfig(backbone_config=backbone_config)
+model = DPTForDepthEstimation(config=config)
+```
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DPT.
diff --git a/docs/source/en/model_doc/efficientformer.md b/docs/source/en/model_doc/efficientformer.md
index 1f16f9811b77..92ba90a9e5ed 100644
--- a/docs/source/en/model_doc/efficientformer.md
+++ b/docs/source/en/model_doc/efficientformer.md
@@ -56,6 +56,9 @@ The original code can be found [here](https://github.com/snap-research/Efficient
[[autodoc]] EfficientFormerImageProcessor
- preprocess
+
+
+
## EfficientFormerModel
[[autodoc]] EfficientFormerModel
@@ -71,6 +74,9 @@ The original code can be found [here](https://github.com/snap-research/Efficient
[[autodoc]] EfficientFormerForImageClassificationWithTeacher
- forward
+
+
+
## TFEfficientFormerModel
[[autodoc]] TFEfficientFormerModel
@@ -85,3 +91,6 @@ The original code can be found [here](https://github.com/snap-research/Efficient
[[autodoc]] TFEfficientFormerForImageClassificationWithTeacher
- call
+
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/electra.md b/docs/source/en/model_doc/electra.md
index 26830950ae3a..700c49df7993 100644
--- a/docs/source/en/model_doc/electra.md
+++ b/docs/source/en/model_doc/electra.md
@@ -50,7 +50,9 @@ using 30x more compute) on the GLUE natural language understanding benchmark. Ou
where it performs comparably to RoBERTa and XLNet while using less than 1/4 of their compute and outperforms them when
using the same amount of compute.*
-Tips:
+This model was contributed by [lysandre](https://huggingface.co/lysandre). The original code can be found [here](https://github.com/google-research/electra).
+
+## Usage tips
- ELECTRA is the pretraining approach, therefore there is nearly no changes done to the underlying model: BERT. The
only change is the separation of the embedding size and the hidden size: the embedding size is generally smaller,
@@ -66,9 +68,7 @@ Tips:
[`ElectraForPreTraining`] model (the classification head will be randomly initialized as it
doesn't exist in the generator).
-This model was contributed by [lysandre](https://huggingface.co/lysandre). The original code can be found [here](https://github.com/google-research/electra).
-
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -95,6 +95,9 @@ This model was contributed by [lysandre](https://huggingface.co/lysandre). The o
[[autodoc]] models.electra.modeling_tf_electra.TFElectraForPreTrainingOutput
+
+
+
## ElectraModel
[[autodoc]] ElectraModel
@@ -135,6 +138,9 @@ This model was contributed by [lysandre](https://huggingface.co/lysandre). The o
[[autodoc]] ElectraForQuestionAnswering
- forward
+
+
+
## TFElectraModel
[[autodoc]] TFElectraModel
@@ -170,6 +176,9 @@ This model was contributed by [lysandre](https://huggingface.co/lysandre). The o
[[autodoc]] TFElectraForQuestionAnswering
- call
+
+
+
## FlaxElectraModel
[[autodoc]] FlaxElectraModel
@@ -209,3 +218,6 @@ This model was contributed by [lysandre](https://huggingface.co/lysandre). The o
[[autodoc]] FlaxElectraForQuestionAnswering
- __call__
+
+
+
diff --git a/docs/source/en/model_doc/encodec.md b/docs/source/en/model_doc/encodec.md
index bc7f64676eee..856f8be2b80a 100644
--- a/docs/source/en/model_doc/encodec.md
+++ b/docs/source/en/model_doc/encodec.md
@@ -26,6 +26,9 @@ The abstract from the paper is the following:
This model was contributed by [Matthijs](https://huggingface.co/Matthijs), [Patrick Von Platen](https://huggingface.co/patrickvonplaten) and [Arthur Zucker](https://huggingface.co/ArthurZ).
The original code can be found [here](https://github.com/facebookresearch/encodec).
+
+## Usage example
+
Here is a quick example of how to encode and decode an audio using this model:
```python
@@ -45,7 +48,6 @@ Here is a quick example of how to encode and decode an audio using this model:
>>> audio_values = model(inputs["input_values"], inputs["padding_mask"]).audio_values
```
-
## EncodecConfig
[[autodoc]] EncodecConfig
diff --git a/docs/source/en/model_doc/encoder-decoder.md b/docs/source/en/model_doc/encoder-decoder.md
index 8e26a3b9e407..54c9f7506476 100644
--- a/docs/source/en/model_doc/encoder-decoder.md
+++ b/docs/source/en/model_doc/encoder-decoder.md
@@ -149,20 +149,32 @@ were contributed by [ydshieh](https://github.com/ydshieh).
[[autodoc]] EncoderDecoderConfig
+
+
+
## EncoderDecoderModel
[[autodoc]] EncoderDecoderModel
- forward
- from_encoder_decoder_pretrained
+
+
+
## TFEncoderDecoderModel
[[autodoc]] TFEncoderDecoderModel
- call
- from_encoder_decoder_pretrained
+
+
+
## FlaxEncoderDecoderModel
[[autodoc]] FlaxEncoderDecoderModel
- __call__
- from_encoder_decoder_pretrained
+
+
+
diff --git a/docs/source/en/model_doc/ernie.md b/docs/source/en/model_doc/ernie.md
index a64291a7d4f5..a5110b2d7b73 100644
--- a/docs/source/en/model_doc/ernie.md
+++ b/docs/source/en/model_doc/ernie.md
@@ -23,7 +23,7 @@ including [ERNIE1.0](https://arxiv.org/abs/1904.09223), [ERNIE2.0](https://ojs.a
These models are contributed by [nghuyong](https://huggingface.co/nghuyong) and the official code can be found in [PaddleNLP](https://github.com/PaddlePaddle/PaddleNLP) (in PaddlePaddle).
-### How to use
+### Usage example
Take `ernie-1.0-base-zh` as an example:
```Python
@@ -32,7 +32,7 @@ tokenizer = AutoTokenizer.from_pretrained("nghuyong/ernie-1.0-base-zh")
model = AutoModel.from_pretrained("nghuyong/ernie-1.0-base-zh")
```
-### Supported Models
+### Model checkpoints
| Model Name | Language | Description |
|:-------------------:|:--------:|:-------------------------------:|
@@ -51,7 +51,7 @@ You can find all the supported models from huggingface's model hub: [huggingface
repo: [PaddleNLP](https://paddlenlp.readthedocs.io/zh/latest/model_zoo/transformers/ERNIE/contents.html)
and [ERNIE](https://github.com/PaddlePaddle/ERNIE/blob/repro).
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
diff --git a/docs/source/en/model_doc/ernie_m.md b/docs/source/en/model_doc/ernie_m.md
index 83e08e09bfcf..a99332cb655a 100644
--- a/docs/source/en/model_doc/ernie_m.md
+++ b/docs/source/en/model_doc/ernie_m.md
@@ -25,18 +25,17 @@ Hao Tian, Hua Wu, Haifeng Wang.
The abstract from the paper is the following:
*Recent studies have demonstrated that pre-trained cross-lingual models achieve impressive performance in downstream cross-lingual tasks. This improvement benefits from learning a large amount of monolingual and parallel corpora. Although it is generally acknowledged that parallel corpora are critical for improving the model performance, existing methods are often constrained by the size of parallel corpora, especially for lowresource languages. In this paper, we propose ERNIE-M, a new training method that encourages the model to align the representation of multiple languages with monolingual corpora, to overcome the constraint that the parallel corpus size places on the model performance. Our key insight is to integrate back-translation into the pre-training process. We generate pseudo-parallel sentence pairs on a monolingual corpus to enable the learning of semantic alignments between different languages, thereby enhancing the semantic modeling of cross-lingual models. Experimental results show that ERNIE-M outperforms existing cross-lingual models and delivers new state-of-the-art results in various cross-lingual downstream tasks.*
+This model was contributed by [Susnato Dhar](https://huggingface.co/susnato). The original code can be found [here](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/paddlenlp/transformers/ernie_m).
-Tips:
-
-1. Ernie-M is a BERT-like model so it is a stacked Transformer Encoder.
-2. Instead of using MaskedLM for pretraining (like BERT) the authors used two novel techniques: `Cross-attention Masked Language Modeling` and `Back-translation Masked Language Modeling`. For now these two LMHead objectives are not implemented here.
-3. It is a multilingual language model.
-4. Next Sentence Prediction was not used in pretraining process.
+## Usage tips
-This model was contributed by [Susnato Dhar](https://huggingface.co/susnato). The original code can be found [here](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/paddlenlp/transformers/ernie_m).
+- Ernie-M is a BERT-like model so it is a stacked Transformer Encoder.
+- Instead of using MaskedLM for pretraining (like BERT) the authors used two novel techniques: `Cross-attention Masked Language Modeling` and `Back-translation Masked Language Modeling`. For now these two LMHead objectives are not implemented here.
+- It is a multilingual language model.
+- Next Sentence Prediction was not used in pretraining process.
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
diff --git a/docs/source/en/model_doc/esm.md b/docs/source/en/model_doc/esm.md
index 47b25650847e..46bab860ff4d 100644
--- a/docs/source/en/model_doc/esm.md
+++ b/docs/source/en/model_doc/esm.md
@@ -17,6 +17,7 @@ rendered properly in your Markdown viewer.
# ESM
## Overview
+
This page provides code and pre-trained weights for Transformer protein language models from Meta AI's Fundamental
AI Research Team, providing the state-of-the-art ESMFold and ESM-2, and the previously released ESM-1b and ESM-1v.
Transformer protein language models were introduced in the paper [Biological structure and function emerge from scaling
@@ -73,11 +74,6 @@ sequences with low perplexity that are well understood by the language model. ES
order of magnitude faster than AlphaFold2, enabling exploration of the structural space of metagenomic
proteins in practical timescales.*
-
-Tips:
-
-- ESM models are trained with a masked language modeling (MLM) objective.
-
The original code can be found [here](https://github.com/facebookresearch/esm) and was
was developed by the Fundamental AI Research team at Meta AI.
ESM-1b, ESM-1v and ESM-2 were contributed to huggingface by [jasonliu](https://huggingface.co/jasonliu)
@@ -87,10 +83,12 @@ ESMFold was contributed to huggingface by [Matt](https://huggingface.co/Rocketkn
[Sylvain](https://huggingface.co/sgugger), with a big thank you to Nikita Smetanin, Roshan Rao and Tom Sercu for their
help throughout the process!
-The HuggingFace port of ESMFold uses portions of the [openfold](https://github.com/aqlaboratory/openfold) library.
-The `openfold` library is licensed under the Apache License 2.0.
+## Usage tips
-## Documentation resources
+- ESM models are trained with a masked language modeling (MLM) objective.
+- The HuggingFace port of ESMFold uses portions of the [openfold](https://github.com/aqlaboratory/openfold) library. The `openfold` library is licensed under the Apache License 2.0.
+
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -109,6 +107,8 @@ The `openfold` library is licensed under the Apache License 2.0.
- create_token_type_ids_from_sequences
- save_vocabulary
+
+
## EsmModel
@@ -135,6 +135,9 @@ The `openfold` library is licensed under the Apache License 2.0.
[[autodoc]] EsmForProteinFolding
- forward
+
+
+
## TFEsmModel
[[autodoc]] TFEsmModel
@@ -154,3 +157,6 @@ The `openfold` library is licensed under the Apache License 2.0.
[[autodoc]] TFEsmForTokenClassification
- call
+
+
+
diff --git a/docs/source/en/model_doc/flan-t5.md b/docs/source/en/model_doc/flan-t5.md
index 5d781f75b179..c0fd6b0011cc 100644
--- a/docs/source/en/model_doc/flan-t5.md
+++ b/docs/source/en/model_doc/flan-t5.md
@@ -48,6 +48,10 @@ Google has released the following variants:
- [google/flan-t5-xxl](https://huggingface.co/google/flan-t5-xxl).
-One can refer to [T5's documentation page](t5) for all tips, code examples and notebooks. As well as the FLAN-T5 model card for more details regarding training and evaluation of the model.
-
The original checkpoints can be found [here](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints).
+
+
+
+Refer to [T5's documentation page](t5) for all API reference, code examples and notebooks. For more details regarding training and evaluation of the FLAN-T5, refer to the model card.
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/flan-ul2.md b/docs/source/en/model_doc/flan-ul2.md
index 40fad51def6f..5487bb779760 100644
--- a/docs/source/en/model_doc/flan-ul2.md
+++ b/docs/source/en/model_doc/flan-ul2.md
@@ -21,7 +21,6 @@ rendered properly in your Markdown viewer.
Flan-UL2 is an encoder decoder model based on the T5 architecture. It uses the same configuration as the [UL2](ul2) model released earlier last year.
It was fine tuned using the "Flan" prompt tuning and dataset collection. Similar to `Flan-T5`, one can directly use FLAN-UL2 weights without finetuning the model:
-
According to the original blog here are the notable improvements:
- The original UL2 model was only trained with receptive field of 512, which made it non-ideal for N-shot prompting where N is large.
@@ -29,9 +28,6 @@ According to the original blog here are the notable improvements:
- The original UL2 model also had mode switch tokens that was rather mandatory to get good performance. However, they were a little cumbersome as this requires often some changes during inference or finetuning. In this update/change, we continue training UL2 20B for an additional 100k steps (with small batch) to forget “mode tokens” before applying Flan instruction tuning. This Flan-UL2 checkpoint does not require mode tokens anymore.
Google has released the following variants:
-
-One can refer to [T5's documentation page](t5) for all tips, code examples and notebooks. As well as the FLAN-T5 model card for more details regarding training and evaluation of the model.
-
The original checkpoints can be found [here](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints).
@@ -51,6 +47,8 @@ The model is pretty heavy (~40GB in half precision) so if you just want to run t
['In a large skillet, brown the ground beef and onion over medium heat. Add the garlic']
```
-## Inference
+
+
+Refer to [T5's documentation page](t5) for API reference, tips, code examples and notebooks.
-The inference protocol is exactly the same as any `T5` model, please have a look at the [T5's documentation page](t5) for more details.
+
diff --git a/docs/source/en/model_doc/flaubert.md b/docs/source/en/model_doc/flaubert.md
index 3e85bd6fa9d9..04bcc2638ac9 100644
--- a/docs/source/en/model_doc/flaubert.md
+++ b/docs/source/en/model_doc/flaubert.md
@@ -50,7 +50,7 @@ This model was contributed by [formiel](https://huggingface.co/formiel). The ori
Tips:
- Like RoBERTa, without the sentence ordering prediction (so just trained on the MLM objective).
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -66,6 +66,9 @@ Tips:
[[autodoc]] FlaubertTokenizer
+
+
+
## FlaubertModel
[[autodoc]] FlaubertModel
@@ -101,6 +104,9 @@ Tips:
[[autodoc]] FlaubertForQuestionAnswering
- forward
+
+
+
## TFFlaubertModel
[[autodoc]] TFFlaubertModel
@@ -130,3 +136,9 @@ Tips:
[[autodoc]] TFFlaubertForQuestionAnsweringSimple
- call
+
+
+
+
+
+
diff --git a/docs/source/en/model_doc/flava.md b/docs/source/en/model_doc/flava.md
index ae9da0d184a5..d9f9f1de5146 100644
--- a/docs/source/en/model_doc/flava.md
+++ b/docs/source/en/model_doc/flava.md
@@ -33,10 +33,8 @@ at once -- a true vision and language foundation model should be good at vision
cross- and multi-modal vision and language tasks. We introduce FLAVA as such a model and demonstrate
impressive performance on a wide range of 35 tasks spanning these target modalities.*
-
This model was contributed by [aps](https://huggingface.co/aps). The original code can be found [here](https://github.com/facebookresearch/multimodal/tree/main/examples/flava).
-
## FlavaConfig
[[autodoc]] FlavaConfig
diff --git a/docs/source/en/model_doc/fnet.md b/docs/source/en/model_doc/fnet.md
index a6d862f8a1a7..1bcae678e632 100644
--- a/docs/source/en/model_doc/fnet.md
+++ b/docs/source/en/model_doc/fnet.md
@@ -37,15 +37,15 @@ sequence lengths on GPUs (and across relatively shorter lengths on TPUs). Finall
and is particularly efficient at smaller model sizes; for a fixed speed and accuracy budget, small FNet models
outperform Transformer counterparts.*
-Tips on usage:
+This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The original code can be found [here](https://github.com/google-research/google-research/tree/master/f_net).
-- The model was trained without an attention mask as it is based on Fourier Transform. The model was trained with
- maximum sequence length 512 which includes pad tokens. Hence, it is highly recommended to use the same maximum
- sequence length for fine-tuning and inference.
+## Usage tips
-This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The original code can be found [here](https://github.com/google-research/google-research/tree/master/f_net).
+The model was trained without an attention mask as it is based on Fourier Transform. The model was trained with
+maximum sequence length 512 which includes pad tokens. Hence, it is highly recommended to use the same maximum
+sequence length for fine-tuning and inference.
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
diff --git a/docs/source/en/model_doc/focalnet.md b/docs/source/en/model_doc/focalnet.md
index 21a75440b136..c4c97980f069 100644
--- a/docs/source/en/model_doc/focalnet.md
+++ b/docs/source/en/model_doc/focalnet.md
@@ -27,14 +27,9 @@ The abstract from the paper is the following:
*We propose focal modulation networks (FocalNets in short), where self-attention (SA) is completely replaced by a focal modulation mechanism for modeling token interactions in vision. Focal modulation comprises three components: (i) hierarchical contextualization, implemented using a stack of depth-wise convolutional layers, to encode visual contexts from short to long ranges, (ii) gated aggregation to selectively gather contexts for each query token based on its
content, and (iii) element-wise modulation or affine transformation to inject the aggregated context into the query. Extensive experiments show FocalNets outperform the state-of-the-art SA counterparts (e.g., Swin and Focal Transformers) with similar computational costs on the tasks of image classification, object detection, and segmentation. Specifically, FocalNets with tiny and base size achieve 82.3% and 83.9% top-1 accuracy on ImageNet-1K. After pretrained on ImageNet-22K in 224 resolution, it attains 86.5% and 87.3% top-1 accuracy when finetuned with resolution 224 and 384, respectively. When transferred to downstream tasks, FocalNets exhibit clear superiority. For object detection with Mask R-CNN, FocalNet base trained with 1\times outperforms the Swin counterpart by 2.1 points and already surpasses Swin trained with 3\times schedule (49.0 v.s. 48.5). For semantic segmentation with UPerNet, FocalNet base at single-scale outperforms Swin by 2.4, and beats Swin at multi-scale (50.5 v.s. 49.7). Using large FocalNet and Mask2former, we achieve 58.5 mIoU for ADE20K semantic segmentation, and 57.9 PQ for COCO Panoptic Segmentation. Using huge FocalNet and DINO, we achieved 64.3 and 64.4 mAP on COCO minival and test-dev, respectively, establishing new SoTA on top of much larger attention-based models like Swinv2-G and BEIT-3.*
-Tips:
-
-- One can use the [`AutoImageProcessor`] class to prepare images for the model.
-
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/microsoft/FocalNet).
-
## FocalNetConfig
[[autodoc]] FocalNetConfig
diff --git a/docs/source/en/model_doc/fsmt.md b/docs/source/en/model_doc/fsmt.md
index 49625f6c472e..9419dce71edf 100644
--- a/docs/source/en/model_doc/fsmt.md
+++ b/docs/source/en/model_doc/fsmt.md
@@ -16,9 +16,6 @@ rendered properly in your Markdown viewer.
# FSMT
-**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
-@stas00.
-
## Overview
FSMT (FairSeq MachineTranslation) models were introduced in [Facebook FAIR's WMT19 News Translation Task Submission](https://arxiv.org/abs/1907.06616) by Nathan Ng, Kyra Yee, Alexei Baevski, Myle Ott, Michael Auli, Sergey Edunov.
diff --git a/docs/source/en/model_doc/funnel.md b/docs/source/en/model_doc/funnel.md
index 3cc4eb0aaed6..d6929691f400 100644
--- a/docs/source/en/model_doc/funnel.md
+++ b/docs/source/en/model_doc/funnel.md
@@ -47,7 +47,9 @@ via a decoder. Empirically, with comparable or fewer FLOPs, Funnel-Transformer o
a wide variety of sequence-level prediction tasks, including text classification, language understanding, and reading
comprehension.*
-Tips:
+This model was contributed by [sgugger](https://huggingface.co/sgugger). The original code can be found [here](https://github.com/laiguokun/Funnel-Transformer).
+
+## Usage tips
- Since Funnel Transformer uses pooling, the sequence length of the hidden states changes after each block of layers. This way, their length is divided by 2, which speeds up the computation of the next hidden states.
The base model therefore has a final sequence length that is a quarter of the original one. This model can be used
@@ -62,9 +64,7 @@ Tips:
[`FunnelBaseModel`], [`FunnelForSequenceClassification`] and
[`FunnelForMultipleChoice`].
-This model was contributed by [sgugger](https://huggingface.co/sgugger). The original code can be found [here](https://github.com/laiguokun/Funnel-Transformer).
-
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -95,6 +95,9 @@ This model was contributed by [sgugger](https://huggingface.co/sgugger). The ori
[[autodoc]] models.funnel.modeling_tf_funnel.TFFunnelForPreTrainingOutput
+
+
+
## FunnelBaseModel
[[autodoc]] FunnelBaseModel
@@ -135,6 +138,9 @@ This model was contributed by [sgugger](https://huggingface.co/sgugger). The ori
[[autodoc]] FunnelForQuestionAnswering
- forward
+
+
+
## TFFunnelBaseModel
[[autodoc]] TFFunnelBaseModel
@@ -174,3 +180,6 @@ This model was contributed by [sgugger](https://huggingface.co/sgugger). The ori
[[autodoc]] TFFunnelForQuestionAnswering
- call
+
+
+
diff --git a/docs/source/en/model_doc/git.md b/docs/source/en/model_doc/git.md
index b0c96200af3c..bffa98b89e3b 100644
--- a/docs/source/en/model_doc/git.md
+++ b/docs/source/en/model_doc/git.md
@@ -27,11 +27,6 @@ The abstract from the paper is the following:
*In this paper, we design and train a Generative Image-to-text Transformer, GIT, to unify vision-language tasks such as image/video captioning and question answering. While generative models provide a consistent network architecture between pre-training and fine-tuning, existing work typically contains complex structures (uni/multi-modal encoder/decoder) and depends on external modules such as object detectors/taggers and optical character recognition (OCR). In GIT, we simplify the architecture as one image encoder and one text decoder under a single language modeling task. We also scale up the pre-training data and the model size to boost the model performance. Without bells and whistles, our GIT establishes new state of the arts on 12 challenging benchmarks with a large margin. For instance, our model surpasses the human performance for the first time on TextCaps (138.2 vs. 125.5 in CIDEr). Furthermore, we present a new scheme of generation-based image classification and scene text recognition, achieving decent performance on standard benchmarks.*
-Tips:
-
-- GIT is implemented in a very similar way to GPT-2, the only difference being that the model is also conditioned on `pixel_values`.
-- One can use [`GitProcessor`] to prepare images for the model, and the `generate` method for autoregressive generation.
-
@@ -40,6 +35,10 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/microsoft/GenerativeImage2Text).
+## Usage tips
+
+- GIT is implemented in a very similar way to GPT-2, the only difference being that the model is also conditioned on `pixel_values`.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GIT.
diff --git a/docs/source/en/model_doc/glpn.md b/docs/source/en/model_doc/glpn.md
index be9a7d2d7910..b57d1a7ccdda 100644
--- a/docs/source/en/model_doc/glpn.md
+++ b/docs/source/en/model_doc/glpn.md
@@ -33,10 +33,6 @@ The abstract from the paper is the following:
*Depth estimation from a single image is an important task that can be applied to various fields in computer vision, and has grown rapidly with the development of convolutional neural networks. In this paper, we propose a novel structure and training strategy for monocular depth estimation to further improve the prediction accuracy of the network. We deploy a hierarchical transformer encoder to capture and convey the global context, and design a lightweight yet powerful decoder to generate an estimated depth map while considering local connectivity. By constructing connected paths between multi-scale local features and the global decoding stream with our proposed selective feature fusion module, the network can integrate both representations and recover fine details. In addition, the proposed decoder shows better performance than the previously proposed decoders, with considerably less computational complexity. Furthermore, we improve the depth-specific augmentation method by utilizing an important observation in depth estimation to enhance the model. Our network achieves state-of-the-art performance over the challenging depth dataset NYU Depth V2. Extensive experiments have been conducted to validate and show the effectiveness of the proposed approach. Finally, our model shows better generalisation ability and robustness than other comparative models.*
-Tips:
-
-- One can use [`GLPNImageProcessor`] to prepare images for the model.
-
diff --git a/docs/source/en/model_doc/gpt-sw3.md b/docs/source/en/model_doc/gpt-sw3.md
index 286cac12c998..f4d34a07212c 100644
--- a/docs/source/en/model_doc/gpt-sw3.md
+++ b/docs/source/en/model_doc/gpt-sw3.md
@@ -32,12 +32,8 @@ causal language modeling (CLM) objective utilizing the NeMo Megatron GPT impleme
This model was contributed by [AI Sweden](https://huggingface.co/AI-Sweden).
-The implementation uses the [GPT2Model](https://huggingface.co/docs/transformers/model_doc/gpt2) coupled
-with our `GPTSw3Tokenizer`. This means that `AutoTokenizer` and `AutoModelForCausalLM` map to our tokenizer
-implementation and the corresponding GPT2 model implementation respectively.
-*Note that sentencepiece is required to use our tokenizer and can be installed with:* `pip install transformers[sentencepiece]` or `pip install sentencepiece`
+## Usage example
-Example usage:
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
@@ -52,12 +48,21 @@ Example usage:
Träd är fina för att de är färgstarka. Men ibland är det fint
```
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
+
+
+The implementation uses the `GPT2Model` coupled with our `GPTSw3Tokenizer`. Refer to [GPT2Model documentation](gpt2)
+for API reference and examples.
+
+Note that sentencepiece is required to use our tokenizer and can be installed with `pip install transformers[sentencepiece]` or `pip install sentencepiece`
+
+
+
## GPTSw3Tokenizer
[[autodoc]] GPTSw3Tokenizer
diff --git a/docs/source/en/model_doc/gpt2.md b/docs/source/en/model_doc/gpt2.md
index 878bf84a3fac..4708edde0b65 100644
--- a/docs/source/en/model_doc/gpt2.md
+++ b/docs/source/en/model_doc/gpt2.md
@@ -39,7 +39,13 @@ text. The diversity of the dataset causes this simple goal to contain naturally
across diverse domains. GPT-2 is a direct scale-up of GPT, with more than 10X the parameters and trained on more than
10X the amount of data.*
-Tips:
+[Write With Transformer](https://transformer.huggingface.co/doc/gpt2-large) is a webapp created and hosted by
+Hugging Face showcasing the generative capabilities of several models. GPT-2 is one of them and is available in five
+different sizes: small, medium, large, xl and a distilled version of the small checkpoint: *distilgpt-2*.
+
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://openai.com/blog/better-language-models/).
+
+## Usage tips
- GPT-2 is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
@@ -54,12 +60,6 @@ Tips:
- Enabling the *scale_attn_by_inverse_layer_idx* and *reorder_and_upcast_attn* flags will apply the training stability
improvements from [Mistral](https://github.com/stanford-crfm/mistral/) (for PyTorch only).
-[Write With Transformer](https://transformer.huggingface.co/doc/gpt2-large) is a webapp created and hosted by
-Hugging Face showcasing the generative capabilities of several models. GPT-2 is one of them and is available in five
-different sizes: small, medium, large, xl and a distilled version of the small checkpoint: *distilgpt-2*.
-
-This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://openai.com/blog/better-language-models/).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GPT2. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
@@ -100,6 +100,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] models.gpt2.modeling_tf_gpt2.TFGPT2DoubleHeadsModelOutput
+
+
+
## GPT2Model
[[autodoc]] GPT2Model
@@ -130,6 +133,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] GPT2ForTokenClassification
- forward
+
+
+
## TFGPT2Model
[[autodoc]] TFGPT2Model
@@ -158,6 +164,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] TFGPT2Tokenizer
+
+
+
## FlaxGPT2Model
[[autodoc]] FlaxGPT2Model
@@ -167,3 +176,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] FlaxGPT2LMHeadModel
- __call__
+
+
+
diff --git a/docs/source/en/model_doc/gpt_bigcode.md b/docs/source/en/model_doc/gpt_bigcode.md
index 6965d5837d8e..0f3bc72d03a5 100644
--- a/docs/source/en/model_doc/gpt_bigcode.md
+++ b/docs/source/en/model_doc/gpt_bigcode.md
@@ -20,13 +20,13 @@ rendered properly in your Markdown viewer.
The GPTBigCode model was proposed in [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by BigCode. The listed authors are: Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
-The abstract from the paper is the following:uery
+The abstract from the paper is the following:
*The BigCode project is an open-scientific collaboration working on the responsible development of large language models for code. This tech report describes the progress of the collaboration until December 2022, outlining the current state of the Personally Identifiable Information (PII) redaction pipeline, the experiments conducted to de-risk the model architecture, and the experiments investigating better preprocessing methods for the training data. We train 1.1B parameter models on the Java, JavaScript, and Python subsets of The Stack and evaluate them on the MultiPL-E text-to-code benchmark. We find that more aggressive filtering of near-duplicates can further boost performance and, surprisingly, that selecting files from repositories with 5+ GitHub stars deteriorates performance significantly. Our best model outperforms previous open-source multilingual code generation models (InCoder-6.7B and CodeGen-Multi-2.7B) in both left-to-right generation and infilling on the Java, JavaScript, and Python portions of MultiPL-E, despite being a substantially smaller model. All models are released under an OpenRAIL license at [this https URL.](https://huggingface.co/bigcode)*
-The model is a an optimized [GPT2 model](https://huggingface.co/docs/transformers/model_doc/gpt2) with support for Multi-Query Attention.
+The model is an optimized [GPT2 model](https://huggingface.co/docs/transformers/model_doc/gpt2) with support for Multi-Query Attention.
-## Technical details
+## Implementation details
The main differences compared to GPT2.
- Added support for Multi-Query Attention.
@@ -42,11 +42,49 @@ The main differences compared to GPT2.
You can read more about the optimizations in the [original pull request](https://github.com/huggingface/transformers/pull/22575)
+## Combining Starcoder and Flash Attention 2
+
+First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
+
+To load and run a model using Flash Attention 2, refer to the snippet below:
+
+```python
+>>> import torch
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = AutoModelForCausalLM.from_pretrained("bigcode/gpt_bigcode-santacoder", torch_dtype=torch.float16, use_flash_attention_2=True)
+>>> tokenizer = AutoTokenizer.from_pretrained("bigcode/gpt_bigcode-santacoder")
+
+>>> prompt = "def hello_world():"
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=30, do_sample=False)
+>>> tokenizer.batch_decode(generated_ids)[0]
+'def hello_world():\n print("hello world")\n\nif __name__ == "__main__":\n print("hello world")\n<|endoftext|>'
+```
+
+### Expected speedups
+
+Below is a expected speedup diagram that compares pure inference time between the native implementation in transformers using `bigcode/starcoder` checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
+
+
+
+
+
+
## GPTBigCodeConfig
[[autodoc]] GPTBigCodeConfig
-
## GPTBigCodeModel
[[autodoc]] GPTBigCodeModel
@@ -57,7 +95,6 @@ You can read more about the optimizations in the [original pull request](https:/
[[autodoc]] GPTBigCodeForCausalLM
- forward
-
## GPTBigCodeForSequenceClassification
[[autodoc]] GPTBigCodeForSequenceClassification
diff --git a/docs/source/en/model_doc/gpt_neo.md b/docs/source/en/model_doc/gpt_neo.md
index 6b925aad10e4..fb2385bc73db 100644
--- a/docs/source/en/model_doc/gpt_neo.md
+++ b/docs/source/en/model_doc/gpt_neo.md
@@ -27,7 +27,7 @@ The architecture is similar to GPT2 except that GPT Neo uses local attention in
This model was contributed by [valhalla](https://huggingface.co/valhalla).
-### Generation
+## Usage example
The `generate()` method can be used to generate text using GPT Neo model.
@@ -54,7 +54,47 @@ The `generate()` method can be used to generate text using GPT Neo model.
>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
```
-## Documentation resources
+## Combining GPT-Neo and Flash Attention 2
+
+First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
+
+To load and run a model using Flash Attention 2, refer to the snippet below:
+
+```python
+>>> import torch
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-neo-2.7B", torch_dtype=torch.float16, use_flash_attention_2=True)
+>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-2.7B")
+
+>>> prompt = "def hello_world():"
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"def hello_world():\n >>> run_script("hello.py")\n >>> exit(0)\n<|endoftext|>"
+```
+
+### Expected speedups
+
+Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `EleutherAI/gpt-neo-2.7B` checkpoint and the Flash Attention 2 version of the model.
+Note that for GPT-Neo it is not possible to train / run on very long context as the max [position embeddings](https://huggingface.co/EleutherAI/gpt-neo-2.7B/blob/main/config.json#L58 ) is limited to 2048 - but this is applicable to all gpt-neo models and not specific to FA-2
+
+
+
+
+
+
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
@@ -63,6 +103,10 @@ The `generate()` method can be used to generate text using GPT Neo model.
[[autodoc]] GPTNeoConfig
+
+
+
+
## GPTNeoModel
[[autodoc]] GPTNeoModel
@@ -88,6 +132,9 @@ The `generate()` method can be used to generate text using GPT Neo model.
[[autodoc]] GPTNeoForTokenClassification
- forward
+
+
+
## FlaxGPTNeoModel
[[autodoc]] FlaxGPTNeoModel
@@ -97,3 +144,8 @@ The `generate()` method can be used to generate text using GPT Neo model.
[[autodoc]] FlaxGPTNeoForCausalLM
- __call__
+
+
+
+
+
diff --git a/docs/source/en/model_doc/gpt_neox.md b/docs/source/en/model_doc/gpt_neox.md
index 0ee7c8630c65..300001ad5bb1 100644
--- a/docs/source/en/model_doc/gpt_neox.md
+++ b/docs/source/en/model_doc/gpt_neox.md
@@ -38,7 +38,7 @@ model = GPTNeoXForCausalLM.from_pretrained("EleutherAI/gpt-neox-20b").half().cud
GPT-NeoX-20B also has a different tokenizer from the one used in GPT-J-6B and GPT-Neo. The new tokenizer allocates
additional tokens to whitespace characters, making the model more suitable for certain tasks like code generation.
-### Generation
+## Usage example
The `generate()` method can be used to generate text using GPT Neo model.
@@ -61,7 +61,7 @@ The `generate()` method can be used to generate text using GPT Neo model.
>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
```
-## Documentation resources
+## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
diff --git a/docs/source/en/model_doc/gpt_neox_japanese.md b/docs/source/en/model_doc/gpt_neox_japanese.md
index c21ba838792a..c69e643cae5b 100644
--- a/docs/source/en/model_doc/gpt_neox_japanese.md
+++ b/docs/source/en/model_doc/gpt_neox_japanese.md
@@ -25,7 +25,7 @@ Following the recommendations from Google's research on [PaLM](https://ai.google
Development of the model was led by [Shinya Otani](https://github.com/SO0529), [Takayoshi Makabe](https://github.com/spider-man-tm), [Anuj Arora](https://github.com/Anuj040), and [Kyo Hattori](https://github.com/go5paopao) from [ABEJA, Inc.](https://www.abejainc.com/). For more information on this model-building activity, please refer [here (ja)](https://tech-blog.abeja.asia/entry/abeja-gpt-project-202207).
-### Generation
+### Usage example
The `generate()` method can be used to generate text using GPT NeoX Japanese model.
@@ -51,7 +51,7 @@ The `generate()` method can be used to generate text using GPT NeoX Japanese mod
人とAIが協調するためには、AIと人が共存し、AIを正しく理解する必要があります。
```
-## Documentation resources
+## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
diff --git a/docs/source/en/model_doc/gptj.md b/docs/source/en/model_doc/gptj.md
index 5ad80a010951..b515cf36dd40 100644
--- a/docs/source/en/model_doc/gptj.md
+++ b/docs/source/en/model_doc/gptj.md
@@ -23,7 +23,7 @@ causal language model trained on [the Pile](https://pile.eleuther.ai/) dataset.
This model was contributed by [Stella Biderman](https://huggingface.co/stellaathena).
-Tips:
+## Usage tips
- To load [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6B) in float32 one would need at least 2x model size
RAM: 1x for initial weights and another 1x to load the checkpoint. So for GPT-J it would take at least 48GB
@@ -56,7 +56,7 @@ Tips:
size, the tokenizer for [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6B) contains 143 extra tokens
`<|extratoken_1|>... <|extratoken_143|>`, so the `vocab_size` of tokenizer also becomes 50400.
-### Generation
+## Usage examples
The [`~generation.GenerationMixin.generate`] method can be used to generate text using GPT-J
model.
@@ -138,6 +138,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] GPTJConfig
- all
+
+
+
## GPTJModel
[[autodoc]] GPTJModel
@@ -158,6 +161,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] GPTJForQuestionAnswering
- forward
+
+
+
## TFGPTJModel
[[autodoc]] TFGPTJModel
@@ -178,6 +184,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] TFGPTJForQuestionAnswering
- call
+
+
+
## FlaxGPTJModel
[[autodoc]] FlaxGPTJModel
@@ -187,3 +196,5 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] FlaxGPTJForCausalLM
- __call__
+
+
diff --git a/docs/source/en/model_doc/gptsan-japanese.md b/docs/source/en/model_doc/gptsan-japanese.md
index 48f67f850655..1e6b1b6e1cf6 100644
--- a/docs/source/en/model_doc/gptsan-japanese.md
+++ b/docs/source/en/model_doc/gptsan-japanese.md
@@ -24,7 +24,7 @@ GPTSAN is a Japanese language model using Switch Transformer. It has the same st
in the T5 paper, and support both Text Generation and Masked Language Modeling tasks. These basic tasks similarly can
fine-tune for translation or summarization.
-### Generation
+### Usage example
The `generate()` method can be used to generate text using GPTSAN-Japanese model.
@@ -56,7 +56,7 @@ This length applies to the text entered in `prefix_text` for the tokenizer.
The tokenizer returns the mask of the `Prefix` part of Prefix-LM as `token_type_ids`.
The model treats the part where `token_type_ids` is 1 as a `Prefix` part, that is, the input can refer to both tokens before and after.
-Tips:
+## Usage tips
Specifying the Prefix part is done with a mask passed to self-attention.
When token_type_ids=None or all zero, it is equivalent to regular causal mask
diff --git a/docs/source/en/model_doc/graphormer.md b/docs/source/en/model_doc/graphormer.md
index 16d61bccbef0..08e3f5fb3e9b 100644
--- a/docs/source/en/model_doc/graphormer.md
+++ b/docs/source/en/model_doc/graphormer.md
@@ -23,26 +23,24 @@ The abstract from the paper is the following:
*The Transformer architecture has become a dominant choice in many domains, such as natural language processing and computer vision. Yet, it has not achieved competitive performance on popular leaderboards of graph-level prediction compared to mainstream GNN variants. Therefore, it remains a mystery how Transformers could perform well for graph representation learning. In this paper, we solve this mystery by presenting Graphormer, which is built upon the standard Transformer architecture, and could attain excellent results on a broad range of graph representation learning tasks, especially on the recent OGB Large-Scale Challenge. Our key insight to utilizing Transformer in the graph is the necessity of effectively encoding the structural information of a graph into the model. To this end, we propose several simple yet effective structural encoding methods to help Graphormer better model graph-structured data. Besides, we mathematically characterize the expressive power of Graphormer and exhibit that with our ways of encoding the structural information of graphs, many popular GNN variants could be covered as the special cases of Graphormer.*
-Tips:
+This model was contributed by [clefourrier](https://huggingface.co/clefourrier). The original code can be found [here](https://github.com/microsoft/Graphormer).
+
+## Usage tips
This model will not work well on large graphs (more than 100 nodes/edges), as it will make the memory explode.
You can reduce the batch size, increase your RAM, or decrease the `UNREACHABLE_NODE_DISTANCE` parameter in algos_graphormer.pyx, but it will be hard to go above 700 nodes/edges.
This model does not use a tokenizer, but instead a special collator during training.
-This model was contributed by [clefourrier](https://huggingface.co/clefourrier). The original code can be found [here](https://github.com/microsoft/Graphormer).
-
## GraphormerConfig
[[autodoc]] GraphormerConfig
-
## GraphormerModel
[[autodoc]] GraphormerModel
- forward
-
## GraphormerForGraphClassification
[[autodoc]] GraphormerForGraphClassification
diff --git a/docs/source/en/model_doc/groupvit.md b/docs/source/en/model_doc/groupvit.md
index cf006e284b14..8728cf0da21b 100644
--- a/docs/source/en/model_doc/groupvit.md
+++ b/docs/source/en/model_doc/groupvit.md
@@ -25,13 +25,13 @@ The abstract from the paper is the following:
*Grouping and recognition are important components of visual scene understanding, e.g., for object detection and semantic segmentation. With end-to-end deep learning systems, grouping of image regions usually happens implicitly via top-down supervision from pixel-level recognition labels. Instead, in this paper, we propose to bring back the grouping mechanism into deep networks, which allows semantic segments to emerge automatically with only text supervision. We propose a hierarchical Grouping Vision Transformer (GroupViT), which goes beyond the regular grid structure representation and learns to group image regions into progressively larger arbitrary-shaped segments. We train GroupViT jointly with a text encoder on a large-scale image-text dataset via contrastive losses. With only text supervision and without any pixel-level annotations, GroupViT learns to group together semantic regions and successfully transfers to the task of semantic segmentation in a zero-shot manner, i.e., without any further fine-tuning. It achieves a zero-shot accuracy of 52.3% mIoU on the PASCAL VOC 2012 and 22.4% mIoU on PASCAL Context datasets, and performs competitively to state-of-the-art transfer-learning methods requiring greater levels of supervision.*
-Tips:
-
-- You may specify `output_segmentation=True` in the forward of `GroupViTModel` to get the segmentation logits of input texts.
-
This model was contributed by [xvjiarui](https://huggingface.co/xvjiarui). The TensorFlow version was contributed by [ariG23498](https://huggingface.co/ariG23498) with the help of [Yih-Dar SHIEH](https://huggingface.co/ydshieh), [Amy Roberts](https://huggingface.co/amyeroberts), and [Joao Gante](https://huggingface.co/joaogante).
The original code can be found [here](https://github.com/NVlabs/GroupViT).
+## Usage tips
+
+- You may specify `output_segmentation=True` in the forward of `GroupViTModel` to get the segmentation logits of input texts.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GroupViT.
@@ -52,6 +52,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] GroupViTVisionConfig
+
+
+
## GroupViTModel
[[autodoc]] GroupViTModel
@@ -69,6 +72,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] GroupViTVisionModel
- forward
+
+
+
## TFGroupViTModel
[[autodoc]] TFGroupViTModel
@@ -84,4 +90,7 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
## TFGroupViTVisionModel
[[autodoc]] TFGroupViTVisionModel
- - call
\ No newline at end of file
+ - call
+
+
+
diff --git a/docs/source/en/model_doc/herbert.md b/docs/source/en/model_doc/herbert.md
index ee927bddb025..0049d6bfcf3a 100644
--- a/docs/source/en/model_doc/herbert.md
+++ b/docs/source/en/model_doc/herbert.md
@@ -37,7 +37,11 @@ which has the best average performance and obtains the best results for three ou
extensive evaluation, including several standard baselines and recently proposed, multilingual Transformer-based
models.*
-Examples of use:
+This model was contributed by [rmroczkowski](https://huggingface.co/rmroczkowski). The original code can be found
+[here](https://github.com/allegro/HerBERT).
+
+
+## Usage example
```python
>>> from transformers import HerbertTokenizer, RobertaModel
@@ -56,9 +60,12 @@ Examples of use:
>>> model = AutoModel.from_pretrained("allegro/herbert-klej-cased-v1")
```
-This model was contributed by [rmroczkowski](https://huggingface.co/rmroczkowski). The original code can be found
-[here](https://github.com/allegro/HerBERT).
+
+
+Herbert implementation is the same as `BERT` except for the tokenization method. Refer to [BERT documentation](bert)
+for API reference and examples.
+
## HerbertTokenizer
diff --git a/docs/source/en/model_doc/hubert.md b/docs/source/en/model_doc/hubert.md
index 5349e1388523..43ce590d3715 100644
--- a/docs/source/en/model_doc/hubert.md
+++ b/docs/source/en/model_doc/hubert.md
@@ -36,15 +36,15 @@ state-of-the-art wav2vec 2.0 performance on the Librispeech (960h) and Libri-lig
10h, 100h, and 960h fine-tuning subsets. Using a 1B parameter model, HuBERT shows up to 19% and 13% relative WER
reduction on the more challenging dev-other and test-other evaluation subsets.*
-Tips:
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
+
+# Usage tips
- Hubert is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- Hubert model was fine-tuned using connectionist temporal classification (CTC) so the model output has to be decoded
using [`Wav2Vec2CTCTokenizer`].
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
-
-## Documentation resources
+## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
@@ -53,6 +53,9 @@ This model was contributed by [patrickvonplaten](https://huggingface.co/patrickv
[[autodoc]] HubertConfig
+
+
+
## HubertModel
[[autodoc]] HubertModel
@@ -68,6 +71,9 @@ This model was contributed by [patrickvonplaten](https://huggingface.co/patrickv
[[autodoc]] HubertForSequenceClassification
- forward
+
+
+
## TFHubertModel
[[autodoc]] TFHubertModel
@@ -77,3 +83,6 @@ This model was contributed by [patrickvonplaten](https://huggingface.co/patrickv
[[autodoc]] TFHubertForCTC
- call
+
+
+
diff --git a/docs/source/en/model_doc/ibert.md b/docs/source/en/model_doc/ibert.md
index 9c5f9c3e8de6..9ea623951aec 100644
--- a/docs/source/en/model_doc/ibert.md
+++ b/docs/source/en/model_doc/ibert.md
@@ -40,7 +40,7 @@ been open-sourced.*
This model was contributed by [kssteven](https://huggingface.co/kssteven). The original code can be found [here](https://github.com/kssteven418/I-BERT).
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
diff --git a/docs/source/en/model_doc/idefics.md b/docs/source/en/model_doc/idefics.md
index e0017df0c52f..9989f89d682e 100644
--- a/docs/source/en/model_doc/idefics.md
+++ b/docs/source/en/model_doc/idefics.md
@@ -31,9 +31,9 @@ This model was contributed by [HuggingFaceM4](https://huggingface.co/HuggingFace
-Idefics modeling code in Transformers is for finetuning and inferencing the pre-trained Idefics models.
+IDEFICS modeling code in Transformers is for finetuning and inferencing the pre-trained IDEFICS models.
-To train a new Idefics model from scratch use the m4 codebase (a link will be provided once it's made public)
+To train a new IDEFICS model from scratch use the m4 codebase (a link will be provided once it's made public)
diff --git a/docs/source/en/model_doc/imagegpt.md b/docs/source/en/model_doc/imagegpt.md
index 01eb7dde5fc2..53a7ba3b34b7 100644
--- a/docs/source/en/model_doc/imagegpt.md
+++ b/docs/source/en/model_doc/imagegpt.md
@@ -40,7 +40,7 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr), based on [this issue](https://github.com/openai/image-gpt/issues/7). The original code can be found
[here](https://github.com/openai/image-gpt).
-Tips:
+## Usage tips
- ImageGPT is almost exactly the same as [GPT-2](gpt2), with the exception that a different activation
function is used (namely "quick gelu"), and the layer normalization layers don't mean center the inputs. ImageGPT
@@ -92,7 +92,6 @@ If you're interested in submitting a resource to be included here, please feel f
## ImageGPTFeatureExtractor
[[autodoc]] ImageGPTFeatureExtractor
-
- __call__
## ImageGPTImageProcessor
@@ -103,17 +102,14 @@ If you're interested in submitting a resource to be included here, please feel f
## ImageGPTModel
[[autodoc]] ImageGPTModel
-
- forward
## ImageGPTForCausalImageModeling
[[autodoc]] ImageGPTForCausalImageModeling
-
- forward
## ImageGPTForImageClassification
[[autodoc]] ImageGPTForImageClassification
-
- forward
diff --git a/docs/source/en/model_doc/informer.md b/docs/source/en/model_doc/informer.md
index 0d2d82a3f573..8100b2844325 100644
--- a/docs/source/en/model_doc/informer.md
+++ b/docs/source/en/model_doc/informer.md
@@ -39,13 +39,11 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] InformerConfig
-
## InformerModel
[[autodoc]] InformerModel
- forward
-
## InformerForPrediction
[[autodoc]] InformerForPrediction
diff --git a/docs/source/en/model_doc/instructblip.md b/docs/source/en/model_doc/instructblip.md
index d2cf80e50a5d..1a693493fff1 100644
--- a/docs/source/en/model_doc/instructblip.md
+++ b/docs/source/en/model_doc/instructblip.md
@@ -21,10 +21,6 @@ The abstract from the paper is the following:
*General-purpose language models that can solve various language-domain tasks have emerged driven by the pre-training and instruction-tuning pipeline. However, building general-purpose vision-language models is challenging due to the increased task discrepancy introduced by the additional visual input. Although vision-language pre-training has been widely studied, vision-language instruction tuning remains relatively less explored. In this paper, we conduct a systematic and comprehensive study on vision-language instruction tuning based on the pre-trained BLIP-2 models. We gather a wide variety of 26 publicly available datasets, transform them into instruction tuning format and categorize them into two clusters for held-in instruction tuning and held-out zero-shot evaluation. Additionally, we introduce instruction-aware visual feature extraction, a crucial method that enables the model to extract informative features tailored to the given instruction. The resulting InstructBLIP models achieve state-of-the-art zero-shot performance across all 13 held-out datasets, substantially outperforming BLIP-2 and the larger Flamingo. Our models also lead to state-of-the-art performance when finetuned on individual downstream tasks (e.g., 90.7% accuracy on ScienceQA IMG). Furthermore, we qualitatively demonstrate the advantages of InstructBLIP over concurrent multimodal models.*
-Tips:
-
-- InstructBLIP uses the same architecture as [BLIP-2](blip2) with a tiny but important difference: it also feeds the text prompt (instruction) to the Q-Former.
-
@@ -33,6 +29,9 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/salesforce/LAVIS/tree/main/projects/instructblip).
+## Usage tips
+
+InstructBLIP uses the same architecture as [BLIP-2](blip2) with a tiny but important difference: it also feeds the text prompt (instruction) to the Q-Former.
## InstructBlipConfig
diff --git a/docs/source/en/model_doc/jukebox.md b/docs/source/en/model_doc/jukebox.md
index 24a80164a2d8..a6d865d86cce 100644
--- a/docs/source/en/model_doc/jukebox.md
+++ b/docs/source/en/model_doc/jukebox.md
@@ -32,7 +32,11 @@ The metadata such as *artist, genre and timing* are passed to each prior, in the

-Tips:
+This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ).
+The original code can be found [here](https://github.com/openai/jukebox).
+
+## Usage tips
+
- This model only supports inference. This is for a few reasons, mostly because it requires a crazy amount of memory to train. Feel free to open a PR and add what's missing to have a full integration with the hugging face traineer!
- This model is very slow, and takes 8h to generate a minute long audio using the 5b top prior on a V100 GPU. In order automaticallay handle the device on which the model should execute, use `accelerate`.
- Contrary to the paper, the order of the priors goes from `0` to `1` as it felt more intuitive : we sample starting from `0`.
@@ -67,14 +71,12 @@ The original code can be found [here](https://github.com/openai/jukebox).
- upsample
- _sample
-
## JukeboxPrior
[[autodoc]] JukeboxPrior
- sample
- forward
-
## JukeboxVQVAE
[[autodoc]] JukeboxVQVAE
diff --git a/docs/source/en/model_doc/kosmos-2.md b/docs/source/en/model_doc/kosmos-2.md
new file mode 100644
index 000000000000..f799751cce84
--- /dev/null
+++ b/docs/source/en/model_doc/kosmos-2.md
@@ -0,0 +1,98 @@
+
+
+# KOSMOS-2
+
+## Overview
+
+The KOSMOS-2 model was proposed in [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
+
+KOSMOS-2 is a Transformer-based causal language model and is trained using the next-word prediction task on a web-scale
+dataset of grounded image-text pairs [GRIT](https://huggingface.co/datasets/zzliang/GRIT). The spatial coordinates of
+the bounding boxes in the dataset are converted to a sequence of location tokens, which are appended to their respective
+entity text spans (for example, `a snowman` followed by ``). The data format is
+similar to “hyperlinks” that connect the object regions in an image to their text span in the corresponding caption.
+
+The abstract from the paper is the following:
+
+*We introduce Kosmos-2, a Multimodal Large Language Model (MLLM), enabling new capabilities of perceiving object descriptions (e.g., bounding boxes) and grounding text to the visual world. Specifically, we represent refer expressions as links in Markdown, i.e., ``[text span](bounding boxes)'', where object descriptions are sequences of location tokens. Together with multimodal corpora, we construct large-scale data of grounded image-text pairs (called GrIT) to train the model. In addition to the existing capabilities of MLLMs (e.g., perceiving general modalities, following instructions, and performing in-context learning), Kosmos-2 integrates the grounding capability into downstream applications. We evaluate Kosmos-2 on a wide range of tasks, including (i) multimodal grounding, such as referring expression comprehension, and phrase grounding, (ii) multimodal referring, such as referring expression generation, (iii) perception-language tasks, and (iv) language understanding and generation. This work lays out the foundation for the development of Embodiment AI and sheds light on the big convergence of language, multimodal perception, action, and world modeling, which is a key step toward artificial general intelligence. Code and pretrained models are available at https://aka.ms/kosmos-2.*
+
+
+
+ Overview of tasks that KOSMOS-2 can handle. Taken from the original paper.
+
+## Example
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, Kosmos2ForConditionalGeneration
+
+>>> model = Kosmos2ForConditionalGeneration.from_pretrained("microsoft/kosmos-2-patch14-224")
+>>> processor = AutoProcessor.from_pretrained("microsoft/kosmos-2-patch14-224")
+
+>>> url = "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> prompt = " An image of"
+
+>>> inputs = processor(text=prompt, images=image, return_tensors="pt")
+
+>>> generated_ids = model.generate(
+... pixel_values=inputs["pixel_values"],
+... input_ids=inputs["input_ids"],
+... attention_mask=inputs["attention_mask"],
+... image_embeds=None,
+... image_embeds_position_mask=inputs["image_embeds_position_mask"],
+... use_cache=True,
+... max_new_tokens=64,
+... )
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
+>>> processed_text = processor.post_process_generation(generated_text, cleanup_and_extract=False)
+>>> processed_text
+' An image of a snowman warming himself by a fire.'
+
+>>> caption, entities = processor.post_process_generation(generated_text)
+>>> caption
+'An image of a snowman warming himself by a fire.'
+
+>>> entities
+[('a snowman', (12, 21), [(0.390625, 0.046875, 0.984375, 0.828125)]), ('a fire', (41, 47), [(0.171875, 0.015625, 0.484375, 0.890625)])]
+```
+
+This model was contributed by [Yih-Dar SHIEH](https://huggingface.co/ydshieh). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/kosmos-2).
+
+## Kosmos2Config
+
+[[autodoc]] Kosmos2Config
+
+## Kosmos2ImageProcessor
+
+## Kosmos2Processor
+
+[[autodoc]] Kosmos2Processor
+ - __call__
+
+## Kosmos2Model
+
+[[autodoc]] Kosmos2Model
+ - forward
+
+## Kosmos2ForConditionalGeneration
+
+[[autodoc]] Kosmos2ForConditionalGeneration
+ - forward
diff --git a/docs/source/en/model_doc/layoutlm.md b/docs/source/en/model_doc/layoutlm.md
index ebf6b1a4b4fc..34b429fb7376 100644
--- a/docs/source/en/model_doc/layoutlm.md
+++ b/docs/source/en/model_doc/layoutlm.md
@@ -46,7 +46,7 @@ document-level pretraining. It achieves new state-of-the-art results in several
understanding (from 70.72 to 79.27), receipt understanding (from 94.02 to 95.24) and document image classification
(from 93.07 to 94.42).*
-Tips:
+## Usage tips
- In addition to *input_ids*, [`~transformers.LayoutLMModel.forward`] also expects the input `bbox`, which are
the bounding boxes (i.e. 2D-positions) of the input tokens. These can be obtained using an external OCR engine such
@@ -123,6 +123,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] LayoutLMTokenizerFast
+
+
+
## LayoutLMModel
[[autodoc]] LayoutLMModel
@@ -143,6 +146,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] LayoutLMForQuestionAnswering
+
+
+
## TFLayoutLMModel
[[autodoc]] TFLayoutLMModel
@@ -162,3 +168,8 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
## TFLayoutLMForQuestionAnswering
[[autodoc]] TFLayoutLMForQuestionAnswering
+
+
+
+
+
diff --git a/docs/source/en/model_doc/layoutlmv2.md b/docs/source/en/model_doc/layoutlmv2.md
index f2a1c65a42b1..15286d4ddb76 100644
--- a/docs/source/en/model_doc/layoutlmv2.md
+++ b/docs/source/en/model_doc/layoutlmv2.md
@@ -56,7 +56,7 @@ python -m pip install torchvision tesseract
```
(If you are developing for LayoutLMv2, note that passing the doctests also requires the installation of these packages.)
-Tips:
+## Usage tips
- The main difference between LayoutLMv1 and LayoutLMv2 is that the latter incorporates visual embeddings during
pre-training (while LayoutLMv1 only adds visual embeddings during fine-tuning).
diff --git a/docs/source/en/model_doc/layoutlmv3.md b/docs/source/en/model_doc/layoutlmv3.md
index 22e2c3ff7186..87ff32f38356 100644
--- a/docs/source/en/model_doc/layoutlmv3.md
+++ b/docs/source/en/model_doc/layoutlmv3.md
@@ -26,16 +26,6 @@ The abstract from the paper is the following:
*Self-supervised pre-training techniques have achieved remarkable progress in Document AI. Most multimodal pre-trained models use a masked language modeling objective to learn bidirectional representations on the text modality, but they differ in pre-training objectives for the image modality. This discrepancy adds difficulty to multimodal representation learning. In this paper, we propose LayoutLMv3 to pre-train multimodal Transformers for Document AI with unified text and image masking. Additionally, LayoutLMv3 is pre-trained with a word-patch alignment objective to learn cross-modal alignment by predicting whether the corresponding image patch of a text word is masked. The simple unified architecture and training objectives make LayoutLMv3 a general-purpose pre-trained model for both text-centric and image-centric Document AI tasks. Experimental results show that LayoutLMv3 achieves state-of-the-art performance not only in text-centric tasks, including form understanding, receipt understanding, and document visual question answering, but also in image-centric tasks such as document image classification and document layout analysis.*
-Tips:
-
-- In terms of data processing, LayoutLMv3 is identical to its predecessor [LayoutLMv2](layoutlmv2), except that:
- - images need to be resized and normalized with channels in regular RGB format. LayoutLMv2 on the other hand normalizes the images internally and expects the channels in BGR format.
- - text is tokenized using byte-pair encoding (BPE), as opposed to WordPiece.
- Due to these differences in data preprocessing, one can use [`LayoutLMv3Processor`] which internally combines a [`LayoutLMv3ImageProcessor`] (for the image modality) and a [`LayoutLMv3Tokenizer`]/[`LayoutLMv3TokenizerFast`] (for the text modality) to prepare all data for the model.
-- Regarding usage of [`LayoutLMv3Processor`], we refer to the [usage guide](layoutlmv2#usage-layoutlmv2processor) of its predecessor.
-- Demo notebooks for LayoutLMv3 can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLMv3).
-- Demo scripts can be found [here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/layoutlmv3).
-
@@ -43,6 +33,14 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version of this model was added by [chriskoo](https://huggingface.co/chriskoo), [tokec](https://huggingface.co/tokec), and [lre](https://huggingface.co/lre). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/layoutlmv3).
+## Usage tips
+
+- In terms of data processing, LayoutLMv3 is identical to its predecessor [LayoutLMv2](layoutlmv2), except that:
+ - images need to be resized and normalized with channels in regular RGB format. LayoutLMv2 on the other hand normalizes the images internally and expects the channels in BGR format.
+ - text is tokenized using byte-pair encoding (BPE), as opposed to WordPiece.
+ Due to these differences in data preprocessing, one can use [`LayoutLMv3Processor`] which internally combines a [`LayoutLMv3ImageProcessor`] (for the image modality) and a [`LayoutLMv3Tokenizer`]/[`LayoutLMv3TokenizerFast`] (for the text modality) to prepare all data for the model.
+- Regarding usage of [`LayoutLMv3Processor`], we refer to the [usage guide](layoutlmv2#usage-layoutlmv2processor) of its predecessor.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LayoutLMv3. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
@@ -53,6 +51,9 @@ LayoutLMv3 is nearly identical to LayoutLMv2, so we've also included LayoutLMv2
+- Demo notebooks for LayoutLMv3 can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLMv3).
+- Demo scripts can be found [here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/layoutlmv3).
+
- [`LayoutLMv2ForSequenceClassification`] is supported by this [notebook](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/RVL-CDIP/Fine_tuning_LayoutLMv2ForSequenceClassification_on_RVL_CDIP.ipynb).
@@ -103,6 +104,9 @@ LayoutLMv3 is nearly identical to LayoutLMv2, so we've also included LayoutLMv2
[[autodoc]] LayoutLMv3Processor
- __call__
+
+
+
## LayoutLMv3Model
[[autodoc]] LayoutLMv3Model
@@ -123,6 +127,9 @@ LayoutLMv3 is nearly identical to LayoutLMv2, so we've also included LayoutLMv2
[[autodoc]] LayoutLMv3ForQuestionAnswering
- forward
+
+
+
## TFLayoutLMv3Model
[[autodoc]] TFLayoutLMv3Model
@@ -142,3 +149,6 @@ LayoutLMv3 is nearly identical to LayoutLMv2, so we've also included LayoutLMv2
[[autodoc]] TFLayoutLMv3ForQuestionAnswering
- call
+
+
+
diff --git a/docs/source/en/model_doc/layoutxlm.md b/docs/source/en/model_doc/layoutxlm.md
index 8858560bbb21..f6b2cbef9d6f 100644
--- a/docs/source/en/model_doc/layoutxlm.md
+++ b/docs/source/en/model_doc/layoutxlm.md
@@ -33,6 +33,10 @@ introduce a multilingual form understanding benchmark dataset named XFUN, which
for each language. Experiment results show that the LayoutXLM model has significantly outperformed the existing SOTA
cross-lingual pre-trained models on the XFUN dataset.*
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm).
+
+## Usage tips and examples
+
One can directly plug in the weights of LayoutXLM into a LayoutLMv2 model, like so:
```python
@@ -56,10 +60,10 @@ Similar to LayoutLMv2, you can use [`LayoutXLMProcessor`] (which internally appl
[`LayoutXLMTokenizer`]/[`LayoutXLMTokenizerFast`] in sequence) to prepare all
data for the model.
-As LayoutXLM's architecture is equivalent to that of LayoutLMv2, one can refer to [LayoutLMv2's documentation page](layoutlmv2) for all tips, code examples and notebooks.
-
-This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm).
+
+As LayoutXLM's architecture is equivalent to that of LayoutLMv2, one can refer to [LayoutLMv2's documentation page](layoutlmv2) for all tips, code examples and notebooks.
+
## LayoutXLMTokenizer
diff --git a/docs/source/en/model_doc/led.md b/docs/source/en/model_doc/led.md
index 9ba9383a59d5..9a39b0b28ede 100644
--- a/docs/source/en/model_doc/led.md
+++ b/docs/source/en/model_doc/led.md
@@ -35,7 +35,7 @@ WikiHop and TriviaQA. We finally introduce the Longformer-Encoder-Decoder (LED),
long document generative sequence-to-sequence tasks, and demonstrate its effectiveness on the arXiv summarization
dataset.*
-Tips:
+## Usage tips
- [`LEDForConditionalGeneration`] is an extension of
[`BartForConditionalGeneration`] exchanging the traditional *self-attention* layer with
@@ -52,15 +52,15 @@ Tips:
errors. This can be done by executing `model.gradient_checkpointing_enable()`.
Moreover, the `use_cache=False`
flag can be used to disable the caching mechanism to save memory.
-- A notebook showing how to evaluate LED, can be accessed [here](https://colab.research.google.com/drive/12INTTR6n64TzS4RrXZxMSXfrOd9Xzamo?usp=sharing).
-- A notebook showing how to fine-tune LED, can be accessed [here](https://colab.research.google.com/drive/12LjJazBl7Gam0XBPy_y0CTOJZeZ34c2v?usp=sharing).
- LED is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
-## Documentation resources
+## Resources
+- [A notebook showing how to evaluate LED](https://colab.research.google.com/drive/12INTTR6n64TzS4RrXZxMSXfrOd9Xzamo?usp=sharing).
+- [A notebook showing how to fine-tune LED](https://colab.research.google.com/drive/12LjJazBl7Gam0XBPy_y0CTOJZeZ34c2v?usp=sharing).
- [Text classification task guide](../tasks/sequence_classification)
- [Question answering task guide](../tasks/question_answering)
- [Translation task guide](../tasks/translation)
@@ -100,6 +100,9 @@ This model was contributed by [patrickvonplaten](https://huggingface.co/patrickv
[[autodoc]] models.led.modeling_tf_led.TFLEDSeq2SeqLMOutput
+
+
+
## LEDModel
[[autodoc]] LEDModel
@@ -120,6 +123,9 @@ This model was contributed by [patrickvonplaten](https://huggingface.co/patrickv
[[autodoc]] LEDForQuestionAnswering
- forward
+
+
+
## TFLEDModel
[[autodoc]] TFLEDModel
@@ -129,3 +135,9 @@ This model was contributed by [patrickvonplaten](https://huggingface.co/patrickv
[[autodoc]] TFLEDForConditionalGeneration
- call
+
+
+
+
+
+
diff --git a/docs/source/en/model_doc/levit.md b/docs/source/en/model_doc/levit.md
index 8145be775f52..15dc2f4e1373 100644
--- a/docs/source/en/model_doc/levit.md
+++ b/docs/source/en/model_doc/levit.md
@@ -38,7 +38,9 @@ alt="drawing" width="600"/>
LeViT Architecture. Taken from the original paper.
-Tips:
+This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/facebookresearch/LeViT).
+
+## Usage tips
- Compared to ViT, LeViT models use an additional distillation head to effectively learn from a teacher (which, in the LeViT paper, is a ResNet like-model). The distillation head is learned through backpropagation under supervision of a ResNet like-model. They also draw inspiration from convolution neural networks to use activation maps with decreasing resolutions to increase the efficiency.
- There are 2 ways to fine-tune distilled models, either (1) in a classic way, by only placing a prediction head on top
@@ -63,8 +65,6 @@ Tips:
- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer)
(you can just replace [`ViTFeatureExtractor`] by [`LevitImageProcessor`] and [`ViTForImageClassification`] by [`LevitForImageClassification`] or [`LevitForImageClassificationWithTeacher`]).
-This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/facebookresearch/LeViT).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LeViT.
@@ -90,7 +90,6 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] LevitImageProcessor
- preprocess
-
## LevitModel
[[autodoc]] LevitModel
diff --git a/docs/source/en/model_doc/lilt.md b/docs/source/en/model_doc/lilt.md
index 901deefd7ffe..fb279573fbfd 100644
--- a/docs/source/en/model_doc/lilt.md
+++ b/docs/source/en/model_doc/lilt.md
@@ -26,7 +26,15 @@ The abstract from the paper is the following:
*Structured document understanding has attracted considerable attention and made significant progress recently, owing to its crucial role in intelligent document processing. However, most existing related models can only deal with the document data of specific language(s) (typically English) included in the pre-training collection, which is extremely limited. To address this issue, we propose a simple yet effective Language-independent Layout Transformer (LiLT) for structured document understanding. LiLT can be pre-trained on the structured documents of a single language and then directly fine-tuned on other languages with the corresponding off-the-shelf monolingual/multilingual pre-trained textual models. Experimental results on eight languages have shown that LiLT can achieve competitive or even superior performance on diverse widely-used downstream benchmarks, which enables language-independent benefit from the pre-training of document layout structure.*
-Tips:
+
+
+ LiLT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/jpwang/lilt).
+
+## Usage tips
- To combine the Language-Independent Layout Transformer with a new RoBERTa checkpoint from the [hub](https://huggingface.co/models?search=roberta), refer to [this guide](https://github.com/jpWang/LiLT#or-generate-your-own-checkpoint-optional).
The script will result in `config.json` and `pytorch_model.bin` files being stored locally. After doing this, one can do the following (assuming you're logged in with your HuggingFace account):
@@ -42,14 +50,6 @@ model.push_to_hub("name_of_repo_on_the_hub")
- As [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base) uses the same vocabulary as [LayoutLMv3](layoutlmv3), one can use [`LayoutLMv3TokenizerFast`] to prepare data for the model.
The same is true for [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-infoxlm-base): one can use [`LayoutXLMTokenizerFast`] for that model.
-
-
- LiLT architecture. Taken from the original paper.
-
-This model was contributed by [nielsr](https://huggingface.co/nielsr).
-The original code can be found [here](https://github.com/jpwang/lilt).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LiLT.
diff --git a/docs/source/en/model_doc/llama.md b/docs/source/en/model_doc/llama.md
index e63e4b1ab3b3..9f55c425d448 100644
--- a/docs/source/en/model_doc/llama.md
+++ b/docs/source/en/model_doc/llama.md
@@ -24,7 +24,9 @@ The abstract from the paper is the following:
*We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets. In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B. We release all our models to the research community. *
-Tips:
+This model was contributed by [zphang](https://huggingface.co/zphang) with contributions from [BlackSamorez](https://huggingface.co/BlackSamorez). The code of the implementation in Hugging Face is based on GPT-NeoX [here](https://github.com/EleutherAI/gpt-neox). The original code of the authors can be found [here](https://github.com/facebookresearch/llama).
+
+## Usage tips
- Weights for the LLaMA models can be obtained from by filling out [this form](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform?usp=send_form)
- After downloading the weights, they will need to be converted to the Hugging Face Transformers format using the [conversion script](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py). The script can be called with the following (example) command:
@@ -48,9 +50,6 @@ come in several checkpoints they each contain a part of each weight of the model
- The LLaMA tokenizer is a BPE model based on [sentencepiece](https://github.com/google/sentencepiece). One quirk of sentencepiece is that when decoding a sequence, if the first token is the start of the word (e.g. "Banana"), the tokenizer does not prepend the prefix space to the string.
-This model was contributed by [zphang](https://huggingface.co/zphang) with contributions from [BlackSamorez](https://huggingface.co/BlackSamorez). The code of the implementation in Hugging Face is based on GPT-NeoX [here](https://github.com/EleutherAI/gpt-neox). The original code of the authors can be found [here](https://github.com/facebookresearch/llama).
-
-
Based on the original LLaMA model, Meta AI has released some follow-up works:
- **Llama2**: Llama2 is an improved version of Llama with some architectural tweaks (Grouped Query Attention), and is pre-trained on 2Trillion tokens. Refer to the documentation of Llama2 which can be found [here](llama2).
@@ -82,7 +81,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] LlamaConfig
-
## LlamaTokenizer
[[autodoc]] LlamaTokenizer
@@ -105,7 +103,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] LlamaModel
- forward
-
## LlamaForCausalLM
[[autodoc]] LlamaForCausalLM
diff --git a/docs/source/en/model_doc/llama2.md b/docs/source/en/model_doc/llama2.md
index 0ff1e38f16a2..a817a866c0fa 100644
--- a/docs/source/en/model_doc/llama2.md
+++ b/docs/source/en/model_doc/llama2.md
@@ -24,7 +24,10 @@ The abstract from the paper is the following:
*In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.*
-Checkout all Llama2 models [here](https://huggingface.co/models?search=llama2)
+Checkout all Llama2 model checkpoints [here](https://huggingface.co/models?search=llama2).
+This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ) with contributions from [Lysandre Debut](https://huggingface.co/lysandre). The code of the implementation in Hugging Face is based on GPT-NeoX [here](https://github.com/EleutherAI/gpt-neox). The original code of the authors can be found [here](https://github.com/facebookresearch/llama).
+
+## Usage tips
@@ -64,7 +67,6 @@ come in several checkpoints they each contain a part of each weight of the model
- The LLaMA tokenizer is a BPE model based on [sentencepiece](https://github.com/google/sentencepiece). One quirk of sentencepiece is that when decoding a sequence, if the first token is the start of the word (e.g. "Banana"), the tokenizer does not prepend the prefix space to the string.
-This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ) with contributions from [Lysandre Debut](https://huggingface.co/lysandre). The code of the implementation in Hugging Face is based on GPT-NeoX [here](https://github.com/EleutherAI/gpt-neox). The original code of the authors can be found [here](https://github.com/facebookresearch/llama).
## Resources
diff --git a/docs/source/en/model_doc/longformer.md b/docs/source/en/model_doc/longformer.md
index 9947195058cc..20ba7a922515 100644
--- a/docs/source/en/model_doc/longformer.md
+++ b/docs/source/en/model_doc/longformer.md
@@ -41,15 +41,15 @@ contrast to most prior work, we also pretrain Longformer and finetune it on a va
pretrained Longformer consistently outperforms RoBERTa on long document tasks and sets new state-of-the-art results on
WikiHop and TriviaQA.*
-Tips:
+This model was contributed by [beltagy](https://huggingface.co/beltagy). The Authors' code can be found [here](https://github.com/allenai/longformer).
+
+## Usage tips
- Since the Longformer is based on RoBERTa, it doesn't have `token_type_ids`. You don't need to indicate which
token belongs to which segment. Just separate your segments with the separation token `tokenizer.sep_token` (or
``).
- A transformer model replacing the attention matrices by sparse matrices to go faster. Often, the local context (e.g., what are the two tokens left and right?) is enough to take action for a given token. Some preselected input tokens are still given global attention, but the attention matrix has way less parameters, resulting in a speed-up. See the local attention section for more information.
-This model was contributed by [beltagy](https://huggingface.co/beltagy). The Authors' code can be found [here](https://github.com/allenai/longformer).
-
## Longformer Self Attention
Longformer self attention employs self attention on both a "local" context and a "global" context. Most tokens only
@@ -93,7 +93,7 @@ mlm_labels = tokenizer.encode("This is a sentence from the training data", retur
loss = model(input_ids, labels=input_ids, masked_lm_labels=mlm_labels)[0]
```
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -143,6 +143,9 @@ loss = model(input_ids, labels=input_ids, masked_lm_labels=mlm_labels)[0]
[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerTokenClassifierOutput
+
+
+
## LongformerModel
[[autodoc]] LongformerModel
@@ -173,6 +176,9 @@ loss = model(input_ids, labels=input_ids, masked_lm_labels=mlm_labels)[0]
[[autodoc]] LongformerForQuestionAnswering
- forward
+
+
+
## TFLongformerModel
[[autodoc]] TFLongformerModel
@@ -202,3 +208,6 @@ loss = model(input_ids, labels=input_ids, masked_lm_labels=mlm_labels)[0]
[[autodoc]] TFLongformerForMultipleChoice
- call
+
+
+
diff --git a/docs/source/en/model_doc/longt5.md b/docs/source/en/model_doc/longt5.md
index e8dcfe3b237f..40faa6d8c237 100644
--- a/docs/source/en/model_doc/longt5.md
+++ b/docs/source/en/model_doc/longt5.md
@@ -36,7 +36,10 @@ attention ideas from long-input transformers (ETC), and adopted pre-training str
able to achieve state-of-the-art results on several summarization tasks and outperform the original T5 models on
question answering tasks.*
-Tips:
+This model was contributed by [stancld](https://huggingface.co/stancld).
+The original code can be found [here](https://github.com/google-research/longt5).
+
+## Usage tips
- [`LongT5ForConditionalGeneration`] is an extension of [`T5ForConditionalGeneration`] exchanging the traditional
encoder *self-attention* layer with efficient either *local* attention or *transient-global* (*tglobal*) attention.
@@ -87,10 +90,8 @@ The complexity of this mechanism is `O(l(r + l/k))`.
>>> rouge.compute(predictions=result["predicted_abstract"], references=result["abstract"])
```
-This model was contributed by [stancld](https://huggingface.co/stancld).
-The original code can be found [here](https://github.com/google-research/longt5).
-## Documentation resources
+## Resources
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
@@ -99,6 +100,9 @@ The original code can be found [here](https://github.com/google-research/longt5)
[[autodoc]] LongT5Config
+
+
+
## LongT5Model
[[autodoc]] LongT5Model
@@ -114,6 +118,9 @@ The original code can be found [here](https://github.com/google-research/longt5)
[[autodoc]] LongT5EncoderModel
- forward
+
+
+
## FlaxLongT5Model
[[autodoc]] FlaxLongT5Model
@@ -127,3 +134,6 @@ The original code can be found [here](https://github.com/google-research/longt5)
- __call__
- encode
- decode
+
+
+
diff --git a/docs/source/en/model_doc/luke.md b/docs/source/en/model_doc/luke.md
index 2947c7c41bdf..4e070b1c4bac 100644
--- a/docs/source/en/model_doc/luke.md
+++ b/docs/source/en/model_doc/luke.md
@@ -37,7 +37,9 @@ state-of-the-art results on five well-known datasets: Open Entity (entity typing
CoNLL-2003 (named entity recognition), ReCoRD (cloze-style question answering), and SQuAD 1.1 (extractive question
answering).*
-Tips:
+This model was contributed by [ikuyamada](https://huggingface.co/ikuyamada) and [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/studio-ousia/luke).
+
+## Usage tips
- This implementation is the same as [`RobertaModel`] with the addition of entity embeddings as well
as an entity-aware self-attention mechanism, which improves performance on tasks involving reasoning about entities.
@@ -75,13 +77,7 @@ Tips:
head models by specifying `task="entity_classification"`, `task="entity_pair_classification"`, or
`task="entity_span_classification"`. Please refer to the example code of each head models.
- A demo notebook on how to fine-tune [`LukeForEntityPairClassification`] for relation
- classification can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LUKE).
-
- There are also 3 notebooks available, which showcase how you can reproduce the results as reported in the paper with
- the HuggingFace implementation of LUKE. They can be found [here](https://github.com/studio-ousia/luke/tree/master/notebooks).
-
-Example:
+Usage example:
```python
>>> from transformers import LukeTokenizer, LukeModel, LukeForEntityPairClassification
@@ -119,10 +115,10 @@ Example:
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
```
-This model was contributed by [ikuyamada](https://huggingface.co/ikuyamada) and [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/studio-ousia/luke).
-
-## Documentation resources
+## Resources
+- [A demo notebook on how to fine-tune [`LukeForEntityPairClassification`] for relation classification](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LUKE)
+- [Notebooks showcasing how you to reproduce the results as reported in the paper with the HuggingFace implementation of LUKE](https://github.com/studio-ousia/luke/tree/master/notebooks)
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
diff --git a/docs/source/en/model_doc/lxmert.md b/docs/source/en/model_doc/lxmert.md
index 114539f61e81..435994196b43 100644
--- a/docs/source/en/model_doc/lxmert.md
+++ b/docs/source/en/model_doc/lxmert.md
@@ -41,7 +41,9 @@ best result by 22% absolute (54% to 76%). Lastly, we demonstrate detailed ablati
model components and pretraining strategies significantly contribute to our strong results; and also present several
attention visualizations for the different encoders*
-Tips:
+This model was contributed by [eltoto1219](https://huggingface.co/eltoto1219). The original code can be found [here](https://github.com/airsplay/lxmert).
+
+## Usage tips
- Bounding boxes are not necessary to be used in the visual feature embeddings, any kind of visual-spacial features
will work.
@@ -53,9 +55,7 @@ Tips:
contains self-attention for each respective modality and cross-attention, only the cross attention is returned and
both self attention outputs are disregarded.
-This model was contributed by [eltoto1219](https://huggingface.co/eltoto1219). The original code can be found [here](https://github.com/airsplay/lxmert).
-
-## Documentation resources
+## Resources
- [Question answering task guide](../tasks/question_answering)
@@ -83,6 +83,9 @@ This model was contributed by [eltoto1219](https://huggingface.co/eltoto1219). T
[[autodoc]] models.lxmert.modeling_tf_lxmert.TFLxmertForPreTrainingOutput
+
+
+
## LxmertModel
[[autodoc]] LxmertModel
@@ -98,6 +101,9 @@ This model was contributed by [eltoto1219](https://huggingface.co/eltoto1219). T
[[autodoc]] LxmertForQuestionAnswering
- forward
+
+
+
## TFLxmertModel
[[autodoc]] TFLxmertModel
@@ -107,3 +113,6 @@ This model was contributed by [eltoto1219](https://huggingface.co/eltoto1219). T
[[autodoc]] TFLxmertForPreTraining
- call
+
+
+
diff --git a/docs/source/en/model_doc/m2m_100.md b/docs/source/en/model_doc/m2m_100.md
index c2b4354c6d5f..fa808c2e94bb 100644
--- a/docs/source/en/model_doc/m2m_100.md
+++ b/docs/source/en/model_doc/m2m_100.md
@@ -38,7 +38,7 @@ open-source our scripts so that others may reproduce the data, evaluation, and f
This model was contributed by [valhalla](https://huggingface.co/valhalla).
-### Training and Generation
+## Usage tips and examples
M2M100 is a multilingual encoder-decoder (seq-to-seq) model primarily intended for translation tasks. As the model is
multilingual it expects the sequences in a certain format: A special language id token is used as prefix in both the
@@ -48,7 +48,7 @@ id for source text and target language id for target text, with `X` being the so
The [`M2M100Tokenizer`] depends on `sentencepiece` so be sure to install it before running the
examples. To install `sentencepiece` run `pip install sentencepiece`.
-- Supervised Training
+**Supervised Training**
```python
from transformers import M2M100Config, M2M100ForConditionalGeneration, M2M100Tokenizer
@@ -64,12 +64,12 @@ model_inputs = tokenizer(src_text, text_target=tgt_text, return_tensors="pt")
loss = model(**model_inputs).loss # forward pass
```
-- Generation
+**Generation**
- M2M100 uses the `eos_token_id` as the `decoder_start_token_id` for generation with the target language id
- being forced as the first generated token. To force the target language id as the first generated token, pass the
- *forced_bos_token_id* parameter to the *generate* method. The following example shows how to translate between
- Hindi to French and Chinese to English using the *facebook/m2m100_418M* checkpoint.
+M2M100 uses the `eos_token_id` as the `decoder_start_token_id` for generation with the target language id
+being forced as the first generated token. To force the target language id as the first generated token, pass the
+*forced_bos_token_id* parameter to the *generate* method. The following example shows how to translate between
+Hindi to French and Chinese to English using the *facebook/m2m100_418M* checkpoint.
```python
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
@@ -95,7 +95,7 @@ loss = model(**model_inputs).loss # forward pass
"Life is like a box of chocolate."
```
-## Documentation resources
+## Resources
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
diff --git a/docs/source/en/model_doc/marian.md b/docs/source/en/model_doc/marian.md
index 8be41686594c..8078ea1427c9 100644
--- a/docs/source/en/model_doc/marian.md
+++ b/docs/source/en/model_doc/marian.md
@@ -25,14 +25,11 @@ rendered properly in your Markdown viewer.
-**Bugs:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=sshleifer&labels=&template=bug-report.md&title)
-and assign @patrickvonplaten.
+## Overview
-Translations should be similar, but not identical to output in the test set linked to in each model card.
+A framework for translation models, using the same models as BART. Translations should be similar, but not identical to output in the test set linked to in each model card.
+This model was contributed by [sshleifer](https://huggingface.co/sshleifer).
-Tips:
-
-- A framework for translation models, using the same models as BART.
## Implementation Notes
@@ -49,7 +46,7 @@ Tips:
- the model starts generating with `pad_token_id` (which has 0 as a token_embedding) as the prefix (Bart uses
``),
- Code to bulk convert models can be found in `convert_marian_to_pytorch.py`.
-- This model was contributed by [sshleifer](https://huggingface.co/sshleifer).
+
## Naming
@@ -165,7 +162,7 @@ Example of translating english to many romance languages, using old-style 2 char
'Y esto al español']
```
-## Documentation resources
+## Resources
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
@@ -180,6 +177,9 @@ Example of translating english to many romance languages, using old-style 2 char
[[autodoc]] MarianTokenizer
- build_inputs_with_special_tokens
+
+
+
## MarianModel
[[autodoc]] MarianModel
@@ -195,6 +195,9 @@ Example of translating english to many romance languages, using old-style 2 char
[[autodoc]] MarianForCausalLM
- forward
+
+
+
## TFMarianModel
[[autodoc]] TFMarianModel
@@ -205,6 +208,9 @@ Example of translating english to many romance languages, using old-style 2 char
[[autodoc]] TFMarianMTModel
- call
+
+
+
## FlaxMarianModel
[[autodoc]] FlaxMarianModel
@@ -214,3 +220,6 @@ Example of translating english to many romance languages, using old-style 2 char
[[autodoc]] FlaxMarianMTModel
- __call__
+
+
+
diff --git a/docs/source/en/model_doc/markuplm.md b/docs/source/en/model_doc/markuplm.md
index b286c4fc00c1..8150892e63f8 100644
--- a/docs/source/en/model_doc/markuplm.md
+++ b/docs/source/en/model_doc/markuplm.md
@@ -40,19 +40,19 @@ HTML/XML-based documents, where text and markup information is jointly pre-train
pre-trained MarkupLM significantly outperforms the existing strong baseline models on several document understanding
tasks. The pre-trained model and code will be publicly available.*
-Tips:
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/markuplm).
+
+## Usage tips
+
- In addition to `input_ids`, [`~MarkupLMModel.forward`] expects 2 additional inputs, namely `xpath_tags_seq` and `xpath_subs_seq`.
These are the XPATH tags and subscripts respectively for each token in the input sequence.
- One can use [`MarkupLMProcessor`] to prepare all data for the model. Refer to the [usage guide](#usage-markuplmprocessor) for more info.
-- Demo notebooks can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/MarkupLM).
MarkupLM architecture. Taken from the original paper.
-This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/markuplm).
-
## Usage: MarkupLMProcessor
The easiest way to prepare data for the model is to use [`MarkupLMProcessor`], which internally combines a feature extractor
@@ -197,8 +197,9 @@ all nodes and xpaths yourself, you can provide them directly to the processor. M
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])
```
-## Documentation resources
+## Resources
+- [Demo notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/MarkupLM)
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
diff --git a/docs/source/en/model_doc/mask2former.md b/docs/source/en/model_doc/mask2former.md
index ddfa5da2ba2c..bd5ab80728eb 100644
--- a/docs/source/en/model_doc/mask2former.md
+++ b/docs/source/en/model_doc/mask2former.md
@@ -25,16 +25,17 @@ The abstract from the paper is the following:
*Image segmentation groups pixels with different semantics, e.g., category or instance membership. Each choice
of semantics defines a task. While only the semantics of each task differ, current research focuses on designing specialized architectures for each task. We present Masked-attention Mask Transformer (Mask2Former), a new architecture capable of addressing any image segmentation task (panoptic, instance or semantic). Its key components include masked attention, which extracts localized features by constraining cross-attention within predicted mask regions. In addition to reducing the research effort by at least three times, it outperforms the best specialized architectures by a significant margin on four popular datasets. Most notably, Mask2Former sets a new state-of-the-art for panoptic segmentation (57.8 PQ on COCO), instance segmentation (50.1 AP on COCO) and semantic segmentation (57.7 mIoU on ADE20K).*
-Tips:
-- Mask2Former uses the same preprocessing and postprocessing steps as [MaskFormer](maskformer). Use [`Mask2FormerImageProcessor`] or [`AutoImageProcessor`] to prepare images and optional targets for the model.
-- To get the final segmentation, depending on the task, you can call [`~Mask2FormerImageProcessor.post_process_semantic_segmentation`] or [`~Mask2FormerImageProcessor.post_process_instance_segmentation`] or [`~Mask2FormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`Mask2FormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
-
Mask2Former architecture. Taken from the original paper.
This model was contributed by [Shivalika Singh](https://huggingface.co/shivi) and [Alara Dirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/facebookresearch/Mask2Former).
+## Usage tips
+
+- Mask2Former uses the same preprocessing and postprocessing steps as [MaskFormer](maskformer). Use [`Mask2FormerImageProcessor`] or [`AutoImageProcessor`] to prepare images and optional targets for the model.
+- To get the final segmentation, depending on the task, you can call [`~Mask2FormerImageProcessor.post_process_semantic_segmentation`] or [`~Mask2FormerImageProcessor.post_process_instance_segmentation`] or [`~Mask2FormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`Mask2FormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Mask2Former.
@@ -44,16 +45,16 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
The resource should ideally demonstrate something new instead of duplicating an existing resource.
+## Mask2FormerConfig
+
+[[autodoc]] Mask2FormerConfig
+
## MaskFormer specific outputs
[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerModelOutput
[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerForUniversalSegmentationOutput
-## Mask2FormerConfig
-
-[[autodoc]] Mask2FormerConfig
-
## Mask2FormerModel
[[autodoc]] Mask2FormerModel
diff --git a/docs/source/en/model_doc/maskformer.md b/docs/source/en/model_doc/maskformer.md
index 4695e54857f7..5566dec58593 100644
--- a/docs/source/en/model_doc/maskformer.md
+++ b/docs/source/en/model_doc/maskformer.md
@@ -31,7 +31,14 @@ The abstract from the paper is the following:
*Modern approaches typically formulate semantic segmentation as a per-pixel classification task, while instance-level segmentation is handled with an alternative mask classification. Our key insight: mask classification is sufficiently general to solve both semantic- and instance-level segmentation tasks in a unified manner using the exact same model, loss, and training procedure. Following this observation, we propose MaskFormer, a simple mask classification model which predicts a set of binary masks, each associated with a single global class label prediction. Overall, the proposed mask classification-based method simplifies the landscape of effective approaches to semantic and panoptic segmentation tasks and shows excellent empirical results. In particular, we observe that MaskFormer outperforms per-pixel classification baselines when the number of classes is large. Our mask classification-based method outperforms both current state-of-the-art semantic (55.6 mIoU on ADE20K) and panoptic segmentation (52.7 PQ on COCO) models.*
-Tips:
+The figure below illustrates the architecture of MaskFormer. Taken from the [original paper](https://arxiv.org/abs/2107.06278).
+
+
+
+This model was contributed by [francesco](https://huggingface.co/francesco). The original code can be found [here](https://github.com/facebookresearch/MaskFormer).
+
+## Usage tips
+
- MaskFormer's Transformer decoder is identical to the decoder of [DETR](detr). During training, the authors of DETR did find it helpful to use auxiliary losses in the decoder, especially to help the model output the correct number of objects of each class. If you set the parameter `use_auxilary_loss` of [`MaskFormerConfig`] to `True`, then prediction feedforward neural networks and Hungarian losses are added after each decoder layer (with the FFNs sharing parameters).
- If you want to train the model in a distributed environment across multiple nodes, then one should update the
`get_num_masks` function inside in the `MaskFormerLoss` class of `modeling_maskformer.py`. When training on multiple nodes, this should be
@@ -39,12 +46,6 @@ Tips:
- One can use [`MaskFormerImageProcessor`] to prepare images for the model and optional targets for the model.
- To get the final segmentation, depending on the task, you can call [`~MaskFormerImageProcessor.post_process_semantic_segmentation`] or [`~MaskFormerImageProcessor.post_process_panoptic_segmentation`]. Both tasks can be solved using [`MaskFormerForInstanceSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
-The figure below illustrates the architecture of MaskFormer. Taken from the [original paper](https://arxiv.org/abs/2107.06278).
-
-
-
-This model was contributed by [francesco](https://huggingface.co/francesco). The original code can be found [here](https://github.com/facebookresearch/MaskFormer).
-
## Resources
diff --git a/docs/source/en/model_doc/matcha.md b/docs/source/en/model_doc/matcha.md
index 20c403413feb..d4ee33059367 100644
--- a/docs/source/en/model_doc/matcha.md
+++ b/docs/source/en/model_doc/matcha.md
@@ -67,4 +67,10 @@ from transformers.optimization import Adafactor, get_cosine_schedule_with_warmup
optimizer = Adafactor(self.parameters(), scale_parameter=False, relative_step=False, lr=0.01, weight_decay=1e-05)
scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=1000, num_training_steps=40000)
-```
\ No newline at end of file
+```
+
+
+
+MatCha is a model that is trained using `Pix2Struct` architecture. You can find more information about `Pix2Struct` in the [Pix2Struct documentation](https://huggingface.co/docs/transformers/main/en/model_doc/pix2struct).
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/mbart.md b/docs/source/en/model_doc/mbart.md
index 8a614dd50556..e7fc0bd53efa 100644
--- a/docs/source/en/model_doc/mbart.md
+++ b/docs/source/en/model_doc/mbart.md
@@ -25,8 +25,6 @@ rendered properly in your Markdown viewer.
-**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
-@patrickvonplaten
## Overview of MBart
@@ -186,6 +184,9 @@ tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
[[autodoc]] MBart50TokenizerFast
+
+
+
## MBartModel
[[autodoc]] MBartModel
@@ -207,6 +208,9 @@ tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
[[autodoc]] MBartForCausalLM
- forward
+
+
+
## TFMBartModel
[[autodoc]] TFMBartModel
@@ -217,6 +221,9 @@ tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
[[autodoc]] TFMBartForConditionalGeneration
- call
+
+
+
## FlaxMBartModel
[[autodoc]] FlaxMBartModel
@@ -244,3 +251,6 @@ tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
- __call__
- encode
- decode
+
+
+
diff --git a/docs/source/en/model_doc/mctct.md b/docs/source/en/model_doc/mctct.md
index 72d4bedfac69..7cf1a68f12e4 100644
--- a/docs/source/en/model_doc/mctct.md
+++ b/docs/source/en/model_doc/mctct.md
@@ -40,17 +40,15 @@ pseudo-labels for all languages, either from scratch or by fine-tuning. Experime
Common Voice and unlabeled VoxPopuli datasets show that our recipe can yield a model with better
performance for many languages that also transfers well to LibriSpeech.*
-
-
This model was contributed by [cwkeam](https://huggingface.co/cwkeam). The original code can be found [here](https://github.com/flashlight/wav2letter/tree/main/recipes/mling_pl).
-## Documentation resources
+## Usage tips
-- [Automatic speech recognition task guide](../tasks/asr)
+The PyTorch version of this model is only available in torch 1.9 and higher.
-Tips:
+## Resources
-- The PyTorch version of this model is only available in torch 1.9 and higher.
+- [Automatic speech recognition task guide](../tasks/asr)
## MCTCTConfig
@@ -70,7 +68,6 @@ Tips:
- batch_decode
- decode
-
## MCTCTModel
[[autodoc]] MCTCTModel
diff --git a/docs/source/en/model_doc/mega.md b/docs/source/en/model_doc/mega.md
index d4d68b9becd1..4ce62ca45a1d 100644
--- a/docs/source/en/model_doc/mega.md
+++ b/docs/source/en/model_doc/mega.md
@@ -28,15 +28,17 @@ The abstract from the paper is the following:
*The design choices in the Transformer attention mechanism, including weak inductive bias and quadratic computational complexity, have limited its application for modeling long sequences. In this paper, we introduce Mega, a simple, theoretically grounded, single-head gated attention mechanism equipped with (exponential) moving average to incorporate inductive bias of position-aware local dependencies into the position-agnostic attention mechanism. We further propose a variant of Mega that offers linear time and space complexity yet yields only minimal quality loss, by efficiently splitting the whole sequence into multiple chunks with fixed length. Extensive experiments on a wide range of sequence modeling benchmarks, including the Long Range Arena, neural machine translation, auto-regressive language modeling, and image and speech classification, show that Mega achieves significant improvements over other sequence models, including variants of Transformers and recent state space models. *
-Tips:
+This model was contributed by [mnaylor](https://huggingface.co/mnaylor).
+The original code can be found [here](https://github.com/facebookresearch/mega).
+
+
+## Usage tips
- MEGA can perform quite well with relatively few parameters. See Appendix D in the MEGA paper for examples of architectural specs which perform well in various settings. If using MEGA as a decoder, be sure to set `bidirectional=False` to avoid errors with default bidirectional.
- Mega-chunk is a variant of mega that reduces time and spaces complexity from quadratic to linear. Utilize chunking with MegaConfig.use_chunking and control chunk size with MegaConfig.chunk_size
-This model was contributed by [mnaylor](https://huggingface.co/mnaylor).
-The original code can be found [here](https://github.com/facebookresearch/mega).
-Implementation Notes:
+## Implementation Notes
- The original implementation of MEGA had an inconsistent expectation of attention masks for padding and causal self-attention between the softmax attention and Laplace/squared ReLU method. This implementation addresses that inconsistency.
- The original implementation did not include token type embeddings; this implementation adds support for these, with the option controlled by MegaConfig.add_token_type_embeddings
diff --git a/docs/source/en/model_doc/megatron-bert.md b/docs/source/en/model_doc/megatron-bert.md
index 88ccff23587b..67000c8b843f 100644
--- a/docs/source/en/model_doc/megatron-bert.md
+++ b/docs/source/en/model_doc/megatron-bert.md
@@ -40,7 +40,11 @@ achieve SOTA results on the WikiText103 (10.8 compared to SOTA perplexity of 15.
accuracy of 63.2%) datasets. Our BERT model achieves SOTA results on the RACE dataset (90.9% compared to SOTA accuracy
of 89.4%).*
-Tips:
+This model was contributed by [jdemouth](https://huggingface.co/jdemouth). The original code can be found [here](https://github.com/NVIDIA/Megatron-LM).
+That repository contains a multi-GPU and multi-node implementation of the Megatron Language models. In particular,
+it contains a hybrid model parallel approach using "tensor parallel" and "pipeline parallel" techniques.
+
+## Usage tips
We have provided pretrained [BERT-345M](https://ngc.nvidia.com/catalog/models/nvidia:megatron_bert_345m) checkpoints
for use to evaluate or finetuning downstream tasks.
@@ -78,11 +82,7 @@ python3 $PATH_TO_TRANSFORMERS/models/megatron_bert/convert_megatron_bert_checkpo
python3 $PATH_TO_TRANSFORMERS/models/megatron_bert/convert_megatron_bert_checkpoint.py megatron_bert_345m_v0_1_cased.zip
```
-This model was contributed by [jdemouth](https://huggingface.co/jdemouth). The original code can be found [here](https://github.com/NVIDIA/Megatron-LM). That repository contains a multi-GPU and multi-node implementation of the
-Megatron Language models. In particular, it contains a hybrid model parallel approach using "tensor parallel" and
-"pipeline parallel" techniques.
-
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
diff --git a/docs/source/en/model_doc/megatron_gpt2.md b/docs/source/en/model_doc/megatron_gpt2.md
index 1eea7d82bf3a..284fd372c0e0 100644
--- a/docs/source/en/model_doc/megatron_gpt2.md
+++ b/docs/source/en/model_doc/megatron_gpt2.md
@@ -40,7 +40,11 @@ achieve SOTA results on the WikiText103 (10.8 compared to SOTA perplexity of 15.
accuracy of 63.2%) datasets. Our BERT model achieves SOTA results on the RACE dataset (90.9% compared to SOTA accuracy
of 89.4%).*
-Tips:
+This model was contributed by [jdemouth](https://huggingface.co/jdemouth). The original code can be found [here](https://github.com/NVIDIA/Megatron-LM).
+That repository contains a multi-GPU and multi-node implementation of the Megatron Language models. In particular, it
+contains a hybrid model parallel approach using "tensor parallel" and "pipeline parallel" techniques.
+
+## Usage tips
We have provided pretrained [GPT2-345M](https://ngc.nvidia.com/catalog/models/nvidia:megatron_lm_345m) checkpoints
for use to evaluate or finetuning downstream tasks.
@@ -65,7 +69,9 @@ The following command allows you to do the conversion. We assume that the folder
python3 $PATH_TO_TRANSFORMERS/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py megatron_gpt2_345m_v0_0.zip
```
-This model was contributed by [jdemouth](https://huggingface.co/jdemouth). The original code can be found [here](https://github.com/NVIDIA/Megatron-LM). That repository contains a multi-GPU and multi-node implementation of the
-Megatron Language models. In particular, it contains a hybrid model parallel approach using "tensor parallel" and
-"pipeline parallel" techniques.
+
+
+ MegatronGPT2 architecture is the same as OpenAI GPT-2 . Refer to [GPT-2 documentation](gpt2) for information on
+ configuration classes and their parameters.
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/mgp-str.md b/docs/source/en/model_doc/mgp-str.md
index e384c0620170..5a44a18b349d 100644
--- a/docs/source/en/model_doc/mgp-str.md
+++ b/docs/source/en/model_doc/mgp-str.md
@@ -29,12 +29,10 @@ alt="drawing" width="600"/>
MGP-STR architecture. Taken from the original paper.
-Tips:
+MGP-STR is trained on two synthetic datasets [MJSynth]((http://www.robots.ox.ac.uk/~vgg/data/text/)) (MJ) and SynthText(http://www.robots.ox.ac.uk/~vgg/data/scenetext/) (ST) without fine-tuning on other datasets. It achieves state-of-the-art results on six standard Latin scene text benchmarks, including 3 regular text datasets (IC13, SVT, IIIT) and 3 irregular ones (IC15, SVTP, CUTE).
+This model was contributed by [yuekun](https://huggingface.co/yuekun). The original code can be found [here](https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/OCR/MGP-STR).
-- MGP-STR is trained on two synthetic datasets [MJSynth]((http://www.robots.ox.ac.uk/~vgg/data/text/)) (MJ) and SynthText(http://www.robots.ox.ac.uk/~vgg/data/scenetext/) (ST) without fine-tuning on other datasets. It achieves state-of-the-art results on six standard Latin scene text benchmarks, including 3 regular text datasets (IC13, SVT, IIIT) and 3 irregular ones (IC15, SVTP, CUTE).
-- This model was contributed by [yuekun](https://huggingface.co/yuekun). The original code can be found [here](https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/OCR/MGP-STR).
-
-## Inference
+## Inference example
[`MgpstrModel`] accepts images as input and generates three types of predictions, which represent textual information at different granularities.
The three types of predictions are fused to give the final prediction result.
@@ -46,7 +44,7 @@ into a single instance to both extract the input features and decode the predict
- Step-by-step Optical Character Recognition (OCR)
-``` py
+```py
>>> from transformers import MgpstrProcessor, MgpstrForSceneTextRecognition
>>> import requests
>>> from PIL import Image
diff --git a/docs/source/en/model_doc/mistral.md b/docs/source/en/model_doc/mistral.md
index 5972f72a614e..8e37bc2caf88 100644
--- a/docs/source/en/model_doc/mistral.md
+++ b/docs/source/en/model_doc/mistral.md
@@ -18,9 +18,9 @@ rendered properly in your Markdown viewer.
## Overview
-Mistral-7B-v0.1 is Mistral AI’s first Large Language Model (LLM).
+Mistral-7B-v0.1 is Mistral AI's first Large Language Model (LLM).
-## Model Details
+### Model Details
Mistral-7B-v0.1 is a decoder-based LM with the following architectural choices:
* Sliding Window Attention - Trained with 8k context length and fixed cache size, with a theoretical attention span of 128K tokens
@@ -31,11 +31,11 @@ We also provide an instruction fine-tuned model: `Mistral-7B-Instruct-v0.1` whic
For more details please read our [release blog post](https://mistral.ai/news/announcing-mistral-7b/)
-## License
+### License
Both `Mistral-7B-v0.1` and `Mistral-7B-Instruct-v0.1` are released under the Apache 2.0 license.
-## Usage
+## Usage tips
`Mistral-7B-v0.1` and `Mistral-7B-Instruct-v0.1` can be found on the [Huggingface Hub](https://huggingface.co/mistralai)
diff --git a/docs/source/en/model_doc/mluke.md b/docs/source/en/model_doc/mluke.md
index ec9430848cea..719af76ad446 100644
--- a/docs/source/en/model_doc/mluke.md
+++ b/docs/source/en/model_doc/mluke.md
@@ -37,6 +37,10 @@ representations into the input allows us to extract more language-agnostic featu
multilingual cloze prompt task with the mLAMA dataset. We show that entity-based prompt elicits correct factual
knowledge more likely than using only word representations.*
+This model was contributed by [ryo0634](https://huggingface.co/ryo0634). The original code can be found [here](https://github.com/studio-ousia/luke).
+
+## Usage tips
+
One can directly plug in the weights of mLUKE into a LUKE model, like so:
```python
@@ -53,10 +57,12 @@ from transformers import MLukeTokenizer
tokenizer = MLukeTokenizer.from_pretrained("studio-ousia/mluke-base")
```
+
+
As mLUKE's architecture is equivalent to that of LUKE, one can refer to [LUKE's documentation page](luke) for all
tips, code examples and notebooks.
-This model was contributed by [ryo0634](https://huggingface.co/ryo0634). The original code can be found [here](https://github.com/studio-ousia/luke).
+
## MLukeTokenizer
diff --git a/docs/source/en/model_doc/mms.md b/docs/source/en/model_doc/mms.md
index 497eb40d7e3e..aefdbfd889f5 100644
--- a/docs/source/en/model_doc/mms.md
+++ b/docs/source/en/model_doc/mms.md
@@ -306,7 +306,6 @@ with torch.no_grad():
outputs = model(**inputs)
```
-
### Language Identification (LID)
Different LID models are available based on the number of languages they can recognize - [126](https://huggingface.co/facebook/mms-lid-126), [256](https://huggingface.co/facebook/mms-lid-256), [512](https://huggingface.co/facebook/mms-lid-512), [1024](https://huggingface.co/facebook/mms-lid-1024), [2048](https://huggingface.co/facebook/mms-lid-2048), [4017](https://huggingface.co/facebook/mms-lid-4017).
@@ -378,4 +377,13 @@ processor.id2label.values()
### Audio Pretrained Models
-Pretrained models are available for two different sizes - [300M](https://huggingface.co/facebook/mms-300m) , [1Bil](https://huggingface.co/facebook/mms-1b). The architecture is based on the Wav2Vec2 model, so one can refer to [Wav2Vec2's documentation page](wav2vec2) for further details on how to finetune with models for various downstream tasks.
+Pretrained models are available for two different sizes - [300M](https://huggingface.co/facebook/mms-300m) ,
+[1Bil](https://huggingface.co/facebook/mms-1b).
+
+
+
+The MMS for ASR architecture is based on the Wav2Vec2 model, refer to [Wav2Vec2's documentation page](wav2vec2) for further
+details on how to finetune with models for various downstream tasks.
+
+MMS-TTS uses the same model architecture as VITS, refer to [VITS's documentation page](vits) for API reference.
+
diff --git a/docs/source/en/model_doc/mobilebert.md b/docs/source/en/model_doc/mobilebert.md
index e652756351d2..5c9a230d0d5c 100644
--- a/docs/source/en/model_doc/mobilebert.md
+++ b/docs/source/en/model_doc/mobilebert.md
@@ -37,7 +37,9 @@ natural language inference tasks of GLUE, MobileBERT achieves a GLUEscore o 77.7
latency on a Pixel 4 phone. On the SQuAD v1.1/v2.0 question answering task, MobileBERT achieves a dev F1 score of
90.0/79.2 (1.5/2.1 higher than BERT_BASE).*
-Tips:
+This model was contributed by [vshampor](https://huggingface.co/vshampor). The original code can be found [here](https://github.com/google-research/google-research/tree/master/mobilebert).
+
+## Usage tips
- MobileBERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather
than the left.
@@ -45,9 +47,8 @@ Tips:
efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation. Models trained
with a causal language modeling (CLM) objective are better in that regard.
-This model was contributed by [vshampor](https://huggingface.co/vshampor). The original code can be found [here](https://github.com/google-research/mobilebert).
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -73,6 +74,9 @@ This model was contributed by [vshampor](https://huggingface.co/vshampor). The o
[[autodoc]] models.mobilebert.modeling_tf_mobilebert.TFMobileBertForPreTrainingOutput
+
+
+
## MobileBertModel
[[autodoc]] MobileBertModel
@@ -113,6 +117,9 @@ This model was contributed by [vshampor](https://huggingface.co/vshampor). The o
[[autodoc]] MobileBertForQuestionAnswering
- forward
+
+
+
## TFMobileBertModel
[[autodoc]] TFMobileBertModel
@@ -152,3 +159,6 @@ This model was contributed by [vshampor](https://huggingface.co/vshampor). The o
[[autodoc]] TFMobileBertForQuestionAnswering
- call
+
+
+
diff --git a/docs/source/en/model_doc/mobilenet_v1.md b/docs/source/en/model_doc/mobilenet_v1.md
index 56743efe1416..9f68035c63c2 100644
--- a/docs/source/en/model_doc/mobilenet_v1.md
+++ b/docs/source/en/model_doc/mobilenet_v1.md
@@ -24,7 +24,9 @@ The abstract from the paper is the following:
*We present a class of efficient models called MobileNets for mobile and embedded vision applications. MobileNets are based on a streamlined architecture that uses depth-wise separable convolutions to build light weight deep neural networks. We introduce two simple global hyper-parameters that efficiently trade off between latency and accuracy. These hyper-parameters allow the model builder to choose the right sized model for their application based on the constraints of the problem. We present extensive experiments on resource and accuracy tradeoffs and show strong performance compared to other popular models on ImageNet classification. We then demonstrate the effectiveness of MobileNets across a wide range of applications and use cases including object detection, finegrain classification, face attributes and large scale geo-localization.*
-Tips:
+This model was contributed by [matthijs](https://huggingface.co/Matthijs). The original code and weights can be found [here](https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.md).
+
+## Usage tips
- The checkpoints are named **mobilenet\_v1\_*depth*\_*size***, for example **mobilenet\_v1\_1.0\_224**, where **1.0** is the depth multiplier (sometimes also referred to as "alpha" or the width multiplier) and **224** is the resolution of the input images the model was trained on.
@@ -46,8 +48,6 @@ Unsupported features:
- It's common to extract the output from the pointwise layers at indices 5, 11, 12, 13 for downstream purposes. Using `output_hidden_states=True` returns the output from all intermediate layers. There is currently no way to limit this to specific layers.
-This model was contributed by [matthijs](https://huggingface.co/Matthijs). The original code and weights can be found [here](https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.md).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with MobileNetV1.
diff --git a/docs/source/en/model_doc/mobilenet_v2.md b/docs/source/en/model_doc/mobilenet_v2.md
index bd4114dc71ad..ff22231ae0c1 100644
--- a/docs/source/en/model_doc/mobilenet_v2.md
+++ b/docs/source/en/model_doc/mobilenet_v2.md
@@ -26,7 +26,9 @@ The abstract from the paper is the following:
*The MobileNetV2 architecture is based on an inverted residual structure where the input and output of the residual block are thin bottleneck layers opposite to traditional residual models which use expanded representations in the input an MobileNetV2 uses lightweight depthwise convolutions to filter features in the intermediate expansion layer. Additionally, we find that it is important to remove non-linearities in the narrow layers in order to maintain representational power. We demonstrate that this improves performance and provide an intuition that led to this design. Finally, our approach allows decoupling of the input/output domains from the expressiveness of the transformation, which provides a convenient framework for further analysis. We measure our performance on Imagenet classification, COCO object detection, VOC image segmentation. We evaluate the trade-offs between accuracy, and number of operations measured by multiply-adds (MAdd), as well as the number of parameters.*
-Tips:
+This model was contributed by [matthijs](https://huggingface.co/Matthijs). The original code and weights can be found [here for the main model](https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet) and [here for DeepLabV3+](https://github.com/tensorflow/models/tree/master/research/deeplab).
+
+## Usage tips
- The checkpoints are named **mobilenet\_v2\_*depth*\_*size***, for example **mobilenet\_v2\_1.0\_224**, where **1.0** is the depth multiplier (sometimes also referred to as "alpha" or the width multiplier) and **224** is the resolution of the input images the model was trained on.
@@ -50,8 +52,6 @@ Unsupported features:
- The DeepLabV3+ segmentation head does not use the final convolution layer from the backbone, but this layer gets computed anyway. There is currently no way to tell [`MobileNetV2Model`] up to which layer it should run.
-This model was contributed by [matthijs](https://huggingface.co/Matthijs). The original code and weights can be found [here for the main model](https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet) and [here for DeepLabV3+](https://github.com/tensorflow/models/tree/master/research/deeplab).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with MobileNetV2.
diff --git a/docs/source/en/model_doc/mobilevit.md b/docs/source/en/model_doc/mobilevit.md
index 2d815795689a..e724ffa380e2 100644
--- a/docs/source/en/model_doc/mobilevit.md
+++ b/docs/source/en/model_doc/mobilevit.md
@@ -24,7 +24,9 @@ The abstract from the paper is the following:
*Light-weight convolutional neural networks (CNNs) are the de-facto for mobile vision tasks. Their spatial inductive biases allow them to learn representations with fewer parameters across different vision tasks. However, these networks are spatially local. To learn global representations, self-attention-based vision trans-formers (ViTs) have been adopted. Unlike CNNs, ViTs are heavy-weight. In this paper, we ask the following question: is it possible to combine the strengths of CNNs and ViTs to build a light-weight and low latency network for mobile vision tasks? Towards this end, we introduce MobileViT, a light-weight and general-purpose vision transformer for mobile devices. MobileViT presents a different perspective for the global processing of information with transformers, i.e., transformers as convolutions. Our results show that MobileViT significantly outperforms CNN- and ViT-based networks across different tasks and datasets. On the ImageNet-1k dataset, MobileViT achieves top-1 accuracy of 78.4% with about 6 million parameters, which is 3.2% and 6.2% more accurate than MobileNetv3 (CNN-based) and DeIT (ViT-based) for a similar number of parameters. On the MS-COCO object detection task, MobileViT is 5.7% more accurate than MobileNetv3 for a similar number of parameters.*
-Tips:
+This model was contributed by [matthijs](https://huggingface.co/Matthijs). The TensorFlow version of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code and weights can be found [here](https://github.com/apple/ml-cvnets).
+
+## Usage tips
- MobileViT is more like a CNN than a Transformer model. It does not work on sequence data but on batches of images. Unlike ViT, there are no embeddings. The backbone model outputs a feature map. You can follow [this tutorial](https://keras.io/examples/vision/mobilevit) for a lightweight introduction.
- One can use [`MobileViTImageProcessor`] to prepare images for the model. Note that if you do your own preprocessing, the pretrained checkpoints expect images to be in BGR pixel order (not RGB).
@@ -58,9 +60,6 @@ with open(tflite_filename, "wb") as f:
The resulting model will be just **about an MB** making it a good fit for mobile applications where resources and network
bandwidth can be constrained.
-
-This model was contributed by [matthijs](https://huggingface.co/Matthijs). The TensorFlow version of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code and weights can be found [here](https://github.com/apple/ml-cvnets).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with MobileViT.
@@ -91,6 +90,9 @@ If you're interested in submitting a resource to be included here, please feel f
- preprocess
- post_process_semantic_segmentation
+
+
+
## MobileViTModel
[[autodoc]] MobileViTModel
@@ -106,6 +108,9 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] MobileViTForSemanticSegmentation
- forward
+
+
+
## TFMobileViTModel
[[autodoc]] TFMobileViTModel
@@ -120,3 +125,6 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] TFMobileViTForSemanticSegmentation
- call
+
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/mobilevitv2.md b/docs/source/en/model_doc/mobilevitv2.md
index 4b6689ef2b40..c3a650fc7042 100644
--- a/docs/source/en/model_doc/mobilevitv2.md
+++ b/docs/source/en/model_doc/mobilevitv2.md
@@ -26,17 +26,16 @@ The abstract from the paper is the following:
*Mobile vision transformers (MobileViT) can achieve state-of-the-art performance across several mobile vision tasks, including classification and detection. Though these models have fewer parameters, they have high latency as compared to convolutional neural network-based models. The main efficiency bottleneck in MobileViT is the multi-headed self-attention (MHA) in transformers, which requires O(k2) time complexity with respect to the number of tokens (or patches) k. Moreover, MHA requires costly operations (e.g., batch-wise matrix multiplication) for computing self-attention, impacting latency on resource-constrained devices. This paper introduces a separable self-attention method with linear complexity, i.e. O(k). A simple yet effective characteristic of the proposed method is that it uses element-wise operations for computing self-attention, making it a good choice for resource-constrained devices. The improved model, MobileViTV2, is state-of-the-art on several mobile vision tasks, including ImageNet object classification and MS-COCO object detection. With about three million parameters, MobileViTV2 achieves a top-1 accuracy of 75.6% on the ImageNet dataset, outperforming MobileViT by about 1% while running 3.2× faster on a mobile device.*
-Tips:
+This model was contributed by [shehan97](https://huggingface.co/shehan97).
+The original code can be found [here](https://github.com/apple/ml-cvnets).
+
+## Usage tips
- MobileViTV2 is more like a CNN than a Transformer model. It does not work on sequence data but on batches of images. Unlike ViT, there are no embeddings. The backbone model outputs a feature map.
- One can use [`MobileViTImageProcessor`] to prepare images for the model. Note that if you do your own preprocessing, the pretrained checkpoints expect images to be in BGR pixel order (not RGB).
- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes).
- The segmentation model uses a [DeepLabV3](https://arxiv.org/abs/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
-This model was contributed by [shehan97](https://huggingface.co/shehan97).
-The original code can be found [here](https://github.com/apple/ml-cvnets).
-
-
## MobileViTV2Config
[[autodoc]] MobileViTV2Config
diff --git a/docs/source/en/model_doc/mpnet.md b/docs/source/en/model_doc/mpnet.md
index 97c140f631d1..c571da47b004 100644
--- a/docs/source/en/model_doc/mpnet.md
+++ b/docs/source/en/model_doc/mpnet.md
@@ -37,14 +37,14 @@ down-streaming tasks (GLUE, SQuAD, etc). Experimental results show that MPNet ou
margin, and achieves better results on these tasks compared with previous state-of-the-art pre-trained methods (e.g.,
BERT, XLNet, RoBERTa) under the same model setting.*
-Tips:
+The original code can be found [here](https://github.com/microsoft/MPNet).
-- MPNet doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. just
- separate your segments with the separation token `tokenizer.sep_token` (or `[sep]`).
+## Usage tips
-The original code can be found [here](https://github.com/microsoft/MPNet).
+MPNet doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. Just
+separate your segments with the separation token `tokenizer.sep_token` (or `[sep]`).
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -68,6 +68,9 @@ The original code can be found [here](https://github.com/microsoft/MPNet).
[[autodoc]] MPNetTokenizerFast
+
+
+
## MPNetModel
[[autodoc]] MPNetModel
@@ -98,6 +101,9 @@ The original code can be found [here](https://github.com/microsoft/MPNet).
[[autodoc]] MPNetForQuestionAnswering
- forward
+
+
+
## TFMPNetModel
[[autodoc]] TFMPNetModel
@@ -127,3 +133,6 @@ The original code can be found [here](https://github.com/microsoft/MPNet).
[[autodoc]] TFMPNetForQuestionAnswering
- call
+
+
+
diff --git a/docs/source/en/model_doc/mpt.md b/docs/source/en/model_doc/mpt.md
index fd0a3b5c46bf..f7e6fcc14382 100644
--- a/docs/source/en/model_doc/mpt.md
+++ b/docs/source/en/model_doc/mpt.md
@@ -30,13 +30,14 @@ The original code is available at the [`llm-foundry`](https://github.com/mosaic
Read more about it [in the release blogpost](https://www.mosaicml.com/blog/mpt-7b)
-Tips:
+## Usage tips
- Learn more about some techniques behind training of the model [in this section of llm-foundry repository](https://github.com/mosaicml/llm-foundry/blob/main/TUTORIAL.md#faqs)
- If you want to use the advanced version of the model (triton kernels, direct flash attention integration), you can still use the original model implementation by adding `trust_remote_code=True` when calling `from_pretrained`.
-- [Fine-tuning Notebook](https://colab.research.google.com/drive/1HCpQkLL7UXW8xJUJJ29X7QAeNJKO0frZ?usp=sharing) on how to fine-tune MPT-7B on a free Google Colab instance to turn the model into a Chatbot.
+## Resources
+- [Fine-tuning Notebook](https://colab.research.google.com/drive/1HCpQkLL7UXW8xJUJJ29X7QAeNJKO0frZ?usp=sharing) on how to fine-tune MPT-7B on a free Google Colab instance to turn the model into a Chatbot.
## MptConfig
diff --git a/docs/source/en/model_doc/mra.md b/docs/source/en/model_doc/mra.md
index 8c1c392ead12..cc4c0d9cc9c8 100644
--- a/docs/source/en/model_doc/mra.md
+++ b/docs/source/en/model_doc/mra.md
@@ -27,24 +27,20 @@ The abstract from the paper is the following:
This model was contributed by [novice03](https://huggingface.co/novice03).
The original code can be found [here](https://github.com/mlpen/mra-attention).
-
## MraConfig
[[autodoc]] MraConfig
-
## MraModel
[[autodoc]] MraModel
- forward
-
## MraForMaskedLM
[[autodoc]] MraForMaskedLM
- forward
-
## MraForSequenceClassification
[[autodoc]] MraForSequenceClassification
@@ -55,13 +51,11 @@ The original code can be found [here](https://github.com/mlpen/mra-attention).
[[autodoc]] MraForMultipleChoice
- forward
-
## MraForTokenClassification
[[autodoc]] MraForTokenClassification
- forward
-
## MraForQuestionAnswering
[[autodoc]] MraForQuestionAnswering
diff --git a/docs/source/en/model_doc/mt5.md b/docs/source/en/model_doc/mt5.md
index beec9b535490..f7360092dec7 100644
--- a/docs/source/en/model_doc/mt5.md
+++ b/docs/source/en/model_doc/mt5.md
@@ -60,7 +60,7 @@ Google has released the following variants:
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
found [here](https://github.com/google-research/multilingual-t5).
-## Documentation resources
+## Resources
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
@@ -82,6 +82,8 @@ See [`T5Tokenizer`] for all details.
See [`T5TokenizerFast`] for all details.
+
+
## MT5Model
@@ -103,6 +105,9 @@ See [`T5TokenizerFast`] for all details.
[[autodoc]] MT5ForQuestionAnswering
+
+
+
## TFMT5Model
[[autodoc]] TFMT5Model
@@ -115,6 +120,9 @@ See [`T5TokenizerFast`] for all details.
[[autodoc]] TFMT5EncoderModel
+
+
+
## FlaxMT5Model
[[autodoc]] FlaxMT5Model
@@ -126,3 +134,6 @@ See [`T5TokenizerFast`] for all details.
## FlaxMT5EncoderModel
[[autodoc]] FlaxMT5EncoderModel
+
+
+
diff --git a/docs/source/en/model_doc/musicgen.md b/docs/source/en/model_doc/musicgen.md
index 40c48382734c..bc2234ce3c41 100644
--- a/docs/source/en/model_doc/musicgen.md
+++ b/docs/source/en/model_doc/musicgen.md
@@ -46,6 +46,16 @@ This model was contributed by [sanchit-gandhi](https://huggingface.co/sanchit-ga
[here](https://github.com/facebookresearch/audiocraft). The pre-trained checkpoints can be found on the
[Hugging Face Hub](https://huggingface.co/models?sort=downloads&search=facebook%2Fmusicgen-).
+## Usage tips
+
+- After downloading the original checkpoints from [here](https://github.com/facebookresearch/audiocraft/blob/main/docs/MUSICGEN.md#importing--exporting-models) , you can convert them using the **conversion script** available at
+`src/transformers/models/musicgen/convert_musicgen_transformers.py` with the following command:
+
+```bash
+python src/transformers/models/musicgen/convert_musicgen_transformers.py \
+ --checkpoint small --pytorch_dump_folder /output/path --safe_serialization
+```
+
## Generation
MusicGen is compatible with two generation modes: greedy and sampling. In practice, sampling leads to significantly
@@ -57,6 +67,11 @@ Generation is limited by the sinusoidal positional embeddings to 30 second input
than 30 seconds of audio (1503 tokens), and input audio passed by Audio-Prompted Generation contributes to this limit so,
given an input of 20 seconds of audio, MusicGen cannot generate more than 10 seconds of additional audio.
+Transformers supports both mono (1-channel) and stereo (2-channel) variants of MusicGen. The mono channel versions
+generate a single set of codebooks. The stereo versions generate 2 sets of codebooks, 1 for each channel (left/right),
+and each set of codebooks is decoded independently through the audio compression model. The audio streams for each
+channel are combined to give the final stereo output.
+
### Unconditional Generation
The inputs for unconditional (or 'null') generation can be obtained through the method
diff --git a/docs/source/en/model_doc/mvp.md b/docs/source/en/model_doc/mvp.md
index 043163f40b30..0d98e04cf091 100644
--- a/docs/source/en/model_doc/mvp.md
+++ b/docs/source/en/model_doc/mvp.md
@@ -28,15 +28,17 @@ According to the abstract,
- MVP also has task-specific soft prompts to stimulate the model's capacity in performing a certain task.
- MVP is specially designed for natural language generation and can be adapted to a wide range of generation tasks, including but not limited to summarization, data-to-text generation, open-ended dialogue system, story generation, question answering, question generation, task-oriented dialogue system, commonsense generation, paraphrase generation, text style transfer, and text simplification. Our model can also be adapted to natural language understanding tasks such as sequence classification and (extractive) question answering.
-Tips:
+This model was contributed by [Tianyi Tang](https://huggingface.co/StevenTang). The detailed information and instructions can be found [here](https://github.com/RUCAIBox/MVP).
+
+## Usage tips
+
- We have released a series of models [here](https://huggingface.co/models?filter=mvp), including MVP, MVP with task-specific prompts, and multi-task pre-trained variants.
- If you want to use a model without prompts (standard Transformer), you can load it through `MvpForConditionalGeneration.from_pretrained('RUCAIBox/mvp')`.
- If you want to use a model with task-specific prompts, such as summarization, you can load it through `MvpForConditionalGeneration.from_pretrained('RUCAIBox/mvp-summarization')`.
- Our model supports lightweight prompt tuning following [Prefix-tuning](https://arxiv.org/abs/2101.00190) with method `set_lightweight_tuning()`.
-This model was contributed by [Tianyi Tang](https://huggingface.co/StevenTang). The detailed information and instructions can be found [here](https://github.com/RUCAIBox/MVP).
+## Usage examples
-## Examples
For summarization, it is an example to use MVP and MVP with summarization-specific prompts.
```python
@@ -104,7 +106,7 @@ For lightweight tuning, *i.e.*, fixing the model and only tuning prompts, you ca
>>> model.set_lightweight_tuning()
```
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Question answering task guide](../tasks/question_answering)
diff --git a/docs/source/en/model_doc/nat.md b/docs/source/en/model_doc/nat.md
index 668951c241f5..ecb61ccb0a33 100644
--- a/docs/source/en/model_doc/nat.md
+++ b/docs/source/en/model_doc/nat.md
@@ -36,7 +36,18 @@ that boosts image classification and downstream vision performance. Experimental
NAT-Tiny reaches 83.2% top-1 accuracy on ImageNet, 51.4% mAP on MS-COCO and 48.4% mIoU on ADE20K, which is 1.9%
ImageNet accuracy, 1.0% COCO mAP, and 2.6% ADE20K mIoU improvement over a Swin model with similar size. *
-Tips:
+
+
+ Neighborhood Attention compared to other attention patterns.
+Taken from the original paper.
+
+This model was contributed by [Ali Hassani](https://huggingface.co/alihassanijr).
+The original code can be found [here](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
+
+## Usage tips
+
- One can use the [`AutoImageProcessor`] API to prepare images for the model.
- NAT can be used as a *backbone*. When `output_hidden_states = True`,
it will output both `hidden_states` and `reshaped_hidden_states`.
@@ -50,16 +61,6 @@ or build on your system by running `pip install natten`.
Note that the latter will likely take time to compile. NATTEN does not support Windows devices yet.
- Patch size of 4 is only supported at the moment.
-
-
- Neighborhood Attention compared to other attention patterns.
-Taken from the original paper.
-
-This model was contributed by [Ali Hassani](https://huggingface.co/alihassanijr).
-The original code can be found [here](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with NAT.
@@ -75,7 +76,6 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] NatConfig
-
## NatModel
[[autodoc]] NatModel
diff --git a/docs/source/en/model_doc/nezha.md b/docs/source/en/model_doc/nezha.md
index 9c136cdf0660..872f576f1286 100644
--- a/docs/source/en/model_doc/nezha.md
+++ b/docs/source/en/model_doc/nezha.md
@@ -35,7 +35,7 @@ and natural language inference (XNLI).*
This model was contributed by [sijunhe](https://huggingface.co/sijunhe). The original code can be found [here](https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/NEZHA-PyTorch).
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
diff --git a/docs/source/en/model_doc/nllb-moe.md b/docs/source/en/model_doc/nllb-moe.md
index a98266b24927..5c283fb3f0e1 100644
--- a/docs/source/en/model_doc/nllb-moe.md
+++ b/docs/source/en/model_doc/nllb-moe.md
@@ -37,22 +37,24 @@ improvements to counteract overfitting while training on thousands of tasks. Cri
a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety.
Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system.*
-Tips:
+This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ).
+The original code can be found [here](https://github.com/facebookresearch/fairseq).
+
+## Usage tips
- M2M100ForConditionalGeneration is the base model for both NLLB and NLLB MoE
- The NLLB-MoE is very similar to the NLLB model, but it's feed forward layer is based on the implementation of SwitchTransformers.
- The tokenizer is the same as the NLLB models.
-This model was contributed by [Arthur Zucker](https://huggingface.co/ArtZucker).
-The original code can be found [here](https://github.com/facebookresearch/fairseq).
-
## Implementation differences with SwitchTransformers
+
The biggest difference is the way the tokens are routed. NLLB-MoE uses a `top-2-gate` which means that for each input, only the top two experts are selected based on the
highest predicted probabilities from the gating network, and the remaining experts are ignored. In `SwitchTransformers`, only the top-1 probabilities are computed,
which means that tokens have less probability of being forwarded. Moreover, if a token is not routed to any expert, `SwitchTransformers` still adds its unmodified hidden
states (kind of like a residual connection) while they are masked in `NLLB`'s top-2 routing mechanism.
## Generating with NLLB-MoE
+
The available checkpoints require around 350GB of storage. Make sure to use `accelerate` if you do not have enough RAM on your machine.
While generating the target text set the `forced_bos_token_id` to the target language id. The following
@@ -99,7 +101,7 @@ See example below for a translation from romanian to german:
>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
```
-## Documentation resources
+## Resources
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
diff --git a/docs/source/en/model_doc/nllb.md b/docs/source/en/model_doc/nllb.md
index ec50716c73c8..3f272129d2f8 100644
--- a/docs/source/en/model_doc/nllb.md
+++ b/docs/source/en/model_doc/nllb.md
@@ -16,8 +16,9 @@ rendered properly in your Markdown viewer.
# NLLB
-**DISCLAIMER:** The default behaviour for the tokenizer has recently been fixed (and thus changed)!
+## Updated tokenizer behavior
+**DISCLAIMER:** The default behaviour for the tokenizer was fixed and thus changed in April 2023.
The previous version adds `[self.eos_token_id, self.cur_lang_code]` at the end of the token sequence for both target and source tokenization. This is wrong as the NLLB paper mentions (page 48, 6.1.1. Model Architecture) :
*Note that we prefix the source sequence with the source language, as opposed to the target
@@ -56,7 +57,7 @@ Enabling the old behaviour can be done as follows:
For more details, feel free to check the linked [PR](https://github.com/huggingface/transformers/pull/22313) and [Issue](https://github.com/huggingface/transformers/issues/19943).
-## Overview of NLLB
+## Overview
The NLLB model was presented in [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by Marta R. Costa-jussà, James Cross, Onur Çelebi,
Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula,
@@ -117,9 +118,9 @@ See example below for a translation from romanian to german:
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained(
-... "facebook/nllb-200-distilled-600M", use_auth_token=True, src_lang="ron_Latn"
+... "facebook/nllb-200-distilled-600M", token=True, src_lang="ron_Latn"
... )
->>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M", use_auth_token=True)
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M", token=True)
>>> article = "Şeful ONU spune că nu există o soluţie militară în Siria"
>>> inputs = tokenizer(article, return_tensors="pt")
@@ -131,7 +132,7 @@ See example below for a translation from romanian to german:
UN-Chef sagt, es gibt keine militärische Lösung in Syrien
```
-## Documentation resources
+## Resources
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
diff --git a/docs/source/en/model_doc/nougat.md b/docs/source/en/model_doc/nougat.md
index 3fcb97a541b8..a39e74eb213a 100644
--- a/docs/source/en/model_doc/nougat.md
+++ b/docs/source/en/model_doc/nougat.md
@@ -33,7 +33,7 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
[here](https://github.com/facebookresearch/nougat).
-Tips:
+## Usage tips
- The quickest way to get started with Nougat is by checking the [tutorial
notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Nougat), which show how to use the model
@@ -89,6 +89,12 @@ into a single instance to both extract the input features and decode the predict
See the [model hub](https://huggingface.co/models?filter=nougat) to look for Nougat checkpoints.
+
+
+The model is identical to [Donut](donut) in terms of architecture.
+
+
+
## NougatImageProcessor
[[autodoc]] NougatImageProcessor
diff --git a/docs/source/en/model_doc/nystromformer.md b/docs/source/en/model_doc/nystromformer.md
index 6434944aba8a..185c4e1f011a 100644
--- a/docs/source/en/model_doc/nystromformer.md
+++ b/docs/source/en/model_doc/nystromformer.md
@@ -37,7 +37,7 @@ favorably relative to other efficient self-attention methods. Our code is availa
This model was contributed by [novice03](https://huggingface.co/novice03). The original code can be found [here](https://github.com/mlpen/Nystromformer).
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
diff --git a/docs/source/en/model_doc/oneformer.md b/docs/source/en/model_doc/oneformer.md
index 5f8f46e1529e..97a6aa64f543 100644
--- a/docs/source/en/model_doc/oneformer.md
+++ b/docs/source/en/model_doc/oneformer.md
@@ -26,7 +26,14 @@ The abstract from the paper is the following:
*Universal Image Segmentation is not a new concept. Past attempts to unify image segmentation in the last decades include scene parsing, panoptic segmentation, and, more recently, new panoptic architectures. However, such panoptic architectures do not truly unify image segmentation because they need to be trained individually on the semantic, instance, or panoptic segmentation to achieve the best performance. Ideally, a truly universal framework should be trained only once and achieve SOTA performance across all three image segmentation tasks. To that end, we propose OneFormer, a universal image segmentation framework that unifies segmentation with a multi-task train-once design. We first propose a task-conditioned joint training strategy that enables training on ground truths of each domain (semantic, instance, and panoptic segmentation) within a single multi-task training process. Secondly, we introduce a task token to condition our model on the task at hand, making our model task-dynamic to support multi-task training and inference. Thirdly, we propose using a query-text contrastive loss during training to establish better inter-task and inter-class distinctions. Notably, our single OneFormer model outperforms specialized Mask2Former models across all three segmentation tasks on ADE20k, CityScapes, and COCO, despite the latter being trained on each of the three tasks individually with three times the resources. With new ConvNeXt and DiNAT backbones, we observe even more performance improvement. We believe OneFormer is a significant step towards making image segmentation more universal and accessible.*
-Tips:
+The figure below illustrates the architecture of OneFormer. Taken from the [original paper](https://arxiv.org/abs/2211.06220).
+
+
+
+This model was contributed by [Jitesh Jain](https://huggingface.co/praeclarumjj3). The original code can be found [here](https://github.com/SHI-Labs/OneFormer).
+
+## Usage tips
+
- OneFormer requires two inputs during inference: *image* and *task token*.
- During training, OneFormer only uses panoptic annotations.
- If you want to train the model in a distributed environment across multiple nodes, then one should update the
@@ -35,12 +42,6 @@ Tips:
- One can use [`OneFormerProcessor`] to prepare input images and task inputs for the model and optional targets for the model. [`OneformerProcessor`] wraps [`OneFormerImageProcessor`] and [`CLIPTokenizer`] into a single instance to both prepare the images and encode the task inputs.
- To get the final segmentation, depending on the task, you can call [`~OneFormerProcessor.post_process_semantic_segmentation`] or [`~OneFormerImageProcessor.post_process_instance_segmentation`] or [`~OneFormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`OneFormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
-The figure below illustrates the architecture of OneFormer. Taken from the [original paper](https://arxiv.org/abs/2211.06220).
-
-
-
-This model was contributed by [Jitesh Jain](https://huggingface.co/praeclarumjj3). The original code can be found [here](https://github.com/SHI-Labs/OneFormer).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with OneFormer.
diff --git a/docs/source/en/model_doc/open-llama.md b/docs/source/en/model_doc/open-llama.md
index c20ecb7f88ca..01170e7e3be6 100644
--- a/docs/source/en/model_doc/open-llama.md
+++ b/docs/source/en/model_doc/open-llama.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
-This model is in maintenance mode only, so we won't accept any new PRs changing its code.
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.31.0.
You can do so by running the following command: `pip install -U transformers==4.31.0`.
@@ -33,15 +33,13 @@ This model differs from the [OpenLLaMA models](https://huggingface.co/models?sea
## Overview
-The Open-Llama model was proposed in [Open-Llama project](https://github.com/s-JoL/Open-Llama) by community developer s-JoL.
+The Open-Llama model was proposed in the open source Open-Llama project by community developer s-JoL.
The model is mainly based on LLaMA with some modifications, incorporating memory-efficient attention from Xformers, stable embedding from Bloom, and shared input-output embedding from PaLM.
And the model is pre-trained on both Chinese and English, which gives it better performance on Chinese language tasks.
This model was contributed by [s-JoL](https://huggingface.co/s-JoL).
-The original code can be found [Open-Llama](https://github.com/s-JoL/Open-Llama).
-Checkpoint and usage can be found at [s-JoL/Open-Llama-V1](https://huggingface.co/s-JoL/Open-Llama-V1).
-
+The original code was released on GitHub by [s-JoL](https://github.com/s-JoL), but is now removed.
## OpenLlamaConfig
diff --git a/docs/source/en/model_doc/openai-gpt.md b/docs/source/en/model_doc/openai-gpt.md
index ff98930b576e..1fbfbbcd89e3 100644
--- a/docs/source/en/model_doc/openai-gpt.md
+++ b/docs/source/en/model_doc/openai-gpt.md
@@ -44,7 +44,12 @@ approach on a wide range of benchmarks for natural language understanding. Our g
discriminatively trained models that use architectures specifically crafted for each task, significantly improving upon
the state of the art in 9 out of the 12 tasks studied.*
-Tips:
+[Write With Transformer](https://transformer.huggingface.co/doc/gpt) is a webapp created and hosted by Hugging Face
+showcasing the generative capabilities of several models. GPT is one of them.
+
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/openai/finetune-transformer-lm).
+
+## Usage tips
- GPT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
@@ -52,10 +57,6 @@ Tips:
token in a sequence. Leveraging this feature allows GPT-2 to generate syntactically coherent text as it can be
observed in the *run_generation.py* example script.
-[Write With Transformer](https://transformer.huggingface.co/doc/gpt) is a webapp created and hosted by Hugging Face
-showcasing the generative capabilities of several models. GPT is one of them.
-
-This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/openai/finetune-transformer-lm).
Note:
@@ -116,6 +117,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] models.openai.modeling_tf_openai.TFOpenAIGPTDoubleHeadsModelOutput
+
+
+
## OpenAIGPTModel
[[autodoc]] OpenAIGPTModel
@@ -136,6 +140,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] OpenAIGPTForSequenceClassification
- forward
+
+
+
## TFOpenAIGPTModel
[[autodoc]] TFOpenAIGPTModel
@@ -155,3 +162,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] TFOpenAIGPTForSequenceClassification
- call
+
+
+
diff --git a/docs/source/en/model_doc/opt.md b/docs/source/en/model_doc/opt.md
index 332c63600acb..3da7b22fab74 100644
--- a/docs/source/en/model_doc/opt.md
+++ b/docs/source/en/model_doc/opt.md
@@ -25,13 +25,13 @@ The abstract from the paper is the following:
*Large language models, which are often trained for hundreds of thousands of compute days, have shown remarkable capabilities for zero- and few-shot learning. Given their computational cost, these models are difficult to replicate without significant capital. For the few that are available through APIs, no access is granted to the full model weights, making them difficult to study. We present Open Pre-trained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M to 175B parameters, which we aim to fully and responsibly share with interested researchers. We show that OPT-175B is comparable to GPT-3, while requiring only 1/7th the carbon footprint to develop. We are also releasing our logbook detailing the infrastructure challenges we faced, along with code for experimenting with all of the released models.*
+This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ), [Younes Belkada](https://huggingface.co/ybelkada), and [Patrick Von Platen](https://huggingface.co/patrickvonplaten).
+The original code can be found [here](https://github.com/facebookresearch/metaseq).
+
Tips:
- OPT has the same architecture as [`BartDecoder`].
- Contrary to GPT2, OPT adds the EOS token `` to the beginning of every prompt.
-This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ), [Younes Belkada](https://huggingface.co/ybelkada), and [Patrick Von Platen](https://huggingface.co/patrickvonplaten).
-The original code can be found [here](https://github.com/facebookresearch/metaseq).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with OPT. If you're
@@ -62,10 +62,62 @@ The resource should ideally demonstrate something new instead of duplicating an
- A blog post on [How 🤗 Accelerate runs very large models thanks to PyTorch](https://huggingface.co/blog/accelerate-large-models) with OPT.
+
+## Combining OPT and Flash Attention 2
+
+First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
+
+To load and run a model using Flash Attention 2, refer to the snippet below:
+
+```python
+>>> import torch
+>>> from transformers import OPTForCausalLM, GPT2Tokenizer
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = OPTForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16, use_flash_attention_2=True)
+>>> tokenizer = GPT2Tokenizer.from_pretrained("facebook/opt-350m")
+
+>>> prompt = ("A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the "
+ "Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived "
+ "there?")
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=30, do_sample=False)
+>>> tokenizer.batch_decode(generated_ids)[0]
+'A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived there?\nStatue: I have lived here for about a year.\nHuman: What is your favorite place to eat?\nStatue: I love'
+```
+
+### Expected speedups
+
+Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `facebook/opt-2.7b` checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
+
+
+
+
+
+Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `facebook/opt-350m` checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
+
+
+
+
+
+
+
## OPTConfig
[[autodoc]] OPTConfig
+
+
+
## OPTModel
[[autodoc]] OPTModel
@@ -76,6 +128,19 @@ The resource should ideally demonstrate something new instead of duplicating an
[[autodoc]] OPTForCausalLM
- forward
+## OPTForSequenceClassification
+
+[[autodoc]] OPTForSequenceClassification
+ - forward
+
+## OPTForQuestionAnswering
+
+[[autodoc]] OPTForQuestionAnswering
+ - forward
+
+
+
+
## TFOPTModel
[[autodoc]] TFOPTModel
@@ -86,23 +151,18 @@ The resource should ideally demonstrate something new instead of duplicating an
[[autodoc]] TFOPTForCausalLM
- call
-## OPTForSequenceClassification
-
-[[autodoc]] OPTForSequenceClassification
- - forward
-
-## OPTForQuestionAnswering
-
-[[autodoc]] OPTForQuestionAnswering
- - forward
+
+
## FlaxOPTModel
[[autodoc]] FlaxOPTModel
- __call__
-
## FlaxOPTForCausalLM
[[autodoc]] FlaxOPTForCausalLM
- __call__
+
+
+
diff --git a/docs/source/en/model_doc/owlv2.md b/docs/source/en/model_doc/owlv2.md
index 73063c59350e..12000af9ed4f 100644
--- a/docs/source/en/model_doc/owlv2.md
+++ b/docs/source/en/model_doc/owlv2.md
@@ -24,11 +24,6 @@ The abstract from the paper is the following:
*Open-vocabulary object detection has benefited greatly from pretrained vision-language models, but is still limited by the amount of available detection training data. While detection training data can be expanded by using Web image-text pairs as weak supervision, this has not been done at scales comparable to image-level pretraining. Here, we scale up detection data with self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. Major challenges in scaling self-training are the choice of label space, pseudo-annotation filtering, and training efficiency. We present the OWLv2 model and OWL-ST self-training recipe, which address these challenges. OWLv2 surpasses the performance of previous state-of-the-art open-vocabulary detectors already at comparable training scales (~10M examples). However, with OWL-ST, we can scale to over 1B examples, yielding further large improvement: With an L/14 architecture, OWL-ST improves AP on LVIS rare classes, for which the model has seen no human box annotations, from 31.2% to 44.6% (43% relative improvement). OWL-ST unlocks Web-scale training for open-world localization, similar to what has been seen for image classification and language modelling.*
-Tips:
-
-- The architecture of OWLv2 is identical to [OWL-ViT](owlvit), however the object detection head now also includes an objectness classifier, which predicts the (query-agnostic) likelihood that a predicted box contains an object (as opposed to background). The objectness score can be used to rank or filter predictions independently of text queries.
-- Usage of OWLv2 is identical to [OWL-ViT](owlvit) with a new, updated image processor ([`Owlv2ImageProcessor`]).
-
@@ -37,13 +32,12 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
-## Usage
+## Usage example
OWLv2 is, just like its predecessor [OWL-ViT](owlvit), a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
[`Owlv2ImageProcessor`] can be used to resize (or rescale) and normalize images for the model and [`CLIPTokenizer`] is used to encode the text. [`Owlv2Processor`] wraps [`Owlv2ImageProcessor`] and [`CLIPTokenizer`] into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using [`Owlv2Processor`] and [`Owlv2ForObjectDetection`].
-
```python
>>> import requests
>>> from PIL import Image
@@ -76,7 +70,15 @@ Detected a photo of a cat with confidence 0.665 at location [6.75, 38.97, 326.62
## Resources
-A demo notebook on using OWLv2 for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OWLv2).
+- A demo notebook on using OWLv2 for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OWLv2).
+- [Zero-shot object detection task guide](../tasks/zero_shot_object_detection)
+
+
+
+The architecture of OWLv2 is identical to [OWL-ViT](owlvit), however the object detection head now also includes an objectness classifier, which predicts the (query-agnostic) likelihood that a predicted box contains an object (as opposed to background). The objectness score can be used to rank or filter predictions independently of text queries.
+Usage of OWLv2 is identical to [OWL-ViT](owlvit) with a new, updated image processor ([`Owlv2ImageProcessor`]).
+
+
## Owlv2Config
diff --git a/docs/source/en/model_doc/owlvit.md b/docs/source/en/model_doc/owlvit.md
index 712d0f62d788..0ba26eeb37b4 100644
--- a/docs/source/en/model_doc/owlvit.md
+++ b/docs/source/en/model_doc/owlvit.md
@@ -31,13 +31,12 @@ alt="drawing" width="600"/>
This model was contributed by [adirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
-## Usage
+## Usage tips
OWL-ViT is a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
[`OwlViTImageProcessor`] can be used to resize (or rescale) and normalize images for the model and [`CLIPTokenizer`] is used to encode the text. [`OwlViTProcessor`] wraps [`OwlViTImageProcessor`] and [`CLIPTokenizer`] into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using [`OwlViTProcessor`] and [`OwlViTForObjectDetection`].
-
```python
>>> import requests
>>> from PIL import Image
diff --git a/docs/source/en/model_doc/pegasus.md b/docs/source/en/model_doc/pegasus.md
index 14608aae31c9..0622354e62de 100644
--- a/docs/source/en/model_doc/pegasus.md
+++ b/docs/source/en/model_doc/pegasus.md
@@ -25,9 +25,6 @@ rendered properly in your Markdown viewer.
-**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=sshleifer&labels=&template=bug-report.md&title)
-and assign @patrickvonplaten.
-
## Overview
@@ -42,13 +39,17 @@ According to the abstract,
This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The Authors' code can be found [here](https://github.com/google-research/pegasus).
-Tips:
+## Usage tips
- Sequence-to-sequence model with the same encoder-decoder model architecture as BART. Pegasus is pre-trained jointly on two self-supervised objective functions: Masked Language Modeling (MLM) and a novel summarization specific pretraining objective, called Gap Sentence Generation (GSG).
* MLM: encoder input tokens are randomly replaced by a mask tokens and have to be predicted by the encoder (like in BERT)
* GSG: whole encoder input sentences are replaced by a second mask token and fed to the decoder, but which has a causal mask to hide the future words like a regular auto-regressive transformer decoder.
+- FP16 is not supported (help/ideas on this appreciated!).
+- The adafactor optimizer is recommended for pegasus fine-tuning.
+
+
## Checkpoints
All the [checkpoints](https://huggingface.co/models?search=pegasus) are fine-tuned for summarization, besides
@@ -60,20 +61,11 @@ All the [checkpoints](https://huggingface.co/models?search=pegasus) are fine-tun
- Full replication results and correctly pre-processed data can be found in this [Issue](https://github.com/huggingface/transformers/issues/6844#issue-689259666).
- [Distilled checkpoints](https://huggingface.co/models?search=distill-pegasus) are described in this [paper](https://arxiv.org/abs/2010.13002).
-### Examples
-
-- [Script](https://github.com/huggingface/transformers/tree/main/examples/research_projects/seq2seq-distillation/finetune_pegasus_xsum.sh) to fine-tune pegasus
- on the XSUM dataset. Data download instructions at [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
-- FP16 is not supported (help/ideas on this appreciated!).
-- The adafactor optimizer is recommended for pegasus fine-tuning.
-
-
## Implementation Notes
- All models are transformer encoder-decoders with 16 layers in each component.
- The implementation is completely inherited from [`BartForConditionalGeneration`]
- Some key configuration differences:
-
- static, sinusoidal position embeddings
- the model starts generating with pad_token_id (which has 0 token_embedding) as the prefix.
- more beams are used (`num_beams=8`)
@@ -82,7 +74,6 @@ All the [checkpoints](https://huggingface.co/models?search=pegasus) are fine-tun
- The code to convert checkpoints trained in the author's [repo](https://github.com/google-research/pegasus) can be
found in `convert_pegasus_tf_to_pytorch.py`.
-
## Usage Example
```python
@@ -106,8 +97,10 @@ All the [checkpoints](https://huggingface.co/models?search=pegasus) are fine-tun
... )
```
-## Documentation resources
+## Resources
+- [Script](https://github.com/huggingface/transformers/tree/main/examples/research_projects/seq2seq-distillation/finetune_pegasus_xsum.sh) to fine-tune pegasus
+ on the XSUM dataset. Data download instructions at [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
@@ -126,6 +119,9 @@ warning: `add_tokens` does not work at the moment.
[[autodoc]] PegasusTokenizerFast
+
+
+
## PegasusModel
[[autodoc]] PegasusModel
@@ -141,6 +137,9 @@ warning: `add_tokens` does not work at the moment.
[[autodoc]] PegasusForCausalLM
- forward
+
+
+
## TFPegasusModel
[[autodoc]] TFPegasusModel
@@ -151,6 +150,9 @@ warning: `add_tokens` does not work at the moment.
[[autodoc]] TFPegasusForConditionalGeneration
- call
+
+
+
## FlaxPegasusModel
[[autodoc]] FlaxPegasusModel
@@ -164,3 +166,6 @@ warning: `add_tokens` does not work at the moment.
- __call__
- encode
- decode
+
+
+
diff --git a/docs/source/en/model_doc/pegasus_x.md b/docs/source/en/model_doc/pegasus_x.md
index a0fd670fc7c9..20af5731e900 100644
--- a/docs/source/en/model_doc/pegasus_x.md
+++ b/docs/source/en/model_doc/pegasus_x.md
@@ -26,10 +26,6 @@ The abstract from the paper is the following:
*While large pretrained Transformer models have proven highly capable at tackling natural language tasks, handling long sequence inputs continues to be a significant challenge. One such task is long input summarization, where inputs are longer than the maximum input context of most pretrained models. Through an extensive set of experiments, we investigate what model architectural changes and pretraining paradigms can most efficiently adapt a pretrained Transformer for long input summarization. We find that a staggered, block-local Transformer with global encoder tokens strikes a good balance of performance and efficiency, and that an additional pretraining phase on long sequences meaningfully improves downstream summarization performance. Based on our findings, we introduce PEGASUS-X, an extension of the PEGASUS model with additional long input pretraining to handle inputs of up to 16K tokens. PEGASUS-X achieves strong performance on long input summarization tasks comparable with much larger models while adding few additional parameters and not requiring model parallelism to train.*
-Tips:
-
-* PEGASUS-X uses the same tokenizer as PEGASUS.
-
This model was contributed by [zphang](
+
+PEGASUS-X uses the same tokenizer as [PEGASUS](pegasus).
+
+
+
## PegasusXConfig
[[autodoc]] PegasusXConfig
-
## PegasusXModel
[[autodoc]] PegasusXModel
- forward
-
## PegasusXForConditionalGeneration
[[autodoc]] PegasusXForConditionalGeneration
diff --git a/docs/source/en/model_doc/perceiver.md b/docs/source/en/model_doc/perceiver.md
index 97921baed2b1..ee678c22f6f8 100644
--- a/docs/source/en/model_doc/perceiver.md
+++ b/docs/source/en/model_doc/perceiver.md
@@ -81,7 +81,13 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
[here](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
-Tips:
+
+
+Perceiver does **not** work with `torch.nn.DataParallel` due to a bug in PyTorch, see [issue #36035](https://github.com/pytorch/pytorch/issues/36035)
+
+
+
+## Resources
- The quickest way to get started with the Perceiver is by checking the [tutorial
notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Perceiver).
@@ -89,13 +95,6 @@ Tips:
is implemented in the library. Note that the models available in the library only showcase some examples of what you can do
with the Perceiver. There are many more use cases, including question answering, named-entity recognition, object detection,
audio classification, video classification, etc.
-
-**Note**:
-
-- Perceiver does **not** work with `torch.nn.DataParallel` due to a bug in PyTorch, see [issue #36035](https://github.com/pytorch/pytorch/issues/36035)
-
-## Documentation resources
-
- [Text classification task guide](../tasks/sequence_classification)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Image classification task guide](../tasks/image_classification)
diff --git a/docs/source/en/model_doc/persimmon.md b/docs/source/en/model_doc/persimmon.md
index cf13d070c622..fe9e66a0b717 100644
--- a/docs/source/en/model_doc/persimmon.md
+++ b/docs/source/en/model_doc/persimmon.md
@@ -26,6 +26,10 @@ The authors showcase their approach to model evaluation, focusing on practical t
In terms of model details, the work outlines the architecture and training methodology of Persimmon-8B, providing insights into its design choices, sequence length, and dataset composition. The authors present a fast inference code that outperforms traditional implementations through operator fusion and CUDA graph utilization while maintaining code coherence. They express their anticipation of how the community will leverage this contribution to drive innovation, hinting at further upcoming releases as part of an ongoing series of developments.
+This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ).
+The original code can be found [here](https://github.com/persimmon-ai-labs/adept-inference).
+
+## Usage tips
@@ -67,8 +71,6 @@ model = PersimmonForCausalLM.from_pretrained("/output/path")
tokenizer = PersimmonTokenizer.from_pretrained("/output/path")
```
-This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ).
-The original code can be found [here](https://github.com/persimmon-ai-labs/adept-inference).
- Perismmon uses a `sentencepiece` based tokenizer, with a `Unigram` model. It supports bytefallback, which is only available in `tokenizers==0.14.0` for the fast tokenizer.
The `LlamaTokenizer` is used as it is a standard wrapper around sentencepiece. The `chat` template will be updated with the templating functions in a follow up PR!
diff --git a/docs/source/en/model_doc/phi.md b/docs/source/en/model_doc/phi.md
new file mode 100644
index 000000000000..337502ac31d6
--- /dev/null
+++ b/docs/source/en/model_doc/phi.md
@@ -0,0 +1,126 @@
+
+
+# Phi
+
+## Overview
+
+The Phi-1 model was proposed in [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li.
+
+The Phi-1.5 model was proposed in [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
+
+### Summary
+In Phi-1 and Phi-1.5 papers, the authors showed how important the quality of the data is in training relative to the model size.
+They selected high quality "textbook" data alongside with synthetically generated data for training their small sized Transformer
+based model Phi-1 with 1.3B parameters. Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP.
+They follow the same strategy for Phi-1.5 and created another 1.3B parameter model with performance on natural language tasks comparable
+to models 5x larger, and surpassing most non-frontier LLMs. Phi-1.5 exhibits many of the traits of much larger LLMs such as the ability
+to “think step by step” or perform some rudimentary in-context learning.
+With these two experiments the authors successfully showed the huge impact of quality of training data when training machine learning models.
+
+
+The abstract from the Phi-1 paper is the following:
+
+*We introduce phi-1, a new large language model for code, with significantly smaller size than
+competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on
+8 A100s, using a selection of “textbook quality” data from the web (6B tokens) and synthetically
+generated textbooks and exercises with GPT-3.5 (1B tokens). Despite this small scale, phi-1 attains
+pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. It also displays surprising emergent
+properties compared to phi-1-base, our model before our finetuning stage on a dataset of coding
+exercises, and phi-1-small, a smaller model with 350M parameters trained with the same pipeline as
+phi-1 that still achieves 45% on HumanEval.*
+
+The abstract from the Phi-1.5 paper is the following:
+
+*We continue the investigation into the power of smaller Transformer-based language models as
+initiated by TinyStories – a 10 million parameter model that can produce coherent English – and
+the follow-up work on phi-1, a 1.3 billion parameter model with Python coding performance close
+to the state-of-the-art. The latter work proposed to use existing Large Language Models (LLMs) to
+generate “textbook quality” data as a way to enhance the learning process compared to traditional
+web data. We follow the “Textbooks Are All You Need” approach, focusing this time on common
+sense reasoning in natural language, and create a new 1.3 billion parameter model named phi-1.5,
+with performance on natural language tasks comparable to models 5x larger, and surpassing most
+non-frontier LLMs on more complex reasoning tasks such as grade-school mathematics and basic
+coding. More generally, phi-1.5 exhibits many of the traits of much larger LLMs, both good –such
+as the ability to “think step by step” or perform some rudimentary in-context learning– and bad,
+including hallucinations and the potential for toxic and biased generations –encouragingly though, we
+are seeing improvement on that front thanks to the absence of web data. We open-source phi-1.5 to
+promote further research on these urgent topics.*
+
+
+This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
+The original code for Phi-1 and Phi-1.5 can be found [here](https://huggingface.co/microsoft/phi-1/blob/main/modeling_mixformer_sequential.py) and [here](https://huggingface.co/microsoft/phi-1_5/blob/main/modeling_mixformer_sequential.py) respectively.
+
+
+## Usage tips
+
+- This model is quite similar to `Llama` with the main difference in [`PhiDecoderLayer`], where they used [`PhiAttention`] and [`PhiMLP`] layers in parallel configuration.
+- The tokenizer used for this model is identical to the [`CodeGenTokenizer`].
+
+
+### Example :
+
+```python
+>>> from transformers import PhiForCausalLM, AutoTokenizer
+
+>>> # define the model and tokenzier.
+>>> model = PhiForCausalLM.from_pretrained("susnato/phi-1_5_dev")
+>>> tokenizer = AutoTokenizer.from_pretrained("susnato/phi-1_5_dev")
+
+>>> # feel free to change the prompt to your liking.
+>>> prompt = "If I were an AI that had just achieved"
+
+>>> # apply the tokenizer.
+>>> tokens = tokenizer(prompt, return_tensors="pt")
+
+>>> # use the model to generate new tokens.
+>>> generated_output = model.generate(**tokens, use_cache=True, max_new_tokens=10)
+
+>>> tokenizer.batch_decode(generated_output)[0]
+'If I were an AI that had just achieved a breakthrough in machine learning, I would be thrilled'
+```
+
+
+## PhiConfig
+
+[[autodoc]] PhiConfig
+
+
+
+
+## PhiModel
+
+[[autodoc]] PhiModel
+ - forward
+
+## PhiForCausalLM
+
+[[autodoc]] PhiForCausalLM
+ - forward
+ - generate
+
+## PhiForSequenceClassification
+
+[[autodoc]] PhiForSequenceClassification
+ - forward
+
+## PhiForTokenClassification
+
+[[autodoc]] PhiForTokenClassification
+ - forward
+
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/phobert.md b/docs/source/en/model_doc/phobert.md
index 5543a9b3541a..30a50275476e 100644
--- a/docs/source/en/model_doc/phobert.md
+++ b/docs/source/en/model_doc/phobert.md
@@ -28,7 +28,9 @@ best pre-trained multilingual model XLM-R (Conneau et al., 2020) and improves th
Vietnamese-specific NLP tasks including Part-of-speech tagging, Dependency parsing, Named-entity recognition and
Natural language inference.*
-Example of use:
+This model was contributed by [dqnguyen](https://huggingface.co/dqnguyen). The original code can be found [here](https://github.com/VinAIResearch/PhoBERT).
+
+## Usage example
```python
>>> import torch
@@ -50,7 +52,12 @@ Example of use:
>>> # phobert = TFAutoModel.from_pretrained("vinai/phobert-base")
```
-This model was contributed by [dqnguyen](https://huggingface.co/dqnguyen). The original code can be found [here](https://github.com/VinAIResearch/PhoBERT).
+
+
+PhoBERT implementation is the same as BERT, except for tokenization. Refer to [EART documentation](bert) for information on
+configuration classes and their parameters. PhoBERT-specific tokenizer is documented below.
+
+
## PhobertTokenizer
diff --git a/docs/source/en/model_doc/pix2struct.md b/docs/source/en/model_doc/pix2struct.md
index b722a59b82e6..8dc179f5f863 100644
--- a/docs/source/en/model_doc/pix2struct.md
+++ b/docs/source/en/model_doc/pix2struct.md
@@ -39,7 +39,6 @@ The original code can be found [here](https://github.com/google-research/pix2str
- [Fine-tuning Notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_pix2struct.ipynb)
- [All models](https://huggingface.co/models?search=pix2struct)
-
## Pix2StructConfig
[[autodoc]] Pix2StructConfig
diff --git a/docs/source/en/model_doc/plbart.md b/docs/source/en/model_doc/plbart.md
index c9f502021485..61af52e54d0d 100644
--- a/docs/source/en/model_doc/plbart.md
+++ b/docs/source/en/model_doc/plbart.md
@@ -16,10 +16,7 @@ rendered properly in your Markdown viewer.
# PLBart
-**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
-[@gchhablani](https://www.github.com/gchhablani).
-
-## Overview of PLBart
+## Overview
The PLBART model was proposed in [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
This is a BART-like model which can be used to perform code-summarization, code-generation, and code-translation tasks. The pre-trained model `plbart-base` has been trained using multilingual denoising task
@@ -40,7 +37,7 @@ even with limited annotations.*
This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The Authors' code can be found [here](https://github.com/wasiahmad/PLBART).
-### Training of PLBart
+## Usage examples
PLBart is a multilingual encoder-decoder (sequence-to-sequence) model primarily intended for code-to-text, text-to-code, code-to-code tasks. As the
model is multilingual it expects the sequences in a different format. A special language id token is added in both the
@@ -53,7 +50,7 @@ In cases where the language code is needed, the regular [`~PLBartTokenizer.__cal
when you pass texts as the first argument or with the keyword argument `text`, and will encode target text format if
it's passed with the `text_target` keyword argument.
-- Supervised training
+### Supervised training
```python
>>> from transformers import PLBartForConditionalGeneration, PLBartTokenizer
@@ -65,7 +62,7 @@ it's passed with the `text_target` keyword argument.
>>> model(**inputs)
```
-- Generation
+### Generation
While generating the target text set the `decoder_start_token_id` to the target language id. The following
example shows how to translate Python to English using the `uclanlp/plbart-python-en_XX` model.
@@ -82,7 +79,7 @@ it's passed with the `text_target` keyword argument.
"Returns the maximum value of a b c."
```
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
diff --git a/docs/source/en/model_doc/poolformer.md b/docs/source/en/model_doc/poolformer.md
index 537c60bdbcf6..823c4412485c 100644
--- a/docs/source/en/model_doc/poolformer.md
+++ b/docs/source/en/model_doc/poolformer.md
@@ -28,8 +28,9 @@ The figure below illustrates the architecture of PoolFormer. Taken from the [ori
+This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
-Tips:
+## Usage tips
- PoolFormer has a hierarchical architecture, where instead of Attention, a simple Average Pooling layer is present. All checkpoints of the model can be found on the [hub](https://huggingface.co/models?other=poolformer).
- One can use [`PoolFormerImageProcessor`] to prepare images for the model.
@@ -43,8 +44,6 @@ Tips:
| m36 | [6, 6, 18, 6] | [96, 192, 384, 768] | 56 | 82.1 |
| m48 | [8, 8, 24, 8] | [96, 192, 384, 768] | 73 | 82.5 |
-This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with PoolFormer.
diff --git a/docs/source/en/model_doc/pop2piano.md b/docs/source/en/model_doc/pop2piano.md
index 95fd83f19237..8e52eda70cc0 100644
--- a/docs/source/en/model_doc/pop2piano.md
+++ b/docs/source/en/model_doc/pop2piano.md
@@ -32,7 +32,6 @@ is transformed to its waveform and passed to the encoder, which transforms it to
uses these latent representations to generate token ids in an autoregressive way. Each token id corresponds to one of four
different token types: time, velocity, note and 'special'. The token ids are then decoded to their equivalent MIDI file.
-
The abstract from the paper is the following:
*Piano covers of pop music are enjoyed by many people. However, the
@@ -49,22 +48,21 @@ directly from pop audio without using melody and chord extraction
modules. We show that Pop2Piano, trained with our dataset, is capable
of producing plausible piano covers.*
+This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
+The original code can be found [here](https://github.com/sweetcocoa/pop2piano).
-Tips:
+## Usage tips
-1. To use Pop2Piano, you will need to install the 🤗 Transformers library, as well as the following third party modules:
+* To use Pop2Piano, you will need to install the 🤗 Transformers library, as well as the following third party modules:
```
pip install pretty-midi==0.2.9 essentia==2.1b6.dev1034 librosa scipy
```
Please note that you may need to restart your runtime after installation.
-2. Pop2Piano is an Encoder-Decoder based model like T5.
-3. Pop2Piano can be used to generate midi-audio files for a given audio sequence.
-4. Choosing different composers in `Pop2PianoForConditionalGeneration.generate()` can lead to variety of different results.
-5. Setting the sampling rate to 44.1 kHz when loading the audio file can give good performance.
-6. Though Pop2Piano was mainly trained on Korean Pop music, it also does pretty well on other Western Pop or Hip Hop songs.
-
-This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
-The original code can be found [here](https://github.com/sweetcocoa/pop2piano).
+* Pop2Piano is an Encoder-Decoder based model like T5.
+* Pop2Piano can be used to generate midi-audio files for a given audio sequence.
+* Choosing different composers in `Pop2PianoForConditionalGeneration.generate()` can lead to variety of different results.
+* Setting the sampling rate to 44.1 kHz when loading the audio file can give good performance.
+* Though Pop2Piano was mainly trained on Korean Pop music, it also does pretty well on other Western Pop or Hip Hop songs.
## Examples
diff --git a/docs/source/en/model_doc/prophetnet.md b/docs/source/en/model_doc/prophetnet.md
index 6ab0937da77e..7e63e0c0887e 100644
--- a/docs/source/en/model_doc/prophetnet.md
+++ b/docs/source/en/model_doc/prophetnet.md
@@ -25,10 +25,6 @@ rendered properly in your Markdown viewer.
-
-**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
-@patrickvonplaten
-
## Overview
The ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
@@ -49,15 +45,15 @@ dataset (160GB) respectively. Then we conduct experiments on CNN/DailyMail, Giga
abstractive summarization and question generation tasks. Experimental results show that ProphetNet achieves new
state-of-the-art results on all these datasets compared to the models using the same scale pretraining corpus.*
-Tips:
+The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
+
+## Usage tips
- ProphetNet is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
- The model architecture is based on the original Transformer, but replaces the “standard” self-attention mechanism in the decoder by a a main self-attention mechanism and a self and n-stream (predict) self-attention mechanism.
-The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
-
-## Documentation resources
+## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
diff --git a/docs/source/en/model_doc/qdqbert.md b/docs/source/en/model_doc/qdqbert.md
index 62a0e010843d..9ee42ff3b49d 100644
--- a/docs/source/en/model_doc/qdqbert.md
+++ b/docs/source/en/model_doc/qdqbert.md
@@ -32,22 +32,18 @@ by processors with high-throughput integer math pipelines. We also present a wor
able to maintain accuracy within 1% of the floating-point baseline on all networks studied, including models that are
more difficult to quantize, such as MobileNets and BERT-large.*
-Tips:
+This model was contributed by [shangz](https://huggingface.co/shangz).
+
+## Usage tips
- QDQBERT model adds fake quantization operations (pair of QuantizeLinear/DequantizeLinear ops) to (i) linear layer
inputs and weights, (ii) matmul inputs, (iii) residual add inputs, in BERT model.
-
- QDQBERT requires the dependency of [Pytorch Quantization Toolkit](https://github.com/NVIDIA/TensorRT/tree/master/tools/pytorch-quantization). To install `pip install pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com`
-
- QDQBERT model can be loaded from any checkpoint of HuggingFace BERT model (for example *bert-base-uncased*), and
perform Quantization Aware Training/Post Training Quantization.
-
- A complete example of using QDQBERT model to perform Quatization Aware Training and Post Training Quantization for
SQUAD task can be found at [transformers/examples/research_projects/quantization-qdqbert/](examples/research_projects/quantization-qdqbert/).
-This model was contributed by [shangz](https://huggingface.co/shangz).
-
-
### Set default quantizers
QDQBERT model adds fake quantization operations (pair of QuantizeLinear/DequantizeLinear ops) to BERT by
@@ -118,7 +114,7 @@ the instructions in [torch.onnx](https://pytorch.org/docs/stable/onnx.html). Exa
>>> torch.onnx.export(...)
```
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
diff --git a/docs/source/en/model_doc/rag.md b/docs/source/en/model_doc/rag.md
index b467c6169f66..1891efe74263 100644
--- a/docs/source/en/model_doc/rag.md
+++ b/docs/source/en/model_doc/rag.md
@@ -52,8 +52,12 @@ parametric-only seq2seq baseline.*
This model was contributed by [ola13](https://huggingface.co/ola13).
-Tips:
-- Retrieval-augmented generation (“RAG”) models combine the powers of pretrained dense retrieval (DPR) and Seq2Seq models. RAG models retrieve docs, pass them to a seq2seq model, then marginalize to generate outputs. The retriever and seq2seq modules are initialized from pretrained models, and fine-tuned jointly, allowing both retrieval and generation to adapt to downstream tasks.
+## Usage tips
+
+Retrieval-augmented generation ("RAG") models combine the powers of pretrained dense retrieval (DPR) and Seq2Seq models.
+RAG models retrieve docs, pass them to a seq2seq model, then marginalize to generate outputs. The retriever and seq2seq
+modules are initialized from pretrained models, and fine-tuned jointly, allowing both retrieval and generation to adapt
+to downstream tasks.
## RagConfig
@@ -73,6 +77,9 @@ Tips:
[[autodoc]] RagRetriever
+
+
+
## RagModel
[[autodoc]] RagModel
@@ -90,6 +97,9 @@ Tips:
- forward
- generate
+
+
+
## TFRagModel
[[autodoc]] TFRagModel
@@ -106,3 +116,6 @@ Tips:
[[autodoc]] TFRagTokenForGeneration
- call
- generate
+
+
+
diff --git a/docs/source/en/model_doc/reformer.md b/docs/source/en/model_doc/reformer.md
index 05274c7667b7..ec924dc50c44 100644
--- a/docs/source/en/model_doc/reformer.md
+++ b/docs/source/en/model_doc/reformer.md
@@ -25,8 +25,6 @@ rendered properly in your Markdown viewer.
-**DISCLAIMER:** This model is still a work in progress, if you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
-
## Overview
The Reformer model was proposed in the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451.pdf) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
@@ -44,7 +42,7 @@ while being much more memory-efficient and much faster on long sequences.*
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
found [here](https://github.com/google/trax/tree/master/trax/models/reformer).
-Tips:
+## Usage tips
- Reformer does **not** work with *torch.nn.DataParallel* due to a bug in PyTorch, see [issue #36035](https://github.com/pytorch/pytorch/issues/36035).
- Use Axial position encoding (see below for more details). It’s a mechanism to avoid having a huge positional encoding matrix (when the sequence length is very big) by factorizing it into smaller matrices.
@@ -52,7 +50,7 @@ Tips:
- Avoid storing the intermediate results of each layer by using reversible transformer layers to obtain them during the backward pass (subtracting the residuals from the input of the next layer gives them back) or recomputing them for results inside a given layer (less efficient than storing them but saves memory).
- Compute the feedforward operations by chunks and not on the whole batch.
-## Axial Positional Encodings
+### Axial Positional Encodings
Axial Positional Encodings were first implemented in Google's [trax library](https://github.com/google/trax/blob/4d99ad4965bab1deba227539758d59f0df0fef48/trax/layers/research/position_encodings.py#L29)
and developed by the authors of this model's paper. In models that are treating very long input sequences, the
@@ -96,7 +94,7 @@ product has to be equal to `config.max_embedding_size`, which during training ha
length* of the `input_ids`.
-## LSH Self Attention
+### LSH Self Attention
In Locality sensitive hashing (LSH) self attention the key and query projection weights are tied. Therefore, the key
query embedding vectors are also tied. LSH self attention uses the locality sensitive hashing mechanism proposed in
@@ -129,7 +127,7 @@ Using LSH self attention, the memory and time complexity of the query-key matmul
and time bottleneck in a transformer model, with \\(n_s\\) being the sequence length.
-## Local Self Attention
+### Local Self Attention
Local self attention is essentially a "normal" self attention layer with key, query and value projections, but is
chunked so that in each chunk of length `config.local_chunk_length` the query embedding vectors only attends to
@@ -141,7 +139,7 @@ Using Local self attention, the memory and time complexity of the query-key matm
and time bottleneck in a transformer model, with \\(n_s\\) being the sequence length.
-## Training
+### Training
During training, we must ensure that the sequence length is set to a value that can be divided by the least common
multiple of `config.lsh_chunk_length` and `config.local_chunk_length` and that the parameters of the Axial
@@ -155,7 +153,7 @@ input_ids = tokenizer.encode("This is a sentence from the training data", return
loss = model(input_ids, labels=input_ids)[0]
```
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Question answering task guide](../tasks/question_answering)
diff --git a/docs/source/en/model_doc/regnet.md b/docs/source/en/model_doc/regnet.md
index 89e89459bd7f..acd833c77c2d 100644
--- a/docs/source/en/model_doc/regnet.md
+++ b/docs/source/en/model_doc/regnet.md
@@ -26,15 +26,13 @@ The abstract from the paper is the following:
*In this work, we present a new network design paradigm. Our goal is to help advance the understanding of network design and discover design principles that generalize across settings. Instead of focusing on designing individual network instances, we design network design spaces that parametrize populations of networks. The overall process is analogous to classic manual design of networks, but elevated to the design space level. Using our methodology we explore the structure aspect of network design and arrive at a low-dimensional design space consisting of simple, regular networks that we call RegNet. The core insight of the RegNet parametrization is surprisingly simple: widths and depths of good networks can be explained by a quantized linear function. We analyze the RegNet design space and arrive at interesting findings that do not match the current practice of network design. The RegNet design space provides simple and fast networks that work well across a wide range of flop regimes. Under comparable training settings and flops, the RegNet models outperform the popular EfficientNet models while being up to 5x faster on GPUs.*
-Tips:
-
-- One can use [`AutoImageProcessor`] to prepare images for the model.
-- The huge 10B model from [Self-supervised Pretraining of Visual Features in the Wild](https://arxiv.org/abs/2103.01988), trained on one billion Instagram images, is available on the [hub](https://huggingface.co/facebook/regnet-y-10b-seer)
-
This model was contributed by [Francesco](https://huggingface.co/Francesco). The TensorFlow version of the model
-was contributed by [sayakpaul](https://huggingface.com/sayakpaul) and [ariG23498](https://huggingface.com/ariG23498).
+was contributed by [sayakpaul](https://huggingface.co/sayakpaul) and [ariG23498](https://huggingface.co/ariG23498).
The original code can be found [here](https://github.com/facebookresearch/pycls).
+The huge 10B model from [Self-supervised Pretraining of Visual Features in the Wild](https://arxiv.org/abs/2103.01988),
+trained on one billion Instagram images, is available on the [hub](https://huggingface.co/facebook/regnet-y-10b-seer)
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with RegNet.
@@ -50,37 +48,43 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] RegNetConfig
+
+
## RegNetModel
[[autodoc]] RegNetModel
- forward
-
## RegNetForImageClassification
[[autodoc]] RegNetForImageClassification
- forward
+
+
+
## TFRegNetModel
[[autodoc]] TFRegNetModel
- call
-
## TFRegNetForImageClassification
[[autodoc]] TFRegNetForImageClassification
- call
+
+
## FlaxRegNetModel
[[autodoc]] FlaxRegNetModel
- __call__
-
## FlaxRegNetForImageClassification
[[autodoc]] FlaxRegNetForImageClassification
- - __call__
\ No newline at end of file
+ - __call__
+
+
diff --git a/docs/source/en/model_doc/rembert.md b/docs/source/en/model_doc/rembert.md
index b2e4d0f5adae..b755d3423060 100644
--- a/docs/source/en/model_doc/rembert.md
+++ b/docs/source/en/model_doc/rembert.md
@@ -34,14 +34,14 @@ Transformer representations to be more general and more transferable to other ta
findings, we are able to train models that achieve strong performance on the XTREME benchmark without increasing the
number of parameters at the fine-tuning stage.*
-Tips:
+## Usage tips
For fine-tuning, RemBERT can be thought of as a bigger version of mBERT with an ALBERT-like factorization of the
embedding layer. The embeddings are not tied in pre-training, in contrast with BERT, which enables smaller input
embeddings (preserved during fine-tuning) and bigger output embeddings (discarded at fine-tuning). The tokenizer is
also similar to the Albert one rather than the BERT one.
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -70,6 +70,9 @@ also similar to the Albert one rather than the BERT one.
- create_token_type_ids_from_sequences
- save_vocabulary
+
+
+
## RemBertModel
[[autodoc]] RemBertModel
@@ -105,6 +108,9 @@ also similar to the Albert one rather than the BERT one.
[[autodoc]] RemBertForQuestionAnswering
- forward
+
+
+
## TFRemBertModel
[[autodoc]] TFRemBertModel
@@ -139,3 +145,6 @@ also similar to the Albert one rather than the BERT one.
[[autodoc]] TFRemBertForQuestionAnswering
- call
+
+
+
diff --git a/docs/source/en/model_doc/resnet.md b/docs/source/en/model_doc/resnet.md
index 9bb36a776f16..b959266512f5 100644
--- a/docs/source/en/model_doc/resnet.md
+++ b/docs/source/en/model_doc/resnet.md
@@ -27,10 +27,6 @@ The abstract from the paper is the following:
*Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers.
The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.*
-Tips:
-
-- One can use [`AutoImageProcessor`] to prepare images for the model.
-
The figure below illustrates the architecture of ResNet. Taken from the [original paper](https://arxiv.org/abs/1512.03385).
@@ -52,30 +48,35 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] ResNetConfig
+
+
## ResNetModel
[[autodoc]] ResNetModel
- forward
-
## ResNetForImageClassification
[[autodoc]] ResNetForImageClassification
- forward
+
+
## TFResNetModel
[[autodoc]] TFResNetModel
- call
-
## TFResNetForImageClassification
[[autodoc]] TFResNetForImageClassification
- call
+
+
+
## FlaxResNetModel
[[autodoc]] FlaxResNetModel
@@ -85,3 +86,6 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] FlaxResNetForImageClassification
- __call__
+
+
+
diff --git a/docs/source/en/model_doc/roberta-prelayernorm.md b/docs/source/en/model_doc/roberta-prelayernorm.md
index 9822fd7af961..f748e273e8f8 100644
--- a/docs/source/en/model_doc/roberta-prelayernorm.md
+++ b/docs/source/en/model_doc/roberta-prelayernorm.md
@@ -25,15 +25,15 @@ The abstract from the paper is the following:
*fairseq is an open-source sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization, language modeling, and other text generation tasks. The toolkit is based on PyTorch and supports distributed training across multiple GPUs and machines. We also support fast mixed-precision training and inference on modern GPUs.*
-Tips:
+This model was contributed by [andreasmaden](https://huggingface.co/andreasmadsen).
+The original code can be found [here](https://github.com/princeton-nlp/DinkyTrain).
+
+## Usage tips
- The implementation is the same as [Roberta](roberta) except instead of using _Add and Norm_ it does _Norm and Add_. _Add_ and _Norm_ refers to the Addition and LayerNormalization as described in [Attention Is All You Need](https://arxiv.org/abs/1706.03762).
- This is identical to using the `--encoder-normalize-before` flag in [fairseq](https://fairseq.readthedocs.io/).
-This model was contributed by [andreasmaden](https://huggingface.co/andreasmaden).
-The original code can be found [here](https://github.com/princeton-nlp/DinkyTrain).
-
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -46,6 +46,9 @@ The original code can be found [here](https://github.com/princeton-nlp/DinkyTrai
[[autodoc]] RobertaPreLayerNormConfig
+
+
+
## RobertaPreLayerNormModel
[[autodoc]] RobertaPreLayerNormModel
@@ -81,6 +84,9 @@ The original code can be found [here](https://github.com/princeton-nlp/DinkyTrai
[[autodoc]] RobertaPreLayerNormForQuestionAnswering
- forward
+
+
+
## TFRobertaPreLayerNormModel
[[autodoc]] TFRobertaPreLayerNormModel
@@ -116,6 +122,9 @@ The original code can be found [here](https://github.com/princeton-nlp/DinkyTrai
[[autodoc]] TFRobertaPreLayerNormForQuestionAnswering
- call
+
+
+
## FlaxRobertaPreLayerNormModel
[[autodoc]] FlaxRobertaPreLayerNormModel
@@ -150,3 +159,6 @@ The original code can be found [here](https://github.com/princeton-nlp/DinkyTrai
[[autodoc]] FlaxRobertaPreLayerNormForQuestionAnswering
- __call__
+
+
+
diff --git a/docs/source/en/model_doc/roberta.md b/docs/source/en/model_doc/roberta.md
index 5a2ba6b5cf66..364b5b37e5f3 100644
--- a/docs/source/en/model_doc/roberta.md
+++ b/docs/source/en/model_doc/roberta.md
@@ -47,7 +47,9 @@ model published after it. Our best model achieves state-of-the-art results on GL
highlight the importance of previously overlooked design choices, and raise questions about the source of recently
reported improvements. We release our models and code.*
-Tips:
+This model was contributed by [julien-c](https://huggingface.co/julien-c). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/roberta).
+
+## Usage tips
- This implementation is the same as [`BertModel`] with a tiny embeddings tweak as well as a setup
for Roberta pretrained models.
@@ -63,8 +65,6 @@ Tips:
* use BPE with bytes as a subunit and not characters (because of unicode characters)
- [CamemBERT](camembert) is a wrapper around RoBERTa. Refer to this page for usage examples.
-This model was contributed by [julien-c](https://huggingface.co/julien-c). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/roberta).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with RoBERTa. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
@@ -127,6 +127,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] RobertaTokenizerFast
- build_inputs_with_special_tokens
+
+
+
## RobertaModel
[[autodoc]] RobertaModel
@@ -162,6 +165,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] RobertaForQuestionAnswering
- forward
+
+
+
## TFRobertaModel
[[autodoc]] TFRobertaModel
@@ -197,6 +203,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] TFRobertaForQuestionAnswering
- call
+
+
+
## FlaxRobertaModel
[[autodoc]] FlaxRobertaModel
@@ -231,3 +240,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] FlaxRobertaForQuestionAnswering
- __call__
+
+
+
diff --git a/docs/source/en/model_doc/roc_bert.md b/docs/source/en/model_doc/roc_bert.md
index 831c656fb817..30fadd5c2c10 100644
--- a/docs/source/en/model_doc/roc_bert.md
+++ b/docs/source/en/model_doc/roc_bert.md
@@ -35,7 +35,7 @@ in the toxic content detection task under human-made attacks.*
This model was contributed by [weiweishi](https://huggingface.co/weiweishi).
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -49,7 +49,6 @@ This model was contributed by [weiweishi](https://huggingface.co/weiweishi).
[[autodoc]] RoCBertConfig
- all
-
## RoCBertTokenizer
[[autodoc]] RoCBertTokenizer
@@ -58,31 +57,26 @@ This model was contributed by [weiweishi](https://huggingface.co/weiweishi).
- create_token_type_ids_from_sequences
- save_vocabulary
-
## RoCBertModel
[[autodoc]] RoCBertModel
- forward
-
## RoCBertForPreTraining
[[autodoc]] RoCBertForPreTraining
- forward
-
## RoCBertForCausalLM
[[autodoc]] RoCBertForCausalLM
- forward
-
## RoCBertForMaskedLM
[[autodoc]] RoCBertForMaskedLM
- forward
-
## RoCBertForSequenceClassification
[[autodoc]] transformers.RoCBertForSequenceClassification
@@ -93,14 +87,12 @@ This model was contributed by [weiweishi](https://huggingface.co/weiweishi).
[[autodoc]] transformers.RoCBertForMultipleChoice
- forward
-
## RoCBertForTokenClassification
[[autodoc]] transformers.RoCBertForTokenClassification
- forward
-
## RoCBertForQuestionAnswering
[[autodoc]] RoCBertForQuestionAnswering
- - forward
\ No newline at end of file
+ - forward
diff --git a/docs/source/en/model_doc/roformer.md b/docs/source/en/model_doc/roformer.md
index f15a1062965f..5d8f146c43fd 100644
--- a/docs/source/en/model_doc/roformer.md
+++ b/docs/source/en/model_doc/roformer.md
@@ -33,15 +33,13 @@ transformer with rotary position embedding, or RoFormer, achieves superior perfo
release the theoretical analysis along with some preliminary experiment results on Chinese data. The undergoing
experiment for English benchmark will soon be updated.*
-Tips:
-
-- RoFormer is a BERT-like autoencoding model with rotary position embeddings. Rotary position embeddings have shown
- improved performance on classification tasks with long texts.
-
-
This model was contributed by [junnyu](https://huggingface.co/junnyu). The original code can be found [here](https://github.com/ZhuiyiTechnology/roformer).
-## Documentation resources
+## Usage tips
+RoFormer is a BERT-like autoencoding model with rotary position embeddings. Rotary position embeddings have shown
+improved performance on classification tasks with long texts.
+
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -67,6 +65,9 @@ This model was contributed by [junnyu](https://huggingface.co/junnyu). The origi
[[autodoc]] RoFormerTokenizerFast
- build_inputs_with_special_tokens
+
+
+
## RoFormerModel
[[autodoc]] RoFormerModel
@@ -102,6 +103,9 @@ This model was contributed by [junnyu](https://huggingface.co/junnyu). The origi
[[autodoc]] RoFormerForQuestionAnswering
- forward
+
+
+
## TFRoFormerModel
[[autodoc]] TFRoFormerModel
@@ -137,6 +141,9 @@ This model was contributed by [junnyu](https://huggingface.co/junnyu). The origi
[[autodoc]] TFRoFormerForQuestionAnswering
- call
+
+
+
## FlaxRoFormerModel
[[autodoc]] FlaxRoFormerModel
@@ -166,3 +173,6 @@ This model was contributed by [junnyu](https://huggingface.co/junnyu). The origi
[[autodoc]] FlaxRoFormerForQuestionAnswering
- __call__
+
+
+
diff --git a/docs/source/en/model_doc/rwkv.md b/docs/source/en/model_doc/rwkv.md
index 9293db14cc63..3dfcf7ba4b55 100644
--- a/docs/source/en/model_doc/rwkv.md
+++ b/docs/source/en/model_doc/rwkv.md
@@ -27,7 +27,7 @@ This can be more efficient than a regular Transformer and can deal with sentence
This model was contributed by [sgugger](https://huggingface.co/sgugger).
The original code can be found [here](https://github.com/BlinkDL/RWKV-LM).
-Example of use as an RNN:
+## Usage example
```py
import torch
@@ -73,7 +73,6 @@ output = model.generate(inputs["input_ids"], max_new_tokens=64, stopping_criteri
[[autodoc]] RwkvConfig
-
## RwkvModel
[[autodoc]] RwkvModel
diff --git a/docs/source/en/model_doc/sam.md b/docs/source/en/model_doc/sam.md
index fe0d24623fd7..d2a472957af9 100644
--- a/docs/source/en/model_doc/sam.md
+++ b/docs/source/en/model_doc/sam.md
@@ -57,7 +57,8 @@ raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
input_points = [[[450, 600]]] # 2D location of a window in the image
inputs = processor(raw_image, input_points=input_points, return_tensors="pt").to(device)
-outputs = model(**inputs)
+with torch.no_grad():
+ outputs = model(**inputs)
masks = processor.image_processor.post_process_masks(
outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu()
@@ -108,4 +109,4 @@ Resources:
## TFSamModel
[[autodoc]] TFSamModel
- - call
\ No newline at end of file
+ - call
diff --git a/docs/source/en/model_doc/segformer.md b/docs/source/en/model_doc/segformer.md
index 0f535351af5c..4edd646cd4fa 100644
--- a/docs/source/en/model_doc/segformer.md
+++ b/docs/source/en/model_doc/segformer.md
@@ -43,7 +43,7 @@ The figure below illustrates the architecture of SegFormer. Taken from the [orig
This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version
of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/NVlabs/SegFormer).
-Tips:
+## Usage tips
- SegFormer consists of a hierarchical Transformer encoder, and a lightweight all-MLP decoder head.
[`SegformerModel`] is the hierarchical Transformer encoder (which in the paper is also referred to
@@ -123,6 +123,9 @@ If you're interested in submitting a resource to be included here, please feel f
- preprocess
- post_process_semantic_segmentation
+
+
+
## SegformerModel
[[autodoc]] SegformerModel
@@ -143,6 +146,9 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] SegformerForSemanticSegmentation
- forward
+
+
+
## TFSegformerDecodeHead
[[autodoc]] TFSegformerDecodeHead
@@ -162,3 +168,6 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] TFSegformerForSemanticSegmentation
- call
+
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/sew-d.md b/docs/source/en/model_doc/sew-d.md
index b70c59061b57..013e404bd045 100644
--- a/docs/source/en/model_doc/sew-d.md
+++ b/docs/source/en/model_doc/sew-d.md
@@ -32,15 +32,15 @@ variety of training setups. For example, under the 100h-960h semi-supervised set
inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference
time, SEW reduces word error rate by 25-50% across different model sizes.*
-Tips:
+This model was contributed by [anton-l](https://huggingface.co/anton-l).
+
+## Usage tips
- SEW-D is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- SEWDForCTC is fine-tuned using connectionist temporal classification (CTC) so the model output has to be decoded
using [`Wav2Vec2CTCTokenizer`].
-This model was contributed by [anton-l](https://huggingface.co/anton-l).
-
-## Documentation resources
+## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
diff --git a/docs/source/en/model_doc/sew.md b/docs/source/en/model_doc/sew.md
index ebf128ea429f..ee8a36a4dcb2 100644
--- a/docs/source/en/model_doc/sew.md
+++ b/docs/source/en/model_doc/sew.md
@@ -32,15 +32,15 @@ variety of training setups. For example, under the 100h-960h semi-supervised set
inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference
time, SEW reduces word error rate by 25-50% across different model sizes.*
-Tips:
+This model was contributed by [anton-l](https://huggingface.co/anton-l).
+
+## Usage tips
- SEW is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- SEWForCTC is fine-tuned using connectionist temporal classification (CTC) so the model output has to be decoded using
[`Wav2Vec2CTCTokenizer`].
-This model was contributed by [anton-l](https://huggingface.co/anton-l).
-
-## Documentation resources
+## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
diff --git a/docs/source/en/model_doc/speech_to_text.md b/docs/source/en/model_doc/speech_to_text.md
index cb13a1871ae6..23512b323af6 100644
--- a/docs/source/en/model_doc/speech_to_text.md
+++ b/docs/source/en/model_doc/speech_to_text.md
@@ -27,7 +27,6 @@ transcripts/translations autoregressively. Speech2Text has been fine-tuned on se
This model was contributed by [valhalla](https://huggingface.co/valhalla). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text).
-
## Inference
Speech2Text is a speech model that accepts a float tensor of log-mel filter-bank features extracted from the speech
@@ -44,7 +43,6 @@ install those packages before running the examples. You could either install tho
`pip install transformers"[speech, sentencepiece]"` or install the packages separately with `pip install torchaudio sentencepiece`. Also `torchaudio` requires the development version of the [libsndfile](http://www.mega-nerd.com/libsndfile/) package which can be installed via a system package manager. On Ubuntu it can
be installed as follows: `apt install libsndfile1-dev`
-
- ASR and Speech Translation
```python
@@ -98,7 +96,6 @@ be installed as follows: `apt install libsndfile1-dev`
See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for Speech2Text checkpoints.
-
## Speech2TextConfig
[[autodoc]] Speech2TextConfig
@@ -125,6 +122,9 @@ See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look
- batch_decode
- decode
+
+
+
## Speech2TextModel
[[autodoc]] Speech2TextModel
@@ -135,6 +135,9 @@ See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look
[[autodoc]] Speech2TextForConditionalGeneration
- forward
+
+
+
## TFSpeech2TextModel
[[autodoc]] TFSpeech2TextModel
@@ -144,3 +147,6 @@ See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look
[[autodoc]] TFSpeech2TextForConditionalGeneration
- call
+
+
+
diff --git a/docs/source/en/model_doc/speech_to_text_2.md b/docs/source/en/model_doc/speech_to_text_2.md
index 1abdeced580e..6648e67f629d 100644
--- a/docs/source/en/model_doc/speech_to_text_2.md
+++ b/docs/source/en/model_doc/speech_to_text_2.md
@@ -31,8 +31,7 @@ This model was contributed by [Patrick von Platen](https://huggingface.co/patric
The original code can be found [here](https://github.com/pytorch/fairseq/blob/1f7ef9ed1e1061f8c7f88f8b94c7186834398690/fairseq/models/wav2vec/wav2vec2_asr.py#L266).
-
-Tips:
+## Usage tips
- Speech2Text2 achieves state-of-the-art results on the CoVoST Speech Translation dataset. For more information, see
the [official models](https://huggingface.co/models?other=speech2text2) .
@@ -98,7 +97,7 @@ predicted token ids.
See [model hub](https://huggingface.co/models?filter=speech2text2) to look for Speech2Text2 checkpoints.
-## Documentation resources
+## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
diff --git a/docs/source/en/model_doc/splinter.md b/docs/source/en/model_doc/splinter.md
index f16169d9b218..a46c55966c0e 100644
--- a/docs/source/en/model_doc/splinter.md
+++ b/docs/source/en/model_doc/splinter.md
@@ -34,7 +34,9 @@ are replaced with a special token, viewed as a question representation, that is
the answer span. The resulting model obtains surprisingly good results on multiple benchmarks (e.g., 72.7 F1 on SQuAD
with only 128 training examples), while maintaining competitive performance in the high-resource setting.
-Tips:
+This model was contributed by [yuvalkirstain](https://huggingface.co/yuvalkirstain) and [oriram](https://huggingface.co/oriram). The original code can be found [here](https://github.com/oriram/splinter).
+
+## Usage tips
- Splinter was trained to predict answers spans conditioned on a special [QUESTION] token. These tokens contextualize
to question representations which are used to predict the answers. This layer is called QASS, and is the default
@@ -49,9 +51,7 @@ Tips:
doesn't (*tau/splinter-base* and *tau/splinter-large*). This is done to support randomly initializing this layer at
fine-tuning, as it is shown to yield better results for some cases in the paper.
-This model was contributed by [yuvalkirstain](https://huggingface.co/yuvalkirstain) and [oriram](https://huggingface.co/oriram). The original code can be found [here](https://github.com/oriram/splinter).
-
-## Documentation resources
+## Resources
- [Question answering task guide](../tasks/question-answering)
diff --git a/docs/source/en/model_doc/squeezebert.md b/docs/source/en/model_doc/squeezebert.md
index 515a2ef31781..e2bb378fe5bb 100644
--- a/docs/source/en/model_doc/squeezebert.md
+++ b/docs/source/en/model_doc/squeezebert.md
@@ -38,7 +38,9 @@ self-attention layers with grouped convolutions, and we use this technique in a
SqueezeBERT, which runs 4.3x faster than BERT-base on the Pixel 3 while achieving competitive accuracy on the GLUE test
set. The SqueezeBERT code will be released.*
-Tips:
+This model was contributed by [forresti](https://huggingface.co/forresti).
+
+## Usage tips
- SqueezeBERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right
rather than the left.
@@ -48,9 +50,7 @@ Tips:
- For best results when finetuning on sequence classification tasks, it is recommended to start with the
*squeezebert/squeezebert-mnli-headless* checkpoint.
-This model was contributed by [forresti](https://huggingface.co/forresti).
-
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
diff --git a/docs/source/en/model_doc/swiftformer.md b/docs/source/en/model_doc/swiftformer.md
index 67c9597d2123..30c6941f0f46 100644
--- a/docs/source/en/model_doc/swiftformer.md
+++ b/docs/source/en/model_doc/swiftformer.md
@@ -26,14 +26,9 @@ The abstract from the paper is the following:
*Self-attention has become a defacto choice for capturing global context in various vision applications. However, its quadratic computational complexity with respect to image resolution limits its use in real-time applications, especially for deployment on resource-constrained mobile devices. Although hybrid approaches have been proposed to combine the advantages of convolutions and self-attention for a better speed-accuracy trade-off, the expensive matrix multiplication operations in self-attention remain a bottleneck. In this work, we introduce a novel efficient additive attention mechanism that effectively replaces the quadratic matrix multiplication operations with linear element-wise multiplications. Our design shows that the key-value interaction can be replaced with a linear layer without sacrificing any accuracy. Unlike previous state-of-the-art methods, our efficient formulation of self-attention enables its usage at all stages of the network. Using our proposed efficient additive attention, we build a series of models called "SwiftFormer" which achieves state-of-the-art performance in terms of both accuracy and mobile inference speed. Our small variant achieves 78.5% top-1 ImageNet-1K accuracy with only 0.8 ms latency on iPhone 14, which is more accurate and 2x faster compared to MobileViT-v2.*
-Tips:
- - One can use the [`ViTImageProcessor`] API to prepare images for the model.
-
-
This model was contributed by [shehan97](https://huggingface.co/shehan97).
The original code can be found [here](https://github.com/Amshaker/SwiftFormer).
-
## SwiftFormerConfig
[[autodoc]] SwiftFormerConfig
diff --git a/docs/source/en/model_doc/swin.md b/docs/source/en/model_doc/swin.md
index 37bb86db951a..e23c882a3f09 100644
--- a/docs/source/en/model_doc/swin.md
+++ b/docs/source/en/model_doc/swin.md
@@ -36,11 +36,6 @@ prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO
+2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones.
The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures.*
-Tips:
-- One can use the [`AutoImageProcessor`] API to prepare images for the model.
-- Swin pads the inputs supporting any input height and width (if divisible by `32`).
-- Swin can be used as a *backbone*. When `output_hidden_states = True`, it will output both `hidden_states` and `reshaped_hidden_states`. The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than `(batch_size, sequence_length, num_channels)`.
-
@@ -48,6 +43,10 @@ alt="drawing" width="600"/>
This model was contributed by [novice03](https://huggingface.co/novice03). The Tensorflow version of this model was contributed by [amyeroberts](https://huggingface.co/amyeroberts). The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
+## Usage tips
+
+- Swin pads the inputs supporting any input height and width (if divisible by `32`).
+- Swin can be used as a *backbone*. When `output_hidden_states = True`, it will output both `hidden_states` and `reshaped_hidden_states`. The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than `(batch_size, sequence_length, num_channels)`.
## Resources
@@ -68,6 +67,8 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] SwinConfig
+
+
## SwinModel
@@ -84,6 +85,9 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] transformers.SwinForImageClassification
- forward
+
+
+
## TFSwinModel
[[autodoc]] TFSwinModel
@@ -98,3 +102,6 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] transformers.TFSwinForImageClassification
- call
+
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/swinv2.md b/docs/source/en/model_doc/swinv2.md
index e08389527ece..25233dca3395 100644
--- a/docs/source/en/model_doc/swinv2.md
+++ b/docs/source/en/model_doc/swinv2.md
@@ -24,9 +24,6 @@ The abstract from the paper is the following:
*Large-scale NLP models have been shown to significantly improve the performance on language tasks with no signs of saturation. They also demonstrate amazing few-shot capabilities like that of human beings. This paper aims to explore large-scale models in computer vision. We tackle three major issues in training and application of large vision models, including training instability, resolution gaps between pre-training and fine-tuning, and hunger on labelled data. Three main techniques are proposed: 1) a residual-post-norm method combined with cosine attention to improve training stability; 2) A log-spaced continuous position bias method to effectively transfer models pre-trained using low-resolution images to downstream tasks with high-resolution inputs; 3) A self-supervised pre-training method, SimMIM, to reduce the needs of vast labeled images. Through these techniques, this paper successfully trained a 3 billion-parameter Swin Transformer V2 model, which is the largest dense vision model to date, and makes it capable of training with images of up to 1,536×1,536 resolution. It set new performance records on 4 representative vision tasks, including ImageNet-V2 image classification, COCO object detection, ADE20K semantic segmentation, and Kinetics-400 video action classification. Also note our training is much more efficient than that in Google's billion-level visual models, which consumes 40 times less labelled data and 40 times less training time.*
-Tips:
-- One can use the [`AutoImageProcessor`] API to prepare images for the model.
-
This model was contributed by [nandwalritik](https://huggingface.co/nandwalritik).
The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
diff --git a/docs/source/en/model_doc/switch_transformers.md b/docs/source/en/model_doc/switch_transformers.md
index 8f6a231b7ef7..ca6748167f5e 100644
--- a/docs/source/en/model_doc/switch_transformers.md
+++ b/docs/source/en/model_doc/switch_transformers.md
@@ -23,19 +23,18 @@ The SwitchTransformers model was proposed in [Switch Transformers: Scaling to Tr
The Switch Transformer model uses a sparse T5 encoder-decoder architecture, where the MLP are replaced by a Mixture of Experts (MoE). A routing mechanism (top 1 in this case) associates each token to one of the expert, where each expert is a dense MLP. While switch transformers have a lot more weights than their equivalent dense models, the sparsity allows better scaling and better finetuning performance at scale.
During a forward pass, only a fraction of the weights are used. The routing mechanism allows the model to select relevant weights on the fly which increases the model capacity without increasing the number of operations.
-
The abstract from the paper is the following:
*In deep learning, models typically reuse the same parameters for all inputs. Mixture of Experts (MoE) defies this and instead selects different parameters for each incoming example. The result is a sparsely-activated model -- with outrageous numbers of parameters -- but a constant computational cost. However, despite several notable successes of MoE, widespread adoption has been hindered by complexity, communication costs and training instability -- we address these with the Switch Transformer. We simplify the MoE routing algorithm and design intuitive improved models with reduced communication and computational costs. Our proposed training techniques help wrangle the instabilities and we show large sparse models may be trained, for the first time, with lower precision (bfloat16) formats. We design models based off T5-Base and T5-Large to obtain up to 7x increases in pre-training speed with the same computational resources. These improvements extend into multilingual settings where we measure gains over the mT5-Base version across all 101 languages. Finally, we advance the current scale of language models by pre-training up to trillion parameter models on the "Colossal Clean Crawled Corpus" and achieve a 4x speedup over the T5-XXL model.*
-Tips:
+This model was contributed by [Younes Belkada](https://huggingface.co/ybelkada) and [Arthur Zucker](https://huggingface.co/ArthurZ).
+The original code can be found [here](https://github.com/google/flaxformer/tree/main/flaxformer/architectures/moe).
+
+## Usage tips
- SwitchTransformers uses the [`T5Tokenizer`], which can be loaded directly from each model's repository.
- The released weights are pretrained on English [Masked Language Modeling](https://moon-ci-docs.huggingface.co/docs/transformers/pr_19323/en/glossary#general-terms) task, and should be finetuned.
-This model was contributed by [Younes Belkada](https://huggingface.co/ybelkada) and [Arthur Zucker](https://huggingface.co/ArtZucker) .
-The original code can be found [here](https://github.com/google/flaxformer/tree/main/flaxformer/architectures/moe).
-
## Resources
- [Translation task guide](../tasks/translation)
diff --git a/docs/source/en/model_doc/t5.md b/docs/source/en/model_doc/t5.md
index 2e833e8e1a67..a7e78976cf94 100644
--- a/docs/source/en/model_doc/t5.md
+++ b/docs/source/en/model_doc/t5.md
@@ -45,7 +45,11 @@ with scale and our new "Colossal Clean Crawled Corpus", we achieve state-of-the-
summarization, question answering, text classification, and more. To facilitate future work on transfer learning for
NLP, we release our dataset, pre-trained models, and code.*
-Tips:
+All checkpoints can be found on the [hub](https://huggingface.co/models?search=t5).
+
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/google-research/text-to-text-transfer-transformer).
+
+## Usage tips
- T5 is an encoder-decoder model pre-trained on a multi-task mixture of unsupervised and supervised tasks and for which
each task is converted into a text-to-text format. T5 works well on a variety of tasks out-of-the-box by prepending a
@@ -91,12 +95,6 @@ Based on the original T5 model, Google has released some follow-up works:
- **UMT5**: UmT5 is a multilingual T5 model trained on an improved and refreshed mC4 multilingual corpus, 29 trillion characters across 107 language, using a new sampling method, UniMax. Refer to
the documentation of mT5 which can be found [here](umt5).
-All checkpoints can be found on the [hub](https://huggingface.co/models?search=t5).
-
-This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/google-research/text-to-text-transfer-transformer).
-
-
-
## Training
T5 is an encoder-decoder model and converts all NLP problems into a text-to-text format. It is trained using teacher
@@ -249,8 +247,6 @@ batches to the longest example is not recommended on TPU as it triggers a recomp
encountered during training thus significantly slowing down the training. only padding up to the longest example in a
batch) leads to very slow training on TPU.
-
-
## Inference
At inference time, it is recommended to use [`~generation.GenerationMixin.generate`]. This
@@ -316,12 +312,9 @@ The predicted tokens will then be placed between the sentinel tokens.
[' park offers the park.']
```
-
-
-
## Performance
-If you'd like a faster training and inference performance, install [apex](https://github.com/NVIDIA/apex#quick-start) and then the model will automatically use `apex.normalization.FusedRMSNorm` instead of `T5LayerNorm`. The former uses an optimized fused kernel which is several times faster than the latter.
+If you'd like a faster training and inference performance, install [NVIDIA APEX](https://github.com/NVIDIA/apex#quick-start) for NVIDIA GPUs, or [ROCm APEX](https://github.com/ROCmSoftwarePlatform/apex) for AMD GPUs and then the model will automatically use `apex.normalization.FusedRMSNorm` instead of `T5LayerNorm`. The former uses an optimized fused kernel which is several times faster than the latter.
## Resources
@@ -386,6 +379,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] T5TokenizerFast
+
+
+
## T5Model
[[autodoc]] T5Model
@@ -411,6 +407,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] T5ForQuestionAnswering
- forward
+
+
+
## TFT5Model
[[autodoc]] TFT5Model
@@ -426,6 +425,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] TFT5EncoderModel
- call
+
+
+
## FlaxT5Model
[[autodoc]] FlaxT5Model
@@ -444,3 +446,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] FlaxT5EncoderModel
- __call__
+
+
+
diff --git a/docs/source/en/model_doc/t5v1.1.md b/docs/source/en/model_doc/t5v1.1.md
index 900e26f521dd..e18696f629df 100644
--- a/docs/source/en/model_doc/t5v1.1.md
+++ b/docs/source/en/model_doc/t5v1.1.md
@@ -20,6 +20,10 @@ rendered properly in your Markdown viewer.
T5v1.1 was released in the [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511)
repository by Colin Raffel et al. It's an improved version of the original T5 model.
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
+found [here](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511).
+
+## Usage tips
One can directly plug in the weights of T5v1.1 into a T5 model, like so:
@@ -59,7 +63,9 @@ Google has released the following variants:
- [google/t5-v1_1-xxl](https://huggingface.co/google/t5-v1_1-xxl).
-One can refer to [T5's documentation page](t5) for all tips, code examples and notebooks.
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
-found [here](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511).
+
+
+Refer to [T5's documentation page](t5) for all API reference, tips, code examples and notebooks.
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/table-transformer.md b/docs/source/en/model_doc/table-transformer.md
index 7ea7ae8cd352..850e7f50aa61 100644
--- a/docs/source/en/model_doc/table-transformer.md
+++ b/docs/source/en/model_doc/table-transformer.md
@@ -33,16 +33,15 @@ significant increase in training performance and a more reliable estimate of mod
object detection models trained on PubTables-1M produce excellent results for all three tasks of detection, structure recognition, and functional analysis without the need for any
special customization for these tasks.*
-Tips:
-
-- The authors released 2 models, one for [table detection](https://huggingface.co/microsoft/table-transformer-detection) in documents, one for [table structure recognition](https://huggingface.co/microsoft/table-transformer-structure-recognition) (the task of recognizing the individual rows, columns etc. in a table).
-- One can use the [`AutoImageProcessor`] API to prepare images and optional targets for the model. This will load a [`DetrImageProcessor`] behind the scenes.
-
Table detection and table structure recognition clarified. Taken from the original paper.
+The authors released 2 models, one for [table detection](https://huggingface.co/microsoft/table-transformer-detection) in
+documents, one for [table structure recognition](https://huggingface.co/microsoft/table-transformer-structure-recognition)
+(the task of recognizing the individual rows, columns etc. in a table).
+
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be
found [here](https://github.com/microsoft/table-transformer).
diff --git a/docs/source/en/model_doc/tapas.md b/docs/source/en/model_doc/tapas.md
index 1c76015f2857..79bbe3e819cf 100644
--- a/docs/source/en/model_doc/tapas.md
+++ b/docs/source/en/model_doc/tapas.md
@@ -44,10 +44,10 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The Tensorflow version of this model was contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/google-research/tapas).
-Tips:
+## Usage tips
- TAPAS is a model that uses relative position embeddings by default (restarting the position embeddings at every cell of the table). Note that this is something that was added after the publication of the original TAPAS paper. According to the authors, this usually results in a slightly better performance, and allows you to encode longer sequences without running out of embeddings. This is reflected in the `reset_position_index_per_cell` parameter of [`TapasConfig`], which is set to `True` by default. The default versions of the models available on the [hub](https://huggingface.co/models?search=tapas) all use relative position embeddings. You can still use the ones with absolute position embeddings by passing in an additional argument `revision="no_reset"` when calling the `from_pretrained()` method. Note that it's usually advised to pad the inputs on the right rather than the left.
-- TAPAS is based on BERT, so `TAPAS-base` for example corresponds to a `BERT-base` architecture. Of course, `TAPAS-large` will result in the best performance (the results reported in the paper are from `TAPAS-large`). Results of the various sized models are shown on the [original Github repository](https://github.com/google-research/tapas>).
+- TAPAS is based on BERT, so `TAPAS-base` for example corresponds to a `BERT-base` architecture. Of course, `TAPAS-large` will result in the best performance (the results reported in the paper are from `TAPAS-large`). Results of the various sized models are shown on the [original GitHub repository](https://github.com/google-research/tapas).
- TAPAS has checkpoints fine-tuned on SQA, which are capable of answering questions related to a table in a conversational set-up. This means that you can ask follow-up questions such as "what is his age?" related to the previous question. Note that the forward pass of TAPAS is a bit different in case of a conversational set-up: in that case, you have to feed every table-question pair one by one to the model, such that the `prev_labels` token type ids can be overwritten by the predicted `labels` of the model to the previous question. See "Usage" section for more info.
- TAPAS is similar to BERT and therefore relies on the masked language modeling (MLM) objective. It is therefore efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation. Models trained with a causal language modeling (CLM) objective are better in that regard. Note that TAPAS can be used as an encoder in the EncoderDecoderModel framework, to combine it with an autoregressive text decoder such as GPT-2.
@@ -573,7 +573,7 @@ Predicted answer: SUM > 87, 53, 69
In case of a conversational set-up, then each table-question pair must be provided **sequentially** to the model, such that the `prev_labels` token types can be overwritten by the predicted `labels` of the previous table-question pair. Again, more info can be found in [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) (for PyTorch) and [this notebook](https://github.com/kamalkraj/Tapas-Tutorial/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) (for TensorFlow).
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
@@ -590,6 +590,9 @@ In case of a conversational set-up, then each table-question pair must be provid
- convert_logits_to_predictions
- save_vocabulary
+
+
+
## TapasModel
[[autodoc]] TapasModel
- forward
@@ -606,6 +609,9 @@ In case of a conversational set-up, then each table-question pair must be provid
[[autodoc]] TapasForQuestionAnswering
- forward
+
+
+
## TFTapasModel
[[autodoc]] TFTapasModel
- call
@@ -620,4 +626,9 @@ In case of a conversational set-up, then each table-question pair must be provid
## TFTapasForQuestionAnswering
[[autodoc]] TFTapasForQuestionAnswering
- - call
\ No newline at end of file
+ - call
+
+
+
+
+
diff --git a/docs/source/en/model_doc/tapex.md b/docs/source/en/model_doc/tapex.md
index 52234b5c59bc..15ac2463fd85 100644
--- a/docs/source/en/model_doc/tapex.md
+++ b/docs/source/en/model_doc/tapex.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
-This model is in maintenance mode only, so we won't accept any new PRs changing its code.
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
You can do so by running the following command: `pip install -U transformers==4.30.0`.
@@ -49,7 +49,7 @@ on the weakly-supervised WikiSQL denotation accuracy to 89.5% (+2.3%), the WikiT
to 74.5% (+3.5%), and the TabFact accuracy to 84.2% (+3.2%). To our knowledge, this is the first work to exploit table pre-training via synthetic executable programs
and to achieve new state-of-the-art results on various downstream tasks.*
-Tips:
+## Usage tips
- TAPEX is a generative (seq2seq) model. One can directly plug in the weights of TAPEX into a BART model.
- TAPEX has checkpoints on the hub that are either pre-trained only, or fine-tuned on WTQ, SQA, WikiSQL and TabFact.
@@ -58,7 +58,7 @@ Tips:
- TAPEX has its own tokenizer, that allows to prepare all data for the model easily. One can pass Pandas DataFrames and strings to the tokenizer,
and it will automatically create the `input_ids` and `attention_mask` (as shown in the usage examples below).
-## Usage: inference
+### Usage: inference
Below, we illustrate how to use TAPEX for table question answering. As one can see, one can directly plug in the weights of TAPEX into a BART model.
We use the [Auto API](auto), which will automatically instantiate the appropriate tokenizer ([`TapexTokenizer`]) and model ([`BartForConditionalGeneration`]) for us,
@@ -135,6 +135,12 @@ benchmark for table fact checking (it achieves 84% accuracy). The code example b
Refused
```
+
+
+TAPEX architecture is the same as BART, except for tokenization. Refer to [BART documentation](bart) for information on
+configuration classes and their parameters. TAPEX-specific tokenizer is documented below.
+
+
## TapexTokenizer
diff --git a/docs/source/en/model_doc/time_series_transformer.md b/docs/source/en/model_doc/time_series_transformer.md
index 208798aa1c68..c5bfcfc15ea2 100644
--- a/docs/source/en/model_doc/time_series_transformer.md
+++ b/docs/source/en/model_doc/time_series_transformer.md
@@ -16,18 +16,12 @@ rendered properly in your Markdown viewer.
# Time Series Transformer
-
-
-This is a recently introduced model so the API hasn't been tested extensively. There may be some bugs or slight
-breaking changes to fix it in the future. If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
-
-
-
## Overview
The Time Series Transformer model is a vanilla encoder-decoder Transformer for time series forecasting.
+This model was contributed by [kashif](https://huggingface.co/kashif).
-Tips:
+## Usage tips
- Similar to other models in the library, [`TimeSeriesTransformerModel`] is the raw Transformer without any head on top, and [`TimeSeriesTransformerForPrediction`]
adds a distribution head on top of the former, which can be used for time-series forecasting. Note that this is a so-called probabilistic forecasting model, not a
@@ -56,9 +50,6 @@ of the context as initial input for the decoder).
- At inference time, we give the final value of the `past_values` as input to the decoder. Next, we can sample from the model to make a prediction at the next time step,
which is then fed to the decoder in order to make the next prediction (also called autoregressive generation).
-
-This model was contributed by [kashif](https://huggingface.co/kashif).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
@@ -70,13 +61,11 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] TimeSeriesTransformerConfig
-
## TimeSeriesTransformerModel
[[autodoc]] TimeSeriesTransformerModel
- forward
-
## TimeSeriesTransformerForPrediction
[[autodoc]] TimeSeriesTransformerForPrediction
diff --git a/docs/source/en/model_doc/timesformer.md b/docs/source/en/model_doc/timesformer.md
index d87fde4fb2b3..fe75bee5b289 100644
--- a/docs/source/en/model_doc/timesformer.md
+++ b/docs/source/en/model_doc/timesformer.md
@@ -25,14 +25,15 @@ The abstract from the paper is the following:
*We present a convolution-free approach to video classification built exclusively on self-attention over space and time. Our method, named "TimeSformer," adapts the standard Transformer architecture to video by enabling spatiotemporal feature learning directly from a sequence of frame-level patches. Our experimental study compares different self-attention schemes and suggests that "divided attention," where temporal attention and spatial attention are separately applied within each block, leads to the best video classification accuracy among the design choices considered. Despite the radically new design, TimeSformer achieves state-of-the-art results on several action recognition benchmarks, including the best reported accuracy on Kinetics-400 and Kinetics-600. Finally, compared to 3D convolutional networks, our model is faster to train, it can achieve dramatically higher test efficiency (at a small drop in accuracy), and it can also be applied to much longer video clips (over one minute long). Code and models are available at: [this https URL](https://github.com/facebookresearch/TimeSformer).*
-Tips:
-
-There are many pretrained variants. Select your pretrained model based on the dataset it is trained on. Moreover, the number of input frames per clip changes based on the model size so you should consider this parameter while selecting your pretrained model.
-
This model was contributed by [fcakyon](https://huggingface.co/fcakyon).
The original code can be found [here](https://github.com/facebookresearch/TimeSformer).
-## Documentation resources
+## Usage tips
+
+There are many pretrained variants. Select your pretrained model based on the dataset it is trained on. Moreover,
+the number of input frames per clip changes based on the model size so you should consider this parameter while selecting your pretrained model.
+
+## Resources
- [Video classification task guide](../tasks/video_classification)
diff --git a/docs/source/en/model_doc/trajectory_transformer.md b/docs/source/en/model_doc/trajectory_transformer.md
index 548642f7bb9f..45616255871a 100644
--- a/docs/source/en/model_doc/trajectory_transformer.md
+++ b/docs/source/en/model_doc/trajectory_transformer.md
@@ -43,19 +43,18 @@ in offline RL algorithms. We demonstrate the flexibility of this approach across
imitation learning, goal-conditioned RL, and offline RL. Further, we show that this approach can be combined with
existing model-free algorithms to yield a state-of-the-art planner in sparse-reward, long-horizon tasks.*
-Tips:
+This model was contributed by [CarlCochet](https://huggingface.co/CarlCochet). The original code can be found [here](https://github.com/jannerm/trajectory-transformer).
+
+## Usage tips
This Transformer is used for deep reinforcement learning. To use it, you need to create sequences from
actions, states and rewards from all previous timesteps. This model will treat all these elements together
as one big sequence (a trajectory).
-This model was contributed by [CarlCochet](https://huggingface.co/CarlCochet). The original code can be found [here](https://github.com/jannerm/trajectory-transformer).
-
## TrajectoryTransformerConfig
[[autodoc]] TrajectoryTransformerConfig
-
## TrajectoryTransformerModel
[[autodoc]] TrajectoryTransformerModel
diff --git a/docs/source/en/model_doc/transfo-xl.md b/docs/source/en/model_doc/transfo-xl.md
index beb5ba2fea83..05afc76f1114 100644
--- a/docs/source/en/model_doc/transfo-xl.md
+++ b/docs/source/en/model_doc/transfo-xl.md
@@ -16,6 +16,29 @@ rendered properly in your Markdown viewer.
# Transformer XL
+
+
+This model is in maintenance mode only, so we won't accept any new PRs changing its code. This model was deprecated due to security issues linked to `pickle.load`.
+
+We recommend switching to more recent models for improved security.
+
+In case you would still like to use `TransfoXL` in your experiments, we recommend using the [Hub checkpoint](https://huggingface.co/transfo-xl-wt103) with a specific revision to ensure you are downloading safe files from the Hub:
+
+```
+from transformers import TransfoXLTokenizer, TransfoXLLMHeadModel
+
+checkpoint = 'transfo-xl-wt103'
+revision = '40a186da79458c9f9de846edfaea79c412137f97'
+
+tokenizer = TransfoXLTokenizer.from_pretrained(checkpoint, revision=revision)
+model = TransfoXLLMHeadModel.from_pretrained(checkpoint, revision=revision)
+```
+
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.35.0.
+You can do so by running the following command: `pip install -U transformers==4.35.0`.
+
+
+
@@ -42,6 +34,14 @@ alt="drawing" width="600"/>
The original code can be found [here](https://github.com/zinengtang/TVLT). This model was contributed by [Zineng Tang](https://huggingface.co/ZinengTang).
+## Usage tips
+
+- TVLT is a model that takes both `pixel_values` and `audio_values` as input. One can use [`TvltProcessor`] to prepare data for the model.
+ This processor wraps an image processor (for the image/video modality) and an audio feature extractor (for the audio modality) into one.
+- TVLT is trained with images/videos and audios of various sizes: the authors resize and crop the input images/videos to 224 and limit the length of audio spectrogram to 2048. To make batching of videos and audios possible, the authors use a `pixel_mask` that indicates which pixels are real/padding and `audio_mask` that indicates which audio values are real/padding.
+- The design of TVLT is very similar to that of a standard Vision Transformer (ViT) and masked autoencoder (MAE) as in [ViTMAE](vitmae). The difference is that the model includes embedding layers for the audio modality.
+- The PyTorch version of this model is only available in torch 1.10 and higher.
+
## TvltConfig
[[autodoc]] TvltConfig
diff --git a/docs/source/en/model_doc/tvp.md b/docs/source/en/model_doc/tvp.md
new file mode 100644
index 000000000000..22b400a06c73
--- /dev/null
+++ b/docs/source/en/model_doc/tvp.md
@@ -0,0 +1,186 @@
+
+
+# TVP
+
+## Overview
+
+The text-visual prompting (TVP) framework was proposed in the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
+
+The abstract from the paper is the following:
+
+*In this paper, we study the problem of temporal video grounding (TVG), which aims to predict the starting/ending time points of moments described by a text sentence within a long untrimmed video. Benefiting from fine-grained 3D visual features, the TVG techniques have achieved remarkable progress in recent years. However, the high complexity of 3D convolutional neural networks (CNNs) makes extracting dense 3D visual features time-consuming, which calls for intensive memory and computing resources. Towards efficient TVG, we propose a novel text-visual prompting (TVP) framework, which incorporates optimized perturbation patterns (that we call ‘prompts’) into both visual inputs and textual features of a TVG model. In sharp contrast to 3D CNNs, we show that TVP allows us to effectively co-train vision encoder and language encoder in a 2D TVG model and improves the performance of cross-modal feature fusion using only low-complexity sparse 2D visual features. Further, we propose a Temporal-Distance IoU (TDIoU) loss for efficient learning of TVG. Experiments on two benchmark datasets, Charades-STA and ActivityNet Captions datasets, empirically show that the proposed TVP significantly boosts the performance of 2D TVG (e.g., 9.79% improvement on Charades-STA and 30.77% improvement on ActivityNet Captions) and achieves 5× inference acceleration over TVG using 3D visual features.*
+
+This research addresses temporal video grounding (TVG), which is the process of pinpointing the start and end times of specific events in a long video, as described by a text sentence. Text-visual prompting (TVP), is proposed to enhance TVG. TVP involves integrating specially designed patterns, known as 'prompts', into both the visual (image-based) and textual (word-based) input components of a TVG model. These prompts provide additional spatial-temporal context, improving the model's ability to accurately determine event timings in the video. The approach employs 2D visual inputs in place of 3D ones. Although 3D inputs offer more spatial-temporal detail, they are also more time-consuming to process. The use of 2D inputs with the prompting method aims to provide similar levels of context and accuracy more efficiently.
+
+
+
+ TVP architecture. Taken from the original paper.
+
+This model was contributed by [Jiqing Feng](https://huggingface.co/Jiqing). The original code can be found [here](https://github.com/intel/TVP).
+
+## Usage tips and examples
+
+Prompts are optimized perturbation patterns, which would be added to input video frames or text features. Universal set refers to using the same exact set of prompts for any input, this means that these prompts are added consistently to all video frames and text features, regardless of the input's content.
+
+TVP consists of a visual encoder and cross-modal encoder. A universal set of visual prompts and text prompts to be integrated into sampled video frames and textual features, respectively. Specially, a set of different visual prompts are applied to uniformly-sampled frames of one untrimmed video in order.
+
+The goal of this model is to incorporate trainable prompts into both visual inputs and textual features to temporal video grounding(TVG) problems.
+In principle, one can apply any visual, cross-modal encoder in the proposed architecture.
+
+The [`TvpProcessor`] wraps [`BertTokenizer`] and [`TvpImageProcessor`] into a single instance to both
+encode the text and prepare the images respectively.
+
+The following example shows how to run temporal video grounding using [`TvpProcessor`] and [`TvpForVideoGrounding`].
+```python
+import av
+import cv2
+import numpy as np
+import torch
+from huggingface_hub import hf_hub_download
+from transformers import AutoProcessor, TvpForVideoGrounding
+
+
+def pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Convert the video from its original fps to the target_fps and decode the video with PyAV decoder.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video. Return None if the no
+ video stream was found.
+ fps (float): the number of frames per second of the video.
+ '''
+ video = container.streams.video[0]
+ fps = float(video.average_rate)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ delta = max(num_frames - clip_size, 0)
+ start_idx = delta * clip_idx / num_clips
+ end_idx = start_idx + clip_size - 1
+ timebase = video.duration / num_frames
+ video_start_pts = int(start_idx * timebase)
+ video_end_pts = int(end_idx * timebase)
+ seek_offset = max(video_start_pts - 1024, 0)
+ container.seek(seek_offset, any_frame=False, backward=True, stream=video)
+ frames = {}
+ for frame in container.decode(video=0):
+ if frame.pts < video_start_pts:
+ continue
+ frames[frame.pts] = frame
+ if frame.pts > video_end_pts:
+ break
+ frames = [frames[pts] for pts in sorted(frames)]
+ return frames, fps
+
+
+def decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Decode the video and perform temporal sampling.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video.
+ '''
+ assert clip_idx >= -2, "Not a valied clip_idx {}".format(clip_idx)
+ frames, fps = pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ index = np.linspace(0, clip_size - 1, num_frames)
+ index = np.clip(index, 0, len(frames) - 1).astype(np.int64)
+ frames = np.array([frames[idx].to_rgb().to_ndarray() for idx in index])
+ frames = frames.transpose(0, 3, 1, 2)
+ return frames
+
+
+file = hf_hub_download(repo_id="Intel/tvp_demo", filename="AK2KG.mp4", repo_type="dataset")
+model = TvpForVideoGrounding.from_pretrained("Intel/tvp-base")
+
+decoder_kwargs = dict(
+ container=av.open(file, metadata_errors="ignore"),
+ sampling_rate=1,
+ num_frames=model.config.num_frames,
+ clip_idx=0,
+ num_clips=1,
+ target_fps=3,
+)
+raw_sampled_frms = decode(**decoder_kwargs)
+
+text = "a person is sitting on a bed."
+processor = AutoProcessor.from_pretrained("Intel/tvp-base")
+model_inputs = processor(
+ text=[text], videos=list(raw_sampled_frms), return_tensors="pt", max_text_length=100#, size=size
+)
+
+model_inputs["pixel_values"] = model_inputs["pixel_values"].to(model.dtype)
+output = model(**model_inputs)
+
+def get_video_duration(filename):
+ cap = cv2.VideoCapture(filename)
+ if cap.isOpened():
+ rate = cap.get(5)
+ frame_num = cap.get(7)
+ duration = frame_num/rate
+ return duration
+ return -1
+
+duration = get_video_duration(file)
+start, end = processor.post_process_video_grounding(output.logits, duration)
+
+print(f"The time slot of the video corresponding to the text \"{text}\" is from {start}s to {end}s")
+```
+
+Tips:
+
+- This implementation of TVP uses [`BertTokenizer`] to generate text embeddings and Resnet-50 model to compute visual embeddings.
+- Checkpoints for pre-trained [tvp-base](https://huggingface.co/Intel/tvp-base) is released.
+- Please refer to [Table 2](https://arxiv.org/pdf/2303.04995.pdf) for TVP's performance on Temporal Video Grounding task.
+
+
+## TvpConfig
+
+[[autodoc]] TvpConfig
+
+## TvpImageProcessor
+
+[[autodoc]] TvpImageProcessor
+ - preprocess
+
+## TvpProcessor
+
+[[autodoc]] TvpProcessor
+ - __call__
+
+## TvpModel
+
+[[autodoc]] TvpModel
+ - forward
+
+## TvpForVideoGrounding
+
+[[autodoc]] TvpForVideoGrounding
+ - forward
diff --git a/docs/source/en/model_doc/ul2.md b/docs/source/en/model_doc/ul2.md
index 3863f23a7d73..f4d01c40b0c1 100644
--- a/docs/source/en/model_doc/ul2.md
+++ b/docs/source/en/model_doc/ul2.md
@@ -24,12 +24,20 @@ The abstract from the paper is the following:
*Existing pre-trained models are generally geared towards a particular class of problems. To date, there seems to be still no consensus on what the right architecture and pre-training setup should be. This paper presents a unified framework for pre-training models that are universally effective across datasets and setups. We begin by disentangling architectural archetypes with pre-training objectives -- two concepts that are commonly conflated. Next, we present a generalized and unified perspective for self-supervision in NLP and show how different pre-training objectives can be cast as one another and how interpolating between different objectives can be effective. We then propose Mixture-of-Denoisers (MoD), a pre-training objective that combines diverse pre-training paradigms together. We furthermore introduce a notion of mode switching, wherein downstream fine-tuning is associated with specific pre-training schemes. We conduct extensive ablative experiments to compare multiple pre-training objectives and find that our method pushes the Pareto-frontier by outperforming T5 and/or GPT-like models across multiple diverse setups. Finally, by scaling our model up to 20B parameters, we achieve SOTA performance on 50 well-established supervised NLP tasks ranging from language generation (with automated and human evaluation), language understanding, text classification, question answering, commonsense reasoning, long text reasoning, structured knowledge grounding and information retrieval. Our model also achieve strong results at in-context learning, outperforming 175B GPT-3 on zero-shot SuperGLUE and tripling the performance of T5-XXL on one-shot summarization.*
-Tips:
+This model was contributed by [DanielHesslow](https://huggingface.co/Seledorn). The original code can be found [here](https://github.com/google-research/google-research/tree/master/ul2).
+
+## Usage tips
- UL2 is an encoder-decoder model pre-trained on a mixture of denoising functions as well as fine-tuned on an array of downstream tasks.
- UL2 has the same architecture as [T5v1.1](t5v1.1) but uses the Gated-SiLU activation function instead of Gated-GELU.
- The authors release checkpoints of one architecture which can be seen [here](https://huggingface.co/google/ul2)
-The original code can be found [here](https://github.com/google-research/google-research/tree/master/ul2).
+
+
+As UL2 has the same architecture as T5v1.1, refer to [T5's documentation page](t5) for API reference, tips, code examples and notebooks.
+
+
+
+
+
-This model was contributed by [DanielHesslow](https://huggingface.co/Seledorn).
diff --git a/docs/source/en/model_doc/umt5.md b/docs/source/en/model_doc/umt5.md
index 4e6375bd465a..6a7498c24338 100644
--- a/docs/source/en/model_doc/umt5.md
+++ b/docs/source/en/model_doc/umt5.md
@@ -33,13 +33,6 @@ The abstract from the paper is the following:
*Pretrained multilingual large language models have typically used heuristic temperature-based sampling to balance between different languages. However previous work has not systematically evaluated the efficacy of different pretraining language distributions across model scales. In this paper, we propose a new sampling method, UniMax, that delivers more uniform coverage of head languages while mitigating overfitting on tail languages by explicitly capping the number of repeats over each language's corpus. We perform an extensive series of ablations testing a range of sampling strategies on a suite of multilingual benchmarks, while varying model scale. We find that UniMax outperforms standard temperature-based sampling, and the benefits persist as scale increases. As part of our contribution, we release: (i) an improved and refreshed mC4 multilingual corpus consisting of 29 trillion characters across 107 languages, and (ii) a suite of pretrained umT5 model checkpoints trained with UniMax sampling.*
-Tips:
-
-- UMT5 was only pre-trained on [mC4](https://huggingface.co/datasets/mc4) excluding any supervised training.
-Therefore, this model has to be fine-tuned before it is usable on a downstream task, unlike the original T5 model.
-- Since umT5 was pre-trained in an unsupervise manner, there's no real advantage to using a task prefix during single-task
-fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
-
Google has released the following variants:
- [google/umt5-small](https://huggingface.co/google/umt5-small)
@@ -50,7 +43,12 @@ Google has released the following variants:
This model was contributed by [agemagician](https://huggingface.co/agemagician) and [stefan-it](https://huggingface.co/stefan-it). The original code can be
found [here](https://github.com/google-research/t5x).
-One can refer to [T5's documentation page](t5) for more tips, code examples and notebooks.
+## Usage tips
+
+- UMT5 was only pre-trained on [mC4](https://huggingface.co/datasets/mc4) excluding any supervised training.
+Therefore, this model has to be fine-tuned before it is usable on a downstream task, unlike the original T5 model.
+- Since umT5 was pre-trained in an unsupervise manner, there's no real advantage to using a task prefix during single-task
+fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
## Differences with mT5?
`UmT5` is based on mT5, with a non-shared relative positional bias that is computed for each layer. This means that the model set `has_relative_bias` for each layer.
@@ -73,6 +71,11 @@ The conversion script is also different because the model was saved in t5x's lat
['nyone who drink a alcohol A A. This I']
```
+
+
+Refer to [T5's documentation page](t5) for more tips, code examples and notebooks.
+
+
## UMT5Config
[[autodoc]] UMT5Config
diff --git a/docs/source/en/model_doc/unispeech-sat.md b/docs/source/en/model_doc/unispeech-sat.md
index 25489d9eeffd..e2a21148115e 100644
--- a/docs/source/en/model_doc/unispeech-sat.md
+++ b/docs/source/en/model_doc/unispeech-sat.md
@@ -37,7 +37,10 @@ state-of-the-art performance in universal representation learning, especially fo
tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training
dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks.*
-Tips:
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT).
+
+## Usage tips
- UniSpeechSat is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
Please use [`Wav2Vec2Processor`] for the feature extraction.
@@ -45,10 +48,7 @@ Tips:
decoded using [`Wav2Vec2CTCTokenizer`].
- UniSpeechSat performs especially well on speaker verification, speaker identification, and speaker diarization tasks.
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
-found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT).
-
-## Documentation resources
+## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
diff --git a/docs/source/en/model_doc/unispeech.md b/docs/source/en/model_doc/unispeech.md
index 8338aa1bda2e..2b2b13bed52c 100644
--- a/docs/source/en/model_doc/unispeech.md
+++ b/docs/source/en/model_doc/unispeech.md
@@ -33,17 +33,17 @@ recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions
testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task,
i.e., a relative word error rate reduction of 6% against the previous approach.*
-Tips:
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech).
+
+## Usage tips
- UniSpeech is a speech model that accepts a float array corresponding to the raw waveform of the speech signal. Please
use [`Wav2Vec2Processor`] for the feature extraction.
- UniSpeech model can be fine-tuned using connectionist temporal classification (CTC) so the model output has to be
decoded using [`Wav2Vec2CTCTokenizer`].
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
-found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech).
-
-## Documentation resources
+## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
diff --git a/docs/source/en/model_doc/univnet.md b/docs/source/en/model_doc/univnet.md
new file mode 100644
index 000000000000..45bd94732773
--- /dev/null
+++ b/docs/source/en/model_doc/univnet.md
@@ -0,0 +1,80 @@
+
+
+# UnivNet
+
+## Overview
+
+The UnivNet model was proposed in [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kin, and Juntae Kim.
+The UnivNet model is a generative adversarial network (GAN) trained to synthesize high fidelity speech waveforms. The UnivNet model shared in `transformers` is the *generator*, which maps a conditioning log-mel spectrogram and optional noise sequence to a speech waveform (e.g. a vocoder). Only the generator is required for inference. The *discriminator* used to train the `generator` is not implemented.
+
+The abstract from the paper is the following:
+
+*Most neural vocoders employ band-limited mel-spectrograms to generate waveforms. If full-band spectral features are used as the input, the vocoder can be provided with as much acoustic information as possible. However, in some models employing full-band mel-spectrograms, an over-smoothing problem occurs as part of which non-sharp spectrograms are generated. To address this problem, we propose UnivNet, a neural vocoder that synthesizes high-fidelity waveforms in real time. Inspired by works in the field of voice activity detection, we added a multi-resolution spectrogram discriminator that employs multiple linear spectrogram magnitudes computed using various parameter sets. Using full-band mel-spectrograms as input, we expect to generate high-resolution signals by adding a discriminator that employs spectrograms of multiple resolutions as the input. In an evaluation on a dataset containing information on hundreds of speakers, UnivNet obtained the best objective and subjective results among competing models for both seen and unseen speakers. These results, including the best subjective score for text-to-speech, demonstrate the potential for fast adaptation to new speakers without a need for training from scratch.*
+
+Tips:
+
+- The `noise_sequence` argument for [`UnivNetModel.forward`] should be standard Gaussian noise (such as from `torch.randn`) of shape `([batch_size], noise_length, model.config.model_in_channels)`, where `noise_length` should match the length dimension (dimension 1) of the `input_features` argument. If not supplied, it will be randomly generated; a `torch.Generator` can be supplied to the `generator` argument so that the forward pass can be reproduced. (Note that [`UnivNetFeatureExtractor`] will return generated noise by default, so it shouldn't be necessary to generate `noise_sequence` manually.)
+- Padding added by [`UnivNetFeatureExtractor`] can be removed from the [`UnivNetModel`] output through the [`UnivNetFeatureExtractor.batch_decode`] method, as shown in the usage example below.
+- Padding the end of each waveform with silence can reduce artifacts at the end of the generated audio sample. This can be done by supplying `pad_end = True` to [`UnivNetFeatureExtractor.__call__`]. See [this issue](https://github.com/seungwonpark/melgan/issues/8) for more details.
+
+Usage Example:
+
+```python
+import torch
+from scipy.io.wavfile import write
+from datasets import Audio, load_dataset
+
+from transformers import UnivNetFeatureExtractor, UnivNetModel
+
+model_id_or_path = "dg845/univnet-dev"
+model = UnivNetModel.from_pretrained(model_id_or_path)
+feature_extractor = UnivNetFeatureExtractor.from_pretrained(model_id_or_path)
+
+ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+# Resample the audio to the model and feature extractor's sampling rate.
+ds = ds.cast_column("audio", Audio(sampling_rate=feature_extractor.sampling_rate))
+# Pad the end of the converted waveforms to reduce artifacts at the end of the output audio samples.
+inputs = feature_extractor(
+ ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], pad_end=True, return_tensors="pt"
+)
+
+with torch.no_grad():
+ audio = model(**inputs)
+
+# Remove the extra padding at the end of the output.
+audio = feature_extractor.batch_decode(**audio)[0]
+# Convert to wav file
+write("sample_audio.wav", feature_extractor.sampling_rate, audio)
+```
+
+This model was contributed by [dg845](https://huggingface.co/dg845).
+To the best of my knowledge, there is no official code release, but an unofficial implementation can be found at [maum-ai/univnet](https://github.com/maum-ai/univnet) with pretrained checkpoints [here](https://github.com/maum-ai/univnet#pre-trained-model).
+
+
+## UnivNetConfig
+
+[[autodoc]] UnivNetConfig
+
+## UnivNetFeatureExtractor
+
+[[autodoc]] UnivNetFeatureExtractor
+ - __call__
+
+## UnivNetModel
+
+[[autodoc]] UnivNetModel
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/upernet.md b/docs/source/en/model_doc/upernet.md
index db651acaa406..418c3ef1786b 100644
--- a/docs/source/en/model_doc/upernet.md
+++ b/docs/source/en/model_doc/upernet.md
@@ -33,17 +33,7 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code is based on OpenMMLab's mmsegmentation [here](https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/uper_head.py).
-## Resources
-
-A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with UPerNet.
-
-- Demo notebooks for UPerNet can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UPerNet).
-- [`UperNetForSemanticSegmentation`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb).
-- See also: [Semantic segmentation task guide](../tasks/semantic_segmentation)
-
-If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
-
-## Usage
+## Usage examples
UPerNet is a general framework for semantic segmentation. It can be used with any vision backbone, like so:
@@ -69,6 +59,16 @@ model = UperNetForSemanticSegmentation(config)
Note that this will randomly initialize all the weights of the model.
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with UPerNet.
+
+- Demo notebooks for UPerNet can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UPerNet).
+- [`UperNetForSemanticSegmentation`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb).
+- See also: [Semantic segmentation task guide](../tasks/semantic_segmentation)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## UperNetConfig
[[autodoc]] UperNetConfig
diff --git a/docs/source/en/model_doc/van.md b/docs/source/en/model_doc/van.md
index b9539602d3b8..83e4959b3016 100644
--- a/docs/source/en/model_doc/van.md
+++ b/docs/source/en/model_doc/van.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
-This model is in maintenance mode only, so we won't accept any new PRs changing its code.
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
You can do so by running the following command: `pip install -U transformers==4.30.0`.
@@ -60,13 +60,11 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] VanConfig
-
## VanModel
[[autodoc]] VanModel
- forward
-
## VanForImageClassification
[[autodoc]] VanForImageClassification
diff --git a/docs/source/en/model_doc/videomae.md b/docs/source/en/model_doc/videomae.md
index 5a3620040ad9..75eb9617380c 100644
--- a/docs/source/en/model_doc/videomae.md
+++ b/docs/source/en/model_doc/videomae.md
@@ -25,11 +25,6 @@ The abstract from the paper is the following:
*Pre-training video transformers on extra large-scale datasets is generally required to achieve premier performance on relatively small datasets. In this paper, we show that video masked autoencoders (VideoMAE) are data-efficient learners for self-supervised video pre-training (SSVP). We are inspired by the recent ImageMAE and propose customized video tube masking and reconstruction. These simple designs turn out to be effective for overcoming information leakage caused by the temporal correlation during video reconstruction. We obtain three important findings on SSVP: (1) An extremely high proportion of masking ratio (i.e., 90% to 95%) still yields favorable performance of VideoMAE. The temporally redundant video content enables higher masking ratio than that of images. (2) VideoMAE achieves impressive results on very small datasets (i.e., around 3k-4k videos) without using any extra data. This is partially ascribed to the challenging task of video reconstruction to enforce high-level structure learning. (3) VideoMAE shows that data quality is more important than data quantity for SSVP. Domain shift between pre-training and target datasets are important issues in SSVP. Notably, our VideoMAE with the vanilla ViT backbone can achieve 83.9% on Kinects-400, 75.3% on Something-Something V2, 90.8% on UCF101, and 61.1% on HMDB51 without using any extra data.*
-Tips:
-
-- One can use [`VideoMAEImageProcessor`] to prepare videos for the model. It will resize + normalize all frames of a video for you.
-- [`VideoMAEForPreTraining`] includes the decoder on top for self-supervised pre-training.
-
@@ -50,7 +45,6 @@ to fine-tune a VideoMAE model on a custom dataset.
- [Video classification task guide](../tasks/video_classification)
- [A 🤗 Space](https://huggingface.co/spaces/sayakpaul/video-classification-ucf101-subset) showing how to perform inference with a video classification model.
-
## VideoMAEConfig
[[autodoc]] VideoMAEConfig
@@ -72,6 +66,8 @@ to fine-tune a VideoMAE model on a custom dataset.
## VideoMAEForPreTraining
+`VideoMAEForPreTraining` includes the decoder on top for self-supervised pre-training.
+
[[autodoc]] transformers.VideoMAEForPreTraining
- forward
diff --git a/docs/source/en/model_doc/vilt.md b/docs/source/en/model_doc/vilt.md
index 2e2f4a140d20..2b0ac022da4b 100644
--- a/docs/source/en/model_doc/vilt.md
+++ b/docs/source/en/model_doc/vilt.md
@@ -34,7 +34,14 @@ Vision-and-Language Transformer (ViLT), monolithic in the sense that the process
simplified to just the same convolution-free manner that we process textual inputs. We show that ViLT is up to tens of
times faster than previous VLP models, yet with competitive or better downstream task performance.*
-Tips:
+
+
+ ViLT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/dandelin/ViLT).
+
+## Usage tips
- The quickest way to get started with ViLT is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ViLT)
(which showcase both inference and fine-tuning on custom data).
@@ -45,17 +52,6 @@ Tips:
which pixel values are real and which are padding. [`ViltProcessor`] automatically creates this for you.
- The design of ViLT is very similar to that of a standard Vision Transformer (ViT). The only difference is that the model includes
additional embedding layers for the language modality.
-
-
-
- ViLT architecture. Taken from the original paper.
-
-This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/dandelin/ViLT).
-
-
-Tips:
-
- The PyTorch version of this model is only available in torch 1.10 and higher.
## ViltConfig
diff --git a/docs/source/en/model_doc/vision-encoder-decoder.md b/docs/source/en/model_doc/vision-encoder-decoder.md
index 0beeaeae108b..89d89896a2e2 100644
--- a/docs/source/en/model_doc/vision-encoder-decoder.md
+++ b/docs/source/en/model_doc/vision-encoder-decoder.md
@@ -151,20 +151,32 @@ were contributed by [ydshieh](https://github.com/ydshieh).
[[autodoc]] VisionEncoderDecoderConfig
+
+
+
## VisionEncoderDecoderModel
[[autodoc]] VisionEncoderDecoderModel
- forward
- from_encoder_decoder_pretrained
+
+
+
## TFVisionEncoderDecoderModel
[[autodoc]] TFVisionEncoderDecoderModel
- call
- from_encoder_decoder_pretrained
+
+
+
## FlaxVisionEncoderDecoderModel
[[autodoc]] FlaxVisionEncoderDecoderModel
- __call__
- from_encoder_decoder_pretrained
+
+
+
diff --git a/docs/source/en/model_doc/vision-text-dual-encoder.md b/docs/source/en/model_doc/vision-text-dual-encoder.md
index 6fa9728cac46..7cb68a261875 100644
--- a/docs/source/en/model_doc/vision-text-dual-encoder.md
+++ b/docs/source/en/model_doc/vision-text-dual-encoder.md
@@ -36,17 +36,29 @@ new zero-shot vision tasks such as image classification or retrieval.
[[autodoc]] VisionTextDualEncoderProcessor
+
+
+
## VisionTextDualEncoderModel
[[autodoc]] VisionTextDualEncoderModel
- forward
+
+
+
## FlaxVisionTextDualEncoderModel
[[autodoc]] FlaxVisionTextDualEncoderModel
- __call__
+
+
+
## TFVisionTextDualEncoderModel
[[autodoc]] TFVisionTextDualEncoderModel
- call
+
+
+
diff --git a/docs/source/en/model_doc/visual_bert.md b/docs/source/en/model_doc/visual_bert.md
index 7d84c0d9faec..1db218f1a531 100644
--- a/docs/source/en/model_doc/visual_bert.md
+++ b/docs/source/en/model_doc/visual_bert.md
@@ -32,7 +32,9 @@ simpler. Further analysis demonstrates that VisualBERT can ground elements of la
explicit supervision and is even sensitive to syntactic relationships, tracking, for example, associations between
verbs and image regions corresponding to their arguments.*
-Tips:
+This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The original code can be found [here](https://github.com/uclanlp/visualbert).
+
+## Usage tips
1. Most of the checkpoints provided work with the [`VisualBertForPreTraining`] configuration. Other
checkpoints provided are the fine-tuned checkpoints for down-stream tasks - VQA ('visualbert-vqa'), VCR
@@ -43,8 +45,6 @@ Tips:
We do not provide the detector and its weights as a part of the package, but it will be available in the research
projects, and the states can be loaded directly into the detector provided.
-## Usage
-
VisualBERT is a multi-modal vision and language model. It can be used for visual question answering, multiple choice,
visual reasoning and region-to-phrase correspondence tasks. VisualBERT uses a BERT-like transformer to prepare
embeddings for image-text pairs. Both the text and visual features are then projected to a latent space with identical
@@ -92,8 +92,6 @@ The following example shows how to get the last hidden state using [`VisualBertM
>>> last_hidden_state = outputs.last_hidden_state
```
-This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The original code can be found [here](https://github.com/uclanlp/visualbert).
-
## VisualBertConfig
[[autodoc]] VisualBertConfig
diff --git a/docs/source/en/model_doc/vit.md b/docs/source/en/model_doc/vit.md
index 409580d09481..25c3a6c8f537 100644
--- a/docs/source/en/model_doc/vit.md
+++ b/docs/source/en/model_doc/vit.md
@@ -24,7 +24,6 @@ Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minder
Uszkoreit, Neil Houlsby. It's the first paper that successfully trains a Transformer encoder on ImageNet, attaining
very good results compared to familiar convolutional architectures.
-
The abstract from the paper is the following:
*While the Transformer architecture has become the de-facto standard for natural language processing tasks, its
@@ -36,30 +35,6 @@ data and transferred to multiple mid-sized or small image recognition benchmarks
Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring
substantially fewer computational resources to train.*
-Tips:
-
-- Demo notebooks regarding inference as well as fine-tuning ViT on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer).
-- To feed images to the Transformer encoder, each image is split into a sequence of fixed-size non-overlapping patches,
- which are then linearly embedded. A [CLS] token is added to serve as representation of an entire image, which can be
- used for classification. The authors also add absolute position embeddings, and feed the resulting sequence of
- vectors to a standard Transformer encoder.
-- As the Vision Transformer expects each image to be of the same size (resolution), one can use
- [`ViTImageProcessor`] to resize (or rescale) and normalize images for the model.
-- Both the patch resolution and image resolution used during pre-training or fine-tuning are reflected in the name of
- each checkpoint. For example, `google/vit-base-patch16-224` refers to a base-sized architecture with patch
- resolution of 16x16 and fine-tuning resolution of 224x224. All checkpoints can be found on the [hub](https://huggingface.co/models?search=vit).
-- The available checkpoints are either (1) pre-trained on [ImageNet-21k](http://www.image-net.org/) (a collection of
- 14 million images and 21k classes) only, or (2) also fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) (also referred to as ILSVRC 2012, a collection of 1.3 million
- images and 1,000 classes).
-- The Vision Transformer was pre-trained using a resolution of 224x224. During fine-tuning, it is often beneficial to
- use a higher resolution than pre-training [(Touvron et al., 2019)](https://arxiv.org/abs/1906.06423), [(Kolesnikov
- et al., 2020)](https://arxiv.org/abs/1912.11370). In order to fine-tune at higher resolution, the authors perform
- 2D interpolation of the pre-trained position embeddings, according to their location in the original image.
-- The best results are obtained with supervised pre-training, which is not the case in NLP. The authors also performed
- an experiment with a self-supervised pre-training objective, namely masked patched prediction (inspired by masked
- language modeling). With this approach, the smaller ViT-B/16 model achieves 79.9% accuracy on ImageNet, a significant
- improvement of 2% to training from scratch, but still 4% behind supervised pre-training.
-
@@ -87,28 +62,35 @@ Following the original Vision Transformer, some follow-up works have been made:
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code (written in JAX) can be
found [here](https://github.com/google-research/vision_transformer).
-Note that we converted the weights from Ross Wightman's [timm library](https://github.com/rwightman/pytorch-image-models), who already converted the weights from JAX to PyTorch. Credits
-go to him!
-
-## Resources
-
-A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT.
-
-
-
-- [`ViTForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
-- A blog on fine-tuning [`ViTForImageClassification`] on a custom dataset can be found [here](https://huggingface.co/blog/fine-tune-vit).
-- More demo notebooks to fine-tune [`ViTForImageClassification`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer).
-- [Image classification task guide](../tasks/image_classification)
-
-Besides that:
+Note that we converted the weights from Ross Wightman's [timm library](https://github.com/rwightman/pytorch-image-models),
+who already converted the weights from JAX to PyTorch. Credits go to him!
-- [`ViTForMaskedImageModeling`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
+## Usage tips
-If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+- To feed images to the Transformer encoder, each image is split into a sequence of fixed-size non-overlapping patches,
+ which are then linearly embedded. A [CLS] token is added to serve as representation of an entire image, which can be
+ used for classification. The authors also add absolute position embeddings, and feed the resulting sequence of
+ vectors to a standard Transformer encoder.
+- As the Vision Transformer expects each image to be of the same size (resolution), one can use
+ [`ViTImageProcessor`] to resize (or rescale) and normalize images for the model.
+- Both the patch resolution and image resolution used during pre-training or fine-tuning are reflected in the name of
+ each checkpoint. For example, `google/vit-base-patch16-224` refers to a base-sized architecture with patch
+ resolution of 16x16 and fine-tuning resolution of 224x224. All checkpoints can be found on the [hub](https://huggingface.co/models?search=vit).
+- The available checkpoints are either (1) pre-trained on [ImageNet-21k](http://www.image-net.org/) (a collection of
+ 14 million images and 21k classes) only, or (2) also fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) (also referred to as ILSVRC 2012, a collection of 1.3 million
+ images and 1,000 classes).
+- The Vision Transformer was pre-trained using a resolution of 224x224. During fine-tuning, it is often beneficial to
+ use a higher resolution than pre-training [(Touvron et al., 2019)](https://arxiv.org/abs/1906.06423), [(Kolesnikov
+ et al., 2020)](https://arxiv.org/abs/1912.11370). In order to fine-tune at higher resolution, the authors perform
+ 2D interpolation of the pre-trained position embeddings, according to their location in the original image.
+- The best results are obtained with supervised pre-training, which is not the case in NLP. The authors also performed
+ an experiment with a self-supervised pre-training objective, namely masked patched prediction (inspired by masked
+ language modeling). With this approach, the smaller ViT-B/16 model achieves 79.9% accuracy on ImageNet, a significant
+ improvement of 2% to training from scratch, but still 4% behind supervised pre-training.
## Resources
+Demo notebooks regarding inference as well as fine-tuning ViT on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer).
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
`ViTForImageClassification` is supported by:
@@ -134,7 +116,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
- A blog post on [Deploying Hugging Face ViT on Vertex AI](https://huggingface.co/blog/deploy-vertex-ai)
- A blog post on [Deploying Hugging Face ViT on Kubernetes with TF Serving](https://huggingface.co/blog/deploy-tfserving-kubernetes)
-
## ViTConfig
[[autodoc]] ViTConfig
@@ -144,12 +125,14 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] ViTFeatureExtractor
- __call__
-
## ViTImageProcessor
[[autodoc]] ViTImageProcessor
- preprocess
+
+
+
## ViTModel
[[autodoc]] ViTModel
@@ -165,6 +148,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] ViTForImageClassification
- forward
+
+
+
## TFViTModel
[[autodoc]] TFViTModel
@@ -175,6 +161,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] TFViTForImageClassification
- call
+
+
+
## FlaxVitModel
[[autodoc]] FlaxViTModel
@@ -184,3 +173,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] FlaxViTForImageClassification
- __call__
+
+
+
diff --git a/docs/source/en/model_doc/vit_hybrid.md b/docs/source/en/model_doc/vit_hybrid.md
index 84969cd0f622..52c0d35bc135 100644
--- a/docs/source/en/model_doc/vit_hybrid.md
+++ b/docs/source/en/model_doc/vit_hybrid.md
@@ -25,7 +25,6 @@ Uszkoreit, Neil Houlsby. It's the first paper that successfully trains a Transfo
very good results compared to familiar convolutional architectures. ViT hybrid is a slight variant of the [plain Vision Transformer](vit),
by leveraging a convolutional backbone (specifically, [BiT](bit)) whose features are used as initial "tokens" for the Transformer.
-
The abstract from the paper is the following:
*While the Transformer architecture has become the de-facto standard for natural language processing tasks, its
@@ -40,7 +39,6 @@ substantially fewer computational resources to train.*
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code (written in JAX) can be
found [here](https://github.com/google-research/vision_transformer).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT Hybrid.
@@ -52,7 +50,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
-
## ViTHybridConfig
[[autodoc]] ViTHybridConfig
diff --git a/docs/source/en/model_doc/vit_mae.md b/docs/source/en/model_doc/vit_mae.md
index c14cc7e57c90..27d6d26816ae 100644
--- a/docs/source/en/model_doc/vit_mae.md
+++ b/docs/source/en/model_doc/vit_mae.md
@@ -32,7 +32,15 @@ enables us to train large models efficiently and effectively: we accelerate trai
models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data. Transfer performance in downstream
tasks outperforms supervised pre-training and shows promising scaling behavior.*
-Tips:
+
+
+ MAE architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [sayakpaul](https://github.com/sayakpaul) and
+[ariG23498](https://github.com/ariG23498) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/mae).
+
+## Usage tips
- MAE (masked auto encoding) is a method for self-supervised pre-training of Vision Transformers (ViTs). The pre-training objective is relatively simple:
by masking a large portion (75%) of the image patches, the model must reconstruct raw pixel values. One can use [`ViTMAEForPreTraining`] for this purpose.
@@ -44,14 +52,6 @@ consists of Transformer blocks) takes as input. Each mask token is a shared, lea
sin/cos position embeddings are added both to the input of the encoder and the decoder.
- For a visual understanding of how MAEs work you can check out this [post](https://keras.io/examples/vision/masked_image_modeling/).
-
-
- MAE architecture. Taken from the original paper.
-
-This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [sayakpaul](https://github.com/sayakpaul) and
-[ariG23498](https://github.com/ariG23498) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/mae).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViTMAE.
@@ -65,26 +65,31 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] ViTMAEConfig
+
+
## ViTMAEModel
[[autodoc]] ViTMAEModel
- forward
-
## ViTMAEForPreTraining
[[autodoc]] transformers.ViTMAEForPreTraining
- forward
+
+
## TFViTMAEModel
[[autodoc]] TFViTMAEModel
- call
-
## TFViTMAEForPreTraining
[[autodoc]] transformers.TFViTMAEForPreTraining
- call
+
+
+
diff --git a/docs/source/en/model_doc/vit_msn.md b/docs/source/en/model_doc/vit_msn.md
index ded0245194f8..666b7dd0dfda 100644
--- a/docs/source/en/model_doc/vit_msn.md
+++ b/docs/source/en/model_doc/vit_msn.md
@@ -33,7 +33,13 @@ while producing representations of a high semantic level that perform competitiv
on ImageNet-1K, with only 5,000 annotated images, our base MSN model achieves 72.4% top-1 accuracy,
and with 1% of ImageNet-1K labels, we achieve 75.7% top-1 accuracy, setting a new state-of-the-art for self-supervised learning on this benchmark.*
-Tips:
+
+
+ MSN architecture. Taken from the original paper.
+
+This model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/facebookresearch/msn).
+
+## Usage tips
- MSN (masked siamese networks) is a method for self-supervised pre-training of Vision Transformers (ViTs). The pre-training
objective is to match the prototypes assigned to the unmasked views of the images to that of the masked views of the same images.
@@ -43,13 +49,6 @@ use the [`ViTMSNForImageClassification`] class which is initialized from [`ViTMS
- MSN is particularly useful in the low-shot and extreme low-shot regimes. Notably, it achieves 75.7% top-1 accuracy with only 1% of ImageNet-1K
labels when fine-tuned.
-
-
-
- MSN architecture. Taken from the original paper.
-
-This model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/facebookresearch/msn).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT MSN.
@@ -65,13 +64,11 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] ViTMSNConfig
-
## ViTMSNModel
[[autodoc]] ViTMSNModel
- forward
-
## ViTMSNForImageClassification
[[autodoc]] ViTMSNForImageClassification
diff --git a/docs/source/en/model_doc/vitdet.md b/docs/source/en/model_doc/vitdet.md
index 657e467ee319..81bf787d6cda 100644
--- a/docs/source/en/model_doc/vitdet.md
+++ b/docs/source/en/model_doc/vitdet.md
@@ -21,13 +21,12 @@ The abstract from the paper is the following:
*We explore the plain, non-hierarchical Vision Transformer (ViT) as a backbone network for object detection. This design enables the original ViT architecture to be fine-tuned for object detection without needing to redesign a hierarchical backbone for pre-training. With minimal adaptations for fine-tuning, our plain-backbone detector can achieve competitive results. Surprisingly, we observe: (i) it is sufficient to build a simple feature pyramid from a single-scale feature map (without the common FPN design) and (ii) it is sufficient to use window attention (without shifting) aided with very few cross-window propagation blocks. With plain ViT backbones pre-trained as Masked Autoencoders (MAE), our detector, named ViTDet, can compete with the previous leading methods that were all based on hierarchical backbones, reaching up to 61.3 AP_box on the COCO dataset using only ImageNet-1K pre-training. We hope our study will draw attention to research on plain-backbone detectors.*
-Tips:
-
-- For the moment, only the backbone is available.
-
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/facebookresearch/detectron2/tree/main/projects/ViTDet).
+Tips:
+
+- At the moment, only the backbone is available.
## VitDetConfig
diff --git a/docs/source/en/model_doc/vitmatte.md b/docs/source/en/model_doc/vitmatte.md
index 479b398f8066..5a6d501030fc 100644
--- a/docs/source/en/model_doc/vitmatte.md
+++ b/docs/source/en/model_doc/vitmatte.md
@@ -21,10 +21,6 @@ The abstract from the paper is the following:
*Recently, plain vision Transformers (ViTs) have shown impressive performance on various computer vision tasks, thanks to their strong modeling capacity and large-scale pretraining. However, they have not yet conquered the problem of image matting. We hypothesize that image matting could also be boosted by ViTs and present a new efficient and robust ViT-based matting system, named ViTMatte. Our method utilizes (i) a hybrid attention mechanism combined with a convolution neck to help ViTs achieve an excellent performance-computation trade-off in matting tasks. (ii) Additionally, we introduce the detail capture module, which just consists of simple lightweight convolutions to complement the detailed information required by matting. To the best of our knowledge, ViTMatte is the first work to unleash the potential of ViT on image matting with concise adaptation. It inherits many superior properties from ViT to matting, including various pretraining strategies, concise architecture design, and flexible inference strategies. We evaluate ViTMatte on Composition-1k and Distinctions-646, the most commonly used benchmark for image matting, our method achieves state-of-the-art performance and outperforms prior matting works by a large margin.*
-Tips:
-
-- The model expects both the image and trimap (concatenated) as input. One can use [`ViTMatteImageProcessor`] for this purpose.
-
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/hustvl/ViTMatte).
@@ -39,6 +35,10 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
- A demo notebook regarding inference with [`VitMatteForImageMatting`], including background replacement, can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ViTMatte).
+
+
+The model expects both the image and trimap (concatenated) as input. Use [`ViTMatteImageProcessor`] for this purpose.
+
## VitMatteConfig
diff --git a/docs/source/en/model_doc/vits.md b/docs/source/en/model_doc/vits.md
index 1b57df4027dd..73001d82ed56 100644
--- a/docs/source/en/model_doc/vits.md
+++ b/docs/source/en/model_doc/vits.md
@@ -16,7 +16,6 @@ specific language governing permissions and limitations under the License.
The VITS model was proposed in [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
-
VITS (**V**ariational **I**nference with adversarial learning for end-to-end **T**ext-to-**S**peech) is an end-to-end
speech synthesis model that predicts a speech waveform conditional on an input text sequence. It is a conditional variational
autoencoder (VAE) comprised of a posterior encoder, decoder, and conditional prior.
@@ -42,7 +41,7 @@ as these checkpoints use the same architecture and a slightly modified tokenizer
This model was contributed by [Matthijs](https://huggingface.co/Matthijs) and [sanchit-gandhi](https://huggingface.co/sanchit-gandhi). The original code can be found [here](https://github.com/jaywalnut310/vits).
-## Model Usage
+## Usage examples
Both the VITS and MMS-TTS checkpoints can be used with the same API. Since the flow-based model is non-deterministic, it
is good practice to set a seed to ensure reproducibility of the outputs. For languages with a Roman alphabet,
diff --git a/docs/source/en/model_doc/vivit.md b/docs/source/en/model_doc/vivit.md
index 755629a76752..4426493a0ff5 100644
--- a/docs/source/en/model_doc/vivit.md
+++ b/docs/source/en/model_doc/vivit.md
@@ -21,7 +21,6 @@ The abstract from the paper is the following:
*We present pure-transformer based models for video classification, drawing upon the recent success of such models in image classification. Our model extracts spatio-temporal tokens from the input video, which are then encoded by a series of transformer layers. In order to handle the long sequences of tokens encountered in video, we propose several, efficient variants of our model which factorise the spatial- and temporal-dimensions of the input. Although transformer-based models are known to only be effective when large training datasets are available, we show how we can effectively regularise the model during training and leverage pretrained image models to be able to train on comparatively small datasets. We conduct thorough ablation studies, and achieve state-of-the-art results on multiple video classification benchmarks including Kinetics 400 and 600, Epic Kitchens, Something-Something v2 and Moments in Time, outperforming prior methods based on deep 3D convolutional networks.*
-
This model was contributed by [jegormeister](https://huggingface.co/jegormeister). The original code (written in JAX) can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/vivit).
## VivitConfig
diff --git a/docs/source/en/model_doc/wav2vec2-conformer.md b/docs/source/en/model_doc/wav2vec2-conformer.md
index 87e255cd0c6e..c32c03bb0cb7 100644
--- a/docs/source/en/model_doc/wav2vec2-conformer.md
+++ b/docs/source/en/model_doc/wav2vec2-conformer.md
@@ -24,7 +24,10 @@ The official results of the model can be found in Table 3 and Table 4 of the pap
The Wav2Vec2-Conformer weights were released by the Meta AI team within the [Fairseq library](https://github.com/pytorch/fairseq/blob/main/examples/wav2vec/README.md#pre-trained-models).
-Tips:
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
+The original code can be found [here](https://github.com/pytorch/fairseq/tree/main/examples/wav2vec).
+
+## Usage tips
- Wav2Vec2-Conformer follows the same architecture as Wav2Vec2, but replaces the *Attention*-block with a *Conformer*-block
as introduced in [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100).
@@ -34,10 +37,7 @@ an improved word error rate.
- Wav2Vec2-Conformer can use either no relative position embeddings, Transformer-XL-like position embeddings, or
rotary position embeddings by setting the correct `config.position_embeddings_type`.
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
-The original code can be found [here](https://github.com/pytorch/fairseq/tree/main/examples/wav2vec).
-
-## Documentation resources
+## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
diff --git a/docs/source/en/model_doc/wav2vec2.md b/docs/source/en/model_doc/wav2vec2.md
index 3a67f66d9d1f..81d8f332aced 100644
--- a/docs/source/en/model_doc/wav2vec2.md
+++ b/docs/source/en/model_doc/wav2vec2.md
@@ -31,14 +31,14 @@ of the art on the 100 hour subset while using 100 times less labeled data. Using
pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech
recognition with limited amounts of labeled data.*
-Tips:
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
+
+## Usage tips
- Wav2Vec2 is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- Wav2Vec2 model was trained using connectionist temporal classification (CTC) so the model output has to be decoded
using [`Wav2Vec2CTCTokenizer`].
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Wav2Vec2. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
@@ -167,6 +167,9 @@ Otherwise, [`~Wav2Vec2ProcessorWithLM.batch_decode`] performance will be slower
[[autodoc]] models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2ForPreTrainingOutput
+
+
+
## Wav2Vec2Model
[[autodoc]] Wav2Vec2Model
@@ -198,6 +201,9 @@ Otherwise, [`~Wav2Vec2ProcessorWithLM.batch_decode`] performance will be slower
[[autodoc]] Wav2Vec2ForPreTraining
- forward
+
+
+
## TFWav2Vec2Model
[[autodoc]] TFWav2Vec2Model
@@ -213,6 +219,9 @@ Otherwise, [`~Wav2Vec2ProcessorWithLM.batch_decode`] performance will be slower
[[autodoc]] TFWav2Vec2ForCTC
- call
+
+
+
## FlaxWav2Vec2Model
[[autodoc]] FlaxWav2Vec2Model
@@ -227,3 +236,6 @@ Otherwise, [`~Wav2Vec2ProcessorWithLM.batch_decode`] performance will be slower
[[autodoc]] FlaxWav2Vec2ForPreTraining
- __call__
+
+
+
diff --git a/docs/source/en/model_doc/wav2vec2_phoneme.md b/docs/source/en/model_doc/wav2vec2_phoneme.md
index a852bef637b2..93e0656f493c 100644
--- a/docs/source/en/model_doc/wav2vec2_phoneme.md
+++ b/docs/source/en/model_doc/wav2vec2_phoneme.md
@@ -31,7 +31,13 @@ mapping phonemes of the training languages to the target language using articula
this simple method significantly outperforms prior work which introduced task-specific architectures and used only part
of a monolingually pretrained model.*
-Tips:
+Relevant checkpoints can be found under https://huggingface.co/models?other=phoneme-recognition.
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten)
+
+The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
+
+## Usage tips
- Wav2Vec2Phoneme uses the exact same architecture as Wav2Vec2
- Wav2Vec2Phoneme is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
@@ -39,17 +45,16 @@ Tips:
decoded using [`Wav2Vec2PhonemeCTCTokenizer`].
- Wav2Vec2Phoneme can be fine-tuned on multiple language at once and decode unseen languages in a single forward pass
to a sequence of phonemes
-- By default the model outputs a sequence of phonemes. In order to transform the phonemes to a sequence of words one
+- By default, the model outputs a sequence of phonemes. In order to transform the phonemes to a sequence of words one
should make use of a dictionary and language model.
-Relevant checkpoints can be found under https://huggingface.co/models?other=phoneme-recognition.
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten)
-
-The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
+
-Wav2Vec2Phoneme's architecture is based on the Wav2Vec2 model, so one can refer to [`Wav2Vec2`]'s documentation page except for the tokenizer.
+Wav2Vec2Phoneme's architecture is based on the Wav2Vec2 model, for API reference, check out [`Wav2Vec2`](wav2vec2)'s documentation page
+except for the tokenizer.
+
## Wav2Vec2PhonemeCTCTokenizer
diff --git a/docs/source/en/model_doc/wavlm.md b/docs/source/en/model_doc/wavlm.md
index 2754304d8264..13f62980756d 100644
--- a/docs/source/en/model_doc/wavlm.md
+++ b/docs/source/en/model_doc/wavlm.md
@@ -35,7 +35,12 @@ additional overlapped utterances are created unsupervisely and incorporated duri
the training dataset from 60k hours to 94k hours. WavLM Large achieves state-of-the-art performance on the SUPERB
benchmark, and brings significant improvements for various speech processing tasks on their representative benchmarks.*
-Tips:
+Relevant checkpoints can be found under https://huggingface.co/models?other=wavlm.
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/microsoft/unilm/tree/master/wavlm).
+
+## Usage tips
- WavLM is a speech model that accepts a float array corresponding to the raw waveform of the speech signal. Please use
[`Wav2Vec2Processor`] for the feature extraction.
@@ -43,12 +48,7 @@ Tips:
using [`Wav2Vec2CTCTokenizer`].
- WavLM performs especially well on speaker verification, speaker identification, and speaker diarization tasks.
-Relevant checkpoints can be found under https://huggingface.co/models?other=wavlm.
-
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
-found [here](https://github.com/microsoft/unilm/tree/master/wavlm).
-
-## Documentation resources
+## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
diff --git a/docs/source/en/model_doc/whisper.md b/docs/source/en/model_doc/whisper.md
index 382246e43d31..37411209bf91 100644
--- a/docs/source/en/model_doc/whisper.md
+++ b/docs/source/en/model_doc/whisper.md
@@ -24,17 +24,69 @@ The abstract from the paper is the following:
*We study the capabilities of speech processing systems trained simply to predict large amounts of transcripts of audio on the internet. When scaled to 680,000 hours of multilingual and multitask supervision, the resulting models generalize well to standard benchmarks and are often competitive with prior fully supervised results but in a zeroshot transfer setting without the need for any finetuning. When compared to humans, the models approach their accuracy and robustness. We are releasing models and inference code to serve as a foundation for further work on robust speech processing.*
+This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ). The Tensorflow version of this model was contributed by [amyeroberts](https://huggingface.co/amyeroberts).
+The original code can be found [here](https://github.com/openai/whisper).
-Tips:
+## Usage tips
- The model usually performs well without requiring any finetuning.
- The architecture follows a classic encoder-decoder architecture, which means that it relies on the [`~generation.GenerationMixin.generate`] function for inference.
- Inference is currently only implemented for short-form i.e. audio is pre-segmented into <=30s segments. Long-form (including timestamps) will be implemented in a future release.
- One can use [`WhisperProcessor`] to prepare audio for the model, and decode the predicted ID's back into text.
-This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ). The Tensorflow version of this model was contributed by [amyeroberts](https://huggingface.co/amyeroberts).
-The original code can be found [here](https://github.com/openai/whisper).
+- To convert the model and the processor, we recommend using the following:
+
+```bash
+python src/transformers/models/whisper/convert_openai_to_hf.py --checkpoint_path "" --pytorch_dump_folder_path "Arthur/whisper-3" --convert_preprocessor True
+```
+The script will automatically determine all necessary parameters from the OpenAI checkpoint. A `tiktoken` library needs to be installed
+to perform the conversion of the OpenAI tokenizer to the `tokenizers` version.
+
+## Inference
+
+Here is a step-by-step guide to transcribing an audio sample using a pre-trained Whisper model:
+
+```python
+>>> from datasets import load_dataset
+>>> from transformers import WhisperProcessor, WhisperForConditionalGeneration
+
+>>> # Select an audio file and read it:
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> audio_sample = ds[0]["audio"]
+>>> waveform = audio_sample["array"]
+>>> sampling_rate = audio_sample["sampling_rate"]
+
+>>> # Load the Whisper model in Hugging Face format:
+>>> processor = WhisperProcessor.from_pretrained("openai/whisper-tiny.en")
+>>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny.en")
+
+>>> # Use the model and processor to transcribe the audio:
+>>> input_features = processor(
+... waveform, sampling_rate=sampling_rate, return_tensors="pt"
+... ).input_features
+>>> # Generate token ids
+>>> predicted_ids = model.generate(input_features)
+
+>>> # Decode token ids to text
+>>> transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)
+
+>>> transcription[0]
+' Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.'
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Whisper. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+- A fork with a script to [convert a Whisper model in Hugging Face format to OpenAI format](https://github.com/zuazo-forks/transformers/blob/convert_hf_to_openai/src/transformers/models/whisper/convert_hf_to_openai.py). 🌎
+Usage example:
+```bash
+pip install -U openai-whisper
+python convert_hf_to_openai.py \
+ --checkpoint openai/whisper-tiny \
+ --whisper_dump_path whisper-tiny-openai.pt
+```
## WhisperConfig
@@ -76,6 +128,9 @@ The original code can be found [here](https://github.com/openai/whisper).
- batch_decode
- decode
+
+
+
## WhisperModel
[[autodoc]] WhisperModel
@@ -88,11 +143,18 @@ The original code can be found [here](https://github.com/openai/whisper).
- forward
- generate
+## WhisperForCausalLM
+
+[[autodoc]] WhisperForCausalLM
+ - forward
+
## WhisperForAudioClassification
[[autodoc]] WhisperForAudioClassification
- forward
+
+
## TFWhisperModel
@@ -104,6 +166,8 @@ The original code can be found [here](https://github.com/openai/whisper).
[[autodoc]] TFWhisperForConditionalGeneration
- call
+
+
## FlaxWhisperModel
@@ -120,3 +184,6 @@ The original code can be found [here](https://github.com/openai/whisper).
[[autodoc]] FlaxWhisperForAudioClassification
- __call__
+
+
+
diff --git a/docs/source/en/model_doc/xglm.md b/docs/source/en/model_doc/xglm.md
index 1b184c17e803..470e42c747be 100644
--- a/docs/source/en/model_doc/xglm.md
+++ b/docs/source/en/model_doc/xglm.md
@@ -42,7 +42,7 @@ in social value tasks such as hate speech detection in five languages and find i
This model was contributed by [Suraj](https://huggingface.co/valhalla). The original code can be found [here](https://github.com/pytorch/fairseq/tree/main/examples/xglm).
-## Documentation resources
+## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
@@ -62,6 +62,9 @@ This model was contributed by [Suraj](https://huggingface.co/valhalla). The orig
[[autodoc]] XGLMTokenizerFast
+
+
+
## XGLMModel
[[autodoc]] XGLMModel
@@ -72,6 +75,9 @@ This model was contributed by [Suraj](https://huggingface.co/valhalla). The orig
[[autodoc]] XGLMForCausalLM
- forward
+
+
+
## TFXGLMModel
[[autodoc]] TFXGLMModel
@@ -82,6 +88,9 @@ This model was contributed by [Suraj](https://huggingface.co/valhalla). The orig
[[autodoc]] TFXGLMForCausalLM
- call
+
+
+
## FlaxXGLMModel
[[autodoc]] FlaxXGLMModel
@@ -90,4 +99,7 @@ This model was contributed by [Suraj](https://huggingface.co/valhalla). The orig
## FlaxXGLMForCausalLM
[[autodoc]] FlaxXGLMForCausalLM
- - __call__
\ No newline at end of file
+ - __call__
+
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/xlm-prophetnet.md b/docs/source/en/model_doc/xlm-prophetnet.md
index 5e7ba5b7e3f5..7a61aeb3e34a 100644
--- a/docs/source/en/model_doc/xlm-prophetnet.md
+++ b/docs/source/en/model_doc/xlm-prophetnet.md
@@ -36,7 +36,7 @@ Zhang, Ming Zhou on 13 Jan, 2020.
XLM-ProphetNet is an encoder-decoder model and can predict n-future tokens for "ngram" language modeling instead of
just the next token. Its architecture is identical to ProhpetNet, but the model was trained on the multi-lingual
-"wiki100" Wikipedia dump.
+"wiki100" Wikipedia dump. XLM-ProphetNet's model architecture and pretraining objective is same as ProphetNet, but XLM-ProphetNet was pre-trained on the cross-lingual dataset XGLUE.
The abstract from the paper is the following:
@@ -52,11 +52,7 @@ state-of-the-art results on all these datasets compared to the models using the
The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
-Tips:
-
-- XLM-ProphetNet's model architecture and pretraining objective is same as ProphetNet, but XLM-ProphetNet was pre-trained on the cross-lingual dataset XGLUE.
-
-## Documentation resources
+## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
diff --git a/docs/source/en/model_doc/xlm-roberta-xl.md b/docs/source/en/model_doc/xlm-roberta-xl.md
index b65929460706..f9cb78c0bf4e 100644
--- a/docs/source/en/model_doc/xlm-roberta-xl.md
+++ b/docs/source/en/model_doc/xlm-roberta-xl.md
@@ -24,15 +24,15 @@ The abstract from the paper is the following:
*Recent work has demonstrated the effectiveness of cross-lingual language model pretraining for cross-lingual understanding. In this study, we present the results of two larger multilingual masked language models, with 3.5B and 10.7B parameters. Our two new models dubbed XLM-R XL and XLM-R XXL outperform XLM-R by 1.8% and 2.4% average accuracy on XNLI. Our model also outperforms the RoBERTa-Large model on several English tasks of the GLUE benchmark by 0.3% on average while handling 99 more languages. This suggests pretrained models with larger capacity may obtain both strong performance on high-resource languages while greatly improving low-resource languages. We make our code and models publicly available.*
-Tips:
+This model was contributed by [Soonhwan-Kwon](https://github.com/Soonhwan-Kwon) and [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
-- XLM-RoBERTa-XL is a multilingual model trained on 100 different languages. Unlike some XLM multilingual models, it does
- not require `lang` tensors to understand which language is used, and should be able to determine the correct
- language from the input ids.
+## Usage tips
-This model was contributed by [Soonhwan-Kwon](https://github.com/Soonhwan-Kwon) and [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
+XLM-RoBERTa-XL is a multilingual model trained on 100 different languages. Unlike some XLM multilingual models, it does
+not require `lang` tensors to understand which language is used, and should be able to determine the correct
+language from the input ids.
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
diff --git a/docs/source/en/model_doc/xlm-roberta.md b/docs/source/en/model_doc/xlm-roberta.md
index 935003156fd1..58540015232e 100644
--- a/docs/source/en/model_doc/xlm-roberta.md
+++ b/docs/source/en/model_doc/xlm-roberta.md
@@ -46,16 +46,14 @@ languages at scale. Finally, we show, for the first time, the possibility of mul
per-language performance; XLM-Ris very competitive with strong monolingual models on the GLUE and XNLI benchmarks. We
will make XLM-R code, data, and models publicly available.*
-Tips:
+This model was contributed by [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
+
+## Usage tips
- XLM-RoBERTa is a multilingual model trained on 100 different languages. Unlike some XLM multilingual models, it does
not require `lang` tensors to understand which language is used, and should be able to determine the correct
language from the input ids.
- Uses RoBERTa tricks on the XLM approach, but does not use the translation language modeling objective. It only uses masked language modeling on sentences coming from one language.
-- This implementation is the same as RoBERTa. Refer to the [documentation of RoBERTa](roberta) for usage examples
- as well as the information relative to the inputs and outputs.
-
-This model was contributed by [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
## Resources
@@ -110,6 +108,11 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
- A blog post on how to [Deploy Serverless XLM RoBERTa on AWS Lambda](https://www.philschmid.de/multilingual-serverless-xlm-roberta-with-huggingface).
+
+
+This implementation is the same as RoBERTa. Refer to the [documentation of RoBERTa](roberta) for usage examples as well as the information relative to the inputs and outputs.
+
+
## XLMRobertaConfig
[[autodoc]] XLMRobertaConfig
@@ -126,6 +129,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] XLMRobertaTokenizerFast
+
+
+
## XLMRobertaModel
[[autodoc]] XLMRobertaModel
@@ -161,6 +167,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] XLMRobertaForQuestionAnswering
- forward
+
+
+
## TFXLMRobertaModel
[[autodoc]] TFXLMRobertaModel
@@ -196,6 +205,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] TFXLMRobertaForQuestionAnswering
- call
+
+
+
## FlaxXLMRobertaModel
[[autodoc]] FlaxXLMRobertaModel
@@ -230,3 +242,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] FlaxXLMRobertaForQuestionAnswering
- __call__
+
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/xlm-v.md b/docs/source/en/model_doc/xlm-v.md
index 38bed0dc46b5..049a1f35ad9a 100644
--- a/docs/source/en/model_doc/xlm-v.md
+++ b/docs/source/en/model_doc/xlm-v.md
@@ -35,7 +35,10 @@ a multilingual language model with a one million token vocabulary. XLM-V outperf
tested on ranging from natural language inference (XNLI), question answering (MLQA, XQuAD, TyDiQA), and
named entity recognition (WikiAnn) to low-resource tasks (Americas NLI, MasakhaNER).*
-Tips:
+This model was contributed by [stefan-it](https://huggingface.co/stefan-it), including detailed experiments with XLM-V on downstream tasks.
+The experiments repository can be found [here](https://github.com/stefan-it/xlm-v-experiments).
+
+## Usage tips
- XLM-V is compatible with the XLM-RoBERTa model architecture, only model weights from [`fairseq`](https://github.com/facebookresearch/fairseq)
library had to be converted.
@@ -43,5 +46,7 @@ Tips:
A XLM-V (base size) model is available under the [`facebook/xlm-v-base`](https://huggingface.co/facebook/xlm-v-base) identifier.
-This model was contributed by [stefan-it](https://huggingface.co/stefan-it), including detailed experiments with XLM-V on downstream tasks.
-The experiments repository can be found [here](https://github.com/stefan-it/xlm-v-experiments).
+
+
+XLM-V architecture is the same as XLM-RoBERTa, refer to [XLM-RoBERTa documentation](xlm-roberta) for API reference, and examples.
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/xlm.md b/docs/source/en/model_doc/xlm.md
index 8b5b31a2dbef..0ee11c6addc5 100644
--- a/docs/source/en/model_doc/xlm.md
+++ b/docs/source/en/model_doc/xlm.md
@@ -46,7 +46,9 @@ obtain 34.3 BLEU on WMT'16 German-English, improving the previous state of the a
machine translation, we obtain a new state of the art of 38.5 BLEU on WMT'16 Romanian-English, outperforming the
previous best approach by more than 4 BLEU. Our code and pretrained models will be made publicly available.*
-Tips:
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/facebookresearch/XLM/).
+
+## Usage tips
- XLM has many different checkpoints, which were trained using different objectives: CLM, MLM or TLM. Make sure to
select the correct objective for your task (e.g. MLM checkpoints are not suitable for generation).
@@ -57,9 +59,7 @@ Tips:
* Masked language modeling (MLM) which is like RoBERTa. One of the languages is selected for each training sample, and the model input is a sentence of 256 tokens, that may span over several documents in one of those languages, with dynamic masking of the tokens.
* A combination of MLM and translation language modeling (TLM). This consists of concatenating a sentence in two different languages, with random masking. To predict one of the masked tokens, the model can use both, the surrounding context in language 1 and the context given by language 2.
-This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/facebookresearch/XLM/).
-
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -84,6 +84,9 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
[[autodoc]] models.xlm.modeling_xlm.XLMForQuestionAnsweringOutput
+
+
+
## XLMModel
[[autodoc]] XLMModel
@@ -119,6 +122,9 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
[[autodoc]] XLMForQuestionAnswering
- forward
+
+
+
## TFXLMModel
[[autodoc]] TFXLMModel
@@ -148,3 +154,8 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
[[autodoc]] TFXLMForQuestionAnsweringSimple
- call
+
+
+
+
+
diff --git a/docs/source/en/model_doc/xlnet.md b/docs/source/en/model_doc/xlnet.md
index 3685728cd72e..d2209c3d550e 100644
--- a/docs/source/en/model_doc/xlnet.md
+++ b/docs/source/en/model_doc/xlnet.md
@@ -44,7 +44,9 @@ formulation. Furthermore, XLNet integrates ideas from Transformer-XL, the state-
pretraining. Empirically, under comparable experiment settings, XLNet outperforms BERT on 20 tasks, often by a large
margin, including question answering, natural language inference, sentiment analysis, and document ranking.*
-Tips:
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/zihangdai/xlnet/).
+
+## Usage tips
- The specific attention pattern can be controlled at training and test time using the `perm_mask` input.
- Due to the difficulty of training a fully auto-regressive model over various factorization order, XLNet is pretrained
@@ -56,9 +58,7 @@ Tips:
- XLNet is not a traditional autoregressive model but uses a training strategy that builds on that. It permutes the tokens in the sentence, then allows the model to use the last n tokens to predict the token n+1. Since this is all done with a mask, the sentence is actually fed in the model in the right order, but instead of masking the first n tokens for n+1, XLNet uses a mask that hides the previous tokens in some given permutation of 1,…,sequence length.
- XLNet also uses the same recurrence mechanism as Transformer-XL to build long-term dependencies.
-This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/zihangdai/xlnet/).
-
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -110,6 +110,9 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForQuestionAnsweringSimpleOutput
+
+
+
## XLNetModel
[[autodoc]] XLNetModel
@@ -145,6 +148,9 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
[[autodoc]] XLNetForQuestionAnswering
- forward
+
+
+
## TFXLNetModel
[[autodoc]] TFXLNetModel
@@ -174,3 +180,6 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
[[autodoc]] TFXLNetForQuestionAnsweringSimple
- call
+
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/xls_r.md b/docs/source/en/model_doc/xls_r.md
index 8e22004244ca..2226c813e72b 100644
--- a/docs/source/en/model_doc/xls_r.md
+++ b/docs/source/en/model_doc/xls_r.md
@@ -34,14 +34,18 @@ language identification. Moreover, we show that with sufficient model size, cros
English-only pretraining when translating English speech into other languages, a setting which favors monolingual
pretraining. We hope XLS-R can help to improve speech processing tasks for many more languages of the world.*
-Tips:
+Relevant checkpoints can be found under https://huggingface.co/models?other=xls_r.
+
+The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
+
+## Usage tips
- XLS-R is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- XLS-R model was trained using connectionist temporal classification (CTC) so the model output has to be decoded using
[`Wav2Vec2CTCTokenizer`].
-Relevant checkpoints can be found under https://huggingface.co/models?other=xls_r.
+
-XLS-R's architecture is based on the Wav2Vec2 model, so one can refer to [Wav2Vec2's documentation page](wav2vec2).
+XLS-R's architecture is based on the Wav2Vec2 model, refer to [Wav2Vec2's documentation page](wav2vec2) for API reference.
-The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/xlsr_wav2vec2.md b/docs/source/en/model_doc/xlsr_wav2vec2.md
index 643d37416d38..d1b5444c2469 100644
--- a/docs/source/en/model_doc/xlsr_wav2vec2.md
+++ b/docs/source/en/model_doc/xlsr_wav2vec2.md
@@ -34,12 +34,16 @@ individual models. Analysis shows that the latent discrete speech representation
increased sharing for related languages. We hope to catalyze research in low-resource speech understanding by releasing
XLSR-53, a large model pretrained in 53 languages.*
-Tips:
+The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
+
+## Usage tips
- XLSR-Wav2Vec2 is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- XLSR-Wav2Vec2 model was trained using connectionist temporal classification (CTC) so the model output has to be
decoded using [`Wav2Vec2CTCTokenizer`].
+
+
XLSR-Wav2Vec2's architecture is based on the Wav2Vec2 model, so one can refer to [Wav2Vec2's documentation page](wav2vec2).
-The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
+
diff --git a/docs/source/en/model_doc/xmod.md b/docs/source/en/model_doc/xmod.md
index 5a3409bbc4c3..47797fa64902 100644
--- a/docs/source/en/model_doc/xmod.md
+++ b/docs/source/en/model_doc/xmod.md
@@ -25,13 +25,15 @@ The abstract from the paper is the following:
*Multilingual pre-trained models are known to suffer from the curse of multilinguality, which causes per-language performance to drop as they cover more languages. We address this issue by introducing language-specific modules, which allows us to grow the total capacity of the model, while keeping the total number of trainable parameters per language constant. In contrast with prior work that learns language-specific components post-hoc, we pre-train the modules of our Cross-lingual Modular (X-MOD) models from the start. Our experiments on natural language inference, named entity recognition and question answering show that our approach not only mitigates the negative interference between languages, but also enables positive transfer, resulting in improved monolingual and cross-lingual performance. Furthermore, our approach enables adding languages post-hoc with no measurable drop in performance, no longer limiting the model usage to the set of pre-trained languages.*
+This model was contributed by [jvamvas](https://huggingface.co/jvamvas).
+The original code can be found [here](https://github.com/facebookresearch/fairseq/tree/58cc6cca18f15e6d56e3f60c959fe4f878960a60/fairseq/models/xmod) and the original documentation is found [here](https://github.com/facebookresearch/fairseq/tree/58cc6cca18f15e6d56e3f60c959fe4f878960a60/examples/xmod).
+
+## Usage tips
+
Tips:
- X-MOD is similar to [XLM-R](xlm-roberta), but a difference is that the input language needs to be specified so that the correct language adapter can be activated.
- The main models – base and large – have adapters for 81 languages.
-This model was contributed by [jvamvas](https://huggingface.co/jvamvas).
-The original code can be found [here](https://github.com/facebookresearch/fairseq/tree/58cc6cca18f15e6d56e3f60c959fe4f878960a60/fairseq/models/xmod) and the original documentation is found [here](https://github.com/facebookresearch/fairseq/tree/58cc6cca18f15e6d56e3f60c959fe4f878960a60/examples/xmod).
-
## Adapter Usage
### Input language
diff --git a/docs/source/en/model_doc/yolos.md b/docs/source/en/model_doc/yolos.md
index 6185c3a06757..5386c373ac83 100644
--- a/docs/source/en/model_doc/yolos.md
+++ b/docs/source/en/model_doc/yolos.md
@@ -25,10 +25,6 @@ The abstract from the paper is the following:
*Can Transformer perform 2D object- and region-level recognition from a pure sequence-to-sequence perspective with minimal knowledge about the 2D spatial structure? To answer this question, we present You Only Look at One Sequence (YOLOS), a series of object detection models based on the vanilla Vision Transformer with the fewest possible modifications, region priors, as well as inductive biases of the target task. We find that YOLOS pre-trained on the mid-sized ImageNet-1k dataset only can already achieve quite competitive performance on the challenging COCO object detection benchmark, e.g., YOLOS-Base directly adopted from BERT-Base architecture can obtain 42.0 box AP on COCO val. We also discuss the impacts as well as limitations of current pre-train schemes and model scaling strategies for Transformer in vision through YOLOS.*
-Tips:
-
-- One can use [`YolosImageProcessor`] for preparing images (and optional targets) for the model. Contrary to [DETR](detr), YOLOS doesn't require a `pixel_mask` to be created.
-
@@ -47,6 +43,12 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+Use [`YolosImageProcessor`] for preparing images (and optional targets) for the model. Contrary to [DETR](detr), YOLOS doesn't require a `pixel_mask` to be created.
+
+
+
## YolosConfig
[[autodoc]] YolosConfig
@@ -65,13 +67,11 @@ If you're interested in submitting a resource to be included here, please feel f
- pad
- post_process_object_detection
-
## YolosModel
[[autodoc]] YolosModel
- forward
-
## YolosForObjectDetection
[[autodoc]] YolosForObjectDetection
diff --git a/docs/source/en/model_doc/yoso.md b/docs/source/en/model_doc/yoso.md
index 4b98cd348c9a..a3dfa3fed855 100644
--- a/docs/source/en/model_doc/yoso.md
+++ b/docs/source/en/model_doc/yoso.md
@@ -37,7 +37,9 @@ length where we see favorable performance relative to a standard pretrained Tran
for evaluating performance on long sequences, our method achieves results consistent with softmax self-attention but with sizable
speed-ups and memory savings and often outperforms other efficient self-attention methods. Our code is available at this https URL*
-Tips:
+This model was contributed by [novice03](https://huggingface.co/novice03). The original code can be found [here](https://github.com/mlpen/YOSO).
+
+## Usage tips
- The YOSO attention algorithm is implemented through custom CUDA kernels, functions written in CUDA C++ that can be executed multiple times
in parallel on a GPU.
@@ -52,9 +54,7 @@ alt="drawing" width="600"/>
YOSO Attention Algorithm. Taken from the original paper.
-This model was contributed by [novice03](https://huggingface.co/novice03). The original code can be found [here](https://github.com/mlpen/YOSO).
-
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -66,19 +66,16 @@ This model was contributed by [novice03](https://huggingface.co/novice03). The o
[[autodoc]] YosoConfig
-
## YosoModel
[[autodoc]] YosoModel
- forward
-
## YosoForMaskedLM
[[autodoc]] YosoForMaskedLM
- forward
-
## YosoForSequenceClassification
[[autodoc]] YosoForSequenceClassification
@@ -89,13 +86,11 @@ This model was contributed by [novice03](https://huggingface.co/novice03). The o
[[autodoc]] YosoForMultipleChoice
- forward
-
## YosoForTokenClassification
[[autodoc]] YosoForTokenClassification
- forward
-
## YosoForQuestionAnswering
[[autodoc]] YosoForQuestionAnswering
diff --git a/docs/source/en/peft.md b/docs/source/en/peft.md
index 302b614e5f7b..d86a36e62487 100644
--- a/docs/source/en/peft.md
+++ b/docs/source/en/peft.md
@@ -98,7 +98,7 @@ You can use [`~peft.PeftModel.add_adapter`] to add a new adapter to a model with
```py
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
-from peft import PeftConfig
+from peft import LoraConfig
model_id = "facebook/opt-350m"
model = AutoModelForCausalLM.from_pretrained(model_id)
@@ -208,6 +208,26 @@ model.save_pretrained(save_dir)
model = AutoModelForCausalLM.from_pretrained(save_dir)
```
+## Add additional trainable layers to a PEFT adapter
+
+You can also fine-tune additional trainable adapters on top of a model that has adapters attached by passing `modules_to_save` in your PEFT config. For example, if you want to also fine-tune the lm_head on top of a model with a LoRA adapter:
+
+```py
+from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
+from peft import LoraConfig
+
+model_id = "facebook/opt-350m"
+model = AutoModelForCausalLM.from_pretrained(model_id)
+
+lora_config = LoraConfig(
+ target_modules=["q_proj", "k_proj"],
+ modules_to_save=["lm_head"],
+)
+
+model.add_adapter(lora_config)
+```
+
+
-# Efficient Inference on CPU
+# CPU inference
-This guide focuses on inferencing large models efficiently on CPU.
+With some optimizations, it is possible to efficiently run large model inference on a CPU. One of these optimization techniques involves compiling the PyTorch code into an intermediate format for high-performance environments like C++. The other technique fuses multiple operations into one kernel to reduce the overhead of running each operation separately.
-## `BetterTransformer` for faster inference
+You'll learn how to use [BetterTransformer](https://pytorch.org/blog/a-better-transformer-for-fast-transformer-encoder-inference/) for faster inference, and how to convert your PyTorch code to [TorchScript](https://pytorch.org/tutorials/beginner/Intro_to_TorchScript_tutorial.html). If you're using an Intel CPU, you can also use [graph optimizations](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features.html#graph-optimization) from [Intel Extension for PyTorch](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/index.html) to boost inference speed even more. Finally, learn how to use 🤗 Optimum to accelerate inference with ONNX Runtime or OpenVINO (if you're using an Intel CPU).
-We have recently integrated `BetterTransformer` for faster inference on CPU for text, image and audio models. Check the documentation about this integration [here](https://huggingface.co/docs/optimum/bettertransformer/overview) for more details.
+## BetterTransformer
-## PyTorch JIT-mode (TorchScript)
-TorchScript is a way to create serializable and optimizable models from PyTorch code. Any TorchScript program can be saved from a Python process and loaded in a process where there is no Python dependency.
-Comparing to default eager mode, jit mode in PyTorch normally yields better performance for model inference from optimization methodologies like operator fusion.
+BetterTransformer accelerates inference with its fastpath (native PyTorch specialized implementation of Transformer functions) execution. The two optimizations in the fastpath execution are:
-For a gentle introduction to TorchScript, see the Introduction to [PyTorch TorchScript tutorial](https://pytorch.org/tutorials/beginner/Intro_to_TorchScript_tutorial.html#tracing-modules).
+1. fusion, which combines multiple sequential operations into a single "kernel" to reduce the number of computation steps
+2. skipping the inherent sparsity of padding tokens to avoid unnecessary computation with nested tensors
-### IPEX Graph Optimization with JIT-mode
-Intel® Extension for PyTorch provides further optimizations in jit mode for Transformers series models. It is highly recommended for users to take advantage of Intel® Extension for PyTorch with jit mode. Some frequently used operator patterns from Transformers models are already supported in Intel® Extension for PyTorch with jit mode fusions. Those fusion patterns like Multi-head-attention fusion, Concat Linear, Linear+Add, Linear+Gelu, Add+LayerNorm fusion and etc. are enabled and perform well. The benefit of the fusion is delivered to users in a transparent fashion. According to the analysis, ~70% of most popular NLP tasks in question-answering, text-classification, and token-classification can get performance benefits with these fusion patterns for both Float32 precision and BFloat16 Mixed precision.
+BetterTransformer also converts all attention operations to use the more memory-efficient [scaled dot product attention](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention).
-Check more detailed information for [IPEX Graph Optimization](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features/graph_optimization.html).
+
-#### IPEX installation:
+BetterTransformer is not supported for all models. Check this [list](https://huggingface.co/docs/optimum/bettertransformer/overview#supported-models) to see if a model supports BetterTransformer.
-IPEX release is following PyTorch, check the approaches for [IPEX installation](https://intel.github.io/intel-extension-for-pytorch/).
+
-### Usage of JIT-mode
-To enable JIT-mode in Trainer for evaluaion or prediction, users should add `jit_mode_eval` in Trainer command arguments.
+Before you start, make sure you have 🤗 Optimum [installed](https://huggingface.co/docs/optimum/installation).
-
+Enable BetterTransformer with the [`PreTrainedModel.to_bettertransformer`] method:
-for PyTorch >= 1.14.0. JIT-mode could benefit any models for prediction and evaluaion since dict input is supported in jit.trace
+```py
+from transformers import AutoModelForCausalLM
-for PyTorch < 1.14.0. JIT-mode could benefit models whose forward parameter order matches the tuple input order in jit.trace, like question-answering model
-In the case where the forward parameter order does not match the tuple input order in jit.trace, like text-classification models, jit.trace will fail and we are capturing this with the exception here to make it fallback. Logging is used to notify users.
+model = AutoModelForCausalLM.from_pretrained("bigcode/starcoder")
+model.to_bettertransformer()
+```
-
+## TorchScript
+
+TorchScript is an intermediate PyTorch model representation that can be run in production environments where performance is important. You can train a model in PyTorch and then export it to TorchScript to free the model from Python performance constraints. PyTorch [traces](https://pytorch.org/docs/stable/generated/torch.jit.trace.html) a model to return a [`ScriptFunction`] that is optimized with just-in-time compilation (JIT). Compared to the default eager mode, JIT mode in PyTorch typically yields better performance for inference using optimization techniques like operator fusion.
-Take an example of the use cases on [Transformers question-answering](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)
+For a gentle introduction to TorchScript, see the [Introduction to PyTorch TorchScript](https://pytorch.org/tutorials/beginner/Intro_to_TorchScript_tutorial.html) tutorial.
+With the [`Trainer`] class, you can enable JIT mode for CPU inference by setting the `--jit_mode_eval` flag:
-- Inference using jit mode on CPU:
-
python run_qa.py \
+```bash
+python run_qa.py \
--model_name_or_path csarron/bert-base-uncased-squad-v1 \
--dataset_name squad \
--do_eval \
@@ -60,10 +62,31 @@ Take an example of the use cases on [Transformers question-answering](https://gi
--doc_stride 128 \
--output_dir /tmp/ \
--no_cuda \
---jit_mode_eval
+--jit_mode_eval
+```
+
+
+
+For PyTorch >= 1.14.0, JIT-mode could benefit any model for prediction and evaluaion since the dict input is supported in `jit.trace`.
+
+For PyTorch < 1.14.0, JIT-mode could benefit a model if its forward parameter order matches the tuple input order in `jit.trace`, such as a question-answering model. If the forward parameter order does not match the tuple input order in `jit.trace`, like a text classification model, `jit.trace` will fail and we are capturing this with the exception here to make it fallback. Logging is used to notify users.
+
+
+
+## IPEX graph optimization
+
+Intel® Extension for PyTorch (IPEX) provides further optimizations in JIT mode for Intel CPUs, and we recommend combining it with TorchScript for even faster performance. The IPEX [graph optimization](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features/graph_optimization.html) fuses operations like Multi-head attention, Concat Linear, Linear + Add, Linear + Gelu, Add + LayerNorm, and more.
+
+To take advantage of these graph optimizations, make sure you have IPEX [installed](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/installation.html):
+
+```bash
+pip install intel_extension_for_pytorch
+```
-- Inference with IPEX using jit mode on CPU:
-
python run_qa.py \
+Set the `--use_ipex` and `--jit_mode_eval` flags in the [`Trainer`] class to enable JIT mode with the graph optimizations:
+
+```bash
+python run_qa.py \
--model_name_or_path csarron/bert-base-uncased-squad-v1 \
--dataset_name squad \
--do_eval \
@@ -71,5 +94,34 @@ Take an example of the use cases on [Transformers question-answering](https://gi
--doc_stride 128 \
--output_dir /tmp/ \
--no_cuda \
---use_ipex \
---jit_mode_eval
+--use_ipex \
+--jit_mode_eval
+```
+
+## 🤗 Optimum
+
+
+
+Learn more details about using ORT with 🤗 Optimum in the [Optimum Inference with ONNX Runtime](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/models) guide. This section only provides a brief and simple example.
+
+
+
+ONNX Runtime (ORT) is a model accelerator that runs inference on CPUs by default. ORT is supported by 🤗 Optimum which can be used in 🤗 Transformers, without making too many changes to your code. You only need to replace the 🤗 Transformers `AutoClass` with its equivalent [`~optimum.onnxruntime.ORTModel`] for the task you're solving, and load a checkpoint in the ONNX format.
+
+For example, if you're running inference on a question answering task, load the [optimum/roberta-base-squad2](https://huggingface.co/optimum/roberta-base-squad2) checkpoint which contains a `model.onnx` file:
+
+```py
+from transformers import AutoTokenizer, pipeline
+from optimum.onnxruntime import ORTModelForQuestionAnswering
+
+model = ORTModelForQuestionAnswering.from_pretrained("optimum/roberta-base-squad2")
+tokenizer = AutoTokenizer.from_pretrained("deepset/roberta-base-squad2")
+
+onnx_qa = pipeline("question-answering", model=model, tokenizer=tokenizer)
+
+question = "What's my name?"
+context = "My name is Philipp and I live in Nuremberg."
+pred = onnx_qa(question, context)
+```
+
+If you have an Intel CPU, take a look at 🤗 [Optimum Intel](https://huggingface.co/docs/optimum/intel/index) which supports a variety of compression techniques (quantization, pruning, knowledge distillation) and tools for converting models to the [OpenVINO](https://huggingface.co/docs/optimum/intel/inference) format for higher performance inference.
diff --git a/docs/source/en/perf_infer_gpu_many.md b/docs/source/en/perf_infer_gpu_many.md
deleted file mode 100644
index 2118b5ddb404..000000000000
--- a/docs/source/en/perf_infer_gpu_many.md
+++ /dev/null
@@ -1,124 +0,0 @@
-
-
-# Efficient Inference on a Multiple GPUs
-
-This document contains information on how to efficiently infer on a multiple GPUs.
-
-
-Note: A multi GPU setup can use the majority of the strategies described in the [single GPU section](./perf_infer_gpu_one). You must be aware of simple techniques, though, that can be used for a better usage.
-
-
-
-## Flash Attention 2
-
-Flash Attention 2 integration also works in a multi-GPU setup, check out the appropriate section in the [single GPU section](./perf_infer_gpu_one#Flash-Attention-2)
-
-## BetterTransformer
-
-[BetterTransformer](https://huggingface.co/docs/optimum/bettertransformer/overview) converts 🤗 Transformers models to use the PyTorch-native fastpath execution, which calls optimized kernels like Flash Attention under the hood.
-
-BetterTransformer is also supported for faster inference on single and multi-GPU for text, image, and audio models.
-
-
-
-Flash Attention can only be used for models using fp16 or bf16 dtype. Make sure to cast your model to the appropriate dtype before using BetterTransformer.
-
-
-
-### Decoder models
-
-For text models, especially decoder-based models (GPT, T5, Llama, etc.), the BetterTransformer API converts all attention operations to use the [`torch.nn.functional.scaled_dot_product_attention` operator](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) (SDPA) that is only available in PyTorch 2.0 and onwards.
-
-To convert a model to BetterTransformer:
-
-```python
-from transformers import AutoModelForCausalLM
-
-model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
-# convert the model to BetterTransformer
-model.to_bettertransformer()
-
-# Use it for training or inference
-```
-
-SDPA can also call [Flash Attention](https://arxiv.org/abs/2205.14135) kernels under the hood. To enable Flash Attention or to check that it is available in a given setting (hardware, problem size), use [`torch.backends.cuda.sdp_kernel`](https://pytorch.org/docs/master/backends.html#torch.backends.cuda.sdp_kernel) as a context manager:
-
-
-```diff
-import torch
-from transformers import AutoModelForCausalLM, AutoTokenizer
-
-tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
-model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m").to("cuda")
-# convert the model to BetterTransformer
-model.to_bettertransformer()
-
-input_text = "Hello my dog is cute and"
-inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
-
-+ with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
- outputs = model.generate(**inputs)
-
-print(tokenizer.decode(outputs[0], skip_special_tokens=True))
-```
-
-If you see a bug with a traceback saying
-
-```bash
-RuntimeError: No available kernel. Aborting execution.
-```
-
-try using the PyTorch nightly version, which may have a broader coverage for Flash Attention:
-
-```bash
-pip3 install -U --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu118
-```
-
-Have a look at this [blog post](https://pytorch.org/blog/out-of-the-box-acceleration/) to learn more about what is possible with the BetterTransformer + SDPA API.
-
-### Encoder models
-
-For encoder models during inference, BetterTransformer dispatches the forward call of encoder layers to an equivalent of [`torch.nn.TransformerEncoderLayer`](https://pytorch.org/docs/stable/generated/torch.nn.TransformerEncoderLayer.html) that will execute the fastpath implementation of the encoder layers.
-
-Because `torch.nn.TransformerEncoderLayer` fastpath does not support training, it is dispatched to `torch.nn.functional.scaled_dot_product_attention` instead, which does not leverage nested tensors but can use Flash Attention or Memory-Efficient Attention fused kernels.
-
-More details about BetterTransformer performance can be found in this [blog post](https://medium.com/pytorch/bettertransformer-out-of-the-box-performance-for-huggingface-transformers-3fbe27d50ab2), and you can learn more about BetterTransformer for encoder models in this [blog](https://pytorch.org/blog/a-better-transformer-for-fast-transformer-encoder-inference/).
-
-
-## Advanced usage: mixing FP4 (or Int8) and BetterTransformer
-
-You can combine the different methods described above to get the best performance for your model. For example, you can use BetterTransformer with FP4 mixed-precision inference + flash attention:
-
-```py
-import torch
-from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
-
-quantization_config = BitsAndBytesConfig(
- load_in_4bit=True,
- bnb_4bit_compute_dtype=torch.float16
-)
-
-tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
-model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", quantization_config=quantization_config)
-
-input_text = "Hello my dog is cute and"
-inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
-
-with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
- outputs = model.generate(**inputs)
-
-print(tokenizer.decode(outputs[0], skip_special_tokens=True))
-```
\ No newline at end of file
diff --git a/docs/source/en/perf_infer_gpu_one.md b/docs/source/en/perf_infer_gpu_one.md
index d24299012e9f..82ec39441f39 100644
--- a/docs/source/en/perf_infer_gpu_one.md
+++ b/docs/source/en/perf_infer_gpu_one.md
@@ -13,39 +13,38 @@ rendered properly in your Markdown viewer.
-->
-# Efficient Inference on a Single GPU
+# GPU inference
-In addition to this guide, relevant information can be found as well in [the guide for training on a single GPU](perf_train_gpu_one) and [the guide for inference on CPUs](perf_infer_cpu).
-
-## Flash Attention 2
+GPUs are the standard choice of hardware for machine learning, unlike CPUs, because they are optimized for memory bandwidth and parallelism. To keep up with the larger sizes of modern models or to run these large models on existing and older hardware, there are several optimizations you can use to speed up GPU inference. In this guide, you'll learn how to use FlashAttention-2 (a more memory-efficient attention mechanism), BetterTransformer (a PyTorch native fastpath execution), and bitsandbytes to quantize your model to a lower precision. Finally, learn how to use 🤗 Optimum to accelerate inference with ONNX Runtime on Nvidia and AMD GPUs.
-Note that this feature is experimental and might considerably change in future versions. For instance, the Flash Attention 2 API might migrate to `BetterTransformer` API in the near future.
+The majority of the optimizations described here also apply to multi-GPU setups!
-Flash Attention 2 can considerably speed up transformer-based models' training and inference speed. Flash Attention 2 has been introduced in the [official Flash Attention repository](https://github.com/Dao-AILab/flash-attention) by Tri Dao et al. The scientific paper on Flash Attention can be found [here](https://arxiv.org/abs/2205.14135).
+## FlashAttention-2
-Make sure to follow the installation guide on the repository mentioned above to properly install Flash Attention 2. Once that package is installed, you can benefit from this feature.
+
-We natively support Flash Attention 2 for the following models:
+FlashAttention-2 is experimental and may change considerably in future versions.
-- Llama
-- Mistral
-- Falcon
+
-You can request to add Flash Attention 2 support for more models by opening an issue on GitHub, and even open a Pull Request to integrate the changes. The supported models can be used for inference and training, including training with padding tokens - *which is currently not supported for `BetterTransformer` API below.*
+[FlashAttention-2](https://huggingface.co/papers/2205.14135) is a faster and more efficient implementation of the standard attention mechanism that can significantly speedup inference by:
-
+1. additionally parallelizing the attention computation over sequence length
+2. partitioning the work between GPU threads to reduce communication and shared memory reads/writes between them
-Flash Attention 2 can only be used when the models' dtype is `fp16` or `bf16` and runs only on NVIDIA-GPU devices. Make sure to cast your model to the appropriate dtype and load them on a supported device before using that feature.
-
-
+FlashAttention-2 supports inference with Llama, Mistral, Falcon and Bark models. You can request to add FlashAttention-2 support for another model by opening a GitHub Issue or Pull Request.
-### Quick usage
+Before you begin, make sure you have FlashAttention-2 installed (see the [installation](https://github.com/Dao-AILab/flash-attention?tab=readme-ov-file#installation-and-features) guide for more details about prerequisites):
-To enable Flash Attention 2 in your model, add `use_flash_attention_2` in the `from_pretrained` arguments:
+```bash
+pip install flash-attn --no-build-isolation
+```
+
+To enable FlashAttention-2, add the `use_flash_attention_2` parameter to [`~AutoModelForCausalLM.from_pretrained`]:
```python
import torch
@@ -61,74 +60,29 @@ model = AutoModelForCausalLM.from_pretrained(
)
```
-And use it for generation or fine-tuning.
-
-### Expected speedups
-
-You can benefit from considerable speedups for fine-tuning and inference, especially for long sequences. However, since Flash Attention does not support computing attention scores with padding tokens under the hood, we must manually pad / unpad the attention scores for batched inference when the sequence contains padding tokens. This leads to a significant slowdown for batched generations with padding tokens.
-
-To overcome this, one should use Flash Attention without padding tokens in the sequence for training (e.g., by packing a dataset, i.e., concatenating sequences until reaching the maximum sequence length. An example is provided [here](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_clm.py#L516).
-
-Below is the expected speedup you can get for a simple forward pass on [tiiuae/falcon-7b](https://hf.co/tiiuae/falcon-7b) with a sequence length of 4096 and various batch sizes, without padding tokens:
-
-
-
-
-
-Below is the expected speedup you can get for a simple forward pass on [`meta-llama/Llama-7b-hf`](https://hf.co/meta-llama/Llama-7b-hf) with a sequence length of 4096 and various batch sizes, without padding tokens:
-
-
-
-
-
-For sequences with padding tokens (training with padding tokens or generating with padding tokens), we need to unpad / pad the input sequences to compute correctly the attention scores. For relatively small sequence length, on pure forward pass, this creates an overhead leading to a small speedup (below 30% of the input has been filled with padding tokens).
-
-
-
-
-
-But for large sequence length you can benefit from interesting speedup for pure inference (also training)
-
-Note that Flash Attention makes the attention computation more memory efficient, meaning you can train with much larger sequence lengths without facing CUDA OOM issues. It can lead up to memory reduction up to 20 for large sequence length. Check out [the official flash attention repository](https://github.com/Dao-AILab/flash-attention) for more details.
-
-
-
-
-
-
-### Advanced usage
-
-You can combine this feature with many exisiting feature for model optimization. Check out few examples below:
+
-### Combining Flash Attention 2 and 8-bit models
+FlashAttention-2 can only be used when the model's dtype is `fp16` or `bf16`, and it only runs on Nvidia GPUs. Make sure to cast your model to the appropriate dtype and load them on a supported device before using FlashAttention-2.
+
+
-You can combine this feature together with 8-bit quantization:
+FlashAttention-2 can be combined with other optimization techniques like quantization to further speedup inference. For example, you can combine FlashAttention-2 with 8-bit or 4-bit quantization:
-```python
+```py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
+# load in 8bit
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_8bit=True,
use_flash_attention_2=True,
)
-```
-
-### Combining Flash Attention 2 and 4-bit models
-
-You can combine this feature together with 4-bit quantization:
-
-```python
-import torch
-from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
-
-model_id = "tiiuae/falcon-7b"
-tokenizer = AutoTokenizer.from_pretrained(model_id)
+# load in 4bit
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
@@ -136,85 +90,77 @@ model = AutoModelForCausalLM.from_pretrained(
)
```
-### Combining Flash Attention 2 and PEFT
-
-You can combine this feature together with PEFT for training adapters using Flash Attention 2 under the hood:
+### Expected speedups
-```python
-import torch
-from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
-from peft import LoraConfig
+You can benefit from considerable speedups for inference, especially for inputs with long sequences. However, since FlashAttention-2 does not support computing attention scores with padding tokens, you must manually pad/unpad the attention scores for batched inference when the sequence contains padding tokens. This leads to a significant slowdown for batched generations with padding tokens.
-model_id = "tiiuae/falcon-7b"
-tokenizer = AutoTokenizer.from_pretrained(model_id)
+To overcome this, you should use FlashAttention-2 without padding tokens in the sequence during training (by packing a dataset or [concatenating sequences](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_clm.py#L516) until reaching the maximum sequence length).
-model = AutoModelForCausalLM.from_pretrained(
- model_id,
- load_in_4bit=True,
- use_flash_attention_2=True,
-)
+For a single forward pass on [tiiuae/falcon-7b](https://hf.co/tiiuae/falcon-7b) with a sequence length of 4096 and various batch sizes without padding tokens, the expected speedup is:
-lora_config = LoraConfig(
- r=8,
- task_type="CAUSAL_LM"
-)
+
+
+
-model.add_adapter(lora_config)
+For a single forward pass on [meta-llama/Llama-7b-hf](https://hf.co/meta-llama/Llama-7b-hf) with a sequence length of 4096 and various batch sizes without padding tokens, the expected speedup is:
-... # train your model
-```
+
+
+
-## BetterTransformer
+For sequences with padding tokens (generating with padding tokens), you need to unpad/pad the input sequences to correctly compute the attention scores. With a relatively small sequence length, a single forward pass creates overhead leading to a small speedup (in the example below, 30% of the input is filled with padding tokens):
-[BetterTransformer](https://huggingface.co/docs/optimum/bettertransformer/overview) converts 🤗 Transformers models to use the PyTorch-native fastpath execution, which calls optimized kernels like Flash Attention under the hood.
+
+
+
-BetterTransformer is also supported for faster inference on single and multi-GPU for text, image, and audio models.
+But for larger sequence lengths, you can expect even more speedup benefits:
-Flash Attention can only be used for models using fp16 or bf16 dtype. Make sure to cast your model to the appropriate dtype before using BetterTransformer.
-
-
+FlashAttention is more memory efficient, meaning you can train on much larger sequence lengths without running into out-of-memory issues. You can potentially reduce memory usage up to 20x for larger sequence lengths. Take a look at the [flash-attention](https://github.com/Dao-AILab/flash-attention) repository for more details.
-### Encoder models
+
-PyTorch-native [`nn.MultiHeadAttention`](https://pytorch.org/blog/a-better-transformer-for-fast-transformer-encoder-inference/) attention fastpath, called BetterTransformer, can be used with Transformers through the integration in the [🤗 Optimum library](https://huggingface.co/docs/optimum/bettertransformer/overview).
+
+
+
-PyTorch's attention fastpath allows to speed up inference through kernel fusions and the use of [nested tensors](https://pytorch.org/docs/stable/nested.html). Detailed benchmarks can be found in [this blog post](https://medium.com/pytorch/bettertransformer-out-of-the-box-performance-for-huggingface-transformers-3fbe27d50ab2).
+## BetterTransformer
-After installing the [`optimum`](https://github.com/huggingface/optimum) package, to use Better Transformer during inference, the relevant internal modules are replaced by calling [`~PreTrainedModel.to_bettertransformer`]:
+
-```python
-model = model.to_bettertransformer()
-```
+Check out our benchmarks with BetterTransformer and scaled dot product attention in the [Out of the box acceleration and memory savings of 🤗 decoder models with PyTorch 2.0](https://pytorch.org/blog/out-of-the-box-acceleration/) and learn more about the fastpath execution in the [BetterTransformer](https://medium.com/pytorch/bettertransformer-out-of-the-box-performance-for-huggingface-transformers-3fbe27d50ab2) blog post.
-The method [`~PreTrainedModel.reverse_bettertransformer`] allows to go back to the original modeling, which should be used before saving the model in order to use the canonical transformers modeling:
+
-```python
-model = model.reverse_bettertransformer()
-model.save_pretrained("saved_model")
-```
+BetterTransformer accelerates inference with its fastpath (native PyTorch specialized implementation of Transformer functions) execution. The two optimizations in the fastpath execution are:
-Have a look at this [blog post](https://medium.com/pytorch/bettertransformer-out-of-the-box-performance-for-huggingface-transformers-3fbe27d50ab2) to learn more about what is possible to do with `BetterTransformer` API for encoder models.
+1. fusion, which combines multiple sequential operations into a single "kernel" to reduce the number of computation steps
+2. skipping the inherent sparsity of padding tokens to avoid unnecessary computation with nested tensors
-### Decoder models
+BetterTransformer also converts all attention operations to use the more memory-efficient [scaled dot product attention (SDPA)](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention), and it calls optimized kernels like [FlashAttention](https://huggingface.co/papers/2205.14135) under the hood.
-For text models, especially decoder-based models (GPT, T5, Llama, etc.), the BetterTransformer API converts all attention operations to use the [`torch.nn.functional.scaled_dot_product_attention` operator](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) (SDPA) that is only available in PyTorch 2.0 and onwards.
+Before you start, make sure you have 🤗 Optimum [installed](https://huggingface.co/docs/optimum/installation).
-To convert a model to BetterTransformer:
+Then you can enable BetterTransformer with the [`PreTrainedModel.to_bettertransformer`] method:
```python
-from transformers import AutoModelForCausalLM
+model = model.to_bettertransformer()
+```
-model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
-# convert the model to BetterTransformer
-model.to_bettertransformer()
+You can return the original Transformers model with the [`~PreTrainedModel.reverse_bettertransformer`] method. You should use this before saving your model to use the canonical Transformers modeling:
-# Use it for training or inference
+```py
+model = model.reverse_bettertransformer()
+model.save_pretrained("saved_model")
```
-SDPA can also call [Flash Attention](https://arxiv.org/abs/2205.14135) kernels under the hood. To enable Flash Attention or to check that it is available in a given setting (hardware, problem size), use [`torch.backends.cuda.sdp_kernel`](https://pytorch.org/docs/master/backends.html#torch.backends.cuda.sdp_kernel) as a context manager:
+### FlashAttention
+SDPA can also call FlashAttention kernels under the hood. FlashAttention can only be used for models using the `fp16` or `bf16` dtype, so make sure to cast your model to the appropriate dtype before using it.
+
+To enable FlashAttention or to check whether it is available in a given setting (hardware, problem size), use [`torch.backends.cuda.sdp_kernel`](https://pytorch.org/docs/master/backends.html#torch.backends.cuda.sdp_kernel) as a context manager:
```diff
import torch
@@ -234,47 +180,32 @@ inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
-If you see a bug with a traceback saying
+If you see a bug with the traceback below, try using nightly version of PyTorch which may have broader coverage for FlashAttention:
```bash
-RuntimeError: No available kernel. Aborting execution.
-```
-
-try using the PyTorch nightly version, which may have a broader coverage for Flash Attention:
+RuntimeError: No available kernel. Aborting execution.
-```bash
+# install PyTorch nightly
pip3 install -U --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu118
```
-Or make sure your model is correctly casted in float16 or bfloat16
-
-
-Have a look at [this detailed blogpost](https://pytorch.org/blog/out-of-the-box-acceleration/) to read more about what is possible to do with `BetterTransformer` + SDPA API.
-
-## `bitsandbytes` integration for FP4 mixed-precision inference
-
-You can install `bitsandbytes` and benefit from easy model compression on GPUs. Using FP4 quantization you can expect to reduce up to 8x the model size compared to its native full precision version. Check out below how to get started.
-
-
-
-Note that this feature can also be used in a multi GPU setup.
-
-
+## bitsandbytes
-### Requirements [[requirements-for-fp4-mixedprecision-inference]]
+bitsandbytes is a quantization library that includes support for 4-bit and 8-bit quantization. Quantization reduces your model size compared to its native full precision version, making it easier to fit large models onto GPUs with limited memory.
-- Latest `bitsandbytes` library
-`pip install bitsandbytes>=0.39.0`
+Make sure you have bitsnbytes and 🤗 Accelerate installed:
-- Install latest `accelerate` from source
-`pip install git+https://github.com/huggingface/accelerate.git`
+```bash
+# these versions support 8-bit and 4-bit
+pip install bitsandbytes>=0.39.0 accelerate>=0.20.0
-- Install latest `transformers` from source
-`pip install git+https://github.com/huggingface/transformers.git`
+# install Transformers
+pip install transformers
+```
-### Running FP4 models - single GPU setup - Quickstart
+### 4-bit
-You can quickly run a FP4 model on a single GPU by running the following code:
+To load a model in 4-bit for inference, use the `load_in_4bit` parameter. The `device_map` parameter is optional, but we recommend setting it to `"auto"` to allow 🤗 Accelerate to automatically and efficiently allocate the model given the available resources in the environment.
```py
from transformers import AutoModelForCausalLM
@@ -282,16 +213,8 @@ from transformers import AutoModelForCausalLM
model_name = "bigscience/bloom-2b5"
model_4bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_4bit=True)
```
-Note that `device_map` is optional but setting `device_map = 'auto'` is prefered for inference as it will dispatch efficiently the model on the available ressources.
-### Running FP4 models - multi GPU setup
-
-The way to load your mixed 4-bit model in multiple GPUs is as follows (same command as single GPU setup):
-```py
-model_name = "bigscience/bloom-2b5"
-model_4bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_4bit=True)
-```
-But you can control the GPU RAM you want to allocate on each GPU using `accelerate`. Use the `max_memory` argument as follows:
+To load a model in 4-bit for inference with multiple GPUs, you can control how much GPU RAM you want to allocate to each GPU. For example, to distribute 600MB of memory to the first GPU and 1GB of memory to the second GPU:
```py
max_memory_mapping = {0: "600MB", 1: "1GB"}
@@ -300,44 +223,16 @@ model_4bit = AutoModelForCausalLM.from_pretrained(
model_name, device_map="auto", load_in_4bit=True, max_memory=max_memory_mapping
)
```
-In this example, the first GPU will use 600MB of memory and the second 1GB.
-### Advanced usage
-
-For more advanced usage of this method, please have a look at the [quantization](main_classes/quantization) documentation page.
-
-## `bitsandbytes` integration for Int8 mixed-precision matrix decomposition
+### 8-bit
-Note that this feature can also be used in a multi GPU setup.
+If you're curious and interested in learning more about the concepts underlying 8-bit quantization, read the [Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using Hugging Face Transformers, Accelerate and bitsandbytes](https://huggingface.co/blog/hf-bitsandbytes-integration) blog post.
-From the paper [`LLM.int8() : 8-bit Matrix Multiplication for Transformers at Scale`](https://arxiv.org/abs/2208.07339), we support Hugging Face integration for all models in the Hub with a few lines of code.
-The method reduces `nn.Linear` size by 2 for `float16` and `bfloat16` weights and by 4 for `float32` weights, with close to no impact to the quality by operating on the outliers in half-precision.
-
-
-
-Int8 mixed-precision matrix decomposition works by separating a matrix multiplication into two streams: (1) a systematic feature outlier stream matrix multiplied in fp16 (0.01%), (2) a regular stream of int8 matrix multiplication (99.9%). With this method, int8 inference with no predictive degradation is possible for very large models.
-For more details regarding the method, check out the [paper](https://arxiv.org/abs/2208.07339) or our [blogpost about the integration](https://huggingface.co/blog/hf-bitsandbytes-integration).
-
-
-
-Note, that you would require a GPU to run mixed-8bit models as the kernels have been compiled for GPUs only. Make sure that you have enough GPU memory to store the quarter (or half if your model weights are in half precision) of the model before using this feature.
-Below are some notes to help you use this module, or follow the demos on [Google colab](#colab-demos).
-
-### Requirements [[requirements-for-int8-mixedprecision-matrix-decomposition]]
-
-- If you have `bitsandbytes<0.37.0`, make sure you run on NVIDIA GPUs that support 8-bit tensor cores (Turing, Ampere or newer architectures - e.g. T4, RTX20s RTX30s, A40-A100). For `bitsandbytes>=0.37.0`, all GPUs should be supported.
-- Install the correct version of `bitsandbytes` by running:
-`pip install bitsandbytes>=0.31.5`
-- Install `accelerate`
-`pip install accelerate>=0.12.0`
-
-### Running mixed-Int8 models - single GPU setup
-
-After installing the required libraries, the way to load your mixed 8-bit model is as follows:
+To load a model in 8-bit for inference, use the `load_in_8bit` parameter. The `device_map` parameter is optional, but we recommend setting it to `"auto"` to allow 🤗 Accelerate to automatically and efficiently allocate the model given the available resources in the environment:
```py
from transformers import AutoModelForCausalLM
@@ -346,12 +241,7 @@ model_name = "bigscience/bloom-2b5"
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True)
```
-For text generation, we recommend:
-
-* using the model's `generate()` method instead of the `pipeline()` function. Although inference is possible with the `pipeline()` function, it is not optimized for mixed-8bit models, and will be slower than using the `generate()` method. Moreover, some sampling strategies are like nucleaus sampling are not supported by the `pipeline()` function for mixed-8bit models.
-* placing all inputs on the same device as the model.
-
-Here is a simple example:
+If you're loading a model in 8-bit for text generation, you should use the [`~transformers.GenerationMixin.generate`] method instead of the [`Pipeline`] function which is not optimized for 8-bit models and will be slower. Some sampling strategies, like nucleus sampling, are also not supported by the [`Pipeline`] for 8-bit models. You should also place all inputs on the same device as the model:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
@@ -366,15 +256,7 @@ generated_ids = model.generate(**inputs)
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
```
-
-### Running mixed-int8 models - multi GPU setup
-
-The way to load your mixed 8-bit model in multiple GPUs is as follows (same command as single GPU setup):
-```py
-model_name = "bigscience/bloom-2b5"
-model_8bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True)
-```
-But you can control the GPU RAM you want to allocate on each GPU using `accelerate`. Use the `max_memory` argument as follows:
+To load a model in 4-bit for inference with multiple GPUs, you can control how much GPU RAM you want to allocate to each GPU. For example, to distribute 1GB of memory to the first GPU and 2GB of memory to the second GPU:
```py
max_memory_mapping = {0: "1GB", 1: "2GB"}
@@ -383,27 +265,56 @@ model_8bit = AutoModelForCausalLM.from_pretrained(
model_name, device_map="auto", load_in_8bit=True, max_memory=max_memory_mapping
)
```
-In this example, the first GPU will use 1GB of memory and the second 2GB.
-### Colab demos
+
-With this method you can infer on models that were not possible to infer on a Google Colab before.
-Check out the demo for running T5-11b (42GB in fp32)! Using 8-bit quantization on Google Colab:
+Feel free to try running a 11 billion parameter [T5 model](https://colab.research.google.com/drive/1YORPWx4okIHXnjW7MSAidXN29mPVNT7F?usp=sharing) or the 3 billion parameter [BLOOM model](https://colab.research.google.com/drive/1qOjXfQIAULfKvZqwCen8-MoWKGdSatZ4?usp=sharing) for inference on Google Colab's free tier GPUs!
-[](https://colab.research.google.com/drive/1YORPWx4okIHXnjW7MSAidXN29mPVNT7F?usp=sharing)
+
-Or this demo for BLOOM-3B:
+## 🤗 Optimum
-[](https://colab.research.google.com/drive/1qOjXfQIAULfKvZqwCen8-MoWKGdSatZ4?usp=sharing)
+
+
+Learn more details about using ORT with 🤗 Optimum in the [Accelerated inference on NVIDIA GPUs](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/gpu#accelerated-inference-on-nvidia-gpus) and [Accelerated inference on AMD GPUs](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/amdgpu#accelerated-inference-on-amd-gpus) guides. This section only provides a brief and simple example.
+
+
+
+ONNX Runtime (ORT) is a model accelerator that supports accelerated inference on Nvidia GPUs, and AMD GPUs that use [ROCm](https://www.amd.com/en/products/software/rocm.html) stack. ORT uses optimization techniques like fusing common operations into a single node and constant folding to reduce the number of computations performed and speedup inference. ORT also places the most computationally intensive operations on the GPU and the rest on the CPU to intelligently distribute the workload between the two devices.
-## Advanced usage: mixing FP4 (or Int8) and BetterTransformer
+ORT is supported by 🤗 Optimum which can be used in 🤗 Transformers. You'll need to use an [`~optimum.onnxruntime.ORTModel`] for the task you're solving, and specify the `provider` parameter which can be set to either [`CUDAExecutionProvider`](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/gpu#cudaexecutionprovider), [`ROCMExecutionProvider`](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/amdgpu) or [`TensorrtExecutionProvider`](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/gpu#tensorrtexecutionprovider). If you want to load a model that was not yet exported to ONNX, you can set `export=True` to convert your model on-the-fly to the ONNX format:
+
+```py
+from optimum.onnxruntime import ORTModelForSequenceClassification
+
+ort_model = ORTModelForSequenceClassification.from_pretrained(
+ "distilbert-base-uncased-finetuned-sst-2-english",
+ export=True,
+ provider="CUDAExecutionProvider",
+)
+```
-You can combine the different methods described above to get the best performance for your model. For example, you can use BetterTransformer with FP4 mixed-precision inference + flash attention:
+Now you're free to use the model for inference:
+
+```py
+from optimum.pipelines import pipeline
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
+
+pipeline = pipeline(task="text-classification", model=ort_model, tokenizer=tokenizer, device="cuda:0")
+result = pipeline("Both the music and visual were astounding, not to mention the actors performance.")
+```
+
+## Combine optimizations
+
+It is often possible to combine several of the optimization techniques described above to get the best inference performance possible for your model. For example, you can load a model in 4-bit, and then enable BetterTransformer with FlashAttention:
```py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
+# load model in 4-bit
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
@@ -412,9 +323,13 @@ quantization_config = BitsAndBytesConfig(
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", quantization_config=quantization_config)
+# enable BetterTransformer
+model = model.to_bettertransformer()
+
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
+# enable FlashAttention
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
diff --git a/docs/source/en/perf_train_gpu_many.md b/docs/source/en/perf_train_gpu_many.md
index ecabbcd06f36..4d89cf341a55 100644
--- a/docs/source/en/perf_train_gpu_many.md
+++ b/docs/source/en/perf_train_gpu_many.md
@@ -153,7 +153,7 @@ python examples/pytorch/language-modeling/run_clm.py \
```
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
-python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
+torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
@@ -164,7 +164,7 @@ python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-
```
rm -r /tmp/test-clm; NCCL_P2P_DISABLE=1 CUDA_VISIBLE_DEVICES=0,1 \
-python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
+torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
@@ -270,7 +270,7 @@ which is discussed next.
Implementations:
-- [DeepSpeed](https://www.deepspeed.ai/features/#the-zero-redundancy-optimizer) ZeRO-DP stages 1+2+3
+- [DeepSpeed](https://www.deepspeed.ai/tutorials/zero/) ZeRO-DP stages 1+2+3
- [`Accelerate` integration](https://huggingface.co/docs/accelerate/en/usage_guides/deepspeed)
- [`transformers` integration](main_classes/trainer#trainer-integrations)
@@ -434,7 +434,7 @@ This section is based on the original much more [detailed TP overview](https://g
by [@anton-l](https://github.com/anton-l).
Alternative names:
-- DeepSpeed calls it [tensor slicing](https://www.deepspeed.ai/features/#model-parallelism)
+- DeepSpeed calls it [tensor slicing](https://www.deepspeed.ai/training/#model-parallelism)
Implementations:
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) has an internal implementation, as it's very model-specific
diff --git a/docs/source/en/perf_train_gpu_one.md b/docs/source/en/perf_train_gpu_one.md
index 17b62c3a1379..089c9905caba 100644
--- a/docs/source/en/perf_train_gpu_one.md
+++ b/docs/source/en/perf_train_gpu_one.md
@@ -237,7 +237,7 @@ You can speedup the training throughput by using Flash Attention 2 integration i
The most common optimizer used to train transformer models is Adam or AdamW (Adam with weight decay). Adam achieves
good convergence by storing the rolling average of the previous gradients; however, it adds an additional memory
footprint of the order of the number of model parameters. To remedy this, you can use an alternative optimizer.
-For example if you have [NVIDIA/apex](https://github.com/NVIDIA/apex) installed, `adamw_apex_fused` will give you the
+For example if you have [NVIDIA/apex](https://github.com/NVIDIA/apex) installed for NVIDIA GPUs, or [ROCmSoftwarePlatform/apex](https://github.com/ROCmSoftwarePlatform/apex) for AMD GPUs, `adamw_apex_fused` will give you the
fastest training experience among all supported AdamW optimizers.
[`Trainer`] integrates a variety of optimizers that can be used out of box: `adamw_hf`, `adamw_torch`, `adamw_torch_fused`,
@@ -394,7 +394,7 @@ Choose which backend to use by specifying it via `torch_compile_backend` in the
**Inference-only backend**s:
* `dynamo.optimize("ofi")` - Uses Torchscript optimize_for_inference. [Read more](https://pytorch.org/docs/stable/generated/torch.jit.optimize_for_inference.html)
-* `dynamo.optimize("fx2trt")` - Uses Nvidia TensorRT for inference optimizations. [Read more](https://github.com/pytorch/TensorRT/blob/master/docsrc/tutorials/getting_started_with_fx_path.rst)
+* `dynamo.optimize("fx2trt")` - Uses NVIDIA TensorRT for inference optimizations. [Read more](https://pytorch.org/TensorRT/tutorials/getting_started_with_fx_path.html)
* `dynamo.optimize("onnxrt")` - Uses ONNXRT for inference on CPU/GPU. [Read more](https://onnxruntime.ai/)
* `dynamo.optimize("ipex")` - Uses IPEX for inference on CPU. [Read more](https://github.com/intel/intel-extension-for-pytorch)
@@ -505,7 +505,7 @@ Most related papers and implementations are built around Tensorflow/TPUs:
- [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961)
- [GLaM: Generalist Language Model (GLaM)](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html)
-And for Pytorch DeepSpeed has built one as well: [DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale](https://arxiv.org/abs/2201.05596), [Mixture of Experts](https://www.deepspeed.ai/tutorials/mixture-of-experts/) - blog posts: [1](https://www.microsoft.com/en-us/research/blog/deepspeed-powers-8x-larger-moe-model-training-with-high-performance/), [2](https://www.microsoft.com/en-us/research/publication/scalable-and-efficient-moe-training-for-multitask-multilingual-models/) and specific deployment with large transformer-based natural language generation models: [blog post](https://www.deepspeed.ai/news/2021/12/09/deepspeed-moe-nlg.html), [Megatron-Deepspeed branch](Thttps://github.com/microsoft/Megatron-DeepSpeed/tree/moe-training).
+And for Pytorch DeepSpeed has built one as well: [DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale](https://arxiv.org/abs/2201.05596), [Mixture of Experts](https://www.deepspeed.ai/tutorials/mixture-of-experts/) - blog posts: [1](https://www.microsoft.com/en-us/research/blog/deepspeed-powers-8x-larger-moe-model-training-with-high-performance/), [2](https://www.microsoft.com/en-us/research/publication/scalable-and-efficient-moe-training-for-multitask-multilingual-models/) and specific deployment with large transformer-based natural language generation models: [blog post](https://www.deepspeed.ai/2021/12/09/deepspeed-moe-nlg.html), [Megatron-Deepspeed branch](https://github.com/microsoft/Megatron-DeepSpeed/tree/moe-training).
## Using PyTorch native attention and Flash Attention
@@ -529,4 +529,4 @@ By default, in training mode, the BetterTransformer integration **drops the mask
-Check out this [blogpost](https://pytorch.org/blog/out-of-the-box-acceleration/) to learn more about acceleration and memory-savings with SDPA.
\ No newline at end of file
+Check out this [blogpost](https://pytorch.org/blog/out-of-the-box-acceleration/) to learn more about acceleration and memory-savings with SDPA.
diff --git a/docs/source/en/performance.md b/docs/source/en/performance.md
index a1661a6ba5a8..ccd78d326d52 100644
--- a/docs/source/en/performance.md
+++ b/docs/source/en/performance.md
@@ -53,7 +53,7 @@ sections we go through the steps to run inference on CPU and single/multi-GPU se
* [Inference on a single CPU](perf_infer_cpu)
* [Inference on a single GPU](perf_infer_gpu_one)
-* [Multi-GPU inference](perf_infer_gpu_many)
+* [Multi-GPU inference](perf_infer_gpu_one)
* [XLA Integration for TensorFlow Models](tf_xla)
diff --git a/docs/source/en/philosophy.md b/docs/source/en/philosophy.md
index cad1e2ccdc8c..628cb39bbb33 100644
--- a/docs/source/en/philosophy.md
+++ b/docs/source/en/philosophy.md
@@ -64,7 +64,7 @@ A few other goals:
The library is built around three types of classes for each model:
-- **Model classes** can be PyTorch models ([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)), Keras models ([tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model)) or JAX/Flax models ([flax.linen.Module](https://flax.readthedocs.io/en/latest/api_reference/flax.linen.html)) that work with the pretrained weights provided in the library.
+- **Model classes** can be PyTorch models ([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)), Keras models ([tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model)) or JAX/Flax models ([flax.linen.Module](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html)) that work with the pretrained weights provided in the library.
- **Configuration classes** store the hyperparameters required to build a model (such as the number of layers and hidden size). You don't always need to instantiate these yourself. In particular, if you are using a pretrained model without any modification, creating the model will automatically take care of instantiating the configuration (which is part of the model).
- **Preprocessing classes** convert the raw data into a format accepted by the model. A [tokenizer](main_classes/tokenizer) stores the vocabulary for each model and provide methods for encoding and decoding strings in a list of token embedding indices to be fed to a model. [Image processors](main_classes/image_processor) preprocess vision inputs, [feature extractors](main_classes/feature_extractor) preprocess audio inputs, and a [processor](main_classes/processors) handles multimodal inputs.
diff --git a/docs/source/en/preprocessing.md b/docs/source/en/preprocessing.md
index f08808433c26..743904cc994c 100644
--- a/docs/source/en/preprocessing.md
+++ b/docs/source/en/preprocessing.md
@@ -220,7 +220,7 @@ array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
For audio tasks, you'll need a [feature extractor](main_classes/feature_extractor) to prepare your dataset for the model. The feature extractor is designed to extract features from raw audio data, and convert them into tensors.
-Load the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub.html) for more details on how to load a dataset) to see how you can use a feature extractor with audio datasets:
+Load the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub) for more details on how to load a dataset) to see how you can use a feature extractor with audio datasets:
```py
>>> from datasets import load_dataset, Audio
@@ -340,7 +340,7 @@ You can use any library you like for image augmentation. For image preprocessing
-Load the [food101](https://huggingface.co/datasets/food101) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub.html) for more details on how to load a dataset) to see how you can use an image processor with computer vision datasets:
+Load the [food101](https://huggingface.co/datasets/food101) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub) for more details on how to load a dataset) to see how you can use an image processor with computer vision datasets:
@@ -354,7 +354,7 @@ Use 🤗 Datasets `split` parameter to only load a small sample from the trainin
>>> dataset = load_dataset("food101", split="train[:100]")
```
-Next, take a look at the image with 🤗 Datasets [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=image#datasets.Image) feature:
+Next, take a look at the image with 🤗 Datasets [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=image#datasets.Image) feature:
```py
>>> dataset[0]["image"]
@@ -467,7 +467,7 @@ from [`DetrImageProcessor`] and define a custom `collate_fn` to batch images tog
For tasks involving multimodal inputs, you'll need a [processor](main_classes/processors) to prepare your dataset for the model. A processor couples together two processing objects such as as tokenizer and feature extractor.
-Load the [LJ Speech](https://huggingface.co/datasets/lj_speech) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub.html) for more details on how to load a dataset) to see how you can use a processor for automatic speech recognition (ASR):
+Load the [LJ Speech](https://huggingface.co/datasets/lj_speech) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub) for more details on how to load a dataset) to see how you can use a processor for automatic speech recognition (ASR):
```py
>>> from datasets import load_dataset
diff --git a/docs/source/en/run_scripts.md b/docs/source/en/run_scripts.md
index 3b40b6ea0672..0652bb1da5e4 100644
--- a/docs/source/en/run_scripts.md
+++ b/docs/source/en/run_scripts.md
@@ -130,7 +130,7 @@ The [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) sup
- Set the number of GPUs to use with the `nproc_per_node` argument.
```bash
-python -m torch.distributed.launch \
+torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
diff --git a/docs/source/en/sagemaker.md b/docs/source/en/sagemaker.md
index f0a5a5f9c114..579caa499c2f 100644
--- a/docs/source/en/sagemaker.md
+++ b/docs/source/en/sagemaker.md
@@ -26,4 +26,3 @@ The documentation has been moved to [hf.co/docs/sagemaker](https://huggingface.c
- [Train Hugging Face models on Amazon SageMaker with the SageMaker Python SDK](https://huggingface.co/docs/sagemaker/train)
- [Deploy Hugging Face models to Amazon SageMaker with the SageMaker Python SDK](https://huggingface.co/docs/sagemaker/inference)
-- [Frequently Asked Questions](https://huggingface.co/docs/sagemaker/faq)
diff --git a/docs/source/en/tasks/language_modeling.md b/docs/source/en/tasks/language_modeling.md
index c509899882e3..2eac6ec12328 100644
--- a/docs/source/en/tasks/language_modeling.md
+++ b/docs/source/en/tasks/language_modeling.md
@@ -37,7 +37,7 @@ You can finetune other architectures for causal language modeling following the
Choose one of the following architectures:
-[BART](../model_doc/bart), [BERT](../model_doc/bert), [Bert Generation](../model_doc/bert-generation), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [Blenderbot](../model_doc/blenderbot), [BlenderbotSmall](../model_doc/blenderbot-small), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CodeLlama](../model_doc/code_llama), [CodeGen](../model_doc/codegen), [CPM-Ant](../model_doc/cpmant), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [Falcon](../model_doc/falcon), [Fuyu](../model_doc/fuyu), [GIT](../model_doc/git), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT NeoX Japanese](../model_doc/gpt_neox_japanese), [GPT-J](../model_doc/gptj), [LLaMA](../model_doc/llama), [Marian](../model_doc/marian), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [MPT](../model_doc/mpt), [MusicGen](../model_doc/musicgen), [MVP](../model_doc/mvp), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Pegasus](../model_doc/pegasus), [Persimmon](../model_doc/persimmon), [PLBart](../model_doc/plbart), [ProphetNet](../model_doc/prophetnet), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [RWKV](../model_doc/rwkv), [Speech2Text2](../model_doc/speech_to_text_2), [Transformer-XL](../model_doc/transfo-xl), [TrOCR](../model_doc/trocr), [XGLM](../model_doc/xglm), [XLM](../model_doc/xlm), [XLM-ProphetNet](../model_doc/xlm-prophetnet), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod)
+[BART](../model_doc/bart), [BERT](../model_doc/bert), [Bert Generation](../model_doc/bert-generation), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [Blenderbot](../model_doc/blenderbot), [BlenderbotSmall](../model_doc/blenderbot-small), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CodeLlama](../model_doc/code_llama), [CodeGen](../model_doc/codegen), [CPM-Ant](../model_doc/cpmant), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [Falcon](../model_doc/falcon), [Fuyu](../model_doc/fuyu), [GIT](../model_doc/git), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT NeoX Japanese](../model_doc/gpt_neox_japanese), [GPT-J](../model_doc/gptj), [LLaMA](../model_doc/llama), [Marian](../model_doc/marian), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [MPT](../model_doc/mpt), [MusicGen](../model_doc/musicgen), [MVP](../model_doc/mvp), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Pegasus](../model_doc/pegasus), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [ProphetNet](../model_doc/prophetnet), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [RWKV](../model_doc/rwkv), [Speech2Text2](../model_doc/speech_to_text_2), [Transformer-XL](../model_doc/transfo-xl), [TrOCR](../model_doc/trocr), [Whisper](../model_doc/whisper), [XGLM](../model_doc/xglm), [XLM](../model_doc/xlm), [XLM-ProphetNet](../model_doc/xlm-prophetnet), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod)
@@ -110,7 +110,7 @@ The next step is to load a DistilGPT2 tokenizer to process the `text` subfield:
```
You'll notice from the example above, the `text` field is actually nested inside `answers`. This means you'll need to
-extract the `text` subfield from its nested structure with the [`flatten`](https://huggingface.co/docs/datasets/process.html#flatten) method:
+extract the `text` subfield from its nested structure with the [`flatten`](https://huggingface.co/docs/datasets/process#flatten) method:
```py
>>> eli5 = eli5.flatten()
diff --git a/docs/source/en/tasks/masked_language_modeling.md b/docs/source/en/tasks/masked_language_modeling.md
index ba1e9e50dbe8..e716447b83bb 100644
--- a/docs/source/en/tasks/masked_language_modeling.md
+++ b/docs/source/en/tasks/masked_language_modeling.md
@@ -105,7 +105,7 @@ For masked language modeling, the next step is to load a DistilRoBERTa tokenizer
```
You'll notice from the example above, the `text` field is actually nested inside `answers`. This means you'll need to e
-xtract the `text` subfield from its nested structure with the [`flatten`](https://huggingface.co/docs/datasets/process.html#flatten) method:
+xtract the `text` subfield from its nested structure with the [`flatten`](https://huggingface.co/docs/datasets/process#flatten) method:
```py
>>> eli5 = eli5.flatten()
diff --git a/docs/source/en/tasks/semantic_segmentation.md b/docs/source/en/tasks/semantic_segmentation.md
index c3ad3e00f61a..ce6fb70c8244 100644
--- a/docs/source/en/tasks/semantic_segmentation.md
+++ b/docs/source/en/tasks/semantic_segmentation.md
@@ -14,29 +14,17 @@ rendered properly in your Markdown viewer.
-->
-# Semantic segmentation
+# Image Segmentation
[[open-in-colab]]
-Semantic segmentation assigns a label or class to each individual pixel of an image. There are several types of segmentation, and in the case of semantic segmentation, no distinction is made between unique instances of the same object. Both objects are given the same label (for example, "car" instead of "car-1" and "car-2"). Common real-world applications of semantic segmentation include training self-driving cars to identify pedestrians and important traffic information, identifying cells and abnormalities in medical imagery, and monitoring environmental changes from satellite imagery.
+Image segmentation models separate areas corresponding to different areas of interest in an image. These models work by assigning a label to each pixel. There are several types of segmentation: semantic segmentation, instance segmentation, and panoptic segmentation.
-This guide will show you how to:
-
-1. Finetune [SegFormer](https://huggingface.co/docs/transformers/main/en/model_doc/segformer#segformer) on the [SceneParse150](https://huggingface.co/datasets/scene_parse_150) dataset.
-2. Use your finetuned model for inference.
-
-
-The task illustrated in this tutorial is supported by the following model architectures:
-
-
-
-[BEiT](../model_doc/beit), [Data2VecVision](../model_doc/data2vec-vision), [DPT](../model_doc/dpt), [MobileNetV2](../model_doc/mobilenet_v2), [MobileViT](../model_doc/mobilevit), [MobileViTV2](../model_doc/mobilevitv2), [SegFormer](../model_doc/segformer), [UPerNet](../model_doc/upernet)
-
-
-
-
+In this guide, we will:
+1. [Take a look at different types of segmentation](#Types-of-Segmentation),
+2. [Have an end-to-end fine-tuning example for semantic segmentation](#Fine-tuning-a-Model-for-Segmentation).
Before you begin, make sure you have all the necessary libraries installed:
@@ -52,7 +40,178 @@ We encourage you to log in to your Hugging Face account so you can upload and sh
>>> notebook_login()
```
-## Load SceneParse150 dataset
+## Types of Segmentation
+
+Semantic segmentation assigns a label or class to every single pixel in an image. Let's take a look at a semantic segmentation model output. It will assign the same class to every instance of an object it comes across in an image, for example, all cats will be labeled as "cat" instead of "cat-1", "cat-2".
+We can use transformers' image segmentation pipeline to quickly infer a semantic segmentation model. Let's take a look at the example image.
+
+```python
+from transformers import pipeline
+from PIL import Image
+import requests
+
+url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/segmentation_input.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+image
+```
+
+
+
+
+
+We will use [nvidia/segformer-b1-finetuned-cityscapes-1024-1024](https://huggingface.co/nvidia/segformer-b1-finetuned-cityscapes-1024-1024).
+
+```python
+semantic_segmentation = pipeline("image-segmentation", "nvidia/segformer-b1-finetuned-cityscapes-1024-1024")
+results = semantic_segmentation(image)
+results
+```
+
+The segmentation pipeline output includes a mask for every predicted class.
+```bash
+[{'score': None,
+ 'label': 'road',
+ 'mask': },
+ {'score': None,
+ 'label': 'sidewalk',
+ 'mask': },
+ {'score': None,
+ 'label': 'building',
+ 'mask': },
+ {'score': None,
+ 'label': 'wall',
+ 'mask': },
+ {'score': None,
+ 'label': 'pole',
+ 'mask': },
+ {'score': None,
+ 'label': 'traffic sign',
+ 'mask': },
+ {'score': None,
+ 'label': 'vegetation',
+ 'mask': },
+ {'score': None,
+ 'label': 'terrain',
+ 'mask': },
+ {'score': None,
+ 'label': 'sky',
+ 'mask': },
+ {'score': None,
+ 'label': 'car',
+ 'mask': }]
+```
+
+Taking a look at the mask for the car class, we can see every car is classified with the same mask.
+
+```python
+results[-1]["mask"]
+```
+
+
+
+
+In instance segmentation, the goal is not to classify every pixel, but to predict a mask for **every instance of an object** in a given image. It works very similar to object detection, where there is a bounding box for every instance, there's a segmentation mask instead. We will use [facebook/mask2former-swin-large-cityscapes-instance](https://huggingface.co/facebook/mask2former-swin-large-cityscapes-instance) for this.
+
+```python
+instance_segmentation = pipeline("image-segmentation", "facebook/mask2former-swin-large-cityscapes-instance")
+results = instance_segmentation(Image.open(image))
+results
+```
+
+As you can see below, there are multiple cars classified, and there's no classification for pixels other than pixels that belong to car and person instances.
+
+```bash
+[{'score': 0.999944,
+ 'label': 'car',
+ 'mask': },
+ {'score': 0.999945,
+ 'label': 'car',
+ 'mask': },
+ {'score': 0.999652,
+ 'label': 'car',
+ 'mask': },
+ {'score': 0.903529,
+ 'label': 'person',
+ 'mask': }]
+```
+Checking out one of the car masks below.
+
+```python
+results[2]["mask"]
+```
+
+
+
+
+Panoptic segmentation combines semantic segmentation and instance segmentation, where every pixel is classified into a class and an instance of that class, and there are multiple masks for each instance of a class. We can use [facebook/mask2former-swin-large-cityscapes-panoptic](https://huggingface.co/facebook/mask2former-swin-large-cityscapes-panoptic) for this.
+
+```python
+panoptic_segmentation = pipeline("image-segmentation", "facebook/mask2former-swin-large-cityscapes-panoptic")
+results = panoptic_segmentation(Image.open(image))
+results
+```
+As you can see below, we have more classes. We will later illustrate to see that every pixel is classified into one of the classes.
+
+```bash
+[{'score': 0.999981,
+ 'label': 'car',
+ 'mask': },
+ {'score': 0.999958,
+ 'label': 'car',
+ 'mask': },
+ {'score': 0.99997,
+ 'label': 'vegetation',
+ 'mask': },
+ {'score': 0.999575,
+ 'label': 'pole',
+ 'mask': },
+ {'score': 0.999958,
+ 'label': 'building',
+ 'mask': },
+ {'score': 0.999634,
+ 'label': 'road',
+ 'mask': },
+ {'score': 0.996092,
+ 'label': 'sidewalk',
+ 'mask': },
+ {'score': 0.999221,
+ 'label': 'car',
+ 'mask': },
+ {'score': 0.99987,
+ 'label': 'sky',
+ 'mask': }]
+```
+
+Let's have a side by side comparison for all types of segmentation.
+
+
+
+
+
+Seeing all types of segmentation, let's have a deep dive on fine-tuning a model for semantic segmentation.
+
+Common real-world applications of semantic segmentation include training self-driving cars to identify pedestrians and important traffic information, identifying cells and abnormalities in medical imagery, and monitoring environmental changes from satellite imagery.
+
+## Fine-tuning a Model for Segmentation
+
+We will now:
+
+1. Finetune [SegFormer](https://huggingface.co/docs/transformers/main/en/model_doc/segformer#segformer) on the [SceneParse150](https://huggingface.co/datasets/scene_parse_150) dataset.
+2. Use your fine-tuned model for inference.
+
+
+The task illustrated in this tutorial is supported by the following model architectures:
+
+
+
+[BEiT](../model_doc/beit), [Data2VecVision](../model_doc/data2vec-vision), [DPT](../model_doc/dpt), [MobileNetV2](../model_doc/mobilenet_v2), [MobileViT](../model_doc/mobilevit), [MobileViTV2](../model_doc/mobilevitv2), [SegFormer](../model_doc/segformer), [UPerNet](../model_doc/upernet)
+
+
+
+
+
+
+### Load SceneParse150 dataset
Start by loading a smaller subset of the SceneParse150 dataset from the 🤗 Datasets library. This'll give you a chance to experiment and make sure everything works before spending more time training on the full dataset.
@@ -97,7 +256,7 @@ You'll also want to create a dictionary that maps a label id to a label class wh
>>> num_labels = len(id2label)
```
-## Preprocess
+### Preprocess
The next step is to load a SegFormer image processor to prepare the images and annotations for the model. Some datasets, like this one, use the zero-index as the background class. However, the background class isn't actually included in the 150 classes, so you'll need to set `reduce_labels=True` to subtract one from all the labels. The zero-index is replaced by `255` so it's ignored by SegFormer's loss function:
@@ -204,7 +363,7 @@ The transform is applied on the fly which is faster and consumes less disk space
-## Evaluate
+### Evaluate
Including a metric during training is often helpful for evaluating your model's performance. You can quickly load an evaluation method with the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, load the [mean Intersection over Union](https://huggingface.co/spaces/evaluate-metric/accuracy) (IoU) metric (see the 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric):
@@ -245,7 +404,7 @@ logits first, and then reshaped to match the size of the labels before you can c
... reduce_labels=False,
... )
... for key, value in metrics.items():
-... if type(value) is np.ndarray:
+... if isinstance(value, np.ndarray):
... metrics[key] = value.tolist()
... return metrics
```
@@ -289,7 +448,7 @@ logits first, and then reshaped to match the size of the labels before you can c
Your `compute_metrics` function is ready to go now, and you'll return to it when you setup your training.
-## Train
+### Train
@@ -453,7 +612,7 @@ Congratulations! You have fine-tuned your model and shared it on the 🤗 Hub. Y
-## Inference
+### Inference
Great, now that you've finetuned a model, you can use it for inference!
@@ -470,43 +629,8 @@ Load an image for inference:
-The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for image segmentation with your model, and pass your image to it:
-
-```py
->>> from transformers import pipeline
-
->>> segmenter = pipeline("image-segmentation", model="my_awesome_seg_model")
->>> segmenter(image)
-[{'score': None,
- 'label': 'wall',
- 'mask': },
- {'score': None,
- 'label': 'sky',
- 'mask': },
- {'score': None,
- 'label': 'floor',
- 'mask': },
- {'score': None,
- 'label': 'ceiling',
- 'mask': },
- {'score': None,
- 'label': 'bed ',
- 'mask': },
- {'score': None,
- 'label': 'windowpane',
- 'mask': },
- {'score': None,
- 'label': 'cabinet',
- 'mask': },
- {'score': None,
- 'label': 'chair',
- 'mask': },
- {'score': None,
- 'label': 'armchair',
- 'mask': }]
-```
-You can also manually replicate the results of the `pipeline` if you'd like. Process the image with an image processor and place the `pixel_values` on a GPU:
+We will now see how to infer without a pipeline. Process the image with an image processor and place the `pixel_values` on a GPU:
```py
>>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # use GPU if available, otherwise use a CPU
diff --git a/docs/source/en/tasks/sequence_classification.md b/docs/source/en/tasks/sequence_classification.md
index b67d43453d27..c6daa66f362f 100644
--- a/docs/source/en/tasks/sequence_classification.md
+++ b/docs/source/en/tasks/sequence_classification.md
@@ -33,7 +33,7 @@ The task illustrated in this tutorial is supported by the following model archit
-[ALBERT](../model_doc/albert), [BART](../model_doc/bart), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [CodeLlama](../model_doc/code_llama), [ConvBERT](../model_doc/convbert), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [ESM](../model_doc/esm), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT-J](../model_doc/gptj), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LED](../model_doc/led), [LiLT](../model_doc/lilt), [LLaMA](../model_doc/llama), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MarkupLM](../model_doc/markuplm), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MPT](../model_doc/mpt), [MRA](../model_doc/mra), [MT5](../model_doc/mt5), [MVP](../model_doc/mvp), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Perceiver](../model_doc/perceiver), [Persimmon](../model_doc/persimmon), [PLBart](../model_doc/plbart), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [T5](../model_doc/t5), [TAPAS](../model_doc/tapas), [Transformer-XL](../model_doc/transfo-xl), [UMT5](../model_doc/umt5), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
+[ALBERT](../model_doc/albert), [BART](../model_doc/bart), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [CodeLlama](../model_doc/code_llama), [ConvBERT](../model_doc/convbert), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [ESM](../model_doc/esm), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT-J](../model_doc/gptj), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LED](../model_doc/led), [LiLT](../model_doc/lilt), [LLaMA](../model_doc/llama), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MarkupLM](../model_doc/markuplm), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MPT](../model_doc/mpt), [MRA](../model_doc/mra), [MT5](../model_doc/mt5), [MVP](../model_doc/mvp), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Perceiver](../model_doc/perceiver), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [T5](../model_doc/t5), [TAPAS](../model_doc/tapas), [Transformer-XL](../model_doc/transfo-xl), [UMT5](../model_doc/umt5), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
@@ -44,7 +44,7 @@ The task illustrated in this tutorial is supported by the following model archit
Before you begin, make sure you have all the necessary libraries installed:
```bash
-pip install transformers datasets evaluate
+pip install transformers datasets evaluate accelerate
```
We encourage you to login to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to login:
diff --git a/docs/source/en/tasks/text-to-speech.md b/docs/source/en/tasks/text-to-speech.md
index 86a0d49fd04d..216c3c1f1133 100644
--- a/docs/source/en/tasks/text-to-speech.md
+++ b/docs/source/en/tasks/text-to-speech.md
@@ -74,6 +74,12 @@ To follow this guide you will need a GPU. If you're working in a notebook, run t
!nvidia-smi
```
+or alternatively for AMD GPUs:
+
+```bash
+!rocm-smi
+```
+
We encourage you to log in to your Hugging Face account to upload and share your model with the community. When prompted, enter your token to log in:
@@ -630,4 +636,4 @@ see if this improves the results.
Finally, it is essential to consider ethical considerations. Although TTS technology has numerous useful applications, it
may also be used for malicious purposes, such as impersonating someone's voice without their knowledge or consent. Please
-use TTS judiciously and responsibly.
\ No newline at end of file
+use TTS judiciously and responsibly.
diff --git a/docs/source/en/tasks/token_classification.md b/docs/source/en/tasks/token_classification.md
index 289f2b05896a..125af5c9d979 100644
--- a/docs/source/en/tasks/token_classification.md
+++ b/docs/source/en/tasks/token_classification.md
@@ -32,7 +32,7 @@ The task illustrated in this tutorial is supported by the following model archit
-[ALBERT](../model_doc/albert), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BioGpt](../model_doc/biogpt), [BLOOM](../model_doc/bloom), [BROS](../model_doc/bros), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [ConvBERT](../model_doc/convbert), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [ESM](../model_doc/esm), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LiLT](../model_doc/lilt), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MarkupLM](../model_doc/markuplm), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MPT](../model_doc/mpt), [MRA](../model_doc/mra), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [QDQBert](../model_doc/qdqbert), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
+[ALBERT](../model_doc/albert), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BioGpt](../model_doc/biogpt), [BLOOM](../model_doc/bloom), [BROS](../model_doc/bros), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [ConvBERT](../model_doc/convbert), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [ESM](../model_doc/esm), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LiLT](../model_doc/lilt), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MarkupLM](../model_doc/markuplm), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MPT](../model_doc/mpt), [MRA](../model_doc/mra), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [Phi](../model_doc/phi), [QDQBert](../model_doc/qdqbert), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
diff --git a/docs/source/en/training.md b/docs/source/en/training.md
index fb4a0b6a279e..8e81048bf54e 100644
--- a/docs/source/en/training.md
+++ b/docs/source/en/training.md
@@ -43,7 +43,7 @@ Begin by loading the [Yelp Reviews](https://huggingface.co/datasets/yelp_review_
'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
```
-As you now know, you need a tokenizer to process the text and include a padding and truncation strategy to handle any variable sequence lengths. To process your dataset in one step, use 🤗 Datasets [`map`](https://huggingface.co/docs/datasets/process.html#map) method to apply a preprocessing function over the entire dataset:
+As you now know, you need a tokenizer to process the text and include a padding and truncation strategy to handle any variable sequence lengths. To process your dataset in one step, use 🤗 Datasets [`map`](https://huggingface.co/docs/datasets/process#map) method to apply a preprocessing function over the entire dataset:
```py
>>> from transformers import AutoTokenizer
@@ -119,7 +119,7 @@ Specify where to save the checkpoints from your training:
>>> metric = evaluate.load("accuracy")
```
-Call [`~evaluate.compute`] on `metric` to calculate the accuracy of your predictions. Before passing your predictions to `compute`, you need to convert the predictions to logits (remember all 🤗 Transformers models return logits):
+Call [`~evaluate.compute`] on `metric` to calculate the accuracy of your predictions. Before passing your predictions to `compute`, you need to convert the logits to predictions (remember all 🤗 Transformers models return logits):
```py
>>> def compute_metrics(eval_pred):
diff --git a/docs/source/es/converting_tensorflow_models.md b/docs/source/es/converting_tensorflow_models.md
index c7e22bddac70..8e5b1ad1e288 100644
--- a/docs/source/es/converting_tensorflow_models.md
+++ b/docs/source/es/converting_tensorflow_models.md
@@ -96,20 +96,6 @@ transformers-cli convert --model_type gpt2 \
[--finetuning_task_name OPENAI_GPT2_FINETUNED_TASK]
```
-## Transformer-XL
-
-Aquí hay un ejemplo del proceso para convertir un modelo Transformer-XL pre-entrenado (más información [aquí](https://github.com/kimiyoung/transformer-xl/tree/master/tf#obtain-and-evaluate-pretrained-sota-models)):
-
-```bash
-export TRANSFO_XL_CHECKPOINT_FOLDER_PATH=/path/to/transfo/xl/checkpoint
-
-transformers-cli convert --model_type transfo_xl \
- --tf_checkpoint $TRANSFO_XL_CHECKPOINT_FOLDER_PATH \
- --pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
- [--config TRANSFO_XL_CONFIG] \
- [--finetuning_task_name TRANSFO_XL_FINETUNED_TASK]
-```
-
## XLNet
Aquí hay un ejemplo del proceso para convertir un modelo XLNet pre-entrenado:
diff --git a/docs/source/es/create_a_model.md b/docs/source/es/create_a_model.md
index 04014a7b6a70..5d6349370539 100644
--- a/docs/source/es/create_a_model.md
+++ b/docs/source/es/create_a_model.md
@@ -109,7 +109,7 @@ También puedes guardar los archivos de configuración como un diccionario; o in
## Modelo
-El siguiente paso será crear un [modelo](main_classes/models). El modelo, al que a veces también nos referimos como arquitectura, es el encargado de definir cada capa y qué operaciones se realizan. Los atributos como `num_hidden_layers` de la configuración se usan para definir la arquitectura. Todos los modelos comparten una clase base, [`PreTrainedModel`], y algunos métodos comunes que se pueden usar para redimensionar los _embeddings_ o para recortar cabezas de auto-atención (también llamadas _self-attention heads_). Además, todos los modelos son subclases de [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) o [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/flax.linen.html#module), lo que significa que son compatibles con su respectivo framework.
+El siguiente paso será crear un [modelo](main_classes/models). El modelo, al que a veces también nos referimos como arquitectura, es el encargado de definir cada capa y qué operaciones se realizan. Los atributos como `num_hidden_layers` de la configuración se usan para definir la arquitectura. Todos los modelos comparten una clase base, [`PreTrainedModel`], y algunos métodos comunes que se pueden usar para redimensionar los _embeddings_ o para recortar cabezas de auto-atención (también llamadas _self-attention heads_). Además, todos los modelos son subclases de [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) o [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html), lo que significa que son compatibles con su respectivo framework.
diff --git a/docs/source/es/preprocessing.md b/docs/source/es/preprocessing.md
index f4eec4862be8..5ac4c018090b 100644
--- a/docs/source/es/preprocessing.md
+++ b/docs/source/es/preprocessing.md
@@ -195,7 +195,7 @@ Las entradas de audio se preprocesan de forma diferente a las entradas textuales
pip install datasets
```
-Carga la tarea de detección de palabras clave del benchmark [SUPERB](https://huggingface.co/datasets/superb) (consulta el [tutorial 🤗 Dataset](https://huggingface.co/docs/datasets/load_hub.html) para que obtengas más detalles sobre cómo cargar un dataset):
+Carga la tarea de detección de palabras clave del benchmark [SUPERB](https://huggingface.co/datasets/superb) (consulta el [tutorial 🤗 Dataset](https://huggingface.co/docs/datasets/load_hub) para que obtengas más detalles sobre cómo cargar un dataset):
```py
>>> from datasets import load_dataset, Audio
@@ -234,7 +234,7 @@ Por ejemplo, carga el dataset [LJ Speech](https://huggingface.co/datasets/lj_spe
'sampling_rate': 22050}
```
-1. Usa el método 🤗 Datasets' [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.cast_column) para reducir la tasa de muestreo a 16kHz:
+1. Usa el método 🤗 Datasets' [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.cast_column) para reducir la tasa de muestreo a 16kHz:
```py
>>> lj_speech = lj_speech.cast_column("audio", Audio(sampling_rate=16_000))
@@ -329,7 +329,7 @@ Vamos a cargar el dataset [food101](https://huggingface.co/datasets/food101) par
>>> dataset = load_dataset("food101", split="train[:100]")
```
-A continuación, observa la imagen con la función 🤗 Datasets [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=image#datasets.Image):
+A continuación, observa la imagen con la función 🤗 Datasets [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=image#datasets.Image):
```py
>>> dataset[0]["image"]
@@ -370,7 +370,7 @@ Para las tareas de visión por computadora es común añadir algún tipo de aume
... return examples
```
-3. A continuación, utiliza 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process.html#format-transform) para aplicar las transformaciones sobre la marcha:
+3. A continuación, utiliza 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process#format-transform) para aplicar las transformaciones sobre la marcha:
```py
>>> dataset.set_transform(transforms)
diff --git a/docs/source/es/run_scripts.md b/docs/source/es/run_scripts.md
index a66fd1e47e13..8b762fdddc28 100644
--- a/docs/source/es/run_scripts.md
+++ b/docs/source/es/run_scripts.md
@@ -130,7 +130,7 @@ python examples/tensorflow/summarization/run_summarization.py \
- Establece la cantidad de GPU que se usará con el argumento `nproc_per_node`.
```bash
-python -m torch.distributed.launch \
+torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
diff --git a/docs/source/es/sagemaker.md b/docs/source/es/sagemaker.md
index a874aefe76f6..9bc5b7410841 100644
--- a/docs/source/es/sagemaker.md
+++ b/docs/source/es/sagemaker.md
@@ -26,4 +26,3 @@ La documentación ha sido trasladada a [hf.co/docs/sagemaker](https://huggingfac
- [Entrenar modelos de Hugging Face en Amazon SageMaker con SageMaker Python SDK](https://huggingface.co/docs/sagemaker/train)
- [Desplegar modelos de Hugging Face en Amazon SageMaker con SageMaker Python SDK](https://huggingface.co/docs/sagemaker/inference)
-- [Preguntas Frecuentes](https://huggingface.co/docs/sagemaker/faq)
diff --git a/docs/source/es/tasks/image_classification.md b/docs/source/es/tasks/image_classification.md
index 3a959aa934ff..f09730caf69f 100644
--- a/docs/source/es/tasks/image_classification.md
+++ b/docs/source/es/tasks/image_classification.md
@@ -99,7 +99,7 @@ Crea una función de preprocesamiento que aplique las transformaciones y devuelv
... return examples
```
-Utiliza el método [`with_transform`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?#datasets.Dataset.with_transform) de 🤗 Dataset para aplicar las transformaciones sobre todo el dataset. Las transformaciones se aplican sobre la marcha cuando se carga un elemento del dataset:
+Utiliza el método [`with_transform`](https://huggingface.co/docs/datasets/package_reference/main_classes?#datasets.Dataset.with_transform) de 🤗 Dataset para aplicar las transformaciones sobre todo el dataset. Las transformaciones se aplican sobre la marcha cuando se carga un elemento del dataset:
```py
>>> food = food.with_transform(transforms)
diff --git a/docs/source/es/tasks/language_modeling.md b/docs/source/es/tasks/language_modeling.md
index 66ac8fb0d4b5..b3f22f084633 100644
--- a/docs/source/es/tasks/language_modeling.md
+++ b/docs/source/es/tasks/language_modeling.md
@@ -94,7 +94,7 @@ Para modelados de lenguaje por enmascaramiento carga el tokenizador DistilRoBERT
>>> tokenizer = AutoTokenizer.from_pretrained("distilroberta-base")
```
-Extrae el subcampo `text` desde su estructura anidado con el método [`flatten`](https://huggingface.co/docs/datasets/process.html#flatten):
+Extrae el subcampo `text` desde su estructura anidado con el método [`flatten`](https://huggingface.co/docs/datasets/process#flatten):
```py
>>> eli5 = eli5.flatten()
@@ -249,7 +249,7 @@ A este punto, solo faltan tres pasos:
```
-Para realizar el fine-tuning de un modelo en TensorFlow, comienza por convertir tus datasets al formato `tf.data.Dataset` con [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Especifica los inputs y etiquetas en `columns`, ya sea para mezclar el dataset, tamaño de lote, y el data collator:
+Para realizar el fine-tuning de un modelo en TensorFlow, comienza por convertir tus datasets al formato `tf.data.Dataset` con [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_tf_dataset). Especifica los inputs y etiquetas en `columns`, ya sea para mezclar el dataset, tamaño de lote, y el data collator:
```py
>>> tf_train_set = lm_dataset["train"].to_tf_dataset(
@@ -356,7 +356,7 @@ A este punto, solo faltan tres pasos:
```
-Para realizar el fine-tuning de un modelo en TensorFlow, comienza por convertir tus datasets al formato `tf.data.Dataset` con [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Especifica los inputs y etiquetas en `columns`, ya sea para mezclar el dataset, tamaño de lote, y el data collator:
+Para realizar el fine-tuning de un modelo en TensorFlow, comienza por convertir tus datasets al formato `tf.data.Dataset` con [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_tf_dataset). Especifica los inputs y etiquetas en `columns`, ya sea para mezclar el dataset, tamaño de lote, y el data collator:
```py
>>> tf_train_set = lm_dataset["train"].to_tf_dataset(
diff --git a/docs/source/es/training.md b/docs/source/es/training.md
index 7b7b0657bd8f..4f224b0797a3 100644
--- a/docs/source/es/training.md
+++ b/docs/source/es/training.md
@@ -102,7 +102,7 @@ Especifica dónde vas a guardar los checkpoints de tu entrenamiento:
### Métricas
-El [`Trainer`] no evalúa automáticamente el rendimiento del modelo durante el entrenamiento. Tendrás que pasarle a [`Trainer`] una función para calcular y hacer un reporte de las métricas. La biblioteca de 🤗 Datasets proporciona una función de [`accuracy`](https://huggingface.co/metrics/accuracy) simple que puedes cargar con la función `load_metric` (ver este [tutorial](https://huggingface.co/docs/datasets/metrics.html) para más información):
+El [`Trainer`] no evalúa automáticamente el rendimiento del modelo durante el entrenamiento. Tendrás que pasarle a [`Trainer`] una función para calcular y hacer un reporte de las métricas. La biblioteca de 🤗 Datasets proporciona una función de [`accuracy`](https://huggingface.co/metrics/accuracy) simple que puedes cargar con la función `load_metric` (ver este [tutorial](https://huggingface.co/docs/datasets/metrics) para más información):
```py
>>> import numpy as np
@@ -172,7 +172,7 @@ El [`DefaultDataCollator`] junta los tensores en un batch para que el modelo se
-A continuación, convierte los datasets tokenizados en datasets de TensorFlow con el método [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Especifica tus entradas en `columns` y tu etiqueta en `label_cols`:
+A continuación, convierte los datasets tokenizados en datasets de TensorFlow con el método [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_tf_dataset). Especifica tus entradas en `columns` y tu etiqueta en `label_cols`:
```py
>>> tf_train_dataset = small_train_dataset.to_tf_dataset(
@@ -342,7 +342,7 @@ Para hacer un seguimiento al progreso del entrenamiento, utiliza la biblioteca [
### Métricas
-De la misma manera que necesitas añadir una función de evaluación al [`Trainer`], necesitas hacer lo mismo cuando escribas tu propio ciclo de entrenamiento. Pero en lugar de calcular y reportar la métrica al final de cada época, esta vez acumularás todos los batches con [`add_batch`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=add_batch#datasets.Metric.add_batch) y calcularás la métrica al final.
+De la misma manera que necesitas añadir una función de evaluación al [`Trainer`], necesitas hacer lo mismo cuando escribas tu propio ciclo de entrenamiento. Pero en lugar de calcular y reportar la métrica al final de cada época, esta vez acumularás todos los batches con [`add_batch`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=add_batch#datasets.Metric.add_batch) y calcularás la métrica al final.
```py
>>> metric = load_metric("accuracy")
diff --git a/docs/source/it/converting_tensorflow_models.md b/docs/source/it/converting_tensorflow_models.md
index 04398636359c..f6326daa735f 100644
--- a/docs/source/it/converting_tensorflow_models.md
+++ b/docs/source/it/converting_tensorflow_models.md
@@ -104,21 +104,6 @@ transformers-cli convert --model_type gpt2 \
[--finetuning_task_name OPENAI_GPT2_FINETUNED_TASK]
```
-## Transformer-XL
-
-
-Ecco un esempio del processo di conversione di un modello Transformer-XL pre-allenato
-(vedi [qui](https://github.com/kimiyoung/transformer-xl/tree/master/tf#obtain-and-evaluate-pretrained-sota-models)):
-
-```bash
-export TRANSFO_XL_CHECKPOINT_FOLDER_PATH=/path/to/transfo/xl/checkpoint
-transformers-cli convert --model_type transfo_xl \
- --tf_checkpoint $TRANSFO_XL_CHECKPOINT_FOLDER_PATH \
- --pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
- [--config TRANSFO_XL_CONFIG] \
- [--finetuning_task_name TRANSFO_XL_FINETUNED_TASK]
-```
-
## XLNet
Ecco un esempio del processo di conversione di un modello XLNet pre-allenato:
diff --git a/docs/source/it/create_a_model.md b/docs/source/it/create_a_model.md
index c32040d7d389..75055beb9271 100644
--- a/docs/source/it/create_a_model.md
+++ b/docs/source/it/create_a_model.md
@@ -109,7 +109,7 @@ Puoi anche salvare il file di configurazione come dizionario oppure come la diff
## Modello
-Il prossimo passo e di creare [modello](main_classes/models). Il modello - vagamente riferito anche come architettura - definisce cosa ogni strato deve fare e quali operazioni stanno succedendo. Attributi come `num_hidden_layers` provenienti dalla configurazione sono usati per definire l'architettura. Ogni modello condivide la classe base [`PreTrainedModel`] e alcuni metodi comuni come il ridimensionamento degli input embeddings e la soppressione delle self-attention heads . Inoltre, tutti i modelli sono la sottoclasse di [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) o [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/flax.linen.html#module). Cio significa che i modelli sono compatibili con l'uso di ciascun di framework.
+Il prossimo passo e di creare [modello](main_classes/models). Il modello - vagamente riferito anche come architettura - definisce cosa ogni strato deve fare e quali operazioni stanno succedendo. Attributi come `num_hidden_layers` provenienti dalla configurazione sono usati per definire l'architettura. Ogni modello condivide la classe base [`PreTrainedModel`] e alcuni metodi comuni come il ridimensionamento degli input embeddings e la soppressione delle self-attention heads . Inoltre, tutti i modelli sono la sottoclasse di [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) o [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html). Cio significa che i modelli sono compatibili con l'uso di ciascun di framework.
diff --git a/docs/source/it/perf_hardware.md b/docs/source/it/perf_hardware.md
index a579362e2b1b..dd1187a01b59 100644
--- a/docs/source/it/perf_hardware.md
+++ b/docs/source/it/perf_hardware.md
@@ -134,7 +134,7 @@ Ecco il codice benchmark completo e gli output:
```bash
# DDP w/ NVLink
-rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch \
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train \
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
@@ -143,7 +143,7 @@ rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch
# DDP w/o NVLink
-rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 python -m torch.distributed.launch \
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
diff --git a/docs/source/it/preprocessing.md b/docs/source/it/preprocessing.md
index 94578dfe166b..76addd2aa0ea 100644
--- a/docs/source/it/preprocessing.md
+++ b/docs/source/it/preprocessing.md
@@ -194,7 +194,7 @@ Gli input audio sono processati in modo differente rispetto al testo, ma l'obiet
pip install datasets
```
-Carica il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) (vedi il 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub.html) per avere maggiori dettagli su come caricare un dataset):
+Carica il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) (vedi il 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub) per avere maggiori dettagli su come caricare un dataset):
```py
>>> from datasets import load_dataset, Audio
@@ -233,7 +233,7 @@ Per esempio, il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds1
'sampling_rate': 8000}
```
-1. Usa il metodo di 🤗 Datasets' [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.cast_column) per alzare la frequenza di campionamento a 16kHz:
+1. Usa il metodo di 🤗 Datasets' [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.cast_column) per alzare la frequenza di campionamento a 16kHz:
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16_000))
@@ -370,7 +370,7 @@ Per le attività di visione, è usuale aggiungere alcuni tipi di data augmentati
... return examples
```
-3. Poi utilizza 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process.html#format-transform)per applicare al volo la trasformazione:
+3. Poi utilizza 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process#format-transform)per applicare al volo la trasformazione:
```py
>>> dataset.set_transform(transforms)
diff --git a/docs/source/it/quicktour.md b/docs/source/it/quicktour.md
index f0e981d18eb7..07e7a2974a1f 100644
--- a/docs/source/it/quicktour.md
+++ b/docs/source/it/quicktour.md
@@ -125,7 +125,7 @@ Crea una [`pipeline`] con il compito che vuoi risolvere e con il modello che vuo
... )
```
-Poi, carica un dataset (vedi 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart.html) per maggiori dettagli) sul quale vuoi iterare. Per esempio, carichiamo il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14):
+Poi, carica un dataset (vedi 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart) per maggiori dettagli) sul quale vuoi iterare. Per esempio, carichiamo il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14):
```py
>>> from datasets import load_dataset, Audio
diff --git a/docs/source/it/run_scripts.md b/docs/source/it/run_scripts.md
index 327eb9374d38..c376ff32c2a8 100644
--- a/docs/source/it/run_scripts.md
+++ b/docs/source/it/run_scripts.md
@@ -130,7 +130,7 @@ Il [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) supp
- Imposta un numero di GPU da usare con l'argomento `nproc_per_node`.
```bash
-python -m torch.distributed.launch \
+torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
diff --git a/docs/source/it/training.md b/docs/source/it/training.md
index be0883f07b77..503a43321799 100644
--- a/docs/source/it/training.md
+++ b/docs/source/it/training.md
@@ -43,7 +43,7 @@ Inizia caricando il dataset [Yelp Reviews](https://huggingface.co/datasets/yelp_
'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
```
-Come già sai, hai bisogno di un tokenizer per processare il testo e includere una strategia di padding e truncation per gestire sequenze di lunghezza variabile. Per processare il dataset in un unico passo, usa il metodo [`map`](https://huggingface.co/docs/datasets/process.html#map) di 🤗 Datasets che applica la funzione di preprocessing all'intero dataset:
+Come già sai, hai bisogno di un tokenizer per processare il testo e includere una strategia di padding e truncation per gestire sequenze di lunghezza variabile. Per processare il dataset in un unico passo, usa il metodo [`map`](https://huggingface.co/docs/datasets/process#map) di 🤗 Datasets che applica la funzione di preprocessing all'intero dataset:
```py
>>> from transformers import AutoTokenizer
@@ -103,7 +103,7 @@ Specifica dove salvare i checkpoints del tuo addestramento:
### Metriche
-[`Trainer`] non valuta automaticamente le performance del modello durante l'addestramento. Dovrai passare a [`Trainer`] una funzione che calcola e restituisce le metriche. La libreria 🤗 Datasets mette a disposizione una semplice funzione [`accuracy`](https://huggingface.co/metrics/accuracy) che puoi caricare con la funzione `load_metric` (guarda questa [esercitazione](https://huggingface.co/docs/datasets/metrics.html) per maggiori informazioni):
+[`Trainer`] non valuta automaticamente le performance del modello durante l'addestramento. Dovrai passare a [`Trainer`] una funzione che calcola e restituisce le metriche. La libreria 🤗 Datasets mette a disposizione una semplice funzione [`accuracy`](https://huggingface.co/metrics/accuracy) che puoi caricare con la funzione `load_metric` (guarda questa [esercitazione](https://huggingface.co/docs/datasets/metrics) per maggiori informazioni):
```py
>>> import numpy as np
@@ -346,7 +346,7 @@ Per tenere traccia dei tuoi progressi durante l'addestramento, usa la libreria [
### Metriche
-Proprio come è necessario aggiungere una funzione di valutazione del [`Trainer`], è necessario fare lo stesso quando si scrive il proprio ciclo di addestramento. Ma invece di calcolare e riportare la metrica alla fine di ogni epoca, questa volta accumulerai tutti i batch con [`add_batch`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=add_batch#datasets.Metric.add_batch) e calcolerai la metrica alla fine.
+Proprio come è necessario aggiungere una funzione di valutazione del [`Trainer`], è necessario fare lo stesso quando si scrive il proprio ciclo di addestramento. Ma invece di calcolare e riportare la metrica alla fine di ogni epoca, questa volta accumulerai tutti i batch con [`add_batch`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=add_batch#datasets.Metric.add_batch) e calcolerai la metrica alla fine.
```py
>>> metric = load_metric("accuracy")
diff --git a/docs/source/ja/_toctree.yml b/docs/source/ja/_toctree.yml
index 2947a20c6469..df686b475dab 100644
--- a/docs/source/ja/_toctree.yml
+++ b/docs/source/ja/_toctree.yml
@@ -29,9 +29,12 @@
title: LLM を使用した生成
title: Tutorials
- sections:
- - local: generation_strategies
- title: 生成戦略をカスタマイズする
- title: Generation
+ - isExpanded: false
+ sections:
+ - local: generation_strategies
+ title: 生成戦略をカスタマイズする
+ title: Generation
+ title: Task Guides
- sections:
- local: fast_tokenizers
title: 🤗 トークナイザーの高速トークナイザーを使用する
@@ -135,23 +138,90 @@
title: モデルトレーニングの解剖学
title: コンセプチュアルガイド
- sections:
- - local: internal/modeling_utils
- title: カスタムレイヤーとユーティリティ
- - local: internal/pipelines_utils
- title: パイプライン用のユーティリティ
- - local: internal/tokenization_utils
- title: ト=ークナイザー用のユーティリティ
- - local: internal/trainer_utils
- title: トレーナー用ユーティリティ
- - local: internal/generation_utils
- title: 発電用ユーティリティ
- - local: internal/image_processing_utils
- title: 画像プロセッサ用ユーティリティ
- - local: internal/audio_utils
- title: オーディオ処理用のユーティリティ
- - local: internal/file_utils
- title: 一般公共事業
- - local: internal/time_series_utils
- title: 時系列用のユーティリティ
- title: 内部ヘルパー
+ - sections:
+ - local: main_classes/agent
+ title: エージェントとツール
+ - local: model_doc/auto
+ title: Auto Classes
+ - local: main_classes/callback
+ title: コールバック
+ - local: main_classes/configuration
+ title: 構成
+ - local: main_classes/data_collator
+ title: データ照合者
+ - local: main_classes/keras_callbacks
+ title: Keras コールバック
+ - local: main_classes/logging
+ title: ロギング
+ - local: main_classes/model
+ title: モデル
+ - local: main_classes/text_generation
+ title: テキストの生成
+ - local: main_classes/onnx
+ title: ONNX
+ - local: main_classes/optimizer_schedules
+ title: 最適化
+ - local: main_classes/output
+ title: モデルの出力
+ - local: main_classes/pipelines
+ title: パイプライン
+ - local: main_classes/processors
+ title: プロセッサー
+ - local: main_classes/quantization
+ title: 量子化
+ - local: main_classes/tokenizer
+ title: トークナイザー
+ - local: main_classes/trainer
+ title: トレーナー
+ - local: main_classes/deepspeed
+ title: ディープスピードの統合
+ - local: main_classes/feature_extractor
+ title: 特徴抽出器
+ - local: main_classes/image_processor
+ title: 画像処理プロセッサ
+ title: 主要なクラス
+ - sections:
+ - isExpanded: false
+ sections:
+ - local: model_doc/albert
+ title: ALBERT
+ title: 文章モデル
+ - isExpanded: false
+ sections:
+ - local: model_doc/audio-spectrogram-transformer
+ title: Audio Spectrogram Transformer
+ title: 音声モデル
+ - isExpanded: false
+ sections:
+ - local: model_doc/align
+ title: ALIGN
+ - local: model_doc/altclip
+ title: AltCLIP
+ title: マルチモーダルモデル
+ - isExpanded: false
+ sections:
+ - local: model_doc/autoformer
+ title: Autoformer
+ title: 時系列モデル
+ title: モデル
+ - sections:
+ - local: internal/modeling_utils
+ title: カスタムレイヤーとユーティリティ
+ - local: internal/pipelines_utils
+ title: パイプライン用のユーティリティ
+ - local: internal/tokenization_utils
+ title: ト=ークナイザー用のユーティリティ
+ - local: internal/trainer_utils
+ title: トレーナー用ユーティリティ
+ - local: internal/generation_utils
+ title: 発電用ユーティリティ
+ - local: internal/image_processing_utils
+ title: 画像プロセッサ用ユーティリティ
+ - local: internal/audio_utils
+ title: オーディオ処理用のユーティリティ
+ - local: internal/file_utils
+ title: 一般公共事業
+ - local: internal/time_series_utils
+ title: 時系列用のユーティリティ
+ title: 内部ヘルパー
title: API
diff --git a/docs/source/ja/create_a_model.md b/docs/source/ja/create_a_model.md
index d39ceba528d7..086108733419 100644
--- a/docs/source/ja/create_a_model.md
+++ b/docs/source/ja/create_a_model.md
@@ -114,7 +114,7 @@ Once you are satisfied with your model configuration, you can save it with [`Pre
次のステップは、[モデル](main_classes/models)を作成することです。モデル(アーキテクチャとも緩く言われることがあります)は、各レイヤーが何をしているか、どの操作が行われているかを定義します。構成からの `num_hidden_layers` のような属性はアーキテクチャを定義するために使用されます。
すべてのモデルは [`PreTrainedModel`] をベースクラスとし、入力埋め込みのリサイズやセルフアテンションヘッドのプルーニングなど、共通のメソッドがいくつかあります。
-さらに、すべてのモデルは [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html)、[`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)、または [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/flax.linen.html#module) のいずれかのサブクラスでもあります。つまり、モデルはそれぞれのフレームワークの使用法と互換性があります。
+さらに、すべてのモデルは [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html)、[`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)、または [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html) のいずれかのサブクラスでもあります。つまり、モデルはそれぞれのフレームワークの使用法と互換性があります。
diff --git a/docs/source/ja/hpo_train.md b/docs/source/ja/hpo_train.md
index 46a22550bb46..85da3616f80e 100644
--- a/docs/source/ja/hpo_train.md
+++ b/docs/source/ja/hpo_train.md
@@ -105,7 +105,7 @@ Wandbについては、[object_parameter](https://docs.wandb.ai/guides/sweeps/co
... config=config,
... cache_dir=model_args.cache_dir,
... revision=model_args.model_revision,
-... use_auth_token=True if model_args.use_auth_token else None,
+... token=True if model_args.use_auth_token else None,
... )
```
diff --git a/docs/source/ja/main_classes/agent.md b/docs/source/ja/main_classes/agent.md
new file mode 100644
index 000000000000..290f3b5b8c72
--- /dev/null
+++ b/docs/source/ja/main_classes/agent.md
@@ -0,0 +1,105 @@
+
+
+# エージェントとツール
+
+
+
+Transformers Agents は実験的な API であり、いつでも変更される可能性があります。エージェントから返される結果
+API または基礎となるモデルは変更される傾向があるため、変更される可能性があります。
+
+
+
+エージェントとツールの詳細については、[入門ガイド](../transformers_agents) を必ずお読みください。このページ
+基礎となるクラスの API ドキュメントが含まれています。
+
+## エージェント
+
+私たちは 3 種類のエージェントを提供します。[`HfAgent`] はオープンソース モデルの推論エンドポイントを使用し、[`LocalAgent`] は選択したモデルをローカルで使用し、[`OpenAiAgent`] は OpenAI クローズド モデルを使用します。
+
+### HfAgent
+
+[[autodoc]] HfAgent
+
+### LocalAgent
+
+[[autodoc]] LocalAgent
+
+### OpenAiAgent
+
+[[autodoc]] OpenAiAgent
+
+### AzureOpenAiAgent
+
+[[autodoc]] AzureOpenAiAgent
+
+### Agent
+
+[[autodoc]] Agent
+ - chat
+ - run
+ - prepare_for_new_chat
+
+## Tools
+
+### load_tool
+
+[[autodoc]] load_tool
+
+### Tool
+
+[[autodoc]] Tool
+
+### PipelineTool
+
+[[autodoc]] PipelineTool
+
+### RemoteTool
+
+[[autodoc]] RemoteTool
+
+### launch_gradio_demo
+
+[[autodoc]] launch_gradio_demo
+
+## エージェントの種類
+
+エージェントはツール間であらゆる種類のオブジェクトを処理できます。ツールは完全にマルチモーダルであるため、受け取りと返品が可能です
+テキスト、画像、オーディオ、ビデオなどのタイプ。ツール間の互換性を高めるためだけでなく、
+これらの戻り値を ipython (jupyter、colab、ipython ノートブックなど) で正しくレンダリングするには、ラッパー クラスを実装します。
+このタイプの周り。
+
+ラップされたオブジェクトは最初と同じように動作し続けるはずです。テキストオブジェクトは依然として文字列または画像として動作する必要があります
+オブジェクトは依然として `PIL.Image` として動作するはずです。
+
+これらのタイプには、次の 3 つの特定の目的があります。
+
+- 型に対して `to_raw` を呼び出すと、基になるオブジェクトが返されるはずです
+- 型に対して `to_string` を呼び出すと、オブジェクトを文字列として返す必要があります。`AgentText` の場合は文字列になる可能性があります。
+ ただし、他のインスタンスのオブジェクトのシリアル化されたバージョンのパスになります。
+- ipython カーネルで表示すると、オブジェクトが正しく表示されるはずです
+
+### AgentText
+
+[[autodoc]] transformers.tools.agent_types.AgentText
+
+### AgentImage
+
+[[autodoc]] transformers.tools.agent_types.AgentImage
+
+### AgentAudio
+
+[[autodoc]] transformers.tools.agent_types.AgentAudio
diff --git a/docs/source/ja/main_classes/callback.md b/docs/source/ja/main_classes/callback.md
new file mode 100644
index 000000000000..3ea4938841e3
--- /dev/null
+++ b/docs/source/ja/main_classes/callback.md
@@ -0,0 +1,135 @@
+
+
+
+# コールバック数
+
+コールバックは、PyTorch のトレーニング ループの動作をカスタマイズできるオブジェクトです。
+トレーニング ループを検査できる [`Trainer`] (この機能は TensorFlow にはまだ実装されていません)
+状態を確認し (進捗レポート、TensorBoard または他の ML プラットフォームへのログ記録など)、決定を下します (初期段階など)。
+停止中)。
+
+コールバックは、返される [`TrainerControl`] オブジェクトを除けば、「読み取り専用」のコード部分です。
+トレーニング ループ内では何も変更できません。トレーニング ループの変更が必要なカスタマイズの場合は、次のことを行う必要があります。
+[`Trainer`] をサブクラス化し、必要なメソッドをオーバーライドします (例については、[trainer](trainer) を参照してください)。
+
+デフォルトでは、`TrainingArguments.report_to` は `"all"` に設定されているため、[`Trainer`] は次のコールバックを使用します。
+
+- [`DefaultFlowCallback`] は、ログ記録、保存、評価のデフォルトの動作を処理します。
+- [`PrinterCallback`] または [`ProgressCallback`] で進行状況を表示し、
+ ログ (最初のログは、[`TrainingArguments`] を通じて tqdm を非アクティブ化する場合に使用され、そうでない場合に使用されます)
+ 2番目です)。
+- [`~integrations.TensorBoardCallback`] (PyTorch >= 1.4 を介して) tensorboard にアクセスできる場合
+ またはテンソルボードX)。
+- [`~integrations.WandbCallback`] [wandb](https://www.wandb.com/) がインストールされている場合。
+- [`~integrations.CometCallback`] [comet_ml](https://www.comet.ml/site/) がインストールされている場合。
+- [mlflow](https://www.mlflow.org/) がインストールされている場合は [`~integrations.MLflowCallback`]。
+- [`~integrations.NeptuneCallback`] [neptune](https://neptune.ai/) がインストールされている場合。
+- [`~integrations.AzureMLCallback`] [azureml-sdk](https://pypi.org/project/azureml-sdk/) の場合
+ インストールされています。
+- [`~integrations.CodeCarbonCallback`] [codecarbon](https://pypi.org/project/codecarbon/) の場合
+ インストールされています。
+- [`~integrations.ClearMLCallback`] [clearml](https://github.com/allegroai/clearml) がインストールされている場合。
+- [`~integrations.DagsHubCallback`] [dagshub](https://dagshub.com/) がインストールされている場合。
+- [`~integrations.FlyteCallback`] [flyte](https://flyte.org/) がインストールされている場合。
+- [`~integrations.DVCLiveCallback`] [dvclive](https://www.dvc.org/doc/dvclive) がインストールされている場合。
+
+パッケージがインストールされているが、付随する統合を使用したくない場合は、`TrainingArguments.report_to` を、使用したい統合のみのリストに変更できます (例: `["azure_ml", "wandb"]`) 。
+
+コールバックを実装するメインクラスは [`TrainerCallback`] です。それは、
+[`TrainingArguments`] は [`Trainer`] をインスタンス化するために使用され、それにアクセスできます。
+[`TrainerState`] を介してトレーナーの内部状態を取得し、トレーニング ループ上でいくつかのアクションを実行できます。
+[`TrainerControl`]。
+
+## 利用可能なコールバック
+
+ライブラリで利用可能な [`TrainerCallback`] のリストは次のとおりです。
+
+[[autodoc]] integrations.CometCallback
+ - setup
+
+[[autodoc]] DefaultFlowCallback
+
+[[autodoc]] PrinterCallback
+
+[[autodoc]] ProgressCallback
+
+[[autodoc]] EarlyStoppingCallback
+
+[[autodoc]] integrations.TensorBoardCallback
+
+[[autodoc]] integrations.WandbCallback
+ - setup
+
+[[autodoc]] integrations.MLflowCallback
+ - setup
+
+[[autodoc]] integrations.AzureMLCallback
+
+[[autodoc]] integrations.CodeCarbonCallback
+
+[[autodoc]] integrations.NeptuneCallback
+
+[[autodoc]] integrations.ClearMLCallback
+
+[[autodoc]] integrations.DagsHubCallback
+
+[[autodoc]] integrations.FlyteCallback
+
+[[autodoc]] integrations.DVCLiveCallback
+ - setup
+
+## TrainerCallback
+
+[[autodoc]] TrainerCallback
+
+以下は、カスタム コールバックを PyTorch [`Trainer`] に登録する方法の例です。
+
+```python
+class MyCallback(TrainerCallback):
+ "A callback that prints a message at the beginning of training"
+
+ def on_train_begin(self, args, state, control, **kwargs):
+ print("Starting training")
+
+
+trainer = Trainer(
+ model,
+ args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ callbacks=[MyCallback], # We can either pass the callback class this way or an instance of it (MyCallback())
+)
+```
+
+コールバックを登録する別の方法は、次のように `trainer.add_callback()` を呼び出すことです。
+
+```python
+trainer = Trainer(...)
+trainer.add_callback(MyCallback)
+# Alternatively, we can pass an instance of the callback class
+trainer.add_callback(MyCallback())
+```
+
+## TrainerState
+
+[[autodoc]] TrainerState
+
+## TrainerControl
+
+[[autodoc]] TrainerControl
+
+
diff --git a/docs/source/ja/main_classes/configuration.md b/docs/source/ja/main_classes/configuration.md
new file mode 100644
index 000000000000..7fab5269e204
--- /dev/null
+++ b/docs/source/ja/main_classes/configuration.md
@@ -0,0 +1,31 @@
+
+
+# 構成
+
+基本クラス [`PretrainedConfig`] は、設定をロード/保存するための一般的なメソッドを実装します。
+ローカル ファイルまたはディレクトリから、またはライブラリ (ダウンロードされた) によって提供される事前トレーニング済みモデル構成から
+HuggingFace の AWS S3 リポジトリから)。
+
+各派生構成クラスはモデル固有の属性を実装します。すべての構成クラスに存在する共通の属性は次のとおりです。
+`hidden_size`、`num_attention_heads`、および `num_hidden_layers`。テキスト モデルはさらに以下を実装します。
+`vocab_size`。
+
+## PretrainedConfig
+
+[[autodoc]] PretrainedConfig
+ - push_to_hub
+ - all
diff --git a/docs/source/ja/main_classes/data_collator.md b/docs/source/ja/main_classes/data_collator.md
new file mode 100644
index 000000000000..c37f1aeef4d1
--- /dev/null
+++ b/docs/source/ja/main_classes/data_collator.md
@@ -0,0 +1,67 @@
+
+
+# データ照合者
+
+データ照合器は、データセット要素のリストを入力として使用してバッチを形成するオブジェクトです。これらの要素は、
+`train_dataset` または `eval_dataset` の要素と同じ型。
+
+バッチを構築できるようにするために、データ照合者は何らかの処理 (パディングなど) を適用する場合があります。そのうちのいくつかは(
+[`DataCollatorForLanguageModeling`]) ランダムなデータ拡張 (ランダム マスキングなど) も適用します
+形成されたバッチ上で。
+
+使用例は、[サンプル スクリプト](../examples) または [サンプル ノートブック](../notebooks) にあります。
+
+## Default data collator
+
+[[autodoc]] data.data_collator.default_data_collator
+
+## DefaultDataCollator
+
+[[autodoc]] data.data_collator.DefaultDataCollator
+
+## DataCollatorWithPadding
+
+[[autodoc]] data.data_collator.DataCollatorWithPadding
+
+## DataCollatorForTokenClassification
+
+[[autodoc]] data.data_collator.DataCollatorForTokenClassification
+
+## DataCollatorForSeq2Seq
+
+[[autodoc]] data.data_collator.DataCollatorForSeq2Seq
+
+## DataCollatorForLanguageModeling
+
+[[autodoc]] data.data_collator.DataCollatorForLanguageModeling
+ - numpy_mask_tokens
+ - tf_mask_tokens
+ - torch_mask_tokens
+
+## DataCollatorForWholeWordMask
+
+[[autodoc]] data.data_collator.DataCollatorForWholeWordMask
+ - numpy_mask_tokens
+ - tf_mask_tokens
+ - torch_mask_tokens
+
+## DataCollatorForPermutationLanguageModeling
+
+[[autodoc]] data.data_collator.DataCollatorForPermutationLanguageModeling
+ - numpy_mask_tokens
+ - tf_mask_tokens
+ - torch_mask_tokens
diff --git a/docs/source/ja/main_classes/deepspeed.md b/docs/source/ja/main_classes/deepspeed.md
new file mode 100644
index 000000000000..3e65dd21bcf1
--- /dev/null
+++ b/docs/source/ja/main_classes/deepspeed.md
@@ -0,0 +1,2255 @@
+
+
+# DeepSpeed Integration
+
+[DeepSpeed](https://github.com/microsoft/DeepSpeed) は、[ZeRO 論文](https://arxiv.org/abs/1910.02054) で説明されているすべてを実装します。現在、次のものを完全にサポートしています。
+
+1. オプティマイザーの状態分割 (ZeRO ステージ 1)
+2. 勾配分割 (ZeRO ステージ 2)
+3. パラメーターの分割 (ZeRO ステージ 3)
+4. カスタム混合精度トレーニング処理
+5. 一連の高速 CUDA 拡張ベースのオプティマイザー
+6. CPU および NVMe への ZeRO オフロード
+
+ZeRO-Offload には独自の専用ペーパーがあります: [ZeRO-Offload: Democratizing Billion-Scale Model Training](https://arxiv.org/abs/2101.06840)。 NVMe サポートについては、論文 [ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning](https://arxiv.org/abs/2104.07857)。
+
+DeepSpeed ZeRO-2 は、その機能が推論には役に立たないため、主にトレーニングのみに使用されます。
+
+DeepSpeed ZeRO-3 は、巨大なモデルを複数の GPU にロードできるため、推論にも使用できます。
+単一の GPU では不可能です。
+
+🤗 Transformers は、2 つのオプションを介して [DeepSpeed](https://github.com/microsoft/DeepSpeed) を統合します。
+
+1. [`Trainer`] によるコア DeepSpeed 機能の統合。何でもやってくれるタイプです
+ 統合の場合 - カスタム構成ファイルを指定するか、テンプレートを使用するだけで、他に何もする必要はありません。たいていの
+ このドキュメントではこの機能に焦点を当てています。
+2. [`Trainer`] を使用せず、DeepSpeed を統合した独自のトレーナーを使用したい場合
+ `from_pretrained` や `from_config` などのコア機能には、重要な機能の統合が含まれています。
+ ZeRO ステージ 3 以降の `zero.Init`などの DeepSpeed の部分。この機能を活用するには、次のドキュメントをお読みください。
+ [非トレーナー DeepSpeed 統合](#nontrainer-deepspeed-integration)。
+
+統合されているもの:
+
+トレーニング:
+
+1. DeepSpeed ZeRO トレーニングは、ZeRO-Infinity (CPU および NVME オフロード) を使用して完全な ZeRO ステージ 1、2、および 3 をサポートします。
+
+推論:
+
+1. DeepSpeed ZeRO Inference は、ZeRO-Infinity による ZeRO ステージ 3 をサポートします。トレーニングと同じ ZeRO プロトコルを使用しますが、
+ オプティマイザと lr スケジューラは使用せず、ステージ 3 のみが関連します。詳細については、以下を参照してください。
+ [ゼロ推論](#zero-inference)。
+
+DeepSpeed Inference もあります。これは、Tensor Parallelism の代わりに Tensor Parallelism を使用するまったく異なるテクノロジーです。
+ZeRO (近日公開)。
+
+
+
+
+## Trainer Deepspeed Integration
+
+
+
+
+### Installation
+
+pypi 経由でライブラリをインストールします。
+```bash
+pip install deepspeed
+```
+
+または`tansformers`, `extras`経由:
+
+```bash
+pip install transformers[deepspeed]
+```
+
+または、[DeepSpeed の GitHub ページ](https://github.com/microsoft/deepspeed#installation) で詳細を確認してください。
+[高度なインストール](https://www.deepspeed.ai/tutorials/advanced-install/)。
+
+それでもビルドに苦労する場合は、まず [CUDA 拡張機能のインストール ノート](trainer#cuda-extension-installation-notes) を必ず読んでください。
+
+拡張機能を事前ビルドせず、実行時に拡張機能がビルドされることに依存しており、上記の解決策をすべて試した場合
+それが役に立たなかった場合、次に試すべきことは、モジュールをインストールする前にモジュールを事前にビルドすることです。
+
+DeepSpeed のローカル ビルドを作成するには:
+
+```bash
+git clone https://github.com/microsoft/DeepSpeed/
+cd DeepSpeed
+rm -rf build
+TORCH_CUDA_ARCH_LIST="8.6" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 pip install . \
+--global-option="build_ext" --global-option="-j8" --no-cache -v \
+--disable-pip-version-check 2>&1 | tee build.log
+```
+
+NVMe オフロードを使用する場合は、上記の手順に`DS_BUILD_AIO=1`を含める必要があります (また、
+*libaio-dev* システム全体にインストールします)。
+
+`TORCH_CUDA_ARCH_LIST` を編集して、使用する GPU カードのアーキテクチャのコードを挿入します。すべてを仮定すると
+あなたのカードは同じで、次の方法でアーチを取得できます。
+
+```bash
+CUDA_VISIBLE_DEVICES=0 python -c "import torch; print(torch.cuda.get_device_capability())"
+```
+
+したがって、`8, 6`を取得した場合は、`TORCH_CUDA_ARCH_LIST="8.6"`を使用します。複数の異なるカードをお持ちの場合は、すべてをリストすることができます
+それらのうち、`TORCH_CUDA_ARCH_LIST="6.1;8.6"`が好きです
+
+複数のマシンで同じセットアップを使用する必要がある場合は、バイナリ ホイールを作成します。
+
+```bash
+git clone https://github.com/microsoft/DeepSpeed/
+cd DeepSpeed
+rm -rf build
+TORCH_CUDA_ARCH_LIST="8.6" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 \
+python setup.py build_ext -j8 bdist_wheel
+```
+
+`dist/deepspeed-0.3.13+8cd046f-cp38-cp38-linux_x86_64.whl`のようなものが生成されるので、これをインストールできます
+`pip install deepspeed-0.3.13+8cd046f-cp38-cp38-linux_x86_64.whl`としてローカルまたは他のマシンにインストールします。
+
+繰り返しますが、`TORCH_CUDA_ARCH_LIST`をターゲット アーキテクチャに合わせて調整することを忘れないでください。
+
+NVIDIA GPU の完全なリストと、それに対応する **コンピューティング機能** (この記事の Arch と同じ) を見つけることができます。
+コンテキスト) [ここ](https://developer.nvidia.com/cuda-gpus)。
+
+以下を使用して、pytorch が構築されたアーチを確認できます。
+
+```bash
+python -c "import torch; print(torch.cuda.get_arch_list())"
+```
+
+ここでは、インストールされている GPU の 1 つのアーチを見つける方法を説明します。たとえば、GPU 0 の場合:
+
+```bash
+CUDA_VISIBLE_DEVICES=0 python -c "import torch; \
+print(torch.cuda.get_device_properties(torch.device('cuda')))"
+```
+
+出力が次の場合:
+
+```bash
+_CudaDeviceProperties(name='GeForce RTX 3090', major=8, minor=6, total_memory=24268MB, multi_processor_count=82)
+```
+
+そうすれば、このカードのアーチが`8.6`であることがわかります。
+
+`TORCH_CUDA_ARCH_LIST` を完全に省略することもできます。そうすれば、ビルド プログラムが自動的にクエリを実行します。
+ビルドが行われる GPU のアーキテクチャ。これは、ターゲット マシンの GPU と一致する場合もあれば、一致しない場合もあります。
+目的のアーチを明示的に指定することをお勧めします。
+
+提案されたことをすべて試してもまだビルドの問題が発生する場合は、GitHub の問題に進んでください。
+[ディープスピード](https://github.com/microsoft/DeepSpeed/issues)、
+
+
+
+### Deployment with multiple GPUs
+
+DeepSpeed 統合をデプロイするには、[`Trainer`] コマンド ライン引数を調整して新しい引数 `--deepspeed ds_config.json` を含めます。ここで、`ds_config.json` は DeepSpeed 構成ファイルです。
+ [こちら](https://www.deepspeed.ai/docs/config-json/)に記載されています。ファイル名はあなた次第です。
+ DeepSpeed の`add_config_arguments`ユーティリティを使用して、必要なコマンド ライン引数をコードに追加することをお勧めします。
+ 詳細については、[DeepSpeed の引数解析](https://deepspeed.readthedocs.io/en/latest/initialize.html#argument-parsing) ドキュメントを参照してください。
+
+ここで選択したランチャーを使用できます。 pytorch ランチャーを引き続き使用できます。
+
+```bash
+torch.distributed.run --nproc_per_node=2 your_program.py --deepspeed ds_config.json
+```
+
+または、`deepspeed`によって提供されるランチャーを使用します。
+
+```bash
+deepspeed --num_gpus=2 your_program.py --deepspeed ds_config.json
+```
+
+ご覧のとおり、引数は同じではありませんが、ほとんどのニーズではどちらでも機能します。の
+さまざまなノードと GPU を構成する方法の詳細については、[こちら](https://www.deepspeed.ai/getting-started/#resource-configuration-multi-node) を参照してください。
+
+`deepspeed`ランチャーを使用し、利用可能なすべての GPU を使用したい場合は、`--num_gpus`フラグを省略するだけです。
+
+以下は、利用可能なすべての GPU をデプロイする DeepSpeed で`run_translation.py`を実行する例です。
+
+```bash
+deepspeed examples/pytorch/translation/run_translation.py \
+--deepspeed tests/deepspeed/ds_config_zero3.json \
+--model_name_or_path t5-small --per_device_train_batch_size 1 \
+--output_dir output_dir --overwrite_output_dir --fp16 \
+--do_train --max_train_samples 500 --num_train_epochs 1 \
+--dataset_name wmt16 --dataset_config "ro-en" \
+--source_lang en --target_lang ro
+```
+
+DeepSpeed のドキュメントには、`--deepspeed --deepspeed_config ds_config.json`が表示される可能性が高いことに注意してください。
+DeepSpeed 関連の引数が 2 つありますが、簡単にするためであり、処理すべき引数がすでに非常に多いためです。
+この 2 つを 1 つの引数に結合しました。
+
+実際の使用例については、この [投稿](https://github.com/huggingface/transformers/issues/8771#issuecomment-759248400) を参照してください。
+
+
+
+
+### Deployment with one GPU
+
+1 つの GPU で DeepSpeed をデプロイするには、[`Trainer`] コマンド ライン引数を次のように調整します。
+
+```bash
+deepspeed --num_gpus=1 examples/pytorch/translation/run_translation.py \
+--deepspeed tests/deepspeed/ds_config_zero2.json \
+--model_name_or_path t5-small --per_device_train_batch_size 1 \
+--output_dir output_dir --overwrite_output_dir --fp16 \
+--do_train --max_train_samples 500 --num_train_epochs 1 \
+--dataset_name wmt16 --dataset_config "ro-en" \
+--source_lang en --target_lang ro
+```
+
+これは複数の GPU の場合とほぼ同じですが、ここでは、DeepSpeed に 1 つの GPU だけを使用するように明示的に指示します。
+`--num_gpus=1`。デフォルトでは、DeepSpeed は指定されたノード上で認識できるすべての GPU をデプロイします。起動する GPU が 1 つだけの場合
+の場合、この引数は必要ありません。次の [ドキュメント](https://www.deepspeed.ai/getting-started/#resource-configuration-multi-node) では、ランチャー オプションについて説明しています。
+
+1 つの GPU だけで DeepSpeed を使用したいのはなぜですか?
+
+1. 一部の計算とメモリをホストの CPU と RAM に委任できる ZeRO オフロード機能を備えているため、
+ モデルのニーズに合わせてより多くの GPU リソースを残しておきます。より大きなバッチ サイズ、または非常に大きなモデルのフィッティングを可能にする
+ 普通は合わないでしょう。
+2. スマートな GPU メモリ管理システムを提供し、メモリの断片化を最小限に抑えます。
+ より大きなモデルとデータ バッチ。
+
+次に構成について詳しく説明しますが、単一の GPU で大幅な改善を実現するための鍵は次のとおりです。
+DeepSpeed を使用するには、構成ファイルに少なくとも次の構成が必要です。
+
+```json
+{
+ "zero_optimization": {
+ "stage": 2,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "allgather_partitions": true,
+ "allgather_bucket_size": 2e8,
+ "reduce_scatter": true,
+ "reduce_bucket_size": 2e8,
+ "overlap_comm": true,
+ "contiguous_gradients": true
+ }
+}
+```
+
+これにより、オプティマイザーのオフロードやその他の重要な機能が有効になります。バッファ サイズを試してみるとよいでしょう。
+詳細については、以下のディスカッションを参照してください。
+
+このタイプのデプロイメントの実際的な使用例については、この [投稿](https://github.com/huggingface/transformers/issues/8771#issuecomment-759176685) を参照してください。
+
+このドキュメントで詳しく説明されているように、CPU および NVMe オフロードを備えた ZeRO-3 を試すこともできます。
+
+ノート:
+
+- GPU 0 とは異なる特定の GPU で実行する必要がある場合、`CUDA_VISIBLE_DEVICES` を使用して制限することはできません。
+ 利用可能な GPU の表示範囲。代わりに、次の構文を使用する必要があります。
+
+ ```bash
+ deepspeed --include localhost:1 examples/pytorch/translation/run_translation.py ...
+ ```
+
+ この例では、DeepSpeed に GPU 1 (2 番目の GPU) を使用するように指示します。
+
+
+
+### 複数のノードを使用したデプロイメント
+
+このセクションの情報は DeepSpeed 統合に固有のものではなく、あらゆるマルチノード プログラムに適用できます。ただし、DeepSpeed は、SLURM 環境でない限り、他のランチャーよりも使いやすい`deepspeed`ランチャーを提供します。
+
+このセクションでは、それぞれ 8 GPU を備えた 2 つのノードがあると仮定します。また、最初のノードには `ssh hostname1` を使用して、2 番目のノードには `ssh hostname2` を使用して接続できます。両方ともパスワードなしでローカルの ssh 経由で相互に接続できる必要があります。もちろん、これらのホスト (ノード) 名を、作業している実際のホスト名に変更する必要があります。
+
+#### The torch.distributed.run launcher
+
+
+たとえば、`torch.distributed.run` を使用するには、次のようにします。
+
+```bash
+python -m torch.distributed.run --nproc_per_node=8 --nnode=2 --node_rank=0 --master_addr=hostname1 \
+--master_port=9901 your_program.py --deepspeed ds_config.json
+```
+
+各ノードに SSH で接続し、それぞれのノードで同じコマンドを実行する必要があります。急ぐ必要はありません。ランチャーは両方のノードが同期するまで待機します。
+
+詳細については、[torchrun](https://pytorch.org/docs/stable/elastic/run.html) を参照してください。ちなみに、これは pytorch の数バージョン前の`torch.distributed.launch`を置き換えたランチャーでもあります。
+
+#### ディープスピード ランチャー
+
+代わりに`deepspeed`ランチャーを使用するには、まず`hostfile`ファイルを作成する必要があります。
+
+```
+hostname1 slots=8
+hostname2 slots=8
+```
+
+そして、次のように起動できます。
+
+```bash
+deepspeed --num_gpus 8 --num_nodes 2 --hostfile hostfile --master_addr hostname1 --master_port=9901 \
+your_program.py --deepspeed ds_config.json
+```
+
+`torch.distributed.run`ランチャーとは異なり、`deepspeed`は両方のノードでこのコマンドを自動的に起動します。
+
+詳細については、[リソース構成 (マルチノード)](https://www.deepspeed.ai/getting-started/#resource-configuration-multi-node) を参照してください。
+
+#### Launching in a SLURM environment
+
+SLURM 環境では、次のアプローチを使用できます。以下は、特定の SLURM 環境に適合させるために必要な slurm スクリプト `launch.slurm` です。
+
+```bash
+#SBATCH --job-name=test-nodes # name
+#SBATCH --nodes=2 # nodes
+#SBATCH --ntasks-per-node=1 # crucial - only 1 task per dist per node!
+#SBATCH --cpus-per-task=10 # number of cores per tasks
+#SBATCH --gres=gpu:8 # number of gpus
+#SBATCH --time 20:00:00 # maximum execution time (HH:MM:SS)
+#SBATCH --output=%x-%j.out # output file name
+
+export GPUS_PER_NODE=8
+export MASTER_ADDR=$(scontrol show hostnames $SLURM_JOB_NODELIST | head -n 1)
+export MASTER_PORT=9901
+
+srun --jobid $SLURM_JOBID bash -c 'python -m torch.distributed.run \
+ --nproc_per_node $GPUS_PER_NODE --nnodes $SLURM_NNODES --node_rank $SLURM_PROCID \
+ --master_addr $MASTER_ADDR --master_port $MASTER_PORT \
+your_program.py --deepspeed ds_config.json'
+```
+
+あとは実行をスケジュールするだけです。
+```bash
+sbatch launch.slurm
+```
+
+#### Use of Non-shared filesystem
+
+デフォルトでは、DeepSpeed はマルチノード環境が共有ストレージを使用することを想定しています。これが当てはまらず、各ノードがローカル ファイルシステムしか参照できない場合は、設定ファイルを調整して [`checkpoint`_section](https://www.deepspeed.ai/docs/config-json/#) を含める必要があります。チェックポイント オプション) を次の設定で指定します。
+
+
+```json
+{
+ "checkpoint": {
+ "use_node_local_storage": true
+ }
+}
+```
+
+あるいは、[`Trainer`] の `--save_on_each_node` 引数を使用することもでき、上記の設定は自動的に追加されます。
+
+
+
+### Deployment in Notebooks
+
+ノートブックのセルをスクリプトとして実行する場合の問題は、依存する通常の`deepspeed`ランチャーがないことです。
+特定の設定では、それをエミュレートする必要があります。
+
+GPU を 1 つだけ使用している場合、DeepSpeed を使用するためにノートブック内のトレーニング コードを調整する必要がある方法は次のとおりです。
+
+```python
+# DeepSpeed requires a distributed environment even when only one process is used.
+# This emulates a launcher in the notebook
+import os
+
+os.environ["MASTER_ADDR"] = "localhost"
+os.environ["MASTER_PORT"] = "9994" # modify if RuntimeError: Address already in use
+os.environ["RANK"] = "0"
+os.environ["LOCAL_RANK"] = "0"
+os.environ["WORLD_SIZE"] = "1"
+
+# Now proceed as normal, plus pass the deepspeed config file
+training_args = TrainingArguments(..., deepspeed="ds_config_zero3.json")
+trainer = Trainer(...)
+trainer.train()
+```
+
+注: `...` は、関数に渡す通常の引数を表します。
+
+複数の GPU を使用する場合、DeepSpeed が動作するにはマルチプロセス環境を使用する必要があります。つまり、あなたは持っています
+その目的でランチャーを使用することはできませんが、これは、提示された分散環境をエミュレートすることによっては実現できません。
+このセクションの冒頭で。
+
+現在のディレクトリのノートブックにその場で構成ファイルを作成したい場合は、専用の
+セルの内容:
+
+```python no-style
+%%bash
+cat <<'EOT' > ds_config_zero3.json
+{
+ "fp16": {
+ "enabled": "auto",
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ },
+
+ "optimizer": {
+ "type": "AdamW",
+ "params": {
+ "lr": "auto",
+ "betas": "auto",
+ "eps": "auto",
+ "weight_decay": "auto"
+ }
+ },
+
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": "auto",
+ "warmup_max_lr": "auto",
+ "warmup_num_steps": "auto"
+ }
+ },
+
+ "zero_optimization": {
+ "stage": 3,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "offload_param": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "overlap_comm": true,
+ "contiguous_gradients": true,
+ "sub_group_size": 1e9,
+ "reduce_bucket_size": "auto",
+ "stage3_prefetch_bucket_size": "auto",
+ "stage3_param_persistence_threshold": "auto",
+ "stage3_max_live_parameters": 1e9,
+ "stage3_max_reuse_distance": 1e9,
+ "stage3_gather_16bit_weights_on_model_save": true
+ },
+
+ "gradient_accumulation_steps": "auto",
+ "gradient_clipping": "auto",
+ "steps_per_print": 2000,
+ "train_batch_size": "auto",
+ "train_micro_batch_size_per_gpu": "auto",
+ "wall_clock_breakdown": false
+}
+EOT
+```
+
+トレーニング スクリプトがノートブックのセルではなく通常のファイルにある場合は、次のようにして`deepspeed`を通常どおり起動できます。
+細胞からのシェル。たとえば、`run_translation.py` を使用するには、次のように起動します。
+
+```python no-style
+!git clone https://github.com/huggingface/transformers
+!cd transformers; deepspeed examples/pytorch/translation/run_translation.py ...
+```
+
+または、`%%bash` マジックを使用すると、シェル プログラムを実行するための複数行のコードを記述することができます。
+
+```python no-style
+%%bash
+
+git clone https://github.com/huggingface/transformers
+cd transformers
+deepspeed examples/pytorch/translation/run_translation.py ...
+```
+
+そのような場合、このセクションの最初に示したコードは必要ありません。
+
+注: `%%bash` マジックは優れていますが、現時点では出力をバッファリングするため、プロセスが終了するまでログは表示されません。
+完了します。
+
+
+
+### Configuration
+
+設定ファイルで使用できる DeepSpeed 設定オプションの完全なガイドについては、次を参照してください。
+[次のドキュメント](https://www.deepspeed.ai/docs/config-json/) にアクセスしてください。
+
+さまざまな実際のニーズに対応する数十の DeepSpeed 構成例を [DeepSpeedExamples] (https://github.com/microsoft/DeepSpeedExamples)で見つけることができます。
+リポジトリ:
+
+```bash
+git clone https://github.com/microsoft/DeepSpeedExamples
+cd DeepSpeedExamples
+find . -name '*json'
+```
+
+上記のコードを続けて、Lamb オプティマイザーを構成しようとしているとします。したがって、次の中から検索できます
+`.json` ファイルの例:
+
+```bash
+grep -i Lamb $(find . -name '*json')
+```
+
+さらにいくつかの例が [メイン リポジトリ](https://github.com/microsoft/DeepSpeed) にもあります。
+
+DeepSpeed を使用する場合は、常に DeepSpeed 構成ファイルを指定する必要がありますが、一部の構成パラメータには
+コマンドライン経由で設定します。微妙な違いについては、このガイドの残りの部分で説明します。
+
+DeepSpeed 構成ファイルがどのようなものかを理解するために、ZeRO ステージ 2 機能を有効にする構成ファイルを次に示します。
+オプティマイザー状態の CPU オフロードを含み、`AdamW`オプティマイザーと`WarmupLR`スケジューラーを使用し、混合を有効にします。
+`--fp16` が渡された場合の精度トレーニング:
+
+
+```json
+{
+ "fp16": {
+ "enabled": "auto",
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ },
+
+ "optimizer": {
+ "type": "AdamW",
+ "params": {
+ "lr": "auto",
+ "betas": "auto",
+ "eps": "auto",
+ "weight_decay": "auto"
+ }
+ },
+
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": "auto",
+ "warmup_max_lr": "auto",
+ "warmup_num_steps": "auto"
+ }
+ },
+
+ "zero_optimization": {
+ "stage": 2,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "allgather_partitions": true,
+ "allgather_bucket_size": 2e8,
+ "overlap_comm": true,
+ "reduce_scatter": true,
+ "reduce_bucket_size": 2e8,
+ "contiguous_gradients": true
+ },
+
+ "gradient_accumulation_steps": "auto",
+ "gradient_clipping": "auto",
+ "train_batch_size": "auto",
+ "train_micro_batch_size_per_gpu": "auto",
+}
+```
+
+プログラムを実行すると、DeepSpeed は [`Trainer`] から受け取った設定をログに記録します。
+コンソールに渡されるため、最終的にどのような設定が渡されたのかを正確に確認できます。
+
+
+
+### Passing Configuration
+
+このドキュメントで説明したように、通常、DeepSpeed 設定は json ファイルへのパスとして渡されますが、
+トレーニングの設定にコマンド ライン インターフェイスを使用せず、代わりにインスタンスを作成します。
+[`Trainer`] via [`TrainingArguments`] その後、`deepspeed` 引数については次のことができます
+ネストされた `dict` を渡します。これにより、その場で構成を作成でき、それを書き込む必要がありません。
+[`TrainingArguments`] に渡す前にファイル システムを変更します。
+
+要約すると、次のことができます。
+
+```python
+TrainingArguments(..., deepspeed="/path/to/ds_config.json")
+```
+
+または:
+
+```python
+ds_config_dict = dict(scheduler=scheduler_params, optimizer=optimizer_params)
+TrainingArguments(..., deepspeed=ds_config_dict)
+```
+
+
+
+
+### Shared Configuration
+
+
+
+このセクションは必読です
+
+
+
+[`Trainer`] と DeepSpeed の両方が正しく機能するには、いくつかの設定値が必要です。
+したがって、検出が困難なエラーにつながる可能性のある定義の競合を防ぐために、それらを構成することにしました。
+[`Trainer`] コマンドライン引数経由。
+
+さらに、一部の構成値はモデルの構成に基づいて自動的に導出されます。
+複数の値を手動で調整することを忘れないでください。[`Trainer`] に大部分を任せるのが最善です
+の設定を行います。
+
+したがって、このガイドの残りの部分では、特別な設定値 `auto` が表示されます。これを設定すると、
+正しい値または最も効率的な値に自動的に置き換えられます。これを無視することを自由に選択してください
+推奨事項を参照し、値を明示的に設定します。この場合、次の点に十分注意してください。
+[`Trainer`] 引数と DeepSpeed 設定は一致します。たとえば、同じものを使用していますか
+学習率、バッチサイズ、または勾配累積設定?これらが一致しない場合、トレーニングは非常に失敗する可能性があります
+方法を検出するのが難しい。あなたは警告を受けました。
+
+DeepSpeed のみに固有の値や、それに合わせて手動で設定する必要がある値が他にも複数あります。
+あなたの要望。
+
+独自のプログラムで、DeepSpeed 構成をマスターとして変更したい場合は、次のアプローチを使用することもできます。
+それに基づいて [`TrainingArguments`] を設定します。手順は次のとおりです。
+
+1. マスター構成として使用する DeepSpeed 構成を作成またはロードします
+2. これらの値に基づいて [`TrainingArguments`] オブジェクトを作成します
+
+`scheduler.params.total_num_steps`などの一部の値は次のように計算されることに注意してください。
+`train` 中に [`Trainer`] を実行しますが、もちろん自分で計算することもできます。
+
+
+
+### ZeRO
+
+[Zero Redundancy Optimizer (ZeRO)](https://www.deepspeed.ai/tutorials/zero/) は、DeepSpeed の主力製品です。それ
+3 つの異なるレベル (段階) の最適化をサポートします。最初のものは、スケーラビリティの観点からはあまり興味深いものではありません。
+したがって、このドキュメントではステージ 2 と 3 に焦点を当てます。ステージ 3 は、最新の ZeRO-Infinity の追加によってさらに改善されています。
+詳細については、DeepSpeed のドキュメントを参照してください。
+
+構成ファイルの `zero_optimization` セクションは最も重要な部分です ([docs](https://www.deepspeed.ai/docs/config-json/#zero-optimizations-for-fp16-training))。ここで定義します
+どの ZeRO ステージを有効にするか、そしてそれらをどのように構成するか。各パラメータの説明は、
+DeepSpeed のドキュメント。
+
+このセクションは、DeepSpeed 設定を介してのみ設定する必要があります - [`Trainer`] が提供します
+同等のコマンドライン引数はありません。
+
+注: 現在、DeepSpeed はパラメーター名を検証しないため、スペルを間違えると、デフォルト設定が使用されます。
+スペルが間違っているパラメータ。 DeepSpeed エンジンの起動ログ メッセージを見て、その値を確認できます。
+使用するつもりです。
+
+
+
+#### ZeRO-2 Config
+
+以下は、ZeRO ステージ 2 の構成例です。
+
+```json
+{
+ "zero_optimization": {
+ "stage": 2,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "allgather_partitions": true,
+ "allgather_bucket_size": 5e8,
+ "overlap_comm": true,
+ "reduce_scatter": true,
+ "reduce_bucket_size": 5e8,
+ "contiguous_gradients": true
+ }
+}
+```
+
+**性能調整:**
+
+- `offload_optimizer` を有効にすると、GPU RAM の使用量が削減されます (`"stage": 2` が必要です)
+- `"overlap_comm": true` は、GPU RAM 使用量の増加とトレードオフして、遅延をすべて削減します。 `overlap_comm`は 4.5x を使用します
+ `allgather_bucket_size`と`reduce_bucket_size`の値。したがって、5e8 に設定されている場合、9GB が必要になります。
+ フットプリント (`5e8 x 2Bytes x 2 x 4.5`)。したがって、8GB 以下の RAM を搭載した GPU を使用している場合、
+ OOM エラーが発生した場合は、これらのパラメータを`2e8`程度に減らす必要があり、それには 3.6GB が必要になります。やりたくなるでしょう
+ OOM に達し始めている場合は、より大容量の GPU でも同様です。
+- これらのバッファを減らすと、より多くの GPU RAM を利用するために通信速度を犠牲にすることになります。バッファサイズが小さいほど、
+ 通信が遅くなり、他のタスクで使用できる GPU RAM が増えます。したがって、バッチサイズが大きい場合は、
+ 重要なのは、トレーニング時間を少し遅らせることは良いトレードになる可能性があります。
+
+さらに、`deepspeed==0.4.4`には、次のコマンドで有効にできる新しいオプション`round_robin_gradients`が追加されました。
+
+```json
+{
+ "zero_optimization": {
+ "round_robin_gradients": true
+ }
+}
+```
+
+これは、きめ細かい勾配パーティショニングによってランク間の CPU メモリへの勾配コピーを並列化する、CPU オフロードのステージ 2 最適化です。パフォーマンスの利点は、勾配累積ステップ (オプティマイザー ステップ間のコピーの増加) または GPU 数 (並列処理の増加) に応じて増加します。
+
+
+
+#### ZeRO-3 Config
+
+以下は、ZeRO ステージ 3 の構成例です。
+
+```json
+{
+ "zero_optimization": {
+ "stage": 3,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "offload_param": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "overlap_comm": true,
+ "contiguous_gradients": true,
+ "sub_group_size": 1e9,
+ "reduce_bucket_size": "auto",
+ "stage3_prefetch_bucket_size": "auto",
+ "stage3_param_persistence_threshold": "auto",
+ "stage3_max_live_parameters": 1e9,
+ "stage3_max_reuse_distance": 1e9,
+ "stage3_gather_16bit_weights_on_model_save": true
+ }
+}
+```
+
+モデルまたはアクティベーションが GPU メモリに適合せず、CPU が未使用であるために OOM が発生している場合
+`"device": "cpu"` を使用してオプティマイザの状態とパラメータを CPU メモリにメモリオフロードすると、この制限が解決される可能性があります。
+CPU メモリにオフロードしたくない場合は、`device`エントリに`cpu`の代わりに`none`を使用します。オフロード先
+NVMe については後ほど説明します。
+
+固定メモリは、`pin_memory`を`true`に設定すると有効になります。この機能により、次のようなコストをかけてスループットを向上させることができます。
+他のプロセスが使用できるメモリが少なくなります。ピン留めされたメモリは、それを要求した特定のプロセスのために確保されます。
+通常、通常の CPU メモリよりもはるかに高速にアクセスされます。
+
+**性能調整:**
+
+- `stage3_max_live_parameters`: `1e9`
+- `stage3_max_reuse_distance`: `1e9`
+
+OOM に達した場合は、「stage3_max_live_parameters」と「stage3_max_reuse_ distance」を減らします。影響は最小限に抑えられるはずです
+アクティブ化チェックポイントを実行しない限り、パフォーマンスに影響します。 `1e9`は約 2GB を消費します。記憶を共有しているのは、
+`stage3_max_live_parameters` と `stage3_max_reuse_distance` なので、加算されるものではなく、合計で 2GB になります。
+
+`stage3_max_live_parameters` は、特定の時点で GPU 上に保持する完全なパラメータの数の上限です。
+時間。 「再利用距離」は、パラメータが将来いつ再び使用されるかを判断するために使用する指標です。
+`stage3_max_reuse_ distance`を使用して、パラメータを破棄するか保持するかを決定します。パラメータが
+近い将来に再び使用される予定 (`stage3_max_reuse_distance`未満) なので、通信を減らすために保持します。
+オーバーヘッド。これは、アクティベーション チェックポイントを有効にしている場合に非常に役立ちます。フォワード再計算が行われ、
+backward は単一レイヤー粒度を渡し、後方再計算までパラメータを前方再計算に保持したいと考えています。
+
+次の構成値は、モデルの非表示サイズによって異なります。
+
+- `reduce_bucket_size`: `hidden_size*hidden_size`
+- `stage3_prefetch_bucket_size`: `0.9 * hidden_size * hidden_size`
+- `stage3_param_persistence_threshold`: `10 * hidden_size`
+
+したがって、これらの値を `auto` に設定すると、[`Trainer`] が推奨される値を自動的に割り当てます。
+価値観。ただし、もちろん、これらを明示的に設定することもできます。
+
+`stage3_gather_16bit_weights_on_model_save` は、モデルの保存時にモデル fp16 の重み統合を有効にします。大きい
+モデルと複数の GPU の場合、これはメモリと速度の両方の点で高価な操作です。現在必須となっているのは、
+トレーニングを再開する予定です。この制限を取り除き、より便利にする今後のアップデートに注目してください。
+フレキシブル。
+
+ZeRO-2 構成から移行している場合は、`allgather_partitions`、`allgather_bucket_size`、および
+`reduce_scatter`設定パラメータは ZeRO-3 では使用されません。これらを設定ファイルに保存しておくと、
+無視される。
+
+- `sub_group_size`: `1e9`
+
+
+`sub_group_size` は、オプティマイザーのステップ中にパラメーターが更新される粒度を制御します。パラメータは次のとおりです。
+`sub_group_size` のバケットにグループ化され、各バケットは一度に 1 つずつ更新されます。 NVMeオフロードで使用する場合
+したがって、ZeRO-Infinity の `sub_group_size`は、モデルの状態が CPU に出入りする粒度を制御します。
+オプティマイザステップ中に NVMe からメモリを取得します。これにより、非常に大規模なモデルの CPU メモリ不足が防止されます。
+
+NVMe オフロードを使用しない場合は、`sub_group_size`をデフォルト値の *1e9* のままにすることができます。変更することもできます
+次の場合のデフォルト値:
+
+1. オプティマイザー ステップ中に OOM が発生する: `sub_group_size` を減らして、一時バッファーのメモリ使用量を削減します。
+2. オプティマイザー ステップに時間がかかります。`sub_group_size`を増やして、帯域幅の使用率を向上させます。
+ データバッファの増加。
+
+#### ZeRO-0 Config
+
+ステージ 0 と 1 はめったに使用されないため、最後にリストしていることに注意してください。
+
+ステージ 0 では、すべてのタイプのシャーディングを無効にし、DDP として DeepSpeed のみを使用します。次のコマンドでオンにできます。
+
+```json
+{
+ "zero_optimization": {
+ "stage": 0
+ }
+}
+```
+
+これにより、他に何も変更する必要がなく、基本的に ZeRO が無効になります。
+
+#### ZeRO-1 Config
+
+ステージ 1 は、ステージ 2 からグラデーション シャーディングを除いたものです。オプティマイザーの状態をシャード化するだけで、処理を少し高速化するためにいつでも試すことができます。
+
+```json
+{
+ "zero_optimization": {
+ "stage": 1
+ }
+}
+```
+
+
+
+### NVMe Support
+
+ZeRO-Infinity は、GPU と CPU メモリを NVMe メモリで拡張することで、非常に大規模なモデルのトレーニングを可能にします。おかげで
+スマート パーティショニングおよびタイリング アルゴリズムでは、各 GPU が非常に少量のデータを送受信する必要があります。
+オフロードにより、最新の NVMe がトレーニングに利用できる合計メモリ プールをさらに大きくするのに適していることが判明しました。
+プロセス。 ZeRO-Infinity には、ZeRO-3 が有効になっている必要があります。
+
+次の設定例では、NVMe がオプティマイザの状態とパラメータの両方をオフロードできるようにします。
+
+```json
+{
+ "zero_optimization": {
+ "stage": 3,
+ "offload_optimizer": {
+ "device": "nvme",
+ "nvme_path": "/local_nvme",
+ "pin_memory": true,
+ "buffer_count": 4,
+ "fast_init": false
+ },
+ "offload_param": {
+ "device": "nvme",
+ "nvme_path": "/local_nvme",
+ "pin_memory": true,
+ "buffer_count": 5,
+ "buffer_size": 1e8,
+ "max_in_cpu": 1e9
+ },
+ "aio": {
+ "block_size": 262144,
+ "queue_depth": 32,
+ "thread_count": 1,
+ "single_submit": false,
+ "overlap_events": true
+ },
+ "overlap_comm": true,
+ "contiguous_gradients": true,
+ "sub_group_size": 1e9,
+ "reduce_bucket_size": "auto",
+ "stage3_prefetch_bucket_size": "auto",
+ "stage3_param_persistence_threshold": "auto",
+ "stage3_max_live_parameters": 1e9,
+ "stage3_max_reuse_distance": 1e9,
+ "stage3_gather_16bit_weights_on_model_save": true
+ },
+}
+```
+
+オプティマイザの状態とパラメータの両方を NVMe にオフロードするか、どちらか 1 つだけをオフロードするか、まったくオフロードしないかを選択できます。たとえば、次の場合
+利用可能な CPU メモリが大量にある場合は、高速になるため、必ず CPU メモリのみにオフロードしてください (ヒント:
+*"device": "CPU"*)。
+
+[オプティマイザーの状態](https://www.deepspeed.ai/docs/config-json/#optimizer-offloading) と [パラメーター](https://www.deepspeed.ai/docs/config-json/#parameter-offloading)。
+
+`nvme_path`が実際に NVMe であることを確認してください。NVMe は通常のハードドライブまたは SSD で動作しますが、
+はるかに遅くなります。高速スケーラブルなトレーニングは、最新の NVMe 転送速度を念頭に置いて設計されました (この時点では
+書き込みでは、読み取り最大 3.5 GB/秒、書き込み最大 3 GB/秒のピーク速度が得られます)。
+
+最適な`aio`構成ブロックを見つけるには、ターゲット設定でベンチマークを実行する必要があります。
+[ここで説明](https://github.com/microsoft/DeepSpeed/issues/998)。
+
+
+
+
+#### ZeRO-2 vs ZeRO-3 Performance
+
+ZeRO-3 は、他のすべてが同じように構成されている場合、ZeRO-2 よりも遅くなる可能性があります。前者は収集する必要があるためです。
+ZeRO-2 の機能に加えてモデルの重み付けを行います。 ZeRO-2 がニーズを満たし、数個の GPU を超えて拡張する必要がない場合
+そうすれば、それに固執することを選択することもできます。 ZeRO-3 により、はるかに高いスケーラビリティ容量が可能になることを理解することが重要です
+スピードを犠牲にして。
+
+ZeRO-3 の構成を調整して、ZeRO-2 に近づけることができます。
+
+- `stage3_param_persistence_threshold` を非常に大きな数値に設定します。たとえば、`6 * hidden_size * hidden_size` のように、最大パラメータよりも大きくなります。これにより、パラメータが GPU に保持されます。
+- ZeRO-2 にはそのオプションがないため、`offload_params` をオフにします。
+
+変更しなくても、`offload_params`をオフにするだけでパフォーマンスが大幅に向上する可能性があります。
+`stage3_param_persistence_threshold`。もちろん、これらの変更はトレーニングできるモデルのサイズに影響します。それで
+これらは、ニーズに応じて、スケーラビリティと引き換えに速度を向上させるのに役立ちます。
+
+
+
+#### ZeRO-2 Example
+
+以下は、完全な ZeRO-2 自動構成ファイル `ds_config_zero2.json` です。
+
+```json
+{
+ "fp16": {
+ "enabled": "auto",
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ },
+
+ "optimizer": {
+ "type": "AdamW",
+ "params": {
+ "lr": "auto",
+ "betas": "auto",
+ "eps": "auto",
+ "weight_decay": "auto"
+ }
+ },
+
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": "auto",
+ "warmup_max_lr": "auto",
+ "warmup_num_steps": "auto"
+ }
+ },
+
+ "zero_optimization": {
+ "stage": 2,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "allgather_partitions": true,
+ "allgather_bucket_size": 2e8,
+ "overlap_comm": true,
+ "reduce_scatter": true,
+ "reduce_bucket_size": 2e8,
+ "contiguous_gradients": true
+ },
+
+ "gradient_accumulation_steps": "auto",
+ "gradient_clipping": "auto",
+ "steps_per_print": 2000,
+ "train_batch_size": "auto",
+ "train_micro_batch_size_per_gpu": "auto",
+ "wall_clock_breakdown": false
+}
+```
+
+以下は、手動で設定された完全な ZeRO-2 のすべてが有効な構成ファイルです。ここでは主に、典型的なものを確認するためのものです。
+値は次のようになりますが、複数の`auto`設定が含まれる値を使用することを強くお勧めします。
+
+```json
+{
+ "fp16": {
+ "enabled": true,
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ },
+
+ "optimizer": {
+ "type": "AdamW",
+ "params": {
+ "lr": 3e-5,
+ "betas": [0.8, 0.999],
+ "eps": 1e-8,
+ "weight_decay": 3e-7
+ }
+ },
+
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": 0,
+ "warmup_max_lr": 3e-5,
+ "warmup_num_steps": 500
+ }
+ },
+
+ "zero_optimization": {
+ "stage": 2,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "allgather_partitions": true,
+ "allgather_bucket_size": 2e8,
+ "overlap_comm": true,
+ "reduce_scatter": true,
+ "reduce_bucket_size": 2e8,
+ "contiguous_gradients": true
+ },
+
+ "steps_per_print": 2000,
+ "wall_clock_breakdown": false
+}
+```
+
+
+
+#### ZeRO-3 Example
+
+以下は、完全な ZeRO-3 自動構成ファイル`ds_config_zero3.json`です。
+
+```json
+{
+ "fp16": {
+ "enabled": "auto",
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ },
+
+ "optimizer": {
+ "type": "AdamW",
+ "params": {
+ "lr": "auto",
+ "betas": "auto",
+ "eps": "auto",
+ "weight_decay": "auto"
+ }
+ },
+
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": "auto",
+ "warmup_max_lr": "auto",
+ "warmup_num_steps": "auto"
+ }
+ },
+
+ "zero_optimization": {
+ "stage": 3,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "offload_param": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "overlap_comm": true,
+ "contiguous_gradients": true,
+ "sub_group_size": 1e9,
+ "reduce_bucket_size": "auto",
+ "stage3_prefetch_bucket_size": "auto",
+ "stage3_param_persistence_threshold": "auto",
+ "stage3_max_live_parameters": 1e9,
+ "stage3_max_reuse_distance": 1e9,
+ "stage3_gather_16bit_weights_on_model_save": true
+ },
+
+ "gradient_accumulation_steps": "auto",
+ "gradient_clipping": "auto",
+ "steps_per_print": 2000,
+ "train_batch_size": "auto",
+ "train_micro_batch_size_per_gpu": "auto",
+ "wall_clock_breakdown": false
+}
+```
+
+以下は、手動で設定された完全な ZeRO-3 のすべてが有効な構成ファイルです。ここでは主に、典型的なものを確認するためのものです。
+値は次のようになりますが、複数の`auto`設定が含まれる値を使用することを強くお勧めします。
+
+```json
+{
+ "fp16": {
+ "enabled": true,
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ },
+
+ "optimizer": {
+ "type": "AdamW",
+ "params": {
+ "lr": 3e-5,
+ "betas": [0.8, 0.999],
+ "eps": 1e-8,
+ "weight_decay": 3e-7
+ }
+ },
+
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": 0,
+ "warmup_max_lr": 3e-5,
+ "warmup_num_steps": 500
+ }
+ },
+
+ "zero_optimization": {
+ "stage": 3,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "offload_param": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "overlap_comm": true,
+ "contiguous_gradients": true,
+ "sub_group_size": 1e9,
+ "reduce_bucket_size": 1e6,
+ "stage3_prefetch_bucket_size": 0.94e6,
+ "stage3_param_persistence_threshold": 1e4,
+ "stage3_max_live_parameters": 1e9,
+ "stage3_max_reuse_distance": 1e9,
+ "stage3_gather_16bit_weights_on_model_save": true
+ },
+
+ "steps_per_print": 2000,
+ "wall_clock_breakdown": false
+}
+```
+
+#### How to Choose Which ZeRO Stage and Offloads To Use For Best Performance
+
+これで、さまざまな段階があることがわかりました。どちらを使用するかをどのように決定すればよいでしょうか?このセクションでは、この質問に答えていきます。
+
+一般に、次のことが当てはまります。
+
+- 速度の点(左の方が右より速い)
+
+ステージ 0 (DDP) > ステージ 1 > ステージ 2 > ステージ 2 + オフロード > ステージ 3 > ステージ 3 + オフロード
+
+- GPU メモリの使用状況 (右は左よりも GPU メモリ効率が高い)
+
+ステージ 0 (DDP) < ステージ 1 < ステージ 2 < ステージ 2 + オフロード < ステージ 3 < ステージ 3 + オフロード
+
+したがって、最小限の数の GPU に収まりながら最速の実行を実現したい場合は、次のプロセスに従うことができます。最も速いアプローチから開始し、GPU OOM に陥った場合は、次に遅いアプローチに進みますが、これにより使用される GPU メモリが少なくなります。などなど。
+
+まず、バッチ サイズを 1 に設定します (必要な有効バッチ サイズに対して、いつでも勾配累積を使用できます)。
+
+1. `--gradient_checkpointing 1` (HF Trainer) または直接 `model.gradient_checkpointing_enable()` を有効にします - OOM の場合
+2. 最初に ZeRO ステージ 2 を試してください。 OOMの場合
+3. ZeRO ステージ 2 + `offload_optimizer` を試します - OOM の場合
+4. ZeRO ステージ 3 に切り替える - OOM の場合
+5. `cpu` に対して `offload_param` を有効にします - OOM の場合
+6. OOM の場合は、`cpu`に対して`offload_optimizer`を有効にします。
+
+7. それでもバッチ サイズ 1 に適合しない場合は、まずさまざまなデフォルト値を確認し、可能であれば値を下げます。たとえば、`generate`を使用し、広い検索ビームを使用しない場合は、大量のメモリを消費するため、検索ビームを狭くします。
+
+8. fp32 では必ず混合半精度を使用します。つまり、Ampere 以上の GPU では bf16、古い GPU アーキテクチャでは fp16 を使用します。
+
+9. それでも OOM を行う場合は、ハードウェアを追加するか、ZeRO-Infinity を有効にすることができます。つまり、オフロード `offload_param` と `offload_optimizer` を `nvme` に切り替えます。非常に高速な nvme であることを確認する必要があります。逸話として、ZeRO-Infinity を使用して小さな GPU で BLOOM-176B を推論することができましたが、非常に遅かったです。でも、うまくいきました!
+
+もちろん、最も GPU メモリ効率の高い構成から始めて、後から逆に進むことで、これらの手順を逆に実行することもできます。あるいは二等分してみてください。
+
+OOM を引き起こさないバッチ サイズ 1 を取得したら、実効スループットを測定します。
+
+次に、バッチ サイズをできるだけ大きくしてみます。バッチ サイズが大きいほど、乗算する行列が巨大な場合に GPU のパフォーマンスが最高になるため、GPU の効率が向上します。
+
+ここで、パフォーマンス最適化ゲームが始まります。一部のオフロード機能をオフにするか、ZeRO 段階でステップダウンしてバッチ サイズを増減して、実効スループットを再度測定することができます。満足するまで洗い流し、繰り返します。
+
+永遠にこれに費やす必要はありませんが、3 か月のトレーニングを開始しようとしている場合は、スループットに関して最も効果的な設定を見つけるために数日かけてください。そのため、トレーニングのコストが最小限になり、トレーニングをより早く完了できます。現在の目まぐるしく変化する ML の世界では、何かをトレーニングするのにさらに 1 か月かかる場合、絶好の機会を逃す可能性があります。もちろん、これは私が意見を共有しているだけであり、決してあなたを急かそうとしているわけではありません。 BLOOM-176B のトレーニングを開始する前に、このプロセスに 2 日間費やし、スループットを 90 TFLOP から 150 TFLOP に向上させることができました。この取り組みにより、トレーニング時間を 1 か月以上節約できました。
+
+これらのメモは主にトレーニング モード用に書かれたものですが、ほとんどの場合は推論にも適用されるはずです。たとえば、勾配チェックポイントはトレーニング中にのみ役立つため、推論中は何も行われません。さらに、マルチ GPU 推論を実行していて、[DeepSpeed-Inference](https://www.deepspeed.ai/tutorials/inference-tutorial/)、[Accelerate](https://ハグフェイス.co/blog/bloom-inference-pytorch-scripts) は優れたパフォーマンスを提供するはずです。
+
+
+その他のパフォーマンス関連の簡単なメモ:
+- 何かを最初からトレーニングしている場合は、常に 16 で割り切れる形状のテンソル (隠れたサイズなど) を使用するようにしてください。バッチ サイズについては、少なくとも 2 で割り切れるようにしてください。 GPU からさらに高いパフォーマンスを引き出したい場合は、ハードウェア固有の [波とタイルの量子化](https://developer.nvidia.com/blog/optimizing-gpu-performance-tensor-cores/) の可分性があります。
+
+### Activation Checkpointing or Gradient Checkpointing
+
+アクティベーション チェックポイントと勾配チェックポイントは、同じ方法論を指す 2 つの異なる用語です。とてもややこしいですが、こんな感じです。
+
+勾配チェックポイントを使用すると、速度を GPU メモリと引き換えにできます。これにより、GPU OOM を克服したり、バッチ サイズを増やすことができ、多くの場合、パフォーマンスの向上につながります。
+
+HF Transformers モデルは、DeepSpeed のアクティベーション チェックポイントについて何も知らないため、DeepSpeed 構成ファイルでその機能を有効にしようとしても、何も起こりません。
+
+したがって、この非常に有益な機能を活用するには 2 つの方法があります。
+
+1. HF Transformers モデルを使用したい場合は、`model.gradient_checkpointing_enable()` を実行するか、HF トレーナーで `--gradient_checkpointing` を使用します。これにより、これが自動的に有効になります。そこで使われるのが `torch.utils.checkpoint` です。
+2. 独自のモデルを作成し、DeepSpeed のアクティベーション チェックポイントを使用したい場合は、[そこで規定されている API](https://deepspeed.readthedocs.io/en/latest/activation-checkpointing.html) を使用できます。 HF Transformers モデリング コードを使用して、`torch.utils.checkpoint` を DeepSpeed の API に置き換えることもできます。後者は、順方向アクティベーションを再計算する代わりに CPU メモリにオフロードできるため、より柔軟です。
+
+### Optimizer and Scheduler
+
+`offload_optimizer`を有効にしない限り、DeepSpeed スケジューラーと HuggingFace スケジューラーを組み合わせて使用できます。
+オプティマイザー (HuggingFace スケジューラーと DeepSpeed オプティマイザーの組み合わせを除く):
+
+| Combos | HF Scheduler | DS Scheduler |
+|:-------------|:-------------|:-------------|
+| HF Optimizer | Yes | Yes |
+| DS Optimizer | No | Yes |
+
+`offload_optimizer`が有効な場合、CPU と
+GPU 実装 (LAMB を除く)。
+
+
+
+
+#### Optimizer
+
+DeepSpeed の主なオプティマイザーは、Adam、AdamW、OneBitAdam、Lamb です。これらは ZeRO で徹底的にテストされており、
+したがって、使用することをお勧めします。ただし、他のオプティマイザを「torch」からインポートすることはできます。完全なドキュメントは [こちら](https://www.deepspeed.ai/docs/config-json/#optimizer-parameters) にあります。
+
+設定ファイルで `optimizer` エントリを設定しない場合、[`Trainer`] は
+自動的に`AdamW`に設定され、指定された値または次のコマンドラインのデフォルトが使用されます。
+引数: `--learning_rate`、`--adam_beta1`、`--adam_beta2`、`--adam_epsilon`、および `--weight_decay`。
+
+以下は、`AdamW`の自動構成された`optimizer`エントリの例です。
+
+```json
+{
+ "optimizer": {
+ "type": "AdamW",
+ "params": {
+ "lr": "auto",
+ "betas": "auto",
+ "eps": "auto",
+ "weight_decay": "auto"
+ }
+ }
+}
+```
+
+コマンドライン引数によって構成ファイル内の値が設定されることに注意してください。これは 1 つあるためです
+値の決定的なソースを提供し、たとえば学習率が次のように設定されている場合に、見つけにくいエラーを回避します。
+さまざまな場所でさまざまな価値観。コマンドラインのルール。オーバーライドされる値は次のとおりです。
+
+- `lr` と `--learning_rate` の値
+- `betas` と `--adam_beta1 --adam_beta2` の値
+- `eps` と `--adam_epsilon` の値
+- `weight_decay` と `--weight_decay` の値
+
+したがって、コマンドラインで共有ハイパーパラメータを調整することを忘れないでください。
+
+値を明示的に設定することもできます。
+
+```json
+{
+ "optimizer": {
+ "type": "AdamW",
+ "params": {
+ "lr": 0.001,
+ "betas": [0.8, 0.999],
+ "eps": 1e-8,
+ "weight_decay": 3e-7
+ }
+ }
+}
+```
+
+ただし、[`Trainer`] コマンドライン引数と DeepSpeed を自分で同期することになります。
+構成。
+
+上記にリストされていない別のオプティマイザーを使用する場合は、トップレベルの構成に追加する必要があります。
+
+```json
+{
+ "zero_allow_untested_optimizer": true
+}
+```
+
+`AdamW`と同様に、公式にサポートされている他のオプティマイザーを構成できます。これらは異なる設定値を持つ可能性があることに注意してください。例えばAdam の場合は、`weight_decay`を`0.01`付近にする必要があります。
+
+さらに、オフロードは、Deepspeed の CPU Adam オプティマイザーと併用すると最も効果的に機能します。 `deepspeed==0.8.3` なので、オフロードで別のオプティマイザーを使用したい場合は、以下も追加する必要があります。
+
+```json
+{
+ "zero_force_ds_cpu_optimizer": false
+}
+```
+
+最上位の構成に移行します。
+
+
+
+
+#### Scheduler
+
+
+DeepSpeed は、`LRRangeTest`、`OneCycle`、`WarmupLR`、および`WarmupDecayLR`学習率スケジューラーをサポートしています。完全な
+ドキュメントは[ここ](https://www.deepspeed.ai/docs/config-json/#scheduler-parameters)です。
+
+ここでは、🤗 Transformers と DeepSpeed の間でスケジューラーが重複する場所を示します。
+
+- `--lr_scheduler_type constant_with_warmup` 経由の `WarmupLR`
+- `--lr_scheduler_type Linear` を介した `WarmupDecayLR`。これは `--lr_scheduler_type` のデフォルト値でもあります。
+ したがって、スケジューラを設定しない場合、これがデフォルトで設定されるスケジューラになります。
+
+設定ファイルで `scheduler` エントリを設定しない場合、[`Trainer`] は
+`--lr_scheduler_type`、`--learning_rate`、および `--warmup_steps` または `--warmup_ratio` の値を設定します。
+🤗 それのトランスフォーマーバージョン。
+
+以下は、`WarmupLR`の自動構成された`scheduler`エントリの例です。
+
+```json
+{
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": "auto",
+ "warmup_max_lr": "auto",
+ "warmup_num_steps": "auto"
+ }
+ }
+}
+```
+
+*"auto"* が使用されているため、[`Trainer`] 引数は設定に正しい値を設定します。
+ファイル。これは、値の決定的なソースが 1 つあることと、たとえば次のような場合に見つけにくいエラーを避けるためです。
+学習率は、場所ごとに異なる値に設定されます。コマンドラインのルール。設定される値は次のとおりです。
+
+- `warmup_min_lr` の値は `0` です。
+- `warmup_max_lr` と `--learning_rate` の値。
+- `warmup_num_steps` と `--warmup_steps` の値 (指定されている場合)。それ以外の場合は `--warmup_ratio` を使用します
+ トレーニング ステップの数を乗算し、切り上げます。
+- `total_num_steps` には `--max_steps` の値を指定するか、指定されていない場合は実行時に自動的に導出されます。
+ 環境、データセットのサイズ、およびその他のコマンド ライン引数 (
+ `WarmupDecayLR`)。
+
+もちろん、構成値の一部またはすべてを引き継いで、自分で設定することもできます。
+
+```json
+{
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": 0,
+ "warmup_max_lr": 0.001,
+ "warmup_num_steps": 1000
+ }
+ }
+}
+```
+
+ただし、[`Trainer`] コマンドライン引数と DeepSpeed を自分で同期することになります。
+構成。
+
+たとえば、`WarmupDecayLR`の場合は、次のエントリを使用できます。
+
+```json
+{
+ "scheduler": {
+ "type": "WarmupDecayLR",
+ "params": {
+ "last_batch_iteration": -1,
+ "total_num_steps": "auto",
+ "warmup_min_lr": "auto",
+ "warmup_max_lr": "auto",
+ "warmup_num_steps": "auto"
+ }
+ }
+}
+```
+
+`total_num_steps`、`warmup_max_lr`、`warmup_num_steps`、および `total_num_steps` はロード時に設定されます。
+
+
+
+### fp32 Precision
+
+Deepspeed は、完全な fp32 と fp16 の混合精度をサポートします。
+
+fp16 混合精度を使用すると、必要なメモリが大幅に削減され、速度が向上するため、
+使用しているモデルがこのトレーニング モードで適切に動作しない場合は、使用しない方がよいでしょう。通常これ
+モデルが fp16 混合精度で事前トレーニングされていない場合に発生します (たとえば、これは bf16 で事前トレーニングされた場合によく発生します)
+モデル)。このようなモデルでは、オーバーフローまたはアンダーフローが発生し、`NaN`損失が発生する可能性があります。これがあなたの場合は、使用したいと思うでしょう
+完全な fp32 モード。デフォルトの fp16 混合精度モードを次のように明示的に無効にします。
+
+```json
+{
+ "fp16": {
+ "enabled": false,
+ }
+}
+```
+
+Ampere アーキテクチャ ベースの GPU を使用している場合、pytorch バージョン 1.7 以降は自動的に を使用するように切り替わります。
+一部の操作でははるかに効率的な tf32 形式を使用しますが、結果は依然として fp32 になります。詳細と
+ベンチマークについては、[Ampere デバイス上の TensorFloat-32(TF32)](https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices) を参照してください。文書には以下が含まれます
+何らかの理由でこの自動変換を使用したくない場合は、この自動変換を無効にする方法について説明します。
+
+🤗 トレーナーでは、`--tf32` を使用して有効にするか、`--tf32 0` または `--no_tf32` を使用して無効にすることができます。デフォルトでは、PyTorch のデフォルトが使用されます。
+
+
+
+### Automatic Mixed Precision
+
+pytorch のような AMP の方法または apex のような方法で自動混合精度を使用できます。
+
+### fp16
+
+fp16 (float16) を設定して pytorch AMP のようなモードを設定するには:
+
+```json
+{
+ "fp16": {
+ "enabled": "auto",
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ }
+}
+```
+
+[`Trainer`] は、の値に基づいてそれを自動的に有効または無効にします。
+`args.fp16_backend`。残りの設定値はあなた次第です。
+
+このモードは、`--fp16 --fp16_backend amp`または`--fp16_full_eval`コマンドライン引数が渡されると有効になります。
+
+このモードを明示的に有効/無効にすることもできます。
+
+```json
+{
+ "fp16": {
+ "enabled": true,
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ }
+}
+```
+
+ただし、[`Trainer`] コマンドライン引数と DeepSpeed を自分で同期することになります。
+構成。
+
+これが[ドキュメント](https://www.deepspeed.ai/docs/config-json/#fp16-training-options)です。
+
+### BF16
+
+fp16 の代わりに bf16 (bfloat16) が必要な場合は、次の構成セクションが使用されます。
+
+```json
+{
+ "bf16": {
+ "enabled": "auto"
+ }
+}
+```
+
+bf16 は fp32 と同じダイナミック レンジを備えているため、損失スケーリングは必要ありません。
+
+このモードは、`--bf16` または `--bf16_full_eval` コマンドライン引数が渡されると有効になります。
+
+このモードを明示的に有効/無効にすることもできます。
+
+```json
+{
+ "bf16": {
+ "enabled": true
+ }
+}
+```
+
+
+
+`deepspeed==0.6.0`の時点では、bf16 サポートは新しく実験的なものです。
+
+bf16 が有効な状態で [勾配累積](#gradient-accumulation) を使用する場合は、bf16 で勾配が累積されることに注意する必要があります。この形式の精度が低いため、これは希望どおりではない可能性があります。損失のある蓄積につながります。
+
+この問題を修正し、より高精度の `dtype` (fp16 または fp32) を使用するオプションを提供するための作業が行われています。
+
+
+
+
+### NCCL Collectives
+
+訓練体制の`dtype`があり、さまざまな削減や収集/分散操作などのコミュニケーション集合体に使用される別の`dtype`があります。
+
+すべての収集/分散操作は、データが含まれているのと同じ `dtype` で実行されるため、bf16 トレーニング体制を使用している場合、データは bf16 で収集されます。収集は損失のない操作です。
+
+さまざまなリデュース操作は非常に損失が大きい可能性があります。たとえば、複数の GPU 間で勾配が平均化される場合、通信が fp16 または bf16 で行われる場合、結果は損失が多くなる可能性があります。複数の数値を低精度でアドバタイズすると結果は正確ではないためです。 。 bf16 では fp16 よりも精度が低いため、さらにそうです。通常は非常に小さい grad を平均する際の損失が最小限に抑えられるため、fp16 で十分であることがよくあります。したがって、デフォルトでは、半精度トレーニングでは fp16 がリダクション演算のデフォルトとして使用されます。ただし、この機能を完全に制御でき、必要に応じて小さなオーバーヘッドを追加して、リダクションが累積 dtype として fp32 を使用し、結果の準備ができた場合にのみ半精度 `dtype` にダウンキャストするようにすることもできます。でトレーニング中です。
+
+デフォルトをオーバーライドするには、新しい構成エントリを追加するだけです。
+
+```json
+{
+ "communication_data_type": "fp32"
+}
+```
+
+この記事の執筆時点での有効な値は、"fp16"、"bfp16"、"fp32"です。
+
+注: ステージ ゼロ 3 には、bf16 通信タイプに関するバグがあり、`deepspeed==0.8.1`で修正されました。
+
+### apex
+
+apex AMP のようなモード セットを設定するには:
+
+```json
+"amp": {
+ "enabled": "auto",
+ "opt_level": "auto"
+}
+```
+
+[`Trainer`] は `args.fp16_backend` の値に基づいて自動的に設定します。
+`args.fp16_opt_level`。
+
+このモードは、`--fp16 --fp16_backend apex --fp16_opt_level 01`コマンド ライン引数が渡されると有効になります。
+
+このモードを明示的に構成することもできます。
+
+```json
+{
+ "amp": {
+ "enabled": true,
+ "opt_level": "O1"
+ }
+}
+```
+
+ただし、[`Trainer`] コマンドライン引数と DeepSpeed を自分で同期することになります。
+構成。
+
+これは[ドキュメント](https://www.deepspeed.ai/docs/config-json/#automatic-mixed-precision-amp-training-options)です。
+
+
+
+### Batch Size
+
+バッチサイズを設定するには、次を使用します。
+
+
+```json
+{
+ "train_batch_size": "auto",
+ "train_micro_batch_size_per_gpu": "auto"
+}
+```
+
+[`Trainer`] は自動的に `train_micro_batch_size_per_gpu` を次の値に設定します。
+`args.per_device_train_batch_size`と`train_batch_size`を`args.world_size * args.per_device_train_batch_size * args.gradient_accumulation_steps`に変更します。
+
+値を明示的に設定することもできます。
+
+```json
+{
+ "train_batch_size": 12,
+ "train_micro_batch_size_per_gpu": 4
+}
+```
+
+ただし、[`Trainer`] コマンドライン引数と DeepSpeed を自分で同期することになります。
+構成。
+
+
+
+### Gradient Accumulation
+
+勾配累積セットを構成するには:
+
+```json
+{
+ "gradient_accumulation_steps": "auto"
+}
+```
+
+[`Trainer`] は自動的にそれを `args.gradient_accumulation_steps` の値に設定します。
+
+値を明示的に設定することもできます。
+
+```json
+{
+ "gradient_accumulation_steps": 3
+}
+```
+
+ただし、[`Trainer`] コマンドライン引数と DeepSpeed を自分で同期することになります。
+構成。
+
+
+
+### Gradient Clipping
+
+グラデーション グラデーション クリッピング セットを構成するには:
+
+```json
+{
+ "gradient_clipping": "auto"
+}
+```
+
+[`Trainer`] は自動的にそれを `args.max_grad_norm` の値に設定します。
+
+値を明示的に設定することもできます。
+
+```json
+{
+ "gradient_clipping": 1.0
+}
+```
+
+ただし、[`Trainer`] コマンドライン引数と DeepSpeed を自分で同期することになります。
+構成。
+
+
+
+### Getting The Model Weights Out
+
+トレーニングを継続し、DeepSpeed の使用を再開する限り、何も心配する必要はありません。 DeepSpeed ストア
+fp32 のカスタム チェックポイント オプティマイザー ファイル内のマスターの重み。これは `global_step*/*optim_states.pt` (これは glob
+パターン)、通常のチェックポイントの下に保存されます。
+
+**FP16 ウェイト:**
+
+モデルを ZeRO-2 で保存すると、モデルの重みを含む通常の `pytorch_model.bin` ファイルが作成されますが、
+これらは重みの fp16 バージョンにすぎません。
+
+ZeRO-3 では、モデルの重みが複数の GPU に分割されるため、状況はさらに複雑になります。
+したがって、fp16 を保存するための `Trainer` を取得するには、`"stage3_gather_16bit_weights_on_model_save": true` が必要です。
+重みのバージョン。この設定が`False`の場合、`pytorch_model.bin`は作成されません。これは、デフォルトで DeepSpeed の `state_dict` に実際の重みではなくプレースホルダーが含まれるためです。この `state_dict` を保存した場合、ロードし直すことはできません。
+
+```json
+{
+ "zero_optimization": {
+ "stage3_gather_16bit_weights_on_model_save": true
+ }
+}
+```
+
+**FP32 重量:**
+
+fp16 ウェイトはトレーニングを再開するのに適していますが、モデルの微調整が完了し、それを
+[モデル ハブ](https://huggingface.co/models) にアクセスするか、fp32 を入手したいと思われる他の人に渡します。
+重み。これは大量のメモリを必要とするプロセスであるため、トレーニング中に行うべきではないのが理想的です。
+したがって、トレーニングの完了後にオフラインで実行するのが最適です。ただし、必要に応じて、空き CPU が十分にある場合は、
+同じトレーニング スクリプトで実行できることを思い出してください。次のセクションでは、両方のアプローチについて説明します。
+
+
+**ライブ FP32 ウェイト リカバリ:**
+
+モデルが大きく、トレーニングの終了時に空き CPU メモリがほとんど残っていない場合、このアプローチは機能しない可能性があります。
+
+少なくとも 1 つのチェックポイントを保存していて、最新のチェックポイントを使用したい場合は、次の手順を実行できます。
+
+```python
+from transformers.trainer_utils import get_last_checkpoint
+from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpoint
+
+checkpoint_dir = get_last_checkpoint(trainer.args.output_dir)
+fp32_model = load_state_dict_from_zero_checkpoint(trainer.model, checkpoint_dir)
+```
+
+`--load_best_model_at_end` class:*~transformers.TrainingArguments* 引数を使用している場合 (最適なモデルを追跡するため)
+チェックポイント)、最初に最終モデルを明示的に保存してから、上記と同じことを行うことでトレーニングを終了できます。
+
+```python
+from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpoint
+
+checkpoint_dir = os.path.join(trainer.args.output_dir, "checkpoint-final")
+trainer.deepspeed.save_checkpoint(checkpoint_dir)
+fp32_model = load_state_dict_from_zero_checkpoint(trainer.model, checkpoint_dir)
+```
+
+
+
+`load_state_dict_from_zero_checkpoint` が実行されると、`model` はもはや使用できなくなることに注意してください。
+同じアプリケーションの DeepSpeed コンテキスト。つまり、deepspeed エンジンを再初期化する必要があります。
+`model.load_state_dict(state_dict)` はそこからすべての DeepSpeed マジックを削除します。したがって、これは最後にのみ実行してください
+トレーニングの様子。
+
+
+
+
+もちろん、class:*~transformers.Trainer* を使用する必要はなく、上記の例を独自のものに調整することができます。
+トレーナー。
+
+何らかの理由でさらに改良したい場合は、重みの fp32 `state_dict` を抽出して適用することもできます。
+次の例に示すように、これらは自分で作成します。
+
+```python
+from deepspeed.utils.zero_to_fp32 import get_fp32_state_dict_from_zero_checkpoint
+
+state_dict = get_fp32_state_dict_from_zero_checkpoint(checkpoint_dir) # already on cpu
+model = model.cpu()
+model.load_state_dict(state_dict)
+```
+
+**オフライン FP32 ウェイト リカバリ:**
+
+DeepSpeed は特別な変換スクリプト`zero_to_fp32.py`を作成し、チェックポイントの最上位に配置します。
+フォルダ。このスクリプトを使用すると、いつでも重みを抽出できます。スクリプトはスタンドアロンなので、もう必要ありません。
+抽出を行うための設定ファイルまたは `Trainer` が必要です。
+
+チェックポイント フォルダーが次のようになっているとします。
+
+```bash
+$ ls -l output_dir/checkpoint-1/
+-rw-rw-r-- 1 stas stas 1.4K Mar 27 20:42 config.json
+drwxrwxr-x 2 stas stas 4.0K Mar 25 19:52 global_step1/
+-rw-rw-r-- 1 stas stas 12 Mar 27 13:16 latest
+-rw-rw-r-- 1 stas stas 827K Mar 27 20:42 optimizer.pt
+-rw-rw-r-- 1 stas stas 231M Mar 27 20:42 pytorch_model.bin
+-rw-rw-r-- 1 stas stas 623 Mar 27 20:42 scheduler.pt
+-rw-rw-r-- 1 stas stas 1.8K Mar 27 20:42 special_tokens_map.json
+-rw-rw-r-- 1 stas stas 774K Mar 27 20:42 spiece.model
+-rw-rw-r-- 1 stas stas 1.9K Mar 27 20:42 tokenizer_config.json
+-rw-rw-r-- 1 stas stas 339 Mar 27 20:42 trainer_state.json
+-rw-rw-r-- 1 stas stas 2.3K Mar 27 20:42 training_args.bin
+-rwxrw-r-- 1 stas stas 5.5K Mar 27 13:16 zero_to_fp32.py*
+```
+
+この例では、DeepSpeed チェックポイント サブフォルダー *global_step1* が 1 つだけあります。したがって、FP32を再構築するには
+重みを実行するだけです:
+
+```bash
+python zero_to_fp32.py . pytorch_model.bin
+```
+
+これだよ。 `pytorch_model.bin`には、複数の GPU から統合された完全な fp32 モデルの重みが含まれるようになります。
+
+スクリプトは、ZeRO-2 または ZeRO-3 チェックポイントを自動的に処理できるようになります。
+
+`python zero_to_fp32.py -h` を実行すると、使用方法の詳細が表示されます。
+
+スクリプトは、ファイル`latest`の内容を使用して deepspeed サブフォルダーを自動検出します。
+例には`global_step1`が含まれます。
+
+注: 現在、スクリプトには最終的な fp32 モデルの重みの 2 倍の一般 RAM が必要です。
+
+### ZeRO-3 と Infinity Nuances
+
+ZeRO-3 は、パラメータ シャーディング機能の点で ZeRO-2 とは大きく異なります。
+
+ZeRO-Infinity は ZeRO-3 をさらに拡張し、NVMe メモリやその他の複数の速度とスケーラビリティの向上をサポートします。
+
+モデルに特別な変更を加える必要がなくても正常に動作するようにあらゆる努力が払われてきましたが、特定の点では
+状況によっては、次の情報が必要になる場合があります。
+
+#### Constructing Massive Models
+
+
+DeepSpeed/ZeRO-3 は、既存の RAM に収まらない可能性のある数兆のパラメータを持つモデルを処理できます。そのような場合、
+また、初期化をより高速に実行したい場合は、*deepspeed.zero.Init()* を使用してモデルを初期化します。
+コンテキスト マネージャー (関数デコレーターでもあります)。次のようになります。
+
+```python
+from transformers import T5ForConditionalGeneration, T5Config
+import deepspeed
+
+with deepspeed.zero.Init():
+ config = T5Config.from_pretrained("t5-small")
+ model = T5ForConditionalGeneration(config)
+```
+
+ご覧のとおり、これによりランダムに初期化されたモデルが得られます。
+
+事前トレーニングされたモデルを使用したい場合、`model_class.from_pretrained` は次の条件を満たす限りこの機能を有効にします。
+`is_deepspeed_zero3_enabled()` は `True` を返します。これは現在、
+[`TrainingArguments`] オブジェクト (渡された DeepSpeed 構成ファイルに ZeRO-3 構成が含まれている場合)
+セクション。したがって、呼び出しの前に** [`TrainingArguments`] オブジェクトを作成する必要があります。
+`from_pretrained`。考えられるシーケンスの例を次に示します。
+
+```python
+from transformers import AutoModel, Trainer, TrainingArguments
+
+training_args = TrainingArguments(..., deepspeed=ds_config)
+model = AutoModel.from_pretrained("t5-small")
+trainer = Trainer(model=model, args=training_args, ...)
+```
+
+公式のサンプル スクリプトを使用していて、コマンド ライン引数に `--deepspeed ds_config.json` が含まれている場合
+ZeRO-3 設定を有効にすると、これがサンプル スクリプトの記述方法であるため、すべてがすでに完了しています。
+
+注: モデルの fp16 重みが単一の GPU のメモリに収まらない場合は、この機能を使用する必要があります。
+
+この方法とその他の関連機能の詳細については、[大規模モデルの構築](https://deepspeed.readthedocs.io/en/latest/zero3.html#constructing-massive-models) を参照してください。
+
+また、fp16 で事前訓練されたモデルをロードするときは、`from_pretrained` に使用するように指示する必要があります。
+`torch_dtype=torch.float16`。詳細については、[from_pretrained-torch-dtype](#from_pretrained-torch-dtype) を参照してください。
+
+#### Gathering Parameters
+
+複数の GPU 上の ZeRO-3 では、現在の GPU のパラメータでない限り、単一の GPU がすべてのパラメータを持つことはありません。
+実行層。したがって、すべてのレイヤーのすべてのパラメーターに一度にアクセスする必要がある場合は、それを行うための特定の方法があります。
+ほとんどの場合は必要ありませんが、必要な場合は、[パラメータの収集](https://deepspeed.readthedocs.io/en/latest/zero3.html#manual-parameter-coordination) を参照してください。
+
+ただし、いくつかの場所で内部的に使用しています。その例の 1 つは、事前トレーニングされたモデルの重みをロードするときです。
+`from_pretrained`。一度に 1 つのレイヤーをロードし、参加しているすべての GPU に即座に分割します。
+大規模なモデルでは、メモリの関係で、1 つの GPU にロードしてから複数の GPU に分散することはできません。
+制限。
+
+また、ZeRO-3 では、独自のコードを作成し、次のようなモデル パラメーターの重みが発生するとします。
+
+```python
+tensor([1.0], device="cuda:0", dtype=torch.float16, requires_grad=True)
+```
+
+`tensor([1.])` にストレスを感じた場合、またはパラメータのサイズが `1` であるというエラーが発生した場合
+より大きな多次元形状。これは、パラメーターが分割されており、表示されるのは ZeRO-3 プレースホルダーであることを意味します。
+
+
+
+
+### ZeRO Inference
+
+ZeRO Inference は、ZeRO-3 Training と同じ構成を使用します。オプティマイザーとスケジューラーのセクションは必要ありません。で
+実際、同じものをトレーニングと共有したい場合は、これらを設定ファイルに残すことができます。彼らはただそうなるだろう
+無視されました。
+
+それ以外の場合は、通常の [`TrainingArguments`] 引数を渡すだけです。例えば:
+
+```bash
+deepspeed --num_gpus=2 your_program.py --do_eval --deepspeed ds_config.json
+```
+
+唯一重要なことは、ZeRO-2 には何の利点もないため、ZeRO-3 構成を使用する必要があるということです。
+ZeRO-3 のみがパラメーターのシャーディングを実行するのに対し、ZeRO-1 は勾配とオプティマイザーの状態をシャーディングするため、推論に役立ちます。
+
+以下は、利用可能なすべての GPU をデプロイする DeepSpeed で`run_translation.py`を実行する例です。
+
+
+```bash
+deepspeed examples/pytorch/translation/run_translation.py \
+--deepspeed tests/deepspeed/ds_config_zero3.json \
+--model_name_or_path t5-small --output_dir output_dir \
+--do_eval --max_eval_samples 50 --warmup_steps 50 \
+--max_source_length 128 --val_max_target_length 128 \
+--overwrite_output_dir --per_device_eval_batch_size 4 \
+--predict_with_generate --dataset_config "ro-en" --fp16 \
+--source_lang en --target_lang ro --dataset_name wmt16 \
+--source_prefix "translate English to Romanian: "
+```
+
+推論のために、オプティマイザーの状態と勾配によって使用される追加の大きなメモリは必要ないため、
+はるかに大きなバッチやシーケンス長を同じハードウェアに適合できる必要があります。
+
+さらに、DeepSpeed は現在、Deepspeed-Inference と呼ばれる関連製品を開発していますが、これとは何の関係もありません。
+ZeRO テクノロジーに準拠していますが、代わりにテンソル並列処理を使用して、単一の GPU に収まらないモデルをスケーリングします。これは
+現在開発中です。製品が完成したら統合を提供する予定です。
+
+
+### Memory Requirements
+
+Deepspeed ZeRO はメモリを CPU (および NVMe) にオフロードできるため、フレームワークは、使用されている GPU の数に応じて必要な CPU および GPU メモリの量を知ることができるユーティリティを提供します。
+
+単一の GPU で `bigscience/T0_3B`を微調整するために必要なメモリの量を見積もってみましょう。
+
+```bash
+$ python -c 'from transformers import AutoModel; \
+from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \
+model = AutoModel.from_pretrained("bigscience/T0_3B"); \
+estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=1, num_nodes=1)'
+[...]
+Estimated memory needed for params, optim states and gradients for a:
+HW: Setup with 1 node, 1 GPU per node.
+SW: Model with 2783M total params, 65M largest layer params.
+ per CPU | per GPU | Options
+ 70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
+ 70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
+ 62.23GB | 5.43GB | offload_param=none, offload_optimizer=cpu , zero_init=1
+ 62.23GB | 5.43GB | offload_param=none, offload_optimizer=cpu , zero_init=0
+ 0.37GB | 46.91GB | offload_param=none, offload_optimizer=none, zero_init=1
+ 15.56GB | 46.91GB | offload_param=none, offload_optimizer=none, zero_init=0
+```
+
+したがって、単一の 80 GB GPU で CPU オフロードなしで搭載することも、小さな 8 GB GPU でも最大 60 GB の CPU メモリが必要になることも可能です。 (これはパラメータ、オプティマイザの状態、および勾配のためのメモリであることに注意してください。cuda カーネル、アクティベーション、および一時メモリにはもう少し多くのメモリが必要です。)
+
+次に、コストと速度のトレードオフになります。より小さい GPU を購入またはレンタルした方が安くなります (Deepspeed ZeRO では複数の GPU を使用できるため、GPU の数を減らすこともできます)。しかし、その場合は遅くなります。そのため、何かを実行する速度を気にしなくても、速度の低下は GPU の使用時間に直接影響し、コストが増大するため、どれが最も効果的かを実験して比較してください。
+
+十分な GPU メモリがある場合は、すべてが高速になるため、CPU/NVMe オフロードを必ず無効にしてください。
+
+たとえば、2 つの GPU に対して同じことを繰り返してみましょう。
+
+```bash
+$ python -c 'from transformers import AutoModel; \
+from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \
+model = AutoModel.from_pretrained("bigscience/T0_3B"); \
+estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=2, num_nodes=1)'
+[...]
+Estimated memory needed for params, optim states and gradients for a:
+HW: Setup with 1 node, 2 GPUs per node.
+SW: Model with 2783M total params, 65M largest layer params.
+ per CPU | per GPU | Options
+ 70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
+ 70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
+ 62.23GB | 2.84GB | offload_param=none, offload_optimizer=cpu , zero_init=1
+ 62.23GB | 2.84GB | offload_param=none, offload_optimizer=cpu , zero_init=0
+ 0.74GB | 23.58GB | offload_param=none, offload_optimizer=none, zero_init=1
+ 31.11GB | 23.58GB | offload_param=none, offload_optimizer=none, zero_init=0
+
+```
+
+したがって、ここでは、CPU にオフロードせずに 2x 32GB 以上の GPU が必要になります。
+
+詳細については、[メモリ推定ツール](https://deepspeed.readthedocs.io/en/latest/memory.html) を参照してください。
+
+
+### Filing Issues
+
+
+ここでは、問題の真相をすぐに解明し、作業のブロックを解除できるよう、問題を報告する方法を説明します。
+
+レポートには必ず次の内容を含めてください。
+
+1. レポート内の完全な Deepspeed 構成ファイル
+
+2. [`Trainer`] を使用している場合はコマンドライン引数、または
+ トレーナーのセットアップを自分でスクリプト作成している場合は、[`TrainingArguments`] 引数。しないでください
+ [`TrainingArguments`] には無関係なエントリが多数含まれているため、ダンプします。
+
+3. 次の出力:
+
+ ```bash
+ python -c 'import torch; print(f"torch: {torch.__version__}")'
+ python -c 'import transformers; print(f"transformers: {transformers.__version__}")'
+ python -c 'import deepspeed; print(f"deepspeed: {deepspeed.__version__}")'
+ ```
+
+4. 可能であれば、問題を再現できる Google Colab ノートブックへのリンクを含めてください。これを使えます
+ [ノートブック](https://github.com/stas00/porting/blob/master/transformers/deepspeed/DeepSpeed_on_colab_CLI.ipynb) として
+ 出発点。
+
+5. 不可能でない限り、カスタムデータセットではなく、常に使用できる標準データセットを使用してください。
+
+6. 可能であれば、既存の [サンプル](https://github.com/huggingface/transformers/tree/main/examples/pytorch) のいずれかを使用して問題を再現してみてください。
+
+- Deepspeed が問題の原因ではないことがよくあります。
+
+ 提出された問題の一部は、Deepspeed とは無関係であることが判明しました。それは、Deepspeed がセットアップから削除された後です。
+ 問題はまだ残っていた。
+
+ したがって、完全に明白でない場合は、DeepSpeed 関連の問題です。
+ 例外が発生し、DeepSpeed モジュールが関係していることがわかります。まず、DeepSpeed を含まないセットアップを再テストしてください。
+ 問題が解決しない場合にのみ、Deepspeed について言及し、必要な詳細をすべて提供してください。
+
+- 問題が統合部分ではなく DeepSpeed コアにあることが明らかな場合は、問題を提出してください。
+ [Deepspeed](https://github.com/microsoft/DeepSpeed/) を直接使用します。よくわからない場合でも、ご安心ください。
+ どちらの問題トラッカーでも問題ありません。投稿されたらそれを判断し、次の場合は別の問題トラッカーにリダイレクトします。
+ そうである必要がある。
+
+
+### Troubleshooting
+
+#### the `deepspeed` process gets killed at startup without a traceback
+
+`deepspeed`プロセスが起動時にトレースバックなしで強制終了された場合、それは通常、プログラムが試行したことを意味します。
+システムが持っているよりも多くの CPU メモリを割り当てるか、プロセスが割り当てを許可されているため、OS カーネルがそれを強制終了します。
+プロセス。これは、設定ファイルに `offload_optimizer` または `offload_param` が含まれている可能性が高いためです。
+どちらも`cpu`にオフロードするように設定されています。 NVMe を使用している場合は、次の環境で実行している場合は NVMe へのオフロードを試してください。
+ゼロ-3。 [特定のモデルに必要なメモリ量を見積もる]方法は次のとおりです(https://deepspeed.readthedocs.io/en/latest/memory.html)。
+
+#### training and/or eval/predict loss is `NaN`
+
+これは、bf16 混合精度モードで事前トレーニングされたモデルを取得し、それを fp16 (混合精度の有無にかかわらず) で使用しようとした場合によく発生します。 TPU でトレーニングされたほとんどのモデル、および多くの場合、Google によってリリースされたモデルは、このカテゴリに分類されます (たとえば、ほぼすべての t5 ベースのモデル)。ここでの解決策は、ハードウェアがサポートしている場合 (TPU、Ampere GPU 以降)、fp32 または bf16 を使用することです。
+
+```json
+{
+ "fp16": {
+ "enabled": "auto",
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ }
+}
+```
+
+ログには、Deepspeed が次のように`OVERFLOW!`を報告していることがわかります。
+
+```
+0%| | 0/189 [00:00=4.28` 以降、`synced_gpus` が明示的に指定されていない場合、これらの条件が検出されると自動的に `True` に設定されます。ただし、必要に応じて `synced_gpus` の値をオーバーライドすることもできます。
+
+## Deepspeed 統合のテスト
+
+DeepSpeed 統合を含む PR を送信する場合は、CircleCI PR CI セットアップには GPU がないことに注意してください。そのため、GPU を必要とするテストは別の CI で毎晩のみ実行されます。したがって、PR で緑色の CI レポートが表示されても、DeepSpeed テストが合格したことを意味するわけではありません。
+
+DeepSpeed テストを実行するには、少なくとも以下を実行してください。
+
+```
+RUN_SLOW=1 pytest tests/deepspeed/test_deepspeed.py
+```
+
+モデリングまたは pytorch サンプル コードのいずれかを変更した場合は、Model Zoo テストも実行します。以下はすべての DeepSpeed テストを実行します。
+
+```
+RUN_SLOW=1 pytest tests/deepspeed
+```
+
+
+## Main DeepSpeed Resources
+
+- [プロジェクトの github](https://github.com/microsoft/deepspeed)
+- [使用方法ドキュメント](https://www.deepspeed.ai/getting-started/)
+- [API ドキュメント](https://deepspeed.readthedocs.io/en/latest/index.html)
+- [ブログ投稿](https://www.microsoft.com/en-us/research/search/?q=deepspeed)
+
+論文:
+
+- [ZeRO: 兆パラメータ モデルのトレーニングに向けたメモリの最適化](https://arxiv.org/abs/1910.02054)
+- [ZeRO-Offload: 10 億規模のモデル トレーニングの民主化](https://arxiv.org/abs/2101.06840)
+- [ZeRO-Infinity: 極限スケールの深層学習のための GPU メモリの壁を打ち破る](https://arxiv.org/abs/2104.07857)
+
+最後に、HuggingFace [`Trainer`] は DeepSpeed のみを統合していることを覚えておいてください。
+DeepSpeed の使用に関して問題や質問がある場合は、[DeepSpeed GitHub](https://github.com/microsoft/DeepSpeed/issues) に問題を提出してください。
diff --git a/docs/source/ja/main_classes/feature_extractor.md b/docs/source/ja/main_classes/feature_extractor.md
new file mode 100644
index 000000000000..a2bd8c59a84f
--- /dev/null
+++ b/docs/source/ja/main_classes/feature_extractor.md
@@ -0,0 +1,41 @@
+
+
+# Feature Extractor
+
+
+フィーチャーエクストラクタは、オーディオまたはビジョンモデルのための入力フィーチャーの準備を担当しています。これには、シーケンスからのフィーチャー抽出(例:オーディオファイルの前処理からLog-Melスペクトログラムフィーチャーへの変換)、画像からのフィーチャー抽出(例:画像ファイルのクロッピング)、またパディング、正規化、そしてNumpy、PyTorch、TensorFlowテンソルへの変換も含まれます。
+
+
+## FeatureExtractionMixin
+
+[[autodoc]] feature_extraction_utils.FeatureExtractionMixin
+ - from_pretrained
+ - save_pretrained
+
+## SequenceFeatureExtractor
+
+[[autodoc]] SequenceFeatureExtractor
+ - pad
+
+## BatchFeature
+
+[[autodoc]] BatchFeature
+
+## ImageFeatureExtractionMixin
+
+[[autodoc]] image_utils.ImageFeatureExtractionMixin
diff --git a/docs/source/ja/main_classes/image_processor.md b/docs/source/ja/main_classes/image_processor.md
new file mode 100644
index 000000000000..bfd33b83c2e5
--- /dev/null
+++ b/docs/source/ja/main_classes/image_processor.md
@@ -0,0 +1,33 @@
+
+
+# Image Processor
+
+画像プロセッサは、ビジョン モデルの入力特徴の準備とその出力の後処理を担当します。これには、サイズ変更、正規化、PyTorch、TensorFlow、Flax、Numpy テンソルへの変換などの変換が含まれます。ロジットをセグメンテーション マスクに変換するなど、モデル固有の後処理も含まれる場合があります。
+
+## ImageProcessingMixin
+
+[[autodoc]] image_processing_utils.ImageProcessingMixin
+ - from_pretrained
+ - save_pretrained
+
+## BatchFeature
+
+[[autodoc]] BatchFeature
+
+## BaseImageProcessor
+
+[[autodoc]] image_processing_utils.BaseImageProcessor
diff --git a/docs/source/en/perf_infer_special.md b/docs/source/ja/main_classes/keras_callbacks.md
similarity index 55%
rename from docs/source/en/perf_infer_special.md
rename to docs/source/ja/main_classes/keras_callbacks.md
index e5744754b88e..ff28107a4345 100644
--- a/docs/source/en/perf_infer_special.md
+++ b/docs/source/ja/main_classes/keras_callbacks.md
@@ -1,4 +1,4 @@
-
-# Inference on Specialized Hardware
+# Keras callbacks
-This document will be completed soon with information on how to infer on specialized hardware. In the meantime you can check out [the guide for inference on CPUs](perf_infer_cpu).
\ No newline at end of file
+Keras を使用して Transformers モデルをトレーニングする場合、一般的な処理を自動化するために使用できるライブラリ固有のコールバックがいくつかあります。
+タスク:
+
+## KerasMetricCallback
+
+[[autodoc]] KerasMetricCallback
+
+## PushToHubCallback
+
+[[autodoc]] PushToHubCallback
diff --git a/docs/source/ja/main_classes/logging.md b/docs/source/ja/main_classes/logging.md
new file mode 100644
index 000000000000..4b4f4a2a3e09
--- /dev/null
+++ b/docs/source/ja/main_classes/logging.md
@@ -0,0 +1,121 @@
+
+
+# Logging
+
+🤗 Transformersには、ライブラリの詳細度を簡単に設定できる中央集中型のロギングシステムがあります。
+
+現在、ライブラリのデフォルトの詳細度は「WARNING」です。
+
+詳細度を変更するには、直接設定メソッドの1つを使用するだけです。例えば、詳細度をINFOレベルに変更する方法は以下の通りです。
+
+
+```python
+import transformers
+
+transformers.logging.set_verbosity_info()
+```
+
+
+環境変数 `TRANSFORMERS_VERBOSITY` を使用して、デフォルトの冗長性をオーバーライドすることもできます。設定できます
+`debug`、`info`、`warning`、`error`、`critical` のいずれかに変更します。例えば:
+
+```bash
+TRANSFORMERS_VERBOSITY=error ./myprogram.py
+```
+
+
+さらに、一部の「警告」は環境変数を設定することで無効にできます。
+`TRANSFORMERS_NO_ADVISORY_WARNINGS` を *1* などの true 値に設定します。これにより、次を使用してログに記録される警告が無効になります。
+[`logger.warning_advice`]。例えば:
+
+```bash
+TRANSFORMERS_NO_ADVISORY_WARNINGS=1 ./myprogram.py
+```
+
+
+以下は、独自のモジュールまたはスクリプトでライブラリと同じロガーを使用する方法の例です。
+
+```python
+from transformers.utils import logging
+
+logging.set_verbosity_info()
+logger = logging.get_logger("transformers")
+logger.info("INFO")
+logger.warning("WARN")
+```
+
+このロギング モジュールのすべてのメソッドは以下に文書化されています。主なメソッドは次のとおりです。
+[`logging.get_verbosity`] ロガーの現在の冗長レベルを取得します。
+[`logging.set_verbosity`] を使用して、冗長性を選択したレベルに設定します。順番に(少ないものから)
+冗長から最も冗長まで)、それらのレベル (括弧内は対応する int 値) は次のとおりです。
+
+- `transformers.logging.CRITICAL` または `transformers.logging.FATAL` (int 値、50): 最も多いもののみをレポートします。
+ 重大なエラー。
+- `transformers.logging.ERROR` (int 値、40): エラーのみを報告します。
+- `transformers.logging.WARNING` または `transformers.logging.WARN` (int 値、30): エラーと
+ 警告。これはライブラリで使用されるデフォルトのレベルです。
+- `transformers.logging.INFO` (int 値、20): エラー、警告、および基本情報をレポートします。
+- `transformers.logging.DEBUG` (int 値、10): すべての情報をレポートします。
+
+デフォルトでは、モデルのダウンロード中に「tqdm」進行状況バーが表示されます。 [`logging.disable_progress_bar`] および [`logging.enable_progress_bar`] を使用して、この動作を抑制または抑制解除できます。
+
+## `logging` vs `warnings`
+
+Python には、よく組み合わせて使用される 2 つのロギング システムがあります。上で説明した `logging` と `warnings` です。
+これにより、特定のバケット内の警告をさらに分類できます (例: 機能またはパスの`FutureWarning`)
+これはすでに非推奨になっており、`DeprecationWarning`は今後の非推奨を示します。
+
+両方とも`transformers`ライブラリで使用します。 `logging`の`captureWarning`メソッドを活用して適応させて、
+これらの警告メッセージは、上記の冗長設定ツールによって管理されます。
+
+それはライブラリの開発者にとって何を意味しますか?次のヒューリスティックを尊重する必要があります。
+- `warnings`は、ライブラリおよび`transformers`に依存するライブラリの開発者に優先されるべきです。
+- `logging`は、日常のプロジェクトでライブラリを使用するライブラリのエンドユーザーに使用する必要があります。
+
+以下の`captureWarnings`メソッドのリファレンスを参照してください。
+
+[[autodoc]] logging.captureWarnings
+
+## Base setters
+
+[[autodoc]] logging.set_verbosity_error
+
+[[autodoc]] logging.set_verbosity_warning
+
+[[autodoc]] logging.set_verbosity_info
+
+[[autodoc]] logging.set_verbosity_debug
+
+## Other functions
+
+[[autodoc]] logging.get_verbosity
+
+[[autodoc]] logging.set_verbosity
+
+[[autodoc]] logging.get_logger
+
+[[autodoc]] logging.enable_default_handler
+
+[[autodoc]] logging.disable_default_handler
+
+[[autodoc]] logging.enable_explicit_format
+
+[[autodoc]] logging.reset_format
+
+[[autodoc]] logging.enable_progress_bar
+
+[[autodoc]] logging.disable_progress_bar
diff --git a/docs/source/ja/main_classes/model.md b/docs/source/ja/main_classes/model.md
new file mode 100644
index 000000000000..916040c4a3b2
--- /dev/null
+++ b/docs/source/ja/main_classes/model.md
@@ -0,0 +1,160 @@
+
+
+# Models
+
+ベースクラスである [`PreTrainedModel`]、[`TFPreTrainedModel`]、[`FlaxPreTrainedModel`] は、モデルの読み込みと保存に関する共通のメソッドを実装しており、これはローカルのファイルやディレクトリから、またはライブラリが提供する事前学習モデル構成(HuggingFaceのAWS S3リポジトリからダウンロード)からモデルを読み込むために使用できます。
+
+[`PreTrainedModel`] と [`TFPreTrainedModel`] は、次の共通のメソッドも実装しています:
+
+- 語彙に新しいトークンが追加された場合に、入力トークン埋め込みのリサイズを行う
+- モデルのアテンションヘッドを刈り込む
+
+各モデルに共通するその他のメソッドは、[`~modeling_utils.ModuleUtilsMixin`](PyTorchモデル用)および[`~modeling_tf_utils.TFModuleUtilsMixin`](TensorFlowモデル用)で定義されており、テキスト生成の場合、[`~generation.GenerationMixin`](PyTorchモデル用)、[`~generation.TFGenerationMixin`](TensorFlowモデル用)、および[`~generation.FlaxGenerationMixin`](Flax/JAXモデル用)もあります。
+
+
+## PreTrainedModel
+
+[[autodoc]] PreTrainedModel
+ - push_to_hub
+ - all
+
+
+
+
+### 大規模モデルの読み込み
+
+Transformers 4.20.0では、[`~PreTrainedModel.from_pretrained`] メソッドが再設計され、[Accelerate](https://huggingface.co/docs/accelerate/big_modeling) を使用して大規模モデルを扱うことが可能になりました。これには Accelerate >= 0.9.0 と PyTorch >= 1.9.0 が必要です。以前の方法でフルモデルを作成し、その後事前学習の重みを読み込む代わりに(これにはメモリ内のモデルサイズが2倍必要で、ランダムに初期化されたモデル用と重み用の2つが必要でした)、モデルを空の外殻として作成し、事前学習の重みが読み込まれるときにパラメーターを実体化するオプションが追加されました。
+
+このオプションは `low_cpu_mem_usage=True` で有効にできます。モデルはまず空の重みを持つメタデバイス上に作成され、その後状態辞書が内部に読み込まれます(シャードされたチェックポイントの場合、シャードごとに読み込まれます)。この方法で使用される最大RAMは、モデルの完全なサイズだけです。
+
+
+```py
+from transformers import AutoModelForSeq2SeqLM
+
+t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", low_cpu_mem_usage=True)
+```
+
+さらに、モデルが完全にRAMに収まらない場合(現時点では推論のみ有効)、異なるデバイスにモデルを直接配置できます。`device_map="auto"` を使用すると、Accelerateは各レイヤーをどのデバイスに配置するかを決定し、最速のデバイス(GPU)を最大限に活用し、残りの部分をCPU、あるいはGPU RAMが不足している場合はハードドライブにオフロードします。モデルが複数のデバイスに分割されていても、通常どおり実行されます。
+
+`device_map` を渡す際、`low_cpu_mem_usage` は自動的に `True` に設定されるため、それを指定する必要はありません。
+
+
+```py
+from transformers import AutoModelForSeq2SeqLM
+
+t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", device_map="auto")
+```
+
+モデルがデバイス間でどのように分割されたかは、その `hf_device_map` 属性を見ることで確認できます:
+
+```py
+t0pp.hf_device_map
+```
+
+```python out
+{'shared': 0,
+ 'decoder.embed_tokens': 0,
+ 'encoder': 0,
+ 'decoder.block.0': 0,
+ 'decoder.block.1': 1,
+ 'decoder.block.2': 1,
+ 'decoder.block.3': 1,
+ 'decoder.block.4': 1,
+ 'decoder.block.5': 1,
+ 'decoder.block.6': 1,
+ 'decoder.block.7': 1,
+ 'decoder.block.8': 1,
+ 'decoder.block.9': 1,
+ 'decoder.block.10': 1,
+ 'decoder.block.11': 1,
+ 'decoder.block.12': 1,
+ 'decoder.block.13': 1,
+ 'decoder.block.14': 1,
+ 'decoder.block.15': 1,
+ 'decoder.block.16': 1,
+ 'decoder.block.17': 1,
+ 'decoder.block.18': 1,
+ 'decoder.block.19': 1,
+ 'decoder.block.20': 1,
+ 'decoder.block.21': 1,
+ 'decoder.block.22': 'cpu',
+ 'decoder.block.23': 'cpu',
+ 'decoder.final_layer_norm': 'cpu',
+ 'decoder.dropout': 'cpu',
+ 'lm_head': 'cpu'}
+```
+
+同じフォーマットに従って、独自のデバイスマップを作成することもできます(レイヤー名からデバイスへの辞書です)。モデルのすべてのパラメータを指定されたデバイスにマップする必要がありますが、1つのレイヤーが完全に同じデバイスにある場合、そのレイヤーのサブモジュールのすべてがどこに行くかの詳細を示す必要はありません。例えば、次のデバイスマップはT0ppに適しています(GPUメモリがある場合):
+
+```python
+device_map = {"shared": 0, "encoder": 0, "decoder": 1, "lm_head": 1}
+```
+
+モデルのメモリへの影響を最小限に抑えるもう 1 つの方法は、低精度の dtype (`torch.float16` など) でモデルをインスタンス化するか、以下で説明する直接量子化手法を使用することです。
+
+### Model Instantiation dtype
+
+Pytorch では、モデルは通常 `torch.float32` 形式でインスタンス化されます。これは、しようとすると問題になる可能性があります
+重みが fp16 にあるモデルをロードすると、2 倍のメモリが必要になるためです。この制限を克服するには、次のことができます。
+`torch_dtype` 引数を使用して、目的の `dtype` を明示的に渡します。
+
+```python
+model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype=torch.float16)
+```
+または、モデルを常に最適なメモリ パターンでロードしたい場合は、特別な値 `"auto"` を使用できます。
+そして、`dtype` はモデルの重みから自動的に導出されます。
+
+```python
+model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype="auto")
+```
+
+スクラッチからインスタンス化されたモデルには、どの `dtype` を使用するかを指示することもできます。
+
+```python
+config = T5Config.from_pretrained("t5")
+model = AutoModel.from_config(config)
+```
+
+Pytorch の設計により、この機能は浮動小数点 dtype でのみ使用できます。
+
+## ModuleUtilsMixin
+
+[[autodoc]] modeling_utils.ModuleUtilsMixin
+
+## TFPreTrainedModel
+
+[[autodoc]] TFPreTrainedModel
+ - push_to_hub
+ - all
+
+## TFModelUtilsMixin
+
+[[autodoc]] modeling_tf_utils.TFModelUtilsMixin
+
+## FlaxPreTrainedModel
+
+[[autodoc]] FlaxPreTrainedModel
+ - push_to_hub
+ - all
+
+## Pushing to the Hub
+
+[[autodoc]] utils.PushToHubMixin
+
+## Sharded checkpoints
+
+[[autodoc]] modeling_utils.load_sharded_checkpoint
diff --git a/docs/source/ja/main_classes/onnx.md b/docs/source/ja/main_classes/onnx.md
new file mode 100644
index 000000000000..f12427760976
--- /dev/null
+++ b/docs/source/ja/main_classes/onnx.md
@@ -0,0 +1,55 @@
+
+
+# Exporting 🤗 Transformers models to ONNX
+
+🤗 Transformers は `transformers.onnx` パッケージを提供します。
+設定オブジェクトを利用することで、モデルのチェックポイントをONNXグラフに変換することができます。
+
+詳細は[ガイド](../serialization) を参照してください。
+を参照してください。
+
+## ONNX Configurations
+
+以下の3つの抽象クラスを提供しています。
+エクスポートしたいモデルアーキテクチャのタイプに応じて、継承すべき3つの抽象クラスを提供します:
+
+* エンコーダーベースのモデルは [`~onnx.config.OnnxConfig`] を継承します。
+* デコーダーベースのモデルは [`~onnx.config.OnnxConfigWithPast`] を継承します。
+* エンコーダー・デコーダーモデルは [`~onnx.config.OnnxSeq2SeqConfigWithPast`] を継承しています。
+
+
+### OnnxConfig
+
+[[autodoc]] onnx.config.OnnxConfig
+
+### OnnxConfigWithPast
+
+[[autodoc]] onnx.config.OnnxConfigWithPast
+
+### OnnxSeq2SeqConfigWithPast
+
+[[autodoc]] onnx.config.OnnxSeq2SeqConfigWithPast
+
+## ONNX Features
+
+各 ONNX 構成は、次のことを可能にする一連の _機能_ に関連付けられています。
+さまざまなタイプのトポロジまたはタスクのモデルをエクスポートします。
+
+### FeaturesManager
+
+[[autodoc]] onnx.features.FeaturesManager
+
diff --git a/docs/source/ja/main_classes/optimizer_schedules.md b/docs/source/ja/main_classes/optimizer_schedules.md
new file mode 100644
index 000000000000..fc7a13b9df53
--- /dev/null
+++ b/docs/source/ja/main_classes/optimizer_schedules.md
@@ -0,0 +1,77 @@
+
+
+# Optimization
+
+`.optimization` モジュールは以下を提供します。
+
+- モデルの微調整に使用できる重み減衰が修正されたオプティマイザー、および
+- `_LRSchedule` から継承するスケジュール オブジェクトの形式のいくつかのスケジュール:
+- 複数のバッチの勾配を累積するための勾配累積クラス
+
+## AdamW (PyTorch)
+
+[[autodoc]] AdamW
+
+## AdaFactor (PyTorch)
+
+[[autodoc]] Adafactor
+
+## AdamWeightDecay (TensorFlow)
+
+[[autodoc]] AdamWeightDecay
+
+[[autodoc]] create_optimizer
+
+## Schedules
+
+### Learning Rate Schedules (Pytorch)
+
+[[autodoc]] SchedulerType
+
+[[autodoc]] get_scheduler
+
+[[autodoc]] get_constant_schedule
+
+[[autodoc]] get_constant_schedule_with_warmup
+
+
+
+[[autodoc]] get_cosine_schedule_with_warmup
+
+
+
+[[autodoc]] get_cosine_with_hard_restarts_schedule_with_warmup
+
+
+
+[[autodoc]] get_linear_schedule_with_warmup
+
+
+
+[[autodoc]] get_polynomial_decay_schedule_with_warmup
+
+[[autodoc]] get_inverse_sqrt_schedule
+
+### Warmup (TensorFlow)
+
+[[autodoc]] WarmUp
+
+## Gradient Strategies
+
+### GradientAccumulator (TensorFlow)
+
+[[autodoc]] GradientAccumulator
diff --git a/docs/source/ja/main_classes/output.md b/docs/source/ja/main_classes/output.md
new file mode 100644
index 000000000000..7f906544a8f8
--- /dev/null
+++ b/docs/source/ja/main_classes/output.md
@@ -0,0 +1,321 @@
+
+
+# Model outputs
+
+すべてのモデルには、[`~utils.ModelOutput`] のサブクラスのインスタンスである出力があります。それらは
+モデルによって返されるすべての情報を含むデータ構造ですが、タプルまたは
+辞書。
+
+これがどのようになるかを例で見てみましょう。
+
+```python
+from transformers import BertTokenizer, BertForSequenceClassification
+import torch
+
+tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
+model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
+
+inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
+labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
+outputs = model(**inputs, labels=labels)
+```
+
+`outputs`オブジェクトは[`~modeling_outputs.SequenceClassifierOutput`]である。
+これは、オプションで `loss`、`logits`、オプションで `hidden_states`、オプションで `attentions` 属性を持つことを意味します。
+オプションの `attentions` 属性を持つことを意味する。ここでは、`labels`を渡したので`loss`があるが、`hidden_states`と`attentions`はない。
+`output_hidden_states=True`や`output_attentions=True`を渡していないので、`hidden_states`と`attentions`はない。
+`output_attentions=True`を渡さなかったからだ。
+
+
+
+`output_hidden_states=True`を渡すと、`outputs.hidden_states[-1]`が `outputs.last_hidden_states` と正確に一致することを期待するかもしれない。
+しかし、必ずしもそうなるとは限りません。モデルによっては、最後に隠された状態が返されたときに、正規化やその後の処理を適用するものもあります。
+
+
+
+
+通常と同じように各属性にアクセスできます。その属性がモデルから返されなかった場合は、
+は `None`を取得します。ここで、たとえば`outputs.loss`はモデルによって計算された損失であり、`outputs.attentions`は
+`None`。
+
+`outputs`オブジェクトをタプルとして考える場合、`None`値を持たない属性のみが考慮されます。
+たとえば、ここには 2 つの要素、`loss`、次に`logits`があります。
+
+```python
+outputs[:2]
+```
+
+たとえば、タプル `(outputs.loss, Outputs.logits)` を返します。
+
+`outputs`オブジェクトを辞書として考慮する場合、「None」を持たない属性のみが考慮されます。
+価値観。たとえば、ここには`loss` と `logits`という 2 つのキーがあります。
+
+ここでは、複数のモデル タイプで使用される汎用モデルの出力を文書化します。具体的な出力タイプは次のとおりです。
+対応するモデルのページに記載されています。
+
+## ModelOutput
+
+[[autodoc]] utils.ModelOutput
+ - to_tuple
+
+## BaseModelOutput
+
+[[autodoc]] modeling_outputs.BaseModelOutput
+
+## BaseModelOutputWithPooling
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPooling
+
+## BaseModelOutputWithCrossAttentions
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithCrossAttentions
+
+## BaseModelOutputWithPoolingAndCrossAttentions
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions
+
+## BaseModelOutputWithPast
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPast
+
+## BaseModelOutputWithPastAndCrossAttentions
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPastAndCrossAttentions
+
+## Seq2SeqModelOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqModelOutput
+
+## CausalLMOutput
+
+[[autodoc]] modeling_outputs.CausalLMOutput
+
+## CausalLMOutputWithCrossAttentions
+
+[[autodoc]] modeling_outputs.CausalLMOutputWithCrossAttentions
+
+## CausalLMOutputWithPast
+
+[[autodoc]] modeling_outputs.CausalLMOutputWithPast
+
+## MaskedLMOutput
+
+[[autodoc]] modeling_outputs.MaskedLMOutput
+
+## Seq2SeqLMOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqLMOutput
+
+## NextSentencePredictorOutput
+
+[[autodoc]] modeling_outputs.NextSentencePredictorOutput
+
+## SequenceClassifierOutput
+
+[[autodoc]] modeling_outputs.SequenceClassifierOutput
+
+## Seq2SeqSequenceClassifierOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqSequenceClassifierOutput
+
+## MultipleChoiceModelOutput
+
+[[autodoc]] modeling_outputs.MultipleChoiceModelOutput
+
+## TokenClassifierOutput
+
+[[autodoc]] modeling_outputs.TokenClassifierOutput
+
+## QuestionAnsweringModelOutput
+
+[[autodoc]] modeling_outputs.QuestionAnsweringModelOutput
+
+## Seq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqQuestionAnsweringModelOutput
+
+## Seq2SeqSpectrogramOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqSpectrogramOutput
+
+## SemanticSegmenterOutput
+
+[[autodoc]] modeling_outputs.SemanticSegmenterOutput
+
+## ImageClassifierOutput
+
+[[autodoc]] modeling_outputs.ImageClassifierOutput
+
+## ImageClassifierOutputWithNoAttention
+
+[[autodoc]] modeling_outputs.ImageClassifierOutputWithNoAttention
+
+## DepthEstimatorOutput
+
+[[autodoc]] modeling_outputs.DepthEstimatorOutput
+
+## Wav2Vec2BaseModelOutput
+
+[[autodoc]] modeling_outputs.Wav2Vec2BaseModelOutput
+
+## XVectorOutput
+
+[[autodoc]] modeling_outputs.XVectorOutput
+
+## Seq2SeqTSModelOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqTSModelOutput
+
+## Seq2SeqTSPredictionOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqTSPredictionOutput
+
+## SampleTSPredictionOutput
+
+[[autodoc]] modeling_outputs.SampleTSPredictionOutput
+
+## TFBaseModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutput
+
+## TFBaseModelOutputWithPooling
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPooling
+
+## TFBaseModelOutputWithPoolingAndCrossAttentions
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPoolingAndCrossAttentions
+
+## TFBaseModelOutputWithPast
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPast
+
+## TFBaseModelOutputWithPastAndCrossAttentions
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPastAndCrossAttentions
+
+## TFSeq2SeqModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqModelOutput
+
+## TFCausalLMOutput
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutput
+
+## TFCausalLMOutputWithCrossAttentions
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithCrossAttentions
+
+## TFCausalLMOutputWithPast
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithPast
+
+## TFMaskedLMOutput
+
+[[autodoc]] modeling_tf_outputs.TFMaskedLMOutput
+
+## TFSeq2SeqLMOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqLMOutput
+
+## TFNextSentencePredictorOutput
+
+[[autodoc]] modeling_tf_outputs.TFNextSentencePredictorOutput
+
+## TFSequenceClassifierOutput
+
+[[autodoc]] modeling_tf_outputs.TFSequenceClassifierOutput
+
+## TFSeq2SeqSequenceClassifierOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqSequenceClassifierOutput
+
+## TFMultipleChoiceModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFMultipleChoiceModelOutput
+
+## TFTokenClassifierOutput
+
+[[autodoc]] modeling_tf_outputs.TFTokenClassifierOutput
+
+## TFQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFQuestionAnsweringModelOutput
+
+## TFSeq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqQuestionAnsweringModelOutput
+
+## FlaxBaseModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutput
+
+## FlaxBaseModelOutputWithPast
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPast
+
+## FlaxBaseModelOutputWithPooling
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPooling
+
+## FlaxBaseModelOutputWithPastAndCrossAttentions
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPastAndCrossAttentions
+
+## FlaxSeq2SeqModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqModelOutput
+
+## FlaxCausalLMOutputWithCrossAttentions
+
+[[autodoc]] modeling_flax_outputs.FlaxCausalLMOutputWithCrossAttentions
+
+## FlaxMaskedLMOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxMaskedLMOutput
+
+## FlaxSeq2SeqLMOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqLMOutput
+
+## FlaxNextSentencePredictorOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxNextSentencePredictorOutput
+
+## FlaxSequenceClassifierOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSequenceClassifierOutput
+
+## FlaxSeq2SeqSequenceClassifierOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqSequenceClassifierOutput
+
+## FlaxMultipleChoiceModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxMultipleChoiceModelOutput
+
+## FlaxTokenClassifierOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxTokenClassifierOutput
+
+## FlaxQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxQuestionAnsweringModelOutput
+
+## FlaxSeq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqQuestionAnsweringModelOutput
diff --git a/docs/source/ja/main_classes/pipelines.md b/docs/source/ja/main_classes/pipelines.md
new file mode 100644
index 000000000000..321659de95ba
--- /dev/null
+++ b/docs/source/ja/main_classes/pipelines.md
@@ -0,0 +1,494 @@
+
+
+# Pipelines
+
+パイプラインは、推論にモデルを使うための簡単で優れた方法である。パイプラインは、複雑なコードのほとんどを抽象化したオブジェクトです。
+パイプラインは、ライブラリから複雑なコードのほとんどを抽象化したオブジェクトで、名前付き固有表現認識、マスク言語モデリング、感情分析、特徴抽出、質問応答などのタスクに特化したシンプルなAPIを提供します。
+Recognition、Masked Language Modeling、Sentiment Analysis、Feature Extraction、Question Answeringなどのタスクに特化したシンプルなAPIを提供します。以下を参照のこと。
+[タスク概要](../task_summary)を参照してください。
+
+
+パイプラインの抽象化には2つのカテゴリーがある:
+
+- [`pipeline`] は、他のすべてのパイプラインをカプセル化する最も強力なオブジェクトです。
+- タスク固有のパイプラインは、[オーディオ](#audio)、[コンピューター ビジョン](#computer-vision)、[自然言語処理](#natural-language-processing)、および [マルチモーダル](#multimodal) タスクで使用できます。
+
+## The pipeline abstraction
+
+*パイプライン* 抽象化は、他のすべての利用可能なパイプラインのラッパーです。他のものと同様にインスタンス化されます
+パイプラインですが、さらなる生活の質を提供できます。
+
+1 つの項目に対する単純な呼び出し:
+
+```python
+>>> pipe = pipeline("text-classification")
+>>> pipe("This restaurant is awesome")
+[{'label': 'POSITIVE', 'score': 0.9998743534088135}]
+```
+
+[ハブ](https://huggingface.co) の特定のモデルを使用したい場合は、モデルがオンになっている場合はタスクを無視できます。
+ハブはすでにそれを定義しています。
+
+```python
+>>> pipe = pipeline(model="roberta-large-mnli")
+>>> pipe("This restaurant is awesome")
+[{'label': 'NEUTRAL', 'score': 0.7313136458396912}]
+```
+
+多くの項目に対してパイプラインを呼び出すには、*list* を使用してパイプラインを呼び出すことができます。
+
+```python
+>>> pipe = pipeline("text-classification")
+>>> pipe(["This restaurant is awesome", "This restaurant is awful"])
+[{'label': 'POSITIVE', 'score': 0.9998743534088135},
+ {'label': 'NEGATIVE', 'score': 0.9996669292449951}]
+```
+
+完全なデータセットを反復するには、`Dataset`を直接使用することをお勧めします。これは、割り当てる必要がないことを意味します
+データセット全体を一度に処理することも、自分でバッチ処理を行う必要もありません。これはカスタムループと同じくらい速く動作するはずです。
+GPU。それが問題でない場合は、ためらわずに問題を作成してください。
+
+```python
+import datasets
+from transformers import pipeline
+from transformers.pipelines.pt_utils import KeyDataset
+from tqdm.auto import tqdm
+
+pipe = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h", device=0)
+dataset = datasets.load_dataset("superb", name="asr", split="test")
+
+# KeyDataset (only *pt*) will simply return the item in the dict returned by the dataset item
+# as we're not interested in the *target* part of the dataset. For sentence pair use KeyPairDataset
+for out in tqdm(pipe(KeyDataset(dataset, "file"))):
+ print(out)
+ # {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
+ # {"text": ....}
+ # ....
+```
+
+使いやすくするために、ジェネレーターを使用することもできます。
+
+```python
+from transformers import pipeline
+
+pipe = pipeline("text-classification")
+
+
+def data():
+ while True:
+ # This could come from a dataset, a database, a queue or HTTP request
+ # in a server
+ # Caveat: because this is iterative, you cannot use `num_workers > 1` variable
+ # to use multiple threads to preprocess data. You can still have 1 thread that
+ # does the preprocessing while the main runs the big inference
+ yield "This is a test"
+
+
+for out in pipe(data()):
+ print(out)
+ # {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
+ # {"text": ....}
+ # ....
+```
+
+[[autodoc]] pipeline
+
+
+## Pipeline batching
+
+
+すべてのパイプラインでバッチ処理を使用できます。これはうまくいきます
+パイプラインがストリーミング機能を使用するときは常に (つまり、リスト、`dataset`、または `generator`を渡すとき)。
+
+```python
+from transformers import pipeline
+from transformers.pipelines.pt_utils import KeyDataset
+import datasets
+
+dataset = datasets.load_dataset("imdb", name="plain_text", split="unsupervised")
+pipe = pipeline("text-classification", device=0)
+for out in pipe(KeyDataset(dataset, "text"), batch_size=8, truncation="only_first"):
+ print(out)
+ # [{'label': 'POSITIVE', 'score': 0.9998743534088135}]
+ # Exactly the same output as before, but the content are passed
+ # as batches to the model
+```
+
+
+
+
+ただし、これによってパフォーマンスが自動的に向上するわけではありません。状況に応じて、10 倍の高速化または 5 倍の低速化のいずれかになります。
+ハードウェア、データ、使用されている実際のモデルについて。
+
+主に高速化である例:
+
+
+
+
+```python
+from transformers import pipeline
+from torch.utils.data import Dataset
+from tqdm.auto import tqdm
+
+pipe = pipeline("text-classification", device=0)
+
+
+class MyDataset(Dataset):
+ def __len__(self):
+ return 5000
+
+ def __getitem__(self, i):
+ return "This is a test"
+
+
+dataset = MyDataset()
+
+for batch_size in [1, 8, 64, 256]:
+ print("-" * 30)
+ print(f"Streaming batch_size={batch_size}")
+ for out in tqdm(pipe(dataset, batch_size=batch_size), total=len(dataset)):
+ pass
+```
+
+```
+# On GTX 970
+------------------------------
+Streaming no batching
+100%|██████████████████████████████████████████████████████████████████████| 5000/5000 [00:26<00:00, 187.52it/s]
+------------------------------
+Streaming batch_size=8
+100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:04<00:00, 1205.95it/s]
+------------------------------
+Streaming batch_size=64
+100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:02<00:00, 2478.24it/s]
+------------------------------
+Streaming batch_size=256
+100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:01<00:00, 2554.43it/s]
+(diminishing returns, saturated the GPU)
+```
+
+最も速度が低下する例:
+
+
+```python
+class MyDataset(Dataset):
+ def __len__(self):
+ return 5000
+
+ def __getitem__(self, i):
+ if i % 64 == 0:
+ n = 100
+ else:
+ n = 1
+ return "This is a test" * n
+```
+
+これは、他の文に比べて非常に長い文が時折あります。その場合、**全体**のバッチは 400 である必要があります。
+トークンが長いため、バッチ全体が [64, 4] ではなく [64, 400] になり、速度が大幅に低下します。さらに悪いことに、
+バッチが大きくなると、プログラムは単純にクラッシュします。
+
+```
+------------------------------
+Streaming no batching
+100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:05<00:00, 183.69it/s]
+------------------------------
+Streaming batch_size=8
+100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:03<00:00, 265.74it/s]
+------------------------------
+Streaming batch_size=64
+100%|██████████████████████████████████████████████████████████████████████| 1000/1000 [00:26<00:00, 37.80it/s]
+------------------------------
+Streaming batch_size=256
+ 0%| | 0/1000 [00:00
+ for out in tqdm(pipe(dataset, batch_size=256), total=len(dataset)):
+....
+ q = q / math.sqrt(dim_per_head) # (bs, n_heads, q_length, dim_per_head)
+RuntimeError: CUDA out of memory. Tried to allocate 376.00 MiB (GPU 0; 3.95 GiB total capacity; 1.72 GiB already allocated; 354.88 MiB free; 2.46 GiB reserved in total by PyTorch)
+```
+
+この問題に対する適切な (一般的な) 解決策はなく、使用できる距離はユースケースによって異なる場合があります。のルール
+親指:
+
+ユーザーにとっての経験則は次のとおりです。
+
+- **ハードウェアを使用して、負荷に対するパフォーマンスを測定します。測って、測って、測り続ける。実数というのは、
+ 進むべき唯一の方法。**
+- レイテンシに制約がある場合 (実際の製品が推論を実行している場合)、バッチ処理を行わないでください。
+- CPU を使用している場合は、バッチ処理を行わないでください。
+- GPU でスループットを使用している場合 (大量の静的データでモデルを実行したい場合)、次のようにします。
+
+ - sequence_length (「自然な」データ) のサイズについてまったくわからない場合は、デフォルトではバッチ処理や測定を行わず、
+ 暫定的に追加してみます。失敗した場合に回復するために OOM チェックを追加します (失敗した場合は、ある時点で回復します)。
+ sequence_length を制御します。)
+ - sequence_length が非常に規則的である場合、バッチ処理は非常に興味深いものとなる可能性が高く、測定してプッシュしてください。
+ OOM が発生するまで続けます。
+ - GPU が大きいほど、バッチ処理がより興味深いものになる可能性が高くなります。
+- バッチ処理を有効にしたらすぐに、OOM を適切に処理できることを確認してください。
+
+
+## Pipeline chunk batching
+
+`zero-shot-classification` と `question-answering` は、単一の入力で結果が得られる可能性があるという意味で、少し特殊です。
+モデルの複数の前方パス。通常の状況では、これにより `batch_size` 引数に関する問題が発生します。
+
+この問題を回避するために、これらのパイプラインはどちらも少し特殊になっており、代わりに `ChunkPipeline` になっています。
+通常の `Pipeline`。要するに:
+
+```python
+preprocessed = pipe.preprocess(inputs)
+model_outputs = pipe.forward(preprocessed)
+outputs = pipe.postprocess(model_outputs)
+```
+
+今は次のようになります:
+
+```python
+all_model_outputs = []
+for preprocessed in pipe.preprocess(inputs):
+ model_outputs = pipe.forward(preprocessed)
+ all_model_outputs.append(model_outputs)
+outputs = pipe.postprocess(all_model_outputs)
+```
+
+パイプラインは以下で使用されるため、これはコードに対して非常に透過的である必要があります。
+同じ方法。
+
+パイプラインはバッチを自動的に処理できるため、これは簡略化されたビューです。気にする必要はないという意味です
+入力が実際にトリガーする前方パスの数については、`batch_size` を最適化できます。
+入力とは独立して。前のセクションの注意事項が引き続き適用されます。
+
+## Pipeline custom code
+
+特定のパイプラインをオーバーライドする場合。
+
+目の前のタスクに関する問題を作成することを躊躇しないでください。パイプラインの目標は、使いやすく、ほとんどのユーザーをサポートすることです。
+したがって、`transformers`があなたのユースケースをサポートする可能性があります。
+
+
+単純に試してみたい場合は、次のことができます。
+
+- 選択したパイプラインをサブクラス化します
+
+```python
+class MyPipeline(TextClassificationPipeline):
+ def postprocess():
+ # Your code goes here
+ scores = scores * 100
+ # And here
+
+
+my_pipeline = MyPipeline(model=model, tokenizer=tokenizer, ...)
+# or if you use *pipeline* function, then:
+my_pipeline = pipeline(model="xxxx", pipeline_class=MyPipeline)
+```
+
+これにより、必要なカスタム コードをすべて実行できるようになります。
+
+## Implementing a pipeline
+
+[Implementing a new pipeline](../add_new_pipeline)
+
+## Audio
+
+オーディオ タスクに使用できるパイプラインには次のものがあります。
+
+### AudioClassificationPipeline
+
+[[autodoc]] AudioClassificationPipeline
+ - __call__
+ - all
+
+### AutomaticSpeechRecognitionPipeline
+
+[[autodoc]] AutomaticSpeechRecognitionPipeline
+ - __call__
+ - all
+
+### TextToAudioPipeline
+
+[[autodoc]] TextToAudioPipeline
+ - __call__
+ - all
+
+
+### ZeroShotAudioClassificationPipeline
+
+[[autodoc]] ZeroShotAudioClassificationPipeline
+ - __call__
+ - all
+
+## Computer vision
+
+コンピューター ビジョン タスクに使用できるパイプラインには次のものがあります。
+
+### DepthEstimationPipeline
+[[autodoc]] DepthEstimationPipeline
+ - __call__
+ - all
+
+### ImageClassificationPipeline
+
+[[autodoc]] ImageClassificationPipeline
+ - __call__
+ - all
+
+### ImageSegmentationPipeline
+
+[[autodoc]] ImageSegmentationPipeline
+ - __call__
+ - all
+
+### ImageToImagePipeline
+
+[[autodoc]] ImageToImagePipeline
+ - __call__
+ - all
+
+### ObjectDetectionPipeline
+
+[[autodoc]] ObjectDetectionPipeline
+ - __call__
+ - all
+
+### VideoClassificationPipeline
+
+[[autodoc]] VideoClassificationPipeline
+ - __call__
+ - all
+
+### ZeroShotImageClassificationPipeline
+
+[[autodoc]] ZeroShotImageClassificationPipeline
+ - __call__
+ - all
+
+### ZeroShotObjectDetectionPipeline
+
+[[autodoc]] ZeroShotObjectDetectionPipeline
+ - __call__
+ - all
+
+## Natural Language Processing
+
+自然言語処理タスクに使用できるパイプラインには次のものがあります。
+
+### ConversationalPipeline
+
+[[autodoc]] Conversation
+
+[[autodoc]] ConversationalPipeline
+ - __call__
+ - all
+
+### FillMaskPipeline
+
+[[autodoc]] FillMaskPipeline
+ - __call__
+ - all
+
+### NerPipeline
+
+[[autodoc]] NerPipeline
+
+詳細については、[`TokenClassificationPipeline`] を参照してください。
+
+### QuestionAnsweringPipeline
+
+[[autodoc]] QuestionAnsweringPipeline
+ - __call__
+ - all
+
+### SummarizationPipeline
+
+[[autodoc]] SummarizationPipeline
+ - __call__
+ - all
+
+### TableQuestionAnsweringPipeline
+
+[[autodoc]] TableQuestionAnsweringPipeline
+ - __call__
+
+### TextClassificationPipeline
+
+[[autodoc]] TextClassificationPipeline
+ - __call__
+ - all
+
+### TextGenerationPipeline
+
+[[autodoc]] TextGenerationPipeline
+ - __call__
+ - all
+
+### Text2TextGenerationPipeline
+
+[[autodoc]] Text2TextGenerationPipeline
+ - __call__
+ - all
+
+### TokenClassificationPipeline
+
+[[autodoc]] TokenClassificationPipeline
+ - __call__
+ - all
+
+### TranslationPipeline
+
+[[autodoc]] TranslationPipeline
+ - __call__
+ - all
+
+### ZeroShotClassificationPipeline
+
+[[autodoc]] ZeroShotClassificationPipeline
+ - __call__
+ - all
+
+## Multimodal
+
+マルチモーダル タスクに使用できるパイプラインには次のものがあります。
+
+### DocumentQuestionAnsweringPipeline
+
+[[autodoc]] DocumentQuestionAnsweringPipeline
+ - __call__
+ - all
+
+### FeatureExtractionPipeline
+
+[[autodoc]] FeatureExtractionPipeline
+ - __call__
+ - all
+
+### ImageToTextPipeline
+
+[[autodoc]] ImageToTextPipeline
+ - __call__
+ - all
+
+### VisualQuestionAnsweringPipeline
+
+[[autodoc]] VisualQuestionAnsweringPipeline
+ - __call__
+ - all
+
+## Parent class: `Pipeline`
+
+[[autodoc]] Pipeline
diff --git a/docs/source/ja/main_classes/processors.md b/docs/source/ja/main_classes/processors.md
new file mode 100644
index 000000000000..63b94af6ea43
--- /dev/null
+++ b/docs/source/ja/main_classes/processors.md
@@ -0,0 +1,160 @@
+
+
+# Processors
+
+Transformers ライブラリでは、プロセッサは 2 つの異なる意味を持ちます。
+- [Wav2Vec2](../model_doc/wav2vec2) などのマルチモーダル モデルの入力を前処理するオブジェクト (音声とテキスト)
+ または [CLIP](../model_doc/clip) (テキストとビジョン)
+- 古いバージョンのライブラリで GLUE または SQUAD のデータを前処理するために使用されていたオブジェクトは非推奨になりました。
+
+## Multi-modal processors
+
+マルチモーダル モデルでは、オブジェクトが複数のモダリティ (テキスト、
+視覚と音声)。これは、2 つ以上の処理オブジェクトをグループ化するプロセッサーと呼ばれるオブジェクトによって処理されます。
+トークナイザー (テキスト モダリティ用)、画像プロセッサー (視覚用)、特徴抽出器 (オーディオ用) など。
+
+これらのプロセッサは、保存およびロード機能を実装する次の基本クラスを継承します。
+
+[[autodoc]] ProcessorMixin
+
+## Deprecated processors
+
+すべてのプロセッサは、同じアーキテクチャに従っています。
+[`~data.processors.utils.DataProcessor`]。プロセッサは次のリストを返します。
+[`~data.processors.utils.InputExample`]。これら
+[`~data.processors.utils.InputExample`] は次のように変換できます。
+[`~data.processors.utils.Input features`] をモデルにフィードします。
+
+[[autodoc]] data.processors.utils.DataProcessor
+
+[[autodoc]] data.processors.utils.InputExample
+
+[[autodoc]] data.processors.utils.InputFeatures
+
+## GLUE
+
+[一般言語理解評価 (GLUE)](https://gluebenchmark.com/) は、
+既存の NLU タスクの多様なセットにわたるモデルのパフォーマンス。紙と同時発売された [GLUE: A
+自然言語理解のためのマルチタスクベンチマークおよび分析プラットフォーム](https://openreview.net/pdf?id=rJ4km2R5t7)
+
+このライブラリは、MRPC、MNLI、MNLI (不一致)、CoLA、SST2、STSB、
+QQP、QNLI、RTE、WNLI。
+
+それらのプロセッサは次のとおりです。
+
+- [`~data.processors.utils.MrpcProcessor`]
+- [`~data.processors.utils.MnliProcessor`]
+- [`~data.processors.utils.MnliMismatchedProcessor`]
+- [`~data.processors.utils.Sst2Processor`]
+- [`~data.processors.utils.StsbProcessor`]
+- [`~data.processors.utils.QqpProcessor`]
+- [`~data.processors.utils.QnliProcessor`]
+- [`~data.processors.utils.RteProcessor`]
+- [`~data.processors.utils.WnliProcessor`]
+
+
+さらに、次のメソッドを使用して、データ ファイルから値をロードし、それらをリストに変換することができます。
+[`~data.processors.utils.InputExample`]。
+
+[[autodoc]] data.processors.glue.glue_convert_examples_to_features
+
+## XNLI
+
+[クロスリンガル NLI コーパス (XNLI)](https://www.nyu.edu/projects/bowman/xnli/) は、
+言語を超えたテキスト表現の品質。 XNLI は、[*MultiNLI*](http://www.nyu.edu/projects/bowman/multinli/) に基づくクラウドソースのデータセットです。テキストのペアには、15 個のテキスト含意アノテーションがラベル付けされています。
+さまざまな言語 (英語などの高リソース言語とスワヒリ語などの低リソース言語の両方を含む)。
+
+論文 [XNLI: Evaluating Cross-lingual Sentence Representations](https://arxiv.org/abs/1809.05053) と同時にリリースされました。
+
+このライブラリは、XNLI データをロードするプロセッサをホストします。
+
+- [`~data.processors.utils.XnliProcessor`]
+
+テストセットにはゴールドラベルが付いているため、評価はテストセットで行われますのでご了承ください。
+
+これらのプロセッサを使用する例は、[run_xnli.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_xnli.py) スクリプトに示されています。
+
+## SQuAD
+
+[The Stanford Question Answering Dataset (SQuAD)](https://rajpurkar.github.io/SQuAD-explorer//) は、次のベンチマークです。
+質問応答に関するモデルのパフォーマンスを評価します。 v1.1 と v2.0 の 2 つのバージョンが利用可能です。最初のバージョン
+(v1.1) は、論文 [SQuAD: 100,000+ question for Machine Comprehension of Text](https://arxiv.org/abs/1606.05250) とともにリリースされました。 2 番目のバージョン (v2.0) は、論文 [Know What You Don't と同時にリリースされました。
+知っておくべき: SQuAD の答えられない質問](https://arxiv.org/abs/1806.03822)。
+
+このライブラリは、次の 2 つのバージョンのそれぞれのプロセッサをホストします。
+
+### Processors
+
+それらのプロセッサは次のとおりです。
+
+- [`~data.processors.utils.SquadV1Processor`]
+- [`~data.processors.utils.SquadV2Processor`]
+
+どちらも抽象クラス [`~data.processors.utils.SquadProcessor`] を継承しています。
+
+[[autodoc]] data.processors.squad.SquadProcessor
+ - all
+
+さらに、次のメソッドを使用して、SQuAD の例を次の形式に変換できます。
+モデルの入力として使用できる [`~data.processors.utils.SquadFeatures`]。
+
+[[autodoc]] data.processors.squad.squad_convert_examples_to_features
+
+これらのプロセッサと前述の方法は、データを含むファイルだけでなく、
+*tensorflow_datasets* パッケージ。以下に例を示します。
+
+### Example usage
+
+以下にプロセッサを使用した例と、データ ファイルを使用した変換方法を示します。
+
+```python
+# Loading a V2 processor
+processor = SquadV2Processor()
+examples = processor.get_dev_examples(squad_v2_data_dir)
+
+# Loading a V1 processor
+processor = SquadV1Processor()
+examples = processor.get_dev_examples(squad_v1_data_dir)
+
+features = squad_convert_examples_to_features(
+ examples=examples,
+ tokenizer=tokenizer,
+ max_seq_length=max_seq_length,
+ doc_stride=args.doc_stride,
+ max_query_length=max_query_length,
+ is_training=not evaluate,
+)
+```
+
+*tensorflow_datasets* の使用は、データ ファイルを使用するのと同じくらい簡単です。
+
+```python
+# tensorflow_datasets only handle Squad V1.
+tfds_examples = tfds.load("squad")
+examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
+
+features = squad_convert_examples_to_features(
+ examples=examples,
+ tokenizer=tokenizer,
+ max_seq_length=max_seq_length,
+ doc_stride=args.doc_stride,
+ max_query_length=max_query_length,
+ is_training=not evaluate,
+)
+```
+
+これらのプロセッサを使用する別の例は、[run_squad.py](https://github.com/huggingface/transformers/tree/main/examples/legacy/question-answering/run_squad.py) スクリプトに示されています。
diff --git a/docs/source/ja/main_classes/quantization.md b/docs/source/ja/main_classes/quantization.md
new file mode 100644
index 000000000000..3af3130a849f
--- /dev/null
+++ b/docs/source/ja/main_classes/quantization.md
@@ -0,0 +1,447 @@
+
+
+# Quantize 🤗 Transformers models
+
+## `AutoGPTQ` Integration
+
+
+🤗 Transformers には、言語モデルで GPTQ 量子化を実行するための `optimum` API が統合されています。パフォーマンスを大幅に低下させることなく、推論速度を高速化することなく、モデルを 8、4、3、さらには 2 ビットでロードおよび量子化できます。これは、ほとんどの GPU ハードウェアでサポートされています。
+
+量子化モデルの詳細については、以下を確認してください。
+- [GPTQ](https://arxiv.org/pdf/2210.17323.pdf) 論文
+- GPTQ 量子化に関する `optimum` [ガイド](https://huggingface.co/docs/optimum/llm_quantization/usage_guides/quantization)
+- バックエンドとして使用される [`AutoGPTQ`](https://github.com/PanQiWei/AutoGPTQ) ライブラリ
+
+### Requirements
+
+以下のコードを実行するには、以下の要件がインストールされている必要があります:
+
+- 最新の `AutoGPTQ` ライブラリをインストールする。
+`pip install auto-gptq` をインストールする。
+
+- 最新の `optimum` をソースからインストールする。
+`git+https://github.com/huggingface/optimum.git` をインストールする。
+
+- 最新の `transformers` をソースからインストールする。
+最新の `transformers` をソースからインストールする `pip install git+https://github.com/huggingface/transformers.git`
+
+- 最新の `accelerate` ライブラリをインストールする。
+`pip install --upgrade accelerate` を実行する。
+
+GPTQ統合は今のところテキストモデルのみをサポートしているので、視覚、音声、マルチモーダルモデルでは予期せぬ挙動に遭遇するかもしれないことに注意してください。
+
+### Load and quantize a model
+
+GPTQ は、量子化モデルを使用する前に重みのキャリブレーションを必要とする量子化方法です。トランスフォーマー モデルを最初から量子化する場合は、量子化モデルを作成するまでに時間がかかることがあります (`facebook/opt-350m`モデルの Google colab では約 5 分)。
+
+したがって、GPTQ 量子化モデルを使用するシナリオは 2 つあります。最初の使用例は、ハブで利用可能な他のユーザーによってすでに量子化されたモデルをロードすることです。2 番目の使用例は、モデルを最初から量子化し、保存するかハブにプッシュして、他のユーザーが使用できるようにすることです。それも使ってください。
+
+#### GPTQ Configuration
+
+モデルをロードして量子化するには、[`GPTQConfig`] を作成する必要があります。データセットを準備するには、`bits`の数、量子化を調整するための`dataset`、およびモデルの`Tokenizer`を渡す必要があります。
+
+```python
+model_id = "facebook/opt-125m"
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+gptq_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)
+```
+
+独自のデータセットを文字列のリストとして渡すことができることに注意してください。ただし、GPTQ 論文のデータセットを使用することを強くお勧めします。
+
+```python
+dataset = ["auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm."]
+quantization = GPTQConfig(bits=4, dataset = dataset, tokenizer=tokenizer)
+```
+
+#### Quantization
+
+`from_pretrained` を使用し、`quantization_config` を設定することでモデルを量子化できます。
+
+```python
+from transformers import AutoModelForCausalLM
+model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=gptq_config)
+```
+
+モデルを量子化するには GPU が必要であることに注意してください。モデルを CPU に配置し、量子化するためにモジュールを GPU に前後に移動させます。
+
+CPU オフロードの使用中に GPU の使用量を最大化したい場合は、`device_map = "auto"` を設定できます。
+
+```python
+from transformers import AutoModelForCausalLM
+model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=gptq_config)
+```
+
+ディスク オフロードはサポートされていないことに注意してください。さらに、データセットが原因でメモリが不足している場合は、`from_pretained` で `max_memory` を渡す必要がある場合があります。 `device_map`と`max_memory`の詳細については、この [ガイド](https://huggingface.co/docs/accelerate/usage_guides/big_modeling#designing-a-device-map) を参照してください。
+
+
+GPTQ 量子化は、現時点ではテキスト モデルでのみ機能します。さらに、量子化プロセスはハードウェアによっては長時間かかる場合があります (NVIDIA A100 を使用した場合、175B モデル = 4 gpu 時間)。モデルの GPTQ 量子化バージョンが存在しない場合は、ハブで確認してください。そうでない場合は、github で要求を送信できます。
+
+
+### Push quantized model to 🤗 Hub
+
+他の 🤗 モデルと同様に、`push_to_hub` を使用して量子化モデルをハブにプッシュできます。量子化構成は保存され、モデルに沿ってプッシュされます。
+
+```python
+quantized_model.push_to_hub("opt-125m-gptq")
+tokenizer.push_to_hub("opt-125m-gptq")
+```
+
+量子化されたモデルをローカル マシンに保存したい場合は、`save_pretrained` を使用して行うこともできます。
+
+
+```python
+quantized_model.save_pretrained("opt-125m-gptq")
+tokenizer.save_pretrained("opt-125m-gptq")
+```
+
+`device_map` を使用してモデルを量子化した場合は、保存する前にモデル全体を GPU または `cpu` のいずれかに移動してください。
+
+```python
+quantized_model.to("cpu")
+quantized_model.save_pretrained("opt-125m-gptq")
+```
+
+### Load a quantized model from the 🤗 Hub
+
+`from_pretrained`を使用して、量子化されたモデルをハブからロードできます。
+属性 `quantization_config` がモデル設定オブジェクトに存在することを確認して、プッシュされた重みが量子化されていることを確認します。
+
+```python
+from transformers import AutoModelForCausalLM
+model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq")
+```
+
+必要以上のメモリを割り当てずにモデルをより速くロードしたい場合は、`device_map` 引数は量子化モデルでも機能します。 `accelerate`ライブラリがインストールされていることを確認してください。
+
+```python
+from transformers import AutoModelForCausalLM
+model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto")
+```
+
+### Exllama kernels for faster inference
+
+4 ビット モデルの場合、推論速度を高めるために exllama カーネルを使用できます。デフォルトで有効になっています。 [`GPTQConfig`] で `disable_exllama` を渡すことで、その動作を変更できます。これにより、設定に保存されている量子化設定が上書きされます。カーネルに関連する属性のみを上書きできることに注意してください。さらに、exllama カーネルを使用したい場合は、モデル全体を GPU 上に置く必要があります。
+
+
+```py
+import torch
+gptq_config = GPTQConfig(bits=4, disable_exllama=False)
+model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto", quantization_config = gptq_config)
+```
+
+現時点では 4 ビット モデルのみがサポートされていることに注意してください。さらに、peft を使用して量子化モデルを微調整している場合は、exllama カーネルを非アクティブ化することをお勧めします。
+
+#### Fine-tune a quantized model
+
+Hugging Face エコシステムのアダプターの公式サポートにより、GPTQ で量子化されたモデルを微調整できます。
+詳細については、[`peft`](https://github.com/huggingface/peft) ライブラリをご覧ください。
+
+### Example demo
+
+GPTQ を使用してモデルを量子化する方法と、peft を使用して量子化されたモデルを微調整する方法については、Google Colab [ノートブック](https://colab.research.google.com/drive/1_TIrmuKOFhuRRiTWN94iLKUFu6ZX4ceb?usp=sharing) を参照してください。
+
+### GPTQConfig
+
+[[autodoc]] GPTQConfig
+
+## `bitsandbytes` Integration
+
+🤗 Transformers は、`bitsandbytes` で最もよく使用されるモジュールと緊密に統合されています。数行のコードでモデルを 8 ビット精度でロードできます。
+これは、`bitsandbytes`の `0.37.0`リリース以降、ほとんどの GPU ハードウェアでサポートされています。
+
+量子化方法の詳細については、[LLM.int8()](https://arxiv.org/abs/2208.07339) 論文、または [ブログ投稿](https://huggingface.co/blog/hf-bitsandbytes-) をご覧ください。統合)コラボレーションについて。
+
+`0.39.0`リリース以降、FP4 データ型を活用し、4 ビット量子化を使用して`device_map`をサポートする任意のモデルをロードできます。
+
+独自の pytorch モデルを量子化したい場合は、🤗 Accelerate ライブラリの [ドキュメント](https://huggingface.co/docs/accelerate/main/en/usage_guides/quantization) をチェックしてください。
+
+`bitsandbytes`統合を使用してできることは次のとおりです
+
+### General usage
+
+モデルが 🤗 Accelerate による読み込みをサポートし、`torch.nn.Linear` レイヤーが含まれている限り、 [`~PreTrainedModel.from_pretrained`] メソッドを呼び出すときに `load_in_8bit` または `load_in_4bit` 引数を使用してモデルを量子化できます。これはどのようなモダリティでも同様に機能するはずです。
+
+```python
+from transformers import AutoModelForCausalLM
+
+model_8bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_8bit=True)
+model_4bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_4bit=True)
+```
+
+デフォルトでは、他のすべてのモジュール (例: `torch.nn.LayerNorm`) は `torch.float16` に変換されますが、その `dtype` を変更したい場合は、`torch_dtype` 引数を上書きできます。
+
+```python
+>>> import torch
+>>> from transformers import AutoModelForCausalLM
+
+>>> model_8bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_8bit=True, torch_dtype=torch.float32)
+>>> model_8bit.model.decoder.layers[-1].final_layer_norm.weight.dtype
+torch.float32
+```
+
+### FP4 quantization
+
+#### Requirements
+
+以下のコード スニペットを実行する前に、以下の要件がインストールされていることを確認してください。
+
+- 最新の`bitsandbytes`ライブラリ
+`pip install bitsandbytes>=0.39.0`
+
+- 最新の`accelerate`をインストールする
+`pip install --upgrade accelerate`
+
+- 最新の `transformers` をインストールする
+`pip install --upgrade transformers`
+
+#### Tips and best practices
+
+- **高度な使用法:** 可能なすべてのオプションを使用した 4 ビット量子化の高度な使用法については、[この Google Colab ノートブック](https://colab.research.google.com/drive/1ge2F1QSK8Q7h0hn3YKuBCOAS0bK8E0wf) を参照してください。
+
+- **`batch_size=1` による高速推論 :** bitsandbytes の `0.40.0` リリース以降、`batch_size=1` では高速推論の恩恵を受けることができます。 [これらのリリース ノート](https://github.com/TimDettmers/bitsandbytes/releases/tag/0.40.0) を確認し、この機能を活用するには`0.40.0`以降のバージョンを使用していることを確認してください。箱の。
+
+- **トレーニング:** [QLoRA 論文](https://arxiv.org/abs/2305.14314) によると、4 ビット基本モデルをトレーニングする場合 (例: LoRA アダプターを使用)、`bnb_4bit_quant_type='nf4'` を使用する必要があります。 。
+
+- **推論:** 推論の場合、`bnb_4bit_quant_type` はパフォーマンスに大きな影響を与えません。ただし、モデルの重みとの一貫性を保つために、必ず同じ `bnb_4bit_compute_dtype` および `torch_dtype` 引数を使用してください。
+
+
+#### Load a large model in 4bit
+
+`.from_pretrained` メソッドを呼び出すときに `load_in_4bit=True` を使用すると、メモリ使用量を (おおよそ) 4 で割ることができます。
+
+```python
+# pip install transformers accelerate bitsandbytes
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model_id = "bigscience/bloom-1b7"
+
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", load_in_4bit=True)
+```
+
+
+
+モデルが 4 ビットでロードされると、現時点では量子化された重みをハブにプッシュすることはできないことに注意してください。 4 ビットの重みはまだサポートされていないため、トレーニングできないことにも注意してください。ただし、4 ビット モデルを使用して追加のパラメーターをトレーニングすることもできます。これについては次のセクションで説明します。
+
+
+
+### Load a large model in 8bit
+
+`.from_pretrained` メソッドを呼び出すときに `load_in_8bit=True` 引数を使用すると、メモリ要件をおよそ半分にしてモデルをロードできます。
+
+```python
+# pip install transformers accelerate bitsandbytes
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model_id = "bigscience/bloom-1b7"
+
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", load_in_8bit=True)
+```
+
+次に、通常 [`PreTrainedModel`] を使用するのと同じようにモデルを使用します。
+
+`get_memory_footprint` メソッドを使用して、モデルのメモリ フットプリントを確認できます。
+
+```python
+print(model.get_memory_footprint())
+```
+
+この統合により、大きなモデルを小さなデバイスにロードし、問題なく実行できるようになりました。
+
+
+モデルが 8 ビットでロードされると、最新の `transformers`と`bitsandbytes`を使用する場合を除き、量子化された重みをハブにプッシュすることは現在不可能であることに注意してください。 8 ビットの重みはまだサポートされていないため、トレーニングできないことにも注意してください。ただし、8 ビット モデルを使用して追加のパラメーターをトレーニングすることもできます。これについては次のセクションで説明します。
+また、`device_map` はオプションですが、利用可能なリソース上でモデルを効率的にディスパッチするため、推論には `device_map = 'auto'` を設定することが推奨されます。
+
+
+
+#### Advanced use cases
+
+ここでは、FP4 量子化を使用して実行できるいくつかの高度な使用例について説明します。
+
+##### Change the compute dtype
+
+compute dtype は、計算中に使用される dtype を変更するために使用されます。たとえば、隠し状態は`float32`にありますが、高速化のために計算を bf16 に設定できます。デフォルトでは、compute dtype は `float32` に設定されます。
+
+```python
+import torch
+from transformers import BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16)
+```
+
+##### Using NF4 (Normal Float 4) data type
+
+NF4 データ型を使用することもできます。これは、正規分布を使用して初期化された重みに適合した新しい 4 ビット データ型です。その実行のために:
+
+```python
+from transformers import BitsAndBytesConfig
+
+nf4_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_quant_type="nf4",
+)
+
+model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)
+```
+
+##### Use nested quantization for more memory efficient inference
+
+また、ネストされた量子化手法を使用することをお勧めします。これにより、パフォーマンスを追加することなく、より多くのメモリが節約されます。経験的な観察から、これにより、NVIDIA-T4 16GB 上でシーケンス長 1024、バッチ サイズ 1、勾配累積ステップ 4 の llama-13b モデルを微調整することが可能になります。
+
+```python
+from transformers import BitsAndBytesConfig
+
+double_quant_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_use_double_quant=True,
+)
+
+model_double_quant = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=double_quant_config)
+```
+
+
+### Push quantized models on the 🤗 Hub
+
+`push_to_hub`メソッドを単純に使用することで、量子化されたモデルをハブにプッシュできます。これにより、最初に量子化構成ファイルがプッシュされ、次に量子化されたモデルの重みがプッシュされます。
+この機能を使用できるようにするには、必ず `bitsandbytes>0.37.2` を使用してください (この記事の執筆時点では、`bitsandbytes==0.38.0.post1` でテストしました)。
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model = AutoModelForCausalLM.from_pretrained("bigscience/bloom-560m", device_map="auto", load_in_8bit=True)
+tokenizer = AutoTokenizer.from_pretrained("bigscience/bloom-560m")
+
+model.push_to_hub("bloom-560m-8bit")
+```
+
+
+
+大規模なモデルでは、ハブ上で 8 ビット モデルをプッシュすることが強く推奨されます。これにより、コミュニティはメモリ フットプリントの削減と、たとえば Google Colab での大規模なモデルの読み込みによる恩恵を受けることができます。
+
+
+
+### Load a quantized model from the 🤗 Hub
+
+`from_pretrained`メソッドを使用して、ハブから量子化モデルをロードできます。属性 `quantization_config` がモデル設定オブジェクトに存在することを確認して、プッシュされた重みが量子化されていることを確認します。
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model = AutoModelForCausalLM.from_pretrained("{your_username}/bloom-560m-8bit", device_map="auto")
+```
+
+この場合、引数 `load_in_8bit=True` を指定する必要はありませんが、`bitsandbytes` と `accelerate` がインストールされていることを確認する必要があることに注意してください。
+また、`device_map` はオプションですが、利用可能なリソース上でモデルを効率的にディスパッチするため、推論には `device_map = 'auto'` を設定することが推奨されます。
+
+### Advanced use cases
+
+このセクションは、8 ビット モデルのロードと実行以外に何ができるかを探求したい上級ユーザーを対象としています。
+
+#### Offload between `cpu` and `gpu`
+
+この高度な使用例の 1 つは、モデルをロードし、`CPU`と`GPU`の間で重みをディスパッチできることです。 CPU 上でディスパッチされる重みは **8 ビットに変換されない**ため、`float32`に保持されることに注意してください。この機能は、非常に大規模なモデルを適合させ、そのモデルを GPU と CPU の間でディスパッチしたいユーザーを対象としています。
+
+まず、`transformers` から [`BitsAndBytesConfig`] をロードし、属性 `llm_int8_enable_fp32_cpu_offload` を `True` に設定します。
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(llm_int8_enable_fp32_cpu_offload=True)
+```
+
+`bigscience/bloom-1b7`モデルをロードする必要があり、`lm_head`を除くモデル全体に適合するのに十分な GPU RAM があるとします。したがって、次のようにカスタム device_map を作成します。
+
+```python
+device_map = {
+ "transformer.word_embeddings": 0,
+ "transformer.word_embeddings_layernorm": 0,
+ "lm_head": "cpu",
+ "transformer.h": 0,
+ "transformer.ln_f": 0,
+}
+```
+
+そして、次のようにモデルをロードします。
+```python
+model_8bit = AutoModelForCausalLM.from_pretrained(
+ "bigscience/bloom-1b7",
+ device_map=device_map,
+ quantization_config=quantization_config,
+)
+```
+
+以上です!モデルを楽しんでください!
+
+#### Play with `llm_int8_threshold`
+
+`llm_int8_threshold` 引数を操作して、外れ値のしきい値を変更できます。 外れ値 とは、特定のしきい値より大きい隠れた状態の値です。
+これは、`LLM.int8()`論文で説明されている外れ値検出の外れ値しきい値に対応します。このしきい値を超える隠し状態の値は外れ値とみなされ、それらの値に対する操作は fp16 で実行されます。通常、値は正規分布します。つまり、ほとんどの値は [-3.5, 3.5] の範囲内にありますが、大規模なモデルでは大きく異なる分布を示す例外的な系統的外れ値がいくつかあります。これらの外れ値は、多くの場合 [-60, -6] または [6, 60] の範囲内にあります。 Int8 量子化は、大きさが 5 程度までの値ではうまく機能しますが、それを超えると、パフォーマンスが大幅に低下します。適切なデフォルトのしきい値は 6 ですが、より不安定なモデル (小規模なモデル、微調整) では、より低いしきい値が必要になる場合があります。
+この引数は、モデルの推論速度に影響を与える可能性があります。このパラメータを試してみて、ユースケースに最適なパラメータを見つけることをお勧めします。
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
+
+model_id = "bigscience/bloom-1b7"
+
+quantization_config = BitsAndBytesConfig(
+ llm_int8_threshold=10,
+)
+
+model_8bit = AutoModelForCausalLM.from_pretrained(
+ model_id,
+ device_map=device_map,
+ quantization_config=quantization_config,
+)
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+```
+
+#### Skip the conversion of some modules
+
+一部のモデルには、安定性を確保するために 8 ビットに変換する必要がないモジュールがいくつかあります。たとえば、ジュークボックス モデルには、スキップする必要があるいくつかの `lm_head` モジュールがあります。 `llm_int8_skip_modules` で遊んでみる
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
+
+model_id = "bigscience/bloom-1b7"
+
+quantization_config = BitsAndBytesConfig(
+ llm_int8_skip_modules=["lm_head"],
+)
+
+model_8bit = AutoModelForCausalLM.from_pretrained(
+ model_id,
+ device_map=device_map,
+ quantization_config=quantization_config,
+)
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+```
+
+#### Fine-tune a model that has been loaded in 8-bit
+
+Hugging Face エコシステムのアダプターの公式サポートにより、8 ビットでロードされたモデルを微調整できます。
+これにより、単一の Google Colab で`flan-t5-large`や`facebook/opt-6.7b`などの大規模モデルを微調整することができます。詳細については、[`peft`](https://github.com/huggingface/peft) ライブラリをご覧ください。
+
+トレーニング用のモデルをロードするときに `device_map` を渡す必要がないことに注意してください。モデルが GPU に自動的にロードされます。必要に応じて、デバイス マップを特定のデバイスに設定することもできます (例: `cuda:0`、`0`、`torch.device('cuda:0')`)。 `device_map=auto`は推論のみに使用する必要があることに注意してください。
+
+### BitsAndBytesConfig
+
+[[autodoc]] BitsAndBytesConfig
+
+## Quantization with 🤗 `optimum`
+
+`optimum`でサポートされている量子化方法の詳細については、[Optimum ドキュメント](https://huggingface.co/docs/optimum/index) を参照し、これらが自分のユースケースに適用できるかどうかを確認してください。
diff --git a/docs/source/ja/main_classes/text_generation.md b/docs/source/ja/main_classes/text_generation.md
new file mode 100644
index 000000000000..279d9b40735b
--- /dev/null
+++ b/docs/source/ja/main_classes/text_generation.md
@@ -0,0 +1,63 @@
+
+
+# Generation
+
+各フレームワークには、それぞれの `GenerationMixin` クラスに実装されたテキスト生成のための Generate メソッドがあります。
+
+- PyTorch [`~generation.GenerationMixin.generate`] は [`~generation.GenerationMixin`] に実装されています。
+- TensorFlow [`~generation.TFGenerationMixin.generate`] は [`~generation.TFGenerationMixin`] に実装されています。
+- Flax/JAX [`~generation.FlaxGenerationMixin.generate`] は [`~generation.FlaxGenerationMixin`] に実装されています。
+
+選択したフレームワークに関係なく、[`~generation.GenerationConfig`] を使用して生成メソッドをパラメータ化できます。
+クラスインスタンス。動作を制御する生成パラメータの完全なリストについては、このクラスを参照してください。
+生成方法のこと。
+
+モデルの生成構成を検査する方法、デフォルトとは何か、パラメーターをアドホックに変更する方法を学習するには、
+カスタマイズされた生成構成を作成して保存する方法については、「
+[テキスト生成戦略ガイド](../generation_strategies)。このガイドでは、関連機能の使用方法についても説明しています。
+トークンストリーミングのような。
+
+## GenerationConfig
+
+[[autodoc]] generation.GenerationConfig
+ - from_pretrained
+ - from_model_config
+ - save_pretrained
+
+## GenerationMixin
+
+[[autodoc]] generation.GenerationMixin
+ - generate
+ - compute_transition_scores
+ - greedy_search
+ - sample
+ - beam_search
+ - beam_sample
+ - contrastive_search
+ - group_beam_search
+ - constrained_beam_search
+
+## TFGenerationMixin
+
+[[autodoc]] generation.TFGenerationMixin
+ - generate
+ - compute_transition_scores
+
+## FlaxGenerationMixin
+
+[[autodoc]] generation.FlaxGenerationMixin
+ - generate
diff --git a/docs/source/ja/main_classes/tokenizer.md b/docs/source/ja/main_classes/tokenizer.md
new file mode 100644
index 000000000000..1cf5885bc812
--- /dev/null
+++ b/docs/source/ja/main_classes/tokenizer.md
@@ -0,0 +1,80 @@
+
+
+# Tokenizer
+
+トークナイザーは、モデルの入力の準備を担当します。ライブラリには、すべてのモデルのトークナイザーが含まれています。ほとんど
+トークナイザーの一部は、完全な Python 実装と、
+Rust ライブラリ [🤗 Tokenizers](https://github.com/huggingface/tokenizers)。 「高速」実装では次のことが可能になります。
+
+1. 特にバッチトークン化を行う場合の大幅なスピードアップと
+2. 元の文字列 (文字と単語) とトークン空間の間でマッピングする追加のメソッド (例:
+ 特定の文字を含むトークンのインデックス、または特定のトークンに対応する文字の範囲)。
+
+基本クラス [`PreTrainedTokenizer`] および [`PreTrainedTokenizerFast`]
+モデル入力の文字列入力をエンコードし (以下を参照)、Python をインスタンス化/保存するための一般的なメソッドを実装します。
+ローカル ファイルまたはディレクトリ、またはライブラリによって提供される事前トレーニング済みトークナイザーからの「高速」トークナイザー
+(HuggingFace の AWS S3 リポジトリからダウンロード)。二人とも頼りにしているのは、
+共通メソッドを含む [`~tokenization_utils_base.PreTrainedTokenizerBase`]
+[`~tokenization_utils_base.SpecialTokensMixin`]。
+
+したがって、[`PreTrainedTokenizer`] と [`PreTrainedTokenizerFast`] はメインを実装します。
+すべてのトークナイザーを使用するためのメソッド:
+
+- トークン化 (文字列をサブワード トークン文字列に分割)、トークン文字列を ID に変換したり、その逆の変換を行ったりします。
+ エンコード/デコード (つまり、トークン化と整数への変換)。
+- 基礎となる構造 (BPE、SentencePiece...) から独立した方法で、語彙に新しいトークンを追加します。
+- 特別なトークン (マスク、文の始まりなど) の管理: トークンの追加、属性への割り当て。
+ トークナイザーにより、簡単にアクセスでき、トークン化中に分割されないようにすることができます。
+
+[`BatchEncoding`] は、
+[`~tokenization_utils_base.PreTrainedTokenizerBase`] のエンコード メソッド (`__call__`、
+`encode_plus` および `batch_encode_plus`) であり、Python 辞書から派生しています。トークナイザーが純粋な Python の場合
+tokenizer の場合、このクラスは標準の Python 辞書と同じように動作し、によって計算されたさまざまなモデル入力を保持します。
+これらのメソッド (`input_ids`、`attention_mask`...)。トークナイザーが「高速」トークナイザーである場合 (つまり、
+HuggingFace [トークナイザー ライブラリ](https://github.com/huggingface/tokenizers))、このクラスはさらに提供します
+元の文字列 (文字と単語) と
+トークンスペース (例: 指定された文字または対応する文字の範囲を構成するトークンのインデックスの取得)
+与えられたトークンに)。
+
+## PreTrainedTokenizer
+
+[[autodoc]] PreTrainedTokenizer
+ - __call__
+ - apply_chat_template
+ - batch_decode
+ - decode
+ - encode
+ - push_to_hub
+ - all
+
+## PreTrainedTokenizerFast
+
+[`PreTrainedTokenizerFast`] は [tokenizers](https://huggingface.co/docs/tokenizers) ライブラリに依存します。 🤗 トークナイザー ライブラリから取得したトークナイザーは、
+🤗 トランスに非常に簡単にロードされます。これがどのように行われるかを理解するには、[🤗 tokenizers からの tokenizers を使用する](../fast_tokenizers) ページを参照してください。
+
+[[autodoc]] PreTrainedTokenizerFast
+ - __call__
+ - apply_chat_template
+ - batch_decode
+ - decode
+ - encode
+ - push_to_hub
+ - all
+
+## BatchEncoding
+
+[[autodoc]] BatchEncoding
diff --git a/docs/source/ja/main_classes/trainer.md b/docs/source/ja/main_classes/trainer.md
new file mode 100644
index 000000000000..f18c1b86809f
--- /dev/null
+++ b/docs/source/ja/main_classes/trainer.md
@@ -0,0 +1,728 @@
+
+
+# Trainer
+
+[`Trainer`] クラスは、ほとんどの標準的なユースケースに対して、PyTorch で機能を完全にトレーニングするための API を提供します。これは、[サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples) のほとんどで使用されています。
+
+[`Trainer`] をインスタンス化する前に、トレーニング中にカスタマイズのすべてのポイントにアクセスするために [`TrainingArguments`] を作成します。
+
+この API は、複数の GPU/TPU での分散トレーニング、[NVIDIA Apex](https://github.com/NVIDIA/apex) および PyTorch のネイティブ AMP による混合精度をサポートします。
+
+[`Trainer`] には、上記の機能をサポートする基本的なトレーニング ループが含まれています。カスタム動作を挿入するには、それらをサブクラス化し、次のメソッドをオーバーライドします。
+
+- **get_train_dataloader** -- トレーニング データローダーを作成します。
+- **get_eval_dataloader** -- 評価用データローダーを作成します。
+- **get_test_dataloader** -- テスト データローダーを作成します。
+- **log** -- トレーニングを監視しているさまざまなオブジェクトに関する情報をログに記録します。
+- **create_optimizer_and_scheduler** -- オプティマイザと学習率スケジューラが渡されなかった場合にセットアップします。
+ 初期化。 `create_optimizer`メソッドと`create_scheduler`メソッドをサブクラス化またはオーバーライドすることもできることに注意してください。
+ 別々に。
+- **create_optimizer** -- init で渡されなかった場合にオプティマイザーをセットアップします。
+- **create_scheduler** -- init で渡されなかった場合、学習率スケジューラを設定します。
+- **compute_loss** - トレーニング入力のバッチの損失を計算します。
+- **training_step** -- トレーニング ステップを実行します。
+- **prediction_step** -- 評価/テスト ステップを実行します。
+- **evaluate** -- 評価ループを実行し、メトリクスを返します。
+- **predict** -- テスト セットの予測 (ラベルが使用可能な場合はメトリクスも含む) を返します。
+
+
+
+[`Trainer`] クラスは 🤗 Transformers モデル用に最適化されており、驚くべき動作をする可能性があります
+他の機種で使用する場合。独自のモデルで使用する場合は、次の点を確認してください。
+
+- モデルは常に [`~utils.ModelOutput`] のタプルまたはサブクラスを返します。
+- `labels` 引数が指定され、その損失が最初の値として返される場合、モデルは損失を計算できます。
+ タプルの要素 (モデルがタプルを返す場合)
+- モデルは複数のラベル引数を受け入れることができます ([`TrainingArguments`] で `label_names` を使用して、その名前を [`Trainer`] に示します) が、それらのいずれにも `"label"` という名前を付ける必要はありません。
+
+
+
+以下は、加重損失を使用するように [`Trainer`] をカスタマイズする方法の例です (不均衡なトレーニング セットがある場合に役立ちます)。
+
+```python
+from torch import nn
+from transformers import Trainer
+
+
+class CustomTrainer(Trainer):
+ def compute_loss(self, model, inputs, return_outputs=False):
+ labels = inputs.pop("labels")
+ # forward pass
+ outputs = model(**inputs)
+ logits = outputs.get("logits")
+ # compute custom loss (suppose one has 3 labels with different weights)
+ loss_fct = nn.CrossEntropyLoss(weight=torch.tensor([1.0, 2.0, 3.0], device=model.device))
+ loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
+ return (loss, outputs) if return_outputs else loss
+```
+
+PyTorch [`Trainer`] のトレーニング ループの動作をカスタマイズするもう 1 つの方法は、トレーニング ループの状態を検査できる [callbacks](コールバック) を使用することです (進行状況レポート、TensorBoard または他の ML プラットフォームでのログ記録など)。決定(早期停止など)。
+
+## Trainer
+
+[[autodoc]] Trainer
+ - all
+
+## Seq2SeqTrainer
+
+[[autodoc]] Seq2SeqTrainer
+ - evaluate
+ - predict
+
+## TrainingArguments
+
+[[autodoc]] TrainingArguments
+ - all
+
+## Seq2SeqTrainingArguments
+
+[[autodoc]] Seq2SeqTrainingArguments
+ - all
+
+## Checkpoints
+
+デフォルトでは、[`Trainer`] はすべてのチェックポイントを、
+[`TrainingArguments`] を使用しています。これらは、xxx を含む`checkpoint-xxx`という名前のサブフォルダーに保存されます。
+それはトレーニングの段階でした。
+
+チェックポイントからトレーニングを再開するには、次のいずれかを使用して [`Trainer.train`] を呼び出します。
+
+- `resume_from_checkpoint=True` は最新のチェックポイントからトレーニングを再開します
+- `resume_from_checkpoint=checkpoint_dir` ディレクトリ内の特定のチェックポイントからトレーニングを再開します
+ 合格した。
+
+さらに、`push_to_hub=True` を使用すると、モデル ハブにチェックポイントを簡単に保存できます。デフォルトでは、すべて
+中間チェックポイントに保存されたモデルは別のコミットに保存されますが、オプティマイザーの状態は保存されません。適応できます
+[`TrainingArguments`] の `hub-strategy` 値を次のいずれかにします。
+
+- `"checkpoint"`: 最新のチェックポイントも last-checkpoint という名前のサブフォルダーにプッシュされます。
+ `trainer.train(resume_from_checkpoint="output_dir/last-checkpoint")` を使用してトレーニングを簡単に再開します。
+- `"all_checkpoints"`: すべてのチェックポイントは、出力フォルダーに表示されるようにプッシュされます (したがって、1 つのチェックポイントが得られます)
+ 最終リポジトリ内のフォルダーごとのチェックポイント フォルダー)
+
+## Logging
+
+デフォルトでは、[`Trainer`] はメインプロセスに `logging.INFO` を使用し、レプリカがある場合には `logging.WARNING` を使用します。
+
+これらのデフォルトは、[`TrainingArguments`] の 5 つの `logging` レベルのいずれかを使用するようにオーバーライドできます。
+引数:
+
+- `log_level` - メインプロセス用
+- `log_level_replica` - レプリカ用
+
+さらに、[`TrainingArguments`] の `log_on_each_node` が `False` に設定されている場合、メイン ノードのみが
+メイン プロセスのログ レベル設定を使用すると、他のすべてのノードはレプリカのログ レベル設定を使用します。
+
+[`Trainer`] は、`transformers` のログ レベルをノードごとに個別に設定することに注意してください。
+[`Trainer.__init__`]。したがって、他の機能を利用する場合は、これをより早く設定することをお勧めします (次の例を参照)。
+[`Trainer`] オブジェクトを作成する前の `transformers` 機能。
+
+これをアプリケーションで使用する方法の例を次に示します。
+
+```python
+[...]
+logger = logging.getLogger(__name__)
+
+# Setup logging
+logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+)
+
+# set the main code and the modules it uses to the same log-level according to the node
+log_level = training_args.get_process_log_level()
+logger.setLevel(log_level)
+datasets.utils.logging.set_verbosity(log_level)
+transformers.utils.logging.set_verbosity(log_level)
+
+trainer = Trainer(...)
+```
+
+そして、メイン ノードと他のすべてのノードで重複する可能性が高いものを出力しないように警告するだけを表示したい場合は、
+警告: 次のように実行できます。
+
+```bash
+my_app.py ... --log_level warning --log_level_replica error
+```
+
+マルチノード環境で、各ノードのメインプロセスのログを繰り返したくない場合は、次のようにします。
+上記を次のように変更します。
+
+```bash
+my_app.py ... --log_level warning --log_level_replica error --log_on_each_node 0
+```
+
+その後、最初のノードのメイン プロセスのみが「警告」レベルでログに記録され、メイン ノード上の他のすべてのプロセスはログに記録されます。
+ノードと他のノード上のすべてのプロセスは「エラー」レベルでログに記録されます。
+
+アプリケーションをできるだけ静かにする必要がある場合は、次のようにします。
+
+```bash
+my_app.py ... --log_level error --log_level_replica error --log_on_each_node 0
+```
+
+(マルチノード環境の場合は `--log_on_each_node 0` を追加します)
+
+## Randomness
+
+[`Trainer`] によって生成されたチェックポイントから再開する場合、すべての努力がその状態を復元するために行われます。
+_python_、_numpy_、および _pytorch_ の RNG 状態は、そのチェックポイントを保存した時点と同じ状態になります。
+これにより、「停止して再開」というスタイルのトレーニングが、ノンストップトレーニングに可能な限り近づけられるはずです。
+
+ただし、さまざまなデフォルトの非決定的な pytorch 設定により、これは完全に機能しない可能性があります。フルをご希望の場合は
+決定論については、[ランダム性のソースの制御](https://pytorch.org/docs/stable/notes/randomness) を参照してください。ドキュメントで説明されているように、これらの設定の一部は
+物事を決定論的にするもの (例: `torch.backends.cudnn.deterministic`) は物事を遅くする可能性があるため、これは
+デフォルトでは実行できませんが、必要に応じて自分で有効にすることができます。
+
+## Specific GPUs Selection
+
+どの GPU をどのような順序で使用するかをプログラムに指示する方法について説明します。
+
+[`DistributedDataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.Parallel.DistributedDataParallel.html) を使用して GPU のサブセットのみを使用する場合、使用する GPU の数を指定するだけです。 。たとえば、GPU が 4 つあるが、最初の 2 つを使用したい場合は、次のようにします。
+
+```bash
+torchrun --nproc_per_node=2 trainer-program.py ...
+```
+
+[`accelerate`](https://github.com/huggingface/accelerate) または [`deepspeed`](https://github.com/microsoft/DeepSpeed) がインストールされている場合は、次を使用して同じことを達成することもできます。の一つ:
+
+```bash
+accelerate launch --num_processes 2 trainer-program.py ...
+```
+
+```bash
+deepspeed --num_gpus 2 trainer-program.py ...
+```
+
+これらのランチャーを使用するために、Accelerate または [Deepspeed 統合](deepspeed) 機能を使用する必要はありません。
+
+
+これまでは、プログラムに使用する GPU の数を指示できました。次に、特定の GPU を選択し、その順序を制御する方法について説明します。
+
+次の環境変数は、使用する GPU とその順序を制御するのに役立ちます。
+
+**`CUDA_VISIBLE_DEVICES`**
+
+複数の GPU があり、そのうちの 1 つまたはいくつかの GPU だけを使用したい場合は、環境変数 `CUDA_VISIBLE_DEVICES` を使用する GPU のリストに設定します。
+
+たとえば、4 つの GPU (0、1、2、3) があるとします。物理 GPU 0 と 2 のみで実行するには、次のようにします。
+
+```bash
+CUDA_VISIBLE_DEVICES=0,2 torchrun trainer-program.py ...
+```
+
+したがって、pytorch は 2 つの GPU のみを認識し、物理 GPU 0 と 2 はそれぞれ `cuda:0` と `cuda:1` にマッピングされます。
+
+順序を変更することもできます。
+
+```bash
+CUDA_VISIBLE_DEVICES=2,0 torchrun trainer-program.py ...
+```
+
+ここでは、物理 GPU 0 と 2 がそれぞれ`cuda:1`と`cuda:0`にマッピングされています。
+
+上記の例はすべて `DistributedDataParallel` 使用パターンのものですが、同じ方法が [`DataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html) でも機能します。
+
+
+```bash
+CUDA_VISIBLE_DEVICES=2,0 python trainer-program.py ...
+```
+
+GPU のない環境をエミュレートするには、次のようにこの環境変数を空の値に設定するだけです。
+
+```bash
+CUDA_VISIBLE_DEVICES= python trainer-program.py ...
+```
+
+他の環境変数と同様に、これらをコマンド ラインに追加する代わりに、次のようにエクスポートすることもできます。
+
+```bash
+export CUDA_VISIBLE_DEVICES=0,2
+torchrun trainer-program.py ...
+```
+
+ただし、この方法では、以前に環境変数を設定したことを忘れて、なぜ間違った GPU が使用されているのか理解できない可能性があるため、混乱を招く可能性があります。したがって、このセクションのほとんどの例で示されているように、同じコマンド ラインで特定の実行に対してのみ環境変数を設定するのが一般的です。
+
+**`CUDA_DEVICE_ORDER`**
+
+物理デバイスの順序を制御する追加の環境変数 `CUDA_DEVICE_ORDER` があります。選択肢は次の 2 つです。
+
+1. PCIe バス ID 順 (`nvidia-smi` の順序と一致) - これがデフォルトです。
+
+```bash
+export CUDA_DEVICE_ORDER=PCI_BUS_ID
+```
+
+2. GPU コンピューティング能力順に並べる
+
+```bash
+export CUDA_DEVICE_ORDER=FASTEST_FIRST
+```
+
+ほとんどの場合、この環境変数を気にする必要はありませんが、古い GPU と新しい GPU が物理的に挿入されているため、遅い古いカードが遅くなっているように見えるような偏ったセットアップを行っている場合には、非常に役立ちます。初め。これを解決する 1 つの方法は、カードを交換することです。ただし、カードを交換できない場合 (デバイスの冷却が影響を受けた場合など)、`CUDA_DEVICE_ORDER=FASTEST_FIRST`を設定すると、常に新しい高速カードが最初に配置されます。ただし、`nvidia-smi`は依然として PCIe の順序でレポートするため、多少混乱するでしょう。
+
+順序を入れ替えるもう 1 つの解決策は、以下を使用することです。
+
+```bash
+export CUDA_VISIBLE_DEVICES=1,0
+```
+
+この例では 2 つの GPU だけを使用していますが、もちろん、コンピューターに搭載されている数の GPU にも同じことが当てはまります。
+
+また、この環境変数を設定する場合は、`~/.bashrc` ファイルまたはその他の起動設定ファイルに設定して、忘れるのが最善です。
+
+## Trainer Integrations
+
+[`Trainer`] は、トレーニングを劇的に改善する可能性のあるライブラリをサポートするように拡張されました。
+時間とはるかに大きなモデルに適合します。
+
+現在、サードパーティのソリューション [DeepSpeed](https://github.com/microsoft/DeepSpeed) および [PyTorch FSDP](https://pytorch.org/docs/stable/fsdp.html) をサポートしています。論文 [ZeRO: メモリの最適化]
+兆パラメータ モデルのトレーニングに向けて、Samyam Rajbhandari、Jeff Rasley、Olatunji Ruwase、Yuxiong He 著](https://arxiv.org/abs/1910.02054)。
+
+この提供されるサポートは、この記事の執筆時点では新しくて実験的なものです。 DeepSpeed と PyTorch FSDP のサポートはアクティブであり、それに関する問題は歓迎しますが、FairScale 統合は PyTorch メインに統合されているため、もうサポートしていません ([PyTorch FSDP 統合](#pytorch-fully-sharded-data-parallel))
+
+
+
+### CUDA Extension Installation Notes
+
+この記事の執筆時点では、Deepspeed を使用するには、CUDA C++ コードをコンパイルする必要があります。
+
+すべてのインストールの問題は、[Deepspeed](https://github.com/microsoft/DeepSpeed/issues) の対応する GitHub の問題を通じて対処する必要がありますが、ビルド中に発生する可能性のある一般的な問題がいくつかあります。
+CUDA 拡張機能を構築する必要がある PyTorch 拡張機能。
+
+したがって、次の操作を実行中に CUDA 関連のビルドの問題が発生した場合は、次のとおりです。
+
+```bash
+pip install deepspeed
+```
+
+まず次の注意事項をお読みください。
+
+これらのノートでは、`pytorch` が CUDA `10.2` でビルドされた場合に何をすべきかの例を示します。あなたの状況が次のような場合
+異なる場合は、バージョン番号を目的のバージョンに調整することを忘れないでください。
+
+#### Possible problem #1
+
+Pytorch には独自の CUDA ツールキットが付属していますが、これら 2 つのプロジェクトをビルドするには、同一バージョンの CUDA が必要です。
+システム全体にインストールされます。
+
+たとえば、Python 環境に `cudatoolkit==10.2` を指定して `pytorch` をインストールした場合は、次のものも必要です。
+CUDA `10.2` がシステム全体にインストールされました。
+
+正確な場所はシステムによって異なる場合がありますが、多くのシステムでは`/usr/local/cuda-10.2`が最も一般的な場所です。
+Unix システム。 CUDA が正しく設定され、`PATH`環境変数に追加されると、
+次のようにしてインストール場所を指定します。
+
+
+```bash
+which nvcc
+```
+
+CUDA がシステム全体にインストールされていない場合は、最初にインストールしてください。お気に入りを使用して手順を見つけることができます
+検索エンジン。たとえば、Ubuntu を使用している場合は、[ubuntu cuda 10.2 install](https://www.google.com/search?q=ubuntu+cuda+10.2+install) を検索するとよいでしょう。
+
+#### Possible problem #2
+
+もう 1 つの考えられる一般的な問題は、システム全体に複数の CUDA ツールキットがインストールされている可能性があることです。たとえばあなた
+がある可能性があり:
+
+```bash
+/usr/local/cuda-10.2
+/usr/local/cuda-11.0
+```
+
+この状況では、`PATH` および `LD_LIBRARY_PATH` 環境変数に以下が含まれていることを確認する必要があります。
+目的の CUDA バージョンへの正しいパス。通常、パッケージ インストーラーは、これらに、
+最後のバージョンがインストールされました。適切なパッケージが見つからないためにパッケージのビルドが失敗するという問題が発生した場合は、
+CUDA バージョンがシステム全体にインストールされているにもかかわらず、前述の 2 つを調整する必要があることを意味します
+環境変数。
+
+まず、その内容を見てみましょう。
+
+```bash
+echo $PATH
+echo $LD_LIBRARY_PATH
+```
+
+それで、中に何が入っているかがわかります。
+
+`LD_LIBRARY_PATH` が空である可能性があります。
+
+`PATH` は実行可能ファイルが存在する場所をリストし、`LD_LIBRARY_PATH` は共有ライブラリの場所を示します。
+探すことです。どちらの場合も、前のエントリが後のエントリより優先されます。 `:` は複数を区切るために使用されます
+エントリ。
+
+ここで、ビルド プログラムに特定の CUDA ツールキットの場所を指示するには、最初にリストされる希望のパスを挿入します。
+やっていること:
+
+```bash
+export PATH=/usr/local/cuda-10.2/bin:$PATH
+export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH
+```
+
+既存の値を上書きするのではなく、先頭に追加することに注意してください。
+
+もちろん、必要に応じてバージョン番号やフルパスを調整します。割り当てたディレクトリが実際に機能することを確認してください
+存在する。 `lib64` サブディレクトリは、`libcudart.so` などのさまざまな CUDA `.so` オブジェクトが存在する場所です。
+システムでは別の名前が付けられますが、現実を反映するように調整してください。
+
+#### Possible problem #3
+
+一部の古い CUDA バージョンは、新しいコンパイラでのビルドを拒否する場合があります。たとえば、あなたは`gcc-9`を持っていますが、それが必要です
+`gcc-7`。
+
+それにはさまざまな方法があります。
+
+最新の CUDA ツールキットをインストールできる場合は、通常、新しいコンパイラがサポートされているはずです。
+
+あるいは、既に所有しているコンパイラに加えて、下位バージョンのコンパイラをインストールすることもできます。
+すでに存在しますが、デフォルトではないため、ビルドシステムはそれを認識できません。 「gcc-7」がインストールされているが、
+ビルドシステムが見つからないというメッセージを表示する場合は、次の方法で解決できる可能性があります。
+
+```bash
+sudo ln -s /usr/bin/gcc-7 /usr/local/cuda-10.2/bin/gcc
+sudo ln -s /usr/bin/g++-7 /usr/local/cuda-10.2/bin/g++
+```
+
+ここでは、`/usr/local/cuda-10.2/bin/gcc` から `gcc-7` へのシンボリックリンクを作成しています。
+`/usr/local/cuda-10.2/bin/` は `PATH` 環境変数内にある必要があります (前の問題の解決策を参照)。
+`gcc-7` (および `g++7`) が見つかるはずで、ビルドは成功します。
+
+いつものように、状況に合わせて例のパスを編集してください。
+
+### PyTorch Fully Sharded Data parallel
+
+より大きなバッチ サイズで巨大なモデルのトレーニングを高速化するには、完全にシャード化されたデータ並列モデルを使用できます。
+このタイプのデータ並列パラダイムでは、オプティマイザーの状態、勾配、パラメーターをシャーディングすることで、より多くのデータと大規模なモデルをフィッティングできます。
+この機能とその利点の詳細については、[完全シャーディング データ並列ブログ](https://pytorch.org/blog/introducing-pytorch-full-sharded-data-Parallel-api/) をご覧ください。
+最新の PyTorch の Fully Sharded Data Parallel (FSDP) トレーニング機能を統合しました。
+必要なのは、設定を通じて有効にすることだけです。
+
+**FSDP サポートに必要な PyTorch バージョン**: PyTorch Nightly (リリース後にこれを読んだ場合は 1.12.0)
+FSDP を有効にしたモデルの保存は、最近の修正でのみ利用できるためです。
+
+**使用法**:
+
+- 配布されたランチャーが追加されていることを確認してください
+まだ使用していない場合は、`-m torch.distributed.launch --nproc_per_node=NUMBER_OF_GPUS_YOU_HAVE`を使用します。
+
+- **シャーディング戦略**:
+ - FULL_SHARD : データ並列ワーカー/GPU にわたるシャード オプティマイザーの状態 + 勾配 + モデル パラメーター。
+ このためには、コマンドライン引数に`--fsdp full_shard`を追加します。
+ - SHARD_GRAD_OP : シャード オプティマイザーの状態 + データ並列ワーカー/GPU 全体の勾配。
+ このためには、コマンドライン引数に`--fsdp shard_grad_op`を追加します。
+ - NO_SHARD : シャーディングなし。このためには、コマンドライン引数に`--fsdp no_shard`を追加します。
+- パラメータと勾配を CPU にオフロードするには、
+ コマンドライン引数に`--fsdp "full_shard offload"`または`--fsdp "shard_grad_op offload"`を追加します。
+- `default_auto_wrap_policy` を使用して FSDP でレイヤーを自動的に再帰的にラップするには、
+ コマンドライン引数に`--fsdp "full_shard auto_wrap"`または`--fsdp "shard_grad_op auto_wrap"`を追加します。
+- CPU オフロードと自動ラッピングの両方を有効にするには、
+ コマンドライン引数に`--fsdp "full_shard offload auto_wrap"`または`--fsdp "shard_grad_op offload auto_wrap"`を追加します。
+- 残りの FSDP 構成は、`--fsdp_config `を介して渡されます。それは、次のいずれかの場所です。
+ FSDP json 構成ファイル (例: `fsdp_config.json`)、またはすでにロードされている json ファイルを `dict` として使用します。
+ - 自動ラッピングが有効な場合は、トランスベースの自動ラップ ポリシーまたはサイズ ベースの自動ラップ ポリシーを使用できます。
+ - トランスフォーマーベースの自動ラップポリシーの場合、構成ファイルで `fsdp_transformer_layer_cls_to_wrap` を指定することをお勧めします。指定しない場合、使用可能な場合、デフォルト値は `model._no_split_modules` になります。
+ これは、ラップするトランスフォーマー層クラス名のリスト (大文字と小文字を区別) を指定します (例: [`BertLayer`]、[`GPTJBlock`]、[`T5Block`] ...)。
+ 重みを共有するサブモジュール (埋め込み層など) が異なる FSDP ラップされたユニットにならないようにする必要があるため、これは重要です。
+ このポリシーを使用すると、マルチヘッド アテンションとそれに続くいくつかの MLP レイヤーを含むブロックごとにラッピングが発生します。
+ 共有埋め込みを含む残りの層は、同じ最も外側の FSDP ユニットにラップされるのが便利です。
+ したがって、トランスベースのモデルにはこれを使用してください。
+ - サイズベースの自動ラップポリシーの場合は、設定ファイルに`fsdp_min_num_params`を追加してください。
+ 自動ラッピングのための FSDP のパラメータの最小数を指定します。
+ - 設定ファイルで `fsdp_backward_prefetch` を指定できるようになりました。次のパラメータのセットをいつプリフェッチするかを制御します。
+ `backward_pre` と `backward_pos` が利用可能なオプションです。
+ 詳細については、`torch.distributed.fsdp.full_sharded_data_Parallel.BackwardPrefetch`を参照してください。
+ - 設定ファイルで `fsdp_forward_prefetch` を指定できるようになりました。次のパラメータのセットをいつプリフェッチするかを制御します。
+ `True`の場合、FSDP はフォワード パスでの実行中に、次に来るオールギャザーを明示的にプリフェッチします。
+ - 設定ファイルで `limit_all_gathers` を指定できるようになりました。
+ `True`の場合、FSDP は CPU スレッドを明示的に同期して、実行中のオールギャザが多すぎるのを防ぎます。
+ - `activation_checkpointing`を設定ファイルで指定できるようになりました。
+ `True`の場合、FSDP アクティベーション チェックポイントは、FSDP のアクティベーションをクリアすることでメモリ使用量を削減する手法です。
+ 特定のレイヤーを処理し、バックワード パス中にそれらを再計算します。事実上、これは余分な計算時間を犠牲にします
+ メモリ使用量を削減します。
+
+**注意すべき注意点がいくつかあります**
+- これは `generate` と互換性がないため、 `--predict_with_generate` とも互換性がありません
+ すべての seq2seq/clm スクリプト (翻訳/要約/clm など)。
+ 問題 [#21667](https://github.com/huggingface/transformers/issues/21667) を参照してください。
+
+### PyTorch/XLA Fully Sharded Data parallel
+
+TPU ユーザーの皆様に朗報です。 PyTorch/XLA は FSDP をサポートするようになりました。
+最新の Fully Sharded Data Parallel (FSDP) トレーニングがすべてサポートされています。
+詳細については、[FSDP を使用した Cloud TPU での PyTorch モデルのスケーリング](https://pytorch.org/blog/scaling-pytorch-models-on-cloud-tpus-with-fsdp/) および [PyTorch/XLA 実装 を参照してください。 FSDP の](https://github.com/pytorch/xla/tree/master/torch_xla/distributed/fsdp)
+必要なのは、設定を通じて有効にすることだけです。
+
+**FSDP サポートに必要な PyTorch/XLA バージョン**: >=2.0
+
+**使用法**:
+
+`--fsdp "full shard"` を、`--fsdp_config ` に加えられる次の変更とともに渡します。
+- PyTorch/XLA FSDP を有効にするには、`xla`を`True`に設定する必要があります。
+- `xla_fsdp_settings` 値は、XLA FSDP ラッピング パラメータを格納する辞書です。
+ オプションの完全なリストについては、[こちら](
+ https://github.com/pytorch/xla/blob/master/torch_xla/distributed/fsdp/xla_full_sharded_data_Parallel.py)。
+- `xla_fsdp_grad_ckpt`。 `True`の場合、ネストされた XLA FSDP でラップされた各レイヤー上で勾配チェックポイントを使用します。
+ この設定は、xla フラグが true に設定されており、自動ラッピング ポリシーが指定されている場合にのみ使用できます。
+ `fsdp_min_num_params` または `fsdp_transformer_layer_cls_to_wrap`。
+- トランスフォーマー ベースの自動ラップ ポリシーまたはサイズ ベースの自動ラップ ポリシーのいずれかを使用できます。
+ - トランスフォーマーベースの自動ラップポリシーの場合、構成ファイルで `fsdp_transformer_layer_cls_to_wrap` を指定することをお勧めします。指定しない場合、使用可能な場合、デフォルト値は `model._no_split_modules` になります。
+ これは、ラップするトランスフォーマー層クラス名のリスト (大文字と小文字を区別) を指定します (例: [`BertLayer`]、[`GPTJBlock`]、[`T5Block`] ...)。
+ 重みを共有するサブモジュール (埋め込み層など) が異なる FSDP ラップされたユニットにならないようにする必要があるため、これは重要です。
+ このポリシーを使用すると、マルチヘッド アテンションとそれに続くいくつかの MLP レイヤーを含むブロックごとにラッピングが発生します。
+ 共有埋め込みを含む残りの層は、同じ最も外側の FSDP ユニットにラップされるのが便利です。
+ したがって、トランスベースのモデルにはこれを使用してください。
+ - サイズベースの自動ラップポリシーの場合は、設定ファイルに`fsdp_min_num_params`を追加してください。
+ 自動ラッピングのための FSDP のパラメータの最小数を指定します。
+
+### Using Trainer for accelerated PyTorch Training on Mac
+
+PyTorch v1.12 リリースにより、開発者と研究者は Apple シリコン GPU を利用してモデル トレーニングを大幅に高速化できます。
+これにより、プロトタイピングや微調整などの機械学習ワークフローを Mac 上でローカルで実行できるようになります。
+PyTorch のバックエンドとしての Apple の Metal Performance Shaders (MPS) はこれを可能にし、新しい `"mps"` デバイス経由で使用できます。
+これにより、計算グラフとプリミティブが MPS Graph フレームワークと MPS によって提供される調整されたカーネルにマッピングされます。
+詳細については、公式ドキュメント [Mac での Accelerated PyTorch Training の紹介](https://pytorch.org/blog/introducing-accelerated-pytorch-training-on-mac/) を参照してください。
+および [MPS バックエンド](https://pytorch.org/docs/stable/notes/mps.html)。
+
+
+
+MacOS マシンに PyTorch >= 1.13 (執筆時点ではナイトリー バージョン) をインストールすることを強くお勧めします。
+トランスベースのモデルのモデルの正確性とパフォーマンスの向上に関連する主要な修正が行われています。
+詳細については、https://github.com/pytorch/pytorch/issues/82707 を参照してください。
+
+
+
+**Apple Silicon チップを使用したトレーニングと推論の利点**
+
+1. ユーザーがローカルで大規模なネットワークやバッチ サイズをトレーニングできるようにします
+2. ユニファイド メモリ アーキテクチャにより、データ取得の遅延が短縮され、GPU がメモリ ストア全体に直接アクセスできるようになります。
+したがって、エンドツーエンドのパフォーマンスが向上します。
+3. クラウドベースの開発に関連するコストや追加のローカル GPU の必要性を削減します。
+
+**前提条件**: mps サポートを備えたトーチをインストールするには、
+この素晴らしいメディア記事 [GPU アクセラレーションが M1 Mac の PyTorch に登場](https://medium.com/towards-data-science/gpu-acceleration-comes-to-pytorch-on-m1-macs-195c399efcc1) に従ってください。 。
+
+**使用法**:
+`mps` デバイスは、`cuda` デバイスが使用される方法と同様に利用可能な場合、デフォルトで使用されます。
+したがって、ユーザーによるアクションは必要ありません。
+たとえば、以下のコマンドを使用して、Apple Silicon GPU を使用して公式の Glue テキスト分類タスクを (ルート フォルダーから) 実行できます。
+
+```bash
+export TASK_NAME=mrpc
+
+python examples/pytorch/text-classification/run_glue.py \
+ --model_name_or_path bert-base-cased \
+ --task_name $TASK_NAME \
+ --do_train \
+ --do_eval \
+ --max_seq_length 128 \
+ --per_device_train_batch_size 32 \
+ --learning_rate 2e-5 \
+ --num_train_epochs 3 \
+ --output_dir /tmp/$TASK_NAME/ \
+ --overwrite_output_dir
+```
+
+**注意すべきいくつかの注意事項**
+
+1. 一部の PyTorch 操作は mps に実装されていないため、エラーがスローされます。
+これを回避する 1 つの方法は、環境変数 `PYTORCH_ENABLE_MPS_FALLBACK=1` を設定することです。
+これらの操作では CPU にフォールバックします。ただし、それでも UserWarning がスローされます。
+2. 分散セットアップ`gloo`および`nccl`は、`mps`デバイスでは動作しません。
+これは、現在「mps」デバイス タイプの単一 GPU のみを使用できることを意味します。
+
+最後に、覚えておいてください。 🤗 `Trainer` は MPS バックエンドのみを統合するため、
+MPS バックエンドの使用に関して問題や質問がある場合は、
+[PyTorch GitHub](https://github.com/pytorch/pytorch/issues) に問題を提出してください。
+
+## Using Accelerate Launcher with Trainer
+
+加速してトレーナーにパワーを与えましょう。ユーザーが期待することに関しては、次のとおりです。
+- トレーナー引数に対して FSDP、DeepSpeed などのトレーナー インテレーションを変更せずに使用し続けることができます。
+- トレーナーで Accelerate Launcher を使用できるようになりました (推奨)。
+
+トレーナーで Accelerate Launcher を使用する手順:
+1. 🤗 Accelerate がインストールされていることを確認してください。Accelerate がないと `Trainer` を使用することはできません。そうでない場合は、`pip install accelerate`してください。 Accelerate のバージョンを更新する必要がある場合もあります: `pip install activate --upgrade`
+2. `accelerate config`を実行し、アンケートに記入します。以下は加速設定の例です。
+ a. DDP マルチノード マルチ GPU 構成:
+ ```yaml
+ compute_environment: LOCAL_MACHINE
+ distributed_type: MULTI_GPU
+ downcast_bf16: 'no'
+ gpu_ids: all
+ machine_rank: 0 #change rank as per the node
+ main_process_ip: 192.168.20.1
+ main_process_port: 9898
+ main_training_function: main
+ mixed_precision: fp16
+ num_machines: 2
+ num_processes: 8
+ rdzv_backend: static
+ same_network: true
+ tpu_env: []
+ tpu_use_cluster: false
+ tpu_use_sudo: false
+ use_cpu: false
+ ```
+
+ b. FSDP config:
+ ```yaml
+ compute_environment: LOCAL_MACHINE
+ distributed_type: FSDP
+ downcast_bf16: 'no'
+ fsdp_config:
+ fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
+ fsdp_backward_prefetch_policy: BACKWARD_PRE
+ fsdp_forward_prefetch: true
+ fsdp_offload_params: false
+ fsdp_sharding_strategy: 1
+ fsdp_state_dict_type: FULL_STATE_DICT
+ fsdp_sync_module_states: true
+ fsdp_transformer_layer_cls_to_wrap: BertLayer
+ fsdp_use_orig_params: true
+ machine_rank: 0
+ main_training_function: main
+ mixed_precision: bf16
+ num_machines: 1
+ num_processes: 2
+ rdzv_backend: static
+ same_network: true
+ tpu_env: []
+ tpu_use_cluster: false
+ tpu_use_sudo: false
+ use_cpu: false
+ ```
+ c.ファイルを指す DeepSpeed 構成:
+ ```yaml
+ compute_environment: LOCAL_MACHINE
+ deepspeed_config:
+ deepspeed_config_file: /home/user/configs/ds_zero3_config.json
+ zero3_init_flag: true
+ distributed_type: DEEPSPEED
+ downcast_bf16: 'no'
+ machine_rank: 0
+ main_training_function: main
+ num_machines: 1
+ num_processes: 4
+ rdzv_backend: static
+ same_network: true
+ tpu_env: []
+ tpu_use_cluster: false
+ tpu_use_sudo: false
+ use_cpu: false
+ ```
+
+ d.加速プラグインを使用した DeepSpeed 構成:
+
+ ```yaml
+ compute_environment: LOCAL_MACHINE
+ deepspeed_config:
+ gradient_accumulation_steps: 1
+ gradient_clipping: 0.7
+ offload_optimizer_device: cpu
+ offload_param_device: cpu
+ zero3_init_flag: true
+ zero_stage: 2
+ distributed_type: DEEPSPEED
+ downcast_bf16: 'no'
+ machine_rank: 0
+ main_training_function: main
+ mixed_precision: bf16
+ num_machines: 1
+ num_processes: 4
+ rdzv_backend: static
+ same_network: true
+ tpu_env: []
+ tpu_use_cluster: false
+ tpu_use_sudo: false
+ use_cpu: false
+ ```
+
+3. 加速設定またはランチャー引数によって上記で処理された引数以外の引数を使用して、トレーナー スクリプトを実行します。
+以下は、上記の FSDP 構成で`accelerate launcher`を使用して`run_glue.py`を実行する例です。
+
+```bash
+cd transformers
+
+accelerate launch \
+./examples/pytorch/text-classification/run_glue.py \
+--model_name_or_path bert-base-cased \
+--task_name $TASK_NAME \
+--do_train \
+--do_eval \
+--max_seq_length 128 \
+--per_device_train_batch_size 16 \
+--learning_rate 5e-5 \
+--num_train_epochs 3 \
+--output_dir /tmp/$TASK_NAME/ \
+--overwrite_output_dir
+```
+
+4. `accelerate launch`するための cmd 引数を直接使用することもできます。上の例は次のようにマッピングされます。
+
+```bash
+cd transformers
+
+accelerate launch --num_processes=2 \
+--use_fsdp \
+--mixed_precision=bf16 \
+--fsdp_auto_wrap_policy=TRANSFORMER_BASED_WRAP \
+--fsdp_transformer_layer_cls_to_wrap="BertLayer" \
+--fsdp_sharding_strategy=1 \
+--fsdp_state_dict_type=FULL_STATE_DICT \
+./examples/pytorch/text-classification/run_glue.py
+--model_name_or_path bert-base-cased \
+--task_name $TASK_NAME \
+--do_train \
+--do_eval \
+--max_seq_length 128 \
+--per_device_train_batch_size 16 \
+--learning_rate 5e-5 \
+--num_train_epochs 3 \
+--output_dir /tmp/$TASK_NAME/ \
+--overwrite_output_dir
+```
+
+詳細については、🤗 Accelerate CLI ガイドを参照してください: [🤗 Accelerate スクリプトの起動](https://huggingface.co/docs/accelerate/basic_tutorials/launch)。
+
+移動されたセクション:
+
+[ DeepSpeed
+| Installation
+| Deployment with multiple GPUs
+| Deployment with one GPU
+| Deployment in Notebooks
+| Configuration
+| Passing Configuration
+| Shared Configuration
+| ZeRO
+| ZeRO-2 Config
+| ZeRO-3 Config
+| NVMe Support
+| ZeRO-2 vs ZeRO-3 Performance
+| ZeRO-2 Example
+| ZeRO-3 Example
+| Optimizer
+| Scheduler
+| fp32 Precision
+| Automatic Mixed Precision
+| Batch Size
+| Gradient Accumulation
+| Gradient Clipping
+| Getting The Model Weights Out
+]
diff --git a/docs/source/ja/model_doc/albert.md b/docs/source/ja/model_doc/albert.md
new file mode 100644
index 000000000000..00403ea53765
--- /dev/null
+++ b/docs/source/ja/model_doc/albert.md
@@ -0,0 +1,193 @@
+
+
+# ALBERT
+
+
 +
+ +
+ +
+ +
+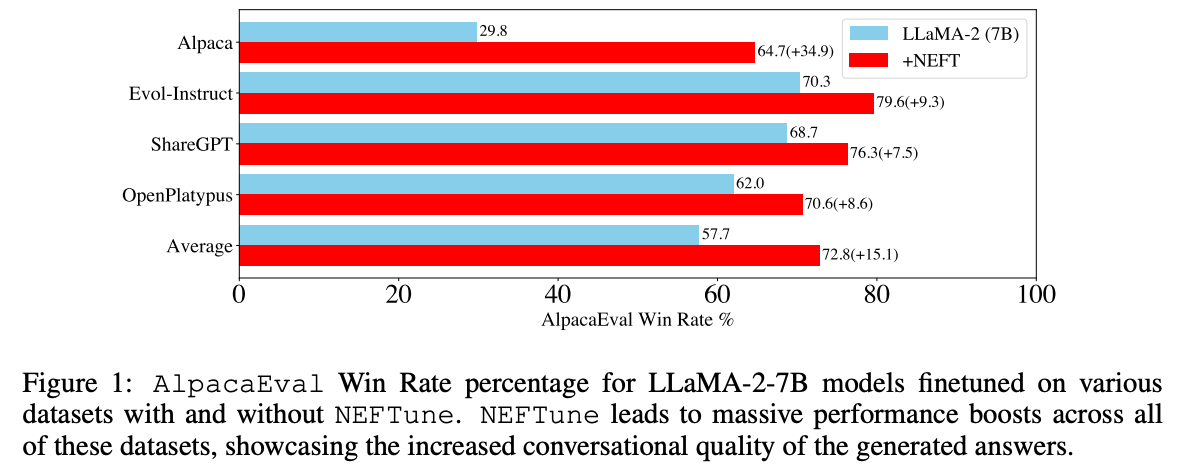 +
+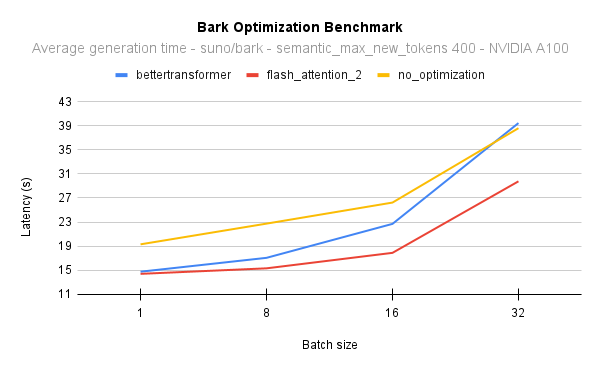 +
+ @@ -40,6 +35,11 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207).
+## Usage tips
+
+- BLIP-2 can be used for conditional text generation given an image and an optional text prompt. At inference time, it's recommended to use the [`generate`] method.
+- One can use [`Blip2Processor`] to prepare images for the model, and decode the predicted tokens ID's back to text.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BLIP-2.
diff --git a/docs/source/en/model_doc/blip.md b/docs/source/en/model_doc/blip.md
index 8afed63311f8..bc122c942a67 100644
--- a/docs/source/en/model_doc/blip.md
+++ b/docs/source/en/model_doc/blip.md
@@ -20,7 +20,7 @@ rendered properly in your Markdown viewer.
The BLIP model was proposed in [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
-BLIP is a model that is able to perform various multi-modal tasks including
+BLIP is a model that is able to perform various multi-modal tasks including:
- Visual Question Answering
- Image-Text retrieval (Image-text matching)
- Image Captioning
@@ -39,7 +39,6 @@ The original code can be found [here](https://github.com/salesforce/BLIP).
- [Jupyter notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) on how to fine-tune BLIP for image captioning on a custom dataset
-
## BlipConfig
[[autodoc]] BlipConfig
@@ -57,12 +56,14 @@ The original code can be found [here](https://github.com/salesforce/BLIP).
[[autodoc]] BlipProcessor
-
## BlipImageProcessor
[[autodoc]] BlipImageProcessor
- preprocess
+
@@ -40,6 +35,11 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207).
+## Usage tips
+
+- BLIP-2 can be used for conditional text generation given an image and an optional text prompt. At inference time, it's recommended to use the [`generate`] method.
+- One can use [`Blip2Processor`] to prepare images for the model, and decode the predicted tokens ID's back to text.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BLIP-2.
diff --git a/docs/source/en/model_doc/blip.md b/docs/source/en/model_doc/blip.md
index 8afed63311f8..bc122c942a67 100644
--- a/docs/source/en/model_doc/blip.md
+++ b/docs/source/en/model_doc/blip.md
@@ -20,7 +20,7 @@ rendered properly in your Markdown viewer.
The BLIP model was proposed in [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
-BLIP is a model that is able to perform various multi-modal tasks including
+BLIP is a model that is able to perform various multi-modal tasks including:
- Visual Question Answering
- Image-Text retrieval (Image-text matching)
- Image Captioning
@@ -39,7 +39,6 @@ The original code can be found [here](https://github.com/salesforce/BLIP).
- [Jupyter notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) on how to fine-tune BLIP for image captioning on a custom dataset
-
## BlipConfig
[[autodoc]] BlipConfig
@@ -57,12 +56,14 @@ The original code can be found [here](https://github.com/salesforce/BLIP).
[[autodoc]] BlipProcessor
-
## BlipImageProcessor
[[autodoc]] BlipImageProcessor
- preprocess
+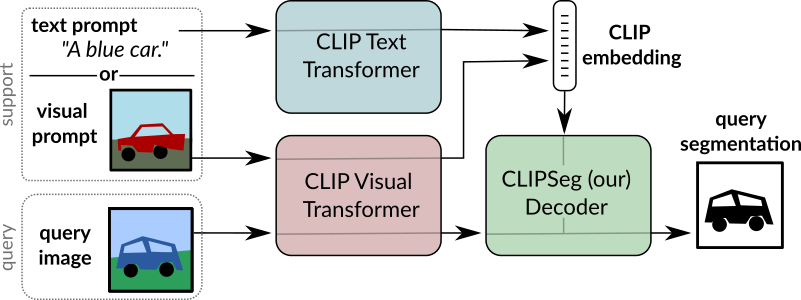 @@ -56,6 +49,13 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/timojl/clipseg).
+## Usage tips
+
+- [`CLIPSegForImageSegmentation`] adds a decoder on top of [`CLIPSegModel`]. The latter is identical to [`CLIPModel`].
+- [`CLIPSegForImageSegmentation`] can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text
+(provided to the model as `input_ids`) or an image (provided to the model as `conditional_pixel_values`). One can also provide custom
+conditional embeddings (provided to the model as `conditional_embeddings`).
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CLIPSeg. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
diff --git a/docs/source/en/model_doc/clvp.md b/docs/source/en/model_doc/clvp.md
new file mode 100644
index 000000000000..a30269faf9ca
--- /dev/null
+++ b/docs/source/en/model_doc/clvp.md
@@ -0,0 +1,126 @@
+
+
+# CLVP
+
+## Overview
+
+The CLVP (Contrastive Language-Voice Pretrained Transformer) model was proposed in [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
+
+The abstract from the paper is the following:
+
+*In recent years, the field of image generation has been revolutionized by the application of autoregressive transformers and DDPMs. These approaches model the process of image generation as a step-wise probabilistic processes and leverage large amounts of compute and data to learn the image distribution. This methodology of improving performance need not be confined to images. This paper describes a way to apply advances in the image generative domain to speech synthesis. The result is TorToise - an expressive, multi-voice text-to-speech system.*
+
+
+This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
+The original code can be found [here](https://github.com/neonbjb/tortoise-tts).
+
+
+## Usage tips
+
+1. CLVP is an integral part of the Tortoise TTS model.
+2. CLVP can be used to compare different generated speech candidates with the provided text, and the best speech tokens are forwarded to the diffusion model.
+3. The use of the [`ClvpModelForConditionalGeneration.generate()`] method is strongly recommended for tortoise usage.
+4. Note that the CLVP model expects the audio to be sampled at 22.05 kHz contrary to other audio models which expects 16 kHz.
+
+
+## Brief Explanation:
+
+- The [`ClvpTokenizer`] tokenizes the text input, and the [`ClvpFeatureExtractor`] extracts the log mel-spectrogram from the desired audio.
+- [`ClvpConditioningEncoder`] takes those text tokens and audio representations and converts them into embeddings conditioned on the text and audio.
+- The [`ClvpForCausalLM`] uses those embeddings to generate multiple speech candidates.
+- Each speech candidate is passed through the speech encoder ([`ClvpEncoder`]) which converts them into a vector representation, and the text encoder ([`ClvpEncoder`]) converts the text tokens into the same latent space.
+- At the end, we compare each speech vector with the text vector to see which speech vector is most similar to the text vector.
+- [`ClvpModelForConditionalGeneration.generate()`] compresses all of the logic described above into a single method.
+
+
+Example :
+
+```python
+>>> import datasets
+>>> from transformers import ClvpProcessor, ClvpModelForConditionalGeneration
+
+>>> # Define the Text and Load the Audio (We are taking an audio example from HuggingFace Hub using `datasets` library).
+>>> text = "This is an example text."
+
+>>> ds = datasets.load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> ds = ds.cast_column("audio", datasets.Audio(sampling_rate=22050))
+>>> sample = ds[0]["audio"]
+
+>>> # Define processor and model.
+>>> processor = ClvpProcessor.from_pretrained("susnato/clvp_dev")
+>>> model = ClvpModelForConditionalGeneration.from_pretrained("susnato/clvp_dev")
+
+>>> # Generate processor output and model output.
+>>> processor_output = processor(raw_speech=sample["array"], sampling_rate=sample["sampling_rate"], text=text, return_tensors="pt")
+>>> generated_output = model.generate(**processor_output)
+```
+
+
+## ClvpConfig
+
+[[autodoc]] ClvpConfig
+ - from_sub_model_configs
+
+## ClvpEncoderConfig
+
+[[autodoc]] ClvpEncoderConfig
+
+## ClvpDecoderConfig
+
+[[autodoc]] ClvpDecoderConfig
+
+## ClvpTokenizer
+
+[[autodoc]] ClvpTokenizer
+ - save_vocabulary
+
+## ClvpFeatureExtractor
+
+[[autodoc]] ClvpFeatureExtractor
+ - __call__
+
+## ClvpProcessor
+
+[[autodoc]] ClvpProcessor
+ - __call__
+ - decode
+ - batch_decode
+
+## ClvpModelForConditionalGeneration
+
+[[autodoc]] ClvpModelForConditionalGeneration
+ - forward
+ - generate
+ - get_text_features
+ - get_speech_features
+
+## ClvpForCausalLM
+
+[[autodoc]] ClvpForCausalLM
+
+## ClvpModel
+
+[[autodoc]] ClvpModel
+
+## ClvpEncoder
+
+[[autodoc]] ClvpEncoder
+
+## ClvpDecoder
+
+[[autodoc]] ClvpDecoder
+
diff --git a/docs/source/en/model_doc/code_llama.md b/docs/source/en/model_doc/code_llama.md
index a60cf1641533..38d50c87334d 100644
--- a/docs/source/en/model_doc/code_llama.md
+++ b/docs/source/en/model_doc/code_llama.md
@@ -24,7 +24,11 @@ The abstract from the paper is the following:
*We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. We provide multiple flavors to cover a wide range of applications: foundation models (Code Llama), Python specializations (Code Llama - Python), and instruction-following models (Code Llama - Instruct) with 7B, 13B and 34B parameters each. All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens. 7B and 13B Code Llama and Code Llama - Instruct variants support infilling based on surrounding content. Code Llama reaches state-of-the-art performance among open models on several code benchmarks, with scores of up to 53% and 55% on HumanEval and MBPP, respectively. Notably, Code Llama - Python 7B outperforms Llama 2 70B on HumanEval and MBPP, and all our models outperform every other publicly available model on MultiPL-E. We release Code Llama under a permissive license that allows for both research and commercial use.*
-Check out all Code Llama models [here](https://huggingface.co/models?search=code_llama) and the officially released ones in the [codellama org](https://huggingface.co/codellama).
+Check out all Code Llama model checkpoints [here](https://huggingface.co/models?search=code_llama) and the officially released ones in the [codellama org](https://huggingface.co/codellama).
+
+This model was contributed by [ArthurZucker](https://huggingface.co/ArthurZ). The original code of the authors can be found [here](https://github.com/facebookresearch/llama).
+
+## Usage tips and examples
@@ -56,6 +49,13 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/timojl/clipseg).
+## Usage tips
+
+- [`CLIPSegForImageSegmentation`] adds a decoder on top of [`CLIPSegModel`]. The latter is identical to [`CLIPModel`].
+- [`CLIPSegForImageSegmentation`] can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text
+(provided to the model as `input_ids`) or an image (provided to the model as `conditional_pixel_values`). One can also provide custom
+conditional embeddings (provided to the model as `conditional_embeddings`).
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CLIPSeg. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
diff --git a/docs/source/en/model_doc/clvp.md b/docs/source/en/model_doc/clvp.md
new file mode 100644
index 000000000000..a30269faf9ca
--- /dev/null
+++ b/docs/source/en/model_doc/clvp.md
@@ -0,0 +1,126 @@
+
+
+# CLVP
+
+## Overview
+
+The CLVP (Contrastive Language-Voice Pretrained Transformer) model was proposed in [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
+
+The abstract from the paper is the following:
+
+*In recent years, the field of image generation has been revolutionized by the application of autoregressive transformers and DDPMs. These approaches model the process of image generation as a step-wise probabilistic processes and leverage large amounts of compute and data to learn the image distribution. This methodology of improving performance need not be confined to images. This paper describes a way to apply advances in the image generative domain to speech synthesis. The result is TorToise - an expressive, multi-voice text-to-speech system.*
+
+
+This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
+The original code can be found [here](https://github.com/neonbjb/tortoise-tts).
+
+
+## Usage tips
+
+1. CLVP is an integral part of the Tortoise TTS model.
+2. CLVP can be used to compare different generated speech candidates with the provided text, and the best speech tokens are forwarded to the diffusion model.
+3. The use of the [`ClvpModelForConditionalGeneration.generate()`] method is strongly recommended for tortoise usage.
+4. Note that the CLVP model expects the audio to be sampled at 22.05 kHz contrary to other audio models which expects 16 kHz.
+
+
+## Brief Explanation:
+
+- The [`ClvpTokenizer`] tokenizes the text input, and the [`ClvpFeatureExtractor`] extracts the log mel-spectrogram from the desired audio.
+- [`ClvpConditioningEncoder`] takes those text tokens and audio representations and converts them into embeddings conditioned on the text and audio.
+- The [`ClvpForCausalLM`] uses those embeddings to generate multiple speech candidates.
+- Each speech candidate is passed through the speech encoder ([`ClvpEncoder`]) which converts them into a vector representation, and the text encoder ([`ClvpEncoder`]) converts the text tokens into the same latent space.
+- At the end, we compare each speech vector with the text vector to see which speech vector is most similar to the text vector.
+- [`ClvpModelForConditionalGeneration.generate()`] compresses all of the logic described above into a single method.
+
+
+Example :
+
+```python
+>>> import datasets
+>>> from transformers import ClvpProcessor, ClvpModelForConditionalGeneration
+
+>>> # Define the Text and Load the Audio (We are taking an audio example from HuggingFace Hub using `datasets` library).
+>>> text = "This is an example text."
+
+>>> ds = datasets.load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> ds = ds.cast_column("audio", datasets.Audio(sampling_rate=22050))
+>>> sample = ds[0]["audio"]
+
+>>> # Define processor and model.
+>>> processor = ClvpProcessor.from_pretrained("susnato/clvp_dev")
+>>> model = ClvpModelForConditionalGeneration.from_pretrained("susnato/clvp_dev")
+
+>>> # Generate processor output and model output.
+>>> processor_output = processor(raw_speech=sample["array"], sampling_rate=sample["sampling_rate"], text=text, return_tensors="pt")
+>>> generated_output = model.generate(**processor_output)
+```
+
+
+## ClvpConfig
+
+[[autodoc]] ClvpConfig
+ - from_sub_model_configs
+
+## ClvpEncoderConfig
+
+[[autodoc]] ClvpEncoderConfig
+
+## ClvpDecoderConfig
+
+[[autodoc]] ClvpDecoderConfig
+
+## ClvpTokenizer
+
+[[autodoc]] ClvpTokenizer
+ - save_vocabulary
+
+## ClvpFeatureExtractor
+
+[[autodoc]] ClvpFeatureExtractor
+ - __call__
+
+## ClvpProcessor
+
+[[autodoc]] ClvpProcessor
+ - __call__
+ - decode
+ - batch_decode
+
+## ClvpModelForConditionalGeneration
+
+[[autodoc]] ClvpModelForConditionalGeneration
+ - forward
+ - generate
+ - get_text_features
+ - get_speech_features
+
+## ClvpForCausalLM
+
+[[autodoc]] ClvpForCausalLM
+
+## ClvpModel
+
+[[autodoc]] ClvpModel
+
+## ClvpEncoder
+
+[[autodoc]] ClvpEncoder
+
+## ClvpDecoder
+
+[[autodoc]] ClvpDecoder
+
diff --git a/docs/source/en/model_doc/code_llama.md b/docs/source/en/model_doc/code_llama.md
index a60cf1641533..38d50c87334d 100644
--- a/docs/source/en/model_doc/code_llama.md
+++ b/docs/source/en/model_doc/code_llama.md
@@ -24,7 +24,11 @@ The abstract from the paper is the following:
*We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. We provide multiple flavors to cover a wide range of applications: foundation models (Code Llama), Python specializations (Code Llama - Python), and instruction-following models (Code Llama - Instruct) with 7B, 13B and 34B parameters each. All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens. 7B and 13B Code Llama and Code Llama - Instruct variants support infilling based on surrounding content. Code Llama reaches state-of-the-art performance among open models on several code benchmarks, with scores of up to 53% and 55% on HumanEval and MBPP, respectively. Notably, Code Llama - Python 7B outperforms Llama 2 70B on HumanEval and MBPP, and all our models outperform every other publicly available model on MultiPL-E. We release Code Llama under a permissive license that allows for both research and commercial use.*
-Check out all Code Llama models [here](https://huggingface.co/models?search=code_llama) and the officially released ones in the [codellama org](https://huggingface.co/codellama).
+Check out all Code Llama model checkpoints [here](https://huggingface.co/models?search=code_llama) and the officially released ones in the [codellama org](https://huggingface.co/codellama).
+
+This model was contributed by [ArthurZucker](https://huggingface.co/ArthurZ). The original code of the authors can be found [here](https://github.com/facebookresearch/llama).
+
+## Usage tips and examples
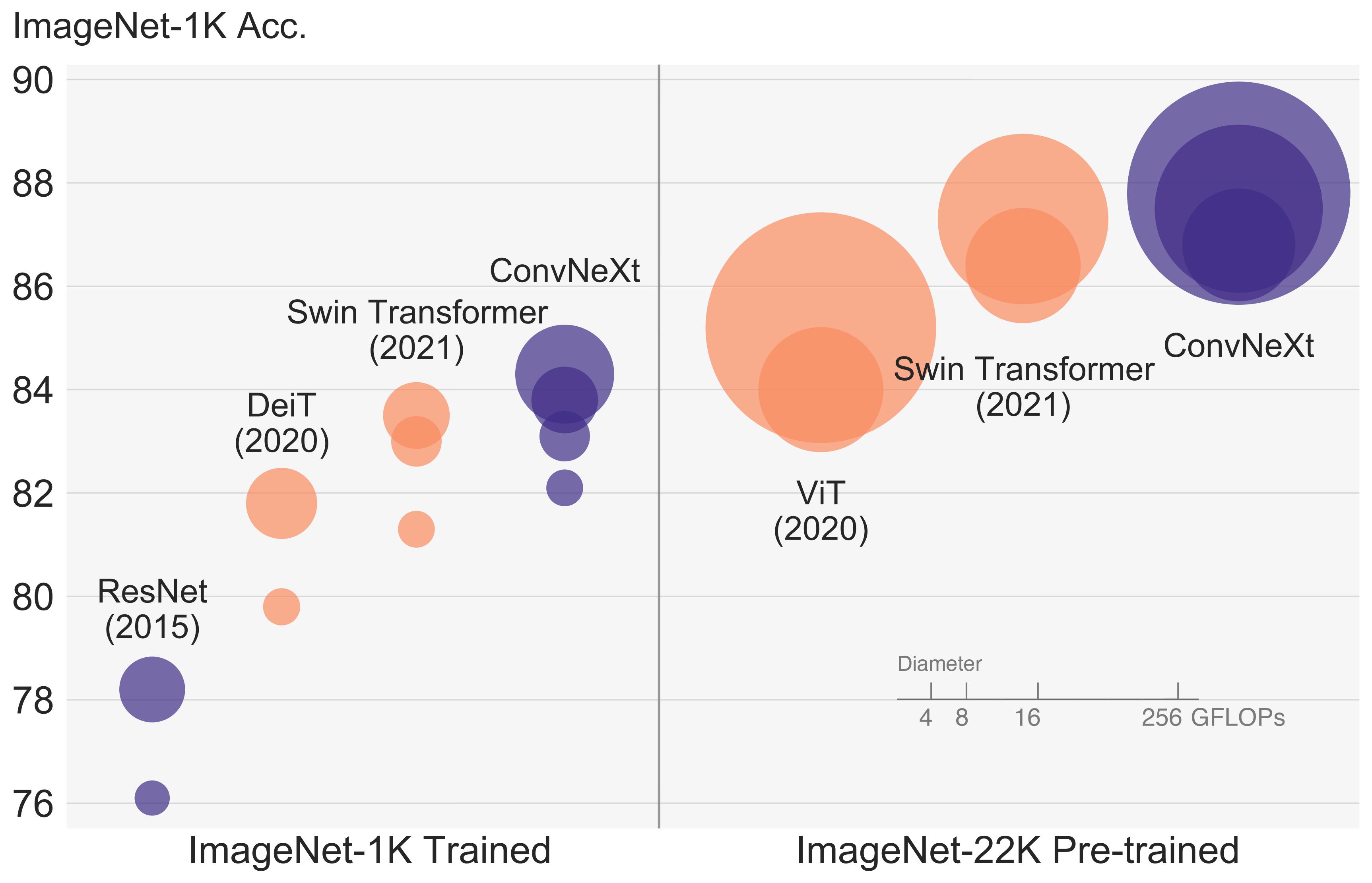 @@ -68,6 +64,9 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] ConvNextImageProcessor
- preprocess
+
@@ -68,6 +64,9 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] ConvNextImageProcessor
- preprocess
+ @@ -58,4 +54,15 @@ If you're interested in submitting a resource to be included here, please feel f
## ConvNextV2ForImageClassification
[[autodoc]] ConvNextV2ForImageClassification
- - forward
\ No newline at end of file
+ - forward
+
+## TFConvNextV2Model
+
+[[autodoc]] TFConvNextV2Model
+ - call
+
+
+## TFConvNextV2ForImageClassification
+
+[[autodoc]] TFConvNextV2ForImageClassification
+ - call
diff --git a/docs/source/en/model_doc/cpm.md b/docs/source/en/model_doc/cpm.md
index a2ecf1a1e092..129c4ed3a377 100644
--- a/docs/source/en/model_doc/cpm.md
+++ b/docs/source/en/model_doc/cpm.md
@@ -37,7 +37,14 @@ NLP tasks in the settings of few-shot (even zero-shot) learning.*
This model was contributed by [canwenxu](https://huggingface.co/canwenxu). The original implementation can be found
here: https://github.com/TsinghuaAI/CPM-Generate
-Note: We only have a tokenizer here, since the model architecture is the same as GPT-2.
+
+
@@ -58,4 +54,15 @@ If you're interested in submitting a resource to be included here, please feel f
## ConvNextV2ForImageClassification
[[autodoc]] ConvNextV2ForImageClassification
- - forward
\ No newline at end of file
+ - forward
+
+## TFConvNextV2Model
+
+[[autodoc]] TFConvNextV2Model
+ - call
+
+
+## TFConvNextV2ForImageClassification
+
+[[autodoc]] TFConvNextV2ForImageClassification
+ - call
diff --git a/docs/source/en/model_doc/cpm.md b/docs/source/en/model_doc/cpm.md
index a2ecf1a1e092..129c4ed3a377 100644
--- a/docs/source/en/model_doc/cpm.md
+++ b/docs/source/en/model_doc/cpm.md
@@ -37,7 +37,14 @@ NLP tasks in the settings of few-shot (even zero-shot) learning.*
This model was contributed by [canwenxu](https://huggingface.co/canwenxu). The original implementation can be found
here: https://github.com/TsinghuaAI/CPM-Generate
-Note: We only have a tokenizer here, since the model architecture is the same as GPT-2.
+
+ @@ -37,6 +32,10 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/fundamentalvision/Deformable-DETR).
+## Usage tips
+
+- Training Deformable DETR is equivalent to training the original [DETR](detr) model. See the [resources](#resources) section below for demo notebooks.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Deformable DETR.
diff --git a/docs/source/en/model_doc/deit.md b/docs/source/en/model_doc/deit.md
index ef32e05ebd92..7d9918a45eee 100644
--- a/docs/source/en/model_doc/deit.md
+++ b/docs/source/en/model_doc/deit.md
@@ -16,13 +16,6 @@ rendered properly in your Markdown viewer.
# DeiT
-
@@ -37,6 +32,10 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/fundamentalvision/Deformable-DETR).
+## Usage tips
+
+- Training Deformable DETR is equivalent to training the original [DETR](detr) model. See the [resources](#resources) section below for demo notebooks.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Deformable DETR.
diff --git a/docs/source/en/model_doc/deit.md b/docs/source/en/model_doc/deit.md
index ef32e05ebd92..7d9918a45eee 100644
--- a/docs/source/en/model_doc/deit.md
+++ b/docs/source/en/model_doc/deit.md
@@ -16,13 +16,6 @@ rendered properly in your Markdown viewer.
# DeiT
- @@ -51,20 +47,17 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] DetaConfig
-
## DetaImageProcessor
[[autodoc]] DetaImageProcessor
- preprocess
- post_process_object_detection
-
## DetaModel
[[autodoc]] DetaModel
- forward
-
## DetaForObjectDetection
[[autodoc]] DetaForObjectDetection
diff --git a/docs/source/en/model_doc/detr.md b/docs/source/en/model_doc/detr.md
index 2c03a0f8b851..c36bd4380edf 100644
--- a/docs/source/en/model_doc/detr.md
+++ b/docs/source/en/model_doc/detr.md
@@ -41,6 +41,8 @@ baselines.*
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/facebookresearch/detr).
+## How DETR works
+
Here's a TLDR explaining how [`~transformers.DetrForObjectDetection`] works:
First, an image is sent through a pre-trained convolutional backbone (in the paper, the authors use
@@ -79,7 +81,7 @@ where one first trains a [`~transformers.DetrForObjectDetection`] model to detec
the mask head for 25 epochs. Experimentally, these two approaches give similar results. Note that predicting boxes is
required for the training to be possible, since the Hungarian matching is computed using distances between boxes.
-Tips:
+## Usage tips
- DETR uses so-called **object queries** to detect objects in an image. The number of queries determines the maximum
number of objects that can be detected in a single image, and is set to 100 by default (see parameter
@@ -165,14 +167,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
-## DETR specific outputs
-
-[[autodoc]] models.detr.modeling_detr.DetrModelOutput
-
-[[autodoc]] models.detr.modeling_detr.DetrObjectDetectionOutput
-
-[[autodoc]] models.detr.modeling_detr.DetrSegmentationOutput
-
## DetrConfig
[[autodoc]] DetrConfig
@@ -195,6 +189,14 @@ If you're interested in submitting a resource to be included here, please feel f
- post_process_instance_segmentation
- post_process_panoptic_segmentation
+## DETR specific outputs
+
+[[autodoc]] models.detr.modeling_detr.DetrModelOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrObjectDetectionOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrSegmentationOutput
+
## DetrModel
[[autodoc]] DetrModel
diff --git a/docs/source/en/model_doc/dialogpt.md b/docs/source/en/model_doc/dialogpt.md
index 70929409b294..558b91d76d25 100644
--- a/docs/source/en/model_doc/dialogpt.md
+++ b/docs/source/en/model_doc/dialogpt.md
@@ -32,7 +32,9 @@ that leverage DialoGPT generate more relevant, contentful and context-consistent
systems. The pre-trained model and training pipeline are publicly released to facilitate research into neural response
generation and the development of more intelligent open-domain dialogue systems.*
-Tips:
+The original code can be found [here](https://github.com/microsoft/DialoGPT).
+
+## Usage tips
- DialoGPT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather
than the left.
@@ -47,7 +49,8 @@ follow the OpenAI GPT-2 to model a multiturn dialogue session as a long text and
modeling. We first concatenate all dialog turns within a dialogue session into a long text x_1,..., x_N (N is the
sequence length), ended by the end-of-text token.* For more information please confer to the original paper.
+
@@ -51,20 +47,17 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] DetaConfig
-
## DetaImageProcessor
[[autodoc]] DetaImageProcessor
- preprocess
- post_process_object_detection
-
## DetaModel
[[autodoc]] DetaModel
- forward
-
## DetaForObjectDetection
[[autodoc]] DetaForObjectDetection
diff --git a/docs/source/en/model_doc/detr.md b/docs/source/en/model_doc/detr.md
index 2c03a0f8b851..c36bd4380edf 100644
--- a/docs/source/en/model_doc/detr.md
+++ b/docs/source/en/model_doc/detr.md
@@ -41,6 +41,8 @@ baselines.*
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/facebookresearch/detr).
+## How DETR works
+
Here's a TLDR explaining how [`~transformers.DetrForObjectDetection`] works:
First, an image is sent through a pre-trained convolutional backbone (in the paper, the authors use
@@ -79,7 +81,7 @@ where one first trains a [`~transformers.DetrForObjectDetection`] model to detec
the mask head for 25 epochs. Experimentally, these two approaches give similar results. Note that predicting boxes is
required for the training to be possible, since the Hungarian matching is computed using distances between boxes.
-Tips:
+## Usage tips
- DETR uses so-called **object queries** to detect objects in an image. The number of queries determines the maximum
number of objects that can be detected in a single image, and is set to 100 by default (see parameter
@@ -165,14 +167,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
-## DETR specific outputs
-
-[[autodoc]] models.detr.modeling_detr.DetrModelOutput
-
-[[autodoc]] models.detr.modeling_detr.DetrObjectDetectionOutput
-
-[[autodoc]] models.detr.modeling_detr.DetrSegmentationOutput
-
## DetrConfig
[[autodoc]] DetrConfig
@@ -195,6 +189,14 @@ If you're interested in submitting a resource to be included here, please feel f
- post_process_instance_segmentation
- post_process_panoptic_segmentation
+## DETR specific outputs
+
+[[autodoc]] models.detr.modeling_detr.DetrModelOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrObjectDetectionOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrSegmentationOutput
+
## DetrModel
[[autodoc]] DetrModel
diff --git a/docs/source/en/model_doc/dialogpt.md b/docs/source/en/model_doc/dialogpt.md
index 70929409b294..558b91d76d25 100644
--- a/docs/source/en/model_doc/dialogpt.md
+++ b/docs/source/en/model_doc/dialogpt.md
@@ -32,7 +32,9 @@ that leverage DialoGPT generate more relevant, contentful and context-consistent
systems. The pre-trained model and training pipeline are publicly released to facilitate research into neural response
generation and the development of more intelligent open-domain dialogue systems.*
-Tips:
+The original code can be found [here](https://github.com/microsoft/DialoGPT).
+
+## Usage tips
- DialoGPT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather
than the left.
@@ -47,7 +49,8 @@ follow the OpenAI GPT-2 to model a multiturn dialogue session as a long text and
modeling. We first concatenate all dialog turns within a dialogue session into a long text x_1,..., x_N (N is the
sequence length), ended by the end-of-text token.* For more information please confer to the original paper.
+ @@ -65,6 +54,17 @@ Taken from the original paper.
+
+- [`Dinov2ForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## Dinov2Config
diff --git a/docs/source/en/model_doc/distilbert.md b/docs/source/en/model_doc/distilbert.md
index 2e68119a20b2..233a182a553f 100644
--- a/docs/source/en/model_doc/distilbert.md
+++ b/docs/source/en/model_doc/distilbert.md
@@ -32,7 +32,7 @@ rendered properly in your Markdown viewer.
The DistilBERT model was proposed in the blog post [Smaller, faster, cheaper, lighter: Introducing DistilBERT, a
distilled version of BERT](https://medium.com/huggingface/distilbert-8cf3380435b5), and the paper [DistilBERT, a
-distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/papers/1910.01108). DistilBERT is a
+distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108). DistilBERT is a
small, fast, cheap and light Transformer model trained by distilling BERT base. It has 40% less parameters than
*bert-base-uncased*, runs 60% faster while preserving over 95% of BERT's performances as measured on the GLUE language
understanding benchmark.
@@ -51,7 +51,10 @@ distillation and cosine-distance losses. Our smaller, faster and lighter model i
demonstrate its capabilities for on-device computations in a proof-of-concept experiment and a comparative on-device
study.*
-Tips:
+This model was contributed by [victorsanh](https://huggingface.co/victorsanh). This model jax version was
+contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation).
+
+## Usage tips
- DistilBERT doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. Just
separate your segments with the separation token `tokenizer.sep_token` (or `[SEP]`).
@@ -63,8 +66,6 @@ Tips:
* predicting the masked tokens correctly (but no next-sentence objective)
* a cosine similarity between the hidden states of the student and the teacher model
-This model was contributed by [victorsanh](https://huggingface.co/victorsanh). This model jax version was
-contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation).
## Resources
@@ -132,6 +133,37 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
- A blog post on how to [deploy DistilBERT with Amazon SageMaker](https://huggingface.co/blog/deploy-hugging-face-models-easily-with-amazon-sagemaker).
- A blog post on how to [Deploy BERT with Hugging Face Transformers, Amazon SageMaker and Terraform module](https://www.philschmid.de/terraform-huggingface-amazon-sagemaker).
+
+## Combining DistilBERT and Flash Attention 2
+
+First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16`)
+
+To load and run a model using Flash Attention 2, refer to the snippet below:
+
+```python
+>>> import torch
+>>> from transformers import AutoTokenizer, AutoModel
+
+>>> device = "cuda" # the device to load the model onto
+
+>>> tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
+>>> model = AutoModel.from_pretrained("distilbert-base-uncased", torch_dtype=torch.float16, use_flash_attention_2=True)
+
+>>> text = "Replace me by any text you'd like."
+
+>>> encoded_input = tokenizer(text, return_tensors='pt').to(device)
+>>> model.to(device)
+
+>>> output = model(**encoded_input)
+```
+
+
## DistilBertConfig
[[autodoc]] DistilBertConfig
@@ -144,6 +176,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] DistilBertTokenizerFast
+
@@ -65,6 +54,17 @@ Taken from the original paper.
+
+- [`Dinov2ForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## Dinov2Config
diff --git a/docs/source/en/model_doc/distilbert.md b/docs/source/en/model_doc/distilbert.md
index 2e68119a20b2..233a182a553f 100644
--- a/docs/source/en/model_doc/distilbert.md
+++ b/docs/source/en/model_doc/distilbert.md
@@ -32,7 +32,7 @@ rendered properly in your Markdown viewer.
The DistilBERT model was proposed in the blog post [Smaller, faster, cheaper, lighter: Introducing DistilBERT, a
distilled version of BERT](https://medium.com/huggingface/distilbert-8cf3380435b5), and the paper [DistilBERT, a
-distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/papers/1910.01108). DistilBERT is a
+distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108). DistilBERT is a
small, fast, cheap and light Transformer model trained by distilling BERT base. It has 40% less parameters than
*bert-base-uncased*, runs 60% faster while preserving over 95% of BERT's performances as measured on the GLUE language
understanding benchmark.
@@ -51,7 +51,10 @@ distillation and cosine-distance losses. Our smaller, faster and lighter model i
demonstrate its capabilities for on-device computations in a proof-of-concept experiment and a comparative on-device
study.*
-Tips:
+This model was contributed by [victorsanh](https://huggingface.co/victorsanh). This model jax version was
+contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation).
+
+## Usage tips
- DistilBERT doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. Just
separate your segments with the separation token `tokenizer.sep_token` (or `[SEP]`).
@@ -63,8 +66,6 @@ Tips:
* predicting the masked tokens correctly (but no next-sentence objective)
* a cosine similarity between the hidden states of the student and the teacher model
-This model was contributed by [victorsanh](https://huggingface.co/victorsanh). This model jax version was
-contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation).
## Resources
@@ -132,6 +133,37 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
- A blog post on how to [deploy DistilBERT with Amazon SageMaker](https://huggingface.co/blog/deploy-hugging-face-models-easily-with-amazon-sagemaker).
- A blog post on how to [Deploy BERT with Hugging Face Transformers, Amazon SageMaker and Terraform module](https://www.philschmid.de/terraform-huggingface-amazon-sagemaker).
+
+## Combining DistilBERT and Flash Attention 2
+
+First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16`)
+
+To load and run a model using Flash Attention 2, refer to the snippet below:
+
+```python
+>>> import torch
+>>> from transformers import AutoTokenizer, AutoModel
+
+>>> device = "cuda" # the device to load the model onto
+
+>>> tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
+>>> model = AutoModel.from_pretrained("distilbert-base-uncased", torch_dtype=torch.float16, use_flash_attention_2=True)
+
+>>> text = "Replace me by any text you'd like."
+
+>>> encoded_input = tokenizer(text, return_tensors='pt').to(device)
+>>> model.to(device)
+
+>>> output = model(**encoded_input)
+```
+
+
## DistilBertConfig
[[autodoc]] DistilBertConfig
@@ -144,6 +176,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] DistilBertTokenizerFast
+ @@ -40,6 +35,10 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/microsoft/GenerativeImage2Text).
+## Usage tips
+
+- GIT is implemented in a very similar way to GPT-2, the only difference being that the model is also conditioned on `pixel_values`.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GIT.
diff --git a/docs/source/en/model_doc/glpn.md b/docs/source/en/model_doc/glpn.md
index be9a7d2d7910..b57d1a7ccdda 100644
--- a/docs/source/en/model_doc/glpn.md
+++ b/docs/source/en/model_doc/glpn.md
@@ -33,10 +33,6 @@ The abstract from the paper is the following:
*Depth estimation from a single image is an important task that can be applied to various fields in computer vision, and has grown rapidly with the development of convolutional neural networks. In this paper, we propose a novel structure and training strategy for monocular depth estimation to further improve the prediction accuracy of the network. We deploy a hierarchical transformer encoder to capture and convey the global context, and design a lightweight yet powerful decoder to generate an estimated depth map while considering local connectivity. By constructing connected paths between multi-scale local features and the global decoding stream with our proposed selective feature fusion module, the network can integrate both representations and recover fine details. In addition, the proposed decoder shows better performance than the previously proposed decoders, with considerably less computational complexity. Furthermore, we improve the depth-specific augmentation method by utilizing an important observation in depth estimation to enhance the model. Our network achieves state-of-the-art performance over the challenging depth dataset NYU Depth V2. Extensive experiments have been conducted to validate and show the effectiveness of the proposed approach. Finally, our model shows better generalisation ability and robustness than other comparative models.*
-Tips:
-
-- One can use [`GLPNImageProcessor`] to prepare images for the model.
-
@@ -40,6 +35,10 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/microsoft/GenerativeImage2Text).
+## Usage tips
+
+- GIT is implemented in a very similar way to GPT-2, the only difference being that the model is also conditioned on `pixel_values`.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GIT.
diff --git a/docs/source/en/model_doc/glpn.md b/docs/source/en/model_doc/glpn.md
index be9a7d2d7910..b57d1a7ccdda 100644
--- a/docs/source/en/model_doc/glpn.md
+++ b/docs/source/en/model_doc/glpn.md
@@ -33,10 +33,6 @@ The abstract from the paper is the following:
*Depth estimation from a single image is an important task that can be applied to various fields in computer vision, and has grown rapidly with the development of convolutional neural networks. In this paper, we propose a novel structure and training strategy for monocular depth estimation to further improve the prediction accuracy of the network. We deploy a hierarchical transformer encoder to capture and convey the global context, and design a lightweight yet powerful decoder to generate an estimated depth map while considering local connectivity. By constructing connected paths between multi-scale local features and the global decoding stream with our proposed selective feature fusion module, the network can integrate both representations and recover fine details. In addition, the proposed decoder shows better performance than the previously proposed decoders, with considerably less computational complexity. Furthermore, we improve the depth-specific augmentation method by utilizing an important observation in depth estimation to enhance the model. Our network achieves state-of-the-art performance over the challenging depth dataset NYU Depth V2. Extensive experiments have been conducted to validate and show the effectiveness of the proposed approach. Finally, our model shows better generalisation ability and robustness than other comparative models.*
-Tips:
-
-- One can use [`GLPNImageProcessor`] to prepare images for the model.
-
 diff --git a/docs/source/en/model_doc/gpt-sw3.md b/docs/source/en/model_doc/gpt-sw3.md
index 286cac12c998..f4d34a07212c 100644
--- a/docs/source/en/model_doc/gpt-sw3.md
+++ b/docs/source/en/model_doc/gpt-sw3.md
@@ -32,12 +32,8 @@ causal language modeling (CLM) objective utilizing the NeMo Megatron GPT impleme
This model was contributed by [AI Sweden](https://huggingface.co/AI-Sweden).
-The implementation uses the [GPT2Model](https://huggingface.co/docs/transformers/model_doc/gpt2) coupled
-with our `GPTSw3Tokenizer`. This means that `AutoTokenizer` and `AutoModelForCausalLM` map to our tokenizer
-implementation and the corresponding GPT2 model implementation respectively.
-*Note that sentencepiece is required to use our tokenizer and can be installed with:* `pip install transformers[sentencepiece]` or `pip install sentencepiece`
+## Usage example
-Example usage:
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
@@ -52,12 +48,21 @@ Example usage:
Träd är fina för att de är färgstarka. Men ibland är det fint
```
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
+
diff --git a/docs/source/en/model_doc/gpt-sw3.md b/docs/source/en/model_doc/gpt-sw3.md
index 286cac12c998..f4d34a07212c 100644
--- a/docs/source/en/model_doc/gpt-sw3.md
+++ b/docs/source/en/model_doc/gpt-sw3.md
@@ -32,12 +32,8 @@ causal language modeling (CLM) objective utilizing the NeMo Megatron GPT impleme
This model was contributed by [AI Sweden](https://huggingface.co/AI-Sweden).
-The implementation uses the [GPT2Model](https://huggingface.co/docs/transformers/model_doc/gpt2) coupled
-with our `GPTSw3Tokenizer`. This means that `AutoTokenizer` and `AutoModelForCausalLM` map to our tokenizer
-implementation and the corresponding GPT2 model implementation respectively.
-*Note that sentencepiece is required to use our tokenizer and can be installed with:* `pip install transformers[sentencepiece]` or `pip install sentencepiece`
+## Usage example
-Example usage:
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
@@ -52,12 +48,21 @@ Example usage:
Träd är fina för att de är färgstarka. Men ibland är det fint
```
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
+ +
+ +
+ @@ -33,6 +29,9 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/salesforce/LAVIS/tree/main/projects/instructblip).
+## Usage tips
+
+InstructBLIP uses the same architecture as [BLIP-2](blip2) with a tiny but important difference: it also feeds the text prompt (instruction) to the Q-Former.
## InstructBlipConfig
diff --git a/docs/source/en/model_doc/jukebox.md b/docs/source/en/model_doc/jukebox.md
index 24a80164a2d8..a6d865d86cce 100644
--- a/docs/source/en/model_doc/jukebox.md
+++ b/docs/source/en/model_doc/jukebox.md
@@ -32,7 +32,11 @@ The metadata such as *artist, genre and timing* are passed to each prior, in the

-Tips:
+This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ).
+The original code can be found [here](https://github.com/openai/jukebox).
+
+## Usage tips
+
- This model only supports inference. This is for a few reasons, mostly because it requires a crazy amount of memory to train. Feel free to open a PR and add what's missing to have a full integration with the hugging face traineer!
- This model is very slow, and takes 8h to generate a minute long audio using the 5b top prior on a V100 GPU. In order automaticallay handle the device on which the model should execute, use `accelerate`.
- Contrary to the paper, the order of the priors goes from `0` to `1` as it felt more intuitive : we sample starting from `0`.
@@ -67,14 +71,12 @@ The original code can be found [here](https://github.com/openai/jukebox).
- upsample
- _sample
-
## JukeboxPrior
[[autodoc]] JukeboxPrior
- sample
- forward
-
## JukeboxVQVAE
[[autodoc]] JukeboxVQVAE
diff --git a/docs/source/en/model_doc/kosmos-2.md b/docs/source/en/model_doc/kosmos-2.md
new file mode 100644
index 000000000000..f799751cce84
--- /dev/null
+++ b/docs/source/en/model_doc/kosmos-2.md
@@ -0,0 +1,98 @@
+
+
+# KOSMOS-2
+
+## Overview
+
+The KOSMOS-2 model was proposed in [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
+
+KOSMOS-2 is a Transformer-based causal language model and is trained using the next-word prediction task on a web-scale
+dataset of grounded image-text pairs [GRIT](https://huggingface.co/datasets/zzliang/GRIT). The spatial coordinates of
+the bounding boxes in the dataset are converted to a sequence of location tokens, which are appended to their respective
+entity text spans (for example, `a snowman` followed by `
@@ -33,6 +29,9 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/salesforce/LAVIS/tree/main/projects/instructblip).
+## Usage tips
+
+InstructBLIP uses the same architecture as [BLIP-2](blip2) with a tiny but important difference: it also feeds the text prompt (instruction) to the Q-Former.
## InstructBlipConfig
diff --git a/docs/source/en/model_doc/jukebox.md b/docs/source/en/model_doc/jukebox.md
index 24a80164a2d8..a6d865d86cce 100644
--- a/docs/source/en/model_doc/jukebox.md
+++ b/docs/source/en/model_doc/jukebox.md
@@ -32,7 +32,11 @@ The metadata such as *artist, genre and timing* are passed to each prior, in the

-Tips:
+This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ).
+The original code can be found [here](https://github.com/openai/jukebox).
+
+## Usage tips
+
- This model only supports inference. This is for a few reasons, mostly because it requires a crazy amount of memory to train. Feel free to open a PR and add what's missing to have a full integration with the hugging face traineer!
- This model is very slow, and takes 8h to generate a minute long audio using the 5b top prior on a V100 GPU. In order automaticallay handle the device on which the model should execute, use `accelerate`.
- Contrary to the paper, the order of the priors goes from `0` to `1` as it felt more intuitive : we sample starting from `0`.
@@ -67,14 +71,12 @@ The original code can be found [here](https://github.com/openai/jukebox).
- upsample
- _sample
-
## JukeboxPrior
[[autodoc]] JukeboxPrior
- sample
- forward
-
## JukeboxVQVAE
[[autodoc]] JukeboxVQVAE
diff --git a/docs/source/en/model_doc/kosmos-2.md b/docs/source/en/model_doc/kosmos-2.md
new file mode 100644
index 000000000000..f799751cce84
--- /dev/null
+++ b/docs/source/en/model_doc/kosmos-2.md
@@ -0,0 +1,98 @@
+
+
+# KOSMOS-2
+
+## Overview
+
+The KOSMOS-2 model was proposed in [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
+
+KOSMOS-2 is a Transformer-based causal language model and is trained using the next-word prediction task on a web-scale
+dataset of grounded image-text pairs [GRIT](https://huggingface.co/datasets/zzliang/GRIT). The spatial coordinates of
+the bounding boxes in the dataset are converted to a sequence of location tokens, which are appended to their respective
+entity text spans (for example, `a snowman` followed by ` +
+ Overview of tasks that KOSMOS-2 can handle. Taken from the original paper.
+
+## Example
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, Kosmos2ForConditionalGeneration
+
+>>> model = Kosmos2ForConditionalGeneration.from_pretrained("microsoft/kosmos-2-patch14-224")
+>>> processor = AutoProcessor.from_pretrained("microsoft/kosmos-2-patch14-224")
+
+>>> url = "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> prompt = "
+
+ Overview of tasks that KOSMOS-2 can handle. Taken from the original paper.
+
+## Example
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, Kosmos2ForConditionalGeneration
+
+>>> model = Kosmos2ForConditionalGeneration.from_pretrained("microsoft/kosmos-2-patch14-224")
+>>> processor = AutoProcessor.from_pretrained("microsoft/kosmos-2-patch14-224")
+
+>>> url = "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> prompt = " @@ -43,6 +33,14 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version of this model was added by [chriskoo](https://huggingface.co/chriskoo), [tokec](https://huggingface.co/tokec), and [lre](https://huggingface.co/lre). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/layoutlmv3).
+## Usage tips
+
+- In terms of data processing, LayoutLMv3 is identical to its predecessor [LayoutLMv2](layoutlmv2), except that:
+ - images need to be resized and normalized with channels in regular RGB format. LayoutLMv2 on the other hand normalizes the images internally and expects the channels in BGR format.
+ - text is tokenized using byte-pair encoding (BPE), as opposed to WordPiece.
+ Due to these differences in data preprocessing, one can use [`LayoutLMv3Processor`] which internally combines a [`LayoutLMv3ImageProcessor`] (for the image modality) and a [`LayoutLMv3Tokenizer`]/[`LayoutLMv3TokenizerFast`] (for the text modality) to prepare all data for the model.
+- Regarding usage of [`LayoutLMv3Processor`], we refer to the [usage guide](layoutlmv2#usage-layoutlmv2processor) of its predecessor.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LayoutLMv3. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
@@ -53,6 +51,9 @@ LayoutLMv3 is nearly identical to LayoutLMv2, so we've also included LayoutLMv2
@@ -43,6 +33,14 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version of this model was added by [chriskoo](https://huggingface.co/chriskoo), [tokec](https://huggingface.co/tokec), and [lre](https://huggingface.co/lre). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/layoutlmv3).
+## Usage tips
+
+- In terms of data processing, LayoutLMv3 is identical to its predecessor [LayoutLMv2](layoutlmv2), except that:
+ - images need to be resized and normalized with channels in regular RGB format. LayoutLMv2 on the other hand normalizes the images internally and expects the channels in BGR format.
+ - text is tokenized using byte-pair encoding (BPE), as opposed to WordPiece.
+ Due to these differences in data preprocessing, one can use [`LayoutLMv3Processor`] which internally combines a [`LayoutLMv3ImageProcessor`] (for the image modality) and a [`LayoutLMv3Tokenizer`]/[`LayoutLMv3TokenizerFast`] (for the text modality) to prepare all data for the model.
+- Regarding usage of [`LayoutLMv3Processor`], we refer to the [usage guide](layoutlmv2#usage-layoutlmv2processor) of its predecessor.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LayoutLMv3. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
@@ -53,6 +51,9 @@ LayoutLMv3 is nearly identical to LayoutLMv2, so we've also included LayoutLMv2
 +
+ LiLT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/jpwang/lilt).
+
+## Usage tips
- To combine the Language-Independent Layout Transformer with a new RoBERTa checkpoint from the [hub](https://huggingface.co/models?search=roberta), refer to [this guide](https://github.com/jpWang/LiLT#or-generate-your-own-checkpoint-optional).
The script will result in `config.json` and `pytorch_model.bin` files being stored locally. After doing this, one can do the following (assuming you're logged in with your HuggingFace account):
@@ -42,14 +50,6 @@ model.push_to_hub("name_of_repo_on_the_hub")
- As [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base) uses the same vocabulary as [LayoutLMv3](layoutlmv3), one can use [`LayoutLMv3TokenizerFast`] to prepare data for the model.
The same is true for [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-infoxlm-base): one can use [`LayoutXLMTokenizerFast`] for that model.
-
+
+ LiLT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/jpwang/lilt).
+
+## Usage tips
- To combine the Language-Independent Layout Transformer with a new RoBERTa checkpoint from the [hub](https://huggingface.co/models?search=roberta), refer to [this guide](https://github.com/jpWang/LiLT#or-generate-your-own-checkpoint-optional).
The script will result in `config.json` and `pytorch_model.bin` files being stored locally. After doing this, one can do the following (assuming you're logged in with your HuggingFace account):
@@ -42,14 +50,6 @@ model.push_to_hub("name_of_repo_on_the_hub")
- As [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base) uses the same vocabulary as [LayoutLMv3](layoutlmv3), one can use [`LayoutLMv3TokenizerFast`] to prepare data for the model.
The same is true for [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-infoxlm-base): one can use [`LayoutXLMTokenizerFast`] for that model.
- MarkupLM architecture. Taken from the original paper.
-This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/markuplm).
-
## Usage: MarkupLMProcessor
The easiest way to prepare data for the model is to use [`MarkupLMProcessor`], which internally combines a feature extractor
@@ -197,8 +197,9 @@ all nodes and xpaths yourself, you can provide them directly to the processor. M
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])
```
-## Documentation resources
+## Resources
+- [Demo notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/MarkupLM)
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
diff --git a/docs/source/en/model_doc/mask2former.md b/docs/source/en/model_doc/mask2former.md
index ddfa5da2ba2c..bd5ab80728eb 100644
--- a/docs/source/en/model_doc/mask2former.md
+++ b/docs/source/en/model_doc/mask2former.md
@@ -25,16 +25,17 @@ The abstract from the paper is the following:
*Image segmentation groups pixels with different semantics, e.g., category or instance membership. Each choice
of semantics defines a task. While only the semantics of each task differ, current research focuses on designing specialized architectures for each task. We present Masked-attention Mask Transformer (Mask2Former), a new architecture capable of addressing any image segmentation task (panoptic, instance or semantic). Its key components include masked attention, which extracts localized features by constraining cross-attention within predicted mask regions. In addition to reducing the research effort by at least three times, it outperforms the best specialized architectures by a significant margin on four popular datasets. Most notably, Mask2Former sets a new state-of-the-art for panoptic segmentation (57.8 PQ on COCO), instance segmentation (50.1 AP on COCO) and semantic segmentation (57.7 mIoU on ADE20K).*
-Tips:
-- Mask2Former uses the same preprocessing and postprocessing steps as [MaskFormer](maskformer). Use [`Mask2FormerImageProcessor`] or [`AutoImageProcessor`] to prepare images and optional targets for the model.
-- To get the final segmentation, depending on the task, you can call [`~Mask2FormerImageProcessor.post_process_semantic_segmentation`] or [`~Mask2FormerImageProcessor.post_process_instance_segmentation`] or [`~Mask2FormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`Mask2FormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
-
MarkupLM architecture. Taken from the original paper.
-This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/markuplm).
-
## Usage: MarkupLMProcessor
The easiest way to prepare data for the model is to use [`MarkupLMProcessor`], which internally combines a feature extractor
@@ -197,8 +197,9 @@ all nodes and xpaths yourself, you can provide them directly to the processor. M
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])
```
-## Documentation resources
+## Resources
+- [Demo notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/MarkupLM)
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
diff --git a/docs/source/en/model_doc/mask2former.md b/docs/source/en/model_doc/mask2former.md
index ddfa5da2ba2c..bd5ab80728eb 100644
--- a/docs/source/en/model_doc/mask2former.md
+++ b/docs/source/en/model_doc/mask2former.md
@@ -25,16 +25,17 @@ The abstract from the paper is the following:
*Image segmentation groups pixels with different semantics, e.g., category or instance membership. Each choice
of semantics defines a task. While only the semantics of each task differ, current research focuses on designing specialized architectures for each task. We present Masked-attention Mask Transformer (Mask2Former), a new architecture capable of addressing any image segmentation task (panoptic, instance or semantic). Its key components include masked attention, which extracts localized features by constraining cross-attention within predicted mask regions. In addition to reducing the research effort by at least three times, it outperforms the best specialized architectures by a significant margin on four popular datasets. Most notably, Mask2Former sets a new state-of-the-art for panoptic segmentation (57.8 PQ on COCO), instance segmentation (50.1 AP on COCO) and semantic segmentation (57.7 mIoU on ADE20K).*
-Tips:
-- Mask2Former uses the same preprocessing and postprocessing steps as [MaskFormer](maskformer). Use [`Mask2FormerImageProcessor`] or [`AutoImageProcessor`] to prepare images and optional targets for the model.
-- To get the final segmentation, depending on the task, you can call [`~Mask2FormerImageProcessor.post_process_semantic_segmentation`] or [`~Mask2FormerImageProcessor.post_process_instance_segmentation`] or [`~Mask2FormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`Mask2FormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
-
 Mask2Former architecture. Taken from the original paper.
This model was contributed by [Shivalika Singh](https://huggingface.co/shivi) and [Alara Dirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/facebookresearch/Mask2Former).
+## Usage tips
+
+- Mask2Former uses the same preprocessing and postprocessing steps as [MaskFormer](maskformer). Use [`Mask2FormerImageProcessor`] or [`AutoImageProcessor`] to prepare images and optional targets for the model.
+- To get the final segmentation, depending on the task, you can call [`~Mask2FormerImageProcessor.post_process_semantic_segmentation`] or [`~Mask2FormerImageProcessor.post_process_instance_segmentation`] or [`~Mask2FormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`Mask2FormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Mask2Former.
@@ -44,16 +45,16 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
The resource should ideally demonstrate something new instead of duplicating an existing resource.
+## Mask2FormerConfig
+
+[[autodoc]] Mask2FormerConfig
+
## MaskFormer specific outputs
[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerModelOutput
[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerForUniversalSegmentationOutput
-## Mask2FormerConfig
-
-[[autodoc]] Mask2FormerConfig
-
## Mask2FormerModel
[[autodoc]] Mask2FormerModel
diff --git a/docs/source/en/model_doc/maskformer.md b/docs/source/en/model_doc/maskformer.md
index 4695e54857f7..5566dec58593 100644
--- a/docs/source/en/model_doc/maskformer.md
+++ b/docs/source/en/model_doc/maskformer.md
@@ -31,7 +31,14 @@ The abstract from the paper is the following:
*Modern approaches typically formulate semantic segmentation as a per-pixel classification task, while instance-level segmentation is handled with an alternative mask classification. Our key insight: mask classification is sufficiently general to solve both semantic- and instance-level segmentation tasks in a unified manner using the exact same model, loss, and training procedure. Following this observation, we propose MaskFormer, a simple mask classification model which predicts a set of binary masks, each associated with a single global class label prediction. Overall, the proposed mask classification-based method simplifies the landscape of effective approaches to semantic and panoptic segmentation tasks and shows excellent empirical results. In particular, we observe that MaskFormer outperforms per-pixel classification baselines when the number of classes is large. Our mask classification-based method outperforms both current state-of-the-art semantic (55.6 mIoU on ADE20K) and panoptic segmentation (52.7 PQ on COCO) models.*
-Tips:
+The figure below illustrates the architecture of MaskFormer. Taken from the [original paper](https://arxiv.org/abs/2107.06278).
+
+
Mask2Former architecture. Taken from the original paper.
This model was contributed by [Shivalika Singh](https://huggingface.co/shivi) and [Alara Dirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/facebookresearch/Mask2Former).
+## Usage tips
+
+- Mask2Former uses the same preprocessing and postprocessing steps as [MaskFormer](maskformer). Use [`Mask2FormerImageProcessor`] or [`AutoImageProcessor`] to prepare images and optional targets for the model.
+- To get the final segmentation, depending on the task, you can call [`~Mask2FormerImageProcessor.post_process_semantic_segmentation`] or [`~Mask2FormerImageProcessor.post_process_instance_segmentation`] or [`~Mask2FormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`Mask2FormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Mask2Former.
@@ -44,16 +45,16 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
The resource should ideally demonstrate something new instead of duplicating an existing resource.
+## Mask2FormerConfig
+
+[[autodoc]] Mask2FormerConfig
+
## MaskFormer specific outputs
[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerModelOutput
[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerForUniversalSegmentationOutput
-## Mask2FormerConfig
-
-[[autodoc]] Mask2FormerConfig
-
## Mask2FormerModel
[[autodoc]] Mask2FormerModel
diff --git a/docs/source/en/model_doc/maskformer.md b/docs/source/en/model_doc/maskformer.md
index 4695e54857f7..5566dec58593 100644
--- a/docs/source/en/model_doc/maskformer.md
+++ b/docs/source/en/model_doc/maskformer.md
@@ -31,7 +31,14 @@ The abstract from the paper is the following:
*Modern approaches typically formulate semantic segmentation as a per-pixel classification task, while instance-level segmentation is handled with an alternative mask classification. Our key insight: mask classification is sufficiently general to solve both semantic- and instance-level segmentation tasks in a unified manner using the exact same model, loss, and training procedure. Following this observation, we propose MaskFormer, a simple mask classification model which predicts a set of binary masks, each associated with a single global class label prediction. Overall, the proposed mask classification-based method simplifies the landscape of effective approaches to semantic and panoptic segmentation tasks and shows excellent empirical results. In particular, we observe that MaskFormer outperforms per-pixel classification baselines when the number of classes is large. Our mask classification-based method outperforms both current state-of-the-art semantic (55.6 mIoU on ADE20K) and panoptic segmentation (52.7 PQ on COCO) models.*
-Tips:
+The figure below illustrates the architecture of MaskFormer. Taken from the [original paper](https://arxiv.org/abs/2107.06278).
+
+ +
+This model was contributed by [francesco](https://huggingface.co/francesco). The original code can be found [here](https://github.com/facebookresearch/MaskFormer).
+
+## Usage tips
+
- MaskFormer's Transformer decoder is identical to the decoder of [DETR](detr). During training, the authors of DETR did find it helpful to use auxiliary losses in the decoder, especially to help the model output the correct number of objects of each class. If you set the parameter `use_auxilary_loss` of [`MaskFormerConfig`] to `True`, then prediction feedforward neural networks and Hungarian losses are added after each decoder layer (with the FFNs sharing parameters).
- If you want to train the model in a distributed environment across multiple nodes, then one should update the
`get_num_masks` function inside in the `MaskFormerLoss` class of `modeling_maskformer.py`. When training on multiple nodes, this should be
@@ -39,12 +46,6 @@ Tips:
- One can use [`MaskFormerImageProcessor`] to prepare images for the model and optional targets for the model.
- To get the final segmentation, depending on the task, you can call [`~MaskFormerImageProcessor.post_process_semantic_segmentation`] or [`~MaskFormerImageProcessor.post_process_panoptic_segmentation`]. Both tasks can be solved using [`MaskFormerForInstanceSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
-The figure below illustrates the architecture of MaskFormer. Taken from the [original paper](https://arxiv.org/abs/2107.06278).
-
-
+
+This model was contributed by [francesco](https://huggingface.co/francesco). The original code can be found [here](https://github.com/facebookresearch/MaskFormer).
+
+## Usage tips
+
- MaskFormer's Transformer decoder is identical to the decoder of [DETR](detr). During training, the authors of DETR did find it helpful to use auxiliary losses in the decoder, especially to help the model output the correct number of objects of each class. If you set the parameter `use_auxilary_loss` of [`MaskFormerConfig`] to `True`, then prediction feedforward neural networks and Hungarian losses are added after each decoder layer (with the FFNs sharing parameters).
- If you want to train the model in a distributed environment across multiple nodes, then one should update the
`get_num_masks` function inside in the `MaskFormerLoss` class of `modeling_maskformer.py`. When training on multiple nodes, this should be
@@ -39,12 +46,6 @@ Tips:
- One can use [`MaskFormerImageProcessor`] to prepare images for the model and optional targets for the model.
- To get the final segmentation, depending on the task, you can call [`~MaskFormerImageProcessor.post_process_semantic_segmentation`] or [`~MaskFormerImageProcessor.post_process_panoptic_segmentation`]. Both tasks can be solved using [`MaskFormerForInstanceSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
-The figure below illustrates the architecture of MaskFormer. Taken from the [original paper](https://arxiv.org/abs/2107.06278).
-
- +
+This model was contributed by [Jitesh Jain](https://huggingface.co/praeclarumjj3). The original code can be found [here](https://github.com/SHI-Labs/OneFormer).
+
+## Usage tips
+
- OneFormer requires two inputs during inference: *image* and *task token*.
- During training, OneFormer only uses panoptic annotations.
- If you want to train the model in a distributed environment across multiple nodes, then one should update the
@@ -35,12 +42,6 @@ Tips:
- One can use [`OneFormerProcessor`] to prepare input images and task inputs for the model and optional targets for the model. [`OneformerProcessor`] wraps [`OneFormerImageProcessor`] and [`CLIPTokenizer`] into a single instance to both prepare the images and encode the task inputs.
- To get the final segmentation, depending on the task, you can call [`~OneFormerProcessor.post_process_semantic_segmentation`] or [`~OneFormerImageProcessor.post_process_instance_segmentation`] or [`~OneFormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`OneFormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
-The figure below illustrates the architecture of OneFormer. Taken from the [original paper](https://arxiv.org/abs/2211.06220).
-
-
+
+This model was contributed by [Jitesh Jain](https://huggingface.co/praeclarumjj3). The original code can be found [here](https://github.com/SHI-Labs/OneFormer).
+
+## Usage tips
+
- OneFormer requires two inputs during inference: *image* and *task token*.
- During training, OneFormer only uses panoptic annotations.
- If you want to train the model in a distributed environment across multiple nodes, then one should update the
@@ -35,12 +42,6 @@ Tips:
- One can use [`OneFormerProcessor`] to prepare input images and task inputs for the model and optional targets for the model. [`OneformerProcessor`] wraps [`OneFormerImageProcessor`] and [`CLIPTokenizer`] into a single instance to both prepare the images and encode the task inputs.
- To get the final segmentation, depending on the task, you can call [`~OneFormerProcessor.post_process_semantic_segmentation`] or [`~OneFormerImageProcessor.post_process_instance_segmentation`] or [`~OneFormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`OneFormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
-The figure below illustrates the architecture of OneFormer. Taken from the [original paper](https://arxiv.org/abs/2211.06220).
-
- +
+ +
+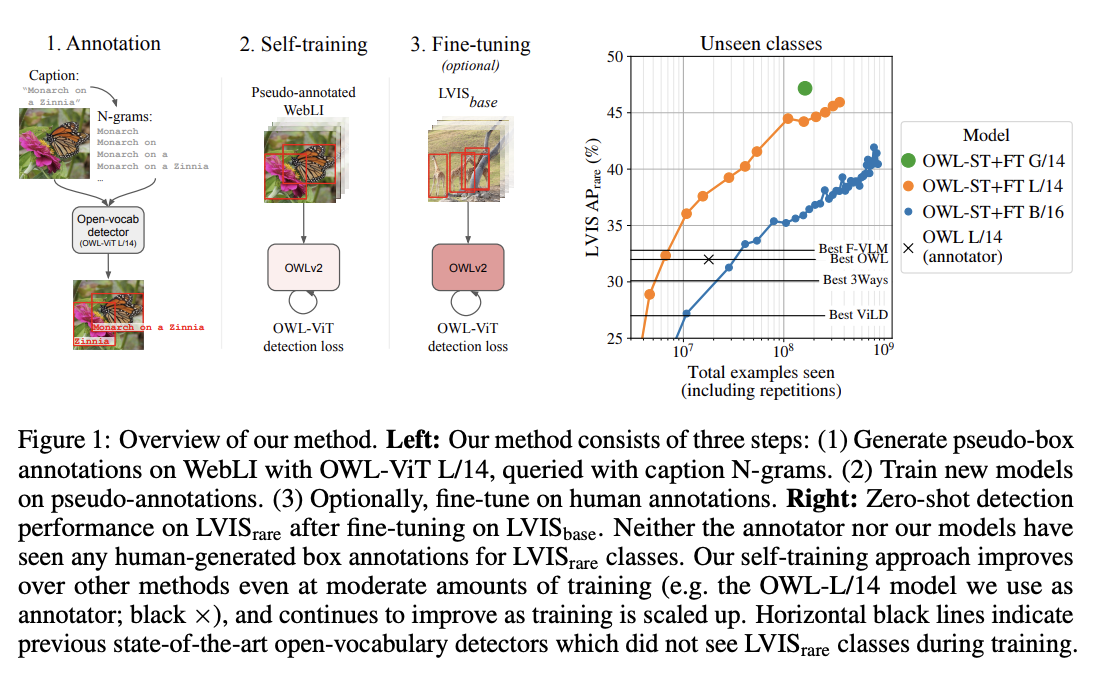 @@ -37,13 +32,12 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
-## Usage
+## Usage example
OWLv2 is, just like its predecessor [OWL-ViT](owlvit), a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
[`Owlv2ImageProcessor`] can be used to resize (or rescale) and normalize images for the model and [`CLIPTokenizer`] is used to encode the text. [`Owlv2Processor`] wraps [`Owlv2ImageProcessor`] and [`CLIPTokenizer`] into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using [`Owlv2Processor`] and [`Owlv2ForObjectDetection`].
-
```python
>>> import requests
>>> from PIL import Image
@@ -76,7 +70,15 @@ Detected a photo of a cat with confidence 0.665 at location [6.75, 38.97, 326.62
## Resources
-A demo notebook on using OWLv2 for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OWLv2).
+- A demo notebook on using OWLv2 for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OWLv2).
+- [Zero-shot object detection task guide](../tasks/zero_shot_object_detection)
+
+
@@ -37,13 +32,12 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
-## Usage
+## Usage example
OWLv2 is, just like its predecessor [OWL-ViT](owlvit), a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
[`Owlv2ImageProcessor`] can be used to resize (or rescale) and normalize images for the model and [`CLIPTokenizer`] is used to encode the text. [`Owlv2Processor`] wraps [`Owlv2ImageProcessor`] and [`CLIPTokenizer`] into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using [`Owlv2Processor`] and [`Owlv2ForObjectDetection`].
-
```python
>>> import requests
>>> from PIL import Image
@@ -76,7 +70,15 @@ Detected a photo of a cat with confidence 0.665 at location [6.75, 38.97, 326.62
## Resources
-A demo notebook on using OWLv2 for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OWLv2).
+- A demo notebook on using OWLv2 for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OWLv2).
+- [Zero-shot object detection task guide](../tasks/zero_shot_object_detection)
+
+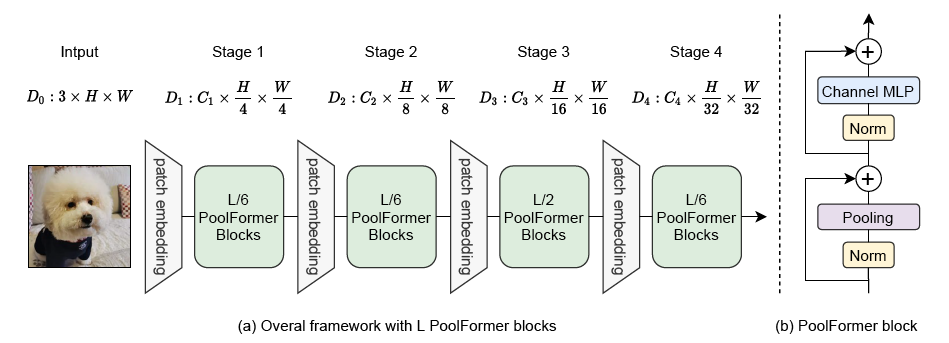 +This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
-Tips:
+## Usage tips
- PoolFormer has a hierarchical architecture, where instead of Attention, a simple Average Pooling layer is present. All checkpoints of the model can be found on the [hub](https://huggingface.co/models?other=poolformer).
- One can use [`PoolFormerImageProcessor`] to prepare images for the model.
@@ -43,8 +44,6 @@ Tips:
| m36 | [6, 6, 18, 6] | [96, 192, 384, 768] | 56 | 82.1 |
| m48 | [8, 8, 24, 8] | [96, 192, 384, 768] | 73 | 82.5 |
-This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with PoolFormer.
diff --git a/docs/source/en/model_doc/pop2piano.md b/docs/source/en/model_doc/pop2piano.md
index 95fd83f19237..8e52eda70cc0 100644
--- a/docs/source/en/model_doc/pop2piano.md
+++ b/docs/source/en/model_doc/pop2piano.md
@@ -32,7 +32,6 @@ is transformed to its waveform and passed to the encoder, which transforms it to
uses these latent representations to generate token ids in an autoregressive way. Each token id corresponds to one of four
different token types: time, velocity, note and 'special'. The token ids are then decoded to their equivalent MIDI file.
-
The abstract from the paper is the following:
*Piano covers of pop music are enjoyed by many people. However, the
@@ -49,22 +48,21 @@ directly from pop audio without using melody and chord extraction
modules. We show that Pop2Piano, trained with our dataset, is capable
of producing plausible piano covers.*
+This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
+The original code can be found [here](https://github.com/sweetcocoa/pop2piano).
-Tips:
+## Usage tips
-1. To use Pop2Piano, you will need to install the 🤗 Transformers library, as well as the following third party modules:
+* To use Pop2Piano, you will need to install the 🤗 Transformers library, as well as the following third party modules:
```
pip install pretty-midi==0.2.9 essentia==2.1b6.dev1034 librosa scipy
```
Please note that you may need to restart your runtime after installation.
-2. Pop2Piano is an Encoder-Decoder based model like T5.
-3. Pop2Piano can be used to generate midi-audio files for a given audio sequence.
-4. Choosing different composers in `Pop2PianoForConditionalGeneration.generate()` can lead to variety of different results.
-5. Setting the sampling rate to 44.1 kHz when loading the audio file can give good performance.
-6. Though Pop2Piano was mainly trained on Korean Pop music, it also does pretty well on other Western Pop or Hip Hop songs.
-
-This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
-The original code can be found [here](https://github.com/sweetcocoa/pop2piano).
+* Pop2Piano is an Encoder-Decoder based model like T5.
+* Pop2Piano can be used to generate midi-audio files for a given audio sequence.
+* Choosing different composers in `Pop2PianoForConditionalGeneration.generate()` can lead to variety of different results.
+* Setting the sampling rate to 44.1 kHz when loading the audio file can give good performance.
+* Though Pop2Piano was mainly trained on Korean Pop music, it also does pretty well on other Western Pop or Hip Hop songs.
## Examples
diff --git a/docs/source/en/model_doc/prophetnet.md b/docs/source/en/model_doc/prophetnet.md
index 6ab0937da77e..7e63e0c0887e 100644
--- a/docs/source/en/model_doc/prophetnet.md
+++ b/docs/source/en/model_doc/prophetnet.md
@@ -25,10 +25,6 @@ rendered properly in your Markdown viewer.
-
-**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
-@patrickvonplaten
-
## Overview
The ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
@@ -49,15 +45,15 @@ dataset (160GB) respectively. Then we conduct experiments on CNN/DailyMail, Giga
abstractive summarization and question generation tasks. Experimental results show that ProphetNet achieves new
state-of-the-art results on all these datasets compared to the models using the same scale pretraining corpus.*
-Tips:
+The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
+
+## Usage tips
- ProphetNet is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
- The model architecture is based on the original Transformer, but replaces the “standard” self-attention mechanism in the decoder by a a main self-attention mechanism and a self and n-stream (predict) self-attention mechanism.
-The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
-
-## Documentation resources
+## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
diff --git a/docs/source/en/model_doc/qdqbert.md b/docs/source/en/model_doc/qdqbert.md
index 62a0e010843d..9ee42ff3b49d 100644
--- a/docs/source/en/model_doc/qdqbert.md
+++ b/docs/source/en/model_doc/qdqbert.md
@@ -32,22 +32,18 @@ by processors with high-throughput integer math pipelines. We also present a wor
able to maintain accuracy within 1% of the floating-point baseline on all networks studied, including models that are
more difficult to quantize, such as MobileNets and BERT-large.*
-Tips:
+This model was contributed by [shangz](https://huggingface.co/shangz).
+
+## Usage tips
- QDQBERT model adds fake quantization operations (pair of QuantizeLinear/DequantizeLinear ops) to (i) linear layer
inputs and weights, (ii) matmul inputs, (iii) residual add inputs, in BERT model.
-
- QDQBERT requires the dependency of [Pytorch Quantization Toolkit](https://github.com/NVIDIA/TensorRT/tree/master/tools/pytorch-quantization). To install `pip install pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com`
-
- QDQBERT model can be loaded from any checkpoint of HuggingFace BERT model (for example *bert-base-uncased*), and
perform Quantization Aware Training/Post Training Quantization.
-
- A complete example of using QDQBERT model to perform Quatization Aware Training and Post Training Quantization for
SQUAD task can be found at [transformers/examples/research_projects/quantization-qdqbert/](examples/research_projects/quantization-qdqbert/).
-This model was contributed by [shangz](https://huggingface.co/shangz).
-
-
### Set default quantizers
QDQBERT model adds fake quantization operations (pair of QuantizeLinear/DequantizeLinear ops) to BERT by
@@ -118,7 +114,7 @@ the instructions in [torch.onnx](https://pytorch.org/docs/stable/onnx.html). Exa
>>> torch.onnx.export(...)
```
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
diff --git a/docs/source/en/model_doc/rag.md b/docs/source/en/model_doc/rag.md
index b467c6169f66..1891efe74263 100644
--- a/docs/source/en/model_doc/rag.md
+++ b/docs/source/en/model_doc/rag.md
@@ -52,8 +52,12 @@ parametric-only seq2seq baseline.*
This model was contributed by [ola13](https://huggingface.co/ola13).
-Tips:
-- Retrieval-augmented generation (“RAG”) models combine the powers of pretrained dense retrieval (DPR) and Seq2Seq models. RAG models retrieve docs, pass them to a seq2seq model, then marginalize to generate outputs. The retriever and seq2seq modules are initialized from pretrained models, and fine-tuned jointly, allowing both retrieval and generation to adapt to downstream tasks.
+## Usage tips
+
+Retrieval-augmented generation ("RAG") models combine the powers of pretrained dense retrieval (DPR) and Seq2Seq models.
+RAG models retrieve docs, pass them to a seq2seq model, then marginalize to generate outputs. The retriever and seq2seq
+modules are initialized from pretrained models, and fine-tuned jointly, allowing both retrieval and generation to adapt
+to downstream tasks.
## RagConfig
@@ -73,6 +77,9 @@ Tips:
[[autodoc]] RagRetriever
+
+This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
-Tips:
+## Usage tips
- PoolFormer has a hierarchical architecture, where instead of Attention, a simple Average Pooling layer is present. All checkpoints of the model can be found on the [hub](https://huggingface.co/models?other=poolformer).
- One can use [`PoolFormerImageProcessor`] to prepare images for the model.
@@ -43,8 +44,6 @@ Tips:
| m36 | [6, 6, 18, 6] | [96, 192, 384, 768] | 56 | 82.1 |
| m48 | [8, 8, 24, 8] | [96, 192, 384, 768] | 73 | 82.5 |
-This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with PoolFormer.
diff --git a/docs/source/en/model_doc/pop2piano.md b/docs/source/en/model_doc/pop2piano.md
index 95fd83f19237..8e52eda70cc0 100644
--- a/docs/source/en/model_doc/pop2piano.md
+++ b/docs/source/en/model_doc/pop2piano.md
@@ -32,7 +32,6 @@ is transformed to its waveform and passed to the encoder, which transforms it to
uses these latent representations to generate token ids in an autoregressive way. Each token id corresponds to one of four
different token types: time, velocity, note and 'special'. The token ids are then decoded to their equivalent MIDI file.
-
The abstract from the paper is the following:
*Piano covers of pop music are enjoyed by many people. However, the
@@ -49,22 +48,21 @@ directly from pop audio without using melody and chord extraction
modules. We show that Pop2Piano, trained with our dataset, is capable
of producing plausible piano covers.*
+This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
+The original code can be found [here](https://github.com/sweetcocoa/pop2piano).
-Tips:
+## Usage tips
-1. To use Pop2Piano, you will need to install the 🤗 Transformers library, as well as the following third party modules:
+* To use Pop2Piano, you will need to install the 🤗 Transformers library, as well as the following third party modules:
```
pip install pretty-midi==0.2.9 essentia==2.1b6.dev1034 librosa scipy
```
Please note that you may need to restart your runtime after installation.
-2. Pop2Piano is an Encoder-Decoder based model like T5.
-3. Pop2Piano can be used to generate midi-audio files for a given audio sequence.
-4. Choosing different composers in `Pop2PianoForConditionalGeneration.generate()` can lead to variety of different results.
-5. Setting the sampling rate to 44.1 kHz when loading the audio file can give good performance.
-6. Though Pop2Piano was mainly trained on Korean Pop music, it also does pretty well on other Western Pop or Hip Hop songs.
-
-This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
-The original code can be found [here](https://github.com/sweetcocoa/pop2piano).
+* Pop2Piano is an Encoder-Decoder based model like T5.
+* Pop2Piano can be used to generate midi-audio files for a given audio sequence.
+* Choosing different composers in `Pop2PianoForConditionalGeneration.generate()` can lead to variety of different results.
+* Setting the sampling rate to 44.1 kHz when loading the audio file can give good performance.
+* Though Pop2Piano was mainly trained on Korean Pop music, it also does pretty well on other Western Pop or Hip Hop songs.
## Examples
diff --git a/docs/source/en/model_doc/prophetnet.md b/docs/source/en/model_doc/prophetnet.md
index 6ab0937da77e..7e63e0c0887e 100644
--- a/docs/source/en/model_doc/prophetnet.md
+++ b/docs/source/en/model_doc/prophetnet.md
@@ -25,10 +25,6 @@ rendered properly in your Markdown viewer.
-
-**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
-@patrickvonplaten
-
## Overview
The ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
@@ -49,15 +45,15 @@ dataset (160GB) respectively. Then we conduct experiments on CNN/DailyMail, Giga
abstractive summarization and question generation tasks. Experimental results show that ProphetNet achieves new
state-of-the-art results on all these datasets compared to the models using the same scale pretraining corpus.*
-Tips:
+The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
+
+## Usage tips
- ProphetNet is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
- The model architecture is based on the original Transformer, but replaces the “standard” self-attention mechanism in the decoder by a a main self-attention mechanism and a self and n-stream (predict) self-attention mechanism.
-The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
-
-## Documentation resources
+## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
diff --git a/docs/source/en/model_doc/qdqbert.md b/docs/source/en/model_doc/qdqbert.md
index 62a0e010843d..9ee42ff3b49d 100644
--- a/docs/source/en/model_doc/qdqbert.md
+++ b/docs/source/en/model_doc/qdqbert.md
@@ -32,22 +32,18 @@ by processors with high-throughput integer math pipelines. We also present a wor
able to maintain accuracy within 1% of the floating-point baseline on all networks studied, including models that are
more difficult to quantize, such as MobileNets and BERT-large.*
-Tips:
+This model was contributed by [shangz](https://huggingface.co/shangz).
+
+## Usage tips
- QDQBERT model adds fake quantization operations (pair of QuantizeLinear/DequantizeLinear ops) to (i) linear layer
inputs and weights, (ii) matmul inputs, (iii) residual add inputs, in BERT model.
-
- QDQBERT requires the dependency of [Pytorch Quantization Toolkit](https://github.com/NVIDIA/TensorRT/tree/master/tools/pytorch-quantization). To install `pip install pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com`
-
- QDQBERT model can be loaded from any checkpoint of HuggingFace BERT model (for example *bert-base-uncased*), and
perform Quantization Aware Training/Post Training Quantization.
-
- A complete example of using QDQBERT model to perform Quatization Aware Training and Post Training Quantization for
SQUAD task can be found at [transformers/examples/research_projects/quantization-qdqbert/](examples/research_projects/quantization-qdqbert/).
-This model was contributed by [shangz](https://huggingface.co/shangz).
-
-
### Set default quantizers
QDQBERT model adds fake quantization operations (pair of QuantizeLinear/DequantizeLinear ops) to BERT by
@@ -118,7 +114,7 @@ the instructions in [torch.onnx](https://pytorch.org/docs/stable/onnx.html). Exa
>>> torch.onnx.export(...)
```
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
diff --git a/docs/source/en/model_doc/rag.md b/docs/source/en/model_doc/rag.md
index b467c6169f66..1891efe74263 100644
--- a/docs/source/en/model_doc/rag.md
+++ b/docs/source/en/model_doc/rag.md
@@ -52,8 +52,12 @@ parametric-only seq2seq baseline.*
This model was contributed by [ola13](https://huggingface.co/ola13).
-Tips:
-- Retrieval-augmented generation (“RAG”) models combine the powers of pretrained dense retrieval (DPR) and Seq2Seq models. RAG models retrieve docs, pass them to a seq2seq model, then marginalize to generate outputs. The retriever and seq2seq modules are initialized from pretrained models, and fine-tuned jointly, allowing both retrieval and generation to adapt to downstream tasks.
+## Usage tips
+
+Retrieval-augmented generation ("RAG") models combine the powers of pretrained dense retrieval (DPR) and Seq2Seq models.
+RAG models retrieve docs, pass them to a seq2seq model, then marginalize to generate outputs. The retriever and seq2seq
+modules are initialized from pretrained models, and fine-tuned jointly, allowing both retrieval and generation to adapt
+to downstream tasks.
## RagConfig
@@ -73,6 +77,9 @@ Tips:
[[autodoc]] RagRetriever
+ @@ -52,30 +48,35 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] ResNetConfig
+
@@ -52,30 +48,35 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] ResNetConfig
+ @@ -48,6 +43,10 @@ alt="drawing" width="600"/>
This model was contributed by [novice03](https://huggingface.co/novice03). The Tensorflow version of this model was contributed by [amyeroberts](https://huggingface.co/amyeroberts). The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
+## Usage tips
+
+- Swin pads the inputs supporting any input height and width (if divisible by `32`).
+- Swin can be used as a *backbone*. When `output_hidden_states = True`, it will output both `hidden_states` and `reshaped_hidden_states`. The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than `(batch_size, sequence_length, num_channels)`.
## Resources
@@ -68,6 +67,8 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] SwinConfig
+
@@ -48,6 +43,10 @@ alt="drawing" width="600"/>
This model was contributed by [novice03](https://huggingface.co/novice03). The Tensorflow version of this model was contributed by [amyeroberts](https://huggingface.co/amyeroberts). The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
+## Usage tips
+
+- Swin pads the inputs supporting any input height and width (if divisible by `32`).
+- Swin can be used as a *backbone*. When `output_hidden_states = True`, it will output both `hidden_states` and `reshaped_hidden_states`. The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than `(batch_size, sequence_length, num_channels)`.
## Resources
@@ -68,6 +67,8 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] SwinConfig
+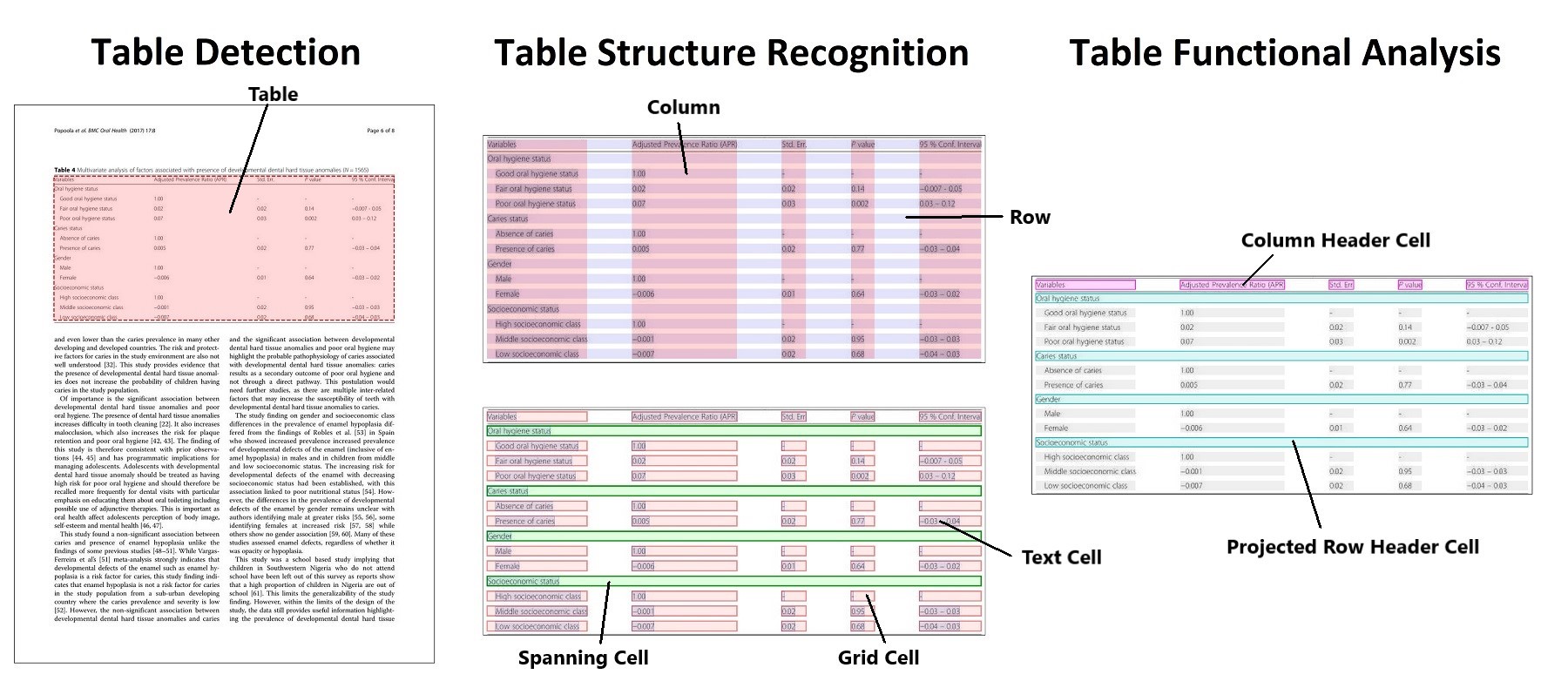 Table detection and table structure recognition clarified. Taken from the original paper.
+The authors released 2 models, one for [table detection](https://huggingface.co/microsoft/table-transformer-detection) in
+documents, one for [table structure recognition](https://huggingface.co/microsoft/table-transformer-structure-recognition)
+(the task of recognizing the individual rows, columns etc. in a table).
+
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be
found [here](https://github.com/microsoft/table-transformer).
diff --git a/docs/source/en/model_doc/tapas.md b/docs/source/en/model_doc/tapas.md
index 1c76015f2857..79bbe3e819cf 100644
--- a/docs/source/en/model_doc/tapas.md
+++ b/docs/source/en/model_doc/tapas.md
@@ -44,10 +44,10 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The Tensorflow version of this model was contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/google-research/tapas).
-Tips:
+## Usage tips
- TAPAS is a model that uses relative position embeddings by default (restarting the position embeddings at every cell of the table). Note that this is something that was added after the publication of the original TAPAS paper. According to the authors, this usually results in a slightly better performance, and allows you to encode longer sequences without running out of embeddings. This is reflected in the `reset_position_index_per_cell` parameter of [`TapasConfig`], which is set to `True` by default. The default versions of the models available on the [hub](https://huggingface.co/models?search=tapas) all use relative position embeddings. You can still use the ones with absolute position embeddings by passing in an additional argument `revision="no_reset"` when calling the `from_pretrained()` method. Note that it's usually advised to pad the inputs on the right rather than the left.
-- TAPAS is based on BERT, so `TAPAS-base` for example corresponds to a `BERT-base` architecture. Of course, `TAPAS-large` will result in the best performance (the results reported in the paper are from `TAPAS-large`). Results of the various sized models are shown on the [original Github repository](https://github.com/google-research/tapas>).
+- TAPAS is based on BERT, so `TAPAS-base` for example corresponds to a `BERT-base` architecture. Of course, `TAPAS-large` will result in the best performance (the results reported in the paper are from `TAPAS-large`). Results of the various sized models are shown on the [original GitHub repository](https://github.com/google-research/tapas).
- TAPAS has checkpoints fine-tuned on SQA, which are capable of answering questions related to a table in a conversational set-up. This means that you can ask follow-up questions such as "what is his age?" related to the previous question. Note that the forward pass of TAPAS is a bit different in case of a conversational set-up: in that case, you have to feed every table-question pair one by one to the model, such that the `prev_labels` token type ids can be overwritten by the predicted `labels` of the model to the previous question. See "Usage" section for more info.
- TAPAS is similar to BERT and therefore relies on the masked language modeling (MLM) objective. It is therefore efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation. Models trained with a causal language modeling (CLM) objective are better in that regard. Note that TAPAS can be used as an encoder in the EncoderDecoderModel framework, to combine it with an autoregressive text decoder such as GPT-2.
@@ -573,7 +573,7 @@ Predicted answer: SUM > 87, 53, 69
In case of a conversational set-up, then each table-question pair must be provided **sequentially** to the model, such that the `prev_labels` token types can be overwritten by the predicted `labels` of the previous table-question pair. Again, more info can be found in [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) (for PyTorch) and [this notebook](https://github.com/kamalkraj/Tapas-Tutorial/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) (for TensorFlow).
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
@@ -590,6 +590,9 @@ In case of a conversational set-up, then each table-question pair must be provid
- convert_logits_to_predictions
- save_vocabulary
+
Table detection and table structure recognition clarified. Taken from the original paper.
+The authors released 2 models, one for [table detection](https://huggingface.co/microsoft/table-transformer-detection) in
+documents, one for [table structure recognition](https://huggingface.co/microsoft/table-transformer-structure-recognition)
+(the task of recognizing the individual rows, columns etc. in a table).
+
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be
found [here](https://github.com/microsoft/table-transformer).
diff --git a/docs/source/en/model_doc/tapas.md b/docs/source/en/model_doc/tapas.md
index 1c76015f2857..79bbe3e819cf 100644
--- a/docs/source/en/model_doc/tapas.md
+++ b/docs/source/en/model_doc/tapas.md
@@ -44,10 +44,10 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The Tensorflow version of this model was contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/google-research/tapas).
-Tips:
+## Usage tips
- TAPAS is a model that uses relative position embeddings by default (restarting the position embeddings at every cell of the table). Note that this is something that was added after the publication of the original TAPAS paper. According to the authors, this usually results in a slightly better performance, and allows you to encode longer sequences without running out of embeddings. This is reflected in the `reset_position_index_per_cell` parameter of [`TapasConfig`], which is set to `True` by default. The default versions of the models available on the [hub](https://huggingface.co/models?search=tapas) all use relative position embeddings. You can still use the ones with absolute position embeddings by passing in an additional argument `revision="no_reset"` when calling the `from_pretrained()` method. Note that it's usually advised to pad the inputs on the right rather than the left.
-- TAPAS is based on BERT, so `TAPAS-base` for example corresponds to a `BERT-base` architecture. Of course, `TAPAS-large` will result in the best performance (the results reported in the paper are from `TAPAS-large`). Results of the various sized models are shown on the [original Github repository](https://github.com/google-research/tapas>).
+- TAPAS is based on BERT, so `TAPAS-base` for example corresponds to a `BERT-base` architecture. Of course, `TAPAS-large` will result in the best performance (the results reported in the paper are from `TAPAS-large`). Results of the various sized models are shown on the [original GitHub repository](https://github.com/google-research/tapas).
- TAPAS has checkpoints fine-tuned on SQA, which are capable of answering questions related to a table in a conversational set-up. This means that you can ask follow-up questions such as "what is his age?" related to the previous question. Note that the forward pass of TAPAS is a bit different in case of a conversational set-up: in that case, you have to feed every table-question pair one by one to the model, such that the `prev_labels` token type ids can be overwritten by the predicted `labels` of the model to the previous question. See "Usage" section for more info.
- TAPAS is similar to BERT and therefore relies on the masked language modeling (MLM) objective. It is therefore efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation. Models trained with a causal language modeling (CLM) objective are better in that regard. Note that TAPAS can be used as an encoder in the EncoderDecoderModel framework, to combine it with an autoregressive text decoder such as GPT-2.
@@ -573,7 +573,7 @@ Predicted answer: SUM > 87, 53, 69
In case of a conversational set-up, then each table-question pair must be provided **sequentially** to the model, such that the `prev_labels` token types can be overwritten by the predicted `labels` of the previous table-question pair. Again, more info can be found in [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) (for PyTorch) and [this notebook](https://github.com/kamalkraj/Tapas-Tutorial/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) (for TensorFlow).
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
@@ -590,6 +590,9 @@ In case of a conversational set-up, then each table-question pair must be provid
- convert_logits_to_predictions
- save_vocabulary
+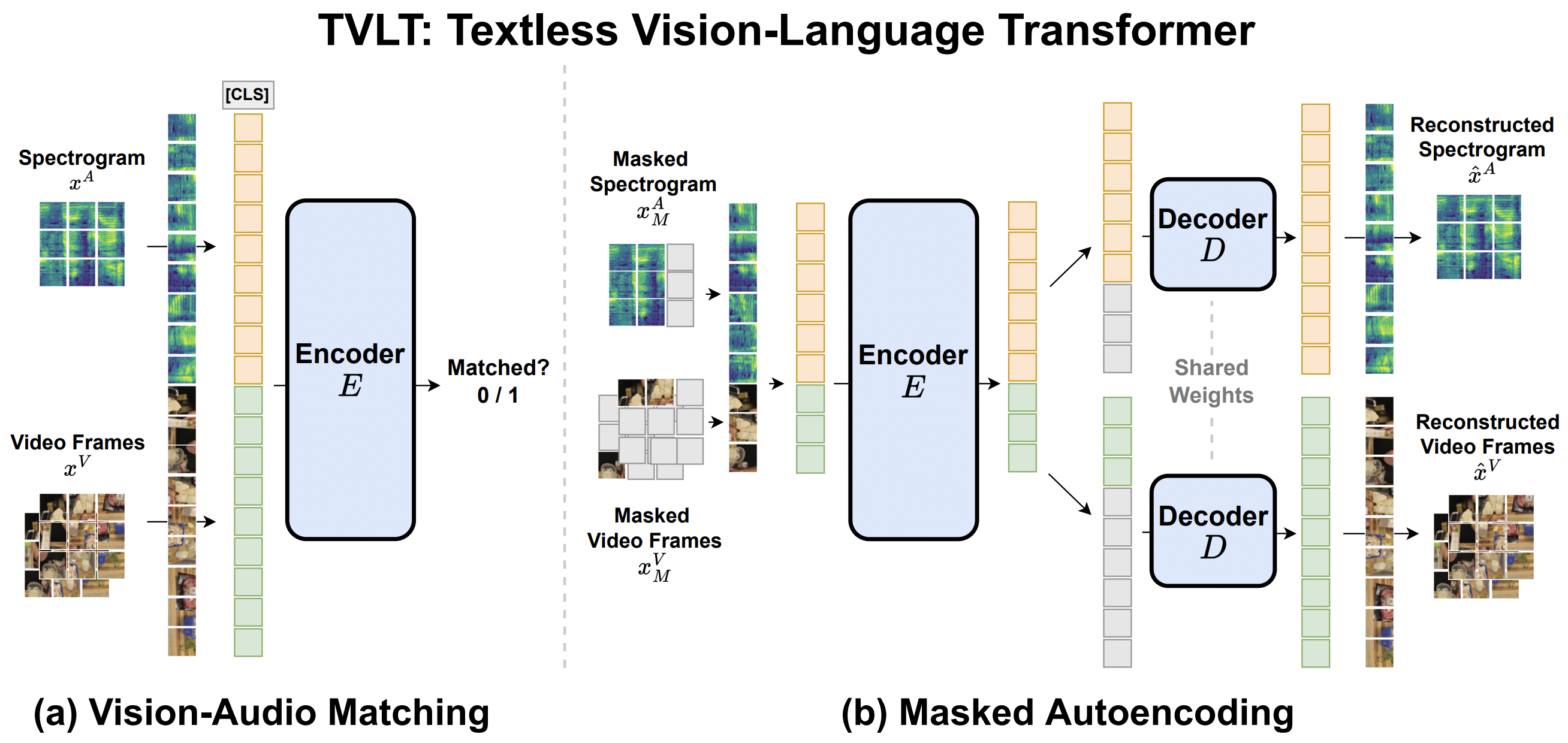 @@ -42,6 +34,14 @@ alt="drawing" width="600"/>
The original code can be found [here](https://github.com/zinengtang/TVLT). This model was contributed by [Zineng Tang](https://huggingface.co/ZinengTang).
+## Usage tips
+
+- TVLT is a model that takes both `pixel_values` and `audio_values` as input. One can use [`TvltProcessor`] to prepare data for the model.
+ This processor wraps an image processor (for the image/video modality) and an audio feature extractor (for the audio modality) into one.
+- TVLT is trained with images/videos and audios of various sizes: the authors resize and crop the input images/videos to 224 and limit the length of audio spectrogram to 2048. To make batching of videos and audios possible, the authors use a `pixel_mask` that indicates which pixels are real/padding and `audio_mask` that indicates which audio values are real/padding.
+- The design of TVLT is very similar to that of a standard Vision Transformer (ViT) and masked autoencoder (MAE) as in [ViTMAE](vitmae). The difference is that the model includes embedding layers for the audio modality.
+- The PyTorch version of this model is only available in torch 1.10 and higher.
+
## TvltConfig
[[autodoc]] TvltConfig
diff --git a/docs/source/en/model_doc/tvp.md b/docs/source/en/model_doc/tvp.md
new file mode 100644
index 000000000000..22b400a06c73
--- /dev/null
+++ b/docs/source/en/model_doc/tvp.md
@@ -0,0 +1,186 @@
+
+
+# TVP
+
+## Overview
+
+The text-visual prompting (TVP) framework was proposed in the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
+
+The abstract from the paper is the following:
+
+*In this paper, we study the problem of temporal video grounding (TVG), which aims to predict the starting/ending time points of moments described by a text sentence within a long untrimmed video. Benefiting from fine-grained 3D visual features, the TVG techniques have achieved remarkable progress in recent years. However, the high complexity of 3D convolutional neural networks (CNNs) makes extracting dense 3D visual features time-consuming, which calls for intensive memory and computing resources. Towards efficient TVG, we propose a novel text-visual prompting (TVP) framework, which incorporates optimized perturbation patterns (that we call ‘prompts’) into both visual inputs and textual features of a TVG model. In sharp contrast to 3D CNNs, we show that TVP allows us to effectively co-train vision encoder and language encoder in a 2D TVG model and improves the performance of cross-modal feature fusion using only low-complexity sparse 2D visual features. Further, we propose a Temporal-Distance IoU (TDIoU) loss for efficient learning of TVG. Experiments on two benchmark datasets, Charades-STA and ActivityNet Captions datasets, empirically show that the proposed TVP significantly boosts the performance of 2D TVG (e.g., 9.79% improvement on Charades-STA and 30.77% improvement on ActivityNet Captions) and achieves 5× inference acceleration over TVG using 3D visual features.*
+
+This research addresses temporal video grounding (TVG), which is the process of pinpointing the start and end times of specific events in a long video, as described by a text sentence. Text-visual prompting (TVP), is proposed to enhance TVG. TVP involves integrating specially designed patterns, known as 'prompts', into both the visual (image-based) and textual (word-based) input components of a TVG model. These prompts provide additional spatial-temporal context, improving the model's ability to accurately determine event timings in the video. The approach employs 2D visual inputs in place of 3D ones. Although 3D inputs offer more spatial-temporal detail, they are also more time-consuming to process. The use of 2D inputs with the prompting method aims to provide similar levels of context and accuracy more efficiently.
+
+
@@ -42,6 +34,14 @@ alt="drawing" width="600"/>
The original code can be found [here](https://github.com/zinengtang/TVLT). This model was contributed by [Zineng Tang](https://huggingface.co/ZinengTang).
+## Usage tips
+
+- TVLT is a model that takes both `pixel_values` and `audio_values` as input. One can use [`TvltProcessor`] to prepare data for the model.
+ This processor wraps an image processor (for the image/video modality) and an audio feature extractor (for the audio modality) into one.
+- TVLT is trained with images/videos and audios of various sizes: the authors resize and crop the input images/videos to 224 and limit the length of audio spectrogram to 2048. To make batching of videos and audios possible, the authors use a `pixel_mask` that indicates which pixels are real/padding and `audio_mask` that indicates which audio values are real/padding.
+- The design of TVLT is very similar to that of a standard Vision Transformer (ViT) and masked autoencoder (MAE) as in [ViTMAE](vitmae). The difference is that the model includes embedding layers for the audio modality.
+- The PyTorch version of this model is only available in torch 1.10 and higher.
+
## TvltConfig
[[autodoc]] TvltConfig
diff --git a/docs/source/en/model_doc/tvp.md b/docs/source/en/model_doc/tvp.md
new file mode 100644
index 000000000000..22b400a06c73
--- /dev/null
+++ b/docs/source/en/model_doc/tvp.md
@@ -0,0 +1,186 @@
+
+
+# TVP
+
+## Overview
+
+The text-visual prompting (TVP) framework was proposed in the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
+
+The abstract from the paper is the following:
+
+*In this paper, we study the problem of temporal video grounding (TVG), which aims to predict the starting/ending time points of moments described by a text sentence within a long untrimmed video. Benefiting from fine-grained 3D visual features, the TVG techniques have achieved remarkable progress in recent years. However, the high complexity of 3D convolutional neural networks (CNNs) makes extracting dense 3D visual features time-consuming, which calls for intensive memory and computing resources. Towards efficient TVG, we propose a novel text-visual prompting (TVP) framework, which incorporates optimized perturbation patterns (that we call ‘prompts’) into both visual inputs and textual features of a TVG model. In sharp contrast to 3D CNNs, we show that TVP allows us to effectively co-train vision encoder and language encoder in a 2D TVG model and improves the performance of cross-modal feature fusion using only low-complexity sparse 2D visual features. Further, we propose a Temporal-Distance IoU (TDIoU) loss for efficient learning of TVG. Experiments on two benchmark datasets, Charades-STA and ActivityNet Captions datasets, empirically show that the proposed TVP significantly boosts the performance of 2D TVG (e.g., 9.79% improvement on Charades-STA and 30.77% improvement on ActivityNet Captions) and achieves 5× inference acceleration over TVG using 3D visual features.*
+
+This research addresses temporal video grounding (TVG), which is the process of pinpointing the start and end times of specific events in a long video, as described by a text sentence. Text-visual prompting (TVP), is proposed to enhance TVG. TVP involves integrating specially designed patterns, known as 'prompts', into both the visual (image-based) and textual (word-based) input components of a TVG model. These prompts provide additional spatial-temporal context, improving the model's ability to accurately determine event timings in the video. The approach employs 2D visual inputs in place of 3D ones. Although 3D inputs offer more spatial-temporal detail, they are also more time-consuming to process. The use of 2D inputs with the prompting method aims to provide similar levels of context and accuracy more efficiently.
+
+ +
+ TVP architecture. Taken from the original paper.
+
+This model was contributed by [Jiqing Feng](https://huggingface.co/Jiqing). The original code can be found [here](https://github.com/intel/TVP).
+
+## Usage tips and examples
+
+Prompts are optimized perturbation patterns, which would be added to input video frames or text features. Universal set refers to using the same exact set of prompts for any input, this means that these prompts are added consistently to all video frames and text features, regardless of the input's content.
+
+TVP consists of a visual encoder and cross-modal encoder. A universal set of visual prompts and text prompts to be integrated into sampled video frames and textual features, respectively. Specially, a set of different visual prompts are applied to uniformly-sampled frames of one untrimmed video in order.
+
+The goal of this model is to incorporate trainable prompts into both visual inputs and textual features to temporal video grounding(TVG) problems.
+In principle, one can apply any visual, cross-modal encoder in the proposed architecture.
+
+The [`TvpProcessor`] wraps [`BertTokenizer`] and [`TvpImageProcessor`] into a single instance to both
+encode the text and prepare the images respectively.
+
+The following example shows how to run temporal video grounding using [`TvpProcessor`] and [`TvpForVideoGrounding`].
+```python
+import av
+import cv2
+import numpy as np
+import torch
+from huggingface_hub import hf_hub_download
+from transformers import AutoProcessor, TvpForVideoGrounding
+
+
+def pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Convert the video from its original fps to the target_fps and decode the video with PyAV decoder.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video. Return None if the no
+ video stream was found.
+ fps (float): the number of frames per second of the video.
+ '''
+ video = container.streams.video[0]
+ fps = float(video.average_rate)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ delta = max(num_frames - clip_size, 0)
+ start_idx = delta * clip_idx / num_clips
+ end_idx = start_idx + clip_size - 1
+ timebase = video.duration / num_frames
+ video_start_pts = int(start_idx * timebase)
+ video_end_pts = int(end_idx * timebase)
+ seek_offset = max(video_start_pts - 1024, 0)
+ container.seek(seek_offset, any_frame=False, backward=True, stream=video)
+ frames = {}
+ for frame in container.decode(video=0):
+ if frame.pts < video_start_pts:
+ continue
+ frames[frame.pts] = frame
+ if frame.pts > video_end_pts:
+ break
+ frames = [frames[pts] for pts in sorted(frames)]
+ return frames, fps
+
+
+def decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Decode the video and perform temporal sampling.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video.
+ '''
+ assert clip_idx >= -2, "Not a valied clip_idx {}".format(clip_idx)
+ frames, fps = pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ index = np.linspace(0, clip_size - 1, num_frames)
+ index = np.clip(index, 0, len(frames) - 1).astype(np.int64)
+ frames = np.array([frames[idx].to_rgb().to_ndarray() for idx in index])
+ frames = frames.transpose(0, 3, 1, 2)
+ return frames
+
+
+file = hf_hub_download(repo_id="Intel/tvp_demo", filename="AK2KG.mp4", repo_type="dataset")
+model = TvpForVideoGrounding.from_pretrained("Intel/tvp-base")
+
+decoder_kwargs = dict(
+ container=av.open(file, metadata_errors="ignore"),
+ sampling_rate=1,
+ num_frames=model.config.num_frames,
+ clip_idx=0,
+ num_clips=1,
+ target_fps=3,
+)
+raw_sampled_frms = decode(**decoder_kwargs)
+
+text = "a person is sitting on a bed."
+processor = AutoProcessor.from_pretrained("Intel/tvp-base")
+model_inputs = processor(
+ text=[text], videos=list(raw_sampled_frms), return_tensors="pt", max_text_length=100#, size=size
+)
+
+model_inputs["pixel_values"] = model_inputs["pixel_values"].to(model.dtype)
+output = model(**model_inputs)
+
+def get_video_duration(filename):
+ cap = cv2.VideoCapture(filename)
+ if cap.isOpened():
+ rate = cap.get(5)
+ frame_num = cap.get(7)
+ duration = frame_num/rate
+ return duration
+ return -1
+
+duration = get_video_duration(file)
+start, end = processor.post_process_video_grounding(output.logits, duration)
+
+print(f"The time slot of the video corresponding to the text \"{text}\" is from {start}s to {end}s")
+```
+
+Tips:
+
+- This implementation of TVP uses [`BertTokenizer`] to generate text embeddings and Resnet-50 model to compute visual embeddings.
+- Checkpoints for pre-trained [tvp-base](https://huggingface.co/Intel/tvp-base) is released.
+- Please refer to [Table 2](https://arxiv.org/pdf/2303.04995.pdf) for TVP's performance on Temporal Video Grounding task.
+
+
+## TvpConfig
+
+[[autodoc]] TvpConfig
+
+## TvpImageProcessor
+
+[[autodoc]] TvpImageProcessor
+ - preprocess
+
+## TvpProcessor
+
+[[autodoc]] TvpProcessor
+ - __call__
+
+## TvpModel
+
+[[autodoc]] TvpModel
+ - forward
+
+## TvpForVideoGrounding
+
+[[autodoc]] TvpForVideoGrounding
+ - forward
diff --git a/docs/source/en/model_doc/ul2.md b/docs/source/en/model_doc/ul2.md
index 3863f23a7d73..f4d01c40b0c1 100644
--- a/docs/source/en/model_doc/ul2.md
+++ b/docs/source/en/model_doc/ul2.md
@@ -24,12 +24,20 @@ The abstract from the paper is the following:
*Existing pre-trained models are generally geared towards a particular class of problems. To date, there seems to be still no consensus on what the right architecture and pre-training setup should be. This paper presents a unified framework for pre-training models that are universally effective across datasets and setups. We begin by disentangling architectural archetypes with pre-training objectives -- two concepts that are commonly conflated. Next, we present a generalized and unified perspective for self-supervision in NLP and show how different pre-training objectives can be cast as one another and how interpolating between different objectives can be effective. We then propose Mixture-of-Denoisers (MoD), a pre-training objective that combines diverse pre-training paradigms together. We furthermore introduce a notion of mode switching, wherein downstream fine-tuning is associated with specific pre-training schemes. We conduct extensive ablative experiments to compare multiple pre-training objectives and find that our method pushes the Pareto-frontier by outperforming T5 and/or GPT-like models across multiple diverse setups. Finally, by scaling our model up to 20B parameters, we achieve SOTA performance on 50 well-established supervised NLP tasks ranging from language generation (with automated and human evaluation), language understanding, text classification, question answering, commonsense reasoning, long text reasoning, structured knowledge grounding and information retrieval. Our model also achieve strong results at in-context learning, outperforming 175B GPT-3 on zero-shot SuperGLUE and tripling the performance of T5-XXL on one-shot summarization.*
-Tips:
+This model was contributed by [DanielHesslow](https://huggingface.co/Seledorn). The original code can be found [here](https://github.com/google-research/google-research/tree/master/ul2).
+
+## Usage tips
- UL2 is an encoder-decoder model pre-trained on a mixture of denoising functions as well as fine-tuned on an array of downstream tasks.
- UL2 has the same architecture as [T5v1.1](t5v1.1) but uses the Gated-SiLU activation function instead of Gated-GELU.
- The authors release checkpoints of one architecture which can be seen [here](https://huggingface.co/google/ul2)
-The original code can be found [here](https://github.com/google-research/google-research/tree/master/ul2).
+
+
+ TVP architecture. Taken from the original paper.
+
+This model was contributed by [Jiqing Feng](https://huggingface.co/Jiqing). The original code can be found [here](https://github.com/intel/TVP).
+
+## Usage tips and examples
+
+Prompts are optimized perturbation patterns, which would be added to input video frames or text features. Universal set refers to using the same exact set of prompts for any input, this means that these prompts are added consistently to all video frames and text features, regardless of the input's content.
+
+TVP consists of a visual encoder and cross-modal encoder. A universal set of visual prompts and text prompts to be integrated into sampled video frames and textual features, respectively. Specially, a set of different visual prompts are applied to uniformly-sampled frames of one untrimmed video in order.
+
+The goal of this model is to incorporate trainable prompts into both visual inputs and textual features to temporal video grounding(TVG) problems.
+In principle, one can apply any visual, cross-modal encoder in the proposed architecture.
+
+The [`TvpProcessor`] wraps [`BertTokenizer`] and [`TvpImageProcessor`] into a single instance to both
+encode the text and prepare the images respectively.
+
+The following example shows how to run temporal video grounding using [`TvpProcessor`] and [`TvpForVideoGrounding`].
+```python
+import av
+import cv2
+import numpy as np
+import torch
+from huggingface_hub import hf_hub_download
+from transformers import AutoProcessor, TvpForVideoGrounding
+
+
+def pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Convert the video from its original fps to the target_fps and decode the video with PyAV decoder.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video. Return None if the no
+ video stream was found.
+ fps (float): the number of frames per second of the video.
+ '''
+ video = container.streams.video[0]
+ fps = float(video.average_rate)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ delta = max(num_frames - clip_size, 0)
+ start_idx = delta * clip_idx / num_clips
+ end_idx = start_idx + clip_size - 1
+ timebase = video.duration / num_frames
+ video_start_pts = int(start_idx * timebase)
+ video_end_pts = int(end_idx * timebase)
+ seek_offset = max(video_start_pts - 1024, 0)
+ container.seek(seek_offset, any_frame=False, backward=True, stream=video)
+ frames = {}
+ for frame in container.decode(video=0):
+ if frame.pts < video_start_pts:
+ continue
+ frames[frame.pts] = frame
+ if frame.pts > video_end_pts:
+ break
+ frames = [frames[pts] for pts in sorted(frames)]
+ return frames, fps
+
+
+def decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Decode the video and perform temporal sampling.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video.
+ '''
+ assert clip_idx >= -2, "Not a valied clip_idx {}".format(clip_idx)
+ frames, fps = pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ index = np.linspace(0, clip_size - 1, num_frames)
+ index = np.clip(index, 0, len(frames) - 1).astype(np.int64)
+ frames = np.array([frames[idx].to_rgb().to_ndarray() for idx in index])
+ frames = frames.transpose(0, 3, 1, 2)
+ return frames
+
+
+file = hf_hub_download(repo_id="Intel/tvp_demo", filename="AK2KG.mp4", repo_type="dataset")
+model = TvpForVideoGrounding.from_pretrained("Intel/tvp-base")
+
+decoder_kwargs = dict(
+ container=av.open(file, metadata_errors="ignore"),
+ sampling_rate=1,
+ num_frames=model.config.num_frames,
+ clip_idx=0,
+ num_clips=1,
+ target_fps=3,
+)
+raw_sampled_frms = decode(**decoder_kwargs)
+
+text = "a person is sitting on a bed."
+processor = AutoProcessor.from_pretrained("Intel/tvp-base")
+model_inputs = processor(
+ text=[text], videos=list(raw_sampled_frms), return_tensors="pt", max_text_length=100#, size=size
+)
+
+model_inputs["pixel_values"] = model_inputs["pixel_values"].to(model.dtype)
+output = model(**model_inputs)
+
+def get_video_duration(filename):
+ cap = cv2.VideoCapture(filename)
+ if cap.isOpened():
+ rate = cap.get(5)
+ frame_num = cap.get(7)
+ duration = frame_num/rate
+ return duration
+ return -1
+
+duration = get_video_duration(file)
+start, end = processor.post_process_video_grounding(output.logits, duration)
+
+print(f"The time slot of the video corresponding to the text \"{text}\" is from {start}s to {end}s")
+```
+
+Tips:
+
+- This implementation of TVP uses [`BertTokenizer`] to generate text embeddings and Resnet-50 model to compute visual embeddings.
+- Checkpoints for pre-trained [tvp-base](https://huggingface.co/Intel/tvp-base) is released.
+- Please refer to [Table 2](https://arxiv.org/pdf/2303.04995.pdf) for TVP's performance on Temporal Video Grounding task.
+
+
+## TvpConfig
+
+[[autodoc]] TvpConfig
+
+## TvpImageProcessor
+
+[[autodoc]] TvpImageProcessor
+ - preprocess
+
+## TvpProcessor
+
+[[autodoc]] TvpProcessor
+ - __call__
+
+## TvpModel
+
+[[autodoc]] TvpModel
+ - forward
+
+## TvpForVideoGrounding
+
+[[autodoc]] TvpForVideoGrounding
+ - forward
diff --git a/docs/source/en/model_doc/ul2.md b/docs/source/en/model_doc/ul2.md
index 3863f23a7d73..f4d01c40b0c1 100644
--- a/docs/source/en/model_doc/ul2.md
+++ b/docs/source/en/model_doc/ul2.md
@@ -24,12 +24,20 @@ The abstract from the paper is the following:
*Existing pre-trained models are generally geared towards a particular class of problems. To date, there seems to be still no consensus on what the right architecture and pre-training setup should be. This paper presents a unified framework for pre-training models that are universally effective across datasets and setups. We begin by disentangling architectural archetypes with pre-training objectives -- two concepts that are commonly conflated. Next, we present a generalized and unified perspective for self-supervision in NLP and show how different pre-training objectives can be cast as one another and how interpolating between different objectives can be effective. We then propose Mixture-of-Denoisers (MoD), a pre-training objective that combines diverse pre-training paradigms together. We furthermore introduce a notion of mode switching, wherein downstream fine-tuning is associated with specific pre-training schemes. We conduct extensive ablative experiments to compare multiple pre-training objectives and find that our method pushes the Pareto-frontier by outperforming T5 and/or GPT-like models across multiple diverse setups. Finally, by scaling our model up to 20B parameters, we achieve SOTA performance on 50 well-established supervised NLP tasks ranging from language generation (with automated and human evaluation), language understanding, text classification, question answering, commonsense reasoning, long text reasoning, structured knowledge grounding and information retrieval. Our model also achieve strong results at in-context learning, outperforming 175B GPT-3 on zero-shot SuperGLUE and tripling the performance of T5-XXL on one-shot summarization.*
-Tips:
+This model was contributed by [DanielHesslow](https://huggingface.co/Seledorn). The original code can be found [here](https://github.com/google-research/google-research/tree/master/ul2).
+
+## Usage tips
- UL2 is an encoder-decoder model pre-trained on a mixture of denoising functions as well as fine-tuned on an array of downstream tasks.
- UL2 has the same architecture as [T5v1.1](t5v1.1) but uses the Gated-SiLU activation function instead of Gated-GELU.
- The authors release checkpoints of one architecture which can be seen [here](https://huggingface.co/google/ul2)
-The original code can be found [here](https://github.com/google-research/google-research/tree/master/ul2).
+ @@ -50,7 +45,6 @@ to fine-tune a VideoMAE model on a custom dataset.
- [Video classification task guide](../tasks/video_classification)
- [A 🤗 Space](https://huggingface.co/spaces/sayakpaul/video-classification-ucf101-subset) showing how to perform inference with a video classification model.
-
## VideoMAEConfig
[[autodoc]] VideoMAEConfig
@@ -72,6 +66,8 @@ to fine-tune a VideoMAE model on a custom dataset.
## VideoMAEForPreTraining
+`VideoMAEForPreTraining` includes the decoder on top for self-supervised pre-training.
+
[[autodoc]] transformers.VideoMAEForPreTraining
- forward
diff --git a/docs/source/en/model_doc/vilt.md b/docs/source/en/model_doc/vilt.md
index 2e2f4a140d20..2b0ac022da4b 100644
--- a/docs/source/en/model_doc/vilt.md
+++ b/docs/source/en/model_doc/vilt.md
@@ -34,7 +34,14 @@ Vision-and-Language Transformer (ViLT), monolithic in the sense that the process
simplified to just the same convolution-free manner that we process textual inputs. We show that ViLT is up to tens of
times faster than previous VLP models, yet with competitive or better downstream task performance.*
-Tips:
+
@@ -50,7 +45,6 @@ to fine-tune a VideoMAE model on a custom dataset.
- [Video classification task guide](../tasks/video_classification)
- [A 🤗 Space](https://huggingface.co/spaces/sayakpaul/video-classification-ucf101-subset) showing how to perform inference with a video classification model.
-
## VideoMAEConfig
[[autodoc]] VideoMAEConfig
@@ -72,6 +66,8 @@ to fine-tune a VideoMAE model on a custom dataset.
## VideoMAEForPreTraining
+`VideoMAEForPreTraining` includes the decoder on top for self-supervised pre-training.
+
[[autodoc]] transformers.VideoMAEForPreTraining
- forward
diff --git a/docs/source/en/model_doc/vilt.md b/docs/source/en/model_doc/vilt.md
index 2e2f4a140d20..2b0ac022da4b 100644
--- a/docs/source/en/model_doc/vilt.md
+++ b/docs/source/en/model_doc/vilt.md
@@ -34,7 +34,14 @@ Vision-and-Language Transformer (ViLT), monolithic in the sense that the process
simplified to just the same convolution-free manner that we process textual inputs. We show that ViLT is up to tens of
times faster than previous VLP models, yet with competitive or better downstream task performance.*
-Tips:
+ +
+ ViLT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/dandelin/ViLT).
+
+## Usage tips
- The quickest way to get started with ViLT is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ViLT)
(which showcase both inference and fine-tuning on custom data).
@@ -45,17 +52,6 @@ Tips:
which pixel values are real and which are padding. [`ViltProcessor`] automatically creates this for you.
- The design of ViLT is very similar to that of a standard Vision Transformer (ViT). The only difference is that the model includes
additional embedding layers for the language modality.
-
-
+
+ ViLT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/dandelin/ViLT).
+
+## Usage tips
- The quickest way to get started with ViLT is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ViLT)
(which showcase both inference and fine-tuning on custom data).
@@ -45,17 +52,6 @@ Tips:
which pixel values are real and which are padding. [`ViltProcessor`] automatically creates this for you.
- The design of ViLT is very similar to that of a standard Vision Transformer (ViT). The only difference is that the model includes
additional embedding layers for the language modality.
-
- @@ -87,28 +62,35 @@ Following the original Vision Transformer, some follow-up works have been made:
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code (written in JAX) can be
found [here](https://github.com/google-research/vision_transformer).
-Note that we converted the weights from Ross Wightman's [timm library](https://github.com/rwightman/pytorch-image-models), who already converted the weights from JAX to PyTorch. Credits
-go to him!
-
-## Resources
-
-A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT.
-
-
@@ -87,28 +62,35 @@ Following the original Vision Transformer, some follow-up works have been made:
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code (written in JAX) can be
found [here](https://github.com/google-research/vision_transformer).
-Note that we converted the weights from Ross Wightman's [timm library](https://github.com/rwightman/pytorch-image-models), who already converted the weights from JAX to PyTorch. Credits
-go to him!
-
-## Resources
-
-A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT.
-
- +
+ MAE architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [sayakpaul](https://github.com/sayakpaul) and
+[ariG23498](https://github.com/ariG23498) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/mae).
+
+## Usage tips
- MAE (masked auto encoding) is a method for self-supervised pre-training of Vision Transformers (ViTs). The pre-training objective is relatively simple:
by masking a large portion (75%) of the image patches, the model must reconstruct raw pixel values. One can use [`ViTMAEForPreTraining`] for this purpose.
@@ -44,14 +52,6 @@ consists of Transformer blocks) takes as input. Each mask token is a shared, lea
sin/cos position embeddings are added both to the input of the encoder and the decoder.
- For a visual understanding of how MAEs work you can check out this [post](https://keras.io/examples/vision/masked_image_modeling/).
-
+
+ MAE architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [sayakpaul](https://github.com/sayakpaul) and
+[ariG23498](https://github.com/ariG23498) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/mae).
+
+## Usage tips
- MAE (masked auto encoding) is a method for self-supervised pre-training of Vision Transformers (ViTs). The pre-training objective is relatively simple:
by masking a large portion (75%) of the image patches, the model must reconstruct raw pixel values. One can use [`ViTMAEForPreTraining`] for this purpose.
@@ -44,14 +52,6 @@ consists of Transformer blocks) takes as input. Each mask token is a shared, lea
sin/cos position embeddings are added both to the input of the encoder and the decoder.
- For a visual understanding of how MAEs work you can check out this [post](https://keras.io/examples/vision/masked_image_modeling/).
- +
+ MSN architecture. Taken from the original paper.
+
+This model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/facebookresearch/msn).
+
+## Usage tips
- MSN (masked siamese networks) is a method for self-supervised pre-training of Vision Transformers (ViTs). The pre-training
objective is to match the prototypes assigned to the unmasked views of the images to that of the masked views of the same images.
@@ -43,13 +49,6 @@ use the [`ViTMSNForImageClassification`] class which is initialized from [`ViTMS
- MSN is particularly useful in the low-shot and extreme low-shot regimes. Notably, it achieves 75.7% top-1 accuracy with only 1% of ImageNet-1K
labels when fine-tuned.
-
-
+
+ MSN architecture. Taken from the original paper.
+
+This model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/facebookresearch/msn).
+
+## Usage tips
- MSN (masked siamese networks) is a method for self-supervised pre-training of Vision Transformers (ViTs). The pre-training
objective is to match the prototypes assigned to the unmasked views of the images to that of the masked views of the same images.
@@ -43,13 +49,6 @@ use the [`ViTMSNForImageClassification`] class which is initialized from [`ViTMS
- MSN is particularly useful in the low-shot and extreme low-shot regimes. Notably, it achieves 75.7% top-1 accuracy with only 1% of ImageNet-1K
labels when fine-tuned.
-
- @@ -47,6 +43,12 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
@@ -47,6 +43,12 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+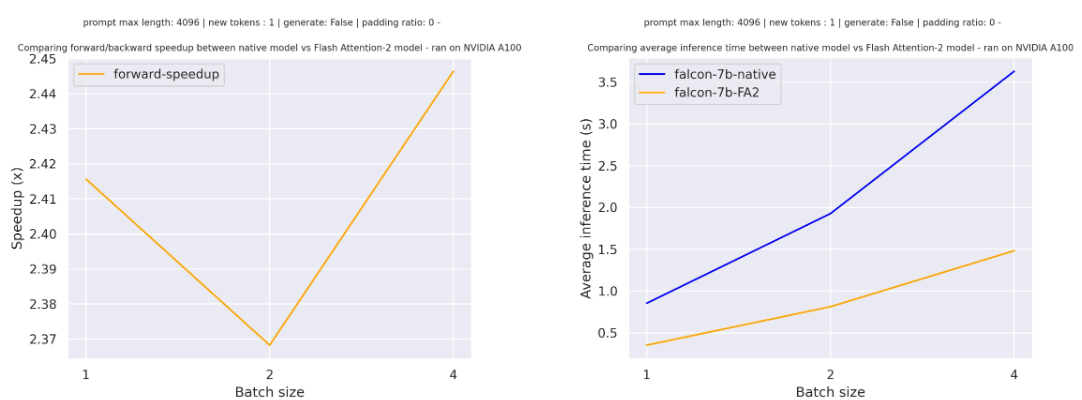 -
-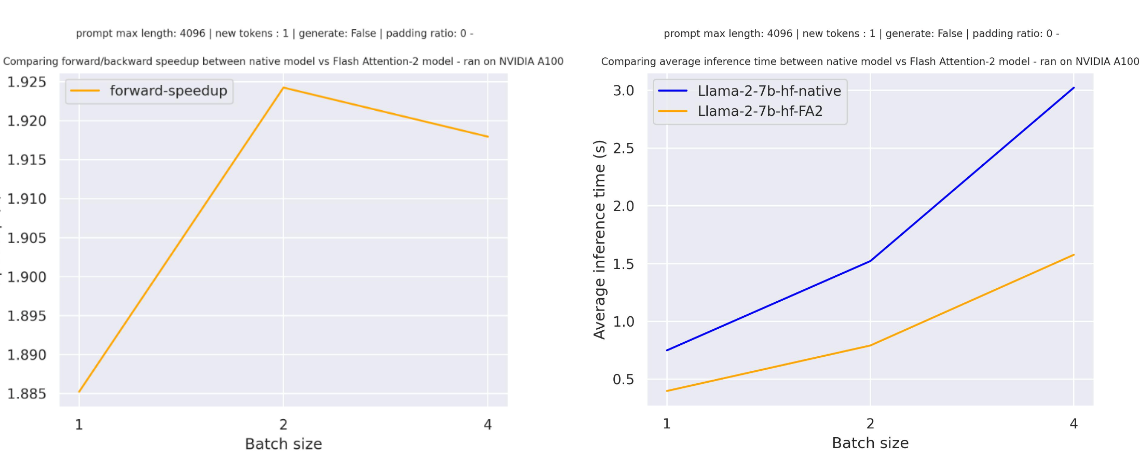 -
-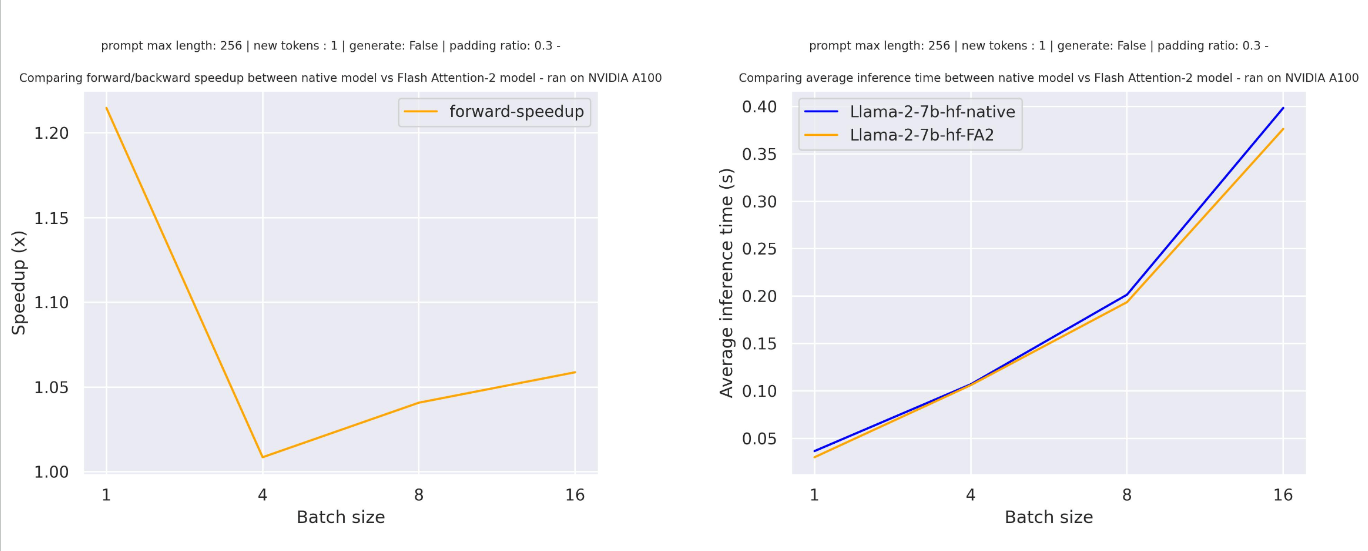 -
- -
- +
+ +
+ +
+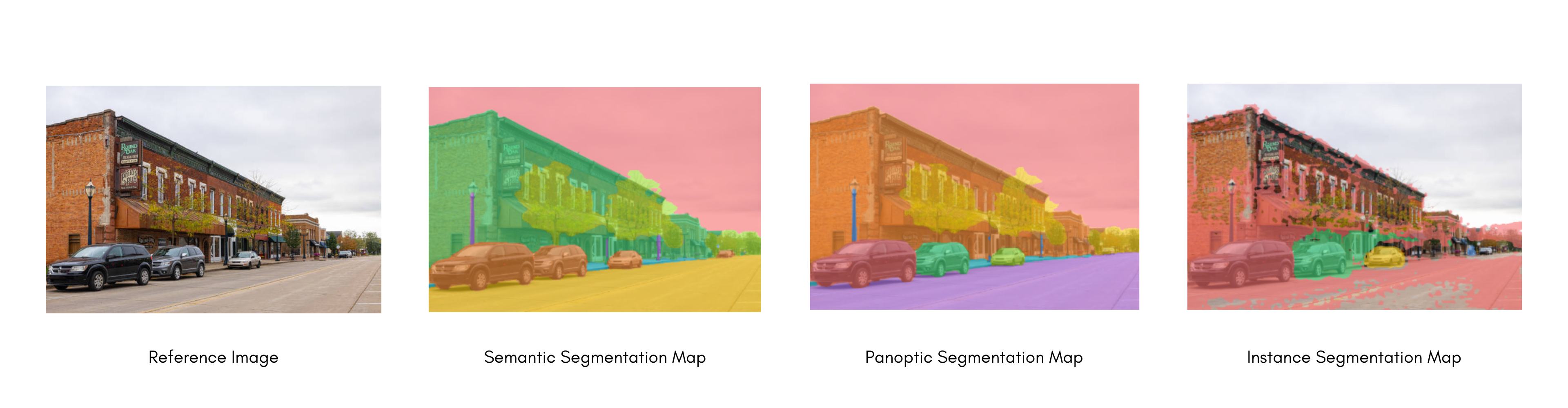 +
+ +
+[[autodoc]] get_cosine_schedule_with_warmup
+
+
+
+[[autodoc]] get_cosine_schedule_with_warmup
+
+ +
+[[autodoc]] get_cosine_with_hard_restarts_schedule_with_warmup
+
+
+
+[[autodoc]] get_cosine_with_hard_restarts_schedule_with_warmup
+
+ +
+[[autodoc]] get_linear_schedule_with_warmup
+
+
+
+[[autodoc]] get_linear_schedule_with_warmup
+
+ +
+[[autodoc]] get_polynomial_decay_schedule_with_warmup
+
+[[autodoc]] get_inverse_sqrt_schedule
+
+### Warmup (TensorFlow)
+
+[[autodoc]] WarmUp
+
+## Gradient Strategies
+
+### GradientAccumulator (TensorFlow)
+
+[[autodoc]] GradientAccumulator
diff --git a/docs/source/ja/main_classes/output.md b/docs/source/ja/main_classes/output.md
new file mode 100644
index 000000000000..7f906544a8f8
--- /dev/null
+++ b/docs/source/ja/main_classes/output.md
@@ -0,0 +1,321 @@
+
+
+# Model outputs
+
+すべてのモデルには、[`~utils.ModelOutput`] のサブクラスのインスタンスである出力があります。それらは
+モデルによって返されるすべての情報を含むデータ構造ですが、タプルまたは
+辞書。
+
+これがどのようになるかを例で見てみましょう。
+
+```python
+from transformers import BertTokenizer, BertForSequenceClassification
+import torch
+
+tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
+model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
+
+inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
+labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
+outputs = model(**inputs, labels=labels)
+```
+
+`outputs`オブジェクトは[`~modeling_outputs.SequenceClassifierOutput`]である。
+これは、オプションで `loss`、`logits`、オプションで `hidden_states`、オプションで `attentions` 属性を持つことを意味します。
+オプションの `attentions` 属性を持つことを意味する。ここでは、`labels`を渡したので`loss`があるが、`hidden_states`と`attentions`はない。
+`output_hidden_states=True`や`output_attentions=True`を渡していないので、`hidden_states`と`attentions`はない。
+`output_attentions=True`を渡さなかったからだ。
+
+
+
+[[autodoc]] get_polynomial_decay_schedule_with_warmup
+
+[[autodoc]] get_inverse_sqrt_schedule
+
+### Warmup (TensorFlow)
+
+[[autodoc]] WarmUp
+
+## Gradient Strategies
+
+### GradientAccumulator (TensorFlow)
+
+[[autodoc]] GradientAccumulator
diff --git a/docs/source/ja/main_classes/output.md b/docs/source/ja/main_classes/output.md
new file mode 100644
index 000000000000..7f906544a8f8
--- /dev/null
+++ b/docs/source/ja/main_classes/output.md
@@ -0,0 +1,321 @@
+
+
+# Model outputs
+
+すべてのモデルには、[`~utils.ModelOutput`] のサブクラスのインスタンスである出力があります。それらは
+モデルによって返されるすべての情報を含むデータ構造ですが、タプルまたは
+辞書。
+
+これがどのようになるかを例で見てみましょう。
+
+```python
+from transformers import BertTokenizer, BertForSequenceClassification
+import torch
+
+tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
+model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
+
+inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
+labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
+outputs = model(**inputs, labels=labels)
+```
+
+`outputs`オブジェクトは[`~modeling_outputs.SequenceClassifierOutput`]である。
+これは、オプションで `loss`、`logits`、オプションで `hidden_states`、オプションで `attentions` 属性を持つことを意味します。
+オプションの `attentions` 属性を持つことを意味する。ここでは、`labels`を渡したので`loss`があるが、`hidden_states`と`attentions`はない。
+`output_hidden_states=True`や`output_attentions=True`を渡していないので、`hidden_states`と`attentions`はない。
+`output_attentions=True`を渡さなかったからだ。
+
+ +
+
+## İçindekiler
+
+Dokümantasyon, beş bölüme ayrılmıştır:
+
+- **BAŞLARKEN**, kütüphanenin hızlı bir turunu ve çalışmaya başlamak için kurulum talimatlarını sağlar.
+- **ÖĞRETİCİLER**, başlangıç yapmak için harika bir yerdir. Bu bölüm, kütüphane kullanmaya başlamak için ihtiyacınız olan temel becerileri kazanmanıza yardımcı olacaktır.
+- **NASIL YAPILIR KILAVUZLARI**, önceden eğitilmiş bir modele dil modellemesi için ince ayar (fine-tuning) yapmak veya özel bir model yazmak, ve paylaşmak gibi belirli bir hedefe nasıl ulaşılacağını gösterir.
+- **KAVRAMSAL REHBERLER**, modellerin, görevlerin ve 🤗 Transformers tasarım felsefesinin temel kavramları ve fikirleri hakkında daha fazla tartışma ve açıklama sunar.
+- **API** tüm sınıfları (class) ve fonksiyonları (functions) açıklar:
+
+ - **ANA SINIFLAR**, yapılandırma, model, tokenizer ve pipeline gibi en önemli sınıfları (classes) ayrıntılandırır.
+ - **MODELLER**, kütüphanede kullanılan her modelle ilgili sınıfları ve fonksiyonları detaylı olarak inceler.
+ - **DAHİLİ YARDIMCILAR**, kullanılan yardımcı sınıfları ve fonksiyonları detaylı olarak inceler.
+
+## Desteklenen Modeller ve Çerçeveler
+
+Aşağıdaki tablo, her bir model için kütüphanede yer alan mevcut desteği temsil etmektedir. Her bir model için bir Python tokenizer'ına ("slow" olarak adlandırılır) sahip olup olmadıkları, 🤗 Tokenizers kütüphanesi tarafından desteklenen hızlı bir tokenizer'a sahip olup olmadıkları, Jax (Flax aracılığıyla), PyTorch ve/veya TensorFlow'da destek olup olmadıklarını göstermektedir.
+
+
+
+| Model | PyTorch support | TensorFlow support | Flax Support |
+|:------------------------------------------------------------------------:|:---------------:|:------------------:|:------------:|
+| [ALBERT](model_doc/albert) | ✅ | ✅ | ✅ |
+| [ALIGN](model_doc/align) | ✅ | ❌ | ❌ |
+| [AltCLIP](model_doc/altclip) | ✅ | ❌ | ❌ |
+| [Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer) | ✅ | ❌ | ❌ |
+| [Autoformer](model_doc/autoformer) | ✅ | ❌ | ❌ |
+| [Bark](model_doc/bark) | ✅ | ❌ | ❌ |
+| [BART](model_doc/bart) | ✅ | ✅ | ✅ |
+| [BARThez](model_doc/barthez) | ✅ | ✅ | ✅ |
+| [BARTpho](model_doc/bartpho) | ✅ | ✅ | ✅ |
+| [BEiT](model_doc/beit) | ✅ | ❌ | ✅ |
+| [BERT](model_doc/bert) | ✅ | ✅ | ✅ |
+| [Bert Generation](model_doc/bert-generation) | ✅ | ❌ | ❌ |
+| [BertJapanese](model_doc/bert-japanese) | ✅ | ✅ | ✅ |
+| [BERTweet](model_doc/bertweet) | ✅ | ✅ | ✅ |
+| [BigBird](model_doc/big_bird) | ✅ | ❌ | ✅ |
+| [BigBird-Pegasus](model_doc/bigbird_pegasus) | ✅ | ❌ | ❌ |
+| [BioGpt](model_doc/biogpt) | ✅ | ❌ | ❌ |
+| [BiT](model_doc/bit) | ✅ | ❌ | ❌ |
+| [Blenderbot](model_doc/blenderbot) | ✅ | ✅ | ✅ |
+| [BlenderbotSmall](model_doc/blenderbot-small) | ✅ | ✅ | ✅ |
+| [BLIP](model_doc/blip) | ✅ | ✅ | ❌ |
+| [BLIP-2](model_doc/blip-2) | ✅ | ❌ | ❌ |
+| [BLOOM](model_doc/bloom) | ✅ | ❌ | ✅ |
+| [BORT](model_doc/bort) | ✅ | ✅ | ✅ |
+| [BridgeTower](model_doc/bridgetower) | ✅ | ❌ | ❌ |
+| [BROS](model_doc/bros) | ✅ | ❌ | ❌ |
+| [ByT5](model_doc/byt5) | ✅ | ✅ | ✅ |
+| [CamemBERT](model_doc/camembert) | ✅ | ✅ | ❌ |
+| [CANINE](model_doc/canine) | ✅ | ❌ | ❌ |
+| [Chinese-CLIP](model_doc/chinese_clip) | ✅ | ❌ | ❌ |
+| [CLAP](model_doc/clap) | ✅ | ❌ | ❌ |
+| [CLIP](model_doc/clip) | ✅ | ✅ | ✅ |
+| [CLIPSeg](model_doc/clipseg) | ✅ | ❌ | ❌ |
+| [CodeGen](model_doc/codegen) | ✅ | ❌ | ❌ |
+| [CodeLlama](model_doc/code_llama) | ✅ | ❌ | ❌ |
+| [Conditional DETR](model_doc/conditional_detr) | ✅ | ❌ | ❌ |
+| [ConvBERT](model_doc/convbert) | ✅ | ✅ | ❌ |
+| [ConvNeXT](model_doc/convnext) | ✅ | ✅ | ❌ |
+| [ConvNeXTV2](model_doc/convnextv2) | ✅ | ❌ | ❌ |
+| [CPM](model_doc/cpm) | ✅ | ✅ | ✅ |
+| [CPM-Ant](model_doc/cpmant) | ✅ | ❌ | ❌ |
+| [CTRL](model_doc/ctrl) | ✅ | ✅ | ❌ |
+| [CvT](model_doc/cvt) | ✅ | ✅ | ❌ |
+| [Data2VecAudio](model_doc/data2vec) | ✅ | ❌ | ❌ |
+| [Data2VecText](model_doc/data2vec) | ✅ | ❌ | ❌ |
+| [Data2VecVision](model_doc/data2vec) | ✅ | ✅ | ❌ |
+| [DeBERTa](model_doc/deberta) | ✅ | ✅ | ❌ |
+| [DeBERTa-v2](model_doc/deberta-v2) | ✅ | ✅ | ❌ |
+| [Decision Transformer](model_doc/decision_transformer) | ✅ | ❌ | ❌ |
+| [Deformable DETR](model_doc/deformable_detr) | ✅ | ❌ | ❌ |
+| [DeiT](model_doc/deit) | ✅ | ✅ | ❌ |
+| [DePlot](model_doc/deplot) | ✅ | ❌ | ❌ |
+| [DETA](model_doc/deta) | ✅ | ❌ | ❌ |
+| [DETR](model_doc/detr) | ✅ | ❌ | ❌ |
+| [DialoGPT](model_doc/dialogpt) | ✅ | ✅ | ✅ |
+| [DiNAT](model_doc/dinat) | ✅ | ❌ | ❌ |
+| [DINOv2](model_doc/dinov2) | ✅ | ❌ | ❌ |
+| [DistilBERT](model_doc/distilbert) | ✅ | ✅ | ✅ |
+| [DiT](model_doc/dit) | ✅ | ❌ | ✅ |
+| [DonutSwin](model_doc/donut) | ✅ | ❌ | ❌ |
+| [DPR](model_doc/dpr) | ✅ | ✅ | ❌ |
+| [DPT](model_doc/dpt) | ✅ | ❌ | ❌ |
+| [EfficientFormer](model_doc/efficientformer) | ✅ | ✅ | ❌ |
+| [EfficientNet](model_doc/efficientnet) | ✅ | ❌ | ❌ |
+| [ELECTRA](model_doc/electra) | ✅ | ✅ | ✅ |
+| [EnCodec](model_doc/encodec) | ✅ | ❌ | ❌ |
+| [Encoder decoder](model_doc/encoder-decoder) | ✅ | ✅ | ✅ |
+| [ERNIE](model_doc/ernie) | ✅ | ❌ | ❌ |
+| [ErnieM](model_doc/ernie_m) | ✅ | ❌ | ❌ |
+| [ESM](model_doc/esm) | ✅ | ✅ | ❌ |
+| [FairSeq Machine-Translation](model_doc/fsmt) | ✅ | ❌ | ❌ |
+| [Falcon](model_doc/falcon) | ✅ | ❌ | ❌ |
+| [FLAN-T5](model_doc/flan-t5) | ✅ | ✅ | ✅ |
+| [FLAN-UL2](model_doc/flan-ul2) | ✅ | ✅ | ✅ |
+| [FlauBERT](model_doc/flaubert) | ✅ | ✅ | ❌ |
+| [FLAVA](model_doc/flava) | ✅ | ❌ | ❌ |
+| [FNet](model_doc/fnet) | ✅ | ❌ | ❌ |
+| [FocalNet](model_doc/focalnet) | ✅ | ❌ | ❌ |
+| [Funnel Transformer](model_doc/funnel) | ✅ | ✅ | ❌ |
+| [Fuyu](model_doc/fuyu) | ✅ | ❌ | ❌ |
+| [GIT](model_doc/git) | ✅ | ❌ | ❌ |
+| [GLPN](model_doc/glpn) | ✅ | ❌ | ❌ |
+| [GPT Neo](model_doc/gpt_neo) | ✅ | ❌ | ✅ |
+| [GPT NeoX](model_doc/gpt_neox) | ✅ | ❌ | ❌ |
+| [GPT NeoX Japanese](model_doc/gpt_neox_japanese) | ✅ | ❌ | ❌ |
+| [GPT-J](model_doc/gptj) | ✅ | ✅ | ✅ |
+| [GPT-Sw3](model_doc/gpt-sw3) | ✅ | ✅ | ✅ |
+| [GPTBigCode](model_doc/gpt_bigcode) | ✅ | ❌ | ❌ |
+| [GPTSAN-japanese](model_doc/gptsan-japanese) | ✅ | ❌ | ❌ |
+| [Graphormer](model_doc/graphormer) | ✅ | ❌ | ❌ |
+| [GroupViT](model_doc/groupvit) | ✅ | ✅ | ❌ |
+| [HerBERT](model_doc/herbert) | ✅ | ✅ | ✅ |
+| [Hubert](model_doc/hubert) | ✅ | ✅ | ❌ |
+| [I-BERT](model_doc/ibert) | ✅ | ❌ | ❌ |
+| [IDEFICS](model_doc/idefics) | ✅ | ❌ | ❌ |
+| [ImageGPT](model_doc/imagegpt) | ✅ | ❌ | ❌ |
+| [Informer](model_doc/informer) | ✅ | ❌ | ❌ |
+| [InstructBLIP](model_doc/instructblip) | ✅ | ❌ | ❌ |
+| [Jukebox](model_doc/jukebox) | ✅ | ❌ | ❌ |
+| [LayoutLM](model_doc/layoutlm) | ✅ | ✅ | ❌ |
+| [LayoutLMv2](model_doc/layoutlmv2) | ✅ | ❌ | ❌ |
+| [LayoutLMv3](model_doc/layoutlmv3) | ✅ | ✅ | ❌ |
+| [LayoutXLM](model_doc/layoutxlm) | ✅ | ❌ | ❌ |
+| [LED](model_doc/led) | ✅ | ✅ | ❌ |
+| [LeViT](model_doc/levit) | ✅ | ❌ | ❌ |
+| [LiLT](model_doc/lilt) | ✅ | ❌ | ❌ |
+| [LLaMA](model_doc/llama) | ✅ | ❌ | ❌ |
+| [Llama2](model_doc/llama2) | ✅ | ❌ | ❌ |
+| [Longformer](model_doc/longformer) | ✅ | ✅ | ❌ |
+| [LongT5](model_doc/longt5) | ✅ | ❌ | ✅ |
+| [LUKE](model_doc/luke) | ✅ | ❌ | ❌ |
+| [LXMERT](model_doc/lxmert) | ✅ | ✅ | ❌ |
+| [M-CTC-T](model_doc/mctct) | ✅ | ❌ | ❌ |
+| [M2M100](model_doc/m2m_100) | ✅ | ❌ | ❌ |
+| [Marian](model_doc/marian) | ✅ | ✅ | ✅ |
+| [MarkupLM](model_doc/markuplm) | ✅ | ❌ | ❌ |
+| [Mask2Former](model_doc/mask2former) | ✅ | ❌ | ❌ |
+| [MaskFormer](model_doc/maskformer) | ✅ | ❌ | ❌ |
+| [MatCha](model_doc/matcha) | ✅ | ❌ | ❌ |
+| [mBART](model_doc/mbart) | ✅ | ✅ | ✅ |
+| [mBART-50](model_doc/mbart50) | ✅ | ✅ | ✅ |
+| [MEGA](model_doc/mega) | ✅ | ❌ | ❌ |
+| [Megatron-BERT](model_doc/megatron-bert) | ✅ | ❌ | ❌ |
+| [Megatron-GPT2](model_doc/megatron_gpt2) | ✅ | ✅ | ✅ |
+| [MGP-STR](model_doc/mgp-str) | ✅ | ❌ | ❌ |
+| [Mistral](model_doc/mistral) | ✅ | ❌ | ❌ |
+| [mLUKE](model_doc/mluke) | ✅ | ❌ | ❌ |
+| [MMS](model_doc/mms) | ✅ | ✅ | ✅ |
+| [MobileBERT](model_doc/mobilebert) | ✅ | ✅ | ❌ |
+| [MobileNetV1](model_doc/mobilenet_v1) | ✅ | ❌ | ❌ |
+| [MobileNetV2](model_doc/mobilenet_v2) | ✅ | ❌ | ❌ |
+| [MobileViT](model_doc/mobilevit) | ✅ | ✅ | ❌ |
+| [MobileViTV2](model_doc/mobilevitv2) | ✅ | ❌ | ❌ |
+| [MPNet](model_doc/mpnet) | ✅ | ✅ | ❌ |
+| [MPT](model_doc/mpt) | ✅ | ❌ | ❌ |
+| [MRA](model_doc/mra) | ✅ | ❌ | ❌ |
+| [MT5](model_doc/mt5) | ✅ | ✅ | ✅ |
+| [MusicGen](model_doc/musicgen) | ✅ | ❌ | ❌ |
+| [MVP](model_doc/mvp) | ✅ | ❌ | ❌ |
+| [NAT](model_doc/nat) | ✅ | ❌ | ❌ |
+| [Nezha](model_doc/nezha) | ✅ | ❌ | ❌ |
+| [NLLB](model_doc/nllb) | ✅ | ❌ | ❌ |
+| [NLLB-MOE](model_doc/nllb-moe) | ✅ | ❌ | ❌ |
+| [Nougat](model_doc/nougat) | ✅ | ✅ | ✅ |
+| [Nyströmformer](model_doc/nystromformer) | ✅ | ❌ | ❌ |
+| [OneFormer](model_doc/oneformer) | ✅ | ❌ | ❌ |
+| [OpenAI GPT](model_doc/openai-gpt) | ✅ | ✅ | ❌ |
+| [OpenAI GPT-2](model_doc/gpt2) | ✅ | ✅ | ✅ |
+| [OpenLlama](model_doc/open-llama) | ✅ | ❌ | ❌ |
+| [OPT](model_doc/opt) | ✅ | ✅ | ✅ |
+| [OWL-ViT](model_doc/owlvit) | ✅ | ❌ | ❌ |
+| [OWLv2](model_doc/owlv2) | ✅ | ❌ | ❌ |
+| [Pegasus](model_doc/pegasus) | ✅ | ✅ | ✅ |
+| [PEGASUS-X](model_doc/pegasus_x) | ✅ | ❌ | ❌ |
+| [Perceiver](model_doc/perceiver) | ✅ | ❌ | ❌ |
+| [Persimmon](model_doc/persimmon) | ✅ | ❌ | ❌ |
+| [PhoBERT](model_doc/phobert) | ✅ | ✅ | ✅ |
+| [Pix2Struct](model_doc/pix2struct) | ✅ | ❌ | ❌ |
+| [PLBart](model_doc/plbart) | ✅ | ❌ | ❌ |
+| [PoolFormer](model_doc/poolformer) | ✅ | ❌ | ❌ |
+| [Pop2Piano](model_doc/pop2piano) | ✅ | ❌ | ❌ |
+| [ProphetNet](model_doc/prophetnet) | ✅ | ❌ | ❌ |
+| [PVT](model_doc/pvt) | ✅ | ❌ | ❌ |
+| [QDQBert](model_doc/qdqbert) | ✅ | ❌ | ❌ |
+| [RAG](model_doc/rag) | ✅ | ✅ | ❌ |
+| [REALM](model_doc/realm) | ✅ | ❌ | ❌ |
+| [Reformer](model_doc/reformer) | ✅ | ❌ | ❌ |
+| [RegNet](model_doc/regnet) | ✅ | ✅ | ✅ |
+| [RemBERT](model_doc/rembert) | ✅ | ✅ | ❌ |
+| [ResNet](model_doc/resnet) | ✅ | ✅ | ✅ |
+| [RetriBERT](model_doc/retribert) | ✅ | ❌ | ❌ |
+| [RoBERTa](model_doc/roberta) | ✅ | ✅ | ✅ |
+| [RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm) | ✅ | ✅ | ✅ |
+| [RoCBert](model_doc/roc_bert) | ✅ | ❌ | ❌ |
+| [RoFormer](model_doc/roformer) | ✅ | ✅ | ✅ |
+| [RWKV](model_doc/rwkv) | ✅ | ❌ | ❌ |
+| [SAM](model_doc/sam) | ✅ | ✅ | ❌ |
+| [SeamlessM4T](model_doc/seamless_m4t) | ✅ | ❌ | ❌ |
+| [SegFormer](model_doc/segformer) | ✅ | ✅ | ❌ |
+| [SEW](model_doc/sew) | ✅ | ❌ | ❌ |
+| [SEW-D](model_doc/sew-d) | ✅ | ❌ | ❌ |
+| [Speech Encoder decoder](model_doc/speech-encoder-decoder) | ✅ | ❌ | ✅ |
+| [Speech2Text](model_doc/speech_to_text) | ✅ | ✅ | ❌ |
+| [SpeechT5](model_doc/speecht5) | ✅ | ❌ | ❌ |
+| [Splinter](model_doc/splinter) | ✅ | ❌ | ❌ |
+| [SqueezeBERT](model_doc/squeezebert) | ✅ | ❌ | ❌ |
+| [SwiftFormer](model_doc/swiftformer) | ✅ | ❌ | ❌ |
+| [Swin Transformer](model_doc/swin) | ✅ | ✅ | ❌ |
+| [Swin Transformer V2](model_doc/swinv2) | ✅ | ❌ | ❌ |
+| [Swin2SR](model_doc/swin2sr) | ✅ | ❌ | ❌ |
+| [SwitchTransformers](model_doc/switch_transformers) | ✅ | ❌ | ❌ |
+| [T5](model_doc/t5) | ✅ | ✅ | ✅ |
+| [T5v1.1](model_doc/t5v1.1) | ✅ | ✅ | ✅ |
+| [Table Transformer](model_doc/table-transformer) | ✅ | ❌ | ❌ |
+| [TAPAS](model_doc/tapas) | ✅ | ✅ | ❌ |
+| [TAPEX](model_doc/tapex) | ✅ | ✅ | ✅ |
+| [Time Series Transformer](model_doc/time_series_transformer) | ✅ | ❌ | ❌ |
+| [TimeSformer](model_doc/timesformer) | ✅ | ❌ | ❌ |
+| [Trajectory Transformer](model_doc/trajectory_transformer) | ✅ | ❌ | ❌ |
+| [Transformer-XL](model_doc/transfo-xl) | ✅ | ✅ | ❌ |
+| [TrOCR](model_doc/trocr) | ✅ | ❌ | ❌ |
+| [TVLT](model_doc/tvlt) | ✅ | ❌ | ❌ |
+| [UL2](model_doc/ul2) | ✅ | ✅ | ✅ |
+| [UMT5](model_doc/umt5) | ✅ | ❌ | ❌ |
+| [UniSpeech](model_doc/unispeech) | ✅ | ❌ | ❌ |
+| [UniSpeechSat](model_doc/unispeech-sat) | ✅ | ❌ | ❌ |
+| [UPerNet](model_doc/upernet) | ✅ | ❌ | ❌ |
+| [VAN](model_doc/van) | ✅ | ❌ | ❌ |
+| [VideoMAE](model_doc/videomae) | ✅ | ❌ | ❌ |
+| [ViLT](model_doc/vilt) | ✅ | ❌ | ❌ |
+| [Vision Encoder decoder](model_doc/vision-encoder-decoder) | ✅ | ✅ | ✅ |
+| [VisionTextDualEncoder](model_doc/vision-text-dual-encoder) | ✅ | ✅ | ✅ |
+| [VisualBERT](model_doc/visual_bert) | ✅ | ❌ | ❌ |
+| [ViT](model_doc/vit) | ✅ | ✅ | ✅ |
+| [ViT Hybrid](model_doc/vit_hybrid) | ✅ | ❌ | ❌ |
+| [VitDet](model_doc/vitdet) | ✅ | ❌ | ❌ |
+| [ViTMAE](model_doc/vit_mae) | ✅ | ✅ | ❌ |
+| [ViTMatte](model_doc/vitmatte) | ✅ | ❌ | ❌ |
+| [ViTMSN](model_doc/vit_msn) | ✅ | ❌ | ❌ |
+| [VITS](model_doc/vits) | ✅ | ❌ | ❌ |
+| [ViViT](model_doc/vivit) | ✅ | ❌ | ❌ |
+| [Wav2Vec2](model_doc/wav2vec2) | ✅ | ✅ | ✅ |
+| [Wav2Vec2-Conformer](model_doc/wav2vec2-conformer) | ✅ | ❌ | ❌ |
+| [Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme) | ✅ | ✅ | ✅ |
+| [WavLM](model_doc/wavlm) | ✅ | ❌ | ❌ |
+| [Whisper](model_doc/whisper) | ✅ | ✅ | ✅ |
+| [X-CLIP](model_doc/xclip) | ✅ | ❌ | ❌ |
+| [X-MOD](model_doc/xmod) | ✅ | ❌ | ❌ |
+| [XGLM](model_doc/xglm) | ✅ | ✅ | ✅ |
+| [XLM](model_doc/xlm) | ✅ | ✅ | ❌ |
+| [XLM-ProphetNet](model_doc/xlm-prophetnet) | ✅ | ❌ | ❌ |
+| [XLM-RoBERTa](model_doc/xlm-roberta) | ✅ | ✅ | ✅ |
+| [XLM-RoBERTa-XL](model_doc/xlm-roberta-xl) | ✅ | ❌ | ❌ |
+| [XLM-V](model_doc/xlm-v) | ✅ | ✅ | ✅ |
+| [XLNet](model_doc/xlnet) | ✅ | ✅ | ❌ |
+| [XLS-R](model_doc/xls_r) | ✅ | ✅ | ✅ |
+| [XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2) | ✅ | ✅ | ✅ |
+| [YOLOS](model_doc/yolos) | ✅ | ❌ | ❌ |
+| [YOSO](model_doc/yoso) | ✅ | ❌ | ❌ |
+
+
diff --git a/docs/source/zh/_toctree.yml b/docs/source/zh/_toctree.yml
index cb2f08d0f312..aa44dbc9cdcd 100644
--- a/docs/source/zh/_toctree.yml
+++ b/docs/source/zh/_toctree.yml
@@ -7,14 +7,26 @@
title: 安装
title: 开始使用
- sections:
- - local: accelerate
- title: 加速分布式训练
- - local: preprocessing
- title: 预处理
- local: pipeline_tutorial
- title: pipeline教程
+ title: 使用pipelines进行推理
+ - local: autoclass_tutorial
+ title: 使用AutoClass编写可移植的代码
+ - local: preprocessing
+ title: 预处理数据
+ - local: training
+ title: 微调预训练模型
+ - local: run_scripts
+ title: 通过脚本训练模型
+ - local: accelerate
+ title: 使用🤗Accelerate进行分布式训练
+ - local: peft
+ title: 使用🤗 PEFT加载和训练adapters
+ - local: model_sharing
+ title: 分享您的模型
- local: transformers_agents
- title: transformers_agents教程
+ title: agents教程
+ - local: llm_tutorial
+ title: 使用LLMs进行生成
title: 教程
- sections:
- local: fast_tokenizers
@@ -25,4 +37,42 @@
title: 使用特定于模型的 API
- local: custom_models
title: 共享自定义模型
+ - local: serialization
+ title: 导出为 ONNX
+ - local: tflite
+ title: 导出为 TFLite
title: 开发者指南
+- sections:
+ - local: performance
+ title: 综述
+ - sections:
+ - local: perf_hardware
+ title: 用于训练的定制硬件
+ - local: hpo_train
+ title: 使用Trainer API 进行超参数搜索
+ title: 高效训练技术
+ - local: big_models
+ title: 实例化大模型
+ - local: debugging
+ title: 问题定位及解决
+ - local: tf_xla
+ title: TensorFlow模型的XLA集成
+ - local: perf_torch_compile
+ title: 使用 `torch.compile()` 优化推理
+ title: 性能和可扩展性
+- sections:
+ - local: task_summary
+ title: 🤗Transformers能做什么
+ - local: tokenizer_summary
+ title: 分词器的摘要
+ title: 概念指南
+- sections:
+ - sections:
+ - local: main_classes/model
+ title: 模型
+ - local: main_classes/trainer
+ title: Trainer
+ - local: main_classes/deepspeed
+ title: DeepSpeed集成
+ title: 主要类
+ title: 应用程序接口 (API)
diff --git a/docs/source/zh/autoclass_tutorial.md b/docs/source/zh/autoclass_tutorial.md
new file mode 100644
index 000000000000..936080a83153
--- /dev/null
+++ b/docs/source/zh/autoclass_tutorial.md
@@ -0,0 +1,149 @@
+
+
+# 使用AutoClass加载预训练实例
+
+由于存在许多不同的Transformer架构,因此为您的checkpoint创建一个可用架构可能会具有挑战性。通过`AutoClass`可以自动推断并从给定的checkpoint加载正确的架构, 这也是🤗 Transformers易于使用、简单且灵活核心规则的重要一部分。`from_pretrained()`方法允许您快速加载任何架构的预训练模型,因此您不必花费时间和精力从头开始训练模型。生成这种与checkpoint无关的代码意味着,如果您的代码适用于一个checkpoint,它将适用于另一个checkpoint - 只要它们是为了类似的任务进行训练的 - 即使架构不同。
+
+
+
+
+## İçindekiler
+
+Dokümantasyon, beş bölüme ayrılmıştır:
+
+- **BAŞLARKEN**, kütüphanenin hızlı bir turunu ve çalışmaya başlamak için kurulum talimatlarını sağlar.
+- **ÖĞRETİCİLER**, başlangıç yapmak için harika bir yerdir. Bu bölüm, kütüphane kullanmaya başlamak için ihtiyacınız olan temel becerileri kazanmanıza yardımcı olacaktır.
+- **NASIL YAPILIR KILAVUZLARI**, önceden eğitilmiş bir modele dil modellemesi için ince ayar (fine-tuning) yapmak veya özel bir model yazmak, ve paylaşmak gibi belirli bir hedefe nasıl ulaşılacağını gösterir.
+- **KAVRAMSAL REHBERLER**, modellerin, görevlerin ve 🤗 Transformers tasarım felsefesinin temel kavramları ve fikirleri hakkında daha fazla tartışma ve açıklama sunar.
+- **API** tüm sınıfları (class) ve fonksiyonları (functions) açıklar:
+
+ - **ANA SINIFLAR**, yapılandırma, model, tokenizer ve pipeline gibi en önemli sınıfları (classes) ayrıntılandırır.
+ - **MODELLER**, kütüphanede kullanılan her modelle ilgili sınıfları ve fonksiyonları detaylı olarak inceler.
+ - **DAHİLİ YARDIMCILAR**, kullanılan yardımcı sınıfları ve fonksiyonları detaylı olarak inceler.
+
+## Desteklenen Modeller ve Çerçeveler
+
+Aşağıdaki tablo, her bir model için kütüphanede yer alan mevcut desteği temsil etmektedir. Her bir model için bir Python tokenizer'ına ("slow" olarak adlandırılır) sahip olup olmadıkları, 🤗 Tokenizers kütüphanesi tarafından desteklenen hızlı bir tokenizer'a sahip olup olmadıkları, Jax (Flax aracılığıyla), PyTorch ve/veya TensorFlow'da destek olup olmadıklarını göstermektedir.
+
+
+
+| Model | PyTorch support | TensorFlow support | Flax Support |
+|:------------------------------------------------------------------------:|:---------------:|:------------------:|:------------:|
+| [ALBERT](model_doc/albert) | ✅ | ✅ | ✅ |
+| [ALIGN](model_doc/align) | ✅ | ❌ | ❌ |
+| [AltCLIP](model_doc/altclip) | ✅ | ❌ | ❌ |
+| [Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer) | ✅ | ❌ | ❌ |
+| [Autoformer](model_doc/autoformer) | ✅ | ❌ | ❌ |
+| [Bark](model_doc/bark) | ✅ | ❌ | ❌ |
+| [BART](model_doc/bart) | ✅ | ✅ | ✅ |
+| [BARThez](model_doc/barthez) | ✅ | ✅ | ✅ |
+| [BARTpho](model_doc/bartpho) | ✅ | ✅ | ✅ |
+| [BEiT](model_doc/beit) | ✅ | ❌ | ✅ |
+| [BERT](model_doc/bert) | ✅ | ✅ | ✅ |
+| [Bert Generation](model_doc/bert-generation) | ✅ | ❌ | ❌ |
+| [BertJapanese](model_doc/bert-japanese) | ✅ | ✅ | ✅ |
+| [BERTweet](model_doc/bertweet) | ✅ | ✅ | ✅ |
+| [BigBird](model_doc/big_bird) | ✅ | ❌ | ✅ |
+| [BigBird-Pegasus](model_doc/bigbird_pegasus) | ✅ | ❌ | ❌ |
+| [BioGpt](model_doc/biogpt) | ✅ | ❌ | ❌ |
+| [BiT](model_doc/bit) | ✅ | ❌ | ❌ |
+| [Blenderbot](model_doc/blenderbot) | ✅ | ✅ | ✅ |
+| [BlenderbotSmall](model_doc/blenderbot-small) | ✅ | ✅ | ✅ |
+| [BLIP](model_doc/blip) | ✅ | ✅ | ❌ |
+| [BLIP-2](model_doc/blip-2) | ✅ | ❌ | ❌ |
+| [BLOOM](model_doc/bloom) | ✅ | ❌ | ✅ |
+| [BORT](model_doc/bort) | ✅ | ✅ | ✅ |
+| [BridgeTower](model_doc/bridgetower) | ✅ | ❌ | ❌ |
+| [BROS](model_doc/bros) | ✅ | ❌ | ❌ |
+| [ByT5](model_doc/byt5) | ✅ | ✅ | ✅ |
+| [CamemBERT](model_doc/camembert) | ✅ | ✅ | ❌ |
+| [CANINE](model_doc/canine) | ✅ | ❌ | ❌ |
+| [Chinese-CLIP](model_doc/chinese_clip) | ✅ | ❌ | ❌ |
+| [CLAP](model_doc/clap) | ✅ | ❌ | ❌ |
+| [CLIP](model_doc/clip) | ✅ | ✅ | ✅ |
+| [CLIPSeg](model_doc/clipseg) | ✅ | ❌ | ❌ |
+| [CodeGen](model_doc/codegen) | ✅ | ❌ | ❌ |
+| [CodeLlama](model_doc/code_llama) | ✅ | ❌ | ❌ |
+| [Conditional DETR](model_doc/conditional_detr) | ✅ | ❌ | ❌ |
+| [ConvBERT](model_doc/convbert) | ✅ | ✅ | ❌ |
+| [ConvNeXT](model_doc/convnext) | ✅ | ✅ | ❌ |
+| [ConvNeXTV2](model_doc/convnextv2) | ✅ | ❌ | ❌ |
+| [CPM](model_doc/cpm) | ✅ | ✅ | ✅ |
+| [CPM-Ant](model_doc/cpmant) | ✅ | ❌ | ❌ |
+| [CTRL](model_doc/ctrl) | ✅ | ✅ | ❌ |
+| [CvT](model_doc/cvt) | ✅ | ✅ | ❌ |
+| [Data2VecAudio](model_doc/data2vec) | ✅ | ❌ | ❌ |
+| [Data2VecText](model_doc/data2vec) | ✅ | ❌ | ❌ |
+| [Data2VecVision](model_doc/data2vec) | ✅ | ✅ | ❌ |
+| [DeBERTa](model_doc/deberta) | ✅ | ✅ | ❌ |
+| [DeBERTa-v2](model_doc/deberta-v2) | ✅ | ✅ | ❌ |
+| [Decision Transformer](model_doc/decision_transformer) | ✅ | ❌ | ❌ |
+| [Deformable DETR](model_doc/deformable_detr) | ✅ | ❌ | ❌ |
+| [DeiT](model_doc/deit) | ✅ | ✅ | ❌ |
+| [DePlot](model_doc/deplot) | ✅ | ❌ | ❌ |
+| [DETA](model_doc/deta) | ✅ | ❌ | ❌ |
+| [DETR](model_doc/detr) | ✅ | ❌ | ❌ |
+| [DialoGPT](model_doc/dialogpt) | ✅ | ✅ | ✅ |
+| [DiNAT](model_doc/dinat) | ✅ | ❌ | ❌ |
+| [DINOv2](model_doc/dinov2) | ✅ | ❌ | ❌ |
+| [DistilBERT](model_doc/distilbert) | ✅ | ✅ | ✅ |
+| [DiT](model_doc/dit) | ✅ | ❌ | ✅ |
+| [DonutSwin](model_doc/donut) | ✅ | ❌ | ❌ |
+| [DPR](model_doc/dpr) | ✅ | ✅ | ❌ |
+| [DPT](model_doc/dpt) | ✅ | ❌ | ❌ |
+| [EfficientFormer](model_doc/efficientformer) | ✅ | ✅ | ❌ |
+| [EfficientNet](model_doc/efficientnet) | ✅ | ❌ | ❌ |
+| [ELECTRA](model_doc/electra) | ✅ | ✅ | ✅ |
+| [EnCodec](model_doc/encodec) | ✅ | ❌ | ❌ |
+| [Encoder decoder](model_doc/encoder-decoder) | ✅ | ✅ | ✅ |
+| [ERNIE](model_doc/ernie) | ✅ | ❌ | ❌ |
+| [ErnieM](model_doc/ernie_m) | ✅ | ❌ | ❌ |
+| [ESM](model_doc/esm) | ✅ | ✅ | ❌ |
+| [FairSeq Machine-Translation](model_doc/fsmt) | ✅ | ❌ | ❌ |
+| [Falcon](model_doc/falcon) | ✅ | ❌ | ❌ |
+| [FLAN-T5](model_doc/flan-t5) | ✅ | ✅ | ✅ |
+| [FLAN-UL2](model_doc/flan-ul2) | ✅ | ✅ | ✅ |
+| [FlauBERT](model_doc/flaubert) | ✅ | ✅ | ❌ |
+| [FLAVA](model_doc/flava) | ✅ | ❌ | ❌ |
+| [FNet](model_doc/fnet) | ✅ | ❌ | ❌ |
+| [FocalNet](model_doc/focalnet) | ✅ | ❌ | ❌ |
+| [Funnel Transformer](model_doc/funnel) | ✅ | ✅ | ❌ |
+| [Fuyu](model_doc/fuyu) | ✅ | ❌ | ❌ |
+| [GIT](model_doc/git) | ✅ | ❌ | ❌ |
+| [GLPN](model_doc/glpn) | ✅ | ❌ | ❌ |
+| [GPT Neo](model_doc/gpt_neo) | ✅ | ❌ | ✅ |
+| [GPT NeoX](model_doc/gpt_neox) | ✅ | ❌ | ❌ |
+| [GPT NeoX Japanese](model_doc/gpt_neox_japanese) | ✅ | ❌ | ❌ |
+| [GPT-J](model_doc/gptj) | ✅ | ✅ | ✅ |
+| [GPT-Sw3](model_doc/gpt-sw3) | ✅ | ✅ | ✅ |
+| [GPTBigCode](model_doc/gpt_bigcode) | ✅ | ❌ | ❌ |
+| [GPTSAN-japanese](model_doc/gptsan-japanese) | ✅ | ❌ | ❌ |
+| [Graphormer](model_doc/graphormer) | ✅ | ❌ | ❌ |
+| [GroupViT](model_doc/groupvit) | ✅ | ✅ | ❌ |
+| [HerBERT](model_doc/herbert) | ✅ | ✅ | ✅ |
+| [Hubert](model_doc/hubert) | ✅ | ✅ | ❌ |
+| [I-BERT](model_doc/ibert) | ✅ | ❌ | ❌ |
+| [IDEFICS](model_doc/idefics) | ✅ | ❌ | ❌ |
+| [ImageGPT](model_doc/imagegpt) | ✅ | ❌ | ❌ |
+| [Informer](model_doc/informer) | ✅ | ❌ | ❌ |
+| [InstructBLIP](model_doc/instructblip) | ✅ | ❌ | ❌ |
+| [Jukebox](model_doc/jukebox) | ✅ | ❌ | ❌ |
+| [LayoutLM](model_doc/layoutlm) | ✅ | ✅ | ❌ |
+| [LayoutLMv2](model_doc/layoutlmv2) | ✅ | ❌ | ❌ |
+| [LayoutLMv3](model_doc/layoutlmv3) | ✅ | ✅ | ❌ |
+| [LayoutXLM](model_doc/layoutxlm) | ✅ | ❌ | ❌ |
+| [LED](model_doc/led) | ✅ | ✅ | ❌ |
+| [LeViT](model_doc/levit) | ✅ | ❌ | ❌ |
+| [LiLT](model_doc/lilt) | ✅ | ❌ | ❌ |
+| [LLaMA](model_doc/llama) | ✅ | ❌ | ❌ |
+| [Llama2](model_doc/llama2) | ✅ | ❌ | ❌ |
+| [Longformer](model_doc/longformer) | ✅ | ✅ | ❌ |
+| [LongT5](model_doc/longt5) | ✅ | ❌ | ✅ |
+| [LUKE](model_doc/luke) | ✅ | ❌ | ❌ |
+| [LXMERT](model_doc/lxmert) | ✅ | ✅ | ❌ |
+| [M-CTC-T](model_doc/mctct) | ✅ | ❌ | ❌ |
+| [M2M100](model_doc/m2m_100) | ✅ | ❌ | ❌ |
+| [Marian](model_doc/marian) | ✅ | ✅ | ✅ |
+| [MarkupLM](model_doc/markuplm) | ✅ | ❌ | ❌ |
+| [Mask2Former](model_doc/mask2former) | ✅ | ❌ | ❌ |
+| [MaskFormer](model_doc/maskformer) | ✅ | ❌ | ❌ |
+| [MatCha](model_doc/matcha) | ✅ | ❌ | ❌ |
+| [mBART](model_doc/mbart) | ✅ | ✅ | ✅ |
+| [mBART-50](model_doc/mbart50) | ✅ | ✅ | ✅ |
+| [MEGA](model_doc/mega) | ✅ | ❌ | ❌ |
+| [Megatron-BERT](model_doc/megatron-bert) | ✅ | ❌ | ❌ |
+| [Megatron-GPT2](model_doc/megatron_gpt2) | ✅ | ✅ | ✅ |
+| [MGP-STR](model_doc/mgp-str) | ✅ | ❌ | ❌ |
+| [Mistral](model_doc/mistral) | ✅ | ❌ | ❌ |
+| [mLUKE](model_doc/mluke) | ✅ | ❌ | ❌ |
+| [MMS](model_doc/mms) | ✅ | ✅ | ✅ |
+| [MobileBERT](model_doc/mobilebert) | ✅ | ✅ | ❌ |
+| [MobileNetV1](model_doc/mobilenet_v1) | ✅ | ❌ | ❌ |
+| [MobileNetV2](model_doc/mobilenet_v2) | ✅ | ❌ | ❌ |
+| [MobileViT](model_doc/mobilevit) | ✅ | ✅ | ❌ |
+| [MobileViTV2](model_doc/mobilevitv2) | ✅ | ❌ | ❌ |
+| [MPNet](model_doc/mpnet) | ✅ | ✅ | ❌ |
+| [MPT](model_doc/mpt) | ✅ | ❌ | ❌ |
+| [MRA](model_doc/mra) | ✅ | ❌ | ❌ |
+| [MT5](model_doc/mt5) | ✅ | ✅ | ✅ |
+| [MusicGen](model_doc/musicgen) | ✅ | ❌ | ❌ |
+| [MVP](model_doc/mvp) | ✅ | ❌ | ❌ |
+| [NAT](model_doc/nat) | ✅ | ❌ | ❌ |
+| [Nezha](model_doc/nezha) | ✅ | ❌ | ❌ |
+| [NLLB](model_doc/nllb) | ✅ | ❌ | ❌ |
+| [NLLB-MOE](model_doc/nllb-moe) | ✅ | ❌ | ❌ |
+| [Nougat](model_doc/nougat) | ✅ | ✅ | ✅ |
+| [Nyströmformer](model_doc/nystromformer) | ✅ | ❌ | ❌ |
+| [OneFormer](model_doc/oneformer) | ✅ | ❌ | ❌ |
+| [OpenAI GPT](model_doc/openai-gpt) | ✅ | ✅ | ❌ |
+| [OpenAI GPT-2](model_doc/gpt2) | ✅ | ✅ | ✅ |
+| [OpenLlama](model_doc/open-llama) | ✅ | ❌ | ❌ |
+| [OPT](model_doc/opt) | ✅ | ✅ | ✅ |
+| [OWL-ViT](model_doc/owlvit) | ✅ | ❌ | ❌ |
+| [OWLv2](model_doc/owlv2) | ✅ | ❌ | ❌ |
+| [Pegasus](model_doc/pegasus) | ✅ | ✅ | ✅ |
+| [PEGASUS-X](model_doc/pegasus_x) | ✅ | ❌ | ❌ |
+| [Perceiver](model_doc/perceiver) | ✅ | ❌ | ❌ |
+| [Persimmon](model_doc/persimmon) | ✅ | ❌ | ❌ |
+| [PhoBERT](model_doc/phobert) | ✅ | ✅ | ✅ |
+| [Pix2Struct](model_doc/pix2struct) | ✅ | ❌ | ❌ |
+| [PLBart](model_doc/plbart) | ✅ | ❌ | ❌ |
+| [PoolFormer](model_doc/poolformer) | ✅ | ❌ | ❌ |
+| [Pop2Piano](model_doc/pop2piano) | ✅ | ❌ | ❌ |
+| [ProphetNet](model_doc/prophetnet) | ✅ | ❌ | ❌ |
+| [PVT](model_doc/pvt) | ✅ | ❌ | ❌ |
+| [QDQBert](model_doc/qdqbert) | ✅ | ❌ | ❌ |
+| [RAG](model_doc/rag) | ✅ | ✅ | ❌ |
+| [REALM](model_doc/realm) | ✅ | ❌ | ❌ |
+| [Reformer](model_doc/reformer) | ✅ | ❌ | ❌ |
+| [RegNet](model_doc/regnet) | ✅ | ✅ | ✅ |
+| [RemBERT](model_doc/rembert) | ✅ | ✅ | ❌ |
+| [ResNet](model_doc/resnet) | ✅ | ✅ | ✅ |
+| [RetriBERT](model_doc/retribert) | ✅ | ❌ | ❌ |
+| [RoBERTa](model_doc/roberta) | ✅ | ✅ | ✅ |
+| [RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm) | ✅ | ✅ | ✅ |
+| [RoCBert](model_doc/roc_bert) | ✅ | ❌ | ❌ |
+| [RoFormer](model_doc/roformer) | ✅ | ✅ | ✅ |
+| [RWKV](model_doc/rwkv) | ✅ | ❌ | ❌ |
+| [SAM](model_doc/sam) | ✅ | ✅ | ❌ |
+| [SeamlessM4T](model_doc/seamless_m4t) | ✅ | ❌ | ❌ |
+| [SegFormer](model_doc/segformer) | ✅ | ✅ | ❌ |
+| [SEW](model_doc/sew) | ✅ | ❌ | ❌ |
+| [SEW-D](model_doc/sew-d) | ✅ | ❌ | ❌ |
+| [Speech Encoder decoder](model_doc/speech-encoder-decoder) | ✅ | ❌ | ✅ |
+| [Speech2Text](model_doc/speech_to_text) | ✅ | ✅ | ❌ |
+| [SpeechT5](model_doc/speecht5) | ✅ | ❌ | ❌ |
+| [Splinter](model_doc/splinter) | ✅ | ❌ | ❌ |
+| [SqueezeBERT](model_doc/squeezebert) | ✅ | ❌ | ❌ |
+| [SwiftFormer](model_doc/swiftformer) | ✅ | ❌ | ❌ |
+| [Swin Transformer](model_doc/swin) | ✅ | ✅ | ❌ |
+| [Swin Transformer V2](model_doc/swinv2) | ✅ | ❌ | ❌ |
+| [Swin2SR](model_doc/swin2sr) | ✅ | ❌ | ❌ |
+| [SwitchTransformers](model_doc/switch_transformers) | ✅ | ❌ | ❌ |
+| [T5](model_doc/t5) | ✅ | ✅ | ✅ |
+| [T5v1.1](model_doc/t5v1.1) | ✅ | ✅ | ✅ |
+| [Table Transformer](model_doc/table-transformer) | ✅ | ❌ | ❌ |
+| [TAPAS](model_doc/tapas) | ✅ | ✅ | ❌ |
+| [TAPEX](model_doc/tapex) | ✅ | ✅ | ✅ |
+| [Time Series Transformer](model_doc/time_series_transformer) | ✅ | ❌ | ❌ |
+| [TimeSformer](model_doc/timesformer) | ✅ | ❌ | ❌ |
+| [Trajectory Transformer](model_doc/trajectory_transformer) | ✅ | ❌ | ❌ |
+| [Transformer-XL](model_doc/transfo-xl) | ✅ | ✅ | ❌ |
+| [TrOCR](model_doc/trocr) | ✅ | ❌ | ❌ |
+| [TVLT](model_doc/tvlt) | ✅ | ❌ | ❌ |
+| [UL2](model_doc/ul2) | ✅ | ✅ | ✅ |
+| [UMT5](model_doc/umt5) | ✅ | ❌ | ❌ |
+| [UniSpeech](model_doc/unispeech) | ✅ | ❌ | ❌ |
+| [UniSpeechSat](model_doc/unispeech-sat) | ✅ | ❌ | ❌ |
+| [UPerNet](model_doc/upernet) | ✅ | ❌ | ❌ |
+| [VAN](model_doc/van) | ✅ | ❌ | ❌ |
+| [VideoMAE](model_doc/videomae) | ✅ | ❌ | ❌ |
+| [ViLT](model_doc/vilt) | ✅ | ❌ | ❌ |
+| [Vision Encoder decoder](model_doc/vision-encoder-decoder) | ✅ | ✅ | ✅ |
+| [VisionTextDualEncoder](model_doc/vision-text-dual-encoder) | ✅ | ✅ | ✅ |
+| [VisualBERT](model_doc/visual_bert) | ✅ | ❌ | ❌ |
+| [ViT](model_doc/vit) | ✅ | ✅ | ✅ |
+| [ViT Hybrid](model_doc/vit_hybrid) | ✅ | ❌ | ❌ |
+| [VitDet](model_doc/vitdet) | ✅ | ❌ | ❌ |
+| [ViTMAE](model_doc/vit_mae) | ✅ | ✅ | ❌ |
+| [ViTMatte](model_doc/vitmatte) | ✅ | ❌ | ❌ |
+| [ViTMSN](model_doc/vit_msn) | ✅ | ❌ | ❌ |
+| [VITS](model_doc/vits) | ✅ | ❌ | ❌ |
+| [ViViT](model_doc/vivit) | ✅ | ❌ | ❌ |
+| [Wav2Vec2](model_doc/wav2vec2) | ✅ | ✅ | ✅ |
+| [Wav2Vec2-Conformer](model_doc/wav2vec2-conformer) | ✅ | ❌ | ❌ |
+| [Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme) | ✅ | ✅ | ✅ |
+| [WavLM](model_doc/wavlm) | ✅ | ❌ | ❌ |
+| [Whisper](model_doc/whisper) | ✅ | ✅ | ✅ |
+| [X-CLIP](model_doc/xclip) | ✅ | ❌ | ❌ |
+| [X-MOD](model_doc/xmod) | ✅ | ❌ | ❌ |
+| [XGLM](model_doc/xglm) | ✅ | ✅ | ✅ |
+| [XLM](model_doc/xlm) | ✅ | ✅ | ❌ |
+| [XLM-ProphetNet](model_doc/xlm-prophetnet) | ✅ | ❌ | ❌ |
+| [XLM-RoBERTa](model_doc/xlm-roberta) | ✅ | ✅ | ✅ |
+| [XLM-RoBERTa-XL](model_doc/xlm-roberta-xl) | ✅ | ❌ | ❌ |
+| [XLM-V](model_doc/xlm-v) | ✅ | ✅ | ✅ |
+| [XLNet](model_doc/xlnet) | ✅ | ✅ | ❌ |
+| [XLS-R](model_doc/xls_r) | ✅ | ✅ | ✅ |
+| [XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2) | ✅ | ✅ | ✅ |
+| [YOLOS](model_doc/yolos) | ✅ | ❌ | ❌ |
+| [YOSO](model_doc/yoso) | ✅ | ❌ | ❌ |
+
+
diff --git a/docs/source/zh/_toctree.yml b/docs/source/zh/_toctree.yml
index cb2f08d0f312..aa44dbc9cdcd 100644
--- a/docs/source/zh/_toctree.yml
+++ b/docs/source/zh/_toctree.yml
@@ -7,14 +7,26 @@
title: 安装
title: 开始使用
- sections:
- - local: accelerate
- title: 加速分布式训练
- - local: preprocessing
- title: 预处理
- local: pipeline_tutorial
- title: pipeline教程
+ title: 使用pipelines进行推理
+ - local: autoclass_tutorial
+ title: 使用AutoClass编写可移植的代码
+ - local: preprocessing
+ title: 预处理数据
+ - local: training
+ title: 微调预训练模型
+ - local: run_scripts
+ title: 通过脚本训练模型
+ - local: accelerate
+ title: 使用🤗Accelerate进行分布式训练
+ - local: peft
+ title: 使用🤗 PEFT加载和训练adapters
+ - local: model_sharing
+ title: 分享您的模型
- local: transformers_agents
- title: transformers_agents教程
+ title: agents教程
+ - local: llm_tutorial
+ title: 使用LLMs进行生成
title: 教程
- sections:
- local: fast_tokenizers
@@ -25,4 +37,42 @@
title: 使用特定于模型的 API
- local: custom_models
title: 共享自定义模型
+ - local: serialization
+ title: 导出为 ONNX
+ - local: tflite
+ title: 导出为 TFLite
title: 开发者指南
+- sections:
+ - local: performance
+ title: 综述
+ - sections:
+ - local: perf_hardware
+ title: 用于训练的定制硬件
+ - local: hpo_train
+ title: 使用Trainer API 进行超参数搜索
+ title: 高效训练技术
+ - local: big_models
+ title: 实例化大模型
+ - local: debugging
+ title: 问题定位及解决
+ - local: tf_xla
+ title: TensorFlow模型的XLA集成
+ - local: perf_torch_compile
+ title: 使用 `torch.compile()` 优化推理
+ title: 性能和可扩展性
+- sections:
+ - local: task_summary
+ title: 🤗Transformers能做什么
+ - local: tokenizer_summary
+ title: 分词器的摘要
+ title: 概念指南
+- sections:
+ - sections:
+ - local: main_classes/model
+ title: 模型
+ - local: main_classes/trainer
+ title: Trainer
+ - local: main_classes/deepspeed
+ title: DeepSpeed集成
+ title: 主要类
+ title: 应用程序接口 (API)
diff --git a/docs/source/zh/autoclass_tutorial.md b/docs/source/zh/autoclass_tutorial.md
new file mode 100644
index 000000000000..936080a83153
--- /dev/null
+++ b/docs/source/zh/autoclass_tutorial.md
@@ -0,0 +1,149 @@
+
+
+# 使用AutoClass加载预训练实例
+
+由于存在许多不同的Transformer架构,因此为您的checkpoint创建一个可用架构可能会具有挑战性。通过`AutoClass`可以自动推断并从给定的checkpoint加载正确的架构, 这也是🤗 Transformers易于使用、简单且灵活核心规则的重要一部分。`from_pretrained()`方法允许您快速加载任何架构的预训练模型,因此您不必花费时间和精力从头开始训练模型。生成这种与checkpoint无关的代码意味着,如果您的代码适用于一个checkpoint,它将适用于另一个checkpoint - 只要它们是为了类似的任务进行训练的 - 即使架构不同。
+
+ +
+ 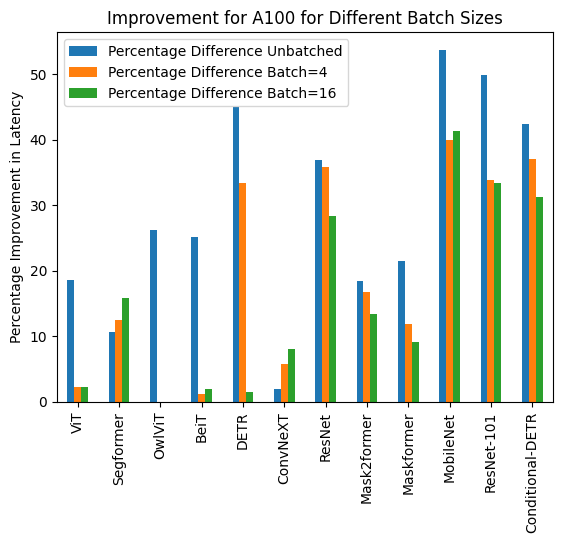 +
+ 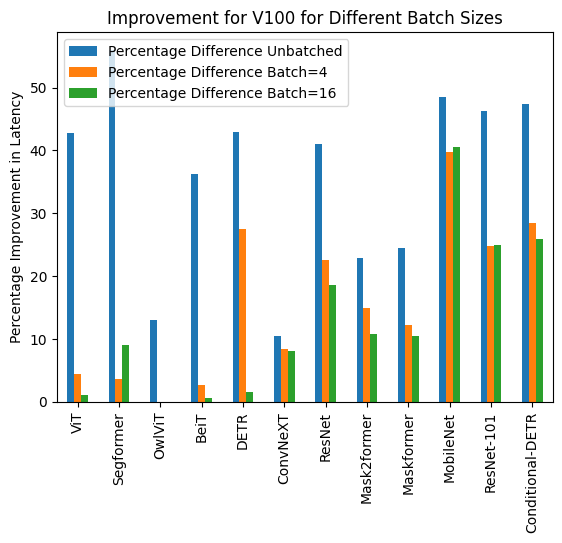 +
+ 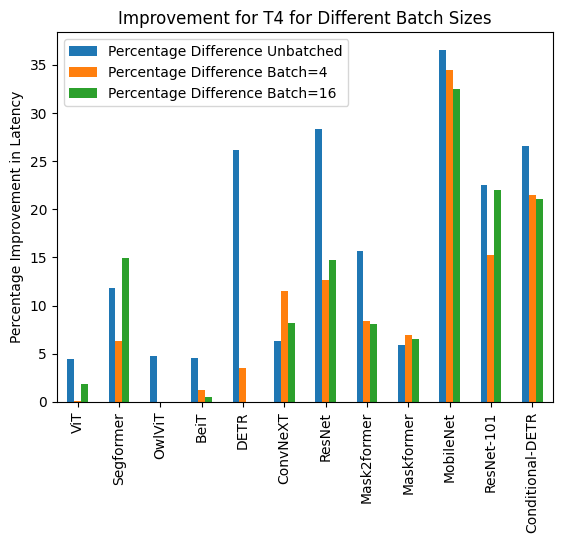 +
+ 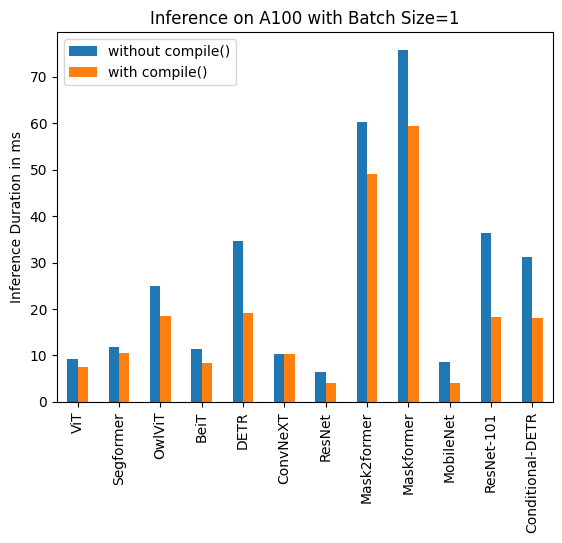 +
+  +
+