Implementation of OpenMP parallelization of berry module #275
Labels
Milestone
Comments
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
What is new
This branch
https://github.com/qiaojunfeng/wannier90/tree/shc_openmp
implements OpenMP parallelization of berry module, including spin Hall conductivity (SHC), anomalous Hall conductivity (AHC), orbital magnetization, Kubo optical conductivity, and shift current.
Why
It all started from an effort to improve the performance of calculating SHC. I am using a computer cluster with dozens of nodes, and each node contains 12 cores and 24GB memory, so each core can use 2GB memory at most. For large systems, a lot of Wannier functions are needed and
postw90.xmay stop running due to insufficient memory. The biggest obstacle is the real space matrics, e.g.SR_R,SHR_R, andSH_Ringet_oper.F90.wannier90/src/postw90/get_oper.F90
Lines 31 to 56 in 280f382
So in these cases, MPI parallelization leads to duplicated large real space matrics thus a waste of memory. OpenMP shared memory parallelization can be used to avoid memory waste. For example, 10 MPI process can be started on 10 nodes and each MPI process can start 12 threads, thus no waste of CPU cores and memory.
How to use
Two exemplary
make.incfiles are included:config/make.inc.gfort.openmpandconfig/make.inc.ifort.openmp. Two variables need to be modified for the compilation:COMMS = mpi openmpandFCOPTS = -O3 -fopenmp.For running
postw90.x, two environmental variables need to be set:OMP_NUM_THREADS=12OMP_STACKSIZE=2GOMP_NUM_THREADSsets the number of threads to be started in each MPI process, usually the numbers of cores in each node.OMP_STACKSIZEis particularly important for avoiding segmentation faults. It sets the stack size limit of OMP threads, and the default of4MBis too small for large calculations. I haven't tested the influence of the exact number on performance. On my cluster, the default value leads to segmentation fault and/or bus error, while2Gworks fine for me.For some systems, you may need to run
ulimit -sto get rid of the stack size limit set by the operating system.Ref: https://stackoverflow.com/questions/13264274/why-segmentation-fault-is-happening-in-this-openmp-code
Then run
postw90.xas usual. If you are using a job submission system, take care of the arguments for assigning the number of nodes and number of process to be used.Technical details
However, the introduction of OpenMP results in some major changes to wannier90, and I list it here to help you understand what I have done to this branch:
utility_rotatewithutility_rotate_new, replacingmatmulwithutility_zgemm_new, as suggested by the wannier90 v3 review paper. Besides, the dimensions of variablesSR_R,SHR_R,SH_Rand some others have been reduced to save memory.postw90_common.F90, the call tows_translate_dist(nrpts, irvec)in subroutinepw90common_fourier_R_to_kand related subroutines has been moved to subroutinepw90common_wanint_setup. The reason is thatws_translate_distsubroutine is not thread-safe, thus calling it inpw90common_fourier_R_to_kcan result in data races which must be avoided. In fact,ws_translate_distshould be called before entering the looploop_xyz, same as callingget_AA_Rofget_oper.F90before the loop. Another reason is that the interpolationpw90common_fourier_R_to_kis used widely throughout the whole program, thus it is better to place it inpw90common_wanint_setupduring the initial setup.get_HH_Rshould be called before the loop, so I removed theget_HH_Rinwham_get_eig_deleigand similar subroutines inwan_ham.F90to make them thread-safe. I have checked the wholepostw90code that uses thosewham_get_eig_deleig*, and luckily they all calledget_HH_Rbefore entering the loop, so removing the call toget_HH_Rshould have no side effects. However, in future codes using those subroutines, it is developers' duty to call the initializingget_HH_Rbefore doing interpolation, this makes sense. Also, the removing ofget_HH_Rcan significantly reduce the number of calls to it, as reported in the timing info printed out in.wpoutwhen settingtiming_level > 1, possibly increases the speed a bit.OPENMP, so if compiled without this macro, the code should work as before.reductionclause requires variables in its list already allocated before entering OpenMPparallel doconstruct, so unused arrays are allocated as well, e.g.allocate (jdos(1)). Also, variables inreductionclause need to be initialized as wanted.DEBUGto print info about the assignment ofloop_xyzon each node and thread, so as to directly know whether MPI and OpenMP cooperate well or not. ModifyFCOPTSinmake.inctoFCOPTS = -fopenmp -DDEBUGto enable this feature.berry.F90contains OpenMP directives, all the source files need to be compiled with the corresponding OpenMP flags. This is especially true for Intel compilers, if not all of them are compiled with the-qopenmpflag, then the calculation results can be unpredictable. Forgfortran, although this phenomenon does not happen, it is still safer to compile all the source file with-openmpflag.Performances
Following are some tests carried out on TianHe-1A system, with 12 cores/24 GB memory on each node. The tests are the SHC calculation of Pt located in
test-suite/tests/testpostw90_pt_shcwithberry_kmeshchanged to50. The recorded wall time is theTotal Execution Timeprinted out in the.wpoutfile. Wannier90 is compiled withifort13.0.0 20120731 +MPICH3.0.4, with-O2optimization level.Tests on OpenMP
using 1 node, 1 MPI process, 1 to 12 threads within MPI process.
Tests on MPI inter node
using 1 thread in each MPI process, starting 1 MPI process in each node, using 1 to 12 nodes.
Tests on MPI intra node
using 1 thread in each MPI process, using 1 node, starting 1 to 12 MPI process in 1 node.
The above test results are compiled in the following charts.
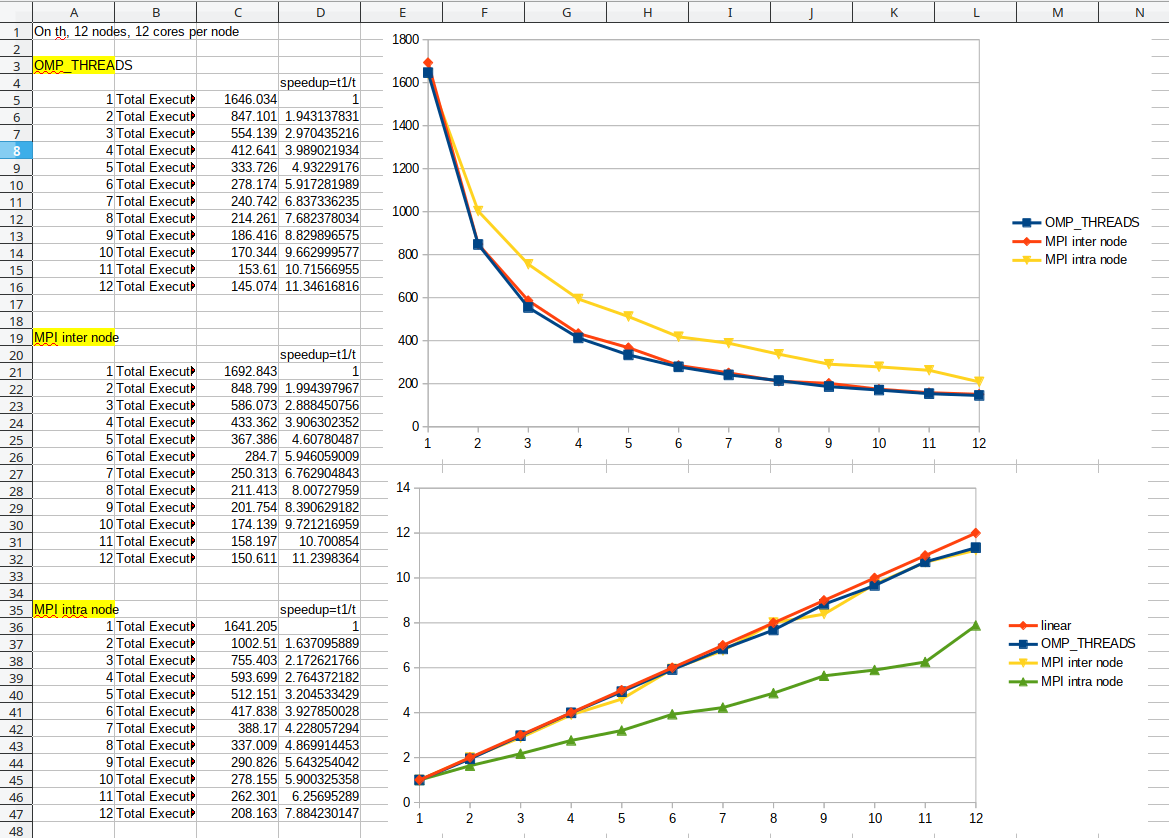
The first block
OMP_THREADSshows results of test 1, the second blockMPI inter nodeshows results of test 2, the third blockMPI intra nodeshows results of test 3. As shown in the speedup chart,OMP_THREADSandMPI inter nodeshow almost linear scaling relative to the number of threads or nodes. However, theMPI intra noderesults are not ideal, and I have run several repeated test ofMPI intra nodeand they all suffered from this bad scaling behavior. Thus OpenMP multi-threading can be used to bypass the bad scaling of MPI intra node communication, at least on TianHe-1A.Then I ran tests on MPI+OpenMP hybrid parallelization. In this case, 1 MPI process was started on each node and each MPI process started 1 to 12 threads, and the number of nodes varied from 1 to 12. In this case, the left chart is almost identical to the right chart, meaning that in terms of performance OpenMP is identical to
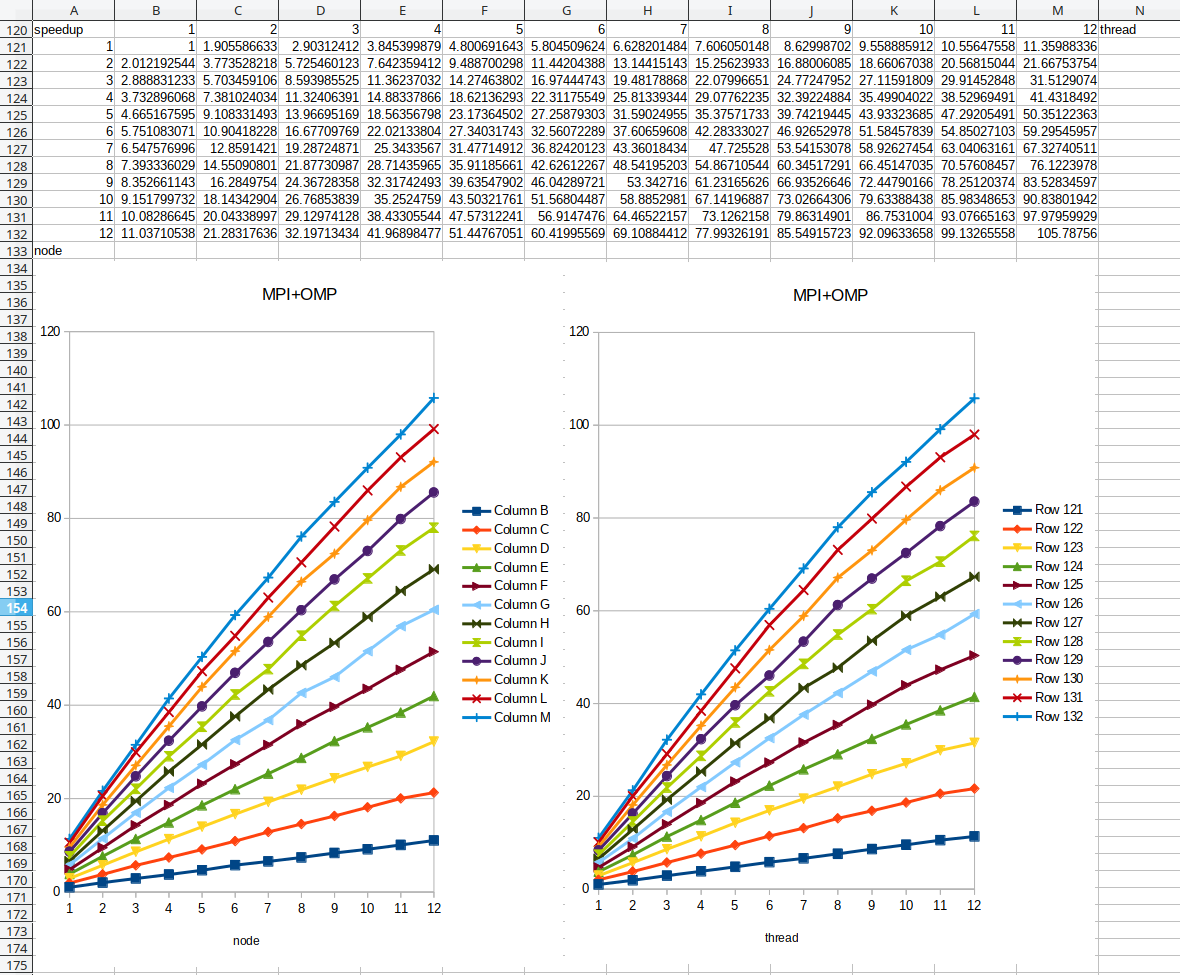
MPI inter node.To illustrate the scaling behavior, in the following 3D bar charts, the deviations from linear scaling
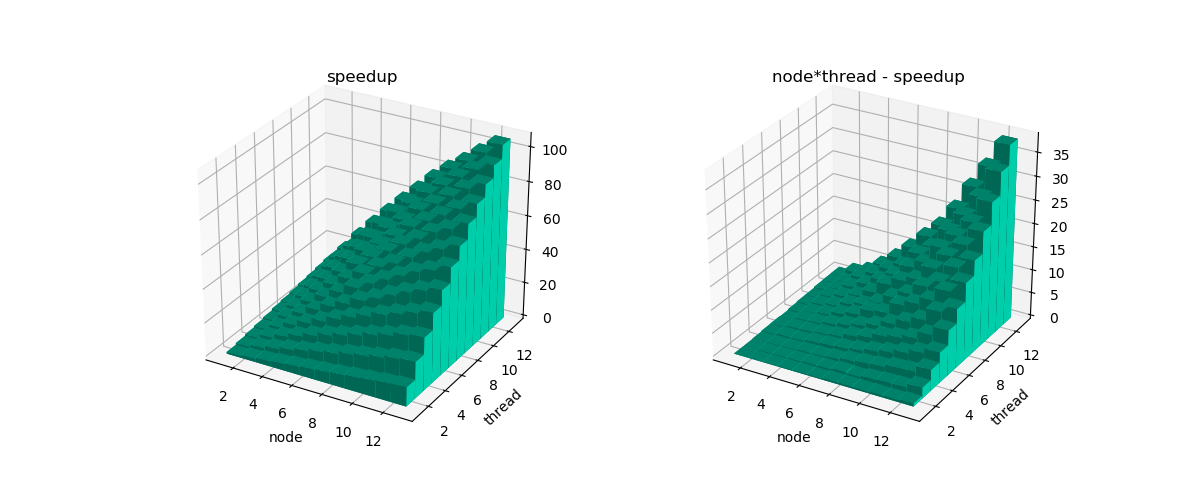
node * thread - speedupis shown in the right panel. With an increasing number of threads & nodes, MPI+OpenMP hybrid parallelization starts to deviate from linear scaling.Overall, considering within each node OpenMP outperforms MPI intra node, MPI+OpenMP on 144 cores should be better than using pure MPI on 144 cores.
Test suites
The code has been tested with three compilers:
gfortran8.3.0 +Open MPI4.0.1ifort13.0.0 20120731 +MPICH3.0.4ifort19.0.0.117 20180804 +Intel MPIIntel parallel studio 2019I have run the test suites with different combinations of the number of MPI processes and the number of OpenMP threads, the test suites worked fine (Note I have applied the fix in pull request [#273], so you have to regenerate benchmark files to make comparisons).
I have also run postw90 on SHC calculations of large systems and the results are identical to ordinary MPI-parallelized cases.
I have checked other parts of the code in berry module such as AHC, and the OpenMP directives should work fine with those calculations. However, since I am not the author of those codes, I think the addition of OpenMP should be reviewed by the corresponding authors to ensure OpenMP doesn't interfere with their code destructively.
Summary
By adopting OpenMP, the memory issues I encountered has been totally eliminated, thus greatly expanding the size of the system we can study. Moreover, the speed of OpenMP slightly outperforms MPI intra node, so calculation speed could increase a bit. Possibly the time for MPI broadcasting large matrices can be reduced so the code may run faster. Thanks to independence among k-points, the berry module is a perfect place for implementing OpenMP parallelization. Moreover, the hybrid parallelization of MPI+OpenMP may enable better scaling when system size becomes larger, at least this is true on TianHe-1A. More tests on other systems remain to be seen.
Since the addition of OpenMP changes wannier90 to a large extent, I didn't create a pull request but rather post an issue here, I would like to hear from you any comments and suggestions to this branch. If you think it is worthwhile to include OpenMP parallelization into wannier90, I am happy to create a pull request and write some additional user guide on using OpenMP-parallelized wannier90. Thank you.
The text was updated successfully, but these errors were encountered: